
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_33879
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-9068
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Delete base85 algorithm
### Describe your change:
Re #6216
Normally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.
Per `CONTRIBTUING.md`
> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values
This `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library
This repository should not contains examples on how to use a certain library, that would be the library documentation here
https://docs.python.org/3/library/base64.html
* [ ] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
* [x] Delete an algorithm
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.
* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): "Fixes #ISSUE-NUMBER".
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ciphers/base32.py`
Content:
```
1 import base64
2
3
4 def base32_encode(string: str) -> bytes:
5 """
6 Encodes a given string to base32, returning a bytes-like object
7 >>> base32_encode("Hello World!")
8 b'JBSWY3DPEBLW64TMMQQQ===='
9 >>> base32_encode("123456")
10 b'GEZDGNBVGY======'
11 >>> base32_encode("some long complex string")
12 b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='
13 """
14
15 # encoded the input (we need a bytes like object)
16 # then, b32encoded the bytes-like object
17 return base64.b32encode(string.encode("utf-8"))
18
19
20 def base32_decode(encoded_bytes: bytes) -> str:
21 """
22 Decodes a given bytes-like object to a string, returning a string
23 >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')
24 'Hello World!'
25 >>> base32_decode(b'GEZDGNBVGY======')
26 '123456'
27 >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')
28 'some long complex string'
29 """
30
31 # decode the bytes from base32
32 # then, decode the bytes-like object to return as a string
33 return base64.b32decode(encoded_bytes).decode("utf-8")
34
35
36 if __name__ == "__main__":
37 test = "Hello World!"
38 encoded = base32_encode(test)
39 print(encoded)
40
41 decoded = base32_decode(encoded)
42 print(decoded)
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ciphers/base32.py b/ciphers/base32.py
--- a/ciphers/base32.py
+++ b/ciphers/base32.py
@@ -1,42 +1,45 @@
-import base64
+"""
+Base32 encoding and decoding
+https://en.wikipedia.org/wiki/Base32
+"""
+B32_CHARSET = "ABCDEFGHIJKLMNOPQRSTUVWXYZ234567"
-def base32_encode(string: str) -> bytes:
+
+def base32_encode(data: bytes) -> bytes:
"""
- Encodes a given string to base32, returning a bytes-like object
- >>> base32_encode("Hello World!")
+ >>> base32_encode(b"Hello World!")
b'JBSWY3DPEBLW64TMMQQQ===='
- >>> base32_encode("123456")
+ >>> base32_encode(b"123456")
b'GEZDGNBVGY======'
- >>> base32_encode("some long complex string")
+ >>> base32_encode(b"some long complex string")
b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='
"""
-
- # encoded the input (we need a bytes like object)
- # then, b32encoded the bytes-like object
- return base64.b32encode(string.encode("utf-8"))
+ binary_data = "".join(bin(ord(d))[2:].zfill(8) for d in data.decode("utf-8"))
+ binary_data = binary_data.ljust(5 * ((len(binary_data) // 5) + 1), "0")
+ b32_chunks = map("".join, zip(*[iter(binary_data)] * 5))
+ b32_result = "".join(B32_CHARSET[int(chunk, 2)] for chunk in b32_chunks)
+ return bytes(b32_result.ljust(8 * ((len(b32_result) // 8) + 1), "="), "utf-8")
-def base32_decode(encoded_bytes: bytes) -> str:
+def base32_decode(data: bytes) -> bytes:
"""
- Decodes a given bytes-like object to a string, returning a string
>>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')
- 'Hello World!'
+ b'Hello World!'
>>> base32_decode(b'GEZDGNBVGY======')
- '123456'
+ b'123456'
>>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')
- 'some long complex string'
+ b'some long complex string'
"""
-
- # decode the bytes from base32
- # then, decode the bytes-like object to return as a string
- return base64.b32decode(encoded_bytes).decode("utf-8")
+ binary_chunks = "".join(
+ bin(B32_CHARSET.index(_d))[2:].zfill(5)
+ for _d in data.decode("utf-8").strip("=")
+ )
+ binary_data = list(map("".join, zip(*[iter(binary_chunks)] * 8)))
+ return bytes("".join([chr(int(_d, 2)) for _d in binary_data]), "utf-8")
if __name__ == "__main__":
- test = "Hello World!"
- encoded = base32_encode(test)
- print(encoded)
+ import doctest
- decoded = base32_decode(encoded)
- print(decoded)
+ doctest.testmod()
|
{"golden_diff": "diff --git a/ciphers/base32.py b/ciphers/base32.py\n--- a/ciphers/base32.py\n+++ b/ciphers/base32.py\n@@ -1,42 +1,45 @@\n-import base64\n+\"\"\"\n+Base32 encoding and decoding\n \n+https://en.wikipedia.org/wiki/Base32\n+\"\"\"\n+B32_CHARSET = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ234567\"\n \n-def base32_encode(string: str) -> bytes:\n+\n+def base32_encode(data: bytes) -> bytes:\n \"\"\"\n- Encodes a given string to base32, returning a bytes-like object\n- >>> base32_encode(\"Hello World!\")\n+ >>> base32_encode(b\"Hello World!\")\n b'JBSWY3DPEBLW64TMMQQQ===='\n- >>> base32_encode(\"123456\")\n+ >>> base32_encode(b\"123456\")\n b'GEZDGNBVGY======'\n- >>> base32_encode(\"some long complex string\")\n+ >>> base32_encode(b\"some long complex string\")\n b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='\n \"\"\"\n-\n- # encoded the input (we need a bytes like object)\n- # then, b32encoded the bytes-like object\n- return base64.b32encode(string.encode(\"utf-8\"))\n+ binary_data = \"\".join(bin(ord(d))[2:].zfill(8) for d in data.decode(\"utf-8\"))\n+ binary_data = binary_data.ljust(5 * ((len(binary_data) // 5) + 1), \"0\")\n+ b32_chunks = map(\"\".join, zip(*[iter(binary_data)] * 5))\n+ b32_result = \"\".join(B32_CHARSET[int(chunk, 2)] for chunk in b32_chunks)\n+ return bytes(b32_result.ljust(8 * ((len(b32_result) // 8) + 1), \"=\"), \"utf-8\")\n \n \n-def base32_decode(encoded_bytes: bytes) -> str:\n+def base32_decode(data: bytes) -> bytes:\n \"\"\"\n- Decodes a given bytes-like object to a string, returning a string\n >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')\n- 'Hello World!'\n+ b'Hello World!'\n >>> base32_decode(b'GEZDGNBVGY======')\n- '123456'\n+ b'123456'\n >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')\n- 'some long complex string'\n+ b'some long complex string'\n \"\"\"\n-\n- # decode the bytes from base32\n- # then, decode the bytes-like object to return as a string\n- return base64.b32decode(encoded_bytes).decode(\"utf-8\")\n+ binary_chunks = \"\".join(\n+ bin(B32_CHARSET.index(_d))[2:].zfill(5)\n+ for _d in data.decode(\"utf-8\").strip(\"=\")\n+ )\n+ binary_data = list(map(\"\".join, zip(*[iter(binary_chunks)] * 8)))\n+ return bytes(\"\".join([chr(int(_d, 2)) for _d in binary_data]), \"utf-8\")\n \n \n if __name__ == \"__main__\":\n- test = \"Hello World!\"\n- encoded = base32_encode(test)\n- print(encoded)\n+ import doctest\n \n- decoded = base32_decode(encoded)\n- print(decoded)\n+ doctest.testmod()\n", "issue": "Delete base85 algorithm\n### Describe your change:\r\nRe #6216\r\n\r\nNormally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.\r\n\r\nPer `CONTRIBTUING.md`\r\n> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values\r\nThis `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library\r\n\r\nThis repository should not contains examples on how to use a certain library, that would be the library documentation here\r\nhttps://docs.python.org/3/library/base64.html\r\n\r\n\r\n* [ ] Add an algorithm?\r\n* [ ] Fix a bug or typo in an existing algorithm?\r\n* [ ] Documentation change?\r\n* [x] Delete an algorithm\r\n\r\n### Checklist:\r\n* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).\r\n* [x] This pull request is all my own work -- I have not plagiarized.\r\n* [x] I know that pull requests will not be merged if they fail the automated tests.\r\n* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.\r\n* [x] All new Python files are placed inside an existing directory.\r\n* [x] All filenames are in all lowercase characters with no spaces or dashes.\r\n* [x] All functions and variable names follow Python naming conventions.\r\n* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).\r\n* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.\r\n* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.\r\n* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): \"Fixes #ISSUE-NUMBER\".\r\n\n", "before_files": [{"content": "import base64\n\n\ndef base32_encode(string: str) -> bytes:\n \"\"\"\n Encodes a given string to base32, returning a bytes-like object\n >>> base32_encode(\"Hello World!\")\n b'JBSWY3DPEBLW64TMMQQQ===='\n >>> base32_encode(\"123456\")\n b'GEZDGNBVGY======'\n >>> base32_encode(\"some long complex string\")\n b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='\n \"\"\"\n\n # encoded the input (we need a bytes like object)\n # then, b32encoded the bytes-like object\n return base64.b32encode(string.encode(\"utf-8\"))\n\n\ndef base32_decode(encoded_bytes: bytes) -> str:\n \"\"\"\n Decodes a given bytes-like object to a string, returning a string\n >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')\n 'Hello World!'\n >>> base32_decode(b'GEZDGNBVGY======')\n '123456'\n >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')\n 'some long complex string'\n \"\"\"\n\n # decode the bytes from base32\n # then, decode the bytes-like object to return as a string\n return base64.b32decode(encoded_bytes).decode(\"utf-8\")\n\n\nif __name__ == \"__main__\":\n test = \"Hello World!\"\n encoded = base32_encode(test)\n print(encoded)\n\n decoded = base32_decode(encoded)\n print(decoded)\n", "path": "ciphers/base32.py"}], "after_files": [{"content": "\"\"\"\nBase32 encoding and decoding\n\nhttps://en.wikipedia.org/wiki/Base32\n\"\"\"\nB32_CHARSET = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ234567\"\n\n\ndef base32_encode(data: bytes) -> bytes:\n \"\"\"\n >>> base32_encode(b\"Hello World!\")\n b'JBSWY3DPEBLW64TMMQQQ===='\n >>> base32_encode(b\"123456\")\n b'GEZDGNBVGY======'\n >>> base32_encode(b\"some long complex string\")\n b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='\n \"\"\"\n binary_data = \"\".join(bin(ord(d))[2:].zfill(8) for d in data.decode(\"utf-8\"))\n binary_data = binary_data.ljust(5 * ((len(binary_data) // 5) + 1), \"0\")\n b32_chunks = map(\"\".join, zip(*[iter(binary_data)] * 5))\n b32_result = \"\".join(B32_CHARSET[int(chunk, 2)] for chunk in b32_chunks)\n return bytes(b32_result.ljust(8 * ((len(b32_result) // 8) + 1), \"=\"), \"utf-8\")\n\n\ndef base32_decode(data: bytes) -> bytes:\n \"\"\"\n >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')\n b'Hello World!'\n >>> base32_decode(b'GEZDGNBVGY======')\n b'123456'\n >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')\n b'some long complex string'\n \"\"\"\n binary_chunks = \"\".join(\n bin(B32_CHARSET.index(_d))[2:].zfill(5)\n for _d in data.decode(\"utf-8\").strip(\"=\")\n )\n binary_data = list(map(\"\".join, zip(*[iter(binary_chunks)] * 8)))\n return bytes(\"\".join([chr(int(_d, 2)) for _d in binary_data]), \"utf-8\")\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "ciphers/base32.py"}]}
| 1,239 | 855 |
gh_patches_debug_20056
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-400
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: wrong arguments for ChatGLM
Code:
```
from xinference.client import RESTfulClient
endpoint = 'http://localhost:9997'
client = RESTfulClient(endpoint)
uid = client.launch_model(model_name='chatglm2', model_format='ggmlv3')
model = client.get_model(model_uid=uid)
model.chat('What is the largest animal in the world?')
```
Response:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[2], line 2
1 model = client.get_model(model_uid=uid)
----> 2 model.chat('What is the largest animal in the world?')
File ~/Desktop/cs/inference/xinference/client.py:463, in RESTfulChatglmCppChatModelHandle.chat(self, prompt, chat_history, generate_config)
460 response = requests.post(url, json=request_body, stream=stream)
462 if response.status_code != 200:
--> 463 raise RuntimeError(
464 f"Failed to generate chat completion, detail: {response.json()['detail']}"
465 )
467 if stream:
468 return chat_streaming_response_iterator(response.iter_lines())
RuntimeError: Failed to generate chat completion, detail: [address=127.0.0.1:63785, pid=63229] Pipeline.chat() got an unexpected keyword argument 'mirostat_mode'
```
Seems like the default arguments passed in the `chat` function are customized for Llama.cpp models, causing an error.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xinference/model/llm/ggml/chatglm.py`
Content:
```
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import os
17 import time
18 import uuid
19 from pathlib import Path
20 from typing import TYPE_CHECKING, Iterator, List, Optional, TypedDict, Union
21
22 from ....types import ChatCompletion, ChatCompletionChunk, ChatCompletionMessage
23 from .. import LLMFamilyV1, LLMSpecV1
24 from ..core import LLM
25
26 if TYPE_CHECKING:
27 from chatglm_cpp import Pipeline
28
29
30 logger = logging.getLogger(__name__)
31
32
33 class ChatglmCppModelConfig(TypedDict, total=False):
34 pass
35
36
37 class ChatglmCppGenerateConfig(TypedDict, total=False):
38 max_tokens: int
39 top_p: float
40 temperature: float
41 stream: bool
42
43
44 class ChatglmCppChatModel(LLM):
45 def __init__(
46 self,
47 model_uid: str,
48 model_family: "LLMFamilyV1",
49 model_spec: "LLMSpecV1",
50 quantization: str,
51 model_path: str,
52 model_config: Optional[ChatglmCppModelConfig] = None,
53 ):
54 super().__init__(model_uid, model_family, model_spec, quantization, model_path)
55 self._llm: Optional["Pipeline"] = None
56
57 # just a placeholder for now as the chatglm_cpp repo doesn't support model config.
58 self._model_config = model_config
59
60 @classmethod
61 def _sanitize_generate_config(
62 cls,
63 chatglmcpp_generate_config: Optional[ChatglmCppGenerateConfig],
64 ) -> ChatglmCppGenerateConfig:
65 if chatglmcpp_generate_config is None:
66 chatglmcpp_generate_config = ChatglmCppGenerateConfig()
67 chatglmcpp_generate_config.setdefault("stream", False)
68 return chatglmcpp_generate_config
69
70 def load(self):
71 try:
72 import chatglm_cpp
73 except ImportError:
74 error_message = "Failed to import module 'chatglm_cpp'"
75 installation_guide = [
76 "Please make sure 'chatglm_cpp' is installed. ",
77 "You can install it by running the following command in the terminal:\n",
78 "pip install git+https://github.com/li-plus/chatglm.cpp.git@main\n\n",
79 "Or visit the original git repo if the above command fails:\n",
80 "https://github.com/li-plus/chatglm.cpp",
81 ]
82
83 raise ImportError(f"{error_message}\n\n{''.join(installation_guide)}")
84
85 model_file_path = os.path.join(
86 self.model_path,
87 self.model_spec.model_file_name_template.format(
88 quantization=self.quantization
89 ),
90 )
91
92 # handle legacy cache.
93 legacy_model_file_path = os.path.join(self.model_path, "model.bin")
94 if os.path.exists(legacy_model_file_path):
95 model_file_path = legacy_model_file_path
96
97 self._llm = chatglm_cpp.Pipeline(Path(model_file_path))
98
99 @classmethod
100 def match(cls, llm_family: "LLMFamilyV1", llm_spec: "LLMSpecV1") -> bool:
101 if llm_spec.model_format != "ggmlv3":
102 return False
103 if "chatglm" not in llm_family.model_name:
104 return False
105 if "chat" not in llm_family.model_ability:
106 return False
107 return True
108
109 @staticmethod
110 def _convert_raw_text_chunks_to_chat(
111 tokens: Iterator[str], model_name: str
112 ) -> Iterator[ChatCompletionChunk]:
113 yield {
114 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
115 "model": model_name,
116 "object": "chat.completion.chunk",
117 "created": int(time.time()),
118 "choices": [
119 {
120 "index": 0,
121 "delta": {
122 "role": "assistant",
123 },
124 "finish_reason": None,
125 }
126 ],
127 }
128 for token in enumerate(tokens):
129 yield {
130 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
131 "model": model_name,
132 "object": "chat.completion.chunk",
133 "created": int(time.time()),
134 "choices": [
135 {
136 "index": 0,
137 "delta": {
138 "content": token[1],
139 },
140 "finish_reason": None,
141 }
142 ],
143 }
144
145 @staticmethod
146 def _convert_raw_text_completion_to_chat(
147 text: str, model_name: str
148 ) -> ChatCompletion:
149 return {
150 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
151 "model": model_name,
152 "object": "chat.completion",
153 "created": int(time.time()),
154 "choices": [
155 {
156 "index": 0,
157 "message": {
158 "role": "assistant",
159 "content": text,
160 },
161 "finish_reason": None,
162 }
163 ],
164 "usage": {
165 "prompt_tokens": -1,
166 "completion_tokens": -1,
167 "total_tokens": -1,
168 },
169 }
170
171 def chat(
172 self,
173 prompt: str,
174 chat_history: Optional[List[ChatCompletionMessage]] = None,
175 generate_config: Optional[ChatglmCppGenerateConfig] = None,
176 ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:
177 if chat_history is not None:
178 chat_history_list = [message["content"] for message in chat_history]
179 else:
180 chat_history_list = []
181
182 chat_history_list.append(prompt)
183 logger.debug("Full conversation history:\n%s", str(chat_history_list))
184
185 generate_config = self._sanitize_generate_config(generate_config)
186 params = dict(generate_config)
187 if "max_tokens" in params:
188 params["max_length"] = params.pop("max_tokens")
189
190 assert self._llm is not None
191
192 if params.pop("stream", False):
193 it = self._llm.stream_chat(
194 chat_history_list,
195 **params,
196 )
197 assert not isinstance(it, str)
198 return self._convert_raw_text_chunks_to_chat(it, self.model_uid)
199 else:
200 c = self._llm.chat(
201 chat_history_list,
202 **params,
203 )
204 assert not isinstance(c, Iterator)
205 return self._convert_raw_text_completion_to_chat(c, self.model_uid)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xinference/model/llm/ggml/chatglm.py b/xinference/model/llm/ggml/chatglm.py
--- a/xinference/model/llm/ggml/chatglm.py
+++ b/xinference/model/llm/ggml/chatglm.py
@@ -183,13 +183,21 @@
logger.debug("Full conversation history:\n%s", str(chat_history_list))
generate_config = self._sanitize_generate_config(generate_config)
- params = dict(generate_config)
- if "max_tokens" in params:
- params["max_length"] = params.pop("max_tokens")
+
+ params = {
+ "max_length": generate_config.get("max_tokens"),
+ "max_context_length": generate_config.get("max_tokens"),
+ "top_k": generate_config.get("top_k"),
+ "top_p": generate_config.get("top_p"),
+ "temperature": generate_config.get("temperature"),
+ }
+
+ # Remove None values to exclude missing keys from params
+ params = {k: v for k, v in params.items() if v is not None}
assert self._llm is not None
- if params.pop("stream", False):
+ if generate_config["stream"]:
it = self._llm.stream_chat(
chat_history_list,
**params,
|
{"golden_diff": "diff --git a/xinference/model/llm/ggml/chatglm.py b/xinference/model/llm/ggml/chatglm.py\n--- a/xinference/model/llm/ggml/chatglm.py\n+++ b/xinference/model/llm/ggml/chatglm.py\n@@ -183,13 +183,21 @@\n logger.debug(\"Full conversation history:\\n%s\", str(chat_history_list))\n \n generate_config = self._sanitize_generate_config(generate_config)\n- params = dict(generate_config)\n- if \"max_tokens\" in params:\n- params[\"max_length\"] = params.pop(\"max_tokens\")\n+\n+ params = {\n+ \"max_length\": generate_config.get(\"max_tokens\"),\n+ \"max_context_length\": generate_config.get(\"max_tokens\"),\n+ \"top_k\": generate_config.get(\"top_k\"),\n+ \"top_p\": generate_config.get(\"top_p\"),\n+ \"temperature\": generate_config.get(\"temperature\"),\n+ }\n+\n+ # Remove None values to exclude missing keys from params\n+ params = {k: v for k, v in params.items() if v is not None}\n \n assert self._llm is not None\n \n- if params.pop(\"stream\", False):\n+ if generate_config[\"stream\"]:\n it = self._llm.stream_chat(\n chat_history_list,\n **params,\n", "issue": "BUG: wrong arguments for ChatGLM\nCode:\r\n\r\n```\r\nfrom xinference.client import RESTfulClient\r\nendpoint = 'http://localhost:9997'\r\nclient = RESTfulClient(endpoint)\r\nuid = client.launch_model(model_name='chatglm2', model_format='ggmlv3')\r\nmodel = client.get_model(model_uid=uid)\r\nmodel.chat('What is the largest animal in the world?')\r\n```\r\n\r\nResponse:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\nCell In[2], line 2\r\n 1 model = client.get_model(model_uid=uid)\r\n----> 2 model.chat('What is the largest animal in the world?')\r\n\r\nFile ~/Desktop/cs/inference/xinference/client.py:463, in RESTfulChatglmCppChatModelHandle.chat(self, prompt, chat_history, generate_config)\r\n 460 response = requests.post(url, json=request_body, stream=stream)\r\n 462 if response.status_code != 200:\r\n--> 463 raise RuntimeError(\r\n 464 f\"Failed to generate chat completion, detail: {response.json()['detail']}\"\r\n 465 )\r\n 467 if stream:\r\n 468 return chat_streaming_response_iterator(response.iter_lines())\r\n\r\nRuntimeError: Failed to generate chat completion, detail: [address=127.0.0.1:63785, pid=63229] Pipeline.chat() got an unexpected keyword argument 'mirostat_mode'\r\n```\r\n\r\nSeems like the default arguments passed in the `chat` function are customized for Llama.cpp models, causing an error.\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nimport time\nimport uuid\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Iterator, List, Optional, TypedDict, Union\n\nfrom ....types import ChatCompletion, ChatCompletionChunk, ChatCompletionMessage\nfrom .. import LLMFamilyV1, LLMSpecV1\nfrom ..core import LLM\n\nif TYPE_CHECKING:\n from chatglm_cpp import Pipeline\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ChatglmCppModelConfig(TypedDict, total=False):\n pass\n\n\nclass ChatglmCppGenerateConfig(TypedDict, total=False):\n max_tokens: int\n top_p: float\n temperature: float\n stream: bool\n\n\nclass ChatglmCppChatModel(LLM):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n model_config: Optional[ChatglmCppModelConfig] = None,\n ):\n super().__init__(model_uid, model_family, model_spec, quantization, model_path)\n self._llm: Optional[\"Pipeline\"] = None\n\n # just a placeholder for now as the chatglm_cpp repo doesn't support model config.\n self._model_config = model_config\n\n @classmethod\n def _sanitize_generate_config(\n cls,\n chatglmcpp_generate_config: Optional[ChatglmCppGenerateConfig],\n ) -> ChatglmCppGenerateConfig:\n if chatglmcpp_generate_config is None:\n chatglmcpp_generate_config = ChatglmCppGenerateConfig()\n chatglmcpp_generate_config.setdefault(\"stream\", False)\n return chatglmcpp_generate_config\n\n def load(self):\n try:\n import chatglm_cpp\n except ImportError:\n error_message = \"Failed to import module 'chatglm_cpp'\"\n installation_guide = [\n \"Please make sure 'chatglm_cpp' is installed. \",\n \"You can install it by running the following command in the terminal:\\n\",\n \"pip install git+https://github.com/li-plus/chatglm.cpp.git@main\\n\\n\",\n \"Or visit the original git repo if the above command fails:\\n\",\n \"https://github.com/li-plus/chatglm.cpp\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n model_file_path = os.path.join(\n self.model_path,\n self.model_spec.model_file_name_template.format(\n quantization=self.quantization\n ),\n )\n\n # handle legacy cache.\n legacy_model_file_path = os.path.join(self.model_path, \"model.bin\")\n if os.path.exists(legacy_model_file_path):\n model_file_path = legacy_model_file_path\n\n self._llm = chatglm_cpp.Pipeline(Path(model_file_path))\n\n @classmethod\n def match(cls, llm_family: \"LLMFamilyV1\", llm_spec: \"LLMSpecV1\") -> bool:\n if llm_spec.model_format != \"ggmlv3\":\n return False\n if \"chatglm\" not in llm_family.model_name:\n return False\n if \"chat\" not in llm_family.model_ability:\n return False\n return True\n\n @staticmethod\n def _convert_raw_text_chunks_to_chat(\n tokens: Iterator[str], model_name: str\n ) -> Iterator[ChatCompletionChunk]:\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"role\": \"assistant\",\n },\n \"finish_reason\": None,\n }\n ],\n }\n for token in enumerate(tokens):\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"content\": token[1],\n },\n \"finish_reason\": None,\n }\n ],\n }\n\n @staticmethod\n def _convert_raw_text_completion_to_chat(\n text: str, model_name: str\n ) -> ChatCompletion:\n return {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": text,\n },\n \"finish_reason\": None,\n }\n ],\n \"usage\": {\n \"prompt_tokens\": -1,\n \"completion_tokens\": -1,\n \"total_tokens\": -1,\n },\n }\n\n def chat(\n self,\n prompt: str,\n chat_history: Optional[List[ChatCompletionMessage]] = None,\n generate_config: Optional[ChatglmCppGenerateConfig] = None,\n ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:\n if chat_history is not None:\n chat_history_list = [message[\"content\"] for message in chat_history]\n else:\n chat_history_list = []\n\n chat_history_list.append(prompt)\n logger.debug(\"Full conversation history:\\n%s\", str(chat_history_list))\n\n generate_config = self._sanitize_generate_config(generate_config)\n params = dict(generate_config)\n if \"max_tokens\" in params:\n params[\"max_length\"] = params.pop(\"max_tokens\")\n\n assert self._llm is not None\n\n if params.pop(\"stream\", False):\n it = self._llm.stream_chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(it, str)\n return self._convert_raw_text_chunks_to_chat(it, self.model_uid)\n else:\n c = self._llm.chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(c, Iterator)\n return self._convert_raw_text_completion_to_chat(c, self.model_uid)\n", "path": "xinference/model/llm/ggml/chatglm.py"}], "after_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nimport time\nimport uuid\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Iterator, List, Optional, TypedDict, Union\n\nfrom ....types import ChatCompletion, ChatCompletionChunk, ChatCompletionMessage\nfrom .. import LLMFamilyV1, LLMSpecV1\nfrom ..core import LLM\n\nif TYPE_CHECKING:\n from chatglm_cpp import Pipeline\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ChatglmCppModelConfig(TypedDict, total=False):\n pass\n\n\nclass ChatglmCppGenerateConfig(TypedDict, total=False):\n max_tokens: int\n top_p: float\n temperature: float\n stream: bool\n\n\nclass ChatglmCppChatModel(LLM):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n model_config: Optional[ChatglmCppModelConfig] = None,\n ):\n super().__init__(model_uid, model_family, model_spec, quantization, model_path)\n self._llm: Optional[\"Pipeline\"] = None\n\n # just a placeholder for now as the chatglm_cpp repo doesn't support model config.\n self._model_config = model_config\n\n @classmethod\n def _sanitize_generate_config(\n cls,\n chatglmcpp_generate_config: Optional[ChatglmCppGenerateConfig],\n ) -> ChatglmCppGenerateConfig:\n if chatglmcpp_generate_config is None:\n chatglmcpp_generate_config = ChatglmCppGenerateConfig()\n chatglmcpp_generate_config.setdefault(\"stream\", False)\n return chatglmcpp_generate_config\n\n def load(self):\n try:\n import chatglm_cpp\n except ImportError:\n error_message = \"Failed to import module 'chatglm_cpp'\"\n installation_guide = [\n \"Please make sure 'chatglm_cpp' is installed. \",\n \"You can install it by running the following command in the terminal:\\n\",\n \"pip install git+https://github.com/li-plus/chatglm.cpp.git@main\\n\\n\",\n \"Or visit the original git repo if the above command fails:\\n\",\n \"https://github.com/li-plus/chatglm.cpp\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n model_file_path = os.path.join(\n self.model_path,\n self.model_spec.model_file_name_template.format(\n quantization=self.quantization\n ),\n )\n\n # handle legacy cache.\n legacy_model_file_path = os.path.join(self.model_path, \"model.bin\")\n if os.path.exists(legacy_model_file_path):\n model_file_path = legacy_model_file_path\n\n self._llm = chatglm_cpp.Pipeline(Path(model_file_path))\n\n @classmethod\n def match(cls, llm_family: \"LLMFamilyV1\", llm_spec: \"LLMSpecV1\") -> bool:\n if llm_spec.model_format != \"ggmlv3\":\n return False\n if \"chatglm\" not in llm_family.model_name:\n return False\n if \"chat\" not in llm_family.model_ability:\n return False\n return True\n\n @staticmethod\n def _convert_raw_text_chunks_to_chat(\n tokens: Iterator[str], model_name: str\n ) -> Iterator[ChatCompletionChunk]:\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"role\": \"assistant\",\n },\n \"finish_reason\": None,\n }\n ],\n }\n for token in enumerate(tokens):\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"content\": token[1],\n },\n \"finish_reason\": None,\n }\n ],\n }\n\n @staticmethod\n def _convert_raw_text_completion_to_chat(\n text: str, model_name: str\n ) -> ChatCompletion:\n return {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": text,\n },\n \"finish_reason\": None,\n }\n ],\n \"usage\": {\n \"prompt_tokens\": -1,\n \"completion_tokens\": -1,\n \"total_tokens\": -1,\n },\n }\n\n def chat(\n self,\n prompt: str,\n chat_history: Optional[List[ChatCompletionMessage]] = None,\n generate_config: Optional[ChatglmCppGenerateConfig] = None,\n ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:\n if chat_history is not None:\n chat_history_list = [message[\"content\"] for message in chat_history]\n else:\n chat_history_list = []\n\n chat_history_list.append(prompt)\n logger.debug(\"Full conversation history:\\n%s\", str(chat_history_list))\n\n generate_config = self._sanitize_generate_config(generate_config)\n\n params = {\n \"max_length\": generate_config.get(\"max_tokens\"),\n \"max_context_length\": generate_config.get(\"max_tokens\"),\n \"top_k\": generate_config.get(\"top_k\"),\n \"top_p\": generate_config.get(\"top_p\"),\n \"temperature\": generate_config.get(\"temperature\"),\n }\n\n # Remove None values to exclude missing keys from params\n params = {k: v for k, v in params.items() if v is not None}\n\n assert self._llm is not None\n\n if generate_config[\"stream\"]:\n it = self._llm.stream_chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(it, str)\n return self._convert_raw_text_chunks_to_chat(it, self.model_uid)\n else:\n c = self._llm.chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(c, Iterator)\n return self._convert_raw_text_completion_to_chat(c, self.model_uid)\n", "path": "xinference/model/llm/ggml/chatglm.py"}]}
| 2,613 | 300 |
gh_patches_debug_22394
|
rasdani/github-patches
|
git_diff
|
google__fuzzbench-506
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dynamic report generation
Though we already provide things like ipython notebooks to generate reports, I think we should lower the bar so that people can modify the report from the experiment from the report page.
I can think of two ways to do this:
1. Allow dynamic report generation using some kind of webapp.
2. Having a link to an ipython notebook that uses the data for the report on each report page.
Option 1 is a bit of a challenge because we generate reports server side and they take a while to do.
Option 2 is not ideal because I assume there is startup time for ipython notebooks and because it puts a greater burden on users.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `analysis/data_utils.py`
Content:
```
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Utility functions for data (frame) transformations."""
15 from analysis import stat_tests
16 from common import environment
17
18
19 class EmptyDataError(ValueError):
20 """An exception for when the data is empty."""
21
22
23 def validate_data(experiment_df):
24 """Checks if the experiment data is valid."""
25 if experiment_df.empty:
26 raise EmptyDataError('Empty experiment data.')
27
28 expected_columns = {
29 'experiment', 'benchmark', 'fuzzer', 'trial_id', 'time_started',
30 'time_ended', 'time', 'edges_covered'
31 }
32 missing_columns = expected_columns.difference(experiment_df.columns)
33 if missing_columns:
34 raise ValueError(
35 'Missing columns in experiment data: {}'.format(missing_columns))
36
37
38 def drop_uninteresting_columns(experiment_df):
39 """Returns table with only interesting columns."""
40 return experiment_df[[
41 'benchmark', 'fuzzer', 'trial_id', 'time', 'edges_covered'
42 ]]
43
44
45 def clobber_experiments_data(df, experiments):
46 """Clobber experiment data that is part of lower priority (generally
47 earlier) versions of the same trials in |df|. For example in experiment-1 we
48 may test fuzzer-a on benchmark-1. In experiment-2 we may again test fuzzer-a
49 on benchmark-1 because fuzzer-a was updated. This function will remove the
50 snapshots from fuzzer-a,benchmark-1,experiment-1 from |df| because we want
51 the report to only contain the up-to-date data. Experiment priority is
52 determined by order of each experiment in |experiments| with the highest
53 priority experiment coming last in that list."""
54 # We don't call |df| "experiment_df" because it is a misnomer and leads to
55 # confusion in this case where it contains data from multiple experiments.
56
57 # Include everything from the last experiment.
58 experiments = experiments.copy() # Copy so we dont mutate experiments.
59 experiments.reverse()
60 highest_rank_experiment = experiments[0]
61 result = df[df.experiment == highest_rank_experiment]
62
63 for experiment in experiments[1:]:
64 # Include data for not yet covered benchmark/fuzzer pairs.
65 covered_pairs = result[['benchmark', 'fuzzer']].drop_duplicates()
66 covered_pairs = covered_pairs.apply(tuple, axis=1)
67 experiment_data = df[df.experiment == experiment]
68 experiment_pairs = experiment_data[['benchmark',
69 'fuzzer']].apply(tuple, axis=1)
70 to_include = experiment_data[~experiment_pairs.isin(covered_pairs)]
71 result = result.append(to_include)
72 return result
73
74
75 def filter_fuzzers(experiment_df, included_fuzzers):
76 """Returns table with only rows where fuzzer is in |included_fuzzers|."""
77 return experiment_df[experiment_df['fuzzer'].isin(included_fuzzers)]
78
79
80 def filter_benchmarks(experiment_df, included_benchmarks):
81 """Returns table with only rows where benchmark is in
82 |included_benchmarks|."""
83 return experiment_df[experiment_df['benchmark'].isin(included_benchmarks)]
84
85
86 def label_fuzzers_by_experiment(experiment_df):
87 """Returns table where every fuzzer is labeled by the experiment it
88 was run in."""
89 experiment_df['fuzzer'] = (experiment_df['fuzzer'] + '-' +
90 experiment_df['experiment'])
91
92 return experiment_df
93
94
95 def filter_max_time(experiment_df, max_time):
96 """Returns table with snapshots that have time less than or equal to
97 |max_time|."""
98 return experiment_df[experiment_df['time'] <= max_time]
99
100
101 # Creating "snapshots" (see README.md for definition).
102
103 _DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD = 1.0
104
105
106 def get_benchmark_snapshot(benchmark_df,
107 threshold=_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD):
108 """Finds the latest time where all trials were still running
109 (or |threshold| * trials were still running). In most cases, this is the end
110 of the experiment. However, if some trials (or more than (1 - |threshold|) *
111 trials) ended earlier, we will use an earlier "snapshot" time for comparing
112 results.
113
114 Returns data frame that only contains the measurements of the picked
115 snapshot time.
116 """
117 # Allow overriding threshold with environment variable as well.
118 threshold = environment.get('BENCHMARK_SAMPLE_NUM_THRESHOLD', threshold)
119
120 num_trials = benchmark_df.trial_id.nunique()
121 trials_running_at_time = benchmark_df.time.value_counts()
122 criteria = trials_running_at_time >= threshold * num_trials
123 ok_times = trials_running_at_time[criteria]
124 latest_ok_time = ok_times.index.max()
125 benchmark_snapshot_df = benchmark_df[benchmark_df.time == latest_ok_time]
126 return benchmark_snapshot_df
127
128
129 _DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD = 0.8
130
131
132 def get_fuzzers_with_not_enough_samples(
133 benchmark_snapshot_df, threshold=_DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD):
134 """Returns fuzzers that didn't have enough trials running at snapshot time.
135 It takes a benchmark snapshot and finds the fuzzers that have a sample size
136 smaller than 80% of the largest sample size. Default threshold can be
137 overridden.
138 """
139 # Allow overriding threshold with environment variable as well.
140 threshold = environment.get('FUZZER_SAMPLE_NUM_THRESHOLD', threshold)
141
142 samples_per_fuzzer = benchmark_snapshot_df.fuzzer.value_counts()
143 max_samples = samples_per_fuzzer.max()
144 few_sample_criteria = samples_per_fuzzer < threshold * max_samples
145 few_sample_fuzzers = samples_per_fuzzer[few_sample_criteria].index
146 return few_sample_fuzzers.tolist()
147
148
149 def get_experiment_snapshots(experiment_df):
150 """Finds a good snapshot time for each benchmark in the experiment data.
151
152 Returns the data frame that only contains the measurements made at these
153 snapshot times.
154 """
155 benchmark_groups = experiment_df.groupby('benchmark')
156 experiment_snapshots = benchmark_groups.apply(get_benchmark_snapshot)
157 # We don't need the extra index added by the groupby('benchmark').
158 experiment_snapshots.reset_index(drop=True, inplace=True)
159 return experiment_snapshots
160
161
162 # Summary tables containing statistics on the samples.
163
164
165 def benchmark_summary(benchmark_snapshot_df):
166 """Creates summary table for a benchmark snapshot with columns:
167 |fuzzer|time||count|mean|std|min|25%|median|75%|max|
168 """
169 groups = benchmark_snapshot_df.groupby(['fuzzer', 'time'])
170 summary = groups['edges_covered'].describe()
171 summary.rename(columns={'50%': 'median'}, inplace=True)
172 return summary.sort_values(('median'), ascending=False)
173
174
175 def experiment_summary(experiment_snapshots_df):
176 """Creates summary table for all benchmarks in experiment, i.e. table like:
177 |benchmark|| < benchmark level summary >
178 """
179 groups = experiment_snapshots_df.groupby('benchmark')
180 summaries = groups.apply(benchmark_summary)
181 return summaries
182
183
184 # Per-benchmark fuzzer ranking options.
185
186
187 def benchmark_rank_by_mean(benchmark_snapshot_df):
188 """Returns ranking of fuzzers based on mean coverage."""
189 assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'
190 means = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].mean()
191 means.rename('mean cov', inplace=True)
192 return means.sort_values(ascending=False)
193
194
195 def benchmark_rank_by_median(benchmark_snapshot_df):
196 """Returns ranking of fuzzers based on median coverage."""
197 assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'
198 medians = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].median()
199 medians.rename('median cov', inplace=True)
200 return medians.sort_values(ascending=False)
201
202
203 def benchmark_rank_by_average_rank(benchmark_snapshot_df):
204 """Ranks all coverage measurements in the snapshot across fuzzers.
205
206 Returns the average rank by fuzzer.
207 """
208 # Make a copy of the dataframe view, because we want to add a new column.
209 measurements = benchmark_snapshot_df[['fuzzer', 'edges_covered']].copy()
210 measurements['rank'] = measurements['edges_covered'].rank()
211 avg_rank = measurements.groupby('fuzzer').mean()
212 avg_rank.rename(columns={'rank': 'avg rank'}, inplace=True)
213 avg_rank.sort_values('avg rank', ascending=False, inplace=True)
214 return avg_rank['avg rank']
215
216
217 def benchmark_rank_by_stat_test_wins(benchmark_snapshot_df):
218 """Carries out one-tailed statistical tests for each fuzzer pair.
219
220 Returns ranking according to the number of statistical test wins.
221 """
222 p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)
223
224 # Turn "significant" p-values into 1-s.
225 better_than = p_values.applymap(
226 lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)
227 better_than = better_than.applymap(int)
228
229 score = better_than.sum(axis=1).sort_values(ascending=False)
230 score.rename('stat wins', inplace=True)
231
232 return score
233
234
235 def create_better_than_table(benchmark_snapshot_df):
236 """Creates table showing whether fuzzer in row is statistically
237 significantly better than the fuzzer in the column."""
238 p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)
239
240 # Turn "significant" p-values into 1-s.
241 better_than = p_values.applymap(
242 lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)
243 better_than = better_than.applymap(int)
244
245 # Order rows and columns of matrix according to score ranking.
246 score = better_than.sum(axis=1).sort_values(ascending=False)
247 better_than = better_than.reindex(index=score.index,
248 columns=score.index[::-1])
249 return better_than
250
251
252 # Experiment level ranking of fuzzers (across-benchmarks).
253 # Experiment level ranking depends on the per-benchmark ranking method.
254
255
256 def experiment_pivot_table(experiment_snapshots_df,
257 benchmark_level_ranking_function):
258 """Creates a pivot table according to a given per benchmark ranking, where
259 the columns are the fuzzers, the rows are the benchmarks, and the values
260 are the scores according to the per benchmark ranking."""
261 benchmark_blocks = experiment_snapshots_df.groupby('benchmark')
262 groups_ranked = benchmark_blocks.apply(benchmark_level_ranking_function)
263 already_unstacked = groups_ranked.index.names == ['benchmark']
264 pivot_df = groups_ranked if already_unstacked else groups_ranked.unstack()
265 return pivot_df
266
267
268 def experiment_rank_by_average_rank(experiment_pivot_df):
269 """Creates experiment level ranking of fuzzers.
270
271 Takes a pivot table representing per benchmark ranking scores. Ranks
272 fuzzers per benchmark, then takes the average rank across benchmarks
273 (smaller is better).
274 """
275 # Rank fuzzers in each benchmark block.
276 pivot_ranked = experiment_pivot_df.rank('columns',
277 na_option='keep',
278 ascending=False)
279 average_ranks = pivot_ranked.mean().sort_values()
280 return average_ranks.rename('average rank')
281
282
283 def experiment_rank_by_num_firsts(experiment_pivot_df):
284 """Creates experiment level ranking by number of first places in per
285 benchmark rankings (higher is better)."""
286 # Rank fuzzers in each benchmark block.
287 pivot_ranked = experiment_pivot_df.rank('columns',
288 na_option='keep',
289 ascending=False)
290 # Count first places for each fuzzer.
291 firsts = pivot_ranked[pivot_ranked == 1]
292 num_firsts = firsts.sum().sort_values(ascending=False)
293 return num_firsts.rename('number of wins')
294
295
296 def experiment_rank_by_average_normalized_score(experiment_pivot_df):
297 """Creates experiment level ranking by taking the average of normalized per
298 benchmark scores from 0 to 100, where 100 is the highest reach coverage."""
299 # Normalize coverage values.
300 benchmark_maximum = experiment_pivot_df.max(axis='columns')
301 normalized_score = experiment_pivot_df.div(benchmark_maximum,
302 axis='index').mul(100)
303
304 average_score = normalized_score.mean().sort_values(ascending=False)
305 return average_score.rename('average normalized score')
306
307
308 def experiment_level_ranking(experiment_snapshots_df,
309 benchmark_level_ranking_function,
310 experiment_level_ranking_function):
311 """Returns an aggregate ranking of fuzzers across all benchmarks."""
312 pivot_table = experiment_pivot_table(experiment_snapshots_df,
313 benchmark_level_ranking_function)
314 return experiment_level_ranking_function(pivot_table)
315
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/analysis/data_utils.py b/analysis/data_utils.py
--- a/analysis/data_utils.py
+++ b/analysis/data_utils.py
@@ -100,18 +100,17 @@
# Creating "snapshots" (see README.md for definition).
-_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD = 1.0
+_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT = 0.5
def get_benchmark_snapshot(benchmark_df,
- threshold=_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD):
- """Finds the latest time where all trials were still running
- (or |threshold| * trials were still running). In most cases, this is the end
- of the experiment. However, if some trials (or more than (1 - |threshold|) *
- trials) ended earlier, we will use an earlier "snapshot" time for comparing
- results.
-
- Returns data frame that only contains the measurements of the picked
+ threshold=_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT):
+ """Finds the latest time where |threshold| fraction of the trials were still
+ running. In most cases, this is the end of the experiment. However, if less
+ than |threshold| fraction of the trials reached the end of the experiment,
+ then we will use an earlier "snapshot" time for comparing results.
+
+ Returns a data frame that only contains the measurements of the picked
snapshot time.
"""
# Allow overriding threshold with environment variable as well.
|
{"golden_diff": "diff --git a/analysis/data_utils.py b/analysis/data_utils.py\n--- a/analysis/data_utils.py\n+++ b/analysis/data_utils.py\n@@ -100,18 +100,17 @@\n \n # Creating \"snapshots\" (see README.md for definition).\n \n-_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD = 1.0\n+_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT = 0.5\n \n \n def get_benchmark_snapshot(benchmark_df,\n- threshold=_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD):\n- \"\"\"Finds the latest time where all trials were still running\n- (or |threshold| * trials were still running). In most cases, this is the end\n- of the experiment. However, if some trials (or more than (1 - |threshold|) *\n- trials) ended earlier, we will use an earlier \"snapshot\" time for comparing\n- results.\n-\n- Returns data frame that only contains the measurements of the picked\n+ threshold=_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT):\n+ \"\"\"Finds the latest time where |threshold| fraction of the trials were still\n+ running. In most cases, this is the end of the experiment. However, if less\n+ than |threshold| fraction of the trials reached the end of the experiment,\n+ then we will use an earlier \"snapshot\" time for comparing results.\n+\n+ Returns a data frame that only contains the measurements of the picked\n snapshot time.\n \"\"\"\n # Allow overriding threshold with environment variable as well.\n", "issue": "Dynamic report generation\nThough we already provide things like ipython notebooks to generate reports, I think we should lower the bar so that people can modify the report from the experiment from the report page.\r\nI can think of two ways to do this:\r\n1. Allow dynamic report generation using some kind of webapp.\r\n2. Having a link to an ipython notebook that uses the data for the report on each report page.\r\n\r\nOption 1 is a bit of a challenge because we generate reports server side and they take a while to do.\r\nOption 2 is not ideal because I assume there is startup time for ipython notebooks and because it puts a greater burden on users.\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Utility functions for data (frame) transformations.\"\"\"\nfrom analysis import stat_tests\nfrom common import environment\n\n\nclass EmptyDataError(ValueError):\n \"\"\"An exception for when the data is empty.\"\"\"\n\n\ndef validate_data(experiment_df):\n \"\"\"Checks if the experiment data is valid.\"\"\"\n if experiment_df.empty:\n raise EmptyDataError('Empty experiment data.')\n\n expected_columns = {\n 'experiment', 'benchmark', 'fuzzer', 'trial_id', 'time_started',\n 'time_ended', 'time', 'edges_covered'\n }\n missing_columns = expected_columns.difference(experiment_df.columns)\n if missing_columns:\n raise ValueError(\n 'Missing columns in experiment data: {}'.format(missing_columns))\n\n\ndef drop_uninteresting_columns(experiment_df):\n \"\"\"Returns table with only interesting columns.\"\"\"\n return experiment_df[[\n 'benchmark', 'fuzzer', 'trial_id', 'time', 'edges_covered'\n ]]\n\n\ndef clobber_experiments_data(df, experiments):\n \"\"\"Clobber experiment data that is part of lower priority (generally\n earlier) versions of the same trials in |df|. For example in experiment-1 we\n may test fuzzer-a on benchmark-1. In experiment-2 we may again test fuzzer-a\n on benchmark-1 because fuzzer-a was updated. This function will remove the\n snapshots from fuzzer-a,benchmark-1,experiment-1 from |df| because we want\n the report to only contain the up-to-date data. Experiment priority is\n determined by order of each experiment in |experiments| with the highest\n priority experiment coming last in that list.\"\"\"\n # We don't call |df| \"experiment_df\" because it is a misnomer and leads to\n # confusion in this case where it contains data from multiple experiments.\n\n # Include everything from the last experiment.\n experiments = experiments.copy() # Copy so we dont mutate experiments.\n experiments.reverse()\n highest_rank_experiment = experiments[0]\n result = df[df.experiment == highest_rank_experiment]\n\n for experiment in experiments[1:]:\n # Include data for not yet covered benchmark/fuzzer pairs.\n covered_pairs = result[['benchmark', 'fuzzer']].drop_duplicates()\n covered_pairs = covered_pairs.apply(tuple, axis=1)\n experiment_data = df[df.experiment == experiment]\n experiment_pairs = experiment_data[['benchmark',\n 'fuzzer']].apply(tuple, axis=1)\n to_include = experiment_data[~experiment_pairs.isin(covered_pairs)]\n result = result.append(to_include)\n return result\n\n\ndef filter_fuzzers(experiment_df, included_fuzzers):\n \"\"\"Returns table with only rows where fuzzer is in |included_fuzzers|.\"\"\"\n return experiment_df[experiment_df['fuzzer'].isin(included_fuzzers)]\n\n\ndef filter_benchmarks(experiment_df, included_benchmarks):\n \"\"\"Returns table with only rows where benchmark is in\n |included_benchmarks|.\"\"\"\n return experiment_df[experiment_df['benchmark'].isin(included_benchmarks)]\n\n\ndef label_fuzzers_by_experiment(experiment_df):\n \"\"\"Returns table where every fuzzer is labeled by the experiment it\n was run in.\"\"\"\n experiment_df['fuzzer'] = (experiment_df['fuzzer'] + '-' +\n experiment_df['experiment'])\n\n return experiment_df\n\n\ndef filter_max_time(experiment_df, max_time):\n \"\"\"Returns table with snapshots that have time less than or equal to\n |max_time|.\"\"\"\n return experiment_df[experiment_df['time'] <= max_time]\n\n\n# Creating \"snapshots\" (see README.md for definition).\n\n_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD = 1.0\n\n\ndef get_benchmark_snapshot(benchmark_df,\n threshold=_DEFAULT_BENCHMARK_SAMPLE_NUM_THRESHOLD):\n \"\"\"Finds the latest time where all trials were still running\n (or |threshold| * trials were still running). In most cases, this is the end\n of the experiment. However, if some trials (or more than (1 - |threshold|) *\n trials) ended earlier, we will use an earlier \"snapshot\" time for comparing\n results.\n\n Returns data frame that only contains the measurements of the picked\n snapshot time.\n \"\"\"\n # Allow overriding threshold with environment variable as well.\n threshold = environment.get('BENCHMARK_SAMPLE_NUM_THRESHOLD', threshold)\n\n num_trials = benchmark_df.trial_id.nunique()\n trials_running_at_time = benchmark_df.time.value_counts()\n criteria = trials_running_at_time >= threshold * num_trials\n ok_times = trials_running_at_time[criteria]\n latest_ok_time = ok_times.index.max()\n benchmark_snapshot_df = benchmark_df[benchmark_df.time == latest_ok_time]\n return benchmark_snapshot_df\n\n\n_DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD = 0.8\n\n\ndef get_fuzzers_with_not_enough_samples(\n benchmark_snapshot_df, threshold=_DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD):\n \"\"\"Returns fuzzers that didn't have enough trials running at snapshot time.\n It takes a benchmark snapshot and finds the fuzzers that have a sample size\n smaller than 80% of the largest sample size. Default threshold can be\n overridden.\n \"\"\"\n # Allow overriding threshold with environment variable as well.\n threshold = environment.get('FUZZER_SAMPLE_NUM_THRESHOLD', threshold)\n\n samples_per_fuzzer = benchmark_snapshot_df.fuzzer.value_counts()\n max_samples = samples_per_fuzzer.max()\n few_sample_criteria = samples_per_fuzzer < threshold * max_samples\n few_sample_fuzzers = samples_per_fuzzer[few_sample_criteria].index\n return few_sample_fuzzers.tolist()\n\n\ndef get_experiment_snapshots(experiment_df):\n \"\"\"Finds a good snapshot time for each benchmark in the experiment data.\n\n Returns the data frame that only contains the measurements made at these\n snapshot times.\n \"\"\"\n benchmark_groups = experiment_df.groupby('benchmark')\n experiment_snapshots = benchmark_groups.apply(get_benchmark_snapshot)\n # We don't need the extra index added by the groupby('benchmark').\n experiment_snapshots.reset_index(drop=True, inplace=True)\n return experiment_snapshots\n\n\n# Summary tables containing statistics on the samples.\n\n\ndef benchmark_summary(benchmark_snapshot_df):\n \"\"\"Creates summary table for a benchmark snapshot with columns:\n |fuzzer|time||count|mean|std|min|25%|median|75%|max|\n \"\"\"\n groups = benchmark_snapshot_df.groupby(['fuzzer', 'time'])\n summary = groups['edges_covered'].describe()\n summary.rename(columns={'50%': 'median'}, inplace=True)\n return summary.sort_values(('median'), ascending=False)\n\n\ndef experiment_summary(experiment_snapshots_df):\n \"\"\"Creates summary table for all benchmarks in experiment, i.e. table like:\n |benchmark|| < benchmark level summary >\n \"\"\"\n groups = experiment_snapshots_df.groupby('benchmark')\n summaries = groups.apply(benchmark_summary)\n return summaries\n\n\n# Per-benchmark fuzzer ranking options.\n\n\ndef benchmark_rank_by_mean(benchmark_snapshot_df):\n \"\"\"Returns ranking of fuzzers based on mean coverage.\"\"\"\n assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'\n means = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].mean()\n means.rename('mean cov', inplace=True)\n return means.sort_values(ascending=False)\n\n\ndef benchmark_rank_by_median(benchmark_snapshot_df):\n \"\"\"Returns ranking of fuzzers based on median coverage.\"\"\"\n assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'\n medians = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].median()\n medians.rename('median cov', inplace=True)\n return medians.sort_values(ascending=False)\n\n\ndef benchmark_rank_by_average_rank(benchmark_snapshot_df):\n \"\"\"Ranks all coverage measurements in the snapshot across fuzzers.\n\n Returns the average rank by fuzzer.\n \"\"\"\n # Make a copy of the dataframe view, because we want to add a new column.\n measurements = benchmark_snapshot_df[['fuzzer', 'edges_covered']].copy()\n measurements['rank'] = measurements['edges_covered'].rank()\n avg_rank = measurements.groupby('fuzzer').mean()\n avg_rank.rename(columns={'rank': 'avg rank'}, inplace=True)\n avg_rank.sort_values('avg rank', ascending=False, inplace=True)\n return avg_rank['avg rank']\n\n\ndef benchmark_rank_by_stat_test_wins(benchmark_snapshot_df):\n \"\"\"Carries out one-tailed statistical tests for each fuzzer pair.\n\n Returns ranking according to the number of statistical test wins.\n \"\"\"\n p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)\n\n # Turn \"significant\" p-values into 1-s.\n better_than = p_values.applymap(\n lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)\n better_than = better_than.applymap(int)\n\n score = better_than.sum(axis=1).sort_values(ascending=False)\n score.rename('stat wins', inplace=True)\n\n return score\n\n\ndef create_better_than_table(benchmark_snapshot_df):\n \"\"\"Creates table showing whether fuzzer in row is statistically\n significantly better than the fuzzer in the column.\"\"\"\n p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)\n\n # Turn \"significant\" p-values into 1-s.\n better_than = p_values.applymap(\n lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)\n better_than = better_than.applymap(int)\n\n # Order rows and columns of matrix according to score ranking.\n score = better_than.sum(axis=1).sort_values(ascending=False)\n better_than = better_than.reindex(index=score.index,\n columns=score.index[::-1])\n return better_than\n\n\n# Experiment level ranking of fuzzers (across-benchmarks).\n# Experiment level ranking depends on the per-benchmark ranking method.\n\n\ndef experiment_pivot_table(experiment_snapshots_df,\n benchmark_level_ranking_function):\n \"\"\"Creates a pivot table according to a given per benchmark ranking, where\n the columns are the fuzzers, the rows are the benchmarks, and the values\n are the scores according to the per benchmark ranking.\"\"\"\n benchmark_blocks = experiment_snapshots_df.groupby('benchmark')\n groups_ranked = benchmark_blocks.apply(benchmark_level_ranking_function)\n already_unstacked = groups_ranked.index.names == ['benchmark']\n pivot_df = groups_ranked if already_unstacked else groups_ranked.unstack()\n return pivot_df\n\n\ndef experiment_rank_by_average_rank(experiment_pivot_df):\n \"\"\"Creates experiment level ranking of fuzzers.\n\n Takes a pivot table representing per benchmark ranking scores. Ranks\n fuzzers per benchmark, then takes the average rank across benchmarks\n (smaller is better).\n \"\"\"\n # Rank fuzzers in each benchmark block.\n pivot_ranked = experiment_pivot_df.rank('columns',\n na_option='keep',\n ascending=False)\n average_ranks = pivot_ranked.mean().sort_values()\n return average_ranks.rename('average rank')\n\n\ndef experiment_rank_by_num_firsts(experiment_pivot_df):\n \"\"\"Creates experiment level ranking by number of first places in per\n benchmark rankings (higher is better).\"\"\"\n # Rank fuzzers in each benchmark block.\n pivot_ranked = experiment_pivot_df.rank('columns',\n na_option='keep',\n ascending=False)\n # Count first places for each fuzzer.\n firsts = pivot_ranked[pivot_ranked == 1]\n num_firsts = firsts.sum().sort_values(ascending=False)\n return num_firsts.rename('number of wins')\n\n\ndef experiment_rank_by_average_normalized_score(experiment_pivot_df):\n \"\"\"Creates experiment level ranking by taking the average of normalized per\n benchmark scores from 0 to 100, where 100 is the highest reach coverage.\"\"\"\n # Normalize coverage values.\n benchmark_maximum = experiment_pivot_df.max(axis='columns')\n normalized_score = experiment_pivot_df.div(benchmark_maximum,\n axis='index').mul(100)\n\n average_score = normalized_score.mean().sort_values(ascending=False)\n return average_score.rename('average normalized score')\n\n\ndef experiment_level_ranking(experiment_snapshots_df,\n benchmark_level_ranking_function,\n experiment_level_ranking_function):\n \"\"\"Returns an aggregate ranking of fuzzers across all benchmarks.\"\"\"\n pivot_table = experiment_pivot_table(experiment_snapshots_df,\n benchmark_level_ranking_function)\n return experiment_level_ranking_function(pivot_table)\n", "path": "analysis/data_utils.py"}], "after_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Utility functions for data (frame) transformations.\"\"\"\nfrom analysis import stat_tests\nfrom common import environment\n\n\nclass EmptyDataError(ValueError):\n \"\"\"An exception for when the data is empty.\"\"\"\n\n\ndef validate_data(experiment_df):\n \"\"\"Checks if the experiment data is valid.\"\"\"\n if experiment_df.empty:\n raise EmptyDataError('Empty experiment data.')\n\n expected_columns = {\n 'experiment', 'benchmark', 'fuzzer', 'trial_id', 'time_started',\n 'time_ended', 'time', 'edges_covered'\n }\n missing_columns = expected_columns.difference(experiment_df.columns)\n if missing_columns:\n raise ValueError(\n 'Missing columns in experiment data: {}'.format(missing_columns))\n\n\ndef drop_uninteresting_columns(experiment_df):\n \"\"\"Returns table with only interesting columns.\"\"\"\n return experiment_df[[\n 'benchmark', 'fuzzer', 'trial_id', 'time', 'edges_covered'\n ]]\n\n\ndef clobber_experiments_data(df, experiments):\n \"\"\"Clobber experiment data that is part of lower priority (generally\n earlier) versions of the same trials in |df|. For example in experiment-1 we\n may test fuzzer-a on benchmark-1. In experiment-2 we may again test fuzzer-a\n on benchmark-1 because fuzzer-a was updated. This function will remove the\n snapshots from fuzzer-a,benchmark-1,experiment-1 from |df| because we want\n the report to only contain the up-to-date data. Experiment priority is\n determined by order of each experiment in |experiments| with the highest\n priority experiment coming last in that list.\"\"\"\n # We don't call |df| \"experiment_df\" because it is a misnomer and leads to\n # confusion in this case where it contains data from multiple experiments.\n\n # Include everything from the last experiment.\n experiments = experiments.copy() # Copy so we dont mutate experiments.\n experiments.reverse()\n highest_rank_experiment = experiments[0]\n result = df[df.experiment == highest_rank_experiment]\n\n for experiment in experiments[1:]:\n # Include data for not yet covered benchmark/fuzzer pairs.\n covered_pairs = result[['benchmark', 'fuzzer']].drop_duplicates()\n covered_pairs = covered_pairs.apply(tuple, axis=1)\n experiment_data = df[df.experiment == experiment]\n experiment_pairs = experiment_data[['benchmark',\n 'fuzzer']].apply(tuple, axis=1)\n to_include = experiment_data[~experiment_pairs.isin(covered_pairs)]\n result = result.append(to_include)\n return result\n\n\ndef filter_fuzzers(experiment_df, included_fuzzers):\n \"\"\"Returns table with only rows where fuzzer is in |included_fuzzers|.\"\"\"\n return experiment_df[experiment_df['fuzzer'].isin(included_fuzzers)]\n\n\ndef filter_benchmarks(experiment_df, included_benchmarks):\n \"\"\"Returns table with only rows where benchmark is in\n |included_benchmarks|.\"\"\"\n return experiment_df[experiment_df['benchmark'].isin(included_benchmarks)]\n\n\ndef label_fuzzers_by_experiment(experiment_df):\n \"\"\"Returns table where every fuzzer is labeled by the experiment it\n was run in.\"\"\"\n experiment_df['fuzzer'] = (experiment_df['fuzzer'] + '-' +\n experiment_df['experiment'])\n\n return experiment_df\n\n\ndef filter_max_time(experiment_df, max_time):\n \"\"\"Returns table with snapshots that have time less than or equal to\n |max_time|.\"\"\"\n return experiment_df[experiment_df['time'] <= max_time]\n\n\n# Creating \"snapshots\" (see README.md for definition).\n\n_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT = 0.5\n\n\ndef get_benchmark_snapshot(benchmark_df,\n threshold=_MIN_FRACTION_OF_ALIVE_TRIALS_AT_SNAPSHOT):\n \"\"\"Finds the latest time where |threshold| fraction of the trials were still\n running. In most cases, this is the end of the experiment. However, if less\n than |threshold| fraction of the trials reached the end of the experiment,\n then we will use an earlier \"snapshot\" time for comparing results.\n\n Returns a data frame that only contains the measurements of the picked\n snapshot time.\n \"\"\"\n # Allow overriding threshold with environment variable as well.\n threshold = environment.get('BENCHMARK_SAMPLE_NUM_THRESHOLD', threshold)\n\n num_trials = benchmark_df.trial_id.nunique()\n trials_running_at_time = benchmark_df.time.value_counts()\n criteria = trials_running_at_time >= threshold * num_trials\n ok_times = trials_running_at_time[criteria]\n latest_ok_time = ok_times.index.max()\n benchmark_snapshot_df = benchmark_df[benchmark_df.time == latest_ok_time]\n return benchmark_snapshot_df\n\n\n_DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD = 0.8\n\n\ndef get_fuzzers_with_not_enough_samples(\n benchmark_snapshot_df, threshold=_DEFAULT_FUZZER_SAMPLE_NUM_THRESHOLD):\n \"\"\"Returns fuzzers that didn't have enough trials running at snapshot time.\n It takes a benchmark snapshot and finds the fuzzers that have a sample size\n smaller than 80% of the largest sample size. Default threshold can be\n overridden.\n \"\"\"\n # Allow overriding threshold with environment variable as well.\n threshold = environment.get('FUZZER_SAMPLE_NUM_THRESHOLD', threshold)\n\n samples_per_fuzzer = benchmark_snapshot_df.fuzzer.value_counts()\n max_samples = samples_per_fuzzer.max()\n few_sample_criteria = samples_per_fuzzer < threshold * max_samples\n few_sample_fuzzers = samples_per_fuzzer[few_sample_criteria].index\n return few_sample_fuzzers.tolist()\n\n\ndef get_experiment_snapshots(experiment_df):\n \"\"\"Finds a good snapshot time for each benchmark in the experiment data.\n\n Returns the data frame that only contains the measurements made at these\n snapshot times.\n \"\"\"\n benchmark_groups = experiment_df.groupby('benchmark')\n experiment_snapshots = benchmark_groups.apply(get_benchmark_snapshot)\n # We don't need the extra index added by the groupby('benchmark').\n experiment_snapshots.reset_index(drop=True, inplace=True)\n return experiment_snapshots\n\n\n# Summary tables containing statistics on the samples.\n\n\ndef benchmark_summary(benchmark_snapshot_df):\n \"\"\"Creates summary table for a benchmark snapshot with columns:\n |fuzzer|time||count|mean|std|min|25%|median|75%|max|\n \"\"\"\n groups = benchmark_snapshot_df.groupby(['fuzzer', 'time'])\n summary = groups['edges_covered'].describe()\n summary.rename(columns={'50%': 'median'}, inplace=True)\n return summary.sort_values(('median'), ascending=False)\n\n\ndef experiment_summary(experiment_snapshots_df):\n \"\"\"Creates summary table for all benchmarks in experiment, i.e. table like:\n |benchmark|| < benchmark level summary >\n \"\"\"\n groups = experiment_snapshots_df.groupby('benchmark')\n summaries = groups.apply(benchmark_summary)\n return summaries\n\n\n# Per-benchmark fuzzer ranking options.\n\n\ndef benchmark_rank_by_mean(benchmark_snapshot_df):\n \"\"\"Returns ranking of fuzzers based on mean coverage.\"\"\"\n assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'\n means = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].mean()\n means.rename('mean cov', inplace=True)\n return means.sort_values(ascending=False)\n\n\ndef benchmark_rank_by_median(benchmark_snapshot_df):\n \"\"\"Returns ranking of fuzzers based on median coverage.\"\"\"\n assert benchmark_snapshot_df.time.nunique() == 1, 'Not a snapshot!'\n medians = benchmark_snapshot_df.groupby('fuzzer')['edges_covered'].median()\n medians.rename('median cov', inplace=True)\n return medians.sort_values(ascending=False)\n\n\ndef benchmark_rank_by_average_rank(benchmark_snapshot_df):\n \"\"\"Ranks all coverage measurements in the snapshot across fuzzers.\n\n Returns the average rank by fuzzer.\n \"\"\"\n # Make a copy of the dataframe view, because we want to add a new column.\n measurements = benchmark_snapshot_df[['fuzzer', 'edges_covered']].copy()\n measurements['rank'] = measurements['edges_covered'].rank()\n avg_rank = measurements.groupby('fuzzer').mean()\n avg_rank.rename(columns={'rank': 'avg rank'}, inplace=True)\n avg_rank.sort_values('avg rank', ascending=False, inplace=True)\n return avg_rank['avg rank']\n\n\ndef benchmark_rank_by_stat_test_wins(benchmark_snapshot_df):\n \"\"\"Carries out one-tailed statistical tests for each fuzzer pair.\n\n Returns ranking according to the number of statistical test wins.\n \"\"\"\n p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)\n\n # Turn \"significant\" p-values into 1-s.\n better_than = p_values.applymap(\n lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)\n better_than = better_than.applymap(int)\n\n score = better_than.sum(axis=1).sort_values(ascending=False)\n score.rename('stat wins', inplace=True)\n\n return score\n\n\ndef create_better_than_table(benchmark_snapshot_df):\n \"\"\"Creates table showing whether fuzzer in row is statistically\n significantly better than the fuzzer in the column.\"\"\"\n p_values = stat_tests.one_sided_u_test(benchmark_snapshot_df)\n\n # Turn \"significant\" p-values into 1-s.\n better_than = p_values.applymap(\n lambda p: p < stat_tests.SIGNIFICANCE_THRESHOLD)\n better_than = better_than.applymap(int)\n\n # Order rows and columns of matrix according to score ranking.\n score = better_than.sum(axis=1).sort_values(ascending=False)\n better_than = better_than.reindex(index=score.index,\n columns=score.index[::-1])\n return better_than\n\n\n# Experiment level ranking of fuzzers (across-benchmarks).\n# Experiment level ranking depends on the per-benchmark ranking method.\n\n\ndef experiment_pivot_table(experiment_snapshots_df,\n benchmark_level_ranking_function):\n \"\"\"Creates a pivot table according to a given per benchmark ranking, where\n the columns are the fuzzers, the rows are the benchmarks, and the values\n are the scores according to the per benchmark ranking.\"\"\"\n benchmark_blocks = experiment_snapshots_df.groupby('benchmark')\n groups_ranked = benchmark_blocks.apply(benchmark_level_ranking_function)\n already_unstacked = groups_ranked.index.names == ['benchmark']\n pivot_df = groups_ranked if already_unstacked else groups_ranked.unstack()\n return pivot_df\n\n\ndef experiment_rank_by_average_rank(experiment_pivot_df):\n \"\"\"Creates experiment level ranking of fuzzers.\n\n Takes a pivot table representing per benchmark ranking scores. Ranks\n fuzzers per benchmark, then takes the average rank across benchmarks\n (smaller is better).\n \"\"\"\n # Rank fuzzers in each benchmark block.\n pivot_ranked = experiment_pivot_df.rank('columns',\n na_option='keep',\n ascending=False)\n average_ranks = pivot_ranked.mean().sort_values()\n return average_ranks.rename('average rank')\n\n\ndef experiment_rank_by_num_firsts(experiment_pivot_df):\n \"\"\"Creates experiment level ranking by number of first places in per\n benchmark rankings (higher is better).\"\"\"\n # Rank fuzzers in each benchmark block.\n pivot_ranked = experiment_pivot_df.rank('columns',\n na_option='keep',\n ascending=False)\n # Count first places for each fuzzer.\n firsts = pivot_ranked[pivot_ranked == 1]\n num_firsts = firsts.sum().sort_values(ascending=False)\n return num_firsts.rename('number of wins')\n\n\ndef experiment_rank_by_average_normalized_score(experiment_pivot_df):\n \"\"\"Creates experiment level ranking by taking the average of normalized per\n benchmark scores from 0 to 100, where 100 is the highest reach coverage.\"\"\"\n # Normalize coverage values.\n benchmark_maximum = experiment_pivot_df.max(axis='columns')\n normalized_score = experiment_pivot_df.div(benchmark_maximum,\n axis='index').mul(100)\n\n average_score = normalized_score.mean().sort_values(ascending=False)\n return average_score.rename('average normalized score')\n\n\ndef experiment_level_ranking(experiment_snapshots_df,\n benchmark_level_ranking_function,\n experiment_level_ranking_function):\n \"\"\"Returns an aggregate ranking of fuzzers across all benchmarks.\"\"\"\n pivot_table = experiment_pivot_table(experiment_snapshots_df,\n benchmark_level_ranking_function)\n return experiment_level_ranking_function(pivot_table)\n", "path": "analysis/data_utils.py"}]}
| 4,054 | 337 |
gh_patches_debug_1834
|
rasdani/github-patches
|
git_diff
|
mozilla__pontoon-3003
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GetText check fails incorrectly on newline
https://pontoon.mozilla.org/en-GB/all-projects/all-resources/?string=286055
If you copy the source string, an extra line is added at the back, and that fails the checks for GetText.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pontoon/translations/forms.py`
Content:
```
1 from django import forms
2 from django.contrib.postgres.forms import SimpleArrayField
3
4 from pontoon.base.models import (
5 Entity,
6 Locale,
7 )
8
9
10 class CreateTranslationForm(forms.Form):
11 """
12 Form for parameters to the `entities` view.
13 """
14
15 entity = forms.IntegerField()
16 locale = forms.CharField()
17 plural_form = forms.CharField()
18
19 # Some file formats allow empty original strings and translations.
20 # We must allow both here. Validation is handled in pontoon.checks module.
21 original = forms.CharField(required=False)
22 translation = forms.CharField(required=False)
23
24 ignore_warnings = forms.BooleanField(required=False)
25 approve = forms.BooleanField(required=False)
26 force_suggestions = forms.BooleanField(required=False)
27 paths = forms.MultipleChoiceField(required=False)
28 machinery_sources = SimpleArrayField(forms.CharField(max_length=30), required=False)
29
30 def clean_paths(self):
31 try:
32 return self.data.getlist("paths[]")
33 except AttributeError:
34 # If the data source is not a QueryDict, it won't have a `getlist` method.
35 return self.data.get("paths[]") or []
36
37 def clean_entity(self):
38 try:
39 return Entity.objects.get(pk=self.cleaned_data["entity"])
40 except Entity.DoesNotExist:
41 raise forms.ValidationError(f"Entity `{self.entity}` could not be found")
42
43 def clean_locale(self):
44 try:
45 return Locale.objects.get(code=self.cleaned_data["locale"])
46 except Locale.DoesNotExist:
47 raise forms.ValidationError(f"Locale `{self.entity}` could not be found")
48
49 def clean_plural_form(self):
50 if self.cleaned_data["plural_form"] == "-1":
51 return None
52 return self.cleaned_data["plural_form"]
53
54 def clean_translation(self):
55 return self.data.get("translation", "")
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pontoon/translations/forms.py b/pontoon/translations/forms.py
--- a/pontoon/translations/forms.py
+++ b/pontoon/translations/forms.py
@@ -51,5 +51,8 @@
return None
return self.cleaned_data["plural_form"]
+ def clean_original(self):
+ return self.data.get("original", "")
+
def clean_translation(self):
return self.data.get("translation", "")
|
{"golden_diff": "diff --git a/pontoon/translations/forms.py b/pontoon/translations/forms.py\n--- a/pontoon/translations/forms.py\n+++ b/pontoon/translations/forms.py\n@@ -51,5 +51,8 @@\n return None\n return self.cleaned_data[\"plural_form\"]\n \n+ def clean_original(self):\n+ return self.data.get(\"original\", \"\")\n+\n def clean_translation(self):\n return self.data.get(\"translation\", \"\")\n", "issue": "GetText check fails incorrectly on newline\nhttps://pontoon.mozilla.org/en-GB/all-projects/all-resources/?string=286055\r\n\r\nIf you copy the source string, an extra line is added at the back, and that fails the checks for GetText.\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\nfrom pontoon.base.models import (\n Entity,\n Locale,\n)\n\n\nclass CreateTranslationForm(forms.Form):\n \"\"\"\n Form for parameters to the `entities` view.\n \"\"\"\n\n entity = forms.IntegerField()\n locale = forms.CharField()\n plural_form = forms.CharField()\n\n # Some file formats allow empty original strings and translations.\n # We must allow both here. Validation is handled in pontoon.checks module.\n original = forms.CharField(required=False)\n translation = forms.CharField(required=False)\n\n ignore_warnings = forms.BooleanField(required=False)\n approve = forms.BooleanField(required=False)\n force_suggestions = forms.BooleanField(required=False)\n paths = forms.MultipleChoiceField(required=False)\n machinery_sources = SimpleArrayField(forms.CharField(max_length=30), required=False)\n\n def clean_paths(self):\n try:\n return self.data.getlist(\"paths[]\")\n except AttributeError:\n # If the data source is not a QueryDict, it won't have a `getlist` method.\n return self.data.get(\"paths[]\") or []\n\n def clean_entity(self):\n try:\n return Entity.objects.get(pk=self.cleaned_data[\"entity\"])\n except Entity.DoesNotExist:\n raise forms.ValidationError(f\"Entity `{self.entity}` could not be found\")\n\n def clean_locale(self):\n try:\n return Locale.objects.get(code=self.cleaned_data[\"locale\"])\n except Locale.DoesNotExist:\n raise forms.ValidationError(f\"Locale `{self.entity}` could not be found\")\n\n def clean_plural_form(self):\n if self.cleaned_data[\"plural_form\"] == \"-1\":\n return None\n return self.cleaned_data[\"plural_form\"]\n\n def clean_translation(self):\n return self.data.get(\"translation\", \"\")\n", "path": "pontoon/translations/forms.py"}], "after_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\nfrom pontoon.base.models import (\n Entity,\n Locale,\n)\n\n\nclass CreateTranslationForm(forms.Form):\n \"\"\"\n Form for parameters to the `entities` view.\n \"\"\"\n\n entity = forms.IntegerField()\n locale = forms.CharField()\n plural_form = forms.CharField()\n\n # Some file formats allow empty original strings and translations.\n # We must allow both here. Validation is handled in pontoon.checks module.\n original = forms.CharField(required=False)\n translation = forms.CharField(required=False)\n\n ignore_warnings = forms.BooleanField(required=False)\n approve = forms.BooleanField(required=False)\n force_suggestions = forms.BooleanField(required=False)\n paths = forms.MultipleChoiceField(required=False)\n machinery_sources = SimpleArrayField(forms.CharField(max_length=30), required=False)\n\n def clean_paths(self):\n try:\n return self.data.getlist(\"paths[]\")\n except AttributeError:\n # If the data source is not a QueryDict, it won't have a `getlist` method.\n return self.data.get(\"paths[]\") or []\n\n def clean_entity(self):\n try:\n return Entity.objects.get(pk=self.cleaned_data[\"entity\"])\n except Entity.DoesNotExist:\n raise forms.ValidationError(f\"Entity `{self.entity}` could not be found\")\n\n def clean_locale(self):\n try:\n return Locale.objects.get(code=self.cleaned_data[\"locale\"])\n except Locale.DoesNotExist:\n raise forms.ValidationError(f\"Locale `{self.entity}` could not be found\")\n\n def clean_plural_form(self):\n if self.cleaned_data[\"plural_form\"] == \"-1\":\n return None\n return self.cleaned_data[\"plural_form\"]\n\n def clean_original(self):\n return self.data.get(\"original\", \"\")\n\n def clean_translation(self):\n return self.data.get(\"translation\", \"\")\n", "path": "pontoon/translations/forms.py"}]}
| 795 | 99 |
gh_patches_debug_8461
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-7603
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add e2e tests for pipeline evaluation for 2.x
Test eval for 2.x with tiny dataset, check dataframes, isolated, integrated eval (migrate existing integration tests to e2e tests for 2.x)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/evaluation/eval_run_result.py`
Content:
```
1 from abc import ABC, abstractmethod
2 from copy import deepcopy
3 from typing import Any, Dict, List
4 from warnings import warn
5
6 from pandas import DataFrame
7 from pandas import concat as pd_concat
8
9
10 class BaseEvaluationRunResult(ABC):
11 """
12 Represents the results of an evaluation run.
13 """
14
15 @abstractmethod
16 def to_pandas(self) -> "DataFrame":
17 """
18 Creates a Pandas DataFrame containing the scores of each metric for every input sample.
19
20 :returns:
21 Pandas DataFrame with the scores.
22 """
23
24 @abstractmethod
25 def score_report(self) -> "DataFrame":
26 """
27 Transforms the results into a Pandas DataFrame with the aggregated scores for each metric.
28
29 :returns:
30 Pandas DataFrame with the aggregated scores.
31 """
32
33 @abstractmethod
34 def comparative_individual_scores_report(self, other: "BaseEvaluationRunResult") -> "DataFrame":
35 """
36 Creates a Pandas DataFrame with the scores for each metric in the results of two different evaluation runs.
37
38 The inputs to both evaluation runs is assumed to be the same.
39
40 :param other:
41 Results of another evaluation run to compare with.
42 :returns:
43 Pandas DataFrame with the score comparison.
44 """
45
46
47 class EvaluationRunResult(BaseEvaluationRunResult):
48 """
49 Contains the inputs and the outputs of an evaluation pipeline and provides methods to inspect them.
50 """
51
52 def __init__(self, run_name: str, inputs: Dict[str, List[Any]], results: Dict[str, Dict[str, Any]]):
53 """
54 Initialize a new evaluation run result.
55
56 :param run_name:
57 Name of the evaluation run.
58 :param inputs:
59 Dictionary containing the inputs used for the run.
60 Each key is the name of the input and its value is
61 a list of input values. The length of the lists should
62 be the same.
63 :param results:
64 Dictionary containing the results of the evaluators
65 used in the evaluation pipeline. Each key is the name
66 of the metric and its value is dictionary with the following
67 keys:
68 - 'score': The aggregated score for the metric.
69 - 'individual_scores': A list of scores for each input sample.
70 """
71 self.run_name = run_name
72 self.inputs = deepcopy(inputs)
73 self.results = deepcopy(results)
74
75 if len(inputs) == 0:
76 raise ValueError("No inputs provided.")
77 if len({len(l) for l in inputs.values()}) != 1:
78 raise ValueError("Lengths of the inputs should be the same.")
79
80 expected_len = len(next(iter(inputs.values())))
81
82 for metric, outputs in results.items():
83 if "score" not in outputs:
84 raise ValueError(f"Aggregate score missing for {metric}.")
85 if "individual_scores" not in outputs:
86 raise ValueError(f"Individual scores missing for {metric}.")
87
88 if len(outputs["individual_scores"]) != expected_len:
89 raise ValueError(
90 f"Length of individual scores for '{metric}' should be the same as the inputs. "
91 f"Got {len(outputs['individual_scores'])} but expected {expected_len}."
92 )
93
94 def score_report(self) -> DataFrame: # noqa: D102
95 results = {k: v["score"] for k, v in self.results.items()}
96 return DataFrame.from_dict(results, orient="index", columns=["score"])
97
98 def to_pandas(self) -> DataFrame: # noqa: D102
99 inputs_columns = list(self.inputs.keys())
100 inputs_values = list(self.inputs.values())
101 inputs_values = list(map(list, zip(*inputs_values))) # transpose the values
102 df_inputs = DataFrame(inputs_values, columns=inputs_columns)
103
104 scores_columns = list(self.results.keys())
105 scores_values = [v["individual_scores"] for v in self.results.values()]
106 scores_values = list(map(list, zip(*scores_values))) # transpose the values
107 df_scores = DataFrame(scores_values, columns=scores_columns)
108
109 return df_inputs.join(df_scores)
110
111 def comparative_individual_scores_report(self, other: "BaseEvaluationRunResult") -> DataFrame: # noqa: D102
112 if not isinstance(other, EvaluationRunResult):
113 raise ValueError("Comparative scores can only be computed between EvaluationRunResults.")
114
115 this_name = self.run_name
116 other_name = other.run_name
117 if this_name == other_name:
118 warn(f"The run names of the two evaluation results are the same ('{this_name}')")
119 this_name = f"{this_name}_first"
120 other_name = f"{other_name}_second"
121
122 if self.inputs != other.inputs:
123 warn(f"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.")
124
125 pipe_a_df = self.to_pandas()
126 pipe_b_df = other.to_pandas()
127
128 ignore = list(self.inputs.keys())
129 pipe_b_df.drop(columns=ignore, inplace=True, errors="ignore")
130 pipe_b_df.columns = [f"{other_name}_{column}" for column in pipe_b_df.columns] # type: ignore
131 pipe_a_df.columns = [
132 f"{this_name}_{col}" if col not in ignore else col for col in pipe_a_df.columns
133 ] # type: ignore
134
135 results_df = pd_concat([pipe_a_df, pipe_b_df], axis=1)
136 return results_df
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/haystack/evaluation/eval_run_result.py b/haystack/evaluation/eval_run_result.py
--- a/haystack/evaluation/eval_run_result.py
+++ b/haystack/evaluation/eval_run_result.py
@@ -119,8 +119,8 @@
this_name = f"{this_name}_first"
other_name = f"{other_name}_second"
- if self.inputs != other.inputs:
- warn(f"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.")
+ if self.inputs.keys() != other.inputs.keys():
+ warn(f"The input columns differ between the results; using the input columns of '{this_name}'.")
pipe_a_df = self.to_pandas()
pipe_b_df = other.to_pandas()
|
{"golden_diff": "diff --git a/haystack/evaluation/eval_run_result.py b/haystack/evaluation/eval_run_result.py\n--- a/haystack/evaluation/eval_run_result.py\n+++ b/haystack/evaluation/eval_run_result.py\n@@ -119,8 +119,8 @@\n this_name = f\"{this_name}_first\"\n other_name = f\"{other_name}_second\"\n \n- if self.inputs != other.inputs:\n- warn(f\"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.\")\n+ if self.inputs.keys() != other.inputs.keys():\n+ warn(f\"The input columns differ between the results; using the input columns of '{this_name}'.\")\n \n pipe_a_df = self.to_pandas()\n pipe_b_df = other.to_pandas()\n", "issue": "Add e2e tests for pipeline evaluation for 2.x\nTest eval for 2.x with tiny dataset, check dataframes, isolated, integrated eval (migrate existing integration tests to e2e tests for 2.x)\n", "before_files": [{"content": "from abc import ABC, abstractmethod\nfrom copy import deepcopy\nfrom typing import Any, Dict, List\nfrom warnings import warn\n\nfrom pandas import DataFrame\nfrom pandas import concat as pd_concat\n\n\nclass BaseEvaluationRunResult(ABC):\n \"\"\"\n Represents the results of an evaluation run.\n \"\"\"\n\n @abstractmethod\n def to_pandas(self) -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame containing the scores of each metric for every input sample.\n\n :returns:\n Pandas DataFrame with the scores.\n \"\"\"\n\n @abstractmethod\n def score_report(self) -> \"DataFrame\":\n \"\"\"\n Transforms the results into a Pandas DataFrame with the aggregated scores for each metric.\n\n :returns:\n Pandas DataFrame with the aggregated scores.\n \"\"\"\n\n @abstractmethod\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame with the scores for each metric in the results of two different evaluation runs.\n\n The inputs to both evaluation runs is assumed to be the same.\n\n :param other:\n Results of another evaluation run to compare with.\n :returns:\n Pandas DataFrame with the score comparison.\n \"\"\"\n\n\nclass EvaluationRunResult(BaseEvaluationRunResult):\n \"\"\"\n Contains the inputs and the outputs of an evaluation pipeline and provides methods to inspect them.\n \"\"\"\n\n def __init__(self, run_name: str, inputs: Dict[str, List[Any]], results: Dict[str, Dict[str, Any]]):\n \"\"\"\n Initialize a new evaluation run result.\n\n :param run_name:\n Name of the evaluation run.\n :param inputs:\n Dictionary containing the inputs used for the run.\n Each key is the name of the input and its value is\n a list of input values. The length of the lists should\n be the same.\n :param results:\n Dictionary containing the results of the evaluators\n used in the evaluation pipeline. Each key is the name\n of the metric and its value is dictionary with the following\n keys:\n - 'score': The aggregated score for the metric.\n - 'individual_scores': A list of scores for each input sample.\n \"\"\"\n self.run_name = run_name\n self.inputs = deepcopy(inputs)\n self.results = deepcopy(results)\n\n if len(inputs) == 0:\n raise ValueError(\"No inputs provided.\")\n if len({len(l) for l in inputs.values()}) != 1:\n raise ValueError(\"Lengths of the inputs should be the same.\")\n\n expected_len = len(next(iter(inputs.values())))\n\n for metric, outputs in results.items():\n if \"score\" not in outputs:\n raise ValueError(f\"Aggregate score missing for {metric}.\")\n if \"individual_scores\" not in outputs:\n raise ValueError(f\"Individual scores missing for {metric}.\")\n\n if len(outputs[\"individual_scores\"]) != expected_len:\n raise ValueError(\n f\"Length of individual scores for '{metric}' should be the same as the inputs. \"\n f\"Got {len(outputs['individual_scores'])} but expected {expected_len}.\"\n )\n\n def score_report(self) -> DataFrame: # noqa: D102\n results = {k: v[\"score\"] for k, v in self.results.items()}\n return DataFrame.from_dict(results, orient=\"index\", columns=[\"score\"])\n\n def to_pandas(self) -> DataFrame: # noqa: D102\n inputs_columns = list(self.inputs.keys())\n inputs_values = list(self.inputs.values())\n inputs_values = list(map(list, zip(*inputs_values))) # transpose the values\n df_inputs = DataFrame(inputs_values, columns=inputs_columns)\n\n scores_columns = list(self.results.keys())\n scores_values = [v[\"individual_scores\"] for v in self.results.values()]\n scores_values = list(map(list, zip(*scores_values))) # transpose the values\n df_scores = DataFrame(scores_values, columns=scores_columns)\n\n return df_inputs.join(df_scores)\n\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> DataFrame: # noqa: D102\n if not isinstance(other, EvaluationRunResult):\n raise ValueError(\"Comparative scores can only be computed between EvaluationRunResults.\")\n\n this_name = self.run_name\n other_name = other.run_name\n if this_name == other_name:\n warn(f\"The run names of the two evaluation results are the same ('{this_name}')\")\n this_name = f\"{this_name}_first\"\n other_name = f\"{other_name}_second\"\n\n if self.inputs != other.inputs:\n warn(f\"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.\")\n\n pipe_a_df = self.to_pandas()\n pipe_b_df = other.to_pandas()\n\n ignore = list(self.inputs.keys())\n pipe_b_df.drop(columns=ignore, inplace=True, errors=\"ignore\")\n pipe_b_df.columns = [f\"{other_name}_{column}\" for column in pipe_b_df.columns] # type: ignore\n pipe_a_df.columns = [\n f\"{this_name}_{col}\" if col not in ignore else col for col in pipe_a_df.columns\n ] # type: ignore\n\n results_df = pd_concat([pipe_a_df, pipe_b_df], axis=1)\n return results_df\n", "path": "haystack/evaluation/eval_run_result.py"}], "after_files": [{"content": "from abc import ABC, abstractmethod\nfrom copy import deepcopy\nfrom typing import Any, Dict, List\nfrom warnings import warn\n\nfrom pandas import DataFrame\nfrom pandas import concat as pd_concat\n\n\nclass BaseEvaluationRunResult(ABC):\n \"\"\"\n Represents the results of an evaluation run.\n \"\"\"\n\n @abstractmethod\n def to_pandas(self) -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame containing the scores of each metric for every input sample.\n\n :returns:\n Pandas DataFrame with the scores.\n \"\"\"\n\n @abstractmethod\n def score_report(self) -> \"DataFrame\":\n \"\"\"\n Transforms the results into a Pandas DataFrame with the aggregated scores for each metric.\n\n :returns:\n Pandas DataFrame with the aggregated scores.\n \"\"\"\n\n @abstractmethod\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame with the scores for each metric in the results of two different evaluation runs.\n\n The inputs to both evaluation runs is assumed to be the same.\n\n :param other:\n Results of another evaluation run to compare with.\n :returns:\n Pandas DataFrame with the score comparison.\n \"\"\"\n\n\nclass EvaluationRunResult(BaseEvaluationRunResult):\n \"\"\"\n Contains the inputs and the outputs of an evaluation pipeline and provides methods to inspect them.\n \"\"\"\n\n def __init__(self, run_name: str, inputs: Dict[str, List[Any]], results: Dict[str, Dict[str, Any]]):\n \"\"\"\n Initialize a new evaluation run result.\n\n :param run_name:\n Name of the evaluation run.\n :param inputs:\n Dictionary containing the inputs used for the run.\n Each key is the name of the input and its value is\n a list of input values. The length of the lists should\n be the same.\n :param results:\n Dictionary containing the results of the evaluators\n used in the evaluation pipeline. Each key is the name\n of the metric and its value is dictionary with the following\n keys:\n - 'score': The aggregated score for the metric.\n - 'individual_scores': A list of scores for each input sample.\n \"\"\"\n self.run_name = run_name\n self.inputs = deepcopy(inputs)\n self.results = deepcopy(results)\n\n if len(inputs) == 0:\n raise ValueError(\"No inputs provided.\")\n if len({len(l) for l in inputs.values()}) != 1:\n raise ValueError(\"Lengths of the inputs should be the same.\")\n\n expected_len = len(next(iter(inputs.values())))\n\n for metric, outputs in results.items():\n if \"score\" not in outputs:\n raise ValueError(f\"Aggregate score missing for {metric}.\")\n if \"individual_scores\" not in outputs:\n raise ValueError(f\"Individual scores missing for {metric}.\")\n\n if len(outputs[\"individual_scores\"]) != expected_len:\n raise ValueError(\n f\"Length of individual scores for '{metric}' should be the same as the inputs. \"\n f\"Got {len(outputs['individual_scores'])} but expected {expected_len}.\"\n )\n\n def score_report(self) -> DataFrame: # noqa: D102\n results = {k: v[\"score\"] for k, v in self.results.items()}\n return DataFrame.from_dict(results, orient=\"index\", columns=[\"score\"])\n\n def to_pandas(self) -> DataFrame: # noqa: D102\n inputs_columns = list(self.inputs.keys())\n inputs_values = list(self.inputs.values())\n inputs_values = list(map(list, zip(*inputs_values))) # transpose the values\n df_inputs = DataFrame(inputs_values, columns=inputs_columns)\n\n scores_columns = list(self.results.keys())\n scores_values = [v[\"individual_scores\"] for v in self.results.values()]\n scores_values = list(map(list, zip(*scores_values))) # transpose the values\n df_scores = DataFrame(scores_values, columns=scores_columns)\n\n return df_inputs.join(df_scores)\n\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> DataFrame: # noqa: D102\n if not isinstance(other, EvaluationRunResult):\n raise ValueError(\"Comparative scores can only be computed between EvaluationRunResults.\")\n\n this_name = self.run_name\n other_name = other.run_name\n if this_name == other_name:\n warn(f\"The run names of the two evaluation results are the same ('{this_name}')\")\n this_name = f\"{this_name}_first\"\n other_name = f\"{other_name}_second\"\n\n if self.inputs.keys() != other.inputs.keys():\n warn(f\"The input columns differ between the results; using the input columns of '{this_name}'.\")\n\n pipe_a_df = self.to_pandas()\n pipe_b_df = other.to_pandas()\n\n ignore = list(self.inputs.keys())\n pipe_b_df.drop(columns=ignore, inplace=True, errors=\"ignore\")\n pipe_b_df.columns = [f\"{other_name}_{column}\" for column in pipe_b_df.columns] # type: ignore\n pipe_a_df.columns = [\n f\"{this_name}_{col}\" if col not in ignore else col for col in pipe_a_df.columns\n ] # type: ignore\n\n results_df = pd_concat([pipe_a_df, pipe_b_df], axis=1)\n return results_df\n", "path": "haystack/evaluation/eval_run_result.py"}]}
| 1,758 | 175 |
gh_patches_debug_13129
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-613
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
datetimepicker unique ids
<img width="980" alt="screen shot 2017-06-01 at 15 59 21" src="https://cloud.githubusercontent.com/assets/16354712/26683219/61f8eb4c-46e3-11e7-851b-148bff927bd4.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/contrib/widgets.py`
Content:
```
1 import datetime
2 from itertools import chain
3
4 import django_filters
5 from django.contrib.staticfiles.storage import staticfiles_storage
6 from django.db.models.fields import BLANK_CHOICE_DASH
7 from django.forms import widgets as form_widgets
8 from django.forms.widgets import flatatt
9 from django.template.loader import render_to_string
10 from django.utils import formats
11 from django.utils.timezone import localtime
12 from django.utils.translation import ugettext as _
13
14
15 class DropdownLinkWidget(django_filters.widgets.LinkWidget):
16 label = None
17 right = False
18 template = 'meinberlin_contrib/widgets/dropdown_link.html'
19
20 def get_option_label(self, value, choices=()):
21 option_label = BLANK_CHOICE_DASH[0][1]
22
23 for v, label in chain(self.choices, choices):
24 if str(v) == value:
25 option_label = label
26 break
27
28 if option_label == BLANK_CHOICE_DASH[0][1]:
29 option_label = _('All')
30
31 return option_label
32
33 def render(self, name, value, attrs=None, choices=()):
34 all_choices = list(chain(self.choices, choices))
35
36 if len(all_choices) <= 1:
37 return ''
38
39 if value is None:
40 value = all_choices[0][0]
41
42 _id = attrs.pop('id')
43 final_attrs = flatatt(self.build_attrs(attrs))
44 value_label = self.get_option_label(value, choices=choices)
45
46 options = super().render(name, value, attrs={
47 'class': 'dropdown-menu',
48 'aria-labelledby': _id,
49 }, choices=choices)
50
51 return render_to_string(self.template, {
52 'options': options,
53 'id': _id,
54 'attrs': final_attrs,
55 'value_label': value_label,
56 'label': self.label,
57 'right': self.right,
58 })
59
60
61 class DateTimeInput(form_widgets.SplitDateTimeWidget):
62 class Media:
63 js = (
64 staticfiles_storage.url('datepicker.js'),
65 )
66 css = {'all': [
67 staticfiles_storage.url('datepicker.css'),
68 ]}
69
70 def render(self, name, value, attrs=None):
71 date_attrs = self.build_attrs(attrs)
72 date_attrs.update({
73 'class': 'datepicker',
74 'placeholder': formats.localize_input(datetime.date.today())
75 })
76 time_attrs = self.build_attrs(attrs)
77 time_attrs.update({
78 'class': 'timepicker',
79 'placeholder': '00:00',
80 })
81
82 if isinstance(value, datetime.datetime):
83 value = localtime(value)
84 date = value.date()
85 time = value.time()
86 else:
87 # value's just a list in case of an error
88 date = value[0] if value else None
89 time = value[1] if value else '00:00'
90
91 return render_to_string('datetime_input.html', {
92 'date': self.widgets[0].render(
93 name + '_0',
94 date,
95 date_attrs
96 ),
97 'time': self.widgets[1].render(
98 name + '_1',
99 time,
100 time_attrs
101 )
102 })
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/contrib/widgets.py b/apps/contrib/widgets.py
--- a/apps/contrib/widgets.py
+++ b/apps/contrib/widgets.py
@@ -71,12 +71,14 @@
date_attrs = self.build_attrs(attrs)
date_attrs.update({
'class': 'datepicker',
- 'placeholder': formats.localize_input(datetime.date.today())
+ 'placeholder': formats.localize_input(datetime.date.today()),
+ 'id': name + '_date'
})
time_attrs = self.build_attrs(attrs)
time_attrs.update({
'class': 'timepicker',
'placeholder': '00:00',
+ 'id': name + '_time'
})
if isinstance(value, datetime.datetime):
|
{"golden_diff": "diff --git a/apps/contrib/widgets.py b/apps/contrib/widgets.py\n--- a/apps/contrib/widgets.py\n+++ b/apps/contrib/widgets.py\n@@ -71,12 +71,14 @@\n date_attrs = self.build_attrs(attrs)\n date_attrs.update({\n 'class': 'datepicker',\n- 'placeholder': formats.localize_input(datetime.date.today())\n+ 'placeholder': formats.localize_input(datetime.date.today()),\n+ 'id': name + '_date'\n })\n time_attrs = self.build_attrs(attrs)\n time_attrs.update({\n 'class': 'timepicker',\n 'placeholder': '00:00',\n+ 'id': name + '_time'\n })\n \n if isinstance(value, datetime.datetime):\n", "issue": "datetimepicker unique ids\n<img width=\"980\" alt=\"screen shot 2017-06-01 at 15 59 21\" src=\"https://cloud.githubusercontent.com/assets/16354712/26683219/61f8eb4c-46e3-11e7-851b-148bff927bd4.png\">\r\n\n", "before_files": [{"content": "import datetime\nfrom itertools import chain\n\nimport django_filters\nfrom django.contrib.staticfiles.storage import staticfiles_storage\nfrom django.db.models.fields import BLANK_CHOICE_DASH\nfrom django.forms import widgets as form_widgets\nfrom django.forms.widgets import flatatt\nfrom django.template.loader import render_to_string\nfrom django.utils import formats\nfrom django.utils.timezone import localtime\nfrom django.utils.translation import ugettext as _\n\n\nclass DropdownLinkWidget(django_filters.widgets.LinkWidget):\n label = None\n right = False\n template = 'meinberlin_contrib/widgets/dropdown_link.html'\n\n def get_option_label(self, value, choices=()):\n option_label = BLANK_CHOICE_DASH[0][1]\n\n for v, label in chain(self.choices, choices):\n if str(v) == value:\n option_label = label\n break\n\n if option_label == BLANK_CHOICE_DASH[0][1]:\n option_label = _('All')\n\n return option_label\n\n def render(self, name, value, attrs=None, choices=()):\n all_choices = list(chain(self.choices, choices))\n\n if len(all_choices) <= 1:\n return ''\n\n if value is None:\n value = all_choices[0][0]\n\n _id = attrs.pop('id')\n final_attrs = flatatt(self.build_attrs(attrs))\n value_label = self.get_option_label(value, choices=choices)\n\n options = super().render(name, value, attrs={\n 'class': 'dropdown-menu',\n 'aria-labelledby': _id,\n }, choices=choices)\n\n return render_to_string(self.template, {\n 'options': options,\n 'id': _id,\n 'attrs': final_attrs,\n 'value_label': value_label,\n 'label': self.label,\n 'right': self.right,\n })\n\n\nclass DateTimeInput(form_widgets.SplitDateTimeWidget):\n class Media:\n js = (\n staticfiles_storage.url('datepicker.js'),\n )\n css = {'all': [\n staticfiles_storage.url('datepicker.css'),\n ]}\n\n def render(self, name, value, attrs=None):\n date_attrs = self.build_attrs(attrs)\n date_attrs.update({\n 'class': 'datepicker',\n 'placeholder': formats.localize_input(datetime.date.today())\n })\n time_attrs = self.build_attrs(attrs)\n time_attrs.update({\n 'class': 'timepicker',\n 'placeholder': '00:00',\n })\n\n if isinstance(value, datetime.datetime):\n value = localtime(value)\n date = value.date()\n time = value.time()\n else:\n # value's just a list in case of an error\n date = value[0] if value else None\n time = value[1] if value else '00:00'\n\n return render_to_string('datetime_input.html', {\n 'date': self.widgets[0].render(\n name + '_0',\n date,\n date_attrs\n ),\n 'time': self.widgets[1].render(\n name + '_1',\n time,\n time_attrs\n )\n })\n", "path": "apps/contrib/widgets.py"}], "after_files": [{"content": "import datetime\nfrom itertools import chain\n\nimport django_filters\nfrom django.contrib.staticfiles.storage import staticfiles_storage\nfrom django.db.models.fields import BLANK_CHOICE_DASH\nfrom django.forms import widgets as form_widgets\nfrom django.forms.widgets import flatatt\nfrom django.template.loader import render_to_string\nfrom django.utils import formats\nfrom django.utils.timezone import localtime\nfrom django.utils.translation import ugettext as _\n\n\nclass DropdownLinkWidget(django_filters.widgets.LinkWidget):\n label = None\n right = False\n template = 'meinberlin_contrib/widgets/dropdown_link.html'\n\n def get_option_label(self, value, choices=()):\n option_label = BLANK_CHOICE_DASH[0][1]\n\n for v, label in chain(self.choices, choices):\n if str(v) == value:\n option_label = label\n break\n\n if option_label == BLANK_CHOICE_DASH[0][1]:\n option_label = _('All')\n\n return option_label\n\n def render(self, name, value, attrs=None, choices=()):\n all_choices = list(chain(self.choices, choices))\n\n if len(all_choices) <= 1:\n return ''\n\n if value is None:\n value = all_choices[0][0]\n\n _id = attrs.pop('id')\n final_attrs = flatatt(self.build_attrs(attrs))\n value_label = self.get_option_label(value, choices=choices)\n\n options = super().render(name, value, attrs={\n 'class': 'dropdown-menu',\n 'aria-labelledby': _id,\n }, choices=choices)\n\n return render_to_string(self.template, {\n 'options': options,\n 'id': _id,\n 'attrs': final_attrs,\n 'value_label': value_label,\n 'label': self.label,\n 'right': self.right,\n })\n\n\nclass DateTimeInput(form_widgets.SplitDateTimeWidget):\n class Media:\n js = (\n staticfiles_storage.url('datepicker.js'),\n )\n css = {'all': [\n staticfiles_storage.url('datepicker.css'),\n ]}\n\n def render(self, name, value, attrs=None):\n date_attrs = self.build_attrs(attrs)\n date_attrs.update({\n 'class': 'datepicker',\n 'placeholder': formats.localize_input(datetime.date.today()),\n 'id': name + '_date'\n })\n time_attrs = self.build_attrs(attrs)\n time_attrs.update({\n 'class': 'timepicker',\n 'placeholder': '00:00',\n 'id': name + '_time'\n })\n\n if isinstance(value, datetime.datetime):\n value = localtime(value)\n date = value.date()\n time = value.time()\n else:\n # value's just a list in case of an error\n date = value[0] if value else None\n time = value[1] if value else '00:00'\n\n return render_to_string('datetime_input.html', {\n 'date': self.widgets[0].render(\n name + '_0',\n date,\n date_attrs\n ),\n 'time': self.widgets[1].render(\n name + '_1',\n time,\n time_attrs\n )\n })\n", "path": "apps/contrib/widgets.py"}]}
| 1,223 | 159 |
gh_patches_debug_17569
|
rasdani/github-patches
|
git_diff
|
python-discord__site-304
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make newlines visible in the deleted messages front-end
The deleted messages front-end currently doesn't display newlines if they're consecutive, i.e., if the lines are otherwise empty (`"\n\n\n\n\n\n\n\n\n"`). This makes it difficult to interpret what actually happened in chat. A good solution to this would be to make newlines character visible using the `↵` character, printed in a light gray color (similar to how IDEs do it).
**before**

**proposed after**

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pydis_site/apps/staff/templatetags/deletedmessage_filters.py`
Content:
```
1 from datetime import datetime
2
3 from django import template
4
5 register = template.Library()
6
7
8 @register.filter
9 def hex_colour(color: int) -> str:
10 """Converts an integer representation of a colour to the RGB hex value."""
11 return f"#{color:0>6X}"
12
13
14 @register.filter
15 def footer_datetime(timestamp: str) -> datetime:
16 """Takes an embed timestamp and returns a timezone-aware datetime object."""
17 return datetime.fromisoformat(timestamp)
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
@@ -7,11 +7,22 @@
@register.filter
def hex_colour(color: int) -> str:
- """Converts an integer representation of a colour to the RGB hex value."""
- return f"#{color:0>6X}"
+ """
+ Converts an integer representation of a colour to the RGB hex value.
+
+ As we are using a Discord dark theme analogue, black colours are returned as white instead.
+ """
+ colour = f"#{color:0>6X}"
+ return colour if colour != "#000000" else "#FFFFFF"
@register.filter
def footer_datetime(timestamp: str) -> datetime:
"""Takes an embed timestamp and returns a timezone-aware datetime object."""
return datetime.fromisoformat(timestamp)
+
+
[email protected]
+def visible_newlines(text: str) -> str:
+ """Takes an embed timestamp and returns a timezone-aware datetime object."""
+ return text.replace("\n", " <span class='has-text-grey'>↵</span><br>")
|
{"golden_diff": "diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n@@ -7,11 +7,22 @@\n \n @register.filter\n def hex_colour(color: int) -> str:\n- \"\"\"Converts an integer representation of a colour to the RGB hex value.\"\"\"\n- return f\"#{color:0>6X}\"\n+ \"\"\"\n+ Converts an integer representation of a colour to the RGB hex value.\n+\n+ As we are using a Discord dark theme analogue, black colours are returned as white instead.\n+ \"\"\"\n+ colour = f\"#{color:0>6X}\"\n+ return colour if colour != \"#000000\" else \"#FFFFFF\"\n \n \n @register.filter\n def footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n+\n+\[email protected]\n+def visible_newlines(text: str) -> str:\n+ \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n+ return text.replace(\"\\n\", \" <span class='has-text-grey'>\u21b5</span><br>\")\n", "issue": "Make newlines visible in the deleted messages front-end\nThe deleted messages front-end currently doesn't display newlines if they're consecutive, i.e., if the lines are otherwise empty (`\"\\n\\n\\n\\n\\n\\n\\n\\n\\n\"`). This makes it difficult to interpret what actually happened in chat. A good solution to this would be to make newlines character visible using the `\u21b5` character, printed in a light gray color (similar to how IDEs do it).\r\n\r\n**before**\r\n\r\n\r\n**proposed after**\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]\ndef hex_colour(color: int) -> str:\n \"\"\"Converts an integer representation of a colour to the RGB hex value.\"\"\"\n return f\"#{color:0>6X}\"\n\n\[email protected]\ndef footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n", "path": "pydis_site/apps/staff/templatetags/deletedmessage_filters.py"}], "after_files": [{"content": "from datetime import datetime\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]\ndef hex_colour(color: int) -> str:\n \"\"\"\n Converts an integer representation of a colour to the RGB hex value.\n\n As we are using a Discord dark theme analogue, black colours are returned as white instead.\n \"\"\"\n colour = f\"#{color:0>6X}\"\n return colour if colour != \"#000000\" else \"#FFFFFF\"\n\n\[email protected]\ndef footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n\n\[email protected]\ndef visible_newlines(text: str) -> str:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return text.replace(\"\\n\", \" <span class='has-text-grey'>\u21b5</span><br>\")\n", "path": "pydis_site/apps/staff/templatetags/deletedmessage_filters.py"}]}
| 659 | 304 |
gh_patches_debug_18377
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection-4300
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Empirical attention with ResNext backbone
In mmdetectiom v1 I used ResNext backbone with empirical attention 0010_dcn but in v2 I got an error.
