
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_8043
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-226
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Name Django Admin Views clearer
Currently, Django Admin views are captured with confusingly internal names. We should capture something clearer

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/django/middleware.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5
6 from scout_apm.core.ignore import ignore_path
7 from scout_apm.core.queue_time import track_request_queue_time
8 from scout_apm.core.tracked_request import TrackedRequest
9
10 logger = logging.getLogger(__name__)
11
12
13 def get_operation_name(request):
14 view_name = request.resolver_match._func_path
15 return "Controller/" + view_name
16
17
18 def track_request_view_data(request, tracked_request):
19 tracked_request.tag("path", request.path)
20 if ignore_path(request.path):
21 tracked_request.tag("ignore_transaction", True)
22
23 try:
24 # Determine a remote IP to associate with the request. The value is
25 # spoofable by the requester so this is not suitable to use in any
26 # security sensitive context.
27 user_ip = (
28 request.META.get("HTTP_X_FORWARDED_FOR", "").split(",")[0]
29 or request.META.get("HTTP_CLIENT_IP", "").split(",")[0]
30 or request.META.get("REMOTE_ADDR", None)
31 )
32 tracked_request.tag("user_ip", user_ip)
33 except Exception:
34 pass
35
36 user = getattr(request, "user", None)
37 if user is not None:
38 try:
39 tracked_request.tag("username", user.get_username())
40 except Exception:
41 pass
42
43
44 class MiddlewareTimingMiddleware(object):
45 """
46 Insert as early into the Middleware stack as possible (outermost layers),
47 so that other middlewares called after can be timed.
48 """
49
50 def __init__(self, get_response):
51 self.get_response = get_response
52
53 def __call__(self, request):
54 tracked_request = TrackedRequest.instance()
55
56 tracked_request.start_span(operation="Middleware")
57 queue_time = request.META.get("HTTP_X_QUEUE_START") or request.META.get(
58 "HTTP_X_REQUEST_START", ""
59 )
60 track_request_queue_time(queue_time, tracked_request)
61
62 try:
63 return self.get_response(request)
64 finally:
65 TrackedRequest.instance().stop_span()
66
67
68 class ViewTimingMiddleware(object):
69 """
70 Insert as deep into the middleware stack as possible, ideally wrapping no
71 other middleware. Designed to time the View itself
72 """
73
74 def __init__(self, get_response):
75 self.get_response = get_response
76
77 def __call__(self, request):
78 """
79 Wrap a single incoming request with start and stop calls.
80 This will start timing, but relies on the process_view callback to
81 capture more details about what view was really called, and other
82 similar info.
83
84 If process_view isn't called, then the request will not
85 be recorded. This can happen if a middleware further along the stack
86 doesn't call onward, and instead returns a response directly.
87 """
88 tracked_request = TrackedRequest.instance()
89
90 # This operation name won't be recorded unless changed later in
91 # process_view
92 tracked_request.start_span(operation="Unknown")
93 try:
94 response = self.get_response(request)
95 finally:
96 tracked_request.stop_span()
97 return response
98
99 def process_view(self, request, view_func, view_args, view_kwargs):
100 """
101 Capture details about the view_func that is about to execute
102 """
103 tracked_request = TrackedRequest.instance()
104 tracked_request.mark_real_request()
105
106 track_request_view_data(request, tracked_request)
107
108 span = tracked_request.current_span()
109 if span is not None:
110 span.operation = get_operation_name(request)
111
112 def process_exception(self, request, exception):
113 """
114 Mark this request as having errored out
115
116 Does not modify or catch or otherwise change the exception thrown
117 """
118 TrackedRequest.instance().tag("error", "true")
119
120
121 class OldStyleMiddlewareTimingMiddleware(object):
122 """
123 Insert as early into the Middleware stack as possible (outermost layers),
124 so that other middlewares called after can be timed.
125 """
126
127 def process_request(self, request):
128 tracked_request = TrackedRequest.instance()
129 request._scout_tracked_request = tracked_request
130
131 queue_time = request.META.get("HTTP_X_QUEUE_START") or request.META.get(
132 "HTTP_X_REQUEST_START", ""
133 )
134 track_request_queue_time(queue_time, tracked_request)
135
136 tracked_request.start_span(operation="Middleware")
137
138 def process_response(self, request, response):
139 # Only stop span if there's a request, but presume we are balanced,
140 # i.e. that custom instrumentation within the application is not
141 # causing errors
142 tracked_request = getattr(request, "_scout_tracked_request", None)
143 if tracked_request is not None:
144 tracked_request.stop_span()
145 return response
146
147
148 class OldStyleViewMiddleware(object):
149 def process_view(self, request, view_func, view_func_args, view_func_kwargs):
150 tracked_request = getattr(request, "_scout_tracked_request", None)
151 if tracked_request is None:
152 # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so
153 # don't do anything
154 return
155
156 tracked_request.mark_real_request()
157
158 track_request_view_data(request, tracked_request)
159
160 span = tracked_request.start_span(operation=get_operation_name(request))
161 # Save the span into the request, so we can check
162 # if we're matched up when stopping
163 request._scout_view_span = span
164
165 def process_response(self, request, response):
166 tracked_request = getattr(request, "_scout_tracked_request", None)
167 if tracked_request is None:
168 # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so
169 # don't do anything
170 return response
171
172 # Only stop span if we started, but presume we are balanced, i.e. that
173 # custom instrumentation within the application is not causing errors
174 span = getattr(request, "_scout_view_span", None)
175 if span is not None:
176 tracked_request.stop_span()
177 return response
178
179 def process_exception(self, request, exception):
180 tracked_request = getattr(request, "_scout_tracked_request", None)
181 if tracked_request is None:
182 # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so
183 # don't do anything
184 return
185
186 tracked_request.tag("error", "true")
187
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/scout_apm/django/middleware.py b/src/scout_apm/django/middleware.py
--- a/src/scout_apm/django/middleware.py
+++ b/src/scout_apm/django/middleware.py
@@ -11,7 +11,20 @@
def get_operation_name(request):
+ view_func = request.resolver_match.func
view_name = request.resolver_match._func_path
+
+ if hasattr(view_func, "model_admin"):
+ # Seems to comes from Django admin (attribute only set on Django 1.9+)
+ admin_class = view_func.model_admin.__class__
+ view_name = (
+ admin_class.__module__
+ + "."
+ + admin_class.__name__
+ + "."
+ + view_func.__name__
+ )
+
return "Controller/" + view_name
|
{"golden_diff": "diff --git a/src/scout_apm/django/middleware.py b/src/scout_apm/django/middleware.py\n--- a/src/scout_apm/django/middleware.py\n+++ b/src/scout_apm/django/middleware.py\n@@ -11,7 +11,20 @@\n \n \n def get_operation_name(request):\n+ view_func = request.resolver_match.func\n view_name = request.resolver_match._func_path\n+\n+ if hasattr(view_func, \"model_admin\"):\n+ # Seems to comes from Django admin (attribute only set on Django 1.9+)\n+ admin_class = view_func.model_admin.__class__\n+ view_name = (\n+ admin_class.__module__\n+ + \".\"\n+ + admin_class.__name__\n+ + \".\"\n+ + view_func.__name__\n+ )\n+\n return \"Controller/\" + view_name\n", "issue": "Name Django Admin Views clearer\nCurrently, Django Admin views are captured with confusingly internal names. We should capture something clearer\r\n\r\n\r\n\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nfrom scout_apm.core.ignore import ignore_path\nfrom scout_apm.core.queue_time import track_request_queue_time\nfrom scout_apm.core.tracked_request import TrackedRequest\n\nlogger = logging.getLogger(__name__)\n\n\ndef get_operation_name(request):\n view_name = request.resolver_match._func_path\n return \"Controller/\" + view_name\n\n\ndef track_request_view_data(request, tracked_request):\n tracked_request.tag(\"path\", request.path)\n if ignore_path(request.path):\n tracked_request.tag(\"ignore_transaction\", True)\n\n try:\n # Determine a remote IP to associate with the request. The value is\n # spoofable by the requester so this is not suitable to use in any\n # security sensitive context.\n user_ip = (\n request.META.get(\"HTTP_X_FORWARDED_FOR\", \"\").split(\",\")[0]\n or request.META.get(\"HTTP_CLIENT_IP\", \"\").split(\",\")[0]\n or request.META.get(\"REMOTE_ADDR\", None)\n )\n tracked_request.tag(\"user_ip\", user_ip)\n except Exception:\n pass\n\n user = getattr(request, \"user\", None)\n if user is not None:\n try:\n tracked_request.tag(\"username\", user.get_username())\n except Exception:\n pass\n\n\nclass MiddlewareTimingMiddleware(object):\n \"\"\"\n Insert as early into the Middleware stack as possible (outermost layers),\n so that other middlewares called after can be timed.\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n tracked_request = TrackedRequest.instance()\n\n tracked_request.start_span(operation=\"Middleware\")\n queue_time = request.META.get(\"HTTP_X_QUEUE_START\") or request.META.get(\n \"HTTP_X_REQUEST_START\", \"\"\n )\n track_request_queue_time(queue_time, tracked_request)\n\n try:\n return self.get_response(request)\n finally:\n TrackedRequest.instance().stop_span()\n\n\nclass ViewTimingMiddleware(object):\n \"\"\"\n Insert as deep into the middleware stack as possible, ideally wrapping no\n other middleware. Designed to time the View itself\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n \"\"\"\n Wrap a single incoming request with start and stop calls.\n This will start timing, but relies on the process_view callback to\n capture more details about what view was really called, and other\n similar info.\n\n If process_view isn't called, then the request will not\n be recorded. This can happen if a middleware further along the stack\n doesn't call onward, and instead returns a response directly.\n \"\"\"\n tracked_request = TrackedRequest.instance()\n\n # This operation name won't be recorded unless changed later in\n # process_view\n tracked_request.start_span(operation=\"Unknown\")\n try:\n response = self.get_response(request)\n finally:\n tracked_request.stop_span()\n return response\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n \"\"\"\n Capture details about the view_func that is about to execute\n \"\"\"\n tracked_request = TrackedRequest.instance()\n tracked_request.mark_real_request()\n\n track_request_view_data(request, tracked_request)\n\n span = tracked_request.current_span()\n if span is not None:\n span.operation = get_operation_name(request)\n\n def process_exception(self, request, exception):\n \"\"\"\n Mark this request as having errored out\n\n Does not modify or catch or otherwise change the exception thrown\n \"\"\"\n TrackedRequest.instance().tag(\"error\", \"true\")\n\n\nclass OldStyleMiddlewareTimingMiddleware(object):\n \"\"\"\n Insert as early into the Middleware stack as possible (outermost layers),\n so that other middlewares called after can be timed.\n \"\"\"\n\n def process_request(self, request):\n tracked_request = TrackedRequest.instance()\n request._scout_tracked_request = tracked_request\n\n queue_time = request.META.get(\"HTTP_X_QUEUE_START\") or request.META.get(\n \"HTTP_X_REQUEST_START\", \"\"\n )\n track_request_queue_time(queue_time, tracked_request)\n\n tracked_request.start_span(operation=\"Middleware\")\n\n def process_response(self, request, response):\n # Only stop span if there's a request, but presume we are balanced,\n # i.e. that custom instrumentation within the application is not\n # causing errors\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is not None:\n tracked_request.stop_span()\n return response\n\n\nclass OldStyleViewMiddleware(object):\n def process_view(self, request, view_func, view_func_args, view_func_kwargs):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return\n\n tracked_request.mark_real_request()\n\n track_request_view_data(request, tracked_request)\n\n span = tracked_request.start_span(operation=get_operation_name(request))\n # Save the span into the request, so we can check\n # if we're matched up when stopping\n request._scout_view_span = span\n\n def process_response(self, request, response):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return response\n\n # Only stop span if we started, but presume we are balanced, i.e. that\n # custom instrumentation within the application is not causing errors\n span = getattr(request, \"_scout_view_span\", None)\n if span is not None:\n tracked_request.stop_span()\n return response\n\n def process_exception(self, request, exception):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return\n\n tracked_request.tag(\"error\", \"true\")\n", "path": "src/scout_apm/django/middleware.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nfrom scout_apm.core.ignore import ignore_path\nfrom scout_apm.core.queue_time import track_request_queue_time\nfrom scout_apm.core.tracked_request import TrackedRequest\n\nlogger = logging.getLogger(__name__)\n\n\ndef get_operation_name(request):\n view_func = request.resolver_match.func\n view_name = request.resolver_match._func_path\n\n if hasattr(view_func, \"model_admin\"):\n # Seems to comes from Django admin (attribute only set on Django 1.9+)\n admin_class = view_func.model_admin.__class__\n view_name = (\n admin_class.__module__\n + \".\"\n + admin_class.__name__\n + \".\"\n + view_func.__name__\n )\n\n return \"Controller/\" + view_name\n\n\ndef track_request_view_data(request, tracked_request):\n tracked_request.tag(\"path\", request.path)\n if ignore_path(request.path):\n tracked_request.tag(\"ignore_transaction\", True)\n\n try:\n # Determine a remote IP to associate with the request. The value is\n # spoofable by the requester so this is not suitable to use in any\n # security sensitive context.\n user_ip = (\n request.META.get(\"HTTP_X_FORWARDED_FOR\", \"\").split(\",\")[0]\n or request.META.get(\"HTTP_CLIENT_IP\", \"\").split(\",\")[0]\n or request.META.get(\"REMOTE_ADDR\", None)\n )\n tracked_request.tag(\"user_ip\", user_ip)\n except Exception:\n pass\n\n user = getattr(request, \"user\", None)\n if user is not None:\n try:\n tracked_request.tag(\"username\", user.get_username())\n except Exception:\n pass\n\n\nclass MiddlewareTimingMiddleware(object):\n \"\"\"\n Insert as early into the Middleware stack as possible (outermost layers),\n so that other middlewares called after can be timed.\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n tracked_request = TrackedRequest.instance()\n\n tracked_request.start_span(operation=\"Middleware\")\n queue_time = request.META.get(\"HTTP_X_QUEUE_START\") or request.META.get(\n \"HTTP_X_REQUEST_START\", \"\"\n )\n track_request_queue_time(queue_time, tracked_request)\n\n try:\n return self.get_response(request)\n finally:\n TrackedRequest.instance().stop_span()\n\n\nclass ViewTimingMiddleware(object):\n \"\"\"\n Insert as deep into the middleware stack as possible, ideally wrapping no\n other middleware. Designed to time the View itself\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n \"\"\"\n Wrap a single incoming request with start and stop calls.\n This will start timing, but relies on the process_view callback to\n capture more details about what view was really called, and other\n similar info.\n\n If process_view isn't called, then the request will not\n be recorded. This can happen if a middleware further along the stack\n doesn't call onward, and instead returns a response directly.\n \"\"\"\n tracked_request = TrackedRequest.instance()\n\n # This operation name won't be recorded unless changed later in\n # process_view\n tracked_request.start_span(operation=\"Unknown\")\n try:\n response = self.get_response(request)\n finally:\n tracked_request.stop_span()\n return response\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n \"\"\"\n Capture details about the view_func that is about to execute\n \"\"\"\n tracked_request = TrackedRequest.instance()\n tracked_request.mark_real_request()\n\n track_request_view_data(request, tracked_request)\n\n span = tracked_request.current_span()\n if span is not None:\n span.operation = get_operation_name(request)\n\n def process_exception(self, request, exception):\n \"\"\"\n Mark this request as having errored out\n\n Does not modify or catch or otherwise change the exception thrown\n \"\"\"\n TrackedRequest.instance().tag(\"error\", \"true\")\n\n\nclass OldStyleMiddlewareTimingMiddleware(object):\n \"\"\"\n Insert as early into the Middleware stack as possible (outermost layers),\n so that other middlewares called after can be timed.\n \"\"\"\n\n def process_request(self, request):\n tracked_request = TrackedRequest.instance()\n request._scout_tracked_request = tracked_request\n\n queue_time = request.META.get(\"HTTP_X_QUEUE_START\") or request.META.get(\n \"HTTP_X_REQUEST_START\", \"\"\n )\n track_request_queue_time(queue_time, tracked_request)\n\n tracked_request.start_span(operation=\"Middleware\")\n\n def process_response(self, request, response):\n # Only stop span if there's a request, but presume we are balanced,\n # i.e. that custom instrumentation within the application is not\n # causing errors\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is not None:\n tracked_request.stop_span()\n return response\n\n\nclass OldStyleViewMiddleware(object):\n def process_view(self, request, view_func, view_func_args, view_func_kwargs):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return\n\n tracked_request.mark_real_request()\n\n track_request_view_data(request, tracked_request)\n\n span = tracked_request.start_span(operation=get_operation_name(request))\n # Save the span into the request, so we can check\n # if we're matched up when stopping\n request._scout_view_span = span\n\n def process_response(self, request, response):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return response\n\n # Only stop span if we started, but presume we are balanced, i.e. that\n # custom instrumentation within the application is not causing errors\n span = getattr(request, \"_scout_view_span\", None)\n if span is not None:\n tracked_request.stop_span()\n return response\n\n def process_exception(self, request, exception):\n tracked_request = getattr(request, \"_scout_tracked_request\", None)\n if tracked_request is None:\n # Looks like OldStyleMiddlewareTimingMiddleware didn't run, so\n # don't do anything\n return\n\n tracked_request.tag(\"error\", \"true\")\n", "path": "src/scout_apm/django/middleware.py"}]}
| 2,156 | 192 |
gh_patches_debug_1074
|
rasdani/github-patches
|
git_diff
|
huggingface__diffusers-1052
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve the precision of our integration tests
We currently have a rather low precision when testing our pipeline due to due reasons.
1. - Our reference is an image and not a numpy array. This means that when we created our reference image we lost float precision which is unnecessary
2. - We only test for `.max() < 1e-2` . IMO we should test for `.max() < 1e-4` with the numpy arrays. In my experiements across multiple devices I have **not** seen differences bigger than `.max() < 1e-4` when using full precision.
IMO this could have also prevented: https://github.com/huggingface/diffusers/issues/902
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/diffusers/utils/__init__.py`
Content:
```
1 # Copyright 2022 The HuggingFace Inc. team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import os
17
18 from .deprecation_utils import deprecate
19 from .import_utils import (
20 ENV_VARS_TRUE_AND_AUTO_VALUES,
21 ENV_VARS_TRUE_VALUES,
22 USE_JAX,
23 USE_TF,
24 USE_TORCH,
25 DummyObject,
26 is_accelerate_available,
27 is_flax_available,
28 is_inflect_available,
29 is_modelcards_available,
30 is_onnx_available,
31 is_scipy_available,
32 is_tf_available,
33 is_torch_available,
34 is_transformers_available,
35 is_unidecode_available,
36 requires_backends,
37 )
38 from .logging import get_logger
39 from .outputs import BaseOutput
40
41
42 if is_torch_available():
43 from .testing_utils import (
44 floats_tensor,
45 load_image,
46 load_numpy,
47 parse_flag_from_env,
48 require_torch_gpu,
49 slow,
50 torch_all_close,
51 torch_device,
52 )
53
54
55 logger = get_logger(__name__)
56
57
58 hf_cache_home = os.path.expanduser(
59 os.getenv("HF_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "huggingface"))
60 )
61 default_cache_path = os.path.join(hf_cache_home, "diffusers")
62
63
64 CONFIG_NAME = "config.json"
65 WEIGHTS_NAME = "diffusion_pytorch_model.bin"
66 FLAX_WEIGHTS_NAME = "diffusion_flax_model.msgpack"
67 ONNX_WEIGHTS_NAME = "model.onnx"
68 HUGGINGFACE_CO_RESOLVE_ENDPOINT = "https://huggingface.co"
69 DIFFUSERS_CACHE = default_cache_path
70 DIFFUSERS_DYNAMIC_MODULE_NAME = "diffusers_modules"
71 HF_MODULES_CACHE = os.getenv("HF_MODULES_CACHE", os.path.join(hf_cache_home, "modules"))
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/diffusers/utils/__init__.py b/src/diffusers/utils/__init__.py
--- a/src/diffusers/utils/__init__.py
+++ b/src/diffusers/utils/__init__.py
@@ -42,6 +42,7 @@
if is_torch_available():
from .testing_utils import (
floats_tensor,
+ load_hf_numpy,
load_image,
load_numpy,
parse_flag_from_env,
|
{"golden_diff": "diff --git a/src/diffusers/utils/__init__.py b/src/diffusers/utils/__init__.py\n--- a/src/diffusers/utils/__init__.py\n+++ b/src/diffusers/utils/__init__.py\n@@ -42,6 +42,7 @@\n if is_torch_available():\n from .testing_utils import (\n floats_tensor,\n+ load_hf_numpy,\n load_image,\n load_numpy,\n parse_flag_from_env,\n", "issue": "Improve the precision of our integration tests\nWe currently have a rather low precision when testing our pipeline due to due reasons. \r\n1. - Our reference is an image and not a numpy array. This means that when we created our reference image we lost float precision which is unnecessary\r\n2. - We only test for `.max() < 1e-2` . IMO we should test for `.max() < 1e-4` with the numpy arrays. In my experiements across multiple devices I have **not** seen differences bigger than `.max() < 1e-4` when using full precision.\r\n\r\nIMO this could have also prevented: https://github.com/huggingface/diffusers/issues/902\n", "before_files": [{"content": "# Copyright 2022 The HuggingFace Inc. team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\n\nfrom .deprecation_utils import deprecate\nfrom .import_utils import (\n ENV_VARS_TRUE_AND_AUTO_VALUES,\n ENV_VARS_TRUE_VALUES,\n USE_JAX,\n USE_TF,\n USE_TORCH,\n DummyObject,\n is_accelerate_available,\n is_flax_available,\n is_inflect_available,\n is_modelcards_available,\n is_onnx_available,\n is_scipy_available,\n is_tf_available,\n is_torch_available,\n is_transformers_available,\n is_unidecode_available,\n requires_backends,\n)\nfrom .logging import get_logger\nfrom .outputs import BaseOutput\n\n\nif is_torch_available():\n from .testing_utils import (\n floats_tensor,\n load_image,\n load_numpy,\n parse_flag_from_env,\n require_torch_gpu,\n slow,\n torch_all_close,\n torch_device,\n )\n\n\nlogger = get_logger(__name__)\n\n\nhf_cache_home = os.path.expanduser(\n os.getenv(\"HF_HOME\", os.path.join(os.getenv(\"XDG_CACHE_HOME\", \"~/.cache\"), \"huggingface\"))\n)\ndefault_cache_path = os.path.join(hf_cache_home, \"diffusers\")\n\n\nCONFIG_NAME = \"config.json\"\nWEIGHTS_NAME = \"diffusion_pytorch_model.bin\"\nFLAX_WEIGHTS_NAME = \"diffusion_flax_model.msgpack\"\nONNX_WEIGHTS_NAME = \"model.onnx\"\nHUGGINGFACE_CO_RESOLVE_ENDPOINT = \"https://huggingface.co\"\nDIFFUSERS_CACHE = default_cache_path\nDIFFUSERS_DYNAMIC_MODULE_NAME = \"diffusers_modules\"\nHF_MODULES_CACHE = os.getenv(\"HF_MODULES_CACHE\", os.path.join(hf_cache_home, \"modules\"))\n", "path": "src/diffusers/utils/__init__.py"}], "after_files": [{"content": "# Copyright 2022 The HuggingFace Inc. team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\n\nfrom .deprecation_utils import deprecate\nfrom .import_utils import (\n ENV_VARS_TRUE_AND_AUTO_VALUES,\n ENV_VARS_TRUE_VALUES,\n USE_JAX,\n USE_TF,\n USE_TORCH,\n DummyObject,\n is_accelerate_available,\n is_flax_available,\n is_inflect_available,\n is_modelcards_available,\n is_onnx_available,\n is_scipy_available,\n is_tf_available,\n is_torch_available,\n is_transformers_available,\n is_unidecode_available,\n requires_backends,\n)\nfrom .logging import get_logger\nfrom .outputs import BaseOutput\n\n\nif is_torch_available():\n from .testing_utils import (\n floats_tensor,\n load_hf_numpy,\n load_image,\n load_numpy,\n parse_flag_from_env,\n require_torch_gpu,\n slow,\n torch_all_close,\n torch_device,\n )\n\n\nlogger = get_logger(__name__)\n\n\nhf_cache_home = os.path.expanduser(\n os.getenv(\"HF_HOME\", os.path.join(os.getenv(\"XDG_CACHE_HOME\", \"~/.cache\"), \"huggingface\"))\n)\ndefault_cache_path = os.path.join(hf_cache_home, \"diffusers\")\n\n\nCONFIG_NAME = \"config.json\"\nWEIGHTS_NAME = \"diffusion_pytorch_model.bin\"\nFLAX_WEIGHTS_NAME = \"diffusion_flax_model.msgpack\"\nONNX_WEIGHTS_NAME = \"model.onnx\"\nHUGGINGFACE_CO_RESOLVE_ENDPOINT = \"https://huggingface.co\"\nDIFFUSERS_CACHE = default_cache_path\nDIFFUSERS_DYNAMIC_MODULE_NAME = \"diffusers_modules\"\nHF_MODULES_CACHE = os.getenv(\"HF_MODULES_CACHE\", os.path.join(hf_cache_home, \"modules\"))\n", "path": "src/diffusers/utils/__init__.py"}]}
| 1,046 | 98 |
gh_patches_debug_24220
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-4407
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Schedule editor icons need to be more distinct
From @flynnliz
The various “person” icons are confusing. It’s hard to know at a glance in the grid which conflicts are “person who must be present” and which are “chair conflict,” and it’s even more confusing that in the session request data box on the bottom right, the “requested by” icon is the same as the chair conflict. Can these three be more distinct from each other?

- The “technology overlap” chain icon shows up really faintly and it’s very tiny, so it’s easy to miss. Same with the “key participant overlap” key icon — those two are really difficult to distinguish from each other when they are so small. Can these be made larger or even just changed to something that takes up more vertical space so they’re easier to distinguish?

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/meeting/templatetags/editor_tags.py`
Content:
```
1 # Copyright The IETF Trust 2022, All Rights Reserved
2 # -*- coding: utf-8 -*-
3
4 """Custom tags for the schedule editor"""
5 import debug # pyflakes: ignore
6
7 from django import template
8 from django.utils.html import format_html
9
10 register = template.Library()
11
12
13 @register.simple_tag
14 def constraint_icon_for(constraint_name, count=None):
15 # icons must be valid HTML and kept up to date with tests.EditorTagTests.test_constraint_icon_for()
16 icons = {
17 'conflict': '<span class="encircled">{reversed}1</span>',
18 'conflic2': '<span class="encircled">{reversed}2</span>',
19 'conflic3': '<span class="encircled">{reversed}3</span>',
20 'bethere': '<i class="bi bi-person"></i>{count}',
21 'timerange': '<i class="bi bi-calendar"></i>',
22 'time_relation': 'Δ',
23 'wg_adjacent': '{reversed}<i class="bi bi-skip-end"></i>',
24 'chair_conflict': '{reversed}<i class="bi bi-person-circle"></i>',
25 'tech_overlap': '{reversed}<i class="bi bi-link"></i>',
26 'key_participant': '{reversed}<i class="bi bi-key"></i>',
27 'joint_with_groups': '<i class="bi bi-merge"></i>',
28 'responsible_ad': '<span class="encircled">AD</span>',
29 }
30 reversed_suffix = '-reversed'
31 if constraint_name.slug.endswith(reversed_suffix):
32 reversed = True
33 cn = constraint_name.slug[: -len(reversed_suffix)]
34 else:
35 reversed = False
36 cn = constraint_name.slug
37 return format_html(
38 icons[cn],
39 count=count or '',
40 reversed='-' if reversed else '',
41 )
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/meeting/templatetags/editor_tags.py b/ietf/meeting/templatetags/editor_tags.py
--- a/ietf/meeting/templatetags/editor_tags.py
+++ b/ietf/meeting/templatetags/editor_tags.py
@@ -17,13 +17,13 @@
'conflict': '<span class="encircled">{reversed}1</span>',
'conflic2': '<span class="encircled">{reversed}2</span>',
'conflic3': '<span class="encircled">{reversed}3</span>',
- 'bethere': '<i class="bi bi-person"></i>{count}',
+ 'bethere': '<i class="bi bi-people-fill"></i>{count}',
'timerange': '<i class="bi bi-calendar"></i>',
'time_relation': 'Δ',
'wg_adjacent': '{reversed}<i class="bi bi-skip-end"></i>',
- 'chair_conflict': '{reversed}<i class="bi bi-person-circle"></i>',
- 'tech_overlap': '{reversed}<i class="bi bi-link"></i>',
- 'key_participant': '{reversed}<i class="bi bi-key"></i>',
+ 'chair_conflict': '{reversed}<i class="bi bi-circle-fill"></i>',
+ 'tech_overlap': '{reversed}<i class="bi bi-link-45deg"></i>',
+ 'key_participant': '{reversed}<i class="bi bi-star"></i>',
'joint_with_groups': '<i class="bi bi-merge"></i>',
'responsible_ad': '<span class="encircled">AD</span>',
}
|
{"golden_diff": "diff --git a/ietf/meeting/templatetags/editor_tags.py b/ietf/meeting/templatetags/editor_tags.py\n--- a/ietf/meeting/templatetags/editor_tags.py\n+++ b/ietf/meeting/templatetags/editor_tags.py\n@@ -17,13 +17,13 @@\n 'conflict': '<span class=\"encircled\">{reversed}1</span>',\n 'conflic2': '<span class=\"encircled\">{reversed}2</span>',\n 'conflic3': '<span class=\"encircled\">{reversed}3</span>',\n- 'bethere': '<i class=\"bi bi-person\"></i>{count}',\n+ 'bethere': '<i class=\"bi bi-people-fill\"></i>{count}',\n 'timerange': '<i class=\"bi bi-calendar\"></i>',\n 'time_relation': 'Δ',\n 'wg_adjacent': '{reversed}<i class=\"bi bi-skip-end\"></i>',\n- 'chair_conflict': '{reversed}<i class=\"bi bi-person-circle\"></i>',\n- 'tech_overlap': '{reversed}<i class=\"bi bi-link\"></i>',\n- 'key_participant': '{reversed}<i class=\"bi bi-key\"></i>',\n+ 'chair_conflict': '{reversed}<i class=\"bi bi-circle-fill\"></i>',\n+ 'tech_overlap': '{reversed}<i class=\"bi bi-link-45deg\"></i>',\n+ 'key_participant': '{reversed}<i class=\"bi bi-star\"></i>',\n 'joint_with_groups': '<i class=\"bi bi-merge\"></i>',\n 'responsible_ad': '<span class=\"encircled\">AD</span>',\n }\n", "issue": "Schedule editor icons need to be more distinct\nFrom @flynnliz\r\n\r\nThe various \u201cperson\u201d icons are confusing. It\u2019s hard to know at a glance in the grid which conflicts are \u201cperson who must be present\u201d and which are \u201cchair conflict,\u201d and it\u2019s even more confusing that in the session request data box on the bottom right, the \u201crequested by\u201d icon is the same as the chair conflict. Can these three be more distinct from each other? \r\n\r\n\r\n\r\n\r\n- The \u201ctechnology overlap\u201d chain icon shows up really faintly and it\u2019s very tiny, so it\u2019s easy to miss. Same with the \u201ckey participant overlap\u201d key icon \u2014 those two are really difficult to distinguish from each other when they are so small. Can these be made larger or even just changed to something that takes up more vertical space so they\u2019re easier to distinguish?\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright The IETF Trust 2022, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n\"\"\"Custom tags for the schedule editor\"\"\"\nimport debug # pyflakes: ignore\n\nfrom django import template\nfrom django.utils.html import format_html\n\nregister = template.Library()\n\n\[email protected]_tag\ndef constraint_icon_for(constraint_name, count=None):\n # icons must be valid HTML and kept up to date with tests.EditorTagTests.test_constraint_icon_for()\n icons = {\n 'conflict': '<span class=\"encircled\">{reversed}1</span>',\n 'conflic2': '<span class=\"encircled\">{reversed}2</span>',\n 'conflic3': '<span class=\"encircled\">{reversed}3</span>',\n 'bethere': '<i class=\"bi bi-person\"></i>{count}',\n 'timerange': '<i class=\"bi bi-calendar\"></i>',\n 'time_relation': 'Δ',\n 'wg_adjacent': '{reversed}<i class=\"bi bi-skip-end\"></i>',\n 'chair_conflict': '{reversed}<i class=\"bi bi-person-circle\"></i>',\n 'tech_overlap': '{reversed}<i class=\"bi bi-link\"></i>',\n 'key_participant': '{reversed}<i class=\"bi bi-key\"></i>',\n 'joint_with_groups': '<i class=\"bi bi-merge\"></i>',\n 'responsible_ad': '<span class=\"encircled\">AD</span>',\n }\n reversed_suffix = '-reversed'\n if constraint_name.slug.endswith(reversed_suffix):\n reversed = True\n cn = constraint_name.slug[: -len(reversed_suffix)]\n else:\n reversed = False\n cn = constraint_name.slug\n return format_html(\n icons[cn],\n count=count or '',\n reversed='-' if reversed else '',\n )\n", "path": "ietf/meeting/templatetags/editor_tags.py"}], "after_files": [{"content": "# Copyright The IETF Trust 2022, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n\"\"\"Custom tags for the schedule editor\"\"\"\nimport debug # pyflakes: ignore\n\nfrom django import template\nfrom django.utils.html import format_html\n\nregister = template.Library()\n\n\[email protected]_tag\ndef constraint_icon_for(constraint_name, count=None):\n # icons must be valid HTML and kept up to date with tests.EditorTagTests.test_constraint_icon_for()\n icons = {\n 'conflict': '<span class=\"encircled\">{reversed}1</span>',\n 'conflic2': '<span class=\"encircled\">{reversed}2</span>',\n 'conflic3': '<span class=\"encircled\">{reversed}3</span>',\n 'bethere': '<i class=\"bi bi-people-fill\"></i>{count}',\n 'timerange': '<i class=\"bi bi-calendar\"></i>',\n 'time_relation': 'Δ',\n 'wg_adjacent': '{reversed}<i class=\"bi bi-skip-end\"></i>',\n 'chair_conflict': '{reversed}<i class=\"bi bi-circle-fill\"></i>',\n 'tech_overlap': '{reversed}<i class=\"bi bi-link-45deg\"></i>',\n 'key_participant': '{reversed}<i class=\"bi bi-star\"></i>',\n 'joint_with_groups': '<i class=\"bi bi-merge\"></i>',\n 'responsible_ad': '<span class=\"encircled\">AD</span>',\n }\n reversed_suffix = '-reversed'\n if constraint_name.slug.endswith(reversed_suffix):\n reversed = True\n cn = constraint_name.slug[: -len(reversed_suffix)]\n else:\n reversed = False\n cn = constraint_name.slug\n return format_html(\n icons[cn],\n count=count or '',\n reversed='-' if reversed else '',\n )\n", "path": "ietf/meeting/templatetags/editor_tags.py"}]}
| 1,041 | 379 |
gh_patches_debug_1063
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rename `ConsoleExporter` to `ConsoleLogExporter`?
As suggested by @lonewolf3739, we should rename the ConsoleExporter to ConsoleLogExporter to follow the pattern established by the ConsoleSpanExporter.
Not in this PR; Should we rename this to `ConsoleLogExporter`?
_Originally posted by @lonewolf3739 in https://github.com/open-telemetry/opentelemetry-python/pull/2253#r759589860_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import abc
16 import collections
17 import enum
18 import logging
19 import os
20 import sys
21 import threading
22 from os import linesep
23 from typing import IO, Callable, Deque, List, Optional, Sequence
24
25 from opentelemetry.context import attach, detach, set_value
26 from opentelemetry.sdk._logs import LogData, LogProcessor, LogRecord
27 from opentelemetry.util._time import _time_ns
28
29 _logger = logging.getLogger(__name__)
30
31
32 class LogExportResult(enum.Enum):
33 SUCCESS = 0
34 FAILURE = 1
35
36
37 class LogExporter(abc.ABC):
38 """Interface for exporting logs.
39
40 Interface to be implemented by services that want to export logs received
41 in their own format.
42
43 To export data this MUST be registered to the :class`opentelemetry.sdk._logs.LogEmitter` using a
44 log processor.
45 """
46
47 @abc.abstractmethod
48 def export(self, batch: Sequence[LogData]):
49 """Exports a batch of logs.
50
51 Args:
52 batch: The list of `LogData` objects to be exported
53
54 Returns:
55 The result of the export
56 """
57
58 @abc.abstractmethod
59 def shutdown(self):
60 """Shuts down the exporter.
61
62 Called when the SDK is shut down.
63 """
64
65
66 class ConsoleExporter(LogExporter):
67 """Implementation of :class:`LogExporter` that prints log records to the
68 console.
69
70 This class can be used for diagnostic purposes. It prints the exported
71 log records to the console STDOUT.
72 """
73
74 def __init__(
75 self,
76 out: IO = sys.stdout,
77 formatter: Callable[[LogRecord], str] = lambda record: record.to_json()
78 + linesep,
79 ):
80 self.out = out
81 self.formatter = formatter
82
83 def export(self, batch: Sequence[LogData]):
84 for data in batch:
85 self.out.write(self.formatter(data.log_record))
86 self.out.flush()
87 return LogExportResult.SUCCESS
88
89 def shutdown(self):
90 pass
91
92
93 class SimpleLogProcessor(LogProcessor):
94 """This is an implementation of LogProcessor which passes
95 received logs in the export-friendly LogData representation to the
96 configured LogExporter, as soon as they are emitted.
97 """
98
99 def __init__(self, exporter: LogExporter):
100 self._exporter = exporter
101 self._shutdown = False
102
103 def emit(self, log_data: LogData):
104 if self._shutdown:
105 _logger.warning("Processor is already shutdown, ignoring call")
106 return
107 token = attach(set_value("suppress_instrumentation", True))
108 try:
109 self._exporter.export((log_data,))
110 except Exception: # pylint: disable=broad-except
111 _logger.exception("Exception while exporting logs.")
112 detach(token)
113
114 def shutdown(self):
115 self._shutdown = True
116 self._exporter.shutdown()
117
118 def force_flush(
119 self, timeout_millis: int = 30000
120 ) -> bool: # pylint: disable=no-self-use
121 return True
122
123
124 class _FlushRequest:
125 __slots__ = ["event", "num_log_records"]
126
127 def __init__(self):
128 self.event = threading.Event()
129 self.num_log_records = 0
130
131
132 class BatchLogProcessor(LogProcessor):
133 """This is an implementation of LogProcessor which creates batches of
134 received logs in the export-friendly LogData representation and
135 send to the configured LogExporter, as soon as they are emitted.
136 """
137
138 def __init__(
139 self,
140 exporter: LogExporter,
141 schedule_delay_millis: int = 5000,
142 max_export_batch_size: int = 512,
143 export_timeout_millis: int = 30000,
144 ):
145 self._exporter = exporter
146 self._schedule_delay_millis = schedule_delay_millis
147 self._max_export_batch_size = max_export_batch_size
148 self._export_timeout_millis = export_timeout_millis
149 self._queue = collections.deque() # type: Deque[LogData]
150 self._worker_thread = threading.Thread(target=self.worker, daemon=True)
151 self._condition = threading.Condition(threading.Lock())
152 self._shutdown = False
153 self._flush_request = None # type: Optional[_FlushRequest]
154 self._log_records = [
155 None
156 ] * self._max_export_batch_size # type: List[Optional[LogData]]
157 self._worker_thread.start()
158 # Only available in *nix since py37.
159 if hasattr(os, "register_at_fork"):
160 os.register_at_fork(
161 after_in_child=self._at_fork_reinit
162 ) # pylint: disable=protected-access
163
164 def _at_fork_reinit(self):
165 self._condition = threading.Condition(threading.Lock())
166 self._queue.clear()
167 self._worker_thread = threading.Thread(target=self.worker, daemon=True)
168 self._worker_thread.start()
169
170 def worker(self):
171 timeout = self._schedule_delay_millis / 1e3
172 flush_request = None # type: Optional[_FlushRequest]
173 while not self._shutdown:
174 with self._condition:
175 if self._shutdown:
176 # shutdown may have been called, avoid further processing
177 break
178 flush_request = self._get_and_unset_flush_request()
179 if (
180 len(self._queue) < self._max_export_batch_size
181 and self._flush_request is None
182 ):
183 self._condition.wait(timeout)
184
185 flush_request = self._get_and_unset_flush_request()
186 if not self._queue:
187 timeout = self._schedule_delay_millis / 1e3
188 self._notify_flush_request_finished(flush_request)
189 flush_request = None
190 continue
191 if self._shutdown:
192 break
193
194 start_ns = _time_ns()
195 self._export(flush_request)
196 end_ns = _time_ns()
197 # subtract the duration of this export call to the next timeout
198 timeout = self._schedule_delay_millis / 1e3 - (
199 (end_ns - start_ns) / 1e9
200 )
201
202 self._notify_flush_request_finished(flush_request)
203 flush_request = None
204
205 # there might have been a new flush request while export was running
206 # and before the done flag switched to true
207 with self._condition:
208 shutdown_flush_request = self._get_and_unset_flush_request()
209
210 # flush the remaining logs
211 self._drain_queue()
212 self._notify_flush_request_finished(flush_request)
213 self._notify_flush_request_finished(shutdown_flush_request)
214
215 def _export(self, flush_request: Optional[_FlushRequest] = None):
216 """Exports logs considering the given flush_request.
217
218 If flush_request is not None then logs are exported in batches
219 until the number of exported logs reached or exceeded the num of logs in
220 flush_request, otherwise exports at max max_export_batch_size logs.
221 """
222 if flush_request is None:
223 self._export_batch()
224 return
225
226 num_log_records = flush_request.num_log_records
227 while self._queue:
228 exported = self._export_batch()
229 num_log_records -= exported
230
231 if num_log_records <= 0:
232 break
233
234 def _export_batch(self) -> int:
235 """Exports at most max_export_batch_size logs and returns the number of
236 exported logs.
237 """
238 idx = 0
239 while idx < self._max_export_batch_size and self._queue:
240 record = self._queue.pop()
241 self._log_records[idx] = record
242 idx += 1
243 token = attach(set_value("suppress_instrumentation", True))
244 try:
245 self._exporter.export(self._log_records[:idx]) # type: ignore
246 except Exception: # pylint: disable=broad-except
247 _logger.exception("Exception while exporting logs.")
248 detach(token)
249
250 for index in range(idx):
251 self._log_records[index] = None
252 return idx
253
254 def _drain_queue(self):
255 """Export all elements until queue is empty.
256
257 Can only be called from the worker thread context because it invokes
258 `export` that is not thread safe.
259 """
260 while self._queue:
261 self._export_batch()
262
263 def _get_and_unset_flush_request(self) -> Optional[_FlushRequest]:
264 flush_request = self._flush_request
265 self._flush_request = None
266 if flush_request is not None:
267 flush_request.num_log_records = len(self._queue)
268 return flush_request
269
270 @staticmethod
271 def _notify_flush_request_finished(
272 flush_request: Optional[_FlushRequest] = None,
273 ):
274 if flush_request is not None:
275 flush_request.event.set()
276
277 def _get_or_create_flush_request(self) -> _FlushRequest:
278 if self._flush_request is None:
279 self._flush_request = _FlushRequest()
280 return self._flush_request
281
282 def emit(self, log_data: LogData) -> None:
283 """Adds the `LogData` to queue and notifies the waiting threads
284 when size of queue reaches max_export_batch_size.
285 """
286 if self._shutdown:
287 return
288 self._queue.appendleft(log_data)
289 if len(self._queue) >= self._max_export_batch_size:
290 with self._condition:
291 self._condition.notify()
292
293 def shutdown(self):
294 self._shutdown = True
295 with self._condition:
296 self._condition.notify_all()
297 self._worker_thread.join()
298 self._exporter.shutdown()
299
300 def force_flush(self, timeout_millis: Optional[int] = None) -> bool:
301 if timeout_millis is None:
302 timeout_millis = self._export_timeout_millis
303 if self._shutdown:
304 return True
305
306 with self._condition:
307 flush_request = self._get_or_create_flush_request()
308 self._condition.notify_all()
309
310 ret = flush_request.event.wait(timeout_millis / 1e3)
311 if not ret:
312 _logger.warning("Timeout was exceeded in force_flush().")
313 return ret
314
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py
@@ -63,7 +63,7 @@
"""
-class ConsoleExporter(LogExporter):
+class ConsoleLogExporter(LogExporter):
"""Implementation of :class:`LogExporter` that prints log records to the
console.
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py b/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py\n@@ -63,7 +63,7 @@\n \"\"\"\n \n \n-class ConsoleExporter(LogExporter):\n+class ConsoleLogExporter(LogExporter):\n \"\"\"Implementation of :class:`LogExporter` that prints log records to the\n console.\n", "issue": "Rename `ConsoleExporter` to `ConsoleLogExporter`?\nAs suggested by @lonewolf3739, we should rename the ConsoleExporter to ConsoleLogExporter to follow the pattern established by the ConsoleSpanExporter.\r\n\r\nNot in this PR; Should we rename this to `ConsoleLogExporter`?\r\n\r\n_Originally posted by @lonewolf3739 in https://github.com/open-telemetry/opentelemetry-python/pull/2253#r759589860_\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport abc\nimport collections\nimport enum\nimport logging\nimport os\nimport sys\nimport threading\nfrom os import linesep\nfrom typing import IO, Callable, Deque, List, Optional, Sequence\n\nfrom opentelemetry.context import attach, detach, set_value\nfrom opentelemetry.sdk._logs import LogData, LogProcessor, LogRecord\nfrom opentelemetry.util._time import _time_ns\n\n_logger = logging.getLogger(__name__)\n\n\nclass LogExportResult(enum.Enum):\n SUCCESS = 0\n FAILURE = 1\n\n\nclass LogExporter(abc.ABC):\n \"\"\"Interface for exporting logs.\n\n Interface to be implemented by services that want to export logs received\n in their own format.\n\n To export data this MUST be registered to the :class`opentelemetry.sdk._logs.LogEmitter` using a\n log processor.\n \"\"\"\n\n @abc.abstractmethod\n def export(self, batch: Sequence[LogData]):\n \"\"\"Exports a batch of logs.\n\n Args:\n batch: The list of `LogData` objects to be exported\n\n Returns:\n The result of the export\n \"\"\"\n\n @abc.abstractmethod\n def shutdown(self):\n \"\"\"Shuts down the exporter.\n\n Called when the SDK is shut down.\n \"\"\"\n\n\nclass ConsoleExporter(LogExporter):\n \"\"\"Implementation of :class:`LogExporter` that prints log records to the\n console.\n\n This class can be used for diagnostic purposes. It prints the exported\n log records to the console STDOUT.\n \"\"\"\n\n def __init__(\n self,\n out: IO = sys.stdout,\n formatter: Callable[[LogRecord], str] = lambda record: record.to_json()\n + linesep,\n ):\n self.out = out\n self.formatter = formatter\n\n def export(self, batch: Sequence[LogData]):\n for data in batch:\n self.out.write(self.formatter(data.log_record))\n self.out.flush()\n return LogExportResult.SUCCESS\n\n def shutdown(self):\n pass\n\n\nclass SimpleLogProcessor(LogProcessor):\n \"\"\"This is an implementation of LogProcessor which passes\n received logs in the export-friendly LogData representation to the\n configured LogExporter, as soon as they are emitted.\n \"\"\"\n\n def __init__(self, exporter: LogExporter):\n self._exporter = exporter\n self._shutdown = False\n\n def emit(self, log_data: LogData):\n if self._shutdown:\n _logger.warning(\"Processor is already shutdown, ignoring call\")\n return\n token = attach(set_value(\"suppress_instrumentation\", True))\n try:\n self._exporter.export((log_data,))\n except Exception: # pylint: disable=broad-except\n _logger.exception(\"Exception while exporting logs.\")\n detach(token)\n\n def shutdown(self):\n self._shutdown = True\n self._exporter.shutdown()\n\n def force_flush(\n self, timeout_millis: int = 30000\n ) -> bool: # pylint: disable=no-self-use\n return True\n\n\nclass _FlushRequest:\n __slots__ = [\"event\", \"num_log_records\"]\n\n def __init__(self):\n self.event = threading.Event()\n self.num_log_records = 0\n\n\nclass BatchLogProcessor(LogProcessor):\n \"\"\"This is an implementation of LogProcessor which creates batches of\n received logs in the export-friendly LogData representation and\n send to the configured LogExporter, as soon as they are emitted.\n \"\"\"\n\n def __init__(\n self,\n exporter: LogExporter,\n schedule_delay_millis: int = 5000,\n max_export_batch_size: int = 512,\n export_timeout_millis: int = 30000,\n ):\n self._exporter = exporter\n self._schedule_delay_millis = schedule_delay_millis\n self._max_export_batch_size = max_export_batch_size\n self._export_timeout_millis = export_timeout_millis\n self._queue = collections.deque() # type: Deque[LogData]\n self._worker_thread = threading.Thread(target=self.worker, daemon=True)\n self._condition = threading.Condition(threading.Lock())\n self._shutdown = False\n self._flush_request = None # type: Optional[_FlushRequest]\n self._log_records = [\n None\n ] * self._max_export_batch_size # type: List[Optional[LogData]]\n self._worker_thread.start()\n # Only available in *nix since py37.\n if hasattr(os, \"register_at_fork\"):\n os.register_at_fork(\n after_in_child=self._at_fork_reinit\n ) # pylint: disable=protected-access\n\n def _at_fork_reinit(self):\n self._condition = threading.Condition(threading.Lock())\n self._queue.clear()\n self._worker_thread = threading.Thread(target=self.worker, daemon=True)\n self._worker_thread.start()\n\n def worker(self):\n timeout = self._schedule_delay_millis / 1e3\n flush_request = None # type: Optional[_FlushRequest]\n while not self._shutdown:\n with self._condition:\n if self._shutdown:\n # shutdown may have been called, avoid further processing\n break\n flush_request = self._get_and_unset_flush_request()\n if (\n len(self._queue) < self._max_export_batch_size\n and self._flush_request is None\n ):\n self._condition.wait(timeout)\n\n flush_request = self._get_and_unset_flush_request()\n if not self._queue:\n timeout = self._schedule_delay_millis / 1e3\n self._notify_flush_request_finished(flush_request)\n flush_request = None\n continue\n if self._shutdown:\n break\n\n start_ns = _time_ns()\n self._export(flush_request)\n end_ns = _time_ns()\n # subtract the duration of this export call to the next timeout\n timeout = self._schedule_delay_millis / 1e3 - (\n (end_ns - start_ns) / 1e9\n )\n\n self._notify_flush_request_finished(flush_request)\n flush_request = None\n\n # there might have been a new flush request while export was running\n # and before the done flag switched to true\n with self._condition:\n shutdown_flush_request = self._get_and_unset_flush_request()\n\n # flush the remaining logs\n self._drain_queue()\n self._notify_flush_request_finished(flush_request)\n self._notify_flush_request_finished(shutdown_flush_request)\n\n def _export(self, flush_request: Optional[_FlushRequest] = None):\n \"\"\"Exports logs considering the given flush_request.\n\n If flush_request is not None then logs are exported in batches\n until the number of exported logs reached or exceeded the num of logs in\n flush_request, otherwise exports at max max_export_batch_size logs.\n \"\"\"\n if flush_request is None:\n self._export_batch()\n return\n\n num_log_records = flush_request.num_log_records\n while self._queue:\n exported = self._export_batch()\n num_log_records -= exported\n\n if num_log_records <= 0:\n break\n\n def _export_batch(self) -> int:\n \"\"\"Exports at most max_export_batch_size logs and returns the number of\n exported logs.\n \"\"\"\n idx = 0\n while idx < self._max_export_batch_size and self._queue:\n record = self._queue.pop()\n self._log_records[idx] = record\n idx += 1\n token = attach(set_value(\"suppress_instrumentation\", True))\n try:\n self._exporter.export(self._log_records[:idx]) # type: ignore\n except Exception: # pylint: disable=broad-except\n _logger.exception(\"Exception while exporting logs.\")\n detach(token)\n\n for index in range(idx):\n self._log_records[index] = None\n return idx\n\n def _drain_queue(self):\n \"\"\"Export all elements until queue is empty.\n\n Can only be called from the worker thread context because it invokes\n `export` that is not thread safe.\n \"\"\"\n while self._queue:\n self._export_batch()\n\n def _get_and_unset_flush_request(self) -> Optional[_FlushRequest]:\n flush_request = self._flush_request\n self._flush_request = None\n if flush_request is not None:\n flush_request.num_log_records = len(self._queue)\n return flush_request\n\n @staticmethod\n def _notify_flush_request_finished(\n flush_request: Optional[_FlushRequest] = None,\n ):\n if flush_request is not None:\n flush_request.event.set()\n\n def _get_or_create_flush_request(self) -> _FlushRequest:\n if self._flush_request is None:\n self._flush_request = _FlushRequest()\n return self._flush_request\n\n def emit(self, log_data: LogData) -> None:\n \"\"\"Adds the `LogData` to queue and notifies the waiting threads\n when size of queue reaches max_export_batch_size.\n \"\"\"\n if self._shutdown:\n return\n self._queue.appendleft(log_data)\n if len(self._queue) >= self._max_export_batch_size:\n with self._condition:\n self._condition.notify()\n\n def shutdown(self):\n self._shutdown = True\n with self._condition:\n self._condition.notify_all()\n self._worker_thread.join()\n self._exporter.shutdown()\n\n def force_flush(self, timeout_millis: Optional[int] = None) -> bool:\n if timeout_millis is None:\n timeout_millis = self._export_timeout_millis\n if self._shutdown:\n return True\n\n with self._condition:\n flush_request = self._get_or_create_flush_request()\n self._condition.notify_all()\n\n ret = flush_request.event.wait(timeout_millis / 1e3)\n if not ret:\n _logger.warning(\"Timeout was exceeded in force_flush().\")\n return ret\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport abc\nimport collections\nimport enum\nimport logging\nimport os\nimport sys\nimport threading\nfrom os import linesep\nfrom typing import IO, Callable, Deque, List, Optional, Sequence\n\nfrom opentelemetry.context import attach, detach, set_value\nfrom opentelemetry.sdk._logs import LogData, LogProcessor, LogRecord\nfrom opentelemetry.util._time import _time_ns\n\n_logger = logging.getLogger(__name__)\n\n\nclass LogExportResult(enum.Enum):\n SUCCESS = 0\n FAILURE = 1\n\n\nclass LogExporter(abc.ABC):\n \"\"\"Interface for exporting logs.\n\n Interface to be implemented by services that want to export logs received\n in their own format.\n\n To export data this MUST be registered to the :class`opentelemetry.sdk._logs.LogEmitter` using a\n log processor.\n \"\"\"\n\n @abc.abstractmethod\n def export(self, batch: Sequence[LogData]):\n \"\"\"Exports a batch of logs.\n\n Args:\n batch: The list of `LogData` objects to be exported\n\n Returns:\n The result of the export\n \"\"\"\n\n @abc.abstractmethod\n def shutdown(self):\n \"\"\"Shuts down the exporter.\n\n Called when the SDK is shut down.\n \"\"\"\n\n\nclass ConsoleLogExporter(LogExporter):\n \"\"\"Implementation of :class:`LogExporter` that prints log records to the\n console.\n\n This class can be used for diagnostic purposes. It prints the exported\n log records to the console STDOUT.\n \"\"\"\n\n def __init__(\n self,\n out: IO = sys.stdout,\n formatter: Callable[[LogRecord], str] = lambda record: record.to_json()\n + linesep,\n ):\n self.out = out\n self.formatter = formatter\n\n def export(self, batch: Sequence[LogData]):\n for data in batch:\n self.out.write(self.formatter(data.log_record))\n self.out.flush()\n return LogExportResult.SUCCESS\n\n def shutdown(self):\n pass\n\n\nclass SimpleLogProcessor(LogProcessor):\n \"\"\"This is an implementation of LogProcessor which passes\n received logs in the export-friendly LogData representation to the\n configured LogExporter, as soon as they are emitted.\n \"\"\"\n\n def __init__(self, exporter: LogExporter):\n self._exporter = exporter\n self._shutdown = False\n\n def emit(self, log_data: LogData):\n if self._shutdown:\n _logger.warning(\"Processor is already shutdown, ignoring call\")\n return\n token = attach(set_value(\"suppress_instrumentation\", True))\n try:\n self._exporter.export((log_data,))\n except Exception: # pylint: disable=broad-except\n _logger.exception(\"Exception while exporting logs.\")\n detach(token)\n\n def shutdown(self):\n self._shutdown = True\n self._exporter.shutdown()\n\n def force_flush(\n self, timeout_millis: int = 30000\n ) -> bool: # pylint: disable=no-self-use\n return True\n\n\nclass _FlushRequest:\n __slots__ = [\"event\", \"num_log_records\"]\n\n def __init__(self):\n self.event = threading.Event()\n self.num_log_records = 0\n\n\nclass BatchLogProcessor(LogProcessor):\n \"\"\"This is an implementation of LogProcessor which creates batches of\n received logs in the export-friendly LogData representation and\n send to the configured LogExporter, as soon as they are emitted.\n \"\"\"\n\n def __init__(\n self,\n exporter: LogExporter,\n schedule_delay_millis: int = 5000,\n max_export_batch_size: int = 512,\n export_timeout_millis: int = 30000,\n ):\n self._exporter = exporter\n self._schedule_delay_millis = schedule_delay_millis\n self._max_export_batch_size = max_export_batch_size\n self._export_timeout_millis = export_timeout_millis\n self._queue = collections.deque() # type: Deque[LogData]\n self._worker_thread = threading.Thread(target=self.worker, daemon=True)\n self._condition = threading.Condition(threading.Lock())\n self._shutdown = False\n self._flush_request = None # type: Optional[_FlushRequest]\n self._log_records = [\n None\n ] * self._max_export_batch_size # type: List[Optional[LogData]]\n self._worker_thread.start()\n # Only available in *nix since py37.\n if hasattr(os, \"register_at_fork\"):\n os.register_at_fork(\n after_in_child=self._at_fork_reinit\n ) # pylint: disable=protected-access\n\n def _at_fork_reinit(self):\n self._condition = threading.Condition(threading.Lock())\n self._queue.clear()\n self._worker_thread = threading.Thread(target=self.worker, daemon=True)\n self._worker_thread.start()\n\n def worker(self):\n timeout = self._schedule_delay_millis / 1e3\n flush_request = None # type: Optional[_FlushRequest]\n while not self._shutdown:\n with self._condition:\n if self._shutdown:\n # shutdown may have been called, avoid further processing\n break\n flush_request = self._get_and_unset_flush_request()\n if (\n len(self._queue) < self._max_export_batch_size\n and self._flush_request is None\n ):\n self._condition.wait(timeout)\n\n flush_request = self._get_and_unset_flush_request()\n if not self._queue:\n timeout = self._schedule_delay_millis / 1e3\n self._notify_flush_request_finished(flush_request)\n flush_request = None\n continue\n if self._shutdown:\n break\n\n start_ns = _time_ns()\n self._export(flush_request)\n end_ns = _time_ns()\n # subtract the duration of this export call to the next timeout\n timeout = self._schedule_delay_millis / 1e3 - (\n (end_ns - start_ns) / 1e9\n )\n\n self._notify_flush_request_finished(flush_request)\n flush_request = None\n\n # there might have been a new flush request while export was running\n # and before the done flag switched to true\n with self._condition:\n shutdown_flush_request = self._get_and_unset_flush_request()\n\n # flush the remaining logs\n self._drain_queue()\n self._notify_flush_request_finished(flush_request)\n self._notify_flush_request_finished(shutdown_flush_request)\n\n def _export(self, flush_request: Optional[_FlushRequest] = None):\n \"\"\"Exports logs considering the given flush_request.\n\n If flush_request is not None then logs are exported in batches\n until the number of exported logs reached or exceeded the num of logs in\n flush_request, otherwise exports at max max_export_batch_size logs.\n \"\"\"\n if flush_request is None:\n self._export_batch()\n return\n\n num_log_records = flush_request.num_log_records\n while self._queue:\n exported = self._export_batch()\n num_log_records -= exported\n\n if num_log_records <= 0:\n break\n\n def _export_batch(self) -> int:\n \"\"\"Exports at most max_export_batch_size logs and returns the number of\n exported logs.\n \"\"\"\n idx = 0\n while idx < self._max_export_batch_size and self._queue:\n record = self._queue.pop()\n self._log_records[idx] = record\n idx += 1\n token = attach(set_value(\"suppress_instrumentation\", True))\n try:\n self._exporter.export(self._log_records[:idx]) # type: ignore\n except Exception: # pylint: disable=broad-except\n _logger.exception(\"Exception while exporting logs.\")\n detach(token)\n\n for index in range(idx):\n self._log_records[index] = None\n return idx\n\n def _drain_queue(self):\n \"\"\"Export all elements until queue is empty.\n\n Can only be called from the worker thread context because it invokes\n `export` that is not thread safe.\n \"\"\"\n while self._queue:\n self._export_batch()\n\n def _get_and_unset_flush_request(self) -> Optional[_FlushRequest]:\n flush_request = self._flush_request\n self._flush_request = None\n if flush_request is not None:\n flush_request.num_log_records = len(self._queue)\n return flush_request\n\n @staticmethod\n def _notify_flush_request_finished(\n flush_request: Optional[_FlushRequest] = None,\n ):\n if flush_request is not None:\n flush_request.event.set()\n\n def _get_or_create_flush_request(self) -> _FlushRequest:\n if self._flush_request is None:\n self._flush_request = _FlushRequest()\n return self._flush_request\n\n def emit(self, log_data: LogData) -> None:\n \"\"\"Adds the `LogData` to queue and notifies the waiting threads\n when size of queue reaches max_export_batch_size.\n \"\"\"\n if self._shutdown:\n return\n self._queue.appendleft(log_data)\n if len(self._queue) >= self._max_export_batch_size:\n with self._condition:\n self._condition.notify()\n\n def shutdown(self):\n self._shutdown = True\n with self._condition:\n self._condition.notify_all()\n self._worker_thread.join()\n self._exporter.shutdown()\n\n def force_flush(self, timeout_millis: Optional[int] = None) -> bool:\n if timeout_millis is None:\n timeout_millis = self._export_timeout_millis\n if self._shutdown:\n return True\n\n with self._condition:\n flush_request = self._get_or_create_flush_request()\n self._condition.notify_all()\n\n ret = flush_request.event.wait(timeout_millis / 1e3)\n if not ret:\n _logger.warning(\"Timeout was exceeded in force_flush().\")\n return ret\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_logs/export/__init__.py"}]}
| 3,507 | 125 |
gh_patches_debug_6152
|
rasdani/github-patches
|
git_diff
|
tobymao__sqlglot-1549
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FROM_UNIXTIME has different types in Trino and SparkSQL
```FROM_UNIXTIME(`created`)``` in Trino SQL returns a datetime, but ```FROM_UNIXTIME(`created`)``` in SparkSQL returns a string, which can cause queries to fail.
I would expect:
```select FROM_UNIXTIME(`created`) from a``` # (read='trino')
to convert to
```select CAST(FROM_UNIXTIME('created') as timestamp) from a``` # (write='spark')
https://docs.databricks.com/sql/language-manual/functions/from_unixtime.html
https://spark.apache.org/docs/3.0.0/api/sql/#from_unixtime
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sqlglot/dialects/spark2.py`
Content:
```
1 from __future__ import annotations
2
3 import typing as t
4
5 from sqlglot import exp, parser
6 from sqlglot.dialects.dialect import create_with_partitions_sql, rename_func, trim_sql
7 from sqlglot.dialects.hive import Hive
8 from sqlglot.helper import seq_get
9
10
11 def _create_sql(self: Hive.Generator, e: exp.Create) -> str:
12 kind = e.args["kind"]
13 properties = e.args.get("properties")
14
15 if kind.upper() == "TABLE" and any(
16 isinstance(prop, exp.TemporaryProperty)
17 for prop in (properties.expressions if properties else [])
18 ):
19 return f"CREATE TEMPORARY VIEW {self.sql(e, 'this')} AS {self.sql(e, 'expression')}"
20 return create_with_partitions_sql(self, e)
21
22
23 def _map_sql(self: Hive.Generator, expression: exp.Map) -> str:
24 keys = self.sql(expression.args["keys"])
25 values = self.sql(expression.args["values"])
26 return f"MAP_FROM_ARRAYS({keys}, {values})"
27
28
29 def _parse_as_cast(to_type: str) -> t.Callable[[t.Sequence], exp.Expression]:
30 return lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build(to_type))
31
32
33 def _str_to_date(self: Hive.Generator, expression: exp.StrToDate) -> str:
34 this = self.sql(expression, "this")
35 time_format = self.format_time(expression)
36 if time_format == Hive.date_format:
37 return f"TO_DATE({this})"
38 return f"TO_DATE({this}, {time_format})"
39
40
41 def _unix_to_time_sql(self: Hive.Generator, expression: exp.UnixToTime) -> str:
42 scale = expression.args.get("scale")
43 timestamp = self.sql(expression, "this")
44 if scale is None:
45 return f"FROM_UNIXTIME({timestamp})"
46 if scale == exp.UnixToTime.SECONDS:
47 return f"TIMESTAMP_SECONDS({timestamp})"
48 if scale == exp.UnixToTime.MILLIS:
49 return f"TIMESTAMP_MILLIS({timestamp})"
50 if scale == exp.UnixToTime.MICROS:
51 return f"TIMESTAMP_MICROS({timestamp})"
52
53 raise ValueError("Improper scale for timestamp")
54
55
56 class Spark2(Hive):
57 class Parser(Hive.Parser):
58 FUNCTIONS = {
59 **Hive.Parser.FUNCTIONS, # type: ignore
60 "MAP_FROM_ARRAYS": exp.Map.from_arg_list,
61 "TO_UNIX_TIMESTAMP": exp.StrToUnix.from_arg_list,
62 "LEFT": lambda args: exp.Substring(
63 this=seq_get(args, 0),
64 start=exp.Literal.number(1),
65 length=seq_get(args, 1),
66 ),
67 "SHIFTLEFT": lambda args: exp.BitwiseLeftShift(
68 this=seq_get(args, 0),
69 expression=seq_get(args, 1),
70 ),
71 "SHIFTRIGHT": lambda args: exp.BitwiseRightShift(
72 this=seq_get(args, 0),
73 expression=seq_get(args, 1),
74 ),
75 "RIGHT": lambda args: exp.Substring(
76 this=seq_get(args, 0),
77 start=exp.Sub(
78 this=exp.Length(this=seq_get(args, 0)),
79 expression=exp.Add(this=seq_get(args, 1), expression=exp.Literal.number(1)),
80 ),
81 length=seq_get(args, 1),
82 ),
83 "APPROX_PERCENTILE": exp.ApproxQuantile.from_arg_list,
84 "IIF": exp.If.from_arg_list,
85 "AGGREGATE": exp.Reduce.from_arg_list,
86 "DAYOFWEEK": lambda args: exp.DayOfWeek(
87 this=exp.TsOrDsToDate(this=seq_get(args, 0)),
88 ),
89 "DAYOFMONTH": lambda args: exp.DayOfMonth(
90 this=exp.TsOrDsToDate(this=seq_get(args, 0)),
91 ),
92 "DAYOFYEAR": lambda args: exp.DayOfYear(
93 this=exp.TsOrDsToDate(this=seq_get(args, 0)),
94 ),
95 "WEEKOFYEAR": lambda args: exp.WeekOfYear(
96 this=exp.TsOrDsToDate(this=seq_get(args, 0)),
97 ),
98 "DATE": lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build("date")),
99 "DATE_TRUNC": lambda args: exp.TimestampTrunc(
100 this=seq_get(args, 1),
101 unit=exp.var(seq_get(args, 0)),
102 ),
103 "TRUNC": lambda args: exp.DateTrunc(unit=seq_get(args, 1), this=seq_get(args, 0)),
104 "BOOLEAN": _parse_as_cast("boolean"),
105 "DOUBLE": _parse_as_cast("double"),
106 "FLOAT": _parse_as_cast("float"),
107 "INT": _parse_as_cast("int"),
108 "STRING": _parse_as_cast("string"),
109 "TIMESTAMP": _parse_as_cast("timestamp"),
110 }
111
112 FUNCTION_PARSERS = {
113 **parser.Parser.FUNCTION_PARSERS, # type: ignore
114 "BROADCAST": lambda self: self._parse_join_hint("BROADCAST"),
115 "BROADCASTJOIN": lambda self: self._parse_join_hint("BROADCASTJOIN"),
116 "MAPJOIN": lambda self: self._parse_join_hint("MAPJOIN"),
117 "MERGE": lambda self: self._parse_join_hint("MERGE"),
118 "SHUFFLEMERGE": lambda self: self._parse_join_hint("SHUFFLEMERGE"),
119 "MERGEJOIN": lambda self: self._parse_join_hint("MERGEJOIN"),
120 "SHUFFLE_HASH": lambda self: self._parse_join_hint("SHUFFLE_HASH"),
121 "SHUFFLE_REPLICATE_NL": lambda self: self._parse_join_hint("SHUFFLE_REPLICATE_NL"),
122 }
123
124 def _parse_add_column(self) -> t.Optional[exp.Expression]:
125 return self._match_text_seq("ADD", "COLUMNS") and self._parse_schema()
126
127 def _parse_drop_column(self) -> t.Optional[exp.Expression]:
128 return self._match_text_seq("DROP", "COLUMNS") and self.expression(
129 exp.Drop,
130 this=self._parse_schema(),
131 kind="COLUMNS",
132 )
133
134 def _pivot_column_names(self, pivot_columns: t.List[exp.Expression]) -> t.List[str]:
135 # Spark doesn't add a suffix to the pivot columns when there's a single aggregation
136 if len(pivot_columns) == 1:
137 return [""]
138
139 names = []
140 for agg in pivot_columns:
141 if isinstance(agg, exp.Alias):
142 names.append(agg.alias)
143 else:
144 """
145 This case corresponds to aggregations without aliases being used as suffixes
146 (e.g. col_avg(foo)). We need to unquote identifiers because they're going to
147 be quoted in the base parser's `_parse_pivot` method, due to `to_identifier`.
148 Otherwise, we'd end up with `col_avg(`foo`)` (notice the double quotes).
149
150 Moreover, function names are lowercased in order to mimic Spark's naming scheme.
151 """
152 agg_all_unquoted = agg.transform(
153 lambda node: exp.Identifier(this=node.name, quoted=False)
154 if isinstance(node, exp.Identifier)
155 else node
156 )
157 names.append(agg_all_unquoted.sql(dialect="spark", normalize_functions="lower"))
158
159 return names
160
161 class Generator(Hive.Generator):
162 TYPE_MAPPING = {
163 **Hive.Generator.TYPE_MAPPING, # type: ignore
164 exp.DataType.Type.TINYINT: "BYTE",
165 exp.DataType.Type.SMALLINT: "SHORT",
166 exp.DataType.Type.BIGINT: "LONG",
167 }
168
169 PROPERTIES_LOCATION = {
170 **Hive.Generator.PROPERTIES_LOCATION, # type: ignore
171 exp.EngineProperty: exp.Properties.Location.UNSUPPORTED,
172 exp.AutoIncrementProperty: exp.Properties.Location.UNSUPPORTED,
173 exp.CharacterSetProperty: exp.Properties.Location.UNSUPPORTED,
174 exp.CollateProperty: exp.Properties.Location.UNSUPPORTED,
175 }
176
177 TRANSFORMS = {
178 **Hive.Generator.TRANSFORMS, # type: ignore
179 exp.ApproxDistinct: rename_func("APPROX_COUNT_DISTINCT"),
180 exp.FileFormatProperty: lambda self, e: f"USING {e.name.upper()}",
181 exp.ArraySum: lambda self, e: f"AGGREGATE({self.sql(e, 'this')}, 0, (acc, x) -> acc + x, acc -> acc)",
182 exp.BitwiseLeftShift: rename_func("SHIFTLEFT"),
183 exp.BitwiseRightShift: rename_func("SHIFTRIGHT"),
184 exp.DateTrunc: lambda self, e: self.func("TRUNC", e.this, e.args.get("unit")),
185 exp.Hint: lambda self, e: f" /*+ {self.expressions(e).strip()} */",
186 exp.StrToDate: _str_to_date,
187 exp.StrToTime: lambda self, e: f"TO_TIMESTAMP({self.sql(e, 'this')}, {self.format_time(e)})",
188 exp.UnixToTime: _unix_to_time_sql,
189 exp.Create: _create_sql,
190 exp.Map: _map_sql,
191 exp.Reduce: rename_func("AGGREGATE"),
192 exp.StructKwarg: lambda self, e: f"{self.sql(e, 'this')}: {self.sql(e, 'expression')}",
193 exp.TimestampTrunc: lambda self, e: self.func(
194 "DATE_TRUNC", exp.Literal.string(e.text("unit")), e.this
195 ),
196 exp.Trim: trim_sql,
197 exp.VariancePop: rename_func("VAR_POP"),
198 exp.DateFromParts: rename_func("MAKE_DATE"),
199 exp.LogicalOr: rename_func("BOOL_OR"),
200 exp.LogicalAnd: rename_func("BOOL_AND"),
201 exp.DayOfWeek: rename_func("DAYOFWEEK"),
202 exp.DayOfMonth: rename_func("DAYOFMONTH"),
203 exp.DayOfYear: rename_func("DAYOFYEAR"),
204 exp.WeekOfYear: rename_func("WEEKOFYEAR"),
205 exp.AtTimeZone: lambda self, e: f"FROM_UTC_TIMESTAMP({self.sql(e, 'this')}, {self.sql(e, 'zone')})",
206 }
207 TRANSFORMS.pop(exp.ArraySort)
208 TRANSFORMS.pop(exp.ILike)
209
210 WRAP_DERIVED_VALUES = False
211 CREATE_FUNCTION_RETURN_AS = False
212
213 def cast_sql(self, expression: exp.Cast) -> str:
214 if isinstance(expression.this, exp.Cast) and expression.this.is_type(
215 exp.DataType.Type.JSON
216 ):
217 schema = f"'{self.sql(expression, 'to')}'"
218 return self.func("FROM_JSON", expression.this.this, schema)
219 if expression.to.is_type(exp.DataType.Type.JSON):
220 return self.func("TO_JSON", expression.this)
221
222 return super(Hive.Generator, self).cast_sql(expression)
223
224 class Tokenizer(Hive.Tokenizer):
225 HEX_STRINGS = [("X'", "'")]
226
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sqlglot/dialects/spark2.py b/sqlglot/dialects/spark2.py
--- a/sqlglot/dialects/spark2.py
+++ b/sqlglot/dialects/spark2.py
@@ -42,7 +42,7 @@
scale = expression.args.get("scale")
timestamp = self.sql(expression, "this")
if scale is None:
- return f"FROM_UNIXTIME({timestamp})"
+ return f"CAST(FROM_UNIXTIME({timestamp}) AS TIMESTAMP)"
if scale == exp.UnixToTime.SECONDS:
return f"TIMESTAMP_SECONDS({timestamp})"
if scale == exp.UnixToTime.MILLIS:
|
{"golden_diff": "diff --git a/sqlglot/dialects/spark2.py b/sqlglot/dialects/spark2.py\n--- a/sqlglot/dialects/spark2.py\n+++ b/sqlglot/dialects/spark2.py\n@@ -42,7 +42,7 @@\n scale = expression.args.get(\"scale\")\n timestamp = self.sql(expression, \"this\")\n if scale is None:\n- return f\"FROM_UNIXTIME({timestamp})\"\n+ return f\"CAST(FROM_UNIXTIME({timestamp}) AS TIMESTAMP)\"\n if scale == exp.UnixToTime.SECONDS:\n return f\"TIMESTAMP_SECONDS({timestamp})\"\n if scale == exp.UnixToTime.MILLIS:\n", "issue": "FROM_UNIXTIME has different types in Trino and SparkSQL\n```FROM_UNIXTIME(`created`)``` in Trino SQL returns a datetime, but ```FROM_UNIXTIME(`created`)``` in SparkSQL returns a string, which can cause queries to fail.\r\n\r\nI would expect:\r\n```select FROM_UNIXTIME(`created`) from a``` # (read='trino') \r\nto convert to\r\n```select CAST(FROM_UNIXTIME('created') as timestamp) from a``` # (write='spark')\r\n\r\nhttps://docs.databricks.com/sql/language-manual/functions/from_unixtime.html\r\nhttps://spark.apache.org/docs/3.0.0/api/sql/#from_unixtime\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, parser\nfrom sqlglot.dialects.dialect import create_with_partitions_sql, rename_func, trim_sql\nfrom sqlglot.dialects.hive import Hive\nfrom sqlglot.helper import seq_get\n\n\ndef _create_sql(self: Hive.Generator, e: exp.Create) -> str:\n kind = e.args[\"kind\"]\n properties = e.args.get(\"properties\")\n\n if kind.upper() == \"TABLE\" and any(\n isinstance(prop, exp.TemporaryProperty)\n for prop in (properties.expressions if properties else [])\n ):\n return f\"CREATE TEMPORARY VIEW {self.sql(e, 'this')} AS {self.sql(e, 'expression')}\"\n return create_with_partitions_sql(self, e)\n\n\ndef _map_sql(self: Hive.Generator, expression: exp.Map) -> str:\n keys = self.sql(expression.args[\"keys\"])\n values = self.sql(expression.args[\"values\"])\n return f\"MAP_FROM_ARRAYS({keys}, {values})\"\n\n\ndef _parse_as_cast(to_type: str) -> t.Callable[[t.Sequence], exp.Expression]:\n return lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build(to_type))\n\n\ndef _str_to_date(self: Hive.Generator, expression: exp.StrToDate) -> str:\n this = self.sql(expression, \"this\")\n time_format = self.format_time(expression)\n if time_format == Hive.date_format:\n return f\"TO_DATE({this})\"\n return f\"TO_DATE({this}, {time_format})\"\n\n\ndef _unix_to_time_sql(self: Hive.Generator, expression: exp.UnixToTime) -> str:\n scale = expression.args.get(\"scale\")\n timestamp = self.sql(expression, \"this\")\n if scale is None:\n return f\"FROM_UNIXTIME({timestamp})\"\n if scale == exp.UnixToTime.SECONDS:\n return f\"TIMESTAMP_SECONDS({timestamp})\"\n if scale == exp.UnixToTime.MILLIS:\n return f\"TIMESTAMP_MILLIS({timestamp})\"\n if scale == exp.UnixToTime.MICROS:\n return f\"TIMESTAMP_MICROS({timestamp})\"\n\n raise ValueError(\"Improper scale for timestamp\")\n\n\nclass Spark2(Hive):\n class Parser(Hive.Parser):\n FUNCTIONS = {\n **Hive.Parser.FUNCTIONS, # type: ignore\n \"MAP_FROM_ARRAYS\": exp.Map.from_arg_list,\n \"TO_UNIX_TIMESTAMP\": exp.StrToUnix.from_arg_list,\n \"LEFT\": lambda args: exp.Substring(\n this=seq_get(args, 0),\n start=exp.Literal.number(1),\n length=seq_get(args, 1),\n ),\n \"SHIFTLEFT\": lambda args: exp.BitwiseLeftShift(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n ),\n \"SHIFTRIGHT\": lambda args: exp.BitwiseRightShift(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n ),\n \"RIGHT\": lambda args: exp.Substring(\n this=seq_get(args, 0),\n start=exp.Sub(\n this=exp.Length(this=seq_get(args, 0)),\n expression=exp.Add(this=seq_get(args, 1), expression=exp.Literal.number(1)),\n ),\n length=seq_get(args, 1),\n ),\n \"APPROX_PERCENTILE\": exp.ApproxQuantile.from_arg_list,\n \"IIF\": exp.If.from_arg_list,\n \"AGGREGATE\": exp.Reduce.from_arg_list,\n \"DAYOFWEEK\": lambda args: exp.DayOfWeek(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DAYOFMONTH\": lambda args: exp.DayOfMonth(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DAYOFYEAR\": lambda args: exp.DayOfYear(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"WEEKOFYEAR\": lambda args: exp.WeekOfYear(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DATE\": lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build(\"date\")),\n \"DATE_TRUNC\": lambda args: exp.TimestampTrunc(\n this=seq_get(args, 1),\n unit=exp.var(seq_get(args, 0)),\n ),\n \"TRUNC\": lambda args: exp.DateTrunc(unit=seq_get(args, 1), this=seq_get(args, 0)),\n \"BOOLEAN\": _parse_as_cast(\"boolean\"),\n \"DOUBLE\": _parse_as_cast(\"double\"),\n \"FLOAT\": _parse_as_cast(\"float\"),\n \"INT\": _parse_as_cast(\"int\"),\n \"STRING\": _parse_as_cast(\"string\"),\n \"TIMESTAMP\": _parse_as_cast(\"timestamp\"),\n }\n\n FUNCTION_PARSERS = {\n **parser.Parser.FUNCTION_PARSERS, # type: ignore\n \"BROADCAST\": lambda self: self._parse_join_hint(\"BROADCAST\"),\n \"BROADCASTJOIN\": lambda self: self._parse_join_hint(\"BROADCASTJOIN\"),\n \"MAPJOIN\": lambda self: self._parse_join_hint(\"MAPJOIN\"),\n \"MERGE\": lambda self: self._parse_join_hint(\"MERGE\"),\n \"SHUFFLEMERGE\": lambda self: self._parse_join_hint(\"SHUFFLEMERGE\"),\n \"MERGEJOIN\": lambda self: self._parse_join_hint(\"MERGEJOIN\"),\n \"SHUFFLE_HASH\": lambda self: self._parse_join_hint(\"SHUFFLE_HASH\"),\n \"SHUFFLE_REPLICATE_NL\": lambda self: self._parse_join_hint(\"SHUFFLE_REPLICATE_NL\"),\n }\n\n def _parse_add_column(self) -> t.Optional[exp.Expression]:\n return self._match_text_seq(\"ADD\", \"COLUMNS\") and self._parse_schema()\n\n def _parse_drop_column(self) -> t.Optional[exp.Expression]:\n return self._match_text_seq(\"DROP\", \"COLUMNS\") and self.expression(\n exp.Drop,\n this=self._parse_schema(),\n kind=\"COLUMNS\",\n )\n\n def _pivot_column_names(self, pivot_columns: t.List[exp.Expression]) -> t.List[str]:\n # Spark doesn't add a suffix to the pivot columns when there's a single aggregation\n if len(pivot_columns) == 1:\n return [\"\"]\n\n names = []\n for agg in pivot_columns:\n if isinstance(agg, exp.Alias):\n names.append(agg.alias)\n else:\n \"\"\"\n This case corresponds to aggregations without aliases being used as suffixes\n (e.g. col_avg(foo)). We need to unquote identifiers because they're going to\n be quoted in the base parser's `_parse_pivot` method, due to `to_identifier`.\n Otherwise, we'd end up with `col_avg(`foo`)` (notice the double quotes).\n\n Moreover, function names are lowercased in order to mimic Spark's naming scheme.\n \"\"\"\n agg_all_unquoted = agg.transform(\n lambda node: exp.Identifier(this=node.name, quoted=False)\n if isinstance(node, exp.Identifier)\n else node\n )\n names.append(agg_all_unquoted.sql(dialect=\"spark\", normalize_functions=\"lower\"))\n\n return names\n\n class Generator(Hive.Generator):\n TYPE_MAPPING = {\n **Hive.Generator.TYPE_MAPPING, # type: ignore\n exp.DataType.Type.TINYINT: \"BYTE\",\n exp.DataType.Type.SMALLINT: \"SHORT\",\n exp.DataType.Type.BIGINT: \"LONG\",\n }\n\n PROPERTIES_LOCATION = {\n **Hive.Generator.PROPERTIES_LOCATION, # type: ignore\n exp.EngineProperty: exp.Properties.Location.UNSUPPORTED,\n exp.AutoIncrementProperty: exp.Properties.Location.UNSUPPORTED,\n exp.CharacterSetProperty: exp.Properties.Location.UNSUPPORTED,\n exp.CollateProperty: exp.Properties.Location.UNSUPPORTED,\n }\n\n TRANSFORMS = {\n **Hive.Generator.TRANSFORMS, # type: ignore\n exp.ApproxDistinct: rename_func(\"APPROX_COUNT_DISTINCT\"),\n exp.FileFormatProperty: lambda self, e: f\"USING {e.name.upper()}\",\n exp.ArraySum: lambda self, e: f\"AGGREGATE({self.sql(e, 'this')}, 0, (acc, x) -> acc + x, acc -> acc)\",\n exp.BitwiseLeftShift: rename_func(\"SHIFTLEFT\"),\n exp.BitwiseRightShift: rename_func(\"SHIFTRIGHT\"),\n exp.DateTrunc: lambda self, e: self.func(\"TRUNC\", e.this, e.args.get(\"unit\")),\n exp.Hint: lambda self, e: f\" /*+ {self.expressions(e).strip()} */\",\n exp.StrToDate: _str_to_date,\n exp.StrToTime: lambda self, e: f\"TO_TIMESTAMP({self.sql(e, 'this')}, {self.format_time(e)})\",\n exp.UnixToTime: _unix_to_time_sql,\n exp.Create: _create_sql,\n exp.Map: _map_sql,\n exp.Reduce: rename_func(\"AGGREGATE\"),\n exp.StructKwarg: lambda self, e: f\"{self.sql(e, 'this')}: {self.sql(e, 'expression')}\",\n exp.TimestampTrunc: lambda self, e: self.func(\n \"DATE_TRUNC\", exp.Literal.string(e.text(\"unit\")), e.this\n ),\n exp.Trim: trim_sql,\n exp.VariancePop: rename_func(\"VAR_POP\"),\n exp.DateFromParts: rename_func(\"MAKE_DATE\"),\n exp.LogicalOr: rename_func(\"BOOL_OR\"),\n exp.LogicalAnd: rename_func(\"BOOL_AND\"),\n exp.DayOfWeek: rename_func(\"DAYOFWEEK\"),\n exp.DayOfMonth: rename_func(\"DAYOFMONTH\"),\n exp.DayOfYear: rename_func(\"DAYOFYEAR\"),\n exp.WeekOfYear: rename_func(\"WEEKOFYEAR\"),\n exp.AtTimeZone: lambda self, e: f\"FROM_UTC_TIMESTAMP({self.sql(e, 'this')}, {self.sql(e, 'zone')})\",\n }\n TRANSFORMS.pop(exp.ArraySort)\n TRANSFORMS.pop(exp.ILike)\n\n WRAP_DERIVED_VALUES = False\n CREATE_FUNCTION_RETURN_AS = False\n\n def cast_sql(self, expression: exp.Cast) -> str:\n if isinstance(expression.this, exp.Cast) and expression.this.is_type(\n exp.DataType.Type.JSON\n ):\n schema = f\"'{self.sql(expression, 'to')}'\"\n return self.func(\"FROM_JSON\", expression.this.this, schema)\n if expression.to.is_type(exp.DataType.Type.JSON):\n return self.func(\"TO_JSON\", expression.this)\n\n return super(Hive.Generator, self).cast_sql(expression)\n\n class Tokenizer(Hive.Tokenizer):\n HEX_STRINGS = [(\"X'\", \"'\")]\n", "path": "sqlglot/dialects/spark2.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, parser\nfrom sqlglot.dialects.dialect import create_with_partitions_sql, rename_func, trim_sql\nfrom sqlglot.dialects.hive import Hive\nfrom sqlglot.helper import seq_get\n\n\ndef _create_sql(self: Hive.Generator, e: exp.Create) -> str:\n kind = e.args[\"kind\"]\n properties = e.args.get(\"properties\")\n\n if kind.upper() == \"TABLE\" and any(\n isinstance(prop, exp.TemporaryProperty)\n for prop in (properties.expressions if properties else [])\n ):\n return f\"CREATE TEMPORARY VIEW {self.sql(e, 'this')} AS {self.sql(e, 'expression')}\"\n return create_with_partitions_sql(self, e)\n\n\ndef _map_sql(self: Hive.Generator, expression: exp.Map) -> str:\n keys = self.sql(expression.args[\"keys\"])\n values = self.sql(expression.args[\"values\"])\n return f\"MAP_FROM_ARRAYS({keys}, {values})\"\n\n\ndef _parse_as_cast(to_type: str) -> t.Callable[[t.Sequence], exp.Expression]:\n return lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build(to_type))\n\n\ndef _str_to_date(self: Hive.Generator, expression: exp.StrToDate) -> str:\n this = self.sql(expression, \"this\")\n time_format = self.format_time(expression)\n if time_format == Hive.date_format:\n return f\"TO_DATE({this})\"\n return f\"TO_DATE({this}, {time_format})\"\n\n\ndef _unix_to_time_sql(self: Hive.Generator, expression: exp.UnixToTime) -> str:\n scale = expression.args.get(\"scale\")\n timestamp = self.sql(expression, \"this\")\n if scale is None:\n return f\"CAST(FROM_UNIXTIME({timestamp}) AS TIMESTAMP)\"\n if scale == exp.UnixToTime.SECONDS:\n return f\"TIMESTAMP_SECONDS({timestamp})\"\n if scale == exp.UnixToTime.MILLIS:\n return f\"TIMESTAMP_MILLIS({timestamp})\"\n if scale == exp.UnixToTime.MICROS:\n return f\"TIMESTAMP_MICROS({timestamp})\"\n\n raise ValueError(\"Improper scale for timestamp\")\n\n\nclass Spark2(Hive):\n class Parser(Hive.Parser):\n FUNCTIONS = {\n **Hive.Parser.FUNCTIONS, # type: ignore\n \"MAP_FROM_ARRAYS\": exp.Map.from_arg_list,\n \"TO_UNIX_TIMESTAMP\": exp.StrToUnix.from_arg_list,\n \"LEFT\": lambda args: exp.Substring(\n this=seq_get(args, 0),\n start=exp.Literal.number(1),\n length=seq_get(args, 1),\n ),\n \"SHIFTLEFT\": lambda args: exp.BitwiseLeftShift(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n ),\n \"SHIFTRIGHT\": lambda args: exp.BitwiseRightShift(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n ),\n \"RIGHT\": lambda args: exp.Substring(\n this=seq_get(args, 0),\n start=exp.Sub(\n this=exp.Length(this=seq_get(args, 0)),\n expression=exp.Add(this=seq_get(args, 1), expression=exp.Literal.number(1)),\n ),\n length=seq_get(args, 1),\n ),\n \"APPROX_PERCENTILE\": exp.ApproxQuantile.from_arg_list,\n \"IIF\": exp.If.from_arg_list,\n \"AGGREGATE\": exp.Reduce.from_arg_list,\n \"DAYOFWEEK\": lambda args: exp.DayOfWeek(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DAYOFMONTH\": lambda args: exp.DayOfMonth(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DAYOFYEAR\": lambda args: exp.DayOfYear(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"WEEKOFYEAR\": lambda args: exp.WeekOfYear(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n ),\n \"DATE\": lambda args: exp.Cast(this=seq_get(args, 0), to=exp.DataType.build(\"date\")),\n \"DATE_TRUNC\": lambda args: exp.TimestampTrunc(\n this=seq_get(args, 1),\n unit=exp.var(seq_get(args, 0)),\n ),\n \"TRUNC\": lambda args: exp.DateTrunc(unit=seq_get(args, 1), this=seq_get(args, 0)),\n \"BOOLEAN\": _parse_as_cast(\"boolean\"),\n \"DOUBLE\": _parse_as_cast(\"double\"),\n \"FLOAT\": _parse_as_cast(\"float\"),\n \"INT\": _parse_as_cast(\"int\"),\n \"STRING\": _parse_as_cast(\"string\"),\n \"TIMESTAMP\": _parse_as_cast(\"timestamp\"),\n }\n\n FUNCTION_PARSERS = {\n **parser.Parser.FUNCTION_PARSERS, # type: ignore\n \"BROADCAST\": lambda self: self._parse_join_hint(\"BROADCAST\"),\n \"BROADCASTJOIN\": lambda self: self._parse_join_hint(\"BROADCASTJOIN\"),\n \"MAPJOIN\": lambda self: self._parse_join_hint(\"MAPJOIN\"),\n \"MERGE\": lambda self: self._parse_join_hint(\"MERGE\"),\n \"SHUFFLEMERGE\": lambda self: self._parse_join_hint(\"SHUFFLEMERGE\"),\n \"MERGEJOIN\": lambda self: self._parse_join_hint(\"MERGEJOIN\"),\n \"SHUFFLE_HASH\": lambda self: self._parse_join_hint(\"SHUFFLE_HASH\"),\n \"SHUFFLE_REPLICATE_NL\": lambda self: self._parse_join_hint(\"SHUFFLE_REPLICATE_NL\"),\n }\n\n def _parse_add_column(self) -> t.Optional[exp.Expression]:\n return self._match_text_seq(\"ADD\", \"COLUMNS\") and self._parse_schema()\n\n def _parse_drop_column(self) -> t.Optional[exp.Expression]:\n return self._match_text_seq(\"DROP\", \"COLUMNS\") and self.expression(\n exp.Drop,\n this=self._parse_schema(),\n kind=\"COLUMNS\",\n )\n\n def _pivot_column_names(self, pivot_columns: t.List[exp.Expression]) -> t.List[str]:\n # Spark doesn't add a suffix to the pivot columns when there's a single aggregation\n if len(pivot_columns) == 1:\n return [\"\"]\n\n names = []\n for agg in pivot_columns:\n if isinstance(agg, exp.Alias):\n names.append(agg.alias)\n else:\n \"\"\"\n This case corresponds to aggregations without aliases being used as suffixes\n (e.g. col_avg(foo)). We need to unquote identifiers because they're going to\n be quoted in the base parser's `_parse_pivot` method, due to `to_identifier`.\n Otherwise, we'd end up with `col_avg(`foo`)` (notice the double quotes).\n\n Moreover, function names are lowercased in order to mimic Spark's naming scheme.\n \"\"\"\n agg_all_unquoted = agg.transform(\n lambda node: exp.Identifier(this=node.name, quoted=False)\n if isinstance(node, exp.Identifier)\n else node\n )\n names.append(agg_all_unquoted.sql(dialect=\"spark\", normalize_functions=\"lower\"))\n\n return names\n\n class Generator(Hive.Generator):\n TYPE_MAPPING = {\n **Hive.Generator.TYPE_MAPPING, # type: ignore\n exp.DataType.Type.TINYINT: \"BYTE\",\n exp.DataType.Type.SMALLINT: \"SHORT\",\n exp.DataType.Type.BIGINT: \"LONG\",\n }\n\n PROPERTIES_LOCATION = {\n **Hive.Generator.PROPERTIES_LOCATION, # type: ignore\n exp.EngineProperty: exp.Properties.Location.UNSUPPORTED,\n exp.AutoIncrementProperty: exp.Properties.Location.UNSUPPORTED,\n exp.CharacterSetProperty: exp.Properties.Location.UNSUPPORTED,\n exp.CollateProperty: exp.Properties.Location.UNSUPPORTED,\n }\n\n TRANSFORMS = {\n **Hive.Generator.TRANSFORMS, # type: ignore\n exp.ApproxDistinct: rename_func(\"APPROX_COUNT_DISTINCT\"),\n exp.FileFormatProperty: lambda self, e: f\"USING {e.name.upper()}\",\n exp.ArraySum: lambda self, e: f\"AGGREGATE({self.sql(e, 'this')}, 0, (acc, x) -> acc + x, acc -> acc)\",\n exp.BitwiseLeftShift: rename_func(\"SHIFTLEFT\"),\n exp.BitwiseRightShift: rename_func(\"SHIFTRIGHT\"),\n exp.DateTrunc: lambda self, e: self.func(\"TRUNC\", e.this, e.args.get(\"unit\")),\n exp.Hint: lambda self, e: f\" /*+ {self.expressions(e).strip()} */\",\n exp.StrToDate: _str_to_date,\n exp.StrToTime: lambda self, e: f\"TO_TIMESTAMP({self.sql(e, 'this')}, {self.format_time(e)})\",\n exp.UnixToTime: _unix_to_time_sql,\n exp.Create: _create_sql,\n exp.Map: _map_sql,\n exp.Reduce: rename_func(\"AGGREGATE\"),\n exp.StructKwarg: lambda self, e: f\"{self.sql(e, 'this')}: {self.sql(e, 'expression')}\",\n exp.TimestampTrunc: lambda self, e: self.func(\n \"DATE_TRUNC\", exp.Literal.string(e.text(\"unit\")), e.this\n ),\n exp.Trim: trim_sql,\n exp.VariancePop: rename_func(\"VAR_POP\"),\n exp.DateFromParts: rename_func(\"MAKE_DATE\"),\n exp.LogicalOr: rename_func(\"BOOL_OR\"),\n exp.LogicalAnd: rename_func(\"BOOL_AND\"),\n exp.DayOfWeek: rename_func(\"DAYOFWEEK\"),\n exp.DayOfMonth: rename_func(\"DAYOFMONTH\"),\n exp.DayOfYear: rename_func(\"DAYOFYEAR\"),\n exp.WeekOfYear: rename_func(\"WEEKOFYEAR\"),\n exp.AtTimeZone: lambda self, e: f\"FROM_UTC_TIMESTAMP({self.sql(e, 'this')}, {self.sql(e, 'zone')})\",\n }\n TRANSFORMS.pop(exp.ArraySort)\n TRANSFORMS.pop(exp.ILike)\n\n WRAP_DERIVED_VALUES = False\n CREATE_FUNCTION_RETURN_AS = False\n\n def cast_sql(self, expression: exp.Cast) -> str:\n if isinstance(expression.this, exp.Cast) and expression.this.is_type(\n exp.DataType.Type.JSON\n ):\n schema = f\"'{self.sql(expression, 'to')}'\"\n return self.func(\"FROM_JSON\", expression.this.this, schema)\n if expression.to.is_type(exp.DataType.Type.JSON):\n return self.func(\"TO_JSON\", expression.this)\n\n return super(Hive.Generator, self).cast_sql(expression)\n\n class Tokenizer(Hive.Tokenizer):\n HEX_STRINGS = [(\"X'\", \"'\")]\n", "path": "sqlglot/dialects/spark2.py"}]}
| 3,353 | 150 |
gh_patches_debug_9164
|
rasdani/github-patches
|
git_diff
|
vega__altair-1986
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Multiple views in JupyterLab blank with default html renderer
To reproduce:
1. Create an environment with JupyterLab 1.2.6 and altair 4.0.1:
```
conda create -c conda-forge -yn testenv jupyterlab altair pandas
conda activate testenv
```
2. Start JupyterLab:
```
jupyter lab
```
3. Create a new notebook with an example plot:
```
import altair as alt
import numpy as np
import pandas as pd
# Compute x^2 + y^2 across a 2D grid
x, y = np.meshgrid(range(-5, 5), range(-5, 5))
z = x ** 2 + y ** 2
# Convert this grid to columnar data expected by Altair
source = pd.DataFrame({'x': x.ravel(),
'y': y.ravel(),
'z': z.ravel()})
alt.Chart(source).mark_rect().encode(
x='x:O',
y='y:O',
color='z:Q'
)
```
4. Right-click on the plot and choose "Create New view for output" to open a new jlab tab for the plot. The new tab is blank:
<img width="622" alt="Screen Shot 2020-02-24 at 11 22 23 AM" src="https://user-images.githubusercontent.com/192614/75183729-f70da980-56f7-11ea-8e25-bf11bfda8b9f.png">
I also see the same issue if opening a new view of the notebook (right-clicking on the file's tab, selecting "New View for Notebook"
I think at least part of the problem is that the plot div has a hard-coded id, and ids should be unique on a page, so viewing the same output multiple times can be a problem. There may be other issues with the js not knowing to redraw the plot in the new jlab tab, etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `altair/utils/html.py`
Content:
```
1 from __future__ import unicode_literals
2 import json
3 import jinja2
4
5
6 HTML_TEMPLATE = jinja2.Template("""
7 {%- if fullhtml -%}
8 <!DOCTYPE html>
9 <html>
10 <head>
11 {%- endif %}
12 <style>
13 .error {
14 color: red;
15 }
16 </style>
17 {%- if not requirejs %}
18 <script type="text/javascript" src="{{ base_url }}/vega@{{ vega_version }}"></script>
19 {%- if mode == 'vega-lite' %}
20 <script type="text/javascript" src="{{ base_url }}/vega-lite@{{ vegalite_version }}"></script>
21 {%- endif %}
22 <script type="text/javascript" src="{{ base_url }}/vega-embed@{{ vegaembed_version }}"></script>
23 {%- endif %}
24 {%- if fullhtml %}
25 {%- if requirejs %}
26 <script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.6/require.min.js"></script>
27 <script>
28 requirejs.config({
29 "paths": {
30 "vega": "{{ base_url }}/vega@{{ vega_version }}?noext",
31 "vega-lib": "{{ base_url }}/vega-lib?noext",
32 "vega-lite": "{{ base_url }}/vega-lite@{{ vegalite_version }}?noext",
33 "vega-embed": "{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext",
34 }
35 });
36 </script>
37 {%- endif %}
38 </head>
39 <body>
40 {%- endif %}
41 <div id="{{ output_div }}"></div>
42 <script>
43 {%- if requirejs and not fullhtml %}
44 requirejs.config({
45 "paths": {
46 "vega": "{{ base_url }}/vega@{{ vega_version }}?noext",
47 "vega-lib": "{{ base_url }}/vega-lib?noext",
48 "vega-lite": "{{ base_url }}/vega-lite@{{ vegalite_version }}?noext",
49 "vega-embed": "{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext",
50 }
51 });
52 {% endif %}
53 {% if requirejs -%}
54 require(['vega-embed'],
55 {%- else -%}
56 (
57 {%- endif -%}
58 function(vegaEmbed) {
59 var spec = {{ spec }};
60 var embedOpt = {{ embed_options }};
61
62 function showError(el, error){
63 el.innerHTML = ('<div class="error" style="color:red;">'
64 + '<p>JavaScript Error: ' + error.message + '</p>'
65 + "<p>This usually means there's a typo in your chart specification. "
66 + "See the javascript console for the full traceback.</p>"
67 + '</div>');
68 throw error;
69 }
70 const el = document.getElementById('{{ output_div }}');
71 vegaEmbed("#{{ output_div }}", spec, embedOpt)
72 .catch(error => showError(el, error));
73 }){% if not requirejs %}(vegaEmbed){% endif %};
74
75 </script>
76 {%- if fullhtml %}
77 </body>
78 </html>
79 {%- endif %}
80 """
81 )
82
83
84 HTML_TEMPLATE_UNIVERSAL = jinja2.Template("""
85 <div id="{{ output_div }}"></div>
86 <script type="text/javascript">
87 (function(spec, embedOpt){
88 const outputDiv = document.getElementById("{{ output_div }}");
89 const paths = {
90 "vega": "{{ base_url }}/vega@{{ vega_version }}?noext",
91 "vega-lib": "{{ base_url }}/vega-lib?noext",
92 "vega-lite": "{{ base_url }}/vega-lite@{{ vegalite_version }}?noext",
93 "vega-embed": "{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext",
94 };
95
96 function loadScript(lib) {
97 return new Promise(function(resolve, reject) {
98 var s = document.createElement('script');
99 s.src = paths[lib];
100 s.async = true;
101 s.onload = () => resolve(paths[lib]);
102 s.onerror = () => reject(`Error loading script: ${paths[lib]}`);
103 document.getElementsByTagName("head")[0].appendChild(s);
104 });
105 }
106
107 function showError(err) {
108 outputDiv.innerHTML = `<div class="error" style="color:red;">${err}</div>`;
109 throw err;
110 }
111
112 function displayChart(vegaEmbed) {
113 vegaEmbed(outputDiv, spec, embedOpt)
114 .catch(err => showError(`Javascript Error: ${err.message}<br>This usually means there's a typo in your chart specification. See the javascript console for the full traceback.`));
115 }
116
117 if(typeof define === "function" && define.amd) {
118 requirejs.config({paths});
119 require(["vega-embed"], displayChart, err => showError(`Error loading script: ${err.message}`));
120 } else if (typeof vegaEmbed === "function") {
121 displayChart(vegaEmbed);
122 } else {
123 loadScript("vega")
124 .then(() => loadScript("vega-lite"))
125 .then(() => loadScript("vega-embed"))
126 .catch(showError)
127 .then(() => displayChart(vegaEmbed));
128 }
129 })({{ spec }}, {{ embed_options }});
130 </script>
131 """)
132
133
134 TEMPLATES = {
135 'standard': HTML_TEMPLATE,
136 'universal': HTML_TEMPLATE_UNIVERSAL,
137 }
138
139
140 def spec_to_html(spec, mode,
141 vega_version, vegaembed_version, vegalite_version=None,
142 base_url="https://cdn.jsdelivr.net/npm/",
143 output_div='vis', embed_options=None, json_kwds=None,
144 fullhtml=True, requirejs=False, template='standard'):
145 """Embed a Vega/Vega-Lite spec into an HTML page
146
147 Parameters
148 ----------
149 spec : dict
150 a dictionary representing a vega-lite plot spec.
151 mode : string {'vega' | 'vega-lite'}
152 The rendering mode. This value is overridden by embed_options['mode'],
153 if it is present.
154 vega_version : string
155 For html output, the version of vega.js to use.
156 vegalite_version : string
157 For html output, the version of vegalite.js to use.
158 vegaembed_version : string
159 For html output, the version of vegaembed.js to use.
160 base_url : string (optional)
161 The base url from which to load the javascript libraries.
162 output_div : string (optional)
163 The id of the div element where the plot will be shown.
164 embed_options : dict (optional)
165 Dictionary of options to pass to the vega-embed script. Default
166 entry is {'mode': mode}.
167 json_kwds : dict (optional)
168 Dictionary of keywords to pass to json.dumps().
169 fullhtml : boolean (optional)
170 If True (default) then return a full html page. If False, then return
171 an HTML snippet that can be embedded into an HTML page.
172 requirejs : boolean (optional)
173 If False (default) then load libraries from base_url using <script>
174 tags. If True, then load libraries using requirejs
175 template : jinja2.Template or string (optional)
176 Specify the template to use (default = 'standard'). If template is a
177 string, it must be one of {'universal', 'standard'}. Otherwise, it
178 can be a jinja2.Template object containing a custom template.
179
180 Returns
181 -------
182 output : string
183 an HTML string for rendering the chart.
184 """
185 embed_options = embed_options or {}
186 json_kwds = json_kwds or {}
187
188 mode = embed_options.setdefault('mode', mode)
189
190 if mode not in ['vega', 'vega-lite']:
191 raise ValueError("mode must be either 'vega' or 'vega-lite'")
192
193 if vega_version is None:
194 raise ValueError("must specify vega_version")
195
196 if vegaembed_version is None:
197 raise ValueError("must specify vegaembed_version")
198
199 if mode == 'vega-lite' and vegalite_version is None:
200 raise ValueError("must specify vega-lite version for mode='vega-lite'")
201
202 template = TEMPLATES.get(template, template)
203 if not hasattr(template, 'render'):
204 raise ValueError("Invalid template: {0}".format(template))
205
206 return template.render(
207 spec=json.dumps(spec, **json_kwds),
208 embed_options=json.dumps(embed_options),
209 mode=mode,
210 vega_version=vega_version,
211 vegalite_version=vegalite_version,
212 vegaembed_version=vegaembed_version,
213 base_url=base_url,
214 output_div=output_div,
215 fullhtml=fullhtml,
216 requirejs=requirejs
217 )
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/altair/utils/html.py b/altair/utils/html.py
--- a/altair/utils/html.py
+++ b/altair/utils/html.py
@@ -85,7 +85,10 @@
<div id="{{ output_div }}"></div>
<script type="text/javascript">
(function(spec, embedOpt){
- const outputDiv = document.getElementById("{{ output_div }}");
+ let outputDiv = document.currentScript.previousElementSibling;
+ if (outputDiv.id !== "{{ output_div }}") {
+ outputDiv = document.getElementById("{{ output_div }}");
+ }
const paths = {
"vega": "{{ base_url }}/vega@{{ vega_version }}?noext",
"vega-lib": "{{ base_url }}/vega-lib?noext",
|
{"golden_diff": "diff --git a/altair/utils/html.py b/altair/utils/html.py\n--- a/altair/utils/html.py\n+++ b/altair/utils/html.py\n@@ -85,7 +85,10 @@\n <div id=\"{{ output_div }}\"></div>\n <script type=\"text/javascript\">\n (function(spec, embedOpt){\n- const outputDiv = document.getElementById(\"{{ output_div }}\");\n+ let outputDiv = document.currentScript.previousElementSibling;\n+ if (outputDiv.id !== \"{{ output_div }}\") {\n+ outputDiv = document.getElementById(\"{{ output_div }}\");\n+ }\n const paths = {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n", "issue": "Multiple views in JupyterLab blank with default html renderer\nTo reproduce:\r\n\r\n1. Create an environment with JupyterLab 1.2.6 and altair 4.0.1:\r\n\r\n```\r\nconda create -c conda-forge -yn testenv jupyterlab altair pandas\r\nconda activate testenv\r\n```\r\n\r\n2. Start JupyterLab:\r\n```\r\njupyter lab\r\n```\r\n3. Create a new notebook with an example plot:\r\n\r\n```\r\nimport altair as alt\r\nimport numpy as np\r\nimport pandas as pd\r\n\r\n# Compute x^2 + y^2 across a 2D grid\r\nx, y = np.meshgrid(range(-5, 5), range(-5, 5))\r\nz = x ** 2 + y ** 2\r\n\r\n# Convert this grid to columnar data expected by Altair\r\nsource = pd.DataFrame({'x': x.ravel(),\r\n 'y': y.ravel(),\r\n 'z': z.ravel()})\r\n\r\nalt.Chart(source).mark_rect().encode(\r\n x='x:O',\r\n y='y:O',\r\n color='z:Q'\r\n)\r\n```\r\n4. Right-click on the plot and choose \"Create New view for output\" to open a new jlab tab for the plot. The new tab is blank:\r\n<img width=\"622\" alt=\"Screen Shot 2020-02-24 at 11 22 23 AM\" src=\"https://user-images.githubusercontent.com/192614/75183729-f70da980-56f7-11ea-8e25-bf11bfda8b9f.png\">\r\n\r\nI also see the same issue if opening a new view of the notebook (right-clicking on the file's tab, selecting \"New View for Notebook\"\r\n\r\nI think at least part of the problem is that the plot div has a hard-coded id, and ids should be unique on a page, so viewing the same output multiple times can be a problem. There may be other issues with the js not knowing to redraw the plot in the new jlab tab, etc.\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nimport json\nimport jinja2\n\n\nHTML_TEMPLATE = jinja2.Template(\"\"\"\n{%- if fullhtml -%}\n<!DOCTYPE html>\n<html>\n<head>\n{%- endif %}\n <style>\n .error {\n color: red;\n }\n </style>\n{%- if not requirejs %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega@{{ vega_version }}\"></script>\n {%- if mode == 'vega-lite' %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega-lite@{{ vegalite_version }}\"></script>\n {%- endif %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega-embed@{{ vegaembed_version }}\"></script>\n{%- endif %}\n{%- if fullhtml %}\n{%- if requirejs %}\n<script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.6/require.min.js\"></script>\n<script>\nrequirejs.config({\n \"paths\": {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n }\n});\n</script>\n{%- endif %}\n</head>\n<body>\n{%- endif %}\n <div id=\"{{ output_div }}\"></div>\n <script>\n {%- if requirejs and not fullhtml %}\n requirejs.config({\n \"paths\": {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n }\n });\n {% endif %}\n {% if requirejs -%}\n require(['vega-embed'],\n {%- else -%}\n (\n {%- endif -%}\n function(vegaEmbed) {\n var spec = {{ spec }};\n var embedOpt = {{ embed_options }};\n\n function showError(el, error){\n el.innerHTML = ('<div class=\"error\" style=\"color:red;\">'\n + '<p>JavaScript Error: ' + error.message + '</p>'\n + \"<p>This usually means there's a typo in your chart specification. \"\n + \"See the javascript console for the full traceback.</p>\"\n + '</div>');\n throw error;\n }\n const el = document.getElementById('{{ output_div }}');\n vegaEmbed(\"#{{ output_div }}\", spec, embedOpt)\n .catch(error => showError(el, error));\n }){% if not requirejs %}(vegaEmbed){% endif %};\n\n </script>\n{%- if fullhtml %}\n</body>\n</html>\n{%- endif %}\n\"\"\"\n)\n\n\nHTML_TEMPLATE_UNIVERSAL = jinja2.Template(\"\"\"\n<div id=\"{{ output_div }}\"></div>\n<script type=\"text/javascript\">\n (function(spec, embedOpt){\n const outputDiv = document.getElementById(\"{{ output_div }}\");\n const paths = {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n };\n\n function loadScript(lib) {\n return new Promise(function(resolve, reject) {\n var s = document.createElement('script');\n s.src = paths[lib];\n s.async = true;\n s.onload = () => resolve(paths[lib]);\n s.onerror = () => reject(`Error loading script: ${paths[lib]}`);\n document.getElementsByTagName(\"head\")[0].appendChild(s);\n });\n }\n\n function showError(err) {\n outputDiv.innerHTML = `<div class=\"error\" style=\"color:red;\">${err}</div>`;\n throw err;\n }\n\n function displayChart(vegaEmbed) {\n vegaEmbed(outputDiv, spec, embedOpt)\n .catch(err => showError(`Javascript Error: ${err.message}<br>This usually means there's a typo in your chart specification. See the javascript console for the full traceback.`));\n }\n\n if(typeof define === \"function\" && define.amd) {\n requirejs.config({paths});\n require([\"vega-embed\"], displayChart, err => showError(`Error loading script: ${err.message}`));\n } else if (typeof vegaEmbed === \"function\") {\n displayChart(vegaEmbed);\n } else {\n loadScript(\"vega\")\n .then(() => loadScript(\"vega-lite\"))\n .then(() => loadScript(\"vega-embed\"))\n .catch(showError)\n .then(() => displayChart(vegaEmbed));\n }\n })({{ spec }}, {{ embed_options }});\n</script>\n\"\"\")\n\n\nTEMPLATES = {\n 'standard': HTML_TEMPLATE,\n 'universal': HTML_TEMPLATE_UNIVERSAL,\n}\n\n\ndef spec_to_html(spec, mode,\n vega_version, vegaembed_version, vegalite_version=None,\n base_url=\"https://cdn.jsdelivr.net/npm/\",\n output_div='vis', embed_options=None, json_kwds=None,\n fullhtml=True, requirejs=False, template='standard'):\n \"\"\"Embed a Vega/Vega-Lite spec into an HTML page\n\n Parameters\n ----------\n spec : dict\n a dictionary representing a vega-lite plot spec.\n mode : string {'vega' | 'vega-lite'}\n The rendering mode. This value is overridden by embed_options['mode'],\n if it is present.\n vega_version : string\n For html output, the version of vega.js to use.\n vegalite_version : string\n For html output, the version of vegalite.js to use.\n vegaembed_version : string\n For html output, the version of vegaembed.js to use.\n base_url : string (optional)\n The base url from which to load the javascript libraries.\n output_div : string (optional)\n The id of the div element where the plot will be shown.\n embed_options : dict (optional)\n Dictionary of options to pass to the vega-embed script. Default\n entry is {'mode': mode}.\n json_kwds : dict (optional)\n Dictionary of keywords to pass to json.dumps().\n fullhtml : boolean (optional)\n If True (default) then return a full html page. If False, then return\n an HTML snippet that can be embedded into an HTML page.\n requirejs : boolean (optional)\n If False (default) then load libraries from base_url using <script>\n tags. If True, then load libraries using requirejs\n template : jinja2.Template or string (optional)\n Specify the template to use (default = 'standard'). If template is a\n string, it must be one of {'universal', 'standard'}. Otherwise, it\n can be a jinja2.Template object containing a custom template.\n\n Returns\n -------\n output : string\n an HTML string for rendering the chart.\n \"\"\"\n embed_options = embed_options or {}\n json_kwds = json_kwds or {}\n\n mode = embed_options.setdefault('mode', mode)\n\n if mode not in ['vega', 'vega-lite']:\n raise ValueError(\"mode must be either 'vega' or 'vega-lite'\")\n\n if vega_version is None:\n raise ValueError(\"must specify vega_version\")\n\n if vegaembed_version is None:\n raise ValueError(\"must specify vegaembed_version\")\n\n if mode == 'vega-lite' and vegalite_version is None:\n raise ValueError(\"must specify vega-lite version for mode='vega-lite'\")\n\n template = TEMPLATES.get(template, template)\n if not hasattr(template, 'render'):\n raise ValueError(\"Invalid template: {0}\".format(template))\n\n return template.render(\n spec=json.dumps(spec, **json_kwds),\n embed_options=json.dumps(embed_options),\n mode=mode,\n vega_version=vega_version,\n vegalite_version=vegalite_version,\n vegaembed_version=vegaembed_version,\n base_url=base_url,\n output_div=output_div,\n fullhtml=fullhtml,\n requirejs=requirejs\n )\n", "path": "altair/utils/html.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nimport json\nimport jinja2\n\n\nHTML_TEMPLATE = jinja2.Template(\"\"\"\n{%- if fullhtml -%}\n<!DOCTYPE html>\n<html>\n<head>\n{%- endif %}\n <style>\n .error {\n color: red;\n }\n </style>\n{%- if not requirejs %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega@{{ vega_version }}\"></script>\n {%- if mode == 'vega-lite' %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega-lite@{{ vegalite_version }}\"></script>\n {%- endif %}\n <script type=\"text/javascript\" src=\"{{ base_url }}/vega-embed@{{ vegaembed_version }}\"></script>\n{%- endif %}\n{%- if fullhtml %}\n{%- if requirejs %}\n<script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.6/require.min.js\"></script>\n<script>\nrequirejs.config({\n \"paths\": {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n }\n});\n</script>\n{%- endif %}\n</head>\n<body>\n{%- endif %}\n <div id=\"{{ output_div }}\"></div>\n <script>\n {%- if requirejs and not fullhtml %}\n requirejs.config({\n \"paths\": {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n }\n });\n {% endif %}\n {% if requirejs -%}\n require(['vega-embed'],\n {%- else -%}\n (\n {%- endif -%}\n function(vegaEmbed) {\n var spec = {{ spec }};\n var embedOpt = {{ embed_options }};\n\n function showError(el, error){\n el.innerHTML = ('<div class=\"error\" style=\"color:red;\">'\n + '<p>JavaScript Error: ' + error.message + '</p>'\n + \"<p>This usually means there's a typo in your chart specification. \"\n + \"See the javascript console for the full traceback.</p>\"\n + '</div>');\n throw error;\n }\n const el = document.getElementById('{{ output_div }}');\n vegaEmbed(\"#{{ output_div }}\", spec, embedOpt)\n .catch(error => showError(el, error));\n }){% if not requirejs %}(vegaEmbed){% endif %};\n\n </script>\n{%- if fullhtml %}\n</body>\n</html>\n{%- endif %}\n\"\"\"\n)\n\n\nHTML_TEMPLATE_UNIVERSAL = jinja2.Template(\"\"\"\n<div id=\"{{ output_div }}\"></div>\n<script type=\"text/javascript\">\n (function(spec, embedOpt){\n let outputDiv = document.currentScript.previousElementSibling;\n if (outputDiv.id !== \"{{ output_div }}\") {\n outputDiv = document.getElementById(\"{{ output_div }}\");\n }\n const paths = {\n \"vega\": \"{{ base_url }}/vega@{{ vega_version }}?noext\",\n \"vega-lib\": \"{{ base_url }}/vega-lib?noext\",\n \"vega-lite\": \"{{ base_url }}/vega-lite@{{ vegalite_version }}?noext\",\n \"vega-embed\": \"{{ base_url }}/vega-embed@{{ vegaembed_version }}?noext\",\n };\n\n function loadScript(lib) {\n return new Promise(function(resolve, reject) {\n var s = document.createElement('script');\n s.src = paths[lib];\n s.async = true;\n s.onload = () => resolve(paths[lib]);\n s.onerror = () => reject(`Error loading script: ${paths[lib]}`);\n document.getElementsByTagName(\"head\")[0].appendChild(s);\n });\n }\n\n function showError(err) {\n outputDiv.innerHTML = `<div class=\"error\" style=\"color:red;\">${err}</div>`;\n throw err;\n }\n\n function displayChart(vegaEmbed) {\n vegaEmbed(outputDiv, spec, embedOpt)\n .catch(err => showError(`Javascript Error: ${err.message}<br>This usually means there's a typo in your chart specification. See the javascript console for the full traceback.`));\n }\n\n if(typeof define === \"function\" && define.amd) {\n requirejs.config({paths});\n require([\"vega-embed\"], displayChart, err => showError(`Error loading script: ${err.message}`));\n } else if (typeof vegaEmbed === \"function\") {\n displayChart(vegaEmbed);\n } else {\n loadScript(\"vega\")\n .then(() => loadScript(\"vega-lite\"))\n .then(() => loadScript(\"vega-embed\"))\n .catch(showError)\n .then(() => displayChart(vegaEmbed));\n }\n })({{ spec }}, {{ embed_options }});\n</script>\n\"\"\")\n\n\nTEMPLATES = {\n 'standard': HTML_TEMPLATE,\n 'universal': HTML_TEMPLATE_UNIVERSAL,\n}\n\n\ndef spec_to_html(spec, mode,\n vega_version, vegaembed_version, vegalite_version=None,\n base_url=\"https://cdn.jsdelivr.net/npm/\",\n output_div='vis', embed_options=None, json_kwds=None,\n fullhtml=True, requirejs=False, template='standard'):\n \"\"\"Embed a Vega/Vega-Lite spec into an HTML page\n\n Parameters\n ----------\n spec : dict\n a dictionary representing a vega-lite plot spec.\n mode : string {'vega' | 'vega-lite'}\n The rendering mode. This value is overridden by embed_options['mode'],\n if it is present.\n vega_version : string\n For html output, the version of vega.js to use.\n vegalite_version : string\n For html output, the version of vegalite.js to use.\n vegaembed_version : string\n For html output, the version of vegaembed.js to use.\n base_url : string (optional)\n The base url from which to load the javascript libraries.\n output_div : string (optional)\n The id of the div element where the plot will be shown.\n embed_options : dict (optional)\n Dictionary of options to pass to the vega-embed script. Default\n entry is {'mode': mode}.\n json_kwds : dict (optional)\n Dictionary of keywords to pass to json.dumps().\n fullhtml : boolean (optional)\n If True (default) then return a full html page. If False, then return\n an HTML snippet that can be embedded into an HTML page.\n requirejs : boolean (optional)\n If False (default) then load libraries from base_url using <script>\n tags. If True, then load libraries using requirejs\n template : jinja2.Template or string (optional)\n Specify the template to use (default = 'standard'). If template is a\n string, it must be one of {'universal', 'standard'}. Otherwise, it\n can be a jinja2.Template object containing a custom template.\n\n Returns\n -------\n output : string\n an HTML string for rendering the chart.\n \"\"\"\n embed_options = embed_options or {}\n json_kwds = json_kwds or {}\n\n mode = embed_options.setdefault('mode', mode)\n\n if mode not in ['vega', 'vega-lite']:\n raise ValueError(\"mode must be either 'vega' or 'vega-lite'\")\n\n if vega_version is None:\n raise ValueError(\"must specify vega_version\")\n\n if vegaembed_version is None:\n raise ValueError(\"must specify vegaembed_version\")\n\n if mode == 'vega-lite' and vegalite_version is None:\n raise ValueError(\"must specify vega-lite version for mode='vega-lite'\")\n\n template = TEMPLATES.get(template, template)\n if not hasattr(template, 'render'):\n raise ValueError(\"Invalid template: {0}\".format(template))\n\n return template.render(\n spec=json.dumps(spec, **json_kwds),\n embed_options=json.dumps(embed_options),\n mode=mode,\n vega_version=vega_version,\n vegalite_version=vegalite_version,\n vegaembed_version=vegaembed_version,\n base_url=base_url,\n output_div=output_div,\n fullhtml=fullhtml,\n requirejs=requirejs\n )\n", "path": "altair/utils/html.py"}]}
| 3,148 | 173 |
gh_patches_debug_23481
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-900
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rename "bundle" to "distribution"?
**Is your feature request related to a problem? Please describe.**
We've been calling our output a bundle, but it's really a distribution.
**Describe the solution you'd like**
Rename bundle to distribution everywhere.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/assemble_workflow/bundle_recorder.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import os
8 from urllib.parse import urljoin
9
10 from manifests.bundle_manifest import BundleManifest
11
12
13 class BundleRecorder:
14 def __init__(self, build, output_dir, artifacts_dir, base_url):
15 self.output_dir = output_dir
16 self.build_id = build.id
17 self.base_url = base_url
18 self.version = build.version
19 self.package_name = self.__get_package_name(build)
20 self.artifacts_dir = artifacts_dir
21 self.architecture = build.architecture
22 self.bundle_manifest = self.BundleManifestBuilder(
23 build.id,
24 build.name,
25 build.version,
26 build.platform,
27 build.architecture,
28 self.__get_package_location(),
29 )
30
31 def __get_package_name(self, build):
32 parts = [
33 build.name.lower().replace(" ", "-"),
34 build.version,
35 build.platform,
36 build.architecture,
37 ]
38 return "-".join(parts) + (".zip" if build.platform == "windows" else ".tar.gz")
39
40 def __get_public_url_path(self, folder, rel_path):
41 path = "/".join((folder, rel_path))
42 return urljoin(self.base_url + "/", path)
43
44 def __get_location(self, folder_name, rel_path, abs_path):
45 if self.base_url:
46 return self.__get_public_url_path(folder_name, rel_path)
47 return abs_path
48
49 # Assembled bundles are expected to be served from a separate "bundles" folder
50 # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id
51 def __get_package_location(self):
52 return self.__get_location("dist", self.package_name, os.path.join(self.output_dir, self.package_name))
53
54 # Build artifacts are expected to be served from a "builds" folder
55 # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>
56 def __get_component_location(self, component_rel_path):
57 abs_path = os.path.join(self.artifacts_dir, component_rel_path)
58 return self.__get_location("builds", component_rel_path, abs_path)
59
60 def record_component(self, component, rel_path):
61 self.bundle_manifest.append_component(
62 component.name,
63 component.repository,
64 component.ref,
65 component.commit_id,
66 self.__get_component_location(rel_path),
67 )
68
69 def get_manifest(self):
70 return self.bundle_manifest.to_manifest()
71
72 def write_manifest(self, folder):
73 manifest_path = os.path.join(folder, "manifest.yml")
74 self.get_manifest().to_file(manifest_path)
75
76 class BundleManifestBuilder:
77 def __init__(self, build_id, name, version, platform, architecture, location):
78 self.data = {}
79 self.data["build"] = {}
80 self.data["build"]["id"] = build_id
81 self.data["build"]["name"] = name
82 self.data["build"]["version"] = str(version)
83 self.data["build"]["platform"] = platform
84 self.data["build"]["architecture"] = architecture
85 self.data["build"]["location"] = location
86 self.data["schema-version"] = "1.1"
87 # We need to store components as a hash so that we can append artifacts by component name
88 # When we convert to a BundleManifest this will get converted back into a list
89 self.data["components"] = []
90
91 def append_component(self, name, repository_url, ref, commit_id, location):
92 component = {
93 "name": name,
94 "repository": repository_url,
95 "ref": ref,
96 "commit_id": commit_id,
97 "location": location,
98 }
99 self.data["components"].append(component)
100
101 def to_manifest(self):
102 return BundleManifest(self.data)
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/assemble_workflow/bundle_recorder.py b/src/assemble_workflow/bundle_recorder.py
--- a/src/assemble_workflow/bundle_recorder.py
+++ b/src/assemble_workflow/bundle_recorder.py
@@ -46,13 +46,13 @@
return self.__get_public_url_path(folder_name, rel_path)
return abs_path
- # Assembled bundles are expected to be served from a separate "bundles" folder
- # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id
+ # Assembled output are expected to be served from a separate "dist" folder
+ # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/dist/
def __get_package_location(self):
return self.__get_location("dist", self.package_name, os.path.join(self.output_dir, self.package_name))
# Build artifacts are expected to be served from a "builds" folder
- # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>
+ # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/builds/
def __get_component_location(self, component_rel_path):
abs_path = os.path.join(self.artifacts_dir, component_rel_path)
return self.__get_location("builds", component_rel_path, abs_path)
|
{"golden_diff": "diff --git a/src/assemble_workflow/bundle_recorder.py b/src/assemble_workflow/bundle_recorder.py\n--- a/src/assemble_workflow/bundle_recorder.py\n+++ b/src/assemble_workflow/bundle_recorder.py\n@@ -46,13 +46,13 @@\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n \n- # Assembled bundles are expected to be served from a separate \"bundles\" folder\n- # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id\n+ # Assembled output are expected to be served from a separate \"dist\" folder\n+ # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/dist/\n def __get_package_location(self):\n return self.__get_location(\"dist\", self.package_name, os.path.join(self.output_dir, self.package_name))\n \n # Build artifacts are expected to be served from a \"builds\" folder\n- # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>\n+ # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/builds/\n def __get_component_location(self, component_rel_path):\n abs_path = os.path.join(self.artifacts_dir, component_rel_path)\n return self.__get_location(\"builds\", component_rel_path, abs_path)\n", "issue": "Rename \"bundle\" to \"distribution\"?\n**Is your feature request related to a problem? Please describe.**\r\nWe've been calling our output a bundle, but it's really a distribution.\r\n\r\n**Describe the solution you'd like**\r\nRename bundle to distribution everywhere.\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom urllib.parse import urljoin\n\nfrom manifests.bundle_manifest import BundleManifest\n\n\nclass BundleRecorder:\n def __init__(self, build, output_dir, artifacts_dir, base_url):\n self.output_dir = output_dir\n self.build_id = build.id\n self.base_url = base_url\n self.version = build.version\n self.package_name = self.__get_package_name(build)\n self.artifacts_dir = artifacts_dir\n self.architecture = build.architecture\n self.bundle_manifest = self.BundleManifestBuilder(\n build.id,\n build.name,\n build.version,\n build.platform,\n build.architecture,\n self.__get_package_location(),\n )\n\n def __get_package_name(self, build):\n parts = [\n build.name.lower().replace(\" \", \"-\"),\n build.version,\n build.platform,\n build.architecture,\n ]\n return \"-\".join(parts) + (\".zip\" if build.platform == \"windows\" else \".tar.gz\")\n\n def __get_public_url_path(self, folder, rel_path):\n path = \"/\".join((folder, rel_path))\n return urljoin(self.base_url + \"/\", path)\n\n def __get_location(self, folder_name, rel_path, abs_path):\n if self.base_url:\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n\n # Assembled bundles are expected to be served from a separate \"bundles\" folder\n # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id\n def __get_package_location(self):\n return self.__get_location(\"dist\", self.package_name, os.path.join(self.output_dir, self.package_name))\n\n # Build artifacts are expected to be served from a \"builds\" folder\n # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>\n def __get_component_location(self, component_rel_path):\n abs_path = os.path.join(self.artifacts_dir, component_rel_path)\n return self.__get_location(\"builds\", component_rel_path, abs_path)\n\n def record_component(self, component, rel_path):\n self.bundle_manifest.append_component(\n component.name,\n component.repository,\n component.ref,\n component.commit_id,\n self.__get_component_location(rel_path),\n )\n\n def get_manifest(self):\n return self.bundle_manifest.to_manifest()\n\n def write_manifest(self, folder):\n manifest_path = os.path.join(folder, \"manifest.yml\")\n self.get_manifest().to_file(manifest_path)\n\n class BundleManifestBuilder:\n def __init__(self, build_id, name, version, platform, architecture, location):\n self.data = {}\n self.data[\"build\"] = {}\n self.data[\"build\"][\"id\"] = build_id\n self.data[\"build\"][\"name\"] = name\n self.data[\"build\"][\"version\"] = str(version)\n self.data[\"build\"][\"platform\"] = platform\n self.data[\"build\"][\"architecture\"] = architecture\n self.data[\"build\"][\"location\"] = location\n self.data[\"schema-version\"] = \"1.1\"\n # We need to store components as a hash so that we can append artifacts by component name\n # When we convert to a BundleManifest this will get converted back into a list\n self.data[\"components\"] = []\n\n def append_component(self, name, repository_url, ref, commit_id, location):\n component = {\n \"name\": name,\n \"repository\": repository_url,\n \"ref\": ref,\n \"commit_id\": commit_id,\n \"location\": location,\n }\n self.data[\"components\"].append(component)\n\n def to_manifest(self):\n return BundleManifest(self.data)\n", "path": "src/assemble_workflow/bundle_recorder.py"}], "after_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom urllib.parse import urljoin\n\nfrom manifests.bundle_manifest import BundleManifest\n\n\nclass BundleRecorder:\n def __init__(self, build, output_dir, artifacts_dir, base_url):\n self.output_dir = output_dir\n self.build_id = build.id\n self.base_url = base_url\n self.version = build.version\n self.package_name = self.__get_package_name(build)\n self.artifacts_dir = artifacts_dir\n self.architecture = build.architecture\n self.bundle_manifest = self.BundleManifestBuilder(\n build.id,\n build.name,\n build.version,\n build.platform,\n build.architecture,\n self.__get_package_location(),\n )\n\n def __get_package_name(self, build):\n parts = [\n build.name.lower().replace(\" \", \"-\"),\n build.version,\n build.platform,\n build.architecture,\n ]\n return \"-\".join(parts) + (\".zip\" if build.platform == \"windows\" else \".tar.gz\")\n\n def __get_public_url_path(self, folder, rel_path):\n path = \"/\".join((folder, rel_path))\n return urljoin(self.base_url + \"/\", path)\n\n def __get_location(self, folder_name, rel_path, abs_path):\n if self.base_url:\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n\n # Assembled output are expected to be served from a separate \"dist\" folder\n # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/dist/\n def __get_package_location(self):\n return self.__get_location(\"dist\", self.package_name, os.path.join(self.output_dir, self.package_name))\n\n # Build artifacts are expected to be served from a \"builds\" folder\n # Example: https://ci.opensearch.org/ci/dbc/bundle-build/1.2.0/build-id/linux/x64/builds/\n def __get_component_location(self, component_rel_path):\n abs_path = os.path.join(self.artifacts_dir, component_rel_path)\n return self.__get_location(\"builds\", component_rel_path, abs_path)\n\n def record_component(self, component, rel_path):\n self.bundle_manifest.append_component(\n component.name,\n component.repository,\n component.ref,\n component.commit_id,\n self.__get_component_location(rel_path),\n )\n\n def get_manifest(self):\n return self.bundle_manifest.to_manifest()\n\n def write_manifest(self, folder):\n manifest_path = os.path.join(folder, \"manifest.yml\")\n self.get_manifest().to_file(manifest_path)\n\n class BundleManifestBuilder:\n def __init__(self, build_id, name, version, platform, architecture, location):\n self.data = {}\n self.data[\"build\"] = {}\n self.data[\"build\"][\"id\"] = build_id\n self.data[\"build\"][\"name\"] = name\n self.data[\"build\"][\"version\"] = str(version)\n self.data[\"build\"][\"platform\"] = platform\n self.data[\"build\"][\"architecture\"] = architecture\n self.data[\"build\"][\"location\"] = location\n self.data[\"schema-version\"] = \"1.1\"\n # We need to store components as a hash so that we can append artifacts by component name\n # When we convert to a BundleManifest this will get converted back into a list\n self.data[\"components\"] = []\n\n def append_component(self, name, repository_url, ref, commit_id, location):\n component = {\n \"name\": name,\n \"repository\": repository_url,\n \"ref\": ref,\n \"commit_id\": commit_id,\n \"location\": location,\n }\n self.data[\"components\"].append(component)\n\n def to_manifest(self):\n return BundleManifest(self.data)\n", "path": "src/assemble_workflow/bundle_recorder.py"}]}
| 1,357 | 331 |
gh_patches_debug_8433
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-1350
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Post release bump of version to 2.4.1-dev
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 """Use the following command to install retriever: python setup.py install"""
2 from __future__ import absolute_import
3
4 import os
5 import re
6 import platform
7
8 from pkg_resources import parse_version
9 from setuptools import setup, find_packages
10
11 current_platform = platform.system().lower()
12 extra_includes = []
13 if current_platform == "windows":
14 extra_includes += ["pypyodbc"]
15
16 if os.path.exists(".git/hooks"): # check if we are in git repo
17 os.system("cp hooks/pre-commit .git/hooks/pre-commit")
18 os.system("chmod +x .git/hooks/pre-commit")
19
20 app_data = "~/.retriever/scripts"
21 if os.path.exists(app_data):
22 os.system("rm -r {}".format(app_data))
23
24 __version__ = 'v2.4.0'
25 with open(os.path.join("retriever", "_version.py"), "w") as version_file:
26 version_file.write("__version__ = " + "'" + __version__ + "'\n")
27 version_file.close()
28
29
30 def clean_version(v):
31 return parse_version(v).__repr__().lstrip("<Version('").rstrip("')>")
32
33
34 def read(*names, **kwargs):
35 return open(
36 os.path.join(os.path.dirname(__file__), *names),
37 ).read()
38
39 includes = [
40 'xlrd',
41 'future',
42 'argcomplete',
43 'pymysql',
44 'psycopg2-binary',
45 'sqlite3',
46 ] + extra_includes
47
48 excludes = [
49 'pyreadline',
50 'doctest',
51 'pickle',
52 'pdb',
53 'pywin', 'pywin.debugger',
54 'pywin.debugger.dbgcon',
55 'pywin.dialogs', 'pywin.dialogs.list',
56 'Tkconstants', 'Tkinter', 'tcl', 'tk'
57 ]
58
59 setup(
60 name='retriever',
61 version=clean_version(__version__),
62 description='Data Retriever',
63 long_description='{a}'.format(a=read('README.md')),
64 long_description_content_type='text/markdown',
65 author='Ben Morris, Shivam Negi, Akash Goel, Andrew Zhang, Henry Senyondo, Ethan White',
66 author_email='[email protected]',
67 url='https://github.com/weecology/retriever',
68 classifiers=[
69 'Intended Audience :: Science/Research',
70 'License :: OSI Approved :: MIT License',
71 'Operating System :: Microsoft :: Windows',
72 'Operating System :: POSIX',
73 'Operating System :: Unix',
74 'Programming Language :: Python',
75 'Programming Language :: Python :: 3',
76 'Programming Language :: Python :: 3.4',
77 'Programming Language :: Python :: 3.5',
78 'Programming Language :: Python :: 3.6',
79 'Programming Language :: Python :: 3.7',
80 'Programming Language :: Python :: Implementation :: PyPy',
81 'Topic :: Software Development :: Libraries :: Python Modules',
82 'Topic :: Scientific/Engineering :: GIS',
83 'Topic :: Scientific/Engineering :: Information Analysis',
84 'Topic :: Database',
85 ],
86 packages=find_packages(
87 exclude=['hooks',
88 'docs',
89 'tests',
90 'scripts',
91 'docker',
92 ".cache"]),
93 entry_points={
94 'console_scripts': [
95 'retriever = retriever.__main__:main',
96 ],
97 },
98 install_requires=[
99 'xlrd',
100 'future',
101 'argcomplete',
102 'tqdm',
103 'requests',
104 'pandas'
105 ],
106 data_files=[('', ['CITATION'])],
107 setup_requires=[],
108 )
109
110 # windows doesn't have bash. No point in using bash-completion
111 if current_platform != "windows":
112 # if platform is OS X use "~/.bash_profile"
113 if current_platform == "darwin":
114 bash_file = "~/.bash_profile"
115 # if platform is Linux use "~/.bashrc
116 elif current_platform == "linux":
117 bash_file = "~/.bashrc"
118 # else write and discard
119 else:
120 bash_file = "/dev/null"
121
122 argcomplete_command = 'eval "$(register-python-argcomplete retriever)"'
123 with open(os.path.expanduser(bash_file), "a+") as bashrc:
124 bashrc.seek(0)
125 # register retriever for arg-completion if not already registered
126 # whenever a new shell is spawned
127 if argcomplete_command not in bashrc.read():
128 bashrc.write(argcomplete_command + "\n")
129 bashrc.close()
130 os.system("activate-global-python-argcomplete")
131 # register for the current shell
132 os.system(argcomplete_command)
133
134 try:
135 from retriever.compile import compile
136 from retriever.lib.repository import check_for_updates
137
138 check_for_updates()
139 compile()
140 except:
141 pass
142
```
Path: `retriever/_version.py`
Content:
```
1 __version__ = 'v2.4.0'
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/retriever/_version.py b/retriever/_version.py
--- a/retriever/_version.py
+++ b/retriever/_version.py
@@ -1 +1 @@
-__version__ = 'v2.4.0'
+__version__ = 'v2.4.1.dev'
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,7 +21,7 @@
if os.path.exists(app_data):
os.system("rm -r {}".format(app_data))
-__version__ = 'v2.4.0'
+__version__ = 'v2.4.1.dev'
with open(os.path.join("retriever", "_version.py"), "w") as version_file:
version_file.write("__version__ = " + "'" + __version__ + "'\n")
version_file.close()
|
{"golden_diff": "diff --git a/retriever/_version.py b/retriever/_version.py\n--- a/retriever/_version.py\n+++ b/retriever/_version.py\n@@ -1 +1 @@\n-__version__ = 'v2.4.0'\n+__version__ = 'v2.4.1.dev'\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,7 +21,7 @@\n if os.path.exists(app_data):\n os.system(\"rm -r {}\".format(app_data))\n \n-__version__ = 'v2.4.0'\n+__version__ = 'v2.4.1.dev'\n with open(os.path.join(\"retriever\", \"_version.py\"), \"w\") as version_file:\n version_file.write(\"__version__ = \" + \"'\" + __version__ + \"'\\n\")\n version_file.close()\n", "issue": "Post release bump of version to 2.4.1-dev\n\n", "before_files": [{"content": "\"\"\"Use the following command to install retriever: python setup.py install\"\"\"\nfrom __future__ import absolute_import\n\nimport os\nimport re\nimport platform\n\nfrom pkg_resources import parse_version\nfrom setuptools import setup, find_packages\n\ncurrent_platform = platform.system().lower()\nextra_includes = []\nif current_platform == \"windows\":\n extra_includes += [\"pypyodbc\"]\n\nif os.path.exists(\".git/hooks\"): # check if we are in git repo\n os.system(\"cp hooks/pre-commit .git/hooks/pre-commit\")\n os.system(\"chmod +x .git/hooks/pre-commit\")\n\napp_data = \"~/.retriever/scripts\"\nif os.path.exists(app_data):\n os.system(\"rm -r {}\".format(app_data))\n\n__version__ = 'v2.4.0'\nwith open(os.path.join(\"retriever\", \"_version.py\"), \"w\") as version_file:\n version_file.write(\"__version__ = \" + \"'\" + __version__ + \"'\\n\")\n version_file.close()\n\n\ndef clean_version(v):\n return parse_version(v).__repr__().lstrip(\"<Version('\").rstrip(\"')>\")\n\n\ndef read(*names, **kwargs):\n return open(\n os.path.join(os.path.dirname(__file__), *names),\n ).read()\n\nincludes = [\n 'xlrd',\n 'future',\n 'argcomplete',\n 'pymysql',\n 'psycopg2-binary',\n 'sqlite3',\n ] + extra_includes\n\nexcludes = [\n 'pyreadline',\n 'doctest',\n 'pickle',\n 'pdb',\n 'pywin', 'pywin.debugger',\n 'pywin.debugger.dbgcon',\n 'pywin.dialogs', 'pywin.dialogs.list',\n 'Tkconstants', 'Tkinter', 'tcl', 'tk'\n]\n\nsetup(\n name='retriever',\n version=clean_version(__version__),\n description='Data Retriever',\n long_description='{a}'.format(a=read('README.md')),\n long_description_content_type='text/markdown',\n author='Ben Morris, Shivam Negi, Akash Goel, Andrew Zhang, Henry Senyondo, Ethan White',\n author_email='[email protected]',\n url='https://github.com/weecology/retriever',\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Scientific/Engineering :: GIS',\n 'Topic :: Scientific/Engineering :: Information Analysis',\n 'Topic :: Database',\n ],\n packages=find_packages(\n exclude=['hooks',\n 'docs',\n 'tests',\n 'scripts',\n 'docker',\n \".cache\"]),\n entry_points={\n 'console_scripts': [\n 'retriever = retriever.__main__:main',\n ],\n },\n install_requires=[\n 'xlrd',\n 'future',\n 'argcomplete',\n 'tqdm',\n 'requests',\n 'pandas'\n ],\n data_files=[('', ['CITATION'])],\n setup_requires=[],\n)\n\n# windows doesn't have bash. No point in using bash-completion\nif current_platform != \"windows\":\n # if platform is OS X use \"~/.bash_profile\"\n if current_platform == \"darwin\":\n bash_file = \"~/.bash_profile\"\n # if platform is Linux use \"~/.bashrc\n elif current_platform == \"linux\":\n bash_file = \"~/.bashrc\"\n # else write and discard\n else:\n bash_file = \"/dev/null\"\n\n argcomplete_command = 'eval \"$(register-python-argcomplete retriever)\"'\n with open(os.path.expanduser(bash_file), \"a+\") as bashrc:\n bashrc.seek(0)\n # register retriever for arg-completion if not already registered\n # whenever a new shell is spawned\n if argcomplete_command not in bashrc.read():\n bashrc.write(argcomplete_command + \"\\n\")\n bashrc.close()\n os.system(\"activate-global-python-argcomplete\")\n # register for the current shell\n os.system(argcomplete_command)\n\ntry:\n from retriever.compile import compile\n from retriever.lib.repository import check_for_updates\n\n check_for_updates()\n compile()\nexcept:\n pass\n", "path": "setup.py"}, {"content": "__version__ = 'v2.4.0'\n", "path": "retriever/_version.py"}], "after_files": [{"content": "\"\"\"Use the following command to install retriever: python setup.py install\"\"\"\nfrom __future__ import absolute_import\n\nimport os\nimport re\nimport platform\n\nfrom pkg_resources import parse_version\nfrom setuptools import setup, find_packages\n\ncurrent_platform = platform.system().lower()\nextra_includes = []\nif current_platform == \"windows\":\n extra_includes += [\"pypyodbc\"]\n\nif os.path.exists(\".git/hooks\"): # check if we are in git repo\n os.system(\"cp hooks/pre-commit .git/hooks/pre-commit\")\n os.system(\"chmod +x .git/hooks/pre-commit\")\n\napp_data = \"~/.retriever/scripts\"\nif os.path.exists(app_data):\n os.system(\"rm -r {}\".format(app_data))\n\n__version__ = 'v2.4.1.dev'\nwith open(os.path.join(\"retriever\", \"_version.py\"), \"w\") as version_file:\n version_file.write(\"__version__ = \" + \"'\" + __version__ + \"'\\n\")\n version_file.close()\n\n\ndef clean_version(v):\n return parse_version(v).__repr__().lstrip(\"<Version('\").rstrip(\"')>\")\n\n\ndef read(*names, **kwargs):\n return open(\n os.path.join(os.path.dirname(__file__), *names),\n ).read()\n\nincludes = [\n 'xlrd',\n 'future',\n 'argcomplete',\n 'pymysql',\n 'psycopg2-binary',\n 'sqlite3',\n ] + extra_includes\n\nexcludes = [\n 'pyreadline',\n 'doctest',\n 'pickle',\n 'pdb',\n 'pywin', 'pywin.debugger',\n 'pywin.debugger.dbgcon',\n 'pywin.dialogs', 'pywin.dialogs.list',\n 'Tkconstants', 'Tkinter', 'tcl', 'tk'\n]\n\nsetup(\n name='retriever',\n version=clean_version(__version__),\n description='Data Retriever',\n long_description='{a}'.format(a=read('README.md')),\n long_description_content_type='text/markdown',\n author='Ben Morris, Shivam Negi, Akash Goel, Andrew Zhang, Henry Senyondo, Ethan White',\n author_email='[email protected]',\n url='https://github.com/weecology/retriever',\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Scientific/Engineering :: GIS',\n 'Topic :: Scientific/Engineering :: Information Analysis',\n 'Topic :: Database',\n ],\n packages=find_packages(\n exclude=['hooks',\n 'docs',\n 'tests',\n 'scripts',\n 'docker',\n \".cache\"]),\n entry_points={\n 'console_scripts': [\n 'retriever = retriever.__main__:main',\n ],\n },\n install_requires=[\n 'xlrd',\n 'future',\n 'argcomplete',\n 'tqdm',\n 'requests',\n 'pandas'\n ],\n data_files=[('', ['CITATION'])],\n setup_requires=[],\n)\n\n# windows doesn't have bash. No point in using bash-completion\nif current_platform != \"windows\":\n # if platform is OS X use \"~/.bash_profile\"\n if current_platform == \"darwin\":\n bash_file = \"~/.bash_profile\"\n # if platform is Linux use \"~/.bashrc\n elif current_platform == \"linux\":\n bash_file = \"~/.bashrc\"\n # else write and discard\n else:\n bash_file = \"/dev/null\"\n\n argcomplete_command = 'eval \"$(register-python-argcomplete retriever)\"'\n with open(os.path.expanduser(bash_file), \"a+\") as bashrc:\n bashrc.seek(0)\n # register retriever for arg-completion if not already registered\n # whenever a new shell is spawned\n if argcomplete_command not in bashrc.read():\n bashrc.write(argcomplete_command + \"\\n\")\n bashrc.close()\n os.system(\"activate-global-python-argcomplete\")\n # register for the current shell\n os.system(argcomplete_command)\n\ntry:\n from retriever.compile import compile\n from retriever.lib.repository import check_for_updates\n\n check_for_updates()\n compile()\nexcept:\n pass\n", "path": "setup.py"}, {"content": "__version__ = 'v2.4.1.dev'\n", "path": "retriever/_version.py"}]}
| 1,641 | 194 |
gh_patches_debug_3437
|
rasdani/github-patches
|
git_diff
|
vacanza__python-holidays-794
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DeprecationWarning upon "import holidays" in version 0.17
The implementation of deprecating the Swaziland calendar contains a bug. Just importing the holidays package is enough to fire the `DeprecationWarning`.
**Steps to reproduce (in bash):**
```bash
# Setup
python -m venv demo
source demo/bin/activate
pip install --upgrade pip
# Bad version
pip install holidays==0.17
# Expose bug
python -W error::DeprecationWarning -c 'import holidays'
# Workoround
pip uninstall -y holidays
pip install holidays!=0.17
python -W error::DeprecationWarning -c 'import holidays'
# Cleanup
deactivate
rm -rf demo
```
**Expected behavior:**
The `DeprecationWarning` should only fire when the user constructs an instance of the `Swaziland` or a subclass.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `holidays/countries/eswatini.py`
Content:
```
1 # python-holidays
2 # ---------------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: dr-prodigy <[email protected]> (c) 2017-2022
8 # ryanss <[email protected]> (c) 2014-2017
9 # Website: https://github.com/dr-prodigy/python-holidays
10 # License: MIT (see LICENSE file)
11
12 import warnings
13 from datetime import date
14
15 from dateutil.easter import easter
16 from dateutil.relativedelta import relativedelta as rd
17
18 from holidays.constants import SUN, JAN, APR, MAY, JUL, SEP, DEC
19 from holidays.holiday_base import HolidayBase
20
21
22 class Eswatini(HolidayBase):
23 """
24 https://swazilii.org/sz/legislation/act/1938/71
25 https://www.officeholidays.com/countries/swaziland
26 """
27
28 country = "SZ"
29
30 def _populate(self, year):
31 super()._populate(year)
32
33 # Observed since 1938
34 if year > 1938:
35 self[date(year, JAN, 1)] = "New Year's Day"
36
37 e = easter(year)
38 good_friday = e - rd(days=2)
39 easter_monday = e + rd(days=1)
40 ascension_day = e + rd(days=39)
41 self[good_friday] = "Good Friday"
42 self[easter_monday] = "Easter Monday"
43 self[ascension_day] = "Ascension Day"
44
45 if year > 1968:
46 self[date(year, APR, 25)] = "National Flag Day"
47
48 if year > 1982:
49 # https://www.officeholidays.com/holidays/swaziland/birthday-of-late-king-sobhuza
50 self[date(year, JUL, 22)] = "Birthday of Late King Sobhuza"
51
52 if year > 1986:
53 # https://www.officeholidays.com/holidays/swaziland/birthday-of-king-mswati-iii
54 self[date(year, APR, 19)] = "King's Birthday"
55
56 self[date(year, MAY, 1)] = "Worker's Day"
57 self[date(year, SEP, 6)] = "Independence Day"
58 self[date(year, DEC, 25)] = "Christmas Day"
59 self[date(year, DEC, 26)] = "Boxing Day"
60
61 # Once-off public holidays
62 y2k = "Y2K changeover"
63
64 if year == 1999:
65 # https://mg.co.za/article/1999-12-09-swaziland-declares-bank-holidays/
66 self[date(1999, DEC, 31)] = y2k
67 if year == 2000:
68 self[date(2000, JAN, 3)] = y2k
69
70 # As of 2021/1/1, whenever a public holiday falls on a
71 # Sunday
72 # it rolls over to the following Monday
73 for k, v in list(self.items()):
74
75 if self.observed and k.weekday() == SUN and k.year == year:
76 add_days = 1
77 while self.get(k + rd(days=add_days)) is not None:
78 add_days += 1
79 self[k + rd(days=add_days)] = v + " (Day Off)"
80
81
82 class Swaziland(Eswatini):
83 warnings.warn(
84 "Swaziland is deprecated, use Eswatini instead.",
85 DeprecationWarning,
86 )
87 pass
88
89
90 class SZ(Eswatini):
91 pass
92
93
94 class SZW(Eswatini):
95 pass
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/holidays/countries/eswatini.py b/holidays/countries/eswatini.py
--- a/holidays/countries/eswatini.py
+++ b/holidays/countries/eswatini.py
@@ -80,11 +80,13 @@
class Swaziland(Eswatini):
- warnings.warn(
- "Swaziland is deprecated, use Eswatini instead.",
- DeprecationWarning,
- )
- pass
+ def __init__(self, *args, **kwargs) -> None:
+ warnings.warn(
+ "Swaziland is deprecated, use Eswatini instead.",
+ DeprecationWarning,
+ )
+
+ super().__init__(*args, **kwargs)
class SZ(Eswatini):
|
{"golden_diff": "diff --git a/holidays/countries/eswatini.py b/holidays/countries/eswatini.py\n--- a/holidays/countries/eswatini.py\n+++ b/holidays/countries/eswatini.py\n@@ -80,11 +80,13 @@\n \n \n class Swaziland(Eswatini):\n- warnings.warn(\n- \"Swaziland is deprecated, use Eswatini instead.\",\n- DeprecationWarning,\n- )\n- pass\n+ def __init__(self, *args, **kwargs) -> None:\n+ warnings.warn(\n+ \"Swaziland is deprecated, use Eswatini instead.\",\n+ DeprecationWarning,\n+ )\n+\n+ super().__init__(*args, **kwargs)\n \n \n class SZ(Eswatini):\n", "issue": "DeprecationWarning upon \"import holidays\" in version 0.17\nThe implementation of deprecating the Swaziland calendar contains a bug. Just importing the holidays package is enough to fire the `DeprecationWarning`.\r\n\r\n**Steps to reproduce (in bash):**\r\n\r\n```bash\r\n# Setup\r\npython -m venv demo\r\nsource demo/bin/activate\r\npip install --upgrade pip\r\n\r\n# Bad version\r\npip install holidays==0.17\r\n\r\n# Expose bug\r\npython -W error::DeprecationWarning -c 'import holidays'\r\n\r\n# Workoround\r\npip uninstall -y holidays\r\npip install holidays!=0.17\r\npython -W error::DeprecationWarning -c 'import holidays'\r\n\r\n# Cleanup\r\ndeactivate\r\nrm -rf demo\r\n```\r\n\r\n**Expected behavior:**\r\n\r\nThe `DeprecationWarning` should only fire when the user constructs an instance of the `Swaziland` or a subclass.\r\n\n", "before_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2022\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport warnings\nfrom datetime import date\n\nfrom dateutil.easter import easter\nfrom dateutil.relativedelta import relativedelta as rd\n\nfrom holidays.constants import SUN, JAN, APR, MAY, JUL, SEP, DEC\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Eswatini(HolidayBase):\n \"\"\"\n https://swazilii.org/sz/legislation/act/1938/71\n https://www.officeholidays.com/countries/swaziland\n \"\"\"\n\n country = \"SZ\"\n\n def _populate(self, year):\n super()._populate(year)\n\n # Observed since 1938\n if year > 1938:\n self[date(year, JAN, 1)] = \"New Year's Day\"\n\n e = easter(year)\n good_friday = e - rd(days=2)\n easter_monday = e + rd(days=1)\n ascension_day = e + rd(days=39)\n self[good_friday] = \"Good Friday\"\n self[easter_monday] = \"Easter Monday\"\n self[ascension_day] = \"Ascension Day\"\n\n if year > 1968:\n self[date(year, APR, 25)] = \"National Flag Day\"\n\n if year > 1982:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-late-king-sobhuza\n self[date(year, JUL, 22)] = \"Birthday of Late King Sobhuza\"\n\n if year > 1986:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-king-mswati-iii\n self[date(year, APR, 19)] = \"King's Birthday\"\n\n self[date(year, MAY, 1)] = \"Worker's Day\"\n self[date(year, SEP, 6)] = \"Independence Day\"\n self[date(year, DEC, 25)] = \"Christmas Day\"\n self[date(year, DEC, 26)] = \"Boxing Day\"\n\n # Once-off public holidays\n y2k = \"Y2K changeover\"\n\n if year == 1999:\n # https://mg.co.za/article/1999-12-09-swaziland-declares-bank-holidays/\n self[date(1999, DEC, 31)] = y2k\n if year == 2000:\n self[date(2000, JAN, 3)] = y2k\n\n # As of 2021/1/1, whenever a public holiday falls on a\n # Sunday\n # it rolls over to the following Monday\n for k, v in list(self.items()):\n\n if self.observed and k.weekday() == SUN and k.year == year:\n add_days = 1\n while self.get(k + rd(days=add_days)) is not None:\n add_days += 1\n self[k + rd(days=add_days)] = v + \" (Day Off)\"\n\n\nclass Swaziland(Eswatini):\n warnings.warn(\n \"Swaziland is deprecated, use Eswatini instead.\",\n DeprecationWarning,\n )\n pass\n\n\nclass SZ(Eswatini):\n pass\n\n\nclass SZW(Eswatini):\n pass\n", "path": "holidays/countries/eswatini.py"}], "after_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2022\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport warnings\nfrom datetime import date\n\nfrom dateutil.easter import easter\nfrom dateutil.relativedelta import relativedelta as rd\n\nfrom holidays.constants import SUN, JAN, APR, MAY, JUL, SEP, DEC\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Eswatini(HolidayBase):\n \"\"\"\n https://swazilii.org/sz/legislation/act/1938/71\n https://www.officeholidays.com/countries/swaziland\n \"\"\"\n\n country = \"SZ\"\n\n def _populate(self, year):\n super()._populate(year)\n\n # Observed since 1938\n if year > 1938:\n self[date(year, JAN, 1)] = \"New Year's Day\"\n\n e = easter(year)\n good_friday = e - rd(days=2)\n easter_monday = e + rd(days=1)\n ascension_day = e + rd(days=39)\n self[good_friday] = \"Good Friday\"\n self[easter_monday] = \"Easter Monday\"\n self[ascension_day] = \"Ascension Day\"\n\n if year > 1968:\n self[date(year, APR, 25)] = \"National Flag Day\"\n\n if year > 1982:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-late-king-sobhuza\n self[date(year, JUL, 22)] = \"Birthday of Late King Sobhuza\"\n\n if year > 1986:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-king-mswati-iii\n self[date(year, APR, 19)] = \"King's Birthday\"\n\n self[date(year, MAY, 1)] = \"Worker's Day\"\n self[date(year, SEP, 6)] = \"Independence Day\"\n self[date(year, DEC, 25)] = \"Christmas Day\"\n self[date(year, DEC, 26)] = \"Boxing Day\"\n\n # Once-off public holidays\n y2k = \"Y2K changeover\"\n\n if year == 1999:\n # https://mg.co.za/article/1999-12-09-swaziland-declares-bank-holidays/\n self[date(1999, DEC, 31)] = y2k\n if year == 2000:\n self[date(2000, JAN, 3)] = y2k\n\n # As of 2021/1/1, whenever a public holiday falls on a\n # Sunday\n # it rolls over to the following Monday\n for k, v in list(self.items()):\n\n if self.observed and k.weekday() == SUN and k.year == year:\n add_days = 1\n while self.get(k + rd(days=add_days)) is not None:\n add_days += 1\n self[k + rd(days=add_days)] = v + \" (Day Off)\"\n\n\nclass Swaziland(Eswatini):\n def __init__(self, *args, **kwargs) -> None:\n warnings.warn(\n \"Swaziland is deprecated, use Eswatini instead.\",\n DeprecationWarning,\n )\n\n super().__init__(*args, **kwargs)\n\n\nclass SZ(Eswatini):\n pass\n\n\nclass SZW(Eswatini):\n pass\n", "path": "holidays/countries/eswatini.py"}]}
| 1,542 | 171 |
gh_patches_debug_43401
|
rasdani/github-patches
|
git_diff
|
dynaconf__dynaconf-438
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[feature] opt-out for warning about missing environments
**Is your feature request related to a problem? Please describe.**
in a project where environments are used and plugins supply their own default settings in the global section,
the warnings about missing other environments are misleading/unneeded
additionally the warnings only apply to the currently used environment, so different setup raise different warnings
**Describe the solution you'd like**
A way to opt out of the warnings for either a subset of the files or all of them
**Describe alternatives you've considered**
no longer warning about missing envs
**Additional context**
```
$ ENV_FOR_DYNACONF=prod iqe
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.polarion.yaml
warnings.warn(message)
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.default.yaml
warnings.warn(message)
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/advisor/iqe_advisor/conf/settings.default.yaml
warnings.warn(message)
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/clientv3/iqe_clientv3/conf/settings.default.yaml
....
$ iqe
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.polarion.yaml
warnings.warn(message)
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.default.yaml
warnings.warn(message)
/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/advisor/iqe_advisor/conf/settings.default.yaml
warnings.warn(message)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dynaconf/loaders/base.py`
Content:
```
1 import io
2 import warnings
3
4 from dynaconf.utils import build_env_list
5 from dynaconf.utils import ensure_a_list
6 from dynaconf.utils import upperfy
7
8
9 class BaseLoader:
10 """Base loader for dynaconf source files.
11
12 :param obj: {[LazySettings]} -- [Dynaconf settings]
13 :param env: {[string]} -- [the current env to be loaded defaults to
14 [development]]
15 :param identifier: {[string]} -- [identifier ini, yaml, json, py, toml]
16 :param extensions: {[list]} -- [List of extensions with dots ['.a', '.b']]
17 :param file_reader: {[callable]} -- [reads file return dict]
18 :param string_reader: {[callable]} -- [reads string return dict]
19 """
20
21 def __init__(
22 self, obj, env, identifier, extensions, file_reader, string_reader
23 ):
24 """Instantiates a loader for different sources"""
25 self.obj = obj
26 self.env = env or obj.current_env
27 self.identifier = identifier
28 self.extensions = extensions
29 self.file_reader = file_reader
30 self.string_reader = string_reader
31
32 @staticmethod
33 def warn_not_installed(obj, identifier): # pragma: no cover
34 if identifier not in obj._not_installed_warnings:
35 warnings.warn(
36 f"{identifier} support is not installed in your environment. "
37 f"`pip install dynaconf[{identifier}]`"
38 )
39 obj._not_installed_warnings.append(identifier)
40
41 def load(self, filename=None, key=None, silent=True):
42 """
43 Reads and loads in to `self.obj` a single key or all keys from source
44
45 :param filename: Optional filename to load
46 :param key: if provided load a single key
47 :param silent: if load erros should be silenced
48 """
49 filename = filename or self.obj.get(self.identifier.upper())
50 if not filename:
51 return
52
53 if not isinstance(filename, (list, tuple)):
54 split_files = ensure_a_list(filename)
55 if all([f.endswith(self.extensions) for f in split_files]): # noqa
56 files = split_files # it is a ['file.ext', ...]
57 else: # it is a single config as string
58 files = [filename]
59 else: # it is already a list/tuple
60 files = filename
61
62 source_data = self.get_source_date(files)
63
64 if self.obj.get("ENVIRONMENTS_FOR_DYNACONF") is False:
65 self._envless_load(source_data, silent, key)
66 else:
67 self._load_all_envs(source_data, silent, key)
68
69 def get_source_date(self, files):
70 """Reads each file and returns source data for each file
71 {"path/to/file.ext": {"key": "value"}}
72 """
73 data = {}
74 for source_file in files:
75 if source_file.endswith(self.extensions):
76 try:
77 with io.open(
78 source_file,
79 encoding=self.obj.get(
80 "ENCODING_FOR_DYNACONF", "utf-8"
81 ),
82 ) as open_file:
83 content = self.file_reader(open_file)
84 self.obj._loaded_files.append(source_file)
85 if content:
86 data[source_file] = content
87 except IOError as e:
88 if ".local." not in source_file:
89 warnings.warn(
90 f"{self.identifier}_loader: {source_file} "
91 f":{str(e)}"
92 )
93 else:
94 # for tests it is possible to pass string
95 content = self.string_reader(source_file)
96 if content:
97 data[source_file] = content
98 return data
99
100 def _envless_load(self, source_data, silent=True, key=None):
101 """Load all the keys from each file without env separation"""
102 for source_file, file_data in source_data.items():
103 self._set_data_to_obj(
104 file_data, self.identifier, source_file, key=key
105 )
106
107 def _load_all_envs(self, source_data, silent=True, key=None):
108 """Load configs from files separating by each environment"""
109
110 for source_file, file_data in source_data.items():
111
112 # env name is checked in lower
113 file_data = {k.lower(): value for k, value in file_data.items()}
114
115 # is there a `dynaconf_merge` on top level of file?
116 file_merge = file_data.get("dynaconf_merge")
117
118 # all lower case for comparison
119 base_envs = [
120 # DYNACONF or MYPROGRAM
121 (self.obj.get("ENVVAR_PREFIX_FOR_DYNACONF") or "").lower(),
122 # DEFAULT
123 self.obj.get("DEFAULT_ENV_FOR_DYNACONF").lower(),
124 # default active env unless ENV_FOR_DYNACONF is changed
125 "development",
126 # backwards compatibility for global
127 "dynaconf",
128 # global that rules all
129 "global",
130 ]
131
132 for env in build_env_list(self.obj, self.env):
133 env = env.lower() # lower for better comparison
134 data = {}
135 try:
136 data = file_data[env] or {}
137 except KeyError:
138 if env not in base_envs:
139 message = (
140 f"{self.identifier}_loader: {env} env not"
141 f"defined in {source_file}"
142 )
143 if silent:
144 warnings.warn(message)
145 else:
146 raise KeyError(message)
147 continue
148
149 if env != self.obj.get("DEFAULT_ENV_FOR_DYNACONF").lower():
150 identifier = f"{self.identifier}_{env}"
151 else:
152 identifier = self.identifier
153
154 self._set_data_to_obj(
155 data, identifier, source_file, file_merge, key, env
156 )
157
158 def _set_data_to_obj(
159 self,
160 data,
161 identifier,
162 source_file,
163 file_merge=None,
164 key=False,
165 env=False,
166 ):
167 """Calls setttings.set to add the keys"""
168
169 # data 1st level keys should be transformed to upper case.
170 data = {upperfy(k): v for k, v in data.items()}
171 if key:
172 key = upperfy(key)
173
174 # is there a `dynaconf_merge` inside an `[env]`?
175 file_merge = file_merge or data.pop("DYNACONF_MERGE", False)
176
177 if not key:
178 self.obj.update(
179 data, loader_identifier=identifier, merge=file_merge,
180 )
181 elif key in data:
182 self.obj.set(
183 key,
184 data.get(key),
185 loader_identifier=identifier,
186 merge=file_merge,
187 )
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dynaconf/loaders/base.py b/dynaconf/loaders/base.py
--- a/dynaconf/loaders/base.py
+++ b/dynaconf/loaders/base.py
@@ -59,14 +59,14 @@
else: # it is already a list/tuple
files = filename
- source_data = self.get_source_date(files)
+ source_data = self.get_source_data(files)
if self.obj.get("ENVIRONMENTS_FOR_DYNACONF") is False:
self._envless_load(source_data, silent, key)
else:
self._load_all_envs(source_data, silent, key)
- def get_source_date(self, files):
+ def get_source_data(self, files):
"""Reads each file and returns source data for each file
{"path/to/file.ext": {"key": "value"}}
"""
@@ -99,15 +99,13 @@
def _envless_load(self, source_data, silent=True, key=None):
"""Load all the keys from each file without env separation"""
- for source_file, file_data in source_data.items():
- self._set_data_to_obj(
- file_data, self.identifier, source_file, key=key
- )
+ for file_data in source_data.values():
+ self._set_data_to_obj(file_data, self.identifier, key=key)
def _load_all_envs(self, source_data, silent=True, key=None):
"""Load configs from files separating by each environment"""
- for source_file, file_data in source_data.items():
+ for file_data in source_data.values():
# env name is checked in lower
file_data = {k.lower(): value for k, value in file_data.items()}
@@ -115,35 +113,18 @@
# is there a `dynaconf_merge` on top level of file?
file_merge = file_data.get("dynaconf_merge")
- # all lower case for comparison
- base_envs = [
- # DYNACONF or MYPROGRAM
- (self.obj.get("ENVVAR_PREFIX_FOR_DYNACONF") or "").lower(),
- # DEFAULT
- self.obj.get("DEFAULT_ENV_FOR_DYNACONF").lower(),
- # default active env unless ENV_FOR_DYNACONF is changed
- "development",
- # backwards compatibility for global
- "dynaconf",
- # global that rules all
- "global",
- ]
-
for env in build_env_list(self.obj, self.env):
env = env.lower() # lower for better comparison
data = {}
+
try:
data = file_data[env] or {}
except KeyError:
- if env not in base_envs:
- message = (
- f"{self.identifier}_loader: {env} env not"
- f"defined in {source_file}"
- )
- if silent:
- warnings.warn(message)
- else:
- raise KeyError(message)
+ if silent:
+ continue
+ raise
+
+ if not data:
continue
if env != self.obj.get("DEFAULT_ENV_FOR_DYNACONF").lower():
@@ -151,18 +132,10 @@
else:
identifier = self.identifier
- self._set_data_to_obj(
- data, identifier, source_file, file_merge, key, env
- )
+ self._set_data_to_obj(data, identifier, file_merge, key)
def _set_data_to_obj(
- self,
- data,
- identifier,
- source_file,
- file_merge=None,
- key=False,
- env=False,
+ self, data, identifier, file_merge=None, key=False,
):
"""Calls setttings.set to add the keys"""
|
{"golden_diff": "diff --git a/dynaconf/loaders/base.py b/dynaconf/loaders/base.py\n--- a/dynaconf/loaders/base.py\n+++ b/dynaconf/loaders/base.py\n@@ -59,14 +59,14 @@\n else: # it is already a list/tuple\n files = filename\n \n- source_data = self.get_source_date(files)\n+ source_data = self.get_source_data(files)\n \n if self.obj.get(\"ENVIRONMENTS_FOR_DYNACONF\") is False:\n self._envless_load(source_data, silent, key)\n else:\n self._load_all_envs(source_data, silent, key)\n \n- def get_source_date(self, files):\n+ def get_source_data(self, files):\n \"\"\"Reads each file and returns source data for each file\n {\"path/to/file.ext\": {\"key\": \"value\"}}\n \"\"\"\n@@ -99,15 +99,13 @@\n \n def _envless_load(self, source_data, silent=True, key=None):\n \"\"\"Load all the keys from each file without env separation\"\"\"\n- for source_file, file_data in source_data.items():\n- self._set_data_to_obj(\n- file_data, self.identifier, source_file, key=key\n- )\n+ for file_data in source_data.values():\n+ self._set_data_to_obj(file_data, self.identifier, key=key)\n \n def _load_all_envs(self, source_data, silent=True, key=None):\n \"\"\"Load configs from files separating by each environment\"\"\"\n \n- for source_file, file_data in source_data.items():\n+ for file_data in source_data.values():\n \n # env name is checked in lower\n file_data = {k.lower(): value for k, value in file_data.items()}\n@@ -115,35 +113,18 @@\n # is there a `dynaconf_merge` on top level of file?\n file_merge = file_data.get(\"dynaconf_merge\")\n \n- # all lower case for comparison\n- base_envs = [\n- # DYNACONF or MYPROGRAM\n- (self.obj.get(\"ENVVAR_PREFIX_FOR_DYNACONF\") or \"\").lower(),\n- # DEFAULT\n- self.obj.get(\"DEFAULT_ENV_FOR_DYNACONF\").lower(),\n- # default active env unless ENV_FOR_DYNACONF is changed\n- \"development\",\n- # backwards compatibility for global\n- \"dynaconf\",\n- # global that rules all\n- \"global\",\n- ]\n-\n for env in build_env_list(self.obj, self.env):\n env = env.lower() # lower for better comparison\n data = {}\n+\n try:\n data = file_data[env] or {}\n except KeyError:\n- if env not in base_envs:\n- message = (\n- f\"{self.identifier}_loader: {env} env not\"\n- f\"defined in {source_file}\"\n- )\n- if silent:\n- warnings.warn(message)\n- else:\n- raise KeyError(message)\n+ if silent:\n+ continue\n+ raise\n+\n+ if not data:\n continue\n \n if env != self.obj.get(\"DEFAULT_ENV_FOR_DYNACONF\").lower():\n@@ -151,18 +132,10 @@\n else:\n identifier = self.identifier\n \n- self._set_data_to_obj(\n- data, identifier, source_file, file_merge, key, env\n- )\n+ self._set_data_to_obj(data, identifier, file_merge, key)\n \n def _set_data_to_obj(\n- self,\n- data,\n- identifier,\n- source_file,\n- file_merge=None,\n- key=False,\n- env=False,\n+ self, data, identifier, file_merge=None, key=False,\n ):\n \"\"\"Calls setttings.set to add the keys\"\"\"\n", "issue": "[feature] opt-out for warning about missing environments\n**Is your feature request related to a problem? Please describe.**\r\n\r\nin a project where environments are used and plugins supply their own default settings in the global section,\r\nthe warnings about missing other environments are misleading/unneeded\r\n\r\nadditionally the warnings only apply to the currently used environment, so different setup raise different warnings\r\n\r\n**Describe the solution you'd like**\r\n\r\nA way to opt out of the warnings for either a subset of the files or all of them\r\n\r\n**Describe alternatives you've considered**\r\n\r\nno longer warning about missing envs\r\n\r\n**Additional context**\r\n```\r\n$ ENV_FOR_DYNACONF=prod iqe\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.polarion.yaml\r\n warnings.warn(message)\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.default.yaml\r\n warnings.warn(message)\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/advisor/iqe_advisor/conf/settings.default.yaml\r\n warnings.warn(message)\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: prod env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/clientv3/iqe_clientv3/conf/settings.default.yaml\r\n....\r\n\r\n$ iqe\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.polarion.yaml\r\n warnings.warn(message)\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/iqe-tests/iqe/conf/settings.default.yaml\r\n warnings.warn(message)\r\n/home/rpfannsc/Projects/insights-qe/venv-iqe/lib/python3.8/site-packages/dynaconf/loaders/base.py:145: UserWarning: yaml_loader: qa env notdefined in /home/rpfannsc/Projects/insights-qe/checkouts/advisor/iqe_advisor/conf/settings.default.yaml\r\n warnings.warn(message)\r\n```\r\n\n", "before_files": [{"content": "import io\nimport warnings\n\nfrom dynaconf.utils import build_env_list\nfrom dynaconf.utils import ensure_a_list\nfrom dynaconf.utils import upperfy\n\n\nclass BaseLoader:\n \"\"\"Base loader for dynaconf source files.\n\n :param obj: {[LazySettings]} -- [Dynaconf settings]\n :param env: {[string]} -- [the current env to be loaded defaults to\n [development]]\n :param identifier: {[string]} -- [identifier ini, yaml, json, py, toml]\n :param extensions: {[list]} -- [List of extensions with dots ['.a', '.b']]\n :param file_reader: {[callable]} -- [reads file return dict]\n :param string_reader: {[callable]} -- [reads string return dict]\n \"\"\"\n\n def __init__(\n self, obj, env, identifier, extensions, file_reader, string_reader\n ):\n \"\"\"Instantiates a loader for different sources\"\"\"\n self.obj = obj\n self.env = env or obj.current_env\n self.identifier = identifier\n self.extensions = extensions\n self.file_reader = file_reader\n self.string_reader = string_reader\n\n @staticmethod\n def warn_not_installed(obj, identifier): # pragma: no cover\n if identifier not in obj._not_installed_warnings:\n warnings.warn(\n f\"{identifier} support is not installed in your environment. \"\n f\"`pip install dynaconf[{identifier}]`\"\n )\n obj._not_installed_warnings.append(identifier)\n\n def load(self, filename=None, key=None, silent=True):\n \"\"\"\n Reads and loads in to `self.obj` a single key or all keys from source\n\n :param filename: Optional filename to load\n :param key: if provided load a single key\n :param silent: if load erros should be silenced\n \"\"\"\n filename = filename or self.obj.get(self.identifier.upper())\n if not filename:\n return\n\n if not isinstance(filename, (list, tuple)):\n split_files = ensure_a_list(filename)\n if all([f.endswith(self.extensions) for f in split_files]): # noqa\n files = split_files # it is a ['file.ext', ...]\n else: # it is a single config as string\n files = [filename]\n else: # it is already a list/tuple\n files = filename\n\n source_data = self.get_source_date(files)\n\n if self.obj.get(\"ENVIRONMENTS_FOR_DYNACONF\") is False:\n self._envless_load(source_data, silent, key)\n else:\n self._load_all_envs(source_data, silent, key)\n\n def get_source_date(self, files):\n \"\"\"Reads each file and returns source data for each file\n {\"path/to/file.ext\": {\"key\": \"value\"}}\n \"\"\"\n data = {}\n for source_file in files:\n if source_file.endswith(self.extensions):\n try:\n with io.open(\n source_file,\n encoding=self.obj.get(\n \"ENCODING_FOR_DYNACONF\", \"utf-8\"\n ),\n ) as open_file:\n content = self.file_reader(open_file)\n self.obj._loaded_files.append(source_file)\n if content:\n data[source_file] = content\n except IOError as e:\n if \".local.\" not in source_file:\n warnings.warn(\n f\"{self.identifier}_loader: {source_file} \"\n f\":{str(e)}\"\n )\n else:\n # for tests it is possible to pass string\n content = self.string_reader(source_file)\n if content:\n data[source_file] = content\n return data\n\n def _envless_load(self, source_data, silent=True, key=None):\n \"\"\"Load all the keys from each file without env separation\"\"\"\n for source_file, file_data in source_data.items():\n self._set_data_to_obj(\n file_data, self.identifier, source_file, key=key\n )\n\n def _load_all_envs(self, source_data, silent=True, key=None):\n \"\"\"Load configs from files separating by each environment\"\"\"\n\n for source_file, file_data in source_data.items():\n\n # env name is checked in lower\n file_data = {k.lower(): value for k, value in file_data.items()}\n\n # is there a `dynaconf_merge` on top level of file?\n file_merge = file_data.get(\"dynaconf_merge\")\n\n # all lower case for comparison\n base_envs = [\n # DYNACONF or MYPROGRAM\n (self.obj.get(\"ENVVAR_PREFIX_FOR_DYNACONF\") or \"\").lower(),\n # DEFAULT\n self.obj.get(\"DEFAULT_ENV_FOR_DYNACONF\").lower(),\n # default active env unless ENV_FOR_DYNACONF is changed\n \"development\",\n # backwards compatibility for global\n \"dynaconf\",\n # global that rules all\n \"global\",\n ]\n\n for env in build_env_list(self.obj, self.env):\n env = env.lower() # lower for better comparison\n data = {}\n try:\n data = file_data[env] or {}\n except KeyError:\n if env not in base_envs:\n message = (\n f\"{self.identifier}_loader: {env} env not\"\n f\"defined in {source_file}\"\n )\n if silent:\n warnings.warn(message)\n else:\n raise KeyError(message)\n continue\n\n if env != self.obj.get(\"DEFAULT_ENV_FOR_DYNACONF\").lower():\n identifier = f\"{self.identifier}_{env}\"\n else:\n identifier = self.identifier\n\n self._set_data_to_obj(\n data, identifier, source_file, file_merge, key, env\n )\n\n def _set_data_to_obj(\n self,\n data,\n identifier,\n source_file,\n file_merge=None,\n key=False,\n env=False,\n ):\n \"\"\"Calls setttings.set to add the keys\"\"\"\n\n # data 1st level keys should be transformed to upper case.\n data = {upperfy(k): v for k, v in data.items()}\n if key:\n key = upperfy(key)\n\n # is there a `dynaconf_merge` inside an `[env]`?\n file_merge = file_merge or data.pop(\"DYNACONF_MERGE\", False)\n\n if not key:\n self.obj.update(\n data, loader_identifier=identifier, merge=file_merge,\n )\n elif key in data:\n self.obj.set(\n key,\n data.get(key),\n loader_identifier=identifier,\n merge=file_merge,\n )\n", "path": "dynaconf/loaders/base.py"}], "after_files": [{"content": "import io\nimport warnings\n\nfrom dynaconf.utils import build_env_list\nfrom dynaconf.utils import ensure_a_list\nfrom dynaconf.utils import upperfy\n\n\nclass BaseLoader:\n \"\"\"Base loader for dynaconf source files.\n\n :param obj: {[LazySettings]} -- [Dynaconf settings]\n :param env: {[string]} -- [the current env to be loaded defaults to\n [development]]\n :param identifier: {[string]} -- [identifier ini, yaml, json, py, toml]\n :param extensions: {[list]} -- [List of extensions with dots ['.a', '.b']]\n :param file_reader: {[callable]} -- [reads file return dict]\n :param string_reader: {[callable]} -- [reads string return dict]\n \"\"\"\n\n def __init__(\n self, obj, env, identifier, extensions, file_reader, string_reader\n ):\n \"\"\"Instantiates a loader for different sources\"\"\"\n self.obj = obj\n self.env = env or obj.current_env\n self.identifier = identifier\n self.extensions = extensions\n self.file_reader = file_reader\n self.string_reader = string_reader\n\n @staticmethod\n def warn_not_installed(obj, identifier): # pragma: no cover\n if identifier not in obj._not_installed_warnings:\n warnings.warn(\n f\"{identifier} support is not installed in your environment. \"\n f\"`pip install dynaconf[{identifier}]`\"\n )\n obj._not_installed_warnings.append(identifier)\n\n def load(self, filename=None, key=None, silent=True):\n \"\"\"\n Reads and loads in to `self.obj` a single key or all keys from source\n\n :param filename: Optional filename to load\n :param key: if provided load a single key\n :param silent: if load erros should be silenced\n \"\"\"\n filename = filename or self.obj.get(self.identifier.upper())\n if not filename:\n return\n\n if not isinstance(filename, (list, tuple)):\n split_files = ensure_a_list(filename)\n if all([f.endswith(self.extensions) for f in split_files]): # noqa\n files = split_files # it is a ['file.ext', ...]\n else: # it is a single config as string\n files = [filename]\n else: # it is already a list/tuple\n files = filename\n\n source_data = self.get_source_data(files)\n\n if self.obj.get(\"ENVIRONMENTS_FOR_DYNACONF\") is False:\n self._envless_load(source_data, silent, key)\n else:\n self._load_all_envs(source_data, silent, key)\n\n def get_source_data(self, files):\n \"\"\"Reads each file and returns source data for each file\n {\"path/to/file.ext\": {\"key\": \"value\"}}\n \"\"\"\n data = {}\n for source_file in files:\n if source_file.endswith(self.extensions):\n try:\n with io.open(\n source_file,\n encoding=self.obj.get(\n \"ENCODING_FOR_DYNACONF\", \"utf-8\"\n ),\n ) as open_file:\n content = self.file_reader(open_file)\n self.obj._loaded_files.append(source_file)\n if content:\n data[source_file] = content\n except IOError as e:\n if \".local.\" not in source_file:\n warnings.warn(\n f\"{self.identifier}_loader: {source_file} \"\n f\":{str(e)}\"\n )\n else:\n # for tests it is possible to pass string\n content = self.string_reader(source_file)\n if content:\n data[source_file] = content\n return data\n\n def _envless_load(self, source_data, silent=True, key=None):\n \"\"\"Load all the keys from each file without env separation\"\"\"\n for file_data in source_data.values():\n self._set_data_to_obj(file_data, self.identifier, key=key)\n\n def _load_all_envs(self, source_data, silent=True, key=None):\n \"\"\"Load configs from files separating by each environment\"\"\"\n\n for file_data in source_data.values():\n\n # env name is checked in lower\n file_data = {k.lower(): value for k, value in file_data.items()}\n\n # is there a `dynaconf_merge` on top level of file?\n file_merge = file_data.get(\"dynaconf_merge\")\n\n for env in build_env_list(self.obj, self.env):\n env = env.lower() # lower for better comparison\n data = {}\n\n try:\n data = file_data[env] or {}\n except KeyError:\n if silent:\n continue\n raise\n\n if not data:\n continue\n\n if env != self.obj.get(\"DEFAULT_ENV_FOR_DYNACONF\").lower():\n identifier = f\"{self.identifier}_{env}\"\n else:\n identifier = self.identifier\n\n self._set_data_to_obj(data, identifier, file_merge, key)\n\n def _set_data_to_obj(\n self, data, identifier, file_merge=None, key=False,\n ):\n \"\"\"Calls setttings.set to add the keys\"\"\"\n\n # data 1st level keys should be transformed to upper case.\n data = {upperfy(k): v for k, v in data.items()}\n if key:\n key = upperfy(key)\n\n # is there a `dynaconf_merge` inside an `[env]`?\n file_merge = file_merge or data.pop(\"DYNACONF_MERGE\", False)\n\n if not key:\n self.obj.update(\n data, loader_identifier=identifier, merge=file_merge,\n )\n elif key in data:\n self.obj.set(\n key,\n data.get(key),\n loader_identifier=identifier,\n merge=file_merge,\n )\n", "path": "dynaconf/loaders/base.py"}]}
| 2,831 | 853 |
gh_patches_debug_40105
|
rasdani/github-patches
|
git_diff
|
encode__httpx-2716
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add `socket_options` to `httpx.HTTPTransport`.
Since [version 0.17.2](https://github.com/encode/httpcore/pull/697#issuecomment-1559059612) the `httpcore` package has support for a `socket_options` parameter.
We should add a corresponding parameter to `httpx.HTTPTransport`, which can be passed through to the connection pool.
This will resolve the use-case raised in discussion https://github.com/encode/httpx/discussions/2635...
```python
>>> import httpx
>>> socket_options = [(socket.SOL_SOCKET, socket.SO_BINDTODEVICE, b"ETH999")]
>>> transport = httpx.HTTPTransport(socket_options=socket_options)
>>> client = httpx.Client(transport=transport)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `httpx/_transports/default.py`
Content:
```
1 """
2 Custom transports, with nicely configured defaults.
3
4 The following additional keyword arguments are currently supported by httpcore...
5
6 * uds: str
7 * local_address: str
8 * retries: int
9
10 Example usages...
11
12 # Disable HTTP/2 on a single specific domain.
13 mounts = {
14 "all://": httpx.HTTPTransport(http2=True),
15 "all://*example.org": httpx.HTTPTransport()
16 }
17
18 # Using advanced httpcore configuration, with connection retries.
19 transport = httpx.HTTPTransport(retries=1)
20 client = httpx.Client(transport=transport)
21
22 # Using advanced httpcore configuration, with unix domain sockets.
23 transport = httpx.HTTPTransport(uds="socket.uds")
24 client = httpx.Client(transport=transport)
25 """
26 import contextlib
27 import typing
28 from types import TracebackType
29
30 import httpcore
31
32 from .._config import DEFAULT_LIMITS, Limits, Proxy, create_ssl_context
33 from .._exceptions import (
34 ConnectError,
35 ConnectTimeout,
36 LocalProtocolError,
37 NetworkError,
38 PoolTimeout,
39 ProtocolError,
40 ProxyError,
41 ReadError,
42 ReadTimeout,
43 RemoteProtocolError,
44 TimeoutException,
45 UnsupportedProtocol,
46 WriteError,
47 WriteTimeout,
48 )
49 from .._models import Request, Response
50 from .._types import AsyncByteStream, CertTypes, SyncByteStream, VerifyTypes
51 from .base import AsyncBaseTransport, BaseTransport
52
53 T = typing.TypeVar("T", bound="HTTPTransport")
54 A = typing.TypeVar("A", bound="AsyncHTTPTransport")
55
56
57 @contextlib.contextmanager
58 def map_httpcore_exceptions() -> typing.Iterator[None]:
59 try:
60 yield
61 except Exception as exc: # noqa: PIE-786
62 mapped_exc = None
63
64 for from_exc, to_exc in HTTPCORE_EXC_MAP.items():
65 if not isinstance(exc, from_exc):
66 continue
67 # We want to map to the most specific exception we can find.
68 # Eg if `exc` is an `httpcore.ReadTimeout`, we want to map to
69 # `httpx.ReadTimeout`, not just `httpx.TimeoutException`.
70 if mapped_exc is None or issubclass(to_exc, mapped_exc):
71 mapped_exc = to_exc
72
73 if mapped_exc is None: # pragma: no cover
74 raise
75
76 message = str(exc)
77 raise mapped_exc(message) from exc
78
79
80 HTTPCORE_EXC_MAP = {
81 httpcore.TimeoutException: TimeoutException,
82 httpcore.ConnectTimeout: ConnectTimeout,
83 httpcore.ReadTimeout: ReadTimeout,
84 httpcore.WriteTimeout: WriteTimeout,
85 httpcore.PoolTimeout: PoolTimeout,
86 httpcore.NetworkError: NetworkError,
87 httpcore.ConnectError: ConnectError,
88 httpcore.ReadError: ReadError,
89 httpcore.WriteError: WriteError,
90 httpcore.ProxyError: ProxyError,
91 httpcore.UnsupportedProtocol: UnsupportedProtocol,
92 httpcore.ProtocolError: ProtocolError,
93 httpcore.LocalProtocolError: LocalProtocolError,
94 httpcore.RemoteProtocolError: RemoteProtocolError,
95 }
96
97
98 class ResponseStream(SyncByteStream):
99 def __init__(self, httpcore_stream: typing.Iterable[bytes]):
100 self._httpcore_stream = httpcore_stream
101
102 def __iter__(self) -> typing.Iterator[bytes]:
103 with map_httpcore_exceptions():
104 for part in self._httpcore_stream:
105 yield part
106
107 def close(self) -> None:
108 if hasattr(self._httpcore_stream, "close"):
109 self._httpcore_stream.close()
110
111
112 class HTTPTransport(BaseTransport):
113 def __init__(
114 self,
115 verify: VerifyTypes = True,
116 cert: typing.Optional[CertTypes] = None,
117 http1: bool = True,
118 http2: bool = False,
119 limits: Limits = DEFAULT_LIMITS,
120 trust_env: bool = True,
121 proxy: typing.Optional[Proxy] = None,
122 uds: typing.Optional[str] = None,
123 local_address: typing.Optional[str] = None,
124 retries: int = 0,
125 ) -> None:
126 ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)
127
128 if proxy is None:
129 self._pool = httpcore.ConnectionPool(
130 ssl_context=ssl_context,
131 max_connections=limits.max_connections,
132 max_keepalive_connections=limits.max_keepalive_connections,
133 keepalive_expiry=limits.keepalive_expiry,
134 http1=http1,
135 http2=http2,
136 uds=uds,
137 local_address=local_address,
138 retries=retries,
139 )
140 elif proxy.url.scheme in ("http", "https"):
141 self._pool = httpcore.HTTPProxy(
142 proxy_url=httpcore.URL(
143 scheme=proxy.url.raw_scheme,
144 host=proxy.url.raw_host,
145 port=proxy.url.port,
146 target=proxy.url.raw_path,
147 ),
148 proxy_auth=proxy.raw_auth,
149 proxy_headers=proxy.headers.raw,
150 ssl_context=ssl_context,
151 max_connections=limits.max_connections,
152 max_keepalive_connections=limits.max_keepalive_connections,
153 keepalive_expiry=limits.keepalive_expiry,
154 http1=http1,
155 http2=http2,
156 )
157 elif proxy.url.scheme == "socks5":
158 try:
159 import socksio # noqa
160 except ImportError: # pragma: no cover
161 raise ImportError(
162 "Using SOCKS proxy, but the 'socksio' package is not installed. "
163 "Make sure to install httpx using `pip install httpx[socks]`."
164 ) from None
165
166 self._pool = httpcore.SOCKSProxy(
167 proxy_url=httpcore.URL(
168 scheme=proxy.url.raw_scheme,
169 host=proxy.url.raw_host,
170 port=proxy.url.port,
171 target=proxy.url.raw_path,
172 ),
173 proxy_auth=proxy.raw_auth,
174 ssl_context=ssl_context,
175 max_connections=limits.max_connections,
176 max_keepalive_connections=limits.max_keepalive_connections,
177 keepalive_expiry=limits.keepalive_expiry,
178 http1=http1,
179 http2=http2,
180 )
181 else: # pragma: no cover
182 raise ValueError(
183 f"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}."
184 )
185
186 def __enter__(self: T) -> T: # Use generics for subclass support.
187 self._pool.__enter__()
188 return self
189
190 def __exit__(
191 self,
192 exc_type: typing.Optional[typing.Type[BaseException]] = None,
193 exc_value: typing.Optional[BaseException] = None,
194 traceback: typing.Optional[TracebackType] = None,
195 ) -> None:
196 with map_httpcore_exceptions():
197 self._pool.__exit__(exc_type, exc_value, traceback)
198
199 def handle_request(
200 self,
201 request: Request,
202 ) -> Response:
203 assert isinstance(request.stream, SyncByteStream)
204
205 req = httpcore.Request(
206 method=request.method,
207 url=httpcore.URL(
208 scheme=request.url.raw_scheme,
209 host=request.url.raw_host,
210 port=request.url.port,
211 target=request.url.raw_path,
212 ),
213 headers=request.headers.raw,
214 content=request.stream,
215 extensions=request.extensions,
216 )
217 with map_httpcore_exceptions():
218 resp = self._pool.handle_request(req)
219
220 assert isinstance(resp.stream, typing.Iterable)
221
222 return Response(
223 status_code=resp.status,
224 headers=resp.headers,
225 stream=ResponseStream(resp.stream),
226 extensions=resp.extensions,
227 )
228
229 def close(self) -> None:
230 self._pool.close()
231
232
233 class AsyncResponseStream(AsyncByteStream):
234 def __init__(self, httpcore_stream: typing.AsyncIterable[bytes]):
235 self._httpcore_stream = httpcore_stream
236
237 async def __aiter__(self) -> typing.AsyncIterator[bytes]:
238 with map_httpcore_exceptions():
239 async for part in self._httpcore_stream:
240 yield part
241
242 async def aclose(self) -> None:
243 if hasattr(self._httpcore_stream, "aclose"):
244 await self._httpcore_stream.aclose()
245
246
247 class AsyncHTTPTransport(AsyncBaseTransport):
248 def __init__(
249 self,
250 verify: VerifyTypes = True,
251 cert: typing.Optional[CertTypes] = None,
252 http1: bool = True,
253 http2: bool = False,
254 limits: Limits = DEFAULT_LIMITS,
255 trust_env: bool = True,
256 proxy: typing.Optional[Proxy] = None,
257 uds: typing.Optional[str] = None,
258 local_address: typing.Optional[str] = None,
259 retries: int = 0,
260 ) -> None:
261 ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)
262
263 if proxy is None:
264 self._pool = httpcore.AsyncConnectionPool(
265 ssl_context=ssl_context,
266 max_connections=limits.max_connections,
267 max_keepalive_connections=limits.max_keepalive_connections,
268 keepalive_expiry=limits.keepalive_expiry,
269 http1=http1,
270 http2=http2,
271 uds=uds,
272 local_address=local_address,
273 retries=retries,
274 )
275 elif proxy.url.scheme in ("http", "https"):
276 self._pool = httpcore.AsyncHTTPProxy(
277 proxy_url=httpcore.URL(
278 scheme=proxy.url.raw_scheme,
279 host=proxy.url.raw_host,
280 port=proxy.url.port,
281 target=proxy.url.raw_path,
282 ),
283 proxy_auth=proxy.raw_auth,
284 proxy_headers=proxy.headers.raw,
285 ssl_context=ssl_context,
286 max_connections=limits.max_connections,
287 max_keepalive_connections=limits.max_keepalive_connections,
288 keepalive_expiry=limits.keepalive_expiry,
289 http1=http1,
290 http2=http2,
291 )
292 elif proxy.url.scheme == "socks5":
293 try:
294 import socksio # noqa
295 except ImportError: # pragma: no cover
296 raise ImportError(
297 "Using SOCKS proxy, but the 'socksio' package is not installed. "
298 "Make sure to install httpx using `pip install httpx[socks]`."
299 ) from None
300
301 self._pool = httpcore.AsyncSOCKSProxy(
302 proxy_url=httpcore.URL(
303 scheme=proxy.url.raw_scheme,
304 host=proxy.url.raw_host,
305 port=proxy.url.port,
306 target=proxy.url.raw_path,
307 ),
308 proxy_auth=proxy.raw_auth,
309 ssl_context=ssl_context,
310 max_connections=limits.max_connections,
311 max_keepalive_connections=limits.max_keepalive_connections,
312 keepalive_expiry=limits.keepalive_expiry,
313 http1=http1,
314 http2=http2,
315 )
316 else: # pragma: no cover
317 raise ValueError(
318 f"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}."
319 )
320
321 async def __aenter__(self: A) -> A: # Use generics for subclass support.
322 await self._pool.__aenter__()
323 return self
324
325 async def __aexit__(
326 self,
327 exc_type: typing.Optional[typing.Type[BaseException]] = None,
328 exc_value: typing.Optional[BaseException] = None,
329 traceback: typing.Optional[TracebackType] = None,
330 ) -> None:
331 with map_httpcore_exceptions():
332 await self._pool.__aexit__(exc_type, exc_value, traceback)
333
334 async def handle_async_request(
335 self,
336 request: Request,
337 ) -> Response:
338 assert isinstance(request.stream, AsyncByteStream)
339
340 req = httpcore.Request(
341 method=request.method,
342 url=httpcore.URL(
343 scheme=request.url.raw_scheme,
344 host=request.url.raw_host,
345 port=request.url.port,
346 target=request.url.raw_path,
347 ),
348 headers=request.headers.raw,
349 content=request.stream,
350 extensions=request.extensions,
351 )
352 with map_httpcore_exceptions():
353 resp = await self._pool.handle_async_request(req)
354
355 assert isinstance(resp.stream, typing.AsyncIterable)
356
357 return Response(
358 status_code=resp.status,
359 headers=resp.headers,
360 stream=AsyncResponseStream(resp.stream),
361 extensions=resp.extensions,
362 )
363
364 async def aclose(self) -> None:
365 await self._pool.aclose()
366
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/httpx/_transports/default.py b/httpx/_transports/default.py
--- a/httpx/_transports/default.py
+++ b/httpx/_transports/default.py
@@ -53,6 +53,12 @@
T = typing.TypeVar("T", bound="HTTPTransport")
A = typing.TypeVar("A", bound="AsyncHTTPTransport")
+SOCKET_OPTION = typing.Union[
+ typing.Tuple[int, int, int],
+ typing.Tuple[int, int, typing.Union[bytes, bytearray]],
+ typing.Tuple[int, int, None, int],
+]
+
@contextlib.contextmanager
def map_httpcore_exceptions() -> typing.Iterator[None]:
@@ -122,6 +128,7 @@
uds: typing.Optional[str] = None,
local_address: typing.Optional[str] = None,
retries: int = 0,
+ socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
) -> None:
ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)
@@ -136,6 +143,7 @@
uds=uds,
local_address=local_address,
retries=retries,
+ socket_options=socket_options,
)
elif proxy.url.scheme in ("http", "https"):
self._pool = httpcore.HTTPProxy(
@@ -153,6 +161,7 @@
keepalive_expiry=limits.keepalive_expiry,
http1=http1,
http2=http2,
+ socket_options=socket_options,
)
elif proxy.url.scheme == "socks5":
try:
@@ -257,6 +266,7 @@
uds: typing.Optional[str] = None,
local_address: typing.Optional[str] = None,
retries: int = 0,
+ socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
) -> None:
ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)
@@ -271,6 +281,7 @@
uds=uds,
local_address=local_address,
retries=retries,
+ socket_options=socket_options,
)
elif proxy.url.scheme in ("http", "https"):
self._pool = httpcore.AsyncHTTPProxy(
@@ -288,6 +299,7 @@
keepalive_expiry=limits.keepalive_expiry,
http1=http1,
http2=http2,
+ socket_options=socket_options,
)
elif proxy.url.scheme == "socks5":
try:
|
{"golden_diff": "diff --git a/httpx/_transports/default.py b/httpx/_transports/default.py\n--- a/httpx/_transports/default.py\n+++ b/httpx/_transports/default.py\n@@ -53,6 +53,12 @@\n T = typing.TypeVar(\"T\", bound=\"HTTPTransport\")\n A = typing.TypeVar(\"A\", bound=\"AsyncHTTPTransport\")\n \n+SOCKET_OPTION = typing.Union[\n+ typing.Tuple[int, int, int],\n+ typing.Tuple[int, int, typing.Union[bytes, bytearray]],\n+ typing.Tuple[int, int, None, int],\n+]\n+\n \n @contextlib.contextmanager\n def map_httpcore_exceptions() -> typing.Iterator[None]:\n@@ -122,6 +128,7 @@\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n+ socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n \n@@ -136,6 +143,7 @@\n uds=uds,\n local_address=local_address,\n retries=retries,\n+ socket_options=socket_options,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.HTTPProxy(\n@@ -153,6 +161,7 @@\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n+ socket_options=socket_options,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n@@ -257,6 +266,7 @@\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n+ socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n \n@@ -271,6 +281,7 @@\n uds=uds,\n local_address=local_address,\n retries=retries,\n+ socket_options=socket_options,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.AsyncHTTPProxy(\n@@ -288,6 +299,7 @@\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n+ socket_options=socket_options,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n", "issue": "Add `socket_options` to `httpx.HTTPTransport`.\nSince [version 0.17.2](https://github.com/encode/httpcore/pull/697#issuecomment-1559059612) the `httpcore` package has support for a `socket_options` parameter.\r\nWe should add a corresponding parameter to `httpx.HTTPTransport`, which can be passed through to the connection pool.\r\n\r\nThis will resolve the use-case raised in discussion https://github.com/encode/httpx/discussions/2635...\r\n\r\n```python\r\n>>> import httpx\r\n>>> socket_options = [(socket.SOL_SOCKET, socket.SO_BINDTODEVICE, b\"ETH999\")]\r\n>>> transport = httpx.HTTPTransport(socket_options=socket_options)\r\n>>> client = httpx.Client(transport=transport)\r\n```\n", "before_files": [{"content": "\"\"\"\nCustom transports, with nicely configured defaults.\n\nThe following additional keyword arguments are currently supported by httpcore...\n\n* uds: str\n* local_address: str\n* retries: int\n\nExample usages...\n\n# Disable HTTP/2 on a single specific domain.\nmounts = {\n \"all://\": httpx.HTTPTransport(http2=True),\n \"all://*example.org\": httpx.HTTPTransport()\n}\n\n# Using advanced httpcore configuration, with connection retries.\ntransport = httpx.HTTPTransport(retries=1)\nclient = httpx.Client(transport=transport)\n\n# Using advanced httpcore configuration, with unix domain sockets.\ntransport = httpx.HTTPTransport(uds=\"socket.uds\")\nclient = httpx.Client(transport=transport)\n\"\"\"\nimport contextlib\nimport typing\nfrom types import TracebackType\n\nimport httpcore\n\nfrom .._config import DEFAULT_LIMITS, Limits, Proxy, create_ssl_context\nfrom .._exceptions import (\n ConnectError,\n ConnectTimeout,\n LocalProtocolError,\n NetworkError,\n PoolTimeout,\n ProtocolError,\n ProxyError,\n ReadError,\n ReadTimeout,\n RemoteProtocolError,\n TimeoutException,\n UnsupportedProtocol,\n WriteError,\n WriteTimeout,\n)\nfrom .._models import Request, Response\nfrom .._types import AsyncByteStream, CertTypes, SyncByteStream, VerifyTypes\nfrom .base import AsyncBaseTransport, BaseTransport\n\nT = typing.TypeVar(\"T\", bound=\"HTTPTransport\")\nA = typing.TypeVar(\"A\", bound=\"AsyncHTTPTransport\")\n\n\[email protected]\ndef map_httpcore_exceptions() -> typing.Iterator[None]:\n try:\n yield\n except Exception as exc: # noqa: PIE-786\n mapped_exc = None\n\n for from_exc, to_exc in HTTPCORE_EXC_MAP.items():\n if not isinstance(exc, from_exc):\n continue\n # We want to map to the most specific exception we can find.\n # Eg if `exc` is an `httpcore.ReadTimeout`, we want to map to\n # `httpx.ReadTimeout`, not just `httpx.TimeoutException`.\n if mapped_exc is None or issubclass(to_exc, mapped_exc):\n mapped_exc = to_exc\n\n if mapped_exc is None: # pragma: no cover\n raise\n\n message = str(exc)\n raise mapped_exc(message) from exc\n\n\nHTTPCORE_EXC_MAP = {\n httpcore.TimeoutException: TimeoutException,\n httpcore.ConnectTimeout: ConnectTimeout,\n httpcore.ReadTimeout: ReadTimeout,\n httpcore.WriteTimeout: WriteTimeout,\n httpcore.PoolTimeout: PoolTimeout,\n httpcore.NetworkError: NetworkError,\n httpcore.ConnectError: ConnectError,\n httpcore.ReadError: ReadError,\n httpcore.WriteError: WriteError,\n httpcore.ProxyError: ProxyError,\n httpcore.UnsupportedProtocol: UnsupportedProtocol,\n httpcore.ProtocolError: ProtocolError,\n httpcore.LocalProtocolError: LocalProtocolError,\n httpcore.RemoteProtocolError: RemoteProtocolError,\n}\n\n\nclass ResponseStream(SyncByteStream):\n def __init__(self, httpcore_stream: typing.Iterable[bytes]):\n self._httpcore_stream = httpcore_stream\n\n def __iter__(self) -> typing.Iterator[bytes]:\n with map_httpcore_exceptions():\n for part in self._httpcore_stream:\n yield part\n\n def close(self) -> None:\n if hasattr(self._httpcore_stream, \"close\"):\n self._httpcore_stream.close()\n\n\nclass HTTPTransport(BaseTransport):\n def __init__(\n self,\n verify: VerifyTypes = True,\n cert: typing.Optional[CertTypes] = None,\n http1: bool = True,\n http2: bool = False,\n limits: Limits = DEFAULT_LIMITS,\n trust_env: bool = True,\n proxy: typing.Optional[Proxy] = None,\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n\n if proxy is None:\n self._pool = httpcore.ConnectionPool(\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n uds=uds,\n local_address=local_address,\n retries=retries,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.HTTPProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n proxy_headers=proxy.headers.raw,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n import socksio # noqa\n except ImportError: # pragma: no cover\n raise ImportError(\n \"Using SOCKS proxy, but the 'socksio' package is not installed. \"\n \"Make sure to install httpx using `pip install httpx[socks]`.\"\n ) from None\n\n self._pool = httpcore.SOCKSProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n else: # pragma: no cover\n raise ValueError(\n f\"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}.\"\n )\n\n def __enter__(self: T) -> T: # Use generics for subclass support.\n self._pool.__enter__()\n return self\n\n def __exit__(\n self,\n exc_type: typing.Optional[typing.Type[BaseException]] = None,\n exc_value: typing.Optional[BaseException] = None,\n traceback: typing.Optional[TracebackType] = None,\n ) -> None:\n with map_httpcore_exceptions():\n self._pool.__exit__(exc_type, exc_value, traceback)\n\n def handle_request(\n self,\n request: Request,\n ) -> Response:\n assert isinstance(request.stream, SyncByteStream)\n\n req = httpcore.Request(\n method=request.method,\n url=httpcore.URL(\n scheme=request.url.raw_scheme,\n host=request.url.raw_host,\n port=request.url.port,\n target=request.url.raw_path,\n ),\n headers=request.headers.raw,\n content=request.stream,\n extensions=request.extensions,\n )\n with map_httpcore_exceptions():\n resp = self._pool.handle_request(req)\n\n assert isinstance(resp.stream, typing.Iterable)\n\n return Response(\n status_code=resp.status,\n headers=resp.headers,\n stream=ResponseStream(resp.stream),\n extensions=resp.extensions,\n )\n\n def close(self) -> None:\n self._pool.close()\n\n\nclass AsyncResponseStream(AsyncByteStream):\n def __init__(self, httpcore_stream: typing.AsyncIterable[bytes]):\n self._httpcore_stream = httpcore_stream\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n with map_httpcore_exceptions():\n async for part in self._httpcore_stream:\n yield part\n\n async def aclose(self) -> None:\n if hasattr(self._httpcore_stream, \"aclose\"):\n await self._httpcore_stream.aclose()\n\n\nclass AsyncHTTPTransport(AsyncBaseTransport):\n def __init__(\n self,\n verify: VerifyTypes = True,\n cert: typing.Optional[CertTypes] = None,\n http1: bool = True,\n http2: bool = False,\n limits: Limits = DEFAULT_LIMITS,\n trust_env: bool = True,\n proxy: typing.Optional[Proxy] = None,\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n\n if proxy is None:\n self._pool = httpcore.AsyncConnectionPool(\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n uds=uds,\n local_address=local_address,\n retries=retries,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.AsyncHTTPProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n proxy_headers=proxy.headers.raw,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n import socksio # noqa\n except ImportError: # pragma: no cover\n raise ImportError(\n \"Using SOCKS proxy, but the 'socksio' package is not installed. \"\n \"Make sure to install httpx using `pip install httpx[socks]`.\"\n ) from None\n\n self._pool = httpcore.AsyncSOCKSProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n else: # pragma: no cover\n raise ValueError(\n f\"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}.\"\n )\n\n async def __aenter__(self: A) -> A: # Use generics for subclass support.\n await self._pool.__aenter__()\n return self\n\n async def __aexit__(\n self,\n exc_type: typing.Optional[typing.Type[BaseException]] = None,\n exc_value: typing.Optional[BaseException] = None,\n traceback: typing.Optional[TracebackType] = None,\n ) -> None:\n with map_httpcore_exceptions():\n await self._pool.__aexit__(exc_type, exc_value, traceback)\n\n async def handle_async_request(\n self,\n request: Request,\n ) -> Response:\n assert isinstance(request.stream, AsyncByteStream)\n\n req = httpcore.Request(\n method=request.method,\n url=httpcore.URL(\n scheme=request.url.raw_scheme,\n host=request.url.raw_host,\n port=request.url.port,\n target=request.url.raw_path,\n ),\n headers=request.headers.raw,\n content=request.stream,\n extensions=request.extensions,\n )\n with map_httpcore_exceptions():\n resp = await self._pool.handle_async_request(req)\n\n assert isinstance(resp.stream, typing.AsyncIterable)\n\n return Response(\n status_code=resp.status,\n headers=resp.headers,\n stream=AsyncResponseStream(resp.stream),\n extensions=resp.extensions,\n )\n\n async def aclose(self) -> None:\n await self._pool.aclose()\n", "path": "httpx/_transports/default.py"}], "after_files": [{"content": "\"\"\"\nCustom transports, with nicely configured defaults.\n\nThe following additional keyword arguments are currently supported by httpcore...\n\n* uds: str\n* local_address: str\n* retries: int\n\nExample usages...\n\n# Disable HTTP/2 on a single specific domain.\nmounts = {\n \"all://\": httpx.HTTPTransport(http2=True),\n \"all://*example.org\": httpx.HTTPTransport()\n}\n\n# Using advanced httpcore configuration, with connection retries.\ntransport = httpx.HTTPTransport(retries=1)\nclient = httpx.Client(transport=transport)\n\n# Using advanced httpcore configuration, with unix domain sockets.\ntransport = httpx.HTTPTransport(uds=\"socket.uds\")\nclient = httpx.Client(transport=transport)\n\"\"\"\nimport contextlib\nimport typing\nfrom types import TracebackType\n\nimport httpcore\n\nfrom .._config import DEFAULT_LIMITS, Limits, Proxy, create_ssl_context\nfrom .._exceptions import (\n ConnectError,\n ConnectTimeout,\n LocalProtocolError,\n NetworkError,\n PoolTimeout,\n ProtocolError,\n ProxyError,\n ReadError,\n ReadTimeout,\n RemoteProtocolError,\n TimeoutException,\n UnsupportedProtocol,\n WriteError,\n WriteTimeout,\n)\nfrom .._models import Request, Response\nfrom .._types import AsyncByteStream, CertTypes, SyncByteStream, VerifyTypes\nfrom .base import AsyncBaseTransport, BaseTransport\n\nT = typing.TypeVar(\"T\", bound=\"HTTPTransport\")\nA = typing.TypeVar(\"A\", bound=\"AsyncHTTPTransport\")\n\nSOCKET_OPTION = typing.Union[\n typing.Tuple[int, int, int],\n typing.Tuple[int, int, typing.Union[bytes, bytearray]],\n typing.Tuple[int, int, None, int],\n]\n\n\[email protected]\ndef map_httpcore_exceptions() -> typing.Iterator[None]:\n try:\n yield\n except Exception as exc: # noqa: PIE-786\n mapped_exc = None\n\n for from_exc, to_exc in HTTPCORE_EXC_MAP.items():\n if not isinstance(exc, from_exc):\n continue\n # We want to map to the most specific exception we can find.\n # Eg if `exc` is an `httpcore.ReadTimeout`, we want to map to\n # `httpx.ReadTimeout`, not just `httpx.TimeoutException`.\n if mapped_exc is None or issubclass(to_exc, mapped_exc):\n mapped_exc = to_exc\n\n if mapped_exc is None: # pragma: no cover\n raise\n\n message = str(exc)\n raise mapped_exc(message) from exc\n\n\nHTTPCORE_EXC_MAP = {\n httpcore.TimeoutException: TimeoutException,\n httpcore.ConnectTimeout: ConnectTimeout,\n httpcore.ReadTimeout: ReadTimeout,\n httpcore.WriteTimeout: WriteTimeout,\n httpcore.PoolTimeout: PoolTimeout,\n httpcore.NetworkError: NetworkError,\n httpcore.ConnectError: ConnectError,\n httpcore.ReadError: ReadError,\n httpcore.WriteError: WriteError,\n httpcore.ProxyError: ProxyError,\n httpcore.UnsupportedProtocol: UnsupportedProtocol,\n httpcore.ProtocolError: ProtocolError,\n httpcore.LocalProtocolError: LocalProtocolError,\n httpcore.RemoteProtocolError: RemoteProtocolError,\n}\n\n\nclass ResponseStream(SyncByteStream):\n def __init__(self, httpcore_stream: typing.Iterable[bytes]):\n self._httpcore_stream = httpcore_stream\n\n def __iter__(self) -> typing.Iterator[bytes]:\n with map_httpcore_exceptions():\n for part in self._httpcore_stream:\n yield part\n\n def close(self) -> None:\n if hasattr(self._httpcore_stream, \"close\"):\n self._httpcore_stream.close()\n\n\nclass HTTPTransport(BaseTransport):\n def __init__(\n self,\n verify: VerifyTypes = True,\n cert: typing.Optional[CertTypes] = None,\n http1: bool = True,\n http2: bool = False,\n limits: Limits = DEFAULT_LIMITS,\n trust_env: bool = True,\n proxy: typing.Optional[Proxy] = None,\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n\n if proxy is None:\n self._pool = httpcore.ConnectionPool(\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n uds=uds,\n local_address=local_address,\n retries=retries,\n socket_options=socket_options,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.HTTPProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n proxy_headers=proxy.headers.raw,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n socket_options=socket_options,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n import socksio # noqa\n except ImportError: # pragma: no cover\n raise ImportError(\n \"Using SOCKS proxy, but the 'socksio' package is not installed. \"\n \"Make sure to install httpx using `pip install httpx[socks]`.\"\n ) from None\n\n self._pool = httpcore.SOCKSProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n else: # pragma: no cover\n raise ValueError(\n f\"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}.\"\n )\n\n def __enter__(self: T) -> T: # Use generics for subclass support.\n self._pool.__enter__()\n return self\n\n def __exit__(\n self,\n exc_type: typing.Optional[typing.Type[BaseException]] = None,\n exc_value: typing.Optional[BaseException] = None,\n traceback: typing.Optional[TracebackType] = None,\n ) -> None:\n with map_httpcore_exceptions():\n self._pool.__exit__(exc_type, exc_value, traceback)\n\n def handle_request(\n self,\n request: Request,\n ) -> Response:\n assert isinstance(request.stream, SyncByteStream)\n\n req = httpcore.Request(\n method=request.method,\n url=httpcore.URL(\n scheme=request.url.raw_scheme,\n host=request.url.raw_host,\n port=request.url.port,\n target=request.url.raw_path,\n ),\n headers=request.headers.raw,\n content=request.stream,\n extensions=request.extensions,\n )\n with map_httpcore_exceptions():\n resp = self._pool.handle_request(req)\n\n assert isinstance(resp.stream, typing.Iterable)\n\n return Response(\n status_code=resp.status,\n headers=resp.headers,\n stream=ResponseStream(resp.stream),\n extensions=resp.extensions,\n )\n\n def close(self) -> None:\n self._pool.close()\n\n\nclass AsyncResponseStream(AsyncByteStream):\n def __init__(self, httpcore_stream: typing.AsyncIterable[bytes]):\n self._httpcore_stream = httpcore_stream\n\n async def __aiter__(self) -> typing.AsyncIterator[bytes]:\n with map_httpcore_exceptions():\n async for part in self._httpcore_stream:\n yield part\n\n async def aclose(self) -> None:\n if hasattr(self._httpcore_stream, \"aclose\"):\n await self._httpcore_stream.aclose()\n\n\nclass AsyncHTTPTransport(AsyncBaseTransport):\n def __init__(\n self,\n verify: VerifyTypes = True,\n cert: typing.Optional[CertTypes] = None,\n http1: bool = True,\n http2: bool = False,\n limits: Limits = DEFAULT_LIMITS,\n trust_env: bool = True,\n proxy: typing.Optional[Proxy] = None,\n uds: typing.Optional[str] = None,\n local_address: typing.Optional[str] = None,\n retries: int = 0,\n socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,\n ) -> None:\n ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env)\n\n if proxy is None:\n self._pool = httpcore.AsyncConnectionPool(\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n uds=uds,\n local_address=local_address,\n retries=retries,\n socket_options=socket_options,\n )\n elif proxy.url.scheme in (\"http\", \"https\"):\n self._pool = httpcore.AsyncHTTPProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n proxy_headers=proxy.headers.raw,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n socket_options=socket_options,\n )\n elif proxy.url.scheme == \"socks5\":\n try:\n import socksio # noqa\n except ImportError: # pragma: no cover\n raise ImportError(\n \"Using SOCKS proxy, but the 'socksio' package is not installed. \"\n \"Make sure to install httpx using `pip install httpx[socks]`.\"\n ) from None\n\n self._pool = httpcore.AsyncSOCKSProxy(\n proxy_url=httpcore.URL(\n scheme=proxy.url.raw_scheme,\n host=proxy.url.raw_host,\n port=proxy.url.port,\n target=proxy.url.raw_path,\n ),\n proxy_auth=proxy.raw_auth,\n ssl_context=ssl_context,\n max_connections=limits.max_connections,\n max_keepalive_connections=limits.max_keepalive_connections,\n keepalive_expiry=limits.keepalive_expiry,\n http1=http1,\n http2=http2,\n )\n else: # pragma: no cover\n raise ValueError(\n f\"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}.\"\n )\n\n async def __aenter__(self: A) -> A: # Use generics for subclass support.\n await self._pool.__aenter__()\n return self\n\n async def __aexit__(\n self,\n exc_type: typing.Optional[typing.Type[BaseException]] = None,\n exc_value: typing.Optional[BaseException] = None,\n traceback: typing.Optional[TracebackType] = None,\n ) -> None:\n with map_httpcore_exceptions():\n await self._pool.__aexit__(exc_type, exc_value, traceback)\n\n async def handle_async_request(\n self,\n request: Request,\n ) -> Response:\n assert isinstance(request.stream, AsyncByteStream)\n\n req = httpcore.Request(\n method=request.method,\n url=httpcore.URL(\n scheme=request.url.raw_scheme,\n host=request.url.raw_host,\n port=request.url.port,\n target=request.url.raw_path,\n ),\n headers=request.headers.raw,\n content=request.stream,\n extensions=request.extensions,\n )\n with map_httpcore_exceptions():\n resp = await self._pool.handle_async_request(req)\n\n assert isinstance(resp.stream, typing.AsyncIterable)\n\n return Response(\n status_code=resp.status,\n headers=resp.headers,\n stream=AsyncResponseStream(resp.stream),\n extensions=resp.extensions,\n )\n\n async def aclose(self) -> None:\n await self._pool.aclose()\n", "path": "httpx/_transports/default.py"}]}
| 4,060 | 584 |
gh_patches_debug_32462
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-59557
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate the ProjectCombinedRuleIndexEndpoint
[GCP API access logs](https://console.cloud.google.com/logs/query;query=resource.type%20%3D%20k8s_container%0Aresource.labels.namespace_name%20%3D%20default%0Aresource.labels.container_name%20%3D%20sentry%0Alabels.name%20%3D%20sentry.access.api%0AjsonPayload.view%3D~%22ProjectCombinedRuleIndexEndpoint%22;summaryFields=:true:32:beginning;lfeCustomFields=jsonPayload%252Fview,jsonPayload%252Forganization_id;cursorTimestamp=2023-09-06T18:29:05.855473577Z;startTime=2023-09-06T16:51:17.461Z;endTime=2023-09-06T23:51:17.461482Z?project=internal-sentry) show that it's not used by us, and only by 2 customers. It's an undocumented endpoint so we can [set the deprecation header](https://www.notion.so/sentry/Sentry-API-Deprecation-Policy-ccbdea15a34c4fdeb50985685adc3368) and get rid of it.
Related to https://github.com/getsentry/sentry/issues/54005
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/incidents/endpoints/project_alert_rule_index.py`
Content:
```
1 from __future__ import annotations
2
3 from rest_framework.request import Request
4 from rest_framework.response import Response
5
6 from sentry import features
7 from sentry.api.api_publish_status import ApiPublishStatus
8 from sentry.api.base import region_silo_endpoint
9 from sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint
10 from sentry.api.paginator import CombinedQuerysetIntermediary, CombinedQuerysetPaginator
11 from sentry.api.serializers import CombinedRuleSerializer, serialize
12 from sentry.constants import ObjectStatus
13 from sentry.incidents.endpoints.organization_alert_rule_index import AlertRuleIndexMixin
14 from sentry.incidents.models import AlertRule
15 from sentry.models.rule import Rule
16 from sentry.snuba.dataset import Dataset
17
18
19 @region_silo_endpoint
20 class ProjectCombinedRuleIndexEndpoint(ProjectEndpoint):
21 publish_status = {
22 "GET": ApiPublishStatus.UNKNOWN,
23 }
24
25 def get(self, request: Request, project) -> Response:
26 """
27 Fetches alert rules and legacy rules for a project
28 """
29 alert_rules = AlertRule.objects.fetch_for_project(project)
30 if not features.has("organizations:performance-view", project.organization):
31 # Filter to only error alert rules
32 alert_rules = alert_rules.filter(snuba_query__dataset=Dataset.Events.value)
33
34 alert_rule_intermediary = CombinedQuerysetIntermediary(alert_rules, ["date_added"])
35 rule_intermediary = CombinedQuerysetIntermediary(
36 Rule.objects.filter(
37 project=project,
38 status=ObjectStatus.ACTIVE,
39 ),
40 ["date_added"],
41 )
42
43 return self.paginate(
44 request,
45 paginator_cls=CombinedQuerysetPaginator,
46 on_results=lambda x: serialize(x, request.user, CombinedRuleSerializer()),
47 default_per_page=25,
48 intermediaries=[alert_rule_intermediary, rule_intermediary],
49 desc=True,
50 )
51
52
53 @region_silo_endpoint
54 class ProjectAlertRuleIndexEndpoint(ProjectEndpoint, AlertRuleIndexMixin):
55 publish_status = {
56 "GET": ApiPublishStatus.UNKNOWN,
57 "POST": ApiPublishStatus.UNKNOWN,
58 }
59 permission_classes = (ProjectAlertRulePermission,)
60
61 def get(self, request: Request, project) -> Response:
62 """
63 Fetches metric alert rules for a project - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.
64 """
65 return self.fetch_metric_alert(request, project.organization, project)
66
67 def post(self, request: Request, project) -> Response:
68 """
69 Create an alert rule - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.
70 """
71 return self.create_metric_alert(request, project.organization, project)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/sentry/incidents/endpoints/project_alert_rule_index.py b/src/sentry/incidents/endpoints/project_alert_rule_index.py
--- a/src/sentry/incidents/endpoints/project_alert_rule_index.py
+++ b/src/sentry/incidents/endpoints/project_alert_rule_index.py
@@ -1,5 +1,7 @@
from __future__ import annotations
+from datetime import datetime
+
from rest_framework.request import Request
from rest_framework.response import Response
@@ -7,6 +9,7 @@
from sentry.api.api_publish_status import ApiPublishStatus
from sentry.api.base import region_silo_endpoint
from sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint
+from sentry.api.helpers.deprecation import deprecated
from sentry.api.paginator import CombinedQuerysetIntermediary, CombinedQuerysetPaginator
from sentry.api.serializers import CombinedRuleSerializer, serialize
from sentry.constants import ObjectStatus
@@ -18,13 +21,15 @@
@region_silo_endpoint
class ProjectCombinedRuleIndexEndpoint(ProjectEndpoint):
+ DEPRECATION_DATE = datetime.fromisoformat("2024-02-07T00:00:00+00:00:00")
publish_status = {
"GET": ApiPublishStatus.UNKNOWN,
}
+ @deprecated(DEPRECATION_DATE, "sentry-api-0-organization-combined-rules")
def get(self, request: Request, project) -> Response:
"""
- Fetches alert rules and legacy rules for a project
+ Fetches alert rules and legacy rules for a project. @deprecated. Use OrganizationCombinedRuleIndexEndpoint instead.
"""
alert_rules = AlertRule.objects.fetch_for_project(project)
if not features.has("organizations:performance-view", project.organization):
|
{"golden_diff": "diff --git a/src/sentry/incidents/endpoints/project_alert_rule_index.py b/src/sentry/incidents/endpoints/project_alert_rule_index.py\n--- a/src/sentry/incidents/endpoints/project_alert_rule_index.py\n+++ b/src/sentry/incidents/endpoints/project_alert_rule_index.py\n@@ -1,5 +1,7 @@\n from __future__ import annotations\n \n+from datetime import datetime\n+\n from rest_framework.request import Request\n from rest_framework.response import Response\n \n@@ -7,6 +9,7 @@\n from sentry.api.api_publish_status import ApiPublishStatus\n from sentry.api.base import region_silo_endpoint\n from sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint\n+from sentry.api.helpers.deprecation import deprecated\n from sentry.api.paginator import CombinedQuerysetIntermediary, CombinedQuerysetPaginator\n from sentry.api.serializers import CombinedRuleSerializer, serialize\n from sentry.constants import ObjectStatus\n@@ -18,13 +21,15 @@\n \n @region_silo_endpoint\n class ProjectCombinedRuleIndexEndpoint(ProjectEndpoint):\n+ DEPRECATION_DATE = datetime.fromisoformat(\"2024-02-07T00:00:00+00:00:00\")\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n }\n \n+ @deprecated(DEPRECATION_DATE, \"sentry-api-0-organization-combined-rules\")\n def get(self, request: Request, project) -> Response:\n \"\"\"\n- Fetches alert rules and legacy rules for a project\n+ Fetches alert rules and legacy rules for a project. @deprecated. Use OrganizationCombinedRuleIndexEndpoint instead.\n \"\"\"\n alert_rules = AlertRule.objects.fetch_for_project(project)\n if not features.has(\"organizations:performance-view\", project.organization):\n", "issue": "Deprecate the ProjectCombinedRuleIndexEndpoint\n[GCP API access logs](https://console.cloud.google.com/logs/query;query=resource.type%20%3D%20k8s_container%0Aresource.labels.namespace_name%20%3D%20default%0Aresource.labels.container_name%20%3D%20sentry%0Alabels.name%20%3D%20sentry.access.api%0AjsonPayload.view%3D~%22ProjectCombinedRuleIndexEndpoint%22;summaryFields=:true:32:beginning;lfeCustomFields=jsonPayload%252Fview,jsonPayload%252Forganization_id;cursorTimestamp=2023-09-06T18:29:05.855473577Z;startTime=2023-09-06T16:51:17.461Z;endTime=2023-09-06T23:51:17.461482Z?project=internal-sentry) show that it's not used by us, and only by 2 customers. It's an undocumented endpoint so we can [set the deprecation header](https://www.notion.so/sentry/Sentry-API-Deprecation-Policy-ccbdea15a34c4fdeb50985685adc3368) and get rid of it. \n\nRelated to https://github.com/getsentry/sentry/issues/54005\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom sentry import features\nfrom sentry.api.api_publish_status import ApiPublishStatus\nfrom sentry.api.base import region_silo_endpoint\nfrom sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint\nfrom sentry.api.paginator import CombinedQuerysetIntermediary, CombinedQuerysetPaginator\nfrom sentry.api.serializers import CombinedRuleSerializer, serialize\nfrom sentry.constants import ObjectStatus\nfrom sentry.incidents.endpoints.organization_alert_rule_index import AlertRuleIndexMixin\nfrom sentry.incidents.models import AlertRule\nfrom sentry.models.rule import Rule\nfrom sentry.snuba.dataset import Dataset\n\n\n@region_silo_endpoint\nclass ProjectCombinedRuleIndexEndpoint(ProjectEndpoint):\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n }\n\n def get(self, request: Request, project) -> Response:\n \"\"\"\n Fetches alert rules and legacy rules for a project\n \"\"\"\n alert_rules = AlertRule.objects.fetch_for_project(project)\n if not features.has(\"organizations:performance-view\", project.organization):\n # Filter to only error alert rules\n alert_rules = alert_rules.filter(snuba_query__dataset=Dataset.Events.value)\n\n alert_rule_intermediary = CombinedQuerysetIntermediary(alert_rules, [\"date_added\"])\n rule_intermediary = CombinedQuerysetIntermediary(\n Rule.objects.filter(\n project=project,\n status=ObjectStatus.ACTIVE,\n ),\n [\"date_added\"],\n )\n\n return self.paginate(\n request,\n paginator_cls=CombinedQuerysetPaginator,\n on_results=lambda x: serialize(x, request.user, CombinedRuleSerializer()),\n default_per_page=25,\n intermediaries=[alert_rule_intermediary, rule_intermediary],\n desc=True,\n )\n\n\n@region_silo_endpoint\nclass ProjectAlertRuleIndexEndpoint(ProjectEndpoint, AlertRuleIndexMixin):\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n \"POST\": ApiPublishStatus.UNKNOWN,\n }\n permission_classes = (ProjectAlertRulePermission,)\n\n def get(self, request: Request, project) -> Response:\n \"\"\"\n Fetches metric alert rules for a project - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.\n \"\"\"\n return self.fetch_metric_alert(request, project.organization, project)\n\n def post(self, request: Request, project) -> Response:\n \"\"\"\n Create an alert rule - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.\n \"\"\"\n return self.create_metric_alert(request, project.organization, project)\n", "path": "src/sentry/incidents/endpoints/project_alert_rule_index.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom datetime import datetime\n\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom sentry import features\nfrom sentry.api.api_publish_status import ApiPublishStatus\nfrom sentry.api.base import region_silo_endpoint\nfrom sentry.api.bases.project import ProjectAlertRulePermission, ProjectEndpoint\nfrom sentry.api.helpers.deprecation import deprecated\nfrom sentry.api.paginator import CombinedQuerysetIntermediary, CombinedQuerysetPaginator\nfrom sentry.api.serializers import CombinedRuleSerializer, serialize\nfrom sentry.constants import ObjectStatus\nfrom sentry.incidents.endpoints.organization_alert_rule_index import AlertRuleIndexMixin\nfrom sentry.incidents.models import AlertRule\nfrom sentry.models.rule import Rule\nfrom sentry.snuba.dataset import Dataset\n\n\n@region_silo_endpoint\nclass ProjectCombinedRuleIndexEndpoint(ProjectEndpoint):\n DEPRECATION_DATE = datetime.fromisoformat(\"2024-02-07T00:00:00+00:00:00\")\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n }\n\n @deprecated(DEPRECATION_DATE, \"sentry-api-0-organization-combined-rules\")\n def get(self, request: Request, project) -> Response:\n \"\"\"\n Fetches alert rules and legacy rules for a project. @deprecated. Use OrganizationCombinedRuleIndexEndpoint instead.\n \"\"\"\n alert_rules = AlertRule.objects.fetch_for_project(project)\n if not features.has(\"organizations:performance-view\", project.organization):\n # Filter to only error alert rules\n alert_rules = alert_rules.filter(snuba_query__dataset=Dataset.Events.value)\n\n alert_rule_intermediary = CombinedQuerysetIntermediary(alert_rules, [\"date_added\"])\n rule_intermediary = CombinedQuerysetIntermediary(\n Rule.objects.filter(\n project=project,\n status=ObjectStatus.ACTIVE,\n ),\n [\"date_added\"],\n )\n\n return self.paginate(\n request,\n paginator_cls=CombinedQuerysetPaginator,\n on_results=lambda x: serialize(x, request.user, CombinedRuleSerializer()),\n default_per_page=25,\n intermediaries=[alert_rule_intermediary, rule_intermediary],\n desc=True,\n )\n\n\n@region_silo_endpoint\nclass ProjectAlertRuleIndexEndpoint(ProjectEndpoint, AlertRuleIndexMixin):\n publish_status = {\n \"GET\": ApiPublishStatus.UNKNOWN,\n \"POST\": ApiPublishStatus.UNKNOWN,\n }\n permission_classes = (ProjectAlertRulePermission,)\n\n def get(self, request: Request, project) -> Response:\n \"\"\"\n Fetches metric alert rules for a project - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.\n \"\"\"\n return self.fetch_metric_alert(request, project.organization, project)\n\n def post(self, request: Request, project) -> Response:\n \"\"\"\n Create an alert rule - @deprecated. Use OrganizationAlertRuleIndexEndpoint instead.\n \"\"\"\n return self.create_metric_alert(request, project.organization, project)\n", "path": "src/sentry/incidents/endpoints/project_alert_rule_index.py"}]}
| 1,298 | 389 |
gh_patches_debug_35605
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-2200
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Boucle de requêtes SQL sur les alertes
On a des requêtes en boucle sur les alertes : une requête de chaque type par alerte.
# Requête 1
Dans `zds-site/templates/base.html` ligne 358 : `{% with alerts=user|alerts_list nb_alerts=user|alerts_count %}`
``` sql
SELECT
`utils_comment`.`id`,
`utils_comment`.`author_id`,
`utils_comment`.`editor_id`,
`utils_comment`.`ip_address`,
`utils_comment`.`position`,
`utils_comment`.`text`,
`utils_comment`.`text_html`,
`utils_comment`.`like`,
`utils_comment`.`dislike`,
`utils_comment`.`pubdate`,
`utils_comment`.`update`,
`utils_comment`.`is_visible`,
`utils_comment`.`text_hidden`
FROM
`utils_comment`
WHERE
`utils_comment`.`id` = <ID>
```
# Requête 2
Dans `zds-site/templates/base.html` ligne 358 : `{% with alerts=user|alerts_list nb_alerts=user|alerts_count %}` (oui, c'est la même ligne que la 1) :
``` sql
SELECT
`utils_comment`.`id`,
`utils_comment`.`author_id`,
`utils_comment`.`editor_id`,
`utils_comment`.`ip_address`,
`utils_comment`.`position`,
`utils_comment`.`text`,
`utils_comment`.`text_html`,
`utils_comment`.`like`,
`utils_comment`.`dislike`,
`utils_comment`.`pubdate`,
`utils_comment`.`update`,
`utils_comment`.`is_visible`,
`utils_comment`.`text_hidden`,
`forum_post`.`comment_ptr_id`,
`forum_post`.`topic_id`,
`forum_post`.`is_useful`,
`forum_topic`.`id`,
`forum_topic`.`title`,
`forum_topic`.`subtitle`,
`forum_topic`.`forum_id`,
`forum_topic`.`author_id`,
`forum_topic`.`last_message_id`,
`forum_topic`.`pubdate`,
`forum_topic`.`is_solved`,
`forum_topic`.`is_locked`,
`forum_topic`.`is_sticky`,
`forum_topic`.`key`
FROM
`forum_post`
INNER JOIN
`utils_comment` ON (`forum_post`.`comment_ptr_id` = `utils_comment`.`id`)
INNER JOIN
`forum_topic` ON (`forum_post`.`topic_id` = `forum_topic`.`id`)
WHERE
`forum_post`.`comment_ptr_id` = <ID>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/utils/templatetags/interventions.py`
Content:
```
1 # coding: utf-8
2
3 from datetime import datetime, timedelta
4 import time
5
6 from django import template
7 from django.db.models import Q, F
8
9 from zds.article.models import Reaction, ArticleRead
10 from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead
11 from zds.mp.models import PrivateTopic, PrivateTopicRead
12 from zds.tutorial.models import Note, TutorialRead
13 from zds.utils.models import Alert
14
15
16 register = template.Library()
17
18
19 @register.filter('is_read')
20 def is_read(topic):
21 if never_read_topic(topic):
22 return False
23 else:
24 return True
25
26
27 @register.filter('humane_delta')
28 def humane_delta(value):
29 # mapping between label day and key
30 const = {1: "Aujourd'hui", 2: "Hier", 3: "Cette semaine", 4: "Ce mois-ci", 5: "Cette année"}
31
32 return const[value]
33
34
35 @register.filter('followed_topics')
36 def followed_topics(user):
37 topicsfollowed = TopicFollowed.objects.select_related("topic").filter(user=user)\
38 .order_by('-topic__last_message__pubdate')[:10]
39 # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with
40 # the number of days for which we can say we're still in the period
41 # for exemple, the tuple (2, 1) means for the period "2" corresponding to "Yesterday" according
42 # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at "Yesterday"
43 # Number is use for index for sort map easily
44 period = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))
45 topics = {}
46 for tf in topicsfollowed:
47 for p in period:
48 if tf.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(p[1]),
49 hours=0, minutes=0,
50 seconds=0)).date():
51 if p[0] in topics:
52 topics[p[0]].append(tf.topic)
53 else:
54 topics[p[0]] = [tf.topic]
55 break
56 return topics
57
58
59 def comp(d1, d2):
60 v1 = int(time.mktime(d1['pubdate'].timetuple()))
61 v2 = int(time.mktime(d2['pubdate'].timetuple()))
62 if v1 > v2:
63 return -1
64 elif v1 < v2:
65 return 1
66 else:
67 return 0
68
69
70 @register.filter('interventions_topics')
71 def interventions_topics(user):
72 topicsfollowed = TopicFollowed.objects.filter(user=user).values("topic").distinct().all()
73
74 topics_never_read = TopicRead.objects\
75 .filter(user=user)\
76 .filter(topic__in=topicsfollowed)\
77 .select_related("topic")\
78 .exclude(post=F('topic__last_message'))
79
80 articlesfollowed = Reaction.objects\
81 .filter(author=user, article__sha_public__isnull=False)\
82 .values('article')\
83 .distinct().all()
84
85 articles_never_read = ArticleRead.objects\
86 .filter(user=user)\
87 .filter(article__in=articlesfollowed)\
88 .select_related("article")\
89 .exclude(reaction=F('article__last_reaction'))
90
91 tutorialsfollowed = Note.objects\
92 .filter(author=user, tutorial__sha_public__isnull=False)\
93 .values('tutorial')\
94 .distinct().all()
95
96 tutorials_never_read = TutorialRead.objects\
97 .filter(user=user)\
98 .filter(tutorial__in=tutorialsfollowed)\
99 .exclude(note=F('tutorial__last_note'))
100
101 posts_unread = []
102
103 for art in articles_never_read:
104 content = art.article.first_unread_reaction()
105 posts_unread.append({'pubdate': content.pubdate,
106 'author': content.author,
107 'title': art.article.title,
108 'url': content.get_absolute_url()})
109
110 for tuto in tutorials_never_read:
111 content = tuto.tutorial.first_unread_note()
112 posts_unread.append({'pubdate': content.pubdate,
113 'author': content.author,
114 'title': tuto.tutorial.title,
115 'url': content.get_absolute_url()})
116
117 for top in topics_never_read:
118 content = top.topic.first_unread_post()
119 if content is None:
120 content = top.topic.last_message
121 posts_unread.append({'pubdate': content.pubdate,
122 'author': content.author,
123 'title': top.topic.title,
124 'url': content.get_absolute_url()})
125
126 posts_unread.sort(cmp=comp)
127
128 return posts_unread
129
130
131 @register.filter('interventions_privatetopics')
132 def interventions_privatetopics(user):
133
134 topics_never_read = list(PrivateTopicRead.objects
135 .filter(user=user)
136 .filter(privatepost=F('privatetopic__last_message')).all())
137
138 tnrs = []
139 for tnr in topics_never_read:
140 tnrs.append(tnr.privatetopic.pk)
141
142 privatetopics_unread = PrivateTopic.objects\
143 .filter(Q(author=user) | Q(participants__in=[user]))\
144 .exclude(pk__in=tnrs)\
145 .select_related("privatetopic")\
146 .order_by("-pubdate")\
147 .distinct()
148
149 return {'unread': privatetopics_unread}
150
151
152 @register.filter(name='alerts_list')
153 def alerts_list(user):
154 total = []
155 alerts = Alert.objects.select_related("author").all().order_by('-pubdate')[:10]
156 for alert in alerts:
157 if alert.scope == Alert.FORUM:
158 post = Post.objects.select_related("topic").get(pk=alert.comment.pk)
159 total.append({'title': post.topic.title,
160 'url': post.get_absolute_url(),
161 'pubdate': alert.pubdate,
162 'author': alert.author,
163 'text': alert.text})
164 if alert.scope == Alert.ARTICLE:
165 reaction = Reaction.objects.select_related("article").get(pk=alert.comment.pk)
166 total.append({'title': reaction.article.title,
167 'url': reaction.get_absolute_url(),
168 'pubdate': alert.pubdate,
169 'author': alert.author,
170 'text': alert.text})
171 if alert.scope == Alert.TUTORIAL:
172 note = Note.objects.select_related("tutorial").get(pk=alert.comment.pk)
173 total.append({'title': note.tutorial.title,
174 'url': note.get_absolute_url(),
175 'pubdate': alert.pubdate,
176 'author': alert.author,
177 'text': alert.text})
178
179 return total
180
181
182 @register.filter(name='alerts_count')
183 def alerts_count(user):
184 if user.is_authenticated():
185 return Alert.objects.count()
186 else:
187 return 0
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py
--- a/zds/utils/templatetags/interventions.py
+++ b/zds/utils/templatetags/interventions.py
@@ -152,24 +152,24 @@
@register.filter(name='alerts_list')
def alerts_list(user):
total = []
- alerts = Alert.objects.select_related("author").all().order_by('-pubdate')[:10]
+ alerts = Alert.objects.select_related('author').all().order_by('-pubdate')[:10]
for alert in alerts:
if alert.scope == Alert.FORUM:
- post = Post.objects.select_related("topic").get(pk=alert.comment.pk)
+ post = Post.objects.select_related('topic').get(pk=alert.comment.pk)
total.append({'title': post.topic.title,
'url': post.get_absolute_url(),
'pubdate': alert.pubdate,
'author': alert.author,
'text': alert.text})
if alert.scope == Alert.ARTICLE:
- reaction = Reaction.objects.select_related("article").get(pk=alert.comment.pk)
+ reaction = Reaction.objects.select_related('article').get(pk=alert.comment.pk)
total.append({'title': reaction.article.title,
'url': reaction.get_absolute_url(),
'pubdate': alert.pubdate,
'author': alert.author,
'text': alert.text})
if alert.scope == Alert.TUTORIAL:
- note = Note.objects.select_related("tutorial").get(pk=alert.comment.pk)
+ note = Note.objects.select_related('tutorial').get(pk=alert.comment.pk)
total.append({'title': note.tutorial.title,
'url': note.get_absolute_url(),
'pubdate': alert.pubdate,
@@ -177,11 +177,3 @@
'text': alert.text})
return total
-
-
[email protected](name='alerts_count')
-def alerts_count(user):
- if user.is_authenticated():
- return Alert.objects.count()
- else:
- return 0
|
{"golden_diff": "diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py\n--- a/zds/utils/templatetags/interventions.py\n+++ b/zds/utils/templatetags/interventions.py\n@@ -152,24 +152,24 @@\n @register.filter(name='alerts_list')\n def alerts_list(user):\n total = []\n- alerts = Alert.objects.select_related(\"author\").all().order_by('-pubdate')[:10]\n+ alerts = Alert.objects.select_related('author').all().order_by('-pubdate')[:10]\n for alert in alerts:\n if alert.scope == Alert.FORUM:\n- post = Post.objects.select_related(\"topic\").get(pk=alert.comment.pk)\n+ post = Post.objects.select_related('topic').get(pk=alert.comment.pk)\n total.append({'title': post.topic.title,\n 'url': post.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.ARTICLE:\n- reaction = Reaction.objects.select_related(\"article\").get(pk=alert.comment.pk)\n+ reaction = Reaction.objects.select_related('article').get(pk=alert.comment.pk)\n total.append({'title': reaction.article.title,\n 'url': reaction.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.TUTORIAL:\n- note = Note.objects.select_related(\"tutorial\").get(pk=alert.comment.pk)\n+ note = Note.objects.select_related('tutorial').get(pk=alert.comment.pk)\n total.append({'title': note.tutorial.title,\n 'url': note.get_absolute_url(),\n 'pubdate': alert.pubdate,\n@@ -177,11 +177,3 @@\n 'text': alert.text})\n \n return total\n-\n-\[email protected](name='alerts_count')\n-def alerts_count(user):\n- if user.is_authenticated():\n- return Alert.objects.count()\n- else:\n- return 0\n", "issue": "Boucle de requ\u00eates SQL sur les alertes\nOn a des requ\u00eates en boucle sur les alertes : une requ\u00eate de chaque type par alerte.\n# Requ\u00eate 1\n\nDans `zds-site/templates/base.html` ligne 358 : `{% with alerts=user|alerts_list nb_alerts=user|alerts_count %}`\n\n``` sql\nSELECT \n `utils_comment`.`id`,\n `utils_comment`.`author_id`,\n `utils_comment`.`editor_id`,\n `utils_comment`.`ip_address`,\n `utils_comment`.`position`,\n `utils_comment`.`text`,\n `utils_comment`.`text_html`,\n `utils_comment`.`like`,\n `utils_comment`.`dislike`,\n `utils_comment`.`pubdate`,\n `utils_comment`.`update`,\n `utils_comment`.`is_visible`,\n `utils_comment`.`text_hidden`\nFROM\n `utils_comment`\nWHERE\n `utils_comment`.`id` = <ID>\n```\n# Requ\u00eate 2\n\nDans `zds-site/templates/base.html` ligne 358 : `{% with alerts=user|alerts_list nb_alerts=user|alerts_count %}` (oui, c'est la m\u00eame ligne que la 1) :\n\n``` sql\n SELECT \n `utils_comment`.`id`,\n `utils_comment`.`author_id`,\n `utils_comment`.`editor_id`,\n `utils_comment`.`ip_address`,\n `utils_comment`.`position`,\n `utils_comment`.`text`,\n `utils_comment`.`text_html`,\n `utils_comment`.`like`,\n `utils_comment`.`dislike`,\n `utils_comment`.`pubdate`,\n `utils_comment`.`update`,\n `utils_comment`.`is_visible`,\n `utils_comment`.`text_hidden`,\n `forum_post`.`comment_ptr_id`,\n `forum_post`.`topic_id`,\n `forum_post`.`is_useful`,\n `forum_topic`.`id`,\n `forum_topic`.`title`,\n `forum_topic`.`subtitle`,\n `forum_topic`.`forum_id`,\n `forum_topic`.`author_id`,\n `forum_topic`.`last_message_id`,\n `forum_topic`.`pubdate`,\n `forum_topic`.`is_solved`,\n `forum_topic`.`is_locked`,\n `forum_topic`.`is_sticky`,\n `forum_topic`.`key`\nFROM\n `forum_post`\n INNER JOIN\n `utils_comment` ON (`forum_post`.`comment_ptr_id` = `utils_comment`.`id`)\n INNER JOIN\n `forum_topic` ON (`forum_post`.`topic_id` = `forum_topic`.`id`)\nWHERE\n `forum_post`.`comment_ptr_id` = <ID>\n```\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom datetime import datetime, timedelta\nimport time\n\nfrom django import template\nfrom django.db.models import Q, F\n\nfrom zds.article.models import Reaction, ArticleRead\nfrom zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\nfrom zds.mp.models import PrivateTopic, PrivateTopicRead\nfrom zds.tutorial.models import Note, TutorialRead\nfrom zds.utils.models import Alert\n\n\nregister = template.Library()\n\n\[email protected]('is_read')\ndef is_read(topic):\n if never_read_topic(topic):\n return False\n else:\n return True\n\n\[email protected]('humane_delta')\ndef humane_delta(value):\n # mapping between label day and key\n const = {1: \"Aujourd'hui\", 2: \"Hier\", 3: \"Cette semaine\", 4: \"Ce mois-ci\", 5: \"Cette ann\u00e9e\"}\n\n return const[value]\n\n\[email protected]('followed_topics')\ndef followed_topics(user):\n topicsfollowed = TopicFollowed.objects.select_related(\"topic\").filter(user=user)\\\n .order_by('-topic__last_message__pubdate')[:10]\n # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with\n # the number of days for which we can say we're still in the period\n # for exemple, the tuple (2, 1) means for the period \"2\" corresponding to \"Yesterday\" according\n # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at \"Yesterday\"\n # Number is use for index for sort map easily\n period = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))\n topics = {}\n for tf in topicsfollowed:\n for p in period:\n if tf.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(p[1]),\n hours=0, minutes=0,\n seconds=0)).date():\n if p[0] in topics:\n topics[p[0]].append(tf.topic)\n else:\n topics[p[0]] = [tf.topic]\n break\n return topics\n\n\ndef comp(d1, d2):\n v1 = int(time.mktime(d1['pubdate'].timetuple()))\n v2 = int(time.mktime(d2['pubdate'].timetuple()))\n if v1 > v2:\n return -1\n elif v1 < v2:\n return 1\n else:\n return 0\n\n\[email protected]('interventions_topics')\ndef interventions_topics(user):\n topicsfollowed = TopicFollowed.objects.filter(user=user).values(\"topic\").distinct().all()\n\n topics_never_read = TopicRead.objects\\\n .filter(user=user)\\\n .filter(topic__in=topicsfollowed)\\\n .select_related(\"topic\")\\\n .exclude(post=F('topic__last_message'))\n\n articlesfollowed = Reaction.objects\\\n .filter(author=user, article__sha_public__isnull=False)\\\n .values('article')\\\n .distinct().all()\n\n articles_never_read = ArticleRead.objects\\\n .filter(user=user)\\\n .filter(article__in=articlesfollowed)\\\n .select_related(\"article\")\\\n .exclude(reaction=F('article__last_reaction'))\n\n tutorialsfollowed = Note.objects\\\n .filter(author=user, tutorial__sha_public__isnull=False)\\\n .values('tutorial')\\\n .distinct().all()\n\n tutorials_never_read = TutorialRead.objects\\\n .filter(user=user)\\\n .filter(tutorial__in=tutorialsfollowed)\\\n .exclude(note=F('tutorial__last_note'))\n\n posts_unread = []\n\n for art in articles_never_read:\n content = art.article.first_unread_reaction()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': art.article.title,\n 'url': content.get_absolute_url()})\n\n for tuto in tutorials_never_read:\n content = tuto.tutorial.first_unread_note()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': tuto.tutorial.title,\n 'url': content.get_absolute_url()})\n\n for top in topics_never_read:\n content = top.topic.first_unread_post()\n if content is None:\n content = top.topic.last_message\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': top.topic.title,\n 'url': content.get_absolute_url()})\n\n posts_unread.sort(cmp=comp)\n\n return posts_unread\n\n\[email protected]('interventions_privatetopics')\ndef interventions_privatetopics(user):\n\n topics_never_read = list(PrivateTopicRead.objects\n .filter(user=user)\n .filter(privatepost=F('privatetopic__last_message')).all())\n\n tnrs = []\n for tnr in topics_never_read:\n tnrs.append(tnr.privatetopic.pk)\n\n privatetopics_unread = PrivateTopic.objects\\\n .filter(Q(author=user) | Q(participants__in=[user]))\\\n .exclude(pk__in=tnrs)\\\n .select_related(\"privatetopic\")\\\n .order_by(\"-pubdate\")\\\n .distinct()\n\n return {'unread': privatetopics_unread}\n\n\[email protected](name='alerts_list')\ndef alerts_list(user):\n total = []\n alerts = Alert.objects.select_related(\"author\").all().order_by('-pubdate')[:10]\n for alert in alerts:\n if alert.scope == Alert.FORUM:\n post = Post.objects.select_related(\"topic\").get(pk=alert.comment.pk)\n total.append({'title': post.topic.title,\n 'url': post.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.ARTICLE:\n reaction = Reaction.objects.select_related(\"article\").get(pk=alert.comment.pk)\n total.append({'title': reaction.article.title,\n 'url': reaction.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.TUTORIAL:\n note = Note.objects.select_related(\"tutorial\").get(pk=alert.comment.pk)\n total.append({'title': note.tutorial.title,\n 'url': note.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n\n return total\n\n\[email protected](name='alerts_count')\ndef alerts_count(user):\n if user.is_authenticated():\n return Alert.objects.count()\n else:\n return 0\n", "path": "zds/utils/templatetags/interventions.py"}], "after_files": [{"content": "# coding: utf-8\n\nfrom datetime import datetime, timedelta\nimport time\n\nfrom django import template\nfrom django.db.models import Q, F\n\nfrom zds.article.models import Reaction, ArticleRead\nfrom zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\nfrom zds.mp.models import PrivateTopic, PrivateTopicRead\nfrom zds.tutorial.models import Note, TutorialRead\nfrom zds.utils.models import Alert\n\n\nregister = template.Library()\n\n\[email protected]('is_read')\ndef is_read(topic):\n if never_read_topic(topic):\n return False\n else:\n return True\n\n\[email protected]('humane_delta')\ndef humane_delta(value):\n # mapping between label day and key\n const = {1: \"Aujourd'hui\", 2: \"Hier\", 3: \"Cette semaine\", 4: \"Ce mois-ci\", 5: \"Cette ann\u00e9e\"}\n\n return const[value]\n\n\[email protected]('followed_topics')\ndef followed_topics(user):\n topicsfollowed = TopicFollowed.objects.select_related(\"topic\").filter(user=user)\\\n .order_by('-topic__last_message__pubdate')[:10]\n # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with\n # the number of days for which we can say we're still in the period\n # for exemple, the tuple (2, 1) means for the period \"2\" corresponding to \"Yesterday\" according\n # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at \"Yesterday\"\n # Number is use for index for sort map easily\n period = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))\n topics = {}\n for tf in topicsfollowed:\n for p in period:\n if tf.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(p[1]),\n hours=0, minutes=0,\n seconds=0)).date():\n if p[0] in topics:\n topics[p[0]].append(tf.topic)\n else:\n topics[p[0]] = [tf.topic]\n break\n return topics\n\n\ndef comp(d1, d2):\n v1 = int(time.mktime(d1['pubdate'].timetuple()))\n v2 = int(time.mktime(d2['pubdate'].timetuple()))\n if v1 > v2:\n return -1\n elif v1 < v2:\n return 1\n else:\n return 0\n\n\[email protected]('interventions_topics')\ndef interventions_topics(user):\n topicsfollowed = TopicFollowed.objects.filter(user=user).values(\"topic\").distinct().all()\n\n topics_never_read = TopicRead.objects\\\n .filter(user=user)\\\n .filter(topic__in=topicsfollowed)\\\n .select_related(\"topic\")\\\n .exclude(post=F('topic__last_message'))\n\n articlesfollowed = Reaction.objects\\\n .filter(author=user, article__sha_public__isnull=False)\\\n .values('article')\\\n .distinct().all()\n\n articles_never_read = ArticleRead.objects\\\n .filter(user=user)\\\n .filter(article__in=articlesfollowed)\\\n .select_related(\"article\")\\\n .exclude(reaction=F('article__last_reaction'))\n\n tutorialsfollowed = Note.objects\\\n .filter(author=user, tutorial__sha_public__isnull=False)\\\n .values('tutorial')\\\n .distinct().all()\n\n tutorials_never_read = TutorialRead.objects\\\n .filter(user=user)\\\n .filter(tutorial__in=tutorialsfollowed)\\\n .exclude(note=F('tutorial__last_note'))\n\n posts_unread = []\n\n for art in articles_never_read:\n content = art.article.first_unread_reaction()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': art.article.title,\n 'url': content.get_absolute_url()})\n\n for tuto in tutorials_never_read:\n content = tuto.tutorial.first_unread_note()\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': tuto.tutorial.title,\n 'url': content.get_absolute_url()})\n\n for top in topics_never_read:\n content = top.topic.first_unread_post()\n if content is None:\n content = top.topic.last_message\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': top.topic.title,\n 'url': content.get_absolute_url()})\n\n posts_unread.sort(cmp=comp)\n\n return posts_unread\n\n\[email protected]('interventions_privatetopics')\ndef interventions_privatetopics(user):\n\n topics_never_read = list(PrivateTopicRead.objects\n .filter(user=user)\n .filter(privatepost=F('privatetopic__last_message')).all())\n\n tnrs = []\n for tnr in topics_never_read:\n tnrs.append(tnr.privatetopic.pk)\n\n privatetopics_unread = PrivateTopic.objects\\\n .filter(Q(author=user) | Q(participants__in=[user]))\\\n .exclude(pk__in=tnrs)\\\n .select_related(\"privatetopic\")\\\n .order_by(\"-pubdate\")\\\n .distinct()\n\n return {'unread': privatetopics_unread}\n\n\[email protected](name='alerts_list')\ndef alerts_list(user):\n total = []\n alerts = Alert.objects.select_related('author').all().order_by('-pubdate')[:10]\n for alert in alerts:\n if alert.scope == Alert.FORUM:\n post = Post.objects.select_related('topic').get(pk=alert.comment.pk)\n total.append({'title': post.topic.title,\n 'url': post.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.ARTICLE:\n reaction = Reaction.objects.select_related('article').get(pk=alert.comment.pk)\n total.append({'title': reaction.article.title,\n 'url': reaction.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n if alert.scope == Alert.TUTORIAL:\n note = Note.objects.select_related('tutorial').get(pk=alert.comment.pk)\n total.append({'title': note.tutorial.title,\n 'url': note.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n\n return total\n", "path": "zds/utils/templatetags/interventions.py"}]}
| 2,767 | 463 |
gh_patches_debug_11991
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-6343
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Lien erroné dans le MP d'ajout à la rédaction d'un contenu
**Description du bug**
Le second lien du MP que l'on reçoit lorsqu'on est ajouté comme auteur à un contenu mène vers une page 404.
**Comment reproduire ?**
La liste des étapes qui permet de reproduire le bug :
1. Avec `user1`, créer un billet
2. Ajouter `user2` comme co-auteur du billet
3. Se connecter comme `user2`et consulter le MP reçu correspondant à l'ajout comme auteur au billet
4. Dans le contenu du MP, le second lien (_Il a été ajouté à la liste de vos contenus en rédaction **ici**._) mène vers une 404.
**Comportement attendu**
Je ne sais pas vraiment quel lien est attendu ici... La liste des contenus en cours de rédaction ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/tutorialv2/views/authors.py`
Content:
```
1 from django.conf import settings
2 from django.contrib import messages
3 from django.contrib.auth.models import User
4 from django.shortcuts import get_object_or_404, redirect
5 from django.template.loader import render_to_string
6 from django.urls import reverse
7 from django.utils.text import format_lazy
8 from django.utils.translation import gettext_lazy as _
9
10 from zds.gallery.models import UserGallery, GALLERY_WRITE
11 from zds.member.decorator import LoggedWithReadWriteHability
12 from zds.tutorialv2 import signals
13
14 from zds.tutorialv2.forms import AuthorForm, RemoveAuthorForm
15 from zds.tutorialv2.mixins import SingleContentFormViewMixin
16 from zds.utils.models import get_hat_from_settings
17 from zds.mp.utils import send_mp
18
19
20 class AddAuthorToContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):
21 only_draft_version = True
22 must_be_author = True
23 form_class = AuthorForm
24 authorized_for_staff = True
25
26 def get(self, request, *args, **kwargs):
27 content = self.get_object()
28 url = "content:find-{}".format("tutorial" if content.is_tutorial() else content.type.lower())
29 return redirect(url, self.request.user)
30
31 def form_valid(self, form):
32
33 _type = _("de l'article")
34
35 if self.object.is_tutorial:
36 _type = _("du tutoriel")
37 elif self.object.is_opinion:
38 _type = _("du billet")
39
40 bot = get_object_or_404(User, username=settings.ZDS_APP["member"]["bot_account"])
41 all_authors_pk = [author.pk for author in self.object.authors.all()]
42 for user in form.cleaned_data["users"]:
43 if user.pk not in all_authors_pk:
44 self.object.authors.add(user)
45 if self.object.validation_private_message:
46 self.object.validation_private_message.add_participant(user)
47 all_authors_pk.append(user.pk)
48 if user != self.request.user:
49 url_index = reverse(self.object.type.lower() + ":find-" + self.object.type.lower(), args=[user.pk])
50 send_mp(
51 bot,
52 [user],
53 format_lazy("{}{}", _("Ajout à la rédaction "), _type),
54 self.versioned_object.title,
55 render_to_string(
56 "tutorialv2/messages/add_author_pm.md",
57 {
58 "content": self.object,
59 "type": _type,
60 "url": self.object.get_absolute_url(),
61 "index": url_index,
62 "user": user.username,
63 },
64 ),
65 hat=get_hat_from_settings("validation"),
66 )
67 UserGallery(gallery=self.object.gallery, user=user, mode=GALLERY_WRITE).save()
68 signals.authors_management.send(
69 sender=self.__class__, content=self.object, performer=self.request.user, author=user, action="add"
70 )
71 self.object.save()
72 self.success_url = self.object.get_absolute_url()
73
74 return super().form_valid(form)
75
76 def form_invalid(self, form):
77 messages.error(self.request, _("Les auteurs sélectionnés n'existent pas."))
78 self.success_url = self.object.get_absolute_url()
79 return super().form_valid(form)
80
81
82 class RemoveAuthorFromContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):
83
84 form_class = RemoveAuthorForm
85 only_draft_version = True
86 must_be_author = True
87 authorized_for_staff = True
88
89 @staticmethod
90 def remove_author(content, user):
91 """Remove a user from the authors and ensure that he is access to the content's gallery is also removed.
92 The last author is not removed.
93
94 :param content: the content
95 :type content: zds.tutorialv2.models.database.PublishableContent
96 :param user: the author
97 :type user: User
98 :return: ``True`` if the author was removed, ``False`` otherwise
99 """
100 if user in content.authors.all() and content.authors.count() > 1:
101 gallery = UserGallery.objects.filter(user__pk=user.pk, gallery__pk=content.gallery.pk).first()
102
103 if gallery:
104 gallery.delete()
105
106 content.authors.remove(user)
107 return True
108
109 return False
110
111 def form_valid(self, form):
112
113 current_user = False
114 users = form.cleaned_data["users"]
115
116 _type = (_("cet article"), _("de l'article"))
117 if self.object.is_tutorial:
118 _type = (_("ce tutoriel"), _("du tutoriel"))
119 elif self.object.is_opinion:
120 _type = (_("ce billet"), _("du billet"))
121
122 bot = get_object_or_404(User, username=settings.ZDS_APP["member"]["bot_account"])
123 for user in users:
124 if RemoveAuthorFromContent.remove_author(self.object, user):
125 if user.pk == self.request.user.pk:
126 current_user = True
127 else:
128 send_mp(
129 bot,
130 [user],
131 format_lazy("{}{}", _("Retrait de la rédaction "), _type[1]),
132 self.versioned_object.title,
133 render_to_string(
134 "tutorialv2/messages/remove_author_pm.md",
135 {
136 "content": self.object,
137 "user": user.username,
138 },
139 ),
140 hat=get_hat_from_settings("validation"),
141 )
142 signals.authors_management.send(
143 sender=self.__class__,
144 content=self.object,
145 performer=self.request.user,
146 author=user,
147 action="remove",
148 )
149 else: # if user is incorrect or alone
150 messages.error(
151 self.request,
152 _(
153 "Vous êtes le seul auteur de {} ou le membre sélectionné " "en a déjà quitté la rédaction."
154 ).format(_type[0]),
155 )
156 return redirect(self.object.get_absolute_url())
157
158 self.object.save()
159
160 authors_list = ""
161
162 for index, user in enumerate(form.cleaned_data["users"]):
163 if index > 0:
164 if index == len(users) - 1:
165 authors_list += _(" et ")
166 else:
167 authors_list += _(", ")
168 authors_list += user.username
169
170 if not current_user: # if the removed author is not current user
171 messages.success(
172 self.request, _("Vous avez enlevé {} de la liste des auteurs de {}.").format(authors_list, _type[0])
173 )
174 self.success_url = self.object.get_absolute_url()
175 else: # if current user is leaving the content's redaction, redirect him to a more suitable page
176 messages.success(self.request, _("Vous avez bien quitté la rédaction de {}.").format(_type[0]))
177 self.success_url = reverse(
178 self.object.type.lower() + ":find-" + self.object.type.lower(), args=[self.request.user.username]
179 )
180 return super().form_valid(form)
181
182 def form_invalid(self, form):
183 messages.error(self.request, _("Les auteurs sélectionnés n'existent pas."))
184 self.success_url = self.object.get_absolute_url()
185 return super().form_valid(form)
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zds/tutorialv2/views/authors.py b/zds/tutorialv2/views/authors.py
--- a/zds/tutorialv2/views/authors.py
+++ b/zds/tutorialv2/views/authors.py
@@ -46,7 +46,9 @@
self.object.validation_private_message.add_participant(user)
all_authors_pk.append(user.pk)
if user != self.request.user:
- url_index = reverse(self.object.type.lower() + ":find-" + self.object.type.lower(), args=[user.pk])
+ url_index = reverse(
+ self.object.type.lower() + ":find-" + self.object.type.lower(), args=[user.username]
+ )
send_mp(
bot,
[user],
|
{"golden_diff": "diff --git a/zds/tutorialv2/views/authors.py b/zds/tutorialv2/views/authors.py\n--- a/zds/tutorialv2/views/authors.py\n+++ b/zds/tutorialv2/views/authors.py\n@@ -46,7 +46,9 @@\n self.object.validation_private_message.add_participant(user)\n all_authors_pk.append(user.pk)\n if user != self.request.user:\n- url_index = reverse(self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[user.pk])\n+ url_index = reverse(\n+ self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[user.username]\n+ )\n send_mp(\n bot,\n [user],\n", "issue": "Lien erron\u00e9 dans le MP d'ajout \u00e0 la r\u00e9daction d'un contenu\n**Description du bug**\r\n\r\nLe second lien du MP que l'on re\u00e7oit lorsqu'on est ajout\u00e9 comme auteur \u00e0 un contenu m\u00e8ne vers une page 404.\r\n\r\n\r\n**Comment reproduire ?**\r\n\r\nLa liste des \u00e9tapes qui permet de reproduire le bug :\r\n\r\n1. Avec `user1`, cr\u00e9er un billet\r\n2. Ajouter `user2` comme co-auteur du billet\r\n3. Se connecter comme `user2`et consulter le MP re\u00e7u correspondant \u00e0 l'ajout comme auteur au billet\r\n4. Dans le contenu du MP, le second lien (_Il a \u00e9t\u00e9 ajout\u00e9 \u00e0 la liste de vos contenus en r\u00e9daction **ici**._) m\u00e8ne vers une 404.\r\n\r\n**Comportement attendu**\r\n\r\nJe ne sais pas vraiment quel lien est attendu ici... La liste des contenus en cours de r\u00e9daction ?\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.models import User\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.template.loader import render_to_string\nfrom django.urls import reverse\nfrom django.utils.text import format_lazy\nfrom django.utils.translation import gettext_lazy as _\n\nfrom zds.gallery.models import UserGallery, GALLERY_WRITE\nfrom zds.member.decorator import LoggedWithReadWriteHability\nfrom zds.tutorialv2 import signals\n\nfrom zds.tutorialv2.forms import AuthorForm, RemoveAuthorForm\nfrom zds.tutorialv2.mixins import SingleContentFormViewMixin\nfrom zds.utils.models import get_hat_from_settings\nfrom zds.mp.utils import send_mp\n\n\nclass AddAuthorToContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):\n only_draft_version = True\n must_be_author = True\n form_class = AuthorForm\n authorized_for_staff = True\n\n def get(self, request, *args, **kwargs):\n content = self.get_object()\n url = \"content:find-{}\".format(\"tutorial\" if content.is_tutorial() else content.type.lower())\n return redirect(url, self.request.user)\n\n def form_valid(self, form):\n\n _type = _(\"de l'article\")\n\n if self.object.is_tutorial:\n _type = _(\"du tutoriel\")\n elif self.object.is_opinion:\n _type = _(\"du billet\")\n\n bot = get_object_or_404(User, username=settings.ZDS_APP[\"member\"][\"bot_account\"])\n all_authors_pk = [author.pk for author in self.object.authors.all()]\n for user in form.cleaned_data[\"users\"]:\n if user.pk not in all_authors_pk:\n self.object.authors.add(user)\n if self.object.validation_private_message:\n self.object.validation_private_message.add_participant(user)\n all_authors_pk.append(user.pk)\n if user != self.request.user:\n url_index = reverse(self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[user.pk])\n send_mp(\n bot,\n [user],\n format_lazy(\"{}{}\", _(\"Ajout \u00e0 la r\u00e9daction \"), _type),\n self.versioned_object.title,\n render_to_string(\n \"tutorialv2/messages/add_author_pm.md\",\n {\n \"content\": self.object,\n \"type\": _type,\n \"url\": self.object.get_absolute_url(),\n \"index\": url_index,\n \"user\": user.username,\n },\n ),\n hat=get_hat_from_settings(\"validation\"),\n )\n UserGallery(gallery=self.object.gallery, user=user, mode=GALLERY_WRITE).save()\n signals.authors_management.send(\n sender=self.__class__, content=self.object, performer=self.request.user, author=user, action=\"add\"\n )\n self.object.save()\n self.success_url = self.object.get_absolute_url()\n\n return super().form_valid(form)\n\n def form_invalid(self, form):\n messages.error(self.request, _(\"Les auteurs s\u00e9lectionn\u00e9s n'existent pas.\"))\n self.success_url = self.object.get_absolute_url()\n return super().form_valid(form)\n\n\nclass RemoveAuthorFromContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):\n\n form_class = RemoveAuthorForm\n only_draft_version = True\n must_be_author = True\n authorized_for_staff = True\n\n @staticmethod\n def remove_author(content, user):\n \"\"\"Remove a user from the authors and ensure that he is access to the content's gallery is also removed.\n The last author is not removed.\n\n :param content: the content\n :type content: zds.tutorialv2.models.database.PublishableContent\n :param user: the author\n :type user: User\n :return: ``True`` if the author was removed, ``False`` otherwise\n \"\"\"\n if user in content.authors.all() and content.authors.count() > 1:\n gallery = UserGallery.objects.filter(user__pk=user.pk, gallery__pk=content.gallery.pk).first()\n\n if gallery:\n gallery.delete()\n\n content.authors.remove(user)\n return True\n\n return False\n\n def form_valid(self, form):\n\n current_user = False\n users = form.cleaned_data[\"users\"]\n\n _type = (_(\"cet article\"), _(\"de l'article\"))\n if self.object.is_tutorial:\n _type = (_(\"ce tutoriel\"), _(\"du tutoriel\"))\n elif self.object.is_opinion:\n _type = (_(\"ce billet\"), _(\"du billet\"))\n\n bot = get_object_or_404(User, username=settings.ZDS_APP[\"member\"][\"bot_account\"])\n for user in users:\n if RemoveAuthorFromContent.remove_author(self.object, user):\n if user.pk == self.request.user.pk:\n current_user = True\n else:\n send_mp(\n bot,\n [user],\n format_lazy(\"{}{}\", _(\"Retrait de la r\u00e9daction \"), _type[1]),\n self.versioned_object.title,\n render_to_string(\n \"tutorialv2/messages/remove_author_pm.md\",\n {\n \"content\": self.object,\n \"user\": user.username,\n },\n ),\n hat=get_hat_from_settings(\"validation\"),\n )\n signals.authors_management.send(\n sender=self.__class__,\n content=self.object,\n performer=self.request.user,\n author=user,\n action=\"remove\",\n )\n else: # if user is incorrect or alone\n messages.error(\n self.request,\n _(\n \"Vous \u00eates le seul auteur de {} ou le membre s\u00e9lectionn\u00e9 \" \"en a d\u00e9j\u00e0 quitt\u00e9 la r\u00e9daction.\"\n ).format(_type[0]),\n )\n return redirect(self.object.get_absolute_url())\n\n self.object.save()\n\n authors_list = \"\"\n\n for index, user in enumerate(form.cleaned_data[\"users\"]):\n if index > 0:\n if index == len(users) - 1:\n authors_list += _(\" et \")\n else:\n authors_list += _(\", \")\n authors_list += user.username\n\n if not current_user: # if the removed author is not current user\n messages.success(\n self.request, _(\"Vous avez enlev\u00e9 {} de la liste des auteurs de {}.\").format(authors_list, _type[0])\n )\n self.success_url = self.object.get_absolute_url()\n else: # if current user is leaving the content's redaction, redirect him to a more suitable page\n messages.success(self.request, _(\"Vous avez bien quitt\u00e9 la r\u00e9daction de {}.\").format(_type[0]))\n self.success_url = reverse(\n self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[self.request.user.username]\n )\n return super().form_valid(form)\n\n def form_invalid(self, form):\n messages.error(self.request, _(\"Les auteurs s\u00e9lectionn\u00e9s n'existent pas.\"))\n self.success_url = self.object.get_absolute_url()\n return super().form_valid(form)\n", "path": "zds/tutorialv2/views/authors.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.models import User\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.template.loader import render_to_string\nfrom django.urls import reverse\nfrom django.utils.text import format_lazy\nfrom django.utils.translation import gettext_lazy as _\n\nfrom zds.gallery.models import UserGallery, GALLERY_WRITE\nfrom zds.member.decorator import LoggedWithReadWriteHability\nfrom zds.tutorialv2 import signals\n\nfrom zds.tutorialv2.forms import AuthorForm, RemoveAuthorForm\nfrom zds.tutorialv2.mixins import SingleContentFormViewMixin\nfrom zds.utils.models import get_hat_from_settings\nfrom zds.mp.utils import send_mp\n\n\nclass AddAuthorToContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):\n only_draft_version = True\n must_be_author = True\n form_class = AuthorForm\n authorized_for_staff = True\n\n def get(self, request, *args, **kwargs):\n content = self.get_object()\n url = \"content:find-{}\".format(\"tutorial\" if content.is_tutorial() else content.type.lower())\n return redirect(url, self.request.user)\n\n def form_valid(self, form):\n\n _type = _(\"de l'article\")\n\n if self.object.is_tutorial:\n _type = _(\"du tutoriel\")\n elif self.object.is_opinion:\n _type = _(\"du billet\")\n\n bot = get_object_or_404(User, username=settings.ZDS_APP[\"member\"][\"bot_account\"])\n all_authors_pk = [author.pk for author in self.object.authors.all()]\n for user in form.cleaned_data[\"users\"]:\n if user.pk not in all_authors_pk:\n self.object.authors.add(user)\n if self.object.validation_private_message:\n self.object.validation_private_message.add_participant(user)\n all_authors_pk.append(user.pk)\n if user != self.request.user:\n url_index = reverse(\n self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[user.username]\n )\n send_mp(\n bot,\n [user],\n format_lazy(\"{}{}\", _(\"Ajout \u00e0 la r\u00e9daction \"), _type),\n self.versioned_object.title,\n render_to_string(\n \"tutorialv2/messages/add_author_pm.md\",\n {\n \"content\": self.object,\n \"type\": _type,\n \"url\": self.object.get_absolute_url(),\n \"index\": url_index,\n \"user\": user.username,\n },\n ),\n hat=get_hat_from_settings(\"validation\"),\n )\n UserGallery(gallery=self.object.gallery, user=user, mode=GALLERY_WRITE).save()\n signals.authors_management.send(\n sender=self.__class__, content=self.object, performer=self.request.user, author=user, action=\"add\"\n )\n self.object.save()\n self.success_url = self.object.get_absolute_url()\n\n return super().form_valid(form)\n\n def form_invalid(self, form):\n messages.error(self.request, _(\"Les auteurs s\u00e9lectionn\u00e9s n'existent pas.\"))\n self.success_url = self.object.get_absolute_url()\n return super().form_valid(form)\n\n\nclass RemoveAuthorFromContent(LoggedWithReadWriteHability, SingleContentFormViewMixin):\n\n form_class = RemoveAuthorForm\n only_draft_version = True\n must_be_author = True\n authorized_for_staff = True\n\n @staticmethod\n def remove_author(content, user):\n \"\"\"Remove a user from the authors and ensure that he is access to the content's gallery is also removed.\n The last author is not removed.\n\n :param content: the content\n :type content: zds.tutorialv2.models.database.PublishableContent\n :param user: the author\n :type user: User\n :return: ``True`` if the author was removed, ``False`` otherwise\n \"\"\"\n if user in content.authors.all() and content.authors.count() > 1:\n gallery = UserGallery.objects.filter(user__pk=user.pk, gallery__pk=content.gallery.pk).first()\n\n if gallery:\n gallery.delete()\n\n content.authors.remove(user)\n return True\n\n return False\n\n def form_valid(self, form):\n\n current_user = False\n users = form.cleaned_data[\"users\"]\n\n _type = (_(\"cet article\"), _(\"de l'article\"))\n if self.object.is_tutorial:\n _type = (_(\"ce tutoriel\"), _(\"du tutoriel\"))\n elif self.object.is_opinion:\n _type = (_(\"ce billet\"), _(\"du billet\"))\n\n bot = get_object_or_404(User, username=settings.ZDS_APP[\"member\"][\"bot_account\"])\n for user in users:\n if RemoveAuthorFromContent.remove_author(self.object, user):\n if user.pk == self.request.user.pk:\n current_user = True\n else:\n send_mp(\n bot,\n [user],\n format_lazy(\"{}{}\", _(\"Retrait de la r\u00e9daction \"), _type[1]),\n self.versioned_object.title,\n render_to_string(\n \"tutorialv2/messages/remove_author_pm.md\",\n {\n \"content\": self.object,\n \"user\": user.username,\n },\n ),\n hat=get_hat_from_settings(\"validation\"),\n )\n signals.authors_management.send(\n sender=self.__class__,\n content=self.object,\n performer=self.request.user,\n author=user,\n action=\"remove\",\n )\n else: # if user is incorrect or alone\n messages.error(\n self.request,\n _(\n \"Vous \u00eates le seul auteur de {} ou le membre s\u00e9lectionn\u00e9 \" \"en a d\u00e9j\u00e0 quitt\u00e9 la r\u00e9daction.\"\n ).format(_type[0]),\n )\n return redirect(self.object.get_absolute_url())\n\n self.object.save()\n\n authors_list = \"\"\n\n for index, user in enumerate(form.cleaned_data[\"users\"]):\n if index > 0:\n if index == len(users) - 1:\n authors_list += _(\" et \")\n else:\n authors_list += _(\", \")\n authors_list += user.username\n\n if not current_user: # if the removed author is not current user\n messages.success(\n self.request, _(\"Vous avez enlev\u00e9 {} de la liste des auteurs de {}.\").format(authors_list, _type[0])\n )\n self.success_url = self.object.get_absolute_url()\n else: # if current user is leaving the content's redaction, redirect him to a more suitable page\n messages.success(self.request, _(\"Vous avez bien quitt\u00e9 la r\u00e9daction de {}.\").format(_type[0]))\n self.success_url = reverse(\n self.object.type.lower() + \":find-\" + self.object.type.lower(), args=[self.request.user.username]\n )\n return super().form_valid(form)\n\n def form_invalid(self, form):\n messages.error(self.request, _(\"Les auteurs s\u00e9lectionn\u00e9s n'existent pas.\"))\n self.success_url = self.object.get_absolute_url()\n return super().form_valid(form)\n", "path": "zds/tutorialv2/views/authors.py"}]}
| 2,435 | 157 |
gh_patches_debug_20394
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1522
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Collection events for sbazv_de double in calendar
### I Have A Problem With:
A specific source
### What's Your Problem
Collection dates and types are pulled correctly into the calendar but events show up twice per day. Sensor for next collection ('AbfallTermin') reads 'Gelber Sack, Gelber Sack in 7 Tagen'. Config and logs look ok.

### Source (if relevant)
sbazv_de
### Logs
```Shell
no relevant logs
```
### Relevant Configuration
```YAML
waste_collection_schedule:
sources:
- name: sbazv_de
args:
city: Schönefeld
district: Großziethen
street: Kxxxxxxxx
customize:
- type: Restmülltonnen
alias: Restmuell
icon: mdi:trash-can
- type: Gelbe Säcke
alias: GelberSack
icon: mdi:recycle
- type: Papiertonnen
alias: Altpapier
icon: mdi:file-document
- type: Laubsäcke
alias: Laubsack
icon: mdi:trash-can
use_dedicated_calendar: false
dedicated_calendar_title: SBAZV
fetch_time: "04:00"
day_switch_time: "12:00"
sensor:
# ------- Waste Collection Schedule -------
# Nächster Abholtermin
- platform: waste_collection_schedule
name: "AbfallTermin"
value_template: '{{value.types|join(", ")}}{% if value.daysTo == 0 %} Heute{% elif value.daysTo == 1 %} Morgen{% else %} in {{value.daysTo}} Tagen{% endif %}'
```
### Checklist Source Error
- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [X] Checked that the website of your service provider is still working
- [X] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py`
Content:
```
1 import requests
2 from waste_collection_schedule import Collection # type: ignore[attr-defined]
3 from waste_collection_schedule.service.ICS import ICS
4
5 TITLE = "Südbrandenburgischer Abfallzweckverband"
6 DESCRIPTION = "SBAZV Brandenburg, Deutschland"
7 URL = "https://www.sbazv.de"
8 TEST_CASES = {
9 "Wildau": {"city": "wildau", "district": "Wildau", "street": "Miersdorfer Str."}
10 }
11
12 ICON_MAP = {
13 "Restmülltonnen": "mdi:trash-can",
14 "Laubsäcke": "mdi:leaf",
15 "Gelbe Säcke": "mdi:sack",
16 "Papiertonnen": "mdi:package-variant",
17 "Weihnachtsbäume": "mdi:pine-tree",
18 }
19
20 # _LOGGER = logging.getLogger(__name__)
21
22
23 class Source:
24 def __init__(self, city, district, street=None):
25 self._city = city
26 self._district = district
27 self._street = street
28 self._ics = ICS()
29
30 def fetch(self):
31 args = {
32 "city": self._city,
33 "district": self._district,
34 "street": self._street,
35 }
36
37 # get ics file
38 # https://www.sbazv.de/entsorgungstermine/klein.ics?city=Wildau&district=Wildau&street=Miersdorfer+Str.
39 r = requests.get(
40 "https://www.sbazv.de/entsorgungstermine/klein.ics", params=args
41 )
42
43 # parse ics file
44 dates = self._ics.convert(r.text)
45
46 entries = []
47 for d in dates:
48 waste_type = d[1].strip()
49 next_pickup_date = d[0]
50
51 entries.append(
52 Collection(
53 date=next_pickup_date,
54 t=waste_type,
55 icon=ICON_MAP.get(waste_type),
56 )
57 )
58
59 return entries
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py
@@ -6,7 +6,12 @@
DESCRIPTION = "SBAZV Brandenburg, Deutschland"
URL = "https://www.sbazv.de"
TEST_CASES = {
- "Wildau": {"city": "wildau", "district": "Wildau", "street": "Miersdorfer Str."}
+ "Wildau": {"city": "wildau", "district": "Wildau", "street": "Miersdorfer Str."},
+ "Schönefeld": {
+ "city": "Schönefeld",
+ "district": "Großziethen",
+ "street": "kleistring",
+ },
}
ICON_MAP = {
@@ -47,7 +52,11 @@
for d in dates:
waste_type = d[1].strip()
next_pickup_date = d[0]
-
+ # remove duplicates
+ if any(
+ e.date == next_pickup_date and e.type == waste_type for e in entries
+ ):
+ continue
entries.append(
Collection(
date=next_pickup_date,
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py\n@@ -6,7 +6,12 @@\n DESCRIPTION = \"SBAZV Brandenburg, Deutschland\"\n URL = \"https://www.sbazv.de\"\n TEST_CASES = {\n- \"Wildau\": {\"city\": \"wildau\", \"district\": \"Wildau\", \"street\": \"Miersdorfer Str.\"}\n+ \"Wildau\": {\"city\": \"wildau\", \"district\": \"Wildau\", \"street\": \"Miersdorfer Str.\"},\n+ \"Sch\u00f6nefeld\": {\n+ \"city\": \"Sch\u00f6nefeld\",\n+ \"district\": \"Gro\u00dfziethen\",\n+ \"street\": \"kleistring\",\n+ },\n }\n \n ICON_MAP = {\n@@ -47,7 +52,11 @@\n for d in dates:\n waste_type = d[1].strip()\n next_pickup_date = d[0]\n-\n+ # remove duplicates\n+ if any(\n+ e.date == next_pickup_date and e.type == waste_type for e in entries\n+ ):\n+ continue\n entries.append(\n Collection(\n date=next_pickup_date,\n", "issue": "[Bug]: Collection events for sbazv_de double in calendar\n### I Have A Problem With:\n\nA specific source\n\n### What's Your Problem\n\nCollection dates and types are pulled correctly into the calendar but events show up twice per day. Sensor for next collection ('AbfallTermin') reads 'Gelber Sack, Gelber Sack in 7 Tagen'. Config and logs look ok.\r\n\r\n\r\n\n\n### Source (if relevant)\n\nsbazv_de\n\n### Logs\n\n```Shell\nno relevant logs\n```\n\n\n### Relevant Configuration\n\n```YAML\nwaste_collection_schedule:\r\n sources:\r\n - name: sbazv_de\r\n args:\r\n city: Sch\u00f6nefeld\r\n district: Gro\u00dfziethen\r\n street: Kxxxxxxxx\r\n customize:\r\n - type: Restm\u00fclltonnen\r\n alias: Restmuell\r\n icon: mdi:trash-can \r\n - type: Gelbe S\u00e4cke\r\n alias: GelberSack\r\n icon: mdi:recycle\r\n - type: Papiertonnen\r\n alias: Altpapier\r\n icon: mdi:file-document\r\n - type: Laubs\u00e4cke\r\n alias: Laubsack\r\n icon: mdi:trash-can\r\n use_dedicated_calendar: false\r\n dedicated_calendar_title: SBAZV\r\n fetch_time: \"04:00\"\r\n day_switch_time: \"12:00\"\r\n\r\nsensor:\r\n # ------- Waste Collection Schedule ------- \r\n # N\u00e4chster Abholtermin\r\n - platform: waste_collection_schedule\r\n name: \"AbfallTermin\"\r\n value_template: '{{value.types|join(\", \")}}{% if value.daysTo == 0 %} Heute{% elif value.daysTo == 1 %} Morgen{% else %} in {{value.daysTo}} Tagen{% endif %}'\n```\n\n\n### Checklist Source Error\n\n- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\n- [X] Checked that the website of your service provider is still working\n- [X] Tested my attributes on the service provider website (if possible)\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\n\n### Checklist Sensor Error\n\n- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\n\n### Required\n\n- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "import requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"S\u00fcdbrandenburgischer Abfallzweckverband\"\nDESCRIPTION = \"SBAZV Brandenburg, Deutschland\"\nURL = \"https://www.sbazv.de\"\nTEST_CASES = {\n \"Wildau\": {\"city\": \"wildau\", \"district\": \"Wildau\", \"street\": \"Miersdorfer Str.\"}\n}\n\nICON_MAP = {\n \"Restm\u00fclltonnen\": \"mdi:trash-can\",\n \"Laubs\u00e4cke\": \"mdi:leaf\",\n \"Gelbe S\u00e4cke\": \"mdi:sack\",\n \"Papiertonnen\": \"mdi:package-variant\",\n \"Weihnachtsb\u00e4ume\": \"mdi:pine-tree\",\n}\n\n# _LOGGER = logging.getLogger(__name__)\n\n\nclass Source:\n def __init__(self, city, district, street=None):\n self._city = city\n self._district = district\n self._street = street\n self._ics = ICS()\n\n def fetch(self):\n args = {\n \"city\": self._city,\n \"district\": self._district,\n \"street\": self._street,\n }\n\n # get ics file\n # https://www.sbazv.de/entsorgungstermine/klein.ics?city=Wildau&district=Wildau&street=Miersdorfer+Str.\n r = requests.get(\n \"https://www.sbazv.de/entsorgungstermine/klein.ics\", params=args\n )\n\n # parse ics file\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n waste_type = d[1].strip()\n next_pickup_date = d[0]\n\n entries.append(\n Collection(\n date=next_pickup_date,\n t=waste_type,\n icon=ICON_MAP.get(waste_type),\n )\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py"}], "after_files": [{"content": "import requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"S\u00fcdbrandenburgischer Abfallzweckverband\"\nDESCRIPTION = \"SBAZV Brandenburg, Deutschland\"\nURL = \"https://www.sbazv.de\"\nTEST_CASES = {\n \"Wildau\": {\"city\": \"wildau\", \"district\": \"Wildau\", \"street\": \"Miersdorfer Str.\"},\n \"Sch\u00f6nefeld\": {\n \"city\": \"Sch\u00f6nefeld\",\n \"district\": \"Gro\u00dfziethen\",\n \"street\": \"kleistring\",\n },\n}\n\nICON_MAP = {\n \"Restm\u00fclltonnen\": \"mdi:trash-can\",\n \"Laubs\u00e4cke\": \"mdi:leaf\",\n \"Gelbe S\u00e4cke\": \"mdi:sack\",\n \"Papiertonnen\": \"mdi:package-variant\",\n \"Weihnachtsb\u00e4ume\": \"mdi:pine-tree\",\n}\n\n# _LOGGER = logging.getLogger(__name__)\n\n\nclass Source:\n def __init__(self, city, district, street=None):\n self._city = city\n self._district = district\n self._street = street\n self._ics = ICS()\n\n def fetch(self):\n args = {\n \"city\": self._city,\n \"district\": self._district,\n \"street\": self._street,\n }\n\n # get ics file\n # https://www.sbazv.de/entsorgungstermine/klein.ics?city=Wildau&district=Wildau&street=Miersdorfer+Str.\n r = requests.get(\n \"https://www.sbazv.de/entsorgungstermine/klein.ics\", params=args\n )\n\n # parse ics file\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n waste_type = d[1].strip()\n next_pickup_date = d[0]\n # remove duplicates\n if any(\n e.date == next_pickup_date and e.type == waste_type for e in entries\n ):\n continue\n entries.append(\n Collection(\n date=next_pickup_date,\n t=waste_type,\n icon=ICON_MAP.get(waste_type),\n )\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/sbazv_de.py"}]}
| 1,489 | 319 |
gh_patches_debug_23188
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-873
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Vega plot not displaying within a holoviz panel in jupyter notebook
Apparently, vega plots have issues being shown when within a panel in a jupyter notebook. This might have something to do with Panel not serialising the data correctly.
For a minimal script showing the issue, see at the bottom of this question.
My findings:
* The vega import works nicely when used outside of a panel: the Vega specification copy/pasted from https://vega.github.io/editor/#/examples/vega/force-directed-layout is visualised as it should be using `Vega(spec)`.
* When using `pn.pane.Vega(spec)` I get an empty space. Running the visualisation externally using `pn.pane.Vega(spec).show()` and looking at the source code, I see that the div is empty.
Versions:
* panel 0.7.0
* bokeh 1.4.0
* vega 2.6.0
* jupyter 1.0.0
```
#!/usr/bin/env python
import panel as pn
from bokeh.plotting import figure, output_notebook, show
from vega import VegaLite, Vega
pn.extension()
pn.extension('vega')
output_notebook()
spec = {
"$schema": "https://vega.github.io/schema/vega/v5.json",
"width": 400,
"height": 200,
"data": [
{
"name": "table",
"values": [
{"category": "A", "amount": 28},
{"category": "B", "amount": 55},
{"category": "C", "amount": 43}
]
}
],
"scales": [
{
"name": "xscale",
"type": "band",
"domain": {"data": "table", "field": "category"},
"range": "width"
},
{
"name": "yscale",
"domain": {"data": "table", "field": "amount"},
"range": "height"
}
],
"marks": [
{
"type": "rect",
"from": {"data":"table"},
"encode": {
"enter": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "amount"},
"y2": {"scale": "yscale", "value": 0}
},
"update": {
"fill": {"value": "steelblue"}
}
}
}
]
}
Vega(spec) # => shows barchart => OK
pn.Column(pn.panel("## Vega test"),
pn.pane.Vega(spec),
pn.panel("_end of test_"))
# => shows "Vega test", then empty space, the "end of test"
pn.Column(pn.panel("## Vega test"),
pn.panel(spec),
pn.panel("_end of test_"))
# => shows "Vega test", then empty space, the "end of test"
```
Thank you,
jan.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `panel/pane/vega.py`
Content:
```
1 from __future__ import absolute_import, division, unicode_literals
2
3 import sys
4
5 import param
6 import numpy as np
7
8 from bokeh.models import ColumnDataSource
9 from pyviz_comms import JupyterComm
10
11 from ..viewable import Layoutable
12 from .base import PaneBase
13
14
15 def ds_as_cds(dataset):
16 """
17 Converts Vega dataset into Bokeh ColumnDataSource data
18 """
19 if len(dataset) == 0:
20 return {}
21 data = {k: [] for k, v in dataset[0].items()}
22 for item in dataset:
23 for k, v in item.items():
24 data[k].append(v)
25 data = {k: np.asarray(v) for k, v in data.items()}
26 return data
27
28
29 class Vega(PaneBase):
30 """
31 Vega panes allow rendering Vega plots and traces.
32
33 For efficiency any array objects found inside a Figure are added
34 to a ColumnDataSource which allows using binary transport to sync
35 the figure on bokeh server and via Comms.
36 """
37
38 margin = param.Parameter(default=(5, 5, 30, 5), doc="""
39 Allows to create additional space around the component. May
40 be specified as a two-tuple of the form (vertical, horizontal)
41 or a four-tuple (top, right, bottom, left).""")
42
43 priority = 0.8
44
45 _updates = True
46
47 @classmethod
48 def is_altair(cls, obj):
49 if 'altair' in sys.modules:
50 import altair as alt
51 return isinstance(obj, alt.api.TopLevelMixin)
52 return False
53
54 @classmethod
55 def applies(cls, obj):
56 if isinstance(obj, dict) and 'vega' in obj.get('$schema', '').lower():
57 return True
58 return cls.is_altair(obj)
59
60 @classmethod
61 def _to_json(cls, obj):
62 if isinstance(obj, dict):
63 json = dict(obj)
64 if 'data' in json:
65 json['data'] = dict(json['data'])
66 return json
67 return obj.to_dict()
68
69 def _get_sources(self, json, sources):
70 datasets = json.get('datasets', {})
71 for name in list(datasets):
72 if name in sources or isinstance(datasets[name], dict):
73 continue
74 data = datasets.pop(name)
75 columns = set(data[0]) if data else []
76 if self.is_altair(self.object):
77 import altair as alt
78 if (not isinstance(self.object.data, (alt.Data, alt.UrlData)) and
79 columns == set(self.object.data)):
80 data = ColumnDataSource.from_df(self.object.data)
81 else:
82 data = ds_as_cds(data)
83 sources[name] = ColumnDataSource(data=data)
84 else:
85 sources[name] = ColumnDataSource(data=ds_as_cds(data))
86 data = json.get('data', {}).pop('values', {})
87 if data:
88 sources['data'] = ColumnDataSource(data=ds_as_cds(data))
89
90
91 @classmethod
92 def _get_dimensions(cls, json, props):
93 if json is None:
94 return
95
96 view = {}
97 if 'width' in json:
98 view['width'] = json['width']
99 if 'height' in json:
100 view['height'] = json['height']
101 if 'config' in json and 'view' in json['config']:
102 view = json['config']['view']
103 for p in ('width', 'height'):
104 if p not in view:
105 continue
106 if props.get(p) is None or p in view and props.get(p) < view[p]:
107 v = view[p]
108 props[p] = v+22 if isinstance(v, int) else v
109
110 def _get_model(self, doc, root=None, parent=None, comm=None):
111 if 'panel.models.vega' not in sys.modules:
112 if isinstance(comm, JupyterComm):
113 self.param.warning('VegaPlot was not imported on instantiation '
114 'and may not render in a notebook. Restart '
115 'the notebook kernel and ensure you load '
116 'it as part of the extension using:'
117 '\n\npn.extension(\'vega\')\n')
118 from ..models.vega import VegaPlot
119 else:
120 VegaPlot = getattr(sys.modules['panel.models.vega'], 'VegaPlot')
121
122 sources = {}
123 if self.object is None:
124 json = None
125 else:
126 json = self._to_json(self.object)
127 self._get_sources(json, sources)
128 props = self._process_param_change(self._init_properties())
129 self._get_dimensions(json, props)
130 model = VegaPlot(data=json, data_sources=sources, **props)
131 if root is None:
132 root = model
133 self._models[root.ref['id']] = (model, parent)
134 return model
135
136 def _update(self, model):
137 if self.object is None:
138 json = None
139 else:
140 json = self._to_json(self.object)
141 self._get_sources(json, model.data_sources)
142 props = {p : getattr(self, p) for p in list(Layoutable.param)
143 if getattr(self, p) is not None}
144 self._get_dimensions(json, props)
145 props['data'] = json
146 model.update(**props)
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/panel/pane/vega.py b/panel/pane/vega.py
--- a/panel/pane/vega.py
+++ b/panel/pane/vega.py
@@ -62,7 +62,11 @@
if isinstance(obj, dict):
json = dict(obj)
if 'data' in json:
- json['data'] = dict(json['data'])
+ data = json['data']
+ if isinstance(data, dict):
+ json['data'] = dict(data)
+ elif isinstance(data, list):
+ json['data'] = [dict(d) for d in data]
return json
return obj.to_dict()
@@ -83,9 +87,15 @@
sources[name] = ColumnDataSource(data=data)
else:
sources[name] = ColumnDataSource(data=ds_as_cds(data))
- data = json.get('data', {}).pop('values', {})
- if data:
- sources['data'] = ColumnDataSource(data=ds_as_cds(data))
+ data = json.get('data', {})
+ if isinstance(data, dict):
+ data = data.pop('values', {})
+ if data:
+ sources['data'] = ColumnDataSource(data=ds_as_cds(data))
+ elif isinstance(data, list):
+ for d in data:
+ sources[d['name']] = ColumnDataSource(data=ds_as_cds(d['values']))
+
@classmethod
|
{"golden_diff": "diff --git a/panel/pane/vega.py b/panel/pane/vega.py\n--- a/panel/pane/vega.py\n+++ b/panel/pane/vega.py\n@@ -62,7 +62,11 @@\n if isinstance(obj, dict):\n json = dict(obj)\n if 'data' in json:\n- json['data'] = dict(json['data'])\n+ data = json['data']\n+ if isinstance(data, dict):\n+ json['data'] = dict(data)\n+ elif isinstance(data, list):\n+ json['data'] = [dict(d) for d in data]\n return json\n return obj.to_dict()\n \n@@ -83,9 +87,15 @@\n sources[name] = ColumnDataSource(data=data)\n else:\n sources[name] = ColumnDataSource(data=ds_as_cds(data))\n- data = json.get('data', {}).pop('values', {})\n- if data:\n- sources['data'] = ColumnDataSource(data=ds_as_cds(data))\n+ data = json.get('data', {})\n+ if isinstance(data, dict):\n+ data = data.pop('values', {})\n+ if data:\n+ sources['data'] = ColumnDataSource(data=ds_as_cds(data))\n+ elif isinstance(data, list):\n+ for d in data:\n+ sources[d['name']] = ColumnDataSource(data=ds_as_cds(d['values']))\n+ \n \n \n @classmethod\n", "issue": "Vega plot not displaying within a holoviz panel in jupyter notebook\nApparently, vega plots have issues being shown when within a panel in a jupyter notebook. This might have something to do with Panel not serialising the data correctly.\r\n\r\nFor a minimal script showing the issue, see at the bottom of this question.\r\n\r\nMy findings:\r\n\r\n* The vega import works nicely when used outside of a panel: the Vega specification copy/pasted from https://vega.github.io/editor/#/examples/vega/force-directed-layout is visualised as it should be using `Vega(spec)`.\r\n* When using `pn.pane.Vega(spec)` I get an empty space. Running the visualisation externally using `pn.pane.Vega(spec).show()` and looking at the source code, I see that the div is empty.\r\n\r\nVersions:\r\n\r\n* panel 0.7.0\r\n* bokeh 1.4.0\r\n* vega 2.6.0\r\n* jupyter 1.0.0\r\n\r\n\r\n```\r\n#!/usr/bin/env python\r\nimport panel as pn\r\nfrom bokeh.plotting import figure, output_notebook, show\r\nfrom vega import VegaLite, Vega\r\npn.extension()\r\npn.extension('vega')\r\noutput_notebook()\r\n\r\nspec = {\r\n \"$schema\": \"https://vega.github.io/schema/vega/v5.json\",\r\n \"width\": 400,\r\n \"height\": 200,\r\n\r\n \"data\": [\r\n {\r\n \"name\": \"table\",\r\n \"values\": [\r\n {\"category\": \"A\", \"amount\": 28},\r\n {\"category\": \"B\", \"amount\": 55},\r\n {\"category\": \"C\", \"amount\": 43}\r\n ]\r\n }\r\n ],\r\n\r\n \"scales\": [\r\n {\r\n \"name\": \"xscale\",\r\n \"type\": \"band\",\r\n \"domain\": {\"data\": \"table\", \"field\": \"category\"},\r\n \"range\": \"width\"\r\n },\r\n {\r\n \"name\": \"yscale\",\r\n \"domain\": {\"data\": \"table\", \"field\": \"amount\"},\r\n \"range\": \"height\"\r\n }\r\n ],\r\n\r\n \"marks\": [\r\n {\r\n \"type\": \"rect\",\r\n \"from\": {\"data\":\"table\"},\r\n \"encode\": {\r\n \"enter\": {\r\n \"x\": {\"scale\": \"xscale\", \"field\": \"category\"},\r\n \"width\": {\"scale\": \"xscale\", \"band\": 1},\r\n \"y\": {\"scale\": \"yscale\", \"field\": \"amount\"},\r\n \"y2\": {\"scale\": \"yscale\", \"value\": 0}\r\n },\r\n \"update\": {\r\n \"fill\": {\"value\": \"steelblue\"}\r\n }\r\n }\r\n }\r\n ]\r\n}\r\n\r\nVega(spec) # => shows barchart => OK\r\n\r\npn.Column(pn.panel(\"## Vega test\"),\r\n pn.pane.Vega(spec),\r\n pn.panel(\"_end of test_\"))\r\n# => shows \"Vega test\", then empty space, the \"end of test\"\r\n\r\npn.Column(pn.panel(\"## Vega test\"),\r\n pn.panel(spec),\r\n pn.panel(\"_end of test_\"))\r\n# => shows \"Vega test\", then empty space, the \"end of test\"\r\n```\r\n\r\nThank you,\r\njan.\n", "before_files": [{"content": "from __future__ import absolute_import, division, unicode_literals\n\nimport sys\n\nimport param\nimport numpy as np\n\nfrom bokeh.models import ColumnDataSource\nfrom pyviz_comms import JupyterComm\n\nfrom ..viewable import Layoutable\nfrom .base import PaneBase\n\n\ndef ds_as_cds(dataset):\n \"\"\"\n Converts Vega dataset into Bokeh ColumnDataSource data\n \"\"\"\n if len(dataset) == 0:\n return {}\n data = {k: [] for k, v in dataset[0].items()}\n for item in dataset:\n for k, v in item.items():\n data[k].append(v)\n data = {k: np.asarray(v) for k, v in data.items()}\n return data\n\n\nclass Vega(PaneBase):\n \"\"\"\n Vega panes allow rendering Vega plots and traces.\n\n For efficiency any array objects found inside a Figure are added\n to a ColumnDataSource which allows using binary transport to sync\n the figure on bokeh server and via Comms.\n \"\"\"\n\n margin = param.Parameter(default=(5, 5, 30, 5), doc=\"\"\"\n Allows to create additional space around the component. May\n be specified as a two-tuple of the form (vertical, horizontal)\n or a four-tuple (top, right, bottom, left).\"\"\")\n\n priority = 0.8\n\n _updates = True\n\n @classmethod\n def is_altair(cls, obj):\n if 'altair' in sys.modules:\n import altair as alt\n return isinstance(obj, alt.api.TopLevelMixin)\n return False\n\n @classmethod\n def applies(cls, obj):\n if isinstance(obj, dict) and 'vega' in obj.get('$schema', '').lower():\n return True\n return cls.is_altair(obj)\n\n @classmethod\n def _to_json(cls, obj):\n if isinstance(obj, dict):\n json = dict(obj)\n if 'data' in json:\n json['data'] = dict(json['data'])\n return json\n return obj.to_dict()\n\n def _get_sources(self, json, sources):\n datasets = json.get('datasets', {})\n for name in list(datasets):\n if name in sources or isinstance(datasets[name], dict):\n continue\n data = datasets.pop(name)\n columns = set(data[0]) if data else []\n if self.is_altair(self.object):\n import altair as alt\n if (not isinstance(self.object.data, (alt.Data, alt.UrlData)) and\n columns == set(self.object.data)):\n data = ColumnDataSource.from_df(self.object.data)\n else:\n data = ds_as_cds(data)\n sources[name] = ColumnDataSource(data=data)\n else:\n sources[name] = ColumnDataSource(data=ds_as_cds(data))\n data = json.get('data', {}).pop('values', {})\n if data:\n sources['data'] = ColumnDataSource(data=ds_as_cds(data))\n\n\n @classmethod\n def _get_dimensions(cls, json, props):\n if json is None:\n return\n\n view = {}\n if 'width' in json:\n view['width'] = json['width']\n if 'height' in json:\n view['height'] = json['height']\n if 'config' in json and 'view' in json['config']:\n view = json['config']['view']\n for p in ('width', 'height'):\n if p not in view:\n continue\n if props.get(p) is None or p in view and props.get(p) < view[p]:\n v = view[p]\n props[p] = v+22 if isinstance(v, int) else v\n\n def _get_model(self, doc, root=None, parent=None, comm=None):\n if 'panel.models.vega' not in sys.modules:\n if isinstance(comm, JupyterComm):\n self.param.warning('VegaPlot was not imported on instantiation '\n 'and may not render in a notebook. Restart '\n 'the notebook kernel and ensure you load '\n 'it as part of the extension using:'\n '\\n\\npn.extension(\\'vega\\')\\n')\n from ..models.vega import VegaPlot\n else:\n VegaPlot = getattr(sys.modules['panel.models.vega'], 'VegaPlot')\n\n sources = {}\n if self.object is None:\n json = None\n else:\n json = self._to_json(self.object)\n self._get_sources(json, sources)\n props = self._process_param_change(self._init_properties())\n self._get_dimensions(json, props)\n model = VegaPlot(data=json, data_sources=sources, **props)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n return model\n\n def _update(self, model):\n if self.object is None:\n json = None\n else:\n json = self._to_json(self.object)\n self._get_sources(json, model.data_sources)\n props = {p : getattr(self, p) for p in list(Layoutable.param)\n if getattr(self, p) is not None}\n self._get_dimensions(json, props)\n props['data'] = json\n model.update(**props)\n", "path": "panel/pane/vega.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, unicode_literals\n\nimport sys\n\nimport param\nimport numpy as np\n\nfrom bokeh.models import ColumnDataSource\nfrom pyviz_comms import JupyterComm\n\nfrom ..viewable import Layoutable\nfrom .base import PaneBase\n\n\ndef ds_as_cds(dataset):\n \"\"\"\n Converts Vega dataset into Bokeh ColumnDataSource data\n \"\"\"\n if len(dataset) == 0:\n return {}\n data = {k: [] for k, v in dataset[0].items()}\n for item in dataset:\n for k, v in item.items():\n data[k].append(v)\n data = {k: np.asarray(v) for k, v in data.items()}\n return data\n\n\nclass Vega(PaneBase):\n \"\"\"\n Vega panes allow rendering Vega plots and traces.\n\n For efficiency any array objects found inside a Figure are added\n to a ColumnDataSource which allows using binary transport to sync\n the figure on bokeh server and via Comms.\n \"\"\"\n\n margin = param.Parameter(default=(5, 5, 30, 5), doc=\"\"\"\n Allows to create additional space around the component. May\n be specified as a two-tuple of the form (vertical, horizontal)\n or a four-tuple (top, right, bottom, left).\"\"\")\n\n priority = 0.8\n\n _updates = True\n\n @classmethod\n def is_altair(cls, obj):\n if 'altair' in sys.modules:\n import altair as alt\n return isinstance(obj, alt.api.TopLevelMixin)\n return False\n\n @classmethod\n def applies(cls, obj):\n if isinstance(obj, dict) and 'vega' in obj.get('$schema', '').lower():\n return True\n return cls.is_altair(obj)\n\n @classmethod\n def _to_json(cls, obj):\n if isinstance(obj, dict):\n json = dict(obj)\n if 'data' in json:\n data = json['data']\n if isinstance(data, dict):\n json['data'] = dict(data)\n elif isinstance(data, list):\n json['data'] = [dict(d) for d in data]\n return json\n return obj.to_dict()\n\n def _get_sources(self, json, sources):\n datasets = json.get('datasets', {})\n for name in list(datasets):\n if name in sources or isinstance(datasets[name], dict):\n continue\n data = datasets.pop(name)\n columns = set(data[0]) if data else []\n if self.is_altair(self.object):\n import altair as alt\n if (not isinstance(self.object.data, (alt.Data, alt.UrlData)) and\n columns == set(self.object.data)):\n data = ColumnDataSource.from_df(self.object.data)\n else:\n data = ds_as_cds(data)\n sources[name] = ColumnDataSource(data=data)\n else:\n sources[name] = ColumnDataSource(data=ds_as_cds(data))\n data = json.get('data', {})\n if isinstance(data, dict):\n data = data.pop('values', {})\n if data:\n sources['data'] = ColumnDataSource(data=ds_as_cds(data))\n elif isinstance(data, list):\n for d in data:\n sources[d['name']] = ColumnDataSource(data=ds_as_cds(d['values']))\n \n\n\n @classmethod\n def _get_dimensions(cls, json, props):\n if json is None:\n return\n\n view = {}\n if 'width' in json:\n view['width'] = json['width']\n if 'height' in json:\n view['height'] = json['height']\n if 'config' in json and 'view' in json['config']:\n view = json['config']['view']\n for p in ('width', 'height'):\n if p not in view:\n continue\n if props.get(p) is None or p in view and props.get(p) < view[p]:\n v = view[p]\n props[p] = v+22 if isinstance(v, int) else v\n\n def _get_model(self, doc, root=None, parent=None, comm=None):\n if 'panel.models.vega' not in sys.modules:\n if isinstance(comm, JupyterComm):\n self.param.warning('VegaPlot was not imported on instantiation '\n 'and may not render in a notebook. Restart '\n 'the notebook kernel and ensure you load '\n 'it as part of the extension using:'\n '\\n\\npn.extension(\\'vega\\')\\n')\n from ..models.vega import VegaPlot\n else:\n VegaPlot = getattr(sys.modules['panel.models.vega'], 'VegaPlot')\n\n sources = {}\n if self.object is None:\n json = None\n else:\n json = self._to_json(self.object)\n self._get_sources(json, sources)\n props = self._process_param_change(self._init_properties())\n self._get_dimensions(json, props)\n model = VegaPlot(data=json, data_sources=sources, **props)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n return model\n\n def _update(self, model):\n if self.object is None:\n json = None\n else:\n json = self._to_json(self.object)\n self._get_sources(json, model.data_sources)\n props = {p : getattr(self, p) for p in list(Layoutable.param)\n if getattr(self, p) is not None}\n self._get_dimensions(json, props)\n props['data'] = json\n model.update(**props)\n", "path": "panel/pane/vega.py"}]}
| 2,426 | 321 |
gh_patches_debug_6833
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1820
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update bleach to 2.0.0
There's a new version of [bleach](https://pypi.python.org/pypi/bleach) available.
You are currently using **1.5.0**. I have updated it to **2.0.0**
These links might come in handy: <a href="http://pypi.python.org/pypi/bleach">PyPI</a> | <a href="https://pyup.io/changelogs/bleach/">Changelog</a> | <a href="http://github.com/mozilla/bleach">Repo</a> | <a href="http://pythonhosted.org/bleach/">Docs</a>
### Changelog
>
>### 2.0
>-----------------------------
>**Backwards incompatible changes**
>* Removed support for Python 2.6. 206
>* Removed support for Python 3.2. 224
>* Bleach no longer supports html5lib < 0.99999999 (8 9s).
> This version is a rewrite to use the new sanitizing API since the old
> one was dropped in html5lib 0.99999999 (8 9s).
>* ``bleach.clean`` and friends were rewritten
> ``clean`` was reimplemented as an html5lib filter and happens at a different
> step in the HTML parsing -> traversing -> serializing process. Because of
> that, there are some differences in clean's output as compared with previous
> versions.
> Amongst other things, this version will add end tags even if the tag in
> question is to be escaped.
>* ``bleach.clean`` and friends attribute callables now take three arguments:
> tag, attribute name and attribute value. Previously they only took attribute
> name and attribute value.
> All attribute callables will need to be updated.
>* ``bleach.linkify`` was rewritten
> ``linkify`` was reimplemented as an html5lib Filter. As such, it no longer
> accepts a ``tokenizer`` argument.
> The callback functions for adjusting link attributes now takes a namespaced
> attribute.
> Previously you'd do something like this::
> def check_protocol(attrs, is_new):
> if not attrs.get('href', '').startswith('http:', 'https:')):
> return None
> return attrs
> Now it's more like this::
> def check_protocol(attrs, is_new):
> if not attrs.get((None, u'href'), u'').startswith(('http:', 'https:')):
> ^^^^^^^^^^^^^^^
> return None
> return attrs
> Further, you need to make sure you're always using unicode values. If you
> don't then html5lib will raise an assertion error that the value is not
> unicode.
> All linkify filters will need to be updated.
>* ``bleach.linkify`` and friends had a ``skip_pre`` argument--that's been
> replaced with a more general ``skip_tags`` argument.
> Before, you might do::
> bleach.linkify(some_text, skip_pre=True)
> The equivalent with Bleach 2.0 is::
> bleach.linkify(some_text, skip_tags=['pre'])
> You can skip other tags, too, like ``style`` or ``script`` or other places
> where you don't want linkification happening.
> All uses of linkify that use ``skip_pre`` will need to be updated.
>**Changes**
>* Supports Python 3.6.
>* Supports html5lib >= 0.99999999 (8 9s).
>* There's a ``bleach.sanitizer.Cleaner`` class that you can instantiate with your
> favorite clean settings for easy reuse.
>* There's a ``bleach.linkifier.Linker`` class that you can instantiate with your
> favorite linkify settings for easy reuse.
>* There's a ``bleach.linkifier.LinkifyFilter`` which is an htm5lib filter that
> you can pass as a filter to ``bleach.sanitizer.Cleaner`` allowing you to clean
> and linkify in one pass.
>* ``bleach.clean`` and friends can now take a callable as an attributes arg value.
>* Tons of bug fixes.
>* Cleaned up tests.
>* Documentation fixes.
*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*
Happy merging! 🤖
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/filters.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import binascii
14 import collections
15 import enum
16 import hmac
17 import json
18 import re
19 import urllib.parse
20
21 import html5lib
22 import html5lib.serializer
23 import html5lib.treewalkers
24 import jinja2
25
26 import readme_renderer.rst
27 import readme_renderer.txt
28
29 from pyramid.threadlocal import get_current_request
30
31 from warehouse.utils.http import is_valid_uri
32
33
34 class PackageType(enum.Enum):
35 bdist_dmg = "OSX Disk Image"
36 bdist_dumb = "Dumb Binary"
37 bdist_egg = "Egg"
38 bdist_msi = "Windows MSI Installer"
39 bdist_rpm = "RPM"
40 bdist_wheel = "Wheel"
41 bdist_wininst = "Windows Installer"
42 sdist = "Source"
43
44
45 def format_package_type(value):
46 try:
47 return PackageType[value].value
48 except KeyError:
49 return value
50
51
52 def _camo_url(camo_url, camo_key, url):
53 camo_key = camo_key.encode("utf8")
54 url = url.encode("utf8")
55
56 path = "/".join([
57 hmac.new(camo_key, url, digestmod="sha1").hexdigest(),
58 binascii.hexlify(url).decode("utf8"),
59 ])
60
61 return urllib.parse.urljoin(camo_url, path)
62
63
64 @jinja2.contextfilter
65 def readme(ctx, value, *, format):
66 request = ctx.get("request") or get_current_request()
67
68 camo_url = request.registry.settings["camo.url"].format(request=request)
69 camo_key = request.registry.settings["camo.key"]
70
71 # The format parameter is here so we can more easily expand this to cover
72 # READMEs which do not use restructuredtext, but for now rst is the only
73 # format we support.
74 assert format == "rst", "We currently only support rst rendering."
75
76 # Actually render the given value, this will not only render the value, but
77 # also ensure that it's had any disallowed markup removed.
78 rendered = readme_renderer.rst.render(value)
79
80 # If the content was not rendered, we'll replace the newlines with breaks
81 # so that it shows up nicer when rendered.
82 if rendered is None:
83 rendered = readme_renderer.txt.render(value)
84
85 # Parse the rendered output and replace any inline images that don't point
86 # to HTTPS with camouflaged images.
87 tree_builder = html5lib.treebuilders.getTreeBuilder("dom")
88 parser = html5lib.html5parser.HTMLParser(tree=tree_builder)
89 dom = parser.parse(rendered)
90
91 for element in dom.getElementsByTagName("img"):
92 src = element.getAttribute("src")
93 if src:
94 element.setAttribute("src", _camo_url(camo_url, camo_key, src))
95
96 tree_walker = html5lib.treewalkers.getTreeWalker("dom")
97 html_serializer = html5lib.serializer.htmlserializer.HTMLSerializer()
98 rendered = "".join(html_serializer.serialize(tree_walker(dom)))
99
100 return jinja2.Markup(rendered)
101
102
103 _SI_SYMBOLS = ["k", "M", "G", "T", "P", "E", "Z", "Y"]
104
105
106 def shorten_number(value):
107 for i, symbol in enumerate(_SI_SYMBOLS):
108 magnitude = value / (1000 ** (i + 1))
109 if magnitude >= 1 and magnitude < 1000:
110 return "{:.3g}{}".format(magnitude, symbol)
111
112 return str(value)
113
114
115 def tojson(value):
116 return json.dumps(value, sort_keys=True, separators=(",", ":"))
117
118
119 def urlparse(value):
120 return urllib.parse.urlparse(value)
121
122
123 def format_tags(tags):
124 # split tags
125 if re.search(r',', tags):
126 split_tags = re.split(r'\s*,\s*', tags)
127 elif re.search(r';', tags):
128 split_tags = re.split(r'\s*;\s*', tags)
129 else:
130 split_tags = re.split(r'\s+', tags)
131
132 # strip whitespace, quotes, double quotes
133 stripped_tags = [re.sub(r'^["\'\s]+|["\'\s]+$', '', t) for t in split_tags]
134
135 # remove any empty tags
136 formatted_tags = [t for t in stripped_tags if t]
137
138 return formatted_tags
139
140
141 def format_classifiers(classifiers):
142 structured = collections.defaultdict(list)
143
144 # Split up our classifiers into our data structure
145 for classifier in classifiers:
146 key, *value = classifier.split(" :: ", 1)
147 if value:
148 structured[key].append(value[0])
149
150 # Go thorugh and ensure that all of the lists in our classifiers are in
151 # sorted order.
152 structured = {k: sorted(v) for k, v in structured.items()}
153
154 # Now, we'll ensure that our keys themselves are in sorted order, using an
155 # OrderedDict to preserve this ordering when we pass this data back up to
156 # our caller.
157 structured = collections.OrderedDict(sorted(structured.items()))
158
159 return structured
160
161
162 def contains_valid_uris(items):
163 """Returns boolean representing whether the input list contains any valid
164 URIs
165 """
166 return any(is_valid_uri(i) for i in items)
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/filters.py b/warehouse/filters.py
--- a/warehouse/filters.py
+++ b/warehouse/filters.py
@@ -94,7 +94,7 @@
element.setAttribute("src", _camo_url(camo_url, camo_key, src))
tree_walker = html5lib.treewalkers.getTreeWalker("dom")
- html_serializer = html5lib.serializer.htmlserializer.HTMLSerializer()
+ html_serializer = html5lib.serializer.HTMLSerializer()
rendered = "".join(html_serializer.serialize(tree_walker(dom)))
return jinja2.Markup(rendered)
|
{"golden_diff": "diff --git a/warehouse/filters.py b/warehouse/filters.py\n--- a/warehouse/filters.py\n+++ b/warehouse/filters.py\n@@ -94,7 +94,7 @@\n element.setAttribute(\"src\", _camo_url(camo_url, camo_key, src))\n \n tree_walker = html5lib.treewalkers.getTreeWalker(\"dom\")\n- html_serializer = html5lib.serializer.htmlserializer.HTMLSerializer()\n+ html_serializer = html5lib.serializer.HTMLSerializer()\n rendered = \"\".join(html_serializer.serialize(tree_walker(dom)))\n \n return jinja2.Markup(rendered)\n", "issue": "Update bleach to 2.0.0\n\nThere's a new version of [bleach](https://pypi.python.org/pypi/bleach) available.\nYou are currently using **1.5.0**. I have updated it to **2.0.0**\n\n\n\nThese links might come in handy: <a href=\"http://pypi.python.org/pypi/bleach\">PyPI</a> | <a href=\"https://pyup.io/changelogs/bleach/\">Changelog</a> | <a href=\"http://github.com/mozilla/bleach\">Repo</a> | <a href=\"http://pythonhosted.org/bleach/\">Docs</a> \n\n\n\n### Changelog\n> \n>### 2.0\n\n>-----------------------------\n\n>**Backwards incompatible changes**\n\n>* Removed support for Python 2.6. 206\n\n>* Removed support for Python 3.2. 224\n\n>* Bleach no longer supports html5lib < 0.99999999 (8 9s).\n\n> This version is a rewrite to use the new sanitizing API since the old\n> one was dropped in html5lib 0.99999999 (8 9s).\n\n>* ``bleach.clean`` and friends were rewritten\n\n> ``clean`` was reimplemented as an html5lib filter and happens at a different\n> step in the HTML parsing -> traversing -> serializing process. Because of\n> that, there are some differences in clean's output as compared with previous\n> versions.\n\n> Amongst other things, this version will add end tags even if the tag in\n> question is to be escaped.\n\n>* ``bleach.clean`` and friends attribute callables now take three arguments:\n> tag, attribute name and attribute value. Previously they only took attribute\n> name and attribute value.\n\n> All attribute callables will need to be updated.\n\n>* ``bleach.linkify`` was rewritten\n\n> ``linkify`` was reimplemented as an html5lib Filter. As such, it no longer\n> accepts a ``tokenizer`` argument.\n\n> The callback functions for adjusting link attributes now takes a namespaced\n> attribute.\n\n> Previously you'd do something like this::\n\n> def check_protocol(attrs, is_new):\n> if not attrs.get('href', '').startswith('http:', 'https:')):\n> return None\n> return attrs\n\n> Now it's more like this::\n\n> def check_protocol(attrs, is_new):\n> if not attrs.get((None, u'href'), u'').startswith(('http:', 'https:')):\n> ^^^^^^^^^^^^^^^\n> return None\n> return attrs\n\n> Further, you need to make sure you're always using unicode values. If you\n> don't then html5lib will raise an assertion error that the value is not\n> unicode.\n\n> All linkify filters will need to be updated.\n\n>* ``bleach.linkify`` and friends had a ``skip_pre`` argument--that's been\n> replaced with a more general ``skip_tags`` argument.\n\n> Before, you might do::\n\n> bleach.linkify(some_text, skip_pre=True)\n\n> The equivalent with Bleach 2.0 is::\n\n> bleach.linkify(some_text, skip_tags=['pre'])\n\n> You can skip other tags, too, like ``style`` or ``script`` or other places\n> where you don't want linkification happening.\n\n> All uses of linkify that use ``skip_pre`` will need to be updated.\n\n\n>**Changes**\n\n>* Supports Python 3.6.\n\n>* Supports html5lib >= 0.99999999 (8 9s).\n\n>* There's a ``bleach.sanitizer.Cleaner`` class that you can instantiate with your\n> favorite clean settings for easy reuse.\n\n>* There's a ``bleach.linkifier.Linker`` class that you can instantiate with your\n> favorite linkify settings for easy reuse.\n\n>* There's a ``bleach.linkifier.LinkifyFilter`` which is an htm5lib filter that\n> you can pass as a filter to ``bleach.sanitizer.Cleaner`` allowing you to clean\n> and linkify in one pass.\n\n>* ``bleach.clean`` and friends can now take a callable as an attributes arg value.\n\n>* Tons of bug fixes.\n\n>* Cleaned up tests.\n\n>* Documentation fixes.\n\n\n\n\n\n\n\n\n*Got merge conflicts? Close this PR and delete the branch. I'll create a new PR for you.*\n\nHappy merging! \ud83e\udd16\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport collections\nimport enum\nimport hmac\nimport json\nimport re\nimport urllib.parse\n\nimport html5lib\nimport html5lib.serializer\nimport html5lib.treewalkers\nimport jinja2\n\nimport readme_renderer.rst\nimport readme_renderer.txt\n\nfrom pyramid.threadlocal import get_current_request\n\nfrom warehouse.utils.http import is_valid_uri\n\n\nclass PackageType(enum.Enum):\n bdist_dmg = \"OSX Disk Image\"\n bdist_dumb = \"Dumb Binary\"\n bdist_egg = \"Egg\"\n bdist_msi = \"Windows MSI Installer\"\n bdist_rpm = \"RPM\"\n bdist_wheel = \"Wheel\"\n bdist_wininst = \"Windows Installer\"\n sdist = \"Source\"\n\n\ndef format_package_type(value):\n try:\n return PackageType[value].value\n except KeyError:\n return value\n\n\ndef _camo_url(camo_url, camo_key, url):\n camo_key = camo_key.encode(\"utf8\")\n url = url.encode(\"utf8\")\n\n path = \"/\".join([\n hmac.new(camo_key, url, digestmod=\"sha1\").hexdigest(),\n binascii.hexlify(url).decode(\"utf8\"),\n ])\n\n return urllib.parse.urljoin(camo_url, path)\n\n\[email protected]\ndef readme(ctx, value, *, format):\n request = ctx.get(\"request\") or get_current_request()\n\n camo_url = request.registry.settings[\"camo.url\"].format(request=request)\n camo_key = request.registry.settings[\"camo.key\"]\n\n # The format parameter is here so we can more easily expand this to cover\n # READMEs which do not use restructuredtext, but for now rst is the only\n # format we support.\n assert format == \"rst\", \"We currently only support rst rendering.\"\n\n # Actually render the given value, this will not only render the value, but\n # also ensure that it's had any disallowed markup removed.\n rendered = readme_renderer.rst.render(value)\n\n # If the content was not rendered, we'll replace the newlines with breaks\n # so that it shows up nicer when rendered.\n if rendered is None:\n rendered = readme_renderer.txt.render(value)\n\n # Parse the rendered output and replace any inline images that don't point\n # to HTTPS with camouflaged images.\n tree_builder = html5lib.treebuilders.getTreeBuilder(\"dom\")\n parser = html5lib.html5parser.HTMLParser(tree=tree_builder)\n dom = parser.parse(rendered)\n\n for element in dom.getElementsByTagName(\"img\"):\n src = element.getAttribute(\"src\")\n if src:\n element.setAttribute(\"src\", _camo_url(camo_url, camo_key, src))\n\n tree_walker = html5lib.treewalkers.getTreeWalker(\"dom\")\n html_serializer = html5lib.serializer.htmlserializer.HTMLSerializer()\n rendered = \"\".join(html_serializer.serialize(tree_walker(dom)))\n\n return jinja2.Markup(rendered)\n\n\n_SI_SYMBOLS = [\"k\", \"M\", \"G\", \"T\", \"P\", \"E\", \"Z\", \"Y\"]\n\n\ndef shorten_number(value):\n for i, symbol in enumerate(_SI_SYMBOLS):\n magnitude = value / (1000 ** (i + 1))\n if magnitude >= 1 and magnitude < 1000:\n return \"{:.3g}{}\".format(magnitude, symbol)\n\n return str(value)\n\n\ndef tojson(value):\n return json.dumps(value, sort_keys=True, separators=(\",\", \":\"))\n\n\ndef urlparse(value):\n return urllib.parse.urlparse(value)\n\n\ndef format_tags(tags):\n # split tags\n if re.search(r',', tags):\n split_tags = re.split(r'\\s*,\\s*', tags)\n elif re.search(r';', tags):\n split_tags = re.split(r'\\s*;\\s*', tags)\n else:\n split_tags = re.split(r'\\s+', tags)\n\n # strip whitespace, quotes, double quotes\n stripped_tags = [re.sub(r'^[\"\\'\\s]+|[\"\\'\\s]+$', '', t) for t in split_tags]\n\n # remove any empty tags\n formatted_tags = [t for t in stripped_tags if t]\n\n return formatted_tags\n\n\ndef format_classifiers(classifiers):\n structured = collections.defaultdict(list)\n\n # Split up our classifiers into our data structure\n for classifier in classifiers:\n key, *value = classifier.split(\" :: \", 1)\n if value:\n structured[key].append(value[0])\n\n # Go thorugh and ensure that all of the lists in our classifiers are in\n # sorted order.\n structured = {k: sorted(v) for k, v in structured.items()}\n\n # Now, we'll ensure that our keys themselves are in sorted order, using an\n # OrderedDict to preserve this ordering when we pass this data back up to\n # our caller.\n structured = collections.OrderedDict(sorted(structured.items()))\n\n return structured\n\n\ndef contains_valid_uris(items):\n \"\"\"Returns boolean representing whether the input list contains any valid\n URIs\n \"\"\"\n return any(is_valid_uri(i) for i in items)\n", "path": "warehouse/filters.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport collections\nimport enum\nimport hmac\nimport json\nimport re\nimport urllib.parse\n\nimport html5lib\nimport html5lib.serializer\nimport html5lib.treewalkers\nimport jinja2\n\nimport readme_renderer.rst\nimport readme_renderer.txt\n\nfrom pyramid.threadlocal import get_current_request\n\nfrom warehouse.utils.http import is_valid_uri\n\n\nclass PackageType(enum.Enum):\n bdist_dmg = \"OSX Disk Image\"\n bdist_dumb = \"Dumb Binary\"\n bdist_egg = \"Egg\"\n bdist_msi = \"Windows MSI Installer\"\n bdist_rpm = \"RPM\"\n bdist_wheel = \"Wheel\"\n bdist_wininst = \"Windows Installer\"\n sdist = \"Source\"\n\n\ndef format_package_type(value):\n try:\n return PackageType[value].value\n except KeyError:\n return value\n\n\ndef _camo_url(camo_url, camo_key, url):\n camo_key = camo_key.encode(\"utf8\")\n url = url.encode(\"utf8\")\n\n path = \"/\".join([\n hmac.new(camo_key, url, digestmod=\"sha1\").hexdigest(),\n binascii.hexlify(url).decode(\"utf8\"),\n ])\n\n return urllib.parse.urljoin(camo_url, path)\n\n\[email protected]\ndef readme(ctx, value, *, format):\n request = ctx.get(\"request\") or get_current_request()\n\n camo_url = request.registry.settings[\"camo.url\"].format(request=request)\n camo_key = request.registry.settings[\"camo.key\"]\n\n # The format parameter is here so we can more easily expand this to cover\n # READMEs which do not use restructuredtext, but for now rst is the only\n # format we support.\n assert format == \"rst\", \"We currently only support rst rendering.\"\n\n # Actually render the given value, this will not only render the value, but\n # also ensure that it's had any disallowed markup removed.\n rendered = readme_renderer.rst.render(value)\n\n # If the content was not rendered, we'll replace the newlines with breaks\n # so that it shows up nicer when rendered.\n if rendered is None:\n rendered = readme_renderer.txt.render(value)\n\n # Parse the rendered output and replace any inline images that don't point\n # to HTTPS with camouflaged images.\n tree_builder = html5lib.treebuilders.getTreeBuilder(\"dom\")\n parser = html5lib.html5parser.HTMLParser(tree=tree_builder)\n dom = parser.parse(rendered)\n\n for element in dom.getElementsByTagName(\"img\"):\n src = element.getAttribute(\"src\")\n if src:\n element.setAttribute(\"src\", _camo_url(camo_url, camo_key, src))\n\n tree_walker = html5lib.treewalkers.getTreeWalker(\"dom\")\n html_serializer = html5lib.serializer.HTMLSerializer()\n rendered = \"\".join(html_serializer.serialize(tree_walker(dom)))\n\n return jinja2.Markup(rendered)\n\n\n_SI_SYMBOLS = [\"k\", \"M\", \"G\", \"T\", \"P\", \"E\", \"Z\", \"Y\"]\n\n\ndef shorten_number(value):\n for i, symbol in enumerate(_SI_SYMBOLS):\n magnitude = value / (1000 ** (i + 1))\n if magnitude >= 1 and magnitude < 1000:\n return \"{:.3g}{}\".format(magnitude, symbol)\n\n return str(value)\n\n\ndef tojson(value):\n return json.dumps(value, sort_keys=True, separators=(\",\", \":\"))\n\n\ndef urlparse(value):\n return urllib.parse.urlparse(value)\n\n\ndef format_tags(tags):\n # split tags\n if re.search(r',', tags):\n split_tags = re.split(r'\\s*,\\s*', tags)\n elif re.search(r';', tags):\n split_tags = re.split(r'\\s*;\\s*', tags)\n else:\n split_tags = re.split(r'\\s+', tags)\n\n # strip whitespace, quotes, double quotes\n stripped_tags = [re.sub(r'^[\"\\'\\s]+|[\"\\'\\s]+$', '', t) for t in split_tags]\n\n # remove any empty tags\n formatted_tags = [t for t in stripped_tags if t]\n\n return formatted_tags\n\n\ndef format_classifiers(classifiers):\n structured = collections.defaultdict(list)\n\n # Split up our classifiers into our data structure\n for classifier in classifiers:\n key, *value = classifier.split(\" :: \", 1)\n if value:\n structured[key].append(value[0])\n\n # Go thorugh and ensure that all of the lists in our classifiers are in\n # sorted order.\n structured = {k: sorted(v) for k, v in structured.items()}\n\n # Now, we'll ensure that our keys themselves are in sorted order, using an\n # OrderedDict to preserve this ordering when we pass this data back up to\n # our caller.\n structured = collections.OrderedDict(sorted(structured.items()))\n\n return structured\n\n\ndef contains_valid_uris(items):\n \"\"\"Returns boolean representing whether the input list contains any valid\n URIs\n \"\"\"\n return any(is_valid_uri(i) for i in items)\n", "path": "warehouse/filters.py"}]}
| 3,019 | 134 |
gh_patches_debug_2340
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-18776
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
download from d.tube fails
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2019.01.02*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2019.01.02**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [x] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for __re__adding support for an existing site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:
Add the `-v` flag to **your command line**
```
user@mymachine:~$ youtube-dl --verbose
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['--verbose']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2019.01.02
[debug] Python version 3.5.3 (CPython) - Linux-4.9.0-4-amd64-x86_64-with-debian-9.2
[debug] exe versions: none
[debug] Proxy map: {}
Usage: youtube-dl [OPTIONS] URL [URL...]
youtube-dl: error: You must provide at least one URL.
Type youtube-dl --help to see a list of all options.
user@ mymachine:~$ youtube-dl --verbose "https://d.tube/#!/v/dennisxxx/lgfrcata"
bash: !/v/dennisxxx/lgfrcata: event not found
```
### Description of your *issue*, suggested solution and other information
Download from d.tube failed. I am sorry to not being able to provide more information. If I can help/try anything else I will gladly do though....
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/dtube.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import json
5 import re
6 from socket import timeout
7
8 from .common import InfoExtractor
9 from ..utils import (
10 int_or_none,
11 parse_iso8601,
12 )
13
14
15 class DTubeIE(InfoExtractor):
16 _VALID_URL = r'https?://(?:www\.)?d\.tube/(?:#!/)?v/(?P<uploader_id>[0-9a-z.-]+)/(?P<id>[0-9a-z]{8})'
17 _TEST = {
18 'url': 'https://d.tube/#!/v/benswann/zqd630em',
19 'md5': 'a03eaa186618ffa7a3145945543a251e',
20 'info_dict': {
21 'id': 'zqd630em',
22 'ext': 'mp4',
23 'title': 'Reality Check: FDA\'s Disinformation Campaign on Kratom',
24 'description': 'md5:700d164e066b87f9eac057949e4227c2',
25 'uploader_id': 'benswann',
26 'upload_date': '20180222',
27 'timestamp': 1519328958,
28 },
29 'params': {
30 'format': '480p',
31 },
32 }
33
34 def _real_extract(self, url):
35 uploader_id, video_id = re.match(self._VALID_URL, url).groups()
36 result = self._download_json('https://api.steemit.com/', video_id, data=json.dumps({
37 'jsonrpc': '2.0',
38 'method': 'get_content',
39 'params': [uploader_id, video_id],
40 }).encode())['result']
41
42 metadata = json.loads(result['json_metadata'])
43 video = metadata['video']
44 content = video['content']
45 info = video.get('info', {})
46 title = info.get('title') or result['title']
47
48 def canonical_url(h):
49 if not h:
50 return None
51 return 'https://ipfs.io/ipfs/' + h
52
53 formats = []
54 for q in ('240', '480', '720', '1080', ''):
55 video_url = canonical_url(content.get('video%shash' % q))
56 if not video_url:
57 continue
58 format_id = (q + 'p') if q else 'Source'
59 try:
60 self.to_screen('%s: Checking %s video format URL' % (video_id, format_id))
61 self._downloader._opener.open(video_url, timeout=5).close()
62 except timeout:
63 self.to_screen(
64 '%s: %s URL is invalid, skipping' % (video_id, format_id))
65 continue
66 formats.append({
67 'format_id': format_id,
68 'url': video_url,
69 'height': int_or_none(q),
70 'ext': 'mp4',
71 })
72
73 return {
74 'id': video_id,
75 'title': title,
76 'description': content.get('description'),
77 'thumbnail': canonical_url(info.get('snaphash')),
78 'tags': content.get('tags') or metadata.get('tags'),
79 'duration': info.get('duration'),
80 'formats': formats,
81 'timestamp': parse_iso8601(result.get('created')),
82 'uploader_id': uploader_id,
83 }
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/dtube.py b/youtube_dl/extractor/dtube.py
--- a/youtube_dl/extractor/dtube.py
+++ b/youtube_dl/extractor/dtube.py
@@ -48,7 +48,7 @@
def canonical_url(h):
if not h:
return None
- return 'https://ipfs.io/ipfs/' + h
+ return 'https://video.dtube.top/ipfs/' + h
formats = []
for q in ('240', '480', '720', '1080', ''):
|
{"golden_diff": "diff --git a/youtube_dl/extractor/dtube.py b/youtube_dl/extractor/dtube.py\n--- a/youtube_dl/extractor/dtube.py\n+++ b/youtube_dl/extractor/dtube.py\n@@ -48,7 +48,7 @@\n def canonical_url(h):\n if not h:\n return None\n- return 'https://ipfs.io/ipfs/' + h\n+ return 'https://video.dtube.top/ipfs/' + h\n \n formats = []\n for q in ('240', '480', '720', '1080', ''):\n", "issue": "download from d.tube fails\n### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2019.01.02*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.\r\n- [x] I've **verified** and **I assure** that I'm running youtube-dl **2019.01.02**\r\n\r\n### Before submitting an *issue* make sure you have:\r\n- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections\r\n- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones\r\n- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser\r\n\r\n### What is the purpose of your *issue*?\r\n- [x] Bug report (encountered problems with youtube-dl)\r\n- [x] Site support request (request for __re__adding support for an existing site)\r\n- [ ] Feature request (request for a new functionality)\r\n- [ ] Question\r\n- [ ] Other\r\n\r\n### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:\r\n\r\nAdd the `-v` flag to **your command line** \r\n\r\n```\r\nuser@mymachine:~$ youtube-dl --verbose\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: ['--verbose']\r\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2019.01.02\r\n[debug] Python version 3.5.3 (CPython) - Linux-4.9.0-4-amd64-x86_64-with-debian-9.2\r\n[debug] exe versions: none\r\n[debug] Proxy map: {}\r\nUsage: youtube-dl [OPTIONS] URL [URL...]\r\n\r\nyoutube-dl: error: You must provide at least one URL.\r\nType youtube-dl --help to see a list of all options.\r\nuser@ mymachine:~$ youtube-dl --verbose \"https://d.tube/#!/v/dennisxxx/lgfrcata\"\r\nbash: !/v/dennisxxx/lgfrcata: event not found\r\n```\r\n### Description of your *issue*, suggested solution and other information\r\n\r\nDownload from d.tube failed. I am sorry to not being able to provide more information. If I can help/try anything else I will gladly do though....\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport json\nimport re\nfrom socket import timeout\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n parse_iso8601,\n)\n\n\nclass DTubeIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?d\\.tube/(?:#!/)?v/(?P<uploader_id>[0-9a-z.-]+)/(?P<id>[0-9a-z]{8})'\n _TEST = {\n 'url': 'https://d.tube/#!/v/benswann/zqd630em',\n 'md5': 'a03eaa186618ffa7a3145945543a251e',\n 'info_dict': {\n 'id': 'zqd630em',\n 'ext': 'mp4',\n 'title': 'Reality Check: FDA\\'s Disinformation Campaign on Kratom',\n 'description': 'md5:700d164e066b87f9eac057949e4227c2',\n 'uploader_id': 'benswann',\n 'upload_date': '20180222',\n 'timestamp': 1519328958,\n },\n 'params': {\n 'format': '480p',\n },\n }\n\n def _real_extract(self, url):\n uploader_id, video_id = re.match(self._VALID_URL, url).groups()\n result = self._download_json('https://api.steemit.com/', video_id, data=json.dumps({\n 'jsonrpc': '2.0',\n 'method': 'get_content',\n 'params': [uploader_id, video_id],\n }).encode())['result']\n\n metadata = json.loads(result['json_metadata'])\n video = metadata['video']\n content = video['content']\n info = video.get('info', {})\n title = info.get('title') or result['title']\n\n def canonical_url(h):\n if not h:\n return None\n return 'https://ipfs.io/ipfs/' + h\n\n formats = []\n for q in ('240', '480', '720', '1080', ''):\n video_url = canonical_url(content.get('video%shash' % q))\n if not video_url:\n continue\n format_id = (q + 'p') if q else 'Source'\n try:\n self.to_screen('%s: Checking %s video format URL' % (video_id, format_id))\n self._downloader._opener.open(video_url, timeout=5).close()\n except timeout:\n self.to_screen(\n '%s: %s URL is invalid, skipping' % (video_id, format_id))\n continue\n formats.append({\n 'format_id': format_id,\n 'url': video_url,\n 'height': int_or_none(q),\n 'ext': 'mp4',\n })\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': content.get('description'),\n 'thumbnail': canonical_url(info.get('snaphash')),\n 'tags': content.get('tags') or metadata.get('tags'),\n 'duration': info.get('duration'),\n 'formats': formats,\n 'timestamp': parse_iso8601(result.get('created')),\n 'uploader_id': uploader_id,\n }\n", "path": "youtube_dl/extractor/dtube.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport json\nimport re\nfrom socket import timeout\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n int_or_none,\n parse_iso8601,\n)\n\n\nclass DTubeIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?d\\.tube/(?:#!/)?v/(?P<uploader_id>[0-9a-z.-]+)/(?P<id>[0-9a-z]{8})'\n _TEST = {\n 'url': 'https://d.tube/#!/v/benswann/zqd630em',\n 'md5': 'a03eaa186618ffa7a3145945543a251e',\n 'info_dict': {\n 'id': 'zqd630em',\n 'ext': 'mp4',\n 'title': 'Reality Check: FDA\\'s Disinformation Campaign on Kratom',\n 'description': 'md5:700d164e066b87f9eac057949e4227c2',\n 'uploader_id': 'benswann',\n 'upload_date': '20180222',\n 'timestamp': 1519328958,\n },\n 'params': {\n 'format': '480p',\n },\n }\n\n def _real_extract(self, url):\n uploader_id, video_id = re.match(self._VALID_URL, url).groups()\n result = self._download_json('https://api.steemit.com/', video_id, data=json.dumps({\n 'jsonrpc': '2.0',\n 'method': 'get_content',\n 'params': [uploader_id, video_id],\n }).encode())['result']\n\n metadata = json.loads(result['json_metadata'])\n video = metadata['video']\n content = video['content']\n info = video.get('info', {})\n title = info.get('title') or result['title']\n\n def canonical_url(h):\n if not h:\n return None\n return 'https://video.dtube.top/ipfs/' + h\n\n formats = []\n for q in ('240', '480', '720', '1080', ''):\n video_url = canonical_url(content.get('video%shash' % q))\n if not video_url:\n continue\n format_id = (q + 'p') if q else 'Source'\n try:\n self.to_screen('%s: Checking %s video format URL' % (video_id, format_id))\n self._downloader._opener.open(video_url, timeout=5).close()\n except timeout:\n self.to_screen(\n '%s: %s URL is invalid, skipping' % (video_id, format_id))\n continue\n formats.append({\n 'format_id': format_id,\n 'url': video_url,\n 'height': int_or_none(q),\n 'ext': 'mp4',\n })\n\n return {\n 'id': video_id,\n 'title': title,\n 'description': content.get('description'),\n 'thumbnail': canonical_url(info.get('snaphash')),\n 'tags': content.get('tags') or metadata.get('tags'),\n 'duration': info.get('duration'),\n 'formats': formats,\n 'timestamp': parse_iso8601(result.get('created')),\n 'uploader_id': uploader_id,\n }\n", "path": "youtube_dl/extractor/dtube.py"}]}
| 1,862 | 137 |
gh_patches_debug_11547
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-1120
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issue with caching when views outside of dbt schemas select from dbt-managed schemas
## Issue
### Issue description
dbt's caching will fail hard on PG/Redshift if there exists a view _outside_ of a dbt-controlled schema that depends on a relation _inside_ of a dbt controlled schema.
### Results
```
InternalException: Cache inconsistency detected: in add_link, dependent link key _ReferenceKey(schema=u'dbt_airflow_events', identifier=u'tracking_l30d') not in cache!
```
### System information
The output of `dbt --version`:
```
0.12.0
```
### Steps to reproduce
1. Create and run an example model
```
-- models/test_it.sql
select 1 as id
```
2. Run the model
```
dbt run
```
3. Create an external dependency on this model
```
create schema debug;
create view debug.debug as (
select * from analytics.test_it -- the model created above
)
```
4. Run dbt again
```
# this will fail
dbt run
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dbt/adapters/postgres/impl.py`
Content:
```
1 import psycopg2
2
3 from contextlib import contextmanager
4
5 import dbt.adapters.default
6 import dbt.compat
7 import dbt.exceptions
8 import agate
9
10 from dbt.logger import GLOBAL_LOGGER as logger
11
12
13 GET_RELATIONS_OPERATION_NAME = 'get_relations_data'
14
15
16 class PostgresAdapter(dbt.adapters.default.DefaultAdapter):
17
18 DEFAULT_TCP_KEEPALIVE = 0 # 0 means to use the default value
19
20 @contextmanager
21 def exception_handler(self, sql, model_name=None, connection_name=None):
22 try:
23 yield
24
25 except psycopg2.DatabaseError as e:
26 logger.debug('Postgres error: {}'.format(str(e)))
27
28 try:
29 # attempt to release the connection
30 self.release_connection(connection_name)
31 except psycopg2.Error:
32 logger.debug("Failed to release connection!")
33 pass
34
35 raise dbt.exceptions.DatabaseException(
36 dbt.compat.to_string(e).strip())
37
38 except Exception as e:
39 logger.debug("Error running SQL: %s", sql)
40 logger.debug("Rolling back transaction.")
41 self.release_connection(connection_name)
42 raise dbt.exceptions.RuntimeException(e)
43
44 @classmethod
45 def type(cls):
46 return 'postgres'
47
48 @classmethod
49 def date_function(cls):
50 return 'datenow()'
51
52 @classmethod
53 def get_status(cls, cursor):
54 return cursor.statusmessage
55
56 @classmethod
57 def get_credentials(cls, credentials):
58 return credentials
59
60 @classmethod
61 def open_connection(cls, connection):
62 if connection.state == 'open':
63 logger.debug('Connection is already open, skipping open.')
64 return connection
65
66 base_credentials = connection.credentials
67 credentials = cls.get_credentials(connection.credentials.incorporate())
68 kwargs = {}
69 keepalives_idle = credentials.get('keepalives_idle',
70 cls.DEFAULT_TCP_KEEPALIVE)
71 # we don't want to pass 0 along to connect() as postgres will try to
72 # call an invalid setsockopt() call (contrary to the docs).
73 if keepalives_idle:
74 kwargs['keepalives_idle'] = keepalives_idle
75
76 try:
77 handle = psycopg2.connect(
78 dbname=credentials.dbname,
79 user=credentials.user,
80 host=credentials.host,
81 password=credentials.password,
82 port=credentials.port,
83 connect_timeout=10,
84 **kwargs)
85
86 connection.handle = handle
87 connection.state = 'open'
88 except psycopg2.Error as e:
89 logger.debug("Got an error when attempting to open a postgres "
90 "connection: '{}'"
91 .format(e))
92
93 connection.handle = None
94 connection.state = 'fail'
95
96 raise dbt.exceptions.FailedToConnectException(str(e))
97
98 return connection
99
100 def cancel_connection(self, connection):
101 connection_name = connection.name
102 pid = connection.handle.get_backend_pid()
103
104 sql = "select pg_terminate_backend({})".format(pid)
105
106 logger.debug("Cancelling query '{}' ({})".format(connection_name, pid))
107
108 _, cursor = self.add_query(sql, 'master')
109 res = cursor.fetchone()
110
111 logger.debug("Cancel query '{}': {}".format(connection_name, res))
112
113 # DATABASE INSPECTION FUNCTIONS
114 # These require the profile AND project, as they need to know
115 # database-specific configs at the project level.
116 def alter_column_type(self, schema, table, column_name,
117 new_column_type, model_name=None):
118 """
119 1. Create a new column (w/ temp name and correct type)
120 2. Copy data over to it
121 3. Drop the existing column (cascade!)
122 4. Rename the new column to existing column
123 """
124
125 relation = self.Relation.create(
126 schema=schema,
127 identifier=table,
128 quote_policy=self.config.quoting
129 )
130
131 opts = {
132 "relation": relation,
133 "old_column": column_name,
134 "tmp_column": "{}__dbt_alter".format(column_name),
135 "dtype": new_column_type
136 }
137
138 sql = """
139 alter table {relation} add column "{tmp_column}" {dtype};
140 update {relation} set "{tmp_column}" = "{old_column}";
141 alter table {relation} drop column "{old_column}" cascade;
142 alter table {relation} rename column "{tmp_column}" to "{old_column}";
143 """.format(**opts).strip() # noqa
144
145 connection, cursor = self.add_query(sql, model_name)
146
147 return connection, cursor
148
149 def _link_cached_relations(self, manifest, schemas):
150 try:
151 table = self.run_operation(manifest, GET_RELATIONS_OPERATION_NAME)
152 finally:
153 self.release_connection(GET_RELATIONS_OPERATION_NAME)
154 table = self._relations_filter_table(table, schemas)
155
156 for (refed_schema, refed_name, dep_schema, dep_name) in table:
157 referenced = self.Relation.create(schema=refed_schema,
158 identifier=refed_name)
159 dependent = self.Relation.create(schema=dep_schema,
160 identifier=dep_name)
161 self.cache.add_link(dependent, referenced)
162
163 def _list_relations(self, schema, model_name=None):
164 sql = """
165 select tablename as name, schemaname as schema, 'table' as type from pg_tables
166 where schemaname ilike '{schema}'
167 union all
168 select viewname as name, schemaname as schema, 'view' as type from pg_views
169 where schemaname ilike '{schema}'
170 """.format(schema=schema).strip() # noqa
171
172 connection, cursor = self.add_query(sql, model_name, auto_begin=False)
173
174 results = cursor.fetchall()
175
176 return [self.Relation.create(
177 database=self.config.credentials.dbname,
178 schema=_schema,
179 identifier=name,
180 quote_policy={
181 'schema': True,
182 'identifier': True
183 },
184 type=type)
185 for (name, _schema, type) in results]
186
187 def get_existing_schemas(self, model_name=None):
188 sql = "select distinct nspname from pg_namespace"
189
190 connection, cursor = self.add_query(sql, model_name, auto_begin=False)
191 results = cursor.fetchall()
192
193 return [row[0] for row in results]
194
195 def check_schema_exists(self, schema, model_name=None):
196 sql = """
197 select count(*) from pg_namespace where nspname = '{schema}'
198 """.format(schema=schema).strip() # noqa
199
200 connection, cursor = self.add_query(sql, model_name,
201 auto_begin=False)
202 results = cursor.fetchone()
203
204 return results[0] > 0
205
206 @classmethod
207 def convert_text_type(cls, agate_table, col_idx):
208 return "text"
209
210 @classmethod
211 def convert_number_type(cls, agate_table, col_idx):
212 decimals = agate_table.aggregate(agate.MaxPrecision(col_idx))
213 return "float8" if decimals else "integer"
214
215 @classmethod
216 def convert_boolean_type(cls, agate_table, col_idx):
217 return "boolean"
218
219 @classmethod
220 def convert_datetime_type(cls, agate_table, col_idx):
221 return "timestamp without time zone"
222
223 @classmethod
224 def convert_date_type(cls, agate_table, col_idx):
225 return "date"
226
227 @classmethod
228 def convert_time_type(cls, agate_table, col_idx):
229 return "time"
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dbt/adapters/postgres/impl.py b/dbt/adapters/postgres/impl.py
--- a/dbt/adapters/postgres/impl.py
+++ b/dbt/adapters/postgres/impl.py
@@ -158,7 +158,10 @@
identifier=refed_name)
dependent = self.Relation.create(schema=dep_schema,
identifier=dep_name)
- self.cache.add_link(dependent, referenced)
+
+ # don't record in cache if this relation isn't in a relevant schema
+ if refed_schema.lower() in schemas:
+ self.cache.add_link(dependent, referenced)
def _list_relations(self, schema, model_name=None):
sql = """
|
{"golden_diff": "diff --git a/dbt/adapters/postgres/impl.py b/dbt/adapters/postgres/impl.py\n--- a/dbt/adapters/postgres/impl.py\n+++ b/dbt/adapters/postgres/impl.py\n@@ -158,7 +158,10 @@\n identifier=refed_name)\n dependent = self.Relation.create(schema=dep_schema,\n identifier=dep_name)\n- self.cache.add_link(dependent, referenced)\n+\n+ # don't record in cache if this relation isn't in a relevant schema\n+ if refed_schema.lower() in schemas:\n+ self.cache.add_link(dependent, referenced)\n \n def _list_relations(self, schema, model_name=None):\n sql = \"\"\"\n", "issue": "Issue with caching when views outside of dbt schemas select from dbt-managed schemas\n## Issue\r\n\r\n### Issue description\r\ndbt's caching will fail hard on PG/Redshift if there exists a view _outside_ of a dbt-controlled schema that depends on a relation _inside_ of a dbt controlled schema.\r\n\r\n### Results\r\n```\r\nInternalException: Cache inconsistency detected: in add_link, dependent link key _ReferenceKey(schema=u'dbt_airflow_events', identifier=u'tracking_l30d') not in cache!\r\n```\r\n\r\n### System information\r\nThe output of `dbt --version`:\r\n```\r\n0.12.0\r\n```\r\n\r\n### Steps to reproduce\r\n\r\n1. Create and run an example model\r\n```\r\n-- models/test_it.sql\r\n\r\nselect 1 as id\r\n```\r\n\r\n2. Run the model\r\n```\r\ndbt run\r\n```\r\n\r\n3. Create an external dependency on this model\r\n```\r\ncreate schema debug;\r\ncreate view debug.debug as (\r\n select * from analytics.test_it -- the model created above\r\n)\r\n```\r\n\r\n4. Run dbt again\r\n```\r\n# this will fail\r\ndbt run\r\n```\n", "before_files": [{"content": "import psycopg2\n\nfrom contextlib import contextmanager\n\nimport dbt.adapters.default\nimport dbt.compat\nimport dbt.exceptions\nimport agate\n\nfrom dbt.logger import GLOBAL_LOGGER as logger\n\n\nGET_RELATIONS_OPERATION_NAME = 'get_relations_data'\n\n\nclass PostgresAdapter(dbt.adapters.default.DefaultAdapter):\n\n DEFAULT_TCP_KEEPALIVE = 0 # 0 means to use the default value\n\n @contextmanager\n def exception_handler(self, sql, model_name=None, connection_name=None):\n try:\n yield\n\n except psycopg2.DatabaseError as e:\n logger.debug('Postgres error: {}'.format(str(e)))\n\n try:\n # attempt to release the connection\n self.release_connection(connection_name)\n except psycopg2.Error:\n logger.debug(\"Failed to release connection!\")\n pass\n\n raise dbt.exceptions.DatabaseException(\n dbt.compat.to_string(e).strip())\n\n except Exception as e:\n logger.debug(\"Error running SQL: %s\", sql)\n logger.debug(\"Rolling back transaction.\")\n self.release_connection(connection_name)\n raise dbt.exceptions.RuntimeException(e)\n\n @classmethod\n def type(cls):\n return 'postgres'\n\n @classmethod\n def date_function(cls):\n return 'datenow()'\n\n @classmethod\n def get_status(cls, cursor):\n return cursor.statusmessage\n\n @classmethod\n def get_credentials(cls, credentials):\n return credentials\n\n @classmethod\n def open_connection(cls, connection):\n if connection.state == 'open':\n logger.debug('Connection is already open, skipping open.')\n return connection\n\n base_credentials = connection.credentials\n credentials = cls.get_credentials(connection.credentials.incorporate())\n kwargs = {}\n keepalives_idle = credentials.get('keepalives_idle',\n cls.DEFAULT_TCP_KEEPALIVE)\n # we don't want to pass 0 along to connect() as postgres will try to\n # call an invalid setsockopt() call (contrary to the docs).\n if keepalives_idle:\n kwargs['keepalives_idle'] = keepalives_idle\n\n try:\n handle = psycopg2.connect(\n dbname=credentials.dbname,\n user=credentials.user,\n host=credentials.host,\n password=credentials.password,\n port=credentials.port,\n connect_timeout=10,\n **kwargs)\n\n connection.handle = handle\n connection.state = 'open'\n except psycopg2.Error as e:\n logger.debug(\"Got an error when attempting to open a postgres \"\n \"connection: '{}'\"\n .format(e))\n\n connection.handle = None\n connection.state = 'fail'\n\n raise dbt.exceptions.FailedToConnectException(str(e))\n\n return connection\n\n def cancel_connection(self, connection):\n connection_name = connection.name\n pid = connection.handle.get_backend_pid()\n\n sql = \"select pg_terminate_backend({})\".format(pid)\n\n logger.debug(\"Cancelling query '{}' ({})\".format(connection_name, pid))\n\n _, cursor = self.add_query(sql, 'master')\n res = cursor.fetchone()\n\n logger.debug(\"Cancel query '{}': {}\".format(connection_name, res))\n\n # DATABASE INSPECTION FUNCTIONS\n # These require the profile AND project, as they need to know\n # database-specific configs at the project level.\n def alter_column_type(self, schema, table, column_name,\n new_column_type, model_name=None):\n \"\"\"\n 1. Create a new column (w/ temp name and correct type)\n 2. Copy data over to it\n 3. Drop the existing column (cascade!)\n 4. Rename the new column to existing column\n \"\"\"\n\n relation = self.Relation.create(\n schema=schema,\n identifier=table,\n quote_policy=self.config.quoting\n )\n\n opts = {\n \"relation\": relation,\n \"old_column\": column_name,\n \"tmp_column\": \"{}__dbt_alter\".format(column_name),\n \"dtype\": new_column_type\n }\n\n sql = \"\"\"\n alter table {relation} add column \"{tmp_column}\" {dtype};\n update {relation} set \"{tmp_column}\" = \"{old_column}\";\n alter table {relation} drop column \"{old_column}\" cascade;\n alter table {relation} rename column \"{tmp_column}\" to \"{old_column}\";\n \"\"\".format(**opts).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name)\n\n return connection, cursor\n\n def _link_cached_relations(self, manifest, schemas):\n try:\n table = self.run_operation(manifest, GET_RELATIONS_OPERATION_NAME)\n finally:\n self.release_connection(GET_RELATIONS_OPERATION_NAME)\n table = self._relations_filter_table(table, schemas)\n\n for (refed_schema, refed_name, dep_schema, dep_name) in table:\n referenced = self.Relation.create(schema=refed_schema,\n identifier=refed_name)\n dependent = self.Relation.create(schema=dep_schema,\n identifier=dep_name)\n self.cache.add_link(dependent, referenced)\n\n def _list_relations(self, schema, model_name=None):\n sql = \"\"\"\n select tablename as name, schemaname as schema, 'table' as type from pg_tables\n where schemaname ilike '{schema}'\n union all\n select viewname as name, schemaname as schema, 'view' as type from pg_views\n where schemaname ilike '{schema}'\n \"\"\".format(schema=schema).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name, auto_begin=False)\n\n results = cursor.fetchall()\n\n return [self.Relation.create(\n database=self.config.credentials.dbname,\n schema=_schema,\n identifier=name,\n quote_policy={\n 'schema': True,\n 'identifier': True\n },\n type=type)\n for (name, _schema, type) in results]\n\n def get_existing_schemas(self, model_name=None):\n sql = \"select distinct nspname from pg_namespace\"\n\n connection, cursor = self.add_query(sql, model_name, auto_begin=False)\n results = cursor.fetchall()\n\n return [row[0] for row in results]\n\n def check_schema_exists(self, schema, model_name=None):\n sql = \"\"\"\n select count(*) from pg_namespace where nspname = '{schema}'\n \"\"\".format(schema=schema).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name,\n auto_begin=False)\n results = cursor.fetchone()\n\n return results[0] > 0\n\n @classmethod\n def convert_text_type(cls, agate_table, col_idx):\n return \"text\"\n\n @classmethod\n def convert_number_type(cls, agate_table, col_idx):\n decimals = agate_table.aggregate(agate.MaxPrecision(col_idx))\n return \"float8\" if decimals else \"integer\"\n\n @classmethod\n def convert_boolean_type(cls, agate_table, col_idx):\n return \"boolean\"\n\n @classmethod\n def convert_datetime_type(cls, agate_table, col_idx):\n return \"timestamp without time zone\"\n\n @classmethod\n def convert_date_type(cls, agate_table, col_idx):\n return \"date\"\n\n @classmethod\n def convert_time_type(cls, agate_table, col_idx):\n return \"time\"\n", "path": "dbt/adapters/postgres/impl.py"}], "after_files": [{"content": "import psycopg2\n\nfrom contextlib import contextmanager\n\nimport dbt.adapters.default\nimport dbt.compat\nimport dbt.exceptions\nimport agate\n\nfrom dbt.logger import GLOBAL_LOGGER as logger\n\n\nGET_RELATIONS_OPERATION_NAME = 'get_relations_data'\n\n\nclass PostgresAdapter(dbt.adapters.default.DefaultAdapter):\n\n DEFAULT_TCP_KEEPALIVE = 0 # 0 means to use the default value\n\n @contextmanager\n def exception_handler(self, sql, model_name=None, connection_name=None):\n try:\n yield\n\n except psycopg2.DatabaseError as e:\n logger.debug('Postgres error: {}'.format(str(e)))\n\n try:\n # attempt to release the connection\n self.release_connection(connection_name)\n except psycopg2.Error:\n logger.debug(\"Failed to release connection!\")\n pass\n\n raise dbt.exceptions.DatabaseException(\n dbt.compat.to_string(e).strip())\n\n except Exception as e:\n logger.debug(\"Error running SQL: %s\", sql)\n logger.debug(\"Rolling back transaction.\")\n self.release_connection(connection_name)\n raise dbt.exceptions.RuntimeException(e)\n\n @classmethod\n def type(cls):\n return 'postgres'\n\n @classmethod\n def date_function(cls):\n return 'datenow()'\n\n @classmethod\n def get_status(cls, cursor):\n return cursor.statusmessage\n\n @classmethod\n def get_credentials(cls, credentials):\n return credentials\n\n @classmethod\n def open_connection(cls, connection):\n if connection.state == 'open':\n logger.debug('Connection is already open, skipping open.')\n return connection\n\n base_credentials = connection.credentials\n credentials = cls.get_credentials(connection.credentials.incorporate())\n kwargs = {}\n keepalives_idle = credentials.get('keepalives_idle',\n cls.DEFAULT_TCP_KEEPALIVE)\n # we don't want to pass 0 along to connect() as postgres will try to\n # call an invalid setsockopt() call (contrary to the docs).\n if keepalives_idle:\n kwargs['keepalives_idle'] = keepalives_idle\n\n try:\n handle = psycopg2.connect(\n dbname=credentials.dbname,\n user=credentials.user,\n host=credentials.host,\n password=credentials.password,\n port=credentials.port,\n connect_timeout=10,\n **kwargs)\n\n connection.handle = handle\n connection.state = 'open'\n except psycopg2.Error as e:\n logger.debug(\"Got an error when attempting to open a postgres \"\n \"connection: '{}'\"\n .format(e))\n\n connection.handle = None\n connection.state = 'fail'\n\n raise dbt.exceptions.FailedToConnectException(str(e))\n\n return connection\n\n def cancel_connection(self, connection):\n connection_name = connection.name\n pid = connection.handle.get_backend_pid()\n\n sql = \"select pg_terminate_backend({})\".format(pid)\n\n logger.debug(\"Cancelling query '{}' ({})\".format(connection_name, pid))\n\n _, cursor = self.add_query(sql, 'master')\n res = cursor.fetchone()\n\n logger.debug(\"Cancel query '{}': {}\".format(connection_name, res))\n\n # DATABASE INSPECTION FUNCTIONS\n # These require the profile AND project, as they need to know\n # database-specific configs at the project level.\n def alter_column_type(self, schema, table, column_name,\n new_column_type, model_name=None):\n \"\"\"\n 1. Create a new column (w/ temp name and correct type)\n 2. Copy data over to it\n 3. Drop the existing column (cascade!)\n 4. Rename the new column to existing column\n \"\"\"\n\n relation = self.Relation.create(\n schema=schema,\n identifier=table,\n quote_policy=self.config.quoting\n )\n\n opts = {\n \"relation\": relation,\n \"old_column\": column_name,\n \"tmp_column\": \"{}__dbt_alter\".format(column_name),\n \"dtype\": new_column_type\n }\n\n sql = \"\"\"\n alter table {relation} add column \"{tmp_column}\" {dtype};\n update {relation} set \"{tmp_column}\" = \"{old_column}\";\n alter table {relation} drop column \"{old_column}\" cascade;\n alter table {relation} rename column \"{tmp_column}\" to \"{old_column}\";\n \"\"\".format(**opts).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name)\n\n return connection, cursor\n\n def _link_cached_relations(self, manifest, schemas):\n try:\n table = self.run_operation(manifest, GET_RELATIONS_OPERATION_NAME)\n finally:\n self.release_connection(GET_RELATIONS_OPERATION_NAME)\n table = self._relations_filter_table(table, schemas)\n\n for (refed_schema, refed_name, dep_schema, dep_name) in table:\n referenced = self.Relation.create(schema=refed_schema,\n identifier=refed_name)\n dependent = self.Relation.create(schema=dep_schema,\n identifier=dep_name)\n\n # don't record in cache if this relation isn't in a relevant schema\n if refed_schema.lower() in schemas:\n self.cache.add_link(dependent, referenced)\n\n def _list_relations(self, schema, model_name=None):\n sql = \"\"\"\n select tablename as name, schemaname as schema, 'table' as type from pg_tables\n where schemaname ilike '{schema}'\n union all\n select viewname as name, schemaname as schema, 'view' as type from pg_views\n where schemaname ilike '{schema}'\n \"\"\".format(schema=schema).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name, auto_begin=False)\n\n results = cursor.fetchall()\n\n return [self.Relation.create(\n database=self.config.credentials.dbname,\n schema=_schema,\n identifier=name,\n quote_policy={\n 'schema': True,\n 'identifier': True\n },\n type=type)\n for (name, _schema, type) in results]\n\n def get_existing_schemas(self, model_name=None):\n sql = \"select distinct nspname from pg_namespace\"\n\n connection, cursor = self.add_query(sql, model_name, auto_begin=False)\n results = cursor.fetchall()\n\n return [row[0] for row in results]\n\n def check_schema_exists(self, schema, model_name=None):\n sql = \"\"\"\n select count(*) from pg_namespace where nspname = '{schema}'\n \"\"\".format(schema=schema).strip() # noqa\n\n connection, cursor = self.add_query(sql, model_name,\n auto_begin=False)\n results = cursor.fetchone()\n\n return results[0] > 0\n\n @classmethod\n def convert_text_type(cls, agate_table, col_idx):\n return \"text\"\n\n @classmethod\n def convert_number_type(cls, agate_table, col_idx):\n decimals = agate_table.aggregate(agate.MaxPrecision(col_idx))\n return \"float8\" if decimals else \"integer\"\n\n @classmethod\n def convert_boolean_type(cls, agate_table, col_idx):\n return \"boolean\"\n\n @classmethod\n def convert_datetime_type(cls, agate_table, col_idx):\n return \"timestamp without time zone\"\n\n @classmethod\n def convert_date_type(cls, agate_table, col_idx):\n return \"date\"\n\n @classmethod\n def convert_time_type(cls, agate_table, col_idx):\n return \"time\"\n", "path": "dbt/adapters/postgres/impl.py"}]}
| 2,668 | 158 |
gh_patches_debug_57244
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6333
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Uvicorn Windows message points to wrong flag
```2022-06-30T19:52:16.704167Z [warning ] Add ff.start_uvicorn: True to your meltano.yml to supress this waring```
Should point to
ff.enable_uvicorn [env: MELTANO_FF_ENABLE_UVICORN] current value: False (default)
Should be an easy one!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/api/workers/api_worker.py`
Content:
```
1 """Starts WSGI Webserver that will run the API App for a Meltano Project."""
2 import logging
3 import platform
4 import threading
5
6 from meltano.core.meltano_invoker import MeltanoInvoker
7 from meltano.core.project import Project
8 from meltano.core.project_settings_service import ProjectSettingsService
9 from meltano.core.settings_service import FeatureFlags
10 from meltano.core.utils.pidfile import PIDFile
11
12
13 class APIWorker(threading.Thread):
14 """The Base APIWorker Class."""
15
16 def __init__(self, project: Project, reload=False):
17 """Initialize the API Worker class with the project config.
18
19 Args:
20 project: Project class.
21 reload: Boolean.
22 """
23 super().__init__()
24
25 self.project = project
26 self.reload = reload
27 self.pid_file = PIDFile(self.project.run_dir("gunicorn.pid"))
28 self.settings_service = ProjectSettingsService(self.project.find())
29
30 def run(self):
31 """Run the initalized API Workers with the App Server requested."""
32 with self.settings_service.feature_flag(
33 FeatureFlags.ENABLE_UVICORN, raise_error=False
34 ) as allow:
35
36 enable_uvicorn = allow
37
38 # Use Uvicorn when on Windows
39 if platform.system() == "Windows":
40 if enable_uvicorn:
41 logging.debug("ff.enable_uvicorn enabled, starting uvicorn.")
42 else:
43 logging.warning(
44 "Windows OS detected auto setting ff.enable_uvicorn"
45 )
46 logging.warning(
47 "Add ff.start_uvicorn: True to your meltano.yml to supress this waring"
48 )
49 enable_uvicorn = True
50
51 # Start uvicorn to serve API and Ui
52 if enable_uvicorn:
53 settings_for_apiworker = self.settings_service
54
55 arg_bind_host = str(settings_for_apiworker.get("ui.bind_host"))
56 arg_bind_port = str(settings_for_apiworker.get("ui.bind_port"))
57 arg_loglevel = str(settings_for_apiworker.get("cli.log_level"))
58 arg_forwarded_allow_ips = str(
59 settings_for_apiworker.get("ui.forwarded_allow_ips")
60 )
61
62 # If windows and 127.0.0.1 only allowed changing bind host to accomidate
63 if platform.system() == "Windows":
64 if (
65 arg_forwarded_allow_ips == "127.0.0.1"
66 and arg_bind_host == "0.0.0.0" # noqa: S104
67 ):
68 # If left at 0.0.0.0 the server will respond to any request receieved on any interface
69 arg_bind_host = "127.0.0.1"
70
71 # Setup args for uvicorn using bind info from the project setings service
72 args = [
73 "--host",
74 arg_bind_host,
75 "--port",
76 arg_bind_port,
77 "--loop",
78 "asyncio",
79 "--interface",
80 "wsgi",
81 "--log-level",
82 arg_loglevel,
83 "--forwarded-allow-ips",
84 arg_forwarded_allow_ips,
85 "--timeout-keep-alive",
86 "600",
87 ]
88
89 # Add reload argument if reload is true
90 if self.reload:
91
92 args += [
93 "--reload",
94 ]
95
96 # Add the Meltano API app, factory create_app function combo to the args
97 args += [
98 "--factory",
99 "meltano.api.app:create_app",
100 ]
101
102 # Start uvicorn using the MeltanoInvoker
103 MeltanoInvoker(self.project).invoke(args, command="uvicorn")
104
105 else:
106 # Use Gunicorn when feature flag start_uvicorn is not set
107
108 args = [
109 "--config",
110 "python:meltano.api.wsgi",
111 "--pid",
112 str(self.pid_file),
113 ]
114
115 if self.reload:
116 args += ["--reload"]
117
118 args += ["meltano.api.app:create_app()"]
119
120 MeltanoInvoker(self.project).invoke(args, command="gunicorn")
121
122 def pid_path(self):
123 """Give the path name of the projects gunicorn.pid file location.
124
125 Returns:
126 Path object that gives the direct locationo of the gunicorn.pid file.
127 """
128 return self.project.run_dir("gunicorn.pid")
129
130 def stop(self):
131 """Terminnate active gunicorn workers that have placed a PID in the project's gunicorn.pid file."""
132 self.pid_file.process.terminate()
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/api/workers/api_worker.py b/src/meltano/api/workers/api_worker.py
--- a/src/meltano/api/workers/api_worker.py
+++ b/src/meltano/api/workers/api_worker.py
@@ -44,7 +44,7 @@
"Windows OS detected auto setting ff.enable_uvicorn"
)
logging.warning(
- "Add ff.start_uvicorn: True to your meltano.yml to supress this waring"
+ "Add ff.enable_uvicorn: True to your meltano.yml to supress this waring"
)
enable_uvicorn = True
|
{"golden_diff": "diff --git a/src/meltano/api/workers/api_worker.py b/src/meltano/api/workers/api_worker.py\n--- a/src/meltano/api/workers/api_worker.py\n+++ b/src/meltano/api/workers/api_worker.py\n@@ -44,7 +44,7 @@\n \"Windows OS detected auto setting ff.enable_uvicorn\"\n )\n logging.warning(\n- \"Add ff.start_uvicorn: True to your meltano.yml to supress this waring\"\n+ \"Add ff.enable_uvicorn: True to your meltano.yml to supress this waring\"\n )\n enable_uvicorn = True\n", "issue": "Uvicorn Windows message points to wrong flag\n```2022-06-30T19:52:16.704167Z [warning ] Add ff.start_uvicorn: True to your meltano.yml to supress this waring```\r\n\r\nShould point to\r\n\r\nff.enable_uvicorn [env: MELTANO_FF_ENABLE_UVICORN] current value: False (default)\r\n\r\nShould be an easy one!\n", "before_files": [{"content": "\"\"\"Starts WSGI Webserver that will run the API App for a Meltano Project.\"\"\"\nimport logging\nimport platform\nimport threading\n\nfrom meltano.core.meltano_invoker import MeltanoInvoker\nfrom meltano.core.project import Project\nfrom meltano.core.project_settings_service import ProjectSettingsService\nfrom meltano.core.settings_service import FeatureFlags\nfrom meltano.core.utils.pidfile import PIDFile\n\n\nclass APIWorker(threading.Thread):\n \"\"\"The Base APIWorker Class.\"\"\"\n\n def __init__(self, project: Project, reload=False):\n \"\"\"Initialize the API Worker class with the project config.\n\n Args:\n project: Project class.\n reload: Boolean.\n \"\"\"\n super().__init__()\n\n self.project = project\n self.reload = reload\n self.pid_file = PIDFile(self.project.run_dir(\"gunicorn.pid\"))\n self.settings_service = ProjectSettingsService(self.project.find())\n\n def run(self):\n \"\"\"Run the initalized API Workers with the App Server requested.\"\"\"\n with self.settings_service.feature_flag(\n FeatureFlags.ENABLE_UVICORN, raise_error=False\n ) as allow:\n\n enable_uvicorn = allow\n\n # Use Uvicorn when on Windows\n if platform.system() == \"Windows\":\n if enable_uvicorn:\n logging.debug(\"ff.enable_uvicorn enabled, starting uvicorn.\")\n else:\n logging.warning(\n \"Windows OS detected auto setting ff.enable_uvicorn\"\n )\n logging.warning(\n \"Add ff.start_uvicorn: True to your meltano.yml to supress this waring\"\n )\n enable_uvicorn = True\n\n # Start uvicorn to serve API and Ui\n if enable_uvicorn:\n settings_for_apiworker = self.settings_service\n\n arg_bind_host = str(settings_for_apiworker.get(\"ui.bind_host\"))\n arg_bind_port = str(settings_for_apiworker.get(\"ui.bind_port\"))\n arg_loglevel = str(settings_for_apiworker.get(\"cli.log_level\"))\n arg_forwarded_allow_ips = str(\n settings_for_apiworker.get(\"ui.forwarded_allow_ips\")\n )\n\n # If windows and 127.0.0.1 only allowed changing bind host to accomidate\n if platform.system() == \"Windows\":\n if (\n arg_forwarded_allow_ips == \"127.0.0.1\"\n and arg_bind_host == \"0.0.0.0\" # noqa: S104\n ):\n # If left at 0.0.0.0 the server will respond to any request receieved on any interface\n arg_bind_host = \"127.0.0.1\"\n\n # Setup args for uvicorn using bind info from the project setings service\n args = [\n \"--host\",\n arg_bind_host,\n \"--port\",\n arg_bind_port,\n \"--loop\",\n \"asyncio\",\n \"--interface\",\n \"wsgi\",\n \"--log-level\",\n arg_loglevel,\n \"--forwarded-allow-ips\",\n arg_forwarded_allow_ips,\n \"--timeout-keep-alive\",\n \"600\",\n ]\n\n # Add reload argument if reload is true\n if self.reload:\n\n args += [\n \"--reload\",\n ]\n\n # Add the Meltano API app, factory create_app function combo to the args\n args += [\n \"--factory\",\n \"meltano.api.app:create_app\",\n ]\n\n # Start uvicorn using the MeltanoInvoker\n MeltanoInvoker(self.project).invoke(args, command=\"uvicorn\")\n\n else:\n # Use Gunicorn when feature flag start_uvicorn is not set\n\n args = [\n \"--config\",\n \"python:meltano.api.wsgi\",\n \"--pid\",\n str(self.pid_file),\n ]\n\n if self.reload:\n args += [\"--reload\"]\n\n args += [\"meltano.api.app:create_app()\"]\n\n MeltanoInvoker(self.project).invoke(args, command=\"gunicorn\")\n\n def pid_path(self):\n \"\"\"Give the path name of the projects gunicorn.pid file location.\n\n Returns:\n Path object that gives the direct locationo of the gunicorn.pid file.\n \"\"\"\n return self.project.run_dir(\"gunicorn.pid\")\n\n def stop(self):\n \"\"\"Terminnate active gunicorn workers that have placed a PID in the project's gunicorn.pid file.\"\"\"\n self.pid_file.process.terminate()\n", "path": "src/meltano/api/workers/api_worker.py"}], "after_files": [{"content": "\"\"\"Starts WSGI Webserver that will run the API App for a Meltano Project.\"\"\"\nimport logging\nimport platform\nimport threading\n\nfrom meltano.core.meltano_invoker import MeltanoInvoker\nfrom meltano.core.project import Project\nfrom meltano.core.project_settings_service import ProjectSettingsService\nfrom meltano.core.settings_service import FeatureFlags\nfrom meltano.core.utils.pidfile import PIDFile\n\n\nclass APIWorker(threading.Thread):\n \"\"\"The Base APIWorker Class.\"\"\"\n\n def __init__(self, project: Project, reload=False):\n \"\"\"Initialize the API Worker class with the project config.\n\n Args:\n project: Project class.\n reload: Boolean.\n \"\"\"\n super().__init__()\n\n self.project = project\n self.reload = reload\n self.pid_file = PIDFile(self.project.run_dir(\"gunicorn.pid\"))\n self.settings_service = ProjectSettingsService(self.project.find())\n\n def run(self):\n \"\"\"Run the initalized API Workers with the App Server requested.\"\"\"\n with self.settings_service.feature_flag(\n FeatureFlags.ENABLE_UVICORN, raise_error=False\n ) as allow:\n\n enable_uvicorn = allow\n\n # Use Uvicorn when on Windows\n if platform.system() == \"Windows\":\n if enable_uvicorn:\n logging.debug(\"ff.enable_uvicorn enabled, starting uvicorn.\")\n else:\n logging.warning(\n \"Windows OS detected auto setting ff.enable_uvicorn\"\n )\n logging.warning(\n \"Add ff.enable_uvicorn: True to your meltano.yml to supress this waring\"\n )\n enable_uvicorn = True\n\n # Start uvicorn to serve API and Ui\n if enable_uvicorn:\n settings_for_apiworker = self.settings_service\n\n arg_bind_host = str(settings_for_apiworker.get(\"ui.bind_host\"))\n arg_bind_port = str(settings_for_apiworker.get(\"ui.bind_port\"))\n arg_loglevel = str(settings_for_apiworker.get(\"cli.log_level\"))\n arg_forwarded_allow_ips = str(\n settings_for_apiworker.get(\"ui.forwarded_allow_ips\")\n )\n\n # If windows and 127.0.0.1 only allowed changing bind host to accomidate\n if platform.system() == \"Windows\":\n if (\n arg_forwarded_allow_ips == \"127.0.0.1\"\n and arg_bind_host == \"0.0.0.0\" # noqa: S104\n ):\n # If left at 0.0.0.0 the server will respond to any request receieved on any interface\n arg_bind_host = \"127.0.0.1\"\n\n # Setup args for uvicorn using bind info from the project setings service\n args = [\n \"--host\",\n arg_bind_host,\n \"--port\",\n arg_bind_port,\n \"--loop\",\n \"asyncio\",\n \"--interface\",\n \"wsgi\",\n \"--log-level\",\n arg_loglevel,\n \"--forwarded-allow-ips\",\n arg_forwarded_allow_ips,\n \"--timeout-keep-alive\",\n \"600\",\n ]\n\n # Add reload argument if reload is true\n if self.reload:\n\n args += [\n \"--reload\",\n ]\n\n # Add the Meltano API app, factory create_app function combo to the args\n args += [\n \"--factory\",\n \"meltano.api.app:create_app\",\n ]\n\n # Start uvicorn using the MeltanoInvoker\n MeltanoInvoker(self.project).invoke(args, command=\"uvicorn\")\n\n else:\n # Use Gunicorn when feature flag start_uvicorn is not set\n\n args = [\n \"--config\",\n \"python:meltano.api.wsgi\",\n \"--pid\",\n str(self.pid_file),\n ]\n\n if self.reload:\n args += [\"--reload\"]\n\n args += [\"meltano.api.app:create_app()\"]\n\n MeltanoInvoker(self.project).invoke(args, command=\"gunicorn\")\n\n def pid_path(self):\n \"\"\"Give the path name of the projects gunicorn.pid file location.\n\n Returns:\n Path object that gives the direct locationo of the gunicorn.pid file.\n \"\"\"\n return self.project.run_dir(\"gunicorn.pid\")\n\n def stop(self):\n \"\"\"Terminnate active gunicorn workers that have placed a PID in the project's gunicorn.pid file.\"\"\"\n self.pid_file.process.terminate()\n", "path": "src/meltano/api/workers/api_worker.py"}]}
| 1,612 | 139 |
gh_patches_debug_1286
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-1585
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bump fastavro version
**Is your feature request related to a problem? Please describe.**
The version of Fastavro that we're using is kinda old and may be buggy soon. It's also causing some version conflicts with packages that have already upgraded to the newer (1.xx) versions.
**Describe the solution you'd like**
Bump Fastavro to 1.x.x
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/setup.py`
Content:
```
1 # Copyright 2019 The Feast Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import glob
15 import os
16 import re
17 import subprocess
18
19 from distutils.cmd import Command
20 from setuptools import find_packages
21
22 try:
23 from setuptools import setup
24 from setuptools.command.install import install
25 from setuptools.command.develop import develop
26 from setuptools.command.egg_info import egg_info
27 from setuptools.command.sdist import sdist
28 from setuptools.command.build_py import build_py
29 except ImportError:
30 from distutils.core import setup
31 from distutils.command.install import install
32 from distutils.command.build_py import build_py
33
34 NAME = "feast"
35 DESCRIPTION = "Python SDK for Feast"
36 URL = "https://github.com/feast-dev/feast"
37 AUTHOR = "Feast"
38 REQUIRES_PYTHON = ">=3.7.0"
39
40 REQUIRED = [
41 "Click==7.*",
42 "colorama>=0.3.9",
43 "fastavro>=0.22.11,<0.23",
44 "google-api-core>=1.23.0",
45 "googleapis-common-protos==1.52.*",
46 "grpcio>=1.34.0",
47 "Jinja2>=2.0.0",
48 "jsonschema",
49 "mmh3",
50 "pandas>=1.0.0",
51 "pandavro==1.5.*",
52 "protobuf>=3.10",
53 "pyarrow>=2.0.0",
54 "pydantic>=1.0.0",
55 "PyYAML==5.3.*",
56 "tabulate==0.8.*",
57 "toml==0.10.*",
58 "tqdm==4.*",
59 ]
60
61 GCP_REQUIRED = [
62 "google-cloud-bigquery>=2.0.*",
63 "google-cloud-bigquery-storage >= 2.0.0",
64 "google-cloud-datastore>=2.1.*",
65 "google-cloud-storage>=1.20.*",
66 "google-cloud-core==1.4.*",
67 ]
68
69 REDIS_REQUIRED = [
70 "redis-py-cluster==2.1.2",
71 ]
72
73 CI_REQUIRED = [
74 "cryptography==3.3.2",
75 "flake8",
76 "black==19.10b0",
77 "isort>=5",
78 "grpcio-tools==1.34.0",
79 "grpcio-testing==1.34.0",
80 "mock==2.0.0",
81 "moto",
82 "mypy==0.790",
83 "mypy-protobuf==1.24",
84 "avro==1.10.0",
85 "gcsfs",
86 "urllib3>=1.25.4",
87 "pytest==6.0.0",
88 "pytest-cov",
89 "pytest-lazy-fixture==0.6.3",
90 "pytest-timeout==1.4.2",
91 "pytest-ordering==0.6.*",
92 "pytest-mock==1.10.4",
93 "Sphinx!=4.0.0",
94 "sphinx-rtd-theme",
95 "tenacity",
96 "adlfs==0.5.9",
97 "firebase-admin==4.5.2",
98 "pre-commit",
99 "assertpy==1.1",
100 "google-cloud-bigquery>=2.0.*",
101 "google-cloud-bigquery-storage >= 2.0.0",
102 "google-cloud-datastore>=2.1.*",
103 "google-cloud-storage>=1.20.*",
104 "google-cloud-core==1.4.*",
105 "redis-py-cluster==2.1.2",
106 ]
107
108 # README file from Feast repo root directory
109 repo_root = (
110 subprocess.Popen(["git", "rev-parse", "--show-toplevel"], stdout=subprocess.PIPE)
111 .communicate()[0]
112 .rstrip()
113 .decode("utf-8")
114 )
115 README_FILE = os.path.join(repo_root, "README.md")
116 with open(README_FILE, "r") as f:
117 LONG_DESCRIPTION = f.read()
118
119 # Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.
120 # Regex modified from default tag regex in:
121 # https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9
122 TAG_REGEX = re.compile(
123 r"^(?:[\/\w-]+)?(?P<version>[vV]?\d+(?:\.\d+){0,2}[^\+]*)(?:\+.*)?$"
124 )
125
126
127 class BuildProtoCommand(Command):
128 description = "Builds the proto files into python files."
129
130 def initialize_options(self):
131 self.protoc = ["python", "-m", "grpc_tools.protoc"] # find_executable("protoc")
132 self.proto_folder = os.path.join(repo_root, "protos")
133 self.this_package = os.path.join(os.path.dirname(__file__) or os.getcwd(), 'feast/protos')
134 self.sub_folders = ["core", "serving", "types", "storage"]
135
136 def finalize_options(self):
137 pass
138
139 def _generate_protos(self, path):
140 proto_files = glob.glob(os.path.join(self.proto_folder, path))
141
142 subprocess.check_call(self.protoc + [
143 '-I', self.proto_folder,
144 '--python_out', self.this_package,
145 '--grpc_python_out', self.this_package,
146 '--mypy_out', self.this_package] + proto_files)
147
148 def run(self):
149 for sub_folder in self.sub_folders:
150 self._generate_protos(f'feast/{sub_folder}/*.proto')
151
152 from pathlib import Path
153
154 for path in Path('feast/protos').rglob('*.py'):
155 for folder in self.sub_folders:
156 # Read in the file
157 with open(path, 'r') as file:
158 filedata = file.read()
159
160 # Replace the target string
161 filedata = filedata.replace(f'from feast.{folder}', f'from feast.protos.feast.{folder}')
162
163 # Write the file out again
164 with open(path, 'w') as file:
165 file.write(filedata)
166
167
168 class BuildCommand(build_py):
169 """Custom build command."""
170
171 def run(self):
172 self.run_command('build_proto')
173 build_py.run(self)
174
175
176 class DevelopCommand(develop):
177 """Custom develop command."""
178
179 def run(self):
180 self.run_command('build_proto')
181 develop.run(self)
182
183
184 setup(
185 name=NAME,
186 author=AUTHOR,
187 description=DESCRIPTION,
188 long_description=LONG_DESCRIPTION,
189 long_description_content_type="text/markdown",
190 python_requires=REQUIRES_PYTHON,
191 url=URL,
192 packages=find_packages(exclude=("tests",)),
193 install_requires=REQUIRED,
194 # https://stackoverflow.com/questions/28509965/setuptools-development-requirements
195 # Install dev requirements with: pip install -e .[dev]
196 extras_require={
197 "dev": ["mypy-protobuf==1.*", "grpcio-testing==1.*"],
198 "ci": CI_REQUIRED,
199 "gcp": GCP_REQUIRED,
200 "redis": REDIS_REQUIRED,
201 },
202 include_package_data=True,
203 license="Apache",
204 classifiers=[
205 # Trove classifiers
206 # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers
207 "License :: OSI Approved :: Apache Software License",
208 "Programming Language :: Python",
209 "Programming Language :: Python :: 3",
210 "Programming Language :: Python :: 3.7",
211 ],
212 entry_points={"console_scripts": ["feast=feast.cli:cli"]},
213 use_scm_version={"root": "../..", "relative_to": __file__, "tag_regex": TAG_REGEX},
214 setup_requires=["setuptools_scm", "grpcio", "grpcio-tools==1.34.0", "mypy-protobuf", "sphinx!=4.0.0"],
215 package_data={
216 "": [
217 "protos/feast/**/*.proto",
218 "protos/feast/third_party/grpc/health/v1/*.proto",
219 "protos/tensorflow_metadata/proto/v0/*.proto",
220 "feast/protos/feast/**/*.py",
221 "tensorflow_metadata/proto/v0/*.py"
222 ],
223 },
224 cmdclass={
225 "build_proto": BuildProtoCommand,
226 "build_py": BuildCommand,
227 "develop": DevelopCommand,
228 },
229 )
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/setup.py b/sdk/python/setup.py
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -40,7 +40,7 @@
REQUIRED = [
"Click==7.*",
"colorama>=0.3.9",
- "fastavro>=0.22.11,<0.23",
+ "fastavro>=1.1.0",
"google-api-core>=1.23.0",
"googleapis-common-protos==1.52.*",
"grpcio>=1.34.0",
|
{"golden_diff": "diff --git a/sdk/python/setup.py b/sdk/python/setup.py\n--- a/sdk/python/setup.py\n+++ b/sdk/python/setup.py\n@@ -40,7 +40,7 @@\n REQUIRED = [\n \"Click==7.*\",\n \"colorama>=0.3.9\",\n- \"fastavro>=0.22.11,<0.23\",\n+ \"fastavro>=1.1.0\",\n \"google-api-core>=1.23.0\",\n \"googleapis-common-protos==1.52.*\",\n \"grpcio>=1.34.0\",\n", "issue": "Bump fastavro version\n**Is your feature request related to a problem? Please describe.**\r\nThe version of Fastavro that we're using is kinda old and may be buggy soon. It's also causing some version conflicts with packages that have already upgraded to the newer (1.xx) versions.\r\n\r\n**Describe the solution you'd like**\r\nBump Fastavro to 1.x.x\r\n\n", "before_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nimport re\nimport subprocess\n\nfrom distutils.cmd import Command\nfrom setuptools import find_packages\n\ntry:\n from setuptools import setup\n from setuptools.command.install import install\n from setuptools.command.develop import develop\n from setuptools.command.egg_info import egg_info\n from setuptools.command.sdist import sdist\n from setuptools.command.build_py import build_py\nexcept ImportError:\n from distutils.core import setup\n from distutils.command.install import install\n from distutils.command.build_py import build_py\n\nNAME = \"feast\"\nDESCRIPTION = \"Python SDK for Feast\"\nURL = \"https://github.com/feast-dev/feast\"\nAUTHOR = \"Feast\"\nREQUIRES_PYTHON = \">=3.7.0\"\n\nREQUIRED = [\n \"Click==7.*\",\n \"colorama>=0.3.9\",\n \"fastavro>=0.22.11,<0.23\",\n \"google-api-core>=1.23.0\",\n \"googleapis-common-protos==1.52.*\",\n \"grpcio>=1.34.0\",\n \"Jinja2>=2.0.0\",\n \"jsonschema\",\n \"mmh3\",\n \"pandas>=1.0.0\",\n \"pandavro==1.5.*\",\n \"protobuf>=3.10\",\n \"pyarrow>=2.0.0\",\n \"pydantic>=1.0.0\",\n \"PyYAML==5.3.*\",\n \"tabulate==0.8.*\",\n \"toml==0.10.*\",\n \"tqdm==4.*\",\n]\n\nGCP_REQUIRED = [\n \"google-cloud-bigquery>=2.0.*\",\n \"google-cloud-bigquery-storage >= 2.0.0\",\n \"google-cloud-datastore>=2.1.*\",\n \"google-cloud-storage>=1.20.*\",\n \"google-cloud-core==1.4.*\",\n]\n\nREDIS_REQUIRED = [\n \"redis-py-cluster==2.1.2\",\n]\n\nCI_REQUIRED = [\n \"cryptography==3.3.2\",\n \"flake8\",\n \"black==19.10b0\",\n \"isort>=5\",\n \"grpcio-tools==1.34.0\",\n \"grpcio-testing==1.34.0\",\n \"mock==2.0.0\",\n \"moto\",\n \"mypy==0.790\",\n \"mypy-protobuf==1.24\",\n \"avro==1.10.0\",\n \"gcsfs\",\n \"urllib3>=1.25.4\",\n \"pytest==6.0.0\",\n \"pytest-cov\",\n \"pytest-lazy-fixture==0.6.3\",\n \"pytest-timeout==1.4.2\",\n \"pytest-ordering==0.6.*\",\n \"pytest-mock==1.10.4\",\n \"Sphinx!=4.0.0\",\n \"sphinx-rtd-theme\",\n \"tenacity\",\n \"adlfs==0.5.9\",\n \"firebase-admin==4.5.2\",\n \"pre-commit\",\n \"assertpy==1.1\",\n \"google-cloud-bigquery>=2.0.*\",\n \"google-cloud-bigquery-storage >= 2.0.0\",\n \"google-cloud-datastore>=2.1.*\",\n \"google-cloud-storage>=1.20.*\",\n \"google-cloud-core==1.4.*\",\n \"redis-py-cluster==2.1.2\",\n]\n\n# README file from Feast repo root directory\nrepo_root = (\n subprocess.Popen([\"git\", \"rev-parse\", \"--show-toplevel\"], stdout=subprocess.PIPE)\n .communicate()[0]\n .rstrip()\n .decode(\"utf-8\")\n)\nREADME_FILE = os.path.join(repo_root, \"README.md\")\nwith open(README_FILE, \"r\") as f:\n LONG_DESCRIPTION = f.read()\n\n# Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.\n# Regex modified from default tag regex in:\n# https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9\nTAG_REGEX = re.compile(\n r\"^(?:[\\/\\w-]+)?(?P<version>[vV]?\\d+(?:\\.\\d+){0,2}[^\\+]*)(?:\\+.*)?$\"\n)\n\n\nclass BuildProtoCommand(Command):\n description = \"Builds the proto files into python files.\"\n\n def initialize_options(self):\n self.protoc = [\"python\", \"-m\", \"grpc_tools.protoc\"] # find_executable(\"protoc\")\n self.proto_folder = os.path.join(repo_root, \"protos\")\n self.this_package = os.path.join(os.path.dirname(__file__) or os.getcwd(), 'feast/protos')\n self.sub_folders = [\"core\", \"serving\", \"types\", \"storage\"]\n\n def finalize_options(self):\n pass\n\n def _generate_protos(self, path):\n proto_files = glob.glob(os.path.join(self.proto_folder, path))\n\n subprocess.check_call(self.protoc + [\n '-I', self.proto_folder,\n '--python_out', self.this_package,\n '--grpc_python_out', self.this_package,\n '--mypy_out', self.this_package] + proto_files)\n\n def run(self):\n for sub_folder in self.sub_folders:\n self._generate_protos(f'feast/{sub_folder}/*.proto')\n\n from pathlib import Path\n\n for path in Path('feast/protos').rglob('*.py'):\n for folder in self.sub_folders:\n # Read in the file\n with open(path, 'r') as file:\n filedata = file.read()\n\n # Replace the target string\n filedata = filedata.replace(f'from feast.{folder}', f'from feast.protos.feast.{folder}')\n\n # Write the file out again\n with open(path, 'w') as file:\n file.write(filedata)\n\n\nclass BuildCommand(build_py):\n \"\"\"Custom build command.\"\"\"\n\n def run(self):\n self.run_command('build_proto')\n build_py.run(self)\n\n\nclass DevelopCommand(develop):\n \"\"\"Custom develop command.\"\"\"\n\n def run(self):\n self.run_command('build_proto')\n develop.run(self)\n\n\nsetup(\n name=NAME,\n author=AUTHOR,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n python_requires=REQUIRES_PYTHON,\n url=URL,\n packages=find_packages(exclude=(\"tests\",)),\n install_requires=REQUIRED,\n # https://stackoverflow.com/questions/28509965/setuptools-development-requirements\n # Install dev requirements with: pip install -e .[dev]\n extras_require={\n \"dev\": [\"mypy-protobuf==1.*\", \"grpcio-testing==1.*\"],\n \"ci\": CI_REQUIRED,\n \"gcp\": GCP_REQUIRED,\n \"redis\": REDIS_REQUIRED,\n },\n include_package_data=True,\n license=\"Apache\",\n classifiers=[\n # Trove classifiers\n # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n use_scm_version={\"root\": \"../..\", \"relative_to\": __file__, \"tag_regex\": TAG_REGEX},\n setup_requires=[\"setuptools_scm\", \"grpcio\", \"grpcio-tools==1.34.0\", \"mypy-protobuf\", \"sphinx!=4.0.0\"],\n package_data={\n \"\": [\n \"protos/feast/**/*.proto\",\n \"protos/feast/third_party/grpc/health/v1/*.proto\",\n \"protos/tensorflow_metadata/proto/v0/*.proto\",\n \"feast/protos/feast/**/*.py\",\n \"tensorflow_metadata/proto/v0/*.py\"\n ],\n },\n cmdclass={\n \"build_proto\": BuildProtoCommand,\n \"build_py\": BuildCommand,\n \"develop\": DevelopCommand,\n },\n)\n", "path": "sdk/python/setup.py"}], "after_files": [{"content": "# Copyright 2019 The Feast Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nimport re\nimport subprocess\n\nfrom distutils.cmd import Command\nfrom setuptools import find_packages\n\ntry:\n from setuptools import setup\n from setuptools.command.install import install\n from setuptools.command.develop import develop\n from setuptools.command.egg_info import egg_info\n from setuptools.command.sdist import sdist\n from setuptools.command.build_py import build_py\nexcept ImportError:\n from distutils.core import setup\n from distutils.command.install import install\n from distutils.command.build_py import build_py\n\nNAME = \"feast\"\nDESCRIPTION = \"Python SDK for Feast\"\nURL = \"https://github.com/feast-dev/feast\"\nAUTHOR = \"Feast\"\nREQUIRES_PYTHON = \">=3.7.0\"\n\nREQUIRED = [\n \"Click==7.*\",\n \"colorama>=0.3.9\",\n \"fastavro>=1.1.0\",\n \"google-api-core>=1.23.0\",\n \"googleapis-common-protos==1.52.*\",\n \"grpcio>=1.34.0\",\n \"Jinja2>=2.0.0\",\n \"jsonschema\",\n \"mmh3\",\n \"pandas>=1.0.0\",\n \"pandavro==1.5.*\",\n \"protobuf>=3.10\",\n \"pyarrow>=2.0.0\",\n \"pydantic>=1.0.0\",\n \"PyYAML==5.3.*\",\n \"tabulate==0.8.*\",\n \"toml==0.10.*\",\n \"tqdm==4.*\",\n]\n\nGCP_REQUIRED = [\n \"google-cloud-bigquery>=2.0.*\",\n \"google-cloud-bigquery-storage >= 2.0.0\",\n \"google-cloud-datastore>=2.1.*\",\n \"google-cloud-storage>=1.20.*\",\n \"google-cloud-core==1.4.*\",\n]\n\nCI_REQUIRED = [\n \"cryptography==3.3.2\",\n \"flake8\",\n \"black==19.10b0\",\n \"isort>=5\",\n \"grpcio-tools==1.34.0\",\n \"grpcio-testing==1.34.0\",\n \"mock==2.0.0\",\n \"moto\",\n \"mypy==0.790\",\n \"mypy-protobuf==1.24\",\n \"avro==1.10.0\",\n \"gcsfs\",\n \"urllib3>=1.25.4\",\n \"pytest==6.0.0\",\n \"pytest-cov\",\n \"pytest-lazy-fixture==0.6.3\",\n \"pytest-timeout==1.4.2\",\n \"pytest-ordering==0.6.*\",\n \"pytest-mock==1.10.4\",\n \"Sphinx!=4.0.0\",\n \"sphinx-rtd-theme\",\n \"tenacity\",\n \"adlfs==0.5.9\",\n \"firebase-admin==4.5.2\",\n \"pre-commit\",\n \"assertpy==1.1\",\n \"google-cloud-bigquery>=2.0.*\",\n \"google-cloud-bigquery-storage >= 2.0.0\",\n \"google-cloud-datastore>=2.1.*\",\n \"google-cloud-storage>=1.20.*\",\n \"google-cloud-core==1.4.*\",\n]\n\n# README file from Feast repo root directory\nrepo_root = (\n subprocess.Popen([\"git\", \"rev-parse\", \"--show-toplevel\"], stdout=subprocess.PIPE)\n .communicate()[0]\n .rstrip()\n .decode(\"utf-8\")\n)\nREADME_FILE = os.path.join(repo_root, \"README.md\")\nwith open(README_FILE, \"r\") as f:\n LONG_DESCRIPTION = f.read()\n\n# Add Support for parsing tags that have a prefix containing '/' (ie 'sdk/go') to setuptools_scm.\n# Regex modified from default tag regex in:\n# https://github.com/pypa/setuptools_scm/blob/2a1b46d38fb2b8aeac09853e660bcd0d7c1bc7be/src/setuptools_scm/config.py#L9\nTAG_REGEX = re.compile(\n r\"^(?:[\\/\\w-]+)?(?P<version>[vV]?\\d+(?:\\.\\d+){0,2}[^\\+]*)(?:\\+.*)?$\"\n)\n\n\nclass BuildProtoCommand(Command):\n description = \"Builds the proto files into python files.\"\n\n def initialize_options(self):\n self.protoc = [\"python\", \"-m\", \"grpc_tools.protoc\"] # find_executable(\"protoc\")\n self.proto_folder = os.path.join(repo_root, \"protos\")\n self.this_package = os.path.join(os.path.dirname(__file__) or os.getcwd(), 'feast/protos')\n self.sub_folders = [\"core\", \"serving\", \"types\", \"storage\"]\n\n def finalize_options(self):\n pass\n\n def _generate_protos(self, path):\n proto_files = glob.glob(os.path.join(self.proto_folder, path))\n\n subprocess.check_call(self.protoc + [\n '-I', self.proto_folder,\n '--python_out', self.this_package,\n '--grpc_python_out', self.this_package,\n '--mypy_out', self.this_package] + proto_files)\n\n def run(self):\n for sub_folder in self.sub_folders:\n self._generate_protos(f'feast/{sub_folder}/*.proto')\n\n from pathlib import Path\n\n for path in Path('feast/protos').rglob('*.py'):\n for folder in self.sub_folders:\n # Read in the file\n with open(path, 'r') as file:\n filedata = file.read()\n\n # Replace the target string\n filedata = filedata.replace(f'from feast.{folder}', f'from feast.protos.feast.{folder}')\n\n # Write the file out again\n with open(path, 'w') as file:\n file.write(filedata)\n\n\nclass BuildCommand(build_py):\n \"\"\"Custom build command.\"\"\"\n\n def run(self):\n self.run_command('build_proto')\n build_py.run(self)\n\n\nclass DevelopCommand(develop):\n \"\"\"Custom develop command.\"\"\"\n\n def run(self):\n self.run_command('build_proto')\n develop.run(self)\n\n\nsetup(\n name=NAME,\n author=AUTHOR,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n python_requires=REQUIRES_PYTHON,\n url=URL,\n packages=find_packages(exclude=(\"tests\",)),\n install_requires=REQUIRED,\n # https://stackoverflow.com/questions/28509965/setuptools-development-requirements\n # Install dev requirements with: pip install -e .[dev]\n extras_require={\n \"dev\": [\"mypy-protobuf==1.*\", \"grpcio-testing==1.*\"],\n \"ci\": CI_REQUIRED,\n \"gcp\": GCP_REQUIRED,\n },\n include_package_data=True,\n license=\"Apache\",\n classifiers=[\n # Trove classifiers\n # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n ],\n entry_points={\"console_scripts\": [\"feast=feast.cli:cli\"]},\n use_scm_version={\"root\": \"../..\", \"relative_to\": __file__, \"tag_regex\": TAG_REGEX},\n setup_requires=[\"setuptools_scm\", \"grpcio\", \"grpcio-tools==1.34.0\", \"mypy-protobuf\", \"sphinx!=4.0.0\"],\n package_data={\n \"\": [\n \"protos/feast/**/*.proto\",\n \"protos/feast/third_party/grpc/health/v1/*.proto\",\n \"protos/tensorflow_metadata/proto/v0/*.proto\",\n \"feast/protos/feast/**/*.py\",\n \"tensorflow_metadata/proto/v0/*.py\"\n ],\n },\n cmdclass={\n \"build_proto\": BuildProtoCommand,\n \"build_py\": BuildCommand,\n \"develop\": DevelopCommand,\n },\n)\n", "path": "sdk/python/setup.py"}]}
| 2,917 | 134 |
gh_patches_debug_6871
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1495
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The worker should wait all channels are ready.
If the worker has started to train and the grpc channels to connect PS are not ready, a connection error will be raised.
```
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses"
debug_error_string = "{"created":"@1574320322.398282300","description":"Failed to pick subchannel","file":"src/core/ext/filters/client_channel/client_channel.cc","file_line":3876,"referenced_errors":[{"created":"@1574320322.398280426","description":"failed to connect to all addresses","file":"src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc","file_line":395,"grpc_status":14}]}"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/worker/main.py`
Content:
```
1 import time
2
3 import grpc
4 from kubernetes import client, config
5
6 from elasticdl.python.common import log_utils
7 from elasticdl.python.common.args import parse_worker_args
8 from elasticdl.python.common.constants import GRPC
9 from elasticdl.python.common.grpc_utils import build_channel
10 from elasticdl.python.worker.worker import Worker
11
12
13 def main():
14 args = parse_worker_args()
15 logger = log_utils.get_logger(__name__)
16 logger.info("Starting worker %d", args.worker_id)
17 if args.master_addr is None:
18 raise ValueError("master_addr is missing for worker")
19
20 master_channel = build_channel(args.master_addr)
21
22 ps_channels = []
23 if args.ps_addrs:
24 # TODO: use ps_addrs from master directly after ps service is working.
25 # Get ps pod ip for ps grpc connection for now.
26 ps_addrs = args.ps_addrs.split(",")
27
28 config.load_incluster_config()
29 api = client.CoreV1Api()
30
31 for addr in ps_addrs:
32 # addr is in the form as "ps-pod-name.namespace.svc:port"
33 addr_splitted = addr.split(".")
34 while True:
35 pod = api.read_namespaced_pod(
36 namespace=addr_splitted[1], name=addr_splitted[0]
37 )
38 if pod.status.pod_ip:
39 break
40 # If ps pod is not ready yet, sleep 2 seconds and try again.
41 time.sleep(2)
42 addr = pod.status.pod_ip + ":" + addr.split(":")[-1]
43 channel = grpc.insecure_channel(
44 addr,
45 options=[
46 (
47 "grpc.max_send_message_length",
48 GRPC.MAX_SEND_MESSAGE_LENGTH,
49 ),
50 (
51 "grpc.max_receive_message_length",
52 GRPC.MAX_RECEIVE_MESSAGE_LENGTH,
53 ),
54 ],
55 )
56 ps_channels.append(channel)
57
58 worker = Worker(args, channel=master_channel, ps_channels=ps_channels)
59 worker.run()
60
61
62 if __name__ == "__main__":
63 main()
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/worker/main.py b/elasticdl/python/worker/main.py
--- a/elasticdl/python/worker/main.py
+++ b/elasticdl/python/worker/main.py
@@ -53,6 +53,13 @@
),
],
)
+
+ # Wait the channel is ready by a Future object.
+ grpc.channel_ready_future(channel).result()
+ logger.info(
+ "grpc channel %s to connect pod %s is ready"
+ % (addr, pod.metadata.name)
+ )
ps_channels.append(channel)
worker = Worker(args, channel=master_channel, ps_channels=ps_channels)
|
{"golden_diff": "diff --git a/elasticdl/python/worker/main.py b/elasticdl/python/worker/main.py\n--- a/elasticdl/python/worker/main.py\n+++ b/elasticdl/python/worker/main.py\n@@ -53,6 +53,13 @@\n ),\n ],\n )\n+\n+ # Wait the channel is ready by a Future object.\n+ grpc.channel_ready_future(channel).result()\n+ logger.info(\n+ \"grpc channel %s to connect pod %s is ready\"\n+ % (addr, pod.metadata.name)\n+ )\n ps_channels.append(channel)\n \n worker = Worker(args, channel=master_channel, ps_channels=ps_channels)\n", "issue": "The worker should wait all channels are ready.\nIf the worker has started to train and the grpc channels to connect PS are not ready, a connection error will be raised.\r\n\r\n```\r\ngrpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:\r\n\tstatus = StatusCode.UNAVAILABLE\r\n\tdetails = \"failed to connect to all addresses\"\r\n\tdebug_error_string = \"{\"created\":\"@1574320322.398282300\",\"description\":\"Failed to pick subchannel\",\"file\":\"src/core/ext/filters/client_channel/client_channel.cc\",\"file_line\":3876,\"referenced_errors\":[{\"created\":\"@1574320322.398280426\",\"description\":\"failed to connect to all addresses\",\"file\":\"src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc\",\"file_line\":395,\"grpc_status\":14}]}\"\r\n```\n", "before_files": [{"content": "import time\n\nimport grpc\nfrom kubernetes import client, config\n\nfrom elasticdl.python.common import log_utils\nfrom elasticdl.python.common.args import parse_worker_args\nfrom elasticdl.python.common.constants import GRPC\nfrom elasticdl.python.common.grpc_utils import build_channel\nfrom elasticdl.python.worker.worker import Worker\n\n\ndef main():\n args = parse_worker_args()\n logger = log_utils.get_logger(__name__)\n logger.info(\"Starting worker %d\", args.worker_id)\n if args.master_addr is None:\n raise ValueError(\"master_addr is missing for worker\")\n\n master_channel = build_channel(args.master_addr)\n\n ps_channels = []\n if args.ps_addrs:\n # TODO: use ps_addrs from master directly after ps service is working.\n # Get ps pod ip for ps grpc connection for now.\n ps_addrs = args.ps_addrs.split(\",\")\n\n config.load_incluster_config()\n api = client.CoreV1Api()\n\n for addr in ps_addrs:\n # addr is in the form as \"ps-pod-name.namespace.svc:port\"\n addr_splitted = addr.split(\".\")\n while True:\n pod = api.read_namespaced_pod(\n namespace=addr_splitted[1], name=addr_splitted[0]\n )\n if pod.status.pod_ip:\n break\n # If ps pod is not ready yet, sleep 2 seconds and try again.\n time.sleep(2)\n addr = pod.status.pod_ip + \":\" + addr.split(\":\")[-1]\n channel = grpc.insecure_channel(\n addr,\n options=[\n (\n \"grpc.max_send_message_length\",\n GRPC.MAX_SEND_MESSAGE_LENGTH,\n ),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n ps_channels.append(channel)\n\n worker = Worker(args, channel=master_channel, ps_channels=ps_channels)\n worker.run()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/worker/main.py"}], "after_files": [{"content": "import time\n\nimport grpc\nfrom kubernetes import client, config\n\nfrom elasticdl.python.common import log_utils\nfrom elasticdl.python.common.args import parse_worker_args\nfrom elasticdl.python.common.constants import GRPC\nfrom elasticdl.python.common.grpc_utils import build_channel\nfrom elasticdl.python.worker.worker import Worker\n\n\ndef main():\n args = parse_worker_args()\n logger = log_utils.get_logger(__name__)\n logger.info(\"Starting worker %d\", args.worker_id)\n if args.master_addr is None:\n raise ValueError(\"master_addr is missing for worker\")\n\n master_channel = build_channel(args.master_addr)\n\n ps_channels = []\n if args.ps_addrs:\n # TODO: use ps_addrs from master directly after ps service is working.\n # Get ps pod ip for ps grpc connection for now.\n ps_addrs = args.ps_addrs.split(\",\")\n\n config.load_incluster_config()\n api = client.CoreV1Api()\n\n for addr in ps_addrs:\n # addr is in the form as \"ps-pod-name.namespace.svc:port\"\n addr_splitted = addr.split(\".\")\n while True:\n pod = api.read_namespaced_pod(\n namespace=addr_splitted[1], name=addr_splitted[0]\n )\n if pod.status.pod_ip:\n break\n # If ps pod is not ready yet, sleep 2 seconds and try again.\n time.sleep(2)\n addr = pod.status.pod_ip + \":\" + addr.split(\":\")[-1]\n channel = grpc.insecure_channel(\n addr,\n options=[\n (\n \"grpc.max_send_message_length\",\n GRPC.MAX_SEND_MESSAGE_LENGTH,\n ),\n (\n \"grpc.max_receive_message_length\",\n GRPC.MAX_RECEIVE_MESSAGE_LENGTH,\n ),\n ],\n )\n\n # Wait the channel is ready by a Future object.\n grpc.channel_ready_future(channel).result()\n logger.info(\n \"grpc channel %s to connect pod %s is ready\"\n % (addr, pod.metadata.name)\n )\n ps_channels.append(channel)\n\n worker = Worker(args, channel=master_channel, ps_channels=ps_channels)\n worker.run()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/python/worker/main.py"}]}
| 1,012 | 144 |
gh_patches_debug_5410
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-5100
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The KFP preloaded XGboost sample is broken and out-dated.
**TL;DR: The preload XGBoost sample is currently broken.
Proposing we remove this sample from KFP preload and from sample test until we got a chance to refresh the sample.**
------------
The direct cause was that it used the Dataproc 1.2 image which is based on Python 2.7, and pip 21.0 dropped support for Python 2.7.
The symptom is that `dataproc_create_cluster` fails on initialization.

and the specific error is mentioned [here](https://github.com/kubeflow/pipelines/issues/5007#issuecomment-769637030).
https://github.com/kubeflow/pipelines/pull/5062 made an attempted fix by upgrading to Dataproc 1.5 image. It fixed the Dataproc cluster creation issue, but we hit [an error](https://github.com/kubeflow/pipelines/issues/5007#issuecomment-770182313) later at the Trainer step.
We were advised that newer versions of Dataproc images likely don't have XGBoost library preinstalled, as there's now [an initialization action that goes through extra steps to install XGBoost libraries](https://github.com/GoogleCloudDataproc/initialization-actions/tree/master/rapids).
Following that route, I tried installing the default XGBoost version using the rapids script, then hit the error as follows:
```
21/02/03 18:34:20 INFO org.spark_project.jetty.util.log: Logging initialized @3037ms
21/02/03 18:34:20 INFO org.spark_project.jetty.server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
21/02/03 18:34:20 INFO org.spark_project.jetty.server.Server: Started @3169ms
21/02/03 18:34:20 INFO org.spark_project.jetty.server.AbstractConnector: Started ServerConnector@4159e81b{HTTP/1.1,[http/1.1]}{0.0.0.0:37489}
21/02/03 18:34:20 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at xgb-bdd8f29b-fb13-4ec2-abcf-38b3699e7ca3-m/10.128.0.101:8032
21/02/03 18:34:21 INFO org.apache.hadoop.yarn.client.AHSProxy: Connecting to Application History server at xgb-bdd8f29b-fb13-4ec2-abcf-38b3699e7ca3-m/10.128.0.101:10200
21/02/03 18:34:21 INFO org.apache.hadoop.conf.Configuration: resource-types.xml not found
21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Unable to find 'resource-types.xml'.
21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
21/02/03 18:34:23 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1612377093662_0003
21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1
21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1
21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0
21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1
21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1
21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0
Exception in thread "main" java.lang.NoSuchMethodError: ml.dmlc.xgboost4j.scala.spark.XGBoost$.trainWithDataFrame$default$5()Lml/dmlc/xgboost4j/scala/ObjectiveTrait;
at ml.dmlc.xgboost4j.scala.example.spark.XGBoostTrainer$.main(XGBoostTrainer.scala:120)
at ml.dmlc.xgboost4j.scala.example.spark.XGBoostTrainer.main(XGBoostTrainer.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:845)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
21/02/03 18:34:39 INFO org.spark_project.jetty.server.AbstractConnector: Stopped Spark@4159e81b{HTTP/1.1,[http/1.1]}{0.0.0.0:0}
Job output is complete
```
I then realized that the sample is based on the code from the deprecated component path, which was deleted by https://github.com/kubeflow/pipelines/pull/5045.
Specifically, the not found method from the above error was used here:
https://github.com/kubeflow/pipelines/blob/32ce8d8f90bfc8f89a2a3c347ad906f99ba776a8/components/deprecated/dataproc/train/src/XGBoostTrainer.scala#L121
And `trainWithDataFrame` only [exists in XGBoost 0.72](https://xgboost.readthedocs.io/en/release_0.72/jvm/scaladocs/xgboost4j-spark/index.html#ml.dmlc.xgboost4j.scala.spark.XGBoost$@trainWithDataFrame(trainingData:org.apache.spark.sql.Dataset[_],params:Map[String,Any],round:Int,nWorkers:Int,obj:ml.dmlc.xgboost4j.scala.ObjectiveTrait,eval:ml.dmlc.xgboost4j.scala.EvalTrait,useExternalMemory:Boolean,missing:Float,featureCol:String,labelCol:String):ml.dmlc.xgboost4j.scala.spark.XGBoostModel), but not seen from any versions beyond.
XGBoost 0.72 is too old and not even available from https://repo1.maven.org/maven2/com/nvidia/, which is [used by rapids to download XGBoost](https://github.com/GoogleCloudDataproc/initialization-actions/blob/8980d37d16ae580ad1d3eba7a40da59da52ff175/rapids/rapids.sh#L90).
At this point, I feel like we'd rather invest to rewrite the XGBoost sample using the latest XGBoost library than patching the existing one if we do think it's worth demoing running a XGBoost-on-Dataproc pipeline.
Util we have the sample working, I propose we remove it from the KFP preloaded pipelines and sample-tests.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `samples/core/train_until_good/train_until_good.py`
Content:
```
1 #!/usr/bin/env python3
2 # Copyright 2020 The Kubeflow Pipleines authors
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 # This sample demonstrates continuous training using a train-eval-check recursive loop.
17 # The main pipeline trains the initial model and then gradually trains the model
18 # some more until the model evaluation metrics are good enough.
19
20 import kfp
21 from kfp import components
22
23
24 chicago_taxi_dataset_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/e3337b8bdcd63636934954e592d4b32c95b49129/components/datasets/Chicago%20Taxi/component.yaml')
25 xgboost_train_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Train/component.yaml')
26 xgboost_predict_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Predict/component.yaml')
27
28 pandas_transform_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/6162d55998b176b50267d351241100bb0ee715bc/components/pandas/Transform_DataFrame/in_CSV_format/component.yaml')
29 drop_header_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/02c9638287468c849632cf9f7885b51de4c66f86/components/tables/Remove_header/component.yaml')
30 calculate_regression_metrics_from_csv_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/616542ac0f789914f4eb53438da713dd3004fba4/components/ml_metrics/Calculate_regression_metrics/from_CSV/component.yaml')
31
32
33 # This recursive sub-pipeline trains a model, evaluates it, calculates the metrics and checks them.
34 # If the model error is too high, then more training is performed until the model is good.
35 @kfp.dsl.graph_component
36 def train_until_low_error(starting_model, training_data, true_values):
37 # Training
38 model = xgboost_train_on_csv_op(
39 training_data=training_data,
40 starting_model=starting_model,
41 label_column=0,
42 objective='reg:squarederror',
43 num_iterations=50,
44 ).outputs['model']
45
46 # Predicting
47 predictions = xgboost_predict_on_csv_op(
48 data=training_data,
49 model=model,
50 label_column=0,
51 ).output
52
53 # Calculating the regression metrics
54 metrics_task = calculate_regression_metrics_from_csv_op(
55 true_values=true_values,
56 predicted_values=predictions,
57 )
58
59 # Checking the metrics
60 with kfp.dsl.Condition(metrics_task.outputs['mean_squared_error'] > 0.01):
61 # Training some more
62 train_until_low_error(
63 starting_model=model,
64 training_data=training_data,
65 true_values=true_values,
66 )
67
68
69 # The main pipleine trains the initial model and then gradually trains the model some more until the model evaluation metrics are good enough.
70 def train_until_good_pipeline():
71 # Preparing the training data
72 training_data = chicago_taxi_dataset_op(
73 where='trip_start_timestamp >= "2019-01-01" AND trip_start_timestamp < "2019-02-01"',
74 select='tips,trip_seconds,trip_miles,pickup_community_area,dropoff_community_area,fare,tolls,extras,trip_total',
75 limit=10000,
76 ).output
77
78 # Preparing the true values
79 true_values_table = pandas_transform_csv_op(
80 table=training_data,
81 transform_code='df = df[["tips"]]',
82 ).output
83
84 true_values = drop_header_op(true_values_table).output
85
86 # Initial model training
87 first_model = xgboost_train_on_csv_op(
88 training_data=training_data,
89 label_column=0,
90 objective='reg:squarederror',
91 num_iterations=100,
92 ).outputs['model']
93
94 # Recursively training until the error becomes low
95 train_until_low_error(
96 starting_model=first_model,
97 training_data=training_data,
98 true_values=true_values,
99 )
100
101
102 if __name__ == '__main__':
103 kfp_endpoint=None
104 kfp.Client(host=kfp_endpoint).create_run_from_pipeline_func(train_until_good_pipeline, arguments={})
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/samples/core/train_until_good/train_until_good.py b/samples/core/train_until_good/train_until_good.py
--- a/samples/core/train_until_good/train_until_good.py
+++ b/samples/core/train_until_good/train_until_good.py
@@ -67,6 +67,7 @@
# The main pipleine trains the initial model and then gradually trains the model some more until the model evaluation metrics are good enough.
[email protected]()
def train_until_good_pipeline():
# Preparing the training data
training_data = chicago_taxi_dataset_op(
|
{"golden_diff": "diff --git a/samples/core/train_until_good/train_until_good.py b/samples/core/train_until_good/train_until_good.py\n--- a/samples/core/train_until_good/train_until_good.py\n+++ b/samples/core/train_until_good/train_until_good.py\n@@ -67,6 +67,7 @@\n \n \n # The main pipleine trains the initial model and then gradually trains the model some more until the model evaluation metrics are good enough.\[email protected]()\n def train_until_good_pipeline():\n # Preparing the training data\n training_data = chicago_taxi_dataset_op(\n", "issue": "The KFP preloaded XGboost sample is broken and out-dated. \n**TL;DR: The preload XGBoost sample is currently broken. \r\nProposing we remove this sample from KFP preload and from sample test until we got a chance to refresh the sample.**\r\n\r\n------------\r\nThe direct cause was that it used the Dataproc 1.2 image which is based on Python 2.7, and pip 21.0 dropped support for Python 2.7.\r\nThe symptom is that `dataproc_create_cluster` fails on initialization. \r\n\r\nand the specific error is mentioned [here](https://github.com/kubeflow/pipelines/issues/5007#issuecomment-769637030).\r\n\r\nhttps://github.com/kubeflow/pipelines/pull/5062 made an attempted fix by upgrading to Dataproc 1.5 image. It fixed the Dataproc cluster creation issue, but we hit [an error](https://github.com/kubeflow/pipelines/issues/5007#issuecomment-770182313) later at the Trainer step.\r\n\r\nWe were advised that newer versions of Dataproc images likely don't have XGBoost library preinstalled, as there's now [an initialization action that goes through extra steps to install XGBoost libraries](https://github.com/GoogleCloudDataproc/initialization-actions/tree/master/rapids).\r\n\r\nFollowing that route, I tried installing the default XGBoost version using the rapids script, then hit the error as follows:\r\n```\r\n21/02/03 18:34:20 INFO org.spark_project.jetty.util.log: Logging initialized @3037ms\r\n21/02/03 18:34:20 INFO org.spark_project.jetty.server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown\r\n21/02/03 18:34:20 INFO org.spark_project.jetty.server.Server: Started @3169ms\r\n21/02/03 18:34:20 INFO org.spark_project.jetty.server.AbstractConnector: Started ServerConnector@4159e81b{HTTP/1.1,[http/1.1]}{0.0.0.0:37489}\r\n21/02/03 18:34:20 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at xgb-bdd8f29b-fb13-4ec2-abcf-38b3699e7ca3-m/10.128.0.101:8032\r\n21/02/03 18:34:21 INFO org.apache.hadoop.yarn.client.AHSProxy: Connecting to Application History server at xgb-bdd8f29b-fb13-4ec2-abcf-38b3699e7ca3-m/10.128.0.101:10200\r\n21/02/03 18:34:21 INFO org.apache.hadoop.conf.Configuration: resource-types.xml not found\r\n21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Unable to find 'resource-types.xml'.\r\n21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE\r\n21/02/03 18:34:21 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE\r\n21/02/03 18:34:23 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1612377093662_0003\r\n21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1\r\n21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1\r\n21/02/03 18:34:30 INFO org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0\r\n21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1\r\n21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat: Total input files to process : 1\r\n21/02/03 18:34:36 INFO org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat: DEBUG: Terminated node allocation with : CompletedNodes: 1, size left: 0\r\nException in thread \"main\" java.lang.NoSuchMethodError: ml.dmlc.xgboost4j.scala.spark.XGBoost$.trainWithDataFrame$default$5()Lml/dmlc/xgboost4j/scala/ObjectiveTrait;\r\n\tat ml.dmlc.xgboost4j.scala.example.spark.XGBoostTrainer$.main(XGBoostTrainer.scala:120)\r\n\tat ml.dmlc.xgboost4j.scala.example.spark.XGBoostTrainer.main(XGBoostTrainer.scala)\r\n\tat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\r\n\tat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\r\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\r\n\tat java.lang.reflect.Method.invoke(Method.java:498)\r\n\tat org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)\r\n\tat org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:845)\r\n\tat org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)\r\n\tat org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)\r\n\tat org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)\r\n\tat org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)\r\n\tat org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)\r\n\tat org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)\r\n21/02/03 18:34:39 INFO org.spark_project.jetty.server.AbstractConnector: Stopped Spark@4159e81b{HTTP/1.1,[http/1.1]}{0.0.0.0:0}\r\nJob output is complete\r\n```\r\n\r\nI then realized that the sample is based on the code from the deprecated component path, which was deleted by https://github.com/kubeflow/pipelines/pull/5045.\r\n\r\nSpecifically, the not found method from the above error was used here: \r\nhttps://github.com/kubeflow/pipelines/blob/32ce8d8f90bfc8f89a2a3c347ad906f99ba776a8/components/deprecated/dataproc/train/src/XGBoostTrainer.scala#L121\r\n\r\nAnd `trainWithDataFrame` only [exists in XGBoost 0.72](https://xgboost.readthedocs.io/en/release_0.72/jvm/scaladocs/xgboost4j-spark/index.html#ml.dmlc.xgboost4j.scala.spark.XGBoost$@trainWithDataFrame(trainingData:org.apache.spark.sql.Dataset[_],params:Map[String,Any],round:Int,nWorkers:Int,obj:ml.dmlc.xgboost4j.scala.ObjectiveTrait,eval:ml.dmlc.xgboost4j.scala.EvalTrait,useExternalMemory:Boolean,missing:Float,featureCol:String,labelCol:String):ml.dmlc.xgboost4j.scala.spark.XGBoostModel), but not seen from any versions beyond. \r\n\r\nXGBoost 0.72 is too old and not even available from https://repo1.maven.org/maven2/com/nvidia/, which is [used by rapids to download XGBoost](https://github.com/GoogleCloudDataproc/initialization-actions/blob/8980d37d16ae580ad1d3eba7a40da59da52ff175/rapids/rapids.sh#L90).\r\n\r\nAt this point, I feel like we'd rather invest to rewrite the XGBoost sample using the latest XGBoost library than patching the existing one if we do think it's worth demoing running a XGBoost-on-Dataproc pipeline. \r\nUtil we have the sample working, I propose we remove it from the KFP preloaded pipelines and sample-tests.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2020 The Kubeflow Pipleines authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# This sample demonstrates continuous training using a train-eval-check recursive loop.\n# The main pipeline trains the initial model and then gradually trains the model\n# some more until the model evaluation metrics are good enough.\n\nimport kfp\nfrom kfp import components\n\n\nchicago_taxi_dataset_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/e3337b8bdcd63636934954e592d4b32c95b49129/components/datasets/Chicago%20Taxi/component.yaml')\nxgboost_train_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Train/component.yaml')\nxgboost_predict_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Predict/component.yaml')\n\npandas_transform_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/6162d55998b176b50267d351241100bb0ee715bc/components/pandas/Transform_DataFrame/in_CSV_format/component.yaml')\ndrop_header_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/02c9638287468c849632cf9f7885b51de4c66f86/components/tables/Remove_header/component.yaml')\ncalculate_regression_metrics_from_csv_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/616542ac0f789914f4eb53438da713dd3004fba4/components/ml_metrics/Calculate_regression_metrics/from_CSV/component.yaml')\n\n\n# This recursive sub-pipeline trains a model, evaluates it, calculates the metrics and checks them.\n# If the model error is too high, then more training is performed until the model is good.\[email protected]_component\ndef train_until_low_error(starting_model, training_data, true_values):\n # Training\n model = xgboost_train_on_csv_op(\n training_data=training_data,\n starting_model=starting_model,\n label_column=0,\n objective='reg:squarederror',\n num_iterations=50,\n ).outputs['model']\n\n # Predicting\n predictions = xgboost_predict_on_csv_op(\n data=training_data,\n model=model,\n label_column=0,\n ).output\n\n # Calculating the regression metrics \n metrics_task = calculate_regression_metrics_from_csv_op(\n true_values=true_values,\n predicted_values=predictions,\n )\n\n # Checking the metrics\n with kfp.dsl.Condition(metrics_task.outputs['mean_squared_error'] > 0.01):\n # Training some more\n train_until_low_error(\n starting_model=model,\n training_data=training_data,\n true_values=true_values,\n )\n\n\n# The main pipleine trains the initial model and then gradually trains the model some more until the model evaluation metrics are good enough.\ndef train_until_good_pipeline():\n # Preparing the training data\n training_data = chicago_taxi_dataset_op(\n where='trip_start_timestamp >= \"2019-01-01\" AND trip_start_timestamp < \"2019-02-01\"',\n select='tips,trip_seconds,trip_miles,pickup_community_area,dropoff_community_area,fare,tolls,extras,trip_total',\n limit=10000,\n ).output\n\n # Preparing the true values\n true_values_table = pandas_transform_csv_op(\n table=training_data,\n transform_code='df = df[[\"tips\"]]',\n ).output\n \n true_values = drop_header_op(true_values_table).output\n\n # Initial model training\n first_model = xgboost_train_on_csv_op(\n training_data=training_data,\n label_column=0,\n objective='reg:squarederror',\n num_iterations=100,\n ).outputs['model']\n\n # Recursively training until the error becomes low\n train_until_low_error(\n starting_model=first_model,\n training_data=training_data,\n true_values=true_values,\n )\n\n\nif __name__ == '__main__':\n kfp_endpoint=None\n kfp.Client(host=kfp_endpoint).create_run_from_pipeline_func(train_until_good_pipeline, arguments={})\n", "path": "samples/core/train_until_good/train_until_good.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2020 The Kubeflow Pipleines authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# This sample demonstrates continuous training using a train-eval-check recursive loop.\n# The main pipeline trains the initial model and then gradually trains the model\n# some more until the model evaluation metrics are good enough.\n\nimport kfp\nfrom kfp import components\n\n\nchicago_taxi_dataset_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/e3337b8bdcd63636934954e592d4b32c95b49129/components/datasets/Chicago%20Taxi/component.yaml')\nxgboost_train_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Train/component.yaml')\nxgboost_predict_on_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/567c04c51ff00a1ee525b3458425b17adbe3df61/components/XGBoost/Predict/component.yaml')\n\npandas_transform_csv_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/6162d55998b176b50267d351241100bb0ee715bc/components/pandas/Transform_DataFrame/in_CSV_format/component.yaml')\ndrop_header_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/02c9638287468c849632cf9f7885b51de4c66f86/components/tables/Remove_header/component.yaml')\ncalculate_regression_metrics_from_csv_op = kfp.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/616542ac0f789914f4eb53438da713dd3004fba4/components/ml_metrics/Calculate_regression_metrics/from_CSV/component.yaml')\n\n\n# This recursive sub-pipeline trains a model, evaluates it, calculates the metrics and checks them.\n# If the model error is too high, then more training is performed until the model is good.\[email protected]_component\ndef train_until_low_error(starting_model, training_data, true_values):\n # Training\n model = xgboost_train_on_csv_op(\n training_data=training_data,\n starting_model=starting_model,\n label_column=0,\n objective='reg:squarederror',\n num_iterations=50,\n ).outputs['model']\n\n # Predicting\n predictions = xgboost_predict_on_csv_op(\n data=training_data,\n model=model,\n label_column=0,\n ).output\n\n # Calculating the regression metrics \n metrics_task = calculate_regression_metrics_from_csv_op(\n true_values=true_values,\n predicted_values=predictions,\n )\n\n # Checking the metrics\n with kfp.dsl.Condition(metrics_task.outputs['mean_squared_error'] > 0.01):\n # Training some more\n train_until_low_error(\n starting_model=model,\n training_data=training_data,\n true_values=true_values,\n )\n\n\n# The main pipleine trains the initial model and then gradually trains the model some more until the model evaluation metrics are good enough.\[email protected]()\ndef train_until_good_pipeline():\n # Preparing the training data\n training_data = chicago_taxi_dataset_op(\n where='trip_start_timestamp >= \"2019-01-01\" AND trip_start_timestamp < \"2019-02-01\"',\n select='tips,trip_seconds,trip_miles,pickup_community_area,dropoff_community_area,fare,tolls,extras,trip_total',\n limit=10000,\n ).output\n\n # Preparing the true values\n true_values_table = pandas_transform_csv_op(\n table=training_data,\n transform_code='df = df[[\"tips\"]]',\n ).output\n \n true_values = drop_header_op(true_values_table).output\n\n # Initial model training\n first_model = xgboost_train_on_csv_op(\n training_data=training_data,\n label_column=0,\n objective='reg:squarederror',\n num_iterations=100,\n ).outputs['model']\n\n # Recursively training until the error becomes low\n train_until_low_error(\n starting_model=first_model,\n training_data=training_data,\n true_values=true_values,\n )\n\n\nif __name__ == '__main__':\n kfp_endpoint=None\n kfp.Client(host=kfp_endpoint).create_run_from_pipeline_func(train_until_good_pipeline, arguments={})\n", "path": "samples/core/train_until_good/train_until_good.py"}]}
| 3,762 | 123 |
gh_patches_debug_42504
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-1750
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
readFileStream deadlocks when not read through completely
I think I was aware of this at one point, but using readFileStream without reading all the way to EOF will totally deadlock the worker process on anything but the file jobStore. This is pretty unintuitive (surely this is one of the only use cases for streaming the file?). It may be especially confusing to new users who aren't used to toil deadlocks.
Unfortunately, it's not easy to fix. The writing thread will be blocked on write, so there's no way to wake it up and tell the writing thread to quit. Python threads can't (safely) be killed from their parents. The thread *should* have dropped the GIL while blocked on the write, so we might barely get away with killing its PID. But I'd suggest adjusting the ReadableThread/WritableThread classes to use processes rather than threads. They already use pipes, so very little would need to change. There would be a bit of added overhead from the extra fork(), but surely that's worth getting rid of some of these GIL nightmares.
readFileStream deadlocks when not read through completely
I think I was aware of this at one point, but using readFileStream without reading all the way to EOF will totally deadlock the worker process on anything but the file jobStore. This is pretty unintuitive (surely this is one of the only use cases for streaming the file?). It may be especially confusing to new users who aren't used to toil deadlocks.
Unfortunately, it's not easy to fix. The writing thread will be blocked on write, so there's no way to wake it up and tell the writing thread to quit. Python threads can't (safely) be killed from their parents. The thread *should* have dropped the GIL while blocked on the write, so we might barely get away with killing its PID. But I'd suggest adjusting the ReadableThread/WritableThread classes to use processes rather than threads. They already use pipes, so very little would need to change. There would be a bit of added overhead from the extra fork(), but surely that's worth getting rid of some of these GIL nightmares.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/toil/jobStores/utils.py`
Content:
```
1 import logging
2 import os
3 from abc import ABCMeta
4 from abc import abstractmethod
5
6 from bd2k.util.threading import ExceptionalThread
7
8 log = logging.getLogger(__name__)
9
10 class WritablePipe(object):
11 """
12 An object-oriented wrapper for os.pipe. Clients should subclass it, implement
13 :meth:`.readFrom` to consume the readable end of the pipe, then instantiate the class as a
14 context manager to get the writable end. See the example below.
15
16 >>> import sys, shutil
17 >>> class MyPipe(WritablePipe):
18 ... def readFrom(self, readable):
19 ... shutil.copyfileobj(readable, sys.stdout)
20 >>> with MyPipe() as writable:
21 ... writable.write('Hello, world!\\n')
22 Hello, world!
23
24 Each instance of this class creates a thread and invokes the readFrom method in that thread.
25 The thread will be join()ed upon normal exit from the context manager, i.e. the body of the
26 `with` statement. If an exception occurs, the thread will not be joined but a well-behaved
27 :meth:`.readFrom` implementation will terminate shortly thereafter due to the pipe having
28 been closed.
29
30 Now, exceptions in the reader thread will be reraised in the main thread:
31
32 >>> class MyPipe(WritablePipe):
33 ... def readFrom(self, readable):
34 ... raise RuntimeError('Hello, world!')
35 >>> with MyPipe() as writable:
36 ... pass
37 Traceback (most recent call last):
38 ...
39 RuntimeError: Hello, world!
40
41 More complicated, less illustrative tests:
42
43 Same as above, but provving that handles are closed:
44
45 >>> x = os.dup(0); os.close(x)
46 >>> class MyPipe(WritablePipe):
47 ... def readFrom(self, readable):
48 ... raise RuntimeError('Hello, world!')
49 >>> with MyPipe() as writable:
50 ... pass
51 Traceback (most recent call last):
52 ...
53 RuntimeError: Hello, world!
54 >>> y = os.dup(0); os.close(y); x == y
55 True
56
57 Exceptions in the body of the with statement aren't masked, and handles are closed:
58
59 >>> x = os.dup(0); os.close(x)
60 >>> class MyPipe(WritablePipe):
61 ... def readFrom(self, readable):
62 ... pass
63 >>> with MyPipe() as writable:
64 ... raise RuntimeError('Hello, world!')
65 Traceback (most recent call last):
66 ...
67 RuntimeError: Hello, world!
68 >>> y = os.dup(0); os.close(y); x == y
69 True
70 """
71
72 __metaclass__ = ABCMeta
73
74 @abstractmethod
75 def readFrom(self, readable):
76 """
77 Implement this method to read data from the pipe.
78
79 :param file readable: the file object representing the readable end of the pipe. Do not
80 explicitly invoke the close() method of the object, that will be done automatically.
81 """
82 raise NotImplementedError()
83
84 def _reader(self):
85 with os.fdopen(self.readable_fh, 'r') as readable:
86 # FIXME: another race here, causing a redundant attempt to close in the main thread
87 self.readable_fh = None # signal to parent thread that we've taken over
88 self.readFrom(readable)
89
90 def __init__(self):
91 super(WritablePipe, self).__init__()
92 self.readable_fh = None
93 self.writable = None
94 self.thread = None
95
96 def __enter__(self):
97 self.readable_fh, writable_fh = os.pipe()
98 self.writable = os.fdopen(writable_fh, 'w')
99 self.thread = ExceptionalThread(target=self._reader)
100 self.thread.start()
101 return self.writable
102
103 def __exit__(self, exc_type, exc_val, exc_tb):
104 try:
105 self.writable.close()
106 # Closeing the writable end will send EOF to the readable and cause the reader thread
107 # to finish.
108 if exc_type is None:
109 if self.thread is not None:
110 # reraises any exception that was raised in the thread
111 self.thread.join()
112 finally:
113 # The responsibility for closing the readable end is generally that of the reader
114 # thread. To cover the small window before the reader takes over we also close it here.
115 readable_fh = self.readable_fh
116 if readable_fh is not None:
117 # FIXME: This is still racy. The reader thread could close it now, and someone
118 # else may immediately open a new file, reusing the file handle.
119 os.close(readable_fh)
120
121
122 # FIXME: Unfortunately these two classes are almost an exact mirror image of each other.
123 # Basically, read and write are swapped. The only asymmetry lies in how shutdown is handled. I
124 # tried generalizing but the code becomes inscrutable. Until I (or someone else) has a better
125 # idea how to solve this, I think its better to have code that is readable at the expense of
126 # duplication.
127
128
129 class ReadablePipe(object):
130 """
131 An object-oriented wrapper for os.pipe. Clients should subclass it, implement
132 :meth:`.writeTo` to place data into the writable end of the pipe, then instantiate the class
133 as a context manager to get the writable end. See the example below.
134
135 >>> import sys, shutil
136 >>> class MyPipe(ReadablePipe):
137 ... def writeTo(self, writable):
138 ... writable.write('Hello, world!\\n')
139 >>> with MyPipe() as readable:
140 ... shutil.copyfileobj(readable, sys.stdout)
141 Hello, world!
142
143 Each instance of this class creates a thread and invokes the :meth:`.writeTo` method in that
144 thread. The thread will be join()ed upon normal exit from the context manager, i.e. the body
145 of the `with` statement. If an exception occurs, the thread will not be joined but a
146 well-behaved :meth:`.writeTo` implementation will terminate shortly thereafter due to the
147 pipe having been closed.
148
149 Now, exceptions in the reader thread will be reraised in the main thread:
150
151 >>> class MyPipe(ReadablePipe):
152 ... def writeTo(self, writable):
153 ... raise RuntimeError('Hello, world!')
154 >>> with MyPipe() as readable:
155 ... pass
156 Traceback (most recent call last):
157 ...
158 RuntimeError: Hello, world!
159
160 More complicated, less illustrative tests:
161
162 Same as above, but provving that handles are closed:
163
164 >>> x = os.dup(0); os.close(x)
165 >>> class MyPipe(ReadablePipe):
166 ... def writeTo(self, writable):
167 ... raise RuntimeError('Hello, world!')
168 >>> with MyPipe() as readable:
169 ... pass
170 Traceback (most recent call last):
171 ...
172 RuntimeError: Hello, world!
173 >>> y = os.dup(0); os.close(y); x == y
174 True
175
176 Exceptions in the body of the with statement aren't masked, and handles are closed:
177
178 >>> x = os.dup(0); os.close(x)
179 >>> class MyPipe(ReadablePipe):
180 ... def writeTo(self, writable):
181 ... pass
182 >>> with MyPipe() as readable:
183 ... raise RuntimeError('Hello, world!')
184 Traceback (most recent call last):
185 ...
186 RuntimeError: Hello, world!
187 >>> y = os.dup(0); os.close(y); x == y
188 True
189 """
190
191 __metaclass__ = ABCMeta
192
193 @abstractmethod
194 def writeTo(self, writable):
195 """
196 Implement this method to read data from the pipe.
197
198 :param file writable: the file object representing the writable end of the pipe. Do not
199 explicitly invoke the close() method of the object, that will be done automatically.
200 """
201 raise NotImplementedError()
202
203 def _writer(self):
204 with os.fdopen(self.writable_fh, 'w') as writable:
205 # FIXME: another race here, causing a redundant attempt to close in the main thread
206 self.writable_fh = None # signal to parent thread that we've taken over
207 self.writeTo(writable)
208
209 def __init__(self):
210 super(ReadablePipe, self).__init__()
211 self.writable_fh = None
212 self.readable = None
213 self.thread = None
214
215 def __enter__(self):
216 readable_fh, self.writable_fh = os.pipe()
217 self.readable = os.fdopen(readable_fh, 'r')
218 self.thread = ExceptionalThread(target=self._writer)
219 self.thread.start()
220 return self.readable
221
222 def __exit__(self, exc_type, exc_val, exc_tb):
223 try:
224 if exc_type is None:
225 if self.thread is not None:
226 # reraises any exception that was raised in the thread
227 self.thread.join()
228 finally:
229 self.readable.close()
230 # The responsibility for closing the writable end is generally that of the writer
231 # thread. To cover the small window before the writer takes over we also close it here.
232 writable_fh = self.writable_fh
233 if writable_fh is not None:
234 # FIXME: This is still racy. The writer thread could close it now, and someone
235 # else may immediately open a new file, reusing the file handle.
236 os.close(writable_fh)
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/toil/jobStores/utils.py b/src/toil/jobStores/utils.py
--- a/src/toil/jobStores/utils.py
+++ b/src/toil/jobStores/utils.py
@@ -1,5 +1,6 @@
import logging
import os
+import errno
from abc import ABCMeta
from abc import abstractmethod
@@ -105,10 +106,14 @@
self.writable.close()
# Closeing the writable end will send EOF to the readable and cause the reader thread
# to finish.
+ if self.thread is not None:
+ # reraises any exception that was raised in the thread
+ self.thread.join()
+ except:
if exc_type is None:
- if self.thread is not None:
- # reraises any exception that was raised in the thread
- self.thread.join()
+ # Only raise the child exception if there wasn't
+ # already an exception in the main thread
+ raise
finally:
# The responsibility for closing the readable end is generally that of the reader
# thread. To cover the small window before the reader takes over we also close it here.
@@ -119,13 +124,6 @@
os.close(readable_fh)
-# FIXME: Unfortunately these two classes are almost an exact mirror image of each other.
-# Basically, read and write are swapped. The only asymmetry lies in how shutdown is handled. I
-# tried generalizing but the code becomes inscrutable. Until I (or someone else) has a better
-# idea how to solve this, I think its better to have code that is readable at the expense of
-# duplication.
-
-
class ReadablePipe(object):
"""
An object-oriented wrapper for os.pipe. Clients should subclass it, implement
@@ -201,10 +199,14 @@
raise NotImplementedError()
def _writer(self):
- with os.fdopen(self.writable_fh, 'w') as writable:
- # FIXME: another race here, causing a redundant attempt to close in the main thread
- self.writable_fh = None # signal to parent thread that we've taken over
- self.writeTo(writable)
+ try:
+ with os.fdopen(self.writable_fh, 'w') as writable:
+ self.writeTo(writable)
+ except IOError as e:
+ # The other side of the pipe may have been closed by the
+ # reading thread, which is OK.
+ if e.errno != errno.EPIPE:
+ raise
def __init__(self):
super(ReadablePipe, self).__init__()
@@ -220,17 +222,16 @@
return self.readable
def __exit__(self, exc_type, exc_val, exc_tb):
+ # Close the read end of the pipe. The writing thread may
+ # still be writing to the other end, but this will wake it up
+ # if that's the case.
+ self.readable.close()
try:
+ if self.thread is not None:
+ # reraises any exception that was raised in the thread
+ self.thread.join()
+ except:
if exc_type is None:
- if self.thread is not None:
- # reraises any exception that was raised in the thread
- self.thread.join()
- finally:
- self.readable.close()
- # The responsibility for closing the writable end is generally that of the writer
- # thread. To cover the small window before the writer takes over we also close it here.
- writable_fh = self.writable_fh
- if writable_fh is not None:
- # FIXME: This is still racy. The writer thread could close it now, and someone
- # else may immediately open a new file, reusing the file handle.
- os.close(writable_fh)
+ # Only raise the child exception if there wasn't
+ # already an exception in the main thread
+ raise
|
{"golden_diff": "diff --git a/src/toil/jobStores/utils.py b/src/toil/jobStores/utils.py\n--- a/src/toil/jobStores/utils.py\n+++ b/src/toil/jobStores/utils.py\n@@ -1,5 +1,6 @@\n import logging\n import os\n+import errno\n from abc import ABCMeta\n from abc import abstractmethod\n \n@@ -105,10 +106,14 @@\n self.writable.close()\n # Closeing the writable end will send EOF to the readable and cause the reader thread\n # to finish.\n+ if self.thread is not None:\n+ # reraises any exception that was raised in the thread\n+ self.thread.join()\n+ except:\n if exc_type is None:\n- if self.thread is not None:\n- # reraises any exception that was raised in the thread\n- self.thread.join()\n+ # Only raise the child exception if there wasn't\n+ # already an exception in the main thread\n+ raise\n finally:\n # The responsibility for closing the readable end is generally that of the reader\n # thread. To cover the small window before the reader takes over we also close it here.\n@@ -119,13 +124,6 @@\n os.close(readable_fh)\n \n \n-# FIXME: Unfortunately these two classes are almost an exact mirror image of each other.\n-# Basically, read and write are swapped. The only asymmetry lies in how shutdown is handled. I\n-# tried generalizing but the code becomes inscrutable. Until I (or someone else) has a better\n-# idea how to solve this, I think its better to have code that is readable at the expense of\n-# duplication.\n-\n-\n class ReadablePipe(object):\n \"\"\"\n An object-oriented wrapper for os.pipe. Clients should subclass it, implement\n@@ -201,10 +199,14 @@\n raise NotImplementedError()\n \n def _writer(self):\n- with os.fdopen(self.writable_fh, 'w') as writable:\n- # FIXME: another race here, causing a redundant attempt to close in the main thread\n- self.writable_fh = None # signal to parent thread that we've taken over\n- self.writeTo(writable)\n+ try:\n+ with os.fdopen(self.writable_fh, 'w') as writable:\n+ self.writeTo(writable)\n+ except IOError as e:\n+ # The other side of the pipe may have been closed by the\n+ # reading thread, which is OK.\n+ if e.errno != errno.EPIPE:\n+ raise\n \n def __init__(self):\n super(ReadablePipe, self).__init__()\n@@ -220,17 +222,16 @@\n return self.readable\n \n def __exit__(self, exc_type, exc_val, exc_tb):\n+ # Close the read end of the pipe. The writing thread may\n+ # still be writing to the other end, but this will wake it up\n+ # if that's the case.\n+ self.readable.close()\n try:\n+ if self.thread is not None:\n+ # reraises any exception that was raised in the thread\n+ self.thread.join()\n+ except:\n if exc_type is None:\n- if self.thread is not None:\n- # reraises any exception that was raised in the thread\n- self.thread.join()\n- finally:\n- self.readable.close()\n- # The responsibility for closing the writable end is generally that of the writer\n- # thread. To cover the small window before the writer takes over we also close it here.\n- writable_fh = self.writable_fh\n- if writable_fh is not None:\n- # FIXME: This is still racy. The writer thread could close it now, and someone\n- # else may immediately open a new file, reusing the file handle.\n- os.close(writable_fh)\n+ # Only raise the child exception if there wasn't\n+ # already an exception in the main thread\n+ raise\n", "issue": "readFileStream deadlocks when not read through completely\nI think I was aware of this at one point, but using readFileStream without reading all the way to EOF will totally deadlock the worker process on anything but the file jobStore. This is pretty unintuitive (surely this is one of the only use cases for streaming the file?). It may be especially confusing to new users who aren't used to toil deadlocks.\r\n\r\nUnfortunately, it's not easy to fix. The writing thread will be blocked on write, so there's no way to wake it up and tell the writing thread to quit. Python threads can't (safely) be killed from their parents. The thread *should* have dropped the GIL while blocked on the write, so we might barely get away with killing its PID. But I'd suggest adjusting the ReadableThread/WritableThread classes to use processes rather than threads. They already use pipes, so very little would need to change. There would be a bit of added overhead from the extra fork(), but surely that's worth getting rid of some of these GIL nightmares.\nreadFileStream deadlocks when not read through completely\nI think I was aware of this at one point, but using readFileStream without reading all the way to EOF will totally deadlock the worker process on anything but the file jobStore. This is pretty unintuitive (surely this is one of the only use cases for streaming the file?). It may be especially confusing to new users who aren't used to toil deadlocks.\r\n\r\nUnfortunately, it's not easy to fix. The writing thread will be blocked on write, so there's no way to wake it up and tell the writing thread to quit. Python threads can't (safely) be killed from their parents. The thread *should* have dropped the GIL while blocked on the write, so we might barely get away with killing its PID. But I'd suggest adjusting the ReadableThread/WritableThread classes to use processes rather than threads. They already use pipes, so very little would need to change. There would be a bit of added overhead from the extra fork(), but surely that's worth getting rid of some of these GIL nightmares.\n", "before_files": [{"content": "import logging\nimport os\nfrom abc import ABCMeta\nfrom abc import abstractmethod\n\nfrom bd2k.util.threading import ExceptionalThread\n\nlog = logging.getLogger(__name__)\n\nclass WritablePipe(object):\n \"\"\"\n An object-oriented wrapper for os.pipe. Clients should subclass it, implement\n :meth:`.readFrom` to consume the readable end of the pipe, then instantiate the class as a\n context manager to get the writable end. See the example below.\n\n >>> import sys, shutil\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... shutil.copyfileobj(readable, sys.stdout)\n >>> with MyPipe() as writable:\n ... writable.write('Hello, world!\\\\n')\n Hello, world!\n\n Each instance of this class creates a thread and invokes the readFrom method in that thread.\n The thread will be join()ed upon normal exit from the context manager, i.e. the body of the\n `with` statement. If an exception occurs, the thread will not be joined but a well-behaved\n :meth:`.readFrom` implementation will terminate shortly thereafter due to the pipe having\n been closed.\n\n Now, exceptions in the reader thread will be reraised in the main thread:\n\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as writable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n\n More complicated, less illustrative tests:\n\n Same as above, but provving that handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as writable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n\n Exceptions in the body of the with statement aren't masked, and handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... pass\n >>> with MyPipe() as writable:\n ... raise RuntimeError('Hello, world!')\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n \"\"\"\n\n __metaclass__ = ABCMeta\n\n @abstractmethod\n def readFrom(self, readable):\n \"\"\"\n Implement this method to read data from the pipe.\n\n :param file readable: the file object representing the readable end of the pipe. Do not\n explicitly invoke the close() method of the object, that will be done automatically.\n \"\"\"\n raise NotImplementedError()\n\n def _reader(self):\n with os.fdopen(self.readable_fh, 'r') as readable:\n # FIXME: another race here, causing a redundant attempt to close in the main thread\n self.readable_fh = None # signal to parent thread that we've taken over\n self.readFrom(readable)\n\n def __init__(self):\n super(WritablePipe, self).__init__()\n self.readable_fh = None\n self.writable = None\n self.thread = None\n\n def __enter__(self):\n self.readable_fh, writable_fh = os.pipe()\n self.writable = os.fdopen(writable_fh, 'w')\n self.thread = ExceptionalThread(target=self._reader)\n self.thread.start()\n return self.writable\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n try:\n self.writable.close()\n # Closeing the writable end will send EOF to the readable and cause the reader thread\n # to finish.\n if exc_type is None:\n if self.thread is not None:\n # reraises any exception that was raised in the thread\n self.thread.join()\n finally:\n # The responsibility for closing the readable end is generally that of the reader\n # thread. To cover the small window before the reader takes over we also close it here.\n readable_fh = self.readable_fh\n if readable_fh is not None:\n # FIXME: This is still racy. The reader thread could close it now, and someone\n # else may immediately open a new file, reusing the file handle.\n os.close(readable_fh)\n\n\n# FIXME: Unfortunately these two classes are almost an exact mirror image of each other.\n# Basically, read and write are swapped. The only asymmetry lies in how shutdown is handled. I\n# tried generalizing but the code becomes inscrutable. Until I (or someone else) has a better\n# idea how to solve this, I think its better to have code that is readable at the expense of\n# duplication.\n\n\nclass ReadablePipe(object):\n \"\"\"\n An object-oriented wrapper for os.pipe. Clients should subclass it, implement\n :meth:`.writeTo` to place data into the writable end of the pipe, then instantiate the class\n as a context manager to get the writable end. See the example below.\n\n >>> import sys, shutil\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... writable.write('Hello, world!\\\\n')\n >>> with MyPipe() as readable:\n ... shutil.copyfileobj(readable, sys.stdout)\n Hello, world!\n\n Each instance of this class creates a thread and invokes the :meth:`.writeTo` method in that\n thread. The thread will be join()ed upon normal exit from the context manager, i.e. the body\n of the `with` statement. If an exception occurs, the thread will not be joined but a\n well-behaved :meth:`.writeTo` implementation will terminate shortly thereafter due to the\n pipe having been closed.\n\n Now, exceptions in the reader thread will be reraised in the main thread:\n\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as readable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n\n More complicated, less illustrative tests:\n\n Same as above, but provving that handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as readable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n\n Exceptions in the body of the with statement aren't masked, and handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... pass\n >>> with MyPipe() as readable:\n ... raise RuntimeError('Hello, world!')\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n \"\"\"\n\n __metaclass__ = ABCMeta\n\n @abstractmethod\n def writeTo(self, writable):\n \"\"\"\n Implement this method to read data from the pipe.\n\n :param file writable: the file object representing the writable end of the pipe. Do not\n explicitly invoke the close() method of the object, that will be done automatically.\n \"\"\"\n raise NotImplementedError()\n\n def _writer(self):\n with os.fdopen(self.writable_fh, 'w') as writable:\n # FIXME: another race here, causing a redundant attempt to close in the main thread\n self.writable_fh = None # signal to parent thread that we've taken over\n self.writeTo(writable)\n\n def __init__(self):\n super(ReadablePipe, self).__init__()\n self.writable_fh = None\n self.readable = None\n self.thread = None\n\n def __enter__(self):\n readable_fh, self.writable_fh = os.pipe()\n self.readable = os.fdopen(readable_fh, 'r')\n self.thread = ExceptionalThread(target=self._writer)\n self.thread.start()\n return self.readable\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n try:\n if exc_type is None:\n if self.thread is not None:\n # reraises any exception that was raised in the thread\n self.thread.join()\n finally:\n self.readable.close()\n # The responsibility for closing the writable end is generally that of the writer\n # thread. To cover the small window before the writer takes over we also close it here.\n writable_fh = self.writable_fh\n if writable_fh is not None:\n # FIXME: This is still racy. The writer thread could close it now, and someone\n # else may immediately open a new file, reusing the file handle.\n os.close(writable_fh)\n", "path": "src/toil/jobStores/utils.py"}], "after_files": [{"content": "import logging\nimport os\nimport errno\nfrom abc import ABCMeta\nfrom abc import abstractmethod\n\nfrom bd2k.util.threading import ExceptionalThread\n\nlog = logging.getLogger(__name__)\n\nclass WritablePipe(object):\n \"\"\"\n An object-oriented wrapper for os.pipe. Clients should subclass it, implement\n :meth:`.readFrom` to consume the readable end of the pipe, then instantiate the class as a\n context manager to get the writable end. See the example below.\n\n >>> import sys, shutil\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... shutil.copyfileobj(readable, sys.stdout)\n >>> with MyPipe() as writable:\n ... writable.write('Hello, world!\\\\n')\n Hello, world!\n\n Each instance of this class creates a thread and invokes the readFrom method in that thread.\n The thread will be join()ed upon normal exit from the context manager, i.e. the body of the\n `with` statement. If an exception occurs, the thread will not be joined but a well-behaved\n :meth:`.readFrom` implementation will terminate shortly thereafter due to the pipe having\n been closed.\n\n Now, exceptions in the reader thread will be reraised in the main thread:\n\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as writable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n\n More complicated, less illustrative tests:\n\n Same as above, but provving that handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as writable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n\n Exceptions in the body of the with statement aren't masked, and handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(WritablePipe):\n ... def readFrom(self, readable):\n ... pass\n >>> with MyPipe() as writable:\n ... raise RuntimeError('Hello, world!')\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n \"\"\"\n\n __metaclass__ = ABCMeta\n\n @abstractmethod\n def readFrom(self, readable):\n \"\"\"\n Implement this method to read data from the pipe.\n\n :param file readable: the file object representing the readable end of the pipe. Do not\n explicitly invoke the close() method of the object, that will be done automatically.\n \"\"\"\n raise NotImplementedError()\n\n def _reader(self):\n with os.fdopen(self.readable_fh, 'r') as readable:\n # FIXME: another race here, causing a redundant attempt to close in the main thread\n self.readable_fh = None # signal to parent thread that we've taken over\n self.readFrom(readable)\n\n def __init__(self):\n super(WritablePipe, self).__init__()\n self.readable_fh = None\n self.writable = None\n self.thread = None\n\n def __enter__(self):\n self.readable_fh, writable_fh = os.pipe()\n self.writable = os.fdopen(writable_fh, 'w')\n self.thread = ExceptionalThread(target=self._reader)\n self.thread.start()\n return self.writable\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n try:\n self.writable.close()\n # Closeing the writable end will send EOF to the readable and cause the reader thread\n # to finish.\n if self.thread is not None:\n # reraises any exception that was raised in the thread\n self.thread.join()\n except:\n if exc_type is None:\n # Only raise the child exception if there wasn't\n # already an exception in the main thread\n raise\n finally:\n # The responsibility for closing the readable end is generally that of the reader\n # thread. To cover the small window before the reader takes over we also close it here.\n readable_fh = self.readable_fh\n if readable_fh is not None:\n # FIXME: This is still racy. The reader thread could close it now, and someone\n # else may immediately open a new file, reusing the file handle.\n os.close(readable_fh)\n\n\nclass ReadablePipe(object):\n \"\"\"\n An object-oriented wrapper for os.pipe. Clients should subclass it, implement\n :meth:`.writeTo` to place data into the writable end of the pipe, then instantiate the class\n as a context manager to get the writable end. See the example below.\n\n >>> import sys, shutil\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... writable.write('Hello, world!\\\\n')\n >>> with MyPipe() as readable:\n ... shutil.copyfileobj(readable, sys.stdout)\n Hello, world!\n\n Each instance of this class creates a thread and invokes the :meth:`.writeTo` method in that\n thread. The thread will be join()ed upon normal exit from the context manager, i.e. the body\n of the `with` statement. If an exception occurs, the thread will not be joined but a\n well-behaved :meth:`.writeTo` implementation will terminate shortly thereafter due to the\n pipe having been closed.\n\n Now, exceptions in the reader thread will be reraised in the main thread:\n\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as readable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n\n More complicated, less illustrative tests:\n\n Same as above, but provving that handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... raise RuntimeError('Hello, world!')\n >>> with MyPipe() as readable:\n ... pass\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n\n Exceptions in the body of the with statement aren't masked, and handles are closed:\n\n >>> x = os.dup(0); os.close(x)\n >>> class MyPipe(ReadablePipe):\n ... def writeTo(self, writable):\n ... pass\n >>> with MyPipe() as readable:\n ... raise RuntimeError('Hello, world!')\n Traceback (most recent call last):\n ...\n RuntimeError: Hello, world!\n >>> y = os.dup(0); os.close(y); x == y\n True\n \"\"\"\n\n __metaclass__ = ABCMeta\n\n @abstractmethod\n def writeTo(self, writable):\n \"\"\"\n Implement this method to read data from the pipe.\n\n :param file writable: the file object representing the writable end of the pipe. Do not\n explicitly invoke the close() method of the object, that will be done automatically.\n \"\"\"\n raise NotImplementedError()\n\n def _writer(self):\n try:\n with os.fdopen(self.writable_fh, 'w') as writable:\n self.writeTo(writable)\n except IOError as e:\n # The other side of the pipe may have been closed by the\n # reading thread, which is OK.\n if e.errno != errno.EPIPE:\n raise\n\n def __init__(self):\n super(ReadablePipe, self).__init__()\n self.writable_fh = None\n self.readable = None\n self.thread = None\n\n def __enter__(self):\n readable_fh, self.writable_fh = os.pipe()\n self.readable = os.fdopen(readable_fh, 'r')\n self.thread = ExceptionalThread(target=self._writer)\n self.thread.start()\n return self.readable\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n # Close the read end of the pipe. The writing thread may\n # still be writing to the other end, but this will wake it up\n # if that's the case.\n self.readable.close()\n try:\n if self.thread is not None:\n # reraises any exception that was raised in the thread\n self.thread.join()\n except:\n if exc_type is None:\n # Only raise the child exception if there wasn't\n # already an exception in the main thread\n raise\n", "path": "src/toil/jobStores/utils.py"}]}
| 3,350 | 888 |
gh_patches_debug_14345
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-5765
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix reference to tuplematch in base reporters
The tuplematch object was not referenced in the ReporterBase class when referenced from the GitHubStatusPush class.
It seems this is not an issue when it is executed from the test but only occures when called from GitHubStatusPush. I don't know how I can test this.
Fixes #5765
## Contributor Checklist:
* [ ] I have updated the unit tests
* [x] I have created a file in the `master/buildbot/newsfragments` directory (and read the `README.txt` in that directory)
* [x] I have updated the appropriate documentation
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/reporters/base.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 import abc
17
18 from twisted.internet import defer
19 from twisted.python import log
20
21 from buildbot import config
22 from buildbot import util
23 from buildbot.reporters import utils
24 from buildbot.util import service
25
26 ENCODING = 'utf-8'
27
28
29 class ReporterBase(service.BuildbotService):
30 name = None
31 __meta__ = abc.ABCMeta
32
33 compare_attrs = ['generators']
34
35 def __init__(self, *args, **kwargs):
36 super().__init__(*args, **kwargs)
37 self.generators = None
38 self._event_consumers = []
39
40 def checkConfig(self, generators):
41 if not isinstance(generators, list):
42 config.error('{}: generators argument must be a list')
43
44 for g in generators:
45 g.check()
46
47 if self.name is None:
48 self.name = self.__class__.__name__
49 for g in generators:
50 self.name += "_" + g.generate_name()
51
52 @defer.inlineCallbacks
53 def reconfigService(self, generators):
54
55 for consumer in self._event_consumers:
56 yield consumer.stopConsuming()
57 self._event_consumers = []
58
59 self.generators = generators
60
61 wanted_event_keys = set()
62 for g in self.generators:
63 wanted_event_keys.update(g.wanted_event_keys)
64
65 for key in sorted(list(wanted_event_keys)):
66 consumer = yield self.master.mq.startConsuming(self._got_event, key)
67 self._event_consumers.append(consumer)
68
69 @defer.inlineCallbacks
70 def stopService(self):
71 for consumer in self._event_consumers:
72 yield consumer.stopConsuming()
73 self._event_consumers = []
74 yield super().stopService()
75
76 def _does_generator_want_key(self, generator, key):
77 for filter in generator.wanted_event_keys:
78 if util.tuplematch.matchTuple(key, filter):
79 return True
80 return False
81
82 @defer.inlineCallbacks
83 def _got_event(self, key, msg):
84 try:
85 reports = []
86 for g in self.generators:
87 if self._does_generator_want_key(g, key):
88 report = yield g.generate(self.master, self, key, msg)
89 if report is not None:
90 reports.append(report)
91
92 if reports:
93 yield self.sendMessage(reports)
94 except Exception as e:
95 log.err(e, 'Got exception when handling reporter events')
96
97 def getResponsibleUsersForBuild(self, master, buildid):
98 # Use library method but subclassers may want to override that
99 return utils.getResponsibleUsersForBuild(master, buildid)
100
101 @abc.abstractmethod
102 def sendMessage(self, reports):
103 pass
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/reporters/base.py b/master/buildbot/reporters/base.py
--- a/master/buildbot/reporters/base.py
+++ b/master/buildbot/reporters/base.py
@@ -19,9 +19,9 @@
from twisted.python import log
from buildbot import config
-from buildbot import util
from buildbot.reporters import utils
from buildbot.util import service
+from buildbot.util import tuplematch
ENCODING = 'utf-8'
@@ -75,7 +75,7 @@
def _does_generator_want_key(self, generator, key):
for filter in generator.wanted_event_keys:
- if util.tuplematch.matchTuple(key, filter):
+ if tuplematch.matchTuple(key, filter):
return True
return False
|
{"golden_diff": "diff --git a/master/buildbot/reporters/base.py b/master/buildbot/reporters/base.py\n--- a/master/buildbot/reporters/base.py\n+++ b/master/buildbot/reporters/base.py\n@@ -19,9 +19,9 @@\n from twisted.python import log\n \n from buildbot import config\n-from buildbot import util\n from buildbot.reporters import utils\n from buildbot.util import service\n+from buildbot.util import tuplematch\n \n ENCODING = 'utf-8'\n \n@@ -75,7 +75,7 @@\n \n def _does_generator_want_key(self, generator, key):\n for filter in generator.wanted_event_keys:\n- if util.tuplematch.matchTuple(key, filter):\n+ if tuplematch.matchTuple(key, filter):\n return True\n return False\n", "issue": "Fix reference to tuplematch in base reporters\nThe tuplematch object was not referenced in the ReporterBase class when referenced from the GitHubStatusPush class.\r\n\r\nIt seems this is not an issue when it is executed from the test but only occures when called from GitHubStatusPush. I don't know how I can test this.\r\n\r\nFixes #5765 \r\n\r\n\r\n## Contributor Checklist:\r\n\r\n* [ ] I have updated the unit tests\r\n* [x] I have created a file in the `master/buildbot/newsfragments` directory (and read the `README.txt` in that directory)\r\n* [x] I have updated the appropriate documentation\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport abc\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot import config\nfrom buildbot import util\nfrom buildbot.reporters import utils\nfrom buildbot.util import service\n\nENCODING = 'utf-8'\n\n\nclass ReporterBase(service.BuildbotService):\n name = None\n __meta__ = abc.ABCMeta\n\n compare_attrs = ['generators']\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.generators = None\n self._event_consumers = []\n\n def checkConfig(self, generators):\n if not isinstance(generators, list):\n config.error('{}: generators argument must be a list')\n\n for g in generators:\n g.check()\n\n if self.name is None:\n self.name = self.__class__.__name__\n for g in generators:\n self.name += \"_\" + g.generate_name()\n\n @defer.inlineCallbacks\n def reconfigService(self, generators):\n\n for consumer in self._event_consumers:\n yield consumer.stopConsuming()\n self._event_consumers = []\n\n self.generators = generators\n\n wanted_event_keys = set()\n for g in self.generators:\n wanted_event_keys.update(g.wanted_event_keys)\n\n for key in sorted(list(wanted_event_keys)):\n consumer = yield self.master.mq.startConsuming(self._got_event, key)\n self._event_consumers.append(consumer)\n\n @defer.inlineCallbacks\n def stopService(self):\n for consumer in self._event_consumers:\n yield consumer.stopConsuming()\n self._event_consumers = []\n yield super().stopService()\n\n def _does_generator_want_key(self, generator, key):\n for filter in generator.wanted_event_keys:\n if util.tuplematch.matchTuple(key, filter):\n return True\n return False\n\n @defer.inlineCallbacks\n def _got_event(self, key, msg):\n try:\n reports = []\n for g in self.generators:\n if self._does_generator_want_key(g, key):\n report = yield g.generate(self.master, self, key, msg)\n if report is not None:\n reports.append(report)\n\n if reports:\n yield self.sendMessage(reports)\n except Exception as e:\n log.err(e, 'Got exception when handling reporter events')\n\n def getResponsibleUsersForBuild(self, master, buildid):\n # Use library method but subclassers may want to override that\n return utils.getResponsibleUsersForBuild(master, buildid)\n\n @abc.abstractmethod\n def sendMessage(self, reports):\n pass\n", "path": "master/buildbot/reporters/base.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport abc\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot import config\nfrom buildbot.reporters import utils\nfrom buildbot.util import service\nfrom buildbot.util import tuplematch\n\nENCODING = 'utf-8'\n\n\nclass ReporterBase(service.BuildbotService):\n name = None\n __meta__ = abc.ABCMeta\n\n compare_attrs = ['generators']\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.generators = None\n self._event_consumers = []\n\n def checkConfig(self, generators):\n if not isinstance(generators, list):\n config.error('{}: generators argument must be a list')\n\n for g in generators:\n g.check()\n\n if self.name is None:\n self.name = self.__class__.__name__\n for g in generators:\n self.name += \"_\" + g.generate_name()\n\n @defer.inlineCallbacks\n def reconfigService(self, generators):\n\n for consumer in self._event_consumers:\n yield consumer.stopConsuming()\n self._event_consumers = []\n\n self.generators = generators\n\n wanted_event_keys = set()\n for g in self.generators:\n wanted_event_keys.update(g.wanted_event_keys)\n\n for key in sorted(list(wanted_event_keys)):\n consumer = yield self.master.mq.startConsuming(self._got_event, key)\n self._event_consumers.append(consumer)\n\n @defer.inlineCallbacks\n def stopService(self):\n for consumer in self._event_consumers:\n yield consumer.stopConsuming()\n self._event_consumers = []\n yield super().stopService()\n\n def _does_generator_want_key(self, generator, key):\n for filter in generator.wanted_event_keys:\n if tuplematch.matchTuple(key, filter):\n return True\n return False\n\n @defer.inlineCallbacks\n def _got_event(self, key, msg):\n try:\n reports = []\n for g in self.generators:\n if self._does_generator_want_key(g, key):\n report = yield g.generate(self.master, self, key, msg)\n if report is not None:\n reports.append(report)\n\n if reports:\n yield self.sendMessage(reports)\n except Exception as e:\n log.err(e, 'Got exception when handling reporter events')\n\n def getResponsibleUsersForBuild(self, master, buildid):\n # Use library method but subclassers may want to override that\n return utils.getResponsibleUsersForBuild(master, buildid)\n\n @abc.abstractmethod\n def sendMessage(self, reports):\n pass\n", "path": "master/buildbot/reporters/base.py"}]}
| 1,344 | 176 |
gh_patches_debug_14268
|
rasdani/github-patches
|
git_diff
|
voxel51__fiftyone-1838
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] loading segmentation torch models errror, has no attribute 'load_state_dict_from_url'
### System information
- **OS Platform and Distribution**: `Ubuntu 20.04`
- **FiftyOne installed from (pip or source)**: `pip`, from within `conda` environment
- **FiftyOne version (run `fiftyone --version`)**: `FiftyOne v0.16.0, Voxel51, Inc.`
- **Python version**: `Python 3.9.7`
- **Torch version**: `1.11.0`
- **Torchvision version**: `0.12.0`
### Code to reproduce
```
import fiftyone.zoo as foz
model = foz.load_zoo_model("deeplabv3-resnet101-coco-torch")
```
### Describe the problem
The model fails to load (was taken from the [semantic segmentation evaluation doc](https://voxel51.com/docs/fiftyone/user_guide/evaluation.html#semantic-segmentations). Ultimately the error is `AttributeError: module 'torchvision.models.segmentation.deeplabv3' has no attribute 'load_state_dict_from_url'`. This applies to all the PyTorch segmentation models listed [here](https://voxel51.com/docs/fiftyone/user_guide/model_zoo/models.html).
### Other info / logs
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [2], in <cell line: 3>()
1 import fiftyone.zoo as foz
----> 3 model = foz.load_zoo_model("deeplabv3-resnet101-coco-torch")
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/__init__.py:207, in load_zoo_model(name, download_if_necessary, install_requirements, error_level, **kwargs)
204 config_dict = deepcopy(model.default_deployment_config_dict)
205 model_path = model.get_path_in_dir(models_dir)
--> 207 return fom.load_model(config_dict, model_path=model_path, **kwargs)
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/core/models.py:1505, in load_model(model_config_dict, model_path, **kwargs)
1499 raise ValueError(
1500 "Model config must implement the %s interface"
1501 % etal.HasPublishedModel
1502 )
1504 # Build model
-> 1505 return config.build()
File ~/miniconda3/lib/python3.9/site-packages/eta/core/learning.py:296, in ModelConfig.build(self)
289 def build(self):
290 """Factory method that builds the Model instance from the config
291 specified by this class.
292
293 Returns:
294 a Model instance
295 """
--> 296 return self._model_cls(self.config)
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/utils/torch.py:230, in TorchImageModel.__init__(self, config)
226 self._device = torch.device("cuda:0" if self._using_gpu else "cpu")
227 self._using_half_precision = (
228 self.config.use_half_precision is True
229 ) and self._using_gpu
--> 230 self._model = self._load_model(config)
231 self._no_grad = None
232 self._benchmark_orig = None
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/utils/torch.py:471, in TorchImageModel._load_model(self, config)
468 def _load_model(self, config):
469 self._download_model(config)
--> 471 model = self._load_network(config)
473 model = model.to(self._device)
474 if self._using_half_precision:
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/torch.py:97, in TorchvisionImageModel._load_network(self, config)
94 kwargs = config.entrypoint_args or {}
95 model_dir = fo.config.model_zoo_dir
---> 97 monkey_patcher = _make_load_state_dict_from_url_monkey_patcher(
98 entrypoint, model_dir
99 )
100 with monkey_patcher:
101 # Builds net and loads state dict from `model_dir`
102 model = entrypoint(**kwargs)
File ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/torch.py:114, in _make_load_state_dict_from_url_monkey_patcher(entrypoint, model_dir)
108 """Monkey patches all instances of ``load_state_dict_from_url()`` that are
109 reachable from the given ``entrypoint`` function in the
110 :mod:`torchvision:torchvision.models` namespace so that models will be
111 loaded from ``model_dir`` and not from the Torch Hub cache directory.
112 """
113 entrypoint_module = inspect.getmodule(entrypoint)
--> 114 load_state_dict_from_url = entrypoint_module.load_state_dict_from_url
116 def custom_load_state_dict_from_url(url, **kwargs):
117 return load_state_dict_from_url(url, model_dir=model_dir, **kwargs)
AttributeError: module 'torchvision.models.segmentation.deeplabv3' has no attribute 'load_state_dict_from_url'
```
### What areas of FiftyOne does this bug affect?
- [ ] `App`: FiftyOne application issue
- [x] `Core`: Core `fiftyone` Python library issue
- [ ] `Server`: Fiftyone server issue
### Willingness to contribute
The FiftyOne Community encourages bug fix contributions. Would you or another
member of your organization be willing to contribute a fix for this bug to the
FiftyOne codebase?
- [ ] Yes. I can contribute a fix for this bug independently.
- [x] Yes. I would be willing to contribute a fix for this bug with guidance
from the FiftyOne community.
- [ ] No. I cannot contribute a bug fix at this time.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fiftyone/zoo/models/torch.py`
Content:
```
1 """
2 FiftyOne Zoo models provided by :mod:`torchvision:torchvision.models`.
3
4 | Copyright 2017-2022, Voxel51, Inc.
5 | `voxel51.com <https://voxel51.com/>`_
6 |
7 """
8 import inspect
9
10 import eta.core.utils as etau
11
12 import fiftyone as fo
13 import fiftyone.core.utils as fou
14 import fiftyone.utils.torch as fout
15 import fiftyone.zoo.models as fozm
16
17 fou.ensure_torch()
18 import torchvision
19
20
21 class TorchvisionImageModelConfig(
22 fout.TorchImageModelConfig, fozm.HasZooModel
23 ):
24 """Configuration for running a :class:`TorchvisionImageModel`.
25
26 Args:
27 entrypoint_fcn: a fully-qualified function string like
28 ``"torchvision.models.inception_v3"`` specifying the entrypoint
29 function that loads the model
30 entrypoint_args (None): a dictionary of arguments for
31 ``entrypoint_fcn``
32 output_processor_cls: a string like
33 ``"fifytone.utils.torch.ClassifierOutputProcessor"`` specifying the
34 :class:`fifytone.utils.torch.OutputProcessor` to use
35 output_processor_args (None): a dictionary of arguments for
36 ``output_processor_cls(classes=classes, **kwargs)``
37 confidence_thresh (None): an optional confidence threshold apply to any
38 applicable predictions generated by the model
39 labels_string (None): a comma-separated list of the class names for the
40 model, if applicable
41 labels_path (None): the path to the labels map for the model, if
42 applicable
43 mask_targets (None): a mask targets dict for the model, if applicable
44 mask_targets_path (None): the path to a mask targets map for the model,
45 if applicable
46 skeleton (None): a keypoint skeleton dict for the model, if applicable
47 image_min_size (None): resize the input images during preprocessing, if
48 necessary, so that the image dimensions are at least this
49 ``(width, height)``
50 image_min_dim (None): resize input images during preprocessing, if
51 necessary, so that the smaller image dimension is at least this
52 value
53 image_max_size (None): resize the input images during preprocessing, if
54 necessary, so that the image dimensions are at most this
55 ``(width, height)``
56 image_max_dim (None): resize input images during preprocessing, if
57 necessary, so that the largest image dimension is at most this
58 value.
59 image_size (None): a ``(width, height)`` to which to resize the input
60 images during preprocessing
61 image_dim (None): resize the smaller input dimension to this value
62 during preprocessing
63 image_mean (None): a 3-array of mean values in ``[0, 1]`` for
64 preprocessing the input images
65 image_std (None): a 3-array of std values in ``[0, 1]`` for
66 preprocessing the input images
67 inputs that are lists of Tensors
68 embeddings_layer (None): the name of a layer whose output to expose as
69 embeddings. Prepend ``"<"`` to save the input tensor instead
70 use_half_precision (None): whether to use half precision (only
71 supported when using GPU)
72 cudnn_benchmark (None): a value to use for
73 :attr:`torch:torch.backends.cudnn.benchmark` while the model is
74 running
75 """
76
77 def __init__(self, d):
78 d = self.init(d)
79 super().__init__(d)
80
81
82 class TorchvisionImageModel(fout.TorchImageModel):
83 """Wrapper for evaluating a :mod:`torchvision:torchvision.models` model on images.
84
85 Args:
86 config: an :class:`TorchvisionImageModelConfig`
87 """
88
89 def _download_model(self, config):
90 config.download_model_if_necessary()
91
92 def _load_network(self, config):
93 entrypoint = etau.get_function(config.entrypoint_fcn)
94 kwargs = config.entrypoint_args or {}
95 model_dir = fo.config.model_zoo_dir
96
97 monkey_patcher = _make_load_state_dict_from_url_monkey_patcher(
98 entrypoint, model_dir
99 )
100 with monkey_patcher:
101 # Builds net and loads state dict from `model_dir`
102 model = entrypoint(**kwargs)
103
104 return model
105
106
107 def _make_load_state_dict_from_url_monkey_patcher(entrypoint, model_dir):
108 """Monkey patches all instances of ``load_state_dict_from_url()`` that are
109 reachable from the given ``entrypoint`` function in the
110 :mod:`torchvision:torchvision.models` namespace so that models will be
111 loaded from ``model_dir`` and not from the Torch Hub cache directory.
112 """
113 entrypoint_module = inspect.getmodule(entrypoint)
114 load_state_dict_from_url = entrypoint_module.load_state_dict_from_url
115
116 def custom_load_state_dict_from_url(url, **kwargs):
117 return load_state_dict_from_url(url, model_dir=model_dir, **kwargs)
118
119 return fou.MonkeyPatchFunction(
120 entrypoint_module,
121 custom_load_state_dict_from_url,
122 fcn_name=load_state_dict_from_url.__name__,
123 namespace=torchvision.models,
124 )
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fiftyone/zoo/models/torch.py b/fiftyone/zoo/models/torch.py
--- a/fiftyone/zoo/models/torch.py
+++ b/fiftyone/zoo/models/torch.py
@@ -6,6 +6,7 @@
|
"""
import inspect
+from packaging import version
import eta.core.utils as etau
@@ -111,6 +112,8 @@
loaded from ``model_dir`` and not from the Torch Hub cache directory.
"""
entrypoint_module = inspect.getmodule(entrypoint)
+ if version.parse(torchvision.__version__) >= version.parse("0.12.0"):
+ entrypoint_module = torchvision._internally_replaced_utils
load_state_dict_from_url = entrypoint_module.load_state_dict_from_url
def custom_load_state_dict_from_url(url, **kwargs):
|
{"golden_diff": "diff --git a/fiftyone/zoo/models/torch.py b/fiftyone/zoo/models/torch.py\n--- a/fiftyone/zoo/models/torch.py\n+++ b/fiftyone/zoo/models/torch.py\n@@ -6,6 +6,7 @@\n |\n \"\"\"\n import inspect\n+from packaging import version\n \n import eta.core.utils as etau\n \n@@ -111,6 +112,8 @@\n loaded from ``model_dir`` and not from the Torch Hub cache directory.\n \"\"\"\n entrypoint_module = inspect.getmodule(entrypoint)\n+ if version.parse(torchvision.__version__) >= version.parse(\"0.12.0\"):\n+ entrypoint_module = torchvision._internally_replaced_utils\n load_state_dict_from_url = entrypoint_module.load_state_dict_from_url\n \n def custom_load_state_dict_from_url(url, **kwargs):\n", "issue": "[BUG] loading segmentation torch models errror, has no attribute 'load_state_dict_from_url'\n### System information\r\n\r\n- **OS Platform and Distribution**: `Ubuntu 20.04`\r\n- **FiftyOne installed from (pip or source)**: `pip`, from within `conda` environment\r\n- **FiftyOne version (run `fiftyone --version`)**: `FiftyOne v0.16.0, Voxel51, Inc.`\r\n- **Python version**: `Python 3.9.7`\r\n- **Torch version**: `1.11.0`\r\n- **Torchvision version**: `0.12.0`\r\n\r\n### Code to reproduce\r\n\r\n```\r\nimport fiftyone.zoo as foz\r\nmodel = foz.load_zoo_model(\"deeplabv3-resnet101-coco-torch\")\r\n```\r\n\r\n### Describe the problem\r\nThe model fails to load (was taken from the [semantic segmentation evaluation doc](https://voxel51.com/docs/fiftyone/user_guide/evaluation.html#semantic-segmentations). Ultimately the error is `AttributeError: module 'torchvision.models.segmentation.deeplabv3' has no attribute 'load_state_dict_from_url'`. This applies to all the PyTorch segmentation models listed [here](https://voxel51.com/docs/fiftyone/user_guide/model_zoo/models.html).\r\n\r\n### Other info / logs\r\n```\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\nInput In [2], in <cell line: 3>()\r\n 1 import fiftyone.zoo as foz\r\n----> 3 model = foz.load_zoo_model(\"deeplabv3-resnet101-coco-torch\")\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/__init__.py:207, in load_zoo_model(name, download_if_necessary, install_requirements, error_level, **kwargs)\r\n 204 config_dict = deepcopy(model.default_deployment_config_dict)\r\n 205 model_path = model.get_path_in_dir(models_dir)\r\n--> 207 return fom.load_model(config_dict, model_path=model_path, **kwargs)\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/core/models.py:1505, in load_model(model_config_dict, model_path, **kwargs)\r\n 1499 raise ValueError(\r\n 1500 \"Model config must implement the %s interface\"\r\n 1501 % etal.HasPublishedModel\r\n 1502 )\r\n 1504 # Build model\r\n-> 1505 return config.build()\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/eta/core/learning.py:296, in ModelConfig.build(self)\r\n 289 def build(self):\r\n 290 \"\"\"Factory method that builds the Model instance from the config\r\n 291 specified by this class.\r\n 292 \r\n 293 Returns:\r\n 294 a Model instance\r\n 295 \"\"\"\r\n--> 296 return self._model_cls(self.config)\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/utils/torch.py:230, in TorchImageModel.__init__(self, config)\r\n 226 self._device = torch.device(\"cuda:0\" if self._using_gpu else \"cpu\")\r\n 227 self._using_half_precision = (\r\n 228 self.config.use_half_precision is True\r\n 229 ) and self._using_gpu\r\n--> 230 self._model = self._load_model(config)\r\n 231 self._no_grad = None\r\n 232 self._benchmark_orig = None\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/utils/torch.py:471, in TorchImageModel._load_model(self, config)\r\n 468 def _load_model(self, config):\r\n 469 self._download_model(config)\r\n--> 471 model = self._load_network(config)\r\n 473 model = model.to(self._device)\r\n 474 if self._using_half_precision:\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/torch.py:97, in TorchvisionImageModel._load_network(self, config)\r\n 94 kwargs = config.entrypoint_args or {}\r\n 95 model_dir = fo.config.model_zoo_dir\r\n---> 97 monkey_patcher = _make_load_state_dict_from_url_monkey_patcher(\r\n 98 entrypoint, model_dir\r\n 99 )\r\n 100 with monkey_patcher:\r\n 101 # Builds net and loads state dict from `model_dir`\r\n 102 model = entrypoint(**kwargs)\r\n\r\nFile ~/miniconda3/lib/python3.9/site-packages/fiftyone/zoo/models/torch.py:114, in _make_load_state_dict_from_url_monkey_patcher(entrypoint, model_dir)\r\n 108 \"\"\"Monkey patches all instances of ``load_state_dict_from_url()`` that are\r\n 109 reachable from the given ``entrypoint`` function in the\r\n 110 :mod:`torchvision:torchvision.models` namespace so that models will be\r\n 111 loaded from ``model_dir`` and not from the Torch Hub cache directory.\r\n 112 \"\"\"\r\n 113 entrypoint_module = inspect.getmodule(entrypoint)\r\n--> 114 load_state_dict_from_url = entrypoint_module.load_state_dict_from_url\r\n 116 def custom_load_state_dict_from_url(url, **kwargs):\r\n 117 return load_state_dict_from_url(url, model_dir=model_dir, **kwargs)\r\n\r\nAttributeError: module 'torchvision.models.segmentation.deeplabv3' has no attribute 'load_state_dict_from_url'\r\n```\r\n\r\n### What areas of FiftyOne does this bug affect?\r\n\r\n- [ ] `App`: FiftyOne application issue\r\n- [x] `Core`: Core `fiftyone` Python library issue\r\n- [ ] `Server`: Fiftyone server issue\r\n\r\n### Willingness to contribute\r\n\r\nThe FiftyOne Community encourages bug fix contributions. Would you or another\r\nmember of your organization be willing to contribute a fix for this bug to the\r\nFiftyOne codebase?\r\n\r\n- [ ] Yes. I can contribute a fix for this bug independently.\r\n- [x] Yes. I would be willing to contribute a fix for this bug with guidance\r\n from the FiftyOne community.\r\n- [ ] No. I cannot contribute a bug fix at this time.\r\n\n", "before_files": [{"content": "\"\"\"\nFiftyOne Zoo models provided by :mod:`torchvision:torchvision.models`.\n\n| Copyright 2017-2022, Voxel51, Inc.\n| `voxel51.com <https://voxel51.com/>`_\n|\n\"\"\"\nimport inspect\n\nimport eta.core.utils as etau\n\nimport fiftyone as fo\nimport fiftyone.core.utils as fou\nimport fiftyone.utils.torch as fout\nimport fiftyone.zoo.models as fozm\n\nfou.ensure_torch()\nimport torchvision\n\n\nclass TorchvisionImageModelConfig(\n fout.TorchImageModelConfig, fozm.HasZooModel\n):\n \"\"\"Configuration for running a :class:`TorchvisionImageModel`.\n\n Args:\n entrypoint_fcn: a fully-qualified function string like\n ``\"torchvision.models.inception_v3\"`` specifying the entrypoint\n function that loads the model\n entrypoint_args (None): a dictionary of arguments for\n ``entrypoint_fcn``\n output_processor_cls: a string like\n ``\"fifytone.utils.torch.ClassifierOutputProcessor\"`` specifying the\n :class:`fifytone.utils.torch.OutputProcessor` to use\n output_processor_args (None): a dictionary of arguments for\n ``output_processor_cls(classes=classes, **kwargs)``\n confidence_thresh (None): an optional confidence threshold apply to any\n applicable predictions generated by the model\n labels_string (None): a comma-separated list of the class names for the\n model, if applicable\n labels_path (None): the path to the labels map for the model, if\n applicable\n mask_targets (None): a mask targets dict for the model, if applicable\n mask_targets_path (None): the path to a mask targets map for the model,\n if applicable\n skeleton (None): a keypoint skeleton dict for the model, if applicable\n image_min_size (None): resize the input images during preprocessing, if\n necessary, so that the image dimensions are at least this\n ``(width, height)``\n image_min_dim (None): resize input images during preprocessing, if\n necessary, so that the smaller image dimension is at least this\n value\n image_max_size (None): resize the input images during preprocessing, if\n necessary, so that the image dimensions are at most this\n ``(width, height)``\n image_max_dim (None): resize input images during preprocessing, if\n necessary, so that the largest image dimension is at most this\n value.\n image_size (None): a ``(width, height)`` to which to resize the input\n images during preprocessing\n image_dim (None): resize the smaller input dimension to this value\n during preprocessing\n image_mean (None): a 3-array of mean values in ``[0, 1]`` for\n preprocessing the input images\n image_std (None): a 3-array of std values in ``[0, 1]`` for\n preprocessing the input images\n inputs that are lists of Tensors\n embeddings_layer (None): the name of a layer whose output to expose as\n embeddings. Prepend ``\"<\"`` to save the input tensor instead\n use_half_precision (None): whether to use half precision (only\n supported when using GPU)\n cudnn_benchmark (None): a value to use for\n :attr:`torch:torch.backends.cudnn.benchmark` while the model is\n running\n \"\"\"\n\n def __init__(self, d):\n d = self.init(d)\n super().__init__(d)\n\n\nclass TorchvisionImageModel(fout.TorchImageModel):\n \"\"\"Wrapper for evaluating a :mod:`torchvision:torchvision.models` model on images.\n\n Args:\n config: an :class:`TorchvisionImageModelConfig`\n \"\"\"\n\n def _download_model(self, config):\n config.download_model_if_necessary()\n\n def _load_network(self, config):\n entrypoint = etau.get_function(config.entrypoint_fcn)\n kwargs = config.entrypoint_args or {}\n model_dir = fo.config.model_zoo_dir\n\n monkey_patcher = _make_load_state_dict_from_url_monkey_patcher(\n entrypoint, model_dir\n )\n with monkey_patcher:\n # Builds net and loads state dict from `model_dir`\n model = entrypoint(**kwargs)\n\n return model\n\n\ndef _make_load_state_dict_from_url_monkey_patcher(entrypoint, model_dir):\n \"\"\"Monkey patches all instances of ``load_state_dict_from_url()`` that are\n reachable from the given ``entrypoint`` function in the\n :mod:`torchvision:torchvision.models` namespace so that models will be\n loaded from ``model_dir`` and not from the Torch Hub cache directory.\n \"\"\"\n entrypoint_module = inspect.getmodule(entrypoint)\n load_state_dict_from_url = entrypoint_module.load_state_dict_from_url\n\n def custom_load_state_dict_from_url(url, **kwargs):\n return load_state_dict_from_url(url, model_dir=model_dir, **kwargs)\n\n return fou.MonkeyPatchFunction(\n entrypoint_module,\n custom_load_state_dict_from_url,\n fcn_name=load_state_dict_from_url.__name__,\n namespace=torchvision.models,\n )\n", "path": "fiftyone/zoo/models/torch.py"}], "after_files": [{"content": "\"\"\"\nFiftyOne Zoo models provided by :mod:`torchvision:torchvision.models`.\n\n| Copyright 2017-2022, Voxel51, Inc.\n| `voxel51.com <https://voxel51.com/>`_\n|\n\"\"\"\nimport inspect\nfrom packaging import version\n\nimport eta.core.utils as etau\n\nimport fiftyone as fo\nimport fiftyone.core.utils as fou\nimport fiftyone.utils.torch as fout\nimport fiftyone.zoo.models as fozm\n\nfou.ensure_torch()\nimport torchvision\n\n\nclass TorchvisionImageModelConfig(\n fout.TorchImageModelConfig, fozm.HasZooModel\n):\n \"\"\"Configuration for running a :class:`TorchvisionImageModel`.\n\n Args:\n entrypoint_fcn: a fully-qualified function string like\n ``\"torchvision.models.inception_v3\"`` specifying the entrypoint\n function that loads the model\n entrypoint_args (None): a dictionary of arguments for\n ``entrypoint_fcn``\n output_processor_cls: a string like\n ``\"fifytone.utils.torch.ClassifierOutputProcessor\"`` specifying the\n :class:`fifytone.utils.torch.OutputProcessor` to use\n output_processor_args (None): a dictionary of arguments for\n ``output_processor_cls(classes=classes, **kwargs)``\n confidence_thresh (None): an optional confidence threshold apply to any\n applicable predictions generated by the model\n labels_string (None): a comma-separated list of the class names for the\n model, if applicable\n labels_path (None): the path to the labels map for the model, if\n applicable\n mask_targets (None): a mask targets dict for the model, if applicable\n mask_targets_path (None): the path to a mask targets map for the model,\n if applicable\n skeleton (None): a keypoint skeleton dict for the model, if applicable\n image_min_size (None): resize the input images during preprocessing, if\n necessary, so that the image dimensions are at least this\n ``(width, height)``\n image_min_dim (None): resize input images during preprocessing, if\n necessary, so that the smaller image dimension is at least this\n value\n image_max_size (None): resize the input images during preprocessing, if\n necessary, so that the image dimensions are at most this\n ``(width, height)``\n image_max_dim (None): resize input images during preprocessing, if\n necessary, so that the largest image dimension is at most this\n value.\n image_size (None): a ``(width, height)`` to which to resize the input\n images during preprocessing\n image_dim (None): resize the smaller input dimension to this value\n during preprocessing\n image_mean (None): a 3-array of mean values in ``[0, 1]`` for\n preprocessing the input images\n image_std (None): a 3-array of std values in ``[0, 1]`` for\n preprocessing the input images\n inputs that are lists of Tensors\n embeddings_layer (None): the name of a layer whose output to expose as\n embeddings. Prepend ``\"<\"`` to save the input tensor instead\n use_half_precision (None): whether to use half precision (only\n supported when using GPU)\n cudnn_benchmark (None): a value to use for\n :attr:`torch:torch.backends.cudnn.benchmark` while the model is\n running\n \"\"\"\n\n def __init__(self, d):\n d = self.init(d)\n super().__init__(d)\n\n\nclass TorchvisionImageModel(fout.TorchImageModel):\n \"\"\"Wrapper for evaluating a :mod:`torchvision:torchvision.models` model on images.\n\n Args:\n config: an :class:`TorchvisionImageModelConfig`\n \"\"\"\n\n def _download_model(self, config):\n config.download_model_if_necessary()\n\n def _load_network(self, config):\n entrypoint = etau.get_function(config.entrypoint_fcn)\n kwargs = config.entrypoint_args or {}\n model_dir = fo.config.model_zoo_dir\n\n monkey_patcher = _make_load_state_dict_from_url_monkey_patcher(\n entrypoint, model_dir\n )\n with monkey_patcher:\n # Builds net and loads state dict from `model_dir`\n model = entrypoint(**kwargs)\n\n return model\n\n\ndef _make_load_state_dict_from_url_monkey_patcher(entrypoint, model_dir):\n \"\"\"Monkey patches all instances of ``load_state_dict_from_url()`` that are\n reachable from the given ``entrypoint`` function in the\n :mod:`torchvision:torchvision.models` namespace so that models will be\n loaded from ``model_dir`` and not from the Torch Hub cache directory.\n \"\"\"\n entrypoint_module = inspect.getmodule(entrypoint)\n if version.parse(torchvision.__version__) >= version.parse(\"0.12.0\"):\n entrypoint_module = torchvision._internally_replaced_utils\n load_state_dict_from_url = entrypoint_module.load_state_dict_from_url\n\n def custom_load_state_dict_from_url(url, **kwargs):\n return load_state_dict_from_url(url, model_dir=model_dir, **kwargs)\n\n return fou.MonkeyPatchFunction(\n entrypoint_module,\n custom_load_state_dict_from_url,\n fcn_name=load_state_dict_from_url.__name__,\n namespace=torchvision.models,\n )\n", "path": "fiftyone/zoo/models/torch.py"}]}
| 3,142 | 184 |
gh_patches_debug_36862
|
rasdani/github-patches
|
git_diff
|
google__mobly-47
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Snippet client is unable to make connection on mac
Because the convoluted timeout scheme of JsonRpcClientBase.connect.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mobly/controllers/android_device_lib/jsonrpc_client_base.py`
Content:
```
1 #/usr/bin/env python3.4
2 #
3 # Copyright 2016 Google Inc.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """Base class for clients that communicate with apps over a JSON RPC interface.