Any ideas how to fix this?
My updated config file:
```
_base_ = '../faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
model = dict(
pretrained='open-mmlab://resnext50_32x4d',
backbone=dict(
type='ResNeXt',
depth=50,
groups=32,
base_width=4,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
style='pytorch',
plugins=[
dict(
cfg=dict(
type='GeneralizedAttention',
spatial_range=-1,
num_heads=8,
attention_type='0010',
kv_stride=2),
stages=(False, False, True, True),
position='after_conv2')
],
dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)))
```
Error:
```
RuntimeError: Given groups=1, weight of size [256, 256, 1, 1], expected input[2, 512, 41, 73] to have 256 channels, but got 512 channels instead
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmdet/models/backbones/resnext.py`
Content:
```
1 import math
2
3 from mmcv.cnn import build_conv_layer, build_norm_layer
4
5 from ..builder import BACKBONES
6 from ..utils import ResLayer
7 from .resnet import Bottleneck as _Bottleneck
8 from .resnet import ResNet
9
10
11 class Bottleneck(_Bottleneck):
12 expansion = 4
13
14 def __init__(self,
15 inplanes,
16 planes,
17 groups=1,
18 base_width=4,
19 base_channels=64,
20 **kwargs):
21 """Bottleneck block for ResNeXt.
22
23 If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
24 it is "caffe", the stride-two layer is the first 1x1 conv layer.
25 """
26 super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
27
28 if groups == 1:
29 width = self.planes
30 else:
31 width = math.floor(self.planes *
32 (base_width / base_channels)) * groups
33
34 self.norm1_name, norm1 = build_norm_layer(
35 self.norm_cfg, width, postfix=1)
36 self.norm2_name, norm2 = build_norm_layer(
37 self.norm_cfg, width, postfix=2)
38 self.norm3_name, norm3 = build_norm_layer(
39 self.norm_cfg, self.planes * self.expansion, postfix=3)
40
41 self.conv1 = build_conv_layer(
42 self.conv_cfg,
43 self.inplanes,
44 width,
45 kernel_size=1,
46 stride=self.conv1_stride,
47 bias=False)
48 self.add_module(self.norm1_name, norm1)
49 fallback_on_stride = False
50 self.with_modulated_dcn = False
51 if self.with_dcn:
52 fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
53 if not self.with_dcn or fallback_on_stride:
54 self.conv2 = build_conv_layer(
55 self.conv_cfg,
56 width,
57 width,
58 kernel_size=3,
59 stride=self.conv2_stride,
60 padding=self.dilation,
61 dilation=self.dilation,
62 groups=groups,
63 bias=False)
64 else:
65 assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
66 self.conv2 = build_conv_layer(
67 self.dcn,
68 width,
69 width,
70 kernel_size=3,
71 stride=self.conv2_stride,
72 padding=self.dilation,
73 dilation=self.dilation,
74 groups=groups,
75 bias=False)
76
77 self.add_module(self.norm2_name, norm2)
78 self.conv3 = build_conv_layer(
79 self.conv_cfg,
80 width,
81 self.planes * self.expansion,
82 kernel_size=1,
83 bias=False)
84 self.add_module(self.norm3_name, norm3)
85
86
87 @BACKBONES.register_module()
88 class ResNeXt(ResNet):
89 """ResNeXt backbone.
90
91 Args:
92 depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
93 in_channels (int): Number of input image channels. Default: 3.
94 num_stages (int): Resnet stages. Default: 4.
95 groups (int): Group of resnext.
96 base_width (int): Base width of resnext.
97 strides (Sequence[int]): Strides of the first block of each stage.
98 dilations (Sequence[int]): Dilation of each stage.
99 out_indices (Sequence[int]): Output from which stages.
100 style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
101 layer is the 3x3 conv layer, otherwise the stride-two layer is
102 the first 1x1 conv layer.
103 frozen_stages (int): Stages to be frozen (all param fixed). -1 means
104 not freezing any parameters.
105 norm_cfg (dict): dictionary to construct and config norm layer.
106 norm_eval (bool): Whether to set norm layers to eval mode, namely,
107 freeze running stats (mean and var). Note: Effect on Batch Norm
108 and its variants only.
109 with_cp (bool): Use checkpoint or not. Using checkpoint will save some
110 memory while slowing down the training speed.
111 zero_init_residual (bool): whether to use zero init for last norm layer
112 in resblocks to let them behave as identity.
113 """
114
115 arch_settings = {
116 50: (Bottleneck, (3, 4, 6, 3)),
117 101: (Bottleneck, (3, 4, 23, 3)),
118 152: (Bottleneck, (3, 8, 36, 3))
119 }
120
121 def __init__(self, groups=1, base_width=4, **kwargs):
122 self.groups = groups
123 self.base_width = base_width
124 super(ResNeXt, self).__init__(**kwargs)
125
126 def make_res_layer(self, **kwargs):
127 """Pack all blocks in a stage into a ``ResLayer``"""
128 return ResLayer(
129 groups=self.groups,
130 base_width=self.base_width,
131 base_channels=self.base_channels,
132 **kwargs)
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmdet/models/backbones/resnext.py b/mmdet/models/backbones/resnext.py
--- a/mmdet/models/backbones/resnext.py
+++ b/mmdet/models/backbones/resnext.py
@@ -83,6 +83,27 @@
bias=False)
self.add_module(self.norm3_name, norm3)
+ if self.with_plugins:
+ self._del_block_plugins(self.after_conv1_plugin_names +
+ self.after_conv2_plugin_names +
+ self.after_conv3_plugin_names)
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ width, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ width, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ self.planes * self.expansion, self.after_conv3_plugins)
+
+ def _del_block_plugins(self, plugin_names):
+ """delete plugins for block if exist.
+
+ Args:
+ plugin_names (list[str]): List of plugins name to delete.
+ """
+ assert isinstance(plugin_names, list)
+ for plugin_name in plugin_names:
+ del self._modules[plugin_name]
+
@BACKBONES.register_module()
class ResNeXt(ResNet):
|
{"golden_diff": "diff --git a/mmdet/models/backbones/resnext.py b/mmdet/models/backbones/resnext.py\n--- a/mmdet/models/backbones/resnext.py\n+++ b/mmdet/models/backbones/resnext.py\n@@ -83,6 +83,27 @@\n bias=False)\n self.add_module(self.norm3_name, norm3)\n \n+ if self.with_plugins:\n+ self._del_block_plugins(self.after_conv1_plugin_names +\n+ self.after_conv2_plugin_names +\n+ self.after_conv3_plugin_names)\n+ self.after_conv1_plugin_names = self.make_block_plugins(\n+ width, self.after_conv1_plugins)\n+ self.after_conv2_plugin_names = self.make_block_plugins(\n+ width, self.after_conv2_plugins)\n+ self.after_conv3_plugin_names = self.make_block_plugins(\n+ self.planes * self.expansion, self.after_conv3_plugins)\n+\n+ def _del_block_plugins(self, plugin_names):\n+ \"\"\"delete plugins for block if exist.\n+\n+ Args:\n+ plugin_names (list[str]): List of plugins name to delete.\n+ \"\"\"\n+ assert isinstance(plugin_names, list)\n+ for plugin_name in plugin_names:\n+ del self._modules[plugin_name]\n+\n \n @BACKBONES.register_module()\n class ResNeXt(ResNet):\n", "issue": "Empirical attention with ResNext backbone\nIn mmdetectiom v1 I used ResNext backbone with empirical attention 0010_dcn but in v2 I got an error.\r\nAny ideas how to fix this?\r\n\r\nMy updated config file:\r\n```\r\n_base_ = '../faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'\r\nmodel = dict(\r\n\r\n pretrained='open-mmlab://resnext50_32x4d',\r\n backbone=dict(\r\n type='ResNeXt',\r\n depth=50,\r\n groups=32,\r\n base_width=4,\r\n num_stages=4,\r\n out_indices=(0, 1, 2, 3),\r\n frozen_stages=1,\r\n norm_cfg=dict(type='BN', requires_grad=True),\r\n style='pytorch',\r\n plugins=[\r\n dict(\r\n cfg=dict(\r\n type='GeneralizedAttention',\r\n spatial_range=-1,\r\n num_heads=8,\r\n attention_type='0010',\r\n kv_stride=2),\r\n stages=(False, False, True, True),\r\n position='after_conv2')\r\n ],\r\n dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),\r\n stage_with_dcn=(False, True, True, True)))\r\n```\r\n\r\nError:\r\n```\r\nRuntimeError: Given groups=1, weight of size [256, 256, 1, 1], expected input[2, 512, 41, 73] to have 256 channels, but got 512 channels instead\r\n```\n", "before_files": [{"content": "import math\n\nfrom mmcv.cnn import build_conv_layer, build_norm_layer\n\nfrom ..builder import BACKBONES\nfrom ..utils import ResLayer\nfrom .resnet import Bottleneck as _Bottleneck\nfrom .resnet import ResNet\n\n\nclass Bottleneck(_Bottleneck):\n expansion = 4\n\n def __init__(self,\n inplanes,\n planes,\n groups=1,\n base_width=4,\n base_channels=64,\n **kwargs):\n \"\"\"Bottleneck block for ResNeXt.\n\n If style is \"pytorch\", the stride-two layer is the 3x3 conv layer, if\n it is \"caffe\", the stride-two layer is the first 1x1 conv layer.\n \"\"\"\n super(Bottleneck, self).__init__(inplanes, planes, **kwargs)\n\n if groups == 1:\n width = self.planes\n else:\n width = math.floor(self.planes *\n (base_width / base_channels)) * groups\n\n self.norm1_name, norm1 = build_norm_layer(\n self.norm_cfg, width, postfix=1)\n self.norm2_name, norm2 = build_norm_layer(\n self.norm_cfg, width, postfix=2)\n self.norm3_name, norm3 = build_norm_layer(\n self.norm_cfg, self.planes * self.expansion, postfix=3)\n\n self.conv1 = build_conv_layer(\n self.conv_cfg,\n self.inplanes,\n width,\n kernel_size=1,\n stride=self.conv1_stride,\n bias=False)\n self.add_module(self.norm1_name, norm1)\n fallback_on_stride = False\n self.with_modulated_dcn = False\n if self.with_dcn:\n fallback_on_stride = self.dcn.pop('fallback_on_stride', False)\n if not self.with_dcn or fallback_on_stride:\n self.conv2 = build_conv_layer(\n self.conv_cfg,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n else:\n assert self.conv_cfg is None, 'conv_cfg must be None for DCN'\n self.conv2 = build_conv_layer(\n self.dcn,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n\n self.add_module(self.norm2_name, norm2)\n self.conv3 = build_conv_layer(\n self.conv_cfg,\n width,\n self.planes * self.expansion,\n kernel_size=1,\n bias=False)\n self.add_module(self.norm3_name, norm3)\n\n\[email protected]_module()\nclass ResNeXt(ResNet):\n \"\"\"ResNeXt backbone.\n\n Args:\n depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.\n in_channels (int): Number of input image channels. Default: 3.\n num_stages (int): Resnet stages. Default: 4.\n groups (int): Group of resnext.\n base_width (int): Base width of resnext.\n strides (Sequence[int]): Strides of the first block of each stage.\n dilations (Sequence[int]): Dilation of each stage.\n out_indices (Sequence[int]): Output from which stages.\n style (str): `pytorch` or `caffe`. If set to \"pytorch\", the stride-two\n layer is the 3x3 conv layer, otherwise the stride-two layer is\n the first 1x1 conv layer.\n frozen_stages (int): Stages to be frozen (all param fixed). -1 means\n not freezing any parameters.\n norm_cfg (dict): dictionary to construct and config norm layer.\n norm_eval (bool): Whether to set norm layers to eval mode, namely,\n freeze running stats (mean and var). Note: Effect on Batch Norm\n and its variants only.\n with_cp (bool): Use checkpoint or not. Using checkpoint will save some\n memory while slowing down the training speed.\n zero_init_residual (bool): whether to use zero init for last norm layer\n in resblocks to let them behave as identity.\n \"\"\"\n\n arch_settings = {\n 50: (Bottleneck, (3, 4, 6, 3)),\n 101: (Bottleneck, (3, 4, 23, 3)),\n 152: (Bottleneck, (3, 8, 36, 3))\n }\n\n def __init__(self, groups=1, base_width=4, **kwargs):\n self.groups = groups\n self.base_width = base_width\n super(ResNeXt, self).__init__(**kwargs)\n\n def make_res_layer(self, **kwargs):\n \"\"\"Pack all blocks in a stage into a ``ResLayer``\"\"\"\n return ResLayer(\n groups=self.groups,\n base_width=self.base_width,\n base_channels=self.base_channels,\n **kwargs)\n", "path": "mmdet/models/backbones/resnext.py"}], "after_files": [{"content": "import math\n\nfrom mmcv.cnn import build_conv_layer, build_norm_layer\n\nfrom ..builder import BACKBONES\nfrom ..utils import ResLayer\nfrom .resnet import Bottleneck as _Bottleneck\nfrom .resnet import ResNet\n\n\nclass Bottleneck(_Bottleneck):\n expansion = 4\n\n def __init__(self,\n inplanes,\n planes,\n groups=1,\n base_width=4,\n base_channels=64,\n **kwargs):\n \"\"\"Bottleneck block for ResNeXt.\n\n If style is \"pytorch\", the stride-two layer is the 3x3 conv layer, if\n it is \"caffe\", the stride-two layer is the first 1x1 conv layer.\n \"\"\"\n super(Bottleneck, self).__init__(inplanes, planes, **kwargs)\n\n if groups == 1:\n width = self.planes\n else:\n width = math.floor(self.planes *\n (base_width / base_channels)) * groups\n\n self.norm1_name, norm1 = build_norm_layer(\n self.norm_cfg, width, postfix=1)\n self.norm2_name, norm2 = build_norm_layer(\n self.norm_cfg, width, postfix=2)\n self.norm3_name, norm3 = build_norm_layer(\n self.norm_cfg, self.planes * self.expansion, postfix=3)\n\n self.conv1 = build_conv_layer(\n self.conv_cfg,\n self.inplanes,\n width,\n kernel_size=1,\n stride=self.conv1_stride,\n bias=False)\n self.add_module(self.norm1_name, norm1)\n fallback_on_stride = False\n self.with_modulated_dcn = False\n if self.with_dcn:\n fallback_on_stride = self.dcn.pop('fallback_on_stride', False)\n if not self.with_dcn or fallback_on_stride:\n self.conv2 = build_conv_layer(\n self.conv_cfg,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n else:\n assert self.conv_cfg is None, 'conv_cfg must be None for DCN'\n self.conv2 = build_conv_layer(\n self.dcn,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n\n self.add_module(self.norm2_name, norm2)\n self.conv3 = build_conv_layer(\n self.conv_cfg,\n width,\n self.planes * self.expansion,\n kernel_size=1,\n bias=False)\n self.add_module(self.norm3_name, norm3)\n\n if self.with_plugins:\n self._del_block_plugins(self.after_conv1_plugin_names +\n self.after_conv2_plugin_names +\n self.after_conv3_plugin_names)\n self.after_conv1_plugin_names = self.make_block_plugins(\n width, self.after_conv1_plugins)\n self.after_conv2_plugin_names = self.make_block_plugins(\n width, self.after_conv2_plugins)\n self.after_conv3_plugin_names = self.make_block_plugins(\n self.planes * self.expansion, self.after_conv3_plugins)\n\n def _del_block_plugins(self, plugin_names):\n \"\"\"delete plugins for block if exist.\n\n Args:\n plugin_names (list[str]): List of plugins name to delete.\n \"\"\"\n assert isinstance(plugin_names, list)\n for plugin_name in plugin_names:\n del self._modules[plugin_name]\n\n\[email protected]_module()\nclass ResNeXt(ResNet):\n \"\"\"ResNeXt backbone.\n\n Args:\n depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.\n in_channels (int): Number of input image channels. Default: 3.\n num_stages (int): Resnet stages. Default: 4.\n groups (int): Group of resnext.\n base_width (int): Base width of resnext.\n strides (Sequence[int]): Strides of the first block of each stage.\n dilations (Sequence[int]): Dilation of each stage.\n out_indices (Sequence[int]): Output from which stages.\n style (str): `pytorch` or `caffe`. If set to \"pytorch\", the stride-two\n layer is the 3x3 conv layer, otherwise the stride-two layer is\n the first 1x1 conv layer.\n frozen_stages (int): Stages to be frozen (all param fixed). -1 means\n not freezing any parameters.\n norm_cfg (dict): dictionary to construct and config norm layer.\n norm_eval (bool): Whether to set norm layers to eval mode, namely,\n freeze running stats (mean and var). Note: Effect on Batch Norm\n and its variants only.\n with_cp (bool): Use checkpoint or not. Using checkpoint will save some\n memory while slowing down the training speed.\n zero_init_residual (bool): whether to use zero init for last norm layer\n in resblocks to let them behave as identity.\n \"\"\"\n\n arch_settings = {\n 50: (Bottleneck, (3, 4, 6, 3)),\n 101: (Bottleneck, (3, 4, 23, 3)),\n 152: (Bottleneck, (3, 8, 36, 3))\n }\n\n def __init__(self, groups=1, base_width=4, **kwargs):\n self.groups = groups\n self.base_width = base_width\n super(ResNeXt, self).__init__(**kwargs)\n\n def make_res_layer(self, **kwargs):\n \"\"\"Pack all blocks in a stage into a ``ResLayer``\"\"\"\n return ResLayer(\n groups=self.groups,\n base_width=self.base_width,\n base_channels=self.base_channels,\n **kwargs)\n", "path": "mmdet/models/backbones/resnext.py"}]}
| 2,024 | 287 |
gh_patches_debug_1191
|
rasdani/github-patches
|
git_diff
|
huggingface__dataset-viewer-2409
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Retry jobs that finish with `ClientConnection` error?
Maybe here: https://github.com/huggingface/datasets-server/blob/f311a9212aaa91dd0373e5c2d4f5da9b6bdabcb5/chart/env/prod.yaml#L209
Internal conversation on Slack: https://huggingface.slack.com/archives/C0311GZ7R6K/p1698224875005729
Anyway: I'm wondering if we can have the error now that the dataset scripts are disabled by default.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libs/libcommon/src/libcommon/constants.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 # Copyright 2022 The HuggingFace Authors.
3
4 CACHE_COLLECTION_RESPONSES = "cachedResponsesBlue"
5 CACHE_MONGOENGINE_ALIAS = "cache"
6 HF_DATASETS_CACHE_APPNAME = "hf_datasets_cache"
7 PARQUET_METADATA_CACHE_APPNAME = "datasets_server_parquet_metadata"
8 DESCRIPTIVE_STATISTICS_CACHE_APPNAME = "datasets_server_descriptive_statistics"
9 DUCKDB_INDEX_CACHE_APPNAME = "datasets_server_duckdb_index"
10 DUCKDB_INDEX_DOWNLOADS_SUBDIRECTORY = "downloads"
11 DUCKDB_INDEX_JOB_RUNNER_SUBDIRECTORY = "job_runner"
12 CACHE_METRICS_COLLECTION = "cacheTotalMetric"
13 QUEUE_METRICS_COLLECTION = "jobTotalMetric"
14 METRICS_MONGOENGINE_ALIAS = "metrics"
15 QUEUE_COLLECTION_JOBS = "jobsBlue"
16 QUEUE_COLLECTION_LOCKS = "locks"
17 QUEUE_MONGOENGINE_ALIAS = "queue"
18 QUEUE_TTL_SECONDS = 600 # 10 minutes
19 LOCK_TTL_SECONDS_NO_OWNER = 600 # 10 minutes
20 LOCK_TTL_SECONDS_TO_START_JOB = 600 # 10 minutes
21 LOCK_TTL_SECONDS_TO_WRITE_ON_GIT_BRANCH = 3600 # 1 hour
22
23 MAX_FAILED_RUNS = 3
24 DATASET_SEPARATOR = "--"
25 DEFAULT_DIFFICULTY = 50
26 DEFAULT_DIFFICULTY_MAX = 100
27 DEFAULT_DIFFICULTY_MIN = 0
28 DEFAULT_INPUT_TYPE = "dataset"
29 DEFAULT_JOB_RUNNER_VERSION = 1
30 DIFFICULTY_BONUS_BY_FAILED_RUNS = 20
31 MIN_BYTES_FOR_BONUS_DIFFICULTY = 3_000_000_000
32
33 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_AUDIO_DATASETS = 100
34 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_IMAGE_DATASETS = 100
35 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_BINARY_DATASETS = 100
36 PARQUET_REVISION = "refs/convert/parquet"
37
38 ERROR_CODES_TO_RETRY = {
39 "CreateCommitError",
40 "ExternalServerError",
41 "JobManagerCrashedError",
42 "LockedDatasetTimeoutError",
43 "StreamingRowsError",
44 }
45
46 EXTERNAL_DATASET_SCRIPT_PATTERN = "datasets_modules/datasets"
47
48 # Arrays are not immutable, we have to take care of not modifying them
49 # Anyway: in all this file, we allow constant reassignment (no use of Final)
50 CONFIG_HAS_VIEWER_KINDS = ["config-size"]
51 CONFIG_INFO_KINDS = ["config-info"]
52 CONFIG_PARQUET_METADATA_KINDS = ["config-parquet-metadata"]
53 CONFIG_PARQUET_AND_METADATA_KINDS = ["config-parquet", "config-parquet-metadata"]
54 CONFIG_SPLIT_NAMES_KINDS = ["config-split-names-from-info", "config-split-names-from-streaming"]
55 DATASET_CONFIG_NAMES_KINDS = ["dataset-config-names"]
56 DATASET_INFO_KINDS = ["dataset-info"]
57 SPLIT_DUCKDB_INDEX_KINDS = ["split-duckdb-index"]
58 SPLIT_HAS_PREVIEW_KINDS = ["split-first-rows-from-streaming", "split-first-rows-from-parquet"]
59 SPLIT_HAS_SEARCH_KINDS = ["split-duckdb-index"]
60 PARALLEL_STEPS_LISTS = [
61 CONFIG_SPLIT_NAMES_KINDS,
62 SPLIT_HAS_PREVIEW_KINDS,
63 ]
64
65 CROISSANT_MAX_CONFIGS = 100
66 MAX_NUM_ROWS_PER_PAGE = 100
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libs/libcommon/src/libcommon/constants.py b/libs/libcommon/src/libcommon/constants.py
--- a/libs/libcommon/src/libcommon/constants.py
+++ b/libs/libcommon/src/libcommon/constants.py
@@ -36,6 +36,7 @@
PARQUET_REVISION = "refs/convert/parquet"
ERROR_CODES_TO_RETRY = {
+ "ConnectionError",
"CreateCommitError",
"ExternalServerError",
"JobManagerCrashedError",
|
{"golden_diff": "diff --git a/libs/libcommon/src/libcommon/constants.py b/libs/libcommon/src/libcommon/constants.py\n--- a/libs/libcommon/src/libcommon/constants.py\n+++ b/libs/libcommon/src/libcommon/constants.py\n@@ -36,6 +36,7 @@\n PARQUET_REVISION = \"refs/convert/parquet\"\n \n ERROR_CODES_TO_RETRY = {\n+ \"ConnectionError\",\n \"CreateCommitError\",\n \"ExternalServerError\",\n \"JobManagerCrashedError\",\n", "issue": "Retry jobs that finish with `ClientConnection` error?\nMaybe here: https://github.com/huggingface/datasets-server/blob/f311a9212aaa91dd0373e5c2d4f5da9b6bdabcb5/chart/env/prod.yaml#L209\r\n\r\nInternal conversation on Slack: https://huggingface.slack.com/archives/C0311GZ7R6K/p1698224875005729\r\n\r\nAnyway: I'm wondering if we can have the error now that the dataset scripts are disabled by default.\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n# Copyright 2022 The HuggingFace Authors.\n\nCACHE_COLLECTION_RESPONSES = \"cachedResponsesBlue\"\nCACHE_MONGOENGINE_ALIAS = \"cache\"\nHF_DATASETS_CACHE_APPNAME = \"hf_datasets_cache\"\nPARQUET_METADATA_CACHE_APPNAME = \"datasets_server_parquet_metadata\"\nDESCRIPTIVE_STATISTICS_CACHE_APPNAME = \"datasets_server_descriptive_statistics\"\nDUCKDB_INDEX_CACHE_APPNAME = \"datasets_server_duckdb_index\"\nDUCKDB_INDEX_DOWNLOADS_SUBDIRECTORY = \"downloads\"\nDUCKDB_INDEX_JOB_RUNNER_SUBDIRECTORY = \"job_runner\"\nCACHE_METRICS_COLLECTION = \"cacheTotalMetric\"\nQUEUE_METRICS_COLLECTION = \"jobTotalMetric\"\nMETRICS_MONGOENGINE_ALIAS = \"metrics\"\nQUEUE_COLLECTION_JOBS = \"jobsBlue\"\nQUEUE_COLLECTION_LOCKS = \"locks\"\nQUEUE_MONGOENGINE_ALIAS = \"queue\"\nQUEUE_TTL_SECONDS = 600 # 10 minutes\nLOCK_TTL_SECONDS_NO_OWNER = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_START_JOB = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_WRITE_ON_GIT_BRANCH = 3600 # 1 hour\n\nMAX_FAILED_RUNS = 3\nDATASET_SEPARATOR = \"--\"\nDEFAULT_DIFFICULTY = 50\nDEFAULT_DIFFICULTY_MAX = 100\nDEFAULT_DIFFICULTY_MIN = 0\nDEFAULT_INPUT_TYPE = \"dataset\"\nDEFAULT_JOB_RUNNER_VERSION = 1\nDIFFICULTY_BONUS_BY_FAILED_RUNS = 20\nMIN_BYTES_FOR_BONUS_DIFFICULTY = 3_000_000_000\n\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_AUDIO_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_IMAGE_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_BINARY_DATASETS = 100\nPARQUET_REVISION = \"refs/convert/parquet\"\n\nERROR_CODES_TO_RETRY = {\n \"CreateCommitError\",\n \"ExternalServerError\",\n \"JobManagerCrashedError\",\n \"LockedDatasetTimeoutError\",\n \"StreamingRowsError\",\n}\n\nEXTERNAL_DATASET_SCRIPT_PATTERN = \"datasets_modules/datasets\"\n\n# Arrays are not immutable, we have to take care of not modifying them\n# Anyway: in all this file, we allow constant reassignment (no use of Final)\nCONFIG_HAS_VIEWER_KINDS = [\"config-size\"]\nCONFIG_INFO_KINDS = [\"config-info\"]\nCONFIG_PARQUET_METADATA_KINDS = [\"config-parquet-metadata\"]\nCONFIG_PARQUET_AND_METADATA_KINDS = [\"config-parquet\", \"config-parquet-metadata\"]\nCONFIG_SPLIT_NAMES_KINDS = [\"config-split-names-from-info\", \"config-split-names-from-streaming\"]\nDATASET_CONFIG_NAMES_KINDS = [\"dataset-config-names\"]\nDATASET_INFO_KINDS = [\"dataset-info\"]\nSPLIT_DUCKDB_INDEX_KINDS = [\"split-duckdb-index\"]\nSPLIT_HAS_PREVIEW_KINDS = [\"split-first-rows-from-streaming\", \"split-first-rows-from-parquet\"]\nSPLIT_HAS_SEARCH_KINDS = [\"split-duckdb-index\"]\nPARALLEL_STEPS_LISTS = [\n CONFIG_SPLIT_NAMES_KINDS,\n SPLIT_HAS_PREVIEW_KINDS,\n]\n\nCROISSANT_MAX_CONFIGS = 100\nMAX_NUM_ROWS_PER_PAGE = 100\n", "path": "libs/libcommon/src/libcommon/constants.py"}], "after_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n# Copyright 2022 The HuggingFace Authors.\n\nCACHE_COLLECTION_RESPONSES = \"cachedResponsesBlue\"\nCACHE_MONGOENGINE_ALIAS = \"cache\"\nHF_DATASETS_CACHE_APPNAME = \"hf_datasets_cache\"\nPARQUET_METADATA_CACHE_APPNAME = \"datasets_server_parquet_metadata\"\nDESCRIPTIVE_STATISTICS_CACHE_APPNAME = \"datasets_server_descriptive_statistics\"\nDUCKDB_INDEX_CACHE_APPNAME = \"datasets_server_duckdb_index\"\nDUCKDB_INDEX_DOWNLOADS_SUBDIRECTORY = \"downloads\"\nDUCKDB_INDEX_JOB_RUNNER_SUBDIRECTORY = \"job_runner\"\nCACHE_METRICS_COLLECTION = \"cacheTotalMetric\"\nQUEUE_METRICS_COLLECTION = \"jobTotalMetric\"\nMETRICS_MONGOENGINE_ALIAS = \"metrics\"\nQUEUE_COLLECTION_JOBS = \"jobsBlue\"\nQUEUE_COLLECTION_LOCKS = \"locks\"\nQUEUE_MONGOENGINE_ALIAS = \"queue\"\nQUEUE_TTL_SECONDS = 600 # 10 minutes\nLOCK_TTL_SECONDS_NO_OWNER = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_START_JOB = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_WRITE_ON_GIT_BRANCH = 3600 # 1 hour\n\nMAX_FAILED_RUNS = 3\nDATASET_SEPARATOR = \"--\"\nDEFAULT_DIFFICULTY = 50\nDEFAULT_DIFFICULTY_MAX = 100\nDEFAULT_DIFFICULTY_MIN = 0\nDEFAULT_INPUT_TYPE = \"dataset\"\nDEFAULT_JOB_RUNNER_VERSION = 1\nDIFFICULTY_BONUS_BY_FAILED_RUNS = 20\nMIN_BYTES_FOR_BONUS_DIFFICULTY = 3_000_000_000\n\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_AUDIO_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_IMAGE_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_BINARY_DATASETS = 100\nPARQUET_REVISION = \"refs/convert/parquet\"\n\nERROR_CODES_TO_RETRY = {\n \"ConnectionError\",\n \"CreateCommitError\",\n \"ExternalServerError\",\n \"JobManagerCrashedError\",\n \"LockedDatasetTimeoutError\",\n \"StreamingRowsError\",\n}\n\nEXTERNAL_DATASET_SCRIPT_PATTERN = \"datasets_modules/datasets\"\n\n# Arrays are not immutable, we have to take care of not modifying them\n# Anyway: in all this file, we allow constant reassignment (no use of Final)\nCONFIG_HAS_VIEWER_KINDS = [\"config-size\"]\nCONFIG_INFO_KINDS = [\"config-info\"]\nCONFIG_PARQUET_METADATA_KINDS = [\"config-parquet-metadata\"]\nCONFIG_PARQUET_AND_METADATA_KINDS = [\"config-parquet\", \"config-parquet-metadata\"]\nCONFIG_SPLIT_NAMES_KINDS = [\"config-split-names-from-info\", \"config-split-names-from-streaming\"]\nDATASET_CONFIG_NAMES_KINDS = [\"dataset-config-names\"]\nDATASET_INFO_KINDS = [\"dataset-info\"]\nSPLIT_DUCKDB_INDEX_KINDS = [\"split-duckdb-index\"]\nSPLIT_HAS_PREVIEW_KINDS = [\"split-first-rows-from-streaming\", \"split-first-rows-from-parquet\"]\nSPLIT_HAS_SEARCH_KINDS = [\"split-duckdb-index\"]\nPARALLEL_STEPS_LISTS = [\n CONFIG_SPLIT_NAMES_KINDS,\n SPLIT_HAS_PREVIEW_KINDS,\n]\n\nMAX_NUM_ROWS_PER_PAGE = 100\n", "path": "libs/libcommon/src/libcommon/constants.py"}]}
| 1,260 | 102 |
gh_patches_debug_8293
|
rasdani/github-patches
|
git_diff
|
wandb__wandb-963
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fastai WandbCallback with multilabel datasets
* Weights and Biases version: 0.8.9
* Python version: 3.6.9
* Operating System: Linux-4.14.133-88.112.amzn1.x86_64-x86_64-with-Ubuntu-16.04-xenial
### Description
I'm trying to see prediction samples for fastai image classification, where the images are multilabel. I'd like it to be ran on the validation data at the end of each epoch and to see captions of ground truth/predictions.
When I use a multilabel dataset, instead of ground truth/prediction captions for each image, I get a three copies of each image side by side, where each is labeled, "Input data", "Prediction", "Ground Truth" (but not the actual categories)
### What I Did
`callback_fns += [partial(WandbCallback, input_type='images', monitor='acc_thresholded')]`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wandb/fastai/__init__.py`
Content:
```
1 '''
2 This module hooks fast.ai Learners to Weights & Biases through a callback.
3 Requested logged data can be configured through the callback constructor.
4
5 Examples:
6 WandbCallback can be used when initializing the Learner::
7
8 ```
9 from wandb.fastai import WandbCallback
10 [...]
11 learn = Learner(data, ..., callback_fns=WandbCallback)
12 learn.fit(epochs)
13 ```
14
15 Custom parameters can be given using functools.partial::
16
17 ```
18 from wandb.fastai import WandbCallback
19 from functools import partial
20 [...]
21 learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))
22 learn.fit(epochs)
23 ```
24
25 Finally, it is possible to use WandbCallback only when starting
26 training. In this case it must be instantiated::
27
28 ```
29 learn.fit(..., callbacks=WandbCallback(learn))
30 ```
31
32 or, with custom parameters::
33
34 ```
35 learn.fit(..., callbacks=WandbCallback(learn, ...))
36 ```
37 '''
38 import wandb
39 import fastai
40 from fastai.callbacks import TrackerCallback
41 from pathlib import Path
42 import random
43 try:
44 import matplotlib
45 matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)
46 import matplotlib.pyplot as plt
47 except:
48 print('Warning: matplotlib required if logging sample image predictions')
49
50
51 class WandbCallback(TrackerCallback):
52 """
53 Automatically saves model topology, losses & metrics.
54 Optionally logs weights, gradients, sample predictions and best trained model.
55
56 Args:
57 learn (fastai.basic_train.Learner): the fast.ai learner to hook.
58 log (str): "gradients", "parameters", "all", or None. Losses & metrics are always logged.
59 save_model (bool): save model at the end of each epoch. It will also load best model at the end of training.
60 monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.
61 mode (str): "auto", "min" or "max" to compare "monitor" values and define best model.
62 input_type (str): "images" or None. Used to display sample predictions.
63 validation_data (list): data used for sample predictions if input_type is set.
64 predictions (int): number of predictions to make if input_type is set and validation_data is None.
65 seed (int): initialize random generator for sample predictions if input_type is set and validation_data is None.
66 """
67
68 # Record if watch has been called previously (even in another instance)
69 _watch_called = False
70
71 def __init__(self,
72 learn,
73 log="gradients",
74 save_model=True,
75 monitor=None,
76 mode='auto',
77 input_type=None,
78 validation_data=None,
79 predictions=36,
80 seed=12345):
81
82 # Check if wandb.init has been called
83 if wandb.run is None:
84 raise ValueError(
85 'You must call wandb.init() before WandbCallback()')
86
87 # Adapted from fast.ai "SaveModelCallback"
88 if monitor is None:
89 # use default TrackerCallback monitor value
90 super().__init__(learn, mode=mode)
91 else:
92 super().__init__(learn, monitor=monitor, mode=mode)
93 self.save_model = save_model
94 self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'
95
96 self.log = log
97 self.input_type = input_type
98 self.best = None
99
100 # Select items for sample predictions to see evolution along training
101 self.validation_data = validation_data
102 if input_type and not self.validation_data:
103 wandbRandom = random.Random(seed) # For repeatability
104 predictions = min(predictions, len(learn.data.valid_ds))
105 indices = wandbRandom.sample(range(len(learn.data.valid_ds)),
106 predictions)
107 self.validation_data = [learn.data.valid_ds[i] for i in indices]
108
109 def on_train_begin(self, **kwargs):
110 "Call watch method to log model topology, gradients & weights"
111
112 # Set self.best, method inherited from "TrackerCallback" by "SaveModelCallback"
113 super().on_train_begin()
114
115 # Ensure we don't call "watch" multiple times
116 if not WandbCallback._watch_called:
117 WandbCallback._watch_called = True
118
119 # Logs model topology and optionally gradients and weights
120 wandb.watch(self.learn.model, log=self.log)
121
122 def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):
123 "Logs training loss, validation loss and custom metrics & log prediction samples & save model"
124
125 if self.save_model:
126 # Adapted from fast.ai "SaveModelCallback"
127 current = self.get_monitor_value()
128 if current is not None and self.operator(current, self.best):
129 print(
130 'Better model found at epoch {} with {} value: {}.'.format(
131 epoch, self.monitor, current))
132 self.best = current
133
134 # Save within wandb folder
135 with self.model_path.open('wb') as model_file:
136 self.learn.save(model_file)
137
138 # Log sample predictions if learn.predict is available
139 if self.validation_data:
140 try:
141 self._wandb_log_predictions()
142 except FastaiError as e:
143 wandb.termwarn(e.message)
144 self.validation_data = None # prevent from trying again on next loop
145 except Exception as e:
146 wandb.termwarn("Unable to log prediction samples.\n{}".format(e))
147 self.validation_data=None # prevent from trying again on next loop
148
149 # Log losses & metrics
150 # Adapted from fast.ai "CSVLogger"
151 logs = {
152 name: stat
153 for name, stat in list(
154 zip(self.learn.recorder.names, [epoch, smooth_loss] +
155 last_metrics))
156 }
157 wandb.log(logs)
158
159 def on_train_end(self, **kwargs):
160 "Load the best model."
161
162 if self.save_model:
163 # Adapted from fast.ai "SaveModelCallback"
164 if self.model_path.is_file():
165 with self.model_path.open('rb') as model_file:
166 self.learn.load(model_file, purge=False)
167 print('Loaded best saved model from {}'.format(
168 self.model_path))
169
170 def _wandb_log_predictions(self):
171 "Log prediction samples"
172
173 pred_log = []
174
175 for x, y in self.validation_data:
176 try:
177 pred=self.learn.predict(x)
178 except:
179 raise FastaiError('Unable to run "predict" method from Learner to log prediction samples.')
180
181 # scalar -> likely to be a category
182 if not pred[1].shape:
183 pred_log.append(
184 wandb.Image(
185 x.data,
186 caption='Ground Truth: {}\nPrediction: {}'.format(
187 y, pred[0])))
188
189 # most vision datasets have a "show" function we can use
190 elif hasattr(x, "show"):
191 # log input data
192 pred_log.append(
193 wandb.Image(x.data, caption='Input data', grouping=3))
194
195 # log label and prediction
196 for im, capt in ((pred[0], "Prediction"),
197 (y, "Ground Truth")):
198 # Resize plot to image resolution
199 # from https://stackoverflow.com/a/13714915
200 my_dpi = 100
201 fig = plt.figure(frameon=False, dpi=my_dpi)
202 h, w = x.size
203 fig.set_size_inches(w / my_dpi, h / my_dpi)
204 ax = plt.Axes(fig, [0., 0., 1., 1.])
205 ax.set_axis_off()
206 fig.add_axes(ax)
207
208 # Superpose label or prediction to input image
209 x.show(ax=ax, y=im)
210 pred_log.append(wandb.Image(fig, caption=capt))
211 plt.close(fig)
212
213 # likely to be an image
214 elif hasattr(y, "shape") and (
215 (len(y.shape) == 2) or
216 (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):
217
218 pred_log.extend([
219 wandb.Image(x.data, caption='Input data', grouping=3),
220 wandb.Image(pred[0].data, caption='Prediction'),
221 wandb.Image(y.data, caption='Ground Truth')
222 ])
223
224 # we just log input data
225 else:
226 pred_log.append(wandb.Image(x.data, caption='Input data'))
227
228 wandb.log({"Prediction Samples": pred_log}, commit=False)
229
230
231 class FastaiError(wandb.Error):
232 pass
233
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py
--- a/wandb/fastai/__init__.py
+++ b/wandb/fastai/__init__.py
@@ -179,7 +179,8 @@
raise FastaiError('Unable to run "predict" method from Learner to log prediction samples.')
# scalar -> likely to be a category
- if not pred[1].shape:
+ # tensor of dim 1 -> likely to be multicategory
+ if not pred[1].shape or pred[1].dim() == 1:
pred_log.append(
wandb.Image(
x.data,
|
{"golden_diff": "diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py\n--- a/wandb/fastai/__init__.py\n+++ b/wandb/fastai/__init__.py\n@@ -179,7 +179,8 @@\n raise FastaiError('Unable to run \"predict\" method from Learner to log prediction samples.')\n \n # scalar -> likely to be a category\n- if not pred[1].shape:\n+ # tensor of dim 1 -> likely to be multicategory\n+ if not pred[1].shape or pred[1].dim() == 1:\n pred_log.append(\n wandb.Image(\n x.data,\n", "issue": "Fastai WandbCallback with multilabel datasets\n* Weights and Biases version: 0.8.9\r\n* Python version: 3.6.9\r\n* Operating System: Linux-4.14.133-88.112.amzn1.x86_64-x86_64-with-Ubuntu-16.04-xenial\r\n\r\n### Description\r\n\r\nI'm trying to see prediction samples for fastai image classification, where the images are multilabel. I'd like it to be ran on the validation data at the end of each epoch and to see captions of ground truth/predictions.\r\n\r\nWhen I use a multilabel dataset, instead of ground truth/prediction captions for each image, I get a three copies of each image side by side, where each is labeled, \"Input data\", \"Prediction\", \"Ground Truth\" (but not the actual categories)\r\n\r\n### What I Did\r\n\r\n`callback_fns += [partial(WandbCallback, input_type='images', monitor='acc_thresholded')]`\r\n\r\n\n", "before_files": [{"content": "'''\nThis module hooks fast.ai Learners to Weights & Biases through a callback.\nRequested logged data can be configured through the callback constructor.\n\nExamples:\n WandbCallback can be used when initializing the Learner::\n\n ```\n from wandb.fastai import WandbCallback\n [...]\n learn = Learner(data, ..., callback_fns=WandbCallback)\n learn.fit(epochs)\n ```\n\n Custom parameters can be given using functools.partial::\n\n ```\n from wandb.fastai import WandbCallback\n from functools import partial\n [...]\n learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))\n learn.fit(epochs)\n ```\n\n Finally, it is possible to use WandbCallback only when starting\n training. In this case it must be instantiated::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn))\n ```\n\n or, with custom parameters::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn, ...))\n ```\n'''\nimport wandb\nimport fastai\nfrom fastai.callbacks import TrackerCallback\nfrom pathlib import Path\nimport random\ntry:\n import matplotlib\n matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)\n import matplotlib.pyplot as plt\nexcept:\n print('Warning: matplotlib required if logging sample image predictions')\n\n\nclass WandbCallback(TrackerCallback):\n \"\"\"\n Automatically saves model topology, losses & metrics.\n Optionally logs weights, gradients, sample predictions and best trained model.\n\n Args:\n learn (fastai.basic_train.Learner): the fast.ai learner to hook.\n log (str): \"gradients\", \"parameters\", \"all\", or None. Losses & metrics are always logged.\n save_model (bool): save model at the end of each epoch. It will also load best model at the end of training.\n monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.\n mode (str): \"auto\", \"min\" or \"max\" to compare \"monitor\" values and define best model.\n input_type (str): \"images\" or None. Used to display sample predictions.\n validation_data (list): data used for sample predictions if input_type is set.\n predictions (int): number of predictions to make if input_type is set and validation_data is None.\n seed (int): initialize random generator for sample predictions if input_type is set and validation_data is None.\n \"\"\"\n\n # Record if watch has been called previously (even in another instance)\n _watch_called = False\n\n def __init__(self,\n learn,\n log=\"gradients\",\n save_model=True,\n monitor=None,\n mode='auto',\n input_type=None,\n validation_data=None,\n predictions=36,\n seed=12345):\n\n # Check if wandb.init has been called\n if wandb.run is None:\n raise ValueError(\n 'You must call wandb.init() before WandbCallback()')\n\n # Adapted from fast.ai \"SaveModelCallback\"\n if monitor is None:\n # use default TrackerCallback monitor value\n super().__init__(learn, mode=mode)\n else:\n super().__init__(learn, monitor=monitor, mode=mode)\n self.save_model = save_model\n self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'\n\n self.log = log\n self.input_type = input_type\n self.best = None\n\n # Select items for sample predictions to see evolution along training\n self.validation_data = validation_data\n if input_type and not self.validation_data:\n wandbRandom = random.Random(seed) # For repeatability\n predictions = min(predictions, len(learn.data.valid_ds))\n indices = wandbRandom.sample(range(len(learn.data.valid_ds)),\n predictions)\n self.validation_data = [learn.data.valid_ds[i] for i in indices]\n\n def on_train_begin(self, **kwargs):\n \"Call watch method to log model topology, gradients & weights\"\n\n # Set self.best, method inherited from \"TrackerCallback\" by \"SaveModelCallback\"\n super().on_train_begin()\n\n # Ensure we don't call \"watch\" multiple times\n if not WandbCallback._watch_called:\n WandbCallback._watch_called = True\n\n # Logs model topology and optionally gradients and weights\n wandb.watch(self.learn.model, log=self.log)\n\n def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):\n \"Logs training loss, validation loss and custom metrics & log prediction samples & save model\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n current = self.get_monitor_value()\n if current is not None and self.operator(current, self.best):\n print(\n 'Better model found at epoch {} with {} value: {}.'.format(\n epoch, self.monitor, current))\n self.best = current\n\n # Save within wandb folder\n with self.model_path.open('wb') as model_file:\n self.learn.save(model_file)\n\n # Log sample predictions if learn.predict is available\n if self.validation_data:\n try:\n self._wandb_log_predictions()\n except FastaiError as e:\n wandb.termwarn(e.message)\n self.validation_data = None # prevent from trying again on next loop\n except Exception as e:\n wandb.termwarn(\"Unable to log prediction samples.\\n{}\".format(e))\n self.validation_data=None # prevent from trying again on next loop\n\n # Log losses & metrics\n # Adapted from fast.ai \"CSVLogger\"\n logs = {\n name: stat\n for name, stat in list(\n zip(self.learn.recorder.names, [epoch, smooth_loss] +\n last_metrics))\n }\n wandb.log(logs)\n\n def on_train_end(self, **kwargs):\n \"Load the best model.\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n if self.model_path.is_file():\n with self.model_path.open('rb') as model_file:\n self.learn.load(model_file, purge=False)\n print('Loaded best saved model from {}'.format(\n self.model_path))\n\n def _wandb_log_predictions(self):\n \"Log prediction samples\"\n\n pred_log = []\n\n for x, y in self.validation_data:\n try:\n pred=self.learn.predict(x)\n except:\n raise FastaiError('Unable to run \"predict\" method from Learner to log prediction samples.')\n\n # scalar -> likely to be a category\n if not pred[1].shape:\n pred_log.append(\n wandb.Image(\n x.data,\n caption='Ground Truth: {}\\nPrediction: {}'.format(\n y, pred[0])))\n\n # most vision datasets have a \"show\" function we can use\n elif hasattr(x, \"show\"):\n # log input data\n pred_log.append(\n wandb.Image(x.data, caption='Input data', grouping=3))\n\n # log label and prediction\n for im, capt in ((pred[0], \"Prediction\"),\n (y, \"Ground Truth\")):\n # Resize plot to image resolution\n # from https://stackoverflow.com/a/13714915\n my_dpi = 100\n fig = plt.figure(frameon=False, dpi=my_dpi)\n h, w = x.size\n fig.set_size_inches(w / my_dpi, h / my_dpi)\n ax = plt.Axes(fig, [0., 0., 1., 1.])\n ax.set_axis_off()\n fig.add_axes(ax)\n\n # Superpose label or prediction to input image\n x.show(ax=ax, y=im)\n pred_log.append(wandb.Image(fig, caption=capt))\n plt.close(fig)\n\n # likely to be an image\n elif hasattr(y, \"shape\") and (\n (len(y.shape) == 2) or\n (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):\n\n pred_log.extend([\n wandb.Image(x.data, caption='Input data', grouping=3),\n wandb.Image(pred[0].data, caption='Prediction'),\n wandb.Image(y.data, caption='Ground Truth')\n ])\n\n # we just log input data\n else:\n pred_log.append(wandb.Image(x.data, caption='Input data'))\n\n wandb.log({\"Prediction Samples\": pred_log}, commit=False)\n\n\nclass FastaiError(wandb.Error):\n pass\n", "path": "wandb/fastai/__init__.py"}], "after_files": [{"content": "'''\nThis module hooks fast.ai Learners to Weights & Biases through a callback.\nRequested logged data can be configured through the callback constructor.\n\nExamples:\n WandbCallback can be used when initializing the Learner::\n\n ```\n from wandb.fastai import WandbCallback\n [...]\n learn = Learner(data, ..., callback_fns=WandbCallback)\n learn.fit(epochs)\n ```\n\n Custom parameters can be given using functools.partial::\n\n ```\n from wandb.fastai import WandbCallback\n from functools import partial\n [...]\n learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))\n learn.fit(epochs)\n ```\n\n Finally, it is possible to use WandbCallback only when starting\n training. In this case it must be instantiated::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn))\n ```\n\n or, with custom parameters::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn, ...))\n ```\n'''\nimport wandb\nimport fastai\nfrom fastai.callbacks import TrackerCallback\nfrom pathlib import Path\nimport random\ntry:\n import matplotlib\n matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)\n import matplotlib.pyplot as plt\nexcept:\n print('Warning: matplotlib required if logging sample image predictions')\n\n\nclass WandbCallback(TrackerCallback):\n \"\"\"\n Automatically saves model topology, losses & metrics.\n Optionally logs weights, gradients, sample predictions and best trained model.\n\n Args:\n learn (fastai.basic_train.Learner): the fast.ai learner to hook.\n log (str): \"gradients\", \"parameters\", \"all\", or None. Losses & metrics are always logged.\n save_model (bool): save model at the end of each epoch. It will also load best model at the end of training.\n monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.\n mode (str): \"auto\", \"min\" or \"max\" to compare \"monitor\" values and define best model.\n input_type (str): \"images\" or None. Used to display sample predictions.\n validation_data (list): data used for sample predictions if input_type is set.\n predictions (int): number of predictions to make if input_type is set and validation_data is None.\n seed (int): initialize random generator for sample predictions if input_type is set and validation_data is None.\n \"\"\"\n\n # Record if watch has been called previously (even in another instance)\n _watch_called = False\n\n def __init__(self,\n learn,\n log=\"gradients\",\n save_model=True,\n monitor=None,\n mode='auto',\n input_type=None,\n validation_data=None,\n predictions=36,\n seed=12345):\n\n # Check if wandb.init has been called\n if wandb.run is None:\n raise ValueError(\n 'You must call wandb.init() before WandbCallback()')\n\n # Adapted from fast.ai \"SaveModelCallback\"\n if monitor is None:\n # use default TrackerCallback monitor value\n super().__init__(learn, mode=mode)\n else:\n super().__init__(learn, monitor=monitor, mode=mode)\n self.save_model = save_model\n self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'\n\n self.log = log\n self.input_type = input_type\n self.best = None\n\n # Select items for sample predictions to see evolution along training\n self.validation_data = validation_data\n if input_type and not self.validation_data:\n wandbRandom = random.Random(seed) # For repeatability\n predictions = min(predictions, len(learn.data.valid_ds))\n indices = wandbRandom.sample(range(len(learn.data.valid_ds)),\n predictions)\n self.validation_data = [learn.data.valid_ds[i] for i in indices]\n\n def on_train_begin(self, **kwargs):\n \"Call watch method to log model topology, gradients & weights\"\n\n # Set self.best, method inherited from \"TrackerCallback\" by \"SaveModelCallback\"\n super().on_train_begin()\n\n # Ensure we don't call \"watch\" multiple times\n if not WandbCallback._watch_called:\n WandbCallback._watch_called = True\n\n # Logs model topology and optionally gradients and weights\n wandb.watch(self.learn.model, log=self.log)\n\n def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):\n \"Logs training loss, validation loss and custom metrics & log prediction samples & save model\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n current = self.get_monitor_value()\n if current is not None and self.operator(current, self.best):\n print(\n 'Better model found at epoch {} with {} value: {}.'.format(\n epoch, self.monitor, current))\n self.best = current\n\n # Save within wandb folder\n with self.model_path.open('wb') as model_file:\n self.learn.save(model_file)\n\n # Log sample predictions if learn.predict is available\n if self.validation_data:\n try:\n self._wandb_log_predictions()\n except FastaiError as e:\n wandb.termwarn(e.message)\n self.validation_data = None # prevent from trying again on next loop\n except Exception as e:\n wandb.termwarn(\"Unable to log prediction samples.\\n{}\".format(e))\n self.validation_data=None # prevent from trying again on next loop\n\n # Log losses & metrics\n # Adapted from fast.ai \"CSVLogger\"\n logs = {\n name: stat\n for name, stat in list(\n zip(self.learn.recorder.names, [epoch, smooth_loss] +\n last_metrics))\n }\n wandb.log(logs)\n\n def on_train_end(self, **kwargs):\n \"Load the best model.\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n if self.model_path.is_file():\n with self.model_path.open('rb') as model_file:\n self.learn.load(model_file, purge=False)\n print('Loaded best saved model from {}'.format(\n self.model_path))\n\n def _wandb_log_predictions(self):\n \"Log prediction samples\"\n\n pred_log = []\n\n for x, y in self.validation_data:\n try:\n pred=self.learn.predict(x)\n except:\n raise FastaiError('Unable to run \"predict\" method from Learner to log prediction samples.')\n\n # scalar -> likely to be a category\n # tensor of dim 1 -> likely to be multicategory\n if not pred[1].shape or pred[1].dim() == 1:\n pred_log.append(\n wandb.Image(\n x.data,\n caption='Ground Truth: {}\\nPrediction: {}'.format(\n y, pred[0])))\n\n # most vision datasets have a \"show\" function we can use\n elif hasattr(x, \"show\"):\n # log input data\n pred_log.append(\n wandb.Image(x.data, caption='Input data', grouping=3))\n\n # log label and prediction\n for im, capt in ((pred[0], \"Prediction\"),\n (y, \"Ground Truth\")):\n # Resize plot to image resolution\n # from https://stackoverflow.com/a/13714915\n my_dpi = 100\n fig = plt.figure(frameon=False, dpi=my_dpi)\n h, w = x.size\n fig.set_size_inches(w / my_dpi, h / my_dpi)\n ax = plt.Axes(fig, [0., 0., 1., 1.])\n ax.set_axis_off()\n fig.add_axes(ax)\n\n # Superpose label or prediction to input image\n x.show(ax=ax, y=im)\n pred_log.append(wandb.Image(fig, caption=capt))\n plt.close(fig)\n\n # likely to be an image\n elif hasattr(y, \"shape\") and (\n (len(y.shape) == 2) or\n (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):\n\n pred_log.extend([\n wandb.Image(x.data, caption='Input data', grouping=3),\n wandb.Image(pred[0].data, caption='Prediction'),\n wandb.Image(y.data, caption='Ground Truth')\n ])\n\n # we just log input data\n else:\n pred_log.append(wandb.Image(x.data, caption='Input data'))\n\n wandb.log({\"Prediction Samples\": pred_log}, commit=False)\n\n\nclass FastaiError(wandb.Error):\n pass\n", "path": "wandb/fastai/__init__.py"}]}
| 2,942 | 153 |
gh_patches_debug_812
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__codeforlife-portal-412
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update models search field values in admin
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `portal/models.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Code for Life
3 #
4 # Copyright (C) 2016, Ocado Innovation Limited
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as
8 # published by the Free Software Foundation, either version 3 of the
9 # License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 # ADDITIONAL TERMS – Section 7 GNU General Public Licence
20 #
21 # This licence does not grant any right, title or interest in any “Ocado” logos,
22 # trade names or the trademark “Ocado” or any other trademarks or domain names
23 # owned by Ocado Innovation Limited or the Ocado group of companies or any other
24 # distinctive brand features of “Ocado” as may be secured from time to time. You
25 # must not distribute any modification of this program using the trademark
26 # “Ocado” or claim any affiliation or association with Ocado or its employees.
27 #
28 # You are not authorised to use the name Ocado (or any of its trade names) or
29 # the names of any author or contributor in advertising or for publicity purposes
30 # pertaining to the distribution of this program, without the prior written
31 # authorisation of Ocado.
32 #
33 # Any propagation, distribution or conveyance of this program must include this
34 # copyright notice and these terms. You must not misrepresent the origins of this
35 # program; modified versions of the program must be marked as such and not
36 # identified as the original program.
37 from __future__ import absolute_import
38
39 import re
40 import datetime
41
42 from django.contrib.auth.models import User
43 from django.db import models
44 from django_countries.fields import CountryField
45 from django.core.cache import cache
46 from django.utils import timezone
47
48 from online_status.status import CACHE_USERS
49
50
51 class UserProfile(models.Model):
52 user = models.OneToOneField(User)
53 can_view_aggregated_data = models.BooleanField(default=False)
54 developer = models.BooleanField(default=False)
55
56 awaiting_email_verification = models.BooleanField(default=False)
57
58 def __unicode__(self):
59 return self.user.username
60
61 def joined_recently(self):
62 now = timezone.now()
63 return now - datetime.timedelta(days=7) <= self.user.date_joined
64
65
66 class School(models.Model):
67 name = models.CharField(max_length=200)
68 postcode = models.CharField(max_length=10)
69 town = models.CharField(max_length=200)
70 latitude = models.CharField(max_length=20)
71 longitude = models.CharField(max_length=20)
72 country = CountryField(blank_label='(select country)')
73
74 class Meta:
75 permissions = (
76 ('view_aggregated_data', "Can see available aggregated data"),
77 ('view_map_data', "Can see schools' location displayed on map")
78 )
79
80 def __unicode__(self):
81 return self.name
82
83
84 class TeacherModelManager(models.Manager):
85 def factory(self, title, first_name, last_name, email, password):
86 from portal.helpers.generators import get_random_username
87
88 user = User.objects.create_user(
89 username=email,
90 email=email,
91 password=password,
92 first_name=first_name,
93 last_name=last_name)
94
95 user_profile = UserProfile.objects.create(user=user)
96
97 return Teacher.objects.create(user=user_profile, new_user=user, title=title)
98
99
100 class Teacher(models.Model):
101 title = models.CharField(max_length=35)
102 user = models.OneToOneField(UserProfile)
103 new_user = models.OneToOneField(User, related_name='new_teacher', null=True, blank=True)
104 school = models.ForeignKey(School, related_name='teacher_school', null=True)
105 is_admin = models.BooleanField(default=False)
106 pending_join_request = models.ForeignKey(School, related_name='join_request', null=True)
107
108 objects = TeacherModelManager()
109
110 def teaches(self, userprofile):
111 if hasattr(userprofile, 'student'):
112 student = userprofile.student
113 return not student.is_independent() and student.class_field.teacher == self
114
115 def has_school(self):
116 return self.school is not (None or "")
117
118 def has_class(self):
119 classes = self.class_teacher.all()
120 return classes.count() != 0
121
122 def class_(self):
123 if self.has_class():
124 classes = self.class_teacher.all()
125 return classes[0]
126 return None
127
128 def __unicode__(self):
129 return '%s %s' % (self.user.first_name, self.user.last_name)
130
131
132 class Class(models.Model):
133 name = models.CharField(max_length=200)
134 teacher = models.ForeignKey(Teacher, related_name='class_teacher')
135 access_code = models.CharField(max_length=5)
136 classmates_data_viewable = models.BooleanField(default=False)
137 always_accept_requests = models.BooleanField(default=False)
138 accept_requests_until = models.DateTimeField(null=True)
139
140 def __unicode__(self):
141 return self.name
142
143 def has_students(self):
144 students = self.students.all()
145 return students.count() != 0
146
147 def get_logged_in_students(self):
148 ONLINE = 1
149
150 """This gets all the students who are logged in."""
151 users_status = cache.get(CACHE_USERS)
152 online_users_status = filter(lambda status: status.status == ONLINE, users_status)
153 online_user_ids = map(lambda status: status.user.id, online_users_status)
154
155 # Query all logged in users based on id list
156 return Student.objects.filter(class_field=self).filter(new_user__id__in=online_user_ids)
157
158 class Meta:
159 verbose_name_plural = "classes"
160
161
162 class StudentModelManager(models.Manager):
163 def schoolFactory(self, klass, name, password):
164 from portal.helpers.generators import get_random_username
165
166 user = User.objects.create_user(
167 username=get_random_username(),
168 password=password,
169 first_name=name)
170
171 user_profile = UserProfile.objects.create(user=user)
172 return Student.objects.create(class_field=klass, user=user_profile, new_user=user)
173
174 def independentStudentFactory(self, username, name, email, password):
175 user = User.objects.create_user(
176 username=username,
177 email=email,
178 password=password,
179 first_name=name)
180
181 user_profile = UserProfile.objects.create(user=user)
182
183 return Student.objects.create(user=user_profile, new_user=user)
184
185
186 class Student(models.Model):
187 class_field = models.ForeignKey(Class, related_name='students', null=True)
188 user = models.OneToOneField(UserProfile)
189 new_user = models.OneToOneField(User, related_name='new_student', null=True, blank=True)
190 pending_class_request = models.ForeignKey(Class, related_name='class_request', null=True)
191
192 objects = StudentModelManager()
193
194 def is_independent(self):
195 return not self.class_field
196
197 def __unicode__(self):
198 return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
199
200
201 def stripStudentName(name):
202 return re.sub('[ \t]+', ' ', name.strip())
203
204
205 class Guardian(models.Model):
206 name = models.CharField(max_length=200)
207 children = models.ManyToManyField(Student)
208 user = models.OneToOneField(UserProfile)
209 new_user = models.OneToOneField(User, related_name='new_guardian', null=True, blank=True)
210
211 def __unicode__(self):
212 return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
213
214
215 class EmailVerification(models.Model):
216 user = models.ForeignKey(User, related_name='email_verifications', null=True, blank=True)
217 token = models.CharField(max_length=30)
218 email = models.CharField(max_length=200, null=True, default=None, blank=True)
219 expiry = models.DateTimeField()
220 verified = models.BooleanField(default=False)
221
222
223 class FrontPageNews(models.Model):
224 title = models.CharField(max_length=200)
225 text = models.CharField(max_length=1000)
226 link = models.CharField(max_length=500)
227 link_text = models.CharField(max_length=200)
228 added_dstamp = models.DateTimeField()
229
230 class Meta:
231 verbose_name_plural = "front page news"
232
233 def __unicode__(self):
234 return self.title
235
236
237 from . import handlers # noqa
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/portal/models.py b/portal/models.py
--- a/portal/models.py
+++ b/portal/models.py
@@ -126,7 +126,7 @@
return None
def __unicode__(self):
- return '%s %s' % (self.user.first_name, self.user.last_name)
+ return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
class Class(models.Model):
|
{"golden_diff": "diff --git a/portal/models.py b/portal/models.py\n--- a/portal/models.py\n+++ b/portal/models.py\n@@ -126,7 +126,7 @@\n return None\n \n def __unicode__(self):\n- return '%s %s' % (self.user.first_name, self.user.last_name)\n+ return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n \n \n class Class(models.Model):\n", "issue": "Update models search field values in admin\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Code for Life\n#\n# Copyright (C) 2016, Ocado Innovation Limited\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n# ADDITIONAL TERMS \u2013 Section 7 GNU General Public Licence\n#\n# This licence does not grant any right, title or interest in any \u201cOcado\u201d logos,\n# trade names or the trademark \u201cOcado\u201d or any other trademarks or domain names\n# owned by Ocado Innovation Limited or the Ocado group of companies or any other\n# distinctive brand features of \u201cOcado\u201d as may be secured from time to time. You\n# must not distribute any modification of this program using the trademark\n# \u201cOcado\u201d or claim any affiliation or association with Ocado or its employees.\n#\n# You are not authorised to use the name Ocado (or any of its trade names) or\n# the names of any author or contributor in advertising or for publicity purposes\n# pertaining to the distribution of this program, without the prior written\n# authorisation of Ocado.\n#\n# Any propagation, distribution or conveyance of this program must include this\n# copyright notice and these terms. You must not misrepresent the origins of this\n# program; modified versions of the program must be marked as such and not\n# identified as the original program.\nfrom __future__ import absolute_import\n\nimport re\nimport datetime\n\nfrom django.contrib.auth.models import User\nfrom django.db import models\nfrom django_countries.fields import CountryField\nfrom django.core.cache import cache\nfrom django.utils import timezone\n\nfrom online_status.status import CACHE_USERS\n\n\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n can_view_aggregated_data = models.BooleanField(default=False)\n developer = models.BooleanField(default=False)\n\n awaiting_email_verification = models.BooleanField(default=False)\n\n def __unicode__(self):\n return self.user.username\n\n def joined_recently(self):\n now = timezone.now()\n return now - datetime.timedelta(days=7) <= self.user.date_joined\n\n\nclass School(models.Model):\n name = models.CharField(max_length=200)\n postcode = models.CharField(max_length=10)\n town = models.CharField(max_length=200)\n latitude = models.CharField(max_length=20)\n longitude = models.CharField(max_length=20)\n country = CountryField(blank_label='(select country)')\n\n class Meta:\n permissions = (\n ('view_aggregated_data', \"Can see available aggregated data\"),\n ('view_map_data', \"Can see schools' location displayed on map\")\n )\n\n def __unicode__(self):\n return self.name\n\n\nclass TeacherModelManager(models.Manager):\n def factory(self, title, first_name, last_name, email, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=email,\n email=email,\n password=password,\n first_name=first_name,\n last_name=last_name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Teacher.objects.create(user=user_profile, new_user=user, title=title)\n\n\nclass Teacher(models.Model):\n title = models.CharField(max_length=35)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_teacher', null=True, blank=True)\n school = models.ForeignKey(School, related_name='teacher_school', null=True)\n is_admin = models.BooleanField(default=False)\n pending_join_request = models.ForeignKey(School, related_name='join_request', null=True)\n\n objects = TeacherModelManager()\n\n def teaches(self, userprofile):\n if hasattr(userprofile, 'student'):\n student = userprofile.student\n return not student.is_independent() and student.class_field.teacher == self\n\n def has_school(self):\n return self.school is not (None or \"\")\n\n def has_class(self):\n classes = self.class_teacher.all()\n return classes.count() != 0\n\n def class_(self):\n if self.has_class():\n classes = self.class_teacher.all()\n return classes[0]\n return None\n\n def __unicode__(self):\n return '%s %s' % (self.user.first_name, self.user.last_name)\n\n\nclass Class(models.Model):\n name = models.CharField(max_length=200)\n teacher = models.ForeignKey(Teacher, related_name='class_teacher')\n access_code = models.CharField(max_length=5)\n classmates_data_viewable = models.BooleanField(default=False)\n always_accept_requests = models.BooleanField(default=False)\n accept_requests_until = models.DateTimeField(null=True)\n\n def __unicode__(self):\n return self.name\n\n def has_students(self):\n students = self.students.all()\n return students.count() != 0\n\n def get_logged_in_students(self):\n ONLINE = 1\n\n \"\"\"This gets all the students who are logged in.\"\"\"\n users_status = cache.get(CACHE_USERS)\n online_users_status = filter(lambda status: status.status == ONLINE, users_status)\n online_user_ids = map(lambda status: status.user.id, online_users_status)\n\n # Query all logged in users based on id list\n return Student.objects.filter(class_field=self).filter(new_user__id__in=online_user_ids)\n\n class Meta:\n verbose_name_plural = \"classes\"\n\n\nclass StudentModelManager(models.Manager):\n def schoolFactory(self, klass, name, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=get_random_username(),\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n return Student.objects.create(class_field=klass, user=user_profile, new_user=user)\n\n def independentStudentFactory(self, username, name, email, password):\n user = User.objects.create_user(\n username=username,\n email=email,\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Student.objects.create(user=user_profile, new_user=user)\n\n\nclass Student(models.Model):\n class_field = models.ForeignKey(Class, related_name='students', null=True)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_student', null=True, blank=True)\n pending_class_request = models.ForeignKey(Class, related_name='class_request', null=True)\n\n objects = StudentModelManager()\n\n def is_independent(self):\n return not self.class_field\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\ndef stripStudentName(name):\n return re.sub('[ \\t]+', ' ', name.strip())\n\n\nclass Guardian(models.Model):\n name = models.CharField(max_length=200)\n children = models.ManyToManyField(Student)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_guardian', null=True, blank=True)\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\nclass EmailVerification(models.Model):\n user = models.ForeignKey(User, related_name='email_verifications', null=True, blank=True)\n token = models.CharField(max_length=30)\n email = models.CharField(max_length=200, null=True, default=None, blank=True)\n expiry = models.DateTimeField()\n verified = models.BooleanField(default=False)\n\n\nclass FrontPageNews(models.Model):\n title = models.CharField(max_length=200)\n text = models.CharField(max_length=1000)\n link = models.CharField(max_length=500)\n link_text = models.CharField(max_length=200)\n added_dstamp = models.DateTimeField()\n\n class Meta:\n verbose_name_plural = \"front page news\"\n\n def __unicode__(self):\n return self.title\n\n\nfrom . import handlers # noqa\n", "path": "portal/models.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Code for Life\n#\n# Copyright (C) 2016, Ocado Innovation Limited\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n# ADDITIONAL TERMS \u2013 Section 7 GNU General Public Licence\n#\n# This licence does not grant any right, title or interest in any \u201cOcado\u201d logos,\n# trade names or the trademark \u201cOcado\u201d or any other trademarks or domain names\n# owned by Ocado Innovation Limited or the Ocado group of companies or any other\n# distinctive brand features of \u201cOcado\u201d as may be secured from time to time. You\n# must not distribute any modification of this program using the trademark\n# \u201cOcado\u201d or claim any affiliation or association with Ocado or its employees.\n#\n# You are not authorised to use the name Ocado (or any of its trade names) or\n# the names of any author or contributor in advertising or for publicity purposes\n# pertaining to the distribution of this program, without the prior written\n# authorisation of Ocado.\n#\n# Any propagation, distribution or conveyance of this program must include this\n# copyright notice and these terms. You must not misrepresent the origins of this\n# program; modified versions of the program must be marked as such and not\n# identified as the original program.\nfrom __future__ import absolute_import\n\nimport re\nimport datetime\n\nfrom django.contrib.auth.models import User\nfrom django.db import models\nfrom django_countries.fields import CountryField\nfrom django.core.cache import cache\nfrom django.utils import timezone\n\nfrom online_status.status import CACHE_USERS\n\n\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n can_view_aggregated_data = models.BooleanField(default=False)\n developer = models.BooleanField(default=False)\n\n awaiting_email_verification = models.BooleanField(default=False)\n\n def __unicode__(self):\n return self.user.username\n\n def joined_recently(self):\n now = timezone.now()\n return now - datetime.timedelta(days=7) <= self.user.date_joined\n\n\nclass School(models.Model):\n name = models.CharField(max_length=200)\n postcode = models.CharField(max_length=10)\n town = models.CharField(max_length=200)\n latitude = models.CharField(max_length=20)\n longitude = models.CharField(max_length=20)\n country = CountryField(blank_label='(select country)')\n\n class Meta:\n permissions = (\n ('view_aggregated_data', \"Can see available aggregated data\"),\n ('view_map_data', \"Can see schools' location displayed on map\")\n )\n\n def __unicode__(self):\n return self.name\n\n\nclass TeacherModelManager(models.Manager):\n def factory(self, title, first_name, last_name, email, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=email,\n email=email,\n password=password,\n first_name=first_name,\n last_name=last_name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Teacher.objects.create(user=user_profile, new_user=user, title=title)\n\n\nclass Teacher(models.Model):\n title = models.CharField(max_length=35)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_teacher', null=True, blank=True)\n school = models.ForeignKey(School, related_name='teacher_school', null=True)\n is_admin = models.BooleanField(default=False)\n pending_join_request = models.ForeignKey(School, related_name='join_request', null=True)\n\n objects = TeacherModelManager()\n\n def teaches(self, userprofile):\n if hasattr(userprofile, 'student'):\n student = userprofile.student\n return not student.is_independent() and student.class_field.teacher == self\n\n def has_school(self):\n return self.school is not (None or \"\")\n\n def has_class(self):\n classes = self.class_teacher.all()\n return classes.count() != 0\n\n def class_(self):\n if self.has_class():\n classes = self.class_teacher.all()\n return classes[0]\n return None\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\nclass Class(models.Model):\n name = models.CharField(max_length=200)\n teacher = models.ForeignKey(Teacher, related_name='class_teacher')\n access_code = models.CharField(max_length=5)\n classmates_data_viewable = models.BooleanField(default=False)\n always_accept_requests = models.BooleanField(default=False)\n accept_requests_until = models.DateTimeField(null=True)\n\n def __unicode__(self):\n return self.name\n\n def has_students(self):\n students = self.students.all()\n return students.count() != 0\n\n def get_logged_in_students(self):\n ONLINE = 1\n\n \"\"\"This gets all the students who are logged in.\"\"\"\n users_status = cache.get(CACHE_USERS)\n online_users_status = filter(lambda status: status.status == ONLINE, users_status)\n online_user_ids = map(lambda status: status.user.id, online_users_status)\n\n # Query all logged in users based on id list\n return Student.objects.filter(class_field=self).filter(new_user__id__in=online_user_ids)\n\n class Meta:\n verbose_name_plural = \"classes\"\n\n\nclass StudentModelManager(models.Manager):\n def schoolFactory(self, klass, name, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=get_random_username(),\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n return Student.objects.create(class_field=klass, user=user_profile, new_user=user)\n\n def independentStudentFactory(self, username, name, email, password):\n user = User.objects.create_user(\n username=username,\n email=email,\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Student.objects.create(user=user_profile, new_user=user)\n\n\nclass Student(models.Model):\n class_field = models.ForeignKey(Class, related_name='students', null=True)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_student', null=True, blank=True)\n pending_class_request = models.ForeignKey(Class, related_name='class_request', null=True)\n\n objects = StudentModelManager()\n\n def is_independent(self):\n return not self.class_field\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\ndef stripStudentName(name):\n return re.sub('[ \\t]+', ' ', name.strip())\n\n\nclass Guardian(models.Model):\n name = models.CharField(max_length=200)\n children = models.ManyToManyField(Student)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_guardian', null=True, blank=True)\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\nclass EmailVerification(models.Model):\n user = models.ForeignKey(User, related_name='email_verifications', null=True, blank=True)\n token = models.CharField(max_length=30)\n email = models.CharField(max_length=200, null=True, default=None, blank=True)\n expiry = models.DateTimeField()\n verified = models.BooleanField(default=False)\n\n\nclass FrontPageNews(models.Model):\n title = models.CharField(max_length=200)\n text = models.CharField(max_length=1000)\n link = models.CharField(max_length=500)\n link_text = models.CharField(max_length=200)\n added_dstamp = models.DateTimeField()\n\n class Meta:\n verbose_name_plural = \"front page news\"\n\n def __unicode__(self):\n return self.title\n\n\nfrom . import handlers # noqa\n", "path": "portal/models.py"}]}
| 2,698 | 101 |
gh_patches_debug_13338
|
rasdani/github-patches
|
git_diff
|
holoviz__hvplot-247
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Run more tests on CI
I just realized that we haven't been running all our unit tests on CI. I think we should at least have one job that has `xarray, rasterio, geoviews, cartopy, dask, pandas, and streamz`
This will probably also help with our coverage. Subset from https://travis-ci.org/pyviz/hvplot/jobs/560028289:
```
Name Stmts Miss Cover
-----------------------------------------
hvplot/__init__.py 251 123 51%
hvplot/converter.py 900 537 40%
hvplot/util.py 193 156 19%
hvplot/utilities.py 28 22 21%
-----------------------------------------
TOTAL 1372 838 39%
----------------------------------------------------------------------
Ran 74 tests in 1.296s
OK (SKIP=27)
```
These ones are failing locally for me on master:
```python-traceback
test_process_1d_xarray_dataarray_with_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_1d_xarray_dataarray_with_coords_and_name (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_1d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_2d_xarray_dataarray_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_2d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_2d_xarray_dataarray_with_no_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_3d_xarray_dataset_with_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR
test_process_3d_xarray_dataset_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR
======================================================================
ERROR: test_process_1d_xarray_dataarray_with_coords (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 55, in test_process_1d_xarray_dataarray_with_coords
data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_1d_xarray_dataarray_with_coords_and_name (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 72, in test_process_1d_xarray_dataarray_with_coords_and_name
data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_1d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 39, in test_process_1d_xarray_dataarray_with_no_coords
data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_2d_xarray_dataarray_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 119, in test_process_2d_xarray_dataarray_with_coords_as_gridded
data, x, y, by, groupby = process_xarray(data=da, **kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_2d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 85, in test_process_2d_xarray_dataarray_with_no_coords
data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_2d_xarray_dataarray_with_no_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 100, in test_process_2d_xarray_dataarray_with_no_coords_as_gridded
data, x, y, by, groupby = process_xarray(data=da, **kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_3d_xarray_dataset_with_coords (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 130, in test_process_3d_xarray_dataset_with_coords
data, x, y, by, groupby = process_xarray(data=self.ds, **self.default_kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
======================================================================
ERROR: test_process_3d_xarray_dataset_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/jsignell/hvplot/hvplot/tests/testutil.py", line 143, in test_process_3d_xarray_dataset_with_coords_as_gridded
data, x, y, by, groupby = process_xarray(data=self.ds, **kwargs)
TypeError: process_xarray() missing 1 required positional argument: 'other_dims'
----------------------------------------------------------------------
Ran 80 tests in 8.333s
FAILED (SKIP=10, errors=8)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import sys
3 import shutil
4 from collections import defaultdict
5 from setuptools import setup, find_packages
6
7
8 ########## autover ##########
9
10 def embed_version(basepath, ref='v0.2.2'):
11 """
12 Autover is purely a build time dependency in all cases (conda and
13 pip) except for when you use pip's remote git support [git+url] as
14 1) you need a dynamically changing version and 2) the environment
15 starts off clean with zero dependencies installed.
16 This function acts as a fallback to make Version available until
17 PEP518 is commonly supported by pip to express build dependencies.
18 """
19 import io, zipfile, importlib
20 try: from urllib.request import urlopen
21 except: from urllib import urlopen
22 try:
23 url = 'https://github.com/ioam/autover/archive/{ref}.zip'
24 response = urlopen(url.format(ref=ref))
25 zf = zipfile.ZipFile(io.BytesIO(response.read()))
26 ref = ref[1:] if ref.startswith('v') else ref
27 embed_version = zf.read('autover-{ref}/autover/version.py'.format(ref=ref))
28 with open(os.path.join(basepath, 'version.py'), 'wb') as f:
29 f.write(embed_version)
30 return importlib.import_module("version")
31 except:
32 return None
33
34 def get_setup_version(reponame):
35 """
36 Helper to get the current version from either git describe or the
37 .version file (if available).
38 """
39 import json
40 basepath = os.path.split(__file__)[0]
41 version_file_path = os.path.join(basepath, reponame, '.version')
42 try:
43 from param import version
44 except:
45 version = embed_version(basepath)
46 if version is not None:
47 return version.Version.setup_version(basepath, reponame, archive_commit="$Format:%h$")
48 else:
49 print("WARNING: param>=1.6.0 unavailable. If you are installing a package, this warning can safely be ignored. If you are creating a package or otherwise operating in a git repository, you should install param>=1.6.0.")
50 return json.load(open(version_file_path, 'r'))['version_string']
51
52 ########## examples ##########
53
54 def check_pseudo_package(path):
55 """
56 Verifies that a fake subpackage path for assets (notebooks, svgs,
57 pngs etc) both exists and is populated with files.
58 """
59 if not os.path.isdir(path):
60 raise Exception("Please make sure pseudo-package %s exists." % path)
61 else:
62 assets = os.listdir(path)
63 if len(assets) == 0:
64 raise Exception("Please make sure pseudo-package %s is populated." % path)
65
66
67 excludes = ['DS_Store', '.log', 'ipynb_checkpoints']
68 packages = []
69 extensions = defaultdict(list)
70
71 def walker(top, names):
72 """
73 Walks a directory and records all packages and file extensions.
74 """
75 global packages, extensions
76 if any(exc in top for exc in excludes):
77 return
78 package = top[top.rfind('hvplot'):].replace(os.path.sep, '.')
79 packages.append(package)
80 for name in names:
81 ext = '.'.join(name.split('.')[1:])
82 ext_str = '*.%s' % ext
83 if ext and ext not in excludes and ext_str not in extensions[package]:
84 extensions[package].append(ext_str)
85
86
87 def examples(path='hvplot-examples', verbose=False, force=False, root=__file__):
88 """
89 Copies the notebooks to the supplied path.
90 """
91 filepath = os.path.abspath(os.path.dirname(root))
92 example_dir = os.path.join(filepath, './examples')
93 if not os.path.exists(example_dir):
94 example_dir = os.path.join(filepath, '../examples')
95 if os.path.exists(path):
96 if not force:
97 print('%s directory already exists, either delete it or set the force flag' % path)
98 return
99 shutil.rmtree(path)
100 ignore = shutil.ignore_patterns('.ipynb_checkpoints', '*.pyc', '*~')
101 tree_root = os.path.abspath(example_dir)
102 if os.path.isdir(tree_root):
103 shutil.copytree(tree_root, path, ignore=ignore, symlinks=True)
104 else:
105 print('Cannot find %s' % tree_root)
106
107
108
109 def package_assets(example_path):
110 """
111 Generates pseudo-packages for the examples directory.
112 """
113 examples(example_path, force=True, root=__file__)
114 for root, dirs, files in os.walk(example_path):
115 walker(root, dirs+files)
116 setup_args['packages'] += packages
117 for p, exts in extensions.items():
118 if exts:
119 setup_args['package_data'][p] = exts
120
121
122 ########## dependencies ##########
123
124 install_requires = [
125 'bokeh >=1.0.0',
126 'holoviews >=1.11.0',
127 'pandas'
128 ]
129
130 _examples_extra = [
131 'geoviews >=1.6.0',
132 'geopandas',
133 'xarray',
134 'networkx',
135 'pygraphviz',
136 'streamz >=0.3.0',
137 'intake',
138 'intake-parquet',
139 'dask',
140 'datashader >=0.6.5',
141 'notebook >=5.4',
142 's3fs',
143 'scipy',
144 'pillow',
145 'selenium',
146 'phantomjs',
147 ]
148
149 extras_require = {
150 'tests': [
151 'coveralls',
152 'nose',
153 'flake8',
154 'parameterized',
155 'pytest',
156 'nbsmoke >=0.2.0'
157 ],
158 'examples': _examples_extra,
159 'doc': _examples_extra + [
160 'nbsite >=0.5.1',
161 'sphinx_ioam_theme',
162 'tornado <6.0'
163 ]
164 }
165
166 # until pyproject.toml/equivalent is widely supported (setup_requires
167 # doesn't work well with pip)
168 extras_require['build'] = [
169 'param >=1.6.1',
170 'setuptools' # should make this pip now
171 ]
172
173 extras_require['all'] = sorted(set(sum(extras_require.values(), [])))
174
175 ########## metadata for setuptools ##########
176
177 setup_args = dict(
178 name='hvplot',
179 version=get_setup_version("hvplot"),
180 description='A high-level plotting API for the PyData ecosystem built on HoloViews.',
181 long_description=open("README.md").read(),
182 long_description_content_type="text/markdown",
183 author= "Philipp Rudiger",
184 author_email= "[email protected]",
185 maintainer="PyViz developers",
186 maintainer_email="[email protected]",
187 packages=find_packages()+packages,
188 package_data={'hvplot': ['.version']},
189 platforms=['Windows', 'Mac OS X', 'Linux'],
190 license='BSD',
191 url='https://hvplot.pyviz.org',
192 classifiers = [
193 "License :: OSI Approved :: BSD License",
194 "Development Status :: 5 - Production/Stable",
195 "Programming Language :: Python :: 2",
196 "Programming Language :: Python :: 2.7",
197 "Programming Language :: Python :: 3.5",
198 "Programming Language :: Python :: 3.6",
199 "Operating System :: OS Independent",
200 "Intended Audience :: Science/Research",
201 "Intended Audience :: Developers",
202 "Natural Language :: English",
203 "Topic :: Scientific/Engineering",
204 "Topic :: Software Development :: Libraries"],
205 python_requires=">=2.7",
206 install_requires=install_requires,
207 extras_require=extras_require,
208 tests_require=extras_require['tests'],
209 entry_points={
210 'console_scripts': [
211 'hvplot = hvplot.__main__:main'
212 ]
213 },
214 )
215
216
217 if __name__ == '__main__':
218 example_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
219 'hvplot','examples')
220 if 'develop' not in sys.argv:
221 package_assets(example_path)
222
223 setup(**setup_args)
224
225 if os.path.isdir(example_path):
226 shutil.rmtree(example_path)
227
228
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -139,6 +139,7 @@
'dask',
'datashader >=0.6.5',
'notebook >=5.4',
+ 'rasterio',
's3fs',
'scipy',
'pillow',
@@ -153,7 +154,7 @@
'flake8',
'parameterized',
'pytest',
- 'nbsmoke >=0.2.0'
+ 'nbsmoke >=0.2.0',
],
'examples': _examples_extra,
'doc': _examples_extra + [
@@ -224,4 +225,3 @@
if os.path.isdir(example_path):
shutil.rmtree(example_path)
-
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -139,6 +139,7 @@\n 'dask',\n 'datashader >=0.6.5',\n 'notebook >=5.4',\n+ 'rasterio',\n 's3fs',\n 'scipy',\n 'pillow',\n@@ -153,7 +154,7 @@\n 'flake8',\n 'parameterized',\n 'pytest',\n- 'nbsmoke >=0.2.0'\n+ 'nbsmoke >=0.2.0',\n ],\n 'examples': _examples_extra,\n 'doc': _examples_extra + [\n@@ -224,4 +225,3 @@\n \n if os.path.isdir(example_path):\n shutil.rmtree(example_path)\n-\n", "issue": "Run more tests on CI\n\r\n\r\nI just realized that we haven't been running all our unit tests on CI. I think we should at least have one job that has `xarray, rasterio, geoviews, cartopy, dask, pandas, and streamz`\r\n\r\nThis will probably also help with our coverage. Subset from https://travis-ci.org/pyviz/hvplot/jobs/560028289:\r\n```\r\nName Stmts Miss Cover\r\n-----------------------------------------\r\nhvplot/__init__.py 251 123 51%\r\nhvplot/converter.py 900 537 40%\r\nhvplot/util.py 193 156 19%\r\nhvplot/utilities.py 28 22 21%\r\n-----------------------------------------\r\nTOTAL 1372 838 39%\r\n----------------------------------------------------------------------\r\nRan 74 tests in 1.296s\r\nOK (SKIP=27)\r\n```\r\n\r\nThese ones are failing locally for me on master:\r\n\r\n```python-traceback\r\ntest_process_1d_xarray_dataarray_with_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_1d_xarray_dataarray_with_coords_and_name (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_1d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_2d_xarray_dataarray_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_2d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_2d_xarray_dataarray_with_no_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_3d_xarray_dataset_with_coords (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\ntest_process_3d_xarray_dataset_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray) ... ERROR\r\n\r\n======================================================================\r\nERROR: test_process_1d_xarray_dataarray_with_coords (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 55, in test_process_1d_xarray_dataarray_with_coords\r\n data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_1d_xarray_dataarray_with_coords_and_name (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 72, in test_process_1d_xarray_dataarray_with_coords_and_name\r\n data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_1d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 39, in test_process_1d_xarray_dataarray_with_no_coords\r\n data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_2d_xarray_dataarray_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 119, in test_process_2d_xarray_dataarray_with_coords_as_gridded\r\n data, x, y, by, groupby = process_xarray(data=da, **kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_2d_xarray_dataarray_with_no_coords (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 85, in test_process_2d_xarray_dataarray_with_no_coords\r\n data, x, y, by, groupby = process_xarray(data=da, **self.default_kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_2d_xarray_dataarray_with_no_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 100, in test_process_2d_xarray_dataarray_with_no_coords_as_gridded\r\n data, x, y, by, groupby = process_xarray(data=da, **kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_3d_xarray_dataset_with_coords (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 130, in test_process_3d_xarray_dataset_with_coords\r\n data, x, y, by, groupby = process_xarray(data=self.ds, **self.default_kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n======================================================================\r\nERROR: test_process_3d_xarray_dataset_with_coords_as_gridded (hvplot.tests.testutil.TestProcessXarray)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/jsignell/hvplot/hvplot/tests/testutil.py\", line 143, in test_process_3d_xarray_dataset_with_coords_as_gridded\r\n data, x, y, by, groupby = process_xarray(data=self.ds, **kwargs)\r\nTypeError: process_xarray() missing 1 required positional argument: 'other_dims'\r\n\r\n----------------------------------------------------------------------\r\nRan 80 tests in 8.333s\r\n\r\nFAILED (SKIP=10, errors=8)\r\n```\n", "before_files": [{"content": "import os\nimport sys\nimport shutil\nfrom collections import defaultdict\nfrom setuptools import setup, find_packages\n\n\n########## autover ##########\n\ndef embed_version(basepath, ref='v0.2.2'):\n \"\"\"\n Autover is purely a build time dependency in all cases (conda and\n pip) except for when you use pip's remote git support [git+url] as\n 1) you need a dynamically changing version and 2) the environment\n starts off clean with zero dependencies installed.\n This function acts as a fallback to make Version available until\n PEP518 is commonly supported by pip to express build dependencies.\n \"\"\"\n import io, zipfile, importlib\n try: from urllib.request import urlopen\n except: from urllib import urlopen\n try:\n url = 'https://github.com/ioam/autover/archive/{ref}.zip'\n response = urlopen(url.format(ref=ref))\n zf = zipfile.ZipFile(io.BytesIO(response.read()))\n ref = ref[1:] if ref.startswith('v') else ref\n embed_version = zf.read('autover-{ref}/autover/version.py'.format(ref=ref))\n with open(os.path.join(basepath, 'version.py'), 'wb') as f:\n f.write(embed_version)\n return importlib.import_module(\"version\")\n except:\n return None\n\ndef get_setup_version(reponame):\n \"\"\"\n Helper to get the current version from either git describe or the\n .version file (if available).\n \"\"\"\n import json\n basepath = os.path.split(__file__)[0]\n version_file_path = os.path.join(basepath, reponame, '.version')\n try:\n from param import version\n except:\n version = embed_version(basepath)\n if version is not None:\n return version.Version.setup_version(basepath, reponame, archive_commit=\"$Format:%h$\")\n else:\n print(\"WARNING: param>=1.6.0 unavailable. If you are installing a package, this warning can safely be ignored. If you are creating a package or otherwise operating in a git repository, you should install param>=1.6.0.\")\n return json.load(open(version_file_path, 'r'))['version_string']\n\n########## examples ##########\n\ndef check_pseudo_package(path):\n \"\"\"\n Verifies that a fake subpackage path for assets (notebooks, svgs,\n pngs etc) both exists and is populated with files.\n \"\"\"\n if not os.path.isdir(path):\n raise Exception(\"Please make sure pseudo-package %s exists.\" % path)\n else:\n assets = os.listdir(path)\n if len(assets) == 0:\n raise Exception(\"Please make sure pseudo-package %s is populated.\" % path)\n\n\nexcludes = ['DS_Store', '.log', 'ipynb_checkpoints']\npackages = []\nextensions = defaultdict(list)\n\ndef walker(top, names):\n \"\"\"\n Walks a directory and records all packages and file extensions.\n \"\"\"\n global packages, extensions\n if any(exc in top for exc in excludes):\n return\n package = top[top.rfind('hvplot'):].replace(os.path.sep, '.')\n packages.append(package)\n for name in names:\n ext = '.'.join(name.split('.')[1:])\n ext_str = '*.%s' % ext\n if ext and ext not in excludes and ext_str not in extensions[package]:\n extensions[package].append(ext_str)\n\n\ndef examples(path='hvplot-examples', verbose=False, force=False, root=__file__):\n \"\"\"\n Copies the notebooks to the supplied path.\n \"\"\"\n filepath = os.path.abspath(os.path.dirname(root))\n example_dir = os.path.join(filepath, './examples')\n if not os.path.exists(example_dir):\n example_dir = os.path.join(filepath, '../examples')\n if os.path.exists(path):\n if not force:\n print('%s directory already exists, either delete it or set the force flag' % path)\n return\n shutil.rmtree(path)\n ignore = shutil.ignore_patterns('.ipynb_checkpoints', '*.pyc', '*~')\n tree_root = os.path.abspath(example_dir)\n if os.path.isdir(tree_root):\n shutil.copytree(tree_root, path, ignore=ignore, symlinks=True)\n else:\n print('Cannot find %s' % tree_root)\n\n\n\ndef package_assets(example_path):\n \"\"\"\n Generates pseudo-packages for the examples directory.\n \"\"\"\n examples(example_path, force=True, root=__file__)\n for root, dirs, files in os.walk(example_path):\n walker(root, dirs+files)\n setup_args['packages'] += packages\n for p, exts in extensions.items():\n if exts:\n setup_args['package_data'][p] = exts\n\n\n########## dependencies ##########\n\ninstall_requires = [\n 'bokeh >=1.0.0',\n 'holoviews >=1.11.0',\n 'pandas'\n]\n\n_examples_extra = [\n 'geoviews >=1.6.0',\n 'geopandas',\n 'xarray',\n 'networkx',\n 'pygraphviz',\n 'streamz >=0.3.0',\n 'intake',\n 'intake-parquet',\n 'dask',\n 'datashader >=0.6.5',\n 'notebook >=5.4',\n 's3fs',\n 'scipy',\n 'pillow',\n 'selenium',\n 'phantomjs',\n]\n\nextras_require = {\n 'tests': [\n 'coveralls',\n 'nose',\n 'flake8',\n 'parameterized',\n 'pytest',\n 'nbsmoke >=0.2.0'\n ],\n 'examples': _examples_extra,\n 'doc': _examples_extra + [\n 'nbsite >=0.5.1',\n 'sphinx_ioam_theme',\n 'tornado <6.0'\n ]\n}\n\n# until pyproject.toml/equivalent is widely supported (setup_requires\n# doesn't work well with pip)\nextras_require['build'] = [\n 'param >=1.6.1',\n 'setuptools' # should make this pip now\n]\n\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\n########## metadata for setuptools ##########\n\nsetup_args = dict(\n name='hvplot',\n version=get_setup_version(\"hvplot\"),\n description='A high-level plotting API for the PyData ecosystem built on HoloViews.',\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n author= \"Philipp Rudiger\",\n author_email= \"[email protected]\",\n maintainer=\"PyViz developers\",\n maintainer_email=\"[email protected]\",\n packages=find_packages()+packages,\n package_data={'hvplot': ['.version']},\n platforms=['Windows', 'Mac OS X', 'Linux'],\n license='BSD',\n url='https://hvplot.pyviz.org',\n classifiers = [\n \"License :: OSI Approved :: BSD License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Operating System :: OS Independent\",\n \"Intended Audience :: Science/Research\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Software Development :: Libraries\"],\n python_requires=\">=2.7\",\n install_requires=install_requires,\n extras_require=extras_require,\n tests_require=extras_require['tests'],\n entry_points={\n 'console_scripts': [\n 'hvplot = hvplot.__main__:main'\n ]\n },\n)\n\n\nif __name__ == '__main__':\n example_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),\n 'hvplot','examples')\n if 'develop' not in sys.argv:\n package_assets(example_path)\n\n setup(**setup_args)\n\n if os.path.isdir(example_path):\n shutil.rmtree(example_path)\n\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport sys\nimport shutil\nfrom collections import defaultdict\nfrom setuptools import setup, find_packages\n\n\n########## autover ##########\n\ndef embed_version(basepath, ref='v0.2.2'):\n \"\"\"\n Autover is purely a build time dependency in all cases (conda and\n pip) except for when you use pip's remote git support [git+url] as\n 1) you need a dynamically changing version and 2) the environment\n starts off clean with zero dependencies installed.\n This function acts as a fallback to make Version available until\n PEP518 is commonly supported by pip to express build dependencies.\n \"\"\"\n import io, zipfile, importlib\n try: from urllib.request import urlopen\n except: from urllib import urlopen\n try:\n url = 'https://github.com/ioam/autover/archive/{ref}.zip'\n response = urlopen(url.format(ref=ref))\n zf = zipfile.ZipFile(io.BytesIO(response.read()))\n ref = ref[1:] if ref.startswith('v') else ref\n embed_version = zf.read('autover-{ref}/autover/version.py'.format(ref=ref))\n with open(os.path.join(basepath, 'version.py'), 'wb') as f:\n f.write(embed_version)\n return importlib.import_module(\"version\")\n except:\n return None\n\ndef get_setup_version(reponame):\n \"\"\"\n Helper to get the current version from either git describe or the\n .version file (if available).\n \"\"\"\n import json\n basepath = os.path.split(__file__)[0]\n version_file_path = os.path.join(basepath, reponame, '.version')\n try:\n from param import version\n except:\n version = embed_version(basepath)\n if version is not None:\n return version.Version.setup_version(basepath, reponame, archive_commit=\"$Format:%h$\")\n else:\n print(\"WARNING: param>=1.6.0 unavailable. If you are installing a package, this warning can safely be ignored. If you are creating a package or otherwise operating in a git repository, you should install param>=1.6.0.\")\n return json.load(open(version_file_path, 'r'))['version_string']\n\n########## examples ##########\n\ndef check_pseudo_package(path):\n \"\"\"\n Verifies that a fake subpackage path for assets (notebooks, svgs,\n pngs etc) both exists and is populated with files.\n \"\"\"\n if not os.path.isdir(path):\n raise Exception(\"Please make sure pseudo-package %s exists.\" % path)\n else:\n assets = os.listdir(path)\n if len(assets) == 0:\n raise Exception(\"Please make sure pseudo-package %s is populated.\" % path)\n\n\nexcludes = ['DS_Store', '.log', 'ipynb_checkpoints']\npackages = []\nextensions = defaultdict(list)\n\ndef walker(top, names):\n \"\"\"\n Walks a directory and records all packages and file extensions.\n \"\"\"\n global packages, extensions\n if any(exc in top for exc in excludes):\n return\n package = top[top.rfind('hvplot'):].replace(os.path.sep, '.')\n packages.append(package)\n for name in names:\n ext = '.'.join(name.split('.')[1:])\n ext_str = '*.%s' % ext\n if ext and ext not in excludes and ext_str not in extensions[package]:\n extensions[package].append(ext_str)\n\n\ndef examples(path='hvplot-examples', verbose=False, force=False, root=__file__):\n \"\"\"\n Copies the notebooks to the supplied path.\n \"\"\"\n filepath = os.path.abspath(os.path.dirname(root))\n example_dir = os.path.join(filepath, './examples')\n if not os.path.exists(example_dir):\n example_dir = os.path.join(filepath, '../examples')\n if os.path.exists(path):\n if not force:\n print('%s directory already exists, either delete it or set the force flag' % path)\n return\n shutil.rmtree(path)\n ignore = shutil.ignore_patterns('.ipynb_checkpoints', '*.pyc', '*~')\n tree_root = os.path.abspath(example_dir)\n if os.path.isdir(tree_root):\n shutil.copytree(tree_root, path, ignore=ignore, symlinks=True)\n else:\n print('Cannot find %s' % tree_root)\n\n\n\ndef package_assets(example_path):\n \"\"\"\n Generates pseudo-packages for the examples directory.\n \"\"\"\n examples(example_path, force=True, root=__file__)\n for root, dirs, files in os.walk(example_path):\n walker(root, dirs+files)\n setup_args['packages'] += packages\n for p, exts in extensions.items():\n if exts:\n setup_args['package_data'][p] = exts\n\n\n########## dependencies ##########\n\ninstall_requires = [\n 'bokeh >=1.0.0',\n 'holoviews >=1.11.0',\n 'pandas'\n]\n\n_examples_extra = [\n 'geoviews >=1.6.0',\n 'geopandas',\n 'xarray',\n 'networkx',\n 'pygraphviz',\n 'streamz >=0.3.0',\n 'intake',\n 'intake-parquet',\n 'dask',\n 'datashader >=0.6.5',\n 'notebook >=5.4',\n 'rasterio',\n 's3fs',\n 'scipy',\n 'pillow',\n 'selenium',\n 'phantomjs',\n]\n\nextras_require = {\n 'tests': [\n 'coveralls',\n 'nose',\n 'flake8',\n 'parameterized',\n 'pytest',\n 'nbsmoke >=0.2.0',\n ],\n 'examples': _examples_extra,\n 'doc': _examples_extra + [\n 'nbsite >=0.5.1',\n 'sphinx_ioam_theme',\n 'tornado <6.0'\n ]\n}\n\n# until pyproject.toml/equivalent is widely supported (setup_requires\n# doesn't work well with pip)\nextras_require['build'] = [\n 'param >=1.6.1',\n 'setuptools' # should make this pip now\n]\n\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\n########## metadata for setuptools ##########\n\nsetup_args = dict(\n name='hvplot',\n version=get_setup_version(\"hvplot\"),\n description='A high-level plotting API for the PyData ecosystem built on HoloViews.',\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n author= \"Philipp Rudiger\",\n author_email= \"[email protected]\",\n maintainer=\"PyViz developers\",\n maintainer_email=\"[email protected]\",\n packages=find_packages()+packages,\n package_data={'hvplot': ['.version']},\n platforms=['Windows', 'Mac OS X', 'Linux'],\n license='BSD',\n url='https://hvplot.pyviz.org',\n classifiers = [\n \"License :: OSI Approved :: BSD License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Operating System :: OS Independent\",\n \"Intended Audience :: Science/Research\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Software Development :: Libraries\"],\n python_requires=\">=2.7\",\n install_requires=install_requires,\n extras_require=extras_require,\n tests_require=extras_require['tests'],\n entry_points={\n 'console_scripts': [\n 'hvplot = hvplot.__main__:main'\n ]\n },\n)\n\n\nif __name__ == '__main__':\n example_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),\n 'hvplot','examples')\n if 'develop' not in sys.argv:\n package_assets(example_path)\n\n setup(**setup_args)\n\n if os.path.isdir(example_path):\n shutil.rmtree(example_path)\n", "path": "setup.py"}]}
| 4,025 | 188 |
gh_patches_debug_35411
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1394
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ParentBased sampler ignores sample decision of parent when creating span via implicit Context
When having a `ParentBased` sampler setup and creating a span via `tracer.start_span` without explicitly providing a `context` as parent, possible parent spans in the current `Context` are ignored [ignored](https://github.com/open-telemetry/opentelemetry-python/blob/v0.15b0/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py#L230).
Since for implicit parents the passed `context` is always `None` the `ParentBased` sampler needs to consider also parent Spans in the current `Context` and, if available, respect their sampling flag instead of forwarding to the delegate sampler.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 For general information about sampling, see `the specification <https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/sdk.md#sampling>`_.
17
18 OpenTelemetry provides two types of samplers:
19
20 - `StaticSampler`
21 - `TraceIdRatioBased`
22
23 A `StaticSampler` always returns the same sampling result regardless of the conditions. Both possible StaticSamplers are already created:
24
25 - Always sample spans: ALWAYS_ON
26 - Never sample spans: ALWAYS_OFF
27
28 A `TraceIdRatioBased` sampler makes a random sampling result based on the sampling probability given.
29
30 If the span being sampled has a parent, `ParentBased` will respect the parent span's sampling result. Otherwise, it returns the sampling result from the given delegate sampler.
31
32 Currently, sampling results are always made during the creation of the span. However, this might not always be the case in the future (see `OTEP #115 <https://github.com/open-telemetry/oteps/pull/115>`_).
33
34 Custom samplers can be created by subclassing `Sampler` and implementing `Sampler.should_sample` as well as `Sampler.get_description`.
35
36 To use a sampler, pass it into the tracer provider constructor. For example:
37
38 .. code:: python
39
40 from opentelemetry import trace
41 from opentelemetry.sdk.trace import TracerProvider
42 from opentelemetry.sdk.trace.export import (
43 ConsoleSpanExporter,
44 SimpleExportSpanProcessor,
45 )
46 from opentelemetry.sdk.trace.sampling import TraceIdRatioBased
47
48 # sample 1 in every 1000 traces
49 sampler = TraceIdRatioBased(1/1000)
50
51 # set the sampler onto the global tracer provider
52 trace.set_tracer_provider(TracerProvider(sampler=sampler))
53
54 # set up an exporter for sampled spans
55 trace.get_tracer_provider().add_span_processor(
56 SimpleExportSpanProcessor(ConsoleSpanExporter())
57 )
58
59 # created spans will now be sampled by the TraceIdRatioBased sampler
60 with trace.get_tracer(__name__).start_as_current_span("Test Span"):
61 ...
62 """
63 import abc
64 import enum
65 from types import MappingProxyType
66 from typing import Optional, Sequence
67
68 # pylint: disable=unused-import
69 from opentelemetry.context import Context
70 from opentelemetry.trace import Link, get_current_span
71 from opentelemetry.trace.span import TraceState
72 from opentelemetry.util.types import Attributes
73
74
75 class Decision(enum.Enum):
76 # IsRecording() == false, span will not be recorded and all events and attributes will be dropped.
77 DROP = 0
78 # IsRecording() == true, but Sampled flag MUST NOT be set.
79 RECORD_ONLY = 1
80 # IsRecording() == true AND Sampled flag` MUST be set.
81 RECORD_AND_SAMPLE = 2
82
83 def is_recording(self):
84 return self in (Decision.RECORD_ONLY, Decision.RECORD_AND_SAMPLE)
85
86 def is_sampled(self):
87 return self is Decision.RECORD_AND_SAMPLE
88
89
90 class SamplingResult:
91 """A sampling result as applied to a newly-created Span.
92
93 Args:
94 decision: A sampling decision based off of whether the span is recorded
95 and the sampled flag in trace flags in the span context.
96 attributes: Attributes to add to the `opentelemetry.trace.Span`.
97 trace_state: The tracestate used for the `opentelemetry.trace.Span`.
98 Could possibly have been modified by the sampler.
99 """
100
101 def __repr__(self) -> str:
102 return "{}({}, attributes={})".format(
103 type(self).__name__, str(self.decision), str(self.attributes)
104 )
105
106 def __init__(
107 self,
108 decision: Decision,
109 attributes: "Attributes" = None,
110 trace_state: "TraceState" = None,
111 ) -> None:
112 self.decision = decision
113 if attributes is None:
114 self.attributes = MappingProxyType({})
115 else:
116 self.attributes = MappingProxyType(attributes)
117 self.trace_state = trace_state
118
119
120 class Sampler(abc.ABC):
121 @abc.abstractmethod
122 def should_sample(
123 self,
124 parent_context: Optional["Context"],
125 trace_id: int,
126 name: str,
127 attributes: Attributes = None,
128 links: Sequence["Link"] = None,
129 trace_state: "TraceState" = None,
130 ) -> "SamplingResult":
131 pass
132
133 @abc.abstractmethod
134 def get_description(self) -> str:
135 pass
136
137
138 class StaticSampler(Sampler):
139 """Sampler that always returns the same decision."""
140
141 def __init__(self, decision: "Decision"):
142 self._decision = decision
143
144 def should_sample(
145 self,
146 parent_context: Optional["Context"],
147 trace_id: int,
148 name: str,
149 attributes: Attributes = None,
150 links: Sequence["Link"] = None,
151 trace_state: "TraceState" = None,
152 ) -> "SamplingResult":
153 if self._decision is Decision.DROP:
154 return SamplingResult(self._decision)
155 return SamplingResult(self._decision, attributes, trace_state)
156
157 def get_description(self) -> str:
158 if self._decision is Decision.DROP:
159 return "AlwaysOffSampler"
160 return "AlwaysOnSampler"
161
162
163 class TraceIdRatioBased(Sampler):
164 """
165 Sampler that makes sampling decisions probabalistically based on `rate`,
166 while also respecting the parent span sampling decision.
167
168 Args:
169 rate: Probability (between 0 and 1) that a span will be sampled
170 """
171
172 def __init__(self, rate: float):
173 if rate < 0.0 or rate > 1.0:
174 raise ValueError("Probability must be in range [0.0, 1.0].")
175 self._rate = rate
176 self._bound = self.get_bound_for_rate(self._rate)
177
178 # For compatibility with 64 bit trace IDs, the sampler checks the 64
179 # low-order bits of the trace ID to decide whether to sample a given trace.
180 TRACE_ID_LIMIT = (1 << 64) - 1
181
182 @classmethod
183 def get_bound_for_rate(cls, rate: float) -> int:
184 return round(rate * (cls.TRACE_ID_LIMIT + 1))
185
186 @property
187 def rate(self) -> float:
188 return self._rate
189
190 @rate.setter
191 def rate(self, new_rate: float) -> None:
192 self._rate = new_rate
193 self._bound = self.get_bound_for_rate(self._rate)
194
195 @property
196 def bound(self) -> int:
197 return self._bound
198
199 def should_sample(
200 self,
201 parent_context: Optional["Context"],
202 trace_id: int,
203 name: str,
204 attributes: Attributes = None,
205 links: Sequence["Link"] = None,
206 trace_state: "TraceState" = None,
207 ) -> "SamplingResult":
208 decision = Decision.DROP
209 if trace_id & self.TRACE_ID_LIMIT < self.bound:
210 decision = Decision.RECORD_AND_SAMPLE
211 if decision is Decision.DROP:
212 return SamplingResult(decision)
213 return SamplingResult(decision, attributes)
214
215 def get_description(self) -> str:
216 return "TraceIdRatioBased{{{}}}".format(self._rate)
217
218
219 class ParentBased(Sampler):
220 """
221 If a parent is set, follows the same sampling decision as the parent.
222 Otherwise, uses the delegate provided at initialization to make a
223 decision.
224
225 Args:
226 delegate: The delegate sampler to use if parent is not set.
227 """
228
229 def __init__(self, delegate: Sampler):
230 self._delegate = delegate
231
232 def should_sample(
233 self,
234 parent_context: Optional["Context"],
235 trace_id: int,
236 name: str,
237 attributes: Attributes = None,
238 links: Sequence["Link"] = None,
239 trace_state: "TraceState" = None,
240 ) -> "SamplingResult":
241 if parent_context is not None:
242 parent_span_context = get_current_span(
243 parent_context
244 ).get_span_context()
245 # only drop if parent exists and is not a root span
246 if (
247 parent_span_context is not None
248 and parent_span_context.is_valid
249 and not parent_span_context.trace_flags.sampled
250 ):
251 return SamplingResult(Decision.DROP)
252 return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)
253
254 return self._delegate.should_sample(
255 parent_context=parent_context,
256 trace_id=trace_id,
257 name=name,
258 attributes=attributes,
259 links=links,
260 trace_state=trace_state,
261 )
262
263 def get_description(self):
264 return "ParentBased{{{}}}".format(self._delegate.get_description())
265
266
267 ALWAYS_OFF = StaticSampler(Decision.DROP)
268 """Sampler that never samples spans, regardless of the parent span's sampling decision."""
269
270 ALWAYS_ON = StaticSampler(Decision.RECORD_AND_SAMPLE)
271 """Sampler that always samples spans, regardless of the parent span's sampling decision."""
272
273 DEFAULT_OFF = ParentBased(ALWAYS_OFF)
274 """Sampler that respects its parent span's sampling decision, but otherwise never samples."""
275
276 DEFAULT_ON = ParentBased(ALWAYS_ON)
277 """Sampler that respects its parent span's sampling decision, but otherwise always samples."""
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
@@ -151,7 +151,7 @@
trace_state: "TraceState" = None,
) -> "SamplingResult":
if self._decision is Decision.DROP:
- return SamplingResult(self._decision)
+ attributes = None
return SamplingResult(self._decision, attributes, trace_state)
def get_description(self) -> str:
@@ -209,8 +209,8 @@
if trace_id & self.TRACE_ID_LIMIT < self.bound:
decision = Decision.RECORD_AND_SAMPLE
if decision is Decision.DROP:
- return SamplingResult(decision)
- return SamplingResult(decision, attributes)
+ attributes = None
+ return SamplingResult(decision, attributes, trace_state)
def get_description(self) -> str:
return "TraceIdRatioBased{{{}}}".format(self._rate)
@@ -238,18 +238,16 @@
links: Sequence["Link"] = None,
trace_state: "TraceState" = None,
) -> "SamplingResult":
- if parent_context is not None:
- parent_span_context = get_current_span(
- parent_context
- ).get_span_context()
- # only drop if parent exists and is not a root span
- if (
- parent_span_context is not None
- and parent_span_context.is_valid
- and not parent_span_context.trace_flags.sampled
- ):
- return SamplingResult(Decision.DROP)
- return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)
+ parent_span_context = get_current_span(
+ parent_context
+ ).get_span_context()
+ # respect the sampling flag of the parent if present
+ if parent_span_context is not None and parent_span_context.is_valid:
+ decision = Decision.RECORD_AND_SAMPLE
+ if not parent_span_context.trace_flags.sampled:
+ decision = Decision.DROP
+ attributes = None
+ return SamplingResult(decision, attributes, trace_state)
return self._delegate.should_sample(
parent_context=parent_context,
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n@@ -151,7 +151,7 @@\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if self._decision is Decision.DROP:\n- return SamplingResult(self._decision)\n+ attributes = None\n return SamplingResult(self._decision, attributes, trace_state)\n \n def get_description(self) -> str:\n@@ -209,8 +209,8 @@\n if trace_id & self.TRACE_ID_LIMIT < self.bound:\n decision = Decision.RECORD_AND_SAMPLE\n if decision is Decision.DROP:\n- return SamplingResult(decision)\n- return SamplingResult(decision, attributes)\n+ attributes = None\n+ return SamplingResult(decision, attributes, trace_state)\n \n def get_description(self) -> str:\n return \"TraceIdRatioBased{{{}}}\".format(self._rate)\n@@ -238,18 +238,16 @@\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n- if parent_context is not None:\n- parent_span_context = get_current_span(\n- parent_context\n- ).get_span_context()\n- # only drop if parent exists and is not a root span\n- if (\n- parent_span_context is not None\n- and parent_span_context.is_valid\n- and not parent_span_context.trace_flags.sampled\n- ):\n- return SamplingResult(Decision.DROP)\n- return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)\n+ parent_span_context = get_current_span(\n+ parent_context\n+ ).get_span_context()\n+ # respect the sampling flag of the parent if present\n+ if parent_span_context is not None and parent_span_context.is_valid:\n+ decision = Decision.RECORD_AND_SAMPLE\n+ if not parent_span_context.trace_flags.sampled:\n+ decision = Decision.DROP\n+ attributes = None\n+ return SamplingResult(decision, attributes, trace_state)\n \n return self._delegate.should_sample(\n parent_context=parent_context,\n", "issue": "ParentBased sampler ignores sample decision of parent when creating span via implicit Context\nWhen having a `ParentBased` sampler setup and creating a span via `tracer.start_span` without explicitly providing a `context` as parent, possible parent spans in the current `Context` are ignored [ignored](https://github.com/open-telemetry/opentelemetry-python/blob/v0.15b0/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py#L230). \r\nSince for implicit parents the passed `context` is always `None` the `ParentBased` sampler needs to consider also parent Spans in the current `Context` and, if available, respect their sampling flag instead of forwarding to the delegate sampler.\r\n\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nFor general information about sampling, see `the specification <https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/sdk.md#sampling>`_.\n\nOpenTelemetry provides two types of samplers:\n\n- `StaticSampler`\n- `TraceIdRatioBased`\n\nA `StaticSampler` always returns the same sampling result regardless of the conditions. Both possible StaticSamplers are already created:\n\n- Always sample spans: ALWAYS_ON\n- Never sample spans: ALWAYS_OFF\n\nA `TraceIdRatioBased` sampler makes a random sampling result based on the sampling probability given.\n\nIf the span being sampled has a parent, `ParentBased` will respect the parent span's sampling result. Otherwise, it returns the sampling result from the given delegate sampler.\n\nCurrently, sampling results are always made during the creation of the span. However, this might not always be the case in the future (see `OTEP #115 <https://github.com/open-telemetry/oteps/pull/115>`_).\n\nCustom samplers can be created by subclassing `Sampler` and implementing `Sampler.should_sample` as well as `Sampler.get_description`.\n\nTo use a sampler, pass it into the tracer provider constructor. For example:\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n )\n from opentelemetry.sdk.trace.sampling import TraceIdRatioBased\n\n # sample 1 in every 1000 traces\n sampler = TraceIdRatioBased(1/1000)\n\n # set the sampler onto the global tracer provider\n trace.set_tracer_provider(TracerProvider(sampler=sampler))\n\n # set up an exporter for sampled spans\n trace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n )\n\n # created spans will now be sampled by the TraceIdRatioBased sampler\n with trace.get_tracer(__name__).start_as_current_span(\"Test Span\"):\n ...\n\"\"\"\nimport abc\nimport enum\nfrom types import MappingProxyType\nfrom typing import Optional, Sequence\n\n# pylint: disable=unused-import\nfrom opentelemetry.context import Context\nfrom opentelemetry.trace import Link, get_current_span\nfrom opentelemetry.trace.span import TraceState\nfrom opentelemetry.util.types import Attributes\n\n\nclass Decision(enum.Enum):\n # IsRecording() == false, span will not be recorded and all events and attributes will be dropped.\n DROP = 0\n # IsRecording() == true, but Sampled flag MUST NOT be set.\n RECORD_ONLY = 1\n # IsRecording() == true AND Sampled flag` MUST be set.\n RECORD_AND_SAMPLE = 2\n\n def is_recording(self):\n return self in (Decision.RECORD_ONLY, Decision.RECORD_AND_SAMPLE)\n\n def is_sampled(self):\n return self is Decision.RECORD_AND_SAMPLE\n\n\nclass SamplingResult:\n \"\"\"A sampling result as applied to a newly-created Span.\n\n Args:\n decision: A sampling decision based off of whether the span is recorded\n and the sampled flag in trace flags in the span context.\n attributes: Attributes to add to the `opentelemetry.trace.Span`.\n trace_state: The tracestate used for the `opentelemetry.trace.Span`.\n Could possibly have been modified by the sampler.\n \"\"\"\n\n def __repr__(self) -> str:\n return \"{}({}, attributes={})\".format(\n type(self).__name__, str(self.decision), str(self.attributes)\n )\n\n def __init__(\n self,\n decision: Decision,\n attributes: \"Attributes\" = None,\n trace_state: \"TraceState\" = None,\n ) -> None:\n self.decision = decision\n if attributes is None:\n self.attributes = MappingProxyType({})\n else:\n self.attributes = MappingProxyType(attributes)\n self.trace_state = trace_state\n\n\nclass Sampler(abc.ABC):\n @abc.abstractmethod\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n pass\n\n @abc.abstractmethod\n def get_description(self) -> str:\n pass\n\n\nclass StaticSampler(Sampler):\n \"\"\"Sampler that always returns the same decision.\"\"\"\n\n def __init__(self, decision: \"Decision\"):\n self._decision = decision\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if self._decision is Decision.DROP:\n return SamplingResult(self._decision)\n return SamplingResult(self._decision, attributes, trace_state)\n\n def get_description(self) -> str:\n if self._decision is Decision.DROP:\n return \"AlwaysOffSampler\"\n return \"AlwaysOnSampler\"\n\n\nclass TraceIdRatioBased(Sampler):\n \"\"\"\n Sampler that makes sampling decisions probabalistically based on `rate`,\n while also respecting the parent span sampling decision.\n\n Args:\n rate: Probability (between 0 and 1) that a span will be sampled\n \"\"\"\n\n def __init__(self, rate: float):\n if rate < 0.0 or rate > 1.0:\n raise ValueError(\"Probability must be in range [0.0, 1.0].\")\n self._rate = rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n # For compatibility with 64 bit trace IDs, the sampler checks the 64\n # low-order bits of the trace ID to decide whether to sample a given trace.\n TRACE_ID_LIMIT = (1 << 64) - 1\n\n @classmethod\n def get_bound_for_rate(cls, rate: float) -> int:\n return round(rate * (cls.TRACE_ID_LIMIT + 1))\n\n @property\n def rate(self) -> float:\n return self._rate\n\n @rate.setter\n def rate(self, new_rate: float) -> None:\n self._rate = new_rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n @property\n def bound(self) -> int:\n return self._bound\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n decision = Decision.DROP\n if trace_id & self.TRACE_ID_LIMIT < self.bound:\n decision = Decision.RECORD_AND_SAMPLE\n if decision is Decision.DROP:\n return SamplingResult(decision)\n return SamplingResult(decision, attributes)\n\n def get_description(self) -> str:\n return \"TraceIdRatioBased{{{}}}\".format(self._rate)\n\n\nclass ParentBased(Sampler):\n \"\"\"\n If a parent is set, follows the same sampling decision as the parent.\n Otherwise, uses the delegate provided at initialization to make a\n decision.\n\n Args:\n delegate: The delegate sampler to use if parent is not set.\n \"\"\"\n\n def __init__(self, delegate: Sampler):\n self._delegate = delegate\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if parent_context is not None:\n parent_span_context = get_current_span(\n parent_context\n ).get_span_context()\n # only drop if parent exists and is not a root span\n if (\n parent_span_context is not None\n and parent_span_context.is_valid\n and not parent_span_context.trace_flags.sampled\n ):\n return SamplingResult(Decision.DROP)\n return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)\n\n return self._delegate.should_sample(\n parent_context=parent_context,\n trace_id=trace_id,\n name=name,\n attributes=attributes,\n links=links,\n trace_state=trace_state,\n )\n\n def get_description(self):\n return \"ParentBased{{{}}}\".format(self._delegate.get_description())\n\n\nALWAYS_OFF = StaticSampler(Decision.DROP)\n\"\"\"Sampler that never samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nALWAYS_ON = StaticSampler(Decision.RECORD_AND_SAMPLE)\n\"\"\"Sampler that always samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nDEFAULT_OFF = ParentBased(ALWAYS_OFF)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise never samples.\"\"\"\n\nDEFAULT_ON = ParentBased(ALWAYS_ON)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise always samples.\"\"\"\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nFor general information about sampling, see `the specification <https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/sdk.md#sampling>`_.\n\nOpenTelemetry provides two types of samplers:\n\n- `StaticSampler`\n- `TraceIdRatioBased`\n\nA `StaticSampler` always returns the same sampling result regardless of the conditions. Both possible StaticSamplers are already created:\n\n- Always sample spans: ALWAYS_ON\n- Never sample spans: ALWAYS_OFF\n\nA `TraceIdRatioBased` sampler makes a random sampling result based on the sampling probability given.\n\nIf the span being sampled has a parent, `ParentBased` will respect the parent span's sampling result. Otherwise, it returns the sampling result from the given delegate sampler.\n\nCurrently, sampling results are always made during the creation of the span. However, this might not always be the case in the future (see `OTEP #115 <https://github.com/open-telemetry/oteps/pull/115>`_).\n\nCustom samplers can be created by subclassing `Sampler` and implementing `Sampler.should_sample` as well as `Sampler.get_description`.\n\nTo use a sampler, pass it into the tracer provider constructor. For example:\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n )\n from opentelemetry.sdk.trace.sampling import TraceIdRatioBased\n\n # sample 1 in every 1000 traces\n sampler = TraceIdRatioBased(1/1000)\n\n # set the sampler onto the global tracer provider\n trace.set_tracer_provider(TracerProvider(sampler=sampler))\n\n # set up an exporter for sampled spans\n trace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n )\n\n # created spans will now be sampled by the TraceIdRatioBased sampler\n with trace.get_tracer(__name__).start_as_current_span(\"Test Span\"):\n ...\n\"\"\"\nimport abc\nimport enum\nfrom types import MappingProxyType\nfrom typing import Optional, Sequence\n\n# pylint: disable=unused-import\nfrom opentelemetry.context import Context\nfrom opentelemetry.trace import Link, get_current_span\nfrom opentelemetry.trace.span import TraceState\nfrom opentelemetry.util.types import Attributes\n\n\nclass Decision(enum.Enum):\n # IsRecording() == false, span will not be recorded and all events and attributes will be dropped.\n DROP = 0\n # IsRecording() == true, but Sampled flag MUST NOT be set.\n RECORD_ONLY = 1\n # IsRecording() == true AND Sampled flag` MUST be set.\n RECORD_AND_SAMPLE = 2\n\n def is_recording(self):\n return self in (Decision.RECORD_ONLY, Decision.RECORD_AND_SAMPLE)\n\n def is_sampled(self):\n return self is Decision.RECORD_AND_SAMPLE\n\n\nclass SamplingResult:\n \"\"\"A sampling result as applied to a newly-created Span.\n\n Args:\n decision: A sampling decision based off of whether the span is recorded\n and the sampled flag in trace flags in the span context.\n attributes: Attributes to add to the `opentelemetry.trace.Span`.\n trace_state: The tracestate used for the `opentelemetry.trace.Span`.\n Could possibly have been modified by the sampler.\n \"\"\"\n\n def __repr__(self) -> str:\n return \"{}({}, attributes={})\".format(\n type(self).__name__, str(self.decision), str(self.attributes)\n )\n\n def __init__(\n self,\n decision: Decision,\n attributes: \"Attributes\" = None,\n trace_state: \"TraceState\" = None,\n ) -> None:\n self.decision = decision\n if attributes is None:\n self.attributes = MappingProxyType({})\n else:\n self.attributes = MappingProxyType(attributes)\n self.trace_state = trace_state\n\n\nclass Sampler(abc.ABC):\n @abc.abstractmethod\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n pass\n\n @abc.abstractmethod\n def get_description(self) -> str:\n pass\n\n\nclass StaticSampler(Sampler):\n \"\"\"Sampler that always returns the same decision.\"\"\"\n\n def __init__(self, decision: \"Decision\"):\n self._decision = decision\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if self._decision is Decision.DROP:\n attributes = None\n return SamplingResult(self._decision, attributes, trace_state)\n\n def get_description(self) -> str:\n if self._decision is Decision.DROP:\n return \"AlwaysOffSampler\"\n return \"AlwaysOnSampler\"\n\n\nclass TraceIdRatioBased(Sampler):\n \"\"\"\n Sampler that makes sampling decisions probabalistically based on `rate`,\n while also respecting the parent span sampling decision.\n\n Args:\n rate: Probability (between 0 and 1) that a span will be sampled\n \"\"\"\n\n def __init__(self, rate: float):\n if rate < 0.0 or rate > 1.0:\n raise ValueError(\"Probability must be in range [0.0, 1.0].\")\n self._rate = rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n # For compatibility with 64 bit trace IDs, the sampler checks the 64\n # low-order bits of the trace ID to decide whether to sample a given trace.\n TRACE_ID_LIMIT = (1 << 64) - 1\n\n @classmethod\n def get_bound_for_rate(cls, rate: float) -> int:\n return round(rate * (cls.TRACE_ID_LIMIT + 1))\n\n @property\n def rate(self) -> float:\n return self._rate\n\n @rate.setter\n def rate(self, new_rate: float) -> None:\n self._rate = new_rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n @property\n def bound(self) -> int:\n return self._bound\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n decision = Decision.DROP\n if trace_id & self.TRACE_ID_LIMIT < self.bound:\n decision = Decision.RECORD_AND_SAMPLE\n if decision is Decision.DROP:\n attributes = None\n return SamplingResult(decision, attributes, trace_state)\n\n def get_description(self) -> str:\n return \"TraceIdRatioBased{{{}}}\".format(self._rate)\n\n\nclass ParentBased(Sampler):\n \"\"\"\n If a parent is set, follows the same sampling decision as the parent.\n Otherwise, uses the delegate provided at initialization to make a\n decision.\n\n Args:\n delegate: The delegate sampler to use if parent is not set.\n \"\"\"\n\n def __init__(self, delegate: Sampler):\n self._delegate = delegate\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n parent_span_context = get_current_span(\n parent_context\n ).get_span_context()\n # respect the sampling flag of the parent if present\n if parent_span_context is not None and parent_span_context.is_valid:\n decision = Decision.RECORD_AND_SAMPLE\n if not parent_span_context.trace_flags.sampled:\n decision = Decision.DROP\n attributes = None\n return SamplingResult(decision, attributes, trace_state)\n\n return self._delegate.should_sample(\n parent_context=parent_context,\n trace_id=trace_id,\n name=name,\n attributes=attributes,\n links=links,\n trace_state=trace_state,\n )\n\n def get_description(self):\n return \"ParentBased{{{}}}\".format(self._delegate.get_description())\n\n\nALWAYS_OFF = StaticSampler(Decision.DROP)\n\"\"\"Sampler that never samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nALWAYS_ON = StaticSampler(Decision.RECORD_AND_SAMPLE)\n\"\"\"Sampler that always samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nDEFAULT_OFF = ParentBased(ALWAYS_OFF)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise never samples.\"\"\"\n\nDEFAULT_ON = ParentBased(ALWAYS_ON)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise always samples.\"\"\"\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py"}]}
| 3,256 | 523 |
gh_patches_debug_10313
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-4049
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[DOC] Fix Sphinx issues related to adding new experimental module and typing
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe your proposed suggestion in detail.
1. Linkcode extension error https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739213117 and related workaround: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/sphinxext/github_link.py#L43-L44
2. See Sphinx warning https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739630179 and related hotfix of remving sphinx role here: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/modules/experimental.rst?plain=1#L10
3. Sphinx autodoc has an issue with resolving external libraries like numpy when using typehints. It seems to be a bug similar to what is reported here https://github.com/sphinx-doc/sphinx/issues/10785. For now this autodoc argument is added to hide the typehints from the integrated typing https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/conf.py#L57
And if we have both docstrings and the typehints we have double rendering in the docs of the description of a e.g. class and this is redundant and looks ugly so we should also discuss how we want to approach adding docstrings + typing and how to configure what will be displayed. I'll post an example once the dev docs are built
### List any pages that would be impacted.
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/sphinxext/github_link.py`
Content:
```
1 import inspect
2 import os
3 import subprocess
4 import sys
5 from functools import partial
6 from operator import attrgetter
7
8 REVISION_CMD = "git rev-parse --short HEAD"
9
10
11 def _get_git_revision():
12 try:
13 revision = subprocess.check_output(REVISION_CMD.split()).strip()
14 except (subprocess.CalledProcessError, OSError):
15 print("Failed to execute git to get revision")
16 return None
17 return revision.decode("utf-8")
18
19
20 def _linkcode_resolve(domain, info, package, url_fmt, revision):
21 """Determine a link to online source for a class/method/function.
22
23 This is called by sphinx.ext.linkcode
24
25 An example with a long-untouched module that everyone has
26 >>> _linkcode_resolve('py', {'module': 'tty',
27 ... 'fullname': 'setraw'},
28 ... package='tty',
29 ... url_fmt='http://hg.python.org/cpython/file/'
30 ... '{revision}/Lib/{package}/{path}#L{lineno}',
31 ... revision='xxxx')
32 'http://hg.python.org/cpython/file/xxxx/Lib/tty/tty.py#L18'
33 """
34 if revision is None:
35 return
36 if domain not in ("py", "pyx"):
37 return
38 if not info.get("module") or not info.get("fullname"):
39 return
40
41 class_name = info["fullname"].split(".")[0]
42 module = __import__(info["module"], fromlist=[class_name])
43 if info["module"] == "nilearn.experimental.surface":
44 return
45 obj = attrgetter(info["fullname"])(module)
46
47 # Unwrap the object to get the correct source
48 # file in case that is wrapped by a decorator
49 obj = inspect.unwrap(obj)
50
51 try:
52 fn = inspect.getsourcefile(obj)
53 except Exception:
54 fn = None
55 if not fn:
56 try:
57 fn = inspect.getsourcefile(sys.modules[obj.__module__])
58 except Exception:
59 fn = None
60 if not fn:
61 return
62
63 # Don't include filenames from outside this package's tree
64 if os.path.dirname(__import__(package).__file__) not in fn:
65 return
66
67 fn = os.path.relpath(
68 fn, start=os.path.dirname(__import__(package).__file__)
69 )
70 try:
71 lineno = inspect.getsourcelines(obj)[1]
72 except Exception:
73 lineno = ""
74 return url_fmt.format(
75 revision=revision, package=package, path=fn, lineno=lineno
76 )
77
78
79 def make_linkcode_resolve(package, url_fmt):
80 """Return a linkcode_resolve function for the given URL format.
81
82 revision is a git commit reference (hash or name)
83
84 package is the name of the root module of the package
85
86 url_fmt is along the lines of ('https://github.com/USER/PROJECT/'
87 'blob/{revision}/{package}/'
88 '{path}#L{lineno}')
89 """
90 revision = _get_git_revision()
91 return partial(
92 _linkcode_resolve, revision=revision, package=package, url_fmt=url_fmt
93 )
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/sphinxext/github_link.py b/doc/sphinxext/github_link.py
--- a/doc/sphinxext/github_link.py
+++ b/doc/sphinxext/github_link.py
@@ -40,9 +40,12 @@
class_name = info["fullname"].split(".")[0]
module = __import__(info["module"], fromlist=[class_name])
- if info["module"] == "nilearn.experimental.surface":
+ # For typed parameters, this will try to get uninitialized attributes
+ # and fail
+ try:
+ obj = attrgetter(info["fullname"])(module)
+ except AttributeError:
return
- obj = attrgetter(info["fullname"])(module)
# Unwrap the object to get the correct source
# file in case that is wrapped by a decorator
|
{"golden_diff": "diff --git a/doc/sphinxext/github_link.py b/doc/sphinxext/github_link.py\n--- a/doc/sphinxext/github_link.py\n+++ b/doc/sphinxext/github_link.py\n@@ -40,9 +40,12 @@\n \n class_name = info[\"fullname\"].split(\".\")[0]\n module = __import__(info[\"module\"], fromlist=[class_name])\n- if info[\"module\"] == \"nilearn.experimental.surface\":\n+ # For typed parameters, this will try to get uninitialized attributes\n+ # and fail\n+ try:\n+ obj = attrgetter(info[\"fullname\"])(module)\n+ except AttributeError:\n return\n- obj = attrgetter(info[\"fullname\"])(module)\n \n # Unwrap the object to get the correct source\n # file in case that is wrapped by a decorator\n", "issue": "[DOC] Fix Sphinx issues related to adding new experimental module and typing\n### Is there an existing issue for this?\r\n\r\n- [X] I have searched the existing issues\r\n\r\n### Describe your proposed suggestion in detail.\r\n\r\n1. Linkcode extension error https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739213117 and related workaround: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/sphinxext/github_link.py#L43-L44\r\n\r\n2. See Sphinx warning https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739630179 and related hotfix of remving sphinx role here: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/modules/experimental.rst?plain=1#L10\r\n\r\n3. Sphinx autodoc has an issue with resolving external libraries like numpy when using typehints. It seems to be a bug similar to what is reported here https://github.com/sphinx-doc/sphinx/issues/10785. For now this autodoc argument is added to hide the typehints from the integrated typing https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/conf.py#L57\r\nAnd if we have both docstrings and the typehints we have double rendering in the docs of the description of a e.g. class and this is redundant and looks ugly so we should also discuss how we want to approach adding docstrings + typing and how to configure what will be displayed. I'll post an example once the dev docs are built\r\n\r\n### List any pages that would be impacted.\r\n\r\n_No response_\n", "before_files": [{"content": "import inspect\nimport os\nimport subprocess\nimport sys\nfrom functools import partial\nfrom operator import attrgetter\n\nREVISION_CMD = \"git rev-parse --short HEAD\"\n\n\ndef _get_git_revision():\n try:\n revision = subprocess.check_output(REVISION_CMD.split()).strip()\n except (subprocess.CalledProcessError, OSError):\n print(\"Failed to execute git to get revision\")\n return None\n return revision.decode(\"utf-8\")\n\n\ndef _linkcode_resolve(domain, info, package, url_fmt, revision):\n \"\"\"Determine a link to online source for a class/method/function.\n\n This is called by sphinx.ext.linkcode\n\n An example with a long-untouched module that everyone has\n >>> _linkcode_resolve('py', {'module': 'tty',\n ... 'fullname': 'setraw'},\n ... package='tty',\n ... url_fmt='http://hg.python.org/cpython/file/'\n ... '{revision}/Lib/{package}/{path}#L{lineno}',\n ... revision='xxxx')\n 'http://hg.python.org/cpython/file/xxxx/Lib/tty/tty.py#L18'\n \"\"\"\n if revision is None:\n return\n if domain not in (\"py\", \"pyx\"):\n return\n if not info.get(\"module\") or not info.get(\"fullname\"):\n return\n\n class_name = info[\"fullname\"].split(\".\")[0]\n module = __import__(info[\"module\"], fromlist=[class_name])\n if info[\"module\"] == \"nilearn.experimental.surface\":\n return\n obj = attrgetter(info[\"fullname\"])(module)\n\n # Unwrap the object to get the correct source\n # file in case that is wrapped by a decorator\n obj = inspect.unwrap(obj)\n\n try:\n fn = inspect.getsourcefile(obj)\n except Exception:\n fn = None\n if not fn:\n try:\n fn = inspect.getsourcefile(sys.modules[obj.__module__])\n except Exception:\n fn = None\n if not fn:\n return\n\n # Don't include filenames from outside this package's tree\n if os.path.dirname(__import__(package).__file__) not in fn:\n return\n\n fn = os.path.relpath(\n fn, start=os.path.dirname(__import__(package).__file__)\n )\n try:\n lineno = inspect.getsourcelines(obj)[1]\n except Exception:\n lineno = \"\"\n return url_fmt.format(\n revision=revision, package=package, path=fn, lineno=lineno\n )\n\n\ndef make_linkcode_resolve(package, url_fmt):\n \"\"\"Return a linkcode_resolve function for the given URL format.\n\n revision is a git commit reference (hash or name)\n\n package is the name of the root module of the package\n\n url_fmt is along the lines of ('https://github.com/USER/PROJECT/'\n 'blob/{revision}/{package}/'\n '{path}#L{lineno}')\n \"\"\"\n revision = _get_git_revision()\n return partial(\n _linkcode_resolve, revision=revision, package=package, url_fmt=url_fmt\n )\n", "path": "doc/sphinxext/github_link.py"}], "after_files": [{"content": "import inspect\nimport os\nimport subprocess\nimport sys\nfrom functools import partial\nfrom operator import attrgetter\n\nREVISION_CMD = \"git rev-parse --short HEAD\"\n\n\ndef _get_git_revision():\n try:\n revision = subprocess.check_output(REVISION_CMD.split()).strip()\n except (subprocess.CalledProcessError, OSError):\n print(\"Failed to execute git to get revision\")\n return None\n return revision.decode(\"utf-8\")\n\n\ndef _linkcode_resolve(domain, info, package, url_fmt, revision):\n \"\"\"Determine a link to online source for a class/method/function.\n\n This is called by sphinx.ext.linkcode\n\n An example with a long-untouched module that everyone has\n >>> _linkcode_resolve('py', {'module': 'tty',\n ... 'fullname': 'setraw'},\n ... package='tty',\n ... url_fmt='http://hg.python.org/cpython/file/'\n ... '{revision}/Lib/{package}/{path}#L{lineno}',\n ... revision='xxxx')\n 'http://hg.python.org/cpython/file/xxxx/Lib/tty/tty.py#L18'\n \"\"\"\n if revision is None:\n return\n if domain not in (\"py\", \"pyx\"):\n return\n if not info.get(\"module\") or not info.get(\"fullname\"):\n return\n\n class_name = info[\"fullname\"].split(\".\")[0]\n module = __import__(info[\"module\"], fromlist=[class_name])\n # For typed parameters, this will try to get uninitialized attributes\n # and fail\n try:\n obj = attrgetter(info[\"fullname\"])(module)\n except AttributeError:\n return\n\n # Unwrap the object to get the correct source\n # file in case that is wrapped by a decorator\n obj = inspect.unwrap(obj)\n\n try:\n fn = inspect.getsourcefile(obj)\n except Exception:\n fn = None\n if not fn:\n try:\n fn = inspect.getsourcefile(sys.modules[obj.__module__])\n except Exception:\n fn = None\n if not fn:\n return\n\n # Don't include filenames from outside this package's tree\n if os.path.dirname(__import__(package).__file__) not in fn:\n return\n\n fn = os.path.relpath(\n fn, start=os.path.dirname(__import__(package).__file__)\n )\n try:\n lineno = inspect.getsourcelines(obj)[1]\n except Exception:\n lineno = \"\"\n return url_fmt.format(\n revision=revision, package=package, path=fn, lineno=lineno\n )\n\n\ndef make_linkcode_resolve(package, url_fmt):\n \"\"\"Return a linkcode_resolve function for the given URL format.\n\n revision is a git commit reference (hash or name)\n\n package is the name of the root module of the package\n\n url_fmt is along the lines of ('https://github.com/USER/PROJECT/'\n 'blob/{revision}/{package}/'\n '{path}#L{lineno}')\n \"\"\"\n revision = _get_git_revision()\n return partial(\n _linkcode_resolve, revision=revision, package=package, url_fmt=url_fmt\n )\n", "path": "doc/sphinxext/github_link.py"}]}
| 1,580 | 182 |
gh_patches_debug_31327
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-8162
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Resources loading on Windows (follow-up from #8159)
## Observed behavior
After Promise.polyfill issue was fixed to restore IE11 compatibility in #8159, resources (HTML5, videos) are not loading on all browsers on Windows, but those on Ubuntu Linux are not affected.
HTML on IE11 | HTML on Firefox | videos on FF & Chrome
--- | --- | ---
 |  |  <br> 
## Errors and logs
…
## Expected behavior
Resources loading correctly on IE11, Firefox and Chrome on Windows.
## User-facing consequences
...
## Steps to reproduce
…
## Context
* Kolibri version: 0.15/develop
* Operating system: Windows 7
* Browser: all
cc @rtibbles
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/utils/kolibri_whitenoise.py`
Content:
```
1 import os
2 import re
3 import stat
4 from collections import OrderedDict
5
6 from django.contrib.staticfiles import finders
7 from django.core.files.storage import FileSystemStorage
8 from whitenoise import WhiteNoise
9 from whitenoise.string_utils import decode_path_info
10
11
12 class FileFinder(finders.FileSystemFinder):
13 """
14 A modified version of the Django FileSystemFinder class
15 which allows us to pass in arbitrary locations to find files
16 """
17
18 def __init__(self, locations):
19 # List of locations with static files
20 self.locations = []
21 self.prefixes = set()
22 # Maps dir paths to an appropriate storage instance
23 self.storages = OrderedDict()
24 if not isinstance(locations, (list, tuple)):
25 raise TypeError("locations argument is not a tuple or list")
26 for root in locations:
27 prefix, root = root
28 # Django requires paths, even on Windows, to use forward slashes
29 # do this substitution that will be idempotent on Unix
30 root = root.replace(os.sep, "/")
31 if not prefix:
32 raise ValueError(
33 "Cannot use unprefixed locations for dynamic locations"
34 )
35 else:
36 prefix = prefix.rstrip("/")
37 if (prefix, root) not in self.locations:
38 self.locations.append((prefix, root))
39 self.prefixes.add(prefix)
40 for prefix, root in self.locations:
41 filesystem_storage = FileSystemStorage(location=root)
42 filesystem_storage.prefix = prefix
43 self.storages[root] = filesystem_storage
44
45 def find(self, path, all=False):
46 path = path.replace("/", os.sep)
47 return super(FileFinder, self).find(path, all=all)
48
49
50 class DynamicWhiteNoise(WhiteNoise):
51 def __init__(self, application, dynamic_locations=None, **kwargs):
52 whitenoise_settings = {
53 # Use 1 day as the default cache time for static assets
54 "max_age": 24 * 60 * 60,
55 # Add a test for any file name that contains a semantic version number
56 # or a 32 digit number (assumed to be a file hash)
57 # these files will be cached indefinitely
58 "immutable_file_test": r"((0|[1-9]\d*)\.(0|[1-9]\d*)\.(0|[1-9]\d*)|[a-f0-9]{32})",
59 "autorefresh": os.environ.get("KOLIBRI_DEVELOPER_MODE", False),
60 }
61 kwargs.update(whitenoise_settings)
62 super(DynamicWhiteNoise, self).__init__(application, **kwargs)
63 self.dynamic_finder = FileFinder(dynamic_locations or [])
64 # Generate a regex to check if a path matches one of our dynamic
65 # location prefixes
66 self.dynamic_check = (
67 re.compile("^({})".format("|".join(self.dynamic_finder.prefixes)))
68 if self.dynamic_finder.prefixes
69 else None
70 )
71
72 def __call__(self, environ, start_response):
73 path = decode_path_info(environ.get("PATH_INFO", ""))
74 if self.autorefresh:
75 static_file = self.find_file(path)
76 else:
77 static_file = self.files.get(path)
78 if static_file is None:
79 static_file = self.find_and_cache_dynamic_file(path)
80 if static_file is None:
81 return self.application(environ, start_response)
82 else:
83 return self.serve(static_file, environ, start_response)
84
85 def find_and_cache_dynamic_file(self, url):
86 path = self.get_dynamic_path(url)
87 if path:
88 file_stat = os.stat(path)
89 # Only try to do matches for regular files.
90 if stat.S_ISREG(file_stat.st_mode):
91 stat_cache = {path: os.stat(path)}
92 self.add_file_to_dictionary(url, path, stat_cache=stat_cache)
93 return self.files.get(url)
94
95 def get_dynamic_path(self, url):
96 if self.dynamic_check is not None and self.dynamic_check.match(url):
97 return self.dynamic_finder.find(url)
98
99 def candidate_paths_for_url(self, url):
100 paths = super(DynamicWhiteNoise, self).candidate_paths_for_url(url)
101 for path in paths:
102 yield path
103 path = self.get_dynamic_path(url)
104 if path:
105 yield path
106
107
108 class DjangoWhiteNoise(DynamicWhiteNoise):
109 def __init__(self, application, static_prefix=None, **kwargs):
110 super(DjangoWhiteNoise, self).__init__(application, **kwargs)
111 self.static_prefix = static_prefix
112 if not self.autorefresh and self.static_prefix:
113 self.add_files_from_finders()
114
115 def add_files_from_finders(self):
116 files = {}
117 for finder in finders.get_finders():
118 for path, storage in finder.list(None):
119 prefix = (getattr(storage, "prefix", None) or "").strip("/")
120 url = u"".join(
121 (
122 self.static_prefix,
123 prefix,
124 "/" if prefix else "",
125 path.replace("\\", "/"),
126 )
127 )
128 # Use setdefault as only first matching file should be used
129 files.setdefault(url, storage.path(path))
130 stat_cache = {path: os.stat(path) for path in files.values()}
131 for url, path in files.items():
132 self.add_file_to_dictionary(url, path, stat_cache=stat_cache)
133
134 def candidate_paths_for_url(self, url):
135 paths = super(DjangoWhiteNoise, self).candidate_paths_for_url(url)
136 for path in paths:
137 yield path
138 if self.autorefresh and url.startswith(self.static_prefix):
139 path = finders.find(url[len(self.static_prefix) :])
140 if path:
141 yield path
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/utils/kolibri_whitenoise.py b/kolibri/utils/kolibri_whitenoise.py
--- a/kolibri/utils/kolibri_whitenoise.py
+++ b/kolibri/utils/kolibri_whitenoise.py
@@ -5,6 +5,7 @@
from django.contrib.staticfiles import finders
from django.core.files.storage import FileSystemStorage
+from django.utils._os import safe_join
from whitenoise import WhiteNoise
from whitenoise.string_utils import decode_path_info
@@ -25,9 +26,6 @@
raise TypeError("locations argument is not a tuple or list")
for root in locations:
prefix, root = root
- # Django requires paths, even on Windows, to use forward slashes
- # do this substitution that will be idempotent on Unix
- root = root.replace(os.sep, "/")
if not prefix:
raise ValueError(
"Cannot use unprefixed locations for dynamic locations"
@@ -42,9 +40,20 @@
filesystem_storage.prefix = prefix
self.storages[root] = filesystem_storage
- def find(self, path, all=False):
- path = path.replace("/", os.sep)
- return super(FileFinder, self).find(path, all=all)
+ def find_location(self, root, path, prefix=None):
+ """
+ Finds a requested static file in a location, returning the found
+ absolute path (or ``None`` if no match).
+ Vendored from Django to handle being passed a URL path instead of a file path.
+ """
+ if prefix:
+ prefix = prefix + "/"
+ if not path.startswith(prefix):
+ return None
+ path = path[len(prefix) :]
+ path = safe_join(root, path)
+ if os.path.exists(path):
+ return path
class DynamicWhiteNoise(WhiteNoise):
|
{"golden_diff": "diff --git a/kolibri/utils/kolibri_whitenoise.py b/kolibri/utils/kolibri_whitenoise.py\n--- a/kolibri/utils/kolibri_whitenoise.py\n+++ b/kolibri/utils/kolibri_whitenoise.py\n@@ -5,6 +5,7 @@\n \n from django.contrib.staticfiles import finders\n from django.core.files.storage import FileSystemStorage\n+from django.utils._os import safe_join\n from whitenoise import WhiteNoise\n from whitenoise.string_utils import decode_path_info\n \n@@ -25,9 +26,6 @@\n raise TypeError(\"locations argument is not a tuple or list\")\n for root in locations:\n prefix, root = root\n- # Django requires paths, even on Windows, to use forward slashes\n- # do this substitution that will be idempotent on Unix\n- root = root.replace(os.sep, \"/\")\n if not prefix:\n raise ValueError(\n \"Cannot use unprefixed locations for dynamic locations\"\n@@ -42,9 +40,20 @@\n filesystem_storage.prefix = prefix\n self.storages[root] = filesystem_storage\n \n- def find(self, path, all=False):\n- path = path.replace(\"/\", os.sep)\n- return super(FileFinder, self).find(path, all=all)\n+ def find_location(self, root, path, prefix=None):\n+ \"\"\"\n+ Finds a requested static file in a location, returning the found\n+ absolute path (or ``None`` if no match).\n+ Vendored from Django to handle being passed a URL path instead of a file path.\n+ \"\"\"\n+ if prefix:\n+ prefix = prefix + \"/\"\n+ if not path.startswith(prefix):\n+ return None\n+ path = path[len(prefix) :]\n+ path = safe_join(root, path)\n+ if os.path.exists(path):\n+ return path\n \n \n class DynamicWhiteNoise(WhiteNoise):\n", "issue": "Resources loading on Windows (follow-up from #8159)\n\r\n## Observed behavior\r\nAfter Promise.polyfill issue was fixed to restore IE11 compatibility in #8159, resources (HTML5, videos) are not loading on all browsers on Windows, but those on Ubuntu Linux are not affected.\r\n\r\nHTML on IE11 | HTML on Firefox | videos on FF & Chrome\r\n--- | --- | --- \r\n |  |  <br> \r\n\r\n## Errors and logs\r\n\u2026\r\n\r\n## Expected behavior\r\nResources loading correctly on IE11, Firefox and Chrome on Windows.\r\n\r\n## User-facing consequences\r\n...\r\n\r\n## Steps to reproduce\r\n\u2026\r\n\r\n## Context\r\n * Kolibri version: 0.15/develop\r\n * Operating system: Windows 7\r\n * Browser: all\r\n\r\ncc @rtibbles \r\n\n", "before_files": [{"content": "import os\nimport re\nimport stat\nfrom collections import OrderedDict\n\nfrom django.contrib.staticfiles import finders\nfrom django.core.files.storage import FileSystemStorage\nfrom whitenoise import WhiteNoise\nfrom whitenoise.string_utils import decode_path_info\n\n\nclass FileFinder(finders.FileSystemFinder):\n \"\"\"\n A modified version of the Django FileSystemFinder class\n which allows us to pass in arbitrary locations to find files\n \"\"\"\n\n def __init__(self, locations):\n # List of locations with static files\n self.locations = []\n self.prefixes = set()\n # Maps dir paths to an appropriate storage instance\n self.storages = OrderedDict()\n if not isinstance(locations, (list, tuple)):\n raise TypeError(\"locations argument is not a tuple or list\")\n for root in locations:\n prefix, root = root\n # Django requires paths, even on Windows, to use forward slashes\n # do this substitution that will be idempotent on Unix\n root = root.replace(os.sep, \"/\")\n if not prefix:\n raise ValueError(\n \"Cannot use unprefixed locations for dynamic locations\"\n )\n else:\n prefix = prefix.rstrip(\"/\")\n if (prefix, root) not in self.locations:\n self.locations.append((prefix, root))\n self.prefixes.add(prefix)\n for prefix, root in self.locations:\n filesystem_storage = FileSystemStorage(location=root)\n filesystem_storage.prefix = prefix\n self.storages[root] = filesystem_storage\n\n def find(self, path, all=False):\n path = path.replace(\"/\", os.sep)\n return super(FileFinder, self).find(path, all=all)\n\n\nclass DynamicWhiteNoise(WhiteNoise):\n def __init__(self, application, dynamic_locations=None, **kwargs):\n whitenoise_settings = {\n # Use 1 day as the default cache time for static assets\n \"max_age\": 24 * 60 * 60,\n # Add a test for any file name that contains a semantic version number\n # or a 32 digit number (assumed to be a file hash)\n # these files will be cached indefinitely\n \"immutable_file_test\": r\"((0|[1-9]\\d*)\\.(0|[1-9]\\d*)\\.(0|[1-9]\\d*)|[a-f0-9]{32})\",\n \"autorefresh\": os.environ.get(\"KOLIBRI_DEVELOPER_MODE\", False),\n }\n kwargs.update(whitenoise_settings)\n super(DynamicWhiteNoise, self).__init__(application, **kwargs)\n self.dynamic_finder = FileFinder(dynamic_locations or [])\n # Generate a regex to check if a path matches one of our dynamic\n # location prefixes\n self.dynamic_check = (\n re.compile(\"^({})\".format(\"|\".join(self.dynamic_finder.prefixes)))\n if self.dynamic_finder.prefixes\n else None\n )\n\n def __call__(self, environ, start_response):\n path = decode_path_info(environ.get(\"PATH_INFO\", \"\"))\n if self.autorefresh:\n static_file = self.find_file(path)\n else:\n static_file = self.files.get(path)\n if static_file is None:\n static_file = self.find_and_cache_dynamic_file(path)\n if static_file is None:\n return self.application(environ, start_response)\n else:\n return self.serve(static_file, environ, start_response)\n\n def find_and_cache_dynamic_file(self, url):\n path = self.get_dynamic_path(url)\n if path:\n file_stat = os.stat(path)\n # Only try to do matches for regular files.\n if stat.S_ISREG(file_stat.st_mode):\n stat_cache = {path: os.stat(path)}\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n return self.files.get(url)\n\n def get_dynamic_path(self, url):\n if self.dynamic_check is not None and self.dynamic_check.match(url):\n return self.dynamic_finder.find(url)\n\n def candidate_paths_for_url(self, url):\n paths = super(DynamicWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n path = self.get_dynamic_path(url)\n if path:\n yield path\n\n\nclass DjangoWhiteNoise(DynamicWhiteNoise):\n def __init__(self, application, static_prefix=None, **kwargs):\n super(DjangoWhiteNoise, self).__init__(application, **kwargs)\n self.static_prefix = static_prefix\n if not self.autorefresh and self.static_prefix:\n self.add_files_from_finders()\n\n def add_files_from_finders(self):\n files = {}\n for finder in finders.get_finders():\n for path, storage in finder.list(None):\n prefix = (getattr(storage, \"prefix\", None) or \"\").strip(\"/\")\n url = u\"\".join(\n (\n self.static_prefix,\n prefix,\n \"/\" if prefix else \"\",\n path.replace(\"\\\\\", \"/\"),\n )\n )\n # Use setdefault as only first matching file should be used\n files.setdefault(url, storage.path(path))\n stat_cache = {path: os.stat(path) for path in files.values()}\n for url, path in files.items():\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n\n def candidate_paths_for_url(self, url):\n paths = super(DjangoWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n if self.autorefresh and url.startswith(self.static_prefix):\n path = finders.find(url[len(self.static_prefix) :])\n if path:\n yield path\n", "path": "kolibri/utils/kolibri_whitenoise.py"}], "after_files": [{"content": "import os\nimport re\nimport stat\nfrom collections import OrderedDict\n\nfrom django.contrib.staticfiles import finders\nfrom django.core.files.storage import FileSystemStorage\nfrom django.utils._os import safe_join\nfrom whitenoise import WhiteNoise\nfrom whitenoise.string_utils import decode_path_info\n\n\nclass FileFinder(finders.FileSystemFinder):\n \"\"\"\n A modified version of the Django FileSystemFinder class\n which allows us to pass in arbitrary locations to find files\n \"\"\"\n\n def __init__(self, locations):\n # List of locations with static files\n self.locations = []\n self.prefixes = set()\n # Maps dir paths to an appropriate storage instance\n self.storages = OrderedDict()\n if not isinstance(locations, (list, tuple)):\n raise TypeError(\"locations argument is not a tuple or list\")\n for root in locations:\n prefix, root = root\n if not prefix:\n raise ValueError(\n \"Cannot use unprefixed locations for dynamic locations\"\n )\n else:\n prefix = prefix.rstrip(\"/\")\n if (prefix, root) not in self.locations:\n self.locations.append((prefix, root))\n self.prefixes.add(prefix)\n for prefix, root in self.locations:\n filesystem_storage = FileSystemStorage(location=root)\n filesystem_storage.prefix = prefix\n self.storages[root] = filesystem_storage\n\n def find_location(self, root, path, prefix=None):\n \"\"\"\n Finds a requested static file in a location, returning the found\n absolute path (or ``None`` if no match).\n Vendored from Django to handle being passed a URL path instead of a file path.\n \"\"\"\n if prefix:\n prefix = prefix + \"/\"\n if not path.startswith(prefix):\n return None\n path = path[len(prefix) :]\n path = safe_join(root, path)\n if os.path.exists(path):\n return path\n\n\nclass DynamicWhiteNoise(WhiteNoise):\n def __init__(self, application, dynamic_locations=None, **kwargs):\n whitenoise_settings = {\n # Use 1 day as the default cache time for static assets\n \"max_age\": 24 * 60 * 60,\n # Add a test for any file name that contains a semantic version number\n # or a 32 digit number (assumed to be a file hash)\n # these files will be cached indefinitely\n \"immutable_file_test\": r\"((0|[1-9]\\d*)\\.(0|[1-9]\\d*)\\.(0|[1-9]\\d*)|[a-f0-9]{32})\",\n \"autorefresh\": os.environ.get(\"KOLIBRI_DEVELOPER_MODE\", False),\n }\n kwargs.update(whitenoise_settings)\n super(DynamicWhiteNoise, self).__init__(application, **kwargs)\n self.dynamic_finder = FileFinder(dynamic_locations or [])\n # Generate a regex to check if a path matches one of our dynamic\n # location prefixes\n self.dynamic_check = (\n re.compile(\"^({})\".format(\"|\".join(self.dynamic_finder.prefixes)))\n if self.dynamic_finder.prefixes\n else None\n )\n\n def __call__(self, environ, start_response):\n path = decode_path_info(environ.get(\"PATH_INFO\", \"\"))\n if self.autorefresh:\n static_file = self.find_file(path)\n else:\n static_file = self.files.get(path)\n if static_file is None:\n static_file = self.find_and_cache_dynamic_file(path)\n if static_file is None:\n return self.application(environ, start_response)\n else:\n return self.serve(static_file, environ, start_response)\n\n def find_and_cache_dynamic_file(self, url):\n path = self.get_dynamic_path(url)\n if path:\n file_stat = os.stat(path)\n # Only try to do matches for regular files.\n if stat.S_ISREG(file_stat.st_mode):\n stat_cache = {path: os.stat(path)}\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n return self.files.get(url)\n\n def get_dynamic_path(self, url):\n if self.dynamic_check is not None and self.dynamic_check.match(url):\n return self.dynamic_finder.find(url)\n\n def candidate_paths_for_url(self, url):\n paths = super(DynamicWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n path = self.get_dynamic_path(url)\n if path:\n yield path\n\n\nclass DjangoWhiteNoise(DynamicWhiteNoise):\n def __init__(self, application, static_prefix=None, **kwargs):\n super(DjangoWhiteNoise, self).__init__(application, **kwargs)\n self.static_prefix = static_prefix\n if not self.autorefresh and self.static_prefix:\n self.add_files_from_finders()\n\n def add_files_from_finders(self):\n files = {}\n for finder in finders.get_finders():\n for path, storage in finder.list(None):\n prefix = (getattr(storage, \"prefix\", None) or \"\").strip(\"/\")\n url = u\"\".join(\n (\n self.static_prefix,\n prefix,\n \"/\" if prefix else \"\",\n path.replace(\"\\\\\", \"/\"),\n )\n )\n # Use setdefault as only first matching file should be used\n files.setdefault(url, storage.path(path))\n stat_cache = {path: os.stat(path) for path in files.values()}\n for url, path in files.items():\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n\n def candidate_paths_for_url(self, url):\n paths = super(DjangoWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n if self.autorefresh and url.startswith(self.static_prefix):\n path = finders.find(url[len(self.static_prefix) :])\n if path:\n yield path\n", "path": "kolibri/utils/kolibri_whitenoise.py"}]}
| 2,249 | 419 |
gh_patches_debug_451
|
rasdani/github-patches
|
git_diff
|
ros__ros_comm-683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
unregister() method to message_filter.Subscriber on python
Do you have plan to implement this?
Or there is other way to achieve this?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `utilities/message_filters/src/message_filters/__init__.py`
Content:
```
1 # Copyright (c) 2009, Willow Garage, Inc.
2 # All rights reserved.
3 #
4 # Redistribution and use in source and binary forms, with or without
5 # modification, are permitted provided that the following conditions are met:
6 #
7 # * Redistributions of source code must retain the above copyright
8 # notice, this list of conditions and the following disclaimer.
9 # * Redistributions in binary form must reproduce the above copyright
10 # notice, this list of conditions and the following disclaimer in the
11 # documentation and/or other materials provided with the distribution.
12 # * Neither the name of the Willow Garage, Inc. nor the names of its
13 # contributors may be used to endorse or promote products derived from
14 # this software without specific prior written permission.
15 #
16 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
17 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
18 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
19 # ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
20 # LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
21 # CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
22 # SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
23 # INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
24 # CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
25 # ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
26 # POSSIBILITY OF SUCH DAMAGE.
27
28 """
29 Message Filter Objects
30 ======================
31 """
32
33 import itertools
34 import threading
35 import rospy
36
37 class SimpleFilter:
38
39 def __init__(self):
40 self.callbacks = {}
41
42 def registerCallback(self, cb, *args):
43 """
44 Register a callback function `cb` to be called when this filter
45 has output.
46 The filter calls the function ``cb`` with a filter-dependent list of arguments,
47 followed by the call-supplied arguments ``args``.
48 """
49
50 conn = len(self.callbacks)
51 self.callbacks[conn] = (cb, args)
52 return conn
53
54 def signalMessage(self, *msg):
55 for (cb, args) in self.callbacks.values():
56 cb(*(msg + args))
57
58 class Subscriber(SimpleFilter):
59
60 """
61 ROS subscription filter. Identical arguments as :class:`rospy.Subscriber`.
62
63 This class acts as a highest-level filter, simply passing messages
64 from a ROS subscription through to the filters which have connected
65 to it.
66 """
67 def __init__(self, *args, **kwargs):
68 SimpleFilter.__init__(self)
69 self.topic = args[0]
70 kwargs['callback'] = self.callback
71 self.sub = rospy.Subscriber(*args, **kwargs)
72
73 def callback(self, msg):
74 self.signalMessage(msg)
75
76 def getTopic(self):
77 return self.topic
78
79 class Cache(SimpleFilter):
80
81 """
82 Stores a time history of messages.
83
84 Given a stream of messages, the most recent ``cache_size`` messages
85 are cached in a ring buffer, from which time intervals of the cache
86 can then be retrieved by the client.
87 """
88
89 def __init__(self, f, cache_size = 1):
90 SimpleFilter.__init__(self)
91 self.connectInput(f)
92 self.cache_size = cache_size
93 # Array to store messages
94 self.cache_msgs = []
95 # Array to store msgs times, auxiliary structure to facilitate
96 # sorted insertion
97 self.cache_times = []
98
99 def connectInput(self, f):
100 self.incoming_connection = f.registerCallback(self.add)
101
102 def add(self, msg):
103 # Cannot use message filters with non-stamped messages
104 if not hasattr(msg, 'header') or not hasattr(msg.header, 'stamp'):
105 rospy.logwarn("Cannot use message filters with non-stamped messages")
106 return
107
108 # Insert sorted
109 stamp = msg.header.stamp
110 self.cache_times.append(stamp)
111 self.cache_msgs.append(msg)
112
113 # Implement a ring buffer, discard older if oversized
114 if (len(self.cache_msgs) > self.cache_size):
115 del self.cache_msgs[0]
116 del self.cache_times[0]
117
118 # Signal new input
119 self.signalMessage(msg)
120
121 def getInterval(self, from_stamp, to_stamp):
122 """Query the current cache content between from_stamp to to_stamp."""
123 assert from_stamp <= to_stamp
124 return [m for m in self.cache_msgs
125 if m.header.stamp >= from_stamp and m.header.stamp <= to_stamp]
126
127 def getElemAfterTime(self, stamp):
128 """Return the oldest element after or equal the passed time stamp."""
129 newer = [m for m in self.cache_msgs if m.header.stamp >= stamp]
130 if not newer:
131 return None
132 return newer[0]
133
134 def getElemBeforeTime(self, stamp):
135 """Return the newest element before or equal the passed time stamp."""
136 older = [m for m in self.cache_msgs if m.header.stamp <= stamp]
137 if not older:
138 return None
139 return older[-1]
140
141 def getLastestTime(self):
142 """Return the newest recorded timestamp."""
143 if not self.cache_times:
144 return None
145 return self.cache_times[-1]
146
147 def getOldestTime(self):
148 """Return the oldest recorded timestamp."""
149 if not self.cache_times:
150 return None
151 return self.cache_times[0]
152
153
154 class TimeSynchronizer(SimpleFilter):
155
156 """
157 Synchronizes messages by their timestamps.
158
159 :class:`TimeSynchronizer` synchronizes incoming message filters by the
160 timestamps contained in their messages' headers. TimeSynchronizer
161 listens on multiple input message filters ``fs``, and invokes the callback
162 when it has a collection of messages with matching timestamps.
163
164 The signature of the callback function is::
165
166 def callback(msg1, ... msgN):
167
168 where N is the number of input message filters, and each message is
169 the output of the corresponding filter in ``fs``.
170 The required ``queue size`` parameter specifies how many sets of
171 messages it should store from each input filter (by timestamp)
172 while waiting for messages to arrive and complete their "set".
173 """
174
175 def __init__(self, fs, queue_size):
176 SimpleFilter.__init__(self)
177 self.connectInput(fs)
178 self.queue_size = queue_size
179 self.lock = threading.Lock()
180
181 def connectInput(self, fs):
182 self.queues = [{} for f in fs]
183 self.input_connections = [f.registerCallback(self.add, q) for (f, q) in zip(fs, self.queues)]
184
185 def add(self, msg, my_queue):
186 self.lock.acquire()
187 my_queue[msg.header.stamp] = msg
188 while len(my_queue) > self.queue_size:
189 del my_queue[min(my_queue)]
190 # common is the set of timestamps that occur in all queues
191 common = reduce(set.intersection, [set(q) for q in self.queues])
192 for t in sorted(common):
193 # msgs is list of msgs (one from each queue) with stamp t
194 msgs = [q[t] for q in self.queues]
195 self.signalMessage(*msgs)
196 for q in self.queues:
197 del q[t]
198 self.lock.release()
199
200 class ApproximateTimeSynchronizer(TimeSynchronizer):
201
202 """
203 Approximately synchronizes messages by their timestamps.
204
205 :class:`ApproximateTimeSynchronizer` synchronizes incoming message filters by the
206 timestamps contained in their messages' headers. The API is the same as TimeSynchronizer
207 except for an extra `slop` parameter in the constructor that defines the delay (in seconds)
208 with which messages can be synchronized
209 """
210
211 def __init__(self, fs, queue_size, slop):
212 TimeSynchronizer.__init__(self, fs, queue_size)
213 self.slop = rospy.Duration.from_sec(slop)
214
215 def add(self, msg, my_queue):
216 self.lock.acquire()
217 my_queue[msg.header.stamp] = msg
218 while len(my_queue) > self.queue_size:
219 del my_queue[min(my_queue)]
220 for vv in itertools.product(*[list(q.keys()) for q in self.queues]):
221 qt = list(zip(self.queues, vv))
222 if ( ((max(vv) - min(vv)) < self.slop) and
223 (len([1 for q,t in qt if t not in q]) == 0) ):
224 msgs = [q[t] for q,t in qt]
225 self.signalMessage(*msgs)
226 for q,t in qt:
227 del q[t]
228 self.lock.release()
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/utilities/message_filters/src/message_filters/__init__.py b/utilities/message_filters/src/message_filters/__init__.py
--- a/utilities/message_filters/src/message_filters/__init__.py
+++ b/utilities/message_filters/src/message_filters/__init__.py
@@ -76,6 +76,9 @@
def getTopic(self):
return self.topic
+ def unregister(self):
+ self.sub.unregister()
+
class Cache(SimpleFilter):
"""
|
{"golden_diff": "diff --git a/utilities/message_filters/src/message_filters/__init__.py b/utilities/message_filters/src/message_filters/__init__.py\n--- a/utilities/message_filters/src/message_filters/__init__.py\n+++ b/utilities/message_filters/src/message_filters/__init__.py\n@@ -76,6 +76,9 @@\n def getTopic(self):\n return self.topic\n \n+ def unregister(self):\n+ self.sub.unregister()\n+\n class Cache(SimpleFilter):\n \n \"\"\"\n", "issue": "unregister() method to message_filter.Subscriber on python\nDo you have plan to implement this?\nOr there is other way to achieve this?\n\n", "before_files": [{"content": "# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of the Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE\n# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR\n# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF\n# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS\n# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN\n# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)\n# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nMessage Filter Objects\n======================\n\"\"\"\n\nimport itertools\nimport threading\nimport rospy\n\nclass SimpleFilter:\n\n def __init__(self):\n self.callbacks = {}\n\n def registerCallback(self, cb, *args):\n \"\"\"\n Register a callback function `cb` to be called when this filter\n has output.\n The filter calls the function ``cb`` with a filter-dependent list of arguments,\n followed by the call-supplied arguments ``args``.\n \"\"\"\n\n conn = len(self.callbacks)\n self.callbacks[conn] = (cb, args)\n return conn\n\n def signalMessage(self, *msg):\n for (cb, args) in self.callbacks.values():\n cb(*(msg + args))\n\nclass Subscriber(SimpleFilter):\n \n \"\"\"\n ROS subscription filter. Identical arguments as :class:`rospy.Subscriber`.\n\n This class acts as a highest-level filter, simply passing messages\n from a ROS subscription through to the filters which have connected\n to it.\n \"\"\"\n def __init__(self, *args, **kwargs):\n SimpleFilter.__init__(self)\n self.topic = args[0]\n kwargs['callback'] = self.callback\n self.sub = rospy.Subscriber(*args, **kwargs)\n\n def callback(self, msg):\n self.signalMessage(msg)\n\n def getTopic(self):\n return self.topic\n\nclass Cache(SimpleFilter):\n\n \"\"\"\n Stores a time history of messages.\n\n Given a stream of messages, the most recent ``cache_size`` messages\n are cached in a ring buffer, from which time intervals of the cache\n can then be retrieved by the client.\n \"\"\"\n\n def __init__(self, f, cache_size = 1):\n SimpleFilter.__init__(self)\n self.connectInput(f)\n self.cache_size = cache_size\n # Array to store messages\n self.cache_msgs = []\n # Array to store msgs times, auxiliary structure to facilitate\n # sorted insertion\n self.cache_times = []\n\n def connectInput(self, f):\n self.incoming_connection = f.registerCallback(self.add)\n\n def add(self, msg):\n # Cannot use message filters with non-stamped messages\n if not hasattr(msg, 'header') or not hasattr(msg.header, 'stamp'):\n rospy.logwarn(\"Cannot use message filters with non-stamped messages\")\n return\n\n # Insert sorted\n stamp = msg.header.stamp\n self.cache_times.append(stamp)\n self.cache_msgs.append(msg)\n\n # Implement a ring buffer, discard older if oversized\n if (len(self.cache_msgs) > self.cache_size):\n del self.cache_msgs[0]\n del self.cache_times[0]\n\n # Signal new input\n self.signalMessage(msg)\n\n def getInterval(self, from_stamp, to_stamp):\n \"\"\"Query the current cache content between from_stamp to to_stamp.\"\"\"\n assert from_stamp <= to_stamp\n return [m for m in self.cache_msgs\n if m.header.stamp >= from_stamp and m.header.stamp <= to_stamp]\n\n def getElemAfterTime(self, stamp):\n \"\"\"Return the oldest element after or equal the passed time stamp.\"\"\"\n newer = [m for m in self.cache_msgs if m.header.stamp >= stamp]\n if not newer:\n return None\n return newer[0]\n\n def getElemBeforeTime(self, stamp):\n \"\"\"Return the newest element before or equal the passed time stamp.\"\"\"\n older = [m for m in self.cache_msgs if m.header.stamp <= stamp]\n if not older:\n return None\n return older[-1]\n\n def getLastestTime(self):\n \"\"\"Return the newest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[-1]\n\n def getOldestTime(self):\n \"\"\"Return the oldest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[0]\n\n\nclass TimeSynchronizer(SimpleFilter):\n\n \"\"\"\n Synchronizes messages by their timestamps.\n\n :class:`TimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. TimeSynchronizer\n listens on multiple input message filters ``fs``, and invokes the callback\n when it has a collection of messages with matching timestamps.\n\n The signature of the callback function is::\n\n def callback(msg1, ... msgN):\n\n where N is the number of input message filters, and each message is\n the output of the corresponding filter in ``fs``.\n The required ``queue size`` parameter specifies how many sets of\n messages it should store from each input filter (by timestamp)\n while waiting for messages to arrive and complete their \"set\".\n \"\"\"\n\n def __init__(self, fs, queue_size):\n SimpleFilter.__init__(self)\n self.connectInput(fs)\n self.queue_size = queue_size\n self.lock = threading.Lock()\n\n def connectInput(self, fs):\n self.queues = [{} for f in fs]\n self.input_connections = [f.registerCallback(self.add, q) for (f, q) in zip(fs, self.queues)]\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n # common is the set of timestamps that occur in all queues\n common = reduce(set.intersection, [set(q) for q in self.queues])\n for t in sorted(common):\n # msgs is list of msgs (one from each queue) with stamp t\n msgs = [q[t] for q in self.queues]\n self.signalMessage(*msgs)\n for q in self.queues:\n del q[t]\n self.lock.release()\n\nclass ApproximateTimeSynchronizer(TimeSynchronizer):\n\n \"\"\"\n Approximately synchronizes messages by their timestamps.\n\n :class:`ApproximateTimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. The API is the same as TimeSynchronizer\n except for an extra `slop` parameter in the constructor that defines the delay (in seconds)\n with which messages can be synchronized\n \"\"\"\n\n def __init__(self, fs, queue_size, slop):\n TimeSynchronizer.__init__(self, fs, queue_size)\n self.slop = rospy.Duration.from_sec(slop)\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n for vv in itertools.product(*[list(q.keys()) for q in self.queues]):\n qt = list(zip(self.queues, vv))\n if ( ((max(vv) - min(vv)) < self.slop) and\n (len([1 for q,t in qt if t not in q]) == 0) ):\n msgs = [q[t] for q,t in qt]\n self.signalMessage(*msgs)\n for q,t in qt:\n del q[t]\n self.lock.release()\n", "path": "utilities/message_filters/src/message_filters/__init__.py"}], "after_files": [{"content": "# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of the Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE\n# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR\n# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF\n# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS\n# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN\n# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)\n# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nMessage Filter Objects\n======================\n\"\"\"\n\nimport itertools\nimport threading\nimport rospy\n\nclass SimpleFilter:\n\n def __init__(self):\n self.callbacks = {}\n\n def registerCallback(self, cb, *args):\n \"\"\"\n Register a callback function `cb` to be called when this filter\n has output.\n The filter calls the function ``cb`` with a filter-dependent list of arguments,\n followed by the call-supplied arguments ``args``.\n \"\"\"\n\n conn = len(self.callbacks)\n self.callbacks[conn] = (cb, args)\n return conn\n\n def signalMessage(self, *msg):\n for (cb, args) in self.callbacks.values():\n cb(*(msg + args))\n\nclass Subscriber(SimpleFilter):\n \n \"\"\"\n ROS subscription filter. Identical arguments as :class:`rospy.Subscriber`.\n\n This class acts as a highest-level filter, simply passing messages\n from a ROS subscription through to the filters which have connected\n to it.\n \"\"\"\n def __init__(self, *args, **kwargs):\n SimpleFilter.__init__(self)\n self.topic = args[0]\n kwargs['callback'] = self.callback\n self.sub = rospy.Subscriber(*args, **kwargs)\n\n def callback(self, msg):\n self.signalMessage(msg)\n\n def getTopic(self):\n return self.topic\n\n def unregister(self):\n self.sub.unregister()\n\nclass Cache(SimpleFilter):\n\n \"\"\"\n Stores a time history of messages.\n\n Given a stream of messages, the most recent ``cache_size`` messages\n are cached in a ring buffer, from which time intervals of the cache\n can then be retrieved by the client.\n \"\"\"\n\n def __init__(self, f, cache_size = 1):\n SimpleFilter.__init__(self)\n self.connectInput(f)\n self.cache_size = cache_size\n # Array to store messages\n self.cache_msgs = []\n # Array to store msgs times, auxiliary structure to facilitate\n # sorted insertion\n self.cache_times = []\n\n def connectInput(self, f):\n self.incoming_connection = f.registerCallback(self.add)\n\n def add(self, msg):\n # Cannot use message filters with non-stamped messages\n if not hasattr(msg, 'header') or not hasattr(msg.header, 'stamp'):\n rospy.logwarn(\"Cannot use message filters with non-stamped messages\")\n return\n\n # Insert sorted\n stamp = msg.header.stamp\n self.cache_times.append(stamp)\n self.cache_msgs.append(msg)\n\n # Implement a ring buffer, discard older if oversized\n if (len(self.cache_msgs) > self.cache_size):\n del self.cache_msgs[0]\n del self.cache_times[0]\n\n # Signal new input\n self.signalMessage(msg)\n\n def getInterval(self, from_stamp, to_stamp):\n \"\"\"Query the current cache content between from_stamp to to_stamp.\"\"\"\n assert from_stamp <= to_stamp\n return [m for m in self.cache_msgs\n if m.header.stamp >= from_stamp and m.header.stamp <= to_stamp]\n\n def getElemAfterTime(self, stamp):\n \"\"\"Return the oldest element after or equal the passed time stamp.\"\"\"\n newer = [m for m in self.cache_msgs if m.header.stamp >= stamp]\n if not newer:\n return None\n return newer[0]\n\n def getElemBeforeTime(self, stamp):\n \"\"\"Return the newest element before or equal the passed time stamp.\"\"\"\n older = [m for m in self.cache_msgs if m.header.stamp <= stamp]\n if not older:\n return None\n return older[-1]\n\n def getLastestTime(self):\n \"\"\"Return the newest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[-1]\n\n def getOldestTime(self):\n \"\"\"Return the oldest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[0]\n\n\nclass TimeSynchronizer(SimpleFilter):\n\n \"\"\"\n Synchronizes messages by their timestamps.\n\n :class:`TimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. TimeSynchronizer\n listens on multiple input message filters ``fs``, and invokes the callback\n when it has a collection of messages with matching timestamps.\n\n The signature of the callback function is::\n\n def callback(msg1, ... msgN):\n\n where N is the number of input message filters, and each message is\n the output of the corresponding filter in ``fs``.\n The required ``queue size`` parameter specifies how many sets of\n messages it should store from each input filter (by timestamp)\n while waiting for messages to arrive and complete their \"set\".\n \"\"\"\n\n def __init__(self, fs, queue_size):\n SimpleFilter.__init__(self)\n self.connectInput(fs)\n self.queue_size = queue_size\n self.lock = threading.Lock()\n\n def connectInput(self, fs):\n self.queues = [{} for f in fs]\n self.input_connections = [f.registerCallback(self.add, q) for (f, q) in zip(fs, self.queues)]\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n # common is the set of timestamps that occur in all queues\n common = reduce(set.intersection, [set(q) for q in self.queues])\n for t in sorted(common):\n # msgs is list of msgs (one from each queue) with stamp t\n msgs = [q[t] for q in self.queues]\n self.signalMessage(*msgs)\n for q in self.queues:\n del q[t]\n self.lock.release()\n\nclass ApproximateTimeSynchronizer(TimeSynchronizer):\n\n \"\"\"\n Approximately synchronizes messages by their timestamps.\n\n :class:`ApproximateTimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. The API is the same as TimeSynchronizer\n except for an extra `slop` parameter in the constructor that defines the delay (in seconds)\n with which messages can be synchronized\n \"\"\"\n\n def __init__(self, fs, queue_size, slop):\n TimeSynchronizer.__init__(self, fs, queue_size)\n self.slop = rospy.Duration.from_sec(slop)\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n for vv in itertools.product(*[list(q.keys()) for q in self.queues]):\n qt = list(zip(self.queues, vv))\n if ( ((max(vv) - min(vv)) < self.slop) and\n (len([1 for q,t in qt if t not in q]) == 0) ):\n msgs = [q[t] for q,t in qt]\n self.signalMessage(*msgs)\n for q,t in qt:\n del q[t]\n self.lock.release()\n", "path": "utilities/message_filters/src/message_filters/__init__.py"}]}
| 2,729 | 101 |
gh_patches_debug_39543
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-2009
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Accordion's active does not work correctly
#### ALL software version info
Python 3.7.6, panel==0.10.3
#### Description of expected behavior and the observed behavior
1. I would expect `accordion.active` to return list of active cards. Now it returns an empty list even if some card is open.
2. Also setting values to `accordion.active` I would expect to open only selected cards. Now it opens selected cards, but does not close the ones that were not selected.
#### Complete, minimal, self-contained example code that reproduces the issue
```python
# based on https://panel.holoviz.org/reference/layouts/Accordion.html
import panel as pn
pn.extension()
from bokeh.plotting import figure
p1 = figure(width=300, height=80, name='Scatter', margin=5)
p1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
p2 = figure(width=300, height=80, name='Line', margin=5)
p2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
accordion = pn.Accordion(p1, p2)
accordion
```
```
accordion.active
```
```
accordion.active = [0]
```
#### Screenshots or screencasts of the bug in action

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `panel/layout/card.py`
Content:
```
1 import param
2
3 from ..models import Card as BkCard
4 from .base import Column, Row, ListPanel
5
6
7 class Card(Column):
8 """
9 A Card layout allows arranging multiple panel objects in a
10 collapsible, vertical container with a header bar.
11 """
12
13 active_header_background = param.String(doc="""
14 A valid CSS color for the header background when not collapsed.""")
15
16 button_css_classes = param.List(['card-button'], doc="""
17 CSS classes to apply to the button element.""")
18
19 collapsible = param.Boolean(default=True, doc="""
20 Whether the Card should be expandable and collapsible.""")
21
22 collapsed = param.Boolean(default=False, doc="""
23 Whether the contents of the Card are collapsed.""")
24
25 css_classes = param.List(['card'], doc="""
26 CSS classes to apply to the overall Card.""")
27
28 header = param.Parameter(doc="""
29 A Panel component to display in the header bar of the Card.
30 Will override the given title if defined.""")
31
32 header_background = param.String(doc="""
33 A valid CSS color for the header background.""")
34
35 header_color = param.String(doc="""
36 A valid CSS color to apply to the header text.""")
37
38 header_css_classes = param.List(['card-header'], doc="""
39 CSS classes to apply to the header element.""")
40
41 title_css_classes = param.List(['card-title'], doc="""
42 CSS classes to apply to the header title.""")
43
44 margin = param.Parameter(default=5)
45
46 title = param.String(doc="""
47 A title to be displayed in the Card header, will be overridden
48 by the header if defined.""")
49
50 _bokeh_model = BkCard
51
52 _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)
53
54 def __init__(self, *objects, **params):
55 self._header_layout = Row(css_classes=['card-header-row'],
56 sizing_mode='stretch_width')
57 super().__init__(*objects, **params)
58 self.param.watch(self._update_header, ['title', 'header', 'title_css_classes'])
59 self._update_header()
60
61 def _cleanup(self, root):
62 super()._cleanup(root)
63 self._header_layout._cleanup(root)
64
65 def _process_param_change(self, params):
66 scroll = params.pop('scroll', None)
67 css_classes = self.css_classes or []
68 if scroll:
69 params['css_classes'] = css_classes + ['scrollable']
70 elif scroll == False:
71 params['css_classes'] = css_classes
72 return super(ListPanel, self)._process_param_change(params)
73
74 def _update_header(self, *events):
75 from ..pane import HTML, panel
76 if self.header is None:
77 item = HTML('%s' % (self.title or "​"),
78 css_classes=self.title_css_classes,
79 sizing_mode='stretch_width',
80 margin=(2, 5))
81 else:
82 item = panel(self.header)
83 self._header_layout[:] = [item]
84
85 def _get_objects(self, model, old_objects, doc, root, comm=None):
86 ref = root.ref['id']
87 if ref in self._header_layout._models:
88 header = self._header_layout._models[ref][0]
89 else:
90 header = self._header_layout._get_model(doc, root, model, comm)
91 objects = super()._get_objects(model, old_objects, doc, root, comm)
92 return [header]+objects
93
```
Path: `panel/layout/accordion.py`
Content:
```
1 import param
2
3 from bokeh.models import Column as BkColumn, CustomJS
4
5 from .base import NamedListPanel
6 from .card import Card
7
8
9 class Accordion(NamedListPanel):
10
11 active_header_background = param.String(default='#ccc', doc="""
12 Color for currently active headers.""")
13
14 active = param.List(default=[], doc="""
15 List of indexes of active cards.""")
16
17 header_color = param.String(doc="""
18 A valid CSS color to apply to the expand button.""")
19
20 header_background = param.String(doc="""
21 A valid CSS color for the header background.""")
22
23 toggle = param.Boolean(default=False, doc="""
24 Whether to toggle between active cards or allow multiple cards""")
25
26 _bokeh_model = BkColumn
27
28 _rename = {'active': None, 'active_header_background': None,
29 'header_background': None, 'objects': 'children',
30 'dynamic': None, 'toggle': None, 'header_color': None}
31
32 _toggle = """
33 for (var child of accordion.children) {
34 if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {
35 child.collapsed = !cb_obj.collapsed
36 }
37 }
38 """
39
40 _synced_properties = [
41 'active_header_background', 'header_background', 'width',
42 'sizing_mode', 'width_policy', 'height_policy', 'header_color'
43 ]
44
45 def __init__(self, *objects, **params):
46 super().__init__(*objects, **params)
47 self.param.watch(self._update_active, ['active'])
48 self.param.watch(self._update_cards, self._synced_properties)
49
50 def _get_objects(self, model, old_objects, doc, root, comm=None):
51 """
52 Returns new child models for the layout while reusing unchanged
53 models and cleaning up any dropped objects.
54 """
55 from panel.pane.base import RerenderError, panel
56 new_models = []
57 if len(self._names) != len(self):
58 raise ValueError('Accordion names do not match objects, ensure '
59 'that the Tabs.objects are not modified '
60 'directly. Found %d names, expected %d.' %
61 (len(self._names), len(self)))
62 for i, (name, pane) in enumerate(zip(self._names, self)):
63 pane = panel(pane, name=name)
64 self.objects[i] = pane
65
66 for obj in old_objects:
67 if obj not in self.objects:
68 self._panels[id(obj)]._cleanup(root)
69
70 params = {k: v for k, v in self.param.get_param_values()
71 if k in self._synced_properties}
72
73 ref = root.ref['id']
74 current_objects = list(self)
75 for i, (name, pane) in enumerate(zip(self._names, self)):
76 params.update(self._apply_style(i))
77 if id(pane) in self._panels:
78 card = self._panels[id(pane)]
79 else:
80 card = Card(
81 pane, title=name, css_classes=['accordion'],
82 header_css_classes=['accordion-header'],
83 margin=self.margin
84 )
85 self._panels[id(pane)] = card
86 card.param.set_param(**params)
87 if ref in card._models:
88 panel = card._models[ref][0]
89 else:
90 try:
91 panel = card._get_model(doc, root, model, comm)
92 if self.toggle:
93 cb = CustomJS(args={'accordion': model}, code=self._toggle)
94 panel.js_on_change('collapsed', cb)
95 except RerenderError:
96 return self._get_objects(model, current_objects[:i], doc, root, comm)
97
98 new_models.append(panel)
99 self._update_cards()
100 self._update_active()
101 return new_models
102
103 def _cleanup(self, root):
104 for panel in self._panels.values():
105 panel._cleanup(root)
106 super()._cleanup(root)
107
108 def _apply_style(self, i):
109 if i == 0:
110 margin = (5, 5, 0, 5)
111 elif i == (len(self)-1):
112 margin = (0, 5, 5, 5)
113 else:
114 margin = (0, 5, 0, 5)
115 return dict(margin=margin, collapsed = i not in self.active)
116
117 def _update_active(self, *events):
118 for i, pane in enumerate(self.objects):
119 if id(pane) not in self._panels:
120 continue
121 self._panels[id(pane)].collapsed = i not in self.active
122
123 def _update_cards(self, *events):
124 params = {k: v for k, v in self.param.get_param_values()
125 if k in self._synced_properties}
126 for panel in self._panels.values():
127 panel.param.set_param(**params)
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py
--- a/panel/layout/accordion.py
+++ b/panel/layout/accordion.py
@@ -44,6 +44,7 @@
def __init__(self, *objects, **params):
super().__init__(*objects, **params)
+ self._updating_active = False
self.param.watch(self._update_active, ['active'])
self.param.watch(self._update_cards, self._synced_properties)
@@ -82,6 +83,7 @@
header_css_classes=['accordion-header'],
margin=self.margin
)
+ card.param.watch(self._set_active, ['collapsed'])
self._panels[id(pane)] = card
card.param.set_param(**params)
if ref in card._models:
@@ -94,7 +96,6 @@
panel.js_on_change('collapsed', cb)
except RerenderError:
return self._get_objects(model, current_objects[:i], doc, root, comm)
-
new_models.append(panel)
self._update_cards()
self._update_active()
@@ -114,11 +115,32 @@
margin = (0, 5, 0, 5)
return dict(margin=margin, collapsed = i not in self.active)
+ def _set_active(self, *events):
+ if self._updating_active:
+ return
+ active = []
+ self._updating_active = True
+ try:
+ for i, pane in enumerate(self.objects):
+ if id(pane) not in self._panels:
+ continue
+ elif not self._panels[id(pane)].collapsed:
+ active.append(i)
+ self.active = active
+ finally:
+ self._updating_active = False
+
def _update_active(self, *events):
- for i, pane in enumerate(self.objects):
- if id(pane) not in self._panels:
- continue
- self._panels[id(pane)].collapsed = i not in self.active
+ if self._updating_active:
+ return
+ self._updating_active = True
+ try:
+ for i, pane in enumerate(self.objects):
+ if id(pane) not in self._panels:
+ continue
+ self._panels[id(pane)].collapsed = i not in self.active
+ finally:
+ self._updating_active = False
def _update_cards(self, *events):
params = {k: v for k, v in self.param.get_param_values()
diff --git a/panel/layout/card.py b/panel/layout/card.py
--- a/panel/layout/card.py
+++ b/panel/layout/card.py
@@ -49,6 +49,8 @@
_bokeh_model = BkCard
+ _linked_props = ['collapsed']
+
_rename = dict(Column._rename, title=None, header=None, title_css_classes=None)
def __init__(self, *objects, **params):
|
{"golden_diff": "diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py\n--- a/panel/layout/accordion.py\n+++ b/panel/layout/accordion.py\n@@ -44,6 +44,7 @@\n \n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n+ self._updating_active = False\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n \n@@ -82,6 +83,7 @@\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n+ card.param.watch(self._set_active, ['collapsed'])\n self._panels[id(pane)] = card\n card.param.set_param(**params)\n if ref in card._models:\n@@ -94,7 +96,6 @@\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n- \n new_models.append(panel)\n self._update_cards()\n self._update_active()\n@@ -114,11 +115,32 @@\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n \n+ def _set_active(self, *events):\n+ if self._updating_active:\n+ return\n+ active = []\n+ self._updating_active = True\n+ try:\n+ for i, pane in enumerate(self.objects):\n+ if id(pane) not in self._panels:\n+ continue\n+ elif not self._panels[id(pane)].collapsed:\n+ active.append(i)\n+ self.active = active\n+ finally:\n+ self._updating_active = False\n+\n def _update_active(self, *events):\n- for i, pane in enumerate(self.objects):\n- if id(pane) not in self._panels:\n- continue\n- self._panels[id(pane)].collapsed = i not in self.active\n+ if self._updating_active:\n+ return\n+ self._updating_active = True\n+ try:\n+ for i, pane in enumerate(self.objects):\n+ if id(pane) not in self._panels:\n+ continue\n+ self._panels[id(pane)].collapsed = i not in self.active\n+ finally:\n+ self._updating_active = False\n \n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.get_param_values()\ndiff --git a/panel/layout/card.py b/panel/layout/card.py\n--- a/panel/layout/card.py\n+++ b/panel/layout/card.py\n@@ -49,6 +49,8 @@\n \n _bokeh_model = BkCard\n \n+ _linked_props = ['collapsed']\n+\n _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)\n \n def __init__(self, *objects, **params):\n", "issue": "Accordion's active does not work correctly\n#### ALL software version info\r\nPython 3.7.6, panel==0.10.3\r\n\r\n#### Description of expected behavior and the observed behavior\r\n1. I would expect `accordion.active` to return list of active cards. Now it returns an empty list even if some card is open.\r\n2. Also setting values to `accordion.active` I would expect to open only selected cards. Now it opens selected cards, but does not close the ones that were not selected.\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\n```python\r\n# based on https://panel.holoviz.org/reference/layouts/Accordion.html\r\nimport panel as pn\r\npn.extension()\r\n\r\nfrom bokeh.plotting import figure\r\n\r\np1 = figure(width=300, height=80, name='Scatter', margin=5)\r\np1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\np2 = figure(width=300, height=80, name='Line', margin=5)\r\np2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\naccordion = pn.Accordion(p1, p2)\r\naccordion\r\n\r\n```\r\n\r\n```\r\naccordion.active\r\n```\r\n\r\n```\r\naccordion.active = [0]\r\n```\r\n\r\n#### Screenshots or screencasts of the bug in action\r\n\r\n\n", "before_files": [{"content": "import param\n\nfrom ..models import Card as BkCard\nfrom .base import Column, Row, ListPanel\n\n\nclass Card(Column):\n \"\"\"\n A Card layout allows arranging multiple panel objects in a\n collapsible, vertical container with a header bar.\n \"\"\"\n\n active_header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background when not collapsed.\"\"\")\n\n button_css_classes = param.List(['card-button'], doc=\"\"\"\n CSS classes to apply to the button element.\"\"\")\n\n collapsible = param.Boolean(default=True, doc=\"\"\"\n Whether the Card should be expandable and collapsible.\"\"\")\n\n collapsed = param.Boolean(default=False, doc=\"\"\"\n Whether the contents of the Card are collapsed.\"\"\")\n\n css_classes = param.List(['card'], doc=\"\"\"\n CSS classes to apply to the overall Card.\"\"\")\n\n header = param.Parameter(doc=\"\"\"\n A Panel component to display in the header bar of the Card.\n Will override the given title if defined.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the header text.\"\"\")\n\n header_css_classes = param.List(['card-header'], doc=\"\"\"\n CSS classes to apply to the header element.\"\"\")\n\n title_css_classes = param.List(['card-title'], doc=\"\"\"\n CSS classes to apply to the header title.\"\"\")\n\n margin = param.Parameter(default=5)\n\n title = param.String(doc=\"\"\"\n A title to be displayed in the Card header, will be overridden\n by the header if defined.\"\"\")\n\n _bokeh_model = BkCard\n \n _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)\n\n def __init__(self, *objects, **params):\n self._header_layout = Row(css_classes=['card-header-row'],\n sizing_mode='stretch_width')\n super().__init__(*objects, **params)\n self.param.watch(self._update_header, ['title', 'header', 'title_css_classes'])\n self._update_header()\n\n def _cleanup(self, root):\n super()._cleanup(root)\n self._header_layout._cleanup(root)\n\n def _process_param_change(self, params):\n scroll = params.pop('scroll', None)\n css_classes = self.css_classes or []\n if scroll:\n params['css_classes'] = css_classes + ['scrollable']\n elif scroll == False:\n params['css_classes'] = css_classes\n return super(ListPanel, self)._process_param_change(params)\n\n def _update_header(self, *events):\n from ..pane import HTML, panel\n if self.header is None:\n item = HTML('%s' % (self.title or \"​\"),\n css_classes=self.title_css_classes,\n sizing_mode='stretch_width',\n margin=(2, 5))\n else:\n item = panel(self.header)\n self._header_layout[:] = [item]\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n ref = root.ref['id']\n if ref in self._header_layout._models:\n header = self._header_layout._models[ref][0]\n else:\n header = self._header_layout._get_model(doc, root, model, comm)\n objects = super()._get_objects(model, old_objects, doc, root, comm)\n return [header]+objects\n", "path": "panel/layout/card.py"}, {"content": "import param\n\nfrom bokeh.models import Column as BkColumn, CustomJS\n\nfrom .base import NamedListPanel\nfrom .card import Card\n\n\nclass Accordion(NamedListPanel):\n \n active_header_background = param.String(default='#ccc', doc=\"\"\"\n Color for currently active headers.\"\"\")\n\n active = param.List(default=[], doc=\"\"\"\n List of indexes of active cards.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the expand button.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n toggle = param.Boolean(default=False, doc=\"\"\"\n Whether to toggle between active cards or allow multiple cards\"\"\")\n\n _bokeh_model = BkColumn\n \n _rename = {'active': None, 'active_header_background': None,\n 'header_background': None, 'objects': 'children',\n 'dynamic': None, 'toggle': None, 'header_color': None}\n\n _toggle = \"\"\"\n for (var child of accordion.children) {\n if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {\n child.collapsed = !cb_obj.collapsed\n }\n }\n \"\"\"\n\n _synced_properties = [\n 'active_header_background', 'header_background', 'width',\n 'sizing_mode', 'width_policy', 'height_policy', 'header_color'\n ]\n\n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n \"\"\"\n Returns new child models for the layout while reusing unchanged\n models and cleaning up any dropped objects.\n \"\"\"\n from panel.pane.base import RerenderError, panel\n new_models = []\n if len(self._names) != len(self):\n raise ValueError('Accordion names do not match objects, ensure '\n 'that the Tabs.objects are not modified '\n 'directly. Found %d names, expected %d.' %\n (len(self._names), len(self)))\n for i, (name, pane) in enumerate(zip(self._names, self)):\n pane = panel(pane, name=name)\n self.objects[i] = pane\n\n for obj in old_objects:\n if obj not in self.objects:\n self._panels[id(obj)]._cleanup(root)\n\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n\n ref = root.ref['id']\n current_objects = list(self)\n for i, (name, pane) in enumerate(zip(self._names, self)):\n params.update(self._apply_style(i))\n if id(pane) in self._panels:\n card = self._panels[id(pane)]\n else:\n card = Card(\n pane, title=name, css_classes=['accordion'],\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n self._panels[id(pane)] = card\n card.param.set_param(**params)\n if ref in card._models:\n panel = card._models[ref][0]\n else:\n try:\n panel = card._get_model(doc, root, model, comm)\n if self.toggle:\n cb = CustomJS(args={'accordion': model}, code=self._toggle)\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n \n new_models.append(panel)\n self._update_cards()\n self._update_active()\n return new_models\n\n def _cleanup(self, root):\n for panel in self._panels.values():\n panel._cleanup(root)\n super()._cleanup(root)\n\n def _apply_style(self, i):\n if i == 0:\n margin = (5, 5, 0, 5)\n elif i == (len(self)-1):\n margin = (0, 5, 5, 5)\n else:\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n\n def _update_active(self, *events):\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n self._panels[id(pane)].collapsed = i not in self.active\n\n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n for panel in self._panels.values():\n panel.param.set_param(**params)\n", "path": "panel/layout/accordion.py"}], "after_files": [{"content": "import param\n\nfrom ..models import Card as BkCard\nfrom .base import Column, Row, ListPanel\n\n\nclass Card(Column):\n \"\"\"\n A Card layout allows arranging multiple panel objects in a\n collapsible, vertical container with a header bar.\n \"\"\"\n\n active_header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background when not collapsed.\"\"\")\n\n button_css_classes = param.List(['card-button'], doc=\"\"\"\n CSS classes to apply to the button element.\"\"\")\n\n collapsible = param.Boolean(default=True, doc=\"\"\"\n Whether the Card should be expandable and collapsible.\"\"\")\n\n collapsed = param.Boolean(default=False, doc=\"\"\"\n Whether the contents of the Card are collapsed.\"\"\")\n\n css_classes = param.List(['card'], doc=\"\"\"\n CSS classes to apply to the overall Card.\"\"\")\n\n header = param.Parameter(doc=\"\"\"\n A Panel component to display in the header bar of the Card.\n Will override the given title if defined.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the header text.\"\"\")\n\n header_css_classes = param.List(['card-header'], doc=\"\"\"\n CSS classes to apply to the header element.\"\"\")\n\n title_css_classes = param.List(['card-title'], doc=\"\"\"\n CSS classes to apply to the header title.\"\"\")\n\n margin = param.Parameter(default=5)\n\n title = param.String(doc=\"\"\"\n A title to be displayed in the Card header, will be overridden\n by the header if defined.\"\"\")\n\n _bokeh_model = BkCard\n \n _linked_props = ['collapsed']\n\n _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)\n\n def __init__(self, *objects, **params):\n self._header_layout = Row(css_classes=['card-header-row'],\n sizing_mode='stretch_width')\n super().__init__(*objects, **params)\n self.param.watch(self._update_header, ['title', 'header', 'title_css_classes'])\n self._update_header()\n\n def _cleanup(self, root):\n super()._cleanup(root)\n self._header_layout._cleanup(root)\n\n def _process_param_change(self, params):\n scroll = params.pop('scroll', None)\n css_classes = self.css_classes or []\n if scroll:\n params['css_classes'] = css_classes + ['scrollable']\n elif scroll == False:\n params['css_classes'] = css_classes\n return super(ListPanel, self)._process_param_change(params)\n\n def _update_header(self, *events):\n from ..pane import HTML, panel\n if self.header is None:\n item = HTML('%s' % (self.title or \"​\"),\n css_classes=self.title_css_classes,\n sizing_mode='stretch_width',\n margin=(2, 5))\n else:\n item = panel(self.header)\n self._header_layout[:] = [item]\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n ref = root.ref['id']\n if ref in self._header_layout._models:\n header = self._header_layout._models[ref][0]\n else:\n header = self._header_layout._get_model(doc, root, model, comm)\n objects = super()._get_objects(model, old_objects, doc, root, comm)\n return [header]+objects\n", "path": "panel/layout/card.py"}, {"content": "import param\n\nfrom bokeh.models import Column as BkColumn, CustomJS\n\nfrom .base import NamedListPanel\nfrom .card import Card\n\n\nclass Accordion(NamedListPanel):\n \n active_header_background = param.String(default='#ccc', doc=\"\"\"\n Color for currently active headers.\"\"\")\n\n active = param.List(default=[], doc=\"\"\"\n List of indexes of active cards.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the expand button.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n toggle = param.Boolean(default=False, doc=\"\"\"\n Whether to toggle between active cards or allow multiple cards\"\"\")\n\n _bokeh_model = BkColumn\n \n _rename = {'active': None, 'active_header_background': None,\n 'header_background': None, 'objects': 'children',\n 'dynamic': None, 'toggle': None, 'header_color': None}\n\n _toggle = \"\"\"\n for (var child of accordion.children) {\n if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {\n child.collapsed = !cb_obj.collapsed\n }\n }\n \"\"\"\n\n _synced_properties = [\n 'active_header_background', 'header_background', 'width',\n 'sizing_mode', 'width_policy', 'height_policy', 'header_color'\n ]\n\n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n self._updating_active = False\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n \"\"\"\n Returns new child models for the layout while reusing unchanged\n models and cleaning up any dropped objects.\n \"\"\"\n from panel.pane.base import RerenderError, panel\n new_models = []\n if len(self._names) != len(self):\n raise ValueError('Accordion names do not match objects, ensure '\n 'that the Tabs.objects are not modified '\n 'directly. Found %d names, expected %d.' %\n (len(self._names), len(self)))\n for i, (name, pane) in enumerate(zip(self._names, self)):\n pane = panel(pane, name=name)\n self.objects[i] = pane\n\n for obj in old_objects:\n if obj not in self.objects:\n self._panels[id(obj)]._cleanup(root)\n\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n\n ref = root.ref['id']\n current_objects = list(self)\n for i, (name, pane) in enumerate(zip(self._names, self)):\n params.update(self._apply_style(i))\n if id(pane) in self._panels:\n card = self._panels[id(pane)]\n else:\n card = Card(\n pane, title=name, css_classes=['accordion'],\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n card.param.watch(self._set_active, ['collapsed'])\n self._panels[id(pane)] = card\n card.param.set_param(**params)\n if ref in card._models:\n panel = card._models[ref][0]\n else:\n try:\n panel = card._get_model(doc, root, model, comm)\n if self.toggle:\n cb = CustomJS(args={'accordion': model}, code=self._toggle)\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n new_models.append(panel)\n self._update_cards()\n self._update_active()\n return new_models\n\n def _cleanup(self, root):\n for panel in self._panels.values():\n panel._cleanup(root)\n super()._cleanup(root)\n\n def _apply_style(self, i):\n if i == 0:\n margin = (5, 5, 0, 5)\n elif i == (len(self)-1):\n margin = (0, 5, 5, 5)\n else:\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n\n def _set_active(self, *events):\n if self._updating_active:\n return\n active = []\n self._updating_active = True\n try:\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n elif not self._panels[id(pane)].collapsed:\n active.append(i)\n self.active = active\n finally:\n self._updating_active = False\n\n def _update_active(self, *events):\n if self._updating_active:\n return\n self._updating_active = True\n try:\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n self._panels[id(pane)].collapsed = i not in self.active\n finally:\n self._updating_active = False\n\n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n for panel in self._panels.values():\n panel.param.set_param(**params)\n", "path": "panel/layout/accordion.py"}]}
| 2,944 | 666 |
gh_patches_debug_14871
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2610
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
preview in text commenting does not work
URL: https://meinberlin-dev.liqd.net/dashboard/projects/textkommentierung/basic/
user: initiator
expected behaviour: should be able to see preview
behaviour: get 405 error
Comment/Question: I checked brainstorming and it works. After I enter content for the document it also works, so I guess it has to do with the module text commenting. We also have the problem on prod, so I guess we need a hot fix.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/documents/views.py`
Content:
```
1 from django.http import Http404
2 from django.urls import reverse
3 from django.utils.functional import cached_property
4 from django.utils.translation import ugettext_lazy as _
5 from django.views import generic
6
7 from adhocracy4.dashboard import mixins as dashboard_mixins
8 from adhocracy4.projects.mixins import DisplayProjectOrModuleMixin
9 from adhocracy4.projects.mixins import ProjectMixin
10 from adhocracy4.rules import mixins as rules_mixins
11 from meinberlin.apps.exports.views import DashboardExportView
12
13 from . import models
14
15
16 class DocumentDashboardView(ProjectMixin,
17 dashboard_mixins.DashboardBaseMixin,
18 dashboard_mixins.DashboardComponentMixin,
19 generic.TemplateView):
20 template_name = 'meinberlin_documents/document_dashboard.html'
21 permission_required = 'a4projects.change_project'
22
23 def get_permission_object(self):
24 return self.project
25
26
27 class ChapterDetailView(ProjectMixin,
28 rules_mixins.PermissionRequiredMixin,
29 generic.DetailView,
30 DisplayProjectOrModuleMixin):
31 model = models.Chapter
32 permission_required = 'meinberlin_documents.view_chapter'
33 get_context_from_object = True
34
35 def get_context_data(self, **kwargs):
36 context = super().get_context_data(**kwargs)
37 context['chapter_list'] = self.chapter_list
38 return context
39
40 @property
41 def chapter_list(self):
42 return models.Chapter.objects.filter(module=self.module)
43
44 @cached_property
45 def extends(self):
46 if self.url_name == 'module-detail':
47 return 'a4modules/module_detail.html'
48 if self.url_name == 'chapter-detail':
49 if self.module.is_in_module_cluster:
50 return 'a4modules/module_detail.html'
51 return 'a4projects/project_detail.html'
52
53
54 class DocumentDetailView(ChapterDetailView):
55 get_context_from_object = False
56
57 def get_object(self):
58 first_chapter = models.Chapter.objects \
59 .filter(module=self.module) \
60 .first()
61
62 if not first_chapter:
63 raise Http404(_('Document has no chapters defined.'))
64 return first_chapter
65
66
67 class ParagraphDetailView(ProjectMixin,
68 rules_mixins.PermissionRequiredMixin,
69 generic.DetailView):
70 model = models.Paragraph
71 permission_required = 'meinberlin_documents.view_paragraph'
72
73
74 class DocumentDashboardExportView(DashboardExportView):
75 template_name = 'meinberlin_exports/export_dashboard.html'
76
77 def get_context_data(self, **kwargs):
78 context = super().get_context_data(**kwargs)
79 context['comment_export'] = reverse(
80 'a4dashboard:document-comment-export',
81 kwargs={'module_slug': self.module.slug})
82 return context
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py
--- a/meinberlin/apps/documents/views.py
+++ b/meinberlin/apps/documents/views.py
@@ -1,7 +1,5 @@
-from django.http import Http404
from django.urls import reverse
from django.utils.functional import cached_property
-from django.utils.translation import ugettext_lazy as _
from django.views import generic
from adhocracy4.dashboard import mixins as dashboard_mixins
@@ -58,9 +56,6 @@
first_chapter = models.Chapter.objects \
.filter(module=self.module) \
.first()
-
- if not first_chapter:
- raise Http404(_('Document has no chapters defined.'))
return first_chapter
|
{"golden_diff": "diff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py\n--- a/meinberlin/apps/documents/views.py\n+++ b/meinberlin/apps/documents/views.py\n@@ -1,7 +1,5 @@\n-from django.http import Http404\n from django.urls import reverse\n from django.utils.functional import cached_property\n-from django.utils.translation import ugettext_lazy as _\n from django.views import generic\n \n from adhocracy4.dashboard import mixins as dashboard_mixins\n@@ -58,9 +56,6 @@\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n-\n- if not first_chapter:\n- raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n", "issue": "preview in text commenting does not work\nURL: https://meinberlin-dev.liqd.net/dashboard/projects/textkommentierung/basic/\r\nuser: initiator\r\nexpected behaviour: should be able to see preview\r\nbehaviour: get 405 error\r\nComment/Question: I checked brainstorming and it works. After I enter content for the document it also works, so I guess it has to do with the module text commenting. We also have the problem on prod, so I guess we need a hot fix.\n", "before_files": [{"content": "from django.http import Http404\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom adhocracy4.projects.mixins import ProjectMixin\nfrom adhocracy4.rules import mixins as rules_mixins\nfrom meinberlin.apps.exports.views import DashboardExportView\n\nfrom . import models\n\n\nclass DocumentDashboardView(ProjectMixin,\n dashboard_mixins.DashboardBaseMixin,\n dashboard_mixins.DashboardComponentMixin,\n generic.TemplateView):\n template_name = 'meinberlin_documents/document_dashboard.html'\n permission_required = 'a4projects.change_project'\n\n def get_permission_object(self):\n return self.project\n\n\nclass ChapterDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView,\n DisplayProjectOrModuleMixin):\n model = models.Chapter\n permission_required = 'meinberlin_documents.view_chapter'\n get_context_from_object = True\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n\n @property\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n\n @cached_property\n def extends(self):\n if self.url_name == 'module-detail':\n return 'a4modules/module_detail.html'\n if self.url_name == 'chapter-detail':\n if self.module.is_in_module_cluster:\n return 'a4modules/module_detail.html'\n return 'a4projects/project_detail.html'\n\n\nclass DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n\n def get_object(self):\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n\n if not first_chapter:\n raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n\n\nclass ParagraphDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView):\n model = models.Paragraph\n permission_required = 'meinberlin_documents.view_paragraph'\n\n\nclass DocumentDashboardExportView(DashboardExportView):\n template_name = 'meinberlin_exports/export_dashboard.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['comment_export'] = reverse(\n 'a4dashboard:document-comment-export',\n kwargs={'module_slug': self.module.slug})\n return context\n", "path": "meinberlin/apps/documents/views.py"}], "after_files": [{"content": "from django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom adhocracy4.projects.mixins import ProjectMixin\nfrom adhocracy4.rules import mixins as rules_mixins\nfrom meinberlin.apps.exports.views import DashboardExportView\n\nfrom . import models\n\n\nclass DocumentDashboardView(ProjectMixin,\n dashboard_mixins.DashboardBaseMixin,\n dashboard_mixins.DashboardComponentMixin,\n generic.TemplateView):\n template_name = 'meinberlin_documents/document_dashboard.html'\n permission_required = 'a4projects.change_project'\n\n def get_permission_object(self):\n return self.project\n\n\nclass ChapterDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView,\n DisplayProjectOrModuleMixin):\n model = models.Chapter\n permission_required = 'meinberlin_documents.view_chapter'\n get_context_from_object = True\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n\n @property\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n\n @cached_property\n def extends(self):\n if self.url_name == 'module-detail':\n return 'a4modules/module_detail.html'\n if self.url_name == 'chapter-detail':\n if self.module.is_in_module_cluster:\n return 'a4modules/module_detail.html'\n return 'a4projects/project_detail.html'\n\n\nclass DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n\n def get_object(self):\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n return first_chapter\n\n\nclass ParagraphDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView):\n model = models.Paragraph\n permission_required = 'meinberlin_documents.view_paragraph'\n\n\nclass DocumentDashboardExportView(DashboardExportView):\n template_name = 'meinberlin_exports/export_dashboard.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['comment_export'] = reverse(\n 'a4dashboard:document-comment-export',\n kwargs={'module_slug': self.module.slug})\n return context\n", "path": "meinberlin/apps/documents/views.py"}]}
| 1,085 | 170 |
gh_patches_debug_8603
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-272
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update CI files for branch 3.22
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/settings.py`
Content:
```
1 """
2 Django settings for the Pulp Platform application
3
4 Never import this module directly, instead `from django.conf import settings`, see
5 https://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code
6
7 For the full list of settings and their values, see
8 https://docs.djangoproject.com/en/1.11/ref/settings/
9 """
10
11 import os
12 from contextlib import suppress
13 from importlib import import_module
14 from pkg_resources import iter_entry_points
15
16 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
17 BASE_DIR = os.path.dirname(os.path.abspath(__file__))
18
19 # Quick-start development settings - unsuitable for production
20 # See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/
21
22 # SECURITY WARNING: don't run with debug turned on in production!