18
19 The JSON protocol expected by this module is:
20
21 Request:
22 {
23 "id": <monotonically increasing integer containing the ID of this request>
24 "method": <string containing the name of the method to execute>
25 "params": <JSON array containing the arguments to the method>
26 }
27
28 Response:
29 {
30 "id": <int id of request that this response maps to>,
31 "result": <Arbitrary JSON object containing the result of executing the
32 method. If the method could not be executed or returned void,
33 contains 'null'.>,
34 "error": <String containing the error thrown by executing the method.
35 If no error occurred, contains 'null'.>
36 }
37 """
38
39 from builtins import str
40
41 import json
42 import logging
43 import socket
44 import sys
45 import threading
46 import time
47
48 # Maximum time to wait for the app to start on the device.
49 APP_START_WAIT_TIME = 15
50
51 # UID of the 'unknown' jsonrpc session. Will cause creation of a new session.
52 UNKNOWN_UID = -1
53
54 # Maximum time to wait for the socket to open on the device.
55 _SOCKET_TIMEOUT = 60
56
57
58 class Error(Exception):
59 pass
60
61
62 class AppStartError(Error):
63 """Raised when the app is not able to be started."""
64
65
66 class ApiError(Error):
67 """Raised when remote API reports an error."""
68
69
70 class ProtocolError(Error):
71 """Raised when there is some error in exchanging data with server."""
72 NO_RESPONSE_FROM_HANDSHAKE = "No response from handshake."
73 NO_RESPONSE_FROM_SERVER = "No response from server."
74 MISMATCHED_API_ID = "Mismatched API id."
75
76
77 class JsonRpcCommand(object):
78 """Commands that can be invoked on all jsonrpc clients.
79
80 INIT: Initializes a new session.
81 CONTINUE: Creates a connection.
82 """
83 INIT = 'initiate'
84 CONTINUE = 'continue'
85
86
87 class JsonRpcClientBase(object):
88 """Base class for jsonrpc clients that connect to remote servers.
89
90 Connects to a remote device running a jsonrpc-compatible app. Before opening
91 a connection a port forward must be setup to go over usb. This be done using
92 adb.tcp_forward(). This calls the shell command adb forward <local> remote>.
93 Once the port has been forwarded it can be used in this object as the port
94 of communication.
95
96 Attributes:
97 uid: (int) The uid of this session.
98 app_name: (str) The user-visible name of the app being communicated
99 with. Must be set by the superclass.
100 """
101 def __init__(self, adb_proxy):
102 """
103 Args:
104 adb_proxy: adb.AdbProxy, The adb proxy to use to start the app
105 """
106 self.uid = None
107 self._adb = adb_proxy
108 self._client = None # prevent close errors on connect failure
109 self._conn = None
110 self._counter = None
111 self._lock = threading.Lock()
112
113 def __del__(self):
114 self.close()
115
116 # Methods to be implemented by subclasses.
117
118 def _do_start_app(self):
119 """Starts the server app on the android device.
120
121 Must be implemented by subclasses.
122 """
123 raise NotImplementedError()
124
125 def stop_app(self):
126 """Kills any running instance of the app.
127
128 Must be implemented by subclasses.
129 """
130 raise NotImplementedError()
131
132 def _is_app_installed(self):
133 """Checks if app is installed.
134
135 Must be implemented by subclasses.
136
137 Returns:
138 True if installed, False otherwise.
139 """
140 raise NotImplementedError()
141
142 def _is_app_running(self):
143 """Checks if the app is currently running on an android device.
144
145 Must be implemented by subclasses.
146
147 Returns:
148 True if the app is running, False otherwise.
149 """
150 raise NotImplementedError()
151
152 # Rest of the client methods.
153
154 def check_app_installed(self):
155 if not self._is_app_installed():
156 raise AppStartError(
157 '%s is not installed on %s' % (self.app_name, self._adb.serial))
158
159 def start_app(self, wait_time=APP_START_WAIT_TIME):
160 """Starts the server app on the android device.
161
162 Args:
163 wait_time: float, The time to wait for the app to come up before
164 raising an error.
165
166 Raises:
167 AppStartError: When the app was not able to be started.
168 """
169 self.check_app_installed()
170 self._do_start_app()
171 for _ in range(wait_time):
172 time.sleep(1)
173 if self._is_app_running():
174 return
175 raise AppStartError(
176 '%s failed to start on %s.' % (self.app_name, self._adb.serial))
177
178 def connect(self, port, addr='localhost', uid=UNKNOWN_UID,
179 connection_timeout=None, cmd=JsonRpcCommand.INIT):
180 """
181 Opens a connection to the remote client.
182
183 Opens a connection to a remote client. The connection will error out if
184 it takes longer than the connection_timeout time. Once connected if the
185 socket takes longer than _SOCKET_TIMEOUT to respond the connection will
186 be closed.
187
188 Args:
189 port: int, The port this client should connect to.
190 addr: str, The address this client should connect to.
191 uid: int, The uid of the session to join, or UNKNOWN_UID to start a
192 new session.
193 connection_timeout: int, The time to wait for the connection to come
194 up.
195 cmd: JsonRpcCommand, The command to use for creating the connection.
196
197 Raises:
198 IOError: Raised when the socket times out from io error
199 socket.timeout: Raised when the socket waits to long for connection.
200 ProtocolError: Raised when there is an error in the protocol.
201 """
202 if connection_timeout:
203 timeout_time = time.time() + connection_timeout
204 else:
205 timeout_time = sys.maxsize
206 self._counter = self._id_counter()
207 while True:
208 try:
209 self._conn = socket.create_connection(
210 (addr, port), max(1, timeout_time - time.time()))
211 self._conn.settimeout(_SOCKET_TIMEOUT)
212 break
213 except socket.timeout:
214 logging.exception("Failed to create socket connection!")
215 raise
216 except (socket.error, IOError):
217 # TODO: optimize to only forgive some errors here
218 # error values are OS-specific so this will require
219 # additional tuning to fail faster
220 if time.time() + 1 >= timeout_time:
221 logging.exception("Failed to create socket connection!")
222 raise
223 time.sleep(1)
224 self.port = port
225 self._client = self._conn.makefile(mode="brw")
226
227 resp = self._cmd(cmd, uid)
228 if not resp:
229 raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_HANDSHAKE)
230 result = json.loads(str(resp, encoding="utf8"))
231 if result['status']:
232 self.uid = result['uid']
233 else:
234 self.uid = UNKNOWN_UID
235
236 def close(self):
237 """Close the connection to the remote client."""
238 if self._conn:
239 self._conn.close()
240 self._conn = None
241
242 def _cmd(self, command, uid=None):
243 """Send a command to the server.
244
245 Args:
246 command: str, The name of the command to execute.
247 uid: int, the uid of the session to send the command to.
248
249 Returns:
250 The line that was written back.
251 """
252 if not uid:
253 uid = self.uid
254 self._client.write(
255 json.dumps({'cmd': command, 'uid': uid}).encode("utf8") + b'\n')
256 self._client.flush()
257 return self._client.readline()
258
259 def _rpc(self, method, *args):
260 """Sends an rpc to the app.
261
262 Args:
263 method: str, The name of the method to execute.
264 args: any, The args of the method.
265
266 Returns:
267 The result of the rpc.
268
269 Raises:
270 ProtocolError: Something went wrong with the protocol.
271 ApiError: The rpc went through, however executed with errors.
272 """
273 with self._lock:
274 apiid = next(self._counter)
275 data = {'id': apiid, 'method': method, 'params': args}
276 request = json.dumps(data)
277 self._client.write(request.encode("utf8") + b'\n')
278 self._client.flush()
279 response = self._client.readline()
280 if not response:
281 raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_SERVER)
282 result = json.loads(str(response, encoding="utf8"))
283 if result['error']:
284 raise ApiError(result['error'])
285 if result['id'] != apiid:
286 raise ProtocolError(ProtocolError.MISMATCHED_API_ID)
287 return result['result']
288
289 def __getattr__(self, name):
290 """Wrapper for python magic to turn method calls into RPC calls."""
291 def rpc_call(*args):
292 return self._rpc(name, *args)
293 return rpc_call
294
295 def _id_counter(self):
296 i = 0
297 while True:
298 yield i
299 i += 1
300
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mobly/controllers/android_device_lib/jsonrpc_client_base.py b/mobly/controllers/android_device_lib/jsonrpc_client_base.py
--- a/mobly/controllers/android_device_lib/jsonrpc_client_base.py
+++ b/mobly/controllers/android_device_lib/jsonrpc_client_base.py
@@ -176,14 +176,13 @@
'%s failed to start on %s.' % (self.app_name, self._adb.serial))
def connect(self, port, addr='localhost', uid=UNKNOWN_UID,
- connection_timeout=None, cmd=JsonRpcCommand.INIT):
- """
- Opens a connection to the remote client.
+ cmd=JsonRpcCommand.INIT):
+ """Opens a connection to a JSON RPC server.
- Opens a connection to a remote client. The connection will error out if
- it takes longer than the connection_timeout time. Once connected if the
- socket takes longer than _SOCKET_TIMEOUT to respond the connection will
- be closed.
+ Opens a connection to a remote client. The connection attempt will time
+ out if it takes longer than _SOCKET_TIMEOUT seconds. Each subsequent
+ operation over this socket will time out after _SOCKET_TIMEOUT seconds
+ as well.
Args:
port: int, The port this client should connect to.
@@ -199,28 +198,14 @@
socket.timeout: Raised when the socket waits to long for connection.
ProtocolError: Raised when there is an error in the protocol.
"""
- if connection_timeout:
- timeout_time = time.time() + connection_timeout
- else:
- timeout_time = sys.maxsize
self._counter = self._id_counter()
- while True:
- try:
- self._conn = socket.create_connection(
- (addr, port), max(1, timeout_time - time.time()))
- self._conn.settimeout(_SOCKET_TIMEOUT)
- break
- except socket.timeout:
- logging.exception("Failed to create socket connection!")
- raise
- except (socket.error, IOError):
- # TODO: optimize to only forgive some errors here
- # error values are OS-specific so this will require
- # additional tuning to fail faster
- if time.time() + 1 >= timeout_time:
- logging.exception("Failed to create socket connection!")
- raise
- time.sleep(1)
+ try:
+ self._conn = socket.create_connection((addr, port),
+ _SOCKET_TIMEOUT)
+ self._conn.settimeout(_SOCKET_TIMEOUT)
+ except (socket.timeout, socket.error, IOError):
+ logging.exception("Failed to create socket connection!")
+ raise
self.port = port
self._client = self._conn.makefile(mode="brw")
|
{"golden_diff": "diff --git a/mobly/controllers/android_device_lib/jsonrpc_client_base.py b/mobly/controllers/android_device_lib/jsonrpc_client_base.py\n--- a/mobly/controllers/android_device_lib/jsonrpc_client_base.py\n+++ b/mobly/controllers/android_device_lib/jsonrpc_client_base.py\n@@ -176,14 +176,13 @@\n '%s failed to start on %s.' % (self.app_name, self._adb.serial))\n \n def connect(self, port, addr='localhost', uid=UNKNOWN_UID,\n- connection_timeout=None, cmd=JsonRpcCommand.INIT):\n- \"\"\"\n- Opens a connection to the remote client.\n+ cmd=JsonRpcCommand.INIT):\n+ \"\"\"Opens a connection to a JSON RPC server.\n \n- Opens a connection to a remote client. The connection will error out if\n- it takes longer than the connection_timeout time. Once connected if the\n- socket takes longer than _SOCKET_TIMEOUT to respond the connection will\n- be closed.\n+ Opens a connection to a remote client. The connection attempt will time\n+ out if it takes longer than _SOCKET_TIMEOUT seconds. Each subsequent\n+ operation over this socket will time out after _SOCKET_TIMEOUT seconds\n+ as well.\n \n Args:\n port: int, The port this client should connect to.\n@@ -199,28 +198,14 @@\n socket.timeout: Raised when the socket waits to long for connection.\n ProtocolError: Raised when there is an error in the protocol.\n \"\"\"\n- if connection_timeout:\n- timeout_time = time.time() + connection_timeout\n- else:\n- timeout_time = sys.maxsize\n self._counter = self._id_counter()\n- while True:\n- try:\n- self._conn = socket.create_connection(\n- (addr, port), max(1, timeout_time - time.time()))\n- self._conn.settimeout(_SOCKET_TIMEOUT)\n- break\n- except socket.timeout:\n- logging.exception(\"Failed to create socket connection!\")\n- raise\n- except (socket.error, IOError):\n- # TODO: optimize to only forgive some errors here\n- # error values are OS-specific so this will require\n- # additional tuning to fail faster\n- if time.time() + 1 >= timeout_time:\n- logging.exception(\"Failed to create socket connection!\")\n- raise\n- time.sleep(1)\n+ try:\n+ self._conn = socket.create_connection((addr, port),\n+ _SOCKET_TIMEOUT)\n+ self._conn.settimeout(_SOCKET_TIMEOUT)\n+ except (socket.timeout, socket.error, IOError):\n+ logging.exception(\"Failed to create socket connection!\")\n+ raise\n self.port = port\n self._client = self._conn.makefile(mode=\"brw\")\n", "issue": "Snippet client is unable to make connection on mac\nBecause the convoluted timeout scheme of JsonRpcClientBase.connect.\r\n\n", "before_files": [{"content": "#/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Base class for clients that communicate with apps over a JSON RPC interface.\n\nThe JSON protocol expected by this module is:\n\nRequest:\n{\n \"id\": <monotonically increasing integer containing the ID of this request>\n \"method\": <string containing the name of the method to execute>\n \"params\": <JSON array containing the arguments to the method>\n}\n\nResponse:\n{\n \"id\": <int id of request that this response maps to>,\n \"result\": <Arbitrary JSON object containing the result of executing the\n method. If the method could not be executed or returned void,\n contains 'null'.>,\n \"error\": <String containing the error thrown by executing the method.\n If no error occurred, contains 'null'.>\n}\n\"\"\"\n\nfrom builtins import str\n\nimport json\nimport logging\nimport socket\nimport sys\nimport threading\nimport time\n\n# Maximum time to wait for the app to start on the device.\nAPP_START_WAIT_TIME = 15\n\n# UID of the 'unknown' jsonrpc session. Will cause creation of a new session.\nUNKNOWN_UID = -1\n\n# Maximum time to wait for the socket to open on the device.\n_SOCKET_TIMEOUT = 60\n\n\nclass Error(Exception):\n pass\n\n\nclass AppStartError(Error):\n \"\"\"Raised when the app is not able to be started.\"\"\"\n\n\nclass ApiError(Error):\n \"\"\"Raised when remote API reports an error.\"\"\"\n\n\nclass ProtocolError(Error):\n \"\"\"Raised when there is some error in exchanging data with server.\"\"\"\n NO_RESPONSE_FROM_HANDSHAKE = \"No response from handshake.\"\n NO_RESPONSE_FROM_SERVER = \"No response from server.\"\n MISMATCHED_API_ID = \"Mismatched API id.\"\n\n\nclass JsonRpcCommand(object):\n \"\"\"Commands that can be invoked on all jsonrpc clients.\n\n INIT: Initializes a new session.\n CONTINUE: Creates a connection.\n \"\"\"\n INIT = 'initiate'\n CONTINUE = 'continue'\n\n\nclass JsonRpcClientBase(object):\n \"\"\"Base class for jsonrpc clients that connect to remote servers.\n\n Connects to a remote device running a jsonrpc-compatible app. Before opening\n a connection a port forward must be setup to go over usb. This be done using\n adb.tcp_forward(). This calls the shell command adb forward <local> remote>.\n Once the port has been forwarded it can be used in this object as the port\n of communication.\n\n Attributes:\n uid: (int) The uid of this session.\n app_name: (str) The user-visible name of the app being communicated\n with. Must be set by the superclass.\n \"\"\"\n def __init__(self, adb_proxy):\n \"\"\"\n Args:\n adb_proxy: adb.AdbProxy, The adb proxy to use to start the app\n \"\"\"\n self.uid = None\n self._adb = adb_proxy\n self._client = None # prevent close errors on connect failure\n self._conn = None\n self._counter = None\n self._lock = threading.Lock()\n\n def __del__(self):\n self.close()\n\n # Methods to be implemented by subclasses.\n\n def _do_start_app(self):\n \"\"\"Starts the server app on the android device.\n\n Must be implemented by subclasses.\n \"\"\"\n raise NotImplementedError()\n\n def stop_app(self):\n \"\"\"Kills any running instance of the app.\n\n Must be implemented by subclasses.\n \"\"\"\n raise NotImplementedError()\n\n def _is_app_installed(self):\n \"\"\"Checks if app is installed.\n\n Must be implemented by subclasses.\n\n Returns:\n True if installed, False otherwise.\n \"\"\"\n raise NotImplementedError()\n\n def _is_app_running(self):\n \"\"\"Checks if the app is currently running on an android device.\n\n Must be implemented by subclasses.\n\n Returns:\n True if the app is running, False otherwise.\n \"\"\"\n raise NotImplementedError()\n\n # Rest of the client methods.\n\n def check_app_installed(self):\n if not self._is_app_installed():\n raise AppStartError(\n '%s is not installed on %s' % (self.app_name, self._adb.serial))\n\n def start_app(self, wait_time=APP_START_WAIT_TIME):\n \"\"\"Starts the server app on the android device.\n\n Args:\n wait_time: float, The time to wait for the app to come up before\n raising an error.\n\n Raises:\n AppStartError: When the app was not able to be started.\n \"\"\"\n self.check_app_installed()\n self._do_start_app()\n for _ in range(wait_time):\n time.sleep(1)\n if self._is_app_running():\n return\n raise AppStartError(\n '%s failed to start on %s.' % (self.app_name, self._adb.serial))\n\n def connect(self, port, addr='localhost', uid=UNKNOWN_UID,\n connection_timeout=None, cmd=JsonRpcCommand.INIT):\n \"\"\"\n Opens a connection to the remote client.\n\n Opens a connection to a remote client. The connection will error out if\n it takes longer than the connection_timeout time. Once connected if the\n socket takes longer than _SOCKET_TIMEOUT to respond the connection will\n be closed.\n\n Args:\n port: int, The port this client should connect to.\n addr: str, The address this client should connect to.\n uid: int, The uid of the session to join, or UNKNOWN_UID to start a\n new session.\n connection_timeout: int, The time to wait for the connection to come\n up.\n cmd: JsonRpcCommand, The command to use for creating the connection.\n\n Raises:\n IOError: Raised when the socket times out from io error\n socket.timeout: Raised when the socket waits to long for connection.\n ProtocolError: Raised when there is an error in the protocol.\n \"\"\"\n if connection_timeout:\n timeout_time = time.time() + connection_timeout\n else:\n timeout_time = sys.maxsize\n self._counter = self._id_counter()\n while True:\n try:\n self._conn = socket.create_connection(\n (addr, port), max(1, timeout_time - time.time()))\n self._conn.settimeout(_SOCKET_TIMEOUT)\n break\n except socket.timeout:\n logging.exception(\"Failed to create socket connection!\")\n raise\n except (socket.error, IOError):\n # TODO: optimize to only forgive some errors here\n # error values are OS-specific so this will require\n # additional tuning to fail faster\n if time.time() + 1 >= timeout_time:\n logging.exception(\"Failed to create socket connection!\")\n raise\n time.sleep(1)\n self.port = port\n self._client = self._conn.makefile(mode=\"brw\")\n\n resp = self._cmd(cmd, uid)\n if not resp:\n raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_HANDSHAKE)\n result = json.loads(str(resp, encoding=\"utf8\"))\n if result['status']:\n self.uid = result['uid']\n else:\n self.uid = UNKNOWN_UID\n\n def close(self):\n \"\"\"Close the connection to the remote client.\"\"\"\n if self._conn:\n self._conn.close()\n self._conn = None\n\n def _cmd(self, command, uid=None):\n \"\"\"Send a command to the server.\n\n Args:\n command: str, The name of the command to execute.\n uid: int, the uid of the session to send the command to.\n\n Returns:\n The line that was written back.\n \"\"\"\n if not uid:\n uid = self.uid\n self._client.write(\n json.dumps({'cmd': command, 'uid': uid}).encode(\"utf8\") + b'\\n')\n self._client.flush()\n return self._client.readline()\n\n def _rpc(self, method, *args):\n \"\"\"Sends an rpc to the app.\n\n Args:\n method: str, The name of the method to execute.\n args: any, The args of the method.\n\n Returns:\n The result of the rpc.\n\n Raises:\n ProtocolError: Something went wrong with the protocol.\n ApiError: The rpc went through, however executed with errors.\n \"\"\"\n with self._lock:\n apiid = next(self._counter)\n data = {'id': apiid, 'method': method, 'params': args}\n request = json.dumps(data)\n self._client.write(request.encode(\"utf8\") + b'\\n')\n self._client.flush()\n response = self._client.readline()\n if not response:\n raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_SERVER)\n result = json.loads(str(response, encoding=\"utf8\"))\n if result['error']:\n raise ApiError(result['error'])\n if result['id'] != apiid:\n raise ProtocolError(ProtocolError.MISMATCHED_API_ID)\n return result['result']\n\n def __getattr__(self, name):\n \"\"\"Wrapper for python magic to turn method calls into RPC calls.\"\"\"\n def rpc_call(*args):\n return self._rpc(name, *args)\n return rpc_call\n\n def _id_counter(self):\n i = 0\n while True:\n yield i\n i += 1\n", "path": "mobly/controllers/android_device_lib/jsonrpc_client_base.py"}], "after_files": [{"content": "#/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Base class for clients that communicate with apps over a JSON RPC interface.\n\nThe JSON protocol expected by this module is:\n\nRequest:\n{\n \"id\": <monotonically increasing integer containing the ID of this request>\n \"method\": <string containing the name of the method to execute>\n \"params\": <JSON array containing the arguments to the method>\n}\n\nResponse:\n{\n \"id\": <int id of request that this response maps to>,\n \"result\": <Arbitrary JSON object containing the result of executing the\n method. If the method could not be executed or returned void,\n contains 'null'.>,\n \"error\": <String containing the error thrown by executing the method.\n If no error occurred, contains 'null'.>\n}\n\"\"\"\n\nfrom builtins import str\n\nimport json\nimport logging\nimport socket\nimport sys\nimport threading\nimport time\n\n# Maximum time to wait for the app to start on the device.\nAPP_START_WAIT_TIME = 15\n\n# UID of the 'unknown' jsonrpc session. Will cause creation of a new session.\nUNKNOWN_UID = -1\n\n# Maximum time to wait for the socket to open on the device.\n_SOCKET_TIMEOUT = 60\n\n\nclass Error(Exception):\n pass\n\n\nclass AppStartError(Error):\n \"\"\"Raised when the app is not able to be started.\"\"\"\n\n\nclass ApiError(Error):\n \"\"\"Raised when remote API reports an error.\"\"\"\n\n\nclass ProtocolError(Error):\n \"\"\"Raised when there is some error in exchanging data with server.\"\"\"\n NO_RESPONSE_FROM_HANDSHAKE = \"No response from handshake.\"\n NO_RESPONSE_FROM_SERVER = \"No response from server.\"\n MISMATCHED_API_ID = \"Mismatched API id.\"\n\n\nclass JsonRpcCommand(object):\n \"\"\"Commands that can be invoked on all jsonrpc clients.\n\n INIT: Initializes a new session.\n CONTINUE: Creates a connection.\n \"\"\"\n INIT = 'initiate'\n CONTINUE = 'continue'\n\n\nclass JsonRpcClientBase(object):\n \"\"\"Base class for jsonrpc clients that connect to remote servers.\n\n Connects to a remote device running a jsonrpc-compatible app. Before opening\n a connection a port forward must be setup to go over usb. This be done using\n adb.tcp_forward(). This calls the shell command adb forward <local> remote>.\n Once the port has been forwarded it can be used in this object as the port\n of communication.\n\n Attributes:\n uid: (int) The uid of this session.\n app_name: (str) The user-visible name of the app being communicated\n with. Must be set by the superclass.\n \"\"\"\n def __init__(self, adb_proxy):\n \"\"\"\n Args:\n adb_proxy: adb.AdbProxy, The adb proxy to use to start the app\n \"\"\"\n self.uid = None\n self._adb = adb_proxy\n self._client = None # prevent close errors on connect failure\n self._conn = None\n self._counter = None\n self._lock = threading.Lock()\n\n def __del__(self):\n self.close()\n\n # Methods to be implemented by subclasses.\n\n def _do_start_app(self):\n \"\"\"Starts the server app on the android device.\n\n Must be implemented by subclasses.\n \"\"\"\n raise NotImplementedError()\n\n def stop_app(self):\n \"\"\"Kills any running instance of the app.\n\n Must be implemented by subclasses.\n \"\"\"\n raise NotImplementedError()\n\n def _is_app_installed(self):\n \"\"\"Checks if app is installed.\n\n Must be implemented by subclasses.\n\n Returns:\n True if installed, False otherwise.\n \"\"\"\n raise NotImplementedError()\n\n def _is_app_running(self):\n \"\"\"Checks if the app is currently running on an android device.\n\n Must be implemented by subclasses.\n\n Returns:\n True if the app is running, False otherwise.\n \"\"\"\n raise NotImplementedError()\n\n # Rest of the client methods.\n\n def check_app_installed(self):\n if not self._is_app_installed():\n raise AppStartError(\n '%s is not installed on %s' % (self.app_name, self._adb.serial))\n\n def start_app(self, wait_time=APP_START_WAIT_TIME):\n \"\"\"Starts the server app on the android device.\n\n Args:\n wait_time: float, The time to wait for the app to come up before\n raising an error.\n\n Raises:\n AppStartError: When the app was not able to be started.\n \"\"\"\n self.check_app_installed()\n self._do_start_app()\n for _ in range(wait_time):\n time.sleep(1)\n if self._is_app_running():\n return\n raise AppStartError(\n '%s failed to start on %s.' % (self.app_name, self._adb.serial))\n\n def connect(self, port, addr='localhost', uid=UNKNOWN_UID,\n cmd=JsonRpcCommand.INIT):\n \"\"\"Opens a connection to a JSON RPC server.\n\n Opens a connection to a remote client. The connection attempt will time\n out if it takes longer than _SOCKET_TIMEOUT seconds. Each subsequent\n operation over this socket will time out after _SOCKET_TIMEOUT seconds\n as well.\n\n Args:\n port: int, The port this client should connect to.\n addr: str, The address this client should connect to.\n uid: int, The uid of the session to join, or UNKNOWN_UID to start a\n new session.\n connection_timeout: int, The time to wait for the connection to come\n up.\n cmd: JsonRpcCommand, The command to use for creating the connection.\n\n Raises:\n IOError: Raised when the socket times out from io error\n socket.timeout: Raised when the socket waits to long for connection.\n ProtocolError: Raised when there is an error in the protocol.\n \"\"\"\n self._counter = self._id_counter()\n try:\n self._conn = socket.create_connection((addr, port),\n _SOCKET_TIMEOUT)\n self._conn.settimeout(_SOCKET_TIMEOUT)\n except (socket.timeout, socket.error, IOError):\n logging.exception(\"Failed to create socket connection!\")\n raise\n self.port = port\n self._client = self._conn.makefile(mode=\"brw\")\n\n resp = self._cmd(cmd, uid)\n if not resp:\n raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_HANDSHAKE)\n result = json.loads(str(resp, encoding=\"utf8\"))\n if result['status']:\n self.uid = result['uid']\n else:\n self.uid = UNKNOWN_UID\n\n def close(self):\n \"\"\"Close the connection to the remote client.\"\"\"\n if self._conn:\n self._conn.close()\n self._conn = None\n\n def _cmd(self, command, uid=None):\n \"\"\"Send a command to the server.\n\n Args:\n command: str, The name of the command to execute.\n uid: int, the uid of the session to send the command to.\n\n Returns:\n The line that was written back.\n \"\"\"\n if not uid:\n uid = self.uid\n self._client.write(\n json.dumps({'cmd': command, 'uid': uid}).encode(\"utf8\") + b'\\n')\n self._client.flush()\n return self._client.readline()\n\n def _rpc(self, method, *args):\n \"\"\"Sends an rpc to the app.\n\n Args:\n method: str, The name of the method to execute.\n args: any, The args of the method.\n\n Returns:\n The result of the rpc.\n\n Raises:\n ProtocolError: Something went wrong with the protocol.\n ApiError: The rpc went through, however executed with errors.\n \"\"\"\n with self._lock:\n apiid = next(self._counter)\n data = {'id': apiid, 'method': method, 'params': args}\n request = json.dumps(data)\n self._client.write(request.encode(\"utf8\") + b'\\n')\n self._client.flush()\n response = self._client.readline()\n if not response:\n raise ProtocolError(ProtocolError.NO_RESPONSE_FROM_SERVER)\n result = json.loads(str(response, encoding=\"utf8\"))\n if result['error']:\n raise ApiError(result['error'])\n if result['id'] != apiid:\n raise ProtocolError(ProtocolError.MISMATCHED_API_ID)\n return result['result']\n\n def __getattr__(self, name):\n \"\"\"Wrapper for python magic to turn method calls into RPC calls.\"\"\"\n def rpc_call(*args):\n return self._rpc(name, *args)\n return rpc_call\n\n def _id_counter(self):\n i = 0\n while True:\n yield i\n i += 1\n", "path": "mobly/controllers/android_device_lib/jsonrpc_client_base.py"}]}
| 3,207 | 613 |
gh_patches_debug_6707
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1187
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing dependency python-dateutil in setup.py
I noticed that `python-dateutil` is missing from setup.py in `main`. The line "python-dateutil >= 2.7.2, <3.0dev", was removed in https://github.com/googleapis/python-bigquery/commit/76d88fbb1316317a61fa1a63c101bc6f42f23af8.
I'm seeing failures in samples testing for other projects:
https://source.cloud.google.com/results/invocations/8e737a80-a041-468e-a2de-184d5ec1662f/log
```
******************** TESTING PROJECTS ********************
------------------------------------------------------------
- testing samples/snippets
------------------------------------------------------------
nox > Running session py-3.10
nox > Creating virtual environment (virtualenv) using python3.10 in .nox/py-3-10
nox > python -m pip install -r requirements.txt
nox > python -m pip install -r requirements-test.txt
nox > python -m pip install -e /workspace
nox > pytest --junitxml=sponge_log.xml
ImportError while loading conftest '/workspace/samples/snippets/conftest.py'.
conftest.py:23: in <module>
from google.cloud import bigquery
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/__init__.py:35: in <module>
from google.cloud.bigquery.client import Client
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/client.py:64: in <module>
from google.cloud.bigquery import _job_helpers
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/_job_helpers.py:24: in <module>
from google.cloud.bigquery import job
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/job/__init__.py:17: in <module>
from google.cloud.bigquery.job.base import _AsyncJob
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:27: in <module>
from google.cloud.bigquery import _helpers
.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/_helpers.py:24: in <module>
from dateutil import relativedelta
E ModuleNotFoundError: No module named 'dateutil'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "grpcio >= 1.38.1, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/695
33 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
34 # Until this issue is closed
35 # https://github.com/googleapis/google-cloud-python/issues/10566
36 "google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0",
37 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
38 "proto-plus >= 1.15.0",
39 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
40 # Until this issue is closed
41 # https://github.com/googleapis/google-cloud-python/issues/10566
42 "google-cloud-core >= 1.4.1, <3.0.0dev",
43 "google-resumable-media >= 0.6.0, < 3.0dev",
44 "packaging >= 14.3",
45 "proto-plus >= 1.10.0", # For the legacy proto-based types.
46 "protobuf >= 3.12.0", # For the legacy proto-based types.
47 "pyarrow >= 3.0.0, < 8.0dev",
48 "requests >= 2.18.0, < 3.0.0dev",
49 ]
50 extras = {
51 # Keep the no-op bqstorage extra for backward compatibility.
52 # See: https://github.com/googleapis/python-bigquery/issues/757
53 "bqstorage": [],
54 "pandas": ["pandas>=1.0.0", "db-dtypes>=0.3.0,<2.0.0dev"],
55 "geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.6.0, <2.0dev"],
56 "ipython": ["ipython>=7.0.1,!=8.1.0"],
57 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
58 "opentelemetry": [
59 "opentelemetry-api >= 1.1.0",
60 "opentelemetry-sdk >= 1.1.0",
61 "opentelemetry-instrumentation >= 0.20b0",
62 ],
63 }
64
65 all_extras = []
66
67 for extra in extras:
68 all_extras.extend(extras[extra])
69
70 extras["all"] = all_extras
71
72 # Setup boilerplate below this line.
73
74 package_root = os.path.abspath(os.path.dirname(__file__))
75
76 readme_filename = os.path.join(package_root, "README.rst")
77 with io.open(readme_filename, encoding="utf-8") as readme_file:
78 readme = readme_file.read()
79
80 version = {}
81 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
82 exec(fp.read(), version)
83 version = version["__version__"]
84
85 # Only include packages under the 'google' namespace. Do not include tests,
86 # benchmarks, etc.
87 packages = [
88 package
89 for package in setuptools.PEP420PackageFinder.find()
90 if package.startswith("google")
91 ]
92
93 # Determine which namespaces are needed.
94 namespaces = ["google"]
95 if "google.cloud" in packages:
96 namespaces.append("google.cloud")
97
98
99 setuptools.setup(
100 name=name,
101 version=version,
102 description=description,
103 long_description=readme,
104 author="Google LLC",
105 author_email="[email protected]",
106 license="Apache 2.0",
107 url="https://github.com/googleapis/python-bigquery",
108 classifiers=[
109 release_status,
110 "Intended Audience :: Developers",
111 "License :: OSI Approved :: Apache Software License",
112 "Programming Language :: Python",
113 "Programming Language :: Python :: 3",
114 "Programming Language :: Python :: 3.6",
115 "Programming Language :: Python :: 3.7",
116 "Programming Language :: Python :: 3.8",
117 "Programming Language :: Python :: 3.9",
118 "Programming Language :: Python :: 3.10",
119 "Operating System :: OS Independent",
120 "Topic :: Internet",
121 ],
122 platforms="Posix; MacOS X; Windows",
123 packages=packages,
124 namespace_packages=namespaces,
125 install_requires=dependencies,
126 extras_require=extras,
127 python_requires=">=3.6, <3.11",
128 include_package_data=True,
129 zip_safe=False,
130 )
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,8 +42,8 @@
"google-cloud-core >= 1.4.1, <3.0.0dev",
"google-resumable-media >= 0.6.0, < 3.0dev",
"packaging >= 14.3",
- "proto-plus >= 1.10.0", # For the legacy proto-based types.
"protobuf >= 3.12.0", # For the legacy proto-based types.
+ "python-dateutil >= 2.7.2, <3.0dev",
"pyarrow >= 3.0.0, < 8.0dev",
"requests >= 2.18.0, < 3.0.0dev",
]
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,8 +42,8 @@\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n- \"proto-plus >= 1.10.0\", # For the legacy proto-based types.\n \"protobuf >= 3.12.0\", # For the legacy proto-based types.\n+ \"python-dateutil >= 2.7.2, <3.0dev\",\n \"pyarrow >= 3.0.0, < 8.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n ]\n", "issue": "Missing dependency python-dateutil in setup.py\nI noticed that `python-dateutil` is missing from setup.py in `main`. The line \"python-dateutil >= 2.7.2, <3.0dev\", was removed in https://github.com/googleapis/python-bigquery/commit/76d88fbb1316317a61fa1a63c101bc6f42f23af8. \r\n\r\nI'm seeing failures in samples testing for other projects:\r\nhttps://source.cloud.google.com/results/invocations/8e737a80-a041-468e-a2de-184d5ec1662f/log\r\n\r\n```\r\n******************** TESTING PROJECTS ********************\r\n------------------------------------------------------------\r\n- testing samples/snippets\r\n------------------------------------------------------------\r\nnox > Running session py-3.10\r\nnox > Creating virtual environment (virtualenv) using python3.10 in .nox/py-3-10\r\nnox > python -m pip install -r requirements.txt\r\nnox > python -m pip install -r requirements-test.txt\r\nnox > python -m pip install -e /workspace\r\nnox > pytest --junitxml=sponge_log.xml\r\nImportError while loading conftest '/workspace/samples/snippets/conftest.py'.\r\nconftest.py:23: in <module>\r\n from google.cloud import bigquery\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/__init__.py:35: in <module>\r\n from google.cloud.bigquery.client import Client\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/client.py:64: in <module>\r\n from google.cloud.bigquery import _job_helpers\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/_job_helpers.py:24: in <module>\r\n from google.cloud.bigquery import job\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/job/__init__.py:17: in <module>\r\n from google.cloud.bigquery.job.base import _AsyncJob\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/job/base.py:27: in <module>\r\n from google.cloud.bigquery import _helpers\r\n.nox/py-3-10/lib/python3.10/site-packages/google/cloud/bigquery/_helpers.py:24: in <module>\r\n from dateutil import relativedelta\r\nE ModuleNotFoundError: No module named 'dateutil'\r\n```\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0\",\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n \"proto-plus >= 1.15.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"proto-plus >= 1.10.0\", # For the legacy proto-based types.\n \"protobuf >= 3.12.0\", # For the legacy proto-based types.\n \"pyarrow >= 3.0.0, < 8.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n # Keep the no-op bqstorage extra for backward compatibility.\n # See: https://github.com/googleapis/python-bigquery/issues/757\n \"bqstorage\": [],\n \"pandas\": [\"pandas>=1.0.0\", \"db-dtypes>=0.3.0,<2.0.0dev\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.6.0, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.11\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0\",\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n \"proto-plus >= 1.15.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\", # For the legacy proto-based types.\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"pyarrow >= 3.0.0, < 8.0dev\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n # Keep the no-op bqstorage extra for backward compatibility.\n # See: https://github.com/googleapis/python-bigquery/issues/757\n \"bqstorage\": [],\n \"pandas\": [\"pandas>=1.0.0\", \"db-dtypes>=0.3.0,<2.0.0dev\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.6.0, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.11\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,352 | 191 |
gh_patches_debug_12553
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-5860
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adding units for CDF files of Solar Orbiter/EPD [sunpy.io.cdf]
### Description
The nice new function `sunpy.io.cdf.read_cdf` has problems understanding the units for differential intensity from the CDF files of the Solar Orbiter EPD instrument suite (EPT, STEP, HET, SIS).
``` python
>>> read_cdf('solo_L2_epd-ept-sun-rates_20210728_V01.cdf')
WARNING: SunpyUserWarning: astropy did not recognize units of "particles / (s cm^2 sr MeV)". Assigning dimensionless units. If you think this unit should not be dimensionless, please raise an issue at https://github.com/sunpy/sunpy/issues [sunpy.io.cdf]
```
### Steps to Reproduce
<!--
Please include code that reproduces the issue whenever possible.
The best reproductions are self-contained scripts with minimal dependencies.
-->
```python
from sunpy.net import Fido
from sunpy.net import attrs as a
from sunpy.io.cdf import read_cdf
trange = a.Time('2021/07/28', '2021/07/28')
dataset = a.cdaweb.Dataset('SOLO_L2_EPD-EPT-SUN-RATES')
result = Fido.search(trange, dataset)
file = Fido.fetch(result[0])
read_cdf(file[0])
```
### System Details
<!--
We need to know the the package version you are using.
We provide a short function in sunpy (``sunpy.util.system_info()``) that will provide most of the below information.
-->
- SunPy Version: 3.1.3
- Astropy Version: 4.2.1
- Python Version: 3.9.5
- OS information: Ubuntu 20.04.3 LTS
Relates to #5692
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/io/cdf.py`
Content:
```
1 import cdflib
2 import pandas as pd
3 from cdflib.epochs import CDFepoch
4
5 import astropy.units as u
6
7 from sunpy import log
8 from sunpy.timeseries import GenericTimeSeries
9 from sunpy.util.exceptions import warn_user
10
11 __all__ = ['read_cdf']
12
13
14 def read_cdf(fname):
15 """
16 Read a CDF file that follows the ISTP/IACG guidelines.
17
18 Parameters
19 ----------
20 fname : path-like
21 Location of single CDF file to read.
22
23 Returns
24 -------
25 list[GenericTimeSeries]
26 A list of time series objects, one for each unique time index within
27 the CDF file.
28
29 References
30 ----------
31 Space Physics Guidelines for CDF https://spdf.gsfc.nasa.gov/sp_use_of_cdf.html
32 """
33 cdf = cdflib.CDF(str(fname))
34
35 # Extract the time varying variables
36 cdf_info = cdf.cdf_info()
37 meta = cdf.globalattsget()
38 all_var_keys = cdf_info['rVariables'] + cdf_info['zVariables']
39 var_attrs = {key: cdf.varattsget(key) for key in all_var_keys}
40 # Get keys that depend on time
41 var_keys = [var for var in var_attrs if 'DEPEND_0' in var_attrs[var]]
42
43 # Get unique time index keys
44 time_index_keys = sorted(set([var_attrs[var]['DEPEND_0'] for var in var_keys]))
45
46 all_ts = []
47 # For each time index, construct a GenericTimeSeries
48 for index_key in time_index_keys:
49 try:
50 index = cdf.varget(index_key)
51 except ValueError:
52 # Empty index for cdflib >= 0.3.20
53 continue
54 if index is None:
55 # Empty index for cdflib <0.3.20
56 continue
57 # TODO: use to_astropy_time() instead here when we drop pandas in timeseries
58 index = CDFepoch.to_datetime(index)
59 df = pd.DataFrame(index=pd.DatetimeIndex(name=index_key, data=index))
60 units = {}
61
62 for var_key in sorted(var_keys):
63 attrs = var_attrs[var_key]
64 if attrs['DEPEND_0'] != index_key:
65 continue
66
67 # Get data
68 if cdf.varinq(var_key)['Last_Rec'] == -1:
69 log.debug(f'Skipping {var_key} in {fname} as it has zero elements')
70 continue
71
72 data = cdf.varget(var_key)
73 # Get units
74 unit_str = attrs['UNITS']
75 try:
76 unit = u.Unit(unit_str)
77 except ValueError:
78 if unit_str in _known_units:
79 unit = _known_units[unit_str]
80 else:
81 warn_user(f'astropy did not recognize units of "{unit_str}". '
82 'Assigning dimensionless units. '
83 'If you think this unit should not be dimensionless, '
84 'please raise an issue at https://github.com/sunpy/sunpy/issues')
85 unit = u.dimensionless_unscaled
86
87 if data.ndim == 2:
88 # Multiple columns, give each column a unique label
89 for i, col in enumerate(data.T):
90 df[var_key + f'_{i}'] = col
91 units[var_key + f'_{i}'] = unit
92 else:
93 # Single column
94 df[var_key] = data
95 units[var_key] = unit
96
97 all_ts.append(GenericTimeSeries(data=df, units=units, meta=meta))
98
99 if not len(all_ts):
100 log.debug(f'No data found in file {fname}')
101 return all_ts
102
103
104 _known_units = {'ratio': u.dimensionless_unscaled,
105 'NOTEXIST': u.dimensionless_unscaled,
106 'Unitless': u.dimensionless_unscaled,
107 'unitless': u.dimensionless_unscaled,
108 'Quality_Flag': u.dimensionless_unscaled,
109 'None': u.dimensionless_unscaled,
110 'none': u.dimensionless_unscaled,
111 ' none': u.dimensionless_unscaled,
112
113 'microW m^-2': u.mW * u.m**-2,
114
115 'years': u.yr,
116 'days': u.d,
117
118 '#/cc': u.cm**-3,
119 '#/cm^3': u.cm**-3,
120 'cm^{-3}': u.cm**-3,
121 'particles cm^-3': u.cm**-3,
122 'n/cc (from moments)': u.cm**-3,
123 'n/cc (from fits)': u.cm**-3,
124 'Per cc': u.cm**-3,
125 '#/cm3': u.cm**-3,
126 'n/cc': u.cm**-3,
127
128 'km/sec': u.km / u.s,
129 'km/sec (from fits)': u.km / u.s,
130 'km/sec (from moments)': u.km / u.s,
131 'Km/s': u.km / u.s,
132
133 'Volts': u.V,
134
135 'earth radii': u.earthRad,
136 'Re': u.earthRad,
137 'Earth Radii': u.earthRad,
138 'Re (1min)': u.earthRad,
139 'Re (1hr)': u.earthRad,
140
141 'Degrees': u.deg,
142 'degrees': u.deg,
143 'Deg': u.deg,
144 'deg (from fits)': u.deg,
145 'deg (from moments)': u.deg,
146 'deg (>200)': u.deg,
147
148 'Deg K': u.K,
149 'deg_K': u.K,
150 '#/{cc*(cm/s)^3}': (u.cm**3 * (u.cm / u.s)**3)**-1,
151 'sec': u.s,
152 'Samples/s': 1 / u.s,
153
154 'seconds': u.s,
155 'nT GSE': u.nT,
156 'nT GSM': u.nT,
157 'nT DSL': u.nT,
158 'nT SSL': u.nT,
159 'nT (1min)': u.nT,
160 'nT (3sec)': u.nT,
161 'nT (1hr)': u.nT,
162 'nT (>200)': u.nT,
163
164 'msec': u.ms,
165 'milliseconds': u.ms,
166
167 '#/cm2-ster-eV-sec': 1 / (u.cm**2 * u.sr * u.eV * u.s),
168 '1/(cm2 Sr sec MeV/nucleon)': 1 / (u.cm**2 * u.sr * u.s * u.MeV),
169 '1/(cm**2-s-sr-MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
170 '1/(cm**2-s-sr-MeV/nuc.)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
171 '1/(cm^2 sec ster MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
172
173 '1/(cm**2-s-sr)': 1 / (u.cm**2 * u.s * u.sr),
174 '1/(SQcm-ster-s)': 1 / (u.cm**2 * u.s * u.sr),
175 '1/(SQcm-ster-s)..': 1 / (u.cm**2 * u.s * u.sr),
176
177 'Counts/256sec': 1 / (256 * u.s),
178 'Counts/hour': 1 / u.hr,
179 'counts / s': 1/u.s,
180 }
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sunpy/io/cdf.py b/sunpy/io/cdf.py
--- a/sunpy/io/cdf.py
+++ b/sunpy/io/cdf.py
@@ -170,6 +170,9 @@
'1/(cm**2-s-sr-MeV/nuc.)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
'1/(cm^2 sec ster MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
+ 'particles / (s cm^2 sr MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
+ 'particles / (s cm^2 sr MeV/n)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),
+
'1/(cm**2-s-sr)': 1 / (u.cm**2 * u.s * u.sr),
'1/(SQcm-ster-s)': 1 / (u.cm**2 * u.s * u.sr),
'1/(SQcm-ster-s)..': 1 / (u.cm**2 * u.s * u.sr),
|
{"golden_diff": "diff --git a/sunpy/io/cdf.py b/sunpy/io/cdf.py\n--- a/sunpy/io/cdf.py\n+++ b/sunpy/io/cdf.py\n@@ -170,6 +170,9 @@\n '1/(cm**2-s-sr-MeV/nuc.)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n '1/(cm^2 sec ster MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n \n+ 'particles / (s cm^2 sr MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n+ 'particles / (s cm^2 sr MeV/n)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n+\n '1/(cm**2-s-sr)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)..': 1 / (u.cm**2 * u.s * u.sr),\n", "issue": "Adding units for CDF files of Solar Orbiter/EPD [sunpy.io.cdf] \n### Description\r\n\r\nThe nice new function `sunpy.io.cdf.read_cdf` has problems understanding the units for differential intensity from the CDF files of the Solar Orbiter EPD instrument suite (EPT, STEP, HET, SIS).\r\n\r\n``` python\r\n>>> read_cdf('solo_L2_epd-ept-sun-rates_20210728_V01.cdf')\r\nWARNING: SunpyUserWarning: astropy did not recognize units of \"particles / (s cm^2 sr MeV)\". Assigning dimensionless units. If you think this unit should not be dimensionless, please raise an issue at https://github.com/sunpy/sunpy/issues [sunpy.io.cdf]\r\n```\r\n\r\n### Steps to Reproduce\r\n\r\n<!--\r\nPlease include code that reproduces the issue whenever possible.\r\nThe best reproductions are self-contained scripts with minimal dependencies.\r\n-->\r\n\r\n```python\r\nfrom sunpy.net import Fido\r\nfrom sunpy.net import attrs as a\r\nfrom sunpy.io.cdf import read_cdf\r\n\r\ntrange = a.Time('2021/07/28', '2021/07/28')\r\ndataset = a.cdaweb.Dataset('SOLO_L2_EPD-EPT-SUN-RATES')\r\nresult = Fido.search(trange, dataset)\r\nfile = Fido.fetch(result[0])\r\nread_cdf(file[0])\r\n```\r\n\r\n### System Details\r\n\r\n<!--\r\nWe need to know the the package version you are using.\r\nWe provide a short function in sunpy (``sunpy.util.system_info()``) that will provide most of the below information.\r\n-->\r\n\r\n- SunPy Version: 3.1.3\r\n- Astropy Version: 4.2.1\r\n- Python Version: 3.9.5\r\n- OS information: Ubuntu 20.04.3 LTS\r\n\r\nRelates to #5692\r\n\n", "before_files": [{"content": "import cdflib\nimport pandas as pd\nfrom cdflib.epochs import CDFepoch\n\nimport astropy.units as u\n\nfrom sunpy import log\nfrom sunpy.timeseries import GenericTimeSeries\nfrom sunpy.util.exceptions import warn_user\n\n__all__ = ['read_cdf']\n\n\ndef read_cdf(fname):\n \"\"\"\n Read a CDF file that follows the ISTP/IACG guidelines.\n\n Parameters\n ----------\n fname : path-like\n Location of single CDF file to read.\n\n Returns\n -------\n list[GenericTimeSeries]\n A list of time series objects, one for each unique time index within\n the CDF file.\n\n References\n ----------\n Space Physics Guidelines for CDF https://spdf.gsfc.nasa.gov/sp_use_of_cdf.html\n \"\"\"\n cdf = cdflib.CDF(str(fname))\n\n # Extract the time varying variables\n cdf_info = cdf.cdf_info()\n meta = cdf.globalattsget()\n all_var_keys = cdf_info['rVariables'] + cdf_info['zVariables']\n var_attrs = {key: cdf.varattsget(key) for key in all_var_keys}\n # Get keys that depend on time\n var_keys = [var for var in var_attrs if 'DEPEND_0' in var_attrs[var]]\n\n # Get unique time index keys\n time_index_keys = sorted(set([var_attrs[var]['DEPEND_0'] for var in var_keys]))\n\n all_ts = []\n # For each time index, construct a GenericTimeSeries\n for index_key in time_index_keys:\n try:\n index = cdf.varget(index_key)\n except ValueError:\n # Empty index for cdflib >= 0.3.20\n continue\n if index is None:\n # Empty index for cdflib <0.3.20\n continue\n # TODO: use to_astropy_time() instead here when we drop pandas in timeseries\n index = CDFepoch.to_datetime(index)\n df = pd.DataFrame(index=pd.DatetimeIndex(name=index_key, data=index))\n units = {}\n\n for var_key in sorted(var_keys):\n attrs = var_attrs[var_key]\n if attrs['DEPEND_0'] != index_key:\n continue\n\n # Get data\n if cdf.varinq(var_key)['Last_Rec'] == -1:\n log.debug(f'Skipping {var_key} in {fname} as it has zero elements')\n continue\n\n data = cdf.varget(var_key)\n # Get units\n unit_str = attrs['UNITS']\n try:\n unit = u.Unit(unit_str)\n except ValueError:\n if unit_str in _known_units:\n unit = _known_units[unit_str]\n else:\n warn_user(f'astropy did not recognize units of \"{unit_str}\". '\n 'Assigning dimensionless units. '\n 'If you think this unit should not be dimensionless, '\n 'please raise an issue at https://github.com/sunpy/sunpy/issues')\n unit = u.dimensionless_unscaled\n\n if data.ndim == 2:\n # Multiple columns, give each column a unique label\n for i, col in enumerate(data.T):\n df[var_key + f'_{i}'] = col\n units[var_key + f'_{i}'] = unit\n else:\n # Single column\n df[var_key] = data\n units[var_key] = unit\n\n all_ts.append(GenericTimeSeries(data=df, units=units, meta=meta))\n\n if not len(all_ts):\n log.debug(f'No data found in file {fname}')\n return all_ts\n\n\n_known_units = {'ratio': u.dimensionless_unscaled,\n 'NOTEXIST': u.dimensionless_unscaled,\n 'Unitless': u.dimensionless_unscaled,\n 'unitless': u.dimensionless_unscaled,\n 'Quality_Flag': u.dimensionless_unscaled,\n 'None': u.dimensionless_unscaled,\n 'none': u.dimensionless_unscaled,\n ' none': u.dimensionless_unscaled,\n\n 'microW m^-2': u.mW * u.m**-2,\n\n 'years': u.yr,\n 'days': u.d,\n\n '#/cc': u.cm**-3,\n '#/cm^3': u.cm**-3,\n 'cm^{-3}': u.cm**-3,\n 'particles cm^-3': u.cm**-3,\n 'n/cc (from moments)': u.cm**-3,\n 'n/cc (from fits)': u.cm**-3,\n 'Per cc': u.cm**-3,\n '#/cm3': u.cm**-3,\n 'n/cc': u.cm**-3,\n\n 'km/sec': u.km / u.s,\n 'km/sec (from fits)': u.km / u.s,\n 'km/sec (from moments)': u.km / u.s,\n 'Km/s': u.km / u.s,\n\n 'Volts': u.V,\n\n 'earth radii': u.earthRad,\n 'Re': u.earthRad,\n 'Earth Radii': u.earthRad,\n 'Re (1min)': u.earthRad,\n 'Re (1hr)': u.earthRad,\n\n 'Degrees': u.deg,\n 'degrees': u.deg,\n 'Deg': u.deg,\n 'deg (from fits)': u.deg,\n 'deg (from moments)': u.deg,\n 'deg (>200)': u.deg,\n\n 'Deg K': u.K,\n 'deg_K': u.K,\n '#/{cc*(cm/s)^3}': (u.cm**3 * (u.cm / u.s)**3)**-1,\n 'sec': u.s,\n 'Samples/s': 1 / u.s,\n\n 'seconds': u.s,\n 'nT GSE': u.nT,\n 'nT GSM': u.nT,\n 'nT DSL': u.nT,\n 'nT SSL': u.nT,\n 'nT (1min)': u.nT,\n 'nT (3sec)': u.nT,\n 'nT (1hr)': u.nT,\n 'nT (>200)': u.nT,\n\n 'msec': u.ms,\n 'milliseconds': u.ms,\n\n '#/cm2-ster-eV-sec': 1 / (u.cm**2 * u.sr * u.eV * u.s),\n '1/(cm2 Sr sec MeV/nucleon)': 1 / (u.cm**2 * u.sr * u.s * u.MeV),\n '1/(cm**2-s-sr-MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n '1/(cm**2-s-sr-MeV/nuc.)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n '1/(cm^2 sec ster MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n\n '1/(cm**2-s-sr)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)..': 1 / (u.cm**2 * u.s * u.sr),\n\n 'Counts/256sec': 1 / (256 * u.s),\n 'Counts/hour': 1 / u.hr,\n 'counts / s': 1/u.s,\n }\n", "path": "sunpy/io/cdf.py"}], "after_files": [{"content": "import cdflib\nimport pandas as pd\nfrom cdflib.epochs import CDFepoch\n\nimport astropy.units as u\n\nfrom sunpy import log\nfrom sunpy.timeseries import GenericTimeSeries\nfrom sunpy.util.exceptions import warn_user\n\n__all__ = ['read_cdf']\n\n\ndef read_cdf(fname):\n \"\"\"\n Read a CDF file that follows the ISTP/IACG guidelines.\n\n Parameters\n ----------\n fname : path-like\n Location of single CDF file to read.\n\n Returns\n -------\n list[GenericTimeSeries]\n A list of time series objects, one for each unique time index within\n the CDF file.\n\n References\n ----------\n Space Physics Guidelines for CDF https://spdf.gsfc.nasa.gov/sp_use_of_cdf.html\n \"\"\"\n cdf = cdflib.CDF(str(fname))\n\n # Extract the time varying variables\n cdf_info = cdf.cdf_info()\n meta = cdf.globalattsget()\n all_var_keys = cdf_info['rVariables'] + cdf_info['zVariables']\n var_attrs = {key: cdf.varattsget(key) for key in all_var_keys}\n # Get keys that depend on time\n var_keys = [var for var in var_attrs if 'DEPEND_0' in var_attrs[var]]\n\n # Get unique time index keys\n time_index_keys = sorted(set([var_attrs[var]['DEPEND_0'] for var in var_keys]))\n\n all_ts = []\n # For each time index, construct a GenericTimeSeries\n for index_key in time_index_keys:\n try:\n index = cdf.varget(index_key)\n except ValueError:\n # Empty index for cdflib >= 0.3.20\n continue\n if index is None:\n # Empty index for cdflib <0.3.20\n continue\n # TODO: use to_astropy_time() instead here when we drop pandas in timeseries\n index = CDFepoch.to_datetime(index)\n df = pd.DataFrame(index=pd.DatetimeIndex(name=index_key, data=index))\n units = {}\n\n for var_key in sorted(var_keys):\n attrs = var_attrs[var_key]\n if attrs['DEPEND_0'] != index_key:\n continue\n\n # Get data\n if cdf.varinq(var_key)['Last_Rec'] == -1:\n log.debug(f'Skipping {var_key} in {fname} as it has zero elements')\n continue\n\n data = cdf.varget(var_key)\n # Get units\n unit_str = attrs['UNITS']\n try:\n unit = u.Unit(unit_str)\n except ValueError:\n if unit_str in _known_units:\n unit = _known_units[unit_str]\n else:\n warn_user(f'astropy did not recognize units of \"{unit_str}\". '\n 'Assigning dimensionless units. '\n 'If you think this unit should not be dimensionless, '\n 'please raise an issue at https://github.com/sunpy/sunpy/issues')\n unit = u.dimensionless_unscaled\n\n if data.ndim == 2:\n # Multiple columns, give each column a unique label\n for i, col in enumerate(data.T):\n df[var_key + f'_{i}'] = col\n units[var_key + f'_{i}'] = unit\n else:\n # Single column\n df[var_key] = data\n units[var_key] = unit\n\n all_ts.append(GenericTimeSeries(data=df, units=units, meta=meta))\n\n if not len(all_ts):\n log.debug(f'No data found in file {fname}')\n return all_ts\n\n\n_known_units = {'ratio': u.dimensionless_unscaled,\n 'NOTEXIST': u.dimensionless_unscaled,\n 'Unitless': u.dimensionless_unscaled,\n 'unitless': u.dimensionless_unscaled,\n 'Quality_Flag': u.dimensionless_unscaled,\n 'None': u.dimensionless_unscaled,\n 'none': u.dimensionless_unscaled,\n ' none': u.dimensionless_unscaled,\n\n 'microW m^-2': u.mW * u.m**-2,\n\n 'years': u.yr,\n 'days': u.d,\n\n '#/cc': u.cm**-3,\n '#/cm^3': u.cm**-3,\n 'cm^{-3}': u.cm**-3,\n 'particles cm^-3': u.cm**-3,\n 'n/cc (from moments)': u.cm**-3,\n 'n/cc (from fits)': u.cm**-3,\n 'Per cc': u.cm**-3,\n '#/cm3': u.cm**-3,\n 'n/cc': u.cm**-3,\n\n 'km/sec': u.km / u.s,\n 'km/sec (from fits)': u.km / u.s,\n 'km/sec (from moments)': u.km / u.s,\n 'Km/s': u.km / u.s,\n\n 'Volts': u.V,\n\n 'earth radii': u.earthRad,\n 'Re': u.earthRad,\n 'Earth Radii': u.earthRad,\n 'Re (1min)': u.earthRad,\n 'Re (1hr)': u.earthRad,\n\n 'Degrees': u.deg,\n 'degrees': u.deg,\n 'Deg': u.deg,\n 'deg (from fits)': u.deg,\n 'deg (from moments)': u.deg,\n 'deg (>200)': u.deg,\n\n 'Deg K': u.K,\n 'deg_K': u.K,\n '#/{cc*(cm/s)^3}': (u.cm**3 * (u.cm / u.s)**3)**-1,\n 'sec': u.s,\n 'Samples/s': 1 / u.s,\n\n 'seconds': u.s,\n 'nT GSE': u.nT,\n 'nT GSM': u.nT,\n 'nT DSL': u.nT,\n 'nT SSL': u.nT,\n 'nT (1min)': u.nT,\n 'nT (3sec)': u.nT,\n 'nT (1hr)': u.nT,\n 'nT (>200)': u.nT,\n\n 'msec': u.ms,\n 'milliseconds': u.ms,\n\n '#/cm2-ster-eV-sec': 1 / (u.cm**2 * u.sr * u.eV * u.s),\n '1/(cm2 Sr sec MeV/nucleon)': 1 / (u.cm**2 * u.sr * u.s * u.MeV),\n '1/(cm**2-s-sr-MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n '1/(cm**2-s-sr-MeV/nuc.)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n '1/(cm^2 sec ster MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n\n 'particles / (s cm^2 sr MeV)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n 'particles / (s cm^2 sr MeV/n)': 1 / (u.cm**2 * u.s * u.sr * u.MeV),\n\n '1/(cm**2-s-sr)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)': 1 / (u.cm**2 * u.s * u.sr),\n '1/(SQcm-ster-s)..': 1 / (u.cm**2 * u.s * u.sr),\n\n 'Counts/256sec': 1 / (256 * u.s),\n 'Counts/hour': 1 / u.hr,\n 'counts / s': 1/u.s,\n }\n", "path": "sunpy/io/cdf.py"}]}
| 2,808 | 274 |
gh_patches_debug_40988
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-1918
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplifying the Function interface
The arguments of a function `f` can be listed: `f.func_code.co_varnames[:f.func_code.co_argcount]`.
Currently, I'm decorating functions like so:
``` Python
def nipype_function(*output_names, **kwargs):
def decorator(func):
kwargs.setdefault('output_names', output_names or ['output'])
kwargs.update({
'function': func,
'input_names': func.func_code.co_varnames[:func.func_code.co_argcount]})
fn = util.Function(**kwargs)
fn.inputs.function_str = u'\n'.join(
fn.inputs.function_str.split(u'\n')[1:])
return fn
return decorator
@nipype_decorator('out_list')
def mergelists(lists):
return [elem for lst in lists for elem in lst]
```
So two questions:
1. Would something like this decorator be useful to include in nipype?
2. Would it be useful to permit `nipype.interfaces.utility.Function` to derive `input_names` from the function or function string? I would probably also set a default output name. Thus you could generally write:
``` Python
def func(arg1, arg2):
return arg1 + arg2
fi = Function(function=func)
fi.inputs.arg1 = 2
fi.inputs.arg2 = 3
res = fi.run()
assert res.outputs.out == 5
```
I know I'm kind of throwing a flurry of things at y'all without polishing each first, so thanks for your continued attention.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/interfaces/utility/wrappers.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
3 # vi: set ft=python sts=4 ts=4 sw=4 et:
4 """Various utilities
5
6 Change directory to provide relative paths for doctests
7 >>> import os
8 >>> filepath = os.path.dirname(os.path.realpath(__file__))
9 >>> datadir = os.path.realpath(os.path.join(filepath,
10 ... '../../testing/data'))
11 >>> os.chdir(datadir)
12
13
14 """
15 from __future__ import print_function, division, unicode_literals, absolute_import
16
17 from future import standard_library
18 standard_library.install_aliases()
19
20 from builtins import str, bytes
21
22 from nipype import logging
23 from ..base import (traits, DynamicTraitedSpec, Undefined, isdefined, runtime_profile,
24 BaseInterfaceInputSpec)
25 from ..io import IOBase, add_traits
26 from ...utils.filemanip import filename_to_list
27 from ...utils.misc import getsource, create_function_from_source
28
29 logger = logging.getLogger('interface')
30 if runtime_profile:
31 try:
32 import psutil
33 except ImportError as exc:
34 logger.info('Unable to import packages needed for runtime profiling. '\
35 'Turning off runtime profiler. Reason: %s' % exc)
36 runtime_profile = False
37
38
39 class FunctionInputSpec(DynamicTraitedSpec, BaseInterfaceInputSpec):
40 function_str = traits.Str(mandatory=True, desc='code for function')
41
42
43 class Function(IOBase):
44 """Runs arbitrary function as an interface
45
46 Examples
47 --------
48
49 >>> func = 'def func(arg1, arg2=5): return arg1 + arg2'
50 >>> fi = Function(input_names=['arg1', 'arg2'], output_names=['out'])
51 >>> fi.inputs.function_str = func
52 >>> res = fi.run(arg1=1)
53 >>> res.outputs.out
54 6
55
56 """
57
58 input_spec = FunctionInputSpec
59 output_spec = DynamicTraitedSpec
60
61 def __init__(self, input_names, output_names, function=None, imports=None,
62 **inputs):
63 """
64
65 Parameters
66 ----------
67
68 input_names: single str or list
69 names corresponding to function inputs
70 output_names: single str or list
71 names corresponding to function outputs.
72 has to match the number of outputs
73 function : callable
74 callable python object. must be able to execute in an
75 isolated namespace (possibly in concert with the ``imports``
76 parameter)
77 imports : list of strings
78 list of import statements that allow the function to execute
79 in an otherwise empty namespace
80 """
81
82 super(Function, self).__init__(**inputs)
83 if function:
84 if hasattr(function, '__call__'):
85 try:
86 self.inputs.function_str = getsource(function)
87 except IOError:
88 raise Exception('Interface Function does not accept '
89 'function objects defined interactively '
90 'in a python session')
91 elif isinstance(function, (str, bytes)):
92 self.inputs.function_str = function
93 else:
94 raise Exception('Unknown type of function')
95 self.inputs.on_trait_change(self._set_function_string,
96 'function_str')
97 self._input_names = filename_to_list(input_names)
98 self._output_names = filename_to_list(output_names)
99 add_traits(self.inputs, [name for name in self._input_names])
100 self.imports = imports
101 self._out = {}
102 for name in self._output_names:
103 self._out[name] = None
104
105 def _set_function_string(self, obj, name, old, new):
106 if name == 'function_str':
107 if hasattr(new, '__call__'):
108 function_source = getsource(new)
109 elif isinstance(new, (str, bytes)):
110 function_source = new
111 self.inputs.trait_set(trait_change_notify=False,
112 **{'%s' % name: function_source})
113
114 def _add_output_traits(self, base):
115 undefined_traits = {}
116 for key in self._output_names:
117 base.add_trait(key, traits.Any)
118 undefined_traits[key] = Undefined
119 base.trait_set(trait_change_notify=False, **undefined_traits)
120 return base
121
122 def _run_interface(self, runtime):
123 # Get workflow logger for runtime profile error reporting
124 from nipype import logging
125 logger = logging.getLogger('workflow')
126
127 # Create function handle
128 function_handle = create_function_from_source(self.inputs.function_str,
129 self.imports)
130
131 # Wrapper for running function handle in multiprocessing.Process
132 # Can catch exceptions and report output via multiprocessing.Queue
133 def _function_handle_wrapper(queue, **kwargs):
134 try:
135 out = function_handle(**kwargs)
136 queue.put(out)
137 except Exception as exc:
138 queue.put(exc)
139
140 # Get function args
141 args = {}
142 for name in self._input_names:
143 value = getattr(self.inputs, name)
144 if isdefined(value):
145 args[name] = value
146
147 # Profile resources if set
148 if runtime_profile:
149 from nipype.interfaces.base import get_max_resources_used
150 import multiprocessing
151 # Init communication queue and proc objs
152 queue = multiprocessing.Queue()
153 proc = multiprocessing.Process(target=_function_handle_wrapper,
154 args=(queue,), kwargs=args)
155
156 # Init memory and threads before profiling
157 mem_mb = 0
158 num_threads = 0
159
160 # Start process and profile while it's alive
161 proc.start()
162 while proc.is_alive():
163 mem_mb, num_threads = \
164 get_max_resources_used(proc.pid, mem_mb, num_threads,
165 pyfunc=True)
166
167 # Get result from process queue
168 out = queue.get()
169 # If it is an exception, raise it
170 if isinstance(out, Exception):
171 raise out
172
173 # Function ran successfully, populate runtime stats
174 setattr(runtime, 'runtime_memory_gb', mem_mb / 1024.0)
175 setattr(runtime, 'runtime_threads', num_threads)
176 else:
177 out = function_handle(**args)
178
179 if len(self._output_names) == 1:
180 self._out[self._output_names[0]] = out
181 else:
182 if isinstance(out, tuple) and (len(out) != len(self._output_names)):
183 raise RuntimeError('Mismatch in number of expected outputs')
184
185 else:
186 for idx, name in enumerate(self._output_names):
187 self._out[name] = out[idx]
188
189 return runtime
190
191 def _list_outputs(self):
192 outputs = self._outputs().get()
193 for key in self._output_names:
194 outputs[key] = self._out[key]
195 return outputs
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/interfaces/utility/wrappers.py b/nipype/interfaces/utility/wrappers.py
--- a/nipype/interfaces/utility/wrappers.py
+++ b/nipype/interfaces/utility/wrappers.py
@@ -58,18 +58,19 @@
input_spec = FunctionInputSpec
output_spec = DynamicTraitedSpec
- def __init__(self, input_names, output_names, function=None, imports=None,
- **inputs):
+ def __init__(self, input_names=None, output_names='out', function=None,
+ imports=None, **inputs):
"""
Parameters
----------
- input_names: single str or list
+ input_names: single str or list or None
names corresponding to function inputs
+ if ``None``, derive input names from function argument names
output_names: single str or list
- names corresponding to function outputs.
- has to match the number of outputs
+ names corresponding to function outputs (default: 'out').
+ if list of length > 1, has to match the number of outputs
function : callable
callable python object. must be able to execute in an
isolated namespace (possibly in concert with the ``imports``
@@ -88,10 +89,18 @@
raise Exception('Interface Function does not accept '
'function objects defined interactively '
'in a python session')
+ else:
+ if input_names is None:
+ fninfo = function.__code__
elif isinstance(function, (str, bytes)):
self.inputs.function_str = function
+ if input_names is None:
+ fninfo = create_function_from_source(
+ function, imports).__code__
else:
raise Exception('Unknown type of function')
+ if input_names is None:
+ input_names = fninfo.co_varnames[:fninfo.co_argcount]
self.inputs.on_trait_change(self._set_function_string,
'function_str')
self._input_names = filename_to_list(input_names)
@@ -106,10 +115,18 @@
if name == 'function_str':
if hasattr(new, '__call__'):
function_source = getsource(new)
+ fninfo = new.__code__
elif isinstance(new, (str, bytes)):
function_source = new
+ fninfo = create_function_from_source(
+ new, self.imports).__code__
self.inputs.trait_set(trait_change_notify=False,
**{'%s' % name: function_source})
+ # Update input traits
+ input_names = fninfo.co_varnames[:fninfo.co_argcount]
+ new_names = set(input_names) - set(self._input_names)
+ add_traits(self.inputs, list(new_names))
+ self._input_names.extend(new_names)
def _add_output_traits(self, base):
undefined_traits = {}
|
{"golden_diff": "diff --git a/nipype/interfaces/utility/wrappers.py b/nipype/interfaces/utility/wrappers.py\n--- a/nipype/interfaces/utility/wrappers.py\n+++ b/nipype/interfaces/utility/wrappers.py\n@@ -58,18 +58,19 @@\n input_spec = FunctionInputSpec\n output_spec = DynamicTraitedSpec\n \n- def __init__(self, input_names, output_names, function=None, imports=None,\n- **inputs):\n+ def __init__(self, input_names=None, output_names='out', function=None,\n+ imports=None, **inputs):\n \"\"\"\n \n Parameters\n ----------\n \n- input_names: single str or list\n+ input_names: single str or list or None\n names corresponding to function inputs\n+ if ``None``, derive input names from function argument names\n output_names: single str or list\n- names corresponding to function outputs.\n- has to match the number of outputs\n+ names corresponding to function outputs (default: 'out').\n+ if list of length > 1, has to match the number of outputs\n function : callable\n callable python object. must be able to execute in an\n isolated namespace (possibly in concert with the ``imports``\n@@ -88,10 +89,18 @@\n raise Exception('Interface Function does not accept '\n 'function objects defined interactively '\n 'in a python session')\n+ else:\n+ if input_names is None:\n+ fninfo = function.__code__\n elif isinstance(function, (str, bytes)):\n self.inputs.function_str = function\n+ if input_names is None:\n+ fninfo = create_function_from_source(\n+ function, imports).__code__\n else:\n raise Exception('Unknown type of function')\n+ if input_names is None:\n+ input_names = fninfo.co_varnames[:fninfo.co_argcount]\n self.inputs.on_trait_change(self._set_function_string,\n 'function_str')\n self._input_names = filename_to_list(input_names)\n@@ -106,10 +115,18 @@\n if name == 'function_str':\n if hasattr(new, '__call__'):\n function_source = getsource(new)\n+ fninfo = new.__code__\n elif isinstance(new, (str, bytes)):\n function_source = new\n+ fninfo = create_function_from_source(\n+ new, self.imports).__code__\n self.inputs.trait_set(trait_change_notify=False,\n **{'%s' % name: function_source})\n+ # Update input traits\n+ input_names = fninfo.co_varnames[:fninfo.co_argcount]\n+ new_names = set(input_names) - set(self._input_names)\n+ add_traits(self.inputs, list(new_names))\n+ self._input_names.extend(new_names)\n \n def _add_output_traits(self, base):\n undefined_traits = {}\n", "issue": "Simplifying the Function interface\nThe arguments of a function `f` can be listed: `f.func_code.co_varnames[:f.func_code.co_argcount]`.\n\nCurrently, I'm decorating functions like so:\n\n``` Python\ndef nipype_function(*output_names, **kwargs):\n def decorator(func):\n kwargs.setdefault('output_names', output_names or ['output'])\n kwargs.update({\n 'function': func,\n 'input_names': func.func_code.co_varnames[:func.func_code.co_argcount]})\n fn = util.Function(**kwargs)\n fn.inputs.function_str = u'\\n'.join(\n fn.inputs.function_str.split(u'\\n')[1:])\n return fn\n return decorator\n\n@nipype_decorator('out_list')\ndef mergelists(lists):\n return [elem for lst in lists for elem in lst]\n```\n\nSo two questions:\n1. Would something like this decorator be useful to include in nipype?\n2. Would it be useful to permit `nipype.interfaces.utility.Function` to derive `input_names` from the function or function string? I would probably also set a default output name. Thus you could generally write:\n\n``` Python\ndef func(arg1, arg2):\n return arg1 + arg2\n\nfi = Function(function=func)\nfi.inputs.arg1 = 2\nfi.inputs.arg2 = 3\nres = fi.run()\nassert res.outputs.out == 5\n```\n\nI know I'm kind of throwing a flurry of things at y'all without polishing each first, so thanks for your continued attention.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"Various utilities\n\n Change directory to provide relative paths for doctests\n >>> import os\n >>> filepath = os.path.dirname(os.path.realpath(__file__))\n >>> datadir = os.path.realpath(os.path.join(filepath,\n ... '../../testing/data'))\n >>> os.chdir(datadir)\n\n\n\"\"\"\nfrom __future__ import print_function, division, unicode_literals, absolute_import\n\nfrom future import standard_library\nstandard_library.install_aliases()\n\nfrom builtins import str, bytes\n\nfrom nipype import logging\nfrom ..base import (traits, DynamicTraitedSpec, Undefined, isdefined, runtime_profile,\n BaseInterfaceInputSpec)\nfrom ..io import IOBase, add_traits\nfrom ...utils.filemanip import filename_to_list\nfrom ...utils.misc import getsource, create_function_from_source\n\nlogger = logging.getLogger('interface')\nif runtime_profile:\n try:\n import psutil\n except ImportError as exc:\n logger.info('Unable to import packages needed for runtime profiling. '\\\n 'Turning off runtime profiler. Reason: %s' % exc)\n runtime_profile = False\n\n\nclass FunctionInputSpec(DynamicTraitedSpec, BaseInterfaceInputSpec):\n function_str = traits.Str(mandatory=True, desc='code for function')\n\n\nclass Function(IOBase):\n \"\"\"Runs arbitrary function as an interface\n\n Examples\n --------\n\n >>> func = 'def func(arg1, arg2=5): return arg1 + arg2'\n >>> fi = Function(input_names=['arg1', 'arg2'], output_names=['out'])\n >>> fi.inputs.function_str = func\n >>> res = fi.run(arg1=1)\n >>> res.outputs.out\n 6\n\n \"\"\"\n\n input_spec = FunctionInputSpec\n output_spec = DynamicTraitedSpec\n\n def __init__(self, input_names, output_names, function=None, imports=None,\n **inputs):\n \"\"\"\n\n Parameters\n ----------\n\n input_names: single str or list\n names corresponding to function inputs\n output_names: single str or list\n names corresponding to function outputs.\n has to match the number of outputs\n function : callable\n callable python object. must be able to execute in an\n isolated namespace (possibly in concert with the ``imports``\n parameter)\n imports : list of strings\n list of import statements that allow the function to execute\n in an otherwise empty namespace\n \"\"\"\n\n super(Function, self).__init__(**inputs)\n if function:\n if hasattr(function, '__call__'):\n try:\n self.inputs.function_str = getsource(function)\n except IOError:\n raise Exception('Interface Function does not accept '\n 'function objects defined interactively '\n 'in a python session')\n elif isinstance(function, (str, bytes)):\n self.inputs.function_str = function\n else:\n raise Exception('Unknown type of function')\n self.inputs.on_trait_change(self._set_function_string,\n 'function_str')\n self._input_names = filename_to_list(input_names)\n self._output_names = filename_to_list(output_names)\n add_traits(self.inputs, [name for name in self._input_names])\n self.imports = imports\n self._out = {}\n for name in self._output_names:\n self._out[name] = None\n\n def _set_function_string(self, obj, name, old, new):\n if name == 'function_str':\n if hasattr(new, '__call__'):\n function_source = getsource(new)\n elif isinstance(new, (str, bytes)):\n function_source = new\n self.inputs.trait_set(trait_change_notify=False,\n **{'%s' % name: function_source})\n\n def _add_output_traits(self, base):\n undefined_traits = {}\n for key in self._output_names:\n base.add_trait(key, traits.Any)\n undefined_traits[key] = Undefined\n base.trait_set(trait_change_notify=False, **undefined_traits)\n return base\n\n def _run_interface(self, runtime):\n # Get workflow logger for runtime profile error reporting\n from nipype import logging\n logger = logging.getLogger('workflow')\n\n # Create function handle\n function_handle = create_function_from_source(self.inputs.function_str,\n self.imports)\n\n # Wrapper for running function handle in multiprocessing.Process\n # Can catch exceptions and report output via multiprocessing.Queue\n def _function_handle_wrapper(queue, **kwargs):\n try:\n out = function_handle(**kwargs)\n queue.put(out)\n except Exception as exc:\n queue.put(exc)\n\n # Get function args\n args = {}\n for name in self._input_names:\n value = getattr(self.inputs, name)\n if isdefined(value):\n args[name] = value\n\n # Profile resources if set\n if runtime_profile:\n from nipype.interfaces.base import get_max_resources_used\n import multiprocessing\n # Init communication queue and proc objs\n queue = multiprocessing.Queue()\n proc = multiprocessing.Process(target=_function_handle_wrapper,\n args=(queue,), kwargs=args)\n\n # Init memory and threads before profiling\n mem_mb = 0\n num_threads = 0\n\n # Start process and profile while it's alive\n proc.start()\n while proc.is_alive():\n mem_mb, num_threads = \\\n get_max_resources_used(proc.pid, mem_mb, num_threads,\n pyfunc=True)\n\n # Get result from process queue\n out = queue.get()\n # If it is an exception, raise it\n if isinstance(out, Exception):\n raise out\n\n # Function ran successfully, populate runtime stats\n setattr(runtime, 'runtime_memory_gb', mem_mb / 1024.0)\n setattr(runtime, 'runtime_threads', num_threads)\n else:\n out = function_handle(**args)\n\n if len(self._output_names) == 1:\n self._out[self._output_names[0]] = out\n else:\n if isinstance(out, tuple) and (len(out) != len(self._output_names)):\n raise RuntimeError('Mismatch in number of expected outputs')\n\n else:\n for idx, name in enumerate(self._output_names):\n self._out[name] = out[idx]\n\n return runtime\n\n def _list_outputs(self):\n outputs = self._outputs().get()\n for key in self._output_names:\n outputs[key] = self._out[key]\n return outputs\n", "path": "nipype/interfaces/utility/wrappers.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"Various utilities\n\n Change directory to provide relative paths for doctests\n >>> import os\n >>> filepath = os.path.dirname(os.path.realpath(__file__))\n >>> datadir = os.path.realpath(os.path.join(filepath,\n ... '../../testing/data'))\n >>> os.chdir(datadir)\n\n\n\"\"\"\nfrom __future__ import print_function, division, unicode_literals, absolute_import\n\nfrom future import standard_library\nstandard_library.install_aliases()\n\nfrom builtins import str, bytes\n\nfrom nipype import logging\nfrom ..base import (traits, DynamicTraitedSpec, Undefined, isdefined, runtime_profile,\n BaseInterfaceInputSpec)\nfrom ..io import IOBase, add_traits\nfrom ...utils.filemanip import filename_to_list\nfrom ...utils.misc import getsource, create_function_from_source\n\nlogger = logging.getLogger('interface')\nif runtime_profile:\n try:\n import psutil\n except ImportError as exc:\n logger.info('Unable to import packages needed for runtime profiling. '\\\n 'Turning off runtime profiler. Reason: %s' % exc)\n runtime_profile = False\n\n\nclass FunctionInputSpec(DynamicTraitedSpec, BaseInterfaceInputSpec):\n function_str = traits.Str(mandatory=True, desc='code for function')\n\n\nclass Function(IOBase):\n \"\"\"Runs arbitrary function as an interface\n\n Examples\n --------\n\n >>> func = 'def func(arg1, arg2=5): return arg1 + arg2'\n >>> fi = Function(input_names=['arg1', 'arg2'], output_names=['out'])\n >>> fi.inputs.function_str = func\n >>> res = fi.run(arg1=1)\n >>> res.outputs.out\n 6\n\n \"\"\"\n\n input_spec = FunctionInputSpec\n output_spec = DynamicTraitedSpec\n\n def __init__(self, input_names=None, output_names='out', function=None,\n imports=None, **inputs):\n \"\"\"\n\n Parameters\n ----------\n\n input_names: single str or list or None\n names corresponding to function inputs\n if ``None``, derive input names from function argument names\n output_names: single str or list\n names corresponding to function outputs (default: 'out').\n if list of length > 1, has to match the number of outputs\n function : callable\n callable python object. must be able to execute in an\n isolated namespace (possibly in concert with the ``imports``\n parameter)\n imports : list of strings\n list of import statements that allow the function to execute\n in an otherwise empty namespace\n \"\"\"\n\n super(Function, self).__init__(**inputs)\n if function:\n if hasattr(function, '__call__'):\n try:\n self.inputs.function_str = getsource(function)\n except IOError:\n raise Exception('Interface Function does not accept '\n 'function objects defined interactively '\n 'in a python session')\n else:\n if input_names is None:\n fninfo = function.__code__\n elif isinstance(function, (str, bytes)):\n self.inputs.function_str = function\n if input_names is None:\n fninfo = create_function_from_source(\n function, imports).__code__\n else:\n raise Exception('Unknown type of function')\n if input_names is None:\n input_names = fninfo.co_varnames[:fninfo.co_argcount]\n self.inputs.on_trait_change(self._set_function_string,\n 'function_str')\n self._input_names = filename_to_list(input_names)\n self._output_names = filename_to_list(output_names)\n add_traits(self.inputs, [name for name in self._input_names])\n self.imports = imports\n self._out = {}\n for name in self._output_names:\n self._out[name] = None\n\n def _set_function_string(self, obj, name, old, new):\n if name == 'function_str':\n if hasattr(new, '__call__'):\n function_source = getsource(new)\n fninfo = new.__code__\n elif isinstance(new, (str, bytes)):\n function_source = new\n fninfo = create_function_from_source(\n new, self.imports).__code__\n self.inputs.trait_set(trait_change_notify=False,\n **{'%s' % name: function_source})\n # Update input traits\n input_names = fninfo.co_varnames[:fninfo.co_argcount]\n new_names = set(input_names) - set(self._input_names)\n add_traits(self.inputs, list(new_names))\n self._input_names.extend(new_names)\n\n def _add_output_traits(self, base):\n undefined_traits = {}\n for key in self._output_names:\n base.add_trait(key, traits.Any)\n undefined_traits[key] = Undefined\n base.trait_set(trait_change_notify=False, **undefined_traits)\n return base\n\n def _run_interface(self, runtime):\n # Get workflow logger for runtime profile error reporting\n from nipype import logging\n logger = logging.getLogger('workflow')\n\n # Create function handle\n function_handle = create_function_from_source(self.inputs.function_str,\n self.imports)\n\n # Wrapper for running function handle in multiprocessing.Process\n # Can catch exceptions and report output via multiprocessing.Queue\n def _function_handle_wrapper(queue, **kwargs):\n try:\n out = function_handle(**kwargs)\n queue.put(out)\n except Exception as exc:\n queue.put(exc)\n\n # Get function args\n args = {}\n for name in self._input_names:\n value = getattr(self.inputs, name)\n if isdefined(value):\n args[name] = value\n\n # Profile resources if set\n if runtime_profile:\n from nipype.interfaces.base import get_max_resources_used\n import multiprocessing\n # Init communication queue and proc objs\n queue = multiprocessing.Queue()\n proc = multiprocessing.Process(target=_function_handle_wrapper,\n args=(queue,), kwargs=args)\n\n # Init memory and threads before profiling\n mem_mb = 0\n num_threads = 0\n\n # Start process and profile while it's alive\n proc.start()\n while proc.is_alive():\n mem_mb, num_threads = \\\n get_max_resources_used(proc.pid, mem_mb, num_threads,\n pyfunc=True)\n\n # Get result from process queue\n out = queue.get()\n # If it is an exception, raise it\n if isinstance(out, Exception):\n raise out\n\n # Function ran successfully, populate runtime stats\n setattr(runtime, 'runtime_memory_gb', mem_mb / 1024.0)\n setattr(runtime, 'runtime_threads', num_threads)\n else:\n out = function_handle(**args)\n\n if len(self._output_names) == 1:\n self._out[self._output_names[0]] = out\n else:\n if isinstance(out, tuple) and (len(out) != len(self._output_names)):\n raise RuntimeError('Mismatch in number of expected outputs')\n\n else:\n for idx, name in enumerate(self._output_names):\n self._out[name] = out[idx]\n\n return runtime\n\n def _list_outputs(self):\n outputs = self._outputs().get()\n for key in self._output_names:\n outputs[key] = self._out[key]\n return outputs\n", "path": "nipype/interfaces/utility/wrappers.py"}]}
| 2,475 | 629 |
gh_patches_debug_31590
|
rasdani/github-patches
|
git_diff
|
Textualize__rich-369
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[REQUEST]Please consider adding MAC/OUI highlighting - similar to IP Address/URL highlighting
**Add MAC-address oui highlighting**
It'd be a useful addition if Rich could consistently handle highlighting of the multiple mac-address/oui formats that exist
e.g.
000c.298c.500f
0:c:29:8c:50:f
00:0C:29:8C:50:0F
00-0C-29-8C-50-0F
00:0c:29:8c:50:0f
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rich/default_styles.py`
Content:
```
1 from typing import Dict
2
3 from .style import Style
4
5 DEFAULT_STYLES: Dict[str, Style] = {
6 "none": Style.null(),
7 "reset": Style(
8 color="default",
9 bgcolor="default",
10 dim=False,
11 bold=False,
12 italic=False,
13 underline=False,
14 blink=False,
15 blink2=False,
16 reverse=False,
17 conceal=False,
18 strike=False,
19 ),
20 "dim": Style(dim=True),
21 "bright": Style(dim=False),
22 "bold": Style(bold=True),
23 "strong": Style(bold=True),
24 "code": Style(reverse=True, bold=True),
25 "italic": Style(italic=True),
26 "emphasize": Style(italic=True),
27 "underline": Style(underline=True),
28 "blink": Style(blink=True),
29 "blink2": Style(blink2=True),
30 "reverse": Style(reverse=True),
31 "strike": Style(strike=True),
32 "black": Style(color="black"),
33 "red": Style(color="red"),
34 "green": Style(color="green"),
35 "yellow": Style(color="yellow"),
36 "magenta": Style(color="magenta"),
37 "cyan": Style(color="cyan"),
38 "white": Style(color="white"),
39 "inspect.attr": Style(color="yellow", italic=True),
40 "inspect.attr.dunder": Style(color="yellow", italic=True, dim=True),
41 "inspect.callable": Style(bold=True, color="red"),
42 "inspect.def": Style(italic=True, color="bright_cyan"),
43 "inspect.error": Style(bold=True, color="red"),
44 "inspect.equals": Style(),
45 "inspect.help": Style(color="cyan"),
46 "inspect.doc": Style(dim=True),
47 "logging.keyword": Style(bold=True, color="yellow"),
48 "logging.level.notset": Style(dim=True),
49 "logging.level.debug": Style(color="green"),
50 "logging.level.info": Style(color="blue"),
51 "logging.level.warning": Style(color="red"),
52 "logging.level.error": Style(color="red", bold=True),
53 "logging.level.critical": Style(color="red", bold=True, reverse=True),
54 "log.level": Style.null(),
55 "log.time": Style(color="cyan", dim=True),
56 "log.message": Style.null(),
57 "log.path": Style(dim=True),
58 "repr.error": Style(color="red", bold=True),
59 "repr.str": Style(color="green", italic=False, bold=False),
60 "repr.brace": Style(bold=True),
61 "repr.comma": Style(bold=True),
62 "repr.ipv4": Style(bold=True, color="bright_green"),
63 "repr.ipv6": Style(bold=True, color="bright_green"),
64 "repr.tag_start": Style(bold=True),
65 "repr.tag_name": Style(color="bright_magenta", bold=True),
66 "repr.tag_contents": Style(color="default"),
67 "repr.tag_end": Style(bold=True),
68 "repr.attrib_name": Style(color="yellow", italic=True),
69 "repr.attrib_equal": Style(bold=True),
70 "repr.attrib_value": Style(color="magenta", italic=False),
71 "repr.number": Style(color="blue", bold=True, italic=False),
72 "repr.bool_true": Style(color="bright_green", italic=True),
73 "repr.bool_false": Style(color="bright_red", italic=True),
74 "repr.none": Style(color="magenta", italic=True),
75 "repr.url": Style(underline=True, color="bright_blue", italic=False, bold=False),
76 "repr.uuid": Style(color="bright_yellow", bold=False),
77 "rule.line": Style(color="bright_green"),
78 "rule.text": Style.null(),
79 "prompt": Style.null(),
80 "prompt.choices": Style(color="magenta", bold=True),
81 "prompt.default": Style(color="cyan", bold=True),
82 "prompt.invalid": Style(color="red"),
83 "prompt.invalid.choice": Style(color="red"),
84 "pretty": Style.null(),
85 "scope.border": Style(color="blue"),
86 "scope.key": Style(color="yellow", italic=True),
87 "scope.key.special": Style(color="yellow", italic=True, dim=True),
88 "scope.equals": Style(color="red"),
89 "repr.path": Style(color="magenta"),
90 "repr.filename": Style(color="bright_magenta"),
91 "table.header": Style(bold=True),
92 "table.footer": Style(bold=True),
93 "table.cell": Style.null(),
94 "table.title": Style(italic=True),
95 "table.caption": Style(italic=True, dim=True),
96 "traceback.border.syntax_error": Style(color="bright_red"),
97 "traceback.border": Style(color="red"),
98 "traceback.text": Style.null(),
99 "traceback.title": Style(color="red", bold=True),
100 "traceback.exc_type": Style(color="bright_red", bold=True),
101 "traceback.exc_value": Style.null(),
102 "traceback.offset": Style(color="bright_red", bold=True),
103 "bar.back": Style(color="grey23"),
104 "bar.complete": Style(color="rgb(249,38,114)"),
105 "bar.finished": Style(color="rgb(114,156,31)"),
106 "bar.pulse": Style(color="rgb(249,38,114)"),
107 "progress.description": Style.null(),
108 "progress.filesize": Style(color="green"),
109 "progress.filesize.total": Style(color="green"),
110 "progress.download": Style(color="green"),
111 "progress.percentage": Style(color="magenta"),
112 "progress.remaining": Style(color="cyan"),
113 "progress.data.speed": Style(color="red"),
114 }
115
116 MARKDOWN_STYLES = {
117 "markdown.paragraph": Style(),
118 "markdown.text": Style(),
119 "markdown.emph": Style(italic=True),
120 "markdown.strong": Style(bold=True),
121 "markdown.code": Style(bgcolor="black", color="bright_white"),
122 "markdown.code_block": Style(dim=True, color="cyan", bgcolor="black"),
123 "markdown.block_quote": Style(color="magenta"),
124 "markdown.list": Style(color="cyan"),
125 "markdown.item": Style(),
126 "markdown.item.bullet": Style(color="yellow", bold=True),
127 "markdown.item.number": Style(color="yellow", bold=True),
128 "markdown.hr": Style(color="yellow"),
129 "markdown.h1.border": Style(),
130 "markdown.h1": Style(bold=True),
131 "markdown.h2": Style(bold=True, underline=True),
132 "markdown.h3": Style(bold=True),
133 "markdown.h4": Style(bold=True, dim=True),
134 "markdown.h5": Style(underline=True),
135 "markdown.h6": Style(italic=True),
136 "markdown.h7": Style(italic=True, dim=True),
137 "markdown.link": Style(color="bright_blue"),
138 "markdown.link_url": Style(color="blue"),
139 }
140
141
142 DEFAULT_STYLES.update(MARKDOWN_STYLES)
143
```
Path: `rich/highlighter.py`
Content:
```
1 from abc import ABC, abstractmethod
2 from typing import List, Union
3
4 from .text import Text
5
6
7 class Highlighter(ABC):
8 """Abstract base class for highlighters."""
9
10 def __call__(self, text: Union[str, Text]) -> Text:
11 """Highlight a str or Text instance.
12
13 Args:
14 text (Union[str, ~Text]): Text to highlight.
15
16 Raises:
17 TypeError: If not called with text or str.
18
19 Returns:
20 Text: A test instance with highlighting applied.
21 """
22 if isinstance(text, str):
23 highlight_text = Text(text)
24 elif isinstance(text, Text):
25 highlight_text = text.copy()
26 else:
27 raise TypeError(f"str or Text instance required, not {text!r}")
28 self.highlight(highlight_text)
29 return highlight_text
30
31 @abstractmethod
32 def highlight(self, text: Text) -> None:
33 """Apply highlighting in place to text.
34
35 Args:
36 text (~Text): A text object highlight.
37 """
38
39
40 class NullHighlighter(Highlighter):
41 """A highlighter object that doesn't highlight.
42
43 May be used to disable highlighting entirely.
44
45 """
46
47 def highlight(self, text: Text) -> None:
48 """Nothing to do"""
49
50
51 class RegexHighlighter(Highlighter):
52 """Applies highlighting from a list of regular expressions."""
53
54 highlights: List[str] = []
55 base_style: str = ""
56
57 def highlight(self, text: Text) -> None:
58 """Highlight :class:`rich.text.Text` using regular expressions.
59
60 Args:
61 text (~Text): Text to highlighted.
62
63 """
64 highlight_regex = text.highlight_regex
65 for re_highlight in self.highlights:
66 highlight_regex(re_highlight, style_prefix=self.base_style)
67
68
69 class ReprHighlighter(RegexHighlighter):
70 """Highlights the text typically produced from ``__repr__`` methods."""
71
72 base_style = "repr."
73 highlights = [
74 r"(?P<brace>[\{\[\(\)\]\}])",
75 r"(?P<tag_start>\<)(?P<tag_name>[\w\-\.\:]*)(?P<tag_contents>.*?)(?P<tag_end>\>)",
76 r"(?P<attrib_name>\w+?)=(?P<attrib_value>\"?[\w_]+\"?)?",
77 r"(?P<bool_true>True)|(?P<bool_false>False)|(?P<none>None)",
78 r"(?P<number>(?<!\w)\-?[0-9]+\.?[0-9]*(e[\-\+]?\d+?)?\b)",
79 r"(?P<number>0x[0-9a-f]*)",
80 r"(?P<path>\B(\/[\w\.\-\_\+]+)*\/)(?P<filename>[\w\.\-\_\+]*)?",
81 r"(?P<ipv4>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})",
82 r"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})",
83 r"(?<!\\)(?P<str>b?\'\'\'.*?(?<!\\)\'\'\'|b?\'.*?(?<!\\)\'|b?\"\"\".*?(?<!\\)\"\"\"|b?\".*?(?<!\\)\")",
84 r"(?P<url>https?:\/\/[0-9a-zA-Z\$\-\_\+\!`\(\)\,\.\?\/\;\:\&\=\%\#]*)",
85 r"(?P<uuid>[a-fA-F0-9]{8}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{12})",
86 ]
87
88
89 if __name__ == "__main__": # pragma: no cover
90 from .console import Console
91
92 console = Console()
93 console.print("[bold green]hello world![/bold green]")
94 console.print("'[bold green]hello world![/bold green]'")
95
96 console.print(" /foo")
97 console.print("/foo/")
98 console.print("/foo/bar")
99 console.print("foo/bar/baz")
100
101 console.print("/foo/bar/baz?foo=bar+egg&egg=baz")
102 console.print("/foo/bar/baz/")
103 console.print("/foo/bar/baz/egg")
104 console.print("/foo/bar/baz/egg.py")
105 console.print("/foo/bar/baz/egg.py word")
106 console.print(" /foo/bar/baz/egg.py word")
107 console.print("foo /foo/bar/baz/egg.py word")
108 console.print("foo /foo/bar/ba._++z/egg+.py word")
109 console.print("https://example.org?foo=bar#header")
110
111 console.print(1234567.34)
112 console.print(1 / 2)
113 console.print(-1 / 123123123123)
114
115 console.print(
116 "127.0.1.1 bar 192.168.1.4 2001:0db8:85a3:0000:0000:8a2e:0370:7334 foo"
117 )
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rich/default_styles.py b/rich/default_styles.py
--- a/rich/default_styles.py
+++ b/rich/default_styles.py
@@ -61,6 +61,8 @@
"repr.comma": Style(bold=True),
"repr.ipv4": Style(bold=True, color="bright_green"),
"repr.ipv6": Style(bold=True, color="bright_green"),
+ "repr.eui48": Style(bold=True, color="bright_green"),
+ "repr.eui64": Style(bold=True, color="bright_green"),
"repr.tag_start": Style(bold=True),
"repr.tag_name": Style(color="bright_magenta", bold=True),
"repr.tag_contents": Style(color="default"),
diff --git a/rich/highlighter.py b/rich/highlighter.py
--- a/rich/highlighter.py
+++ b/rich/highlighter.py
@@ -80,6 +80,12 @@
r"(?P<path>\B(\/[\w\.\-\_\+]+)*\/)(?P<filename>[\w\.\-\_\+]*)?",
r"(?P<ipv4>[0-9]{1,3}\.[0-9]{1,3}\.[0-gt9]{1,3}\.[0-9]{1,3})",
r"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})",
+ r"(?P<eui48>([0-9A-Fa-f]{1,2}-){5}[0-9A-Fa-f]{1,2})", # EUI-48 6x2 hyphen
+ r"(?P<eui64>([0-9A-Fa-f]{1,2}-){7}[0-9A-Fa-f]{1,2})", # EUI-64 8x2 hyphen
+ r"(?P<eui48>([0-9A-Fa-f]{1,2}:){5}[0-9A-Fa-f]{1,2})", # EUI-48 6x2 colon
+ r"(?P<eui64>([0-9A-Fa-f]{1,2}:){7}[0-9A-Fa-f]{1,2})", # EUI-64 8x2 colon
+ r"(?P<eui48>([0-9A-Fa-f]{4}\.){2}[0-9A-Fa-f]{4})", # EUI-48 3x4 dot
+ r"(?P<eui64>([0-9A-Fa-f]{4}\.){3}[0-9A-Fa-f]{4})", # EUI-64 4x4 dot
r"(?<!\\)(?P<str>b?\'\'\'.*?(?<!\\)\'\'\'|b?\'.*?(?<!\\)\'|b?\"\"\".*?(?<!\\)\"\"\"|b?\".*?(?<!\\)\")",
r"(?P<url>https?:\/\/[0-9a-zA-Z\$\-\_\+\!`\(\)\,\.\?\/\;\:\&\=\%\#]*)",
r"(?P<uuid>[a-fA-F0-9]{8}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{4}\-[a-fA-F0-9]{12})",
|
{"golden_diff": "diff --git a/rich/default_styles.py b/rich/default_styles.py\n--- a/rich/default_styles.py\n+++ b/rich/default_styles.py\n@@ -61,6 +61,8 @@\n \"repr.comma\": Style(bold=True),\n \"repr.ipv4\": Style(bold=True, color=\"bright_green\"),\n \"repr.ipv6\": Style(bold=True, color=\"bright_green\"),\n+ \"repr.eui48\": Style(bold=True, color=\"bright_green\"),\n+ \"repr.eui64\": Style(bold=True, color=\"bright_green\"),\n \"repr.tag_start\": Style(bold=True),\n \"repr.tag_name\": Style(color=\"bright_magenta\", bold=True),\n \"repr.tag_contents\": Style(color=\"default\"),\ndiff --git a/rich/highlighter.py b/rich/highlighter.py\n--- a/rich/highlighter.py\n+++ b/rich/highlighter.py\n@@ -80,6 +80,12 @@\n r\"(?P<path>\\B(\\/[\\w\\.\\-\\_\\+]+)*\\/)(?P<filename>[\\w\\.\\-\\_\\+]*)?\",\n r\"(?P<ipv4>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-gt9]{1,3}\\.[0-9]{1,3})\",\n r\"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})\",\n+ r\"(?P<eui48>([0-9A-Fa-f]{1,2}-){5}[0-9A-Fa-f]{1,2})\", # EUI-48 6x2 hyphen\n+ r\"(?P<eui64>([0-9A-Fa-f]{1,2}-){7}[0-9A-Fa-f]{1,2})\", # EUI-64 8x2 hyphen\n+ r\"(?P<eui48>([0-9A-Fa-f]{1,2}:){5}[0-9A-Fa-f]{1,2})\", # EUI-48 6x2 colon\n+ r\"(?P<eui64>([0-9A-Fa-f]{1,2}:){7}[0-9A-Fa-f]{1,2})\", # EUI-64 8x2 colon\n+ r\"(?P<eui48>([0-9A-Fa-f]{4}\\.){2}[0-9A-Fa-f]{4})\", # EUI-48 3x4 dot\n+ r\"(?P<eui64>([0-9A-Fa-f]{4}\\.){3}[0-9A-Fa-f]{4})\", # EUI-64 4x4 dot\n r\"(?<!\\\\)(?P<str>b?\\'\\'\\'.*?(?<!\\\\)\\'\\'\\'|b?\\'.*?(?<!\\\\)\\'|b?\\\"\\\"\\\".*?(?<!\\\\)\\\"\\\"\\\"|b?\\\".*?(?<!\\\\)\\\")\",\n r\"(?P<url>https?:\\/\\/[0-9a-zA-Z\\$\\-\\_\\+\\!`\\(\\)\\,\\.\\?\\/\\;\\:\\&\\=\\%\\#]*)\",\n r\"(?P<uuid>[a-fA-F0-9]{8}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{12})\",\n", "issue": "[REQUEST]Please consider adding MAC/OUI highlighting - similar to IP Address/URL highlighting \n**Add MAC-address oui highlighting**\r\n\r\nIt'd be a useful addition if Rich could consistently handle highlighting of the multiple mac-address/oui formats that exist\r\n\r\ne.g.\r\n000c.298c.500f\r\n0:c:29:8c:50:f\r\n00:0C:29:8C:50:0F\r\n00-0C-29-8C-50-0F\r\n00:0c:29:8c:50:0f\r\n\n", "before_files": [{"content": "from typing import Dict\n\nfrom .style import Style\n\nDEFAULT_STYLES: Dict[str, Style] = {\n \"none\": Style.null(),\n \"reset\": Style(\n color=\"default\",\n bgcolor=\"default\",\n dim=False,\n bold=False,\n italic=False,\n underline=False,\n blink=False,\n blink2=False,\n reverse=False,\n conceal=False,\n strike=False,\n ),\n \"dim\": Style(dim=True),\n \"bright\": Style(dim=False),\n \"bold\": Style(bold=True),\n \"strong\": Style(bold=True),\n \"code\": Style(reverse=True, bold=True),\n \"italic\": Style(italic=True),\n \"emphasize\": Style(italic=True),\n \"underline\": Style(underline=True),\n \"blink\": Style(blink=True),\n \"blink2\": Style(blink2=True),\n \"reverse\": Style(reverse=True),\n \"strike\": Style(strike=True),\n \"black\": Style(color=\"black\"),\n \"red\": Style(color=\"red\"),\n \"green\": Style(color=\"green\"),\n \"yellow\": Style(color=\"yellow\"),\n \"magenta\": Style(color=\"magenta\"),\n \"cyan\": Style(color=\"cyan\"),\n \"white\": Style(color=\"white\"),\n \"inspect.attr\": Style(color=\"yellow\", italic=True),\n \"inspect.attr.dunder\": Style(color=\"yellow\", italic=True, dim=True),\n \"inspect.callable\": Style(bold=True, color=\"red\"),\n \"inspect.def\": Style(italic=True, color=\"bright_cyan\"),\n \"inspect.error\": Style(bold=True, color=\"red\"),\n \"inspect.equals\": Style(),\n \"inspect.help\": Style(color=\"cyan\"),\n \"inspect.doc\": Style(dim=True),\n \"logging.keyword\": Style(bold=True, color=\"yellow\"),\n \"logging.level.notset\": Style(dim=True),\n \"logging.level.debug\": Style(color=\"green\"),\n \"logging.level.info\": Style(color=\"blue\"),\n \"logging.level.warning\": Style(color=\"red\"),\n \"logging.level.error\": Style(color=\"red\", bold=True),\n \"logging.level.critical\": Style(color=\"red\", bold=True, reverse=True),\n \"log.level\": Style.null(),\n \"log.time\": Style(color=\"cyan\", dim=True),\n \"log.message\": Style.null(),\n \"log.path\": Style(dim=True),\n \"repr.error\": Style(color=\"red\", bold=True),\n \"repr.str\": Style(color=\"green\", italic=False, bold=False),\n \"repr.brace\": Style(bold=True),\n \"repr.comma\": Style(bold=True),\n \"repr.ipv4\": Style(bold=True, color=\"bright_green\"),\n \"repr.ipv6\": Style(bold=True, color=\"bright_green\"),\n \"repr.tag_start\": Style(bold=True),\n \"repr.tag_name\": Style(color=\"bright_magenta\", bold=True),\n \"repr.tag_contents\": Style(color=\"default\"),\n \"repr.tag_end\": Style(bold=True),\n \"repr.attrib_name\": Style(color=\"yellow\", italic=True),\n \"repr.attrib_equal\": Style(bold=True),\n \"repr.attrib_value\": Style(color=\"magenta\", italic=False),\n \"repr.number\": Style(color=\"blue\", bold=True, italic=False),\n \"repr.bool_true\": Style(color=\"bright_green\", italic=True),\n \"repr.bool_false\": Style(color=\"bright_red\", italic=True),\n \"repr.none\": Style(color=\"magenta\", italic=True),\n \"repr.url\": Style(underline=True, color=\"bright_blue\", italic=False, bold=False),\n \"repr.uuid\": Style(color=\"bright_yellow\", bold=False),\n \"rule.line\": Style(color=\"bright_green\"),\n \"rule.text\": Style.null(),\n \"prompt\": Style.null(),\n \"prompt.choices\": Style(color=\"magenta\", bold=True),\n \"prompt.default\": Style(color=\"cyan\", bold=True),\n \"prompt.invalid\": Style(color=\"red\"),\n \"prompt.invalid.choice\": Style(color=\"red\"),\n \"pretty\": Style.null(),\n \"scope.border\": Style(color=\"blue\"),\n \"scope.key\": Style(color=\"yellow\", italic=True),\n \"scope.key.special\": Style(color=\"yellow\", italic=True, dim=True),\n \"scope.equals\": Style(color=\"red\"),\n \"repr.path\": Style(color=\"magenta\"),\n \"repr.filename\": Style(color=\"bright_magenta\"),\n \"table.header\": Style(bold=True),\n \"table.footer\": Style(bold=True),\n \"table.cell\": Style.null(),\n \"table.title\": Style(italic=True),\n \"table.caption\": Style(italic=True, dim=True),\n \"traceback.border.syntax_error\": Style(color=\"bright_red\"),\n \"traceback.border\": Style(color=\"red\"),\n \"traceback.text\": Style.null(),\n \"traceback.title\": Style(color=\"red\", bold=True),\n \"traceback.exc_type\": Style(color=\"bright_red\", bold=True),\n \"traceback.exc_value\": Style.null(),\n \"traceback.offset\": Style(color=\"bright_red\", bold=True),\n \"bar.back\": Style(color=\"grey23\"),\n \"bar.complete\": Style(color=\"rgb(249,38,114)\"),\n \"bar.finished\": Style(color=\"rgb(114,156,31)\"),\n \"bar.pulse\": Style(color=\"rgb(249,38,114)\"),\n \"progress.description\": Style.null(),\n \"progress.filesize\": Style(color=\"green\"),\n \"progress.filesize.total\": Style(color=\"green\"),\n \"progress.download\": Style(color=\"green\"),\n \"progress.percentage\": Style(color=\"magenta\"),\n \"progress.remaining\": Style(color=\"cyan\"),\n \"progress.data.speed\": Style(color=\"red\"),\n}\n\nMARKDOWN_STYLES = {\n \"markdown.paragraph\": Style(),\n \"markdown.text\": Style(),\n \"markdown.emph\": Style(italic=True),\n \"markdown.strong\": Style(bold=True),\n \"markdown.code\": Style(bgcolor=\"black\", color=\"bright_white\"),\n \"markdown.code_block\": Style(dim=True, color=\"cyan\", bgcolor=\"black\"),\n \"markdown.block_quote\": Style(color=\"magenta\"),\n \"markdown.list\": Style(color=\"cyan\"),\n \"markdown.item\": Style(),\n \"markdown.item.bullet\": Style(color=\"yellow\", bold=True),\n \"markdown.item.number\": Style(color=\"yellow\", bold=True),\n \"markdown.hr\": Style(color=\"yellow\"),\n \"markdown.h1.border\": Style(),\n \"markdown.h1\": Style(bold=True),\n \"markdown.h2\": Style(bold=True, underline=True),\n \"markdown.h3\": Style(bold=True),\n \"markdown.h4\": Style(bold=True, dim=True),\n \"markdown.h5\": Style(underline=True),\n \"markdown.h6\": Style(italic=True),\n \"markdown.h7\": Style(italic=True, dim=True),\n \"markdown.link\": Style(color=\"bright_blue\"),\n \"markdown.link_url\": Style(color=\"blue\"),\n}\n\n\nDEFAULT_STYLES.update(MARKDOWN_STYLES)\n", "path": "rich/default_styles.py"}, {"content": "from abc import ABC, abstractmethod\nfrom typing import List, Union\n\nfrom .text import Text\n\n\nclass Highlighter(ABC):\n \"\"\"Abstract base class for highlighters.\"\"\"\n\n def __call__(self, text: Union[str, Text]) -> Text:\n \"\"\"Highlight a str or Text instance.\n\n Args:\n text (Union[str, ~Text]): Text to highlight.\n\n Raises:\n TypeError: If not called with text or str.\n\n Returns:\n Text: A test instance with highlighting applied.\n \"\"\"\n if isinstance(text, str):\n highlight_text = Text(text)\n elif isinstance(text, Text):\n highlight_text = text.copy()\n else:\n raise TypeError(f\"str or Text instance required, not {text!r}\")\n self.highlight(highlight_text)\n return highlight_text\n\n @abstractmethod\n def highlight(self, text: Text) -> None:\n \"\"\"Apply highlighting in place to text.\n\n Args:\n text (~Text): A text object highlight.\n \"\"\"\n\n\nclass NullHighlighter(Highlighter):\n \"\"\"A highlighter object that doesn't highlight.\n\n May be used to disable highlighting entirely.\n\n \"\"\"\n\n def highlight(self, text: Text) -> None:\n \"\"\"Nothing to do\"\"\"\n\n\nclass RegexHighlighter(Highlighter):\n \"\"\"Applies highlighting from a list of regular expressions.\"\"\"\n\n highlights: List[str] = []\n base_style: str = \"\"\n\n def highlight(self, text: Text) -> None:\n \"\"\"Highlight :class:`rich.text.Text` using regular expressions.\n\n Args:\n text (~Text): Text to highlighted.\n\n \"\"\"\n highlight_regex = text.highlight_regex\n for re_highlight in self.highlights:\n highlight_regex(re_highlight, style_prefix=self.base_style)\n\n\nclass ReprHighlighter(RegexHighlighter):\n \"\"\"Highlights the text typically produced from ``__repr__`` methods.\"\"\"\n\n base_style = \"repr.\"\n highlights = [\n r\"(?P<brace>[\\{\\[\\(\\)\\]\\}])\",\n r\"(?P<tag_start>\\<)(?P<tag_name>[\\w\\-\\.\\:]*)(?P<tag_contents>.*?)(?P<tag_end>\\>)\",\n r\"(?P<attrib_name>\\w+?)=(?P<attrib_value>\\\"?[\\w_]+\\\"?)?\",\n r\"(?P<bool_true>True)|(?P<bool_false>False)|(?P<none>None)\",\n r\"(?P<number>(?<!\\w)\\-?[0-9]+\\.?[0-9]*(e[\\-\\+]?\\d+?)?\\b)\",\n r\"(?P<number>0x[0-9a-f]*)\",\n r\"(?P<path>\\B(\\/[\\w\\.\\-\\_\\+]+)*\\/)(?P<filename>[\\w\\.\\-\\_\\+]*)?\",\n r\"(?P<ipv4>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3})\",\n r\"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})\",\n r\"(?<!\\\\)(?P<str>b?\\'\\'\\'.*?(?<!\\\\)\\'\\'\\'|b?\\'.*?(?<!\\\\)\\'|b?\\\"\\\"\\\".*?(?<!\\\\)\\\"\\\"\\\"|b?\\\".*?(?<!\\\\)\\\")\",\n r\"(?P<url>https?:\\/\\/[0-9a-zA-Z\\$\\-\\_\\+\\!`\\(\\)\\,\\.\\?\\/\\;\\:\\&\\=\\%\\#]*)\",\n r\"(?P<uuid>[a-fA-F0-9]{8}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{12})\",\n ]\n\n\nif __name__ == \"__main__\": # pragma: no cover\n from .console import Console\n\n console = Console()\n console.print(\"[bold green]hello world![/bold green]\")\n console.print(\"'[bold green]hello world![/bold green]'\")\n\n console.print(\" /foo\")\n console.print(\"/foo/\")\n console.print(\"/foo/bar\")\n console.print(\"foo/bar/baz\")\n\n console.print(\"/foo/bar/baz?foo=bar+egg&egg=baz\")\n console.print(\"/foo/bar/baz/\")\n console.print(\"/foo/bar/baz/egg\")\n console.print(\"/foo/bar/baz/egg.py\")\n console.print(\"/foo/bar/baz/egg.py word\")\n console.print(\" /foo/bar/baz/egg.py word\")\n console.print(\"foo /foo/bar/baz/egg.py word\")\n console.print(\"foo /foo/bar/ba._++z/egg+.py word\")\n console.print(\"https://example.org?foo=bar#header\")\n\n console.print(1234567.34)\n console.print(1 / 2)\n console.print(-1 / 123123123123)\n\n console.print(\n \"127.0.1.1 bar 192.168.1.4 2001:0db8:85a3:0000:0000:8a2e:0370:7334 foo\"\n )\n", "path": "rich/highlighter.py"}], "after_files": [{"content": "from typing import Dict\n\nfrom .style import Style\n\nDEFAULT_STYLES: Dict[str, Style] = {\n \"none\": Style.null(),\n \"reset\": Style(\n color=\"default\",\n bgcolor=\"default\",\n dim=False,\n bold=False,\n italic=False,\n underline=False,\n blink=False,\n blink2=False,\n reverse=False,\n conceal=False,\n strike=False,\n ),\n \"dim\": Style(dim=True),\n \"bright\": Style(dim=False),\n \"bold\": Style(bold=True),\n \"strong\": Style(bold=True),\n \"code\": Style(reverse=True, bold=True),\n \"italic\": Style(italic=True),\n \"emphasize\": Style(italic=True),\n \"underline\": Style(underline=True),\n \"blink\": Style(blink=True),\n \"blink2\": Style(blink2=True),\n \"reverse\": Style(reverse=True),\n \"strike\": Style(strike=True),\n \"black\": Style(color=\"black\"),\n \"red\": Style(color=\"red\"),\n \"green\": Style(color=\"green\"),\n \"yellow\": Style(color=\"yellow\"),\n \"magenta\": Style(color=\"magenta\"),\n \"cyan\": Style(color=\"cyan\"),\n \"white\": Style(color=\"white\"),\n \"inspect.attr\": Style(color=\"yellow\", italic=True),\n \"inspect.attr.dunder\": Style(color=\"yellow\", italic=True, dim=True),\n \"inspect.callable\": Style(bold=True, color=\"red\"),\n \"inspect.def\": Style(italic=True, color=\"bright_cyan\"),\n \"inspect.error\": Style(bold=True, color=\"red\"),\n \"inspect.equals\": Style(),\n \"inspect.help\": Style(color=\"cyan\"),\n \"inspect.doc\": Style(dim=True),\n \"logging.keyword\": Style(bold=True, color=\"yellow\"),\n \"logging.level.notset\": Style(dim=True),\n \"logging.level.debug\": Style(color=\"green\"),\n \"logging.level.info\": Style(color=\"blue\"),\n \"logging.level.warning\": Style(color=\"red\"),\n \"logging.level.error\": Style(color=\"red\", bold=True),\n \"logging.level.critical\": Style(color=\"red\", bold=True, reverse=True),\n \"log.level\": Style.null(),\n \"log.time\": Style(color=\"cyan\", dim=True),\n \"log.message\": Style.null(),\n \"log.path\": Style(dim=True),\n \"repr.error\": Style(color=\"red\", bold=True),\n \"repr.str\": Style(color=\"green\", italic=False, bold=False),\n \"repr.brace\": Style(bold=True),\n \"repr.comma\": Style(bold=True),\n \"repr.ipv4\": Style(bold=True, color=\"bright_green\"),\n \"repr.ipv6\": Style(bold=True, color=\"bright_green\"),\n \"repr.eui48\": Style(bold=True, color=\"bright_green\"),\n \"repr.eui64\": Style(bold=True, color=\"bright_green\"),\n \"repr.tag_start\": Style(bold=True),\n \"repr.tag_name\": Style(color=\"bright_magenta\", bold=True),\n \"repr.tag_contents\": Style(color=\"default\"),\n \"repr.tag_end\": Style(bold=True),\n \"repr.attrib_name\": Style(color=\"yellow\", italic=True),\n \"repr.attrib_equal\": Style(bold=True),\n \"repr.attrib_value\": Style(color=\"magenta\", italic=False),\n \"repr.number\": Style(color=\"blue\", bold=True, italic=False),\n \"repr.bool_true\": Style(color=\"bright_green\", italic=True),\n \"repr.bool_false\": Style(color=\"bright_red\", italic=True),\n \"repr.none\": Style(color=\"magenta\", italic=True),\n \"repr.url\": Style(underline=True, color=\"bright_blue\", italic=False, bold=False),\n \"repr.uuid\": Style(color=\"bright_yellow\", bold=False),\n \"rule.line\": Style(color=\"bright_green\"),\n \"rule.text\": Style.null(),\n \"prompt\": Style.null(),\n \"prompt.choices\": Style(color=\"magenta\", bold=True),\n \"prompt.default\": Style(color=\"cyan\", bold=True),\n \"prompt.invalid\": Style(color=\"red\"),\n \"prompt.invalid.choice\": Style(color=\"red\"),\n \"pretty\": Style.null(),\n \"scope.border\": Style(color=\"blue\"),\n \"scope.key\": Style(color=\"yellow\", italic=True),\n \"scope.key.special\": Style(color=\"yellow\", italic=True, dim=True),\n \"scope.equals\": Style(color=\"red\"),\n \"repr.path\": Style(color=\"magenta\"),\n \"repr.filename\": Style(color=\"bright_magenta\"),\n \"table.header\": Style(bold=True),\n \"table.footer\": Style(bold=True),\n \"table.cell\": Style.null(),\n \"table.title\": Style(italic=True),\n \"table.caption\": Style(italic=True, dim=True),\n \"traceback.border.syntax_error\": Style(color=\"bright_red\"),\n \"traceback.border\": Style(color=\"red\"),\n \"traceback.text\": Style.null(),\n \"traceback.title\": Style(color=\"red\", bold=True),\n \"traceback.exc_type\": Style(color=\"bright_red\", bold=True),\n \"traceback.exc_value\": Style.null(),\n \"traceback.offset\": Style(color=\"bright_red\", bold=True),\n \"bar.back\": Style(color=\"grey23\"),\n \"bar.complete\": Style(color=\"rgb(249,38,114)\"),\n \"bar.finished\": Style(color=\"rgb(114,156,31)\"),\n \"bar.pulse\": Style(color=\"rgb(249,38,114)\"),\n \"progress.description\": Style.null(),\n \"progress.filesize\": Style(color=\"green\"),\n \"progress.filesize.total\": Style(color=\"green\"),\n \"progress.download\": Style(color=\"green\"),\n \"progress.percentage\": Style(color=\"magenta\"),\n \"progress.remaining\": Style(color=\"cyan\"),\n \"progress.data.speed\": Style(color=\"red\"),\n}\n\nMARKDOWN_STYLES = {\n \"markdown.paragraph\": Style(),\n \"markdown.text\": Style(),\n \"markdown.emph\": Style(italic=True),\n \"markdown.strong\": Style(bold=True),\n \"markdown.code\": Style(bgcolor=\"black\", color=\"bright_white\"),\n \"markdown.code_block\": Style(dim=True, color=\"cyan\", bgcolor=\"black\"),\n \"markdown.block_quote\": Style(color=\"magenta\"),\n \"markdown.list\": Style(color=\"cyan\"),\n \"markdown.item\": Style(),\n \"markdown.item.bullet\": Style(color=\"yellow\", bold=True),\n \"markdown.item.number\": Style(color=\"yellow\", bold=True),\n \"markdown.hr\": Style(color=\"yellow\"),\n \"markdown.h1.border\": Style(),\n \"markdown.h1\": Style(bold=True),\n \"markdown.h2\": Style(bold=True, underline=True),\n \"markdown.h3\": Style(bold=True),\n \"markdown.h4\": Style(bold=True, dim=True),\n \"markdown.h5\": Style(underline=True),\n \"markdown.h6\": Style(italic=True),\n \"markdown.h7\": Style(italic=True, dim=True),\n \"markdown.link\": Style(color=\"bright_blue\"),\n \"markdown.link_url\": Style(color=\"blue\"),\n}\n\n\nDEFAULT_STYLES.update(MARKDOWN_STYLES)\n", "path": "rich/default_styles.py"}, {"content": "from abc import ABC, abstractmethod\nfrom typing import List, Union\n\nfrom .text import Text\n\n\nclass Highlighter(ABC):\n \"\"\"Abstract base class for highlighters.\"\"\"\n\n def __call__(self, text: Union[str, Text]) -> Text:\n \"\"\"Highlight a str or Text instance.\n\n Args:\n text (Union[str, ~Text]): Text to highlight.\n\n Raises:\n TypeError: If not called with text or str.\n\n Returns:\n Text: A test instance with highlighting applied.\n \"\"\"\n if isinstance(text, str):\n highlight_text = Text(text)\n elif isinstance(text, Text):\n highlight_text = text.copy()\n else:\n raise TypeError(f\"str or Text instance required, not {text!r}\")\n self.highlight(highlight_text)\n return highlight_text\n\n @abstractmethod\n def highlight(self, text: Text) -> None:\n \"\"\"Apply highlighting in place to text.\n\n Args:\n text (~Text): A text object highlight.\n \"\"\"\n\n\nclass NullHighlighter(Highlighter):\n \"\"\"A highlighter object that doesn't highlight.\n\n May be used to disable highlighting entirely.\n\n \"\"\"\n\n def highlight(self, text: Text) -> None:\n \"\"\"Nothing to do\"\"\"\n\n\nclass RegexHighlighter(Highlighter):\n \"\"\"Applies highlighting from a list of regular expressions.\"\"\"\n\n highlights: List[str] = []\n base_style: str = \"\"\n\n def highlight(self, text: Text) -> None:\n \"\"\"Highlight :class:`rich.text.Text` using regular expressions.\n\n Args:\n text (~Text): Text to highlighted.\n\n \"\"\"\n highlight_regex = text.highlight_regex\n for re_highlight in self.highlights:\n highlight_regex(re_highlight, style_prefix=self.base_style)\n\n\nclass ReprHighlighter(RegexHighlighter):\n \"\"\"Highlights the text typically produced from ``__repr__`` methods.\"\"\"\n\n base_style = \"repr.\"\n highlights = [\n r\"(?P<brace>[\\{\\[\\(\\)\\]\\}])\",\n r\"(?P<tag_start>\\<)(?P<tag_name>[\\w\\-\\.\\:]*)(?P<tag_contents>.*?)(?P<tag_end>\\>)\",\n r\"(?P<attrib_name>\\w+?)=(?P<attrib_value>\\\"?[\\w_]+\\\"?)?\",\n r\"(?P<bool_true>True)|(?P<bool_false>False)|(?P<none>None)\",\n r\"(?P<number>(?<!\\w)\\-?[0-9]+\\.?[0-9]*(e[\\-\\+]?\\d+?)?\\b)\",\n r\"(?P<number>0x[0-9a-f]*)\",\n r\"(?P<path>\\B(\\/[\\w\\.\\-\\_\\+]+)*\\/)(?P<filename>[\\w\\.\\-\\_\\+]*)?\",\n r\"(?P<ipv4>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-gt9]{1,3}\\.[0-9]{1,3})\",\n r\"(?P<ipv6>([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})\",\n r\"(?P<eui48>([0-9A-Fa-f]{1,2}-){5}[0-9A-Fa-f]{1,2})\", # EUI-48 6x2 hyphen\n r\"(?P<eui64>([0-9A-Fa-f]{1,2}-){7}[0-9A-Fa-f]{1,2})\", # EUI-64 8x2 hyphen\n r\"(?P<eui48>([0-9A-Fa-f]{1,2}:){5}[0-9A-Fa-f]{1,2})\", # EUI-48 6x2 colon\n r\"(?P<eui64>([0-9A-Fa-f]{1,2}:){7}[0-9A-Fa-f]{1,2})\", # EUI-64 8x2 colon\n r\"(?P<eui48>([0-9A-Fa-f]{4}\\.){2}[0-9A-Fa-f]{4})\", # EUI-48 3x4 dot\n r\"(?P<eui64>([0-9A-Fa-f]{4}\\.){3}[0-9A-Fa-f]{4})\", # EUI-64 4x4 dot\n r\"(?<!\\\\)(?P<str>b?\\'\\'\\'.*?(?<!\\\\)\\'\\'\\'|b?\\'.*?(?<!\\\\)\\'|b?\\\"\\\"\\\".*?(?<!\\\\)\\\"\\\"\\\"|b?\\\".*?(?<!\\\\)\\\")\",\n r\"(?P<url>https?:\\/\\/[0-9a-zA-Z\\$\\-\\_\\+\\!`\\(\\)\\,\\.\\?\\/\\;\\:\\&\\=\\%\\#]*)\",\n r\"(?P<uuid>[a-fA-F0-9]{8}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{4}\\-[a-fA-F0-9]{12})\",\n ]\n\n\nif __name__ == \"__main__\": # pragma: no cover\n from .console import Console\n\n console = Console()\n console.print(\"[bold green]hello world![/bold green]\")\n console.print(\"'[bold green]hello world![/bold green]'\")\n\n console.print(\" /foo\")\n console.print(\"/foo/\")\n console.print(\"/foo/bar\")\n console.print(\"foo/bar/baz\")\n\n console.print(\"/foo/bar/baz?foo=bar+egg&egg=baz\")\n console.print(\"/foo/bar/baz/\")\n console.print(\"/foo/bar/baz/egg\")\n console.print(\"/foo/bar/baz/egg.py\")\n console.print(\"/foo/bar/baz/egg.py word\")\n console.print(\" /foo/bar/baz/egg.py word\")\n console.print(\"foo /foo/bar/baz/egg.py word\")\n console.print(\"foo /foo/bar/ba._++z/egg+.py word\")\n console.print(\"https://example.org?foo=bar#header\")\n\n console.print(1234567.34)\n console.print(1 / 2)\n console.print(-1 / 123123123123)\n\n console.print(\n \"127.0.1.1 bar 192.168.1.4 2001:0db8:85a3:0000:0000:8a2e:0370:7334 foo\"\n )\n", "path": "rich/highlighter.py"}]}
| 3,664 | 815 |
gh_patches_debug_8036
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2345
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Featured products section should not be shown if there is none
If there is no featured products, the home page should not show the empty section.
### Screenshots

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/core/views.py`
Content:
```
1 import json
2
3 from django.contrib import messages
4 from django.template.response import TemplateResponse
5 from django.utils.translation import pgettext_lazy
6 from impersonate.views import impersonate as orig_impersonate
7
8 from ..account.models import User
9 from ..dashboard.views import staff_member_required
10 from ..product.utils import products_for_homepage
11 from ..product.utils.availability import products_with_availability
12 from ..seo.schema.webpage import get_webpage_schema
13
14
15 def home(request):
16 products = products_for_homepage()[:8]
17 products = products_with_availability(
18 products, discounts=request.discounts, taxes=request.taxes,
19 local_currency=request.currency)
20 webpage_schema = get_webpage_schema(request)
21 return TemplateResponse(
22 request, 'home.html', {
23 'parent': None,
24 'products': products,
25 'webpage_schema': json.dumps(webpage_schema)})
26
27
28 @staff_member_required
29 def styleguide(request):
30 return TemplateResponse(request, 'styleguide.html')
31
32
33 def impersonate(request, uid):
34 response = orig_impersonate(request, uid)
35 if request.session.modified:
36 msg = pgettext_lazy(
37 'Impersonation message',
38 'You are now logged as {}'.format(User.objects.get(pk=uid)))
39 messages.success(request, msg)
40 return response
41
42
43 def handle_404(request, exception=None):
44 return TemplateResponse(request, '404.html', status=404)
45
46
47 def manifest(request):
48 return TemplateResponse(
49 request, 'manifest.json', content_type='application/json')
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/core/views.py b/saleor/core/views.py
--- a/saleor/core/views.py
+++ b/saleor/core/views.py
@@ -14,9 +14,9 @@
def home(request):
products = products_for_homepage()[:8]
- products = products_with_availability(
+ products = list(products_with_availability(
products, discounts=request.discounts, taxes=request.taxes,
- local_currency=request.currency)
+ local_currency=request.currency))
webpage_schema = get_webpage_schema(request)
return TemplateResponse(
request, 'home.html', {
|
{"golden_diff": "diff --git a/saleor/core/views.py b/saleor/core/views.py\n--- a/saleor/core/views.py\n+++ b/saleor/core/views.py\n@@ -14,9 +14,9 @@\n \n def home(request):\n products = products_for_homepage()[:8]\n- products = products_with_availability(\n+ products = list(products_with_availability(\n products, discounts=request.discounts, taxes=request.taxes,\n- local_currency=request.currency)\n+ local_currency=request.currency))\n webpage_schema = get_webpage_schema(request)\n return TemplateResponse(\n request, 'home.html', {\n", "issue": "Featured products section should not be shown if there is none\nIf there is no featured products, the home page should not show the empty section.\r\n\r\n### Screenshots\r\n\r\n\n", "before_files": [{"content": "import json\n\nfrom django.contrib import messages\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import pgettext_lazy\nfrom impersonate.views import impersonate as orig_impersonate\n\nfrom ..account.models import User\nfrom ..dashboard.views import staff_member_required\nfrom ..product.utils import products_for_homepage\nfrom ..product.utils.availability import products_with_availability\nfrom ..seo.schema.webpage import get_webpage_schema\n\n\ndef home(request):\n products = products_for_homepage()[:8]\n products = products_with_availability(\n products, discounts=request.discounts, taxes=request.taxes,\n local_currency=request.currency)\n webpage_schema = get_webpage_schema(request)\n return TemplateResponse(\n request, 'home.html', {\n 'parent': None,\n 'products': products,\n 'webpage_schema': json.dumps(webpage_schema)})\n\n\n@staff_member_required\ndef styleguide(request):\n return TemplateResponse(request, 'styleguide.html')\n\n\ndef impersonate(request, uid):\n response = orig_impersonate(request, uid)\n if request.session.modified:\n msg = pgettext_lazy(\n 'Impersonation message',\n 'You are now logged as {}'.format(User.objects.get(pk=uid)))\n messages.success(request, msg)\n return response\n\n\ndef handle_404(request, exception=None):\n return TemplateResponse(request, '404.html', status=404)\n\n\ndef manifest(request):\n return TemplateResponse(\n request, 'manifest.json', content_type='application/json')\n", "path": "saleor/core/views.py"}], "after_files": [{"content": "import json\n\nfrom django.contrib import messages\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import pgettext_lazy\nfrom impersonate.views import impersonate as orig_impersonate\n\nfrom ..account.models import User\nfrom ..dashboard.views import staff_member_required\nfrom ..product.utils import products_for_homepage\nfrom ..product.utils.availability import products_with_availability\nfrom ..seo.schema.webpage import get_webpage_schema\n\n\ndef home(request):\n products = products_for_homepage()[:8]\n products = list(products_with_availability(\n products, discounts=request.discounts, taxes=request.taxes,\n local_currency=request.currency))\n webpage_schema = get_webpage_schema(request)\n return TemplateResponse(\n request, 'home.html', {\n 'parent': None,\n 'products': products,\n 'webpage_schema': json.dumps(webpage_schema)})\n\n\n@staff_member_required\ndef styleguide(request):\n return TemplateResponse(request, 'styleguide.html')\n\n\ndef impersonate(request, uid):\n response = orig_impersonate(request, uid)\n if request.session.modified:\n msg = pgettext_lazy(\n 'Impersonation message',\n 'You are now logged as {}'.format(User.objects.get(pk=uid)))\n messages.success(request, msg)\n return response\n\n\ndef handle_404(request, exception=None):\n return TemplateResponse(request, '404.html', status=404)\n\n\ndef manifest(request):\n return TemplateResponse(\n request, 'manifest.json', content_type='application/json')\n", "path": "saleor/core/views.py"}]}
| 728 | 133 |
gh_patches_debug_39577
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3366
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix or remove language
I was checking the code
https://github.com/plone/Products.CMFPlone/blob/36a66a82d8ff975148634626a70fd8b01f7e95b9/Products/CMFPlone/Portal.py#L150-L157
`cmp` should not be used because it was removed in Python3.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/Portal.py`
Content:
```
1 from AccessControl import ClassSecurityInfo
2 from AccessControl import Unauthorized
3 from AccessControl.class_init import InitializeClass
4 from Acquisition import aq_base
5 from ComputedAttribute import ComputedAttribute
6 from five.localsitemanager.registry import PersistentComponents
7 from OFS.ObjectManager import REPLACEABLE
8 from plone.dexterity.content import Container
9 from plone.i18n.locales.interfaces import IMetadataLanguageAvailability
10 from Products.CMFCore import permissions
11 from Products.CMFCore.interfaces import IContentish
12 from Products.CMFCore.interfaces import ISiteRoot
13 from Products.CMFCore.permissions import AccessContentsInformation
14 from Products.CMFCore.permissions import AddPortalMember
15 from Products.CMFCore.permissions import MailForgottenPassword
16 from Products.CMFCore.permissions import RequestReview
17 from Products.CMFCore.permissions import ReviewPortalContent
18 from Products.CMFCore.permissions import SetOwnPassword
19 from Products.CMFCore.permissions import SetOwnProperties
20 from Products.CMFCore.PortalFolder import PortalFolderBase
21 from Products.CMFCore.PortalObject import PortalObjectBase
22 from Products.CMFCore.Skinnable import SkinnableObjectManager
23 from Products.CMFCore.utils import _checkPermission
24 from Products.CMFCore.utils import getToolByName
25 from Products.CMFCore.utils import UniqueObject
26 from Products.CMFPlone import bbb
27 from Products.CMFPlone import PloneMessageFactory as _
28 from Products.CMFPlone.interfaces.siteroot import IPloneSiteRoot
29 from Products.CMFPlone.interfaces.syndication import ISyndicatable
30 from Products.CMFPlone.permissions import AddPortalContent
31 from Products.CMFPlone.permissions import AddPortalFolders
32 from Products.CMFPlone.permissions import ListPortalMembers
33 from Products.CMFPlone.permissions import ModifyPortalContent
34 from Products.CMFPlone.permissions import ReplyToItem
35 from Products.CMFPlone.permissions import View
36 from Products.Five.component.interfaces import IObjectManagerSite
37 from zope.component import queryUtility
38 from zope.interface.interfaces import ComponentLookupError
39 from zope.event import notify
40 from zope.interface import classImplementsOnly
41 from zope.interface import implementedBy
42 from zope.interface import implementer
43 from zope.traversing.interfaces import BeforeTraverseEvent
44
45
46 if bbb.HAS_ZSERVER:
47 from webdav.NullResource import NullResource
48
49
50 @implementer(IPloneSiteRoot, ISiteRoot, ISyndicatable, IObjectManagerSite)
51 class PloneSite(Container, SkinnableObjectManager, UniqueObject):
52 """ The Plone site object. """
53
54 security = ClassSecurityInfo()
55 meta_type = portal_type = 'Plone Site'
56
57 # Ensure certain attributes come from the correct base class.
58 _checkId = SkinnableObjectManager._checkId
59 manage_main = PortalFolderBase.manage_main
60
61 def __getattr__(self, name):
62 try:
63 # Try DX
64 return super().__getattr__(name)
65 except AttributeError:
66 # Check portal_skins
67 return SkinnableObjectManager.__getattr__(self, name)
68
69 def __setattr__(self, name, obj):
70 # handle re setting an item as an attribute
71 if self._tree is not None and name in self:
72 del self[name]
73 self[name] = obj
74 else:
75 super().__setattr__(name, obj)
76
77 def __delattr__(self, name):
78 try:
79 return super().__delattr__(name)
80 except AttributeError:
81 return self.__delitem__(name)
82
83 # Removes the 'Components Folder'
84
85 manage_options = (
86 Container.manage_options[:2] +
87 Container.manage_options[3:])
88
89 __ac_permissions__ = (
90 (AccessContentsInformation, ()),
91 (AddPortalMember, ()),
92 (SetOwnPassword, ()),
93 (SetOwnProperties, ()),
94 (MailForgottenPassword, ()),
95 (RequestReview, ()),
96 (ReviewPortalContent, ()),
97 (AddPortalContent, ()),
98 (AddPortalFolders, ()),
99 (ListPortalMembers, ()),
100 (ReplyToItem, ()),
101 (View, ('isEffective',)),
102 (ModifyPortalContent, ('manage_cutObjects', 'manage_pasteObjects',
103 'manage_renameForm', 'manage_renameObject',
104 'manage_renameObjects')))
105
106 # Switch off ZMI ordering interface as it assumes a slightly
107 # different functionality
108 has_order_support = 0
109 management_page_charset = 'utf-8'
110 _default_sort_key = 'id'
111 _properties = (
112 {'id': 'title', 'type': 'string', 'mode': 'w'},
113 {'id': 'description', 'type': 'text', 'mode': 'w'},
114 )
115 title = ''
116 description = ''
117 icon = 'misc_/CMFPlone/tool.gif'
118
119 # From PortalObjectBase
120 def __init__(self, id, title=''):
121 super(PloneSite, self).__init__(id, title=title)
122 components = PersistentComponents('++etc++site')
123 components.__parent__ = self
124 self.setSiteManager(components)
125
126 # From PortalObjectBase
127 def __before_publishing_traverse__(self, arg1, arg2=None):
128 """ Pre-traversal hook.
129 """
130 # XXX hack around a bug(?) in BeforeTraverse.MultiHook
131 REQUEST = arg2 or arg1
132
133 try:
134 notify(BeforeTraverseEvent(self, REQUEST))
135 except ComponentLookupError:
136 # allow ZMI access, even if the portal's site manager is missing
137 pass
138 self.setupCurrentSkin(REQUEST)
139
140 super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)
141
142 def __browser_default__(self, request):
143 """ Set default so we can return whatever we want instead
144 of index_html """
145 return getToolByName(self, 'plone_utils').browserDefault(self)
146
147 def index_html(self):
148 """ Acquire if not present. """
149 request = getattr(self, 'REQUEST', None)
150 if (
151 request is not None
152 and 'REQUEST_METHOD' in request
153 and request.maybe_webdav_client
154 ):
155 method = request['REQUEST_METHOD']
156 if bbb.HAS_ZSERVER and method in ('PUT', ):
157 # Very likely a WebDAV client trying to create something
158 result = NullResource(self, 'index_html')
159 setattr(result, '__replaceable__', REPLACEABLE)
160 return result
161 elif method not in ('GET', 'HEAD', 'POST'):
162 raise AttributeError('index_html')
163 # Acquire from skin.
164 _target = self.__getattr__('index_html')
165 result = aq_base(_target).__of__(self)
166 setattr(result, '__replaceable__', REPLACEABLE)
167 return result
168
169 index_html = ComputedAttribute(index_html, 1)
170
171 def manage_beforeDelete(self, container, item):
172 # Should send out an Event before Site is being deleted.
173 self.removal_inprogress = 1
174 PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,
175 item)
176
177 security.declareProtected(permissions.DeleteObjects, 'manage_delObjects')
178
179 def manage_delObjects(self, ids=None, REQUEST=None):
180 """We need to enforce security."""
181 if ids is None:
182 ids = []
183 if isinstance(ids, str):
184 ids = [ids]
185 for id in ids:
186 item = self._getOb(id)
187 if not _checkPermission(permissions.DeleteObjects, item):
188 raise Unauthorized(
189 "Do not have permissions to remove this object")
190 return PortalObjectBase.manage_delObjects(self, ids, REQUEST=REQUEST)
191
192 def view(self):
193 """ Ensure that we get a plain view of the object, via a delegation to
194 __call__(), which is defined in BrowserDefaultMixin
195 """
196 return self()
197
198 security.declareProtected(permissions.AccessContentsInformation,
199 'folderlistingFolderContents')
200
201 def folderlistingFolderContents(self, contentFilter=None):
202 """Calls listFolderContents in protected only by ACI so that
203 folder_listing can work without the List folder contents permission.
204
205 This is copied from Archetypes Basefolder and is needed by the
206 reference browser.
207 """
208 return self.listFolderContents(contentFilter)
209
210 security.declarePublic('availableLanguages')
211
212 def availableLanguages(self):
213 util = queryUtility(IMetadataLanguageAvailability)
214 languages = util.getLanguageListing()
215 languages.sort(lambda x, y: cmp(x[1], y[1]))
216 # Put language neutral at the top.
217 languages.insert(0, ('', _('Language neutral (site default)')))
218
219 return languages
220
221 def isEffective(self, date):
222 # Override DefaultDublinCoreImpl's test, since we are always viewable.
223 return 1
224
225
226 # Remove the IContentish interface so we don't listen to events that won't
227 # apply to the site root, ie handleUidAnnotationEvent
228 classImplementsOnly(PloneSite, implementedBy(PloneSite) - IContentish)
229
230 InitializeClass(PloneSite)
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/Portal.py b/Products/CMFPlone/Portal.py
--- a/Products/CMFPlone/Portal.py
+++ b/Products/CMFPlone/Portal.py
@@ -6,7 +6,6 @@
from five.localsitemanager.registry import PersistentComponents
from OFS.ObjectManager import REPLACEABLE
from plone.dexterity.content import Container
-from plone.i18n.locales.interfaces import IMetadataLanguageAvailability
from Products.CMFCore import permissions
from Products.CMFCore.interfaces import IContentish
from Products.CMFCore.interfaces import ISiteRoot
@@ -34,7 +33,6 @@
from Products.CMFPlone.permissions import ReplyToItem
from Products.CMFPlone.permissions import View
from Products.Five.component.interfaces import IObjectManagerSite
-from zope.component import queryUtility
from zope.interface.interfaces import ComponentLookupError
from zope.event import notify
from zope.interface import classImplementsOnly
@@ -174,8 +172,7 @@
PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,
item)
- security.declareProtected(permissions.DeleteObjects, 'manage_delObjects')
-
+ @security.protected(permissions.DeleteObjects)
def manage_delObjects(self, ids=None, REQUEST=None):
"""We need to enforce security."""
if ids is None:
@@ -195,9 +192,7 @@
"""
return self()
- security.declareProtected(permissions.AccessContentsInformation,
- 'folderlistingFolderContents')
-
+ @security.protected(permissions.AccessContentsInformation)
def folderlistingFolderContents(self, contentFilter=None):
"""Calls listFolderContents in protected only by ACI so that
folder_listing can work without the List folder contents permission.
@@ -207,17 +202,6 @@
"""
return self.listFolderContents(contentFilter)
- security.declarePublic('availableLanguages')
-
- def availableLanguages(self):
- util = queryUtility(IMetadataLanguageAvailability)
- languages = util.getLanguageListing()
- languages.sort(lambda x, y: cmp(x[1], y[1]))
- # Put language neutral at the top.
- languages.insert(0, ('', _('Language neutral (site default)')))
-
- return languages
-
def isEffective(self, date):
# Override DefaultDublinCoreImpl's test, since we are always viewable.
return 1
|
{"golden_diff": "diff --git a/Products/CMFPlone/Portal.py b/Products/CMFPlone/Portal.py\n--- a/Products/CMFPlone/Portal.py\n+++ b/Products/CMFPlone/Portal.py\n@@ -6,7 +6,6 @@\n from five.localsitemanager.registry import PersistentComponents\n from OFS.ObjectManager import REPLACEABLE\n from plone.dexterity.content import Container\n-from plone.i18n.locales.interfaces import IMetadataLanguageAvailability\n from Products.CMFCore import permissions\n from Products.CMFCore.interfaces import IContentish\n from Products.CMFCore.interfaces import ISiteRoot\n@@ -34,7 +33,6 @@\n from Products.CMFPlone.permissions import ReplyToItem\n from Products.CMFPlone.permissions import View\n from Products.Five.component.interfaces import IObjectManagerSite\n-from zope.component import queryUtility\n from zope.interface.interfaces import ComponentLookupError\n from zope.event import notify\n from zope.interface import classImplementsOnly\n@@ -174,8 +172,7 @@\n PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,\n item)\n \n- security.declareProtected(permissions.DeleteObjects, 'manage_delObjects')\n-\n+ @security.protected(permissions.DeleteObjects)\n def manage_delObjects(self, ids=None, REQUEST=None):\n \"\"\"We need to enforce security.\"\"\"\n if ids is None:\n@@ -195,9 +192,7 @@\n \"\"\"\n return self()\n \n- security.declareProtected(permissions.AccessContentsInformation,\n- 'folderlistingFolderContents')\n-\n+ @security.protected(permissions.AccessContentsInformation)\n def folderlistingFolderContents(self, contentFilter=None):\n \"\"\"Calls listFolderContents in protected only by ACI so that\n folder_listing can work without the List folder contents permission.\n@@ -207,17 +202,6 @@\n \"\"\"\n return self.listFolderContents(contentFilter)\n \n- security.declarePublic('availableLanguages')\n-\n- def availableLanguages(self):\n- util = queryUtility(IMetadataLanguageAvailability)\n- languages = util.getLanguageListing()\n- languages.sort(lambda x, y: cmp(x[1], y[1]))\n- # Put language neutral at the top.\n- languages.insert(0, ('', _('Language neutral (site default)')))\n-\n- return languages\n-\n def isEffective(self, date):\n # Override DefaultDublinCoreImpl's test, since we are always viewable.\n return 1\n", "issue": "Fix or remove language\nI was checking the code\r\nhttps://github.com/plone/Products.CMFPlone/blob/36a66a82d8ff975148634626a70fd8b01f7e95b9/Products/CMFPlone/Portal.py#L150-L157\r\n\r\n`cmp` should not be used because it was removed in Python3.\n", "before_files": [{"content": "from AccessControl import ClassSecurityInfo\nfrom AccessControl import Unauthorized\nfrom AccessControl.class_init import InitializeClass\nfrom Acquisition import aq_base\nfrom ComputedAttribute import ComputedAttribute\nfrom five.localsitemanager.registry import PersistentComponents\nfrom OFS.ObjectManager import REPLACEABLE\nfrom plone.dexterity.content import Container\nfrom plone.i18n.locales.interfaces import IMetadataLanguageAvailability\nfrom Products.CMFCore import permissions\nfrom Products.CMFCore.interfaces import IContentish\nfrom Products.CMFCore.interfaces import ISiteRoot\nfrom Products.CMFCore.permissions import AccessContentsInformation\nfrom Products.CMFCore.permissions import AddPortalMember\nfrom Products.CMFCore.permissions import MailForgottenPassword\nfrom Products.CMFCore.permissions import RequestReview\nfrom Products.CMFCore.permissions import ReviewPortalContent\nfrom Products.CMFCore.permissions import SetOwnPassword\nfrom Products.CMFCore.permissions import SetOwnProperties\nfrom Products.CMFCore.PortalFolder import PortalFolderBase\nfrom Products.CMFCore.PortalObject import PortalObjectBase\nfrom Products.CMFCore.Skinnable import SkinnableObjectManager\nfrom Products.CMFCore.utils import _checkPermission\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFCore.utils import UniqueObject\nfrom Products.CMFPlone import bbb\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.interfaces.siteroot import IPloneSiteRoot\nfrom Products.CMFPlone.interfaces.syndication import ISyndicatable\nfrom Products.CMFPlone.permissions import AddPortalContent\nfrom Products.CMFPlone.permissions import AddPortalFolders\nfrom Products.CMFPlone.permissions import ListPortalMembers\nfrom Products.CMFPlone.permissions import ModifyPortalContent\nfrom Products.CMFPlone.permissions import ReplyToItem\nfrom Products.CMFPlone.permissions import View\nfrom Products.Five.component.interfaces import IObjectManagerSite\nfrom zope.component import queryUtility\nfrom zope.interface.interfaces import ComponentLookupError\nfrom zope.event import notify\nfrom zope.interface import classImplementsOnly\nfrom zope.interface import implementedBy\nfrom zope.interface import implementer\nfrom zope.traversing.interfaces import BeforeTraverseEvent\n\n\nif bbb.HAS_ZSERVER:\n from webdav.NullResource import NullResource\n\n\n@implementer(IPloneSiteRoot, ISiteRoot, ISyndicatable, IObjectManagerSite)\nclass PloneSite(Container, SkinnableObjectManager, UniqueObject):\n \"\"\" The Plone site object. \"\"\"\n\n security = ClassSecurityInfo()\n meta_type = portal_type = 'Plone Site'\n\n # Ensure certain attributes come from the correct base class.\n _checkId = SkinnableObjectManager._checkId\n manage_main = PortalFolderBase.manage_main\n\n def __getattr__(self, name):\n try:\n # Try DX\n return super().__getattr__(name)\n except AttributeError:\n # Check portal_skins\n return SkinnableObjectManager.__getattr__(self, name)\n\n def __setattr__(self, name, obj):\n # handle re setting an item as an attribute\n if self._tree is not None and name in self:\n del self[name]\n self[name] = obj\n else:\n super().__setattr__(name, obj)\n\n def __delattr__(self, name):\n try:\n return super().__delattr__(name)\n except AttributeError:\n return self.__delitem__(name)\n\n # Removes the 'Components Folder'\n\n manage_options = (\n Container.manage_options[:2] +\n Container.manage_options[3:])\n\n __ac_permissions__ = (\n (AccessContentsInformation, ()),\n (AddPortalMember, ()),\n (SetOwnPassword, ()),\n (SetOwnProperties, ()),\n (MailForgottenPassword, ()),\n (RequestReview, ()),\n (ReviewPortalContent, ()),\n (AddPortalContent, ()),\n (AddPortalFolders, ()),\n (ListPortalMembers, ()),\n (ReplyToItem, ()),\n (View, ('isEffective',)),\n (ModifyPortalContent, ('manage_cutObjects', 'manage_pasteObjects',\n 'manage_renameForm', 'manage_renameObject',\n 'manage_renameObjects')))\n\n # Switch off ZMI ordering interface as it assumes a slightly\n # different functionality\n has_order_support = 0\n management_page_charset = 'utf-8'\n _default_sort_key = 'id'\n _properties = (\n {'id': 'title', 'type': 'string', 'mode': 'w'},\n {'id': 'description', 'type': 'text', 'mode': 'w'},\n )\n title = ''\n description = ''\n icon = 'misc_/CMFPlone/tool.gif'\n\n # From PortalObjectBase\n def __init__(self, id, title=''):\n super(PloneSite, self).__init__(id, title=title)\n components = PersistentComponents('++etc++site')\n components.__parent__ = self\n self.setSiteManager(components)\n\n # From PortalObjectBase\n def __before_publishing_traverse__(self, arg1, arg2=None):\n \"\"\" Pre-traversal hook.\n \"\"\"\n # XXX hack around a bug(?) in BeforeTraverse.MultiHook\n REQUEST = arg2 or arg1\n\n try:\n notify(BeforeTraverseEvent(self, REQUEST))\n except ComponentLookupError:\n # allow ZMI access, even if the portal's site manager is missing\n pass\n self.setupCurrentSkin(REQUEST)\n\n super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)\n\n def __browser_default__(self, request):\n \"\"\" Set default so we can return whatever we want instead\n of index_html \"\"\"\n return getToolByName(self, 'plone_utils').browserDefault(self)\n\n def index_html(self):\n \"\"\" Acquire if not present. \"\"\"\n request = getattr(self, 'REQUEST', None)\n if (\n request is not None\n and 'REQUEST_METHOD' in request\n and request.maybe_webdav_client\n ):\n method = request['REQUEST_METHOD']\n if bbb.HAS_ZSERVER and method in ('PUT', ):\n # Very likely a WebDAV client trying to create something\n result = NullResource(self, 'index_html')\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n elif method not in ('GET', 'HEAD', 'POST'):\n raise AttributeError('index_html')\n # Acquire from skin.\n _target = self.__getattr__('index_html')\n result = aq_base(_target).__of__(self)\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n\n index_html = ComputedAttribute(index_html, 1)\n\n def manage_beforeDelete(self, container, item):\n # Should send out an Event before Site is being deleted.\n self.removal_inprogress = 1\n PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,\n item)\n\n security.declareProtected(permissions.DeleteObjects, 'manage_delObjects')\n\n def manage_delObjects(self, ids=None, REQUEST=None):\n \"\"\"We need to enforce security.\"\"\"\n if ids is None:\n ids = []\n if isinstance(ids, str):\n ids = [ids]\n for id in ids:\n item = self._getOb(id)\n if not _checkPermission(permissions.DeleteObjects, item):\n raise Unauthorized(\n \"Do not have permissions to remove this object\")\n return PortalObjectBase.manage_delObjects(self, ids, REQUEST=REQUEST)\n\n def view(self):\n \"\"\" Ensure that we get a plain view of the object, via a delegation to\n __call__(), which is defined in BrowserDefaultMixin\n \"\"\"\n return self()\n\n security.declareProtected(permissions.AccessContentsInformation,\n 'folderlistingFolderContents')\n\n def folderlistingFolderContents(self, contentFilter=None):\n \"\"\"Calls listFolderContents in protected only by ACI so that\n folder_listing can work without the List folder contents permission.\n\n This is copied from Archetypes Basefolder and is needed by the\n reference browser.\n \"\"\"\n return self.listFolderContents(contentFilter)\n\n security.declarePublic('availableLanguages')\n\n def availableLanguages(self):\n util = queryUtility(IMetadataLanguageAvailability)\n languages = util.getLanguageListing()\n languages.sort(lambda x, y: cmp(x[1], y[1]))\n # Put language neutral at the top.\n languages.insert(0, ('', _('Language neutral (site default)')))\n\n return languages\n\n def isEffective(self, date):\n # Override DefaultDublinCoreImpl's test, since we are always viewable.\n return 1\n\n\n# Remove the IContentish interface so we don't listen to events that won't\n# apply to the site root, ie handleUidAnnotationEvent\nclassImplementsOnly(PloneSite, implementedBy(PloneSite) - IContentish)\n\nInitializeClass(PloneSite)\n", "path": "Products/CMFPlone/Portal.py"}], "after_files": [{"content": "from AccessControl import ClassSecurityInfo\nfrom AccessControl import Unauthorized\nfrom AccessControl.class_init import InitializeClass\nfrom Acquisition import aq_base\nfrom ComputedAttribute import ComputedAttribute\nfrom five.localsitemanager.registry import PersistentComponents\nfrom OFS.ObjectManager import REPLACEABLE\nfrom plone.dexterity.content import Container\nfrom Products.CMFCore import permissions\nfrom Products.CMFCore.interfaces import IContentish\nfrom Products.CMFCore.interfaces import ISiteRoot\nfrom Products.CMFCore.permissions import AccessContentsInformation\nfrom Products.CMFCore.permissions import AddPortalMember\nfrom Products.CMFCore.permissions import MailForgottenPassword\nfrom Products.CMFCore.permissions import RequestReview\nfrom Products.CMFCore.permissions import ReviewPortalContent\nfrom Products.CMFCore.permissions import SetOwnPassword\nfrom Products.CMFCore.permissions import SetOwnProperties\nfrom Products.CMFCore.PortalFolder import PortalFolderBase\nfrom Products.CMFCore.PortalObject import PortalObjectBase\nfrom Products.CMFCore.Skinnable import SkinnableObjectManager\nfrom Products.CMFCore.utils import _checkPermission\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFCore.utils import UniqueObject\nfrom Products.CMFPlone import bbb\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.interfaces.siteroot import IPloneSiteRoot\nfrom Products.CMFPlone.interfaces.syndication import ISyndicatable\nfrom Products.CMFPlone.permissions import AddPortalContent\nfrom Products.CMFPlone.permissions import AddPortalFolders\nfrom Products.CMFPlone.permissions import ListPortalMembers\nfrom Products.CMFPlone.permissions import ModifyPortalContent\nfrom Products.CMFPlone.permissions import ReplyToItem\nfrom Products.CMFPlone.permissions import View\nfrom Products.Five.component.interfaces import IObjectManagerSite\nfrom zope.interface.interfaces import ComponentLookupError\nfrom zope.event import notify\nfrom zope.interface import classImplementsOnly\nfrom zope.interface import implementedBy\nfrom zope.interface import implementer\nfrom zope.traversing.interfaces import BeforeTraverseEvent\n\n\nif bbb.HAS_ZSERVER:\n from webdav.NullResource import NullResource\n\n\n@implementer(IPloneSiteRoot, ISiteRoot, ISyndicatable, IObjectManagerSite)\nclass PloneSite(Container, SkinnableObjectManager, UniqueObject):\n \"\"\" The Plone site object. \"\"\"\n\n security = ClassSecurityInfo()\n meta_type = portal_type = 'Plone Site'\n\n # Ensure certain attributes come from the correct base class.\n _checkId = SkinnableObjectManager._checkId\n manage_main = PortalFolderBase.manage_main\n\n def __getattr__(self, name):\n try:\n # Try DX\n return super().__getattr__(name)\n except AttributeError:\n # Check portal_skins\n return SkinnableObjectManager.__getattr__(self, name)\n\n def __setattr__(self, name, obj):\n # handle re setting an item as an attribute\n if self._tree is not None and name in self:\n del self[name]\n self[name] = obj\n else:\n super().__setattr__(name, obj)\n\n def __delattr__(self, name):\n try:\n return super().__delattr__(name)\n except AttributeError:\n return self.__delitem__(name)\n\n # Removes the 'Components Folder'\n\n manage_options = (\n Container.manage_options[:2] +\n Container.manage_options[3:])\n\n __ac_permissions__ = (\n (AccessContentsInformation, ()),\n (AddPortalMember, ()),\n (SetOwnPassword, ()),\n (SetOwnProperties, ()),\n (MailForgottenPassword, ()),\n (RequestReview, ()),\n (ReviewPortalContent, ()),\n (AddPortalContent, ()),\n (AddPortalFolders, ()),\n (ListPortalMembers, ()),\n (ReplyToItem, ()),\n (View, ('isEffective',)),\n (ModifyPortalContent, ('manage_cutObjects', 'manage_pasteObjects',\n 'manage_renameForm', 'manage_renameObject',\n 'manage_renameObjects')))\n\n # Switch off ZMI ordering interface as it assumes a slightly\n # different functionality\n has_order_support = 0\n management_page_charset = 'utf-8'\n _default_sort_key = 'id'\n _properties = (\n {'id': 'title', 'type': 'string', 'mode': 'w'},\n {'id': 'description', 'type': 'text', 'mode': 'w'},\n )\n title = ''\n description = ''\n icon = 'misc_/CMFPlone/tool.gif'\n\n # From PortalObjectBase\n def __init__(self, id, title=''):\n super(PloneSite, self).__init__(id, title=title)\n components = PersistentComponents('++etc++site')\n components.__parent__ = self\n self.setSiteManager(components)\n\n # From PortalObjectBase\n def __before_publishing_traverse__(self, arg1, arg2=None):\n \"\"\" Pre-traversal hook.\n \"\"\"\n # XXX hack around a bug(?) in BeforeTraverse.MultiHook\n REQUEST = arg2 or arg1\n\n try:\n notify(BeforeTraverseEvent(self, REQUEST))\n except ComponentLookupError:\n # allow ZMI access, even if the portal's site manager is missing\n pass\n self.setupCurrentSkin(REQUEST)\n\n super(PloneSite, self).__before_publishing_traverse__(arg1, arg2)\n\n def __browser_default__(self, request):\n \"\"\" Set default so we can return whatever we want instead\n of index_html \"\"\"\n return getToolByName(self, 'plone_utils').browserDefault(self)\n\n def index_html(self):\n \"\"\" Acquire if not present. \"\"\"\n request = getattr(self, 'REQUEST', None)\n if (\n request is not None\n and 'REQUEST_METHOD' in request\n and request.maybe_webdav_client\n ):\n method = request['REQUEST_METHOD']\n if bbb.HAS_ZSERVER and method in ('PUT', ):\n # Very likely a WebDAV client trying to create something\n result = NullResource(self, 'index_html')\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n elif method not in ('GET', 'HEAD', 'POST'):\n raise AttributeError('index_html')\n # Acquire from skin.\n _target = self.__getattr__('index_html')\n result = aq_base(_target).__of__(self)\n setattr(result, '__replaceable__', REPLACEABLE)\n return result\n\n index_html = ComputedAttribute(index_html, 1)\n\n def manage_beforeDelete(self, container, item):\n # Should send out an Event before Site is being deleted.\n self.removal_inprogress = 1\n PloneSite.inheritedAttribute('manage_beforeDelete')(self, container,\n item)\n\n @security.protected(permissions.DeleteObjects)\n def manage_delObjects(self, ids=None, REQUEST=None):\n \"\"\"We need to enforce security.\"\"\"\n if ids is None:\n ids = []\n if isinstance(ids, str):\n ids = [ids]\n for id in ids:\n item = self._getOb(id)\n if not _checkPermission(permissions.DeleteObjects, item):\n raise Unauthorized(\n \"Do not have permissions to remove this object\")\n return PortalObjectBase.manage_delObjects(self, ids, REQUEST=REQUEST)\n\n def view(self):\n \"\"\" Ensure that we get a plain view of the object, via a delegation to\n __call__(), which is defined in BrowserDefaultMixin\n \"\"\"\n return self()\n\n @security.protected(permissions.AccessContentsInformation)\n def folderlistingFolderContents(self, contentFilter=None):\n \"\"\"Calls listFolderContents in protected only by ACI so that\n folder_listing can work without the List folder contents permission.\n\n This is copied from Archetypes Basefolder and is needed by the\n reference browser.\n \"\"\"\n return self.listFolderContents(contentFilter)\n\n def isEffective(self, date):\n # Override DefaultDublinCoreImpl's test, since we are always viewable.\n return 1\n\n\n# Remove the IContentish interface so we don't listen to events that won't\n# apply to the site root, ie handleUidAnnotationEvent\nclassImplementsOnly(PloneSite, implementedBy(PloneSite) - IContentish)\n\nInitializeClass(PloneSite)\n", "path": "Products/CMFPlone/Portal.py"}]}
| 2,888 | 547 |
gh_patches_debug_4222
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-8449
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Single user syncing - Lesson completion is not restored after second setup of the same learner account
## Observed behavior
I have setup a learner-only device and have completed a lesson assigned to the learner user which is then synced correctly to the server. After that I've deleted the android app storage and cache and repeated the setup for the same user expecting the lesson progress to be restored while in reality it does not get restored and the learner has to start over.
## Expected behavior
Any synced user data should be restored.
## Steps to reproduce the issue
1. Install this Windows [build](https://buildkite.com/learningequality/kolibri-windows/builds/1930) and this Android [build](https://buildkite.com/learningequality/kolibri-android-installer/builds/2692)
2. Setup the Windows app as a server and setup a learner device on Android.
3. As a learner complete an assigned lesson.
4. As an admin go to Coach>Reports>Lessons and verify that the lesson progress is synced correctly.
5. Delete the cache and storage of the android app and setup the same learner user again. Observe that there is no indication for the progress made so far.
## Additional information
Admin:
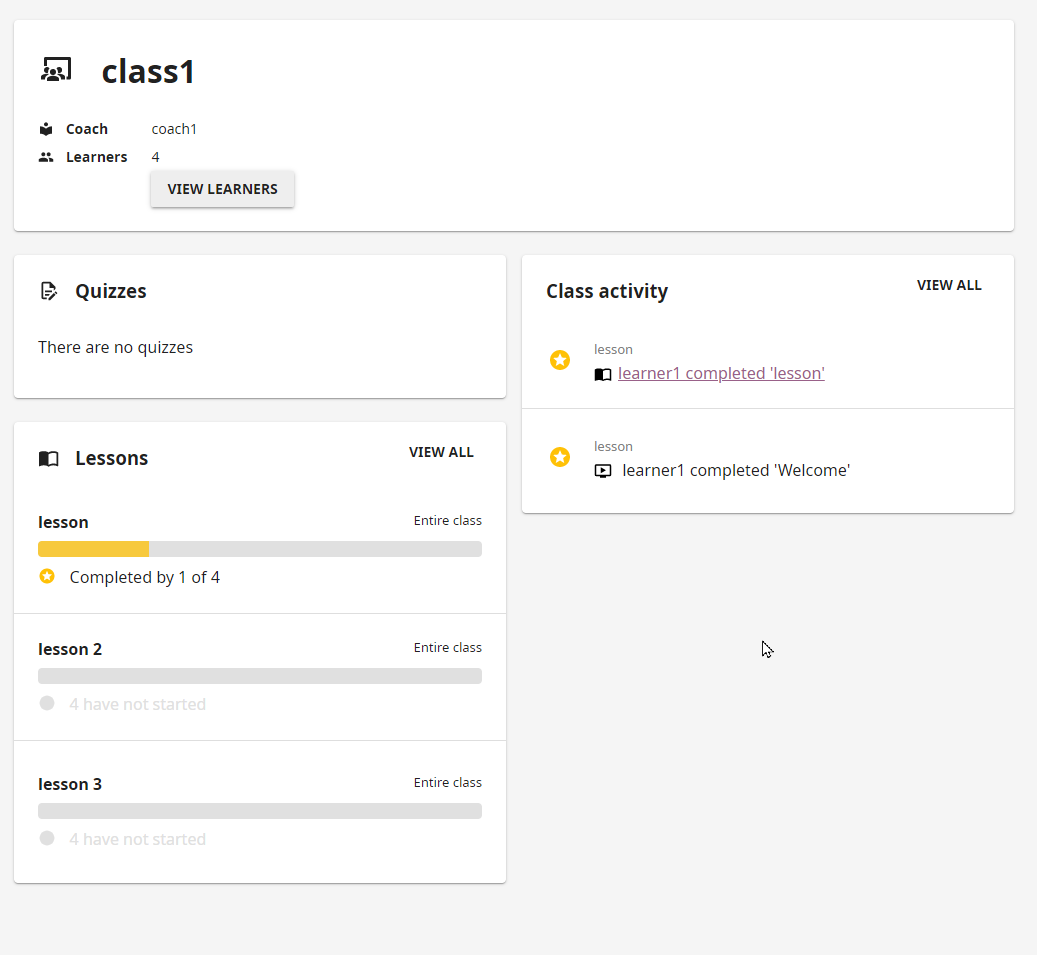
Learner with completed lesson:
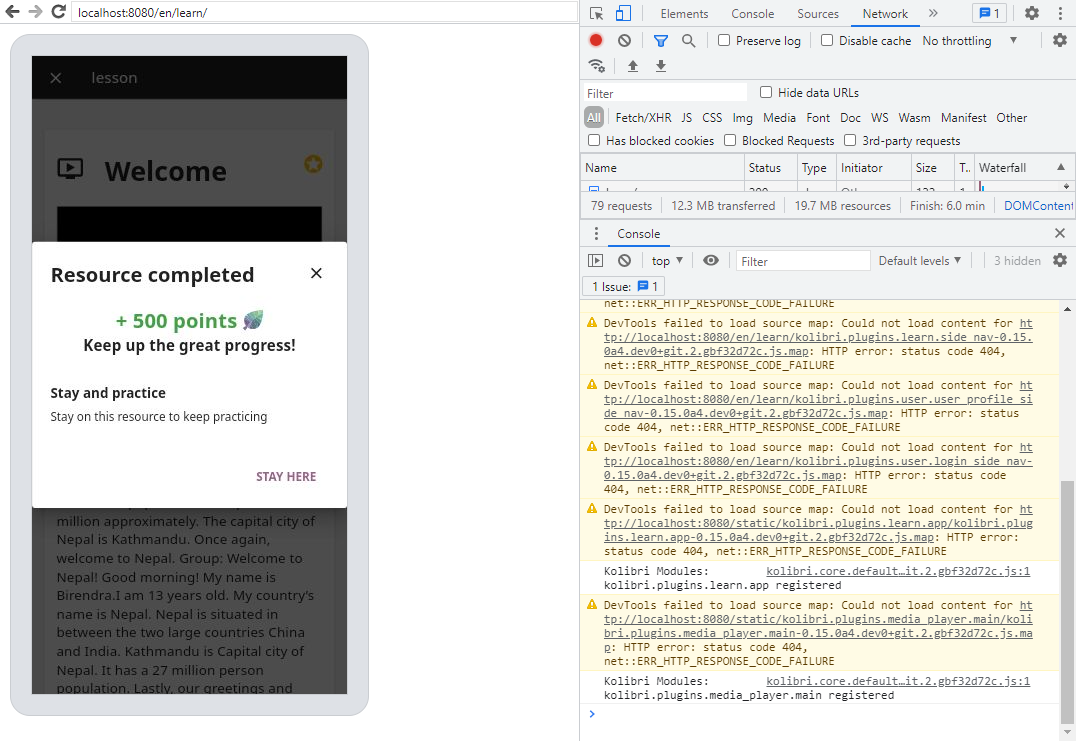
Restored learner device without any indication of the progress made:
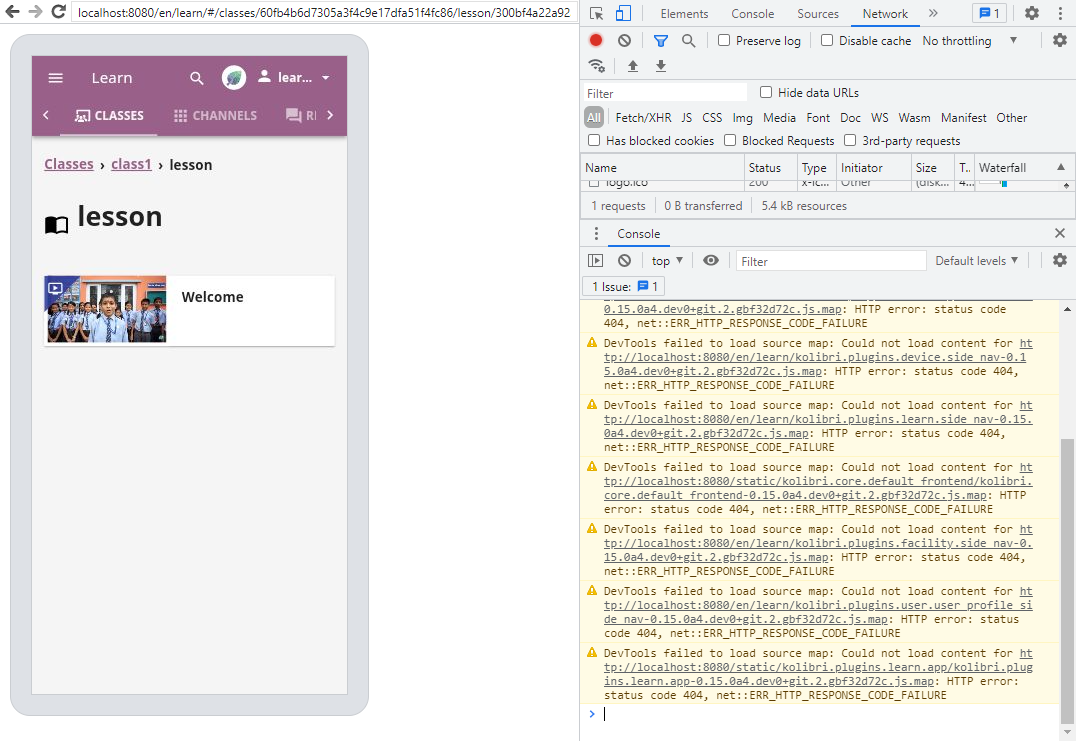
## Windows Logs
[logs.zip](https://github.com/learningequality/kolibri/files/7176855/logs.zip)
## Android and Ubuntu Logs and DB files
https://drive.google.com/file/d/1RAZG77NHuX92puj-KxA-GtkSpx3JxjyZ/view?usp=sharing
## Usage Details
- OS: Windows 10, Android 11
- Browser: Chrome
Single user syncing - Lesson completion is not restored after second setup of the same learner account
## Observed behavior
I have setup a learner-only device and have completed a lesson assigned to the learner user which is then synced correctly to the server. After that I've deleted the android app storage and cache and repeated the setup for the same user expecting the lesson progress to be restored while in reality it does not get restored and the learner has to start over.
## Expected behavior
Any synced user data should be restored.
## Steps to reproduce the issue
1. Install this Windows [build](https://buildkite.com/learningequality/kolibri-windows/builds/1930) and this Android [build](https://buildkite.com/learningequality/kolibri-android-installer/builds/2692)
2. Setup the Windows app as a server and setup a learner device on Android.
3. As a learner complete an assigned lesson.
4. As an admin go to Coach>Reports>Lessons and verify that the lesson progress is synced correctly.
5. Delete the cache and storage of the android app and setup the same learner user again. Observe that there is no indication for the progress made so far.
## Additional information
Admin:

Learner with completed lesson:

Restored learner device without any indication of the progress made:

## Windows Logs
[logs.zip](https://github.com/learningequality/kolibri/files/7176855/logs.zip)
## Android and Ubuntu Logs and DB files
https://drive.google.com/file/d/1RAZG77NHuX92puj-KxA-GtkSpx3JxjyZ/view?usp=sharing
## Usage Details
- OS: Windows 10, Android 11
- Browser: Chrome
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/core/exams/kolibri_plugin.py`
Content:
```
1 # To reinstate the original functionality, please remove this header comment
2 # and uncomment the code below
3 # from .single_user_assignment_utils import (
4 # update_assignments_from_individual_syncable_exams,
5 # )
6 # from .single_user_assignment_utils import (
7 # update_individual_syncable_exams_from_assignments,
8 # )
9 # from kolibri.core.auth.hooks import FacilityDataSyncHook
10 # from kolibri.plugins.hooks import register_hook
11 # @register_hook
12 # class SingleUserExamSyncHook(FacilityDataSyncHook):
13 # def pre_transfer(
14 # self,
15 # dataset_id,
16 # local_is_single_user,
17 # remote_is_single_user,
18 # single_user_id,
19 # context,
20 # ):
21 # # if we're about to send data to a single-user device, prep the syncable exam assignments
22 # if context.is_producer and remote_is_single_user:
23 # update_individual_syncable_exams_from_assignments(single_user_id)
24 # def post_transfer(
25 # self,
26 # dataset_id,
27 # local_is_single_user,
28 # remote_is_single_user,
29 # single_user_id,
30 # context,
31 # ):
32 # # if we've just received data on a single-user device, update the exams and assignments
33 # if context.is_receiver and local_is_single_user:
34 # update_assignments_from_individual_syncable_exams(single_user_id)
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/core/exams/kolibri_plugin.py b/kolibri/core/exams/kolibri_plugin.py
--- a/kolibri/core/exams/kolibri_plugin.py
+++ b/kolibri/core/exams/kolibri_plugin.py
@@ -1,5 +1,5 @@
# To reinstate the original functionality, please remove this header comment
-# and uncomment the code below
+# and uncomment the code below (and re-enable exams in test_single_user_assignment_sync, search for "TODO")
# from .single_user_assignment_utils import (
# update_assignments_from_individual_syncable_exams,
# )
|
{"golden_diff": "diff --git a/kolibri/core/exams/kolibri_plugin.py b/kolibri/core/exams/kolibri_plugin.py\n--- a/kolibri/core/exams/kolibri_plugin.py\n+++ b/kolibri/core/exams/kolibri_plugin.py\n@@ -1,5 +1,5 @@\n # To reinstate the original functionality, please remove this header comment\n-# and uncomment the code below\n+# and uncomment the code below (and re-enable exams in test_single_user_assignment_sync, search for \"TODO\")\n # from .single_user_assignment_utils import (\n # update_assignments_from_individual_syncable_exams,\n # )\n", "issue": "Single user syncing - Lesson completion is not restored after second setup of the same learner account\n## Observed behavior\r\nI have setup a learner-only device and have completed a lesson assigned to the learner user which is then synced correctly to the server. After that I've deleted the android app storage and cache and repeated the setup for the same user expecting the lesson progress to be restored while in reality it does not get restored and the learner has to start over.\r\n\r\n## Expected behavior\r\nAny synced user data should be restored.\r\n\r\n## Steps to reproduce the issue\r\n1. Install this Windows [build](https://buildkite.com/learningequality/kolibri-windows/builds/1930) and this Android [build](https://buildkite.com/learningequality/kolibri-android-installer/builds/2692)\r\n2. Setup the Windows app as a server and setup a learner device on Android.\r\n3. As a learner complete an assigned lesson.\r\n4. As an admin go to Coach>Reports>Lessons and verify that the lesson progress is synced correctly.\r\n5. Delete the cache and storage of the android app and setup the same learner user again. Observe that there is no indication for the progress made so far.\r\n\r\n## Additional information\r\nAdmin:\r\n\r\n\r\nLearner with completed lesson:\r\n\r\n\r\nRestored learner device without any indication of the progress made:\r\n\r\n\r\n\r\n## Windows Logs\r\n[logs.zip](https://github.com/learningequality/kolibri/files/7176855/logs.zip)\r\n\r\n## Android and Ubuntu Logs and DB files\r\nhttps://drive.google.com/file/d/1RAZG77NHuX92puj-KxA-GtkSpx3JxjyZ/view?usp=sharing\r\n\r\n## Usage Details\r\n - OS: Windows 10, Android 11\r\n - Browser: Chrome\nSingle user syncing - Lesson completion is not restored after second setup of the same learner account\n## Observed behavior\r\nI have setup a learner-only device and have completed a lesson assigned to the learner user which is then synced correctly to the server. After that I've deleted the android app storage and cache and repeated the setup for the same user expecting the lesson progress to be restored while in reality it does not get restored and the learner has to start over.\r\n\r\n## Expected behavior\r\nAny synced user data should be restored.\r\n\r\n## Steps to reproduce the issue\r\n1. Install this Windows [build](https://buildkite.com/learningequality/kolibri-windows/builds/1930) and this Android [build](https://buildkite.com/learningequality/kolibri-android-installer/builds/2692)\r\n2. Setup the Windows app as a server and setup a learner device on Android.\r\n3. As a learner complete an assigned lesson.\r\n4. As an admin go to Coach>Reports>Lessons and verify that the lesson progress is synced correctly.\r\n5. Delete the cache and storage of the android app and setup the same learner user again. Observe that there is no indication for the progress made so far.\r\n\r\n## Additional information\r\nAdmin:\r\n\r\n\r\nLearner with completed lesson:\r\n\r\n\r\nRestored learner device without any indication of the progress made:\r\n\r\n\r\n\r\n## Windows Logs\r\n[logs.zip](https://github.com/learningequality/kolibri/files/7176855/logs.zip)\r\n\r\n## Android and Ubuntu Logs and DB files\r\nhttps://drive.google.com/file/d/1RAZG77NHuX92puj-KxA-GtkSpx3JxjyZ/view?usp=sharing\r\n\r\n## Usage Details\r\n - OS: Windows 10, Android 11\r\n - Browser: Chrome\n", "before_files": [{"content": "# To reinstate the original functionality, please remove this header comment\n# and uncomment the code below\n# from .single_user_assignment_utils import (\n# update_assignments_from_individual_syncable_exams,\n# )\n# from .single_user_assignment_utils import (\n# update_individual_syncable_exams_from_assignments,\n# )\n# from kolibri.core.auth.hooks import FacilityDataSyncHook\n# from kolibri.plugins.hooks import register_hook\n# @register_hook\n# class SingleUserExamSyncHook(FacilityDataSyncHook):\n# def pre_transfer(\n# self,\n# dataset_id,\n# local_is_single_user,\n# remote_is_single_user,\n# single_user_id,\n# context,\n# ):\n# # if we're about to send data to a single-user device, prep the syncable exam assignments\n# if context.is_producer and remote_is_single_user:\n# update_individual_syncable_exams_from_assignments(single_user_id)\n# def post_transfer(\n# self,\n# dataset_id,\n# local_is_single_user,\n# remote_is_single_user,\n# single_user_id,\n# context,\n# ):\n# # if we've just received data on a single-user device, update the exams and assignments\n# if context.is_receiver and local_is_single_user:\n# update_assignments_from_individual_syncable_exams(single_user_id)\n", "path": "kolibri/core/exams/kolibri_plugin.py"}], "after_files": [{"content": "# To reinstate the original functionality, please remove this header comment\n# and uncomment the code below (and re-enable exams in test_single_user_assignment_sync, search for \"TODO\")\n# from .single_user_assignment_utils import (\n# update_assignments_from_individual_syncable_exams,\n# )\n# from .single_user_assignment_utils import (\n# update_individual_syncable_exams_from_assignments,\n# )\n# from kolibri.core.auth.hooks import FacilityDataSyncHook\n# from kolibri.plugins.hooks import register_hook\n# @register_hook\n# class SingleUserExamSyncHook(FacilityDataSyncHook):\n# def pre_transfer(\n# self,\n# dataset_id,\n# local_is_single_user,\n# remote_is_single_user,\n# single_user_id,\n# context,\n# ):\n# # if we're about to send data to a single-user device, prep the syncable exam assignments\n# if context.is_producer and remote_is_single_user:\n# update_individual_syncable_exams_from_assignments(single_user_id)\n# def post_transfer(\n# self,\n# dataset_id,\n# local_is_single_user,\n# remote_is_single_user,\n# single_user_id,\n# context,\n# ):\n# # if we've just received data on a single-user device, update the exams and assignments\n# if context.is_receiver and local_is_single_user:\n# update_assignments_from_individual_syncable_exams(single_user_id)\n", "path": "kolibri/core/exams/kolibri_plugin.py"}]}
| 1,845 | 134 |
gh_patches_debug_1146
|
rasdani/github-patches
|
git_diff
|
locustio__locust-1760
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Locust stopped working after Flast 2.0 got released
in setup.py I can see:
` "flask>=1.1.2", `
I guess it should be hardcoded to ==1.1.2 for now.
it crashes with:
```
File "/root/.local/share/virtualenvs/xxxxxxx/lib/python3.6/site-packages/locust/web.py", line 102, in __init__
app.jinja_options["extensions"].append("jinja2.ext.do")
KeyError: 'extensions'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import ast
3 import os
4 import re
5 import sys
6
7 from setuptools import find_packages, setup
8
9 ROOT_PATH = os.path.abspath(os.path.dirname(__file__))
10
11 # parse version from locust/__init__.py
12 _version_re = re.compile(r"__version__\s+=\s+(.*)")
13 _init_file = os.path.join(ROOT_PATH, "locust", "__init__.py")
14 with open(_init_file, "rb") as f:
15 version = str(ast.literal_eval(_version_re.search(f.read().decode("utf-8")).group(1)))
16
17 setup(
18 name="locust",
19 version=version,
20 install_requires=[
21 "gevent>=20.9.0",
22 "flask>=1.1.2",
23 "Werkzeug>=1.0.1",
24 "requests>=2.9.1",
25 "msgpack>=0.6.2",
26 "pyzmq>=16.0.2",
27 "geventhttpclient>=1.4.4",
28 "ConfigArgParse>=1.0",
29 "psutil>=5.6.7",
30 "Flask-BasicAuth>=0.2.0",
31 ],
32 test_suite="locust.test",
33 tests_require=[
34 "cryptography",
35 "mock",
36 "pyquery",
37 ],
38 extras_require={
39 ":sys_platform == 'win32'": ["pywin32"],
40 },
41 )
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -19,7 +19,7 @@
version=version,
install_requires=[
"gevent>=20.9.0",
- "flask>=1.1.2",
+ "flask==1.1.2",
"Werkzeug>=1.0.1",
"requests>=2.9.1",
"msgpack>=0.6.2",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -19,7 +19,7 @@\n version=version,\n install_requires=[\n \"gevent>=20.9.0\",\n- \"flask>=1.1.2\",\n+ \"flask==1.1.2\",\n \"Werkzeug>=1.0.1\",\n \"requests>=2.9.1\",\n \"msgpack>=0.6.2\",\n", "issue": "Locust stopped working after Flast 2.0 got released\nin setup.py I can see:\r\n` \"flask>=1.1.2\", `\r\nI guess it should be hardcoded to ==1.1.2 for now.\r\n\r\nit crashes with:\r\n```\r\nFile \"/root/.local/share/virtualenvs/xxxxxxx/lib/python3.6/site-packages/locust/web.py\", line 102, in __init__\r\napp.jinja_options[\"extensions\"].append(\"jinja2.ext.do\")\r\nKeyError: 'extensions'\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport ast\nimport os\nimport re\nimport sys\n\nfrom setuptools import find_packages, setup\n\nROOT_PATH = os.path.abspath(os.path.dirname(__file__))\n\n# parse version from locust/__init__.py\n_version_re = re.compile(r\"__version__\\s+=\\s+(.*)\")\n_init_file = os.path.join(ROOT_PATH, \"locust\", \"__init__.py\")\nwith open(_init_file, \"rb\") as f:\n version = str(ast.literal_eval(_version_re.search(f.read().decode(\"utf-8\")).group(1)))\n\nsetup(\n name=\"locust\",\n version=version,\n install_requires=[\n \"gevent>=20.9.0\",\n \"flask>=1.1.2\",\n \"Werkzeug>=1.0.1\",\n \"requests>=2.9.1\",\n \"msgpack>=0.6.2\",\n \"pyzmq>=16.0.2\",\n \"geventhttpclient>=1.4.4\",\n \"ConfigArgParse>=1.0\",\n \"psutil>=5.6.7\",\n \"Flask-BasicAuth>=0.2.0\",\n ],\n test_suite=\"locust.test\",\n tests_require=[\n \"cryptography\",\n \"mock\",\n \"pyquery\",\n ],\n extras_require={\n \":sys_platform == 'win32'\": [\"pywin32\"],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport ast\nimport os\nimport re\nimport sys\n\nfrom setuptools import find_packages, setup\n\nROOT_PATH = os.path.abspath(os.path.dirname(__file__))\n\n# parse version from locust/__init__.py\n_version_re = re.compile(r\"__version__\\s+=\\s+(.*)\")\n_init_file = os.path.join(ROOT_PATH, \"locust\", \"__init__.py\")\nwith open(_init_file, \"rb\") as f:\n version = str(ast.literal_eval(_version_re.search(f.read().decode(\"utf-8\")).group(1)))\n\nsetup(\n name=\"locust\",\n version=version,\n install_requires=[\n \"gevent>=20.9.0\",\n \"flask==1.1.2\",\n \"Werkzeug>=1.0.1\",\n \"requests>=2.9.1\",\n \"msgpack>=0.6.2\",\n \"pyzmq>=16.0.2\",\n \"geventhttpclient>=1.4.4\",\n \"ConfigArgParse>=1.0\",\n \"psutil>=5.6.7\",\n \"Flask-BasicAuth>=0.2.0\",\n ],\n test_suite=\"locust.test\",\n tests_require=[\n \"cryptography\",\n \"mock\",\n \"pyquery\",\n ],\n extras_require={\n \":sys_platform == 'win32'\": [\"pywin32\"],\n },\n)\n", "path": "setup.py"}]}
| 763 | 110 |
gh_patches_debug_7642
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-546
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Handle "::" in URLs specially
Split from #542. /cc @flvi0
> What exactly are those :: links anyways, is that a standard URI form for external applications? Maybe we can parse/qualify it somehow differently to make searching for scoped C++ symbols work as expected?
[QUrl](http://doc.qt.io/qt-5/qurl.html) parses `foo::bar` as a valid URL with `foo` as scheme and `:bar` as path. I'm not sure if this is something sensible to do according to the URL standard. I guess `qutebrowser.urlutils.is_url` should handle this as a special case, and maybe a Qt bug should be submitted if this is invalid according to [RFC3986](https://tools.ietf.org/html/rfc3986) and the [WHATWG living URL standard](https://url.spec.whatwg.org/)?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/utils/urlutils.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2015 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Utils regarding URL handling."""
21
22 import re
23 import os.path
24 import ipaddress
25 import posixpath
26 import urllib.parse
27
28 from PyQt5.QtCore import QUrl
29 from PyQt5.QtNetwork import QHostInfo, QHostAddress
30
31 from qutebrowser.config import config, configexc
32 from qutebrowser.utils import log, qtutils, message
33 from qutebrowser.commands import cmdexc
34
35
36 # FIXME: we probably could raise some exceptions on invalid URLs
37 # https://github.com/The-Compiler/qutebrowser/issues/108
38
39
40 def _parse_search_term(s):
41 """Get a search engine name and search term from a string.
42
43 Args:
44 s: The string to get a search engine for.
45
46 Return:
47 A (engine, term) tuple, where engine is None for the default engine.
48 """
49 m = re.search(r'(^\w+)\s+(.+)($|\s+)', s)
50 if m:
51 engine = m.group(1)
52 try:
53 config.get('searchengines', engine)
54 except configexc.NoOptionError:
55 engine = None
56 term = s
57 else:
58 term = m.group(2).rstrip()
59 else:
60 engine = None
61 term = s
62 log.url.debug("engine {}, term '{}'".format(engine, term))
63 return (engine, term)
64
65
66 def _get_search_url(txt):
67 """Get a search engine URL for a text.
68
69 Args:
70 txt: Text to search for.
71
72 Return:
73 The search URL as a QUrl.
74 """
75 log.url.debug("Finding search engine for '{}'".format(txt))
76 engine, term = _parse_search_term(txt)
77 if not term:
78 raise FuzzyUrlError("No search term given")
79 if engine is None:
80 template = config.get('searchengines', 'DEFAULT')
81 else:
82 template = config.get('searchengines', engine)
83 url = qurl_from_user_input(template.format(urllib.parse.quote(term)))
84 qtutils.ensure_valid(url)
85 return url
86
87
88 def _is_url_naive(urlstr):
89 """Naive check if given URL is really a URL.
90
91 Args:
92 urlstr: The URL to check for, as string.
93
94 Return:
95 True if the URL really is a URL, False otherwise.
96 """
97 url = qurl_from_user_input(urlstr)
98 try:
99 ipaddress.ip_address(urlstr)
100 except ValueError:
101 pass
102 else:
103 # Valid IPv4/IPv6 address
104 return True
105
106 # Qt treats things like "23.42" or "1337" or "0xDEAD" as valid URLs
107 # which we don't want to. Note we already filtered *real* valid IPs
108 # above.
109 if not QHostAddress(urlstr).isNull():
110 return False
111
112 if not url.isValid():
113 return False
114 elif '.' in url.host():
115 return True
116 elif url.host() == 'localhost':
117 return True
118 else:
119 return False
120
121
122 def _is_url_dns(url):
123 """Check if a URL is really a URL via DNS.
124
125 Args:
126 url: The URL to check for as QUrl, ideally via qurl_from_user_input.
127
128 Return:
129 True if the URL really is a URL, False otherwise.
130 """
131 if not url.isValid():
132 return False
133 host = url.host()
134 log.url.debug("DNS request for {}".format(host))
135 if not host:
136 return False
137 info = QHostInfo.fromName(host)
138 return not info.error()
139
140
141 def fuzzy_url(urlstr, cwd=None, relative=False, do_search=True):
142 """Get a QUrl based on an user input which is URL or search term.
143
144 Args:
145 urlstr: URL to load as a string.
146 cwd: The current working directory, or None.
147 relative: Whether to resolve relative files.
148 do_search: Whether to perform a search on non-URLs.
149
150 Return:
151 A target QUrl to a searchpage or the original URL.
152 """
153 expanded = os.path.expanduser(urlstr)
154 if relative and cwd:
155 path = os.path.join(cwd, expanded)
156 elif relative:
157 try:
158 path = os.path.abspath(expanded)
159 except OSError:
160 path = None
161 elif os.path.isabs(expanded):
162 path = expanded
163 else:
164 path = None
165
166 stripped = urlstr.strip()
167 if path is not None and os.path.exists(path):
168 log.url.debug("URL is a local file")
169 url = QUrl.fromLocalFile(path)
170 elif (not do_search) or is_url(stripped):
171 # probably an address
172 log.url.debug("URL is a fuzzy address")
173 url = qurl_from_user_input(urlstr)
174 else: # probably a search term
175 log.url.debug("URL is a fuzzy search term")
176 try:
177 url = _get_search_url(urlstr)
178 except ValueError: # invalid search engine
179 url = qurl_from_user_input(stripped)
180 log.url.debug("Converting fuzzy term {} to URL -> {}".format(
181 urlstr, url.toDisplayString()))
182 if do_search and config.get('general', 'auto-search'):
183 qtutils.ensure_valid(url)
184 else:
185 if not url.isValid():
186 raise FuzzyUrlError("Invalid URL '{}'!".format(urlstr))
187 return url
188
189
190 def _has_explicit_scheme(url):
191 """Check if an url has an explicit scheme given.
192
193 Args:
194 url: The URL as QUrl.
195 """
196 return url.isValid() and url.scheme() and not url.path().startswith(' ')
197
198
199 def is_special_url(url):
200 """Return True if url is an about:... or other special URL.
201
202 Args:
203 url: The URL as QUrl.
204 """
205 if not url.isValid():
206 return False
207 special_schemes = ('about', 'qute', 'file')
208 return url.scheme() in special_schemes
209
210
211 def is_url(urlstr):
212 """Check if url seems to be a valid URL.
213
214 Args:
215 urlstr: The URL as string.
216
217 Return:
218 True if it is a valid URL, False otherwise.
219 """
220 autosearch = config.get('general', 'auto-search')
221
222 log.url.debug("Checking if '{}' is a URL (autosearch={}).".format(
223 urlstr, autosearch))
224
225 urlstr = urlstr.strip()
226 qurl = QUrl(urlstr)
227
228 if not autosearch:
229 # no autosearch, so everything is a URL unless it has an explicit
230 # search engine.
231 engine, _term = _parse_search_term(urlstr)
232 if engine is None:
233 return True
234 else:
235 return False
236
237 if _has_explicit_scheme(qurl):
238 # URLs with explicit schemes are always URLs
239 log.url.debug("Contains explicit scheme")
240 url = True
241 elif ' ' in urlstr:
242 # A URL will never contain a space
243 log.url.debug("Contains space -> no URL")
244 url = False
245 elif is_special_url(qurl):
246 # Special URLs are always URLs, even with autosearch=False
247 log.url.debug("Is an special URL.")
248 url = True
249 elif autosearch == 'dns':
250 log.url.debug("Checking via DNS")
251 # We want to use qurl_from_user_input here, as the user might enter
252 # "foo.de" and that should be treated as URL here.
253 url = _is_url_dns(qurl_from_user_input(urlstr))
254 elif autosearch == 'naive':
255 log.url.debug("Checking via naive check")
256 url = _is_url_naive(urlstr)
257 else:
258 raise ValueError("Invalid autosearch value")
259 return url and qurl_from_user_input(urlstr).isValid()
260
261
262 def qurl_from_user_input(urlstr):
263 """Get a QUrl based on an user input. Additionally handles IPv6 addresses.
264
265 QUrl.fromUserInput handles something like '::1' as a file URL instead of an
266 IPv6, so we first try to handle it as a valid IPv6, and if that fails we
267 use QUrl.fromUserInput.
268
269 WORKAROUND - https://bugreports.qt-project.org/browse/QTBUG-41089
270 FIXME - Maybe https://codereview.qt-project.org/#/c/93851/ has a better way
271 to solve this?
272 https://github.com/The-Compiler/qutebrowser/issues/109
273
274 Args:
275 urlstr: The URL as string.
276
277 Return:
278 The converted QUrl.
279 """
280 # First we try very liberally to separate something like an IPv6 from the
281 # rest (e.g. path info or parameters)
282 match = re.match(r'\[?([0-9a-fA-F:.]+)\]?(.*)', urlstr.strip())
283 if match:
284 ipstr, rest = match.groups()
285 else:
286 ipstr = urlstr.strip()
287 rest = ''
288 # Then we try to parse it as an IPv6, and if we fail use
289 # QUrl.fromUserInput.
290 try:
291 ipaddress.IPv6Address(ipstr)
292 except ipaddress.AddressValueError:
293 return QUrl.fromUserInput(urlstr)
294 else:
295 return QUrl('http://[{}]{}'.format(ipstr, rest))
296
297
298 def invalid_url_error(win_id, url, action):
299 """Display an error message for an URL.
300
301 Args:
302 win_id: The window ID to show the error message in.
303 action: The action which was interrupted by the error.
304 """
305 if url.isValid():
306 raise ValueError("Calling invalid_url_error with valid URL {}".format(
307 url.toDisplayString()))
308 errstring = "Trying to {} with invalid URL".format(action)
309 if url.errorString():
310 errstring += " - {}".format(url.errorString())
311 message.error(win_id, errstring)
312
313
314 def raise_cmdexc_if_invalid(url):
315 """Check if the given QUrl is invalid, and if so, raise a CommandError."""
316 if not url.isValid():
317 errstr = "Invalid URL {}".format(url.toDisplayString())
318 url_error = url.errorString()
319 if url_error:
320 errstr += " - {}".format(url_error)
321 raise cmdexc.CommandError(errstr)
322
323
324 def filename_from_url(url):
325 """Get a suitable filename from an URL.
326
327 Args:
328 url: The URL to parse, as a QUrl.
329
330 Return:
331 The suggested filename as a string, or None.
332 """
333 if not url.isValid():
334 return None
335 pathname = posixpath.basename(url.path())
336 if pathname:
337 return pathname
338 elif url.host():
339 return url.host() + '.html'
340 else:
341 return None
342
343
344 def host_tuple(url):
345 """Get a (scheme, host, port) tuple.
346
347 This is suitable to identify a connection, e.g. for SSL errors.
348 """
349 return (url.scheme(), url.host(), url.port())
350
351
352 class FuzzyUrlError(Exception):
353
354 """Exception raised by fuzzy_url on problems."""
355
356 pass
357
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/utils/urlutils.py b/qutebrowser/utils/urlutils.py
--- a/qutebrowser/utils/urlutils.py
+++ b/qutebrowser/utils/urlutils.py
@@ -193,7 +193,14 @@
Args:
url: The URL as QUrl.
"""
- return url.isValid() and url.scheme() and not url.path().startswith(' ')
+
+ # Note that generic URI syntax actually would allow a second colon
+ # after the scheme delimiter. Since we don't know of any URIs
+ # using this and want to support e.g. searching for scoped C++
+ # symbols, we treat this as not an URI anyways.
+ return (url.isValid() and url.scheme()
+ and not url.path().startswith(' ')
+ and not url.path().startswith(':'))
def is_special_url(url):
|
{"golden_diff": "diff --git a/qutebrowser/utils/urlutils.py b/qutebrowser/utils/urlutils.py\n--- a/qutebrowser/utils/urlutils.py\n+++ b/qutebrowser/utils/urlutils.py\n@@ -193,7 +193,14 @@\n Args:\n url: The URL as QUrl.\n \"\"\"\n- return url.isValid() and url.scheme() and not url.path().startswith(' ')\n+\n+ # Note that generic URI syntax actually would allow a second colon\n+ # after the scheme delimiter. Since we don't know of any URIs\n+ # using this and want to support e.g. searching for scoped C++\n+ # symbols, we treat this as not an URI anyways.\n+ return (url.isValid() and url.scheme()\n+ and not url.path().startswith(' ')\n+ and not url.path().startswith(':'))\n \n \n def is_special_url(url):\n", "issue": "Handle \"::\" in URLs specially\nSplit from #542. /cc @flvi0\n\n> What exactly are those :: links anyways, is that a standard URI form for external applications? Maybe we can parse/qualify it somehow differently to make searching for scoped C++ symbols work as expected?\n\n[QUrl](http://doc.qt.io/qt-5/qurl.html) parses `foo::bar` as a valid URL with `foo` as scheme and `:bar` as path. I'm not sure if this is something sensible to do according to the URL standard. I guess `qutebrowser.urlutils.is_url` should handle this as a special case, and maybe a Qt bug should be submitted if this is invalid according to [RFC3986](https://tools.ietf.org/html/rfc3986) and the [WHATWG living URL standard](https://url.spec.whatwg.org/)?\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2015 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Utils regarding URL handling.\"\"\"\n\nimport re\nimport os.path\nimport ipaddress\nimport posixpath\nimport urllib.parse\n\nfrom PyQt5.QtCore import QUrl\nfrom PyQt5.QtNetwork import QHostInfo, QHostAddress\n\nfrom qutebrowser.config import config, configexc\nfrom qutebrowser.utils import log, qtutils, message\nfrom qutebrowser.commands import cmdexc\n\n\n# FIXME: we probably could raise some exceptions on invalid URLs\n# https://github.com/The-Compiler/qutebrowser/issues/108\n\n\ndef _parse_search_term(s):\n \"\"\"Get a search engine name and search term from a string.\n\n Args:\n s: The string to get a search engine for.\n\n Return:\n A (engine, term) tuple, where engine is None for the default engine.\n \"\"\"\n m = re.search(r'(^\\w+)\\s+(.+)($|\\s+)', s)\n if m:\n engine = m.group(1)\n try:\n config.get('searchengines', engine)\n except configexc.NoOptionError:\n engine = None\n term = s\n else:\n term = m.group(2).rstrip()\n else:\n engine = None\n term = s\n log.url.debug(\"engine {}, term '{}'\".format(engine, term))\n return (engine, term)\n\n\ndef _get_search_url(txt):\n \"\"\"Get a search engine URL for a text.\n\n Args:\n txt: Text to search for.\n\n Return:\n The search URL as a QUrl.\n \"\"\"\n log.url.debug(\"Finding search engine for '{}'\".format(txt))\n engine, term = _parse_search_term(txt)\n if not term:\n raise FuzzyUrlError(\"No search term given\")\n if engine is None:\n template = config.get('searchengines', 'DEFAULT')\n else:\n template = config.get('searchengines', engine)\n url = qurl_from_user_input(template.format(urllib.parse.quote(term)))\n qtutils.ensure_valid(url)\n return url\n\n\ndef _is_url_naive(urlstr):\n \"\"\"Naive check if given URL is really a URL.\n\n Args:\n urlstr: The URL to check for, as string.\n\n Return:\n True if the URL really is a URL, False otherwise.\n \"\"\"\n url = qurl_from_user_input(urlstr)\n try:\n ipaddress.ip_address(urlstr)\n except ValueError:\n pass\n else:\n # Valid IPv4/IPv6 address\n return True\n\n # Qt treats things like \"23.42\" or \"1337\" or \"0xDEAD\" as valid URLs\n # which we don't want to. Note we already filtered *real* valid IPs\n # above.\n if not QHostAddress(urlstr).isNull():\n return False\n\n if not url.isValid():\n return False\n elif '.' in url.host():\n return True\n elif url.host() == 'localhost':\n return True\n else:\n return False\n\n\ndef _is_url_dns(url):\n \"\"\"Check if a URL is really a URL via DNS.\n\n Args:\n url: The URL to check for as QUrl, ideally via qurl_from_user_input.\n\n Return:\n True if the URL really is a URL, False otherwise.\n \"\"\"\n if not url.isValid():\n return False\n host = url.host()\n log.url.debug(\"DNS request for {}\".format(host))\n if not host:\n return False\n info = QHostInfo.fromName(host)\n return not info.error()\n\n\ndef fuzzy_url(urlstr, cwd=None, relative=False, do_search=True):\n \"\"\"Get a QUrl based on an user input which is URL or search term.\n\n Args:\n urlstr: URL to load as a string.\n cwd: The current working directory, or None.\n relative: Whether to resolve relative files.\n do_search: Whether to perform a search on non-URLs.\n\n Return:\n A target QUrl to a searchpage or the original URL.\n \"\"\"\n expanded = os.path.expanduser(urlstr)\n if relative and cwd:\n path = os.path.join(cwd, expanded)\n elif relative:\n try:\n path = os.path.abspath(expanded)\n except OSError:\n path = None\n elif os.path.isabs(expanded):\n path = expanded\n else:\n path = None\n\n stripped = urlstr.strip()\n if path is not None and os.path.exists(path):\n log.url.debug(\"URL is a local file\")\n url = QUrl.fromLocalFile(path)\n elif (not do_search) or is_url(stripped):\n # probably an address\n log.url.debug(\"URL is a fuzzy address\")\n url = qurl_from_user_input(urlstr)\n else: # probably a search term\n log.url.debug(\"URL is a fuzzy search term\")\n try:\n url = _get_search_url(urlstr)\n except ValueError: # invalid search engine\n url = qurl_from_user_input(stripped)\n log.url.debug(\"Converting fuzzy term {} to URL -> {}\".format(\n urlstr, url.toDisplayString()))\n if do_search and config.get('general', 'auto-search'):\n qtutils.ensure_valid(url)\n else:\n if not url.isValid():\n raise FuzzyUrlError(\"Invalid URL '{}'!\".format(urlstr))\n return url\n\n\ndef _has_explicit_scheme(url):\n \"\"\"Check if an url has an explicit scheme given.\n\n Args:\n url: The URL as QUrl.\n \"\"\"\n return url.isValid() and url.scheme() and not url.path().startswith(' ')\n\n\ndef is_special_url(url):\n \"\"\"Return True if url is an about:... or other special URL.\n\n Args:\n url: The URL as QUrl.\n \"\"\"\n if not url.isValid():\n return False\n special_schemes = ('about', 'qute', 'file')\n return url.scheme() in special_schemes\n\n\ndef is_url(urlstr):\n \"\"\"Check if url seems to be a valid URL.\n\n Args:\n urlstr: The URL as string.\n\n Return:\n True if it is a valid URL, False otherwise.\n \"\"\"\n autosearch = config.get('general', 'auto-search')\n\n log.url.debug(\"Checking if '{}' is a URL (autosearch={}).\".format(\n urlstr, autosearch))\n\n urlstr = urlstr.strip()\n qurl = QUrl(urlstr)\n\n if not autosearch:\n # no autosearch, so everything is a URL unless it has an explicit\n # search engine.\n engine, _term = _parse_search_term(urlstr)\n if engine is None:\n return True\n else:\n return False\n\n if _has_explicit_scheme(qurl):\n # URLs with explicit schemes are always URLs\n log.url.debug(\"Contains explicit scheme\")\n url = True\n elif ' ' in urlstr:\n # A URL will never contain a space\n log.url.debug(\"Contains space -> no URL\")\n url = False\n elif is_special_url(qurl):\n # Special URLs are always URLs, even with autosearch=False\n log.url.debug(\"Is an special URL.\")\n url = True\n elif autosearch == 'dns':\n log.url.debug(\"Checking via DNS\")\n # We want to use qurl_from_user_input here, as the user might enter\n # \"foo.de\" and that should be treated as URL here.\n url = _is_url_dns(qurl_from_user_input(urlstr))\n elif autosearch == 'naive':\n log.url.debug(\"Checking via naive check\")\n url = _is_url_naive(urlstr)\n else:\n raise ValueError(\"Invalid autosearch value\")\n return url and qurl_from_user_input(urlstr).isValid()\n\n\ndef qurl_from_user_input(urlstr):\n \"\"\"Get a QUrl based on an user input. Additionally handles IPv6 addresses.\n\n QUrl.fromUserInput handles something like '::1' as a file URL instead of an\n IPv6, so we first try to handle it as a valid IPv6, and if that fails we\n use QUrl.fromUserInput.\n\n WORKAROUND - https://bugreports.qt-project.org/browse/QTBUG-41089\n FIXME - Maybe https://codereview.qt-project.org/#/c/93851/ has a better way\n to solve this?\n https://github.com/The-Compiler/qutebrowser/issues/109\n\n Args:\n urlstr: The URL as string.\n\n Return:\n The converted QUrl.\n \"\"\"\n # First we try very liberally to separate something like an IPv6 from the\n # rest (e.g. path info or parameters)\n match = re.match(r'\\[?([0-9a-fA-F:.]+)\\]?(.*)', urlstr.strip())\n if match:\n ipstr, rest = match.groups()\n else:\n ipstr = urlstr.strip()\n rest = ''\n # Then we try to parse it as an IPv6, and if we fail use\n # QUrl.fromUserInput.\n try:\n ipaddress.IPv6Address(ipstr)\n except ipaddress.AddressValueError:\n return QUrl.fromUserInput(urlstr)\n else:\n return QUrl('http://[{}]{}'.format(ipstr, rest))\n\n\ndef invalid_url_error(win_id, url, action):\n \"\"\"Display an error message for an URL.\n\n Args:\n win_id: The window ID to show the error message in.\n action: The action which was interrupted by the error.\n \"\"\"\n if url.isValid():\n raise ValueError(\"Calling invalid_url_error with valid URL {}\".format(\n url.toDisplayString()))\n errstring = \"Trying to {} with invalid URL\".format(action)\n if url.errorString():\n errstring += \" - {}\".format(url.errorString())\n message.error(win_id, errstring)\n\n\ndef raise_cmdexc_if_invalid(url):\n \"\"\"Check if the given QUrl is invalid, and if so, raise a CommandError.\"\"\"\n if not url.isValid():\n errstr = \"Invalid URL {}\".format(url.toDisplayString())\n url_error = url.errorString()\n if url_error:\n errstr += \" - {}\".format(url_error)\n raise cmdexc.CommandError(errstr)\n\n\ndef filename_from_url(url):\n \"\"\"Get a suitable filename from an URL.\n\n Args:\n url: The URL to parse, as a QUrl.\n\n Return:\n The suggested filename as a string, or None.\n \"\"\"\n if not url.isValid():\n return None\n pathname = posixpath.basename(url.path())\n if pathname:\n return pathname\n elif url.host():\n return url.host() + '.html'\n else:\n return None\n\n\ndef host_tuple(url):\n \"\"\"Get a (scheme, host, port) tuple.\n\n This is suitable to identify a connection, e.g. for SSL errors.\n \"\"\"\n return (url.scheme(), url.host(), url.port())\n\n\nclass FuzzyUrlError(Exception):\n\n \"\"\"Exception raised by fuzzy_url on problems.\"\"\"\n\n pass\n", "path": "qutebrowser/utils/urlutils.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2015 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Utils regarding URL handling.\"\"\"\n\nimport re\nimport os.path\nimport ipaddress\nimport posixpath\nimport urllib.parse\n\nfrom PyQt5.QtCore import QUrl\nfrom PyQt5.QtNetwork import QHostInfo, QHostAddress\n\nfrom qutebrowser.config import config, configexc\nfrom qutebrowser.utils import log, qtutils, message\nfrom qutebrowser.commands import cmdexc\n\n\n# FIXME: we probably could raise some exceptions on invalid URLs\n# https://github.com/The-Compiler/qutebrowser/issues/108\n\n\ndef _parse_search_term(s):\n \"\"\"Get a search engine name and search term from a string.\n\n Args:\n s: The string to get a search engine for.\n\n Return:\n A (engine, term) tuple, where engine is None for the default engine.\n \"\"\"\n m = re.search(r'(^\\w+)\\s+(.+)($|\\s+)', s)\n if m:\n engine = m.group(1)\n try:\n config.get('searchengines', engine)\n except configexc.NoOptionError:\n engine = None\n term = s\n else:\n term = m.group(2).rstrip()\n else:\n engine = None\n term = s\n log.url.debug(\"engine {}, term '{}'\".format(engine, term))\n return (engine, term)\n\n\ndef _get_search_url(txt):\n \"\"\"Get a search engine URL for a text.\n\n Args:\n txt: Text to search for.\n\n Return:\n The search URL as a QUrl.\n \"\"\"\n log.url.debug(\"Finding search engine for '{}'\".format(txt))\n engine, term = _parse_search_term(txt)\n if not term:\n raise FuzzyUrlError(\"No search term given\")\n if engine is None:\n template = config.get('searchengines', 'DEFAULT')\n else:\n template = config.get('searchengines', engine)\n url = qurl_from_user_input(template.format(urllib.parse.quote(term)))\n qtutils.ensure_valid(url)\n return url\n\n\ndef _is_url_naive(urlstr):\n \"\"\"Naive check if given URL is really a URL.\n\n Args:\n urlstr: The URL to check for, as string.\n\n Return:\n True if the URL really is a URL, False otherwise.\n \"\"\"\n url = qurl_from_user_input(urlstr)\n try:\n ipaddress.ip_address(urlstr)\n except ValueError:\n pass\n else:\n # Valid IPv4/IPv6 address\n return True\n\n # Qt treats things like \"23.42\" or \"1337\" or \"0xDEAD\" as valid URLs\n # which we don't want to. Note we already filtered *real* valid IPs\n # above.\n if not QHostAddress(urlstr).isNull():\n return False\n\n if not url.isValid():\n return False\n elif '.' in url.host():\n return True\n elif url.host() == 'localhost':\n return True\n else:\n return False\n\n\ndef _is_url_dns(url):\n \"\"\"Check if a URL is really a URL via DNS.\n\n Args:\n url: The URL to check for as QUrl, ideally via qurl_from_user_input.\n\n Return:\n True if the URL really is a URL, False otherwise.\n \"\"\"\n if not url.isValid():\n return False\n host = url.host()\n log.url.debug(\"DNS request for {}\".format(host))\n if not host:\n return False\n info = QHostInfo.fromName(host)\n return not info.error()\n\n\ndef fuzzy_url(urlstr, cwd=None, relative=False, do_search=True):\n \"\"\"Get a QUrl based on an user input which is URL or search term.\n\n Args:\n urlstr: URL to load as a string.\n cwd: The current working directory, or None.\n relative: Whether to resolve relative files.\n do_search: Whether to perform a search on non-URLs.\n\n Return:\n A target QUrl to a searchpage or the original URL.\n \"\"\"\n expanded = os.path.expanduser(urlstr)\n if relative and cwd:\n path = os.path.join(cwd, expanded)\n elif relative:\n try:\n path = os.path.abspath(expanded)\n except OSError:\n path = None\n elif os.path.isabs(expanded):\n path = expanded\n else:\n path = None\n\n stripped = urlstr.strip()\n if path is not None and os.path.exists(path):\n log.url.debug(\"URL is a local file\")\n url = QUrl.fromLocalFile(path)\n elif (not do_search) or is_url(stripped):\n # probably an address\n log.url.debug(\"URL is a fuzzy address\")\n url = qurl_from_user_input(urlstr)\n else: # probably a search term\n log.url.debug(\"URL is a fuzzy search term\")\n try:\n url = _get_search_url(urlstr)\n except ValueError: # invalid search engine\n url = qurl_from_user_input(stripped)\n log.url.debug(\"Converting fuzzy term {} to URL -> {}\".format(\n urlstr, url.toDisplayString()))\n if do_search and config.get('general', 'auto-search'):\n qtutils.ensure_valid(url)\n else:\n if not url.isValid():\n raise FuzzyUrlError(\"Invalid URL '{}'!\".format(urlstr))\n return url\n\n\ndef _has_explicit_scheme(url):\n \"\"\"Check if an url has an explicit scheme given.\n\n Args:\n url: The URL as QUrl.\n \"\"\"\n\n # Note that generic URI syntax actually would allow a second colon\n # after the scheme delimiter. Since we don't know of any URIs\n # using this and want to support e.g. searching for scoped C++\n # symbols, we treat this as not an URI anyways.\n return (url.isValid() and url.scheme()\n and not url.path().startswith(' ')\n and not url.path().startswith(':'))\n\n\ndef is_special_url(url):\n \"\"\"Return True if url is an about:... or other special URL.\n\n Args:\n url: The URL as QUrl.\n \"\"\"\n if not url.isValid():\n return False\n special_schemes = ('about', 'qute', 'file')\n return url.scheme() in special_schemes\n\n\ndef is_url(urlstr):\n \"\"\"Check if url seems to be a valid URL.\n\n Args:\n urlstr: The URL as string.\n\n Return:\n True if it is a valid URL, False otherwise.\n \"\"\"\n autosearch = config.get('general', 'auto-search')\n\n log.url.debug(\"Checking if '{}' is a URL (autosearch={}).\".format(\n urlstr, autosearch))\n\n urlstr = urlstr.strip()\n qurl = QUrl(urlstr)\n\n if not autosearch:\n # no autosearch, so everything is a URL unless it has an explicit\n # search engine.\n engine, _term = _parse_search_term(urlstr)\n if engine is None:\n return True\n else:\n return False\n\n if _has_explicit_scheme(qurl):\n # URLs with explicit schemes are always URLs\n log.url.debug(\"Contains explicit scheme\")\n url = True\n elif ' ' in urlstr:\n # A URL will never contain a space\n log.url.debug(\"Contains space -> no URL\")\n url = False\n elif is_special_url(qurl):\n # Special URLs are always URLs, even with autosearch=False\n log.url.debug(\"Is an special URL.\")\n url = True\n elif autosearch == 'dns':\n log.url.debug(\"Checking via DNS\")\n # We want to use qurl_from_user_input here, as the user might enter\n # \"foo.de\" and that should be treated as URL here.\n url = _is_url_dns(qurl_from_user_input(urlstr))\n elif autosearch == 'naive':\n log.url.debug(\"Checking via naive check\")\n url = _is_url_naive(urlstr)\n else:\n raise ValueError(\"Invalid autosearch value\")\n return url and qurl_from_user_input(urlstr).isValid()\n\n\ndef qurl_from_user_input(urlstr):\n \"\"\"Get a QUrl based on an user input. Additionally handles IPv6 addresses.\n\n QUrl.fromUserInput handles something like '::1' as a file URL instead of an\n IPv6, so we first try to handle it as a valid IPv6, and if that fails we\n use QUrl.fromUserInput.\n\n WORKAROUND - https://bugreports.qt-project.org/browse/QTBUG-41089\n FIXME - Maybe https://codereview.qt-project.org/#/c/93851/ has a better way\n to solve this?\n https://github.com/The-Compiler/qutebrowser/issues/109\n\n Args:\n urlstr: The URL as string.\n\n Return:\n The converted QUrl.\n \"\"\"\n # First we try very liberally to separate something like an IPv6 from the\n # rest (e.g. path info or parameters)\n match = re.match(r'\\[?([0-9a-fA-F:.]+)\\]?(.*)', urlstr.strip())\n if match:\n ipstr, rest = match.groups()\n else:\n ipstr = urlstr.strip()\n rest = ''\n # Then we try to parse it as an IPv6, and if we fail use\n # QUrl.fromUserInput.\n try:\n ipaddress.IPv6Address(ipstr)\n except ipaddress.AddressValueError:\n return QUrl.fromUserInput(urlstr)\n else:\n return QUrl('http://[{}]{}'.format(ipstr, rest))\n\n\ndef invalid_url_error(win_id, url, action):\n \"\"\"Display an error message for an URL.\n\n Args:\n win_id: The window ID to show the error message in.\n action: The action which was interrupted by the error.\n \"\"\"\n if url.isValid():\n raise ValueError(\"Calling invalid_url_error with valid URL {}\".format(\n url.toDisplayString()))\n errstring = \"Trying to {} with invalid URL\".format(action)\n if url.errorString():\n errstring += \" - {}\".format(url.errorString())\n message.error(win_id, errstring)\n\n\ndef raise_cmdexc_if_invalid(url):\n \"\"\"Check if the given QUrl is invalid, and if so, raise a CommandError.\"\"\"\n if not url.isValid():\n errstr = \"Invalid URL {}\".format(url.toDisplayString())\n url_error = url.errorString()\n if url_error:\n errstr += \" - {}\".format(url_error)\n raise cmdexc.CommandError(errstr)\n\n\ndef filename_from_url(url):\n \"\"\"Get a suitable filename from an URL.\n\n Args:\n url: The URL to parse, as a QUrl.\n\n Return:\n The suggested filename as a string, or None.\n \"\"\"\n if not url.isValid():\n return None\n pathname = posixpath.basename(url.path())\n if pathname:\n return pathname\n elif url.host():\n return url.host() + '.html'\n else:\n return None\n\n\ndef host_tuple(url):\n \"\"\"Get a (scheme, host, port) tuple.\n\n This is suitable to identify a connection, e.g. for SSL errors.\n \"\"\"\n return (url.scheme(), url.host(), url.port())\n\n\nclass FuzzyUrlError(Exception):\n\n \"\"\"Exception raised by fuzzy_url on problems.\"\"\"\n\n pass\n", "path": "qutebrowser/utils/urlutils.py"}]}
| 4,043 | 190 |
gh_patches_debug_33387
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-791
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_nons function is not used in scrapy.contrib.linkextractors.lxmlhtml
There is either a bug or some stray code in https://github.com/scrapy/scrapy/blob/master/scrapy/contrib/linkextractors/lxmlhtml.py#L37: `tag = _nons(el.tag)` local variable is not used, and so `_nons` function is also unused. @redapple - what was the intended behavior?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/contrib/linkextractors/lxmlhtml.py`
Content:
```
1 """
2 Link extractor based on lxml.html
3 """
4
5 import re
6 from urlparse import urlparse, urljoin
7
8 import lxml.etree as etree
9
10 from scrapy.selector import Selector
11 from scrapy.link import Link
12 from scrapy.utils.misc import arg_to_iter
13 from scrapy.utils.python import unique as unique_list, str_to_unicode
14 from scrapy.linkextractor import FilteringLinkExtractor
15 from scrapy.utils.response import get_base_url
16
17
18 # from lxml/src/lxml/html/__init__.py
19 XHTML_NAMESPACE = "http://www.w3.org/1999/xhtml"
20
21 _collect_string_content = etree.XPath("string()")
22
23 def _nons(tag):
24 if isinstance(tag, basestring):
25 if tag[0] == '{' and tag[1:len(XHTML_NAMESPACE)+1] == XHTML_NAMESPACE:
26 return tag.split('}')[-1]
27 return tag
28
29
30 class LxmlParserLinkExtractor(object):
31 def __init__(self, tag="a", attr="href", process=None, unique=False):
32 self.scan_tag = tag if callable(tag) else lambda t: t == tag
33 self.scan_attr = attr if callable(attr) else lambda a: a == attr
34 self.process_attr = process if callable(process) else lambda v: v
35 self.unique = unique
36
37 def _iter_links(self, document):
38 for el in document.iter(etree.Element):
39 tag = _nons(el.tag)
40 if not self.scan_tag(el.tag):
41 continue
42 attribs = el.attrib
43 for attrib in attribs:
44 yield (el, attrib, attribs[attrib])
45
46 def _extract_links(self, selector, response_url, response_encoding, base_url):
47 links = []
48 # hacky way to get the underlying lxml parsed document
49 for el, attr, attr_val in self._iter_links(selector._root):
50 if self.scan_tag(el.tag) and self.scan_attr(attr):
51 # pseudo _root.make_links_absolute(base_url)
52 attr_val = urljoin(base_url, attr_val)
53 url = self.process_attr(attr_val)
54 if url is None:
55 continue
56 if isinstance(url, unicode):
57 url = url.encode(response_encoding)
58 # to fix relative links after process_value
59 url = urljoin(response_url, url)
60 link = Link(url, _collect_string_content(el) or u'',
61 nofollow=True if el.get('rel') == 'nofollow' else False)
62 links.append(link)
63
64 return unique_list(links, key=lambda link: link.url) \
65 if self.unique else links
66
67 def extract_links(self, response):
68 html = Selector(response)
69 base_url = get_base_url(response)
70 return self._extract_links(html, response.url, response.encoding, base_url)
71
72 def _process_links(self, links):
73 """ Normalize and filter extracted links
74
75 The subclass should override it if neccessary
76 """
77 links = unique_list(links, key=lambda link: link.url) if self.unique else links
78 return links
79
80
81 class LxmlLinkExtractor(FilteringLinkExtractor):
82
83 def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),
84 tags=('a', 'area'), attrs=('href',), canonicalize=True, unique=True, process_value=None,
85 deny_extensions=None):
86 tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))
87 tag_func = lambda x: x in tags
88 attr_func = lambda x: x in attrs
89 lx = LxmlParserLinkExtractor(tag=tag_func, attr=attr_func,
90 unique=unique, process=process_value)
91
92 super(LxmlLinkExtractor, self).__init__(lx, allow, deny,
93 allow_domains, deny_domains, restrict_xpaths, canonicalize,
94 deny_extensions)
95
96 def extract_links(self, response):
97 html = Selector(response)
98 base_url = get_base_url(response)
99 if self.restrict_xpaths:
100 docs = [subdoc
101 for x in self.restrict_xpaths
102 for subdoc in html.xpath(x)]
103 else:
104 docs = [html]
105 all_links = []
106 for doc in docs:
107 links = self._extract_links(doc, response.url, response.encoding, base_url)
108 all_links.extend(self._process_links(links))
109 return unique_list(all_links)
110
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/contrib/linkextractors/lxmlhtml.py b/scrapy/contrib/linkextractors/lxmlhtml.py
--- a/scrapy/contrib/linkextractors/lxmlhtml.py
+++ b/scrapy/contrib/linkextractors/lxmlhtml.py
@@ -36,30 +36,30 @@
def _iter_links(self, document):
for el in document.iter(etree.Element):
- tag = _nons(el.tag)
- if not self.scan_tag(el.tag):
+ if not self.scan_tag(_nons(el.tag)):
continue
attribs = el.attrib
for attrib in attribs:
+ if not self.scan_attr(attrib):
+ continue
yield (el, attrib, attribs[attrib])
def _extract_links(self, selector, response_url, response_encoding, base_url):
links = []
# hacky way to get the underlying lxml parsed document
for el, attr, attr_val in self._iter_links(selector._root):
- if self.scan_tag(el.tag) and self.scan_attr(attr):
- # pseudo _root.make_links_absolute(base_url)
- attr_val = urljoin(base_url, attr_val)
- url = self.process_attr(attr_val)
- if url is None:
- continue
- if isinstance(url, unicode):
- url = url.encode(response_encoding)
- # to fix relative links after process_value
- url = urljoin(response_url, url)
- link = Link(url, _collect_string_content(el) or u'',
- nofollow=True if el.get('rel') == 'nofollow' else False)
- links.append(link)
+ # pseudo lxml.html.HtmlElement.make_links_absolute(base_url)
+ attr_val = urljoin(base_url, attr_val)
+ url = self.process_attr(attr_val)
+ if url is None:
+ continue
+ if isinstance(url, unicode):
+ url = url.encode(response_encoding)
+ # to fix relative links after process_value
+ url = urljoin(response_url, url)
+ link = Link(url, _collect_string_content(el) or u'',
+ nofollow=True if el.get('rel') == 'nofollow' else False)
+ links.append(link)
return unique_list(links, key=lambda link: link.url) \
if self.unique else links
|
{"golden_diff": "diff --git a/scrapy/contrib/linkextractors/lxmlhtml.py b/scrapy/contrib/linkextractors/lxmlhtml.py\n--- a/scrapy/contrib/linkextractors/lxmlhtml.py\n+++ b/scrapy/contrib/linkextractors/lxmlhtml.py\n@@ -36,30 +36,30 @@\n \n def _iter_links(self, document):\n for el in document.iter(etree.Element):\n- tag = _nons(el.tag)\n- if not self.scan_tag(el.tag):\n+ if not self.scan_tag(_nons(el.tag)):\n continue\n attribs = el.attrib\n for attrib in attribs:\n+ if not self.scan_attr(attrib):\n+ continue\n yield (el, attrib, attribs[attrib])\n \n def _extract_links(self, selector, response_url, response_encoding, base_url):\n links = []\n # hacky way to get the underlying lxml parsed document\n for el, attr, attr_val in self._iter_links(selector._root):\n- if self.scan_tag(el.tag) and self.scan_attr(attr):\n- # pseudo _root.make_links_absolute(base_url)\n- attr_val = urljoin(base_url, attr_val)\n- url = self.process_attr(attr_val)\n- if url is None:\n- continue\n- if isinstance(url, unicode):\n- url = url.encode(response_encoding)\n- # to fix relative links after process_value\n- url = urljoin(response_url, url)\n- link = Link(url, _collect_string_content(el) or u'',\n- nofollow=True if el.get('rel') == 'nofollow' else False)\n- links.append(link)\n+ # pseudo lxml.html.HtmlElement.make_links_absolute(base_url)\n+ attr_val = urljoin(base_url, attr_val)\n+ url = self.process_attr(attr_val)\n+ if url is None:\n+ continue\n+ if isinstance(url, unicode):\n+ url = url.encode(response_encoding)\n+ # to fix relative links after process_value\n+ url = urljoin(response_url, url)\n+ link = Link(url, _collect_string_content(el) or u'',\n+ nofollow=True if el.get('rel') == 'nofollow' else False)\n+ links.append(link)\n \n return unique_list(links, key=lambda link: link.url) \\\n if self.unique else links\n", "issue": "_nons function is not used in scrapy.contrib.linkextractors.lxmlhtml\nThere is either a bug or some stray code in https://github.com/scrapy/scrapy/blob/master/scrapy/contrib/linkextractors/lxmlhtml.py#L37: `tag = _nons(el.tag)` local variable is not used, and so `_nons` function is also unused. @redapple - what was the intended behavior?\n\n", "before_files": [{"content": "\"\"\"\nLink extractor based on lxml.html\n\"\"\"\n\nimport re\nfrom urlparse import urlparse, urljoin\n\nimport lxml.etree as etree\n\nfrom scrapy.selector import Selector\nfrom scrapy.link import Link\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.python import unique as unique_list, str_to_unicode\nfrom scrapy.linkextractor import FilteringLinkExtractor\nfrom scrapy.utils.response import get_base_url\n\n\n# from lxml/src/lxml/html/__init__.py\nXHTML_NAMESPACE = \"http://www.w3.org/1999/xhtml\"\n\n_collect_string_content = etree.XPath(\"string()\")\n\ndef _nons(tag):\n if isinstance(tag, basestring):\n if tag[0] == '{' and tag[1:len(XHTML_NAMESPACE)+1] == XHTML_NAMESPACE:\n return tag.split('}')[-1]\n return tag\n\n\nclass LxmlParserLinkExtractor(object):\n def __init__(self, tag=\"a\", attr=\"href\", process=None, unique=False):\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n self.scan_attr = attr if callable(attr) else lambda a: a == attr\n self.process_attr = process if callable(process) else lambda v: v\n self.unique = unique\n\n def _iter_links(self, document):\n for el in document.iter(etree.Element):\n tag = _nons(el.tag)\n if not self.scan_tag(el.tag):\n continue\n attribs = el.attrib\n for attrib in attribs:\n yield (el, attrib, attribs[attrib])\n\n def _extract_links(self, selector, response_url, response_encoding, base_url):\n links = []\n # hacky way to get the underlying lxml parsed document\n for el, attr, attr_val in self._iter_links(selector._root):\n if self.scan_tag(el.tag) and self.scan_attr(attr):\n # pseudo _root.make_links_absolute(base_url)\n attr_val = urljoin(base_url, attr_val)\n url = self.process_attr(attr_val)\n if url is None:\n continue\n if isinstance(url, unicode):\n url = url.encode(response_encoding)\n # to fix relative links after process_value\n url = urljoin(response_url, url)\n link = Link(url, _collect_string_content(el) or u'',\n nofollow=True if el.get('rel') == 'nofollow' else False)\n links.append(link)\n\n return unique_list(links, key=lambda link: link.url) \\\n if self.unique else links\n\n def extract_links(self, response):\n html = Selector(response)\n base_url = get_base_url(response)\n return self._extract_links(html, response.url, response.encoding, base_url)\n\n def _process_links(self, links):\n \"\"\" Normalize and filter extracted links\n\n The subclass should override it if neccessary\n \"\"\"\n links = unique_list(links, key=lambda link: link.url) if self.unique else links\n return links\n\n\nclass LxmlLinkExtractor(FilteringLinkExtractor):\n\n def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),\n tags=('a', 'area'), attrs=('href',), canonicalize=True, unique=True, process_value=None,\n deny_extensions=None):\n tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))\n tag_func = lambda x: x in tags\n attr_func = lambda x: x in attrs\n lx = LxmlParserLinkExtractor(tag=tag_func, attr=attr_func,\n unique=unique, process=process_value)\n\n super(LxmlLinkExtractor, self).__init__(lx, allow, deny,\n allow_domains, deny_domains, restrict_xpaths, canonicalize,\n deny_extensions)\n\n def extract_links(self, response):\n html = Selector(response)\n base_url = get_base_url(response)\n if self.restrict_xpaths:\n docs = [subdoc\n for x in self.restrict_xpaths\n for subdoc in html.xpath(x)]\n else:\n docs = [html]\n all_links = []\n for doc in docs:\n links = self._extract_links(doc, response.url, response.encoding, base_url)\n all_links.extend(self._process_links(links))\n return unique_list(all_links)\n\n", "path": "scrapy/contrib/linkextractors/lxmlhtml.py"}], "after_files": [{"content": "\"\"\"\nLink extractor based on lxml.html\n\"\"\"\n\nimport re\nfrom urlparse import urlparse, urljoin\n\nimport lxml.etree as etree\n\nfrom scrapy.selector import Selector\nfrom scrapy.link import Link\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.python import unique as unique_list, str_to_unicode\nfrom scrapy.linkextractor import FilteringLinkExtractor\nfrom scrapy.utils.response import get_base_url\n\n\n# from lxml/src/lxml/html/__init__.py\nXHTML_NAMESPACE = \"http://www.w3.org/1999/xhtml\"\n\n_collect_string_content = etree.XPath(\"string()\")\n\ndef _nons(tag):\n if isinstance(tag, basestring):\n if tag[0] == '{' and tag[1:len(XHTML_NAMESPACE)+1] == XHTML_NAMESPACE:\n return tag.split('}')[-1]\n return tag\n\n\nclass LxmlParserLinkExtractor(object):\n def __init__(self, tag=\"a\", attr=\"href\", process=None, unique=False):\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n self.scan_attr = attr if callable(attr) else lambda a: a == attr\n self.process_attr = process if callable(process) else lambda v: v\n self.unique = unique\n\n def _iter_links(self, document):\n for el in document.iter(etree.Element):\n if not self.scan_tag(_nons(el.tag)):\n continue\n attribs = el.attrib\n for attrib in attribs:\n if not self.scan_attr(attrib):\n continue\n yield (el, attrib, attribs[attrib])\n\n def _extract_links(self, selector, response_url, response_encoding, base_url):\n links = []\n # hacky way to get the underlying lxml parsed document\n for el, attr, attr_val in self._iter_links(selector._root):\n # pseudo lxml.html.HtmlElement.make_links_absolute(base_url)\n attr_val = urljoin(base_url, attr_val)\n url = self.process_attr(attr_val)\n if url is None:\n continue\n if isinstance(url, unicode):\n url = url.encode(response_encoding)\n # to fix relative links after process_value\n url = urljoin(response_url, url)\n link = Link(url, _collect_string_content(el) or u'',\n nofollow=True if el.get('rel') == 'nofollow' else False)\n links.append(link)\n\n return unique_list(links, key=lambda link: link.url) \\\n if self.unique else links\n\n def extract_links(self, response):\n html = Selector(response)\n base_url = get_base_url(response)\n return self._extract_links(html, response.url, response.encoding, base_url)\n\n def _process_links(self, links):\n \"\"\" Normalize and filter extracted links\n\n The subclass should override it if neccessary\n \"\"\"\n links = unique_list(links, key=lambda link: link.url) if self.unique else links\n return links\n\n\nclass LxmlLinkExtractor(FilteringLinkExtractor):\n\n def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),\n tags=('a', 'area'), attrs=('href',), canonicalize=True, unique=True, process_value=None,\n deny_extensions=None):\n tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))\n tag_func = lambda x: x in tags\n attr_func = lambda x: x in attrs\n lx = LxmlParserLinkExtractor(tag=tag_func, attr=attr_func,\n unique=unique, process=process_value)\n\n super(LxmlLinkExtractor, self).__init__(lx, allow, deny,\n allow_domains, deny_domains, restrict_xpaths, canonicalize,\n deny_extensions)\n\n def extract_links(self, response):\n html = Selector(response)\n base_url = get_base_url(response)\n if self.restrict_xpaths:\n docs = [subdoc\n for x in self.restrict_xpaths\n for subdoc in html.xpath(x)]\n else:\n docs = [html]\n all_links = []\n for doc in docs:\n links = self._extract_links(doc, response.url, response.encoding, base_url)\n all_links.extend(self._process_links(links))\n return unique_list(all_links)\n\n", "path": "scrapy/contrib/linkextractors/lxmlhtml.py"}]}
| 1,497 | 510 |
gh_patches_debug_4157
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-648
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reproducibility using seeds
Been running some experiments, and it seems I cannot get the same reproducible result even when setting numpy and tensorflow seeds at the top of the script like
```
np.random.seed(72)
tf.set_random_seed(72)
```
Naturally, either I'm setting them wrong or I'm missing a RNG. I call Param.randomize() and Model.optimize(), and they seem to be the only sources of randomness at the moment (and I'm not even sure about the latter) so one of them is likely the culprit. Is there any way to either set the seed appropriately without messing with the source code or maybe adding an option allowing seeds to be set in the future?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpflow/training/optimizer.py`
Content:
```
1 # Copyright 2017 Artem Artemev @awav
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # pylint: disable=no-self-use
16 # pylint: disable=too-few-public-methods
17
18 import abc
19
20
21 class Optimizer:
22 @abc.abstractmethod
23 def make_optimize_tensor(self, model, session=None, var_list=None, **kwargs):
24 """
25 Make optimization tensor.
26 The `make_optimize_tensor` method builds optimization tensor and initializes
27 all necessary variables created by optimizer.
28
29 :param model: GPflow model.
30 :param session: Tensorflow session.
31 :param var_list: List of variables for training.
32 :param kwargs: Dictionary of extra parameters necessary for building
33 optimizer tensor.
34 :return: Tensorflow optimization tensor or operation.
35 """
36 pass
37
38 @abc.abstractmethod
39 def minimize(self, model, session=None, var_list=None, feed_dict=None,
40 maxiter=1000, initialize=True, anchor=True, **kwargs):
41 raise NotImplementedError()
42
43 @staticmethod
44 def _gen_var_list(model, var_list):
45 var_list = var_list or []
46 return list(set(model.trainable_tensors).union(var_list))
47
48 @staticmethod
49 def _gen_feed_dict(model, feed_dict):
50 feed_dict = feed_dict or {}
51 model_feeds = {} if model.feeds is None else model.feeds
52 feed_dict.update(model_feeds)
53 if feed_dict == {}:
54 return None
55 return feed_dict
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gpflow/training/optimizer.py b/gpflow/training/optimizer.py
--- a/gpflow/training/optimizer.py
+++ b/gpflow/training/optimizer.py
@@ -43,7 +43,8 @@
@staticmethod
def _gen_var_list(model, var_list):
var_list = var_list or []
- return list(set(model.trainable_tensors).union(var_list))
+ all_vars = list(set(model.trainable_tensors).union(var_list))
+ return sorted(all_vars, key=lambda x: x.name)
@staticmethod
def _gen_feed_dict(model, feed_dict):
|
{"golden_diff": "diff --git a/gpflow/training/optimizer.py b/gpflow/training/optimizer.py\n--- a/gpflow/training/optimizer.py\n+++ b/gpflow/training/optimizer.py\n@@ -43,7 +43,8 @@\n @staticmethod\n def _gen_var_list(model, var_list):\n var_list = var_list or []\n- return list(set(model.trainable_tensors).union(var_list))\n+ all_vars = list(set(model.trainable_tensors).union(var_list))\n+ return sorted(all_vars, key=lambda x: x.name)\n \n @staticmethod\n def _gen_feed_dict(model, feed_dict):\n", "issue": "Reproducibility using seeds\nBeen running some experiments, and it seems I cannot get the same reproducible result even when setting numpy and tensorflow seeds at the top of the script like\r\n\r\n```\r\nnp.random.seed(72)\r\ntf.set_random_seed(72)\r\n```\r\n\r\nNaturally, either I'm setting them wrong or I'm missing a RNG. I call Param.randomize() and Model.optimize(), and they seem to be the only sources of randomness at the moment (and I'm not even sure about the latter) so one of them is likely the culprit. Is there any way to either set the seed appropriately without messing with the source code or maybe adding an option allowing seeds to be set in the future?\n", "before_files": [{"content": "# Copyright 2017 Artem Artemev @awav\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# pylint: disable=no-self-use\n# pylint: disable=too-few-public-methods\n\nimport abc\n\n\nclass Optimizer:\n @abc.abstractmethod\n def make_optimize_tensor(self, model, session=None, var_list=None, **kwargs):\n \"\"\"\n Make optimization tensor.\n The `make_optimize_tensor` method builds optimization tensor and initializes\n all necessary variables created by optimizer.\n\n :param model: GPflow model.\n :param session: Tensorflow session.\n :param var_list: List of variables for training.\n :param kwargs: Dictionary of extra parameters necessary for building\n optimizer tensor.\n :return: Tensorflow optimization tensor or operation.\n \"\"\"\n pass\n\n @abc.abstractmethod\n def minimize(self, model, session=None, var_list=None, feed_dict=None,\n maxiter=1000, initialize=True, anchor=True, **kwargs):\n raise NotImplementedError()\n\n @staticmethod\n def _gen_var_list(model, var_list):\n var_list = var_list or []\n return list(set(model.trainable_tensors).union(var_list))\n\n @staticmethod\n def _gen_feed_dict(model, feed_dict):\n feed_dict = feed_dict or {}\n model_feeds = {} if model.feeds is None else model.feeds\n feed_dict.update(model_feeds)\n if feed_dict == {}:\n return None\n return feed_dict\n", "path": "gpflow/training/optimizer.py"}], "after_files": [{"content": "# Copyright 2017 Artem Artemev @awav\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# pylint: disable=no-self-use\n# pylint: disable=too-few-public-methods\n\nimport abc\n\n\nclass Optimizer:\n @abc.abstractmethod\n def make_optimize_tensor(self, model, session=None, var_list=None, **kwargs):\n \"\"\"\n Make optimization tensor.\n The `make_optimize_tensor` method builds optimization tensor and initializes\n all necessary variables created by optimizer.\n\n :param model: GPflow model.\n :param session: Tensorflow session.\n :param var_list: List of variables for training.\n :param kwargs: Dictionary of extra parameters necessary for building\n optimizer tensor.\n :return: Tensorflow optimization tensor or operation.\n \"\"\"\n pass\n\n @abc.abstractmethod\n def minimize(self, model, session=None, var_list=None, feed_dict=None,\n maxiter=1000, initialize=True, anchor=True, **kwargs):\n raise NotImplementedError()\n\n @staticmethod\n def _gen_var_list(model, var_list):\n var_list = var_list or []\n all_vars = list(set(model.trainable_tensors).union(var_list))\n return sorted(all_vars, key=lambda x: x.name)\n\n @staticmethod\n def _gen_feed_dict(model, feed_dict):\n feed_dict = feed_dict or {}\n model_feeds = {} if model.feeds is None else model.feeds\n feed_dict.update(model_feeds)\n if feed_dict == {}:\n return None\n return feed_dict\n", "path": "gpflow/training/optimizer.py"}]}
| 943 | 139 |
gh_patches_debug_3024
|
rasdani/github-patches
|
git_diff
|
MongoEngine__mongoengine-1454
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rename modifier missing from update
Not sure if this is intentional or not but it would be useful to have the `$rename` operator (or "modifier" for the update method for QuerySet and Document) available.