23 DEBUG = False
24
25 ALLOWED_HOSTS = ['*']
26
27 MEDIA_ROOT = '/var/lib/pulp/'
28 STATIC_ROOT = os.path.join(MEDIA_ROOT, 'static/')
29
30 DEFAULT_FILE_STORAGE = 'pulpcore.app.models.storage.FileSystem'
31
32 FILE_UPLOAD_TEMP_DIR = os.path.join(MEDIA_ROOT, 'tmp/')
33 WORKING_DIRECTORY = os.path.join(MEDIA_ROOT, 'tmp/')
34
35 # List of upload handler classes to be applied in order.
36 FILE_UPLOAD_HANDLERS = ('pulpcore.app.files.HashingFileUploadHandler',)
37
38 SECRET_KEY = True
39
40 # Application definition
41
42 INSTALLED_APPS = [
43 # django stuff
44 'django.contrib.admin',
45 'django.contrib.auth',
46 'django.contrib.contenttypes',
47 'django.contrib.sessions',
48 'django.contrib.messages',
49 'django.contrib.staticfiles',
50 # third-party
51 'django_filters',
52 'drf_yasg',
53 'rest_framework',
54 # pulp core app
55 'pulpcore.app',
56 ]
57
58 # Enumerate the installed Pulp plugins during the loading process for use in the status API
59 INSTALLED_PULP_PLUGINS = []
60
61 for entry_point in iter_entry_points('pulpcore.plugin'):
62 plugin_app_config = entry_point.load()
63 INSTALLED_PULP_PLUGINS.append(entry_point.module_name)
64 INSTALLED_APPS.append(plugin_app_config)
65
66 # Optional apps that help with development, or augment Pulp in some non-critical way
67 OPTIONAL_APPS = [
68 'crispy_forms',
69 'django_extensions',
70 'storages',
71 ]
72
73 for app in OPTIONAL_APPS:
74 # only import if app is installed
75 with suppress(ImportError):
76 import_module(app)
77 INSTALLED_APPS.append(app)
78
79 MIDDLEWARE = [
80 'django.middleware.security.SecurityMiddleware',
81 'whitenoise.middleware.WhiteNoiseMiddleware',
82 'django.contrib.sessions.middleware.SessionMiddleware',
83 'django.middleware.common.CommonMiddleware',
84 'django.middleware.csrf.CsrfViewMiddleware',
85 'django.contrib.auth.middleware.AuthenticationMiddleware',
86 'pulpcore.app.middleware.PulpRemoteUserMiddleware',
87 'django.contrib.messages.middleware.MessageMiddleware',
88 'django.middleware.clickjacking.XFrameOptionsMiddleware',
89 ]
90
91 AUTHENTICATION_BACKENDS = [
92 'django.contrib.auth.backends.ModelBackend',
93 'django.contrib.auth.backends.RemoteUserBackend',
94 ]
95
96 ROOT_URLCONF = 'pulpcore.app.urls'
97
98 TEMPLATES = [
99 {
100 'BACKEND': 'django.template.backends.django.DjangoTemplates',
101 'DIRS': [os.path.join(BASE_DIR, 'templates')],
102 'APP_DIRS': True,
103 'OPTIONS': {
104 'context_processors': [
105 'django.template.context_processors.debug',
106 'django.template.context_processors.request',
107 'django.contrib.auth.context_processors.auth',
108 'django.contrib.messages.context_processors.messages',
109 ],
110 },
111 },
112 ]
113
114 WSGI_APPLICATION = 'pulpcore.app.wsgi.application'
115
116 REST_FRAMEWORK = {
117 'URL_FIELD_NAME': '_href',
118 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),
119 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
120 'PAGE_SIZE': 100,
121 'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',),
122 'DEFAULT_AUTHENTICATION_CLASSES': (
123 'rest_framework.authentication.SessionAuthentication',
124 'rest_framework.authentication.RemoteUserAuthentication',
125 'rest_framework.authentication.BasicAuthentication',
126 ),
127 'UPLOADED_FILES_USE_URL': False,
128 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',
129 }
130
131 # Password validation
132 # https://docs.djangoproject.com/en/dev/ref/settings/#auth-password-validators
133
134 AUTH_PASSWORD_VALIDATORS = [
135 {
136 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
137 },
138 {
139 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
140 },
141 {
142 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
143 },
144 {
145 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
146 },
147 ]
148
149
150 # Internationalization
151 # https://docs.djangoproject.com/en/1.11/topics/i18n/
152
153 LANGUAGE_CODE = 'en-us'
154
155 TIME_ZONE = 'UTC'
156
157 USE_I18N = 'USE_I18N', True
158
159 USE_L10N = True
160
161 USE_TZ = True
162
163
164 # Static files (CSS, JavaScript, Images)
165 # https://docs.djangoproject.com/en/1.11/howto/static-files/
166
167 STATIC_URL = '/static/'
168
169 # A set of default settings to use if the configuration file in
170 # /etc/pulp/ is missing or if it does not have values for every setting
171
172 # https://docs.djangoproject.com/en/1.11/ref/settings/#databases
173 DATABASES = {
174 'default': {
175 'ENGINE': 'django.db.backends.postgresql_psycopg2',
176 'NAME': 'pulp',
177 'USER': 'pulp',
178 'CONN_MAX_AGE': 0,
179 },
180 }
181 # https://docs.djangoproject.com/en/1.11/ref/settings/#logging and
182 # https://docs.python.org/3/library/logging.config.html
183 LOGGING = {
184 'version': 1,
185 'disable_existing_loggers': False,
186 'formatters': {
187 'simple': {'format': 'pulp: %(name)s:%(levelname)s: %(message)s'},
188 },
189 'handlers': {
190 'console': {
191 'class': 'logging.StreamHandler',
192 'formatter': 'simple'
193 }
194 },
195 'loggers': {
196 '': {
197 # The root logger
198 'handlers': ['console'],
199 'level': 'INFO'
200 },
201 }
202 }
203
204 CONTENT_HOST = ''
205 CONTENT_PATH_PREFIX = '/pulp/content/'
206 CONTENT_APP_TTL = 30
207
208 REMOTE_USER_ENVIRON_NAME = "REMOTE_USER"
209
210 PROFILE_STAGES_API = False
211
212 SWAGGER_SETTINGS = {
213 'DEFAULT_GENERATOR_CLASS': 'pulpcore.app.openapigenerator.PulpOpenAPISchemaGenerator',
214 'DEFAULT_AUTO_SCHEMA_CLASS': 'pulpcore.app.openapigenerator.PulpAutoSchema',
215 'DEFAULT_INFO': 'pulpcore.app.urls.api_info',
216 }
217
218 # HERE STARTS DYNACONF EXTENSION LOAD (Keep at the very bottom of settings.py)
219 # Read more at https://dynaconf.readthedocs.io/en/latest/guides/django.html
220 import dynaconf # noqa
221 settings = dynaconf.DjangoDynaconf(
222 __name__,
223 GLOBAL_ENV_FOR_DYNACONF='PULP',
224 ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',
225 SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',
226 INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],
227 ENVVAR_FOR_DYNACONF='PULP_SETTINGS',
228 )
229 # HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/settings.py b/pulpcore/app/settings.py
--- a/pulpcore/app/settings.py
+++ b/pulpcore/app/settings.py
@@ -223,7 +223,10 @@
GLOBAL_ENV_FOR_DYNACONF='PULP',
ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',
SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',
- INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],
+ INCLUDES_FOR_DYNACONF=[
+ '{}.app.settings'.format(plugin_name)
+ for plugin_name in INSTALLED_PULP_PLUGINS
+ ],
ENVVAR_FOR_DYNACONF='PULP_SETTINGS',
)
# HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)
|
{"golden_diff": "diff --git a/pulpcore/app/settings.py b/pulpcore/app/settings.py\n--- a/pulpcore/app/settings.py\n+++ b/pulpcore/app/settings.py\n@@ -223,7 +223,10 @@\n GLOBAL_ENV_FOR_DYNACONF='PULP',\n ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',\n SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',\n- INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],\n+ INCLUDES_FOR_DYNACONF=[\n+ '{}.app.settings'.format(plugin_name)\n+ for plugin_name in INSTALLED_PULP_PLUGINS\n+ ],\n ENVVAR_FOR_DYNACONF='PULP_SETTINGS',\n )\n # HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)\n", "issue": "Update CI files for branch 3.22\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for the Pulp Platform application\n\nNever import this module directly, instead `from django.conf import settings`, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.11/ref/settings/\n\"\"\"\n\nimport os\nfrom contextlib import suppress\nfrom importlib import import_module\nfrom pkg_resources import iter_entry_points\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\nALLOWED_HOSTS = ['*']\n\nMEDIA_ROOT = '/var/lib/pulp/'\nSTATIC_ROOT = os.path.join(MEDIA_ROOT, 'static/')\n\nDEFAULT_FILE_STORAGE = 'pulpcore.app.models.storage.FileSystem'\n\nFILE_UPLOAD_TEMP_DIR = os.path.join(MEDIA_ROOT, 'tmp/')\nWORKING_DIRECTORY = os.path.join(MEDIA_ROOT, 'tmp/')\n\n# List of upload handler classes to be applied in order.\nFILE_UPLOAD_HANDLERS = ('pulpcore.app.files.HashingFileUploadHandler',)\n\nSECRET_KEY = True\n\n# Application definition\n\nINSTALLED_APPS = [\n # django stuff\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n # third-party\n 'django_filters',\n 'drf_yasg',\n 'rest_framework',\n # pulp core app\n 'pulpcore.app',\n]\n\n# Enumerate the installed Pulp plugins during the loading process for use in the status API\nINSTALLED_PULP_PLUGINS = []\n\nfor entry_point in iter_entry_points('pulpcore.plugin'):\n plugin_app_config = entry_point.load()\n INSTALLED_PULP_PLUGINS.append(entry_point.module_name)\n INSTALLED_APPS.append(plugin_app_config)\n\n# Optional apps that help with development, or augment Pulp in some non-critical way\nOPTIONAL_APPS = [\n 'crispy_forms',\n 'django_extensions',\n 'storages',\n]\n\nfor app in OPTIONAL_APPS:\n # only import if app is installed\n with suppress(ImportError):\n import_module(app)\n INSTALLED_APPS.append(app)\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'pulpcore.app.middleware.PulpRemoteUserMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nAUTHENTICATION_BACKENDS = [\n 'django.contrib.auth.backends.ModelBackend',\n 'django.contrib.auth.backends.RemoteUserBackend',\n]\n\nROOT_URLCONF = 'pulpcore.app.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'pulpcore.app.wsgi.application'\n\nREST_FRAMEWORK = {\n 'URL_FIELD_NAME': '_href',\n 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),\n 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',\n 'PAGE_SIZE': 100,\n 'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',),\n 'DEFAULT_AUTHENTICATION_CLASSES': (\n 'rest_framework.authentication.SessionAuthentication',\n 'rest_framework.authentication.RemoteUserAuthentication',\n 'rest_framework.authentication.BasicAuthentication',\n ),\n 'UPLOADED_FILES_USE_URL': False,\n 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/dev/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.11/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = 'USE_I18N', True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.11/howto/static-files/\n\nSTATIC_URL = '/static/'\n\n# A set of default settings to use if the configuration file in\n# /etc/pulp/ is missing or if it does not have values for every setting\n\n# https://docs.djangoproject.com/en/1.11/ref/settings/#databases\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql_psycopg2',\n 'NAME': 'pulp',\n 'USER': 'pulp',\n 'CONN_MAX_AGE': 0,\n },\n}\n# https://docs.djangoproject.com/en/1.11/ref/settings/#logging and\n# https://docs.python.org/3/library/logging.config.html\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'simple': {'format': 'pulp: %(name)s:%(levelname)s: %(message)s'},\n },\n 'handlers': {\n 'console': {\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n }\n },\n 'loggers': {\n '': {\n # The root logger\n 'handlers': ['console'],\n 'level': 'INFO'\n },\n }\n}\n\nCONTENT_HOST = ''\nCONTENT_PATH_PREFIX = '/pulp/content/'\nCONTENT_APP_TTL = 30\n\nREMOTE_USER_ENVIRON_NAME = \"REMOTE_USER\"\n\nPROFILE_STAGES_API = False\n\nSWAGGER_SETTINGS = {\n 'DEFAULT_GENERATOR_CLASS': 'pulpcore.app.openapigenerator.PulpOpenAPISchemaGenerator',\n 'DEFAULT_AUTO_SCHEMA_CLASS': 'pulpcore.app.openapigenerator.PulpAutoSchema',\n 'DEFAULT_INFO': 'pulpcore.app.urls.api_info',\n}\n\n# HERE STARTS DYNACONF EXTENSION LOAD (Keep at the very bottom of settings.py)\n# Read more at https://dynaconf.readthedocs.io/en/latest/guides/django.html\nimport dynaconf # noqa\nsettings = dynaconf.DjangoDynaconf(\n __name__,\n GLOBAL_ENV_FOR_DYNACONF='PULP',\n ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',\n SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',\n INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],\n ENVVAR_FOR_DYNACONF='PULP_SETTINGS',\n)\n# HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)\n", "path": "pulpcore/app/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for the Pulp Platform application\n\nNever import this module directly, instead `from django.conf import settings`, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.11/ref/settings/\n\"\"\"\n\nimport os\nfrom contextlib import suppress\nfrom importlib import import_module\nfrom pkg_resources import iter_entry_points\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\nALLOWED_HOSTS = ['*']\n\nMEDIA_ROOT = '/var/lib/pulp/'\nSTATIC_ROOT = os.path.join(MEDIA_ROOT, 'static/')\n\nDEFAULT_FILE_STORAGE = 'pulpcore.app.models.storage.FileSystem'\n\nFILE_UPLOAD_TEMP_DIR = os.path.join(MEDIA_ROOT, 'tmp/')\nWORKING_DIRECTORY = os.path.join(MEDIA_ROOT, 'tmp/')\n\n# List of upload handler classes to be applied in order.\nFILE_UPLOAD_HANDLERS = ('pulpcore.app.files.HashingFileUploadHandler',)\n\nSECRET_KEY = True\n\n# Application definition\n\nINSTALLED_APPS = [\n # django stuff\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n # third-party\n 'django_filters',\n 'drf_yasg',\n 'rest_framework',\n # pulp core app\n 'pulpcore.app',\n]\n\n# Enumerate the installed Pulp plugins during the loading process for use in the status API\nINSTALLED_PULP_PLUGINS = []\n\nfor entry_point in iter_entry_points('pulpcore.plugin'):\n plugin_app_config = entry_point.load()\n INSTALLED_PULP_PLUGINS.append(entry_point.module_name)\n INSTALLED_APPS.append(plugin_app_config)\n\n# Optional apps that help with development, or augment Pulp in some non-critical way\nOPTIONAL_APPS = [\n 'crispy_forms',\n 'django_extensions',\n 'storages',\n]\n\nfor app in OPTIONAL_APPS:\n # only import if app is installed\n with suppress(ImportError):\n import_module(app)\n INSTALLED_APPS.append(app)\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'pulpcore.app.middleware.PulpRemoteUserMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nAUTHENTICATION_BACKENDS = [\n 'django.contrib.auth.backends.ModelBackend',\n 'django.contrib.auth.backends.RemoteUserBackend',\n]\n\nROOT_URLCONF = 'pulpcore.app.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'pulpcore.app.wsgi.application'\n\nREST_FRAMEWORK = {\n 'URL_FIELD_NAME': '_href',\n 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),\n 'DEFAULT_PAGINATION_CLASS': 'pulpcore.app.pagination.IDPagination',\n 'PAGE_SIZE': 100,\n 'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',),\n 'DEFAULT_AUTHENTICATION_CLASSES': (\n 'rest_framework.authentication.SessionAuthentication',\n 'rest_framework.authentication.RemoteUserAuthentication',\n 'rest_framework.authentication.BasicAuthentication',\n ),\n 'UPLOADED_FILES_USE_URL': False,\n 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/dev/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.11/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = 'USE_I18N', True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.11/howto/static-files/\n\nSTATIC_URL = '/static/'\n\n# A set of default settings to use if the configuration file in\n# /etc/pulp/ is missing or if it does not have values for every setting\n\n# https://docs.djangoproject.com/en/1.11/ref/settings/#databases\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql_psycopg2',\n 'NAME': 'pulp',\n 'USER': 'pulp',\n 'CONN_MAX_AGE': 0,\n },\n}\n# https://docs.djangoproject.com/en/1.11/ref/settings/#logging and\n# https://docs.python.org/3/library/logging.config.html\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'simple': {'format': 'pulp: %(name)s:%(levelname)s: %(message)s'},\n },\n 'handlers': {\n 'console': {\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n }\n },\n 'loggers': {\n '': {\n # The root logger\n 'handlers': ['console'],\n 'level': 'INFO'\n },\n }\n}\n\nCONTENT_HOST = ''\nCONTENT_PATH_PREFIX = '/pulp/content/'\nCONTENT_APP_TTL = 30\n\nREMOTE_USER_ENVIRON_NAME = \"REMOTE_USER\"\n\nPROFILE_STAGES_API = False\n\nSWAGGER_SETTINGS = {\n 'DEFAULT_GENERATOR_CLASS': 'pulpcore.app.openapigenerator.PulpOpenAPISchemaGenerator',\n 'DEFAULT_AUTO_SCHEMA_CLASS': 'pulpcore.app.openapigenerator.PulpAutoSchema',\n 'DEFAULT_INFO': 'pulpcore.app.urls.api_info',\n}\n\n# HERE STARTS DYNACONF EXTENSION LOAD (Keep at the very bottom of settings.py)\n# Read more at https://dynaconf.readthedocs.io/en/latest/guides/django.html\nimport dynaconf # noqa\nsettings = dynaconf.DjangoDynaconf(\n __name__,\n GLOBAL_ENV_FOR_DYNACONF='PULP',\n ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',\n SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',\n INCLUDES_FOR_DYNACONF=[\n '{}.app.settings'.format(plugin_name)\n for plugin_name in INSTALLED_PULP_PLUGINS\n ],\n ENVVAR_FOR_DYNACONF='PULP_SETTINGS',\n)\n# HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)\n", "path": "pulpcore/app/settings.py"}]}
| 2,515 | 190 |
gh_patches_debug_598
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1733
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.82
On the docket:
+ [x] Pex resolve checking does not allow resolved pre-releases when --no-pre. #1730
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.81"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.81"
+__version__ = "2.1.82"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.81\"\n+__version__ = \"2.1.82\"\n", "issue": "Release 2.1.82\nOn the docket:\r\n+ [x] Pex resolve checking does not allow resolved pre-releases when --no-pre. #1730 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.81\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.82\"\n", "path": "pex/version.py"}]}
| 347 | 96 |
gh_patches_debug_66995
|
rasdani/github-patches
|
git_diff
|
spack__spack-12972
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Automatically use Python 3 if available
As discussed during today's BoF, some people would like Spack to use Python 3 if available. Since we cannot depend on any version of Python being available on all systems, this needs a slightly complex approach: The spack binary is moved to spack-real and replaced by a shell script that checks for available versions of Python (preferring Python 3) and invokes spack-real accordingly.
This should also take care of the situation where no python binary is available (as will be on RHEL 8 by default).
Not sure if this is really the best way to go but I have been meaning to take a stab at this for a while now. (Only tested on Linux.)
@tgamblin @alalazo @becker33 @adamjstewart
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/spack/spack/cmd/license.py`
Content:
```
1 # Copyright 2013-2019 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from __future__ import print_function
7
8 import os
9 import re
10 from collections import defaultdict
11
12 import llnl.util.tty as tty
13
14 import spack.paths
15 from spack.util.executable import which
16
17 description = 'list and check license headers on files in spack'
18 section = "developer"
19 level = "long"
20
21 #: need the git command to check new files
22 git = which('git')
23
24 #: SPDX license id must appear in the first <license_lines> lines of a file
25 license_lines = 6
26
27 #: Spack's license identifier
28 apache2_mit_spdx = "(Apache-2.0 OR MIT)"
29
30 #: regular expressions for licensed files.
31 licensed_files = [
32 # spack scripts
33 r'^bin/spack$',
34 r'^bin/spack-python$',
35 r'^bin/sbang$',
36
37 # all of spack core
38 r'^lib/spack/spack/.*\.py$',
39 r'^lib/spack/spack/.*\.sh$',
40 r'^lib/spack/llnl/.*\.py$',
41 r'^lib/spack/env/cc$',
42
43 # rst files in documentation
44 r'^lib/spack/docs/(?!command_index|spack|llnl).*\.rst$',
45 r'^lib/spack/docs/.*\.py$',
46
47 # 2 files in external
48 r'^lib/spack/external/__init__.py$',
49 r'^lib/spack/external/ordereddict_backport.py$',
50
51 # shell scripts in share
52 r'^share/spack/.*\.sh$',
53 r'^share/spack/.*\.bash$',
54 r'^share/spack/.*\.csh$',
55 r'^share/spack/qa/run-[^/]*$',
56
57 # all packages
58 r'^var/spack/repos/.*/package.py$'
59 ]
60
61 #: licensed files that can have LGPL language in them
62 #: so far, just this command -- so it can find LGPL things elsewhere
63 lgpl_exceptions = [
64 r'lib/spack/spack/cmd/license.py',
65 r'lib/spack/spack/test/cmd/license.py',
66 ]
67
68
69 def _all_spack_files(root=spack.paths.prefix):
70 """Generates root-relative paths of all files in the spack repository."""
71 visited = set()
72 for cur_root, folders, files in os.walk(root):
73 for filename in files:
74 path = os.path.realpath(os.path.join(cur_root, filename))
75
76 if path not in visited:
77 yield os.path.relpath(path, root)
78 visited.add(path)
79
80
81 def _licensed_files(root=spack.paths.prefix):
82 for relpath in _all_spack_files(root):
83 if any(regex.match(relpath) for regex in licensed_files):
84 yield relpath
85
86
87 def list_files(args):
88 """list files in spack that should have license headers"""
89 for relpath in sorted(_licensed_files()):
90 print(os.path.join(spack.paths.spack_root, relpath))
91
92
93 # Error codes for license verification. All values are chosen such that
94 # bool(value) evaluates to True
95 OLD_LICENSE, SPDX_MISMATCH, GENERAL_MISMATCH = range(1, 4)
96
97
98 class LicenseError(object):
99 def __init__(self):
100 self.error_counts = defaultdict(int)
101
102 def add_error(self, error):
103 self.error_counts[error] += 1
104
105 def has_errors(self):
106 return sum(self.error_counts.values()) > 0
107
108 def error_messages(self):
109 total = sum(self.error_counts.values())
110 missing = self.error_counts[GENERAL_MISMATCH]
111 spdx_mismatch = self.error_counts[SPDX_MISMATCH]
112 old_license = self.error_counts[OLD_LICENSE]
113 return (
114 '%d improperly licensed files' % (total),
115 'files with wrong SPDX-License-Identifier: %d' % spdx_mismatch,
116 'files with old license header: %d' % old_license,
117 'files not containing expected license: %d' % missing)
118
119
120 def _check_license(lines, path):
121 license_lines = [
122 r'Copyright 2013-(?:201[789]|202\d) Lawrence Livermore National Security, LLC and other', # noqa: E501
123 r'Spack Project Developers\. See the top-level COPYRIGHT file for details.', # noqa: E501
124 r'SPDX-License-Identifier: \(Apache-2\.0 OR MIT\)'
125 ]
126
127 strict_date = r'Copyright 2013-2019'
128
129 found = []
130
131 for line in lines:
132 line = re.sub(r'^[\s#\.]*', '', line)
133 line = line.rstrip()
134 for i, license_line in enumerate(license_lines):
135 if re.match(license_line, line):
136 # The first line of the license contains the copyright date.
137 # We allow it to be out of date but print a warning if it is
138 # out of date.
139 if i == 0:
140 if not re.search(strict_date, line):
141 tty.debug('{0}: copyright date mismatch'.format(path))
142 found.append(i)
143
144 if len(found) == len(license_lines) and found == list(sorted(found)):
145 return
146
147 def old_license(line, path):
148 if re.search('This program is free software', line):
149 print('{0}: has old LGPL license header'.format(path))
150 return OLD_LICENSE
151
152 # If the SPDX identifier is present, then there is a mismatch (since it
153 # did not match the above regex)
154 def wrong_spdx_identifier(line, path):
155 m = re.search(r'SPDX-License-Identifier: ([^\n]*)', line)
156 if m and m.group(1) != apache2_mit_spdx:
157 print('{0}: SPDX license identifier mismatch'
158 '(expecting {1}, found {2})'
159 .format(path, apache2_mit_spdx, m.group(1)))
160 return SPDX_MISMATCH
161
162 checks = [old_license, wrong_spdx_identifier]
163
164 for line in lines:
165 for check in checks:
166 error = check(line, path)
167 if error:
168 return error
169
170 print('{0}: the license does not match the expected format'.format(path))
171 return GENERAL_MISMATCH
172
173
174 def verify(args):
175 """verify that files in spack have the right license header"""
176
177 license_errors = LicenseError()
178
179 for relpath in _licensed_files(args.root):
180 path = os.path.join(args.root, relpath)
181 with open(path) as f:
182 lines = [line for line in f][:license_lines]
183
184 error = _check_license(lines, path)
185 if error:
186 license_errors.add_error(error)
187
188 if license_errors.has_errors():
189 tty.die(*license_errors.error_messages())
190 else:
191 tty.msg('No license issues found.')
192
193
194 def setup_parser(subparser):
195 sp = subparser.add_subparsers(metavar='SUBCOMMAND', dest='license_command')
196 sp.add_parser('list-files', help=list_files.__doc__)
197
198 verify_parser = sp.add_parser('verify', help=verify.__doc__)
199 verify_parser.add_argument(
200 '--root', action='store', default=spack.paths.prefix,
201 help='scan a different prefix for license issues')
202
203
204 def license(parser, args):
205 if not git:
206 tty.die('spack license requires git in your environment')
207
208 licensed_files[:] = [re.compile(regex) for regex in licensed_files]
209
210 commands = {
211 'list-files': list_files,
212 'verify': verify,
213 }
214 return commands[args.license_command](args)
215
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/spack/spack/cmd/license.py b/lib/spack/spack/cmd/license.py
--- a/lib/spack/spack/cmd/license.py
+++ b/lib/spack/spack/cmd/license.py
@@ -22,7 +22,7 @@
git = which('git')
#: SPDX license id must appear in the first <license_lines> lines of a file
-license_lines = 6
+license_lines = 7
#: Spack's license identifier
apache2_mit_spdx = "(Apache-2.0 OR MIT)"
|
{"golden_diff": "diff --git a/lib/spack/spack/cmd/license.py b/lib/spack/spack/cmd/license.py\n--- a/lib/spack/spack/cmd/license.py\n+++ b/lib/spack/spack/cmd/license.py\n@@ -22,7 +22,7 @@\n git = which('git')\n \n #: SPDX license id must appear in the first <license_lines> lines of a file\n-license_lines = 6\n+license_lines = 7\n \n #: Spack's license identifier\n apache2_mit_spdx = \"(Apache-2.0 OR MIT)\"\n", "issue": "Automatically use Python 3 if available\nAs discussed during today's BoF, some people would like Spack to use Python 3 if available. Since we cannot depend on any version of Python being available on all systems, this needs a slightly complex approach: The spack binary is moved to spack-real and replaced by a shell script that checks for available versions of Python (preferring Python 3) and invokes spack-real accordingly.\r\n\r\nThis should also take care of the situation where no python binary is available (as will be on RHEL 8 by default).\r\n\r\nNot sure if this is really the best way to go but I have been meaning to take a stab at this for a while now. (Only tested on Linux.)\r\n@tgamblin @alalazo @becker33 @adamjstewart\n", "before_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport os\nimport re\nfrom collections import defaultdict\n\nimport llnl.util.tty as tty\n\nimport spack.paths\nfrom spack.util.executable import which\n\ndescription = 'list and check license headers on files in spack'\nsection = \"developer\"\nlevel = \"long\"\n\n#: need the git command to check new files\ngit = which('git')\n\n#: SPDX license id must appear in the first <license_lines> lines of a file\nlicense_lines = 6\n\n#: Spack's license identifier\napache2_mit_spdx = \"(Apache-2.0 OR MIT)\"\n\n#: regular expressions for licensed files.\nlicensed_files = [\n # spack scripts\n r'^bin/spack$',\n r'^bin/spack-python$',\n r'^bin/sbang$',\n\n # all of spack core\n r'^lib/spack/spack/.*\\.py$',\n r'^lib/spack/spack/.*\\.sh$',\n r'^lib/spack/llnl/.*\\.py$',\n r'^lib/spack/env/cc$',\n\n # rst files in documentation\n r'^lib/spack/docs/(?!command_index|spack|llnl).*\\.rst$',\n r'^lib/spack/docs/.*\\.py$',\n\n # 2 files in external\n r'^lib/spack/external/__init__.py$',\n r'^lib/spack/external/ordereddict_backport.py$',\n\n # shell scripts in share\n r'^share/spack/.*\\.sh$',\n r'^share/spack/.*\\.bash$',\n r'^share/spack/.*\\.csh$',\n r'^share/spack/qa/run-[^/]*$',\n\n # all packages\n r'^var/spack/repos/.*/package.py$'\n]\n\n#: licensed files that can have LGPL language in them\n#: so far, just this command -- so it can find LGPL things elsewhere\nlgpl_exceptions = [\n r'lib/spack/spack/cmd/license.py',\n r'lib/spack/spack/test/cmd/license.py',\n]\n\n\ndef _all_spack_files(root=spack.paths.prefix):\n \"\"\"Generates root-relative paths of all files in the spack repository.\"\"\"\n visited = set()\n for cur_root, folders, files in os.walk(root):\n for filename in files:\n path = os.path.realpath(os.path.join(cur_root, filename))\n\n if path not in visited:\n yield os.path.relpath(path, root)\n visited.add(path)\n\n\ndef _licensed_files(root=spack.paths.prefix):\n for relpath in _all_spack_files(root):\n if any(regex.match(relpath) for regex in licensed_files):\n yield relpath\n\n\ndef list_files(args):\n \"\"\"list files in spack that should have license headers\"\"\"\n for relpath in sorted(_licensed_files()):\n print(os.path.join(spack.paths.spack_root, relpath))\n\n\n# Error codes for license verification. All values are chosen such that\n# bool(value) evaluates to True\nOLD_LICENSE, SPDX_MISMATCH, GENERAL_MISMATCH = range(1, 4)\n\n\nclass LicenseError(object):\n def __init__(self):\n self.error_counts = defaultdict(int)\n\n def add_error(self, error):\n self.error_counts[error] += 1\n\n def has_errors(self):\n return sum(self.error_counts.values()) > 0\n\n def error_messages(self):\n total = sum(self.error_counts.values())\n missing = self.error_counts[GENERAL_MISMATCH]\n spdx_mismatch = self.error_counts[SPDX_MISMATCH]\n old_license = self.error_counts[OLD_LICENSE]\n return (\n '%d improperly licensed files' % (total),\n 'files with wrong SPDX-License-Identifier: %d' % spdx_mismatch,\n 'files with old license header: %d' % old_license,\n 'files not containing expected license: %d' % missing)\n\n\ndef _check_license(lines, path):\n license_lines = [\n r'Copyright 2013-(?:201[789]|202\\d) Lawrence Livermore National Security, LLC and other', # noqa: E501\n r'Spack Project Developers\\. See the top-level COPYRIGHT file for details.', # noqa: E501\n r'SPDX-License-Identifier: \\(Apache-2\\.0 OR MIT\\)'\n ]\n\n strict_date = r'Copyright 2013-2019'\n\n found = []\n\n for line in lines:\n line = re.sub(r'^[\\s#\\.]*', '', line)\n line = line.rstrip()\n for i, license_line in enumerate(license_lines):\n if re.match(license_line, line):\n # The first line of the license contains the copyright date.\n # We allow it to be out of date but print a warning if it is\n # out of date.\n if i == 0:\n if not re.search(strict_date, line):\n tty.debug('{0}: copyright date mismatch'.format(path))\n found.append(i)\n\n if len(found) == len(license_lines) and found == list(sorted(found)):\n return\n\n def old_license(line, path):\n if re.search('This program is free software', line):\n print('{0}: has old LGPL license header'.format(path))\n return OLD_LICENSE\n\n # If the SPDX identifier is present, then there is a mismatch (since it\n # did not match the above regex)\n def wrong_spdx_identifier(line, path):\n m = re.search(r'SPDX-License-Identifier: ([^\\n]*)', line)\n if m and m.group(1) != apache2_mit_spdx:\n print('{0}: SPDX license identifier mismatch'\n '(expecting {1}, found {2})'\n .format(path, apache2_mit_spdx, m.group(1)))\n return SPDX_MISMATCH\n\n checks = [old_license, wrong_spdx_identifier]\n\n for line in lines:\n for check in checks:\n error = check(line, path)\n if error:\n return error\n\n print('{0}: the license does not match the expected format'.format(path))\n return GENERAL_MISMATCH\n\n\ndef verify(args):\n \"\"\"verify that files in spack have the right license header\"\"\"\n\n license_errors = LicenseError()\n\n for relpath in _licensed_files(args.root):\n path = os.path.join(args.root, relpath)\n with open(path) as f:\n lines = [line for line in f][:license_lines]\n\n error = _check_license(lines, path)\n if error:\n license_errors.add_error(error)\n\n if license_errors.has_errors():\n tty.die(*license_errors.error_messages())\n else:\n tty.msg('No license issues found.')\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(metavar='SUBCOMMAND', dest='license_command')\n sp.add_parser('list-files', help=list_files.__doc__)\n\n verify_parser = sp.add_parser('verify', help=verify.__doc__)\n verify_parser.add_argument(\n '--root', action='store', default=spack.paths.prefix,\n help='scan a different prefix for license issues')\n\n\ndef license(parser, args):\n if not git:\n tty.die('spack license requires git in your environment')\n\n licensed_files[:] = [re.compile(regex) for regex in licensed_files]\n\n commands = {\n 'list-files': list_files,\n 'verify': verify,\n }\n return commands[args.license_command](args)\n", "path": "lib/spack/spack/cmd/license.py"}], "after_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport os\nimport re\nfrom collections import defaultdict\n\nimport llnl.util.tty as tty\n\nimport spack.paths\nfrom spack.util.executable import which\n\ndescription = 'list and check license headers on files in spack'\nsection = \"developer\"\nlevel = \"long\"\n\n#: need the git command to check new files\ngit = which('git')\n\n#: SPDX license id must appear in the first <license_lines> lines of a file\nlicense_lines = 7\n\n#: Spack's license identifier\napache2_mit_spdx = \"(Apache-2.0 OR MIT)\"\n\n#: regular expressions for licensed files.\nlicensed_files = [\n # spack scripts\n r'^bin/spack$',\n r'^bin/spack-python$',\n r'^bin/sbang$',\n\n # all of spack core\n r'^lib/spack/spack/.*\\.py$',\n r'^lib/spack/spack/.*\\.sh$',\n r'^lib/spack/llnl/.*\\.py$',\n r'^lib/spack/env/cc$',\n\n # rst files in documentation\n r'^lib/spack/docs/(?!command_index|spack|llnl).*\\.rst$',\n r'^lib/spack/docs/.*\\.py$',\n\n # 2 files in external\n r'^lib/spack/external/__init__.py$',\n r'^lib/spack/external/ordereddict_backport.py$',\n\n # shell scripts in share\n r'^share/spack/.*\\.sh$',\n r'^share/spack/.*\\.bash$',\n r'^share/spack/.*\\.csh$',\n r'^share/spack/qa/run-[^/]*$',\n\n # all packages\n r'^var/spack/repos/.*/package.py$'\n]\n\n#: licensed files that can have LGPL language in them\n#: so far, just this command -- so it can find LGPL things elsewhere\nlgpl_exceptions = [\n r'lib/spack/spack/cmd/license.py',\n r'lib/spack/spack/test/cmd/license.py',\n]\n\n\ndef _all_spack_files(root=spack.paths.prefix):\n \"\"\"Generates root-relative paths of all files in the spack repository.\"\"\"\n visited = set()\n for cur_root, folders, files in os.walk(root):\n for filename in files:\n path = os.path.realpath(os.path.join(cur_root, filename))\n\n if path not in visited:\n yield os.path.relpath(path, root)\n visited.add(path)\n\n\ndef _licensed_files(root=spack.paths.prefix):\n for relpath in _all_spack_files(root):\n if any(regex.match(relpath) for regex in licensed_files):\n yield relpath\n\n\ndef list_files(args):\n \"\"\"list files in spack that should have license headers\"\"\"\n for relpath in sorted(_licensed_files()):\n print(os.path.join(spack.paths.spack_root, relpath))\n\n\n# Error codes for license verification. All values are chosen such that\n# bool(value) evaluates to True\nOLD_LICENSE, SPDX_MISMATCH, GENERAL_MISMATCH = range(1, 4)\n\n\nclass LicenseError(object):\n def __init__(self):\n self.error_counts = defaultdict(int)\n\n def add_error(self, error):\n self.error_counts[error] += 1\n\n def has_errors(self):\n return sum(self.error_counts.values()) > 0\n\n def error_messages(self):\n total = sum(self.error_counts.values())\n missing = self.error_counts[GENERAL_MISMATCH]\n spdx_mismatch = self.error_counts[SPDX_MISMATCH]\n old_license = self.error_counts[OLD_LICENSE]\n return (\n '%d improperly licensed files' % (total),\n 'files with wrong SPDX-License-Identifier: %d' % spdx_mismatch,\n 'files with old license header: %d' % old_license,\n 'files not containing expected license: %d' % missing)\n\n\ndef _check_license(lines, path):\n license_lines = [\n r'Copyright 2013-(?:201[789]|202\\d) Lawrence Livermore National Security, LLC and other', # noqa: E501\n r'Spack Project Developers\\. See the top-level COPYRIGHT file for details.', # noqa: E501\n r'SPDX-License-Identifier: \\(Apache-2\\.0 OR MIT\\)'\n ]\n\n strict_date = r'Copyright 2013-2019'\n\n found = []\n\n for line in lines:\n line = re.sub(r'^[\\s#\\.]*', '', line)\n line = line.rstrip()\n for i, license_line in enumerate(license_lines):\n if re.match(license_line, line):\n # The first line of the license contains the copyright date.\n # We allow it to be out of date but print a warning if it is\n # out of date.\n if i == 0:\n if not re.search(strict_date, line):\n tty.debug('{0}: copyright date mismatch'.format(path))\n found.append(i)\n\n if len(found) == len(license_lines) and found == list(sorted(found)):\n return\n\n def old_license(line, path):\n if re.search('This program is free software', line):\n print('{0}: has old LGPL license header'.format(path))\n return OLD_LICENSE\n\n # If the SPDX identifier is present, then there is a mismatch (since it\n # did not match the above regex)\n def wrong_spdx_identifier(line, path):\n m = re.search(r'SPDX-License-Identifier: ([^\\n]*)', line)\n if m and m.group(1) != apache2_mit_spdx:\n print('{0}: SPDX license identifier mismatch'\n '(expecting {1}, found {2})'\n .format(path, apache2_mit_spdx, m.group(1)))\n return SPDX_MISMATCH\n\n checks = [old_license, wrong_spdx_identifier]\n\n for line in lines:\n for check in checks:\n error = check(line, path)\n if error:\n return error\n\n print('{0}: the license does not match the expected format'.format(path))\n return GENERAL_MISMATCH\n\n\ndef verify(args):\n \"\"\"verify that files in spack have the right license header\"\"\"\n\n license_errors = LicenseError()\n\n for relpath in _licensed_files(args.root):\n path = os.path.join(args.root, relpath)\n with open(path) as f:\n lines = [line for line in f][:license_lines]\n\n error = _check_license(lines, path)\n if error:\n license_errors.add_error(error)\n\n if license_errors.has_errors():\n tty.die(*license_errors.error_messages())\n else:\n tty.msg('No license issues found.')\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(metavar='SUBCOMMAND', dest='license_command')\n sp.add_parser('list-files', help=list_files.__doc__)\n\n verify_parser = sp.add_parser('verify', help=verify.__doc__)\n verify_parser.add_argument(\n '--root', action='store', default=spack.paths.prefix,\n help='scan a different prefix for license issues')\n\n\ndef license(parser, args):\n if not git:\n tty.die('spack license requires git in your environment')\n\n licensed_files[:] = [re.compile(regex) for regex in licensed_files]\n\n commands = {\n 'list-files': list_files,\n 'verify': verify,\n }\n return commands[args.license_command](args)\n", "path": "lib/spack/spack/cmd/license.py"}]}
| 2,676 | 117 |
gh_patches_debug_63248
|
rasdani/github-patches
|
git_diff
|
conda__conda-3931
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Regression: cannot install from explicit conda package filenames
This command used to work, but now it gives the following error/traceback:
Example: `conda install bzip2-1.0.6-vc14_3.tar.bz2 --dry-run`
```
An unexpected error has occurred.
Please consider posting the following information to the
conda GitHub issue tracker at:
https://github.com/conda/conda/issues
Current conda install:
platform : win-64
conda version : 4.2.12
conda is private : False
conda-env version : 4.2.12
conda-build version : 2.0.7
python version : 3.5.2.final.0
requests version : 2.10.0
root environment : C:\Miniconda3 (writable)
default environment : C:\Miniconda3\envs\test_conda
envs directories : C:\Miniconda3\envs
package cache : C:\Miniconda3\pkgs
channel URLs : https://repo.continuum.io/pkgs/free/win-64
https://repo.continuum.io/pkgs/free/noarch
https://repo.continuum.io/pkgs/pro/win-64
https://repo.continuum.io/pkgs/pro/noarch
https://repo.continuum.io/pkgs/msys2/win-64
https://repo.continuum.io/pkgs/msys2/noarch
config file : None
offline mode : False
`$ C:\Miniconda3\Scripts\conda-script.py install bzip2-1.0.6-vc14_3.tar.bz2 --dry-run`
Traceback (most recent call last):
File "C:\Miniconda3\lib\site-packages\conda\exceptions.py", line 479, in conda_exception_handler
return_value = func(*args, **kwargs)
File "C:\Miniconda3\lib\site-packages\conda\cli\main.py", line 145, in _main
exit_code = args.func(args, p)
File "C:\Miniconda3\lib\site-packages\conda\cli\main_install.py", line 80, in execute
install(args, parser, 'install')
File "C:\Miniconda3\lib\site-packages\conda\cli\install.py", line 209, in install
explicit(args.packages, prefix, verbose=not context.quiet)
File "C:\Miniconda3\lib\site-packages\conda\misc.py", line 66, in explicit
if not is_url(url_p):
File "C:\Miniconda3\lib\site-packages\conda\common\url.py", line 72, in is_url
p = urlparse(url)
File "C:\Miniconda3\lib\site-packages\conda\_vendor\auxlib\decorators.py", line 56, in _memoized_func
result = func(*args, **kwargs)
File "C:\Miniconda3\lib\site-packages\conda\common\url.py", line 55, in urlparse
if on_win and url.startswith('file:'):
AttributeError: 'NoneType' object has no attribute 'startswith'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/common/url.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import re
5 import socket
6 import sys
7 from getpass import getpass
8 from logging import getLogger
9 from os.path import abspath, expanduser
10
11 try:
12 # Python 3
13 from urllib.parse import (quote, quote_plus, unquote, unquote_plus, # NOQA
14 urlunparse as stdlib_urlparse, urljoin) # NOQA
15 from urllib.request import pathname2url # NOQA
16 except ImportError:
17 # Python 2
18 from urllib import quote, quote_plus, unquote, unquote_plus, pathname2url # NOQA
19 from urlparse import urlunparse as stdlib_urlparse, urljoin # NOQA
20
21 from requests.packages.urllib3.exceptions import LocationParseError
22 from requests.packages.urllib3.util.url import Url, parse_url
23
24 from .._vendor.auxlib.decorators import memoize
25
26 log = getLogger(__name__)
27
28
29 on_win = bool(sys.platform == "win32")
30
31
32 @memoize
33 def path_to_url(path):
34 path = abspath(expanduser(path))
35 url = urljoin('file:', pathname2url(path))
36 log.debug("%s converted to %s", path, url)
37 return url
38
39
40 def url_to_path(url): # NOQA
41 """Convert a file:// URL to a path."""
42 assert url.startswith('file:'), "You can only turn file: urls into filenames (not %r)" % url
43 path = url[len('file:'):].lstrip('/')
44 path = unquote(path)
45 if re.match('^([a-z])[:|]', path, re.I):
46 path = path[0] + ':' + path[2:]
47 elif not path.startswith(r'\\'):
48 # if not a Windows UNC path
49 path = '/' + path
50 return path
51
52
53 @memoize
54 def urlparse(url):
55 if on_win and url.startswith('file:'):
56 url.replace('\\', '/')
57 return parse_url(url)
58
59
60 def url_to_s3_info(url):
61 """
62 Convert a S3 url to a tuple of bucket and key
63 """
64 parsed_url = parse_url(url)
65 assert parsed_url.scheme == 's3', "You can only use s3: urls (not %r)" % url
66 bucket, key = parsed_url.host, parsed_url.path
67 return bucket, key
68
69
70 def is_url(url):
71 try:
72 p = urlparse(url)
73 return p.netloc is not None or p.scheme == "file"
74 except LocationParseError:
75 log.debug("Could not parse url ({0}).".format(url))
76 return False
77
78
79 def is_ipv4_address(string_ip):
80 """
81 Examples:
82 >>> [is_ipv4_address(ip) for ip in ('8.8.8.8', '192.168.10.10', '255.255.255.255')]
83 [True, True, True]
84 >>> [is_ipv4_address(ip) for ip in ('8.8.8', '192.168.10.10.20', '256.255.255.255', '::1')]
85 [False, False, False, False]
86 """
87 try:
88 socket.inet_aton(string_ip)
89 except socket.error:
90 return False
91 return string_ip.count('.') == 3
92
93
94 def is_ipv6_address(string_ip):
95 """
96 Examples:
97 >>> [is_ipv6_address(ip) for ip in ('::1', '2001:db8:85a3::370:7334', '1234:'*7+'1234')]
98 [True, True, True]
99 >>> [is_ipv6_address(ip) for ip in ('192.168.10.10', '1234:'*8+'1234')]
100 [False, False]
101 """
102 try:
103 socket.inet_pton(socket.AF_INET6, string_ip)
104 except socket.error:
105 return False
106 return True
107
108
109 def is_ip_address(string_ip):
110 """
111 Examples:
112 >>> is_ip_address('192.168.10.10')
113 True
114 >>> is_ip_address('::1')
115 True
116 >>> is_ip_address('www.google.com')
117 False
118 """
119 return is_ipv4_address(string_ip) or is_ipv6_address(string_ip)
120
121
122 def join(*args):
123 start = '/' if not args[0] or args[0].startswith('/') else ''
124 return start + '/'.join(y for y in (x.strip('/') for x in args if x) if y)
125
126
127 join_url = join
128
129
130 def has_scheme(value):
131 return re.match(r'[a-z][a-z0-9]{0,11}://', value)
132
133
134 def strip_scheme(url):
135 return url.split('://', 1)[-1]
136
137
138 def mask_anaconda_token(url):
139 _, token = split_anaconda_token(url)
140 return url.replace(token, "<TOKEN>", 1) if token else url
141
142
143 def split_anaconda_token(url):
144 """
145 Examples:
146 >>> split_anaconda_token("https://1.2.3.4/t/tk-123-456/path")
147 (u'https://1.2.3.4/path', u'tk-123-456')
148 >>> split_anaconda_token("https://1.2.3.4/t//path")
149 (u'https://1.2.3.4/path', u'')
150 >>> split_anaconda_token("https://some.domain/api/t/tk-123-456/path")
151 (u'https://some.domain/api/path', u'tk-123-456')
152 >>> split_anaconda_token("https://1.2.3.4/conda/t/tk-123-456/path")
153 (u'https://1.2.3.4/conda/path', u'tk-123-456')
154 >>> split_anaconda_token("https://1.2.3.4/path")
155 (u'https://1.2.3.4/path', None)
156 >>> split_anaconda_token("https://10.2.3.4:8080/conda/t/tk-123-45")
157 (u'https://10.2.3.4:8080/conda', u'tk-123-45')
158 """
159 _token_match = re.search(r'/t/([a-zA-Z0-9-]*)', url)
160 token = _token_match.groups()[0] if _token_match else None
161 cleaned_url = url.replace('/t/' + token, '', 1) if token is not None else url
162 return cleaned_url.rstrip('/'), token
163
164
165 def split_platform(url):
166 """
167
168 Examples:
169 >>> split_platform("https://1.2.3.4/t/tk-123/osx-64/path")
170 (u'https://1.2.3.4/t/tk-123/path', u'osx-64')
171
172 """
173 from conda.base.constants import PLATFORM_DIRECTORIES
174 _platform_match_regex = r'/(%s)/?' % r'|'.join(r'%s' % d for d in PLATFORM_DIRECTORIES)
175 _platform_match = re.search(_platform_match_regex, url, re.IGNORECASE)
176 platform = _platform_match.groups()[0] if _platform_match else None
177 cleaned_url = url.replace('/' + platform, '', 1) if platform is not None else url
178 return cleaned_url.rstrip('/'), platform
179
180
181 def split_package_filename(url):
182 cleaned_url, package_filename = (url.rsplit('/', 1) if url.endswith(('.tar.bz2', '.json'))
183 else (url, None))
184 return cleaned_url, package_filename
185
186
187 def split_scheme_auth_token(url):
188 if not url:
189 return None, None, None, None
190 cleaned_url, token = split_anaconda_token(url)
191 url_parts = urlparse(cleaned_url)
192 remainder_url = Url(host=url_parts.host, port=url_parts.port, path=url_parts.path,
193 query=url_parts.query).url
194 return remainder_url, url_parts.scheme, url_parts.auth, token
195
196
197 def split_conda_url_easy_parts(url):
198 # scheme, auth, token, platform, package_filename, host, port, path, query
199 cleaned_url, token = split_anaconda_token(url)
200 cleaned_url, platform = split_platform(cleaned_url)
201 cleaned_url, package_filename = split_package_filename(cleaned_url)
202
203 # TODO: split out namespace using regex
204
205 url_parts = urlparse(cleaned_url)
206
207 return (url_parts.scheme, url_parts.auth, token, platform, package_filename, url_parts.host,
208 url_parts.port, url_parts.path, url_parts.query)
209
210
211 def is_windows_path(value):
212 return re.match(r'[a-z]:[/\\]', value, re.IGNORECASE)
213
214
215 @memoize
216 def get_proxy_username_and_pass(scheme):
217 username = input("\n%s proxy username: " % scheme)
218 passwd = getpass("Password:")
219 return username, passwd
220
221
222 def add_username_and_password(url, username, password):
223 url_parts = parse_url(url)._asdict()
224 url_parts['auth'] = username + ':' + quote(password, '')
225 return Url(**url_parts).url
226
227
228 def maybe_add_auth(url, auth, force=False):
229 """add auth if the url doesn't currently have it"""
230 if not auth:
231 return url
232 url_parts = urlparse(url)._asdict()
233 if url_parts['auth'] and not force:
234 return url
235 url_parts['auth'] = auth
236 return Url(**url_parts).url
237
238
239 if __name__ == "__main__":
240 import doctest
241 doctest.testmod()
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/common/url.py b/conda/common/url.py
--- a/conda/common/url.py
+++ b/conda/common/url.py
@@ -68,6 +68,8 @@
def is_url(url):
+ if not url:
+ return False
try:
p = urlparse(url)
return p.netloc is not None or p.scheme == "file"
|
{"golden_diff": "diff --git a/conda/common/url.py b/conda/common/url.py\n--- a/conda/common/url.py\n+++ b/conda/common/url.py\n@@ -68,6 +68,8 @@\n \n \n def is_url(url):\n+ if not url:\n+ return False\n try:\n p = urlparse(url)\n return p.netloc is not None or p.scheme == \"file\"\n", "issue": "Regression: cannot install from explicit conda package filenames\nThis command used to work, but now it gives the following error/traceback:\r\n\r\nExample: `conda install bzip2-1.0.6-vc14_3.tar.bz2 --dry-run`\r\n\r\n```\r\nAn unexpected error has occurred.\r\nPlease consider posting the following information to the\r\nconda GitHub issue tracker at:\r\n\r\n https://github.com/conda/conda/issues\r\n\r\n\r\n\r\nCurrent conda install:\r\n\r\n platform : win-64\r\n conda version : 4.2.12\r\n conda is private : False\r\n conda-env version : 4.2.12\r\n conda-build version : 2.0.7\r\n python version : 3.5.2.final.0\r\n requests version : 2.10.0\r\n root environment : C:\\Miniconda3 (writable)\r\n default environment : C:\\Miniconda3\\envs\\test_conda\r\n envs directories : C:\\Miniconda3\\envs\r\n package cache : C:\\Miniconda3\\pkgs\r\n channel URLs : https://repo.continuum.io/pkgs/free/win-64\r\n https://repo.continuum.io/pkgs/free/noarch\r\n https://repo.continuum.io/pkgs/pro/win-64\r\n https://repo.continuum.io/pkgs/pro/noarch\r\n https://repo.continuum.io/pkgs/msys2/win-64\r\n https://repo.continuum.io/pkgs/msys2/noarch\r\n config file : None\r\n offline mode : False\r\n\r\n\r\n\r\n`$ C:\\Miniconda3\\Scripts\\conda-script.py install bzip2-1.0.6-vc14_3.tar.bz2 --dry-run`\r\n\r\n\r\n\r\n\r\n Traceback (most recent call last):\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\exceptions.py\", line 479, in conda_exception_handler\r\n return_value = func(*args, **kwargs)\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\cli\\main.py\", line 145, in _main\r\n exit_code = args.func(args, p)\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\cli\\main_install.py\", line 80, in execute\r\n install(args, parser, 'install')\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\cli\\install.py\", line 209, in install\r\n explicit(args.packages, prefix, verbose=not context.quiet)\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\misc.py\", line 66, in explicit\r\n if not is_url(url_p):\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\common\\url.py\", line 72, in is_url\r\n p = urlparse(url)\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\_vendor\\auxlib\\decorators.py\", line 56, in _memoized_func\r\n result = func(*args, **kwargs)\r\n File \"C:\\Miniconda3\\lib\\site-packages\\conda\\common\\url.py\", line 55, in urlparse\r\n if on_win and url.startswith('file:'):\r\n AttributeError: 'NoneType' object has no attribute 'startswith'\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport re\nimport socket\nimport sys\nfrom getpass import getpass\nfrom logging import getLogger\nfrom os.path import abspath, expanduser\n\ntry:\n # Python 3\n from urllib.parse import (quote, quote_plus, unquote, unquote_plus, # NOQA\n urlunparse as stdlib_urlparse, urljoin) # NOQA\n from urllib.request import pathname2url # NOQA\nexcept ImportError:\n # Python 2\n from urllib import quote, quote_plus, unquote, unquote_plus, pathname2url # NOQA\n from urlparse import urlunparse as stdlib_urlparse, urljoin # NOQA\n\nfrom requests.packages.urllib3.exceptions import LocationParseError\nfrom requests.packages.urllib3.util.url import Url, parse_url\n\nfrom .._vendor.auxlib.decorators import memoize\n\nlog = getLogger(__name__)\n\n\non_win = bool(sys.platform == \"win32\")\n\n\n@memoize\ndef path_to_url(path):\n path = abspath(expanduser(path))\n url = urljoin('file:', pathname2url(path))\n log.debug(\"%s converted to %s\", path, url)\n return url\n\n\ndef url_to_path(url): # NOQA\n \"\"\"Convert a file:// URL to a path.\"\"\"\n assert url.startswith('file:'), \"You can only turn file: urls into filenames (not %r)\" % url\n path = url[len('file:'):].lstrip('/')\n path = unquote(path)\n if re.match('^([a-z])[:|]', path, re.I):\n path = path[0] + ':' + path[2:]\n elif not path.startswith(r'\\\\'):\n # if not a Windows UNC path\n path = '/' + path\n return path\n\n\n@memoize\ndef urlparse(url):\n if on_win and url.startswith('file:'):\n url.replace('\\\\', '/')\n return parse_url(url)\n\n\ndef url_to_s3_info(url):\n \"\"\"\n Convert a S3 url to a tuple of bucket and key\n \"\"\"\n parsed_url = parse_url(url)\n assert parsed_url.scheme == 's3', \"You can only use s3: urls (not %r)\" % url\n bucket, key = parsed_url.host, parsed_url.path\n return bucket, key\n\n\ndef is_url(url):\n try:\n p = urlparse(url)\n return p.netloc is not None or p.scheme == \"file\"\n except LocationParseError:\n log.debug(\"Could not parse url ({0}).\".format(url))\n return False\n\n\ndef is_ipv4_address(string_ip):\n \"\"\"\n Examples:\n >>> [is_ipv4_address(ip) for ip in ('8.8.8.8', '192.168.10.10', '255.255.255.255')]\n [True, True, True]\n >>> [is_ipv4_address(ip) for ip in ('8.8.8', '192.168.10.10.20', '256.255.255.255', '::1')]\n [False, False, False, False]\n \"\"\"\n try:\n socket.inet_aton(string_ip)\n except socket.error:\n return False\n return string_ip.count('.') == 3\n\n\ndef is_ipv6_address(string_ip):\n \"\"\"\n Examples:\n >>> [is_ipv6_address(ip) for ip in ('::1', '2001:db8:85a3::370:7334', '1234:'*7+'1234')]\n [True, True, True]\n >>> [is_ipv6_address(ip) for ip in ('192.168.10.10', '1234:'*8+'1234')]\n [False, False]\n \"\"\"\n try:\n socket.inet_pton(socket.AF_INET6, string_ip)\n except socket.error:\n return False\n return True\n\n\ndef is_ip_address(string_ip):\n \"\"\"\n Examples:\n >>> is_ip_address('192.168.10.10')\n True\n >>> is_ip_address('::1')\n True\n >>> is_ip_address('www.google.com')\n False\n \"\"\"\n return is_ipv4_address(string_ip) or is_ipv6_address(string_ip)\n\n\ndef join(*args):\n start = '/' if not args[0] or args[0].startswith('/') else ''\n return start + '/'.join(y for y in (x.strip('/') for x in args if x) if y)\n\n\njoin_url = join\n\n\ndef has_scheme(value):\n return re.match(r'[a-z][a-z0-9]{0,11}://', value)\n\n\ndef strip_scheme(url):\n return url.split('://', 1)[-1]\n\n\ndef mask_anaconda_token(url):\n _, token = split_anaconda_token(url)\n return url.replace(token, \"<TOKEN>\", 1) if token else url\n\n\ndef split_anaconda_token(url):\n \"\"\"\n Examples:\n >>> split_anaconda_token(\"https://1.2.3.4/t/tk-123-456/path\")\n (u'https://1.2.3.4/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/t//path\")\n (u'https://1.2.3.4/path', u'')\n >>> split_anaconda_token(\"https://some.domain/api/t/tk-123-456/path\")\n (u'https://some.domain/api/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/conda/t/tk-123-456/path\")\n (u'https://1.2.3.4/conda/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/path\")\n (u'https://1.2.3.4/path', None)\n >>> split_anaconda_token(\"https://10.2.3.4:8080/conda/t/tk-123-45\")\n (u'https://10.2.3.4:8080/conda', u'tk-123-45')\n \"\"\"\n _token_match = re.search(r'/t/([a-zA-Z0-9-]*)', url)\n token = _token_match.groups()[0] if _token_match else None\n cleaned_url = url.replace('/t/' + token, '', 1) if token is not None else url\n return cleaned_url.rstrip('/'), token\n\n\ndef split_platform(url):\n \"\"\"\n\n Examples:\n >>> split_platform(\"https://1.2.3.4/t/tk-123/osx-64/path\")\n (u'https://1.2.3.4/t/tk-123/path', u'osx-64')\n\n \"\"\"\n from conda.base.constants import PLATFORM_DIRECTORIES\n _platform_match_regex = r'/(%s)/?' % r'|'.join(r'%s' % d for d in PLATFORM_DIRECTORIES)\n _platform_match = re.search(_platform_match_regex, url, re.IGNORECASE)\n platform = _platform_match.groups()[0] if _platform_match else None\n cleaned_url = url.replace('/' + platform, '', 1) if platform is not None else url\n return cleaned_url.rstrip('/'), platform\n\n\ndef split_package_filename(url):\n cleaned_url, package_filename = (url.rsplit('/', 1) if url.endswith(('.tar.bz2', '.json'))\n else (url, None))\n return cleaned_url, package_filename\n\n\ndef split_scheme_auth_token(url):\n if not url:\n return None, None, None, None\n cleaned_url, token = split_anaconda_token(url)\n url_parts = urlparse(cleaned_url)\n remainder_url = Url(host=url_parts.host, port=url_parts.port, path=url_parts.path,\n query=url_parts.query).url\n return remainder_url, url_parts.scheme, url_parts.auth, token\n\n\ndef split_conda_url_easy_parts(url):\n # scheme, auth, token, platform, package_filename, host, port, path, query\n cleaned_url, token = split_anaconda_token(url)\n cleaned_url, platform = split_platform(cleaned_url)\n cleaned_url, package_filename = split_package_filename(cleaned_url)\n\n # TODO: split out namespace using regex\n\n url_parts = urlparse(cleaned_url)\n\n return (url_parts.scheme, url_parts.auth, token, platform, package_filename, url_parts.host,\n url_parts.port, url_parts.path, url_parts.query)\n\n\ndef is_windows_path(value):\n return re.match(r'[a-z]:[/\\\\]', value, re.IGNORECASE)\n\n\n@memoize\ndef get_proxy_username_and_pass(scheme):\n username = input(\"\\n%s proxy username: \" % scheme)\n passwd = getpass(\"Password:\")\n return username, passwd\n\n\ndef add_username_and_password(url, username, password):\n url_parts = parse_url(url)._asdict()\n url_parts['auth'] = username + ':' + quote(password, '')\n return Url(**url_parts).url\n\n\ndef maybe_add_auth(url, auth, force=False):\n \"\"\"add auth if the url doesn't currently have it\"\"\"\n if not auth:\n return url\n url_parts = urlparse(url)._asdict()\n if url_parts['auth'] and not force:\n return url\n url_parts['auth'] = auth\n return Url(**url_parts).url\n\n\nif __name__ == \"__main__\":\n import doctest\n doctest.testmod()\n", "path": "conda/common/url.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport re\nimport socket\nimport sys\nfrom getpass import getpass\nfrom logging import getLogger\nfrom os.path import abspath, expanduser\n\ntry:\n # Python 3\n from urllib.parse import (quote, quote_plus, unquote, unquote_plus, # NOQA\n urlunparse as stdlib_urlparse, urljoin) # NOQA\n from urllib.request import pathname2url # NOQA\nexcept ImportError:\n # Python 2\n from urllib import quote, quote_plus, unquote, unquote_plus, pathname2url # NOQA\n from urlparse import urlunparse as stdlib_urlparse, urljoin # NOQA\n\nfrom requests.packages.urllib3.exceptions import LocationParseError\nfrom requests.packages.urllib3.util.url import Url, parse_url\n\nfrom .._vendor.auxlib.decorators import memoize\n\nlog = getLogger(__name__)\n\n\non_win = bool(sys.platform == \"win32\")\n\n\n@memoize\ndef path_to_url(path):\n path = abspath(expanduser(path))\n url = urljoin('file:', pathname2url(path))\n log.debug(\"%s converted to %s\", path, url)\n return url\n\n\ndef url_to_path(url): # NOQA\n \"\"\"Convert a file:// URL to a path.\"\"\"\n assert url.startswith('file:'), \"You can only turn file: urls into filenames (not %r)\" % url\n path = url[len('file:'):].lstrip('/')\n path = unquote(path)\n if re.match('^([a-z])[:|]', path, re.I):\n path = path[0] + ':' + path[2:]\n elif not path.startswith(r'\\\\'):\n # if not a Windows UNC path\n path = '/' + path\n return path\n\n\n@memoize\ndef urlparse(url):\n if on_win and url.startswith('file:'):\n url.replace('\\\\', '/')\n return parse_url(url)\n\n\ndef url_to_s3_info(url):\n \"\"\"\n Convert a S3 url to a tuple of bucket and key\n \"\"\"\n parsed_url = parse_url(url)\n assert parsed_url.scheme == 's3', \"You can only use s3: urls (not %r)\" % url\n bucket, key = parsed_url.host, parsed_url.path\n return bucket, key\n\n\ndef is_url(url):\n if not url:\n return False\n try:\n p = urlparse(url)\n return p.netloc is not None or p.scheme == \"file\"\n except LocationParseError:\n log.debug(\"Could not parse url ({0}).\".format(url))\n return False\n\n\ndef is_ipv4_address(string_ip):\n \"\"\"\n Examples:\n >>> [is_ipv4_address(ip) for ip in ('8.8.8.8', '192.168.10.10', '255.255.255.255')]\n [True, True, True]\n >>> [is_ipv4_address(ip) for ip in ('8.8.8', '192.168.10.10.20', '256.255.255.255', '::1')]\n [False, False, False, False]\n \"\"\"\n try:\n socket.inet_aton(string_ip)\n except socket.error:\n return False\n return string_ip.count('.') == 3\n\n\ndef is_ipv6_address(string_ip):\n \"\"\"\n Examples:\n >>> [is_ipv6_address(ip) for ip in ('::1', '2001:db8:85a3::370:7334', '1234:'*7+'1234')]\n [True, True, True]\n >>> [is_ipv6_address(ip) for ip in ('192.168.10.10', '1234:'*8+'1234')]\n [False, False]\n \"\"\"\n try:\n socket.inet_pton(socket.AF_INET6, string_ip)\n except socket.error:\n return False\n return True\n\n\ndef is_ip_address(string_ip):\n \"\"\"\n Examples:\n >>> is_ip_address('192.168.10.10')\n True\n >>> is_ip_address('::1')\n True\n >>> is_ip_address('www.google.com')\n False\n \"\"\"\n return is_ipv4_address(string_ip) or is_ipv6_address(string_ip)\n\n\ndef join(*args):\n start = '/' if not args[0] or args[0].startswith('/') else ''\n return start + '/'.join(y for y in (x.strip('/') for x in args if x) if y)\n\n\njoin_url = join\n\n\ndef has_scheme(value):\n return re.match(r'[a-z][a-z0-9]{0,11}://', value)\n\n\ndef strip_scheme(url):\n return url.split('://', 1)[-1]\n\n\ndef mask_anaconda_token(url):\n _, token = split_anaconda_token(url)\n return url.replace(token, \"<TOKEN>\", 1) if token else url\n\n\ndef split_anaconda_token(url):\n \"\"\"\n Examples:\n >>> split_anaconda_token(\"https://1.2.3.4/t/tk-123-456/path\")\n (u'https://1.2.3.4/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/t//path\")\n (u'https://1.2.3.4/path', u'')\n >>> split_anaconda_token(\"https://some.domain/api/t/tk-123-456/path\")\n (u'https://some.domain/api/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/conda/t/tk-123-456/path\")\n (u'https://1.2.3.4/conda/path', u'tk-123-456')\n >>> split_anaconda_token(\"https://1.2.3.4/path\")\n (u'https://1.2.3.4/path', None)\n >>> split_anaconda_token(\"https://10.2.3.4:8080/conda/t/tk-123-45\")\n (u'https://10.2.3.4:8080/conda', u'tk-123-45')\n \"\"\"\n _token_match = re.search(r'/t/([a-zA-Z0-9-]*)', url)\n token = _token_match.groups()[0] if _token_match else None\n cleaned_url = url.replace('/t/' + token, '', 1) if token is not None else url\n return cleaned_url.rstrip('/'), token\n\n\ndef split_platform(url):\n \"\"\"\n\n Examples:\n >>> split_platform(\"https://1.2.3.4/t/tk-123/osx-64/path\")\n (u'https://1.2.3.4/t/tk-123/path', u'osx-64')\n\n \"\"\"\n from conda.base.constants import PLATFORM_DIRECTORIES\n _platform_match_regex = r'/(%s)/?' % r'|'.join(r'%s' % d for d in PLATFORM_DIRECTORIES)\n _platform_match = re.search(_platform_match_regex, url, re.IGNORECASE)\n platform = _platform_match.groups()[0] if _platform_match else None\n cleaned_url = url.replace('/' + platform, '', 1) if platform is not None else url\n return cleaned_url.rstrip('/'), platform\n\n\ndef split_package_filename(url):\n cleaned_url, package_filename = (url.rsplit('/', 1) if url.endswith(('.tar.bz2', '.json'))\n else (url, None))\n return cleaned_url, package_filename\n\n\ndef split_scheme_auth_token(url):\n if not url:\n return None, None, None, None\n cleaned_url, token = split_anaconda_token(url)\n url_parts = urlparse(cleaned_url)\n remainder_url = Url(host=url_parts.host, port=url_parts.port, path=url_parts.path,\n query=url_parts.query).url\n return remainder_url, url_parts.scheme, url_parts.auth, token\n\n\ndef split_conda_url_easy_parts(url):\n # scheme, auth, token, platform, package_filename, host, port, path, query\n cleaned_url, token = split_anaconda_token(url)\n cleaned_url, platform = split_platform(cleaned_url)\n cleaned_url, package_filename = split_package_filename(cleaned_url)\n\n # TODO: split out namespace using regex\n\n url_parts = urlparse(cleaned_url)\n\n return (url_parts.scheme, url_parts.auth, token, platform, package_filename, url_parts.host,\n url_parts.port, url_parts.path, url_parts.query)\n\n\ndef is_windows_path(value):\n return re.match(r'[a-z]:[/\\\\]', value, re.IGNORECASE)\n\n\n@memoize\ndef get_proxy_username_and_pass(scheme):\n username = input(\"\\n%s proxy username: \" % scheme)\n passwd = getpass(\"Password:\")\n return username, passwd\n\n\ndef add_username_and_password(url, username, password):\n url_parts = parse_url(url)._asdict()\n url_parts['auth'] = username + ':' + quote(password, '')\n return Url(**url_parts).url\n\n\ndef maybe_add_auth(url, auth, force=False):\n \"\"\"add auth if the url doesn't currently have it\"\"\"\n if not auth:\n return url\n url_parts = urlparse(url)._asdict()\n if url_parts['auth'] and not force:\n return url\n url_parts['auth'] = auth\n return Url(**url_parts).url\n\n\nif __name__ == \"__main__\":\n import doctest\n doctest.testmod()\n", "path": "conda/common/url.py"}]}
| 3,830 | 85 |
gh_patches_debug_31030
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2468
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Checkout process improvements
During my work on PR #2206 I found out few things that may improve checkout process.
#### Going forward/back between steps
Although we can go back to shipping address step from choosing shipping method, we can't go back from summary step, where billing address is set. I think that passing between steps should be allowed.
#### Clearing cart
We can remove every single item from cart, but there is no button like `Clear cart`. It would be useful, when customer wants to cancel all cart lines at once.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/checkout/urls.py`
Content:
```
1 from django.conf.urls import url
2
3 from . import views
4 from .views.discount import remove_voucher_view
5
6 checkout_urlpatterns = [
7 url(r'^$', views.checkout_index, name='index'),
8 url(r'^shipping-address/', views.checkout_shipping_address,
9 name='shipping-address'),
10 url(r'^shipping-method/', views.checkout_shipping_method,
11 name='shipping-method'),
12 url(r'^summary/', views.checkout_summary, name='summary'),
13 url(r'^remove_voucher/', remove_voucher_view,
14 name='remove-voucher'),
15 url(r'^login/', views.checkout_login, name='login')]
16
17
18 cart_urlpatterns = [
19 url(r'^$', views.cart_index, name='index'),
20 url(r'^update/(?P<variant_id>\d+)/$',
21 views.update_cart_line, name='update-line'),
22 url(r'^summary/$', views.cart_summary, name='summary'),
23 url(r'^shipping-options/$', views.cart_shipping_options,
24 name='shipping-options')]
25
```
Path: `saleor/checkout/views/__init__.py`
Content:
```
1 """Cart and checkout related views."""
2 from django.http import JsonResponse
3 from django.shortcuts import get_object_or_404, redirect, render
4 from django.template.response import TemplateResponse
5
6 from ...account.forms import LoginForm
7 from ...core.utils import (
8 format_money, get_user_shipping_country, to_local_currency)
9 from ...product.models import ProductVariant
10 from ...shipping.utils import get_shipment_options
11 from ..forms import CartShippingMethodForm, CountryForm, ReplaceCartLineForm
12 from ..models import Cart
13 from ..utils import (
14 check_product_availability_and_warn, check_shipping_method, get_cart_data,
15 get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)
16 from .discount import add_voucher_form, validate_voucher
17 from .shipping import (
18 anonymous_user_shipping_address_view, user_shipping_address_view)
19 from .summary import (
20 anonymous_summary_without_shipping, summary_with_shipping_view,
21 summary_without_shipping)
22 from .validators import (
23 validate_cart, validate_is_shipping_required, validate_shipping_address,
24 validate_shipping_method)
25
26
27 @get_or_empty_db_cart(Cart.objects.for_display())
28 @validate_cart
29 def checkout_login(request, cart):
30 """Allow the user to log in prior to checkout."""
31 if request.user.is_authenticated:
32 return redirect('checkout:index')
33 ctx = {'form': LoginForm()}
34 return TemplateResponse(request, 'checkout/login.html', ctx)
35
36
37 @get_or_empty_db_cart(Cart.objects.for_display())
38 @validate_cart
39 @validate_is_shipping_required
40 def checkout_index(request, cart):
41 """Redirect to the initial step of checkout."""
42 return redirect('checkout:shipping-address')
43
44
45 @get_or_empty_db_cart(Cart.objects.for_display())
46 @validate_voucher
47 @validate_cart
48 @validate_is_shipping_required
49 @add_voucher_form
50 def checkout_shipping_address(request, cart):
51 """Display the correct shipping address step."""
52 if request.user.is_authenticated:
53 return user_shipping_address_view(request, cart)
54 return anonymous_user_shipping_address_view(request, cart)
55
56
57 @get_or_empty_db_cart(Cart.objects.for_display())
58 @validate_voucher
59 @validate_cart
60 @validate_is_shipping_required
61 @validate_shipping_address
62 @add_voucher_form
63 def checkout_shipping_method(request, cart):
64 """Display the shipping method selection step."""
65 taxes = get_taxes_for_cart(cart, request.taxes)
66 check_shipping_method(cart)
67 form = CartShippingMethodForm(
68 request.POST or None, taxes=taxes, instance=cart,
69 initial={'shipping_method': cart.shipping_method})
70
71 if form.is_valid():
72 form.save()
73 return redirect('checkout:summary')
74
75 ctx = get_cart_data_for_checkout(cart, request.discounts, taxes)
76 ctx.update({'shipping_method_form': form})
77 return TemplateResponse(request, 'checkout/shipping_method.html', ctx)
78
79
80 @get_or_empty_db_cart(Cart.objects.for_display())
81 @validate_voucher
82 @validate_cart
83 @add_voucher_form
84 def checkout_summary(request, cart):
85 """Display the correct order summary."""
86 if cart.is_shipping_required():
87 view = validate_shipping_method(summary_with_shipping_view)
88 view = validate_shipping_address(view)
89 return view(request, cart)
90 if request.user.is_authenticated:
91 return summary_without_shipping(request, cart)
92 return anonymous_summary_without_shipping(request, cart)
93
94
95 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
96 def cart_index(request, cart):
97 """Display cart details."""
98 discounts = request.discounts
99 taxes = request.taxes
100 cart_lines = []
101 check_product_availability_and_warn(request, cart)
102
103 # refresh required to get updated cart lines and it's quantity
104 try:
105 cart = Cart.objects.prefetch_related(
106 'lines__variant__product__category').get(pk=cart.pk)
107 except Cart.DoesNotExist:
108 pass
109
110 lines = cart.lines.select_related(
111 'variant__product__product_type',
112 'variant__product__category')
113 lines = lines.prefetch_related(
114 'variant__product__collections',
115 'variant__product__images',
116 'variant__product__product_type__variant_attributes')
117 for line in lines:
118 initial = {'quantity': line.quantity}
119 form = ReplaceCartLineForm(
120 None, cart=cart, variant=line.variant, initial=initial,
121 discounts=discounts, taxes=taxes)
122 cart_lines.append({
123 'variant': line.variant,
124 'get_price': line.variant.get_price(discounts, taxes),
125 'get_total': line.get_total(discounts, taxes),
126 'form': form})
127
128 default_country = get_user_shipping_country(request)
129 country_form = CountryForm(initial={'country': default_country})
130 default_country_options = get_shipment_options(default_country, taxes)
131
132 cart_data = get_cart_data(
133 cart, default_country_options, request.currency, discounts, taxes)
134 ctx = {
135 'cart_lines': cart_lines,
136 'country_form': country_form,
137 'default_country_options': default_country_options}
138 ctx.update(cart_data)
139
140 return TemplateResponse(request, 'checkout/index.html', ctx)
141
142
143 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
144 def cart_shipping_options(request, cart):
145 """Display shipping options to get a price estimate."""
146 country_form = CountryForm(request.POST or None, taxes=request.taxes)
147 if country_form.is_valid():
148 shipments = country_form.get_shipment_options()
149 else:
150 shipments = None
151 ctx = {
152 'default_country_options': shipments,
153 'country_form': country_form}
154 cart_data = get_cart_data(
155 cart, shipments, request.currency, request.discounts, request.taxes)
156 ctx.update(cart_data)
157 return TemplateResponse(request, 'checkout/_subtotal_table.html', ctx)
158
159
160 @get_or_empty_db_cart()
161 def update_cart_line(request, cart, variant_id):
162 """Update the line quantities."""
163 if not request.is_ajax():
164 return redirect('cart:index')
165 variant = get_object_or_404(ProductVariant, pk=variant_id)
166 discounts = request.discounts
167 taxes = request.taxes
168 status = None
169 form = ReplaceCartLineForm(
170 request.POST, cart=cart, variant=variant, discounts=discounts,
171 taxes=taxes)
172 if form.is_valid():
173 form.save()
174 response = {
175 'variantId': variant_id,
176 'subtotal': 0,
177 'total': 0,
178 'cart': {
179 'numItems': cart.quantity,
180 'numLines': len(cart)}}
181 updated_line = cart.get_line(form.cart_line.variant)
182 if updated_line:
183 response['subtotal'] = format_money(
184 updated_line.get_total(discounts, taxes).gross)
185 if cart:
186 cart_total = cart.get_subtotal(discounts, taxes)
187 response['total'] = format_money(cart_total.gross)
188 local_cart_total = to_local_currency(cart_total, request.currency)
189 if local_cart_total is not None:
190 response['localTotal'] = format_money(local_cart_total.gross)
191 status = 200
192 elif request.POST is not None:
193 response = {'error': form.errors}
194 status = 400
195 return JsonResponse(response, status=status)
196
197
198 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
199 def cart_summary(request, cart):
200 """Display a cart summary suitable for displaying on all pages."""
201 discounts = request.discounts
202 taxes = request.taxes
203
204 def prepare_line_data(line):
205 first_image = line.variant.get_first_image()
206 return {
207 'product': line.variant.product,
208 'variant': line.variant.name,
209 'quantity': line.quantity,
210 'image': first_image,
211 'line_total': line.get_total(discounts, taxes),
212 'variant_url': line.variant.get_absolute_url()}
213
214 if cart.quantity == 0:
215 data = {'quantity': 0}
216 else:
217 data = {
218 'quantity': cart.quantity,
219 'total': cart.get_subtotal(discounts, taxes),
220 'lines': [prepare_line_data(line) for line in cart]}
221
222 return render(request, 'cart_dropdown.html', data)
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/checkout/urls.py b/saleor/checkout/urls.py
--- a/saleor/checkout/urls.py
+++ b/saleor/checkout/urls.py
@@ -19,6 +19,7 @@
url(r'^$', views.cart_index, name='index'),
url(r'^update/(?P<variant_id>\d+)/$',
views.update_cart_line, name='update-line'),
+ url(r'^clear-cart/$', views.clear_cart, name='clear-cart'),
url(r'^summary/$', views.cart_summary, name='summary'),
url(r'^shipping-options/$', views.cart_shipping_options,
name='shipping-options')]
diff --git a/saleor/checkout/views/__init__.py b/saleor/checkout/views/__init__.py
--- a/saleor/checkout/views/__init__.py
+++ b/saleor/checkout/views/__init__.py
@@ -12,7 +12,8 @@
from ..models import Cart
from ..utils import (
check_product_availability_and_warn, check_shipping_method, get_cart_data,
- get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)
+ get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart,
+ update_cart_quantity)
from .discount import add_voucher_form, validate_voucher
from .shipping import (
anonymous_user_shipping_address_view, user_shipping_address_view)
@@ -195,6 +196,17 @@
return JsonResponse(response, status=status)
+@get_or_empty_db_cart()
+def clear_cart(request, cart):
+ """Clear cart"""
+ if not request.is_ajax():
+ return redirect('cart:index')
+ cart.lines.all().delete()
+ update_cart_quantity(cart)
+ response = {'numItems': 0}
+ return JsonResponse(response)
+
+
@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
def cart_summary(request, cart):
"""Display a cart summary suitable for displaying on all pages."""
|
{"golden_diff": "diff --git a/saleor/checkout/urls.py b/saleor/checkout/urls.py\n--- a/saleor/checkout/urls.py\n+++ b/saleor/checkout/urls.py\n@@ -19,6 +19,7 @@\n url(r'^$', views.cart_index, name='index'),\n url(r'^update/(?P<variant_id>\\d+)/$',\n views.update_cart_line, name='update-line'),\n+ url(r'^clear-cart/$', views.clear_cart, name='clear-cart'),\n url(r'^summary/$', views.cart_summary, name='summary'),\n url(r'^shipping-options/$', views.cart_shipping_options,\n name='shipping-options')]\ndiff --git a/saleor/checkout/views/__init__.py b/saleor/checkout/views/__init__.py\n--- a/saleor/checkout/views/__init__.py\n+++ b/saleor/checkout/views/__init__.py\n@@ -12,7 +12,8 @@\n from ..models import Cart\n from ..utils import (\n check_product_availability_and_warn, check_shipping_method, get_cart_data,\n- get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)\n+ get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart,\n+ update_cart_quantity)\n from .discount import add_voucher_form, validate_voucher\n from .shipping import (\n anonymous_user_shipping_address_view, user_shipping_address_view)\n@@ -195,6 +196,17 @@\n return JsonResponse(response, status=status)\n \n \n+@get_or_empty_db_cart()\n+def clear_cart(request, cart):\n+ \"\"\"Clear cart\"\"\"\n+ if not request.is_ajax():\n+ return redirect('cart:index')\n+ cart.lines.all().delete()\n+ update_cart_quantity(cart)\n+ response = {'numItems': 0}\n+ return JsonResponse(response)\n+\n+\n @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\n def cart_summary(request, cart):\n \"\"\"Display a cart summary suitable for displaying on all pages.\"\"\"\n", "issue": "Checkout process improvements\nDuring my work on PR #2206 I found out few things that may improve checkout process.\r\n\r\n#### Going forward/back between steps\r\n\r\nAlthough we can go back to shipping address step from choosing shipping method, we can't go back from summary step, where billing address is set. I think that passing between steps should be allowed.\r\n\r\n#### Clearing cart\r\n\r\nWe can remove every single item from cart, but there is no button like `Clear cart`. It would be useful, when customer wants to cancel all cart lines at once.\n", "before_files": [{"content": "from django.conf.urls import url\n\nfrom . import views\nfrom .views.discount import remove_voucher_view\n\ncheckout_urlpatterns = [\n url(r'^$', views.checkout_index, name='index'),\n url(r'^shipping-address/', views.checkout_shipping_address,\n name='shipping-address'),\n url(r'^shipping-method/', views.checkout_shipping_method,\n name='shipping-method'),\n url(r'^summary/', views.checkout_summary, name='summary'),\n url(r'^remove_voucher/', remove_voucher_view,\n name='remove-voucher'),\n url(r'^login/', views.checkout_login, name='login')]\n\n\ncart_urlpatterns = [\n url(r'^$', views.cart_index, name='index'),\n url(r'^update/(?P<variant_id>\\d+)/$',\n views.update_cart_line, name='update-line'),\n url(r'^summary/$', views.cart_summary, name='summary'),\n url(r'^shipping-options/$', views.cart_shipping_options,\n name='shipping-options')]\n", "path": "saleor/checkout/urls.py"}, {"content": "\"\"\"Cart and checkout related views.\"\"\"\nfrom django.http import JsonResponse\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.template.response import TemplateResponse\n\nfrom ...account.forms import LoginForm\nfrom ...core.utils import (\n format_money, get_user_shipping_country, to_local_currency)\nfrom ...product.models import ProductVariant\nfrom ...shipping.utils import get_shipment_options\nfrom ..forms import CartShippingMethodForm, CountryForm, ReplaceCartLineForm\nfrom ..models import Cart\nfrom ..utils import (\n check_product_availability_and_warn, check_shipping_method, get_cart_data,\n get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)\nfrom .discount import add_voucher_form, validate_voucher\nfrom .shipping import (\n anonymous_user_shipping_address_view, user_shipping_address_view)\nfrom .summary import (\n anonymous_summary_without_shipping, summary_with_shipping_view,\n summary_without_shipping)\nfrom .validators import (\n validate_cart, validate_is_shipping_required, validate_shipping_address,\n validate_shipping_method)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\ndef checkout_login(request, cart):\n \"\"\"Allow the user to log in prior to checkout.\"\"\"\n if request.user.is_authenticated:\n return redirect('checkout:index')\n ctx = {'form': LoginForm()}\n return TemplateResponse(request, 'checkout/login.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\n@validate_is_shipping_required\ndef checkout_index(request, cart):\n \"\"\"Redirect to the initial step of checkout.\"\"\"\n return redirect('checkout:shipping-address')\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@add_voucher_form\ndef checkout_shipping_address(request, cart):\n \"\"\"Display the correct shipping address step.\"\"\"\n if request.user.is_authenticated:\n return user_shipping_address_view(request, cart)\n return anonymous_user_shipping_address_view(request, cart)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@validate_shipping_address\n@add_voucher_form\ndef checkout_shipping_method(request, cart):\n \"\"\"Display the shipping method selection step.\"\"\"\n taxes = get_taxes_for_cart(cart, request.taxes)\n check_shipping_method(cart)\n form = CartShippingMethodForm(\n request.POST or None, taxes=taxes, instance=cart,\n initial={'shipping_method': cart.shipping_method})\n\n if form.is_valid():\n form.save()\n return redirect('checkout:summary')\n\n ctx = get_cart_data_for_checkout(cart, request.discounts, taxes)\n ctx.update({'shipping_method_form': form})\n return TemplateResponse(request, 'checkout/shipping_method.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@add_voucher_form\ndef checkout_summary(request, cart):\n \"\"\"Display the correct order summary.\"\"\"\n if cart.is_shipping_required():\n view = validate_shipping_method(summary_with_shipping_view)\n view = validate_shipping_address(view)\n return view(request, cart)\n if request.user.is_authenticated:\n return summary_without_shipping(request, cart)\n return anonymous_summary_without_shipping(request, cart)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_index(request, cart):\n \"\"\"Display cart details.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n cart_lines = []\n check_product_availability_and_warn(request, cart)\n\n # refresh required to get updated cart lines and it's quantity\n try:\n cart = Cart.objects.prefetch_related(\n 'lines__variant__product__category').get(pk=cart.pk)\n except Cart.DoesNotExist:\n pass\n\n lines = cart.lines.select_related(\n 'variant__product__product_type',\n 'variant__product__category')\n lines = lines.prefetch_related(\n 'variant__product__collections',\n 'variant__product__images',\n 'variant__product__product_type__variant_attributes')\n for line in lines:\n initial = {'quantity': line.quantity}\n form = ReplaceCartLineForm(\n None, cart=cart, variant=line.variant, initial=initial,\n discounts=discounts, taxes=taxes)\n cart_lines.append({\n 'variant': line.variant,\n 'get_price': line.variant.get_price(discounts, taxes),\n 'get_total': line.get_total(discounts, taxes),\n 'form': form})\n\n default_country = get_user_shipping_country(request)\n country_form = CountryForm(initial={'country': default_country})\n default_country_options = get_shipment_options(default_country, taxes)\n\n cart_data = get_cart_data(\n cart, default_country_options, request.currency, discounts, taxes)\n ctx = {\n 'cart_lines': cart_lines,\n 'country_form': country_form,\n 'default_country_options': default_country_options}\n ctx.update(cart_data)\n\n return TemplateResponse(request, 'checkout/index.html', ctx)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_shipping_options(request, cart):\n \"\"\"Display shipping options to get a price estimate.\"\"\"\n country_form = CountryForm(request.POST or None, taxes=request.taxes)\n if country_form.is_valid():\n shipments = country_form.get_shipment_options()\n else:\n shipments = None\n ctx = {\n 'default_country_options': shipments,\n 'country_form': country_form}\n cart_data = get_cart_data(\n cart, shipments, request.currency, request.discounts, request.taxes)\n ctx.update(cart_data)\n return TemplateResponse(request, 'checkout/_subtotal_table.html', ctx)\n\n\n@get_or_empty_db_cart()\ndef update_cart_line(request, cart, variant_id):\n \"\"\"Update the line quantities.\"\"\"\n if not request.is_ajax():\n return redirect('cart:index')\n variant = get_object_or_404(ProductVariant, pk=variant_id)\n discounts = request.discounts\n taxes = request.taxes\n status = None\n form = ReplaceCartLineForm(\n request.POST, cart=cart, variant=variant, discounts=discounts,\n taxes=taxes)\n if form.is_valid():\n form.save()\n response = {\n 'variantId': variant_id,\n 'subtotal': 0,\n 'total': 0,\n 'cart': {\n 'numItems': cart.quantity,\n 'numLines': len(cart)}}\n updated_line = cart.get_line(form.cart_line.variant)\n if updated_line:\n response['subtotal'] = format_money(\n updated_line.get_total(discounts, taxes).gross)\n if cart:\n cart_total = cart.get_subtotal(discounts, taxes)\n response['total'] = format_money(cart_total.gross)\n local_cart_total = to_local_currency(cart_total, request.currency)\n if local_cart_total is not None:\n response['localTotal'] = format_money(local_cart_total.gross)\n status = 200\n elif request.POST is not None:\n response = {'error': form.errors}\n status = 400\n return JsonResponse(response, status=status)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_summary(request, cart):\n \"\"\"Display a cart summary suitable for displaying on all pages.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n\n def prepare_line_data(line):\n first_image = line.variant.get_first_image()\n return {\n 'product': line.variant.product,\n 'variant': line.variant.name,\n 'quantity': line.quantity,\n 'image': first_image,\n 'line_total': line.get_total(discounts, taxes),\n 'variant_url': line.variant.get_absolute_url()}\n\n if cart.quantity == 0:\n data = {'quantity': 0}\n else:\n data = {\n 'quantity': cart.quantity,\n 'total': cart.get_subtotal(discounts, taxes),\n 'lines': [prepare_line_data(line) for line in cart]}\n\n return render(request, 'cart_dropdown.html', data)\n", "path": "saleor/checkout/views/__init__.py"}], "after_files": [{"content": "from django.conf.urls import url\n\nfrom . import views\nfrom .views.discount import remove_voucher_view\n\ncheckout_urlpatterns = [\n url(r'^$', views.checkout_index, name='index'),\n url(r'^shipping-address/', views.checkout_shipping_address,\n name='shipping-address'),\n url(r'^shipping-method/', views.checkout_shipping_method,\n name='shipping-method'),\n url(r'^summary/', views.checkout_summary, name='summary'),\n url(r'^remove_voucher/', remove_voucher_view,\n name='remove-voucher'),\n url(r'^login/', views.checkout_login, name='login')]\n\n\ncart_urlpatterns = [\n url(r'^$', views.cart_index, name='index'),\n url(r'^update/(?P<variant_id>\\d+)/$',\n views.update_cart_line, name='update-line'),\n url(r'^clear-cart/$', views.clear_cart, name='clear-cart'),\n url(r'^summary/$', views.cart_summary, name='summary'),\n url(r'^shipping-options/$', views.cart_shipping_options,\n name='shipping-options')]\n", "path": "saleor/checkout/urls.py"}, {"content": "\"\"\"Cart and checkout related views.\"\"\"\nfrom django.http import JsonResponse\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.template.response import TemplateResponse\n\nfrom ...account.forms import LoginForm\nfrom ...core.utils import (\n format_money, get_user_shipping_country, to_local_currency)\nfrom ...product.models import ProductVariant\nfrom ...shipping.utils import get_shipment_options\nfrom ..forms import CartShippingMethodForm, CountryForm, ReplaceCartLineForm\nfrom ..models import Cart\nfrom ..utils import (\n check_product_availability_and_warn, check_shipping_method, get_cart_data,\n get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart,\n update_cart_quantity)\nfrom .discount import add_voucher_form, validate_voucher\nfrom .shipping import (\n anonymous_user_shipping_address_view, user_shipping_address_view)\nfrom .summary import (\n anonymous_summary_without_shipping, summary_with_shipping_view,\n summary_without_shipping)\nfrom .validators import (\n validate_cart, validate_is_shipping_required, validate_shipping_address,\n validate_shipping_method)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\ndef checkout_login(request, cart):\n \"\"\"Allow the user to log in prior to checkout.\"\"\"\n if request.user.is_authenticated:\n return redirect('checkout:index')\n ctx = {'form': LoginForm()}\n return TemplateResponse(request, 'checkout/login.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\n@validate_is_shipping_required\ndef checkout_index(request, cart):\n \"\"\"Redirect to the initial step of checkout.\"\"\"\n return redirect('checkout:shipping-address')\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@add_voucher_form\ndef checkout_shipping_address(request, cart):\n \"\"\"Display the correct shipping address step.\"\"\"\n if request.user.is_authenticated:\n return user_shipping_address_view(request, cart)\n return anonymous_user_shipping_address_view(request, cart)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@validate_shipping_address\n@add_voucher_form\ndef checkout_shipping_method(request, cart):\n \"\"\"Display the shipping method selection step.\"\"\"\n taxes = get_taxes_for_cart(cart, request.taxes)\n check_shipping_method(cart)\n form = CartShippingMethodForm(\n request.POST or None, taxes=taxes, instance=cart,\n initial={'shipping_method': cart.shipping_method})\n\n if form.is_valid():\n form.save()\n return redirect('checkout:summary')\n\n ctx = get_cart_data_for_checkout(cart, request.discounts, taxes)\n ctx.update({'shipping_method_form': form})\n return TemplateResponse(request, 'checkout/shipping_method.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@add_voucher_form\ndef checkout_summary(request, cart):\n \"\"\"Display the correct order summary.\"\"\"\n if cart.is_shipping_required():\n view = validate_shipping_method(summary_with_shipping_view)\n view = validate_shipping_address(view)\n return view(request, cart)\n if request.user.is_authenticated:\n return summary_without_shipping(request, cart)\n return anonymous_summary_without_shipping(request, cart)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_index(request, cart):\n \"\"\"Display cart details.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n cart_lines = []\n check_product_availability_and_warn(request, cart)\n\n # refresh required to get updated cart lines and it's quantity\n try:\n cart = Cart.objects.prefetch_related(\n 'lines__variant__product__category').get(pk=cart.pk)\n except Cart.DoesNotExist:\n pass\n\n lines = cart.lines.select_related(\n 'variant__product__product_type',\n 'variant__product__category')\n lines = lines.prefetch_related(\n 'variant__product__collections',\n 'variant__product__images',\n 'variant__product__product_type__variant_attributes')\n for line in lines:\n initial = {'quantity': line.quantity}\n form = ReplaceCartLineForm(\n None, cart=cart, variant=line.variant, initial=initial,\n discounts=discounts, taxes=taxes)\n cart_lines.append({\n 'variant': line.variant,\n 'get_price': line.variant.get_price(discounts, taxes),\n 'get_total': line.get_total(discounts, taxes),\n 'form': form})\n\n default_country = get_user_shipping_country(request)\n country_form = CountryForm(initial={'country': default_country})\n default_country_options = get_shipment_options(default_country, taxes)\n\n cart_data = get_cart_data(\n cart, default_country_options, request.currency, discounts, taxes)\n ctx = {\n 'cart_lines': cart_lines,\n 'country_form': country_form,\n 'default_country_options': default_country_options}\n ctx.update(cart_data)\n\n return TemplateResponse(request, 'checkout/index.html', ctx)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_shipping_options(request, cart):\n \"\"\"Display shipping options to get a price estimate.\"\"\"\n country_form = CountryForm(request.POST or None, taxes=request.taxes)\n if country_form.is_valid():\n shipments = country_form.get_shipment_options()\n else:\n shipments = None\n ctx = {\n 'default_country_options': shipments,\n 'country_form': country_form}\n cart_data = get_cart_data(\n cart, shipments, request.currency, request.discounts, request.taxes)\n ctx.update(cart_data)\n return TemplateResponse(request, 'checkout/_subtotal_table.html', ctx)\n\n\n@get_or_empty_db_cart()\ndef update_cart_line(request, cart, variant_id):\n \"\"\"Update the line quantities.\"\"\"\n if not request.is_ajax():\n return redirect('cart:index')\n variant = get_object_or_404(ProductVariant, pk=variant_id)\n discounts = request.discounts\n taxes = request.taxes\n status = None\n form = ReplaceCartLineForm(\n request.POST, cart=cart, variant=variant, discounts=discounts,\n taxes=taxes)\n if form.is_valid():\n form.save()\n response = {\n 'variantId': variant_id,\n 'subtotal': 0,\n 'total': 0,\n 'cart': {\n 'numItems': cart.quantity,\n 'numLines': len(cart)}}\n updated_line = cart.get_line(form.cart_line.variant)\n if updated_line:\n response['subtotal'] = format_money(\n updated_line.get_total(discounts, taxes).gross)\n if cart:\n cart_total = cart.get_subtotal(discounts, taxes)\n response['total'] = format_money(cart_total.gross)\n local_cart_total = to_local_currency(cart_total, request.currency)\n if local_cart_total is not None:\n response['localTotal'] = format_money(local_cart_total.gross)\n status = 200\n elif request.POST is not None:\n response = {'error': form.errors}\n status = 400\n return JsonResponse(response, status=status)\n\n\n@get_or_empty_db_cart()\ndef clear_cart(request, cart):\n \"\"\"Clear cart\"\"\"\n if not request.is_ajax():\n return redirect('cart:index')\n cart.lines.all().delete()\n update_cart_quantity(cart)\n response = {'numItems': 0}\n return JsonResponse(response)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_summary(request, cart):\n \"\"\"Display a cart summary suitable for displaying on all pages.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n\n def prepare_line_data(line):\n first_image = line.variant.get_first_image()\n return {\n 'product': line.variant.product,\n 'variant': line.variant.name,\n 'quantity': line.quantity,\n 'image': first_image,\n 'line_total': line.get_total(discounts, taxes),\n 'variant_url': line.variant.get_absolute_url()}\n\n if cart.quantity == 0:\n data = {'quantity': 0}\n else:\n data = {\n 'quantity': cart.quantity,\n 'total': cart.get_subtotal(discounts, taxes),\n 'lines': [prepare_line_data(line) for line in cart]}\n\n return render(request, 'cart_dropdown.html', data)\n", "path": "saleor/checkout/views/__init__.py"}]}
| 2,927 | 440 |
gh_patches_debug_16210
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3291
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pagination of projects is incorrect
On the home page, the pagination is off for large sets of projects.
#### Example
Select the EU trust fund for Africa in the organisations filter. The pagination widget shows that there are 22 pages of projects, but the last [two are empty](https://rsr.akvo.org/en/projects/?organisation=3394&page=22)!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/views/project.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Akvo RSR is covered by the GNU Affero General Public License.
3
4 See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 """
7
8 from django.db.models import Q
9 from rest_framework.decorators import api_view
10 from rest_framework.response import Response
11
12 from akvo.codelists.store.codelists_v202 import SECTOR_CATEGORY
13 from akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,
14 ProjectExtraDeepSerializer,
15 ProjectIatiExportSerializer,
16 ProjectUpSerializer,
17 ProjectDirectorySerializer,
18 TypeaheadOrganisationSerializer,
19 TypeaheadSectorSerializer,)
20 from akvo.rest.views.utils import (
21 int_or_none, get_cached_data, get_qs_elements_for_page, set_cached_data
22 )
23 from akvo.rsr.models import Project
24 from akvo.rsr.filters import location_choices, get_m49_filter
25 from akvo.utils import codelist_choices
26 from ..viewsets import PublicProjectViewSet
27
28
29 class ProjectViewSet(PublicProjectViewSet):
30
31 """
32 Viewset providing Project data.
33 """
34 queryset = Project.objects.select_related(
35 'categories',
36 'keywords',
37 'partners',
38 ).prefetch_related(
39 'publishingstatus',
40 )
41 serializer_class = ProjectSerializer
42 project_relation = ''
43
44 def get_queryset(self):
45 """
46 Allow custom filter for sync_owner, since this field has been replaced by the
47 reporting org partnership.
48 """
49
50 sync_owner = self.request.query_params.get('sync_owner', None)
51 reporting_org = self.request.query_params.get('reporting_org', None)
52
53 reporting_org = reporting_org or sync_owner
54 if reporting_org:
55 self.queryset = self.queryset.filter(
56 partnerships__iati_organisation_role=101,
57 partnerships__organisation__pk=reporting_org
58 ).distinct()
59 return super(ProjectViewSet, self).get_queryset()
60
61
62 class ProjectIatiExportViewSet(PublicProjectViewSet):
63 """Lean viewset for project data, as used in the My IATI section of RSR."""
64 queryset = Project.objects.only(
65 'id',
66 'title',
67 'is_public',
68 'status',
69 ).select_related(
70 'partners',
71 ).prefetch_related(
72 'iati_checks',
73 'publishingstatus',
74 'partnerships',
75 )
76 serializer_class = ProjectIatiExportSerializer
77 project_relation = ''
78 paginate_by_param = 'limit'
79 max_paginate_by = 50
80
81 def get_queryset(self):
82 """
83 Allow custom filter for sync_owner, since this field has been replaced by the
84 reporting org partnership.
85 """
86 reporting_org = self.request.query_params.get('reporting_org', None)
87 if reporting_org:
88 self.queryset = self.queryset.filter(
89 partnerships__iati_organisation_role=101,
90 partnerships__organisation__pk=reporting_org
91 ).distinct()
92 return super(ProjectIatiExportViewSet, self).get_queryset()
93
94
95 class ProjectExtraViewSet(ProjectViewSet):
96
97 """
98 Viewset providing extra Project data.
99
100 Allowed parameters are:
101 __limit__ (default 10, max 30),
102 __partnerships\__organisation__ (filter on organisation ID), and
103 __publishingstatus\__status__ (filter on publishing status)
104 """
105
106 queryset = Project.objects.prefetch_related(
107 'publishingstatus',
108 'sectors',
109 'partnerships',
110 'budget_items',
111 'legacy_data',
112 'links',
113 'locations',
114 'locations__country',
115 'planned_disbursements',
116 'policy_markers',
117 'documents',
118 'comments',
119 'conditions',
120 'contacts',
121 'project_updates',
122 'recipient_countries',
123 'recipient_regions',
124 'related_projects',
125 'results',
126 'sectors',
127 'transactions',
128 )
129 serializer_class = ProjectExtraSerializer
130 paginate_by_param = 'limit'
131 paginate_by = 10
132 max_paginate_by = 30
133
134
135 class ProjectExtraDeepViewSet(ProjectViewSet):
136
137 """
138 Viewset providing extra deep (depth=2 or bigger) Project data.
139
140 Allowed parameters are:
141 __limit__ (default 5, max 10),
142 __partnerships\__organisation__ (filter on organisation ID), and
143 __publishingstatus\__status__ (filter on publishing status)
144 """
145
146 queryset = Project.objects.prefetch_related(
147 'publishingstatus',
148 'sectors',
149 'partnerships',
150 'budget_items',
151 'legacy_data',
152 'links',
153 'locations',
154 'locations__country',
155 'planned_disbursements',
156 'policy_markers',
157 'documents',
158 'comments',
159 'conditions',
160 'contacts',
161 'project_updates',
162 'recipient_countries',
163 'recipient_regions',
164 'related_projects',
165 'results',
166 'sectors',
167 'transactions',
168 )
169 serializer_class = ProjectExtraDeepSerializer
170 paginate_by_param = 'limit'
171 paginate_by = 5
172 max_paginate_by = 10
173
174
175 class ProjectUpViewSet(ProjectViewSet):
176
177 """
178 Viewset providing extra data and limited filtering for Up in one go.
179
180 Allowed parameters are:
181 __limit__ (default 30, max 100),
182 __partnerships\__organisation__ (filter on organisation ID), and
183 __publishingstatus\__status__ (filter on publishing status)
184 """
185
186 queryset = Project.objects.select_related(
187 'primary_location',
188 'categories',
189 'keywords',
190 'partners',
191 ).prefetch_related(
192 'publishingstatus',
193 'project_updates',
194 )
195 serializer_class = ProjectUpSerializer
196 paginate_by_param = 'limit'
197 max_paginate_by = 100
198
199
200 ###############################################################################
201 # Project directory
202 ###############################################################################
203
204 @api_view(['GET'])
205 def project_directory(request):
206 """Return the values for various project filters.
207
208 Based on the current filters, it returns new options for all the (other)
209 filters. This is used to generate dynamic filters.
210
211 """
212
213 # Fetch projects based on whether we are an Akvo site or RSR main site
214 page = request.rsr_page
215 projects = page.projects() if page else Project.objects.all().public().published()
216
217 # Exclude projects which don't have an image or a title
218 # FIXME: This happens silently and may be confusing?
219 projects = projects.exclude(Q(title='') | Q(current_image=''))
220
221 # Filter projects based on query parameters
222 filter_, text_filter = _create_filters_query(request)
223 projects = projects.filter(filter_).distinct() if filter_ is not None else projects
224 # NOTE: The text filter is handled differently/separately from the other filters.
225 # The text filter allows users to enter free form text, which could result in no
226 # projects being found for the given text. Other fields only allow selecting from
227 # a list of options, and for every combination that is shown to users and
228 # selectable by them, at least one project exists.
229 # When no projects are returned for a given search string, if the text search is
230 # not handled separately, the options for all the other filters are empty, and
231 # this causes the filters to get cleared automatically. This is very weird UX.