I'm currently working around it with `exec_js`, like so:
``` python
Document.objects.exec_js("""
function() {
db[collection].update({}, {$rename: {foo: 'bar'}});
}""")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mongoengine/base/common.py`
Content:
```
1 from mongoengine.errors import NotRegistered
2
3 __all__ = ('UPDATE_OPERATORS', 'get_document', '_document_registry')
4
5
6 UPDATE_OPERATORS = set(['set', 'unset', 'inc', 'dec', 'pop', 'push',
7 'push_all', 'pull', 'pull_all', 'add_to_set',
8 'set_on_insert', 'min', 'max'])
9
10
11 _document_registry = {}
12
13
14 def get_document(name):
15 """Get a document class by name."""
16 doc = _document_registry.get(name, None)
17 if not doc:
18 # Possible old style name
19 single_end = name.split('.')[-1]
20 compound_end = '.%s' % single_end
21 possible_match = [k for k in _document_registry.keys()
22 if k.endswith(compound_end) or k == single_end]
23 if len(possible_match) == 1:
24 doc = _document_registry.get(possible_match.pop(), None)
25 if not doc:
26 raise NotRegistered("""
27 `%s` has not been registered in the document registry.
28 Importing the document class automatically registers it, has it
29 been imported?
30 """.strip() % name)
31 return doc
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mongoengine/base/common.py b/mongoengine/base/common.py
--- a/mongoengine/base/common.py
+++ b/mongoengine/base/common.py
@@ -5,7 +5,7 @@
UPDATE_OPERATORS = set(['set', 'unset', 'inc', 'dec', 'pop', 'push',
'push_all', 'pull', 'pull_all', 'add_to_set',
- 'set_on_insert', 'min', 'max'])
+ 'set_on_insert', 'min', 'max', 'rename'])
_document_registry = {}
|
{"golden_diff": "diff --git a/mongoengine/base/common.py b/mongoengine/base/common.py\n--- a/mongoengine/base/common.py\n+++ b/mongoengine/base/common.py\n@@ -5,7 +5,7 @@\n \n UPDATE_OPERATORS = set(['set', 'unset', 'inc', 'dec', 'pop', 'push',\n 'push_all', 'pull', 'pull_all', 'add_to_set',\n- 'set_on_insert', 'min', 'max'])\n+ 'set_on_insert', 'min', 'max', 'rename'])\n \n \n _document_registry = {}\n", "issue": "Rename modifier missing from update\nNot sure if this is intentional or not but it would be useful to have the `$rename` operator (or \"modifier\" for the update method for QuerySet and Document) available.\n\nI'm currently working around it with `exec_js`, like so:\n\n``` python\nDocument.objects.exec_js(\"\"\"\nfunction() {\n db[collection].update({}, {$rename: {foo: 'bar'}});\n}\"\"\")\n```\n\n", "before_files": [{"content": "from mongoengine.errors import NotRegistered\n\n__all__ = ('UPDATE_OPERATORS', 'get_document', '_document_registry')\n\n\nUPDATE_OPERATORS = set(['set', 'unset', 'inc', 'dec', 'pop', 'push',\n 'push_all', 'pull', 'pull_all', 'add_to_set',\n 'set_on_insert', 'min', 'max'])\n\n\n_document_registry = {}\n\n\ndef get_document(name):\n \"\"\"Get a document class by name.\"\"\"\n doc = _document_registry.get(name, None)\n if not doc:\n # Possible old style name\n single_end = name.split('.')[-1]\n compound_end = '.%s' % single_end\n possible_match = [k for k in _document_registry.keys()\n if k.endswith(compound_end) or k == single_end]\n if len(possible_match) == 1:\n doc = _document_registry.get(possible_match.pop(), None)\n if not doc:\n raise NotRegistered(\"\"\"\n `%s` has not been registered in the document registry.\n Importing the document class automatically registers it, has it\n been imported?\n \"\"\".strip() % name)\n return doc\n", "path": "mongoengine/base/common.py"}], "after_files": [{"content": "from mongoengine.errors import NotRegistered\n\n__all__ = ('UPDATE_OPERATORS', 'get_document', '_document_registry')\n\n\nUPDATE_OPERATORS = set(['set', 'unset', 'inc', 'dec', 'pop', 'push',\n 'push_all', 'pull', 'pull_all', 'add_to_set',\n 'set_on_insert', 'min', 'max', 'rename'])\n\n\n_document_registry = {}\n\n\ndef get_document(name):\n \"\"\"Get a document class by name.\"\"\"\n doc = _document_registry.get(name, None)\n if not doc:\n # Possible old style name\n single_end = name.split('.')[-1]\n compound_end = '.%s' % single_end\n possible_match = [k for k in _document_registry.keys()\n if k.endswith(compound_end) or k == single_end]\n if len(possible_match) == 1:\n doc = _document_registry.get(possible_match.pop(), None)\n if not doc:\n raise NotRegistered(\"\"\"\n `%s` has not been registered in the document registry.\n Importing the document class automatically registers it, has it\n been imported?\n \"\"\".strip() % name)\n return doc\n", "path": "mongoengine/base/common.py"}]}
| 655 | 122 |
gh_patches_debug_11130
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Breaking change in sync httpx refactor from #1403
elastic/apm-agent-python#1403 refactored a lot of the httpx code. However it seems that the sync version of the instrumentation still calls `self._set_disttracing_headers` which was removed in the same PR, causing any form of sync httpx instrumentation to crash.
**Environment (please complete the following information)**
- Agent version: 6.7.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/instrumentation/packages/httpx/sync/httpcore.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2021, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
32 from elasticapm.instrumentation.packages.httpx import utils
33 from elasticapm.traces import DroppedSpan, capture_span, execution_context
34 from elasticapm.utils import default_ports
35 from elasticapm.utils.disttracing import TracingOptions
36
37
38 class HTTPCoreInstrumentation(AbstractInstrumentedModule):
39 name = "httpcore"
40
41 instrument_list = [
42 ("httpcore._sync.connection", "SyncHTTPConnection.request"), # < httpcore 0.13
43 ("httpcore._sync.connection", "SyncHTTPConnection.handle_request"), # >= httpcore 0.13
44 ("httpcore._sync.connection", "HTTPConnection.handle_request"), # httpcore >= 0.14 (hopefully...)
45 ]
46
47 def call(self, module, method, wrapped, instance, args, kwargs):
48 url, method, headers = utils.get_request_data(args, kwargs)
49 scheme, host, port, target = url
50 if port != default_ports.get(scheme):
51 host += ":" + str(port)
52
53 signature = "%s %s" % (method.upper(), host)
54
55 url = "%s://%s%s" % (scheme, host, target)
56
57 transaction = execution_context.get_transaction()
58
59 with capture_span(
60 signature,
61 span_type="external",
62 span_subtype="http",
63 extra={"http": {"url": url}},
64 leaf=True,
65 ) as span:
66 # if httpcore has been called in a leaf span, this span might be a DroppedSpan.
67 leaf_span = span
68 while isinstance(leaf_span, DroppedSpan):
69 leaf_span = leaf_span.parent
70
71 if headers is not None:
72 # It's possible that there are only dropped spans, e.g. if we started dropping spans.
73 # In this case, the transaction.id is used
74 parent_id = leaf_span.id if leaf_span else transaction.id
75 trace_parent = transaction.trace_parent.copy_from(
76 span_id=parent_id, trace_options=TracingOptions(recorded=True)
77 )
78 utils.set_disttracing_headers(headers, trace_parent, transaction)
79 if leaf_span:
80 leaf_span.dist_tracing_propagated = True
81 response = wrapped(*args, **kwargs)
82 status_code = utils.get_status(response)
83 if status_code:
84 if span.context:
85 span.context["http"]["status_code"] = status_code
86 span.set_success() if status_code < 400 else span.set_failure()
87 return response
88
89 def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):
90 # since we don't have a span, we set the span id to the transaction id
91 trace_parent = transaction.trace_parent.copy_from(
92 span_id=transaction.id, trace_options=TracingOptions(recorded=False)
93 )
94 if "headers" in kwargs:
95 headers = kwargs["headers"]
96 if headers is None:
97 headers = []
98 kwargs["headers"] = headers
99 self._set_disttracing_headers(headers, trace_parent, transaction)
100 return args, kwargs
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/instrumentation/packages/httpx/sync/httpcore.py b/elasticapm/instrumentation/packages/httpx/sync/httpcore.py
--- a/elasticapm/instrumentation/packages/httpx/sync/httpcore.py
+++ b/elasticapm/instrumentation/packages/httpx/sync/httpcore.py
@@ -91,10 +91,6 @@
trace_parent = transaction.trace_parent.copy_from(
span_id=transaction.id, trace_options=TracingOptions(recorded=False)
)
- if "headers" in kwargs:
- headers = kwargs["headers"]
- if headers is None:
- headers = []
- kwargs["headers"] = headers
- self._set_disttracing_headers(headers, trace_parent, transaction)
+ headers = utils.get_request_data(args, kwargs)[2]
+ utils.set_disttracing_headers(headers, trace_parent, transaction)
return args, kwargs
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/httpx/sync/httpcore.py b/elasticapm/instrumentation/packages/httpx/sync/httpcore.py\n--- a/elasticapm/instrumentation/packages/httpx/sync/httpcore.py\n+++ b/elasticapm/instrumentation/packages/httpx/sync/httpcore.py\n@@ -91,10 +91,6 @@\n trace_parent = transaction.trace_parent.copy_from(\n span_id=transaction.id, trace_options=TracingOptions(recorded=False)\n )\n- if \"headers\" in kwargs:\n- headers = kwargs[\"headers\"]\n- if headers is None:\n- headers = []\n- kwargs[\"headers\"] = headers\n- self._set_disttracing_headers(headers, trace_parent, transaction)\n+ headers = utils.get_request_data(args, kwargs)[2]\n+ utils.set_disttracing_headers(headers, trace_parent, transaction)\n return args, kwargs\n", "issue": "Breaking change in sync httpx refactor from #1403\nelastic/apm-agent-python#1403 refactored a lot of the httpx code. However it seems that the sync version of the instrumentation still calls `self._set_disttracing_headers` which was removed in the same PR, causing any form of sync httpx instrumentation to crash.\r\n\r\n**Environment (please complete the following information)**\r\n- Agent version: 6.7.1\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2021, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.instrumentation.packages.httpx import utils\nfrom elasticapm.traces import DroppedSpan, capture_span, execution_context\nfrom elasticapm.utils import default_ports\nfrom elasticapm.utils.disttracing import TracingOptions\n\n\nclass HTTPCoreInstrumentation(AbstractInstrumentedModule):\n name = \"httpcore\"\n\n instrument_list = [\n (\"httpcore._sync.connection\", \"SyncHTTPConnection.request\"), # < httpcore 0.13\n (\"httpcore._sync.connection\", \"SyncHTTPConnection.handle_request\"), # >= httpcore 0.13\n (\"httpcore._sync.connection\", \"HTTPConnection.handle_request\"), # httpcore >= 0.14 (hopefully...)\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n url, method, headers = utils.get_request_data(args, kwargs)\n scheme, host, port, target = url\n if port != default_ports.get(scheme):\n host += \":\" + str(port)\n\n signature = \"%s %s\" % (method.upper(), host)\n\n url = \"%s://%s%s\" % (scheme, host, target)\n\n transaction = execution_context.get_transaction()\n\n with capture_span(\n signature,\n span_type=\"external\",\n span_subtype=\"http\",\n extra={\"http\": {\"url\": url}},\n leaf=True,\n ) as span:\n # if httpcore has been called in a leaf span, this span might be a DroppedSpan.\n leaf_span = span\n while isinstance(leaf_span, DroppedSpan):\n leaf_span = leaf_span.parent\n\n if headers is not None:\n # It's possible that there are only dropped spans, e.g. if we started dropping spans.\n # In this case, the transaction.id is used\n parent_id = leaf_span.id if leaf_span else transaction.id\n trace_parent = transaction.trace_parent.copy_from(\n span_id=parent_id, trace_options=TracingOptions(recorded=True)\n )\n utils.set_disttracing_headers(headers, trace_parent, transaction)\n if leaf_span:\n leaf_span.dist_tracing_propagated = True\n response = wrapped(*args, **kwargs)\n status_code = utils.get_status(response)\n if status_code:\n if span.context:\n span.context[\"http\"][\"status_code\"] = status_code\n span.set_success() if status_code < 400 else span.set_failure()\n return response\n\n def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):\n # since we don't have a span, we set the span id to the transaction id\n trace_parent = transaction.trace_parent.copy_from(\n span_id=transaction.id, trace_options=TracingOptions(recorded=False)\n )\n if \"headers\" in kwargs:\n headers = kwargs[\"headers\"]\n if headers is None:\n headers = []\n kwargs[\"headers\"] = headers\n self._set_disttracing_headers(headers, trace_parent, transaction)\n return args, kwargs\n", "path": "elasticapm/instrumentation/packages/httpx/sync/httpcore.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2021, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.instrumentation.packages.httpx import utils\nfrom elasticapm.traces import DroppedSpan, capture_span, execution_context\nfrom elasticapm.utils import default_ports\nfrom elasticapm.utils.disttracing import TracingOptions\n\n\nclass HTTPCoreInstrumentation(AbstractInstrumentedModule):\n name = \"httpcore\"\n\n instrument_list = [\n (\"httpcore._sync.connection\", \"SyncHTTPConnection.request\"), # < httpcore 0.13\n (\"httpcore._sync.connection\", \"SyncHTTPConnection.handle_request\"), # >= httpcore 0.13\n (\"httpcore._sync.connection\", \"HTTPConnection.handle_request\"), # httpcore >= 0.14 (hopefully...)\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n url, method, headers = utils.get_request_data(args, kwargs)\n scheme, host, port, target = url\n if port != default_ports.get(scheme):\n host += \":\" + str(port)\n\n signature = \"%s %s\" % (method.upper(), host)\n\n url = \"%s://%s%s\" % (scheme, host, target)\n\n transaction = execution_context.get_transaction()\n\n with capture_span(\n signature,\n span_type=\"external\",\n span_subtype=\"http\",\n extra={\"http\": {\"url\": url}},\n leaf=True,\n ) as span:\n # if httpcore has been called in a leaf span, this span might be a DroppedSpan.\n leaf_span = span\n while isinstance(leaf_span, DroppedSpan):\n leaf_span = leaf_span.parent\n\n if headers is not None:\n # It's possible that there are only dropped spans, e.g. if we started dropping spans.\n # In this case, the transaction.id is used\n parent_id = leaf_span.id if leaf_span else transaction.id\n trace_parent = transaction.trace_parent.copy_from(\n span_id=parent_id, trace_options=TracingOptions(recorded=True)\n )\n utils.set_disttracing_headers(headers, trace_parent, transaction)\n if leaf_span:\n leaf_span.dist_tracing_propagated = True\n response = wrapped(*args, **kwargs)\n status_code = utils.get_status(response)\n if status_code:\n if span.context:\n span.context[\"http\"][\"status_code\"] = status_code\n span.set_success() if status_code < 400 else span.set_failure()\n return response\n\n def mutate_unsampled_call_args(self, module, method, wrapped, instance, args, kwargs, transaction):\n # since we don't have a span, we set the span id to the transaction id\n trace_parent = transaction.trace_parent.copy_from(\n span_id=transaction.id, trace_options=TracingOptions(recorded=False)\n )\n headers = utils.get_request_data(args, kwargs)[2]\n utils.set_disttracing_headers(headers, trace_parent, transaction)\n return args, kwargs\n", "path": "elasticapm/instrumentation/packages/httpx/sync/httpcore.py"}]}
| 1,569 | 203 |
gh_patches_debug_45224
|
rasdani/github-patches
|
git_diff
|
encode__starlette-1472
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Where assert statements are guarding against invalid ASGI messaging, use RuntimeError instead.
### Checklist
- [X] There are no similar issues or pull requests for this yet.
- [X] I discussed this idea on the [community chat](https://gitter.im/encode/community) and feedback is positive.
### Is your feature related to a problem? Please describe.
There are `assert` statements in the source code which raise a vague and hard to debug `AssertionError`. For example on [this line](https://github.com/encode/starlette/blob/f12c92a21500d484b3d48f965bb605c1bbe193bc/starlette/websockets.py#L58).
If some kind of exception (for example something along the lines of: `WebSocketMessageType`) were raised it would make debugging a lot clearer. I spent a lot more time than I should have just working out where exactly this `AssertionError` was coming from and what the root cause was.
### Describe the solution you would like.
This is by no means the right solution but at least it's an idea of the kind of thing that might help:
```python
class WebSocketMessageType(Exception):
pass
class WebSocket(HTTPConnection):
...
async def send(self, message: Message) -> None:
"""
Send ASGI websocket messages, ensuring valid state transitions.
"""
if self.application_state == WebSocketState.CONNECTING:
message_type = message["type"]
if message_type not in {"websocket.accept", "websocket.close"}:
raise WebSocketMessageType("expected message_type to be websocket.accept or websocket.close")
if message_type == "websocket.close":
self.application_state = WebSocketState.DISCONNECTED
else:
self.application_state = WebSocketState.CONNECTED
await self._send(message)
elif self.application_state == WebSocketState.CONNECTED:
message_type = message["type"]
if message_type not in {"websocket.send", "websocket.close"}:
raise WebSocketMessageType("expected message_type to be websocket.send or websocket.close")
if message_type == "websocket.close":
self.application_state = WebSocketState.DISCONNECTED
await self._send(message)
else:
raise RuntimeError('Cannot call "send" once a close message has been sent.')
```
### Describe alternatives you considered
_No response_
### Additional context
The error I was seeing:
```
ERROR root:a_file.py:31 {'message': 'Job processing failed', 'job': <Job coro=<<coroutine object a_class.a_method at 0x7f6d7a7c1ec0>>>, 'exception': AssertionError()}
NoneType: None
```
And this would be it with a `raise` statement: admittedly there is still no mention of `starlette` so a user would still have to diagnose that as the root cause.
```
ERROR root:a_file.py:31 {'message': 'Job processing failed', 'job': <Job coro=<<coroutine object a_class.a_method at 0x7fb99c2ed940>>>, 'exception': WebSocketMessageType('expected message_type to be websocket.accept or websocket.close')}
NoneType: None
```
Also, I have no idea where that `NoneType: None` is coming from or what that means.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/websockets.py`
Content:
```
1 import enum
2 import json
3 import typing
4
5 from starlette.requests import HTTPConnection
6 from starlette.types import Message, Receive, Scope, Send
7
8
9 class WebSocketState(enum.Enum):
10 CONNECTING = 0
11 CONNECTED = 1
12 DISCONNECTED = 2
13
14
15 class WebSocketDisconnect(Exception):
16 def __init__(self, code: int = 1000, reason: str = None) -> None:
17 self.code = code
18 self.reason = reason or ""
19
20
21 class WebSocket(HTTPConnection):
22 def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:
23 super().__init__(scope)
24 assert scope["type"] == "websocket"
25 self._receive = receive
26 self._send = send
27 self.client_state = WebSocketState.CONNECTING
28 self.application_state = WebSocketState.CONNECTING
29
30 async def receive(self) -> Message:
31 """
32 Receive ASGI websocket messages, ensuring valid state transitions.
33 """
34 if self.client_state == WebSocketState.CONNECTING:
35 message = await self._receive()
36 message_type = message["type"]
37 assert message_type == "websocket.connect"
38 self.client_state = WebSocketState.CONNECTED
39 return message
40 elif self.client_state == WebSocketState.CONNECTED:
41 message = await self._receive()
42 message_type = message["type"]
43 assert message_type in {"websocket.receive", "websocket.disconnect"}
44 if message_type == "websocket.disconnect":
45 self.client_state = WebSocketState.DISCONNECTED
46 return message
47 else:
48 raise RuntimeError(
49 'Cannot call "receive" once a disconnect message has been received.'
50 )
51
52 async def send(self, message: Message) -> None:
53 """
54 Send ASGI websocket messages, ensuring valid state transitions.
55 """
56 if self.application_state == WebSocketState.CONNECTING:
57 message_type = message["type"]
58 assert message_type in {"websocket.accept", "websocket.close"}
59 if message_type == "websocket.close":
60 self.application_state = WebSocketState.DISCONNECTED
61 else:
62 self.application_state = WebSocketState.CONNECTED
63 await self._send(message)
64 elif self.application_state == WebSocketState.CONNECTED:
65 message_type = message["type"]
66 assert message_type in {"websocket.send", "websocket.close"}
67 if message_type == "websocket.close":
68 self.application_state = WebSocketState.DISCONNECTED
69 await self._send(message)
70 else:
71 raise RuntimeError('Cannot call "send" once a close message has been sent.')
72
73 async def accept(
74 self,
75 subprotocol: str = None,
76 headers: typing.Iterable[typing.Tuple[bytes, bytes]] = None,
77 ) -> None:
78 headers = headers or []
79
80 if self.client_state == WebSocketState.CONNECTING:
81 # If we haven't yet seen the 'connect' message, then wait for it first.
82 await self.receive()
83 await self.send(
84 {"type": "websocket.accept", "subprotocol": subprotocol, "headers": headers}
85 )
86
87 def _raise_on_disconnect(self, message: Message) -> None:
88 if message["type"] == "websocket.disconnect":
89 raise WebSocketDisconnect(message["code"])
90
91 async def receive_text(self) -> str:
92 assert self.application_state == WebSocketState.CONNECTED
93 message = await self.receive()
94 self._raise_on_disconnect(message)
95 return message["text"]
96
97 async def receive_bytes(self) -> bytes:
98 assert self.application_state == WebSocketState.CONNECTED
99 message = await self.receive()
100 self._raise_on_disconnect(message)
101 return message["bytes"]
102
103 async def receive_json(self, mode: str = "text") -> typing.Any:
104 assert mode in ["text", "binary"]
105 assert self.application_state == WebSocketState.CONNECTED
106 message = await self.receive()
107 self._raise_on_disconnect(message)
108
109 if mode == "text":
110 text = message["text"]
111 else:
112 text = message["bytes"].decode("utf-8")
113 return json.loads(text)
114
115 async def iter_text(self) -> typing.AsyncIterator[str]:
116 try:
117 while True:
118 yield await self.receive_text()
119 except WebSocketDisconnect:
120 pass
121
122 async def iter_bytes(self) -> typing.AsyncIterator[bytes]:
123 try:
124 while True:
125 yield await self.receive_bytes()
126 except WebSocketDisconnect:
127 pass
128
129 async def iter_json(self) -> typing.AsyncIterator[typing.Any]:
130 try:
131 while True:
132 yield await self.receive_json()
133 except WebSocketDisconnect:
134 pass
135
136 async def send_text(self, data: str) -> None:
137 await self.send({"type": "websocket.send", "text": data})
138
139 async def send_bytes(self, data: bytes) -> None:
140 await self.send({"type": "websocket.send", "bytes": data})
141
142 async def send_json(self, data: typing.Any, mode: str = "text") -> None:
143 assert mode in ["text", "binary"]
144 text = json.dumps(data)
145 if mode == "text":
146 await self.send({"type": "websocket.send", "text": text})
147 else:
148 await self.send({"type": "websocket.send", "bytes": text.encode("utf-8")})
149
150 async def close(self, code: int = 1000, reason: str = None) -> None:
151 await self.send(
152 {"type": "websocket.close", "code": code, "reason": reason or ""}
153 )
154
155
156 class WebSocketClose:
157 def __init__(self, code: int = 1000, reason: str = None) -> None:
158 self.code = code
159 self.reason = reason or ""
160
161 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
162 await send(
163 {"type": "websocket.close", "code": self.code, "reason": self.reason}
164 )
165
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlette/websockets.py b/starlette/websockets.py
--- a/starlette/websockets.py
+++ b/starlette/websockets.py
@@ -34,13 +34,21 @@
if self.client_state == WebSocketState.CONNECTING:
message = await self._receive()
message_type = message["type"]
- assert message_type == "websocket.connect"
+ if message_type != "websocket.connect":
+ raise RuntimeError(
+ 'Expected ASGI message "websocket.connect", '
+ f"but got {message_type!r}"
+ )
self.client_state = WebSocketState.CONNECTED
return message
elif self.client_state == WebSocketState.CONNECTED:
message = await self._receive()
message_type = message["type"]
- assert message_type in {"websocket.receive", "websocket.disconnect"}
+ if message_type not in {"websocket.receive", "websocket.disconnect"}:
+ raise RuntimeError(
+ 'Expected ASGI message "websocket.receive" or '
+ f'"websocket.disconnect", but got {message_type!r}'
+ )
if message_type == "websocket.disconnect":
self.client_state = WebSocketState.DISCONNECTED
return message
@@ -55,7 +63,11 @@
"""
if self.application_state == WebSocketState.CONNECTING:
message_type = message["type"]
- assert message_type in {"websocket.accept", "websocket.close"}
+ if message_type not in {"websocket.accept", "websocket.close"}:
+ raise RuntimeError(
+ 'Expected ASGI message "websocket.connect", '
+ f"but got {message_type!r}"
+ )
if message_type == "websocket.close":
self.application_state = WebSocketState.DISCONNECTED
else:
@@ -63,7 +75,11 @@
await self._send(message)
elif self.application_state == WebSocketState.CONNECTED:
message_type = message["type"]
- assert message_type in {"websocket.send", "websocket.close"}
+ if message_type not in {"websocket.send", "websocket.close"}:
+ raise RuntimeError(
+ 'Expected ASGI message "websocket.send" or "websocket.close", '
+ f"but got {message_type!r}"
+ )
if message_type == "websocket.close":
self.application_state = WebSocketState.DISCONNECTED
await self._send(message)
@@ -89,20 +105,30 @@
raise WebSocketDisconnect(message["code"])
async def receive_text(self) -> str:
- assert self.application_state == WebSocketState.CONNECTED
+ if self.application_state != WebSocketState.CONNECTED:
+ raise RuntimeError(
+ 'WebSocket is not connected. Need to call "accept" first.'
+ )
message = await self.receive()
self._raise_on_disconnect(message)
return message["text"]
async def receive_bytes(self) -> bytes:
- assert self.application_state == WebSocketState.CONNECTED
+ if self.application_state != WebSocketState.CONNECTED:
+ raise RuntimeError(
+ 'WebSocket is not connected. Need to call "accept" first.'
+ )
message = await self.receive()
self._raise_on_disconnect(message)
return message["bytes"]
async def receive_json(self, mode: str = "text") -> typing.Any:
- assert mode in ["text", "binary"]
- assert self.application_state == WebSocketState.CONNECTED
+ if mode not in {"text", "binary"}:
+ raise RuntimeError('The "mode" argument should be "text" or "binary".')
+ if self.application_state != WebSocketState.CONNECTED:
+ raise RuntimeError(
+ 'WebSocket is not connected. Need to call "accept" first.'
+ )
message = await self.receive()
self._raise_on_disconnect(message)
@@ -140,7 +166,8 @@
await self.send({"type": "websocket.send", "bytes": data})
async def send_json(self, data: typing.Any, mode: str = "text") -> None:
- assert mode in ["text", "binary"]
+ if mode not in {"text", "binary"}:
+ raise RuntimeError('The "mode" argument should be "text" or "binary".')
text = json.dumps(data)
if mode == "text":
await self.send({"type": "websocket.send", "text": text})
|
{"golden_diff": "diff --git a/starlette/websockets.py b/starlette/websockets.py\n--- a/starlette/websockets.py\n+++ b/starlette/websockets.py\n@@ -34,13 +34,21 @@\n if self.client_state == WebSocketState.CONNECTING:\n message = await self._receive()\n message_type = message[\"type\"]\n- assert message_type == \"websocket.connect\"\n+ if message_type != \"websocket.connect\":\n+ raise RuntimeError(\n+ 'Expected ASGI message \"websocket.connect\", '\n+ f\"but got {message_type!r}\"\n+ )\n self.client_state = WebSocketState.CONNECTED\n return message\n elif self.client_state == WebSocketState.CONNECTED:\n message = await self._receive()\n message_type = message[\"type\"]\n- assert message_type in {\"websocket.receive\", \"websocket.disconnect\"}\n+ if message_type not in {\"websocket.receive\", \"websocket.disconnect\"}:\n+ raise RuntimeError(\n+ 'Expected ASGI message \"websocket.receive\" or '\n+ f'\"websocket.disconnect\", but got {message_type!r}'\n+ )\n if message_type == \"websocket.disconnect\":\n self.client_state = WebSocketState.DISCONNECTED\n return message\n@@ -55,7 +63,11 @@\n \"\"\"\n if self.application_state == WebSocketState.CONNECTING:\n message_type = message[\"type\"]\n- assert message_type in {\"websocket.accept\", \"websocket.close\"}\n+ if message_type not in {\"websocket.accept\", \"websocket.close\"}:\n+ raise RuntimeError(\n+ 'Expected ASGI message \"websocket.connect\", '\n+ f\"but got {message_type!r}\"\n+ )\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n else:\n@@ -63,7 +75,11 @@\n await self._send(message)\n elif self.application_state == WebSocketState.CONNECTED:\n message_type = message[\"type\"]\n- assert message_type in {\"websocket.send\", \"websocket.close\"}\n+ if message_type not in {\"websocket.send\", \"websocket.close\"}:\n+ raise RuntimeError(\n+ 'Expected ASGI message \"websocket.send\" or \"websocket.close\", '\n+ f\"but got {message_type!r}\"\n+ )\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n await self._send(message)\n@@ -89,20 +105,30 @@\n raise WebSocketDisconnect(message[\"code\"])\n \n async def receive_text(self) -> str:\n- assert self.application_state == WebSocketState.CONNECTED\n+ if self.application_state != WebSocketState.CONNECTED:\n+ raise RuntimeError(\n+ 'WebSocket is not connected. Need to call \"accept\" first.'\n+ )\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"text\"]\n \n async def receive_bytes(self) -> bytes:\n- assert self.application_state == WebSocketState.CONNECTED\n+ if self.application_state != WebSocketState.CONNECTED:\n+ raise RuntimeError(\n+ 'WebSocket is not connected. Need to call \"accept\" first.'\n+ )\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"bytes\"]\n \n async def receive_json(self, mode: str = \"text\") -> typing.Any:\n- assert mode in [\"text\", \"binary\"]\n- assert self.application_state == WebSocketState.CONNECTED\n+ if mode not in {\"text\", \"binary\"}:\n+ raise RuntimeError('The \"mode\" argument should be \"text\" or \"binary\".')\n+ if self.application_state != WebSocketState.CONNECTED:\n+ raise RuntimeError(\n+ 'WebSocket is not connected. Need to call \"accept\" first.'\n+ )\n message = await self.receive()\n self._raise_on_disconnect(message)\n \n@@ -140,7 +166,8 @@\n await self.send({\"type\": \"websocket.send\", \"bytes\": data})\n \n async def send_json(self, data: typing.Any, mode: str = \"text\") -> None:\n- assert mode in [\"text\", \"binary\"]\n+ if mode not in {\"text\", \"binary\"}:\n+ raise RuntimeError('The \"mode\" argument should be \"text\" or \"binary\".')\n text = json.dumps(data)\n if mode == \"text\":\n await self.send({\"type\": \"websocket.send\", \"text\": text})\n", "issue": "Where assert statements are guarding against invalid ASGI messaging, use RuntimeError instead.\n### Checklist\r\n\r\n- [X] There are no similar issues or pull requests for this yet.\r\n- [X] I discussed this idea on the [community chat](https://gitter.im/encode/community) and feedback is positive.\r\n\r\n### Is your feature related to a problem? Please describe.\r\n\r\nThere are `assert` statements in the source code which raise a vague and hard to debug `AssertionError`. For example on [this line](https://github.com/encode/starlette/blob/f12c92a21500d484b3d48f965bb605c1bbe193bc/starlette/websockets.py#L58).\r\n\r\nIf some kind of exception (for example something along the lines of: `WebSocketMessageType`) were raised it would make debugging a lot clearer. I spent a lot more time than I should have just working out where exactly this `AssertionError` was coming from and what the root cause was.\r\n\r\n\r\n\r\n### Describe the solution you would like.\r\n\r\nThis is by no means the right solution but at least it's an idea of the kind of thing that might help:\r\n\r\n```python\r\nclass WebSocketMessageType(Exception):\r\n pass\r\n\r\nclass WebSocket(HTTPConnection):\r\n ...\r\n async def send(self, message: Message) -> None:\r\n \"\"\"\r\n Send ASGI websocket messages, ensuring valid state transitions.\r\n \"\"\"\r\n if self.application_state == WebSocketState.CONNECTING:\r\n message_type = message[\"type\"]\r\n if message_type not in {\"websocket.accept\", \"websocket.close\"}:\r\n raise WebSocketMessageType(\"expected message_type to be websocket.accept or websocket.close\")\r\n if message_type == \"websocket.close\":\r\n self.application_state = WebSocketState.DISCONNECTED\r\n else:\r\n self.application_state = WebSocketState.CONNECTED\r\n await self._send(message)\r\n elif self.application_state == WebSocketState.CONNECTED:\r\n message_type = message[\"type\"]\r\n if message_type not in {\"websocket.send\", \"websocket.close\"}:\r\n raise WebSocketMessageType(\"expected message_type to be websocket.send or websocket.close\")\r\n if message_type == \"websocket.close\":\r\n self.application_state = WebSocketState.DISCONNECTED\r\n await self._send(message)\r\n else:\r\n raise RuntimeError('Cannot call \"send\" once a close message has been sent.')\r\n```\r\n\r\n### Describe alternatives you considered\r\n\r\n_No response_\r\n\r\n### Additional context\r\n\r\nThe error I was seeing:\r\n\r\n```\r\nERROR root:a_file.py:31 {'message': 'Job processing failed', 'job': <Job coro=<<coroutine object a_class.a_method at 0x7f6d7a7c1ec0>>>, 'exception': AssertionError()}\r\nNoneType: None\r\n```\r\n\r\nAnd this would be it with a `raise` statement: admittedly there is still no mention of `starlette` so a user would still have to diagnose that as the root cause.\r\n\r\n```\r\nERROR root:a_file.py:31 {'message': 'Job processing failed', 'job': <Job coro=<<coroutine object a_class.a_method at 0x7fb99c2ed940>>>, 'exception': WebSocketMessageType('expected message_type to be websocket.accept or websocket.close')}\r\nNoneType: None\r\n```\r\n\r\nAlso, I have no idea where that `NoneType: None` is coming from or what that means.\n", "before_files": [{"content": "import enum\nimport json\nimport typing\n\nfrom starlette.requests import HTTPConnection\nfrom starlette.types import Message, Receive, Scope, Send\n\n\nclass WebSocketState(enum.Enum):\n CONNECTING = 0\n CONNECTED = 1\n DISCONNECTED = 2\n\n\nclass WebSocketDisconnect(Exception):\n def __init__(self, code: int = 1000, reason: str = None) -> None:\n self.code = code\n self.reason = reason or \"\"\n\n\nclass WebSocket(HTTPConnection):\n def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:\n super().__init__(scope)\n assert scope[\"type\"] == \"websocket\"\n self._receive = receive\n self._send = send\n self.client_state = WebSocketState.CONNECTING\n self.application_state = WebSocketState.CONNECTING\n\n async def receive(self) -> Message:\n \"\"\"\n Receive ASGI websocket messages, ensuring valid state transitions.\n \"\"\"\n if self.client_state == WebSocketState.CONNECTING:\n message = await self._receive()\n message_type = message[\"type\"]\n assert message_type == \"websocket.connect\"\n self.client_state = WebSocketState.CONNECTED\n return message\n elif self.client_state == WebSocketState.CONNECTED:\n message = await self._receive()\n message_type = message[\"type\"]\n assert message_type in {\"websocket.receive\", \"websocket.disconnect\"}\n if message_type == \"websocket.disconnect\":\n self.client_state = WebSocketState.DISCONNECTED\n return message\n else:\n raise RuntimeError(\n 'Cannot call \"receive\" once a disconnect message has been received.'\n )\n\n async def send(self, message: Message) -> None:\n \"\"\"\n Send ASGI websocket messages, ensuring valid state transitions.\n \"\"\"\n if self.application_state == WebSocketState.CONNECTING:\n message_type = message[\"type\"]\n assert message_type in {\"websocket.accept\", \"websocket.close\"}\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n else:\n self.application_state = WebSocketState.CONNECTED\n await self._send(message)\n elif self.application_state == WebSocketState.CONNECTED:\n message_type = message[\"type\"]\n assert message_type in {\"websocket.send\", \"websocket.close\"}\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n await self._send(message)\n else:\n raise RuntimeError('Cannot call \"send\" once a close message has been sent.')\n\n async def accept(\n self,\n subprotocol: str = None,\n headers: typing.Iterable[typing.Tuple[bytes, bytes]] = None,\n ) -> None:\n headers = headers or []\n\n if self.client_state == WebSocketState.CONNECTING:\n # If we haven't yet seen the 'connect' message, then wait for it first.\n await self.receive()\n await self.send(\n {\"type\": \"websocket.accept\", \"subprotocol\": subprotocol, \"headers\": headers}\n )\n\n def _raise_on_disconnect(self, message: Message) -> None:\n if message[\"type\"] == \"websocket.disconnect\":\n raise WebSocketDisconnect(message[\"code\"])\n\n async def receive_text(self) -> str:\n assert self.application_state == WebSocketState.CONNECTED\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"text\"]\n\n async def receive_bytes(self) -> bytes:\n assert self.application_state == WebSocketState.CONNECTED\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"bytes\"]\n\n async def receive_json(self, mode: str = \"text\") -> typing.Any:\n assert mode in [\"text\", \"binary\"]\n assert self.application_state == WebSocketState.CONNECTED\n message = await self.receive()\n self._raise_on_disconnect(message)\n\n if mode == \"text\":\n text = message[\"text\"]\n else:\n text = message[\"bytes\"].decode(\"utf-8\")\n return json.loads(text)\n\n async def iter_text(self) -> typing.AsyncIterator[str]:\n try:\n while True:\n yield await self.receive_text()\n except WebSocketDisconnect:\n pass\n\n async def iter_bytes(self) -> typing.AsyncIterator[bytes]:\n try:\n while True:\n yield await self.receive_bytes()\n except WebSocketDisconnect:\n pass\n\n async def iter_json(self) -> typing.AsyncIterator[typing.Any]:\n try:\n while True:\n yield await self.receive_json()\n except WebSocketDisconnect:\n pass\n\n async def send_text(self, data: str) -> None:\n await self.send({\"type\": \"websocket.send\", \"text\": data})\n\n async def send_bytes(self, data: bytes) -> None:\n await self.send({\"type\": \"websocket.send\", \"bytes\": data})\n\n async def send_json(self, data: typing.Any, mode: str = \"text\") -> None:\n assert mode in [\"text\", \"binary\"]\n text = json.dumps(data)\n if mode == \"text\":\n await self.send({\"type\": \"websocket.send\", \"text\": text})\n else:\n await self.send({\"type\": \"websocket.send\", \"bytes\": text.encode(\"utf-8\")})\n\n async def close(self, code: int = 1000, reason: str = None) -> None:\n await self.send(\n {\"type\": \"websocket.close\", \"code\": code, \"reason\": reason or \"\"}\n )\n\n\nclass WebSocketClose:\n def __init__(self, code: int = 1000, reason: str = None) -> None:\n self.code = code\n self.reason = reason or \"\"\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n await send(\n {\"type\": \"websocket.close\", \"code\": self.code, \"reason\": self.reason}\n )\n", "path": "starlette/websockets.py"}], "after_files": [{"content": "import enum\nimport json\nimport typing\n\nfrom starlette.requests import HTTPConnection\nfrom starlette.types import Message, Receive, Scope, Send\n\n\nclass WebSocketState(enum.Enum):\n CONNECTING = 0\n CONNECTED = 1\n DISCONNECTED = 2\n\n\nclass WebSocketDisconnect(Exception):\n def __init__(self, code: int = 1000, reason: str = None) -> None:\n self.code = code\n self.reason = reason or \"\"\n\n\nclass WebSocket(HTTPConnection):\n def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:\n super().__init__(scope)\n assert scope[\"type\"] == \"websocket\"\n self._receive = receive\n self._send = send\n self.client_state = WebSocketState.CONNECTING\n self.application_state = WebSocketState.CONNECTING\n\n async def receive(self) -> Message:\n \"\"\"\n Receive ASGI websocket messages, ensuring valid state transitions.\n \"\"\"\n if self.client_state == WebSocketState.CONNECTING:\n message = await self._receive()\n message_type = message[\"type\"]\n if message_type != \"websocket.connect\":\n raise RuntimeError(\n 'Expected ASGI message \"websocket.connect\", '\n f\"but got {message_type!r}\"\n )\n self.client_state = WebSocketState.CONNECTED\n return message\n elif self.client_state == WebSocketState.CONNECTED:\n message = await self._receive()\n message_type = message[\"type\"]\n if message_type not in {\"websocket.receive\", \"websocket.disconnect\"}:\n raise RuntimeError(\n 'Expected ASGI message \"websocket.receive\" or '\n f'\"websocket.disconnect\", but got {message_type!r}'\n )\n if message_type == \"websocket.disconnect\":\n self.client_state = WebSocketState.DISCONNECTED\n return message\n else:\n raise RuntimeError(\n 'Cannot call \"receive\" once a disconnect message has been received.'\n )\n\n async def send(self, message: Message) -> None:\n \"\"\"\n Send ASGI websocket messages, ensuring valid state transitions.\n \"\"\"\n if self.application_state == WebSocketState.CONNECTING:\n message_type = message[\"type\"]\n if message_type not in {\"websocket.accept\", \"websocket.close\"}:\n raise RuntimeError(\n 'Expected ASGI message \"websocket.connect\", '\n f\"but got {message_type!r}\"\n )\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n else:\n self.application_state = WebSocketState.CONNECTED\n await self._send(message)\n elif self.application_state == WebSocketState.CONNECTED:\n message_type = message[\"type\"]\n if message_type not in {\"websocket.send\", \"websocket.close\"}:\n raise RuntimeError(\n 'Expected ASGI message \"websocket.send\" or \"websocket.close\", '\n f\"but got {message_type!r}\"\n )\n if message_type == \"websocket.close\":\n self.application_state = WebSocketState.DISCONNECTED\n await self._send(message)\n else:\n raise RuntimeError('Cannot call \"send\" once a close message has been sent.')\n\n async def accept(\n self,\n subprotocol: str = None,\n headers: typing.Iterable[typing.Tuple[bytes, bytes]] = None,\n ) -> None:\n headers = headers or []\n\n if self.client_state == WebSocketState.CONNECTING:\n # If we haven't yet seen the 'connect' message, then wait for it first.\n await self.receive()\n await self.send(\n {\"type\": \"websocket.accept\", \"subprotocol\": subprotocol, \"headers\": headers}\n )\n\n def _raise_on_disconnect(self, message: Message) -> None:\n if message[\"type\"] == \"websocket.disconnect\":\n raise WebSocketDisconnect(message[\"code\"])\n\n async def receive_text(self) -> str:\n if self.application_state != WebSocketState.CONNECTED:\n raise RuntimeError(\n 'WebSocket is not connected. Need to call \"accept\" first.'\n )\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"text\"]\n\n async def receive_bytes(self) -> bytes:\n if self.application_state != WebSocketState.CONNECTED:\n raise RuntimeError(\n 'WebSocket is not connected. Need to call \"accept\" first.'\n )\n message = await self.receive()\n self._raise_on_disconnect(message)\n return message[\"bytes\"]\n\n async def receive_json(self, mode: str = \"text\") -> typing.Any:\n if mode not in {\"text\", \"binary\"}:\n raise RuntimeError('The \"mode\" argument should be \"text\" or \"binary\".')\n if self.application_state != WebSocketState.CONNECTED:\n raise RuntimeError(\n 'WebSocket is not connected. Need to call \"accept\" first.'\n )\n message = await self.receive()\n self._raise_on_disconnect(message)\n\n if mode == \"text\":\n text = message[\"text\"]\n else:\n text = message[\"bytes\"].decode(\"utf-8\")\n return json.loads(text)\n\n async def iter_text(self) -> typing.AsyncIterator[str]:\n try:\n while True:\n yield await self.receive_text()\n except WebSocketDisconnect:\n pass\n\n async def iter_bytes(self) -> typing.AsyncIterator[bytes]:\n try:\n while True:\n yield await self.receive_bytes()\n except WebSocketDisconnect:\n pass\n\n async def iter_json(self) -> typing.AsyncIterator[typing.Any]:\n try:\n while True:\n yield await self.receive_json()\n except WebSocketDisconnect:\n pass\n\n async def send_text(self, data: str) -> None:\n await self.send({\"type\": \"websocket.send\", \"text\": data})\n\n async def send_bytes(self, data: bytes) -> None:\n await self.send({\"type\": \"websocket.send\", \"bytes\": data})\n\n async def send_json(self, data: typing.Any, mode: str = \"text\") -> None:\n if mode not in {\"text\", \"binary\"}:\n raise RuntimeError('The \"mode\" argument should be \"text\" or \"binary\".')\n text = json.dumps(data)\n if mode == \"text\":\n await self.send({\"type\": \"websocket.send\", \"text\": text})\n else:\n await self.send({\"type\": \"websocket.send\", \"bytes\": text.encode(\"utf-8\")})\n\n async def close(self, code: int = 1000, reason: str = None) -> None:\n await self.send(\n {\"type\": \"websocket.close\", \"code\": code, \"reason\": reason or \"\"}\n )\n\n\nclass WebSocketClose:\n def __init__(self, code: int = 1000, reason: str = None) -> None:\n self.code = code\n self.reason = reason or \"\"\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n await send(\n {\"type\": \"websocket.close\", \"code\": self.code, \"reason\": self.reason}\n )\n", "path": "starlette/websockets.py"}]}
| 2,615 | 945 |
gh_patches_debug_17506
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-20349
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pants-provided-Python for Pex CLI doesn't work in docker environments
**Describe the bug**
Trying to use docker_environment to run a test on a machine without Python installed will result in an error:
```
Failed to find a compatible PEX_PYTHON=.python-build-standalone/c12164f0e9228ec20704c1aba97eb31b8e2a482d41943d541cc8e3a9e84f7349/bin/python3.
No interpreters could be found on the system.
```
**Pants version**
2.20
**OS**
Linux host and linux container
**Additional info**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/core/util_rules/adhoc_binaries.py`
Content:
```
1 # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os
7 import sys
8 from dataclasses import dataclass
9 from textwrap import dedent # noqa: PNT20
10
11 from pants.core.subsystems.python_bootstrap import PythonBootstrapSubsystem
12 from pants.core.util_rules.environments import EnvironmentTarget, LocalEnvironmentTarget
13 from pants.core.util_rules.system_binaries import SEARCH_PATHS, BashBinary, TarBinary
14 from pants.engine.env_vars import EnvironmentVars, EnvironmentVarsRequest
15 from pants.engine.fs import DownloadFile
16 from pants.engine.internals.native_engine import Digest, FileDigest
17 from pants.engine.internals.selectors import Get
18 from pants.engine.platform import Platform
19 from pants.engine.process import Process, ProcessCacheScope, ProcessResult
20 from pants.engine.rules import collect_rules, rule
21 from pants.util.frozendict import FrozenDict
22 from pants.util.logging import LogLevel
23
24
25 @dataclass(frozen=True)
26 class PythonBuildStandaloneBinary:
27 """A Python interpreter for use by `@rule` code as an alternative to BashBinary scripts.
28
29 This interpreter is provided by Python Build Standalone https://gregoryszorc.com/docs/python-build-standalone/main/,
30 which has a few caveats. Namely it doesn't play nicely with third-party sdists. Meaning Pants'
31 scripts being run by Python Build Standalone should avoid third-party sdists.
32 """
33
34 _CACHE_DIRNAME = "python_build_standalone"
35 _SYMLINK_DIRNAME = ".python-build-standalone"
36 APPEND_ONLY_CACHES = FrozenDict({_CACHE_DIRNAME: _SYMLINK_DIRNAME})
37
38 path: str # The absolute path to a Python executable
39
40
41 # NB: These private types are solely so we can test the docker-path using the local
42 # environment.
43 class _PythonBuildStandaloneBinary(PythonBuildStandaloneBinary):
44 pass
45
46
47 class _DownloadPythonBuildStandaloneBinaryRequest:
48 pass
49
50
51 @rule
52 async def get_python_for_scripts(env_tgt: EnvironmentTarget) -> PythonBuildStandaloneBinary:
53 if env_tgt.val is None or isinstance(env_tgt.val, LocalEnvironmentTarget):
54 return PythonBuildStandaloneBinary(sys.executable)
55
56 result = await Get(_PythonBuildStandaloneBinary, _DownloadPythonBuildStandaloneBinaryRequest())
57
58 return PythonBuildStandaloneBinary(result.path)
59
60
61 @rule(desc="Downloading Python for scripts", level=LogLevel.TRACE)
62 async def download_python_binary(
63 _: _DownloadPythonBuildStandaloneBinaryRequest,
64 platform: Platform,
65 tar_binary: TarBinary,
66 python_bootstrap: PythonBootstrapSubsystem,
67 bash: BashBinary,
68 ) -> _PythonBuildStandaloneBinary:
69 url, fingerprint, bytelen = python_bootstrap.internal_python_build_standalone_info[
70 platform.value
71 ]
72
73 filename = url.rsplit("/", 1)[-1]
74 python_archive = await Get(
75 Digest,
76 DownloadFile(
77 url,
78 FileDigest(
79 fingerprint=fingerprint,
80 serialized_bytes_length=bytelen,
81 ),
82 ),
83 )
84
85 download_result = await Get(
86 ProcessResult,
87 Process(
88 argv=[tar_binary.path, "-xvf", filename],
89 input_digest=python_archive,
90 env={"PATH": os.pathsep.join(SEARCH_PATHS)},
91 description="Extract Pants' execution Python",
92 level=LogLevel.DEBUG,
93 output_directories=("python",),
94 ),
95 )
96
97 installation_root = f"{PythonBuildStandaloneBinary._SYMLINK_DIRNAME}/{download_result.output_digest.fingerprint}"
98
99 # NB: This is similar to what we do for every Python provider. We should refactor these into
100 # some shared code to centralize the behavior.
101 installation_script = dedent(
102 f"""\
103 if [ ! -f "{installation_root}/DONE" ]; then
104 cp -r python "{installation_root}"
105 touch "{installation_root}/DONE"
106 fi
107 """
108 )
109
110 env_vars = await Get(EnvironmentVars, EnvironmentVarsRequest(["PATH"]))
111 await Get(
112 ProcessResult,
113 Process(
114 [bash.path, "-c", installation_script],
115 level=LogLevel.DEBUG,
116 input_digest=download_result.output_digest,
117 description="Install Python for Pants usage",
118 env={"PATH": env_vars.get("PATH", "")},
119 append_only_caches=PythonBuildStandaloneBinary.APPEND_ONLY_CACHES,
120 # Don't cache, we want this to always be run so that we can assume for the rest of the
121 # session the named_cache destination for this Python is valid, as the Python ecosystem
122 # mainly assumes absolute paths for Python interpreters.
123 cache_scope=ProcessCacheScope.PER_SESSION,
124 ),
125 )
126
127 return _PythonBuildStandaloneBinary(f"{installation_root}/bin/python3")
128
129
130 @dataclass(frozen=True)
131 class GunzipBinaryRequest:
132 pass
133
134
135 @dataclass(frozen=True)
136 class GunzipBinary:
137 python_binary: PythonBuildStandaloneBinary
138
139 def extract_archive_argv(self, archive_path: str, extract_path: str) -> tuple[str, ...]:
140 archive_name = os.path.basename(archive_path)
141 dest_file_name = os.path.splitext(archive_name)[0]
142 dest_path = os.path.join(extract_path, dest_file_name)
143 script = dedent(
144 f"""
145 import gzip
146 import shutil
147 with gzip.GzipFile(filename={archive_path!r}, mode="rb") as source:
148 with open({dest_path!r}, "wb") as dest:
149 shutil.copyfileobj(source, dest)
150 """
151 )
152 return (self.python_binary.path, "-c", script)
153
154
155 @rule
156 def find_gunzip(python_binary: PythonBuildStandaloneBinary) -> GunzipBinary:
157 return GunzipBinary(python_binary)
158
159
160 @rule
161 async def find_gunzip_wrapper(_: GunzipBinaryRequest, gunzip: GunzipBinary) -> GunzipBinary:
162 return gunzip
163
164
165 def rules():
166 return collect_rules()
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/core/util_rules/adhoc_binaries.py b/src/python/pants/core/util_rules/adhoc_binaries.py
--- a/src/python/pants/core/util_rules/adhoc_binaries.py
+++ b/src/python/pants/core/util_rules/adhoc_binaries.py
@@ -104,11 +104,12 @@
cp -r python "{installation_root}"
touch "{installation_root}/DONE"
fi
+ echo "$(realpath "{installation_root}")/bin/python3"
"""
)
env_vars = await Get(EnvironmentVars, EnvironmentVarsRequest(["PATH"]))
- await Get(
+ result = await Get(
ProcessResult,
Process(
[bash.path, "-c", installation_script],
@@ -124,7 +125,7 @@
),
)
- return _PythonBuildStandaloneBinary(f"{installation_root}/bin/python3")
+ return _PythonBuildStandaloneBinary(result.stdout.decode().splitlines()[-1].strip())
@dataclass(frozen=True)
|
{"golden_diff": "diff --git a/src/python/pants/core/util_rules/adhoc_binaries.py b/src/python/pants/core/util_rules/adhoc_binaries.py\n--- a/src/python/pants/core/util_rules/adhoc_binaries.py\n+++ b/src/python/pants/core/util_rules/adhoc_binaries.py\n@@ -104,11 +104,12 @@\n cp -r python \"{installation_root}\"\n touch \"{installation_root}/DONE\"\n fi\n+ echo \"$(realpath \"{installation_root}\")/bin/python3\"\n \"\"\"\n )\n \n env_vars = await Get(EnvironmentVars, EnvironmentVarsRequest([\"PATH\"]))\n- await Get(\n+ result = await Get(\n ProcessResult,\n Process(\n [bash.path, \"-c\", installation_script],\n@@ -124,7 +125,7 @@\n ),\n )\n \n- return _PythonBuildStandaloneBinary(f\"{installation_root}/bin/python3\")\n+ return _PythonBuildStandaloneBinary(result.stdout.decode().splitlines()[-1].strip())\n \n \n @dataclass(frozen=True)\n", "issue": "Pants-provided-Python for Pex CLI doesn't work in docker environments\n**Describe the bug**\r\nTrying to use docker_environment to run a test on a machine without Python installed will result in an error:\r\n\r\n```\r\nFailed to find a compatible PEX_PYTHON=.python-build-standalone/c12164f0e9228ec20704c1aba97eb31b8e2a482d41943d541cc8e3a9e84f7349/bin/python3.\r\n\r\nNo interpreters could be found on the system.\r\n```\r\n\r\n**Pants version**\r\n2.20\r\n\r\n**OS**\r\nLinux host and linux container\r\n\r\n**Additional info**\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nimport sys\nfrom dataclasses import dataclass\nfrom textwrap import dedent # noqa: PNT20\n\nfrom pants.core.subsystems.python_bootstrap import PythonBootstrapSubsystem\nfrom pants.core.util_rules.environments import EnvironmentTarget, LocalEnvironmentTarget\nfrom pants.core.util_rules.system_binaries import SEARCH_PATHS, BashBinary, TarBinary\nfrom pants.engine.env_vars import EnvironmentVars, EnvironmentVarsRequest\nfrom pants.engine.fs import DownloadFile\nfrom pants.engine.internals.native_engine import Digest, FileDigest\nfrom pants.engine.internals.selectors import Get\nfrom pants.engine.platform import Platform\nfrom pants.engine.process import Process, ProcessCacheScope, ProcessResult\nfrom pants.engine.rules import collect_rules, rule\nfrom pants.util.frozendict import FrozenDict\nfrom pants.util.logging import LogLevel\n\n\n@dataclass(frozen=True)\nclass PythonBuildStandaloneBinary:\n \"\"\"A Python interpreter for use by `@rule` code as an alternative to BashBinary scripts.\n\n This interpreter is provided by Python Build Standalone https://gregoryszorc.com/docs/python-build-standalone/main/,\n which has a few caveats. Namely it doesn't play nicely with third-party sdists. Meaning Pants'\n scripts being run by Python Build Standalone should avoid third-party sdists.\n \"\"\"\n\n _CACHE_DIRNAME = \"python_build_standalone\"\n _SYMLINK_DIRNAME = \".python-build-standalone\"\n APPEND_ONLY_CACHES = FrozenDict({_CACHE_DIRNAME: _SYMLINK_DIRNAME})\n\n path: str # The absolute path to a Python executable\n\n\n# NB: These private types are solely so we can test the docker-path using the local\n# environment.\nclass _PythonBuildStandaloneBinary(PythonBuildStandaloneBinary):\n pass\n\n\nclass _DownloadPythonBuildStandaloneBinaryRequest:\n pass\n\n\n@rule\nasync def get_python_for_scripts(env_tgt: EnvironmentTarget) -> PythonBuildStandaloneBinary:\n if env_tgt.val is None or isinstance(env_tgt.val, LocalEnvironmentTarget):\n return PythonBuildStandaloneBinary(sys.executable)\n\n result = await Get(_PythonBuildStandaloneBinary, _DownloadPythonBuildStandaloneBinaryRequest())\n\n return PythonBuildStandaloneBinary(result.path)\n\n\n@rule(desc=\"Downloading Python for scripts\", level=LogLevel.TRACE)\nasync def download_python_binary(\n _: _DownloadPythonBuildStandaloneBinaryRequest,\n platform: Platform,\n tar_binary: TarBinary,\n python_bootstrap: PythonBootstrapSubsystem,\n bash: BashBinary,\n) -> _PythonBuildStandaloneBinary:\n url, fingerprint, bytelen = python_bootstrap.internal_python_build_standalone_info[\n platform.value\n ]\n\n filename = url.rsplit(\"/\", 1)[-1]\n python_archive = await Get(\n Digest,\n DownloadFile(\n url,\n FileDigest(\n fingerprint=fingerprint,\n serialized_bytes_length=bytelen,\n ),\n ),\n )\n\n download_result = await Get(\n ProcessResult,\n Process(\n argv=[tar_binary.path, \"-xvf\", filename],\n input_digest=python_archive,\n env={\"PATH\": os.pathsep.join(SEARCH_PATHS)},\n description=\"Extract Pants' execution Python\",\n level=LogLevel.DEBUG,\n output_directories=(\"python\",),\n ),\n )\n\n installation_root = f\"{PythonBuildStandaloneBinary._SYMLINK_DIRNAME}/{download_result.output_digest.fingerprint}\"\n\n # NB: This is similar to what we do for every Python provider. We should refactor these into\n # some shared code to centralize the behavior.\n installation_script = dedent(\n f\"\"\"\\\n if [ ! -f \"{installation_root}/DONE\" ]; then\n cp -r python \"{installation_root}\"\n touch \"{installation_root}/DONE\"\n fi\n \"\"\"\n )\n\n env_vars = await Get(EnvironmentVars, EnvironmentVarsRequest([\"PATH\"]))\n await Get(\n ProcessResult,\n Process(\n [bash.path, \"-c\", installation_script],\n level=LogLevel.DEBUG,\n input_digest=download_result.output_digest,\n description=\"Install Python for Pants usage\",\n env={\"PATH\": env_vars.get(\"PATH\", \"\")},\n append_only_caches=PythonBuildStandaloneBinary.APPEND_ONLY_CACHES,\n # Don't cache, we want this to always be run so that we can assume for the rest of the\n # session the named_cache destination for this Python is valid, as the Python ecosystem\n # mainly assumes absolute paths for Python interpreters.\n cache_scope=ProcessCacheScope.PER_SESSION,\n ),\n )\n\n return _PythonBuildStandaloneBinary(f\"{installation_root}/bin/python3\")\n\n\n@dataclass(frozen=True)\nclass GunzipBinaryRequest:\n pass\n\n\n@dataclass(frozen=True)\nclass GunzipBinary:\n python_binary: PythonBuildStandaloneBinary\n\n def extract_archive_argv(self, archive_path: str, extract_path: str) -> tuple[str, ...]:\n archive_name = os.path.basename(archive_path)\n dest_file_name = os.path.splitext(archive_name)[0]\n dest_path = os.path.join(extract_path, dest_file_name)\n script = dedent(\n f\"\"\"\n import gzip\n import shutil\n with gzip.GzipFile(filename={archive_path!r}, mode=\"rb\") as source:\n with open({dest_path!r}, \"wb\") as dest:\n shutil.copyfileobj(source, dest)\n \"\"\"\n )\n return (self.python_binary.path, \"-c\", script)\n\n\n@rule\ndef find_gunzip(python_binary: PythonBuildStandaloneBinary) -> GunzipBinary:\n return GunzipBinary(python_binary)\n\n\n@rule\nasync def find_gunzip_wrapper(_: GunzipBinaryRequest, gunzip: GunzipBinary) -> GunzipBinary:\n return gunzip\n\n\ndef rules():\n return collect_rules()\n", "path": "src/python/pants/core/util_rules/adhoc_binaries.py"}], "after_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nimport sys\nfrom dataclasses import dataclass\nfrom textwrap import dedent # noqa: PNT20\n\nfrom pants.core.subsystems.python_bootstrap import PythonBootstrapSubsystem\nfrom pants.core.util_rules.environments import EnvironmentTarget, LocalEnvironmentTarget\nfrom pants.core.util_rules.system_binaries import SEARCH_PATHS, BashBinary, TarBinary\nfrom pants.engine.env_vars import EnvironmentVars, EnvironmentVarsRequest\nfrom pants.engine.fs import DownloadFile\nfrom pants.engine.internals.native_engine import Digest, FileDigest\nfrom pants.engine.internals.selectors import Get\nfrom pants.engine.platform import Platform\nfrom pants.engine.process import Process, ProcessCacheScope, ProcessResult\nfrom pants.engine.rules import collect_rules, rule\nfrom pants.util.frozendict import FrozenDict\nfrom pants.util.logging import LogLevel\n\n\n@dataclass(frozen=True)\nclass PythonBuildStandaloneBinary:\n \"\"\"A Python interpreter for use by `@rule` code as an alternative to BashBinary scripts.\n\n This interpreter is provided by Python Build Standalone https://gregoryszorc.com/docs/python-build-standalone/main/,\n which has a few caveats. Namely it doesn't play nicely with third-party sdists. Meaning Pants'\n scripts being run by Python Build Standalone should avoid third-party sdists.\n \"\"\"\n\n _CACHE_DIRNAME = \"python_build_standalone\"\n _SYMLINK_DIRNAME = \".python-build-standalone\"\n APPEND_ONLY_CACHES = FrozenDict({_CACHE_DIRNAME: _SYMLINK_DIRNAME})\n\n path: str # The absolute path to a Python executable\n\n\n# NB: These private types are solely so we can test the docker-path using the local\n# environment.\nclass _PythonBuildStandaloneBinary(PythonBuildStandaloneBinary):\n pass\n\n\nclass _DownloadPythonBuildStandaloneBinaryRequest:\n pass\n\n\n@rule\nasync def get_python_for_scripts(env_tgt: EnvironmentTarget) -> PythonBuildStandaloneBinary:\n if env_tgt.val is None or isinstance(env_tgt.val, LocalEnvironmentTarget):\n return PythonBuildStandaloneBinary(sys.executable)\n\n result = await Get(_PythonBuildStandaloneBinary, _DownloadPythonBuildStandaloneBinaryRequest())\n\n return PythonBuildStandaloneBinary(result.path)\n\n\n@rule(desc=\"Downloading Python for scripts\", level=LogLevel.TRACE)\nasync def download_python_binary(\n _: _DownloadPythonBuildStandaloneBinaryRequest,\n platform: Platform,\n tar_binary: TarBinary,\n python_bootstrap: PythonBootstrapSubsystem,\n bash: BashBinary,\n) -> _PythonBuildStandaloneBinary:\n url, fingerprint, bytelen = python_bootstrap.internal_python_build_standalone_info[\n platform.value\n ]\n\n filename = url.rsplit(\"/\", 1)[-1]\n python_archive = await Get(\n Digest,\n DownloadFile(\n url,\n FileDigest(\n fingerprint=fingerprint,\n serialized_bytes_length=bytelen,\n ),\n ),\n )\n\n download_result = await Get(\n ProcessResult,\n Process(\n argv=[tar_binary.path, \"-xvf\", filename],\n input_digest=python_archive,\n env={\"PATH\": os.pathsep.join(SEARCH_PATHS)},\n description=\"Extract Pants' execution Python\",\n level=LogLevel.DEBUG,\n output_directories=(\"python\",),\n ),\n )\n\n installation_root = f\"{PythonBuildStandaloneBinary._SYMLINK_DIRNAME}/{download_result.output_digest.fingerprint}\"\n\n # NB: This is similar to what we do for every Python provider. We should refactor these into\n # some shared code to centralize the behavior.\n installation_script = dedent(\n f\"\"\"\\\n if [ ! -f \"{installation_root}/DONE\" ]; then\n cp -r python \"{installation_root}\"\n touch \"{installation_root}/DONE\"\n fi\n echo \"$(realpath \"{installation_root}\")/bin/python3\"\n \"\"\"\n )\n\n env_vars = await Get(EnvironmentVars, EnvironmentVarsRequest([\"PATH\"]))\n result = await Get(\n ProcessResult,\n Process(\n [bash.path, \"-c\", installation_script],\n level=LogLevel.DEBUG,\n input_digest=download_result.output_digest,\n description=\"Install Python for Pants usage\",\n env={\"PATH\": env_vars.get(\"PATH\", \"\")},\n append_only_caches=PythonBuildStandaloneBinary.APPEND_ONLY_CACHES,\n # Don't cache, we want this to always be run so that we can assume for the rest of the\n # session the named_cache destination for this Python is valid, as the Python ecosystem\n # mainly assumes absolute paths for Python interpreters.\n cache_scope=ProcessCacheScope.PER_SESSION,\n ),\n )\n\n return _PythonBuildStandaloneBinary(result.stdout.decode().splitlines()[-1].strip())\n\n\n@dataclass(frozen=True)\nclass GunzipBinaryRequest:\n pass\n\n\n@dataclass(frozen=True)\nclass GunzipBinary:\n python_binary: PythonBuildStandaloneBinary\n\n def extract_archive_argv(self, archive_path: str, extract_path: str) -> tuple[str, ...]:\n archive_name = os.path.basename(archive_path)\n dest_file_name = os.path.splitext(archive_name)[0]\n dest_path = os.path.join(extract_path, dest_file_name)\n script = dedent(\n f\"\"\"\n import gzip\n import shutil\n with gzip.GzipFile(filename={archive_path!r}, mode=\"rb\") as source:\n with open({dest_path!r}, \"wb\") as dest:\n shutil.copyfileobj(source, dest)\n \"\"\"\n )\n return (self.python_binary.path, \"-c\", script)\n\n\n@rule\ndef find_gunzip(python_binary: PythonBuildStandaloneBinary) -> GunzipBinary:\n return GunzipBinary(python_binary)\n\n\n@rule\nasync def find_gunzip_wrapper(_: GunzipBinaryRequest, gunzip: GunzipBinary) -> GunzipBinary:\n return gunzip\n\n\ndef rules():\n return collect_rules()\n", "path": "src/python/pants/core/util_rules/adhoc_binaries.py"}]}
| 2,112 | 227 |
gh_patches_debug_3890
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-3764
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
0.9.0-rc2 does not allow text only submissions
## Description
I believe I found a bug in upgrading from `0.8` to `0.9rc2` in that sources can only submit documents or documents and messages. If I try to send _only_ text or a blank form field I get a "Bad Request, the browser or proxy sent a request that this server could not understand" error.
## Steps to Reproduce
First I installed 0.8.0 on hardware and create a journalist. I then ran ./qa-loader.py -m 25. I logged in and and see submissions. I then added the apt-test key and updated sources.list to `apt.freedom.press` to `apt-test.freedom.press`. Finally I ran `sudo cron-apt -i -s` to update to `0.9rc2`
## Expected Behavior
A source can send text to journalists.
## Actual Behavior
Error in the webapp.
## Comments
I also enabled apache debug logging and attempted to patch the source_app/ code to log anything related to CSRF violations and I was was not able to trigger a debug log.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `securedrop/source_app/main.py`
Content:
```
1 import operator
2 import os
3 import io
4
5 from datetime import datetime
6 from flask import (Blueprint, render_template, flash, redirect, url_for, g,
7 session, current_app, request, Markup, abort)
8 from flask_babel import gettext
9 from sqlalchemy.exc import IntegrityError
10
11 from db import db
12 from models import Source, Submission, Reply, get_one_or_else
13 from source_app.decorators import login_required
14 from source_app.utils import (logged_in, generate_unique_codename,
15 async_genkey, normalize_timestamps,
16 valid_codename, get_entropy_estimate)
17 from source_app.forms import LoginForm
18
19
20 def make_blueprint(config):
21 view = Blueprint('main', __name__)
22
23 @view.route('/')
24 def index():
25 return render_template('index.html')
26
27 @view.route('/generate', methods=('GET', 'POST'))
28 def generate():
29 if logged_in():
30 flash(gettext(
31 "You were redirected because you are already logged in. "
32 "If you want to create a new account, you should log out "
33 "first."),
34 "notification")
35 return redirect(url_for('.lookup'))
36
37 codename = generate_unique_codename(config)
38 session['codename'] = codename
39 session['new_user'] = True
40 return render_template('generate.html', codename=codename)
41
42 @view.route('/org-logo')
43 def select_logo():
44 if os.path.exists(os.path.join(current_app.static_folder, 'i',
45 'custom_logo.png')):
46 return redirect(url_for('static', filename='i/custom_logo.png'))
47 else:
48 return redirect(url_for('static', filename='i/logo.png'))
49
50 @view.route('/create', methods=['POST'])
51 def create():
52 filesystem_id = current_app.crypto_util.hash_codename(
53 session['codename'])
54
55 source = Source(filesystem_id, current_app.crypto_util.display_id())
56 db.session.add(source)
57 try:
58 db.session.commit()
59 except IntegrityError as e:
60 db.session.rollback()
61 current_app.logger.error(
62 "Attempt to create a source with duplicate codename: %s" %
63 (e,))
64
65 # Issue 2386: don't log in on duplicates
66 del session['codename']
67 abort(500)
68 else:
69 os.mkdir(current_app.storage.path(filesystem_id))
70
71 session['logged_in'] = True
72 return redirect(url_for('.lookup'))
73
74 @view.route('/lookup', methods=('GET',))
75 @login_required
76 def lookup():
77 replies = []
78 source_inbox = Reply.query.filter(Reply.source_id == g.source.id) \
79 .filter(Reply.deleted_by_source == False).all() # noqa
80
81 for reply in source_inbox:
82 reply_path = current_app.storage.path(
83 g.filesystem_id,
84 reply.filename,
85 )
86 try:
87 with io.open(reply_path, "rb") as f:
88 contents = f.read()
89 reply.decrypted = current_app.crypto_util.decrypt(
90 g.codename,
91 contents).decode('utf-8')
92 except UnicodeDecodeError:
93 current_app.logger.error("Could not decode reply %s" %
94 reply.filename)
95 else:
96 reply.date = datetime.utcfromtimestamp(
97 os.stat(reply_path).st_mtime)
98 replies.append(reply)
99
100 # Sort the replies by date
101 replies.sort(key=operator.attrgetter('date'), reverse=True)
102
103 # Generate a keypair to encrypt replies from the journalist
104 # Only do this if the journalist has flagged the source as one
105 # that they would like to reply to. (Issue #140.)
106 if not current_app.crypto_util.getkey(g.filesystem_id) and \
107 g.source.flagged:
108 db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']
109 async_genkey(current_app.crypto_util,
110 db_uri,
111 g.filesystem_id,
112 g.codename)
113
114 return render_template(
115 'lookup.html',
116 codename=g.codename,
117 replies=replies,
118 flagged=g.source.flagged,
119 new_user=session.get('new_user', None),
120 haskey=current_app.crypto_util.getkey(
121 g.filesystem_id))
122
123 @view.route('/submit', methods=('POST',))
124 @login_required
125 def submit():
126 msg = request.form['msg']
127 fh = request.files['fh']
128
129 # Don't submit anything if it was an "empty" submission. #878
130 if not (msg or fh):
131 flash(gettext(
132 "You must enter a message or choose a file to submit."),
133 "error")
134 return redirect(url_for('main.lookup'))
135
136 fnames = []
137 journalist_filename = g.source.journalist_filename
138 first_submission = g.source.interaction_count == 0
139
140 if msg:
141 g.source.interaction_count += 1
142 fnames.append(
143 current_app.storage.save_message_submission(
144 g.filesystem_id,
145 g.source.interaction_count,
146 journalist_filename,
147 msg))
148 if fh:
149 g.source.interaction_count += 1
150 fnames.append(
151 current_app.storage.save_file_submission(
152 g.filesystem_id,
153 g.source.interaction_count,
154 journalist_filename,
155 fh.filename,
156 fh.stream))
157
158 if first_submission:
159 msg = render_template('first_submission_flashed_message.html')
160 flash(Markup(msg), "success")
161
162 else:
163 if msg and not fh:
164 html_contents = gettext('Thanks! We received your message.')
165 elif not msg and fh:
166 html_contents = gettext('Thanks! We received your document.')
167 else:
168 html_contents = gettext('Thanks! We received your message and '
169 'document.')
170
171 msg = render_template('next_submission_flashed_message.html',
172 html_contents=html_contents)
173 flash(Markup(msg), "success")
174
175 for fname in fnames:
176 submission = Submission(g.source, fname)
177 db.session.add(submission)
178
179 if g.source.pending:
180 g.source.pending = False
181
182 # Generate a keypair now, if there's enough entropy (issue #303)
183 # (gpg reads 300 bytes from /dev/random)
184 entropy_avail = get_entropy_estimate()
185 if entropy_avail >= 2400:
186 db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']
187
188 async_genkey(current_app.crypto_util,
189 db_uri,
190 g.filesystem_id,
191 g.codename)
192 current_app.logger.info("generating key, entropy: {}".format(
193 entropy_avail))
194 else:
195 current_app.logger.warn(
196 "skipping key generation. entropy: {}".format(
197 entropy_avail))
198
199 g.source.last_updated = datetime.utcnow()
200 db.session.commit()
201 normalize_timestamps(g.filesystem_id)
202
203 return redirect(url_for('main.lookup'))
204
205 @view.route('/delete', methods=('POST',))
206 @login_required
207 def delete():
208 """This deletes the reply from the source's inbox, but preserves
209 the history for journalists such that they can view conversation
210 history.
211 """
212
213 query = Reply.query.filter(
214 Reply.filename == request.form['reply_filename'])
215 reply = get_one_or_else(query, current_app.logger, abort)
216 reply.deleted_by_source = True
217 db.session.add(reply)
218 db.session.commit()
219
220 flash(gettext("Reply deleted"), "notification")
221 return redirect(url_for('.lookup'))
222
223 @view.route('/delete-all', methods=('POST',))
224 @login_required
225 def batch_delete():
226 replies = Reply.query.filter(Reply.source_id == g.source.id) \
227 .filter(Reply.deleted_by_source == False).all() # noqa
228 if len(replies) == 0:
229 current_app.logger.error("Found no replies when at least one was "
230 "expected")
231 return redirect(url_for('.lookup'))
232
233 for reply in replies:
234 reply.deleted_by_source = True
235 db.session.add(reply)
236 db.session.commit()
237
238 flash(gettext("All replies have been deleted"), "notification")
239 return redirect(url_for('.lookup'))
240
241 @view.route('/login', methods=('GET', 'POST'))
242 def login():
243 form = LoginForm()
244 if form.validate_on_submit():
245 codename = request.form['codename'].strip()
246 if valid_codename(codename):
247 session.update(codename=codename, logged_in=True)
248 return redirect(url_for('.lookup', from_login='1'))
249 else:
250 current_app.logger.info(
251 "Login failed for invalid codename")
252 flash(gettext("Sorry, that is not a recognized codename."),
253 "error")
254 return render_template('login.html', form=form)
255
256 @view.route('/logout')
257 def logout():
258 if logged_in():
259 msg = render_template('logout_flashed_message.html')
260
261 # Clear the session after we render the message so it's localized
262 # If a user specified a locale, save it and restore it
263 user_locale = g.locale
264 session.clear()
265 session['locale'] = user_locale
266
267 flash(Markup(msg), "important hide-if-not-tor-browser")
268 return redirect(url_for('.index'))
269
270 return view
271
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/securedrop/source_app/main.py b/securedrop/source_app/main.py
--- a/securedrop/source_app/main.py
+++ b/securedrop/source_app/main.py
@@ -124,7 +124,9 @@
@login_required
def submit():
msg = request.form['msg']
- fh = request.files['fh']
+ fh = None
+ if 'fh' in request.files:
+ fh = request.files['fh']
# Don't submit anything if it was an "empty" submission. #878
if not (msg or fh):
|
{"golden_diff": "diff --git a/securedrop/source_app/main.py b/securedrop/source_app/main.py\n--- a/securedrop/source_app/main.py\n+++ b/securedrop/source_app/main.py\n@@ -124,7 +124,9 @@\n @login_required\n def submit():\n msg = request.form['msg']\n- fh = request.files['fh']\n+ fh = None\n+ if 'fh' in request.files:\n+ fh = request.files['fh']\n \n # Don't submit anything if it was an \"empty\" submission. #878\n if not (msg or fh):\n", "issue": "0.9.0-rc2 does not allow text only submissions\n## Description\r\n\r\nI believe I found a bug in upgrading from `0.8` to `0.9rc2` in that sources can only submit documents or documents and messages. If I try to send _only_ text or a blank form field I get a \"Bad Request, the browser or proxy sent a request that this server could not understand\" error.\r\n\r\n\r\n## Steps to Reproduce\r\n\r\nFirst I installed 0.8.0 on hardware and create a journalist. I then ran ./qa-loader.py -m 25. I logged in and and see submissions. I then added the apt-test key and updated sources.list to `apt.freedom.press` to `apt-test.freedom.press`. Finally I ran `sudo cron-apt -i -s` to update to `0.9rc2`\r\n\r\n## Expected Behavior\r\n\r\nA source can send text to journalists.\r\n\r\n## Actual Behavior\r\n\r\nError in the webapp.\r\n\r\n## Comments\r\n\r\nI also enabled apache debug logging and attempted to patch the source_app/ code to log anything related to CSRF violations and I was was not able to trigger a debug log. \r\n\n", "before_files": [{"content": "import operator\nimport os\nimport io\n\nfrom datetime import datetime\nfrom flask import (Blueprint, render_template, flash, redirect, url_for, g,\n session, current_app, request, Markup, abort)\nfrom flask_babel import gettext\nfrom sqlalchemy.exc import IntegrityError\n\nfrom db import db\nfrom models import Source, Submission, Reply, get_one_or_else\nfrom source_app.decorators import login_required\nfrom source_app.utils import (logged_in, generate_unique_codename,\n async_genkey, normalize_timestamps,\n valid_codename, get_entropy_estimate)\nfrom source_app.forms import LoginForm\n\n\ndef make_blueprint(config):\n view = Blueprint('main', __name__)\n\n @view.route('/')\n def index():\n return render_template('index.html')\n\n @view.route('/generate', methods=('GET', 'POST'))\n def generate():\n if logged_in():\n flash(gettext(\n \"You were redirected because you are already logged in. \"\n \"If you want to create a new account, you should log out \"\n \"first.\"),\n \"notification\")\n return redirect(url_for('.lookup'))\n\n codename = generate_unique_codename(config)\n session['codename'] = codename\n session['new_user'] = True\n return render_template('generate.html', codename=codename)\n\n @view.route('/org-logo')\n def select_logo():\n if os.path.exists(os.path.join(current_app.static_folder, 'i',\n 'custom_logo.png')):\n return redirect(url_for('static', filename='i/custom_logo.png'))\n else:\n return redirect(url_for('static', filename='i/logo.png'))\n\n @view.route('/create', methods=['POST'])\n def create():\n filesystem_id = current_app.crypto_util.hash_codename(\n session['codename'])\n\n source = Source(filesystem_id, current_app.crypto_util.display_id())\n db.session.add(source)\n try:\n db.session.commit()\n except IntegrityError as e:\n db.session.rollback()\n current_app.logger.error(\n \"Attempt to create a source with duplicate codename: %s\" %\n (e,))\n\n # Issue 2386: don't log in on duplicates\n del session['codename']\n abort(500)\n else:\n os.mkdir(current_app.storage.path(filesystem_id))\n\n session['logged_in'] = True\n return redirect(url_for('.lookup'))\n\n @view.route('/lookup', methods=('GET',))\n @login_required\n def lookup():\n replies = []\n source_inbox = Reply.query.filter(Reply.source_id == g.source.id) \\\n .filter(Reply.deleted_by_source == False).all() # noqa\n\n for reply in source_inbox:\n reply_path = current_app.storage.path(\n g.filesystem_id,\n reply.filename,\n )\n try:\n with io.open(reply_path, \"rb\") as f:\n contents = f.read()\n reply.decrypted = current_app.crypto_util.decrypt(\n g.codename,\n contents).decode('utf-8')\n except UnicodeDecodeError:\n current_app.logger.error(\"Could not decode reply %s\" %\n reply.filename)\n else:\n reply.date = datetime.utcfromtimestamp(\n os.stat(reply_path).st_mtime)\n replies.append(reply)\n\n # Sort the replies by date\n replies.sort(key=operator.attrgetter('date'), reverse=True)\n\n # Generate a keypair to encrypt replies from the journalist\n # Only do this if the journalist has flagged the source as one\n # that they would like to reply to. (Issue #140.)\n if not current_app.crypto_util.getkey(g.filesystem_id) and \\\n g.source.flagged:\n db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']\n async_genkey(current_app.crypto_util,\n db_uri,\n g.filesystem_id,\n g.codename)\n\n return render_template(\n 'lookup.html',\n codename=g.codename,\n replies=replies,\n flagged=g.source.flagged,\n new_user=session.get('new_user', None),\n haskey=current_app.crypto_util.getkey(\n g.filesystem_id))\n\n @view.route('/submit', methods=('POST',))\n @login_required\n def submit():\n msg = request.form['msg']\n fh = request.files['fh']\n\n # Don't submit anything if it was an \"empty\" submission. #878\n if not (msg or fh):\n flash(gettext(\n \"You must enter a message or choose a file to submit.\"),\n \"error\")\n return redirect(url_for('main.lookup'))\n\n fnames = []\n journalist_filename = g.source.journalist_filename\n first_submission = g.source.interaction_count == 0\n\n if msg:\n g.source.interaction_count += 1\n fnames.append(\n current_app.storage.save_message_submission(\n g.filesystem_id,\n g.source.interaction_count,\n journalist_filename,\n msg))\n if fh:\n g.source.interaction_count += 1\n fnames.append(\n current_app.storage.save_file_submission(\n g.filesystem_id,\n g.source.interaction_count,\n journalist_filename,\n fh.filename,\n fh.stream))\n\n if first_submission:\n msg = render_template('first_submission_flashed_message.html')\n flash(Markup(msg), \"success\")\n\n else:\n if msg and not fh:\n html_contents = gettext('Thanks! We received your message.')\n elif not msg and fh:\n html_contents = gettext('Thanks! We received your document.')\n else:\n html_contents = gettext('Thanks! We received your message and '\n 'document.')\n\n msg = render_template('next_submission_flashed_message.html',\n html_contents=html_contents)\n flash(Markup(msg), \"success\")\n\n for fname in fnames:\n submission = Submission(g.source, fname)\n db.session.add(submission)\n\n if g.source.pending:\n g.source.pending = False\n\n # Generate a keypair now, if there's enough entropy (issue #303)\n # (gpg reads 300 bytes from /dev/random)\n entropy_avail = get_entropy_estimate()\n if entropy_avail >= 2400:\n db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']\n\n async_genkey(current_app.crypto_util,\n db_uri,\n g.filesystem_id,\n g.codename)\n current_app.logger.info(\"generating key, entropy: {}\".format(\n entropy_avail))\n else:\n current_app.logger.warn(\n \"skipping key generation. entropy: {}\".format(\n entropy_avail))\n\n g.source.last_updated = datetime.utcnow()\n db.session.commit()\n normalize_timestamps(g.filesystem_id)\n\n return redirect(url_for('main.lookup'))\n\n @view.route('/delete', methods=('POST',))\n @login_required\n def delete():\n \"\"\"This deletes the reply from the source's inbox, but preserves\n the history for journalists such that they can view conversation\n history.\n \"\"\"\n\n query = Reply.query.filter(\n Reply.filename == request.form['reply_filename'])\n reply = get_one_or_else(query, current_app.logger, abort)\n reply.deleted_by_source = True\n db.session.add(reply)\n db.session.commit()\n\n flash(gettext(\"Reply deleted\"), \"notification\")\n return redirect(url_for('.lookup'))\n\n @view.route('/delete-all', methods=('POST',))\n @login_required\n def batch_delete():\n replies = Reply.query.filter(Reply.source_id == g.source.id) \\\n .filter(Reply.deleted_by_source == False).all() # noqa\n if len(replies) == 0:\n current_app.logger.error(\"Found no replies when at least one was \"\n \"expected\")\n return redirect(url_for('.lookup'))\n\n for reply in replies:\n reply.deleted_by_source = True\n db.session.add(reply)\n db.session.commit()\n\n flash(gettext(\"All replies have been deleted\"), \"notification\")\n return redirect(url_for('.lookup'))\n\n @view.route('/login', methods=('GET', 'POST'))\n def login():\n form = LoginForm()\n if form.validate_on_submit():\n codename = request.form['codename'].strip()\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n return redirect(url_for('.lookup', from_login='1'))\n else:\n current_app.logger.info(\n \"Login failed for invalid codename\")\n flash(gettext(\"Sorry, that is not a recognized codename.\"),\n \"error\")\n return render_template('login.html', form=form)\n\n @view.route('/logout')\n def logout():\n if logged_in():\n msg = render_template('logout_flashed_message.html')\n\n # Clear the session after we render the message so it's localized\n # If a user specified a locale, save it and restore it\n user_locale = g.locale\n session.clear()\n session['locale'] = user_locale\n\n flash(Markup(msg), \"important hide-if-not-tor-browser\")\n return redirect(url_for('.index'))\n\n return view\n", "path": "securedrop/source_app/main.py"}], "after_files": [{"content": "import operator\nimport os\nimport io\n\nfrom datetime import datetime\nfrom flask import (Blueprint, render_template, flash, redirect, url_for, g,\n session, current_app, request, Markup, abort)\nfrom flask_babel import gettext\nfrom sqlalchemy.exc import IntegrityError\n\nfrom db import db\nfrom models import Source, Submission, Reply, get_one_or_else\nfrom source_app.decorators import login_required\nfrom source_app.utils import (logged_in, generate_unique_codename,\n async_genkey, normalize_timestamps,\n valid_codename, get_entropy_estimate)\nfrom source_app.forms import LoginForm\n\n\ndef make_blueprint(config):\n view = Blueprint('main', __name__)\n\n @view.route('/')\n def index():\n return render_template('index.html')\n\n @view.route('/generate', methods=('GET', 'POST'))\n def generate():\n if logged_in():\n flash(gettext(\n \"You were redirected because you are already logged in. \"\n \"If you want to create a new account, you should log out \"\n \"first.\"),\n \"notification\")\n return redirect(url_for('.lookup'))\n\n codename = generate_unique_codename(config)\n session['codename'] = codename\n session['new_user'] = True\n return render_template('generate.html', codename=codename)\n\n @view.route('/org-logo')\n def select_logo():\n if os.path.exists(os.path.join(current_app.static_folder, 'i',\n 'custom_logo.png')):\n return redirect(url_for('static', filename='i/custom_logo.png'))\n else:\n return redirect(url_for('static', filename='i/logo.png'))\n\n @view.route('/create', methods=['POST'])\n def create():\n filesystem_id = current_app.crypto_util.hash_codename(\n session['codename'])\n\n source = Source(filesystem_id, current_app.crypto_util.display_id())\n db.session.add(source)\n try:\n db.session.commit()\n except IntegrityError as e:\n db.session.rollback()\n current_app.logger.error(\n \"Attempt to create a source with duplicate codename: %s\" %\n (e,))\n\n # Issue 2386: don't log in on duplicates\n del session['codename']\n abort(500)\n else:\n os.mkdir(current_app.storage.path(filesystem_id))\n\n session['logged_in'] = True\n return redirect(url_for('.lookup'))\n\n @view.route('/lookup', methods=('GET',))\n @login_required\n def lookup():\n replies = []\n source_inbox = Reply.query.filter(Reply.source_id == g.source.id) \\\n .filter(Reply.deleted_by_source == False).all() # noqa\n\n for reply in source_inbox:\n reply_path = current_app.storage.path(\n g.filesystem_id,\n reply.filename,\n )\n try:\n with io.open(reply_path, \"rb\") as f:\n contents = f.read()\n reply.decrypted = current_app.crypto_util.decrypt(\n g.codename,\n contents).decode('utf-8')\n except UnicodeDecodeError:\n current_app.logger.error(\"Could not decode reply %s\" %\n reply.filename)\n else:\n reply.date = datetime.utcfromtimestamp(\n os.stat(reply_path).st_mtime)\n replies.append(reply)\n\n # Sort the replies by date\n replies.sort(key=operator.attrgetter('date'), reverse=True)\n\n # Generate a keypair to encrypt replies from the journalist\n # Only do this if the journalist has flagged the source as one\n # that they would like to reply to. (Issue #140.)\n if not current_app.crypto_util.getkey(g.filesystem_id) and \\\n g.source.flagged:\n db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']\n async_genkey(current_app.crypto_util,\n db_uri,\n g.filesystem_id,\n g.codename)\n\n return render_template(\n 'lookup.html',\n codename=g.codename,\n replies=replies,\n flagged=g.source.flagged,\n new_user=session.get('new_user', None),\n haskey=current_app.crypto_util.getkey(\n g.filesystem_id))\n\n @view.route('/submit', methods=('POST',))\n @login_required\n def submit():\n msg = request.form['msg']\n fh = None\n if 'fh' in request.files:\n fh = request.files['fh']\n\n # Don't submit anything if it was an \"empty\" submission. #878\n if not (msg or fh):\n flash(gettext(\n \"You must enter a message or choose a file to submit.\"),\n \"error\")\n return redirect(url_for('main.lookup'))\n\n fnames = []\n journalist_filename = g.source.journalist_filename\n first_submission = g.source.interaction_count == 0\n\n if msg:\n g.source.interaction_count += 1\n fnames.append(\n current_app.storage.save_message_submission(\n g.filesystem_id,\n g.source.interaction_count,\n journalist_filename,\n msg))\n if fh:\n g.source.interaction_count += 1\n fnames.append(\n current_app.storage.save_file_submission(\n g.filesystem_id,\n g.source.interaction_count,\n journalist_filename,\n fh.filename,\n fh.stream))\n\n if first_submission:\n msg = render_template('first_submission_flashed_message.html')\n flash(Markup(msg), \"success\")\n\n else:\n if msg and not fh:\n html_contents = gettext('Thanks! We received your message.')\n elif not msg and fh:\n html_contents = gettext('Thanks! We received your document.')\n else:\n html_contents = gettext('Thanks! We received your message and '\n 'document.')\n\n msg = render_template('next_submission_flashed_message.html',\n html_contents=html_contents)\n flash(Markup(msg), \"success\")\n\n for fname in fnames:\n submission = Submission(g.source, fname)\n db.session.add(submission)\n\n if g.source.pending:\n g.source.pending = False\n\n # Generate a keypair now, if there's enough entropy (issue #303)\n # (gpg reads 300 bytes from /dev/random)\n entropy_avail = get_entropy_estimate()\n if entropy_avail >= 2400:\n db_uri = current_app.config['SQLALCHEMY_DATABASE_URI']\n\n async_genkey(current_app.crypto_util,\n db_uri,\n g.filesystem_id,\n g.codename)\n current_app.logger.info(\"generating key, entropy: {}\".format(\n entropy_avail))\n else:\n current_app.logger.warn(\n \"skipping key generation. entropy: {}\".format(\n entropy_avail))\n\n g.source.last_updated = datetime.utcnow()\n db.session.commit()\n normalize_timestamps(g.filesystem_id)\n\n return redirect(url_for('main.lookup'))\n\n @view.route('/delete', methods=('POST',))\n @login_required\n def delete():\n \"\"\"This deletes the reply from the source's inbox, but preserves\n the history for journalists such that they can view conversation\n history.\n \"\"\"\n\n query = Reply.query.filter(\n Reply.filename == request.form['reply_filename'])\n reply = get_one_or_else(query, current_app.logger, abort)\n reply.deleted_by_source = True\n db.session.add(reply)\n db.session.commit()\n\n flash(gettext(\"Reply deleted\"), \"notification\")\n return redirect(url_for('.lookup'))\n\n @view.route('/delete-all', methods=('POST',))\n @login_required\n def batch_delete():\n replies = Reply.query.filter(Reply.source_id == g.source.id) \\\n .filter(Reply.deleted_by_source == False).all() # noqa\n if len(replies) == 0:\n current_app.logger.error(\"Found no replies when at least one was \"\n \"expected\")\n return redirect(url_for('.lookup'))\n\n for reply in replies:\n reply.deleted_by_source = True\n db.session.add(reply)\n db.session.commit()\n\n flash(gettext(\"All replies have been deleted\"), \"notification\")\n return redirect(url_for('.lookup'))\n\n @view.route('/login', methods=('GET', 'POST'))\n def login():\n form = LoginForm()\n if form.validate_on_submit():\n codename = request.form['codename'].strip()\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n return redirect(url_for('.lookup', from_login='1'))\n else:\n current_app.logger.info(\n \"Login failed for invalid codename\")\n flash(gettext(\"Sorry, that is not a recognized codename.\"),\n \"error\")\n return render_template('login.html', form=form)\n\n @view.route('/logout')\n def logout():\n if logged_in():\n msg = render_template('logout_flashed_message.html')\n\n # Clear the session after we render the message so it's localized\n # If a user specified a locale, save it and restore it\n user_locale = g.locale\n session.clear()\n session['locale'] = user_locale\n\n flash(Markup(msg), \"important hide-if-not-tor-browser\")\n return redirect(url_for('.index'))\n\n return view\n", "path": "securedrop/source_app/main.py"}]}
| 3,165 | 134 |
gh_patches_debug_8015
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3585
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Site title entered in the @@plone-addsite form is not set as site title
Plone site title is set in the @@site-controlpanel form and saved in the registry. But the @@plone-addsite form gets the site title from the user and saves it as a Zope property in the portal object.
Related to https://github.com/plone/plone.app.layout/issues/317
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/factory.py`
Content:
```
1 from logging import getLogger
2 from plone.registry.interfaces import IRegistry
3 from Products.CMFPlone import PloneMessageFactory as _
4 from Products.CMFPlone.events import SiteManagerCreatedEvent
5 from plone.base.interfaces import INonInstallable
6 from Products.CMFPlone.Portal import PloneSite
7 from Products.GenericSetup.tool import SetupTool
8 from zope.component import queryUtility
9 from zope.component.hooks import setSite
10 from zope.event import notify
11 from zope.interface import implementer
12 from zope.lifecycleevent import ObjectCreatedEvent
13
14 _TOOL_ID = 'portal_setup'
15 _DEFAULT_PROFILE = 'Products.CMFPlone:plone'
16 _TYPES_PROFILE = 'plone.app.contenttypes:default'
17 _CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'
18
19 # A little hint for PloneTestCase (pre-Plone 6.0)
20 _IMREALLYPLONE5 = True
21
22 # Marker hints for code that needs to know the major Plone version
23 # Works the same way than zcml condition hints so it contains the current and the
24 # last ones
25 PLONE52MARKER = True
26 PLONE60MARKER = True
27
28 logger = getLogger('Plone')
29
30
31 @implementer(INonInstallable)
32 class NonInstallable:
33
34 def getNonInstallableProducts(self):
35 return [
36 'CMFDefault', 'Products.CMFDefault',
37 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',
38 'CMFTopic', 'Products.CMFTopic',
39 'CMFUid', 'Products.CMFUid',
40 'DCWorkflow', 'Products.DCWorkflow',
41 'PasswordResetTool', 'Products.PasswordResetTool',
42 'PlonePAS', 'Products.PlonePAS',
43 'PloneLanguageTool', 'Products.PloneLanguageTool',
44 'MimetypesRegistry', 'Products.MimetypesRegistry',
45 'PortalTransforms', 'Products.PortalTransforms',
46 'CMFDiffTool', 'Products.CMFDiffTool',
47 'CMFEditions', 'Products.CMFEditions',
48 'Products.NuPlone',
49 'borg.localrole',
50 'plone.app.caching',
51 'plone.app.dexterity',
52 'plone.app.discussion',
53 'plone.app.event',
54 'plone.app.intid',
55 'plone.app.linkintegrity',
56 'plone.app.querystring',
57 'plone.app.registry',
58 'plone.app.referenceablebehavior',
59 'plone.app.relationfield',
60 'plone.app.theming',
61 'plone.app.users',
62 'plone.app.widgets',
63 'plone.app.z3cform',
64 'plone.formwidget.recurrence',
65 'plone.keyring',
66 'plone.outputfilters',
67 'plone.portlet.static',
68 'plone.portlet.collection',
69 'plone.protect',
70 'plone.resource',
71 'plonetheme.barceloneta',
72 ]
73
74 def getNonInstallableProfiles(self):
75 return [_DEFAULT_PROFILE,
76 _CONTENT_PROFILE,
77 'Products.CMFDiffTool:CMFDiffTool',
78 'Products.CMFEditions:CMFEditions',
79 'Products.CMFPlone:dependencies',
80 'Products.CMFPlone:testfixture',
81 'Products.NuPlone:uninstall',
82 'Products.MimetypesRegistry:MimetypesRegistry',
83 'Products.PasswordResetTool:PasswordResetTool',
84 'Products.PortalTransforms:PortalTransforms',
85 'Products.PloneLanguageTool:PloneLanguageTool',
86 'Products.PlonePAS:PlonePAS',
87 'borg.localrole:default',
88 'plone.browserlayer:default',
89 'plone.keyring:default',
90 'plone.outputfilters:default',
91 'plone.portlet.static:default',
92 'plone.portlet.collection:default',
93 'plone.protect:default',
94 'plone.app.contenttypes:default',
95 'plone.app.dexterity:default',
96 'plone.app.discussion:default',
97 'plone.app.event:default',
98 'plone.app.linkintegrity:default',
99 'plone.app.registry:default',
100 'plone.app.relationfield:default',
101 'plone.app.theming:default',
102 'plone.app.users:default',
103 'plone.app.versioningbehavior:default',
104 'plone.app.z3cform:default',
105 'plone.formwidget.recurrence:default',
106 'plone.resource:default',
107 ]
108
109
110 def zmi_constructor(context):
111 """This is a dummy constructor for the ZMI."""
112 url = context.DestinationURL()
113 request = context.REQUEST
114 return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')
115
116
117 def addPloneSite(context, site_id, title='Plone site', description='',
118 profile_id=_DEFAULT_PROFILE,
119 content_profile_id=_CONTENT_PROFILE, snapshot=False,
120 extension_ids=(), setup_content=True,
121 default_language='en', portal_timezone='UTC'):
122 """Add a PloneSite to the context."""
123
124 site = PloneSite(site_id)
125 notify(ObjectCreatedEvent(site))
126 context[site_id] = site
127
128 site = context[site_id]
129 site.setLanguage(default_language)
130 # Set the accepted language for the rest of the request. This makes sure
131 # the front-page text gets the correct translation also when your browser
132 # prefers non-English and you choose English as language for the Plone
133 # Site.
134 request = context.REQUEST
135 request['HTTP_ACCEPT_LANGUAGE'] = default_language
136
137 site[_TOOL_ID] = SetupTool(_TOOL_ID)
138 setup_tool = site[_TOOL_ID]
139
140 notify(SiteManagerCreatedEvent(site))
141 setSite(site)
142
143 try:
144 setup_tool.setBaselineContext('profile-%s' % profile_id)
145 setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)
146
147 reg = queryUtility(IRegistry, context=site)
148 reg['plone.portal_timezone'] = portal_timezone
149 reg['plone.available_timezones'] = [portal_timezone]
150 reg['plone.default_language'] = default_language
151 reg['plone.available_languages'] = [default_language]
152
153 # Install default content types profile if user do not select "example content"
154 # during site creation.
155 content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE
156
157 setup_tool.runAllImportStepsFromProfile(f'profile-{content_types_profile}')
158
159 props = dict(
160 title=title,
161 description=description,
162 )
163 # Do this before applying extension profiles, so the settings from a
164 # properties.xml file are applied and not overwritten by this
165 site.manage_changeProperties(**props)
166
167 for extension_id in extension_ids:
168 try:
169 setup_tool.runAllImportStepsFromProfile(f"profile-{extension_id}")
170 except Exception:
171 logger.error(f"Error while installing profile {extension_id}:")
172 raise
173
174 if snapshot is True:
175 setup_tool.createSnapshot('initial_configuration')
176
177 return site
178 except Exception:
179 setSite(None)
180 raise
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/factory.py b/Products/CMFPlone/factory.py
--- a/Products/CMFPlone/factory.py
+++ b/Products/CMFPlone/factory.py
@@ -149,6 +149,7 @@
reg['plone.available_timezones'] = [portal_timezone]
reg['plone.default_language'] = default_language
reg['plone.available_languages'] = [default_language]
+ reg['plone.site_title'] = title
# Install default content types profile if user do not select "example content"
# during site creation.
|
{"golden_diff": "diff --git a/Products/CMFPlone/factory.py b/Products/CMFPlone/factory.py\n--- a/Products/CMFPlone/factory.py\n+++ b/Products/CMFPlone/factory.py\n@@ -149,6 +149,7 @@\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n+ reg['plone.site_title'] = title\n \n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n", "issue": "Site title entered in the @@plone-addsite form is not set as site title\nPlone site title is set in the @@site-controlpanel form and saved in the registry. But the @@plone-addsite form gets the site title from the user and saves it as a Zope property in the portal object.\r\n\r\n\r\nRelated to https://github.com/plone/plone.app.layout/issues/317\n", "before_files": [{"content": "from logging import getLogger\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.events import SiteManagerCreatedEvent\nfrom plone.base.interfaces import INonInstallable\nfrom Products.CMFPlone.Portal import PloneSite\nfrom Products.GenericSetup.tool import SetupTool\nfrom zope.component import queryUtility\nfrom zope.component.hooks import setSite\nfrom zope.event import notify\nfrom zope.interface import implementer\nfrom zope.lifecycleevent import ObjectCreatedEvent\n\n_TOOL_ID = 'portal_setup'\n_DEFAULT_PROFILE = 'Products.CMFPlone:plone'\n_TYPES_PROFILE = 'plone.app.contenttypes:default'\n_CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'\n\n# A little hint for PloneTestCase (pre-Plone 6.0)\n_IMREALLYPLONE5 = True\n\n# Marker hints for code that needs to know the major Plone version\n# Works the same way than zcml condition hints so it contains the current and the\n# last ones\nPLONE52MARKER = True\nPLONE60MARKER = True\n\nlogger = getLogger('Plone')\n\n\n@implementer(INonInstallable)\nclass NonInstallable:\n\n def getNonInstallableProducts(self):\n return [\n 'CMFDefault', 'Products.CMFDefault',\n 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',\n 'CMFTopic', 'Products.CMFTopic',\n 'CMFUid', 'Products.CMFUid',\n 'DCWorkflow', 'Products.DCWorkflow',\n 'PasswordResetTool', 'Products.PasswordResetTool',\n 'PlonePAS', 'Products.PlonePAS',\n 'PloneLanguageTool', 'Products.PloneLanguageTool',\n 'MimetypesRegistry', 'Products.MimetypesRegistry',\n 'PortalTransforms', 'Products.PortalTransforms',\n 'CMFDiffTool', 'Products.CMFDiffTool',\n 'CMFEditions', 'Products.CMFEditions',\n 'Products.NuPlone',\n 'borg.localrole',\n 'plone.app.caching',\n 'plone.app.dexterity',\n 'plone.app.discussion',\n 'plone.app.event',\n 'plone.app.intid',\n 'plone.app.linkintegrity',\n 'plone.app.querystring',\n 'plone.app.registry',\n 'plone.app.referenceablebehavior',\n 'plone.app.relationfield',\n 'plone.app.theming',\n 'plone.app.users',\n 'plone.app.widgets',\n 'plone.app.z3cform',\n 'plone.formwidget.recurrence',\n 'plone.keyring',\n 'plone.outputfilters',\n 'plone.portlet.static',\n 'plone.portlet.collection',\n 'plone.protect',\n 'plone.resource',\n 'plonetheme.barceloneta',\n ]\n\n def getNonInstallableProfiles(self):\n return [_DEFAULT_PROFILE,\n _CONTENT_PROFILE,\n 'Products.CMFDiffTool:CMFDiffTool',\n 'Products.CMFEditions:CMFEditions',\n 'Products.CMFPlone:dependencies',\n 'Products.CMFPlone:testfixture',\n 'Products.NuPlone:uninstall',\n 'Products.MimetypesRegistry:MimetypesRegistry',\n 'Products.PasswordResetTool:PasswordResetTool',\n 'Products.PortalTransforms:PortalTransforms',\n 'Products.PloneLanguageTool:PloneLanguageTool',\n 'Products.PlonePAS:PlonePAS',\n 'borg.localrole:default',\n 'plone.browserlayer:default',\n 'plone.keyring:default',\n 'plone.outputfilters:default',\n 'plone.portlet.static:default',\n 'plone.portlet.collection:default',\n 'plone.protect:default',\n 'plone.app.contenttypes:default',\n 'plone.app.dexterity:default',\n 'plone.app.discussion:default',\n 'plone.app.event:default',\n 'plone.app.linkintegrity:default',\n 'plone.app.registry:default',\n 'plone.app.relationfield:default',\n 'plone.app.theming:default',\n 'plone.app.users:default',\n 'plone.app.versioningbehavior:default',\n 'plone.app.z3cform:default',\n 'plone.formwidget.recurrence:default',\n 'plone.resource:default',\n ]\n\n\ndef zmi_constructor(context):\n \"\"\"This is a dummy constructor for the ZMI.\"\"\"\n url = context.DestinationURL()\n request = context.REQUEST\n return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')\n\n\ndef addPloneSite(context, site_id, title='Plone site', description='',\n profile_id=_DEFAULT_PROFILE,\n content_profile_id=_CONTENT_PROFILE, snapshot=False,\n extension_ids=(), setup_content=True,\n default_language='en', portal_timezone='UTC'):\n \"\"\"Add a PloneSite to the context.\"\"\"\n\n site = PloneSite(site_id)\n notify(ObjectCreatedEvent(site))\n context[site_id] = site\n\n site = context[site_id]\n site.setLanguage(default_language)\n # Set the accepted language for the rest of the request. This makes sure\n # the front-page text gets the correct translation also when your browser\n # prefers non-English and you choose English as language for the Plone\n # Site.\n request = context.REQUEST\n request['HTTP_ACCEPT_LANGUAGE'] = default_language\n\n site[_TOOL_ID] = SetupTool(_TOOL_ID)\n setup_tool = site[_TOOL_ID]\n\n notify(SiteManagerCreatedEvent(site))\n setSite(site)\n\n try:\n setup_tool.setBaselineContext('profile-%s' % profile_id)\n setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)\n\n reg = queryUtility(IRegistry, context=site)\n reg['plone.portal_timezone'] = portal_timezone\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n\n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE\n\n setup_tool.runAllImportStepsFromProfile(f'profile-{content_types_profile}')\n\n props = dict(\n title=title,\n description=description,\n )\n # Do this before applying extension profiles, so the settings from a\n # properties.xml file are applied and not overwritten by this\n site.manage_changeProperties(**props)\n\n for extension_id in extension_ids:\n try:\n setup_tool.runAllImportStepsFromProfile(f\"profile-{extension_id}\")\n except Exception:\n logger.error(f\"Error while installing profile {extension_id}:\")\n raise\n\n if snapshot is True:\n setup_tool.createSnapshot('initial_configuration')\n\n return site\n except Exception:\n setSite(None)\n raise\n", "path": "Products/CMFPlone/factory.py"}], "after_files": [{"content": "from logging import getLogger\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.events import SiteManagerCreatedEvent\nfrom plone.base.interfaces import INonInstallable\nfrom Products.CMFPlone.Portal import PloneSite\nfrom Products.GenericSetup.tool import SetupTool\nfrom zope.component import queryUtility\nfrom zope.component.hooks import setSite\nfrom zope.event import notify\nfrom zope.interface import implementer\nfrom zope.lifecycleevent import ObjectCreatedEvent\n\n_TOOL_ID = 'portal_setup'\n_DEFAULT_PROFILE = 'Products.CMFPlone:plone'\n_TYPES_PROFILE = 'plone.app.contenttypes:default'\n_CONTENT_PROFILE = 'plone.app.contenttypes:plone-content'\n\n# A little hint for PloneTestCase (pre-Plone 6.0)\n_IMREALLYPLONE5 = True\n\n# Marker hints for code that needs to know the major Plone version\n# Works the same way than zcml condition hints so it contains the current and the\n# last ones\nPLONE52MARKER = True\nPLONE60MARKER = True\n\nlogger = getLogger('Plone')\n\n\n@implementer(INonInstallable)\nclass NonInstallable:\n\n def getNonInstallableProducts(self):\n return [\n 'CMFDefault', 'Products.CMFDefault',\n 'CMFPlone', 'Products.CMFPlone', 'Products.CMFPlone.migrations',\n 'CMFTopic', 'Products.CMFTopic',\n 'CMFUid', 'Products.CMFUid',\n 'DCWorkflow', 'Products.DCWorkflow',\n 'PasswordResetTool', 'Products.PasswordResetTool',\n 'PlonePAS', 'Products.PlonePAS',\n 'PloneLanguageTool', 'Products.PloneLanguageTool',\n 'MimetypesRegistry', 'Products.MimetypesRegistry',\n 'PortalTransforms', 'Products.PortalTransforms',\n 'CMFDiffTool', 'Products.CMFDiffTool',\n 'CMFEditions', 'Products.CMFEditions',\n 'Products.NuPlone',\n 'borg.localrole',\n 'plone.app.caching',\n 'plone.app.dexterity',\n 'plone.app.discussion',\n 'plone.app.event',\n 'plone.app.intid',\n 'plone.app.linkintegrity',\n 'plone.app.querystring',\n 'plone.app.registry',\n 'plone.app.referenceablebehavior',\n 'plone.app.relationfield',\n 'plone.app.theming',\n 'plone.app.users',\n 'plone.app.widgets',\n 'plone.app.z3cform',\n 'plone.formwidget.recurrence',\n 'plone.keyring',\n 'plone.outputfilters',\n 'plone.portlet.static',\n 'plone.portlet.collection',\n 'plone.protect',\n 'plone.resource',\n 'plonetheme.barceloneta',\n ]\n\n def getNonInstallableProfiles(self):\n return [_DEFAULT_PROFILE,\n _CONTENT_PROFILE,\n 'Products.CMFDiffTool:CMFDiffTool',\n 'Products.CMFEditions:CMFEditions',\n 'Products.CMFPlone:dependencies',\n 'Products.CMFPlone:testfixture',\n 'Products.NuPlone:uninstall',\n 'Products.MimetypesRegistry:MimetypesRegistry',\n 'Products.PasswordResetTool:PasswordResetTool',\n 'Products.PortalTransforms:PortalTransforms',\n 'Products.PloneLanguageTool:PloneLanguageTool',\n 'Products.PlonePAS:PlonePAS',\n 'borg.localrole:default',\n 'plone.browserlayer:default',\n 'plone.keyring:default',\n 'plone.outputfilters:default',\n 'plone.portlet.static:default',\n 'plone.portlet.collection:default',\n 'plone.protect:default',\n 'plone.app.contenttypes:default',\n 'plone.app.dexterity:default',\n 'plone.app.discussion:default',\n 'plone.app.event:default',\n 'plone.app.linkintegrity:default',\n 'plone.app.registry:default',\n 'plone.app.relationfield:default',\n 'plone.app.theming:default',\n 'plone.app.users:default',\n 'plone.app.versioningbehavior:default',\n 'plone.app.z3cform:default',\n 'plone.formwidget.recurrence:default',\n 'plone.resource:default',\n ]\n\n\ndef zmi_constructor(context):\n \"\"\"This is a dummy constructor for the ZMI.\"\"\"\n url = context.DestinationURL()\n request = context.REQUEST\n return request.response.redirect(url + '/@@plone-addsite?site_id=Plone')\n\n\ndef addPloneSite(context, site_id, title='Plone site', description='',\n profile_id=_DEFAULT_PROFILE,\n content_profile_id=_CONTENT_PROFILE, snapshot=False,\n extension_ids=(), setup_content=True,\n default_language='en', portal_timezone='UTC'):\n \"\"\"Add a PloneSite to the context.\"\"\"\n\n site = PloneSite(site_id)\n notify(ObjectCreatedEvent(site))\n context[site_id] = site\n\n site = context[site_id]\n site.setLanguage(default_language)\n # Set the accepted language for the rest of the request. This makes sure\n # the front-page text gets the correct translation also when your browser\n # prefers non-English and you choose English as language for the Plone\n # Site.\n request = context.REQUEST\n request['HTTP_ACCEPT_LANGUAGE'] = default_language\n\n site[_TOOL_ID] = SetupTool(_TOOL_ID)\n setup_tool = site[_TOOL_ID]\n\n notify(SiteManagerCreatedEvent(site))\n setSite(site)\n\n try:\n setup_tool.setBaselineContext('profile-%s' % profile_id)\n setup_tool.runAllImportStepsFromProfile('profile-%s' % profile_id)\n\n reg = queryUtility(IRegistry, context=site)\n reg['plone.portal_timezone'] = portal_timezone\n reg['plone.available_timezones'] = [portal_timezone]\n reg['plone.default_language'] = default_language\n reg['plone.available_languages'] = [default_language]\n reg['plone.site_title'] = title\n\n # Install default content types profile if user do not select \"example content\"\n # during site creation.\n content_types_profile = content_profile_id if setup_content else _TYPES_PROFILE\n\n setup_tool.runAllImportStepsFromProfile(f'profile-{content_types_profile}')\n\n props = dict(\n title=title,\n description=description,\n )\n # Do this before applying extension profiles, so the settings from a\n # properties.xml file are applied and not overwritten by this\n site.manage_changeProperties(**props)\n\n for extension_id in extension_ids:\n try:\n setup_tool.runAllImportStepsFromProfile(f\"profile-{extension_id}\")\n except Exception:\n logger.error(f\"Error while installing profile {extension_id}:\")\n raise\n\n if snapshot is True:\n setup_tool.createSnapshot('initial_configuration')\n\n return site\n except Exception:\n setSite(None)\n raise\n", "path": "Products/CMFPlone/factory.py"}]}
| 2,339 | 139 |
gh_patches_debug_28407
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-16295
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not able to load resources when using pants vs sbt
**Describe the bug**
When using sbt we are able to call `Thread.currentThread().getContextClassLoader().getResources` and get a list of URLs. When using pants the list is empty.
This at the moment limits us from using Flyway with pants.
**Pants version**
2.13.0a1 and main.
**OS**
MacOS
**Additional info**
Example repo to reproduce the issue:
https://github.com/somdoron/test-pants-resources
I think the issue is, that pants only compress files in the resources zip file and not the directories.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/jvm/resources.py`
Content:
```
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3 import itertools
4 import logging
5 from itertools import chain
6
7 from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet
8 from pants.core.util_rules import stripped_source_files
9 from pants.core.util_rules.source_files import SourceFilesRequest
10 from pants.core.util_rules.stripped_source_files import StrippedSourceFiles
11 from pants.core.util_rules.system_binaries import ZipBinary
12 from pants.engine.fs import Digest, MergeDigests
13 from pants.engine.internals.selectors import MultiGet
14 from pants.engine.process import Process, ProcessResult
15 from pants.engine.rules import Get, collect_rules, rule
16 from pants.engine.target import SourcesField
17 from pants.engine.unions import UnionRule
18 from pants.jvm import compile
19 from pants.jvm.compile import (
20 ClasspathDependenciesRequest,
21 ClasspathEntry,
22 ClasspathEntryRequest,
23 ClasspathEntryRequests,
24 CompileResult,
25 FallibleClasspathEntries,
26 FallibleClasspathEntry,
27 )
28
29 logger = logging.getLogger(__name__)
30
31
32 class JvmResourcesRequest(ClasspathEntryRequest):
33 field_sets = (
34 ResourcesFieldSet,
35 ResourcesGeneratorFieldSet,
36 )
37
38
39 @rule(desc="Assemble resources")
40 async def assemble_resources_jar(
41 zip: ZipBinary,
42 request: JvmResourcesRequest,
43 ) -> FallibleClasspathEntry:
44 # Request the component's direct dependency classpath, and additionally any prerequisite.
45 # Filter out any dependencies that are generated by our current target so that each resource
46 # only appears in a single input JAR.
47 # NOTE: Generated dependencies will have the same dependencies as the current target, so we
48 # don't need to inspect those dependencies.
49 optional_prereq_request = [*((request.prerequisite,) if request.prerequisite else ())]
50 fallibles = await MultiGet(
51 Get(FallibleClasspathEntries, ClasspathEntryRequests(optional_prereq_request)),
52 Get(FallibleClasspathEntries, ClasspathDependenciesRequest(request, ignore_generated=True)),
53 )
54 direct_dependency_classpath_entries = FallibleClasspathEntries(
55 itertools.chain(*fallibles)
56 ).if_all_succeeded()
57
58 if direct_dependency_classpath_entries is None:
59 return FallibleClasspathEntry(
60 description=str(request.component),
61 result=CompileResult.DEPENDENCY_FAILED,
62 output=None,
63 exit_code=1,
64 )
65
66 source_files = await Get(
67 StrippedSourceFiles,
68 SourceFilesRequest([tgt.get(SourcesField) for tgt in request.component.members]),
69 )
70
71 output_filename = f"{request.component.representative.address.path_safe_spec}.resources.jar"
72 output_files = [output_filename]
73
74 resources_jar_input_digest = source_files.snapshot.digest
75 resources_jar_result = await Get(
76 ProcessResult,
77 Process(
78 argv=[
79 zip.path,
80 output_filename,
81 *source_files.snapshot.files,
82 ],
83 description="Build partial JAR containing resources files",
84 input_digest=resources_jar_input_digest,
85 output_files=output_files,
86 ),
87 )
88
89 cpe = ClasspathEntry(resources_jar_result.output_digest, output_files, [])
90
91 merged_cpe_digest = await Get(
92 Digest,
93 MergeDigests(chain((cpe.digest,), (i.digest for i in direct_dependency_classpath_entries))),
94 )
95
96 merged_cpe = ClasspathEntry.merge(
97 digest=merged_cpe_digest, entries=[cpe, *direct_dependency_classpath_entries]
98 )
99
100 return FallibleClasspathEntry(output_filename, CompileResult.SUCCEEDED, merged_cpe, 0)
101
102
103 def rules():
104 return [
105 *collect_rules(),
106 *compile.rules(),
107 *stripped_source_files.rules(),
108 UnionRule(ClasspathEntryRequest, JvmResourcesRequest),
109 ]
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/jvm/resources.py b/src/python/pants/jvm/resources.py
--- a/src/python/pants/jvm/resources.py
+++ b/src/python/pants/jvm/resources.py
@@ -3,6 +3,7 @@
import itertools
import logging
from itertools import chain
+from pathlib import Path
from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet
from pants.core.util_rules import stripped_source_files
@@ -71,6 +72,13 @@
output_filename = f"{request.component.representative.address.path_safe_spec}.resources.jar"
output_files = [output_filename]
+ # #16231: Valid JAR files need the directories of each resource file as well as the files
+ # themselves.
+
+ paths = {Path(filename) for filename in source_files.snapshot.files}
+ directories = {parent for path in paths for parent in path.parents}
+ input_files = {str(path) for path in chain(paths, directories)}
+
resources_jar_input_digest = source_files.snapshot.digest
resources_jar_result = await Get(
ProcessResult,
@@ -78,7 +86,7 @@
argv=[
zip.path,
output_filename,
- *source_files.snapshot.files,
+ *sorted(input_files),
],
description="Build partial JAR containing resources files",
input_digest=resources_jar_input_digest,
|
{"golden_diff": "diff --git a/src/python/pants/jvm/resources.py b/src/python/pants/jvm/resources.py\n--- a/src/python/pants/jvm/resources.py\n+++ b/src/python/pants/jvm/resources.py\n@@ -3,6 +3,7 @@\n import itertools\n import logging\n from itertools import chain\n+from pathlib import Path\n \n from pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet\n from pants.core.util_rules import stripped_source_files\n@@ -71,6 +72,13 @@\n output_filename = f\"{request.component.representative.address.path_safe_spec}.resources.jar\"\n output_files = [output_filename]\n \n+ # #16231: Valid JAR files need the directories of each resource file as well as the files\n+ # themselves.\n+\n+ paths = {Path(filename) for filename in source_files.snapshot.files}\n+ directories = {parent for path in paths for parent in path.parents}\n+ input_files = {str(path) for path in chain(paths, directories)}\n+\n resources_jar_input_digest = source_files.snapshot.digest\n resources_jar_result = await Get(\n ProcessResult,\n@@ -78,7 +86,7 @@\n argv=[\n zip.path,\n output_filename,\n- *source_files.snapshot.files,\n+ *sorted(input_files),\n ],\n description=\"Build partial JAR containing resources files\",\n input_digest=resources_jar_input_digest,\n", "issue": "Not able to load resources when using pants vs sbt\n**Describe the bug**\r\nWhen using sbt we are able to call `Thread.currentThread().getContextClassLoader().getResources` and get a list of URLs. When using pants the list is empty. \r\n\r\nThis at the moment limits us from using Flyway with pants.\r\n\r\n**Pants version**\r\n2.13.0a1 and main.\r\n\r\n**OS**\r\nMacOS\r\n\r\n**Additional info**\r\nExample repo to reproduce the issue:\r\nhttps://github.com/somdoron/test-pants-resources\r\n\r\nI think the issue is, that pants only compress files in the resources zip file and not the directories.\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nimport itertools\nimport logging\nfrom itertools import chain\n\nfrom pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet\nfrom pants.core.util_rules import stripped_source_files\nfrom pants.core.util_rules.source_files import SourceFilesRequest\nfrom pants.core.util_rules.stripped_source_files import StrippedSourceFiles\nfrom pants.core.util_rules.system_binaries import ZipBinary\nfrom pants.engine.fs import Digest, MergeDigests\nfrom pants.engine.internals.selectors import MultiGet\nfrom pants.engine.process import Process, ProcessResult\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.engine.target import SourcesField\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm import compile\nfrom pants.jvm.compile import (\n ClasspathDependenciesRequest,\n ClasspathEntry,\n ClasspathEntryRequest,\n ClasspathEntryRequests,\n CompileResult,\n FallibleClasspathEntries,\n FallibleClasspathEntry,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass JvmResourcesRequest(ClasspathEntryRequest):\n field_sets = (\n ResourcesFieldSet,\n ResourcesGeneratorFieldSet,\n )\n\n\n@rule(desc=\"Assemble resources\")\nasync def assemble_resources_jar(\n zip: ZipBinary,\n request: JvmResourcesRequest,\n) -> FallibleClasspathEntry:\n # Request the component's direct dependency classpath, and additionally any prerequisite.\n # Filter out any dependencies that are generated by our current target so that each resource\n # only appears in a single input JAR.\n # NOTE: Generated dependencies will have the same dependencies as the current target, so we\n # don't need to inspect those dependencies.\n optional_prereq_request = [*((request.prerequisite,) if request.prerequisite else ())]\n fallibles = await MultiGet(\n Get(FallibleClasspathEntries, ClasspathEntryRequests(optional_prereq_request)),\n Get(FallibleClasspathEntries, ClasspathDependenciesRequest(request, ignore_generated=True)),\n )\n direct_dependency_classpath_entries = FallibleClasspathEntries(\n itertools.chain(*fallibles)\n ).if_all_succeeded()\n\n if direct_dependency_classpath_entries is None:\n return FallibleClasspathEntry(\n description=str(request.component),\n result=CompileResult.DEPENDENCY_FAILED,\n output=None,\n exit_code=1,\n )\n\n source_files = await Get(\n StrippedSourceFiles,\n SourceFilesRequest([tgt.get(SourcesField) for tgt in request.component.members]),\n )\n\n output_filename = f\"{request.component.representative.address.path_safe_spec}.resources.jar\"\n output_files = [output_filename]\n\n resources_jar_input_digest = source_files.snapshot.digest\n resources_jar_result = await Get(\n ProcessResult,\n Process(\n argv=[\n zip.path,\n output_filename,\n *source_files.snapshot.files,\n ],\n description=\"Build partial JAR containing resources files\",\n input_digest=resources_jar_input_digest,\n output_files=output_files,\n ),\n )\n\n cpe = ClasspathEntry(resources_jar_result.output_digest, output_files, [])\n\n merged_cpe_digest = await Get(\n Digest,\n MergeDigests(chain((cpe.digest,), (i.digest for i in direct_dependency_classpath_entries))),\n )\n\n merged_cpe = ClasspathEntry.merge(\n digest=merged_cpe_digest, entries=[cpe, *direct_dependency_classpath_entries]\n )\n\n return FallibleClasspathEntry(output_filename, CompileResult.SUCCEEDED, merged_cpe, 0)\n\n\ndef rules():\n return [\n *collect_rules(),\n *compile.rules(),\n *stripped_source_files.rules(),\n UnionRule(ClasspathEntryRequest, JvmResourcesRequest),\n ]\n", "path": "src/python/pants/jvm/resources.py"}], "after_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nimport itertools\nimport logging\nfrom itertools import chain\nfrom pathlib import Path\n\nfrom pants.core.target_types import ResourcesFieldSet, ResourcesGeneratorFieldSet\nfrom pants.core.util_rules import stripped_source_files\nfrom pants.core.util_rules.source_files import SourceFilesRequest\nfrom pants.core.util_rules.stripped_source_files import StrippedSourceFiles\nfrom pants.core.util_rules.system_binaries import ZipBinary\nfrom pants.engine.fs import Digest, MergeDigests\nfrom pants.engine.internals.selectors import MultiGet\nfrom pants.engine.process import Process, ProcessResult\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.engine.target import SourcesField\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm import compile\nfrom pants.jvm.compile import (\n ClasspathDependenciesRequest,\n ClasspathEntry,\n ClasspathEntryRequest,\n ClasspathEntryRequests,\n CompileResult,\n FallibleClasspathEntries,\n FallibleClasspathEntry,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass JvmResourcesRequest(ClasspathEntryRequest):\n field_sets = (\n ResourcesFieldSet,\n ResourcesGeneratorFieldSet,\n )\n\n\n@rule(desc=\"Assemble resources\")\nasync def assemble_resources_jar(\n zip: ZipBinary,\n request: JvmResourcesRequest,\n) -> FallibleClasspathEntry:\n # Request the component's direct dependency classpath, and additionally any prerequisite.\n # Filter out any dependencies that are generated by our current target so that each resource\n # only appears in a single input JAR.\n # NOTE: Generated dependencies will have the same dependencies as the current target, so we\n # don't need to inspect those dependencies.\n optional_prereq_request = [*((request.prerequisite,) if request.prerequisite else ())]\n fallibles = await MultiGet(\n Get(FallibleClasspathEntries, ClasspathEntryRequests(optional_prereq_request)),\n Get(FallibleClasspathEntries, ClasspathDependenciesRequest(request, ignore_generated=True)),\n )\n direct_dependency_classpath_entries = FallibleClasspathEntries(\n itertools.chain(*fallibles)\n ).if_all_succeeded()\n\n if direct_dependency_classpath_entries is None:\n return FallibleClasspathEntry(\n description=str(request.component),\n result=CompileResult.DEPENDENCY_FAILED,\n output=None,\n exit_code=1,\n )\n\n source_files = await Get(\n StrippedSourceFiles,\n SourceFilesRequest([tgt.get(SourcesField) for tgt in request.component.members]),\n )\n\n output_filename = f\"{request.component.representative.address.path_safe_spec}.resources.jar\"\n output_files = [output_filename]\n\n # #16231: Valid JAR files need the directories of each resource file as well as the files\n # themselves.\n\n paths = {Path(filename) for filename in source_files.snapshot.files}\n directories = {parent for path in paths for parent in path.parents}\n input_files = {str(path) for path in chain(paths, directories)}\n\n resources_jar_input_digest = source_files.snapshot.digest\n resources_jar_result = await Get(\n ProcessResult,\n Process(\n argv=[\n zip.path,\n output_filename,\n *sorted(input_files),\n ],\n description=\"Build partial JAR containing resources files\",\n input_digest=resources_jar_input_digest,\n output_files=output_files,\n ),\n )\n\n cpe = ClasspathEntry(resources_jar_result.output_digest, output_files, [])\n\n merged_cpe_digest = await Get(\n Digest,\n MergeDigests(chain((cpe.digest,), (i.digest for i in direct_dependency_classpath_entries))),\n )\n\n merged_cpe = ClasspathEntry.merge(\n digest=merged_cpe_digest, entries=[cpe, *direct_dependency_classpath_entries]\n )\n\n return FallibleClasspathEntry(output_filename, CompileResult.SUCCEEDED, merged_cpe, 0)\n\n\ndef rules():\n return [\n *collect_rules(),\n *compile.rules(),\n *stripped_source_files.rules(),\n UnionRule(ClasspathEntryRequest, JvmResourcesRequest),\n ]\n", "path": "src/python/pants/jvm/resources.py"}]}
| 1,430 | 306 |
gh_patches_debug_28333
|
rasdani/github-patches
|
git_diff
|
pypa__pip-2766
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Version self check should not warn for post releases
Post releases are explicitly designed to just fix small errors that won't affect the code itself, things like doc updates. However if we release a post release then the pip version self check will tell everyone to go download it, even though using it isn't really all that important.
Ideally this should just ignore post releases.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pip/utils/outdated.py`
Content:
```
1 from __future__ import absolute_import
2
3 import datetime
4 import json
5 import logging
6 import os.path
7 import sys
8
9 from pip._vendor import lockfile
10 from pip._vendor import pkg_resources
11
12 from pip.compat import total_seconds
13 from pip.index import PyPI
14 from pip.locations import USER_CACHE_DIR, running_under_virtualenv
15 from pip.utils import ensure_dir
16 from pip.utils.filesystem import check_path_owner
17
18
19 SELFCHECK_DATE_FMT = "%Y-%m-%dT%H:%M:%SZ"
20
21
22 logger = logging.getLogger(__name__)
23
24
25 class VirtualenvSelfCheckState(object):
26 def __init__(self):
27 self.statefile_path = os.path.join(sys.prefix, "pip-selfcheck.json")
28
29 # Load the existing state
30 try:
31 with open(self.statefile_path) as statefile:
32 self.state = json.load(statefile)
33 except (IOError, ValueError):
34 self.state = {}
35
36 def save(self, pypi_version, current_time):
37 # Attempt to write out our version check file
38 with open(self.statefile_path, "w") as statefile:
39 json.dump(
40 {
41 "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
42 "pypi_version": pypi_version,
43 },
44 statefile,
45 sort_keys=True,
46 separators=(",", ":")
47 )
48
49
50 class GlobalSelfCheckState(object):
51 def __init__(self):
52 self.statefile_path = os.path.join(USER_CACHE_DIR, "selfcheck.json")
53
54 # Load the existing state
55 try:
56 with open(self.statefile_path) as statefile:
57 self.state = json.load(statefile)[sys.prefix]
58 except (IOError, ValueError, KeyError):
59 self.state = {}
60
61 def save(self, pypi_version, current_time):
62 # Check to make sure that we own the directory
63 if not check_path_owner(os.path.dirname(self.statefile_path)):
64 return
65
66 # Now that we've ensured the directory is owned by this user, we'll go
67 # ahead and make sure that all our directories are created.
68 ensure_dir(os.path.dirname(self.statefile_path))
69
70 # Attempt to write out our version check file
71 with lockfile.LockFile(self.statefile_path):
72 if os.path.exists(self.statefile_path):
73 with open(self.statefile_path) as statefile:
74 state = json.load(statefile)
75 else:
76 state = {}
77
78 state[sys.prefix] = {
79 "last_check": current_time.strftime(SELFCHECK_DATE_FMT),
80 "pypi_version": pypi_version,
81 }
82
83 with open(self.statefile_path, "w") as statefile:
84 json.dump(state, statefile, sort_keys=True,
85 separators=(",", ":"))
86
87
88 def load_selfcheck_statefile():
89 if running_under_virtualenv():
90 return VirtualenvSelfCheckState()
91 else:
92 return GlobalSelfCheckState()
93
94
95 def pip_version_check(session):
96 """Check for an update for pip.
97
98 Limit the frequency of checks to once per week. State is stored either in
99 the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix
100 of the pip script path.
101 """
102 import pip # imported here to prevent circular imports
103 pypi_version = None
104
105 try:
106 state = load_selfcheck_statefile()
107
108 current_time = datetime.datetime.utcnow()
109 # Determine if we need to refresh the state
110 if "last_check" in state.state and "pypi_version" in state.state:
111 last_check = datetime.datetime.strptime(
112 state.state["last_check"],
113 SELFCHECK_DATE_FMT
114 )
115 if total_seconds(current_time - last_check) < 7 * 24 * 60 * 60:
116 pypi_version = state.state["pypi_version"]
117
118 # Refresh the version if we need to or just see if we need to warn
119 if pypi_version is None:
120 resp = session.get(
121 PyPI.pip_json_url,
122 headers={"Accept": "application/json"},
123 )
124 resp.raise_for_status()
125 pypi_version = resp.json()["info"]["version"]
126
127 # save that we've performed a check
128 state.save(pypi_version, current_time)
129
130 pip_version = pkg_resources.parse_version(pip.__version__)
131
132 # Determine if our pypi_version is older
133 if pip_version < pkg_resources.parse_version(pypi_version):
134 logger.warning(
135 "You are using pip version %s, however version %s is "
136 "available.\nYou should consider upgrading via the "
137 "'pip install --upgrade pip' command." % (pip.__version__,
138 pypi_version)
139 )
140
141 except Exception:
142 logger.debug(
143 "There was an error checking the latest version of pip",
144 exc_info=True,
145 )
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pip/utils/outdated.py b/pip/utils/outdated.py
--- a/pip/utils/outdated.py
+++ b/pip/utils/outdated.py
@@ -7,7 +7,7 @@
import sys
from pip._vendor import lockfile
-from pip._vendor import pkg_resources
+from pip._vendor.packaging import version as packaging_version
from pip.compat import total_seconds
from pip.index import PyPI
@@ -122,15 +122,23 @@
headers={"Accept": "application/json"},
)
resp.raise_for_status()
- pypi_version = resp.json()["info"]["version"]
+ pypi_version = [
+ v for v in sorted(
+ list(resp.json()["releases"]),
+ key=packaging_version.parse,
+ )
+ if not packaging_version.parse(v).is_prerelease
+ ][-1]
# save that we've performed a check
state.save(pypi_version, current_time)
- pip_version = pkg_resources.parse_version(pip.__version__)
+ pip_version = packaging_version.parse(pip.__version__)
+ remote_version = packaging_version.parse(pypi_version)
# Determine if our pypi_version is older
- if pip_version < pkg_resources.parse_version(pypi_version):
+ if (pip_version < remote_version and
+ pip_version.base_version != remote_version.base_version):
logger.warning(
"You are using pip version %s, however version %s is "
"available.\nYou should consider upgrading via the "
|
{"golden_diff": "diff --git a/pip/utils/outdated.py b/pip/utils/outdated.py\n--- a/pip/utils/outdated.py\n+++ b/pip/utils/outdated.py\n@@ -7,7 +7,7 @@\n import sys\n \n from pip._vendor import lockfile\n-from pip._vendor import pkg_resources\n+from pip._vendor.packaging import version as packaging_version\n \n from pip.compat import total_seconds\n from pip.index import PyPI\n@@ -122,15 +122,23 @@\n headers={\"Accept\": \"application/json\"},\n )\n resp.raise_for_status()\n- pypi_version = resp.json()[\"info\"][\"version\"]\n+ pypi_version = [\n+ v for v in sorted(\n+ list(resp.json()[\"releases\"]),\n+ key=packaging_version.parse,\n+ )\n+ if not packaging_version.parse(v).is_prerelease\n+ ][-1]\n \n # save that we've performed a check\n state.save(pypi_version, current_time)\n \n- pip_version = pkg_resources.parse_version(pip.__version__)\n+ pip_version = packaging_version.parse(pip.__version__)\n+ remote_version = packaging_version.parse(pypi_version)\n \n # Determine if our pypi_version is older\n- if pip_version < pkg_resources.parse_version(pypi_version):\n+ if (pip_version < remote_version and\n+ pip_version.base_version != remote_version.base_version):\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n", "issue": "Version self check should not warn for post releases\nPost releases are explicitly designed to just fix small errors that won't affect the code itself, things like doc updates. However if we release a post release then the pip version self check will tell everyone to go download it, even though using it isn't really all that important.\n\nIdeally this should just ignore post releases.\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import lockfile\nfrom pip._vendor import pkg_resources\n\nfrom pip.compat import total_seconds\nfrom pip.index import PyPI\nfrom pip.locations import USER_CACHE_DIR, running_under_virtualenv\nfrom pip.utils import ensure_dir\nfrom pip.utils.filesystem import check_path_owner\n\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass VirtualenvSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(sys.prefix, \"pip-selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)\n except (IOError, ValueError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Attempt to write out our version check file\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(\n {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n },\n statefile,\n sort_keys=True,\n separators=(\",\", \":\")\n )\n\n\nclass GlobalSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(USER_CACHE_DIR, \"selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)[sys.prefix]\n except (IOError, ValueError, KeyError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n # Attempt to write out our version check file\n with lockfile.LockFile(self.statefile_path):\n if os.path.exists(self.statefile_path):\n with open(self.statefile_path) as statefile:\n state = json.load(statefile)\n else:\n state = {}\n\n state[sys.prefix] = {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(state, statefile, sort_keys=True,\n separators=(\",\", \":\"))\n\n\ndef load_selfcheck_statefile():\n if running_under_virtualenv():\n return VirtualenvSelfCheckState()\n else:\n return GlobalSelfCheckState()\n\n\ndef pip_version_check(session):\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n import pip # imported here to prevent circular imports\n pypi_version = None\n\n try:\n state = load_selfcheck_statefile()\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if total_seconds(current_time - last_check) < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n resp = session.get(\n PyPI.pip_json_url,\n headers={\"Accept\": \"application/json\"},\n )\n resp.raise_for_status()\n pypi_version = resp.json()[\"info\"][\"version\"]\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n pip_version = pkg_resources.parse_version(pip.__version__)\n\n # Determine if our pypi_version is older\n if pip_version < pkg_resources.parse_version(pypi_version):\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'pip install --upgrade pip' command.\" % (pip.__version__,\n pypi_version)\n )\n\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "pip/utils/outdated.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport datetime\nimport json\nimport logging\nimport os.path\nimport sys\n\nfrom pip._vendor import lockfile\nfrom pip._vendor.packaging import version as packaging_version\n\nfrom pip.compat import total_seconds\nfrom pip.index import PyPI\nfrom pip.locations import USER_CACHE_DIR, running_under_virtualenv\nfrom pip.utils import ensure_dir\nfrom pip.utils.filesystem import check_path_owner\n\n\nSELFCHECK_DATE_FMT = \"%Y-%m-%dT%H:%M:%SZ\"\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass VirtualenvSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(sys.prefix, \"pip-selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)\n except (IOError, ValueError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Attempt to write out our version check file\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(\n {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n },\n statefile,\n sort_keys=True,\n separators=(\",\", \":\")\n )\n\n\nclass GlobalSelfCheckState(object):\n def __init__(self):\n self.statefile_path = os.path.join(USER_CACHE_DIR, \"selfcheck.json\")\n\n # Load the existing state\n try:\n with open(self.statefile_path) as statefile:\n self.state = json.load(statefile)[sys.prefix]\n except (IOError, ValueError, KeyError):\n self.state = {}\n\n def save(self, pypi_version, current_time):\n # Check to make sure that we own the directory\n if not check_path_owner(os.path.dirname(self.statefile_path)):\n return\n\n # Now that we've ensured the directory is owned by this user, we'll go\n # ahead and make sure that all our directories are created.\n ensure_dir(os.path.dirname(self.statefile_path))\n\n # Attempt to write out our version check file\n with lockfile.LockFile(self.statefile_path):\n if os.path.exists(self.statefile_path):\n with open(self.statefile_path) as statefile:\n state = json.load(statefile)\n else:\n state = {}\n\n state[sys.prefix] = {\n \"last_check\": current_time.strftime(SELFCHECK_DATE_FMT),\n \"pypi_version\": pypi_version,\n }\n\n with open(self.statefile_path, \"w\") as statefile:\n json.dump(state, statefile, sort_keys=True,\n separators=(\",\", \":\"))\n\n\ndef load_selfcheck_statefile():\n if running_under_virtualenv():\n return VirtualenvSelfCheckState()\n else:\n return GlobalSelfCheckState()\n\n\ndef pip_version_check(session):\n \"\"\"Check for an update for pip.\n\n Limit the frequency of checks to once per week. State is stored either in\n the active virtualenv or in the user's USER_CACHE_DIR keyed off the prefix\n of the pip script path.\n \"\"\"\n import pip # imported here to prevent circular imports\n pypi_version = None\n\n try:\n state = load_selfcheck_statefile()\n\n current_time = datetime.datetime.utcnow()\n # Determine if we need to refresh the state\n if \"last_check\" in state.state and \"pypi_version\" in state.state:\n last_check = datetime.datetime.strptime(\n state.state[\"last_check\"],\n SELFCHECK_DATE_FMT\n )\n if total_seconds(current_time - last_check) < 7 * 24 * 60 * 60:\n pypi_version = state.state[\"pypi_version\"]\n\n # Refresh the version if we need to or just see if we need to warn\n if pypi_version is None:\n resp = session.get(\n PyPI.pip_json_url,\n headers={\"Accept\": \"application/json\"},\n )\n resp.raise_for_status()\n pypi_version = [\n v for v in sorted(\n list(resp.json()[\"releases\"]),\n key=packaging_version.parse,\n )\n if not packaging_version.parse(v).is_prerelease\n ][-1]\n\n # save that we've performed a check\n state.save(pypi_version, current_time)\n\n pip_version = packaging_version.parse(pip.__version__)\n remote_version = packaging_version.parse(pypi_version)\n\n # Determine if our pypi_version is older\n if (pip_version < remote_version and\n pip_version.base_version != remote_version.base_version):\n logger.warning(\n \"You are using pip version %s, however version %s is \"\n \"available.\\nYou should consider upgrading via the \"\n \"'pip install --upgrade pip' command.\" % (pip.__version__,\n pypi_version)\n )\n\n except Exception:\n logger.debug(\n \"There was an error checking the latest version of pip\",\n exc_info=True,\n )\n", "path": "pip/utils/outdated.py"}]}
| 1,691 | 336 |
gh_patches_debug_25473
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-3289
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyTorch throws an exception on import when denormals are flushed to zero
This happens, for example, when you import DyNet before importing PyTorch. The code from #3113 tries to take the log(0) which throws an exception.
My guess is that DyNet is setting FTZ or DAZ (or both). See:
https://software.intel.com/en-us/node/523328
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/_tensor_str.py`
Content:
```
1 import math
2 import torch
3 from functools import reduce
4 from ._utils import _range
5 from sys import float_info
6
7
8 __MIN_LOG_SCALE = math.ceil(math.log(float_info.min * float_info.epsilon, 10))
9
10
11 class __PrinterOptions(object):
12 precision = 4
13 threshold = 1000
14 edgeitems = 3
15 linewidth = 80
16
17
18 PRINT_OPTS = __PrinterOptions()
19 SCALE_FORMAT = '{:.5e} *\n'
20
21
22 # We could use **kwargs, but this will give better docs
23 def set_printoptions(
24 precision=None,
25 threshold=None,
26 edgeitems=None,
27 linewidth=None,
28 profile=None,
29 ):
30 """Set options for printing. Items shamelessly taken from Numpy
31
32 Args:
33 precision: Number of digits of precision for floating point output
34 (default 8).
35 threshold: Total number of array elements which trigger summarization
36 rather than full repr (default 1000).
37 edgeitems: Number of array items in summary at beginning and end of
38 each dimension (default 3).
39 linewidth: The number of characters per line for the purpose of
40 inserting line breaks (default 80). Thresholded matricies will
41 ignore this parameter.
42 profile: Sane defaults for pretty printing. Can override with any of
43 the above options. (default, short, full)
44 """
45 if profile is not None:
46 if profile == "default":
47 PRINT_OPTS.precision = 4
48 PRINT_OPTS.threshold = 1000
49 PRINT_OPTS.edgeitems = 3
50 PRINT_OPTS.linewidth = 80
51 elif profile == "short":
52 PRINT_OPTS.precision = 2
53 PRINT_OPTS.threshold = 1000
54 PRINT_OPTS.edgeitems = 2
55 PRINT_OPTS.linewidth = 80
56 elif profile == "full":
57 PRINT_OPTS.precision = 4
58 PRINT_OPTS.threshold = float('inf')
59 PRINT_OPTS.edgeitems = 3
60 PRINT_OPTS.linewidth = 80
61
62 if precision is not None:
63 PRINT_OPTS.precision = precision
64 if threshold is not None:
65 PRINT_OPTS.threshold = threshold
66 if edgeitems is not None:
67 PRINT_OPTS.edgeitems = edgeitems
68 if linewidth is not None:
69 PRINT_OPTS.linewidth = linewidth
70
71
72 def _number_format(tensor, min_sz=-1):
73 min_sz = max(min_sz, 2)
74 tensor = torch.DoubleTensor(tensor.size()).copy_(tensor).abs_().view(tensor.nelement())
75
76 pos_inf_mask = tensor.eq(float('inf'))
77 neg_inf_mask = tensor.eq(float('-inf'))
78 nan_mask = tensor.ne(tensor)
79 invalid_value_mask = pos_inf_mask + neg_inf_mask + nan_mask
80 if invalid_value_mask.all():
81 example_value = 0
82 else:
83 example_value = tensor[invalid_value_mask.eq(0)][0]
84 tensor[invalid_value_mask] = example_value
85 if invalid_value_mask.any():
86 min_sz = max(min_sz, 3)
87
88 int_mode = True
89 # TODO: use fmod?
90 for value in tensor:
91 if value != math.ceil(value):
92 int_mode = False
93 break
94
95 exp_min = tensor.min()
96 if exp_min != 0:
97 exp_min = math.floor(math.log10(exp_min)) + 1
98 else:
99 exp_min = 1
100 exp_max = tensor.max()
101 if exp_max != 0:
102 exp_max = math.floor(math.log10(exp_max)) + 1
103 else:
104 exp_max = 1
105
106 scale = 1
107 exp_max = int(exp_max)
108 prec = PRINT_OPTS.precision
109 if int_mode:
110 if exp_max > prec + 1:
111 format = '{{:11.{}e}}'.format(prec)
112 sz = max(min_sz, 7 + prec)
113 else:
114 sz = max(min_sz, exp_max + 1)
115 format = '{:' + str(sz) + '.0f}'
116 else:
117 if exp_max - exp_min > prec:
118 sz = 7 + prec
119 if abs(exp_max) > 99 or abs(exp_min) > 99:
120 sz = sz + 1
121 sz = max(min_sz, sz)
122 format = '{{:{}.{}e}}'.format(sz, prec)
123 else:
124 if exp_max > prec + 1 or exp_max < 0:
125 sz = max(min_sz, 7)
126 scale = math.pow(10, max(exp_max - 1, __MIN_LOG_SCALE))
127 else:
128 if exp_max == 0:
129 sz = 7
130 else:
131 sz = exp_max + 6
132 sz = max(min_sz, sz)
133 format = '{{:{}.{}f}}'.format(sz, prec)
134 return format, scale, sz
135
136
137 def _tensor_str(self):
138 n = PRINT_OPTS.edgeitems
139 has_hdots = self.size()[-1] > 2 * n
140 has_vdots = self.size()[-2] > 2 * n
141 print_full_mat = not has_hdots and not has_vdots
142 formatter = _number_format(self, min_sz=3 if not print_full_mat else 0)
143 print_dots = self.numel() >= PRINT_OPTS.threshold
144
145 dim_sz = max(2, max(len(str(x)) for x in self.size()))
146 dim_fmt = "{:^" + str(dim_sz) + "}"
147 dot_fmt = u"{:^" + str(dim_sz + 1) + "}"
148
149 counter_dim = self.ndimension() - 2
150 counter = torch.LongStorage(counter_dim).fill_(0)
151 counter[counter.size() - 1] = -1
152 finished = False
153 strt = ''
154 while True:
155 nrestarted = [False for i in counter]
156 nskipped = [False for i in counter]
157 for i in _range(counter_dim - 1, -1, -1):
158 counter[i] += 1
159 if print_dots and counter[i] == n and self.size(i) > 2 * n:
160 counter[i] = self.size(i) - n
161 nskipped[i] = True
162 if counter[i] == self.size(i):
163 if i == 0:
164 finished = True
165 counter[i] = 0
166 nrestarted[i] = True
167 else:
168 break
169 if finished:
170 break
171 elif print_dots:
172 if any(nskipped):
173 for hdot in nskipped:
174 strt += dot_fmt.format('...') if hdot \
175 else dot_fmt.format('')
176 strt += '\n'
177 if any(nrestarted):
178 strt += ' '
179 for vdot in nrestarted:
180 strt += dot_fmt.format(u'\u22EE' if vdot else '')
181 strt += '\n'
182 if strt != '':
183 strt += '\n'
184 strt += '({},.,.) = \n'.format(
185 ','.join(dim_fmt.format(i) for i in counter))
186 submatrix = reduce(lambda t, i: t.select(0, i), counter, self)
187 strt += _matrix_str(submatrix, ' ', formatter, print_dots)
188 return strt
189
190
191 def __repr_row(row, indent, fmt, scale, sz, truncate=None):
192 if truncate is not None:
193 dotfmt = " {:^5} "
194 return (indent +
195 ' '.join(fmt.format(val / scale) for val in row[:truncate]) +
196 dotfmt.format('...') +
197 ' '.join(fmt.format(val / scale) for val in row[-truncate:]) +
198 '\n')
199 else:
200 return indent + ' '.join(fmt.format(val / scale) for val in row) + '\n'
201
202
203 def _matrix_str(self, indent='', formatter=None, force_truncate=False):
204 n = PRINT_OPTS.edgeitems
205 has_hdots = self.size(1) > 2 * n
206 has_vdots = self.size(0) > 2 * n
207 print_full_mat = not has_hdots and not has_vdots
208
209 if formatter is None:
210 fmt, scale, sz = _number_format(self,
211 min_sz=5 if not print_full_mat else 0)
212 else:
213 fmt, scale, sz = formatter
214 nColumnPerLine = int(math.floor((PRINT_OPTS.linewidth - len(indent)) / (sz + 1)))
215 strt = ''
216 firstColumn = 0
217
218 if not force_truncate and \
219 (self.numel() < PRINT_OPTS.threshold or print_full_mat):
220 while firstColumn < self.size(1):
221 lastColumn = min(firstColumn + nColumnPerLine - 1, self.size(1) - 1)
222 if nColumnPerLine < self.size(1):
223 strt += '\n' if firstColumn != 1 else ''
224 strt += 'Columns {} to {} \n{}'.format(
225 firstColumn, lastColumn, indent)
226 if scale != 1:
227 strt += SCALE_FORMAT.format(scale)
228 for l in _range(self.size(0)):
229 strt += indent + (' ' if scale != 1 else '')
230 row_slice = self[l, firstColumn:lastColumn + 1]
231 strt += ' '.join(fmt.format(val / scale) for val in row_slice)
232 strt += '\n'
233 firstColumn = lastColumn + 1
234 else:
235 if scale != 1:
236 strt += SCALE_FORMAT.format(scale)
237 if has_vdots and has_hdots:
238 vdotfmt = "{:^" + str((sz + 1) * n - 1) + "}"
239 ddotfmt = u"{:^5}"
240 for row in self[:n]:
241 strt += __repr_row(row, indent, fmt, scale, sz, n)
242 strt += indent + ' '.join([vdotfmt.format('...'),
243 ddotfmt.format(u'\u22F1'),
244 vdotfmt.format('...')]) + "\n"
245 for row in self[-n:]:
246 strt += __repr_row(row, indent, fmt, scale, sz, n)
247 elif not has_vdots and has_hdots:
248 for row in self:
249 strt += __repr_row(row, indent, fmt, scale, sz, n)
250 elif has_vdots and not has_hdots:
251 vdotfmt = u"{:^" + \
252 str(len(__repr_row(self[0], '', fmt, scale, sz))) + \
253 "}\n"
254 for row in self[:n]:
255 strt += __repr_row(row, indent, fmt, scale, sz)
256 strt += vdotfmt.format(u'\u22EE')
257 for row in self[-n:]:
258 strt += __repr_row(row, indent, fmt, scale, sz)
259 else:
260 for row in self:
261 strt += __repr_row(row, indent, fmt, scale, sz)
262 return strt
263
264
265 def _vector_str(self):
266 fmt, scale, sz = _number_format(self)
267 strt = ''
268 ident = ''
269 n = PRINT_OPTS.edgeitems
270 dotfmt = u"{:^" + str(sz) + "}\n"
271 if scale != 1:
272 strt += SCALE_FORMAT.format(scale)
273 ident = ' '
274 if self.numel() < PRINT_OPTS.threshold:
275 return (strt +
276 '\n'.join(ident + fmt.format(val / scale) for val in self) +
277 '\n')
278 else:
279 return (strt +
280 '\n'.join(ident + fmt.format(val / scale) for val in self[:n]) +
281 '\n' + (ident + dotfmt.format(u"\u22EE")) +
282 '\n'.join(ident + fmt.format(val / scale) for val in self[-n:]) +
283 '\n')
284
285
286 def _str(self):
287 if self.ndimension() == 0:
288 return '[{} with no dimension]\n'.format(torch.typename(self))
289 elif self.ndimension() == 1:
290 strt = _vector_str(self)
291 elif self.ndimension() == 2:
292 strt = _matrix_str(self)
293 else:
294 strt = _tensor_str(self)
295
296 size_str = 'x'.join(str(size) for size in self.size())
297 device_str = '' if not self.is_cuda else \
298 ' (GPU {})'.format(self.get_device())
299 strt += '[{} of size {}{}]\n'.format(torch.typename(self),
300 size_str, device_str)
301 return '\n' + strt
302
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/_tensor_str.py b/torch/_tensor_str.py
--- a/torch/_tensor_str.py
+++ b/torch/_tensor_str.py
@@ -5,9 +5,6 @@
from sys import float_info
-__MIN_LOG_SCALE = math.ceil(math.log(float_info.min * float_info.epsilon, 10))
-
-
class __PrinterOptions(object):
precision = 4
threshold = 1000
@@ -69,7 +66,15 @@
PRINT_OPTS.linewidth = linewidth
+def _get_min_log_scale():
+ min_positive = float_info.min * float_info.epsilon # get smallest denormal
+ if min_positive == 0: # use smallest normal if DAZ/FTZ is set
+ min_positive = float_info.min
+ return math.ceil(math.log(min_positive, 10))
+
+
def _number_format(tensor, min_sz=-1):
+ _min_log_scale = _get_min_log_scale()
min_sz = max(min_sz, 2)
tensor = torch.DoubleTensor(tensor.size()).copy_(tensor).abs_().view(tensor.nelement())
@@ -123,7 +128,7 @@
else:
if exp_max > prec + 1 or exp_max < 0:
sz = max(min_sz, 7)
- scale = math.pow(10, max(exp_max - 1, __MIN_LOG_SCALE))
+ scale = math.pow(10, max(exp_max - 1, _min_log_scale))
else:
if exp_max == 0:
sz = 7
|
{"golden_diff": "diff --git a/torch/_tensor_str.py b/torch/_tensor_str.py\n--- a/torch/_tensor_str.py\n+++ b/torch/_tensor_str.py\n@@ -5,9 +5,6 @@\n from sys import float_info\n \n \n-__MIN_LOG_SCALE = math.ceil(math.log(float_info.min * float_info.epsilon, 10))\n-\n-\n class __PrinterOptions(object):\n precision = 4\n threshold = 1000\n@@ -69,7 +66,15 @@\n PRINT_OPTS.linewidth = linewidth\n \n \n+def _get_min_log_scale():\n+ min_positive = float_info.min * float_info.epsilon # get smallest denormal\n+ if min_positive == 0: # use smallest normal if DAZ/FTZ is set\n+ min_positive = float_info.min\n+ return math.ceil(math.log(min_positive, 10))\n+\n+\n def _number_format(tensor, min_sz=-1):\n+ _min_log_scale = _get_min_log_scale()\n min_sz = max(min_sz, 2)\n tensor = torch.DoubleTensor(tensor.size()).copy_(tensor).abs_().view(tensor.nelement())\n \n@@ -123,7 +128,7 @@\n else:\n if exp_max > prec + 1 or exp_max < 0:\n sz = max(min_sz, 7)\n- scale = math.pow(10, max(exp_max - 1, __MIN_LOG_SCALE))\n+ scale = math.pow(10, max(exp_max - 1, _min_log_scale))\n else:\n if exp_max == 0:\n sz = 7\n", "issue": "PyTorch throws an exception on import when denormals are flushed to zero\nThis happens, for example, when you import DyNet before importing PyTorch. The code from #3113 tries to take the log(0) which throws an exception.\r\n\r\nMy guess is that DyNet is setting FTZ or DAZ (or both). See:\r\nhttps://software.intel.com/en-us/node/523328\n", "before_files": [{"content": "import math\nimport torch\nfrom functools import reduce\nfrom ._utils import _range\nfrom sys import float_info\n\n\n__MIN_LOG_SCALE = math.ceil(math.log(float_info.min * float_info.epsilon, 10))\n\n\nclass __PrinterOptions(object):\n precision = 4\n threshold = 1000\n edgeitems = 3\n linewidth = 80\n\n\nPRINT_OPTS = __PrinterOptions()\nSCALE_FORMAT = '{:.5e} *\\n'\n\n\n# We could use **kwargs, but this will give better docs\ndef set_printoptions(\n precision=None,\n threshold=None,\n edgeitems=None,\n linewidth=None,\n profile=None,\n):\n \"\"\"Set options for printing. Items shamelessly taken from Numpy\n\n Args:\n precision: Number of digits of precision for floating point output\n (default 8).\n threshold: Total number of array elements which trigger summarization\n rather than full repr (default 1000).\n edgeitems: Number of array items in summary at beginning and end of\n each dimension (default 3).\n linewidth: The number of characters per line for the purpose of\n inserting line breaks (default 80). Thresholded matricies will\n ignore this parameter.\n profile: Sane defaults for pretty printing. Can override with any of\n the above options. (default, short, full)\n \"\"\"\n if profile is not None:\n if profile == \"default\":\n PRINT_OPTS.precision = 4\n PRINT_OPTS.threshold = 1000\n PRINT_OPTS.edgeitems = 3\n PRINT_OPTS.linewidth = 80\n elif profile == \"short\":\n PRINT_OPTS.precision = 2\n PRINT_OPTS.threshold = 1000\n PRINT_OPTS.edgeitems = 2\n PRINT_OPTS.linewidth = 80\n elif profile == \"full\":\n PRINT_OPTS.precision = 4\n PRINT_OPTS.threshold = float('inf')\n PRINT_OPTS.edgeitems = 3\n PRINT_OPTS.linewidth = 80\n\n if precision is not None:\n PRINT_OPTS.precision = precision\n if threshold is not None:\n PRINT_OPTS.threshold = threshold\n if edgeitems is not None:\n PRINT_OPTS.edgeitems = edgeitems\n if linewidth is not None:\n PRINT_OPTS.linewidth = linewidth\n\n\ndef _number_format(tensor, min_sz=-1):\n min_sz = max(min_sz, 2)\n tensor = torch.DoubleTensor(tensor.size()).copy_(tensor).abs_().view(tensor.nelement())\n\n pos_inf_mask = tensor.eq(float('inf'))\n neg_inf_mask = tensor.eq(float('-inf'))\n nan_mask = tensor.ne(tensor)\n invalid_value_mask = pos_inf_mask + neg_inf_mask + nan_mask\n if invalid_value_mask.all():\n example_value = 0\n else:\n example_value = tensor[invalid_value_mask.eq(0)][0]\n tensor[invalid_value_mask] = example_value\n if invalid_value_mask.any():\n min_sz = max(min_sz, 3)\n\n int_mode = True\n # TODO: use fmod?\n for value in tensor:\n if value != math.ceil(value):\n int_mode = False\n break\n\n exp_min = tensor.min()\n if exp_min != 0:\n exp_min = math.floor(math.log10(exp_min)) + 1\n else:\n exp_min = 1\n exp_max = tensor.max()\n if exp_max != 0:\n exp_max = math.floor(math.log10(exp_max)) + 1\n else:\n exp_max = 1\n\n scale = 1\n exp_max = int(exp_max)\n prec = PRINT_OPTS.precision\n if int_mode:\n if exp_max > prec + 1:\n format = '{{:11.{}e}}'.format(prec)\n sz = max(min_sz, 7 + prec)\n else:\n sz = max(min_sz, exp_max + 1)\n format = '{:' + str(sz) + '.0f}'\n else:\n if exp_max - exp_min > prec:\n sz = 7 + prec\n if abs(exp_max) > 99 or abs(exp_min) > 99:\n sz = sz + 1\n sz = max(min_sz, sz)\n format = '{{:{}.{}e}}'.format(sz, prec)\n else:\n if exp_max > prec + 1 or exp_max < 0:\n sz = max(min_sz, 7)\n scale = math.pow(10, max(exp_max - 1, __MIN_LOG_SCALE))\n else:\n if exp_max == 0:\n sz = 7\n else:\n sz = exp_max + 6\n sz = max(min_sz, sz)\n format = '{{:{}.{}f}}'.format(sz, prec)\n return format, scale, sz\n\n\ndef _tensor_str(self):\n n = PRINT_OPTS.edgeitems\n has_hdots = self.size()[-1] > 2 * n\n has_vdots = self.size()[-2] > 2 * n\n print_full_mat = not has_hdots and not has_vdots\n formatter = _number_format(self, min_sz=3 if not print_full_mat else 0)\n print_dots = self.numel() >= PRINT_OPTS.threshold\n\n dim_sz = max(2, max(len(str(x)) for x in self.size()))\n dim_fmt = \"{:^\" + str(dim_sz) + \"}\"\n dot_fmt = u\"{:^\" + str(dim_sz + 1) + \"}\"\n\n counter_dim = self.ndimension() - 2\n counter = torch.LongStorage(counter_dim).fill_(0)\n counter[counter.size() - 1] = -1\n finished = False\n strt = ''\n while True:\n nrestarted = [False for i in counter]\n nskipped = [False for i in counter]\n for i in _range(counter_dim - 1, -1, -1):\n counter[i] += 1\n if print_dots and counter[i] == n and self.size(i) > 2 * n:\n counter[i] = self.size(i) - n\n nskipped[i] = True\n if counter[i] == self.size(i):\n if i == 0:\n finished = True\n counter[i] = 0\n nrestarted[i] = True\n else:\n break\n if finished:\n break\n elif print_dots:\n if any(nskipped):\n for hdot in nskipped:\n strt += dot_fmt.format('...') if hdot \\\n else dot_fmt.format('')\n strt += '\\n'\n if any(nrestarted):\n strt += ' '\n for vdot in nrestarted:\n strt += dot_fmt.format(u'\\u22EE' if vdot else '')\n strt += '\\n'\n if strt != '':\n strt += '\\n'\n strt += '({},.,.) = \\n'.format(\n ','.join(dim_fmt.format(i) for i in counter))\n submatrix = reduce(lambda t, i: t.select(0, i), counter, self)\n strt += _matrix_str(submatrix, ' ', formatter, print_dots)\n return strt\n\n\ndef __repr_row(row, indent, fmt, scale, sz, truncate=None):\n if truncate is not None:\n dotfmt = \" {:^5} \"\n return (indent +\n ' '.join(fmt.format(val / scale) for val in row[:truncate]) +\n dotfmt.format('...') +\n ' '.join(fmt.format(val / scale) for val in row[-truncate:]) +\n '\\n')\n else:\n return indent + ' '.join(fmt.format(val / scale) for val in row) + '\\n'\n\n\ndef _matrix_str(self, indent='', formatter=None, force_truncate=False):\n n = PRINT_OPTS.edgeitems\n has_hdots = self.size(1) > 2 * n\n has_vdots = self.size(0) > 2 * n\n print_full_mat = not has_hdots and not has_vdots\n\n if formatter is None:\n fmt, scale, sz = _number_format(self,\n min_sz=5 if not print_full_mat else 0)\n else:\n fmt, scale, sz = formatter\n nColumnPerLine = int(math.floor((PRINT_OPTS.linewidth - len(indent)) / (sz + 1)))\n strt = ''\n firstColumn = 0\n\n if not force_truncate and \\\n (self.numel() < PRINT_OPTS.threshold or print_full_mat):\n while firstColumn < self.size(1):\n lastColumn = min(firstColumn + nColumnPerLine - 1, self.size(1) - 1)\n if nColumnPerLine < self.size(1):\n strt += '\\n' if firstColumn != 1 else ''\n strt += 'Columns {} to {} \\n{}'.format(\n firstColumn, lastColumn, indent)\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n for l in _range(self.size(0)):\n strt += indent + (' ' if scale != 1 else '')\n row_slice = self[l, firstColumn:lastColumn + 1]\n strt += ' '.join(fmt.format(val / scale) for val in row_slice)\n strt += '\\n'\n firstColumn = lastColumn + 1\n else:\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n if has_vdots and has_hdots:\n vdotfmt = \"{:^\" + str((sz + 1) * n - 1) + \"}\"\n ddotfmt = u\"{:^5}\"\n for row in self[:n]:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n strt += indent + ' '.join([vdotfmt.format('...'),\n ddotfmt.format(u'\\u22F1'),\n vdotfmt.format('...')]) + \"\\n\"\n for row in self[-n:]:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n elif not has_vdots and has_hdots:\n for row in self:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n elif has_vdots and not has_hdots:\n vdotfmt = u\"{:^\" + \\\n str(len(__repr_row(self[0], '', fmt, scale, sz))) + \\\n \"}\\n\"\n for row in self[:n]:\n strt += __repr_row(row, indent, fmt, scale, sz)\n strt += vdotfmt.format(u'\\u22EE')\n for row in self[-n:]:\n strt += __repr_row(row, indent, fmt, scale, sz)\n else:\n for row in self:\n strt += __repr_row(row, indent, fmt, scale, sz)\n return strt\n\n\ndef _vector_str(self):\n fmt, scale, sz = _number_format(self)\n strt = ''\n ident = ''\n n = PRINT_OPTS.edgeitems\n dotfmt = u\"{:^\" + str(sz) + \"}\\n\"\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n ident = ' '\n if self.numel() < PRINT_OPTS.threshold:\n return (strt +\n '\\n'.join(ident + fmt.format(val / scale) for val in self) +\n '\\n')\n else:\n return (strt +\n '\\n'.join(ident + fmt.format(val / scale) for val in self[:n]) +\n '\\n' + (ident + dotfmt.format(u\"\\u22EE\")) +\n '\\n'.join(ident + fmt.format(val / scale) for val in self[-n:]) +\n '\\n')\n\n\ndef _str(self):\n if self.ndimension() == 0:\n return '[{} with no dimension]\\n'.format(torch.typename(self))\n elif self.ndimension() == 1:\n strt = _vector_str(self)\n elif self.ndimension() == 2:\n strt = _matrix_str(self)\n else:\n strt = _tensor_str(self)\n\n size_str = 'x'.join(str(size) for size in self.size())\n device_str = '' if not self.is_cuda else \\\n ' (GPU {})'.format(self.get_device())\n strt += '[{} of size {}{}]\\n'.format(torch.typename(self),\n size_str, device_str)\n return '\\n' + strt\n", "path": "torch/_tensor_str.py"}], "after_files": [{"content": "import math\nimport torch\nfrom functools import reduce\nfrom ._utils import _range\nfrom sys import float_info\n\n\nclass __PrinterOptions(object):\n precision = 4\n threshold = 1000\n edgeitems = 3\n linewidth = 80\n\n\nPRINT_OPTS = __PrinterOptions()\nSCALE_FORMAT = '{:.5e} *\\n'\n\n\n# We could use **kwargs, but this will give better docs\ndef set_printoptions(\n precision=None,\n threshold=None,\n edgeitems=None,\n linewidth=None,\n profile=None,\n):\n \"\"\"Set options for printing. Items shamelessly taken from Numpy\n\n Args:\n precision: Number of digits of precision for floating point output\n (default 8).\n threshold: Total number of array elements which trigger summarization\n rather than full repr (default 1000).\n edgeitems: Number of array items in summary at beginning and end of\n each dimension (default 3).\n linewidth: The number of characters per line for the purpose of\n inserting line breaks (default 80). Thresholded matricies will\n ignore this parameter.\n profile: Sane defaults for pretty printing. Can override with any of\n the above options. (default, short, full)\n \"\"\"\n if profile is not None:\n if profile == \"default\":\n PRINT_OPTS.precision = 4\n PRINT_OPTS.threshold = 1000\n PRINT_OPTS.edgeitems = 3\n PRINT_OPTS.linewidth = 80\n elif profile == \"short\":\n PRINT_OPTS.precision = 2\n PRINT_OPTS.threshold = 1000\n PRINT_OPTS.edgeitems = 2\n PRINT_OPTS.linewidth = 80\n elif profile == \"full\":\n PRINT_OPTS.precision = 4\n PRINT_OPTS.threshold = float('inf')\n PRINT_OPTS.edgeitems = 3\n PRINT_OPTS.linewidth = 80\n\n if precision is not None:\n PRINT_OPTS.precision = precision\n if threshold is not None:\n PRINT_OPTS.threshold = threshold\n if edgeitems is not None:\n PRINT_OPTS.edgeitems = edgeitems\n if linewidth is not None:\n PRINT_OPTS.linewidth = linewidth\n\n\ndef _get_min_log_scale():\n min_positive = float_info.min * float_info.epsilon # get smallest denormal\n if min_positive == 0: # use smallest normal if DAZ/FTZ is set\n min_positive = float_info.min\n return math.ceil(math.log(min_positive, 10))\n\n\ndef _number_format(tensor, min_sz=-1):\n _min_log_scale = _get_min_log_scale()\n min_sz = max(min_sz, 2)\n tensor = torch.DoubleTensor(tensor.size()).copy_(tensor).abs_().view(tensor.nelement())\n\n pos_inf_mask = tensor.eq(float('inf'))\n neg_inf_mask = tensor.eq(float('-inf'))\n nan_mask = tensor.ne(tensor)\n invalid_value_mask = pos_inf_mask + neg_inf_mask + nan_mask\n if invalid_value_mask.all():\n example_value = 0\n else:\n example_value = tensor[invalid_value_mask.eq(0)][0]\n tensor[invalid_value_mask] = example_value\n if invalid_value_mask.any():\n min_sz = max(min_sz, 3)\n\n int_mode = True\n # TODO: use fmod?\n for value in tensor:\n if value != math.ceil(value):\n int_mode = False\n break\n\n exp_min = tensor.min()\n if exp_min != 0:\n exp_min = math.floor(math.log10(exp_min)) + 1\n else:\n exp_min = 1\n exp_max = tensor.max()\n if exp_max != 0:\n exp_max = math.floor(math.log10(exp_max)) + 1\n else:\n exp_max = 1\n\n scale = 1\n exp_max = int(exp_max)\n prec = PRINT_OPTS.precision\n if int_mode:\n if exp_max > prec + 1:\n format = '{{:11.{}e}}'.format(prec)\n sz = max(min_sz, 7 + prec)\n else:\n sz = max(min_sz, exp_max + 1)\n format = '{:' + str(sz) + '.0f}'\n else:\n if exp_max - exp_min > prec:\n sz = 7 + prec\n if abs(exp_max) > 99 or abs(exp_min) > 99:\n sz = sz + 1\n sz = max(min_sz, sz)\n format = '{{:{}.{}e}}'.format(sz, prec)\n else:\n if exp_max > prec + 1 or exp_max < 0:\n sz = max(min_sz, 7)\n scale = math.pow(10, max(exp_max - 1, _min_log_scale))\n else:\n if exp_max == 0:\n sz = 7\n else:\n sz = exp_max + 6\n sz = max(min_sz, sz)\n format = '{{:{}.{}f}}'.format(sz, prec)\n return format, scale, sz\n\n\ndef _tensor_str(self):\n n = PRINT_OPTS.edgeitems\n has_hdots = self.size()[-1] > 2 * n\n has_vdots = self.size()[-2] > 2 * n\n print_full_mat = not has_hdots and not has_vdots\n formatter = _number_format(self, min_sz=3 if not print_full_mat else 0)\n print_dots = self.numel() >= PRINT_OPTS.threshold\n\n dim_sz = max(2, max(len(str(x)) for x in self.size()))\n dim_fmt = \"{:^\" + str(dim_sz) + \"}\"\n dot_fmt = u\"{:^\" + str(dim_sz + 1) + \"}\"\n\n counter_dim = self.ndimension() - 2\n counter = torch.LongStorage(counter_dim).fill_(0)\n counter[counter.size() - 1] = -1\n finished = False\n strt = ''\n while True:\n nrestarted = [False for i in counter]\n nskipped = [False for i in counter]\n for i in _range(counter_dim - 1, -1, -1):\n counter[i] += 1\n if print_dots and counter[i] == n and self.size(i) > 2 * n:\n counter[i] = self.size(i) - n\n nskipped[i] = True\n if counter[i] == self.size(i):\n if i == 0:\n finished = True\n counter[i] = 0\n nrestarted[i] = True\n else:\n break\n if finished:\n break\n elif print_dots:\n if any(nskipped):\n for hdot in nskipped:\n strt += dot_fmt.format('...') if hdot \\\n else dot_fmt.format('')\n strt += '\\n'\n if any(nrestarted):\n strt += ' '\n for vdot in nrestarted:\n strt += dot_fmt.format(u'\\u22EE' if vdot else '')\n strt += '\\n'\n if strt != '':\n strt += '\\n'\n strt += '({},.,.) = \\n'.format(\n ','.join(dim_fmt.format(i) for i in counter))\n submatrix = reduce(lambda t, i: t.select(0, i), counter, self)\n strt += _matrix_str(submatrix, ' ', formatter, print_dots)\n return strt\n\n\ndef __repr_row(row, indent, fmt, scale, sz, truncate=None):\n if truncate is not None:\n dotfmt = \" {:^5} \"\n return (indent +\n ' '.join(fmt.format(val / scale) for val in row[:truncate]) +\n dotfmt.format('...') +\n ' '.join(fmt.format(val / scale) for val in row[-truncate:]) +\n '\\n')\n else:\n return indent + ' '.join(fmt.format(val / scale) for val in row) + '\\n'\n\n\ndef _matrix_str(self, indent='', formatter=None, force_truncate=False):\n n = PRINT_OPTS.edgeitems\n has_hdots = self.size(1) > 2 * n\n has_vdots = self.size(0) > 2 * n\n print_full_mat = not has_hdots and not has_vdots\n\n if formatter is None:\n fmt, scale, sz = _number_format(self,\n min_sz=5 if not print_full_mat else 0)\n else:\n fmt, scale, sz = formatter\n nColumnPerLine = int(math.floor((PRINT_OPTS.linewidth - len(indent)) / (sz + 1)))\n strt = ''\n firstColumn = 0\n\n if not force_truncate and \\\n (self.numel() < PRINT_OPTS.threshold or print_full_mat):\n while firstColumn < self.size(1):\n lastColumn = min(firstColumn + nColumnPerLine - 1, self.size(1) - 1)\n if nColumnPerLine < self.size(1):\n strt += '\\n' if firstColumn != 1 else ''\n strt += 'Columns {} to {} \\n{}'.format(\n firstColumn, lastColumn, indent)\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n for l in _range(self.size(0)):\n strt += indent + (' ' if scale != 1 else '')\n row_slice = self[l, firstColumn:lastColumn + 1]\n strt += ' '.join(fmt.format(val / scale) for val in row_slice)\n strt += '\\n'\n firstColumn = lastColumn + 1\n else:\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n if has_vdots and has_hdots:\n vdotfmt = \"{:^\" + str((sz + 1) * n - 1) + \"}\"\n ddotfmt = u\"{:^5}\"\n for row in self[:n]:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n strt += indent + ' '.join([vdotfmt.format('...'),\n ddotfmt.format(u'\\u22F1'),\n vdotfmt.format('...')]) + \"\\n\"\n for row in self[-n:]:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n elif not has_vdots and has_hdots:\n for row in self:\n strt += __repr_row(row, indent, fmt, scale, sz, n)\n elif has_vdots and not has_hdots:\n vdotfmt = u\"{:^\" + \\\n str(len(__repr_row(self[0], '', fmt, scale, sz))) + \\\n \"}\\n\"\n for row in self[:n]:\n strt += __repr_row(row, indent, fmt, scale, sz)\n strt += vdotfmt.format(u'\\u22EE')\n for row in self[-n:]:\n strt += __repr_row(row, indent, fmt, scale, sz)\n else:\n for row in self:\n strt += __repr_row(row, indent, fmt, scale, sz)\n return strt\n\n\ndef _vector_str(self):\n fmt, scale, sz = _number_format(self)\n strt = ''\n ident = ''\n n = PRINT_OPTS.edgeitems\n dotfmt = u\"{:^\" + str(sz) + \"}\\n\"\n if scale != 1:\n strt += SCALE_FORMAT.format(scale)\n ident = ' '\n if self.numel() < PRINT_OPTS.threshold:\n return (strt +\n '\\n'.join(ident + fmt.format(val / scale) for val in self) +\n '\\n')\n else:\n return (strt +\n '\\n'.join(ident + fmt.format(val / scale) for val in self[:n]) +\n '\\n' + (ident + dotfmt.format(u\"\\u22EE\")) +\n '\\n'.join(ident + fmt.format(val / scale) for val in self[-n:]) +\n '\\n')\n\n\ndef _str(self):\n if self.ndimension() == 0:\n return '[{} with no dimension]\\n'.format(torch.typename(self))\n elif self.ndimension() == 1:\n strt = _vector_str(self)\n elif self.ndimension() == 2:\n strt = _matrix_str(self)\n else:\n strt = _tensor_str(self)\n\n size_str = 'x'.join(str(size) for size in self.size())\n device_str = '' if not self.is_cuda else \\\n ' (GPU {})'.format(self.get_device())\n strt += '[{} of size {}{}]\\n'.format(torch.typename(self),\n size_str, device_str)\n return '\\n' + strt\n", "path": "torch/_tensor_str.py"}]}
| 3,857 | 356 |
gh_patches_debug_22793
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-3770
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
F.inv behaves differently between CPU/GPU
Currently, F.inv ignores error flags (info) from cuBLAS.
https://github.com/chainer/chainer/blob/v3.0.0/chainer/functions/math/inv.py#L56
As a result, it behaves differently between CPU/GPU.
When CPU mode:
```py
chainer.functions.inv(np.zeros(4, dtype=np.float32).reshape((2,2)))
```
raises exception (`numpy.linalg.linalg.LinAlgError: Singular matrix`), while GPU mode:
```py
chainer.functions.inv(cp.zeros(4, dtype=np.float32).reshape((2,2)))
```
no exception occurs and
```py
variable([[ nan, nan],
[ nan, inf]])
```
is returned.
I think it is better to change GPU mode behavior to raise Exception, so that users can notice the error immediately.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/math/inv.py`
Content:
```
1 import numpy.linalg
2
3 from chainer import cuda
4 from chainer import function_node
5 import chainer.functions
6 from chainer.functions.math import matmul
7 from chainer import utils
8 from chainer.utils import type_check
9
10
11 def _inv_gpu(b):
12 # We do a batched LU decomposition on the GPU to compute the inverse
13 # Change the shape of the array to be size=1 minibatch if necessary
14 # Also copy the matrix as the elments will be modified in-place
15 a = matmul._as_batch_mat(b).copy()
16 n = a.shape[1]
17 n_matrices = len(a)
18 # Pivot array
19 p = cuda.cupy.empty((n, n_matrices), dtype=numpy.int32)
20 # Output array
21 c = cuda.cupy.empty_like(a)
22 # These arrays hold information on the execution success
23 # or if the matrix was singular
24 info = cuda.cupy.empty(n_matrices, dtype=numpy.int32)
25 ap = matmul._mat_ptrs(a)
26 cp = matmul._mat_ptrs(c)
27 _, lda = matmul._get_ld(a)
28 _, ldc = matmul._get_ld(c)
29 handle = cuda.Device().cublas_handle
30 cuda.cublas.sgetrfBatched(
31 handle, n, ap.data.ptr, lda, p.data.ptr, info.data.ptr, n_matrices)
32 cuda.cublas.sgetriBatched(
33 handle, n, ap.data.ptr, lda, p.data.ptr, cp.data.ptr, ldc,
34 info.data.ptr, n_matrices)
35 return c, info
36
37
38 class Inv(function_node.FunctionNode):
39
40 def check_type_forward(self, in_types):
41 type_check.expect(in_types.size() == 1)
42 a_type, = in_types
43 type_check.expect(a_type.dtype == numpy.float32)
44 # Only 2D array shapes allowed
45 type_check.expect(a_type.ndim == 2)
46 # Matrix inversion only allowed for square matrices
47 type_check.expect(a_type.shape[0] == a_type.shape[1])
48
49 def forward_cpu(self, x):
50 self.retain_outputs((0,))
51 invx = utils.force_array(numpy.linalg.inv(x[0]))
52 return invx,
53
54 def forward_gpu(self, x):
55 self.retain_outputs((0,))
56 shape = x[0].shape
57 invx = _inv_gpu(x[0].reshape(1, *shape))[0].reshape(shape)
58 return invx,
59
60 def backward(self, x, gy):
61 invx, = self.get_retained_outputs()
62 # Gradient is - x^-T (dx) x^-T
63 invxT = chainer.functions.transpose(invx)
64 gx = chainer.functions.matmul(
65 chainer.functions.matmul(- invxT, gy[0]), invxT)
66 return gx,
67
68
69 class BatchInv(function_node.FunctionNode):
70
71 def check_type_forward(self, in_types):
72 type_check.expect(in_types.size() == 1)
73 a_type, = in_types
74 type_check.expect(a_type.dtype == numpy.float32)
75 # Only a minibatch of 2D array shapes allowed
76 type_check.expect(a_type.ndim == 3)
77 # Matrix inversion only allowed for square matrices
78 # so assert the last two dimensions are equal
79 type_check.expect(a_type.shape[-1] == a_type.shape[-2])
80
81 def forward_cpu(self, x):
82 self.retain_outputs((0,))
83 invx = utils.force_array(numpy.linalg.inv(x[0]))
84 return invx,
85
86 def forward_gpu(self, x):
87 self.retain_outputs((0,))
88 invx, _ = _inv_gpu(x[0])
89 return invx,
90
91 def backward(self, x, gy):
92 invx, = self.get_retained_outputs()
93 # Unpack 1-length tuples
94 gy, = gy
95 # Gradient is - x^-T (dx) x^-T
96 ret = chainer.functions.matmul(-invx, gy, transa=True)
97 ret2 = chainer.functions.matmul(ret, invx, transb=True)
98 return ret2,
99
100
101 def inv(a):
102 """Computes the inverse of square matrix.
103
104 Args:
105 a (Variable): Input array to compute the inverse for. Shape of
106 the array should be ``(n, n)`` where ``n`` is the dimensionality of
107 a square matrix.
108
109 Returns:
110 ~chainer.Variable: Matrix inverse of ``a``.
111 """
112 return Inv().apply((a,))[0]
113
114
115 def batch_inv(a):
116 """Computes the inverse of a batch of square matrices.
117
118 Args:
119 a (Variable): Input array to compute the inverse for. Shape of
120 the array should be ``(m, n, n)`` where ``m`` is the number of
121 matrices in the batch, and ``n`` is the dimensionality of a square
122 matrix.
123
124 Returns:
125 ~chainer.Variable: Inverse of every matrix in the batch of matrices.
126 """
127 return BatchInv().apply((a,))[0]
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/math/inv.py b/chainer/functions/math/inv.py
--- a/chainer/functions/math/inv.py
+++ b/chainer/functions/math/inv.py
@@ -1,5 +1,6 @@
import numpy.linalg
+import chainer
from chainer import cuda
from chainer import function_node
import chainer.functions
@@ -54,7 +55,11 @@
def forward_gpu(self, x):
self.retain_outputs((0,))
shape = x[0].shape
- invx = _inv_gpu(x[0].reshape(1, *shape))[0].reshape(shape)
+ invx, info = _inv_gpu(x[0].reshape(1, *shape))
+ if chainer.is_debug():
+ if cuda.cupy.any(info != 0):
+ raise ValueError('Input has singular matrices.')
+ invx = invx.reshape(shape)
return invx,
def backward(self, x, gy):
@@ -85,7 +90,10 @@
def forward_gpu(self, x):
self.retain_outputs((0,))
- invx, _ = _inv_gpu(x[0])
+ invx, info = _inv_gpu(x[0])
+ if chainer.is_debug():
+ if cuda.cupy.any(info != 0):
+ raise ValueError('Input has singular matrices.')
return invx,
def backward(self, x, gy):
|
{"golden_diff": "diff --git a/chainer/functions/math/inv.py b/chainer/functions/math/inv.py\n--- a/chainer/functions/math/inv.py\n+++ b/chainer/functions/math/inv.py\n@@ -1,5 +1,6 @@\n import numpy.linalg\n \n+import chainer\n from chainer import cuda\n from chainer import function_node\n import chainer.functions\n@@ -54,7 +55,11 @@\n def forward_gpu(self, x):\n self.retain_outputs((0,))\n shape = x[0].shape\n- invx = _inv_gpu(x[0].reshape(1, *shape))[0].reshape(shape)\n+ invx, info = _inv_gpu(x[0].reshape(1, *shape))\n+ if chainer.is_debug():\n+ if cuda.cupy.any(info != 0):\n+ raise ValueError('Input has singular matrices.')\n+ invx = invx.reshape(shape)\n return invx,\n \n def backward(self, x, gy):\n@@ -85,7 +90,10 @@\n \n def forward_gpu(self, x):\n self.retain_outputs((0,))\n- invx, _ = _inv_gpu(x[0])\n+ invx, info = _inv_gpu(x[0])\n+ if chainer.is_debug():\n+ if cuda.cupy.any(info != 0):\n+ raise ValueError('Input has singular matrices.')\n return invx,\n \n def backward(self, x, gy):\n", "issue": "F.inv behaves differently between CPU/GPU\nCurrently, F.inv ignores error flags (info) from cuBLAS.\r\n\r\nhttps://github.com/chainer/chainer/blob/v3.0.0/chainer/functions/math/inv.py#L56\r\n\r\nAs a result, it behaves differently between CPU/GPU.\r\n\r\nWhen CPU mode:\r\n\r\n```py\r\nchainer.functions.inv(np.zeros(4, dtype=np.float32).reshape((2,2)))\r\n```\r\n\r\nraises exception (`numpy.linalg.linalg.LinAlgError: Singular matrix`), while GPU mode:\r\n\r\n```py\r\nchainer.functions.inv(cp.zeros(4, dtype=np.float32).reshape((2,2)))\r\n```\r\n\r\nno exception occurs and\r\n\r\n```py\r\nvariable([[ nan, nan],\r\n [ nan, inf]])\r\n```\r\n\r\nis returned.\r\n\r\nI think it is better to change GPU mode behavior to raise Exception, so that users can notice the error immediately.\n", "before_files": [{"content": "import numpy.linalg\n\nfrom chainer import cuda\nfrom chainer import function_node\nimport chainer.functions\nfrom chainer.functions.math import matmul\nfrom chainer import utils\nfrom chainer.utils import type_check\n\n\ndef _inv_gpu(b):\n # We do a batched LU decomposition on the GPU to compute the inverse\n # Change the shape of the array to be size=1 minibatch if necessary\n # Also copy the matrix as the elments will be modified in-place\n a = matmul._as_batch_mat(b).copy()\n n = a.shape[1]\n n_matrices = len(a)\n # Pivot array\n p = cuda.cupy.empty((n, n_matrices), dtype=numpy.int32)\n # Output array\n c = cuda.cupy.empty_like(a)\n # These arrays hold information on the execution success\n # or if the matrix was singular\n info = cuda.cupy.empty(n_matrices, dtype=numpy.int32)\n ap = matmul._mat_ptrs(a)\n cp = matmul._mat_ptrs(c)\n _, lda = matmul._get_ld(a)\n _, ldc = matmul._get_ld(c)\n handle = cuda.Device().cublas_handle\n cuda.cublas.sgetrfBatched(\n handle, n, ap.data.ptr, lda, p.data.ptr, info.data.ptr, n_matrices)\n cuda.cublas.sgetriBatched(\n handle, n, ap.data.ptr, lda, p.data.ptr, cp.data.ptr, ldc,\n info.data.ptr, n_matrices)\n return c, info\n\n\nclass Inv(function_node.FunctionNode):\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n a_type, = in_types\n type_check.expect(a_type.dtype == numpy.float32)\n # Only 2D array shapes allowed\n type_check.expect(a_type.ndim == 2)\n # Matrix inversion only allowed for square matrices\n type_check.expect(a_type.shape[0] == a_type.shape[1])\n\n def forward_cpu(self, x):\n self.retain_outputs((0,))\n invx = utils.force_array(numpy.linalg.inv(x[0]))\n return invx,\n\n def forward_gpu(self, x):\n self.retain_outputs((0,))\n shape = x[0].shape\n invx = _inv_gpu(x[0].reshape(1, *shape))[0].reshape(shape)\n return invx,\n\n def backward(self, x, gy):\n invx, = self.get_retained_outputs()\n # Gradient is - x^-T (dx) x^-T\n invxT = chainer.functions.transpose(invx)\n gx = chainer.functions.matmul(\n chainer.functions.matmul(- invxT, gy[0]), invxT)\n return gx,\n\n\nclass BatchInv(function_node.FunctionNode):\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n a_type, = in_types\n type_check.expect(a_type.dtype == numpy.float32)\n # Only a minibatch of 2D array shapes allowed\n type_check.expect(a_type.ndim == 3)\n # Matrix inversion only allowed for square matrices\n # so assert the last two dimensions are equal\n type_check.expect(a_type.shape[-1] == a_type.shape[-2])\n\n def forward_cpu(self, x):\n self.retain_outputs((0,))\n invx = utils.force_array(numpy.linalg.inv(x[0]))\n return invx,\n\n def forward_gpu(self, x):\n self.retain_outputs((0,))\n invx, _ = _inv_gpu(x[0])\n return invx,\n\n def backward(self, x, gy):\n invx, = self.get_retained_outputs()\n # Unpack 1-length tuples\n gy, = gy\n # Gradient is - x^-T (dx) x^-T\n ret = chainer.functions.matmul(-invx, gy, transa=True)\n ret2 = chainer.functions.matmul(ret, invx, transb=True)\n return ret2,\n\n\ndef inv(a):\n \"\"\"Computes the inverse of square matrix.\n\n Args:\n a (Variable): Input array to compute the inverse for. Shape of\n the array should be ``(n, n)`` where ``n`` is the dimensionality of\n a square matrix.\n\n Returns:\n ~chainer.Variable: Matrix inverse of ``a``.\n \"\"\"\n return Inv().apply((a,))[0]\n\n\ndef batch_inv(a):\n \"\"\"Computes the inverse of a batch of square matrices.\n\n Args:\n a (Variable): Input array to compute the inverse for. Shape of\n the array should be ``(m, n, n)`` where ``m`` is the number of\n matrices in the batch, and ``n`` is the dimensionality of a square\n matrix.\n\n Returns:\n ~chainer.Variable: Inverse of every matrix in the batch of matrices.\n \"\"\"\n return BatchInv().apply((a,))[0]\n", "path": "chainer/functions/math/inv.py"}], "after_files": [{"content": "import numpy.linalg\n\nimport chainer\nfrom chainer import cuda\nfrom chainer import function_node\nimport chainer.functions\nfrom chainer.functions.math import matmul\nfrom chainer import utils\nfrom chainer.utils import type_check\n\n\ndef _inv_gpu(b):\n # We do a batched LU decomposition on the GPU to compute the inverse\n # Change the shape of the array to be size=1 minibatch if necessary\n # Also copy the matrix as the elments will be modified in-place\n a = matmul._as_batch_mat(b).copy()\n n = a.shape[1]\n n_matrices = len(a)\n # Pivot array\n p = cuda.cupy.empty((n, n_matrices), dtype=numpy.int32)\n # Output array\n c = cuda.cupy.empty_like(a)\n # These arrays hold information on the execution success\n # or if the matrix was singular\n info = cuda.cupy.empty(n_matrices, dtype=numpy.int32)\n ap = matmul._mat_ptrs(a)\n cp = matmul._mat_ptrs(c)\n _, lda = matmul._get_ld(a)\n _, ldc = matmul._get_ld(c)\n handle = cuda.Device().cublas_handle\n cuda.cublas.sgetrfBatched(\n handle, n, ap.data.ptr, lda, p.data.ptr, info.data.ptr, n_matrices)\n cuda.cublas.sgetriBatched(\n handle, n, ap.data.ptr, lda, p.data.ptr, cp.data.ptr, ldc,\n info.data.ptr, n_matrices)\n return c, info\n\n\nclass Inv(function_node.FunctionNode):\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n a_type, = in_types\n type_check.expect(a_type.dtype == numpy.float32)\n # Only 2D array shapes allowed\n type_check.expect(a_type.ndim == 2)\n # Matrix inversion only allowed for square matrices\n type_check.expect(a_type.shape[0] == a_type.shape[1])\n\n def forward_cpu(self, x):\n self.retain_outputs((0,))\n invx = utils.force_array(numpy.linalg.inv(x[0]))\n return invx,\n\n def forward_gpu(self, x):\n self.retain_outputs((0,))\n shape = x[0].shape\n invx, info = _inv_gpu(x[0].reshape(1, *shape))\n if chainer.is_debug():\n if cuda.cupy.any(info != 0):\n raise ValueError('Input has singular matrices.')\n invx = invx.reshape(shape)\n return invx,\n\n def backward(self, x, gy):\n invx, = self.get_retained_outputs()\n # Gradient is - x^-T (dx) x^-T\n invxT = chainer.functions.transpose(invx)\n gx = chainer.functions.matmul(\n chainer.functions.matmul(- invxT, gy[0]), invxT)\n return gx,\n\n\nclass BatchInv(function_node.FunctionNode):\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n a_type, = in_types\n type_check.expect(a_type.dtype == numpy.float32)\n # Only a minibatch of 2D array shapes allowed\n type_check.expect(a_type.ndim == 3)\n # Matrix inversion only allowed for square matrices\n # so assert the last two dimensions are equal\n type_check.expect(a_type.shape[-1] == a_type.shape[-2])\n\n def forward_cpu(self, x):\n self.retain_outputs((0,))\n invx = utils.force_array(numpy.linalg.inv(x[0]))\n return invx,\n\n def forward_gpu(self, x):\n self.retain_outputs((0,))\n invx, info = _inv_gpu(x[0])\n if chainer.is_debug():\n if cuda.cupy.any(info != 0):\n raise ValueError('Input has singular matrices.')\n return invx,\n\n def backward(self, x, gy):\n invx, = self.get_retained_outputs()\n # Unpack 1-length tuples\n gy, = gy\n # Gradient is - x^-T (dx) x^-T\n ret = chainer.functions.matmul(-invx, gy, transa=True)\n ret2 = chainer.functions.matmul(ret, invx, transb=True)\n return ret2,\n\n\ndef inv(a):\n \"\"\"Computes the inverse of square matrix.\n\n Args:\n a (Variable): Input array to compute the inverse for. Shape of\n the array should be ``(n, n)`` where ``n`` is the dimensionality of\n a square matrix.\n\n Returns:\n ~chainer.Variable: Matrix inverse of ``a``.\n \"\"\"\n return Inv().apply((a,))[0]\n\n\ndef batch_inv(a):\n \"\"\"Computes the inverse of a batch of square matrices.\n\n Args:\n a (Variable): Input array to compute the inverse for. Shape of\n the array should be ``(m, n, n)`` where ``m`` is the number of\n matrices in the batch, and ``n`` is the dimensionality of a square\n matrix.\n\n Returns:\n ~chainer.Variable: Inverse of every matrix in the batch of matrices.\n \"\"\"\n return BatchInv().apply((a,))[0]\n", "path": "chainer/functions/math/inv.py"}]}
| 1,825 | 318 |
gh_patches_debug_10318
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1856
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: calculating "date 2" on Feb.29 ("now.year + 1" = 2025-02-29 does not exist!)
### I Have A Problem With:
The integration in general
### What's Your Problem
The date calculation for synchronizing the calendar has an error in the leap year (02/29).
### Source (if relevant)
_No response_
### Logs
```Shell
Logger: waste_collection_schedule.source_shell
Source: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136
Integration: waste_collection_schedule (documentation)
First occurred: 08:35:09 (1 occurrences)
Last logged: 08:35:09
fetch failed for source Abfall.IO / AbfallPlus: Traceback (most recent call last): File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py", line 145, in fetch date2 = now.replace(year=now.year + 1) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ValueError: day is out of range for month
```
### Relevant Configuration
_No response_
### Checklist Source Error
- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [X] Checked that the website of your service provider is still working
- [X] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [ ] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py`
Content:
```
1 import datetime
2 import logging
3 import re
4 from html.parser import HTMLParser
5
6 import requests
7 from waste_collection_schedule import Collection # type: ignore[attr-defined]
8 from waste_collection_schedule.service.AbfallIO import SERVICE_MAP
9 from waste_collection_schedule.service.ICS import ICS
10
11 TITLE = "Abfall.IO / AbfallPlus"
12 DESCRIPTION = (
13 "Source for AbfallPlus.de waste collection. Service is hosted on abfall.io."
14 )
15 URL = "https://www.abfallplus.de"
16 COUNTRY = "de"
17
18
19 def EXTRA_INFO():
20 return [{"title": s["title"], "url": s["url"]} for s in SERVICE_MAP]
21
22
23 TEST_CASES = {
24 "Waldenbuch": {
25 "key": "8215c62763967916979e0e8566b6172e",
26 "f_id_kommune": 2999,
27 "f_id_strasse": 1087,
28 # "f_abfallarten": [50, 53, 31, 299, 328, 325]
29 },
30 "Landshut": {
31 "key": "bd0c2d0177a0849a905cded5cb734a6f",
32 "f_id_kommune": 2655,
33 "f_id_bezirk": 2655,
34 "f_id_strasse": 763,
35 # "f_abfallarten": [31, 17, 19, 218]
36 },
37 "Schoenmackers": {
38 "key": "e5543a3e190cb8d91c645660ad60965f",
39 "f_id_kommune": 3682,
40 "f_id_strasse": "3682adenauerplatz",
41 "f_id_strasse_hnr": "20417",
42 # "f_abfallarten": [691,692,696,695,694,701,700,693,703,704,697,699],
43 },
44 "Freudenstadt": {
45 "key": "595f903540a36fe8610ec39aa3a06f6a",
46 "f_id_kommune": 3447,
47 "f_id_bezirk": 22017,
48 "f_id_strasse": 22155,
49 },
50 "Ludwigshafen am Rhein": {
51 "key": "6efba91e69a5b454ac0ae3497978fe1d",
52 "f_id_kommune": "5916",
53 "f_id_strasse": "5916abteistrasse",
54 "f_id_strasse_hnr": 33,
55 },
56 "Traunstein": {
57 "key": "279cc5db4db838d1cfbf42f6f0176a90",
58 "f_id_kommune": "2911",
59 "f_id_strasse": "2374",
60 },
61 "AWB Limburg-Weilburg": {
62 "key": "0ff491ffdf614d6f34870659c0c8d917",
63 "f_id_kommune": 6031,
64 "f_id_strasse": 621,
65 "f_id_strasse_hnr": 872,
66 "f_abfallarten": [27, 28, 17, 67],
67 },
68 "ALBA Berlin": {
69 "key": "9583a2fa1df97ed95363382c73b41b1b",
70 "f_id_kommune": 3227,
71 "f_id_strasse": 3475,
72 "f_id_strasse_hnr": 185575,
73 },
74 }
75 _LOGGER = logging.getLogger(__name__)
76
77 MODUS_KEY = "d6c5855a62cf32a4dadbc2831f0f295f"
78 HEADERS = {"user-agent": "Mozilla/5.0 (xxxx Windows NT 10.0; Win64; x64)"}
79
80
81 # Parser for HTML input (hidden) text
82 class HiddenInputParser(HTMLParser):
83 def __init__(self):
84 super().__init__()
85 self._args = {}
86
87 @property
88 def args(self):
89 return self._args
90
91 def handle_starttag(self, tag, attrs):
92 if tag == "input":
93 d = dict(attrs)
94 if d["type"] == "hidden":
95 self._args[d["name"]] = d["value"]
96
97
98 class Source:
99 def __init__(
100 self,
101 key,
102 f_id_kommune,
103 f_id_strasse,
104 f_id_bezirk=None,
105 f_id_strasse_hnr=None,
106 f_abfallarten=[],
107 ):
108 self._key = key
109 self._kommune = f_id_kommune
110 self._bezirk = f_id_bezirk
111 self._strasse = f_id_strasse
112 self._strasse_hnr = f_id_strasse_hnr
113 self._abfallarten = f_abfallarten # list of integers
114 self._ics = ICS()
115
116 def fetch(self):
117 # get token
118 params = {"key": self._key, "modus": MODUS_KEY, "waction": "init"}
119
120 r = requests.post("https://api.abfall.io", params=params, headers=HEADERS)
121
122 # add all hidden input fields to form data
123 # There is one hidden field which acts as a token:
124 # It consists of a UUID key and a UUID value.
125 p = HiddenInputParser()
126 p.feed(r.text)
127 args = p.args
128
129 args["f_id_kommune"] = self._kommune
130 args["f_id_strasse"] = self._strasse
131
132 if self._bezirk is not None:
133 args["f_id_bezirk"] = self._bezirk
134
135 if self._strasse_hnr is not None:
136 args["f_id_strasse_hnr"] = self._strasse_hnr
137
138 for i in range(len(self._abfallarten)):
139 args[f"f_id_abfalltyp_{i}"] = self._abfallarten[i]
140
141 args["f_abfallarten_index_max"] = len(self._abfallarten)
142 args["f_abfallarten"] = ",".join(map(lambda x: str(x), self._abfallarten))
143
144 now = datetime.datetime.now()
145 date2 = now.replace(year=now.year + 1)
146 args["f_zeitraum"] = f"{now.strftime('%Y%m%d')}-{date2.strftime('%Y%m%d')}"
147
148 params = {"key": self._key, "modus": MODUS_KEY, "waction": "export_ics"}
149
150 # get csv file
151 r = requests.post(
152 "https://api.abfall.io", params=params, data=args, headers=HEADERS
153 )
154
155 # parse ics file
156 r.encoding = "utf-8" # requests doesn't guess the encoding correctly
157 ics_file = r.text
158
159 # Remove all lines starting with <b
160 # This warning are caused for customers which use an extra radiobutton
161 # list to add special waste types:
162 # - AWB Limburg-Weilheim uses this list to select a "Sonderabfall <city>"
163 # waste type. The warning could be removed by adding the extra config
164 # option "f_abfallarten" with the following values [27, 28, 17, 67]
165 html_warnings = re.findall(r"\<b.*", ics_file)
166 if html_warnings:
167 ics_file = re.sub(r"\<br.*|\<b.*", "\\r", ics_file)
168 # _LOGGER.warning("Html tags removed from ics file: " + ', '.join(html_warnings))
169
170 dates = self._ics.convert(ics_file)
171
172 entries = []
173 for d in dates:
174 entries.append(Collection(d[0], d[1]))
175 return entries
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py
@@ -142,7 +142,7 @@
args["f_abfallarten"] = ",".join(map(lambda x: str(x), self._abfallarten))
now = datetime.datetime.now()
- date2 = now.replace(year=now.year + 1)
+ date2 = now + datetime.timedelta(days=365)
args["f_zeitraum"] = f"{now.strftime('%Y%m%d')}-{date2.strftime('%Y%m%d')}"
params = {"key": self._key, "modus": MODUS_KEY, "waction": "export_ics"}
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py\n@@ -142,7 +142,7 @@\n args[\"f_abfallarten\"] = \",\".join(map(lambda x: str(x), self._abfallarten))\n \n now = datetime.datetime.now()\n- date2 = now.replace(year=now.year + 1)\n+ date2 = now + datetime.timedelta(days=365)\n args[\"f_zeitraum\"] = f\"{now.strftime('%Y%m%d')}-{date2.strftime('%Y%m%d')}\"\n \n params = {\"key\": self._key, \"modus\": MODUS_KEY, \"waction\": \"export_ics\"}\n", "issue": "[Bug]: calculating \"date 2\" on Feb.29 (\"now.year + 1\" = 2025-02-29 does not exist!)\n### I Have A Problem With:\n\nThe integration in general\n\n### What's Your Problem\n\nThe date calculation for synchronizing the calendar has an error in the leap year (02/29).\n\n### Source (if relevant)\n\n_No response_\n\n### Logs\n\n```Shell\nLogger: waste_collection_schedule.source_shell\r\nSource: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136\r\nIntegration: waste_collection_schedule (documentation)\r\nFirst occurred: 08:35:09 (1 occurrences)\r\nLast logged: 08:35:09\r\nfetch failed for source Abfall.IO / AbfallPlus: Traceback (most recent call last): File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py\", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py\", line 145, in fetch date2 = now.replace(year=now.year + 1) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ValueError: day is out of range for month\n```\n\n\n### Relevant Configuration\n\n_No response_\n\n### Checklist Source Error\n\n- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\n- [X] Checked that the website of your service provider is still working\n- [X] Tested my attributes on the service provider website (if possible)\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\n\n### Checklist Sensor Error\n\n- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\n\n### Required\n\n- [ ] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "import datetime\nimport logging\nimport re\nfrom html.parser import HTMLParser\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.AbfallIO import SERVICE_MAP\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"Abfall.IO / AbfallPlus\"\nDESCRIPTION = (\n \"Source for AbfallPlus.de waste collection. Service is hosted on abfall.io.\"\n)\nURL = \"https://www.abfallplus.de\"\nCOUNTRY = \"de\"\n\n\ndef EXTRA_INFO():\n return [{\"title\": s[\"title\"], \"url\": s[\"url\"]} for s in SERVICE_MAP]\n\n\nTEST_CASES = {\n \"Waldenbuch\": {\n \"key\": \"8215c62763967916979e0e8566b6172e\",\n \"f_id_kommune\": 2999,\n \"f_id_strasse\": 1087,\n # \"f_abfallarten\": [50, 53, 31, 299, 328, 325]\n },\n \"Landshut\": {\n \"key\": \"bd0c2d0177a0849a905cded5cb734a6f\",\n \"f_id_kommune\": 2655,\n \"f_id_bezirk\": 2655,\n \"f_id_strasse\": 763,\n # \"f_abfallarten\": [31, 17, 19, 218]\n },\n \"Schoenmackers\": {\n \"key\": \"e5543a3e190cb8d91c645660ad60965f\",\n \"f_id_kommune\": 3682,\n \"f_id_strasse\": \"3682adenauerplatz\",\n \"f_id_strasse_hnr\": \"20417\",\n # \"f_abfallarten\": [691,692,696,695,694,701,700,693,703,704,697,699],\n },\n \"Freudenstadt\": {\n \"key\": \"595f903540a36fe8610ec39aa3a06f6a\",\n \"f_id_kommune\": 3447,\n \"f_id_bezirk\": 22017,\n \"f_id_strasse\": 22155,\n },\n \"Ludwigshafen am Rhein\": {\n \"key\": \"6efba91e69a5b454ac0ae3497978fe1d\",\n \"f_id_kommune\": \"5916\",\n \"f_id_strasse\": \"5916abteistrasse\",\n \"f_id_strasse_hnr\": 33,\n },\n \"Traunstein\": {\n \"key\": \"279cc5db4db838d1cfbf42f6f0176a90\",\n \"f_id_kommune\": \"2911\",\n \"f_id_strasse\": \"2374\",\n },\n \"AWB Limburg-Weilburg\": {\n \"key\": \"0ff491ffdf614d6f34870659c0c8d917\",\n \"f_id_kommune\": 6031,\n \"f_id_strasse\": 621,\n \"f_id_strasse_hnr\": 872,\n \"f_abfallarten\": [27, 28, 17, 67],\n },\n \"ALBA Berlin\": {\n \"key\": \"9583a2fa1df97ed95363382c73b41b1b\",\n \"f_id_kommune\": 3227,\n \"f_id_strasse\": 3475,\n \"f_id_strasse_hnr\": 185575,\n },\n}\n_LOGGER = logging.getLogger(__name__)\n\nMODUS_KEY = \"d6c5855a62cf32a4dadbc2831f0f295f\"\nHEADERS = {\"user-agent\": \"Mozilla/5.0 (xxxx Windows NT 10.0; Win64; x64)\"}\n\n\n# Parser for HTML input (hidden) text\nclass HiddenInputParser(HTMLParser):\n def __init__(self):\n super().__init__()\n self._args = {}\n\n @property\n def args(self):\n return self._args\n\n def handle_starttag(self, tag, attrs):\n if tag == \"input\":\n d = dict(attrs)\n if d[\"type\"] == \"hidden\":\n self._args[d[\"name\"]] = d[\"value\"]\n\n\nclass Source:\n def __init__(\n self,\n key,\n f_id_kommune,\n f_id_strasse,\n f_id_bezirk=None,\n f_id_strasse_hnr=None,\n f_abfallarten=[],\n ):\n self._key = key\n self._kommune = f_id_kommune\n self._bezirk = f_id_bezirk\n self._strasse = f_id_strasse\n self._strasse_hnr = f_id_strasse_hnr\n self._abfallarten = f_abfallarten # list of integers\n self._ics = ICS()\n\n def fetch(self):\n # get token\n params = {\"key\": self._key, \"modus\": MODUS_KEY, \"waction\": \"init\"}\n\n r = requests.post(\"https://api.abfall.io\", params=params, headers=HEADERS)\n\n # add all hidden input fields to form data\n # There is one hidden field which acts as a token:\n # It consists of a UUID key and a UUID value.\n p = HiddenInputParser()\n p.feed(r.text)\n args = p.args\n\n args[\"f_id_kommune\"] = self._kommune\n args[\"f_id_strasse\"] = self._strasse\n\n if self._bezirk is not None:\n args[\"f_id_bezirk\"] = self._bezirk\n\n if self._strasse_hnr is not None:\n args[\"f_id_strasse_hnr\"] = self._strasse_hnr\n\n for i in range(len(self._abfallarten)):\n args[f\"f_id_abfalltyp_{i}\"] = self._abfallarten[i]\n\n args[\"f_abfallarten_index_max\"] = len(self._abfallarten)\n args[\"f_abfallarten\"] = \",\".join(map(lambda x: str(x), self._abfallarten))\n\n now = datetime.datetime.now()\n date2 = now.replace(year=now.year + 1)\n args[\"f_zeitraum\"] = f\"{now.strftime('%Y%m%d')}-{date2.strftime('%Y%m%d')}\"\n\n params = {\"key\": self._key, \"modus\": MODUS_KEY, \"waction\": \"export_ics\"}\n\n # get csv file\n r = requests.post(\n \"https://api.abfall.io\", params=params, data=args, headers=HEADERS\n )\n\n # parse ics file\n r.encoding = \"utf-8\" # requests doesn't guess the encoding correctly\n ics_file = r.text\n\n # Remove all lines starting with <b\n # This warning are caused for customers which use an extra radiobutton\n # list to add special waste types:\n # - AWB Limburg-Weilheim uses this list to select a \"Sonderabfall <city>\"\n # waste type. The warning could be removed by adding the extra config\n # option \"f_abfallarten\" with the following values [27, 28, 17, 67]\n html_warnings = re.findall(r\"\\<b.*\", ics_file)\n if html_warnings:\n ics_file = re.sub(r\"\\<br.*|\\<b.*\", \"\\\\r\", ics_file)\n # _LOGGER.warning(\"Html tags removed from ics file: \" + ', '.join(html_warnings))\n\n dates = self._ics.convert(ics_file)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py"}], "after_files": [{"content": "import datetime\nimport logging\nimport re\nfrom html.parser import HTMLParser\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.AbfallIO import SERVICE_MAP\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"Abfall.IO / AbfallPlus\"\nDESCRIPTION = (\n \"Source for AbfallPlus.de waste collection. Service is hosted on abfall.io.\"\n)\nURL = \"https://www.abfallplus.de\"\nCOUNTRY = \"de\"\n\n\ndef EXTRA_INFO():\n return [{\"title\": s[\"title\"], \"url\": s[\"url\"]} for s in SERVICE_MAP]\n\n\nTEST_CASES = {\n \"Waldenbuch\": {\n \"key\": \"8215c62763967916979e0e8566b6172e\",\n \"f_id_kommune\": 2999,\n \"f_id_strasse\": 1087,\n # \"f_abfallarten\": [50, 53, 31, 299, 328, 325]\n },\n \"Landshut\": {\n \"key\": \"bd0c2d0177a0849a905cded5cb734a6f\",\n \"f_id_kommune\": 2655,\n \"f_id_bezirk\": 2655,\n \"f_id_strasse\": 763,\n # \"f_abfallarten\": [31, 17, 19, 218]\n },\n \"Schoenmackers\": {\n \"key\": \"e5543a3e190cb8d91c645660ad60965f\",\n \"f_id_kommune\": 3682,\n \"f_id_strasse\": \"3682adenauerplatz\",\n \"f_id_strasse_hnr\": \"20417\",\n # \"f_abfallarten\": [691,692,696,695,694,701,700,693,703,704,697,699],\n },\n \"Freudenstadt\": {\n \"key\": \"595f903540a36fe8610ec39aa3a06f6a\",\n \"f_id_kommune\": 3447,\n \"f_id_bezirk\": 22017,\n \"f_id_strasse\": 22155,\n },\n \"Ludwigshafen am Rhein\": {\n \"key\": \"6efba91e69a5b454ac0ae3497978fe1d\",\n \"f_id_kommune\": \"5916\",\n \"f_id_strasse\": \"5916abteistrasse\",\n \"f_id_strasse_hnr\": 33,\n },\n \"Traunstein\": {\n \"key\": \"279cc5db4db838d1cfbf42f6f0176a90\",\n \"f_id_kommune\": \"2911\",\n \"f_id_strasse\": \"2374\",\n },\n \"AWB Limburg-Weilburg\": {\n \"key\": \"0ff491ffdf614d6f34870659c0c8d917\",\n \"f_id_kommune\": 6031,\n \"f_id_strasse\": 621,\n \"f_id_strasse_hnr\": 872,\n \"f_abfallarten\": [27, 28, 17, 67],\n },\n \"ALBA Berlin\": {\n \"key\": \"9583a2fa1df97ed95363382c73b41b1b\",\n \"f_id_kommune\": 3227,\n \"f_id_strasse\": 3475,\n \"f_id_strasse_hnr\": 185575,\n },\n}\n_LOGGER = logging.getLogger(__name__)\n\nMODUS_KEY = \"d6c5855a62cf32a4dadbc2831f0f295f\"\nHEADERS = {\"user-agent\": \"Mozilla/5.0 (xxxx Windows NT 10.0; Win64; x64)\"}\n\n\n# Parser for HTML input (hidden) text\nclass HiddenInputParser(HTMLParser):\n def __init__(self):\n super().__init__()\n self._args = {}\n\n @property\n def args(self):\n return self._args\n\n def handle_starttag(self, tag, attrs):\n if tag == \"input\":\n d = dict(attrs)\n if d[\"type\"] == \"hidden\":\n self._args[d[\"name\"]] = d[\"value\"]\n\n\nclass Source:\n def __init__(\n self,\n key,\n f_id_kommune,\n f_id_strasse,\n f_id_bezirk=None,\n f_id_strasse_hnr=None,\n f_abfallarten=[],\n ):\n self._key = key\n self._kommune = f_id_kommune\n self._bezirk = f_id_bezirk\n self._strasse = f_id_strasse\n self._strasse_hnr = f_id_strasse_hnr\n self._abfallarten = f_abfallarten # list of integers\n self._ics = ICS()\n\n def fetch(self):\n # get token\n params = {\"key\": self._key, \"modus\": MODUS_KEY, \"waction\": \"init\"}\n\n r = requests.post(\"https://api.abfall.io\", params=params, headers=HEADERS)\n\n # add all hidden input fields to form data\n # There is one hidden field which acts as a token:\n # It consists of a UUID key and a UUID value.\n p = HiddenInputParser()\n p.feed(r.text)\n args = p.args\n\n args[\"f_id_kommune\"] = self._kommune\n args[\"f_id_strasse\"] = self._strasse\n\n if self._bezirk is not None:\n args[\"f_id_bezirk\"] = self._bezirk\n\n if self._strasse_hnr is not None:\n args[\"f_id_strasse_hnr\"] = self._strasse_hnr\n\n for i in range(len(self._abfallarten)):\n args[f\"f_id_abfalltyp_{i}\"] = self._abfallarten[i]\n\n args[\"f_abfallarten_index_max\"] = len(self._abfallarten)\n args[\"f_abfallarten\"] = \",\".join(map(lambda x: str(x), self._abfallarten))\n\n now = datetime.datetime.now()\n date2 = now + datetime.timedelta(days=365)\n args[\"f_zeitraum\"] = f\"{now.strftime('%Y%m%d')}-{date2.strftime('%Y%m%d')}\"\n\n params = {\"key\": self._key, \"modus\": MODUS_KEY, \"waction\": \"export_ics\"}\n\n # get csv file\n r = requests.post(\n \"https://api.abfall.io\", params=params, data=args, headers=HEADERS\n )\n\n # parse ics file\n r.encoding = \"utf-8\" # requests doesn't guess the encoding correctly\n ics_file = r.text\n\n # Remove all lines starting with <b\n # This warning are caused for customers which use an extra radiobutton\n # list to add special waste types:\n # - AWB Limburg-Weilheim uses this list to select a \"Sonderabfall <city>\"\n # waste type. The warning could be removed by adding the extra config\n # option \"f_abfallarten\" with the following values [27, 28, 17, 67]\n html_warnings = re.findall(r\"\\<b.*\", ics_file)\n if html_warnings:\n ics_file = re.sub(r\"\\<br.*|\\<b.*\", \"\\\\r\", ics_file)\n # _LOGGER.warning(\"Html tags removed from ics file: \" + ', '.join(html_warnings))\n\n dates = self._ics.convert(ics_file)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/abfall_io.py"}]}
| 3,100 | 210 |
gh_patches_debug_40665
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-396
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't show infraction total outside staff channels.
Currently, when we deliver an infraction, it will show the infraction total in the bot's response.

This is a cool feature, but should not happen in public channels. So let's do something about that.
### Infraction total should be allowed in the following channels:
```
#admins ID: 365960823622991872
#admin-spam ID: 563594791770914816
#mod-spam ID: 620607373828030464
#mods ID: 305126844661760000
#helpers ID: 385474242440986624
#organisation ID: 551789653284356126
#defcon ID: 464469101889454091
```
If the command is called in any other channel, **do not show the infraction total**. This applies to all moderation commands that currently show the total.
If any of the above channels are not currently registered as constants, please create new constants for them. The above list of channels can be stored as a group constant called `STAFF_CHANNELS`. Make use of [YAML node anchors](https://yaml.org/spec/1.2/spec.html#&%20anchor//) when you do this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/api.py`
Content:
```
1 from urllib.parse import quote as quote_url
2
3 import aiohttp
4
5 from .constants import Keys, URLs
6
7
8 class ResponseCodeError(ValueError):
9 def __init__(self, response: aiohttp.ClientResponse):
10 self.response = response
11
12
13 class APIClient:
14 def __init__(self, **kwargs):
15 auth_headers = {
16 'Authorization': f"Token {Keys.site_api}"
17 }
18
19 if 'headers' in kwargs:
20 kwargs['headers'].update(auth_headers)
21 else:
22 kwargs['headers'] = auth_headers
23
24 self.session = aiohttp.ClientSession(**kwargs)
25
26 @staticmethod
27 def _url_for(endpoint: str):
28 return f"{URLs.site_schema}{URLs.site_api}/{quote_url(endpoint)}"
29
30 def maybe_raise_for_status(self, response: aiohttp.ClientResponse, should_raise: bool):
31 if should_raise and response.status >= 400:
32 raise ResponseCodeError(response=response)
33
34 async def get(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):
35 async with self.session.get(self._url_for(endpoint), *args, **kwargs) as resp:
36 self.maybe_raise_for_status(resp, raise_for_status)
37 return await resp.json()
38
39 async def patch(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):
40 async with self.session.patch(self._url_for(endpoint), *args, **kwargs) as resp:
41 self.maybe_raise_for_status(resp, raise_for_status)
42 return await resp.json()
43
44 async def post(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):
45 async with self.session.post(self._url_for(endpoint), *args, **kwargs) as resp:
46 self.maybe_raise_for_status(resp, raise_for_status)
47 return await resp.json()
48
49 async def put(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):
50 async with self.session.put(self._url_for(endpoint), *args, **kwargs) as resp:
51 self.maybe_raise_for_status(resp, raise_for_status)
52 return await resp.json()
53
54 async def delete(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):
55 async with self.session.delete(self._url_for(endpoint), *args, **kwargs) as resp:
56 if resp.status == 204:
57 return None
58
59 self.maybe_raise_for_status(resp, raise_for_status)
60 return await resp.json()
61
```
Path: `bot/__main__.py`
Content:
```
1 import asyncio
2 import logging
3 import socket
4
5 from aiohttp import AsyncResolver, ClientSession, TCPConnector
6 from discord import Game
7 from discord.ext.commands import Bot, when_mentioned_or
8
9 from bot.api import APIClient
10 from bot.constants import Bot as BotConfig, DEBUG_MODE
11
12
13 log = logging.getLogger(__name__)
14
15 bot = Bot(
16 command_prefix=when_mentioned_or(BotConfig.prefix),
17 activity=Game(name="Commands: !help"),
18 case_insensitive=True,
19 max_messages=10_000
20 )
21
22 # Global aiohttp session for all cogs
23 # - Uses asyncio for DNS resolution instead of threads, so we don't spam threads
24 # - Uses AF_INET as its socket family to prevent https related problems both locally and in prod.
25 bot.http_session = ClientSession(
26 connector=TCPConnector(
27 resolver=AsyncResolver(),
28 family=socket.AF_INET,
29 )
30 )
31 bot.api_client = APIClient(loop=asyncio.get_event_loop())
32
33 # Internal/debug
34 bot.load_extension("bot.cogs.error_handler")
35 bot.load_extension("bot.cogs.filtering")
36 bot.load_extension("bot.cogs.logging")
37 bot.load_extension("bot.cogs.modlog")
38 bot.load_extension("bot.cogs.security")
39
40 # Commands, etc
41 bot.load_extension("bot.cogs.antispam")
42 bot.load_extension("bot.cogs.bot")
43 bot.load_extension("bot.cogs.clean")
44 bot.load_extension("bot.cogs.cogs")
45 bot.load_extension("bot.cogs.help")
46
47 # Only load this in production
48 if not DEBUG_MODE:
49 bot.load_extension("bot.cogs.doc")
50 bot.load_extension("bot.cogs.verification")
51
52 # Feature cogs
53 bot.load_extension("bot.cogs.alias")
54 bot.load_extension("bot.cogs.defcon")
55 bot.load_extension("bot.cogs.deployment")
56 bot.load_extension("bot.cogs.eval")
57 bot.load_extension("bot.cogs.free")
58 bot.load_extension("bot.cogs.fun")
59 bot.load_extension("bot.cogs.information")
60 bot.load_extension("bot.cogs.jams")
61 bot.load_extension("bot.cogs.moderation")
62 bot.load_extension("bot.cogs.off_topic_names")
63 bot.load_extension("bot.cogs.reddit")
64 bot.load_extension("bot.cogs.reminders")
65 bot.load_extension("bot.cogs.site")
66 bot.load_extension("bot.cogs.snekbox")
67 bot.load_extension("bot.cogs.superstarify")
68 bot.load_extension("bot.cogs.sync")
69 bot.load_extension("bot.cogs.tags")
70 bot.load_extension("bot.cogs.token_remover")
71 bot.load_extension("bot.cogs.utils")
72 bot.load_extension("bot.cogs.watchchannels")
73 bot.load_extension("bot.cogs.wolfram")
74
75 bot.run(BotConfig.token)
76
77 bot.http_session.close() # Close the aiohttp session when the bot finishes running
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/__main__.py b/bot/__main__.py
--- a/bot/__main__.py
+++ b/bot/__main__.py
@@ -6,11 +6,11 @@
from discord import Game
from discord.ext.commands import Bot, when_mentioned_or
-from bot.api import APIClient
+from bot.api import APIClient, APILoggingHandler
from bot.constants import Bot as BotConfig, DEBUG_MODE
-log = logging.getLogger(__name__)
+log = logging.getLogger('bot')
bot = Bot(
command_prefix=when_mentioned_or(BotConfig.prefix),
@@ -29,6 +29,7 @@
)
)
bot.api_client = APIClient(loop=asyncio.get_event_loop())
+log.addHandler(APILoggingHandler(bot.api_client))
# Internal/debug
bot.load_extension("bot.cogs.error_handler")
diff --git a/bot/api.py b/bot/api.py
--- a/bot/api.py
+++ b/bot/api.py
@@ -1,9 +1,13 @@
+import asyncio
+import logging
from urllib.parse import quote as quote_url
import aiohttp
from .constants import Keys, URLs
+log = logging.getLogger(__name__)
+
class ResponseCodeError(ValueError):
def __init__(self, response: aiohttp.ClientResponse):
@@ -58,3 +62,76 @@
self.maybe_raise_for_status(resp, raise_for_status)
return await resp.json()
+
+
+def loop_is_running() -> bool:
+ # asyncio does not have a way to say "call this when the event
+ # loop is running", see e.g. `callWhenRunning` from twisted.
+
+ try:
+ asyncio.get_running_loop()
+ except RuntimeError:
+ return False
+ return True
+
+
+class APILoggingHandler(logging.StreamHandler):
+ def __init__(self, client: APIClient):
+ logging.StreamHandler.__init__(self)
+ self.client = client
+
+ # internal batch of shipoff tasks that must not be scheduled
+ # on the event loop yet - scheduled when the event loop is ready.
+ self.queue = []
+
+ async def ship_off(self, payload: dict):
+ try:
+ await self.client.post('logs', json=payload)
+ except ResponseCodeError as err:
+ log.warning(
+ "Cannot send logging record to the site, got code %d.",
+ err.response.status,
+ extra={'via_handler': True}
+ )
+ except Exception as err:
+ log.warning(
+ "Cannot send logging record to the site: %r",
+ err,
+ extra={'via_handler': True}
+ )
+
+ def emit(self, record: logging.LogRecord):
+ # Ignore logging messages which are sent by this logging handler
+ # itself. This is required because if we were to not ignore
+ # messages emitted by this handler, we would infinitely recurse
+ # back down into this logging handler, making the reactor run
+ # like crazy, and eventually OOM something. Let's not do that...
+ if not record.__dict__.get('via_handler'):
+ payload = {
+ 'application': 'bot',
+ 'logger_name': record.name,
+ 'level': record.levelname.lower(),
+ 'module': record.module,
+ 'line': record.lineno,
+ 'message': self.format(record)
+ }
+
+ task = self.ship_off(payload)
+ if not loop_is_running():
+ self.queue.append(task)
+ else:
+ asyncio.create_task(task)
+ self.schedule_queued_tasks()
+
+ def schedule_queued_tasks(self):
+ for task in self.queue:
+ asyncio.create_task(task)
+
+ if self.queue:
+ log.debug(
+ "Scheduled %d pending logging tasks.",
+ len(self.queue),
+ extra={'via_handler': True}
+ )
+
+ self.queue.clear()
|
{"golden_diff": "diff --git a/bot/__main__.py b/bot/__main__.py\n--- a/bot/__main__.py\n+++ b/bot/__main__.py\n@@ -6,11 +6,11 @@\n from discord import Game\n from discord.ext.commands import Bot, when_mentioned_or\n \n-from bot.api import APIClient\n+from bot.api import APIClient, APILoggingHandler\n from bot.constants import Bot as BotConfig, DEBUG_MODE\n \n \n-log = logging.getLogger(__name__)\n+log = logging.getLogger('bot')\n \n bot = Bot(\n command_prefix=when_mentioned_or(BotConfig.prefix),\n@@ -29,6 +29,7 @@\n )\n )\n bot.api_client = APIClient(loop=asyncio.get_event_loop())\n+log.addHandler(APILoggingHandler(bot.api_client))\n \n # Internal/debug\n bot.load_extension(\"bot.cogs.error_handler\")\ndiff --git a/bot/api.py b/bot/api.py\n--- a/bot/api.py\n+++ b/bot/api.py\n@@ -1,9 +1,13 @@\n+import asyncio\n+import logging\n from urllib.parse import quote as quote_url\n \n import aiohttp\n \n from .constants import Keys, URLs\n \n+log = logging.getLogger(__name__)\n+\n \n class ResponseCodeError(ValueError):\n def __init__(self, response: aiohttp.ClientResponse):\n@@ -58,3 +62,76 @@\n \n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n+\n+\n+def loop_is_running() -> bool:\n+ # asyncio does not have a way to say \"call this when the event\n+ # loop is running\", see e.g. `callWhenRunning` from twisted.\n+\n+ try:\n+ asyncio.get_running_loop()\n+ except RuntimeError:\n+ return False\n+ return True\n+\n+\n+class APILoggingHandler(logging.StreamHandler):\n+ def __init__(self, client: APIClient):\n+ logging.StreamHandler.__init__(self)\n+ self.client = client\n+\n+ # internal batch of shipoff tasks that must not be scheduled\n+ # on the event loop yet - scheduled when the event loop is ready.\n+ self.queue = []\n+\n+ async def ship_off(self, payload: dict):\n+ try:\n+ await self.client.post('logs', json=payload)\n+ except ResponseCodeError as err:\n+ log.warning(\n+ \"Cannot send logging record to the site, got code %d.\",\n+ err.response.status,\n+ extra={'via_handler': True}\n+ )\n+ except Exception as err:\n+ log.warning(\n+ \"Cannot send logging record to the site: %r\",\n+ err,\n+ extra={'via_handler': True}\n+ )\n+\n+ def emit(self, record: logging.LogRecord):\n+ # Ignore logging messages which are sent by this logging handler\n+ # itself. This is required because if we were to not ignore\n+ # messages emitted by this handler, we would infinitely recurse\n+ # back down into this logging handler, making the reactor run\n+ # like crazy, and eventually OOM something. Let's not do that...\n+ if not record.__dict__.get('via_handler'):\n+ payload = {\n+ 'application': 'bot',\n+ 'logger_name': record.name,\n+ 'level': record.levelname.lower(),\n+ 'module': record.module,\n+ 'line': record.lineno,\n+ 'message': self.format(record)\n+ }\n+\n+ task = self.ship_off(payload)\n+ if not loop_is_running():\n+ self.queue.append(task)\n+ else:\n+ asyncio.create_task(task)\n+ self.schedule_queued_tasks()\n+\n+ def schedule_queued_tasks(self):\n+ for task in self.queue:\n+ asyncio.create_task(task)\n+\n+ if self.queue:\n+ log.debug(\n+ \"Scheduled %d pending logging tasks.\",\n+ len(self.queue),\n+ extra={'via_handler': True}\n+ )\n+\n+ self.queue.clear()\n", "issue": "Don't show infraction total outside staff channels.\nCurrently, when we deliver an infraction, it will show the infraction total in the bot's response.\r\n\r\n\r\n\r\nThis is a cool feature, but should not happen in public channels. So let's do something about that.\r\n\r\n### Infraction total should be allowed in the following channels:\r\n```\r\n#admins ID: 365960823622991872\r\n#admin-spam ID: 563594791770914816\r\n#mod-spam ID: 620607373828030464\r\n#mods ID: 305126844661760000\r\n#helpers ID: 385474242440986624\r\n#organisation ID: 551789653284356126\r\n#defcon ID: 464469101889454091\r\n```\r\n\r\nIf the command is called in any other channel, **do not show the infraction total**. This applies to all moderation commands that currently show the total.\r\n\r\nIf any of the above channels are not currently registered as constants, please create new constants for them. The above list of channels can be stored as a group constant called `STAFF_CHANNELS`. Make use of [YAML node anchors](https://yaml.org/spec/1.2/spec.html#&%20anchor//) when you do this.\r\n\n", "before_files": [{"content": "from urllib.parse import quote as quote_url\n\nimport aiohttp\n\nfrom .constants import Keys, URLs\n\n\nclass ResponseCodeError(ValueError):\n def __init__(self, response: aiohttp.ClientResponse):\n self.response = response\n\n\nclass APIClient:\n def __init__(self, **kwargs):\n auth_headers = {\n 'Authorization': f\"Token {Keys.site_api}\"\n }\n\n if 'headers' in kwargs:\n kwargs['headers'].update(auth_headers)\n else:\n kwargs['headers'] = auth_headers\n\n self.session = aiohttp.ClientSession(**kwargs)\n\n @staticmethod\n def _url_for(endpoint: str):\n return f\"{URLs.site_schema}{URLs.site_api}/{quote_url(endpoint)}\"\n\n def maybe_raise_for_status(self, response: aiohttp.ClientResponse, should_raise: bool):\n if should_raise and response.status >= 400:\n raise ResponseCodeError(response=response)\n\n async def get(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.get(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def patch(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.patch(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def post(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.post(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def put(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.put(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def delete(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.delete(self._url_for(endpoint), *args, **kwargs) as resp:\n if resp.status == 204:\n return None\n\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n", "path": "bot/api.py"}, {"content": "import asyncio\nimport logging\nimport socket\n\nfrom aiohttp import AsyncResolver, ClientSession, TCPConnector\nfrom discord import Game\nfrom discord.ext.commands import Bot, when_mentioned_or\n\nfrom bot.api import APIClient\nfrom bot.constants import Bot as BotConfig, DEBUG_MODE\n\n\nlog = logging.getLogger(__name__)\n\nbot = Bot(\n command_prefix=when_mentioned_or(BotConfig.prefix),\n activity=Game(name=\"Commands: !help\"),\n case_insensitive=True,\n max_messages=10_000\n)\n\n# Global aiohttp session for all cogs\n# - Uses asyncio for DNS resolution instead of threads, so we don't spam threads\n# - Uses AF_INET as its socket family to prevent https related problems both locally and in prod.\nbot.http_session = ClientSession(\n connector=TCPConnector(\n resolver=AsyncResolver(),\n family=socket.AF_INET,\n )\n)\nbot.api_client = APIClient(loop=asyncio.get_event_loop())\n\n# Internal/debug\nbot.load_extension(\"bot.cogs.error_handler\")\nbot.load_extension(\"bot.cogs.filtering\")\nbot.load_extension(\"bot.cogs.logging\")\nbot.load_extension(\"bot.cogs.modlog\")\nbot.load_extension(\"bot.cogs.security\")\n\n# Commands, etc\nbot.load_extension(\"bot.cogs.antispam\")\nbot.load_extension(\"bot.cogs.bot\")\nbot.load_extension(\"bot.cogs.clean\")\nbot.load_extension(\"bot.cogs.cogs\")\nbot.load_extension(\"bot.cogs.help\")\n\n# Only load this in production\nif not DEBUG_MODE:\n bot.load_extension(\"bot.cogs.doc\")\n bot.load_extension(\"bot.cogs.verification\")\n\n# Feature cogs\nbot.load_extension(\"bot.cogs.alias\")\nbot.load_extension(\"bot.cogs.defcon\")\nbot.load_extension(\"bot.cogs.deployment\")\nbot.load_extension(\"bot.cogs.eval\")\nbot.load_extension(\"bot.cogs.free\")\nbot.load_extension(\"bot.cogs.fun\")\nbot.load_extension(\"bot.cogs.information\")\nbot.load_extension(\"bot.cogs.jams\")\nbot.load_extension(\"bot.cogs.moderation\")\nbot.load_extension(\"bot.cogs.off_topic_names\")\nbot.load_extension(\"bot.cogs.reddit\")\nbot.load_extension(\"bot.cogs.reminders\")\nbot.load_extension(\"bot.cogs.site\")\nbot.load_extension(\"bot.cogs.snekbox\")\nbot.load_extension(\"bot.cogs.superstarify\")\nbot.load_extension(\"bot.cogs.sync\")\nbot.load_extension(\"bot.cogs.tags\")\nbot.load_extension(\"bot.cogs.token_remover\")\nbot.load_extension(\"bot.cogs.utils\")\nbot.load_extension(\"bot.cogs.watchchannels\")\nbot.load_extension(\"bot.cogs.wolfram\")\n\nbot.run(BotConfig.token)\n\nbot.http_session.close() # Close the aiohttp session when the bot finishes running\n", "path": "bot/__main__.py"}], "after_files": [{"content": "import asyncio\nimport logging\nfrom urllib.parse import quote as quote_url\n\nimport aiohttp\n\nfrom .constants import Keys, URLs\n\nlog = logging.getLogger(__name__)\n\n\nclass ResponseCodeError(ValueError):\n def __init__(self, response: aiohttp.ClientResponse):\n self.response = response\n\n\nclass APIClient:\n def __init__(self, **kwargs):\n auth_headers = {\n 'Authorization': f\"Token {Keys.site_api}\"\n }\n\n if 'headers' in kwargs:\n kwargs['headers'].update(auth_headers)\n else:\n kwargs['headers'] = auth_headers\n\n self.session = aiohttp.ClientSession(**kwargs)\n\n @staticmethod\n def _url_for(endpoint: str):\n return f\"{URLs.site_schema}{URLs.site_api}/{quote_url(endpoint)}\"\n\n def maybe_raise_for_status(self, response: aiohttp.ClientResponse, should_raise: bool):\n if should_raise and response.status >= 400:\n raise ResponseCodeError(response=response)\n\n async def get(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.get(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def patch(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.patch(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def post(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.post(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def put(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.put(self._url_for(endpoint), *args, **kwargs) as resp:\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n async def delete(self, endpoint: str, *args, raise_for_status: bool = True, **kwargs):\n async with self.session.delete(self._url_for(endpoint), *args, **kwargs) as resp:\n if resp.status == 204:\n return None\n\n self.maybe_raise_for_status(resp, raise_for_status)\n return await resp.json()\n\n\ndef loop_is_running() -> bool:\n # asyncio does not have a way to say \"call this when the event\n # loop is running\", see e.g. `callWhenRunning` from twisted.\n\n try:\n asyncio.get_running_loop()\n except RuntimeError:\n return False\n return True\n\n\nclass APILoggingHandler(logging.StreamHandler):\n def __init__(self, client: APIClient):\n logging.StreamHandler.__init__(self)\n self.client = client\n\n # internal batch of shipoff tasks that must not be scheduled\n # on the event loop yet - scheduled when the event loop is ready.\n self.queue = []\n\n async def ship_off(self, payload: dict):\n try:\n await self.client.post('logs', json=payload)\n except ResponseCodeError as err:\n log.warning(\n \"Cannot send logging record to the site, got code %d.\",\n err.response.status,\n extra={'via_handler': True}\n )\n except Exception as err:\n log.warning(\n \"Cannot send logging record to the site: %r\",\n err,\n extra={'via_handler': True}\n )\n\n def emit(self, record: logging.LogRecord):\n # Ignore logging messages which are sent by this logging handler\n # itself. This is required because if we were to not ignore\n # messages emitted by this handler, we would infinitely recurse\n # back down into this logging handler, making the reactor run\n # like crazy, and eventually OOM something. Let's not do that...\n if not record.__dict__.get('via_handler'):\n payload = {\n 'application': 'bot',\n 'logger_name': record.name,\n 'level': record.levelname.lower(),\n 'module': record.module,\n 'line': record.lineno,\n 'message': self.format(record)\n }\n\n task = self.ship_off(payload)\n if not loop_is_running():\n self.queue.append(task)\n else:\n asyncio.create_task(task)\n self.schedule_queued_tasks()\n\n def schedule_queued_tasks(self):\n for task in self.queue:\n asyncio.create_task(task)\n\n if self.queue:\n log.debug(\n \"Scheduled %d pending logging tasks.\",\n len(self.queue),\n extra={'via_handler': True}\n )\n\n self.queue.clear()\n", "path": "bot/api.py"}, {"content": "import asyncio\nimport logging\nimport socket\n\nfrom aiohttp import AsyncResolver, ClientSession, TCPConnector\nfrom discord import Game\nfrom discord.ext.commands import Bot, when_mentioned_or\n\nfrom bot.api import APIClient, APILoggingHandler\nfrom bot.constants import Bot as BotConfig, DEBUG_MODE\n\n\nlog = logging.getLogger('bot')\n\nbot = Bot(\n command_prefix=when_mentioned_or(BotConfig.prefix),\n activity=Game(name=\"Commands: !help\"),\n case_insensitive=True,\n max_messages=10_000\n)\n\n# Global aiohttp session for all cogs\n# - Uses asyncio for DNS resolution instead of threads, so we don't spam threads\n# - Uses AF_INET as its socket family to prevent https related problems both locally and in prod.\nbot.http_session = ClientSession(\n connector=TCPConnector(\n resolver=AsyncResolver(),\n family=socket.AF_INET,\n )\n)\nbot.api_client = APIClient(loop=asyncio.get_event_loop())\nlog.addHandler(APILoggingHandler(bot.api_client))\n\n# Internal/debug\nbot.load_extension(\"bot.cogs.error_handler\")\nbot.load_extension(\"bot.cogs.filtering\")\nbot.load_extension(\"bot.cogs.logging\")\nbot.load_extension(\"bot.cogs.modlog\")\nbot.load_extension(\"bot.cogs.security\")\n\n# Commands, etc\nbot.load_extension(\"bot.cogs.antispam\")\nbot.load_extension(\"bot.cogs.bot\")\nbot.load_extension(\"bot.cogs.clean\")\nbot.load_extension(\"bot.cogs.cogs\")\nbot.load_extension(\"bot.cogs.help\")\n\n# Only load this in production\nif not DEBUG_MODE:\n bot.load_extension(\"bot.cogs.doc\")\n bot.load_extension(\"bot.cogs.verification\")\n\n# Feature cogs\nbot.load_extension(\"bot.cogs.alias\")\nbot.load_extension(\"bot.cogs.defcon\")\nbot.load_extension(\"bot.cogs.deployment\")\nbot.load_extension(\"bot.cogs.eval\")\nbot.load_extension(\"bot.cogs.free\")\nbot.load_extension(\"bot.cogs.fun\")\nbot.load_extension(\"bot.cogs.information\")\nbot.load_extension(\"bot.cogs.jams\")\nbot.load_extension(\"bot.cogs.moderation\")\nbot.load_extension(\"bot.cogs.off_topic_names\")\nbot.load_extension(\"bot.cogs.reddit\")\nbot.load_extension(\"bot.cogs.reminders\")\nbot.load_extension(\"bot.cogs.site\")\nbot.load_extension(\"bot.cogs.snekbox\")\nbot.load_extension(\"bot.cogs.superstarify\")\nbot.load_extension(\"bot.cogs.sync\")\nbot.load_extension(\"bot.cogs.tags\")\nbot.load_extension(\"bot.cogs.token_remover\")\nbot.load_extension(\"bot.cogs.utils\")\nbot.load_extension(\"bot.cogs.watchchannels\")\nbot.load_extension(\"bot.cogs.wolfram\")\n\nbot.run(BotConfig.token)\n\nbot.http_session.close() # Close the aiohttp session when the bot finishes running\n", "path": "bot/__main__.py"}]}
| 2,082 | 873 |
gh_patches_debug_36518
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-924
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Enables min and max values for pydecimal
Currently is not possible to set min or max values to `pydecimal` or `pyfloat`. It would be nice if we could pass these parameters.
If it makes senses I can open a PR.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/python/__init__.py`
Content:
```
1 # coding=utf-8
2
3 from __future__ import unicode_literals
4
5 from decimal import Decimal
6 import sys
7
8 import six
9
10 from .. import BaseProvider
11
12
13 class Provider(BaseProvider):
14 def pybool(self):
15 return self.random_int(0, 1) == 1
16
17 def pystr(self, min_chars=None, max_chars=20):
18 """
19 Generates a random string of upper and lowercase letters.
20 :type min_chars: int
21 :type max_chars: int
22 :return: String. Random of random length between min and max characters.