232 projects_text_filtered = (
233 projects.filter(text_filter) if text_filter is not None else projects
234 )
235 if projects_text_filtered.exists():
236 projects = projects_text_filtered
237
238 # Pre-fetch related fields to make things faster
239 projects = projects.select_related(
240 'primary_location',
241 'primary_organisation',
242 ).prefetch_related(
243 'locations',
244 'locations__country',
245 'recipient_countries',
246 'recipient_countries__country',
247 )
248
249 # Get the relevant data for typeaheads based on filtered projects (minus
250 # text filtering, if no projects were found)
251 cached_locations, _ = get_cached_data(request, 'locations', None, None)
252 if cached_locations is None:
253 cached_locations = [
254 {'id': choice[0], 'name': choice[1]}
255 for choice in location_choices(projects)
256 ]
257 set_cached_data(request, 'locations', cached_locations)
258
259 organisations = projects.all_partners().values('id', 'name', 'long_name')
260
261 # FIXME: Currently only vocabulary 2 is supported (as was the case with
262 # static filters). This could be extended to other vocabularies, in future.
263 valid_sectors = dict(codelist_choices(SECTOR_CATEGORY))
264 sectors = projects.sectors().filter(
265 vocabulary='2', sector_code__in=valid_sectors
266 ).values('sector_code').distinct()
267
268 # NOTE: We use projects_text_filtered for displaying projects
269 count = projects_text_filtered.count()
270 display_projects = get_qs_elements_for_page(projects_text_filtered, request).select_related(
271 'primary_organisation'
272 )
273
274 # NOTE: We use the _get_cached_data function to individually cache small
275 # bits of data to avoid the response from never getting saved in the cache,
276 # because the response is larger than the max size of data that can be
277 # saved in the cache.
278 cached_projects, showing_cached_projects = get_cached_data(
279 request, 'projects', display_projects, ProjectDirectorySerializer
280 )
281 cached_organisations, _ = get_cached_data(
282 request, 'organisations', organisations, TypeaheadOrganisationSerializer
283 )
284
285 response = {
286 'project_count': count,
287 'projects': cached_projects,
288 'showing_cached_projects': showing_cached_projects,
289 'organisation': cached_organisations,
290 'sector': TypeaheadSectorSerializer(sectors, many=True).data,
291 'location': cached_locations,
292 }
293
294 return Response(response)
295
296
297 def _create_filters_query(request):
298 """Returns a Q object expression based on query parameters."""
299 keyword_param = int_or_none(request.GET.get('keyword'))
300 location_param = int_or_none(request.GET.get('location'))
301 status_param = int_or_none(request.GET.get('status'))
302 organisation_param = int_or_none(request.GET.get('organisation'))
303 sector_param = int_or_none(request.GET.get('sector'))
304 title_or_subtitle_param = request.GET.get('title_or_subtitle')
305
306 keyword_filter = Q(keywords__id=keyword_param) if keyword_param else None
307 location_filter = get_m49_filter(location_param) if location_param else None
308 status_filter = Q(iati_status=status_param) if status_param else None
309 organisation_filter = Q(partners__id=organisation_param) if organisation_param else None
310 sector_filter = (
311 Q(sectors__sector_code=sector_param, sectors__vocabulary='2')
312 if sector_param else None
313 )
314 title_or_subtitle_filter = (
315 Q(title__icontains=title_or_subtitle_param) | Q(subtitle__icontains=title_or_subtitle_param)
316 ) if title_or_subtitle_param else None
317 all_filters = [
318 keyword_filter,
319 location_filter,
320 status_filter,
321 organisation_filter,
322 sector_filter,
323 ]
324 filters = filter(None, all_filters)
325 return reduce(lambda x, y: x & y, filters) if filters else None, title_or_subtitle_filter
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py
--- a/akvo/rest/views/project.py
+++ b/akvo/rest/views/project.py
@@ -5,6 +5,7 @@
For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
"""
+from django.conf import settings
from django.db.models import Q
from rest_framework.decorators import api_view
from rest_framework.response import Response
@@ -289,6 +290,7 @@
'organisation': cached_organisations,
'sector': TypeaheadSectorSerializer(sectors, many=True).data,
'location': cached_locations,
+ 'page_size_default': settings.PROJECT_DIRECTORY_PAGE_SIZES[0],
}
return Response(response)
|
{"golden_diff": "diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py\n--- a/akvo/rest/views/project.py\n+++ b/akvo/rest/views/project.py\n@@ -5,6 +5,7 @@\n For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n \"\"\"\n \n+from django.conf import settings\n from django.db.models import Q\n from rest_framework.decorators import api_view\n from rest_framework.response import Response\n@@ -289,6 +290,7 @@\n 'organisation': cached_organisations,\n 'sector': TypeaheadSectorSerializer(sectors, many=True).data,\n 'location': cached_locations,\n+ 'page_size_default': settings.PROJECT_DIRECTORY_PAGE_SIZES[0],\n }\n \n return Response(response)\n", "issue": "Pagination of projects is incorrect\nOn the home page, the pagination is off for large sets of projects. \r\n\r\n#### Example\r\nSelect the EU trust fund for Africa in the organisations filter. The pagination widget shows that there are 22 pages of projects, but the last [two are empty](https://rsr.akvo.org/en/projects/?organisation=3394&page=22)!\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.db.models import Q\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom akvo.codelists.store.codelists_v202 import SECTOR_CATEGORY\nfrom akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,\n ProjectExtraDeepSerializer,\n ProjectIatiExportSerializer,\n ProjectUpSerializer,\n ProjectDirectorySerializer,\n TypeaheadOrganisationSerializer,\n TypeaheadSectorSerializer,)\nfrom akvo.rest.views.utils import (\n int_or_none, get_cached_data, get_qs_elements_for_page, set_cached_data\n)\nfrom akvo.rsr.models import Project\nfrom akvo.rsr.filters import location_choices, get_m49_filter\nfrom akvo.utils import codelist_choices\nfrom ..viewsets import PublicProjectViewSet\n\n\nclass ProjectViewSet(PublicProjectViewSet):\n\n \"\"\"\n Viewset providing Project data.\n \"\"\"\n queryset = Project.objects.select_related(\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n )\n serializer_class = ProjectSerializer\n project_relation = ''\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n\n sync_owner = self.request.query_params.get('sync_owner', None)\n reporting_org = self.request.query_params.get('reporting_org', None)\n\n reporting_org = reporting_org or sync_owner\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectViewSet, self).get_queryset()\n\n\nclass ProjectIatiExportViewSet(PublicProjectViewSet):\n \"\"\"Lean viewset for project data, as used in the My IATI section of RSR.\"\"\"\n queryset = Project.objects.only(\n 'id',\n 'title',\n 'is_public',\n 'status',\n ).select_related(\n 'partners',\n ).prefetch_related(\n 'iati_checks',\n 'publishingstatus',\n 'partnerships',\n )\n serializer_class = ProjectIatiExportSerializer\n project_relation = ''\n paginate_by_param = 'limit'\n max_paginate_by = 50\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n reporting_org = self.request.query_params.get('reporting_org', None)\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectIatiExportViewSet, self).get_queryset()\n\n\nclass ProjectExtraViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra Project data.\n\n Allowed parameters are:\n __limit__ (default 10, max 30),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraSerializer\n paginate_by_param = 'limit'\n paginate_by = 10\n max_paginate_by = 30\n\n\nclass ProjectExtraDeepViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra deep (depth=2 or bigger) Project data.\n\n Allowed parameters are:\n __limit__ (default 5, max 10),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraDeepSerializer\n paginate_by_param = 'limit'\n paginate_by = 5\n max_paginate_by = 10\n\n\nclass ProjectUpViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra data and limited filtering for Up in one go.\n\n Allowed parameters are:\n __limit__ (default 30, max 100),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.select_related(\n 'primary_location',\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n 'project_updates',\n )\n serializer_class = ProjectUpSerializer\n paginate_by_param = 'limit'\n max_paginate_by = 100\n\n\n###############################################################################\n# Project directory\n###############################################################################\n\n@api_view(['GET'])\ndef project_directory(request):\n \"\"\"Return the values for various project filters.\n\n Based on the current filters, it returns new options for all the (other)\n filters. This is used to generate dynamic filters.\n\n \"\"\"\n\n # Fetch projects based on whether we are an Akvo site or RSR main site\n page = request.rsr_page\n projects = page.projects() if page else Project.objects.all().public().published()\n\n # Exclude projects which don't have an image or a title\n # FIXME: This happens silently and may be confusing?\n projects = projects.exclude(Q(title='') | Q(current_image=''))\n\n # Filter projects based on query parameters\n filter_, text_filter = _create_filters_query(request)\n projects = projects.filter(filter_).distinct() if filter_ is not None else projects\n # NOTE: The text filter is handled differently/separately from the other filters.\n # The text filter allows users to enter free form text, which could result in no\n # projects being found for the given text. Other fields only allow selecting from\n # a list of options, and for every combination that is shown to users and\n # selectable by them, at least one project exists.\n # When no projects are returned for a given search string, if the text search is\n # not handled separately, the options for all the other filters are empty, and\n # this causes the filters to get cleared automatically. This is very weird UX.\n projects_text_filtered = (\n projects.filter(text_filter) if text_filter is not None else projects\n )\n if projects_text_filtered.exists():\n projects = projects_text_filtered\n\n # Pre-fetch related fields to make things faster\n projects = projects.select_related(\n 'primary_location',\n 'primary_organisation',\n ).prefetch_related(\n 'locations',\n 'locations__country',\n 'recipient_countries',\n 'recipient_countries__country',\n )\n\n # Get the relevant data for typeaheads based on filtered projects (minus\n # text filtering, if no projects were found)\n cached_locations, _ = get_cached_data(request, 'locations', None, None)\n if cached_locations is None:\n cached_locations = [\n {'id': choice[0], 'name': choice[1]}\n for choice in location_choices(projects)\n ]\n set_cached_data(request, 'locations', cached_locations)\n\n organisations = projects.all_partners().values('id', 'name', 'long_name')\n\n # FIXME: Currently only vocabulary 2 is supported (as was the case with\n # static filters). This could be extended to other vocabularies, in future.\n valid_sectors = dict(codelist_choices(SECTOR_CATEGORY))\n sectors = projects.sectors().filter(\n vocabulary='2', sector_code__in=valid_sectors\n ).values('sector_code').distinct()\n\n # NOTE: We use projects_text_filtered for displaying projects\n count = projects_text_filtered.count()\n display_projects = get_qs_elements_for_page(projects_text_filtered, request).select_related(\n 'primary_organisation'\n )\n\n # NOTE: We use the _get_cached_data function to individually cache small\n # bits of data to avoid the response from never getting saved in the cache,\n # because the response is larger than the max size of data that can be\n # saved in the cache.\n cached_projects, showing_cached_projects = get_cached_data(\n request, 'projects', display_projects, ProjectDirectorySerializer\n )\n cached_organisations, _ = get_cached_data(\n request, 'organisations', organisations, TypeaheadOrganisationSerializer\n )\n\n response = {\n 'project_count': count,\n 'projects': cached_projects,\n 'showing_cached_projects': showing_cached_projects,\n 'organisation': cached_organisations,\n 'sector': TypeaheadSectorSerializer(sectors, many=True).data,\n 'location': cached_locations,\n }\n\n return Response(response)\n\n\ndef _create_filters_query(request):\n \"\"\"Returns a Q object expression based on query parameters.\"\"\"\n keyword_param = int_or_none(request.GET.get('keyword'))\n location_param = int_or_none(request.GET.get('location'))\n status_param = int_or_none(request.GET.get('status'))\n organisation_param = int_or_none(request.GET.get('organisation'))\n sector_param = int_or_none(request.GET.get('sector'))\n title_or_subtitle_param = request.GET.get('title_or_subtitle')\n\n keyword_filter = Q(keywords__id=keyword_param) if keyword_param else None\n location_filter = get_m49_filter(location_param) if location_param else None\n status_filter = Q(iati_status=status_param) if status_param else None\n organisation_filter = Q(partners__id=organisation_param) if organisation_param else None\n sector_filter = (\n Q(sectors__sector_code=sector_param, sectors__vocabulary='2')\n if sector_param else None\n )\n title_or_subtitle_filter = (\n Q(title__icontains=title_or_subtitle_param) | Q(subtitle__icontains=title_or_subtitle_param)\n ) if title_or_subtitle_param else None\n all_filters = [\n keyword_filter,\n location_filter,\n status_filter,\n organisation_filter,\n sector_filter,\n ]\n filters = filter(None, all_filters)\n return reduce(lambda x, y: x & y, filters) if filters else None, title_or_subtitle_filter\n", "path": "akvo/rest/views/project.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.conf import settings\nfrom django.db.models import Q\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom akvo.codelists.store.codelists_v202 import SECTOR_CATEGORY\nfrom akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,\n ProjectExtraDeepSerializer,\n ProjectIatiExportSerializer,\n ProjectUpSerializer,\n ProjectDirectorySerializer,\n TypeaheadOrganisationSerializer,\n TypeaheadSectorSerializer,)\nfrom akvo.rest.views.utils import (\n int_or_none, get_cached_data, get_qs_elements_for_page, set_cached_data\n)\nfrom akvo.rsr.models import Project\nfrom akvo.rsr.filters import location_choices, get_m49_filter\nfrom akvo.utils import codelist_choices\nfrom ..viewsets import PublicProjectViewSet\n\n\nclass ProjectViewSet(PublicProjectViewSet):\n\n \"\"\"\n Viewset providing Project data.\n \"\"\"\n queryset = Project.objects.select_related(\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n )\n serializer_class = ProjectSerializer\n project_relation = ''\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n\n sync_owner = self.request.query_params.get('sync_owner', None)\n reporting_org = self.request.query_params.get('reporting_org', None)\n\n reporting_org = reporting_org or sync_owner\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectViewSet, self).get_queryset()\n\n\nclass ProjectIatiExportViewSet(PublicProjectViewSet):\n \"\"\"Lean viewset for project data, as used in the My IATI section of RSR.\"\"\"\n queryset = Project.objects.only(\n 'id',\n 'title',\n 'is_public',\n 'status',\n ).select_related(\n 'partners',\n ).prefetch_related(\n 'iati_checks',\n 'publishingstatus',\n 'partnerships',\n )\n serializer_class = ProjectIatiExportSerializer\n project_relation = ''\n paginate_by_param = 'limit'\n max_paginate_by = 50\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n reporting_org = self.request.query_params.get('reporting_org', None)\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectIatiExportViewSet, self).get_queryset()\n\n\nclass ProjectExtraViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra Project data.\n\n Allowed parameters are:\n __limit__ (default 10, max 30),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraSerializer\n paginate_by_param = 'limit'\n paginate_by = 10\n max_paginate_by = 30\n\n\nclass ProjectExtraDeepViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra deep (depth=2 or bigger) Project data.\n\n Allowed parameters are:\n __limit__ (default 5, max 10),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraDeepSerializer\n paginate_by_param = 'limit'\n paginate_by = 5\n max_paginate_by = 10\n\n\nclass ProjectUpViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra data and limited filtering for Up in one go.\n\n Allowed parameters are:\n __limit__ (default 30, max 100),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.select_related(\n 'primary_location',\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n 'project_updates',\n )\n serializer_class = ProjectUpSerializer\n paginate_by_param = 'limit'\n max_paginate_by = 100\n\n\n###############################################################################\n# Project directory\n###############################################################################\n\n@api_view(['GET'])\ndef project_directory(request):\n \"\"\"Return the values for various project filters.\n\n Based on the current filters, it returns new options for all the (other)\n filters. This is used to generate dynamic filters.\n\n \"\"\"\n\n # Fetch projects based on whether we are an Akvo site or RSR main site\n page = request.rsr_page\n projects = page.projects() if page else Project.objects.all().public().published()\n\n # Exclude projects which don't have an image or a title\n # FIXME: This happens silently and may be confusing?\n projects = projects.exclude(Q(title='') | Q(current_image=''))\n\n # Filter projects based on query parameters\n filter_, text_filter = _create_filters_query(request)\n projects = projects.filter(filter_).distinct() if filter_ is not None else projects\n # NOTE: The text filter is handled differently/separately from the other filters.\n # The text filter allows users to enter free form text, which could result in no\n # projects being found for the given text. Other fields only allow selecting from\n # a list of options, and for every combination that is shown to users and\n # selectable by them, at least one project exists.\n # When no projects are returned for a given search string, if the text search is\n # not handled separately, the options for all the other filters are empty, and\n # this causes the filters to get cleared automatically. This is very weird UX.\n projects_text_filtered = (\n projects.filter(text_filter) if text_filter is not None else projects\n )\n if projects_text_filtered.exists():\n projects = projects_text_filtered\n\n # Pre-fetch related fields to make things faster\n projects = projects.select_related(\n 'primary_location',\n 'primary_organisation',\n ).prefetch_related(\n 'locations',\n 'locations__country',\n 'recipient_countries',\n 'recipient_countries__country',\n )\n\n # Get the relevant data for typeaheads based on filtered projects (minus\n # text filtering, if no projects were found)\n cached_locations, _ = get_cached_data(request, 'locations', None, None)\n if cached_locations is None:\n cached_locations = [\n {'id': choice[0], 'name': choice[1]}\n for choice in location_choices(projects)\n ]\n set_cached_data(request, 'locations', cached_locations)\n\n organisations = projects.all_partners().values('id', 'name', 'long_name')\n\n # FIXME: Currently only vocabulary 2 is supported (as was the case with\n # static filters). This could be extended to other vocabularies, in future.\n valid_sectors = dict(codelist_choices(SECTOR_CATEGORY))\n sectors = projects.sectors().filter(\n vocabulary='2', sector_code__in=valid_sectors\n ).values('sector_code').distinct()\n\n # NOTE: We use projects_text_filtered for displaying projects\n count = projects_text_filtered.count()\n display_projects = get_qs_elements_for_page(projects_text_filtered, request).select_related(\n 'primary_organisation'\n )\n\n # NOTE: We use the _get_cached_data function to individually cache small\n # bits of data to avoid the response from never getting saved in the cache,\n # because the response is larger than the max size of data that can be\n # saved in the cache.\n cached_projects, showing_cached_projects = get_cached_data(\n request, 'projects', display_projects, ProjectDirectorySerializer\n )\n cached_organisations, _ = get_cached_data(\n request, 'organisations', organisations, TypeaheadOrganisationSerializer\n )\n\n response = {\n 'project_count': count,\n 'projects': cached_projects,\n 'showing_cached_projects': showing_cached_projects,\n 'organisation': cached_organisations,\n 'sector': TypeaheadSectorSerializer(sectors, many=True).data,\n 'location': cached_locations,\n 'page_size_default': settings.PROJECT_DIRECTORY_PAGE_SIZES[0],\n }\n\n return Response(response)\n\n\ndef _create_filters_query(request):\n \"\"\"Returns a Q object expression based on query parameters.\"\"\"\n keyword_param = int_or_none(request.GET.get('keyword'))\n location_param = int_or_none(request.GET.get('location'))\n status_param = int_or_none(request.GET.get('status'))\n organisation_param = int_or_none(request.GET.get('organisation'))\n sector_param = int_or_none(request.GET.get('sector'))\n title_or_subtitle_param = request.GET.get('title_or_subtitle')\n\n keyword_filter = Q(keywords__id=keyword_param) if keyword_param else None\n location_filter = get_m49_filter(location_param) if location_param else None\n status_filter = Q(iati_status=status_param) if status_param else None\n organisation_filter = Q(partners__id=organisation_param) if organisation_param else None\n sector_filter = (\n Q(sectors__sector_code=sector_param, sectors__vocabulary='2')\n if sector_param else None\n )\n title_or_subtitle_filter = (\n Q(title__icontains=title_or_subtitle_param) | Q(subtitle__icontains=title_or_subtitle_param)\n ) if title_or_subtitle_param else None\n all_filters = [\n keyword_filter,\n location_filter,\n status_filter,\n organisation_filter,\n sector_filter,\n ]\n filters = filter(None, all_filters)\n return reduce(lambda x, y: x & y, filters) if filters else None, title_or_subtitle_filter\n", "path": "akvo/rest/views/project.py"}]}
| 3,644 | 174 |
gh_patches_debug_20220
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-4984
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Stable builds are triggered recursively
On Sunday we found that a build for the `stable` version was triggered constantly (Example, http://readthedocs.org/projects/bugzilla/builds/)
@ericholscher hotfixed this with this commit https://github.com/rtfd/readthedocs.org/commit/83caf8fe8 to avoid the "Sunday problem", but we need to research and fix it properly.
We suspect that this could be introduced on #4433 and/or #4876.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/vcs_support/backends/git.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Git-related utilities."""
3
4 from __future__ import (
5 absolute_import,
6 division,
7 print_function,
8 unicode_literals,
9 )
10
11 import logging
12 import os
13 import re
14
15 import git
16 from builtins import str
17 from django.core.exceptions import ValidationError
18 from git.exc import BadName
19
20 from readthedocs.config import ALL
21 from readthedocs.projects.exceptions import RepositoryError
22 from readthedocs.projects.validators import validate_submodule_url
23 from readthedocs.vcs_support.base import BaseVCS, VCSVersion
24
25 log = logging.getLogger(__name__)
26
27
28 class Backend(BaseVCS):
29
30 """Git VCS backend."""
31
32 supports_tags = True
33 supports_branches = True
34 supports_submodules = True
35 fallback_branch = 'master' # default branch
36 repo_depth = 50
37
38 def __init__(self, *args, **kwargs):
39 super(Backend, self).__init__(*args, **kwargs)
40 self.token = kwargs.get('token', None)
41 self.repo_url = self._get_clone_url()
42
43 def _get_clone_url(self):
44 if '://' in self.repo_url:
45 hacked_url = self.repo_url.split('://')[1]
46 hacked_url = re.sub('.git$', '', hacked_url)
47 clone_url = 'https://%s' % hacked_url
48 if self.token:
49 clone_url = 'https://%s@%s' % (self.token, hacked_url)
50 return clone_url
51 # Don't edit URL because all hosts aren't the same
52 # else:
53 # clone_url = 'git://%s' % (hacked_url)
54 return self.repo_url
55
56 def set_remote_url(self, url):
57 return self.run('git', 'remote', 'set-url', 'origin', url)
58
59 def update(self):
60 """Clone or update the repository."""
61 super(Backend, self).update()
62 if self.repo_exists():
63 self.set_remote_url(self.repo_url)
64 return self.fetch()
65 self.make_clean_working_dir()
66 return self.clone()
67
68 def repo_exists(self):
69 code, _, _ = self.run('git', 'status', record=False)
70 return code == 0
71
72 def are_submodules_available(self, config):
73 """Test whether git submodule checkout step should be performed."""
74 # TODO remove this after users migrate to a config file
75 from readthedocs.projects.models import Feature
76 submodules_in_config = (
77 config.submodules.exclude != ALL or
78 config.submodules.include
79 )
80 if (self.project.has_feature(Feature.SKIP_SUBMODULES) or
81 not submodules_in_config):
82 return False
83
84 # Keep compatibility with previous projects
85 code, out, _ = self.run('git', 'submodule', 'status', record=False)
86 return code == 0 and bool(out)
87
88 def validate_submodules(self, config):
89 """
90 Returns the submodules and check that its URLs are valid.
91
92 .. note::
93
94 Allways call after `self.are_submodules_available`.
95
96 :returns: tuple(bool, list)
97
98 Returns true if all required submodules URLs are valid.
99 Returns a list of all required submodules:
100 - Include is `ALL`, returns all submodules avaliable.
101 - Include is a list, returns just those.
102 - Exclude is `ALL` - this should never happen.
103 - Exlude is a list, returns all avaliable submodules
104 but those from the list.
105 """
106 repo = git.Repo(self.working_dir)
107 submodules = {
108 sub.path: sub
109 for sub in repo.submodules
110 }
111
112 for sub_path in config.submodules.exclude:
113 path = sub_path.rstrip('/')
114 if path in submodules:
115 del submodules[path]
116
117 if config.submodules.include != ALL and config.submodules.include:
118 submodules_include = {}
119 for sub_path in config.submodules.include:
120 path = sub_path.rstrip('/')
121 submodules_include[path] = submodules[path]
122 submodules = submodules_include
123
124 for path, submodule in submodules.items():
125 try:
126 validate_submodule_url(submodule.url)
127 except ValidationError:
128 return False, []
129 return True, submodules.keys()
130
131 def fetch(self):
132 code, stdout, stderr = self.run(
133 'git', 'fetch', '--depth', str(self.repo_depth),
134 '--tags', '--prune', '--prune-tags',
135 )
136 if code != 0:
137 raise RepositoryError
138 return code, stdout, stderr
139
140 def checkout_revision(self, revision=None):
141 if not revision:
142 branch = self.default_branch or self.fallback_branch
143 revision = 'origin/%s' % branch
144
145 code, out, err = self.run('git', 'checkout', '--force', revision)
146 if code != 0:
147 log.warning("Failed to checkout revision '%s': %s", revision, code)
148 return [code, out, err]
149
150 def clone(self):
151 """Clones the repository."""
152 code, stdout, stderr = self.run(
153 'git', 'clone', '--depth', str(self.repo_depth),
154 '--no-single-branch', self.repo_url, '.'
155 )
156 if code != 0:
157 raise RepositoryError
158 return code, stdout, stderr
159
160 @property
161 def tags(self):
162 versions = []
163 repo = git.Repo(self.working_dir)
164 for tag in repo.tags:
165 try:
166 versions.append(VCSVersion(self, str(tag.commit), str(tag)))
167 except ValueError as e:
168 # ValueError: Cannot resolve commit as tag TAGNAME points to a
169 # blob object - use the `.object` property instead to access it
170 # This is not a real tag for us, so we skip it
171 # https://github.com/rtfd/readthedocs.org/issues/4440
172 log.warning('Git tag skipped: %s', tag, exc_info=True)
173 continue
174 return versions
175
176 @property
177 def branches(self):
178 repo = git.Repo(self.working_dir)
179 versions = []
180
181 # ``repo.branches`` returns local branches and
182 branches = repo.branches
183 # ``repo.remotes.origin.refs`` returns remote branches
184 if repo.remotes:
185 branches += repo.remotes.origin.refs
186
187 for branch in branches:
188 verbose_name = branch.name
189 if verbose_name.startswith('origin/'):
190 verbose_name = verbose_name.replace('origin/', '')
191 if verbose_name == 'HEAD':
192 continue
193 versions.append(VCSVersion(self, str(branch), verbose_name))
194 return versions
195
196 @property
197 def commit(self):
198 _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')
199 return stdout.strip()
200
201 def checkout(self, identifier=None):
202 """Checkout to identifier or latest."""
203 super(Backend, self).checkout()
204 # Find proper identifier
205 if not identifier:
206 identifier = self.default_branch or self.fallback_branch
207
208 identifier = self.find_ref(identifier)
209
210 # Checkout the correct identifier for this branch.
211 code, out, err = self.checkout_revision(identifier)
212 if code != 0:
213 return code, out, err
214
215 # Clean any remains of previous checkouts
216 self.run('git', 'clean', '-d', '-f', '-f')
217 return code, out, err
218
219 def update_submodules(self, config):
220 if self.are_submodules_available(config):
221 valid, submodules = self.validate_submodules(config)
222 if valid:
223 self.checkout_submodules(submodules, config)
224 else:
225 raise RepositoryError(RepositoryError.INVALID_SUBMODULES)
226
227 def checkout_submodules(self, submodules, config):
228 """Checkout all repository submodules."""
229 self.run('git', 'submodule', 'sync')
230 cmd = [
231 'git',
232 'submodule',
233 'update',
234 '--init',
235 '--force',
236 ]
237 if config.submodules.recursive:
238 cmd.append('--recursive')
239 cmd += submodules
240 self.run(*cmd)
241
242 def find_ref(self, ref):
243 # Check if ref starts with 'origin/'
244 if ref.startswith('origin/'):
245 return ref
246
247 # Check if ref is a branch of the origin remote
248 if self.ref_exists('remotes/origin/' + ref):
249 return 'origin/' + ref
250
251 return ref
252
253 def ref_exists(self, ref):
254 try:
255 r = git.Repo(self.working_dir)
256 if r.commit(ref):
257 return True
258 except (BadName, ValueError):
259 return False
260 return False
261
262 @property
263 def env(self):
264 env = super(Backend, self).env
265 env['GIT_DIR'] = os.path.join(self.working_dir, '.git')
266 # Don't prompt for username, this requires Git 2.3+
267 env['GIT_TERMINAL_PROMPT'] = '0'
268 return env
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py
--- a/readthedocs/vcs_support/backends/git.py
+++ b/readthedocs/vcs_support/backends/git.py
@@ -15,6 +15,7 @@
import git
from builtins import str
from django.core.exceptions import ValidationError
+from django.conf import settings
from git.exc import BadName
from readthedocs.config import ALL
@@ -177,12 +178,13 @@
def branches(self):
repo = git.Repo(self.working_dir)
versions = []
+ branches = []
- # ``repo.branches`` returns local branches and
- branches = repo.branches
# ``repo.remotes.origin.refs`` returns remote branches
if repo.remotes:
branches += repo.remotes.origin.refs
+ if getattr(settings, 'LOCAL_GIT_BRANCHES', False):
+ branches += repo.branches
for branch in branches:
verbose_name = branch.name
|
{"golden_diff": "diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py\n--- a/readthedocs/vcs_support/backends/git.py\n+++ b/readthedocs/vcs_support/backends/git.py\n@@ -15,6 +15,7 @@\n import git\n from builtins import str\n from django.core.exceptions import ValidationError\n+from django.conf import settings\n from git.exc import BadName\n \n from readthedocs.config import ALL\n@@ -177,12 +178,13 @@\n def branches(self):\n repo = git.Repo(self.working_dir)\n versions = []\n+ branches = []\n \n- # ``repo.branches`` returns local branches and\n- branches = repo.branches\n # ``repo.remotes.origin.refs`` returns remote branches\n if repo.remotes:\n branches += repo.remotes.origin.refs\n+ if getattr(settings, 'LOCAL_GIT_BRANCHES', False):\n+ branches += repo.branches\n \n for branch in branches:\n verbose_name = branch.name\n", "issue": "Stable builds are triggered recursively\nOn Sunday we found that a build for the `stable` version was triggered constantly (Example, http://readthedocs.org/projects/bugzilla/builds/)\r\n\r\n@ericholscher hotfixed this with this commit https://github.com/rtfd/readthedocs.org/commit/83caf8fe8 to avoid the \"Sunday problem\", but we need to research and fix it properly.\r\n\r\nWe suspect that this could be introduced on #4433 and/or #4876.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import (\n absolute_import,\n division,\n print_function,\n unicode_literals,\n)\n\nimport logging\nimport os\nimport re\n\nimport git\nfrom builtins import str\nfrom django.core.exceptions import ValidationError\nfrom git.exc import BadName\n\nfrom readthedocs.config import ALL\nfrom readthedocs.projects.exceptions import RepositoryError\nfrom readthedocs.projects.validators import validate_submodule_url\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n supports_submodules = True\n fallback_branch = 'master' # default branch\n repo_depth = 50\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n \"\"\"Clone or update the repository.\"\"\"\n super(Backend, self).update()\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n return self.fetch()\n self.make_clean_working_dir()\n return self.clone()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status', record=False)\n return code == 0\n\n def are_submodules_available(self, config):\n \"\"\"Test whether git submodule checkout step should be performed.\"\"\"\n # TODO remove this after users migrate to a config file\n from readthedocs.projects.models import Feature\n submodules_in_config = (\n config.submodules.exclude != ALL or\n config.submodules.include\n )\n if (self.project.has_feature(Feature.SKIP_SUBMODULES) or\n not submodules_in_config):\n return False\n\n # Keep compatibility with previous projects\n code, out, _ = self.run('git', 'submodule', 'status', record=False)\n return code == 0 and bool(out)\n\n def validate_submodules(self, config):\n \"\"\"\n Returns the submodules and check that its URLs are valid.\n\n .. note::\n\n Allways call after `self.are_submodules_available`.\n\n :returns: tuple(bool, list)\n\n Returns true if all required submodules URLs are valid.\n Returns a list of all required submodules:\n - Include is `ALL`, returns all submodules avaliable.\n - Include is a list, returns just those.\n - Exclude is `ALL` - this should never happen.\n - Exlude is a list, returns all avaliable submodules\n but those from the list.\n \"\"\"\n repo = git.Repo(self.working_dir)\n submodules = {\n sub.path: sub\n for sub in repo.submodules\n }\n\n for sub_path in config.submodules.exclude:\n path = sub_path.rstrip('/')\n if path in submodules:\n del submodules[path]\n\n if config.submodules.include != ALL and config.submodules.include:\n submodules_include = {}\n for sub_path in config.submodules.include:\n path = sub_path.rstrip('/')\n submodules_include[path] = submodules[path]\n submodules = submodules_include\n\n for path, submodule in submodules.items():\n try:\n validate_submodule_url(submodule.url)\n except ValidationError:\n return False, []\n return True, submodules.keys()\n\n def fetch(self):\n code, stdout, stderr = self.run(\n 'git', 'fetch', '--depth', str(self.repo_depth),\n '--tags', '--prune', '--prune-tags',\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout', '--force', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\", revision, code)\n return [code, out, err]\n\n def clone(self):\n \"\"\"Clones the repository.\"\"\"\n code, stdout, stderr = self.run(\n 'git', 'clone', '--depth', str(self.repo_depth),\n '--no-single-branch', self.repo_url, '.'\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n @property\n def tags(self):\n versions = []\n repo = git.Repo(self.working_dir)\n for tag in repo.tags:\n try:\n versions.append(VCSVersion(self, str(tag.commit), str(tag)))\n except ValueError as e:\n # ValueError: Cannot resolve commit as tag TAGNAME points to a\n # blob object - use the `.object` property instead to access it\n # This is not a real tag for us, so we skip it\n # https://github.com/rtfd/readthedocs.org/issues/4440\n log.warning('Git tag skipped: %s', tag, exc_info=True)\n continue\n return versions\n\n @property\n def branches(self):\n repo = git.Repo(self.working_dir)\n versions = []\n\n # ``repo.branches`` returns local branches and\n branches = repo.branches\n # ``repo.remotes.origin.refs`` returns remote branches\n if repo.remotes:\n branches += repo.remotes.origin.refs\n\n for branch in branches:\n verbose_name = branch.name\n if verbose_name.startswith('origin/'):\n verbose_name = verbose_name.replace('origin/', '')\n if verbose_name == 'HEAD':\n continue\n versions.append(VCSVersion(self, str(branch), verbose_name))\n return versions\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n \"\"\"Checkout to identifier or latest.\"\"\"\n super(Backend, self).checkout()\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n return code, out, err\n\n def update_submodules(self, config):\n if self.are_submodules_available(config):\n valid, submodules = self.validate_submodules(config)\n if valid:\n self.checkout_submodules(submodules, config)\n else:\n raise RepositoryError(RepositoryError.INVALID_SUBMODULES)\n\n def checkout_submodules(self, submodules, config):\n \"\"\"Checkout all repository submodules.\"\"\"\n self.run('git', 'submodule', 'sync')\n cmd = [\n 'git',\n 'submodule',\n 'update',\n '--init',\n '--force',\n ]\n if config.submodules.recursive:\n cmd.append('--recursive')\n cmd += submodules\n self.run(*cmd)\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n try:\n r = git.Repo(self.working_dir)\n if r.commit(ref):\n return True\n except (BadName, ValueError):\n return False\n return False\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n # Don't prompt for username, this requires Git 2.3+\n env['GIT_TERMINAL_PROMPT'] = '0'\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import (\n absolute_import,\n division,\n print_function,\n unicode_literals,\n)\n\nimport logging\nimport os\nimport re\n\nimport git\nfrom builtins import str\nfrom django.core.exceptions import ValidationError\nfrom django.conf import settings\nfrom git.exc import BadName\n\nfrom readthedocs.config import ALL\nfrom readthedocs.projects.exceptions import RepositoryError\nfrom readthedocs.projects.validators import validate_submodule_url\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n supports_submodules = True\n fallback_branch = 'master' # default branch\n repo_depth = 50\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n \"\"\"Clone or update the repository.\"\"\"\n super(Backend, self).update()\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n return self.fetch()\n self.make_clean_working_dir()\n return self.clone()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status', record=False)\n return code == 0\n\n def are_submodules_available(self, config):\n \"\"\"Test whether git submodule checkout step should be performed.\"\"\"\n # TODO remove this after users migrate to a config file\n from readthedocs.projects.models import Feature\n submodules_in_config = (\n config.submodules.exclude != ALL or\n config.submodules.include\n )\n if (self.project.has_feature(Feature.SKIP_SUBMODULES) or\n not submodules_in_config):\n return False\n\n # Keep compatibility with previous projects\n code, out, _ = self.run('git', 'submodule', 'status', record=False)\n return code == 0 and bool(out)\n\n def validate_submodules(self, config):\n \"\"\"\n Returns the submodules and check that its URLs are valid.\n\n .. note::\n\n Allways call after `self.are_submodules_available`.\n\n :returns: tuple(bool, list)\n\n Returns true if all required submodules URLs are valid.\n Returns a list of all required submodules:\n - Include is `ALL`, returns all submodules avaliable.\n - Include is a list, returns just those.\n - Exclude is `ALL` - this should never happen.\n - Exlude is a list, returns all avaliable submodules\n but those from the list.\n \"\"\"\n repo = git.Repo(self.working_dir)\n submodules = {\n sub.path: sub\n for sub in repo.submodules\n }\n\n for sub_path in config.submodules.exclude:\n path = sub_path.rstrip('/')\n if path in submodules:\n del submodules[path]\n\n if config.submodules.include != ALL and config.submodules.include:\n submodules_include = {}\n for sub_path in config.submodules.include:\n path = sub_path.rstrip('/')\n submodules_include[path] = submodules[path]\n submodules = submodules_include\n\n for path, submodule in submodules.items():\n try:\n validate_submodule_url(submodule.url)\n except ValidationError:\n return False, []\n return True, submodules.keys()\n\n def fetch(self):\n code, stdout, stderr = self.run(\n 'git', 'fetch', '--depth', str(self.repo_depth),\n '--tags', '--prune', '--prune-tags',\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout', '--force', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\", revision, code)\n return [code, out, err]\n\n def clone(self):\n \"\"\"Clones the repository.\"\"\"\n code, stdout, stderr = self.run(\n 'git', 'clone', '--depth', str(self.repo_depth),\n '--no-single-branch', self.repo_url, '.'\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n @property\n def tags(self):\n versions = []\n repo = git.Repo(self.working_dir)\n for tag in repo.tags:\n try:\n versions.append(VCSVersion(self, str(tag.commit), str(tag)))\n except ValueError as e:\n # ValueError: Cannot resolve commit as tag TAGNAME points to a\n # blob object - use the `.object` property instead to access it\n # This is not a real tag for us, so we skip it\n # https://github.com/rtfd/readthedocs.org/issues/4440\n log.warning('Git tag skipped: %s', tag, exc_info=True)\n continue\n return versions\n\n @property\n def branches(self):\n repo = git.Repo(self.working_dir)\n versions = []\n branches = []\n\n # ``repo.remotes.origin.refs`` returns remote branches\n if repo.remotes:\n branches += repo.remotes.origin.refs\n if getattr(settings, 'LOCAL_GIT_BRANCHES', False):\n branches += repo.branches\n\n for branch in branches:\n verbose_name = branch.name\n if verbose_name.startswith('origin/'):\n verbose_name = verbose_name.replace('origin/', '')\n if verbose_name == 'HEAD':\n continue\n versions.append(VCSVersion(self, str(branch), verbose_name))\n return versions\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n \"\"\"Checkout to identifier or latest.\"\"\"\n super(Backend, self).checkout()\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n return code, out, err\n\n def update_submodules(self, config):\n if self.are_submodules_available(config):\n valid, submodules = self.validate_submodules(config)\n if valid:\n self.checkout_submodules(submodules, config)\n else:\n raise RepositoryError(RepositoryError.INVALID_SUBMODULES)\n\n def checkout_submodules(self, submodules, config):\n \"\"\"Checkout all repository submodules.\"\"\"\n self.run('git', 'submodule', 'sync')\n cmd = [\n 'git',\n 'submodule',\n 'update',\n '--init',\n '--force',\n ]\n if config.submodules.recursive:\n cmd.append('--recursive')\n cmd += submodules\n self.run(*cmd)\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n try:\n r = git.Repo(self.working_dir)\n if r.commit(ref):\n return True\n except (BadName, ValueError):\n return False\n return False\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n # Don't prompt for username, this requires Git 2.3+\n env['GIT_TERMINAL_PROMPT'] = '0'\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}]}
| 3,010 | 229 |
gh_patches_debug_60634
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-881
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Auto wrapping Huggingface models with FullyShardedDataParallel can break them
## 🐛 Bug
If you auto wrap a HuggingFace model with `FullyShardedDataParallel`, depending on what sub-modules are wrapped, and how the output of the modules are accessed in the model, calling `forward` can result in exceptions.
## What happens
Some sub-modules of the HuggingFace model output a child implementation of [`ModelOutput`](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/file_utils.py#L1884), which is itself a descendent of `OrderedDict`.
An example is, for instance, [`CausalLMOutputWithCrossAttentions` ](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/modeling_outputs.py#L375).
You can access attributes of `ModelOutput` instance derivatives in three ways, e.g. like this:
- `hidden_states = transformer_outputs[0]`
- `hidden_states = transformer_outputs.hidden_states`
- `hidden_states = transformer_outputs["hidden_states"]`
In the HuggingFace library these three types of accessing attributes are used interchangeably.
Now, when a sub-module, which outputs a `ModelOutput` derived instance, is wrapped with `FullyShardedDataParallel`, this output instance is converted in to an `OrderedDict`, in the [`apply_to_tensors`](https://github.com/facebookresearch/fairscale/blob/fecb665b812b6bfc38442e1fb1557e21508917f4/fairscale/utils/containers.py#L21) function, in `utils/containers.py`, since the `ModelOutput` derives from `OrderedDict`! :
```
elif isinstance(x, OrderedDict):
od = OrderedDict()
for key, value in x.items():
od[key] = _apply(value)
return od
```
After it has been converted into a plain `OrderedDict` by `FullyShardedDataParallel`, when the output of the submodule is, for instance, accessed using an index (`transformer_outputs[0]`) or attribute accessor (`transformer_outputs. hidden_states`), an exception is thrown, because the `OrderedDict` instance doesn't know how to handle that.
## A simple solution
A simple solution is to replace the `OrderedDict` instantiation above with `od = x.__class__()`, thus:
```
elif isinstance(x, OrderedDict):
od = x.__class__()
for key, value in x.items():
od[key] = _apply(value)
return od
```
In this way we keep on using the original class, with its extended means to access attributes, which is used in the HuggingFace library.
## To Reproduce
Steps to reproduce the behavior:
1. Use a HuggingFace model, e.g. `GPT2LMHeadModel`
```
from transformers import GPT2Config, GPT2LMHeadModel
```
2. Build the model
```
# You could also try, e.g. "gpt2-large"
model_config = GPT2Config.from_pretrained("gpt2")
self._model = GPT2LMHeadModel(model_config)
self._model.to(self._device)
```
3. Auto wrap the model
```
wrap_policy = functools.partial(default_auto_wrap_policy,
min_num_params=1e8)
fsdp_params = {
"mixed_precision": False,
"move_params_to_cpu": False
}
with enable_wrap(wrapper_cls=FullyShardedDDP, auto_wrap_policy=wrap_policy, **fsdp_params):
self._training_model = auto_wrap(self._model)
# Finally wrap root module
self._training_model = FullyShardedDDP(self._training_model, **fsdp_params)
```
4. Use this in a training loop
This results in errors similar to this one where the `OrderedDict` accessed in invalid ways:
```
... transformers/models/gpt2/modeling_gpt2.py", line 1057, in forward
hidden_states = transformer_outputs[0]
KeyError: 0
```
## Expected behavior
No exception should occur, `FullyShardedDataParallel` should not break calling the HuggingFace model.
## Environment
```
$ pip show fairscale
Name: fairscale
Version: 0.4.3
$ pip show transformers
Name: transformers
Version: 4.12.5
$ pip show torch
Name: torch
Version: 1.10.0
$ python --version
Python 3.7.4
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fairscale/utils/containers.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 from collections import OrderedDict
7 from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
8
9 import torch
10 from torch.nn.utils.rnn import PackedSequence
11
12 """Useful functions to deal with tensor types with other python container types."""
13
14
15 def apply_to_tensors(fn: Callable, container: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:
16 """Recursively apply to all tensor in different kinds of container types."""
17
18 def _apply(x: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:
19 if torch.is_tensor(x):
20 return fn(x)
21 elif isinstance(x, OrderedDict):
22 od = OrderedDict()
23 for key, value in x.items():
24 od[key] = _apply(value)
25 return od
26 elif isinstance(x, PackedSequence):
27 _apply(x.data)
28 return x
29 elif isinstance(x, dict):
30 return {key: _apply(value) for key, value in x.items()}
31 elif isinstance(x, list):
32 return [_apply(x) for x in x]
33 elif isinstance(x, tuple):
34 return tuple(_apply(x) for x in x)
35 elif isinstance(x, set):
36 return {_apply(x) for x in x}
37 else:
38 return x
39
40 return _apply(container)
41
42
43 def pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:
44 """
45 Turn argument list into separate key list and value list (unpack_kwargs does the opposite)
46
47 Usage::
48
49 kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)
50 assert kwarg_keys == ("a", "b")
51 assert flat_args == (1, 2, 3, 4)
52 args, kwargs = unpack_kwargs(kwarg_keys, flat_args)
53 assert args == (1, 2)
54 assert kwargs == {"a": 3, "b": 4}
55 """
56 kwarg_keys: List[str] = []
57 flat_args: List[Any] = list(args)
58 for k, v in kwargs.items():
59 kwarg_keys.append(k)
60 flat_args.append(v)
61 return tuple(kwarg_keys), tuple(flat_args)
62
63
64 def unpack_kwargs(kwarg_keys: Tuple[str, ...], flat_args: Tuple[Any, ...]) -> Tuple[Tuple[Any, ...], Dict[str, Any]]:
65 """See pack_kwargs."""
66 assert len(kwarg_keys) <= len(flat_args), f"too many keys {len(kwarg_keys)} vs. {len(flat_args)}"
67 if len(kwarg_keys) == 0:
68 return flat_args, {}
69 args = flat_args[: -len(kwarg_keys)]
70 kwargs = {k: v for k, v in zip(kwarg_keys, flat_args[-len(kwarg_keys) :])}
71 return args, kwargs
72
73
74 def split_non_tensors(
75 mixed: Union[torch.Tensor, Tuple[Any, ...]]
76 ) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:
77 """
78 Split a tuple into a list of tensors and the rest with information
79 for later reconstruction.
80
81 Usage::
82
83 x = torch.Tensor([1])
84 y = torch.Tensor([2])
85 tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))
86 assert tensors == (x, y)
87 assert packed_non_tensors == {
88 "is_tensor": [True, True, False, False],
89 "objects": [None, 3],
90 }
91 recon = unpack_non_tensors(tensors, packed_non_tensors)
92 assert recon == (x, y, None, 3)
93 """
94 if isinstance(mixed, torch.Tensor):
95 return (mixed,), None
96 tensors: List[torch.Tensor] = []
97 packed_non_tensors: Dict[str, List[Any]] = {"is_tensor": [], "objects": []}
98 for o in mixed:
99 if isinstance(o, torch.Tensor):
100 packed_non_tensors["is_tensor"].append(True)
101 tensors.append(o)
102 else:
103 packed_non_tensors["is_tensor"].append(False)
104 packed_non_tensors["objects"].append(o)
105 return tuple(tensors), packed_non_tensors
106
107
108 def unpack_non_tensors(
109 tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]
110 ) -> Tuple[Any, ...]:
111 """See split_non_tensors."""
112 if packed_non_tensors is None:
113 return tensors
114 assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)
115 mixed: List[Any] = []
116 is_tensor_list = packed_non_tensors["is_tensor"]
117 objects = packed_non_tensors["objects"]
118 assert len(tensors) + len(objects) == len(is_tensor_list), (
119 f"len(tensors) {len(tensors)} len(objects) {len(objects)} " f"len(is_tensor_list) {len(is_tensor_list)}"
120 )
121 obj_i = tnsr_i = 0
122 for is_tensor in is_tensor_list:
123 if is_tensor:
124 mixed.append(tensors[tnsr_i])
125 tnsr_i += 1
126 else:
127 mixed.append(objects[obj_i])
128 obj_i += 1
129 return tuple(mixed)
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fairscale/utils/containers.py b/fairscale/utils/containers.py
--- a/fairscale/utils/containers.py
+++ b/fairscale/utils/containers.py
@@ -19,7 +19,7 @@
if torch.is_tensor(x):
return fn(x)
elif isinstance(x, OrderedDict):
- od = OrderedDict()
+ od = x.__class__()
for key, value in x.items():
od[key] = _apply(value)
return od
|
{"golden_diff": "diff --git a/fairscale/utils/containers.py b/fairscale/utils/containers.py\n--- a/fairscale/utils/containers.py\n+++ b/fairscale/utils/containers.py\n@@ -19,7 +19,7 @@\n if torch.is_tensor(x):\n return fn(x)\n elif isinstance(x, OrderedDict):\n- od = OrderedDict()\n+ od = x.__class__()\n for key, value in x.items():\n od[key] = _apply(value)\n return od\n", "issue": "Auto wrapping Huggingface models with FullyShardedDataParallel can break them\n## \ud83d\udc1b Bug\r\n\r\nIf you auto wrap a HuggingFace model with `FullyShardedDataParallel`, depending on what sub-modules are wrapped, and how the output of the modules are accessed in the model, calling `forward` can result in exceptions. \r\n\r\n## What happens\r\n\r\nSome sub-modules of the HuggingFace model output a child implementation of [`ModelOutput`](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/file_utils.py#L1884), which is itself a descendent of `OrderedDict`.\r\n\r\nAn example is, for instance, [`CausalLMOutputWithCrossAttentions` ](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/modeling_outputs.py#L375).\r\n\r\nYou can access attributes of `ModelOutput` instance derivatives in three ways, e.g. like this:\r\n\r\n- `hidden_states = transformer_outputs[0]`\r\n- `hidden_states = transformer_outputs.hidden_states`\r\n- `hidden_states = transformer_outputs[\"hidden_states\"]`\r\n\r\nIn the HuggingFace library these three types of accessing attributes are used interchangeably.\r\n\r\nNow, when a sub-module, which outputs a `ModelOutput` derived instance, is wrapped with `FullyShardedDataParallel`, this output instance is converted in to an `OrderedDict`, in the [`apply_to_tensors`](https://github.com/facebookresearch/fairscale/blob/fecb665b812b6bfc38442e1fb1557e21508917f4/fairscale/utils/containers.py#L21) function, in `utils/containers.py`, since the `ModelOutput` derives from `OrderedDict`! :\r\n\r\n```\r\n elif isinstance(x, OrderedDict):\r\n od = OrderedDict()\r\n for key, value in x.items():\r\n od[key] = _apply(value)\r\n return od\r\n```\r\n\r\nAfter it has been converted into a plain `OrderedDict` by `FullyShardedDataParallel`, when the output of the submodule is, for instance, accessed using an index (`transformer_outputs[0]`) or attribute accessor (`transformer_outputs. hidden_states`), an exception is thrown, because the `OrderedDict` instance doesn't know how to handle that. \r\n\r\n## A simple solution\r\n\r\nA simple solution is to replace the `OrderedDict` instantiation above with `od = x.__class__()`, thus:\r\n\r\n```\r\n elif isinstance(x, OrderedDict):\r\n od = x.__class__()\r\n for key, value in x.items():\r\n od[key] = _apply(value)\r\n return od\r\n```\r\n\r\nIn this way we keep on using the original class, with its extended means to access attributes, which is used in the HuggingFace library.\r\n\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Use a HuggingFace model, e.g. `GPT2LMHeadModel`\r\n```\r\nfrom transformers import GPT2Config, GPT2LMHeadModel\r\n```\r\n\r\n2. Build the model \r\n```\r\n # You could also try, e.g. \"gpt2-large\"\r\n model_config = GPT2Config.from_pretrained(\"gpt2\")\r\n self._model = GPT2LMHeadModel(model_config)\r\n\r\n self._model.to(self._device)\r\n```\r\n\r\n3. Auto wrap the model\r\n```\r\n wrap_policy = functools.partial(default_auto_wrap_policy,\r\n min_num_params=1e8)\r\n\r\n fsdp_params = {\r\n \"mixed_precision\": False,\r\n \"move_params_to_cpu\": False\r\n }\r\n\r\n with enable_wrap(wrapper_cls=FullyShardedDDP, auto_wrap_policy=wrap_policy, **fsdp_params):\r\n self._training_model = auto_wrap(self._model)\r\n\r\n # Finally wrap root module\r\n self._training_model = FullyShardedDDP(self._training_model, **fsdp_params)\r\n```\r\n\r\n4. Use this in a training loop\r\n\r\nThis results in errors similar to this one where the `OrderedDict` accessed in invalid ways:\r\n```\r\n... transformers/models/gpt2/modeling_gpt2.py\", line 1057, in forward\r\n hidden_states = transformer_outputs[0]\r\nKeyError: 0\r\n```\r\n\r\n## Expected behavior\r\n\r\nNo exception should occur, `FullyShardedDataParallel` should not break calling the HuggingFace model.\r\n\r\n## Environment\r\n\r\n```\r\n$ pip show fairscale\r\nName: fairscale\r\nVersion: 0.4.3\r\n\r\n$ pip show transformers\r\nName: transformers\r\nVersion: 4.12.5\r\n\r\n$ pip show torch\r\nName: torch\r\nVersion: 1.10.0\r\n\r\n$ python --version\r\nPython 3.7.4\r\n```\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom collections import OrderedDict\nfrom typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union\n\nimport torch\nfrom torch.nn.utils.rnn import PackedSequence\n\n\"\"\"Useful functions to deal with tensor types with other python container types.\"\"\"\n\n\ndef apply_to_tensors(fn: Callable, container: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n \"\"\"Recursively apply to all tensor in different kinds of container types.\"\"\"\n\n def _apply(x: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n if torch.is_tensor(x):\n return fn(x)\n elif isinstance(x, OrderedDict):\n od = OrderedDict()\n for key, value in x.items():\n od[key] = _apply(value)\n return od\n elif isinstance(x, PackedSequence):\n _apply(x.data)\n return x\n elif isinstance(x, dict):\n return {key: _apply(value) for key, value in x.items()}\n elif isinstance(x, list):\n return [_apply(x) for x in x]\n elif isinstance(x, tuple):\n return tuple(_apply(x) for x in x)\n elif isinstance(x, set):\n return {_apply(x) for x in x}\n else:\n return x\n\n return _apply(container)\n\n\ndef pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:\n \"\"\"\n Turn argument list into separate key list and value list (unpack_kwargs does the opposite)\n\n Usage::\n\n kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)\n assert kwarg_keys == (\"a\", \"b\")\n assert flat_args == (1, 2, 3, 4)\n args, kwargs = unpack_kwargs(kwarg_keys, flat_args)\n assert args == (1, 2)\n assert kwargs == {\"a\": 3, \"b\": 4}\n \"\"\"\n kwarg_keys: List[str] = []\n flat_args: List[Any] = list(args)\n for k, v in kwargs.items():\n kwarg_keys.append(k)\n flat_args.append(v)\n return tuple(kwarg_keys), tuple(flat_args)\n\n\ndef unpack_kwargs(kwarg_keys: Tuple[str, ...], flat_args: Tuple[Any, ...]) -> Tuple[Tuple[Any, ...], Dict[str, Any]]:\n \"\"\"See pack_kwargs.\"\"\"\n assert len(kwarg_keys) <= len(flat_args), f\"too many keys {len(kwarg_keys)} vs. {len(flat_args)}\"\n if len(kwarg_keys) == 0:\n return flat_args, {}\n args = flat_args[: -len(kwarg_keys)]\n kwargs = {k: v for k, v in zip(kwarg_keys, flat_args[-len(kwarg_keys) :])}\n return args, kwargs\n\n\ndef split_non_tensors(\n mixed: Union[torch.Tensor, Tuple[Any, ...]]\n) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:\n \"\"\"\n Split a tuple into a list of tensors and the rest with information\n for later reconstruction.\n\n Usage::\n\n x = torch.Tensor([1])\n y = torch.Tensor([2])\n tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))\n assert tensors == (x, y)\n assert packed_non_tensors == {\n \"is_tensor\": [True, True, False, False],\n \"objects\": [None, 3],\n }\n recon = unpack_non_tensors(tensors, packed_non_tensors)\n assert recon == (x, y, None, 3)\n \"\"\"\n if isinstance(mixed, torch.Tensor):\n return (mixed,), None\n tensors: List[torch.Tensor] = []\n packed_non_tensors: Dict[str, List[Any]] = {\"is_tensor\": [], \"objects\": []}\n for o in mixed:\n if isinstance(o, torch.Tensor):\n packed_non_tensors[\"is_tensor\"].append(True)\n tensors.append(o)\n else:\n packed_non_tensors[\"is_tensor\"].append(False)\n packed_non_tensors[\"objects\"].append(o)\n return tuple(tensors), packed_non_tensors\n\n\ndef unpack_non_tensors(\n tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]\n) -> Tuple[Any, ...]:\n \"\"\"See split_non_tensors.\"\"\"\n if packed_non_tensors is None:\n return tensors\n assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)\n mixed: List[Any] = []\n is_tensor_list = packed_non_tensors[\"is_tensor\"]\n objects = packed_non_tensors[\"objects\"]\n assert len(tensors) + len(objects) == len(is_tensor_list), (\n f\"len(tensors) {len(tensors)} len(objects) {len(objects)} \" f\"len(is_tensor_list) {len(is_tensor_list)}\"\n )\n obj_i = tnsr_i = 0\n for is_tensor in is_tensor_list:\n if is_tensor:\n mixed.append(tensors[tnsr_i])\n tnsr_i += 1\n else:\n mixed.append(objects[obj_i])\n obj_i += 1\n return tuple(mixed)\n", "path": "fairscale/utils/containers.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom collections import OrderedDict\nfrom typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union\n\nimport torch\nfrom torch.nn.utils.rnn import PackedSequence\n\n\"\"\"Useful functions to deal with tensor types with other python container types.\"\"\"\n\n\ndef apply_to_tensors(fn: Callable, container: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n \"\"\"Recursively apply to all tensor in different kinds of container types.\"\"\"\n\n def _apply(x: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n if torch.is_tensor(x):\n return fn(x)\n elif isinstance(x, OrderedDict):\n od = x.__class__()\n for key, value in x.items():\n od[key] = _apply(value)\n return od\n elif isinstance(x, PackedSequence):\n _apply(x.data)\n return x\n elif isinstance(x, dict):\n return {key: _apply(value) for key, value in x.items()}\n elif isinstance(x, list):\n return [_apply(x) for x in x]\n elif isinstance(x, tuple):\n return tuple(_apply(x) for x in x)\n elif isinstance(x, set):\n return {_apply(x) for x in x}\n else:\n return x\n\n return _apply(container)\n\n\ndef pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:\n \"\"\"\n Turn argument list into separate key list and value list (unpack_kwargs does the opposite)\n\n Usage::\n\n kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)\n assert kwarg_keys == (\"a\", \"b\")\n assert flat_args == (1, 2, 3, 4)\n args, kwargs = unpack_kwargs(kwarg_keys, flat_args)\n assert args == (1, 2)\n assert kwargs == {\"a\": 3, \"b\": 4}\n \"\"\"\n kwarg_keys: List[str] = []\n flat_args: List[Any] = list(args)\n for k, v in kwargs.items():\n kwarg_keys.append(k)\n flat_args.append(v)\n return tuple(kwarg_keys), tuple(flat_args)\n\n\ndef unpack_kwargs(kwarg_keys: Tuple[str, ...], flat_args: Tuple[Any, ...]) -> Tuple[Tuple[Any, ...], Dict[str, Any]]:\n \"\"\"See pack_kwargs.\"\"\"\n assert len(kwarg_keys) <= len(flat_args), f\"too many keys {len(kwarg_keys)} vs. {len(flat_args)}\"\n if len(kwarg_keys) == 0:\n return flat_args, {}\n args = flat_args[: -len(kwarg_keys)]\n kwargs = {k: v for k, v in zip(kwarg_keys, flat_args[-len(kwarg_keys) :])}\n return args, kwargs\n\n\ndef split_non_tensors(\n mixed: Union[torch.Tensor, Tuple[Any, ...]]\n) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:\n \"\"\"\n Split a tuple into a list of tensors and the rest with information\n for later reconstruction.\n\n Usage::\n\n x = torch.Tensor([1])\n y = torch.Tensor([2])\n tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))\n assert tensors == (x, y)\n assert packed_non_tensors == {\n \"is_tensor\": [True, True, False, False],\n \"objects\": [None, 3],\n }\n recon = unpack_non_tensors(tensors, packed_non_tensors)\n assert recon == (x, y, None, 3)\n \"\"\"\n if isinstance(mixed, torch.Tensor):\n return (mixed,), None\n tensors: List[torch.Tensor] = []\n packed_non_tensors: Dict[str, List[Any]] = {\"is_tensor\": [], \"objects\": []}\n for o in mixed:\n if isinstance(o, torch.Tensor):\n packed_non_tensors[\"is_tensor\"].append(True)\n tensors.append(o)\n else:\n packed_non_tensors[\"is_tensor\"].append(False)\n packed_non_tensors[\"objects\"].append(o)\n return tuple(tensors), packed_non_tensors\n\n\ndef unpack_non_tensors(\n tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]\n) -> Tuple[Any, ...]:\n \"\"\"See split_non_tensors.\"\"\"\n if packed_non_tensors is None:\n return tensors\n assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)\n mixed: List[Any] = []\n is_tensor_list = packed_non_tensors[\"is_tensor\"]\n objects = packed_non_tensors[\"objects\"]\n assert len(tensors) + len(objects) == len(is_tensor_list), (\n f\"len(tensors) {len(tensors)} len(objects) {len(objects)} \" f\"len(is_tensor_list) {len(is_tensor_list)}\"\n )\n obj_i = tnsr_i = 0\n for is_tensor in is_tensor_list:\n if is_tensor:\n mixed.append(tensors[tnsr_i])\n tnsr_i += 1\n else:\n mixed.append(objects[obj_i])\n obj_i += 1\n return tuple(mixed)\n", "path": "fairscale/utils/containers.py"}]}
| 2,797 | 107 |
gh_patches_debug_15476
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-4196
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
aioredis raises CancelledError in _finish_span
### Which version of dd-trace-py are you using?
~~0.53.0~~ 0.58.0
### Which version of pip are you using?
21.3.1
### Which version of the libraries are you using?
django==3.2.11
django-redis==5.0.0
channels==3.0.4
daphne==3.0.2
### How can we reproduce your problem?
I am using code similar to the following:
asgi.py
```
import django
from channels.routing import get_default_application
from ddtrace.contrib.asgi import TraceMiddleware
django.setup()
application = TraceMiddleware(get_default_application())
```
routing.py
```
from django.urls import re_path
import my_app.consumers
websocket_urlpatterns = [
re_path(r"^ws/test/$", consumers.TestConsumer.as_asgi()),
]
```
my_app/consumers.py
```
from channels.generic.websocket import WebsocketConsumer
class TestConsumer(WebsocketConsumer):
groups = ["broadcast"]
def connect(self):
self.accept()
def receive(self, text_data=None, bytes_data=None):
raise Exception("An test exception")
```
I am running the application with: `ddtrace-run daphne asgi:application --bind 0.0.0.0 --port 8001`
### What is the result that you get?
I don't get any traces at all, and my logs show this:
```
handle: <Handle traced_13_execute_command.<locals>._finish_span(<Future cancelled>) at /usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py:140>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py", line 146, in _finish_span
future.result()
asyncio.exceptions.CancelledError
```
### What is the result that you expected?
No errors
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/contrib/aioredis/patch.py`
Content:
```
1 import asyncio
2 import sys
3
4 import aioredis
5
6 from ddtrace import config
7 from ddtrace.internal.utils.wrappers import unwrap as _u
8 from ddtrace.pin import Pin
9 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
10
11 from .. import trace_utils
12 from ...constants import ANALYTICS_SAMPLE_RATE_KEY
13 from ...constants import SPAN_MEASURED_KEY
14 from ...ext import SpanTypes
15 from ...ext import net
16 from ...ext import redis as redisx
17 from ...internal.utils.formats import stringify_cache_args
18 from ..redis.util import _trace_redis_cmd
19 from ..redis.util import _trace_redis_execute_pipeline
20
21
22 try:
23 from aioredis.commands.transaction import _RedisBuffer
24 except ImportError:
25 _RedisBuffer = None
26
27 config._add("aioredis", dict(_default_service="redis"))
28
29 aioredis_version_str = getattr(aioredis, "__version__", "0.0.0")
30 aioredis_version = tuple([int(i) for i in aioredis_version_str.split(".")])
31
32
33 def patch():
34 if getattr(aioredis, "_datadog_patch", False):
35 return
36 setattr(aioredis, "_datadog_patch", True)
37 pin = Pin()
38 if aioredis_version >= (2, 0):
39 _w("aioredis.client", "Redis.execute_command", traced_execute_command)
40 _w("aioredis.client", "Redis.pipeline", traced_pipeline)
41 _w("aioredis.client", "Pipeline.execute", traced_execute_pipeline)
42 pin.onto(aioredis.client.Redis)
43 else:
44 _w("aioredis", "Redis.execute", traced_13_execute_command)
45 _w("aioredis", "Redis.pipeline", traced_13_pipeline)
46 _w("aioredis.commands.transaction", "Pipeline.execute", traced_13_execute_pipeline)
47 pin.onto(aioredis.Redis)
48
49
50 def unpatch():
51 if not getattr(aioredis, "_datadog_patch", False):
52 return
53
54 setattr(aioredis, "_datadog_patch", False)
55 if aioredis_version >= (2, 0):
56 _u(aioredis.client.Redis, "execute_command")
57 _u(aioredis.client.Redis, "pipeline")
58 _u(aioredis.client.Pipeline, "execute")
59 else:
60 _u(aioredis.Redis, "execute")
61 _u(aioredis.Redis, "pipeline")
62 _u(aioredis.commands.transaction.Pipeline, "execute")
63
64
65 async def traced_execute_command(func, instance, args, kwargs):
66 pin = Pin.get_from(instance)
67 if not pin or not pin.enabled():
68 return await func(*args, **kwargs)
69
70 with _trace_redis_cmd(pin, config.aioredis, instance, args):
71 return await func(*args, **kwargs)
72
73
74 def traced_pipeline(func, instance, args, kwargs):
75 pipeline = func(*args, **kwargs)
76 pin = Pin.get_from(instance)
77 if pin:
78 pin.onto(pipeline)
79 return pipeline
80
81
82 async def traced_execute_pipeline(func, instance, args, kwargs):
83 pin = Pin.get_from(instance)
84 if not pin or not pin.enabled():
85 return await func(*args, **kwargs)
86
87 cmds = [stringify_cache_args(c) for c, _ in instance.command_stack]
88 resource = "\n".join(cmds)
89 with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):
90 return await func(*args, **kwargs)
91
92
93 def traced_13_pipeline(func, instance, args, kwargs):
94 pipeline = func(*args, **kwargs)
95 pin = Pin.get_from(instance)
96 if pin:
97 pin.onto(pipeline)
98 return pipeline
99
100
101 def traced_13_execute_command(func, instance, args, kwargs):
102 # If we have a _RedisBuffer then we are in a pipeline
103 if isinstance(instance.connection, _RedisBuffer):
104 return func(*args, **kwargs)
105
106 pin = Pin.get_from(instance)
107 if not pin or not pin.enabled():
108 return func(*args, **kwargs)
109
110 # Don't activate the span since this operation is performed as a future which concludes sometime later on in
111 # execution so subsequent operations in the stack are not necessarily semantically related
112 # (we don't want this span to be the parent of all other spans created before the future is resolved)
113 parent = pin.tracer.current_span()
114 span = pin.tracer.start_span(
115 redisx.CMD,
116 service=trace_utils.ext_service(pin, config.aioredis),
117 span_type=SpanTypes.REDIS,
118 activate=False,
119 child_of=parent,
120 )
121
122 span.set_tag(SPAN_MEASURED_KEY)
123 query = stringify_cache_args(args)
124 span.resource = query
125 span.set_tag(redisx.RAWCMD, query)
126 if pin.tags:
127 span.set_tags(pin.tags)
128
129 span.set_tags(
130 {
131 net.TARGET_HOST: instance.address[0],
132 net.TARGET_PORT: instance.address[1],
133 redisx.DB: instance.db or 0,
134 }
135 )
136 span.set_metric(redisx.ARGS_LEN, len(args))
137 # set analytics sample rate if enabled
138 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
139
140 def _finish_span(future):
141 try:
142 # Accessing the result will raise an exception if:
143 # - The future was cancelled
144 # - There was an error executing the future (`future.exception()`)
145 # - The future is in an invalid state
146 future.result()
147 except Exception:
148 span.set_exc_info(*sys.exc_info())
149 finally:
150 span.finish()
151
152 task = func(*args, **kwargs)
153 # Execute command returns a coroutine when no free connections are available
154 # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191
155 task = asyncio.ensure_future(task)
156 task.add_done_callback(_finish_span)
157 return task
158
159
160 async def traced_13_execute_pipeline(func, instance, args, kwargs):
161 pin = Pin.get_from(instance)
162 if not pin or not pin.enabled():
163 return await func(*args, **kwargs)
164
165 cmds = []
166 for _, cmd, cmd_args, _ in instance._pipeline:
167 parts = [cmd]
168 parts.extend(cmd_args)
169 cmds.append(stringify_cache_args(parts))
170 resource = "\n".join(cmds)
171 with pin.tracer.trace(
172 redisx.CMD,
173 resource=resource,
174 service=trace_utils.ext_service(pin, config.aioredis),
175 span_type=SpanTypes.REDIS,
176 ) as span:
177
178 span.set_tags(
179 {
180 net.TARGET_HOST: instance._pool_or_conn.address[0],
181 net.TARGET_PORT: instance._pool_or_conn.address[1],
182 redisx.DB: instance._pool_or_conn.db or 0,
183 }
184 )
185
186 span.set_tag(SPAN_MEASURED_KEY)
187 span.set_tag(redisx.RAWCMD, resource)
188 span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))
189 # set analytics sample rate if enabled
190 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
191
192 return await func(*args, **kwargs)
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py
--- a/ddtrace/contrib/aioredis/patch.py
+++ b/ddtrace/contrib/aioredis/patch.py
@@ -140,11 +140,12 @@
def _finish_span(future):
try:
# Accessing the result will raise an exception if:
- # - The future was cancelled
+ # - The future was cancelled (CancelledError)
# - There was an error executing the future (`future.exception()`)
# - The future is in an invalid state
future.result()
- except Exception:
+ # CancelledError exceptions extend from BaseException as of Python 3.8, instead of usual Exception
+ except BaseException:
span.set_exc_info(*sys.exc_info())
finally:
span.finish()
|
{"golden_diff": "diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py\n--- a/ddtrace/contrib/aioredis/patch.py\n+++ b/ddtrace/contrib/aioredis/patch.py\n@@ -140,11 +140,12 @@\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n- # - The future was cancelled\n+ # - The future was cancelled (CancelledError)\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n- except Exception:\n+ # CancelledError exceptions extend from BaseException as of Python 3.8, instead of usual Exception\n+ except BaseException:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n", "issue": "aioredis raises CancelledError in _finish_span \n### Which version of dd-trace-py are you using?\r\n\r\n~~0.53.0~~ 0.58.0\r\n\r\n### Which version of pip are you using?\r\n\r\n21.3.1\r\n\r\n### Which version of the libraries are you using?\r\n\r\ndjango==3.2.11\r\ndjango-redis==5.0.0\r\nchannels==3.0.4\r\ndaphne==3.0.2\r\n\r\n### How can we reproduce your problem?\r\n\r\nI am using code similar to the following:\r\n\r\nasgi.py\r\n\r\n```\r\nimport django\r\nfrom channels.routing import get_default_application\r\nfrom ddtrace.contrib.asgi import TraceMiddleware\r\n\r\ndjango.setup()\r\napplication = TraceMiddleware(get_default_application())\r\n```\r\n\r\nrouting.py\r\n\r\n```\r\nfrom django.urls import re_path\r\nimport my_app.consumers\r\n\r\nwebsocket_urlpatterns = [\r\n re_path(r\"^ws/test/$\", consumers.TestConsumer.as_asgi()),\r\n]\r\n```\r\n\r\nmy_app/consumers.py\r\n\r\n```\r\nfrom channels.generic.websocket import WebsocketConsumer\r\n\r\nclass TestConsumer(WebsocketConsumer):\r\n groups = [\"broadcast\"]\r\n\r\n def connect(self):\r\n self.accept()\r\n\r\n def receive(self, text_data=None, bytes_data=None):\r\n raise Exception(\"An test exception\")\r\n```\r\n\r\nI am running the application with: `ddtrace-run daphne asgi:application --bind 0.0.0.0 --port 8001`\r\n\r\n### What is the result that you get?\r\n\r\nI don't get any traces at all, and my logs show this:\r\n\r\n```\r\nhandle: <Handle traced_13_execute_command.<locals>._finish_span(<Future cancelled>) at /usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py:140>\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/asyncio/events.py\", line 80, in _run\r\n self._context.run(self._callback, *self._args)\r\n File \"/usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py\", line 146, in _finish_span\r\n future.result()\r\nasyncio.exceptions.CancelledError\r\n```\r\n\r\n\r\n### What is the result that you expected?\r\n\r\nNo errors\r\n\n", "before_files": [{"content": "import asyncio\nimport sys\n\nimport aioredis\n\nfrom ddtrace import config\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ...constants import SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...ext import net\nfrom ...ext import redis as redisx\nfrom ...internal.utils.formats import stringify_cache_args\nfrom ..redis.util import _trace_redis_cmd\nfrom ..redis.util import _trace_redis_execute_pipeline\n\n\ntry:\n from aioredis.commands.transaction import _RedisBuffer\nexcept ImportError:\n _RedisBuffer = None\n\nconfig._add(\"aioredis\", dict(_default_service=\"redis\"))\n\naioredis_version_str = getattr(aioredis, \"__version__\", \"0.0.0\")\naioredis_version = tuple([int(i) for i in aioredis_version_str.split(\".\")])\n\n\ndef patch():\n if getattr(aioredis, \"_datadog_patch\", False):\n return\n setattr(aioredis, \"_datadog_patch\", True)\n pin = Pin()\n if aioredis_version >= (2, 0):\n _w(\"aioredis.client\", \"Redis.execute_command\", traced_execute_command)\n _w(\"aioredis.client\", \"Redis.pipeline\", traced_pipeline)\n _w(\"aioredis.client\", \"Pipeline.execute\", traced_execute_pipeline)\n pin.onto(aioredis.client.Redis)\n else:\n _w(\"aioredis\", \"Redis.execute\", traced_13_execute_command)\n _w(\"aioredis\", \"Redis.pipeline\", traced_13_pipeline)\n _w(\"aioredis.commands.transaction\", \"Pipeline.execute\", traced_13_execute_pipeline)\n pin.onto(aioredis.Redis)\n\n\ndef unpatch():\n if not getattr(aioredis, \"_datadog_patch\", False):\n return\n\n setattr(aioredis, \"_datadog_patch\", False)\n if aioredis_version >= (2, 0):\n _u(aioredis.client.Redis, \"execute_command\")\n _u(aioredis.client.Redis, \"pipeline\")\n _u(aioredis.client.Pipeline, \"execute\")\n else:\n _u(aioredis.Redis, \"execute\")\n _u(aioredis.Redis, \"pipeline\")\n _u(aioredis.commands.transaction.Pipeline, \"execute\")\n\n\nasync def traced_execute_command(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n with _trace_redis_cmd(pin, config.aioredis, instance, args):\n return await func(*args, **kwargs)\n\n\ndef traced_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\nasync def traced_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = [stringify_cache_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):\n return await func(*args, **kwargs)\n\n\ndef traced_13_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\ndef traced_13_execute_command(func, instance, args, kwargs):\n # If we have a _RedisBuffer then we are in a pipeline\n if isinstance(instance.connection, _RedisBuffer):\n return func(*args, **kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*args, **kwargs)\n\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n parent = pin.tracer.current_span()\n span = pin.tracer.start_span(\n redisx.CMD,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n activate=False,\n child_of=parent,\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n query = stringify_cache_args(args)\n span.resource = query\n span.set_tag(redisx.RAWCMD, query)\n if pin.tags:\n span.set_tags(pin.tags)\n\n span.set_tags(\n {\n net.TARGET_HOST: instance.address[0],\n net.TARGET_PORT: instance.address[1],\n redisx.DB: instance.db or 0,\n }\n )\n span.set_metric(redisx.ARGS_LEN, len(args))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n # - The future was cancelled\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n except Exception:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n\n task = func(*args, **kwargs)\n # Execute command returns a coroutine when no free connections are available\n # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191\n task = asyncio.ensure_future(task)\n task.add_done_callback(_finish_span)\n return task\n\n\nasync def traced_13_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = []\n for _, cmd, cmd_args, _ in instance._pipeline:\n parts = [cmd]\n parts.extend(cmd_args)\n cmds.append(stringify_cache_args(parts))\n resource = \"\\n\".join(cmds)\n with pin.tracer.trace(\n redisx.CMD,\n resource=resource,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n ) as span:\n\n span.set_tags(\n {\n net.TARGET_HOST: instance._pool_or_conn.address[0],\n net.TARGET_PORT: instance._pool_or_conn.address[1],\n redisx.DB: instance._pool_or_conn.db or 0,\n }\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n span.set_tag(redisx.RAWCMD, resource)\n span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n return await func(*args, **kwargs)\n", "path": "ddtrace/contrib/aioredis/patch.py"}], "after_files": [{"content": "import asyncio\nimport sys\n\nimport aioredis\n\nfrom ddtrace import config\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ...constants import SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...ext import net\nfrom ...ext import redis as redisx\nfrom ...internal.utils.formats import stringify_cache_args\nfrom ..redis.util import _trace_redis_cmd\nfrom ..redis.util import _trace_redis_execute_pipeline\n\n\ntry:\n from aioredis.commands.transaction import _RedisBuffer\nexcept ImportError:\n _RedisBuffer = None\n\nconfig._add(\"aioredis\", dict(_default_service=\"redis\"))\n\naioredis_version_str = getattr(aioredis, \"__version__\", \"0.0.0\")\naioredis_version = tuple([int(i) for i in aioredis_version_str.split(\".\")])\n\n\ndef patch():\n if getattr(aioredis, \"_datadog_patch\", False):\n return\n setattr(aioredis, \"_datadog_patch\", True)\n pin = Pin()\n if aioredis_version >= (2, 0):\n _w(\"aioredis.client\", \"Redis.execute_command\", traced_execute_command)\n _w(\"aioredis.client\", \"Redis.pipeline\", traced_pipeline)\n _w(\"aioredis.client\", \"Pipeline.execute\", traced_execute_pipeline)\n pin.onto(aioredis.client.Redis)\n else:\n _w(\"aioredis\", \"Redis.execute\", traced_13_execute_command)\n _w(\"aioredis\", \"Redis.pipeline\", traced_13_pipeline)\n _w(\"aioredis.commands.transaction\", \"Pipeline.execute\", traced_13_execute_pipeline)\n pin.onto(aioredis.Redis)\n\n\ndef unpatch():\n if not getattr(aioredis, \"_datadog_patch\", False):\n return\n\n setattr(aioredis, \"_datadog_patch\", False)\n if aioredis_version >= (2, 0):\n _u(aioredis.client.Redis, \"execute_command\")\n _u(aioredis.client.Redis, \"pipeline\")\n _u(aioredis.client.Pipeline, \"execute\")\n else:\n _u(aioredis.Redis, \"execute\")\n _u(aioredis.Redis, \"pipeline\")\n _u(aioredis.commands.transaction.Pipeline, \"execute\")\n\n\nasync def traced_execute_command(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n with _trace_redis_cmd(pin, config.aioredis, instance, args):\n return await func(*args, **kwargs)\n\n\ndef traced_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\nasync def traced_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = [stringify_cache_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):\n return await func(*args, **kwargs)\n\n\ndef traced_13_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\ndef traced_13_execute_command(func, instance, args, kwargs):\n # If we have a _RedisBuffer then we are in a pipeline\n if isinstance(instance.connection, _RedisBuffer):\n return func(*args, **kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*args, **kwargs)\n\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n parent = pin.tracer.current_span()\n span = pin.tracer.start_span(\n redisx.CMD,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n activate=False,\n child_of=parent,\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n query = stringify_cache_args(args)\n span.resource = query\n span.set_tag(redisx.RAWCMD, query)\n if pin.tags:\n span.set_tags(pin.tags)\n\n span.set_tags(\n {\n net.TARGET_HOST: instance.address[0],\n net.TARGET_PORT: instance.address[1],\n redisx.DB: instance.db or 0,\n }\n )\n span.set_metric(redisx.ARGS_LEN, len(args))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n # - The future was cancelled (CancelledError)\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n # CancelledError exceptions extend from BaseException as of Python 3.8, instead of usual Exception\n except BaseException:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n\n task = func(*args, **kwargs)\n # Execute command returns a coroutine when no free connections are available\n # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191\n task = asyncio.ensure_future(task)\n task.add_done_callback(_finish_span)\n return task\n\n\nasync def traced_13_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = []\n for _, cmd, cmd_args, _ in instance._pipeline:\n parts = [cmd]\n parts.extend(cmd_args)\n cmds.append(stringify_cache_args(parts))\n resource = \"\\n\".join(cmds)\n with pin.tracer.trace(\n redisx.CMD,\n resource=resource,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n ) as span:\n\n span.set_tags(\n {\n net.TARGET_HOST: instance._pool_or_conn.address[0],\n net.TARGET_PORT: instance._pool_or_conn.address[1],\n redisx.DB: instance._pool_or_conn.db or 0,\n }\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n span.set_tag(redisx.RAWCMD, resource)\n span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n return await func(*args, **kwargs)\n", "path": "ddtrace/contrib/aioredis/patch.py"}]}
| 2,824 | 202 |
gh_patches_debug_4478
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-2168
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
mypy doesn't pick up type hints[BUG]
<!--
Thanks for reporting issues of python-telegram-bot!
Use this template to notify us if you found a bug.
To make it easier for us to help you please enter detailed information below.
Please note, we only support the latest version of python-telegram-bot and
master branch. Please make sure to upgrade & recreate the issue on the latest
version prior to opening an issue.
-->
### Steps to reproduce
1. import python-telegram-bot modules into your `test.py` file (e.g. `from telegram import InlineKeyboardMarkup`)
2. run `mypy test.py`
3. receive the following output `error: Skipping analyzing 'telegram': found module but no type hints or library stubs`
### Expected behaviour
mypy should pickup the typehints as they've been added in the latest release (version `13` )
### Actual behaviour
mypy doesn't pickup the typehints.
I'm confident this can be solved by either
1. adding `python-telegram-bot` to `typeshed`
2. adding a `py.typed` file
More information can be found [here.](https://stackoverflow.com/questions/60856237/mypy-cant-find-type-hints-for-black)
### Configuration
**Operating System:**
Ubuntu 18.04
**Version of Python, python-telegram-bot & dependencies:**
``$ python -m telegram``
python-telegram-bot 13.0
certifi 2020.06.20
Python 3.8.0 (default, Oct 30 2020, 19:06:04) [GCC 7.5.0]
### Logs
```
error: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs
note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports
error: Skipping analyzing 'telegram': found module but no type hints or library stubs
error: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs
error: Skipping analyzing 'telegram': found module but no type hints or library stubs
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 """The setup and build script for the python-telegram-bot library."""
3
4 import codecs
5 import os
6 import sys
7
8 from setuptools import setup, find_packages
9
10
11 def requirements():
12 """Build the requirements list for this project"""
13 requirements_list = []
14
15 with open('requirements.txt') as requirements:
16 for install in requirements:
17 requirements_list.append(install.strip())
18
19 return requirements_list
20
21
22 packages = find_packages(exclude=['tests*'])
23 requirements = requirements()
24
25 # Allow for a package install to not use the vendored urllib3
26 UPSTREAM_URLLIB3_FLAG = '--with-upstream-urllib3'
27 if UPSTREAM_URLLIB3_FLAG in sys.argv:
28 sys.argv.remove(UPSTREAM_URLLIB3_FLAG)
29 requirements.append('urllib3 >= 1.19.1')
30 packages = [x for x in packages if not x.startswith('telegram.vendor.ptb_urllib3')]
31
32 with codecs.open('README.rst', 'r', 'utf-8') as fd:
33 fn = os.path.join('telegram', 'version.py')
34 with open(fn) as fh:
35 code = compile(fh.read(), fn, 'exec')
36 exec(code)
37
38 setup(name='python-telegram-bot',
39 version=__version__,
40 author='Leandro Toledo',
41 author_email='[email protected]',
42 license='LGPLv3',
43 url='https://python-telegram-bot.org/',
44 keywords='python telegram bot api wrapper',
45 description="We have made you a wrapper you can't refuse",
46 long_description=fd.read(),
47 packages=packages,
48 install_requires=requirements,
49 extras_require={
50 'json': 'ujson',
51 'socks': 'PySocks'
52 },
53 include_package_data=True,
54 classifiers=[
55 'Development Status :: 5 - Production/Stable',
56 'Intended Audience :: Developers',
57 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',
58 'Operating System :: OS Independent',
59 'Topic :: Software Development :: Libraries :: Python Modules',
60 'Topic :: Communications :: Chat',
61 'Topic :: Internet',
62 'Programming Language :: Python',
63 'Programming Language :: Python :: 3',
64 'Programming Language :: Python :: 3.6',
65 'Programming Language :: Python :: 3.7',
66 'Programming Language :: Python :: 3.8',
67 'Programming Language :: Python :: 3.9',
68 ],)
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,6 +45,7 @@
description="We have made you a wrapper you can't refuse",
long_description=fd.read(),
packages=packages,
+ package_data={'telegram': ['py.typed']},
install_requires=requirements,
extras_require={
'json': 'ujson',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,6 +45,7 @@\n description=\"We have made you a wrapper you can't refuse\",\n long_description=fd.read(),\n packages=packages,\n+ package_data={'telegram': ['py.typed']},\n install_requires=requirements,\n extras_require={\n 'json': 'ujson',\n", "issue": "mypy doesn't pick up type hints[BUG]\n<!--\r\nThanks for reporting issues of python-telegram-bot!\r\n\r\nUse this template to notify us if you found a bug.\r\n\r\nTo make it easier for us to help you please enter detailed information below.\r\n\r\nPlease note, we only support the latest version of python-telegram-bot and\r\nmaster branch. Please make sure to upgrade & recreate the issue on the latest\r\nversion prior to opening an issue.\r\n-->\r\n### Steps to reproduce\r\n1. import python-telegram-bot modules into your `test.py` file (e.g. `from telegram import InlineKeyboardMarkup`)\r\n\r\n2. run `mypy test.py`\r\n\r\n3. receive the following output `error: Skipping analyzing 'telegram': found module but no type hints or library stubs`\r\n\r\n### Expected behaviour\r\nmypy should pickup the typehints as they've been added in the latest release (version `13` )\r\n\r\n### Actual behaviour\r\nmypy doesn't pickup the typehints.\r\n\r\nI'm confident this can be solved by either\r\n\r\n1. adding `python-telegram-bot` to `typeshed` \r\n2. adding a `py.typed` file\r\n\r\nMore information can be found [here.](https://stackoverflow.com/questions/60856237/mypy-cant-find-type-hints-for-black)\r\n\r\n### Configuration\r\n**Operating System:**\r\nUbuntu 18.04\r\n\r\n**Version of Python, python-telegram-bot & dependencies:**\r\n\r\n``$ python -m telegram``\r\npython-telegram-bot 13.0\r\ncertifi 2020.06.20\r\nPython 3.8.0 (default, Oct 30 2020, 19:06:04) [GCC 7.5.0]\r\n### Logs\r\n```\r\nerror: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs\r\nnote: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports\r\nerror: Skipping analyzing 'telegram': found module but no type hints or library stubs\r\nerror: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs\r\nerror: Skipping analyzing 'telegram': found module but no type hints or library stubs\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"The setup and build script for the python-telegram-bot library.\"\"\"\n\nimport codecs\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\ndef requirements():\n \"\"\"Build the requirements list for this project\"\"\"\n requirements_list = []\n\n with open('requirements.txt') as requirements:\n for install in requirements:\n requirements_list.append(install.strip())\n\n return requirements_list\n\n\npackages = find_packages(exclude=['tests*'])\nrequirements = requirements()\n\n# Allow for a package install to not use the vendored urllib3\nUPSTREAM_URLLIB3_FLAG = '--with-upstream-urllib3'\nif UPSTREAM_URLLIB3_FLAG in sys.argv:\n sys.argv.remove(UPSTREAM_URLLIB3_FLAG)\n requirements.append('urllib3 >= 1.19.1')\n packages = [x for x in packages if not x.startswith('telegram.vendor.ptb_urllib3')]\n\nwith codecs.open('README.rst', 'r', 'utf-8') as fd:\n fn = os.path.join('telegram', 'version.py')\n with open(fn) as fh:\n code = compile(fh.read(), fn, 'exec')\n exec(code)\n\n setup(name='python-telegram-bot',\n version=__version__,\n author='Leandro Toledo',\n author_email='[email protected]',\n license='LGPLv3',\n url='https://python-telegram-bot.org/',\n keywords='python telegram bot api wrapper',\n description=\"We have made you a wrapper you can't refuse\",\n long_description=fd.read(),\n packages=packages,\n install_requires=requirements,\n extras_require={\n 'json': 'ujson',\n 'socks': 'PySocks'\n },\n include_package_data=True,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Communications :: Chat',\n 'Topic :: Internet',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"The setup and build script for the python-telegram-bot library.\"\"\"\n\nimport codecs\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\ndef requirements():\n \"\"\"Build the requirements list for this project\"\"\"\n requirements_list = []\n\n with open('requirements.txt') as requirements:\n for install in requirements:\n requirements_list.append(install.strip())\n\n return requirements_list\n\n\npackages = find_packages(exclude=['tests*'])\nrequirements = requirements()\n\n# Allow for a package install to not use the vendored urllib3\nUPSTREAM_URLLIB3_FLAG = '--with-upstream-urllib3'\nif UPSTREAM_URLLIB3_FLAG in sys.argv:\n sys.argv.remove(UPSTREAM_URLLIB3_FLAG)\n requirements.append('urllib3 >= 1.19.1')\n packages = [x for x in packages if not x.startswith('telegram.vendor.ptb_urllib3')]\n\nwith codecs.open('README.rst', 'r', 'utf-8') as fd:\n fn = os.path.join('telegram', 'version.py')\n with open(fn) as fh:\n code = compile(fh.read(), fn, 'exec')\n exec(code)\n\n setup(name='python-telegram-bot',\n version=__version__,\n author='Leandro Toledo',\n author_email='[email protected]',\n license='LGPLv3',\n url='https://python-telegram-bot.org/',\n keywords='python telegram bot api wrapper',\n description=\"We have made you a wrapper you can't refuse\",\n long_description=fd.read(),\n packages=packages,\n package_data={'telegram': ['py.typed']},\n install_requires=requirements,\n extras_require={\n 'json': 'ujson',\n 'socks': 'PySocks'\n },\n include_package_data=True,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Communications :: Chat',\n 'Topic :: Internet',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],)\n", "path": "setup.py"}]}
| 1,387 | 88 |
gh_patches_debug_3769
|
rasdani/github-patches
|
git_diff
|
lmfit__lmfit-py-949
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sys.module needs to be copied before being iterated over
#### Description
According to https://docs.python.org/3/library/sys.html#sys.modules, one needs to copy `sys.module` to iterate over it. This function [in this file](https://github.com/lmfit/lmfit-py/blob/8781a2dc33288b25fae6f3139595402155e4968b/lmfit/jsonutils.py#L27) does not follow this advice.
It should be replaced by:
```
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
for modname, module in sys.modules.copy().items():
if modname.startswith('__main__'):
continue
t = getattr(module, oname, None)
if t is obj:
return modname
return None
```
Please note `sys.modules.items()` -> `sys.modules.copy().items()`
###### A Minimal, Complete, and Verifiable example
I ran into `RuntimeError: dictionary changed size during iteration` with a large project using lmfit. The solution indicated in the python docs solves it. It is not immediate to create an MVE and I hope the python docs is enough to convince to implement the change.
###### Error message:
<!-- If any, paste the *full* error message inside a code block (starting from line Traceback) -->
```
...
obj = <function test_serde_lmfit_modelresult_with_error.<locals>.custom_error at 0x308a292d0>
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
> for modname, module in sys.modules.items():
E RuntimeError: dictionary changed size during iteration
/.../lib/python3.10/site-packages/lmfit/jsonutils.py:27: RuntimeError
```
###### Version information
Python: 3.10.14 (main, Mar 19 2024, 21:46:16) [Clang 15.0.0 (clang-1500.3.9.4)]
lmfit: 1.3.0, scipy: 1.11.4, numpy: 1.26.3,asteval: 0.9.32, uncertainties: 3.1.6###### Link(s)
<!-- If you started a discussion on the lmfit mailing list, discussion page, or Stack Overflow, please provide the relevant link(s) -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lmfit/jsonutils.py`
Content:
```
1 """JSON utilities."""
2
3 from base64 import b64decode, b64encode
4 from io import StringIO
5 import sys
6 import warnings
7
8 import dill
9 import numpy as np
10 import uncertainties
11
12 HAS_DILL = True
13
14 try:
15 from pandas import DataFrame, Series, read_json
16 except ImportError:
17 DataFrame = Series = type(NotImplemented)
18 read_json = None
19
20
21 pyvers = f'{sys.version_info.major}.{sys.version_info.minor}'
22
23
24 def find_importer(obj):
25 """Find importer of an object."""
26 oname = obj.__name__
27 for modname, module in sys.modules.items():
28 if modname.startswith('__main__'):
29 continue
30 t = getattr(module, oname, None)
31 if t is obj:
32 return modname
33 return None
34
35
36 def import_from(modulepath, objectname):
37 """Wrapper for __import__ for nested objects."""
38 path = modulepath.split('.')
39 top = path.pop(0)
40 parent = __import__(top)
41 while len(path) > 0:
42 parent = getattr(parent, path.pop(0))
43 return getattr(parent, objectname)
44
45
46 def encode4js(obj):
47 """Prepare an object for JSON encoding.
48
49 It has special handling for many Python types, including:
50 - pandas DataFrames and Series
51 - NumPy ndarrays
52 - complex numbers
53
54 """
55 if isinstance(obj, DataFrame):
56 return dict(__class__='PDataFrame', value=obj.to_json())
57 if isinstance(obj, Series):
58 return dict(__class__='PSeries', value=obj.to_json())
59 if isinstance(obj, uncertainties.core.AffineScalarFunc):
60 return dict(__class__='UFloat', val=obj.nominal_value, err=obj.std_dev)
61 if isinstance(obj, np.ndarray):
62 if 'complex' in obj.dtype.name:
63 val = [(obj.real).tolist(), (obj.imag).tolist()]
64 elif obj.dtype.name == 'object':
65 val = [encode4js(item) for item in obj]
66 else:
67 val = obj.flatten().tolist()
68 return dict(__class__='NDArray', __shape__=obj.shape,
69 __dtype__=obj.dtype.name, value=val)
70 if isinstance(obj, float):
71 return float(obj)
72 if isinstance(obj, int):
73 return int(obj)
74 if isinstance(obj, str):
75 try:
76 return str(obj)
77 except UnicodeError:
78 return obj
79 if isinstance(obj, complex):
80 return dict(__class__='Complex', value=(obj.real, obj.imag))
81 if isinstance(obj, (tuple, list)):
82 ctype = 'List'
83 if isinstance(obj, tuple):
84 ctype = 'Tuple'
85 val = [encode4js(item) for item in obj]
86 return dict(__class__=ctype, value=val)
87 if isinstance(obj, dict):
88 out = dict(__class__='Dict')
89 for key, val in obj.items():
90 out[encode4js(key)] = encode4js(val)
91 return out
92 if callable(obj):
93 value = str(b64encode(dill.dumps(obj)), 'utf-8')
94 return dict(__class__='Callable', __name__=obj.__name__,
95 pyversion=pyvers, value=value,
96 importer=find_importer(obj))
97 return obj
98
99
100 def decode4js(obj):
101 """Return decoded Python object from encoded object."""
102 if not isinstance(obj, dict):
103 return obj
104 out = obj
105 classname = obj.pop('__class__', None)
106 if classname is None and isinstance(obj, dict):
107 classname = 'dict'
108 if classname is None:
109 return obj
110 if classname == 'Complex':
111 out = obj['value'][0] + 1j*obj['value'][1]
112 elif classname in ('List', 'Tuple'):
113 out = []
114 for item in obj['value']:
115 out.append(decode4js(item))
116 if classname == 'Tuple':
117 out = tuple(out)
118 elif classname == 'NDArray':
119 if obj['__dtype__'].startswith('complex'):
120 re = np.fromiter(obj['value'][0], dtype='double')
121 im = np.fromiter(obj['value'][1], dtype='double')
122 out = re + 1j*im
123 elif obj['__dtype__'].startswith('object'):
124 val = [decode4js(v) for v in obj['value']]
125 out = np.array(val, dtype=obj['__dtype__'])
126 else:
127 out = np.fromiter(obj['value'], dtype=obj['__dtype__'])
128 out.shape = obj['__shape__']
129 elif classname == 'PDataFrame' and read_json is not None:
130 out = read_json(StringIO(obj['value']))
131 elif classname == 'PSeries' and read_json is not None:
132 out = read_json(StringIO(obj['value']), typ='series')
133 elif classname == 'UFloat':
134 out = uncertainties.ufloat(obj['val'], obj['err'])
135 elif classname == 'Callable':
136 out = obj['__name__']
137 try:
138 out = import_from(obj['importer'], out)
139 unpacked = True
140 except (ImportError, AttributeError):
141 unpacked = False
142 if not unpacked:
143 spyvers = obj.get('pyversion', '?')
144 if not pyvers == spyvers:
145 msg = f"Could not unpack dill-encoded callable '{out}', saved with Python version {spyvers}"
146 warnings.warn(msg)
147
148 try:
149 out = dill.loads(b64decode(obj['value']))
150 except RuntimeError:
151 msg = f"Could not unpack dill-encoded callable '{out}`, saved with Python version {spyvers}"
152 warnings.warn(msg)
153
154 elif classname in ('Dict', 'dict'):
155 out = {}
156 for key, val in obj.items():
157 out[key] = decode4js(val)
158 return out
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lmfit/jsonutils.py b/lmfit/jsonutils.py
--- a/lmfit/jsonutils.py
+++ b/lmfit/jsonutils.py
@@ -24,7 +24,7 @@
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
- for modname, module in sys.modules.items():
+ for modname, module in sys.modules.copy().items():
if modname.startswith('__main__'):
continue
t = getattr(module, oname, None)
|
{"golden_diff": "diff --git a/lmfit/jsonutils.py b/lmfit/jsonutils.py\n--- a/lmfit/jsonutils.py\n+++ b/lmfit/jsonutils.py\n@@ -24,7 +24,7 @@\n def find_importer(obj):\n \"\"\"Find importer of an object.\"\"\"\n oname = obj.__name__\n- for modname, module in sys.modules.items():\n+ for modname, module in sys.modules.copy().items():\n if modname.startswith('__main__'):\n continue\n t = getattr(module, oname, None)\n", "issue": "Sys.module needs to be copied before being iterated over\n#### Description\r\nAccording to https://docs.python.org/3/library/sys.html#sys.modules, one needs to copy `sys.module` to iterate over it. This function [in this file](https://github.com/lmfit/lmfit-py/blob/8781a2dc33288b25fae6f3139595402155e4968b/lmfit/jsonutils.py#L27) does not follow this advice.\r\n\r\nIt should be replaced by:\r\n```\r\ndef find_importer(obj):\r\n \"\"\"Find importer of an object.\"\"\"\r\n oname = obj.__name__\r\n for modname, module in sys.modules.copy().items():\r\n if modname.startswith('__main__'):\r\n continue\r\n t = getattr(module, oname, None)\r\n if t is obj:\r\n return modname\r\n return None\r\n```\r\n\r\nPlease note `sys.modules.items()` -> `sys.modules.copy().items()`\r\n\r\n###### A Minimal, Complete, and Verifiable example\r\nI ran into `RuntimeError: dictionary changed size during iteration` with a large project using lmfit. The solution indicated in the python docs solves it. It is not immediate to create an MVE and I hope the python docs is enough to convince to implement the change.\r\n\r\n###### Error message:\r\n<!-- If any, paste the *full* error message inside a code block (starting from line Traceback) -->\r\n\r\n```\r\n...\r\n\r\nobj = <function test_serde_lmfit_modelresult_with_error.<locals>.custom_error at 0x308a292d0>\r\n\r\n def find_importer(obj):\r\n \"\"\"Find importer of an object.\"\"\"\r\n oname = obj.__name__\r\n> for modname, module in sys.modules.items():\r\nE RuntimeError: dictionary changed size during iteration\r\n\r\n/.../lib/python3.10/site-packages/lmfit/jsonutils.py:27: RuntimeError\r\n```\r\n\r\n###### Version information\r\nPython: 3.10.14 (main, Mar 19 2024, 21:46:16) [Clang 15.0.0 (clang-1500.3.9.4)]\r\n\r\nlmfit: 1.3.0, scipy: 1.11.4, numpy: 1.26.3,asteval: 0.9.32, uncertainties: 3.1.6###### Link(s)\r\n<!-- If you started a discussion on the lmfit mailing list, discussion page, or Stack Overflow, please provide the relevant link(s) -->\r\n\n", "before_files": [{"content": "\"\"\"JSON utilities.\"\"\"\n\nfrom base64 import b64decode, b64encode\nfrom io import StringIO\nimport sys\nimport warnings\n\nimport dill\nimport numpy as np\nimport uncertainties\n\nHAS_DILL = True\n\ntry:\n from pandas import DataFrame, Series, read_json\nexcept ImportError:\n DataFrame = Series = type(NotImplemented)\n read_json = None\n\n\npyvers = f'{sys.version_info.major}.{sys.version_info.minor}'\n\n\ndef find_importer(obj):\n \"\"\"Find importer of an object.\"\"\"\n oname = obj.__name__\n for modname, module in sys.modules.items():\n if modname.startswith('__main__'):\n continue\n t = getattr(module, oname, None)\n if t is obj:\n return modname\n return None\n\n\ndef import_from(modulepath, objectname):\n \"\"\"Wrapper for __import__ for nested objects.\"\"\"\n path = modulepath.split('.')\n top = path.pop(0)\n parent = __import__(top)\n while len(path) > 0:\n parent = getattr(parent, path.pop(0))\n return getattr(parent, objectname)\n\n\ndef encode4js(obj):\n \"\"\"Prepare an object for JSON encoding.\n\n It has special handling for many Python types, including:\n - pandas DataFrames and Series\n - NumPy ndarrays\n - complex numbers\n\n \"\"\"\n if isinstance(obj, DataFrame):\n return dict(__class__='PDataFrame', value=obj.to_json())\n if isinstance(obj, Series):\n return dict(__class__='PSeries', value=obj.to_json())\n if isinstance(obj, uncertainties.core.AffineScalarFunc):\n return dict(__class__='UFloat', val=obj.nominal_value, err=obj.std_dev)\n if isinstance(obj, np.ndarray):\n if 'complex' in obj.dtype.name:\n val = [(obj.real).tolist(), (obj.imag).tolist()]\n elif obj.dtype.name == 'object':\n val = [encode4js(item) for item in obj]\n else:\n val = obj.flatten().tolist()\n return dict(__class__='NDArray', __shape__=obj.shape,\n __dtype__=obj.dtype.name, value=val)\n if isinstance(obj, float):\n return float(obj)\n if isinstance(obj, int):\n return int(obj)\n if isinstance(obj, str):\n try:\n return str(obj)\n except UnicodeError:\n return obj\n if isinstance(obj, complex):\n return dict(__class__='Complex', value=(obj.real, obj.imag))\n if isinstance(obj, (tuple, list)):\n ctype = 'List'\n if isinstance(obj, tuple):\n ctype = 'Tuple'\n val = [encode4js(item) for item in obj]\n return dict(__class__=ctype, value=val)\n if isinstance(obj, dict):\n out = dict(__class__='Dict')\n for key, val in obj.items():\n out[encode4js(key)] = encode4js(val)\n return out\n if callable(obj):\n value = str(b64encode(dill.dumps(obj)), 'utf-8')\n return dict(__class__='Callable', __name__=obj.__name__,\n pyversion=pyvers, value=value,\n importer=find_importer(obj))\n return obj\n\n\ndef decode4js(obj):\n \"\"\"Return decoded Python object from encoded object.\"\"\"\n if not isinstance(obj, dict):\n return obj\n out = obj\n classname = obj.pop('__class__', None)\n if classname is None and isinstance(obj, dict):\n classname = 'dict'\n if classname is None:\n return obj\n if classname == 'Complex':\n out = obj['value'][0] + 1j*obj['value'][1]\n elif classname in ('List', 'Tuple'):\n out = []\n for item in obj['value']:\n out.append(decode4js(item))\n if classname == 'Tuple':\n out = tuple(out)\n elif classname == 'NDArray':\n if obj['__dtype__'].startswith('complex'):\n re = np.fromiter(obj['value'][0], dtype='double')\n im = np.fromiter(obj['value'][1], dtype='double')\n out = re + 1j*im\n elif obj['__dtype__'].startswith('object'):\n val = [decode4js(v) for v in obj['value']]\n out = np.array(val, dtype=obj['__dtype__'])\n else:\n out = np.fromiter(obj['value'], dtype=obj['__dtype__'])\n out.shape = obj['__shape__']\n elif classname == 'PDataFrame' and read_json is not None:\n out = read_json(StringIO(obj['value']))\n elif classname == 'PSeries' and read_json is not None:\n out = read_json(StringIO(obj['value']), typ='series')\n elif classname == 'UFloat':\n out = uncertainties.ufloat(obj['val'], obj['err'])\n elif classname == 'Callable':\n out = obj['__name__']\n try:\n out = import_from(obj['importer'], out)\n unpacked = True\n except (ImportError, AttributeError):\n unpacked = False\n if not unpacked:\n spyvers = obj.get('pyversion', '?')\n if not pyvers == spyvers:\n msg = f\"Could not unpack dill-encoded callable '{out}', saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n try:\n out = dill.loads(b64decode(obj['value']))\n except RuntimeError:\n msg = f\"Could not unpack dill-encoded callable '{out}`, saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n elif classname in ('Dict', 'dict'):\n out = {}\n for key, val in obj.items():\n out[key] = decode4js(val)\n return out\n", "path": "lmfit/jsonutils.py"}], "after_files": [{"content": "\"\"\"JSON utilities.\"\"\"\n\nfrom base64 import b64decode, b64encode\nfrom io import StringIO\nimport sys\nimport warnings\n\nimport dill\nimport numpy as np\nimport uncertainties\n\nHAS_DILL = True\n\ntry:\n from pandas import DataFrame, Series, read_json\nexcept ImportError:\n DataFrame = Series = type(NotImplemented)\n read_json = None\n\n\npyvers = f'{sys.version_info.major}.{sys.version_info.minor}'\n\n\ndef find_importer(obj):\n \"\"\"Find importer of an object.\"\"\"\n oname = obj.__name__\n for modname, module in sys.modules.copy().items():\n if modname.startswith('__main__'):\n continue\n t = getattr(module, oname, None)\n if t is obj:\n return modname\n return None\n\n\ndef import_from(modulepath, objectname):\n \"\"\"Wrapper for __import__ for nested objects.\"\"\"\n path = modulepath.split('.')\n top = path.pop(0)\n parent = __import__(top)\n while len(path) > 0:\n parent = getattr(parent, path.pop(0))\n return getattr(parent, objectname)\n\n\ndef encode4js(obj):\n \"\"\"Prepare an object for JSON encoding.\n\n It has special handling for many Python types, including:\n - pandas DataFrames and Series\n - NumPy ndarrays\n - complex numbers\n\n \"\"\"\n if isinstance(obj, DataFrame):\n return dict(__class__='PDataFrame', value=obj.to_json())\n if isinstance(obj, Series):\n return dict(__class__='PSeries', value=obj.to_json())\n if isinstance(obj, uncertainties.core.AffineScalarFunc):\n return dict(__class__='UFloat', val=obj.nominal_value, err=obj.std_dev)\n if isinstance(obj, np.ndarray):\n if 'complex' in obj.dtype.name:\n val = [(obj.real).tolist(), (obj.imag).tolist()]\n elif obj.dtype.name == 'object':\n val = [encode4js(item) for item in obj]\n else:\n val = obj.flatten().tolist()\n return dict(__class__='NDArray', __shape__=obj.shape,\n __dtype__=obj.dtype.name, value=val)\n if isinstance(obj, float):\n return float(obj)\n if isinstance(obj, int):\n return int(obj)\n if isinstance(obj, str):\n try:\n return str(obj)\n except UnicodeError:\n return obj\n if isinstance(obj, complex):\n return dict(__class__='Complex', value=(obj.real, obj.imag))\n if isinstance(obj, (tuple, list)):\n ctype = 'List'\n if isinstance(obj, tuple):\n ctype = 'Tuple'\n val = [encode4js(item) for item in obj]\n return dict(__class__=ctype, value=val)\n if isinstance(obj, dict):\n out = dict(__class__='Dict')\n for key, val in obj.items():\n out[encode4js(key)] = encode4js(val)\n return out\n if callable(obj):\n value = str(b64encode(dill.dumps(obj)), 'utf-8')\n return dict(__class__='Callable', __name__=obj.__name__,\n pyversion=pyvers, value=value,\n importer=find_importer(obj))\n return obj\n\n\ndef decode4js(obj):\n \"\"\"Return decoded Python object from encoded object.\"\"\"\n if not isinstance(obj, dict):\n return obj\n out = obj\n classname = obj.pop('__class__', None)\n if classname is None and isinstance(obj, dict):\n classname = 'dict'\n if classname is None:\n return obj\n if classname == 'Complex':\n out = obj['value'][0] + 1j*obj['value'][1]\n elif classname in ('List', 'Tuple'):\n out = []\n for item in obj['value']:\n out.append(decode4js(item))\n if classname == 'Tuple':\n out = tuple(out)\n elif classname == 'NDArray':\n if obj['__dtype__'].startswith('complex'):\n re = np.fromiter(obj['value'][0], dtype='double')\n im = np.fromiter(obj['value'][1], dtype='double')\n out = re + 1j*im\n elif obj['__dtype__'].startswith('object'):\n val = [decode4js(v) for v in obj['value']]\n out = np.array(val, dtype=obj['__dtype__'])\n else:\n out = np.fromiter(obj['value'], dtype=obj['__dtype__'])\n out.shape = obj['__shape__']\n elif classname == 'PDataFrame' and read_json is not None:\n out = read_json(StringIO(obj['value']))\n elif classname == 'PSeries' and read_json is not None:\n out = read_json(StringIO(obj['value']), typ='series')\n elif classname == 'UFloat':\n out = uncertainties.ufloat(obj['val'], obj['err'])\n elif classname == 'Callable':\n out = obj['__name__']\n try:\n out = import_from(obj['importer'], out)\n unpacked = True\n except (ImportError, AttributeError):\n unpacked = False\n if not unpacked:\n spyvers = obj.get('pyversion', '?')\n if not pyvers == spyvers:\n msg = f\"Could not unpack dill-encoded callable '{out}', saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n try:\n out = dill.loads(b64decode(obj['value']))\n except RuntimeError:\n msg = f\"Could not unpack dill-encoded callable '{out}`, saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n elif classname in ('Dict', 'dict'):\n out = {}\n for key, val in obj.items():\n out[key] = decode4js(val)\n return out\n", "path": "lmfit/jsonutils.py"}]}
| 2,444 | 119 |
gh_patches_debug_23377
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-5665
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reindex dangerously excludes slugs
The reindexing exludes these slugs: https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L30-L31
But [the way it does it](https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L228) is that it uses `icontains` instead of `startswith` which is more inefficient and it's also potentially excluding slugs that contain any of those strings later. E.g. `Learn/HTML/user:prefixing`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kuma/wiki/search.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import division
3
4 import logging
5 import operator
6 from math import ceil
7
8 from celery import chain
9 from django.conf import settings
10 from django.db.models import Q
11 from django.utils.html import strip_tags
12 from django.utils.translation import ugettext_lazy as _
13 from elasticsearch.helpers import bulk
14 from elasticsearch_dsl import document, field
15 from elasticsearch_dsl.connections import connections
16 from elasticsearch_dsl.mapping import Mapping
17 from elasticsearch_dsl.search import Search
18 from six.moves import reduce
19
20 from kuma.core.utils import chord_flow, chunked
21
22 from .constants import EXPERIMENT_TITLE_PREFIX
23
24
25 log = logging.getLogger('kuma.wiki.search')
26
27
28 class WikiDocumentType(document.Document):
29 excerpt_fields = ['summary', 'content']
30 exclude_slugs = ['Talk:', 'User:', 'User_talk:', 'Template_talk:',
31 'Project_talk:', EXPERIMENT_TITLE_PREFIX]
32
33 boost = field.Float(null_value=1.0)
34 content = field.Text(analyzer='kuma_content',
35 term_vector='with_positions_offsets')
36 css_classnames = field.Keyword()
37 html_attributes = field.Keyword()
38 id = field.Long()
39 kumascript_macros = field.Keyword()
40 locale = field.Keyword()
41 modified = field.Date()
42 parent = field.Object(properties={
43 'id': field.Long(),
44 'title': field.Text(analyzer='kuma_title'),
45 'slug': field.Keyword(),
46 'locale': field.Keyword(),
47 })
48 slug = field.Keyword()
49 summary = field.Text(analyzer='kuma_content',
50 term_vector='with_positions_offsets')
51 tags = field.Keyword()
52 title = field.Text(analyzer='kuma_title')
53
54 class Meta(object):
55 mapping = Mapping('wiki_document')
56 mapping.meta('_all', enabled=False)
57
58 @classmethod
59 def get_connection(cls, alias='default'):
60 return connections.get_connection(alias)
61
62 @classmethod
63 def get_doc_type(cls):
64 return cls._doc_type.name
65
66 @classmethod
67 def case_insensitive_keywords(cls, keywords):
68 '''Create a unique list of lowercased keywords.'''