23 """
24 if min_chars is None:
25 return "".join(self.random_letters(length=max_chars))
26 else:
27 assert (
28 max_chars >= min_chars), "Maximum length must be greater than or equal to minium length"
29 return "".join(
30 self.random_letters(
31 length=self.generator.random.randint(min_chars, max_chars),
32 ),
33 )
34
35 def pyfloat(self, left_digits=None, right_digits=None, positive=False):
36 if left_digits is not None and left_digits < 0:
37 raise ValueError(
38 'A float number cannot have less than 0 digits in its '
39 'integer part')
40 if right_digits is not None and right_digits < 0:
41 raise ValueError(
42 'A float number cannot have less than 0 digits in its '
43 'fractional part')
44 if left_digits == 0 and right_digits == 0:
45 raise ValueError(
46 'A float number cannot have less than 0 digits in total')
47
48 left_digits = left_digits if left_digits is not None else (
49 self.random_int(1, sys.float_info.dig))
50 right_digits = right_digits if right_digits is not None else (
51 self.random_int(0, sys.float_info.dig - left_digits))
52 sign = 1 if positive else self.random_element((-1, 1))
53
54 return float("{0}.{1}".format(
55 sign * self.random_number(left_digits),
56 self.random_number(right_digits),
57 ))
58
59 def pyint(self):
60 return self.generator.random_int()
61
62 def pydecimal(self, left_digits=None, right_digits=None, positive=False):
63 return Decimal(str(self.pyfloat(left_digits, right_digits, positive)))
64
65 def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):
66 return tuple(
67 self.pyset(
68 nb_elements,
69 variable_nb_elements,
70 *value_types))
71
72 def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):
73 return set(
74 self._pyiterable(
75 nb_elements,
76 variable_nb_elements,
77 *value_types))
78
79 def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):
80 return list(
81 self._pyiterable(
82 nb_elements,
83 variable_nb_elements,
84 *value_types))
85
86 def pyiterable(
87 self,
88 nb_elements=10,
89 variable_nb_elements=True,
90 *value_types):
91 return self.random_element([self.pylist, self.pytuple, self.pyset])(
92 nb_elements, variable_nb_elements, *value_types)
93
94 def _random_type(self, type_list):
95 value_type = self.random_element(type_list)
96
97 method_name = "py{0}".format(value_type)
98 if hasattr(self, method_name):
99 value_type = method_name
100
101 return self.generator.format(value_type)
102
103 def _pyiterable(
104 self,
105 nb_elements=10,
106 variable_nb_elements=True,
107 *value_types):
108
109 value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()
110 for t in value_types
111 # avoid recursion
112 if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]
113 if not value_types:
114 value_types = ['str', 'str', 'str', 'str', 'float',
115 'int', 'int', 'decimal', 'date_time', 'uri', 'email']
116
117 if variable_nb_elements:
118 nb_elements = self.randomize_nb_elements(nb_elements, min=1)
119
120 for _ in range(nb_elements):
121 yield self._random_type(value_types)
122
123 def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):
124 """
125 Returns a dictionary.
126
127 :nb_elements: number of elements for dictionary
128 :variable_nb_elements: is use variable number of elements for dictionary
129 :value_types: type of dictionary values
130 """
131 if variable_nb_elements:
132 nb_elements = self.randomize_nb_elements(nb_elements, min=1)
133
134 return dict(zip(
135 self.generator.words(nb_elements),
136 self._pyiterable(nb_elements, False, *value_types),
137 ))
138
139 def pystruct(self, count=10, *value_types):
140
141 value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()
142 for t in value_types
143 # avoid recursion
144 if t != 'struct']
145 if not value_types:
146 value_types = ['str', 'str', 'str', 'str', 'float',
147 'int', 'int', 'decimal', 'date_time', 'uri', 'email']
148
149 types = []
150 d = {}
151 nd = {}
152 for i in range(count):
153 d[self.generator.word()] = self._random_type(value_types)
154 types.append(self._random_type(value_types))
155 nd[self.generator.word()] = {i: self._random_type(value_types),
156 i + 1: [self._random_type(value_types),
157 self._random_type(value_types),
158 self._random_type(value_types)],
159 i + 2: {i: self._random_type(value_types),
160 i + 1: self._random_type(value_types),
161 i + 2: [self._random_type(value_types),
162 self._random_type(value_types)]}}
163 return types, d, nd
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/python/__init__.py b/faker/providers/python/__init__.py
--- a/faker/providers/python/__init__.py
+++ b/faker/providers/python/__init__.py
@@ -32,7 +32,9 @@
),
)
- def pyfloat(self, left_digits=None, right_digits=None, positive=False):
+ def pyfloat(self, left_digits=None, right_digits=None, positive=False,
+ min_value=None, max_value=None):
+
if left_digits is not None and left_digits < 0:
raise ValueError(
'A float number cannot have less than 0 digits in its '
@@ -44,6 +46,8 @@
if left_digits == 0 and right_digits == 0:
raise ValueError(
'A float number cannot have less than 0 digits in total')
+ if None not in (min_value, max_value) and min_value > max_value:
+ raise ValueError('Min value cannot be greater than max value')
left_digits = left_digits if left_digits is not None else (
self.random_int(1, sys.float_info.dig))
@@ -51,16 +55,30 @@
self.random_int(0, sys.float_info.dig - left_digits))
sign = 1 if positive else self.random_element((-1, 1))
+ if (min_value is not None) or (max_value is not None):
+ if min_value is None:
+ min_value = max_value - self.random_int()
+ if max_value is None:
+ max_value = min_value + self.random_int()
+
+ left_number = self.random_int(min_value, max_value)
+ else:
+ left_number = sign * self.random_number(left_digits)
+
return float("{0}.{1}".format(
- sign * self.random_number(left_digits),
+ left_number,
self.random_number(right_digits),
))
def pyint(self):
return self.generator.random_int()
- def pydecimal(self, left_digits=None, right_digits=None, positive=False):
- return Decimal(str(self.pyfloat(left_digits, right_digits, positive)))
+ def pydecimal(self, left_digits=None, right_digits=None, positive=False,
+ min_value=None, max_value=None):
+
+ float_ = self.pyfloat(
+ left_digits, right_digits, positive, min_value, max_value)
+ return Decimal(str(float_))
def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):
return tuple(
|
{"golden_diff": "diff --git a/faker/providers/python/__init__.py b/faker/providers/python/__init__.py\n--- a/faker/providers/python/__init__.py\n+++ b/faker/providers/python/__init__.py\n@@ -32,7 +32,9 @@\n ),\n )\n \n- def pyfloat(self, left_digits=None, right_digits=None, positive=False):\n+ def pyfloat(self, left_digits=None, right_digits=None, positive=False,\n+ min_value=None, max_value=None):\n+\n if left_digits is not None and left_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n@@ -44,6 +46,8 @@\n if left_digits == 0 and right_digits == 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in total')\n+ if None not in (min_value, max_value) and min_value > max_value:\n+ raise ValueError('Min value cannot be greater than max value')\n \n left_digits = left_digits if left_digits is not None else (\n self.random_int(1, sys.float_info.dig))\n@@ -51,16 +55,30 @@\n self.random_int(0, sys.float_info.dig - left_digits))\n sign = 1 if positive else self.random_element((-1, 1))\n \n+ if (min_value is not None) or (max_value is not None):\n+ if min_value is None:\n+ min_value = max_value - self.random_int()\n+ if max_value is None:\n+ max_value = min_value + self.random_int()\n+\n+ left_number = self.random_int(min_value, max_value)\n+ else:\n+ left_number = sign * self.random_number(left_digits)\n+\n return float(\"{0}.{1}\".format(\n- sign * self.random_number(left_digits),\n+ left_number,\n self.random_number(right_digits),\n ))\n \n def pyint(self):\n return self.generator.random_int()\n \n- def pydecimal(self, left_digits=None, right_digits=None, positive=False):\n- return Decimal(str(self.pyfloat(left_digits, right_digits, positive)))\n+ def pydecimal(self, left_digits=None, right_digits=None, positive=False,\n+ min_value=None, max_value=None):\n+\n+ float_ = self.pyfloat(\n+ left_digits, right_digits, positive, min_value, max_value)\n+ return Decimal(str(float_))\n \n def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return tuple(\n", "issue": "Enables min and max values for pydecimal\nCurrently is not possible to set min or max values to `pydecimal` or `pyfloat`. It would be nice if we could pass these parameters.\r\n\r\nIf it makes senses I can open a PR.\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import unicode_literals\n\nfrom decimal import Decimal\nimport sys\n\nimport six\n\nfrom .. import BaseProvider\n\n\nclass Provider(BaseProvider):\n def pybool(self):\n return self.random_int(0, 1) == 1\n\n def pystr(self, min_chars=None, max_chars=20):\n \"\"\"\n Generates a random string of upper and lowercase letters.\n :type min_chars: int\n :type max_chars: int\n :return: String. Random of random length between min and max characters.\n \"\"\"\n if min_chars is None:\n return \"\".join(self.random_letters(length=max_chars))\n else:\n assert (\n max_chars >= min_chars), \"Maximum length must be greater than or equal to minium length\"\n return \"\".join(\n self.random_letters(\n length=self.generator.random.randint(min_chars, max_chars),\n ),\n )\n\n def pyfloat(self, left_digits=None, right_digits=None, positive=False):\n if left_digits is not None and left_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'integer part')\n if right_digits is not None and right_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'fractional part')\n if left_digits == 0 and right_digits == 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in total')\n\n left_digits = left_digits if left_digits is not None else (\n self.random_int(1, sys.float_info.dig))\n right_digits = right_digits if right_digits is not None else (\n self.random_int(0, sys.float_info.dig - left_digits))\n sign = 1 if positive else self.random_element((-1, 1))\n\n return float(\"{0}.{1}\".format(\n sign * self.random_number(left_digits),\n self.random_number(right_digits),\n ))\n\n def pyint(self):\n return self.generator.random_int()\n\n def pydecimal(self, left_digits=None, right_digits=None, positive=False):\n return Decimal(str(self.pyfloat(left_digits, right_digits, positive)))\n\n def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return tuple(\n self.pyset(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return set(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return list(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n return self.random_element([self.pylist, self.pytuple, self.pyset])(\n nb_elements, variable_nb_elements, *value_types)\n\n def _random_type(self, type_list):\n value_type = self.random_element(type_list)\n\n method_name = \"py{0}\".format(value_type)\n if hasattr(self, method_name):\n value_type = method_name\n\n return self.generator.format(value_type)\n\n def _pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n\n value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n for _ in range(nb_elements):\n yield self._random_type(value_types)\n\n def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):\n \"\"\"\n Returns a dictionary.\n\n :nb_elements: number of elements for dictionary\n :variable_nb_elements: is use variable number of elements for dictionary\n :value_types: type of dictionary values\n \"\"\"\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n return dict(zip(\n self.generator.words(nb_elements),\n self._pyiterable(nb_elements, False, *value_types),\n ))\n\n def pystruct(self, count=10, *value_types):\n\n value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t != 'struct']\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n types = []\n d = {}\n nd = {}\n for i in range(count):\n d[self.generator.word()] = self._random_type(value_types)\n types.append(self._random_type(value_types))\n nd[self.generator.word()] = {i: self._random_type(value_types),\n i + 1: [self._random_type(value_types),\n self._random_type(value_types),\n self._random_type(value_types)],\n i + 2: {i: self._random_type(value_types),\n i + 1: self._random_type(value_types),\n i + 2: [self._random_type(value_types),\n self._random_type(value_types)]}}\n return types, d, nd\n", "path": "faker/providers/python/__init__.py"}], "after_files": [{"content": "# coding=utf-8\n\nfrom __future__ import unicode_literals\n\nfrom decimal import Decimal\nimport sys\n\nimport six\n\nfrom .. import BaseProvider\n\n\nclass Provider(BaseProvider):\n def pybool(self):\n return self.random_int(0, 1) == 1\n\n def pystr(self, min_chars=None, max_chars=20):\n \"\"\"\n Generates a random string of upper and lowercase letters.\n :type min_chars: int\n :type max_chars: int\n :return: String. Random of random length between min and max characters.\n \"\"\"\n if min_chars is None:\n return \"\".join(self.random_letters(length=max_chars))\n else:\n assert (\n max_chars >= min_chars), \"Maximum length must be greater than or equal to minium length\"\n return \"\".join(\n self.random_letters(\n length=self.generator.random.randint(min_chars, max_chars),\n ),\n )\n\n def pyfloat(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n\n if left_digits is not None and left_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'integer part')\n if right_digits is not None and right_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'fractional part')\n if left_digits == 0 and right_digits == 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in total')\n if None not in (min_value, max_value) and min_value > max_value:\n raise ValueError('Min value cannot be greater than max value')\n\n left_digits = left_digits if left_digits is not None else (\n self.random_int(1, sys.float_info.dig))\n right_digits = right_digits if right_digits is not None else (\n self.random_int(0, sys.float_info.dig - left_digits))\n sign = 1 if positive else self.random_element((-1, 1))\n\n if (min_value is not None) or (max_value is not None):\n if min_value is None:\n min_value = max_value - self.random_int()\n if max_value is None:\n max_value = min_value + self.random_int()\n\n left_number = self.random_int(min_value, max_value)\n else:\n left_number = sign * self.random_number(left_digits)\n\n return float(\"{0}.{1}\".format(\n left_number,\n self.random_number(right_digits),\n ))\n\n def pyint(self):\n return self.generator.random_int()\n\n def pydecimal(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n\n float_ = self.pyfloat(\n left_digits, right_digits, positive, min_value, max_value)\n return Decimal(str(float_))\n\n def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return tuple(\n self.pyset(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return set(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return list(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n return self.random_element([self.pylist, self.pytuple, self.pyset])(\n nb_elements, variable_nb_elements, *value_types)\n\n def _random_type(self, type_list):\n value_type = self.random_element(type_list)\n\n method_name = \"py{0}\".format(value_type)\n if hasattr(self, method_name):\n value_type = method_name\n\n return self.generator.format(value_type)\n\n def _pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n\n value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n for _ in range(nb_elements):\n yield self._random_type(value_types)\n\n def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):\n \"\"\"\n Returns a dictionary.\n\n :nb_elements: number of elements for dictionary\n :variable_nb_elements: is use variable number of elements for dictionary\n :value_types: type of dictionary values\n \"\"\"\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n return dict(zip(\n self.generator.words(nb_elements),\n self._pyiterable(nb_elements, False, *value_types),\n ))\n\n def pystruct(self, count=10, *value_types):\n\n value_types = [t if isinstance(t, six.string_types) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t != 'struct']\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n types = []\n d = {}\n nd = {}\n for i in range(count):\n d[self.generator.word()] = self._random_type(value_types)\n types.append(self._random_type(value_types))\n nd[self.generator.word()] = {i: self._random_type(value_types),\n i + 1: [self._random_type(value_types),\n self._random_type(value_types),\n self._random_type(value_types)],\n i + 2: {i: self._random_type(value_types),\n i + 1: self._random_type(value_types),\n i + 2: [self._random_type(value_types),\n self._random_type(value_types)]}}\n return types, d, nd\n", "path": "faker/providers/python/__init__.py"}]}
| 1,987 | 558 |
gh_patches_debug_16100
|
rasdani/github-patches
|
git_diff
|
dask__distributed-4963
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add bar chart for worker occupancy
We currently have bar charts for worker memory and the number of tasks processing. A similar chart to number of tasks processing would be worker occupancy, which records the sum of the amount of compute time of all tasks currently residing on the worker. This would be exactly like the number of tasks processing chart, but use `ws.occupancy` rather than `len(ws.processing)`
I would have used this today when trying to diagnose work stealing issues.
The relevant code for the number of processing tasks is here. It's made slightly complex because the code for this chart is currently merged with the memory chart. It might make sense to break these apart.
https://github.com/dask/distributed/blob/9d4f0bf2fc804f955a869febd3b51423c4382908/distributed/dashboard/components/scheduler.py#L1017-L1139
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `distributed/dashboard/scheduler.py`
Content:
```
1 from urllib.parse import urljoin
2
3 from tornado import web
4 from tornado.ioloop import IOLoop
5
6 try:
7 import numpy as np
8 except ImportError:
9 np = False
10
11 from .components.nvml import gpu_doc # noqa: 1708
12 from .components.nvml import NVML_ENABLED, gpu_memory_doc, gpu_utilization_doc
13 from .components.scheduler import (
14 AggregateAction,
15 BandwidthTypes,
16 BandwidthWorkers,
17 ComputePerKey,
18 CurrentLoad,
19 MemoryByKey,
20 NBytes,
21 NBytesCluster,
22 SystemMonitor,
23 TaskGraph,
24 TaskProgress,
25 TaskStream,
26 WorkerTable,
27 events_doc,
28 graph_doc,
29 individual_doc,
30 individual_profile_doc,
31 individual_profile_server_doc,
32 profile_doc,
33 profile_server_doc,
34 status_doc,
35 stealing_doc,
36 systemmonitor_doc,
37 tasks_doc,
38 workers_doc,
39 )
40 from .core import BokehApplication
41 from .worker import counters_doc
42
43 template_variables = {
44 "pages": ["status", "workers", "tasks", "system", "profile", "graph", "info"]
45 }
46
47 if NVML_ENABLED:
48 template_variables["pages"].insert(4, "gpu")
49
50
51 def connect(application, http_server, scheduler, prefix=""):
52 bokeh_app = BokehApplication(
53 applications, scheduler, prefix=prefix, template_variables=template_variables
54 )
55 application.add_application(bokeh_app)
56 bokeh_app.initialize(IOLoop.current())
57
58 bokeh_app.add_handlers(
59 r".*",
60 [
61 (
62 r"/",
63 web.RedirectHandler,
64 {"url": urljoin((prefix or "").strip("/") + "/", r"status")},
65 )
66 ],
67 )
68
69
70 applications = {
71 "/system": systemmonitor_doc,
72 "/stealing": stealing_doc,
73 "/workers": workers_doc,
74 "/events": events_doc,
75 "/counters": counters_doc,
76 "/tasks": tasks_doc,
77 "/status": status_doc,
78 "/profile": profile_doc,
79 "/profile-server": profile_server_doc,
80 "/graph": graph_doc,
81 "/gpu": gpu_doc,
82 "/individual-task-stream": individual_doc(
83 TaskStream, 100, n_rectangles=1000, clear_interval="10s"
84 ),
85 "/individual-progress": individual_doc(TaskProgress, 100, height=160),
86 "/individual-graph": individual_doc(TaskGraph, 200),
87 "/individual-nbytes": individual_doc(NBytes, 100),
88 "/individual-nbytes-cluster": individual_doc(NBytesCluster, 100),
89 "/individual-cpu": individual_doc(CurrentLoad, 100, fig_attr="cpu_figure"),
90 "/individual-nprocessing": individual_doc(
91 CurrentLoad, 100, fig_attr="processing_figure"
92 ),
93 "/individual-workers": individual_doc(WorkerTable, 500),
94 "/individual-bandwidth-types": individual_doc(BandwidthTypes, 500),
95 "/individual-bandwidth-workers": individual_doc(BandwidthWorkers, 500),
96 "/individual-memory-by-key": individual_doc(MemoryByKey, 500),
97 "/individual-compute-time-per-key": individual_doc(ComputePerKey, 500),
98 "/individual-aggregate-time-per-action": individual_doc(AggregateAction, 500),
99 "/individual-scheduler-system": individual_doc(SystemMonitor, 500),
100 "/individual-profile": individual_profile_doc,
101 "/individual-profile-server": individual_profile_server_doc,
102 "/individual-gpu-memory": gpu_memory_doc,
103 "/individual-gpu-utilization": gpu_utilization_doc,
104 }
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/distributed/dashboard/scheduler.py b/distributed/dashboard/scheduler.py
--- a/distributed/dashboard/scheduler.py
+++ b/distributed/dashboard/scheduler.py
@@ -19,6 +19,7 @@
MemoryByKey,
NBytes,
NBytesCluster,
+ Occupancy,
SystemMonitor,
TaskGraph,
TaskProgress,
@@ -90,6 +91,7 @@
"/individual-nprocessing": individual_doc(
CurrentLoad, 100, fig_attr="processing_figure"
),
+ "/individual-occupancy": individual_doc(Occupancy, 100),
"/individual-workers": individual_doc(WorkerTable, 500),
"/individual-bandwidth-types": individual_doc(BandwidthTypes, 500),
"/individual-bandwidth-workers": individual_doc(BandwidthWorkers, 500),
|
{"golden_diff": "diff --git a/distributed/dashboard/scheduler.py b/distributed/dashboard/scheduler.py\n--- a/distributed/dashboard/scheduler.py\n+++ b/distributed/dashboard/scheduler.py\n@@ -19,6 +19,7 @@\n MemoryByKey,\n NBytes,\n NBytesCluster,\n+ Occupancy,\n SystemMonitor,\n TaskGraph,\n TaskProgress,\n@@ -90,6 +91,7 @@\n \"/individual-nprocessing\": individual_doc(\n CurrentLoad, 100, fig_attr=\"processing_figure\"\n ),\n+ \"/individual-occupancy\": individual_doc(Occupancy, 100),\n \"/individual-workers\": individual_doc(WorkerTable, 500),\n \"/individual-bandwidth-types\": individual_doc(BandwidthTypes, 500),\n \"/individual-bandwidth-workers\": individual_doc(BandwidthWorkers, 500),\n", "issue": "Add bar chart for worker occupancy\nWe currently have bar charts for worker memory and the number of tasks processing. A similar chart to number of tasks processing would be worker occupancy, which records the sum of the amount of compute time of all tasks currently residing on the worker. This would be exactly like the number of tasks processing chart, but use `ws.occupancy` rather than `len(ws.processing)`\r\n\r\nI would have used this today when trying to diagnose work stealing issues. \r\n\r\nThe relevant code for the number of processing tasks is here. It's made slightly complex because the code for this chart is currently merged with the memory chart. It might make sense to break these apart.\r\n\r\nhttps://github.com/dask/distributed/blob/9d4f0bf2fc804f955a869febd3b51423c4382908/distributed/dashboard/components/scheduler.py#L1017-L1139\n", "before_files": [{"content": "from urllib.parse import urljoin\n\nfrom tornado import web\nfrom tornado.ioloop import IOLoop\n\ntry:\n import numpy as np\nexcept ImportError:\n np = False\n\nfrom .components.nvml import gpu_doc # noqa: 1708\nfrom .components.nvml import NVML_ENABLED, gpu_memory_doc, gpu_utilization_doc\nfrom .components.scheduler import (\n AggregateAction,\n BandwidthTypes,\n BandwidthWorkers,\n ComputePerKey,\n CurrentLoad,\n MemoryByKey,\n NBytes,\n NBytesCluster,\n SystemMonitor,\n TaskGraph,\n TaskProgress,\n TaskStream,\n WorkerTable,\n events_doc,\n graph_doc,\n individual_doc,\n individual_profile_doc,\n individual_profile_server_doc,\n profile_doc,\n profile_server_doc,\n status_doc,\n stealing_doc,\n systemmonitor_doc,\n tasks_doc,\n workers_doc,\n)\nfrom .core import BokehApplication\nfrom .worker import counters_doc\n\ntemplate_variables = {\n \"pages\": [\"status\", \"workers\", \"tasks\", \"system\", \"profile\", \"graph\", \"info\"]\n}\n\nif NVML_ENABLED:\n template_variables[\"pages\"].insert(4, \"gpu\")\n\n\ndef connect(application, http_server, scheduler, prefix=\"\"):\n bokeh_app = BokehApplication(\n applications, scheduler, prefix=prefix, template_variables=template_variables\n )\n application.add_application(bokeh_app)\n bokeh_app.initialize(IOLoop.current())\n\n bokeh_app.add_handlers(\n r\".*\",\n [\n (\n r\"/\",\n web.RedirectHandler,\n {\"url\": urljoin((prefix or \"\").strip(\"/\") + \"/\", r\"status\")},\n )\n ],\n )\n\n\napplications = {\n \"/system\": systemmonitor_doc,\n \"/stealing\": stealing_doc,\n \"/workers\": workers_doc,\n \"/events\": events_doc,\n \"/counters\": counters_doc,\n \"/tasks\": tasks_doc,\n \"/status\": status_doc,\n \"/profile\": profile_doc,\n \"/profile-server\": profile_server_doc,\n \"/graph\": graph_doc,\n \"/gpu\": gpu_doc,\n \"/individual-task-stream\": individual_doc(\n TaskStream, 100, n_rectangles=1000, clear_interval=\"10s\"\n ),\n \"/individual-progress\": individual_doc(TaskProgress, 100, height=160),\n \"/individual-graph\": individual_doc(TaskGraph, 200),\n \"/individual-nbytes\": individual_doc(NBytes, 100),\n \"/individual-nbytes-cluster\": individual_doc(NBytesCluster, 100),\n \"/individual-cpu\": individual_doc(CurrentLoad, 100, fig_attr=\"cpu_figure\"),\n \"/individual-nprocessing\": individual_doc(\n CurrentLoad, 100, fig_attr=\"processing_figure\"\n ),\n \"/individual-workers\": individual_doc(WorkerTable, 500),\n \"/individual-bandwidth-types\": individual_doc(BandwidthTypes, 500),\n \"/individual-bandwidth-workers\": individual_doc(BandwidthWorkers, 500),\n \"/individual-memory-by-key\": individual_doc(MemoryByKey, 500),\n \"/individual-compute-time-per-key\": individual_doc(ComputePerKey, 500),\n \"/individual-aggregate-time-per-action\": individual_doc(AggregateAction, 500),\n \"/individual-scheduler-system\": individual_doc(SystemMonitor, 500),\n \"/individual-profile\": individual_profile_doc,\n \"/individual-profile-server\": individual_profile_server_doc,\n \"/individual-gpu-memory\": gpu_memory_doc,\n \"/individual-gpu-utilization\": gpu_utilization_doc,\n}\n", "path": "distributed/dashboard/scheduler.py"}], "after_files": [{"content": "from urllib.parse import urljoin\n\nfrom tornado import web\nfrom tornado.ioloop import IOLoop\n\ntry:\n import numpy as np\nexcept ImportError:\n np = False\n\nfrom .components.nvml import gpu_doc # noqa: 1708\nfrom .components.nvml import NVML_ENABLED, gpu_memory_doc, gpu_utilization_doc\nfrom .components.scheduler import (\n AggregateAction,\n BandwidthTypes,\n BandwidthWorkers,\n ComputePerKey,\n CurrentLoad,\n MemoryByKey,\n NBytes,\n NBytesCluster,\n Occupancy,\n SystemMonitor,\n TaskGraph,\n TaskProgress,\n TaskStream,\n WorkerTable,\n events_doc,\n graph_doc,\n individual_doc,\n individual_profile_doc,\n individual_profile_server_doc,\n profile_doc,\n profile_server_doc,\n status_doc,\n stealing_doc,\n systemmonitor_doc,\n tasks_doc,\n workers_doc,\n)\nfrom .core import BokehApplication\nfrom .worker import counters_doc\n\ntemplate_variables = {\n \"pages\": [\"status\", \"workers\", \"tasks\", \"system\", \"profile\", \"graph\", \"info\"]\n}\n\nif NVML_ENABLED:\n template_variables[\"pages\"].insert(4, \"gpu\")\n\n\ndef connect(application, http_server, scheduler, prefix=\"\"):\n bokeh_app = BokehApplication(\n applications, scheduler, prefix=prefix, template_variables=template_variables\n )\n application.add_application(bokeh_app)\n bokeh_app.initialize(IOLoop.current())\n\n bokeh_app.add_handlers(\n r\".*\",\n [\n (\n r\"/\",\n web.RedirectHandler,\n {\"url\": urljoin((prefix or \"\").strip(\"/\") + \"/\", r\"status\")},\n )\n ],\n )\n\n\napplications = {\n \"/system\": systemmonitor_doc,\n \"/stealing\": stealing_doc,\n \"/workers\": workers_doc,\n \"/events\": events_doc,\n \"/counters\": counters_doc,\n \"/tasks\": tasks_doc,\n \"/status\": status_doc,\n \"/profile\": profile_doc,\n \"/profile-server\": profile_server_doc,\n \"/graph\": graph_doc,\n \"/gpu\": gpu_doc,\n \"/individual-task-stream\": individual_doc(\n TaskStream, 100, n_rectangles=1000, clear_interval=\"10s\"\n ),\n \"/individual-progress\": individual_doc(TaskProgress, 100, height=160),\n \"/individual-graph\": individual_doc(TaskGraph, 200),\n \"/individual-nbytes\": individual_doc(NBytes, 100),\n \"/individual-nbytes-cluster\": individual_doc(NBytesCluster, 100),\n \"/individual-cpu\": individual_doc(CurrentLoad, 100, fig_attr=\"cpu_figure\"),\n \"/individual-nprocessing\": individual_doc(\n CurrentLoad, 100, fig_attr=\"processing_figure\"\n ),\n \"/individual-occupancy\": individual_doc(Occupancy, 100),\n \"/individual-workers\": individual_doc(WorkerTable, 500),\n \"/individual-bandwidth-types\": individual_doc(BandwidthTypes, 500),\n \"/individual-bandwidth-workers\": individual_doc(BandwidthWorkers, 500),\n \"/individual-memory-by-key\": individual_doc(MemoryByKey, 500),\n \"/individual-compute-time-per-key\": individual_doc(ComputePerKey, 500),\n \"/individual-aggregate-time-per-action\": individual_doc(AggregateAction, 500),\n \"/individual-scheduler-system\": individual_doc(SystemMonitor, 500),\n \"/individual-profile\": individual_profile_doc,\n \"/individual-profile-server\": individual_profile_server_doc,\n \"/individual-gpu-memory\": gpu_memory_doc,\n \"/individual-gpu-utilization\": gpu_utilization_doc,\n}\n", "path": "distributed/dashboard/scheduler.py"}]}
| 1,460 | 190 |
gh_patches_debug_39285
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-2310
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`ifelse` should behave like a ternary expression
Currently, our conditional `ifelse` operator just sets dependencies in a particular way, but always returns `None`. It would feel much more natural if it returned a task object whose value at runtime behaved like a standard `x = condition ? if_true : if_false` expression
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/tasks/control_flow/conditional.py`
Content:
```
1 from typing import Any, Dict
2
3 import prefect
4 from prefect import Task
5 from prefect.engine import signals
6
7 __all__ = ["switch", "ifelse"]
8
9
10 class Merge(Task):
11 def __init__(self, **kwargs) -> None:
12 if kwargs.setdefault("skip_on_upstream_skip", False):
13 raise ValueError("Merge tasks must have `skip_on_upstream_skip=False`.")
14 kwargs.setdefault("trigger", prefect.triggers.not_all_skipped)
15 super().__init__(**kwargs)
16
17 def run(self, **task_results: Any) -> Any:
18 return next(
19 (v for k, v in sorted(task_results.items()) if v is not None), None,
20 )
21
22
23 class CompareValue(Task):
24 """
25 This task stores a `value` at initialization and compares it to a `value` received at runtime.
26 If the values don't match, it raises a SKIP exception.
27
28 Args:
29 - value (Any): the value this task will attempt to match when it runs
30 - **kwargs: keyword arguments for the Task
31 """
32
33 def __init__(self, value: Any, **kwargs: Any):
34 self.value = value
35 kwargs.setdefault("name", 'CompareValue: "{}"'.format(value))
36 super().__init__(**kwargs)
37
38 def run(self, value: Any) -> None:
39 """
40 Raises a SKIP signal if the passed value does not match the task's match value;
41 succeeds silently otherwise.
42
43 Args:
44 - value (Any): the value that will be matched against the task's value.
45 """
46 if value != self.value:
47 raise signals.SKIP(
48 'Provided value "{}" did not match "{}"'.format(value, self.value)
49 )
50
51
52 def switch(condition: Task, cases: Dict[Any, Task]) -> None:
53 """
54 Adds a SWITCH to a workflow.
55
56 The condition task is evaluated and the result is compared to the keys of the cases
57 dictionary. The task corresponding to the matching key is run; all other tasks are
58 skipped. Any tasks downstream of the skipped tasks are also skipped unless they set
59 `skip_on_upstream_skip=False`.
60
61 Example:
62 ```python
63 @task
64 def condition():
65 return "b" # returning 'b' will take the b_branch
66
67 @task
68 def a_branch():
69 return "A Branch"
70
71 @task
72 def b_branch():
73 return "B Branch"
74
75 with Flow("switch-flow") as flow:
76 switch(condition, dict(a=a_branch, b=b_branch))
77 ```
78
79 Args:
80 - condition (Task): a task whose result forms the condition for the switch
81 - cases (Dict[Any, Task]): a dict representing the "case" statements of the switch.
82 The value of the `condition` task will be compared to the keys of this dict, and
83 the matching task will be executed.
84
85 Raises:
86 - PrefectWarning: if any of the tasks in "cases" have upstream dependencies,
87 then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this
88 is passing a list of tasks as one of the cases, which adds the `List` task
89 to the switch condition but leaves the tasks themselves upstream.
90 """
91
92 with prefect.tags("switch"):
93 for value, task in cases.items():
94 task = prefect.utilities.tasks.as_task(task)
95 match_condition = CompareValue(value=value).bind(value=condition)
96 task.set_dependencies(upstream_tasks=[match_condition])
97
98
99 def ifelse(condition: Task, true_task: Task, false_task: Task) -> None:
100 """
101 Builds a conditional branch into a workflow.
102
103 If the condition evaluates True(ish), the true_task will run. If it
104 evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are
105 all downstream tasks that don't set `skip_on_upstream_skip=False`.
106
107 Args:
108 - condition (Task): a task whose boolean result forms the condition for the ifelse
109 - true_task (Task): a task that will be executed if the condition is True
110 - false_task (Task): a task that will be executed if the condition is False
111 """
112
113 @prefect.task
114 def as_bool(x):
115 return bool(x)
116
117 switch(condition=as_bool(condition), cases={True: true_task, False: false_task})
118
119
120 def merge(*tasks: Task) -> Task:
121 """
122 Merges conditional branches back together.
123
124 A conditional branch in a flow results in one or more tasks proceeding and one or
125 more tasks skipping. It is often convenient to merge those branches back into a
126 single result. This function is a simple way to achieve that goal. By default this
127 task will skip if all its upstream dependencies are also skipped.
128
129 The merge will return the first real result it encounters, or `None`. If multiple
130 tasks might return a result, group them with a list.
131
132 Example:
133 ```python
134 with Flow("My Flow"):
135 true_branch = ActionIfTrue()
136 false_branch = ActionIfFalse()
137 ifelse(CheckCondition(), true_branch, false_branch)
138
139 merged_result = merge(true_branch, false_branch)
140 ```
141
142 Args:
143 - *tasks (Task): tasks whose results should be merged into a single result. The tasks are
144 assumed to all sit downstream of different `switch` branches, such that only
145 one of them will contain a result and the others will all be skipped.
146
147 Returns:
148 - Task: a Task representing the merged result.
149
150 """
151 return Merge().bind(**{"task_{}".format(i + 1): t for i, t in enumerate(tasks)})
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/tasks/control_flow/conditional.py b/src/prefect/tasks/control_flow/conditional.py
--- a/src/prefect/tasks/control_flow/conditional.py
+++ b/src/prefect/tasks/control_flow/conditional.py
@@ -82,11 +82,16 @@
The value of the `condition` task will be compared to the keys of this dict, and
the matching task will be executed.
+ Returns:
+ - Task: a task whose result is the output from the task executed by this switch
+
Raises:
- PrefectWarning: if any of the tasks in "cases" have upstream dependencies,
- then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this
- is passing a list of tasks as one of the cases, which adds the `List` task
- to the switch condition but leaves the tasks themselves upstream.
+ then this task will warn that those upstream tasks may run whether
+ or not the switch condition matches their branch. The most common
+ cause of this is passing a list of tasks as one of the cases, which
+ adds the `List` task to the switch condition but leaves the tasks
+ themselves upstream.
"""
with prefect.tags("switch"):
@@ -94,6 +99,7 @@
task = prefect.utilities.tasks.as_task(task)
match_condition = CompareValue(value=value).bind(value=condition)
task.set_dependencies(upstream_tasks=[match_condition])
+ return merge(*cases.values())
def ifelse(condition: Task, true_task: Task, false_task: Task) -> None:
@@ -101,20 +107,26 @@
Builds a conditional branch into a workflow.
If the condition evaluates True(ish), the true_task will run. If it
- evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are
- all downstream tasks that don't set `skip_on_upstream_skip=False`.
+ evaluates False(ish), the false_task will run. The task that doesn't run is
+ Skipped, as are all downstream tasks that don't set
+ `skip_on_upstream_skip=False`.
Args:
- condition (Task): a task whose boolean result forms the condition for the ifelse
- true_task (Task): a task that will be executed if the condition is True
- false_task (Task): a task that will be executed if the condition is False
+
+ Returns:
+ - Task: a task whose result is the output from the task executed by this ifelse
"""
@prefect.task
def as_bool(x):
return bool(x)
- switch(condition=as_bool(condition), cases={True: true_task, False: false_task})
+ return switch(
+ condition=as_bool(condition), cases={True: true_task, False: false_task}
+ )
def merge(*tasks: Task) -> Task:
|
{"golden_diff": "diff --git a/src/prefect/tasks/control_flow/conditional.py b/src/prefect/tasks/control_flow/conditional.py\n--- a/src/prefect/tasks/control_flow/conditional.py\n+++ b/src/prefect/tasks/control_flow/conditional.py\n@@ -82,11 +82,16 @@\n The value of the `condition` task will be compared to the keys of this dict, and\n the matching task will be executed.\n \n+ Returns:\n+ - Task: a task whose result is the output from the task executed by this switch\n+\n Raises:\n - PrefectWarning: if any of the tasks in \"cases\" have upstream dependencies,\n- then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this\n- is passing a list of tasks as one of the cases, which adds the `List` task\n- to the switch condition but leaves the tasks themselves upstream.\n+ then this task will warn that those upstream tasks may run whether\n+ or not the switch condition matches their branch. The most common\n+ cause of this is passing a list of tasks as one of the cases, which\n+ adds the `List` task to the switch condition but leaves the tasks\n+ themselves upstream.\n \"\"\"\n \n with prefect.tags(\"switch\"):\n@@ -94,6 +99,7 @@\n task = prefect.utilities.tasks.as_task(task)\n match_condition = CompareValue(value=value).bind(value=condition)\n task.set_dependencies(upstream_tasks=[match_condition])\n+ return merge(*cases.values())\n \n \n def ifelse(condition: Task, true_task: Task, false_task: Task) -> None:\n@@ -101,20 +107,26 @@\n Builds a conditional branch into a workflow.\n \n If the condition evaluates True(ish), the true_task will run. If it\n- evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are\n- all downstream tasks that don't set `skip_on_upstream_skip=False`.\n+ evaluates False(ish), the false_task will run. The task that doesn't run is\n+ Skipped, as are all downstream tasks that don't set\n+ `skip_on_upstream_skip=False`.\n \n Args:\n - condition (Task): a task whose boolean result forms the condition for the ifelse\n - true_task (Task): a task that will be executed if the condition is True\n - false_task (Task): a task that will be executed if the condition is False\n+\n+ Returns:\n+ - Task: a task whose result is the output from the task executed by this ifelse\n \"\"\"\n \n @prefect.task\n def as_bool(x):\n return bool(x)\n \n- switch(condition=as_bool(condition), cases={True: true_task, False: false_task})\n+ return switch(\n+ condition=as_bool(condition), cases={True: true_task, False: false_task}\n+ )\n \n \n def merge(*tasks: Task) -> Task:\n", "issue": "`ifelse` should behave like a ternary expression\nCurrently, our conditional `ifelse` operator just sets dependencies in a particular way, but always returns `None`. It would feel much more natural if it returned a task object whose value at runtime behaved like a standard `x = condition ? if_true : if_false` expression\n", "before_files": [{"content": "from typing import Any, Dict\n\nimport prefect\nfrom prefect import Task\nfrom prefect.engine import signals\n\n__all__ = [\"switch\", \"ifelse\"]\n\n\nclass Merge(Task):\n def __init__(self, **kwargs) -> None:\n if kwargs.setdefault(\"skip_on_upstream_skip\", False):\n raise ValueError(\"Merge tasks must have `skip_on_upstream_skip=False`.\")\n kwargs.setdefault(\"trigger\", prefect.triggers.not_all_skipped)\n super().__init__(**kwargs)\n\n def run(self, **task_results: Any) -> Any:\n return next(\n (v for k, v in sorted(task_results.items()) if v is not None), None,\n )\n\n\nclass CompareValue(Task):\n \"\"\"\n This task stores a `value` at initialization and compares it to a `value` received at runtime.\n If the values don't match, it raises a SKIP exception.\n\n Args:\n - value (Any): the value this task will attempt to match when it runs\n - **kwargs: keyword arguments for the Task\n \"\"\"\n\n def __init__(self, value: Any, **kwargs: Any):\n self.value = value\n kwargs.setdefault(\"name\", 'CompareValue: \"{}\"'.format(value))\n super().__init__(**kwargs)\n\n def run(self, value: Any) -> None:\n \"\"\"\n Raises a SKIP signal if the passed value does not match the task's match value;\n succeeds silently otherwise.\n\n Args:\n - value (Any): the value that will be matched against the task's value.\n \"\"\"\n if value != self.value:\n raise signals.SKIP(\n 'Provided value \"{}\" did not match \"{}\"'.format(value, self.value)\n )\n\n\ndef switch(condition: Task, cases: Dict[Any, Task]) -> None:\n \"\"\"\n Adds a SWITCH to a workflow.\n\n The condition task is evaluated and the result is compared to the keys of the cases\n dictionary. The task corresponding to the matching key is run; all other tasks are\n skipped. Any tasks downstream of the skipped tasks are also skipped unless they set\n `skip_on_upstream_skip=False`.\n\n Example:\n ```python\n @task\n def condition():\n return \"b\" # returning 'b' will take the b_branch\n\n @task\n def a_branch():\n return \"A Branch\"\n\n @task\n def b_branch():\n return \"B Branch\"\n\n with Flow(\"switch-flow\") as flow:\n switch(condition, dict(a=a_branch, b=b_branch))\n ```\n\n Args:\n - condition (Task): a task whose result forms the condition for the switch\n - cases (Dict[Any, Task]): a dict representing the \"case\" statements of the switch.\n The value of the `condition` task will be compared to the keys of this dict, and\n the matching task will be executed.\n\n Raises:\n - PrefectWarning: if any of the tasks in \"cases\" have upstream dependencies,\n then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this\n is passing a list of tasks as one of the cases, which adds the `List` task\n to the switch condition but leaves the tasks themselves upstream.\n \"\"\"\n\n with prefect.tags(\"switch\"):\n for value, task in cases.items():\n task = prefect.utilities.tasks.as_task(task)\n match_condition = CompareValue(value=value).bind(value=condition)\n task.set_dependencies(upstream_tasks=[match_condition])\n\n\ndef ifelse(condition: Task, true_task: Task, false_task: Task) -> None:\n \"\"\"\n Builds a conditional branch into a workflow.\n\n If the condition evaluates True(ish), the true_task will run. If it\n evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are\n all downstream tasks that don't set `skip_on_upstream_skip=False`.\n\n Args:\n - condition (Task): a task whose boolean result forms the condition for the ifelse\n - true_task (Task): a task that will be executed if the condition is True\n - false_task (Task): a task that will be executed if the condition is False\n \"\"\"\n\n @prefect.task\n def as_bool(x):\n return bool(x)\n\n switch(condition=as_bool(condition), cases={True: true_task, False: false_task})\n\n\ndef merge(*tasks: Task) -> Task:\n \"\"\"\n Merges conditional branches back together.\n\n A conditional branch in a flow results in one or more tasks proceeding and one or\n more tasks skipping. It is often convenient to merge those branches back into a\n single result. This function is a simple way to achieve that goal. By default this\n task will skip if all its upstream dependencies are also skipped.\n\n The merge will return the first real result it encounters, or `None`. If multiple\n tasks might return a result, group them with a list.\n\n Example:\n ```python\n with Flow(\"My Flow\"):\n true_branch = ActionIfTrue()\n false_branch = ActionIfFalse()\n ifelse(CheckCondition(), true_branch, false_branch)\n\n merged_result = merge(true_branch, false_branch)\n ```\n\n Args:\n - *tasks (Task): tasks whose results should be merged into a single result. The tasks are\n assumed to all sit downstream of different `switch` branches, such that only\n one of them will contain a result and the others will all be skipped.\n\n Returns:\n - Task: a Task representing the merged result.\n\n \"\"\"\n return Merge().bind(**{\"task_{}\".format(i + 1): t for i, t in enumerate(tasks)})\n", "path": "src/prefect/tasks/control_flow/conditional.py"}], "after_files": [{"content": "from typing import Any, Dict\n\nimport prefect\nfrom prefect import Task\nfrom prefect.engine import signals\n\n__all__ = [\"switch\", \"ifelse\"]\n\n\nclass Merge(Task):\n def __init__(self, **kwargs) -> None:\n if kwargs.setdefault(\"skip_on_upstream_skip\", False):\n raise ValueError(\"Merge tasks must have `skip_on_upstream_skip=False`.\")\n kwargs.setdefault(\"trigger\", prefect.triggers.not_all_skipped)\n super().__init__(**kwargs)\n\n def run(self, **task_results: Any) -> Any:\n return next(\n (v for k, v in sorted(task_results.items()) if v is not None), None,\n )\n\n\nclass CompareValue(Task):\n \"\"\"\n This task stores a `value` at initialization and compares it to a `value` received at runtime.\n If the values don't match, it raises a SKIP exception.\n\n Args:\n - value (Any): the value this task will attempt to match when it runs\n - **kwargs: keyword arguments for the Task\n \"\"\"\n\n def __init__(self, value: Any, **kwargs: Any):\n self.value = value\n kwargs.setdefault(\"name\", 'CompareValue: \"{}\"'.format(value))\n super().__init__(**kwargs)\n\n def run(self, value: Any) -> None:\n \"\"\"\n Raises a SKIP signal if the passed value does not match the task's match value;\n succeeds silently otherwise.\n\n Args:\n - value (Any): the value that will be matched against the task's value.\n \"\"\"\n if value != self.value:\n raise signals.SKIP(\n 'Provided value \"{}\" did not match \"{}\"'.format(value, self.value)\n )\n\n\ndef switch(condition: Task, cases: Dict[Any, Task]) -> None:\n \"\"\"\n Adds a SWITCH to a workflow.\n\n The condition task is evaluated and the result is compared to the keys of the cases\n dictionary. The task corresponding to the matching key is run; all other tasks are\n skipped. Any tasks downstream of the skipped tasks are also skipped unless they set\n `skip_on_upstream_skip=False`.\n\n Example:\n ```python\n @task\n def condition():\n return \"b\" # returning 'b' will take the b_branch\n\n @task\n def a_branch():\n return \"A Branch\"\n\n @task\n def b_branch():\n return \"B Branch\"\n\n with Flow(\"switch-flow\") as flow:\n switch(condition, dict(a=a_branch, b=b_branch))\n ```\n\n Args:\n - condition (Task): a task whose result forms the condition for the switch\n - cases (Dict[Any, Task]): a dict representing the \"case\" statements of the switch.\n The value of the `condition` task will be compared to the keys of this dict, and\n the matching task will be executed.\n\n Returns:\n - Task: a task whose result is the output from the task executed by this switch\n\n Raises:\n - PrefectWarning: if any of the tasks in \"cases\" have upstream dependencies,\n then this task will warn that those upstream tasks may run whether\n or not the switch condition matches their branch. The most common\n cause of this is passing a list of tasks as one of the cases, which\n adds the `List` task to the switch condition but leaves the tasks\n themselves upstream.\n \"\"\"\n\n with prefect.tags(\"switch\"):\n for value, task in cases.items():\n task = prefect.utilities.tasks.as_task(task)\n match_condition = CompareValue(value=value).bind(value=condition)\n task.set_dependencies(upstream_tasks=[match_condition])\n return merge(*cases.values())\n\n\ndef ifelse(condition: Task, true_task: Task, false_task: Task) -> None:\n \"\"\"\n Builds a conditional branch into a workflow.\n\n If the condition evaluates True(ish), the true_task will run. If it\n evaluates False(ish), the false_task will run. The task that doesn't run is\n Skipped, as are all downstream tasks that don't set\n `skip_on_upstream_skip=False`.\n\n Args:\n - condition (Task): a task whose boolean result forms the condition for the ifelse\n - true_task (Task): a task that will be executed if the condition is True\n - false_task (Task): a task that will be executed if the condition is False\n\n Returns:\n - Task: a task whose result is the output from the task executed by this ifelse\n \"\"\"\n\n @prefect.task\n def as_bool(x):\n return bool(x)\n\n return switch(\n condition=as_bool(condition), cases={True: true_task, False: false_task}\n )\n\n\ndef merge(*tasks: Task) -> Task:\n \"\"\"\n Merges conditional branches back together.\n\n A conditional branch in a flow results in one or more tasks proceeding and one or\n more tasks skipping. It is often convenient to merge those branches back into a\n single result. This function is a simple way to achieve that goal. By default this\n task will skip if all its upstream dependencies are also skipped.\n\n The merge will return the first real result it encounters, or `None`. If multiple\n tasks might return a result, group them with a list.\n\n Example:\n ```python\n with Flow(\"My Flow\"):\n true_branch = ActionIfTrue()\n false_branch = ActionIfFalse()\n ifelse(CheckCondition(), true_branch, false_branch)\n\n merged_result = merge(true_branch, false_branch)\n ```\n\n Args:\n - *tasks (Task): tasks whose results should be merged into a single result. The tasks are\n assumed to all sit downstream of different `switch` branches, such that only\n one of them will contain a result and the others will all be skipped.\n\n Returns:\n - Task: a Task representing the merged result.\n\n \"\"\"\n return Merge().bind(**{\"task_{}\".format(i + 1): t for i, t in enumerate(tasks)})\n", "path": "src/prefect/tasks/control_flow/conditional.py"}]}
| 1,921 | 665 |
gh_patches_debug_3457
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-1896
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
vae comparison example giving different results for Pyro and PyTorch implementations
Hi,
Pyro version: 3.3
PyTorch: 1.1
Running `examples/vae/vae_comparison.py`
With PyTorch:
```
downloading data
download complete.
downloading data
download complete.
Running PyTorch VAE implementation
====> Epoch: 0
Training loss: 0.0022
Test set loss: 0.0027
====> Epoch: 1
Training loss: 0.0021
Test set loss: 0.0024
====> Epoch: 2
Training loss: 0.0021
Test set loss: 0.0022
====> Epoch: 3
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 4
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 5
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 6
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 7
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 8
Training loss: 0.0021
Test set loss: 0.0021
====> Epoch: 9
Training loss: 0.0021
Test set loss: 0.0021
```
With Pyro:
```
downloading data
download complete.
downloading data
download complete.
Running Pyro VAE implementation
====> Epoch: 0
Training loss: 0.0017
Test set loss: 0.0013
====> Epoch: 1
Training loss: 0.0012
Test set loss: 0.0012
====> Epoch: 2
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 3
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 4
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 5
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 6
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 7
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 8
Training loss: 0.0011
Test set loss: 0.0011
====> Epoch: 9
Training loss: 0.0011
Test set loss: 0.0011
```
Is this difference expected?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/vae/vae_comparison.py`
Content:
```
1 import argparse
2 import itertools
3 import os
4 from abc import ABCMeta, abstractmethod
5
6 import torch
7 import torch.nn as nn
8 from six import add_metaclass
9 from torch.nn import functional
10 from torchvision.utils import save_image
11
12 import pyro
13 from pyro.contrib.examples import util
14 from pyro.distributions import Bernoulli, Normal
15 from pyro.infer import SVI, JitTrace_ELBO, Trace_ELBO
16 from pyro.optim import Adam
17 from utils.mnist_cached import DATA_DIR, RESULTS_DIR
18
19 """
20 Comparison of VAE implementation in PyTorch and Pyro. This example can be
21 used for profiling purposes.
22
23 The PyTorch VAE example is taken (with minor modification) from pytorch/examples.
24 Source: https://github.com/pytorch/examples/tree/master/vae
25 """
26
27 TRAIN = 'train'
28 TEST = 'test'
29 OUTPUT_DIR = RESULTS_DIR
30
31
32 # VAE encoder network
33 class Encoder(nn.Module):
34 def __init__(self):
35 super(Encoder, self).__init__()
36 self.fc1 = nn.Linear(784, 400)
37 self.fc21 = nn.Linear(400, 20)
38 self.fc22 = nn.Linear(400, 20)
39 self.relu = nn.ReLU()
40
41 def forward(self, x):
42 x = x.reshape(-1, 784)
43 h1 = self.relu(self.fc1(x))
44 return self.fc21(h1), torch.exp(self.fc22(h1))
45
46
47 # VAE Decoder network
48 class Decoder(nn.Module):
49 def __init__(self):
50 super(Decoder, self).__init__()
51 self.fc3 = nn.Linear(20, 400)
52 self.fc4 = nn.Linear(400, 784)
53 self.relu = nn.ReLU()
54
55 def forward(self, z):
56 h3 = self.relu(self.fc3(z))
57 return torch.sigmoid(self.fc4(h3))
58
59
60 @add_metaclass(ABCMeta)
61 class VAE(object):
62 """
63 Abstract class for the variational auto-encoder. The abstract method
64 for training the network is implemented by subclasses.
65 """
66
67 def __init__(self, args, train_loader, test_loader):
68 self.args = args
69 self.vae_encoder = Encoder()
70 self.vae_decoder = Decoder()
71 self.train_loader = train_loader
72 self.test_loader = test_loader
73 self.mode = TRAIN
74
75 def set_train(self, is_train=True):
76 if is_train:
77 self.mode = TRAIN
78 self.vae_encoder.train()
79 self.vae_decoder.train()
80 else:
81 self.mode = TEST
82 self.vae_encoder.eval()
83 self.vae_decoder.eval()
84
85 @abstractmethod
86 def compute_loss_and_gradient(self, x):
87 """
88 Given a batch of data `x`, run the optimizer (backpropagate the gradient),
89 and return the computed loss.
90
91 :param x: batch of data or a single datum (MNIST image).
92 :return: loss computed on the data batch.
93 """
94 return
95
96 def model_eval(self, x):
97 """
98 Given a batch of data `x`, run it through the trained VAE network to get
99 the reconstructed image.
100
101 :param x: batch of data or a single datum (MNIST image).
102 :return: reconstructed image, and the latent z's mean and variance.
103 """
104 z_mean, z_var = self.vae_encoder(x)
105 if self.mode == TRAIN:
106 z = Normal(z_mean, z_var.sqrt()).sample()
107 else:
108 z = z_mean
109 return self.vae_decoder(z), z_mean, z_var
110
111 def train(self, epoch):
112 self.set_train(is_train=True)
113 train_loss = 0
114 for batch_idx, (x, _) in enumerate(self.train_loader):
115 loss = self.compute_loss_and_gradient(x)
116 train_loss += loss
117 print('====> Epoch: {} \nTraining loss: {:.4f}'.format(
118 epoch, train_loss / len(self.train_loader.dataset)))
119
120 def test(self, epoch):
121 self.set_train(is_train=False)
122 test_loss = 0
123 for i, (x, _) in enumerate(self.test_loader):
124 with torch.no_grad():
125 recon_x = self.model_eval(x)[0]
126 test_loss += self.compute_loss_and_gradient(x)
127 if i == 0:
128 n = min(x.size(0), 8)
129 comparison = torch.cat([x[:n],
130 recon_x.reshape(self.args.batch_size, 1, 28, 28)[:n]])
131 save_image(comparison.detach().cpu(),
132 os.path.join(OUTPUT_DIR, 'reconstruction_' + str(epoch) + '.png'),
133 nrow=n)
134
135 test_loss /= len(self.test_loader.dataset)
136 print('Test set loss: {:.4f}'.format(test_loss))
137
138
139 class PyTorchVAEImpl(VAE):
140 """
141 Adapted from pytorch/examples.
142 Source: https://github.com/pytorch/examples/tree/master/vae
143 """
144
145 def __init__(self, *args, **kwargs):
146 super(PyTorchVAEImpl, self).__init__(*args, **kwargs)
147 self.optimizer = self.initialize_optimizer(lr=1e-3)
148
149 def compute_loss_and_gradient(self, x):
150 self.optimizer.zero_grad()
151 recon_x, z_mean, z_var = self.model_eval(x)
152 binary_cross_entropy = functional.binary_cross_entropy(recon_x, x.reshape(-1, 784))
153 # Uses analytical KL divergence expression for D_kl(q(z|x) || p(z))
154 # Refer to Appendix B from VAE paper:
155 # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
156 # (https://arxiv.org/abs/1312.6114)
157 kl_div = -0.5 * torch.sum(1 + z_var.log() - z_mean.pow(2) - z_var)
158 kl_div /= self.args.batch_size * 784
159 loss = binary_cross_entropy + kl_div
160 if self.mode == TRAIN:
161 loss.backward()
162 self.optimizer.step()
163 return loss.item()
164
165 def initialize_optimizer(self, lr=1e-3):
166 model_params = itertools.chain(self.vae_encoder.parameters(), self.vae_decoder.parameters())
167 return torch.optim.Adam(model_params, lr)
168
169
170 class PyroVAEImpl(VAE):
171 """
172 Implementation of VAE using Pyro. Only the model and the guide specification
173 is needed to run the optimizer (the objective function does not need to be
174 specified as in the PyTorch implementation).
175 """
176
177 def __init__(self, *args, **kwargs):
178 super(PyroVAEImpl, self).__init__(*args, **kwargs)
179 self.optimizer = self.initialize_optimizer(lr=1e-3)
180
181 def model(self, data):
182 decoder = pyro.module('decoder', self.vae_decoder)
183 z_mean, z_std = torch.zeros([data.size(0), 20]), torch.ones([data.size(0), 20])
184 with pyro.plate('data', data.size(0)):
185 z = pyro.sample('latent', Normal(z_mean, z_std).to_event(1))
186 img = decoder.forward(z)
187 pyro.sample('obs',
188 Bernoulli(img).to_event(1),
189 obs=data.reshape(-1, 784))
190
191 def guide(self, data):
192 encoder = pyro.module('encoder', self.vae_encoder)
193 with pyro.plate('data', data.size(0)):
194 z_mean, z_var = encoder.forward(data)
195 pyro.sample('latent', Normal(z_mean, z_var.sqrt()).to_event(1))
196
197 def compute_loss_and_gradient(self, x):
198 if self.mode == TRAIN:
199 loss = self.optimizer.step(x)
200 else:
201 loss = self.optimizer.evaluate_loss(x)
202 loss /= self.args.batch_size * 784
203 return loss
204
205 def initialize_optimizer(self, lr):
206 optimizer = Adam({'lr': lr})
207 elbo = JitTrace_ELBO() if self.args.jit else Trace_ELBO()
208 return SVI(self.model, self.guide, optimizer, loss=elbo)
209
210
211 def setup(args):
212 pyro.set_rng_seed(args.rng_seed)
213 train_loader = util.get_data_loader(dataset_name='MNIST',
214 data_dir=DATA_DIR,
215 batch_size=args.batch_size,
216 is_training_set=True,
217 shuffle=True)
218 test_loader = util.get_data_loader(dataset_name='MNIST',
219 data_dir=DATA_DIR,
220 batch_size=args.batch_size,
221 is_training_set=False,
222 shuffle=True)
223 global OUTPUT_DIR
224 OUTPUT_DIR = os.path.join(RESULTS_DIR, args.impl)
225 if not os.path.exists(OUTPUT_DIR):
226 os.makedirs(OUTPUT_DIR)
227 pyro.clear_param_store()
228 return train_loader, test_loader
229
230
231 def main(args):
232 train_loader, test_loader = setup(args)
233 if args.impl == 'pyro':
234 vae = PyroVAEImpl(args, train_loader, test_loader)
235 print('Running Pyro VAE implementation')
236 elif args.impl == 'pytorch':
237 vae = PyTorchVAEImpl(args, train_loader, test_loader)
238 print('Running PyTorch VAE implementation')
239 else:
240 raise ValueError('Incorrect implementation specified: {}'.format(args.impl))
241 for i in range(args.num_epochs):
242 vae.train(i)
243 if not args.skip_eval:
244 vae.test(i)
245
246
247 if __name__ == '__main__':
248 assert pyro.__version__.startswith('0.3.3')
249 parser = argparse.ArgumentParser(description='VAE using MNIST dataset')
250 parser.add_argument('-n', '--num-epochs', nargs='?', default=10, type=int)
251 parser.add_argument('--batch_size', nargs='?', default=128, type=int)
252 parser.add_argument('--rng_seed', nargs='?', default=0, type=int)
253 parser.add_argument('--impl', nargs='?', default='pyro', type=str)
254 parser.add_argument('--skip_eval', action='store_true')
255 parser.add_argument('--jit', action='store_true')
256 parser.set_defaults(skip_eval=False)
257 args = parser.parse_args()
258 main(args)
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/vae/vae_comparison.py b/examples/vae/vae_comparison.py
--- a/examples/vae/vae_comparison.py
+++ b/examples/vae/vae_comparison.py
@@ -103,7 +103,7 @@
"""
z_mean, z_var = self.vae_encoder(x)
if self.mode == TRAIN:
- z = Normal(z_mean, z_var.sqrt()).sample()
+ z = Normal(z_mean, z_var.sqrt()).rsample()
else:
z = z_mean
return self.vae_decoder(z), z_mean, z_var
|
{"golden_diff": "diff --git a/examples/vae/vae_comparison.py b/examples/vae/vae_comparison.py\n--- a/examples/vae/vae_comparison.py\n+++ b/examples/vae/vae_comparison.py\n@@ -103,7 +103,7 @@\n \"\"\"\n z_mean, z_var = self.vae_encoder(x)\n if self.mode == TRAIN:\n- z = Normal(z_mean, z_var.sqrt()).sample()\n+ z = Normal(z_mean, z_var.sqrt()).rsample()\n else:\n z = z_mean\n return self.vae_decoder(z), z_mean, z_var\n", "issue": "vae comparison example giving different results for Pyro and PyTorch implementations\nHi,\r\n\r\nPyro version: 3.3\r\nPyTorch: 1.1\r\n\r\nRunning `examples/vae/vae_comparison.py`\r\n\r\nWith PyTorch:\r\n\r\n```\r\ndownloading data\r\ndownload complete.\r\ndownloading data\r\ndownload complete.\r\nRunning PyTorch VAE implementation\r\n====> Epoch: 0 \r\nTraining loss: 0.0022\r\nTest set loss: 0.0027\r\n====> Epoch: 1 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0024\r\n====> Epoch: 2 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0022\r\n====> Epoch: 3 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 4 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 5 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 6 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 7 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 8 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n====> Epoch: 9 \r\nTraining loss: 0.0021\r\nTest set loss: 0.0021\r\n```\r\n\r\nWith Pyro:\r\n\r\n```\r\ndownloading data\r\ndownload complete.\r\ndownloading data\r\ndownload complete.\r\nRunning Pyro VAE implementation\r\n====> Epoch: 0 \r\nTraining loss: 0.0017\r\nTest set loss: 0.0013\r\n====> Epoch: 1 \r\nTraining loss: 0.0012\r\nTest set loss: 0.0012\r\n====> Epoch: 2 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 3 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 4 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 5 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 6 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 7 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 8 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n====> Epoch: 9 \r\nTraining loss: 0.0011\r\nTest set loss: 0.0011\r\n```\r\n\r\nIs this difference expected?\n", "before_files": [{"content": "import argparse\nimport itertools\nimport os\nfrom abc import ABCMeta, abstractmethod\n\nimport torch\nimport torch.nn as nn\nfrom six import add_metaclass\nfrom torch.nn import functional\nfrom torchvision.utils import save_image\n\nimport pyro\nfrom pyro.contrib.examples import util\nfrom pyro.distributions import Bernoulli, Normal\nfrom pyro.infer import SVI, JitTrace_ELBO, Trace_ELBO\nfrom pyro.optim import Adam\nfrom utils.mnist_cached import DATA_DIR, RESULTS_DIR\n\n\"\"\"\nComparison of VAE implementation in PyTorch and Pyro. This example can be\nused for profiling purposes.\n\nThe PyTorch VAE example is taken (with minor modification) from pytorch/examples.\nSource: https://github.com/pytorch/examples/tree/master/vae\n\"\"\"\n\nTRAIN = 'train'\nTEST = 'test'\nOUTPUT_DIR = RESULTS_DIR\n\n\n# VAE encoder network\nclass Encoder(nn.Module):\n def __init__(self):\n super(Encoder, self).__init__()\n self.fc1 = nn.Linear(784, 400)\n self.fc21 = nn.Linear(400, 20)\n self.fc22 = nn.Linear(400, 20)\n self.relu = nn.ReLU()\n\n def forward(self, x):\n x = x.reshape(-1, 784)\n h1 = self.relu(self.fc1(x))\n return self.fc21(h1), torch.exp(self.fc22(h1))\n\n\n# VAE Decoder network\nclass Decoder(nn.Module):\n def __init__(self):\n super(Decoder, self).__init__()\n self.fc3 = nn.Linear(20, 400)\n self.fc4 = nn.Linear(400, 784)\n self.relu = nn.ReLU()\n\n def forward(self, z):\n h3 = self.relu(self.fc3(z))\n return torch.sigmoid(self.fc4(h3))\n\n\n@add_metaclass(ABCMeta)\nclass VAE(object):\n \"\"\"\n Abstract class for the variational auto-encoder. The abstract method\n for training the network is implemented by subclasses.\n \"\"\"\n\n def __init__(self, args, train_loader, test_loader):\n self.args = args\n self.vae_encoder = Encoder()\n self.vae_decoder = Decoder()\n self.train_loader = train_loader\n self.test_loader = test_loader\n self.mode = TRAIN\n\n def set_train(self, is_train=True):\n if is_train:\n self.mode = TRAIN\n self.vae_encoder.train()\n self.vae_decoder.train()\n else:\n self.mode = TEST\n self.vae_encoder.eval()\n self.vae_decoder.eval()\n\n @abstractmethod\n def compute_loss_and_gradient(self, x):\n \"\"\"\n Given a batch of data `x`, run the optimizer (backpropagate the gradient),\n and return the computed loss.\n\n :param x: batch of data or a single datum (MNIST image).\n :return: loss computed on the data batch.\n \"\"\"\n return\n\n def model_eval(self, x):\n \"\"\"\n Given a batch of data `x`, run it through the trained VAE network to get\n the reconstructed image.\n\n :param x: batch of data or a single datum (MNIST image).\n :return: reconstructed image, and the latent z's mean and variance.\n \"\"\"\n z_mean, z_var = self.vae_encoder(x)\n if self.mode == TRAIN:\n z = Normal(z_mean, z_var.sqrt()).sample()\n else:\n z = z_mean\n return self.vae_decoder(z), z_mean, z_var\n\n def train(self, epoch):\n self.set_train(is_train=True)\n train_loss = 0\n for batch_idx, (x, _) in enumerate(self.train_loader):\n loss = self.compute_loss_and_gradient(x)\n train_loss += loss\n print('====> Epoch: {} \\nTraining loss: {:.4f}'.format(\n epoch, train_loss / len(self.train_loader.dataset)))\n\n def test(self, epoch):\n self.set_train(is_train=False)\n test_loss = 0\n for i, (x, _) in enumerate(self.test_loader):\n with torch.no_grad():\n recon_x = self.model_eval(x)[0]\n test_loss += self.compute_loss_and_gradient(x)\n if i == 0:\n n = min(x.size(0), 8)\n comparison = torch.cat([x[:n],\n recon_x.reshape(self.args.batch_size, 1, 28, 28)[:n]])\n save_image(comparison.detach().cpu(),\n os.path.join(OUTPUT_DIR, 'reconstruction_' + str(epoch) + '.png'),\n nrow=n)\n\n test_loss /= len(self.test_loader.dataset)\n print('Test set loss: {:.4f}'.format(test_loss))\n\n\nclass PyTorchVAEImpl(VAE):\n \"\"\"\n Adapted from pytorch/examples.\n Source: https://github.com/pytorch/examples/tree/master/vae\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(PyTorchVAEImpl, self).__init__(*args, **kwargs)\n self.optimizer = self.initialize_optimizer(lr=1e-3)\n\n def compute_loss_and_gradient(self, x):\n self.optimizer.zero_grad()\n recon_x, z_mean, z_var = self.model_eval(x)\n binary_cross_entropy = functional.binary_cross_entropy(recon_x, x.reshape(-1, 784))\n # Uses analytical KL divergence expression for D_kl(q(z|x) || p(z))\n # Refer to Appendix B from VAE paper:\n # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014\n # (https://arxiv.org/abs/1312.6114)\n kl_div = -0.5 * torch.sum(1 + z_var.log() - z_mean.pow(2) - z_var)\n kl_div /= self.args.batch_size * 784\n loss = binary_cross_entropy + kl_div\n if self.mode == TRAIN:\n loss.backward()\n self.optimizer.step()\n return loss.item()\n\n def initialize_optimizer(self, lr=1e-3):\n model_params = itertools.chain(self.vae_encoder.parameters(), self.vae_decoder.parameters())\n return torch.optim.Adam(model_params, lr)\n\n\nclass PyroVAEImpl(VAE):\n \"\"\"\n Implementation of VAE using Pyro. Only the model and the guide specification\n is needed to run the optimizer (the objective function does not need to be\n specified as in the PyTorch implementation).\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(PyroVAEImpl, self).__init__(*args, **kwargs)\n self.optimizer = self.initialize_optimizer(lr=1e-3)\n\n def model(self, data):\n decoder = pyro.module('decoder', self.vae_decoder)\n z_mean, z_std = torch.zeros([data.size(0), 20]), torch.ones([data.size(0), 20])\n with pyro.plate('data', data.size(0)):\n z = pyro.sample('latent', Normal(z_mean, z_std).to_event(1))\n img = decoder.forward(z)\n pyro.sample('obs',\n Bernoulli(img).to_event(1),\n obs=data.reshape(-1, 784))\n\n def guide(self, data):\n encoder = pyro.module('encoder', self.vae_encoder)\n with pyro.plate('data', data.size(0)):\n z_mean, z_var = encoder.forward(data)\n pyro.sample('latent', Normal(z_mean, z_var.sqrt()).to_event(1))\n\n def compute_loss_and_gradient(self, x):\n if self.mode == TRAIN:\n loss = self.optimizer.step(x)\n else:\n loss = self.optimizer.evaluate_loss(x)\n loss /= self.args.batch_size * 784\n return loss\n\n def initialize_optimizer(self, lr):\n optimizer = Adam({'lr': lr})\n elbo = JitTrace_ELBO() if self.args.jit else Trace_ELBO()\n return SVI(self.model, self.guide, optimizer, loss=elbo)\n\n\ndef setup(args):\n pyro.set_rng_seed(args.rng_seed)\n train_loader = util.get_data_loader(dataset_name='MNIST',\n data_dir=DATA_DIR,\n batch_size=args.batch_size,\n is_training_set=True,\n shuffle=True)\n test_loader = util.get_data_loader(dataset_name='MNIST',\n data_dir=DATA_DIR,\n batch_size=args.batch_size,\n is_training_set=False,\n shuffle=True)\n global OUTPUT_DIR\n OUTPUT_DIR = os.path.join(RESULTS_DIR, args.impl)\n if not os.path.exists(OUTPUT_DIR):\n os.makedirs(OUTPUT_DIR)\n pyro.clear_param_store()\n return train_loader, test_loader\n\n\ndef main(args):\n train_loader, test_loader = setup(args)\n if args.impl == 'pyro':\n vae = PyroVAEImpl(args, train_loader, test_loader)\n print('Running Pyro VAE implementation')\n elif args.impl == 'pytorch':\n vae = PyTorchVAEImpl(args, train_loader, test_loader)\n print('Running PyTorch VAE implementation')\n else:\n raise ValueError('Incorrect implementation specified: {}'.format(args.impl))\n for i in range(args.num_epochs):\n vae.train(i)\n if not args.skip_eval:\n vae.test(i)\n\n\nif __name__ == '__main__':\n assert pyro.__version__.startswith('0.3.3')\n parser = argparse.ArgumentParser(description='VAE using MNIST dataset')\n parser.add_argument('-n', '--num-epochs', nargs='?', default=10, type=int)\n parser.add_argument('--batch_size', nargs='?', default=128, type=int)\n parser.add_argument('--rng_seed', nargs='?', default=0, type=int)\n parser.add_argument('--impl', nargs='?', default='pyro', type=str)\n parser.add_argument('--skip_eval', action='store_true')\n parser.add_argument('--jit', action='store_true')\n parser.set_defaults(skip_eval=False)\n args = parser.parse_args()\n main(args)\n", "path": "examples/vae/vae_comparison.py"}], "after_files": [{"content": "import argparse\nimport itertools\nimport os\nfrom abc import ABCMeta, abstractmethod\n\nimport torch\nimport torch.nn as nn\nfrom six import add_metaclass\nfrom torch.nn import functional\nfrom torchvision.utils import save_image\n\nimport pyro\nfrom pyro.contrib.examples import util\nfrom pyro.distributions import Bernoulli, Normal\nfrom pyro.infer import SVI, JitTrace_ELBO, Trace_ELBO\nfrom pyro.optim import Adam\nfrom utils.mnist_cached import DATA_DIR, RESULTS_DIR\n\n\"\"\"\nComparison of VAE implementation in PyTorch and Pyro. This example can be\nused for profiling purposes.\n\nThe PyTorch VAE example is taken (with minor modification) from pytorch/examples.\nSource: https://github.com/pytorch/examples/tree/master/vae\n\"\"\"\n\nTRAIN = 'train'\nTEST = 'test'\nOUTPUT_DIR = RESULTS_DIR\n\n\n# VAE encoder network\nclass Encoder(nn.Module):\n def __init__(self):\n super(Encoder, self).__init__()\n self.fc1 = nn.Linear(784, 400)\n self.fc21 = nn.Linear(400, 20)\n self.fc22 = nn.Linear(400, 20)\n self.relu = nn.ReLU()\n\n def forward(self, x):\n x = x.reshape(-1, 784)\n h1 = self.relu(self.fc1(x))\n return self.fc21(h1), torch.exp(self.fc22(h1))\n\n\n# VAE Decoder network\nclass Decoder(nn.Module):\n def __init__(self):\n super(Decoder, self).__init__()\n self.fc3 = nn.Linear(20, 400)\n self.fc4 = nn.Linear(400, 784)\n self.relu = nn.ReLU()\n\n def forward(self, z):\n h3 = self.relu(self.fc3(z))\n return torch.sigmoid(self.fc4(h3))\n\n\n@add_metaclass(ABCMeta)\nclass VAE(object):\n \"\"\"\n Abstract class for the variational auto-encoder. The abstract method\n for training the network is implemented by subclasses.\n \"\"\"\n\n def __init__(self, args, train_loader, test_loader):\n self.args = args\n self.vae_encoder = Encoder()\n self.vae_decoder = Decoder()\n self.train_loader = train_loader\n self.test_loader = test_loader\n self.mode = TRAIN\n\n def set_train(self, is_train=True):\n if is_train:\n self.mode = TRAIN\n self.vae_encoder.train()\n self.vae_decoder.train()\n else:\n self.mode = TEST\n self.vae_encoder.eval()\n self.vae_decoder.eval()\n\n @abstractmethod\n def compute_loss_and_gradient(self, x):\n \"\"\"\n Given a batch of data `x`, run the optimizer (backpropagate the gradient),\n and return the computed loss.\n\n :param x: batch of data or a single datum (MNIST image).\n :return: loss computed on the data batch.\n \"\"\"\n return\n\n def model_eval(self, x):\n \"\"\"\n Given a batch of data `x`, run it through the trained VAE network to get\n the reconstructed image.\n\n :param x: batch of data or a single datum (MNIST image).\n :return: reconstructed image, and the latent z's mean and variance.\n \"\"\"\n z_mean, z_var = self.vae_encoder(x)\n if self.mode == TRAIN:\n z = Normal(z_mean, z_var.sqrt()).rsample()\n else:\n z = z_mean\n return self.vae_decoder(z), z_mean, z_var\n\n def train(self, epoch):\n self.set_train(is_train=True)\n train_loss = 0\n for batch_idx, (x, _) in enumerate(self.train_loader):\n loss = self.compute_loss_and_gradient(x)\n train_loss += loss\n print('====> Epoch: {} \\nTraining loss: {:.4f}'.format(\n epoch, train_loss / len(self.train_loader.dataset)))\n\n def test(self, epoch):\n self.set_train(is_train=False)\n test_loss = 0\n for i, (x, _) in enumerate(self.test_loader):\n with torch.no_grad():\n recon_x = self.model_eval(x)[0]\n test_loss += self.compute_loss_and_gradient(x)\n if i == 0:\n n = min(x.size(0), 8)\n comparison = torch.cat([x[:n],\n recon_x.reshape(self.args.batch_size, 1, 28, 28)[:n]])\n save_image(comparison.detach().cpu(),\n os.path.join(OUTPUT_DIR, 'reconstruction_' + str(epoch) + '.png'),\n nrow=n)\n\n test_loss /= len(self.test_loader.dataset)\n print('Test set loss: {:.4f}'.format(test_loss))\n\n\nclass PyTorchVAEImpl(VAE):\n \"\"\"\n Adapted from pytorch/examples.\n Source: https://github.com/pytorch/examples/tree/master/vae\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(PyTorchVAEImpl, self).__init__(*args, **kwargs)\n self.optimizer = self.initialize_optimizer(lr=1e-3)\n\n def compute_loss_and_gradient(self, x):\n self.optimizer.zero_grad()\n recon_x, z_mean, z_var = self.model_eval(x)\n binary_cross_entropy = functional.binary_cross_entropy(recon_x, x.reshape(-1, 784))\n # Uses analytical KL divergence expression for D_kl(q(z|x) || p(z))\n # Refer to Appendix B from VAE paper:\n # Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014\n # (https://arxiv.org/abs/1312.6114)\n kl_div = -0.5 * torch.sum(1 + z_var.log() - z_mean.pow(2) - z_var)\n kl_div /= self.args.batch_size * 784\n loss = binary_cross_entropy + kl_div\n if self.mode == TRAIN:\n loss.backward()\n self.optimizer.step()\n return loss.item()\n\n def initialize_optimizer(self, lr=1e-3):\n model_params = itertools.chain(self.vae_encoder.parameters(), self.vae_decoder.parameters())\n return torch.optim.Adam(model_params, lr)\n\n\nclass PyroVAEImpl(VAE):\n \"\"\"\n Implementation of VAE using Pyro. Only the model and the guide specification\n is needed to run the optimizer (the objective function does not need to be\n specified as in the PyTorch implementation).\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(PyroVAEImpl, self).__init__(*args, **kwargs)\n self.optimizer = self.initialize_optimizer(lr=1e-3)\n\n def model(self, data):\n decoder = pyro.module('decoder', self.vae_decoder)\n z_mean, z_std = torch.zeros([data.size(0), 20]), torch.ones([data.size(0), 20])\n with pyro.plate('data', data.size(0)):\n z = pyro.sample('latent', Normal(z_mean, z_std).to_event(1))\n img = decoder.forward(z)\n pyro.sample('obs',\n Bernoulli(img).to_event(1),\n obs=data.reshape(-1, 784))\n\n def guide(self, data):\n encoder = pyro.module('encoder', self.vae_encoder)\n with pyro.plate('data', data.size(0)):\n z_mean, z_var = encoder.forward(data)\n pyro.sample('latent', Normal(z_mean, z_var.sqrt()).to_event(1))\n\n def compute_loss_and_gradient(self, x):\n if self.mode == TRAIN:\n loss = self.optimizer.step(x)\n else:\n loss = self.optimizer.evaluate_loss(x)\n loss /= self.args.batch_size * 784\n return loss\n\n def initialize_optimizer(self, lr):\n optimizer = Adam({'lr': lr})\n elbo = JitTrace_ELBO() if self.args.jit else Trace_ELBO()\n return SVI(self.model, self.guide, optimizer, loss=elbo)\n\n\ndef setup(args):\n pyro.set_rng_seed(args.rng_seed)\n train_loader = util.get_data_loader(dataset_name='MNIST',\n data_dir=DATA_DIR,\n batch_size=args.batch_size,\n is_training_set=True,\n shuffle=True)\n test_loader = util.get_data_loader(dataset_name='MNIST',\n data_dir=DATA_DIR,\n batch_size=args.batch_size,\n is_training_set=False,\n shuffle=True)\n global OUTPUT_DIR\n OUTPUT_DIR = os.path.join(RESULTS_DIR, args.impl)\n if not os.path.exists(OUTPUT_DIR):\n os.makedirs(OUTPUT_DIR)\n pyro.clear_param_store()\n return train_loader, test_loader\n\n\ndef main(args):\n train_loader, test_loader = setup(args)\n if args.impl == 'pyro':\n vae = PyroVAEImpl(args, train_loader, test_loader)\n print('Running Pyro VAE implementation')\n elif args.impl == 'pytorch':\n vae = PyTorchVAEImpl(args, train_loader, test_loader)\n print('Running PyTorch VAE implementation')\n else:\n raise ValueError('Incorrect implementation specified: {}'.format(args.impl))\n for i in range(args.num_epochs):\n vae.train(i)\n if not args.skip_eval:\n vae.test(i)\n\n\nif __name__ == '__main__':\n assert pyro.__version__.startswith('0.3.3')\n parser = argparse.ArgumentParser(description='VAE using MNIST dataset')\n parser.add_argument('-n', '--num-epochs', nargs='?', default=10, type=int)\n parser.add_argument('--batch_size', nargs='?', default=128, type=int)\n parser.add_argument('--rng_seed', nargs='?', default=0, type=int)\n parser.add_argument('--impl', nargs='?', default='pyro', type=str)\n parser.add_argument('--skip_eval', action='store_true')\n parser.add_argument('--jit', action='store_true')\n parser.set_defaults(skip_eval=False)\n args = parser.parse_args()\n main(args)\n", "path": "examples/vae/vae_comparison.py"}]}
| 3,872 | 128 |
gh_patches_debug_28255
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-4652
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
:yank markdown (and asciidoc and html)
I love the [v.1.6.0](https://github.com/qutebrowser/qutebrowser/releases/tag/v1.6.0) `:yank markdown` feature - thank you for that. For those of us who write in asciidoc and html, it would be great to also be able to yank in those formats, i.e., have this:
* :yank markdown
* `[DuckDuckGo — Privacy, simplified.](https://start.duckduckgo.com/)`
* :yank asciidoc
* `https://start.duckduckgo.com/[DuckDuckGo — Privacy, simplified.]`
* :yank html
* `<a href="https://start.duckduckgo.com/">DuckDuckGo — Privacy, simplified.</a>`
Thank you for considering this!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/commands/runners.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2019 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Module containing command managers (SearchRunner and CommandRunner)."""
21
22 import traceback
23 import re
24
25 import attr
26 from PyQt5.QtCore import pyqtSlot, QUrl, QObject
27
28 from qutebrowser.api import cmdutils
29 from qutebrowser.config import config
30 from qutebrowser.commands import cmdexc
31 from qutebrowser.utils import message, objreg, qtutils, usertypes, utils
32 from qutebrowser.misc import split, objects
33
34
35 last_command = {}
36
37
38 @attr.s
39 class ParseResult:
40
41 """The result of parsing a commandline."""
42
43 cmd = attr.ib()
44 args = attr.ib()
45 cmdline = attr.ib()
46
47
48 def _current_url(tabbed_browser):
49 """Convenience method to get the current url."""
50 try:
51 return tabbed_browser.current_url()
52 except qtutils.QtValueError as e:
53 msg = "Current URL is invalid"
54 if e.reason:
55 msg += " ({})".format(e.reason)
56 msg += "!"
57 raise cmdutils.CommandError(msg)
58
59
60 def replace_variables(win_id, arglist):
61 """Utility function to replace variables like {url} in a list of args."""
62 tabbed_browser = objreg.get('tabbed-browser', scope='window',
63 window=win_id)
64
65 variables = {
66 'url': lambda: _current_url(tabbed_browser).toString(
67 QUrl.FullyEncoded | QUrl.RemovePassword),
68 'url:pretty': lambda: _current_url(tabbed_browser).toString(
69 QUrl.DecodeReserved | QUrl.RemovePassword),
70 'url:host': lambda: _current_url(tabbed_browser).host(),
71 'clipboard': utils.get_clipboard,
72 'primary': lambda: utils.get_clipboard(selection=True),
73 }
74
75 for key in list(variables):
76 modified_key = '{' + key + '}'
77 variables[modified_key] = lambda x=modified_key: x
78
79 values = {}
80 args = []
81
82 def repl_cb(matchobj):
83 """Return replacement for given match."""
84 var = matchobj.group("var")
85 if var not in values:
86 values[var] = variables[var]()
87 return values[var]
88 repl_pattern = re.compile("{(?P<var>" + "|".join(variables.keys()) + ")}")
89
90 try:
91 for arg in arglist:
92 # using re.sub with callback function replaces all variables in a
93 # single pass and avoids expansion of nested variables (e.g.
94 # "{url}" from clipboard is not expanded)
95 args.append(repl_pattern.sub(repl_cb, arg))
96 except utils.ClipboardError as e:
97 raise cmdutils.CommandError(e)
98 return args
99
100
101 class CommandParser:
102
103 """Parse qutebrowser commandline commands.
104
105 Attributes:
106 _partial_match: Whether to allow partial command matches.
107 """
108
109 def __init__(self, partial_match=False):
110 self._partial_match = partial_match
111
112 def _get_alias(self, text, default=None):
113 """Get an alias from the config.
114
115 Args:
116 text: The text to parse.
117 default : Default value to return when alias was not found.
118
119 Return:
120 The new command string if an alias was found. Default value
121 otherwise.
122 """
123 parts = text.strip().split(maxsplit=1)
124 try:
125 alias = config.val.aliases[parts[0]]
126 except KeyError:
127 return default
128
129 try:
130 new_cmd = '{} {}'.format(alias, parts[1])
131 except IndexError:
132 new_cmd = alias
133 if text.endswith(' '):
134 new_cmd += ' '
135 return new_cmd
136
137 def _parse_all_gen(self, text, *args, aliases=True, **kwargs):
138 """Split a command on ;; and parse all parts.
139
140 If the first command in the commandline is a non-split one, it only
141 returns that.
142
143 Args:
144 text: Text to parse.
145 aliases: Whether to handle aliases.
146 *args/**kwargs: Passed to parse().
147
148 Yields:
149 ParseResult tuples.
150 """
151 text = text.strip().lstrip(':').strip()
152 if not text:
153 raise cmdexc.NoSuchCommandError("No command given")
154
155 if aliases:
156 text = self._get_alias(text, text)
157
158 if ';;' in text:
159 # Get the first command and check if it doesn't want to have ;;
160 # split.
161 first = text.split(';;')[0]
162 result = self.parse(first, *args, **kwargs)
163 if result.cmd.no_cmd_split:
164 sub_texts = [text]
165 else:
166 sub_texts = [e.strip() for e in text.split(';;')]
167 else:
168 sub_texts = [text]
169 for sub in sub_texts:
170 yield self.parse(sub, *args, **kwargs)
171
172 def parse_all(self, *args, **kwargs):
173 """Wrapper over _parse_all_gen."""
174 return list(self._parse_all_gen(*args, **kwargs))
175
176 def parse(self, text, *, fallback=False, keep=False):
177 """Split the commandline text into command and arguments.
178
179 Args:
180 text: Text to parse.
181 fallback: Whether to do a fallback splitting when the command was
182 unknown.
183 keep: Whether to keep special chars and whitespace
184
185 Return:
186 A ParseResult tuple.
187 """
188 cmdstr, sep, argstr = text.partition(' ')
189
190 if not cmdstr and not fallback:
191 raise cmdexc.NoSuchCommandError("No command given")
192
193 if self._partial_match:
194 cmdstr = self._completion_match(cmdstr)
195
196 try:
197 cmd = objects.commands[cmdstr]
198 except KeyError:
199 if not fallback:
200 raise cmdexc.NoSuchCommandError(
201 '{}: no such command'.format(cmdstr))
202 cmdline = split.split(text, keep=keep)
203 return ParseResult(cmd=None, args=None, cmdline=cmdline)
204
205 args = self._split_args(cmd, argstr, keep)
206 if keep and args:
207 cmdline = [cmdstr, sep + args[0]] + args[1:]
208 elif keep:
209 cmdline = [cmdstr, sep]
210 else:
211 cmdline = [cmdstr] + args[:]
212
213 return ParseResult(cmd=cmd, args=args, cmdline=cmdline)
214
215 def _completion_match(self, cmdstr):
216 """Replace cmdstr with a matching completion if there's only one match.
217
218 Args:
219 cmdstr: The string representing the entered command so far
220
221 Return:
222 cmdstr modified to the matching completion or unmodified
223 """
224 matches = [cmd for cmd in sorted(objects.commands, key=len)
225 if cmdstr in cmd]
226 if len(matches) == 1:
227 cmdstr = matches[0]
228 elif len(matches) > 1 and config.val.completion.use_best_match:
229 cmdstr = matches[0]
230 return cmdstr
231
232 def _split_args(self, cmd, argstr, keep):
233 """Split the arguments from an arg string.
234
235 Args:
236 cmd: The command we're currently handling.
237 argstr: An argument string.
238 keep: Whether to keep special chars and whitespace
239
240 Return:
241 A list containing the split strings.
242 """
243 if not argstr:
244 return []
245 elif cmd.maxsplit is None:
246 return split.split(argstr, keep=keep)
247 else:
248 # If split=False, we still want to split the flags, but not
249 # everything after that.
250 # We first split the arg string and check the index of the first
251 # non-flag args, then we re-split again properly.
252 # example:
253 #
254 # input: "--foo -v bar baz"
255 # first split: ['--foo', '-v', 'bar', 'baz']
256 # 0 1 2 3
257 # second split: ['--foo', '-v', 'bar baz']
258 # (maxsplit=2)
259 split_args = split.simple_split(argstr, keep=keep)
260 flag_arg_count = 0
261 for i, arg in enumerate(split_args):
262 arg = arg.strip()
263 if arg.startswith('-'):
264 if arg in cmd.flags_with_args:
265 flag_arg_count += 1
266 else:
267 maxsplit = i + cmd.maxsplit + flag_arg_count
268 return split.simple_split(argstr, keep=keep,
269 maxsplit=maxsplit)
270
271 # If there are only flags, we got it right on the first try
272 # already.
273 return split_args
274
275
276 class CommandRunner(QObject):
277
278 """Parse and run qutebrowser commandline commands.
279
280 Attributes:
281 _win_id: The window this CommandRunner is associated with.
282 """
283
284 def __init__(self, win_id, partial_match=False, parent=None):
285 super().__init__(parent)
286 self._parser = CommandParser(partial_match=partial_match)
287 self._win_id = win_id
288
289 def run(self, text, count=None):
290 """Parse a command from a line of text and run it.
291
292 Args:
293 text: The text to parse.
294 count: The count to pass to the command.
295 """
296 record_last_command = True
297 record_macro = True
298
299 mode_manager = objreg.get('mode-manager', scope='window',
300 window=self._win_id)
301 cur_mode = mode_manager.mode
302
303 for result in self._parser.parse_all(text):
304 if result.cmd.no_replace_variables:
305 args = result.args
306 else:
307 args = replace_variables(self._win_id, result.args)
308 result.cmd.run(self._win_id, args, count=count)
309
310 if result.cmdline[0] == 'repeat-command':
311 record_last_command = False
312
313 if result.cmdline[0] in ['record-macro', 'run-macro',
314 'set-cmd-text']:
315 record_macro = False
316
317 if record_last_command:
318 last_command[cur_mode] = (text, count)
319
320 if record_macro and cur_mode == usertypes.KeyMode.normal:
321 macro_recorder = objreg.get('macro-recorder')
322 macro_recorder.record_command(text, count)
323
324 @pyqtSlot(str, int)
325 @pyqtSlot(str)
326 def run_safely(self, text, count=None):
327 """Run a command and display exceptions in the statusbar."""
328 try:
329 self.run(text, count)
330 except cmdexc.Error as e:
331 message.error(str(e), stack=traceback.format_exc())
332
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py
--- a/qutebrowser/commands/runners.py
+++ b/qutebrowser/commands/runners.py
@@ -61,13 +61,29 @@
"""Utility function to replace variables like {url} in a list of args."""
tabbed_browser = objreg.get('tabbed-browser', scope='window',
window=win_id)
+ url = lambda: _current_url(tabbed_browser)
variables = {
- 'url': lambda: _current_url(tabbed_browser).toString(
+ 'url': lambda: url().toString(
QUrl.FullyEncoded | QUrl.RemovePassword),
- 'url:pretty': lambda: _current_url(tabbed_browser).toString(
+ 'url:pretty': lambda: url().toString(
QUrl.DecodeReserved | QUrl.RemovePassword),
- 'url:host': lambda: _current_url(tabbed_browser).host(),
+ 'url:domain': lambda: "{}://{}{}".format(
+ url().scheme(),
+ url().host(),
+ ":" + str(url().port()) if url().port() != -1 else ""),
+ 'url:auth': lambda: "{}:{}@".format(
+ url().userName(),
+ url().password()) if url().userName() else "",
+ 'url:scheme': lambda: url().scheme(),
+ 'url:username': lambda: url().userName(),
+ 'url:password': lambda: url().password(),
+ 'url:host': lambda: url().host(),
+ 'url:port': lambda: str(url().port()) if url().port() != -1 else "",
+ 'url:path': lambda: url().path(),
+ 'url:query': lambda: url().query(),
+ 'title': lambda: tabbed_browser.widget.page_title(
+ tabbed_browser.widget.currentIndex()),
'clipboard': utils.get_clipboard,
'primary': lambda: utils.get_clipboard(selection=True),
}
|
{"golden_diff": "diff --git a/qutebrowser/commands/runners.py b/qutebrowser/commands/runners.py\n--- a/qutebrowser/commands/runners.py\n+++ b/qutebrowser/commands/runners.py\n@@ -61,13 +61,29 @@\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n+ url = lambda: _current_url(tabbed_browser)\n \n variables = {\n- 'url': lambda: _current_url(tabbed_browser).toString(\n+ 'url': lambda: url().toString(\n QUrl.FullyEncoded | QUrl.RemovePassword),\n- 'url:pretty': lambda: _current_url(tabbed_browser).toString(\n+ 'url:pretty': lambda: url().toString(\n QUrl.DecodeReserved | QUrl.RemovePassword),\n- 'url:host': lambda: _current_url(tabbed_browser).host(),\n+ 'url:domain': lambda: \"{}://{}{}\".format(\n+ url().scheme(),\n+ url().host(),\n+ \":\" + str(url().port()) if url().port() != -1 else \"\"),\n+ 'url:auth': lambda: \"{}:{}@\".format(\n+ url().userName(),\n+ url().password()) if url().userName() else \"\",\n+ 'url:scheme': lambda: url().scheme(),\n+ 'url:username': lambda: url().userName(),\n+ 'url:password': lambda: url().password(),\n+ 'url:host': lambda: url().host(),\n+ 'url:port': lambda: str(url().port()) if url().port() != -1 else \"\",\n+ 'url:path': lambda: url().path(),\n+ 'url:query': lambda: url().query(),\n+ 'title': lambda: tabbed_browser.widget.page_title(\n+ tabbed_browser.widget.currentIndex()),\n 'clipboard': utils.get_clipboard,\n 'primary': lambda: utils.get_clipboard(selection=True),\n }\n", "issue": ":yank markdown (and asciidoc and html)\nI love the [v.1.6.0](https://github.com/qutebrowser/qutebrowser/releases/tag/v1.6.0) `:yank markdown` feature - thank you for that. For those of us who write in asciidoc and html, it would be great to also be able to yank in those formats, i.e., have this:\r\n\r\n* :yank markdown\r\n * `[DuckDuckGo \u2014 Privacy, simplified.](https://start.duckduckgo.com/)`\r\n* :yank asciidoc\r\n * `https://start.duckduckgo.com/[DuckDuckGo \u2014 Privacy, simplified.]`\r\n* :yank html\r\n * `<a href=\"https://start.duckduckgo.com/\">DuckDuckGo \u2014 Privacy, simplified.</a>`\r\n\r\nThank you for considering this!\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2019 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport traceback\nimport re\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QUrl, QObject\n\nfrom qutebrowser.api import cmdutils\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdexc\nfrom qutebrowser.utils import message, objreg, qtutils, usertypes, utils\nfrom qutebrowser.misc import split, objects\n\n\nlast_command = {}\n\n\[email protected]\nclass ParseResult:\n\n \"\"\"The result of parsing a commandline.\"\"\"\n\n cmd = attr.ib()\n args = attr.ib()\n cmdline = attr.ib()\n\n\ndef _current_url(tabbed_browser):\n \"\"\"Convenience method to get the current url.\"\"\"\n try:\n return tabbed_browser.current_url()\n except qtutils.QtValueError as e:\n msg = \"Current URL is invalid\"\n if e.reason:\n msg += \" ({})\".format(e.reason)\n msg += \"!\"\n raise cmdutils.CommandError(msg)\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n\n variables = {\n 'url': lambda: _current_url(tabbed_browser).toString(\n QUrl.FullyEncoded | QUrl.RemovePassword),\n 'url:pretty': lambda: _current_url(tabbed_browser).toString(\n QUrl.DecodeReserved | QUrl.RemovePassword),\n 'url:host': lambda: _current_url(tabbed_browser).host(),\n 'clipboard': utils.get_clipboard,\n 'primary': lambda: utils.get_clipboard(selection=True),\n }\n\n for key in list(variables):\n modified_key = '{' + key + '}'\n variables[modified_key] = lambda x=modified_key: x\n\n values = {}\n args = []\n\n def repl_cb(matchobj):\n \"\"\"Return replacement for given match.\"\"\"\n var = matchobj.group(\"var\")\n if var not in values:\n values[var] = variables[var]()\n return values[var]\n repl_pattern = re.compile(\"{(?P<var>\" + \"|\".join(variables.keys()) + \")}\")\n\n try:\n for arg in arglist:\n # using re.sub with callback function replaces all variables in a\n # single pass and avoids expansion of nested variables (e.g.\n # \"{url}\" from clipboard is not expanded)\n args.append(repl_pattern.sub(repl_cb, arg))\n except utils.ClipboardError as e:\n raise cmdutils.CommandError(e)\n return args\n\n\nclass CommandParser:\n\n \"\"\"Parse qutebrowser commandline commands.\n\n Attributes:\n _partial_match: Whether to allow partial command matches.\n \"\"\"\n\n def __init__(self, partial_match=False):\n self._partial_match = partial_match\n\n def _get_alias(self, text, default=None):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n default : Default value to return when alias was not found.\n\n Return:\n The new command string if an alias was found. Default value\n otherwise.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.val.aliases[parts[0]]\n except KeyError:\n return default\n\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def _parse_all_gen(self, text, *args, aliases=True, **kwargs):\n \"\"\"Split a command on ;; and parse all parts.\n\n If the first command in the commandline is a non-split one, it only\n returns that.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n *args/**kwargs: Passed to parse().\n\n Yields:\n ParseResult tuples.\n \"\"\"\n text = text.strip().lstrip(':').strip()\n if not text:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if aliases:\n text = self._get_alias(text, text)\n\n if ';;' in text:\n # Get the first command and check if it doesn't want to have ;;\n # split.\n first = text.split(';;')[0]\n result = self.parse(first, *args, **kwargs)\n if result.cmd.no_cmd_split:\n sub_texts = [text]\n else:\n sub_texts = [e.strip() for e in text.split(';;')]\n else:\n sub_texts = [text]\n for sub in sub_texts:\n yield self.parse(sub, *args, **kwargs)\n\n def parse_all(self, *args, **kwargs):\n \"\"\"Wrapper over _parse_all_gen.\"\"\"\n return list(self._parse_all_gen(*args, **kwargs))\n\n def parse(self, text, *, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A ParseResult tuple.\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if self._partial_match:\n cmdstr = self._completion_match(cmdstr)\n\n try:\n cmd = objects.commands[cmdstr]\n except KeyError:\n if not fallback:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n cmdline = split.split(text, keep=keep)\n return ParseResult(cmd=None, args=None, cmdline=cmdline)\n\n args = self._split_args(cmd, argstr, keep)\n if keep and args:\n cmdline = [cmdstr, sep + args[0]] + args[1:]\n elif keep:\n cmdline = [cmdstr, sep]\n else:\n cmdline = [cmdstr] + args[:]\n\n return ParseResult(cmd=cmd, args=args, cmdline=cmdline)\n\n def _completion_match(self, cmdstr):\n \"\"\"Replace cmdstr with a matching completion if there's only one match.\n\n Args:\n cmdstr: The string representing the entered command so far\n\n Return:\n cmdstr modified to the matching completion or unmodified\n \"\"\"\n matches = [cmd for cmd in sorted(objects.commands, key=len)\n if cmdstr in cmd]\n if len(matches) == 1:\n cmdstr = matches[0]\n elif len(matches) > 1 and config.val.completion.use_best_match:\n cmdstr = matches[0]\n return cmdstr\n\n def _split_args(self, cmd, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n cmd: The command we're currently handling.\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the split strings.\n \"\"\"\n if not argstr:\n return []\n elif cmd.maxsplit is None:\n return split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg in cmd.flags_with_args:\n flag_arg_count += 1\n else:\n maxsplit = i + cmd.maxsplit + flag_arg_count\n return split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n\n # If there are only flags, we got it right on the first try\n # already.\n return split_args\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, partial_match=False, parent=None):\n super().__init__(parent)\n self._parser = CommandParser(partial_match=partial_match)\n self._win_id = win_id\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n record_last_command = True\n record_macro = True\n\n mode_manager = objreg.get('mode-manager', scope='window',\n window=self._win_id)\n cur_mode = mode_manager.mode\n\n for result in self._parser.parse_all(text):\n if result.cmd.no_replace_variables:\n args = result.args\n else:\n args = replace_variables(self._win_id, result.args)\n result.cmd.run(self._win_id, args, count=count)\n\n if result.cmdline[0] == 'repeat-command':\n record_last_command = False\n\n if result.cmdline[0] in ['record-macro', 'run-macro',\n 'set-cmd-text']:\n record_macro = False\n\n if record_last_command:\n last_command[cur_mode] = (text, count)\n\n if record_macro and cur_mode == usertypes.KeyMode.normal:\n macro_recorder = objreg.get('macro-recorder')\n macro_recorder.record_command(text, count)\n\n @pyqtSlot(str, int)\n @pyqtSlot(str)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except cmdexc.Error as e:\n message.error(str(e), stack=traceback.format_exc())\n", "path": "qutebrowser/commands/runners.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2019 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Module containing command managers (SearchRunner and CommandRunner).\"\"\"\n\nimport traceback\nimport re\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QUrl, QObject\n\nfrom qutebrowser.api import cmdutils\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdexc\nfrom qutebrowser.utils import message, objreg, qtutils, usertypes, utils\nfrom qutebrowser.misc import split, objects\n\n\nlast_command = {}\n\n\[email protected]\nclass ParseResult:\n\n \"\"\"The result of parsing a commandline.\"\"\"\n\n cmd = attr.ib()\n args = attr.ib()\n cmdline = attr.ib()\n\n\ndef _current_url(tabbed_browser):\n \"\"\"Convenience method to get the current url.\"\"\"\n try:\n return tabbed_browser.current_url()\n except qtutils.QtValueError as e:\n msg = \"Current URL is invalid\"\n if e.reason:\n msg += \" ({})\".format(e.reason)\n msg += \"!\"\n raise cmdutils.CommandError(msg)\n\n\ndef replace_variables(win_id, arglist):\n \"\"\"Utility function to replace variables like {url} in a list of args.\"\"\"\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=win_id)\n url = lambda: _current_url(tabbed_browser)\n\n variables = {\n 'url': lambda: url().toString(\n QUrl.FullyEncoded | QUrl.RemovePassword),\n 'url:pretty': lambda: url().toString(\n QUrl.DecodeReserved | QUrl.RemovePassword),\n 'url:domain': lambda: \"{}://{}{}\".format(\n url().scheme(),\n url().host(),\n \":\" + str(url().port()) if url().port() != -1 else \"\"),\n 'url:auth': lambda: \"{}:{}@\".format(\n url().userName(),\n url().password()) if url().userName() else \"\",\n 'url:scheme': lambda: url().scheme(),\n 'url:username': lambda: url().userName(),\n 'url:password': lambda: url().password(),\n 'url:host': lambda: url().host(),\n 'url:port': lambda: str(url().port()) if url().port() != -1 else \"\",\n 'url:path': lambda: url().path(),\n 'url:query': lambda: url().query(),\n 'title': lambda: tabbed_browser.widget.page_title(\n tabbed_browser.widget.currentIndex()),\n 'clipboard': utils.get_clipboard,\n 'primary': lambda: utils.get_clipboard(selection=True),\n }\n\n for key in list(variables):\n modified_key = '{' + key + '}'\n variables[modified_key] = lambda x=modified_key: x\n\n values = {}\n args = []\n\n def repl_cb(matchobj):\n \"\"\"Return replacement for given match.\"\"\"\n var = matchobj.group(\"var\")\n if var not in values:\n values[var] = variables[var]()\n return values[var]\n repl_pattern = re.compile(\"{(?P<var>\" + \"|\".join(variables.keys()) + \")}\")\n\n try:\n for arg in arglist:\n # using re.sub with callback function replaces all variables in a\n # single pass and avoids expansion of nested variables (e.g.\n # \"{url}\" from clipboard is not expanded)\n args.append(repl_pattern.sub(repl_cb, arg))\n except utils.ClipboardError as e:\n raise cmdutils.CommandError(e)\n return args\n\n\nclass CommandParser:\n\n \"\"\"Parse qutebrowser commandline commands.\n\n Attributes:\n _partial_match: Whether to allow partial command matches.\n \"\"\"\n\n def __init__(self, partial_match=False):\n self._partial_match = partial_match\n\n def _get_alias(self, text, default=None):\n \"\"\"Get an alias from the config.\n\n Args:\n text: The text to parse.\n default : Default value to return when alias was not found.\n\n Return:\n The new command string if an alias was found. Default value\n otherwise.\n \"\"\"\n parts = text.strip().split(maxsplit=1)\n try:\n alias = config.val.aliases[parts[0]]\n except KeyError:\n return default\n\n try:\n new_cmd = '{} {}'.format(alias, parts[1])\n except IndexError:\n new_cmd = alias\n if text.endswith(' '):\n new_cmd += ' '\n return new_cmd\n\n def _parse_all_gen(self, text, *args, aliases=True, **kwargs):\n \"\"\"Split a command on ;; and parse all parts.\n\n If the first command in the commandline is a non-split one, it only\n returns that.\n\n Args:\n text: Text to parse.\n aliases: Whether to handle aliases.\n *args/**kwargs: Passed to parse().\n\n Yields:\n ParseResult tuples.\n \"\"\"\n text = text.strip().lstrip(':').strip()\n if not text:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if aliases:\n text = self._get_alias(text, text)\n\n if ';;' in text:\n # Get the first command and check if it doesn't want to have ;;\n # split.\n first = text.split(';;')[0]\n result = self.parse(first, *args, **kwargs)\n if result.cmd.no_cmd_split:\n sub_texts = [text]\n else:\n sub_texts = [e.strip() for e in text.split(';;')]\n else:\n sub_texts = [text]\n for sub in sub_texts:\n yield self.parse(sub, *args, **kwargs)\n\n def parse_all(self, *args, **kwargs):\n \"\"\"Wrapper over _parse_all_gen.\"\"\"\n return list(self._parse_all_gen(*args, **kwargs))\n\n def parse(self, text, *, fallback=False, keep=False):\n \"\"\"Split the commandline text into command and arguments.\n\n Args:\n text: Text to parse.\n fallback: Whether to do a fallback splitting when the command was\n unknown.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A ParseResult tuple.\n \"\"\"\n cmdstr, sep, argstr = text.partition(' ')\n\n if not cmdstr and not fallback:\n raise cmdexc.NoSuchCommandError(\"No command given\")\n\n if self._partial_match:\n cmdstr = self._completion_match(cmdstr)\n\n try:\n cmd = objects.commands[cmdstr]\n except KeyError:\n if not fallback:\n raise cmdexc.NoSuchCommandError(\n '{}: no such command'.format(cmdstr))\n cmdline = split.split(text, keep=keep)\n return ParseResult(cmd=None, args=None, cmdline=cmdline)\n\n args = self._split_args(cmd, argstr, keep)\n if keep and args:\n cmdline = [cmdstr, sep + args[0]] + args[1:]\n elif keep:\n cmdline = [cmdstr, sep]\n else:\n cmdline = [cmdstr] + args[:]\n\n return ParseResult(cmd=cmd, args=args, cmdline=cmdline)\n\n def _completion_match(self, cmdstr):\n \"\"\"Replace cmdstr with a matching completion if there's only one match.\n\n Args:\n cmdstr: The string representing the entered command so far\n\n Return:\n cmdstr modified to the matching completion or unmodified\n \"\"\"\n matches = [cmd for cmd in sorted(objects.commands, key=len)\n if cmdstr in cmd]\n if len(matches) == 1:\n cmdstr = matches[0]\n elif len(matches) > 1 and config.val.completion.use_best_match:\n cmdstr = matches[0]\n return cmdstr\n\n def _split_args(self, cmd, argstr, keep):\n \"\"\"Split the arguments from an arg string.\n\n Args:\n cmd: The command we're currently handling.\n argstr: An argument string.\n keep: Whether to keep special chars and whitespace\n\n Return:\n A list containing the split strings.\n \"\"\"\n if not argstr:\n return []\n elif cmd.maxsplit is None:\n return split.split(argstr, keep=keep)\n else:\n # If split=False, we still want to split the flags, but not\n # everything after that.\n # We first split the arg string and check the index of the first\n # non-flag args, then we re-split again properly.\n # example:\n #\n # input: \"--foo -v bar baz\"\n # first split: ['--foo', '-v', 'bar', 'baz']\n # 0 1 2 3\n # second split: ['--foo', '-v', 'bar baz']\n # (maxsplit=2)\n split_args = split.simple_split(argstr, keep=keep)\n flag_arg_count = 0\n for i, arg in enumerate(split_args):\n arg = arg.strip()\n if arg.startswith('-'):\n if arg in cmd.flags_with_args:\n flag_arg_count += 1\n else:\n maxsplit = i + cmd.maxsplit + flag_arg_count\n return split.simple_split(argstr, keep=keep,\n maxsplit=maxsplit)\n\n # If there are only flags, we got it right on the first try\n # already.\n return split_args\n\n\nclass CommandRunner(QObject):\n\n \"\"\"Parse and run qutebrowser commandline commands.\n\n Attributes:\n _win_id: The window this CommandRunner is associated with.\n \"\"\"\n\n def __init__(self, win_id, partial_match=False, parent=None):\n super().__init__(parent)\n self._parser = CommandParser(partial_match=partial_match)\n self._win_id = win_id\n\n def run(self, text, count=None):\n \"\"\"Parse a command from a line of text and run it.\n\n Args:\n text: The text to parse.\n count: The count to pass to the command.\n \"\"\"\n record_last_command = True\n record_macro = True\n\n mode_manager = objreg.get('mode-manager', scope='window',\n window=self._win_id)\n cur_mode = mode_manager.mode\n\n for result in self._parser.parse_all(text):\n if result.cmd.no_replace_variables:\n args = result.args\n else:\n args = replace_variables(self._win_id, result.args)\n result.cmd.run(self._win_id, args, count=count)\n\n if result.cmdline[0] == 'repeat-command':\n record_last_command = False\n\n if result.cmdline[0] in ['record-macro', 'run-macro',\n 'set-cmd-text']:\n record_macro = False\n\n if record_last_command:\n last_command[cur_mode] = (text, count)\n\n if record_macro and cur_mode == usertypes.KeyMode.normal:\n macro_recorder = objreg.get('macro-recorder')\n macro_recorder.record_command(text, count)\n\n @pyqtSlot(str, int)\n @pyqtSlot(str)\n def run_safely(self, text, count=None):\n \"\"\"Run a command and display exceptions in the statusbar.\"\"\"\n try:\n self.run(text, count)\n except cmdexc.Error as e:\n message.error(str(e), stack=traceback.format_exc())\n", "path": "qutebrowser/commands/runners.py"}]}
| 3,804 | 440 |
gh_patches_debug_25741
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4044
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conan install fails to distinguish a path from a reference in some circumstances
Hello!
I just noticed that conan 1.9.1 (at least) is not checking the nature of the `path_or_reference` argument to the `install` command properly. Specifically, if you pass it a `conanfile.txt` (or `conanfile.py`) with a relative path made of 3 or 4 elements it will consider it as reference instead of a path.
Here is a straight forward way to reproduce the problem:
```#!bash
$ mkdir -p foo/bar/baz
$ echo '[requires]' > foo/bar/baz/conanfile.txt
$ conan install foo/bar/baz/conanfile.txt
Configuration:
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=5
compiler.libcxx=libstdc++
build_type=Release
[options]
[build_requires]
[env]
foo/bar@baz/conanfile.txt: Not found in local cache, looking in remotes...
foo/bar@baz/conanfile.txt: Trying with 'conan-pix4d'...
ERROR: Failed requirement 'foo/bar@baz/conanfile.txt' from 'PROJECT'
ERROR: Unable to find 'foo/bar@baz/conanfile.txt' in remotes
```
Using a shorter (or two element longer) path works:
```#!bash
$ cd foo
$ conan install bar/baz/conanfile.txt
Configuration:
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=5
compiler.libcxx=libstdc++
build_type=Release
[options]
[build_requires]
[env]
PROJECT: Installing /tmp/foo/bar/baz/conanfile.txt
Requirements
Packages
PROJECT: Generator txt created conanbuildinfo.txt
PROJECT: Generated conaninfo.txt
```
You can work around the problem easily by prefixing the path with `./` as it will then produce an invalid name for the reference and then conan will fall back to the path scenario.
A possible fix would be:
```
--- conans/client/command.py.bak 2018-11-16 17:18:46.984235498 +0100
+++ conans/client/command.py 2018-11-16 17:23:21.910007591 +0100
@@ -370,6 +370,8 @@
info = None
try:
try:
+ if os.path.isfile(args.path_or_reference):
+ raise ConanException()
reference = ConanFileReference.loads(args.path_or_reference)
except ConanException:
info = self._conan.install(path=args.path_or_reference,
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/model/ref.py`
Content:
```
1 from collections import namedtuple
2
3 import re
4 from six import string_types
5
6 from conans.errors import ConanException, InvalidNameException
7 from conans.model.version import Version
8
9
10 def check_valid_ref(ref, allow_pattern):
11 try:
12 if not isinstance(ref, ConanFileReference):
13 ref = ConanFileReference.loads(ref, validate=True)
14 return "*" not in ref or allow_pattern
15 except ConanException:
16 pass
17 return False
18
19
20 class ConanName(object):
21 _max_chars = 51
22 _min_chars = 2
23 _validation_pattern = re.compile("^[a-zA-Z0-9_][a-zA-Z0-9_\+\.-]{%s,%s}$"
24 % (_min_chars - 1, _max_chars - 1))
25
26 _validation_revision_pattern = re.compile("^[a-zA-Z0-9]{1,%s}$" % _max_chars)
27
28 @staticmethod
29 def invalid_name_message(value, reference_token=None):
30 if len(value) > ConanName._max_chars:
31 reason = "is too long. Valid names must contain at most %s characters."\
32 % ConanName._max_chars
33 elif len(value) < ConanName._min_chars:
34 reason = "is too short. Valid names must contain at least %s characters."\
35 % ConanName._min_chars
36 else:
37 reason = ("is an invalid name. Valid names MUST begin with a "
38 "letter, number or underscore, have between %s-%s chars, including "
39 "letters, numbers, underscore, dot and dash"
40 % (ConanName._min_chars, ConanName._max_chars))
41 message = "Value provided{ref_token}, '{value}' (type {type}), {reason}".format(
42 ref_token=" for {}".format(reference_token) if reference_token else "",
43 value=value, type=type(value).__name__, reason=reason
44 )
45 raise InvalidNameException(message)
46
47 @staticmethod
48 def validate_string(value, reference_token=None):
49 """Check for string"""
50 if not isinstance(value, string_types):
51 message = "Value provided{ref_token}, '{value}' (type {type}), {reason}".format(
52 ref_token=" for {}".format(reference_token) if reference_token else "",
53 value=value, type=type(value).__name__,
54 reason="is not a string"
55 )
56 raise InvalidNameException(message)
57
58 @staticmethod
59 def validate_name(name, version=False, reference_token=None):
60 """Check for name compliance with pattern rules"""
61 ConanName.validate_string(name, reference_token=reference_token)
62 if name == "*":
63 return
64 if ConanName._validation_pattern.match(name) is None:
65 if version and name.startswith("[") and name.endswith("]"):
66 return
67 ConanName.invalid_name_message(name, reference_token=reference_token)
68
69 @staticmethod
70 def validate_revision(revision):
71 if ConanName._validation_revision_pattern.match(revision) is None:
72 raise InvalidNameException("The revision field, must contain only letters "
73 "and numbers with a length between 1 and "
74 "%s" % ConanName._max_chars)
75
76
77 class ConanFileReference(namedtuple("ConanFileReference", "name version user channel revision")):
78 """ Full reference of a package recipes, e.g.:
79 opencv/2.4.10@lasote/testing
80 """
81 whitespace_pattern = re.compile(r"\s+")
82 sep_pattern = re.compile("@|/|#")
83
84 def __new__(cls, name, version, user, channel, revision=None, validate=True):
85 """Simple name creation.
86 @param name: string containing the desired name
87 @param version: string containing the desired version
88 @param user: string containing the user name
89 @param channel: string containing the user channel
90 @param revision: string containing the revision (optional)
91 """
92 version = Version(version)
93 obj = super(cls, ConanFileReference).__new__(cls, name, version, user, channel, revision)
94 if validate:
95 obj.validate()
96 return obj
97
98 def validate(self):
99 ConanName.validate_name(self.name, reference_token="package name")
100 ConanName.validate_name(self.version, True, reference_token="package version")
101 ConanName.validate_name(self.user, reference_token="user name")
102 ConanName.validate_name(self.channel, reference_token="channel")
103 if self.revision:
104 ConanName.validate_revision(self.revision)
105
106 def __hash__(self):
107 return hash((self.name, self.version, self.user, self.channel, self.revision))
108
109 @staticmethod
110 def loads(text, validate=True):
111 """ Parses a text string to generate a ConanFileReference object
112 """
113 text = ConanFileReference.whitespace_pattern.sub("", text)
114 tokens = ConanFileReference.sep_pattern.split(text)
115 try:
116 if len(tokens) not in (4, 5):
117 raise ValueError
118 name, version, user, channel = tokens[0:4]
119 revision = tokens[4] if len(tokens) == 5 else None
120 except ValueError:
121 raise ConanException("Wrong package recipe reference %s\nWrite something like "
122 "OpenCV/1.0.6@user/stable" % text)
123 obj = ConanFileReference(name, version, user, channel, revision, validate=validate)
124 return obj
125
126 def __repr__(self):
127 return "%s/%s@%s/%s" % (self.name, self.version, self.user, self.channel)
128
129 def full_repr(self):
130 str_rev = "#%s" % self.revision if self.revision else ""
131 return "%s%s" % (str(self), str_rev)
132
133 def dir_repr(self):
134 return "/".join(self[:-1])
135
136 def copy_with_rev(self, revision):
137 return ConanFileReference(self.name, self.version, self.user, self.channel, revision)
138
139 def copy_clear_rev(self):
140 return ConanFileReference(self.name, self.version, self.user, self.channel, None)
141
142
143 class PackageReference(namedtuple("PackageReference", "conan package_id revision")):
144 """ Full package reference, e.g.:
145 opencv/2.4.10@lasote/testing, fe566a677f77734ae
146 """
147
148 def __new__(cls, conan, package_id, revision=None, validate=True):
149 if "#" in package_id:
150 package_id, revision = package_id.rsplit("#", 1)
151 obj = super(cls, PackageReference).__new__(cls, conan, package_id, revision)
152 if validate:
153 obj.validate()
154 return obj
155
156 def validate(self):
157 if self.revision:
158 ConanName.validate_revision(self.revision)
159
160 @staticmethod
161 def loads(text, validate=True):
162 text = text.strip()
163 tmp = text.split(":")
164 try:
165 conan = ConanFileReference.loads(tmp[0].strip())
166 package_id = tmp[1].strip()
167 except IndexError:
168 raise ConanException("Wrong package reference %s" % text)
169 return PackageReference(conan, package_id, validate=validate)
170
171 def __repr__(self):
172 return "%s:%s" % (self.conan, self.package_id)
173
174 def full_repr(self):
175 str_rev = "#%s" % self.revision if self.revision else ""
176 tmp = "%s:%s%s" % (self.conan.full_repr(), self.package_id, str_rev)
177 return tmp
178
179 def copy_with_revs(self, revision, p_revision):
180 return PackageReference(self.conan.copy_with_rev(revision), self.package_id, p_revision)
181
182 def copy_clear_rev(self):
183 ref = self.conan.copy_clear_rev()
184 return PackageReference(ref, self.package_id, revision=None)
185
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/model/ref.py b/conans/model/ref.py
--- a/conans/model/ref.py
+++ b/conans/model/ref.py
@@ -79,7 +79,7 @@
opencv/2.4.10@lasote/testing
"""
whitespace_pattern = re.compile(r"\s+")
- sep_pattern = re.compile("@|/|#")
+ sep_pattern = re.compile(r"([^/]+)/([^/]+)@([^/]+)/([^/#]+)#?(.+)?")
def __new__(cls, name, version, user, channel, revision=None, validate=True):
"""Simple name creation.
@@ -111,12 +111,9 @@
""" Parses a text string to generate a ConanFileReference object
"""
text = ConanFileReference.whitespace_pattern.sub("", text)
- tokens = ConanFileReference.sep_pattern.split(text)
try:
- if len(tokens) not in (4, 5):
- raise ValueError
- name, version, user, channel = tokens[0:4]
- revision = tokens[4] if len(tokens) == 5 else None
+ # Split returns empty start and end groups
+ _, name, version, user, channel, revision, _ = ConanFileReference.sep_pattern.split(text)
except ValueError:
raise ConanException("Wrong package recipe reference %s\nWrite something like "
"OpenCV/1.0.6@user/stable" % text)
|
{"golden_diff": "diff --git a/conans/model/ref.py b/conans/model/ref.py\n--- a/conans/model/ref.py\n+++ b/conans/model/ref.py\n@@ -79,7 +79,7 @@\n opencv/2.4.10@lasote/testing\n \"\"\"\n whitespace_pattern = re.compile(r\"\\s+\")\n- sep_pattern = re.compile(\"@|/|#\")\n+ sep_pattern = re.compile(r\"([^/]+)/([^/]+)@([^/]+)/([^/#]+)#?(.+)?\")\n \n def __new__(cls, name, version, user, channel, revision=None, validate=True):\n \"\"\"Simple name creation.\n@@ -111,12 +111,9 @@\n \"\"\" Parses a text string to generate a ConanFileReference object\n \"\"\"\n text = ConanFileReference.whitespace_pattern.sub(\"\", text)\n- tokens = ConanFileReference.sep_pattern.split(text)\n try:\n- if len(tokens) not in (4, 5):\n- raise ValueError\n- name, version, user, channel = tokens[0:4]\n- revision = tokens[4] if len(tokens) == 5 else None\n+ # Split returns empty start and end groups\n+ _, name, version, user, channel, revision, _ = ConanFileReference.sep_pattern.split(text)\n except ValueError:\n raise ConanException(\"Wrong package recipe reference %s\\nWrite something like \"\n \"OpenCV/1.0.6@user/stable\" % text)\n", "issue": "conan install fails to distinguish a path from a reference in some circumstances \nHello!\r\n\r\nI just noticed that conan 1.9.1 (at least) is not checking the nature of the `path_or_reference` argument to the `install` command properly. Specifically, if you pass it a `conanfile.txt` (or `conanfile.py`) with a relative path made of 3 or 4 elements it will consider it as reference instead of a path.\r\n\r\nHere is a straight forward way to reproduce the problem:\r\n```#!bash\r\n$ mkdir -p foo/bar/baz\r\n$ echo '[requires]' > foo/bar/baz/conanfile.txt\r\n$ conan install foo/bar/baz/conanfile.txt\r\nConfiguration:\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=5\r\ncompiler.libcxx=libstdc++\r\nbuild_type=Release\r\n[options]\r\n[build_requires]\r\n[env]\r\n\r\nfoo/bar@baz/conanfile.txt: Not found in local cache, looking in remotes...\r\nfoo/bar@baz/conanfile.txt: Trying with 'conan-pix4d'...\r\nERROR: Failed requirement 'foo/bar@baz/conanfile.txt' from 'PROJECT'\r\nERROR: Unable to find 'foo/bar@baz/conanfile.txt' in remotes\r\n```\r\n\r\nUsing a shorter (or two element longer) path works:\r\n```#!bash\r\n$ cd foo\r\n$ conan install bar/baz/conanfile.txt \r\nConfiguration:\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=5\r\ncompiler.libcxx=libstdc++\r\nbuild_type=Release\r\n[options]\r\n[build_requires]\r\n[env]\r\n\r\nPROJECT: Installing /tmp/foo/bar/baz/conanfile.txt\r\nRequirements\r\nPackages\r\n\r\nPROJECT: Generator txt created conanbuildinfo.txt\r\nPROJECT: Generated conaninfo.txt\r\n```\r\n\r\nYou can work around the problem easily by prefixing the path with `./` as it will then produce an invalid name for the reference and then conan will fall back to the path scenario.\r\n\r\nA possible fix would be:\r\n```\r\n--- conans/client/command.py.bak 2018-11-16 17:18:46.984235498 +0100\r\n+++ conans/client/command.py 2018-11-16 17:23:21.910007591 +0100\r\n@@ -370,6 +370,8 @@\r\n info = None\r\n try:\r\n try:\r\n+ if os.path.isfile(args.path_or_reference):\r\n+ raise ConanException()\r\n reference = ConanFileReference.loads(args.path_or_reference)\r\n except ConanException:\r\n info = self._conan.install(path=args.path_or_reference,\r\n```\n", "before_files": [{"content": "from collections import namedtuple\n\nimport re\nfrom six import string_types\n\nfrom conans.errors import ConanException, InvalidNameException\nfrom conans.model.version import Version\n\n\ndef check_valid_ref(ref, allow_pattern):\n try:\n if not isinstance(ref, ConanFileReference):\n ref = ConanFileReference.loads(ref, validate=True)\n return \"*\" not in ref or allow_pattern\n except ConanException:\n pass\n return False\n\n\nclass ConanName(object):\n _max_chars = 51\n _min_chars = 2\n _validation_pattern = re.compile(\"^[a-zA-Z0-9_][a-zA-Z0-9_\\+\\.-]{%s,%s}$\"\n % (_min_chars - 1, _max_chars - 1))\n\n _validation_revision_pattern = re.compile(\"^[a-zA-Z0-9]{1,%s}$\" % _max_chars)\n\n @staticmethod\n def invalid_name_message(value, reference_token=None):\n if len(value) > ConanName._max_chars:\n reason = \"is too long. Valid names must contain at most %s characters.\"\\\n % ConanName._max_chars\n elif len(value) < ConanName._min_chars:\n reason = \"is too short. Valid names must contain at least %s characters.\"\\\n % ConanName._min_chars\n else:\n reason = (\"is an invalid name. Valid names MUST begin with a \"\n \"letter, number or underscore, have between %s-%s chars, including \"\n \"letters, numbers, underscore, dot and dash\"\n % (ConanName._min_chars, ConanName._max_chars))\n message = \"Value provided{ref_token}, '{value}' (type {type}), {reason}\".format(\n ref_token=\" for {}\".format(reference_token) if reference_token else \"\",\n value=value, type=type(value).__name__, reason=reason\n )\n raise InvalidNameException(message)\n\n @staticmethod\n def validate_string(value, reference_token=None):\n \"\"\"Check for string\"\"\"\n if not isinstance(value, string_types):\n message = \"Value provided{ref_token}, '{value}' (type {type}), {reason}\".format(\n ref_token=\" for {}\".format(reference_token) if reference_token else \"\",\n value=value, type=type(value).__name__,\n reason=\"is not a string\"\n )\n raise InvalidNameException(message)\n\n @staticmethod\n def validate_name(name, version=False, reference_token=None):\n \"\"\"Check for name compliance with pattern rules\"\"\"\n ConanName.validate_string(name, reference_token=reference_token)\n if name == \"*\":\n return\n if ConanName._validation_pattern.match(name) is None:\n if version and name.startswith(\"[\") and name.endswith(\"]\"):\n return\n ConanName.invalid_name_message(name, reference_token=reference_token)\n\n @staticmethod\n def validate_revision(revision):\n if ConanName._validation_revision_pattern.match(revision) is None:\n raise InvalidNameException(\"The revision field, must contain only letters \"\n \"and numbers with a length between 1 and \"\n \"%s\" % ConanName._max_chars)\n\n\nclass ConanFileReference(namedtuple(\"ConanFileReference\", \"name version user channel revision\")):\n \"\"\" Full reference of a package recipes, e.g.:\n opencv/2.4.10@lasote/testing\n \"\"\"\n whitespace_pattern = re.compile(r\"\\s+\")\n sep_pattern = re.compile(\"@|/|#\")\n\n def __new__(cls, name, version, user, channel, revision=None, validate=True):\n \"\"\"Simple name creation.\n @param name: string containing the desired name\n @param version: string containing the desired version\n @param user: string containing the user name\n @param channel: string containing the user channel\n @param revision: string containing the revision (optional)\n \"\"\"\n version = Version(version)\n obj = super(cls, ConanFileReference).__new__(cls, name, version, user, channel, revision)\n if validate:\n obj.validate()\n return obj\n\n def validate(self):\n ConanName.validate_name(self.name, reference_token=\"package name\")\n ConanName.validate_name(self.version, True, reference_token=\"package version\")\n ConanName.validate_name(self.user, reference_token=\"user name\")\n ConanName.validate_name(self.channel, reference_token=\"channel\")\n if self.revision:\n ConanName.validate_revision(self.revision)\n\n def __hash__(self):\n return hash((self.name, self.version, self.user, self.channel, self.revision))\n\n @staticmethod\n def loads(text, validate=True):\n \"\"\" Parses a text string to generate a ConanFileReference object\n \"\"\"\n text = ConanFileReference.whitespace_pattern.sub(\"\", text)\n tokens = ConanFileReference.sep_pattern.split(text)\n try:\n if len(tokens) not in (4, 5):\n raise ValueError\n name, version, user, channel = tokens[0:4]\n revision = tokens[4] if len(tokens) == 5 else None\n except ValueError:\n raise ConanException(\"Wrong package recipe reference %s\\nWrite something like \"\n \"OpenCV/1.0.6@user/stable\" % text)\n obj = ConanFileReference(name, version, user, channel, revision, validate=validate)\n return obj\n\n def __repr__(self):\n return \"%s/%s@%s/%s\" % (self.name, self.version, self.user, self.channel)\n\n def full_repr(self):\n str_rev = \"#%s\" % self.revision if self.revision else \"\"\n return \"%s%s\" % (str(self), str_rev)\n\n def dir_repr(self):\n return \"/\".join(self[:-1])\n\n def copy_with_rev(self, revision):\n return ConanFileReference(self.name, self.version, self.user, self.channel, revision)\n\n def copy_clear_rev(self):\n return ConanFileReference(self.name, self.version, self.user, self.channel, None)\n\n\nclass PackageReference(namedtuple(\"PackageReference\", \"conan package_id revision\")):\n \"\"\" Full package reference, e.g.:\n opencv/2.4.10@lasote/testing, fe566a677f77734ae\n \"\"\"\n\n def __new__(cls, conan, package_id, revision=None, validate=True):\n if \"#\" in package_id:\n package_id, revision = package_id.rsplit(\"#\", 1)\n obj = super(cls, PackageReference).__new__(cls, conan, package_id, revision)\n if validate:\n obj.validate()\n return obj\n\n def validate(self):\n if self.revision:\n ConanName.validate_revision(self.revision)\n\n @staticmethod\n def loads(text, validate=True):\n text = text.strip()\n tmp = text.split(\":\")\n try:\n conan = ConanFileReference.loads(tmp[0].strip())\n package_id = tmp[1].strip()\n except IndexError:\n raise ConanException(\"Wrong package reference %s\" % text)\n return PackageReference(conan, package_id, validate=validate)\n\n def __repr__(self):\n return \"%s:%s\" % (self.conan, self.package_id)\n\n def full_repr(self):\n str_rev = \"#%s\" % self.revision if self.revision else \"\"\n tmp = \"%s:%s%s\" % (self.conan.full_repr(), self.package_id, str_rev)\n return tmp\n\n def copy_with_revs(self, revision, p_revision):\n return PackageReference(self.conan.copy_with_rev(revision), self.package_id, p_revision)\n\n def copy_clear_rev(self):\n ref = self.conan.copy_clear_rev()\n return PackageReference(ref, self.package_id, revision=None)\n", "path": "conans/model/ref.py"}], "after_files": [{"content": "from collections import namedtuple\n\nimport re\nfrom six import string_types\n\nfrom conans.errors import ConanException, InvalidNameException\nfrom conans.model.version import Version\n\n\ndef check_valid_ref(ref, allow_pattern):\n try:\n if not isinstance(ref, ConanFileReference):\n ref = ConanFileReference.loads(ref, validate=True)\n return \"*\" not in ref or allow_pattern\n except ConanException:\n pass\n return False\n\n\nclass ConanName(object):\n _max_chars = 51\n _min_chars = 2\n _validation_pattern = re.compile(\"^[a-zA-Z0-9_][a-zA-Z0-9_\\+\\.-]{%s,%s}$\"\n % (_min_chars - 1, _max_chars - 1))\n\n _validation_revision_pattern = re.compile(\"^[a-zA-Z0-9]{1,%s}$\" % _max_chars)\n\n @staticmethod\n def invalid_name_message(value, reference_token=None):\n if len(value) > ConanName._max_chars:\n reason = \"is too long. Valid names must contain at most %s characters.\"\\\n % ConanName._max_chars\n elif len(value) < ConanName._min_chars:\n reason = \"is too short. Valid names must contain at least %s characters.\"\\\n % ConanName._min_chars\n else:\n reason = (\"is an invalid name. Valid names MUST begin with a \"\n \"letter, number or underscore, have between %s-%s chars, including \"\n \"letters, numbers, underscore, dot and dash\"\n % (ConanName._min_chars, ConanName._max_chars))\n message = \"Value provided{ref_token}, '{value}' (type {type}), {reason}\".format(\n ref_token=\" for {}\".format(reference_token) if reference_token else \"\",\n value=value, type=type(value).__name__, reason=reason\n )\n raise InvalidNameException(message)\n\n @staticmethod\n def validate_string(value, reference_token=None):\n \"\"\"Check for string\"\"\"\n if not isinstance(value, string_types):\n message = \"Value provided{ref_token}, '{value}' (type {type}), {reason}\".format(\n ref_token=\" for {}\".format(reference_token) if reference_token else \"\",\n value=value, type=type(value).__name__,\n reason=\"is not a string\"\n )\n raise InvalidNameException(message)\n\n @staticmethod\n def validate_name(name, version=False, reference_token=None):\n \"\"\"Check for name compliance with pattern rules\"\"\"\n ConanName.validate_string(name, reference_token=reference_token)\n if name == \"*\":\n return\n if ConanName._validation_pattern.match(name) is None:\n if version and name.startswith(\"[\") and name.endswith(\"]\"):\n return\n ConanName.invalid_name_message(name, reference_token=reference_token)\n\n @staticmethod\n def validate_revision(revision):\n if ConanName._validation_revision_pattern.match(revision) is None:\n raise InvalidNameException(\"The revision field, must contain only letters \"\n \"and numbers with a length between 1 and \"\n \"%s\" % ConanName._max_chars)\n\n\nclass ConanFileReference(namedtuple(\"ConanFileReference\", \"name version user channel revision\")):\n \"\"\" Full reference of a package recipes, e.g.:\n opencv/2.4.10@lasote/testing\n \"\"\"\n whitespace_pattern = re.compile(r\"\\s+\")\n sep_pattern = re.compile(r\"([^/]+)/([^/]+)@([^/]+)/([^/#]+)#?(.+)?\")\n\n def __new__(cls, name, version, user, channel, revision=None, validate=True):\n \"\"\"Simple name creation.\n @param name: string containing the desired name\n @param version: string containing the desired version\n @param user: string containing the user name\n @param channel: string containing the user channel\n @param revision: string containing the revision (optional)\n \"\"\"\n version = Version(version)\n obj = super(cls, ConanFileReference).__new__(cls, name, version, user, channel, revision)\n if validate:\n obj.validate()\n return obj\n\n def validate(self):\n ConanName.validate_name(self.name, reference_token=\"package name\")\n ConanName.validate_name(self.version, True, reference_token=\"package version\")\n ConanName.validate_name(self.user, reference_token=\"user name\")\n ConanName.validate_name(self.channel, reference_token=\"channel\")\n if self.revision:\n ConanName.validate_revision(self.revision)\n\n def __hash__(self):\n return hash((self.name, self.version, self.user, self.channel, self.revision))\n\n @staticmethod\n def loads(text, validate=True):\n \"\"\" Parses a text string to generate a ConanFileReference object\n \"\"\"\n text = ConanFileReference.whitespace_pattern.sub(\"\", text)\n try:\n # Split returns empty start and end groups\n _, name, version, user, channel, revision, _ = ConanFileReference.sep_pattern.split(text)\n except ValueError:\n raise ConanException(\"Wrong package recipe reference %s\\nWrite something like \"\n \"OpenCV/1.0.6@user/stable\" % text)\n obj = ConanFileReference(name, version, user, channel, revision, validate=validate)\n return obj\n\n def __repr__(self):\n return \"%s/%s@%s/%s\" % (self.name, self.version, self.user, self.channel)\n\n def full_repr(self):\n str_rev = \"#%s\" % self.revision if self.revision else \"\"\n return \"%s%s\" % (str(self), str_rev)\n\n def dir_repr(self):\n return \"/\".join(self[:-1])\n\n def copy_with_rev(self, revision):\n return ConanFileReference(self.name, self.version, self.user, self.channel, revision)\n\n def copy_clear_rev(self):\n return ConanFileReference(self.name, self.version, self.user, self.channel, None)\n\n\nclass PackageReference(namedtuple(\"PackageReference\", \"conan package_id revision\")):\n \"\"\" Full package reference, e.g.:\n opencv/2.4.10@lasote/testing, fe566a677f77734ae\n \"\"\"\n\n def __new__(cls, conan, package_id, revision=None, validate=True):\n if \"#\" in package_id:\n package_id, revision = package_id.rsplit(\"#\", 1)\n obj = super(cls, PackageReference).__new__(cls, conan, package_id, revision)\n if validate:\n obj.validate()\n return obj\n\n def validate(self):\n if self.revision:\n ConanName.validate_revision(self.revision)\n\n @staticmethod\n def loads(text, validate=True):\n text = text.strip()\n tmp = text.split(\":\")\n try:\n conan = ConanFileReference.loads(tmp[0].strip())\n package_id = tmp[1].strip()\n except IndexError:\n raise ConanException(\"Wrong package reference %s\" % text)\n return PackageReference(conan, package_id, validate=validate)\n\n def __repr__(self):\n return \"%s:%s\" % (self.conan, self.package_id)\n\n def full_repr(self):\n str_rev = \"#%s\" % self.revision if self.revision else \"\"\n tmp = \"%s:%s%s\" % (self.conan.full_repr(), self.package_id, str_rev)\n return tmp\n\n def copy_with_revs(self, revision, p_revision):\n return PackageReference(self.conan.copy_with_rev(revision), self.package_id, p_revision)\n\n def copy_clear_rev(self):\n ref = self.conan.copy_clear_rev()\n return PackageReference(ref, self.package_id, revision=None)\n", "path": "conans/model/ref.py"}]}
| 3,029 | 324 |
gh_patches_debug_20565
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-2517
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Uploading large files fails on the "Too many open files" error
Author: @lubosmj (lmjachky)
Redmine Issue: 9634, https://pulp.plan.io/issues/9634
---
Steps to reproduce the behaviour:
```
(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ truncate -s 3G gentoo_root.img
(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ pulp artifact upload --file gentoo_root.img
Uploading file gentoo_root.img
................[truncated the number of dots]...................Upload complete. Creating artifact.
Started background task /pulp/api/v3/tasks/2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30/
........Error: Task /pulp/api/v3/tasks/2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30/ failed: '[Errno 24] Too many open files: '/var/lib/pulp/media/upload/ec2d5c92-57e9-4191-ae95-ff4b9ec94353''
(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ ls -la gentoo_root.img
-rw-r--r--. 1 vagrant vagrant 3221225472 Dec 13 11:32 gentoo_root.img
```
Traceback:
```
Task 2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30 failed ([Errno 24] Too many open files: '/var/lib/pulp/media/upload/ec2d5c92-57e9-4191-ae95-ff4b9ec94353')
pulp [3a3a9ea662994f609eea7d43ac8f30aa]: pulpcore.tasking.pulpcore_worker:INFO: File "/home/vagrant/devel/pulpcore/pulpcore/tasking/pulpcore_worker.py", line 362, in _perform_task
result = func(*args, **kwargs)
File "/home/vagrant/devel/pulpcore/pulpcore/app/tasks/upload.py", line 31, in commit
temp_file.write(chunk.file.read())
File "/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/utils.py", line 42, in <lambda>
read = property(lambda self: self.file.read)
File "/usr/local/lib/pulp/lib64/python3.9/site-packages/django/db/models/fields/files.py", line 45, in _get_file
self._file = self.storage.open(self.name, 'rb')
File "/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/storage.py", line 38, in open
return self._open(name, mode)
File "/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/storage.py", line 238, in _open
return File(open(self.path(name), mode))
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/importexport.py`
Content:
```
1 import os
2 import io
3 import json
4 import tarfile
5 import tempfile
6 import logging
7
8 from django.conf import settings
9 from django.db.models.query import QuerySet
10
11 from pulpcore.app.apps import get_plugin_config
12 from pulpcore.app.models.progress import ProgressReport
13 from pulpcore.app.models.repository import Repository
14 from pulpcore.app.modelresource import (
15 ArtifactResource,
16 ContentArtifactResource,
17 RepositoryResource,
18 )
19 from pulpcore.constants import TASK_STATES, EXPORT_BATCH_SIZE
20
21 log = logging.getLogger(__name__)
22
23
24 def _write_export(the_tarfile, resource, dest_dir=None):
25 """
26 Write the JSON export for the specified resource to the specified tarfile.
27
28 The resulting file will be found at <dest_dir>/<resource.__class__.__name__>.json. If dest_dir
29 is None, the file will be added at the 'top level' of the_tarfile.
30
31 Export-files are UTF-8 encoded.
32
33 Args:
34 the_tarfile (tarfile.Tarfile): tarfile we are writing into
35 resource (import_export.resources.ModelResource): ModelResource to be exported
36 dest_dir str(directory-path): directory 'inside' the tarfile to write to
37 """
38 filename = "{}.{}.json".format(resource.__module__, type(resource).__name__)
39 if dest_dir:
40 dest_filename = os.path.join(dest_dir, filename)
41 else:
42 dest_filename = filename
43
44 # If the resource is the type of QuerySet, then export the data in batch to save memory.
45 # Otherwise, export all data in oneshot. This is because the underlying libraries
46 # (json; django-import-export) do not support to stream the output to file, we export
47 # the data in batches to memory and concatenate the json lists via string manipulation.
48 with tempfile.NamedTemporaryFile(dir=".", mode="w", encoding="utf8") as temp_file:
49 if isinstance(resource.queryset, QuerySet):
50 temp_file.write("[")
51 total = resource.queryset.count()
52 for i in range(0, total, EXPORT_BATCH_SIZE):
53 current_batch = i + EXPORT_BATCH_SIZE
54 dataset = resource.export(resource.queryset[i:current_batch])
55 # Strip "[" and "]" as we are writing the dataset in batch
56 temp_file.write(dataset.json.lstrip("[").rstrip("]"))
57 if current_batch < total:
58 # Write "," if not last loop
59 temp_file.write(", ")
60 temp_file.write("]")
61 else:
62 dataset = resource.export(resource.queryset)
63 temp_file.write(dataset.json)
64
65 temp_file.flush()
66 info = tarfile.TarInfo(name=dest_filename)
67 info.size = os.path.getsize(temp_file.name)
68 with open(temp_file.name, "rb") as fd:
69 the_tarfile.addfile(info, fd)
70
71
72 def export_versions(export, version_info):
73 """
74 Write a JSON list of plugins and their versions as 'versions.json' to export.tarfile
75
76 Output format is [{"component": "<pluginname>", "version": "<pluginversion>"},...]
77
78 Args:
79 export (django.db.models.PulpExport): export instance that's doing the export
80 version_info (set): set of (distribution-label,version) tuples for repos in this export
81 """
82 # build the version-list from the distributions for each component
83 versions = [{"component": label, "version": version} for (label, version) in version_info]
84
85 version_json = json.dumps(versions).encode("utf8")
86 info = tarfile.TarInfo(name="versions.json")
87 info.size = len(version_json)
88 export.tarfile.addfile(info, io.BytesIO(version_json))
89
90
91 def export_artifacts(export, artifacts):
92 """
93 Export a set of Artifacts, ArtifactResources, and RepositoryResources
94
95 Args:
96 export (django.db.models.PulpExport): export instance that's doing the export
97 artifacts (django.db.models.Artifacts): list of artifacts in all repos being exported
98
99 Raises:
100 ValidationError: When path is not in the ALLOWED_EXPORT_PATHS setting
101 """
102 data = dict(message="Exporting Artifacts", code="export.artifacts", total=len(artifacts))
103 with ProgressReport(**data) as pb:
104 for artifact in pb.iter(artifacts):
105 dest = artifact.file.name
106 if settings.DEFAULT_FILE_STORAGE != "pulpcore.app.models.storage.FileSystem":
107 with tempfile.TemporaryDirectory(dir=".") as temp_dir:
108 with tempfile.NamedTemporaryFile(dir=temp_dir) as temp_file:
109 temp_file.write(artifact.file.read())
110 temp_file.flush()
111 export.tarfile.add(temp_file.name, dest)
112 else:
113 export.tarfile.add(artifact.file.path, dest)
114
115 resource = ArtifactResource()
116 resource.queryset = artifacts
117 _write_export(export.tarfile, resource)
118
119 resource = RepositoryResource()
120 resource.queryset = Repository.objects.filter(pk__in=export.exporter.repositories.all())
121 _write_export(export.tarfile, resource)
122
123
124 def export_content(export, repository_version):
125 """
126 Export db-content, and the db-content of the owning repositories
127
128 Args:
129 export (django.db.models.PulpExport): export instance that's doing the export
130 repository_version (django.db.models.RepositoryVersion): RepositoryVersion being exported
131 """
132
133 def _combine_content_mappings(map1, map2):
134 """Combine two content mapping dicts into one by combining ids for for each key."""
135 result = {}
136 for key in map1.keys() | map2.keys():
137 result[key] = list(set(map1.get(key, []) + map2.get(key, [])))
138 return result
139
140 dest_dir = os.path.join(
141 "repository-{}_{}".format(
142 str(repository_version.repository.name), repository_version.number
143 )
144 )
145
146 # content mapping is used by repo versions with subrepos (eg distribution tree repos)
147 content_mapping = {}
148
149 # find and export any ModelResource found in pulp_<repo-type>.app.modelresource
150 plugin_name = repository_version.repository.pulp_type.split(".")[0]
151 cfg = get_plugin_config(plugin_name)
152 if cfg.exportable_classes:
153 for cls in cfg.exportable_classes:
154 resource = cls(repository_version)
155 _write_export(export.tarfile, resource, dest_dir)
156
157 if hasattr(resource, "content_mapping") and resource.content_mapping:
158 content_mapping = _combine_content_mappings(
159 content_mapping, resource.content_mapping
160 )
161
162 # Export the connection between content and artifacts
163 resource = ContentArtifactResource(repository_version, content_mapping)
164 _write_export(export.tarfile, resource, dest_dir)
165
166 msg = (
167 f"Exporting content for {plugin_name} "
168 f"repository-version {repository_version.repository.name}/{repository_version.number}"
169 )
170 content_count = repository_version.content.count()
171 data = dict(
172 message=msg,
173 code="export.repo.version.content",
174 total=content_count,
175 done=content_count,
176 state=TASK_STATES.COMPLETED,
177 )
178 pb = ProgressReport(**data)
179 pb.save()
180
181 if content_mapping:
182 # write the content mapping to tarfile
183 cm_json = json.dumps(content_mapping).encode("utf8")
184 info = tarfile.TarInfo(name=f"{dest_dir}/content_mapping.json")
185 info.size = len(cm_json)
186 export.tarfile.addfile(info, io.BytesIO(cm_json))
187
```
Path: `pulpcore/app/tasks/upload.py`
Content:
```
1 from gettext import gettext as _
2 from logging import getLogger
3 from tempfile import NamedTemporaryFile
4
5 from django.core.files import File
6
7 from pulpcore.app import files, models
8 from pulpcore.app.models import CreatedResource
9 from pulpcore.app.serializers import ArtifactSerializer
10
11 log = getLogger(__name__)
12
13
14 def commit(upload_id, sha256):
15 """
16 Commit the upload and turn it into an artifact.
17
18 Args:
19 upload_id (int): The upload primary key
20 sha256 (str): The checksum for the uploaded file
21 """
22 try:
23 upload = models.Upload.objects.get(pk=upload_id)
24 except models.Upload.DoesNotExist:
25 log.info(_("The upload was not found. Nothing to do."))
26 return
27
28 chunks = models.UploadChunk.objects.filter(upload=upload).order_by("offset")
29 with NamedTemporaryFile("ab") as temp_file:
30 for chunk in chunks:
31 temp_file.write(chunk.file.read())
32 temp_file.flush()
33
34 file = files.PulpTemporaryUploadedFile.from_file(File(open(temp_file.name, "rb")))
35
36 data = {"file": file, "sha256": sha256}
37 serializer = ArtifactSerializer(data=data)
38 serializer.is_valid(raise_exception=True)
39 artifact = serializer.save()
40
41 resource = CreatedResource(content_object=artifact)
42 resource.save()
43
44 # delete the upload since it can't be reused to create another artifact
45 upload.delete()
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/importexport.py b/pulpcore/app/importexport.py
--- a/pulpcore/app/importexport.py
+++ b/pulpcore/app/importexport.py
@@ -108,6 +108,7 @@
with tempfile.NamedTemporaryFile(dir=temp_dir) as temp_file:
temp_file.write(artifact.file.read())
temp_file.flush()
+ artifact.file.close()
export.tarfile.add(temp_file.name, dest)
else:
export.tarfile.add(artifact.file.path, dest)
diff --git a/pulpcore/app/tasks/upload.py b/pulpcore/app/tasks/upload.py
--- a/pulpcore/app/tasks/upload.py
+++ b/pulpcore/app/tasks/upload.py
@@ -29,6 +29,7 @@
with NamedTemporaryFile("ab") as temp_file:
for chunk in chunks:
temp_file.write(chunk.file.read())
+ chunk.file.close()
temp_file.flush()
file = files.PulpTemporaryUploadedFile.from_file(File(open(temp_file.name, "rb")))
|
{"golden_diff": "diff --git a/pulpcore/app/importexport.py b/pulpcore/app/importexport.py\n--- a/pulpcore/app/importexport.py\n+++ b/pulpcore/app/importexport.py\n@@ -108,6 +108,7 @@\n with tempfile.NamedTemporaryFile(dir=temp_dir) as temp_file:\n temp_file.write(artifact.file.read())\n temp_file.flush()\n+ artifact.file.close()\n export.tarfile.add(temp_file.name, dest)\n else:\n export.tarfile.add(artifact.file.path, dest)\ndiff --git a/pulpcore/app/tasks/upload.py b/pulpcore/app/tasks/upload.py\n--- a/pulpcore/app/tasks/upload.py\n+++ b/pulpcore/app/tasks/upload.py\n@@ -29,6 +29,7 @@\n with NamedTemporaryFile(\"ab\") as temp_file:\n for chunk in chunks:\n temp_file.write(chunk.file.read())\n+ chunk.file.close()\n temp_file.flush()\n \n file = files.PulpTemporaryUploadedFile.from_file(File(open(temp_file.name, \"rb\")))\n", "issue": "Uploading large files fails on the \"Too many open files\" error\nAuthor: @lubosmj (lmjachky)\n\n\nRedmine Issue: 9634, https://pulp.plan.io/issues/9634\n\n---\n\nSteps to reproduce the behaviour:\r\n```\r\n(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ truncate -s 3G gentoo_root.img\r\n\r\n(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ pulp artifact upload --file gentoo_root.img\r\nUploading file gentoo_root.img\r\n................[truncated the number of dots]...................Upload complete. Creating artifact.\r\nStarted background task /pulp/api/v3/tasks/2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30/\r\n........Error: Task /pulp/api/v3/tasks/2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30/ failed: '[Errno 24] Too many open files: '/var/lib/pulp/media/upload/ec2d5c92-57e9-4191-ae95-ff4b9ec94353''\r\n\r\n(pulp) [vagrant@pulp3-source-fedora34 pulp_ostree]$ ls -la gentoo_root.img\r\n-rw-r--r--. 1 vagrant vagrant 3221225472 Dec 13 11:32 gentoo_root.img\r\n```\r\n\r\nTraceback:\r\n```\r\nTask 2d3cf569-2d5c-449d-9ac6-7a53ab5f3a30 failed ([Errno 24] Too many open files: '/var/lib/pulp/media/upload/ec2d5c92-57e9-4191-ae95-ff4b9ec94353')\r\npulp [3a3a9ea662994f609eea7d43ac8f30aa]: pulpcore.tasking.pulpcore_worker:INFO: File \"/home/vagrant/devel/pulpcore/pulpcore/tasking/pulpcore_worker.py\", line 362, in _perform_task\r\n result = func(*args, **kwargs)\r\n File \"/home/vagrant/devel/pulpcore/pulpcore/app/tasks/upload.py\", line 31, in commit\r\n temp_file.write(chunk.file.read())\r\n File \"/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/utils.py\", line 42, in <lambda>\r\n read = property(lambda self: self.file.read)\r\n File \"/usr/local/lib/pulp/lib64/python3.9/site-packages/django/db/models/fields/files.py\", line 45, in _get_file\r\n self._file = self.storage.open(self.name, 'rb')\r\n File \"/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/storage.py\", line 38, in open\r\n return self._open(name, mode)\r\n File \"/usr/local/lib/pulp/lib64/python3.9/site-packages/django/core/files/storage.py\", line 238, in _open\r\n return File(open(self.path(name), mode))\r\n```\n\n\n\n", "before_files": [{"content": "import os\nimport io\nimport json\nimport tarfile\nimport tempfile\nimport logging\n\nfrom django.conf import settings\nfrom django.db.models.query import QuerySet\n\nfrom pulpcore.app.apps import get_plugin_config\nfrom pulpcore.app.models.progress import ProgressReport\nfrom pulpcore.app.models.repository import Repository\nfrom pulpcore.app.modelresource import (\n ArtifactResource,\n ContentArtifactResource,\n RepositoryResource,\n)\nfrom pulpcore.constants import TASK_STATES, EXPORT_BATCH_SIZE\n\nlog = logging.getLogger(__name__)\n\n\ndef _write_export(the_tarfile, resource, dest_dir=None):\n \"\"\"\n Write the JSON export for the specified resource to the specified tarfile.\n\n The resulting file will be found at <dest_dir>/<resource.__class__.__name__>.json. If dest_dir\n is None, the file will be added at the 'top level' of the_tarfile.\n\n Export-files are UTF-8 encoded.\n\n Args:\n the_tarfile (tarfile.Tarfile): tarfile we are writing into\n resource (import_export.resources.ModelResource): ModelResource to be exported\n dest_dir str(directory-path): directory 'inside' the tarfile to write to\n \"\"\"\n filename = \"{}.{}.json\".format(resource.__module__, type(resource).__name__)\n if dest_dir:\n dest_filename = os.path.join(dest_dir, filename)\n else:\n dest_filename = filename\n\n # If the resource is the type of QuerySet, then export the data in batch to save memory.\n # Otherwise, export all data in oneshot. This is because the underlying libraries\n # (json; django-import-export) do not support to stream the output to file, we export\n # the data in batches to memory and concatenate the json lists via string manipulation.\n with tempfile.NamedTemporaryFile(dir=\".\", mode=\"w\", encoding=\"utf8\") as temp_file:\n if isinstance(resource.queryset, QuerySet):\n temp_file.write(\"[\")\n total = resource.queryset.count()\n for i in range(0, total, EXPORT_BATCH_SIZE):\n current_batch = i + EXPORT_BATCH_SIZE\n dataset = resource.export(resource.queryset[i:current_batch])\n # Strip \"[\" and \"]\" as we are writing the dataset in batch\n temp_file.write(dataset.json.lstrip(\"[\").rstrip(\"]\"))\n if current_batch < total:\n # Write \",\" if not last loop\n temp_file.write(\", \")\n temp_file.write(\"]\")\n else:\n dataset = resource.export(resource.queryset)\n temp_file.write(dataset.json)\n\n temp_file.flush()\n info = tarfile.TarInfo(name=dest_filename)\n info.size = os.path.getsize(temp_file.name)\n with open(temp_file.name, \"rb\") as fd:\n the_tarfile.addfile(info, fd)\n\n\ndef export_versions(export, version_info):\n \"\"\"\n Write a JSON list of plugins and their versions as 'versions.json' to export.tarfile\n\n Output format is [{\"component\": \"<pluginname>\", \"version\": \"<pluginversion>\"},...]\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n version_info (set): set of (distribution-label,version) tuples for repos in this export\n \"\"\"\n # build the version-list from the distributions for each component\n versions = [{\"component\": label, \"version\": version} for (label, version) in version_info]\n\n version_json = json.dumps(versions).encode(\"utf8\")\n info = tarfile.TarInfo(name=\"versions.json\")\n info.size = len(version_json)\n export.tarfile.addfile(info, io.BytesIO(version_json))\n\n\ndef export_artifacts(export, artifacts):\n \"\"\"\n Export a set of Artifacts, ArtifactResources, and RepositoryResources\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n artifacts (django.db.models.Artifacts): list of artifacts in all repos being exported\n\n Raises:\n ValidationError: When path is not in the ALLOWED_EXPORT_PATHS setting\n \"\"\"\n data = dict(message=\"Exporting Artifacts\", code=\"export.artifacts\", total=len(artifacts))\n with ProgressReport(**data) as pb:\n for artifact in pb.iter(artifacts):\n dest = artifact.file.name\n if settings.DEFAULT_FILE_STORAGE != \"pulpcore.app.models.storage.FileSystem\":\n with tempfile.TemporaryDirectory(dir=\".\") as temp_dir:\n with tempfile.NamedTemporaryFile(dir=temp_dir) as temp_file:\n temp_file.write(artifact.file.read())\n temp_file.flush()\n export.tarfile.add(temp_file.name, dest)\n else:\n export.tarfile.add(artifact.file.path, dest)\n\n resource = ArtifactResource()\n resource.queryset = artifacts\n _write_export(export.tarfile, resource)\n\n resource = RepositoryResource()\n resource.queryset = Repository.objects.filter(pk__in=export.exporter.repositories.all())\n _write_export(export.tarfile, resource)\n\n\ndef export_content(export, repository_version):\n \"\"\"\n Export db-content, and the db-content of the owning repositories\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n repository_version (django.db.models.RepositoryVersion): RepositoryVersion being exported\n \"\"\"\n\n def _combine_content_mappings(map1, map2):\n \"\"\"Combine two content mapping dicts into one by combining ids for for each key.\"\"\"\n result = {}\n for key in map1.keys() | map2.keys():\n result[key] = list(set(map1.get(key, []) + map2.get(key, [])))\n return result\n\n dest_dir = os.path.join(\n \"repository-{}_{}\".format(\n str(repository_version.repository.name), repository_version.number\n )\n )\n\n # content mapping is used by repo versions with subrepos (eg distribution tree repos)\n content_mapping = {}\n\n # find and export any ModelResource found in pulp_<repo-type>.app.modelresource\n plugin_name = repository_version.repository.pulp_type.split(\".\")[0]\n cfg = get_plugin_config(plugin_name)\n if cfg.exportable_classes:\n for cls in cfg.exportable_classes:\n resource = cls(repository_version)\n _write_export(export.tarfile, resource, dest_dir)\n\n if hasattr(resource, \"content_mapping\") and resource.content_mapping:\n content_mapping = _combine_content_mappings(\n content_mapping, resource.content_mapping\n )\n\n # Export the connection between content and artifacts\n resource = ContentArtifactResource(repository_version, content_mapping)\n _write_export(export.tarfile, resource, dest_dir)\n\n msg = (\n f\"Exporting content for {plugin_name} \"\n f\"repository-version {repository_version.repository.name}/{repository_version.number}\"\n )\n content_count = repository_version.content.count()\n data = dict(\n message=msg,\n code=\"export.repo.version.content\",\n total=content_count,\n done=content_count,\n state=TASK_STATES.COMPLETED,\n )\n pb = ProgressReport(**data)\n pb.save()\n\n if content_mapping:\n # write the content mapping to tarfile\n cm_json = json.dumps(content_mapping).encode(\"utf8\")\n info = tarfile.TarInfo(name=f\"{dest_dir}/content_mapping.json\")\n info.size = len(cm_json)\n export.tarfile.addfile(info, io.BytesIO(cm_json))\n", "path": "pulpcore/app/importexport.py"}, {"content": "from gettext import gettext as _\nfrom logging import getLogger\nfrom tempfile import NamedTemporaryFile\n\nfrom django.core.files import File\n\nfrom pulpcore.app import files, models\nfrom pulpcore.app.models import CreatedResource\nfrom pulpcore.app.serializers import ArtifactSerializer\n\nlog = getLogger(__name__)\n\n\ndef commit(upload_id, sha256):\n \"\"\"\n Commit the upload and turn it into an artifact.\n\n Args:\n upload_id (int): The upload primary key\n sha256 (str): The checksum for the uploaded file\n \"\"\"\n try:\n upload = models.Upload.objects.get(pk=upload_id)\n except models.Upload.DoesNotExist:\n log.info(_(\"The upload was not found. Nothing to do.\"))\n return\n\n chunks = models.UploadChunk.objects.filter(upload=upload).order_by(\"offset\")\n with NamedTemporaryFile(\"ab\") as temp_file:\n for chunk in chunks:\n temp_file.write(chunk.file.read())\n temp_file.flush()\n\n file = files.PulpTemporaryUploadedFile.from_file(File(open(temp_file.name, \"rb\")))\n\n data = {\"file\": file, \"sha256\": sha256}\n serializer = ArtifactSerializer(data=data)\n serializer.is_valid(raise_exception=True)\n artifact = serializer.save()\n\n resource = CreatedResource(content_object=artifact)\n resource.save()\n\n # delete the upload since it can't be reused to create another artifact\n upload.delete()\n", "path": "pulpcore/app/tasks/upload.py"}], "after_files": [{"content": "import os\nimport io\nimport json\nimport tarfile\nimport tempfile\nimport logging\n\nfrom django.conf import settings\nfrom django.db.models.query import QuerySet\n\nfrom pulpcore.app.apps import get_plugin_config\nfrom pulpcore.app.models.progress import ProgressReport\nfrom pulpcore.app.models.repository import Repository\nfrom pulpcore.app.modelresource import (\n ArtifactResource,\n ContentArtifactResource,\n RepositoryResource,\n)\nfrom pulpcore.constants import TASK_STATES, EXPORT_BATCH_SIZE\n\nlog = logging.getLogger(__name__)\n\n\ndef _write_export(the_tarfile, resource, dest_dir=None):\n \"\"\"\n Write the JSON export for the specified resource to the specified tarfile.\n\n The resulting file will be found at <dest_dir>/<resource.__class__.__name__>.json. If dest_dir\n is None, the file will be added at the 'top level' of the_tarfile.\n\n Export-files are UTF-8 encoded.\n\n Args:\n the_tarfile (tarfile.Tarfile): tarfile we are writing into\n resource (import_export.resources.ModelResource): ModelResource to be exported\n dest_dir str(directory-path): directory 'inside' the tarfile to write to\n \"\"\"\n filename = \"{}.{}.json\".format(resource.__module__, type(resource).__name__)\n if dest_dir:\n dest_filename = os.path.join(dest_dir, filename)\n else:\n dest_filename = filename\n\n # If the resource is the type of QuerySet, then export the data in batch to save memory.\n # Otherwise, export all data in oneshot. This is because the underlying libraries\n # (json; django-import-export) do not support to stream the output to file, we export\n # the data in batches to memory and concatenate the json lists via string manipulation.\n with tempfile.NamedTemporaryFile(dir=\".\", mode=\"w\", encoding=\"utf8\") as temp_file:\n if isinstance(resource.queryset, QuerySet):\n temp_file.write(\"[\")\n total = resource.queryset.count()\n for i in range(0, total, EXPORT_BATCH_SIZE):\n current_batch = i + EXPORT_BATCH_SIZE\n dataset = resource.export(resource.queryset[i:current_batch])\n # Strip \"[\" and \"]\" as we are writing the dataset in batch\n temp_file.write(dataset.json.lstrip(\"[\").rstrip(\"]\"))\n if current_batch < total:\n # Write \",\" if not last loop\n temp_file.write(\", \")\n temp_file.write(\"]\")\n else:\n dataset = resource.export(resource.queryset)\n temp_file.write(dataset.json)\n\n temp_file.flush()\n info = tarfile.TarInfo(name=dest_filename)\n info.size = os.path.getsize(temp_file.name)\n with open(temp_file.name, \"rb\") as fd:\n the_tarfile.addfile(info, fd)\n\n\ndef export_versions(export, version_info):\n \"\"\"\n Write a JSON list of plugins and their versions as 'versions.json' to export.tarfile\n\n Output format is [{\"component\": \"<pluginname>\", \"version\": \"<pluginversion>\"},...]\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n version_info (set): set of (distribution-label,version) tuples for repos in this export\n \"\"\"\n # build the version-list from the distributions for each component\n versions = [{\"component\": label, \"version\": version} for (label, version) in version_info]\n\n version_json = json.dumps(versions).encode(\"utf8\")\n info = tarfile.TarInfo(name=\"versions.json\")\n info.size = len(version_json)\n export.tarfile.addfile(info, io.BytesIO(version_json))\n\n\ndef export_artifacts(export, artifacts):\n \"\"\"\n Export a set of Artifacts, ArtifactResources, and RepositoryResources\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n artifacts (django.db.models.Artifacts): list of artifacts in all repos being exported\n\n Raises:\n ValidationError: When path is not in the ALLOWED_EXPORT_PATHS setting\n \"\"\"\n data = dict(message=\"Exporting Artifacts\", code=\"export.artifacts\", total=len(artifacts))\n with ProgressReport(**data) as pb:\n for artifact in pb.iter(artifacts):\n dest = artifact.file.name\n if settings.DEFAULT_FILE_STORAGE != \"pulpcore.app.models.storage.FileSystem\":\n with tempfile.TemporaryDirectory(dir=\".\") as temp_dir:\n with tempfile.NamedTemporaryFile(dir=temp_dir) as temp_file:\n temp_file.write(artifact.file.read())\n temp_file.flush()\n artifact.file.close()\n export.tarfile.add(temp_file.name, dest)\n else:\n export.tarfile.add(artifact.file.path, dest)\n\n resource = ArtifactResource()\n resource.queryset = artifacts\n _write_export(export.tarfile, resource)\n\n resource = RepositoryResource()\n resource.queryset = Repository.objects.filter(pk__in=export.exporter.repositories.all())\n _write_export(export.tarfile, resource)\n\n\ndef export_content(export, repository_version):\n \"\"\"\n Export db-content, and the db-content of the owning repositories\n\n Args:\n export (django.db.models.PulpExport): export instance that's doing the export\n repository_version (django.db.models.RepositoryVersion): RepositoryVersion being exported\n \"\"\"\n\n def _combine_content_mappings(map1, map2):\n \"\"\"Combine two content mapping dicts into one by combining ids for for each key.\"\"\"\n result = {}\n for key in map1.keys() | map2.keys():\n result[key] = list(set(map1.get(key, []) + map2.get(key, [])))\n return result\n\n dest_dir = os.path.join(\n \"repository-{}_{}\".format(\n str(repository_version.repository.name), repository_version.number\n )\n )\n\n # content mapping is used by repo versions with subrepos (eg distribution tree repos)\n content_mapping = {}\n\n # find and export any ModelResource found in pulp_<repo-type>.app.modelresource\n plugin_name = repository_version.repository.pulp_type.split(\".\")[0]\n cfg = get_plugin_config(plugin_name)\n if cfg.exportable_classes:\n for cls in cfg.exportable_classes:\n resource = cls(repository_version)\n _write_export(export.tarfile, resource, dest_dir)\n\n if hasattr(resource, \"content_mapping\") and resource.content_mapping:\n content_mapping = _combine_content_mappings(\n content_mapping, resource.content_mapping\n )\n\n # Export the connection between content and artifacts\n resource = ContentArtifactResource(repository_version, content_mapping)\n _write_export(export.tarfile, resource, dest_dir)\n\n msg = (\n f\"Exporting content for {plugin_name} \"\n f\"repository-version {repository_version.repository.name}/{repository_version.number}\"\n )\n content_count = repository_version.content.count()\n data = dict(\n message=msg,\n code=\"export.repo.version.content\",\n total=content_count,\n done=content_count,\n state=TASK_STATES.COMPLETED,\n )\n pb = ProgressReport(**data)\n pb.save()\n\n if content_mapping:\n # write the content mapping to tarfile\n cm_json = json.dumps(content_mapping).encode(\"utf8\")\n info = tarfile.TarInfo(name=f\"{dest_dir}/content_mapping.json\")\n info.size = len(cm_json)\n export.tarfile.addfile(info, io.BytesIO(cm_json))\n", "path": "pulpcore/app/importexport.py"}, {"content": "from gettext import gettext as _\nfrom logging import getLogger\nfrom tempfile import NamedTemporaryFile\n\nfrom django.core.files import File\n\nfrom pulpcore.app import files, models\nfrom pulpcore.app.models import CreatedResource\nfrom pulpcore.app.serializers import ArtifactSerializer\n\nlog = getLogger(__name__)\n\n\ndef commit(upload_id, sha256):\n \"\"\"\n Commit the upload and turn it into an artifact.\n\n Args:\n upload_id (int): The upload primary key\n sha256 (str): The checksum for the uploaded file\n \"\"\"\n try:\n upload = models.Upload.objects.get(pk=upload_id)\n except models.Upload.DoesNotExist:\n log.info(_(\"The upload was not found. Nothing to do.\"))\n return\n\n chunks = models.UploadChunk.objects.filter(upload=upload).order_by(\"offset\")\n with NamedTemporaryFile(\"ab\") as temp_file:\n for chunk in chunks:\n temp_file.write(chunk.file.read())\n chunk.file.close()\n temp_file.flush()\n\n file = files.PulpTemporaryUploadedFile.from_file(File(open(temp_file.name, \"rb\")))\n\n data = {\"file\": file, \"sha256\": sha256}\n serializer = ArtifactSerializer(data=data)\n serializer.is_valid(raise_exception=True)\n artifact = serializer.save()\n\n resource = CreatedResource(content_object=artifact)\n resource.save()\n\n # delete the upload since it can't be reused to create another artifact\n upload.delete()\n", "path": "pulpcore/app/tasks/upload.py"}]}
| 3,450 | 224 |
gh_patches_debug_26850
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3560
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[APP SUBMITTED]: KeyError: "u'version'"
### INFO
**Python Version**: `2.7.13 (default, Dec 18 2016, 21:23:50) [GCC 4.6.4]`
**Operating System**: `Linux-3.2.40-armv7l-with-glibc2.4`
**Locale**: `UTF-8`
**Branch**: [master](../tree/master)
**Database**: `44.8`
**Commit**: pymedusa/Medusa@7b9111eef5836a6846499ef257ffff3f1f35df8f
**Link to Log**: https://gist.github.com/adaeb1415fefd1083f59da7f01134ac6
### ERROR
<pre>
2017-12-29 19:52:25 ERROR FINDPROPERS :: [7b9111e] BraceMessage string formatting failed. Using representation instead.
File "/usr/local/python/lib/python2.7/threading.py", line 774, in __bootstrap
self.__bootstrap_inner()
File "/usr/local/python/lib/python2.7/threading.py", line 801, in __bootstrap_inner
self.run()
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/scheduler.py#L90">SickBeard/medusa/scheduler.py</a>", line 90, in run
self.action.run(self.force)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/proper.py#L65">SickBeard/medusa/search/proper.py</a>", line 65, in run
self._download_propers(propers)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/proper.py#L353">SickBeard/medusa/search/proper.py</a>", line 353, in _download_propers
snatch_episode(cur_proper)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/core.py#L159">SickBeard/medusa/search/core.py</a>", line 159, in snatch_episode
result_downloaded = client.send_torrent(result)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/clients/torrent/generic.py#L254">SickBeard/medusa/clients/torrent/generic.py</a>", line 254, in send_torrent
r_code = self._add_torrent_uri(result)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/clients/torrent/download_station_client.py#L124">SickBeard/medusa/clients/torrent/download_station_client.py</a>", line 124, in _add_torrent_uri
log.debug('Add torrent URI with data: {}'.format(data))
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L89">SickBeard/medusa/logger/adapters/style.py</a>", line 89, in log
self.logger.log(level, brace_msg, **kwargs)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 1489, in log
self.logger.log(level, msg, *args, **kwargs)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 1231, in log
self._log(level, msg, args, **kwargs)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 1286, in _log
self.handle(record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 1296, in handle
self.callHandlers(record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 1336, in callHandlers
hdlr.handle(record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 759, in handle
self.emit(record)
File "/usr/local/python/lib/python2.7/logging/handlers.py", line 78, in emit
logging.FileHandler.emit(self, record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 957, in emit
StreamHandler.emit(self, record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 861, in emit
msg = self.format(record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 734, in format
return fmt.format(record)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/__init__.py#L546">SickBeard/medusa/logger/__init__.py</a>", line 546, in format
msg = super(CensoredFormatter, self).format(record)
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 465, in format
record.message = record.getMessage()
File "/usr/local/python/lib/python2.7/logging/__init__.py", line 325, in getMessage
msg = str(self.msg)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/init/logconfig.py#L80">SickBeard/medusa/init/logconfig.py</a>", line 80, in __str__
result = text_type(self.fmt)
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L49">SickBeard/medusa/logger/adapters/style.py</a>", line 49, in __str__
''.join(traceback.format_stack()),
Traceback (most recent call last):
File "/volume1/@appstore/sickbeard-custom/var/<a href="../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L39">SickBeard/medusa/logger/adapters/style.py</a>", line 39, in __str__
return msg.format(*args, **kwargs)
KeyError: "u'version'"
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/logger/adapters/style.py`
Content:
```
1 # coding=utf-8
2
3 """Style Adapters for Python logging."""
4
5 from __future__ import unicode_literals
6
7 import collections
8 import functools
9 import logging
10 import traceback
11
12 from six import text_type
13
14 log = logging.getLogger(__name__)
15 log.addHandler(logging.NullHandler())
16
17
18 class BraceMessage(object):
19 """Lazily convert a Brace-formatted message."""
20
21 def __init__(self, msg, *args, **kwargs):
22 """Initialize a lazy-formatted message."""
23 self.msg = msg
24 self.args = args
25 self.kwargs = kwargs
26
27 def __str__(self):
28 """Convert to string."""
29 args = self.args
30 kwargs = self.kwargs
31 if args and len(args) == 1:
32 if args[0] and isinstance(args[0], collections.Mapping):
33 args = []
34 kwargs = self.args[0]
35
36 msg = text_type(self.msg)
37
38 try:
39 return msg.format(*args, **kwargs)
40 except IndexError:
41 try:
42 return msg.format(kwargs)
43 except IndexError:
44 return msg
45 except Exception:
46 log.error(
47 'BraceMessage string formatting failed. '
48 'Using representation instead.\n{0}'.format(
49 ''.join(traceback.format_stack()),
50 )
51 )
52 return repr(self)
53
54 def __repr__(self):
55 """Convert to class representation."""
56 sep = ', '
57 kw_repr = '{key}={value!r}'
58 name = self.__class__.__name__
59 args = sep.join(map(text_type, self.args))
60 kwargs = sep.join(kw_repr.format(key=k, value=v)
61 for k, v in self.kwargs.items())
62 return '{cls}({args})'.format(
63 cls=name,
64 args=sep.join([repr(self.msg), args, kwargs])
65 )
66
67 def format(self, *args, **kwargs):
68 """Format a BraceMessage string."""
69 return str(self).format(*args, **kwargs)
70
71
72 class BraceAdapter(logging.LoggerAdapter):
73 """Adapt logger to use Brace-formatted messages."""
74
75 def __init__(self, logger, extra=None):
76 """Initialize the Brace adapter with a logger."""
77 super(BraceAdapter, self).__init__(logger, extra)
78 self.debug = functools.partial(self.log, logging.DEBUG)
79 self.info = functools.partial(self.log, logging.INFO)
80 self.warning = functools.partial(self.log, logging.WARNING)
81 self.error = functools.partial(self.log, logging.ERROR)
82 self.critical = functools.partial(self.log, logging.CRITICAL)
83
84 def log(self, level, msg, *args, **kwargs):
85 """Log a message at the specified level using Brace-formatting."""
86 if self.isEnabledFor(level):
87 msg, kwargs = self.process(msg, kwargs)
88 brace_msg = BraceMessage(msg, *args, **kwargs)
89 self.logger.log(level, brace_msg, **kwargs)
90
91 def exception(self, msg, *args, **kwargs):
92 """Add exception information before delegating to self.log."""
93 kwargs['exc_info'] = 1
94 self.log(logging.ERROR, msg, *args, **kwargs)
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/logger/adapters/style.py b/medusa/logger/adapters/style.py
--- a/medusa/logger/adapters/style.py
+++ b/medusa/logger/adapters/style.py
@@ -33,15 +33,15 @@
args = []
kwargs = self.args[0]
- msg = text_type(self.msg)
-
try:
- return msg.format(*args, **kwargs)
+ return self.msg.format(*args, **kwargs)
except IndexError:
try:
- return msg.format(kwargs)
- except IndexError:
- return msg
+ return self.msg.format(**kwargs)
+ except KeyError:
+ return self.msg
+ except KeyError:
+ return self.msg.format(*args)
except Exception:
log.error(
'BraceMessage string formatting failed. '
@@ -85,8 +85,9 @@
"""Log a message at the specified level using Brace-formatting."""
if self.isEnabledFor(level):
msg, kwargs = self.process(msg, kwargs)
- brace_msg = BraceMessage(msg, *args, **kwargs)
- self.logger.log(level, brace_msg, **kwargs)
+ if not isinstance(msg, BraceMessage):
+ msg = BraceMessage(msg, *args, **kwargs)
+ self.logger.log(level, msg, **kwargs)
def exception(self, msg, *args, **kwargs):
"""Add exception information before delegating to self.log."""
|
{"golden_diff": "diff --git a/medusa/logger/adapters/style.py b/medusa/logger/adapters/style.py\n--- a/medusa/logger/adapters/style.py\n+++ b/medusa/logger/adapters/style.py\n@@ -33,15 +33,15 @@\n args = []\n kwargs = self.args[0]\n \n- msg = text_type(self.msg)\n-\n try:\n- return msg.format(*args, **kwargs)\n+ return self.msg.format(*args, **kwargs)\n except IndexError:\n try:\n- return msg.format(kwargs)\n- except IndexError:\n- return msg\n+ return self.msg.format(**kwargs)\n+ except KeyError:\n+ return self.msg\n+ except KeyError:\n+ return self.msg.format(*args)\n except Exception:\n log.error(\n 'BraceMessage string formatting failed. '\n@@ -85,8 +85,9 @@\n \"\"\"Log a message at the specified level using Brace-formatting.\"\"\"\n if self.isEnabledFor(level):\n msg, kwargs = self.process(msg, kwargs)\n- brace_msg = BraceMessage(msg, *args, **kwargs)\n- self.logger.log(level, brace_msg, **kwargs)\n+ if not isinstance(msg, BraceMessage):\n+ msg = BraceMessage(msg, *args, **kwargs)\n+ self.logger.log(level, msg, **kwargs)\n \n def exception(self, msg, *args, **kwargs):\n \"\"\"Add exception information before delegating to self.log.\"\"\"\n", "issue": "[APP SUBMITTED]: KeyError: \"u'version'\"\n\n### INFO\n**Python Version**: `2.7.13 (default, Dec 18 2016, 21:23:50) [GCC 4.6.4]`\n**Operating System**: `Linux-3.2.40-armv7l-with-glibc2.4`\n**Locale**: `UTF-8`\n**Branch**: [master](../tree/master)\n**Database**: `44.8`\n**Commit**: pymedusa/Medusa@7b9111eef5836a6846499ef257ffff3f1f35df8f\n**Link to Log**: https://gist.github.com/adaeb1415fefd1083f59da7f01134ac6\n### ERROR\n<pre>\n2017-12-29 19:52:25 ERROR FINDPROPERS :: [7b9111e] BraceMessage string formatting failed. Using representation instead.\n File \"/usr/local/python/lib/python2.7/threading.py\", line 774, in __bootstrap\n self.__bootstrap_inner()\n File \"/usr/local/python/lib/python2.7/threading.py\", line 801, in __bootstrap_inner\n self.run()\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/scheduler.py#L90\">SickBeard/medusa/scheduler.py</a>\", line 90, in run\n self.action.run(self.force)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/proper.py#L65\">SickBeard/medusa/search/proper.py</a>\", line 65, in run\n self._download_propers(propers)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/proper.py#L353\">SickBeard/medusa/search/proper.py</a>\", line 353, in _download_propers\n snatch_episode(cur_proper)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/search/core.py#L159\">SickBeard/medusa/search/core.py</a>\", line 159, in snatch_episode\n result_downloaded = client.send_torrent(result)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/clients/torrent/generic.py#L254\">SickBeard/medusa/clients/torrent/generic.py</a>\", line 254, in send_torrent\n r_code = self._add_torrent_uri(result)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/clients/torrent/download_station_client.py#L124\">SickBeard/medusa/clients/torrent/download_station_client.py</a>\", line 124, in _add_torrent_uri\n log.debug('Add torrent URI with data: {}'.format(data))\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L89\">SickBeard/medusa/logger/adapters/style.py</a>\", line 89, in log\n self.logger.log(level, brace_msg, **kwargs)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 1489, in log\n self.logger.log(level, msg, *args, **kwargs)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 1231, in log\n self._log(level, msg, args, **kwargs)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 1286, in _log\n self.handle(record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 1296, in handle\n self.callHandlers(record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 1336, in callHandlers\n hdlr.handle(record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 759, in handle\n self.emit(record)\n File \"/usr/local/python/lib/python2.7/logging/handlers.py\", line 78, in emit\n logging.FileHandler.emit(self, record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 957, in emit\n StreamHandler.emit(self, record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 861, in emit\n msg = self.format(record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 734, in format\n return fmt.format(record)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/__init__.py#L546\">SickBeard/medusa/logger/__init__.py</a>\", line 546, in format\n msg = super(CensoredFormatter, self).format(record)\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 465, in format\n record.message = record.getMessage()\n File \"/usr/local/python/lib/python2.7/logging/__init__.py\", line 325, in getMessage\n msg = str(self.msg)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/init/logconfig.py#L80\">SickBeard/medusa/init/logconfig.py</a>\", line 80, in __str__\n result = text_type(self.fmt)\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L49\">SickBeard/medusa/logger/adapters/style.py</a>\", line 49, in __str__\n ''.join(traceback.format_stack()),\nTraceback (most recent call last):\n File \"/volume1/@appstore/sickbeard-custom/var/<a href=\"../blob/7b9111eef5836a6846499ef257ffff3f1f35df8f/SickBeard/medusa/logger/adapters/style.py#L39\">SickBeard/medusa/logger/adapters/style.py</a>\", line 39, in __str__\n return msg.format(*args, **kwargs)\nKeyError: \"u'version'\"\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Style Adapters for Python logging.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport collections\nimport functools\nimport logging\nimport traceback\n\nfrom six import text_type\n\nlog = logging.getLogger(__name__)\nlog.addHandler(logging.NullHandler())\n\n\nclass BraceMessage(object):\n \"\"\"Lazily convert a Brace-formatted message.\"\"\"\n\n def __init__(self, msg, *args, **kwargs):\n \"\"\"Initialize a lazy-formatted message.\"\"\"\n self.msg = msg\n self.args = args\n self.kwargs = kwargs\n\n def __str__(self):\n \"\"\"Convert to string.\"\"\"\n args = self.args\n kwargs = self.kwargs\n if args and len(args) == 1:\n if args[0] and isinstance(args[0], collections.Mapping):\n args = []\n kwargs = self.args[0]\n\n msg = text_type(self.msg)\n\n try:\n return msg.format(*args, **kwargs)\n except IndexError:\n try:\n return msg.format(kwargs)\n except IndexError:\n return msg\n except Exception:\n log.error(\n 'BraceMessage string formatting failed. '\n 'Using representation instead.\\n{0}'.format(\n ''.join(traceback.format_stack()),\n )\n )\n return repr(self)\n\n def __repr__(self):\n \"\"\"Convert to class representation.\"\"\"\n sep = ', '\n kw_repr = '{key}={value!r}'\n name = self.__class__.__name__\n args = sep.join(map(text_type, self.args))\n kwargs = sep.join(kw_repr.format(key=k, value=v)\n for k, v in self.kwargs.items())\n return '{cls}({args})'.format(\n cls=name,\n args=sep.join([repr(self.msg), args, kwargs])\n )\n\n def format(self, *args, **kwargs):\n \"\"\"Format a BraceMessage string.\"\"\"\n return str(self).format(*args, **kwargs)\n\n\nclass BraceAdapter(logging.LoggerAdapter):\n \"\"\"Adapt logger to use Brace-formatted messages.\"\"\"\n\n def __init__(self, logger, extra=None):\n \"\"\"Initialize the Brace adapter with a logger.\"\"\"\n super(BraceAdapter, self).__init__(logger, extra)\n self.debug = functools.partial(self.log, logging.DEBUG)\n self.info = functools.partial(self.log, logging.INFO)\n self.warning = functools.partial(self.log, logging.WARNING)\n self.error = functools.partial(self.log, logging.ERROR)\n self.critical = functools.partial(self.log, logging.CRITICAL)\n\n def log(self, level, msg, *args, **kwargs):\n \"\"\"Log a message at the specified level using Brace-formatting.\"\"\"\n if self.isEnabledFor(level):\n msg, kwargs = self.process(msg, kwargs)\n brace_msg = BraceMessage(msg, *args, **kwargs)\n self.logger.log(level, brace_msg, **kwargs)\n\n def exception(self, msg, *args, **kwargs):\n \"\"\"Add exception information before delegating to self.log.\"\"\"\n kwargs['exc_info'] = 1\n self.log(logging.ERROR, msg, *args, **kwargs)\n", "path": "medusa/logger/adapters/style.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"Style Adapters for Python logging.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport collections\nimport functools\nimport logging\nimport traceback\n\nfrom six import text_type\n\nlog = logging.getLogger(__name__)\nlog.addHandler(logging.NullHandler())\n\n\nclass BraceMessage(object):\n \"\"\"Lazily convert a Brace-formatted message.\"\"\"\n\n def __init__(self, msg, *args, **kwargs):\n \"\"\"Initialize a lazy-formatted message.\"\"\"\n self.msg = msg\n self.args = args\n self.kwargs = kwargs\n\n def __str__(self):\n \"\"\"Convert to string.\"\"\"\n args = self.args\n kwargs = self.kwargs\n if args and len(args) == 1:\n if args[0] and isinstance(args[0], collections.Mapping):\n args = []\n kwargs = self.args[0]\n\n try:\n return self.msg.format(*args, **kwargs)\n except IndexError:\n try:\n return self.msg.format(**kwargs)\n except KeyError:\n return self.msg\n except KeyError:\n return self.msg.format(*args)\n except Exception:\n log.error(\n 'BraceMessage string formatting failed. '\n 'Using representation instead.\\n{0}'.format(\n ''.join(traceback.format_stack()),\n )\n )\n return repr(self)\n\n def __repr__(self):\n \"\"\"Convert to class representation.\"\"\"\n sep = ', '\n kw_repr = '{key}={value!r}'\n name = self.__class__.__name__\n args = sep.join(map(text_type, self.args))\n kwargs = sep.join(kw_repr.format(key=k, value=v)\n for k, v in self.kwargs.items())\n return '{cls}({args})'.format(\n cls=name,\n args=sep.join([repr(self.msg), args, kwargs])\n )\n\n def format(self, *args, **kwargs):\n \"\"\"Format a BraceMessage string.\"\"\"\n return str(self).format(*args, **kwargs)\n\n\nclass BraceAdapter(logging.LoggerAdapter):\n \"\"\"Adapt logger to use Brace-formatted messages.\"\"\"\n\n def __init__(self, logger, extra=None):\n \"\"\"Initialize the Brace adapter with a logger.\"\"\"\n super(BraceAdapter, self).__init__(logger, extra)\n self.debug = functools.partial(self.log, logging.DEBUG)\n self.info = functools.partial(self.log, logging.INFO)\n self.warning = functools.partial(self.log, logging.WARNING)\n self.error = functools.partial(self.log, logging.ERROR)\n self.critical = functools.partial(self.log, logging.CRITICAL)\n\n def log(self, level, msg, *args, **kwargs):\n \"\"\"Log a message at the specified level using Brace-formatting.\"\"\"\n if self.isEnabledFor(level):\n msg, kwargs = self.process(msg, kwargs)\n if not isinstance(msg, BraceMessage):\n msg = BraceMessage(msg, *args, **kwargs)\n self.logger.log(level, msg, **kwargs)\n\n def exception(self, msg, *args, **kwargs):\n \"\"\"Add exception information before delegating to self.log.\"\"\"\n kwargs['exc_info'] = 1\n self.log(logging.ERROR, msg, *args, **kwargs)\n", "path": "medusa/logger/adapters/style.py"}]}
| 3,024 | 317 |
gh_patches_debug_50578
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-4076
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Slider value visually overlaps with the edge of the sidebar
# Summary
The value label collides with the edges of the sidebar. It should change alignment when it gets close to the edges.
# Steps to reproduce
```py
min_weight = st.sidebar.slider("Minimum weight", 2500, 6500)
```
## Expected behavior:
The value label should not collide with the edges.
## Actual behavior:
<img width="382" alt="Screen Shot 2020-09-30 at 22 42 44" src="https://user-images.githubusercontent.com/589034/94772484-97067200-036e-11eb-9f82-10453aa7452e.png">
## Is this a regression?
no
# Debug info
- Streamlit version: 0.65.2
- Browser version: Chrome
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `e2e/scripts/st_slider.py`
Content:
```
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16
17 w1 = st.slider("Label 1", 0, 100, 25, 1)
18 st.write("Value 1:", w1)
19
20 w2 = st.slider("Label 2", 0.0, 100.0, (25.0, 75.0), 0.5)
21 st.write("Value 2:", w2)
22
23 w3 = st.slider(
24 "Label 3 - This is a very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very long label",
25 0,
26 100,
27 1,
28 1,
29 )
30 st.write("Value 3:", w3)
31
32 if st._is_running_with_streamlit:
33
34 def on_change():
35 st.session_state.slider_changed = True
36
37 st.slider(
38 "Label 4",
39 min_value=0,
40 max_value=100,
41 value=25,
42 step=1,
43 key="slider4",
44 on_change=on_change,
45 )
46 st.write("Value 4:", st.session_state.slider4)
47 st.write("Slider changed:", "slider_changed" in st.session_state)
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/e2e/scripts/st_slider.py b/e2e/scripts/st_slider.py
--- a/e2e/scripts/st_slider.py
+++ b/e2e/scripts/st_slider.py
@@ -14,6 +14,13 @@
import streamlit as st
+s1 = st.sidebar.slider("Label A", 0, 12345678, 12345678)
+st.sidebar.write("Value A:", s1)
+
+with st.sidebar.expander("Expander"):
+ s2 = st.slider("Label B", 10000, 25000, 10000)
+ st.write("Value B:", s2)
+
w1 = st.slider("Label 1", 0, 100, 25, 1)
st.write("Value 1:", w1)
|
{"golden_diff": "diff --git a/e2e/scripts/st_slider.py b/e2e/scripts/st_slider.py\n--- a/e2e/scripts/st_slider.py\n+++ b/e2e/scripts/st_slider.py\n@@ -14,6 +14,13 @@\n \n import streamlit as st\n \n+s1 = st.sidebar.slider(\"Label A\", 0, 12345678, 12345678)\n+st.sidebar.write(\"Value A:\", s1)\n+\n+with st.sidebar.expander(\"Expander\"):\n+ s2 = st.slider(\"Label B\", 10000, 25000, 10000)\n+ st.write(\"Value B:\", s2)\n+\n w1 = st.slider(\"Label 1\", 0, 100, 25, 1)\n st.write(\"Value 1:\", w1)\n", "issue": "Slider value visually overlaps with the edge of the sidebar\n# Summary\r\n\r\nThe value label collides with the edges of the sidebar. It should change alignment when it gets close to the edges. \r\n\r\n# Steps to reproduce\r\n\r\n```py\r\nmin_weight = st.sidebar.slider(\"Minimum weight\", 2500, 6500)\r\n```\r\n\r\n## Expected behavior:\r\n\r\nThe value label should not collide with the edges. \r\n\r\n## Actual behavior:\r\n\r\n<img width=\"382\" alt=\"Screen Shot 2020-09-30 at 22 42 44\" src=\"https://user-images.githubusercontent.com/589034/94772484-97067200-036e-11eb-9f82-10453aa7452e.png\">\r\n\r\n\r\n## Is this a regression?\r\n\r\nno\r\n\r\n# Debug info\r\n\r\n- Streamlit version: 0.65.2\r\n- Browser version: Chrome\r\n\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\nw1 = st.slider(\"Label 1\", 0, 100, 25, 1)\nst.write(\"Value 1:\", w1)\n\nw2 = st.slider(\"Label 2\", 0.0, 100.0, (25.0, 75.0), 0.5)\nst.write(\"Value 2:\", w2)\n\nw3 = st.slider(\n \"Label 3 - This is a very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very long label\",\n 0,\n 100,\n 1,\n 1,\n)\nst.write(\"Value 3:\", w3)\n\nif st._is_running_with_streamlit:\n\n def on_change():\n st.session_state.slider_changed = True\n\n st.slider(\n \"Label 4\",\n min_value=0,\n max_value=100,\n value=25,\n step=1,\n key=\"slider4\",\n on_change=on_change,\n )\n st.write(\"Value 4:\", st.session_state.slider4)\n st.write(\"Slider changed:\", \"slider_changed\" in st.session_state)\n", "path": "e2e/scripts/st_slider.py"}], "after_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\ns1 = st.sidebar.slider(\"Label A\", 0, 12345678, 12345678)\nst.sidebar.write(\"Value A:\", s1)\n\nwith st.sidebar.expander(\"Expander\"):\n s2 = st.slider(\"Label B\", 10000, 25000, 10000)\n st.write(\"Value B:\", s2)\n\nw1 = st.slider(\"Label 1\", 0, 100, 25, 1)\nst.write(\"Value 1:\", w1)\n\nw2 = st.slider(\"Label 2\", 0.0, 100.0, (25.0, 75.0), 0.5)\nst.write(\"Value 2:\", w2)\n\nw3 = st.slider(\n \"Label 3 - This is a very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very long label\",\n 0,\n 100,\n 1,\n 1,\n)\nst.write(\"Value 3:\", w3)\n\nif st._is_running_with_streamlit:\n\n def on_change():\n st.session_state.slider_changed = True\n\n st.slider(\n \"Label 4\",\n min_value=0,\n max_value=100,\n value=25,\n step=1,\n key=\"slider4\",\n on_change=on_change,\n )\n st.write(\"Value 4:\", st.session_state.slider4)\n st.write(\"Slider changed:\", \"slider_changed\" in st.session_state)\n", "path": "e2e/scripts/st_slider.py"}]}
| 994 | 194 |
gh_patches_debug_4954
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-1869
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot have multi-turn conversation with agent via interactive_web.py script
Cannot have multi-turn conversation with agent via interactive_web.py script
**Reproduction steps**
Run interacive_web.py with some model file
```
python3 ../ParlAI/parlai/scripts/interactive_web.py -mf ~/models/model_file
```
communicate with the agent, send any two consecutive messages as shown below.
```
curl -XPOST "http://localhost:8080/interact" "Content-Type: text" -d "Hello"
```
**Expected behavior**
No exception should be thrown, agent should be available for multi-turn conversation.
The second message produces the following stacktrace
```
Exception happened during processing of request from ('127.0.0.1', 55372)
Traceback (most recent call last):
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py", line 320, in _handle_request_noblock
self.process_request(request, client_address)
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py", line 351, in process_request
self.finish_request(request, client_address)
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py", line 364, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py", line 724, in __init__
self.handle()
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/http/server.py", line 418, in handle
self.handle_one_request()
File "/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/http/server.py", line 406, in handle_one_request
method()
File "/Users/johnsmith/ParlAI/parlai/scripts/interactive_web.py", line 155, in do_POST
SHARED.get('opt'), body.decode('utf-8')
File "/Users/johnsmith/ParlAI/parlai/scripts/interactive_web.py", line 139, in interactive_running
SHARED['agent'].observe(reply)
File "/Users/johnsmith/ParlAI/parlai/core/torch_agent.py", line 1545, in observe
reply = self.last_reply(use_reply=self.opt.get('use_reply', 'label'))
File "/Users/johnsmith/ParlAI/parlai/core/torch_agent.py", line 1515, in last_reply
or self.observation['episode_done']
KeyError: 'episode_done'
--------------------------
After second message.
```
### Suggestion
The following edit could be made to prevent this issue.
```
self.observation['episode_done'] --> 'episode_done' in self.observation
```
### Extra
Making the change above allows multi-turn conversation, but now there is the question of some functionality terminating the conversation from the client-side i.e.
```
curl -XPOST "http://localhost:8080/interact" "Content-Type: text" -d "[DONE]"
```
such that user application or human has some option to terminate multi-turn conversations.
If this should be moved to functionality, just let me know!
Thank you 🙏
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parlai/scripts/interactive_web.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6 """ Talk with a model using a web UI. """
7
8
9 from http.server import BaseHTTPRequestHandler, HTTPServer
10 from parlai.scripts.interactive import setup_args
11 from parlai.core.agents import create_agent
12 from parlai.core.worlds import create_task
13
14 import json
15
16 HOST_NAME = 'localhost'
17 PORT = 8080
18 SHARED = {}
19 STYLE_SHEET = "https://cdnjs.cloudflare.com/ajax/libs/bulma/0.7.4/css/bulma.css"
20 FONT_AWESOME = "https://use.fontawesome.com/releases/v5.3.1/js/all.js"
21 WEB_HTML = """
22 <html>
23 <link rel="stylesheet" href={} />
24 <script defer src={}></script>
25 <head><title> Interactive Run </title></head>
26 <body>
27 <div class="columns">
28 <div class="column is-three-fifths is-offset-one-fifth">
29 <section class="hero is-info is-large has-background-light has-text-grey-dark">
30 <div id="parent" class="hero-body">
31 <article class="media">
32 <figure class="media-left">
33 <span class="icon is-large">
34 <i class="fas fa-robot fas fa-2x"></i>
35 </span>
36 </figure>
37 <div class="media-content">
38 <div class="content">
39 <p>
40 <strong>Model</strong>
41 <br>
42 Enter a message, and the model will respond interactively.
43 </p>
44 </div>
45 </div>
46 </article>
47 </div>
48 <div class="hero-foot column is-three-fifths is-offset-one-fifth">
49 <form id = "interact">
50 <div class="field is-grouped">
51 <p class="control is-expanded">
52 <input class="input" type="text" id="userIn" placeholder="Type in a message">
53 </p>
54 <p class="control">
55 <button id="respond" type="submit" class="button has-text-white-ter has-background-grey-dark">
56 Submit
57 </button>
58 </p>
59 </div>
60 </form>
61 </div>
62 </section>
63 </div>
64 </div>
65
66 <script>
67 function createChatRow(agent, text) {{
68 var article = document.createElement("article");
69 article.className = "media"
70
71 var figure = document.createElement("figure");
72 figure.className = "media-left";
73
74 var span = document.createElement("span");
75 span.className = "icon is-large";
76
77 var icon = document.createElement("i");
78 icon.className = "fas fas fa-2x" + (agent === "You" ? " fa-user " : agent === "Model" ? " fa-robot" : "");
79
80 var media = document.createElement("div");
81 media.className = "media-content";
82
83 var content = document.createElement("div");
84 content.className = "content";
85
86 var para = document.createElement("p");
87 var paraText = document.createTextNode(text);
88
89 var strong = document.createElement("strong");
90 strong.innerHTML = agent;
91 var br = document.createElement("br");
92
93 para.appendChild(strong);
94 para.appendChild(br);
95 para.appendChild(paraText);
96 content.appendChild(para);
97 media.appendChild(content);
98
99 span.appendChild(icon);
100 figure.appendChild(span);
101
102 article.appendChild(figure);
103 article.appendChild(media);
104
105 return article;
106 }}
107 document.getElementById("interact").addEventListener("submit", function(event){{
108 event.preventDefault()
109 var text = document.getElementById("userIn").value;
110 document.getElementById('userIn').value = "";
111
112 fetch('/interact', {{
113 headers: {{
114 'Content-Type': 'application/json'
115 }},
116 method: 'POST',
117 body: text
118 }}).then(response=>response.json()).then(data=>{{
119 var parDiv = document.getElementById("parent");
120
121 parDiv.append(createChatRow("You", text));
122
123 // Change info for Model response
124 parDiv.append(createChatRow("Model", data.text));
125 window.scrollTo(0,document.body.scrollHeight);
126 }})
127 }});
128 </script>
129
130 </body>
131 </html>
132 """ # noqa: E501
133
134
135 class MyHandler(BaseHTTPRequestHandler):
136 def interactive_running(self, opt, reply_text):
137 reply = {}
138 reply['text'] = reply_text
139 SHARED['agent'].observe(reply)
140 model_res = SHARED['agent'].act()
141 return model_res
142
143 def do_HEAD(self):
144 self.send_response(200)
145 self.send_header('Content-type', 'text/html')
146 self.end_headers()
147
148 def do_POST(self):
149 if self.path != '/interact':
150 return self.respond({'status': 500})
151
152 content_length = int(self.headers['Content-Length'])
153 body = self.rfile.read(content_length)
154 model_response = self.interactive_running(
155 SHARED.get('opt'), body.decode('utf-8')
156 )
157
158 self.send_response(200)
159 self.send_header('Content-type', 'application/json')
160 self.end_headers()
161 json_str = json.dumps(model_response)
162 self.wfile.write(bytes(json_str, 'utf-8'))
163
164 def do_GET(self):
165 paths = {
166 '/': {'status': 200},
167 '/favicon.ico': {'status': 202}, # Need for chrome
168 }
169 if self.path in paths:
170 self.respond(paths[self.path])
171 else:
172 self.respond({'status': 500})
173
174 def handle_http(self, status_code, path, text=None):
175 self.send_response(status_code)
176 self.send_header('Content-type', 'text/html')
177 self.end_headers()
178 content = WEB_HTML.format(STYLE_SHEET, FONT_AWESOME)
179 return bytes(content, 'UTF-8')
180
181 def respond(self, opts):
182 response = self.handle_http(opts['status'], self.path)
183 self.wfile.write(response)
184
185
186 def setup_interactive(shared):
187 parser = setup_args()
188 SHARED['opt'] = parser.parse_args(print_args=True)
189
190 SHARED['opt']['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'
191
192 # Create model and assign it to the specified task
193 SHARED['agent'] = create_agent(SHARED.get('opt'), requireModelExists=True)
194 SHARED['world'] = create_task(SHARED.get('opt'), SHARED['agent'])
195
196
197 if __name__ == '__main__':
198 setup_interactive(SHARED)
199 server_class = HTTPServer
200 Handler = MyHandler
201 Handler.protocol_version = 'HTTP/1.0'
202 httpd = server_class((HOST_NAME, PORT), Handler)
203 print('http://{}:{}/'.format(HOST_NAME, PORT))
204
205 try:
206 httpd.serve_forever()
207 except KeyboardInterrupt:
208 pass
209 httpd.server_close()
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parlai/scripts/interactive_web.py b/parlai/scripts/interactive_web.py
--- a/parlai/scripts/interactive_web.py
+++ b/parlai/scripts/interactive_web.py
@@ -134,8 +134,7 @@
class MyHandler(BaseHTTPRequestHandler):
def interactive_running(self, opt, reply_text):
- reply = {}
- reply['text'] = reply_text
+ reply = {'episode_done': False, 'text': reply_text}
SHARED['agent'].observe(reply)
model_res = SHARED['agent'].act()
return model_res
|
{"golden_diff": "diff --git a/parlai/scripts/interactive_web.py b/parlai/scripts/interactive_web.py\n--- a/parlai/scripts/interactive_web.py\n+++ b/parlai/scripts/interactive_web.py\n@@ -134,8 +134,7 @@\n \n class MyHandler(BaseHTTPRequestHandler):\n def interactive_running(self, opt, reply_text):\n- reply = {}\n- reply['text'] = reply_text\n+ reply = {'episode_done': False, 'text': reply_text}\n SHARED['agent'].observe(reply)\n model_res = SHARED['agent'].act()\n return model_res\n", "issue": "Cannot have multi-turn conversation with agent via interactive_web.py script\nCannot have multi-turn conversation with agent via interactive_web.py script\r\n\r\n**Reproduction steps**\r\nRun interacive_web.py with some model file \r\n```\r\npython3 ../ParlAI/parlai/scripts/interactive_web.py -mf ~/models/model_file \r\n```\r\ncommunicate with the agent, send any two consecutive messages as shown below.\r\n```\r\ncurl -XPOST \"http://localhost:8080/interact\" \"Content-Type: text\" -d \"Hello\"\r\n```\r\n**Expected behavior**\r\nNo exception should be thrown, agent should be available for multi-turn conversation.\r\n\r\nThe second message produces the following stacktrace\r\n```\r\nException happened during processing of request from ('127.0.0.1', 55372)\r\nTraceback (most recent call last):\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py\", line 320, in _handle_request_noblock\r\n self.process_request(request, client_address)\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py\", line 351, in process_request\r\n self.finish_request(request, client_address)\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py\", line 364, in finish_request\r\n self.RequestHandlerClass(request, client_address, self)\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/socketserver.py\", line 724, in __init__\r\n self.handle()\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/http/server.py\", line 418, in handle\r\n self.handle_one_request()\r\n File \"/Users/johnsmith/miniconda3/envs/rasa-env/lib/python3.6/http/server.py\", line 406, in handle_one_request\r\n method()\r\n File \"/Users/johnsmith/ParlAI/parlai/scripts/interactive_web.py\", line 155, in do_POST\r\n SHARED.get('opt'), body.decode('utf-8')\r\n File \"/Users/johnsmith/ParlAI/parlai/scripts/interactive_web.py\", line 139, in interactive_running\r\n SHARED['agent'].observe(reply)\r\n File \"/Users/johnsmith/ParlAI/parlai/core/torch_agent.py\", line 1545, in observe\r\n reply = self.last_reply(use_reply=self.opt.get('use_reply', 'label'))\r\n File \"/Users/johnsmith/ParlAI/parlai/core/torch_agent.py\", line 1515, in last_reply\r\n or self.observation['episode_done']\r\nKeyError: 'episode_done'\r\n--------------------------\r\n\r\nAfter second message.\r\n```\r\n\r\n### Suggestion\r\nThe following edit could be made to prevent this issue.\r\n```\r\nself.observation['episode_done'] --> 'episode_done' in self.observation\r\n```\r\n### Extra\r\nMaking the change above allows multi-turn conversation, but now there is the question of some functionality terminating the conversation from the client-side i.e.\r\n```\r\ncurl -XPOST \"http://localhost:8080/interact\" \"Content-Type: text\" -d \"[DONE]\"\r\n```\r\nsuch that user application or human has some option to terminate multi-turn conversations. \r\nIf this should be moved to functionality, just let me know!\r\n\r\nThank you \ud83d\ude4f \n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\" Talk with a model using a web UI. \"\"\"\n\n\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\nfrom parlai.scripts.interactive import setup_args\nfrom parlai.core.agents import create_agent\nfrom parlai.core.worlds import create_task\n\nimport json\n\nHOST_NAME = 'localhost'\nPORT = 8080\nSHARED = {}\nSTYLE_SHEET = \"https://cdnjs.cloudflare.com/ajax/libs/bulma/0.7.4/css/bulma.css\"\nFONT_AWESOME = \"https://use.fontawesome.com/releases/v5.3.1/js/all.js\"\nWEB_HTML = \"\"\"\n<html>\n <link rel=\"stylesheet\" href={} />\n <script defer src={}></script>\n <head><title> Interactive Run </title></head>\n <body>\n <div class=\"columns\">\n <div class=\"column is-three-fifths is-offset-one-fifth\">\n <section class=\"hero is-info is-large has-background-light has-text-grey-dark\">\n <div id=\"parent\" class=\"hero-body\">\n <article class=\"media\">\n <figure class=\"media-left\">\n <span class=\"icon is-large\">\n <i class=\"fas fa-robot fas fa-2x\"></i>\n </span>\n </figure>\n <div class=\"media-content\">\n <div class=\"content\">\n <p>\n <strong>Model</strong>\n <br>\n Enter a message, and the model will respond interactively.\n </p>\n </div>\n </div>\n </article>\n </div>\n <div class=\"hero-foot column is-three-fifths is-offset-one-fifth\">\n <form id = \"interact\">\n <div class=\"field is-grouped\">\n <p class=\"control is-expanded\">\n <input class=\"input\" type=\"text\" id=\"userIn\" placeholder=\"Type in a message\">\n </p>\n <p class=\"control\">\n <button id=\"respond\" type=\"submit\" class=\"button has-text-white-ter has-background-grey-dark\">\n Submit\n </button>\n </p>\n </div>\n </form>\n </div>\n </section>\n </div>\n </div>\n\n <script>\n function createChatRow(agent, text) {{\n var article = document.createElement(\"article\");\n article.className = \"media\"\n\n var figure = document.createElement(\"figure\");\n figure.className = \"media-left\";\n\n var span = document.createElement(\"span\");\n span.className = \"icon is-large\";\n\n var icon = document.createElement(\"i\");\n icon.className = \"fas fas fa-2x\" + (agent === \"You\" ? \" fa-user \" : agent === \"Model\" ? \" fa-robot\" : \"\");\n\n var media = document.createElement(\"div\");\n media.className = \"media-content\";\n\n var content = document.createElement(\"div\");\n content.className = \"content\";\n\n var para = document.createElement(\"p\");\n var paraText = document.createTextNode(text);\n\n var strong = document.createElement(\"strong\");\n strong.innerHTML = agent;\n var br = document.createElement(\"br\");\n\n para.appendChild(strong);\n para.appendChild(br);\n para.appendChild(paraText);\n content.appendChild(para);\n media.appendChild(content);\n\n span.appendChild(icon);\n figure.appendChild(span);\n\n article.appendChild(figure);\n article.appendChild(media);\n\n return article;\n }}\n document.getElementById(\"interact\").addEventListener(\"submit\", function(event){{\n event.preventDefault()\n var text = document.getElementById(\"userIn\").value;\n document.getElementById('userIn').value = \"\";\n\n fetch('/interact', {{\n headers: {{\n 'Content-Type': 'application/json'\n }},\n method: 'POST',\n body: text\n }}).then(response=>response.json()).then(data=>{{\n var parDiv = document.getElementById(\"parent\");\n\n parDiv.append(createChatRow(\"You\", text));\n\n // Change info for Model response\n parDiv.append(createChatRow(\"Model\", data.text));\n window.scrollTo(0,document.body.scrollHeight);\n }})\n }});\n </script>\n\n </body>\n</html>\n\"\"\" # noqa: E501\n\n\nclass MyHandler(BaseHTTPRequestHandler):\n def interactive_running(self, opt, reply_text):\n reply = {}\n reply['text'] = reply_text\n SHARED['agent'].observe(reply)\n model_res = SHARED['agent'].act()\n return model_res\n\n def do_HEAD(self):\n self.send_response(200)\n self.send_header('Content-type', 'text/html')\n self.end_headers()\n\n def do_POST(self):\n if self.path != '/interact':\n return self.respond({'status': 500})\n\n content_length = int(self.headers['Content-Length'])\n body = self.rfile.read(content_length)\n model_response = self.interactive_running(\n SHARED.get('opt'), body.decode('utf-8')\n )\n\n self.send_response(200)\n self.send_header('Content-type', 'application/json')\n self.end_headers()\n json_str = json.dumps(model_response)\n self.wfile.write(bytes(json_str, 'utf-8'))\n\n def do_GET(self):\n paths = {\n '/': {'status': 200},\n '/favicon.ico': {'status': 202}, # Need for chrome\n }\n if self.path in paths:\n self.respond(paths[self.path])\n else:\n self.respond({'status': 500})\n\n def handle_http(self, status_code, path, text=None):\n self.send_response(status_code)\n self.send_header('Content-type', 'text/html')\n self.end_headers()\n content = WEB_HTML.format(STYLE_SHEET, FONT_AWESOME)\n return bytes(content, 'UTF-8')\n\n def respond(self, opts):\n response = self.handle_http(opts['status'], self.path)\n self.wfile.write(response)\n\n\ndef setup_interactive(shared):\n parser = setup_args()\n SHARED['opt'] = parser.parse_args(print_args=True)\n\n SHARED['opt']['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'\n\n # Create model and assign it to the specified task\n SHARED['agent'] = create_agent(SHARED.get('opt'), requireModelExists=True)\n SHARED['world'] = create_task(SHARED.get('opt'), SHARED['agent'])\n\n\nif __name__ == '__main__':\n setup_interactive(SHARED)\n server_class = HTTPServer\n Handler = MyHandler\n Handler.protocol_version = 'HTTP/1.0'\n httpd = server_class((HOST_NAME, PORT), Handler)\n print('http://{}:{}/'.format(HOST_NAME, PORT))\n\n try:\n httpd.serve_forever()\n except KeyboardInterrupt:\n pass\n httpd.server_close()\n", "path": "parlai/scripts/interactive_web.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\" Talk with a model using a web UI. \"\"\"\n\n\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\nfrom parlai.scripts.interactive import setup_args\nfrom parlai.core.agents import create_agent\nfrom parlai.core.worlds import create_task\n\nimport json\n\nHOST_NAME = 'localhost'\nPORT = 8080\nSHARED = {}\nSTYLE_SHEET = \"https://cdnjs.cloudflare.com/ajax/libs/bulma/0.7.4/css/bulma.css\"\nFONT_AWESOME = \"https://use.fontawesome.com/releases/v5.3.1/js/all.js\"\nWEB_HTML = \"\"\"\n<html>\n <link rel=\"stylesheet\" href={} />\n <script defer src={}></script>\n <head><title> Interactive Run </title></head>\n <body>\n <div class=\"columns\">\n <div class=\"column is-three-fifths is-offset-one-fifth\">\n <section class=\"hero is-info is-large has-background-light has-text-grey-dark\">\n <div id=\"parent\" class=\"hero-body\">\n <article class=\"media\">\n <figure class=\"media-left\">\n <span class=\"icon is-large\">\n <i class=\"fas fa-robot fas fa-2x\"></i>\n </span>\n </figure>\n <div class=\"media-content\">\n <div class=\"content\">\n <p>\n <strong>Model</strong>\n <br>\n Enter a message, and the model will respond interactively.\n </p>\n </div>\n </div>\n </article>\n </div>\n <div class=\"hero-foot column is-three-fifths is-offset-one-fifth\">\n <form id = \"interact\">\n <div class=\"field is-grouped\">\n <p class=\"control is-expanded\">\n <input class=\"input\" type=\"text\" id=\"userIn\" placeholder=\"Type in a message\">\n </p>\n <p class=\"control\">\n <button id=\"respond\" type=\"submit\" class=\"button has-text-white-ter has-background-grey-dark\">\n Submit\n </button>\n </p>\n </div>\n </form>\n </div>\n </section>\n </div>\n </div>\n\n <script>\n function createChatRow(agent, text) {{\n var article = document.createElement(\"article\");\n article.className = \"media\"\n\n var figure = document.createElement(\"figure\");\n figure.className = \"media-left\";\n\n var span = document.createElement(\"span\");\n span.className = \"icon is-large\";\n\n var icon = document.createElement(\"i\");\n icon.className = \"fas fas fa-2x\" + (agent === \"You\" ? \" fa-user \" : agent === \"Model\" ? \" fa-robot\" : \"\");\n\n var media = document.createElement(\"div\");\n media.className = \"media-content\";\n\n var content = document.createElement(\"div\");\n content.className = \"content\";\n\n var para = document.createElement(\"p\");\n var paraText = document.createTextNode(text);\n\n var strong = document.createElement(\"strong\");\n strong.innerHTML = agent;\n var br = document.createElement(\"br\");\n\n para.appendChild(strong);\n para.appendChild(br);\n para.appendChild(paraText);\n content.appendChild(para);\n media.appendChild(content);\n\n span.appendChild(icon);\n figure.appendChild(span);\n\n article.appendChild(figure);\n article.appendChild(media);\n\n return article;\n }}\n document.getElementById(\"interact\").addEventListener(\"submit\", function(event){{\n event.preventDefault()\n var text = document.getElementById(\"userIn\").value;\n document.getElementById('userIn').value = \"\";\n\n fetch('/interact', {{\n headers: {{\n 'Content-Type': 'application/json'\n }},\n method: 'POST',\n body: text\n }}).then(response=>response.json()).then(data=>{{\n var parDiv = document.getElementById(\"parent\");\n\n parDiv.append(createChatRow(\"You\", text));\n\n // Change info for Model response\n parDiv.append(createChatRow(\"Model\", data.text));\n window.scrollTo(0,document.body.scrollHeight);\n }})\n }});\n </script>\n\n </body>\n</html>\n\"\"\" # noqa: E501\n\n\nclass MyHandler(BaseHTTPRequestHandler):\n def interactive_running(self, opt, reply_text):\n reply = {'episode_done': False, 'text': reply_text}\n SHARED['agent'].observe(reply)\n model_res = SHARED['agent'].act()\n return model_res\n\n def do_HEAD(self):\n self.send_response(200)\n self.send_header('Content-type', 'text/html')\n self.end_headers()\n\n def do_POST(self):\n if self.path != '/interact':\n return self.respond({'status': 500})\n\n content_length = int(self.headers['Content-Length'])\n body = self.rfile.read(content_length)\n model_response = self.interactive_running(\n SHARED.get('opt'), body.decode('utf-8')\n )\n\n self.send_response(200)\n self.send_header('Content-type', 'application/json')\n self.end_headers()\n json_str = json.dumps(model_response)\n self.wfile.write(bytes(json_str, 'utf-8'))\n\n def do_GET(self):\n paths = {\n '/': {'status': 200},\n '/favicon.ico': {'status': 202}, # Need for chrome\n }\n if self.path in paths:\n self.respond(paths[self.path])\n else:\n self.respond({'status': 500})\n\n def handle_http(self, status_code, path, text=None):\n self.send_response(status_code)\n self.send_header('Content-type', 'text/html')\n self.end_headers()\n content = WEB_HTML.format(STYLE_SHEET, FONT_AWESOME)\n return bytes(content, 'UTF-8')\n\n def respond(self, opts):\n response = self.handle_http(opts['status'], self.path)\n self.wfile.write(response)\n\n\ndef setup_interactive(shared):\n parser = setup_args()\n SHARED['opt'] = parser.parse_args(print_args=True)\n\n SHARED['opt']['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'\n\n # Create model and assign it to the specified task\n SHARED['agent'] = create_agent(SHARED.get('opt'), requireModelExists=True)\n SHARED['world'] = create_task(SHARED.get('opt'), SHARED['agent'])\n\n\nif __name__ == '__main__':\n setup_interactive(SHARED)\n server_class = HTTPServer\n Handler = MyHandler\n Handler.protocol_version = 'HTTP/1.0'\n httpd = server_class((HOST_NAME, PORT), Handler)\n print('http://{}:{}/'.format(HOST_NAME, PORT))\n\n try:\n httpd.serve_forever()\n except KeyboardInterrupt:\n pass\n httpd.server_close()\n", "path": "parlai/scripts/interactive_web.py"}]}
| 3,085 | 137 |
gh_patches_debug_14317
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-18911
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error in Documentation
The documentation confuses the ‘channels_last’ input format. It needs to be changed to match the correct format ==> (batch_size, height, width, channels)
https://github.com/keras-team/keras/blob/037ec9f5fc61a53c6e1f4c02b7bf1443429dcd45/keras/layers/convolutional/conv2d_transpose.py#L35
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/layers/convolutional/conv2d_transpose.py`
Content:
```
1 from keras.api_export import keras_export
2 from keras.layers.convolutional.base_conv_transpose import BaseConvTranspose
3
4
5 @keras_export(
6 [
7 "keras.layers.Conv2DTranspose",
8 "keras.layers.Convolution2DTranspose",
9 ]
10 )
11 class Conv2DTranspose(BaseConvTranspose):
12 """2D transposed convolution layer.
13
14 The need for transposed convolutions generally arise from the desire to use
15 a transformation going in the opposite direction of a normal convolution,
16 i.e., from something that has the shape of the output of some convolution
17 to something that has the shape of its input while maintaining a
18 connectivity pattern that is compatible with said convolution.
19
20 Args:
21 filters: int, the dimension of the output space (the number of filters
22 in the transposed convolution).
23 kernel_size: int or tuple/list of 1 integer, specifying the size of the
24 transposed convolution window.
25 strides: int or tuple/list of 1 integer, specifying the stride length
26 of the transposed convolution. `strides > 1` is incompatible with
27 `dilation_rate > 1`.
28 padding: string, either `"valid"` or `"same"` (case-insensitive).
29 `"valid"` means no padding. `"same"` results in padding evenly to
30 the left/right or up/down of the input. When `padding="same"` and
31 `strides=1`, the output has the same size as the input.
32 data_format: string, either `"channels_last"` or `"channels_first"`.
33 The ordering of the dimensions in the inputs. `"channels_last"`
34 corresponds to inputs with shape
35 `(batch_size, channels, height, width)`
36 while `"channels_first"` corresponds to inputs with shape
37 `(batch_size, channels, height, width)`. It defaults to the
38 `image_data_format` value found in your Keras config file at
39 `~/.keras/keras.json`. If you never set it, then it will be
40 `"channels_last"`.
41 dilation_rate: int or tuple/list of 1 integers, specifying the dilation
42 rate to use for dilated transposed convolution.
43 activation: Activation function. If `None`, no activation is applied.
44 use_bias: bool, if `True`, bias will be added to the output.
45 kernel_initializer: Initializer for the convolution kernel. If `None`,
46 the default initializer (`"glorot_uniform"`) will be used.
47 bias_initializer: Initializer for the bias vector. If `None`, the
48 default initializer (`"zeros"`) will be used.
49 kernel_regularizer: Optional regularizer for the convolution kernel.
50 bias_regularizer: Optional regularizer for the bias vector.
51 activity_regularizer: Optional regularizer function for the output.
52 kernel_constraint: Optional projection function to be applied to the
53 kernel after being updated by an `Optimizer` (e.g. used to implement
54 norm constraints or value constraints for layer weights). The
55 function must take as input the unprojected variable and must return
56 the projected variable (which must have the same shape). Constraints
57 are not safe to use when doing asynchronous distributed training.
58 bias_constraint: Optional projection function to be applied to the
59 bias after being updated by an `Optimizer`.
60
61 Input shape:
62 - If `data_format="channels_last"`:
63 A 4D tensor with shape: `(batch_size, height, width, channels)`
64 - If `data_format="channels_first"`:
65 A 4D tensor with shape: `(batch_size, channels, height, width)`
66
67 Output shape:
68 - If `data_format="channels_last"`:
69 A 4D tensor with shape: `(batch_size, new_height, new_width, filters)`
70 - If `data_format="channels_first"`:
71 A 4D tensor with shape: `(batch_size, filters, new_height, new_width)`
72
73 Returns:
74 A 4D tensor representing
75 `activation(conv2d_transpose(inputs, kernel) + bias)`.
76
77 Raises:
78 ValueError: when both `strides > 1` and `dilation_rate > 1`.
79
80 References:
81 - [A guide to convolution arithmetic for deep learning](
82 https://arxiv.org/abs/1603.07285v1)
83 - [Deconvolutional Networks](
84 https://www.matthewzeiler.com/mattzeiler/deconvolutionalnetworks.pdf)
85
86 Examples:
87
88 >>> x = np.random.rand(4, 10, 8, 128)
89 >>> y = keras.layers.Conv2DTranspose(32, 2, 2, activation='relu')(x)
90 >>> print(y.shape)
91 (4, 20, 16, 32)
92 """
93
94 def __init__(
95 self,
96 filters,
97 kernel_size,
98 strides=(1, 1),
99 padding="valid",
100 data_format=None,
101 dilation_rate=(1, 1),
102 activation=None,
103 use_bias=True,
104 kernel_initializer="glorot_uniform",
105 bias_initializer="zeros",
106 kernel_regularizer=None,
107 bias_regularizer=None,
108 activity_regularizer=None,
109 kernel_constraint=None,
110 bias_constraint=None,
111 **kwargs
112 ):
113 super().__init__(
114 rank=2,
115 filters=filters,
116 kernel_size=kernel_size,
117 strides=strides,
118 padding=padding,
119 data_format=data_format,
120 dilation_rate=dilation_rate,
121 activation=activation,
122 use_bias=use_bias,
123 kernel_initializer=kernel_initializer,
124 bias_initializer=bias_initializer,
125 kernel_regularizer=kernel_regularizer,
126 bias_regularizer=bias_regularizer,
127 activity_regularizer=activity_regularizer,
128 kernel_constraint=kernel_constraint,
129 bias_constraint=bias_constraint,
130 **kwargs
131 )
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras/layers/convolutional/conv2d_transpose.py b/keras/layers/convolutional/conv2d_transpose.py
--- a/keras/layers/convolutional/conv2d_transpose.py
+++ b/keras/layers/convolutional/conv2d_transpose.py
@@ -32,7 +32,7 @@
data_format: string, either `"channels_last"` or `"channels_first"`.
The ordering of the dimensions in the inputs. `"channels_last"`
corresponds to inputs with shape
- `(batch_size, channels, height, width)`
+ `(batch_size, height, width, channels)`
while `"channels_first"` corresponds to inputs with shape
`(batch_size, channels, height, width)`. It defaults to the
`image_data_format` value found in your Keras config file at
|
{"golden_diff": "diff --git a/keras/layers/convolutional/conv2d_transpose.py b/keras/layers/convolutional/conv2d_transpose.py\n--- a/keras/layers/convolutional/conv2d_transpose.py\n+++ b/keras/layers/convolutional/conv2d_transpose.py\n@@ -32,7 +32,7 @@\n data_format: string, either `\"channels_last\"` or `\"channels_first\"`.\n The ordering of the dimensions in the inputs. `\"channels_last\"`\n corresponds to inputs with shape\n- `(batch_size, channels, height, width)`\n+ `(batch_size, height, width, channels)`\n while `\"channels_first\"` corresponds to inputs with shape\n `(batch_size, channels, height, width)`. It defaults to the\n `image_data_format` value found in your Keras config file at\n", "issue": "Error in Documentation\nThe documentation confuses the \u2018channels_last\u2019 input format. It needs to be changed to match the correct format ==> (batch_size, height, width, channels)\r\n\r\nhttps://github.com/keras-team/keras/blob/037ec9f5fc61a53c6e1f4c02b7bf1443429dcd45/keras/layers/convolutional/conv2d_transpose.py#L35\n", "before_files": [{"content": "from keras.api_export import keras_export\nfrom keras.layers.convolutional.base_conv_transpose import BaseConvTranspose\n\n\n@keras_export(\n [\n \"keras.layers.Conv2DTranspose\",\n \"keras.layers.Convolution2DTranspose\",\n ]\n)\nclass Conv2DTranspose(BaseConvTranspose):\n \"\"\"2D transposed convolution layer.\n\n The need for transposed convolutions generally arise from the desire to use\n a transformation going in the opposite direction of a normal convolution,\n i.e., from something that has the shape of the output of some convolution\n to something that has the shape of its input while maintaining a\n connectivity pattern that is compatible with said convolution.\n\n Args:\n filters: int, the dimension of the output space (the number of filters\n in the transposed convolution).\n kernel_size: int or tuple/list of 1 integer, specifying the size of the\n transposed convolution window.\n strides: int or tuple/list of 1 integer, specifying the stride length\n of the transposed convolution. `strides > 1` is incompatible with\n `dilation_rate > 1`.\n padding: string, either `\"valid\"` or `\"same\"` (case-insensitive).\n `\"valid\"` means no padding. `\"same\"` results in padding evenly to\n the left/right or up/down of the input. When `padding=\"same\"` and\n `strides=1`, the output has the same size as the input.\n data_format: string, either `\"channels_last\"` or `\"channels_first\"`.\n The ordering of the dimensions in the inputs. `\"channels_last\"`\n corresponds to inputs with shape\n `(batch_size, channels, height, width)`\n while `\"channels_first\"` corresponds to inputs with shape\n `(batch_size, channels, height, width)`. It defaults to the\n `image_data_format` value found in your Keras config file at\n `~/.keras/keras.json`. If you never set it, then it will be\n `\"channels_last\"`.\n dilation_rate: int or tuple/list of 1 integers, specifying the dilation\n rate to use for dilated transposed convolution.\n activation: Activation function. If `None`, no activation is applied.\n use_bias: bool, if `True`, bias will be added to the output.\n kernel_initializer: Initializer for the convolution kernel. If `None`,\n the default initializer (`\"glorot_uniform\"`) will be used.\n bias_initializer: Initializer for the bias vector. If `None`, the\n default initializer (`\"zeros\"`) will be used.\n kernel_regularizer: Optional regularizer for the convolution kernel.\n bias_regularizer: Optional regularizer for the bias vector.\n activity_regularizer: Optional regularizer function for the output.\n kernel_constraint: Optional projection function to be applied to the\n kernel after being updated by an `Optimizer` (e.g. used to implement\n norm constraints or value constraints for layer weights). The\n function must take as input the unprojected variable and must return\n the projected variable (which must have the same shape). Constraints\n are not safe to use when doing asynchronous distributed training.\n bias_constraint: Optional projection function to be applied to the\n bias after being updated by an `Optimizer`.\n\n Input shape:\n - If `data_format=\"channels_last\"`:\n A 4D tensor with shape: `(batch_size, height, width, channels)`\n - If `data_format=\"channels_first\"`:\n A 4D tensor with shape: `(batch_size, channels, height, width)`\n\n Output shape:\n - If `data_format=\"channels_last\"`:\n A 4D tensor with shape: `(batch_size, new_height, new_width, filters)`\n - If `data_format=\"channels_first\"`:\n A 4D tensor with shape: `(batch_size, filters, new_height, new_width)`\n\n Returns:\n A 4D tensor representing\n `activation(conv2d_transpose(inputs, kernel) + bias)`.\n\n Raises:\n ValueError: when both `strides > 1` and `dilation_rate > 1`.\n\n References:\n - [A guide to convolution arithmetic for deep learning](\n https://arxiv.org/abs/1603.07285v1)\n - [Deconvolutional Networks](\n https://www.matthewzeiler.com/mattzeiler/deconvolutionalnetworks.pdf)\n\n Examples:\n\n >>> x = np.random.rand(4, 10, 8, 128)\n >>> y = keras.layers.Conv2DTranspose(32, 2, 2, activation='relu')(x)\n >>> print(y.shape)\n (4, 20, 16, 32)\n \"\"\"\n\n def __init__(\n self,\n filters,\n kernel_size,\n strides=(1, 1),\n padding=\"valid\",\n data_format=None,\n dilation_rate=(1, 1),\n activation=None,\n use_bias=True,\n kernel_initializer=\"glorot_uniform\",\n bias_initializer=\"zeros\",\n kernel_regularizer=None,\n bias_regularizer=None,\n activity_regularizer=None,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs\n ):\n super().__init__(\n rank=2,\n filters=filters,\n kernel_size=kernel_size,\n strides=strides,\n padding=padding,\n data_format=data_format,\n dilation_rate=dilation_rate,\n activation=activation,\n use_bias=use_bias,\n kernel_initializer=kernel_initializer,\n bias_initializer=bias_initializer,\n kernel_regularizer=kernel_regularizer,\n bias_regularizer=bias_regularizer,\n activity_regularizer=activity_regularizer,\n kernel_constraint=kernel_constraint,\n bias_constraint=bias_constraint,\n **kwargs\n )\n", "path": "keras/layers/convolutional/conv2d_transpose.py"}], "after_files": [{"content": "from keras.api_export import keras_export\nfrom keras.layers.convolutional.base_conv_transpose import BaseConvTranspose\n\n\n@keras_export(\n [\n \"keras.layers.Conv2DTranspose\",\n \"keras.layers.Convolution2DTranspose\",\n ]\n)\nclass Conv2DTranspose(BaseConvTranspose):\n \"\"\"2D transposed convolution layer.\n\n The need for transposed convolutions generally arise from the desire to use\n a transformation going in the opposite direction of a normal convolution,\n i.e., from something that has the shape of the output of some convolution\n to something that has the shape of its input while maintaining a\n connectivity pattern that is compatible with said convolution.\n\n Args:\n filters: int, the dimension of the output space (the number of filters\n in the transposed convolution).\n kernel_size: int or tuple/list of 1 integer, specifying the size of the\n transposed convolution window.\n strides: int or tuple/list of 1 integer, specifying the stride length\n of the transposed convolution. `strides > 1` is incompatible with\n `dilation_rate > 1`.\n padding: string, either `\"valid\"` or `\"same\"` (case-insensitive).\n `\"valid\"` means no padding. `\"same\"` results in padding evenly to\n the left/right or up/down of the input. When `padding=\"same\"` and\n `strides=1`, the output has the same size as the input.\n data_format: string, either `\"channels_last\"` or `\"channels_first\"`.\n The ordering of the dimensions in the inputs. `\"channels_last\"`\n corresponds to inputs with shape\n `(batch_size, height, width, channels)`\n while `\"channels_first\"` corresponds to inputs with shape\n `(batch_size, channels, height, width)`. It defaults to the\n `image_data_format` value found in your Keras config file at\n `~/.keras/keras.json`. If you never set it, then it will be\n `\"channels_last\"`.\n dilation_rate: int or tuple/list of 1 integers, specifying the dilation\n rate to use for dilated transposed convolution.\n activation: Activation function. If `None`, no activation is applied.\n use_bias: bool, if `True`, bias will be added to the output.\n kernel_initializer: Initializer for the convolution kernel. If `None`,\n the default initializer (`\"glorot_uniform\"`) will be used.\n bias_initializer: Initializer for the bias vector. If `None`, the\n default initializer (`\"zeros\"`) will be used.\n kernel_regularizer: Optional regularizer for the convolution kernel.\n bias_regularizer: Optional regularizer for the bias vector.\n activity_regularizer: Optional regularizer function for the output.\n kernel_constraint: Optional projection function to be applied to the\n kernel after being updated by an `Optimizer` (e.g. used to implement\n norm constraints or value constraints for layer weights). The\n function must take as input the unprojected variable and must return\n the projected variable (which must have the same shape). Constraints\n are not safe to use when doing asynchronous distributed training.\n bias_constraint: Optional projection function to be applied to the\n bias after being updated by an `Optimizer`.\n\n Input shape:\n - If `data_format=\"channels_last\"`:\n A 4D tensor with shape: `(batch_size, height, width, channels)`\n - If `data_format=\"channels_first\"`:\n A 4D tensor with shape: `(batch_size, channels, height, width)`\n\n Output shape:\n - If `data_format=\"channels_last\"`:\n A 4D tensor with shape: `(batch_size, new_height, new_width, filters)`\n - If `data_format=\"channels_first\"`:\n A 4D tensor with shape: `(batch_size, filters, new_height, new_width)`\n\n Returns:\n A 4D tensor representing\n `activation(conv2d_transpose(inputs, kernel) + bias)`.\n\n Raises:\n ValueError: when both `strides > 1` and `dilation_rate > 1`.\n\n References:\n - [A guide to convolution arithmetic for deep learning](\n https://arxiv.org/abs/1603.07285v1)\n - [Deconvolutional Networks](\n https://www.matthewzeiler.com/mattzeiler/deconvolutionalnetworks.pdf)\n\n Examples:\n\n >>> x = np.random.rand(4, 10, 8, 128)\n >>> y = keras.layers.Conv2DTranspose(32, 2, 2, activation='relu')(x)\n >>> print(y.shape)\n (4, 20, 16, 32)\n \"\"\"\n\n def __init__(\n self,\n filters,\n kernel_size,\n strides=(1, 1),\n padding=\"valid\",\n data_format=None,\n dilation_rate=(1, 1),\n activation=None,\n use_bias=True,\n kernel_initializer=\"glorot_uniform\",\n bias_initializer=\"zeros\",\n kernel_regularizer=None,\n bias_regularizer=None,\n activity_regularizer=None,\n kernel_constraint=None,\n bias_constraint=None,\n **kwargs\n ):\n super().__init__(\n rank=2,\n filters=filters,\n kernel_size=kernel_size,\n strides=strides,\n padding=padding,\n data_format=data_format,\n dilation_rate=dilation_rate,\n activation=activation,\n use_bias=use_bias,\n kernel_initializer=kernel_initializer,\n bias_initializer=bias_initializer,\n kernel_regularizer=kernel_regularizer,\n bias_regularizer=bias_regularizer,\n activity_regularizer=activity_regularizer,\n kernel_constraint=kernel_constraint,\n bias_constraint=bias_constraint,\n **kwargs\n )\n", "path": "keras/layers/convolutional/conv2d_transpose.py"}]}
| 1,905 | 195 |
gh_patches_debug_2419
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1321
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Evaluation preview button visibility
As a teaching assistant, I might be a contributor to a given course and therefore get my own feedback in the main evaluation. If that course also has an exam evaluation, I see that listed on my "own evaluations" page with the option to preview the questionnaire. However, as not being responsible, I miss the access rights to preview the linked page, resulting in an error.
I would like to either don't have the preview button (it already knows while rendering that page that I am not a contributor, shown through the corresponding icon next to the exam evaluation title) or to give me the rights to preview the questionnaire.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/evaluation/templatetags/evaluation_filters.py`
Content:
```
1 from django.forms import TypedChoiceField
2 from django.template import Library
3
4 from evap.evaluation.models import BASE_UNIPOLAR_CHOICES
5 from evap.evaluation.tools import STATES_ORDERED, STATE_DESCRIPTIONS
6 from evap.rewards.tools import can_reward_points_be_used_by
7 from evap.student.forms import HeadingField
8
9
10 register = Library()
11
12
13 @register.filter(name='zip')
14 def _zip(a, b):
15 return zip(a, b)
16
17
18 @register.filter
19 def ordering_index(evaluation):
20 if evaluation.state in ['new', 'prepared', 'editor_approved', 'approved']:
21 return evaluation.days_until_evaluation
22 elif evaluation.state == "in_evaluation":
23 return 100000 + evaluation.days_left_for_evaluation
24 return 200000 + evaluation.days_left_for_evaluation
25
26
27 # from http://www.jongales.com/blog/2009/10/19/percentage-django-template-tag/
28 @register.filter
29 def percentage(fraction, population):
30 try:
31 return "{0:.0f}%".format(int(float(fraction) / float(population) * 100))
32 except ValueError:
33 return None
34 except ZeroDivisionError:
35 return None
36
37
38 @register.filter
39 def percentage_one_decimal(fraction, population):
40 try:
41 return "{0:.1f}%".format((float(fraction) / float(population)) * 100)
42 except ValueError:
43 return None
44 except ZeroDivisionError:
45 return None
46
47
48 @register.filter
49 def percentage_value(fraction, population):
50 try:
51 return "{0:0f}".format((float(fraction) / float(population)) * 100)
52 except ValueError:
53 return None
54 except ZeroDivisionError:
55 return None
56
57
58 @register.filter
59 def to_colors(choices):
60 if not choices:
61 # When displaying the course distribution, there are no associated voting choices.
62 # In that case, we just use the colors of a unipolar scale.
63 return BASE_UNIPOLAR_CHOICES['colors']
64 return choices.colors
65
66
67 @register.filter
68 def statename(state):
69 return STATES_ORDERED.get(state)
70
71
72 @register.filter
73 def statedescription(state):
74 return STATE_DESCRIPTIONS.get(state)
75
76
77 @register.filter
78 def can_results_page_be_seen_by(evaluation, user):
79 return evaluation.can_results_page_be_seen_by(user)
80
81
82 @register.filter(name='can_reward_points_be_used_by')
83 def _can_reward_points_be_used_by(user):
84 return can_reward_points_be_used_by(user)
85
86
87 @register.filter
88 def is_choice_field(field):
89 return isinstance(field.field, TypedChoiceField)
90
91
92 @register.filter
93 def is_heading_field(field):
94 return isinstance(field.field, HeadingField)
95
96
97 @register.filter
98 def is_user_editor_or_delegate(evaluation, user):
99 return evaluation.is_user_editor_or_delegate(user)
100
101
102 @register.filter
103 def message_class(level):
104 return {
105 'debug': 'info',
106 'info': 'info',
107 'success': 'success',
108 'warning': 'warning',
109 'error': 'danger',
110 }.get(level, 'info')
111
112
113 @register.filter
114 def hours_and_minutes(time_left_for_evaluation):
115 hours = time_left_for_evaluation.seconds // 3600
116 minutes = (time_left_for_evaluation.seconds // 60) % 60
117 return "{:02}:{:02}".format(hours, minutes)
118
119
120 @register.filter
121 def has_nonresponsible_editor(evaluation):
122 return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/evaluation/templatetags/evaluation_filters.py b/evap/evaluation/templatetags/evaluation_filters.py
--- a/evap/evaluation/templatetags/evaluation_filters.py
+++ b/evap/evaluation/templatetags/evaluation_filters.py
@@ -99,6 +99,10 @@
return evaluation.is_user_editor_or_delegate(user)
[email protected]
+def is_user_responsible_or_contributor_or_delegate(evaluation, user):
+ return evaluation.is_user_responsible_or_contributor_or_delegate(user)
+
@register.filter
def message_class(level):
return {
|
{"golden_diff": "diff --git a/evap/evaluation/templatetags/evaluation_filters.py b/evap/evaluation/templatetags/evaluation_filters.py\n--- a/evap/evaluation/templatetags/evaluation_filters.py\n+++ b/evap/evaluation/templatetags/evaluation_filters.py\n@@ -99,6 +99,10 @@\n return evaluation.is_user_editor_or_delegate(user)\n \n \[email protected]\n+def is_user_responsible_or_contributor_or_delegate(evaluation, user):\n+ return evaluation.is_user_responsible_or_contributor_or_delegate(user)\n+\n @register.filter\n def message_class(level):\n return {\n", "issue": "Evaluation preview button visibility\nAs a teaching assistant, I might be a contributor to a given course and therefore get my own feedback in the main evaluation. If that course also has an exam evaluation, I see that listed on my \"own evaluations\" page with the option to preview the questionnaire. However, as not being responsible, I miss the access rights to preview the linked page, resulting in an error.\r\n\r\nI would like to either don't have the preview button (it already knows while rendering that page that I am not a contributor, shown through the corresponding icon next to the exam evaluation title) or to give me the rights to preview the questionnaire.\n", "before_files": [{"content": "from django.forms import TypedChoiceField\nfrom django.template import Library\n\nfrom evap.evaluation.models import BASE_UNIPOLAR_CHOICES\nfrom evap.evaluation.tools import STATES_ORDERED, STATE_DESCRIPTIONS\nfrom evap.rewards.tools import can_reward_points_be_used_by\nfrom evap.student.forms import HeadingField\n\n\nregister = Library()\n\n\[email protected](name='zip')\ndef _zip(a, b):\n return zip(a, b)\n\n\[email protected]\ndef ordering_index(evaluation):\n if evaluation.state in ['new', 'prepared', 'editor_approved', 'approved']:\n return evaluation.days_until_evaluation\n elif evaluation.state == \"in_evaluation\":\n return 100000 + evaluation.days_left_for_evaluation\n return 200000 + evaluation.days_left_for_evaluation\n\n\n# from http://www.jongales.com/blog/2009/10/19/percentage-django-template-tag/\[email protected]\ndef percentage(fraction, population):\n try:\n return \"{0:.0f}%\".format(int(float(fraction) / float(population) * 100))\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef percentage_one_decimal(fraction, population):\n try:\n return \"{0:.1f}%\".format((float(fraction) / float(population)) * 100)\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef percentage_value(fraction, population):\n try:\n return \"{0:0f}\".format((float(fraction) / float(population)) * 100)\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef to_colors(choices):\n if not choices:\n # When displaying the course distribution, there are no associated voting choices.\n # In that case, we just use the colors of a unipolar scale.\n return BASE_UNIPOLAR_CHOICES['colors']\n return choices.colors\n\n\[email protected]\ndef statename(state):\n return STATES_ORDERED.get(state)\n\n\[email protected]\ndef statedescription(state):\n return STATE_DESCRIPTIONS.get(state)\n\n\[email protected]\ndef can_results_page_be_seen_by(evaluation, user):\n return evaluation.can_results_page_be_seen_by(user)\n\n\[email protected](name='can_reward_points_be_used_by')\ndef _can_reward_points_be_used_by(user):\n return can_reward_points_be_used_by(user)\n\n\[email protected]\ndef is_choice_field(field):\n return isinstance(field.field, TypedChoiceField)\n\n\[email protected]\ndef is_heading_field(field):\n return isinstance(field.field, HeadingField)\n\n\[email protected]\ndef is_user_editor_or_delegate(evaluation, user):\n return evaluation.is_user_editor_or_delegate(user)\n\n\[email protected]\ndef message_class(level):\n return {\n 'debug': 'info',\n 'info': 'info',\n 'success': 'success',\n 'warning': 'warning',\n 'error': 'danger',\n }.get(level, 'info')\n\n\[email protected]\ndef hours_and_minutes(time_left_for_evaluation):\n hours = time_left_for_evaluation.seconds // 3600\n minutes = (time_left_for_evaluation.seconds // 60) % 60\n return \"{:02}:{:02}\".format(hours, minutes)\n\n\[email protected]\ndef has_nonresponsible_editor(evaluation):\n return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()\n", "path": "evap/evaluation/templatetags/evaluation_filters.py"}], "after_files": [{"content": "from django.forms import TypedChoiceField\nfrom django.template import Library\n\nfrom evap.evaluation.models import BASE_UNIPOLAR_CHOICES\nfrom evap.evaluation.tools import STATES_ORDERED, STATE_DESCRIPTIONS\nfrom evap.rewards.tools import can_reward_points_be_used_by\nfrom evap.student.forms import HeadingField\n\n\nregister = Library()\n\n\[email protected](name='zip')\ndef _zip(a, b):\n return zip(a, b)\n\n\[email protected]\ndef ordering_index(evaluation):\n if evaluation.state in ['new', 'prepared', 'editor_approved', 'approved']:\n return evaluation.days_until_evaluation\n elif evaluation.state == \"in_evaluation\":\n return 100000 + evaluation.days_left_for_evaluation\n return 200000 + evaluation.days_left_for_evaluation\n\n\n# from http://www.jongales.com/blog/2009/10/19/percentage-django-template-tag/\[email protected]\ndef percentage(fraction, population):\n try:\n return \"{0:.0f}%\".format(int(float(fraction) / float(population) * 100))\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef percentage_one_decimal(fraction, population):\n try:\n return \"{0:.1f}%\".format((float(fraction) / float(population)) * 100)\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef percentage_value(fraction, population):\n try:\n return \"{0:0f}\".format((float(fraction) / float(population)) * 100)\n except ValueError:\n return None\n except ZeroDivisionError:\n return None\n\n\[email protected]\ndef to_colors(choices):\n if not choices:\n # When displaying the course distribution, there are no associated voting choices.\n # In that case, we just use the colors of a unipolar scale.\n return BASE_UNIPOLAR_CHOICES['colors']\n return choices.colors\n\n\[email protected]\ndef statename(state):\n return STATES_ORDERED.get(state)\n\n\[email protected]\ndef statedescription(state):\n return STATE_DESCRIPTIONS.get(state)\n\n\[email protected]\ndef can_results_page_be_seen_by(evaluation, user):\n return evaluation.can_results_page_be_seen_by(user)\n\n\[email protected](name='can_reward_points_be_used_by')\ndef _can_reward_points_be_used_by(user):\n return can_reward_points_be_used_by(user)\n\n\[email protected]\ndef is_choice_field(field):\n return isinstance(field.field, TypedChoiceField)\n\n\[email protected]\ndef is_heading_field(field):\n return isinstance(field.field, HeadingField)\n\n\[email protected]\ndef is_user_editor_or_delegate(evaluation, user):\n return evaluation.is_user_editor_or_delegate(user)\n\n\[email protected]\ndef is_user_responsible_or_contributor_or_delegate(evaluation, user):\n return evaluation.is_user_responsible_or_contributor_or_delegate(user)\n\[email protected]\ndef message_class(level):\n return {\n 'debug': 'info',\n 'info': 'info',\n 'success': 'success',\n 'warning': 'warning',\n 'error': 'danger',\n }.get(level, 'info')\n\n\[email protected]\ndef hours_and_minutes(time_left_for_evaluation):\n hours = time_left_for_evaluation.seconds // 3600\n minutes = (time_left_for_evaluation.seconds // 60) % 60\n return \"{:02}:{:02}\".format(hours, minutes)\n\n\[email protected]\ndef has_nonresponsible_editor(evaluation):\n return evaluation.contributions.filter(can_edit=True).exclude(contributor__in=evaluation.course.responsibles.all()).exists()\n", "path": "evap/evaluation/templatetags/evaluation_filters.py"}]}
| 1,441 | 141 |
gh_patches_debug_6187
|
rasdani/github-patches
|
git_diff
|
jupyterhub__zero-to-jupyterhub-k8s-270
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nodeSelector support
I'd like to use node pools on GKE to have a cheaper nodes like `n1-standard-1` host hub related pods and a more expensive nodes host user pods. Is there support for `nodeSelect` pod configuration for the hub and singleuser pods?
https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
My use case is a cluster for long term student projects over the course of the semester, and I'd like to use autoscaler on the expensive node pool to go make it go to zero noes when no students are using the cluster, while leaving the hub up on something cheaper while waiting for a user to log in.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `images/hub/jupyterhub_config.py`
Content:
```
1 import os
2 import sys
3 import yaml
4 from tornado.httpclient import AsyncHTTPClient
5
6 def get_config(key, default=None):
7 """
8 Find a config item of a given name & return it
9
10 Parses everything as YAML, so lists and dicts are available too
11 """
12 path = os.path.join('/etc/jupyterhub/config', key)
13 try:
14 with open(path) as f:
15 data = yaml.safe_load(f)
16 print(key, data)
17 return data
18 except FileNotFoundError:
19 return default
20
21 def get_secret(key, default=None):
22 """Get a secret from /etc/jupyterhub/secret"""
23 path = os.path.join('/etc/jupyterhub/secret', key)
24 try:
25 with open(path) as f:
26 return f.read().strip()
27 except FileNotFoundError:
28 return default
29
30
31 # Configure JupyterHub to use the curl backend for making HTTP requests,
32 # rather than the pure-python implementations. The default one starts
33 # being too slow to make a large number of requests to the proxy API
34 # at the rate required.
35 AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
36
37 c.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'
38
39 # Connect to a proxy running in a different pod
40 c.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))
41 c.ConfigurableHTTPProxy.should_start = False
42
43 # Check that the proxy has routes appropriately setup
44 # This isn't the best named setting :D
45 c.JupyterHub.last_activity_interval = 60
46
47 # Max number of servers that can be spawning at any one time
48 c.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')
49
50 active_server_limit = get_config('hub.active-server-limit', None)
51
52 if active_server_limit is not None:
53 c.JupyterHub.active_server_limit = int(active_server_limit)
54
55 c.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']
56 c.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])
57
58 # the hub should listen on all interfaces, so the proxy can access it
59 c.JupyterHub.hub_ip = '0.0.0.0'
60
61 c.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')
62
63 # Sometimes disks take a while to attach, so let's keep a not-too-short timeout
64 c.KubeSpawner.start_timeout = 5 * 60
65
66 # Use env var for this, since we want hub to restart when this changes
67 c.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']
68
69 c.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})
70
71 c.KubeSpawner.singleuser_uid = get_config('singleuser.uid')
72 c.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')
73
74 # Configure dynamically provisioning pvc
75 storage_type = get_config('singleuser.storage.type')
76 if storage_type == 'dynamic':
77 c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'
78 c.KubeSpawner.user_storage_pvc_ensure = True
79 storage_class = get_config('singleuser.storage.dynamic.storage-class', None)
80 if storage_class:
81 c.KubeSpawner.user_storage_class = storage_class
82 c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']
83 c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')
84
85 # Add volumes to singleuser pods
86 c.KubeSpawner.volumes = [
87 {
88 'name': 'volume-{username}{servername}',
89 'persistentVolumeClaim': {
90 'claimName': 'claim-{username}{servername}'
91 }
92 }
93 ]
94 c.KubeSpawner.volume_mounts = [
95 {
96 'mountPath': get_config('singleuser.storage.home_mount_path'),
97 'name': 'volume-{username}{servername}'
98 }
99 ]
100 elif storage_type == 'static':
101 pvc_claim_name = get_config('singleuser.storage.static.pvc-name')
102 c.KubeSpawner.volumes = [{
103 'name': 'home',
104 'persistentVolumeClaim': {
105 'claimName': pvc_claim_name
106 }
107 }]
108
109 c.KubeSpawner.volume_mounts = [{
110 'mountPath': get_config('singleuser.storage.home_mount_path'),
111 'name': 'home',
112 'subPath': get_config('singleuser.storage.static.sub-path')
113 }]
114
115 c.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))
116 c.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))
117
118 lifecycle_hooks = get_config('singleuser.lifecycle-hooks')
119 if lifecycle_hooks:
120 c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks
121
122 init_containers = get_config('singleuser.init-containers')
123 if init_containers:
124 c.KubeSpawner.singleuser_init_containers = init_containers
125
126 # Gives spawned containers access to the API of the hub
127 c.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']
128 c.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])
129
130 c.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']
131 c.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])
132
133 c.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')
134 c.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')
135 c.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')
136 c.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')
137
138 # Allow switching authenticators easily
139 auth_type = get_config('auth.type')
140 email_domain = 'local'
141
142 if auth_type == 'google':
143 c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'
144 c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')
145 c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')
146 c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')
147 c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')
148 c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')
149 email_domain = get_config('auth.google.hosted-domain')
150 elif auth_type == 'github':
151 c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'
152 c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')
153 c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')
154 c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')
155 elif auth_type == 'cilogon':
156 c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'
157 c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')
158 c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')
159 c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')
160 elif auth_type == 'gitlab':
161 c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'
162 c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')
163 c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')
164 c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')
165 elif auth_type == 'mediawiki':
166 c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'
167 c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')
168 c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')
169 c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')
170 elif auth_type == 'hmac':
171 c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'
172 c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))
173 elif auth_type == 'dummy':
174 c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'
175 c.DummyAuthenticator.password = get_config('auth.dummy.password', None)
176 elif auth_type == 'tmp':
177 c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'
178 elif auth_type == 'custom':
179 # full_class_name looks like "myauthenticator.MyAuthenticator".
180 # To create a docker image with this class availabe, you can just have the
181 # following Dockerifle:
182 # FROM jupyterhub/k8s-hub:v0.4
183 # RUN pip3 install myauthenticator
184 full_class_name = get_config('auth.custom.class-name')
185 c.JupyterHub.authenticator_class = full_class_name
186 auth_class_name = full_class_name.rsplit('.', 1)[-1]
187 auth_config = c[auth_class_name]
188 auth_config.update(get_config('auth.custom.config') or {})
189 else:
190 raise ValueError("Unhandled auth type: %r" % auth_type)
191
192
193 def generate_user_email(spawner):
194 """
195 Used as the EMAIL environment variable
196 """
197 return '{username}@{domain}'.format(
198 username=spawner.user.name, domain=email_domain
199 )
200
201 def generate_user_name(spawner):
202 """
203 Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables
204 """
205 return spawner.user.name
206
207 c.KubeSpawner.environment = {
208 'EMAIL': generate_user_email,
209 # git requires these committer attributes
210 'GIT_AUTHOR_NAME': generate_user_name,
211 'GIT_COMMITTER_NAME': generate_user_name
212 }
213
214 c.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))
215
216 # Enable admins to access user servers
217 c.JupyterHub.admin_access = get_config('auth.admin.access')
218
219
220 c.Authenticator.admin_users = get_config('auth.admin.users', [])
221
222 c.Authenticator.whitelist = get_config('auth.whitelist.users', [])
223
224 c.JupyterHub.services = []
225
226 if get_config('cull.enabled', False):
227 cull_timeout = get_config('cull.timeout')
228 cull_every = get_config('cull.every')
229 cull_cmd = [
230 '/usr/local/bin/cull_idle_servers.py',
231 '--timeout=%s' % cull_timeout,
232 '--cull-every=%s' % cull_every,
233 ]
234 if get_config('cull.users'):
235 cull_cmd.append('--cull-users')
236 c.JupyterHub.services.append({
237 'name': 'cull-idle',
238 'admin': True,
239 'command': cull_cmd,
240 })
241
242 for name, service in get_config('hub.services', {}).items():
243 api_token = get_secret('services.token.%s' % name)
244 # jupyterhub.services is a list of dicts, but
245 # in the helm chart it is a dict of dicts for easier merged-config
246 service.setdefault('name', name)
247 if api_token:
248 service['api_token'] = api_token
249 c.JupyterHub.services.append(service)
250
251 c.JupyterHub.base_url = get_config('hub.base_url')
252
253 c.JupyterHub.db_url = get_config('hub.db_url')
254
255 cmd = get_config('singleuser.cmd', None)
256 if cmd:
257 c.Spawner.cmd = cmd
258
259
260 extra_config_path = '/etc/jupyterhub/config/hub.extra-config.py'
261 if os.path.exists(extra_config_path):
262 load_subconfig(extra_config_path)
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/images/hub/jupyterhub_config.py b/images/hub/jupyterhub_config.py
--- a/images/hub/jupyterhub_config.py
+++ b/images/hub/jupyterhub_config.py
@@ -71,6 +71,7 @@
c.KubeSpawner.singleuser_uid = get_config('singleuser.uid')
c.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')
+c.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')
# Configure dynamically provisioning pvc
storage_type = get_config('singleuser.storage.type')
if storage_type == 'dynamic':
|
{"golden_diff": "diff --git a/images/hub/jupyterhub_config.py b/images/hub/jupyterhub_config.py\n--- a/images/hub/jupyterhub_config.py\n+++ b/images/hub/jupyterhub_config.py\n@@ -71,6 +71,7 @@\n c.KubeSpawner.singleuser_uid = get_config('singleuser.uid')\n c.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')\n \n+c.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')\n # Configure dynamically provisioning pvc\n storage_type = get_config('singleuser.storage.type')\n if storage_type == 'dynamic':\n", "issue": "nodeSelector support\nI'd like to use node pools on GKE to have a cheaper nodes like `n1-standard-1` host hub related pods and a more expensive nodes host user pods. Is there support for `nodeSelect` pod configuration for the hub and singleuser pods?\r\n\r\nhttps://kubernetes.io/docs/concepts/configuration/assign-pod-node/\r\n\r\nMy use case is a cluster for long term student projects over the course of the semester, and I'd like to use autoscaler on the expensive node pool to go make it go to zero noes when no students are using the cluster, while leaving the hub up on something cheaper while waiting for a user to log in.\n", "before_files": [{"content": "import os\nimport sys\nimport yaml\nfrom tornado.httpclient import AsyncHTTPClient\n\ndef get_config(key, default=None):\n \"\"\"\n Find a config item of a given name & return it\n\n Parses everything as YAML, so lists and dicts are available too\n \"\"\"\n path = os.path.join('/etc/jupyterhub/config', key)\n try:\n with open(path) as f:\n data = yaml.safe_load(f)\n print(key, data)\n return data\n except FileNotFoundError:\n return default\n\ndef get_secret(key, default=None):\n \"\"\"Get a secret from /etc/jupyterhub/secret\"\"\"\n path = os.path.join('/etc/jupyterhub/secret', key)\n try:\n with open(path) as f:\n return f.read().strip()\n except FileNotFoundError:\n return default\n\n\n# Configure JupyterHub to use the curl backend for making HTTP requests,\n# rather than the pure-python implementations. The default one starts\n# being too slow to make a large number of requests to the proxy API\n# at the rate required.\nAsyncHTTPClient.configure(\"tornado.curl_httpclient.CurlAsyncHTTPClient\")\n\nc.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'\n\n# Connect to a proxy running in a different pod\nc.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))\nc.ConfigurableHTTPProxy.should_start = False\n\n# Check that the proxy has routes appropriately setup\n# This isn't the best named setting :D\nc.JupyterHub.last_activity_interval = 60\n\n# Max number of servers that can be spawning at any one time\nc.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')\n\nactive_server_limit = get_config('hub.active-server-limit', None)\n\nif active_server_limit is not None:\n c.JupyterHub.active_server_limit = int(active_server_limit)\n\nc.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']\nc.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])\n\n# the hub should listen on all interfaces, so the proxy can access it\nc.JupyterHub.hub_ip = '0.0.0.0'\n\nc.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')\n\n# Sometimes disks take a while to attach, so let's keep a not-too-short timeout\nc.KubeSpawner.start_timeout = 5 * 60\n\n# Use env var for this, since we want hub to restart when this changes\nc.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']\n\nc.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})\n\nc.KubeSpawner.singleuser_uid = get_config('singleuser.uid')\nc.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')\n\n# Configure dynamically provisioning pvc\nstorage_type = get_config('singleuser.storage.type')\nif storage_type == 'dynamic':\n c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'\n c.KubeSpawner.user_storage_pvc_ensure = True\n storage_class = get_config('singleuser.storage.dynamic.storage-class', None)\n if storage_class:\n c.KubeSpawner.user_storage_class = storage_class\n c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']\n c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')\n\n # Add volumes to singleuser pods\n c.KubeSpawner.volumes = [\n {\n 'name': 'volume-{username}{servername}',\n 'persistentVolumeClaim': {\n 'claimName': 'claim-{username}{servername}'\n }\n }\n ]\n c.KubeSpawner.volume_mounts = [\n {\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'volume-{username}{servername}'\n }\n ]\nelif storage_type == 'static':\n pvc_claim_name = get_config('singleuser.storage.static.pvc-name')\n c.KubeSpawner.volumes = [{\n 'name': 'home',\n 'persistentVolumeClaim': {\n 'claimName': pvc_claim_name\n }\n }]\n\n c.KubeSpawner.volume_mounts = [{\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'home',\n 'subPath': get_config('singleuser.storage.static.sub-path')\n }]\n\nc.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))\nc.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))\n\nlifecycle_hooks = get_config('singleuser.lifecycle-hooks')\nif lifecycle_hooks:\n c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks\n\ninit_containers = get_config('singleuser.init-containers')\nif init_containers:\n c.KubeSpawner.singleuser_init_containers = init_containers \n\n# Gives spawned containers access to the API of the hub\nc.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')\nc.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')\nc.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')\nc.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')\n\n# Allow switching authenticators easily\nauth_type = get_config('auth.type')\nemail_domain = 'local'\n\nif auth_type == 'google':\n c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'\n c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')\n c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')\n c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')\n c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')\n c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')\n email_domain = get_config('auth.google.hosted-domain')\nelif auth_type == 'github':\n c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'\n c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')\n c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')\n c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')\nelif auth_type == 'cilogon':\n c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'\n c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')\n c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')\n c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')\nelif auth_type == 'gitlab':\n c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'\n c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')\n c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')\n c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')\nelif auth_type == 'mediawiki':\n c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'\n c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')\n c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')\n c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')\nelif auth_type == 'hmac':\n c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'\n c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))\nelif auth_type == 'dummy':\n c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'\n c.DummyAuthenticator.password = get_config('auth.dummy.password', None)\nelif auth_type == 'tmp':\n c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'\nelif auth_type == 'custom':\n # full_class_name looks like \"myauthenticator.MyAuthenticator\".\n # To create a docker image with this class availabe, you can just have the\n # following Dockerifle:\n # FROM jupyterhub/k8s-hub:v0.4\n # RUN pip3 install myauthenticator\n full_class_name = get_config('auth.custom.class-name')\n c.JupyterHub.authenticator_class = full_class_name\n auth_class_name = full_class_name.rsplit('.', 1)[-1]\n auth_config = c[auth_class_name]\n auth_config.update(get_config('auth.custom.config') or {})\nelse:\n raise ValueError(\"Unhandled auth type: %r\" % auth_type)\n\n\ndef generate_user_email(spawner):\n \"\"\"\n Used as the EMAIL environment variable\n \"\"\"\n return '{username}@{domain}'.format(\n username=spawner.user.name, domain=email_domain\n )\n\ndef generate_user_name(spawner):\n \"\"\"\n Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables\n \"\"\"\n return spawner.user.name\n\nc.KubeSpawner.environment = {\n 'EMAIL': generate_user_email,\n # git requires these committer attributes\n 'GIT_AUTHOR_NAME': generate_user_name,\n 'GIT_COMMITTER_NAME': generate_user_name\n}\n\nc.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))\n\n# Enable admins to access user servers\nc.JupyterHub.admin_access = get_config('auth.admin.access')\n\n\nc.Authenticator.admin_users = get_config('auth.admin.users', [])\n\nc.Authenticator.whitelist = get_config('auth.whitelist.users', [])\n\nc.JupyterHub.services = []\n\nif get_config('cull.enabled', False):\n cull_timeout = get_config('cull.timeout')\n cull_every = get_config('cull.every')\n cull_cmd = [\n '/usr/local/bin/cull_idle_servers.py',\n '--timeout=%s' % cull_timeout,\n '--cull-every=%s' % cull_every,\n ]\n if get_config('cull.users'):\n cull_cmd.append('--cull-users')\n c.JupyterHub.services.append({\n 'name': 'cull-idle',\n 'admin': True,\n 'command': cull_cmd,\n })\n\nfor name, service in get_config('hub.services', {}).items():\n api_token = get_secret('services.token.%s' % name)\n # jupyterhub.services is a list of dicts, but\n # in the helm chart it is a dict of dicts for easier merged-config\n service.setdefault('name', name)\n if api_token:\n service['api_token'] = api_token\n c.JupyterHub.services.append(service)\n\nc.JupyterHub.base_url = get_config('hub.base_url')\n\nc.JupyterHub.db_url = get_config('hub.db_url')\n\ncmd = get_config('singleuser.cmd', None)\nif cmd:\n c.Spawner.cmd = cmd\n\n\nextra_config_path = '/etc/jupyterhub/config/hub.extra-config.py'\nif os.path.exists(extra_config_path):\n load_subconfig(extra_config_path)\n", "path": "images/hub/jupyterhub_config.py"}], "after_files": [{"content": "import os\nimport sys\nimport yaml\nfrom tornado.httpclient import AsyncHTTPClient\n\ndef get_config(key, default=None):\n \"\"\"\n Find a config item of a given name & return it\n\n Parses everything as YAML, so lists and dicts are available too\n \"\"\"\n path = os.path.join('/etc/jupyterhub/config', key)\n try:\n with open(path) as f:\n data = yaml.safe_load(f)\n print(key, data)\n return data\n except FileNotFoundError:\n return default\n\ndef get_secret(key, default=None):\n \"\"\"Get a secret from /etc/jupyterhub/secret\"\"\"\n path = os.path.join('/etc/jupyterhub/secret', key)\n try:\n with open(path) as f:\n return f.read().strip()\n except FileNotFoundError:\n return default\n\n\n# Configure JupyterHub to use the curl backend for making HTTP requests,\n# rather than the pure-python implementations. The default one starts\n# being too slow to make a large number of requests to the proxy API\n# at the rate required.\nAsyncHTTPClient.configure(\"tornado.curl_httpclient.CurlAsyncHTTPClient\")\n\nc.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'\n\n# Connect to a proxy running in a different pod\nc.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))\nc.ConfigurableHTTPProxy.should_start = False\n\n# Check that the proxy has routes appropriately setup\n# This isn't the best named setting :D\nc.JupyterHub.last_activity_interval = 60\n\n# Max number of servers that can be spawning at any one time\nc.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')\n\nactive_server_limit = get_config('hub.active-server-limit', None)\n\nif active_server_limit is not None:\n c.JupyterHub.active_server_limit = int(active_server_limit)\n\nc.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']\nc.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])\n\n# the hub should listen on all interfaces, so the proxy can access it\nc.JupyterHub.hub_ip = '0.0.0.0'\n\nc.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')\n\n# Sometimes disks take a while to attach, so let's keep a not-too-short timeout\nc.KubeSpawner.start_timeout = 5 * 60\n\n# Use env var for this, since we want hub to restart when this changes\nc.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']\n\nc.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})\n\nc.KubeSpawner.singleuser_uid = get_config('singleuser.uid')\nc.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')\n\nc.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')\n# Configure dynamically provisioning pvc\nstorage_type = get_config('singleuser.storage.type')\nif storage_type == 'dynamic':\n c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'\n c.KubeSpawner.user_storage_pvc_ensure = True\n storage_class = get_config('singleuser.storage.dynamic.storage-class', None)\n if storage_class:\n c.KubeSpawner.user_storage_class = storage_class\n c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']\n c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')\n\n # Add volumes to singleuser pods\n c.KubeSpawner.volumes = [\n {\n 'name': 'volume-{username}{servername}',\n 'persistentVolumeClaim': {\n 'claimName': 'claim-{username}{servername}'\n }\n }\n ]\n c.KubeSpawner.volume_mounts = [\n {\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'volume-{username}{servername}'\n }\n ]\nelif storage_type == 'static':\n pvc_claim_name = get_config('singleuser.storage.static.pvc-name')\n c.KubeSpawner.volumes = [{\n 'name': 'home',\n 'persistentVolumeClaim': {\n 'claimName': pvc_claim_name\n }\n }]\n\n c.KubeSpawner.volume_mounts = [{\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'home',\n 'subPath': get_config('singleuser.storage.static.sub-path')\n }]\n\nc.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))\nc.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))\n\nlifecycle_hooks = get_config('singleuser.lifecycle-hooks')\nif lifecycle_hooks:\n c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks\n\ninit_containers = get_config('singleuser.init-containers')\nif init_containers:\n c.KubeSpawner.singleuser_init_containers = init_containers \n\n# Gives spawned containers access to the API of the hub\nc.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')\nc.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')\nc.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')\nc.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')\n\n# Allow switching authenticators easily\nauth_type = get_config('auth.type')\nemail_domain = 'local'\n\nif auth_type == 'google':\n c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'\n c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')\n c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')\n c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')\n c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')\n c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')\n email_domain = get_config('auth.google.hosted-domain')\nelif auth_type == 'github':\n c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'\n c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')\n c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')\n c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')\nelif auth_type == 'cilogon':\n c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'\n c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')\n c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')\n c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')\nelif auth_type == 'gitlab':\n c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'\n c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')\n c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')\n c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')\nelif auth_type == 'mediawiki':\n c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'\n c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')\n c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')\n c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')\nelif auth_type == 'hmac':\n c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'\n c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))\nelif auth_type == 'dummy':\n c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'\n c.DummyAuthenticator.password = get_config('auth.dummy.password', None)\nelif auth_type == 'tmp':\n c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'\nelif auth_type == 'custom':\n # full_class_name looks like \"myauthenticator.MyAuthenticator\".\n # To create a docker image with this class availabe, you can just have the\n # following Dockerifle:\n # FROM jupyterhub/k8s-hub:v0.4\n # RUN pip3 install myauthenticator\n full_class_name = get_config('auth.custom.class-name')\n c.JupyterHub.authenticator_class = full_class_name\n auth_class_name = full_class_name.rsplit('.', 1)[-1]\n auth_config = c[auth_class_name]\n auth_config.update(get_config('auth.custom.config') or {})\nelse:\n raise ValueError(\"Unhandled auth type: %r\" % auth_type)\n\n\ndef generate_user_email(spawner):\n \"\"\"\n Used as the EMAIL environment variable\n \"\"\"\n return '{username}@{domain}'.format(\n username=spawner.user.name, domain=email_domain\n )\n\ndef generate_user_name(spawner):\n \"\"\"\n Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables\n \"\"\"\n return spawner.user.name\n\nc.KubeSpawner.environment = {\n 'EMAIL': generate_user_email,\n # git requires these committer attributes\n 'GIT_AUTHOR_NAME': generate_user_name,\n 'GIT_COMMITTER_NAME': generate_user_name\n}\n\nc.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))\n\n# Enable admins to access user servers\nc.JupyterHub.admin_access = get_config('auth.admin.access')\n\n\nc.Authenticator.admin_users = get_config('auth.admin.users', [])\n\nc.Authenticator.whitelist = get_config('auth.whitelist.users', [])\n\nc.JupyterHub.services = []\n\nif get_config('cull.enabled', False):\n cull_timeout = get_config('cull.timeout')\n cull_every = get_config('cull.every')\n cull_cmd = [\n '/usr/local/bin/cull_idle_servers.py',\n '--timeout=%s' % cull_timeout,\n '--cull-every=%s' % cull_every,\n ]\n if get_config('cull.users'):\n cull_cmd.append('--cull-users')\n c.JupyterHub.services.append({\n 'name': 'cull-idle',\n 'admin': True,\n 'command': cull_cmd,\n })\n\nfor name, service in get_config('hub.services', {}).items():\n api_token = get_secret('services.token.%s' % name)\n # jupyterhub.services is a list of dicts, but\n # in the helm chart it is a dict of dicts for easier merged-config\n service.setdefault('name', name)\n if api_token:\n service['api_token'] = api_token\n c.JupyterHub.services.append(service)\n\nc.JupyterHub.base_url = get_config('hub.base_url')\n\nc.JupyterHub.db_url = get_config('hub.db_url')\n\ncmd = get_config('singleuser.cmd', None)\nif cmd:\n c.Spawner.cmd = cmd\n\n\nextra_config_path = '/etc/jupyterhub/config/hub.extra-config.py'\nif os.path.exists(extra_config_path):\n load_subconfig(extra_config_path)\n", "path": "images/hub/jupyterhub_config.py"}]}
| 3,606 | 135 |
gh_patches_debug_20035
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-12005
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unexpected empty lines in browseable messages (e.g. formatting information)
### Steps to reproduce:
* set the cursor or virtual cursor on a text having formatting information such as text in a web page
* Press two times quickly NVDA+F to get formatting info in a browseable window
* Examine the formatting information line by line by pressing down arrow many times
Extra:
* Open the Python console and type:
`import ui;ui.browseableMessage("Hello\nworld")
`
### Actual behavior:
NVDA reads "blank" one line in two in formatting info as well as in "Hello world" message.
### Expected behavior:
NVDA should not read "blank" between formatting information line nor in "Hello world" message since:
* As a user, we do not need blank lines to examine a text such as formatting information
* Visually, there is no blank line
* The source string of the "Hello world" message does not contain any blank line.
### System configuration
#### NVDA installed/portable/running from source:
all
#### NVDA version:
2020.4beta4
#### Windows version:
10
#### Name and version of other software in use when reproducing the issue:
N/A
#### Other information about your system:
N/A
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
Yes, 2020.3: same issue.
It seems to me that this issue has always been there.
#### If addons are disabled, is your problem still occuring?
Yes
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
No
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/ui.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # A part of NonVisual Desktop Access (NVDA)
3 # Copyright (C) 2008-2020 NV Access Limited, James Teh, Dinesh Kaushal, Davy Kager, André-Abush Clause,
4 # Babbage B.V., Leonard de Ruijter, Michael Curran, Accessolutions, Julien Cochuyt
5 # This file may be used under the terms of the GNU General Public License, version 2 or later.
6 # For more details see: https://www.gnu.org/licenses/gpl-2.0.html
7
8 """User interface functionality.
9 This refers to the user interface presented by the screen reader alone, not the graphical user interface.
10 See L{gui} for the graphical user interface.
11 """
12
13 import os
14 import sys
15 from ctypes import windll, byref, POINTER, addressof
16 from comtypes import IUnknown
17 from comtypes import automation
18 from logHandler import log
19 import gui
20 import speech
21 import braille
22 import globalVars
23 from typing import Optional
24
25
26 # From urlmon.h
27 URL_MK_UNIFORM = 1
28
29 # Dialog box properties
30 DIALOG_OPTIONS = "resizable:yes;help:no"
31
32 #dwDialogFlags for ShowHTMLDialogEx from mshtmhst.h
33 HTMLDLG_NOUI = 0x0010
34 HTMLDLG_MODAL = 0x0020
35 HTMLDLG_MODELESS = 0x0040
36 HTMLDLG_PRINT_TEMPLATE = 0x0080
37 HTMLDLG_VERIFY = 0x0100
38
39
40 def browseableMessage(message,title=None,isHtml=False):
41 """Present a message to the user that can be read in browse mode.
42 The message will be presented in an HTML document.
43 @param message: The message in either html or text.
44 @type message: str
45 @param title: The title for the message.
46 @type title: str
47 @param isHtml: Whether the message is html
48 @type isHtml: boolean
49 """
50 htmlFileName = os.path.join(globalVars.appDir, 'message.html')
51 if not os.path.isfile(htmlFileName ):
52 raise LookupError(htmlFileName )
53 moniker = POINTER(IUnknown)()
54 windll.urlmon.CreateURLMonikerEx(0, htmlFileName, byref(moniker), URL_MK_UNIFORM)
55 if not title:
56 # Translators: The title for the dialog used to present general NVDA messages in browse mode.
57 title = _("NVDA Message")
58 isHtmlArgument = "true" if isHtml else "false"
59 dialogString = u"{isHtml};{title};{message}".format( isHtml = isHtmlArgument , title=title , message=message )
60 dialogArguements = automation.VARIANT( dialogString )
61 gui.mainFrame.prePopup()
62 windll.mshtml.ShowHTMLDialogEx(
63 gui.mainFrame.Handle ,
64 moniker ,
65 HTMLDLG_MODELESS ,
66 addressof( dialogArguements ) ,
67 DIALOG_OPTIONS,
68 None
69 )
70 gui.mainFrame.postPopup()
71
72
73 def message(
74 text: str,
75 speechPriority: Optional[speech.Spri] = None,
76 brailleText: Optional[str] = None,
77 ):
78 """Present a message to the user.
79 The message will be presented in both speech and braille.
80 @param text: The text of the message.
81 @param speechPriority: The speech priority.
82 @param brailleText: If specified, present this alternative text on the braille display.
83 """
84 speech.speakMessage(text, priority=speechPriority)
85 braille.handler.message(brailleText if brailleText is not None else text)
86
87
88 def reviewMessage(text: str, speechPriority: Optional[speech.Spri] = None):
89 """Present a message from review or object navigation to the user.
90 The message will always be presented in speech, and also in braille if it is tethered to review or when auto tethering is on.
91 @param text: The text of the message.
92 @param speechPriority: The speech priority.
93 """
94 speech.speakMessage(text, priority=speechPriority)
95 if braille.handler.shouldAutoTether or braille.handler.getTether() == braille.handler.TETHER_REVIEW:
96 braille.handler.message(text)
97
98
99 def reportTextCopiedToClipboard(text: Optional[str] = None):
100 """Notify about the result of a "Copy to clipboard" operation.
101 @param text: The text that has been copied. Set to `None` to notify of a failed operation.
102 See: `api.copyToClip`
103 """
104 if not text:
105 # Translators: Presented when unable to copy to the clipboard because of an error
106 # or the clipboard content did not match what was just copied.
107 message(_("Unable to copy"))
108 return
109 # Depending on the speech synthesizer, large amount of spoken text can freeze NVDA (#11843)
110 if len(text) < 1024:
111 spokenText = text
112 else:
113 # Translators: Spoken instead of a lengthy text when copied to clipboard.
114 spokenText = _("%d characters") % len(text)
115 message(
116 # Translators: Announced when a text has been copied to clipboard.
117 # {text} is replaced by the copied text.
118 text=_("Copied to clipboard: {text}").format(text=spokenText),
119 # Translators: Displayed in braille when a text has been copied to clipboard.
120 # {text} is replaced by the copied text.
121 brailleText=_("Copied: {text}").format(text=text)
122 )
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/ui.py b/source/ui.py
--- a/source/ui.py
+++ b/source/ui.py
@@ -15,6 +15,7 @@
from ctypes import windll, byref, POINTER, addressof
from comtypes import IUnknown
from comtypes import automation
+from html import escape
from logHandler import log
import gui
import speech
@@ -55,8 +56,9 @@
if not title:
# Translators: The title for the dialog used to present general NVDA messages in browse mode.
title = _("NVDA Message")
- isHtmlArgument = "true" if isHtml else "false"
- dialogString = u"{isHtml};{title};{message}".format( isHtml = isHtmlArgument , title=title , message=message )
+ if not isHtml:
+ message = f"<pre>{escape(message)}</pre>"
+ dialogString = f"{title};{message}"
dialogArguements = automation.VARIANT( dialogString )
gui.mainFrame.prePopup()
windll.mshtml.ShowHTMLDialogEx(
|
{"golden_diff": "diff --git a/source/ui.py b/source/ui.py\n--- a/source/ui.py\n+++ b/source/ui.py\n@@ -15,6 +15,7 @@\n from ctypes import windll, byref, POINTER, addressof\r\n from comtypes import IUnknown\r\n from comtypes import automation \r\n+from html import escape\r\n from logHandler import log\r\n import gui\r\n import speech\r\n@@ -55,8 +56,9 @@\n \tif not title:\r\n \t\t# Translators: The title for the dialog used to present general NVDA messages in browse mode.\r\n \t\ttitle = _(\"NVDA Message\")\r\n-\tisHtmlArgument = \"true\" if isHtml else \"false\"\r\n-\tdialogString = u\"{isHtml};{title};{message}\".format( isHtml = isHtmlArgument , title=title , message=message ) \r\n+\tif not isHtml:\r\n+\t\tmessage = f\"<pre>{escape(message)}</pre>\"\r\n+\tdialogString = f\"{title};{message}\"\r\n \tdialogArguements = automation.VARIANT( dialogString )\r\n \tgui.mainFrame.prePopup() \r\n \twindll.mshtml.ShowHTMLDialogEx(\n", "issue": "Unexpected empty lines in browseable messages (e.g. formatting information)\n### Steps to reproduce:\r\n\r\n* set the cursor or virtual cursor on a text having formatting information such as text in a web page\r\n* Press two times quickly NVDA+F to get formatting info in a browseable window\r\n* Examine the formatting information line by line by pressing down arrow many times\r\n\r\nExtra:\r\n* Open the Python console and type:\r\n `import ui;ui.browseableMessage(\"Hello\\nworld\")\r\n`\r\n\r\n### Actual behavior:\r\n\r\nNVDA reads \"blank\" one line in two in formatting info as well as in \"Hello world\" message.\r\n\r\n\r\n### Expected behavior:\r\n\r\nNVDA should not read \"blank\" between formatting information line nor in \"Hello world\" message since:\r\n* As a user, we do not need blank lines to examine a text such as formatting information\r\n* Visually, there is no blank line\r\n* The source string of the \"Hello world\" message does not contain any blank line.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nall\r\n#### NVDA version:\r\n2020.4beta4\r\n#### Windows version:\r\n10\r\n#### Name and version of other software in use when reproducing the issue:\r\nN/A\r\n#### Other information about your system:\r\nN/A\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nYes, 2020.3: same issue.\r\nIt seems to me that this issue has always been there.\r\n#### If addons are disabled, is your problem still occuring?\r\nYes\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nNo\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\r\n# A part of NonVisual Desktop Access (NVDA)\r\n# Copyright (C) 2008-2020 NV Access Limited, James Teh, Dinesh Kaushal, Davy Kager, Andr\u00e9-Abush Clause,\r\n# Babbage B.V., Leonard de Ruijter, Michael Curran, Accessolutions, Julien Cochuyt\r\n# This file may be used under the terms of the GNU General Public License, version 2 or later.\r\n# For more details see: https://www.gnu.org/licenses/gpl-2.0.html\r\n\r\n\"\"\"User interface functionality.\r\nThis refers to the user interface presented by the screen reader alone, not the graphical user interface.\r\nSee L{gui} for the graphical user interface.\r\n\"\"\"\r\n\r\nimport os\r\nimport sys\r\nfrom ctypes import windll, byref, POINTER, addressof\r\nfrom comtypes import IUnknown\r\nfrom comtypes import automation \r\nfrom logHandler import log\r\nimport gui\r\nimport speech\r\nimport braille\r\nimport globalVars\r\nfrom typing import Optional\r\n\r\n\r\n# From urlmon.h\r\nURL_MK_UNIFORM = 1\r\n\r\n# Dialog box properties\r\nDIALOG_OPTIONS = \"resizable:yes;help:no\"\r\n\r\n#dwDialogFlags for ShowHTMLDialogEx from mshtmhst.h\r\nHTMLDLG_NOUI = 0x0010 \r\nHTMLDLG_MODAL = 0x0020 \r\nHTMLDLG_MODELESS = 0x0040 \r\nHTMLDLG_PRINT_TEMPLATE = 0x0080 \r\nHTMLDLG_VERIFY = 0x0100 \r\n\r\n\r\ndef browseableMessage(message,title=None,isHtml=False):\r\n\t\"\"\"Present a message to the user that can be read in browse mode.\r\n\tThe message will be presented in an HTML document.\r\n\t@param message: The message in either html or text.\r\n\t@type message: str\r\n\t@param title: The title for the message.\r\n\t@type title: str\r\n\t@param isHtml: Whether the message is html\r\n\t@type isHtml: boolean\r\n\t\"\"\"\r\n\thtmlFileName = os.path.join(globalVars.appDir, 'message.html')\r\n\tif not os.path.isfile(htmlFileName ): \r\n\t\traise LookupError(htmlFileName )\r\n\tmoniker = POINTER(IUnknown)()\r\n\twindll.urlmon.CreateURLMonikerEx(0, htmlFileName, byref(moniker), URL_MK_UNIFORM)\r\n\tif not title:\r\n\t\t# Translators: The title for the dialog used to present general NVDA messages in browse mode.\r\n\t\ttitle = _(\"NVDA Message\")\r\n\tisHtmlArgument = \"true\" if isHtml else \"false\"\r\n\tdialogString = u\"{isHtml};{title};{message}\".format( isHtml = isHtmlArgument , title=title , message=message ) \r\n\tdialogArguements = automation.VARIANT( dialogString )\r\n\tgui.mainFrame.prePopup() \r\n\twindll.mshtml.ShowHTMLDialogEx( \r\n\t\tgui.mainFrame.Handle , \r\n\t\tmoniker , \r\n\t\tHTMLDLG_MODELESS , \r\n\t\taddressof( dialogArguements ) , \r\n\t\tDIALOG_OPTIONS, \r\n\t\tNone\r\n\t)\r\n\tgui.mainFrame.postPopup() \r\n\r\n\r\ndef message(\r\n\t\ttext: str,\r\n\t\tspeechPriority: Optional[speech.Spri] = None,\r\n\t\tbrailleText: Optional[str] = None,\r\n):\r\n\t\"\"\"Present a message to the user.\r\n\tThe message will be presented in both speech and braille.\r\n\t@param text: The text of the message.\r\n\t@param speechPriority: The speech priority.\r\n\t@param brailleText: If specified, present this alternative text on the braille display.\r\n\t\"\"\"\r\n\tspeech.speakMessage(text, priority=speechPriority)\r\n\tbraille.handler.message(brailleText if brailleText is not None else text)\r\n\r\n\r\ndef reviewMessage(text: str, speechPriority: Optional[speech.Spri] = None):\r\n\t\"\"\"Present a message from review or object navigation to the user.\r\n\tThe message will always be presented in speech, and also in braille if it is tethered to review or when auto tethering is on.\r\n\t@param text: The text of the message.\r\n\t@param speechPriority: The speech priority.\r\n\t\"\"\"\r\n\tspeech.speakMessage(text, priority=speechPriority)\r\n\tif braille.handler.shouldAutoTether or braille.handler.getTether() == braille.handler.TETHER_REVIEW:\r\n\t\tbraille.handler.message(text)\r\n\r\n\r\ndef reportTextCopiedToClipboard(text: Optional[str] = None):\r\n\t\"\"\"Notify about the result of a \"Copy to clipboard\" operation.\r\n\t@param text: The text that has been copied. Set to `None` to notify of a failed operation.\r\n\tSee: `api.copyToClip`\r\n\t\"\"\"\r\n\tif not text:\r\n\t\t# Translators: Presented when unable to copy to the clipboard because of an error\r\n\t\t# or the clipboard content did not match what was just copied.\r\n\t\tmessage(_(\"Unable to copy\"))\r\n\t\treturn\r\n\t# Depending on the speech synthesizer, large amount of spoken text can freeze NVDA (#11843)\r\n\tif len(text) < 1024:\r\n\t\tspokenText = text\r\n\telse:\r\n\t\t# Translators: Spoken instead of a lengthy text when copied to clipboard.\r\n\t\tspokenText = _(\"%d characters\") % len(text)\r\n\tmessage(\r\n\t\t# Translators: Announced when a text has been copied to clipboard.\r\n\t\t# {text} is replaced by the copied text.\r\n\t\ttext=_(\"Copied to clipboard: {text}\").format(text=spokenText),\r\n\t\t# Translators: Displayed in braille when a text has been copied to clipboard.\r\n\t\t# {text} is replaced by the copied text.\r\n\t\tbrailleText=_(\"Copied: {text}\").format(text=text)\r\n\t)\r\n", "path": "source/ui.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\r\n# A part of NonVisual Desktop Access (NVDA)\r\n# Copyright (C) 2008-2020 NV Access Limited, James Teh, Dinesh Kaushal, Davy Kager, Andr\u00e9-Abush Clause,\r\n# Babbage B.V., Leonard de Ruijter, Michael Curran, Accessolutions, Julien Cochuyt\r\n# This file may be used under the terms of the GNU General Public License, version 2 or later.\r\n# For more details see: https://www.gnu.org/licenses/gpl-2.0.html\r\n\r\n\"\"\"User interface functionality.\r\nThis refers to the user interface presented by the screen reader alone, not the graphical user interface.\r\nSee L{gui} for the graphical user interface.\r\n\"\"\"\r\n\r\nimport os\r\nimport sys\r\nfrom ctypes import windll, byref, POINTER, addressof\r\nfrom comtypes import IUnknown\r\nfrom comtypes import automation \r\nfrom html import escape\r\nfrom logHandler import log\r\nimport gui\r\nimport speech\r\nimport braille\r\nimport globalVars\r\nfrom typing import Optional\r\n\r\n\r\n# From urlmon.h\r\nURL_MK_UNIFORM = 1\r\n\r\n# Dialog box properties\r\nDIALOG_OPTIONS = \"resizable:yes;help:no\"\r\n\r\n#dwDialogFlags for ShowHTMLDialogEx from mshtmhst.h\r\nHTMLDLG_NOUI = 0x0010 \r\nHTMLDLG_MODAL = 0x0020 \r\nHTMLDLG_MODELESS = 0x0040 \r\nHTMLDLG_PRINT_TEMPLATE = 0x0080 \r\nHTMLDLG_VERIFY = 0x0100 \r\n\r\n\r\ndef browseableMessage(message,title=None,isHtml=False):\r\n\t\"\"\"Present a message to the user that can be read in browse mode.\r\n\tThe message will be presented in an HTML document.\r\n\t@param message: The message in either html or text.\r\n\t@type message: str\r\n\t@param title: The title for the message.\r\n\t@type title: str\r\n\t@param isHtml: Whether the message is html\r\n\t@type isHtml: boolean\r\n\t\"\"\"\r\n\thtmlFileName = os.path.join(globalVars.appDir, 'message.html')\r\n\tif not os.path.isfile(htmlFileName ): \r\n\t\traise LookupError(htmlFileName )\r\n\tmoniker = POINTER(IUnknown)()\r\n\twindll.urlmon.CreateURLMonikerEx(0, htmlFileName, byref(moniker), URL_MK_UNIFORM)\r\n\tif not title:\r\n\t\t# Translators: The title for the dialog used to present general NVDA messages in browse mode.\r\n\t\ttitle = _(\"NVDA Message\")\r\n\tif not isHtml:\r\n\t\tmessage = f\"<pre>{escape(message)}</pre>\"\r\n\tdialogString = f\"{title};{message}\"\r\n\tdialogArguements = automation.VARIANT( dialogString )\r\n\tgui.mainFrame.prePopup() \r\n\twindll.mshtml.ShowHTMLDialogEx( \r\n\t\tgui.mainFrame.Handle , \r\n\t\tmoniker , \r\n\t\tHTMLDLG_MODELESS , \r\n\t\taddressof( dialogArguements ) , \r\n\t\tDIALOG_OPTIONS, \r\n\t\tNone\r\n\t)\r\n\tgui.mainFrame.postPopup() \r\n\r\n\r\ndef message(\r\n\t\ttext: str,\r\n\t\tspeechPriority: Optional[speech.Spri] = None,\r\n\t\tbrailleText: Optional[str] = None,\r\n):\r\n\t\"\"\"Present a message to the user.\r\n\tThe message will be presented in both speech and braille.\r\n\t@param text: The text of the message.\r\n\t@param speechPriority: The speech priority.\r\n\t@param brailleText: If specified, present this alternative text on the braille display.\r\n\t\"\"\"\r\n\tspeech.speakMessage(text, priority=speechPriority)\r\n\tbraille.handler.message(brailleText if brailleText is not None else text)\r\n\r\n\r\ndef reviewMessage(text: str, speechPriority: Optional[speech.Spri] = None):\r\n\t\"\"\"Present a message from review or object navigation to the user.\r\n\tThe message will always be presented in speech, and also in braille if it is tethered to review or when auto tethering is on.\r\n\t@param text: The text of the message.\r\n\t@param speechPriority: The speech priority.\r\n\t\"\"\"\r\n\tspeech.speakMessage(text, priority=speechPriority)\r\n\tif braille.handler.shouldAutoTether or braille.handler.getTether() == braille.handler.TETHER_REVIEW:\r\n\t\tbraille.handler.message(text)\r\n\r\n\r\ndef reportTextCopiedToClipboard(text: Optional[str] = None):\r\n\t\"\"\"Notify about the result of a \"Copy to clipboard\" operation.\r\n\t@param text: The text that has been copied. Set to `None` to notify of a failed operation.\r\n\tSee: `api.copyToClip`\r\n\t\"\"\"\r\n\tif not text:\r\n\t\t# Translators: Presented when unable to copy to the clipboard because of an error\r\n\t\t# or the clipboard content did not match what was just copied.\r\n\t\tmessage(_(\"Unable to copy\"))\r\n\t\treturn\r\n\t# Depending on the speech synthesizer, large amount of spoken text can freeze NVDA (#11843)\r\n\tif len(text) < 1024:\r\n\t\tspokenText = text\r\n\telse:\r\n\t\t# Translators: Spoken instead of a lengthy text when copied to clipboard.\r\n\t\tspokenText = _(\"%d characters\") % len(text)\r\n\tmessage(\r\n\t\t# Translators: Announced when a text has been copied to clipboard.\r\n\t\t# {text} is replaced by the copied text.\r\n\t\ttext=_(\"Copied to clipboard: {text}\").format(text=spokenText),\r\n\t\t# Translators: Displayed in braille when a text has been copied to clipboard.\r\n\t\t# {text} is replaced by the copied text.\r\n\t\tbrailleText=_(\"Copied: {text}\").format(text=text)\r\n\t)\r\n", "path": "source/ui.py"}]}
| 2,145 | 238 |
gh_patches_debug_24418
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-956
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nikola auto X doit auto
The nikola auto commands hides the doit auto command.
Both are useful...
What about renaming nikola auto to "liveroload" this way we can use both?
if you guys agree I will make a pull request.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/main.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2013 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 from __future__ import print_function, unicode_literals
28 from operator import attrgetter
29 import os
30 import shutil
31 import sys
32 import traceback
33
34 from doit.loader import generate_tasks
35 from doit.cmd_base import TaskLoader
36 from doit.reporter import ExecutedOnlyReporter
37 from doit.doit_cmd import DoitMain
38 from doit.cmd_help import Help as DoitHelp
39 from doit.cmd_run import Run as DoitRun
40 from doit.cmd_clean import Clean as DoitClean
41 from logbook import NullHandler
42
43 from . import __version__
44 from .nikola import Nikola
45 from .utils import _reload, sys_decode, get_root_dir, LOGGER, STRICT_HANDLER
46
47
48 config = {}
49
50
51 def main(args):
52 quiet = False
53 if len(args) > 0 and args[0] == 'build' and '--strict' in args:
54 LOGGER.notice('Running in strict mode')
55 STRICT_HANDLER.push_application()
56 if len(args) > 0 and args[0] == 'build' and '-q' in args or '--quiet' in args:
57 nullhandler = NullHandler()
58 nullhandler.push_application()
59 quiet = True
60 global config
61
62 root = get_root_dir()
63 if root:
64 os.chdir(root)
65
66 sys.path.append('')
67 try:
68 import conf
69 _reload(conf)
70 config = conf.__dict__
71 except Exception:
72 if os.path.exists('conf.py'):
73 msg = traceback.format_exc(0).splitlines()[1]
74 LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))
75 sys.exit(1)
76 config = {}
77
78 site = Nikola(**config)
79 return DoitNikola(site, quiet).run(args)
80
81
82 class Help(DoitHelp):
83 """show Nikola usage instead of doit """
84
85 @staticmethod
86 def print_usage(cmds):
87 """print nikola "usage" (basic help) instructions"""
88 print("Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com\n\n")
89 print("Available commands:")
90 for cmd in sorted(cmds.values(), key=attrgetter('name')):
91 print(" nikola %-*s %s" % (20, cmd.name, cmd.doc_purpose))
92 print("")
93 print(" nikola help show help / reference")
94 print(" nikola help <command> show command usage")
95 print(" nikola help <task-name> show task usage")
96
97
98 class Build(DoitRun):
99 """expose "run" command as "build" for backward compatibility"""
100 def __init__(self, *args, **kw):
101 opts = list(self.cmd_options)
102 opts.append(
103 {
104 'name': 'strict',
105 'long': 'strict',
106 'default': False,
107 'type': bool,
108 'help': "Fail on things that would normally be warnings.",
109 }
110 )
111 opts.append(
112 {
113 'name': 'quiet',
114 'long': 'quiet',
115 'short': 'q',
116 'default': False,
117 'type': bool,
118 'help': "Run quietly.",
119 }
120 )
121 self.cmd_options = tuple(opts)
122 super(Build, self).__init__(*args, **kw)
123
124
125 class Clean(DoitClean):
126 """A clean that removes cache/"""
127
128 def clean_tasks(self, tasks, dryrun):
129 if not dryrun and config:
130 cache_folder = config.get('CACHE_FOLDER', 'cache')
131 if os.path.exists(cache_folder):
132 shutil.rmtree(cache_folder)
133 return super(Clean, self).clean_tasks(tasks, dryrun)
134
135
136 class NikolaTaskLoader(TaskLoader):
137 """custom task loader to get tasks from Nikola instead of dodo.py file"""
138 def __init__(self, nikola, quiet=False):
139 self.nikola = nikola
140 self.quiet = quiet
141
142 def load_tasks(self, cmd, opt_values, pos_args):
143 if self.quiet:
144 DOIT_CONFIG = {
145 'verbosity': 0,
146 'reporter': 'zero',
147 }
148 else:
149 DOIT_CONFIG = {
150 'reporter': ExecutedOnlyReporter,
151 }
152 DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']
153 tasks = generate_tasks(
154 'render_site',
155 self.nikola.gen_tasks('render_site', "Task", 'Group of tasks to render the site.'))
156 latetasks = generate_tasks(
157 'post_render',
158 self.nikola.gen_tasks('post_render', "LateTask", 'Group of tasks to be executes after site is rendered.'))
159 return tasks + latetasks, DOIT_CONFIG
160
161
162 class DoitNikola(DoitMain):
163 # overwite help command
164 DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean]
165 TASK_LOADER = NikolaTaskLoader
166
167 def __init__(self, nikola, quiet=False):
168 self.nikola = nikola
169 self.task_loader = self.TASK_LOADER(nikola, quiet)
170
171 def get_commands(self):
172 # core doit commands
173 cmds = DoitMain.get_commands(self)
174 # load nikola commands
175 for name, cmd in self.nikola.commands.items():
176 cmds[name] = cmd
177 return cmds
178
179 def run(self, cmd_args):
180 sub_cmds = self.get_commands()
181 args = self.process_args(cmd_args)
182 args = [sys_decode(arg) for arg in args]
183
184 if len(args) == 0 or any(arg in ["--help", '-h'] for arg in args):
185 cmd_args = ['help']
186 args = ['help']
187 # Hide run because Nikola uses build
188 sub_cmds.pop('run')
189
190 if len(args) == 0 or args[0] not in sub_cmds.keys() or \
191 args[0] == 'build':
192 # Check for conf.py before launching run
193 if not self.nikola.configured:
194 LOGGER.error("This command needs to run inside an "
195 "existing Nikola site.")
196 return False
197 return super(DoitNikola, self).run(cmd_args)
198
199 @staticmethod
200 def print_version():
201 print("Nikola version " + __version__)
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/main.py b/nikola/main.py
--- a/nikola/main.py
+++ b/nikola/main.py
@@ -38,6 +38,7 @@
from doit.cmd_help import Help as DoitHelp
from doit.cmd_run import Run as DoitRun
from doit.cmd_clean import Clean as DoitClean
+from doit.cmd_auto import Auto as DoitAuto
from logbook import NullHandler
from . import __version__
@@ -132,6 +133,10 @@
shutil.rmtree(cache_folder)
return super(Clean, self).clean_tasks(tasks, dryrun)
+# Nikola has its own "auto" commands that uses livereload.
+# Expose original doit "auto" command as "doit_auto".
+DoitAuto.name = 'doit_auto'
+
class NikolaTaskLoader(TaskLoader):
"""custom task loader to get tasks from Nikola instead of dodo.py file"""
@@ -161,7 +166,7 @@
class DoitNikola(DoitMain):
# overwite help command
- DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean]
+ DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]
TASK_LOADER = NikolaTaskLoader
def __init__(self, nikola, quiet=False):
|
{"golden_diff": "diff --git a/nikola/main.py b/nikola/main.py\n--- a/nikola/main.py\n+++ b/nikola/main.py\n@@ -38,6 +38,7 @@\n from doit.cmd_help import Help as DoitHelp\n from doit.cmd_run import Run as DoitRun\n from doit.cmd_clean import Clean as DoitClean\n+from doit.cmd_auto import Auto as DoitAuto\n from logbook import NullHandler\n \n from . import __version__\n@@ -132,6 +133,10 @@\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n \n+# Nikola has its own \"auto\" commands that uses livereload.\n+# Expose original doit \"auto\" command as \"doit_auto\".\n+DoitAuto.name = 'doit_auto'\n+\n \n class NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n@@ -161,7 +166,7 @@\n \n class DoitNikola(DoitMain):\n # overwite help command\n- DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean]\n+ DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]\n TASK_LOADER = NikolaTaskLoader\n \n def __init__(self, nikola, quiet=False):\n", "issue": "nikola auto X doit auto\nThe nikola auto commands hides the doit auto command.\n\nBoth are useful...\nWhat about renaming nikola auto to \"liveroload\" this way we can use both?\n\nif you guys agree I will make a pull request.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2013 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\nfrom operator import attrgetter\nimport os\nimport shutil\nimport sys\nimport traceback\n\nfrom doit.loader import generate_tasks\nfrom doit.cmd_base import TaskLoader\nfrom doit.reporter import ExecutedOnlyReporter\nfrom doit.doit_cmd import DoitMain\nfrom doit.cmd_help import Help as DoitHelp\nfrom doit.cmd_run import Run as DoitRun\nfrom doit.cmd_clean import Clean as DoitClean\nfrom logbook import NullHandler\n\nfrom . import __version__\nfrom .nikola import Nikola\nfrom .utils import _reload, sys_decode, get_root_dir, LOGGER, STRICT_HANDLER\n\n\nconfig = {}\n\n\ndef main(args):\n quiet = False\n if len(args) > 0 and args[0] == 'build' and '--strict' in args:\n LOGGER.notice('Running in strict mode')\n STRICT_HANDLER.push_application()\n if len(args) > 0 and args[0] == 'build' and '-q' in args or '--quiet' in args:\n nullhandler = NullHandler()\n nullhandler.push_application()\n quiet = True\n global config\n\n root = get_root_dir()\n if root:\n os.chdir(root)\n\n sys.path.append('')\n try:\n import conf\n _reload(conf)\n config = conf.__dict__\n except Exception:\n if os.path.exists('conf.py'):\n msg = traceback.format_exc(0).splitlines()[1]\n LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))\n sys.exit(1)\n config = {}\n\n site = Nikola(**config)\n return DoitNikola(site, quiet).run(args)\n\n\nclass Help(DoitHelp):\n \"\"\"show Nikola usage instead of doit \"\"\"\n\n @staticmethod\n def print_usage(cmds):\n \"\"\"print nikola \"usage\" (basic help) instructions\"\"\"\n print(\"Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com\\n\\n\")\n print(\"Available commands:\")\n for cmd in sorted(cmds.values(), key=attrgetter('name')):\n print(\" nikola %-*s %s\" % (20, cmd.name, cmd.doc_purpose))\n print(\"\")\n print(\" nikola help show help / reference\")\n print(\" nikola help <command> show command usage\")\n print(\" nikola help <task-name> show task usage\")\n\n\nclass Build(DoitRun):\n \"\"\"expose \"run\" command as \"build\" for backward compatibility\"\"\"\n def __init__(self, *args, **kw):\n opts = list(self.cmd_options)\n opts.append(\n {\n 'name': 'strict',\n 'long': 'strict',\n 'default': False,\n 'type': bool,\n 'help': \"Fail on things that would normally be warnings.\",\n }\n )\n opts.append(\n {\n 'name': 'quiet',\n 'long': 'quiet',\n 'short': 'q',\n 'default': False,\n 'type': bool,\n 'help': \"Run quietly.\",\n }\n )\n self.cmd_options = tuple(opts)\n super(Build, self).__init__(*args, **kw)\n\n\nclass Clean(DoitClean):\n \"\"\"A clean that removes cache/\"\"\"\n\n def clean_tasks(self, tasks, dryrun):\n if not dryrun and config:\n cache_folder = config.get('CACHE_FOLDER', 'cache')\n if os.path.exists(cache_folder):\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n\n\nclass NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.quiet = quiet\n\n def load_tasks(self, cmd, opt_values, pos_args):\n if self.quiet:\n DOIT_CONFIG = {\n 'verbosity': 0,\n 'reporter': 'zero',\n }\n else:\n DOIT_CONFIG = {\n 'reporter': ExecutedOnlyReporter,\n }\n DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']\n tasks = generate_tasks(\n 'render_site',\n self.nikola.gen_tasks('render_site', \"Task\", 'Group of tasks to render the site.'))\n latetasks = generate_tasks(\n 'post_render',\n self.nikola.gen_tasks('post_render', \"LateTask\", 'Group of tasks to be executes after site is rendered.'))\n return tasks + latetasks, DOIT_CONFIG\n\n\nclass DoitNikola(DoitMain):\n # overwite help command\n DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean]\n TASK_LOADER = NikolaTaskLoader\n\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.task_loader = self.TASK_LOADER(nikola, quiet)\n\n def get_commands(self):\n # core doit commands\n cmds = DoitMain.get_commands(self)\n # load nikola commands\n for name, cmd in self.nikola.commands.items():\n cmds[name] = cmd\n return cmds\n\n def run(self, cmd_args):\n sub_cmds = self.get_commands()\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n\n if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n\n if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n args[0] == 'build':\n # Check for conf.py before launching run\n if not self.nikola.configured:\n LOGGER.error(\"This command needs to run inside an \"\n \"existing Nikola site.\")\n return False\n return super(DoitNikola, self).run(cmd_args)\n\n @staticmethod\n def print_version():\n print(\"Nikola version \" + __version__)\n", "path": "nikola/main.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2013 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\nfrom operator import attrgetter\nimport os\nimport shutil\nimport sys\nimport traceback\n\nfrom doit.loader import generate_tasks\nfrom doit.cmd_base import TaskLoader\nfrom doit.reporter import ExecutedOnlyReporter\nfrom doit.doit_cmd import DoitMain\nfrom doit.cmd_help import Help as DoitHelp\nfrom doit.cmd_run import Run as DoitRun\nfrom doit.cmd_clean import Clean as DoitClean\nfrom doit.cmd_auto import Auto as DoitAuto\nfrom logbook import NullHandler\n\nfrom . import __version__\nfrom .nikola import Nikola\nfrom .utils import _reload, sys_decode, get_root_dir, LOGGER, STRICT_HANDLER\n\n\nconfig = {}\n\n\ndef main(args):\n quiet = False\n if len(args) > 0 and args[0] == 'build' and '--strict' in args:\n LOGGER.notice('Running in strict mode')\n STRICT_HANDLER.push_application()\n if len(args) > 0 and args[0] == 'build' and '-q' in args or '--quiet' in args:\n nullhandler = NullHandler()\n nullhandler.push_application()\n quiet = True\n global config\n\n root = get_root_dir()\n if root:\n os.chdir(root)\n\n sys.path.append('')\n try:\n import conf\n _reload(conf)\n config = conf.__dict__\n except Exception:\n if os.path.exists('conf.py'):\n msg = traceback.format_exc(0).splitlines()[1]\n LOGGER.error('In conf.py line {0}: {1}'.format(sys.exc_info()[2].tb_lineno, msg))\n sys.exit(1)\n config = {}\n\n site = Nikola(**config)\n return DoitNikola(site, quiet).run(args)\n\n\nclass Help(DoitHelp):\n \"\"\"show Nikola usage instead of doit \"\"\"\n\n @staticmethod\n def print_usage(cmds):\n \"\"\"print nikola \"usage\" (basic help) instructions\"\"\"\n print(\"Nikola is a tool to create static websites and blogs. For full documentation and more information, please visit http://getnikola.com\\n\\n\")\n print(\"Available commands:\")\n for cmd in sorted(cmds.values(), key=attrgetter('name')):\n print(\" nikola %-*s %s\" % (20, cmd.name, cmd.doc_purpose))\n print(\"\")\n print(\" nikola help show help / reference\")\n print(\" nikola help <command> show command usage\")\n print(\" nikola help <task-name> show task usage\")\n\n\nclass Build(DoitRun):\n \"\"\"expose \"run\" command as \"build\" for backward compatibility\"\"\"\n def __init__(self, *args, **kw):\n opts = list(self.cmd_options)\n opts.append(\n {\n 'name': 'strict',\n 'long': 'strict',\n 'default': False,\n 'type': bool,\n 'help': \"Fail on things that would normally be warnings.\",\n }\n )\n opts.append(\n {\n 'name': 'quiet',\n 'long': 'quiet',\n 'short': 'q',\n 'default': False,\n 'type': bool,\n 'help': \"Run quietly.\",\n }\n )\n self.cmd_options = tuple(opts)\n super(Build, self).__init__(*args, **kw)\n\n\nclass Clean(DoitClean):\n \"\"\"A clean that removes cache/\"\"\"\n\n def clean_tasks(self, tasks, dryrun):\n if not dryrun and config:\n cache_folder = config.get('CACHE_FOLDER', 'cache')\n if os.path.exists(cache_folder):\n shutil.rmtree(cache_folder)\n return super(Clean, self).clean_tasks(tasks, dryrun)\n\n# Nikola has its own \"auto\" commands that uses livereload.\n# Expose original doit \"auto\" command as \"doit_auto\".\nDoitAuto.name = 'doit_auto'\n\n\nclass NikolaTaskLoader(TaskLoader):\n \"\"\"custom task loader to get tasks from Nikola instead of dodo.py file\"\"\"\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.quiet = quiet\n\n def load_tasks(self, cmd, opt_values, pos_args):\n if self.quiet:\n DOIT_CONFIG = {\n 'verbosity': 0,\n 'reporter': 'zero',\n }\n else:\n DOIT_CONFIG = {\n 'reporter': ExecutedOnlyReporter,\n }\n DOIT_CONFIG['default_tasks'] = ['render_site', 'post_render']\n tasks = generate_tasks(\n 'render_site',\n self.nikola.gen_tasks('render_site', \"Task\", 'Group of tasks to render the site.'))\n latetasks = generate_tasks(\n 'post_render',\n self.nikola.gen_tasks('post_render', \"LateTask\", 'Group of tasks to be executes after site is rendered.'))\n return tasks + latetasks, DOIT_CONFIG\n\n\nclass DoitNikola(DoitMain):\n # overwite help command\n DOIT_CMDS = list(DoitMain.DOIT_CMDS) + [Help, Build, Clean, DoitAuto]\n TASK_LOADER = NikolaTaskLoader\n\n def __init__(self, nikola, quiet=False):\n self.nikola = nikola\n self.task_loader = self.TASK_LOADER(nikola, quiet)\n\n def get_commands(self):\n # core doit commands\n cmds = DoitMain.get_commands(self)\n # load nikola commands\n for name, cmd in self.nikola.commands.items():\n cmds[name] = cmd\n return cmds\n\n def run(self, cmd_args):\n sub_cmds = self.get_commands()\n args = self.process_args(cmd_args)\n args = [sys_decode(arg) for arg in args]\n\n if len(args) == 0 or any(arg in [\"--help\", '-h'] for arg in args):\n cmd_args = ['help']\n args = ['help']\n # Hide run because Nikola uses build\n sub_cmds.pop('run')\n\n if len(args) == 0 or args[0] not in sub_cmds.keys() or \\\n args[0] == 'build':\n # Check for conf.py before launching run\n if not self.nikola.configured:\n LOGGER.error(\"This command needs to run inside an \"\n \"existing Nikola site.\")\n return False\n return super(DoitNikola, self).run(cmd_args)\n\n @staticmethod\n def print_version():\n print(\"Nikola version \" + __version__)\n", "path": "nikola/main.py"}]}
| 2,434 | 315 |
gh_patches_debug_3205
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-2841
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nilearn 0.5.0 breaks tests
### Summary
The latest release of nilearn broke master.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/info.py`
Content:
```
1 """ This file contains defines parameters for nipy that we use to fill
2 settings in setup.py, the nipy top-level docstring, and for building the
3 docs. In setup.py in particular, we exec this file, so it cannot import nipy
4 """
5
6 # nipype version information
7 # Remove -dev for release
8 __version__ = "1.5.0-rc1.post-dev"
9
10
11 def get_nipype_gitversion():
12 """Nipype version as reported by the last commit in git
13
14 Returns
15 -------
16 None or str
17 Version of Nipype according to git.
18 """
19 import os
20 import subprocess
21
22 try:
23 import nipype
24
25 gitpath = os.path.realpath(
26 os.path.join(os.path.dirname(nipype.__file__), os.path.pardir)
27 )
28 except:
29 gitpath = os.getcwd()
30 gitpathgit = os.path.join(gitpath, ".git")
31 if not os.path.exists(gitpathgit):
32 return None
33 ver = None
34 try:
35 o, _ = subprocess.Popen(
36 "git describe", shell=True, cwd=gitpath, stdout=subprocess.PIPE
37 ).communicate()
38 except Exception:
39 pass
40 else:
41 ver = o.decode().strip().split("-")[-1]
42 return ver
43
44
45 if __version__.endswith("-dev"):
46 gitversion = get_nipype_gitversion()
47 if gitversion:
48 __version__ = "{}+{}".format(__version__, gitversion)
49
50 CLASSIFIERS = [
51 "Development Status :: 5 - Production/Stable",
52 "Environment :: Console",
53 "Intended Audience :: Science/Research",
54 "License :: OSI Approved :: Apache Software License",
55 "Operating System :: MacOS :: MacOS X",
56 "Operating System :: POSIX :: Linux",
57 "Programming Language :: Python :: 3.6",
58 "Programming Language :: Python :: 3.7",
59 "Programming Language :: Python :: 3.8",
60 "Topic :: Scientific/Engineering",
61 ]
62 PYTHON_REQUIRES = ">= 3.6"
63
64 description = "Neuroimaging in Python: Pipelines and Interfaces"
65
66 # Note: this long_description is actually a copy/paste from the top-level
67 # README.txt, so that it shows up nicely on PyPI. So please remember to edit
68 # it only in one place and sync it correctly.
69 long_description = """========================================================
70 NIPYPE: Neuroimaging in Python: Pipelines and Interfaces
71 ========================================================
72
73 Current neuroimaging software offer users an incredible opportunity to
74 analyze data using a variety of different algorithms. However, this has
75 resulted in a heterogeneous collection of specialized applications
76 without transparent interoperability or a uniform operating interface.
77
78 *Nipype*, an open-source, community-developed initiative under the
79 umbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a
80 uniform interface to existing neuroimaging software and facilitates interaction
81 between these packages within a single workflow. Nipype provides an environment
82 that encourages interactive exploration of algorithms from different
83 packages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,
84 MRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and
85 between packages, and reduces the learning curve necessary to use different \
86 packages. Nipype is creating a collaborative platform for neuroimaging \
87 software development in a high-level language and addressing limitations of \
88 existing pipeline systems.
89
90 *Nipype* allows you to:
91
92 * easily interact with tools from different software packages
93 * combine processing steps from different software packages
94 * develop new workflows faster by reusing common steps from old ones
95 * process data faster by running it in parallel on many cores/machines
96 * make your research easily reproducible
97 * share your processing workflows with the community
98 """
99
100 # versions
101 NIBABEL_MIN_VERSION = "2.1.0"
102 NETWORKX_MIN_VERSION = "1.9"
103 NUMPY_MIN_VERSION = "1.13"
104 # Numpy bug in python 3.7:
105 # https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html
106 NUMPY_MIN_VERSION_37 = "1.15.3"
107 SCIPY_MIN_VERSION = "0.14"
108 TRAITS_MIN_VERSION = "4.6"
109 DATEUTIL_MIN_VERSION = "2.2"
110 FUTURE_MIN_VERSION = "0.16.0"
111 SIMPLEJSON_MIN_VERSION = "3.8.0"
112 PROV_VERSION = "1.5.2"
113 RDFLIB_MIN_VERSION = "5.0.0"
114 CLICK_MIN_VERSION = "6.6.0"
115 PYDOT_MIN_VERSION = "1.2.3"
116
117 NAME = "nipype"
118 MAINTAINER = "nipype developers"
119 MAINTAINER_EMAIL = "[email protected]"
120 DESCRIPTION = description
121 LONG_DESCRIPTION = long_description
122 URL = "http://nipy.org/nipype"
123 DOWNLOAD_URL = "http://github.com/nipy/nipype/archives/master"
124 LICENSE = "Apache License, 2.0"
125 AUTHOR = "nipype developers"
126 AUTHOR_EMAIL = "[email protected]"
127 PLATFORMS = "OS Independent"
128 MAJOR = __version__.split(".")[0]
129 MINOR = __version__.split(".")[1]
130 MICRO = __version__.replace("-", ".").split(".")[2]
131 ISRELEASE = (
132 len(__version__.replace("-", ".").split(".")) == 3
133 or "post" in __version__.replace("-", ".").split(".")[-1]
134 )
135 VERSION = __version__
136 PROVIDES = ["nipype"]
137 REQUIRES = [
138 "click>=%s" % CLICK_MIN_VERSION,
139 "networkx>=%s" % NETWORKX_MIN_VERSION,
140 "nibabel>=%s" % NIBABEL_MIN_VERSION,
141 'numpy>=%s ; python_version < "3.7"' % NUMPY_MIN_VERSION,
142 'numpy>=%s ; python_version >= "3.7"' % NUMPY_MIN_VERSION_37,
143 "packaging",
144 "prov>=%s" % PROV_VERSION,
145 "pydot>=%s" % PYDOT_MIN_VERSION,
146 "pydotplus",
147 "python-dateutil>=%s" % DATEUTIL_MIN_VERSION,
148 "rdflib>=%s" % RDFLIB_MIN_VERSION,
149 "scipy>=%s" % SCIPY_MIN_VERSION,
150 "simplejson>=%s" % SIMPLEJSON_MIN_VERSION,
151 "traits>=%s,!=5.0" % TRAITS_MIN_VERSION,
152 "filelock>=3.0.0",
153 "etelemetry>=0.2.0",
154 ]
155
156 TESTS_REQUIRES = [
157 "codecov",
158 "coverage<5",
159 "pytest",
160 "pytest-cov",
161 "pytest-env",
162 "pytest-timeout",
163 ]
164
165 EXTRA_REQUIRES = {
166 "data": ["datalad"],
167 "doc": [
168 "dipy",
169 "ipython",
170 "matplotlib",
171 "nbsphinx",
172 "sphinx-argparse",
173 "sphinx>=2.1.2",
174 "sphinxcontrib-apidoc",
175 "sphinxcontrib-napoleon",
176 ],
177 "duecredit": ["duecredit"],
178 "nipy": ["nitime", "nilearn<0.5.0", "dipy", "nipy", "matplotlib"],
179 "profiler": ["psutil>=5.0"],
180 "pybids": ["pybids>=0.7.0"],
181 "specs": ["black"],
182 "ssh": ["paramiko"],
183 "tests": TESTS_REQUIRES,
184 "xvfbwrapper": ["xvfbwrapper"],
185 # 'mesh': ['mayavi'] # Enable when it works
186 }
187
188
189 def _list_union(iterable):
190 return list(set(sum(iterable, [])))
191
192
193 # Enable a handle to install all extra dependencies at once
194 EXTRA_REQUIRES["all"] = _list_union(EXTRA_REQUIRES.values())
195 # dev = doc + tests + specs
196 EXTRA_REQUIRES["dev"] = _list_union(
197 val for key, val in EXTRA_REQUIRES.items() if key in ("doc", "tests", "specs")
198 )
199
200 STATUS = "stable"
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/info.py b/nipype/info.py
--- a/nipype/info.py
+++ b/nipype/info.py
@@ -175,7 +175,7 @@
"sphinxcontrib-napoleon",
],
"duecredit": ["duecredit"],
- "nipy": ["nitime", "nilearn<0.5.0", "dipy", "nipy", "matplotlib"],
+ "nipy": ["nitime", "nilearn", "dipy", "nipy", "matplotlib"],
"profiler": ["psutil>=5.0"],
"pybids": ["pybids>=0.7.0"],
"specs": ["black"],
|
{"golden_diff": "diff --git a/nipype/info.py b/nipype/info.py\n--- a/nipype/info.py\n+++ b/nipype/info.py\n@@ -175,7 +175,7 @@\n \"sphinxcontrib-napoleon\",\n ],\n \"duecredit\": [\"duecredit\"],\n- \"nipy\": [\"nitime\", \"nilearn<0.5.0\", \"dipy\", \"nipy\", \"matplotlib\"],\n+ \"nipy\": [\"nitime\", \"nilearn\", \"dipy\", \"nipy\", \"matplotlib\"],\n \"profiler\": [\"psutil>=5.0\"],\n \"pybids\": [\"pybids>=0.7.0\"],\n \"specs\": [\"black\"],\n", "issue": "Nilearn 0.5.0 breaks tests\n### Summary\r\nThe latest release of nilearn broke master.\r\n\n", "before_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\n\n# nipype version information\n# Remove -dev for release\n__version__ = \"1.5.0-rc1.post-dev\"\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n\n try:\n import nipype\n\n gitpath = os.path.realpath(\n os.path.join(os.path.dirname(nipype.__file__), os.path.pardir)\n )\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, \".git\")\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen(\n \"git describe\", shell=True, cwd=gitpath, stdout=subprocess.PIPE\n ).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split(\"-\")[-1]\n return ver\n\n\nif __version__.endswith(\"-dev\"):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = \"{}+{}\".format(__version__, gitversion)\n\nCLASSIFIERS = [\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering\",\n]\nPYTHON_REQUIRES = \">= 3.6\"\n\ndescription = \"Neuroimaging in Python: Pipelines and Interfaces\"\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to\nanalyze data using a variety of different algorithms. However, this has\nresulted in a heterogeneous collection of specialized applications\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the\numbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a\nuniform interface to existing neuroimaging software and facilitates interaction\nbetween these packages within a single workflow. Nipype provides an environment\nthat encourages interactive exploration of algorithms from different\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging \\\nsoftware development in a high-level language and addressing limitations of \\\nexisting pipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = \"2.1.0\"\nNETWORKX_MIN_VERSION = \"1.9\"\nNUMPY_MIN_VERSION = \"1.13\"\n# Numpy bug in python 3.7:\n# https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html\nNUMPY_MIN_VERSION_37 = \"1.15.3\"\nSCIPY_MIN_VERSION = \"0.14\"\nTRAITS_MIN_VERSION = \"4.6\"\nDATEUTIL_MIN_VERSION = \"2.2\"\nFUTURE_MIN_VERSION = \"0.16.0\"\nSIMPLEJSON_MIN_VERSION = \"3.8.0\"\nPROV_VERSION = \"1.5.2\"\nRDFLIB_MIN_VERSION = \"5.0.0\"\nCLICK_MIN_VERSION = \"6.6.0\"\nPYDOT_MIN_VERSION = \"1.2.3\"\n\nNAME = \"nipype\"\nMAINTAINER = \"nipype developers\"\nMAINTAINER_EMAIL = \"[email protected]\"\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = \"http://nipy.org/nipype\"\nDOWNLOAD_URL = \"http://github.com/nipy/nipype/archives/master\"\nLICENSE = \"Apache License, 2.0\"\nAUTHOR = \"nipype developers\"\nAUTHOR_EMAIL = \"[email protected]\"\nPLATFORMS = \"OS Independent\"\nMAJOR = __version__.split(\".\")[0]\nMINOR = __version__.split(\".\")[1]\nMICRO = __version__.replace(\"-\", \".\").split(\".\")[2]\nISRELEASE = (\n len(__version__.replace(\"-\", \".\").split(\".\")) == 3\n or \"post\" in __version__.replace(\"-\", \".\").split(\".\")[-1]\n)\nVERSION = __version__\nPROVIDES = [\"nipype\"]\nREQUIRES = [\n \"click>=%s\" % CLICK_MIN_VERSION,\n \"networkx>=%s\" % NETWORKX_MIN_VERSION,\n \"nibabel>=%s\" % NIBABEL_MIN_VERSION,\n 'numpy>=%s ; python_version < \"3.7\"' % NUMPY_MIN_VERSION,\n 'numpy>=%s ; python_version >= \"3.7\"' % NUMPY_MIN_VERSION_37,\n \"packaging\",\n \"prov>=%s\" % PROV_VERSION,\n \"pydot>=%s\" % PYDOT_MIN_VERSION,\n \"pydotplus\",\n \"python-dateutil>=%s\" % DATEUTIL_MIN_VERSION,\n \"rdflib>=%s\" % RDFLIB_MIN_VERSION,\n \"scipy>=%s\" % SCIPY_MIN_VERSION,\n \"simplejson>=%s\" % SIMPLEJSON_MIN_VERSION,\n \"traits>=%s,!=5.0\" % TRAITS_MIN_VERSION,\n \"filelock>=3.0.0\",\n \"etelemetry>=0.2.0\",\n]\n\nTESTS_REQUIRES = [\n \"codecov\",\n \"coverage<5\",\n \"pytest\",\n \"pytest-cov\",\n \"pytest-env\",\n \"pytest-timeout\",\n]\n\nEXTRA_REQUIRES = {\n \"data\": [\"datalad\"],\n \"doc\": [\n \"dipy\",\n \"ipython\",\n \"matplotlib\",\n \"nbsphinx\",\n \"sphinx-argparse\",\n \"sphinx>=2.1.2\",\n \"sphinxcontrib-apidoc\",\n \"sphinxcontrib-napoleon\",\n ],\n \"duecredit\": [\"duecredit\"],\n \"nipy\": [\"nitime\", \"nilearn<0.5.0\", \"dipy\", \"nipy\", \"matplotlib\"],\n \"profiler\": [\"psutil>=5.0\"],\n \"pybids\": [\"pybids>=0.7.0\"],\n \"specs\": [\"black\"],\n \"ssh\": [\"paramiko\"],\n \"tests\": TESTS_REQUIRES,\n \"xvfbwrapper\": [\"xvfbwrapper\"],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n\ndef _list_union(iterable):\n return list(set(sum(iterable, [])))\n\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES[\"all\"] = _list_union(EXTRA_REQUIRES.values())\n# dev = doc + tests + specs\nEXTRA_REQUIRES[\"dev\"] = _list_union(\n val for key, val in EXTRA_REQUIRES.items() if key in (\"doc\", \"tests\", \"specs\")\n)\n\nSTATUS = \"stable\"\n", "path": "nipype/info.py"}], "after_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\n\n# nipype version information\n# Remove -dev for release\n__version__ = \"1.5.0-rc1.post-dev\"\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n\n try:\n import nipype\n\n gitpath = os.path.realpath(\n os.path.join(os.path.dirname(nipype.__file__), os.path.pardir)\n )\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, \".git\")\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen(\n \"git describe\", shell=True, cwd=gitpath, stdout=subprocess.PIPE\n ).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split(\"-\")[-1]\n return ver\n\n\nif __version__.endswith(\"-dev\"):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = \"{}+{}\".format(__version__, gitversion)\n\nCLASSIFIERS = [\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering\",\n]\nPYTHON_REQUIRES = \">= 3.6\"\n\ndescription = \"Neuroimaging in Python: Pipelines and Interfaces\"\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to\nanalyze data using a variety of different algorithms. However, this has\nresulted in a heterogeneous collection of specialized applications\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the\numbrella of `NiPy <http://nipy.org>`_, is a Python project that provides a\nuniform interface to existing neuroimaging software and facilitates interaction\nbetween these packages within a single workflow. Nipype provides an environment\nthat encourages interactive exploration of algorithms from different\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE,\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging \\\nsoftware development in a high-level language and addressing limitations of \\\nexisting pipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = \"2.1.0\"\nNETWORKX_MIN_VERSION = \"1.9\"\nNUMPY_MIN_VERSION = \"1.13\"\n# Numpy bug in python 3.7:\n# https://www.opensourceanswers.com/blog/you-shouldnt-use-python-37-for-data-science-right-now.html\nNUMPY_MIN_VERSION_37 = \"1.15.3\"\nSCIPY_MIN_VERSION = \"0.14\"\nTRAITS_MIN_VERSION = \"4.6\"\nDATEUTIL_MIN_VERSION = \"2.2\"\nFUTURE_MIN_VERSION = \"0.16.0\"\nSIMPLEJSON_MIN_VERSION = \"3.8.0\"\nPROV_VERSION = \"1.5.2\"\nRDFLIB_MIN_VERSION = \"5.0.0\"\nCLICK_MIN_VERSION = \"6.6.0\"\nPYDOT_MIN_VERSION = \"1.2.3\"\n\nNAME = \"nipype\"\nMAINTAINER = \"nipype developers\"\nMAINTAINER_EMAIL = \"[email protected]\"\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = \"http://nipy.org/nipype\"\nDOWNLOAD_URL = \"http://github.com/nipy/nipype/archives/master\"\nLICENSE = \"Apache License, 2.0\"\nAUTHOR = \"nipype developers\"\nAUTHOR_EMAIL = \"[email protected]\"\nPLATFORMS = \"OS Independent\"\nMAJOR = __version__.split(\".\")[0]\nMINOR = __version__.split(\".\")[1]\nMICRO = __version__.replace(\"-\", \".\").split(\".\")[2]\nISRELEASE = (\n len(__version__.replace(\"-\", \".\").split(\".\")) == 3\n or \"post\" in __version__.replace(\"-\", \".\").split(\".\")[-1]\n)\nVERSION = __version__\nPROVIDES = [\"nipype\"]\nREQUIRES = [\n \"click>=%s\" % CLICK_MIN_VERSION,\n \"networkx>=%s\" % NETWORKX_MIN_VERSION,\n \"nibabel>=%s\" % NIBABEL_MIN_VERSION,\n 'numpy>=%s ; python_version < \"3.7\"' % NUMPY_MIN_VERSION,\n 'numpy>=%s ; python_version >= \"3.7\"' % NUMPY_MIN_VERSION_37,\n \"packaging\",\n \"prov>=%s\" % PROV_VERSION,\n \"pydot>=%s\" % PYDOT_MIN_VERSION,\n \"pydotplus\",\n \"python-dateutil>=%s\" % DATEUTIL_MIN_VERSION,\n \"rdflib>=%s\" % RDFLIB_MIN_VERSION,\n \"scipy>=%s\" % SCIPY_MIN_VERSION,\n \"simplejson>=%s\" % SIMPLEJSON_MIN_VERSION,\n \"traits>=%s,!=5.0\" % TRAITS_MIN_VERSION,\n \"filelock>=3.0.0\",\n \"etelemetry>=0.2.0\",\n]\n\nTESTS_REQUIRES = [\n \"codecov\",\n \"coverage<5\",\n \"pytest\",\n \"pytest-cov\",\n \"pytest-env\",\n \"pytest-timeout\",\n]\n\nEXTRA_REQUIRES = {\n \"data\": [\"datalad\"],\n \"doc\": [\n \"dipy\",\n \"ipython\",\n \"matplotlib\",\n \"nbsphinx\",\n \"sphinx-argparse\",\n \"sphinx>=2.1.2\",\n \"sphinxcontrib-apidoc\",\n \"sphinxcontrib-napoleon\",\n ],\n \"duecredit\": [\"duecredit\"],\n \"nipy\": [\"nitime\", \"nilearn\", \"dipy\", \"nipy\", \"matplotlib\"],\n \"profiler\": [\"psutil>=5.0\"],\n \"pybids\": [\"pybids>=0.7.0\"],\n \"specs\": [\"black\"],\n \"ssh\": [\"paramiko\"],\n \"tests\": TESTS_REQUIRES,\n \"xvfbwrapper\": [\"xvfbwrapper\"],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n\ndef _list_union(iterable):\n return list(set(sum(iterable, [])))\n\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES[\"all\"] = _list_union(EXTRA_REQUIRES.values())\n# dev = doc + tests + specs\nEXTRA_REQUIRES[\"dev\"] = _list_union(\n val for key, val in EXTRA_REQUIRES.items() if key in (\"doc\", \"tests\", \"specs\")\n)\n\nSTATUS = \"stable\"\n", "path": "nipype/info.py"}]}
| 2,570 | 161 |
gh_patches_debug_4519
|
rasdani/github-patches
|
git_diff
|
conda-forge__conda-smithy-1570
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`BUILD_WITH_CONDA_DEBUG` not implemented on macOS
<!--
Thanks for reporting your issue.
Please fill out the sections below.
-->
- [X] I read [the conda-forge documentation](https://conda-forge.org/docs/user/introduction.html#how-can-i-install-packages-from-conda-forge) and could not find the solution for my problem there.
Issue:`BUILD_WITH_CONDA_DEBUG`, and so the `--debug` flag of `build_locally.py`, is not implemented on macOS in `run_osx_build.sh`.
Would a PR that adds that, similar to what is done for Linux in `build_steps.sh`, be welcome ? :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_smithy/github.py`
Content:
```
1 import os
2 from random import choice
3
4 from git import Repo
5
6 from github import Github
7 from github.GithubException import GithubException
8 from github.Organization import Organization
9 from github.Team import Team
10 import github
11
12 import conda_build.api
13 from conda_smithy.utils import get_feedstock_name_from_meta
14
15
16 def gh_token():
17 try:
18 with open(
19 os.path.expanduser("~/.conda-smithy/github.token"), "r"
20 ) as fh:
21 token = fh.read().strip()
22 if not token:
23 raise ValueError()
24 except (IOError, ValueError):
25 msg = (
26 "No github token. Go to https://github.com/settings/tokens/new and generate\n"
27 "a token with repo access. Put it in ~/.conda-smithy/github.token"
28 )
29 raise RuntimeError(msg)
30 return token
31
32
33 def create_team(org, name, description, repo_names=[]):
34 # PyGithub creates secret teams, and has no way of turning that off! :(
35 post_parameters = {
36 "name": name,
37 "description": description,
38 "privacy": "closed",
39 "permission": "push",
40 "repo_names": repo_names,
41 }
42 headers, data = org._requester.requestJsonAndCheck(
43 "POST", org.url + "/teams", input=post_parameters
44 )
45 return Team(org._requester, headers, data, completed=True)
46
47
48 def add_membership(team, member):
49 headers, data = team._requester.requestJsonAndCheck(
50 "PUT", team.url + "/memberships/" + member
51 )
52 return (headers, data)
53
54
55 def remove_membership(team, member):
56 headers, data = team._requester.requestJsonAndCheck(
57 "DELETE", team.url + "/memberships/" + member
58 )
59 return (headers, data)
60
61
62 def has_in_members(team, member):
63 status, headers, data = team._requester.requestJson(
64 "GET", team.url + "/members/" + member
65 )
66 return status == 204
67
68
69 def get_cached_team(org, team_name, description=""):
70 cached_file = os.path.expanduser(
71 "~/.conda-smithy/{}-{}-team".format(org.login, team_name)
72 )
73 try:
74 with open(cached_file, "r") as fh:
75 team_id = int(fh.read().strip())
76 return org.get_team(team_id)
77 except IOError:
78 pass
79
80 try:
81 repo = org.get_repo("{}-feedstock".format(team_name))
82 team = next(
83 (team for team in repo.get_teams() if team.name == team_name), None
84 )
85 if team:
86 return team
87 except GithubException:
88 pass
89
90 team = next(
91 (team for team in org.get_teams() if team.name == team_name), None
92 )
93 if not team:
94 if description:
95 team = create_team(org, team_name, description, [])
96 else:
97 raise RuntimeError("Couldn't find team {}".format(team_name))
98
99 with open(cached_file, "w") as fh:
100 fh.write(str(team.id))
101
102 return team
103
104
105 def create_github_repo(args):
106 token = gh_token()
107 meta = conda_build.api.render(
108 args.feedstock_directory,
109 permit_undefined_jinja=True,
110 finalize=False,
111 bypass_env_check=True,
112 trim_skip=False,
113 )[0][0]
114
115 feedstock_name = get_feedstock_name_from_meta(meta)
116
117 gh = Github(token)
118 user_or_org = None
119 if args.user is not None:
120 pass
121 # User has been defined, and organization has not.
122 user_or_org = gh.get_user()
123 else:
124 # Use the organization provided.
125 user_or_org = gh.get_organization(args.organization)
126
127 repo_name = "{}-feedstock".format(feedstock_name)
128 try:
129 gh_repo = user_or_org.create_repo(
130 repo_name,
131 has_wiki=False,
132 private=args.private,
133 description="A conda-smithy repository for {}.".format(
134 feedstock_name
135 ),
136 )
137 print("Created {} on github".format(gh_repo.full_name))
138 except GithubException as gh_except:
139 if (
140 gh_except.data.get("errors", [{}])[0].get("message", "")
141 != u"name already exists on this account"
142 ):
143 raise
144 gh_repo = user_or_org.get_repo(repo_name)
145 print("Github repository already exists.")
146
147 # Now add this new repo as a remote on the local clone.
148 repo = Repo(args.feedstock_directory)
149 remote_name = args.remote_name.strip()
150 if remote_name:
151 if remote_name in [remote.name for remote in repo.remotes]:
152 existing_remote = repo.remotes[remote_name]
153 if existing_remote.url != gh_repo.ssh_url:
154 print(
155 "Remote {} already exists, and doesn't point to {} "
156 "(it points to {}).".format(
157 remote_name, gh_repo.ssh_url, existing_remote.url
158 )
159 )
160 else:
161 repo.create_remote(remote_name, gh_repo.ssh_url)
162
163 if args.extra_admin_users is not None:
164 for user in args.extra_admin_users:
165 gh_repo.add_to_collaborators(user, "admin")
166
167 if args.add_teams:
168 if isinstance(user_or_org, Organization):
169 configure_github_team(meta, gh_repo, user_or_org, feedstock_name)
170
171
172 def accept_all_repository_invitations(gh):
173 user = gh.get_user()
174 invitations = github.PaginatedList.PaginatedList(
175 github.Invitation.Invitation,
176 user._requester,
177 user.url + "/repository_invitations",
178 None,
179 )
180 for invite in invitations:
181 invite._requester.requestJsonAndCheck("PATCH", invite.url)
182
183
184 def remove_from_project(gh, org, project):
185 user = gh.get_user()
186 repo = gh.get_repo("{}/{}".format(org, project))
187 repo.remove_from_collaborators(user.login)
188
189
190 def configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):
191
192 # Add a team for this repo and add the maintainers to it.
193 superlative = [
194 "awesome",
195 "slick",
196 "formidable",
197 "awe-inspiring",
198 "breathtaking",
199 "magnificent",
200 "wonderous",
201 "stunning",
202 "astonishing",
203 "superb",
204 "splendid",
205 "impressive",
206 "unbeatable",
207 "excellent",
208 "top",
209 "outstanding",
210 "exalted",
211 "standout",
212 "smashing",
213 ]
214
215 maintainers = set(meta.meta.get("extra", {}).get("recipe-maintainers", []))
216 maintainers = set(maintainer.lower() for maintainer in maintainers)
217 maintainer_teams = set(m for m in maintainers if "/" in m)
218 maintainers = set(m for m in maintainers if "/" not in m)
219
220 # Try to get team or create it if it doesn't exist.
221 team_name = feedstock_name
222 current_maintainer_teams = list(gh_repo.get_teams())
223 fs_team = next(
224 (team for team in current_maintainer_teams if team.name == team_name),
225 None,
226 )
227 current_maintainers = set()
228 if not fs_team:
229 fs_team = create_team(
230 org,
231 team_name,
232 "The {} {} contributors!".format(choice(superlative), team_name),
233 )
234 fs_team.add_to_repos(gh_repo)
235 else:
236 current_maintainers = set(
237 [e.login.lower() for e in fs_team.get_members()]
238 )
239
240 # Get the all-members team
241 description = "All of the awesome {} contributors!".format(org.login)
242 all_members_team = get_cached_team(org, "all-members", description)
243 new_org_members = set()
244
245 # Add only the new maintainers to the team.
246 # Also add the new maintainers to all-members if not already included.
247 for new_maintainer in maintainers - current_maintainers:
248 add_membership(fs_team, new_maintainer)
249
250 if not has_in_members(all_members_team, new_maintainer):
251 add_membership(all_members_team, new_maintainer)
252 new_org_members.add(new_maintainer)
253
254 # Remove any maintainers that need to be removed (unlikely here).
255 if remove:
256 for old_maintainer in current_maintainers - maintainers:
257 remove_membership(fs_team, old_maintainer)
258
259 # Add any new maintainer teams
260 maintainer_teams = set(
261 m.split("/")[1]
262 for m in maintainer_teams
263 if m.startswith(str(org.login))
264 )
265 current_maintainer_team_objs = {
266 team.slug: team for team in current_maintainer_teams
267 }
268 current_maintainer_teams = set(
269 [team.slug for team in current_maintainer_teams]
270 )
271 for new_team in maintainer_teams - current_maintainer_teams:
272 team = org.get_team_by_slug(new_team)
273 team.add_to_repos(gh_repo)
274
275 # remove any old teams
276 if remove:
277 for old_team in current_maintainer_teams - maintainer_teams:
278 team = current_maintainer_team_objs.get(
279 old_team, org.get_team_by_slug(old_team)
280 )
281 if team.name == fs_team.name:
282 continue
283 team.remove_from_repos(gh_repo)
284
285 return maintainers, current_maintainers, new_org_members
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_smithy/github.py b/conda_smithy/github.py
--- a/conda_smithy/github.py
+++ b/conda_smithy/github.py
@@ -138,7 +138,7 @@
except GithubException as gh_except:
if (
gh_except.data.get("errors", [{}])[0].get("message", "")
- != u"name already exists on this account"
+ != "name already exists on this account"
):
raise
gh_repo = user_or_org.get_repo(repo_name)
|
{"golden_diff": "diff --git a/conda_smithy/github.py b/conda_smithy/github.py\n--- a/conda_smithy/github.py\n+++ b/conda_smithy/github.py\n@@ -138,7 +138,7 @@\n except GithubException as gh_except:\n if (\n gh_except.data.get(\"errors\", [{}])[0].get(\"message\", \"\")\n- != u\"name already exists on this account\"\n+ != \"name already exists on this account\"\n ):\n raise\n gh_repo = user_or_org.get_repo(repo_name)\n", "issue": "`BUILD_WITH_CONDA_DEBUG`\u00a0not implemented on macOS\n<!--\r\nThanks for reporting your issue.\r\nPlease fill out the sections below.\r\n-->\r\n\r\n- [X] I read [the conda-forge documentation](https://conda-forge.org/docs/user/introduction.html#how-can-i-install-packages-from-conda-forge) and could not find the solution for my problem there.\r\n\r\nIssue:`BUILD_WITH_CONDA_DEBUG`, and so the `--debug` flag of `build_locally.py`, is\u00a0not implemented on macOS in `run_osx_build.sh`. \r\n\r\nWould a PR that adds that, similar to what is done for Linux in `build_steps.sh`, be welcome ? :)\r\n\n", "before_files": [{"content": "import os\nfrom random import choice\n\nfrom git import Repo\n\nfrom github import Github\nfrom github.GithubException import GithubException\nfrom github.Organization import Organization\nfrom github.Team import Team\nimport github\n\nimport conda_build.api\nfrom conda_smithy.utils import get_feedstock_name_from_meta\n\n\ndef gh_token():\n try:\n with open(\n os.path.expanduser(\"~/.conda-smithy/github.token\"), \"r\"\n ) as fh:\n token = fh.read().strip()\n if not token:\n raise ValueError()\n except (IOError, ValueError):\n msg = (\n \"No github token. Go to https://github.com/settings/tokens/new and generate\\n\"\n \"a token with repo access. Put it in ~/.conda-smithy/github.token\"\n )\n raise RuntimeError(msg)\n return token\n\n\ndef create_team(org, name, description, repo_names=[]):\n # PyGithub creates secret teams, and has no way of turning that off! :(\n post_parameters = {\n \"name\": name,\n \"description\": description,\n \"privacy\": \"closed\",\n \"permission\": \"push\",\n \"repo_names\": repo_names,\n }\n headers, data = org._requester.requestJsonAndCheck(\n \"POST\", org.url + \"/teams\", input=post_parameters\n )\n return Team(org._requester, headers, data, completed=True)\n\n\ndef add_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"PUT\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef remove_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"DELETE\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef has_in_members(team, member):\n status, headers, data = team._requester.requestJson(\n \"GET\", team.url + \"/members/\" + member\n )\n return status == 204\n\n\ndef get_cached_team(org, team_name, description=\"\"):\n cached_file = os.path.expanduser(\n \"~/.conda-smithy/{}-{}-team\".format(org.login, team_name)\n )\n try:\n with open(cached_file, \"r\") as fh:\n team_id = int(fh.read().strip())\n return org.get_team(team_id)\n except IOError:\n pass\n\n try:\n repo = org.get_repo(\"{}-feedstock\".format(team_name))\n team = next(\n (team for team in repo.get_teams() if team.name == team_name), None\n )\n if team:\n return team\n except GithubException:\n pass\n\n team = next(\n (team for team in org.get_teams() if team.name == team_name), None\n )\n if not team:\n if description:\n team = create_team(org, team_name, description, [])\n else:\n raise RuntimeError(\"Couldn't find team {}\".format(team_name))\n\n with open(cached_file, \"w\") as fh:\n fh.write(str(team.id))\n\n return team\n\n\ndef create_github_repo(args):\n token = gh_token()\n meta = conda_build.api.render(\n args.feedstock_directory,\n permit_undefined_jinja=True,\n finalize=False,\n bypass_env_check=True,\n trim_skip=False,\n )[0][0]\n\n feedstock_name = get_feedstock_name_from_meta(meta)\n\n gh = Github(token)\n user_or_org = None\n if args.user is not None:\n pass\n # User has been defined, and organization has not.\n user_or_org = gh.get_user()\n else:\n # Use the organization provided.\n user_or_org = gh.get_organization(args.organization)\n\n repo_name = \"{}-feedstock\".format(feedstock_name)\n try:\n gh_repo = user_or_org.create_repo(\n repo_name,\n has_wiki=False,\n private=args.private,\n description=\"A conda-smithy repository for {}.\".format(\n feedstock_name\n ),\n )\n print(\"Created {} on github\".format(gh_repo.full_name))\n except GithubException as gh_except:\n if (\n gh_except.data.get(\"errors\", [{}])[0].get(\"message\", \"\")\n != u\"name already exists on this account\"\n ):\n raise\n gh_repo = user_or_org.get_repo(repo_name)\n print(\"Github repository already exists.\")\n\n # Now add this new repo as a remote on the local clone.\n repo = Repo(args.feedstock_directory)\n remote_name = args.remote_name.strip()\n if remote_name:\n if remote_name in [remote.name for remote in repo.remotes]:\n existing_remote = repo.remotes[remote_name]\n if existing_remote.url != gh_repo.ssh_url:\n print(\n \"Remote {} already exists, and doesn't point to {} \"\n \"(it points to {}).\".format(\n remote_name, gh_repo.ssh_url, existing_remote.url\n )\n )\n else:\n repo.create_remote(remote_name, gh_repo.ssh_url)\n\n if args.extra_admin_users is not None:\n for user in args.extra_admin_users:\n gh_repo.add_to_collaborators(user, \"admin\")\n\n if args.add_teams:\n if isinstance(user_or_org, Organization):\n configure_github_team(meta, gh_repo, user_or_org, feedstock_name)\n\n\ndef accept_all_repository_invitations(gh):\n user = gh.get_user()\n invitations = github.PaginatedList.PaginatedList(\n github.Invitation.Invitation,\n user._requester,\n user.url + \"/repository_invitations\",\n None,\n )\n for invite in invitations:\n invite._requester.requestJsonAndCheck(\"PATCH\", invite.url)\n\n\ndef remove_from_project(gh, org, project):\n user = gh.get_user()\n repo = gh.get_repo(\"{}/{}\".format(org, project))\n repo.remove_from_collaborators(user.login)\n\n\ndef configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):\n\n # Add a team for this repo and add the maintainers to it.\n superlative = [\n \"awesome\",\n \"slick\",\n \"formidable\",\n \"awe-inspiring\",\n \"breathtaking\",\n \"magnificent\",\n \"wonderous\",\n \"stunning\",\n \"astonishing\",\n \"superb\",\n \"splendid\",\n \"impressive\",\n \"unbeatable\",\n \"excellent\",\n \"top\",\n \"outstanding\",\n \"exalted\",\n \"standout\",\n \"smashing\",\n ]\n\n maintainers = set(meta.meta.get(\"extra\", {}).get(\"recipe-maintainers\", []))\n maintainers = set(maintainer.lower() for maintainer in maintainers)\n maintainer_teams = set(m for m in maintainers if \"/\" in m)\n maintainers = set(m for m in maintainers if \"/\" not in m)\n\n # Try to get team or create it if it doesn't exist.\n team_name = feedstock_name\n current_maintainer_teams = list(gh_repo.get_teams())\n fs_team = next(\n (team for team in current_maintainer_teams if team.name == team_name),\n None,\n )\n current_maintainers = set()\n if not fs_team:\n fs_team = create_team(\n org,\n team_name,\n \"The {} {} contributors!\".format(choice(superlative), team_name),\n )\n fs_team.add_to_repos(gh_repo)\n else:\n current_maintainers = set(\n [e.login.lower() for e in fs_team.get_members()]\n )\n\n # Get the all-members team\n description = \"All of the awesome {} contributors!\".format(org.login)\n all_members_team = get_cached_team(org, \"all-members\", description)\n new_org_members = set()\n\n # Add only the new maintainers to the team.\n # Also add the new maintainers to all-members if not already included.\n for new_maintainer in maintainers - current_maintainers:\n add_membership(fs_team, new_maintainer)\n\n if not has_in_members(all_members_team, new_maintainer):\n add_membership(all_members_team, new_maintainer)\n new_org_members.add(new_maintainer)\n\n # Remove any maintainers that need to be removed (unlikely here).\n if remove:\n for old_maintainer in current_maintainers - maintainers:\n remove_membership(fs_team, old_maintainer)\n\n # Add any new maintainer teams\n maintainer_teams = set(\n m.split(\"/\")[1]\n for m in maintainer_teams\n if m.startswith(str(org.login))\n )\n current_maintainer_team_objs = {\n team.slug: team for team in current_maintainer_teams\n }\n current_maintainer_teams = set(\n [team.slug for team in current_maintainer_teams]\n )\n for new_team in maintainer_teams - current_maintainer_teams:\n team = org.get_team_by_slug(new_team)\n team.add_to_repos(gh_repo)\n\n # remove any old teams\n if remove:\n for old_team in current_maintainer_teams - maintainer_teams:\n team = current_maintainer_team_objs.get(\n old_team, org.get_team_by_slug(old_team)\n )\n if team.name == fs_team.name:\n continue\n team.remove_from_repos(gh_repo)\n\n return maintainers, current_maintainers, new_org_members\n", "path": "conda_smithy/github.py"}], "after_files": [{"content": "import os\nfrom random import choice\n\nfrom git import Repo\n\nfrom github import Github\nfrom github.GithubException import GithubException\nfrom github.Organization import Organization\nfrom github.Team import Team\nimport github\n\nimport conda_build.api\nfrom conda_smithy.utils import get_feedstock_name_from_meta\n\n\ndef gh_token():\n try:\n with open(\n os.path.expanduser(\"~/.conda-smithy/github.token\"), \"r\"\n ) as fh:\n token = fh.read().strip()\n if not token:\n raise ValueError()\n except (IOError, ValueError):\n msg = (\n \"No github token. Go to https://github.com/settings/tokens/new and generate\\n\"\n \"a token with repo access. Put it in ~/.conda-smithy/github.token\"\n )\n raise RuntimeError(msg)\n return token\n\n\ndef create_team(org, name, description, repo_names=[]):\n # PyGithub creates secret teams, and has no way of turning that off! :(\n post_parameters = {\n \"name\": name,\n \"description\": description,\n \"privacy\": \"closed\",\n \"permission\": \"push\",\n \"repo_names\": repo_names,\n }\n headers, data = org._requester.requestJsonAndCheck(\n \"POST\", org.url + \"/teams\", input=post_parameters\n )\n return Team(org._requester, headers, data, completed=True)\n\n\ndef add_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"PUT\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef remove_membership(team, member):\n headers, data = team._requester.requestJsonAndCheck(\n \"DELETE\", team.url + \"/memberships/\" + member\n )\n return (headers, data)\n\n\ndef has_in_members(team, member):\n status, headers, data = team._requester.requestJson(\n \"GET\", team.url + \"/members/\" + member\n )\n return status == 204\n\n\ndef get_cached_team(org, team_name, description=\"\"):\n cached_file = os.path.expanduser(\n \"~/.conda-smithy/{}-{}-team\".format(org.login, team_name)\n )\n try:\n with open(cached_file, \"r\") as fh:\n team_id = int(fh.read().strip())\n return org.get_team(team_id)\n except IOError:\n pass\n\n try:\n repo = org.get_repo(\"{}-feedstock\".format(team_name))\n team = next(\n (team for team in repo.get_teams() if team.name == team_name), None\n )\n if team:\n return team\n except GithubException:\n pass\n\n team = next(\n (team for team in org.get_teams() if team.name == team_name), None\n )\n if not team:\n if description:\n team = create_team(org, team_name, description, [])\n else:\n raise RuntimeError(\"Couldn't find team {}\".format(team_name))\n\n with open(cached_file, \"w\") as fh:\n fh.write(str(team.id))\n\n return team\n\n\ndef create_github_repo(args):\n token = gh_token()\n meta = conda_build.api.render(\n args.feedstock_directory,\n permit_undefined_jinja=True,\n finalize=False,\n bypass_env_check=True,\n trim_skip=False,\n )[0][0]\n\n feedstock_name = get_feedstock_name_from_meta(meta)\n\n gh = Github(token)\n user_or_org = None\n if args.user is not None:\n pass\n # User has been defined, and organization has not.\n user_or_org = gh.get_user()\n else:\n # Use the organization provided.\n user_or_org = gh.get_organization(args.organization)\n\n repo_name = \"{}-feedstock\".format(feedstock_name)\n try:\n gh_repo = user_or_org.create_repo(\n repo_name,\n has_wiki=False,\n private=args.private,\n description=\"A conda-smithy repository for {}.\".format(\n feedstock_name\n ),\n )\n print(\"Created {} on github\".format(gh_repo.full_name))\n except GithubException as gh_except:\n if (\n gh_except.data.get(\"errors\", [{}])[0].get(\"message\", \"\")\n != \"name already exists on this account\"\n ):\n raise\n gh_repo = user_or_org.get_repo(repo_name)\n print(\"Github repository already exists.\")\n\n # Now add this new repo as a remote on the local clone.\n repo = Repo(args.feedstock_directory)\n remote_name = args.remote_name.strip()\n if remote_name:\n if remote_name in [remote.name for remote in repo.remotes]:\n existing_remote = repo.remotes[remote_name]\n if existing_remote.url != gh_repo.ssh_url:\n print(\n \"Remote {} already exists, and doesn't point to {} \"\n \"(it points to {}).\".format(\n remote_name, gh_repo.ssh_url, existing_remote.url\n )\n )\n else:\n repo.create_remote(remote_name, gh_repo.ssh_url)\n\n if args.extra_admin_users is not None:\n for user in args.extra_admin_users:\n gh_repo.add_to_collaborators(user, \"admin\")\n\n if args.add_teams:\n if isinstance(user_or_org, Organization):\n configure_github_team(meta, gh_repo, user_or_org, feedstock_name)\n\n\ndef accept_all_repository_invitations(gh):\n user = gh.get_user()\n invitations = github.PaginatedList.PaginatedList(\n github.Invitation.Invitation,\n user._requester,\n user.url + \"/repository_invitations\",\n None,\n )\n for invite in invitations:\n invite._requester.requestJsonAndCheck(\"PATCH\", invite.url)\n\n\ndef remove_from_project(gh, org, project):\n user = gh.get_user()\n repo = gh.get_repo(\"{}/{}\".format(org, project))\n repo.remove_from_collaborators(user.login)\n\n\ndef configure_github_team(meta, gh_repo, org, feedstock_name, remove=True):\n\n # Add a team for this repo and add the maintainers to it.\n superlative = [\n \"awesome\",\n \"slick\",\n \"formidable\",\n \"awe-inspiring\",\n \"breathtaking\",\n \"magnificent\",\n \"wonderous\",\n \"stunning\",\n \"astonishing\",\n \"superb\",\n \"splendid\",\n \"impressive\",\n \"unbeatable\",\n \"excellent\",\n \"top\",\n \"outstanding\",\n \"exalted\",\n \"standout\",\n \"smashing\",\n ]\n\n maintainers = set(meta.meta.get(\"extra\", {}).get(\"recipe-maintainers\", []))\n maintainers = set(maintainer.lower() for maintainer in maintainers)\n maintainer_teams = set(m for m in maintainers if \"/\" in m)\n maintainers = set(m for m in maintainers if \"/\" not in m)\n\n # Try to get team or create it if it doesn't exist.\n team_name = feedstock_name\n current_maintainer_teams = list(gh_repo.get_teams())\n fs_team = next(\n (team for team in current_maintainer_teams if team.name == team_name),\n None,\n )\n current_maintainers = set()\n if not fs_team:\n fs_team = create_team(\n org,\n team_name,\n \"The {} {} contributors!\".format(choice(superlative), team_name),\n )\n fs_team.add_to_repos(gh_repo)\n else:\n current_maintainers = set(\n [e.login.lower() for e in fs_team.get_members()]\n )\n\n # Get the all-members team\n description = \"All of the awesome {} contributors!\".format(org.login)\n all_members_team = get_cached_team(org, \"all-members\", description)\n new_org_members = set()\n\n # Add only the new maintainers to the team.\n # Also add the new maintainers to all-members if not already included.\n for new_maintainer in maintainers - current_maintainers:\n add_membership(fs_team, new_maintainer)\n\n if not has_in_members(all_members_team, new_maintainer):\n add_membership(all_members_team, new_maintainer)\n new_org_members.add(new_maintainer)\n\n # Remove any maintainers that need to be removed (unlikely here).\n if remove:\n for old_maintainer in current_maintainers - maintainers:\n remove_membership(fs_team, old_maintainer)\n\n # Add any new maintainer teams\n maintainer_teams = set(\n m.split(\"/\")[1]\n for m in maintainer_teams\n if m.startswith(str(org.login))\n )\n current_maintainer_team_objs = {\n team.slug: team for team in current_maintainer_teams\n }\n current_maintainer_teams = set(\n [team.slug for team in current_maintainer_teams]\n )\n for new_team in maintainer_teams - current_maintainer_teams:\n team = org.get_team_by_slug(new_team)\n team.add_to_repos(gh_repo)\n\n # remove any old teams\n if remove:\n for old_team in current_maintainer_teams - maintainer_teams:\n team = current_maintainer_team_objs.get(\n old_team, org.get_team_by_slug(old_team)\n )\n if team.name == fs_team.name:\n continue\n team.remove_from_repos(gh_repo)\n\n return maintainers, current_maintainers, new_org_members\n", "path": "conda_smithy/github.py"}]}
| 3,213 | 122 |
gh_patches_debug_17460
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-6192
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix deprecated datetime64 use for NP_EPOCH
From https://github.com/numpy/numpy/pull/6453 this causes a deprecation warning.
/cc @shoyer
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/core/json_encoder.py`
Content:
```
1 ''' Provide a functions and classes to implement a custom JSON encoder for
2 serializing objects for BokehJS.
3
4 The primary interface is provided by the |serialize_json| function, which
5 uses the custom |BokehJSONEncoder| to produce JSON output.
6
7 In general, functions in this module convert values in the following way:
8
9 * Datetime values (Python, Pandas, NumPy) are converted to floating point
10 milliseconds since epoch.
11
12 * Decimal values are converted to floating point.
13
14 * Sequences (Pandas Series, NumPy arrays, python sequences) that are passed
15 though this interface are converted to lists. Note, however, that arrays in
16 data sources inside Bokeh Documents are converted elsewhere, and by default
17 use a binary encoded format.
18
19 * Bokeh ``Model`` instances are usually serialized elsewhere in the context
20 of an entire Bokeh Document. Models passed trough this interface are
21 converted to references.
22
23 * ``HasProps`` (that are not Bokeh models) are converted to key/value dicts or
24 all their properties and values.
25
26 * ``Color`` instances are converted to CSS color values.
27
28 .. |serialize_json| replace:: :class:`~bokeh.core.json_encoder.serialize_json`
29 .. |BokehJSONEncoder| replace:: :class:`~bokeh.core.json_encoder.BokehJSONEncoder`
30
31 '''
32 from __future__ import absolute_import
33
34 import logging
35 log = logging.getLogger(__name__)
36
37 import collections
38 import datetime as dt
39 import decimal
40 import json
41 import time
42
43 import numpy as np
44
45 from ..settings import settings
46 from ..util.dependencies import import_optional
47 from ..util.serialization import transform_series, transform_array
48
49 pd = import_optional('pandas')
50 rd = import_optional("dateutil.relativedelta")
51
52 NP_EPOCH = np.datetime64('1970-01-01T00:00:00Z')
53 NP_MS_DELTA = np.timedelta64(1, 'ms')
54
55 class BokehJSONEncoder(json.JSONEncoder):
56 ''' A custom ``json.JSONEncoder`` subclass for encoding objects in
57 accordance with the BokehJS protocol.
58
59 '''
60 def transform_python_types(self, obj):
61 ''' Handle special scalars such as (Python, NumPy, or Pandas)
62 datetimes, or Decimal values.
63
64 Args:
65 obj (obj) :
66
67 The object to encode. Anything not specifically handled in
68 this method is passed on to the default system JSON encoder.
69
70 '''
71
72 # Pandas Timestamp
73 if pd and isinstance(obj, pd.tslib.Timestamp):
74 return obj.value / 10**6.0 #nanosecond to millisecond
75 elif np.issubdtype(type(obj), np.float):
76 return float(obj)
77 elif np.issubdtype(type(obj), np.integer):
78 return int(obj)
79 elif np.issubdtype(type(obj), np.bool_):
80 return bool(obj)
81
82 # Datetime (datetime is a subclass of date)
83 elif isinstance(obj, dt.datetime):
84 return time.mktime(obj.timetuple()) * 1000. + obj.microsecond / 1000.
85
86 # Timedelta (timedelta is class in the datetime library)
87 elif isinstance(obj, dt.timedelta):
88 return obj.total_seconds() * 1000.
89
90 # Date
91 elif isinstance(obj, dt.date):
92 return time.mktime(obj.timetuple()) * 1000.
93
94 # Numpy datetime64
95 elif isinstance(obj, np.datetime64):
96 epoch_delta = obj - NP_EPOCH
97 return (epoch_delta / NP_MS_DELTA)
98
99 # Time
100 elif isinstance(obj, dt.time):
101 return (obj.hour * 3600 + obj.minute * 60 + obj.second) * 1000 + obj.microsecond / 1000.
102 elif rd and isinstance(obj, rd.relativedelta):
103 return dict(years=obj.years,
104 months=obj.months,
105 days=obj.days,
106 hours=obj.hours,
107 minutes=obj.minutes,
108 seconds=obj.seconds,
109 microseconds=obj.microseconds)
110
111 # Decimal
112 elif isinstance(obj, decimal.Decimal):
113 return float(obj)
114
115 else:
116 return super(BokehJSONEncoder, self).default(obj)
117
118 def default(self, obj):
119 ''' The required ``default`` method for JSONEncoder subclasses.
120
121 Args:
122 obj (obj) :
123
124 The object to encode. Anything not specifically handled in
125 this method is passed on to the default system JSON encoder.
126
127 '''
128
129 from ..model import Model
130 from ..colors import Color
131 from .has_props import HasProps
132
133 # array types -- use force_list here, only binary
134 # encoding CDS columns for now
135 if pd and isinstance(obj, (pd.Series, pd.Index)):
136 return transform_series(obj, force_list=True)
137 elif isinstance(obj, np.ndarray):
138 return transform_array(obj, force_list=True)
139 elif isinstance(obj, collections.deque):
140 return list(map(self.default, obj))
141 elif isinstance(obj, Model):
142 return obj.ref
143 elif isinstance(obj, HasProps):
144 return obj.properties_with_values(include_defaults=False)
145 elif isinstance(obj, Color):
146 return obj.to_css()
147
148 else:
149 return self.transform_python_types(obj)
150
151 def serialize_json(obj, pretty=False, indent=None, **kwargs):
152 ''' Return a serialized JSON representation of objects, suitable to
153 send to BokehJS.
154
155 This function is typically used to serialize single python objects in
156 the manner expected by BokehJS. In particular, many datetime values are
157 automatically normalized to an expected format. Some Bokeh objects can
158 also be passed, but note that Bokeh models are typically properly
159 serialized in the context of an entire Bokeh document.
160
161 The resulting JSON always has sorted keys. By default. the output is
162 as compact as possible unless pretty output or indentation is requested.
163
164 Args:
165 obj (obj) : the object to serialize to JSON format
166
167 pretty (bool, optional) :
168
169 Whether to generate prettified output. If ``True``, spaces are
170 added after added after separators, and indentation and newlines
171 are applied. (default: False)
172
173 Pretty output can also be enabled with the environment variable
174 ``BOKEH_PRETTY``, which overrides this argument, if set.
175
176 indent (int or None, optional) :
177
178 Amount of indentation to use in generated JSON output. If ``None``
179 then no indentation is used, unless pretty output is enabled,
180 in which case two spaces are used. (default: None)
181
182 Any additional keyword arguments are passed to ``json.dumps``, except for
183 some that are computed internally, and cannot be overridden:
184
185 * allow_nan
186 * indent
187 * separators
188 * sort_keys
189
190 Examples:
191
192 .. code-block:: python
193
194 >>> data = dict(b=np.datetime64('2017-01-01'), a = np.arange(3))
195
196 >>>print(serialize_json(data))
197 {"a":[0,1,2],"b":1483228800000.0}
198
199 >>> print(serialize_json(data, pretty=True))
200 {
201 "a": [
202 0,
203 1,
204 2
205 ],
206 "b": 1483228800000.0
207 }
208
209 '''
210
211 # these args to json.dumps are computed internally and should not be passed along
212 for name in ['allow_nan', 'separators', 'sort_keys']:
213 if name in kwargs:
214 raise ValueError("The value of %r is computed internally, overriding is not permissable." % name)
215
216 pretty = settings.pretty(pretty)
217
218 if pretty:
219 separators=(",", ": ")
220 else:
221 separators=(",", ":")
222
223 if pretty and indent is None:
224 indent = 2
225
226 return json.dumps(obj, cls=BokehJSONEncoder, allow_nan=False, indent=indent, separators=separators, sort_keys=True, **kwargs)
227
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/core/json_encoder.py b/bokeh/core/json_encoder.py
--- a/bokeh/core/json_encoder.py
+++ b/bokeh/core/json_encoder.py
@@ -49,8 +49,8 @@
pd = import_optional('pandas')
rd = import_optional("dateutil.relativedelta")
-NP_EPOCH = np.datetime64('1970-01-01T00:00:00Z')
-NP_MS_DELTA = np.timedelta64(1, 'ms')
+_NP_EPOCH = np.datetime64(0, 'ms')
+_NP_MS_DELTA = np.timedelta64(1, 'ms')
class BokehJSONEncoder(json.JSONEncoder):
''' A custom ``json.JSONEncoder`` subclass for encoding objects in
@@ -93,8 +93,8 @@
# Numpy datetime64
elif isinstance(obj, np.datetime64):
- epoch_delta = obj - NP_EPOCH
- return (epoch_delta / NP_MS_DELTA)
+ epoch_delta = obj - _NP_EPOCH
+ return (epoch_delta / _NP_MS_DELTA)
# Time
elif isinstance(obj, dt.time):
|
{"golden_diff": "diff --git a/bokeh/core/json_encoder.py b/bokeh/core/json_encoder.py\n--- a/bokeh/core/json_encoder.py\n+++ b/bokeh/core/json_encoder.py\n@@ -49,8 +49,8 @@\n pd = import_optional('pandas')\n rd = import_optional(\"dateutil.relativedelta\")\n \n-NP_EPOCH = np.datetime64('1970-01-01T00:00:00Z')\n-NP_MS_DELTA = np.timedelta64(1, 'ms')\n+_NP_EPOCH = np.datetime64(0, 'ms')\n+_NP_MS_DELTA = np.timedelta64(1, 'ms')\n \n class BokehJSONEncoder(json.JSONEncoder):\n ''' A custom ``json.JSONEncoder`` subclass for encoding objects in\n@@ -93,8 +93,8 @@\n \n # Numpy datetime64\n elif isinstance(obj, np.datetime64):\n- epoch_delta = obj - NP_EPOCH\n- return (epoch_delta / NP_MS_DELTA)\n+ epoch_delta = obj - _NP_EPOCH\n+ return (epoch_delta / _NP_MS_DELTA)\n \n # Time\n elif isinstance(obj, dt.time):\n", "issue": "Fix deprecated datetime64 use for NP_EPOCH\nFrom https://github.com/numpy/numpy/pull/6453 this causes a deprecation warning.\r\n/cc @shoyer\n", "before_files": [{"content": "''' Provide a functions and classes to implement a custom JSON encoder for\nserializing objects for BokehJS.\n\nThe primary interface is provided by the |serialize_json| function, which\nuses the custom |BokehJSONEncoder| to produce JSON output.\n\nIn general, functions in this module convert values in the following way:\n\n* Datetime values (Python, Pandas, NumPy) are converted to floating point\n milliseconds since epoch.\n\n* Decimal values are converted to floating point.\n\n* Sequences (Pandas Series, NumPy arrays, python sequences) that are passed\n though this interface are converted to lists. Note, however, that arrays in\n data sources inside Bokeh Documents are converted elsewhere, and by default\n use a binary encoded format.\n\n* Bokeh ``Model`` instances are usually serialized elsewhere in the context\n of an entire Bokeh Document. Models passed trough this interface are\n converted to references.\n\n* ``HasProps`` (that are not Bokeh models) are converted to key/value dicts or\n all their properties and values.\n\n* ``Color`` instances are converted to CSS color values.\n\n.. |serialize_json| replace:: :class:`~bokeh.core.json_encoder.serialize_json`\n.. |BokehJSONEncoder| replace:: :class:`~bokeh.core.json_encoder.BokehJSONEncoder`\n\n'''\nfrom __future__ import absolute_import\n\nimport logging\nlog = logging.getLogger(__name__)\n\nimport collections\nimport datetime as dt\nimport decimal\nimport json\nimport time\n\nimport numpy as np\n\nfrom ..settings import settings\nfrom ..util.dependencies import import_optional\nfrom ..util.serialization import transform_series, transform_array\n\npd = import_optional('pandas')\nrd = import_optional(\"dateutil.relativedelta\")\n\nNP_EPOCH = np.datetime64('1970-01-01T00:00:00Z')\nNP_MS_DELTA = np.timedelta64(1, 'ms')\n\nclass BokehJSONEncoder(json.JSONEncoder):\n ''' A custom ``json.JSONEncoder`` subclass for encoding objects in\n accordance with the BokehJS protocol.\n\n '''\n def transform_python_types(self, obj):\n ''' Handle special scalars such as (Python, NumPy, or Pandas)\n datetimes, or Decimal values.\n\n Args:\n obj (obj) :\n\n The object to encode. Anything not specifically handled in\n this method is passed on to the default system JSON encoder.\n\n '''\n\n # Pandas Timestamp\n if pd and isinstance(obj, pd.tslib.Timestamp):\n return obj.value / 10**6.0 #nanosecond to millisecond\n elif np.issubdtype(type(obj), np.float):\n return float(obj)\n elif np.issubdtype(type(obj), np.integer):\n return int(obj)\n elif np.issubdtype(type(obj), np.bool_):\n return bool(obj)\n\n # Datetime (datetime is a subclass of date)\n elif isinstance(obj, dt.datetime):\n return time.mktime(obj.timetuple()) * 1000. + obj.microsecond / 1000.\n\n # Timedelta (timedelta is class in the datetime library)\n elif isinstance(obj, dt.timedelta):\n return obj.total_seconds() * 1000.\n\n # Date\n elif isinstance(obj, dt.date):\n return time.mktime(obj.timetuple()) * 1000.\n\n # Numpy datetime64\n elif isinstance(obj, np.datetime64):\n epoch_delta = obj - NP_EPOCH\n return (epoch_delta / NP_MS_DELTA)\n\n # Time\n elif isinstance(obj, dt.time):\n return (obj.hour * 3600 + obj.minute * 60 + obj.second) * 1000 + obj.microsecond / 1000.\n elif rd and isinstance(obj, rd.relativedelta):\n return dict(years=obj.years,\n months=obj.months,\n days=obj.days,\n hours=obj.hours,\n minutes=obj.minutes,\n seconds=obj.seconds,\n microseconds=obj.microseconds)\n\n # Decimal\n elif isinstance(obj, decimal.Decimal):\n return float(obj)\n\n else:\n return super(BokehJSONEncoder, self).default(obj)\n\n def default(self, obj):\n ''' The required ``default`` method for JSONEncoder subclasses.\n\n Args:\n obj (obj) :\n\n The object to encode. Anything not specifically handled in\n this method is passed on to the default system JSON encoder.\n\n '''\n\n from ..model import Model\n from ..colors import Color\n from .has_props import HasProps\n\n # array types -- use force_list here, only binary\n # encoding CDS columns for now\n if pd and isinstance(obj, (pd.Series, pd.Index)):\n return transform_series(obj, force_list=True)\n elif isinstance(obj, np.ndarray):\n return transform_array(obj, force_list=True)\n elif isinstance(obj, collections.deque):\n return list(map(self.default, obj))\n elif isinstance(obj, Model):\n return obj.ref\n elif isinstance(obj, HasProps):\n return obj.properties_with_values(include_defaults=False)\n elif isinstance(obj, Color):\n return obj.to_css()\n\n else:\n return self.transform_python_types(obj)\n\ndef serialize_json(obj, pretty=False, indent=None, **kwargs):\n ''' Return a serialized JSON representation of objects, suitable to\n send to BokehJS.\n\n This function is typically used to serialize single python objects in\n the manner expected by BokehJS. In particular, many datetime values are\n automatically normalized to an expected format. Some Bokeh objects can\n also be passed, but note that Bokeh models are typically properly\n serialized in the context of an entire Bokeh document.\n\n The resulting JSON always has sorted keys. By default. the output is\n as compact as possible unless pretty output or indentation is requested.\n\n Args:\n obj (obj) : the object to serialize to JSON format\n\n pretty (bool, optional) :\n\n Whether to generate prettified output. If ``True``, spaces are\n added after added after separators, and indentation and newlines\n are applied. (default: False)\n\n Pretty output can also be enabled with the environment variable\n ``BOKEH_PRETTY``, which overrides this argument, if set.\n\n indent (int or None, optional) :\n\n Amount of indentation to use in generated JSON output. If ``None``\n then no indentation is used, unless pretty output is enabled,\n in which case two spaces are used. (default: None)\n\n Any additional keyword arguments are passed to ``json.dumps``, except for\n some that are computed internally, and cannot be overridden:\n\n * allow_nan\n * indent\n * separators\n * sort_keys\n\n Examples:\n\n .. code-block:: python\n\n >>> data = dict(b=np.datetime64('2017-01-01'), a = np.arange(3))\n\n >>>print(serialize_json(data))\n {\"a\":[0,1,2],\"b\":1483228800000.0}\n\n >>> print(serialize_json(data, pretty=True))\n {\n \"a\": [\n 0,\n 1,\n 2\n ],\n \"b\": 1483228800000.0\n }\n\n '''\n\n # these args to json.dumps are computed internally and should not be passed along\n for name in ['allow_nan', 'separators', 'sort_keys']:\n if name in kwargs:\n raise ValueError(\"The value of %r is computed internally, overriding is not permissable.\" % name)\n\n pretty = settings.pretty(pretty)\n\n if pretty:\n separators=(\",\", \": \")\n else:\n separators=(\",\", \":\")\n\n if pretty and indent is None:\n indent = 2\n\n return json.dumps(obj, cls=BokehJSONEncoder, allow_nan=False, indent=indent, separators=separators, sort_keys=True, **kwargs)\n", "path": "bokeh/core/json_encoder.py"}], "after_files": [{"content": "''' Provide a functions and classes to implement a custom JSON encoder for\nserializing objects for BokehJS.\n\nThe primary interface is provided by the |serialize_json| function, which\nuses the custom |BokehJSONEncoder| to produce JSON output.\n\nIn general, functions in this module convert values in the following way:\n\n* Datetime values (Python, Pandas, NumPy) are converted to floating point\n milliseconds since epoch.\n\n* Decimal values are converted to floating point.\n\n* Sequences (Pandas Series, NumPy arrays, python sequences) that are passed\n though this interface are converted to lists. Note, however, that arrays in\n data sources inside Bokeh Documents are converted elsewhere, and by default\n use a binary encoded format.\n\n* Bokeh ``Model`` instances are usually serialized elsewhere in the context\n of an entire Bokeh Document. Models passed trough this interface are\n converted to references.\n\n* ``HasProps`` (that are not Bokeh models) are converted to key/value dicts or\n all their properties and values.\n\n* ``Color`` instances are converted to CSS color values.\n\n.. |serialize_json| replace:: :class:`~bokeh.core.json_encoder.serialize_json`\n.. |BokehJSONEncoder| replace:: :class:`~bokeh.core.json_encoder.BokehJSONEncoder`\n\n'''\nfrom __future__ import absolute_import\n\nimport logging\nlog = logging.getLogger(__name__)\n\nimport collections\nimport datetime as dt\nimport decimal\nimport json\nimport time\n\nimport numpy as np\n\nfrom ..settings import settings\nfrom ..util.dependencies import import_optional\nfrom ..util.serialization import transform_series, transform_array\n\npd = import_optional('pandas')\nrd = import_optional(\"dateutil.relativedelta\")\n\n_NP_EPOCH = np.datetime64(0, 'ms')\n_NP_MS_DELTA = np.timedelta64(1, 'ms')\n\nclass BokehJSONEncoder(json.JSONEncoder):\n ''' A custom ``json.JSONEncoder`` subclass for encoding objects in\n accordance with the BokehJS protocol.\n\n '''\n def transform_python_types(self, obj):\n ''' Handle special scalars such as (Python, NumPy, or Pandas)\n datetimes, or Decimal values.\n\n Args:\n obj (obj) :\n\n The object to encode. Anything not specifically handled in\n this method is passed on to the default system JSON encoder.\n\n '''\n\n # Pandas Timestamp\n if pd and isinstance(obj, pd.tslib.Timestamp):\n return obj.value / 10**6.0 #nanosecond to millisecond\n elif np.issubdtype(type(obj), np.float):\n return float(obj)\n elif np.issubdtype(type(obj), np.integer):\n return int(obj)\n elif np.issubdtype(type(obj), np.bool_):\n return bool(obj)\n\n # Datetime (datetime is a subclass of date)\n elif isinstance(obj, dt.datetime):\n return time.mktime(obj.timetuple()) * 1000. + obj.microsecond / 1000.\n\n # Timedelta (timedelta is class in the datetime library)\n elif isinstance(obj, dt.timedelta):\n return obj.total_seconds() * 1000.\n\n # Date\n elif isinstance(obj, dt.date):\n return time.mktime(obj.timetuple()) * 1000.\n\n # Numpy datetime64\n elif isinstance(obj, np.datetime64):\n epoch_delta = obj - _NP_EPOCH\n return (epoch_delta / _NP_MS_DELTA)\n\n # Time\n elif isinstance(obj, dt.time):\n return (obj.hour * 3600 + obj.minute * 60 + obj.second) * 1000 + obj.microsecond / 1000.\n elif rd and isinstance(obj, rd.relativedelta):\n return dict(years=obj.years,\n months=obj.months,\n days=obj.days,\n hours=obj.hours,\n minutes=obj.minutes,\n seconds=obj.seconds,\n microseconds=obj.microseconds)\n\n # Decimal\n elif isinstance(obj, decimal.Decimal):\n return float(obj)\n\n else:\n return super(BokehJSONEncoder, self).default(obj)\n\n def default(self, obj):\n ''' The required ``default`` method for JSONEncoder subclasses.\n\n Args:\n obj (obj) :\n\n The object to encode. Anything not specifically handled in\n this method is passed on to the default system JSON encoder.\n\n '''\n\n from ..model import Model\n from ..colors import Color\n from .has_props import HasProps\n\n # array types -- use force_list here, only binary\n # encoding CDS columns for now\n if pd and isinstance(obj, (pd.Series, pd.Index)):\n return transform_series(obj, force_list=True)\n elif isinstance(obj, np.ndarray):\n return transform_array(obj, force_list=True)\n elif isinstance(obj, collections.deque):\n return list(map(self.default, obj))\n elif isinstance(obj, Model):\n return obj.ref\n elif isinstance(obj, HasProps):\n return obj.properties_with_values(include_defaults=False)\n elif isinstance(obj, Color):\n return obj.to_css()\n\n else:\n return self.transform_python_types(obj)\n\ndef serialize_json(obj, pretty=False, indent=None, **kwargs):\n ''' Return a serialized JSON representation of objects, suitable to\n send to BokehJS.\n\n This function is typically used to serialize single python objects in\n the manner expected by BokehJS. In particular, many datetime values are\n automatically normalized to an expected format. Some Bokeh objects can\n also be passed, but note that Bokeh models are typically properly\n serialized in the context of an entire Bokeh document.\n\n The resulting JSON always has sorted keys. By default. the output is\n as compact as possible unless pretty output or indentation is requested.\n\n Args:\n obj (obj) : the object to serialize to JSON format\n\n pretty (bool, optional) :\n\n Whether to generate prettified output. If ``True``, spaces are\n added after added after separators, and indentation and newlines\n are applied. (default: False)\n\n Pretty output can also be enabled with the environment variable\n ``BOKEH_PRETTY``, which overrides this argument, if set.\n\n indent (int or None, optional) :\n\n Amount of indentation to use in generated JSON output. If ``None``\n then no indentation is used, unless pretty output is enabled,\n in which case two spaces are used. (default: None)\n\n Any additional keyword arguments are passed to ``json.dumps``, except for\n some that are computed internally, and cannot be overridden:\n\n * allow_nan\n * indent\n * separators\n * sort_keys\n\n Examples:\n\n .. code-block:: python\n\n >>> data = dict(b=np.datetime64('2017-01-01'), a = np.arange(3))\n\n >>>print(serialize_json(data))\n {\"a\":[0,1,2],\"b\":1483228800000.0}\n\n >>> print(serialize_json(data, pretty=True))\n {\n \"a\": [\n 0,\n 1,\n 2\n ],\n \"b\": 1483228800000.0\n }\n\n '''\n\n # these args to json.dumps are computed internally and should not be passed along\n for name in ['allow_nan', 'separators', 'sort_keys']:\n if name in kwargs:\n raise ValueError(\"The value of %r is computed internally, overriding is not permissable.\" % name)\n\n pretty = settings.pretty(pretty)\n\n if pretty:\n separators=(\",\", \": \")\n else:\n separators=(\",\", \":\")\n\n if pretty and indent is None:\n indent = 2\n\n return json.dumps(obj, cls=BokehJSONEncoder, allow_nan=False, indent=indent, separators=separators, sort_keys=True, **kwargs)\n", "path": "bokeh/core/json_encoder.py"}]}
| 2,629 | 264 |
gh_patches_debug_29358
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-809
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
State Abbreviations for en_US have too many
The output of the state provider in address only outputs the 50 states, but the state_abbr has 59 potential outputs
### Steps to reproduce
Generate a value using the state_abbr provider
### Expected behavior
The value should be one of the 50 US states abbreviations
### Actual behavior
The value is one of the 50 US states, Washington DC (DC), American Samoa (AS), Micronesia (FM), Guam (GU), Marshall Islands (MH), Northern Marianas (MP), Palau (PW), Puerto Rico (PR), and Virgin Isles (VI). It appears the list was pulled from sources such as https://www.factmonster.com/us/postal-information/state-abbreviations-and-state-postal-codes that list every possible postal state abbreviation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/address/en_US/__init__.py`
Content:
```
1 from __future__ import unicode_literals
2 from collections import OrderedDict
3
4 from ..en import Provider as AddressProvider
5
6
7 class Provider(AddressProvider):
8 city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')
9
10 city_suffixes = (
11 'town',
12 'ton',
13 'land',
14 'ville',
15 'berg',
16 'burgh',
17 'borough',
18 'bury',
19 'view',
20 'port',
21 'mouth',
22 'stad',
23 'furt',
24 'chester',
25 'mouth',
26 'fort',
27 'haven',
28 'side',
29 'shire')
30
31 building_number_formats = ('#####', '####', '###')
32
33 street_suffixes = (
34 'Alley',
35 'Avenue',
36 'Branch',
37 'Bridge',
38 'Brook',
39 'Brooks',
40 'Burg',
41 'Burgs',
42 'Bypass',
43 'Camp',
44 'Canyon',
45 'Cape',
46 'Causeway',
47 'Center',
48 'Centers',
49 'Circle',
50 'Circles',
51 'Cliff',
52 'Cliffs',
53 'Club',
54 'Common',
55 'Corner',
56 'Corners',
57 'Course',
58 'Court',
59 'Courts',
60 'Cove',
61 'Coves',
62 'Creek',
63 'Crescent',
64 'Crest',
65 'Crossing',
66 'Crossroad',
67 'Curve',
68 'Dale',
69 'Dam',
70 'Divide',
71 'Drive',
72 'Drive',
73 'Drives',
74 'Estate',
75 'Estates',
76 'Expressway',
77 'Extension',
78 'Extensions',
79 'Fall',
80 'Falls',
81 'Ferry',
82 'Field',
83 'Fields',
84 'Flat',
85 'Flats',
86 'Ford',
87 'Fords',
88 'Forest',
89 'Forge',
90 'Forges',
91 'Fork',
92 'Forks',
93 'Fort',
94 'Freeway',
95 'Garden',
96 'Gardens',
97 'Gateway',
98 'Glen',
99 'Glens',
100 'Green',
101 'Greens',
102 'Grove',
103 'Groves',
104 'Harbor',
105 'Harbors',
106 'Haven',
107 'Heights',
108 'Highway',
109 'Hill',
110 'Hills',
111 'Hollow',
112 'Inlet',
113 'Inlet',
114 'Island',
115 'Island',
116 'Islands',
117 'Islands',
118 'Isle',
119 'Isle',
120 'Junction',
121 'Junctions',
122 'Key',
123 'Keys',
124 'Knoll',
125 'Knolls',
126 'Lake',
127 'Lakes',
128 'Land',
129 'Landing',
130 'Lane',
131 'Light',
132 'Lights',
133 'Loaf',
134 'Lock',
135 'Locks',
136 'Locks',
137 'Lodge',
138 'Lodge',
139 'Loop',
140 'Mall',
141 'Manor',
142 'Manors',
143 'Meadow',
144 'Meadows',
145 'Mews',
146 'Mill',
147 'Mills',
148 'Mission',
149 'Mission',
150 'Motorway',
151 'Mount',
152 'Mountain',
153 'Mountain',
154 'Mountains',
155 'Mountains',
156 'Neck',
157 'Orchard',
158 'Oval',
159 'Overpass',
160 'Park',
161 'Parks',
162 'Parkway',
163 'Parkways',
164 'Pass',
165 'Passage',
166 'Path',
167 'Pike',
168 'Pine',
169 'Pines',
170 'Place',
171 'Plain',
172 'Plains',
173 'Plains',
174 'Plaza',
175 'Plaza',
176 'Point',
177 'Points',
178 'Port',
179 'Port',
180 'Ports',
181 'Ports',
182 'Prairie',
183 'Prairie',
184 'Radial',
185 'Ramp',
186 'Ranch',
187 'Rapid',
188 'Rapids',
189 'Rest',
190 'Ridge',
191 'Ridges',
192 'River',
193 'Road',
194 'Road',
195 'Roads',
196 'Roads',
197 'Route',
198 'Row',
199 'Rue',
200 'Run',
201 'Shoal',
202 'Shoals',
203 'Shore',
204 'Shores',
205 'Skyway',
206 'Spring',
207 'Springs',
208 'Springs',
209 'Spur',
210 'Spurs',
211 'Square',
212 'Square',
213 'Squares',
214 'Squares',
215 'Station',
216 'Station',
217 'Stravenue',
218 'Stravenue',
219 'Stream',
220 'Stream',
221 'Street',
222 'Street',
223 'Streets',
224 'Summit',
225 'Summit',
226 'Terrace',
227 'Throughway',
228 'Trace',
229 'Track',
230 'Trafficway',
231 'Trail',
232 'Trail',
233 'Tunnel',
234 'Tunnel',
235 'Turnpike',
236 'Turnpike',
237 'Underpass',
238 'Union',
239 'Unions',
240 'Valley',
241 'Valleys',
242 'Via',
243 'Viaduct',
244 'View',
245 'Views',
246 'Village',
247 'Village',
248 'Villages',
249 'Ville',
250 'Vista',
251 'Vista',
252 'Walk',
253 'Walks',
254 'Wall',
255 'Way',
256 'Ways',
257 'Well',
258 'Wells')
259
260 postcode_formats = ('#####', '#####-####')
261
262 states = (
263 'Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado',
264 'Connecticut', 'Delaware', 'Florida', 'Georgia', 'Hawaii', 'Idaho',
265 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',
266 'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',
267 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',
268 'New Hampshire', 'New Jersey', 'New Mexico', 'New York',
269 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',
270 'Pennsylvania', 'Rhode Island', 'South Carolina', 'South Dakota',
271 'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington',
272 'West Virginia', 'Wisconsin', 'Wyoming',
273 )
274 states_abbr = (
275 'AL', 'AK', 'AS', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FM', 'FL',
276 'GA', 'GU', 'HI', 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MH',
277 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM',
278 'NY', 'NC', 'ND', 'MP', 'OH', 'OK', 'OR', 'PW', 'PA', 'PR', 'RI', 'SC',
279 'SD', 'TN', 'TX', 'UT', 'VT', 'VI', 'VA', 'WA', 'WV', 'WI', 'WY',
280 )
281
282 military_state_abbr = ('AE', 'AA', 'AP')
283
284 military_ship_prefix = ('USS', 'USNS', 'USNV', 'USCGC')
285
286 military_apo_format = ("PSC ####, Box ####")
287
288 military_dpo_format = ("Unit #### Box ####")
289
290 city_formats = (
291 '{{city_prefix}} {{first_name}}{{city_suffix}}',
292 '{{city_prefix}} {{first_name}}',
293 '{{first_name}}{{city_suffix}}',
294 '{{last_name}}{{city_suffix}}',
295 )
296
297 street_name_formats = (
298 '{{first_name}} {{street_suffix}}',
299 '{{last_name}} {{street_suffix}}'
300 )
301
302 street_address_formats = (
303 '{{building_number}} {{street_name}}',
304 '{{building_number}} {{street_name}} {{secondary_address}}',
305 )
306
307 address_formats = (
308 "{{street_address}}\n{{city}}, {{state_abbr}} {{postcode}}",
309 )
310
311 address_formats = OrderedDict((
312 ("{{street_address}}\n{{city}}, {{state_abbr}} {{postcode}}", 25),
313 # military address formatting.
314 ("{{military_apo}}\nAPO {{military_state}} {{postcode}}", 1),
315 ("{{military_ship}} {{last_name}}\nFPO {{military_state}} {{postcode}}", 1),
316 ("{{military_dpo}}\nDPO {{military_state}} {{postcode}}", 1),
317 ))
318
319 secondary_address_formats = ('Apt. ###', 'Suite ###')
320
321 def city_prefix(self):
322 return self.random_element(self.city_prefixes)
323
324 def secondary_address(self):
325 return self.numerify(
326 self.random_element(
327 self.secondary_address_formats))
328
329 def state(self):
330 return self.random_element(self.states)
331
332 def state_abbr(self):
333 return self.random_element(self.states_abbr)
334
335 def postcode(self):
336 return "%05d" % self.generator.random.randint(501, 99950)
337
338 def zipcode_plus4(self):
339 return "%s-%04d" % (self.zipcode(),
340 self.generator.random.randint(1, 9999))
341
342 def military_ship(self):
343 """
344 :example 'USS'
345 """
346 return self.random_element(self.military_ship_prefix)
347
348 def military_state(self):
349 """
350 :example 'APO'
351 """
352 return self.random_element(self.military_state_abbr)
353
354 def military_apo(self):
355 """
356 :example 'PSC 5394 Box 3492
357 """
358 return self.numerify(self.military_apo_format)
359
360 def military_dpo(self):
361 """
362 :example 'Unit 3333 Box 9342'
363 """
364 return self.numerify(self.military_dpo_format)
365
366 # Aliases
367 def zipcode(self):
368 return self.postcode()
369
370 def postalcode(self):
371 return self.postcode()
372
373 def postalcode_plus4(self):
374 return self.zipcode_plus4()
375
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/address/en_US/__init__.py b/faker/providers/address/en_US/__init__.py
--- a/faker/providers/address/en_US/__init__.py
+++ b/faker/providers/address/en_US/__init__.py
@@ -272,13 +272,19 @@
'West Virginia', 'Wisconsin', 'Wyoming',
)
states_abbr = (
- 'AL', 'AK', 'AS', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FM', 'FL',
- 'GA', 'GU', 'HI', 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MH',
- 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM',
- 'NY', 'NC', 'ND', 'MP', 'OH', 'OK', 'OR', 'PW', 'PA', 'PR', 'RI', 'SC',
- 'SD', 'TN', 'TX', 'UT', 'VT', 'VI', 'VA', 'WA', 'WV', 'WI', 'WY',
+ 'AL', 'AK', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FL', 'GA', 'HI',
+ 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MD', 'MA', 'MI', 'MN',
+ 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM', 'NY', 'NC', 'ND', 'OH',
+ 'OK', 'OR', 'PA', 'RI', 'SC', 'SD', 'TN', 'TX', 'UT', 'VT', 'VA', 'WA',
+ 'WV', 'WI', 'WY',
)
+ territories_abbr = (
+ 'AS', 'FM', 'GU', 'MH', 'MP', 'PW', 'PR', 'VI',
+ )
+
+ states_and_territories_abbr = states_abbr + territories_abbr
+
military_state_abbr = ('AE', 'AA', 'AP')
military_ship_prefix = ('USS', 'USNS', 'USNV', 'USCGC')
@@ -329,7 +335,15 @@
def state(self):
return self.random_element(self.states)
- def state_abbr(self):
+ def state_abbr(self, include_territories=True):
+ """
+ :returns: A random state or territory abbreviation.
+
+ :param include_territories: If True, territories will be included.
+ If False, only states will be returned.
+ """
+ if include_territories:
+ self.random_element(self.states_and_territories_abbr)
return self.random_element(self.states_abbr)
def postcode(self):
|
{"golden_diff": "diff --git a/faker/providers/address/en_US/__init__.py b/faker/providers/address/en_US/__init__.py\n--- a/faker/providers/address/en_US/__init__.py\n+++ b/faker/providers/address/en_US/__init__.py\n@@ -272,13 +272,19 @@\n 'West Virginia', 'Wisconsin', 'Wyoming',\n )\n states_abbr = (\n- 'AL', 'AK', 'AS', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FM', 'FL',\n- 'GA', 'GU', 'HI', 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MH',\n- 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM',\n- 'NY', 'NC', 'ND', 'MP', 'OH', 'OK', 'OR', 'PW', 'PA', 'PR', 'RI', 'SC',\n- 'SD', 'TN', 'TX', 'UT', 'VT', 'VI', 'VA', 'WA', 'WV', 'WI', 'WY',\n+ 'AL', 'AK', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FL', 'GA', 'HI',\n+ 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MD', 'MA', 'MI', 'MN',\n+ 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM', 'NY', 'NC', 'ND', 'OH',\n+ 'OK', 'OR', 'PA', 'RI', 'SC', 'SD', 'TN', 'TX', 'UT', 'VT', 'VA', 'WA',\n+ 'WV', 'WI', 'WY',\n )\n \n+ territories_abbr = (\n+ 'AS', 'FM', 'GU', 'MH', 'MP', 'PW', 'PR', 'VI',\n+ )\n+\n+ states_and_territories_abbr = states_abbr + territories_abbr\n+\n military_state_abbr = ('AE', 'AA', 'AP')\n \n military_ship_prefix = ('USS', 'USNS', 'USNV', 'USCGC')\n@@ -329,7 +335,15 @@\n def state(self):\n return self.random_element(self.states)\n \n- def state_abbr(self):\n+ def state_abbr(self, include_territories=True):\n+ \"\"\"\n+ :returns: A random state or territory abbreviation.\n+\n+ :param include_territories: If True, territories will be included.\n+ If False, only states will be returned.\n+ \"\"\"\n+ if include_territories:\n+ self.random_element(self.states_and_territories_abbr)\n return self.random_element(self.states_abbr)\n \n def postcode(self):\n", "issue": "State Abbreviations for en_US have too many\nThe output of the state provider in address only outputs the 50 states, but the state_abbr has 59 potential outputs\r\n\r\n### Steps to reproduce\r\n\r\nGenerate a value using the state_abbr provider\r\n\r\n### Expected behavior\r\n\r\nThe value should be one of the 50 US states abbreviations\r\n\r\n### Actual behavior\r\n\r\nThe value is one of the 50 US states, Washington DC (DC), American Samoa (AS), Micronesia (FM), Guam (GU), Marshall Islands (MH), Northern Marianas (MP), Palau (PW), Puerto Rico (PR), and Virgin Isles (VI). It appears the list was pulled from sources such as https://www.factmonster.com/us/postal-information/state-abbreviations-and-state-postal-codes that list every possible postal state abbreviation. \n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom collections import OrderedDict\n\nfrom ..en import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')\n\n city_suffixes = (\n 'town',\n 'ton',\n 'land',\n 'ville',\n 'berg',\n 'burgh',\n 'borough',\n 'bury',\n 'view',\n 'port',\n 'mouth',\n 'stad',\n 'furt',\n 'chester',\n 'mouth',\n 'fort',\n 'haven',\n 'side',\n 'shire')\n\n building_number_formats = ('#####', '####', '###')\n\n street_suffixes = (\n 'Alley',\n 'Avenue',\n 'Branch',\n 'Bridge',\n 'Brook',\n 'Brooks',\n 'Burg',\n 'Burgs',\n 'Bypass',\n 'Camp',\n 'Canyon',\n 'Cape',\n 'Causeway',\n 'Center',\n 'Centers',\n 'Circle',\n 'Circles',\n 'Cliff',\n 'Cliffs',\n 'Club',\n 'Common',\n 'Corner',\n 'Corners',\n 'Course',\n 'Court',\n 'Courts',\n 'Cove',\n 'Coves',\n 'Creek',\n 'Crescent',\n 'Crest',\n 'Crossing',\n 'Crossroad',\n 'Curve',\n 'Dale',\n 'Dam',\n 'Divide',\n 'Drive',\n 'Drive',\n 'Drives',\n 'Estate',\n 'Estates',\n 'Expressway',\n 'Extension',\n 'Extensions',\n 'Fall',\n 'Falls',\n 'Ferry',\n 'Field',\n 'Fields',\n 'Flat',\n 'Flats',\n 'Ford',\n 'Fords',\n 'Forest',\n 'Forge',\n 'Forges',\n 'Fork',\n 'Forks',\n 'Fort',\n 'Freeway',\n 'Garden',\n 'Gardens',\n 'Gateway',\n 'Glen',\n 'Glens',\n 'Green',\n 'Greens',\n 'Grove',\n 'Groves',\n 'Harbor',\n 'Harbors',\n 'Haven',\n 'Heights',\n 'Highway',\n 'Hill',\n 'Hills',\n 'Hollow',\n 'Inlet',\n 'Inlet',\n 'Island',\n 'Island',\n 'Islands',\n 'Islands',\n 'Isle',\n 'Isle',\n 'Junction',\n 'Junctions',\n 'Key',\n 'Keys',\n 'Knoll',\n 'Knolls',\n 'Lake',\n 'Lakes',\n 'Land',\n 'Landing',\n 'Lane',\n 'Light',\n 'Lights',\n 'Loaf',\n 'Lock',\n 'Locks',\n 'Locks',\n 'Lodge',\n 'Lodge',\n 'Loop',\n 'Mall',\n 'Manor',\n 'Manors',\n 'Meadow',\n 'Meadows',\n 'Mews',\n 'Mill',\n 'Mills',\n 'Mission',\n 'Mission',\n 'Motorway',\n 'Mount',\n 'Mountain',\n 'Mountain',\n 'Mountains',\n 'Mountains',\n 'Neck',\n 'Orchard',\n 'Oval',\n 'Overpass',\n 'Park',\n 'Parks',\n 'Parkway',\n 'Parkways',\n 'Pass',\n 'Passage',\n 'Path',\n 'Pike',\n 'Pine',\n 'Pines',\n 'Place',\n 'Plain',\n 'Plains',\n 'Plains',\n 'Plaza',\n 'Plaza',\n 'Point',\n 'Points',\n 'Port',\n 'Port',\n 'Ports',\n 'Ports',\n 'Prairie',\n 'Prairie',\n 'Radial',\n 'Ramp',\n 'Ranch',\n 'Rapid',\n 'Rapids',\n 'Rest',\n 'Ridge',\n 'Ridges',\n 'River',\n 'Road',\n 'Road',\n 'Roads',\n 'Roads',\n 'Route',\n 'Row',\n 'Rue',\n 'Run',\n 'Shoal',\n 'Shoals',\n 'Shore',\n 'Shores',\n 'Skyway',\n 'Spring',\n 'Springs',\n 'Springs',\n 'Spur',\n 'Spurs',\n 'Square',\n 'Square',\n 'Squares',\n 'Squares',\n 'Station',\n 'Station',\n 'Stravenue',\n 'Stravenue',\n 'Stream',\n 'Stream',\n 'Street',\n 'Street',\n 'Streets',\n 'Summit',\n 'Summit',\n 'Terrace',\n 'Throughway',\n 'Trace',\n 'Track',\n 'Trafficway',\n 'Trail',\n 'Trail',\n 'Tunnel',\n 'Tunnel',\n 'Turnpike',\n 'Turnpike',\n 'Underpass',\n 'Union',\n 'Unions',\n 'Valley',\n 'Valleys',\n 'Via',\n 'Viaduct',\n 'View',\n 'Views',\n 'Village',\n 'Village',\n 'Villages',\n 'Ville',\n 'Vista',\n 'Vista',\n 'Walk',\n 'Walks',\n 'Wall',\n 'Way',\n 'Ways',\n 'Well',\n 'Wells')\n\n postcode_formats = ('#####', '#####-####')\n\n states = (\n 'Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado',\n 'Connecticut', 'Delaware', 'Florida', 'Georgia', 'Hawaii', 'Idaho',\n 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',\n 'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',\n 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',\n 'New Hampshire', 'New Jersey', 'New Mexico', 'New York',\n 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',\n 'Pennsylvania', 'Rhode Island', 'South Carolina', 'South Dakota',\n 'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington',\n 'West Virginia', 'Wisconsin', 'Wyoming',\n )\n states_abbr = (\n 'AL', 'AK', 'AS', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FM', 'FL',\n 'GA', 'GU', 'HI', 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MH',\n 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM',\n 'NY', 'NC', 'ND', 'MP', 'OH', 'OK', 'OR', 'PW', 'PA', 'PR', 'RI', 'SC',\n 'SD', 'TN', 'TX', 'UT', 'VT', 'VI', 'VA', 'WA', 'WV', 'WI', 'WY',\n )\n\n military_state_abbr = ('AE', 'AA', 'AP')\n\n military_ship_prefix = ('USS', 'USNS', 'USNV', 'USCGC')\n\n military_apo_format = (\"PSC ####, Box ####\")\n\n military_dpo_format = (\"Unit #### Box ####\")\n\n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n '{{city_prefix}} {{first_name}}',\n '{{first_name}}{{city_suffix}}',\n '{{last_name}}{{city_suffix}}',\n )\n\n street_name_formats = (\n '{{first_name}} {{street_suffix}}',\n '{{last_name}} {{street_suffix}}'\n )\n\n street_address_formats = (\n '{{building_number}} {{street_name}}',\n '{{building_number}} {{street_name}} {{secondary_address}}',\n )\n\n address_formats = (\n \"{{street_address}}\\n{{city}}, {{state_abbr}} {{postcode}}\",\n )\n\n address_formats = OrderedDict((\n (\"{{street_address}}\\n{{city}}, {{state_abbr}} {{postcode}}\", 25),\n # military address formatting.\n (\"{{military_apo}}\\nAPO {{military_state}} {{postcode}}\", 1),\n (\"{{military_ship}} {{last_name}}\\nFPO {{military_state}} {{postcode}}\", 1),\n (\"{{military_dpo}}\\nDPO {{military_state}} {{postcode}}\", 1),\n ))\n\n secondary_address_formats = ('Apt. ###', 'Suite ###')\n\n def city_prefix(self):\n return self.random_element(self.city_prefixes)\n\n def secondary_address(self):\n return self.numerify(\n self.random_element(\n self.secondary_address_formats))\n\n def state(self):\n return self.random_element(self.states)\n\n def state_abbr(self):\n return self.random_element(self.states_abbr)\n\n def postcode(self):\n return \"%05d\" % self.generator.random.randint(501, 99950)\n\n def zipcode_plus4(self):\n return \"%s-%04d\" % (self.zipcode(),\n self.generator.random.randint(1, 9999))\n\n def military_ship(self):\n \"\"\"\n :example 'USS'\n \"\"\"\n return self.random_element(self.military_ship_prefix)\n\n def military_state(self):\n \"\"\"\n :example 'APO'\n \"\"\"\n return self.random_element(self.military_state_abbr)\n\n def military_apo(self):\n \"\"\"\n :example 'PSC 5394 Box 3492\n \"\"\"\n return self.numerify(self.military_apo_format)\n\n def military_dpo(self):\n \"\"\"\n :example 'Unit 3333 Box 9342'\n \"\"\"\n return self.numerify(self.military_dpo_format)\n\n # Aliases\n def zipcode(self):\n return self.postcode()\n\n def postalcode(self):\n return self.postcode()\n\n def postalcode_plus4(self):\n return self.zipcode_plus4()\n", "path": "faker/providers/address/en_US/__init__.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom collections import OrderedDict\n\nfrom ..en import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')\n\n city_suffixes = (\n 'town',\n 'ton',\n 'land',\n 'ville',\n 'berg',\n 'burgh',\n 'borough',\n 'bury',\n 'view',\n 'port',\n 'mouth',\n 'stad',\n 'furt',\n 'chester',\n 'mouth',\n 'fort',\n 'haven',\n 'side',\n 'shire')\n\n building_number_formats = ('#####', '####', '###')\n\n street_suffixes = (\n 'Alley',\n 'Avenue',\n 'Branch',\n 'Bridge',\n 'Brook',\n 'Brooks',\n 'Burg',\n 'Burgs',\n 'Bypass',\n 'Camp',\n 'Canyon',\n 'Cape',\n 'Causeway',\n 'Center',\n 'Centers',\n 'Circle',\n 'Circles',\n 'Cliff',\n 'Cliffs',\n 'Club',\n 'Common',\n 'Corner',\n 'Corners',\n 'Course',\n 'Court',\n 'Courts',\n 'Cove',\n 'Coves',\n 'Creek',\n 'Crescent',\n 'Crest',\n 'Crossing',\n 'Crossroad',\n 'Curve',\n 'Dale',\n 'Dam',\n 'Divide',\n 'Drive',\n 'Drive',\n 'Drives',\n 'Estate',\n 'Estates',\n 'Expressway',\n 'Extension',\n 'Extensions',\n 'Fall',\n 'Falls',\n 'Ferry',\n 'Field',\n 'Fields',\n 'Flat',\n 'Flats',\n 'Ford',\n 'Fords',\n 'Forest',\n 'Forge',\n 'Forges',\n 'Fork',\n 'Forks',\n 'Fort',\n 'Freeway',\n 'Garden',\n 'Gardens',\n 'Gateway',\n 'Glen',\n 'Glens',\n 'Green',\n 'Greens',\n 'Grove',\n 'Groves',\n 'Harbor',\n 'Harbors',\n 'Haven',\n 'Heights',\n 'Highway',\n 'Hill',\n 'Hills',\n 'Hollow',\n 'Inlet',\n 'Inlet',\n 'Island',\n 'Island',\n 'Islands',\n 'Islands',\n 'Isle',\n 'Isle',\n 'Junction',\n 'Junctions',\n 'Key',\n 'Keys',\n 'Knoll',\n 'Knolls',\n 'Lake',\n 'Lakes',\n 'Land',\n 'Landing',\n 'Lane',\n 'Light',\n 'Lights',\n 'Loaf',\n 'Lock',\n 'Locks',\n 'Locks',\n 'Lodge',\n 'Lodge',\n 'Loop',\n 'Mall',\n 'Manor',\n 'Manors',\n 'Meadow',\n 'Meadows',\n 'Mews',\n 'Mill',\n 'Mills',\n 'Mission',\n 'Mission',\n 'Motorway',\n 'Mount',\n 'Mountain',\n 'Mountain',\n 'Mountains',\n 'Mountains',\n 'Neck',\n 'Orchard',\n 'Oval',\n 'Overpass',\n 'Park',\n 'Parks',\n 'Parkway',\n 'Parkways',\n 'Pass',\n 'Passage',\n 'Path',\n 'Pike',\n 'Pine',\n 'Pines',\n 'Place',\n 'Plain',\n 'Plains',\n 'Plains',\n 'Plaza',\n 'Plaza',\n 'Point',\n 'Points',\n 'Port',\n 'Port',\n 'Ports',\n 'Ports',\n 'Prairie',\n 'Prairie',\n 'Radial',\n 'Ramp',\n 'Ranch',\n 'Rapid',\n 'Rapids',\n 'Rest',\n 'Ridge',\n 'Ridges',\n 'River',\n 'Road',\n 'Road',\n 'Roads',\n 'Roads',\n 'Route',\n 'Row',\n 'Rue',\n 'Run',\n 'Shoal',\n 'Shoals',\n 'Shore',\n 'Shores',\n 'Skyway',\n 'Spring',\n 'Springs',\n 'Springs',\n 'Spur',\n 'Spurs',\n 'Square',\n 'Square',\n 'Squares',\n 'Squares',\n 'Station',\n 'Station',\n 'Stravenue',\n 'Stravenue',\n 'Stream',\n 'Stream',\n 'Street',\n 'Street',\n 'Streets',\n 'Summit',\n 'Summit',\n 'Terrace',\n 'Throughway',\n 'Trace',\n 'Track',\n 'Trafficway',\n 'Trail',\n 'Trail',\n 'Tunnel',\n 'Tunnel',\n 'Turnpike',\n 'Turnpike',\n 'Underpass',\n 'Union',\n 'Unions',\n 'Valley',\n 'Valleys',\n 'Via',\n 'Viaduct',\n 'View',\n 'Views',\n 'Village',\n 'Village',\n 'Villages',\n 'Ville',\n 'Vista',\n 'Vista',\n 'Walk',\n 'Walks',\n 'Wall',\n 'Way',\n 'Ways',\n 'Well',\n 'Wells')\n\n postcode_formats = ('#####', '#####-####')\n\n states = (\n 'Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California', 'Colorado',\n 'Connecticut', 'Delaware', 'Florida', 'Georgia', 'Hawaii', 'Idaho',\n 'Illinois', 'Indiana', 'Iowa', 'Kansas', 'Kentucky', 'Louisiana',\n 'Maine', 'Maryland', 'Massachusetts', 'Michigan', 'Minnesota',\n 'Mississippi', 'Missouri', 'Montana', 'Nebraska', 'Nevada',\n 'New Hampshire', 'New Jersey', 'New Mexico', 'New York',\n 'North Carolina', 'North Dakota', 'Ohio', 'Oklahoma', 'Oregon',\n 'Pennsylvania', 'Rhode Island', 'South Carolina', 'South Dakota',\n 'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia', 'Washington',\n 'West Virginia', 'Wisconsin', 'Wyoming',\n )\n states_abbr = (\n 'AL', 'AK', 'AZ', 'AR', 'CA', 'CO', 'CT', 'DE', 'DC', 'FL', 'GA', 'HI',\n 'ID', 'IL', 'IN', 'IA', 'KS', 'KY', 'LA', 'ME', 'MD', 'MA', 'MI', 'MN',\n 'MS', 'MO', 'MT', 'NE', 'NV', 'NH', 'NJ', 'NM', 'NY', 'NC', 'ND', 'OH',\n 'OK', 'OR', 'PA', 'RI', 'SC', 'SD', 'TN', 'TX', 'UT', 'VT', 'VA', 'WA',\n 'WV', 'WI', 'WY',\n )\n\n territories_abbr = (\n 'AS', 'FM', 'GU', 'MH', 'MP', 'PW', 'PR', 'VI',\n )\n\n states_and_territories_abbr = states_abbr + territories_abbr\n\n military_state_abbr = ('AE', 'AA', 'AP')\n\n military_ship_prefix = ('USS', 'USNS', 'USNV', 'USCGC')\n\n military_apo_format = (\"PSC ####, Box ####\")\n\n military_dpo_format = (\"Unit #### Box ####\")\n\n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n '{{city_prefix}} {{first_name}}',\n '{{first_name}}{{city_suffix}}',\n '{{last_name}}{{city_suffix}}',\n )\n\n street_name_formats = (\n '{{first_name}} {{street_suffix}}',\n '{{last_name}} {{street_suffix}}'\n )\n\n street_address_formats = (\n '{{building_number}} {{street_name}}',\n '{{building_number}} {{street_name}} {{secondary_address}}',\n )\n\n address_formats = (\n \"{{street_address}}\\n{{city}}, {{state_abbr}} {{postcode}}\",\n )\n\n address_formats = OrderedDict((\n (\"{{street_address}}\\n{{city}}, {{state_abbr}} {{postcode}}\", 25),\n # military address formatting.\n (\"{{military_apo}}\\nAPO {{military_state}} {{postcode}}\", 1),\n (\"{{military_ship}} {{last_name}}\\nFPO {{military_state}} {{postcode}}\", 1),\n (\"{{military_dpo}}\\nDPO {{military_state}} {{postcode}}\", 1),\n ))\n\n secondary_address_formats = ('Apt. ###', 'Suite ###')\n\n def city_prefix(self):\n return self.random_element(self.city_prefixes)\n\n def secondary_address(self):\n return self.numerify(\n self.random_element(\n self.secondary_address_formats))\n\n def state(self):\n return self.random_element(self.states)\n\n def state_abbr(self, include_territories=True):\n \"\"\"\n :returns: A random state or territory abbreviation.\n\n :param include_territories: If True, territories will be included.\n If False, only states will be returned.\n \"\"\"\n if include_territories:\n self.random_element(self.states_and_territories_abbr)\n return self.random_element(self.states_abbr)\n\n def postcode(self):\n return \"%05d\" % self.generator.random.randint(501, 99950)\n\n def zipcode_plus4(self):\n return \"%s-%04d\" % (self.zipcode(),\n self.generator.random.randint(1, 9999))\n\n def military_ship(self):\n \"\"\"\n :example 'USS'\n \"\"\"\n return self.random_element(self.military_ship_prefix)\n\n def military_state(self):\n \"\"\"\n :example 'APO'\n \"\"\"\n return self.random_element(self.military_state_abbr)\n\n def military_apo(self):\n \"\"\"\n :example 'PSC 5394 Box 3492\n \"\"\"\n return self.numerify(self.military_apo_format)\n\n def military_dpo(self):\n \"\"\"\n :example 'Unit 3333 Box 9342'\n \"\"\"\n return self.numerify(self.military_dpo_format)\n\n # Aliases\n def zipcode(self):\n return self.postcode()\n\n def postalcode(self):\n return self.postcode()\n\n def postalcode_plus4(self):\n return self.zipcode_plus4()\n", "path": "faker/providers/address/en_US/__init__.py"}]}
| 3,758 | 676 |
gh_patches_debug_2890
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-8179
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dataset is not undirected
### 🐛 Describe the bug
Dataset is not undirected, despite passing ``to_undirected=True`` flag.
```python
# !pip install pyg-nightly
from torch_geometric.datasets import CitationFull
from torch_geometric.utils import is_undirected
edge_index = CitationFull(root=".", name="Cora_ML", to_undirected=True).edge_index
is_undirected(edge_index)
```
The above outputs: *False*
### Environment
* PyG version: 2.4.0.dev20231010
* PyTorch version: 2.0.1+cu118
* OS: Colab
* Python version: 3.10.12
* CUDA/cuDNN version: 11.8
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/datasets/citation_full.py`
Content:
```
1 import os.path as osp
2 from typing import Callable, Optional
3
4 import torch
5
6 from torch_geometric.data import InMemoryDataset, download_url
7 from torch_geometric.io import read_npz
8
9
10 class CitationFull(InMemoryDataset):
11 r"""The full citation network datasets from the
12 `"Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via
13 Ranking" <https://arxiv.org/abs/1707.03815>`_ paper.
14 Nodes represent documents and edges represent citation links.
15 Datasets include :obj:`"Cora"`, :obj:`"Cora_ML"`, :obj:`"CiteSeer"`,
16 :obj:`"DBLP"`, :obj:`"PubMed"`.
17
18 Args:
19 root (str): Root directory where the dataset should be saved.
20 name (str): The name of the dataset (:obj:`"Cora"`, :obj:`"Cora_ML"`
21 :obj:`"CiteSeer"`, :obj:`"DBLP"`, :obj:`"PubMed"`).
22 transform (callable, optional): A function/transform that takes in an
23 :obj:`torch_geometric.data.Data` object and returns a transformed
24 version. The data object will be transformed before every access.
25 (default: :obj:`None`)
26 pre_transform (callable, optional): A function/transform that takes in
27 an :obj:`torch_geometric.data.Data` object and returns a
28 transformed version. The data object will be transformed before
29 being saved to disk. (default: :obj:`None`)
30 to_undirected (bool, optional): Whether the original graph is
31 converted to an undirected one. (default: :obj:`True`)
32
33 **STATS:**
34
35 .. list-table::
36 :widths: 10 10 10 10 10
37 :header-rows: 1
38
39 * - Name
40 - #nodes
41 - #edges
42 - #features
43 - #classes
44 * - Cora
45 - 19,793
46 - 126,842
47 - 8,710
48 - 70
49 * - Cora_ML
50 - 2,995
51 - 16,316
52 - 2,879
53 - 7
54 * - CiteSeer
55 - 4,230
56 - 10,674
57 - 602
58 - 6
59 * - DBLP
60 - 17,716
61 - 105,734
62 - 1,639
63 - 4
64 * - PubMed
65 - 19,717
66 - 88,648
67 - 500
68 - 3
69 """
70
71 url = 'https://github.com/abojchevski/graph2gauss/raw/master/data/{}.npz'
72
73 def __init__(
74 self,
75 root: str,
76 name: str,
77 transform: Optional[Callable] = None,
78 pre_transform: Optional[Callable] = None,
79 to_undirected: bool = True,
80 ):
81 self.name = name.lower()
82 self.to_undirected = to_undirected
83 assert self.name in ['cora', 'cora_ml', 'citeseer', 'dblp', 'pubmed']
84 super().__init__(root, transform, pre_transform)
85 self.data, self.slices = torch.load(self.processed_paths[0])
86
87 @property
88 def raw_dir(self) -> str:
89 return osp.join(self.root, self.name, 'raw')
90
91 @property
92 def processed_dir(self) -> str:
93 return osp.join(self.root, self.name, 'processed')
94
95 @property
96 def raw_file_names(self) -> str:
97 return f'{self.name}.npz'
98
99 @property
100 def processed_file_names(self) -> str:
101 return 'data.pt'
102
103 def download(self):
104 download_url(self.url.format(self.name), self.raw_dir)
105
106 def process(self):
107 data = read_npz(self.raw_paths[0], to_undirected=self.to_undirected)
108 data = data if self.pre_transform is None else self.pre_transform(data)
109 data, slices = self.collate([data])
110 torch.save((data, slices), self.processed_paths[0])
111
112 def __repr__(self) -> str:
113 return f'{self.name.capitalize()}Full()'
114
115
116 class CoraFull(CitationFull):
117 r"""Alias for :class:`~torch_geometric.datasets.CitationFull` with
118 :obj:`name="Cora"`.
119
120 **STATS:**
121
122 .. list-table::
123 :widths: 10 10 10 10
124 :header-rows: 1
125
126 * - #nodes
127 - #edges
128 - #features
129 - #classes
130 * - 19,793
131 - 126,842
132 - 8,710
133 - 70
134 """
135 def __init__(self, root: str, transform: Optional[Callable] = None,
136 pre_transform: Optional[Callable] = None):
137 super().__init__(root, 'cora', transform, pre_transform)
138
139 def download(self):
140 super().download()
141
142 def process(self):
143 super().process()
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/datasets/citation_full.py b/torch_geometric/datasets/citation_full.py
--- a/torch_geometric/datasets/citation_full.py
+++ b/torch_geometric/datasets/citation_full.py
@@ -98,7 +98,8 @@
@property
def processed_file_names(self) -> str:
- return 'data.pt'
+ suffix = 'undirected' if self.to_undirected else 'directed'
+ return f'data_{suffix}.pt'
def download(self):
download_url(self.url.format(self.name), self.raw_dir)
|
{"golden_diff": "diff --git a/torch_geometric/datasets/citation_full.py b/torch_geometric/datasets/citation_full.py\n--- a/torch_geometric/datasets/citation_full.py\n+++ b/torch_geometric/datasets/citation_full.py\n@@ -98,7 +98,8 @@\n \n @property\n def processed_file_names(self) -> str:\n- return 'data.pt'\n+ suffix = 'undirected' if self.to_undirected else 'directed'\n+ return f'data_{suffix}.pt'\n \n def download(self):\n download_url(self.url.format(self.name), self.raw_dir)\n", "issue": "Dataset is not undirected\n### \ud83d\udc1b Describe the bug\n\nDataset is not undirected, despite passing ``to_undirected=True`` flag.\r\n\r\n```python\r\n# !pip install pyg-nightly\r\n\r\nfrom torch_geometric.datasets import CitationFull\r\nfrom torch_geometric.utils import is_undirected\r\n\r\nedge_index = CitationFull(root=\".\", name=\"Cora_ML\", to_undirected=True).edge_index\r\nis_undirected(edge_index)\r\n```\r\nThe above outputs: *False*\n\n### Environment\n\n* PyG version: 2.4.0.dev20231010\r\n* PyTorch version: 2.0.1+cu118\r\n* OS: Colab\r\n* Python version: 3.10.12\r\n* CUDA/cuDNN version: 11.8\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): pip\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`):\r\n\n", "before_files": [{"content": "import os.path as osp\nfrom typing import Callable, Optional\n\nimport torch\n\nfrom torch_geometric.data import InMemoryDataset, download_url\nfrom torch_geometric.io import read_npz\n\n\nclass CitationFull(InMemoryDataset):\n r\"\"\"The full citation network datasets from the\n `\"Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via\n Ranking\" <https://arxiv.org/abs/1707.03815>`_ paper.\n Nodes represent documents and edges represent citation links.\n Datasets include :obj:`\"Cora\"`, :obj:`\"Cora_ML\"`, :obj:`\"CiteSeer\"`,\n :obj:`\"DBLP\"`, :obj:`\"PubMed\"`.\n\n Args:\n root (str): Root directory where the dataset should be saved.\n name (str): The name of the dataset (:obj:`\"Cora\"`, :obj:`\"Cora_ML\"`\n :obj:`\"CiteSeer\"`, :obj:`\"DBLP\"`, :obj:`\"PubMed\"`).\n transform (callable, optional): A function/transform that takes in an\n :obj:`torch_geometric.data.Data` object and returns a transformed\n version. The data object will be transformed before every access.\n (default: :obj:`None`)\n pre_transform (callable, optional): A function/transform that takes in\n an :obj:`torch_geometric.data.Data` object and returns a\n transformed version. The data object will be transformed before\n being saved to disk. (default: :obj:`None`)\n to_undirected (bool, optional): Whether the original graph is\n converted to an undirected one. (default: :obj:`True`)\n\n **STATS:**\n\n .. list-table::\n :widths: 10 10 10 10 10\n :header-rows: 1\n\n * - Name\n - #nodes\n - #edges\n - #features\n - #classes\n * - Cora\n - 19,793\n - 126,842\n - 8,710\n - 70\n * - Cora_ML\n - 2,995\n - 16,316\n - 2,879\n - 7\n * - CiteSeer\n - 4,230\n - 10,674\n - 602\n - 6\n * - DBLP\n - 17,716\n - 105,734\n - 1,639\n - 4\n * - PubMed\n - 19,717\n - 88,648\n - 500\n - 3\n \"\"\"\n\n url = 'https://github.com/abojchevski/graph2gauss/raw/master/data/{}.npz'\n\n def __init__(\n self,\n root: str,\n name: str,\n transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None,\n to_undirected: bool = True,\n ):\n self.name = name.lower()\n self.to_undirected = to_undirected\n assert self.name in ['cora', 'cora_ml', 'citeseer', 'dblp', 'pubmed']\n super().__init__(root, transform, pre_transform)\n self.data, self.slices = torch.load(self.processed_paths[0])\n\n @property\n def raw_dir(self) -> str:\n return osp.join(self.root, self.name, 'raw')\n\n @property\n def processed_dir(self) -> str:\n return osp.join(self.root, self.name, 'processed')\n\n @property\n def raw_file_names(self) -> str:\n return f'{self.name}.npz'\n\n @property\n def processed_file_names(self) -> str:\n return 'data.pt'\n\n def download(self):\n download_url(self.url.format(self.name), self.raw_dir)\n\n def process(self):\n data = read_npz(self.raw_paths[0], to_undirected=self.to_undirected)\n data = data if self.pre_transform is None else self.pre_transform(data)\n data, slices = self.collate([data])\n torch.save((data, slices), self.processed_paths[0])\n\n def __repr__(self) -> str:\n return f'{self.name.capitalize()}Full()'\n\n\nclass CoraFull(CitationFull):\n r\"\"\"Alias for :class:`~torch_geometric.datasets.CitationFull` with\n :obj:`name=\"Cora\"`.\n\n **STATS:**\n\n .. list-table::\n :widths: 10 10 10 10\n :header-rows: 1\n\n * - #nodes\n - #edges\n - #features\n - #classes\n * - 19,793\n - 126,842\n - 8,710\n - 70\n \"\"\"\n def __init__(self, root: str, transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None):\n super().__init__(root, 'cora', transform, pre_transform)\n\n def download(self):\n super().download()\n\n def process(self):\n super().process()\n", "path": "torch_geometric/datasets/citation_full.py"}], "after_files": [{"content": "import os.path as osp\nfrom typing import Callable, Optional\n\nimport torch\n\nfrom torch_geometric.data import InMemoryDataset, download_url\nfrom torch_geometric.io import read_npz\n\n\nclass CitationFull(InMemoryDataset):\n r\"\"\"The full citation network datasets from the\n `\"Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via\n Ranking\" <https://arxiv.org/abs/1707.03815>`_ paper.\n Nodes represent documents and edges represent citation links.\n Datasets include :obj:`\"Cora\"`, :obj:`\"Cora_ML\"`, :obj:`\"CiteSeer\"`,\n :obj:`\"DBLP\"`, :obj:`\"PubMed\"`.\n\n Args:\n root (str): Root directory where the dataset should be saved.\n name (str): The name of the dataset (:obj:`\"Cora\"`, :obj:`\"Cora_ML\"`\n :obj:`\"CiteSeer\"`, :obj:`\"DBLP\"`, :obj:`\"PubMed\"`).\n transform (callable, optional): A function/transform that takes in an\n :obj:`torch_geometric.data.Data` object and returns a transformed\n version. The data object will be transformed before every access.\n (default: :obj:`None`)\n pre_transform (callable, optional): A function/transform that takes in\n an :obj:`torch_geometric.data.Data` object and returns a\n transformed version. The data object will be transformed before\n being saved to disk. (default: :obj:`None`)\n to_undirected (bool, optional): Whether the original graph is\n converted to an undirected one. (default: :obj:`True`)\n\n **STATS:**\n\n .. list-table::\n :widths: 10 10 10 10 10\n :header-rows: 1\n\n * - Name\n - #nodes\n - #edges\n - #features\n - #classes\n * - Cora\n - 19,793\n - 126,842\n - 8,710\n - 70\n * - Cora_ML\n - 2,995\n - 16,316\n - 2,879\n - 7\n * - CiteSeer\n - 4,230\n - 10,674\n - 602\n - 6\n * - DBLP\n - 17,716\n - 105,734\n - 1,639\n - 4\n * - PubMed\n - 19,717\n - 88,648\n - 500\n - 3\n \"\"\"\n\n url = 'https://github.com/abojchevski/graph2gauss/raw/master/data/{}.npz'\n\n def __init__(\n self,\n root: str,\n name: str,\n transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None,\n to_undirected: bool = True,\n ):\n self.name = name.lower()\n self.to_undirected = to_undirected\n assert self.name in ['cora', 'cora_ml', 'citeseer', 'dblp', 'pubmed']\n super().__init__(root, transform, pre_transform)\n self.data, self.slices = torch.load(self.processed_paths[0])\n\n @property\n def raw_dir(self) -> str:\n return osp.join(self.root, self.name, 'raw')\n\n @property\n def processed_dir(self) -> str:\n return osp.join(self.root, self.name, 'processed')\n\n @property\n def raw_file_names(self) -> str:\n return f'{self.name}.npz'\n\n @property\n def processed_file_names(self) -> str:\n suffix = 'undirected' if self.to_undirected else 'directed'\n return f'data_{suffix}.pt'\n\n def download(self):\n download_url(self.url.format(self.name), self.raw_dir)\n\n def process(self):\n data = read_npz(self.raw_paths[0], to_undirected=self.to_undirected)\n data = data if self.pre_transform is None else self.pre_transform(data)\n data, slices = self.collate([data])\n torch.save((data, slices), self.processed_paths[0])\n\n def __repr__(self) -> str:\n return f'{self.name.capitalize()}Full()'\n\n\nclass CoraFull(CitationFull):\n r\"\"\"Alias for :class:`~torch_geometric.datasets.CitationFull` with\n :obj:`name=\"Cora\"`.\n\n **STATS:**\n\n .. list-table::\n :widths: 10 10 10 10\n :header-rows: 1\n\n * - #nodes\n - #edges\n - #features\n - #classes\n * - 19,793\n - 126,842\n - 8,710\n - 70\n \"\"\"\n def __init__(self, root: str, transform: Optional[Callable] = None,\n pre_transform: Optional[Callable] = None):\n super().__init__(root, 'cora', transform, pre_transform)\n\n def download(self):\n super().download()\n\n def process(self):\n super().process()\n", "path": "torch_geometric/datasets/citation_full.py"}]}
| 2,025 | 135 |
gh_patches_debug_3654
|
rasdani/github-patches
|
git_diff
|
spack__spack-2961
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fail to build libmng [AutotoolsPackage]
@alalazo I got this error while installing `libmng`:
```
...
==> Already patched libmng
==> Building libmng [AutotoolsPackage]
==> Executing phase : 'autoreconf'
==> Executing phase : 'configure'
==> Error: ProcessError: Command exited with status 1:
'/my/path/spack/var/spack/stage/libmng-2.0.2-2x5fkukzf3sf4uexegr3n35jwmy5pclu/libmng-2.0.2/configure' '--prefix=/my/path/spack/opt/spack/linux-scientificcernslc6-x86_64/gcc-6.2.0/libmng-2.0.2-2x5fkukzf3sf4uexegr3n35jwmy5pclu'
/my/path/spack/lib/spack/spack/build_systems/autotools.py:265, in configure:
258 def configure(self, spec, prefix):
259 """Runs configure with the arguments specified in :py:meth:`.configure_args`
260 and an appropriately set prefix.
261 """
262 options = ['--prefix={0}'.format(prefix)] + self.configure_args()
263
264 with working_dir(self.build_directory, create=True)
```
And this is the spack-build.out:
```
...
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
configure: error: source directory already configured; run "make distclean" there first
```
Before merge #2859 I could install it correctly but now I get this, do you think that could be related with the commit or maybe I have to install it in a different way now?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/libmng/package.py`
Content:
```
1 ##############################################################################
2 # Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/llnl/spack
10 # Please also see the LICENSE file for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25 from spack import *
26
27
28 class Libmng(AutotoolsPackage):
29 """libmng -THE reference library for reading, displaying, writing
30 and examining Multiple-Image Network Graphics. MNG is the animation
31 extension to the popular PNG image-format."""
32 homepage = "http://sourceforge.net/projects/libmng/"
33 url = "http://downloads.sourceforge.net/project/libmng/libmng-devel/2.0.2/libmng-2.0.2.tar.gz"
34
35 version('2.0.2', '1ffefaed4aac98475ee6267422cbca55')
36
37 depends_on("jpeg")
38 depends_on("zlib")
39 depends_on("lcms")
40
41 def patch(self):
42 # jpeg requires stdio to beincluded before its headrs.
43 filter_file(r'^(\#include \<jpeglib\.h\>)',
44 '#include<stdio.h>\n\\1', 'libmng_types.h')
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/libmng/package.py b/var/spack/repos/builtin/packages/libmng/package.py
--- a/var/spack/repos/builtin/packages/libmng/package.py
+++ b/var/spack/repos/builtin/packages/libmng/package.py
@@ -42,3 +42,7 @@
# jpeg requires stdio to beincluded before its headrs.
filter_file(r'^(\#include \<jpeglib\.h\>)',
'#include<stdio.h>\n\\1', 'libmng_types.h')
+
+ @run_before('configure')
+ def clean_configure_directory(self):
+ make('distclean')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/libmng/package.py b/var/spack/repos/builtin/packages/libmng/package.py\n--- a/var/spack/repos/builtin/packages/libmng/package.py\n+++ b/var/spack/repos/builtin/packages/libmng/package.py\n@@ -42,3 +42,7 @@\n # jpeg requires stdio to beincluded before its headrs.\n filter_file(r'^(\\#include \\<jpeglib\\.h\\>)',\n '#include<stdio.h>\\n\\\\1', 'libmng_types.h')\n+\n+ @run_before('configure')\n+ def clean_configure_directory(self):\n+ make('distclean')\n", "issue": "Fail to build libmng [AutotoolsPackage]\n@alalazo I got this error while installing `libmng`:\r\n\r\n```\r\n...\r\n==> Already patched libmng\r\n==> Building libmng [AutotoolsPackage]\r\n==> Executing phase : 'autoreconf'\r\n==> Executing phase : 'configure'\r\n==> Error: ProcessError: Command exited with status 1:\r\n '/my/path/spack/var/spack/stage/libmng-2.0.2-2x5fkukzf3sf4uexegr3n35jwmy5pclu/libmng-2.0.2/configure' '--prefix=/my/path/spack/opt/spack/linux-scientificcernslc6-x86_64/gcc-6.2.0/libmng-2.0.2-2x5fkukzf3sf4uexegr3n35jwmy5pclu'\r\n/my/path/spack/lib/spack/spack/build_systems/autotools.py:265, in configure:\r\n 258 def configure(self, spec, prefix):\r\n 259 \"\"\"Runs configure with the arguments specified in :py:meth:`.configure_args`\r\n 260 and an appropriately set prefix.\r\n 261 \"\"\"\r\n 262 options = ['--prefix={0}'.format(prefix)] + self.configure_args()\r\n 263 \r\n 264 with working_dir(self.build_directory, create=True)\r\n```\r\n\r\nAnd this is the spack-build.out:\r\n\r\n```\r\n...\r\nchecking for a BSD-compatible install... /usr/bin/install -c\r\nchecking whether build environment is sane... yes\r\nchecking for a thread-safe mkdir -p... /bin/mkdir -p\r\nchecking for gawk... gawk\r\nchecking whether make sets $(MAKE)... yes\r\nchecking whether make supports nested variables... yes\r\nconfigure: error: source directory already configured; run \"make distclean\" there first\r\n```\r\n\r\nBefore merge #2859 I could install it correctly but now I get this, do you think that could be related with the commit or maybe I have to install it in a different way now?\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the LICENSE file for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Libmng(AutotoolsPackage):\n \"\"\"libmng -THE reference library for reading, displaying, writing\n and examining Multiple-Image Network Graphics. MNG is the animation\n extension to the popular PNG image-format.\"\"\"\n homepage = \"http://sourceforge.net/projects/libmng/\"\n url = \"http://downloads.sourceforge.net/project/libmng/libmng-devel/2.0.2/libmng-2.0.2.tar.gz\"\n\n version('2.0.2', '1ffefaed4aac98475ee6267422cbca55')\n\n depends_on(\"jpeg\")\n depends_on(\"zlib\")\n depends_on(\"lcms\")\n\n def patch(self):\n # jpeg requires stdio to beincluded before its headrs.\n filter_file(r'^(\\#include \\<jpeglib\\.h\\>)',\n '#include<stdio.h>\\n\\\\1', 'libmng_types.h')\n", "path": "var/spack/repos/builtin/packages/libmng/package.py"}], "after_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the LICENSE file for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Libmng(AutotoolsPackage):\n \"\"\"libmng -THE reference library for reading, displaying, writing\n and examining Multiple-Image Network Graphics. MNG is the animation\n extension to the popular PNG image-format.\"\"\"\n homepage = \"http://sourceforge.net/projects/libmng/\"\n url = \"http://downloads.sourceforge.net/project/libmng/libmng-devel/2.0.2/libmng-2.0.2.tar.gz\"\n\n version('2.0.2', '1ffefaed4aac98475ee6267422cbca55')\n\n depends_on(\"jpeg\")\n depends_on(\"zlib\")\n depends_on(\"lcms\")\n\n def patch(self):\n # jpeg requires stdio to beincluded before its headrs.\n filter_file(r'^(\\#include \\<jpeglib\\.h\\>)',\n '#include<stdio.h>\\n\\\\1', 'libmng_types.h')\n\n @run_before('configure')\n def clean_configure_directory(self):\n make('distclean')\n", "path": "var/spack/repos/builtin/packages/libmng/package.py"}]}
| 1,312 | 143 |
gh_patches_debug_36111
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-8673
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate using default `--fmt-transitive` and `--lint-transitive` in preparation for switching default to `--no-{fmt,lint}-transitive`
### Problem
Will close https://github.com/pantsbuild/pants/issues/8345.
These options cause tools like isort and Scalafmt to work on the transitive dependencies of the targets you specify, rather than only the targets specified. This is surprising and not how the tools work when called directly—you'd expect isort to only change the files you pass to it, for example.
We decided when adding this option to the V2 rules (https://github.com/pantsbuild/pants/pull/8660) that instead we should deprecate this misfeature.
However, we cannot simply deprecate the option in one fell-swoop because then people who are trying to prepare for the default behavior changing to `--no-transitive` will be met with a deprecation warning that the option will be removed. Leaving off the option so that there's no deprecation warning means that they will have a breaking behavior change in 1.25.0.dev2 when we no longer act transitively.
### Solution
For this deprecation cycle, only warn that the default will change if they are currently relying on the default.
In 1.25.0.dev2, after the default changes, _then_ we can safely deprecate the option outright.
### Result
Users who specified the option get this warning message:
> [WARN] /Users/eric/DocsLocal/code/projects/pants/src/python/pants/task/task.py:265: DeprecationWarning: DEPRECATED: Pants defaulting to --fmt-transitive and --lint-transitive will be removed in version 1.25.0.dev2.
Pants will soon default to --no-fmt-transitive and --no-lint-transitive. Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which means that tools like isort and Scalafmt will work on transitive dependencies as well. This behavior is unexpected. Normally when running tools like isort, you'd expect them to only work on the files you specify.
>
> To prepare, please add to your `pants.ini` under both the `fmt` and the `lint` sections the option `transitive: False`. If you want to keep the default, use `True`, although the option will be removed in Pants 1.27.0.dev2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/task/target_restriction_mixins.py`
Content:
```
1 # Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from pants.base.deprecated import deprecated_conditional
5 from pants.task.goal_options_mixin import GoalOptionsMixin, GoalOptionsRegistrar
6
7
8 class HasTransitiveOptionMixin:
9 """A mixin for tasks that have a --transitive option.
10
11 Some tasks must always act on the entire dependency closure. E.g., when compiling, one must
12 compile all of a target's dependencies before compiling that target.
13
14 Other tasks must always act only on the target roots (the targets explicitly specified by the
15 user on the command line). E.g., when finding paths between two user-specified targets.
16
17 Still other tasks may optionally act on either the target roots or the entire closure,
18 as the user prefers in each case. E.g., when invoking a linter. This mixin supports such tasks.
19
20 Note that this mixin doesn't actually register the --transitive option. It assumes that this
21 option was registered on the task (either directly or recursively from its goal).
22 """
23
24 @property
25 def act_transitively(self):
26 deprecated_conditional(
27 lambda: self.get_options().is_default("transitive"),
28 removal_version="1.25.0.dev2",
29 entity_description="Pants defaulting to `--fmt-transitive` and `--lint-transitive`",
30 hint_message="Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. "
31 "Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which "
32 "means that tools like isort and Scalafmt will work on transitive dependencies "
33 "as well. This behavior is unexpected. Normally when running tools like isort, "
34 "you'd expect them to only work on the files you specify.\n\nTo prepare, "
35 "please add to your `pants.ini` under both the `fmt` and the `lint` "
36 "sections the option `transitive: False`. If you want to keep the default, use "
37 "`True`, although we recommend setting to `False` as the `--transitive` option "
38 "will be removed in a future Pants version."
39 )
40 return self.get_options().transitive
41
42
43 class TransitiveOptionRegistrar:
44 """Registrar of --transitive."""
45
46 @classmethod
47 def register_options(cls, register):
48 super().register_options(register)
49 register('--transitive', type=bool, default=True, fingerprint=True, recursive=True,
50 help="If false, act only on the targets directly specified on the command line. "
51 "If true, act on the transitive dependency closure of those targets.")
52
53
54 class HasSkipOptionMixin:
55 """A mixin for tasks that have a --skip option.
56
57 Some tasks may be skipped during certain usages. E.g., you may not want to apply linters
58 while developing. This mixin supports such tasks.
59
60 Note that this mixin doesn't actually register the --skip option. It assumes that this
61 option was registered on the task (either directly or recursively from its goal).
62 """
63
64 @property
65 def skip_execution(self):
66 return self.get_options().skip
67
68
69 class SkipOptionRegistrar:
70 """Registrar of --skip."""
71
72 @classmethod
73 def register_options(cls, register):
74 super().register_options(register)
75 register('--skip', type=bool, default=False, fingerprint=True, recursive=True,
76 help='Skip task.')
77
78
79 class HasSkipAndTransitiveOptionsMixin(HasSkipOptionMixin, HasTransitiveOptionMixin):
80 """A mixin for tasks that have a --transitive and a --skip option."""
81 pass
82
83
84 class HasSkipAndTransitiveGoalOptionsMixin(GoalOptionsMixin, HasSkipAndTransitiveOptionsMixin):
85 """A mixin for tasks that have a --transitive and a --skip option registered at the goal level."""
86 pass
87
88
89 class SkipAndTransitiveOptionsRegistrar(SkipOptionRegistrar, TransitiveOptionRegistrar):
90 """Registrar of --skip and --transitive."""
91 pass
92
93
94 class SkipAndTransitiveGoalOptionsRegistrar(SkipAndTransitiveOptionsRegistrar,
95 GoalOptionsRegistrar):
96 """Registrar of --skip and --transitive at the goal level."""
97 pass
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/task/target_restriction_mixins.py b/src/python/pants/task/target_restriction_mixins.py
--- a/src/python/pants/task/target_restriction_mixins.py
+++ b/src/python/pants/task/target_restriction_mixins.py
@@ -23,20 +23,6 @@
@property
def act_transitively(self):
- deprecated_conditional(
- lambda: self.get_options().is_default("transitive"),
- removal_version="1.25.0.dev2",
- entity_description="Pants defaulting to `--fmt-transitive` and `--lint-transitive`",
- hint_message="Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. "
- "Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which "
- "means that tools like isort and Scalafmt will work on transitive dependencies "
- "as well. This behavior is unexpected. Normally when running tools like isort, "
- "you'd expect them to only work on the files you specify.\n\nTo prepare, "
- "please add to your `pants.ini` under both the `fmt` and the `lint` "
- "sections the option `transitive: False`. If you want to keep the default, use "
- "`True`, although we recommend setting to `False` as the `--transitive` option "
- "will be removed in a future Pants version."
- )
return self.get_options().transitive
@@ -83,7 +69,24 @@
class HasSkipAndTransitiveGoalOptionsMixin(GoalOptionsMixin, HasSkipAndTransitiveOptionsMixin):
"""A mixin for tasks that have a --transitive and a --skip option registered at the goal level."""
- pass
+
+ @property
+ def act_transitively(self):
+ deprecated_conditional(
+ lambda: self.get_options().is_default("transitive"),
+ removal_version="1.25.0.dev2",
+ entity_description="Pants defaulting to `--fmt-transitive` and `--lint-transitive`",
+ hint_message="Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. "
+ "Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which "
+ "means that tools like isort and Scalafmt will work on transitive dependencies "
+ "as well. This behavior is unexpected. Normally when running tools like isort, "
+ "you'd expect them to only work on the files you specify.\n\nTo prepare, "
+ "please add to your `pants.ini` under both the `fmt` and the `lint` "
+ "sections the option `transitive: False`. If you want to keep the default, use "
+ "`True`, although we recommend setting to `False` as the `--transitive` option "
+ "will be removed in a future Pants version."
+ )
+ return self.get_options().transitive
class SkipAndTransitiveOptionsRegistrar(SkipOptionRegistrar, TransitiveOptionRegistrar):
|
{"golden_diff": "diff --git a/src/python/pants/task/target_restriction_mixins.py b/src/python/pants/task/target_restriction_mixins.py\n--- a/src/python/pants/task/target_restriction_mixins.py\n+++ b/src/python/pants/task/target_restriction_mixins.py\n@@ -23,20 +23,6 @@\n \n @property\n def act_transitively(self):\n- deprecated_conditional(\n- lambda: self.get_options().is_default(\"transitive\"),\n- removal_version=\"1.25.0.dev2\",\n- entity_description=\"Pants defaulting to `--fmt-transitive` and `--lint-transitive`\",\n- hint_message=\"Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. \"\n- \"Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which \"\n- \"means that tools like isort and Scalafmt will work on transitive dependencies \"\n- \"as well. This behavior is unexpected. Normally when running tools like isort, \"\n- \"you'd expect them to only work on the files you specify.\\n\\nTo prepare, \"\n- \"please add to your `pants.ini` under both the `fmt` and the `lint` \"\n- \"sections the option `transitive: False`. If you want to keep the default, use \"\n- \"`True`, although we recommend setting to `False` as the `--transitive` option \"\n- \"will be removed in a future Pants version.\"\n- )\n return self.get_options().transitive\n \n \n@@ -83,7 +69,24 @@\n \n class HasSkipAndTransitiveGoalOptionsMixin(GoalOptionsMixin, HasSkipAndTransitiveOptionsMixin):\n \"\"\"A mixin for tasks that have a --transitive and a --skip option registered at the goal level.\"\"\"\n- pass\n+\n+ @property\n+ def act_transitively(self):\n+ deprecated_conditional(\n+ lambda: self.get_options().is_default(\"transitive\"),\n+ removal_version=\"1.25.0.dev2\",\n+ entity_description=\"Pants defaulting to `--fmt-transitive` and `--lint-transitive`\",\n+ hint_message=\"Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. \"\n+ \"Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which \"\n+ \"means that tools like isort and Scalafmt will work on transitive dependencies \"\n+ \"as well. This behavior is unexpected. Normally when running tools like isort, \"\n+ \"you'd expect them to only work on the files you specify.\\n\\nTo prepare, \"\n+ \"please add to your `pants.ini` under both the `fmt` and the `lint` \"\n+ \"sections the option `transitive: False`. If you want to keep the default, use \"\n+ \"`True`, although we recommend setting to `False` as the `--transitive` option \"\n+ \"will be removed in a future Pants version.\"\n+ )\n+ return self.get_options().transitive\n \n \n class SkipAndTransitiveOptionsRegistrar(SkipOptionRegistrar, TransitiveOptionRegistrar):\n", "issue": "Deprecate using default `--fmt-transitive` and `--lint-transitive` in preparation for switching default to `--no-{fmt,lint}-transitive`\n### Problem\r\n\r\nWill close https://github.com/pantsbuild/pants/issues/8345.\r\n\r\nThese options cause tools like isort and Scalafmt to work on the transitive dependencies of the targets you specify, rather than only the targets specified. This is surprising and not how the tools work when called directly\u2014you'd expect isort to only change the files you pass to it, for example.\r\n\r\nWe decided when adding this option to the V2 rules (https://github.com/pantsbuild/pants/pull/8660) that instead we should deprecate this misfeature.\r\n\r\nHowever, we cannot simply deprecate the option in one fell-swoop because then people who are trying to prepare for the default behavior changing to `--no-transitive` will be met with a deprecation warning that the option will be removed. Leaving off the option so that there's no deprecation warning means that they will have a breaking behavior change in 1.25.0.dev2 when we no longer act transitively.\r\n\r\n### Solution\r\n\r\nFor this deprecation cycle, only warn that the default will change if they are currently relying on the default.\r\n\r\nIn 1.25.0.dev2, after the default changes, _then_ we can safely deprecate the option outright.\r\n\r\n### Result\r\n\r\nUsers who specified the option get this warning message:\r\n\r\n\r\n> [WARN] /Users/eric/DocsLocal/code/projects/pants/src/python/pants/task/task.py:265: DeprecationWarning: DEPRECATED: Pants defaulting to --fmt-transitive and --lint-transitive will be removed in version 1.25.0.dev2.\r\n Pants will soon default to --no-fmt-transitive and --no-lint-transitive. Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which means that tools like isort and Scalafmt will work on transitive dependencies as well. This behavior is unexpected. Normally when running tools like isort, you'd expect them to only work on the files you specify.\r\n> \r\n> To prepare, please add to your `pants.ini` under both the `fmt` and the `lint` sections the option `transitive: False`. If you want to keep the default, use `True`, although the option will be removed in Pants 1.27.0.dev2\n", "before_files": [{"content": "# Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom pants.base.deprecated import deprecated_conditional\nfrom pants.task.goal_options_mixin import GoalOptionsMixin, GoalOptionsRegistrar\n\n\nclass HasTransitiveOptionMixin:\n \"\"\"A mixin for tasks that have a --transitive option.\n\n Some tasks must always act on the entire dependency closure. E.g., when compiling, one must\n compile all of a target's dependencies before compiling that target.\n\n Other tasks must always act only on the target roots (the targets explicitly specified by the\n user on the command line). E.g., when finding paths between two user-specified targets.\n\n Still other tasks may optionally act on either the target roots or the entire closure,\n as the user prefers in each case. E.g., when invoking a linter. This mixin supports such tasks.\n\n Note that this mixin doesn't actually register the --transitive option. It assumes that this\n option was registered on the task (either directly or recursively from its goal).\n \"\"\"\n\n @property\n def act_transitively(self):\n deprecated_conditional(\n lambda: self.get_options().is_default(\"transitive\"),\n removal_version=\"1.25.0.dev2\",\n entity_description=\"Pants defaulting to `--fmt-transitive` and `--lint-transitive`\",\n hint_message=\"Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. \"\n \"Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which \"\n \"means that tools like isort and Scalafmt will work on transitive dependencies \"\n \"as well. This behavior is unexpected. Normally when running tools like isort, \"\n \"you'd expect them to only work on the files you specify.\\n\\nTo prepare, \"\n \"please add to your `pants.ini` under both the `fmt` and the `lint` \"\n \"sections the option `transitive: False`. If you want to keep the default, use \"\n \"`True`, although we recommend setting to `False` as the `--transitive` option \"\n \"will be removed in a future Pants version.\"\n )\n return self.get_options().transitive\n\n\nclass TransitiveOptionRegistrar:\n \"\"\"Registrar of --transitive.\"\"\"\n\n @classmethod\n def register_options(cls, register):\n super().register_options(register)\n register('--transitive', type=bool, default=True, fingerprint=True, recursive=True,\n help=\"If false, act only on the targets directly specified on the command line. \"\n \"If true, act on the transitive dependency closure of those targets.\")\n\n\nclass HasSkipOptionMixin:\n \"\"\"A mixin for tasks that have a --skip option.\n\n Some tasks may be skipped during certain usages. E.g., you may not want to apply linters\n while developing. This mixin supports such tasks.\n\n Note that this mixin doesn't actually register the --skip option. It assumes that this\n option was registered on the task (either directly or recursively from its goal).\n \"\"\"\n\n @property\n def skip_execution(self):\n return self.get_options().skip\n\n\nclass SkipOptionRegistrar:\n \"\"\"Registrar of --skip.\"\"\"\n\n @classmethod\n def register_options(cls, register):\n super().register_options(register)\n register('--skip', type=bool, default=False, fingerprint=True, recursive=True,\n help='Skip task.')\n\n\nclass HasSkipAndTransitiveOptionsMixin(HasSkipOptionMixin, HasTransitiveOptionMixin):\n \"\"\"A mixin for tasks that have a --transitive and a --skip option.\"\"\"\n pass\n\n\nclass HasSkipAndTransitiveGoalOptionsMixin(GoalOptionsMixin, HasSkipAndTransitiveOptionsMixin):\n \"\"\"A mixin for tasks that have a --transitive and a --skip option registered at the goal level.\"\"\"\n pass\n\n\nclass SkipAndTransitiveOptionsRegistrar(SkipOptionRegistrar, TransitiveOptionRegistrar):\n \"\"\"Registrar of --skip and --transitive.\"\"\"\n pass\n\n\nclass SkipAndTransitiveGoalOptionsRegistrar(SkipAndTransitiveOptionsRegistrar,\n GoalOptionsRegistrar):\n \"\"\"Registrar of --skip and --transitive at the goal level.\"\"\"\n pass\n", "path": "src/python/pants/task/target_restriction_mixins.py"}], "after_files": [{"content": "# Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom pants.base.deprecated import deprecated_conditional\nfrom pants.task.goal_options_mixin import GoalOptionsMixin, GoalOptionsRegistrar\n\n\nclass HasTransitiveOptionMixin:\n \"\"\"A mixin for tasks that have a --transitive option.\n\n Some tasks must always act on the entire dependency closure. E.g., when compiling, one must\n compile all of a target's dependencies before compiling that target.\n\n Other tasks must always act only on the target roots (the targets explicitly specified by the\n user on the command line). E.g., when finding paths between two user-specified targets.\n\n Still other tasks may optionally act on either the target roots or the entire closure,\n as the user prefers in each case. E.g., when invoking a linter. This mixin supports such tasks.\n\n Note that this mixin doesn't actually register the --transitive option. It assumes that this\n option was registered on the task (either directly or recursively from its goal).\n \"\"\"\n\n @property\n def act_transitively(self):\n return self.get_options().transitive\n\n\nclass TransitiveOptionRegistrar:\n \"\"\"Registrar of --transitive.\"\"\"\n\n @classmethod\n def register_options(cls, register):\n super().register_options(register)\n register('--transitive', type=bool, default=True, fingerprint=True, recursive=True,\n help=\"If false, act only on the targets directly specified on the command line. \"\n \"If true, act on the transitive dependency closure of those targets.\")\n\n\nclass HasSkipOptionMixin:\n \"\"\"A mixin for tasks that have a --skip option.\n\n Some tasks may be skipped during certain usages. E.g., you may not want to apply linters\n while developing. This mixin supports such tasks.\n\n Note that this mixin doesn't actually register the --skip option. It assumes that this\n option was registered on the task (either directly or recursively from its goal).\n \"\"\"\n\n @property\n def skip_execution(self):\n return self.get_options().skip\n\n\nclass SkipOptionRegistrar:\n \"\"\"Registrar of --skip.\"\"\"\n\n @classmethod\n def register_options(cls, register):\n super().register_options(register)\n register('--skip', type=bool, default=False, fingerprint=True, recursive=True,\n help='Skip task.')\n\n\nclass HasSkipAndTransitiveOptionsMixin(HasSkipOptionMixin, HasTransitiveOptionMixin):\n \"\"\"A mixin for tasks that have a --transitive and a --skip option.\"\"\"\n pass\n\n\nclass HasSkipAndTransitiveGoalOptionsMixin(GoalOptionsMixin, HasSkipAndTransitiveOptionsMixin):\n \"\"\"A mixin for tasks that have a --transitive and a --skip option registered at the goal level.\"\"\"\n\n @property\n def act_transitively(self):\n deprecated_conditional(\n lambda: self.get_options().is_default(\"transitive\"),\n removal_version=\"1.25.0.dev2\",\n entity_description=\"Pants defaulting to `--fmt-transitive` and `--lint-transitive`\",\n hint_message=\"Pants will soon default to `--no-fmt-transitive` and `--no-lint-transitive`. \"\n \"Currently, Pants defaults to `--fmt-transitive` and `--lint-transitive`, which \"\n \"means that tools like isort and Scalafmt will work on transitive dependencies \"\n \"as well. This behavior is unexpected. Normally when running tools like isort, \"\n \"you'd expect them to only work on the files you specify.\\n\\nTo prepare, \"\n \"please add to your `pants.ini` under both the `fmt` and the `lint` \"\n \"sections the option `transitive: False`. If you want to keep the default, use \"\n \"`True`, although we recommend setting to `False` as the `--transitive` option \"\n \"will be removed in a future Pants version.\"\n )\n return self.get_options().transitive\n\n\nclass SkipAndTransitiveOptionsRegistrar(SkipOptionRegistrar, TransitiveOptionRegistrar):\n \"\"\"Registrar of --skip and --transitive.\"\"\"\n pass\n\n\nclass SkipAndTransitiveGoalOptionsRegistrar(SkipAndTransitiveOptionsRegistrar,\n GoalOptionsRegistrar):\n \"\"\"Registrar of --skip and --transitive at the goal level.\"\"\"\n pass\n", "path": "src/python/pants/task/target_restriction_mixins.py"}]}
| 1,904 | 707 |
gh_patches_debug_43845
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-3567
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Scheduler needs to respect MemSlots in QuantumCircuit Measures
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
Known bug from my PR https://github.com/Qiskit/qiskit-terra/pull/2650
### What is the current behavior?
When passing a circuit through the basic scheduler (`qiskit.scheduler.schedule`), the resulting `Schedule` will always measure qubit results into the `MemorySlot` which matches the qubit index.
For example:
```
qc.measure(q[0], c[3])
```
will measure qubit 0 into `MemorySlot(0)` rather than `MemorySlot(3)` -- it will use the default Acquire from the cmd_def which is probably something like `Acquire([0, 1], [MemSlot(0), MemSlot(1)])`. The correct behaviour is to use the classical reg from the instruction and then modify the `AcquireInstruction` from the `Schedule` returned by the `cmd_def`. It's unclear what we should do with the other qubits that are measured within the same `meas_map` group, if the user doesn't specify those other qubits to be measured.
We need a follow up PR to handle this more carefully. The solution likely needs to update the helper function: `qiskit.scheduler.methods.basic.translate_gates_to_pulse_defs.get_measure_schedule`
### Steps to reproduce the problem
### What is the expected behavior?
### Suggested solutions
see above
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/scheduler/methods/basic.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2019.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """The most straightforward scheduling methods: scheduling as early or as late as possible.
16
17 Warning: Currently for both of these methods, the MemorySlots in circuit Measures are ignored.
18 Qubits will be measured into the MemorySlot which matches the measured qubit's index. (Issue #2704)
19 """
20
21 from collections import defaultdict, namedtuple
22 from typing import List
23
24 from qiskit.circuit.measure import Measure
25 from qiskit.circuit.quantumcircuit import QuantumCircuit
26 from qiskit.exceptions import QiskitError
27 from qiskit.extensions.standard.barrier import Barrier
28 from qiskit.pulse.exceptions import PulseError
29 from qiskit.pulse.schedule import Schedule
30
31 from qiskit.scheduler.config import ScheduleConfig
32
33
34 CircuitPulseDef = namedtuple('CircuitPulseDef', [
35 'schedule', # The schedule which implements the quantum circuit command
36 'qubits']) # The labels of the qubits involved in the command according to the circuit
37
38
39 def as_soon_as_possible(circuit: QuantumCircuit,
40 schedule_config: ScheduleConfig) -> Schedule:
41 """
42 Return the pulse Schedule which implements the input circuit using an "as soon as possible"
43 (asap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse
44 Schedules according to the command definition given by the schedule_config. Then, this circuit
45 instruction-equivalent Schedule is appended at the earliest time at which all qubits involved
46 in the instruction are available.
47
48 Args:
49 circuit: The quantum circuit to translate
50 schedule_config: Backend specific parameters used for building the Schedule
51 Returns:
52 A schedule corresponding to the input `circuit` with pulses occurring as early as possible
53 """
54 sched = Schedule(name=circuit.name)
55
56 qubit_time_available = defaultdict(int)
57
58 def update_times(inst_qubits: List[int], time: int = 0) -> None:
59 """Update the time tracker for all inst_qubits to the given time."""
60 for q in inst_qubits:
61 qubit_time_available[q] = time
62
63 circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)
64 for circ_pulse_def in circ_pulse_defs:
65 time = max(qubit_time_available[q] for q in circ_pulse_def.qubits)
66 if isinstance(circ_pulse_def.schedule, Barrier):
67 update_times(circ_pulse_def.qubits, time)
68 else:
69 sched = sched.insert(time, circ_pulse_def.schedule)
70 update_times(circ_pulse_def.qubits, time + circ_pulse_def.schedule.duration)
71 return sched
72
73
74 def as_late_as_possible(circuit: QuantumCircuit,
75 schedule_config: ScheduleConfig) -> Schedule:
76 """
77 Return the pulse Schedule which implements the input circuit using an "as late as possible"
78 (alap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse
79 Schedules according to the command definition given by the schedule_config. Then, this circuit
80 instruction-equivalent Schedule is appended at the latest time that it can be without allowing
81 unnecessary time between instructions or allowing instructions with common qubits to overlap.
82
83 This method should improves the outcome fidelity over ASAP scheduling, because we may
84 maximize the time that the qubit remains in the ground state.
85
86 Args:
87 circuit: The quantum circuit to translate
88 schedule_config: Backend specific parameters used for building the Schedule
89 Returns:
90 A schedule corresponding to the input `circuit` with pulses occurring as late as possible
91 """
92 sched = Schedule(name=circuit.name)
93 # Align channel end times.
94 circuit.barrier()
95 # We schedule in reverse order to get ALAP behaviour. We need to know how far out from t=0 any
96 # qubit will become occupied. We add positive shifts to these times as we go along.
97 # The time is initialized to 0 because all qubits are involved in the final barrier.
98 qubit_available_until = defaultdict(lambda: 0)
99
100 def update_times(inst_qubits: List[int], shift: int = 0, cmd_start_time: int = 0) -> None:
101 """Update the time tracker for all inst_qubits to the given time."""
102 for q in inst_qubits:
103 qubit_available_until[q] = cmd_start_time
104 for q in qubit_available_until.keys():
105 if q not in inst_qubits:
106 # Uninvolved qubits might be free for the duration of the new instruction
107 qubit_available_until[q] += shift
108
109 circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)
110 for circ_pulse_def in reversed(circ_pulse_defs):
111 cmd_sched = circ_pulse_def.schedule
112 # The new instruction should end when one of its qubits becomes occupied
113 cmd_start_time = (min([qubit_available_until[q] for q in circ_pulse_def.qubits])
114 - getattr(cmd_sched, 'duration', 0)) # Barrier has no duration
115 # We have to translate qubit times forward when the cmd_start_time is negative
116 shift_amount = max(0, -cmd_start_time)
117 cmd_start_time = max(cmd_start_time, 0)
118 if not isinstance(circ_pulse_def.schedule, Barrier):
119 sched = cmd_sched.shift(cmd_start_time).insert(shift_amount, sched, name=sched.name)
120 update_times(circ_pulse_def.qubits, shift_amount, cmd_start_time)
121 return sched
122
123
124 def translate_gates_to_pulse_defs(circuit: QuantumCircuit,
125 schedule_config: ScheduleConfig) -> List[CircuitPulseDef]:
126 """
127 Without concern for the final schedule, extract and return a list of Schedules and the qubits
128 they operate on, for each element encountered in the input circuit. Measures are grouped when
129 possible, so qc.measure(q0, c0)/qc.measure(q1, c1) will generate a synchronous measurement
130 pulse.
131
132 Args:
133 circuit: The quantum circuit to translate
134 schedule_config: Backend specific parameters used for building the Schedule
135 Returns:
136 A list of CircuitPulseDefs: the pulse definition for each circuit element
137 Raises:
138 QiskitError: If circuit uses a command that isn't defined in config.cmd_def
139 """
140 circ_pulse_defs = []
141
142 cmd_def = schedule_config.cmd_def
143 measured_qubits = set() # Collect qubits that would like to be measured
144
145 def get_measure_schedule() -> CircuitPulseDef:
146 """Create a schedule to measure the qubits queued for measuring."""
147 measures = set()
148 all_qubits = set()
149 sched = Schedule()
150 for q in measured_qubits:
151 measures.add(tuple(schedule_config.meas_map[q]))
152 for qubits in measures:
153 all_qubits.update(qubits)
154 # TODO (Issue #2704): Respect MemorySlots from the input circuit
155 sched |= cmd_def.get('measure', qubits)
156 measured_qubits.clear()
157 return CircuitPulseDef(schedule=sched, qubits=list(all_qubits))
158
159 for inst, qubits, _ in circuit.data:
160 inst_qubits = [qubit.index for qubit in qubits] # We want only the indices of the qubits
161 if any(q in measured_qubits for q in inst_qubits):
162 # If we are operating on a qubit that was scheduled to be measured, process that first
163 circ_pulse_defs.append(get_measure_schedule())
164 if isinstance(inst, Barrier):
165 circ_pulse_defs.append(CircuitPulseDef(schedule=inst, qubits=inst_qubits))
166 elif isinstance(inst, Measure):
167 measured_qubits.update(inst_qubits)
168 else:
169 try:
170 circ_pulse_defs.append(
171 CircuitPulseDef(schedule=cmd_def.get(inst.name, inst_qubits, *inst.params),
172 qubits=inst_qubits))
173 except PulseError:
174 raise QiskitError("Operation '{0}' on qubit(s) {1} not supported by the backend "
175 "command definition. Did you remember to transpile your input "
176 "circuit for the same backend?".format(inst.name, inst_qubits))
177 if measured_qubits:
178 circ_pulse_defs.append(get_measure_schedule())
179
180 return circ_pulse_defs
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/scheduler/methods/basic.py b/qiskit/scheduler/methods/basic.py
--- a/qiskit/scheduler/methods/basic.py
+++ b/qiskit/scheduler/methods/basic.py
@@ -27,6 +27,8 @@
from qiskit.extensions.standard.barrier import Barrier
from qiskit.pulse.exceptions import PulseError
from qiskit.pulse.schedule import Schedule
+from qiskit.pulse.channels import MemorySlot
+from qiskit.pulse.commands import AcquireInstruction
from qiskit.scheduler.config import ScheduleConfig
@@ -140,31 +142,50 @@
circ_pulse_defs = []
cmd_def = schedule_config.cmd_def
- measured_qubits = set() # Collect qubits that would like to be measured
+ qubit_mem_slots = {} # Map measured qubit index to classical bit index
def get_measure_schedule() -> CircuitPulseDef:
"""Create a schedule to measure the qubits queued for measuring."""
measures = set()
all_qubits = set()
sched = Schedule()
- for q in measured_qubits:
- measures.add(tuple(schedule_config.meas_map[q]))
+ for qubit in qubit_mem_slots:
+ measures.add(tuple(schedule_config.meas_map[qubit]))
for qubits in measures:
all_qubits.update(qubits)
- # TODO (Issue #2704): Respect MemorySlots from the input circuit
- sched |= cmd_def.get('measure', qubits)
- measured_qubits.clear()
+ unused_mem_slots = set(qubits) - set(qubit_mem_slots.values())
+ default_sched = cmd_def.get('measure', qubits)
+ for time, inst in default_sched.instructions:
+ if isinstance(inst, AcquireInstruction):
+ mem_slots = []
+ for channel in inst.acquires:
+ if channel.index in qubit_mem_slots.keys():
+ mem_slots.append(MemorySlot(qubit_mem_slots[channel.index]))
+ else:
+ mem_slots.append(MemorySlot(unused_mem_slots.pop()))
+ new_acquire = AcquireInstruction(command=inst.command,
+ acquires=inst.acquires,
+ mem_slots=mem_slots)
+ sched._union((time, new_acquire))
+ # Measurement pulses should only be added if its qubit was measured by the user
+ elif inst.channels[0].index in qubit_mem_slots.keys():
+ sched._union((time, inst))
+ qubit_mem_slots.clear()
return CircuitPulseDef(schedule=sched, qubits=list(all_qubits))
- for inst, qubits, _ in circuit.data:
+ for inst, qubits, clbits in circuit.data:
inst_qubits = [qubit.index for qubit in qubits] # We want only the indices of the qubits
- if any(q in measured_qubits for q in inst_qubits):
+ if any(q in qubit_mem_slots for q in inst_qubits):
# If we are operating on a qubit that was scheduled to be measured, process that first
circ_pulse_defs.append(get_measure_schedule())
if isinstance(inst, Barrier):
circ_pulse_defs.append(CircuitPulseDef(schedule=inst, qubits=inst_qubits))
elif isinstance(inst, Measure):
- measured_qubits.update(inst_qubits)
+ if (len(inst_qubits) != 1 and len(clbits) != 1):
+ raise QiskitError("Qubit '{0}' or classical bit '{1}' errored because the "
+ "circuit Measure instruction only takes one of "
+ "each.".format(inst_qubits, clbits))
+ qubit_mem_slots[inst_qubits[0]] = clbits[0].index
else:
try:
circ_pulse_defs.append(
@@ -174,7 +195,7 @@
raise QiskitError("Operation '{0}' on qubit(s) {1} not supported by the backend "
"command definition. Did you remember to transpile your input "
"circuit for the same backend?".format(inst.name, inst_qubits))
- if measured_qubits:
+ if qubit_mem_slots:
circ_pulse_defs.append(get_measure_schedule())
return circ_pulse_defs
|
{"golden_diff": "diff --git a/qiskit/scheduler/methods/basic.py b/qiskit/scheduler/methods/basic.py\n--- a/qiskit/scheduler/methods/basic.py\n+++ b/qiskit/scheduler/methods/basic.py\n@@ -27,6 +27,8 @@\n from qiskit.extensions.standard.barrier import Barrier\n from qiskit.pulse.exceptions import PulseError\n from qiskit.pulse.schedule import Schedule\n+from qiskit.pulse.channels import MemorySlot\n+from qiskit.pulse.commands import AcquireInstruction\n \n from qiskit.scheduler.config import ScheduleConfig\n \n@@ -140,31 +142,50 @@\n circ_pulse_defs = []\n \n cmd_def = schedule_config.cmd_def\n- measured_qubits = set() # Collect qubits that would like to be measured\n+ qubit_mem_slots = {} # Map measured qubit index to classical bit index\n \n def get_measure_schedule() -> CircuitPulseDef:\n \"\"\"Create a schedule to measure the qubits queued for measuring.\"\"\"\n measures = set()\n all_qubits = set()\n sched = Schedule()\n- for q in measured_qubits:\n- measures.add(tuple(schedule_config.meas_map[q]))\n+ for qubit in qubit_mem_slots:\n+ measures.add(tuple(schedule_config.meas_map[qubit]))\n for qubits in measures:\n all_qubits.update(qubits)\n- # TODO (Issue #2704): Respect MemorySlots from the input circuit\n- sched |= cmd_def.get('measure', qubits)\n- measured_qubits.clear()\n+ unused_mem_slots = set(qubits) - set(qubit_mem_slots.values())\n+ default_sched = cmd_def.get('measure', qubits)\n+ for time, inst in default_sched.instructions:\n+ if isinstance(inst, AcquireInstruction):\n+ mem_slots = []\n+ for channel in inst.acquires:\n+ if channel.index in qubit_mem_slots.keys():\n+ mem_slots.append(MemorySlot(qubit_mem_slots[channel.index]))\n+ else:\n+ mem_slots.append(MemorySlot(unused_mem_slots.pop()))\n+ new_acquire = AcquireInstruction(command=inst.command,\n+ acquires=inst.acquires,\n+ mem_slots=mem_slots)\n+ sched._union((time, new_acquire))\n+ # Measurement pulses should only be added if its qubit was measured by the user\n+ elif inst.channels[0].index in qubit_mem_slots.keys():\n+ sched._union((time, inst))\n+ qubit_mem_slots.clear()\n return CircuitPulseDef(schedule=sched, qubits=list(all_qubits))\n \n- for inst, qubits, _ in circuit.data:\n+ for inst, qubits, clbits in circuit.data:\n inst_qubits = [qubit.index for qubit in qubits] # We want only the indices of the qubits\n- if any(q in measured_qubits for q in inst_qubits):\n+ if any(q in qubit_mem_slots for q in inst_qubits):\n # If we are operating on a qubit that was scheduled to be measured, process that first\n circ_pulse_defs.append(get_measure_schedule())\n if isinstance(inst, Barrier):\n circ_pulse_defs.append(CircuitPulseDef(schedule=inst, qubits=inst_qubits))\n elif isinstance(inst, Measure):\n- measured_qubits.update(inst_qubits)\n+ if (len(inst_qubits) != 1 and len(clbits) != 1):\n+ raise QiskitError(\"Qubit '{0}' or classical bit '{1}' errored because the \"\n+ \"circuit Measure instruction only takes one of \"\n+ \"each.\".format(inst_qubits, clbits))\n+ qubit_mem_slots[inst_qubits[0]] = clbits[0].index\n else:\n try:\n circ_pulse_defs.append(\n@@ -174,7 +195,7 @@\n raise QiskitError(\"Operation '{0}' on qubit(s) {1} not supported by the backend \"\n \"command definition. Did you remember to transpile your input \"\n \"circuit for the same backend?\".format(inst.name, inst_qubits))\n- if measured_qubits:\n+ if qubit_mem_slots:\n circ_pulse_defs.append(get_measure_schedule())\n \n return circ_pulse_defs\n", "issue": "Scheduler needs to respect MemSlots in QuantumCircuit Measures\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\nKnown bug from my PR https://github.com/Qiskit/qiskit-terra/pull/2650\r\n\r\n### What is the current behavior?\r\nWhen passing a circuit through the basic scheduler (`qiskit.scheduler.schedule`), the resulting `Schedule` will always measure qubit results into the `MemorySlot` which matches the qubit index.\r\nFor example:\r\n```\r\nqc.measure(q[0], c[3])\r\n```\r\nwill measure qubit 0 into `MemorySlot(0)` rather than `MemorySlot(3)` -- it will use the default Acquire from the cmd_def which is probably something like `Acquire([0, 1], [MemSlot(0), MemSlot(1)])`. The correct behaviour is to use the classical reg from the instruction and then modify the `AcquireInstruction` from the `Schedule` returned by the `cmd_def`. It's unclear what we should do with the other qubits that are measured within the same `meas_map` group, if the user doesn't specify those other qubits to be measured.\r\n\r\nWe need a follow up PR to handle this more carefully. The solution likely needs to update the helper function: `qiskit.scheduler.methods.basic.translate_gates_to_pulse_defs.get_measure_schedule`\r\n\r\n\r\n### Steps to reproduce the problem\r\n### What is the expected behavior?\r\n### Suggested solutions\r\nsee above\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"The most straightforward scheduling methods: scheduling as early or as late as possible.\n\nWarning: Currently for both of these methods, the MemorySlots in circuit Measures are ignored.\nQubits will be measured into the MemorySlot which matches the measured qubit's index. (Issue #2704)\n\"\"\"\n\nfrom collections import defaultdict, namedtuple\nfrom typing import List\n\nfrom qiskit.circuit.measure import Measure\nfrom qiskit.circuit.quantumcircuit import QuantumCircuit\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.extensions.standard.barrier import Barrier\nfrom qiskit.pulse.exceptions import PulseError\nfrom qiskit.pulse.schedule import Schedule\n\nfrom qiskit.scheduler.config import ScheduleConfig\n\n\nCircuitPulseDef = namedtuple('CircuitPulseDef', [\n 'schedule', # The schedule which implements the quantum circuit command\n 'qubits']) # The labels of the qubits involved in the command according to the circuit\n\n\ndef as_soon_as_possible(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> Schedule:\n \"\"\"\n Return the pulse Schedule which implements the input circuit using an \"as soon as possible\"\n (asap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse\n Schedules according to the command definition given by the schedule_config. Then, this circuit\n instruction-equivalent Schedule is appended at the earliest time at which all qubits involved\n in the instruction are available.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A schedule corresponding to the input `circuit` with pulses occurring as early as possible\n \"\"\"\n sched = Schedule(name=circuit.name)\n\n qubit_time_available = defaultdict(int)\n\n def update_times(inst_qubits: List[int], time: int = 0) -> None:\n \"\"\"Update the time tracker for all inst_qubits to the given time.\"\"\"\n for q in inst_qubits:\n qubit_time_available[q] = time\n\n circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)\n for circ_pulse_def in circ_pulse_defs:\n time = max(qubit_time_available[q] for q in circ_pulse_def.qubits)\n if isinstance(circ_pulse_def.schedule, Barrier):\n update_times(circ_pulse_def.qubits, time)\n else:\n sched = sched.insert(time, circ_pulse_def.schedule)\n update_times(circ_pulse_def.qubits, time + circ_pulse_def.schedule.duration)\n return sched\n\n\ndef as_late_as_possible(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> Schedule:\n \"\"\"\n Return the pulse Schedule which implements the input circuit using an \"as late as possible\"\n (alap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse\n Schedules according to the command definition given by the schedule_config. Then, this circuit\n instruction-equivalent Schedule is appended at the latest time that it can be without allowing\n unnecessary time between instructions or allowing instructions with common qubits to overlap.\n\n This method should improves the outcome fidelity over ASAP scheduling, because we may\n maximize the time that the qubit remains in the ground state.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A schedule corresponding to the input `circuit` with pulses occurring as late as possible\n \"\"\"\n sched = Schedule(name=circuit.name)\n # Align channel end times.\n circuit.barrier()\n # We schedule in reverse order to get ALAP behaviour. We need to know how far out from t=0 any\n # qubit will become occupied. We add positive shifts to these times as we go along.\n # The time is initialized to 0 because all qubits are involved in the final barrier.\n qubit_available_until = defaultdict(lambda: 0)\n\n def update_times(inst_qubits: List[int], shift: int = 0, cmd_start_time: int = 0) -> None:\n \"\"\"Update the time tracker for all inst_qubits to the given time.\"\"\"\n for q in inst_qubits:\n qubit_available_until[q] = cmd_start_time\n for q in qubit_available_until.keys():\n if q not in inst_qubits:\n # Uninvolved qubits might be free for the duration of the new instruction\n qubit_available_until[q] += shift\n\n circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)\n for circ_pulse_def in reversed(circ_pulse_defs):\n cmd_sched = circ_pulse_def.schedule\n # The new instruction should end when one of its qubits becomes occupied\n cmd_start_time = (min([qubit_available_until[q] for q in circ_pulse_def.qubits])\n - getattr(cmd_sched, 'duration', 0)) # Barrier has no duration\n # We have to translate qubit times forward when the cmd_start_time is negative\n shift_amount = max(0, -cmd_start_time)\n cmd_start_time = max(cmd_start_time, 0)\n if not isinstance(circ_pulse_def.schedule, Barrier):\n sched = cmd_sched.shift(cmd_start_time).insert(shift_amount, sched, name=sched.name)\n update_times(circ_pulse_def.qubits, shift_amount, cmd_start_time)\n return sched\n\n\ndef translate_gates_to_pulse_defs(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> List[CircuitPulseDef]:\n \"\"\"\n Without concern for the final schedule, extract and return a list of Schedules and the qubits\n they operate on, for each element encountered in the input circuit. Measures are grouped when\n possible, so qc.measure(q0, c0)/qc.measure(q1, c1) will generate a synchronous measurement\n pulse.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A list of CircuitPulseDefs: the pulse definition for each circuit element\n Raises:\n QiskitError: If circuit uses a command that isn't defined in config.cmd_def\n \"\"\"\n circ_pulse_defs = []\n\n cmd_def = schedule_config.cmd_def\n measured_qubits = set() # Collect qubits that would like to be measured\n\n def get_measure_schedule() -> CircuitPulseDef:\n \"\"\"Create a schedule to measure the qubits queued for measuring.\"\"\"\n measures = set()\n all_qubits = set()\n sched = Schedule()\n for q in measured_qubits:\n measures.add(tuple(schedule_config.meas_map[q]))\n for qubits in measures:\n all_qubits.update(qubits)\n # TODO (Issue #2704): Respect MemorySlots from the input circuit\n sched |= cmd_def.get('measure', qubits)\n measured_qubits.clear()\n return CircuitPulseDef(schedule=sched, qubits=list(all_qubits))\n\n for inst, qubits, _ in circuit.data:\n inst_qubits = [qubit.index for qubit in qubits] # We want only the indices of the qubits\n if any(q in measured_qubits for q in inst_qubits):\n # If we are operating on a qubit that was scheduled to be measured, process that first\n circ_pulse_defs.append(get_measure_schedule())\n if isinstance(inst, Barrier):\n circ_pulse_defs.append(CircuitPulseDef(schedule=inst, qubits=inst_qubits))\n elif isinstance(inst, Measure):\n measured_qubits.update(inst_qubits)\n else:\n try:\n circ_pulse_defs.append(\n CircuitPulseDef(schedule=cmd_def.get(inst.name, inst_qubits, *inst.params),\n qubits=inst_qubits))\n except PulseError:\n raise QiskitError(\"Operation '{0}' on qubit(s) {1} not supported by the backend \"\n \"command definition. Did you remember to transpile your input \"\n \"circuit for the same backend?\".format(inst.name, inst_qubits))\n if measured_qubits:\n circ_pulse_defs.append(get_measure_schedule())\n\n return circ_pulse_defs\n", "path": "qiskit/scheduler/methods/basic.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"The most straightforward scheduling methods: scheduling as early or as late as possible.\n\nWarning: Currently for both of these methods, the MemorySlots in circuit Measures are ignored.\nQubits will be measured into the MemorySlot which matches the measured qubit's index. (Issue #2704)\n\"\"\"\n\nfrom collections import defaultdict, namedtuple\nfrom typing import List\n\nfrom qiskit.circuit.measure import Measure\nfrom qiskit.circuit.quantumcircuit import QuantumCircuit\nfrom qiskit.exceptions import QiskitError\nfrom qiskit.extensions.standard.barrier import Barrier\nfrom qiskit.pulse.exceptions import PulseError\nfrom qiskit.pulse.schedule import Schedule\nfrom qiskit.pulse.channels import MemorySlot\nfrom qiskit.pulse.commands import AcquireInstruction\n\nfrom qiskit.scheduler.config import ScheduleConfig\n\n\nCircuitPulseDef = namedtuple('CircuitPulseDef', [\n 'schedule', # The schedule which implements the quantum circuit command\n 'qubits']) # The labels of the qubits involved in the command according to the circuit\n\n\ndef as_soon_as_possible(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> Schedule:\n \"\"\"\n Return the pulse Schedule which implements the input circuit using an \"as soon as possible\"\n (asap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse\n Schedules according to the command definition given by the schedule_config. Then, this circuit\n instruction-equivalent Schedule is appended at the earliest time at which all qubits involved\n in the instruction are available.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A schedule corresponding to the input `circuit` with pulses occurring as early as possible\n \"\"\"\n sched = Schedule(name=circuit.name)\n\n qubit_time_available = defaultdict(int)\n\n def update_times(inst_qubits: List[int], time: int = 0) -> None:\n \"\"\"Update the time tracker for all inst_qubits to the given time.\"\"\"\n for q in inst_qubits:\n qubit_time_available[q] = time\n\n circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)\n for circ_pulse_def in circ_pulse_defs:\n time = max(qubit_time_available[q] for q in circ_pulse_def.qubits)\n if isinstance(circ_pulse_def.schedule, Barrier):\n update_times(circ_pulse_def.qubits, time)\n else:\n sched = sched.insert(time, circ_pulse_def.schedule)\n update_times(circ_pulse_def.qubits, time + circ_pulse_def.schedule.duration)\n return sched\n\n\ndef as_late_as_possible(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> Schedule:\n \"\"\"\n Return the pulse Schedule which implements the input circuit using an \"as late as possible\"\n (alap) scheduling policy. Circuit instructions are first each mapped to equivalent pulse\n Schedules according to the command definition given by the schedule_config. Then, this circuit\n instruction-equivalent Schedule is appended at the latest time that it can be without allowing\n unnecessary time between instructions or allowing instructions with common qubits to overlap.\n\n This method should improves the outcome fidelity over ASAP scheduling, because we may\n maximize the time that the qubit remains in the ground state.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A schedule corresponding to the input `circuit` with pulses occurring as late as possible\n \"\"\"\n sched = Schedule(name=circuit.name)\n # Align channel end times.\n circuit.barrier()\n # We schedule in reverse order to get ALAP behaviour. We need to know how far out from t=0 any\n # qubit will become occupied. We add positive shifts to these times as we go along.\n # The time is initialized to 0 because all qubits are involved in the final barrier.\n qubit_available_until = defaultdict(lambda: 0)\n\n def update_times(inst_qubits: List[int], shift: int = 0, cmd_start_time: int = 0) -> None:\n \"\"\"Update the time tracker for all inst_qubits to the given time.\"\"\"\n for q in inst_qubits:\n qubit_available_until[q] = cmd_start_time\n for q in qubit_available_until.keys():\n if q not in inst_qubits:\n # Uninvolved qubits might be free for the duration of the new instruction\n qubit_available_until[q] += shift\n\n circ_pulse_defs = translate_gates_to_pulse_defs(circuit, schedule_config)\n for circ_pulse_def in reversed(circ_pulse_defs):\n cmd_sched = circ_pulse_def.schedule\n # The new instruction should end when one of its qubits becomes occupied\n cmd_start_time = (min([qubit_available_until[q] for q in circ_pulse_def.qubits])\n - getattr(cmd_sched, 'duration', 0)) # Barrier has no duration\n # We have to translate qubit times forward when the cmd_start_time is negative\n shift_amount = max(0, -cmd_start_time)\n cmd_start_time = max(cmd_start_time, 0)\n if not isinstance(circ_pulse_def.schedule, Barrier):\n sched = cmd_sched.shift(cmd_start_time).insert(shift_amount, sched, name=sched.name)\n update_times(circ_pulse_def.qubits, shift_amount, cmd_start_time)\n return sched\n\n\ndef translate_gates_to_pulse_defs(circuit: QuantumCircuit,\n schedule_config: ScheduleConfig) -> List[CircuitPulseDef]:\n \"\"\"\n Without concern for the final schedule, extract and return a list of Schedules and the qubits\n they operate on, for each element encountered in the input circuit. Measures are grouped when\n possible, so qc.measure(q0, c0)/qc.measure(q1, c1) will generate a synchronous measurement\n pulse.\n\n Args:\n circuit: The quantum circuit to translate\n schedule_config: Backend specific parameters used for building the Schedule\n Returns:\n A list of CircuitPulseDefs: the pulse definition for each circuit element\n Raises:\n QiskitError: If circuit uses a command that isn't defined in config.cmd_def\n \"\"\"\n circ_pulse_defs = []\n\n cmd_def = schedule_config.cmd_def\n qubit_mem_slots = {} # Map measured qubit index to classical bit index\n\n def get_measure_schedule() -> CircuitPulseDef:\n \"\"\"Create a schedule to measure the qubits queued for measuring.\"\"\"\n measures = set()\n all_qubits = set()\n sched = Schedule()\n for qubit in qubit_mem_slots:\n measures.add(tuple(schedule_config.meas_map[qubit]))\n for qubits in measures:\n all_qubits.update(qubits)\n unused_mem_slots = set(qubits) - set(qubit_mem_slots.values())\n default_sched = cmd_def.get('measure', qubits)\n for time, inst in default_sched.instructions:\n if isinstance(inst, AcquireInstruction):\n mem_slots = []\n for channel in inst.acquires:\n if channel.index in qubit_mem_slots.keys():\n mem_slots.append(MemorySlot(qubit_mem_slots[channel.index]))\n else:\n mem_slots.append(MemorySlot(unused_mem_slots.pop()))\n new_acquire = AcquireInstruction(command=inst.command,\n acquires=inst.acquires,\n mem_slots=mem_slots)\n sched._union((time, new_acquire))\n # Measurement pulses should only be added if its qubit was measured by the user\n elif inst.channels[0].index in qubit_mem_slots.keys():\n sched._union((time, inst))\n qubit_mem_slots.clear()\n return CircuitPulseDef(schedule=sched, qubits=list(all_qubits))\n\n for inst, qubits, clbits in circuit.data:\n inst_qubits = [qubit.index for qubit in qubits] # We want only the indices of the qubits\n if any(q in qubit_mem_slots for q in inst_qubits):\n # If we are operating on a qubit that was scheduled to be measured, process that first\n circ_pulse_defs.append(get_measure_schedule())\n if isinstance(inst, Barrier):\n circ_pulse_defs.append(CircuitPulseDef(schedule=inst, qubits=inst_qubits))\n elif isinstance(inst, Measure):\n if (len(inst_qubits) != 1 and len(clbits) != 1):\n raise QiskitError(\"Qubit '{0}' or classical bit '{1}' errored because the \"\n \"circuit Measure instruction only takes one of \"\n \"each.\".format(inst_qubits, clbits))\n qubit_mem_slots[inst_qubits[0]] = clbits[0].index\n else:\n try:\n circ_pulse_defs.append(\n CircuitPulseDef(schedule=cmd_def.get(inst.name, inst_qubits, *inst.params),\n qubits=inst_qubits))\n except PulseError:\n raise QiskitError(\"Operation '{0}' on qubit(s) {1} not supported by the backend \"\n \"command definition. Did you remember to transpile your input \"\n \"circuit for the same backend?\".format(inst.name, inst_qubits))\n if qubit_mem_slots:\n circ_pulse_defs.append(get_measure_schedule())\n\n return circ_pulse_defs\n", "path": "qiskit/scheduler/methods/basic.py"}]}
| 2,903 | 935 |
gh_patches_debug_56972
|
rasdani/github-patches
|
git_diff
|
tensorflow__tfx-2189
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Project can't be cloned correctly on macOS due to case insensitivity
Under the `tfx` folder there's a folder called `build` and a bazel file called `BUILD`. Because macOS is by default case insensitive, only the folder is cloned when `git clone` is run. This means that when trying to build locally, bazel won't be able to find the `BUILD` file required to compile the protobuf schemas, and will fail.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Lint as: python2, python3
2 # Copyright 2019 Google LLC. All Rights Reserved.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Package Setup script for TFX."""
16
17 from __future__ import print_function
18
19 import os
20 import subprocess
21
22 import setuptools
23 from setuptools import find_packages
24 from setuptools import setup
25 from setuptools.command import develop
26 # pylint: disable=g-bad-import-order
27 # It is recommended to import setuptools prior to importing distutils to avoid
28 # using legacy behavior from distutils.
29 # https://setuptools.readthedocs.io/en/latest/history.html#v48-0-0
30 from distutils import spawn
31 from distutils.command import build
32 # pylint: enable=g-bad-import-order
33
34 from tfx import dependencies
35 from tfx import version
36 from tfx.tools import resolve_deps
37
38
39 class _BuildCommand(build.build):
40 """Build everything that is needed to install.
41
42 This overrides the original distutils "build" command to to run gen_proto
43 command before any sub_commands.
44
45 build command is also invoked from bdist_wheel and install command, therefore
46 this implementation covers the following commands:
47 - pip install . (which invokes bdist_wheel)
48 - python setup.py install (which invokes install command)
49 - python setup.py bdist_wheel (which invokes bdist_wheel command)
50 """
51
52 def _should_generate_proto(self):
53 """Predicate method for running GenProto command or not."""
54 return True
55
56 # Add "gen_proto" command as the first sub_command of "build". Each
57 # sub_command of "build" (e.g. "build_py", "build_ext", etc.) is executed
58 # sequentially when running a "build" command, if the second item in the tuple
59 # (predicate method) is evaluated to true.
60 sub_commands = [
61 ('gen_proto', _should_generate_proto),
62 ] + build.build.sub_commands
63
64
65 class _DevelopCommand(develop.develop):
66 """Developmental install.
67
68 https://setuptools.readthedocs.io/en/latest/setuptools.html#development-mode
69 Unlike normal package installation where distribution is copied to the
70 site-packages folder, developmental install creates a symbolic link to the
71 source code directory, so that your local code change is immediately visible
72 in runtime without re-installation.
73
74 This is a setuptools-only (i.e. not included in distutils) command that is
75 also used in pip's editable install (pip install -e). Originally it only
76 invokes build_py and install_lib command, but we override it to run gen_proto
77 command in advance.
78
79 This implementation covers the following commands:
80 - pip install -e . (developmental install)
81 - python setup.py develop (which is invoked from developmental install)
82 """
83
84 def run(self):
85 self.run_command('gen_proto')
86 # Run super().initialize_options. Command is an old-style class (i.e.
87 # doesn't inherit object) and super() fails in python 2.
88 develop.develop.run(self)
89
90
91 class _GenProtoCommand(setuptools.Command):
92 """Generate proto stub files in python.
93
94 Running this command will populate foo_pb2.py file next to your foo.proto
95 file.
96 """
97
98 def initialize_options(self):
99 pass
100
101 def finalize_options(self):
102 self._bazel_cmd = spawn.find_executable('bazel')
103 if not self._bazel_cmd:
104 raise RuntimeError(
105 'Could not find "bazel" binary. Please visit '
106 'https://docs.bazel.build/versions/master/install.html for '
107 'installation instruction.')
108
109 def run(self):
110 subprocess.check_call(
111 [self._bazel_cmd, 'run', '//tfx/build:gen_proto'],
112 # Bazel should be invoked in a directory containing bazel WORKSPACE
113 # file, which is the root directory.
114 cwd=os.path.dirname(os.path.realpath(__file__)),)
115
116
117 # Get the long description from the README file.
118 with open('README.md') as fp:
119 _LONG_DESCRIPTION = fp.read()
120
121
122 setup(
123 name='tfx',
124 version=version.__version__,
125 author='Google LLC',
126 author_email='[email protected]',
127 license='Apache 2.0',
128 classifiers=[
129 'Development Status :: 4 - Beta',
130 'Intended Audience :: Developers',
131 'Intended Audience :: Education',
132 'Intended Audience :: Science/Research',
133 'License :: OSI Approved :: Apache Software License',
134 'Operating System :: OS Independent',
135 'Programming Language :: Python',
136 'Programming Language :: Python :: 3',
137 'Programming Language :: Python :: 3.5',
138 'Programming Language :: Python :: 3.6',
139 'Programming Language :: Python :: 3.7',
140 'Programming Language :: Python :: 3 :: Only',
141 'Topic :: Scientific/Engineering',
142 'Topic :: Scientific/Engineering :: Artificial Intelligence',
143 'Topic :: Scientific/Engineering :: Mathematics',
144 'Topic :: Software Development',
145 'Topic :: Software Development :: Libraries',
146 'Topic :: Software Development :: Libraries :: Python Modules',
147 ],
148 namespace_packages=[],
149 install_requires=dependencies.make_required_install_packages(),
150 extras_require={
151 # In order to use 'docker-image' or 'all', system libraries specified
152 # under 'tfx/tools/docker/Dockerfile' are required
153 'docker-image': dependencies.make_extra_packages_docker_image(),
154 'tfjs': dependencies.make_extra_packages_tfjs(),
155 'all': dependencies.make_all_dependency_packages(),
156 },
157 # TODO(b/158761800): Move to [build-system] requires in pyproject.toml.
158 setup_requires=[
159 'pytest-runner',
160 'poetry==1.0.9', # Required for ResolveDeps command.
161 # Poetry API is not officially documented and subject
162 # to change in the future. Thus fix the version.
163 'clikit>=0.4.3,<0.5', # Required for ResolveDeps command.