69 return sorted(set([keyword.lower() for keyword in keywords]))
70
71 @classmethod
72 def from_django(cls, obj):
73 is_root_document = obj.slug.count('/') == 1
74 doc = {
75 'id': obj.id,
76 'boost': 4.0 if is_root_document else 1.0,
77 'title': obj.title,
78 'slug': obj.slug,
79 'summary': obj.get_summary_text(),
80 'locale': obj.locale,
81 'modified': obj.modified,
82 'content': strip_tags(obj.rendered_html or ''),
83 'tags': [o.name for o in obj.tags.all()],
84 'kumascript_macros': cls.case_insensitive_keywords(
85 obj.extract.macro_names()),
86 'css_classnames': cls.case_insensitive_keywords(
87 obj.extract.css_classnames()),
88 'html_attributes': cls.case_insensitive_keywords(
89 obj.extract.html_attributes()),
90 }
91
92 if obj.parent:
93 doc['parent'] = {
94 'id': obj.parent.id,
95 'title': obj.parent.title,
96 'locale': obj.parent.locale,
97 'slug': obj.parent.slug,
98 }
99 else:
100 doc['parent'] = {}
101
102 return doc
103
104 @classmethod
105 def get_mapping(cls):
106 return cls._doc_type.mapping.to_dict()
107
108 @classmethod
109 def get_analysis(cls):
110 return {
111 'filter': {
112 'kuma_word_delimiter': {
113 'type': 'word_delimiter',
114 'preserve_original': True, # hi-fi -> hifi, hi-fi
115 'catenate_words': True, # hi-fi -> hifi
116 'catenate_numbers': True, # 90-210 -> 90210
117 }
118 },
119 'analyzer': {
120 'default': {
121 'tokenizer': 'standard',
122 'filter': ['standard', 'elision']
123 },
124 # a custom analyzer that strips html and uses our own
125 # word delimiter filter and the elision filter
126 # (e.g. L'attribut -> attribut). The rest is the same as
127 # the snowball analyzer
128 'kuma_content': {
129 'type': 'custom',
130 'tokenizer': 'standard',
131 'char_filter': ['html_strip'],
132 'filter': [
133 'elision',
134 'kuma_word_delimiter',
135 'lowercase',
136 'standard',
137 'stop',
138 'snowball',
139 ],
140 },
141 'kuma_title': {
142 'type': 'custom',
143 'tokenizer': 'standard',
144 'filter': [
145 'elision',
146 'kuma_word_delimiter',
147 'lowercase',
148 'standard',
149 'snowball',
150 ],
151 },
152 },
153 }
154
155 @classmethod
156 def get_settings(cls):
157 return {
158 'mappings': cls.get_mapping(),
159 'settings': {
160 'analysis': cls.get_analysis(),
161 'number_of_replicas': settings.ES_DEFAULT_NUM_REPLICAS,
162 'number_of_shards': settings.ES_DEFAULT_NUM_SHARDS,
163 }
164 }
165
166 @classmethod
167 def bulk_index(cls, documents, id_field='id', es=None, index=None):
168 """Index of a bunch of documents."""
169 es = es or cls.get_connection()
170 index = index or cls.get_index()
171 type = cls.get_doc_type()
172
173 actions = [
174 {'_index': index, '_type': type, '_id': d['id'], '_source': d}
175 for d in documents]
176
177 bulk(es, actions)
178
179 @classmethod
180 def bulk_delete(cls, ids, es=None, index=None):
181 """Index of a bunch of documents."""
182 es = es or cls.get_connection()
183 index = index or cls.get_index()
184 type = cls.get_doc_type()
185
186 actions = [
187 {'_op_type': 'delete', '_index': index, '_type': type, '_id': _id}
188 for _id in ids]
189
190 bulk(es, actions)
191
192 @classmethod
193 def get_index(cls):
194 from kuma.search.models import Index
195 return Index.objects.get_current().prefixed_name
196
197 @classmethod
198 def search(cls, **kwargs):
199 options = {
200 'using': connections.get_connection(),
201 'index': cls.get_index(),
202 'doc_type': {cls._doc_type.name: cls.from_es},
203 }
204 options.update(kwargs)
205 sq = Search(**options)
206
207 return sq
208
209 @classmethod
210 def get_model(cls):
211 from kuma.wiki.models import Document
212 return Document
213
214 @classmethod
215 def get_indexable(cls, percent=100):
216 """
217 For this mapping type return a list of model IDs that should be
218 indexed with the management command, in a full reindex.
219
220 WARNING: When changing this code make sure to update the
221 ``should_update`` method below, too!
222
223 """
224 model = cls.get_model()
225
226 excludes = []
227 for exclude in cls.exclude_slugs:
228 excludes.append(Q(slug__icontains=exclude))
229
230 qs = (model.objects
231 .filter(is_redirect=False, deleted=False)
232 .exclude(reduce(operator.or_, excludes)))
233
234 percent = percent / 100
235 if percent < 1:
236 qs = qs[:int(qs.count() * percent)]
237
238 return qs.values_list('id', flat=True)
239
240 @classmethod
241 def should_update(cls, obj):
242 """
243 Given a Document instance should return boolean value
244 whether the instance should be indexed or not.
245
246 WARNING: This *must* mirror the logic of the ``get_indexable``
247 method above!
248 """
249 return (not obj.is_redirect and not obj.deleted and
250 not any([exclude in obj.slug
251 for exclude in cls.exclude_slugs]))
252
253 def get_excerpt(self):
254 highlighted = getattr(self.meta, 'highlight', None)
255 if highlighted:
256 for excerpt_field in self.excerpt_fields:
257 if excerpt_field in highlighted:
258 return u'…'.join(highlighted[excerpt_field])
259 return self.summary
260
261 @classmethod
262 def reindex_all(cls, chunk_size=500, index=None, percent=100):
263 """Rebuild ElasticSearch indexes.
264
265 :arg chunk_size: how many documents to bulk index as a single chunk.
266 :arg index: the `Index` object to reindex into. Uses the current
267 promoted index if none provided.
268 :arg percent: 1 to 100--the percentage of the db to index.
269
270 """
271 from kuma.search.models import Index
272 from kuma.search.tasks import prepare_index, finalize_index
273 from kuma.wiki.tasks import index_documents
274
275 index = index or Index.objects.get_current()
276
277 # Get the list of document IDs to index.
278 indexable = WikiDocumentType.get_indexable(percent)
279
280 total = len(indexable)
281 total_chunks = int(ceil(total / chunk_size))
282
283 pre_task = prepare_index.si(index.pk)
284 post_task = finalize_index.si(index.pk)
285
286 if not total:
287 # If there's no data we still create the index and finalize it.
288 chain(pre_task, post_task).apply_async()
289 else:
290 index_tasks = [index_documents.si(chunk, index.pk)
291 for chunk in chunked(indexable, chunk_size)]
292 chord_flow(pre_task, index_tasks, post_task).apply_async()
293
294 message = _(
295 'Indexing %(total)d documents into %(total_chunks)d chunks of '
296 'size %(size)d into index %(index)s.' % {
297 'total': total,
298 'total_chunks': total_chunks,
299 'size': chunk_size,
300 'index': index.prefixed_name
301 }
302 )
303 return message
304
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kuma/wiki/search.py b/kuma/wiki/search.py
--- a/kuma/wiki/search.py
+++ b/kuma/wiki/search.py
@@ -2,7 +2,6 @@
from __future__ import division
import logging
-import operator
from math import ceil
from celery import chain
@@ -15,7 +14,6 @@
from elasticsearch_dsl.connections import connections
from elasticsearch_dsl.mapping import Mapping
from elasticsearch_dsl.search import Search
-from six.moves import reduce
from kuma.core.utils import chord_flow, chunked
@@ -223,13 +221,11 @@
"""
model = cls.get_model()
- excludes = []
+ excludes = Q()
for exclude in cls.exclude_slugs:
- excludes.append(Q(slug__icontains=exclude))
+ excludes |= Q(slug__startswith=exclude)
- qs = (model.objects
- .filter(is_redirect=False, deleted=False)
- .exclude(reduce(operator.or_, excludes)))
+ qs = model.objects.filter(is_redirect=False).exclude(excludes)
percent = percent / 100
if percent < 1:
|
{"golden_diff": "diff --git a/kuma/wiki/search.py b/kuma/wiki/search.py\n--- a/kuma/wiki/search.py\n+++ b/kuma/wiki/search.py\n@@ -2,7 +2,6 @@\n from __future__ import division\n \n import logging\n-import operator\n from math import ceil\n \n from celery import chain\n@@ -15,7 +14,6 @@\n from elasticsearch_dsl.connections import connections\n from elasticsearch_dsl.mapping import Mapping\n from elasticsearch_dsl.search import Search\n-from six.moves import reduce\n \n from kuma.core.utils import chord_flow, chunked\n \n@@ -223,13 +221,11 @@\n \"\"\"\n model = cls.get_model()\n \n- excludes = []\n+ excludes = Q()\n for exclude in cls.exclude_slugs:\n- excludes.append(Q(slug__icontains=exclude))\n+ excludes |= Q(slug__startswith=exclude)\n \n- qs = (model.objects\n- .filter(is_redirect=False, deleted=False)\n- .exclude(reduce(operator.or_, excludes)))\n+ qs = model.objects.filter(is_redirect=False).exclude(excludes)\n \n percent = percent / 100\n if percent < 1:\n", "issue": "Reindex dangerously excludes slugs\nThe reindexing exludes these slugs: https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L30-L31\r\nBut [the way it does it](https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L228) is that it uses `icontains` instead of `startswith` which is more inefficient and it's also potentially excluding slugs that contain any of those strings later. E.g. `Learn/HTML/user:prefixing`\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import division\n\nimport logging\nimport operator\nfrom math import ceil\n\nfrom celery import chain\nfrom django.conf import settings\nfrom django.db.models import Q\nfrom django.utils.html import strip_tags\nfrom django.utils.translation import ugettext_lazy as _\nfrom elasticsearch.helpers import bulk\nfrom elasticsearch_dsl import document, field\nfrom elasticsearch_dsl.connections import connections\nfrom elasticsearch_dsl.mapping import Mapping\nfrom elasticsearch_dsl.search import Search\nfrom six.moves import reduce\n\nfrom kuma.core.utils import chord_flow, chunked\n\nfrom .constants import EXPERIMENT_TITLE_PREFIX\n\n\nlog = logging.getLogger('kuma.wiki.search')\n\n\nclass WikiDocumentType(document.Document):\n excerpt_fields = ['summary', 'content']\n exclude_slugs = ['Talk:', 'User:', 'User_talk:', 'Template_talk:',\n 'Project_talk:', EXPERIMENT_TITLE_PREFIX]\n\n boost = field.Float(null_value=1.0)\n content = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n css_classnames = field.Keyword()\n html_attributes = field.Keyword()\n id = field.Long()\n kumascript_macros = field.Keyword()\n locale = field.Keyword()\n modified = field.Date()\n parent = field.Object(properties={\n 'id': field.Long(),\n 'title': field.Text(analyzer='kuma_title'),\n 'slug': field.Keyword(),\n 'locale': field.Keyword(),\n })\n slug = field.Keyword()\n summary = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n tags = field.Keyword()\n title = field.Text(analyzer='kuma_title')\n\n class Meta(object):\n mapping = Mapping('wiki_document')\n mapping.meta('_all', enabled=False)\n\n @classmethod\n def get_connection(cls, alias='default'):\n return connections.get_connection(alias)\n\n @classmethod\n def get_doc_type(cls):\n return cls._doc_type.name\n\n @classmethod\n def case_insensitive_keywords(cls, keywords):\n '''Create a unique list of lowercased keywords.'''\n return sorted(set([keyword.lower() for keyword in keywords]))\n\n @classmethod\n def from_django(cls, obj):\n is_root_document = obj.slug.count('/') == 1\n doc = {\n 'id': obj.id,\n 'boost': 4.0 if is_root_document else 1.0,\n 'title': obj.title,\n 'slug': obj.slug,\n 'summary': obj.get_summary_text(),\n 'locale': obj.locale,\n 'modified': obj.modified,\n 'content': strip_tags(obj.rendered_html or ''),\n 'tags': [o.name for o in obj.tags.all()],\n 'kumascript_macros': cls.case_insensitive_keywords(\n obj.extract.macro_names()),\n 'css_classnames': cls.case_insensitive_keywords(\n obj.extract.css_classnames()),\n 'html_attributes': cls.case_insensitive_keywords(\n obj.extract.html_attributes()),\n }\n\n if obj.parent:\n doc['parent'] = {\n 'id': obj.parent.id,\n 'title': obj.parent.title,\n 'locale': obj.parent.locale,\n 'slug': obj.parent.slug,\n }\n else:\n doc['parent'] = {}\n\n return doc\n\n @classmethod\n def get_mapping(cls):\n return cls._doc_type.mapping.to_dict()\n\n @classmethod\n def get_analysis(cls):\n return {\n 'filter': {\n 'kuma_word_delimiter': {\n 'type': 'word_delimiter',\n 'preserve_original': True, # hi-fi -> hifi, hi-fi\n 'catenate_words': True, # hi-fi -> hifi\n 'catenate_numbers': True, # 90-210 -> 90210\n }\n },\n 'analyzer': {\n 'default': {\n 'tokenizer': 'standard',\n 'filter': ['standard', 'elision']\n },\n # a custom analyzer that strips html and uses our own\n # word delimiter filter and the elision filter\n # (e.g. L'attribut -> attribut). The rest is the same as\n # the snowball analyzer\n 'kuma_content': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'char_filter': ['html_strip'],\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'stop',\n 'snowball',\n ],\n },\n 'kuma_title': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'snowball',\n ],\n },\n },\n }\n\n @classmethod\n def get_settings(cls):\n return {\n 'mappings': cls.get_mapping(),\n 'settings': {\n 'analysis': cls.get_analysis(),\n 'number_of_replicas': settings.ES_DEFAULT_NUM_REPLICAS,\n 'number_of_shards': settings.ES_DEFAULT_NUM_SHARDS,\n }\n }\n\n @classmethod\n def bulk_index(cls, documents, id_field='id', es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_index': index, '_type': type, '_id': d['id'], '_source': d}\n for d in documents]\n\n bulk(es, actions)\n\n @classmethod\n def bulk_delete(cls, ids, es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_op_type': 'delete', '_index': index, '_type': type, '_id': _id}\n for _id in ids]\n\n bulk(es, actions)\n\n @classmethod\n def get_index(cls):\n from kuma.search.models import Index\n return Index.objects.get_current().prefixed_name\n\n @classmethod\n def search(cls, **kwargs):\n options = {\n 'using': connections.get_connection(),\n 'index': cls.get_index(),\n 'doc_type': {cls._doc_type.name: cls.from_es},\n }\n options.update(kwargs)\n sq = Search(**options)\n\n return sq\n\n @classmethod\n def get_model(cls):\n from kuma.wiki.models import Document\n return Document\n\n @classmethod\n def get_indexable(cls, percent=100):\n \"\"\"\n For this mapping type return a list of model IDs that should be\n indexed with the management command, in a full reindex.\n\n WARNING: When changing this code make sure to update the\n ``should_update`` method below, too!\n\n \"\"\"\n model = cls.get_model()\n\n excludes = []\n for exclude in cls.exclude_slugs:\n excludes.append(Q(slug__icontains=exclude))\n\n qs = (model.objects\n .filter(is_redirect=False, deleted=False)\n .exclude(reduce(operator.or_, excludes)))\n\n percent = percent / 100\n if percent < 1:\n qs = qs[:int(qs.count() * percent)]\n\n return qs.values_list('id', flat=True)\n\n @classmethod\n def should_update(cls, obj):\n \"\"\"\n Given a Document instance should return boolean value\n whether the instance should be indexed or not.\n\n WARNING: This *must* mirror the logic of the ``get_indexable``\n method above!\n \"\"\"\n return (not obj.is_redirect and not obj.deleted and\n not any([exclude in obj.slug\n for exclude in cls.exclude_slugs]))\n\n def get_excerpt(self):\n highlighted = getattr(self.meta, 'highlight', None)\n if highlighted:\n for excerpt_field in self.excerpt_fields:\n if excerpt_field in highlighted:\n return u'\u2026'.join(highlighted[excerpt_field])\n return self.summary\n\n @classmethod\n def reindex_all(cls, chunk_size=500, index=None, percent=100):\n \"\"\"Rebuild ElasticSearch indexes.\n\n :arg chunk_size: how many documents to bulk index as a single chunk.\n :arg index: the `Index` object to reindex into. Uses the current\n promoted index if none provided.\n :arg percent: 1 to 100--the percentage of the db to index.\n\n \"\"\"\n from kuma.search.models import Index\n from kuma.search.tasks import prepare_index, finalize_index\n from kuma.wiki.tasks import index_documents\n\n index = index or Index.objects.get_current()\n\n # Get the list of document IDs to index.\n indexable = WikiDocumentType.get_indexable(percent)\n\n total = len(indexable)\n total_chunks = int(ceil(total / chunk_size))\n\n pre_task = prepare_index.si(index.pk)\n post_task = finalize_index.si(index.pk)\n\n if not total:\n # If there's no data we still create the index and finalize it.\n chain(pre_task, post_task).apply_async()\n else:\n index_tasks = [index_documents.si(chunk, index.pk)\n for chunk in chunked(indexable, chunk_size)]\n chord_flow(pre_task, index_tasks, post_task).apply_async()\n\n message = _(\n 'Indexing %(total)d documents into %(total_chunks)d chunks of '\n 'size %(size)d into index %(index)s.' % {\n 'total': total,\n 'total_chunks': total_chunks,\n 'size': chunk_size,\n 'index': index.prefixed_name\n }\n )\n return message\n", "path": "kuma/wiki/search.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import division\n\nimport logging\nfrom math import ceil\n\nfrom celery import chain\nfrom django.conf import settings\nfrom django.db.models import Q\nfrom django.utils.html import strip_tags\nfrom django.utils.translation import ugettext_lazy as _\nfrom elasticsearch.helpers import bulk\nfrom elasticsearch_dsl import document, field\nfrom elasticsearch_dsl.connections import connections\nfrom elasticsearch_dsl.mapping import Mapping\nfrom elasticsearch_dsl.search import Search\n\nfrom kuma.core.utils import chord_flow, chunked\n\nfrom .constants import EXPERIMENT_TITLE_PREFIX\n\n\nlog = logging.getLogger('kuma.wiki.search')\n\n\nclass WikiDocumentType(document.Document):\n excerpt_fields = ['summary', 'content']\n exclude_slugs = ['Talk:', 'User:', 'User_talk:', 'Template_talk:',\n 'Project_talk:', EXPERIMENT_TITLE_PREFIX]\n\n boost = field.Float(null_value=1.0)\n content = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n css_classnames = field.Keyword()\n html_attributes = field.Keyword()\n id = field.Long()\n kumascript_macros = field.Keyword()\n locale = field.Keyword()\n modified = field.Date()\n parent = field.Object(properties={\n 'id': field.Long(),\n 'title': field.Text(analyzer='kuma_title'),\n 'slug': field.Keyword(),\n 'locale': field.Keyword(),\n })\n slug = field.Keyword()\n summary = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n tags = field.Keyword()\n title = field.Text(analyzer='kuma_title')\n\n class Meta(object):\n mapping = Mapping('wiki_document')\n mapping.meta('_all', enabled=False)\n\n @classmethod\n def get_connection(cls, alias='default'):\n return connections.get_connection(alias)\n\n @classmethod\n def get_doc_type(cls):\n return cls._doc_type.name\n\n @classmethod\n def case_insensitive_keywords(cls, keywords):\n '''Create a unique list of lowercased keywords.'''\n return sorted(set([keyword.lower() for keyword in keywords]))\n\n @classmethod\n def from_django(cls, obj):\n is_root_document = obj.slug.count('/') == 1\n doc = {\n 'id': obj.id,\n 'boost': 4.0 if is_root_document else 1.0,\n 'title': obj.title,\n 'slug': obj.slug,\n 'summary': obj.get_summary_text(),\n 'locale': obj.locale,\n 'modified': obj.modified,\n 'content': strip_tags(obj.rendered_html or ''),\n 'tags': [o.name for o in obj.tags.all()],\n 'kumascript_macros': cls.case_insensitive_keywords(\n obj.extract.macro_names()),\n 'css_classnames': cls.case_insensitive_keywords(\n obj.extract.css_classnames()),\n 'html_attributes': cls.case_insensitive_keywords(\n obj.extract.html_attributes()),\n }\n\n if obj.parent:\n doc['parent'] = {\n 'id': obj.parent.id,\n 'title': obj.parent.title,\n 'locale': obj.parent.locale,\n 'slug': obj.parent.slug,\n }\n else:\n doc['parent'] = {}\n\n return doc\n\n @classmethod\n def get_mapping(cls):\n return cls._doc_type.mapping.to_dict()\n\n @classmethod\n def get_analysis(cls):\n return {\n 'filter': {\n 'kuma_word_delimiter': {\n 'type': 'word_delimiter',\n 'preserve_original': True, # hi-fi -> hifi, hi-fi\n 'catenate_words': True, # hi-fi -> hifi\n 'catenate_numbers': True, # 90-210 -> 90210\n }\n },\n 'analyzer': {\n 'default': {\n 'tokenizer': 'standard',\n 'filter': ['standard', 'elision']\n },\n # a custom analyzer that strips html and uses our own\n # word delimiter filter and the elision filter\n # (e.g. L'attribut -> attribut). The rest is the same as\n # the snowball analyzer\n 'kuma_content': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'char_filter': ['html_strip'],\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'stop',\n 'snowball',\n ],\n },\n 'kuma_title': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'snowball',\n ],\n },\n },\n }\n\n @classmethod\n def get_settings(cls):\n return {\n 'mappings': cls.get_mapping(),\n 'settings': {\n 'analysis': cls.get_analysis(),\n 'number_of_replicas': settings.ES_DEFAULT_NUM_REPLICAS,\n 'number_of_shards': settings.ES_DEFAULT_NUM_SHARDS,\n }\n }\n\n @classmethod\n def bulk_index(cls, documents, id_field='id', es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_index': index, '_type': type, '_id': d['id'], '_source': d}\n for d in documents]\n\n bulk(es, actions)\n\n @classmethod\n def bulk_delete(cls, ids, es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_op_type': 'delete', '_index': index, '_type': type, '_id': _id}\n for _id in ids]\n\n bulk(es, actions)\n\n @classmethod\n def get_index(cls):\n from kuma.search.models import Index\n return Index.objects.get_current().prefixed_name\n\n @classmethod\n def search(cls, **kwargs):\n options = {\n 'using': connections.get_connection(),\n 'index': cls.get_index(),\n 'doc_type': {cls._doc_type.name: cls.from_es},\n }\n options.update(kwargs)\n sq = Search(**options)\n\n return sq\n\n @classmethod\n def get_model(cls):\n from kuma.wiki.models import Document\n return Document\n\n @classmethod\n def get_indexable(cls, percent=100):\n \"\"\"\n For this mapping type return a list of model IDs that should be\n indexed with the management command, in a full reindex.\n\n WARNING: When changing this code make sure to update the\n ``should_update`` method below, too!\n\n \"\"\"\n model = cls.get_model()\n\n excludes = Q()\n for exclude in cls.exclude_slugs:\n excludes |= Q(slug__startswith=exclude)\n\n qs = model.objects.filter(is_redirect=False).exclude(excludes)\n\n percent = percent / 100\n if percent < 1:\n qs = qs[:int(qs.count() * percent)]\n\n return qs.values_list('id', flat=True)\n\n @classmethod\n def should_update(cls, obj):\n \"\"\"\n Given a Document instance should return boolean value\n whether the instance should be indexed or not.\n\n WARNING: This *must* mirror the logic of the ``get_indexable``\n method above!\n \"\"\"\n return (not obj.is_redirect and not obj.deleted and\n not any([exclude in obj.slug\n for exclude in cls.exclude_slugs]))\n\n def get_excerpt(self):\n highlighted = getattr(self.meta, 'highlight', None)\n if highlighted:\n for excerpt_field in self.excerpt_fields:\n if excerpt_field in highlighted:\n return u'\u2026'.join(highlighted[excerpt_field])\n return self.summary\n\n @classmethod\n def reindex_all(cls, chunk_size=500, index=None, percent=100):\n \"\"\"Rebuild ElasticSearch indexes.\n\n :arg chunk_size: how many documents to bulk index as a single chunk.\n :arg index: the `Index` object to reindex into. Uses the current\n promoted index if none provided.\n :arg percent: 1 to 100--the percentage of the db to index.\n\n \"\"\"\n from kuma.search.models import Index\n from kuma.search.tasks import prepare_index, finalize_index\n from kuma.wiki.tasks import index_documents\n\n index = index or Index.objects.get_current()\n\n # Get the list of document IDs to index.\n indexable = WikiDocumentType.get_indexable(percent)\n\n total = len(indexable)\n total_chunks = int(ceil(total / chunk_size))\n\n pre_task = prepare_index.si(index.pk)\n post_task = finalize_index.si(index.pk)\n\n if not total:\n # If there's no data we still create the index and finalize it.\n chain(pre_task, post_task).apply_async()\n else:\n index_tasks = [index_documents.si(chunk, index.pk)\n for chunk in chunked(indexable, chunk_size)]\n chord_flow(pre_task, index_tasks, post_task).apply_async()\n\n message = _(\n 'Indexing %(total)d documents into %(total_chunks)d chunks of '\n 'size %(size)d into index %(index)s.' % {\n 'total': total,\n 'total_chunks': total_chunks,\n 'size': chunk_size,\n 'index': index.prefixed_name\n }\n )\n return message\n", "path": "kuma/wiki/search.py"}]}
| 3,367 | 254 |
gh_patches_debug_4094
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-841
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyOpenSSL: Fails to import after installation with the provided instructions
The [Security documentation page](https://urllib3.readthedocs.org/en/latest/security.html#openssl-pyopenssl) indicates that to use PyOpenSSL that you must first install:
- pip3 install pyopenssl ndg-httpsclient pyasn1
And then in a Python interpreter run:
- import urllib3.contrib.pyopenssl
- urllib3.contrib.pyopenssl.inject_into_urllib3()
However on Python 3.4.4 (the latest 3.4.x) on OS X 10.11 (the latest OS X) I get the following traceback when executing `import urllib3.contrib.pyopenssl`:
```
Traceback (most recent call last):
File "/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py", line 60, in <module>
from socket import _fileobject
ImportError: cannot import name '_fileobject'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py", line 63, in <module>
from urllib3.packages.backports.makefile import backport_makefile
ImportError: No module named 'urllib3.packages.backports'
```
Perhaps there is some missing step in the documentation?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup
4
5 import os
6 import re
7 import codecs
8
9 base_path = os.path.dirname(__file__)
10
11 # Get the version (borrowed from SQLAlchemy)
12 fp = open(os.path.join(base_path, 'urllib3', '__init__.py'))
13 VERSION = re.compile(r".*__version__ = '(.*?)'",
14 re.S).match(fp.read()).group(1)
15 fp.close()
16
17 readme = codecs.open('README.rst', encoding='utf-8').read()
18 changes = codecs.open('CHANGES.rst', encoding='utf-8').read()
19 version = VERSION
20
21 setup(name='urllib3',
22 version=version,
23 description="HTTP library with thread-safe connection pooling, file post, and more.",
24 long_description=u'\n\n'.join([readme, changes]),
25 classifiers=[
26 'Environment :: Web Environment',
27 'Intended Audience :: Developers',
28 'License :: OSI Approved :: MIT License',
29 'Operating System :: OS Independent',
30 'Programming Language :: Python',
31 'Programming Language :: Python :: 2',
32 'Programming Language :: Python :: 3',
33 'Topic :: Internet :: WWW/HTTP',
34 'Topic :: Software Development :: Libraries',
35 ],
36 keywords='urllib httplib threadsafe filepost http https ssl pooling',
37 author='Andrey Petrov',
38 author_email='[email protected]',
39 url='http://urllib3.readthedocs.org/',
40 license='MIT',
41 packages=['urllib3',
42 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
43 'urllib3.contrib', 'urllib3.util',
44 ],
45 requires=[],
46 tests_require=[
47 # These are a less-specific subset of dev-requirements.txt, for the
48 # convenience of distro package maintainers.
49 'nose',
50 'mock',
51 'tornado',
52 ],
53 test_suite='test',
54 extras_require={
55 'secure': [
56 'pyOpenSSL>=0.13',
57 'ndg-httpsclient',
58 'pyasn1',
59 'certifi',
60 ],
61 'socks': [
62 'PySocks>=1.5.6,<2.0',
63 ]
64 },
65 )
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -40,7 +40,8 @@
license='MIT',
packages=['urllib3',
'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
- 'urllib3.contrib', 'urllib3.util',
+ 'urllib3.packages.backports', 'urllib3.contrib',
+ 'urllib3.util',
],
requires=[],
tests_require=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -40,7 +40,8 @@\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n- 'urllib3.contrib', 'urllib3.util',\n+ 'urllib3.packages.backports', 'urllib3.contrib',\n+ 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n", "issue": "PyOpenSSL: Fails to import after installation with the provided instructions\nThe [Security documentation page](https://urllib3.readthedocs.org/en/latest/security.html#openssl-pyopenssl) indicates that to use PyOpenSSL that you must first install:\n- pip3 install pyopenssl ndg-httpsclient pyasn1\n\nAnd then in a Python interpreter run:\n- import urllib3.contrib.pyopenssl\n- urllib3.contrib.pyopenssl.inject_into_urllib3()\n\nHowever on Python 3.4.4 (the latest 3.4.x) on OS X 10.11 (the latest OS X) I get the following traceback when executing `import urllib3.contrib.pyopenssl`:\n\n```\nTraceback (most recent call last):\n File \"/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py\", line 60, in <module>\n from socket import _fileobject\nImportError: cannot import name '_fileobject'\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py\", line 63, in <module>\n from urllib3.packages.backports.makefile import backport_makefile\nImportError: No module named 'urllib3.packages.backports'\n```\n\nPerhaps there is some missing step in the documentation?\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nimport os\nimport re\nimport codecs\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\nreadme = codecs.open('README.rst', encoding='utf-8').read()\nchanges = codecs.open('CHANGES.rst', encoding='utf-8').read()\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=u'\\n\\n'.join([readme, changes]),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure': [\n 'pyOpenSSL>=0.13',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n 'socks': [\n 'PySocks>=1.5.6,<2.0',\n ]\n },\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nimport os\nimport re\nimport codecs\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\nreadme = codecs.open('README.rst', encoding='utf-8').read()\nchanges = codecs.open('CHANGES.rst', encoding='utf-8').read()\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=u'\\n\\n'.join([readme, changes]),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.packages.backports', 'urllib3.contrib',\n 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure': [\n 'pyOpenSSL>=0.13',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n 'socks': [\n 'PySocks>=1.5.6,<2.0',\n ]\n },\n )\n", "path": "setup.py"}]}
| 1,193 | 111 |
gh_patches_debug_30146
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-4807
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins: add markunmatched
## Description
Add a plugin useful for bulk importers.
## To Do
- [x] Documentation. (If you've add a new command-line flag, for example, find the appropriate page under `docs/` to describe it.)
- [x] Changelog. (Add an entry to `docs/changelog.rst` near the top of the document.)
- [ ] Tests. (Encouraged but not strictly required.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `beetsplug/mbsubmit.py`
Content:
```
1 # This file is part of beets.
2 # Copyright 2016, Adrian Sampson and Diego Moreda.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Aid in submitting information to MusicBrainz.
16
17 This plugin allows the user to print track information in a format that is
18 parseable by the MusicBrainz track parser [1]. Programmatic submitting is not
19 implemented by MusicBrainz yet.
20
21 [1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings
22 """
23
24
25 from beets import ui
26 from beets.autotag import Recommendation
27 from beets.plugins import BeetsPlugin
28 from beets.ui.commands import PromptChoice
29 from beetsplug.info import print_data
30
31
32 class MBSubmitPlugin(BeetsPlugin):
33 def __init__(self):
34 super().__init__()
35
36 self.config.add(
37 {
38 "format": "$track. $title - $artist ($length)",
39 "threshold": "medium",
40 }
41 )
42
43 # Validate and store threshold.
44 self.threshold = self.config["threshold"].as_choice(
45 {
46 "none": Recommendation.none,
47 "low": Recommendation.low,
48 "medium": Recommendation.medium,
49 "strong": Recommendation.strong,
50 }
51 )
52
53 self.register_listener(
54 "before_choose_candidate", self.before_choose_candidate_event
55 )
56
57 def before_choose_candidate_event(self, session, task):
58 if task.rec <= self.threshold:
59 return [PromptChoice("p", "Print tracks", self.print_tracks)]
60
61 def print_tracks(self, session, task):
62 for i in sorted(task.items, key=lambda i: i.track):
63 print_data(None, i, self.config["format"].as_str())
64
65 def commands(self):
66 """Add beet UI commands for mbsubmit."""
67 mbsubmit_cmd = ui.Subcommand(
68 "mbsubmit", help="Submit Tracks to MusicBrainz"
69 )
70
71 def func(lib, opts, args):
72 items = lib.items(ui.decargs(args))
73 self._mbsubmit(items)
74
75 mbsubmit_cmd.func = func
76
77 return [mbsubmit_cmd]
78
79 def _mbsubmit(self, items):
80 """Print track information to be submitted to MusicBrainz."""
81 for i in sorted(items, key=lambda i: i.track):
82 print_data(None, i, self.config["format"].as_str())
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/beetsplug/mbsubmit.py b/beetsplug/mbsubmit.py
--- a/beetsplug/mbsubmit.py
+++ b/beetsplug/mbsubmit.py
@@ -21,11 +21,13 @@
[1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings
"""
+import subprocess
from beets import ui
from beets.autotag import Recommendation
from beets.plugins import BeetsPlugin
from beets.ui.commands import PromptChoice
+from beets.util import displayable_path
from beetsplug.info import print_data
@@ -37,6 +39,7 @@
{
"format": "$track. $title - $artist ($length)",
"threshold": "medium",
+ "picard_path": "picard",
}
)
@@ -56,7 +59,21 @@
def before_choose_candidate_event(self, session, task):
if task.rec <= self.threshold:
- return [PromptChoice("p", "Print tracks", self.print_tracks)]
+ return [
+ PromptChoice("p", "Print tracks", self.print_tracks),
+ PromptChoice("o", "Open files with Picard", self.picard),
+ ]
+
+ def picard(self, session, task):
+ paths = []
+ for p in task.paths:
+ paths.append(displayable_path(p))
+ try:
+ picard_path = self.config["picard_path"].as_str()
+ subprocess.Popen([picard_path] + paths)
+ self._log.info("launched picard from\n{}", picard_path)
+ except OSError as exc:
+ self._log.error(f"Could not open picard, got error:\n{exc}")
def print_tracks(self, session, task):
for i in sorted(task.items, key=lambda i: i.track):
|
{"golden_diff": "diff --git a/beetsplug/mbsubmit.py b/beetsplug/mbsubmit.py\n--- a/beetsplug/mbsubmit.py\n+++ b/beetsplug/mbsubmit.py\n@@ -21,11 +21,13 @@\n [1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings\n \"\"\"\n \n+import subprocess\n \n from beets import ui\n from beets.autotag import Recommendation\n from beets.plugins import BeetsPlugin\n from beets.ui.commands import PromptChoice\n+from beets.util import displayable_path\n from beetsplug.info import print_data\n \n \n@@ -37,6 +39,7 @@\n {\n \"format\": \"$track. $title - $artist ($length)\",\n \"threshold\": \"medium\",\n+ \"picard_path\": \"picard\",\n }\n )\n \n@@ -56,7 +59,21 @@\n \n def before_choose_candidate_event(self, session, task):\n if task.rec <= self.threshold:\n- return [PromptChoice(\"p\", \"Print tracks\", self.print_tracks)]\n+ return [\n+ PromptChoice(\"p\", \"Print tracks\", self.print_tracks),\n+ PromptChoice(\"o\", \"Open files with Picard\", self.picard),\n+ ]\n+\n+ def picard(self, session, task):\n+ paths = []\n+ for p in task.paths:\n+ paths.append(displayable_path(p))\n+ try:\n+ picard_path = self.config[\"picard_path\"].as_str()\n+ subprocess.Popen([picard_path] + paths)\n+ self._log.info(\"launched picard from\\n{}\", picard_path)\n+ except OSError as exc:\n+ self._log.error(f\"Could not open picard, got error:\\n{exc}\")\n \n def print_tracks(self, session, task):\n for i in sorted(task.items, key=lambda i: i.track):\n", "issue": "plugins: add markunmatched\n## Description\r\n\r\nAdd a plugin useful for bulk importers.\r\n\r\n## To Do\r\n\r\n- [x] Documentation. (If you've add a new command-line flag, for example, find the appropriate page under `docs/` to describe it.)\r\n- [x] Changelog. (Add an entry to `docs/changelog.rst` near the top of the document.)\r\n- [ ] Tests. (Encouraged but not strictly required.)\r\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2016, Adrian Sampson and Diego Moreda.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Aid in submitting information to MusicBrainz.\n\nThis plugin allows the user to print track information in a format that is\nparseable by the MusicBrainz track parser [1]. Programmatic submitting is not\nimplemented by MusicBrainz yet.\n\n[1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings\n\"\"\"\n\n\nfrom beets import ui\nfrom beets.autotag import Recommendation\nfrom beets.plugins import BeetsPlugin\nfrom beets.ui.commands import PromptChoice\nfrom beetsplug.info import print_data\n\n\nclass MBSubmitPlugin(BeetsPlugin):\n def __init__(self):\n super().__init__()\n\n self.config.add(\n {\n \"format\": \"$track. $title - $artist ($length)\",\n \"threshold\": \"medium\",\n }\n )\n\n # Validate and store threshold.\n self.threshold = self.config[\"threshold\"].as_choice(\n {\n \"none\": Recommendation.none,\n \"low\": Recommendation.low,\n \"medium\": Recommendation.medium,\n \"strong\": Recommendation.strong,\n }\n )\n\n self.register_listener(\n \"before_choose_candidate\", self.before_choose_candidate_event\n )\n\n def before_choose_candidate_event(self, session, task):\n if task.rec <= self.threshold:\n return [PromptChoice(\"p\", \"Print tracks\", self.print_tracks)]\n\n def print_tracks(self, session, task):\n for i in sorted(task.items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n\n def commands(self):\n \"\"\"Add beet UI commands for mbsubmit.\"\"\"\n mbsubmit_cmd = ui.Subcommand(\n \"mbsubmit\", help=\"Submit Tracks to MusicBrainz\"\n )\n\n def func(lib, opts, args):\n items = lib.items(ui.decargs(args))\n self._mbsubmit(items)\n\n mbsubmit_cmd.func = func\n\n return [mbsubmit_cmd]\n\n def _mbsubmit(self, items):\n \"\"\"Print track information to be submitted to MusicBrainz.\"\"\"\n for i in sorted(items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n", "path": "beetsplug/mbsubmit.py"}], "after_files": [{"content": "# This file is part of beets.\n# Copyright 2016, Adrian Sampson and Diego Moreda.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Aid in submitting information to MusicBrainz.\n\nThis plugin allows the user to print track information in a format that is\nparseable by the MusicBrainz track parser [1]. Programmatic submitting is not\nimplemented by MusicBrainz yet.\n\n[1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings\n\"\"\"\n\nimport subprocess\n\nfrom beets import ui\nfrom beets.autotag import Recommendation\nfrom beets.plugins import BeetsPlugin\nfrom beets.ui.commands import PromptChoice\nfrom beets.util import displayable_path\nfrom beetsplug.info import print_data\n\n\nclass MBSubmitPlugin(BeetsPlugin):\n def __init__(self):\n super().__init__()\n\n self.config.add(\n {\n \"format\": \"$track. $title - $artist ($length)\",\n \"threshold\": \"medium\",\n \"picard_path\": \"picard\",\n }\n )\n\n # Validate and store threshold.\n self.threshold = self.config[\"threshold\"].as_choice(\n {\n \"none\": Recommendation.none,\n \"low\": Recommendation.low,\n \"medium\": Recommendation.medium,\n \"strong\": Recommendation.strong,\n }\n )\n\n self.register_listener(\n \"before_choose_candidate\", self.before_choose_candidate_event\n )\n\n def before_choose_candidate_event(self, session, task):\n if task.rec <= self.threshold:\n return [\n PromptChoice(\"p\", \"Print tracks\", self.print_tracks),\n PromptChoice(\"o\", \"Open files with Picard\", self.picard),\n ]\n\n def picard(self, session, task):\n paths = []\n for p in task.paths:\n paths.append(displayable_path(p))\n try:\n picard_path = self.config[\"picard_path\"].as_str()\n subprocess.Popen([picard_path] + paths)\n self._log.info(\"launched picard from\\n{}\", picard_path)\n except OSError as exc:\n self._log.error(f\"Could not open picard, got error:\\n{exc}\")\n\n def print_tracks(self, session, task):\n for i in sorted(task.items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n\n def commands(self):\n \"\"\"Add beet UI commands for mbsubmit.\"\"\"\n mbsubmit_cmd = ui.Subcommand(\n \"mbsubmit\", help=\"Submit Tracks to MusicBrainz\"\n )\n\n def func(lib, opts, args):\n items = lib.items(ui.decargs(args))\n self._mbsubmit(items)\n\n mbsubmit_cmd.func = func\n\n return [mbsubmit_cmd]\n\n def _mbsubmit(self, items):\n \"\"\"Print track information to be submitted to MusicBrainz.\"\"\"\n for i in sorted(items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n", "path": "beetsplug/mbsubmit.py"}]}
| 1,138 | 415 |
gh_patches_debug_2187
|
rasdani/github-patches
|
git_diff
|
projectmesa__mesa-989
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Color patches takes a long time to load
When you hit "reset" to load the color patches example, it takes a long time to load.
Not sure why. As a result, I thought it was broken.
To recreate...
```
cd examples/color_patches
python run.py
```
Wait for patches to load when browser window pops up.
OR hit reset and wait for color patches to load.
This is what it should look something like...
<img width="407" alt="screen shot 2018-04-01 at 10 03 33 pm" src="https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png">
Color patches takes a long time to load
When you hit "reset" to load the color patches example, it takes a long time to load.
Not sure why. As a result, I thought it was broken.
To recreate...
```
cd examples/color_patches
python run.py
```
Wait for patches to load when browser window pops up.
OR hit reset and wait for color patches to load.
This is what it should look something like...
<img width="407" alt="screen shot 2018-04-01 at 10 03 33 pm" src="https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/color_patches/color_patches/server.py`
Content:
```
1 """
2 handles the definition of the canvas parameters and
3 the drawing of the model representation on the canvas
4 """
5 # import webbrowser
6
7 from mesa.visualization.modules import CanvasGrid
8 from mesa.visualization.ModularVisualization import ModularServer
9
10 from .model import ColorPatches
11
12 _COLORS = [
13 "Aqua",
14 "Blue",
15 "Fuchsia",
16 "Gray",
17 "Green",
18 "Lime",
19 "Maroon",
20 "Navy",
21 "Olive",
22 "Orange",
23 "Purple",
24 "Red",
25 "Silver",
26 "Teal",
27 "White",
28 "Yellow",
29 ]
30
31
32 grid_rows = 50
33 grid_cols = 25
34 cell_size = 10
35 canvas_width = grid_rows * cell_size
36 canvas_height = grid_cols * cell_size
37
38
39 def color_patch_draw(cell):
40 """
41 This function is registered with the visualization server to be called
42 each tick to indicate how to draw the cell in its current state.
43
44 :param cell: the cell in the simulation
45
46 :return: the portrayal dictionary.
47
48 """
49 assert cell is not None
50 portrayal = {"Shape": "rect", "w": 1, "h": 1, "Filled": "true", "Layer": 0}
51 portrayal["x"] = cell.get_row()
52 portrayal["y"] = cell.get_col()
53 portrayal["Color"] = _COLORS[cell.get_state()]
54 return portrayal
55
56
57 canvas_element = CanvasGrid(
58 color_patch_draw, grid_rows, grid_cols, canvas_width, canvas_height
59 )
60
61 server = ModularServer(
62 ColorPatches,
63 [canvas_element],
64 "Color Patches",
65 {"width": canvas_width, "height": canvas_height},
66 )
67
68 # webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/color_patches/color_patches/server.py b/examples/color_patches/color_patches/server.py
--- a/examples/color_patches/color_patches/server.py
+++ b/examples/color_patches/color_patches/server.py
@@ -62,7 +62,7 @@
ColorPatches,
[canvas_element],
"Color Patches",
- {"width": canvas_width, "height": canvas_height},
+ {"width": grid_rows, "height": grid_cols},
)
# webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable
|
{"golden_diff": "diff --git a/examples/color_patches/color_patches/server.py b/examples/color_patches/color_patches/server.py\n--- a/examples/color_patches/color_patches/server.py\n+++ b/examples/color_patches/color_patches/server.py\n@@ -62,7 +62,7 @@\n ColorPatches,\n [canvas_element],\n \"Color Patches\",\n- {\"width\": canvas_width, \"height\": canvas_height},\n+ {\"width\": grid_rows, \"height\": grid_cols},\n )\n \n # webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable\n", "issue": "Color patches takes a long time to load\nWhen you hit \"reset\" to load the color patches example, it takes a long time to load.\r\nNot sure why. As a result, I thought it was broken.\r\n\r\nTo recreate... \r\n```\r\ncd examples/color_patches\r\npython run.py\r\n```\r\n\r\nWait for patches to load when browser window pops up. \r\nOR hit reset and wait for color patches to load.\r\n\r\nThis is what it should look something like...\r\n<img width=\"407\" alt=\"screen shot 2018-04-01 at 10 03 33 pm\" src=\"https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png\">\nColor patches takes a long time to load\nWhen you hit \"reset\" to load the color patches example, it takes a long time to load.\r\nNot sure why. As a result, I thought it was broken.\r\n\r\nTo recreate... \r\n```\r\ncd examples/color_patches\r\npython run.py\r\n```\r\n\r\nWait for patches to load when browser window pops up. \r\nOR hit reset and wait for color patches to load.\r\n\r\nThis is what it should look something like...\r\n<img width=\"407\" alt=\"screen shot 2018-04-01 at 10 03 33 pm\" src=\"https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png\">\n", "before_files": [{"content": "\"\"\"\nhandles the definition of the canvas parameters and\nthe drawing of the model representation on the canvas\n\"\"\"\n# import webbrowser\n\nfrom mesa.visualization.modules import CanvasGrid\nfrom mesa.visualization.ModularVisualization import ModularServer\n\nfrom .model import ColorPatches\n\n_COLORS = [\n \"Aqua\",\n \"Blue\",\n \"Fuchsia\",\n \"Gray\",\n \"Green\",\n \"Lime\",\n \"Maroon\",\n \"Navy\",\n \"Olive\",\n \"Orange\",\n \"Purple\",\n \"Red\",\n \"Silver\",\n \"Teal\",\n \"White\",\n \"Yellow\",\n]\n\n\ngrid_rows = 50\ngrid_cols = 25\ncell_size = 10\ncanvas_width = grid_rows * cell_size\ncanvas_height = grid_cols * cell_size\n\n\ndef color_patch_draw(cell):\n \"\"\"\n This function is registered with the visualization server to be called\n each tick to indicate how to draw the cell in its current state.\n\n :param cell: the cell in the simulation\n\n :return: the portrayal dictionary.\n\n \"\"\"\n assert cell is not None\n portrayal = {\"Shape\": \"rect\", \"w\": 1, \"h\": 1, \"Filled\": \"true\", \"Layer\": 0}\n portrayal[\"x\"] = cell.get_row()\n portrayal[\"y\"] = cell.get_col()\n portrayal[\"Color\"] = _COLORS[cell.get_state()]\n return portrayal\n\n\ncanvas_element = CanvasGrid(\n color_patch_draw, grid_rows, grid_cols, canvas_width, canvas_height\n)\n\nserver = ModularServer(\n ColorPatches,\n [canvas_element],\n \"Color Patches\",\n {\"width\": canvas_width, \"height\": canvas_height},\n)\n\n# webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable\n", "path": "examples/color_patches/color_patches/server.py"}], "after_files": [{"content": "\"\"\"\nhandles the definition of the canvas parameters and\nthe drawing of the model representation on the canvas\n\"\"\"\n# import webbrowser\n\nfrom mesa.visualization.modules import CanvasGrid\nfrom mesa.visualization.ModularVisualization import ModularServer\n\nfrom .model import ColorPatches\n\n_COLORS = [\n \"Aqua\",\n \"Blue\",\n \"Fuchsia\",\n \"Gray\",\n \"Green\",\n \"Lime\",\n \"Maroon\",\n \"Navy\",\n \"Olive\",\n \"Orange\",\n \"Purple\",\n \"Red\",\n \"Silver\",\n \"Teal\",\n \"White\",\n \"Yellow\",\n]\n\n\ngrid_rows = 50\ngrid_cols = 25\ncell_size = 10\ncanvas_width = grid_rows * cell_size\ncanvas_height = grid_cols * cell_size\n\n\ndef color_patch_draw(cell):\n \"\"\"\n This function is registered with the visualization server to be called\n each tick to indicate how to draw the cell in its current state.\n\n :param cell: the cell in the simulation\n\n :return: the portrayal dictionary.\n\n \"\"\"\n assert cell is not None\n portrayal = {\"Shape\": \"rect\", \"w\": 1, \"h\": 1, \"Filled\": \"true\", \"Layer\": 0}\n portrayal[\"x\"] = cell.get_row()\n portrayal[\"y\"] = cell.get_col()\n portrayal[\"Color\"] = _COLORS[cell.get_state()]\n return portrayal\n\n\ncanvas_element = CanvasGrid(\n color_patch_draw, grid_rows, grid_cols, canvas_width, canvas_height\n)\n\nserver = ModularServer(\n ColorPatches,\n [canvas_element],\n \"Color Patches\",\n {\"width\": grid_rows, \"height\": grid_cols},\n)\n\n# webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable\n", "path": "examples/color_patches/color_patches/server.py"}]}
| 1,170 | 128 |
gh_patches_debug_15770
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1793
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Documentation references old propagators module
`propagators.inject` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blob/main/docs/examples/auto-instrumentation/client.py#L40), `propagators.extract` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blame/main/docs/examples/auto-instrumentation/README.rst#L40). They should use `propagate` instead.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/examples/auto-instrumentation/client.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from sys import argv
16
17 from requests import get
18
19 from opentelemetry import propagators, trace
20 from opentelemetry.sdk.trace import TracerProvider
21 from opentelemetry.sdk.trace.export import (
22 ConsoleSpanExporter,
23 SimpleSpanProcessor,
24 )
25
26 trace.set_tracer_provider(TracerProvider())
27 tracer = trace.get_tracer_provider().get_tracer(__name__)
28
29 trace.get_tracer_provider().add_span_processor(
30 SimpleSpanProcessor(ConsoleSpanExporter())
31 )
32
33
34 assert len(argv) == 2
35
36 with tracer.start_as_current_span("client"):
37
38 with tracer.start_as_current_span("client-server"):
39 headers = {}
40 propagators.inject(headers)
41 requested = get(
42 "http://localhost:8082/server_request",
43 params={"param": argv[1]},
44 headers=headers,
45 )
46
47 assert requested.status_code == 200
48
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py
--- a/docs/examples/auto-instrumentation/client.py
+++ b/docs/examples/auto-instrumentation/client.py
@@ -16,7 +16,8 @@
from requests import get
-from opentelemetry import propagators, trace
+from opentelemetry import trace
+from opentelemetry.propagate import inject
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import (
ConsoleSpanExporter,
@@ -37,7 +38,7 @@
with tracer.start_as_current_span("client-server"):
headers = {}
- propagators.inject(headers)
+ inject(headers)
requested = get(
"http://localhost:8082/server_request",
params={"param": argv[1]},
|
{"golden_diff": "diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py\n--- a/docs/examples/auto-instrumentation/client.py\n+++ b/docs/examples/auto-instrumentation/client.py\n@@ -16,7 +16,8 @@\n \n from requests import get\n \n-from opentelemetry import propagators, trace\n+from opentelemetry import trace\n+from opentelemetry.propagate import inject\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n@@ -37,7 +38,7 @@\n \n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n- propagators.inject(headers)\n+ inject(headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n", "issue": "Documentation references old propagators module\n`propagators.inject` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blob/main/docs/examples/auto-instrumentation/client.py#L40), `propagators.extract` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blame/main/docs/examples/auto-instrumentation/README.rst#L40). They should use `propagate` instead.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom sys import argv\n\nfrom requests import get\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleSpanProcessor,\n)\n\ntrace.set_tracer_provider(TracerProvider())\ntracer = trace.get_tracer_provider().get_tracer(__name__)\n\ntrace.get_tracer_provider().add_span_processor(\n SimpleSpanProcessor(ConsoleSpanExporter())\n)\n\n\nassert len(argv) == 2\n\nwith tracer.start_as_current_span(\"client\"):\n\n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n propagators.inject(headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n headers=headers,\n )\n\n assert requested.status_code == 200\n", "path": "docs/examples/auto-instrumentation/client.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom sys import argv\n\nfrom requests import get\n\nfrom opentelemetry import trace\nfrom opentelemetry.propagate import inject\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleSpanProcessor,\n)\n\ntrace.set_tracer_provider(TracerProvider())\ntracer = trace.get_tracer_provider().get_tracer(__name__)\n\ntrace.get_tracer_provider().add_span_processor(\n SimpleSpanProcessor(ConsoleSpanExporter())\n)\n\n\nassert len(argv) == 2\n\nwith tracer.start_as_current_span(\"client\"):\n\n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n inject(headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n headers=headers,\n )\n\n assert requested.status_code == 200\n", "path": "docs/examples/auto-instrumentation/client.py"}]}
| 758 | 182 |
gh_patches_debug_28717
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SBMTD: Update agency card name in user-facing text
SBMTD is renaming its agency card to avoid confusion for riders about the purpose of its various passes. Their agency card is currently named `Mobility Pass` but will change to `Reduced Fare Mobility ID`. We need update our Benefits application copy to display the updated name.
## Acceptance Criteria
<!-- Remember to consider edge cases -->
- [x] There are no instances of `Mobility Pass` in user-facing copy in the Benefits application.
- [x] All references to SBMTD's agency card in user-facing copy in the Benefits application are `Reduced Fare Mobility ID`.
- [ ] ~Design files reflect the two criteria above.~
- [x] [Cal-ITP Benefits Application Copy](https://docs.google.com/spreadsheets/d/1_Gi_YbJr4ZuXCOsnOWaewvHqUO1nC1nKqiVDHvw0118/edit?usp=sharing) master includes the updated name.
## Additional context
A larger research and scoping effort to determine all non-user-facing instances of `Mobility Pass` is being tracked in #1922
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/eligibility/forms.py`
Content:
```
1 """
2 The eligibility application: Form definition for the eligibility verification flow.
3 """
4
5 import logging
6
7 from django import forms
8 from django.utils.translation import gettext_lazy as _
9
10 from benefits.core import models, recaptcha, widgets
11
12
13 logger = logging.getLogger(__name__)
14
15
16 class EligibilityVerifierSelectionForm(forms.Form):
17 """Form to capture eligibility verifier selection."""
18
19 action_url = "eligibility:index"
20 id = "form-verifier-selection"
21 method = "POST"
22
23 verifier = forms.ChoiceField(label="", widget=widgets.VerifierRadioSelect)
24 # sets label to empty string so the radio_select template can override the label style
25 submit_value = _("Choose this Benefit")
26
27 def __init__(self, agency: models.TransitAgency, *args, **kwargs):
28 super().__init__(*args, **kwargs)
29 verifiers = agency.eligibility_verifiers.filter(active=True)
30
31 self.classes = "col-lg-8"
32 # second element is not used since we render the whole label using selection_label_template,
33 # therefore set to None
34 self.fields["verifier"].choices = [(v.id, None) for v in verifiers]
35 self.fields["verifier"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}
36
37 def clean(self):
38 if not recaptcha.verify(self.data):
39 raise forms.ValidationError("reCAPTCHA failed")
40
41
42 class EligibilityVerificationForm(forms.Form):
43 """Form to collect eligibility verification details."""
44
45 action_url = "eligibility:confirm"
46 id = "form-eligibility-verification"
47 method = "POST"
48
49 submit_value = _("Check eligibility")
50 submitting_value = _("Checking")
51
52 _error_messages = {
53 "invalid": _("Check your input. The format looks wrong."),
54 "missing": _("This field is required."),
55 }
56
57 def __init__(
58 self,
59 title,
60 headline,
61 blurb,
62 name_label,
63 name_placeholder,
64 name_help_text,
65 sub_label,
66 sub_placeholder,
67 sub_help_text,
68 name_max_length=None,
69 sub_input_mode=None,
70 sub_max_length=None,
71 sub_pattern=None,
72 *args,
73 **kwargs,
74 ):
75 """Initialize a new EligibilityVerifier form.
76
77 Args:
78 title (str): The page (i.e. tab) title for the form's page.
79
80 headline (str): The <h1> on the form's page.
81
82 blurb (str): Intro <p> on the form's page.
83
84 name_label (str): Label for the name form field.
85
86 name_placeholder (str): Field placeholder for the name form field.
87
88 name_help_text (str): Extra help text for the name form field.
89
90 sub_label (str): Label for the sub form field.
91
92 sub_placeholder (str): Field placeholder for the sub form field.
93
94 sub_help_text (str): Extra help text for the sub form field.
95
96 name_max_length (int): The maximum length accepted for the 'name' API field before sending to this verifier
97
98 sub_input_mode (str): Input mode can be "numeric", "tel", "search", etc. to override default "text" keyboard on
99 mobile devices
100
101 sub_max_length (int): The maximum length accepted for the 'sub' API field before sending to this verifier
102
103 sub_pattern (str): A regular expression used to validate the 'sub' API field before sending to this verifier
104
105 Extra args and kwargs are passed through to the underlying django.forms.Form.
106 """
107 super().__init__(auto_id=True, label_suffix="", *args, **kwargs)
108
109 self.title = title
110 self.headline = headline
111 self.blurb = blurb
112
113 self.classes = "col-lg-6"
114 sub_widget = widgets.FormControlTextInput(placeholder=sub_placeholder)
115 if sub_pattern:
116 sub_widget.attrs.update({"pattern": sub_pattern})
117 if sub_input_mode:
118 sub_widget.attrs.update({"inputmode": sub_input_mode})
119 if sub_max_length:
120 sub_widget.attrs.update({"maxlength": sub_max_length})
121
122 self.fields["sub"] = forms.CharField(
123 label=sub_label,
124 widget=sub_widget,
125 help_text=sub_help_text,
126 )
127
128 name_widget = widgets.FormControlTextInput(placeholder=name_placeholder)
129 if name_max_length:
130 name_widget.attrs.update({"maxlength": name_max_length})
131
132 self.fields["name"] = forms.CharField(label=name_label, widget=name_widget, help_text=name_help_text)
133
134 def clean(self):
135 if not recaptcha.verify(self.data):
136 raise forms.ValidationError("reCAPTCHA failed")
137
138
139 class MSTCourtesyCard(EligibilityVerificationForm):
140 """EligibilityVerification form for the MST Courtesy Card."""
141
142 def __init__(self, *args, **kwargs):
143 super().__init__(
144 title=_("Agency card information"),
145 headline=_("Let’s see if we can confirm your eligibility."),
146 blurb=_("Please input your Courtesy Card number and last name below to confirm your eligibility."),
147 name_label=_("Last name (as it appears on Courtesy Card)"),
148 name_placeholder="Garcia",
149 name_help_text=_("We use this to help confirm your Courtesy Card."),
150 sub_label=_("MST Courtesy Card number"),
151 sub_help_text=_("This is a 5-digit number on the front and back of your card."),
152 sub_placeholder="12345",
153 name_max_length=255,
154 sub_input_mode="numeric",
155 sub_max_length=5,
156 sub_pattern=r"\d{5}",
157 *args,
158 **kwargs,
159 )
160
161
162 class SBMTDMobilityPass(EligibilityVerificationForm):
163 """EligibilityVerification form for the SBMTD Mobility Pass."""
164
165 def __init__(self, *args, **kwargs):
166 super().__init__(
167 title=_("Agency card information"),
168 headline=_("Let’s see if we can confirm your eligibility."),
169 blurb=_("Please input your Mobility Pass number and last name below to confirm your eligibility."),
170 name_label=_("Last name (as it appears on Mobility Pass card)"),
171 name_placeholder="Garcia",
172 name_help_text=_("We use this to help confirm your Mobility Pass."),
173 sub_label=_("SBMTD Mobility Pass number"),
174 sub_help_text=_("This is a 4-digit number on the back of your card."),
175 sub_placeholder="1234",
176 name_max_length=255,
177 sub_input_mode="numeric",
178 sub_max_length=4,
179 sub_pattern=r"\d{4}",
180 *args,
181 **kwargs,
182 )
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py
--- a/benefits/eligibility/forms.py
+++ b/benefits/eligibility/forms.py
@@ -9,7 +9,6 @@
from benefits.core import models, recaptcha, widgets
-
logger = logging.getLogger(__name__)
@@ -160,17 +159,17 @@
class SBMTDMobilityPass(EligibilityVerificationForm):
- """EligibilityVerification form for the SBMTD Mobility Pass."""
+ """EligibilityVerification form for the SBMTD Reduced Fare Mobility ID."""
def __init__(self, *args, **kwargs):
super().__init__(
title=_("Agency card information"),
headline=_("Let’s see if we can confirm your eligibility."),
- blurb=_("Please input your Mobility Pass number and last name below to confirm your eligibility."),
- name_label=_("Last name (as it appears on Mobility Pass card)"),
+ blurb=_("Please input your Reduced Fare Mobility ID number and last name below to confirm your eligibility."),
+ name_label=_("Last name (as it appears on Reduced Fare Mobility ID card)"),
name_placeholder="Garcia",
- name_help_text=_("We use this to help confirm your Mobility Pass."),
- sub_label=_("SBMTD Mobility Pass number"),
+ name_help_text=_("We use this to help confirm your Reduced Fare Mobility ID."),
+ sub_label=_("SBMTD Reduced Fare Mobility ID number"),
sub_help_text=_("This is a 4-digit number on the back of your card."),
sub_placeholder="1234",
name_max_length=255,
|
{"golden_diff": "diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py\n--- a/benefits/eligibility/forms.py\n+++ b/benefits/eligibility/forms.py\n@@ -9,7 +9,6 @@\n \n from benefits.core import models, recaptcha, widgets\n \n-\n logger = logging.getLogger(__name__)\n \n \n@@ -160,17 +159,17 @@\n \n \n class SBMTDMobilityPass(EligibilityVerificationForm):\n- \"\"\"EligibilityVerification form for the SBMTD Mobility Pass.\"\"\"\n+ \"\"\"EligibilityVerification form for the SBMTD Reduced Fare Mobility ID.\"\"\"\n \n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n- blurb=_(\"Please input your Mobility Pass number and last name below to confirm your eligibility.\"),\n- name_label=_(\"Last name (as it appears on Mobility Pass card)\"),\n+ blurb=_(\"Please input your Reduced Fare Mobility ID number and last name below to confirm your eligibility.\"),\n+ name_label=_(\"Last name (as it appears on Reduced Fare Mobility ID card)\"),\n name_placeholder=\"Garcia\",\n- name_help_text=_(\"We use this to help confirm your Mobility Pass.\"),\n- sub_label=_(\"SBMTD Mobility Pass number\"),\n+ name_help_text=_(\"We use this to help confirm your Reduced Fare Mobility ID.\"),\n+ sub_label=_(\"SBMTD Reduced Fare Mobility ID number\"),\n sub_help_text=_(\"This is a 4-digit number on the back of your card.\"),\n sub_placeholder=\"1234\",\n name_max_length=255,\n", "issue": "SBMTD: Update agency card name in user-facing text\nSBMTD is renaming its agency card to avoid confusion for riders about the purpose of its various passes. Their agency card is currently named `Mobility Pass` but will change to `Reduced Fare Mobility ID`. We need update our Benefits application copy to display the updated name.\r\n\r\n## Acceptance Criteria\r\n\r\n<!-- Remember to consider edge cases -->\r\n\r\n- [x] There are no instances of `Mobility Pass` in user-facing copy in the Benefits application.\r\n- [x] All references to SBMTD's agency card in user-facing copy in the Benefits application are `Reduced Fare Mobility ID`.\r\n- [ ] ~Design files reflect the two criteria above.~\r\n- [x] [Cal-ITP Benefits Application Copy](https://docs.google.com/spreadsheets/d/1_Gi_YbJr4ZuXCOsnOWaewvHqUO1nC1nKqiVDHvw0118/edit?usp=sharing) master includes the updated name.\r\n\r\n## Additional context\r\n\r\nA larger research and scoping effort to determine all non-user-facing instances of `Mobility Pass` is being tracked in #1922\n", "before_files": [{"content": "\"\"\"\nThe eligibility application: Form definition for the eligibility verification flow.\n\"\"\"\n\nimport logging\n\nfrom django import forms\nfrom django.utils.translation import gettext_lazy as _\n\nfrom benefits.core import models, recaptcha, widgets\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass EligibilityVerifierSelectionForm(forms.Form):\n \"\"\"Form to capture eligibility verifier selection.\"\"\"\n\n action_url = \"eligibility:index\"\n id = \"form-verifier-selection\"\n method = \"POST\"\n\n verifier = forms.ChoiceField(label=\"\", widget=widgets.VerifierRadioSelect)\n # sets label to empty string so the radio_select template can override the label style\n submit_value = _(\"Choose this Benefit\")\n\n def __init__(self, agency: models.TransitAgency, *args, **kwargs):\n super().__init__(*args, **kwargs)\n verifiers = agency.eligibility_verifiers.filter(active=True)\n\n self.classes = \"col-lg-8\"\n # second element is not used since we render the whole label using selection_label_template,\n # therefore set to None\n self.fields[\"verifier\"].choices = [(v.id, None) for v in verifiers]\n self.fields[\"verifier\"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass EligibilityVerificationForm(forms.Form):\n \"\"\"Form to collect eligibility verification details.\"\"\"\n\n action_url = \"eligibility:confirm\"\n id = \"form-eligibility-verification\"\n method = \"POST\"\n\n submit_value = _(\"Check eligibility\")\n submitting_value = _(\"Checking\")\n\n _error_messages = {\n \"invalid\": _(\"Check your input. The format looks wrong.\"),\n \"missing\": _(\"This field is required.\"),\n }\n\n def __init__(\n self,\n title,\n headline,\n blurb,\n name_label,\n name_placeholder,\n name_help_text,\n sub_label,\n sub_placeholder,\n sub_help_text,\n name_max_length=None,\n sub_input_mode=None,\n sub_max_length=None,\n sub_pattern=None,\n *args,\n **kwargs,\n ):\n \"\"\"Initialize a new EligibilityVerifier form.\n\n Args:\n title (str): The page (i.e. tab) title for the form's page.\n\n headline (str): The <h1> on the form's page.\n\n blurb (str): Intro <p> on the form's page.\n\n name_label (str): Label for the name form field.\n\n name_placeholder (str): Field placeholder for the name form field.\n\n name_help_text (str): Extra help text for the name form field.\n\n sub_label (str): Label for the sub form field.\n\n sub_placeholder (str): Field placeholder for the sub form field.\n\n sub_help_text (str): Extra help text for the sub form field.\n\n name_max_length (int): The maximum length accepted for the 'name' API field before sending to this verifier\n\n sub_input_mode (str): Input mode can be \"numeric\", \"tel\", \"search\", etc. to override default \"text\" keyboard on\n mobile devices\n\n sub_max_length (int): The maximum length accepted for the 'sub' API field before sending to this verifier\n\n sub_pattern (str): A regular expression used to validate the 'sub' API field before sending to this verifier\n\n Extra args and kwargs are passed through to the underlying django.forms.Form.\n \"\"\"\n super().__init__(auto_id=True, label_suffix=\"\", *args, **kwargs)\n\n self.title = title\n self.headline = headline\n self.blurb = blurb\n\n self.classes = \"col-lg-6\"\n sub_widget = widgets.FormControlTextInput(placeholder=sub_placeholder)\n if sub_pattern:\n sub_widget.attrs.update({\"pattern\": sub_pattern})\n if sub_input_mode:\n sub_widget.attrs.update({\"inputmode\": sub_input_mode})\n if sub_max_length:\n sub_widget.attrs.update({\"maxlength\": sub_max_length})\n\n self.fields[\"sub\"] = forms.CharField(\n label=sub_label,\n widget=sub_widget,\n help_text=sub_help_text,\n )\n\n name_widget = widgets.FormControlTextInput(placeholder=name_placeholder)\n if name_max_length:\n name_widget.attrs.update({\"maxlength\": name_max_length})\n\n self.fields[\"name\"] = forms.CharField(label=name_label, widget=name_widget, help_text=name_help_text)\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass MSTCourtesyCard(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the MST Courtesy Card.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Courtesy Card number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Courtesy Card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Courtesy Card.\"),\n sub_label=_(\"MST Courtesy Card number\"),\n sub_help_text=_(\"This is a 5-digit number on the front and back of your card.\"),\n sub_placeholder=\"12345\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=5,\n sub_pattern=r\"\\d{5}\",\n *args,\n **kwargs,\n )\n\n\nclass SBMTDMobilityPass(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the SBMTD Mobility Pass.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Mobility Pass number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Mobility Pass card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Mobility Pass.\"),\n sub_label=_(\"SBMTD Mobility Pass number\"),\n sub_help_text=_(\"This is a 4-digit number on the back of your card.\"),\n sub_placeholder=\"1234\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=4,\n sub_pattern=r\"\\d{4}\",\n *args,\n **kwargs,\n )\n", "path": "benefits/eligibility/forms.py"}], "after_files": [{"content": "\"\"\"\nThe eligibility application: Form definition for the eligibility verification flow.\n\"\"\"\n\nimport logging\n\nfrom django import forms\nfrom django.utils.translation import gettext_lazy as _\n\nfrom benefits.core import models, recaptcha, widgets\n\nlogger = logging.getLogger(__name__)\n\n\nclass EligibilityVerifierSelectionForm(forms.Form):\n \"\"\"Form to capture eligibility verifier selection.\"\"\"\n\n action_url = \"eligibility:index\"\n id = \"form-verifier-selection\"\n method = \"POST\"\n\n verifier = forms.ChoiceField(label=\"\", widget=widgets.VerifierRadioSelect)\n # sets label to empty string so the radio_select template can override the label style\n submit_value = _(\"Choose this Benefit\")\n\n def __init__(self, agency: models.TransitAgency, *args, **kwargs):\n super().__init__(*args, **kwargs)\n verifiers = agency.eligibility_verifiers.filter(active=True)\n\n self.classes = \"col-lg-8\"\n # second element is not used since we render the whole label using selection_label_template,\n # therefore set to None\n self.fields[\"verifier\"].choices = [(v.id, None) for v in verifiers]\n self.fields[\"verifier\"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass EligibilityVerificationForm(forms.Form):\n \"\"\"Form to collect eligibility verification details.\"\"\"\n\n action_url = \"eligibility:confirm\"\n id = \"form-eligibility-verification\"\n method = \"POST\"\n\n submit_value = _(\"Check eligibility\")\n submitting_value = _(\"Checking\")\n\n _error_messages = {\n \"invalid\": _(\"Check your input. The format looks wrong.\"),\n \"missing\": _(\"This field is required.\"),\n }\n\n def __init__(\n self,\n title,\n headline,\n blurb,\n name_label,\n name_placeholder,\n name_help_text,\n sub_label,\n sub_placeholder,\n sub_help_text,\n name_max_length=None,\n sub_input_mode=None,\n sub_max_length=None,\n sub_pattern=None,\n *args,\n **kwargs,\n ):\n \"\"\"Initialize a new EligibilityVerifier form.\n\n Args:\n title (str): The page (i.e. tab) title for the form's page.\n\n headline (str): The <h1> on the form's page.\n\n blurb (str): Intro <p> on the form's page.\n\n name_label (str): Label for the name form field.\n\n name_placeholder (str): Field placeholder for the name form field.\n\n name_help_text (str): Extra help text for the name form field.\n\n sub_label (str): Label for the sub form field.\n\n sub_placeholder (str): Field placeholder for the sub form field.\n\n sub_help_text (str): Extra help text for the sub form field.\n\n name_max_length (int): The maximum length accepted for the 'name' API field before sending to this verifier\n\n sub_input_mode (str): Input mode can be \"numeric\", \"tel\", \"search\", etc. to override default \"text\" keyboard on\n mobile devices\n\n sub_max_length (int): The maximum length accepted for the 'sub' API field before sending to this verifier\n\n sub_pattern (str): A regular expression used to validate the 'sub' API field before sending to this verifier\n\n Extra args and kwargs are passed through to the underlying django.forms.Form.\n \"\"\"\n super().__init__(auto_id=True, label_suffix=\"\", *args, **kwargs)\n\n self.title = title\n self.headline = headline\n self.blurb = blurb\n\n self.classes = \"col-lg-6\"\n sub_widget = widgets.FormControlTextInput(placeholder=sub_placeholder)\n if sub_pattern:\n sub_widget.attrs.update({\"pattern\": sub_pattern})\n if sub_input_mode:\n sub_widget.attrs.update({\"inputmode\": sub_input_mode})\n if sub_max_length:\n sub_widget.attrs.update({\"maxlength\": sub_max_length})\n\n self.fields[\"sub\"] = forms.CharField(\n label=sub_label,\n widget=sub_widget,\n help_text=sub_help_text,\n )\n\n name_widget = widgets.FormControlTextInput(placeholder=name_placeholder)\n if name_max_length:\n name_widget.attrs.update({\"maxlength\": name_max_length})\n\n self.fields[\"name\"] = forms.CharField(label=name_label, widget=name_widget, help_text=name_help_text)\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass MSTCourtesyCard(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the MST Courtesy Card.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Courtesy Card number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Courtesy Card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Courtesy Card.\"),\n sub_label=_(\"MST Courtesy Card number\"),\n sub_help_text=_(\"This is a 5-digit number on the front and back of your card.\"),\n sub_placeholder=\"12345\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=5,\n sub_pattern=r\"\\d{5}\",\n *args,\n **kwargs,\n )\n\n\nclass SBMTDMobilityPass(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the SBMTD Reduced Fare Mobility ID.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Reduced Fare Mobility ID number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Reduced Fare Mobility ID card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Reduced Fare Mobility ID.\"),\n sub_label=_(\"SBMTD Reduced Fare Mobility ID number\"),\n sub_help_text=_(\"This is a 4-digit number on the back of your card.\"),\n sub_placeholder=\"1234\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=4,\n sub_pattern=r\"\\d{4}\",\n *args,\n **kwargs,\n )\n", "path": "benefits/eligibility/forms.py"}]}
| 2,356 | 362 |
gh_patches_debug_17971
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-630
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The DB API Binary function should accept bytes.
```
(3.8) jim@ds9:~/p/g/python-bigquery-sqlalchemy$ python
Python 3.8.5 (default, Jan 27 2021, 15:41:15)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import google.cloud.bigquery.dbapi
>>> google.cloud.bigquery.dbapi.Binary(b'x')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jim/p/g/python-bigquery/google/cloud/bigquery/dbapi/types.py", line 42, in Binary
return string.encode("utf-8")
AttributeError: 'bytes' object has no attribute 'encode'
```
Bytes are the most common way to represent binary data. Accepting strings, as it does now seems at best to be a convenience and at worst a bug magnet.
In SQLAlchemy, if you defined a model that has a binary attribute, you'd store bytes data in it, but that would break for bigquery, di to this issue.
Sqlite's `Binary` function requires bytes data.
I propose to change the function to accept bytes. For the sake of backward compatibility, I propose to continue to accept strings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/dbapi/types.py`
Content:
```
1 # Copyright 2017 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Types used in the Google BigQuery DB-API.
16
17 See `PEP-249`_ for details.
18
19 .. _PEP-249:
20 https://www.python.org/dev/peps/pep-0249/#type-objects-and-constructors
21 """
22
23 import datetime
24
25
26 Date = datetime.date
27 Time = datetime.time
28 Timestamp = datetime.datetime
29 DateFromTicks = datetime.date.fromtimestamp
30 TimestampFromTicks = datetime.datetime.fromtimestamp
31
32
33 def Binary(string):
34 """Contruct a DB-API binary value.
35
36 Args:
37 string (str): A string to encode as a binary value.
38
39 Returns:
40 bytes: The UTF-8 encoded bytes representing the string.
41 """
42 return string.encode("utf-8")
43
44
45 def TimeFromTicks(ticks, tz=None):
46 """Construct a DB-API time value from the given ticks value.
47
48 Args:
49 ticks (float):
50 a number of seconds since the epoch; see the documentation of the
51 standard Python time module for details.
52
53 tz (datetime.tzinfo): (Optional) time zone to use for conversion
54
55 Returns:
56 datetime.time: time represented by ticks.
57 """
58 dt = datetime.datetime.fromtimestamp(ticks, tz=tz)
59 return dt.timetz()
60
61
62 class _DBAPITypeObject(object):
63 """DB-API type object which compares equal to many different strings.
64
65 See `PEP-249`_ for details.
66
67 .. _PEP-249:
68 https://www.python.org/dev/peps/pep-0249/#implementation-hints-for-module-authors
69 """
70
71 def __init__(self, *values):
72 self.values = values
73
74 def __eq__(self, other):
75 return other in self.values
76
77
78 STRING = "STRING"
79 BINARY = _DBAPITypeObject("BYTES", "RECORD", "STRUCT")
80 NUMBER = _DBAPITypeObject(
81 "INTEGER", "INT64", "FLOAT", "FLOAT64", "NUMERIC", "BIGNUMERIC", "BOOLEAN", "BOOL"
82 )
83 DATETIME = _DBAPITypeObject("TIMESTAMP", "DATE", "TIME", "DATETIME")
84 ROWID = "ROWID"
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/dbapi/types.py b/google/cloud/bigquery/dbapi/types.py
--- a/google/cloud/bigquery/dbapi/types.py
+++ b/google/cloud/bigquery/dbapi/types.py
@@ -30,16 +30,28 @@
TimestampFromTicks = datetime.datetime.fromtimestamp
-def Binary(string):
+def Binary(data):
"""Contruct a DB-API binary value.
Args:
- string (str): A string to encode as a binary value.
+ data (bytes-like): An object containing binary data and that
+ can be converted to bytes with the `bytes` builtin.
Returns:
- bytes: The UTF-8 encoded bytes representing the string.
+ bytes: The binary data as a bytes object.
"""
- return string.encode("utf-8")
+ if isinstance(data, int):
+ # This is not the conversion we're looking for, because it
+ # will simply create a bytes object of the given size.
+ raise TypeError("cannot convert `int` object to binary")
+
+ try:
+ return bytes(data)
+ except TypeError:
+ if isinstance(data, str):
+ return data.encode("utf-8")
+ else:
+ raise
def TimeFromTicks(ticks, tz=None):
|
{"golden_diff": "diff --git a/google/cloud/bigquery/dbapi/types.py b/google/cloud/bigquery/dbapi/types.py\n--- a/google/cloud/bigquery/dbapi/types.py\n+++ b/google/cloud/bigquery/dbapi/types.py\n@@ -30,16 +30,28 @@\n TimestampFromTicks = datetime.datetime.fromtimestamp\n \n \n-def Binary(string):\n+def Binary(data):\n \"\"\"Contruct a DB-API binary value.\n \n Args:\n- string (str): A string to encode as a binary value.\n+ data (bytes-like): An object containing binary data and that\n+ can be converted to bytes with the `bytes` builtin.\n \n Returns:\n- bytes: The UTF-8 encoded bytes representing the string.\n+ bytes: The binary data as a bytes object.\n \"\"\"\n- return string.encode(\"utf-8\")\n+ if isinstance(data, int):\n+ # This is not the conversion we're looking for, because it\n+ # will simply create a bytes object of the given size.\n+ raise TypeError(\"cannot convert `int` object to binary\")\n+\n+ try:\n+ return bytes(data)\n+ except TypeError:\n+ if isinstance(data, str):\n+ return data.encode(\"utf-8\")\n+ else:\n+ raise\n \n \n def TimeFromTicks(ticks, tz=None):\n", "issue": "The DB API Binary function should accept bytes.\n```\r\n(3.8) jim@ds9:~/p/g/python-bigquery-sqlalchemy$ python\r\nPython 3.8.5 (default, Jan 27 2021, 15:41:15) \r\n[GCC 9.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import google.cloud.bigquery.dbapi\r\n>>> google.cloud.bigquery.dbapi.Binary(b'x')\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/jim/p/g/python-bigquery/google/cloud/bigquery/dbapi/types.py\", line 42, in Binary\r\n return string.encode(\"utf-8\")\r\nAttributeError: 'bytes' object has no attribute 'encode'\r\n```\r\nBytes are the most common way to represent binary data. Accepting strings, as it does now seems at best to be a convenience and at worst a bug magnet.\r\n\r\nIn SQLAlchemy, if you defined a model that has a binary attribute, you'd store bytes data in it, but that would break for bigquery, di to this issue.\r\n\r\nSqlite's `Binary` function requires bytes data.\r\n\r\nI propose to change the function to accept bytes. For the sake of backward compatibility, I propose to continue to accept strings.\r\n\n", "before_files": [{"content": "# Copyright 2017 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Types used in the Google BigQuery DB-API.\n\nSee `PEP-249`_ for details.\n\n.. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#type-objects-and-constructors\n\"\"\"\n\nimport datetime\n\n\nDate = datetime.date\nTime = datetime.time\nTimestamp = datetime.datetime\nDateFromTicks = datetime.date.fromtimestamp\nTimestampFromTicks = datetime.datetime.fromtimestamp\n\n\ndef Binary(string):\n \"\"\"Contruct a DB-API binary value.\n\n Args:\n string (str): A string to encode as a binary value.\n\n Returns:\n bytes: The UTF-8 encoded bytes representing the string.\n \"\"\"\n return string.encode(\"utf-8\")\n\n\ndef TimeFromTicks(ticks, tz=None):\n \"\"\"Construct a DB-API time value from the given ticks value.\n\n Args:\n ticks (float):\n a number of seconds since the epoch; see the documentation of the\n standard Python time module for details.\n\n tz (datetime.tzinfo): (Optional) time zone to use for conversion\n\n Returns:\n datetime.time: time represented by ticks.\n \"\"\"\n dt = datetime.datetime.fromtimestamp(ticks, tz=tz)\n return dt.timetz()\n\n\nclass _DBAPITypeObject(object):\n \"\"\"DB-API type object which compares equal to many different strings.\n\n See `PEP-249`_ for details.\n\n .. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#implementation-hints-for-module-authors\n \"\"\"\n\n def __init__(self, *values):\n self.values = values\n\n def __eq__(self, other):\n return other in self.values\n\n\nSTRING = \"STRING\"\nBINARY = _DBAPITypeObject(\"BYTES\", \"RECORD\", \"STRUCT\")\nNUMBER = _DBAPITypeObject(\n \"INTEGER\", \"INT64\", \"FLOAT\", \"FLOAT64\", \"NUMERIC\", \"BIGNUMERIC\", \"BOOLEAN\", \"BOOL\"\n)\nDATETIME = _DBAPITypeObject(\"TIMESTAMP\", \"DATE\", \"TIME\", \"DATETIME\")\nROWID = \"ROWID\"\n", "path": "google/cloud/bigquery/dbapi/types.py"}], "after_files": [{"content": "# Copyright 2017 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Types used in the Google BigQuery DB-API.\n\nSee `PEP-249`_ for details.\n\n.. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#type-objects-and-constructors\n\"\"\"\n\nimport datetime\n\n\nDate = datetime.date\nTime = datetime.time\nTimestamp = datetime.datetime\nDateFromTicks = datetime.date.fromtimestamp\nTimestampFromTicks = datetime.datetime.fromtimestamp\n\n\ndef Binary(data):\n \"\"\"Contruct a DB-API binary value.\n\n Args:\n data (bytes-like): An object containing binary data and that\n can be converted to bytes with the `bytes` builtin.\n\n Returns:\n bytes: The binary data as a bytes object.\n \"\"\"\n if isinstance(data, int):\n # This is not the conversion we're looking for, because it\n # will simply create a bytes object of the given size.\n raise TypeError(\"cannot convert `int` object to binary\")\n\n try:\n return bytes(data)\n except TypeError:\n if isinstance(data, str):\n return data.encode(\"utf-8\")\n else:\n raise\n\n\ndef TimeFromTicks(ticks, tz=None):\n \"\"\"Construct a DB-API time value from the given ticks value.\n\n Args:\n ticks (float):\n a number of seconds since the epoch; see the documentation of the\n standard Python time module for details.\n\n tz (datetime.tzinfo): (Optional) time zone to use for conversion\n\n Returns:\n datetime.time: time represented by ticks.\n \"\"\"\n dt = datetime.datetime.fromtimestamp(ticks, tz=tz)\n return dt.timetz()\n\n\nclass _DBAPITypeObject(object):\n \"\"\"DB-API type object which compares equal to many different strings.\n\n See `PEP-249`_ for details.\n\n .. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#implementation-hints-for-module-authors\n \"\"\"\n\n def __init__(self, *values):\n self.values = values\n\n def __eq__(self, other):\n return other in self.values\n\n\nSTRING = \"STRING\"\nBINARY = _DBAPITypeObject(\"BYTES\", \"RECORD\", \"STRUCT\")\nNUMBER = _DBAPITypeObject(\n \"INTEGER\", \"INT64\", \"FLOAT\", \"FLOAT64\", \"NUMERIC\", \"BIGNUMERIC\", \"BOOLEAN\", \"BOOL\"\n)\nDATETIME = _DBAPITypeObject(\"TIMESTAMP\", \"DATE\", \"TIME\", \"DATETIME\")\nROWID = \"ROWID\"\n", "path": "google/cloud/bigquery/dbapi/types.py"}]}
| 1,340 | 282 |
gh_patches_debug_33957
|
rasdani/github-patches
|
git_diff
|
ManageIQ__integration_tests-5099
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ImportError in cfme/infrastructure/test_host.py
PR #4905 removed credential_form from cfme.infrastructure.host, resulting in an ImportError on test setup.
```ImportError while importing test module '/home/mshriver/repos/integration_tests/cfme/tests/infrastructure/test_host.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
cfme/tests/infrastructure/test_host.py:6: in <module>
from cfme.infrastructure.host import credential_form
E ImportError: cannot import name credential_form
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cfme/common/host_views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from widgetastic.utils import ParametrizedLocator
3 from widgetastic.widget import ParametrizedView, Text, View
4 from widgetastic_manageiq import (
5 BaseEntitiesView,
6 BaseEntity,
7 BaseListEntity,
8 BaseQuadIconEntity,
9 BaseTileIconEntity,
10 BootstrapTreeview,
11 BreadCrumb,
12 Button,
13 Checkbox,
14 Input,
15 ItemsToolBarViewSelector,
16 PaginationPane,
17 SummaryTable,
18 Table,
19 TimelinesView
20 )
21 from widgetastic_patternfly import (
22 BootstrapSelect,
23 CheckableBootstrapTreeview,
24 Dropdown,
25 FlashMessages,
26 Tab
27 )
28
29 from cfme.base.login import BaseLoggedInPage
30
31
32 class ComputeInfrastructureHostsView(BaseLoggedInPage):
33 """Common parts for host views."""
34 title = Text('.//div[@id="center_div" or @id="main-content"]//h1')
35 flash = FlashMessages(
36 './/div[@id="flash_msg_div"]/div[@id="flash_text_div" or '
37 'contains(@class, "flash_text_div")]'
38 )
39
40 @property
41 def in_compute_infrastructure_hosts(self):
42 return (
43 self.logged_in_as_current_user and
44 self.navigation.currently_selected == ["Compute", "Infrastructure", "Hosts"]
45 )
46
47
48 class HostQuadIconEntity(BaseQuadIconEntity):
49
50 # TODO Move these properties to one 'data' property
51 @property
52 def no_vm(self):
53 return int(self.browser.text(self.QUADRANT.format(pos="a")))
54
55 @property
56 def status(self):
57 return self.browser.get_attribute("style", self.QUADRANT.format(pos="b"))
58
59 @property
60 def vendor(self):
61 return self.browser.get_attribute("alt", self.QUADRANT.format(pos="c"))
62
63 @property
64 def creds(self):
65 return self.browser.get_attribute("alt", self.QUADRANT.format(pos="d"))
66
67
68 class HostTileIconEntity(BaseTileIconEntity):
69 quad_icon = ParametrizedView.nested(HostQuadIconEntity)
70
71
72 class HostListEntity(BaseListEntity):
73 pass
74
75
76 class HostEntity(BaseEntity):
77 quad_entity = HostQuadIconEntity
78 list_entity = HostListEntity
79 tile_entity = HostTileIconEntity
80
81
82 class HostDetailsToolbar(View):
83 """Represents host toolbar and its controls."""
84 monitoring = Dropdown(text="Monitoring")
85 configuration = Dropdown(text="Configuration")
86 policy = Dropdown(text="Policy")
87 power = Dropdown(text="Power")
88
89
90 class HostDetailsEntities(View):
91 """Represents Details page."""
92 properties = SummaryTable(title="Properties")
93 relationships = SummaryTable(title="Relationships")
94 compliance = SummaryTable(title="Compliance")
95 configuration = SummaryTable(title="Configuration")
96 smart_management = SummaryTable(title="Smart Management")
97 authentication_status = SummaryTable(title="Authentication Status")
98
99
100 class HostDetailsView(ComputeInfrastructureHostsView):
101 """Main Host details page."""
102 breadcrumb = BreadCrumb(locator='.//ol[@class="breadcrumb"]')
103 toolbar = View.nested(HostDetailsToolbar)
104 entities = View.nested(HostDetailsEntities)
105
106 @property
107 def is_displayed(self):
108 title = "{name} (Summary)".format(name=self.context["object"].name)
109 return self.in_compute_infrastructure_hosts and self.breadcrumb.active_location == title
110
111
112 class HostDriftHistory(ComputeInfrastructureHostsView):
113 breadcrumb = BreadCrumb(locator='.//ol[@class="breadcrumb"]')
114 history_table = Table(locator='.//div[@id="main_div"]/table')
115 analyze_button = Button(title="Select up to 10 timestamps for Drift Analysis")
116
117 @property
118 def is_displayed(self):
119 return (
120 self.in_compute_infrastructure_hosts and
121 self.title.text == "Drift History" and
122 self.history_table.is_displayed
123 )
124
125
126 class HostDriftAnalysis(ComputeInfrastructureHostsView):
127 apply_button = Button("Apply")
128 drift_sections = CheckableBootstrapTreeview(tree_id="all_sectionsbox")
129
130 @ParametrizedView.nested
131 class drift_analysis(ParametrizedView): # noqa
132 PARAMETERS = ("drift_section", )
133 CELLS = "../td//i"
134 row = Text(ParametrizedLocator(".//div[@id='compare-grid']/"
135 "/th[normalize-space(.)={drift_section|quote}]"))
136
137 @property
138 def is_changed(self):
139 cells = self.browser.elements(self.CELLS, parent=self.row)
140 attrs = [self.browser.get_attribute("class", cell) for cell in cells]
141 return "drift-delta" in attrs
142
143 @View.nested
144 class toolbar(View): # noqa
145 all_attributes = Button(title="All attributes")
146 different_values_attributes = Button(title="Attributes with different")
147 same_values_attributes = Button(title="Attributes with same values")
148 details_mode = Button(title="Details Mode")
149 exists_mode = Button(title="Exists Mode")
150
151 @property
152 def is_displayed(self):
153 return (
154 self.in_compute_infrastructure_hosts and
155 self.title.text == "'{}' Drift Analysis".format(self.context["object"].name)
156 )
157
158
159 class HostTimelinesView(TimelinesView, ComputeInfrastructureHostsView):
160 """Represents a Host Timelines page."""
161
162 @property
163 def is_displayed(self):
164 return self.in_compute_infrastructure_hosts and super(TimelinesView, self).is_displayed
165
166
167 class HostDiscoverView(ComputeInfrastructureHostsView):
168 """Discover View from Compute/Infrastructure/Hosts page."""
169 esx = Checkbox(name="discover_type_esx")
170 ipmi = Checkbox(name="discover_type_ipmi")
171
172 from_ip1 = Input(name="from_first")
173 from_ip2 = Input(name="from_second")
174 from_ip3 = Input(name="from_third")
175 from_ip4 = Input(name="from_fourth")
176 to_ip4 = Input(name="to_fourth")
177
178 start_button = Button("Start")
179 cancel_button = Button("Cancel")
180
181 @property
182 def is_displayed(self):
183 return self.in_compute_infrastructure_hosts and self.title.text == "Hosts / Nodes Discovery"
184
185
186 class HostManagePoliciesView(BaseLoggedInPage):
187 """Host's Manage Policies view."""
188 policies = BootstrapTreeview("protectbox")
189 save_button = Button("Save")
190 reset_button = Button("Reset")
191 cancel_button = Button("Cancel")
192
193 @property
194 def is_displayed(self):
195 return False
196
197
198 class HostEditTagsView(BaseLoggedInPage):
199 """Host's Edit Tags view."""
200 tag_category = BootstrapSelect("tag_cat")
201 tag = BootstrapSelect("tag_add")
202 chosen_tags = Table(locator='.//div[@id="assignments_div"]/table')
203
204 save_button = Button("Save")
205 reset_button = Button("Reset")
206 cancel_button = Button("Cancel")
207
208 @property
209 def is_displayed(self):
210 return False
211
212
213 class HostsToolbar(View):
214 """Represents hosts toolbar and its controls."""
215 configuration = Dropdown(text="Configuration")
216 policy = Dropdown(text="Policy")
217 lifecycle = Dropdown(text="Lifecycle")
218 monitoring = Dropdown(text="Monitoring")
219 power = Dropdown(text="Power")
220 view_selector = View.nested(ItemsToolBarViewSelector)
221
222
223 class HostSideBar(View):
224 """Represents left side bar. It usually contains navigation, filters, etc."""
225 pass
226
227
228 class HostEntitiesView(BaseEntitiesView):
229 """Represents the view with different items like hosts."""