164 ],
165 cmdclass={
166 'build': _BuildCommand,
167 'develop': _DevelopCommand,
168 'gen_proto': _GenProtoCommand,
169 'resolve_deps': resolve_deps.ResolveDepsCommand,
170 },
171 python_requires='>=3.5,<4',
172 packages=find_packages(),
173 include_package_data=True,
174 description='TensorFlow Extended (TFX) is a TensorFlow-based general-purpose machine learning platform implemented at Google',
175 long_description=_LONG_DESCRIPTION,
176 long_description_content_type='text/markdown',
177 keywords='tensorflow tfx',
178 url='https://www.tensorflow.org/tfx',
179 download_url='https://github.com/tensorflow/tfx/tags',
180 requires=[],
181 # Below console_scripts, each line identifies one console script. The first
182 # part before the equals sign (=) which is 'tfx', is the name of the script
183 # that should be generated, the second part is the import path followed by a
184 # colon (:) with the Click command group. After installation, the user can
185 # invoke the CLI using "tfx <command_group> <sub_command> <flags>"
186 entry_points="""
187 [console_scripts]
188 tfx=tfx.tools.cli.cli_main:cli_group
189 """)
190
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -108,7 +108,7 @@
def run(self):
subprocess.check_call(
- [self._bazel_cmd, 'run', '//tfx/build:gen_proto'],
+ [self._bazel_cmd, 'run', '//build:gen_proto'],
# Bazel should be invoked in a directory containing bazel WORKSPACE
# file, which is the root directory.
cwd=os.path.dirname(os.path.realpath(__file__)),)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -108,7 +108,7 @@\n \n def run(self):\n subprocess.check_call(\n- [self._bazel_cmd, 'run', '//tfx/build:gen_proto'],\n+ [self._bazel_cmd, 'run', '//build:gen_proto'],\n # Bazel should be invoked in a directory containing bazel WORKSPACE\n # file, which is the root directory.\n cwd=os.path.dirname(os.path.realpath(__file__)),)\n", "issue": "Project can't be cloned correctly on macOS due to case insensitivity\nUnder the `tfx` folder there's a folder called `build` and a bazel file called `BUILD`. Because macOS is by default case insensitive, only the folder is cloned when `git clone` is run. This means that when trying to build locally, bazel won't be able to find the `BUILD` file required to compile the protobuf schemas, and will fail.\n", "before_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Package Setup script for TFX.\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport subprocess\n\nimport setuptools\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.command import develop\n# pylint: disable=g-bad-import-order\n# It is recommended to import setuptools prior to importing distutils to avoid\n# using legacy behavior from distutils.\n# https://setuptools.readthedocs.io/en/latest/history.html#v48-0-0\nfrom distutils import spawn\nfrom distutils.command import build\n# pylint: enable=g-bad-import-order\n\nfrom tfx import dependencies\nfrom tfx import version\nfrom tfx.tools import resolve_deps\n\n\nclass _BuildCommand(build.build):\n \"\"\"Build everything that is needed to install.\n\n This overrides the original distutils \"build\" command to to run gen_proto\n command before any sub_commands.\n\n build command is also invoked from bdist_wheel and install command, therefore\n this implementation covers the following commands:\n - pip install . (which invokes bdist_wheel)\n - python setup.py install (which invokes install command)\n - python setup.py bdist_wheel (which invokes bdist_wheel command)\n \"\"\"\n\n def _should_generate_proto(self):\n \"\"\"Predicate method for running GenProto command or not.\"\"\"\n return True\n\n # Add \"gen_proto\" command as the first sub_command of \"build\". Each\n # sub_command of \"build\" (e.g. \"build_py\", \"build_ext\", etc.) is executed\n # sequentially when running a \"build\" command, if the second item in the tuple\n # (predicate method) is evaluated to true.\n sub_commands = [\n ('gen_proto', _should_generate_proto),\n ] + build.build.sub_commands\n\n\nclass _DevelopCommand(develop.develop):\n \"\"\"Developmental install.\n\n https://setuptools.readthedocs.io/en/latest/setuptools.html#development-mode\n Unlike normal package installation where distribution is copied to the\n site-packages folder, developmental install creates a symbolic link to the\n source code directory, so that your local code change is immediately visible\n in runtime without re-installation.\n\n This is a setuptools-only (i.e. not included in distutils) command that is\n also used in pip's editable install (pip install -e). Originally it only\n invokes build_py and install_lib command, but we override it to run gen_proto\n command in advance.\n\n This implementation covers the following commands:\n - pip install -e . (developmental install)\n - python setup.py develop (which is invoked from developmental install)\n \"\"\"\n\n def run(self):\n self.run_command('gen_proto')\n # Run super().initialize_options. Command is an old-style class (i.e.\n # doesn't inherit object) and super() fails in python 2.\n develop.develop.run(self)\n\n\nclass _GenProtoCommand(setuptools.Command):\n \"\"\"Generate proto stub files in python.\n\n Running this command will populate foo_pb2.py file next to your foo.proto\n file.\n \"\"\"\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n self._bazel_cmd = spawn.find_executable('bazel')\n if not self._bazel_cmd:\n raise RuntimeError(\n 'Could not find \"bazel\" binary. Please visit '\n 'https://docs.bazel.build/versions/master/install.html for '\n 'installation instruction.')\n\n def run(self):\n subprocess.check_call(\n [self._bazel_cmd, 'run', '//tfx/build:gen_proto'],\n # Bazel should be invoked in a directory containing bazel WORKSPACE\n # file, which is the root directory.\n cwd=os.path.dirname(os.path.realpath(__file__)),)\n\n\n# Get the long description from the README file.\nwith open('README.md') as fp:\n _LONG_DESCRIPTION = fp.read()\n\n\nsetup(\n name='tfx',\n version=version.__version__,\n author='Google LLC',\n author_email='[email protected]',\n license='Apache 2.0',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3 :: Only',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n namespace_packages=[],\n install_requires=dependencies.make_required_install_packages(),\n extras_require={\n # In order to use 'docker-image' or 'all', system libraries specified\n # under 'tfx/tools/docker/Dockerfile' are required\n 'docker-image': dependencies.make_extra_packages_docker_image(),\n 'tfjs': dependencies.make_extra_packages_tfjs(),\n 'all': dependencies.make_all_dependency_packages(),\n },\n # TODO(b/158761800): Move to [build-system] requires in pyproject.toml.\n setup_requires=[\n 'pytest-runner',\n 'poetry==1.0.9', # Required for ResolveDeps command.\n # Poetry API is not officially documented and subject\n # to change in the future. Thus fix the version.\n 'clikit>=0.4.3,<0.5', # Required for ResolveDeps command.\n ],\n cmdclass={\n 'build': _BuildCommand,\n 'develop': _DevelopCommand,\n 'gen_proto': _GenProtoCommand,\n 'resolve_deps': resolve_deps.ResolveDepsCommand,\n },\n python_requires='>=3.5,<4',\n packages=find_packages(),\n include_package_data=True,\n description='TensorFlow Extended (TFX) is a TensorFlow-based general-purpose machine learning platform implemented at Google',\n long_description=_LONG_DESCRIPTION,\n long_description_content_type='text/markdown',\n keywords='tensorflow tfx',\n url='https://www.tensorflow.org/tfx',\n download_url='https://github.com/tensorflow/tfx/tags',\n requires=[],\n # Below console_scripts, each line identifies one console script. The first\n # part before the equals sign (=) which is 'tfx', is the name of the script\n # that should be generated, the second part is the import path followed by a\n # colon (:) with the Click command group. After installation, the user can\n # invoke the CLI using \"tfx <command_group> <sub_command> <flags>\"\n entry_points=\"\"\"\n [console_scripts]\n tfx=tfx.tools.cli.cli_main:cli_group\n \"\"\")\n", "path": "setup.py"}], "after_files": [{"content": "# Lint as: python2, python3\n# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Package Setup script for TFX.\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport subprocess\n\nimport setuptools\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.command import develop\n# pylint: disable=g-bad-import-order\n# It is recommended to import setuptools prior to importing distutils to avoid\n# using legacy behavior from distutils.\n# https://setuptools.readthedocs.io/en/latest/history.html#v48-0-0\nfrom distutils import spawn\nfrom distutils.command import build\n# pylint: enable=g-bad-import-order\n\nfrom tfx import dependencies\nfrom tfx import version\nfrom tfx.tools import resolve_deps\n\n\nclass _BuildCommand(build.build):\n \"\"\"Build everything that is needed to install.\n\n This overrides the original distutils \"build\" command to to run gen_proto\n command before any sub_commands.\n\n build command is also invoked from bdist_wheel and install command, therefore\n this implementation covers the following commands:\n - pip install . (which invokes bdist_wheel)\n - python setup.py install (which invokes install command)\n - python setup.py bdist_wheel (which invokes bdist_wheel command)\n \"\"\"\n\n def _should_generate_proto(self):\n \"\"\"Predicate method for running GenProto command or not.\"\"\"\n return True\n\n # Add \"gen_proto\" command as the first sub_command of \"build\". Each\n # sub_command of \"build\" (e.g. \"build_py\", \"build_ext\", etc.) is executed\n # sequentially when running a \"build\" command, if the second item in the tuple\n # (predicate method) is evaluated to true.\n sub_commands = [\n ('gen_proto', _should_generate_proto),\n ] + build.build.sub_commands\n\n\nclass _DevelopCommand(develop.develop):\n \"\"\"Developmental install.\n\n https://setuptools.readthedocs.io/en/latest/setuptools.html#development-mode\n Unlike normal package installation where distribution is copied to the\n site-packages folder, developmental install creates a symbolic link to the\n source code directory, so that your local code change is immediately visible\n in runtime without re-installation.\n\n This is a setuptools-only (i.e. not included in distutils) command that is\n also used in pip's editable install (pip install -e). Originally it only\n invokes build_py and install_lib command, but we override it to run gen_proto\n command in advance.\n\n This implementation covers the following commands:\n - pip install -e . (developmental install)\n - python setup.py develop (which is invoked from developmental install)\n \"\"\"\n\n def run(self):\n self.run_command('gen_proto')\n # Run super().initialize_options. Command is an old-style class (i.e.\n # doesn't inherit object) and super() fails in python 2.\n develop.develop.run(self)\n\n\nclass _GenProtoCommand(setuptools.Command):\n \"\"\"Generate proto stub files in python.\n\n Running this command will populate foo_pb2.py file next to your foo.proto\n file.\n \"\"\"\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n self._bazel_cmd = spawn.find_executable('bazel')\n if not self._bazel_cmd:\n raise RuntimeError(\n 'Could not find \"bazel\" binary. Please visit '\n 'https://docs.bazel.build/versions/master/install.html for '\n 'installation instruction.')\n\n def run(self):\n subprocess.check_call(\n [self._bazel_cmd, 'run', '//build:gen_proto'],\n # Bazel should be invoked in a directory containing bazel WORKSPACE\n # file, which is the root directory.\n cwd=os.path.dirname(os.path.realpath(__file__)),)\n\n\n# Get the long description from the README file.\nwith open('README.md') as fp:\n _LONG_DESCRIPTION = fp.read()\n\n\nsetup(\n name='tfx',\n version=version.__version__,\n author='Google LLC',\n author_email='[email protected]',\n license='Apache 2.0',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3 :: Only',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n namespace_packages=[],\n install_requires=dependencies.make_required_install_packages(),\n extras_require={\n # In order to use 'docker-image' or 'all', system libraries specified\n # under 'tfx/tools/docker/Dockerfile' are required\n 'docker-image': dependencies.make_extra_packages_docker_image(),\n 'tfjs': dependencies.make_extra_packages_tfjs(),\n 'all': dependencies.make_all_dependency_packages(),\n },\n # TODO(b/158761800): Move to [build-system] requires in pyproject.toml.\n setup_requires=[\n 'pytest-runner',\n 'poetry==1.0.9', # Required for ResolveDeps command.\n # Poetry API is not officially documented and subject\n # to change in the future. Thus fix the version.\n 'clikit>=0.4.3,<0.5', # Required for ResolveDeps command.\n ],\n cmdclass={\n 'build': _BuildCommand,\n 'develop': _DevelopCommand,\n 'gen_proto': _GenProtoCommand,\n 'resolve_deps': resolve_deps.ResolveDepsCommand,\n },\n python_requires='>=3.5,<4',\n packages=find_packages(),\n include_package_data=True,\n description='TensorFlow Extended (TFX) is a TensorFlow-based general-purpose machine learning platform implemented at Google',\n long_description=_LONG_DESCRIPTION,\n long_description_content_type='text/markdown',\n keywords='tensorflow tfx',\n url='https://www.tensorflow.org/tfx',\n download_url='https://github.com/tensorflow/tfx/tags',\n requires=[],\n # Below console_scripts, each line identifies one console script. The first\n # part before the equals sign (=) which is 'tfx', is the name of the script\n # that should be generated, the second part is the import path followed by a\n # colon (:) with the Click command group. After installation, the user can\n # invoke the CLI using \"tfx <command_group> <sub_command> <flags>\"\n entry_points=\"\"\"\n [console_scripts]\n tfx=tfx.tools.cli.cli_main:cli_group\n \"\"\")\n", "path": "setup.py"}]}
| 2,480 | 122 |
gh_patches_debug_66276
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-979
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
--no-root behavior is inverted on latest develop
[This](https://github.com/sdispater/poetry/commit/37ec1447b3508ee0bbdb41f8e5773ed5bfae0654#diff-427299ba040b8502b4d29846e595c2d0R59) should probably be `if self.option("no-root")`, to _not_ install the root package when `--no-root` is provided.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `poetry/console/commands/install.py`
Content:
```
1 import os
2
3 from .env_command import EnvCommand
4
5
6 class InstallCommand(EnvCommand):
7 """
8 Installs the project dependencies.
9
10 install
11 { --no-dev : Do not install dev dependencies. }
12 { --no-root : Do not install the root package (your project). }
13 { --dry-run : Outputs the operations but will not execute anything
14 (implicitly enables --verbose). }
15 { --E|extras=* : Extra sets of dependencies to install. }
16 { --develop=* : Install given packages in development mode. }
17 """
18
19 help = """The <info>install</info> command reads the <comment>poetry.lock</> file from
20 the current directory, processes it, and downloads and installs all the
21 libraries and dependencies outlined in that file. If the file does not
22 exist it will look for <comment>pyproject.toml</> and do the same.
23
24 <info>poetry install</info>
25 """
26
27 _loggers = ["poetry.repositories.pypi_repository"]
28
29 def handle(self):
30 from clikit.io import NullIO
31 from poetry.installation import Installer
32 from poetry.masonry.builders import SdistBuilder
33 from poetry.masonry.utils.module import ModuleOrPackageNotFound
34 from poetry.utils._compat import decode
35 from poetry.utils.env import NullEnv
36
37 installer = Installer(
38 self.io, self.env, self.poetry.package, self.poetry.locker, self.poetry.pool
39 )
40
41 extras = []
42 for extra in self.option("extras"):
43 if " " in extra:
44 extras += [e.strip() for e in extra.split(" ")]
45 else:
46 extras.append(extra)
47
48 installer.extras(extras)
49 installer.dev_mode(not self.option("no-dev"))
50 installer.develop(self.option("develop"))
51 installer.dry_run(self.option("dry-run"))
52 installer.verbose(self.option("verbose"))
53
54 return_code = installer.run()
55
56 if return_code != 0:
57 return return_code
58
59 if not self.option("no-root"):
60 return 0
61
62 try:
63 builder = SdistBuilder(self.poetry, NullEnv(), NullIO())
64 except ModuleOrPackageNotFound:
65 # This is likely due to the fact that the project is an application
66 # not following the structure expected by Poetry
67 # If this is a true error it will be picked up later by build anyway.
68 return 0
69
70 self.line(
71 " - Installing <info>{}</info> (<comment>{}</comment>)".format(
72 self.poetry.package.pretty_name, self.poetry.package.pretty_version
73 )
74 )
75
76 if self.option("dry-run"):
77 return 0
78
79 setup = self.poetry.file.parent / "setup.py"
80 has_setup = setup.exists()
81
82 if has_setup:
83 self.line("<warning>A setup.py file already exists. Using it.</warning>")
84 else:
85 with setup.open("w", encoding="utf-8") as f:
86 f.write(decode(builder.build_setup()))
87
88 try:
89 self.env.run("pip", "install", "-e", str(setup.parent), "--no-deps")
90 finally:
91 if not has_setup:
92 os.remove(str(setup))
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/poetry/console/commands/install.py b/poetry/console/commands/install.py
--- a/poetry/console/commands/install.py
+++ b/poetry/console/commands/install.py
@@ -56,7 +56,7 @@
if return_code != 0:
return return_code
- if not self.option("no-root"):
+ if self.option("no-root"):
return 0
try:
|
{"golden_diff": "diff --git a/poetry/console/commands/install.py b/poetry/console/commands/install.py\n--- a/poetry/console/commands/install.py\n+++ b/poetry/console/commands/install.py\n@@ -56,7 +56,7 @@\n if return_code != 0:\n return return_code\n \n- if not self.option(\"no-root\"):\n+ if self.option(\"no-root\"):\n return 0\n \n try:\n", "issue": "--no-root behavior is inverted on latest develop\n[This](https://github.com/sdispater/poetry/commit/37ec1447b3508ee0bbdb41f8e5773ed5bfae0654#diff-427299ba040b8502b4d29846e595c2d0R59) should probably be `if self.option(\"no-root\")`, to _not_ install the root package when `--no-root` is provided.\n", "before_files": [{"content": "import os\n\nfrom .env_command import EnvCommand\n\n\nclass InstallCommand(EnvCommand):\n \"\"\"\n Installs the project dependencies.\n\n install\n { --no-dev : Do not install dev dependencies. }\n { --no-root : Do not install the root package (your project). }\n { --dry-run : Outputs the operations but will not execute anything\n (implicitly enables --verbose). }\n { --E|extras=* : Extra sets of dependencies to install. }\n { --develop=* : Install given packages in development mode. }\n \"\"\"\n\n help = \"\"\"The <info>install</info> command reads the <comment>poetry.lock</> file from\nthe current directory, processes it, and downloads and installs all the\nlibraries and dependencies outlined in that file. If the file does not\nexist it will look for <comment>pyproject.toml</> and do the same.\n\n<info>poetry install</info>\n\"\"\"\n\n _loggers = [\"poetry.repositories.pypi_repository\"]\n\n def handle(self):\n from clikit.io import NullIO\n from poetry.installation import Installer\n from poetry.masonry.builders import SdistBuilder\n from poetry.masonry.utils.module import ModuleOrPackageNotFound\n from poetry.utils._compat import decode\n from poetry.utils.env import NullEnv\n\n installer = Installer(\n self.io, self.env, self.poetry.package, self.poetry.locker, self.poetry.pool\n )\n\n extras = []\n for extra in self.option(\"extras\"):\n if \" \" in extra:\n extras += [e.strip() for e in extra.split(\" \")]\n else:\n extras.append(extra)\n\n installer.extras(extras)\n installer.dev_mode(not self.option(\"no-dev\"))\n installer.develop(self.option(\"develop\"))\n installer.dry_run(self.option(\"dry-run\"))\n installer.verbose(self.option(\"verbose\"))\n\n return_code = installer.run()\n\n if return_code != 0:\n return return_code\n\n if not self.option(\"no-root\"):\n return 0\n\n try:\n builder = SdistBuilder(self.poetry, NullEnv(), NullIO())\n except ModuleOrPackageNotFound:\n # This is likely due to the fact that the project is an application\n # not following the structure expected by Poetry\n # If this is a true error it will be picked up later by build anyway.\n return 0\n\n self.line(\n \" - Installing <info>{}</info> (<comment>{}</comment>)\".format(\n self.poetry.package.pretty_name, self.poetry.package.pretty_version\n )\n )\n\n if self.option(\"dry-run\"):\n return 0\n\n setup = self.poetry.file.parent / \"setup.py\"\n has_setup = setup.exists()\n\n if has_setup:\n self.line(\"<warning>A setup.py file already exists. Using it.</warning>\")\n else:\n with setup.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(builder.build_setup()))\n\n try:\n self.env.run(\"pip\", \"install\", \"-e\", str(setup.parent), \"--no-deps\")\n finally:\n if not has_setup:\n os.remove(str(setup))\n", "path": "poetry/console/commands/install.py"}], "after_files": [{"content": "import os\n\nfrom .env_command import EnvCommand\n\n\nclass InstallCommand(EnvCommand):\n \"\"\"\n Installs the project dependencies.\n\n install\n { --no-dev : Do not install dev dependencies. }\n { --no-root : Do not install the root package (your project). }\n { --dry-run : Outputs the operations but will not execute anything\n (implicitly enables --verbose). }\n { --E|extras=* : Extra sets of dependencies to install. }\n { --develop=* : Install given packages in development mode. }\n \"\"\"\n\n help = \"\"\"The <info>install</info> command reads the <comment>poetry.lock</> file from\nthe current directory, processes it, and downloads and installs all the\nlibraries and dependencies outlined in that file. If the file does not\nexist it will look for <comment>pyproject.toml</> and do the same.\n\n<info>poetry install</info>\n\"\"\"\n\n _loggers = [\"poetry.repositories.pypi_repository\"]\n\n def handle(self):\n from clikit.io import NullIO\n from poetry.installation import Installer\n from poetry.masonry.builders import SdistBuilder\n from poetry.masonry.utils.module import ModuleOrPackageNotFound\n from poetry.utils._compat import decode\n from poetry.utils.env import NullEnv\n\n installer = Installer(\n self.io, self.env, self.poetry.package, self.poetry.locker, self.poetry.pool\n )\n\n extras = []\n for extra in self.option(\"extras\"):\n if \" \" in extra:\n extras += [e.strip() for e in extra.split(\" \")]\n else:\n extras.append(extra)\n\n installer.extras(extras)\n installer.dev_mode(not self.option(\"no-dev\"))\n installer.develop(self.option(\"develop\"))\n installer.dry_run(self.option(\"dry-run\"))\n installer.verbose(self.option(\"verbose\"))\n\n return_code = installer.run()\n\n if return_code != 0:\n return return_code\n\n if self.option(\"no-root\"):\n return 0\n\n try:\n builder = SdistBuilder(self.poetry, NullEnv(), NullIO())\n except ModuleOrPackageNotFound:\n # This is likely due to the fact that the project is an application\n # not following the structure expected by Poetry\n # If this is a true error it will be picked up later by build anyway.\n return 0\n\n self.line(\n \" - Installing <info>{}</info> (<comment>{}</comment>)\".format(\n self.poetry.package.pretty_name, self.poetry.package.pretty_version\n )\n )\n\n if self.option(\"dry-run\"):\n return 0\n\n setup = self.poetry.file.parent / \"setup.py\"\n has_setup = setup.exists()\n\n if has_setup:\n self.line(\"<warning>A setup.py file already exists. Using it.</warning>\")\n else:\n with setup.open(\"w\", encoding=\"utf-8\") as f:\n f.write(decode(builder.build_setup()))\n\n try:\n self.env.run(\"pip\", \"install\", \"-e\", str(setup.parent), \"--no-deps\")\n finally:\n if not has_setup:\n os.remove(str(setup))\n", "path": "poetry/console/commands/install.py"}]}
| 1,257 | 96 |
gh_patches_debug_17360
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-1647
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GraphItem fails to draw if no edges
The following code errors:
``` py
import numpy as np
import pyqtgraph as pg
from PyQt4.QtGui import QApplication
app = QApplication([])
item = pg.GraphItem()
item.setData(adj=np.array([], dtype=int),
pos=np.array([[0.1, 0.1],
[0.9, 0.9]]))
item.generatePicture()
```
```
Traceback (most recent call last):
File "/tmp/test_graphitem.py", line 11, in <module>
item.generatePicture()
File "/usr/lib/python3/dist-packages/pyqtgraph/graphicsItems/GraphItem.py", line 122, in generatePicture
pts = pts.reshape((pts.shape[0]*pts.shape[1], pts.shape[2]))
IndexError: tuple index out of range
```
The problem is that empty `pos[adj]` doesn't have three dimensions. To mitigate it, I had to also pass `setData(..., pen=None)`. It makes my code way uglier to have to take care of this in several places, to say the least.
**OT**: I find pyqtgraph's code in general full of really complex invariants, and such an important project would probably benefit hugely from a more dedicated maintainer in the coming era. As you seem to be more passionately invested elsewhere nowadays, have you ever considered searching for your eventual replacement yet? :smiley:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/graphicsItems/GraphItem.py`
Content:
```
1 from .. import functions as fn
2 from .GraphicsObject import GraphicsObject
3 from .ScatterPlotItem import ScatterPlotItem
4 from ..Qt import QtGui, QtCore
5 import numpy as np
6 from .. import getConfigOption
7
8 __all__ = ['GraphItem']
9
10
11 class GraphItem(GraphicsObject):
12 """A GraphItem displays graph information as
13 a set of nodes connected by lines (as in 'graph theory', not 'graphics').
14 Useful for drawing networks, trees, etc.
15 """
16
17 def __init__(self, **kwds):
18 GraphicsObject.__init__(self)
19 self.scatter = ScatterPlotItem()
20 self.scatter.setParentItem(self)
21 self.adjacency = None
22 self.pos = None
23 self.picture = None
24 self.pen = 'default'
25 self.setData(**kwds)
26
27 def setData(self, **kwds):
28 """
29 Change the data displayed by the graph.
30
31 ============== =======================================================================
32 **Arguments:**
33 pos (N,2) array of the positions of each node in the graph.
34 adj (M,2) array of connection data. Each row contains indexes
35 of two nodes that are connected or None to hide lines
36 pen The pen to use when drawing lines between connected
37 nodes. May be one of:
38
39 * QPen
40 * a single argument to pass to pg.mkPen
41 * a record array of length M
42 with fields (red, green, blue, alpha, width). Note
43 that using this option may have a significant performance
44 cost.
45 * None (to disable connection drawing)
46 * 'default' to use the default foreground color.
47
48 symbolPen The pen(s) used for drawing nodes.
49 symbolBrush The brush(es) used for drawing nodes.
50 ``**opts`` All other keyword arguments are given to
51 :func:`ScatterPlotItem.setData() <pyqtgraph.ScatterPlotItem.setData>`
52 to affect the appearance of nodes (symbol, size, brush,
53 etc.)
54 ============== =======================================================================
55 """
56 if 'adj' in kwds:
57 self.adjacency = kwds.pop('adj')
58 if self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':
59 raise Exception("adjacency must be None or an array of either int or unsigned type.")
60 self._update()
61 if 'pos' in kwds:
62 self.pos = kwds['pos']
63 self._update()
64 if 'pen' in kwds:
65 self.setPen(kwds.pop('pen'))
66 self._update()
67
68 if 'symbolPen' in kwds:
69 kwds['pen'] = kwds.pop('symbolPen')
70 if 'symbolBrush' in kwds:
71 kwds['brush'] = kwds.pop('symbolBrush')
72 self.scatter.setData(**kwds)
73 self.informViewBoundsChanged()
74
75 def _update(self):
76 self.picture = None
77 self.prepareGeometryChange()
78 self.update()
79
80 def setPen(self, *args, **kwargs):
81 """
82 Set the pen used to draw graph lines.
83 May be:
84
85 * None to disable line drawing
86 * Record array with fields (red, green, blue, alpha, width)
87 * Any set of arguments and keyword arguments accepted by
88 :func:`mkPen <pyqtgraph.mkPen>`.
89 * 'default' to use the default foreground color.
90 """
91 if len(args) == 1 and len(kwargs) == 0:
92 self.pen = args[0]
93 else:
94 self.pen = fn.mkPen(*args, **kwargs)
95 self.picture = None
96 self.update()
97
98 def generatePicture(self):
99 self.picture = QtGui.QPicture()
100 if self.pen is None or self.pos is None or self.adjacency is None:
101 return
102
103 p = QtGui.QPainter(self.picture)
104 try:
105 pts = self.pos[self.adjacency]
106 pen = self.pen
107 if isinstance(pen, np.ndarray):
108 lastPen = None
109 for i in range(pts.shape[0]):
110 pen = self.pen[i]
111 if np.any(pen != lastPen):
112 lastPen = pen
113 if pen.dtype.fields is None:
114 p.setPen(fn.mkPen(color=(pen[0], pen[1], pen[2], pen[3]), width=1))
115 else:
116 p.setPen(fn.mkPen(color=(pen['red'], pen['green'], pen['blue'], pen['alpha']), width=pen['width']))
117 p.drawLine(QtCore.QPointF(*pts[i][0]), QtCore.QPointF(*pts[i][1]))
118 else:
119 if pen == 'default':
120 pen = getConfigOption('foreground')
121 p.setPen(fn.mkPen(pen))
122 pts = pts.reshape((pts.shape[0]*pts.shape[1], pts.shape[2]))
123 path = fn.arrayToQPath(x=pts[:,0], y=pts[:,1], connect='pairs')
124 p.drawPath(path)
125 finally:
126 p.end()
127
128 def paint(self, p, *args):
129 if self.picture == None:
130 self.generatePicture()
131 if getConfigOption('antialias') is True:
132 p.setRenderHint(p.Antialiasing)
133 self.picture.play(p)
134
135 def boundingRect(self):
136 return self.scatter.boundingRect()
137
138 def dataBounds(self, *args, **kwds):
139 return self.scatter.dataBounds(*args, **kwds)
140
141 def pixelPadding(self):
142 return self.scatter.pixelPadding()
143
144
145
146
147
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyqtgraph/graphicsItems/GraphItem.py b/pyqtgraph/graphicsItems/GraphItem.py
--- a/pyqtgraph/graphicsItems/GraphItem.py
+++ b/pyqtgraph/graphicsItems/GraphItem.py
@@ -55,7 +55,9 @@
"""
if 'adj' in kwds:
self.adjacency = kwds.pop('adj')
- if self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':
+ if hasattr(self.adjacency, '__len__') and len(self.adjacency) == 0:
+ self.adjacency = None
+ elif self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':
raise Exception("adjacency must be None or an array of either int or unsigned type.")
self._update()
if 'pos' in kwds:
@@ -140,8 +142,3 @@
def pixelPadding(self):
return self.scatter.pixelPadding()
-
-
-
-
-
|
{"golden_diff": "diff --git a/pyqtgraph/graphicsItems/GraphItem.py b/pyqtgraph/graphicsItems/GraphItem.py\n--- a/pyqtgraph/graphicsItems/GraphItem.py\n+++ b/pyqtgraph/graphicsItems/GraphItem.py\n@@ -55,7 +55,9 @@\n \"\"\"\n if 'adj' in kwds:\n self.adjacency = kwds.pop('adj')\n- if self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':\n+ if hasattr(self.adjacency, '__len__') and len(self.adjacency) == 0:\n+ self.adjacency = None\n+ elif self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':\n raise Exception(\"adjacency must be None or an array of either int or unsigned type.\")\n self._update()\n if 'pos' in kwds:\n@@ -140,8 +142,3 @@\n \n def pixelPadding(self):\n return self.scatter.pixelPadding()\n- \n- \n- \n- \n-\n", "issue": "GraphItem fails to draw if no edges\nThe following code errors:\n\n``` py\nimport numpy as np\nimport pyqtgraph as pg\nfrom PyQt4.QtGui import QApplication\n\napp = QApplication([])\n\nitem = pg.GraphItem()\nitem.setData(adj=np.array([], dtype=int),\n pos=np.array([[0.1, 0.1],\n [0.9, 0.9]]))\nitem.generatePicture()\n```\n\n```\nTraceback (most recent call last):\n File \"/tmp/test_graphitem.py\", line 11, in <module>\n item.generatePicture()\n File \"/usr/lib/python3/dist-packages/pyqtgraph/graphicsItems/GraphItem.py\", line 122, in generatePicture\n pts = pts.reshape((pts.shape[0]*pts.shape[1], pts.shape[2]))\nIndexError: tuple index out of range\n```\n\nThe problem is that empty `pos[adj]` doesn't have three dimensions. To mitigate it, I had to also pass `setData(..., pen=None)`. It makes my code way uglier to have to take care of this in several places, to say the least.\n\n**OT**: I find pyqtgraph's code in general full of really complex invariants, and such an important project would probably benefit hugely from a more dedicated maintainer in the coming era. As you seem to be more passionately invested elsewhere nowadays, have you ever considered searching for your eventual replacement yet? :smiley:\n\n", "before_files": [{"content": "from .. import functions as fn\nfrom .GraphicsObject import GraphicsObject\nfrom .ScatterPlotItem import ScatterPlotItem\nfrom ..Qt import QtGui, QtCore\nimport numpy as np\nfrom .. import getConfigOption\n\n__all__ = ['GraphItem']\n\n\nclass GraphItem(GraphicsObject):\n \"\"\"A GraphItem displays graph information as\n a set of nodes connected by lines (as in 'graph theory', not 'graphics'). \n Useful for drawing networks, trees, etc.\n \"\"\"\n\n def __init__(self, **kwds):\n GraphicsObject.__init__(self)\n self.scatter = ScatterPlotItem()\n self.scatter.setParentItem(self)\n self.adjacency = None\n self.pos = None\n self.picture = None\n self.pen = 'default'\n self.setData(**kwds)\n \n def setData(self, **kwds):\n \"\"\"\n Change the data displayed by the graph. \n \n ============== =======================================================================\n **Arguments:**\n pos (N,2) array of the positions of each node in the graph.\n adj (M,2) array of connection data. Each row contains indexes\n of two nodes that are connected or None to hide lines\n pen The pen to use when drawing lines between connected\n nodes. May be one of:\n \n * QPen\n * a single argument to pass to pg.mkPen\n * a record array of length M\n with fields (red, green, blue, alpha, width). Note\n that using this option may have a significant performance\n cost.\n * None (to disable connection drawing)\n * 'default' to use the default foreground color.\n \n symbolPen The pen(s) used for drawing nodes.\n symbolBrush The brush(es) used for drawing nodes.\n ``**opts`` All other keyword arguments are given to\n :func:`ScatterPlotItem.setData() <pyqtgraph.ScatterPlotItem.setData>`\n to affect the appearance of nodes (symbol, size, brush,\n etc.)\n ============== =======================================================================\n \"\"\"\n if 'adj' in kwds:\n self.adjacency = kwds.pop('adj')\n if self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':\n raise Exception(\"adjacency must be None or an array of either int or unsigned type.\")\n self._update()\n if 'pos' in kwds:\n self.pos = kwds['pos']\n self._update()\n if 'pen' in kwds:\n self.setPen(kwds.pop('pen'))\n self._update()\n \n if 'symbolPen' in kwds: \n kwds['pen'] = kwds.pop('symbolPen')\n if 'symbolBrush' in kwds: \n kwds['brush'] = kwds.pop('symbolBrush')\n self.scatter.setData(**kwds)\n self.informViewBoundsChanged()\n\n def _update(self):\n self.picture = None\n self.prepareGeometryChange()\n self.update()\n\n def setPen(self, *args, **kwargs):\n \"\"\"\n Set the pen used to draw graph lines.\n May be: \n \n * None to disable line drawing\n * Record array with fields (red, green, blue, alpha, width)\n * Any set of arguments and keyword arguments accepted by \n :func:`mkPen <pyqtgraph.mkPen>`.\n * 'default' to use the default foreground color.\n \"\"\"\n if len(args) == 1 and len(kwargs) == 0:\n self.pen = args[0]\n else:\n self.pen = fn.mkPen(*args, **kwargs)\n self.picture = None\n self.update()\n\n def generatePicture(self):\n self.picture = QtGui.QPicture()\n if self.pen is None or self.pos is None or self.adjacency is None:\n return\n \n p = QtGui.QPainter(self.picture)\n try:\n pts = self.pos[self.adjacency]\n pen = self.pen\n if isinstance(pen, np.ndarray):\n lastPen = None\n for i in range(pts.shape[0]):\n pen = self.pen[i]\n if np.any(pen != lastPen):\n lastPen = pen\n if pen.dtype.fields is None:\n p.setPen(fn.mkPen(color=(pen[0], pen[1], pen[2], pen[3]), width=1)) \n else:\n p.setPen(fn.mkPen(color=(pen['red'], pen['green'], pen['blue'], pen['alpha']), width=pen['width']))\n p.drawLine(QtCore.QPointF(*pts[i][0]), QtCore.QPointF(*pts[i][1]))\n else:\n if pen == 'default':\n pen = getConfigOption('foreground')\n p.setPen(fn.mkPen(pen))\n pts = pts.reshape((pts.shape[0]*pts.shape[1], pts.shape[2]))\n path = fn.arrayToQPath(x=pts[:,0], y=pts[:,1], connect='pairs')\n p.drawPath(path)\n finally:\n p.end()\n\n def paint(self, p, *args):\n if self.picture == None:\n self.generatePicture()\n if getConfigOption('antialias') is True:\n p.setRenderHint(p.Antialiasing)\n self.picture.play(p)\n \n def boundingRect(self):\n return self.scatter.boundingRect()\n \n def dataBounds(self, *args, **kwds):\n return self.scatter.dataBounds(*args, **kwds)\n \n def pixelPadding(self):\n return self.scatter.pixelPadding()\n \n \n \n \n\n", "path": "pyqtgraph/graphicsItems/GraphItem.py"}], "after_files": [{"content": "from .. import functions as fn\nfrom .GraphicsObject import GraphicsObject\nfrom .ScatterPlotItem import ScatterPlotItem\nfrom ..Qt import QtGui, QtCore\nimport numpy as np\nfrom .. import getConfigOption\n\n__all__ = ['GraphItem']\n\n\nclass GraphItem(GraphicsObject):\n \"\"\"A GraphItem displays graph information as\n a set of nodes connected by lines (as in 'graph theory', not 'graphics'). \n Useful for drawing networks, trees, etc.\n \"\"\"\n\n def __init__(self, **kwds):\n GraphicsObject.__init__(self)\n self.scatter = ScatterPlotItem()\n self.scatter.setParentItem(self)\n self.adjacency = None\n self.pos = None\n self.picture = None\n self.pen = 'default'\n self.setData(**kwds)\n \n def setData(self, **kwds):\n \"\"\"\n Change the data displayed by the graph. \n \n ============== =======================================================================\n **Arguments:**\n pos (N,2) array of the positions of each node in the graph.\n adj (M,2) array of connection data. Each row contains indexes\n of two nodes that are connected or None to hide lines\n pen The pen to use when drawing lines between connected\n nodes. May be one of:\n \n * QPen\n * a single argument to pass to pg.mkPen\n * a record array of length M\n with fields (red, green, blue, alpha, width). Note\n that using this option may have a significant performance\n cost.\n * None (to disable connection drawing)\n * 'default' to use the default foreground color.\n \n symbolPen The pen(s) used for drawing nodes.\n symbolBrush The brush(es) used for drawing nodes.\n ``**opts`` All other keyword arguments are given to\n :func:`ScatterPlotItem.setData() <pyqtgraph.ScatterPlotItem.setData>`\n to affect the appearance of nodes (symbol, size, brush,\n etc.)\n ============== =======================================================================\n \"\"\"\n if 'adj' in kwds:\n self.adjacency = kwds.pop('adj')\n if hasattr(self.adjacency, '__len__') and len(self.adjacency) == 0:\n self.adjacency = None\n elif self.adjacency is not None and self.adjacency.dtype.kind not in 'iu':\n raise Exception(\"adjacency must be None or an array of either int or unsigned type.\")\n self._update()\n if 'pos' in kwds:\n self.pos = kwds['pos']\n self._update()\n if 'pen' in kwds:\n self.setPen(kwds.pop('pen'))\n self._update()\n \n if 'symbolPen' in kwds: \n kwds['pen'] = kwds.pop('symbolPen')\n if 'symbolBrush' in kwds: \n kwds['brush'] = kwds.pop('symbolBrush')\n self.scatter.setData(**kwds)\n self.informViewBoundsChanged()\n\n def _update(self):\n self.picture = None\n self.prepareGeometryChange()\n self.update()\n\n def setPen(self, *args, **kwargs):\n \"\"\"\n Set the pen used to draw graph lines.\n May be: \n \n * None to disable line drawing\n * Record array with fields (red, green, blue, alpha, width)\n * Any set of arguments and keyword arguments accepted by \n :func:`mkPen <pyqtgraph.mkPen>`.\n * 'default' to use the default foreground color.\n \"\"\"\n if len(args) == 1 and len(kwargs) == 0:\n self.pen = args[0]\n else:\n self.pen = fn.mkPen(*args, **kwargs)\n self.picture = None\n self.update()\n\n def generatePicture(self):\n self.picture = QtGui.QPicture()\n if self.pen is None or self.pos is None or self.adjacency is None:\n return\n \n p = QtGui.QPainter(self.picture)\n try:\n pts = self.pos[self.adjacency]\n pen = self.pen\n if isinstance(pen, np.ndarray):\n lastPen = None\n for i in range(pts.shape[0]):\n pen = self.pen[i]\n if np.any(pen != lastPen):\n lastPen = pen\n if pen.dtype.fields is None:\n p.setPen(fn.mkPen(color=(pen[0], pen[1], pen[2], pen[3]), width=1)) \n else:\n p.setPen(fn.mkPen(color=(pen['red'], pen['green'], pen['blue'], pen['alpha']), width=pen['width']))\n p.drawLine(QtCore.QPointF(*pts[i][0]), QtCore.QPointF(*pts[i][1]))\n else:\n if pen == 'default':\n pen = getConfigOption('foreground')\n p.setPen(fn.mkPen(pen))\n pts = pts.reshape((pts.shape[0]*pts.shape[1], pts.shape[2]))\n path = fn.arrayToQPath(x=pts[:,0], y=pts[:,1], connect='pairs')\n p.drawPath(path)\n finally:\n p.end()\n\n def paint(self, p, *args):\n if self.picture == None:\n self.generatePicture()\n if getConfigOption('antialias') is True:\n p.setRenderHint(p.Antialiasing)\n self.picture.play(p)\n \n def boundingRect(self):\n return self.scatter.boundingRect()\n \n def dataBounds(self, *args, **kwds):\n return self.scatter.dataBounds(*args, **kwds)\n \n def pixelPadding(self):\n return self.scatter.pixelPadding()\n", "path": "pyqtgraph/graphicsItems/GraphItem.py"}]}
| 2,097 | 226 |
gh_patches_debug_40532
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-1435
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upon receiving a non-ban infraction, the DM from the bot should tell them about ModMail
Currently, users get a message like this one when they get an infraction:
For infractions other than bans (regardless of duration), the embed should tell them to use the ModMail bot if they want to discuss or ask questions about the infraction. We might also except Superstarify infractions.
I'm not sure if this should await the redesign of the infraction system or if we can implement it without sabotaging Scragly's efforts.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/exts/moderation/infraction/_utils.py`
Content:
```
1 import logging
2 import typing as t
3 from datetime import datetime
4
5 import discord
6 from discord.ext.commands import Context
7
8 from bot.api import ResponseCodeError
9 from bot.constants import Colours, Icons
10 from bot.errors import InvalidInfractedUser
11
12 log = logging.getLogger(__name__)
13
14 # apply icon, pardon icon
15 INFRACTION_ICONS = {
16 "ban": (Icons.user_ban, Icons.user_unban),
17 "kick": (Icons.sign_out, None),
18 "mute": (Icons.user_mute, Icons.user_unmute),
19 "note": (Icons.user_warn, None),
20 "superstar": (Icons.superstarify, Icons.unsuperstarify),
21 "warning": (Icons.user_warn, None),
22 "voice_ban": (Icons.voice_state_red, Icons.voice_state_green),
23 }
24 RULES_URL = "https://pythondiscord.com/pages/rules"
25 APPEALABLE_INFRACTIONS = ("ban", "mute", "voice_ban")
26
27 # Type aliases
28 UserObject = t.Union[discord.Member, discord.User]
29 UserSnowflake = t.Union[UserObject, discord.Object]
30 Infraction = t.Dict[str, t.Union[str, int, bool]]
31
32 APPEAL_EMAIL = "[email protected]"
33
34 INFRACTION_TITLE = f"Please review our rules over at {RULES_URL}"
35 INFRACTION_APPEAL_FOOTER = f"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}"
36 INFRACTION_AUTHOR_NAME = "Infraction information"
37
38 INFRACTION_DESCRIPTION_TEMPLATE = (
39 "**Type:** {type}\n"
40 "**Expires:** {expires}\n"
41 "**Reason:** {reason}\n"
42 )
43
44
45 async def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:
46 """
47 Create a new user in the database.
48
49 Used when an infraction needs to be applied on a user absent in the guild.
50 """
51 log.trace(f"Attempting to add user {user.id} to the database.")
52
53 if not isinstance(user, (discord.Member, discord.User)):
54 log.debug("The user being added to the DB is not a Member or User object.")
55
56 payload = {
57 'discriminator': int(getattr(user, 'discriminator', 0)),
58 'id': user.id,
59 'in_guild': False,
60 'name': getattr(user, 'name', 'Name unknown'),
61 'roles': []
62 }
63
64 try:
65 response = await ctx.bot.api_client.post('bot/users', json=payload)
66 log.info(f"User {user.id} added to the DB.")
67 return response
68 except ResponseCodeError as e:
69 log.error(f"Failed to add user {user.id} to the DB. {e}")
70 await ctx.send(f":x: The attempt to add the user to the DB failed: status {e.status}")
71
72
73 async def post_infraction(
74 ctx: Context,
75 user: UserSnowflake,
76 infr_type: str,
77 reason: str,
78 expires_at: datetime = None,
79 hidden: bool = False,
80 active: bool = True
81 ) -> t.Optional[dict]:
82 """Posts an infraction to the API."""
83 if isinstance(user, (discord.Member, discord.User)) and user.bot:
84 log.trace(f"Posting of {infr_type} infraction for {user} to the API aborted. User is a bot.")
85 raise InvalidInfractedUser(user)
86
87 log.trace(f"Posting {infr_type} infraction for {user} to the API.")
88
89 payload = {
90 "actor": ctx.author.id, # Don't use ctx.message.author; antispam only patches ctx.author.
91 "hidden": hidden,
92 "reason": reason,
93 "type": infr_type,
94 "user": user.id,
95 "active": active
96 }
97 if expires_at:
98 payload['expires_at'] = expires_at.isoformat()
99
100 # Try to apply the infraction. If it fails because the user doesn't exist, try to add it.
101 for should_post_user in (True, False):
102 try:
103 response = await ctx.bot.api_client.post('bot/infractions', json=payload)
104 return response
105 except ResponseCodeError as e:
106 if e.status == 400 and 'user' in e.response_json:
107 # Only one attempt to add the user to the database, not two:
108 if not should_post_user or await post_user(ctx, user) is None:
109 return
110 else:
111 log.exception(f"Unexpected error while adding an infraction for {user}:")
112 await ctx.send(f":x: There was an error adding the infraction: status {e.status}.")
113 return
114
115
116 async def get_active_infraction(
117 ctx: Context,
118 user: UserSnowflake,
119 infr_type: str,
120 send_msg: bool = True
121 ) -> t.Optional[dict]:
122 """
123 Retrieves an active infraction of the given type for the user.
124
125 If `send_msg` is True and the user has an active infraction matching the `infr_type` parameter,
126 then a message for the moderator will be sent to the context channel letting them know.
127 Otherwise, no message will be sent.
128 """
129 log.trace(f"Checking if {user} has active infractions of type {infr_type}.")
130
131 active_infractions = await ctx.bot.api_client.get(
132 'bot/infractions',
133 params={
134 'active': 'true',
135 'type': infr_type,
136 'user__id': str(user.id)
137 }
138 )
139 if active_infractions:
140 # Checks to see if the moderator should be told there is an active infraction
141 if send_msg:
142 log.trace(f"{user} has active infractions of type {infr_type}.")
143 await ctx.send(
144 f":x: According to my records, this user already has a {infr_type} infraction. "
145 f"See infraction **#{active_infractions[0]['id']}**."
146 )
147 return active_infractions[0]
148 else:
149 log.trace(f"{user} does not have active infractions of type {infr_type}.")
150
151
152 async def notify_infraction(
153 user: UserObject,
154 infr_type: str,
155 expires_at: t.Optional[str] = None,
156 reason: t.Optional[str] = None,
157 icon_url: str = Icons.token_removed
158 ) -> bool:
159 """DM a user about their new infraction and return True if the DM is successful."""
160 log.trace(f"Sending {user} a DM about their {infr_type} infraction.")
161
162 text = INFRACTION_DESCRIPTION_TEMPLATE.format(
163 type=infr_type.title(),
164 expires=expires_at or "N/A",
165 reason=reason or "No reason provided."
166 )
167
168 # For case when other fields than reason is too long and this reach limit, then force-shorten string
169 if len(text) > 2048:
170 text = f"{text[:2045]}..."
171
172 embed = discord.Embed(
173 description=text,
174 colour=Colours.soft_red
175 )
176
177 embed.set_author(name=INFRACTION_AUTHOR_NAME, icon_url=icon_url, url=RULES_URL)
178 embed.title = INFRACTION_TITLE
179 embed.url = RULES_URL
180
181 if infr_type in APPEALABLE_INFRACTIONS:
182 embed.set_footer(text=INFRACTION_APPEAL_FOOTER)
183
184 return await send_private_embed(user, embed)
185
186
187 async def notify_pardon(
188 user: UserObject,
189 title: str,
190 content: str,
191 icon_url: str = Icons.user_verified
192 ) -> bool:
193 """DM a user about their pardoned infraction and return True if the DM is successful."""
194 log.trace(f"Sending {user} a DM about their pardoned infraction.")
195
196 embed = discord.Embed(
197 description=content,
198 colour=Colours.soft_green
199 )
200
201 embed.set_author(name=title, icon_url=icon_url)
202
203 return await send_private_embed(user, embed)
204
205
206 async def send_private_embed(user: UserObject, embed: discord.Embed) -> bool:
207 """
208 A helper method for sending an embed to a user's DMs.
209
210 Returns a boolean indicator of DM success.
211 """
212 try:
213 await user.send(embed=embed)
214 return True
215 except (discord.HTTPException, discord.Forbidden, discord.NotFound):
216 log.debug(
217 f"Infraction-related information could not be sent to user {user} ({user.id}). "
218 "The user either could not be retrieved or probably disabled their DMs."
219 )
220 return False
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/exts/moderation/infraction/_utils.py b/bot/exts/moderation/infraction/_utils.py
--- a/bot/exts/moderation/infraction/_utils.py
+++ b/bot/exts/moderation/infraction/_utils.py
@@ -22,7 +22,6 @@
"voice_ban": (Icons.voice_state_red, Icons.voice_state_green),
}
RULES_URL = "https://pythondiscord.com/pages/rules"
-APPEALABLE_INFRACTIONS = ("ban", "mute", "voice_ban")
# Type aliases
UserObject = t.Union[discord.Member, discord.User]
@@ -31,8 +30,12 @@
APPEAL_EMAIL = "[email protected]"
-INFRACTION_TITLE = f"Please review our rules over at {RULES_URL}"
-INFRACTION_APPEAL_FOOTER = f"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}"
+INFRACTION_TITLE = "Please review our rules"
+INFRACTION_APPEAL_EMAIL_FOOTER = f"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}"
+INFRACTION_APPEAL_MODMAIL_FOOTER = (
+ 'If you would like to discuss or appeal this infraction, '
+ 'send a message to the ModMail bot'
+)
INFRACTION_AUTHOR_NAME = "Infraction information"
INFRACTION_DESCRIPTION_TEMPLATE = (
@@ -71,13 +74,13 @@
async def post_infraction(
- ctx: Context,
- user: UserSnowflake,
- infr_type: str,
- reason: str,
- expires_at: datetime = None,
- hidden: bool = False,
- active: bool = True
+ ctx: Context,
+ user: UserSnowflake,
+ infr_type: str,
+ reason: str,
+ expires_at: datetime = None,
+ hidden: bool = False,
+ active: bool = True
) -> t.Optional[dict]:
"""Posts an infraction to the API."""
if isinstance(user, (discord.Member, discord.User)) and user.bot:
@@ -150,11 +153,11 @@
async def notify_infraction(
- user: UserObject,
- infr_type: str,
- expires_at: t.Optional[str] = None,
- reason: t.Optional[str] = None,
- icon_url: str = Icons.token_removed
+ user: UserObject,
+ infr_type: str,
+ expires_at: t.Optional[str] = None,
+ reason: t.Optional[str] = None,
+ icon_url: str = Icons.token_removed
) -> bool:
"""DM a user about their new infraction and return True if the DM is successful."""
log.trace(f"Sending {user} a DM about their {infr_type} infraction.")
@@ -178,17 +181,18 @@
embed.title = INFRACTION_TITLE
embed.url = RULES_URL
- if infr_type in APPEALABLE_INFRACTIONS:
- embed.set_footer(text=INFRACTION_APPEAL_FOOTER)
+ embed.set_footer(
+ text=INFRACTION_APPEAL_EMAIL_FOOTER if infr_type == 'Ban' else INFRACTION_APPEAL_MODMAIL_FOOTER
+ )
return await send_private_embed(user, embed)
async def notify_pardon(
- user: UserObject,
- title: str,
- content: str,
- icon_url: str = Icons.user_verified
+ user: UserObject,
+ title: str,
+ content: str,
+ icon_url: str = Icons.user_verified
) -> bool:
"""DM a user about their pardoned infraction and return True if the DM is successful."""
log.trace(f"Sending {user} a DM about their pardoned infraction.")
|
{"golden_diff": "diff --git a/bot/exts/moderation/infraction/_utils.py b/bot/exts/moderation/infraction/_utils.py\n--- a/bot/exts/moderation/infraction/_utils.py\n+++ b/bot/exts/moderation/infraction/_utils.py\n@@ -22,7 +22,6 @@\n \"voice_ban\": (Icons.voice_state_red, Icons.voice_state_green),\n }\n RULES_URL = \"https://pythondiscord.com/pages/rules\"\n-APPEALABLE_INFRACTIONS = (\"ban\", \"mute\", \"voice_ban\")\n \n # Type aliases\n UserObject = t.Union[discord.Member, discord.User]\n@@ -31,8 +30,12 @@\n \n APPEAL_EMAIL = \"[email protected]\"\n \n-INFRACTION_TITLE = f\"Please review our rules over at {RULES_URL}\"\n-INFRACTION_APPEAL_FOOTER = f\"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}\"\n+INFRACTION_TITLE = \"Please review our rules\"\n+INFRACTION_APPEAL_EMAIL_FOOTER = f\"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}\"\n+INFRACTION_APPEAL_MODMAIL_FOOTER = (\n+ 'If you would like to discuss or appeal this infraction, '\n+ 'send a message to the ModMail bot'\n+)\n INFRACTION_AUTHOR_NAME = \"Infraction information\"\n \n INFRACTION_DESCRIPTION_TEMPLATE = (\n@@ -71,13 +74,13 @@\n \n \n async def post_infraction(\n- ctx: Context,\n- user: UserSnowflake,\n- infr_type: str,\n- reason: str,\n- expires_at: datetime = None,\n- hidden: bool = False,\n- active: bool = True\n+ ctx: Context,\n+ user: UserSnowflake,\n+ infr_type: str,\n+ reason: str,\n+ expires_at: datetime = None,\n+ hidden: bool = False,\n+ active: bool = True\n ) -> t.Optional[dict]:\n \"\"\"Posts an infraction to the API.\"\"\"\n if isinstance(user, (discord.Member, discord.User)) and user.bot:\n@@ -150,11 +153,11 @@\n \n \n async def notify_infraction(\n- user: UserObject,\n- infr_type: str,\n- expires_at: t.Optional[str] = None,\n- reason: t.Optional[str] = None,\n- icon_url: str = Icons.token_removed\n+ user: UserObject,\n+ infr_type: str,\n+ expires_at: t.Optional[str] = None,\n+ reason: t.Optional[str] = None,\n+ icon_url: str = Icons.token_removed\n ) -> bool:\n \"\"\"DM a user about their new infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their {infr_type} infraction.\")\n@@ -178,17 +181,18 @@\n embed.title = INFRACTION_TITLE\n embed.url = RULES_URL\n \n- if infr_type in APPEALABLE_INFRACTIONS:\n- embed.set_footer(text=INFRACTION_APPEAL_FOOTER)\n+ embed.set_footer(\n+ text=INFRACTION_APPEAL_EMAIL_FOOTER if infr_type == 'Ban' else INFRACTION_APPEAL_MODMAIL_FOOTER\n+ )\n \n return await send_private_embed(user, embed)\n \n \n async def notify_pardon(\n- user: UserObject,\n- title: str,\n- content: str,\n- icon_url: str = Icons.user_verified\n+ user: UserObject,\n+ title: str,\n+ content: str,\n+ icon_url: str = Icons.user_verified\n ) -> bool:\n \"\"\"DM a user about their pardoned infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their pardoned infraction.\")\n", "issue": "Upon receiving a non-ban infraction, the DM from the bot should tell them about ModMail\nCurrently, users get a message like this one when they get an infraction:\r\n\r\n\r\n\r\nFor infractions other than bans (regardless of duration), the embed should tell them to use the ModMail bot if they want to discuss or ask questions about the infraction. We might also except Superstarify infractions.\r\n\r\nI'm not sure if this should await the redesign of the infraction system or if we can implement it without sabotaging Scragly's efforts.\n", "before_files": [{"content": "import logging\nimport typing as t\nfrom datetime import datetime\n\nimport discord\nfrom discord.ext.commands import Context\n\nfrom bot.api import ResponseCodeError\nfrom bot.constants import Colours, Icons\nfrom bot.errors import InvalidInfractedUser\n\nlog = logging.getLogger(__name__)\n\n# apply icon, pardon icon\nINFRACTION_ICONS = {\n \"ban\": (Icons.user_ban, Icons.user_unban),\n \"kick\": (Icons.sign_out, None),\n \"mute\": (Icons.user_mute, Icons.user_unmute),\n \"note\": (Icons.user_warn, None),\n \"superstar\": (Icons.superstarify, Icons.unsuperstarify),\n \"warning\": (Icons.user_warn, None),\n \"voice_ban\": (Icons.voice_state_red, Icons.voice_state_green),\n}\nRULES_URL = \"https://pythondiscord.com/pages/rules\"\nAPPEALABLE_INFRACTIONS = (\"ban\", \"mute\", \"voice_ban\")\n\n# Type aliases\nUserObject = t.Union[discord.Member, discord.User]\nUserSnowflake = t.Union[UserObject, discord.Object]\nInfraction = t.Dict[str, t.Union[str, int, bool]]\n\nAPPEAL_EMAIL = \"[email protected]\"\n\nINFRACTION_TITLE = f\"Please review our rules over at {RULES_URL}\"\nINFRACTION_APPEAL_FOOTER = f\"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}\"\nINFRACTION_AUTHOR_NAME = \"Infraction information\"\n\nINFRACTION_DESCRIPTION_TEMPLATE = (\n \"**Type:** {type}\\n\"\n \"**Expires:** {expires}\\n\"\n \"**Reason:** {reason}\\n\"\n)\n\n\nasync def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:\n \"\"\"\n Create a new user in the database.\n\n Used when an infraction needs to be applied on a user absent in the guild.\n \"\"\"\n log.trace(f\"Attempting to add user {user.id} to the database.\")\n\n if not isinstance(user, (discord.Member, discord.User)):\n log.debug(\"The user being added to the DB is not a Member or User object.\")\n\n payload = {\n 'discriminator': int(getattr(user, 'discriminator', 0)),\n 'id': user.id,\n 'in_guild': False,\n 'name': getattr(user, 'name', 'Name unknown'),\n 'roles': []\n }\n\n try:\n response = await ctx.bot.api_client.post('bot/users', json=payload)\n log.info(f\"User {user.id} added to the DB.\")\n return response\n except ResponseCodeError as e:\n log.error(f\"Failed to add user {user.id} to the DB. {e}\")\n await ctx.send(f\":x: The attempt to add the user to the DB failed: status {e.status}\")\n\n\nasync def post_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n reason: str,\n expires_at: datetime = None,\n hidden: bool = False,\n active: bool = True\n) -> t.Optional[dict]:\n \"\"\"Posts an infraction to the API.\"\"\"\n if isinstance(user, (discord.Member, discord.User)) and user.bot:\n log.trace(f\"Posting of {infr_type} infraction for {user} to the API aborted. User is a bot.\")\n raise InvalidInfractedUser(user)\n\n log.trace(f\"Posting {infr_type} infraction for {user} to the API.\")\n\n payload = {\n \"actor\": ctx.author.id, # Don't use ctx.message.author; antispam only patches ctx.author.\n \"hidden\": hidden,\n \"reason\": reason,\n \"type\": infr_type,\n \"user\": user.id,\n \"active\": active\n }\n if expires_at:\n payload['expires_at'] = expires_at.isoformat()\n\n # Try to apply the infraction. If it fails because the user doesn't exist, try to add it.\n for should_post_user in (True, False):\n try:\n response = await ctx.bot.api_client.post('bot/infractions', json=payload)\n return response\n except ResponseCodeError as e:\n if e.status == 400 and 'user' in e.response_json:\n # Only one attempt to add the user to the database, not two:\n if not should_post_user or await post_user(ctx, user) is None:\n return\n else:\n log.exception(f\"Unexpected error while adding an infraction for {user}:\")\n await ctx.send(f\":x: There was an error adding the infraction: status {e.status}.\")\n return\n\n\nasync def get_active_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n send_msg: bool = True\n) -> t.Optional[dict]:\n \"\"\"\n Retrieves an active infraction of the given type for the user.\n\n If `send_msg` is True and the user has an active infraction matching the `infr_type` parameter,\n then a message for the moderator will be sent to the context channel letting them know.\n Otherwise, no message will be sent.\n \"\"\"\n log.trace(f\"Checking if {user} has active infractions of type {infr_type}.\")\n\n active_infractions = await ctx.bot.api_client.get(\n 'bot/infractions',\n params={\n 'active': 'true',\n 'type': infr_type,\n 'user__id': str(user.id)\n }\n )\n if active_infractions:\n # Checks to see if the moderator should be told there is an active infraction\n if send_msg:\n log.trace(f\"{user} has active infractions of type {infr_type}.\")\n await ctx.send(\n f\":x: According to my records, this user already has a {infr_type} infraction. \"\n f\"See infraction **#{active_infractions[0]['id']}**.\"\n )\n return active_infractions[0]\n else:\n log.trace(f\"{user} does not have active infractions of type {infr_type}.\")\n\n\nasync def notify_infraction(\n user: UserObject,\n infr_type: str,\n expires_at: t.Optional[str] = None,\n reason: t.Optional[str] = None,\n icon_url: str = Icons.token_removed\n) -> bool:\n \"\"\"DM a user about their new infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their {infr_type} infraction.\")\n\n text = INFRACTION_DESCRIPTION_TEMPLATE.format(\n type=infr_type.title(),\n expires=expires_at or \"N/A\",\n reason=reason or \"No reason provided.\"\n )\n\n # For case when other fields than reason is too long and this reach limit, then force-shorten string\n if len(text) > 2048:\n text = f\"{text[:2045]}...\"\n\n embed = discord.Embed(\n description=text,\n colour=Colours.soft_red\n )\n\n embed.set_author(name=INFRACTION_AUTHOR_NAME, icon_url=icon_url, url=RULES_URL)\n embed.title = INFRACTION_TITLE\n embed.url = RULES_URL\n\n if infr_type in APPEALABLE_INFRACTIONS:\n embed.set_footer(text=INFRACTION_APPEAL_FOOTER)\n\n return await send_private_embed(user, embed)\n\n\nasync def notify_pardon(\n user: UserObject,\n title: str,\n content: str,\n icon_url: str = Icons.user_verified\n) -> bool:\n \"\"\"DM a user about their pardoned infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their pardoned infraction.\")\n\n embed = discord.Embed(\n description=content,\n colour=Colours.soft_green\n )\n\n embed.set_author(name=title, icon_url=icon_url)\n\n return await send_private_embed(user, embed)\n\n\nasync def send_private_embed(user: UserObject, embed: discord.Embed) -> bool:\n \"\"\"\n A helper method for sending an embed to a user's DMs.\n\n Returns a boolean indicator of DM success.\n \"\"\"\n try:\n await user.send(embed=embed)\n return True\n except (discord.HTTPException, discord.Forbidden, discord.NotFound):\n log.debug(\n f\"Infraction-related information could not be sent to user {user} ({user.id}). \"\n \"The user either could not be retrieved or probably disabled their DMs.\"\n )\n return False\n", "path": "bot/exts/moderation/infraction/_utils.py"}], "after_files": [{"content": "import logging\nimport typing as t\nfrom datetime import datetime\n\nimport discord\nfrom discord.ext.commands import Context\n\nfrom bot.api import ResponseCodeError\nfrom bot.constants import Colours, Icons\nfrom bot.errors import InvalidInfractedUser\n\nlog = logging.getLogger(__name__)\n\n# apply icon, pardon icon\nINFRACTION_ICONS = {\n \"ban\": (Icons.user_ban, Icons.user_unban),\n \"kick\": (Icons.sign_out, None),\n \"mute\": (Icons.user_mute, Icons.user_unmute),\n \"note\": (Icons.user_warn, None),\n \"superstar\": (Icons.superstarify, Icons.unsuperstarify),\n \"warning\": (Icons.user_warn, None),\n \"voice_ban\": (Icons.voice_state_red, Icons.voice_state_green),\n}\nRULES_URL = \"https://pythondiscord.com/pages/rules\"\n\n# Type aliases\nUserObject = t.Union[discord.Member, discord.User]\nUserSnowflake = t.Union[UserObject, discord.Object]\nInfraction = t.Dict[str, t.Union[str, int, bool]]\n\nAPPEAL_EMAIL = \"[email protected]\"\n\nINFRACTION_TITLE = \"Please review our rules\"\nINFRACTION_APPEAL_EMAIL_FOOTER = f\"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}\"\nINFRACTION_APPEAL_MODMAIL_FOOTER = (\n 'If you would like to discuss or appeal this infraction, '\n 'send a message to the ModMail bot'\n)\nINFRACTION_AUTHOR_NAME = \"Infraction information\"\n\nINFRACTION_DESCRIPTION_TEMPLATE = (\n \"**Type:** {type}\\n\"\n \"**Expires:** {expires}\\n\"\n \"**Reason:** {reason}\\n\"\n)\n\n\nasync def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:\n \"\"\"\n Create a new user in the database.\n\n Used when an infraction needs to be applied on a user absent in the guild.\n \"\"\"\n log.trace(f\"Attempting to add user {user.id} to the database.\")\n\n if not isinstance(user, (discord.Member, discord.User)):\n log.debug(\"The user being added to the DB is not a Member or User object.\")\n\n payload = {\n 'discriminator': int(getattr(user, 'discriminator', 0)),\n 'id': user.id,\n 'in_guild': False,\n 'name': getattr(user, 'name', 'Name unknown'),\n 'roles': []\n }\n\n try:\n response = await ctx.bot.api_client.post('bot/users', json=payload)\n log.info(f\"User {user.id} added to the DB.\")\n return response\n except ResponseCodeError as e:\n log.error(f\"Failed to add user {user.id} to the DB. {e}\")\n await ctx.send(f\":x: The attempt to add the user to the DB failed: status {e.status}\")\n\n\nasync def post_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n reason: str,\n expires_at: datetime = None,\n hidden: bool = False,\n active: bool = True\n) -> t.Optional[dict]:\n \"\"\"Posts an infraction to the API.\"\"\"\n if isinstance(user, (discord.Member, discord.User)) and user.bot:\n log.trace(f\"Posting of {infr_type} infraction for {user} to the API aborted. User is a bot.\")\n raise InvalidInfractedUser(user)\n\n log.trace(f\"Posting {infr_type} infraction for {user} to the API.\")\n\n payload = {\n \"actor\": ctx.author.id, # Don't use ctx.message.author; antispam only patches ctx.author.\n \"hidden\": hidden,\n \"reason\": reason,\n \"type\": infr_type,\n \"user\": user.id,\n \"active\": active\n }\n if expires_at:\n payload['expires_at'] = expires_at.isoformat()\n\n # Try to apply the infraction. If it fails because the user doesn't exist, try to add it.\n for should_post_user in (True, False):\n try:\n response = await ctx.bot.api_client.post('bot/infractions', json=payload)\n return response\n except ResponseCodeError as e:\n if e.status == 400 and 'user' in e.response_json:\n # Only one attempt to add the user to the database, not two:\n if not should_post_user or await post_user(ctx, user) is None:\n return\n else:\n log.exception(f\"Unexpected error while adding an infraction for {user}:\")\n await ctx.send(f\":x: There was an error adding the infraction: status {e.status}.\")\n return\n\n\nasync def get_active_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n send_msg: bool = True\n) -> t.Optional[dict]:\n \"\"\"\n Retrieves an active infraction of the given type for the user.\n\n If `send_msg` is True and the user has an active infraction matching the `infr_type` parameter,\n then a message for the moderator will be sent to the context channel letting them know.\n Otherwise, no message will be sent.\n \"\"\"\n log.trace(f\"Checking if {user} has active infractions of type {infr_type}.\")\n\n active_infractions = await ctx.bot.api_client.get(\n 'bot/infractions',\n params={\n 'active': 'true',\n 'type': infr_type,\n 'user__id': str(user.id)\n }\n )\n if active_infractions:\n # Checks to see if the moderator should be told there is an active infraction\n if send_msg:\n log.trace(f\"{user} has active infractions of type {infr_type}.\")\n await ctx.send(\n f\":x: According to my records, this user already has a {infr_type} infraction. \"\n f\"See infraction **#{active_infractions[0]['id']}**.\"\n )\n return active_infractions[0]\n else:\n log.trace(f\"{user} does not have active infractions of type {infr_type}.\")\n\n\nasync def notify_infraction(\n user: UserObject,\n infr_type: str,\n expires_at: t.Optional[str] = None,\n reason: t.Optional[str] = None,\n icon_url: str = Icons.token_removed\n) -> bool:\n \"\"\"DM a user about their new infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their {infr_type} infraction.\")\n\n text = INFRACTION_DESCRIPTION_TEMPLATE.format(\n type=infr_type.title(),\n expires=expires_at or \"N/A\",\n reason=reason or \"No reason provided.\"\n )\n\n # For case when other fields than reason is too long and this reach limit, then force-shorten string\n if len(text) > 2048:\n text = f\"{text[:2045]}...\"\n\n embed = discord.Embed(\n description=text,\n colour=Colours.soft_red\n )\n\n embed.set_author(name=INFRACTION_AUTHOR_NAME, icon_url=icon_url, url=RULES_URL)\n embed.title = INFRACTION_TITLE\n embed.url = RULES_URL\n\n embed.set_footer(\n text=INFRACTION_APPEAL_EMAIL_FOOTER if infr_type == 'Ban' else INFRACTION_APPEAL_MODMAIL_FOOTER\n )\n\n return await send_private_embed(user, embed)\n\n\nasync def notify_pardon(\n user: UserObject,\n title: str,\n content: str,\n icon_url: str = Icons.user_verified\n) -> bool:\n \"\"\"DM a user about their pardoned infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their pardoned infraction.\")\n\n embed = discord.Embed(\n description=content,\n colour=Colours.soft_green\n )\n\n embed.set_author(name=title, icon_url=icon_url)\n\n return await send_private_embed(user, embed)\n\n\nasync def send_private_embed(user: UserObject, embed: discord.Embed) -> bool:\n \"\"\"\n A helper method for sending an embed to a user's DMs.\n\n Returns a boolean indicator of DM success.\n \"\"\"\n try:\n await user.send(embed=embed)\n return True\n except (discord.HTTPException, discord.Forbidden, discord.NotFound):\n log.debug(\n f\"Infraction-related information could not be sent to user {user} ({user.id}). \"\n \"The user either could not be retrieved or probably disabled their DMs.\"\n )\n return False\n", "path": "bot/exts/moderation/infraction/_utils.py"}]}
| 2,867 | 874 |
gh_patches_debug_25855
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-4956
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TemplateDoesNotExist: account/email/account_already_exists.de.email, account/email/account_already_exists.en.email
Sentry Issue: [MEINBERLIN-DEV-81](https://sentry.liqd.net/organizations/liqd/issues/2951/?referrer=github_integration)
```
TemplateDoesNotExist: account/email/account_already_exists.de.email, account/email/account_already_exists.en.email
(16 additional frame(s) were not displayed)
...
File "meinberlin/apps/users/adapters.py", line 46, in send_mail
return UserAccountEmail.send(email, template_name=template_prefix, **context)
File "adhocracy4/emails/mixins.py", line 38, in send
return cls().dispatch(object, *args, **kwargs)
File "adhocracy4/emails/base.py", line 127, in dispatch
(subject, text, html) = self.render(template, context)
File "adhocracy4/emails/base.py", line 98, in render
template = select_template(
File "django/template/loader.py", line 47, in select_template
raise TemplateDoesNotExist(', '.join(template_name_list), chain=chain)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/users/forms.py`
Content:
```
1 import collections
2
3 from allauth.account.forms import SignupForm
4 from allauth.socialaccount.forms import SignupForm as SocialSignupForm
5 from django import forms
6 from django.contrib.auth import forms as auth_forms
7 from django.core.exceptions import ValidationError
8 from django.utils.translation import gettext_lazy as _
9 from django.utils.translation import ngettext
10
11 from meinberlin.apps.captcha.fields import CaptcheckCaptchaField
12 from meinberlin.apps.organisations.models import Organisation
13 from meinberlin.apps.users.models import User
14
15
16 class UserAdminForm(auth_forms.UserChangeForm):
17 def clean(self):
18 groups = self.cleaned_data.get("groups")
19 group_list = groups.values_list("id", flat=True)
20 group_organisations = Organisation.objects.filter(
21 groups__in=group_list
22 ).values_list("name", flat=True)
23 duplicates = [
24 item
25 for item, count in collections.Counter(group_organisations).items()
26 if count > 1
27 ]
28 if duplicates:
29 count = len(duplicates)
30 message = ngettext(
31 "User is member in more than one group "
32 "in this organisation: %(duplicates)s.",
33 "User is member in more than one group "
34 "in these organisations: %(duplicates)s.",
35 count,
36 ) % {"duplicates": ", ".join(duplicates)}
37 raise ValidationError(message)
38 return self.cleaned_data
39
40 def clean_username(self):
41
42 username = self.cleaned_data["username"]
43 try:
44 user = User.objects.get(username__iexact=username)
45 if user != self.instance:
46 raise forms.ValidationError(
47 User._meta.get_field("username").error_messages["unique"]
48 )
49 except User.DoesNotExist:
50 pass
51
52 try:
53 user = User.objects.get(email__iexact=username)
54 if user != self.instance:
55 raise forms.ValidationError(
56 User._meta.get_field("username").error_messages["used_as_email"]
57 )
58 except User.DoesNotExist:
59 pass
60
61 return username
62
63
64 class AddUserAdminForm(auth_forms.UserCreationForm):
65 def clean_username(self):
66
67 username = self.cleaned_data["username"]
68 user = User.objects.filter(username__iexact=username)
69 if user.exists():
70 raise forms.ValidationError(
71 User._meta.get_field("username").error_messages["unique"]
72 )
73 else:
74 user = User.objects.filter(email__iexact=username)
75 if user.exists():
76 raise forms.ValidationError(
77 User._meta.get_field("username").error_messages["used_as_email"]
78 )
79 return username
80
81
82 class TermsSignupForm(SignupForm):
83 terms_of_use = forms.BooleanField(label=_("Terms of use"))
84 get_newsletters = forms.BooleanField(
85 label=_("Newsletter"),
86 help_text=_(
87 "Yes, I would like to receive e-mail newsletters about "
88 "the projects I am following."
89 ),
90 required=False,
91 )
92 get_notifications = forms.BooleanField(
93 label=_("Notifications"),
94 help_text=_(
95 "Yes, I would like to be notified by e-mail about the "
96 "start and end of participation opportunities. This "
97 "applies to all projects I follow. I also receive an "
98 "e-mail when someone comments on one of my "
99 "contributions."
100 ),
101 required=False,
102 initial=True,
103 )
104 captcha = CaptcheckCaptchaField(label=_("I am not a robot"))
105
106 def __init__(self, *args, **kwargs):
107 super().__init__(*args, **kwargs)
108 self.fields["username"].help_text = _(
109 "Your username will appear publicly next to your posts."
110 )
111 self.fields["email"].widget.attrs["autofocus"] = True
112
113 def save(self, request):
114 user = super(TermsSignupForm, self).save(request)
115 user.get_newsletters = self.cleaned_data["get_newsletters"]
116 user.get_notifications = self.cleaned_data["get_notifications"]
117 user.save()
118 return user
119
120
121 class SocialTermsSignupForm(SocialSignupForm):
122 terms_of_use = forms.BooleanField(label=_("Terms of use"))
123 get_newsletters = forms.BooleanField(
124 label=_("Newsletter"),
125 help_text=_(
126 "Yes, I would like to receive e-mail newsletters about "
127 "the projects I am following."
128 ),
129 required=False,
130 )
131 get_notifications = forms.BooleanField(
132 label=_("Notifications"),
133 help_text=_(
134 "Yes, I would like to be notified by e-mail about the "
135 "start and end of participation opportunities. This "
136 "applies to all projects I follow. I also receive an "
137 "e-mail when someone comments on one of my "
138 "contributions."
139 ),
140 required=False,
141 initial=True,
142 )
143 email = forms.EmailField(widget=forms.HiddenInput())
144
145 def __init__(self, *args, **kwargs):
146 super().__init__(*args, **kwargs)
147 self.fields["username"].help_text = _(
148 "Your username will appear publicly next to your posts."
149 )
150
151 def save(self, request):
152 user = super(SocialTermsSignupForm, self).save(request)
153 user.get_newsletters = self.cleaned_data["get_newsletters"]
154 user.get_notifications = self.cleaned_data["get_notifications"]
155 user.save()
156 return user
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/users/forms.py b/meinberlin/apps/users/forms.py
--- a/meinberlin/apps/users/forms.py
+++ b/meinberlin/apps/users/forms.py
@@ -38,7 +38,6 @@
return self.cleaned_data
def clean_username(self):
-
username = self.cleaned_data["username"]
try:
user = User.objects.get(username__iexact=username)
@@ -63,7 +62,6 @@
class AddUserAdminForm(auth_forms.UserCreationForm):
def clean_username(self):
-
username = self.cleaned_data["username"]
user = User.objects.filter(username__iexact=username)
if user.exists():
@@ -112,10 +110,11 @@
def save(self, request):
user = super(TermsSignupForm, self).save(request)
- user.get_newsletters = self.cleaned_data["get_newsletters"]
- user.get_notifications = self.cleaned_data["get_notifications"]
- user.save()
- return user
+ if user:
+ user.get_newsletters = self.cleaned_data["get_newsletters"]
+ user.get_notifications = self.cleaned_data["get_notifications"]
+ user.save()
+ return user
class SocialTermsSignupForm(SocialSignupForm):
|
{"golden_diff": "diff --git a/meinberlin/apps/users/forms.py b/meinberlin/apps/users/forms.py\n--- a/meinberlin/apps/users/forms.py\n+++ b/meinberlin/apps/users/forms.py\n@@ -38,7 +38,6 @@\n return self.cleaned_data\n \n def clean_username(self):\n-\n username = self.cleaned_data[\"username\"]\n try:\n user = User.objects.get(username__iexact=username)\n@@ -63,7 +62,6 @@\n \n class AddUserAdminForm(auth_forms.UserCreationForm):\n def clean_username(self):\n-\n username = self.cleaned_data[\"username\"]\n user = User.objects.filter(username__iexact=username)\n if user.exists():\n@@ -112,10 +110,11 @@\n \n def save(self, request):\n user = super(TermsSignupForm, self).save(request)\n- user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n- user.get_notifications = self.cleaned_data[\"get_notifications\"]\n- user.save()\n- return user\n+ if user:\n+ user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n+ user.get_notifications = self.cleaned_data[\"get_notifications\"]\n+ user.save()\n+ return user\n \n \n class SocialTermsSignupForm(SocialSignupForm):\n", "issue": "TemplateDoesNotExist: account/email/account_already_exists.de.email, account/email/account_already_exists.en.email\nSentry Issue: [MEINBERLIN-DEV-81](https://sentry.liqd.net/organizations/liqd/issues/2951/?referrer=github_integration)\n\n```\nTemplateDoesNotExist: account/email/account_already_exists.de.email, account/email/account_already_exists.en.email\n(16 additional frame(s) were not displayed)\n...\n File \"meinberlin/apps/users/adapters.py\", line 46, in send_mail\n return UserAccountEmail.send(email, template_name=template_prefix, **context)\n File \"adhocracy4/emails/mixins.py\", line 38, in send\n return cls().dispatch(object, *args, **kwargs)\n File \"adhocracy4/emails/base.py\", line 127, in dispatch\n (subject, text, html) = self.render(template, context)\n File \"adhocracy4/emails/base.py\", line 98, in render\n template = select_template(\n File \"django/template/loader.py\", line 47, in select_template\n raise TemplateDoesNotExist(', '.join(template_name_list), chain=chain)\n```\n", "before_files": [{"content": "import collections\n\nfrom allauth.account.forms import SignupForm\nfrom allauth.socialaccount.forms import SignupForm as SocialSignupForm\nfrom django import forms\nfrom django.contrib.auth import forms as auth_forms\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import gettext_lazy as _\nfrom django.utils.translation import ngettext\n\nfrom meinberlin.apps.captcha.fields import CaptcheckCaptchaField\nfrom meinberlin.apps.organisations.models import Organisation\nfrom meinberlin.apps.users.models import User\n\n\nclass UserAdminForm(auth_forms.UserChangeForm):\n def clean(self):\n groups = self.cleaned_data.get(\"groups\")\n group_list = groups.values_list(\"id\", flat=True)\n group_organisations = Organisation.objects.filter(\n groups__in=group_list\n ).values_list(\"name\", flat=True)\n duplicates = [\n item\n for item, count in collections.Counter(group_organisations).items()\n if count > 1\n ]\n if duplicates:\n count = len(duplicates)\n message = ngettext(\n \"User is member in more than one group \"\n \"in this organisation: %(duplicates)s.\",\n \"User is member in more than one group \"\n \"in these organisations: %(duplicates)s.\",\n count,\n ) % {\"duplicates\": \", \".join(duplicates)}\n raise ValidationError(message)\n return self.cleaned_data\n\n def clean_username(self):\n\n username = self.cleaned_data[\"username\"]\n try:\n user = User.objects.get(username__iexact=username)\n if user != self.instance:\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"unique\"]\n )\n except User.DoesNotExist:\n pass\n\n try:\n user = User.objects.get(email__iexact=username)\n if user != self.instance:\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"used_as_email\"]\n )\n except User.DoesNotExist:\n pass\n\n return username\n\n\nclass AddUserAdminForm(auth_forms.UserCreationForm):\n def clean_username(self):\n\n username = self.cleaned_data[\"username\"]\n user = User.objects.filter(username__iexact=username)\n if user.exists():\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"unique\"]\n )\n else:\n user = User.objects.filter(email__iexact=username)\n if user.exists():\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"used_as_email\"]\n )\n return username\n\n\nclass TermsSignupForm(SignupForm):\n terms_of_use = forms.BooleanField(label=_(\"Terms of use\"))\n get_newsletters = forms.BooleanField(\n label=_(\"Newsletter\"),\n help_text=_(\n \"Yes, I would like to receive e-mail newsletters about \"\n \"the projects I am following.\"\n ),\n required=False,\n )\n get_notifications = forms.BooleanField(\n label=_(\"Notifications\"),\n help_text=_(\n \"Yes, I would like to be notified by e-mail about the \"\n \"start and end of participation opportunities. This \"\n \"applies to all projects I follow. I also receive an \"\n \"e-mail when someone comments on one of my \"\n \"contributions.\"\n ),\n required=False,\n initial=True,\n )\n captcha = CaptcheckCaptchaField(label=_(\"I am not a robot\"))\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"username\"].help_text = _(\n \"Your username will appear publicly next to your posts.\"\n )\n self.fields[\"email\"].widget.attrs[\"autofocus\"] = True\n\n def save(self, request):\n user = super(TermsSignupForm, self).save(request)\n user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n user.get_notifications = self.cleaned_data[\"get_notifications\"]\n user.save()\n return user\n\n\nclass SocialTermsSignupForm(SocialSignupForm):\n terms_of_use = forms.BooleanField(label=_(\"Terms of use\"))\n get_newsletters = forms.BooleanField(\n label=_(\"Newsletter\"),\n help_text=_(\n \"Yes, I would like to receive e-mail newsletters about \"\n \"the projects I am following.\"\n ),\n required=False,\n )\n get_notifications = forms.BooleanField(\n label=_(\"Notifications\"),\n help_text=_(\n \"Yes, I would like to be notified by e-mail about the \"\n \"start and end of participation opportunities. This \"\n \"applies to all projects I follow. I also receive an \"\n \"e-mail when someone comments on one of my \"\n \"contributions.\"\n ),\n required=False,\n initial=True,\n )\n email = forms.EmailField(widget=forms.HiddenInput())\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"username\"].help_text = _(\n \"Your username will appear publicly next to your posts.\"\n )\n\n def save(self, request):\n user = super(SocialTermsSignupForm, self).save(request)\n user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n user.get_notifications = self.cleaned_data[\"get_notifications\"]\n user.save()\n return user\n", "path": "meinberlin/apps/users/forms.py"}], "after_files": [{"content": "import collections\n\nfrom allauth.account.forms import SignupForm\nfrom allauth.socialaccount.forms import SignupForm as SocialSignupForm\nfrom django import forms\nfrom django.contrib.auth import forms as auth_forms\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import gettext_lazy as _\nfrom django.utils.translation import ngettext\n\nfrom meinberlin.apps.captcha.fields import CaptcheckCaptchaField\nfrom meinberlin.apps.organisations.models import Organisation\nfrom meinberlin.apps.users.models import User\n\n\nclass UserAdminForm(auth_forms.UserChangeForm):\n def clean(self):\n groups = self.cleaned_data.get(\"groups\")\n group_list = groups.values_list(\"id\", flat=True)\n group_organisations = Organisation.objects.filter(\n groups__in=group_list\n ).values_list(\"name\", flat=True)\n duplicates = [\n item\n for item, count in collections.Counter(group_organisations).items()\n if count > 1\n ]\n if duplicates:\n count = len(duplicates)\n message = ngettext(\n \"User is member in more than one group \"\n \"in this organisation: %(duplicates)s.\",\n \"User is member in more than one group \"\n \"in these organisations: %(duplicates)s.\",\n count,\n ) % {\"duplicates\": \", \".join(duplicates)}\n raise ValidationError(message)\n return self.cleaned_data\n\n def clean_username(self):\n username = self.cleaned_data[\"username\"]\n try:\n user = User.objects.get(username__iexact=username)\n if user != self.instance:\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"unique\"]\n )\n except User.DoesNotExist:\n pass\n\n try:\n user = User.objects.get(email__iexact=username)\n if user != self.instance:\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"used_as_email\"]\n )\n except User.DoesNotExist:\n pass\n\n return username\n\n\nclass AddUserAdminForm(auth_forms.UserCreationForm):\n def clean_username(self):\n username = self.cleaned_data[\"username\"]\n user = User.objects.filter(username__iexact=username)\n if user.exists():\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"unique\"]\n )\n else:\n user = User.objects.filter(email__iexact=username)\n if user.exists():\n raise forms.ValidationError(\n User._meta.get_field(\"username\").error_messages[\"used_as_email\"]\n )\n return username\n\n\nclass TermsSignupForm(SignupForm):\n terms_of_use = forms.BooleanField(label=_(\"Terms of use\"))\n get_newsletters = forms.BooleanField(\n label=_(\"Newsletter\"),\n help_text=_(\n \"Yes, I would like to receive e-mail newsletters about \"\n \"the projects I am following.\"\n ),\n required=False,\n )\n get_notifications = forms.BooleanField(\n label=_(\"Notifications\"),\n help_text=_(\n \"Yes, I would like to be notified by e-mail about the \"\n \"start and end of participation opportunities. This \"\n \"applies to all projects I follow. I also receive an \"\n \"e-mail when someone comments on one of my \"\n \"contributions.\"\n ),\n required=False,\n initial=True,\n )\n captcha = CaptcheckCaptchaField(label=_(\"I am not a robot\"))\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"username\"].help_text = _(\n \"Your username will appear publicly next to your posts.\"\n )\n self.fields[\"email\"].widget.attrs[\"autofocus\"] = True\n\n def save(self, request):\n user = super(TermsSignupForm, self).save(request)\n if user:\n user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n user.get_notifications = self.cleaned_data[\"get_notifications\"]\n user.save()\n return user\n\n\nclass SocialTermsSignupForm(SocialSignupForm):\n terms_of_use = forms.BooleanField(label=_(\"Terms of use\"))\n get_newsletters = forms.BooleanField(\n label=_(\"Newsletter\"),\n help_text=_(\n \"Yes, I would like to receive e-mail newsletters about \"\n \"the projects I am following.\"\n ),\n required=False,\n )\n get_notifications = forms.BooleanField(\n label=_(\"Notifications\"),\n help_text=_(\n \"Yes, I would like to be notified by e-mail about the \"\n \"start and end of participation opportunities. This \"\n \"applies to all projects I follow. I also receive an \"\n \"e-mail when someone comments on one of my \"\n \"contributions.\"\n ),\n required=False,\n initial=True,\n )\n email = forms.EmailField(widget=forms.HiddenInput())\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"username\"].help_text = _(\n \"Your username will appear publicly next to your posts.\"\n )\n\n def save(self, request):\n user = super(SocialTermsSignupForm, self).save(request)\n user.get_newsletters = self.cleaned_data[\"get_newsletters\"]\n user.get_notifications = self.cleaned_data[\"get_notifications\"]\n user.save()\n return user\n", "path": "meinberlin/apps/users/forms.py"}]}
| 1,992 | 281 |
gh_patches_debug_1944
|
rasdani/github-patches
|
git_diff
|
napari__napari-277
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
blending mode update error
## 🐛 Bug
When viewing multiple layers with blending, I am experiencing a bug whereby changing the blending mode doesn't result in an immediate update. The update does occur when I change the opacity (at which point is happens immediately).

## To Reproduce
Steps to reproduce the behavior:
1. Open the viewer with multiple layers (e.g. `examples/layers.py`)
2. Reduce the opacity of the top most layer to 0.5
3. Change the blending mode (e.g. `translucent` -> `opaque`)
## Expected behavior
The update to what is rendered should happen immediately upon updating the blending mode.
## Environment
- napari 0.18
- OS X 10.14.3
- Python version: 3.7.2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `napari/layers/_base_layer/_visual_wrapper.py`
Content:
```
1 # TODO: create & use our own transform class
2 from vispy.visuals.transforms import STTransform
3 from vispy.gloo import get_state_presets
4 from ...util.event import EmitterGroup, Event
5
6
7 class VisualWrapper:
8 """Wrapper around ``vispy.scene.VisualNode`` objects.
9 Meant to be subclassed.
10
11 "Hidden" properties:
12 * ``_master_transform``
13 * ``_order``
14 * ``_parent``
15
16 Parameters
17 ----------
18 central_node : vispy.scene.VisualNode
19 Central node/control point with which to interact with the visual.
20 Stored as ``_node``.
21
22 Attributes
23 ----------
24 opacity
25 visible
26 scale
27 blending
28 translate
29 z_index
30
31 Notes
32 -----
33 It is recommended to use the backported ``vispy`` nodes
34 at ``_vispy.scene.visuals`` for various bug fixes.
35 """
36 def __init__(self, central_node):
37 self._node = central_node
38 self._blending = 'translucent'
39 self.events = EmitterGroup(source=self,
40 auto_connect=True,
41 blending=Event,
42 opacity=Event,
43 visible=Event)
44
45 _blending_modes = set(get_state_presets().keys())
46
47 @property
48 def _master_transform(self):
49 """vispy.visuals.transforms.STTransform:
50 Central node's firstmost transform.
51 """
52 # whenever a new parent is set, the transform is reset
53 # to a NullTransform so we reset it here
54 if not isinstance(self._node.transform, STTransform):
55 self._node.transform = STTransform()
56
57 return self._node.transform
58
59 @property
60 def _order(self):
61 """int: Order in which the visual is drawn in the scenegraph.
62 Lower values are closer to the viewer.
63 """
64 return self._node.order
65
66 @_order.setter
67 def _order(self, order):
68 # workaround for opacity (see: #22)
69 order = -order
70 self.z_index = order
71 # end workaround
72 self._node.order = order
73
74 @property
75 def _parent(self):
76 """vispy.scene.Node: Parent node.
77 """
78 return self._node.parent
79
80 @_parent.setter
81 def _parent(self, parent):
82 self._node.parent = parent
83
84 @property
85 def opacity(self):
86 """float: Opacity value between 0.0 and 1.0.
87 """
88 return self._node.opacity
89
90 @opacity.setter
91 def opacity(self, opacity):
92 if not 0.0 <= opacity <= 1.0:
93 raise ValueError('opacity must be between 0.0 and 1.0; '
94 f'got {opacity}')
95
96 self._node.opacity = opacity
97 self.events.opacity()
98
99 @property
100 def blending(self):
101 """{'opaque', 'translucent', 'additive'}: Blending mode.
102 Selects a preset blending mode in vispy that determines how
103 RGB and alpha values get mixed.
104 'opaque'
105 Allows for only the top layer to be visible and corresponds to
106 depth_test=True, cull_face=False, blend=False.
107 'translucent'
108 Allows for multiple layers to be blended with different opacity
109 and corresponds to depth_test=True, cull_face=False,
110 blend=True, blend_func=('src_alpha', 'one_minus_src_alpha').
111 'additive'
112 Allows for multiple layers to be blended together with
113 different colors and opacity. Useful for creating overlays. It
114 corresponds to depth_test=False, cull_face=False, blend=True,
115 blend_func=('src_alpha', 'one').
116 """
117 return self._blending
118
119 @blending.setter
120 def blending(self, blending):
121 if blending not in self._blending_modes:
122 raise ValueError('expected one of '
123 "{'opaque', 'translucent', 'additive'}; "
124 f'got {blending}')
125 self._node.set_gl_state(blending)
126 self._blending = blending
127 self.events.blending()
128
129 @property
130 def visible(self):
131 """bool: Whether the visual is currently being displayed.
132 """
133 return self._node.visible
134
135 @visible.setter
136 def visible(self, visibility):
137 self._node.visible = visibility
138 self.events.visible()
139
140 @property
141 def scale(self):
142 """sequence of float: Scale factors.
143 """
144 return self._master_transform.scale
145
146 @scale.setter
147 def scale(self, scale):
148 self._master_transform.scale = scale
149
150 @property
151 def translate(self):
152 """sequence of float: Translation values.
153 """
154 return self._master_transform.translate
155
156 @translate.setter
157 def translate(self, translate):
158 self._master_transform.translate = translate
159
160 @property
161 def z_index(self):
162 return -self._master_transform.translate[2]
163
164 @z_index.setter
165 def z_index(self, index):
166 tr = self._master_transform
167 tl = tr.translate
168 tl[2] = -index
169
170 tr.translate = tl
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/napari/layers/_base_layer/_visual_wrapper.py b/napari/layers/_base_layer/_visual_wrapper.py
--- a/napari/layers/_base_layer/_visual_wrapper.py
+++ b/napari/layers/_base_layer/_visual_wrapper.py
@@ -124,6 +124,7 @@
f'got {blending}')
self._node.set_gl_state(blending)
self._blending = blending
+ self._node.update()
self.events.blending()
@property
|
{"golden_diff": "diff --git a/napari/layers/_base_layer/_visual_wrapper.py b/napari/layers/_base_layer/_visual_wrapper.py\n--- a/napari/layers/_base_layer/_visual_wrapper.py\n+++ b/napari/layers/_base_layer/_visual_wrapper.py\n@@ -124,6 +124,7 @@\n f'got {blending}')\n self._node.set_gl_state(blending)\n self._blending = blending\n+ self._node.update()\n self.events.blending()\n \n @property\n", "issue": "blending mode update error\n## \ud83d\udc1b Bug\r\n\r\nWhen viewing multiple layers with blending, I am experiencing a bug whereby changing the blending mode doesn't result in an immediate update. The update does occur when I change the opacity (at which point is happens immediately). \r\n\r\n\r\n\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Open the viewer with multiple layers (e.g. `examples/layers.py`)\r\n2. Reduce the opacity of the top most layer to 0.5\r\n3. Change the blending mode (e.g. `translucent` -> `opaque`)\r\n\r\n## Expected behavior\r\n\r\nThe update to what is rendered should happen immediately upon updating the blending mode.\r\n\r\n## Environment\r\n\r\n - napari 0.18\r\n - OS X 10.14.3\r\n - Python version: 3.7.2\r\n\n", "before_files": [{"content": "# TODO: create & use our own transform class\nfrom vispy.visuals.transforms import STTransform\nfrom vispy.gloo import get_state_presets\nfrom ...util.event import EmitterGroup, Event\n\n\nclass VisualWrapper:\n \"\"\"Wrapper around ``vispy.scene.VisualNode`` objects.\n Meant to be subclassed.\n\n \"Hidden\" properties:\n * ``_master_transform``\n * ``_order``\n * ``_parent``\n\n Parameters\n ----------\n central_node : vispy.scene.VisualNode\n Central node/control point with which to interact with the visual.\n Stored as ``_node``.\n\n Attributes\n ----------\n opacity\n visible\n scale\n blending\n translate\n z_index\n\n Notes\n -----\n It is recommended to use the backported ``vispy`` nodes\n at ``_vispy.scene.visuals`` for various bug fixes.\n \"\"\"\n def __init__(self, central_node):\n self._node = central_node\n self._blending = 'translucent'\n self.events = EmitterGroup(source=self,\n auto_connect=True,\n blending=Event,\n opacity=Event,\n visible=Event)\n\n _blending_modes = set(get_state_presets().keys())\n\n @property\n def _master_transform(self):\n \"\"\"vispy.visuals.transforms.STTransform:\n Central node's firstmost transform.\n \"\"\"\n # whenever a new parent is set, the transform is reset\n # to a NullTransform so we reset it here\n if not isinstance(self._node.transform, STTransform):\n self._node.transform = STTransform()\n\n return self._node.transform\n\n @property\n def _order(self):\n \"\"\"int: Order in which the visual is drawn in the scenegraph.\n Lower values are closer to the viewer.\n \"\"\"\n return self._node.order\n\n @_order.setter\n def _order(self, order):\n # workaround for opacity (see: #22)\n order = -order\n self.z_index = order\n # end workaround\n self._node.order = order\n\n @property\n def _parent(self):\n \"\"\"vispy.scene.Node: Parent node.\n \"\"\"\n return self._node.parent\n\n @_parent.setter\n def _parent(self, parent):\n self._node.parent = parent\n\n @property\n def opacity(self):\n \"\"\"float: Opacity value between 0.0 and 1.0.\n \"\"\"\n return self._node.opacity\n\n @opacity.setter\n def opacity(self, opacity):\n if not 0.0 <= opacity <= 1.0:\n raise ValueError('opacity must be between 0.0 and 1.0; '\n f'got {opacity}')\n\n self._node.opacity = opacity\n self.events.opacity()\n\n @property\n def blending(self):\n \"\"\"{'opaque', 'translucent', 'additive'}: Blending mode.\n Selects a preset blending mode in vispy that determines how\n RGB and alpha values get mixed.\n 'opaque'\n Allows for only the top layer to be visible and corresponds to\n depth_test=True, cull_face=False, blend=False.\n 'translucent'\n Allows for multiple layers to be blended with different opacity\n and corresponds to depth_test=True, cull_face=False,\n blend=True, blend_func=('src_alpha', 'one_minus_src_alpha').\n 'additive'\n Allows for multiple layers to be blended together with\n different colors and opacity. Useful for creating overlays. It\n corresponds to depth_test=False, cull_face=False, blend=True,\n blend_func=('src_alpha', 'one').\n \"\"\"\n return self._blending\n\n @blending.setter\n def blending(self, blending):\n if blending not in self._blending_modes:\n raise ValueError('expected one of '\n \"{'opaque', 'translucent', 'additive'}; \"\n f'got {blending}')\n self._node.set_gl_state(blending)\n self._blending = blending\n self.events.blending()\n\n @property\n def visible(self):\n \"\"\"bool: Whether the visual is currently being displayed.\n \"\"\"\n return self._node.visible\n\n @visible.setter\n def visible(self, visibility):\n self._node.visible = visibility\n self.events.visible()\n\n @property\n def scale(self):\n \"\"\"sequence of float: Scale factors.\n \"\"\"\n return self._master_transform.scale\n\n @scale.setter\n def scale(self, scale):\n self._master_transform.scale = scale\n\n @property\n def translate(self):\n \"\"\"sequence of float: Translation values.\n \"\"\"\n return self._master_transform.translate\n\n @translate.setter\n def translate(self, translate):\n self._master_transform.translate = translate\n\n @property\n def z_index(self):\n return -self._master_transform.translate[2]\n\n @z_index.setter\n def z_index(self, index):\n tr = self._master_transform\n tl = tr.translate\n tl[2] = -index\n\n tr.translate = tl\n", "path": "napari/layers/_base_layer/_visual_wrapper.py"}], "after_files": [{"content": "# TODO: create & use our own transform class\nfrom vispy.visuals.transforms import STTransform\nfrom vispy.gloo import get_state_presets\nfrom ...util.event import EmitterGroup, Event\n\n\nclass VisualWrapper:\n \"\"\"Wrapper around ``vispy.scene.VisualNode`` objects.\n Meant to be subclassed.\n\n \"Hidden\" properties:\n * ``_master_transform``\n * ``_order``\n * ``_parent``\n\n Parameters\n ----------\n central_node : vispy.scene.VisualNode\n Central node/control point with which to interact with the visual.\n Stored as ``_node``.\n\n Attributes\n ----------\n opacity\n visible\n scale\n blending\n translate\n z_index\n\n Notes\n -----\n It is recommended to use the backported ``vispy`` nodes\n at ``_vispy.scene.visuals`` for various bug fixes.\n \"\"\"\n def __init__(self, central_node):\n self._node = central_node\n self._blending = 'translucent'\n self.events = EmitterGroup(source=self,\n auto_connect=True,\n blending=Event,\n opacity=Event,\n visible=Event)\n\n _blending_modes = set(get_state_presets().keys())\n\n @property\n def _master_transform(self):\n \"\"\"vispy.visuals.transforms.STTransform:\n Central node's firstmost transform.\n \"\"\"\n # whenever a new parent is set, the transform is reset\n # to a NullTransform so we reset it here\n if not isinstance(self._node.transform, STTransform):\n self._node.transform = STTransform()\n\n return self._node.transform\n\n @property\n def _order(self):\n \"\"\"int: Order in which the visual is drawn in the scenegraph.\n Lower values are closer to the viewer.\n \"\"\"\n return self._node.order\n\n @_order.setter\n def _order(self, order):\n # workaround for opacity (see: #22)\n order = -order\n self.z_index = order\n # end workaround\n self._node.order = order\n\n @property\n def _parent(self):\n \"\"\"vispy.scene.Node: Parent node.\n \"\"\"\n return self._node.parent\n\n @_parent.setter\n def _parent(self, parent):\n self._node.parent = parent\n\n @property\n def opacity(self):\n \"\"\"float: Opacity value between 0.0 and 1.0.\n \"\"\"\n return self._node.opacity\n\n @opacity.setter\n def opacity(self, opacity):\n if not 0.0 <= opacity <= 1.0:\n raise ValueError('opacity must be between 0.0 and 1.0; '\n f'got {opacity}')\n\n self._node.opacity = opacity\n self.events.opacity()\n\n @property\n def blending(self):\n \"\"\"{'opaque', 'translucent', 'additive'}: Blending mode.\n Selects a preset blending mode in vispy that determines how\n RGB and alpha values get mixed.\n 'opaque'\n Allows for only the top layer to be visible and corresponds to\n depth_test=True, cull_face=False, blend=False.\n 'translucent'\n Allows for multiple layers to be blended with different opacity\n and corresponds to depth_test=True, cull_face=False,\n blend=True, blend_func=('src_alpha', 'one_minus_src_alpha').\n 'additive'\n Allows for multiple layers to be blended together with\n different colors and opacity. Useful for creating overlays. It\n corresponds to depth_test=False, cull_face=False, blend=True,\n blend_func=('src_alpha', 'one').\n \"\"\"\n return self._blending\n\n @blending.setter\n def blending(self, blending):\n if blending not in self._blending_modes:\n raise ValueError('expected one of '\n \"{'opaque', 'translucent', 'additive'}; \"\n f'got {blending}')\n self._node.set_gl_state(blending)\n self._blending = blending\n self._node.update()\n self.events.blending()\n\n @property\n def visible(self):\n \"\"\"bool: Whether the visual is currently being displayed.\n \"\"\"\n return self._node.visible\n\n @visible.setter\n def visible(self, visibility):\n self._node.visible = visibility\n self.events.visible()\n\n @property\n def scale(self):\n \"\"\"sequence of float: Scale factors.\n \"\"\"\n return self._master_transform.scale\n\n @scale.setter\n def scale(self, scale):\n self._master_transform.scale = scale\n\n @property\n def translate(self):\n \"\"\"sequence of float: Translation values.\n \"\"\"\n return self._master_transform.translate\n\n @translate.setter\n def translate(self, translate):\n self._master_transform.translate = translate\n\n @property\n def z_index(self):\n return -self._master_transform.translate[2]\n\n @z_index.setter\n def z_index(self, index):\n tr = self._master_transform\n tl = tr.translate\n tl[2] = -index\n\n tr.translate = tl\n", "path": "napari/layers/_base_layer/_visual_wrapper.py"}]}
| 2,015 | 118 |
gh_patches_debug_48851
|
rasdani/github-patches
|
git_diff
|
ultrabug__py3status-2088
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Scratchpad] Buggy in sway
**Describe the bug**
Scratchpad behavior running in sway is buggy.
**Your py3status version**
py3status version 3.36 (python 3.9.2) on sway/Arch.
**To Reproduce**
Weird behavior depending on the formatting string used in config.
1. There are 2 windows in the scratchpad...qutebrowser and firefox. I found this command to list them:
```
swaymsg -t get_tree | jq -r 'recurse(.nodes[]?) | select(.name == "__i3_scratch").floating_nodes[].app_id, select(.name == "__i3_scratch").floating_nodes[].window_properties.title' | grep -v null
```
Result:
```
org.qutebrowser.qutebrowser
firefox
```
2. Configure module like this '....'
```
scratchpad {
color = '#A54242'
format = '[\?not_zero ⌫ [\?color=scratchpad {scratchpad}]]'
on_click 1 = 'scratchpad show'
}
```
No scratchpad indicator.
Changing the format line to the default:
```
scratchpad {
color = '#A54242'
#format = '[\?if=not_zero ⌫ [\?color=scratchpad {scratchpad}]]'
on_click 1 = 'scratchpad show'
}
```
Scratchpad indicator present, color is correct; count is 0 (zero)
The ```on_click 1``` command works as expected.
**Additional context**
No special flags for starting py3status:
```
status_command py3status
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py3status/modules/scratchpad.py`
Content:
```
1 """
2 Display number of scratchpad windows and urgency hints.
3
4 Configuration parameters:
5 cache_timeout: refresh interval for i3-msg or swaymsg (default 5)
6 format: display format for this module
7 (default "\u232b [\\?color=scratchpad {scratchpad}]")
8 thresholds: specify color thresholds to use
9 (default [(0, "darkgray"), (1, "violet")])
10
11 Format placeholders:
12 {scratchpad} number of scratchpads
13 {urgent} number of urgent scratchpads
14
15 Color thresholds:
16 xxx: print a color based on the value of `xxx` placeholder
17
18 Optional:
19 i3ipc: an improved python library to control i3wm and sway
20
21 Examples:
22 ```
23 # hide zero scratchpad
24 scratchpad {
25 format = '[\\?not_zero \u232b [\\?color=scratchpad {scratchpad}]]'
26 }
27
28 # hide non-urgent scratchpad
29 scratchpad {
30 format = '[\\?not_zero \u232b {urgent}]'
31 }
32
33 # bring up scratchpads on clicks
34 scratchpad {
35 on_click 1 = 'scratchpad show'
36 }
37
38 # add more colors
39 scratchpad {
40 thresholds = [
41 (0, "darkgray"), (1, "violet"), (2, "deepskyblue"), (3, "lime"),
42 (4, "yellow"), (5, "orange"), (6, "red"), (7, "tomato"),
43 ]
44 }
45 ```
46
47 @author shadowprince (counter), cornerman (async)
48 @license Eclipse Public License (counter), BSD (async)
49
50 SAMPLE OUTPUT
51 [{'full_text': '\u232b '}, {'full_text': u'0', 'color': '#a9a9a9'}]
52
53 violet
54 [{'full_text': '\u232b '}, {'full_text': u'5', 'color': '#ee82ee'}]
55
56 urgent
57 [{'full_text': '\u232b URGENT 1', 'urgent': True}]
58 """
59
60 STRING_ERROR = "invalid ipc `{}`"
61
62
63 class Ipc:
64 """
65 """
66
67 def __init__(self, parent):
68 self.parent = parent
69 self.setup(parent)
70
71
72 class I3ipc(Ipc):
73 """
74 i3ipc - an improved python library to control i3wm and sway
75 """
76
77 def setup(self, parent):
78 from threading import Thread
79
80 self.parent.cache_timeout = self.parent.py3.CACHE_FOREVER
81 self.scratchpad_data = {"scratchpad": 0, "urgent": 0}
82
83 t = Thread(target=self.start)
84 t.daemon = True
85 t.start()
86
87 def start(self):
88 from i3ipc import Connection
89
90 i3 = Connection()
91 self.update(i3)
92 for event in ["window::move", "window::urgent"]:
93 i3.on(event, self.update)
94 i3.main()
95
96 def update(self, i3, event=None):
97 leaves = i3.get_tree().scratchpad().leaves()
98 temporary = {
99 "ipc": self.parent.ipc,
100 "scratchpad": len(leaves),
101 "urgent": sum(window.urgent for window in leaves),
102 }
103 if self.scratchpad_data != temporary:
104 self.scratchpad_data = temporary
105 self.parent.py3.update()
106
107 def get_scratchpad_data(self):
108 return self.scratchpad_data
109
110
111 class Msg(Ipc):
112 """
113 i3-msg - send messages to i3 window manager
114 swaymsg - send messages to sway window manager
115 """
116
117 def setup(self, parent):
118 from json import loads
119
120 self.json_loads = loads
121 wm_msg = {"i3msg": "i3-msg"}.get(parent.ipc, parent.ipc)
122 self.tree_command = [wm_msg, "-t", "get_tree"]
123
124 def get_scratchpad_data(self):
125 tree = self.json_loads(self.parent.py3.command_output(self.tree_command))
126 leaves = self.find_scratchpad(tree).get("floating_nodes", [])
127 return {
128 "ipc": self.parent.ipc,
129 "scratchpad": len(leaves),
130 "urgent": sum(window["urgent"] for window in leaves),
131 }
132
133 def find_scratchpad(self, tree):
134 if tree.get("name") == "__i3_scratch":
135 return tree
136 for x in tree.get("nodes", []):
137 result = self.find_scratchpad(x)
138 if result:
139 return result
140 return {}
141
142
143 class Py3status:
144 """
145 """
146
147 # available configuration parameters
148 cache_timeout = 5
149 format = "\u232b [\\?color=scratchpad {scratchpad}]"
150 thresholds = [(0, "darkgray"), (1, "violet")]
151
152 def post_config_hook(self):
153 # ipc: specify i3ipc, i3-msg, or swaymsg, otherwise auto
154 self.ipc = getattr(self, "ipc", "")
155 if self.ipc in ["", "i3ipc"]:
156 try:
157 from i3ipc import Connection # noqa f401
158
159 self.ipc = "i3ipc"
160 except Exception:
161 if self.ipc:
162 raise # module not found
163
164 self.ipc = (self.ipc or self.py3.get_wm_msg()).replace("-", "")
165 if self.ipc in ["i3ipc"]:
166 self.backend = I3ipc(self)
167 elif self.ipc in ["i3msg", "swaymsg"]:
168 self.backend = Msg(self)
169 else:
170 raise Exception(STRING_ERROR.format(self.ipc))
171
172 self.thresholds_init = self.py3.get_color_names_list(self.format)
173
174 def scratchpad(self):
175 scratchpad_data = self.backend.get_scratchpad_data()
176
177 for x in self.thresholds_init:
178 if x in scratchpad_data:
179 self.py3.threshold_get_color(scratchpad_data[x], x)
180
181 response = {
182 "cached_until": self.py3.time_in(self.cache_timeout),
183 "full_text": self.py3.safe_format(self.format, scratchpad_data),
184 }
185 if scratchpad_data["urgent"]:
186 response["urgent"] = True
187 return response
188
189
190 if __name__ == "__main__":
191 """
192 Run module in test mode.
193 """
194 from py3status.module_test import module_test
195
196 config = {"format": r"\[{ipc}\] [\?color=scratchpad {scratchpad}]"}
197 module_test(Py3status, config=config)
198
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py3status/modules/scratchpad.py b/py3status/modules/scratchpad.py
--- a/py3status/modules/scratchpad.py
+++ b/py3status/modules/scratchpad.py
@@ -94,7 +94,13 @@
i3.main()
def update(self, i3, event=None):
- leaves = i3.get_tree().scratchpad().leaves()
+ scratchpad = i3.get_tree().scratchpad()
+ if not scratchpad:
+ return
+
+ # Workaround for I3ipc 2.2.1 not finding leaves() in sway. Fixing: #2038
+ leaves = getattr(scratchpad, "floating_nodes", [])
+
temporary = {
"ipc": self.parent.ipc,
"scratchpad": len(leaves),
|
{"golden_diff": "diff --git a/py3status/modules/scratchpad.py b/py3status/modules/scratchpad.py\n--- a/py3status/modules/scratchpad.py\n+++ b/py3status/modules/scratchpad.py\n@@ -94,7 +94,13 @@\n i3.main()\n \n def update(self, i3, event=None):\n- leaves = i3.get_tree().scratchpad().leaves()\n+ scratchpad = i3.get_tree().scratchpad()\n+ if not scratchpad:\n+ return\n+\n+ # Workaround for I3ipc 2.2.1 not finding leaves() in sway. Fixing: #2038\n+ leaves = getattr(scratchpad, \"floating_nodes\", [])\n+\n temporary = {\n \"ipc\": self.parent.ipc,\n \"scratchpad\": len(leaves),\n", "issue": "[Scratchpad] Buggy in sway\n**Describe the bug**\r\n\r\nScratchpad behavior running in sway is buggy.\r\n\r\n**Your py3status version**\r\n\r\npy3status version 3.36 (python 3.9.2) on sway/Arch.\r\n\r\n**To Reproduce**\r\n\r\nWeird behavior depending on the formatting string used in config.\r\n\r\n1. There are 2 windows in the scratchpad...qutebrowser and firefox. I found this command to list them:\r\n\r\n```\r\nswaymsg -t get_tree | jq -r 'recurse(.nodes[]?) | select(.name == \"__i3_scratch\").floating_nodes[].app_id, select(.name == \"__i3_scratch\").floating_nodes[].window_properties.title' | grep -v null\r\n```\r\nResult:\r\n```\r\norg.qutebrowser.qutebrowser\r\nfirefox\r\n```\r\n2. Configure module like this '....'\r\n```\r\nscratchpad {\r\n\tcolor = '#A54242'\r\n\tformat = '[\\?not_zero \u232b [\\?color=scratchpad {scratchpad}]]'\r\n\ton_click 1 = 'scratchpad show'\r\n}\r\n```\r\nNo scratchpad indicator.\r\n\r\nChanging the format line to the default:\r\n\r\n```\r\nscratchpad {\r\n\tcolor = '#A54242'\r\n\t#format = '[\\?if=not_zero \u232b [\\?color=scratchpad {scratchpad}]]'\r\n\ton_click 1 = 'scratchpad show'\r\n}\r\n```\r\nScratchpad indicator present, color is correct; count is 0 (zero)\r\n\r\nThe ```on_click 1``` command works as expected.\r\n\r\n**Additional context**\r\n\r\nNo special flags for starting py3status:\r\n\r\n```\r\nstatus_command py3status\r\n```\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nDisplay number of scratchpad windows and urgency hints.\n\nConfiguration parameters:\n cache_timeout: refresh interval for i3-msg or swaymsg (default 5)\n format: display format for this module\n (default \"\\u232b [\\\\?color=scratchpad {scratchpad}]\")\n thresholds: specify color thresholds to use\n (default [(0, \"darkgray\"), (1, \"violet\")])\n\nFormat placeholders:\n {scratchpad} number of scratchpads\n {urgent} number of urgent scratchpads\n\nColor thresholds:\n xxx: print a color based on the value of `xxx` placeholder\n\nOptional:\n i3ipc: an improved python library to control i3wm and sway\n\nExamples:\n```\n# hide zero scratchpad\nscratchpad {\n format = '[\\\\?not_zero \\u232b [\\\\?color=scratchpad {scratchpad}]]'\n}\n\n# hide non-urgent scratchpad\nscratchpad {\n format = '[\\\\?not_zero \\u232b {urgent}]'\n}\n\n# bring up scratchpads on clicks\nscratchpad {\n on_click 1 = 'scratchpad show'\n}\n\n# add more colors\nscratchpad {\n thresholds = [\n (0, \"darkgray\"), (1, \"violet\"), (2, \"deepskyblue\"), (3, \"lime\"),\n (4, \"yellow\"), (5, \"orange\"), (6, \"red\"), (7, \"tomato\"),\n ]\n}\n```\n\n@author shadowprince (counter), cornerman (async)\n@license Eclipse Public License (counter), BSD (async)\n\nSAMPLE OUTPUT\n[{'full_text': '\\u232b '}, {'full_text': u'0', 'color': '#a9a9a9'}]\n\nviolet\n[{'full_text': '\\u232b '}, {'full_text': u'5', 'color': '#ee82ee'}]\n\nurgent\n[{'full_text': '\\u232b URGENT 1', 'urgent': True}]\n\"\"\"\n\nSTRING_ERROR = \"invalid ipc `{}`\"\n\n\nclass Ipc:\n \"\"\"\n \"\"\"\n\n def __init__(self, parent):\n self.parent = parent\n self.setup(parent)\n\n\nclass I3ipc(Ipc):\n \"\"\"\n i3ipc - an improved python library to control i3wm and sway\n \"\"\"\n\n def setup(self, parent):\n from threading import Thread\n\n self.parent.cache_timeout = self.parent.py3.CACHE_FOREVER\n self.scratchpad_data = {\"scratchpad\": 0, \"urgent\": 0}\n\n t = Thread(target=self.start)\n t.daemon = True\n t.start()\n\n def start(self):\n from i3ipc import Connection\n\n i3 = Connection()\n self.update(i3)\n for event in [\"window::move\", \"window::urgent\"]:\n i3.on(event, self.update)\n i3.main()\n\n def update(self, i3, event=None):\n leaves = i3.get_tree().scratchpad().leaves()\n temporary = {\n \"ipc\": self.parent.ipc,\n \"scratchpad\": len(leaves),\n \"urgent\": sum(window.urgent for window in leaves),\n }\n if self.scratchpad_data != temporary:\n self.scratchpad_data = temporary\n self.parent.py3.update()\n\n def get_scratchpad_data(self):\n return self.scratchpad_data\n\n\nclass Msg(Ipc):\n \"\"\"\n i3-msg - send messages to i3 window manager\n swaymsg - send messages to sway window manager\n \"\"\"\n\n def setup(self, parent):\n from json import loads\n\n self.json_loads = loads\n wm_msg = {\"i3msg\": \"i3-msg\"}.get(parent.ipc, parent.ipc)\n self.tree_command = [wm_msg, \"-t\", \"get_tree\"]\n\n def get_scratchpad_data(self):\n tree = self.json_loads(self.parent.py3.command_output(self.tree_command))\n leaves = self.find_scratchpad(tree).get(\"floating_nodes\", [])\n return {\n \"ipc\": self.parent.ipc,\n \"scratchpad\": len(leaves),\n \"urgent\": sum(window[\"urgent\"] for window in leaves),\n }\n\n def find_scratchpad(self, tree):\n if tree.get(\"name\") == \"__i3_scratch\":\n return tree\n for x in tree.get(\"nodes\", []):\n result = self.find_scratchpad(x)\n if result:\n return result\n return {}\n\n\nclass Py3status:\n \"\"\"\n \"\"\"\n\n # available configuration parameters\n cache_timeout = 5\n format = \"\\u232b [\\\\?color=scratchpad {scratchpad}]\"\n thresholds = [(0, \"darkgray\"), (1, \"violet\")]\n\n def post_config_hook(self):\n # ipc: specify i3ipc, i3-msg, or swaymsg, otherwise auto\n self.ipc = getattr(self, \"ipc\", \"\")\n if self.ipc in [\"\", \"i3ipc\"]:\n try:\n from i3ipc import Connection # noqa f401\n\n self.ipc = \"i3ipc\"\n except Exception:\n if self.ipc:\n raise # module not found\n\n self.ipc = (self.ipc or self.py3.get_wm_msg()).replace(\"-\", \"\")\n if self.ipc in [\"i3ipc\"]:\n self.backend = I3ipc(self)\n elif self.ipc in [\"i3msg\", \"swaymsg\"]:\n self.backend = Msg(self)\n else:\n raise Exception(STRING_ERROR.format(self.ipc))\n\n self.thresholds_init = self.py3.get_color_names_list(self.format)\n\n def scratchpad(self):\n scratchpad_data = self.backend.get_scratchpad_data()\n\n for x in self.thresholds_init:\n if x in scratchpad_data:\n self.py3.threshold_get_color(scratchpad_data[x], x)\n\n response = {\n \"cached_until\": self.py3.time_in(self.cache_timeout),\n \"full_text\": self.py3.safe_format(self.format, scratchpad_data),\n }\n if scratchpad_data[\"urgent\"]:\n response[\"urgent\"] = True\n return response\n\n\nif __name__ == \"__main__\":\n \"\"\"\n Run module in test mode.\n \"\"\"\n from py3status.module_test import module_test\n\n config = {\"format\": r\"\\[{ipc}\\] [\\?color=scratchpad {scratchpad}]\"}\n module_test(Py3status, config=config)\n", "path": "py3status/modules/scratchpad.py"}], "after_files": [{"content": "\"\"\"\nDisplay number of scratchpad windows and urgency hints.\n\nConfiguration parameters:\n cache_timeout: refresh interval for i3-msg or swaymsg (default 5)\n format: display format for this module\n (default \"\\u232b [\\\\?color=scratchpad {scratchpad}]\")\n thresholds: specify color thresholds to use\n (default [(0, \"darkgray\"), (1, \"violet\")])\n\nFormat placeholders:\n {scratchpad} number of scratchpads\n {urgent} number of urgent scratchpads\n\nColor thresholds:\n xxx: print a color based on the value of `xxx` placeholder\n\nOptional:\n i3ipc: an improved python library to control i3wm and sway\n\nExamples:\n```\n# hide zero scratchpad\nscratchpad {\n format = '[\\\\?not_zero \\u232b [\\\\?color=scratchpad {scratchpad}]]'\n}\n\n# hide non-urgent scratchpad\nscratchpad {\n format = '[\\\\?not_zero \\u232b {urgent}]'\n}\n\n# bring up scratchpads on clicks\nscratchpad {\n on_click 1 = 'scratchpad show'\n}\n\n# add more colors\nscratchpad {\n thresholds = [\n (0, \"darkgray\"), (1, \"violet\"), (2, \"deepskyblue\"), (3, \"lime\"),\n (4, \"yellow\"), (5, \"orange\"), (6, \"red\"), (7, \"tomato\"),\n ]\n}\n```\n\n@author shadowprince (counter), cornerman (async)\n@license Eclipse Public License (counter), BSD (async)\n\nSAMPLE OUTPUT\n[{'full_text': '\\u232b '}, {'full_text': u'0', 'color': '#a9a9a9'}]\n\nviolet\n[{'full_text': '\\u232b '}, {'full_text': u'5', 'color': '#ee82ee'}]\n\nurgent\n[{'full_text': '\\u232b URGENT 1', 'urgent': True}]\n\"\"\"\n\nSTRING_ERROR = \"invalid ipc `{}`\"\n\n\nclass Ipc:\n \"\"\"\n \"\"\"\n\n def __init__(self, parent):\n self.parent = parent\n self.setup(parent)\n\n\nclass I3ipc(Ipc):\n \"\"\"\n i3ipc - an improved python library to control i3wm and sway\n \"\"\"\n\n def setup(self, parent):\n from threading import Thread\n\n self.parent.cache_timeout = self.parent.py3.CACHE_FOREVER\n self.scratchpad_data = {\"scratchpad\": 0, \"urgent\": 0}\n\n t = Thread(target=self.start)\n t.daemon = True\n t.start()\n\n def start(self):\n from i3ipc import Connection\n\n i3 = Connection()\n self.update(i3)\n for event in [\"window::move\", \"window::urgent\"]:\n i3.on(event, self.update)\n i3.main()\n\n def update(self, i3, event=None):\n scratchpad = i3.get_tree().scratchpad()\n if not scratchpad:\n return\n\n # Workaround for I3ipc 2.2.1 not finding leaves() in sway. Fixing: #2038\n leaves = getattr(scratchpad, \"floating_nodes\", [])\n\n temporary = {\n \"ipc\": self.parent.ipc,\n \"scratchpad\": len(leaves),\n \"urgent\": sum(window.urgent for window in leaves),\n }\n if self.scratchpad_data != temporary:\n self.scratchpad_data = temporary\n self.parent.py3.update()\n\n def get_scratchpad_data(self):\n return self.scratchpad_data\n\n\nclass Msg(Ipc):\n \"\"\"\n i3-msg - send messages to i3 window manager\n swaymsg - send messages to sway window manager\n \"\"\"\n\n def setup(self, parent):\n from json import loads\n\n self.json_loads = loads\n wm_msg = {\"i3msg\": \"i3-msg\"}.get(parent.ipc, parent.ipc)\n self.tree_command = [wm_msg, \"-t\", \"get_tree\"]\n\n def get_scratchpad_data(self):\n tree = self.json_loads(self.parent.py3.command_output(self.tree_command))\n leaves = self.find_scratchpad(tree).get(\"floating_nodes\", [])\n return {\n \"ipc\": self.parent.ipc,\n \"scratchpad\": len(leaves),\n \"urgent\": sum(window[\"urgent\"] for window in leaves),\n }\n\n def find_scratchpad(self, tree):\n if tree.get(\"name\") == \"__i3_scratch\":\n return tree\n for x in tree.get(\"nodes\", []):\n result = self.find_scratchpad(x)\n if result:\n return result\n return {}\n\n\nclass Py3status:\n \"\"\"\n \"\"\"\n\n # available configuration parameters\n cache_timeout = 5\n format = \"\\u232b [\\\\?color=scratchpad {scratchpad}]\"\n thresholds = [(0, \"darkgray\"), (1, \"violet\")]\n\n def post_config_hook(self):\n # ipc: specify i3ipc, i3-msg, or swaymsg, otherwise auto\n self.ipc = getattr(self, \"ipc\", \"\")\n if self.ipc in [\"\", \"i3ipc\"]:\n try:\n from i3ipc import Connection # noqa f401\n\n self.ipc = \"i3ipc\"\n except Exception:\n if self.ipc:\n raise # module not found\n\n self.ipc = (self.ipc or self.py3.get_wm_msg()).replace(\"-\", \"\")\n if self.ipc in [\"i3ipc\"]:\n self.backend = I3ipc(self)\n elif self.ipc in [\"i3msg\", \"swaymsg\"]:\n self.backend = Msg(self)\n else:\n raise Exception(STRING_ERROR.format(self.ipc))\n\n self.thresholds_init = self.py3.get_color_names_list(self.format)\n\n def scratchpad(self):\n scratchpad_data = self.backend.get_scratchpad_data()\n\n for x in self.thresholds_init:\n if x in scratchpad_data:\n self.py3.threshold_get_color(scratchpad_data[x], x)\n\n response = {\n \"cached_until\": self.py3.time_in(self.cache_timeout),\n \"full_text\": self.py3.safe_format(self.format, scratchpad_data),\n }\n if scratchpad_data[\"urgent\"]:\n response[\"urgent\"] = True\n return response\n\n\nif __name__ == \"__main__\":\n \"\"\"\n Run module in test mode.\n \"\"\"\n from py3status.module_test import module_test\n\n config = {\"format\": r\"\\[{ipc}\\] [\\?color=scratchpad {scratchpad}]\"}\n module_test(Py3status, config=config)\n", "path": "py3status/modules/scratchpad.py"}]}
| 2,534 | 182 |
gh_patches_debug_31555
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-970
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SplitAxis should return a tuple with a single element
`Function.__call__` returns a `Variable` when its forward function returns only one return value. When the number of return values depends on input values, such as `split_axis`, a user need to check the type of the return value of `Function`. A user needs to write a complicated source code.
I have two design choice:
- Only `SplitAxis` always returns a tuple of `Variable`s
- Add keyword argument `force_tuple` to `Function.__call__`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/functions/array/split_axis.py`
Content:
```
1 import collections
2
3 import six
4
5 from chainer import cuda
6 from chainer import function
7 from chainer.utils import type_check
8
9
10 class SplitAxis(function.Function):
11
12 """Function that splits multiple arrays towards the specified axis."""
13
14 def __init__(self, indices_or_sections, axis):
15 if not isinstance(indices_or_sections, (int, collections.Iterable)):
16 raise TypeError('indices_or_sections must be integer or 1-D array')
17 self.indices_or_sections = indices_or_sections
18 self.axis = axis
19
20 def check_type_forward(self, in_types):
21 type_check.expect(in_types.size() == 1)
22 type_check.expect(in_types[0].ndim > self.axis)
23
24 if isinstance(self.indices_or_sections, collections.Iterable):
25 max_index = type_check.Variable(
26 self.indices_or_sections[-1], 'max_index')
27 type_check.expect(in_types[0].shape[self.axis] > max_index)
28 else:
29 sections = type_check.Variable(
30 self.indices_or_sections, 'sections')
31 type_check.expect(in_types[0].shape[self.axis] % sections == 0)
32
33 def forward(self, x):
34 if isinstance(self.indices_or_sections, collections.Iterable):
35 cdimx = x[0].shape[self.axis]
36 ind = list(self.indices_or_sections)
37 ind.append(cdimx)
38 prev_i = 0
39 for i in ind:
40 cdimy = max(0, min(i, cdimx) - prev_i)
41 if cdimy == 0:
42 raise ValueError('Not support if shape contains 0')
43 prev_i = i
44 xp = cuda.get_array_module(*x)
45 return tuple(xp.split(x[0], self.indices_or_sections, self.axis))
46
47 def backward(self, x, gys):
48 xp = cuda.get_array_module(*x)
49 if any(gy is None for gy in gys):
50 gx = xp.zeros_like(x[0])
51 gxs = xp.split(gx, self.indices_or_sections, self.axis)
52 for gxi, gy in six.moves.zip(gxs, gys):
53 if gy is None:
54 continue
55 gxi[:] = gy
56 return gx,
57 else:
58 return xp.concatenate(gys, axis=self.axis),
59
60
61 def split_axis(x, indices_or_sections, axis):
62 """Splits given variables along an axis.
63
64 Args:
65 x (tuple of Variables): Variables to be split.
66 indices_or_sections (int or 1-D array): If this argument is an integer,
67 N, the array will be divided into N equal arrays along axis.
68 If it is a 1-D array of sorted integers, it
69 indicates the positions where the array is split.
70 axis (int): Axis that the input array is split along.
71
72 Returns:
73 tuple or Variable: Tuple of :class:`~chainer.Variable` objects
74 if the number of outputs is more than 1 or
75 :class:`~chainer.Variable` otherwise.
76
77 .. note::
78 This function raises :class:`ValueError` if at least
79 one of the outputs is split to zero-size
80 (i.e. `axis`-th value of its shape is zero).
81
82 """
83 return SplitAxis(indices_or_sections, axis)(x)
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/functions/array/split_axis.py b/chainer/functions/array/split_axis.py
--- a/chainer/functions/array/split_axis.py
+++ b/chainer/functions/array/split_axis.py
@@ -2,6 +2,7 @@
import six
+import chainer
from chainer import cuda
from chainer import function
from chainer.utils import type_check
@@ -58,7 +59,7 @@
return xp.concatenate(gys, axis=self.axis),
-def split_axis(x, indices_or_sections, axis):
+def split_axis(x, indices_or_sections, axis, force_tuple=False):
"""Splits given variables along an axis.
Args:
@@ -68,16 +69,23 @@
If it is a 1-D array of sorted integers, it
indicates the positions where the array is split.
axis (int): Axis that the input array is split along.
+ force_tuple (bool): If ``True``, this method returns a tuple even when
+ the number of outputs is one.
Returns:
tuple or Variable: Tuple of :class:`~chainer.Variable` objects
if the number of outputs is more than 1 or
:class:`~chainer.Variable` otherwise.
+ When ``force_tuple`` is ``True``, returned value is always a tuple
+ regardless of the number of outputs.
.. note::
This function raises :class:`ValueError` if at least
one of the outputs is split to zero-size
- (i.e. `axis`-th value of its shape is zero).
+ (i.e. ``axis``-th value of its shape is zero).
"""
- return SplitAxis(indices_or_sections, axis)(x)
+ res = SplitAxis(indices_or_sections, axis)(x)
+ if force_tuple and isinstance(res, chainer.Variable):
+ res = (res,)
+ return res
|
{"golden_diff": "diff --git a/chainer/functions/array/split_axis.py b/chainer/functions/array/split_axis.py\n--- a/chainer/functions/array/split_axis.py\n+++ b/chainer/functions/array/split_axis.py\n@@ -2,6 +2,7 @@\n \n import six\n \n+import chainer\n from chainer import cuda\n from chainer import function\n from chainer.utils import type_check\n@@ -58,7 +59,7 @@\n return xp.concatenate(gys, axis=self.axis),\n \n \n-def split_axis(x, indices_or_sections, axis):\n+def split_axis(x, indices_or_sections, axis, force_tuple=False):\n \"\"\"Splits given variables along an axis.\n \n Args:\n@@ -68,16 +69,23 @@\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n+ force_tuple (bool): If ``True``, this method returns a tuple even when\n+ the number of outputs is one.\n \n Returns:\n tuple or Variable: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n+ When ``force_tuple`` is ``True``, returned value is always a tuple\n+ regardless of the number of outputs.\n \n .. note::\n This function raises :class:`ValueError` if at least\n one of the outputs is split to zero-size\n- (i.e. `axis`-th value of its shape is zero).\n+ (i.e. ``axis``-th value of its shape is zero).\n \n \"\"\"\n- return SplitAxis(indices_or_sections, axis)(x)\n+ res = SplitAxis(indices_or_sections, axis)(x)\n+ if force_tuple and isinstance(res, chainer.Variable):\n+ res = (res,)\n+ return res\n", "issue": "SplitAxis should return a tuple with a single element\n`Function.__call__` returns a `Variable` when its forward function returns only one return value. When the number of return values depends on input values, such as `split_axis`, a user need to check the type of the return value of `Function`. A user needs to write a complicated source code.\n\nI have two design choice:\n- Only `SplitAxis` always returns a tuple of `Variable`s\n- Add keyword argument `force_tuple` to `Function.__call__`\n\n", "before_files": [{"content": "import collections\n\nimport six\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\nclass SplitAxis(function.Function):\n\n \"\"\"Function that splits multiple arrays towards the specified axis.\"\"\"\n\n def __init__(self, indices_or_sections, axis):\n if not isinstance(indices_or_sections, (int, collections.Iterable)):\n raise TypeError('indices_or_sections must be integer or 1-D array')\n self.indices_or_sections = indices_or_sections\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n type_check.expect(in_types[0].ndim > self.axis)\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n max_index = type_check.Variable(\n self.indices_or_sections[-1], 'max_index')\n type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n type_check.expect(in_types[0].shape[self.axis] % sections == 0)\n\n def forward(self, x):\n if isinstance(self.indices_or_sections, collections.Iterable):\n cdimx = x[0].shape[self.axis]\n ind = list(self.indices_or_sections)\n ind.append(cdimx)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, cdimx) - prev_i)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n prev_i = i\n xp = cuda.get_array_module(*x)\n return tuple(xp.split(x[0], self.indices_or_sections, self.axis))\n\n def backward(self, x, gys):\n xp = cuda.get_array_module(*x)\n if any(gy is None for gy in gys):\n gx = xp.zeros_like(x[0])\n gxs = xp.split(gx, self.indices_or_sections, self.axis)\n for gxi, gy in six.moves.zip(gxs, gys):\n if gy is None:\n continue\n gxi[:] = gy\n return gx,\n else:\n return xp.concatenate(gys, axis=self.axis),\n\n\ndef split_axis(x, indices_or_sections, axis):\n \"\"\"Splits given variables along an axis.\n\n Args:\n x (tuple of Variables): Variables to be split.\n indices_or_sections (int or 1-D array): If this argument is an integer,\n N, the array will be divided into N equal arrays along axis.\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n\n Returns:\n tuple or Variable: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n\n .. note::\n This function raises :class:`ValueError` if at least\n one of the outputs is split to zero-size\n (i.e. `axis`-th value of its shape is zero).\n\n \"\"\"\n return SplitAxis(indices_or_sections, axis)(x)\n", "path": "chainer/functions/array/split_axis.py"}], "after_files": [{"content": "import collections\n\nimport six\n\nimport chainer\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\nclass SplitAxis(function.Function):\n\n \"\"\"Function that splits multiple arrays towards the specified axis.\"\"\"\n\n def __init__(self, indices_or_sections, axis):\n if not isinstance(indices_or_sections, (int, collections.Iterable)):\n raise TypeError('indices_or_sections must be integer or 1-D array')\n self.indices_or_sections = indices_or_sections\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n type_check.expect(in_types[0].ndim > self.axis)\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n max_index = type_check.Variable(\n self.indices_or_sections[-1], 'max_index')\n type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n type_check.expect(in_types[0].shape[self.axis] % sections == 0)\n\n def forward(self, x):\n if isinstance(self.indices_or_sections, collections.Iterable):\n cdimx = x[0].shape[self.axis]\n ind = list(self.indices_or_sections)\n ind.append(cdimx)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, cdimx) - prev_i)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n prev_i = i\n xp = cuda.get_array_module(*x)\n return tuple(xp.split(x[0], self.indices_or_sections, self.axis))\n\n def backward(self, x, gys):\n xp = cuda.get_array_module(*x)\n if any(gy is None for gy in gys):\n gx = xp.zeros_like(x[0])\n gxs = xp.split(gx, self.indices_or_sections, self.axis)\n for gxi, gy in six.moves.zip(gxs, gys):\n if gy is None:\n continue\n gxi[:] = gy\n return gx,\n else:\n return xp.concatenate(gys, axis=self.axis),\n\n\ndef split_axis(x, indices_or_sections, axis, force_tuple=False):\n \"\"\"Splits given variables along an axis.\n\n Args:\n x (tuple of Variables): Variables to be split.\n indices_or_sections (int or 1-D array): If this argument is an integer,\n N, the array will be divided into N equal arrays along axis.\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n force_tuple (bool): If ``True``, this method returns a tuple even when\n the number of outputs is one.\n\n Returns:\n tuple or Variable: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n When ``force_tuple`` is ``True``, returned value is always a tuple\n regardless of the number of outputs.\n\n .. note::\n This function raises :class:`ValueError` if at least\n one of the outputs is split to zero-size\n (i.e. ``axis``-th value of its shape is zero).\n\n \"\"\"\n res = SplitAxis(indices_or_sections, axis)(x)\n if force_tuple and isinstance(res, chainer.Variable):\n res = (res,)\n return res\n", "path": "chainer/functions/array/split_axis.py"}]}
| 1,233 | 420 |
gh_patches_debug_64682
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Seed cannot be fixed via an environment variable
Past version of Chainer supported the CHAINER_SEED environment variable, which is (maybe accidentally) missed in v1.3.0.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/random/generator.py`
Content:
```
1 import atexit
2 import binascii
3 import collections
4 import os
5 import time
6
7 import numpy
8
9 import cupy
10 from cupy import cuda
11 from cupy.cuda import curand
12 from cupy import elementwise
13
14
15 class RandomState(object):
16
17 """Portable container of a pseudo-random number generator.
18
19 An instance of this class holds the state of a random number generator. The
20 state is available only on the device which has been current at the
21 initialization of the instance.
22
23 Functions of :mod:`cupy.random` use global instances of this class.
24 Different instances are used for different devices. The global state for
25 the current device can be obtained by the
26 :func:`cupy.random.get_random_state` function.
27
28 Args:
29 seed (None or int): Seed of the random number generator. See the
30 :meth:`~cupy.random.RandomState.seed` method for detail.
31 method (int): Method of the random number generator. Following values
32 are available::
33
34 cupy.cuda.curand.CURAND_RNG_PSEUDO_DEFAULT
35 cupy.cuda.curand.CURAND_RNG_XORWOW
36 cupy.cuda.curand.CURAND_RNG_MRG32K3A
37 cupy.cuda.curand.CURAND_RNG_MTGP32
38 cupy.cuda.curand.CURAND_RNG_MT19937
39 cupy.cuda.curand.CURAND_RNG_PHILOX4_32_10
40
41 """
42 def __init__(self, seed=None, method=curand.CURAND_RNG_PSEUDO_DEFAULT):
43 self._generator = curand.createGenerator(method)
44 self.seed(seed)
45
46 def __del__(self):
47 curand.destroyGenerator(self._generator)
48
49 def set_stream(self, stream=None):
50 if stream is None:
51 stream = cuda.Stream()
52 curand.setStream(self._generator, stream.ptr)
53
54 # NumPy compatible functions
55
56 def lognormal(self, mean=0.0, sigma=1.0, size=None, dtype=float):
57 """Returns an array of samples drawn from a log normal distribution.
58
59 .. seealso::
60 :func:`cupy.random.lognormal` for full documentation,
61 :meth:`numpy.random.RandomState.lognormal`
62
63 """
64 dtype = _check_and_get_dtype(dtype)
65 size = _get_size(size)
66 out = cupy.empty(size, dtype=dtype)
67 if dtype.char == 'f':
68 func = curand.generateLogNormal
69 else:
70 func = curand.generateLogNormalDouble
71 func(self._generator, out.data.ptr, out.size, mean, sigma)
72 return out
73
74 def normal(self, loc=0.0, scale=1.0, size=None, dtype=float):
75 """Returns an array of normally distributed samples.
76
77 .. seealso::
78 :func:`cupy.random.normal` for full documentation,
79 :meth:`numpy.random.RandomState.normal`
80
81 """
82 dtype = _check_and_get_dtype(dtype)
83 size = _get_size(size)
84 out = cupy.empty(size, dtype=dtype)
85 if dtype.char == 'f':
86 func = curand.generateNormal
87 else:
88 func = curand.generateNormalDouble
89 func(self._generator, out.data.ptr, out.size, loc, scale)
90 return out
91
92 def rand(self, *size, **kwarg):
93 """Returns uniform random values over the interval ``[0, 1)``.
94
95 .. seealso::
96 :func:`cupy.random.rand` for full documentation,
97 :meth:`numpy.random.RandomState.rand`
98
99 """
100 dtype = kwarg.pop('dtype', float)
101 if kwarg:
102 raise TypeError('rand() got unexpected keyword arguments %s'
103 % ', '.join(kwarg.keys()))
104 return self.random_sample(size=size, dtype=dtype)
105
106 def randn(self, *size, **kwarg):
107 """Returns an array of standand normal random values.
108
109 .. seealso::
110 :func:`cupy.random.randn` for full documentation,
111 :meth:`numpy.random.RandomState.randn`
112
113 """
114 dtype = kwarg.pop('dtype', float)
115 if kwarg:
116 raise TypeError('randn() got unexpected keyword arguments %s'
117 % ', '.join(kwarg.keys()))
118 return self.normal(size=size, dtype=dtype)
119
120 _1m_kernel = elementwise.ElementwiseKernel(
121 '', 'T x', 'x = 1 - x', 'cupy_random_1_minus_x')
122
123 def random_sample(self, size=None, dtype=float):
124 """Returns an array of random values over the interval ``[0, 1)``.
125
126 .. seealso::
127 :func:`cupy.random.random_sample` for full documentation,
128 :meth:`numpy.random.RandomState.random_sample`
129
130 """
131 dtype = _check_and_get_dtype(dtype)
132 size = _get_size(size)
133 out = cupy.empty(size, dtype=dtype)
134 if dtype.char == 'f':
135 func = curand.generateUniform
136 else:
137 func = curand.generateUniformDouble
138 func(self._generator, out.data.ptr, out.size)
139 RandomState._1m_kernel(out)
140 return out
141
142 def seed(self, seed=None):
143 """Resets the state of the random number generator with a seed.
144
145 ..seealso::
146 :func:`cupy.random.seed` for full documentation,
147 :meth:`numpy.random.RandomState.seed`
148
149 """
150 if seed is None:
151 try:
152 seed_str = binascii.hexlify(os.urandom(8))
153 seed = numpy.uint64(int(seed_str, 16))
154 except NotImplementedError:
155 seed = numpy.uint64(time.clock() * 1000000)
156 else:
157 seed = numpy.uint64(seed)
158
159 curand.setPseudoRandomGeneratorSeed(self._generator, seed)
160
161 def standard_normal(self, size=None, dtype=float):
162 """Returns samples drawn from the standard normal distribution.
163
164 .. seealso::
165 :func:`cupy.random.standard_normal` for full documentation,
166 :meth:`numpy.random.RandomState.standard_normal`
167
168 """
169 return self.normal(size=size, dtype=dtype)
170
171 def uniform(self, low=0.0, high=1.0, size=None, dtype=float):
172 """Returns an array of uniformlly-distributed samples over an interval.
173
174 .. seealso::
175 :func:`cupy.random.uniform` for full documentation,
176 :meth:`numpy.random.RandomState.uniform`
177
178 """
179 dtype = numpy.dtype(dtype)
180 size = _get_size(size)
181 rand = self.random_sample(size=size, dtype=dtype)
182 return dtype.type(low) + rand * dtype.type(high - low)
183
184
185 def seed(seed=None):
186 """Resets the state of the random number generator with a seed.
187
188 This function resets the state of the global random number generator for
189 the current device. Be careful that generators for other devices are not
190 affected.
191
192 Args:
193 seed (None or int): Seed for the random number generator. If None, it
194 uses :func:`os.urandom` if available or :func:`time.clock`
195 otherwise. Note that this function does not support seeding by an
196 integer array.
197
198 """
199 get_random_state().seed(seed)
200
201
202 # CuPy specific functions
203
204 _random_states = {}
205
206
207 @atexit.register
208 def reset_states():
209 global _random_states
210 _random_states = {}
211
212
213 def get_random_state():
214 """Gets the state of the random number generator for the current device.
215
216 If the state for the current device is not created yet, this function
217 creates a new one, initializes it, and stores it as the state for the
218 current device.
219
220 Returns:
221 RandomState: The state of the random number generator for the
222 device.
223
224 """
225 global _random_states
226 dev = cuda.Device()
227 rs = _random_states.get(dev.id, None)
228 if rs is None:
229 rs = RandomState()
230 _random_states[dev.id] = rs
231 return rs
232
233
234 def _get_size(size):
235 if size is None:
236 return ()
237 elif isinstance(size, collections.Sequence):
238 return tuple(size)
239 elif isinstance(size, int):
240 return size,
241 else:
242 raise ValueError('size should be None, collections.Sequence, or int')
243
244
245 def _check_and_get_dtype(dtype):
246 dtype = numpy.dtype(dtype)
247 if dtype.char not in ('f', 'd'):
248 raise TypeError('cupy.random only supports float32 and float64')
249 return dtype
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupy/random/generator.py b/cupy/random/generator.py
--- a/cupy/random/generator.py
+++ b/cupy/random/generator.py
@@ -226,7 +226,7 @@
dev = cuda.Device()
rs = _random_states.get(dev.id, None)
if rs is None:
- rs = RandomState()
+ rs = RandomState(os.getenv('CHAINER_SEED'))
_random_states[dev.id] = rs
return rs
|
{"golden_diff": "diff --git a/cupy/random/generator.py b/cupy/random/generator.py\n--- a/cupy/random/generator.py\n+++ b/cupy/random/generator.py\n@@ -226,7 +226,7 @@\n dev = cuda.Device()\n rs = _random_states.get(dev.id, None)\n if rs is None:\n- rs = RandomState()\n+ rs = RandomState(os.getenv('CHAINER_SEED'))\n _random_states[dev.id] = rs\n return rs\n", "issue": "Seed cannot be fixed via an environment variable\nPast version of Chainer supported the CHAINER_SEED environment variable, which is (maybe accidentally) missed in v1.3.0.\n\n", "before_files": [{"content": "import atexit\nimport binascii\nimport collections\nimport os\nimport time\n\nimport numpy\n\nimport cupy\nfrom cupy import cuda\nfrom cupy.cuda import curand\nfrom cupy import elementwise\n\n\nclass RandomState(object):\n\n \"\"\"Portable container of a pseudo-random number generator.\n\n An instance of this class holds the state of a random number generator. The\n state is available only on the device which has been current at the\n initialization of the instance.\n\n Functions of :mod:`cupy.random` use global instances of this class.\n Different instances are used for different devices. The global state for\n the current device can be obtained by the\n :func:`cupy.random.get_random_state` function.\n\n Args:\n seed (None or int): Seed of the random number generator. See the\n :meth:`~cupy.random.RandomState.seed` method for detail.\n method (int): Method of the random number generator. Following values\n are available::\n\n cupy.cuda.curand.CURAND_RNG_PSEUDO_DEFAULT\n cupy.cuda.curand.CURAND_RNG_XORWOW\n cupy.cuda.curand.CURAND_RNG_MRG32K3A\n cupy.cuda.curand.CURAND_RNG_MTGP32\n cupy.cuda.curand.CURAND_RNG_MT19937\n cupy.cuda.curand.CURAND_RNG_PHILOX4_32_10\n\n \"\"\"\n def __init__(self, seed=None, method=curand.CURAND_RNG_PSEUDO_DEFAULT):\n self._generator = curand.createGenerator(method)\n self.seed(seed)\n\n def __del__(self):\n curand.destroyGenerator(self._generator)\n\n def set_stream(self, stream=None):\n if stream is None:\n stream = cuda.Stream()\n curand.setStream(self._generator, stream.ptr)\n\n # NumPy compatible functions\n\n def lognormal(self, mean=0.0, sigma=1.0, size=None, dtype=float):\n \"\"\"Returns an array of samples drawn from a log normal distribution.\n\n .. seealso::\n :func:`cupy.random.lognormal` for full documentation,\n :meth:`numpy.random.RandomState.lognormal`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateLogNormal\n else:\n func = curand.generateLogNormalDouble\n func(self._generator, out.data.ptr, out.size, mean, sigma)\n return out\n\n def normal(self, loc=0.0, scale=1.0, size=None, dtype=float):\n \"\"\"Returns an array of normally distributed samples.\n\n .. seealso::\n :func:`cupy.random.normal` for full documentation,\n :meth:`numpy.random.RandomState.normal`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateNormal\n else:\n func = curand.generateNormalDouble\n func(self._generator, out.data.ptr, out.size, loc, scale)\n return out\n\n def rand(self, *size, **kwarg):\n \"\"\"Returns uniform random values over the interval ``[0, 1)``.\n\n .. seealso::\n :func:`cupy.random.rand` for full documentation,\n :meth:`numpy.random.RandomState.rand`\n\n \"\"\"\n dtype = kwarg.pop('dtype', float)\n if kwarg:\n raise TypeError('rand() got unexpected keyword arguments %s'\n % ', '.join(kwarg.keys()))\n return self.random_sample(size=size, dtype=dtype)\n\n def randn(self, *size, **kwarg):\n \"\"\"Returns an array of standand normal random values.\n\n .. seealso::\n :func:`cupy.random.randn` for full documentation,\n :meth:`numpy.random.RandomState.randn`\n\n \"\"\"\n dtype = kwarg.pop('dtype', float)\n if kwarg:\n raise TypeError('randn() got unexpected keyword arguments %s'\n % ', '.join(kwarg.keys()))\n return self.normal(size=size, dtype=dtype)\n\n _1m_kernel = elementwise.ElementwiseKernel(\n '', 'T x', 'x = 1 - x', 'cupy_random_1_minus_x')\n\n def random_sample(self, size=None, dtype=float):\n \"\"\"Returns an array of random values over the interval ``[0, 1)``.\n\n .. seealso::\n :func:`cupy.random.random_sample` for full documentation,\n :meth:`numpy.random.RandomState.random_sample`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateUniform\n else:\n func = curand.generateUniformDouble\n func(self._generator, out.data.ptr, out.size)\n RandomState._1m_kernel(out)\n return out\n\n def seed(self, seed=None):\n \"\"\"Resets the state of the random number generator with a seed.\n\n ..seealso::\n :func:`cupy.random.seed` for full documentation,\n :meth:`numpy.random.RandomState.seed`\n\n \"\"\"\n if seed is None:\n try:\n seed_str = binascii.hexlify(os.urandom(8))\n seed = numpy.uint64(int(seed_str, 16))\n except NotImplementedError:\n seed = numpy.uint64(time.clock() * 1000000)\n else:\n seed = numpy.uint64(seed)\n\n curand.setPseudoRandomGeneratorSeed(self._generator, seed)\n\n def standard_normal(self, size=None, dtype=float):\n \"\"\"Returns samples drawn from the standard normal distribution.\n\n .. seealso::\n :func:`cupy.random.standard_normal` for full documentation,\n :meth:`numpy.random.RandomState.standard_normal`\n\n \"\"\"\n return self.normal(size=size, dtype=dtype)\n\n def uniform(self, low=0.0, high=1.0, size=None, dtype=float):\n \"\"\"Returns an array of uniformlly-distributed samples over an interval.\n\n .. seealso::\n :func:`cupy.random.uniform` for full documentation,\n :meth:`numpy.random.RandomState.uniform`\n\n \"\"\"\n dtype = numpy.dtype(dtype)\n size = _get_size(size)\n rand = self.random_sample(size=size, dtype=dtype)\n return dtype.type(low) + rand * dtype.type(high - low)\n\n\ndef seed(seed=None):\n \"\"\"Resets the state of the random number generator with a seed.\n\n This function resets the state of the global random number generator for\n the current device. Be careful that generators for other devices are not\n affected.\n\n Args:\n seed (None or int): Seed for the random number generator. If None, it\n uses :func:`os.urandom` if available or :func:`time.clock`\n otherwise. Note that this function does not support seeding by an\n integer array.\n\n \"\"\"\n get_random_state().seed(seed)\n\n\n# CuPy specific functions\n\n_random_states = {}\n\n\[email protected]\ndef reset_states():\n global _random_states\n _random_states = {}\n\n\ndef get_random_state():\n \"\"\"Gets the state of the random number generator for the current device.\n\n If the state for the current device is not created yet, this function\n creates a new one, initializes it, and stores it as the state for the\n current device.\n\n Returns:\n RandomState: The state of the random number generator for the\n device.\n\n \"\"\"\n global _random_states\n dev = cuda.Device()\n rs = _random_states.get(dev.id, None)\n if rs is None:\n rs = RandomState()\n _random_states[dev.id] = rs\n return rs\n\n\ndef _get_size(size):\n if size is None:\n return ()\n elif isinstance(size, collections.Sequence):\n return tuple(size)\n elif isinstance(size, int):\n return size,\n else:\n raise ValueError('size should be None, collections.Sequence, or int')\n\n\ndef _check_and_get_dtype(dtype):\n dtype = numpy.dtype(dtype)\n if dtype.char not in ('f', 'd'):\n raise TypeError('cupy.random only supports float32 and float64')\n return dtype\n", "path": "cupy/random/generator.py"}], "after_files": [{"content": "import atexit\nimport binascii\nimport collections\nimport os\nimport time\n\nimport numpy\n\nimport cupy\nfrom cupy import cuda\nfrom cupy.cuda import curand\nfrom cupy import elementwise\n\n\nclass RandomState(object):\n\n \"\"\"Portable container of a pseudo-random number generator.\n\n An instance of this class holds the state of a random number generator. The\n state is available only on the device which has been current at the\n initialization of the instance.\n\n Functions of :mod:`cupy.random` use global instances of this class.\n Different instances are used for different devices. The global state for\n the current device can be obtained by the\n :func:`cupy.random.get_random_state` function.\n\n Args:\n seed (None or int): Seed of the random number generator. See the\n :meth:`~cupy.random.RandomState.seed` method for detail.\n method (int): Method of the random number generator. Following values\n are available::\n\n cupy.cuda.curand.CURAND_RNG_PSEUDO_DEFAULT\n cupy.cuda.curand.CURAND_RNG_XORWOW\n cupy.cuda.curand.CURAND_RNG_MRG32K3A\n cupy.cuda.curand.CURAND_RNG_MTGP32\n cupy.cuda.curand.CURAND_RNG_MT19937\n cupy.cuda.curand.CURAND_RNG_PHILOX4_32_10\n\n \"\"\"\n def __init__(self, seed=None, method=curand.CURAND_RNG_PSEUDO_DEFAULT):\n self._generator = curand.createGenerator(method)\n self.seed(seed)\n\n def __del__(self):\n curand.destroyGenerator(self._generator)\n\n def set_stream(self, stream=None):\n if stream is None:\n stream = cuda.Stream()\n curand.setStream(self._generator, stream.ptr)\n\n # NumPy compatible functions\n\n def lognormal(self, mean=0.0, sigma=1.0, size=None, dtype=float):\n \"\"\"Returns an array of samples drawn from a log normal distribution.\n\n .. seealso::\n :func:`cupy.random.lognormal` for full documentation,\n :meth:`numpy.random.RandomState.lognormal`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateLogNormal\n else:\n func = curand.generateLogNormalDouble\n func(self._generator, out.data.ptr, out.size, mean, sigma)\n return out\n\n def normal(self, loc=0.0, scale=1.0, size=None, dtype=float):\n \"\"\"Returns an array of normally distributed samples.\n\n .. seealso::\n :func:`cupy.random.normal` for full documentation,\n :meth:`numpy.random.RandomState.normal`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateNormal\n else:\n func = curand.generateNormalDouble\n func(self._generator, out.data.ptr, out.size, loc, scale)\n return out\n\n def rand(self, *size, **kwarg):\n \"\"\"Returns uniform random values over the interval ``[0, 1)``.\n\n .. seealso::\n :func:`cupy.random.rand` for full documentation,\n :meth:`numpy.random.RandomState.rand`\n\n \"\"\"\n dtype = kwarg.pop('dtype', float)\n if kwarg:\n raise TypeError('rand() got unexpected keyword arguments %s'\n % ', '.join(kwarg.keys()))\n return self.random_sample(size=size, dtype=dtype)\n\n def randn(self, *size, **kwarg):\n \"\"\"Returns an array of standand normal random values.\n\n .. seealso::\n :func:`cupy.random.randn` for full documentation,\n :meth:`numpy.random.RandomState.randn`\n\n \"\"\"\n dtype = kwarg.pop('dtype', float)\n if kwarg:\n raise TypeError('randn() got unexpected keyword arguments %s'\n % ', '.join(kwarg.keys()))\n return self.normal(size=size, dtype=dtype)\n\n _1m_kernel = elementwise.ElementwiseKernel(\n '', 'T x', 'x = 1 - x', 'cupy_random_1_minus_x')\n\n def random_sample(self, size=None, dtype=float):\n \"\"\"Returns an array of random values over the interval ``[0, 1)``.\n\n .. seealso::\n :func:`cupy.random.random_sample` for full documentation,\n :meth:`numpy.random.RandomState.random_sample`\n\n \"\"\"\n dtype = _check_and_get_dtype(dtype)\n size = _get_size(size)\n out = cupy.empty(size, dtype=dtype)\n if dtype.char == 'f':\n func = curand.generateUniform\n else:\n func = curand.generateUniformDouble\n func(self._generator, out.data.ptr, out.size)\n RandomState._1m_kernel(out)\n return out\n\n def seed(self, seed=None):\n \"\"\"Resets the state of the random number generator with a seed.\n\n ..seealso::\n :func:`cupy.random.seed` for full documentation,\n :meth:`numpy.random.RandomState.seed`\n\n \"\"\"\n if seed is None:\n try:\n seed_str = binascii.hexlify(os.urandom(8))\n seed = numpy.uint64(int(seed_str, 16))\n except NotImplementedError:\n seed = numpy.uint64(time.clock() * 1000000)\n else:\n seed = numpy.uint64(seed)\n\n curand.setPseudoRandomGeneratorSeed(self._generator, seed)\n\n def standard_normal(self, size=None, dtype=float):\n \"\"\"Returns samples drawn from the standard normal distribution.\n\n .. seealso::\n :func:`cupy.random.standard_normal` for full documentation,\n :meth:`numpy.random.RandomState.standard_normal`\n\n \"\"\"\n return self.normal(size=size, dtype=dtype)\n\n def uniform(self, low=0.0, high=1.0, size=None, dtype=float):\n \"\"\"Returns an array of uniformlly-distributed samples over an interval.\n\n .. seealso::\n :func:`cupy.random.uniform` for full documentation,\n :meth:`numpy.random.RandomState.uniform`\n\n \"\"\"\n dtype = numpy.dtype(dtype)\n size = _get_size(size)\n rand = self.random_sample(size=size, dtype=dtype)\n return dtype.type(low) + rand * dtype.type(high - low)\n\n\ndef seed(seed=None):\n \"\"\"Resets the state of the random number generator with a seed.\n\n This function resets the state of the global random number generator for\n the current device. Be careful that generators for other devices are not\n affected.\n\n Args:\n seed (None or int): Seed for the random number generator. If None, it\n uses :func:`os.urandom` if available or :func:`time.clock`\n otherwise. Note that this function does not support seeding by an\n integer array.\n\n \"\"\"\n get_random_state().seed(seed)\n\n\n# CuPy specific functions\n\n_random_states = {}\n\n\[email protected]\ndef reset_states():\n global _random_states\n _random_states = {}\n\n\ndef get_random_state():\n \"\"\"Gets the state of the random number generator for the current device.\n\n If the state for the current device is not created yet, this function\n creates a new one, initializes it, and stores it as the state for the\n current device.\n\n Returns:\n RandomState: The state of the random number generator for the\n device.\n\n \"\"\"\n global _random_states\n dev = cuda.Device()\n rs = _random_states.get(dev.id, None)\n if rs is None:\n rs = RandomState(os.getenv('CHAINER_SEED'))\n _random_states[dev.id] = rs\n return rs\n\n\ndef _get_size(size):\n if size is None:\n return ()\n elif isinstance(size, collections.Sequence):\n return tuple(size)\n elif isinstance(size, int):\n return size,\n else:\n raise ValueError('size should be None, collections.Sequence, or int')\n\n\ndef _check_and_get_dtype(dtype):\n dtype = numpy.dtype(dtype)\n if dtype.char not in ('f', 'd'):\n raise TypeError('cupy.random only supports float32 and float64')\n return dtype\n", "path": "cupy/random/generator.py"}]}
| 2,811 | 110 |
gh_patches_debug_22387
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-3377
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feast push (Redshift/DynamoDb) not work with PushMode.ONLINE_AND_OFFLINE when more than 500 columns
## Expected Behavior
Currently, we have a push source with Redshift Offline Store and DynamoDb Online Store.
We built our view with more than 500 columns. Around 750 columns.
We expected to ingest data in dynamo and redshift when we run
`fs.push("push_source", df, to=PushMode.ONLINE_AND_OFFLINE)`
## Current Behavior
Push command raise an issue like` [ERROR] ValueError: The input dataframe has columns ..`
This issue come from `get_table_column_names_and_types `method in `write_to_offline_store` method.
In the method, we check if `if set(input_columns) != set(source_columns)` and raise the below issue if there are diff.
In case with more than 500 columns we get a diff because source_columns come from `get_table_column_names_and_types` method result where the result is define by MaxResults parameters.
## Steps to reproduce
```
entity= Entity(
name="entity",
join_keys=["entity_id"],
value_type=ValueType.INT64,
)
push_source = PushSource(
name="push_source",
batch_source=RedshiftSource(
table="fs_push_view",
timestamp_field="datecreation",
created_timestamp_column="created_at"),
)
besoin_embedding_push_view = FeatureView(
name="push_view",
entities=[entity],
schema=[Field(name=f"field_{dim}", dtype=types.Float64) for dim in range(768)],
source=push_source
)
fs.push("push_source", df, to=PushMode.ONLINE_AND_OFFLINE)
```
### Specifications
- Version: 0.25.0
- Platform: AWS
- Subsystem:
## Possible Solution
In my mind, we have two solutions:
- Set higher MaxResults in describe_table method
- Use NextToken to iterate through results
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/infra/offline_stores/redshift_source.py`
Content:
```
1 from typing import Callable, Dict, Iterable, Optional, Tuple
2
3 from typeguard import typechecked
4
5 from feast import type_map
6 from feast.data_source import DataSource
7 from feast.errors import (
8 DataSourceNoNameException,
9 DataSourceNotFoundException,
10 RedshiftCredentialsError,
11 )
12 from feast.feature_logging import LoggingDestination
13 from feast.protos.feast.core.DataSource_pb2 import DataSource as DataSourceProto
14 from feast.protos.feast.core.FeatureService_pb2 import (
15 LoggingConfig as LoggingConfigProto,
16 )
17 from feast.protos.feast.core.SavedDataset_pb2 import (
18 SavedDatasetStorage as SavedDatasetStorageProto,
19 )
20 from feast.repo_config import RepoConfig
21 from feast.saved_dataset import SavedDatasetStorage
22 from feast.value_type import ValueType
23
24
25 @typechecked
26 class RedshiftSource(DataSource):
27 def __init__(
28 self,
29 *,
30 name: Optional[str] = None,
31 timestamp_field: Optional[str] = "",
32 table: Optional[str] = None,
33 schema: Optional[str] = None,
34 created_timestamp_column: Optional[str] = "",
35 field_mapping: Optional[Dict[str, str]] = None,
36 query: Optional[str] = None,
37 description: Optional[str] = "",
38 tags: Optional[Dict[str, str]] = None,
39 owner: Optional[str] = "",
40 database: Optional[str] = "",
41 ):
42 """
43 Creates a RedshiftSource object.
44
45 Args:
46 name (optional): Name for the source. Defaults to the table if not specified, in which
47 case the table must be specified.
48 timestamp_field (optional): Event timestamp field used for point in time
49 joins of feature values.
50 table (optional): Redshift table where the features are stored. Exactly one of 'table'
51 and 'query' must be specified.
52 schema (optional): Redshift schema in which the table is located.
53 created_timestamp_column (optional): Timestamp column indicating when the
54 row was created, used for deduplicating rows.
55 field_mapping (optional): A dictionary mapping of column names in this data
56 source to column names in a feature table or view.
57 query (optional): The query to be executed to obtain the features. Exactly one of 'table'
58 and 'query' must be specified.
59 description (optional): A human-readable description.
60 tags (optional): A dictionary of key-value pairs to store arbitrary metadata.
61 owner (optional): The owner of the redshift source, typically the email of the primary
62 maintainer.
63 database (optional): The Redshift database name.
64 """
65 if table is None and query is None:
66 raise ValueError('No "table" or "query" argument provided.')
67
68 # The default Redshift schema is named "public".
69 _schema = "public" if table and not schema else schema
70 self.redshift_options = RedshiftOptions(
71 table=table, schema=_schema, query=query, database=database
72 )
73
74 # If no name, use the table as the default name.
75 if name is None and table is None:
76 raise DataSourceNoNameException()
77 name = name or table
78 assert name
79
80 super().__init__(
81 name=name,
82 timestamp_field=timestamp_field,
83 created_timestamp_column=created_timestamp_column,
84 field_mapping=field_mapping,
85 description=description,
86 tags=tags,
87 owner=owner,
88 )
89
90 @staticmethod
91 def from_proto(data_source: DataSourceProto):
92 """
93 Creates a RedshiftSource from a protobuf representation of a RedshiftSource.
94
95 Args:
96 data_source: A protobuf representation of a RedshiftSource
97
98 Returns:
99 A RedshiftSource object based on the data_source protobuf.
100 """
101 return RedshiftSource(
102 name=data_source.name,
103 timestamp_field=data_source.timestamp_field,
104 table=data_source.redshift_options.table,
105 schema=data_source.redshift_options.schema,
106 created_timestamp_column=data_source.created_timestamp_column,
107 field_mapping=dict(data_source.field_mapping),
108 query=data_source.redshift_options.query,
109 description=data_source.description,
110 tags=dict(data_source.tags),
111 owner=data_source.owner,
112 database=data_source.redshift_options.database,
113 )
114
115 # Note: Python requires redefining hash in child classes that override __eq__
116 def __hash__(self):
117 return super().__hash__()
118
119 def __eq__(self, other):
120 if not isinstance(other, RedshiftSource):
121 raise TypeError(
122 "Comparisons should only involve RedshiftSource class objects."
123 )
124
125 return (
126 super().__eq__(other)
127 and self.redshift_options.table == other.redshift_options.table
128 and self.redshift_options.schema == other.redshift_options.schema
129 and self.redshift_options.query == other.redshift_options.query
130 and self.redshift_options.database == other.redshift_options.database
131 )
132
133 @property
134 def table(self):
135 """Returns the table of this Redshift source."""
136 return self.redshift_options.table
137
138 @property
139 def schema(self):
140 """Returns the schema of this Redshift source."""
141 return self.redshift_options.schema
142
143 @property
144 def query(self):
145 """Returns the Redshift query of this Redshift source."""
146 return self.redshift_options.query
147
148 @property
149 def database(self):
150 """Returns the Redshift database of this Redshift source."""
151 return self.redshift_options.database
152
153 def to_proto(self) -> DataSourceProto:
154 """
155 Converts a RedshiftSource object to its protobuf representation.
156
157 Returns:
158 A DataSourceProto object.
159 """
160 data_source_proto = DataSourceProto(
161 name=self.name,
162 type=DataSourceProto.BATCH_REDSHIFT,
163 field_mapping=self.field_mapping,
164 redshift_options=self.redshift_options.to_proto(),
165 description=self.description,
166 tags=self.tags,
167 owner=self.owner,
168 timestamp_field=self.timestamp_field,
169 created_timestamp_column=self.created_timestamp_column,
170 )
171
172 return data_source_proto
173
174 def validate(self, config: RepoConfig):
175 # As long as the query gets successfully executed, or the table exists,
176 # the data source is validated. We don't need the results though.
177 self.get_table_column_names_and_types(config)
178
179 def get_table_query_string(self) -> str:
180 """Returns a string that can directly be used to reference this table in SQL."""
181 if self.table:
182 return f'"{self.schema}"."{self.table}"'
183 else:
184 return f"({self.query})"
185
186 @staticmethod
187 def source_datatype_to_feast_value_type() -> Callable[[str], ValueType]:
188 return type_map.redshift_to_feast_value_type
189
190 def get_table_column_names_and_types(
191 self, config: RepoConfig
192 ) -> Iterable[Tuple[str, str]]:
193 """
194 Returns a mapping of column names to types for this Redshift source.
195
196 Args:
197 config: A RepoConfig describing the feature repo
198 """
199 from botocore.exceptions import ClientError
200
201 from feast.infra.offline_stores.redshift import RedshiftOfflineStoreConfig
202 from feast.infra.utils import aws_utils
203
204 assert isinstance(config.offline_store, RedshiftOfflineStoreConfig)
205
206 client = aws_utils.get_redshift_data_client(config.offline_store.region)
207 if self.table:
208 try:
209 table = client.describe_table(
210 ClusterIdentifier=config.offline_store.cluster_id,
211 Database=(
212 self.database
213 if self.database
214 else config.offline_store.database
215 ),
216 DbUser=config.offline_store.user,
217 Table=self.table,
218 Schema=self.schema,
219 )
220 except ClientError as e:
221 if e.response["Error"]["Code"] == "ValidationException":
222 raise RedshiftCredentialsError() from e
223 raise
224
225 # The API returns valid JSON with empty column list when the table doesn't exist
226 if len(table["ColumnList"]) == 0:
227 raise DataSourceNotFoundException(self.table)
228
229 columns = table["ColumnList"]
230 else:
231 statement_id = aws_utils.execute_redshift_statement(
232 client,
233 config.offline_store.cluster_id,
234 self.database if self.database else config.offline_store.database,
235 config.offline_store.user,
236 f"SELECT * FROM ({self.query}) LIMIT 1",
237 )
238 columns = aws_utils.get_redshift_statement_result(client, statement_id)[
239 "ColumnMetadata"
240 ]
241
242 return [(column["name"], column["typeName"].upper()) for column in columns]
243
244
245 class RedshiftOptions:
246 """
247 Configuration options for a Redshift data source.
248 """
249
250 def __init__(
251 self,
252 table: Optional[str],
253 schema: Optional[str],
254 query: Optional[str],
255 database: Optional[str],
256 ):
257 self.table = table or ""
258 self.schema = schema or ""
259 self.query = query or ""
260 self.database = database or ""
261
262 @classmethod
263 def from_proto(cls, redshift_options_proto: DataSourceProto.RedshiftOptions):
264 """
265 Creates a RedshiftOptions from a protobuf representation of a Redshift option.
266
267 Args:
268 redshift_options_proto: A protobuf representation of a DataSource
269
270 Returns:
271 A RedshiftOptions object based on the redshift_options protobuf.
272 """
273 redshift_options = cls(
274 table=redshift_options_proto.table,
275 schema=redshift_options_proto.schema,
276 query=redshift_options_proto.query,
277 database=redshift_options_proto.database,
278 )
279
280 return redshift_options
281
282 def to_proto(self) -> DataSourceProto.RedshiftOptions:
283 """
284 Converts an RedshiftOptionsProto object to its protobuf representation.
285
286 Returns:
287 A RedshiftOptionsProto protobuf.
288 """
289 redshift_options_proto = DataSourceProto.RedshiftOptions(
290 table=self.table,
291 schema=self.schema,
292 query=self.query,
293 database=self.database,
294 )
295
296 return redshift_options_proto
297
298
299 class SavedDatasetRedshiftStorage(SavedDatasetStorage):
300 _proto_attr_name = "redshift_storage"
301
302 redshift_options: RedshiftOptions
303
304 def __init__(self, table_ref: str):
305 self.redshift_options = RedshiftOptions(
306 table=table_ref, schema=None, query=None, database=None
307 )
308
309 @staticmethod
310 def from_proto(storage_proto: SavedDatasetStorageProto) -> SavedDatasetStorage:
311
312 return SavedDatasetRedshiftStorage(
313 table_ref=RedshiftOptions.from_proto(storage_proto.redshift_storage).table
314 )
315
316 def to_proto(self) -> SavedDatasetStorageProto:
317 return SavedDatasetStorageProto(
318 redshift_storage=self.redshift_options.to_proto()
319 )
320
321 def to_data_source(self) -> DataSource:
322 return RedshiftSource(table=self.redshift_options.table)
323
324
325 class RedshiftLoggingDestination(LoggingDestination):
326 _proto_kind = "redshift_destination"
327
328 table_name: str
329
330 def __init__(self, *, table_name: str):
331 self.table_name = table_name
332
333 @classmethod
334 def from_proto(cls, config_proto: LoggingConfigProto) -> "LoggingDestination":
335 return RedshiftLoggingDestination(
336 table_name=config_proto.redshift_destination.table_name,
337 )
338
339 def to_proto(self) -> LoggingConfigProto:
340 return LoggingConfigProto(
341 redshift_destination=LoggingConfigProto.RedshiftDestination(
342 table_name=self.table_name
343 )
344 )
345
346 def to_data_source(self) -> DataSource:
347 return RedshiftSource(table=self.table_name)
348
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/feast/infra/offline_stores/redshift_source.py b/sdk/python/feast/infra/offline_stores/redshift_source.py
--- a/sdk/python/feast/infra/offline_stores/redshift_source.py
+++ b/sdk/python/feast/infra/offline_stores/redshift_source.py
@@ -206,7 +206,8 @@
client = aws_utils.get_redshift_data_client(config.offline_store.region)
if self.table:
try:
- table = client.describe_table(
+ paginator = client.get_paginator("describe_table")
+ response_iterator = paginator.paginate(
ClusterIdentifier=config.offline_store.cluster_id,
Database=(
self.database
@@ -217,6 +218,7 @@
Table=self.table,
Schema=self.schema,
)
+ table = response_iterator.build_full_result()
except ClientError as e:
if e.response["Error"]["Code"] == "ValidationException":
raise RedshiftCredentialsError() from e
|
{"golden_diff": "diff --git a/sdk/python/feast/infra/offline_stores/redshift_source.py b/sdk/python/feast/infra/offline_stores/redshift_source.py\n--- a/sdk/python/feast/infra/offline_stores/redshift_source.py\n+++ b/sdk/python/feast/infra/offline_stores/redshift_source.py\n@@ -206,7 +206,8 @@\n client = aws_utils.get_redshift_data_client(config.offline_store.region)\n if self.table:\n try:\n- table = client.describe_table(\n+ paginator = client.get_paginator(\"describe_table\")\n+ response_iterator = paginator.paginate(\n ClusterIdentifier=config.offline_store.cluster_id,\n Database=(\n self.database\n@@ -217,6 +218,7 @@\n Table=self.table,\n Schema=self.schema,\n )\n+ table = response_iterator.build_full_result()\n except ClientError as e:\n if e.response[\"Error\"][\"Code\"] == \"ValidationException\":\n raise RedshiftCredentialsError() from e\n", "issue": "Feast push (Redshift/DynamoDb) not work with PushMode.ONLINE_AND_OFFLINE when more than 500 columns\n## Expected Behavior \r\nCurrently, we have a push source with Redshift Offline Store and DynamoDb Online Store. \r\nWe built our view with more than 500 columns. Around 750 columns. \r\n\r\nWe expected to ingest data in dynamo and redshift when we run \r\n`fs.push(\"push_source\", df, to=PushMode.ONLINE_AND_OFFLINE)`\r\n\r\n## Current Behavior\r\n\r\nPush command raise an issue like` [ERROR] ValueError: The input dataframe has columns ..`\r\nThis issue come from `get_table_column_names_and_types `method in `write_to_offline_store` method.\r\nIn the method, we check if `if set(input_columns) != set(source_columns)` and raise the below issue if there are diff. \r\n\r\nIn case with more than 500 columns we get a diff because source_columns come from `get_table_column_names_and_types` method result where the result is define by MaxResults parameters. \r\n\r\n## Steps to reproduce\r\n```\r\nentity= Entity(\r\n name=\"entity\",\r\n join_keys=[\"entity_id\"],\r\n value_type=ValueType.INT64,\r\n)\r\n\r\npush_source = PushSource(\r\n name=\"push_source\",\r\n batch_source=RedshiftSource(\r\n table=\"fs_push_view\",\r\n timestamp_field=\"datecreation\",\r\n created_timestamp_column=\"created_at\"),\r\n)\r\n\r\nbesoin_embedding_push_view = FeatureView(\r\n name=\"push_view\",\r\n entities=[entity],\r\n schema=[Field(name=f\"field_{dim}\", dtype=types.Float64) for dim in range(768)],\r\n source=push_source \r\n)\r\n\r\nfs.push(\"push_source\", df, to=PushMode.ONLINE_AND_OFFLINE)\r\n\r\n```\r\n\r\n### Specifications\r\n\r\n- Version: 0.25.0\r\n- Platform: AWS\r\n- Subsystem:\r\n\r\n## Possible Solution\r\n\r\nIn my mind, we have two solutions:\r\n\r\n- Set higher MaxResults in describe_table method\r\n- Use NextToken to iterate through results\r\n\r\n\n", "before_files": [{"content": "from typing import Callable, Dict, Iterable, Optional, Tuple\n\nfrom typeguard import typechecked\n\nfrom feast import type_map\nfrom feast.data_source import DataSource\nfrom feast.errors import (\n DataSourceNoNameException,\n DataSourceNotFoundException,\n RedshiftCredentialsError,\n)\nfrom feast.feature_logging import LoggingDestination\nfrom feast.protos.feast.core.DataSource_pb2 import DataSource as DataSourceProto\nfrom feast.protos.feast.core.FeatureService_pb2 import (\n LoggingConfig as LoggingConfigProto,\n)\nfrom feast.protos.feast.core.SavedDataset_pb2 import (\n SavedDatasetStorage as SavedDatasetStorageProto,\n)\nfrom feast.repo_config import RepoConfig\nfrom feast.saved_dataset import SavedDatasetStorage\nfrom feast.value_type import ValueType\n\n\n@typechecked\nclass RedshiftSource(DataSource):\n def __init__(\n self,\n *,\n name: Optional[str] = None,\n timestamp_field: Optional[str] = \"\",\n table: Optional[str] = None,\n schema: Optional[str] = None,\n created_timestamp_column: Optional[str] = \"\",\n field_mapping: Optional[Dict[str, str]] = None,\n query: Optional[str] = None,\n description: Optional[str] = \"\",\n tags: Optional[Dict[str, str]] = None,\n owner: Optional[str] = \"\",\n database: Optional[str] = \"\",\n ):\n \"\"\"\n Creates a RedshiftSource object.\n\n Args:\n name (optional): Name for the source. Defaults to the table if not specified, in which\n case the table must be specified.\n timestamp_field (optional): Event timestamp field used for point in time\n joins of feature values.\n table (optional): Redshift table where the features are stored. Exactly one of 'table'\n and 'query' must be specified.\n schema (optional): Redshift schema in which the table is located.\n created_timestamp_column (optional): Timestamp column indicating when the\n row was created, used for deduplicating rows.\n field_mapping (optional): A dictionary mapping of column names in this data\n source to column names in a feature table or view.\n query (optional): The query to be executed to obtain the features. Exactly one of 'table'\n and 'query' must be specified.\n description (optional): A human-readable description.\n tags (optional): A dictionary of key-value pairs to store arbitrary metadata.\n owner (optional): The owner of the redshift source, typically the email of the primary\n maintainer.\n database (optional): The Redshift database name.\n \"\"\"\n if table is None and query is None:\n raise ValueError('No \"table\" or \"query\" argument provided.')\n\n # The default Redshift schema is named \"public\".\n _schema = \"public\" if table and not schema else schema\n self.redshift_options = RedshiftOptions(\n table=table, schema=_schema, query=query, database=database\n )\n\n # If no name, use the table as the default name.\n if name is None and table is None:\n raise DataSourceNoNameException()\n name = name or table\n assert name\n\n super().__init__(\n name=name,\n timestamp_field=timestamp_field,\n created_timestamp_column=created_timestamp_column,\n field_mapping=field_mapping,\n description=description,\n tags=tags,\n owner=owner,\n )\n\n @staticmethod\n def from_proto(data_source: DataSourceProto):\n \"\"\"\n Creates a RedshiftSource from a protobuf representation of a RedshiftSource.\n\n Args:\n data_source: A protobuf representation of a RedshiftSource\n\n Returns:\n A RedshiftSource object based on the data_source protobuf.\n \"\"\"\n return RedshiftSource(\n name=data_source.name,\n timestamp_field=data_source.timestamp_field,\n table=data_source.redshift_options.table,\n schema=data_source.redshift_options.schema,\n created_timestamp_column=data_source.created_timestamp_column,\n field_mapping=dict(data_source.field_mapping),\n query=data_source.redshift_options.query,\n description=data_source.description,\n tags=dict(data_source.tags),\n owner=data_source.owner,\n database=data_source.redshift_options.database,\n )\n\n # Note: Python requires redefining hash in child classes that override __eq__\n def __hash__(self):\n return super().__hash__()\n\n def __eq__(self, other):\n if not isinstance(other, RedshiftSource):\n raise TypeError(\n \"Comparisons should only involve RedshiftSource class objects.\"\n )\n\n return (\n super().__eq__(other)\n and self.redshift_options.table == other.redshift_options.table\n and self.redshift_options.schema == other.redshift_options.schema\n and self.redshift_options.query == other.redshift_options.query\n and self.redshift_options.database == other.redshift_options.database\n )\n\n @property\n def table(self):\n \"\"\"Returns the table of this Redshift source.\"\"\"\n return self.redshift_options.table\n\n @property\n def schema(self):\n \"\"\"Returns the schema of this Redshift source.\"\"\"\n return self.redshift_options.schema\n\n @property\n def query(self):\n \"\"\"Returns the Redshift query of this Redshift source.\"\"\"\n return self.redshift_options.query\n\n @property\n def database(self):\n \"\"\"Returns the Redshift database of this Redshift source.\"\"\"\n return self.redshift_options.database\n\n def to_proto(self) -> DataSourceProto:\n \"\"\"\n Converts a RedshiftSource object to its protobuf representation.\n\n Returns:\n A DataSourceProto object.\n \"\"\"\n data_source_proto = DataSourceProto(\n name=self.name,\n type=DataSourceProto.BATCH_REDSHIFT,\n field_mapping=self.field_mapping,\n redshift_options=self.redshift_options.to_proto(),\n description=self.description,\n tags=self.tags,\n owner=self.owner,\n timestamp_field=self.timestamp_field,\n created_timestamp_column=self.created_timestamp_column,\n )\n\n return data_source_proto\n\n def validate(self, config: RepoConfig):\n # As long as the query gets successfully executed, or the table exists,\n # the data source is validated. We don't need the results though.\n self.get_table_column_names_and_types(config)\n\n def get_table_query_string(self) -> str:\n \"\"\"Returns a string that can directly be used to reference this table in SQL.\"\"\"\n if self.table:\n return f'\"{self.schema}\".\"{self.table}\"'\n else:\n return f\"({self.query})\"\n\n @staticmethod\n def source_datatype_to_feast_value_type() -> Callable[[str], ValueType]:\n return type_map.redshift_to_feast_value_type\n\n def get_table_column_names_and_types(\n self, config: RepoConfig\n ) -> Iterable[Tuple[str, str]]:\n \"\"\"\n Returns a mapping of column names to types for this Redshift source.\n\n Args:\n config: A RepoConfig describing the feature repo\n \"\"\"\n from botocore.exceptions import ClientError\n\n from feast.infra.offline_stores.redshift import RedshiftOfflineStoreConfig\n from feast.infra.utils import aws_utils\n\n assert isinstance(config.offline_store, RedshiftOfflineStoreConfig)\n\n client = aws_utils.get_redshift_data_client(config.offline_store.region)\n if self.table:\n try:\n table = client.describe_table(\n ClusterIdentifier=config.offline_store.cluster_id,\n Database=(\n self.database\n if self.database\n else config.offline_store.database\n ),\n DbUser=config.offline_store.user,\n Table=self.table,\n Schema=self.schema,\n )\n except ClientError as e:\n if e.response[\"Error\"][\"Code\"] == \"ValidationException\":\n raise RedshiftCredentialsError() from e\n raise\n\n # The API returns valid JSON with empty column list when the table doesn't exist\n if len(table[\"ColumnList\"]) == 0:\n raise DataSourceNotFoundException(self.table)\n\n columns = table[\"ColumnList\"]\n else:\n statement_id = aws_utils.execute_redshift_statement(\n client,\n config.offline_store.cluster_id,\n self.database if self.database else config.offline_store.database,\n config.offline_store.user,\n f\"SELECT * FROM ({self.query}) LIMIT 1\",\n )\n columns = aws_utils.get_redshift_statement_result(client, statement_id)[\n \"ColumnMetadata\"\n ]\n\n return [(column[\"name\"], column[\"typeName\"].upper()) for column in columns]\n\n\nclass RedshiftOptions:\n \"\"\"\n Configuration options for a Redshift data source.\n \"\"\"\n\n def __init__(\n self,\n table: Optional[str],\n schema: Optional[str],\n query: Optional[str],\n database: Optional[str],\n ):\n self.table = table or \"\"\n self.schema = schema or \"\"\n self.query = query or \"\"\n self.database = database or \"\"\n\n @classmethod\n def from_proto(cls, redshift_options_proto: DataSourceProto.RedshiftOptions):\n \"\"\"\n Creates a RedshiftOptions from a protobuf representation of a Redshift option.\n\n Args:\n redshift_options_proto: A protobuf representation of a DataSource\n\n Returns:\n A RedshiftOptions object based on the redshift_options protobuf.\n \"\"\"\n redshift_options = cls(\n table=redshift_options_proto.table,\n schema=redshift_options_proto.schema,\n query=redshift_options_proto.query,\n database=redshift_options_proto.database,\n )\n\n return redshift_options\n\n def to_proto(self) -> DataSourceProto.RedshiftOptions:\n \"\"\"\n Converts an RedshiftOptionsProto object to its protobuf representation.\n\n Returns:\n A RedshiftOptionsProto protobuf.\n \"\"\"\n redshift_options_proto = DataSourceProto.RedshiftOptions(\n table=self.table,\n schema=self.schema,\n query=self.query,\n database=self.database,\n )\n\n return redshift_options_proto\n\n\nclass SavedDatasetRedshiftStorage(SavedDatasetStorage):\n _proto_attr_name = \"redshift_storage\"\n\n redshift_options: RedshiftOptions\n\n def __init__(self, table_ref: str):\n self.redshift_options = RedshiftOptions(\n table=table_ref, schema=None, query=None, database=None\n )\n\n @staticmethod\n def from_proto(storage_proto: SavedDatasetStorageProto) -> SavedDatasetStorage:\n\n return SavedDatasetRedshiftStorage(\n table_ref=RedshiftOptions.from_proto(storage_proto.redshift_storage).table\n )\n\n def to_proto(self) -> SavedDatasetStorageProto:\n return SavedDatasetStorageProto(\n redshift_storage=self.redshift_options.to_proto()\n )\n\n def to_data_source(self) -> DataSource:\n return RedshiftSource(table=self.redshift_options.table)\n\n\nclass RedshiftLoggingDestination(LoggingDestination):\n _proto_kind = \"redshift_destination\"\n\n table_name: str\n\n def __init__(self, *, table_name: str):\n self.table_name = table_name\n\n @classmethod\n def from_proto(cls, config_proto: LoggingConfigProto) -> \"LoggingDestination\":\n return RedshiftLoggingDestination(\n table_name=config_proto.redshift_destination.table_name,\n )\n\n def to_proto(self) -> LoggingConfigProto:\n return LoggingConfigProto(\n redshift_destination=LoggingConfigProto.RedshiftDestination(\n table_name=self.table_name\n )\n )\n\n def to_data_source(self) -> DataSource:\n return RedshiftSource(table=self.table_name)\n", "path": "sdk/python/feast/infra/offline_stores/redshift_source.py"}], "after_files": [{"content": "from typing import Callable, Dict, Iterable, Optional, Tuple\n\nfrom typeguard import typechecked\n\nfrom feast import type_map\nfrom feast.data_source import DataSource\nfrom feast.errors import (\n DataSourceNoNameException,\n DataSourceNotFoundException,\n RedshiftCredentialsError,\n)\nfrom feast.feature_logging import LoggingDestination\nfrom feast.protos.feast.core.DataSource_pb2 import DataSource as DataSourceProto\nfrom feast.protos.feast.core.FeatureService_pb2 import (\n LoggingConfig as LoggingConfigProto,\n)\nfrom feast.protos.feast.core.SavedDataset_pb2 import (\n SavedDatasetStorage as SavedDatasetStorageProto,\n)\nfrom feast.repo_config import RepoConfig\nfrom feast.saved_dataset import SavedDatasetStorage\nfrom feast.value_type import ValueType\n\n\n@typechecked\nclass RedshiftSource(DataSource):\n def __init__(\n self,\n *,\n name: Optional[str] = None,\n timestamp_field: Optional[str] = \"\",\n table: Optional[str] = None,\n schema: Optional[str] = None,\n created_timestamp_column: Optional[str] = \"\",\n field_mapping: Optional[Dict[str, str]] = None,\n query: Optional[str] = None,\n description: Optional[str] = \"\",\n tags: Optional[Dict[str, str]] = None,\n owner: Optional[str] = \"\",\n database: Optional[str] = \"\",\n ):\n \"\"\"\n Creates a RedshiftSource object.\n\n Args:\n name (optional): Name for the source. Defaults to the table if not specified, in which\n case the table must be specified.\n timestamp_field (optional): Event timestamp field used for point in time\n joins of feature values.\n table (optional): Redshift table where the features are stored. Exactly one of 'table'\n and 'query' must be specified.\n schema (optional): Redshift schema in which the table is located.\n created_timestamp_column (optional): Timestamp column indicating when the\n row was created, used for deduplicating rows.\n field_mapping (optional): A dictionary mapping of column names in this data\n source to column names in a feature table or view.\n query (optional): The query to be executed to obtain the features. Exactly one of 'table'\n and 'query' must be specified.\n description (optional): A human-readable description.\n tags (optional): A dictionary of key-value pairs to store arbitrary metadata.\n owner (optional): The owner of the redshift source, typically the email of the primary\n maintainer.\n database (optional): The Redshift database name.\n \"\"\"\n if table is None and query is None:\n raise ValueError('No \"table\" or \"query\" argument provided.')\n\n # The default Redshift schema is named \"public\".\n _schema = \"public\" if table and not schema else schema\n self.redshift_options = RedshiftOptions(\n table=table, schema=_schema, query=query, database=database\n )\n\n # If no name, use the table as the default name.\n if name is None and table is None:\n raise DataSourceNoNameException()\n name = name or table\n assert name\n\n super().__init__(\n name=name,\n timestamp_field=timestamp_field,\n created_timestamp_column=created_timestamp_column,\n field_mapping=field_mapping,\n description=description,\n tags=tags,\n owner=owner,\n )\n\n @staticmethod\n def from_proto(data_source: DataSourceProto):\n \"\"\"\n Creates a RedshiftSource from a protobuf representation of a RedshiftSource.\n\n Args:\n data_source: A protobuf representation of a RedshiftSource\n\n Returns:\n A RedshiftSource object based on the data_source protobuf.\n \"\"\"\n return RedshiftSource(\n name=data_source.name,\n timestamp_field=data_source.timestamp_field,\n table=data_source.redshift_options.table,\n schema=data_source.redshift_options.schema,\n created_timestamp_column=data_source.created_timestamp_column,\n field_mapping=dict(data_source.field_mapping),\n query=data_source.redshift_options.query,\n description=data_source.description,\n tags=dict(data_source.tags),\n owner=data_source.owner,\n database=data_source.redshift_options.database,\n )\n\n # Note: Python requires redefining hash in child classes that override __eq__\n def __hash__(self):\n return super().__hash__()\n\n def __eq__(self, other):\n if not isinstance(other, RedshiftSource):\n raise TypeError(\n \"Comparisons should only involve RedshiftSource class objects.\"\n )\n\n return (\n super().__eq__(other)\n and self.redshift_options.table == other.redshift_options.table\n and self.redshift_options.schema == other.redshift_options.schema\n and self.redshift_options.query == other.redshift_options.query\n and self.redshift_options.database == other.redshift_options.database\n )\n\n @property\n def table(self):\n \"\"\"Returns the table of this Redshift source.\"\"\"\n return self.redshift_options.table\n\n @property\n def schema(self):\n \"\"\"Returns the schema of this Redshift source.\"\"\"\n return self.redshift_options.schema\n\n @property\n def query(self):\n \"\"\"Returns the Redshift query of this Redshift source.\"\"\"\n return self.redshift_options.query\n\n @property\n def database(self):\n \"\"\"Returns the Redshift database of this Redshift source.\"\"\"\n return self.redshift_options.database\n\n def to_proto(self) -> DataSourceProto:\n \"\"\"\n Converts a RedshiftSource object to its protobuf representation.\n\n Returns:\n A DataSourceProto object.\n \"\"\"\n data_source_proto = DataSourceProto(\n name=self.name,\n type=DataSourceProto.BATCH_REDSHIFT,\n field_mapping=self.field_mapping,\n redshift_options=self.redshift_options.to_proto(),\n description=self.description,\n tags=self.tags,\n owner=self.owner,\n timestamp_field=self.timestamp_field,\n created_timestamp_column=self.created_timestamp_column,\n )\n\n return data_source_proto\n\n def validate(self, config: RepoConfig):\n # As long as the query gets successfully executed, or the table exists,\n # the data source is validated. We don't need the results though.\n self.get_table_column_names_and_types(config)\n\n def get_table_query_string(self) -> str:\n \"\"\"Returns a string that can directly be used to reference this table in SQL.\"\"\"\n if self.table:\n return f'\"{self.schema}\".\"{self.table}\"'\n else:\n return f\"({self.query})\"\n\n @staticmethod\n def source_datatype_to_feast_value_type() -> Callable[[str], ValueType]:\n return type_map.redshift_to_feast_value_type\n\n def get_table_column_names_and_types(\n self, config: RepoConfig\n ) -> Iterable[Tuple[str, str]]:\n \"\"\"\n Returns a mapping of column names to types for this Redshift source.\n\n Args:\n config: A RepoConfig describing the feature repo\n \"\"\"\n from botocore.exceptions import ClientError\n\n from feast.infra.offline_stores.redshift import RedshiftOfflineStoreConfig\n from feast.infra.utils import aws_utils\n\n assert isinstance(config.offline_store, RedshiftOfflineStoreConfig)\n\n client = aws_utils.get_redshift_data_client(config.offline_store.region)\n if self.table:\n try:\n paginator = client.get_paginator(\"describe_table\")\n response_iterator = paginator.paginate(\n ClusterIdentifier=config.offline_store.cluster_id,\n Database=(\n self.database\n if self.database\n else config.offline_store.database\n ),\n DbUser=config.offline_store.user,\n Table=self.table,\n Schema=self.schema,\n )\n table = response_iterator.build_full_result()\n except ClientError as e:\n if e.response[\"Error\"][\"Code\"] == \"ValidationException\":\n raise RedshiftCredentialsError() from e\n raise\n\n # The API returns valid JSON with empty column list when the table doesn't exist\n if len(table[\"ColumnList\"]) == 0:\n raise DataSourceNotFoundException(self.table)\n\n columns = table[\"ColumnList\"]\n else:\n statement_id = aws_utils.execute_redshift_statement(\n client,\n config.offline_store.cluster_id,\n self.database if self.database else config.offline_store.database,\n config.offline_store.user,\n f\"SELECT * FROM ({self.query}) LIMIT 1\",\n )\n columns = aws_utils.get_redshift_statement_result(client, statement_id)[\n \"ColumnMetadata\"\n ]\n\n return [(column[\"name\"], column[\"typeName\"].upper()) for column in columns]\n\n\nclass RedshiftOptions:\n \"\"\"\n Configuration options for a Redshift data source.\n \"\"\"\n\n def __init__(\n self,\n table: Optional[str],\n schema: Optional[str],\n query: Optional[str],\n database: Optional[str],\n ):\n self.table = table or \"\"\n self.schema = schema or \"\"\n self.query = query or \"\"\n self.database = database or \"\"\n\n @classmethod\n def from_proto(cls, redshift_options_proto: DataSourceProto.RedshiftOptions):\n \"\"\"\n Creates a RedshiftOptions from a protobuf representation of a Redshift option.\n\n Args:\n redshift_options_proto: A protobuf representation of a DataSource\n\n Returns:\n A RedshiftOptions object based on the redshift_options protobuf.\n \"\"\"\n redshift_options = cls(\n table=redshift_options_proto.table,\n schema=redshift_options_proto.schema,\n query=redshift_options_proto.query,\n database=redshift_options_proto.database,\n )\n\n return redshift_options\n\n def to_proto(self) -> DataSourceProto.RedshiftOptions:\n \"\"\"\n Converts an RedshiftOptionsProto object to its protobuf representation.\n\n Returns:\n A RedshiftOptionsProto protobuf.\n \"\"\"\n redshift_options_proto = DataSourceProto.RedshiftOptions(\n table=self.table,\n schema=self.schema,\n query=self.query,\n database=self.database,\n )\n\n return redshift_options_proto\n\n\nclass SavedDatasetRedshiftStorage(SavedDatasetStorage):\n _proto_attr_name = \"redshift_storage\"\n\n redshift_options: RedshiftOptions\n\n def __init__(self, table_ref: str):\n self.redshift_options = RedshiftOptions(\n table=table_ref, schema=None, query=None, database=None\n )\n\n @staticmethod\n def from_proto(storage_proto: SavedDatasetStorageProto) -> SavedDatasetStorage:\n\n return SavedDatasetRedshiftStorage(\n table_ref=RedshiftOptions.from_proto(storage_proto.redshift_storage).table\n )\n\n def to_proto(self) -> SavedDatasetStorageProto:\n return SavedDatasetStorageProto(\n redshift_storage=self.redshift_options.to_proto()\n )\n\n def to_data_source(self) -> DataSource:\n return RedshiftSource(table=self.redshift_options.table)\n\n\nclass RedshiftLoggingDestination(LoggingDestination):\n _proto_kind = \"redshift_destination\"\n\n table_name: str\n\n def __init__(self, *, table_name: str):\n self.table_name = table_name\n\n @classmethod\n def from_proto(cls, config_proto: LoggingConfigProto) -> \"LoggingDestination\":\n return RedshiftLoggingDestination(\n table_name=config_proto.redshift_destination.table_name,\n )\n\n def to_proto(self) -> LoggingConfigProto:\n return LoggingConfigProto(\n redshift_destination=LoggingConfigProto.RedshiftDestination(\n table_name=self.table_name\n )\n )\n\n def to_data_source(self) -> DataSource:\n return RedshiftSource(table=self.table_name)\n", "path": "sdk/python/feast/infra/offline_stores/redshift_source.py"}]}
| 4,058 | 223 |
gh_patches_debug_9293
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2097
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_clean_attribute shouldn't skip attributes
From attributes [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/common/common.md#attributes)
>_This is required for map/dictionary structures represented as two arrays with indices that are kept in sync (e.g., two attributes header_keys and header_values, both containing an array of strings to represent a mapping header_keys[i] -> header_values[i])._
https://github.com/open-telemetry/opentelemetry-python/blob/653207dd2181db1a766a4a703dcda78fd7703bb2/opentelemetry-api/src/opentelemetry/attributes/__init__.py#L118-L123
https://github.com/open-telemetry/opentelemetry-python/blob/653207dd2181db1a766a4a703dcda78fd7703bb2/opentelemetry-api/src/opentelemetry/attributes/__init__.py#L66-L69
I think we shouldn't be continuing here when decode fails on byte value. Two options I can think of is reject everything by returning None or use empty value (""). What do you think?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-api/src/opentelemetry/attributes/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # type: ignore
15
16 import logging
17 import threading
18 from collections import OrderedDict
19 from collections.abc import MutableMapping
20 from typing import Optional, Sequence, Union
21
22 from opentelemetry.util import types
23
24 # bytes are accepted as a user supplied value for attributes but
25 # decoded to strings internally.
26 _VALID_ATTR_VALUE_TYPES = (bool, str, bytes, int, float)
27
28
29 _logger = logging.getLogger(__name__)
30
31
32 def _clean_attribute(
33 key: str, value: types.AttributeValue, max_len: Optional[int]
34 ) -> Optional[types.AttributeValue]:
35 """Checks if attribute value is valid and cleans it if required.
36
37 The function returns the cleaned value or None if the value is not valid.
38
39 An attribute value is valid if it is either:
40 - A primitive type: string, boolean, double precision floating
41 point (IEEE 754-1985) or integer.
42 - An array of primitive type values. The array MUST be homogeneous,
43 i.e. it MUST NOT contain values of different types.
44
45 An attribute needs cleansing if:
46 - Its length is greater than the maximum allowed length.
47 - It needs to be encoded/decoded e.g, bytes to strings.
48 """
49
50 if not (key and isinstance(key, str)):
51 _logger.warning("invalid key `%s`. must be non-empty string.", key)
52 return None
53
54 if isinstance(value, _VALID_ATTR_VALUE_TYPES):
55 return _clean_attribute_value(value, max_len)
56
57 if isinstance(value, Sequence):
58 sequence_first_valid_type = None
59 cleaned_seq = []
60
61 for element in value:
62 # None is considered valid in any sequence
63 if element is None:
64 cleaned_seq.append(element)
65
66 element = _clean_attribute_value(element, max_len)
67 # reject invalid elements
68 if element is None:
69 continue
70
71 element_type = type(element)
72 # Reject attribute value if sequence contains a value with an incompatible type.
73 if element_type not in _VALID_ATTR_VALUE_TYPES:
74 _logger.warning(
75 "Invalid type %s in attribute value sequence. Expected one of "
76 "%s or None",
77 element_type.__name__,
78 [
79 valid_type.__name__
80 for valid_type in _VALID_ATTR_VALUE_TYPES
81 ],
82 )
83 return None
84
85 # The type of the sequence must be homogeneous. The first non-None
86 # element determines the type of the sequence
87 if sequence_first_valid_type is None:
88 sequence_first_valid_type = element_type
89 # use equality instead of isinstance as isinstance(True, int) evaluates to True
90 elif element_type != sequence_first_valid_type:
91 _logger.warning(
92 "Mixed types %s and %s in attribute value sequence",
93 sequence_first_valid_type.__name__,
94 type(element).__name__,
95 )
96 return None
97
98 cleaned_seq.append(element)
99
100 # Freeze mutable sequences defensively
101 return tuple(cleaned_seq)
102
103 _logger.warning(
104 "Invalid type %s for attribute value. Expected one of %s or a "
105 "sequence of those types",
106 type(value).__name__,
107 [valid_type.__name__ for valid_type in _VALID_ATTR_VALUE_TYPES],
108 )
109 return None
110
111
112 def _clean_attribute_value(
113 value: types.AttributeValue, limit: Optional[int]
114 ) -> Union[types.AttributeValue, None]:
115 if value is None:
116 return None
117
118 if isinstance(value, bytes):
119 try:
120 value = value.decode()
121 except UnicodeDecodeError:
122 _logger.warning("Byte attribute could not be decoded.")
123 return None
124
125 if limit is not None and isinstance(value, str):
126 value = value[:limit]
127 return value
128
129
130 class BoundedAttributes(MutableMapping):
131 """An ordered dict with a fixed max capacity.
132
133 Oldest elements are dropped when the dict is full and a new element is
134 added.
135 """
136
137 def __init__(
138 self,
139 maxlen: Optional[int] = None,
140 attributes: types.Attributes = None,
141 immutable: bool = True,
142 max_value_len: Optional[int] = None,
143 ):
144 if maxlen is not None:
145 if not isinstance(maxlen, int) or maxlen < 0:
146 raise ValueError(
147 "maxlen must be valid int greater or equal to 0"
148 )
149 self.maxlen = maxlen
150 self.dropped = 0
151 self.max_value_len = max_value_len
152 self._dict = OrderedDict() # type: OrderedDict
153 self._lock = threading.Lock() # type: threading.Lock
154 if attributes:
155 for key, value in attributes.items():
156 self[key] = value
157 self._immutable = immutable
158
159 def __repr__(self):
160 return "{}({}, maxlen={})".format(
161 type(self).__name__, dict(self._dict), self.maxlen
162 )
163
164 def __getitem__(self, key):
165 return self._dict[key]
166
167 def __setitem__(self, key, value):
168 if getattr(self, "_immutable", False):
169 raise TypeError
170 with self._lock:
171 if self.maxlen is not None and self.maxlen == 0:
172 self.dropped += 1
173 return
174
175 value = _clean_attribute(key, value, self.max_value_len)
176 if value is not None:
177 if key in self._dict:
178 del self._dict[key]
179 elif (
180 self.maxlen is not None and len(self._dict) == self.maxlen
181 ):
182 self._dict.popitem(last=False)
183 self.dropped += 1
184
185 self._dict[key] = value
186
187 def __delitem__(self, key):
188 if getattr(self, "_immutable", False):
189 raise TypeError
190 with self._lock:
191 del self._dict[key]
192
193 def __iter__(self):
194 with self._lock:
195 return iter(self._dict.copy())
196
197 def __len__(self):
198 return len(self._dict)
199
200 def copy(self):
201 return self._dict.copy()
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-api/src/opentelemetry/attributes/__init__.py b/opentelemetry-api/src/opentelemetry/attributes/__init__.py
--- a/opentelemetry-api/src/opentelemetry/attributes/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/attributes/__init__.py
@@ -59,13 +59,9 @@
cleaned_seq = []
for element in value:
- # None is considered valid in any sequence
- if element is None:
- cleaned_seq.append(element)
-
element = _clean_attribute_value(element, max_len)
- # reject invalid elements
if element is None:
+ cleaned_seq.append(element)
continue
element_type = type(element)
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/attributes/__init__.py b/opentelemetry-api/src/opentelemetry/attributes/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/attributes/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/attributes/__init__.py\n@@ -59,13 +59,9 @@\n cleaned_seq = []\n \n for element in value:\n- # None is considered valid in any sequence\n- if element is None:\n- cleaned_seq.append(element)\n-\n element = _clean_attribute_value(element, max_len)\n- # reject invalid elements\n if element is None:\n+ cleaned_seq.append(element)\n continue\n \n element_type = type(element)\n", "issue": "_clean_attribute shouldn't skip attributes\nFrom attributes [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/common/common.md#attributes)\r\n\r\n>_This is required for map/dictionary structures represented as two arrays with indices that are kept in sync (e.g., two attributes header_keys and header_values, both containing an array of strings to represent a mapping header_keys[i] -> header_values[i])._\r\n\r\nhttps://github.com/open-telemetry/opentelemetry-python/blob/653207dd2181db1a766a4a703dcda78fd7703bb2/opentelemetry-api/src/opentelemetry/attributes/__init__.py#L118-L123\r\n\r\nhttps://github.com/open-telemetry/opentelemetry-python/blob/653207dd2181db1a766a4a703dcda78fd7703bb2/opentelemetry-api/src/opentelemetry/attributes/__init__.py#L66-L69\r\n\r\nI think we shouldn't be continuing here when decode fails on byte value. Two options I can think of is reject everything by returning None or use empty value (\"\"). What do you think?\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# type: ignore\n\nimport logging\nimport threading\nfrom collections import OrderedDict\nfrom collections.abc import MutableMapping\nfrom typing import Optional, Sequence, Union\n\nfrom opentelemetry.util import types\n\n# bytes are accepted as a user supplied value for attributes but\n# decoded to strings internally.\n_VALID_ATTR_VALUE_TYPES = (bool, str, bytes, int, float)\n\n\n_logger = logging.getLogger(__name__)\n\n\ndef _clean_attribute(\n key: str, value: types.AttributeValue, max_len: Optional[int]\n) -> Optional[types.AttributeValue]:\n \"\"\"Checks if attribute value is valid and cleans it if required.\n\n The function returns the cleaned value or None if the value is not valid.\n\n An attribute value is valid if it is either:\n - A primitive type: string, boolean, double precision floating\n point (IEEE 754-1985) or integer.\n - An array of primitive type values. The array MUST be homogeneous,\n i.e. it MUST NOT contain values of different types.\n\n An attribute needs cleansing if:\n - Its length is greater than the maximum allowed length.\n - It needs to be encoded/decoded e.g, bytes to strings.\n \"\"\"\n\n if not (key and isinstance(key, str)):\n _logger.warning(\"invalid key `%s`. must be non-empty string.\", key)\n return None\n\n if isinstance(value, _VALID_ATTR_VALUE_TYPES):\n return _clean_attribute_value(value, max_len)\n\n if isinstance(value, Sequence):\n sequence_first_valid_type = None\n cleaned_seq = []\n\n for element in value:\n # None is considered valid in any sequence\n if element is None:\n cleaned_seq.append(element)\n\n element = _clean_attribute_value(element, max_len)\n # reject invalid elements\n if element is None:\n continue\n\n element_type = type(element)\n # Reject attribute value if sequence contains a value with an incompatible type.\n if element_type not in _VALID_ATTR_VALUE_TYPES:\n _logger.warning(\n \"Invalid type %s in attribute value sequence. Expected one of \"\n \"%s or None\",\n element_type.__name__,\n [\n valid_type.__name__\n for valid_type in _VALID_ATTR_VALUE_TYPES\n ],\n )\n return None\n\n # The type of the sequence must be homogeneous. The first non-None\n # element determines the type of the sequence\n if sequence_first_valid_type is None:\n sequence_first_valid_type = element_type\n # use equality instead of isinstance as isinstance(True, int) evaluates to True\n elif element_type != sequence_first_valid_type:\n _logger.warning(\n \"Mixed types %s and %s in attribute value sequence\",\n sequence_first_valid_type.__name__,\n type(element).__name__,\n )\n return None\n\n cleaned_seq.append(element)\n\n # Freeze mutable sequences defensively\n return tuple(cleaned_seq)\n\n _logger.warning(\n \"Invalid type %s for attribute value. Expected one of %s or a \"\n \"sequence of those types\",\n type(value).__name__,\n [valid_type.__name__ for valid_type in _VALID_ATTR_VALUE_TYPES],\n )\n return None\n\n\ndef _clean_attribute_value(\n value: types.AttributeValue, limit: Optional[int]\n) -> Union[types.AttributeValue, None]:\n if value is None:\n return None\n\n if isinstance(value, bytes):\n try:\n value = value.decode()\n except UnicodeDecodeError:\n _logger.warning(\"Byte attribute could not be decoded.\")\n return None\n\n if limit is not None and isinstance(value, str):\n value = value[:limit]\n return value\n\n\nclass BoundedAttributes(MutableMapping):\n \"\"\"An ordered dict with a fixed max capacity.\n\n Oldest elements are dropped when the dict is full and a new element is\n added.\n \"\"\"\n\n def __init__(\n self,\n maxlen: Optional[int] = None,\n attributes: types.Attributes = None,\n immutable: bool = True,\n max_value_len: Optional[int] = None,\n ):\n if maxlen is not None:\n if not isinstance(maxlen, int) or maxlen < 0:\n raise ValueError(\n \"maxlen must be valid int greater or equal to 0\"\n )\n self.maxlen = maxlen\n self.dropped = 0\n self.max_value_len = max_value_len\n self._dict = OrderedDict() # type: OrderedDict\n self._lock = threading.Lock() # type: threading.Lock\n if attributes:\n for key, value in attributes.items():\n self[key] = value\n self._immutable = immutable\n\n def __repr__(self):\n return \"{}({}, maxlen={})\".format(\n type(self).__name__, dict(self._dict), self.maxlen\n )\n\n def __getitem__(self, key):\n return self._dict[key]\n\n def __setitem__(self, key, value):\n if getattr(self, \"_immutable\", False):\n raise TypeError\n with self._lock:\n if self.maxlen is not None and self.maxlen == 0:\n self.dropped += 1\n return\n\n value = _clean_attribute(key, value, self.max_value_len)\n if value is not None:\n if key in self._dict:\n del self._dict[key]\n elif (\n self.maxlen is not None and len(self._dict) == self.maxlen\n ):\n self._dict.popitem(last=False)\n self.dropped += 1\n\n self._dict[key] = value\n\n def __delitem__(self, key):\n if getattr(self, \"_immutable\", False):\n raise TypeError\n with self._lock:\n del self._dict[key]\n\n def __iter__(self):\n with self._lock:\n return iter(self._dict.copy())\n\n def __len__(self):\n return len(self._dict)\n\n def copy(self):\n return self._dict.copy()\n", "path": "opentelemetry-api/src/opentelemetry/attributes/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# type: ignore\n\nimport logging\nimport threading\nfrom collections import OrderedDict\nfrom collections.abc import MutableMapping\nfrom typing import Optional, Sequence, Union\n\nfrom opentelemetry.util import types\n\n# bytes are accepted as a user supplied value for attributes but\n# decoded to strings internally.\n_VALID_ATTR_VALUE_TYPES = (bool, str, bytes, int, float)\n\n\n_logger = logging.getLogger(__name__)\n\n\ndef _clean_attribute(\n key: str, value: types.AttributeValue, max_len: Optional[int]\n) -> Optional[types.AttributeValue]:\n \"\"\"Checks if attribute value is valid and cleans it if required.\n\n The function returns the cleaned value or None if the value is not valid.\n\n An attribute value is valid if it is either:\n - A primitive type: string, boolean, double precision floating\n point (IEEE 754-1985) or integer.\n - An array of primitive type values. The array MUST be homogeneous,\n i.e. it MUST NOT contain values of different types.\n\n An attribute needs cleansing if:\n - Its length is greater than the maximum allowed length.\n - It needs to be encoded/decoded e.g, bytes to strings.\n \"\"\"\n\n if not (key and isinstance(key, str)):\n _logger.warning(\"invalid key `%s`. must be non-empty string.\", key)\n return None\n\n if isinstance(value, _VALID_ATTR_VALUE_TYPES):\n return _clean_attribute_value(value, max_len)\n\n if isinstance(value, Sequence):\n sequence_first_valid_type = None\n cleaned_seq = []\n\n for element in value:\n element = _clean_attribute_value(element, max_len)\n if element is None:\n cleaned_seq.append(element)\n continue\n\n element_type = type(element)\n # Reject attribute value if sequence contains a value with an incompatible type.\n if element_type not in _VALID_ATTR_VALUE_TYPES:\n _logger.warning(\n \"Invalid type %s in attribute value sequence. Expected one of \"\n \"%s or None\",\n element_type.__name__,\n [\n valid_type.__name__\n for valid_type in _VALID_ATTR_VALUE_TYPES\n ],\n )\n return None\n\n # The type of the sequence must be homogeneous. The first non-None\n # element determines the type of the sequence\n if sequence_first_valid_type is None:\n sequence_first_valid_type = element_type\n # use equality instead of isinstance as isinstance(True, int) evaluates to True\n elif element_type != sequence_first_valid_type:\n _logger.warning(\n \"Mixed types %s and %s in attribute value sequence\",\n sequence_first_valid_type.__name__,\n type(element).__name__,\n )\n return None\n\n cleaned_seq.append(element)\n\n # Freeze mutable sequences defensively\n return tuple(cleaned_seq)\n\n _logger.warning(\n \"Invalid type %s for attribute value. Expected one of %s or a \"\n \"sequence of those types\",\n type(value).__name__,\n [valid_type.__name__ for valid_type in _VALID_ATTR_VALUE_TYPES],\n )\n return None\n\n\ndef _clean_attribute_value(\n value: types.AttributeValue, limit: Optional[int]\n) -> Union[types.AttributeValue, None]:\n if value is None:\n return None\n\n if isinstance(value, bytes):\n try:\n value = value.decode()\n except UnicodeDecodeError:\n _logger.warning(\"Byte attribute could not be decoded.\")\n return None\n\n if limit is not None and isinstance(value, str):\n value = value[:limit]\n return value\n\n\nclass BoundedAttributes(MutableMapping):\n \"\"\"An ordered dict with a fixed max capacity.\n\n Oldest elements are dropped when the dict is full and a new element is\n added.\n \"\"\"\n\n def __init__(\n self,\n maxlen: Optional[int] = None,\n attributes: types.Attributes = None,\n immutable: bool = True,\n max_value_len: Optional[int] = None,\n ):\n if maxlen is not None:\n if not isinstance(maxlen, int) or maxlen < 0:\n raise ValueError(\n \"maxlen must be valid int greater or equal to 0\"\n )\n self.maxlen = maxlen\n self.dropped = 0\n self.max_value_len = max_value_len\n self._dict = OrderedDict() # type: OrderedDict\n self._lock = threading.Lock() # type: threading.Lock\n if attributes:\n for key, value in attributes.items():\n self[key] = value\n self._immutable = immutable\n\n def __repr__(self):\n return \"{}({}, maxlen={})\".format(\n type(self).__name__, dict(self._dict), self.maxlen\n )\n\n def __getitem__(self, key):\n return self._dict[key]\n\n def __setitem__(self, key, value):\n if getattr(self, \"_immutable\", False):\n raise TypeError\n with self._lock:\n if self.maxlen is not None and self.maxlen == 0:\n self.dropped += 1\n return\n\n value = _clean_attribute(key, value, self.max_value_len)\n if value is not None:\n if key in self._dict:\n del self._dict[key]\n elif (\n self.maxlen is not None and len(self._dict) == self.maxlen\n ):\n self._dict.popitem(last=False)\n self.dropped += 1\n\n self._dict[key] = value\n\n def __delitem__(self, key):\n if getattr(self, \"_immutable\", False):\n raise TypeError\n with self._lock:\n del self._dict[key]\n\n def __iter__(self):\n with self._lock:\n return iter(self._dict.copy())\n\n def __len__(self):\n return len(self._dict)\n\n def copy(self):\n return self._dict.copy()\n", "path": "opentelemetry-api/src/opentelemetry/attributes/__init__.py"}]}
| 2,449 | 161 |
gh_patches_debug_920
|
rasdani/github-patches
|
git_diff
|
speechbrain__speechbrain-1127
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Broken docs for `speechbrain.alignment.ctc_segmentation`
Hi, thanks for maintaining such a wonderful library.
Looks like the documentation for `speechbrain.alignment.ctc_segmentation` is broken:
https://speechbrain.readthedocs.io/en/latest/API/speechbrain.alignment.ctc_segmentation.html
I guess this is caused by unneeded shebang, as shown in the following:
https://github.com/speechbrain/speechbrain/blob/develop/speechbrain/alignment/ctc_segmentation.py#L1-L2
Perhaps this could be related to #819 ?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 import os
14 import sys
15 import hyperpyyaml
16
17
18 sys.path.insert(0, os.path.abspath("../speechbrain"))
19
20
21 # -- Project information -----------------------------------------------------
22
23 project = "SpeechBrain"
24 copyright = "2021, SpeechBrain"
25 author = "SpeechBrain"
26
27 # The full version, including alpha/beta/rc tags
28 release = "0.5.0"
29
30
31 # -- General configuration ---------------------------------------------------
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = [
37 "sphinx.ext.autodoc",
38 "sphinx.ext.intersphinx",
39 "sphinx.ext.mathjax",
40 "sphinx.ext.viewcode",
41 "sphinx.ext.autosummary",
42 "sphinx.ext.napoleon",
43 "recommonmark",
44 ]
45
46
47 # Napoleon settings
48 napoleon_google_docstring = False
49 napoleon_numpy_docstring = True
50 napoleon_include_init_with_doc = True
51 napoleon_include_private_with_doc = False
52 napoleon_include_special_with_doc = True
53 napoleon_use_admonition_for_examples = False
54 napoleon_use_admonition_for_notes = True
55 napoleon_use_admonition_for_references = False
56 napoleon_use_ivar = False
57 napoleon_use_param = True
58 napoleon_use_rtype = True
59
60 # Intersphinx mapping:
61 intersphinx_mapping = {
62 "python": ("https://docs.python.org/", None),
63 "numpy": ("http://docs.scipy.org/doc/numpy/", None),
64 "torch": ("https://pytorch.org/docs/master/", None),
65 }
66
67 # AUTODOC:
68
69 autodoc_default_options = {}
70
71 # Autodoc mock extra dependencies:
72 autodoc_mock_imports = ["numba", "sklearn"]
73
74 # Order of API items:
75 autodoc_member_order = "bysource"
76 autodoc_default_options = {"member-order": "bysource"}
77
78 # Don't show inherited docstrings:
79 autodoc_inherit_docstrings = False
80
81 # Add any paths that contain templates here, relative to this directory.
82 templates_path = ["_templates"]
83
84 # List of patterns, relative to source directory, that match files and
85 # directories to ignore when looking for source files.
86 # This pattern also affects html_static_path and html_extra_path.
87 exclude_patterns = ["_apidoc_templates"]
88
89 # -- Better apidoc -----------------------------------------------------------
90
91
92 def run_apidoc(app):
93 """Generage API documentation"""
94 import better_apidoc
95
96 better_apidoc.APP = app
97
98 better_apidoc.main(
99 [
100 "better-apidoc",
101 "-t",
102 "_apidoc_templates",
103 "--force",
104 "--no-toc",
105 "--separate",
106 "-o",
107 "API",
108 os.path.dirname(hyperpyyaml.__file__),
109 ]
110 )
111 better_apidoc.main(
112 [
113 "better-apidoc",
114 "-t",
115 "_apidoc_templates",
116 "--force",
117 "--no-toc",
118 "--separate",
119 "-o",
120 "API",
121 os.path.join("../", "speechbrain"),
122 ]
123 )
124
125
126 # -- Options for HTML output -------------------------------------------------
127
128 # The theme to use for HTML and HTML Help pages. See the documentation for
129 # a list of builtin themes.
130 #
131 html_theme = "sphinx_rtd_theme"
132 # See https://sphinx-rtd-theme.readthedocs.io/en/stable/configuring.html
133 # for rtd theme options
134 html_theme_options = {
135 # Toc options
136 "collapse_navigation": False,
137 "sticky_navigation": True,
138 "navigation_depth": 4,
139 "includehidden": True,
140 }
141
142
143 # Add any paths that contain custom static files (such as style sheets) here,
144 # relative to this directory. They are copied after the builtin static files,
145 # so a file named "default.css" will overwrite the builtin "default.css".
146 html_static_path = ["_static"]
147
148 source_suffix = {
149 ".rst": "restructuredtext",
150 ".txt": "markdown",
151 ".md": "markdown",
152 }
153
154
155 def setup(app):
156 app.connect("builder-inited", run_apidoc)
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -69,7 +69,7 @@
autodoc_default_options = {}
# Autodoc mock extra dependencies:
-autodoc_mock_imports = ["numba", "sklearn"]
+autodoc_mock_imports = ["sklearn"]
# Order of API items:
autodoc_member_order = "bysource"
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -69,7 +69,7 @@\n autodoc_default_options = {}\n \n # Autodoc mock extra dependencies:\n-autodoc_mock_imports = [\"numba\", \"sklearn\"]\n+autodoc_mock_imports = [\"sklearn\"]\n \n # Order of API items:\n autodoc_member_order = \"bysource\"\n", "issue": "Broken docs for `speechbrain.alignment.ctc_segmentation`\nHi, thanks for maintaining such a wonderful library.\r\n\r\nLooks like the documentation for `speechbrain.alignment.ctc_segmentation` is broken:\r\nhttps://speechbrain.readthedocs.io/en/latest/API/speechbrain.alignment.ctc_segmentation.html\r\n\r\nI guess this is caused by unneeded shebang, as shown in the following:\r\nhttps://github.com/speechbrain/speechbrain/blob/develop/speechbrain/alignment/ctc_segmentation.py#L1-L2\r\n\r\nPerhaps this could be related to #819 ?\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport hyperpyyaml\n\n\nsys.path.insert(0, os.path.abspath(\"../speechbrain\"))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = \"SpeechBrain\"\ncopyright = \"2021, SpeechBrain\"\nauthor = \"SpeechBrain\"\n\n# The full version, including alpha/beta/rc tags\nrelease = \"0.5.0\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.mathjax\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.napoleon\",\n \"recommonmark\",\n]\n\n\n# Napoleon settings\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_include_init_with_doc = True\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = True\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = True\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = True\nnapoleon_use_rtype = True\n\n# Intersphinx mapping:\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/\", None),\n \"numpy\": (\"http://docs.scipy.org/doc/numpy/\", None),\n \"torch\": (\"https://pytorch.org/docs/master/\", None),\n}\n\n# AUTODOC:\n\nautodoc_default_options = {}\n\n# Autodoc mock extra dependencies:\nautodoc_mock_imports = [\"numba\", \"sklearn\"]\n\n# Order of API items:\nautodoc_member_order = \"bysource\"\nautodoc_default_options = {\"member-order\": \"bysource\"}\n\n# Don't show inherited docstrings:\nautodoc_inherit_docstrings = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\"_apidoc_templates\"]\n\n# -- Better apidoc -----------------------------------------------------------\n\n\ndef run_apidoc(app):\n \"\"\"Generage API documentation\"\"\"\n import better_apidoc\n\n better_apidoc.APP = app\n\n better_apidoc.main(\n [\n \"better-apidoc\",\n \"-t\",\n \"_apidoc_templates\",\n \"--force\",\n \"--no-toc\",\n \"--separate\",\n \"-o\",\n \"API\",\n os.path.dirname(hyperpyyaml.__file__),\n ]\n )\n better_apidoc.main(\n [\n \"better-apidoc\",\n \"-t\",\n \"_apidoc_templates\",\n \"--force\",\n \"--no-toc\",\n \"--separate\",\n \"-o\",\n \"API\",\n os.path.join(\"../\", \"speechbrain\"),\n ]\n )\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_rtd_theme\"\n# See https://sphinx-rtd-theme.readthedocs.io/en/stable/configuring.html\n# for rtd theme options\nhtml_theme_options = {\n # Toc options\n \"collapse_navigation\": False,\n \"sticky_navigation\": True,\n \"navigation_depth\": 4,\n \"includehidden\": True,\n}\n\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\nsource_suffix = {\n \".rst\": \"restructuredtext\",\n \".txt\": \"markdown\",\n \".md\": \"markdown\",\n}\n\n\ndef setup(app):\n app.connect(\"builder-inited\", run_apidoc)\n", "path": "docs/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport hyperpyyaml\n\n\nsys.path.insert(0, os.path.abspath(\"../speechbrain\"))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = \"SpeechBrain\"\ncopyright = \"2021, SpeechBrain\"\nauthor = \"SpeechBrain\"\n\n# The full version, including alpha/beta/rc tags\nrelease = \"0.5.0\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.mathjax\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.napoleon\",\n \"recommonmark\",\n]\n\n\n# Napoleon settings\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_include_init_with_doc = True\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = True\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = True\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = True\nnapoleon_use_rtype = True\n\n# Intersphinx mapping:\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/\", None),\n \"numpy\": (\"http://docs.scipy.org/doc/numpy/\", None),\n \"torch\": (\"https://pytorch.org/docs/master/\", None),\n}\n\n# AUTODOC:\n\nautodoc_default_options = {}\n\n# Autodoc mock extra dependencies:\nautodoc_mock_imports = [\"sklearn\"]\n\n# Order of API items:\nautodoc_member_order = \"bysource\"\nautodoc_default_options = {\"member-order\": \"bysource\"}\n\n# Don't show inherited docstrings:\nautodoc_inherit_docstrings = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\"_apidoc_templates\"]\n\n# -- Better apidoc -----------------------------------------------------------\n\n\ndef run_apidoc(app):\n \"\"\"Generage API documentation\"\"\"\n import better_apidoc\n\n better_apidoc.APP = app\n\n better_apidoc.main(\n [\n \"better-apidoc\",\n \"-t\",\n \"_apidoc_templates\",\n \"--force\",\n \"--no-toc\",\n \"--separate\",\n \"-o\",\n \"API\",\n os.path.dirname(hyperpyyaml.__file__),\n ]\n )\n better_apidoc.main(\n [\n \"better-apidoc\",\n \"-t\",\n \"_apidoc_templates\",\n \"--force\",\n \"--no-toc\",\n \"--separate\",\n \"-o\",\n \"API\",\n os.path.join(\"../\", \"speechbrain\"),\n ]\n )\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_rtd_theme\"\n# See https://sphinx-rtd-theme.readthedocs.io/en/stable/configuring.html\n# for rtd theme options\nhtml_theme_options = {\n # Toc options\n \"collapse_navigation\": False,\n \"sticky_navigation\": True,\n \"navigation_depth\": 4,\n \"includehidden\": True,\n}\n\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\nsource_suffix = {\n \".rst\": \"restructuredtext\",\n \".txt\": \"markdown\",\n \".md\": \"markdown\",\n}\n\n\ndef setup(app):\n app.connect(\"builder-inited\", run_apidoc)\n", "path": "docs/conf.py"}]}
| 1,751 | 97 |
gh_patches_debug_25381
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1911
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CI tests are failing on BLEU
CI tests on Master are failing on checking Bleu metric:
- https://app.circleci.com/pipelines/github/pytorch/ignite/1755/workflows/00c8cfad-8243-4f5f-9e9e-b8eaeee58b17
- https://github.com/pytorch/ignite/actions/runs/725753501
cc @sdesrozis @gucifer
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/metrics/nlp/bleu.py`
Content:
```
1 import math
2 from collections import Counter
3 from typing import Any, Callable, Sequence, Tuple, Union
4
5 import torch
6
7 from ignite.exceptions import NotComputableError
8 from ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce
9 from ignite.metrics.nlp.utils import modified_precision
10
11 __all__ = ["Bleu"]
12
13
14 def _closest_ref_length(references: Sequence[Sequence[Any]], hyp_len: int) -> int:
15 ref_lens = (len(reference) for reference in references)
16 closest_ref_len = min(ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len))
17 return closest_ref_len
18
19
20 class _Smoother:
21 """
22 Smoothing helper
23 http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf
24 """
25
26 def __init__(self, method: str):
27 valid = ["no_smooth", "smooth1", "nltk_smooth2", "smooth2"]
28 if method not in valid:
29 raise ValueError(f"Smooth is not valid (expected: {valid}, got: {method})")
30 self.smooth = method
31
32 def __call__(self, numerators: Counter, denominators: Counter) -> Sequence[float]:
33 method = getattr(self, self.smooth)
34 return method(numerators, denominators)
35
36 @staticmethod
37 def smooth1(numerators: Counter, denominators: Counter) -> Sequence[float]:
38 epsilon = 0.1
39 denominators_ = [max(1, d) for d in denominators.values()]
40 return [n / d if n != 0 else epsilon / d for n, d in zip(numerators.values(), denominators_)]
41
42 @staticmethod
43 def nltk_smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:
44 denominators_ = [max(1, d) for d in denominators.values()]
45 return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators_)]
46
47 @staticmethod
48 def smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:
49 return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators.values())]
50
51 @staticmethod
52 def no_smooth(numerators: Counter, denominators: Counter) -> Sequence[float]:
53 denominators_ = [max(1, d) for d in denominators.values()]
54 return [n / d for n, d in zip(numerators.values(), denominators_)]
55
56
57 class Bleu(Metric):
58 r"""Calculates the `BLEU score <https://en.wikipedia.org/wiki/BLEU>`_.
59
60 .. math::
61 \text{BLEU} = b_{p} \cdot \exp \left( \sum_{n=1}^{N} w_{n} \: \log p_{n} \right)
62
63 where :math:`N` is the order of n-grams, :math:`b_{p}` is a sentence brevety penalty, :math:`w_{n}` are
64 positive weights summing to one and :math:`p_{n}` are modified n-gram precisions.
65
66 More details can be found in `Papineni et al. 2002`__.
67
68 __ https://www.aclweb.org/anthology/P02-1040.pdf
69
70 In addition, a review of smoothing techniques can be found in `Chen et al. 2014`__
71
72 __ http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf
73
74 Remark :
75
76 This implementation is inspired by nltk
77
78 Args:
79 ngram: order of n-grams.
80 smooth: enable smoothing. Valid are ``no_smooth``, ``smooth1``, ``nltk_smooth2`` or ``smooth2``.
81 Default: ``no_smooth``.
82 output_transform: a callable that is used to transform the
83 :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the
84 form expected by the metric. This can be useful if, for example, you have a multi-output model and
85 you want to compute the metric with respect to one of the outputs.
86 By default, metrics require the output as ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y}``.
87 device: specifies which device updates are accumulated on. Setting the
88 metric's device to be the same as your ``update`` arguments ensures the ``update`` method is
89 non-blocking. By default, CPU.
90
91 Example:
92
93 .. code-block:: python
94
95 from ignite.metrics.nlp import Bleu
96
97 m = Bleu(ngram=4, smooth="smooth1")
98
99 y_pred = "the the the the the the the"
100 y = ["the cat is on the mat", "there is a cat on the mat"]
101
102 m.update((y_pred.split(), [y.split()]))
103
104 print(m.compute())
105
106 .. versionadded:: 0.5.0
107 """
108
109 def __init__(
110 self,
111 ngram: int = 4,
112 smooth: str = "no_smooth",
113 output_transform: Callable = lambda x: x,
114 device: Union[str, torch.device] = torch.device("cpu"),
115 ):
116 if ngram <= 0:
117 raise ValueError(f"ngram order must be greater than zero (got: {ngram})")
118 self.ngrams_order = ngram
119 self.weights = [1 / self.ngrams_order] * self.ngrams_order
120 self.smoother = _Smoother(method=smooth)
121 super(Bleu, self).__init__(output_transform=output_transform, device=device)
122
123 def _corpus_bleu(self, references: Sequence[Sequence[Any]], candidates: Sequence[Sequence[Any]],) -> float:
124 p_numerators: Counter = Counter()
125 p_denominators: Counter = Counter()
126
127 if len(references) != len(candidates):
128 raise ValueError(
129 f"nb of candidates should be equal to nb of reference lists ({len(candidates)} != "
130 f"{len(references)})"
131 )
132
133 # Iterate through each hypothesis and their corresponding references.
134 for refs, hyp in zip(references, candidates):
135 # For each order of ngram, calculate the numerator and
136 # denominator for the corpus-level modified precision.
137 for i in range(1, self.ngrams_order + 1):
138 numerator, denominator = modified_precision(refs, hyp, i)
139 p_numerators[i] += numerator
140 p_denominators[i] += denominator
141
142 # Returns 0 if there's no matching n-grams
143 # We only need to check for p_numerators[1] == 0, since if there's
144 # no unigrams, there won't be any higher order ngrams.
145 if p_numerators[1] == 0:
146 return 0
147
148 # If no smoother, returns 0 if there's at least one a not matching n-grams
149 if self.smoother.smooth == "no_smooth" and min(p_numerators.values()) == 0:
150 return 0
151
152 # Calculate the hypothesis lengths
153 hyp_lengths = [len(hyp) for hyp in candidates]
154
155 # Calculate the closest reference lengths.
156 ref_lengths = [_closest_ref_length(refs, hyp_len) for refs, hyp_len in zip(references, hyp_lengths)]
157
158 # Sum of hypothesis and references lengths
159 hyp_len = sum(hyp_lengths)
160 ref_len = sum(ref_lengths)
161
162 # Calculate corpus-level brevity penalty.
163 if hyp_len < ref_len:
164 bp = math.exp(1 - ref_len / hyp_len) if hyp_len > 0 else 0.0
165 else:
166 bp = 1.0
167
168 # Smoothing
169 p_n = self.smoother(p_numerators, p_denominators)
170
171 # Compute the geometric mean
172 s = [w_i * math.log(p_i) for w_i, p_i in zip(self.weights, p_n)]
173 gm = bp * math.exp(math.fsum(s))
174 return gm
175
176 @reinit__is_reduced
177 def reset(self) -> None:
178 self._sum_of_bleu = torch.tensor(0.0, dtype=torch.double, device=self._device)
179 self._num_sentences = 0
180
181 @reinit__is_reduced
182 def update(self, output: Tuple[Sequence[Any], Sequence[Sequence[Any]]]) -> None:
183 y_pred, y = output
184 self._sum_of_bleu += self._corpus_bleu(references=[y], candidates=[y_pred])
185 self._num_sentences += 1
186
187 @sync_all_reduce("_sum_of_bleu", "_num_sentences")
188 def compute(self) -> torch.Tensor:
189 if self._num_sentences == 0:
190 raise NotComputableError("Bleu must have at least one example before it can be computed.")
191 return self._sum_of_bleu / self._num_sentences
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/metrics/nlp/bleu.py b/ignite/metrics/nlp/bleu.py
--- a/ignite/metrics/nlp/bleu.py
+++ b/ignite/metrics/nlp/bleu.py
@@ -1,6 +1,6 @@
import math
from collections import Counter
-from typing import Any, Callable, Sequence, Tuple, Union
+from typing import Any, Callable, Sequence, Tuple, Union, ValuesView
import torch
@@ -42,11 +42,17 @@
@staticmethod
def nltk_smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:
denominators_ = [max(1, d) for d in denominators.values()]
- return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators_)]
+ return _Smoother._smooth2(numerators.values(), denominators_)
@staticmethod
def smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:
- return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators.values())]
+ return _Smoother._smooth2(numerators.values(), denominators.values())
+
+ @staticmethod
+ def _smooth2(
+ numerators: Union[ValuesView[int], Sequence[int]], denominators: Union[ValuesView[int], Sequence[int]]
+ ) -> Sequence[float]:
+ return [(n + 1) / (d + 1) if i != 0 else n / d for i, (n, d) in enumerate(zip(numerators, denominators))]
@staticmethod
def no_smooth(numerators: Counter, denominators: Counter) -> Sequence[float]:
|
{"golden_diff": "diff --git a/ignite/metrics/nlp/bleu.py b/ignite/metrics/nlp/bleu.py\n--- a/ignite/metrics/nlp/bleu.py\n+++ b/ignite/metrics/nlp/bleu.py\n@@ -1,6 +1,6 @@\n import math\n from collections import Counter\n-from typing import Any, Callable, Sequence, Tuple, Union\n+from typing import Any, Callable, Sequence, Tuple, Union, ValuesView\n \n import torch\n \n@@ -42,11 +42,17 @@\n @staticmethod\n def nltk_smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n denominators_ = [max(1, d) for d in denominators.values()]\n- return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators_)]\n+ return _Smoother._smooth2(numerators.values(), denominators_)\n \n @staticmethod\n def smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n- return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators.values())]\n+ return _Smoother._smooth2(numerators.values(), denominators.values())\n+\n+ @staticmethod\n+ def _smooth2(\n+ numerators: Union[ValuesView[int], Sequence[int]], denominators: Union[ValuesView[int], Sequence[int]]\n+ ) -> Sequence[float]:\n+ return [(n + 1) / (d + 1) if i != 0 else n / d for i, (n, d) in enumerate(zip(numerators, denominators))]\n \n @staticmethod\n def no_smooth(numerators: Counter, denominators: Counter) -> Sequence[float]:\n", "issue": "CI tests are failing on BLEU\nCI tests on Master are failing on checking Bleu metric: \r\n\r\n- https://app.circleci.com/pipelines/github/pytorch/ignite/1755/workflows/00c8cfad-8243-4f5f-9e9e-b8eaeee58b17\r\n- https://github.com/pytorch/ignite/actions/runs/725753501\r\n\r\ncc @sdesrozis @gucifer \n", "before_files": [{"content": "import math\nfrom collections import Counter\nfrom typing import Any, Callable, Sequence, Tuple, Union\n\nimport torch\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\nfrom ignite.metrics.nlp.utils import modified_precision\n\n__all__ = [\"Bleu\"]\n\n\ndef _closest_ref_length(references: Sequence[Sequence[Any]], hyp_len: int) -> int:\n ref_lens = (len(reference) for reference in references)\n closest_ref_len = min(ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len))\n return closest_ref_len\n\n\nclass _Smoother:\n \"\"\"\n Smoothing helper\n http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf\n \"\"\"\n\n def __init__(self, method: str):\n valid = [\"no_smooth\", \"smooth1\", \"nltk_smooth2\", \"smooth2\"]\n if method not in valid:\n raise ValueError(f\"Smooth is not valid (expected: {valid}, got: {method})\")\n self.smooth = method\n\n def __call__(self, numerators: Counter, denominators: Counter) -> Sequence[float]:\n method = getattr(self, self.smooth)\n return method(numerators, denominators)\n\n @staticmethod\n def smooth1(numerators: Counter, denominators: Counter) -> Sequence[float]:\n epsilon = 0.1\n denominators_ = [max(1, d) for d in denominators.values()]\n return [n / d if n != 0 else epsilon / d for n, d in zip(numerators.values(), denominators_)]\n\n @staticmethod\n def nltk_smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n denominators_ = [max(1, d) for d in denominators.values()]\n return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators_)]\n\n @staticmethod\n def smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n return [(n + 1) / (d + 1) for n, d in zip(numerators.values(), denominators.values())]\n\n @staticmethod\n def no_smooth(numerators: Counter, denominators: Counter) -> Sequence[float]:\n denominators_ = [max(1, d) for d in denominators.values()]\n return [n / d for n, d in zip(numerators.values(), denominators_)]\n\n\nclass Bleu(Metric):\n r\"\"\"Calculates the `BLEU score <https://en.wikipedia.org/wiki/BLEU>`_.\n\n .. math::\n \\text{BLEU} = b_{p} \\cdot \\exp \\left( \\sum_{n=1}^{N} w_{n} \\: \\log p_{n} \\right)\n\n where :math:`N` is the order of n-grams, :math:`b_{p}` is a sentence brevety penalty, :math:`w_{n}` are\n positive weights summing to one and :math:`p_{n}` are modified n-gram precisions.\n\n More details can be found in `Papineni et al. 2002`__.\n\n __ https://www.aclweb.org/anthology/P02-1040.pdf\n\n In addition, a review of smoothing techniques can be found in `Chen et al. 2014`__\n\n __ http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf\n\n Remark :\n\n This implementation is inspired by nltk\n\n Args:\n ngram: order of n-grams.\n smooth: enable smoothing. Valid are ``no_smooth``, ``smooth1``, ``nltk_smooth2`` or ``smooth2``.\n Default: ``no_smooth``.\n output_transform: a callable that is used to transform the\n :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n By default, metrics require the output as ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y}``.\n device: specifies which device updates are accumulated on. Setting the\n metric's device to be the same as your ``update`` arguments ensures the ``update`` method is\n non-blocking. By default, CPU.\n\n Example:\n\n .. code-block:: python\n\n from ignite.metrics.nlp import Bleu\n\n m = Bleu(ngram=4, smooth=\"smooth1\")\n\n y_pred = \"the the the the the the the\"\n y = [\"the cat is on the mat\", \"there is a cat on the mat\"]\n\n m.update((y_pred.split(), [y.split()]))\n\n print(m.compute())\n\n .. versionadded:: 0.5.0\n \"\"\"\n\n def __init__(\n self,\n ngram: int = 4,\n smooth: str = \"no_smooth\",\n output_transform: Callable = lambda x: x,\n device: Union[str, torch.device] = torch.device(\"cpu\"),\n ):\n if ngram <= 0:\n raise ValueError(f\"ngram order must be greater than zero (got: {ngram})\")\n self.ngrams_order = ngram\n self.weights = [1 / self.ngrams_order] * self.ngrams_order\n self.smoother = _Smoother(method=smooth)\n super(Bleu, self).__init__(output_transform=output_transform, device=device)\n\n def _corpus_bleu(self, references: Sequence[Sequence[Any]], candidates: Sequence[Sequence[Any]],) -> float:\n p_numerators: Counter = Counter()\n p_denominators: Counter = Counter()\n\n if len(references) != len(candidates):\n raise ValueError(\n f\"nb of candidates should be equal to nb of reference lists ({len(candidates)} != \"\n f\"{len(references)})\"\n )\n\n # Iterate through each hypothesis and their corresponding references.\n for refs, hyp in zip(references, candidates):\n # For each order of ngram, calculate the numerator and\n # denominator for the corpus-level modified precision.\n for i in range(1, self.ngrams_order + 1):\n numerator, denominator = modified_precision(refs, hyp, i)\n p_numerators[i] += numerator\n p_denominators[i] += denominator\n\n # Returns 0 if there's no matching n-grams\n # We only need to check for p_numerators[1] == 0, since if there's\n # no unigrams, there won't be any higher order ngrams.\n if p_numerators[1] == 0:\n return 0\n\n # If no smoother, returns 0 if there's at least one a not matching n-grams\n if self.smoother.smooth == \"no_smooth\" and min(p_numerators.values()) == 0:\n return 0\n\n # Calculate the hypothesis lengths\n hyp_lengths = [len(hyp) for hyp in candidates]\n\n # Calculate the closest reference lengths.\n ref_lengths = [_closest_ref_length(refs, hyp_len) for refs, hyp_len in zip(references, hyp_lengths)]\n\n # Sum of hypothesis and references lengths\n hyp_len = sum(hyp_lengths)\n ref_len = sum(ref_lengths)\n\n # Calculate corpus-level brevity penalty.\n if hyp_len < ref_len:\n bp = math.exp(1 - ref_len / hyp_len) if hyp_len > 0 else 0.0\n else:\n bp = 1.0\n\n # Smoothing\n p_n = self.smoother(p_numerators, p_denominators)\n\n # Compute the geometric mean\n s = [w_i * math.log(p_i) for w_i, p_i in zip(self.weights, p_n)]\n gm = bp * math.exp(math.fsum(s))\n return gm\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._sum_of_bleu = torch.tensor(0.0, dtype=torch.double, device=self._device)\n self._num_sentences = 0\n\n @reinit__is_reduced\n def update(self, output: Tuple[Sequence[Any], Sequence[Sequence[Any]]]) -> None:\n y_pred, y = output\n self._sum_of_bleu += self._corpus_bleu(references=[y], candidates=[y_pred])\n self._num_sentences += 1\n\n @sync_all_reduce(\"_sum_of_bleu\", \"_num_sentences\")\n def compute(self) -> torch.Tensor:\n if self._num_sentences == 0:\n raise NotComputableError(\"Bleu must have at least one example before it can be computed.\")\n return self._sum_of_bleu / self._num_sentences\n", "path": "ignite/metrics/nlp/bleu.py"}], "after_files": [{"content": "import math\nfrom collections import Counter\nfrom typing import Any, Callable, Sequence, Tuple, Union, ValuesView\n\nimport torch\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\nfrom ignite.metrics.nlp.utils import modified_precision\n\n__all__ = [\"Bleu\"]\n\n\ndef _closest_ref_length(references: Sequence[Sequence[Any]], hyp_len: int) -> int:\n ref_lens = (len(reference) for reference in references)\n closest_ref_len = min(ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len))\n return closest_ref_len\n\n\nclass _Smoother:\n \"\"\"\n Smoothing helper\n http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf\n \"\"\"\n\n def __init__(self, method: str):\n valid = [\"no_smooth\", \"smooth1\", \"nltk_smooth2\", \"smooth2\"]\n if method not in valid:\n raise ValueError(f\"Smooth is not valid (expected: {valid}, got: {method})\")\n self.smooth = method\n\n def __call__(self, numerators: Counter, denominators: Counter) -> Sequence[float]:\n method = getattr(self, self.smooth)\n return method(numerators, denominators)\n\n @staticmethod\n def smooth1(numerators: Counter, denominators: Counter) -> Sequence[float]:\n epsilon = 0.1\n denominators_ = [max(1, d) for d in denominators.values()]\n return [n / d if n != 0 else epsilon / d for n, d in zip(numerators.values(), denominators_)]\n\n @staticmethod\n def nltk_smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n denominators_ = [max(1, d) for d in denominators.values()]\n return _Smoother._smooth2(numerators.values(), denominators_)\n\n @staticmethod\n def smooth2(numerators: Counter, denominators: Counter) -> Sequence[float]:\n return _Smoother._smooth2(numerators.values(), denominators.values())\n\n @staticmethod\n def _smooth2(\n numerators: Union[ValuesView[int], Sequence[int]], denominators: Union[ValuesView[int], Sequence[int]]\n ) -> Sequence[float]:\n return [(n + 1) / (d + 1) if i != 0 else n / d for i, (n, d) in enumerate(zip(numerators, denominators))]\n\n @staticmethod\n def no_smooth(numerators: Counter, denominators: Counter) -> Sequence[float]:\n denominators_ = [max(1, d) for d in denominators.values()]\n return [n / d for n, d in zip(numerators.values(), denominators_)]\n\n\nclass Bleu(Metric):\n r\"\"\"Calculates the `BLEU score <https://en.wikipedia.org/wiki/BLEU>`_.\n\n .. math::\n \\text{BLEU} = b_{p} \\cdot \\exp \\left( \\sum_{n=1}^{N} w_{n} \\: \\log p_{n} \\right)\n\n where :math:`N` is the order of n-grams, :math:`b_{p}` is a sentence brevety penalty, :math:`w_{n}` are\n positive weights summing to one and :math:`p_{n}` are modified n-gram precisions.\n\n More details can be found in `Papineni et al. 2002`__.\n\n __ https://www.aclweb.org/anthology/P02-1040.pdf\n\n In addition, a review of smoothing techniques can be found in `Chen et al. 2014`__\n\n __ http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf\n\n Remark :\n\n This implementation is inspired by nltk\n\n Args:\n ngram: order of n-grams.\n smooth: enable smoothing. Valid are ``no_smooth``, ``smooth1``, ``nltk_smooth2`` or ``smooth2``.\n Default: ``no_smooth``.\n output_transform: a callable that is used to transform the\n :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n By default, metrics require the output as ``(y_pred, y)`` or ``{'y_pred': y_pred, 'y': y}``.\n device: specifies which device updates are accumulated on. Setting the\n metric's device to be the same as your ``update`` arguments ensures the ``update`` method is\n non-blocking. By default, CPU.\n\n Example:\n\n .. code-block:: python\n\n from ignite.metrics.nlp import Bleu\n\n m = Bleu(ngram=4, smooth=\"smooth1\")\n\n y_pred = \"the the the the the the the\"\n y = [\"the cat is on the mat\", \"there is a cat on the mat\"]\n\n m.update((y_pred.split(), [y.split()]))\n\n print(m.compute())\n\n .. versionadded:: 0.5.0\n \"\"\"\n\n def __init__(\n self,\n ngram: int = 4,\n smooth: str = \"no_smooth\",\n output_transform: Callable = lambda x: x,\n device: Union[str, torch.device] = torch.device(\"cpu\"),\n ):\n if ngram <= 0:\n raise ValueError(f\"ngram order must be greater than zero (got: {ngram})\")\n self.ngrams_order = ngram\n self.weights = [1 / self.ngrams_order] * self.ngrams_order\n self.smoother = _Smoother(method=smooth)\n super(Bleu, self).__init__(output_transform=output_transform, device=device)\n\n def _corpus_bleu(self, references: Sequence[Sequence[Any]], candidates: Sequence[Sequence[Any]],) -> float:\n p_numerators: Counter = Counter()\n p_denominators: Counter = Counter()\n\n if len(references) != len(candidates):\n raise ValueError(\n f\"nb of candidates should be equal to nb of reference lists ({len(candidates)} != \"\n f\"{len(references)})\"\n )\n\n # Iterate through each hypothesis and their corresponding references.\n for refs, hyp in zip(references, candidates):\n # For each order of ngram, calculate the numerator and\n # denominator for the corpus-level modified precision.\n for i in range(1, self.ngrams_order + 1):\n numerator, denominator = modified_precision(refs, hyp, i)\n p_numerators[i] += numerator\n p_denominators[i] += denominator\n\n # Returns 0 if there's no matching n-grams\n # We only need to check for p_numerators[1] == 0, since if there's\n # no unigrams, there won't be any higher order ngrams.\n if p_numerators[1] == 0:\n return 0\n\n # If no smoother, returns 0 if there's at least one a not matching n-grams\n if self.smoother.smooth == \"no_smooth\" and min(p_numerators.values()) == 0:\n return 0\n\n # Calculate the hypothesis lengths\n hyp_lengths = [len(hyp) for hyp in candidates]\n\n # Calculate the closest reference lengths.\n ref_lengths = [_closest_ref_length(refs, hyp_len) for refs, hyp_len in zip(references, hyp_lengths)]\n\n # Sum of hypothesis and references lengths\n hyp_len = sum(hyp_lengths)\n ref_len = sum(ref_lengths)\n\n # Calculate corpus-level brevity penalty.\n if hyp_len < ref_len:\n bp = math.exp(1 - ref_len / hyp_len) if hyp_len > 0 else 0.0\n else:\n bp = 1.0\n\n # Smoothing\n p_n = self.smoother(p_numerators, p_denominators)\n\n # Compute the geometric mean\n s = [w_i * math.log(p_i) for w_i, p_i in zip(self.weights, p_n)]\n gm = bp * math.exp(math.fsum(s))\n return gm\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._sum_of_bleu = torch.tensor(0.0, dtype=torch.double, device=self._device)\n self._num_sentences = 0\n\n @reinit__is_reduced\n def update(self, output: Tuple[Sequence[Any], Sequence[Sequence[Any]]]) -> None:\n y_pred, y = output\n self._sum_of_bleu += self._corpus_bleu(references=[y], candidates=[y_pred])\n self._num_sentences += 1\n\n @sync_all_reduce(\"_sum_of_bleu\", \"_num_sentences\")\n def compute(self) -> torch.Tensor:\n if self._num_sentences == 0:\n raise NotComputableError(\"Bleu must have at least one example before it can be computed.\")\n return self._sum_of_bleu / self._num_sentences\n", "path": "ignite/metrics/nlp/bleu.py"}]}
| 2,848 | 397 |
gh_patches_debug_6953
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2526
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Vacancies without partner page on homepage lead to 404 errors
### Describe the bug
The vacancy view on the homepage leads to a 404 for vacancies without partner pages, as it tries to go to that page anyway.
### How to reproduce
Steps to reproduce the behaviour:
1. Create an inactive partner
2. Create a vacancy with them
3. Make it appear on the homepage
4. Click it
### Expected behaviour
Going to the vacancy in some way, e.g. on the general vacancy page.
### Screenshots
If applicable, add screenshots to help explain your problem.
### Additional context
I think I sort of fixed this for the main vacancy list, so we can probably share the code there. (Although I believe that that is currently broken too.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/partners/templatetags/frontpage_vacancies.py`
Content:
```
1 from django import template
2 from django.urls import reverse
3
4 from partners.models import Vacancy
5
6 register = template.Library()
7
8
9 @register.inclusion_tag("partners/frontpage_vacancies.html")
10 def render_frontpage_vacancies():
11 vacancies = []
12
13 for vacancy in Vacancy.objects.order_by("?")[:6]:
14 url = "{}#vacancy-{}".format(reverse("partners:vacancies"), vacancy.id)
15 if vacancy.partner:
16 url = "{}#vacancy-{}".format(vacancy.partner.get_absolute_url(), vacancy.id)
17
18 vacancies.append(
19 {
20 "title": vacancy.title,
21 "company_name": vacancy.get_company_name(),
22 "url": url,
23 }
24 )
25
26 return {"vacancies": vacancies}
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/partners/templatetags/frontpage_vacancies.py b/website/partners/templatetags/frontpage_vacancies.py
--- a/website/partners/templatetags/frontpage_vacancies.py
+++ b/website/partners/templatetags/frontpage_vacancies.py
@@ -12,7 +12,7 @@
for vacancy in Vacancy.objects.order_by("?")[:6]:
url = "{}#vacancy-{}".format(reverse("partners:vacancies"), vacancy.id)
- if vacancy.partner:
+ if vacancy.partner and vacancy.partner.is_active:
url = "{}#vacancy-{}".format(vacancy.partner.get_absolute_url(), vacancy.id)
vacancies.append(
|
{"golden_diff": "diff --git a/website/partners/templatetags/frontpage_vacancies.py b/website/partners/templatetags/frontpage_vacancies.py\n--- a/website/partners/templatetags/frontpage_vacancies.py\n+++ b/website/partners/templatetags/frontpage_vacancies.py\n@@ -12,7 +12,7 @@\n \n for vacancy in Vacancy.objects.order_by(\"?\")[:6]:\n url = \"{}#vacancy-{}\".format(reverse(\"partners:vacancies\"), vacancy.id)\n- if vacancy.partner:\n+ if vacancy.partner and vacancy.partner.is_active:\n url = \"{}#vacancy-{}\".format(vacancy.partner.get_absolute_url(), vacancy.id)\n \n vacancies.append(\n", "issue": "Vacancies without partner page on homepage lead to 404 errors\n### Describe the bug\r\nThe vacancy view on the homepage leads to a 404 for vacancies without partner pages, as it tries to go to that page anyway.\r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. Create an inactive partner\r\n2. Create a vacancy with them\r\n3. Make it appear on the homepage\r\n4. Click it\r\n\r\n### Expected behaviour\r\nGoing to the vacancy in some way, e.g. on the general vacancy page.\r\n\r\n### Screenshots\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n### Additional context\r\nI think I sort of fixed this for the main vacancy list, so we can probably share the code there. (Although I believe that that is currently broken too.)\r\n\n", "before_files": [{"content": "from django import template\nfrom django.urls import reverse\n\nfrom partners.models import Vacancy\n\nregister = template.Library()\n\n\[email protected]_tag(\"partners/frontpage_vacancies.html\")\ndef render_frontpage_vacancies():\n vacancies = []\n\n for vacancy in Vacancy.objects.order_by(\"?\")[:6]:\n url = \"{}#vacancy-{}\".format(reverse(\"partners:vacancies\"), vacancy.id)\n if vacancy.partner:\n url = \"{}#vacancy-{}\".format(vacancy.partner.get_absolute_url(), vacancy.id)\n\n vacancies.append(\n {\n \"title\": vacancy.title,\n \"company_name\": vacancy.get_company_name(),\n \"url\": url,\n }\n )\n\n return {\"vacancies\": vacancies}\n", "path": "website/partners/templatetags/frontpage_vacancies.py"}], "after_files": [{"content": "from django import template\nfrom django.urls import reverse\n\nfrom partners.models import Vacancy\n\nregister = template.Library()\n\n\[email protected]_tag(\"partners/frontpage_vacancies.html\")\ndef render_frontpage_vacancies():\n vacancies = []\n\n for vacancy in Vacancy.objects.order_by(\"?\")[:6]:\n url = \"{}#vacancy-{}\".format(reverse(\"partners:vacancies\"), vacancy.id)\n if vacancy.partner and vacancy.partner.is_active:\n url = \"{}#vacancy-{}\".format(vacancy.partner.get_absolute_url(), vacancy.id)\n\n vacancies.append(\n {\n \"title\": vacancy.title,\n \"company_name\": vacancy.get_company_name(),\n \"url\": url,\n }\n )\n\n return {\"vacancies\": vacancies}\n", "path": "website/partners/templatetags/frontpage_vacancies.py"}]}
| 634 | 162 |
gh_patches_debug_7989
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1914
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[nginx] No debug logging when doing Pokémon exception handling
The [nginx code](https://github.com/DataDog/dd-agent/blob/49952b4429b125619bc8d9f51bb6564e7c0d2e12/checks.d/nginx.py#L45-L50) follows a [pattern of catching all exceptions](http://blog.codinghorror.com/new-programming-jargon/) when attempting to submit a metric, which makes sense due to wanting to continue without error. Unfortunately, it additionally eats the real error message and displays a super generic message in the logs. This makes it very difficult to actually debug issues.
I ended up manually modifying the code on my local install to figure out that my `nginx.yaml` had a syntax error in it. It would have been more obvious if the true exception (`unhashable type: 'dict'`) had been printed out. (Additionally, there should probably be error checking when tags are loaded instead of reported.)
I'm willing to fix either or both of these issues, but would like advice on how you would like to see them done (e.g. log at a different level? Log to stderr?). Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checks.d/nginx.py`
Content:
```
1 # stdlib
2 import re
3 import urlparse
4
5 # 3rd party
6 import requests
7 import simplejson as json
8
9 # project
10 from checks import AgentCheck
11 from util import headers
12
13
14 class Nginx(AgentCheck):
15 """Tracks basic nginx metrics via the status module
16 * number of connections
17 * number of requets per second
18
19 Requires nginx to have the status option compiled.
20 See http://wiki.nginx.org/HttpStubStatusModule for more details
21
22 $ curl http://localhost:81/nginx_status/
23 Active connections: 8
24 server accepts handled requests
25 1156958 1156958 4491319
26 Reading: 0 Writing: 2 Waiting: 6
27
28 """
29 def check(self, instance):
30 if 'nginx_status_url' not in instance:
31 raise Exception('NginX instance missing "nginx_status_url" value.')
32 tags = instance.get('tags', [])
33
34 response, content_type = self._get_data(instance)
35 self.log.debug(u"Nginx status `response`: {0}".format(response))
36 self.log.debug(u"Nginx status `content_type`: {0}".format(content_type))
37
38 if content_type.startswith('application/json'):
39 metrics = self.parse_json(response, tags)
40 else:
41 metrics = self.parse_text(response, tags)
42
43 funcs = {
44 'gauge': self.gauge,
45 'rate': self.rate
46 }
47 for row in metrics:
48 try:
49 name, value, tags, metric_type = row
50 func = funcs[metric_type]
51 func(name, value, tags)
52 except Exception:
53 self.log.error(u'Could not submit metric: %s' % repr(row))
54
55 def _get_data(self, instance):
56 url = instance.get('nginx_status_url')
57 ssl_validation = instance.get('ssl_validation', True)
58
59 auth = None
60 if 'user' in instance and 'password' in instance:
61 auth = (instance['user'], instance['password'])
62
63 # Submit a service check for status page availability.
64 parsed_url = urlparse.urlparse(url)
65 nginx_host = parsed_url.hostname
66 nginx_port = parsed_url.port or 80
67 service_check_name = 'nginx.can_connect'
68 service_check_tags = ['host:%s' % nginx_host, 'port:%s' % nginx_port]
69 try:
70 self.log.debug(u"Querying URL: {0}".format(url))
71 r = requests.get(url, auth=auth, headers=headers(self.agentConfig),
72 verify=ssl_validation)
73 r.raise_for_status()
74 except Exception:
75 self.service_check(service_check_name, AgentCheck.CRITICAL,
76 tags=service_check_tags)
77 raise
78 else:
79 self.service_check(service_check_name, AgentCheck.OK,
80 tags=service_check_tags)
81
82 body = r.content
83 resp_headers = r.headers
84 return body, resp_headers.get('content-type', 'text/plain')
85
86 @classmethod
87 def parse_text(cls, raw, tags):
88 # Thanks to http://hostingfu.com/files/nginx/nginxstats.py for this code
89 # Connections
90 output = []
91 parsed = re.search(r'Active connections:\s+(\d+)', raw)
92 if parsed:
93 connections = int(parsed.group(1))
94 output.append(('nginx.net.connections', connections, tags, 'gauge'))
95
96 # Requests per second
97 parsed = re.search(r'\s*(\d+)\s+(\d+)\s+(\d+)', raw)
98 if parsed:
99 conn = int(parsed.group(1))
100 handled = int(parsed.group(2))
101 requests = int(parsed.group(3))
102 output.extend([('nginx.net.conn_opened_per_s', conn, tags, 'rate'),
103 ('nginx.net.conn_dropped_per_s', conn - handled, tags, 'rate'),
104 ('nginx.net.request_per_s', requests, tags, 'rate')])
105
106 # Connection states, reading, writing or waiting for clients
107 parsed = re.search(r'Reading: (\d+)\s+Writing: (\d+)\s+Waiting: (\d+)', raw)
108 if parsed:
109 reading, writing, waiting = parsed.groups()
110 output.extend([
111 ("nginx.net.reading", int(reading), tags, 'gauge'),
112 ("nginx.net.writing", int(writing), tags, 'gauge'),
113 ("nginx.net.waiting", int(waiting), tags, 'gauge'),
114 ])
115 return output
116
117 @classmethod
118 def parse_json(cls, raw, tags=None):
119 if tags is None:
120 tags = []
121 parsed = json.loads(raw)
122 metric_base = 'nginx'
123 output = []
124 all_keys = parsed.keys()
125
126 tagged_keys = [('caches', 'cache'), ('server_zones', 'server_zone'),
127 ('upstreams', 'upstream')]
128
129 # Process the special keys that should turn into tags instead of
130 # getting concatenated to the metric name
131 for key, tag_name in tagged_keys:
132 metric_name = '%s.%s' % (metric_base, tag_name)
133 for tag_val, data in parsed.get(key, {}).iteritems():
134 tag = '%s:%s' % (tag_name, tag_val)
135 output.extend(cls._flatten_json(metric_name, data, tags + [tag]))
136
137 # Process the rest of the keys
138 rest = set(all_keys) - set([k for k, _ in tagged_keys])
139 for key in rest:
140 metric_name = '%s.%s' % (metric_base, key)
141 output.extend(cls._flatten_json(metric_name, parsed[key], tags))
142
143 return output
144
145 @classmethod
146 def _flatten_json(cls, metric_base, val, tags):
147 ''' Recursively flattens the nginx json object. Returns the following:
148 [(metric_name, value, tags)]
149 '''
150 output = []
151 if isinstance(val, dict):
152 # Pull out the server as a tag instead of trying to read as a metric
153 if 'server' in val and val['server']:
154 server = 'server:%s' % val.pop('server')
155 if tags is None:
156 tags = [server]
157 else:
158 tags = tags + [server]
159 for key, val2 in val.iteritems():
160 metric_name = '%s.%s' % (metric_base, key)
161 output.extend(cls._flatten_json(metric_name, val2, tags))
162
163 elif isinstance(val, list):
164 for val2 in val:
165 output.extend(cls._flatten_json(metric_base, val2, tags))
166
167 elif isinstance(val, bool):
168 # Turn bools into 0/1 values
169 if val:
170 val = 1
171 else:
172 val = 0
173 output.append((metric_base, val, tags, 'gauge'))
174
175 elif isinstance(val, (int, float)):
176 output.append((metric_base, val, tags, 'gauge'))
177
178 return output
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checks.d/nginx.py b/checks.d/nginx.py
--- a/checks.d/nginx.py
+++ b/checks.d/nginx.py
@@ -49,8 +49,8 @@
name, value, tags, metric_type = row
func = funcs[metric_type]
func(name, value, tags)
- except Exception:
- self.log.error(u'Could not submit metric: %s' % repr(row))
+ except Exception, e:
+ self.log.error(u'Could not submit metric: %s: %s' % (repr(row), str(e)))
def _get_data(self, instance):
url = instance.get('nginx_status_url')
|
{"golden_diff": "diff --git a/checks.d/nginx.py b/checks.d/nginx.py\n--- a/checks.d/nginx.py\n+++ b/checks.d/nginx.py\n@@ -49,8 +49,8 @@\n name, value, tags, metric_type = row\n func = funcs[metric_type]\n func(name, value, tags)\n- except Exception:\n- self.log.error(u'Could not submit metric: %s' % repr(row))\n+ except Exception, e:\n+ self.log.error(u'Could not submit metric: %s: %s' % (repr(row), str(e)))\n \n def _get_data(self, instance):\n url = instance.get('nginx_status_url')\n", "issue": "[nginx] No debug logging when doing Pok\u00e9mon exception handling\nThe [nginx code](https://github.com/DataDog/dd-agent/blob/49952b4429b125619bc8d9f51bb6564e7c0d2e12/checks.d/nginx.py#L45-L50) follows a [pattern of catching all exceptions](http://blog.codinghorror.com/new-programming-jargon/) when attempting to submit a metric, which makes sense due to wanting to continue without error. Unfortunately, it additionally eats the real error message and displays a super generic message in the logs. This makes it very difficult to actually debug issues.\n\nI ended up manually modifying the code on my local install to figure out that my `nginx.yaml` had a syntax error in it. It would have been more obvious if the true exception (`unhashable type: 'dict'`) had been printed out. (Additionally, there should probably be error checking when tags are loaded instead of reported.)\n\nI'm willing to fix either or both of these issues, but would like advice on how you would like to see them done (e.g. log at a different level? Log to stderr?). Thanks!\n\n", "before_files": [{"content": "# stdlib\nimport re\nimport urlparse\n\n# 3rd party\nimport requests\nimport simplejson as json\n\n# project\nfrom checks import AgentCheck\nfrom util import headers\n\n\nclass Nginx(AgentCheck):\n \"\"\"Tracks basic nginx metrics via the status module\n * number of connections\n * number of requets per second\n\n Requires nginx to have the status option compiled.\n See http://wiki.nginx.org/HttpStubStatusModule for more details\n\n $ curl http://localhost:81/nginx_status/\n Active connections: 8\n server accepts handled requests\n 1156958 1156958 4491319\n Reading: 0 Writing: 2 Waiting: 6\n\n \"\"\"\n def check(self, instance):\n if 'nginx_status_url' not in instance:\n raise Exception('NginX instance missing \"nginx_status_url\" value.')\n tags = instance.get('tags', [])\n\n response, content_type = self._get_data(instance)\n self.log.debug(u\"Nginx status `response`: {0}\".format(response))\n self.log.debug(u\"Nginx status `content_type`: {0}\".format(content_type))\n\n if content_type.startswith('application/json'):\n metrics = self.parse_json(response, tags)\n else:\n metrics = self.parse_text(response, tags)\n\n funcs = {\n 'gauge': self.gauge,\n 'rate': self.rate\n }\n for row in metrics:\n try:\n name, value, tags, metric_type = row\n func = funcs[metric_type]\n func(name, value, tags)\n except Exception:\n self.log.error(u'Could not submit metric: %s' % repr(row))\n\n def _get_data(self, instance):\n url = instance.get('nginx_status_url')\n ssl_validation = instance.get('ssl_validation', True)\n\n auth = None\n if 'user' in instance and 'password' in instance:\n auth = (instance['user'], instance['password'])\n\n # Submit a service check for status page availability.\n parsed_url = urlparse.urlparse(url)\n nginx_host = parsed_url.hostname\n nginx_port = parsed_url.port or 80\n service_check_name = 'nginx.can_connect'\n service_check_tags = ['host:%s' % nginx_host, 'port:%s' % nginx_port]\n try:\n self.log.debug(u\"Querying URL: {0}\".format(url))\n r = requests.get(url, auth=auth, headers=headers(self.agentConfig),\n verify=ssl_validation)\n r.raise_for_status()\n except Exception:\n self.service_check(service_check_name, AgentCheck.CRITICAL,\n tags=service_check_tags)\n raise\n else:\n self.service_check(service_check_name, AgentCheck.OK,\n tags=service_check_tags)\n\n body = r.content\n resp_headers = r.headers\n return body, resp_headers.get('content-type', 'text/plain')\n\n @classmethod\n def parse_text(cls, raw, tags):\n # Thanks to http://hostingfu.com/files/nginx/nginxstats.py for this code\n # Connections\n output = []\n parsed = re.search(r'Active connections:\\s+(\\d+)', raw)\n if parsed:\n connections = int(parsed.group(1))\n output.append(('nginx.net.connections', connections, tags, 'gauge'))\n\n # Requests per second\n parsed = re.search(r'\\s*(\\d+)\\s+(\\d+)\\s+(\\d+)', raw)\n if parsed:\n conn = int(parsed.group(1))\n handled = int(parsed.group(2))\n requests = int(parsed.group(3))\n output.extend([('nginx.net.conn_opened_per_s', conn, tags, 'rate'),\n ('nginx.net.conn_dropped_per_s', conn - handled, tags, 'rate'),\n ('nginx.net.request_per_s', requests, tags, 'rate')])\n\n # Connection states, reading, writing or waiting for clients\n parsed = re.search(r'Reading: (\\d+)\\s+Writing: (\\d+)\\s+Waiting: (\\d+)', raw)\n if parsed:\n reading, writing, waiting = parsed.groups()\n output.extend([\n (\"nginx.net.reading\", int(reading), tags, 'gauge'),\n (\"nginx.net.writing\", int(writing), tags, 'gauge'),\n (\"nginx.net.waiting\", int(waiting), tags, 'gauge'),\n ])\n return output\n\n @classmethod\n def parse_json(cls, raw, tags=None):\n if tags is None:\n tags = []\n parsed = json.loads(raw)\n metric_base = 'nginx'\n output = []\n all_keys = parsed.keys()\n\n tagged_keys = [('caches', 'cache'), ('server_zones', 'server_zone'),\n ('upstreams', 'upstream')]\n\n # Process the special keys that should turn into tags instead of\n # getting concatenated to the metric name\n for key, tag_name in tagged_keys:\n metric_name = '%s.%s' % (metric_base, tag_name)\n for tag_val, data in parsed.get(key, {}).iteritems():\n tag = '%s:%s' % (tag_name, tag_val)\n output.extend(cls._flatten_json(metric_name, data, tags + [tag]))\n\n # Process the rest of the keys\n rest = set(all_keys) - set([k for k, _ in tagged_keys])\n for key in rest:\n metric_name = '%s.%s' % (metric_base, key)\n output.extend(cls._flatten_json(metric_name, parsed[key], tags))\n\n return output\n\n @classmethod\n def _flatten_json(cls, metric_base, val, tags):\n ''' Recursively flattens the nginx json object. Returns the following:\n [(metric_name, value, tags)]\n '''\n output = []\n if isinstance(val, dict):\n # Pull out the server as a tag instead of trying to read as a metric\n if 'server' in val and val['server']:\n server = 'server:%s' % val.pop('server')\n if tags is None:\n tags = [server]\n else:\n tags = tags + [server]\n for key, val2 in val.iteritems():\n metric_name = '%s.%s' % (metric_base, key)\n output.extend(cls._flatten_json(metric_name, val2, tags))\n\n elif isinstance(val, list):\n for val2 in val:\n output.extend(cls._flatten_json(metric_base, val2, tags))\n\n elif isinstance(val, bool):\n # Turn bools into 0/1 values\n if val:\n val = 1\n else:\n val = 0\n output.append((metric_base, val, tags, 'gauge'))\n\n elif isinstance(val, (int, float)):\n output.append((metric_base, val, tags, 'gauge'))\n\n return output\n", "path": "checks.d/nginx.py"}], "after_files": [{"content": "# stdlib\nimport re\nimport urlparse\n\n# 3rd party\nimport requests\nimport simplejson as json\n\n# project\nfrom checks import AgentCheck\nfrom util import headers\n\n\nclass Nginx(AgentCheck):\n \"\"\"Tracks basic nginx metrics via the status module\n * number of connections\n * number of requets per second\n\n Requires nginx to have the status option compiled.\n See http://wiki.nginx.org/HttpStubStatusModule for more details\n\n $ curl http://localhost:81/nginx_status/\n Active connections: 8\n server accepts handled requests\n 1156958 1156958 4491319\n Reading: 0 Writing: 2 Waiting: 6\n\n \"\"\"\n def check(self, instance):\n if 'nginx_status_url' not in instance:\n raise Exception('NginX instance missing \"nginx_status_url\" value.')\n tags = instance.get('tags', [])\n\n response, content_type = self._get_data(instance)\n self.log.debug(u\"Nginx status `response`: {0}\".format(response))\n self.log.debug(u\"Nginx status `content_type`: {0}\".format(content_type))\n\n if content_type.startswith('application/json'):\n metrics = self.parse_json(response, tags)\n else:\n metrics = self.parse_text(response, tags)\n\n funcs = {\n 'gauge': self.gauge,\n 'rate': self.rate\n }\n for row in metrics:\n try:\n name, value, tags, metric_type = row\n func = funcs[metric_type]\n func(name, value, tags)\n except Exception, e:\n self.log.error(u'Could not submit metric: %s: %s' % (repr(row), str(e)))\n\n def _get_data(self, instance):\n url = instance.get('nginx_status_url')\n ssl_validation = instance.get('ssl_validation', True)\n\n auth = None\n if 'user' in instance and 'password' in instance:\n auth = (instance['user'], instance['password'])\n\n # Submit a service check for status page availability.\n parsed_url = urlparse.urlparse(url)\n nginx_host = parsed_url.hostname\n nginx_port = parsed_url.port or 80\n service_check_name = 'nginx.can_connect'\n service_check_tags = ['host:%s' % nginx_host, 'port:%s' % nginx_port]\n try:\n self.log.debug(u\"Querying URL: {0}\".format(url))\n r = requests.get(url, auth=auth, headers=headers(self.agentConfig),\n verify=ssl_validation)\n r.raise_for_status()\n except Exception:\n self.service_check(service_check_name, AgentCheck.CRITICAL,\n tags=service_check_tags)\n raise\n else:\n self.service_check(service_check_name, AgentCheck.OK,\n tags=service_check_tags)\n\n body = r.content\n resp_headers = r.headers\n return body, resp_headers.get('content-type', 'text/plain')\n\n @classmethod\n def parse_text(cls, raw, tags):\n # Thanks to http://hostingfu.com/files/nginx/nginxstats.py for this code\n # Connections\n output = []\n parsed = re.search(r'Active connections:\\s+(\\d+)', raw)\n if parsed:\n connections = int(parsed.group(1))\n output.append(('nginx.net.connections', connections, tags, 'gauge'))\n\n # Requests per second\n parsed = re.search(r'\\s*(\\d+)\\s+(\\d+)\\s+(\\d+)', raw)\n if parsed:\n conn = int(parsed.group(1))\n handled = int(parsed.group(2))\n requests = int(parsed.group(3))\n output.extend([('nginx.net.conn_opened_per_s', conn, tags, 'rate'),\n ('nginx.net.conn_dropped_per_s', conn - handled, tags, 'rate'),\n ('nginx.net.request_per_s', requests, tags, 'rate')])\n\n # Connection states, reading, writing or waiting for clients\n parsed = re.search(r'Reading: (\\d+)\\s+Writing: (\\d+)\\s+Waiting: (\\d+)', raw)\n if parsed:\n reading, writing, waiting = parsed.groups()\n output.extend([\n (\"nginx.net.reading\", int(reading), tags, 'gauge'),\n (\"nginx.net.writing\", int(writing), tags, 'gauge'),\n (\"nginx.net.waiting\", int(waiting), tags, 'gauge'),\n ])\n return output\n\n @classmethod\n def parse_json(cls, raw, tags=None):\n if tags is None:\n tags = []\n parsed = json.loads(raw)\n metric_base = 'nginx'\n output = []\n all_keys = parsed.keys()\n\n tagged_keys = [('caches', 'cache'), ('server_zones', 'server_zone'),\n ('upstreams', 'upstream')]\n\n # Process the special keys that should turn into tags instead of\n # getting concatenated to the metric name\n for key, tag_name in tagged_keys:\n metric_name = '%s.%s' % (metric_base, tag_name)\n for tag_val, data in parsed.get(key, {}).iteritems():\n tag = '%s:%s' % (tag_name, tag_val)\n output.extend(cls._flatten_json(metric_name, data, tags + [tag]))\n\n # Process the rest of the keys\n rest = set(all_keys) - set([k for k, _ in tagged_keys])\n for key in rest:\n metric_name = '%s.%s' % (metric_base, key)\n output.extend(cls._flatten_json(metric_name, parsed[key], tags))\n\n return output\n\n @classmethod\n def _flatten_json(cls, metric_base, val, tags):\n ''' Recursively flattens the nginx json object. Returns the following:\n [(metric_name, value, tags)]\n '''\n output = []\n if isinstance(val, dict):\n # Pull out the server as a tag instead of trying to read as a metric\n if 'server' in val and val['server']:\n server = 'server:%s' % val.pop('server')\n if tags is None:\n tags = [server]\n else:\n tags = tags + [server]\n for key, val2 in val.iteritems():\n metric_name = '%s.%s' % (metric_base, key)\n output.extend(cls._flatten_json(metric_name, val2, tags))\n\n elif isinstance(val, list):\n for val2 in val:\n output.extend(cls._flatten_json(metric_base, val2, tags))\n\n elif isinstance(val, bool):\n # Turn bools into 0/1 values\n if val:\n val = 1\n else:\n val = 0\n output.append((metric_base, val, tags, 'gauge'))\n\n elif isinstance(val, (int, float)):\n output.append((metric_base, val, tags, 'gauge'))\n\n return output\n", "path": "checks.d/nginx.py"}]}
| 2,441 | 149 |
gh_patches_debug_42930
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2416
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tkinter easyblock does not work with `--module-only`
```
== sanity checking...
ERROR: Traceback (most recent call last):
File "/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/main.py", line 117, in build_and_install_software
(ec_res['success'], app_log, err) = build_and_install_one(ec, init_env)
File "/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py", line 3412, in build_and_install_one
result = app.run_all_steps(run_test_cases=run_test_cases)
File "/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py", line 3311, in run_all_steps
self.run_step(step_name, step_methods)
File "/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py", line 3166, in run_step
step_method(self)()
File "/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/easyblocks/t/tkinter.py", line 101, in sanity_check_step
'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],
AttributeError: 'EB_Tkinter' object has no attribute 'tkinter_so_basename'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/easyblocks/t/tkinter.py`
Content:
```
1 ##
2 # Copyright 2009-2021 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing Tkinter. This is the Python core
27 module to use Tcl/Tk.
28
29 @author: Adam Huffman (The Francis Crick Institute)
30 @author: Ward Poelmans (Free University of Brussels)
31 @author: Kenneth Hoste (HPC-UGent)
32 """
33 import glob
34 import os
35 import tempfile
36 from distutils.version import LooseVersion
37
38 import easybuild.tools.environment as env
39 from easybuild.easyblocks.generic.pythonpackage import det_pylibdir
40 from easybuild.easyblocks.python import EB_Python
41 from easybuild.tools.build_log import EasyBuildError
42 from easybuild.tools.filetools import copy, move_file, remove_dir
43 from easybuild.tools.modules import get_software_root
44 from easybuild.tools.systemtools import get_shared_lib_ext
45
46
47 class EB_Tkinter(EB_Python):
48 """Support for building/installing the Python Tkinter module
49 based on the normal Python module. We build a normal python
50 but only install the Tkinter bits.
51 """
52
53 def configure_step(self):
54 """Check for Tk before configuring"""
55 tk = get_software_root('Tk')
56 if not tk:
57 raise EasyBuildError("Tk is mandatory to build Tkinter")
58
59 # avoid that pip (ab)uses $HOME/.cache/pip
60 # cfr. https://pip.pypa.io/en/stable/reference/pip_install/#caching
61 env.setvar('XDG_CACHE_HOME', tempfile.gettempdir())
62 self.log.info("Using %s as pip cache directory", os.environ['XDG_CACHE_HOME'])
63
64 super(EB_Tkinter, self).configure_step()
65
66 def install_step(self):
67 """Install python but only keep the bits we need"""
68 super(EB_Tkinter, self).install_step()
69
70 tmpdir = tempfile.mkdtemp(dir=self.builddir)
71
72 pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))
73 shlib_ext = get_shared_lib_ext()
74 tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)
75 tkinter_so_hits = glob.glob(tkinter_so)
76 if len(tkinter_so_hits) != 1:
77 raise EasyBuildError("Expected to find exactly one _tkinter*.so: %s", tkinter_so_hits)
78 self.tkinter_so_basename = os.path.basename(tkinter_so_hits[0])
79 if LooseVersion(self.version) >= LooseVersion('3'):
80 tkparts = ["tkinter", os.path.join("lib-dynload", self.tkinter_so_basename)]
81 else:
82 tkparts = ["lib-tk", os.path.join("lib-dynload", self.tkinter_so_basename)]
83
84 copy([os.path.join(pylibdir, x) for x in tkparts], tmpdir)
85
86 remove_dir(self.installdir)
87
88 move_file(os.path.join(tmpdir, tkparts[0]), os.path.join(pylibdir, tkparts[0]))
89 tkinter_so = os.path.basename(tkparts[1])
90 move_file(os.path.join(tmpdir, tkinter_so), os.path.join(pylibdir, tkinter_so))
91
92 def sanity_check_step(self):
93 """Custom sanity check for Python."""
94 if LooseVersion(self.version) >= LooseVersion('3'):
95 tkinter = 'tkinter'
96 else:
97 tkinter = 'Tkinter'
98 custom_commands = ["python -c 'import %s'" % tkinter]
99
100 custom_paths = {
101 'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],
102 'dirs': ['lib']
103 }
104 super(EB_Python, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)
105
106 def make_module_extra(self):
107 """Set PYTHONPATH"""
108 txt = super(EB_Tkinter, self).make_module_extra()
109 pylibdir = os.path.dirname(det_pylibdir())
110 txt += self.module_generator.prepend_paths('PYTHONPATH', pylibdir)
111
112 return txt
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/easyblocks/t/tkinter.py b/easybuild/easyblocks/t/tkinter.py
--- a/easybuild/easyblocks/t/tkinter.py
+++ b/easybuild/easyblocks/t/tkinter.py
@@ -39,6 +39,7 @@
from easybuild.easyblocks.generic.pythonpackage import det_pylibdir
from easybuild.easyblocks.python import EB_Python
from easybuild.tools.build_log import EasyBuildError
+from easybuild.tools.config import build_option
from easybuild.tools.filetools import copy, move_file, remove_dir
from easybuild.tools.modules import get_software_root
from easybuild.tools.systemtools import get_shared_lib_ext
@@ -50,6 +51,11 @@
but only install the Tkinter bits.
"""
+ def __init__(self, *args, **kwargs):
+ """Initialize Tkinter-specific variables."""
+ super(EB_Tkinter, self).__init__(*args, **kwargs)
+ self.tkinter_so_basename = ''
+
def configure_step(self):
"""Check for Tk before configuring"""
tk = get_software_root('Tk')
@@ -69,18 +75,14 @@
tmpdir = tempfile.mkdtemp(dir=self.builddir)
- pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))
- shlib_ext = get_shared_lib_ext()
- tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)
- tkinter_so_hits = glob.glob(tkinter_so)
- if len(tkinter_so_hits) != 1:
- raise EasyBuildError("Expected to find exactly one _tkinter*.so: %s", tkinter_so_hits)
- self.tkinter_so_basename = os.path.basename(tkinter_so_hits[0])
+ if not self.tkinter_so_basename:
+ self.tkinter_so_basename = self.get_tkinter_so_basename()
if LooseVersion(self.version) >= LooseVersion('3'):
tkparts = ["tkinter", os.path.join("lib-dynload", self.tkinter_so_basename)]
else:
tkparts = ["lib-tk", os.path.join("lib-dynload", self.tkinter_so_basename)]
+ pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))
copy([os.path.join(pylibdir, x) for x in tkparts], tmpdir)
remove_dir(self.installdir)
@@ -89,6 +91,21 @@
tkinter_so = os.path.basename(tkparts[1])
move_file(os.path.join(tmpdir, tkinter_so), os.path.join(pylibdir, tkinter_so))
+ def get_tkinter_so_basename(self):
+ pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))
+ shlib_ext = get_shared_lib_ext()
+ if build_option('module_only'):
+ # The build has already taken place so the file will have been moved into the final pylibdir
+ tkinter_so = os.path.join(pylibdir, '_tkinter*.' + shlib_ext)
+ else:
+ tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)
+ tkinter_so_hits = glob.glob(tkinter_so)
+ if len(tkinter_so_hits) != 1:
+ raise EasyBuildError("Expected to find exactly one _tkinter*.so: %s", tkinter_so_hits)
+ tkinter_so_basename = os.path.basename(tkinter_so_hits[0])
+
+ return tkinter_so_basename
+
def sanity_check_step(self):
"""Custom sanity check for Python."""
if LooseVersion(self.version) >= LooseVersion('3'):
@@ -97,6 +114,9 @@
tkinter = 'Tkinter'
custom_commands = ["python -c 'import %s'" % tkinter]
+ if not self.tkinter_so_basename:
+ self.tkinter_so_basename = self.get_tkinter_so_basename()
+
custom_paths = {
'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],
'dirs': ['lib']
|
{"golden_diff": "diff --git a/easybuild/easyblocks/t/tkinter.py b/easybuild/easyblocks/t/tkinter.py\n--- a/easybuild/easyblocks/t/tkinter.py\n+++ b/easybuild/easyblocks/t/tkinter.py\n@@ -39,6 +39,7 @@\n from easybuild.easyblocks.generic.pythonpackage import det_pylibdir\n from easybuild.easyblocks.python import EB_Python\n from easybuild.tools.build_log import EasyBuildError\n+from easybuild.tools.config import build_option\n from easybuild.tools.filetools import copy, move_file, remove_dir\n from easybuild.tools.modules import get_software_root\n from easybuild.tools.systemtools import get_shared_lib_ext\n@@ -50,6 +51,11 @@\n but only install the Tkinter bits.\n \"\"\"\n \n+ def __init__(self, *args, **kwargs):\n+ \"\"\"Initialize Tkinter-specific variables.\"\"\"\n+ super(EB_Tkinter, self).__init__(*args, **kwargs)\n+ self.tkinter_so_basename = ''\n+\n def configure_step(self):\n \"\"\"Check for Tk before configuring\"\"\"\n tk = get_software_root('Tk')\n@@ -69,18 +75,14 @@\n \n tmpdir = tempfile.mkdtemp(dir=self.builddir)\n \n- pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n- shlib_ext = get_shared_lib_ext()\n- tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)\n- tkinter_so_hits = glob.glob(tkinter_so)\n- if len(tkinter_so_hits) != 1:\n- raise EasyBuildError(\"Expected to find exactly one _tkinter*.so: %s\", tkinter_so_hits)\n- self.tkinter_so_basename = os.path.basename(tkinter_so_hits[0])\n+ if not self.tkinter_so_basename:\n+ self.tkinter_so_basename = self.get_tkinter_so_basename()\n if LooseVersion(self.version) >= LooseVersion('3'):\n tkparts = [\"tkinter\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n else:\n tkparts = [\"lib-tk\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n \n+ pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n copy([os.path.join(pylibdir, x) for x in tkparts], tmpdir)\n \n remove_dir(self.installdir)\n@@ -89,6 +91,21 @@\n tkinter_so = os.path.basename(tkparts[1])\n move_file(os.path.join(tmpdir, tkinter_so), os.path.join(pylibdir, tkinter_so))\n \n+ def get_tkinter_so_basename(self):\n+ pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n+ shlib_ext = get_shared_lib_ext()\n+ if build_option('module_only'):\n+ # The build has already taken place so the file will have been moved into the final pylibdir\n+ tkinter_so = os.path.join(pylibdir, '_tkinter*.' + shlib_ext)\n+ else:\n+ tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)\n+ tkinter_so_hits = glob.glob(tkinter_so)\n+ if len(tkinter_so_hits) != 1:\n+ raise EasyBuildError(\"Expected to find exactly one _tkinter*.so: %s\", tkinter_so_hits)\n+ tkinter_so_basename = os.path.basename(tkinter_so_hits[0])\n+\n+ return tkinter_so_basename\n+\n def sanity_check_step(self):\n \"\"\"Custom sanity check for Python.\"\"\"\n if LooseVersion(self.version) >= LooseVersion('3'):\n@@ -97,6 +114,9 @@\n tkinter = 'Tkinter'\n custom_commands = [\"python -c 'import %s'\" % tkinter]\n \n+ if not self.tkinter_so_basename:\n+ self.tkinter_so_basename = self.get_tkinter_so_basename()\n+\n custom_paths = {\n 'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],\n 'dirs': ['lib']\n", "issue": "Tkinter easyblock does not work with `--module-only`\n```\r\n== sanity checking...\r\nERROR: Traceback (most recent call last):\r\n File \"/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/main.py\", line 117, in build_and_install_software\r\n (ec_res['success'], app_log, err) = build_and_install_one(ec, init_env)\r\n File \"/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py\", line 3412, in build_and_install_one\r\n result = app.run_all_steps(run_test_cases=run_test_cases)\r\n File \"/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py\", line 3311, in run_all_steps\r\n self.run_step(step_name, step_methods)\r\n File \"/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/framework/easyblock.py\", line 3166, in run_step\r\n step_method(self)()\r\n File \"/project/def-sponsor00/ocaisa/easybuild/software/EasyBuild/4.3.4/lib/python3.8/site-packages/easybuild/easyblocks/t/tkinter.py\", line 101, in sanity_check_step\r\n 'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],\r\nAttributeError: 'EB_Tkinter' object has no attribute 'tkinter_so_basename'\r\n```\n", "before_files": [{"content": "##\n# Copyright 2009-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing Tkinter. This is the Python core\nmodule to use Tcl/Tk.\n\n@author: Adam Huffman (The Francis Crick Institute)\n@author: Ward Poelmans (Free University of Brussels)\n@author: Kenneth Hoste (HPC-UGent)\n\"\"\"\nimport glob\nimport os\nimport tempfile\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.environment as env\nfrom easybuild.easyblocks.generic.pythonpackage import det_pylibdir\nfrom easybuild.easyblocks.python import EB_Python\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import copy, move_file, remove_dir\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.systemtools import get_shared_lib_ext\n\n\nclass EB_Tkinter(EB_Python):\n \"\"\"Support for building/installing the Python Tkinter module\n based on the normal Python module. We build a normal python\n but only install the Tkinter bits.\n \"\"\"\n\n def configure_step(self):\n \"\"\"Check for Tk before configuring\"\"\"\n tk = get_software_root('Tk')\n if not tk:\n raise EasyBuildError(\"Tk is mandatory to build Tkinter\")\n\n # avoid that pip (ab)uses $HOME/.cache/pip\n # cfr. https://pip.pypa.io/en/stable/reference/pip_install/#caching\n env.setvar('XDG_CACHE_HOME', tempfile.gettempdir())\n self.log.info(\"Using %s as pip cache directory\", os.environ['XDG_CACHE_HOME'])\n\n super(EB_Tkinter, self).configure_step()\n\n def install_step(self):\n \"\"\"Install python but only keep the bits we need\"\"\"\n super(EB_Tkinter, self).install_step()\n\n tmpdir = tempfile.mkdtemp(dir=self.builddir)\n\n pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n shlib_ext = get_shared_lib_ext()\n tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)\n tkinter_so_hits = glob.glob(tkinter_so)\n if len(tkinter_so_hits) != 1:\n raise EasyBuildError(\"Expected to find exactly one _tkinter*.so: %s\", tkinter_so_hits)\n self.tkinter_so_basename = os.path.basename(tkinter_so_hits[0])\n if LooseVersion(self.version) >= LooseVersion('3'):\n tkparts = [\"tkinter\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n else:\n tkparts = [\"lib-tk\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n\n copy([os.path.join(pylibdir, x) for x in tkparts], tmpdir)\n\n remove_dir(self.installdir)\n\n move_file(os.path.join(tmpdir, tkparts[0]), os.path.join(pylibdir, tkparts[0]))\n tkinter_so = os.path.basename(tkparts[1])\n move_file(os.path.join(tmpdir, tkinter_so), os.path.join(pylibdir, tkinter_so))\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for Python.\"\"\"\n if LooseVersion(self.version) >= LooseVersion('3'):\n tkinter = 'tkinter'\n else:\n tkinter = 'Tkinter'\n custom_commands = [\"python -c 'import %s'\" % tkinter]\n\n custom_paths = {\n 'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],\n 'dirs': ['lib']\n }\n super(EB_Python, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)\n\n def make_module_extra(self):\n \"\"\"Set PYTHONPATH\"\"\"\n txt = super(EB_Tkinter, self).make_module_extra()\n pylibdir = os.path.dirname(det_pylibdir())\n txt += self.module_generator.prepend_paths('PYTHONPATH', pylibdir)\n\n return txt\n", "path": "easybuild/easyblocks/t/tkinter.py"}], "after_files": [{"content": "##\n# Copyright 2009-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing Tkinter. This is the Python core\nmodule to use Tcl/Tk.\n\n@author: Adam Huffman (The Francis Crick Institute)\n@author: Ward Poelmans (Free University of Brussels)\n@author: Kenneth Hoste (HPC-UGent)\n\"\"\"\nimport glob\nimport os\nimport tempfile\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.environment as env\nfrom easybuild.easyblocks.generic.pythonpackage import det_pylibdir\nfrom easybuild.easyblocks.python import EB_Python\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.config import build_option\nfrom easybuild.tools.filetools import copy, move_file, remove_dir\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.systemtools import get_shared_lib_ext\n\n\nclass EB_Tkinter(EB_Python):\n \"\"\"Support for building/installing the Python Tkinter module\n based on the normal Python module. We build a normal python\n but only install the Tkinter bits.\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Initialize Tkinter-specific variables.\"\"\"\n super(EB_Tkinter, self).__init__(*args, **kwargs)\n self.tkinter_so_basename = ''\n\n def configure_step(self):\n \"\"\"Check for Tk before configuring\"\"\"\n tk = get_software_root('Tk')\n if not tk:\n raise EasyBuildError(\"Tk is mandatory to build Tkinter\")\n\n # avoid that pip (ab)uses $HOME/.cache/pip\n # cfr. https://pip.pypa.io/en/stable/reference/pip_install/#caching\n env.setvar('XDG_CACHE_HOME', tempfile.gettempdir())\n self.log.info(\"Using %s as pip cache directory\", os.environ['XDG_CACHE_HOME'])\n\n super(EB_Tkinter, self).configure_step()\n\n def install_step(self):\n \"\"\"Install python but only keep the bits we need\"\"\"\n super(EB_Tkinter, self).install_step()\n\n tmpdir = tempfile.mkdtemp(dir=self.builddir)\n\n if not self.tkinter_so_basename:\n self.tkinter_so_basename = self.get_tkinter_so_basename()\n if LooseVersion(self.version) >= LooseVersion('3'):\n tkparts = [\"tkinter\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n else:\n tkparts = [\"lib-tk\", os.path.join(\"lib-dynload\", self.tkinter_so_basename)]\n\n pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n copy([os.path.join(pylibdir, x) for x in tkparts], tmpdir)\n\n remove_dir(self.installdir)\n\n move_file(os.path.join(tmpdir, tkparts[0]), os.path.join(pylibdir, tkparts[0]))\n tkinter_so = os.path.basename(tkparts[1])\n move_file(os.path.join(tmpdir, tkinter_so), os.path.join(pylibdir, tkinter_so))\n\n def get_tkinter_so_basename(self):\n pylibdir = os.path.join(self.installdir, os.path.dirname(det_pylibdir()))\n shlib_ext = get_shared_lib_ext()\n if build_option('module_only'):\n # The build has already taken place so the file will have been moved into the final pylibdir\n tkinter_so = os.path.join(pylibdir, '_tkinter*.' + shlib_ext)\n else:\n tkinter_so = os.path.join(pylibdir, 'lib-dynload', '_tkinter*.' + shlib_ext)\n tkinter_so_hits = glob.glob(tkinter_so)\n if len(tkinter_so_hits) != 1:\n raise EasyBuildError(\"Expected to find exactly one _tkinter*.so: %s\", tkinter_so_hits)\n tkinter_so_basename = os.path.basename(tkinter_so_hits[0])\n\n return tkinter_so_basename\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for Python.\"\"\"\n if LooseVersion(self.version) >= LooseVersion('3'):\n tkinter = 'tkinter'\n else:\n tkinter = 'Tkinter'\n custom_commands = [\"python -c 'import %s'\" % tkinter]\n\n if not self.tkinter_so_basename:\n self.tkinter_so_basename = self.get_tkinter_so_basename()\n\n custom_paths = {\n 'files': [os.path.join(os.path.dirname(det_pylibdir()), self.tkinter_so_basename)],\n 'dirs': ['lib']\n }\n super(EB_Python, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)\n\n def make_module_extra(self):\n \"\"\"Set PYTHONPATH\"\"\"\n txt = super(EB_Tkinter, self).make_module_extra()\n pylibdir = os.path.dirname(det_pylibdir())\n txt += self.module_generator.prepend_paths('PYTHONPATH', pylibdir)\n\n return txt\n", "path": "easybuild/easyblocks/t/tkinter.py"}]}
| 2,028 | 937 |
gh_patches_debug_38534
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2338
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider sunoco is broken
During the global build at 2021-07-21-14-42-39, spider **sunoco** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/logs/sunoco.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/output/sunoco.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/output/sunoco.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/sunoco.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4
5 from locations.items import GeojsonPointItem
6 from locations.hours import OpeningHours
7
8
9 class SunocoSpider(scrapy.Spider):
10 name = "sunoco"
11 item_attributes = {'brand': "Sunoco", 'brand_wikidata': "Q1423218"}
12 allowed_domains = ["sunoco.com"]
13
14 start_urls = ['https://www.sunoco.com/js/locations.json']
15
16 def parse(self, response):
17 for location in json.loads(response.body_as_unicode()):
18 opening_hours = OpeningHours()
19
20 for key in [
21 'Hrs of Operation Mon-Sat Open',
22 'Hrs of Operation Mon-Sat Close',
23 'Hrs of Operation Sun Open',
24 'Hrs of Operation Sun Close'
25 ]:
26 if location[key] >= 2400:
27 location[key] -= 2400
28
29 for day in ['Mo', 'Tu', 'We', 'Th', 'Fr', 'Sa']:
30 opening_hours.add_range(day=day,
31 open_time=f"{location['Hrs of Operation Mon-Sat Open']:04d}",
32 close_time=f"{location['Hrs of Operation Mon-Sat Close']:04d}",
33 time_format='%H%M')
34
35 opening_hours.add_range(day='Su',
36 open_time=f"{location['Hrs of Operation Sun Open']:04d}",
37 close_time=f"{location['Hrs of Operation Sun Close']:04d}",
38 time_format='%H%M')
39
40 yield GeojsonPointItem(
41 ref=location['Facility ID'],
42 lon=location['Longitude'],
43 lat=location['Latitude'],
44 # name as shown on the Sunoco site
45 name=f"Sunoco #{location['Facility ID']}",
46 addr_full=location['Address'],
47 city=location['City'],
48 state=location['State'],
49 postcode=location['Zip'],
50 country='US',
51 phone=location['Phone'],
52 opening_hours=opening_hours.as_opening_hours(),
53 extras={
54 'amenity:fuel': True,
55 'atm': int(location['ATM'] or 0) == 1,
56 'car_wash': int(location['Car Wash'] or 0) == 1,
57 'fuel:diesel': int(location['Diesel'] or 0) == 1,
58 'fuel:kerosene': int(location['Kerosene'] or 0) == 1
59 }
60 )
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/sunoco.py b/locations/spiders/sunoco.py
--- a/locations/spiders/sunoco.py
+++ b/locations/spiders/sunoco.py
@@ -17,44 +17,34 @@
for location in json.loads(response.body_as_unicode()):
opening_hours = OpeningHours()
- for key in [
- 'Hrs of Operation Mon-Sat Open',
- 'Hrs of Operation Mon-Sat Close',
- 'Hrs of Operation Sun Open',
- 'Hrs of Operation Sun Close'
- ]:
- if location[key] >= 2400:
- location[key] -= 2400
-
- for day in ['Mo', 'Tu', 'We', 'Th', 'Fr', 'Sa']:
- opening_hours.add_range(day=day,
- open_time=f"{location['Hrs of Operation Mon-Sat Open']:04d}",
- close_time=f"{location['Hrs of Operation Mon-Sat Close']:04d}",
- time_format='%H%M')
-
- opening_hours.add_range(day='Su',
- open_time=f"{location['Hrs of Operation Sun Open']:04d}",
- close_time=f"{location['Hrs of Operation Sun Close']:04d}",
- time_format='%H%M')
+ for key, val in location.items():
+ if not key.endswith('_Hours'):
+ continue
+ day = key[:2].capitalize()
+ if val == '24 hours':
+ open_time = close_time = '12 AM'
+ else:
+ open_time, close_time = val.split(' to ')
+ opening_hours.add_range(day, open_time, close_time, '%I %p')
yield GeojsonPointItem(
- ref=location['Facility ID'],
+ ref=location['Store_ID'],
lon=location['Longitude'],
lat=location['Latitude'],
# name as shown on the Sunoco site
- name=f"Sunoco #{location['Facility ID']}",
- addr_full=location['Address'],
+ name=f"Sunoco #{location['Store_ID']}",
+ addr_full=location['Street_Address'],
city=location['City'],
state=location['State'],
- postcode=location['Zip'],
+ postcode=location['Postalcode'],
country='US',
phone=location['Phone'],
opening_hours=opening_hours.as_opening_hours(),
extras={
'amenity:fuel': True,
- 'atm': int(location['ATM'] or 0) == 1,
- 'car_wash': int(location['Car Wash'] or 0) == 1,
- 'fuel:diesel': int(location['Diesel'] or 0) == 1,
- 'fuel:kerosene': int(location['Kerosene'] or 0) == 1
+ 'atm': location['ATM'] == 'Y',
+ 'car_wash': location['CarWash'],
+ 'fuel:diesel': location['HasDiesel'] == 'Y',
+ 'fuel:kerosene': location['HasKero'] == 'Y'
}
)
|
{"golden_diff": "diff --git a/locations/spiders/sunoco.py b/locations/spiders/sunoco.py\n--- a/locations/spiders/sunoco.py\n+++ b/locations/spiders/sunoco.py\n@@ -17,44 +17,34 @@\n for location in json.loads(response.body_as_unicode()):\n opening_hours = OpeningHours()\n \n- for key in [\n- 'Hrs of Operation Mon-Sat Open',\n- 'Hrs of Operation Mon-Sat Close',\n- 'Hrs of Operation Sun Open',\n- 'Hrs of Operation Sun Close'\n- ]:\n- if location[key] >= 2400:\n- location[key] -= 2400\n-\n- for day in ['Mo', 'Tu', 'We', 'Th', 'Fr', 'Sa']:\n- opening_hours.add_range(day=day,\n- open_time=f\"{location['Hrs of Operation Mon-Sat Open']:04d}\",\n- close_time=f\"{location['Hrs of Operation Mon-Sat Close']:04d}\",\n- time_format='%H%M')\n-\n- opening_hours.add_range(day='Su',\n- open_time=f\"{location['Hrs of Operation Sun Open']:04d}\",\n- close_time=f\"{location['Hrs of Operation Sun Close']:04d}\",\n- time_format='%H%M')\n+ for key, val in location.items():\n+ if not key.endswith('_Hours'):\n+ continue\n+ day = key[:2].capitalize()\n+ if val == '24 hours':\n+ open_time = close_time = '12 AM'\n+ else:\n+ open_time, close_time = val.split(' to ')\n+ opening_hours.add_range(day, open_time, close_time, '%I %p')\n \n yield GeojsonPointItem(\n- ref=location['Facility ID'],\n+ ref=location['Store_ID'],\n lon=location['Longitude'],\n lat=location['Latitude'],\n # name as shown on the Sunoco site\n- name=f\"Sunoco #{location['Facility ID']}\",\n- addr_full=location['Address'],\n+ name=f\"Sunoco #{location['Store_ID']}\",\n+ addr_full=location['Street_Address'],\n city=location['City'],\n state=location['State'],\n- postcode=location['Zip'],\n+ postcode=location['Postalcode'],\n country='US',\n phone=location['Phone'],\n opening_hours=opening_hours.as_opening_hours(),\n extras={\n 'amenity:fuel': True,\n- 'atm': int(location['ATM'] or 0) == 1,\n- 'car_wash': int(location['Car Wash'] or 0) == 1,\n- 'fuel:diesel': int(location['Diesel'] or 0) == 1,\n- 'fuel:kerosene': int(location['Kerosene'] or 0) == 1\n+ 'atm': location['ATM'] == 'Y',\n+ 'car_wash': location['CarWash'],\n+ 'fuel:diesel': location['HasDiesel'] == 'Y',\n+ 'fuel:kerosene': location['HasKero'] == 'Y'\n }\n )\n", "issue": "Spider sunoco is broken\nDuring the global build at 2021-07-21-14-42-39, spider **sunoco** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/logs/sunoco.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/output/sunoco.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-21-14-42-39/output/sunoco.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass SunocoSpider(scrapy.Spider):\n name = \"sunoco\"\n item_attributes = {'brand': \"Sunoco\", 'brand_wikidata': \"Q1423218\"}\n allowed_domains = [\"sunoco.com\"]\n\n start_urls = ['https://www.sunoco.com/js/locations.json']\n\n def parse(self, response):\n for location in json.loads(response.body_as_unicode()):\n opening_hours = OpeningHours()\n\n for key in [\n 'Hrs of Operation Mon-Sat Open',\n 'Hrs of Operation Mon-Sat Close',\n 'Hrs of Operation Sun Open',\n 'Hrs of Operation Sun Close'\n ]:\n if location[key] >= 2400:\n location[key] -= 2400\n\n for day in ['Mo', 'Tu', 'We', 'Th', 'Fr', 'Sa']:\n opening_hours.add_range(day=day,\n open_time=f\"{location['Hrs of Operation Mon-Sat Open']:04d}\",\n close_time=f\"{location['Hrs of Operation Mon-Sat Close']:04d}\",\n time_format='%H%M')\n\n opening_hours.add_range(day='Su',\n open_time=f\"{location['Hrs of Operation Sun Open']:04d}\",\n close_time=f\"{location['Hrs of Operation Sun Close']:04d}\",\n time_format='%H%M')\n\n yield GeojsonPointItem(\n ref=location['Facility ID'],\n lon=location['Longitude'],\n lat=location['Latitude'],\n # name as shown on the Sunoco site\n name=f\"Sunoco #{location['Facility ID']}\",\n addr_full=location['Address'],\n city=location['City'],\n state=location['State'],\n postcode=location['Zip'],\n country='US',\n phone=location['Phone'],\n opening_hours=opening_hours.as_opening_hours(),\n extras={\n 'amenity:fuel': True,\n 'atm': int(location['ATM'] or 0) == 1,\n 'car_wash': int(location['Car Wash'] or 0) == 1,\n 'fuel:diesel': int(location['Diesel'] or 0) == 1,\n 'fuel:kerosene': int(location['Kerosene'] or 0) == 1\n }\n )\n", "path": "locations/spiders/sunoco.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass SunocoSpider(scrapy.Spider):\n name = \"sunoco\"\n item_attributes = {'brand': \"Sunoco\", 'brand_wikidata': \"Q1423218\"}\n allowed_domains = [\"sunoco.com\"]\n\n start_urls = ['https://www.sunoco.com/js/locations.json']\n\n def parse(self, response):\n for location in json.loads(response.body_as_unicode()):\n opening_hours = OpeningHours()\n\n for key, val in location.items():\n if not key.endswith('_Hours'):\n continue\n day = key[:2].capitalize()\n if val == '24 hours':\n open_time = close_time = '12 AM'\n else:\n open_time, close_time = val.split(' to ')\n opening_hours.add_range(day, open_time, close_time, '%I %p')\n\n yield GeojsonPointItem(\n ref=location['Store_ID'],\n lon=location['Longitude'],\n lat=location['Latitude'],\n # name as shown on the Sunoco site\n name=f\"Sunoco #{location['Store_ID']}\",\n addr_full=location['Street_Address'],\n city=location['City'],\n state=location['State'],\n postcode=location['Postalcode'],\n country='US',\n phone=location['Phone'],\n opening_hours=opening_hours.as_opening_hours(),\n extras={\n 'amenity:fuel': True,\n 'atm': location['ATM'] == 'Y',\n 'car_wash': location['CarWash'],\n 'fuel:diesel': location['HasDiesel'] == 'Y',\n 'fuel:kerosene': location['HasKero'] == 'Y'\n }\n )\n", "path": "locations/spiders/sunoco.py"}]}
| 1,094 | 707 |
gh_patches_debug_27168
|
rasdani/github-patches
|
git_diff
|
google__turbinia-1273
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
log2timeline not scanning volumes
log2timeline (PlasoHasher/Parser task) is not scanning volumes like the image_export (FileExtractor task) job does. Log2timeline is missing the ```--volumes all``` option.
https://github.com/google/turbinia/blob/7dfde64b24f0e13d1da771e60a00d244d7e2571b/turbinia/workers/binary_extractor.py#L103
https://github.com/google/turbinia/blob/749a25a065e89994d8fb324ebc31530c1b5efa57/turbinia/workers/plaso.py#L150
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `turbinia/workers/plaso.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright 2015 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Task for running Plaso."""
16
17 from __future__ import unicode_literals
18
19 import os
20 import logging
21
22 from turbinia import config
23 from turbinia.evidence import EvidenceState as state
24 from turbinia.evidence import PlasoFile
25 from turbinia.workers import TurbiniaTask
26 from turbinia.lib import file_helpers
27
28
29 class PlasoTask(TurbiniaTask):
30 """Parent task for PlasoJob sub-tasks."""
31
32 # Plaso requires the Disk to be attached, but doesn't require it be mounted.
33 REQUIRED_STATES = [
34 state.ATTACHED, state.DECOMPRESSED, state.CONTAINER_MOUNTED
35 ]
36
37 def test_yara_rules(self, file_path, result):
38 """Test the given Yara rules for syntactical validity before processing.
39
40 Args:
41 file_path (str): Location on disk of the Yara rules to be tested.
42 result (TurbiniaTaskResult): The object to place task results into.
43
44 Returns:
45 True if rules are good, else False
46 """
47 cmd = ['/opt/fraken/fraken', '-rules', file_path, '-testrules']
48 (ret, _) = self.execute(cmd, result)
49 if ret == 0:
50 return True
51 return False
52
53 def build_plaso_command(self, base_command, conf):
54 """Builds a typical plaso command, contains logic specific to log2timeline.
55
56 Args:
57 base_command (str): Command to invoke log2timeline (e.g. log2timeline.py)
58 conf (dict): Dynamic config containing the parameters for the command.
59
60 Returns:
61 String for valid Log2timeline command.
62 """
63 self.result.log(
64 'Generating Plaso command line from arguments: {0!s}'.format(conf),
65 level=logging.DEBUG)
66 cmd = [base_command]
67 for k, v in conf.items():
68 cli_args = [
69 'status_view', 'hashers', 'hasher_file_size_limit', 'partitions',
70 'vss_stores', 'custom_artifact_definitions', 'parsers',
71 'artifact_filters', 'file_filter', 'yara_rules'
72 ]
73 if (k not in cli_args or not v):
74 continue
75 prepend = '-'
76 if len(k) > 1:
77 prepend = '--'
78 if k == 'file_filter':
79 file_path = file_helpers.write_list_to_temp_file(
80 v, preferred_dir=self.tmp_dir)
81 cmd.extend(['-f', file_path])
82 elif k == 'yara_rules':
83 file_path = file_helpers.write_str_to_temp_file(
84 v, preferred_dir=self.tmp_dir)
85 rules_check = self.test_yara_rules(file_path, self.result)
86 if rules_check:
87 cmd.extend(['--yara_rules', file_path])
88 elif isinstance(v, list):
89 cmd.extend([prepend + k, ','.join(v)])
90 elif isinstance(v, bool):
91 cmd.append(prepend + k)
92 elif isinstance(v, str):
93 cmd.extend([prepend + k, v])
94 return cmd
95
96 def run(self, evidence, result):
97 """Task that process data with Plaso.
98
99 Args:
100 evidence (Evidence object): The evidence we will process.
101 result (TurbiniaTaskResult): The object to place task results into.
102
103 Returns:
104 TurbiniaTaskResult object.
105 """
106
107 config.LoadConfig()
108
109 # Write plaso file into tmp_dir because sqlite has issues with some shared
110 # filesystems (e.g NFS).
111 plaso_file = os.path.join(self.tmp_dir, '{0:s}.plaso'.format(self.id))
112 plaso_evidence = PlasoFile(source_path=plaso_file)
113 plaso_log = os.path.join(self.output_dir, '{0:s}.log'.format(self.id))
114
115 cmd = self.build_plaso_command('log2timeline.py', self.task_config)
116
117 if config.DEBUG_TASKS or self.task_config.get('debug_tasks'):
118 cmd.append('-d')
119
120 if evidence.credentials:
121 for credential_type, credential_data in evidence.credentials:
122 cmd.extend([
123 '--credential', '{0:s}:{1:s}'.format(
124 credential_type, credential_data)
125 ])
126
127 cmd.extend(['--temporary_directory', self.tmp_dir])
128 cmd.extend(['--logfile', plaso_log])
129 cmd.extend(['--unattended'])
130 cmd.extend(['--storage_file', plaso_file])
131 cmd.extend([evidence.local_path])
132
133 result.log('Running {0:s} as [{1:s}]'.format(self.name, ' '.join(cmd)))
134 self.execute(
135 cmd, result, log_files=[plaso_log], new_evidence=[plaso_evidence],
136 close=True)
137
138 return result
139
140
141 class PlasoParserTask(PlasoTask):
142 """Task to run Plaso parsers (log2timeline)."""
143
144 TASK_CONFIG = {
145 # 'none' as indicated in the options for status_view within
146 # the Plaso documentation
147 'status_view': 'none',
148 'hashers': 'none',
149 'hasher_file_size_limit': None,
150 'partitions': 'all',
151 'vss_stores': 'none',
152 # artifact_filters and file_filter are mutually exclusive
153 # parameters and Plaso will error out if both parameters are used.
154 'artifact_filters': None,
155 'file_filter': None,
156 'custom_artifact_definitions': None,
157 # Disable filestat parser. PlasoHasherTask will run it separately.
158 'parsers': '!filestat',
159 'yara_rules': None
160 }
161
162
163 class PlasoHasherTask(PlasoTask):
164 """Task to run Plaso hashers. This task only runs the filestat parser."""
165
166 TASK_CONFIG = {
167 # 'none' as indicated in the options for status_view within
168 # the Plaso documentation
169 'status_view': 'none',
170 'hashers': 'all',
171 'hasher_file_size_limit': '1073741824',
172 'partitions': 'all',
173 'vss_stores': 'none',
174 # artifact_filters and file_filter are mutually exclusive
175 # parameters and Plaso will error out if both parameters are used.
176 'artifact_filters': None,
177 'file_filter': None,
178 'custom_artifact_definitions': None,
179 'parsers': 'filestat',
180 'yara_rules': None
181 }
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/turbinia/workers/plaso.py b/turbinia/workers/plaso.py
--- a/turbinia/workers/plaso.py
+++ b/turbinia/workers/plaso.py
@@ -68,7 +68,7 @@
cli_args = [
'status_view', 'hashers', 'hasher_file_size_limit', 'partitions',
'vss_stores', 'custom_artifact_definitions', 'parsers',
- 'artifact_filters', 'file_filter', 'yara_rules'
+ 'artifact_filters', 'file_filter', 'yara_rules', 'volumes'
]
if (k not in cli_args or not v):
continue
@@ -148,6 +148,7 @@
'hashers': 'none',
'hasher_file_size_limit': None,
'partitions': 'all',
+ 'volumes': 'all',
'vss_stores': 'none',
# artifact_filters and file_filter are mutually exclusive
# parameters and Plaso will error out if both parameters are used.
@@ -170,6 +171,7 @@
'hashers': 'all',
'hasher_file_size_limit': '1073741824',
'partitions': 'all',
+ 'volumes': 'all',
'vss_stores': 'none',
# artifact_filters and file_filter are mutually exclusive
# parameters and Plaso will error out if both parameters are used.
|
{"golden_diff": "diff --git a/turbinia/workers/plaso.py b/turbinia/workers/plaso.py\n--- a/turbinia/workers/plaso.py\n+++ b/turbinia/workers/plaso.py\n@@ -68,7 +68,7 @@\n cli_args = [\n 'status_view', 'hashers', 'hasher_file_size_limit', 'partitions',\n 'vss_stores', 'custom_artifact_definitions', 'parsers',\n- 'artifact_filters', 'file_filter', 'yara_rules'\n+ 'artifact_filters', 'file_filter', 'yara_rules', 'volumes'\n ]\n if (k not in cli_args or not v):\n continue\n@@ -148,6 +148,7 @@\n 'hashers': 'none',\n 'hasher_file_size_limit': None,\n 'partitions': 'all',\n+ 'volumes': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n@@ -170,6 +171,7 @@\n 'hashers': 'all',\n 'hasher_file_size_limit': '1073741824',\n 'partitions': 'all',\n+ 'volumes': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n", "issue": "log2timeline not scanning volumes\nlog2timeline (PlasoHasher/Parser task) is not scanning volumes like the image_export (FileExtractor task) job does. Log2timeline is missing the ```--volumes all``` option.\r\n\r\nhttps://github.com/google/turbinia/blob/7dfde64b24f0e13d1da771e60a00d244d7e2571b/turbinia/workers/binary_extractor.py#L103\r\n\r\nhttps://github.com/google/turbinia/blob/749a25a065e89994d8fb324ebc31530c1b5efa57/turbinia/workers/plaso.py#L150\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Task for running Plaso.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport os\nimport logging\n\nfrom turbinia import config\nfrom turbinia.evidence import EvidenceState as state\nfrom turbinia.evidence import PlasoFile\nfrom turbinia.workers import TurbiniaTask\nfrom turbinia.lib import file_helpers\n\n\nclass PlasoTask(TurbiniaTask):\n \"\"\"Parent task for PlasoJob sub-tasks.\"\"\"\n\n # Plaso requires the Disk to be attached, but doesn't require it be mounted.\n REQUIRED_STATES = [\n state.ATTACHED, state.DECOMPRESSED, state.CONTAINER_MOUNTED\n ]\n\n def test_yara_rules(self, file_path, result):\n \"\"\"Test the given Yara rules for syntactical validity before processing.\n\n Args:\n file_path (str): Location on disk of the Yara rules to be tested.\n result (TurbiniaTaskResult): The object to place task results into.\n \n Returns:\n True if rules are good, else False\n \"\"\"\n cmd = ['/opt/fraken/fraken', '-rules', file_path, '-testrules']\n (ret, _) = self.execute(cmd, result)\n if ret == 0:\n return True\n return False\n\n def build_plaso_command(self, base_command, conf):\n \"\"\"Builds a typical plaso command, contains logic specific to log2timeline.\n\n Args:\n base_command (str): Command to invoke log2timeline (e.g. log2timeline.py)\n conf (dict): Dynamic config containing the parameters for the command.\n\n Returns:\n String for valid Log2timeline command.\n \"\"\"\n self.result.log(\n 'Generating Plaso command line from arguments: {0!s}'.format(conf),\n level=logging.DEBUG)\n cmd = [base_command]\n for k, v in conf.items():\n cli_args = [\n 'status_view', 'hashers', 'hasher_file_size_limit', 'partitions',\n 'vss_stores', 'custom_artifact_definitions', 'parsers',\n 'artifact_filters', 'file_filter', 'yara_rules'\n ]\n if (k not in cli_args or not v):\n continue\n prepend = '-'\n if len(k) > 1:\n prepend = '--'\n if k == 'file_filter':\n file_path = file_helpers.write_list_to_temp_file(\n v, preferred_dir=self.tmp_dir)\n cmd.extend(['-f', file_path])\n elif k == 'yara_rules':\n file_path = file_helpers.write_str_to_temp_file(\n v, preferred_dir=self.tmp_dir)\n rules_check = self.test_yara_rules(file_path, self.result)\n if rules_check:\n cmd.extend(['--yara_rules', file_path])\n elif isinstance(v, list):\n cmd.extend([prepend + k, ','.join(v)])\n elif isinstance(v, bool):\n cmd.append(prepend + k)\n elif isinstance(v, str):\n cmd.extend([prepend + k, v])\n return cmd\n\n def run(self, evidence, result):\n \"\"\"Task that process data with Plaso.\n\n Args:\n evidence (Evidence object): The evidence we will process.\n result (TurbiniaTaskResult): The object to place task results into.\n\n Returns:\n TurbiniaTaskResult object.\n \"\"\"\n\n config.LoadConfig()\n\n # Write plaso file into tmp_dir because sqlite has issues with some shared\n # filesystems (e.g NFS).\n plaso_file = os.path.join(self.tmp_dir, '{0:s}.plaso'.format(self.id))\n plaso_evidence = PlasoFile(source_path=plaso_file)\n plaso_log = os.path.join(self.output_dir, '{0:s}.log'.format(self.id))\n\n cmd = self.build_plaso_command('log2timeline.py', self.task_config)\n\n if config.DEBUG_TASKS or self.task_config.get('debug_tasks'):\n cmd.append('-d')\n\n if evidence.credentials:\n for credential_type, credential_data in evidence.credentials:\n cmd.extend([\n '--credential', '{0:s}:{1:s}'.format(\n credential_type, credential_data)\n ])\n\n cmd.extend(['--temporary_directory', self.tmp_dir])\n cmd.extend(['--logfile', plaso_log])\n cmd.extend(['--unattended'])\n cmd.extend(['--storage_file', plaso_file])\n cmd.extend([evidence.local_path])\n\n result.log('Running {0:s} as [{1:s}]'.format(self.name, ' '.join(cmd)))\n self.execute(\n cmd, result, log_files=[plaso_log], new_evidence=[plaso_evidence],\n close=True)\n\n return result\n\n\nclass PlasoParserTask(PlasoTask):\n \"\"\"Task to run Plaso parsers (log2timeline).\"\"\"\n\n TASK_CONFIG = {\n # 'none' as indicated in the options for status_view within\n # the Plaso documentation\n 'status_view': 'none',\n 'hashers': 'none',\n 'hasher_file_size_limit': None,\n 'partitions': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n 'artifact_filters': None,\n 'file_filter': None,\n 'custom_artifact_definitions': None,\n # Disable filestat parser. PlasoHasherTask will run it separately.\n 'parsers': '!filestat',\n 'yara_rules': None\n }\n\n\nclass PlasoHasherTask(PlasoTask):\n \"\"\"Task to run Plaso hashers. This task only runs the filestat parser.\"\"\"\n\n TASK_CONFIG = {\n # 'none' as indicated in the options for status_view within\n # the Plaso documentation\n 'status_view': 'none',\n 'hashers': 'all',\n 'hasher_file_size_limit': '1073741824',\n 'partitions': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n 'artifact_filters': None,\n 'file_filter': None,\n 'custom_artifact_definitions': None,\n 'parsers': 'filestat',\n 'yara_rules': None\n }\n", "path": "turbinia/workers/plaso.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2015 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Task for running Plaso.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport os\nimport logging\n\nfrom turbinia import config\nfrom turbinia.evidence import EvidenceState as state\nfrom turbinia.evidence import PlasoFile\nfrom turbinia.workers import TurbiniaTask\nfrom turbinia.lib import file_helpers\n\n\nclass PlasoTask(TurbiniaTask):\n \"\"\"Parent task for PlasoJob sub-tasks.\"\"\"\n\n # Plaso requires the Disk to be attached, but doesn't require it be mounted.\n REQUIRED_STATES = [\n state.ATTACHED, state.DECOMPRESSED, state.CONTAINER_MOUNTED\n ]\n\n def test_yara_rules(self, file_path, result):\n \"\"\"Test the given Yara rules for syntactical validity before processing.\n\n Args:\n file_path (str): Location on disk of the Yara rules to be tested.\n result (TurbiniaTaskResult): The object to place task results into.\n \n Returns:\n True if rules are good, else False\n \"\"\"\n cmd = ['/opt/fraken/fraken', '-rules', file_path, '-testrules']\n (ret, _) = self.execute(cmd, result)\n if ret == 0:\n return True\n return False\n\n def build_plaso_command(self, base_command, conf):\n \"\"\"Builds a typical plaso command, contains logic specific to log2timeline.\n\n Args:\n base_command (str): Command to invoke log2timeline (e.g. log2timeline.py)\n conf (dict): Dynamic config containing the parameters for the command.\n\n Returns:\n String for valid Log2timeline command.\n \"\"\"\n self.result.log(\n 'Generating Plaso command line from arguments: {0!s}'.format(conf),\n level=logging.DEBUG)\n cmd = [base_command]\n for k, v in conf.items():\n cli_args = [\n 'status_view', 'hashers', 'hasher_file_size_limit', 'partitions',\n 'vss_stores', 'custom_artifact_definitions', 'parsers',\n 'artifact_filters', 'file_filter', 'yara_rules', 'volumes'\n ]\n if (k not in cli_args or not v):\n continue\n prepend = '-'\n if len(k) > 1:\n prepend = '--'\n if k == 'file_filter':\n file_path = file_helpers.write_list_to_temp_file(\n v, preferred_dir=self.tmp_dir)\n cmd.extend(['-f', file_path])\n elif k == 'yara_rules':\n file_path = file_helpers.write_str_to_temp_file(\n v, preferred_dir=self.tmp_dir)\n rules_check = self.test_yara_rules(file_path, self.result)\n if rules_check:\n cmd.extend(['--yara_rules', file_path])\n elif isinstance(v, list):\n cmd.extend([prepend + k, ','.join(v)])\n elif isinstance(v, bool):\n cmd.append(prepend + k)\n elif isinstance(v, str):\n cmd.extend([prepend + k, v])\n return cmd\n\n def run(self, evidence, result):\n \"\"\"Task that process data with Plaso.\n\n Args:\n evidence (Evidence object): The evidence we will process.\n result (TurbiniaTaskResult): The object to place task results into.\n\n Returns:\n TurbiniaTaskResult object.\n \"\"\"\n\n config.LoadConfig()\n\n # Write plaso file into tmp_dir because sqlite has issues with some shared\n # filesystems (e.g NFS).\n plaso_file = os.path.join(self.tmp_dir, '{0:s}.plaso'.format(self.id))\n plaso_evidence = PlasoFile(source_path=plaso_file)\n plaso_log = os.path.join(self.output_dir, '{0:s}.log'.format(self.id))\n\n cmd = self.build_plaso_command('log2timeline.py', self.task_config)\n\n if config.DEBUG_TASKS or self.task_config.get('debug_tasks'):\n cmd.append('-d')\n\n if evidence.credentials:\n for credential_type, credential_data in evidence.credentials:\n cmd.extend([\n '--credential', '{0:s}:{1:s}'.format(\n credential_type, credential_data)\n ])\n\n cmd.extend(['--temporary_directory', self.tmp_dir])\n cmd.extend(['--logfile', plaso_log])\n cmd.extend(['--unattended'])\n cmd.extend(['--storage_file', plaso_file])\n cmd.extend([evidence.local_path])\n\n result.log('Running {0:s} as [{1:s}]'.format(self.name, ' '.join(cmd)))\n self.execute(\n cmd, result, log_files=[plaso_log], new_evidence=[plaso_evidence],\n close=True)\n\n return result\n\n\nclass PlasoParserTask(PlasoTask):\n \"\"\"Task to run Plaso parsers (log2timeline).\"\"\"\n\n TASK_CONFIG = {\n # 'none' as indicated in the options for status_view within\n # the Plaso documentation\n 'status_view': 'none',\n 'hashers': 'none',\n 'hasher_file_size_limit': None,\n 'partitions': 'all',\n 'volumes': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n 'artifact_filters': None,\n 'file_filter': None,\n 'custom_artifact_definitions': None,\n # Disable filestat parser. PlasoHasherTask will run it separately.\n 'parsers': '!filestat',\n 'yara_rules': None\n }\n\n\nclass PlasoHasherTask(PlasoTask):\n \"\"\"Task to run Plaso hashers. This task only runs the filestat parser.\"\"\"\n\n TASK_CONFIG = {\n # 'none' as indicated in the options for status_view within\n # the Plaso documentation\n 'status_view': 'none',\n 'hashers': 'all',\n 'hasher_file_size_limit': '1073741824',\n 'partitions': 'all',\n 'volumes': 'all',\n 'vss_stores': 'none',\n # artifact_filters and file_filter are mutually exclusive\n # parameters and Plaso will error out if both parameters are used.\n 'artifact_filters': None,\n 'file_filter': None,\n 'custom_artifact_definitions': None,\n 'parsers': 'filestat',\n 'yara_rules': None\n }\n", "path": "turbinia/workers/plaso.py"}]}
| 2,386 | 332 |
gh_patches_debug_24091
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-679
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove all beta dependencies (except eth-account)
* Version: 4
### What was wrong?
In order to mark v4 stable, it needs to not depend on any beta packages. `eth-account` is the exception, awaiting security audit. In order to signal that to users, we will probably make them jump through a hoop to acknowledge the lack of audit.
### How can it be fixed?
Stabilize and release versions of all unstable dependencies, starting with the leaves in the dependency graph.
Dependencies:
- [x] eth-hash - v0.1.0
- [x] eth-utils - v1.0.1
- [x] eth-abi - v1.0.0
- [x] hexbytes - v0.1.0
- [x] eth-rlp v0.1.0
- [x] ~eth-keys~ _(awaiting audit)_
- [ ] ~eth-account~ _(awaiting audit)_ -- Still need to make some kind of *in-your-face* warnings about the pending audit -- tracked in #678
- [x] ~eth-tester~ _(only needed for testing, not prod use; depends too heavily on py-evm, which isn't leaving alpha any time soon)_
Dependent nodes are listed in hierarchy. Because eth-abi depends on eth-utils, it is indented beneath it. eth-utils should be worked on before eth-abi. eth-hash before eth-utils, etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 setup,
5 find_packages,
6 )
7
8
9 setup(
10 name='web3',
11 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
12 version='4.0.0-beta.11',
13 description="""Web3.py""",
14 long_description_markdown_filename='README.md',
15 author='Piper Merriam',
16 author_email='[email protected]',
17 url='https://github.com/ethereum/web3.py',
18 include_package_data=True,
19 install_requires=[
20 "cytoolz>=0.9.0,<1.0.0",
21 "eth-abi>=1.0.0-beta.1,<2",
22 "eth-account>=0.1.0a2,<1.0.0",
23 "eth-utils>=1.0.0b1,<2.0.0",
24 "hexbytes>=0.1.0b1,<1.0.0",
25 "lru-dict>=1.1.6,<2.0.0",
26 "eth-hash[pycryptodome]",
27 "requests>=2.16.0,<3.0.0",
28 ],
29 setup_requires=['setuptools-markdown'],
30 extras_require={
31 'tester': [
32 "eth-tester[py-evm]==0.1.0b19",
33 "py-geth>=2.0.1,<3.0.0",
34 ],
35 'testrpc': ["eth-testrpc>=1.3.3,<2.0.0"],
36 'linter': [
37 "flake8==3.4.1",
38 "isort>=4.2.15,<5",
39 ],
40 'platform_system=="Windows"': [
41 'pypiwin32' # TODO: specify a version number, move under install_requires
42 ],
43 },
44 py_modules=['web3', 'ens'],
45 license="MIT",
46 zip_safe=False,
47 keywords='ethereum',
48 packages=find_packages(exclude=["tests", "tests.*"]),
49 classifiers=[
50 'Development Status :: 4 - Beta',
51 'Intended Audience :: Developers',
52 'License :: OSI Approved :: MIT License',
53 'Natural Language :: English',
54 'Programming Language :: Python :: 3',
55 'Programming Language :: Python :: 3.5',
56 'Programming Language :: Python :: 3.6',
57 ],
58 )
59
```
Path: `web3/providers/eth_tester/middleware.py`
Content:
```
1 import operator
2
3 from cytoolz import (
4 assoc,
5 complement,
6 compose,
7 curry,
8 identity,
9 partial,
10 pipe,
11 )
12 from eth_utils import (
13 is_dict,
14 is_string,
15 )
16
17 from web3.middleware import (
18 construct_fixture_middleware,
19 construct_formatting_middleware,
20 )
21 from web3.utils.formatters import (
22 apply_formatter_if,
23 apply_formatter_to_array,
24 apply_formatters_to_args,
25 apply_formatters_to_dict,
26 apply_key_map,
27 hex_to_integer,
28 integer_to_hex,
29 is_array_of_dicts,
30 static_return,
31 )
32
33
34 def is_named_block(value):
35 return value in {"latest", "earliest", "pending"}
36
37
38 to_integer_if_hex = apply_formatter_if(is_string, hex_to_integer)
39
40
41 is_not_named_block = complement(is_named_block)
42
43
44 TRANSACTION_KEY_MAPPINGS = {
45 'block_hash': 'blockHash',
46 'block_number': 'blockNumber',
47 'gas_price': 'gasPrice',
48 'transaction_hash': 'transactionHash',
49 'transaction_index': 'transactionIndex',
50 }
51
52 transaction_key_remapper = apply_key_map(TRANSACTION_KEY_MAPPINGS)
53
54
55 LOG_KEY_MAPPINGS = {
56 'log_index': 'logIndex',
57 'transaction_index': 'transactionIndex',
58 'transaction_hash': 'transactionHash',
59 'block_hash': 'blockHash',
60 'block_number': 'blockNumber',
61 }
62
63
64 log_key_remapper = apply_key_map(LOG_KEY_MAPPINGS)
65
66
67 RECEIPT_KEY_MAPPINGS = {
68 'block_hash': 'blockHash',
69 'block_number': 'blockNumber',
70 'contract_address': 'contractAddress',
71 'gas_used': 'gasUsed',
72 'cumulative_gas_used': 'cumulativeGasUsed',
73 'transaction_hash': 'transactionHash',
74 'transaction_index': 'transactionIndex',
75 }
76
77
78 receipt_key_remapper = apply_key_map(RECEIPT_KEY_MAPPINGS)
79
80
81 BLOCK_KEY_MAPPINGS = {
82 'gas_limit': 'gasLimit',
83 'sha3_uncles': 'sha3Uncles',
84 'transactions_root': 'transactionsRoot',
85 'parent_hash': 'parentHash',
86 'bloom': 'logsBloom',
87 'state_root': 'stateRoot',
88 'receipt_root': 'receiptsRoot',
89 'total_difficulty': 'totalDifficulty',
90 'extra_data': 'extraData',
91 'gas_used': 'gasUsed',
92 }
93
94
95 block_key_remapper = apply_key_map(BLOCK_KEY_MAPPINGS)
96
97
98 TRANSACTION_PARAMS_MAPPING = {
99 'gasPrice': 'gas_price',
100 }
101
102
103 transaction_params_remapper = apply_key_map(TRANSACTION_PARAMS_MAPPING)
104
105
106 TRANSACTION_PARAMS_FORMATTERS = {
107 'gas': to_integer_if_hex,
108 'gasPrice': to_integer_if_hex,
109 'value': to_integer_if_hex,
110 'nonce': to_integer_if_hex,
111 }
112
113
114 transaction_params_formatter = apply_formatters_to_dict(TRANSACTION_PARAMS_FORMATTERS)
115
116
117 FILTER_PARAMS_MAPPINGS = {
118 'fromBlock': 'from_block',
119 'toBlock': 'to_block',
120 }
121
122 filter_params_remapper = apply_key_map(FILTER_PARAMS_MAPPINGS)
123
124 FILTER_PARAMS_FORMATTERS = {
125 'fromBlock': to_integer_if_hex,
126 'toBlock': to_integer_if_hex,
127 }
128
129 filter_params_formatter = apply_formatters_to_dict(FILTER_PARAMS_FORMATTERS)
130
131 filter_params_transformer = compose(filter_params_remapper, filter_params_formatter)
132
133
134 TRANSACTION_FORMATTERS = {
135 'to': apply_formatter_if(partial(operator.eq, b''), static_return(None)),
136 }
137
138
139 transaction_formatter = apply_formatters_to_dict(TRANSACTION_FORMATTERS)
140
141
142 RECEIPT_FORMATTERS = {
143 'logs': apply_formatter_to_array(log_key_remapper),
144 }
145
146
147 receipt_formatter = apply_formatters_to_dict(RECEIPT_FORMATTERS)
148
149 transaction_params_transformer = compose(transaction_params_remapper, transaction_params_formatter)
150
151 ethereum_tester_middleware = construct_formatting_middleware(
152 request_formatters={
153 # Eth
154 'eth_getBlockByNumber': apply_formatters_to_args(
155 apply_formatter_if(is_not_named_block, to_integer_if_hex),
156 ),
157 'eth_getFilterChanges': apply_formatters_to_args(hex_to_integer),
158 'eth_getFilterLogs': apply_formatters_to_args(hex_to_integer),
159 'eth_getBlockTransactionCountByNumber': apply_formatters_to_args(
160 apply_formatter_if(is_not_named_block, to_integer_if_hex),
161 ),
162 'eth_getUncleCountByBlockNumber': apply_formatters_to_args(
163 apply_formatter_if(is_not_named_block, to_integer_if_hex),
164 ),
165 'eth_getTransactionByBlockHashAndIndex': apply_formatters_to_args(
166 identity,
167 to_integer_if_hex,
168 ),
169 'eth_getTransactionByBlockNumberAndIndex': apply_formatters_to_args(
170 apply_formatter_if(is_not_named_block, to_integer_if_hex),
171 to_integer_if_hex,
172 ),
173 'eth_getUncleByBlockNumberAndIndex': apply_formatters_to_args(
174 apply_formatter_if(is_not_named_block, to_integer_if_hex),
175 to_integer_if_hex,
176 ),
177 'eth_newFilter': apply_formatters_to_args(
178 filter_params_transformer,
179 ),
180 'eth_getLogs': apply_formatters_to_args(
181 filter_params_transformer,
182 ),
183 'eth_sendTransaction': apply_formatters_to_args(
184 transaction_params_transformer,
185 ),
186 'eth_estimateGas': apply_formatters_to_args(
187 transaction_params_transformer,
188 ),
189 'eth_call': apply_formatters_to_args(
190 transaction_params_transformer,
191 ),
192 'eth_uninstallFilter': apply_formatters_to_args(hex_to_integer),
193 # EVM
194 'evm_revert': apply_formatters_to_args(hex_to_integer),
195 # Personal
196 'personal_sendTransaction': apply_formatters_to_args(
197 transaction_params_transformer,
198 identity,
199 ),
200 },
201 result_formatters={
202 'eth_getBlockByHash': apply_formatter_if(
203 is_dict,
204 block_key_remapper,
205 ),
206 'eth_getBlockByNumber': apply_formatter_if(
207 is_dict,
208 block_key_remapper,
209 ),
210 'eth_getBlockTransactionCountByHash': apply_formatter_if(
211 is_dict,
212 transaction_key_remapper,
213 ),
214 'eth_getBlockTransactionCountByNumber': apply_formatter_if(
215 is_dict,
216 transaction_key_remapper,
217 ),
218 'eth_getTransactionByHash': apply_formatter_if(
219 is_dict,
220 compose(transaction_key_remapper, transaction_formatter),
221 ),
222 'eth_getTransactionReceipt': apply_formatter_if(
223 is_dict,
224 compose(receipt_key_remapper, receipt_formatter),
225 ),
226 'eth_newFilter': integer_to_hex,
227 'eth_newBlockFilter': integer_to_hex,
228 'eth_newPendingTransactionFilter': integer_to_hex,
229 'eth_getLogs': apply_formatter_if(
230 is_array_of_dicts,
231 apply_formatter_to_array(log_key_remapper),
232 ),
233 'eth_getFilterChanges': apply_formatter_if(
234 is_array_of_dicts,
235 apply_formatter_to_array(log_key_remapper),
236 ),
237 'eth_getFilterLogs': apply_formatter_if(
238 is_array_of_dicts,
239 apply_formatter_to_array(log_key_remapper),
240 ),
241 # EVM
242 'evm_snapshot': integer_to_hex,
243 },
244 )
245
246
247 ethereum_tester_fixture_middleware = construct_fixture_middleware({
248 # Eth
249 'eth_protocolVersion': '63',
250 'eth_hashrate': 0,
251 'eth_gasPrice': 1,
252 'eth_syncing': False,
253 'eth_mining': False,
254 # Net
255 'net_version': '1',
256 'net_listening': False,
257 'net_peerCount': 0,
258 })
259
260
261 def guess_from(web3, transaction):
262 coinbase = web3.eth.coinbase
263 if coinbase is not None:
264 return coinbase
265
266 try:
267 return web3.eth.accounts[0]
268 except KeyError as e:
269 # no accounts available to pre-fill, carry on
270 pass
271
272 return None
273
274
275 def guess_gas(web3, transaction):
276 return web3.eth.estimateGas(transaction) * 2
277
278
279 @curry
280 def fill_default(field, guess_func, web3, transaction):
281 if field in transaction and transaction[field] is not None:
282 return transaction
283 else:
284 guess_val = guess_func(web3, transaction)
285 return assoc(transaction, field, guess_val)
286
287
288 def default_transaction_fields_middleware(make_request, web3):
289 fill_default_from = fill_default('from', guess_from, web3)
290 fill_default_gas = fill_default('gas', guess_gas, web3)
291
292 def middleware(method, params):
293 # TODO send call to eth-tester without gas, and remove guess_gas entirely
294 if method == 'eth_call':
295 filled_transaction = pipe(
296 params[0],
297 fill_default_from,
298 fill_default_gas,
299 )
300 return make_request(method, [filled_transaction] + params[1:])
301 elif method in (
302 'eth_estimateGas',
303 'eth_sendTransaction',
304 ):
305 filled_transaction = pipe(
306 params[0],
307 fill_default_from,
308 )
309 return make_request(method, [filled_transaction] + params[1:])
310 else:
311 return make_request(method, params)
312 return middleware
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,10 +18,10 @@
include_package_data=True,
install_requires=[
"cytoolz>=0.9.0,<1.0.0",
- "eth-abi>=1.0.0-beta.1,<2",
- "eth-account>=0.1.0a2,<1.0.0",
- "eth-utils>=1.0.0b1,<2.0.0",
- "hexbytes>=0.1.0b1,<1.0.0",
+ "eth-abi>=1.0.0,<2",
+ "eth-account>=0.1.0-alpha.2,<1.0.0",
+ "eth-utils>=1.0.1,<2.0.0",
+ "hexbytes>=0.1.0,<1.0.0",
"lru-dict>=1.1.6,<2.0.0",
"eth-hash[pycryptodome]",
"requests>=2.16.0,<3.0.0",
@@ -29,7 +29,7 @@
setup_requires=['setuptools-markdown'],
extras_require={
'tester': [
- "eth-tester[py-evm]==0.1.0b19",
+ "eth-tester[py-evm]==0.1.0-beta.21",
"py-geth>=2.0.1,<3.0.0",
],
'testrpc': ["eth-testrpc>=1.3.3,<2.0.0"],
diff --git a/web3/providers/eth_tester/middleware.py b/web3/providers/eth_tester/middleware.py
--- a/web3/providers/eth_tester/middleware.py
+++ b/web3/providers/eth_tester/middleware.py
@@ -132,7 +132,7 @@
TRANSACTION_FORMATTERS = {
- 'to': apply_formatter_if(partial(operator.eq, b''), static_return(None)),
+ 'to': apply_formatter_if(partial(operator.eq, ''), static_return(None)),
}
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,10 +18,10 @@\n include_package_data=True,\n install_requires=[\n \"cytoolz>=0.9.0,<1.0.0\",\n- \"eth-abi>=1.0.0-beta.1,<2\",\n- \"eth-account>=0.1.0a2,<1.0.0\",\n- \"eth-utils>=1.0.0b1,<2.0.0\",\n- \"hexbytes>=0.1.0b1,<1.0.0\",\n+ \"eth-abi>=1.0.0,<2\",\n+ \"eth-account>=0.1.0-alpha.2,<1.0.0\",\n+ \"eth-utils>=1.0.1,<2.0.0\",\n+ \"hexbytes>=0.1.0,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]\",\n \"requests>=2.16.0,<3.0.0\",\n@@ -29,7 +29,7 @@\n setup_requires=['setuptools-markdown'],\n extras_require={\n 'tester': [\n- \"eth-tester[py-evm]==0.1.0b19\",\n+ \"eth-tester[py-evm]==0.1.0-beta.21\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\ndiff --git a/web3/providers/eth_tester/middleware.py b/web3/providers/eth_tester/middleware.py\n--- a/web3/providers/eth_tester/middleware.py\n+++ b/web3/providers/eth_tester/middleware.py\n@@ -132,7 +132,7 @@\n \n \n TRANSACTION_FORMATTERS = {\n- 'to': apply_formatter_if(partial(operator.eq, b''), static_return(None)),\n+ 'to': apply_formatter_if(partial(operator.eq, ''), static_return(None)),\n }\n", "issue": "Remove all beta dependencies (except eth-account)\n* Version: 4\r\n\r\n### What was wrong?\r\n\r\nIn order to mark v4 stable, it needs to not depend on any beta packages. `eth-account` is the exception, awaiting security audit. In order to signal that to users, we will probably make them jump through a hoop to acknowledge the lack of audit.\r\n\r\n### How can it be fixed?\r\n\r\nStabilize and release versions of all unstable dependencies, starting with the leaves in the dependency graph.\r\n\r\nDependencies:\r\n\r\n- [x] eth-hash - v0.1.0\r\n - [x] eth-utils - v1.0.1\r\n - [x] eth-abi - v1.0.0\r\n - [x] hexbytes - v0.1.0\r\n- [x] eth-rlp v0.1.0\r\n - [x] ~eth-keys~ _(awaiting audit)_\r\n - [ ] ~eth-account~ _(awaiting audit)_ -- Still need to make some kind of *in-your-face* warnings about the pending audit -- tracked in #678 \r\n- [x] ~eth-tester~ _(only needed for testing, not prod use; depends too heavily on py-evm, which isn't leaving alpha any time soon)_\r\n\r\n\r\n\r\nDependent nodes are listed in hierarchy. Because eth-abi depends on eth-utils, it is indented beneath it. eth-utils should be worked on before eth-abi. eth-hash before eth-utils, etc.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n setup,\n find_packages,\n)\n\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='4.0.0-beta.11',\n description=\"\"\"Web3.py\"\"\",\n long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"cytoolz>=0.9.0,<1.0.0\",\n \"eth-abi>=1.0.0-beta.1,<2\",\n \"eth-account>=0.1.0a2,<1.0.0\",\n \"eth-utils>=1.0.0b1,<2.0.0\",\n \"hexbytes>=0.1.0b1,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]\",\n \"requests>=2.16.0,<3.0.0\",\n ],\n setup_requires=['setuptools-markdown'],\n extras_require={\n 'tester': [\n \"eth-tester[py-evm]==0.1.0b19\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\n 'linter': [\n \"flake8==3.4.1\",\n \"isort>=4.2.15,<5\",\n ],\n 'platform_system==\"Windows\"': [\n 'pypiwin32' # TODO: specify a version number, move under install_requires\n ],\n },\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n)\n", "path": "setup.py"}, {"content": "import operator\n\nfrom cytoolz import (\n assoc,\n complement,\n compose,\n curry,\n identity,\n partial,\n pipe,\n)\nfrom eth_utils import (\n is_dict,\n is_string,\n)\n\nfrom web3.middleware import (\n construct_fixture_middleware,\n construct_formatting_middleware,\n)\nfrom web3.utils.formatters import (\n apply_formatter_if,\n apply_formatter_to_array,\n apply_formatters_to_args,\n apply_formatters_to_dict,\n apply_key_map,\n hex_to_integer,\n integer_to_hex,\n is_array_of_dicts,\n static_return,\n)\n\n\ndef is_named_block(value):\n return value in {\"latest\", \"earliest\", \"pending\"}\n\n\nto_integer_if_hex = apply_formatter_if(is_string, hex_to_integer)\n\n\nis_not_named_block = complement(is_named_block)\n\n\nTRANSACTION_KEY_MAPPINGS = {\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n 'gas_price': 'gasPrice',\n 'transaction_hash': 'transactionHash',\n 'transaction_index': 'transactionIndex',\n}\n\ntransaction_key_remapper = apply_key_map(TRANSACTION_KEY_MAPPINGS)\n\n\nLOG_KEY_MAPPINGS = {\n 'log_index': 'logIndex',\n 'transaction_index': 'transactionIndex',\n 'transaction_hash': 'transactionHash',\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n}\n\n\nlog_key_remapper = apply_key_map(LOG_KEY_MAPPINGS)\n\n\nRECEIPT_KEY_MAPPINGS = {\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n 'contract_address': 'contractAddress',\n 'gas_used': 'gasUsed',\n 'cumulative_gas_used': 'cumulativeGasUsed',\n 'transaction_hash': 'transactionHash',\n 'transaction_index': 'transactionIndex',\n}\n\n\nreceipt_key_remapper = apply_key_map(RECEIPT_KEY_MAPPINGS)\n\n\nBLOCK_KEY_MAPPINGS = {\n 'gas_limit': 'gasLimit',\n 'sha3_uncles': 'sha3Uncles',\n 'transactions_root': 'transactionsRoot',\n 'parent_hash': 'parentHash',\n 'bloom': 'logsBloom',\n 'state_root': 'stateRoot',\n 'receipt_root': 'receiptsRoot',\n 'total_difficulty': 'totalDifficulty',\n 'extra_data': 'extraData',\n 'gas_used': 'gasUsed',\n}\n\n\nblock_key_remapper = apply_key_map(BLOCK_KEY_MAPPINGS)\n\n\nTRANSACTION_PARAMS_MAPPING = {\n 'gasPrice': 'gas_price',\n}\n\n\ntransaction_params_remapper = apply_key_map(TRANSACTION_PARAMS_MAPPING)\n\n\nTRANSACTION_PARAMS_FORMATTERS = {\n 'gas': to_integer_if_hex,\n 'gasPrice': to_integer_if_hex,\n 'value': to_integer_if_hex,\n 'nonce': to_integer_if_hex,\n}\n\n\ntransaction_params_formatter = apply_formatters_to_dict(TRANSACTION_PARAMS_FORMATTERS)\n\n\nFILTER_PARAMS_MAPPINGS = {\n 'fromBlock': 'from_block',\n 'toBlock': 'to_block',\n}\n\nfilter_params_remapper = apply_key_map(FILTER_PARAMS_MAPPINGS)\n\nFILTER_PARAMS_FORMATTERS = {\n 'fromBlock': to_integer_if_hex,\n 'toBlock': to_integer_if_hex,\n}\n\nfilter_params_formatter = apply_formatters_to_dict(FILTER_PARAMS_FORMATTERS)\n\nfilter_params_transformer = compose(filter_params_remapper, filter_params_formatter)\n\n\nTRANSACTION_FORMATTERS = {\n 'to': apply_formatter_if(partial(operator.eq, b''), static_return(None)),\n}\n\n\ntransaction_formatter = apply_formatters_to_dict(TRANSACTION_FORMATTERS)\n\n\nRECEIPT_FORMATTERS = {\n 'logs': apply_formatter_to_array(log_key_remapper),\n}\n\n\nreceipt_formatter = apply_formatters_to_dict(RECEIPT_FORMATTERS)\n\ntransaction_params_transformer = compose(transaction_params_remapper, transaction_params_formatter)\n\nethereum_tester_middleware = construct_formatting_middleware(\n request_formatters={\n # Eth\n 'eth_getBlockByNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getFilterChanges': apply_formatters_to_args(hex_to_integer),\n 'eth_getFilterLogs': apply_formatters_to_args(hex_to_integer),\n 'eth_getBlockTransactionCountByNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getUncleCountByBlockNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getTransactionByBlockHashAndIndex': apply_formatters_to_args(\n identity,\n to_integer_if_hex,\n ),\n 'eth_getTransactionByBlockNumberAndIndex': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n to_integer_if_hex,\n ),\n 'eth_getUncleByBlockNumberAndIndex': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n to_integer_if_hex,\n ),\n 'eth_newFilter': apply_formatters_to_args(\n filter_params_transformer,\n ),\n 'eth_getLogs': apply_formatters_to_args(\n filter_params_transformer,\n ),\n 'eth_sendTransaction': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_estimateGas': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_call': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_uninstallFilter': apply_formatters_to_args(hex_to_integer),\n # EVM\n 'evm_revert': apply_formatters_to_args(hex_to_integer),\n # Personal\n 'personal_sendTransaction': apply_formatters_to_args(\n transaction_params_transformer,\n identity,\n ),\n },\n result_formatters={\n 'eth_getBlockByHash': apply_formatter_if(\n is_dict,\n block_key_remapper,\n ),\n 'eth_getBlockByNumber': apply_formatter_if(\n is_dict,\n block_key_remapper,\n ),\n 'eth_getBlockTransactionCountByHash': apply_formatter_if(\n is_dict,\n transaction_key_remapper,\n ),\n 'eth_getBlockTransactionCountByNumber': apply_formatter_if(\n is_dict,\n transaction_key_remapper,\n ),\n 'eth_getTransactionByHash': apply_formatter_if(\n is_dict,\n compose(transaction_key_remapper, transaction_formatter),\n ),\n 'eth_getTransactionReceipt': apply_formatter_if(\n is_dict,\n compose(receipt_key_remapper, receipt_formatter),\n ),\n 'eth_newFilter': integer_to_hex,\n 'eth_newBlockFilter': integer_to_hex,\n 'eth_newPendingTransactionFilter': integer_to_hex,\n 'eth_getLogs': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n 'eth_getFilterChanges': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n 'eth_getFilterLogs': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n # EVM\n 'evm_snapshot': integer_to_hex,\n },\n)\n\n\nethereum_tester_fixture_middleware = construct_fixture_middleware({\n # Eth\n 'eth_protocolVersion': '63',\n 'eth_hashrate': 0,\n 'eth_gasPrice': 1,\n 'eth_syncing': False,\n 'eth_mining': False,\n # Net\n 'net_version': '1',\n 'net_listening': False,\n 'net_peerCount': 0,\n})\n\n\ndef guess_from(web3, transaction):\n coinbase = web3.eth.coinbase\n if coinbase is not None:\n return coinbase\n\n try:\n return web3.eth.accounts[0]\n except KeyError as e:\n # no accounts available to pre-fill, carry on\n pass\n\n return None\n\n\ndef guess_gas(web3, transaction):\n return web3.eth.estimateGas(transaction) * 2\n\n\n@curry\ndef fill_default(field, guess_func, web3, transaction):\n if field in transaction and transaction[field] is not None:\n return transaction\n else:\n guess_val = guess_func(web3, transaction)\n return assoc(transaction, field, guess_val)\n\n\ndef default_transaction_fields_middleware(make_request, web3):\n fill_default_from = fill_default('from', guess_from, web3)\n fill_default_gas = fill_default('gas', guess_gas, web3)\n\n def middleware(method, params):\n # TODO send call to eth-tester without gas, and remove guess_gas entirely\n if method == 'eth_call':\n filled_transaction = pipe(\n params[0],\n fill_default_from,\n fill_default_gas,\n )\n return make_request(method, [filled_transaction] + params[1:])\n elif method in (\n 'eth_estimateGas',\n 'eth_sendTransaction',\n ):\n filled_transaction = pipe(\n params[0],\n fill_default_from,\n )\n return make_request(method, [filled_transaction] + params[1:])\n else:\n return make_request(method, params)\n return middleware\n", "path": "web3/providers/eth_tester/middleware.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n setup,\n find_packages,\n)\n\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='4.0.0-beta.11',\n description=\"\"\"Web3.py\"\"\",\n long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"cytoolz>=0.9.0,<1.0.0\",\n \"eth-abi>=1.0.0,<2\",\n \"eth-account>=0.1.0-alpha.2,<1.0.0\",\n \"eth-utils>=1.0.1,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]\",\n \"requests>=2.16.0,<3.0.0\",\n ],\n setup_requires=['setuptools-markdown'],\n extras_require={\n 'tester': [\n \"eth-tester[py-evm]==0.1.0-beta.21\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\n 'linter': [\n \"flake8==3.4.1\",\n \"isort>=4.2.15,<5\",\n ],\n 'platform_system==\"Windows\"': [\n 'pypiwin32' # TODO: specify a version number, move under install_requires\n ],\n },\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n)\n", "path": "setup.py"}, {"content": "import operator\n\nfrom cytoolz import (\n assoc,\n complement,\n compose,\n curry,\n identity,\n partial,\n pipe,\n)\nfrom eth_utils import (\n is_dict,\n is_string,\n)\n\nfrom web3.middleware import (\n construct_fixture_middleware,\n construct_formatting_middleware,\n)\nfrom web3.utils.formatters import (\n apply_formatter_if,\n apply_formatter_to_array,\n apply_formatters_to_args,\n apply_formatters_to_dict,\n apply_key_map,\n hex_to_integer,\n integer_to_hex,\n is_array_of_dicts,\n static_return,\n)\n\n\ndef is_named_block(value):\n return value in {\"latest\", \"earliest\", \"pending\"}\n\n\nto_integer_if_hex = apply_formatter_if(is_string, hex_to_integer)\n\n\nis_not_named_block = complement(is_named_block)\n\n\nTRANSACTION_KEY_MAPPINGS = {\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n 'gas_price': 'gasPrice',\n 'transaction_hash': 'transactionHash',\n 'transaction_index': 'transactionIndex',\n}\n\ntransaction_key_remapper = apply_key_map(TRANSACTION_KEY_MAPPINGS)\n\n\nLOG_KEY_MAPPINGS = {\n 'log_index': 'logIndex',\n 'transaction_index': 'transactionIndex',\n 'transaction_hash': 'transactionHash',\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n}\n\n\nlog_key_remapper = apply_key_map(LOG_KEY_MAPPINGS)\n\n\nRECEIPT_KEY_MAPPINGS = {\n 'block_hash': 'blockHash',\n 'block_number': 'blockNumber',\n 'contract_address': 'contractAddress',\n 'gas_used': 'gasUsed',\n 'cumulative_gas_used': 'cumulativeGasUsed',\n 'transaction_hash': 'transactionHash',\n 'transaction_index': 'transactionIndex',\n}\n\n\nreceipt_key_remapper = apply_key_map(RECEIPT_KEY_MAPPINGS)\n\n\nBLOCK_KEY_MAPPINGS = {\n 'gas_limit': 'gasLimit',\n 'sha3_uncles': 'sha3Uncles',\n 'transactions_root': 'transactionsRoot',\n 'parent_hash': 'parentHash',\n 'bloom': 'logsBloom',\n 'state_root': 'stateRoot',\n 'receipt_root': 'receiptsRoot',\n 'total_difficulty': 'totalDifficulty',\n 'extra_data': 'extraData',\n 'gas_used': 'gasUsed',\n}\n\n\nblock_key_remapper = apply_key_map(BLOCK_KEY_MAPPINGS)\n\n\nTRANSACTION_PARAMS_MAPPING = {\n 'gasPrice': 'gas_price',\n}\n\n\ntransaction_params_remapper = apply_key_map(TRANSACTION_PARAMS_MAPPING)\n\n\nTRANSACTION_PARAMS_FORMATTERS = {\n 'gas': to_integer_if_hex,\n 'gasPrice': to_integer_if_hex,\n 'value': to_integer_if_hex,\n 'nonce': to_integer_if_hex,\n}\n\n\ntransaction_params_formatter = apply_formatters_to_dict(TRANSACTION_PARAMS_FORMATTERS)\n\n\nFILTER_PARAMS_MAPPINGS = {\n 'fromBlock': 'from_block',\n 'toBlock': 'to_block',\n}\n\nfilter_params_remapper = apply_key_map(FILTER_PARAMS_MAPPINGS)\n\nFILTER_PARAMS_FORMATTERS = {\n 'fromBlock': to_integer_if_hex,\n 'toBlock': to_integer_if_hex,\n}\n\nfilter_params_formatter = apply_formatters_to_dict(FILTER_PARAMS_FORMATTERS)\n\nfilter_params_transformer = compose(filter_params_remapper, filter_params_formatter)\n\n\nTRANSACTION_FORMATTERS = {\n 'to': apply_formatter_if(partial(operator.eq, ''), static_return(None)),\n}\n\n\ntransaction_formatter = apply_formatters_to_dict(TRANSACTION_FORMATTERS)\n\n\nRECEIPT_FORMATTERS = {\n 'logs': apply_formatter_to_array(log_key_remapper),\n}\n\n\nreceipt_formatter = apply_formatters_to_dict(RECEIPT_FORMATTERS)\n\ntransaction_params_transformer = compose(transaction_params_remapper, transaction_params_formatter)\n\nethereum_tester_middleware = construct_formatting_middleware(\n request_formatters={\n # Eth\n 'eth_getBlockByNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getFilterChanges': apply_formatters_to_args(hex_to_integer),\n 'eth_getFilterLogs': apply_formatters_to_args(hex_to_integer),\n 'eth_getBlockTransactionCountByNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getUncleCountByBlockNumber': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n ),\n 'eth_getTransactionByBlockHashAndIndex': apply_formatters_to_args(\n identity,\n to_integer_if_hex,\n ),\n 'eth_getTransactionByBlockNumberAndIndex': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n to_integer_if_hex,\n ),\n 'eth_getUncleByBlockNumberAndIndex': apply_formatters_to_args(\n apply_formatter_if(is_not_named_block, to_integer_if_hex),\n to_integer_if_hex,\n ),\n 'eth_newFilter': apply_formatters_to_args(\n filter_params_transformer,\n ),\n 'eth_getLogs': apply_formatters_to_args(\n filter_params_transformer,\n ),\n 'eth_sendTransaction': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_estimateGas': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_call': apply_formatters_to_args(\n transaction_params_transformer,\n ),\n 'eth_uninstallFilter': apply_formatters_to_args(hex_to_integer),\n # EVM\n 'evm_revert': apply_formatters_to_args(hex_to_integer),\n # Personal\n 'personal_sendTransaction': apply_formatters_to_args(\n transaction_params_transformer,\n identity,\n ),\n },\n result_formatters={\n 'eth_getBlockByHash': apply_formatter_if(\n is_dict,\n block_key_remapper,\n ),\n 'eth_getBlockByNumber': apply_formatter_if(\n is_dict,\n block_key_remapper,\n ),\n 'eth_getBlockTransactionCountByHash': apply_formatter_if(\n is_dict,\n transaction_key_remapper,\n ),\n 'eth_getBlockTransactionCountByNumber': apply_formatter_if(\n is_dict,\n transaction_key_remapper,\n ),\n 'eth_getTransactionByHash': apply_formatter_if(\n is_dict,\n compose(transaction_key_remapper, transaction_formatter),\n ),\n 'eth_getTransactionReceipt': apply_formatter_if(\n is_dict,\n compose(receipt_key_remapper, receipt_formatter),\n ),\n 'eth_newFilter': integer_to_hex,\n 'eth_newBlockFilter': integer_to_hex,\n 'eth_newPendingTransactionFilter': integer_to_hex,\n 'eth_getLogs': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n 'eth_getFilterChanges': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n 'eth_getFilterLogs': apply_formatter_if(\n is_array_of_dicts,\n apply_formatter_to_array(log_key_remapper),\n ),\n # EVM\n 'evm_snapshot': integer_to_hex,\n },\n)\n\n\nethereum_tester_fixture_middleware = construct_fixture_middleware({\n # Eth\n 'eth_protocolVersion': '63',\n 'eth_hashrate': 0,\n 'eth_gasPrice': 1,\n 'eth_syncing': False,\n 'eth_mining': False,\n # Net\n 'net_version': '1',\n 'net_listening': False,\n 'net_peerCount': 0,\n})\n\n\ndef guess_from(web3, transaction):\n coinbase = web3.eth.coinbase\n if coinbase is not None:\n return coinbase\n\n try:\n return web3.eth.accounts[0]\n except KeyError as e:\n # no accounts available to pre-fill, carry on\n pass\n\n return None\n\n\ndef guess_gas(web3, transaction):\n return web3.eth.estimateGas(transaction) * 2\n\n\n@curry\ndef fill_default(field, guess_func, web3, transaction):\n if field in transaction and transaction[field] is not None:\n return transaction\n else:\n guess_val = guess_func(web3, transaction)\n return assoc(transaction, field, guess_val)\n\n\ndef default_transaction_fields_middleware(make_request, web3):\n fill_default_from = fill_default('from', guess_from, web3)\n fill_default_gas = fill_default('gas', guess_gas, web3)\n\n def middleware(method, params):\n # TODO send call to eth-tester without gas, and remove guess_gas entirely\n if method == 'eth_call':\n filled_transaction = pipe(\n params[0],\n fill_default_from,\n fill_default_gas,\n )\n return make_request(method, [filled_transaction] + params[1:])\n elif method in (\n 'eth_estimateGas',\n 'eth_sendTransaction',\n ):\n filled_transaction = pipe(\n params[0],\n fill_default_from,\n )\n return make_request(method, [filled_transaction] + params[1:])\n else:\n return make_request(method, params)\n return middleware\n", "path": "web3/providers/eth_tester/middleware.py"}]}
| 4,058 | 482 |
gh_patches_debug_5612
|
rasdani/github-patches
|
git_diff
|
spack__spack-13717
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
spack find : always prompt 0 installed packages
On a clean `develop` checkout :
```
$ git clone https://github.com/LLNL/spack.git
Cloning into 'spack'...
remote: Counting objects: 25613, done.
remote: Compressing objects: 100% (42/42), done.
remote: Total 25613 (delta 12), reused 3 (delta 3), pack-reused 25557
Receiving objects: 100% (25613/25613), 6.65 MiB | 6.46 MiB/s, done.
Resolving deltas: 100% (13031/13031), done.
Checking connectivity... done.
$ cd spack
$ . share/spack/setup-env.sh
$ spack compilers
==> Available compilers
-- gcc ----------------------------------------------------------
[email protected]
$ spack install zlib
==> Installing zlib
==> Trying to fetch from file:///home/mculpo/production/spack-mirror/zlib/zlib-1.2.8.tar.gz
######################################################################## 100,0%
==> Staging archive: /home/mculpo/tmp/spack/var/spack/stage/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix/zlib-1.2.8.tar.gz
==> Created stage in /home/mculpo/tmp/spack/var/spack/stage/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix
==> No patches needed for zlib
==> Building zlib
==> Successfully installed zlib
Fetch: 0.01s. Build: 3.69s. Total: 3.70s.
[+] /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix
$ spack find
==> 0 installed packages.
$ spack install szip
==> Installing szip
==> Trying to fetch from file:///home/mculpo/production/spack-mirror/szip/szip-2.1.tar.gz
######################################################################## 100,0%
==> Staging archive: /home/mculpo/tmp/spack/var/spack/stage/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq/szip-2.1.tar.gz
==> Created stage in /home/mculpo/tmp/spack/var/spack/stage/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq
==> No patches needed for szip
==> Building szip
==> Successfully installed szip
Fetch: 0.01s. Build: 8.09s. Total: 8.10s.
[+] /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq
$ spack find
==> 0 installed packages.
```
The db seems to be written correctly :
```
database:
installs:
d6pdl6xvnvap6ihrqcqtgvweghbszmix:
explicit: true
installed: true
path: /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix
ref_count: 0
spec:
zlib:
arch: linux-x86_64
compiler:
name: gcc
version: '4.8'
dependencies: {}
namespace: builtin
parameters:
cflags: []
cppflags: []
cxxflags: []
fflags: []
ldflags: []
ldlibs: []
version: 1.2.8
esfmhl54wbdb7nnnip6y6jbxlbmxs2jq:
explicit: true
installed: true
path: /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq
ref_count: 0
spec:
szip:
arch: linux-x86_64
compiler:
name: gcc
version: '4.8'
dependencies: {}
namespace: builtin
parameters:
cflags: []
cppflags: []
cxxflags: []
fflags: []
ldflags: []
ldlibs: []
version: '2.1'
version: 0.9.1
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/mgis/package.py`
Content:
```
1 # Copyright 2013-2018 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class Mgis(CMakePackage):
10 """
11 The MFrontGenericInterfaceSupport project (MGIS) provides helper
12 functions for various solvers to interact with behaviour written
13 using MFront generic interface.
14
15 MGIS is written in C++.
16 Bindings are provided for C and fortran (2003).
17 A FEniCS binding is also available.
18 """
19
20 homepage = "https://thelfer.github.io/mgis/web/index.html"
21 url = "https://github.com/thelfer/MFrontGenericInterfaceSupport/archive/MFrontGenericInterfaceSupport-1.0.tar.gz"
22 git = "https://github.com/thelfer/MFrontGenericInterfaceSupport.git"
23 maintainers = ['thelfer']
24
25 # development branches
26 version("master", branch="master")
27 version("rliv-1.0", branch="rliv-1.0")
28
29 # released version
30 version('1.0.1', sha256='6102621455bc5d9b1591cd33e93b2e15a9572d2ce59ca6dfa30ba57ae1265c08')
31 version('1.0', sha256='279c98da00fa6855edf29c2b8f8bad6e7732298dc62ef67d028d6bbeaac043b3')
32
33 # variants
34 variant('c', default=True,
35 description='Enables c bindings')
36 variant('fortran', default=True,
37 description='Enables fortran bindings')
38 variant('python', default=True,
39 description='Enables python bindings')
40 variant('build_type', default='Release',
41 description='The build type to build',
42 values=('Debug', 'Release'))
43
44 # dependencies
45 depends_on('[email protected]', when="@1.0")
46 depends_on('[email protected]', when="@1.0.1")
47 depends_on('[email protected]', when="@rliv-1.0")
48 depends_on('tfel@master', when="@master")
49 depends_on('boost+python', when='+python')
50 extends('python', when='+python')
51
52 def cmake_args(self):
53
54 args = []
55
56 for i in ['c', 'fortran', 'python']:
57 if '+' + i in self.spec:
58 args.append("-Denable-{0}-bindings=ON".format(i))
59 else:
60 args.append("-Denable-{0}-bindings=OFF".format(i))
61
62 if '+python' in self.spec:
63 # adding path to python
64 python = self.spec['python']
65 args.append('-DPYTHON_LIBRARY={0}'.
66 format(python.libs[0]))
67 args.append('-DPYTHON_INCLUDE_DIR={0}'.
68 format(python.headers.directories[0]))
69 args.append('-DPython_ADDITIONAL_VERSIONS={0}'.
70 format(python.version.up_to(2)))
71 # adding path to boost
72 args.append('-DBOOST_ROOT={0}'.
73 format(self.spec['boost'].prefix))
74
75 return args
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/mgis/package.py b/var/spack/repos/builtin/packages/mgis/package.py
--- a/var/spack/repos/builtin/packages/mgis/package.py
+++ b/var/spack/repos/builtin/packages/mgis/package.py
@@ -46,7 +46,7 @@
depends_on('[email protected]', when="@1.0.1")
depends_on('[email protected]', when="@rliv-1.0")
depends_on('tfel@master', when="@master")
- depends_on('boost+python', when='+python')
+ depends_on('boost+python+numpy', when='+python')
extends('python', when='+python')
def cmake_args(self):
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/mgis/package.py b/var/spack/repos/builtin/packages/mgis/package.py\n--- a/var/spack/repos/builtin/packages/mgis/package.py\n+++ b/var/spack/repos/builtin/packages/mgis/package.py\n@@ -46,7 +46,7 @@\n depends_on('[email protected]', when=\"@1.0.1\")\n depends_on('[email protected]', when=\"@rliv-1.0\")\n depends_on('tfel@master', when=\"@master\")\n- depends_on('boost+python', when='+python')\n+ depends_on('boost+python+numpy', when='+python')\n extends('python', when='+python')\n \n def cmake_args(self):\n", "issue": "spack find : always prompt 0 installed packages\nOn a clean `develop` checkout : \n\n```\n$ git clone https://github.com/LLNL/spack.git\nCloning into 'spack'...\nremote: Counting objects: 25613, done.\nremote: Compressing objects: 100% (42/42), done.\nremote: Total 25613 (delta 12), reused 3 (delta 3), pack-reused 25557\nReceiving objects: 100% (25613/25613), 6.65 MiB | 6.46 MiB/s, done.\nResolving deltas: 100% (13031/13031), done.\nChecking connectivity... done.\n\n$ cd spack\n$ . share/spack/setup-env.sh \n$ spack compilers\n==> Available compilers\n-- gcc ----------------------------------------------------------\[email protected]\n\n$ spack install zlib\n==> Installing zlib\n==> Trying to fetch from file:///home/mculpo/production/spack-mirror/zlib/zlib-1.2.8.tar.gz\n######################################################################## 100,0%\n==> Staging archive: /home/mculpo/tmp/spack/var/spack/stage/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix/zlib-1.2.8.tar.gz\n==> Created stage in /home/mculpo/tmp/spack/var/spack/stage/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix\n==> No patches needed for zlib\n==> Building zlib\n==> Successfully installed zlib\n Fetch: 0.01s. Build: 3.69s. Total: 3.70s.\n[+] /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix\n\n$ spack find\n==> 0 installed packages.\n\n$ spack install szip\n==> Installing szip\n==> Trying to fetch from file:///home/mculpo/production/spack-mirror/szip/szip-2.1.tar.gz\n######################################################################## 100,0%\n==> Staging archive: /home/mculpo/tmp/spack/var/spack/stage/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq/szip-2.1.tar.gz\n==> Created stage in /home/mculpo/tmp/spack/var/spack/stage/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq\n==> No patches needed for szip\n==> Building szip\n==> Successfully installed szip\n Fetch: 0.01s. Build: 8.09s. Total: 8.10s.\n[+] /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq\n\n$ spack find \n==> 0 installed packages.\n```\n\nThe db seems to be written correctly : \n\n```\ndatabase:\n installs:\n d6pdl6xvnvap6ihrqcqtgvweghbszmix:\n explicit: true\n installed: true\n path: /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/zlib-1.2.8-d6pdl6xvnvap6ihrqcqtgvweghbszmix\n ref_count: 0\n spec:\n zlib:\n arch: linux-x86_64\n compiler:\n name: gcc\n version: '4.8'\n dependencies: {}\n namespace: builtin\n parameters:\n cflags: []\n cppflags: []\n cxxflags: []\n fflags: []\n ldflags: []\n ldlibs: []\n version: 1.2.8\n esfmhl54wbdb7nnnip6y6jbxlbmxs2jq:\n explicit: true\n installed: true\n path: /home/mculpo/tmp/spack/opt/spack/linux-x86_64/gcc-4.8/szip-2.1-esfmhl54wbdb7nnnip6y6jbxlbmxs2jq\n ref_count: 0\n spec:\n szip:\n arch: linux-x86_64\n compiler:\n name: gcc\n version: '4.8'\n dependencies: {}\n namespace: builtin\n parameters:\n cflags: []\n cppflags: []\n cxxflags: []\n fflags: []\n ldflags: []\n ldlibs: []\n version: '2.1'\n version: 0.9.1\n```\n\n", "before_files": [{"content": "# Copyright 2013-2018 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Mgis(CMakePackage):\n \"\"\"\n The MFrontGenericInterfaceSupport project (MGIS) provides helper\n functions for various solvers to interact with behaviour written\n using MFront generic interface.\n\n MGIS is written in C++.\n Bindings are provided for C and fortran (2003).\n A FEniCS binding is also available.\n \"\"\"\n\n homepage = \"https://thelfer.github.io/mgis/web/index.html\"\n url = \"https://github.com/thelfer/MFrontGenericInterfaceSupport/archive/MFrontGenericInterfaceSupport-1.0.tar.gz\"\n git = \"https://github.com/thelfer/MFrontGenericInterfaceSupport.git\"\n maintainers = ['thelfer']\n\n # development branches\n version(\"master\", branch=\"master\")\n version(\"rliv-1.0\", branch=\"rliv-1.0\")\n\n # released version\n version('1.0.1', sha256='6102621455bc5d9b1591cd33e93b2e15a9572d2ce59ca6dfa30ba57ae1265c08')\n version('1.0', sha256='279c98da00fa6855edf29c2b8f8bad6e7732298dc62ef67d028d6bbeaac043b3')\n\n # variants\n variant('c', default=True,\n description='Enables c bindings')\n variant('fortran', default=True,\n description='Enables fortran bindings')\n variant('python', default=True,\n description='Enables python bindings')\n variant('build_type', default='Release',\n description='The build type to build',\n values=('Debug', 'Release'))\n\n # dependencies\n depends_on('[email protected]', when=\"@1.0\")\n depends_on('[email protected]', when=\"@1.0.1\")\n depends_on('[email protected]', when=\"@rliv-1.0\")\n depends_on('tfel@master', when=\"@master\")\n depends_on('boost+python', when='+python')\n extends('python', when='+python')\n\n def cmake_args(self):\n\n args = []\n\n for i in ['c', 'fortran', 'python']:\n if '+' + i in self.spec:\n args.append(\"-Denable-{0}-bindings=ON\".format(i))\n else:\n args.append(\"-Denable-{0}-bindings=OFF\".format(i))\n\n if '+python' in self.spec:\n # adding path to python\n python = self.spec['python']\n args.append('-DPYTHON_LIBRARY={0}'.\n format(python.libs[0]))\n args.append('-DPYTHON_INCLUDE_DIR={0}'.\n format(python.headers.directories[0]))\n args.append('-DPython_ADDITIONAL_VERSIONS={0}'.\n format(python.version.up_to(2)))\n # adding path to boost\n args.append('-DBOOST_ROOT={0}'.\n format(self.spec['boost'].prefix))\n\n return args\n", "path": "var/spack/repos/builtin/packages/mgis/package.py"}], "after_files": [{"content": "# Copyright 2013-2018 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Mgis(CMakePackage):\n \"\"\"\n The MFrontGenericInterfaceSupport project (MGIS) provides helper\n functions for various solvers to interact with behaviour written\n using MFront generic interface.\n\n MGIS is written in C++.\n Bindings are provided for C and fortran (2003).\n A FEniCS binding is also available.\n \"\"\"\n\n homepage = \"https://thelfer.github.io/mgis/web/index.html\"\n url = \"https://github.com/thelfer/MFrontGenericInterfaceSupport/archive/MFrontGenericInterfaceSupport-1.0.tar.gz\"\n git = \"https://github.com/thelfer/MFrontGenericInterfaceSupport.git\"\n maintainers = ['thelfer']\n\n # development branches\n version(\"master\", branch=\"master\")\n version(\"rliv-1.0\", branch=\"rliv-1.0\")\n\n # released version\n version('1.0.1', sha256='6102621455bc5d9b1591cd33e93b2e15a9572d2ce59ca6dfa30ba57ae1265c08')\n version('1.0', sha256='279c98da00fa6855edf29c2b8f8bad6e7732298dc62ef67d028d6bbeaac043b3')\n\n # variants\n variant('c', default=True,\n description='Enables c bindings')\n variant('fortran', default=True,\n description='Enables fortran bindings')\n variant('python', default=True,\n description='Enables python bindings')\n variant('build_type', default='Release',\n description='The build type to build',\n values=('Debug', 'Release'))\n\n # dependencies\n depends_on('[email protected]', when=\"@1.0\")\n depends_on('[email protected]', when=\"@1.0.1\")\n depends_on('[email protected]', when=\"@rliv-1.0\")\n depends_on('tfel@master', when=\"@master\")\n depends_on('boost+python+numpy', when='+python')\n extends('python', when='+python')\n\n def cmake_args(self):\n\n args = []\n\n for i in ['c', 'fortran', 'python']:\n if '+' + i in self.spec:\n args.append(\"-Denable-{0}-bindings=ON\".format(i))\n else:\n args.append(\"-Denable-{0}-bindings=OFF\".format(i))\n\n if '+python' in self.spec:\n # adding path to python\n python = self.spec['python']\n args.append('-DPYTHON_LIBRARY={0}'.\n format(python.libs[0]))\n args.append('-DPYTHON_INCLUDE_DIR={0}'.\n format(python.headers.directories[0]))\n args.append('-DPython_ADDITIONAL_VERSIONS={0}'.\n format(python.version.up_to(2)))\n # adding path to boost\n args.append('-DBOOST_ROOT={0}'.\n format(self.spec['boost'].prefix))\n\n return args\n", "path": "var/spack/repos/builtin/packages/mgis/package.py"}]}
| 2,306 | 169 |
gh_patches_debug_17475
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1335
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Need more informative error message when failing to load kubeconfig
Currently if kubeconfig is not properly setup, we'll receive an error like the following which is not very informative:
```
Traceback (most recent call last):
File "/miniconda/envs/sqlflow-dev/bin/elasticdl", line 11, in <module>
load_entry_point('elasticdl==0.0.1', 'console_scripts', 'elasticdl')()
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/client.py", line 46, in main
args.func(args)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/api.py", line 43, in train
_submit_job(image_name, args, container_args)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/api.py", line 132, in _submit_job
cluster_spec=client_args.cluster_spec,
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/common/k8s_client.py", line 51, in __init__
config.load_kube_config()
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 645, in load_kube_config
persist_config=persist_config)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 613, in _get_kube_config_loader_for_yaml_file
**kwargs)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 153, in __init__
self.set_active_context(active_context)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 173, in set_active_context
context_name = self._config['current-context']
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 495, in __getitem__
v = self.safe_get(key)
File "/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py", line 491, in safe_get
key in self.value):
TypeError: argument of type 'NoneType' is not iterable
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/common/k8s_client.py`
Content:
```
1 import os
2 import threading
3 import traceback
4
5 from kubernetes import client, config, watch
6 from kubernetes.client import (
7 V1EnvVar,
8 V1EnvVarSource,
9 V1ObjectFieldSelector,
10 V1PersistentVolumeClaimVolumeSource,
11 )
12
13 from elasticdl.python.common.k8s_resource import parse as parse_resource
14 from elasticdl.python.common.k8s_volume import parse as parse_volume
15 from elasticdl.python.common.log_utils import default_logger as logger
16 from elasticdl.python.common.model_utils import load_module
17
18 ELASTICDL_APP_NAME = "elasticdl"
19 ELASTICDL_JOB_KEY = "elasticdl-job-name"
20 ELASTICDL_REPLICA_TYPE_KEY = "elasticdl-replica-type"
21 ELASTICDL_REPLICA_INDEX_KEY = "elasticdl-replica-index"
22
23
24 class Client(object):
25 def __init__(
26 self,
27 *,
28 image_name,
29 namespace,
30 job_name,
31 event_callback=None,
32 cluster_spec=""
33 ):
34 """
35 ElasticDL k8s client.
36
37 Args:
38 image_name: Docker image path for ElasticDL pod.
39 namespace: The name of the Kubernetes namespace where ElasticDL
40 pods will be created.
41 job_name: ElasticDL job name, should be unique in the namespace.
42 Used as pod name prefix and value for "elasticdl" label.
43 event_callback: If not None, an event watcher will be created and
44 events passed to the callback.
45 """
46 if os.getenv("KUBERNETES_SERVICE_HOST"):
47 # We are running inside k8s
48 config.load_incluster_config()
49 else:
50 # Use user's kube config
51 config.load_kube_config()
52
53 self.client = client.CoreV1Api()
54 self.namespace = namespace
55 self.job_name = job_name
56 self._image_name = image_name
57 self._event_cb = event_callback
58 if self._event_cb:
59 threading.Thread(
60 target=self._watch, name="event_watcher", daemon=True
61 ).start()
62 self.cluster = None
63 if cluster_spec:
64 cluster_spec_module = load_module(cluster_spec)
65 self.cluster = cluster_spec_module.cluster
66
67 def _watch(self):
68 stream = watch.Watch().stream(
69 self.client.list_namespaced_pod,
70 self.namespace,
71 label_selector=ELASTICDL_JOB_KEY + "=" + self.job_name,
72 )
73 for event in stream:
74 try:
75 self._event_cb(event)
76 except Exception:
77 traceback.print_exc()
78
79 def get_master_pod_name(self):
80 return "elasticdl-%s-master" % self.job_name
81
82 def get_worker_pod_name(self, worker_id):
83 return "elasticdl-%s-worker-%s" % (self.job_name, str(worker_id))
84
85 def get_embedding_service_pod_name(self, embedding_service_id):
86 return "elasticdl-%s-embedding-service-%s" % (
87 self.job_name,
88 str(embedding_service_id),
89 )
90
91 def patch_labels_to_pod(self, pod_name, labels_dict):
92 body = {"metadata": {"labels": labels_dict}}
93 try:
94 return self.client.patch_namespaced_pod(
95 name=pod_name, namespace=self.namespace, body=body
96 )
97 except client.api_client.ApiException as e:
98 logger.warning("Exception when patching labels to pod: %s\n" % e)
99 return None
100
101 def get_master_pod(self):
102 try:
103 return self.client.read_namespaced_pod(
104 name=self.get_master_pod_name(), namespace=self.namespace
105 )
106 except client.api_client.ApiException as e:
107 logger.warning("Exception when reading master pod: %s\n" % e)
108 return None
109
110 def get_worker_pod(self, worker_id):
111 try:
112 return self.client.read_namespaced_pod(
113 name=self.get_worker_pod_name(worker_id),
114 namespace=self.namespace,
115 )
116 except client.api_client.ApiException as e:
117 logger.warning("Exception when reading worker pod: %s\n" % e)
118 return None
119
120 def get_embedding_service_pod(self, embedding_service_id):
121 try:
122 return self.client.read_namespaced_pod(
123 name=self.get_embedding_service_pod_name(embedding_service_id),
124 namespace=self.namespace,
125 )
126 except client.api_client.ApiException as e:
127 logger.warning(
128 "Exception when reading embedding service pod: %s\n" % e
129 )
130 return None
131
132 @staticmethod
133 def create_owner_reference(owner_pod):
134 owner_ref = (
135 [
136 client.V1OwnerReference(
137 api_version="v1",
138 block_owner_deletion=True,
139 kind="Pod",
140 name=owner_pod.metadata.name,
141 uid=owner_pod.metadata.uid,
142 )
143 ]
144 if owner_pod
145 else None
146 )
147 return owner_ref
148
149 def _create_pod(self, **kargs):
150 # Container
151 pod_resource_requests = kargs["resource_requests"]
152 pod_resource_limits = kargs["resource_limits"]
153 pod_resource_limits = (
154 pod_resource_limits
155 if pod_resource_limits
156 else pod_resource_requests
157 )
158 container = client.V1Container(
159 name=kargs["pod_name"],
160 image=kargs["image_name"],
161 command=kargs["command"],
162 resources=client.V1ResourceRequirements(
163 requests=parse_resource(pod_resource_requests),
164 limits=parse_resource(pod_resource_limits),
165 ),
166 args=kargs["container_args"],
167 image_pull_policy=kargs["image_pull_policy"],
168 env=kargs["env"],
169 )
170
171 # Pod
172 spec = client.V1PodSpec(
173 containers=[container],
174 restart_policy=kargs["restart_policy"],
175 priority_class_name=kargs["pod_priority"],
176 )
177
178 # Mount data path
179 if kargs["volume"]:
180 volume_dict = parse_volume(kargs["volume"])
181 volume_name = kargs["pod_name"] + "-volume"
182 volume = client.V1Volume(
183 name=volume_name,
184 persistent_volume_claim=V1PersistentVolumeClaimVolumeSource(
185 claim_name=volume_dict["claim_name"], read_only=False
186 ),
187 )
188 spec.volumes = [volume]
189 container.volume_mounts = [
190 client.V1VolumeMount(
191 name=volume_name, mount_path=volume_dict["mount_path"]
192 )
193 ]
194
195 pod = client.V1Pod(
196 spec=spec,
197 metadata=client.V1ObjectMeta(
198 name=kargs["pod_name"],
199 labels={
200 "app": ELASTICDL_APP_NAME,
201 ELASTICDL_JOB_KEY: kargs["job_name"],
202 },
203 owner_references=self.create_owner_reference(
204 kargs["owner_pod"]
205 ),
206 namespace=self.namespace,
207 ),
208 )
209 if self.cluster:
210 pod = self.cluster.with_pod(pod)
211
212 return pod
213
214 def create_master(self, **kargs):
215 env = [
216 V1EnvVar(
217 name="MY_POD_IP",
218 value_from=V1EnvVarSource(
219 field_ref=V1ObjectFieldSelector(field_path="status.podIP")
220 ),
221 )
222 ]
223 if "envs" in kargs:
224 for key in kargs["envs"]:
225 env.append(V1EnvVar(name=key, value=kargs["envs"][key]))
226
227 pod = self._create_pod(
228 pod_name=self.get_master_pod_name(),
229 job_name=self.job_name,
230 image_name=self._image_name,
231 command=["python"],
232 resource_requests=kargs["resource_requests"],
233 resource_limits=kargs["resource_limits"],
234 container_args=kargs["args"],
235 pod_priority=kargs["pod_priority"],
236 image_pull_policy=kargs["image_pull_policy"],
237 restart_policy=kargs["restart_policy"],
238 volume=kargs["volume"],
239 owner_pod=None,
240 env=env,
241 )
242 # Add replica type and index
243 pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = "master"
244 pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = "0"
245 self.client.create_namespaced_pod(self.namespace, pod)
246 logger.info("Master launched.")
247
248 def _create_worker_pod(self, pod_name, type_key, **kargs):
249 # Find that master pod that will be used as the owner reference
250 # for this worker pod.
251 master_pod = self.get_master_pod()
252 env = kargs["envs"] if "envs" in kargs else None
253 pod = self._create_pod(
254 pod_name=pod_name,
255 job_name=self.job_name,
256 image_name=self._image_name,
257 command=kargs["command"],
258 resource_requests=kargs["resource_requests"],
259 resource_limits=kargs["resource_limits"],
260 container_args=kargs["args"],
261 pod_priority=kargs["pod_priority"],
262 image_pull_policy=kargs["image_pull_policy"],
263 restart_policy=kargs["restart_policy"],
264 volume=kargs["volume"],
265 owner_pod=master_pod,
266 env=env,
267 )
268 # Add replica type and index
269 pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = type_key
270 pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = str(
271 kargs["worker_id"]
272 )
273 return self.client.create_namespaced_pod(self.namespace, pod)
274
275 def create_worker(self, **kargs):
276 pod_name = self.get_worker_pod_name(kargs["worker_id"])
277 return self._create_worker_pod(pod_name, "worker", **kargs)
278
279 def create_embedding_service(self, **kargs):
280 pod_name = self.get_embedding_service_pod_name(kargs["worker_id"])
281 return self._create_worker_pod(pod_name, "embedding_service", **kargs)
282
283 def delete_master(self):
284 logger.info("pod name is %s" % self.get_master_pod_name())
285 self.client.delete_namespaced_pod(
286 self.get_master_pod_name(),
287 self.namespace,
288 body=client.V1DeleteOptions(grace_period_seconds=0),
289 )
290
291 def delete_worker(self, worker_id):
292 self.client.delete_namespaced_pod(
293 self.get_worker_pod_name(worker_id),
294 self.namespace,
295 body=client.V1DeleteOptions(grace_period_seconds=0),
296 )
297
298 def delete_embedding_service(self, embedding_service_id):
299 self.client.delete_namespaced_pod(
300 self.get_embedding_service_pod_name(embedding_service_id),
301 self.namespace,
302 body=client.V1DeleteOptions(grace_period_seconds=0),
303 )
304
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/common/k8s_client.py b/elasticdl/python/common/k8s_client.py
--- a/elasticdl/python/common/k8s_client.py
+++ b/elasticdl/python/common/k8s_client.py
@@ -43,12 +43,18 @@
event_callback: If not None, an event watcher will be created and
events passed to the callback.
"""
- if os.getenv("KUBERNETES_SERVICE_HOST"):
- # We are running inside k8s
- config.load_incluster_config()
- else:
- # Use user's kube config
- config.load_kube_config()
+ try:
+ if os.getenv("KUBERNETES_SERVICE_HOST"):
+ # We are running inside a k8s cluster
+ config.load_incluster_config()
+ else:
+ # Use user's kube config
+ config.load_kube_config()
+ except Exception as ex:
+ traceback.print_exc()
+ raise Exception(
+ "Failed to load configuration for Kubernetes:\n%s" % str(ex)
+ )
self.client = client.CoreV1Api()
self.namespace = namespace
|
{"golden_diff": "diff --git a/elasticdl/python/common/k8s_client.py b/elasticdl/python/common/k8s_client.py\n--- a/elasticdl/python/common/k8s_client.py\n+++ b/elasticdl/python/common/k8s_client.py\n@@ -43,12 +43,18 @@\n event_callback: If not None, an event watcher will be created and\n events passed to the callback.\n \"\"\"\n- if os.getenv(\"KUBERNETES_SERVICE_HOST\"):\n- # We are running inside k8s\n- config.load_incluster_config()\n- else:\n- # Use user's kube config\n- config.load_kube_config()\n+ try:\n+ if os.getenv(\"KUBERNETES_SERVICE_HOST\"):\n+ # We are running inside a k8s cluster\n+ config.load_incluster_config()\n+ else:\n+ # Use user's kube config\n+ config.load_kube_config()\n+ except Exception as ex:\n+ traceback.print_exc()\n+ raise Exception(\n+ \"Failed to load configuration for Kubernetes:\\n%s\" % str(ex)\n+ )\n \n self.client = client.CoreV1Api()\n self.namespace = namespace\n", "issue": "Need more informative error message when failing to load kubeconfig \nCurrently if kubeconfig is not properly setup, we'll receive an error like the following which is not very informative:\r\n```\r\nTraceback (most recent call last):\r\n File \"/miniconda/envs/sqlflow-dev/bin/elasticdl\", line 11, in <module>\r\n load_entry_point('elasticdl==0.0.1', 'console_scripts', 'elasticdl')()\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/client.py\", line 46, in main\r\n args.func(args)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/api.py\", line 43, in train\r\n _submit_job(image_name, args, container_args)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/elasticdl/api.py\", line 132, in _submit_job\r\n cluster_spec=client_args.cluster_spec,\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/elasticdl-0.0.1-py3.6.egg/elasticdl/python/common/k8s_client.py\", line 51, in __init__\r\n config.load_kube_config()\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 645, in load_kube_config\r\n persist_config=persist_config)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 613, in _get_kube_config_loader_for_yaml_file\r\n **kwargs)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 153, in __init__\r\n self.set_active_context(active_context)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 173, in set_active_context\r\n context_name = self._config['current-context']\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 495, in __getitem__\r\n v = self.safe_get(key)\r\n File \"/miniconda/envs/sqlflow-dev/lib/python3.6/site-packages/kubernetes/config/kube_config.py\", line 491, in safe_get\r\n key in self.value):\r\nTypeError: argument of type 'NoneType' is not iterable\r\n```\n", "before_files": [{"content": "import os\nimport threading\nimport traceback\n\nfrom kubernetes import client, config, watch\nfrom kubernetes.client import (\n V1EnvVar,\n V1EnvVarSource,\n V1ObjectFieldSelector,\n V1PersistentVolumeClaimVolumeSource,\n)\n\nfrom elasticdl.python.common.k8s_resource import parse as parse_resource\nfrom elasticdl.python.common.k8s_volume import parse as parse_volume\nfrom elasticdl.python.common.log_utils import default_logger as logger\nfrom elasticdl.python.common.model_utils import load_module\n\nELASTICDL_APP_NAME = \"elasticdl\"\nELASTICDL_JOB_KEY = \"elasticdl-job-name\"\nELASTICDL_REPLICA_TYPE_KEY = \"elasticdl-replica-type\"\nELASTICDL_REPLICA_INDEX_KEY = \"elasticdl-replica-index\"\n\n\nclass Client(object):\n def __init__(\n self,\n *,\n image_name,\n namespace,\n job_name,\n event_callback=None,\n cluster_spec=\"\"\n ):\n \"\"\"\n ElasticDL k8s client.\n\n Args:\n image_name: Docker image path for ElasticDL pod.\n namespace: The name of the Kubernetes namespace where ElasticDL\n pods will be created.\n job_name: ElasticDL job name, should be unique in the namespace.\n Used as pod name prefix and value for \"elasticdl\" label.\n event_callback: If not None, an event watcher will be created and\n events passed to the callback.\n \"\"\"\n if os.getenv(\"KUBERNETES_SERVICE_HOST\"):\n # We are running inside k8s\n config.load_incluster_config()\n else:\n # Use user's kube config\n config.load_kube_config()\n\n self.client = client.CoreV1Api()\n self.namespace = namespace\n self.job_name = job_name\n self._image_name = image_name\n self._event_cb = event_callback\n if self._event_cb:\n threading.Thread(\n target=self._watch, name=\"event_watcher\", daemon=True\n ).start()\n self.cluster = None\n if cluster_spec:\n cluster_spec_module = load_module(cluster_spec)\n self.cluster = cluster_spec_module.cluster\n\n def _watch(self):\n stream = watch.Watch().stream(\n self.client.list_namespaced_pod,\n self.namespace,\n label_selector=ELASTICDL_JOB_KEY + \"=\" + self.job_name,\n )\n for event in stream:\n try:\n self._event_cb(event)\n except Exception:\n traceback.print_exc()\n\n def get_master_pod_name(self):\n return \"elasticdl-%s-master\" % self.job_name\n\n def get_worker_pod_name(self, worker_id):\n return \"elasticdl-%s-worker-%s\" % (self.job_name, str(worker_id))\n\n def get_embedding_service_pod_name(self, embedding_service_id):\n return \"elasticdl-%s-embedding-service-%s\" % (\n self.job_name,\n str(embedding_service_id),\n )\n\n def patch_labels_to_pod(self, pod_name, labels_dict):\n body = {\"metadata\": {\"labels\": labels_dict}}\n try:\n return self.client.patch_namespaced_pod(\n name=pod_name, namespace=self.namespace, body=body\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when patching labels to pod: %s\\n\" % e)\n return None\n\n def get_master_pod(self):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_master_pod_name(), namespace=self.namespace\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when reading master pod: %s\\n\" % e)\n return None\n\n def get_worker_pod(self, worker_id):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_worker_pod_name(worker_id),\n namespace=self.namespace,\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when reading worker pod: %s\\n\" % e)\n return None\n\n def get_embedding_service_pod(self, embedding_service_id):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_embedding_service_pod_name(embedding_service_id),\n namespace=self.namespace,\n )\n except client.api_client.ApiException as e:\n logger.warning(\n \"Exception when reading embedding service pod: %s\\n\" % e\n )\n return None\n\n @staticmethod\n def create_owner_reference(owner_pod):\n owner_ref = (\n [\n client.V1OwnerReference(\n api_version=\"v1\",\n block_owner_deletion=True,\n kind=\"Pod\",\n name=owner_pod.metadata.name,\n uid=owner_pod.metadata.uid,\n )\n ]\n if owner_pod\n else None\n )\n return owner_ref\n\n def _create_pod(self, **kargs):\n # Container\n pod_resource_requests = kargs[\"resource_requests\"]\n pod_resource_limits = kargs[\"resource_limits\"]\n pod_resource_limits = (\n pod_resource_limits\n if pod_resource_limits\n else pod_resource_requests\n )\n container = client.V1Container(\n name=kargs[\"pod_name\"],\n image=kargs[\"image_name\"],\n command=kargs[\"command\"],\n resources=client.V1ResourceRequirements(\n requests=parse_resource(pod_resource_requests),\n limits=parse_resource(pod_resource_limits),\n ),\n args=kargs[\"container_args\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n env=kargs[\"env\"],\n )\n\n # Pod\n spec = client.V1PodSpec(\n containers=[container],\n restart_policy=kargs[\"restart_policy\"],\n priority_class_name=kargs[\"pod_priority\"],\n )\n\n # Mount data path\n if kargs[\"volume\"]:\n volume_dict = parse_volume(kargs[\"volume\"])\n volume_name = kargs[\"pod_name\"] + \"-volume\"\n volume = client.V1Volume(\n name=volume_name,\n persistent_volume_claim=V1PersistentVolumeClaimVolumeSource(\n claim_name=volume_dict[\"claim_name\"], read_only=False\n ),\n )\n spec.volumes = [volume]\n container.volume_mounts = [\n client.V1VolumeMount(\n name=volume_name, mount_path=volume_dict[\"mount_path\"]\n )\n ]\n\n pod = client.V1Pod(\n spec=spec,\n metadata=client.V1ObjectMeta(\n name=kargs[\"pod_name\"],\n labels={\n \"app\": ELASTICDL_APP_NAME,\n ELASTICDL_JOB_KEY: kargs[\"job_name\"],\n },\n owner_references=self.create_owner_reference(\n kargs[\"owner_pod\"]\n ),\n namespace=self.namespace,\n ),\n )\n if self.cluster:\n pod = self.cluster.with_pod(pod)\n\n return pod\n\n def create_master(self, **kargs):\n env = [\n V1EnvVar(\n name=\"MY_POD_IP\",\n value_from=V1EnvVarSource(\n field_ref=V1ObjectFieldSelector(field_path=\"status.podIP\")\n ),\n )\n ]\n if \"envs\" in kargs:\n for key in kargs[\"envs\"]:\n env.append(V1EnvVar(name=key, value=kargs[\"envs\"][key]))\n\n pod = self._create_pod(\n pod_name=self.get_master_pod_name(),\n job_name=self.job_name,\n image_name=self._image_name,\n command=[\"python\"],\n resource_requests=kargs[\"resource_requests\"],\n resource_limits=kargs[\"resource_limits\"],\n container_args=kargs[\"args\"],\n pod_priority=kargs[\"pod_priority\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n restart_policy=kargs[\"restart_policy\"],\n volume=kargs[\"volume\"],\n owner_pod=None,\n env=env,\n )\n # Add replica type and index\n pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = \"master\"\n pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = \"0\"\n self.client.create_namespaced_pod(self.namespace, pod)\n logger.info(\"Master launched.\")\n\n def _create_worker_pod(self, pod_name, type_key, **kargs):\n # Find that master pod that will be used as the owner reference\n # for this worker pod.\n master_pod = self.get_master_pod()\n env = kargs[\"envs\"] if \"envs\" in kargs else None\n pod = self._create_pod(\n pod_name=pod_name,\n job_name=self.job_name,\n image_name=self._image_name,\n command=kargs[\"command\"],\n resource_requests=kargs[\"resource_requests\"],\n resource_limits=kargs[\"resource_limits\"],\n container_args=kargs[\"args\"],\n pod_priority=kargs[\"pod_priority\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n restart_policy=kargs[\"restart_policy\"],\n volume=kargs[\"volume\"],\n owner_pod=master_pod,\n env=env,\n )\n # Add replica type and index\n pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = type_key\n pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = str(\n kargs[\"worker_id\"]\n )\n return self.client.create_namespaced_pod(self.namespace, pod)\n\n def create_worker(self, **kargs):\n pod_name = self.get_worker_pod_name(kargs[\"worker_id\"])\n return self._create_worker_pod(pod_name, \"worker\", **kargs)\n\n def create_embedding_service(self, **kargs):\n pod_name = self.get_embedding_service_pod_name(kargs[\"worker_id\"])\n return self._create_worker_pod(pod_name, \"embedding_service\", **kargs)\n\n def delete_master(self):\n logger.info(\"pod name is %s\" % self.get_master_pod_name())\n self.client.delete_namespaced_pod(\n self.get_master_pod_name(),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n\n def delete_worker(self, worker_id):\n self.client.delete_namespaced_pod(\n self.get_worker_pod_name(worker_id),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n\n def delete_embedding_service(self, embedding_service_id):\n self.client.delete_namespaced_pod(\n self.get_embedding_service_pod_name(embedding_service_id),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n", "path": "elasticdl/python/common/k8s_client.py"}], "after_files": [{"content": "import os\nimport threading\nimport traceback\n\nfrom kubernetes import client, config, watch\nfrom kubernetes.client import (\n V1EnvVar,\n V1EnvVarSource,\n V1ObjectFieldSelector,\n V1PersistentVolumeClaimVolumeSource,\n)\n\nfrom elasticdl.python.common.k8s_resource import parse as parse_resource\nfrom elasticdl.python.common.k8s_volume import parse as parse_volume\nfrom elasticdl.python.common.log_utils import default_logger as logger\nfrom elasticdl.python.common.model_utils import load_module\n\nELASTICDL_APP_NAME = \"elasticdl\"\nELASTICDL_JOB_KEY = \"elasticdl-job-name\"\nELASTICDL_REPLICA_TYPE_KEY = \"elasticdl-replica-type\"\nELASTICDL_REPLICA_INDEX_KEY = \"elasticdl-replica-index\"\n\n\nclass Client(object):\n def __init__(\n self,\n *,\n image_name,\n namespace,\n job_name,\n event_callback=None,\n cluster_spec=\"\"\n ):\n \"\"\"\n ElasticDL k8s client.\n\n Args:\n image_name: Docker image path for ElasticDL pod.\n namespace: The name of the Kubernetes namespace where ElasticDL\n pods will be created.\n job_name: ElasticDL job name, should be unique in the namespace.\n Used as pod name prefix and value for \"elasticdl\" label.\n event_callback: If not None, an event watcher will be created and\n events passed to the callback.\n \"\"\"\n try:\n if os.getenv(\"KUBERNETES_SERVICE_HOST\"):\n # We are running inside a k8s cluster\n config.load_incluster_config()\n else:\n # Use user's kube config\n config.load_kube_config()\n except Exception as ex:\n traceback.print_exc()\n raise Exception(\n \"Failed to load configuration for Kubernetes:\\n%s\" % str(ex)\n )\n\n self.client = client.CoreV1Api()\n self.namespace = namespace\n self.job_name = job_name\n self._image_name = image_name\n self._event_cb = event_callback\n if self._event_cb:\n threading.Thread(\n target=self._watch, name=\"event_watcher\", daemon=True\n ).start()\n self.cluster = None\n if cluster_spec:\n cluster_spec_module = load_module(cluster_spec)\n self.cluster = cluster_spec_module.cluster\n\n def _watch(self):\n stream = watch.Watch().stream(\n self.client.list_namespaced_pod,\n self.namespace,\n label_selector=ELASTICDL_JOB_KEY + \"=\" + self.job_name,\n )\n for event in stream:\n try:\n self._event_cb(event)\n except Exception:\n traceback.print_exc()\n\n def get_master_pod_name(self):\n return \"elasticdl-%s-master\" % self.job_name\n\n def get_worker_pod_name(self, worker_id):\n return \"elasticdl-%s-worker-%s\" % (self.job_name, str(worker_id))\n\n def get_embedding_service_pod_name(self, embedding_service_id):\n return \"elasticdl-%s-embedding-service-%s\" % (\n self.job_name,\n str(embedding_service_id),\n )\n\n def patch_labels_to_pod(self, pod_name, labels_dict):\n body = {\"metadata\": {\"labels\": labels_dict}}\n try:\n return self.client.patch_namespaced_pod(\n name=pod_name, namespace=self.namespace, body=body\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when patching labels to pod: %s\\n\" % e)\n return None\n\n def get_master_pod(self):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_master_pod_name(), namespace=self.namespace\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when reading master pod: %s\\n\" % e)\n return None\n\n def get_worker_pod(self, worker_id):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_worker_pod_name(worker_id),\n namespace=self.namespace,\n )\n except client.api_client.ApiException as e:\n logger.warning(\"Exception when reading worker pod: %s\\n\" % e)\n return None\n\n def get_embedding_service_pod(self, embedding_service_id):\n try:\n return self.client.read_namespaced_pod(\n name=self.get_embedding_service_pod_name(embedding_service_id),\n namespace=self.namespace,\n )\n except client.api_client.ApiException as e:\n logger.warning(\n \"Exception when reading embedding service pod: %s\\n\" % e\n )\n return None\n\n @staticmethod\n def create_owner_reference(owner_pod):\n owner_ref = (\n [\n client.V1OwnerReference(\n api_version=\"v1\",\n block_owner_deletion=True,\n kind=\"Pod\",\n name=owner_pod.metadata.name,\n uid=owner_pod.metadata.uid,\n )\n ]\n if owner_pod\n else None\n )\n return owner_ref\n\n def _create_pod(self, **kargs):\n # Container\n pod_resource_requests = kargs[\"resource_requests\"]\n pod_resource_limits = kargs[\"resource_limits\"]\n pod_resource_limits = (\n pod_resource_limits\n if pod_resource_limits\n else pod_resource_requests\n )\n container = client.V1Container(\n name=kargs[\"pod_name\"],\n image=kargs[\"image_name\"],\n command=kargs[\"command\"],\n resources=client.V1ResourceRequirements(\n requests=parse_resource(pod_resource_requests),\n limits=parse_resource(pod_resource_limits),\n ),\n args=kargs[\"container_args\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n env=kargs[\"env\"],\n )\n\n # Pod\n spec = client.V1PodSpec(\n containers=[container],\n restart_policy=kargs[\"restart_policy\"],\n priority_class_name=kargs[\"pod_priority\"],\n )\n\n # Mount data path\n if kargs[\"volume\"]:\n volume_dict = parse_volume(kargs[\"volume\"])\n volume_name = kargs[\"pod_name\"] + \"-volume\"\n volume = client.V1Volume(\n name=volume_name,\n persistent_volume_claim=V1PersistentVolumeClaimVolumeSource(\n claim_name=volume_dict[\"claim_name\"], read_only=False\n ),\n )\n spec.volumes = [volume]\n container.volume_mounts = [\n client.V1VolumeMount(\n name=volume_name, mount_path=volume_dict[\"mount_path\"]\n )\n ]\n\n pod = client.V1Pod(\n spec=spec,\n metadata=client.V1ObjectMeta(\n name=kargs[\"pod_name\"],\n labels={\n \"app\": ELASTICDL_APP_NAME,\n ELASTICDL_JOB_KEY: kargs[\"job_name\"],\n },\n owner_references=self.create_owner_reference(\n kargs[\"owner_pod\"]\n ),\n namespace=self.namespace,\n ),\n )\n if self.cluster:\n pod = self.cluster.with_pod(pod)\n\n return pod\n\n def create_master(self, **kargs):\n env = [\n V1EnvVar(\n name=\"MY_POD_IP\",\n value_from=V1EnvVarSource(\n field_ref=V1ObjectFieldSelector(field_path=\"status.podIP\")\n ),\n )\n ]\n if \"envs\" in kargs:\n for key in kargs[\"envs\"]:\n env.append(V1EnvVar(name=key, value=kargs[\"envs\"][key]))\n\n pod = self._create_pod(\n pod_name=self.get_master_pod_name(),\n job_name=self.job_name,\n image_name=self._image_name,\n command=[\"python\"],\n resource_requests=kargs[\"resource_requests\"],\n resource_limits=kargs[\"resource_limits\"],\n container_args=kargs[\"args\"],\n pod_priority=kargs[\"pod_priority\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n restart_policy=kargs[\"restart_policy\"],\n volume=kargs[\"volume\"],\n owner_pod=None,\n env=env,\n )\n # Add replica type and index\n pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = \"master\"\n pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = \"0\"\n self.client.create_namespaced_pod(self.namespace, pod)\n logger.info(\"Master launched.\")\n\n def _create_worker_pod(self, pod_name, type_key, **kargs):\n # Find that master pod that will be used as the owner reference\n # for this worker pod.\n master_pod = self.get_master_pod()\n env = kargs[\"envs\"] if \"envs\" in kargs else None\n pod = self._create_pod(\n pod_name=pod_name,\n job_name=self.job_name,\n image_name=self._image_name,\n command=kargs[\"command\"],\n resource_requests=kargs[\"resource_requests\"],\n resource_limits=kargs[\"resource_limits\"],\n container_args=kargs[\"args\"],\n pod_priority=kargs[\"pod_priority\"],\n image_pull_policy=kargs[\"image_pull_policy\"],\n restart_policy=kargs[\"restart_policy\"],\n volume=kargs[\"volume\"],\n owner_pod=master_pod,\n env=env,\n )\n # Add replica type and index\n pod.metadata.labels[ELASTICDL_REPLICA_TYPE_KEY] = type_key\n pod.metadata.labels[ELASTICDL_REPLICA_INDEX_KEY] = str(\n kargs[\"worker_id\"]\n )\n return self.client.create_namespaced_pod(self.namespace, pod)\n\n def create_worker(self, **kargs):\n pod_name = self.get_worker_pod_name(kargs[\"worker_id\"])\n return self._create_worker_pod(pod_name, \"worker\", **kargs)\n\n def create_embedding_service(self, **kargs):\n pod_name = self.get_embedding_service_pod_name(kargs[\"worker_id\"])\n return self._create_worker_pod(pod_name, \"embedding_service\", **kargs)\n\n def delete_master(self):\n logger.info(\"pod name is %s\" % self.get_master_pod_name())\n self.client.delete_namespaced_pod(\n self.get_master_pod_name(),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n\n def delete_worker(self, worker_id):\n self.client.delete_namespaced_pod(\n self.get_worker_pod_name(worker_id),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n\n def delete_embedding_service(self, embedding_service_id):\n self.client.delete_namespaced_pod(\n self.get_embedding_service_pod_name(embedding_service_id),\n self.namespace,\n body=client.V1DeleteOptions(grace_period_seconds=0),\n )\n", "path": "elasticdl/python/common/k8s_client.py"}]}
| 3,910 | 260 |
gh_patches_debug_11940
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-5272
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot upload content via pulp-container because of the change made to the `Upload` model
The following commit broke the pulp-container upload: https://github.com/pulp/pulpcore/commit/9192c2bf0ccb0e0a2df595fd3efdd0980c80ff34.
Traceback:
```
pulp_1 | pulp [adbae673f9b7498d8240989c1bba93ff]: django.request:ERROR: Internal Server Error: /v2/myorg/mygroup/ubuntu/blobs/uploads/
pulp_1 | Traceback (most recent call last):
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django/core/handlers/exception.py", line 55, in inner
pulp_1 | response = get_response(request)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django/core/handlers/base.py", line 197, in _get_response
pulp_1 | response = wrapped_callback(request, *callback_args, **callback_kwargs)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django/views/decorators/csrf.py", line 56, in wrapper_view
pulp_1 | return view_func(*args, **kwargs)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/rest_framework/viewsets.py", line 124, in view
pulp_1 | return self.dispatch(request, *args, **kwargs)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 509, in dispatch
pulp_1 | response = self.handle_exception(exc)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/src/pulp_container/pulp_container/app/registry_api.py", line 271, in handle_exception
pulp_1 | response = super().handle_exception(exc)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 469, in handle_exception
pulp_1 | self.raise_uncaught_exception(exc)
pulp_1 | File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 480, in raise_uncaught_exception
pulp_1 | raise exc
pulp_1 | File "/usr/local/lib/python3.11/site-packages/rest_framework/views.py", line 506, in dispatch
pulp_1 | response = handler(request, *args, **kwargs)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/src/pulp_container/pulp_container/app/registry_api.py", line 758, in create
pulp_1 | upload.save()
pulp_1 | File "/usr/lib64/python3.11/contextlib.py", line 81, in inner
pulp_1 | return func(*args, **kwds)
pulp_1 | ^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py", line 196, in save
pulp_1 | self._run_hooked_methods(AFTER_CREATE, **kwargs)
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py", line 312, in _run_hooked_methods
pulp_1 | method.run(self)
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py", line 46, in run
pulp_1 | self.method(instance)
pulp_1 | File "/usr/local/lib/python3.11/site-packages/django_lifecycle/decorators.py", line 119, in func
pulp_1 | hooked_method(*args, **kwargs)
pulp_1 | File "/src/pulpcore/pulpcore/app/models/access_policy.py", line 70, in add_perms
pulp_1 | viewset = get_viewset_for_model(self)
pulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^
pulp_1 | File "/src/pulpcore/pulpcore/app/util.py", line 188, in get_viewset_for_model
pulp_1 | raise LookupError("Could not determine ViewSet base name for model {}".format(model_class))
```
This is reproducible always when trying to push any image to the Pulp Container Registry.
Affected code:
https://github.com/pulp/pulp_container/blob/742acc52f8fc44c4d18a41621455b21e2b9133ec/pulp_container/app/models.py#L804
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/models/access_policy.py`
Content:
```
1 from django.contrib.auth import get_user_model
2 from django.contrib.auth.models import Group as BaseGroup
3 from django.db import models
4 from django_lifecycle import hook, LifecycleModelMixin
5
6 from pulpcore.app.models import BaseModel
7 from pulpcore.app.util import get_viewset_for_model, get_current_authenticated_user
8
9
10 def _ensure_iterable(obj):
11 if isinstance(obj, str):
12 return [obj]
13 return obj
14
15
16 class AccessPolicy(BaseModel):
17 """
18 A model storing a viewset authorization policy and permission assignment of new objects created.
19
20 Fields:
21
22 creation_hooks (models.JSONField): A list of dictionaries identifying callables on the
23 ``pulpcore.plugin.access_policy.AccessPolicyFromDB`` which can add user or group roles
24 for newly created objects. This is a nullable field due to not all endpoints creating
25 objects.
26 statements (models.JSONField): A list of ``drf-access-policy`` statements.
27 viewset_name (models.TextField): The name of the viewset this instance controls
28 authorization for.
29 customized (BooleanField): False if the AccessPolicy has been user-modified. True otherwise.
30 Defaults to False.
31 queryset_scoping (models.JSONField): A dictionary identifying a callable to perform the
32 queryset scoping. This field can be null if the user doesn't want to perform scoping.
33
34 """
35
36 creation_hooks = models.JSONField(null=True)
37 statements = models.JSONField()
38 viewset_name = models.TextField(unique=True)
39 customized = models.BooleanField(default=False)
40 queryset_scoping = models.JSONField(null=True)
41
42
43 class AutoAddObjPermsMixin:
44 """
45 A mixin that automatically adds roles based on the ``creation_hooks`` data.
46
47 To use this mixin, your model must support ``django-lifecycle``.
48
49 This mixin adds an ``after_create`` hook which properly interprets the ``creation_hooks``
50 data and calls methods also provided by this mixin to add roles.
51
52 These hooks are provided by default:
53
54 * ``add_roles_for_object_creator`` will add the roles to the creator of the object.
55 * ``add_roles_for_users`` will add the roles for one or more users by name.
56 * ``add_roles_for_groups`` will add the roles for one or more groups by name.
57
58 """
59
60 def __init__(self, *args, **kwargs):
61 self.REGISTERED_CREATION_HOOKS = {
62 "add_roles_for_users": self.add_roles_for_users,
63 "add_roles_for_groups": self.add_roles_for_groups,
64 "add_roles_for_object_creator": self.add_roles_for_object_creator,
65 }
66 super().__init__(*args, **kwargs)
67
68 @hook("after_create")
69 def add_perms(self):
70 viewset = get_viewset_for_model(self)
71 for permission_class in viewset.get_permissions(viewset):
72 if hasattr(permission_class, "handle_creation_hooks"):
73 permission_class.handle_creation_hooks(self)
74
75 def add_roles_for_users(self, roles, users):
76 """
77 Adds object-level roles for one or more users for this newly created object.
78
79 Args:
80 roles (str or list): One or more roles to be added at object-level for the users.
81 This can either be a single role as a string, or a list of role names.
82 users (str or list): One or more users who will receive object-level roles. This can
83 either be a single username as a string or a list of usernames.
84
85 Raises:
86 ObjectDoesNotExist: If any of the users do not exist.
87
88 """
89 from pulpcore.app.role_util import assign_role
90
91 roles = _ensure_iterable(roles)
92 users = _ensure_iterable(users)
93 for username in users:
94 user = get_user_model().objects.get(username=username)
95 for role in roles:
96 assign_role(role, user, self)
97
98 def add_roles_for_groups(self, roles, groups):
99 """
100 Adds object-level roles for one or more groups for this newly created object.
101
102 Args:
103 roles (str or list): One or more object-level roles to be added for the groups. This
104 can either be a single role as a string, or list of role names.
105 groups (str or list): One or more groups who will receive object-level roles. This
106 can either be a single group name as a string or a list of group names.
107
108 Raises:
109 ObjectDoesNotExist: If any of the groups do not exist.
110
111 """
112 from pulpcore.app.role_util import assign_role
113
114 roles = _ensure_iterable(roles)
115 groups = _ensure_iterable(groups)
116 for group_name in groups:
117 group = Group.objects.get(name=group_name)
118 for role in roles:
119 assign_role(role, group, self)
120
121 def add_roles_for_object_creator(self, roles):
122 """
123 Adds object-level roles for the user creating the newly created object.
124
125 If the ``get_current_authenticated_user`` returns None because the API client did not
126 provide authentication credentials, *no* permissions are added and this passes silently.
127 This allows endpoints which create objects and do not require authorization to execute
128 without error.
129
130 Args:
131 roles (list or str): One or more roles to be added at the object-level for the user.
132 This can either be a single role as a string, or list of role names.
133
134 """
135 from pulpcore.app.role_util import assign_role
136
137 roles = _ensure_iterable(roles)
138 current_user = get_current_authenticated_user()
139 if current_user:
140 for role in roles:
141 assign_role(role, current_user, self)
142
143
144 class Group(LifecycleModelMixin, BaseGroup, AutoAddObjPermsMixin):
145 class Meta:
146 proxy = True
147 permissions = [
148 ("manage_roles_group", "Can manage role assignments on group"),
149 ]
150
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/models/access_policy.py b/pulpcore/app/models/access_policy.py
--- a/pulpcore/app/models/access_policy.py
+++ b/pulpcore/app/models/access_policy.py
@@ -67,10 +67,14 @@
@hook("after_create")
def add_perms(self):
- viewset = get_viewset_for_model(self)
- for permission_class in viewset.get_permissions(viewset):
- if hasattr(permission_class, "handle_creation_hooks"):
- permission_class.handle_creation_hooks(self)
+ try:
+ viewset = get_viewset_for_model(self)
+ except LookupError:
+ pass
+ else:
+ for permission_class in viewset.get_permissions(viewset):
+ if hasattr(permission_class, "handle_creation_hooks"):
+ permission_class.handle_creation_hooks(self)
def add_roles_for_users(self, roles, users):
"""
|
{"golden_diff": "diff --git a/pulpcore/app/models/access_policy.py b/pulpcore/app/models/access_policy.py\n--- a/pulpcore/app/models/access_policy.py\n+++ b/pulpcore/app/models/access_policy.py\n@@ -67,10 +67,14 @@\n \n @hook(\"after_create\")\n def add_perms(self):\n- viewset = get_viewset_for_model(self)\n- for permission_class in viewset.get_permissions(viewset):\n- if hasattr(permission_class, \"handle_creation_hooks\"):\n- permission_class.handle_creation_hooks(self)\n+ try:\n+ viewset = get_viewset_for_model(self)\n+ except LookupError:\n+ pass\n+ else:\n+ for permission_class in viewset.get_permissions(viewset):\n+ if hasattr(permission_class, \"handle_creation_hooks\"):\n+ permission_class.handle_creation_hooks(self)\n \n def add_roles_for_users(self, roles, users):\n \"\"\"\n", "issue": "Cannot upload content via pulp-container because of the change made to the `Upload` model\nThe following commit broke the pulp-container upload: https://github.com/pulp/pulpcore/commit/9192c2bf0ccb0e0a2df595fd3efdd0980c80ff34.\r\n\r\nTraceback:\r\n```\r\npulp_1 | pulp [adbae673f9b7498d8240989c1bba93ff]: django.request:ERROR: Internal Server Error: /v2/myorg/mygroup/ubuntu/blobs/uploads/\r\npulp_1 | Traceback (most recent call last):\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django/core/handlers/exception.py\", line 55, in inner\r\npulp_1 | response = get_response(request)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django/core/handlers/base.py\", line 197, in _get_response\r\npulp_1 | response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django/views/decorators/csrf.py\", line 56, in wrapper_view\r\npulp_1 | return view_func(*args, **kwargs)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/rest_framework/viewsets.py\", line 124, in view\r\npulp_1 | return self.dispatch(request, *args, **kwargs)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 509, in dispatch\r\npulp_1 | response = self.handle_exception(exc)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/src/pulp_container/pulp_container/app/registry_api.py\", line 271, in handle_exception\r\npulp_1 | response = super().handle_exception(exc)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 469, in handle_exception\r\npulp_1 | self.raise_uncaught_exception(exc)\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 480, in raise_uncaught_exception\r\npulp_1 | raise exc\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/rest_framework/views.py\", line 506, in dispatch\r\npulp_1 | response = handler(request, *args, **kwargs)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/src/pulp_container/pulp_container/app/registry_api.py\", line 758, in create\r\npulp_1 | upload.save()\r\npulp_1 | File \"/usr/lib64/python3.11/contextlib.py\", line 81, in inner\r\npulp_1 | return func(*args, **kwds)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py\", line 196, in save\r\npulp_1 | self._run_hooked_methods(AFTER_CREATE, **kwargs)\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py\", line 312, in _run_hooked_methods\r\npulp_1 | method.run(self)\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django_lifecycle/mixins.py\", line 46, in run\r\npulp_1 | self.method(instance)\r\npulp_1 | File \"/usr/local/lib/python3.11/site-packages/django_lifecycle/decorators.py\", line 119, in func\r\npulp_1 | hooked_method(*args, **kwargs)\r\npulp_1 | File \"/src/pulpcore/pulpcore/app/models/access_policy.py\", line 70, in add_perms\r\npulp_1 | viewset = get_viewset_for_model(self)\r\npulp_1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\npulp_1 | File \"/src/pulpcore/pulpcore/app/util.py\", line 188, in get_viewset_for_model\r\npulp_1 | raise LookupError(\"Could not determine ViewSet base name for model {}\".format(model_class))\r\n```\r\n\r\nThis is reproducible always when trying to push any image to the Pulp Container Registry.\r\n\r\nAffected code:\r\nhttps://github.com/pulp/pulp_container/blob/742acc52f8fc44c4d18a41621455b21e2b9133ec/pulp_container/app/models.py#L804\n", "before_files": [{"content": "from django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as BaseGroup\nfrom django.db import models\nfrom django_lifecycle import hook, LifecycleModelMixin\n\nfrom pulpcore.app.models import BaseModel\nfrom pulpcore.app.util import get_viewset_for_model, get_current_authenticated_user\n\n\ndef _ensure_iterable(obj):\n if isinstance(obj, str):\n return [obj]\n return obj\n\n\nclass AccessPolicy(BaseModel):\n \"\"\"\n A model storing a viewset authorization policy and permission assignment of new objects created.\n\n Fields:\n\n creation_hooks (models.JSONField): A list of dictionaries identifying callables on the\n ``pulpcore.plugin.access_policy.AccessPolicyFromDB`` which can add user or group roles\n for newly created objects. This is a nullable field due to not all endpoints creating\n objects.\n statements (models.JSONField): A list of ``drf-access-policy`` statements.\n viewset_name (models.TextField): The name of the viewset this instance controls\n authorization for.\n customized (BooleanField): False if the AccessPolicy has been user-modified. True otherwise.\n Defaults to False.\n queryset_scoping (models.JSONField): A dictionary identifying a callable to perform the\n queryset scoping. This field can be null if the user doesn't want to perform scoping.\n\n \"\"\"\n\n creation_hooks = models.JSONField(null=True)\n statements = models.JSONField()\n viewset_name = models.TextField(unique=True)\n customized = models.BooleanField(default=False)\n queryset_scoping = models.JSONField(null=True)\n\n\nclass AutoAddObjPermsMixin:\n \"\"\"\n A mixin that automatically adds roles based on the ``creation_hooks`` data.\n\n To use this mixin, your model must support ``django-lifecycle``.\n\n This mixin adds an ``after_create`` hook which properly interprets the ``creation_hooks``\n data and calls methods also provided by this mixin to add roles.\n\n These hooks are provided by default:\n\n * ``add_roles_for_object_creator`` will add the roles to the creator of the object.\n * ``add_roles_for_users`` will add the roles for one or more users by name.\n * ``add_roles_for_groups`` will add the roles for one or more groups by name.\n\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n self.REGISTERED_CREATION_HOOKS = {\n \"add_roles_for_users\": self.add_roles_for_users,\n \"add_roles_for_groups\": self.add_roles_for_groups,\n \"add_roles_for_object_creator\": self.add_roles_for_object_creator,\n }\n super().__init__(*args, **kwargs)\n\n @hook(\"after_create\")\n def add_perms(self):\n viewset = get_viewset_for_model(self)\n for permission_class in viewset.get_permissions(viewset):\n if hasattr(permission_class, \"handle_creation_hooks\"):\n permission_class.handle_creation_hooks(self)\n\n def add_roles_for_users(self, roles, users):\n \"\"\"\n Adds object-level roles for one or more users for this newly created object.\n\n Args:\n roles (str or list): One or more roles to be added at object-level for the users.\n This can either be a single role as a string, or a list of role names.\n users (str or list): One or more users who will receive object-level roles. This can\n either be a single username as a string or a list of usernames.\n\n Raises:\n ObjectDoesNotExist: If any of the users do not exist.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n users = _ensure_iterable(users)\n for username in users:\n user = get_user_model().objects.get(username=username)\n for role in roles:\n assign_role(role, user, self)\n\n def add_roles_for_groups(self, roles, groups):\n \"\"\"\n Adds object-level roles for one or more groups for this newly created object.\n\n Args:\n roles (str or list): One or more object-level roles to be added for the groups. This\n can either be a single role as a string, or list of role names.\n groups (str or list): One or more groups who will receive object-level roles. This\n can either be a single group name as a string or a list of group names.\n\n Raises:\n ObjectDoesNotExist: If any of the groups do not exist.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n groups = _ensure_iterable(groups)\n for group_name in groups:\n group = Group.objects.get(name=group_name)\n for role in roles:\n assign_role(role, group, self)\n\n def add_roles_for_object_creator(self, roles):\n \"\"\"\n Adds object-level roles for the user creating the newly created object.\n\n If the ``get_current_authenticated_user`` returns None because the API client did not\n provide authentication credentials, *no* permissions are added and this passes silently.\n This allows endpoints which create objects and do not require authorization to execute\n without error.\n\n Args:\n roles (list or str): One or more roles to be added at the object-level for the user.\n This can either be a single role as a string, or list of role names.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n current_user = get_current_authenticated_user()\n if current_user:\n for role in roles:\n assign_role(role, current_user, self)\n\n\nclass Group(LifecycleModelMixin, BaseGroup, AutoAddObjPermsMixin):\n class Meta:\n proxy = True\n permissions = [\n (\"manage_roles_group\", \"Can manage role assignments on group\"),\n ]\n", "path": "pulpcore/app/models/access_policy.py"}], "after_files": [{"content": "from django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as BaseGroup\nfrom django.db import models\nfrom django_lifecycle import hook, LifecycleModelMixin\n\nfrom pulpcore.app.models import BaseModel\nfrom pulpcore.app.util import get_viewset_for_model, get_current_authenticated_user\n\n\ndef _ensure_iterable(obj):\n if isinstance(obj, str):\n return [obj]\n return obj\n\n\nclass AccessPolicy(BaseModel):\n \"\"\"\n A model storing a viewset authorization policy and permission assignment of new objects created.\n\n Fields:\n\n creation_hooks (models.JSONField): A list of dictionaries identifying callables on the\n ``pulpcore.plugin.access_policy.AccessPolicyFromDB`` which can add user or group roles\n for newly created objects. This is a nullable field due to not all endpoints creating\n objects.\n statements (models.JSONField): A list of ``drf-access-policy`` statements.\n viewset_name (models.TextField): The name of the viewset this instance controls\n authorization for.\n customized (BooleanField): False if the AccessPolicy has been user-modified. True otherwise.\n Defaults to False.\n queryset_scoping (models.JSONField): A dictionary identifying a callable to perform the\n queryset scoping. This field can be null if the user doesn't want to perform scoping.\n\n \"\"\"\n\n creation_hooks = models.JSONField(null=True)\n statements = models.JSONField()\n viewset_name = models.TextField(unique=True)\n customized = models.BooleanField(default=False)\n queryset_scoping = models.JSONField(null=True)\n\n\nclass AutoAddObjPermsMixin:\n \"\"\"\n A mixin that automatically adds roles based on the ``creation_hooks`` data.\n\n To use this mixin, your model must support ``django-lifecycle``.\n\n This mixin adds an ``after_create`` hook which properly interprets the ``creation_hooks``\n data and calls methods also provided by this mixin to add roles.\n\n These hooks are provided by default:\n\n * ``add_roles_for_object_creator`` will add the roles to the creator of the object.\n * ``add_roles_for_users`` will add the roles for one or more users by name.\n * ``add_roles_for_groups`` will add the roles for one or more groups by name.\n\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n self.REGISTERED_CREATION_HOOKS = {\n \"add_roles_for_users\": self.add_roles_for_users,\n \"add_roles_for_groups\": self.add_roles_for_groups,\n \"add_roles_for_object_creator\": self.add_roles_for_object_creator,\n }\n super().__init__(*args, **kwargs)\n\n @hook(\"after_create\")\n def add_perms(self):\n try:\n viewset = get_viewset_for_model(self)\n except LookupError:\n pass\n else:\n for permission_class in viewset.get_permissions(viewset):\n if hasattr(permission_class, \"handle_creation_hooks\"):\n permission_class.handle_creation_hooks(self)\n\n def add_roles_for_users(self, roles, users):\n \"\"\"\n Adds object-level roles for one or more users for this newly created object.\n\n Args:\n roles (str or list): One or more roles to be added at object-level for the users.\n This can either be a single role as a string, or a list of role names.\n users (str or list): One or more users who will receive object-level roles. This can\n either be a single username as a string or a list of usernames.\n\n Raises:\n ObjectDoesNotExist: If any of the users do not exist.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n users = _ensure_iterable(users)\n for username in users:\n user = get_user_model().objects.get(username=username)\n for role in roles:\n assign_role(role, user, self)\n\n def add_roles_for_groups(self, roles, groups):\n \"\"\"\n Adds object-level roles for one or more groups for this newly created object.\n\n Args:\n roles (str or list): One or more object-level roles to be added for the groups. This\n can either be a single role as a string, or list of role names.\n groups (str or list): One or more groups who will receive object-level roles. This\n can either be a single group name as a string or a list of group names.\n\n Raises:\n ObjectDoesNotExist: If any of the groups do not exist.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n groups = _ensure_iterable(groups)\n for group_name in groups:\n group = Group.objects.get(name=group_name)\n for role in roles:\n assign_role(role, group, self)\n\n def add_roles_for_object_creator(self, roles):\n \"\"\"\n Adds object-level roles for the user creating the newly created object.\n\n If the ``get_current_authenticated_user`` returns None because the API client did not\n provide authentication credentials, *no* permissions are added and this passes silently.\n This allows endpoints which create objects and do not require authorization to execute\n without error.\n\n Args:\n roles (list or str): One or more roles to be added at the object-level for the user.\n This can either be a single role as a string, or list of role names.\n\n \"\"\"\n from pulpcore.app.role_util import assign_role\n\n roles = _ensure_iterable(roles)\n current_user = get_current_authenticated_user()\n if current_user:\n for role in roles:\n assign_role(role, current_user, self)\n\n\nclass Group(LifecycleModelMixin, BaseGroup, AutoAddObjPermsMixin):\n class Meta:\n proxy = True\n permissions = [\n (\"manage_roles_group\", \"Can manage role assignments on group\"),\n ]\n", "path": "pulpcore/app/models/access_policy.py"}]}
| 3,086 | 197 |
gh_patches_debug_12828
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2320
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dependency conflict with py-evm 0.5* series
* Version: 0.5.26
* Python: 3.10
* OS: linux
### What was wrong?
Current web3.py not compatible with py-evm `0.5*`. Below are the relevant lines from `pip install` output:
```
The conflict is caused by:
py-evm 0.5.0a2 depends on eth-utils<3.0.0 and >=2.0.0
web3 5.26.0 depends on eth-utils<2.0.0 and >=1.9.5
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==v0.6.0-beta.4",
11 "py-geth>=3.7.0,<4",
12 ],
13 'linter': [
14 "flake8==3.8.3",
15 "isort>=4.2.15,<4.3.5",
16 "mypy==0.910",
17 "types-setuptools>=57.4.4,<58",
18 "types-requests>=2.26.1,<3",
19 "types-protobuf>=3.18.2,<4",
20 ],
21 'docs': [
22 "mock",
23 "sphinx-better-theme>=0.1.4",
24 "click>=5.1",
25 "configparser==3.5.0",
26 "contextlib2>=0.5.4",
27 "py-geth>=3.6.0,<4",
28 "py-solc>=0.4.0",
29 "pytest>=4.4.0,<5.0.0",
30 "sphinx>=3.0,<4",
31 "sphinx_rtd_theme>=0.1.9",
32 "toposort>=1.4",
33 "towncrier==18.5.0",
34 "urllib3",
35 "wheel"
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.7.0,<4",
40 "hypothesis>=3.31.2,<6",
41 "pytest>=4.4.0,<5.0.0",
42 "pytest-asyncio>=0.10.0,<0.11",
43 "pytest-mock>=1.10,<2",
44 "pytest-pythonpath>=0.3",
45 "pytest-watch>=4.2,<5",
46 "pytest-xdist>=1.29,<2",
47 "setuptools>=38.6.0",
48 "tox>=1.8.0",
49 "tqdm>4.32,<5",
50 "twine>=1.13,<2",
51 "pluggy==0.13.1",
52 "when-changed>=0.3.0,<0.4"
53 ]
54 }
55
56 extras_require['dev'] = (
57 extras_require['tester']
58 + extras_require['linter']
59 + extras_require['docs']
60 + extras_require['dev']
61 )
62
63 with open('./README.md') as readme:
64 long_description = readme.read()
65
66 setup(
67 name='web3',
68 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
69 version='5.26.0',
70 description="""Web3.py""",
71 long_description_content_type='text/markdown',
72 long_description=long_description,
73 author='Piper Merriam',
74 author_email='[email protected]',
75 url='https://github.com/ethereum/web3.py',
76 include_package_data=True,
77 install_requires=[
78 "aiohttp>=3.7.4.post0,<4",
79 "eth-abi>=2.0.0b6,<3.0.0",
80 "eth-account>=0.5.6,<0.6.0",
81 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
82 "eth-typing>=2.0.0,<3.0.0",
83 "eth-utils>=1.9.5,<2.0.0",
84 "hexbytes>=0.1.0,<1.0.0",
85 "ipfshttpclient==0.8.0a2",
86 "jsonschema>=3.2.0,<4.0.0",
87 "lru-dict>=1.1.6,<2.0.0",
88 "protobuf>=3.10.0,<4",
89 "pywin32>=223;platform_system=='Windows'",
90 "requests>=2.16.0,<3.0.0",
91 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
92 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
93 "websockets>=9.1,<10",
94 ],
95 python_requires='>=3.6,<4',
96 extras_require=extras_require,
97 py_modules=['web3', 'ens', 'ethpm'],
98 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
99 license="MIT",
100 zip_safe=False,
101 keywords='ethereum',
102 packages=find_packages(exclude=["tests", "tests.*"]),
103 package_data={"web3": ["py.typed"]},
104 classifiers=[
105 'Development Status :: 5 - Production/Stable',
106 'Intended Audience :: Developers',
107 'License :: OSI Approved :: MIT License',
108 'Natural Language :: English',
109 'Programming Language :: Python :: 3',
110 'Programming Language :: Python :: 3.6',
111 'Programming Language :: Python :: 3.7',
112 'Programming Language :: Python :: 3.8',
113 'Programming Language :: Python :: 3.9',
114 ],
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
extras_require = {
'tester': [
- "eth-tester[py-evm]==v0.6.0-beta.4",
+ "eth-tester[py-evm]==v0.6.0-beta.6",
"py-geth>=3.7.0,<4",
],
'linter': [
@@ -77,7 +77,7 @@
install_requires=[
"aiohttp>=3.7.4.post0,<4",
"eth-abi>=2.0.0b6,<3.0.0",
- "eth-account>=0.5.6,<0.6.0",
+ "eth-account>=0.5.7,<0.6.0",
"eth-hash[pycryptodome]>=0.2.0,<1.0.0",
"eth-typing>=2.0.0,<3.0.0",
"eth-utils>=1.9.5,<2.0.0",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,7 +7,7 @@\n \n extras_require = {\n 'tester': [\n- \"eth-tester[py-evm]==v0.6.0-beta.4\",\n+ \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n@@ -77,7 +77,7 @@\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n- \"eth-account>=0.5.6,<0.6.0\",\n+ \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n", "issue": "dependency conflict with py-evm 0.5* series\n* Version: 0.5.26\r\n* Python: 3.10\r\n* OS: linux\r\n\r\n### What was wrong?\r\n\r\nCurrent web3.py not compatible with py-evm `0.5*`. Below are the relevant lines from `pip install` output:\r\n\r\n```\r\nThe conflict is caused by:\r\n py-evm 0.5.0a2 depends on eth-utils<3.0.0 and >=2.0.0\r\n web3 5.26.0 depends on eth-utils<2.0.0 and >=1.9.5\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.4\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.26.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.6,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.26.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.6,<4',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}]}
| 1,802 | 250 |
gh_patches_debug_2063
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-3060
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Default IPC path is incorrect on Windows with Anaconda 2023.07
* Version: 6.6.1
* Python: 3.11
* OS: win
I updated my Anaconda to the latest version recently, which uses Python 3.11.
web3.py is no longer able to set the default IPC path for IPCProvider on Windows. The problem and fix are as follows:
In [ipc.py](https://github.com/ethereum/web3.py/blob/4b509a7d5fce0b9a67dbe93151e8b8a01e83b3cc/web3/providers/ipc.py#L105), line 105
`ipc_path = os.path.join("\\\\", ".", "pipe", "geth.ipc")`
makes the default IPC path ` '\\\\\\.\\pipe\\geth.ipc'`, which cannot be found with `os.path.exists(ipc_path)` in the next line
### How can it be fixed?
In ipc.py, replace line 105
`ipc_path = os.path.join("\\\\", ".", "pipe", "geth.ipc")`
with
`ipc_path = '\\\.\pipe\geth.ipc'` as is described in the [documentation](https://web3py.readthedocs.io/en/latest/providers.html#web3.providers.ipc.IPCProvider).
```[tasklist]
### Tasks
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/providers/ipc.py`
Content:
```
1 from json import (
2 JSONDecodeError,
3 )
4 import logging
5 import os
6 from pathlib import (
7 Path,
8 )
9 import socket
10 import sys
11 import threading
12 from types import (
13 TracebackType,
14 )
15 from typing import (
16 Any,
17 Optional,
18 Type,
19 Union,
20 )
21
22 from web3._utils.threads import (
23 Timeout,
24 )
25 from web3.types import (
26 RPCEndpoint,
27 RPCResponse,
28 )
29
30 from .base import (
31 JSONBaseProvider,
32 )
33
34
35 def get_ipc_socket(ipc_path: str, timeout: float = 2.0) -> socket.socket:
36 if sys.platform == "win32":
37 # On Windows named pipe is used. Simulate socket with it.
38 from web3._utils.windows import (
39 NamedPipe,
40 )
41
42 return NamedPipe(ipc_path)
43 else:
44 sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
45 sock.connect(ipc_path)
46 sock.settimeout(timeout)
47 return sock
48
49
50 class PersistantSocket:
51 sock = None
52
53 def __init__(self, ipc_path: str) -> None:
54 self.ipc_path = ipc_path
55
56 def __enter__(self) -> socket.socket:
57 if not self.ipc_path:
58 raise FileNotFoundError(
59 f"cannot connect to IPC socket at path: {self.ipc_path!r}"
60 )
61
62 if not self.sock:
63 self.sock = self._open()
64 return self.sock
65
66 def __exit__(
67 self,
68 exc_type: Type[BaseException],
69 exc_value: BaseException,
70 traceback: TracebackType,
71 ) -> None:
72 # only close the socket if there was an error
73 if exc_value is not None:
74 try:
75 self.sock.close()
76 except Exception:
77 pass
78 self.sock = None
79
80 def _open(self) -> socket.socket:
81 return get_ipc_socket(self.ipc_path)
82
83 def reset(self) -> socket.socket:
84 self.sock.close()
85 self.sock = self._open()
86 return self.sock
87
88
89 def get_default_ipc_path() -> Optional[str]:
90 if sys.platform == "darwin":
91 ipc_path = os.path.expanduser(
92 os.path.join("~", "Library", "Ethereum", "geth.ipc")
93 )
94 if os.path.exists(ipc_path):
95 return ipc_path
96 return None
97
98 elif sys.platform.startswith("linux") or sys.platform.startswith("freebsd"):
99 ipc_path = os.path.expanduser(os.path.join("~", ".ethereum", "geth.ipc"))
100 if os.path.exists(ipc_path):
101 return ipc_path
102 return None
103
104 elif sys.platform == "win32":
105 ipc_path = os.path.join("\\\\", ".", "pipe", "geth.ipc")
106 if os.path.exists(ipc_path):
107 return ipc_path
108 return None
109
110 else:
111 raise ValueError(
112 f"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/"
113 "freebsd are supported. You must specify the ipc_path"
114 )
115
116
117 def get_dev_ipc_path() -> Optional[str]:
118 if os.environ.get("WEB3_PROVIDER_URI", ""):
119 ipc_path = os.environ.get("WEB3_PROVIDER_URI")
120 if os.path.exists(ipc_path):
121 return ipc_path
122 return None
123
124 elif sys.platform == "darwin":
125 tmpdir = os.environ.get("TMPDIR", "")
126 ipc_path = os.path.expanduser(os.path.join(tmpdir, "geth.ipc"))
127 if os.path.exists(ipc_path):
128 return ipc_path
129 return None
130
131 elif sys.platform.startswith("linux") or sys.platform.startswith("freebsd"):
132 ipc_path = os.path.expanduser(os.path.join("/tmp", "geth.ipc"))
133 if os.path.exists(ipc_path):
134 return ipc_path
135 return None
136
137 elif sys.platform == "win32":
138 ipc_path = os.path.join("\\\\", ".", "pipe", "geth.ipc")
139 if os.path.exists(ipc_path):
140 return ipc_path
141
142 else:
143 raise ValueError(
144 f"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/"
145 "freebsd are supported. You must specify the ipc_path"
146 )
147
148
149 class IPCProvider(JSONBaseProvider):
150 logger = logging.getLogger("web3.providers.IPCProvider")
151 _socket = None
152
153 def __init__(
154 self,
155 ipc_path: Union[str, Path] = None,
156 timeout: int = 10,
157 *args: Any,
158 **kwargs: Any,
159 ) -> None:
160 if ipc_path is None:
161 self.ipc_path = get_default_ipc_path()
162 elif isinstance(ipc_path, str) or isinstance(ipc_path, Path):
163 self.ipc_path = str(Path(ipc_path).expanduser().resolve())
164 else:
165 raise TypeError("ipc_path must be of type string or pathlib.Path")
166
167 self.timeout = timeout
168 self._lock = threading.Lock()
169 self._socket = PersistantSocket(self.ipc_path)
170 super().__init__()
171
172 def __str__(self) -> str:
173 return f"<{self.__class__.__name__} {self.ipc_path}>"
174
175 def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:
176 self.logger.debug(
177 f"Making request IPC. Path: {self.ipc_path}, Method: {method}"
178 )
179 request = self.encode_rpc_request(method, params)
180
181 with self._lock, self._socket as sock:
182 try:
183 sock.sendall(request)
184 except BrokenPipeError:
185 # one extra attempt, then give up
186 sock = self._socket.reset()
187 sock.sendall(request)
188
189 raw_response = b""
190 with Timeout(self.timeout) as timeout:
191 while True:
192 try:
193 raw_response += sock.recv(4096)
194 except socket.timeout:
195 timeout.sleep(0)
196 continue
197 if raw_response == b"":
198 timeout.sleep(0)
199 elif has_valid_json_rpc_ending(raw_response):
200 try:
201 response = self.decode_rpc_response(raw_response)
202 except JSONDecodeError:
203 timeout.sleep(0)
204 continue
205 else:
206 return response
207 else:
208 timeout.sleep(0)
209 continue
210
211
212 # A valid JSON RPC response can only end in } or ] http://www.jsonrpc.org/specification
213 def has_valid_json_rpc_ending(raw_response: bytes) -> bool:
214 stripped_raw_response = raw_response.rstrip()
215 for valid_ending in [b"}", b"]"]:
216 if stripped_raw_response.endswith(valid_ending):
217 return True
218 else:
219 return False
220
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web3/providers/ipc.py b/web3/providers/ipc.py
--- a/web3/providers/ipc.py
+++ b/web3/providers/ipc.py
@@ -102,7 +102,7 @@
return None
elif sys.platform == "win32":
- ipc_path = os.path.join("\\\\", ".", "pipe", "geth.ipc")
+ ipc_path = r"\\.\pipe\geth.ipc"
if os.path.exists(ipc_path):
return ipc_path
return None
|
{"golden_diff": "diff --git a/web3/providers/ipc.py b/web3/providers/ipc.py\n--- a/web3/providers/ipc.py\n+++ b/web3/providers/ipc.py\n@@ -102,7 +102,7 @@\n return None\n \n elif sys.platform == \"win32\":\n- ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")\n+ ipc_path = r\"\\\\.\\pipe\\geth.ipc\"\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n", "issue": "Default IPC path is incorrect on Windows with Anaconda 2023.07\n* Version: 6.6.1\r\n* Python: 3.11\r\n* OS: win\r\n\r\nI updated my Anaconda to the latest version recently, which uses Python 3.11. \r\nweb3.py is no longer able to set the default IPC path for IPCProvider on Windows. The problem and fix are as follows:\r\n\r\nIn [ipc.py](https://github.com/ethereum/web3.py/blob/4b509a7d5fce0b9a67dbe93151e8b8a01e83b3cc/web3/providers/ipc.py#L105), line 105\r\n`ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")`\r\nmakes the default IPC path ` '\\\\\\\\\\\\.\\\\pipe\\\\geth.ipc'`, which cannot be found with `os.path.exists(ipc_path)` in the next line\r\n\r\n\r\n### How can it be fixed?\r\nIn ipc.py, replace line 105\r\n`ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")`\r\nwith\r\n`ipc_path = '\\\\\\.\\pipe\\geth.ipc'` as is described in the [documentation](https://web3py.readthedocs.io/en/latest/providers.html#web3.providers.ipc.IPCProvider).\r\n\r\n\n```[tasklist]\n### Tasks\n```\n\n", "before_files": [{"content": "from json import (\n JSONDecodeError,\n)\nimport logging\nimport os\nfrom pathlib import (\n Path,\n)\nimport socket\nimport sys\nimport threading\nfrom types import (\n TracebackType,\n)\nfrom typing import (\n Any,\n Optional,\n Type,\n Union,\n)\n\nfrom web3._utils.threads import (\n Timeout,\n)\nfrom web3.types import (\n RPCEndpoint,\n RPCResponse,\n)\n\nfrom .base import (\n JSONBaseProvider,\n)\n\n\ndef get_ipc_socket(ipc_path: str, timeout: float = 2.0) -> socket.socket:\n if sys.platform == \"win32\":\n # On Windows named pipe is used. Simulate socket with it.\n from web3._utils.windows import (\n NamedPipe,\n )\n\n return NamedPipe(ipc_path)\n else:\n sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n sock.connect(ipc_path)\n sock.settimeout(timeout)\n return sock\n\n\nclass PersistantSocket:\n sock = None\n\n def __init__(self, ipc_path: str) -> None:\n self.ipc_path = ipc_path\n\n def __enter__(self) -> socket.socket:\n if not self.ipc_path:\n raise FileNotFoundError(\n f\"cannot connect to IPC socket at path: {self.ipc_path!r}\"\n )\n\n if not self.sock:\n self.sock = self._open()\n return self.sock\n\n def __exit__(\n self,\n exc_type: Type[BaseException],\n exc_value: BaseException,\n traceback: TracebackType,\n ) -> None:\n # only close the socket if there was an error\n if exc_value is not None:\n try:\n self.sock.close()\n except Exception:\n pass\n self.sock = None\n\n def _open(self) -> socket.socket:\n return get_ipc_socket(self.ipc_path)\n\n def reset(self) -> socket.socket:\n self.sock.close()\n self.sock = self._open()\n return self.sock\n\n\ndef get_default_ipc_path() -> Optional[str]:\n if sys.platform == \"darwin\":\n ipc_path = os.path.expanduser(\n os.path.join(\"~\", \"Library\", \"Ethereum\", \"geth.ipc\")\n )\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform.startswith(\"linux\") or sys.platform.startswith(\"freebsd\"):\n ipc_path = os.path.expanduser(os.path.join(\"~\", \".ethereum\", \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"win32\":\n ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n else:\n raise ValueError(\n f\"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/\"\n \"freebsd are supported. You must specify the ipc_path\"\n )\n\n\ndef get_dev_ipc_path() -> Optional[str]:\n if os.environ.get(\"WEB3_PROVIDER_URI\", \"\"):\n ipc_path = os.environ.get(\"WEB3_PROVIDER_URI\")\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"darwin\":\n tmpdir = os.environ.get(\"TMPDIR\", \"\")\n ipc_path = os.path.expanduser(os.path.join(tmpdir, \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform.startswith(\"linux\") or sys.platform.startswith(\"freebsd\"):\n ipc_path = os.path.expanduser(os.path.join(\"/tmp\", \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"win32\":\n ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")\n if os.path.exists(ipc_path):\n return ipc_path\n\n else:\n raise ValueError(\n f\"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/\"\n \"freebsd are supported. You must specify the ipc_path\"\n )\n\n\nclass IPCProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.IPCProvider\")\n _socket = None\n\n def __init__(\n self,\n ipc_path: Union[str, Path] = None,\n timeout: int = 10,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n if ipc_path is None:\n self.ipc_path = get_default_ipc_path()\n elif isinstance(ipc_path, str) or isinstance(ipc_path, Path):\n self.ipc_path = str(Path(ipc_path).expanduser().resolve())\n else:\n raise TypeError(\"ipc_path must be of type string or pathlib.Path\")\n\n self.timeout = timeout\n self._lock = threading.Lock()\n self._socket = PersistantSocket(self.ipc_path)\n super().__init__()\n\n def __str__(self) -> str:\n return f\"<{self.__class__.__name__} {self.ipc_path}>\"\n\n def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:\n self.logger.debug(\n f\"Making request IPC. Path: {self.ipc_path}, Method: {method}\"\n )\n request = self.encode_rpc_request(method, params)\n\n with self._lock, self._socket as sock:\n try:\n sock.sendall(request)\n except BrokenPipeError:\n # one extra attempt, then give up\n sock = self._socket.reset()\n sock.sendall(request)\n\n raw_response = b\"\"\n with Timeout(self.timeout) as timeout:\n while True:\n try:\n raw_response += sock.recv(4096)\n except socket.timeout:\n timeout.sleep(0)\n continue\n if raw_response == b\"\":\n timeout.sleep(0)\n elif has_valid_json_rpc_ending(raw_response):\n try:\n response = self.decode_rpc_response(raw_response)\n except JSONDecodeError:\n timeout.sleep(0)\n continue\n else:\n return response\n else:\n timeout.sleep(0)\n continue\n\n\n# A valid JSON RPC response can only end in } or ] http://www.jsonrpc.org/specification\ndef has_valid_json_rpc_ending(raw_response: bytes) -> bool:\n stripped_raw_response = raw_response.rstrip()\n for valid_ending in [b\"}\", b\"]\"]:\n if stripped_raw_response.endswith(valid_ending):\n return True\n else:\n return False\n", "path": "web3/providers/ipc.py"}], "after_files": [{"content": "from json import (\n JSONDecodeError,\n)\nimport logging\nimport os\nfrom pathlib import (\n Path,\n)\nimport socket\nimport sys\nimport threading\nfrom types import (\n TracebackType,\n)\nfrom typing import (\n Any,\n Optional,\n Type,\n Union,\n)\n\nfrom web3._utils.threads import (\n Timeout,\n)\nfrom web3.types import (\n RPCEndpoint,\n RPCResponse,\n)\n\nfrom .base import (\n JSONBaseProvider,\n)\n\n\ndef get_ipc_socket(ipc_path: str, timeout: float = 2.0) -> socket.socket:\n if sys.platform == \"win32\":\n # On Windows named pipe is used. Simulate socket with it.\n from web3._utils.windows import (\n NamedPipe,\n )\n\n return NamedPipe(ipc_path)\n else:\n sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n sock.connect(ipc_path)\n sock.settimeout(timeout)\n return sock\n\n\nclass PersistantSocket:\n sock = None\n\n def __init__(self, ipc_path: str) -> None:\n self.ipc_path = ipc_path\n\n def __enter__(self) -> socket.socket:\n if not self.ipc_path:\n raise FileNotFoundError(\n f\"cannot connect to IPC socket at path: {self.ipc_path!r}\"\n )\n\n if not self.sock:\n self.sock = self._open()\n return self.sock\n\n def __exit__(\n self,\n exc_type: Type[BaseException],\n exc_value: BaseException,\n traceback: TracebackType,\n ) -> None:\n # only close the socket if there was an error\n if exc_value is not None:\n try:\n self.sock.close()\n except Exception:\n pass\n self.sock = None\n\n def _open(self) -> socket.socket:\n return get_ipc_socket(self.ipc_path)\n\n def reset(self) -> socket.socket:\n self.sock.close()\n self.sock = self._open()\n return self.sock\n\n\ndef get_default_ipc_path() -> Optional[str]:\n if sys.platform == \"darwin\":\n ipc_path = os.path.expanduser(\n os.path.join(\"~\", \"Library\", \"Ethereum\", \"geth.ipc\")\n )\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform.startswith(\"linux\") or sys.platform.startswith(\"freebsd\"):\n ipc_path = os.path.expanduser(os.path.join(\"~\", \".ethereum\", \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"win32\":\n ipc_path = r\"\\\\.\\pipe\\geth.ipc\"\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n else:\n raise ValueError(\n f\"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/\"\n \"freebsd are supported. You must specify the ipc_path\"\n )\n\n\ndef get_dev_ipc_path() -> Optional[str]:\n if os.environ.get(\"WEB3_PROVIDER_URI\", \"\"):\n ipc_path = os.environ.get(\"WEB3_PROVIDER_URI\")\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"darwin\":\n tmpdir = os.environ.get(\"TMPDIR\", \"\")\n ipc_path = os.path.expanduser(os.path.join(tmpdir, \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform.startswith(\"linux\") or sys.platform.startswith(\"freebsd\"):\n ipc_path = os.path.expanduser(os.path.join(\"/tmp\", \"geth.ipc\"))\n if os.path.exists(ipc_path):\n return ipc_path\n return None\n\n elif sys.platform == \"win32\":\n ipc_path = os.path.join(\"\\\\\\\\\", \".\", \"pipe\", \"geth.ipc\")\n if os.path.exists(ipc_path):\n return ipc_path\n\n else:\n raise ValueError(\n f\"Unsupported platform '{sys.platform}'. Only darwin/linux/win32/\"\n \"freebsd are supported. You must specify the ipc_path\"\n )\n\n\nclass IPCProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.IPCProvider\")\n _socket = None\n\n def __init__(\n self,\n ipc_path: Union[str, Path] = None,\n timeout: int = 10,\n *args: Any,\n **kwargs: Any,\n ) -> None:\n if ipc_path is None:\n self.ipc_path = get_default_ipc_path()\n elif isinstance(ipc_path, str) or isinstance(ipc_path, Path):\n self.ipc_path = str(Path(ipc_path).expanduser().resolve())\n else:\n raise TypeError(\"ipc_path must be of type string or pathlib.Path\")\n\n self.timeout = timeout\n self._lock = threading.Lock()\n self._socket = PersistantSocket(self.ipc_path)\n super().__init__()\n\n def __str__(self) -> str:\n return f\"<{self.__class__.__name__} {self.ipc_path}>\"\n\n def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:\n self.logger.debug(\n f\"Making request IPC. Path: {self.ipc_path}, Method: {method}\"\n )\n request = self.encode_rpc_request(method, params)\n\n with self._lock, self._socket as sock:\n try:\n sock.sendall(request)\n except BrokenPipeError:\n # one extra attempt, then give up\n sock = self._socket.reset()\n sock.sendall(request)\n\n raw_response = b\"\"\n with Timeout(self.timeout) as timeout:\n while True:\n try:\n raw_response += sock.recv(4096)\n except socket.timeout:\n timeout.sleep(0)\n continue\n if raw_response == b\"\":\n timeout.sleep(0)\n elif has_valid_json_rpc_ending(raw_response):\n try:\n response = self.decode_rpc_response(raw_response)\n except JSONDecodeError:\n timeout.sleep(0)\n continue\n else:\n return response\n else:\n timeout.sleep(0)\n continue\n\n\n# A valid JSON RPC response can only end in } or ] http://www.jsonrpc.org/specification\ndef has_valid_json_rpc_ending(raw_response: bytes) -> bool:\n stripped_raw_response = raw_response.rstrip()\n for valid_ending in [b\"}\", b\"]\"]:\n if stripped_raw_response.endswith(valid_ending):\n return True\n else:\n return False\n", "path": "web3/providers/ipc.py"}]}
| 2,566 | 119 |
gh_patches_debug_4262
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-772
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
rename /etc/letsencrypt/configs to /etc/letsencrypt/renewal
Since it doesn't contain anything except renewal configuration files, people will probably find the current name confusing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `letsencrypt/constants.py`
Content:
```
1 """Let's Encrypt constants."""
2 import os
3 import logging
4
5 from acme import challenges
6
7
8 SETUPTOOLS_PLUGINS_ENTRY_POINT = "letsencrypt.plugins"
9 """Setuptools entry point group name for plugins."""
10
11 CLI_DEFAULTS = dict(
12 config_files=[
13 "/etc/letsencrypt/cli.ini",
14 # http://freedesktop.org/wiki/Software/xdg-user-dirs/
15 os.path.join(os.environ.get("XDG_CONFIG_HOME", "~/.config"),
16 "letsencrypt", "cli.ini"),
17 ],
18 verbose_count=-(logging.WARNING / 10),
19 server="https://acme-staging.api.letsencrypt.org/directory",
20 rsa_key_size=2048,
21 rollback_checkpoints=1,
22 config_dir="/etc/letsencrypt",
23 work_dir="/var/lib/letsencrypt",
24 logs_dir="/var/log/letsencrypt",
25 no_verify_ssl=False,
26 dvsni_port=challenges.DVSNI.PORT,
27
28 auth_cert_path="./cert.pem",
29 auth_chain_path="./chain.pem",
30 )
31 """Defaults for CLI flags and `.IConfig` attributes."""
32
33
34 RENEWER_DEFAULTS = dict(
35 renewer_enabled="yes",
36 renew_before_expiry="30 days",
37 deploy_before_expiry="20 days",
38 )
39 """Defaults for renewer script."""
40
41
42 EXCLUSIVE_CHALLENGES = frozenset([frozenset([
43 challenges.DVSNI, challenges.SimpleHTTP])])
44 """Mutually exclusive challenges."""
45
46
47 ENHANCEMENTS = ["redirect", "http-header", "ocsp-stapling", "spdy"]
48 """List of possible :class:`letsencrypt.interfaces.IInstaller`
49 enhancements.
50
51 List of expected options parameters:
52 - redirect: None
53 - http-header: TODO
54 - ocsp-stapling: TODO
55 - spdy: TODO
56
57 """
58
59 ARCHIVE_DIR = "archive"
60 """Archive directory, relative to `IConfig.config_dir`."""
61
62 CONFIG_DIRS_MODE = 0o755
63 """Directory mode for ``.IConfig.config_dir`` et al."""
64
65 ACCOUNTS_DIR = "accounts"
66 """Directory where all accounts are saved."""
67
68 BACKUP_DIR = "backups"
69 """Directory (relative to `IConfig.work_dir`) where backups are kept."""
70
71 CERT_DIR = "certs"
72 """See `.IConfig.cert_dir`."""
73
74 CERT_KEY_BACKUP_DIR = "keys-certs"
75 """Directory where all certificates and keys are stored (relative to
76 `IConfig.work_dir`). Used for easy revocation."""
77
78 IN_PROGRESS_DIR = "IN_PROGRESS"
79 """Directory used before a permanent checkpoint is finalized (relative to
80 `IConfig.work_dir`)."""
81
82 KEY_DIR = "keys"
83 """Directory (relative to `IConfig.config_dir`) where keys are saved."""
84
85 LIVE_DIR = "live"
86 """Live directory, relative to `IConfig.config_dir`."""
87
88 TEMP_CHECKPOINT_DIR = "temp_checkpoint"
89 """Temporary checkpoint directory (relative to `IConfig.work_dir`)."""
90
91 RENEWAL_CONFIGS_DIR = "configs"
92 """Renewal configs directory, relative to `IConfig.config_dir`."""
93
94 RENEWER_CONFIG_FILENAME = "renewer.conf"
95 """Renewer config file name (relative to `IConfig.config_dir`)."""
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/letsencrypt/constants.py b/letsencrypt/constants.py
--- a/letsencrypt/constants.py
+++ b/letsencrypt/constants.py
@@ -88,7 +88,7 @@
TEMP_CHECKPOINT_DIR = "temp_checkpoint"
"""Temporary checkpoint directory (relative to `IConfig.work_dir`)."""
-RENEWAL_CONFIGS_DIR = "configs"
+RENEWAL_CONFIGS_DIR = "renewal"
"""Renewal configs directory, relative to `IConfig.config_dir`."""
RENEWER_CONFIG_FILENAME = "renewer.conf"
|
{"golden_diff": "diff --git a/letsencrypt/constants.py b/letsencrypt/constants.py\n--- a/letsencrypt/constants.py\n+++ b/letsencrypt/constants.py\n@@ -88,7 +88,7 @@\n TEMP_CHECKPOINT_DIR = \"temp_checkpoint\"\n \"\"\"Temporary checkpoint directory (relative to `IConfig.work_dir`).\"\"\"\n \n-RENEWAL_CONFIGS_DIR = \"configs\"\n+RENEWAL_CONFIGS_DIR = \"renewal\"\n \"\"\"Renewal configs directory, relative to `IConfig.config_dir`.\"\"\"\n \n RENEWER_CONFIG_FILENAME = \"renewer.conf\"\n", "issue": "rename /etc/letsencrypt/configs to /etc/letsencrypt/renewal\nSince it doesn't contain anything except renewal configuration files, people will probably find the current name confusing.\n\n", "before_files": [{"content": "\"\"\"Let's Encrypt constants.\"\"\"\nimport os\nimport logging\n\nfrom acme import challenges\n\n\nSETUPTOOLS_PLUGINS_ENTRY_POINT = \"letsencrypt.plugins\"\n\"\"\"Setuptools entry point group name for plugins.\"\"\"\n\nCLI_DEFAULTS = dict(\n config_files=[\n \"/etc/letsencrypt/cli.ini\",\n # http://freedesktop.org/wiki/Software/xdg-user-dirs/\n os.path.join(os.environ.get(\"XDG_CONFIG_HOME\", \"~/.config\"),\n \"letsencrypt\", \"cli.ini\"),\n ],\n verbose_count=-(logging.WARNING / 10),\n server=\"https://acme-staging.api.letsencrypt.org/directory\",\n rsa_key_size=2048,\n rollback_checkpoints=1,\n config_dir=\"/etc/letsencrypt\",\n work_dir=\"/var/lib/letsencrypt\",\n logs_dir=\"/var/log/letsencrypt\",\n no_verify_ssl=False,\n dvsni_port=challenges.DVSNI.PORT,\n\n auth_cert_path=\"./cert.pem\",\n auth_chain_path=\"./chain.pem\",\n)\n\"\"\"Defaults for CLI flags and `.IConfig` attributes.\"\"\"\n\n\nRENEWER_DEFAULTS = dict(\n renewer_enabled=\"yes\",\n renew_before_expiry=\"30 days\",\n deploy_before_expiry=\"20 days\",\n)\n\"\"\"Defaults for renewer script.\"\"\"\n\n\nEXCLUSIVE_CHALLENGES = frozenset([frozenset([\n challenges.DVSNI, challenges.SimpleHTTP])])\n\"\"\"Mutually exclusive challenges.\"\"\"\n\n\nENHANCEMENTS = [\"redirect\", \"http-header\", \"ocsp-stapling\", \"spdy\"]\n\"\"\"List of possible :class:`letsencrypt.interfaces.IInstaller`\nenhancements.\n\nList of expected options parameters:\n- redirect: None\n- http-header: TODO\n- ocsp-stapling: TODO\n- spdy: TODO\n\n\"\"\"\n\nARCHIVE_DIR = \"archive\"\n\"\"\"Archive directory, relative to `IConfig.config_dir`.\"\"\"\n\nCONFIG_DIRS_MODE = 0o755\n\"\"\"Directory mode for ``.IConfig.config_dir`` et al.\"\"\"\n\nACCOUNTS_DIR = \"accounts\"\n\"\"\"Directory where all accounts are saved.\"\"\"\n\nBACKUP_DIR = \"backups\"\n\"\"\"Directory (relative to `IConfig.work_dir`) where backups are kept.\"\"\"\n\nCERT_DIR = \"certs\"\n\"\"\"See `.IConfig.cert_dir`.\"\"\"\n\nCERT_KEY_BACKUP_DIR = \"keys-certs\"\n\"\"\"Directory where all certificates and keys are stored (relative to\n`IConfig.work_dir`). Used for easy revocation.\"\"\"\n\nIN_PROGRESS_DIR = \"IN_PROGRESS\"\n\"\"\"Directory used before a permanent checkpoint is finalized (relative to\n`IConfig.work_dir`).\"\"\"\n\nKEY_DIR = \"keys\"\n\"\"\"Directory (relative to `IConfig.config_dir`) where keys are saved.\"\"\"\n\nLIVE_DIR = \"live\"\n\"\"\"Live directory, relative to `IConfig.config_dir`.\"\"\"\n\nTEMP_CHECKPOINT_DIR = \"temp_checkpoint\"\n\"\"\"Temporary checkpoint directory (relative to `IConfig.work_dir`).\"\"\"\n\nRENEWAL_CONFIGS_DIR = \"configs\"\n\"\"\"Renewal configs directory, relative to `IConfig.config_dir`.\"\"\"\n\nRENEWER_CONFIG_FILENAME = \"renewer.conf\"\n\"\"\"Renewer config file name (relative to `IConfig.config_dir`).\"\"\"\n", "path": "letsencrypt/constants.py"}], "after_files": [{"content": "\"\"\"Let's Encrypt constants.\"\"\"\nimport os\nimport logging\n\nfrom acme import challenges\n\n\nSETUPTOOLS_PLUGINS_ENTRY_POINT = \"letsencrypt.plugins\"\n\"\"\"Setuptools entry point group name for plugins.\"\"\"\n\nCLI_DEFAULTS = dict(\n config_files=[\n \"/etc/letsencrypt/cli.ini\",\n # http://freedesktop.org/wiki/Software/xdg-user-dirs/\n os.path.join(os.environ.get(\"XDG_CONFIG_HOME\", \"~/.config\"),\n \"letsencrypt\", \"cli.ini\"),\n ],\n verbose_count=-(logging.WARNING / 10),\n server=\"https://acme-staging.api.letsencrypt.org/directory\",\n rsa_key_size=2048,\n rollback_checkpoints=1,\n config_dir=\"/etc/letsencrypt\",\n work_dir=\"/var/lib/letsencrypt\",\n logs_dir=\"/var/log/letsencrypt\",\n no_verify_ssl=False,\n dvsni_port=challenges.DVSNI.PORT,\n\n auth_cert_path=\"./cert.pem\",\n auth_chain_path=\"./chain.pem\",\n)\n\"\"\"Defaults for CLI flags and `.IConfig` attributes.\"\"\"\n\n\nRENEWER_DEFAULTS = dict(\n renewer_enabled=\"yes\",\n renew_before_expiry=\"30 days\",\n deploy_before_expiry=\"20 days\",\n)\n\"\"\"Defaults for renewer script.\"\"\"\n\n\nEXCLUSIVE_CHALLENGES = frozenset([frozenset([\n challenges.DVSNI, challenges.SimpleHTTP])])\n\"\"\"Mutually exclusive challenges.\"\"\"\n\n\nENHANCEMENTS = [\"redirect\", \"http-header\", \"ocsp-stapling\", \"spdy\"]\n\"\"\"List of possible :class:`letsencrypt.interfaces.IInstaller`\nenhancements.\n\nList of expected options parameters:\n- redirect: None\n- http-header: TODO\n- ocsp-stapling: TODO\n- spdy: TODO\n\n\"\"\"\n\nARCHIVE_DIR = \"archive\"\n\"\"\"Archive directory, relative to `IConfig.config_dir`.\"\"\"\n\nCONFIG_DIRS_MODE = 0o755\n\"\"\"Directory mode for ``.IConfig.config_dir`` et al.\"\"\"\n\nACCOUNTS_DIR = \"accounts\"\n\"\"\"Directory where all accounts are saved.\"\"\"\n\nBACKUP_DIR = \"backups\"\n\"\"\"Directory (relative to `IConfig.work_dir`) where backups are kept.\"\"\"\n\nCERT_DIR = \"certs\"\n\"\"\"See `.IConfig.cert_dir`.\"\"\"\n\nCERT_KEY_BACKUP_DIR = \"keys-certs\"\n\"\"\"Directory where all certificates and keys are stored (relative to\n`IConfig.work_dir`). Used for easy revocation.\"\"\"\n\nIN_PROGRESS_DIR = \"IN_PROGRESS\"\n\"\"\"Directory used before a permanent checkpoint is finalized (relative to\n`IConfig.work_dir`).\"\"\"\n\nKEY_DIR = \"keys\"\n\"\"\"Directory (relative to `IConfig.config_dir`) where keys are saved.\"\"\"\n\nLIVE_DIR = \"live\"\n\"\"\"Live directory, relative to `IConfig.config_dir`.\"\"\"\n\nTEMP_CHECKPOINT_DIR = \"temp_checkpoint\"\n\"\"\"Temporary checkpoint directory (relative to `IConfig.work_dir`).\"\"\"\n\nRENEWAL_CONFIGS_DIR = \"renewal\"\n\"\"\"Renewal configs directory, relative to `IConfig.config_dir`.\"\"\"\n\nRENEWER_CONFIG_FILENAME = \"renewer.conf\"\n\"\"\"Renewer config file name (relative to `IConfig.config_dir`).\"\"\"\n", "path": "letsencrypt/constants.py"}]}
| 1,163 | 121 |
gh_patches_debug_34433
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-14131
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ResolveError: Directory '{mydir}' does not contain any BUILD files (when Dockerizing packages)
**Describe the bug**
Created a repo at https://github.com/sureshjoshi/pantsbuild-14031 to help illustrate this problem.
Essentially, I use custom output paths for my .pex files, and while testing out the `docker_image` target, I noticed some of my components fail with the error
> ResolveError: Directory 'backend' does not contain any BUILD files
After a lot of debugging, I only ran into this problem when my output folders were common to multiple `pex_binary` targets.
For example, in the repo above, I have 3 identical projects (A, B, C) - where they only differ by the `pex_binary` `output_path` (and this location updated in the associated Dockerfile), and one of the projects refuses to compile.
As per the README in the repo:
```bash
# Should create a pex at dist/backend/projecta/projecta.pex
# Docker image created successfully as projecta-container:latest
./pants package backend/projecta::
# Should create a pex at dist/backend.projectc/projectc.pex
# Docker image created successfully as projectc-container:latest
./pants package backend/projectc::
```
```bash
# Should create a pex at dist/backend/projectb.pex
./pants package backend/projectb:projectb
# FAILS: With ResolveError
./pants package backend/projectb:projectb-container
```
So, the difference above is that Project C uses no `output_path` and uses the dot-syntax for the dist folder. ProjectA places the pex file under a `backend/projecta` directory. The failing ProjectB places the pex file directly under `backend`.
This isn't a big issue, and easily worked around, and I'm guessing it has to do with namespacing or module/package semantics, but it's just a weird problem that is difficult to debug based on the error message.
**Pants version**
- 2.8.0
- 2.9.0rc1
**OS**
macOS 12.1
Untested on Linux
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/backend/docker/util_rules/dependencies.py`
Content:
```
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from pants.backend.docker.subsystems.dockerfile_parser import DockerfileInfo, DockerfileInfoRequest
5 from pants.backend.docker.target_types import DockerDependenciesField
6 from pants.core.goals.package import PackageFieldSet
7 from pants.engine.addresses import Addresses, UnparsedAddressInputs
8 from pants.engine.rules import Get, collect_rules, rule
9 from pants.engine.target import (
10 FieldSetsPerTarget,
11 FieldSetsPerTargetRequest,
12 InjectDependenciesRequest,
13 InjectedDependencies,
14 Targets,
15 )
16 from pants.engine.unions import UnionRule
17
18
19 class InjectDockerDependencies(InjectDependenciesRequest):
20 inject_for = DockerDependenciesField
21
22
23 @rule
24 async def inject_docker_dependencies(request: InjectDockerDependencies) -> InjectedDependencies:
25 """Inspects COPY instructions in the Dockerfile for references to known targets."""
26 dockerfile_info = await Get(
27 DockerfileInfo, DockerfileInfoRequest(request.dependencies_field.address)
28 )
29 targets = await Get(
30 Targets,
31 UnparsedAddressInputs(
32 dockerfile_info.putative_target_addresses,
33 owning_address=None,
34 ),
35 )
36 package = await Get(FieldSetsPerTarget, FieldSetsPerTargetRequest(PackageFieldSet, targets))
37 referenced_targets = (
38 field_sets[0].address for field_sets in package.collection if len(field_sets) > 0
39 )
40 return InjectedDependencies(Addresses(referenced_targets))
41
42
43 def rules():
44 return [
45 *collect_rules(),
46 UnionRule(InjectDependenciesRequest, InjectDockerDependencies),
47 ]
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/backend/docker/util_rules/dependencies.py b/src/python/pants/backend/docker/util_rules/dependencies.py
--- a/src/python/pants/backend/docker/util_rules/dependencies.py
+++ b/src/python/pants/backend/docker/util_rules/dependencies.py
@@ -3,6 +3,7 @@
from pants.backend.docker.subsystems.dockerfile_parser import DockerfileInfo, DockerfileInfoRequest
from pants.backend.docker.target_types import DockerDependenciesField
+from pants.base.specs import AddressSpecs, MaybeEmptySiblingAddresses
from pants.core.goals.package import PackageFieldSet
from pants.engine.addresses import Addresses, UnparsedAddressInputs
from pants.engine.rules import Get, collect_rules, rule
@@ -22,17 +23,28 @@
@rule
async def inject_docker_dependencies(request: InjectDockerDependencies) -> InjectedDependencies:
- """Inspects COPY instructions in the Dockerfile for references to known targets."""
+ """Inspects COPY instructions in the Dockerfile for references to known packagable targets."""
dockerfile_info = await Get(
DockerfileInfo, DockerfileInfoRequest(request.dependencies_field.address)
)
- targets = await Get(
- Targets,
+
+ # Parse all putative target addresses.
+ putative_addresses = await Get(
+ Addresses,
UnparsedAddressInputs(
dockerfile_info.putative_target_addresses,
owning_address=None,
),
)
+
+ # Get the target for those addresses that are known.
+ directories = {address.spec_path for address in putative_addresses}
+ all_addresses = await Get(Addresses, AddressSpecs(map(MaybeEmptySiblingAddresses, directories)))
+ targets = await Get(
+ Targets, Addresses((address for address in putative_addresses if address in all_addresses))
+ )
+
+ # Only keep those targets that we can "package".
package = await Get(FieldSetsPerTarget, FieldSetsPerTargetRequest(PackageFieldSet, targets))
referenced_targets = (
field_sets[0].address for field_sets in package.collection if len(field_sets) > 0
|
{"golden_diff": "diff --git a/src/python/pants/backend/docker/util_rules/dependencies.py b/src/python/pants/backend/docker/util_rules/dependencies.py\n--- a/src/python/pants/backend/docker/util_rules/dependencies.py\n+++ b/src/python/pants/backend/docker/util_rules/dependencies.py\n@@ -3,6 +3,7 @@\n \n from pants.backend.docker.subsystems.dockerfile_parser import DockerfileInfo, DockerfileInfoRequest\n from pants.backend.docker.target_types import DockerDependenciesField\n+from pants.base.specs import AddressSpecs, MaybeEmptySiblingAddresses\n from pants.core.goals.package import PackageFieldSet\n from pants.engine.addresses import Addresses, UnparsedAddressInputs\n from pants.engine.rules import Get, collect_rules, rule\n@@ -22,17 +23,28 @@\n \n @rule\n async def inject_docker_dependencies(request: InjectDockerDependencies) -> InjectedDependencies:\n- \"\"\"Inspects COPY instructions in the Dockerfile for references to known targets.\"\"\"\n+ \"\"\"Inspects COPY instructions in the Dockerfile for references to known packagable targets.\"\"\"\n dockerfile_info = await Get(\n DockerfileInfo, DockerfileInfoRequest(request.dependencies_field.address)\n )\n- targets = await Get(\n- Targets,\n+\n+ # Parse all putative target addresses.\n+ putative_addresses = await Get(\n+ Addresses,\n UnparsedAddressInputs(\n dockerfile_info.putative_target_addresses,\n owning_address=None,\n ),\n )\n+\n+ # Get the target for those addresses that are known.\n+ directories = {address.spec_path for address in putative_addresses}\n+ all_addresses = await Get(Addresses, AddressSpecs(map(MaybeEmptySiblingAddresses, directories)))\n+ targets = await Get(\n+ Targets, Addresses((address for address in putative_addresses if address in all_addresses))\n+ )\n+\n+ # Only keep those targets that we can \"package\".\n package = await Get(FieldSetsPerTarget, FieldSetsPerTargetRequest(PackageFieldSet, targets))\n referenced_targets = (\n field_sets[0].address for field_sets in package.collection if len(field_sets) > 0\n", "issue": "ResolveError: Directory '{mydir}' does not contain any BUILD files (when Dockerizing packages)\n**Describe the bug**\r\n\r\nCreated a repo at https://github.com/sureshjoshi/pantsbuild-14031 to help illustrate this problem. \r\n\r\nEssentially, I use custom output paths for my .pex files, and while testing out the `docker_image` target, I noticed some of my components fail with the error \r\n\r\n> ResolveError: Directory 'backend' does not contain any BUILD files\r\n\r\nAfter a lot of debugging, I only ran into this problem when my output folders were common to multiple `pex_binary` targets. \r\n\r\nFor example, in the repo above, I have 3 identical projects (A, B, C) - where they only differ by the `pex_binary` `output_path` (and this location updated in the associated Dockerfile), and one of the projects refuses to compile.\r\n\r\nAs per the README in the repo:\r\n\r\n```bash\r\n# Should create a pex at dist/backend/projecta/projecta.pex\r\n# Docker image created successfully as projecta-container:latest\r\n./pants package backend/projecta::\r\n\r\n# Should create a pex at dist/backend.projectc/projectc.pex\r\n# Docker image created successfully as projectc-container:latest\r\n./pants package backend/projectc::\r\n```\r\n\r\n```bash\r\n# Should create a pex at dist/backend/projectb.pex\r\n./pants package backend/projectb:projectb\r\n\r\n# FAILS: With ResolveError\r\n./pants package backend/projectb:projectb-container \r\n```\r\n\r\nSo, the difference above is that Project C uses no `output_path` and uses the dot-syntax for the dist folder. ProjectA places the pex file under a `backend/projecta` directory. The failing ProjectB places the pex file directly under `backend`.\r\n\r\nThis isn't a big issue, and easily worked around, and I'm guessing it has to do with namespacing or module/package semantics, but it's just a weird problem that is difficult to debug based on the error message.\r\n\r\n**Pants version**\r\n\r\n- 2.8.0\r\n- 2.9.0rc1\r\n\r\n**OS**\r\n\r\nmacOS 12.1\r\nUntested on Linux\r\n\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom pants.backend.docker.subsystems.dockerfile_parser import DockerfileInfo, DockerfileInfoRequest\nfrom pants.backend.docker.target_types import DockerDependenciesField\nfrom pants.core.goals.package import PackageFieldSet\nfrom pants.engine.addresses import Addresses, UnparsedAddressInputs\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.engine.target import (\n FieldSetsPerTarget,\n FieldSetsPerTargetRequest,\n InjectDependenciesRequest,\n InjectedDependencies,\n Targets,\n)\nfrom pants.engine.unions import UnionRule\n\n\nclass InjectDockerDependencies(InjectDependenciesRequest):\n inject_for = DockerDependenciesField\n\n\n@rule\nasync def inject_docker_dependencies(request: InjectDockerDependencies) -> InjectedDependencies:\n \"\"\"Inspects COPY instructions in the Dockerfile for references to known targets.\"\"\"\n dockerfile_info = await Get(\n DockerfileInfo, DockerfileInfoRequest(request.dependencies_field.address)\n )\n targets = await Get(\n Targets,\n UnparsedAddressInputs(\n dockerfile_info.putative_target_addresses,\n owning_address=None,\n ),\n )\n package = await Get(FieldSetsPerTarget, FieldSetsPerTargetRequest(PackageFieldSet, targets))\n referenced_targets = (\n field_sets[0].address for field_sets in package.collection if len(field_sets) > 0\n )\n return InjectedDependencies(Addresses(referenced_targets))\n\n\ndef rules():\n return [\n *collect_rules(),\n UnionRule(InjectDependenciesRequest, InjectDockerDependencies),\n ]\n", "path": "src/python/pants/backend/docker/util_rules/dependencies.py"}], "after_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom pants.backend.docker.subsystems.dockerfile_parser import DockerfileInfo, DockerfileInfoRequest\nfrom pants.backend.docker.target_types import DockerDependenciesField\nfrom pants.base.specs import AddressSpecs, MaybeEmptySiblingAddresses\nfrom pants.core.goals.package import PackageFieldSet\nfrom pants.engine.addresses import Addresses, UnparsedAddressInputs\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.engine.target import (\n FieldSetsPerTarget,\n FieldSetsPerTargetRequest,\n InjectDependenciesRequest,\n InjectedDependencies,\n Targets,\n)\nfrom pants.engine.unions import UnionRule\n\n\nclass InjectDockerDependencies(InjectDependenciesRequest):\n inject_for = DockerDependenciesField\n\n\n@rule\nasync def inject_docker_dependencies(request: InjectDockerDependencies) -> InjectedDependencies:\n \"\"\"Inspects COPY instructions in the Dockerfile for references to known packagable targets.\"\"\"\n dockerfile_info = await Get(\n DockerfileInfo, DockerfileInfoRequest(request.dependencies_field.address)\n )\n\n # Parse all putative target addresses.\n putative_addresses = await Get(\n Addresses,\n UnparsedAddressInputs(\n dockerfile_info.putative_target_addresses,\n owning_address=None,\n ),\n )\n\n # Get the target for those addresses that are known.\n directories = {address.spec_path for address in putative_addresses}\n all_addresses = await Get(Addresses, AddressSpecs(map(MaybeEmptySiblingAddresses, directories)))\n targets = await Get(\n Targets, Addresses((address for address in putative_addresses if address in all_addresses))\n )\n\n # Only keep those targets that we can \"package\".\n package = await Get(FieldSetsPerTarget, FieldSetsPerTargetRequest(PackageFieldSet, targets))\n referenced_targets = (\n field_sets[0].address for field_sets in package.collection if len(field_sets) > 0\n )\n return InjectedDependencies(Addresses(referenced_targets))\n\n\ndef rules():\n return [\n *collect_rules(),\n UnionRule(InjectDependenciesRequest, InjectDockerDependencies),\n ]\n", "path": "src/python/pants/backend/docker/util_rules/dependencies.py"}]}
| 1,169 | 448 |
gh_patches_debug_22472
|
rasdani/github-patches
|
git_diff
|
mozilla__kitsune-3198
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove all references to ethn.io and Treejack
Confirm is ethn.io is something we still use, remove otherwise
https://github.com/mozilla/kitsune/blob/master/kitsune/products/jinja2/products/product.html#L92
- [ ] remove treejack waffle.switch
- [ ] remove waffle.flag('ethnio-all')
Remove all references to ethn.io and Treejack
Confirm is ethn.io is something we still use, remove otherwise
https://github.com/mozilla/kitsune/blob/master/kitsune/products/jinja2/products/product.html#L92
- [ ] remove treejack waffle.switch
- [ ] remove waffle.flag('ethnio-all')
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kitsune/sumo/migrations/0002_initial_data.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from django.db import models, migrations
5
6
7 def create_ratelimit_bypass_perm(apps, schema_editor):
8 # First we get or create the content type.
9 ContentType = apps.get_model('contenttypes', 'ContentType')
10 global_permission_ct, created = ContentType.objects.get_or_create(
11 model='global_permission', app_label='sumo')
12
13 # Then we create a permission attached to that content type.
14 Permission = apps.get_model('auth', 'Permission')
15 perm = Permission.objects.create(
16 name='Bypass Ratelimits',
17 content_type=global_permission_ct,
18 codename='bypass_ratelimit')
19
20
21 def remove_ratelimit_bypass_perm(apps, schema_editor):
22 Permission = apps.get_model('auth', 'Permission')
23 perm = Permission.objects.filter(codename='bypass_ratelimit').delete()
24
25
26 def create_treejack_switch(apps, schema_editor):
27 Switch = apps.get_model('waffle', 'Switch')
28 Switch.objects.create(
29 name='treejack',
30 note='Enables/disables the Treejack snippet.',
31 active=False)
32
33
34 def remove_treejack_switch(apps, schema_editor):
35 Switch = apps.get_model('waffle', 'Switch')
36 Switch.objects.filter(name='treejack').delete()
37
38
39 def create_refresh_survey_flag(apps, schema_editor):
40 Sample = apps.get_model('waffle', 'Sample')
41 Sample.objects.get_or_create(
42 name='refresh-survey',
43 note='Samples users that refresh Firefox to give them a survey.',
44 percent=50.0)
45
46
47 def remove_refresh_survey_flag(apps, schema_editor):
48 Sample = apps.get_model('waffle', 'Sample')
49 Sample.objects.filter(name='refresh-survey').delete()
50
51
52 class Migration(migrations.Migration):
53
54 dependencies = [
55 ('sumo', '0001_initial'),
56 ('auth', '0001_initial'),
57 ('contenttypes', '0001_initial'),
58 ('waffle', '0001_initial'),
59 ]
60
61 operations = [
62 migrations.RunPython(create_ratelimit_bypass_perm, remove_ratelimit_bypass_perm),
63 migrations.RunPython(create_treejack_switch, remove_treejack_switch),
64 migrations.RunPython(create_refresh_survey_flag, remove_refresh_survey_flag),
65 ]
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kitsune/sumo/migrations/0002_initial_data.py b/kitsune/sumo/migrations/0002_initial_data.py
--- a/kitsune/sumo/migrations/0002_initial_data.py
+++ b/kitsune/sumo/migrations/0002_initial_data.py
@@ -23,19 +23,6 @@
perm = Permission.objects.filter(codename='bypass_ratelimit').delete()
-def create_treejack_switch(apps, schema_editor):
- Switch = apps.get_model('waffle', 'Switch')
- Switch.objects.create(
- name='treejack',
- note='Enables/disables the Treejack snippet.',
- active=False)
-
-
-def remove_treejack_switch(apps, schema_editor):
- Switch = apps.get_model('waffle', 'Switch')
- Switch.objects.filter(name='treejack').delete()
-
-
def create_refresh_survey_flag(apps, schema_editor):
Sample = apps.get_model('waffle', 'Sample')
Sample.objects.get_or_create(
@@ -60,6 +47,5 @@
operations = [
migrations.RunPython(create_ratelimit_bypass_perm, remove_ratelimit_bypass_perm),
- migrations.RunPython(create_treejack_switch, remove_treejack_switch),
migrations.RunPython(create_refresh_survey_flag, remove_refresh_survey_flag),
]
|
{"golden_diff": "diff --git a/kitsune/sumo/migrations/0002_initial_data.py b/kitsune/sumo/migrations/0002_initial_data.py\n--- a/kitsune/sumo/migrations/0002_initial_data.py\n+++ b/kitsune/sumo/migrations/0002_initial_data.py\n@@ -23,19 +23,6 @@\n perm = Permission.objects.filter(codename='bypass_ratelimit').delete()\n \n \n-def create_treejack_switch(apps, schema_editor):\n- Switch = apps.get_model('waffle', 'Switch')\n- Switch.objects.create(\n- name='treejack',\n- note='Enables/disables the Treejack snippet.',\n- active=False)\n-\n-\n-def remove_treejack_switch(apps, schema_editor):\n- Switch = apps.get_model('waffle', 'Switch')\n- Switch.objects.filter(name='treejack').delete()\n-\n-\n def create_refresh_survey_flag(apps, schema_editor):\n Sample = apps.get_model('waffle', 'Sample')\n Sample.objects.get_or_create(\n@@ -60,6 +47,5 @@\n \n operations = [\n migrations.RunPython(create_ratelimit_bypass_perm, remove_ratelimit_bypass_perm),\n- migrations.RunPython(create_treejack_switch, remove_treejack_switch),\n migrations.RunPython(create_refresh_survey_flag, remove_refresh_survey_flag),\n ]\n", "issue": "Remove all references to ethn.io and Treejack\nConfirm is ethn.io is something we still use, remove otherwise\r\n\r\nhttps://github.com/mozilla/kitsune/blob/master/kitsune/products/jinja2/products/product.html#L92\r\n\r\n- [ ] remove treejack waffle.switch\r\n- [ ] remove waffle.flag('ethnio-all')\nRemove all references to ethn.io and Treejack\nConfirm is ethn.io is something we still use, remove otherwise\r\n\r\nhttps://github.com/mozilla/kitsune/blob/master/kitsune/products/jinja2/products/product.html#L92\r\n\r\n- [ ] remove treejack waffle.switch\r\n- [ ] remove waffle.flag('ethnio-all')\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\ndef create_ratelimit_bypass_perm(apps, schema_editor):\n # First we get or create the content type.\n ContentType = apps.get_model('contenttypes', 'ContentType')\n global_permission_ct, created = ContentType.objects.get_or_create(\n model='global_permission', app_label='sumo')\n\n # Then we create a permission attached to that content type.\n Permission = apps.get_model('auth', 'Permission')\n perm = Permission.objects.create(\n name='Bypass Ratelimits',\n content_type=global_permission_ct,\n codename='bypass_ratelimit')\n\n\ndef remove_ratelimit_bypass_perm(apps, schema_editor):\n Permission = apps.get_model('auth', 'Permission')\n perm = Permission.objects.filter(codename='bypass_ratelimit').delete()\n\n\ndef create_treejack_switch(apps, schema_editor):\n Switch = apps.get_model('waffle', 'Switch')\n Switch.objects.create(\n name='treejack',\n note='Enables/disables the Treejack snippet.',\n active=False)\n\n\ndef remove_treejack_switch(apps, schema_editor):\n Switch = apps.get_model('waffle', 'Switch')\n Switch.objects.filter(name='treejack').delete()\n\n\ndef create_refresh_survey_flag(apps, schema_editor):\n Sample = apps.get_model('waffle', 'Sample')\n Sample.objects.get_or_create(\n name='refresh-survey',\n note='Samples users that refresh Firefox to give them a survey.',\n percent=50.0)\n\n\ndef remove_refresh_survey_flag(apps, schema_editor):\n Sample = apps.get_model('waffle', 'Sample')\n Sample.objects.filter(name='refresh-survey').delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sumo', '0001_initial'),\n ('auth', '0001_initial'),\n ('contenttypes', '0001_initial'),\n ('waffle', '0001_initial'),\n ]\n\n operations = [\n migrations.RunPython(create_ratelimit_bypass_perm, remove_ratelimit_bypass_perm),\n migrations.RunPython(create_treejack_switch, remove_treejack_switch),\n migrations.RunPython(create_refresh_survey_flag, remove_refresh_survey_flag),\n ]\n", "path": "kitsune/sumo/migrations/0002_initial_data.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\ndef create_ratelimit_bypass_perm(apps, schema_editor):\n # First we get or create the content type.\n ContentType = apps.get_model('contenttypes', 'ContentType')\n global_permission_ct, created = ContentType.objects.get_or_create(\n model='global_permission', app_label='sumo')\n\n # Then we create a permission attached to that content type.\n Permission = apps.get_model('auth', 'Permission')\n perm = Permission.objects.create(\n name='Bypass Ratelimits',\n content_type=global_permission_ct,\n codename='bypass_ratelimit')\n\n\ndef remove_ratelimit_bypass_perm(apps, schema_editor):\n Permission = apps.get_model('auth', 'Permission')\n perm = Permission.objects.filter(codename='bypass_ratelimit').delete()\n\n\ndef create_refresh_survey_flag(apps, schema_editor):\n Sample = apps.get_model('waffle', 'Sample')\n Sample.objects.get_or_create(\n name='refresh-survey',\n note='Samples users that refresh Firefox to give them a survey.',\n percent=50.0)\n\n\ndef remove_refresh_survey_flag(apps, schema_editor):\n Sample = apps.get_model('waffle', 'Sample')\n Sample.objects.filter(name='refresh-survey').delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sumo', '0001_initial'),\n ('auth', '0001_initial'),\n ('contenttypes', '0001_initial'),\n ('waffle', '0001_initial'),\n ]\n\n operations = [\n migrations.RunPython(create_ratelimit_bypass_perm, remove_ratelimit_bypass_perm),\n migrations.RunPython(create_refresh_survey_flag, remove_refresh_survey_flag),\n ]\n", "path": "kitsune/sumo/migrations/0002_initial_data.py"}]}
| 1,040 | 304 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.