230 @property
231 def entity_class(self):
232 return HostEntity
233
234
235 class HostsView(ComputeInfrastructureHostsView):
236 toolbar = View.nested(HostsToolbar)
237 sidebar = View.nested(HostSideBar)
238 paginator = View.nested(PaginationPane)
239 including_entities = View.include(HostEntitiesView, use_parent=True)
240
241 @property
242 def is_displayed(self):
243 return self.in_compute_infrastructure_hosts and self.title.text == "Hosts"
244
245
246 class HostFormView(ComputeInfrastructureHostsView):
247 # Info/Settings
248 title = Text(".//div[@id='main-content']//h1")
249 name = Input(name="name")
250 hostname = Input(name="hostname")
251 custom_ident = Input(name="custom_1")
252 ipmi_address = Input(name="ipmi_address")
253 mac_address = Input(name="mac_address")
254
255 @View.nested
256 class endpoints(View): # noqa
257 @View.nested
258 class default(Tab): # noqa
259 username = Input(name="default_userid")
260 password = Input(name="default_password")
261 confirm_password = Input(name="default_verify")
262 validate_button = Button("Validate")
263
264 @View.nested
265 class remote_login(Tab): # noqa
266 TAB_NAME = "Remote Login"
267 username = Input(name="remote_userid")
268 password = Input(name="remote_password")
269 confirm_password = Input(name="remote_verify")
270 validate_button = Button("Validate")
271
272 @View.nested
273 class web_services(Tab): # noqa
274 TAB_NAME = "Web Services"
275 username = Input(name="ws_userid")
276 password = Input(name="ws_password")
277 confirm_password = Input(name="ws_verify")
278 validate_button = Button("Validate")
279
280 @View.nested
281 class ipmi(Tab): # noqa
282 TAB_NAME = "IPMI"
283 username = Input(name="ipmi_userid")
284 password = Input(name="ipmi_password")
285 confirm_password = Input(name="ipmi_verify")
286 validate_button = Button("Validate")
287
288 cancel_button = Button("Cancel")
289
290
291 class HostAddView(HostFormView):
292 host_platform = BootstrapSelect("user_assigned_os")
293 add_button = Button("Add")
294 cancel_button = Button("Cancel")
295
296 @property
297 def is_displayed(self):
298 return self.in_compute_infrastructure_hosts and self.title.text == "Add New Host"
299
300
301 class HostEditView(HostFormView):
302 save_button = Button("Save")
303 reset_button = Button("Reset")
304 change_stored_password = Text(".//a[contains(@ng-hide, 'bChangeStoredPassword')]")
305
306 @property
307 def is_displayed(self):
308 return self.in_compute_infrastructure_hosts and self.title.text == "Info/Settings"
309
```
Path: `cfme/infrastructure/provider/virtualcenter.py`
Content:
```
1 from cfme.common.provider import DefaultEndpoint, DefaultEndpointForm
2 from . import InfraProvider
3 from wrapanapi.virtualcenter import VMWareSystem
4
5
6 class VirtualCenterEndpoint(DefaultEndpoint):
7 pass
8
9
10 class VirtualCenterEndpointForm(DefaultEndpointForm):
11 pass
12
13
14 class VMwareProvider(InfraProvider):
15 type_name = "virtualcenter"
16 mgmt_class = VMWareSystem
17 db_types = ["Vmware::InfraManager"]
18 endpoints_form = VirtualCenterEndpointForm
19 discover_dict = {"vmware": True}
20
21 def __init__(self, name=None, endpoints=None, key=None, zone=None, hostname=None,
22 ip_address=None, start_ip=None, end_ip=None, provider_data=None, appliance=None):
23 super(VMwareProvider, self).__init__(
24 name=name, endpoints=endpoints, zone=zone, key=key, provider_data=provider_data,
25 appliance=appliance)
26 self.hostname = hostname
27 self.start_ip = start_ip
28 self.end_ip = end_ip
29 if ip_address:
30 self.ip_address = ip_address
31
32 def deployment_helper(self, deploy_args):
33 """ Used in utils.virtual_machines """
34 # Called within a dictionary update. Since we want to remove key/value pairs, return the
35 # entire dictionary
36 deploy_args.pop('username', None)
37 deploy_args.pop('password', None)
38 if "allowed_datastores" not in deploy_args and "allowed_datastores" in self.data:
39 deploy_args['allowed_datastores'] = self.data['allowed_datastores']
40
41 return deploy_args
42
43 @classmethod
44 def from_config(cls, prov_config, prov_key, appliance=None):
45 endpoint = VirtualCenterEndpoint(**prov_config['endpoints']['default'])
46
47 if prov_config.get('discovery_range'):
48 start_ip = prov_config['discovery_range']['start']
49 end_ip = prov_config['discovery_range']['end']
50 else:
51 start_ip = end_ip = prov_config.get('ipaddress')
52 return cls(name=prov_config['name'],
53 endpoints={endpoint.name: endpoint},
54 zone=prov_config['server_zone'],
55 key=prov_key,
56 start_ip=start_ip,
57 end_ip=end_ip,
58 appliance=appliance)
59
60 @property
61 def view_value_mapping(self):
62 return {'name': self.name,
63 'prov_type': 'VMware vCenter'
64 }
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cfme/common/host_views.py b/cfme/common/host_views.py
--- a/cfme/common/host_views.py
+++ b/cfme/common/host_views.py
@@ -299,6 +299,7 @@
class HostEditView(HostFormView):
+ """View for editing a single host"""
save_button = Button("Save")
reset_button = Button("Reset")
change_stored_password = Text(".//a[contains(@ng-hide, 'bChangeStoredPassword')]")
@@ -306,3 +307,16 @@
@property
def is_displayed(self):
return self.in_compute_infrastructure_hosts and self.title.text == "Info/Settings"
+
+
+class HostsEditView(HostEditView):
+ """View when editing multiple hosts
+ Restricted to endpoints section of the form
+ Title changes
+ Must select host before validation
+ """
+ validation_host = BootstrapSelect('validate_id') # only shown when editing multiple hosts
+
+ @property
+ def is_displayed(self):
+ return self.in_compute_infrastructure_hosts and self.title.text == 'Credentials/Settings'
diff --git a/cfme/infrastructure/provider/virtualcenter.py b/cfme/infrastructure/provider/virtualcenter.py
--- a/cfme/infrastructure/provider/virtualcenter.py
+++ b/cfme/infrastructure/provider/virtualcenter.py
@@ -1,6 +1,11 @@
+from navmazing import NavigateToSibling
+from wrapanapi.virtualcenter import VMWareSystem
+
from cfme.common.provider import DefaultEndpoint, DefaultEndpointForm
+from cfme.common.provider_views import ProviderNodesView
+from cfme.exceptions import DestinationNotFound
+from utils.appliance.implementations.ui import CFMENavigateStep, navigator
from . import InfraProvider
-from wrapanapi.virtualcenter import VMWareSystem
class VirtualCenterEndpoint(DefaultEndpoint):
@@ -62,3 +67,15 @@
return {'name': self.name,
'prov_type': 'VMware vCenter'
}
+
+
[email protected](VMwareProvider, 'ProviderNodes') # matching other infra class destinations
+class ProviderNodes(CFMENavigateStep):
+ VIEW = ProviderNodesView
+ prerequisite = NavigateToSibling('Details')
+
+ def step(self):
+ try:
+ self.prerequisite_view.contents.relationships.click_at('Hosts')
+ except NameError:
+ raise DestinationNotFound("Hosts aren't present on details page of this provider")
|
{"golden_diff": "diff --git a/cfme/common/host_views.py b/cfme/common/host_views.py\n--- a/cfme/common/host_views.py\n+++ b/cfme/common/host_views.py\n@@ -299,6 +299,7 @@\n \n \n class HostEditView(HostFormView):\n+ \"\"\"View for editing a single host\"\"\"\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n change_stored_password = Text(\".//a[contains(@ng-hide, 'bChangeStoredPassword')]\")\n@@ -306,3 +307,16 @@\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Info/Settings\"\n+\n+\n+class HostsEditView(HostEditView):\n+ \"\"\"View when editing multiple hosts\n+ Restricted to endpoints section of the form\n+ Title changes\n+ Must select host before validation\n+ \"\"\"\n+ validation_host = BootstrapSelect('validate_id') # only shown when editing multiple hosts\n+\n+ @property\n+ def is_displayed(self):\n+ return self.in_compute_infrastructure_hosts and self.title.text == 'Credentials/Settings'\ndiff --git a/cfme/infrastructure/provider/virtualcenter.py b/cfme/infrastructure/provider/virtualcenter.py\n--- a/cfme/infrastructure/provider/virtualcenter.py\n+++ b/cfme/infrastructure/provider/virtualcenter.py\n@@ -1,6 +1,11 @@\n+from navmazing import NavigateToSibling\n+from wrapanapi.virtualcenter import VMWareSystem\n+\n from cfme.common.provider import DefaultEndpoint, DefaultEndpointForm\n+from cfme.common.provider_views import ProviderNodesView\n+from cfme.exceptions import DestinationNotFound\n+from utils.appliance.implementations.ui import CFMENavigateStep, navigator\n from . import InfraProvider\n-from wrapanapi.virtualcenter import VMWareSystem\n \n \n class VirtualCenterEndpoint(DefaultEndpoint):\n@@ -62,3 +67,15 @@\n return {'name': self.name,\n 'prov_type': 'VMware vCenter'\n }\n+\n+\[email protected](VMwareProvider, 'ProviderNodes') # matching other infra class destinations\n+class ProviderNodes(CFMENavigateStep):\n+ VIEW = ProviderNodesView\n+ prerequisite = NavigateToSibling('Details')\n+\n+ def step(self):\n+ try:\n+ self.prerequisite_view.contents.relationships.click_at('Hosts')\n+ except NameError:\n+ raise DestinationNotFound(\"Hosts aren't present on details page of this provider\")\n", "issue": "ImportError in cfme/infrastructure/test_host.py\nPR #4905 removed credential_form from cfme.infrastructure.host, resulting in an ImportError on test setup.\r\n\r\n```ImportError while importing test module '/home/mshriver/repos/integration_tests/cfme/tests/infrastructure/test_host.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\ncfme/tests/infrastructure/test_host.py:6: in <module>\r\n from cfme.infrastructure.host import credential_form\r\nE ImportError: cannot import name credential_form\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom widgetastic.utils import ParametrizedLocator\nfrom widgetastic.widget import ParametrizedView, Text, View\nfrom widgetastic_manageiq import (\n BaseEntitiesView,\n BaseEntity,\n BaseListEntity,\n BaseQuadIconEntity,\n BaseTileIconEntity,\n BootstrapTreeview,\n BreadCrumb,\n Button,\n Checkbox,\n Input,\n ItemsToolBarViewSelector,\n PaginationPane,\n SummaryTable,\n Table,\n TimelinesView\n)\nfrom widgetastic_patternfly import (\n BootstrapSelect,\n CheckableBootstrapTreeview,\n Dropdown,\n FlashMessages,\n Tab\n)\n\nfrom cfme.base.login import BaseLoggedInPage\n\n\nclass ComputeInfrastructureHostsView(BaseLoggedInPage):\n \"\"\"Common parts for host views.\"\"\"\n title = Text('.//div[@id=\"center_div\" or @id=\"main-content\"]//h1')\n flash = FlashMessages(\n './/div[@id=\"flash_msg_div\"]/div[@id=\"flash_text_div\" or '\n 'contains(@class, \"flash_text_div\")]'\n )\n\n @property\n def in_compute_infrastructure_hosts(self):\n return (\n self.logged_in_as_current_user and\n self.navigation.currently_selected == [\"Compute\", \"Infrastructure\", \"Hosts\"]\n )\n\n\nclass HostQuadIconEntity(BaseQuadIconEntity):\n\n # TODO Move these properties to one 'data' property\n @property\n def no_vm(self):\n return int(self.browser.text(self.QUADRANT.format(pos=\"a\")))\n\n @property\n def status(self):\n return self.browser.get_attribute(\"style\", self.QUADRANT.format(pos=\"b\"))\n\n @property\n def vendor(self):\n return self.browser.get_attribute(\"alt\", self.QUADRANT.format(pos=\"c\"))\n\n @property\n def creds(self):\n return self.browser.get_attribute(\"alt\", self.QUADRANT.format(pos=\"d\"))\n\n\nclass HostTileIconEntity(BaseTileIconEntity):\n quad_icon = ParametrizedView.nested(HostQuadIconEntity)\n\n\nclass HostListEntity(BaseListEntity):\n pass\n\n\nclass HostEntity(BaseEntity):\n quad_entity = HostQuadIconEntity\n list_entity = HostListEntity\n tile_entity = HostTileIconEntity\n\n\nclass HostDetailsToolbar(View):\n \"\"\"Represents host toolbar and its controls.\"\"\"\n monitoring = Dropdown(text=\"Monitoring\")\n configuration = Dropdown(text=\"Configuration\")\n policy = Dropdown(text=\"Policy\")\n power = Dropdown(text=\"Power\")\n\n\nclass HostDetailsEntities(View):\n \"\"\"Represents Details page.\"\"\"\n properties = SummaryTable(title=\"Properties\")\n relationships = SummaryTable(title=\"Relationships\")\n compliance = SummaryTable(title=\"Compliance\")\n configuration = SummaryTable(title=\"Configuration\")\n smart_management = SummaryTable(title=\"Smart Management\")\n authentication_status = SummaryTable(title=\"Authentication Status\")\n\n\nclass HostDetailsView(ComputeInfrastructureHostsView):\n \"\"\"Main Host details page.\"\"\"\n breadcrumb = BreadCrumb(locator='.//ol[@class=\"breadcrumb\"]')\n toolbar = View.nested(HostDetailsToolbar)\n entities = View.nested(HostDetailsEntities)\n\n @property\n def is_displayed(self):\n title = \"{name} (Summary)\".format(name=self.context[\"object\"].name)\n return self.in_compute_infrastructure_hosts and self.breadcrumb.active_location == title\n\n\nclass HostDriftHistory(ComputeInfrastructureHostsView):\n breadcrumb = BreadCrumb(locator='.//ol[@class=\"breadcrumb\"]')\n history_table = Table(locator='.//div[@id=\"main_div\"]/table')\n analyze_button = Button(title=\"Select up to 10 timestamps for Drift Analysis\")\n\n @property\n def is_displayed(self):\n return (\n self.in_compute_infrastructure_hosts and\n self.title.text == \"Drift History\" and\n self.history_table.is_displayed\n )\n\n\nclass HostDriftAnalysis(ComputeInfrastructureHostsView):\n apply_button = Button(\"Apply\")\n drift_sections = CheckableBootstrapTreeview(tree_id=\"all_sectionsbox\")\n\n @ParametrizedView.nested\n class drift_analysis(ParametrizedView): # noqa\n PARAMETERS = (\"drift_section\", )\n CELLS = \"../td//i\"\n row = Text(ParametrizedLocator(\".//div[@id='compare-grid']/\"\n \"/th[normalize-space(.)={drift_section|quote}]\"))\n\n @property\n def is_changed(self):\n cells = self.browser.elements(self.CELLS, parent=self.row)\n attrs = [self.browser.get_attribute(\"class\", cell) for cell in cells]\n return \"drift-delta\" in attrs\n\n @View.nested\n class toolbar(View): # noqa\n all_attributes = Button(title=\"All attributes\")\n different_values_attributes = Button(title=\"Attributes with different\")\n same_values_attributes = Button(title=\"Attributes with same values\")\n details_mode = Button(title=\"Details Mode\")\n exists_mode = Button(title=\"Exists Mode\")\n\n @property\n def is_displayed(self):\n return (\n self.in_compute_infrastructure_hosts and\n self.title.text == \"'{}' Drift Analysis\".format(self.context[\"object\"].name)\n )\n\n\nclass HostTimelinesView(TimelinesView, ComputeInfrastructureHostsView):\n \"\"\"Represents a Host Timelines page.\"\"\"\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and super(TimelinesView, self).is_displayed\n\n\nclass HostDiscoverView(ComputeInfrastructureHostsView):\n \"\"\"Discover View from Compute/Infrastructure/Hosts page.\"\"\"\n esx = Checkbox(name=\"discover_type_esx\")\n ipmi = Checkbox(name=\"discover_type_ipmi\")\n\n from_ip1 = Input(name=\"from_first\")\n from_ip2 = Input(name=\"from_second\")\n from_ip3 = Input(name=\"from_third\")\n from_ip4 = Input(name=\"from_fourth\")\n to_ip4 = Input(name=\"to_fourth\")\n\n start_button = Button(\"Start\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Hosts / Nodes Discovery\"\n\n\nclass HostManagePoliciesView(BaseLoggedInPage):\n \"\"\"Host's Manage Policies view.\"\"\"\n policies = BootstrapTreeview(\"protectbox\")\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return False\n\n\nclass HostEditTagsView(BaseLoggedInPage):\n \"\"\"Host's Edit Tags view.\"\"\"\n tag_category = BootstrapSelect(\"tag_cat\")\n tag = BootstrapSelect(\"tag_add\")\n chosen_tags = Table(locator='.//div[@id=\"assignments_div\"]/table')\n\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return False\n\n\nclass HostsToolbar(View):\n \"\"\"Represents hosts toolbar and its controls.\"\"\"\n configuration = Dropdown(text=\"Configuration\")\n policy = Dropdown(text=\"Policy\")\n lifecycle = Dropdown(text=\"Lifecycle\")\n monitoring = Dropdown(text=\"Monitoring\")\n power = Dropdown(text=\"Power\")\n view_selector = View.nested(ItemsToolBarViewSelector)\n\n\nclass HostSideBar(View):\n \"\"\"Represents left side bar. It usually contains navigation, filters, etc.\"\"\"\n pass\n\n\nclass HostEntitiesView(BaseEntitiesView):\n \"\"\"Represents the view with different items like hosts.\"\"\"\n @property\n def entity_class(self):\n return HostEntity\n\n\nclass HostsView(ComputeInfrastructureHostsView):\n toolbar = View.nested(HostsToolbar)\n sidebar = View.nested(HostSideBar)\n paginator = View.nested(PaginationPane)\n including_entities = View.include(HostEntitiesView, use_parent=True)\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Hosts\"\n\n\nclass HostFormView(ComputeInfrastructureHostsView):\n # Info/Settings\n title = Text(\".//div[@id='main-content']//h1\")\n name = Input(name=\"name\")\n hostname = Input(name=\"hostname\")\n custom_ident = Input(name=\"custom_1\")\n ipmi_address = Input(name=\"ipmi_address\")\n mac_address = Input(name=\"mac_address\")\n\n @View.nested\n class endpoints(View): # noqa\n @View.nested\n class default(Tab): # noqa\n username = Input(name=\"default_userid\")\n password = Input(name=\"default_password\")\n confirm_password = Input(name=\"default_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class remote_login(Tab): # noqa\n TAB_NAME = \"Remote Login\"\n username = Input(name=\"remote_userid\")\n password = Input(name=\"remote_password\")\n confirm_password = Input(name=\"remote_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class web_services(Tab): # noqa\n TAB_NAME = \"Web Services\"\n username = Input(name=\"ws_userid\")\n password = Input(name=\"ws_password\")\n confirm_password = Input(name=\"ws_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class ipmi(Tab): # noqa\n TAB_NAME = \"IPMI\"\n username = Input(name=\"ipmi_userid\")\n password = Input(name=\"ipmi_password\")\n confirm_password = Input(name=\"ipmi_verify\")\n validate_button = Button(\"Validate\")\n\n cancel_button = Button(\"Cancel\")\n\n\nclass HostAddView(HostFormView):\n host_platform = BootstrapSelect(\"user_assigned_os\")\n add_button = Button(\"Add\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Add New Host\"\n\n\nclass HostEditView(HostFormView):\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n change_stored_password = Text(\".//a[contains(@ng-hide, 'bChangeStoredPassword')]\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Info/Settings\"\n", "path": "cfme/common/host_views.py"}, {"content": "from cfme.common.provider import DefaultEndpoint, DefaultEndpointForm\nfrom . import InfraProvider\nfrom wrapanapi.virtualcenter import VMWareSystem\n\n\nclass VirtualCenterEndpoint(DefaultEndpoint):\n pass\n\n\nclass VirtualCenterEndpointForm(DefaultEndpointForm):\n pass\n\n\nclass VMwareProvider(InfraProvider):\n type_name = \"virtualcenter\"\n mgmt_class = VMWareSystem\n db_types = [\"Vmware::InfraManager\"]\n endpoints_form = VirtualCenterEndpointForm\n discover_dict = {\"vmware\": True}\n\n def __init__(self, name=None, endpoints=None, key=None, zone=None, hostname=None,\n ip_address=None, start_ip=None, end_ip=None, provider_data=None, appliance=None):\n super(VMwareProvider, self).__init__(\n name=name, endpoints=endpoints, zone=zone, key=key, provider_data=provider_data,\n appliance=appliance)\n self.hostname = hostname\n self.start_ip = start_ip\n self.end_ip = end_ip\n if ip_address:\n self.ip_address = ip_address\n\n def deployment_helper(self, deploy_args):\n \"\"\" Used in utils.virtual_machines \"\"\"\n # Called within a dictionary update. Since we want to remove key/value pairs, return the\n # entire dictionary\n deploy_args.pop('username', None)\n deploy_args.pop('password', None)\n if \"allowed_datastores\" not in deploy_args and \"allowed_datastores\" in self.data:\n deploy_args['allowed_datastores'] = self.data['allowed_datastores']\n\n return deploy_args\n\n @classmethod\n def from_config(cls, prov_config, prov_key, appliance=None):\n endpoint = VirtualCenterEndpoint(**prov_config['endpoints']['default'])\n\n if prov_config.get('discovery_range'):\n start_ip = prov_config['discovery_range']['start']\n end_ip = prov_config['discovery_range']['end']\n else:\n start_ip = end_ip = prov_config.get('ipaddress')\n return cls(name=prov_config['name'],\n endpoints={endpoint.name: endpoint},\n zone=prov_config['server_zone'],\n key=prov_key,\n start_ip=start_ip,\n end_ip=end_ip,\n appliance=appliance)\n\n @property\n def view_value_mapping(self):\n return {'name': self.name,\n 'prov_type': 'VMware vCenter'\n }\n", "path": "cfme/infrastructure/provider/virtualcenter.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom widgetastic.utils import ParametrizedLocator\nfrom widgetastic.widget import ParametrizedView, Text, View\nfrom widgetastic_manageiq import (\n BaseEntitiesView,\n BaseEntity,\n BaseListEntity,\n BaseQuadIconEntity,\n BaseTileIconEntity,\n BootstrapTreeview,\n BreadCrumb,\n Button,\n Checkbox,\n Input,\n ItemsToolBarViewSelector,\n PaginationPane,\n SummaryTable,\n Table,\n TimelinesView\n)\nfrom widgetastic_patternfly import (\n BootstrapSelect,\n CheckableBootstrapTreeview,\n Dropdown,\n FlashMessages,\n Tab\n)\n\nfrom cfme.base.login import BaseLoggedInPage\n\n\nclass ComputeInfrastructureHostsView(BaseLoggedInPage):\n \"\"\"Common parts for host views.\"\"\"\n title = Text('.//div[@id=\"center_div\" or @id=\"main-content\"]//h1')\n flash = FlashMessages(\n './/div[@id=\"flash_msg_div\"]/div[@id=\"flash_text_div\" or '\n 'contains(@class, \"flash_text_div\")]'\n )\n\n @property\n def in_compute_infrastructure_hosts(self):\n return (\n self.logged_in_as_current_user and\n self.navigation.currently_selected == [\"Compute\", \"Infrastructure\", \"Hosts\"]\n )\n\n\nclass HostQuadIconEntity(BaseQuadIconEntity):\n\n # TODO Move these properties to one 'data' property\n @property\n def no_vm(self):\n return int(self.browser.text(self.QUADRANT.format(pos=\"a\")))\n\n @property\n def status(self):\n return self.browser.get_attribute(\"style\", self.QUADRANT.format(pos=\"b\"))\n\n @property\n def vendor(self):\n return self.browser.get_attribute(\"alt\", self.QUADRANT.format(pos=\"c\"))\n\n @property\n def creds(self):\n return self.browser.get_attribute(\"alt\", self.QUADRANT.format(pos=\"d\"))\n\n\nclass HostTileIconEntity(BaseTileIconEntity):\n quad_icon = ParametrizedView.nested(HostQuadIconEntity)\n\n\nclass HostListEntity(BaseListEntity):\n pass\n\n\nclass HostEntity(BaseEntity):\n quad_entity = HostQuadIconEntity\n list_entity = HostListEntity\n tile_entity = HostTileIconEntity\n\n\nclass HostDetailsToolbar(View):\n \"\"\"Represents host toolbar and its controls.\"\"\"\n monitoring = Dropdown(text=\"Monitoring\")\n configuration = Dropdown(text=\"Configuration\")\n policy = Dropdown(text=\"Policy\")\n power = Dropdown(text=\"Power\")\n\n\nclass HostDetailsEntities(View):\n \"\"\"Represents Details page.\"\"\"\n properties = SummaryTable(title=\"Properties\")\n relationships = SummaryTable(title=\"Relationships\")\n compliance = SummaryTable(title=\"Compliance\")\n configuration = SummaryTable(title=\"Configuration\")\n smart_management = SummaryTable(title=\"Smart Management\")\n authentication_status = SummaryTable(title=\"Authentication Status\")\n\n\nclass HostDetailsView(ComputeInfrastructureHostsView):\n \"\"\"Main Host details page.\"\"\"\n breadcrumb = BreadCrumb(locator='.//ol[@class=\"breadcrumb\"]')\n toolbar = View.nested(HostDetailsToolbar)\n entities = View.nested(HostDetailsEntities)\n\n @property\n def is_displayed(self):\n title = \"{name} (Summary)\".format(name=self.context[\"object\"].name)\n return self.in_compute_infrastructure_hosts and self.breadcrumb.active_location == title\n\n\nclass HostDriftHistory(ComputeInfrastructureHostsView):\n breadcrumb = BreadCrumb(locator='.//ol[@class=\"breadcrumb\"]')\n history_table = Table(locator='.//div[@id=\"main_div\"]/table')\n analyze_button = Button(title=\"Select up to 10 timestamps for Drift Analysis\")\n\n @property\n def is_displayed(self):\n return (\n self.in_compute_infrastructure_hosts and\n self.title.text == \"Drift History\" and\n self.history_table.is_displayed\n )\n\n\nclass HostDriftAnalysis(ComputeInfrastructureHostsView):\n apply_button = Button(\"Apply\")\n drift_sections = CheckableBootstrapTreeview(tree_id=\"all_sectionsbox\")\n\n @ParametrizedView.nested\n class drift_analysis(ParametrizedView): # noqa\n PARAMETERS = (\"drift_section\", )\n CELLS = \"../td//i\"\n row = Text(ParametrizedLocator(\".//div[@id='compare-grid']/\"\n \"/th[normalize-space(.)={drift_section|quote}]\"))\n\n @property\n def is_changed(self):\n cells = self.browser.elements(self.CELLS, parent=self.row)\n attrs = [self.browser.get_attribute(\"class\", cell) for cell in cells]\n return \"drift-delta\" in attrs\n\n @View.nested\n class toolbar(View): # noqa\n all_attributes = Button(title=\"All attributes\")\n different_values_attributes = Button(title=\"Attributes with different\")\n same_values_attributes = Button(title=\"Attributes with same values\")\n details_mode = Button(title=\"Details Mode\")\n exists_mode = Button(title=\"Exists Mode\")\n\n @property\n def is_displayed(self):\n return (\n self.in_compute_infrastructure_hosts and\n self.title.text == \"'{}' Drift Analysis\".format(self.context[\"object\"].name)\n )\n\n\nclass HostTimelinesView(TimelinesView, ComputeInfrastructureHostsView):\n \"\"\"Represents a Host Timelines page.\"\"\"\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and super(TimelinesView, self).is_displayed\n\n\nclass HostDiscoverView(ComputeInfrastructureHostsView):\n \"\"\"Discover View from Compute/Infrastructure/Hosts page.\"\"\"\n esx = Checkbox(name=\"discover_type_esx\")\n ipmi = Checkbox(name=\"discover_type_ipmi\")\n\n from_ip1 = Input(name=\"from_first\")\n from_ip2 = Input(name=\"from_second\")\n from_ip3 = Input(name=\"from_third\")\n from_ip4 = Input(name=\"from_fourth\")\n to_ip4 = Input(name=\"to_fourth\")\n\n start_button = Button(\"Start\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Hosts / Nodes Discovery\"\n\n\nclass HostManagePoliciesView(BaseLoggedInPage):\n \"\"\"Host's Manage Policies view.\"\"\"\n policies = BootstrapTreeview(\"protectbox\")\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return False\n\n\nclass HostEditTagsView(BaseLoggedInPage):\n \"\"\"Host's Edit Tags view.\"\"\"\n tag_category = BootstrapSelect(\"tag_cat\")\n tag = BootstrapSelect(\"tag_add\")\n chosen_tags = Table(locator='.//div[@id=\"assignments_div\"]/table')\n\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return False\n\n\nclass HostsToolbar(View):\n \"\"\"Represents hosts toolbar and its controls.\"\"\"\n configuration = Dropdown(text=\"Configuration\")\n policy = Dropdown(text=\"Policy\")\n lifecycle = Dropdown(text=\"Lifecycle\")\n monitoring = Dropdown(text=\"Monitoring\")\n power = Dropdown(text=\"Power\")\n view_selector = View.nested(ItemsToolBarViewSelector)\n\n\nclass HostSideBar(View):\n \"\"\"Represents left side bar. It usually contains navigation, filters, etc.\"\"\"\n pass\n\n\nclass HostEntitiesView(BaseEntitiesView):\n \"\"\"Represents the view with different items like hosts.\"\"\"\n @property\n def entity_class(self):\n return HostEntity\n\n\nclass HostsView(ComputeInfrastructureHostsView):\n toolbar = View.nested(HostsToolbar)\n sidebar = View.nested(HostSideBar)\n paginator = View.nested(PaginationPane)\n including_entities = View.include(HostEntitiesView, use_parent=True)\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Hosts\"\n\n\nclass HostFormView(ComputeInfrastructureHostsView):\n # Info/Settings\n title = Text(\".//div[@id='main-content']//h1\")\n name = Input(name=\"name\")\n hostname = Input(name=\"hostname\")\n custom_ident = Input(name=\"custom_1\")\n ipmi_address = Input(name=\"ipmi_address\")\n mac_address = Input(name=\"mac_address\")\n\n @View.nested\n class endpoints(View): # noqa\n @View.nested\n class default(Tab): # noqa\n username = Input(name=\"default_userid\")\n password = Input(name=\"default_password\")\n confirm_password = Input(name=\"default_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class remote_login(Tab): # noqa\n TAB_NAME = \"Remote Login\"\n username = Input(name=\"remote_userid\")\n password = Input(name=\"remote_password\")\n confirm_password = Input(name=\"remote_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class web_services(Tab): # noqa\n TAB_NAME = \"Web Services\"\n username = Input(name=\"ws_userid\")\n password = Input(name=\"ws_password\")\n confirm_password = Input(name=\"ws_verify\")\n validate_button = Button(\"Validate\")\n\n @View.nested\n class ipmi(Tab): # noqa\n TAB_NAME = \"IPMI\"\n username = Input(name=\"ipmi_userid\")\n password = Input(name=\"ipmi_password\")\n confirm_password = Input(name=\"ipmi_verify\")\n validate_button = Button(\"Validate\")\n\n cancel_button = Button(\"Cancel\")\n\n\nclass HostAddView(HostFormView):\n host_platform = BootstrapSelect(\"user_assigned_os\")\n add_button = Button(\"Add\")\n cancel_button = Button(\"Cancel\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Add New Host\"\n\n\nclass HostEditView(HostFormView):\n \"\"\"View for editing a single host\"\"\"\n save_button = Button(\"Save\")\n reset_button = Button(\"Reset\")\n change_stored_password = Text(\".//a[contains(@ng-hide, 'bChangeStoredPassword')]\")\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == \"Info/Settings\"\n\n\nclass HostsEditView(HostEditView):\n \"\"\"View when editing multiple hosts\n Restricted to endpoints section of the form\n Title changes\n Must select host before validation\n \"\"\"\n validation_host = BootstrapSelect('validate_id') # only shown when editing multiple hosts\n\n @property\n def is_displayed(self):\n return self.in_compute_infrastructure_hosts and self.title.text == 'Credentials/Settings'\n", "path": "cfme/common/host_views.py"}, {"content": "from navmazing import NavigateToSibling\nfrom wrapanapi.virtualcenter import VMWareSystem\n\nfrom cfme.common.provider import DefaultEndpoint, DefaultEndpointForm\nfrom cfme.common.provider_views import ProviderNodesView\nfrom cfme.exceptions import DestinationNotFound\nfrom utils.appliance.implementations.ui import CFMENavigateStep, navigator\nfrom . import InfraProvider\n\n\nclass VirtualCenterEndpoint(DefaultEndpoint):\n pass\n\n\nclass VirtualCenterEndpointForm(DefaultEndpointForm):\n pass\n\n\nclass VMwareProvider(InfraProvider):\n type_name = \"virtualcenter\"\n mgmt_class = VMWareSystem\n db_types = [\"Vmware::InfraManager\"]\n endpoints_form = VirtualCenterEndpointForm\n discover_dict = {\"vmware\": True}\n\n def __init__(self, name=None, endpoints=None, key=None, zone=None, hostname=None,\n ip_address=None, start_ip=None, end_ip=None, provider_data=None, appliance=None):\n super(VMwareProvider, self).__init__(\n name=name, endpoints=endpoints, zone=zone, key=key, provider_data=provider_data,\n appliance=appliance)\n self.hostname = hostname\n self.start_ip = start_ip\n self.end_ip = end_ip\n if ip_address:\n self.ip_address = ip_address\n\n def deployment_helper(self, deploy_args):\n \"\"\" Used in utils.virtual_machines \"\"\"\n # Called within a dictionary update. Since we want to remove key/value pairs, return the\n # entire dictionary\n deploy_args.pop('username', None)\n deploy_args.pop('password', None)\n if \"allowed_datastores\" not in deploy_args and \"allowed_datastores\" in self.data:\n deploy_args['allowed_datastores'] = self.data['allowed_datastores']\n\n return deploy_args\n\n @classmethod\n def from_config(cls, prov_config, prov_key, appliance=None):\n endpoint = VirtualCenterEndpoint(**prov_config['endpoints']['default'])\n\n if prov_config.get('discovery_range'):\n start_ip = prov_config['discovery_range']['start']\n end_ip = prov_config['discovery_range']['end']\n else:\n start_ip = end_ip = prov_config.get('ipaddress')\n return cls(name=prov_config['name'],\n endpoints={endpoint.name: endpoint},\n zone=prov_config['server_zone'],\n key=prov_key,\n start_ip=start_ip,\n end_ip=end_ip,\n appliance=appliance)\n\n @property\n def view_value_mapping(self):\n return {'name': self.name,\n 'prov_type': 'VMware vCenter'\n }\n\n\[email protected](VMwareProvider, 'ProviderNodes') # matching other infra class destinations\nclass ProviderNodes(CFMENavigateStep):\n VIEW = ProviderNodesView\n prerequisite = NavigateToSibling('Details')\n\n def step(self):\n try:\n self.prerequisite_view.contents.relationships.click_at('Hosts')\n except NameError:\n raise DestinationNotFound(\"Hosts aren't present on details page of this provider\")\n", "path": "cfme/infrastructure/provider/virtualcenter.py"}]}
| 4,079 | 560 |
gh_patches_debug_27461
|
rasdani/github-patches
|
git_diff
|
napari__napari-745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Show logo during startup
## 🚀 Feature
Right now napari takes a long time to launch the viewer. People can get discouraged as they wait, unsure if napari is loading, or if their data is loading, or if it is just hanging. Showing the napari logo, possibly with / without some text during that time might make it feel better.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `napari/_qt/event_loop.py`
Content:
```
1 import sys
2 from contextlib import contextmanager
3
4 from qtpy.QtWidgets import QApplication
5
6
7 @contextmanager
8 def gui_qt():
9 """Start a Qt event loop in which to run the application.
10
11 Notes
12 -----
13 This context manager is not needed if running napari within an interactive
14 IPython session. In this case, use the ``%gui qt`` magic command, or start
15 IPython with the Qt GUI event loop enabled by default by using
16 ``ipython --gui=qt``.
17 """
18 app = QApplication.instance() or QApplication(sys.argv)
19 yield
20 app.exec_()
21
```
Path: `napari/__main__.py`
Content:
```
1 """
2 napari command line viewer.
3 """
4 import argparse
5 import sys
6
7 import numpy as np
8
9 from .util import io
10 from . import Viewer, gui_qt
11
12
13 def main():
14 parser = argparse.ArgumentParser(usage=__doc__)
15 parser.add_argument('images', nargs='*', help='Images to view.')
16 parser.add_argument(
17 '--layers',
18 action='store_true',
19 help='Treat multiple input images as layers.',
20 )
21 parser.add_argument(
22 '-r',
23 '--rgb',
24 help='Treat images as RGB.',
25 action='store_true',
26 default=None,
27 )
28 parser.add_argument(
29 '-g',
30 '--grayscale',
31 dest='rgb',
32 action='store_false',
33 help='interpret all dimensions in the image as spatial',
34 )
35 parser.add_argument(
36 '-D',
37 '--use-dask',
38 action='store_true',
39 help='Use dask to read in images. This conserves memory. This option '
40 'does nothing if a single image is given.',
41 default=None,
42 )
43 parser.add_argument(
44 '-N',
45 '--use-numpy',
46 action='store_false',
47 dest='use_dask',
48 help='Use NumPy to read in images. This can be more performant than '
49 'dask if all the images fit in RAM. This option does nothing if '
50 'only a single image is given.',
51 )
52 args = parser.parse_args()
53 with gui_qt():
54 v = Viewer()
55 if len(args.images) > 0:
56 images = io.magic_imread(
57 args.images, use_dask=args.use_dask, stack=not args.layers
58 )
59 if args.layers:
60 for layer in images:
61 if layer.dtype in (
62 np.int32,
63 np.uint32,
64 np.int64,
65 np.uint64,
66 ):
67 v.add_labels(layer)
68 else:
69 v.add_image(layer, rgb=args.rgb)
70 else:
71 v.add_image(images, rgb=args.rgb)
72
73
74 if __name__ == '__main__':
75 sys.exit(main())
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/napari/__main__.py b/napari/__main__.py
--- a/napari/__main__.py
+++ b/napari/__main__.py
@@ -50,7 +50,7 @@
'only a single image is given.',
)
args = parser.parse_args()
- with gui_qt():
+ with gui_qt(startup_logo=True):
v = Viewer()
if len(args.images) > 0:
images = io.magic_imread(
diff --git a/napari/_qt/event_loop.py b/napari/_qt/event_loop.py
--- a/napari/_qt/event_loop.py
+++ b/napari/_qt/event_loop.py
@@ -1,13 +1,20 @@
import sys
from contextlib import contextmanager
+from os.path import dirname, join
-from qtpy.QtWidgets import QApplication
+from qtpy.QtGui import QPixmap
+from qtpy.QtWidgets import QApplication, QSplashScreen
@contextmanager
-def gui_qt():
+def gui_qt(*, startup_logo=False):
"""Start a Qt event loop in which to run the application.
+ Parameters
+ ----------
+ startup_logo : bool
+ Show a splash screen with the napari logo during startup.
+
Notes
-----
This context manager is not needed if running napari within an interactive
@@ -16,5 +23,11 @@
``ipython --gui=qt``.
"""
app = QApplication.instance() or QApplication(sys.argv)
+ if startup_logo:
+ logopath = join(dirname(__file__), '..', 'resources', 'logo.png')
+ splash_widget = QSplashScreen(QPixmap(logopath).scaled(400, 400))
+ splash_widget.show()
yield
+ if startup_logo:
+ splash_widget.close()
app.exec_()
|
{"golden_diff": "diff --git a/napari/__main__.py b/napari/__main__.py\n--- a/napari/__main__.py\n+++ b/napari/__main__.py\n@@ -50,7 +50,7 @@\n 'only a single image is given.',\n )\n args = parser.parse_args()\n- with gui_qt():\n+ with gui_qt(startup_logo=True):\n v = Viewer()\n if len(args.images) > 0:\n images = io.magic_imread(\ndiff --git a/napari/_qt/event_loop.py b/napari/_qt/event_loop.py\n--- a/napari/_qt/event_loop.py\n+++ b/napari/_qt/event_loop.py\n@@ -1,13 +1,20 @@\n import sys\n from contextlib import contextmanager\n+from os.path import dirname, join\n \n-from qtpy.QtWidgets import QApplication\n+from qtpy.QtGui import QPixmap\n+from qtpy.QtWidgets import QApplication, QSplashScreen\n \n \n @contextmanager\n-def gui_qt():\n+def gui_qt(*, startup_logo=False):\n \"\"\"Start a Qt event loop in which to run the application.\n \n+ Parameters\n+ ----------\n+ startup_logo : bool\n+ Show a splash screen with the napari logo during startup.\n+\n Notes\n -----\n This context manager is not needed if running napari within an interactive\n@@ -16,5 +23,11 @@\n ``ipython --gui=qt``.\n \"\"\"\n app = QApplication.instance() or QApplication(sys.argv)\n+ if startup_logo:\n+ logopath = join(dirname(__file__), '..', 'resources', 'logo.png')\n+ splash_widget = QSplashScreen(QPixmap(logopath).scaled(400, 400))\n+ splash_widget.show()\n yield\n+ if startup_logo:\n+ splash_widget.close()\n app.exec_()\n", "issue": "Show logo during startup\n## \ud83d\ude80 Feature\r\nRight now napari takes a long time to launch the viewer. People can get discouraged as they wait, unsure if napari is loading, or if their data is loading, or if it is just hanging. Showing the napari logo, possibly with / without some text during that time might make it feel better.\n", "before_files": [{"content": "import sys\nfrom contextlib import contextmanager\n\nfrom qtpy.QtWidgets import QApplication\n\n\n@contextmanager\ndef gui_qt():\n \"\"\"Start a Qt event loop in which to run the application.\n\n Notes\n -----\n This context manager is not needed if running napari within an interactive\n IPython session. In this case, use the ``%gui qt`` magic command, or start\n IPython with the Qt GUI event loop enabled by default by using\n ``ipython --gui=qt``.\n \"\"\"\n app = QApplication.instance() or QApplication(sys.argv)\n yield\n app.exec_()\n", "path": "napari/_qt/event_loop.py"}, {"content": "\"\"\"\nnapari command line viewer.\n\"\"\"\nimport argparse\nimport sys\n\nimport numpy as np\n\nfrom .util import io\nfrom . import Viewer, gui_qt\n\n\ndef main():\n parser = argparse.ArgumentParser(usage=__doc__)\n parser.add_argument('images', nargs='*', help='Images to view.')\n parser.add_argument(\n '--layers',\n action='store_true',\n help='Treat multiple input images as layers.',\n )\n parser.add_argument(\n '-r',\n '--rgb',\n help='Treat images as RGB.',\n action='store_true',\n default=None,\n )\n parser.add_argument(\n '-g',\n '--grayscale',\n dest='rgb',\n action='store_false',\n help='interpret all dimensions in the image as spatial',\n )\n parser.add_argument(\n '-D',\n '--use-dask',\n action='store_true',\n help='Use dask to read in images. This conserves memory. This option '\n 'does nothing if a single image is given.',\n default=None,\n )\n parser.add_argument(\n '-N',\n '--use-numpy',\n action='store_false',\n dest='use_dask',\n help='Use NumPy to read in images. This can be more performant than '\n 'dask if all the images fit in RAM. This option does nothing if '\n 'only a single image is given.',\n )\n args = parser.parse_args()\n with gui_qt():\n v = Viewer()\n if len(args.images) > 0:\n images = io.magic_imread(\n args.images, use_dask=args.use_dask, stack=not args.layers\n )\n if args.layers:\n for layer in images:\n if layer.dtype in (\n np.int32,\n np.uint32,\n np.int64,\n np.uint64,\n ):\n v.add_labels(layer)\n else:\n v.add_image(layer, rgb=args.rgb)\n else:\n v.add_image(images, rgb=args.rgb)\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "napari/__main__.py"}], "after_files": [{"content": "import sys\nfrom contextlib import contextmanager\nfrom os.path import dirname, join\n\nfrom qtpy.QtGui import QPixmap\nfrom qtpy.QtWidgets import QApplication, QSplashScreen\n\n\n@contextmanager\ndef gui_qt(*, startup_logo=False):\n \"\"\"Start a Qt event loop in which to run the application.\n\n Parameters\n ----------\n startup_logo : bool\n Show a splash screen with the napari logo during startup.\n\n Notes\n -----\n This context manager is not needed if running napari within an interactive\n IPython session. In this case, use the ``%gui qt`` magic command, or start\n IPython with the Qt GUI event loop enabled by default by using\n ``ipython --gui=qt``.\n \"\"\"\n app = QApplication.instance() or QApplication(sys.argv)\n if startup_logo:\n logopath = join(dirname(__file__), '..', 'resources', 'logo.png')\n splash_widget = QSplashScreen(QPixmap(logopath).scaled(400, 400))\n splash_widget.show()\n yield\n if startup_logo:\n splash_widget.close()\n app.exec_()\n", "path": "napari/_qt/event_loop.py"}, {"content": "\"\"\"\nnapari command line viewer.\n\"\"\"\nimport argparse\nimport sys\n\nimport numpy as np\n\nfrom .util import io\nfrom . import Viewer, gui_qt\n\n\ndef main():\n parser = argparse.ArgumentParser(usage=__doc__)\n parser.add_argument('images', nargs='*', help='Images to view.')\n parser.add_argument(\n '--layers',\n action='store_true',\n help='Treat multiple input images as layers.',\n )\n parser.add_argument(\n '-r',\n '--rgb',\n help='Treat images as RGB.',\n action='store_true',\n default=None,\n )\n parser.add_argument(\n '-g',\n '--grayscale',\n dest='rgb',\n action='store_false',\n help='interpret all dimensions in the image as spatial',\n )\n parser.add_argument(\n '-D',\n '--use-dask',\n action='store_true',\n help='Use dask to read in images. This conserves memory. This option '\n 'does nothing if a single image is given.',\n default=None,\n )\n parser.add_argument(\n '-N',\n '--use-numpy',\n action='store_false',\n dest='use_dask',\n help='Use NumPy to read in images. This can be more performant than '\n 'dask if all the images fit in RAM. This option does nothing if '\n 'only a single image is given.',\n )\n args = parser.parse_args()\n with gui_qt(startup_logo=True):\n v = Viewer()\n if len(args.images) > 0:\n images = io.magic_imread(\n args.images, use_dask=args.use_dask, stack=not args.layers\n )\n if args.layers:\n for layer in images:\n if layer.dtype in (\n np.int32,\n np.uint32,\n np.int64,\n np.uint64,\n ):\n v.add_labels(layer)\n else:\n v.add_image(layer, rgb=args.rgb)\n else:\n v.add_image(images, rgb=args.rgb)\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "napari/__main__.py"}]}
| 1,108 | 413 |
gh_patches_debug_9652
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-19512
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
f
numpy.random.f function
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/numpy/random/functions.py`
Content:
```
1 # local
2 import ivy
3 from ivy.functional.frontends.numpy.func_wrapper import (
4 to_ivy_arrays_and_back,
5 from_zero_dim_arrays_to_scalar,
6 )
7
8
9 @to_ivy_arrays_and_back
10 @from_zero_dim_arrays_to_scalar
11 def random_sample(size=None):
12 return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
13
14
15 @to_ivy_arrays_and_back
16 @from_zero_dim_arrays_to_scalar
17 def dirichlet(alpha, size=None):
18 return ivy.dirichlet(alpha, size=size)
19
20
21 @to_ivy_arrays_and_back
22 @from_zero_dim_arrays_to_scalar
23 def uniform(low=0.0, high=1.0, size=None):
24 return ivy.random_uniform(low=low, high=high, shape=size, dtype="float64")
25
26
27 @to_ivy_arrays_and_back
28 @from_zero_dim_arrays_to_scalar
29 def geometric(p, size=None):
30 if p < 0 or p > 1:
31 raise ValueError("p must be in the interval [0, 1]")
32 oneMinusP = ivy.subtract(1, p)
33 sizeMinusOne = ivy.subtract(size, 1)
34
35 return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)
36
37
38 @to_ivy_arrays_and_back
39 @from_zero_dim_arrays_to_scalar
40 def normal(loc=0.0, scale=1.0, size=None):
41 return ivy.random_normal(mean=loc, std=scale, shape=size, dtype="float64")
42
43
44 @to_ivy_arrays_and_back
45 @from_zero_dim_arrays_to_scalar
46 def poisson(lam=1.0, size=None):
47 return ivy.poisson(lam=lam, shape=size)
48
49
50 @to_ivy_arrays_and_back
51 @from_zero_dim_arrays_to_scalar
52 def multinomial(n, pvals, size=None):
53 assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)
54 batch_size = 1
55 if ivy.exists(size):
56 if len(size) == 2:
57 batch_size = size[0]
58 num_samples = size[1]
59 else:
60 num_samples = size[0]
61 else:
62 num_samples = len(pvals)
63 return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)
64
65
66 @to_ivy_arrays_and_back
67 @from_zero_dim_arrays_to_scalar
68 def permutation(x, /):
69 if isinstance(x, int):
70 x = ivy.arange(x)
71 return ivy.shuffle(x)
72
73
74 @to_ivy_arrays_and_back
75 @from_zero_dim_arrays_to_scalar
76 def beta(a, b, size=None):
77 return ivy.beta(a, b, shape=size)
78
79
80 @to_ivy_arrays_and_back
81 @from_zero_dim_arrays_to_scalar
82 def shuffle(x, axis=0, /):
83 if isinstance(x, int):
84 x = ivy.arange(x)
85 return ivy.shuffle(x, axis)
86
87
88 @to_ivy_arrays_and_back
89 @from_zero_dim_arrays_to_scalar
90 def standard_normal(size=None):
91 return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
92
93
94 @to_ivy_arrays_and_back
95 @from_zero_dim_arrays_to_scalar
96 def standard_gamma(shape, size=None):
97 return ivy.gamma(shape, 1.0, shape=size, dtype="float64")
98
99
100 @to_ivy_arrays_and_back
101 @from_zero_dim_arrays_to_scalar
102 def binomial(n, p, size=None):
103 if p < 0 or p > 1:
104 raise ValueError("p must be in the interval (0, 1)")
105 if n < 0:
106 raise ValueError("n must be strictly positive")
107 if size is None:
108 size = 1
109 else:
110 size = size
111 if isinstance(size, int):
112 size = (size,)
113 lambda_ = ivy.multiply(n, p)
114 return ivy.poisson(lambda_, shape=size)
115
116
117 @to_ivy_arrays_and_back
118 @from_zero_dim_arrays_to_scalar
119 def chisquare(df, size=None):
120 df = ivy.array(df) # scalar ints and floats are also array_like
121 if ivy.any(df <= 0):
122 raise ValueError("df <= 0")
123
124 # ivy.gamma() throws an error if both alpha is an array and a shape is passed
125 # so this part broadcasts df into the shape of `size`` first to keep it happy.
126 if size is not None:
127 df = df * ivy.ones(size)
128
129 return ivy.gamma(df / 2, 2, dtype="float64")
130
131
132 @to_ivy_arrays_and_back
133 @from_zero_dim_arrays_to_scalar
134 def lognormal(mean=0.0, sigma=1.0, size=None):
135 ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype="float64"))
136 return ret
137
138
139 @to_ivy_arrays_and_back
140 @from_zero_dim_arrays_to_scalar
141 def negative_binomial(n, p, size=None):
142 if p <= 0 or p >= 1:
143 raise ValueError("p must be in the interval (0, 1)")
144 if n <= 0:
145 raise ValueError("n must be strictly positive")
146 # numpy implementation uses scale = (1 - p) / p
147 scale = (1 - p) / p
148 # poisson requires shape to be a tuple
149 if isinstance(size, int):
150 size = (size,)
151 lambda_ = ivy.gamma(n, scale, shape=size)
152 return ivy.poisson(lam=lambda_, shape=size)
153
154
155 @to_ivy_arrays_and_back
156 @from_zero_dim_arrays_to_scalar
157 def weibull(a, size=None):
158 if a < 0:
159 return 0
160 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
161 return ivy.pow(-ivy.log(1 - u), 1 / a)
162
163
164 @to_ivy_arrays_and_back
165 @from_zero_dim_arrays_to_scalar
166 def standard_cauchy(size=None):
167 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
168 return ivy.tan(ivy.pi * (u - 0.5))
169
170
171 @to_ivy_arrays_and_back
172 @from_zero_dim_arrays_to_scalar
173 def rayleigh(scale, size=None):
174 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
175 log_u = ivy.log(u)
176 x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))
177 return x
178
179
180 @to_ivy_arrays_and_back
181 @from_zero_dim_arrays_to_scalar
182 def gumbel(loc=0.0, scale=1.0, size=None):
183 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
184 x = loc - scale * ivy.log(-ivy.log(u))
185 return x
186
187
188 @to_ivy_arrays_and_back
189 @from_zero_dim_arrays_to_scalar
190 def gamma(shape, scale=1.0, size=None):
191 return ivy.gamma(shape, scale, shape=size, dtype="float64")
192
193
194 @to_ivy_arrays_and_back
195 @from_zero_dim_arrays_to_scalar
196 def logistic(loc=0.0, scale=1.0, size=None):
197 u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype="float64")
198 x = loc + scale * ivy.log(u / (1 - u))
199 return x
200
201
202 @to_ivy_arrays_and_back
203 @from_zero_dim_arrays_to_scalar
204 def triangular(left, mode, right, size=None):
205 if left > mode or mode > right or left == right:
206 raise ivy.utils.exceptions.IvyValueError(
207 "left < mode < right is not being followed"
208 )
209 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
210 condition = u <= (mode - left) / (right - left)
211 values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5
212 values2 = (
213 right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5
214 )
215 return ivy.where(condition, values1, values2)
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py
--- a/ivy/functional/frontends/numpy/random/functions.py
+++ b/ivy/functional/frontends/numpy/random/functions.py
@@ -185,6 +185,17 @@
return x
+@to_ivy_arrays_and_back
+@from_zero_dim_arrays_to_scalar
+def f(dfn, dfd, size=None):
+ # Generate samples from the uniform distribution
+ x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype="float64")
+ x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype="float64")
+ # Calculate the F-distributed samples
+ samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))
+ return samples
+
+
@to_ivy_arrays_and_back
@from_zero_dim_arrays_to_scalar
def gamma(shape, scale=1.0, size=None):
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py\n--- a/ivy/functional/frontends/numpy/random/functions.py\n+++ b/ivy/functional/frontends/numpy/random/functions.py\n@@ -185,6 +185,17 @@\n return x\n \n \n+@to_ivy_arrays_and_back\n+@from_zero_dim_arrays_to_scalar\n+def f(dfn, dfd, size=None):\n+ # Generate samples from the uniform distribution\n+ x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype=\"float64\")\n+ x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype=\"float64\")\n+ # Calculate the F-distributed samples\n+ samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))\n+ return samples\n+\n+\n @to_ivy_arrays_and_back\n @from_zero_dim_arrays_to_scalar\n def gamma(shape, scale=1.0, size=None):\n", "issue": "f\nnumpy.random.f function\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, axis=0, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x, axis)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_gamma(shape, size=None):\n return ivy.gamma(shape, 1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef binomial(n, p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n < 0:\n raise ValueError(\"n must be strictly positive\")\n if size is None:\n size = 1\n else:\n size = size\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.multiply(n, p)\n return ivy.poisson(lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef chisquare(df, size=None):\n df = ivy.array(df) # scalar ints and floats are also array_like\n if ivy.any(df <= 0):\n raise ValueError(\"df <= 0\")\n\n # ivy.gamma() throws an error if both alpha is an array and a shape is passed\n # so this part broadcasts df into the shape of `size`` first to keep it happy.\n if size is not None:\n df = df * ivy.ones(size)\n\n return ivy.gamma(df / 2, 2, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef lognormal(mean=0.0, sigma=1.0, size=None):\n ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype=\"float64\"))\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef negative_binomial(n, p, size=None):\n if p <= 0 or p >= 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n <= 0:\n raise ValueError(\"n must be strictly positive\")\n # numpy implementation uses scale = (1 - p) / p\n scale = (1 - p) / p\n # poisson requires shape to be a tuple\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.gamma(n, scale, shape=size)\n return ivy.poisson(lam=lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef weibull(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.pow(-ivy.log(1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_cauchy(size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.tan(ivy.pi * (u - 0.5))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef rayleigh(scale, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n log_u = ivy.log(u)\n x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gumbel(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n x = loc - scale * ivy.log(-ivy.log(u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gamma(shape, scale=1.0, size=None):\n return ivy.gamma(shape, scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logistic(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n x = loc + scale * ivy.log(u / (1 - u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef triangular(left, mode, right, size=None):\n if left > mode or mode > right or left == right:\n raise ivy.utils.exceptions.IvyValueError(\n \"left < mode < right is not being followed\"\n )\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n condition = u <= (mode - left) / (right - left)\n values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5\n values2 = (\n right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5\n )\n return ivy.where(condition, values1, values2)\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}], "after_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, axis=0, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x, axis)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_gamma(shape, size=None):\n return ivy.gamma(shape, 1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef binomial(n, p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n < 0:\n raise ValueError(\"n must be strictly positive\")\n if size is None:\n size = 1\n else:\n size = size\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.multiply(n, p)\n return ivy.poisson(lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef chisquare(df, size=None):\n df = ivy.array(df) # scalar ints and floats are also array_like\n if ivy.any(df <= 0):\n raise ValueError(\"df <= 0\")\n\n # ivy.gamma() throws an error if both alpha is an array and a shape is passed\n # so this part broadcasts df into the shape of `size`` first to keep it happy.\n if size is not None:\n df = df * ivy.ones(size)\n\n return ivy.gamma(df / 2, 2, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef lognormal(mean=0.0, sigma=1.0, size=None):\n ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype=\"float64\"))\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef negative_binomial(n, p, size=None):\n if p <= 0 or p >= 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n <= 0:\n raise ValueError(\"n must be strictly positive\")\n # numpy implementation uses scale = (1 - p) / p\n scale = (1 - p) / p\n # poisson requires shape to be a tuple\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.gamma(n, scale, shape=size)\n return ivy.poisson(lam=lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef weibull(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.pow(-ivy.log(1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_cauchy(size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.tan(ivy.pi * (u - 0.5))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef rayleigh(scale, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n log_u = ivy.log(u)\n x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gumbel(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n x = loc - scale * ivy.log(-ivy.log(u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef f(dfn, dfd, size=None):\n # Generate samples from the uniform distribution\n x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype=\"float64\")\n x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype=\"float64\")\n # Calculate the F-distributed samples\n samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))\n return samples\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gamma(shape, scale=1.0, size=None):\n return ivy.gamma(shape, scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logistic(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n x = loc + scale * ivy.log(u / (1 - u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef triangular(left, mode, right, size=None):\n if left > mode or mode > right or left == right:\n raise ivy.utils.exceptions.IvyValueError(\n \"left < mode < right is not being followed\"\n )\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n condition = u <= (mode - left) / (right - left)\n values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5\n values2 = (\n right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5\n )\n return ivy.where(condition, values1, values2)\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}]}
| 2,715 | 263 |
gh_patches_debug_30611
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3192
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
IATI expects baseline year to be a positiveInteger
N/A values for baseline year are not acceptable, and cause the XML to fail validation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/iati/checks/fields/results.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from akvo.rsr.models.result.utils import QUANTITATIVE
8
9 DGIS_VALIDATION_SET_NAME = u"DGIS IATI"
10
11
12 def results(project):
13 """
14 :param project: Project object
15 :return: All checks passed boolean, [Check results]
16 """
17 checks = []
18 all_checks_passed = True
19
20 DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1
21
22 for result in project.results.all():
23 if not result.type:
24 all_checks_passed = False
25 checks.append((u'error', u'result (id: %s) has no type specified' % str(result.pk)))
26
27 if not result.title:
28 all_checks_passed = False
29 checks.append((u'error', u'result (id: %s) has no title specified' % str(result.pk)))
30
31 if not result.indicators.filter(type=QUANTITATIVE):
32 all_checks_passed = False
33 checks.append(
34 (u'error', u'result (id: %s) has no quantitative indicator(s)' % str(result.pk))
35 )
36
37 for indicator in result.indicators.filter(type=QUANTITATIVE):
38 if not indicator.measure:
39 all_checks_passed = False
40 checks.append((u'error', u'indicator (id: %s) has no measure specified' %
41 str(indicator.pk)))
42
43 if not indicator.title:
44 all_checks_passed = False
45 checks.append((u'error', u'indicator (id: %s) has no title specified' %
46 str(indicator.pk)))
47
48 if not indicator.baseline_value:
49 if DGIS_PROJECT:
50 all_checks_passed = False
51 checks.append((u'warning', u'indicator (id: %s) baseline has no value '
52 u'specified, however the value of "N/A" has been '
53 u'set for the attribute' % str(indicator.pk)))
54 elif indicator.baseline_year or indicator.baseline_comment:
55 all_checks_passed = False
56 checks.append((u'error', u'indicator (id: %s) baseline has no value specified' %
57 str(indicator.pk)))
58
59 if not indicator.baseline_year:
60 if DGIS_PROJECT:
61 all_checks_passed = False
62 checks.append((u'warning', u'indicator (id: %s) baseline has no year '
63 u'specified, however the value of "N/A" has been '
64 u'set for the attribute' % str(indicator.pk)))
65 elif indicator.baseline_value or indicator.baseline_comment:
66 all_checks_passed = False
67 checks.append((u'error', u'indicator (id: %s) baseline has no year specified' %
68 str(indicator.pk)))
69
70 for reference in indicator.references.all():
71 if not reference.reference:
72 all_checks_passed = False
73 checks.append((u'error', u'indicator reference (id: %s) has no code '
74 u'specified' % str(reference.pk)))
75
76 if not reference.vocabulary:
77 all_checks_passed = False
78 checks.append((u'error', u'indicator reference (id: %s) has no vocabulary '
79 u'specified' % str(reference.pk)))
80
81 if reference.vocabulary == '99' and not reference.vocabulary_uri:
82 all_checks_passed = False
83 checks.append((u'error', u'indicator reference (id: %s) has vocabulary 99 '
84 u'(reporting organisation) but no vocabulary URI '
85 u'specified' % str(reference.pk)))
86
87 for period in indicator.periods.all():
88 if not period.period_start:
89 all_checks_passed = False
90 checks.append((u'error', u'indicator period (id: %s) has no start date '
91 u'specified' % str(period.pk)))
92
93 if not period.period_end:
94 all_checks_passed = False
95 checks.append((u'error', u'indicator period (id: %s) has no end date '
96 u'specified' % str(period.pk)))
97
98 if period.period_start and period.period_end and \
99 period.period_start > period.period_end:
100 all_checks_passed = False
101 checks.append((u'error', u'indicator period (id: %s) has a start date '
102 u'later than the end date' % str(period.pk)))
103
104 if not period.target_value:
105 if DGIS_PROJECT:
106 all_checks_passed = False
107 checks.append((u'warning', u'indicator period (id: %s) has no target value '
108 u'specified. The value "N/A" has been set for '
109 u'the target value attribute' % str(period.pk)))
110 elif (period.target_comment or period.target_locations.all() or
111 period.target_dimensions.all()):
112 all_checks_passed = False
113 checks.append((u'error', u'indicator period (id: %s) has no target value, '
114 u'but does have a target comment, target '
115 u'location(s) or target dimension(s)' %
116 str(period.pk)))
117
118 if not period.actual_value:
119 if DGIS_PROJECT:
120 all_checks_passed = False
121 checks.append((u'warning', u'indicator period (id: %s) has no actual value '
122 u'specified. The value "N/A" has been set for '
123 u'the actual value attribute' % str(period.pk)))
124 elif (period.actual_comment or period.actual_locations.all() or
125 period.actual_dimensions.all()):
126 all_checks_passed = False
127 checks.append((u'error', u'indicator period (id: %s) has no actual value, '
128 u'but does have a actual comment, actual '
129 u'location(s) or actual dimension(s)' %
130 str(period.pk)))
131
132 if project.results.all() and all_checks_passed:
133 checks.append((u'success', u'has valid result(s)'))
134
135 return all_checks_passed, checks
136
```
Path: `akvo/iati/exports/elements/result.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from lxml import etree
8
9 from akvo.rsr.models.result.utils import QUANTITATIVE
10
11 DGIS_VALIDATION_SET_NAME = u"DGIS IATI"
12 NOT_AVAILABLE = u"N/A"
13
14
15 def result(project):
16 """
17 Generate the result elements.
18
19 :param project: Project object
20 :return: A list of Etree elements
21 """
22 result_elements = []
23
24 DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1
25
26 for res in project.results.all():
27 if res.type or res.aggregation_status is not None or res.title or res.description or \
28 res.indicators.all():
29 element = etree.Element("result")
30
31 if res.type:
32 element.attrib['type'] = res.type
33
34 if res.aggregation_status is not None:
35 element.attrib['aggregation-status'] = '1' if res.aggregation_status else '0'
36
37 if res.title:
38 title_element = etree.SubElement(element, "title")
39 narrative_element = etree.SubElement(title_element, "narrative")
40 narrative_element.text = res.title
41
42 if res.description:
43 description_element = etree.SubElement(element, "description")
44 narrative_element = etree.SubElement(description_element, "narrative")
45 narrative_element.text = res.description
46
47 for indicator in res.indicators.filter(type=QUANTITATIVE):
48 if indicator.measure or indicator.ascending is not None or indicator.title or \
49 indicator.description or indicator.references.all() or \
50 indicator.baseline_year or indicator.baseline_value or \
51 indicator.baseline_comment or indicator.periods.all():
52 indicator_element = etree.SubElement(element, "indicator")
53
54 if indicator.measure:
55 indicator_element.attrib['measure'] = indicator.measure
56
57 if indicator.ascending is not None:
58 indicator_element.attrib['ascending'] = '1' if indicator.ascending else '0'
59
60 if indicator.title:
61 title_element = etree.SubElement(indicator_element, "title")
62 narrative_element = etree.SubElement(title_element, "narrative")
63 narrative_element.text = indicator.title
64
65 if indicator.description:
66 description_element = etree.SubElement(indicator_element, "description")
67 narrative_element = etree.SubElement(description_element, "narrative")
68 narrative_element.text = indicator.description
69
70 for reference in indicator.references.all():
71 if reference.vocabulary or reference.reference or reference.vocabulary_uri:
72 reference_element = etree.SubElement(indicator_element, "reference")
73
74 if reference.vocabulary:
75 reference_element.attrib['vocabulary'] = reference.vocabulary
76
77 if reference.reference:
78 reference_element.attrib['code'] = reference.reference
79
80 if reference.vocabulary_uri:
81 reference_element.attrib['indicator-uri'] = reference.vocabulary_uri
82
83 if DGIS_PROJECT or indicator.baseline_year or indicator.baseline_value or \
84 indicator.baseline_comment:
85 baseline_element = etree.SubElement(indicator_element, "baseline")
86
87 if indicator.baseline_year:
88 baseline_element.attrib['year'] = str(indicator.baseline_year)
89 elif DGIS_PROJECT:
90 baseline_element.attrib['year'] = NOT_AVAILABLE
91
92 if indicator.baseline_value:
93 baseline_element.attrib['value'] = indicator.baseline_value
94 elif DGIS_PROJECT:
95 baseline_element.attrib['value'] = NOT_AVAILABLE
96
97 if indicator.baseline_comment:
98 comment_element = etree.SubElement(baseline_element, "comment")
99 narrative_element = etree.SubElement(comment_element, "narrative")
100 narrative_element.text = indicator.baseline_comment
101
102 for period in indicator.periods.all():
103 if period.period_start or period.period_end or period.target_value or \
104 period.target_locations.all() or period.target_dimensions.all() or \
105 period.target_comment or period.actual_value or \
106 period.actual_locations.all() or period.actual_dimensions.all() or \
107 period.actual_comment:
108 period_element = etree.SubElement(indicator_element, "period")
109
110 if period.period_start:
111 period_start_element = etree.SubElement(period_element,
112 "period-start")
113 period_start_element.attrib['iso-date'] = str(period.period_start)
114
115 if period.period_end:
116 period_end_element = etree.SubElement(period_element, "period-end")
117 period_end_element.attrib['iso-date'] = str(period.period_end)
118
119 if (DGIS_PROJECT or period.target_value or
120 period.target_locations.all() or
121 period.target_dimensions.all() or period.target_comment):
122 target_element = etree.SubElement(period_element, "target")
123
124 if period.target_value:
125 target_element.attrib['value'] = period.target_value
126 elif DGIS_PROJECT:
127 target_element.attrib['value'] = NOT_AVAILABLE
128
129 for target_location in period.target_locations.all():
130 target_location_element = etree.SubElement(target_element,
131 "location")
132 target_location_element.attrib['ref'] = target_location.location
133
134 for target_dimension in period.target_dimensions.all():
135 if target_dimension.name or target_dimension.value:
136 target_dimension_element = etree.SubElement(target_element,
137 "dimension")
138
139 if target_dimension.name:
140 target_dimension_element.attrib['name'] = \
141 target_dimension.name
142
143 if target_dimension.value:
144 target_dimension_element.attrib['value'] = \
145 target_dimension.value
146
147 if period.target_comment:
148 comment_element = etree.SubElement(target_element, "comment")
149 narrative_element = etree.SubElement(comment_element,
150 "narrative")
151 narrative_element.text = period.target_comment
152
153 if (DGIS_PROJECT or period.actual_value or
154 period.actual_locations.all() or
155 period.actual_dimensions.all() or period.actual_comment):
156 actual_element = etree.SubElement(period_element, "actual")
157
158 if period.actual_value:
159 actual_element.attrib['value'] = period.actual_value
160 elif DGIS_PROJECT:
161 actual_element.attrib['value'] = NOT_AVAILABLE
162
163 for actual_location in period.actual_locations.all():
164 actual_location_element = etree.SubElement(actual_element,
165 "location")
166 actual_location_element.attrib['ref'] = actual_location.location
167
168 for actual_dimension in period.actual_dimensions.all():
169 if actual_dimension.name or actual_dimension.value:
170 actual_dimension_element = etree.SubElement(actual_element,
171 "dimension")
172
173 if actual_dimension.name:
174 actual_dimension_element.attrib['name'] = \
175 actual_dimension.name
176
177 if actual_dimension.value:
178 actual_dimension_element.attrib['value'] = \
179 actual_dimension.value
180
181 if period.actual_comment:
182 comment_element = etree.SubElement(actual_element, "comment")
183 narrative_element = etree.SubElement(comment_element,
184 "narrative")
185 narrative_element.text = period.actual_comment
186
187 result_elements.append(element)
188
189 return result_elements
190
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/iati/checks/fields/results.py b/akvo/iati/checks/fields/results.py
--- a/akvo/iati/checks/fields/results.py
+++ b/akvo/iati/checks/fields/results.py
@@ -60,7 +60,7 @@
if DGIS_PROJECT:
all_checks_passed = False
checks.append((u'warning', u'indicator (id: %s) baseline has no year '
- u'specified, however the value of "N/A" has been '
+ u'specified, however the value of "1" has been '
u'set for the attribute' % str(indicator.pk)))
elif indicator.baseline_value or indicator.baseline_comment:
all_checks_passed = False
diff --git a/akvo/iati/exports/elements/result.py b/akvo/iati/exports/elements/result.py
--- a/akvo/iati/exports/elements/result.py
+++ b/akvo/iati/exports/elements/result.py
@@ -10,6 +10,7 @@
DGIS_VALIDATION_SET_NAME = u"DGIS IATI"
NOT_AVAILABLE = u"N/A"
+NOT_AVAILABLE_YEAR = u"1"
def result(project):
@@ -87,7 +88,7 @@
if indicator.baseline_year:
baseline_element.attrib['year'] = str(indicator.baseline_year)
elif DGIS_PROJECT:
- baseline_element.attrib['year'] = NOT_AVAILABLE
+ baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR
if indicator.baseline_value:
baseline_element.attrib['value'] = indicator.baseline_value
|
{"golden_diff": "diff --git a/akvo/iati/checks/fields/results.py b/akvo/iati/checks/fields/results.py\n--- a/akvo/iati/checks/fields/results.py\n+++ b/akvo/iati/checks/fields/results.py\n@@ -60,7 +60,7 @@\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator (id: %s) baseline has no year '\n- u'specified, however the value of \"N/A\" has been '\n+ u'specified, however the value of \"1\" has been '\n u'set for the attribute' % str(indicator.pk)))\n elif indicator.baseline_value or indicator.baseline_comment:\n all_checks_passed = False\ndiff --git a/akvo/iati/exports/elements/result.py b/akvo/iati/exports/elements/result.py\n--- a/akvo/iati/exports/elements/result.py\n+++ b/akvo/iati/exports/elements/result.py\n@@ -10,6 +10,7 @@\n \n DGIS_VALIDATION_SET_NAME = u\"DGIS IATI\"\n NOT_AVAILABLE = u\"N/A\"\n+NOT_AVAILABLE_YEAR = u\"1\"\n \n \n def result(project):\n@@ -87,7 +88,7 @@\n if indicator.baseline_year:\n baseline_element.attrib['year'] = str(indicator.baseline_year)\n elif DGIS_PROJECT:\n- baseline_element.attrib['year'] = NOT_AVAILABLE\n+ baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR\n \n if indicator.baseline_value:\n baseline_element.attrib['value'] = indicator.baseline_value\n", "issue": "IATI expects baseline year to be a positiveInteger\nN/A values for baseline year are not acceptable, and cause the XML to fail validation.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rsr.models.result.utils import QUANTITATIVE\n\nDGIS_VALIDATION_SET_NAME = u\"DGIS IATI\"\n\n\ndef results(project):\n \"\"\"\n :param project: Project object\n :return: All checks passed boolean, [Check results]\n \"\"\"\n checks = []\n all_checks_passed = True\n\n DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1\n\n for result in project.results.all():\n if not result.type:\n all_checks_passed = False\n checks.append((u'error', u'result (id: %s) has no type specified' % str(result.pk)))\n\n if not result.title:\n all_checks_passed = False\n checks.append((u'error', u'result (id: %s) has no title specified' % str(result.pk)))\n\n if not result.indicators.filter(type=QUANTITATIVE):\n all_checks_passed = False\n checks.append(\n (u'error', u'result (id: %s) has no quantitative indicator(s)' % str(result.pk))\n )\n\n for indicator in result.indicators.filter(type=QUANTITATIVE):\n if not indicator.measure:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) has no measure specified' %\n str(indicator.pk)))\n\n if not indicator.title:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) has no title specified' %\n str(indicator.pk)))\n\n if not indicator.baseline_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator (id: %s) baseline has no value '\n u'specified, however the value of \"N/A\" has been '\n u'set for the attribute' % str(indicator.pk)))\n elif indicator.baseline_year or indicator.baseline_comment:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) baseline has no value specified' %\n str(indicator.pk)))\n\n if not indicator.baseline_year:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator (id: %s) baseline has no year '\n u'specified, however the value of \"N/A\" has been '\n u'set for the attribute' % str(indicator.pk)))\n elif indicator.baseline_value or indicator.baseline_comment:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) baseline has no year specified' %\n str(indicator.pk)))\n\n for reference in indicator.references.all():\n if not reference.reference:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has no code '\n u'specified' % str(reference.pk)))\n\n if not reference.vocabulary:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has no vocabulary '\n u'specified' % str(reference.pk)))\n\n if reference.vocabulary == '99' and not reference.vocabulary_uri:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has vocabulary 99 '\n u'(reporting organisation) but no vocabulary URI '\n u'specified' % str(reference.pk)))\n\n for period in indicator.periods.all():\n if not period.period_start:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no start date '\n u'specified' % str(period.pk)))\n\n if not period.period_end:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no end date '\n u'specified' % str(period.pk)))\n\n if period.period_start and period.period_end and \\\n period.period_start > period.period_end:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has a start date '\n u'later than the end date' % str(period.pk)))\n\n if not period.target_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator period (id: %s) has no target value '\n u'specified. The value \"N/A\" has been set for '\n u'the target value attribute' % str(period.pk)))\n elif (period.target_comment or period.target_locations.all() or\n period.target_dimensions.all()):\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no target value, '\n u'but does have a target comment, target '\n u'location(s) or target dimension(s)' %\n str(period.pk)))\n\n if not period.actual_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator period (id: %s) has no actual value '\n u'specified. The value \"N/A\" has been set for '\n u'the actual value attribute' % str(period.pk)))\n elif (period.actual_comment or period.actual_locations.all() or\n period.actual_dimensions.all()):\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no actual value, '\n u'but does have a actual comment, actual '\n u'location(s) or actual dimension(s)' %\n str(period.pk)))\n\n if project.results.all() and all_checks_passed:\n checks.append((u'success', u'has valid result(s)'))\n\n return all_checks_passed, checks\n", "path": "akvo/iati/checks/fields/results.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom lxml import etree\n\nfrom akvo.rsr.models.result.utils import QUANTITATIVE\n\nDGIS_VALIDATION_SET_NAME = u\"DGIS IATI\"\nNOT_AVAILABLE = u\"N/A\"\n\n\ndef result(project):\n \"\"\"\n Generate the result elements.\n\n :param project: Project object\n :return: A list of Etree elements\n \"\"\"\n result_elements = []\n\n DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1\n\n for res in project.results.all():\n if res.type or res.aggregation_status is not None or res.title or res.description or \\\n res.indicators.all():\n element = etree.Element(\"result\")\n\n if res.type:\n element.attrib['type'] = res.type\n\n if res.aggregation_status is not None:\n element.attrib['aggregation-status'] = '1' if res.aggregation_status else '0'\n\n if res.title:\n title_element = etree.SubElement(element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = res.title\n\n if res.description:\n description_element = etree.SubElement(element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = res.description\n\n for indicator in res.indicators.filter(type=QUANTITATIVE):\n if indicator.measure or indicator.ascending is not None or indicator.title or \\\n indicator.description or indicator.references.all() or \\\n indicator.baseline_year or indicator.baseline_value or \\\n indicator.baseline_comment or indicator.periods.all():\n indicator_element = etree.SubElement(element, \"indicator\")\n\n if indicator.measure:\n indicator_element.attrib['measure'] = indicator.measure\n\n if indicator.ascending is not None:\n indicator_element.attrib['ascending'] = '1' if indicator.ascending else '0'\n\n if indicator.title:\n title_element = etree.SubElement(indicator_element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = indicator.title\n\n if indicator.description:\n description_element = etree.SubElement(indicator_element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = indicator.description\n\n for reference in indicator.references.all():\n if reference.vocabulary or reference.reference or reference.vocabulary_uri:\n reference_element = etree.SubElement(indicator_element, \"reference\")\n\n if reference.vocabulary:\n reference_element.attrib['vocabulary'] = reference.vocabulary\n\n if reference.reference:\n reference_element.attrib['code'] = reference.reference\n\n if reference.vocabulary_uri:\n reference_element.attrib['indicator-uri'] = reference.vocabulary_uri\n\n if DGIS_PROJECT or indicator.baseline_year or indicator.baseline_value or \\\n indicator.baseline_comment:\n baseline_element = etree.SubElement(indicator_element, \"baseline\")\n\n if indicator.baseline_year:\n baseline_element.attrib['year'] = str(indicator.baseline_year)\n elif DGIS_PROJECT:\n baseline_element.attrib['year'] = NOT_AVAILABLE\n\n if indicator.baseline_value:\n baseline_element.attrib['value'] = indicator.baseline_value\n elif DGIS_PROJECT:\n baseline_element.attrib['value'] = NOT_AVAILABLE\n\n if indicator.baseline_comment:\n comment_element = etree.SubElement(baseline_element, \"comment\")\n narrative_element = etree.SubElement(comment_element, \"narrative\")\n narrative_element.text = indicator.baseline_comment\n\n for period in indicator.periods.all():\n if period.period_start or period.period_end or period.target_value or \\\n period.target_locations.all() or period.target_dimensions.all() or \\\n period.target_comment or period.actual_value or \\\n period.actual_locations.all() or period.actual_dimensions.all() or \\\n period.actual_comment:\n period_element = etree.SubElement(indicator_element, \"period\")\n\n if period.period_start:\n period_start_element = etree.SubElement(period_element,\n \"period-start\")\n period_start_element.attrib['iso-date'] = str(period.period_start)\n\n if period.period_end:\n period_end_element = etree.SubElement(period_element, \"period-end\")\n period_end_element.attrib['iso-date'] = str(period.period_end)\n\n if (DGIS_PROJECT or period.target_value or\n period.target_locations.all() or\n period.target_dimensions.all() or period.target_comment):\n target_element = etree.SubElement(period_element, \"target\")\n\n if period.target_value:\n target_element.attrib['value'] = period.target_value\n elif DGIS_PROJECT:\n target_element.attrib['value'] = NOT_AVAILABLE\n\n for target_location in period.target_locations.all():\n target_location_element = etree.SubElement(target_element,\n \"location\")\n target_location_element.attrib['ref'] = target_location.location\n\n for target_dimension in period.target_dimensions.all():\n if target_dimension.name or target_dimension.value:\n target_dimension_element = etree.SubElement(target_element,\n \"dimension\")\n\n if target_dimension.name:\n target_dimension_element.attrib['name'] = \\\n target_dimension.name\n\n if target_dimension.value:\n target_dimension_element.attrib['value'] = \\\n target_dimension.value\n\n if period.target_comment:\n comment_element = etree.SubElement(target_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.target_comment\n\n if (DGIS_PROJECT or period.actual_value or\n period.actual_locations.all() or\n period.actual_dimensions.all() or period.actual_comment):\n actual_element = etree.SubElement(period_element, \"actual\")\n\n if period.actual_value:\n actual_element.attrib['value'] = period.actual_value\n elif DGIS_PROJECT:\n actual_element.attrib['value'] = NOT_AVAILABLE\n\n for actual_location in period.actual_locations.all():\n actual_location_element = etree.SubElement(actual_element,\n \"location\")\n actual_location_element.attrib['ref'] = actual_location.location\n\n for actual_dimension in period.actual_dimensions.all():\n if actual_dimension.name or actual_dimension.value:\n actual_dimension_element = etree.SubElement(actual_element,\n \"dimension\")\n\n if actual_dimension.name:\n actual_dimension_element.attrib['name'] = \\\n actual_dimension.name\n\n if actual_dimension.value:\n actual_dimension_element.attrib['value'] = \\\n actual_dimension.value\n\n if period.actual_comment:\n comment_element = etree.SubElement(actual_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.actual_comment\n\n result_elements.append(element)\n\n return result_elements\n", "path": "akvo/iati/exports/elements/result.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rsr.models.result.utils import QUANTITATIVE\n\nDGIS_VALIDATION_SET_NAME = u\"DGIS IATI\"\n\n\ndef results(project):\n \"\"\"\n :param project: Project object\n :return: All checks passed boolean, [Check results]\n \"\"\"\n checks = []\n all_checks_passed = True\n\n DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1\n\n for result in project.results.all():\n if not result.type:\n all_checks_passed = False\n checks.append((u'error', u'result (id: %s) has no type specified' % str(result.pk)))\n\n if not result.title:\n all_checks_passed = False\n checks.append((u'error', u'result (id: %s) has no title specified' % str(result.pk)))\n\n if not result.indicators.filter(type=QUANTITATIVE):\n all_checks_passed = False\n checks.append(\n (u'error', u'result (id: %s) has no quantitative indicator(s)' % str(result.pk))\n )\n\n for indicator in result.indicators.filter(type=QUANTITATIVE):\n if not indicator.measure:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) has no measure specified' %\n str(indicator.pk)))\n\n if not indicator.title:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) has no title specified' %\n str(indicator.pk)))\n\n if not indicator.baseline_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator (id: %s) baseline has no value '\n u'specified, however the value of \"N/A\" has been '\n u'set for the attribute' % str(indicator.pk)))\n elif indicator.baseline_year or indicator.baseline_comment:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) baseline has no value specified' %\n str(indicator.pk)))\n\n if not indicator.baseline_year:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator (id: %s) baseline has no year '\n u'specified, however the value of \"1\" has been '\n u'set for the attribute' % str(indicator.pk)))\n elif indicator.baseline_value or indicator.baseline_comment:\n all_checks_passed = False\n checks.append((u'error', u'indicator (id: %s) baseline has no year specified' %\n str(indicator.pk)))\n\n for reference in indicator.references.all():\n if not reference.reference:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has no code '\n u'specified' % str(reference.pk)))\n\n if not reference.vocabulary:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has no vocabulary '\n u'specified' % str(reference.pk)))\n\n if reference.vocabulary == '99' and not reference.vocabulary_uri:\n all_checks_passed = False\n checks.append((u'error', u'indicator reference (id: %s) has vocabulary 99 '\n u'(reporting organisation) but no vocabulary URI '\n u'specified' % str(reference.pk)))\n\n for period in indicator.periods.all():\n if not period.period_start:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no start date '\n u'specified' % str(period.pk)))\n\n if not period.period_end:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no end date '\n u'specified' % str(period.pk)))\n\n if period.period_start and period.period_end and \\\n period.period_start > period.period_end:\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has a start date '\n u'later than the end date' % str(period.pk)))\n\n if not period.target_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator period (id: %s) has no target value '\n u'specified. The value \"N/A\" has been set for '\n u'the target value attribute' % str(period.pk)))\n elif (period.target_comment or period.target_locations.all() or\n period.target_dimensions.all()):\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no target value, '\n u'but does have a target comment, target '\n u'location(s) or target dimension(s)' %\n str(period.pk)))\n\n if not period.actual_value:\n if DGIS_PROJECT:\n all_checks_passed = False\n checks.append((u'warning', u'indicator period (id: %s) has no actual value '\n u'specified. The value \"N/A\" has been set for '\n u'the actual value attribute' % str(period.pk)))\n elif (period.actual_comment or period.actual_locations.all() or\n period.actual_dimensions.all()):\n all_checks_passed = False\n checks.append((u'error', u'indicator period (id: %s) has no actual value, '\n u'but does have a actual comment, actual '\n u'location(s) or actual dimension(s)' %\n str(period.pk)))\n\n if project.results.all() and all_checks_passed:\n checks.append((u'success', u'has valid result(s)'))\n\n return all_checks_passed, checks\n", "path": "akvo/iati/checks/fields/results.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom lxml import etree\n\nfrom akvo.rsr.models.result.utils import QUANTITATIVE\n\nDGIS_VALIDATION_SET_NAME = u\"DGIS IATI\"\nNOT_AVAILABLE = u\"N/A\"\nNOT_AVAILABLE_YEAR = u\"1\"\n\n\ndef result(project):\n \"\"\"\n Generate the result elements.\n\n :param project: Project object\n :return: A list of Etree elements\n \"\"\"\n result_elements = []\n\n DGIS_PROJECT = project.validations.filter(name=DGIS_VALIDATION_SET_NAME).count() == 1\n\n for res in project.results.all():\n if res.type or res.aggregation_status is not None or res.title or res.description or \\\n res.indicators.all():\n element = etree.Element(\"result\")\n\n if res.type:\n element.attrib['type'] = res.type\n\n if res.aggregation_status is not None:\n element.attrib['aggregation-status'] = '1' if res.aggregation_status else '0'\n\n if res.title:\n title_element = etree.SubElement(element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = res.title\n\n if res.description:\n description_element = etree.SubElement(element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = res.description\n\n for indicator in res.indicators.filter(type=QUANTITATIVE):\n if indicator.measure or indicator.ascending is not None or indicator.title or \\\n indicator.description or indicator.references.all() or \\\n indicator.baseline_year or indicator.baseline_value or \\\n indicator.baseline_comment or indicator.periods.all():\n indicator_element = etree.SubElement(element, \"indicator\")\n\n if indicator.measure:\n indicator_element.attrib['measure'] = indicator.measure\n\n if indicator.ascending is not None:\n indicator_element.attrib['ascending'] = '1' if indicator.ascending else '0'\n\n if indicator.title:\n title_element = etree.SubElement(indicator_element, \"title\")\n narrative_element = etree.SubElement(title_element, \"narrative\")\n narrative_element.text = indicator.title\n\n if indicator.description:\n description_element = etree.SubElement(indicator_element, \"description\")\n narrative_element = etree.SubElement(description_element, \"narrative\")\n narrative_element.text = indicator.description\n\n for reference in indicator.references.all():\n if reference.vocabulary or reference.reference or reference.vocabulary_uri:\n reference_element = etree.SubElement(indicator_element, \"reference\")\n\n if reference.vocabulary:\n reference_element.attrib['vocabulary'] = reference.vocabulary\n\n if reference.reference:\n reference_element.attrib['code'] = reference.reference\n\n if reference.vocabulary_uri:\n reference_element.attrib['indicator-uri'] = reference.vocabulary_uri\n\n if DGIS_PROJECT or indicator.baseline_year or indicator.baseline_value or \\\n indicator.baseline_comment:\n baseline_element = etree.SubElement(indicator_element, \"baseline\")\n\n if indicator.baseline_year:\n baseline_element.attrib['year'] = str(indicator.baseline_year)\n elif DGIS_PROJECT:\n baseline_element.attrib['year'] = NOT_AVAILABLE_YEAR\n\n if indicator.baseline_value:\n baseline_element.attrib['value'] = indicator.baseline_value\n elif DGIS_PROJECT:\n baseline_element.attrib['value'] = NOT_AVAILABLE\n\n if indicator.baseline_comment:\n comment_element = etree.SubElement(baseline_element, \"comment\")\n narrative_element = etree.SubElement(comment_element, \"narrative\")\n narrative_element.text = indicator.baseline_comment\n\n for period in indicator.periods.all():\n if period.period_start or period.period_end or period.target_value or \\\n period.target_locations.all() or period.target_dimensions.all() or \\\n period.target_comment or period.actual_value or \\\n period.actual_locations.all() or period.actual_dimensions.all() or \\\n period.actual_comment:\n period_element = etree.SubElement(indicator_element, \"period\")\n\n if period.period_start:\n period_start_element = etree.SubElement(period_element,\n \"period-start\")\n period_start_element.attrib['iso-date'] = str(period.period_start)\n\n if period.period_end:\n period_end_element = etree.SubElement(period_element, \"period-end\")\n period_end_element.attrib['iso-date'] = str(period.period_end)\n\n if (DGIS_PROJECT or period.target_value or\n period.target_locations.all() or\n period.target_dimensions.all() or period.target_comment):\n target_element = etree.SubElement(period_element, \"target\")\n\n if period.target_value:\n target_element.attrib['value'] = period.target_value\n elif DGIS_PROJECT:\n target_element.attrib['value'] = NOT_AVAILABLE\n\n for target_location in period.target_locations.all():\n target_location_element = etree.SubElement(target_element,\n \"location\")\n target_location_element.attrib['ref'] = target_location.location\n\n for target_dimension in period.target_dimensions.all():\n if target_dimension.name or target_dimension.value:\n target_dimension_element = etree.SubElement(target_element,\n \"dimension\")\n\n if target_dimension.name:\n target_dimension_element.attrib['name'] = \\\n target_dimension.name\n\n if target_dimension.value:\n target_dimension_element.attrib['value'] = \\\n target_dimension.value\n\n if period.target_comment:\n comment_element = etree.SubElement(target_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.target_comment\n\n if (DGIS_PROJECT or period.actual_value or\n period.actual_locations.all() or\n period.actual_dimensions.all() or period.actual_comment):\n actual_element = etree.SubElement(period_element, \"actual\")\n\n if period.actual_value:\n actual_element.attrib['value'] = period.actual_value\n elif DGIS_PROJECT:\n actual_element.attrib['value'] = NOT_AVAILABLE\n\n for actual_location in period.actual_locations.all():\n actual_location_element = etree.SubElement(actual_element,\n \"location\")\n actual_location_element.attrib['ref'] = actual_location.location\n\n for actual_dimension in period.actual_dimensions.all():\n if actual_dimension.name or actual_dimension.value:\n actual_dimension_element = etree.SubElement(actual_element,\n \"dimension\")\n\n if actual_dimension.name:\n actual_dimension_element.attrib['name'] = \\\n actual_dimension.name\n\n if actual_dimension.value:\n actual_dimension_element.attrib['value'] = \\\n actual_dimension.value\n\n if period.actual_comment:\n comment_element = etree.SubElement(actual_element, \"comment\")\n narrative_element = etree.SubElement(comment_element,\n \"narrative\")\n narrative_element.text = period.actual_comment\n\n result_elements.append(element)\n\n return result_elements\n", "path": "akvo/iati/exports/elements/result.py"}]}
| 3,875 | 359 |
gh_patches_debug_31614
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1306
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TRAIL filters
Add "communes, secteurs, type physique, type foncier..." for TRAILS filters as it is in other modules.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geotrek/land/filters.py`
Content:
```
1 from django.utils.translation import ugettext_lazy as _
2
3 from mapentity.filters import MapEntityFilterSet
4
5 from geotrek.common.models import Organism
6 from geotrek.common.filters import StructureRelatedFilterSet
7
8 from geotrek.core.filters import TopologyFilter, PathFilterSet
9 from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
10 from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
11 from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
12 from geotrek.zoning.filters import * # NOQA
13
14 from .models import (
15 CompetenceEdge, LandEdge, LandType, PhysicalEdge, PhysicalType,
16 SignageManagementEdge, WorkManagementEdge,
17 )
18
19
20 class PhysicalEdgeFilterSet(MapEntityFilterSet):
21 class Meta:
22 model = PhysicalEdge
23 fields = ['physical_type']
24
25
26 class LandEdgeFilterSet(StructureRelatedFilterSet):
27 class Meta:
28 model = LandEdge
29 fields = ['land_type']
30
31
32 class OrganismFilterSet(MapEntityFilterSet):
33 class Meta:
34 fields = ['organization']
35
36
37 class CompetenceEdgeFilterSet(OrganismFilterSet):
38 class Meta(OrganismFilterSet.Meta):
39 model = CompetenceEdge
40
41
42 class WorkManagementEdgeFilterSet(OrganismFilterSet):
43 class Meta(OrganismFilterSet.Meta):
44 model = WorkManagementEdge
45
46
47 class SignageManagementEdgeFilterSet(OrganismFilterSet):
48 class Meta(OrganismFilterSet.Meta):
49 model = SignageManagementEdge
50
51
52 """
53
54 Injected filter fields
55
56 """
57
58
59 class TopologyFilterPhysicalType(TopologyFilter):
60 model = PhysicalType
61
62 def value_to_edges(self, value):
63 return value.physicaledge_set.all()
64
65
66 class TopologyFilterLandType(TopologyFilter):
67 model = LandType
68
69 def value_to_edges(self, value):
70 return value.landedge_set.all()
71
72
73 class TopologyFilterCompetenceEdge(TopologyFilter):
74 model = Organism
75
76 def value_to_edges(self, value):
77 return value.competenceedge_set.select_related('organization').all()
78
79
80 class TopologyFilterSignageManagementEdge(TopologyFilter):
81 model = Organism
82
83 def value_to_edges(self, value):
84 return value.signagemanagementedge_set.select_related('organization').all()
85
86
87 class TopologyFilterWorkManagementEdge(TopologyFilter):
88 model = Organism
89
90 def value_to_edges(self, value):
91 return value.workmanagementedge_set.select_related('organization').all()
92
93
94 def add_edge_filters(filter_set):
95 filter_set.add_filters({
96 'physical_type': TopologyFilterPhysicalType(label=_('Physical type'), required=False),
97 'land_type': TopologyFilterLandType(label=_('Land type'), required=False),
98 'competence': TopologyFilterCompetenceEdge(label=_('Competence'), required=False),
99 'signage': TopologyFilterSignageManagementEdge(label=_('Signage management'), required=False),
100 'work': TopologyFilterWorkManagementEdge(label=_('Work management'), required=False),
101 })
102
103
104 add_edge_filters(TrekFilterSet)
105 add_edge_filters(POIFilterSet)
106 add_edge_filters(InterventionFilterSet)
107 add_edge_filters(ProjectFilterSet)
108 add_edge_filters(PathFilterSet)
109 add_edge_filters(InfrastructureFilterSet)
110 add_edge_filters(SignageFilterSet)
111
```
Path: `geotrek/zoning/filters.py`
Content:
```
1 from django.utils.translation import ugettext_lazy as _
2
3 from geotrek.core.filters import TopologyFilter, PathFilterSet
4 from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
5 from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
6 from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
7 from geotrek.tourism.filters import TouristicContentFilterSet, TouristicEventFilterSet
8 from geotrek.zoning.models import City, District
9
10
11 class TopologyFilterCity(TopologyFilter):
12 model = City
13
14 def value_to_edges(self, value):
15 return value.cityedge_set.all()
16
17
18 class TopologyFilterDistrict(TopologyFilter):
19 model = District
20
21 def value_to_edges(self, value):
22 return value.districtedge_set.all()
23
24
25 def add_edge_filters(filter_set):
26 filter_set.add_filters({
27 'city': TopologyFilterCity(label=_('City'), required=False),
28 'district': TopologyFilterDistrict(label=_('District'), required=False),
29 })
30
31
32 add_edge_filters(TrekFilterSet)
33 add_edge_filters(POIFilterSet)
34 add_edge_filters(InterventionFilterSet)
35 add_edge_filters(ProjectFilterSet)
36 add_edge_filters(PathFilterSet)
37 add_edge_filters(InfrastructureFilterSet)
38 add_edge_filters(SignageFilterSet)
39
40
41 class IntersectionFilter(TopologyFilter):
42 """Inherit from ``TopologyFilter``, just to make sure the widgets
43 will be initialized the same way.
44 """
45 def filter(self, qs, value):
46 if not value:
47 return qs
48 return qs.filter(geom__intersects=value.geom)
49
50
51 class IntersectionFilterCity(IntersectionFilter):
52 model = City
53
54
55 class IntersectionFilterDistrict(IntersectionFilter):
56 model = District
57
58
59 TouristicContentFilterSet.add_filters({
60 'city': IntersectionFilterCity(label=_('City'), required=False),
61 'district': IntersectionFilterDistrict(label=_('District'), required=False),
62 })
63
64 TouristicEventFilterSet.add_filters({
65 'city': IntersectionFilterCity(label=_('City'), required=False),
66 'district': IntersectionFilterDistrict(label=_('District'), required=False),
67 })
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geotrek/land/filters.py b/geotrek/land/filters.py
--- a/geotrek/land/filters.py
+++ b/geotrek/land/filters.py
@@ -5,7 +5,7 @@
from geotrek.common.models import Organism
from geotrek.common.filters import StructureRelatedFilterSet
-from geotrek.core.filters import TopologyFilter, PathFilterSet
+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet
from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
@@ -108,3 +108,4 @@
add_edge_filters(PathFilterSet)
add_edge_filters(InfrastructureFilterSet)
add_edge_filters(SignageFilterSet)
+add_edge_filters(TrailFilterSet)
diff --git a/geotrek/zoning/filters.py b/geotrek/zoning/filters.py
--- a/geotrek/zoning/filters.py
+++ b/geotrek/zoning/filters.py
@@ -1,6 +1,6 @@
from django.utils.translation import ugettext_lazy as _
-from geotrek.core.filters import TopologyFilter, PathFilterSet
+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet
from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
@@ -36,6 +36,7 @@
add_edge_filters(PathFilterSet)
add_edge_filters(InfrastructureFilterSet)
add_edge_filters(SignageFilterSet)
+add_edge_filters(TrailFilterSet)
class IntersectionFilter(TopologyFilter):
|
{"golden_diff": "diff --git a/geotrek/land/filters.py b/geotrek/land/filters.py\n--- a/geotrek/land/filters.py\n+++ b/geotrek/land/filters.py\n@@ -5,7 +5,7 @@\n from geotrek.common.models import Organism\n from geotrek.common.filters import StructureRelatedFilterSet\n \n-from geotrek.core.filters import TopologyFilter, PathFilterSet\n+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\n from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\n from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\n from geotrek.trekking.filters import TrekFilterSet, POIFilterSet\n@@ -108,3 +108,4 @@\n add_edge_filters(PathFilterSet)\n add_edge_filters(InfrastructureFilterSet)\n add_edge_filters(SignageFilterSet)\n+add_edge_filters(TrailFilterSet)\ndiff --git a/geotrek/zoning/filters.py b/geotrek/zoning/filters.py\n--- a/geotrek/zoning/filters.py\n+++ b/geotrek/zoning/filters.py\n@@ -1,6 +1,6 @@\n from django.utils.translation import ugettext_lazy as _\n \n-from geotrek.core.filters import TopologyFilter, PathFilterSet\n+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\n from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\n from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\n from geotrek.trekking.filters import TrekFilterSet, POIFilterSet\n@@ -36,6 +36,7 @@\n add_edge_filters(PathFilterSet)\n add_edge_filters(InfrastructureFilterSet)\n add_edge_filters(SignageFilterSet)\n+add_edge_filters(TrailFilterSet)\n \n \n class IntersectionFilter(TopologyFilter):\n", "issue": "TRAIL filters\nAdd \"communes, secteurs, type physique, type foncier...\" for TRAILS filters as it is in other modules.\n\n", "before_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom mapentity.filters import MapEntityFilterSet\n\nfrom geotrek.common.models import Organism\nfrom geotrek.common.filters import StructureRelatedFilterSet\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.zoning.filters import * # NOQA\n\nfrom .models import (\n CompetenceEdge, LandEdge, LandType, PhysicalEdge, PhysicalType,\n SignageManagementEdge, WorkManagementEdge,\n)\n\n\nclass PhysicalEdgeFilterSet(MapEntityFilterSet):\n class Meta:\n model = PhysicalEdge\n fields = ['physical_type']\n\n\nclass LandEdgeFilterSet(StructureRelatedFilterSet):\n class Meta:\n model = LandEdge\n fields = ['land_type']\n\n\nclass OrganismFilterSet(MapEntityFilterSet):\n class Meta:\n fields = ['organization']\n\n\nclass CompetenceEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = CompetenceEdge\n\n\nclass WorkManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = WorkManagementEdge\n\n\nclass SignageManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = SignageManagementEdge\n\n\n\"\"\"\n\n Injected filter fields\n\n\"\"\"\n\n\nclass TopologyFilterPhysicalType(TopologyFilter):\n model = PhysicalType\n\n def value_to_edges(self, value):\n return value.physicaledge_set.all()\n\n\nclass TopologyFilterLandType(TopologyFilter):\n model = LandType\n\n def value_to_edges(self, value):\n return value.landedge_set.all()\n\n\nclass TopologyFilterCompetenceEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.competenceedge_set.select_related('organization').all()\n\n\nclass TopologyFilterSignageManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.signagemanagementedge_set.select_related('organization').all()\n\n\nclass TopologyFilterWorkManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.workmanagementedge_set.select_related('organization').all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'physical_type': TopologyFilterPhysicalType(label=_('Physical type'), required=False),\n 'land_type': TopologyFilterLandType(label=_('Land type'), required=False),\n 'competence': TopologyFilterCompetenceEdge(label=_('Competence'), required=False),\n 'signage': TopologyFilterSignageManagementEdge(label=_('Signage management'), required=False),\n 'work': TopologyFilterWorkManagementEdge(label=_('Work management'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\n", "path": "geotrek/land/filters.py"}, {"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.tourism.filters import TouristicContentFilterSet, TouristicEventFilterSet\nfrom geotrek.zoning.models import City, District\n\n\nclass TopologyFilterCity(TopologyFilter):\n model = City\n\n def value_to_edges(self, value):\n return value.cityedge_set.all()\n\n\nclass TopologyFilterDistrict(TopologyFilter):\n model = District\n\n def value_to_edges(self, value):\n return value.districtedge_set.all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'city': TopologyFilterCity(label=_('City'), required=False),\n 'district': TopologyFilterDistrict(label=_('District'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\n\n\nclass IntersectionFilter(TopologyFilter):\n \"\"\"Inherit from ``TopologyFilter``, just to make sure the widgets\n will be initialized the same way.\n \"\"\"\n def filter(self, qs, value):\n if not value:\n return qs\n return qs.filter(geom__intersects=value.geom)\n\n\nclass IntersectionFilterCity(IntersectionFilter):\n model = City\n\n\nclass IntersectionFilterDistrict(IntersectionFilter):\n model = District\n\n\nTouristicContentFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n\nTouristicEventFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n", "path": "geotrek/zoning/filters.py"}], "after_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom mapentity.filters import MapEntityFilterSet\n\nfrom geotrek.common.models import Organism\nfrom geotrek.common.filters import StructureRelatedFilterSet\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.zoning.filters import * # NOQA\n\nfrom .models import (\n CompetenceEdge, LandEdge, LandType, PhysicalEdge, PhysicalType,\n SignageManagementEdge, WorkManagementEdge,\n)\n\n\nclass PhysicalEdgeFilterSet(MapEntityFilterSet):\n class Meta:\n model = PhysicalEdge\n fields = ['physical_type']\n\n\nclass LandEdgeFilterSet(StructureRelatedFilterSet):\n class Meta:\n model = LandEdge\n fields = ['land_type']\n\n\nclass OrganismFilterSet(MapEntityFilterSet):\n class Meta:\n fields = ['organization']\n\n\nclass CompetenceEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = CompetenceEdge\n\n\nclass WorkManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = WorkManagementEdge\n\n\nclass SignageManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = SignageManagementEdge\n\n\n\"\"\"\n\n Injected filter fields\n\n\"\"\"\n\n\nclass TopologyFilterPhysicalType(TopologyFilter):\n model = PhysicalType\n\n def value_to_edges(self, value):\n return value.physicaledge_set.all()\n\n\nclass TopologyFilterLandType(TopologyFilter):\n model = LandType\n\n def value_to_edges(self, value):\n return value.landedge_set.all()\n\n\nclass TopologyFilterCompetenceEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.competenceedge_set.select_related('organization').all()\n\n\nclass TopologyFilterSignageManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.signagemanagementedge_set.select_related('organization').all()\n\n\nclass TopologyFilterWorkManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.workmanagementedge_set.select_related('organization').all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'physical_type': TopologyFilterPhysicalType(label=_('Physical type'), required=False),\n 'land_type': TopologyFilterLandType(label=_('Land type'), required=False),\n 'competence': TopologyFilterCompetenceEdge(label=_('Competence'), required=False),\n 'signage': TopologyFilterSignageManagementEdge(label=_('Signage management'), required=False),\n 'work': TopologyFilterWorkManagementEdge(label=_('Work management'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\nadd_edge_filters(TrailFilterSet)\n", "path": "geotrek/land/filters.py"}, {"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.tourism.filters import TouristicContentFilterSet, TouristicEventFilterSet\nfrom geotrek.zoning.models import City, District\n\n\nclass TopologyFilterCity(TopologyFilter):\n model = City\n\n def value_to_edges(self, value):\n return value.cityedge_set.all()\n\n\nclass TopologyFilterDistrict(TopologyFilter):\n model = District\n\n def value_to_edges(self, value):\n return value.districtedge_set.all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'city': TopologyFilterCity(label=_('City'), required=False),\n 'district': TopologyFilterDistrict(label=_('District'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\nadd_edge_filters(TrailFilterSet)\n\n\nclass IntersectionFilter(TopologyFilter):\n \"\"\"Inherit from ``TopologyFilter``, just to make sure the widgets\n will be initialized the same way.\n \"\"\"\n def filter(self, qs, value):\n if not value:\n return qs\n return qs.filter(geom__intersects=value.geom)\n\n\nclass IntersectionFilterCity(IntersectionFilter):\n model = City\n\n\nclass IntersectionFilterDistrict(IntersectionFilter):\n model = District\n\n\nTouristicContentFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n\nTouristicEventFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n", "path": "geotrek/zoning/filters.py"}]}
| 1,852 | 414 |
gh_patches_debug_47458
|
rasdani/github-patches
|
git_diff
|
awslabs__gluonts-1132
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update pandas dependency
As documented in #967, pandas will be fixing the breaking change that led us to fix the dependency to `<1.1`, see pandas-dev/pandas#37267
Once that is resolved, we could remove the constraint.
*Edit:* we should also make sure to find a solution to #965 first
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/gluonts/time_feature/_base.py`
Content:
```
1 # Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License").
4 # You may not use this file except in compliance with the License.
5 # A copy of the License is located at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # or in the "license" file accompanying this file. This file is distributed
10 # on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
11 # express or implied. See the License for the specific language governing
12 # permissions and limitations under the License.
13
14 from typing import List
15
16 # Third-party imports
17 import numpy as np
18 import pandas as pd
19 from pandas.tseries import offsets
20 from pandas.tseries.frequencies import to_offset
21
22 # First-party imports
23 from gluonts.core.component import validated
24
25
26 class TimeFeature:
27 """
28 Base class for features that only depend on time.
29 """
30
31 @validated()
32 def __init__(self, normalized: bool = True):
33 self.normalized = normalized
34
35 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
36 pass
37
38 def __repr__(self):
39 return self.__class__.__name__ + "()"
40
41
42 class MinuteOfHour(TimeFeature):
43 """
44 Minute of hour encoded as value between [-0.5, 0.5]
45 """
46
47 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
48 if self.normalized:
49 return index.minute / 59.0 - 0.5
50 else:
51 return index.minute.map(float)
52
53
54 class HourOfDay(TimeFeature):
55 """
56 Hour of day encoded as value between [-0.5, 0.5]
57 """
58
59 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
60 if self.normalized:
61 return index.hour / 23.0 - 0.5
62 else:
63 return index.hour.map(float)
64
65
66 class DayOfWeek(TimeFeature):
67 """
68 Hour of day encoded as value between [-0.5, 0.5]
69 """
70
71 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
72 if self.normalized:
73 return index.dayofweek / 6.0 - 0.5
74 else:
75 return index.dayofweek.map(float)
76
77
78 class DayOfMonth(TimeFeature):
79 """
80 Day of month encoded as value between [-0.5, 0.5]
81 """
82
83 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
84 if self.normalized:
85 return index.day / 30.0 - 0.5
86 else:
87 return index.day.map(float)
88
89
90 class DayOfYear(TimeFeature):
91 """
92 Day of year encoded as value between [-0.5, 0.5]
93 """
94
95 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
96 if self.normalized:
97 return index.dayofyear / 364.0 - 0.5
98 else:
99 return index.dayofyear.map(float)
100
101
102 class MonthOfYear(TimeFeature):
103 """
104 Month of year encoded as value between [-0.5, 0.5]
105 """
106
107 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
108 if self.normalized:
109 return index.month / 11.0 - 0.5
110 else:
111 return index.month.map(float)
112
113
114 class WeekOfYear(TimeFeature):
115 """
116 Week of year encoded as value between [-0.5, 0.5]
117 """
118
119 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
120 if self.normalized:
121 return index.weekofyear / 51.0 - 0.5
122 else:
123 return index.weekofyear.map(float)
124
125
126 def time_features_from_frequency_str(freq_str: str) -> List[TimeFeature]:
127 """
128 Returns a list of time features that will be appropriate for the given frequency string.
129
130 Parameters
131 ----------
132
133 freq_str
134 Frequency string of the form [multiple][granularity] such as "12H", "5min", "1D" etc.
135
136 """
137
138 features_by_offsets = {
139 offsets.YearOffset: [],
140 offsets.MonthOffset: [MonthOfYear],
141 offsets.Week: [DayOfMonth, WeekOfYear],
142 offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],
143 offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],
144 offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear],
145 offsets.Minute: [
146 MinuteOfHour,
147 HourOfDay,
148 DayOfWeek,
149 DayOfMonth,
150 DayOfYear,
151 ],
152 }
153
154 offset = to_offset(freq_str)
155
156 for offset_type, feature_classes in features_by_offsets.items():
157 if isinstance(offset, offset_type):
158 return [cls() for cls in feature_classes]
159
160 supported_freq_msg = f"""
161 Unsupported frequency {freq_str}
162
163 The following frequencies are supported:
164
165 Y - yearly
166 alias: A
167 M - monthly
168 W - weekly
169 D - daily
170 B - business days
171 H - hourly
172 T - minutely
173 alias: min
174 """
175 raise RuntimeError(supported_freq_msg)
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/gluonts/time_feature/_base.py b/src/gluonts/time_feature/_base.py
--- a/src/gluonts/time_feature/_base.py
+++ b/src/gluonts/time_feature/_base.py
@@ -136,8 +136,8 @@
"""
features_by_offsets = {
- offsets.YearOffset: [],
- offsets.MonthOffset: [MonthOfYear],
+ offsets.YearEnd: [],
+ offsets.MonthEnd: [MonthOfYear],
offsets.Week: [DayOfMonth, WeekOfYear],
offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],
offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],
|
{"golden_diff": "diff --git a/src/gluonts/time_feature/_base.py b/src/gluonts/time_feature/_base.py\n--- a/src/gluonts/time_feature/_base.py\n+++ b/src/gluonts/time_feature/_base.py\n@@ -136,8 +136,8 @@\n \"\"\"\n \n features_by_offsets = {\n- offsets.YearOffset: [],\n- offsets.MonthOffset: [MonthOfYear],\n+ offsets.YearEnd: [],\n+ offsets.MonthEnd: [MonthOfYear],\n offsets.Week: [DayOfMonth, WeekOfYear],\n offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],\n", "issue": "Update pandas dependency\nAs documented in #967, pandas will be fixing the breaking change that led us to fix the dependency to `<1.1`, see pandas-dev/pandas#37267\r\n\r\nOnce that is resolved, we could remove the constraint.\r\n\r\n*Edit:* we should also make sure to find a solution to #965 first\n", "before_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\nfrom typing import List\n\n# Third-party imports\nimport numpy as np\nimport pandas as pd\nfrom pandas.tseries import offsets\nfrom pandas.tseries.frequencies import to_offset\n\n# First-party imports\nfrom gluonts.core.component import validated\n\n\nclass TimeFeature:\n \"\"\"\n Base class for features that only depend on time.\n \"\"\"\n\n @validated()\n def __init__(self, normalized: bool = True):\n self.normalized = normalized\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n pass\n\n def __repr__(self):\n return self.__class__.__name__ + \"()\"\n\n\nclass MinuteOfHour(TimeFeature):\n \"\"\"\n Minute of hour encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.minute / 59.0 - 0.5\n else:\n return index.minute.map(float)\n\n\nclass HourOfDay(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.hour / 23.0 - 0.5\n else:\n return index.hour.map(float)\n\n\nclass DayOfWeek(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofweek / 6.0 - 0.5\n else:\n return index.dayofweek.map(float)\n\n\nclass DayOfMonth(TimeFeature):\n \"\"\"\n Day of month encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.day / 30.0 - 0.5\n else:\n return index.day.map(float)\n\n\nclass DayOfYear(TimeFeature):\n \"\"\"\n Day of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofyear / 364.0 - 0.5\n else:\n return index.dayofyear.map(float)\n\n\nclass MonthOfYear(TimeFeature):\n \"\"\"\n Month of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.month / 11.0 - 0.5\n else:\n return index.month.map(float)\n\n\nclass WeekOfYear(TimeFeature):\n \"\"\"\n Week of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.weekofyear / 51.0 - 0.5\n else:\n return index.weekofyear.map(float)\n\n\ndef time_features_from_frequency_str(freq_str: str) -> List[TimeFeature]:\n \"\"\"\n Returns a list of time features that will be appropriate for the given frequency string.\n\n Parameters\n ----------\n\n freq_str\n Frequency string of the form [multiple][granularity] such as \"12H\", \"5min\", \"1D\" etc.\n\n \"\"\"\n\n features_by_offsets = {\n offsets.YearOffset: [],\n offsets.MonthOffset: [MonthOfYear],\n offsets.Week: [DayOfMonth, WeekOfYear],\n offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Minute: [\n MinuteOfHour,\n HourOfDay,\n DayOfWeek,\n DayOfMonth,\n DayOfYear,\n ],\n }\n\n offset = to_offset(freq_str)\n\n for offset_type, feature_classes in features_by_offsets.items():\n if isinstance(offset, offset_type):\n return [cls() for cls in feature_classes]\n\n supported_freq_msg = f\"\"\"\n Unsupported frequency {freq_str}\n\n The following frequencies are supported:\n\n Y - yearly\n alias: A\n M - monthly\n W - weekly\n D - daily\n B - business days\n H - hourly\n T - minutely\n alias: min\n \"\"\"\n raise RuntimeError(supported_freq_msg)\n", "path": "src/gluonts/time_feature/_base.py"}], "after_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\nfrom typing import List\n\n# Third-party imports\nimport numpy as np\nimport pandas as pd\nfrom pandas.tseries import offsets\nfrom pandas.tseries.frequencies import to_offset\n\n# First-party imports\nfrom gluonts.core.component import validated\n\n\nclass TimeFeature:\n \"\"\"\n Base class for features that only depend on time.\n \"\"\"\n\n @validated()\n def __init__(self, normalized: bool = True):\n self.normalized = normalized\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n pass\n\n def __repr__(self):\n return self.__class__.__name__ + \"()\"\n\n\nclass MinuteOfHour(TimeFeature):\n \"\"\"\n Minute of hour encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.minute / 59.0 - 0.5\n else:\n return index.minute.map(float)\n\n\nclass HourOfDay(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.hour / 23.0 - 0.5\n else:\n return index.hour.map(float)\n\n\nclass DayOfWeek(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofweek / 6.0 - 0.5\n else:\n return index.dayofweek.map(float)\n\n\nclass DayOfMonth(TimeFeature):\n \"\"\"\n Day of month encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.day / 30.0 - 0.5\n else:\n return index.day.map(float)\n\n\nclass DayOfYear(TimeFeature):\n \"\"\"\n Day of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofyear / 364.0 - 0.5\n else:\n return index.dayofyear.map(float)\n\n\nclass MonthOfYear(TimeFeature):\n \"\"\"\n Month of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.month / 11.0 - 0.5\n else:\n return index.month.map(float)\n\n\nclass WeekOfYear(TimeFeature):\n \"\"\"\n Week of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.weekofyear / 51.0 - 0.5\n else:\n return index.weekofyear.map(float)\n\n\ndef time_features_from_frequency_str(freq_str: str) -> List[TimeFeature]:\n \"\"\"\n Returns a list of time features that will be appropriate for the given frequency string.\n\n Parameters\n ----------\n\n freq_str\n Frequency string of the form [multiple][granularity] such as \"12H\", \"5min\", \"1D\" etc.\n\n \"\"\"\n\n features_by_offsets = {\n offsets.YearEnd: [],\n offsets.MonthEnd: [MonthOfYear],\n offsets.Week: [DayOfMonth, WeekOfYear],\n offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Minute: [\n MinuteOfHour,\n HourOfDay,\n DayOfWeek,\n DayOfMonth,\n DayOfYear,\n ],\n }\n\n offset = to_offset(freq_str)\n\n for offset_type, feature_classes in features_by_offsets.items():\n if isinstance(offset, offset_type):\n return [cls() for cls in feature_classes]\n\n supported_freq_msg = f\"\"\"\n Unsupported frequency {freq_str}\n\n The following frequencies are supported:\n\n Y - yearly\n alias: A\n M - monthly\n W - weekly\n D - daily\n B - business days\n H - hourly\n T - minutely\n alias: min\n \"\"\"\n raise RuntimeError(supported_freq_msg)\n", "path": "src/gluonts/time_feature/_base.py"}]}
| 1,928 | 150 |
gh_patches_debug_12149
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-813
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add endpoint for mindsdb version
Add HTTP route to get a version of mindsdb: /util/version/
That should return as mindsb version in JSON view:
```
{
"mindsdb": "2.11.2"
}
```
The new endpoint needs to be added in [Utils](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/api/http/namespaces/util.py).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/api/http/namespaces/util.py`
Content:
```
1 from flask import request
2 from flask_restx import Resource, abort
3
4 from mindsdb.api.http.namespaces.configs.util import ns_conf
5
6
7 @ns_conf.route('/ping')
8 class Ping(Resource):
9 @ns_conf.doc('get_ping')
10 def get(self):
11 '''Checks server avaliable'''
12 return {'status': 'ok'}
13
14
15 @ns_conf.route('/shutdown')
16 class Shutdown(Resource):
17 @ns_conf.doc('get_shutdown')
18 def get(self):
19 '''Shutdown server'''
20 if request.host.startswith('127.0.0.1') or request.host.startswith('localhost'):
21 func = request.environ.get('werkzeug.server.shutdown')
22 if func is None:
23 return '', 500
24 func()
25 return '', 200
26 abort(403, "")
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mindsdb/api/http/namespaces/util.py b/mindsdb/api/http/namespaces/util.py
--- a/mindsdb/api/http/namespaces/util.py
+++ b/mindsdb/api/http/namespaces/util.py
@@ -2,7 +2,7 @@
from flask_restx import Resource, abort
from mindsdb.api.http.namespaces.configs.util import ns_conf
-
+from mindsdb import __about__
@ns_conf.route('/ping')
class Ping(Resource):
@@ -24,3 +24,12 @@
func()
return '', 200
abort(403, "")
+
+
+@ns_conf.route('/util/version')
+class Version(Resource):
+ @ns_conf.doc('get_endpoint')
+ def get(self):
+ '''Check endpoint'''
+ return {'mindsdb': "{__about__.__version__}"}
+
|
{"golden_diff": "diff --git a/mindsdb/api/http/namespaces/util.py b/mindsdb/api/http/namespaces/util.py\n--- a/mindsdb/api/http/namespaces/util.py\n+++ b/mindsdb/api/http/namespaces/util.py\n@@ -2,7 +2,7 @@\n from flask_restx import Resource, abort\n \n from mindsdb.api.http.namespaces.configs.util import ns_conf\n-\n+from mindsdb import __about__\n \n @ns_conf.route('/ping')\n class Ping(Resource):\n@@ -24,3 +24,12 @@\n func()\n return '', 200\n abort(403, \"\")\n+\n+ \n+@ns_conf.route('/util/version')\n+class Version(Resource):\n+ @ns_conf.doc('get_endpoint')\n+ def get(self):\n+ '''Check endpoint'''\n+ return {'mindsdb': \"{__about__.__version__}\"}\n+\n", "issue": "Add endpoint for mindsdb version\nAdd HTTP route to get a version of mindsdb: /util/version/\r\nThat should return as mindsb version in JSON view:\r\n```\r\n{\r\n \"mindsdb\": \"2.11.2\"\r\n}\r\n```\r\nThe new endpoint needs to be added in [Utils](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/api/http/namespaces/util.py).\n", "before_files": [{"content": "from flask import request\nfrom flask_restx import Resource, abort\n\nfrom mindsdb.api.http.namespaces.configs.util import ns_conf\n\n\n@ns_conf.route('/ping')\nclass Ping(Resource):\n @ns_conf.doc('get_ping')\n def get(self):\n '''Checks server avaliable'''\n return {'status': 'ok'}\n\n\n@ns_conf.route('/shutdown')\nclass Shutdown(Resource):\n @ns_conf.doc('get_shutdown')\n def get(self):\n '''Shutdown server'''\n if request.host.startswith('127.0.0.1') or request.host.startswith('localhost'):\n func = request.environ.get('werkzeug.server.shutdown')\n if func is None:\n return '', 500\n func()\n return '', 200\n abort(403, \"\")\n", "path": "mindsdb/api/http/namespaces/util.py"}], "after_files": [{"content": "from flask import request\nfrom flask_restx import Resource, abort\n\nfrom mindsdb.api.http.namespaces.configs.util import ns_conf\nfrom mindsdb import __about__\n\n@ns_conf.route('/ping')\nclass Ping(Resource):\n @ns_conf.doc('get_ping')\n def get(self):\n '''Checks server avaliable'''\n return {'status': 'ok'}\n\n\n@ns_conf.route('/shutdown')\nclass Shutdown(Resource):\n @ns_conf.doc('get_shutdown')\n def get(self):\n '''Shutdown server'''\n if request.host.startswith('127.0.0.1') or request.host.startswith('localhost'):\n func = request.environ.get('werkzeug.server.shutdown')\n if func is None:\n return '', 500\n func()\n return '', 200\n abort(403, \"\")\n\n \n@ns_conf.route('/util/version')\nclass Version(Resource):\n @ns_conf.doc('get_endpoint')\n def get(self):\n '''Check endpoint'''\n return {'mindsdb': \"{__about__.__version__}\"}\n \n", "path": "mindsdb/api/http/namespaces/util.py"}]}
| 568 | 194 |
gh_patches_debug_38899
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-10550
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[sdk] Missing optional parameter to v2 `use_config_map_as_volume` and `use_secret_as_volume`
In kfp v1 the config map or secret can be marked as optional when used as a volume source, as shown in the example below.
This capability is missing in the recent added `use_config_map_as_volume` and `use_secret_as_volume` v2 sdk functions. (https://github.com/kubeflow/pipelines/pull/10400, https://github.com/kubeflow/pipelines/pull/10483)
```bash
vol = k8s_client.V1Volume(
name='dummy',
config_map=k8s_client.V1ConfigMapVolumeSource(name='name', optional=True),
)
component.add_pvolumes({mountPoint: vol})
vol = k8s_client.V1Volume(
name='dummy',
secret=k8s_client.V1SecretVolumeSource(secret_name='name', optional=False),
)
component.add_pvolumes({mountPoint: vol})
```
What is the use case or pain point?
Making the secret or config map an optional resource allows the KFP component to function without failing even if those resources are not present.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kubernetes_platform/python/kfp/kubernetes/secret.py`
Content:
```
1 # Copyright 2023 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Dict
16
17 from google.protobuf import json_format
18 from kfp.dsl import PipelineTask
19 from kfp.kubernetes import common
20 from kfp.kubernetes import kubernetes_executor_config_pb2 as pb
21
22
23 def use_secret_as_env(
24 task: PipelineTask,
25 secret_name: str,
26 secret_key_to_env: Dict[str, str],
27 ) -> PipelineTask:
28 """Use a Kubernetes Secret as an environment variable as described by the `Kubernetes documentation
29 https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-environment-variables `_.
30
31 Args:
32 task: Pipeline task.
33 secret_name: Name of the Secret.
34 secret_key_to_env: Dictionary of Secret data key to environment variable name. For example, ``{'password': 'PASSWORD'}`` sets the data of the Secret's password field to the environment variable ``PASSWORD``.
35
36 Returns:
37 Task object with updated secret configuration.
38 """
39
40 msg = common.get_existing_kubernetes_config_as_message(task)
41
42 key_to_env = [
43 pb.SecretAsEnv.SecretKeyToEnvMap(
44 secret_key=secret_key,
45 env_var=env_var,
46 ) for secret_key, env_var in secret_key_to_env.items()
47 ]
48 secret_as_env = pb.SecretAsEnv(
49 secret_name=secret_name,
50 key_to_env=key_to_env,
51 )
52
53 msg.secret_as_env.append(secret_as_env)
54
55 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
56
57 return task
58
59
60 def use_secret_as_volume(
61 task: PipelineTask,
62 secret_name: str,
63 mount_path: str,
64 ) -> PipelineTask:
65 """Use a Kubernetes Secret by mounting its data to the task's container as
66 described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.
67
68 Args:
69 task: Pipeline task.
70 secret_name: Name of the Secret.
71 mount_path: Path to which to mount the Secret data.
72
73 Returns:
74 Task object with updated secret configuration.
75 """
76
77 msg = common.get_existing_kubernetes_config_as_message(task)
78
79 secret_as_vol = pb.SecretAsVolume(
80 secret_name=secret_name,
81 mount_path=mount_path,
82 )
83
84 msg.secret_as_volume.append(secret_as_vol)
85
86 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
87
88 return task
89
```
Path: `kubernetes_platform/python/kfp/kubernetes/config_map.py`
Content:
```
1 # Copyright 2024 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Dict
16
17 from google.protobuf import json_format
18 from kfp.dsl import PipelineTask
19 from kfp.kubernetes import common
20 from kfp.kubernetes import kubernetes_executor_config_pb2 as pb
21
22
23 def use_config_map_as_env(
24 task: PipelineTask,
25 config_map_name: str,
26 config_map_key_to_env: Dict[str, str],
27 ) -> PipelineTask:
28 """Use a Kubernetes ConfigMap as an environment variable as described by the `Kubernetes documentation
29 https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#define-container-environment-variables-using-configmap-data` _.
30
31 Args:
32 task: Pipeline task.
33 config_map_name: Name of the ConfigMap.
34 config_map_key_to_env: Dictionary of ConfigMap key to environment variable name. For example, ``{'foo': 'FOO'}`` sets the value of the ConfigMap's foo field to the environment variable ``FOO``.
35
36 Returns:
37 Task object with updated ConfigMap configuration.
38 """
39
40 msg = common.get_existing_kubernetes_config_as_message(task)
41
42 key_to_env = [
43 pb.ConfigMapAsEnv.ConfigMapKeyToEnvMap(
44 config_map_key=config_map_key,
45 env_var=env_var,
46 ) for config_map_key, env_var in config_map_key_to_env.items()
47 ]
48 config_map_as_env = pb.ConfigMapAsEnv(
49 config_map_name=config_map_name,
50 key_to_env=key_to_env,
51 )
52
53 msg.config_map_as_env.append(config_map_as_env)
54
55 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
56
57 return task
58
59
60 def use_config_map_as_volume(
61 task: PipelineTask,
62 config_map_name: str,
63 mount_path: str,
64 ) -> PipelineTask:
65 """Use a Kubernetes ConfigMap by mounting its data to the task's container as
66 described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.
67
68 Args:
69 task: Pipeline task.
70 config_map_name: Name of the ConfigMap.
71 mount_path: Path to which to mount the ConfigMap data.
72
73 Returns:
74 Task object with updated ConfigMap configuration.
75 """
76
77 msg = common.get_existing_kubernetes_config_as_message(task)
78
79 config_map_as_vol = pb.ConfigMapAsVolume(
80 config_map_name=config_map_name,
81 mount_path=mount_path,
82 )
83 msg.config_map_as_volume.append(config_map_as_vol)
84
85 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
86
87 return task
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kubernetes_platform/python/kfp/kubernetes/config_map.py b/kubernetes_platform/python/kfp/kubernetes/config_map.py
--- a/kubernetes_platform/python/kfp/kubernetes/config_map.py
+++ b/kubernetes_platform/python/kfp/kubernetes/config_map.py
@@ -61,6 +61,7 @@
task: PipelineTask,
config_map_name: str,
mount_path: str,
+ optional: bool = False,
) -> PipelineTask:
"""Use a Kubernetes ConfigMap by mounting its data to the task's container as
described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.
@@ -69,6 +70,7 @@
task: Pipeline task.
config_map_name: Name of the ConfigMap.
mount_path: Path to which to mount the ConfigMap data.
+ optional: Optional field specifying whether the ConfigMap must be defined.
Returns:
Task object with updated ConfigMap configuration.
@@ -79,6 +81,7 @@
config_map_as_vol = pb.ConfigMapAsVolume(
config_map_name=config_map_name,
mount_path=mount_path,
+ optional=optional,
)
msg.config_map_as_volume.append(config_map_as_vol)
diff --git a/kubernetes_platform/python/kfp/kubernetes/secret.py b/kubernetes_platform/python/kfp/kubernetes/secret.py
--- a/kubernetes_platform/python/kfp/kubernetes/secret.py
+++ b/kubernetes_platform/python/kfp/kubernetes/secret.py
@@ -61,6 +61,7 @@
task: PipelineTask,
secret_name: str,
mount_path: str,
+ optional: bool = False,
) -> PipelineTask:
"""Use a Kubernetes Secret by mounting its data to the task's container as
described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.
@@ -69,6 +70,7 @@
task: Pipeline task.
secret_name: Name of the Secret.
mount_path: Path to which to mount the Secret data.
+ optional: Optional field specifying whether the Secret must be defined.
Returns:
Task object with updated secret configuration.
@@ -79,6 +81,7 @@
secret_as_vol = pb.SecretAsVolume(
secret_name=secret_name,
mount_path=mount_path,
+ optional=optional,
)
msg.secret_as_volume.append(secret_as_vol)
|
{"golden_diff": "diff --git a/kubernetes_platform/python/kfp/kubernetes/config_map.py b/kubernetes_platform/python/kfp/kubernetes/config_map.py\n--- a/kubernetes_platform/python/kfp/kubernetes/config_map.py\n+++ b/kubernetes_platform/python/kfp/kubernetes/config_map.py\n@@ -61,6 +61,7 @@\n task: PipelineTask,\n config_map_name: str,\n mount_path: str,\n+ optional: bool = False,\n ) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.\n@@ -69,6 +70,7 @@\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n mount_path: Path to which to mount the ConfigMap data.\n+ optional: Optional field specifying whether the ConfigMap must be defined.\n \n Returns:\n Task object with updated ConfigMap configuration.\n@@ -79,6 +81,7 @@\n config_map_as_vol = pb.ConfigMapAsVolume(\n config_map_name=config_map_name,\n mount_path=mount_path,\n+ optional=optional,\n )\n msg.config_map_as_volume.append(config_map_as_vol)\n \ndiff --git a/kubernetes_platform/python/kfp/kubernetes/secret.py b/kubernetes_platform/python/kfp/kubernetes/secret.py\n--- a/kubernetes_platform/python/kfp/kubernetes/secret.py\n+++ b/kubernetes_platform/python/kfp/kubernetes/secret.py\n@@ -61,6 +61,7 @@\n task: PipelineTask,\n secret_name: str,\n mount_path: str,\n+ optional: bool = False,\n ) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.\n@@ -69,6 +70,7 @@\n task: Pipeline task.\n secret_name: Name of the Secret.\n mount_path: Path to which to mount the Secret data.\n+ optional: Optional field specifying whether the Secret must be defined.\n \n Returns:\n Task object with updated secret configuration.\n@@ -79,6 +81,7 @@\n secret_as_vol = pb.SecretAsVolume(\n secret_name=secret_name,\n mount_path=mount_path,\n+ optional=optional,\n )\n \n msg.secret_as_volume.append(secret_as_vol)\n", "issue": "[sdk] Missing optional parameter to v2 `use_config_map_as_volume` and `use_secret_as_volume` \nIn kfp v1 the config map or secret can be marked as optional when used as a volume source, as shown in the example below.\r\n\r\nThis capability is missing in the recent added `use_config_map_as_volume` and `use_secret_as_volume` v2 sdk functions. (https://github.com/kubeflow/pipelines/pull/10400, https://github.com/kubeflow/pipelines/pull/10483)\r\n\r\n```bash\r\nvol = k8s_client.V1Volume(\r\n name='dummy',\r\n config_map=k8s_client.V1ConfigMapVolumeSource(name='name', optional=True),\r\n )\r\n component.add_pvolumes({mountPoint: vol})\r\n\r\n\r\nvol = k8s_client.V1Volume(\r\n name='dummy',\r\n secret=k8s_client.V1SecretVolumeSource(secret_name='name', optional=False),\r\n )\r\n component.add_pvolumes({mountPoint: vol})\r\n\r\n```\r\n\r\n\r\nWhat is the use case or pain point?\r\n\r\nMaking the secret or config map an optional resource allows the KFP component to function without failing even if those resources are not present.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_secret_as_env(\n task: PipelineTask,\n secret_name: str,\n secret_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-environment-variables `_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n secret_key_to_env: Dictionary of Secret data key to environment variable name. For example, ``{'password': 'PASSWORD'}`` sets the data of the Secret's password field to the environment variable ``PASSWORD``.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.SecretAsEnv.SecretKeyToEnvMap(\n secret_key=secret_key,\n env_var=env_var,\n ) for secret_key, env_var in secret_key_to_env.items()\n ]\n secret_as_env = pb.SecretAsEnv(\n secret_name=secret_name,\n key_to_env=key_to_env,\n )\n\n msg.secret_as_env.append(secret_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_secret_as_volume(\n task: PipelineTask,\n secret_name: str,\n mount_path: str,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n mount_path: Path to which to mount the Secret data.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n secret_as_vol = pb.SecretAsVolume(\n secret_name=secret_name,\n mount_path=mount_path,\n )\n\n msg.secret_as_volume.append(secret_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/secret.py"}, {"content": "# Copyright 2024 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_config_map_as_env(\n task: PipelineTask,\n config_map_name: str,\n config_map_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#define-container-environment-variables-using-configmap-data` _.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n config_map_key_to_env: Dictionary of ConfigMap key to environment variable name. For example, ``{'foo': 'FOO'}`` sets the value of the ConfigMap's foo field to the environment variable ``FOO``.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.ConfigMapAsEnv.ConfigMapKeyToEnvMap(\n config_map_key=config_map_key,\n env_var=env_var,\n ) for config_map_key, env_var in config_map_key_to_env.items()\n ]\n config_map_as_env = pb.ConfigMapAsEnv(\n config_map_name=config_map_name,\n key_to_env=key_to_env,\n )\n\n msg.config_map_as_env.append(config_map_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_config_map_as_volume(\n task: PipelineTask,\n config_map_name: str,\n mount_path: str,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n mount_path: Path to which to mount the ConfigMap data.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n config_map_as_vol = pb.ConfigMapAsVolume(\n config_map_name=config_map_name,\n mount_path=mount_path,\n )\n msg.config_map_as_volume.append(config_map_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/config_map.py"}], "after_files": [{"content": "# Copyright 2023 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_secret_as_env(\n task: PipelineTask,\n secret_name: str,\n secret_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-environment-variables `_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n secret_key_to_env: Dictionary of Secret data key to environment variable name. For example, ``{'password': 'PASSWORD'}`` sets the data of the Secret's password field to the environment variable ``PASSWORD``.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.SecretAsEnv.SecretKeyToEnvMap(\n secret_key=secret_key,\n env_var=env_var,\n ) for secret_key, env_var in secret_key_to_env.items()\n ]\n secret_as_env = pb.SecretAsEnv(\n secret_name=secret_name,\n key_to_env=key_to_env,\n )\n\n msg.secret_as_env.append(secret_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_secret_as_volume(\n task: PipelineTask,\n secret_name: str,\n mount_path: str,\n optional: bool = False,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n mount_path: Path to which to mount the Secret data.\n optional: Optional field specifying whether the Secret must be defined.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n secret_as_vol = pb.SecretAsVolume(\n secret_name=secret_name,\n mount_path=mount_path,\n optional=optional,\n )\n\n msg.secret_as_volume.append(secret_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/secret.py"}, {"content": "# Copyright 2024 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_config_map_as_env(\n task: PipelineTask,\n config_map_name: str,\n config_map_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#define-container-environment-variables-using-configmap-data` _.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n config_map_key_to_env: Dictionary of ConfigMap key to environment variable name. For example, ``{'foo': 'FOO'}`` sets the value of the ConfigMap's foo field to the environment variable ``FOO``.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.ConfigMapAsEnv.ConfigMapKeyToEnvMap(\n config_map_key=config_map_key,\n env_var=env_var,\n ) for config_map_key, env_var in config_map_key_to_env.items()\n ]\n config_map_as_env = pb.ConfigMapAsEnv(\n config_map_name=config_map_name,\n key_to_env=key_to_env,\n )\n\n msg.config_map_as_env.append(config_map_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_config_map_as_volume(\n task: PipelineTask,\n config_map_name: str,\n mount_path: str,\n optional: bool = False,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n mount_path: Path to which to mount the ConfigMap data.\n optional: Optional field specifying whether the ConfigMap must be defined.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n config_map_as_vol = pb.ConfigMapAsVolume(\n config_map_name=config_map_name,\n mount_path=mount_path,\n optional=optional,\n )\n msg.config_map_as_volume.append(config_map_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/config_map.py"}]}
| 2,244 | 541 |
gh_patches_debug_9044
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection3d-687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
An error occurred while creating Scannetv2 data
@Wuziyi616 I am trying to create the Scannet dataset as required, but an error occurred when I operate ```python tools/create_data.py scannet --root-path ./data/scannet --out-dir ./data/scannet --extra-tag scannet```. Here is the error message:
```
scannet info test file is saved to ./data/scannet/scannet_infos_test.pkl
Traceback (most recent call last):
File "tools/create_data.py", line 300, in <module>
workers=args.workers)
File "tools/create_data.py", line 134, in scannet_data_prep
root_path, info_prefix, out_dir, workers=workers)
File "/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/indoor_converter.py", line 87, in create_indoor_info_file
train_dataset.get_seg_infos()
File "/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/scannet_data_utils.py", line 204, in get_seg_infos
scene_idxs, label_weight = self.get_scene_idxs_and_label_weight()
File "/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/scannet_data_utils.py", line 247, in get_scene_idxs_and_label_weight
scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))
TypeError: can't multiply sequence by non-int of type 'numpy.float64'
```
My environment:
- cuda 10.2
- python 3.6
- mmcv-full 1.3.7
- mmdet 2.11.0
- mmdet3d 0.14.0
- mmsegmentation 0.14.0
- numpy 1.18.0
Can anyone help me????
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/data_converter/scannet_data_utils.py`
Content:
```
1 import mmcv
2 import numpy as np
3 from concurrent import futures as futures
4 from os import path as osp
5
6
7 class ScanNetData(object):
8 """ScanNet data.
9
10 Generate scannet infos for scannet_converter.
11
12 Args:
13 root_path (str): Root path of the raw data.
14 split (str): Set split type of the data. Default: 'train'.
15 """
16
17 def __init__(self, root_path, split='train'):
18 self.root_dir = root_path
19 self.split = split
20 self.split_dir = osp.join(root_path)
21 self.classes = [
22 'cabinet', 'bed', 'chair', 'sofa', 'table', 'door', 'window',
23 'bookshelf', 'picture', 'counter', 'desk', 'curtain',
24 'refrigerator', 'showercurtrain', 'toilet', 'sink', 'bathtub',
25 'garbagebin'
26 ]
27 self.cat2label = {cat: self.classes.index(cat) for cat in self.classes}
28 self.label2cat = {self.cat2label[t]: t for t in self.cat2label}
29 self.cat_ids = np.array(
30 [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36, 39])
31 self.cat_ids2class = {
32 nyu40id: i
33 for i, nyu40id in enumerate(list(self.cat_ids))
34 }
35 assert split in ['train', 'val', 'test']
36 split_file = osp.join(self.root_dir, 'meta_data',
37 f'scannetv2_{split}.txt')
38 mmcv.check_file_exist(split_file)
39 self.sample_id_list = mmcv.list_from_file(split_file)
40 self.test_mode = (split == 'test')
41
42 def __len__(self):
43 return len(self.sample_id_list)
44
45 def get_aligned_box_label(self, idx):
46 box_file = osp.join(self.root_dir, 'scannet_instance_data',
47 f'{idx}_aligned_bbox.npy')
48 mmcv.check_file_exist(box_file)
49 return np.load(box_file)
50
51 def get_unaligned_box_label(self, idx):
52 box_file = osp.join(self.root_dir, 'scannet_instance_data',
53 f'{idx}_unaligned_bbox.npy')
54 mmcv.check_file_exist(box_file)
55 return np.load(box_file)
56
57 def get_axis_align_matrix(self, idx):
58 matrix_file = osp.join(self.root_dir, 'scannet_instance_data',
59 f'{idx}_axis_align_matrix.npy')
60 mmcv.check_file_exist(matrix_file)
61 return np.load(matrix_file)
62
63 def get_infos(self, num_workers=4, has_label=True, sample_id_list=None):
64 """Get data infos.
65
66 This method gets information from the raw data.
67
68 Args:
69 num_workers (int): Number of threads to be used. Default: 4.
70 has_label (bool): Whether the data has label. Default: True.
71 sample_id_list (list[int]): Index list of the sample.
72 Default: None.
73
74 Returns:
75 infos (list[dict]): Information of the raw data.
76 """
77
78 def process_single_scene(sample_idx):
79 print(f'{self.split} sample_idx: {sample_idx}')
80 info = dict()
81 pc_info = {'num_features': 6, 'lidar_idx': sample_idx}
82 info['point_cloud'] = pc_info
83 pts_filename = osp.join(self.root_dir, 'scannet_instance_data',
84 f'{sample_idx}_vert.npy')
85 points = np.load(pts_filename)
86 mmcv.mkdir_or_exist(osp.join(self.root_dir, 'points'))
87 points.tofile(
88 osp.join(self.root_dir, 'points', f'{sample_idx}.bin'))
89 info['pts_path'] = osp.join('points', f'{sample_idx}.bin')
90
91 if not self.test_mode:
92 pts_instance_mask_path = osp.join(
93 self.root_dir, 'scannet_instance_data',
94 f'{sample_idx}_ins_label.npy')
95 pts_semantic_mask_path = osp.join(
96 self.root_dir, 'scannet_instance_data',
97 f'{sample_idx}_sem_label.npy')
98
99 pts_instance_mask = np.load(pts_instance_mask_path).astype(
100 np.long)
101 pts_semantic_mask = np.load(pts_semantic_mask_path).astype(
102 np.long)
103
104 mmcv.mkdir_or_exist(osp.join(self.root_dir, 'instance_mask'))
105 mmcv.mkdir_or_exist(osp.join(self.root_dir, 'semantic_mask'))
106
107 pts_instance_mask.tofile(
108 osp.join(self.root_dir, 'instance_mask',
109 f'{sample_idx}.bin'))
110 pts_semantic_mask.tofile(
111 osp.join(self.root_dir, 'semantic_mask',
112 f'{sample_idx}.bin'))
113
114 info['pts_instance_mask_path'] = osp.join(
115 'instance_mask', f'{sample_idx}.bin')
116 info['pts_semantic_mask_path'] = osp.join(
117 'semantic_mask', f'{sample_idx}.bin')
118
119 if has_label:
120 annotations = {}
121 # box is of shape [k, 6 + class]
122 aligned_box_label = self.get_aligned_box_label(sample_idx)
123 unaligned_box_label = self.get_unaligned_box_label(sample_idx)
124 annotations['gt_num'] = aligned_box_label.shape[0]
125 if annotations['gt_num'] != 0:
126 aligned_box = aligned_box_label[:, :-1] # k, 6
127 unaligned_box = unaligned_box_label[:, :-1]
128 classes = aligned_box_label[:, -1] # k
129 annotations['name'] = np.array([
130 self.label2cat[self.cat_ids2class[classes[i]]]
131 for i in range(annotations['gt_num'])
132 ])
133 # default names are given to aligned bbox for compatibility
134 # we also save unaligned bbox info with marked names
135 annotations['location'] = aligned_box[:, :3]
136 annotations['dimensions'] = aligned_box[:, 3:6]
137 annotations['gt_boxes_upright_depth'] = aligned_box
138 annotations['unaligned_location'] = unaligned_box[:, :3]
139 annotations['unaligned_dimensions'] = unaligned_box[:, 3:6]
140 annotations[
141 'unaligned_gt_boxes_upright_depth'] = unaligned_box
142 annotations['index'] = np.arange(
143 annotations['gt_num'], dtype=np.int32)
144 annotations['class'] = np.array([
145 self.cat_ids2class[classes[i]]
146 for i in range(annotations['gt_num'])
147 ])
148 axis_align_matrix = self.get_axis_align_matrix(sample_idx)
149 annotations['axis_align_matrix'] = axis_align_matrix # 4x4
150 info['annos'] = annotations
151 return info
152
153 sample_id_list = sample_id_list if sample_id_list is not None \
154 else self.sample_id_list
155 with futures.ThreadPoolExecutor(num_workers) as executor:
156 infos = executor.map(process_single_scene, sample_id_list)
157 return list(infos)
158
159
160 class ScanNetSegData(object):
161 """ScanNet dataset used to generate infos for semantic segmentation task.
162
163 Args:
164 data_root (str): Root path of the raw data.
165 ann_file (str): The generated scannet infos.
166 split (str): Set split type of the data. Default: 'train'.
167 num_points (int): Number of points in each data input. Default: 8192.
168 label_weight_func (function): Function to compute the label weight.
169 Default: None.
170 """
171
172 def __init__(self,
173 data_root,
174 ann_file,
175 split='train',
176 num_points=8192,
177 label_weight_func=None):
178 self.data_root = data_root
179 self.data_infos = mmcv.load(ann_file)
180 self.split = split
181 assert split in ['train', 'val', 'test']
182 self.num_points = num_points
183
184 self.all_ids = np.arange(41) # all possible ids
185 self.cat_ids = np.array([
186 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36,
187 39
188 ]) # used for seg task
189 self.ignore_index = len(self.cat_ids)
190
191 self.cat_id2class = np.ones((self.all_ids.shape[0],), dtype=np.int) * \
192 self.ignore_index
193 for i, cat_id in enumerate(self.cat_ids):
194 self.cat_id2class[cat_id] = i
195
196 # label weighting function is taken from
197 # https://github.com/charlesq34/pointnet2/blob/master/scannet/scannet_dataset.py#L24
198 self.label_weight_func = (lambda x: 1.0 / np.log(1.2 + x)) if \
199 label_weight_func is None else label_weight_func
200
201 def get_seg_infos(self):
202 if self.split == 'test':
203 return
204 scene_idxs, label_weight = self.get_scene_idxs_and_label_weight()
205 save_folder = osp.join(self.data_root, 'seg_info')
206 mmcv.mkdir_or_exist(save_folder)
207 np.save(
208 osp.join(save_folder, f'{self.split}_resampled_scene_idxs.npy'),
209 scene_idxs)
210 np.save(
211 osp.join(save_folder, f'{self.split}_label_weight.npy'),
212 label_weight)
213 print(f'{self.split} resampled scene index and label weight saved')
214
215 def _convert_to_label(self, mask):
216 """Convert class_id in loaded segmentation mask to label."""
217 if isinstance(mask, str):
218 if mask.endswith('npy'):
219 mask = np.load(mask)
220 else:
221 mask = np.fromfile(mask, dtype=np.long)
222 label = self.cat_id2class[mask]
223 return label
224
225 def get_scene_idxs_and_label_weight(self):
226 """Compute scene_idxs for data sampling and label weight for loss \
227 calculation.
228
229 We sample more times for scenes with more points. Label_weight is
230 inversely proportional to number of class points.
231 """
232 num_classes = len(self.cat_ids)
233 num_point_all = []
234 label_weight = np.zeros((num_classes + 1, )) # ignore_index
235 for data_info in self.data_infos:
236 label = self._convert_to_label(
237 osp.join(self.data_root, data_info['pts_semantic_mask_path']))
238 num_point_all.append(label.shape[0])
239 class_count, _ = np.histogram(label, range(num_classes + 2))
240 label_weight += class_count
241
242 # repeat scene_idx for num_scene_point // num_sample_point times
243 sample_prob = np.array(num_point_all) / float(np.sum(num_point_all))
244 num_iter = int(np.sum(num_point_all) / float(self.num_points))
245 scene_idxs = []
246 for idx in range(len(self.data_infos)):
247 scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))
248 scene_idxs = np.array(scene_idxs).astype(np.int32)
249
250 # calculate label weight, adopted from PointNet++
251 label_weight = label_weight[:-1].astype(np.float32)
252 label_weight = label_weight / label_weight.sum()
253 label_weight = self.label_weight_func(label_weight).astype(np.float32)
254
255 return scene_idxs, label_weight
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/data_converter/scannet_data_utils.py b/tools/data_converter/scannet_data_utils.py
--- a/tools/data_converter/scannet_data_utils.py
+++ b/tools/data_converter/scannet_data_utils.py
@@ -244,7 +244,7 @@
num_iter = int(np.sum(num_point_all) / float(self.num_points))
scene_idxs = []
for idx in range(len(self.data_infos)):
- scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))
+ scene_idxs.extend([idx] * int(round(sample_prob[idx] * num_iter)))
scene_idxs = np.array(scene_idxs).astype(np.int32)
# calculate label weight, adopted from PointNet++
|
{"golden_diff": "diff --git a/tools/data_converter/scannet_data_utils.py b/tools/data_converter/scannet_data_utils.py\n--- a/tools/data_converter/scannet_data_utils.py\n+++ b/tools/data_converter/scannet_data_utils.py\n@@ -244,7 +244,7 @@\n num_iter = int(np.sum(num_point_all) / float(self.num_points))\n scene_idxs = []\n for idx in range(len(self.data_infos)):\n- scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))\n+ scene_idxs.extend([idx] * int(round(sample_prob[idx] * num_iter)))\n scene_idxs = np.array(scene_idxs).astype(np.int32)\n \n # calculate label weight, adopted from PointNet++\n", "issue": "An error occurred while creating Scannetv2 data\n@Wuziyi616 I am trying to create the Scannet dataset as required, but an error occurred when I operate ```python tools/create_data.py scannet --root-path ./data/scannet --out-dir ./data/scannet --extra-tag scannet```. Here is the error message:\r\n```\r\nscannet info test file is saved to ./data/scannet/scannet_infos_test.pkl\r\nTraceback (most recent call last):\r\n File \"tools/create_data.py\", line 300, in <module>\r\n workers=args.workers)\r\n File \"tools/create_data.py\", line 134, in scannet_data_prep\r\n root_path, info_prefix, out_dir, workers=workers)\r\n File \"/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/indoor_converter.py\", line 87, in create_indoor_info_file\r\n train_dataset.get_seg_infos()\r\n File \"/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/scannet_data_utils.py\", line 204, in get_seg_infos\r\n scene_idxs, label_weight = self.get_scene_idxs_and_label_weight()\r\n File \"/scratch1/du014/Auxiliary_Code/mmdetection3d/tools/data_converter/scannet_data_utils.py\", line 247, in get_scene_idxs_and_label_weight\r\n scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))\r\nTypeError: can't multiply sequence by non-int of type 'numpy.float64'\r\n```\r\n\r\nMy environment:\r\n- cuda 10.2\r\n- python 3.6\r\n- mmcv-full 1.3.7\r\n- mmdet 2.11.0\r\n- mmdet3d 0.14.0\r\n- mmsegmentation 0.14.0\r\n- numpy 1.18.0\r\n\r\nCan anyone help me????\n", "before_files": [{"content": "import mmcv\nimport numpy as np\nfrom concurrent import futures as futures\nfrom os import path as osp\n\n\nclass ScanNetData(object):\n \"\"\"ScanNet data.\n\n Generate scannet infos for scannet_converter.\n\n Args:\n root_path (str): Root path of the raw data.\n split (str): Set split type of the data. Default: 'train'.\n \"\"\"\n\n def __init__(self, root_path, split='train'):\n self.root_dir = root_path\n self.split = split\n self.split_dir = osp.join(root_path)\n self.classes = [\n 'cabinet', 'bed', 'chair', 'sofa', 'table', 'door', 'window',\n 'bookshelf', 'picture', 'counter', 'desk', 'curtain',\n 'refrigerator', 'showercurtrain', 'toilet', 'sink', 'bathtub',\n 'garbagebin'\n ]\n self.cat2label = {cat: self.classes.index(cat) for cat in self.classes}\n self.label2cat = {self.cat2label[t]: t for t in self.cat2label}\n self.cat_ids = np.array(\n [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36, 39])\n self.cat_ids2class = {\n nyu40id: i\n for i, nyu40id in enumerate(list(self.cat_ids))\n }\n assert split in ['train', 'val', 'test']\n split_file = osp.join(self.root_dir, 'meta_data',\n f'scannetv2_{split}.txt')\n mmcv.check_file_exist(split_file)\n self.sample_id_list = mmcv.list_from_file(split_file)\n self.test_mode = (split == 'test')\n\n def __len__(self):\n return len(self.sample_id_list)\n\n def get_aligned_box_label(self, idx):\n box_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_aligned_bbox.npy')\n mmcv.check_file_exist(box_file)\n return np.load(box_file)\n\n def get_unaligned_box_label(self, idx):\n box_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_unaligned_bbox.npy')\n mmcv.check_file_exist(box_file)\n return np.load(box_file)\n\n def get_axis_align_matrix(self, idx):\n matrix_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_axis_align_matrix.npy')\n mmcv.check_file_exist(matrix_file)\n return np.load(matrix_file)\n\n def get_infos(self, num_workers=4, has_label=True, sample_id_list=None):\n \"\"\"Get data infos.\n\n This method gets information from the raw data.\n\n Args:\n num_workers (int): Number of threads to be used. Default: 4.\n has_label (bool): Whether the data has label. Default: True.\n sample_id_list (list[int]): Index list of the sample.\n Default: None.\n\n Returns:\n infos (list[dict]): Information of the raw data.\n \"\"\"\n\n def process_single_scene(sample_idx):\n print(f'{self.split} sample_idx: {sample_idx}')\n info = dict()\n pc_info = {'num_features': 6, 'lidar_idx': sample_idx}\n info['point_cloud'] = pc_info\n pts_filename = osp.join(self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_vert.npy')\n points = np.load(pts_filename)\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'points'))\n points.tofile(\n osp.join(self.root_dir, 'points', f'{sample_idx}.bin'))\n info['pts_path'] = osp.join('points', f'{sample_idx}.bin')\n\n if not self.test_mode:\n pts_instance_mask_path = osp.join(\n self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_ins_label.npy')\n pts_semantic_mask_path = osp.join(\n self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_sem_label.npy')\n\n pts_instance_mask = np.load(pts_instance_mask_path).astype(\n np.long)\n pts_semantic_mask = np.load(pts_semantic_mask_path).astype(\n np.long)\n\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'instance_mask'))\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'semantic_mask'))\n\n pts_instance_mask.tofile(\n osp.join(self.root_dir, 'instance_mask',\n f'{sample_idx}.bin'))\n pts_semantic_mask.tofile(\n osp.join(self.root_dir, 'semantic_mask',\n f'{sample_idx}.bin'))\n\n info['pts_instance_mask_path'] = osp.join(\n 'instance_mask', f'{sample_idx}.bin')\n info['pts_semantic_mask_path'] = osp.join(\n 'semantic_mask', f'{sample_idx}.bin')\n\n if has_label:\n annotations = {}\n # box is of shape [k, 6 + class]\n aligned_box_label = self.get_aligned_box_label(sample_idx)\n unaligned_box_label = self.get_unaligned_box_label(sample_idx)\n annotations['gt_num'] = aligned_box_label.shape[0]\n if annotations['gt_num'] != 0:\n aligned_box = aligned_box_label[:, :-1] # k, 6\n unaligned_box = unaligned_box_label[:, :-1]\n classes = aligned_box_label[:, -1] # k\n annotations['name'] = np.array([\n self.label2cat[self.cat_ids2class[classes[i]]]\n for i in range(annotations['gt_num'])\n ])\n # default names are given to aligned bbox for compatibility\n # we also save unaligned bbox info with marked names\n annotations['location'] = aligned_box[:, :3]\n annotations['dimensions'] = aligned_box[:, 3:6]\n annotations['gt_boxes_upright_depth'] = aligned_box\n annotations['unaligned_location'] = unaligned_box[:, :3]\n annotations['unaligned_dimensions'] = unaligned_box[:, 3:6]\n annotations[\n 'unaligned_gt_boxes_upright_depth'] = unaligned_box\n annotations['index'] = np.arange(\n annotations['gt_num'], dtype=np.int32)\n annotations['class'] = np.array([\n self.cat_ids2class[classes[i]]\n for i in range(annotations['gt_num'])\n ])\n axis_align_matrix = self.get_axis_align_matrix(sample_idx)\n annotations['axis_align_matrix'] = axis_align_matrix # 4x4\n info['annos'] = annotations\n return info\n\n sample_id_list = sample_id_list if sample_id_list is not None \\\n else self.sample_id_list\n with futures.ThreadPoolExecutor(num_workers) as executor:\n infos = executor.map(process_single_scene, sample_id_list)\n return list(infos)\n\n\nclass ScanNetSegData(object):\n \"\"\"ScanNet dataset used to generate infos for semantic segmentation task.\n\n Args:\n data_root (str): Root path of the raw data.\n ann_file (str): The generated scannet infos.\n split (str): Set split type of the data. Default: 'train'.\n num_points (int): Number of points in each data input. Default: 8192.\n label_weight_func (function): Function to compute the label weight.\n Default: None.\n \"\"\"\n\n def __init__(self,\n data_root,\n ann_file,\n split='train',\n num_points=8192,\n label_weight_func=None):\n self.data_root = data_root\n self.data_infos = mmcv.load(ann_file)\n self.split = split\n assert split in ['train', 'val', 'test']\n self.num_points = num_points\n\n self.all_ids = np.arange(41) # all possible ids\n self.cat_ids = np.array([\n 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36,\n 39\n ]) # used for seg task\n self.ignore_index = len(self.cat_ids)\n\n self.cat_id2class = np.ones((self.all_ids.shape[0],), dtype=np.int) * \\\n self.ignore_index\n for i, cat_id in enumerate(self.cat_ids):\n self.cat_id2class[cat_id] = i\n\n # label weighting function is taken from\n # https://github.com/charlesq34/pointnet2/blob/master/scannet/scannet_dataset.py#L24\n self.label_weight_func = (lambda x: 1.0 / np.log(1.2 + x)) if \\\n label_weight_func is None else label_weight_func\n\n def get_seg_infos(self):\n if self.split == 'test':\n return\n scene_idxs, label_weight = self.get_scene_idxs_and_label_weight()\n save_folder = osp.join(self.data_root, 'seg_info')\n mmcv.mkdir_or_exist(save_folder)\n np.save(\n osp.join(save_folder, f'{self.split}_resampled_scene_idxs.npy'),\n scene_idxs)\n np.save(\n osp.join(save_folder, f'{self.split}_label_weight.npy'),\n label_weight)\n print(f'{self.split} resampled scene index and label weight saved')\n\n def _convert_to_label(self, mask):\n \"\"\"Convert class_id in loaded segmentation mask to label.\"\"\"\n if isinstance(mask, str):\n if mask.endswith('npy'):\n mask = np.load(mask)\n else:\n mask = np.fromfile(mask, dtype=np.long)\n label = self.cat_id2class[mask]\n return label\n\n def get_scene_idxs_and_label_weight(self):\n \"\"\"Compute scene_idxs for data sampling and label weight for loss \\\n calculation.\n\n We sample more times for scenes with more points. Label_weight is\n inversely proportional to number of class points.\n \"\"\"\n num_classes = len(self.cat_ids)\n num_point_all = []\n label_weight = np.zeros((num_classes + 1, )) # ignore_index\n for data_info in self.data_infos:\n label = self._convert_to_label(\n osp.join(self.data_root, data_info['pts_semantic_mask_path']))\n num_point_all.append(label.shape[0])\n class_count, _ = np.histogram(label, range(num_classes + 2))\n label_weight += class_count\n\n # repeat scene_idx for num_scene_point // num_sample_point times\n sample_prob = np.array(num_point_all) / float(np.sum(num_point_all))\n num_iter = int(np.sum(num_point_all) / float(self.num_points))\n scene_idxs = []\n for idx in range(len(self.data_infos)):\n scene_idxs.extend([idx] * round(sample_prob[idx] * num_iter))\n scene_idxs = np.array(scene_idxs).astype(np.int32)\n\n # calculate label weight, adopted from PointNet++\n label_weight = label_weight[:-1].astype(np.float32)\n label_weight = label_weight / label_weight.sum()\n label_weight = self.label_weight_func(label_weight).astype(np.float32)\n\n return scene_idxs, label_weight\n", "path": "tools/data_converter/scannet_data_utils.py"}], "after_files": [{"content": "import mmcv\nimport numpy as np\nfrom concurrent import futures as futures\nfrom os import path as osp\n\n\nclass ScanNetData(object):\n \"\"\"ScanNet data.\n\n Generate scannet infos for scannet_converter.\n\n Args:\n root_path (str): Root path of the raw data.\n split (str): Set split type of the data. Default: 'train'.\n \"\"\"\n\n def __init__(self, root_path, split='train'):\n self.root_dir = root_path\n self.split = split\n self.split_dir = osp.join(root_path)\n self.classes = [\n 'cabinet', 'bed', 'chair', 'sofa', 'table', 'door', 'window',\n 'bookshelf', 'picture', 'counter', 'desk', 'curtain',\n 'refrigerator', 'showercurtrain', 'toilet', 'sink', 'bathtub',\n 'garbagebin'\n ]\n self.cat2label = {cat: self.classes.index(cat) for cat in self.classes}\n self.label2cat = {self.cat2label[t]: t for t in self.cat2label}\n self.cat_ids = np.array(\n [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36, 39])\n self.cat_ids2class = {\n nyu40id: i\n for i, nyu40id in enumerate(list(self.cat_ids))\n }\n assert split in ['train', 'val', 'test']\n split_file = osp.join(self.root_dir, 'meta_data',\n f'scannetv2_{split}.txt')\n mmcv.check_file_exist(split_file)\n self.sample_id_list = mmcv.list_from_file(split_file)\n self.test_mode = (split == 'test')\n\n def __len__(self):\n return len(self.sample_id_list)\n\n def get_aligned_box_label(self, idx):\n box_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_aligned_bbox.npy')\n mmcv.check_file_exist(box_file)\n return np.load(box_file)\n\n def get_unaligned_box_label(self, idx):\n box_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_unaligned_bbox.npy')\n mmcv.check_file_exist(box_file)\n return np.load(box_file)\n\n def get_axis_align_matrix(self, idx):\n matrix_file = osp.join(self.root_dir, 'scannet_instance_data',\n f'{idx}_axis_align_matrix.npy')\n mmcv.check_file_exist(matrix_file)\n return np.load(matrix_file)\n\n def get_infos(self, num_workers=4, has_label=True, sample_id_list=None):\n \"\"\"Get data infos.\n\n This method gets information from the raw data.\n\n Args:\n num_workers (int): Number of threads to be used. Default: 4.\n has_label (bool): Whether the data has label. Default: True.\n sample_id_list (list[int]): Index list of the sample.\n Default: None.\n\n Returns:\n infos (list[dict]): Information of the raw data.\n \"\"\"\n\n def process_single_scene(sample_idx):\n print(f'{self.split} sample_idx: {sample_idx}')\n info = dict()\n pc_info = {'num_features': 6, 'lidar_idx': sample_idx}\n info['point_cloud'] = pc_info\n pts_filename = osp.join(self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_vert.npy')\n points = np.load(pts_filename)\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'points'))\n points.tofile(\n osp.join(self.root_dir, 'points', f'{sample_idx}.bin'))\n info['pts_path'] = osp.join('points', f'{sample_idx}.bin')\n\n if not self.test_mode:\n pts_instance_mask_path = osp.join(\n self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_ins_label.npy')\n pts_semantic_mask_path = osp.join(\n self.root_dir, 'scannet_instance_data',\n f'{sample_idx}_sem_label.npy')\n\n pts_instance_mask = np.load(pts_instance_mask_path).astype(\n np.long)\n pts_semantic_mask = np.load(pts_semantic_mask_path).astype(\n np.long)\n\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'instance_mask'))\n mmcv.mkdir_or_exist(osp.join(self.root_dir, 'semantic_mask'))\n\n pts_instance_mask.tofile(\n osp.join(self.root_dir, 'instance_mask',\n f'{sample_idx}.bin'))\n pts_semantic_mask.tofile(\n osp.join(self.root_dir, 'semantic_mask',\n f'{sample_idx}.bin'))\n\n info['pts_instance_mask_path'] = osp.join(\n 'instance_mask', f'{sample_idx}.bin')\n info['pts_semantic_mask_path'] = osp.join(\n 'semantic_mask', f'{sample_idx}.bin')\n\n if has_label:\n annotations = {}\n # box is of shape [k, 6 + class]\n aligned_box_label = self.get_aligned_box_label(sample_idx)\n unaligned_box_label = self.get_unaligned_box_label(sample_idx)\n annotations['gt_num'] = aligned_box_label.shape[0]\n if annotations['gt_num'] != 0:\n aligned_box = aligned_box_label[:, :-1] # k, 6\n unaligned_box = unaligned_box_label[:, :-1]\n classes = aligned_box_label[:, -1] # k\n annotations['name'] = np.array([\n self.label2cat[self.cat_ids2class[classes[i]]]\n for i in range(annotations['gt_num'])\n ])\n # default names are given to aligned bbox for compatibility\n # we also save unaligned bbox info with marked names\n annotations['location'] = aligned_box[:, :3]\n annotations['dimensions'] = aligned_box[:, 3:6]\n annotations['gt_boxes_upright_depth'] = aligned_box\n annotations['unaligned_location'] = unaligned_box[:, :3]\n annotations['unaligned_dimensions'] = unaligned_box[:, 3:6]\n annotations[\n 'unaligned_gt_boxes_upright_depth'] = unaligned_box\n annotations['index'] = np.arange(\n annotations['gt_num'], dtype=np.int32)\n annotations['class'] = np.array([\n self.cat_ids2class[classes[i]]\n for i in range(annotations['gt_num'])\n ])\n axis_align_matrix = self.get_axis_align_matrix(sample_idx)\n annotations['axis_align_matrix'] = axis_align_matrix # 4x4\n info['annos'] = annotations\n return info\n\n sample_id_list = sample_id_list if sample_id_list is not None \\\n else self.sample_id_list\n with futures.ThreadPoolExecutor(num_workers) as executor:\n infos = executor.map(process_single_scene, sample_id_list)\n return list(infos)\n\n\nclass ScanNetSegData(object):\n \"\"\"ScanNet dataset used to generate infos for semantic segmentation task.\n\n Args:\n data_root (str): Root path of the raw data.\n ann_file (str): The generated scannet infos.\n split (str): Set split type of the data. Default: 'train'.\n num_points (int): Number of points in each data input. Default: 8192.\n label_weight_func (function): Function to compute the label weight.\n Default: None.\n \"\"\"\n\n def __init__(self,\n data_root,\n ann_file,\n split='train',\n num_points=8192,\n label_weight_func=None):\n self.data_root = data_root\n self.data_infos = mmcv.load(ann_file)\n self.split = split\n assert split in ['train', 'val', 'test']\n self.num_points = num_points\n\n self.all_ids = np.arange(41) # all possible ids\n self.cat_ids = np.array([\n 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34, 36,\n 39\n ]) # used for seg task\n self.ignore_index = len(self.cat_ids)\n\n self.cat_id2class = np.ones((self.all_ids.shape[0],), dtype=np.int) * \\\n self.ignore_index\n for i, cat_id in enumerate(self.cat_ids):\n self.cat_id2class[cat_id] = i\n\n # label weighting function is taken from\n # https://github.com/charlesq34/pointnet2/blob/master/scannet/scannet_dataset.py#L24\n self.label_weight_func = (lambda x: 1.0 / np.log(1.2 + x)) if \\\n label_weight_func is None else label_weight_func\n\n def get_seg_infos(self):\n if self.split == 'test':\n return\n scene_idxs, label_weight = self.get_scene_idxs_and_label_weight()\n save_folder = osp.join(self.data_root, 'seg_info')\n mmcv.mkdir_or_exist(save_folder)\n np.save(\n osp.join(save_folder, f'{self.split}_resampled_scene_idxs.npy'),\n scene_idxs)\n np.save(\n osp.join(save_folder, f'{self.split}_label_weight.npy'),\n label_weight)\n print(f'{self.split} resampled scene index and label weight saved')\n\n def _convert_to_label(self, mask):\n \"\"\"Convert class_id in loaded segmentation mask to label.\"\"\"\n if isinstance(mask, str):\n if mask.endswith('npy'):\n mask = np.load(mask)\n else:\n mask = np.fromfile(mask, dtype=np.long)\n label = self.cat_id2class[mask]\n return label\n\n def get_scene_idxs_and_label_weight(self):\n \"\"\"Compute scene_idxs for data sampling and label weight for loss \\\n calculation.\n\n We sample more times for scenes with more points. Label_weight is\n inversely proportional to number of class points.\n \"\"\"\n num_classes = len(self.cat_ids)\n num_point_all = []\n label_weight = np.zeros((num_classes + 1, )) # ignore_index\n for data_info in self.data_infos:\n label = self._convert_to_label(\n osp.join(self.data_root, data_info['pts_semantic_mask_path']))\n num_point_all.append(label.shape[0])\n class_count, _ = np.histogram(label, range(num_classes + 2))\n label_weight += class_count\n\n # repeat scene_idx for num_scene_point // num_sample_point times\n sample_prob = np.array(num_point_all) / float(np.sum(num_point_all))\n num_iter = int(np.sum(num_point_all) / float(self.num_points))\n scene_idxs = []\n for idx in range(len(self.data_infos)):\n scene_idxs.extend([idx] * int(round(sample_prob[idx] * num_iter)))\n scene_idxs = np.array(scene_idxs).astype(np.int32)\n\n # calculate label weight, adopted from PointNet++\n label_weight = label_weight[:-1].astype(np.float32)\n label_weight = label_weight / label_weight.sum()\n label_weight = self.label_weight_func(label_weight).astype(np.float32)\n\n return scene_idxs, label_weight\n", "path": "tools/data_converter/scannet_data_utils.py"}]}
| 3,861 | 158 |
gh_patches_debug_11524
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1374
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[V3/Config] Clearing a registered data group when no data has been set results in a KeyError.
Please be sure to read through other issues as well to make sure what you are suggesting/reporting has not already
been suggested/reported
### Type:
- [ ] Suggestion
- [x] Bug
### Brief description of the problem
When attempting to use methods such as `.clear_all_members` and `.clear_all_globals`, when no data has been set, will result in a KeyError being raised.
### Expected behavior
Silently passes
### Actual behavior
Key Error is raised.
### Steps to reproduce
1. register some data
2. try to clear all data from that scope
3. Key error is raised
4. You cry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redbot/core/drivers/red_json.py`
Content:
```
1 from pathlib import Path
2 from typing import Tuple
3
4 from ..json_io import JsonIO
5
6 from .red_base import BaseDriver
7
8 __all__ = ["JSON"]
9
10
11 class JSON(BaseDriver):
12 """
13 Subclass of :py:class:`.red_base.BaseDriver`.
14
15 .. py:attribute:: file_name
16
17 The name of the file in which to store JSON data.
18
19 .. py:attribute:: data_path
20
21 The path in which to store the file indicated by :py:attr:`file_name`.
22 """
23 def __init__(self, cog_name, *, data_path_override: Path=None,
24 file_name_override: str="settings.json"):
25 super().__init__(cog_name)
26 self.file_name = file_name_override
27 if data_path_override:
28 self.data_path = data_path_override
29 else:
30 self.data_path = Path.cwd() / 'cogs' / '.data' / self.cog_name
31
32 self.data_path.mkdir(parents=True, exist_ok=True)
33
34 self.data_path = self.data_path / self.file_name
35
36 self.jsonIO = JsonIO(self.data_path)
37
38 try:
39 self.data = self.jsonIO._load_json()
40 except FileNotFoundError:
41 self.data = {}
42 self.jsonIO._save_json(self.data)
43
44 async def get(self, *identifiers: Tuple[str]):
45 partial = self.data
46 full_identifiers = (self.unique_cog_identifier, *identifiers)
47 for i in full_identifiers:
48 partial = partial[i]
49 return partial
50
51 async def set(self, *identifiers: str, value=None):
52 partial = self.data
53 full_identifiers = (self.unique_cog_identifier, *identifiers)
54 for i in full_identifiers[:-1]:
55 if i not in partial:
56 partial[i] = {}
57 partial = partial[i]
58
59 partial[full_identifiers[-1]] = value
60 await self.jsonIO._threadsafe_save_json(self.data)
61
62 async def clear(self, *identifiers: str):
63 partial = self.data
64 full_identifiers = (self.unique_cog_identifier, *identifiers)
65 for i in full_identifiers[:-1]:
66 if i not in partial:
67 break
68 partial = partial[i]
69 else:
70 del partial[identifiers[-1]]
71 await self.jsonIO._threadsafe_save_json(self.data)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redbot/core/drivers/red_json.py b/redbot/core/drivers/red_json.py
--- a/redbot/core/drivers/red_json.py
+++ b/redbot/core/drivers/red_json.py
@@ -62,10 +62,11 @@
async def clear(self, *identifiers: str):
partial = self.data
full_identifiers = (self.unique_cog_identifier, *identifiers)
- for i in full_identifiers[:-1]:
- if i not in partial:
- break
- partial = partial[i]
- else:
+ try:
+ for i in full_identifiers[:-1]:
+ partial = partial[i]
del partial[identifiers[-1]]
- await self.jsonIO._threadsafe_save_json(self.data)
+ except KeyError:
+ pass
+ else:
+ await self.jsonIO._threadsafe_save_json(self.data)
|
{"golden_diff": "diff --git a/redbot/core/drivers/red_json.py b/redbot/core/drivers/red_json.py\n--- a/redbot/core/drivers/red_json.py\n+++ b/redbot/core/drivers/red_json.py\n@@ -62,10 +62,11 @@\n async def clear(self, *identifiers: str):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n- for i in full_identifiers[:-1]:\n- if i not in partial:\n- break\n- partial = partial[i]\n- else:\n+ try:\n+ for i in full_identifiers[:-1]:\n+ partial = partial[i]\n del partial[identifiers[-1]]\n- await self.jsonIO._threadsafe_save_json(self.data)\n+ except KeyError:\n+ pass\n+ else:\n+ await self.jsonIO._threadsafe_save_json(self.data)\n", "issue": "[V3/Config] Clearing a registered data group when no data has been set results in a KeyError.\nPlease be sure to read through other issues as well to make sure what you are suggesting/reporting has not already\r\nbeen suggested/reported\r\n\r\n### Type:\r\n\r\n- [ ] Suggestion\r\n- [x] Bug\r\n\r\n### Brief description of the problem\r\nWhen attempting to use methods such as `.clear_all_members` and `.clear_all_globals`, when no data has been set, will result in a KeyError being raised.\r\n### Expected behavior\r\nSilently passes\r\n### Actual behavior\r\nKey Error is raised.\r\n### Steps to reproduce\r\n\r\n1. register some data\r\n2. try to clear all data from that scope\r\n3. Key error is raised\r\n4. You cry\r\n\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import Tuple\n\nfrom ..json_io import JsonIO\n\nfrom .red_base import BaseDriver\n\n__all__ = [\"JSON\"]\n\n\nclass JSON(BaseDriver):\n \"\"\"\n Subclass of :py:class:`.red_base.BaseDriver`.\n\n .. py:attribute:: file_name\n\n The name of the file in which to store JSON data.\n\n .. py:attribute:: data_path\n\n The path in which to store the file indicated by :py:attr:`file_name`.\n \"\"\"\n def __init__(self, cog_name, *, data_path_override: Path=None,\n file_name_override: str=\"settings.json\"):\n super().__init__(cog_name)\n self.file_name = file_name_override\n if data_path_override:\n self.data_path = data_path_override\n else:\n self.data_path = Path.cwd() / 'cogs' / '.data' / self.cog_name\n\n self.data_path.mkdir(parents=True, exist_ok=True)\n\n self.data_path = self.data_path / self.file_name\n\n self.jsonIO = JsonIO(self.data_path)\n\n try:\n self.data = self.jsonIO._load_json()\n except FileNotFoundError:\n self.data = {}\n self.jsonIO._save_json(self.data)\n\n async def get(self, *identifiers: Tuple[str]):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers:\n partial = partial[i]\n return partial\n\n async def set(self, *identifiers: str, value=None):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers[:-1]:\n if i not in partial:\n partial[i] = {}\n partial = partial[i]\n\n partial[full_identifiers[-1]] = value\n await self.jsonIO._threadsafe_save_json(self.data)\n\n async def clear(self, *identifiers: str):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers[:-1]:\n if i not in partial:\n break\n partial = partial[i]\n else:\n del partial[identifiers[-1]]\n await self.jsonIO._threadsafe_save_json(self.data)\n", "path": "redbot/core/drivers/red_json.py"}], "after_files": [{"content": "from pathlib import Path\nfrom typing import Tuple\n\nfrom ..json_io import JsonIO\n\nfrom .red_base import BaseDriver\n\n__all__ = [\"JSON\"]\n\n\nclass JSON(BaseDriver):\n \"\"\"\n Subclass of :py:class:`.red_base.BaseDriver`.\n\n .. py:attribute:: file_name\n\n The name of the file in which to store JSON data.\n\n .. py:attribute:: data_path\n\n The path in which to store the file indicated by :py:attr:`file_name`.\n \"\"\"\n def __init__(self, cog_name, *, data_path_override: Path=None,\n file_name_override: str=\"settings.json\"):\n super().__init__(cog_name)\n self.file_name = file_name_override\n if data_path_override:\n self.data_path = data_path_override\n else:\n self.data_path = Path.cwd() / 'cogs' / '.data' / self.cog_name\n\n self.data_path.mkdir(parents=True, exist_ok=True)\n\n self.data_path = self.data_path / self.file_name\n\n self.jsonIO = JsonIO(self.data_path)\n\n try:\n self.data = self.jsonIO._load_json()\n except FileNotFoundError:\n self.data = {}\n self.jsonIO._save_json(self.data)\n\n async def get(self, *identifiers: Tuple[str]):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers:\n partial = partial[i]\n return partial\n\n async def set(self, *identifiers: str, value=None):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers[:-1]:\n if i not in partial:\n partial[i] = {}\n partial = partial[i]\n\n partial[full_identifiers[-1]] = value\n await self.jsonIO._threadsafe_save_json(self.data)\n\n async def clear(self, *identifiers: str):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n try:\n for i in full_identifiers[:-1]:\n partial = partial[i]\n del partial[identifiers[-1]]\n except KeyError:\n pass\n else:\n await self.jsonIO._threadsafe_save_json(self.data)\n", "path": "redbot/core/drivers/red_json.py"}]}
| 1,062 | 194 |
gh_patches_debug_31804
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-3161
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Resolving RPM/DEB IntegTest having config modify issues.
Hi,
There are issues modifying the config yml files in RPM/DEB if you dont use sudo/root to run test.sh.
However, the issue being that certain OS process and integTest cannot run on root, thus catch 22.
This issue would be resolved if we assume the current running user of test.sh has sudo permission, while still able to change settings without using root.
Thanks.
------
Even when you have everything on root seems like integTest class is still asking the gradle run to happen on non-root:
```
» ↓ errors and warnings from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log ↓
» ERROR][o.o.b.OpenSearchUncaughtExceptionHandler] [integTest-0] uncaught exception in thread [main]
» org.opensearch.bootstrap.StartupException: java.lang.RuntimeException: can not run opensearch as root
» at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:184) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.execute(OpenSearch.java:171) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:104) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.cli.Command.mainWithoutErrorHandling(Command.java:138) ~[opensearch-cli-2.5.0.jar:2.5.0]
» at org.opensearch.cli.Command.main(Command.java:101) ~[opensearch-cli-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:137) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:103) ~[opensearch-2.5.0.jar:2.5.0]
» Caused by: java.lang.RuntimeException: can not run opensearch as root
» at org.opensearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:124) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.Bootstrap.setup(Bootstrap.java:191) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.Bootstrap.init(Bootstrap.java:404) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:180) ~[opensearch-2.5.0.jar:2.5.0]
» ... 6 more
» ↓ last 40 non error or warning messages from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log ↓
» [2023-01-30T20:10:26.670011235Z] [BUILD] Configuring custom cluster specific distro directory: /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE
» [2023-01-30T20:10:26.710573952Z] [BUILD] Copying additional config files from distro [/tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/log4j2.properties, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options.d, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/opensearch.yml, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options]
» [2023-01-30T20:10:26.711812308Z] [BUILD] installing 1 plugins in a single transaction
» [2023-01-30T20:10:28.341404943Z] [BUILD] installed plugins
» [2023-01-30T20:10:28.341674400Z] [BUILD] Creating opensearch keystore with password set to []
» [2023-01-30T20:10:29.386451250Z] [BUILD] Starting OpenSearch process
» [2023-01-30T20:10:31.909907707Z] [BUILD] Stopping node
```
------
Part of #2994.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/system/process.py`
Content:
```
1 # Copyright OpenSearch Contributors
2 # SPDX-License-Identifier: Apache-2.0
3 #
4 # The OpenSearch Contributors require contributions made to
5 # this file be licensed under the Apache-2.0 license or a
6 # compatible open source license.
7 import logging
8 import os
9 import subprocess
10 import tempfile
11 from typing import Any
12
13 import psutil
14
15
16 class Process:
17 def __init__(self) -> None:
18 self.process: subprocess.Popen[bytes] = None
19 self.stdout: Any = None
20 self.stderr: Any = None
21 self.__stdout_data__: str = None
22 self.__stderr_data__: str = None
23
24 def start(self, command: str, cwd: str) -> None:
25 if self.started:
26 raise ProcessStartedError(self.pid)
27
28 self.stdout = tempfile.NamedTemporaryFile(mode="r+", delete=False)
29 self.stderr = tempfile.NamedTemporaryFile(mode="r+", delete=False)
30
31 self.process = subprocess.Popen(
32 command,
33 cwd=cwd,
34 shell=True,
35 stdout=self.stdout,
36 stderr=self.stderr,
37 )
38
39 def terminate(self) -> int:
40 if not self.started:
41 raise ProcessNotStartedError()
42
43 parent = psutil.Process(self.process.pid)
44 logging.debug("Checking for child processes")
45 child_processes = parent.children(recursive=True)
46 for child in child_processes:
47 logging.debug(f"Found child process with pid {child.pid}")
48 if child.pid != self.process.pid:
49 logging.debug(f"Sending SIGKILL to {child.pid} ")
50 child.kill()
51 logging.info(f"Sending SIGKILL to PID {self.process.pid}")
52
53 self.process.kill()
54
55 logging.info(f"Process killed with exit code {self.process.returncode}")
56
57 if self.stdout:
58 self.__stdout_data__ = open(self.stdout.name, 'r').read()
59 self.stdout.close()
60 os.remove(self.stdout.name)
61 self.stdout = None
62
63 if self.stderr:
64 self.__stderr_data__ = open(self.stderr.name, 'r').read()
65 self.stderr.close()
66 os.remove(self.stderr.name)
67 self.stderr = None
68
69 self.return_code = self.process.returncode
70 self.process = None
71
72 return self.return_code
73
74 @property
75 def started(self) -> bool:
76 return True if self.process else False
77
78 @property
79 def pid(self) -> int:
80 return self.process.pid if self.started else None
81
82 @property
83 def stdout_data(self) -> Any:
84 return self.stdout.read() if self.stdout else self.__stdout_data__
85
86 @property
87 def stderr_data(self) -> Any:
88 return self.stderr.read() if self.stderr else self.__stderr_data__
89
90
91 class ProcessStartedError(Exception):
92 """
93 Indicates that process already started.
94 """
95
96 def __init__(self, pid: int) -> None:
97 self.pid = pid
98 super().__init__(f"Process already started, pid: {pid}")
99
100
101 class ProcessNotStartedError(Exception):
102 """
103 Indicates that process has not started.
104 """
105
106 def __init__(self) -> None:
107 super().__init__("Process has not started")
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/system/process.py b/src/system/process.py
--- a/src/system/process.py
+++ b/src/system/process.py
@@ -16,18 +16,21 @@
class Process:
def __init__(self) -> None:
self.process: subprocess.Popen[bytes] = None
+ self.require_sudo: bool = False
self.stdout: Any = None
self.stderr: Any = None
self.__stdout_data__: str = None
self.__stderr_data__: str = None
- def start(self, command: str, cwd: str) -> None:
+ def start(self, command: str, cwd: str, require_sudo: bool = False) -> None:
if self.started:
raise ProcessStartedError(self.pid)
self.stdout = tempfile.NamedTemporaryFile(mode="r+", delete=False)
self.stderr = tempfile.NamedTemporaryFile(mode="r+", delete=False)
+ self.require_sudo = require_sudo
+
self.process = subprocess.Popen(
command,
cwd=cwd,
@@ -47,10 +50,10 @@
logging.debug(f"Found child process with pid {child.pid}")
if child.pid != self.process.pid:
logging.debug(f"Sending SIGKILL to {child.pid} ")
- child.kill()
+ child.kill() if self.require_sudo is False else subprocess.check_call(f"sudo kill -9 {child.pid}", shell=True)
logging.info(f"Sending SIGKILL to PID {self.process.pid}")
- self.process.kill()
+ self.process.kill() if self.require_sudo is False else subprocess.check_call(f"sudo kill -9 {self.process.pid}", shell=True)
logging.info(f"Process killed with exit code {self.process.returncode}")
|
{"golden_diff": "diff --git a/src/system/process.py b/src/system/process.py\n--- a/src/system/process.py\n+++ b/src/system/process.py\n@@ -16,18 +16,21 @@\n class Process:\n def __init__(self) -> None:\n self.process: subprocess.Popen[bytes] = None\n+ self.require_sudo: bool = False\n self.stdout: Any = None\n self.stderr: Any = None\n self.__stdout_data__: str = None\n self.__stderr_data__: str = None\n \n- def start(self, command: str, cwd: str) -> None:\n+ def start(self, command: str, cwd: str, require_sudo: bool = False) -> None:\n if self.started:\n raise ProcessStartedError(self.pid)\n \n self.stdout = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n self.stderr = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n \n+ self.require_sudo = require_sudo\n+\n self.process = subprocess.Popen(\n command,\n cwd=cwd,\n@@ -47,10 +50,10 @@\n logging.debug(f\"Found child process with pid {child.pid}\")\n if child.pid != self.process.pid:\n logging.debug(f\"Sending SIGKILL to {child.pid} \")\n- child.kill()\n+ child.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {child.pid}\", shell=True)\n logging.info(f\"Sending SIGKILL to PID {self.process.pid}\")\n \n- self.process.kill()\n+ self.process.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {self.process.pid}\", shell=True)\n \n logging.info(f\"Process killed with exit code {self.process.returncode}\")\n", "issue": "Resolving RPM/DEB IntegTest having config modify issues.\nHi,\r\n\r\nThere are issues modifying the config yml files in RPM/DEB if you dont use sudo/root to run test.sh.\r\nHowever, the issue being that certain OS process and integTest cannot run on root, thus catch 22.\r\n\r\nThis issue would be resolved if we assume the current running user of test.sh has sudo permission, while still able to change settings without using root.\r\n\r\nThanks.\r\n\r\n------\r\n\r\nEven when you have everything on root seems like integTest class is still asking the gradle run to happen on non-root:\r\n```\r\n\r\n\u00bb \u2193 errors and warnings from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log \u2193\r\n\u00bb ERROR][o.o.b.OpenSearchUncaughtExceptionHandler] [integTest-0] uncaught exception in thread [main]\r\n\u00bb org.opensearch.bootstrap.StartupException: java.lang.RuntimeException: can not run opensearch as root\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:184) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.execute(OpenSearch.java:171) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:104) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.Command.mainWithoutErrorHandling(Command.java:138) ~[opensearch-cli-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.Command.main(Command.java:101) ~[opensearch-cli-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:137) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:103) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb Caused by: java.lang.RuntimeException: can not run opensearch as root\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:124) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.setup(Bootstrap.java:191) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.init(Bootstrap.java:404) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:180) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb ... 6 more\r\n\u00bb \u2193 last 40 non error or warning messages from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log \u2193\r\n\u00bb [2023-01-30T20:10:26.670011235Z] [BUILD] Configuring custom cluster specific distro directory: /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE\r\n\u00bb [2023-01-30T20:10:26.710573952Z] [BUILD] Copying additional config files from distro [/tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/log4j2.properties, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options.d, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/opensearch.yml, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options]\r\n\u00bb [2023-01-30T20:10:26.711812308Z] [BUILD] installing 1 plugins in a single transaction\r\n\u00bb [2023-01-30T20:10:28.341404943Z] [BUILD] installed plugins\r\n\u00bb [2023-01-30T20:10:28.341674400Z] [BUILD] Creating opensearch keystore with password set to []\r\n\u00bb [2023-01-30T20:10:29.386451250Z] [BUILD] Starting OpenSearch process\r\n\u00bb [2023-01-30T20:10:31.909907707Z] [BUILD] Stopping node\r\n```\r\n\r\n------\r\n\r\nPart of #2994.\n", "before_files": [{"content": "# Copyright OpenSearch Contributors\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\nimport logging\nimport os\nimport subprocess\nimport tempfile\nfrom typing import Any\n\nimport psutil\n\n\nclass Process:\n def __init__(self) -> None:\n self.process: subprocess.Popen[bytes] = None\n self.stdout: Any = None\n self.stderr: Any = None\n self.__stdout_data__: str = None\n self.__stderr_data__: str = None\n\n def start(self, command: str, cwd: str) -> None:\n if self.started:\n raise ProcessStartedError(self.pid)\n\n self.stdout = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n self.stderr = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n\n self.process = subprocess.Popen(\n command,\n cwd=cwd,\n shell=True,\n stdout=self.stdout,\n stderr=self.stderr,\n )\n\n def terminate(self) -> int:\n if not self.started:\n raise ProcessNotStartedError()\n\n parent = psutil.Process(self.process.pid)\n logging.debug(\"Checking for child processes\")\n child_processes = parent.children(recursive=True)\n for child in child_processes:\n logging.debug(f\"Found child process with pid {child.pid}\")\n if child.pid != self.process.pid:\n logging.debug(f\"Sending SIGKILL to {child.pid} \")\n child.kill()\n logging.info(f\"Sending SIGKILL to PID {self.process.pid}\")\n\n self.process.kill()\n\n logging.info(f\"Process killed with exit code {self.process.returncode}\")\n\n if self.stdout:\n self.__stdout_data__ = open(self.stdout.name, 'r').read()\n self.stdout.close()\n os.remove(self.stdout.name)\n self.stdout = None\n\n if self.stderr:\n self.__stderr_data__ = open(self.stderr.name, 'r').read()\n self.stderr.close()\n os.remove(self.stderr.name)\n self.stderr = None\n\n self.return_code = self.process.returncode\n self.process = None\n\n return self.return_code\n\n @property\n def started(self) -> bool:\n return True if self.process else False\n\n @property\n def pid(self) -> int:\n return self.process.pid if self.started else None\n\n @property\n def stdout_data(self) -> Any:\n return self.stdout.read() if self.stdout else self.__stdout_data__\n\n @property\n def stderr_data(self) -> Any:\n return self.stderr.read() if self.stderr else self.__stderr_data__\n\n\nclass ProcessStartedError(Exception):\n \"\"\"\n Indicates that process already started.\n \"\"\"\n\n def __init__(self, pid: int) -> None:\n self.pid = pid\n super().__init__(f\"Process already started, pid: {pid}\")\n\n\nclass ProcessNotStartedError(Exception):\n \"\"\"\n Indicates that process has not started.\n \"\"\"\n\n def __init__(self) -> None:\n super().__init__(\"Process has not started\")\n", "path": "src/system/process.py"}], "after_files": [{"content": "# Copyright OpenSearch Contributors\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\nimport logging\nimport os\nimport subprocess\nimport tempfile\nfrom typing import Any\n\nimport psutil\n\n\nclass Process:\n def __init__(self) -> None:\n self.process: subprocess.Popen[bytes] = None\n self.require_sudo: bool = False\n self.stdout: Any = None\n self.stderr: Any = None\n self.__stdout_data__: str = None\n self.__stderr_data__: str = None\n\n def start(self, command: str, cwd: str, require_sudo: bool = False) -> None:\n if self.started:\n raise ProcessStartedError(self.pid)\n\n self.stdout = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n self.stderr = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n\n self.require_sudo = require_sudo\n\n self.process = subprocess.Popen(\n command,\n cwd=cwd,\n shell=True,\n stdout=self.stdout,\n stderr=self.stderr,\n )\n\n def terminate(self) -> int:\n if not self.started:\n raise ProcessNotStartedError()\n\n parent = psutil.Process(self.process.pid)\n logging.debug(\"Checking for child processes\")\n child_processes = parent.children(recursive=True)\n for child in child_processes:\n logging.debug(f\"Found child process with pid {child.pid}\")\n if child.pid != self.process.pid:\n logging.debug(f\"Sending SIGKILL to {child.pid} \")\n child.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {child.pid}\", shell=True)\n logging.info(f\"Sending SIGKILL to PID {self.process.pid}\")\n\n self.process.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {self.process.pid}\", shell=True)\n\n logging.info(f\"Process killed with exit code {self.process.returncode}\")\n\n if self.stdout:\n self.__stdout_data__ = open(self.stdout.name, 'r').read()\n self.stdout.close()\n os.remove(self.stdout.name)\n self.stdout = None\n\n if self.stderr:\n self.__stderr_data__ = open(self.stderr.name, 'r').read()\n self.stderr.close()\n os.remove(self.stderr.name)\n self.stderr = None\n\n self.return_code = self.process.returncode\n self.process = None\n\n return self.return_code\n\n @property\n def started(self) -> bool:\n return True if self.process else False\n\n @property\n def pid(self) -> int:\n return self.process.pid if self.started else None\n\n @property\n def stdout_data(self) -> Any:\n return self.stdout.read() if self.stdout else self.__stdout_data__\n\n @property\n def stderr_data(self) -> Any:\n return self.stderr.read() if self.stderr else self.__stderr_data__\n\n\nclass ProcessStartedError(Exception):\n \"\"\"\n Indicates that process already started.\n \"\"\"\n\n def __init__(self, pid: int) -> None:\n self.pid = pid\n super().__init__(f\"Process already started, pid: {pid}\")\n\n\nclass ProcessNotStartedError(Exception):\n \"\"\"\n Indicates that process has not started.\n \"\"\"\n\n def __init__(self) -> None:\n super().__init__(\"Process has not started\")\n", "path": "src/system/process.py"}]}
| 2,342 | 385 |
gh_patches_debug_5046
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-204
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
rabbitmq_user fails when no password provided
Even though the `password` param is specified as optional, the `rabbitmq_user` module fails when it is not provided.
```
Stacktrace:
File "<stdin>", line 1595, in <module>
File "<stdin>", line 240, in main
File "<stdin>", line 165, in add
File "<stdin>", line 131, in _exec
File "<stdin>", line 1448, in run_command
File "/usr/lib/python2.7/posixpath.py", line 261, in expanduser
if not path.startswith('~'):
AttributeError: 'NoneType' object has no attribute 'startswith'
```
The bug is [right here](https://github.com/ansible/ansible-modules-extras/blob/a0df36c6ab257281cbaae00b8a4590200802f571/messaging/rabbitmq_user.py#L165). I might send a PR when I get the time to fork and test.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `messaging/rabbitmq_user.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Chatham Financial <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 DOCUMENTATION = '''
22 ---
23 module: rabbitmq_user
24 short_description: Adds or removes users to RabbitMQ
25 description:
26 - Add or remove users to RabbitMQ and assign permissions
27 version_added: "1.1"
28 author: Chris Hoffman
29 options:
30 user:
31 description:
32 - Name of user to add
33 required: true
34 default: null
35 aliases: [username, name]
36 password:
37 description:
38 - Password of user to add.
39 - To change the password of an existing user, you must also specify
40 C(force=yes).
41 required: false
42 default: null
43 tags:
44 description:
45 - User tags specified as comma delimited
46 required: false
47 default: null
48 vhost:
49 description:
50 - vhost to apply access privileges.
51 required: false
52 default: /
53 node:
54 description:
55 - erlang node name of the rabbit we wish to configure
56 required: false
57 default: rabbit
58 version_added: "1.2"
59 configure_priv:
60 description:
61 - Regular expression to restrict configure actions on a resource
62 for the specified vhost.
63 - By default all actions are restricted.
64 required: false
65 default: ^$
66 write_priv:
67 description:
68 - Regular expression to restrict configure actions on a resource
69 for the specified vhost.
70 - By default all actions are restricted.
71 required: false
72 default: ^$
73 read_priv:
74 description:
75 - Regular expression to restrict configure actions on a resource
76 for the specified vhost.
77 - By default all actions are restricted.
78 required: false
79 default: ^$
80 force:
81 description:
82 - Deletes and recreates the user.
83 required: false
84 default: "no"
85 choices: [ "yes", "no" ]
86 state:
87 description:
88 - Specify if user is to be added or removed
89 required: false
90 default: present
91 choices: [present, absent]
92 '''
93
94 EXAMPLES = '''
95 # Add user to server and assign full access control
96 - rabbitmq_user: user=joe
97 password=changeme
98 vhost=/
99 configure_priv=.*
100 read_priv=.*
101 write_priv=.*
102 state=present
103 '''
104
105 class RabbitMqUser(object):
106 def __init__(self, module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node):
107 self.module = module
108 self.username = username
109 self.password = password
110 self.node = node
111 if tags is None:
112 self.tags = list()
113 else:
114 self.tags = tags.split(',')
115
116 permissions = dict(
117 vhost=vhost,
118 configure_priv=configure_priv,
119 write_priv=write_priv,
120 read_priv=read_priv
121 )
122 self.permissions = permissions
123
124 self._tags = None
125 self._permissions = None
126 self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)
127
128 def _exec(self, args, run_in_check_mode=False):
129 if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):
130 cmd = [self._rabbitmqctl, '-q', '-n', self.node]
131 rc, out, err = self.module.run_command(cmd + args, check_rc=True)
132 return out.splitlines()
133 return list()
134
135 def get(self):
136 users = self._exec(['list_users'], True)
137
138 for user_tag in users:
139 user, tags = user_tag.split('\t')
140
141 if user == self.username:
142 for c in ['[',']',' ']:
143 tags = tags.replace(c, '')
144
145 if tags != '':
146 self._tags = tags.split(',')
147 else:
148 self._tags = list()
149
150 self._permissions = self._get_permissions()
151 return True
152 return False
153
154 def _get_permissions(self):
155 perms_out = self._exec(['list_user_permissions', self.username], True)
156
157 for perm in perms_out:
158 vhost, configure_priv, write_priv, read_priv = perm.split('\t')
159 if vhost == self.permissions['vhost']:
160 return dict(vhost=vhost, configure_priv=configure_priv, write_priv=write_priv, read_priv=read_priv)
161
162 return dict()
163
164 def add(self):
165 self._exec(['add_user', self.username, self.password])
166
167 def delete(self):
168 self._exec(['delete_user', self.username])
169
170 def set_tags(self):
171 self._exec(['set_user_tags', self.username] + self.tags)
172
173 def set_permissions(self):
174 cmd = ['set_permissions']
175 cmd.append('-p')
176 cmd.append(self.permissions['vhost'])
177 cmd.append(self.username)
178 cmd.append(self.permissions['configure_priv'])
179 cmd.append(self.permissions['write_priv'])
180 cmd.append(self.permissions['read_priv'])
181 self._exec(cmd)
182
183 def has_tags_modifications(self):
184 return set(self.tags) != set(self._tags)
185
186 def has_permissions_modifications(self):
187 return self._permissions != self.permissions
188
189 def main():
190 arg_spec = dict(
191 user=dict(required=True, aliases=['username', 'name']),
192 password=dict(default=None),
193 tags=dict(default=None),
194 vhost=dict(default='/'),
195 configure_priv=dict(default='^$'),
196 write_priv=dict(default='^$'),
197 read_priv=dict(default='^$'),
198 force=dict(default='no', type='bool'),
199 state=dict(default='present', choices=['present', 'absent']),
200 node=dict(default='rabbit')
201 )
202 module = AnsibleModule(
203 argument_spec=arg_spec,
204 supports_check_mode=True
205 )
206
207 username = module.params['user']
208 password = module.params['password']
209 tags = module.params['tags']
210 vhost = module.params['vhost']
211 configure_priv = module.params['configure_priv']
212 write_priv = module.params['write_priv']
213 read_priv = module.params['read_priv']
214 force = module.params['force']
215 state = module.params['state']
216 node = module.params['node']
217
218 rabbitmq_user = RabbitMqUser(module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node)
219
220 changed = False
221 if rabbitmq_user.get():
222 if state == 'absent':
223 rabbitmq_user.delete()
224 changed = True
225 else:
226 if force:
227 rabbitmq_user.delete()
228 rabbitmq_user.add()
229 rabbitmq_user.get()
230 changed = True
231
232 if rabbitmq_user.has_tags_modifications():
233 rabbitmq_user.set_tags()
234 changed = True
235
236 if rabbitmq_user.has_permissions_modifications():
237 rabbitmq_user.set_permissions()
238 changed = True
239 elif state == 'present':
240 rabbitmq_user.add()
241 rabbitmq_user.set_tags()
242 rabbitmq_user.set_permissions()
243 changed = True
244
245 module.exit_json(changed=changed, user=username, state=state)
246
247 # import module snippets
248 from ansible.module_utils.basic import *
249 main()
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/messaging/rabbitmq_user.py b/messaging/rabbitmq_user.py
--- a/messaging/rabbitmq_user.py
+++ b/messaging/rabbitmq_user.py
@@ -162,7 +162,11 @@
return dict()
def add(self):
- self._exec(['add_user', self.username, self.password])
+ if self.password is not None:
+ self._exec(['add_user', self.username, self.password])
+ else
+ self._exec(['add_user', self.username, ''])
+ self._exec(['clear_password', self.username])
def delete(self):
self._exec(['delete_user', self.username])
|
{"golden_diff": "diff --git a/messaging/rabbitmq_user.py b/messaging/rabbitmq_user.py\n--- a/messaging/rabbitmq_user.py\n+++ b/messaging/rabbitmq_user.py\n@@ -162,7 +162,11 @@\n return dict()\n \n def add(self):\n- self._exec(['add_user', self.username, self.password])\n+ if self.password is not None:\n+ self._exec(['add_user', self.username, self.password])\n+ else\n+ self._exec(['add_user', self.username, ''])\n+ self._exec(['clear_password', self.username])\n \n def delete(self):\n self._exec(['delete_user', self.username])\n", "issue": "rabbitmq_user fails when no password provided\nEven though the `password` param is specified as optional, the `rabbitmq_user` module fails when it is not provided.\n\n```\nStacktrace:\n File \"<stdin>\", line 1595, in <module>\n File \"<stdin>\", line 240, in main\n File \"<stdin>\", line 165, in add\n File \"<stdin>\", line 131, in _exec\n File \"<stdin>\", line 1448, in run_command\n File \"/usr/lib/python2.7/posixpath.py\", line 261, in expanduser\n if not path.startswith('~'):\nAttributeError: 'NoneType' object has no attribute 'startswith'\n```\n\nThe bug is [right here](https://github.com/ansible/ansible-modules-extras/blob/a0df36c6ab257281cbaae00b8a4590200802f571/messaging/rabbitmq_user.py#L165). I might send a PR when I get the time to fork and test.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_user\nshort_description: Adds or removes users to RabbitMQ\ndescription:\n - Add or remove users to RabbitMQ and assign permissions\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n user:\n description:\n - Name of user to add\n required: true\n default: null\n aliases: [username, name]\n password:\n description:\n - Password of user to add.\n - To change the password of an existing user, you must also specify\n C(force=yes).\n required: false\n default: null\n tags:\n description:\n - User tags specified as comma delimited\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n configure_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n write_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n read_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n force:\n description:\n - Deletes and recreates the user.\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [present, absent]\n'''\n\nEXAMPLES = '''\n# Add user to server and assign full access control\n- rabbitmq_user: user=joe\n password=changeme\n vhost=/\n configure_priv=.*\n read_priv=.*\n write_priv=.*\n state=present\n'''\n\nclass RabbitMqUser(object):\n def __init__(self, module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node):\n self.module = module\n self.username = username\n self.password = password\n self.node = node\n if tags is None:\n self.tags = list()\n else:\n self.tags = tags.split(',')\n\n permissions = dict(\n vhost=vhost,\n configure_priv=configure_priv,\n write_priv=write_priv,\n read_priv=read_priv\n )\n self.permissions = permissions\n\n self._tags = None\n self._permissions = None\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n users = self._exec(['list_users'], True)\n\n for user_tag in users:\n user, tags = user_tag.split('\\t')\n\n if user == self.username:\n for c in ['[',']',' ']:\n tags = tags.replace(c, '')\n\n if tags != '':\n self._tags = tags.split(',')\n else:\n self._tags = list()\n\n self._permissions = self._get_permissions()\n return True\n return False\n\n def _get_permissions(self):\n perms_out = self._exec(['list_user_permissions', self.username], True)\n\n for perm in perms_out:\n vhost, configure_priv, write_priv, read_priv = perm.split('\\t')\n if vhost == self.permissions['vhost']:\n return dict(vhost=vhost, configure_priv=configure_priv, write_priv=write_priv, read_priv=read_priv)\n\n return dict()\n\n def add(self):\n self._exec(['add_user', self.username, self.password])\n\n def delete(self):\n self._exec(['delete_user', self.username])\n\n def set_tags(self):\n self._exec(['set_user_tags', self.username] + self.tags)\n\n def set_permissions(self):\n cmd = ['set_permissions']\n cmd.append('-p')\n cmd.append(self.permissions['vhost'])\n cmd.append(self.username)\n cmd.append(self.permissions['configure_priv'])\n cmd.append(self.permissions['write_priv'])\n cmd.append(self.permissions['read_priv'])\n self._exec(cmd)\n\n def has_tags_modifications(self):\n return set(self.tags) != set(self._tags)\n\n def has_permissions_modifications(self):\n return self._permissions != self.permissions\n\ndef main():\n arg_spec = dict(\n user=dict(required=True, aliases=['username', 'name']),\n password=dict(default=None),\n tags=dict(default=None),\n vhost=dict(default='/'),\n configure_priv=dict(default='^$'),\n write_priv=dict(default='^$'),\n read_priv=dict(default='^$'),\n force=dict(default='no', type='bool'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n username = module.params['user']\n password = module.params['password']\n tags = module.params['tags']\n vhost = module.params['vhost']\n configure_priv = module.params['configure_priv']\n write_priv = module.params['write_priv']\n read_priv = module.params['read_priv']\n force = module.params['force']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_user = RabbitMqUser(module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node)\n\n changed = False\n if rabbitmq_user.get():\n if state == 'absent':\n rabbitmq_user.delete()\n changed = True\n else:\n if force:\n rabbitmq_user.delete()\n rabbitmq_user.add()\n rabbitmq_user.get()\n changed = True\n\n if rabbitmq_user.has_tags_modifications():\n rabbitmq_user.set_tags()\n changed = True\n\n if rabbitmq_user.has_permissions_modifications():\n rabbitmq_user.set_permissions()\n changed = True\n elif state == 'present':\n rabbitmq_user.add()\n rabbitmq_user.set_tags()\n rabbitmq_user.set_permissions()\n changed = True\n\n module.exit_json(changed=changed, user=username, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_user.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_user\nshort_description: Adds or removes users to RabbitMQ\ndescription:\n - Add or remove users to RabbitMQ and assign permissions\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n user:\n description:\n - Name of user to add\n required: true\n default: null\n aliases: [username, name]\n password:\n description:\n - Password of user to add.\n - To change the password of an existing user, you must also specify\n C(force=yes).\n required: false\n default: null\n tags:\n description:\n - User tags specified as comma delimited\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n configure_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n write_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n read_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n force:\n description:\n - Deletes and recreates the user.\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [present, absent]\n'''\n\nEXAMPLES = '''\n# Add user to server and assign full access control\n- rabbitmq_user: user=joe\n password=changeme\n vhost=/\n configure_priv=.*\n read_priv=.*\n write_priv=.*\n state=present\n'''\n\nclass RabbitMqUser(object):\n def __init__(self, module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node):\n self.module = module\n self.username = username\n self.password = password\n self.node = node\n if tags is None:\n self.tags = list()\n else:\n self.tags = tags.split(',')\n\n permissions = dict(\n vhost=vhost,\n configure_priv=configure_priv,\n write_priv=write_priv,\n read_priv=read_priv\n )\n self.permissions = permissions\n\n self._tags = None\n self._permissions = None\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n users = self._exec(['list_users'], True)\n\n for user_tag in users:\n user, tags = user_tag.split('\\t')\n\n if user == self.username:\n for c in ['[',']',' ']:\n tags = tags.replace(c, '')\n\n if tags != '':\n self._tags = tags.split(',')\n else:\n self._tags = list()\n\n self._permissions = self._get_permissions()\n return True\n return False\n\n def _get_permissions(self):\n perms_out = self._exec(['list_user_permissions', self.username], True)\n\n for perm in perms_out:\n vhost, configure_priv, write_priv, read_priv = perm.split('\\t')\n if vhost == self.permissions['vhost']:\n return dict(vhost=vhost, configure_priv=configure_priv, write_priv=write_priv, read_priv=read_priv)\n\n return dict()\n\n def add(self):\n if self.password is not None:\n self._exec(['add_user', self.username, self.password])\n else\n self._exec(['add_user', self.username, ''])\n self._exec(['clear_password', self.username])\n\n def delete(self):\n self._exec(['delete_user', self.username])\n\n def set_tags(self):\n self._exec(['set_user_tags', self.username] + self.tags)\n\n def set_permissions(self):\n cmd = ['set_permissions']\n cmd.append('-p')\n cmd.append(self.permissions['vhost'])\n cmd.append(self.username)\n cmd.append(self.permissions['configure_priv'])\n cmd.append(self.permissions['write_priv'])\n cmd.append(self.permissions['read_priv'])\n self._exec(cmd)\n\n def has_tags_modifications(self):\n return set(self.tags) != set(self._tags)\n\n def has_permissions_modifications(self):\n return self._permissions != self.permissions\n\ndef main():\n arg_spec = dict(\n user=dict(required=True, aliases=['username', 'name']),\n password=dict(default=None),\n tags=dict(default=None),\n vhost=dict(default='/'),\n configure_priv=dict(default='^$'),\n write_priv=dict(default='^$'),\n read_priv=dict(default='^$'),\n force=dict(default='no', type='bool'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n username = module.params['user']\n password = module.params['password']\n tags = module.params['tags']\n vhost = module.params['vhost']\n configure_priv = module.params['configure_priv']\n write_priv = module.params['write_priv']\n read_priv = module.params['read_priv']\n force = module.params['force']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_user = RabbitMqUser(module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node)\n\n changed = False\n if rabbitmq_user.get():\n if state == 'absent':\n rabbitmq_user.delete()\n changed = True\n else:\n if force:\n rabbitmq_user.delete()\n rabbitmq_user.add()\n rabbitmq_user.get()\n changed = True\n\n if rabbitmq_user.has_tags_modifications():\n rabbitmq_user.set_tags()\n changed = True\n\n if rabbitmq_user.has_permissions_modifications():\n rabbitmq_user.set_permissions()\n changed = True\n elif state == 'present':\n rabbitmq_user.add()\n rabbitmq_user.set_tags()\n rabbitmq_user.set_permissions()\n changed = True\n\n module.exit_json(changed=changed, user=username, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_user.py"}]}
| 2,843 | 151 |
gh_patches_debug_7462
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-644
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add api docs for plot_energy
https://arviz-devs.github.io/arviz/generated/arviz.plot_energy.html#arviz.plot_energy
See Posterior Docs for example
https://arviz-devs.github.io/arviz/generated/arviz.plot_posterior.html#arviz.plot_posterior
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/plots/energyplot.py`
Content:
```
1 """Plot energy transition distribution in HMC inference."""
2 import numpy as np
3 import matplotlib.pyplot as plt
4
5 from ..data import convert_to_dataset
6 from ..stats import bfmi as e_bfmi
7 from .kdeplot import plot_kde
8 from .plot_utils import _scale_fig_size
9
10
11 def plot_energy(
12 data,
13 kind="kde",
14 bfmi=True,
15 figsize=None,
16 legend=True,
17 fill_alpha=(1, 0.75),
18 fill_color=("C0", "C5"),
19 bw=4.5,
20 textsize=None,
21 fill_kwargs=None,
22 plot_kwargs=None,
23 ax=None,
24 ):
25 """Plot energy transition distribution and marginal energy distribution in HMC algorithms.
26
27 This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.
28
29 Parameters
30 ----------
31 data : xarray dataset, or object that can be converted (must represent
32 `sample_stats` and have an `energy` variable)
33 kind : str
34 Type of plot to display (kde or histogram)
35 bfmi : bool
36 If True add to the plot the value of the estimated Bayesian fraction of missing information
37 figsize : tuple
38 Figure size. If None it will be defined automatically.
39 legend : bool
40 Flag for plotting legend (defaults to True)
41 fill_alpha : tuple of floats
42 Alpha blending value for the shaded area under the curve, between 0
43 (no shade) and 1 (opaque). Defaults to (1, .75)
44 fill_color : tuple of valid matplotlib color
45 Color for Marginal energy distribution and Energy transition distribution.
46 Defaults to ('C0', 'C5')
47 bw : float
48 Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the
49 smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule
50 of thumb (the default rule used by SciPy). Only works if `kind='kde'`
51 textsize: float
52 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
53 on figsize.
54 fill_kwargs : dicts, optional
55 Additional keywords passed to `arviz.plot_kde` (to control the shade)
56 plot_kwargs : dicts, optional
57 Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')
58 ax : axes
59 Matplotlib axes.
60
61 Returns
62 -------
63 ax : matplotlib axes
64 """
65 energy = convert_to_dataset(data, group="sample_stats").energy.values
66
67 if ax is None:
68 _, ax = plt.subplots(figsize=figsize, constrained_layout=True)
69
70 if fill_kwargs is None:
71 fill_kwargs = {}
72
73 if plot_kwargs is None:
74 plot_kwargs = {}
75
76 figsize, _, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)
77
78 series = zip(
79 fill_alpha,
80 fill_color,
81 ("Marginal Energy", "Energy transition"),
82 (energy - energy.mean(), np.diff(energy)),
83 )
84
85 if kind == "kde":
86 for alpha, color, label, value in series:
87 fill_kwargs["alpha"] = alpha
88 fill_kwargs["color"] = color
89 plot_kwargs.setdefault("color", color)
90 plot_kwargs.setdefault("alpha", 0)
91 plot_kwargs.setdefault("linewidth", linewidth)
92 plot_kde(
93 value,
94 bw=bw,
95 label=label,
96 textsize=xt_labelsize,
97 plot_kwargs=plot_kwargs,
98 fill_kwargs=fill_kwargs,
99 ax=ax,
100 )
101
102 elif kind == "hist":
103 for alpha, color, label, value in series:
104 ax.hist(
105 value.flatten(),
106 bins="auto",
107 density=True,
108 alpha=alpha,
109 label=label,
110 color=color,
111 **plot_kwargs
112 )
113
114 else:
115 raise ValueError("Plot type {} not recognized.".format(kind))
116
117 if bfmi:
118 for idx, val in enumerate(e_bfmi(energy)):
119 ax.plot([], label="chain {:>2} BFMI = {:.2f}".format(idx, val), alpha=0)
120
121 ax.set_xticks([])
122 ax.set_yticks([])
123
124 if legend:
125 ax.legend()
126
127 return ax
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py
--- a/arviz/plots/energyplot.py
+++ b/arviz/plots/energyplot.py
@@ -61,6 +61,25 @@
Returns
-------
ax : matplotlib axes
+
+ Examples
+ --------
+ Plot a default energy plot
+
+ .. plot::
+ :context: close-figs
+
+ >>> import arviz as az
+ >>> data = az.load_arviz_data('centered_eight')
+ >>> az.plot_energy(data)
+
+ Represent energy plot via histograms
+
+ .. plot::
+ :context: close-figs
+
+ >>> az.plot_energy(data, kind='hist')
+
"""
energy = convert_to_dataset(data, group="sample_stats").energy.values
|
{"golden_diff": "diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py\n--- a/arviz/plots/energyplot.py\n+++ b/arviz/plots/energyplot.py\n@@ -61,6 +61,25 @@\n Returns\n -------\n ax : matplotlib axes\n+\n+ Examples\n+ --------\n+ Plot a default energy plot\n+\n+ .. plot::\n+ :context: close-figs\n+\n+ >>> import arviz as az\n+ >>> data = az.load_arviz_data('centered_eight')\n+ >>> az.plot_energy(data)\n+\n+ Represent energy plot via histograms\n+\n+ .. plot::\n+ :context: close-figs\n+\n+ >>> az.plot_energy(data, kind='hist')\n+\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n", "issue": "add api docs for plot_energy\nhttps://arviz-devs.github.io/arviz/generated/arviz.plot_energy.html#arviz.plot_energy\r\n\r\nSee Posterior Docs for example\r\nhttps://arviz-devs.github.io/arviz/generated/arviz.plot_posterior.html#arviz.plot_posterior\n", "before_files": [{"content": "\"\"\"Plot energy transition distribution in HMC inference.\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom ..data import convert_to_dataset\nfrom ..stats import bfmi as e_bfmi\nfrom .kdeplot import plot_kde\nfrom .plot_utils import _scale_fig_size\n\n\ndef plot_energy(\n data,\n kind=\"kde\",\n bfmi=True,\n figsize=None,\n legend=True,\n fill_alpha=(1, 0.75),\n fill_color=(\"C0\", \"C5\"),\n bw=4.5,\n textsize=None,\n fill_kwargs=None,\n plot_kwargs=None,\n ax=None,\n):\n \"\"\"Plot energy transition distribution and marginal energy distribution in HMC algorithms.\n\n This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.\n\n Parameters\n ----------\n data : xarray dataset, or object that can be converted (must represent\n `sample_stats` and have an `energy` variable)\n kind : str\n Type of plot to display (kde or histogram)\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n Flag for plotting legend (defaults to True)\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n (no shade) and 1 (opaque). Defaults to (1, .75)\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n Defaults to ('C0', 'C5')\n bw : float\n Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the\n smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule\n of thumb (the default rule used by SciPy). Only works if `kind='kde'`\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` (to control the shade)\n plot_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')\n ax : axes\n Matplotlib axes.\n\n Returns\n -------\n ax : matplotlib axes\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n\n if ax is None:\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\n\n if fill_kwargs is None:\n fill_kwargs = {}\n\n if plot_kwargs is None:\n plot_kwargs = {}\n\n figsize, _, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\n\n series = zip(\n fill_alpha,\n fill_color,\n (\"Marginal Energy\", \"Energy transition\"),\n (energy - energy.mean(), np.diff(energy)),\n )\n\n if kind == \"kde\":\n for alpha, color, label, value in series:\n fill_kwargs[\"alpha\"] = alpha\n fill_kwargs[\"color\"] = color\n plot_kwargs.setdefault(\"color\", color)\n plot_kwargs.setdefault(\"alpha\", 0)\n plot_kwargs.setdefault(\"linewidth\", linewidth)\n plot_kde(\n value,\n bw=bw,\n label=label,\n textsize=xt_labelsize,\n plot_kwargs=plot_kwargs,\n fill_kwargs=fill_kwargs,\n ax=ax,\n )\n\n elif kind == \"hist\":\n for alpha, color, label, value in series:\n ax.hist(\n value.flatten(),\n bins=\"auto\",\n density=True,\n alpha=alpha,\n label=label,\n color=color,\n **plot_kwargs\n )\n\n else:\n raise ValueError(\"Plot type {} not recognized.\".format(kind))\n\n if bfmi:\n for idx, val in enumerate(e_bfmi(energy)):\n ax.plot([], label=\"chain {:>2} BFMI = {:.2f}\".format(idx, val), alpha=0)\n\n ax.set_xticks([])\n ax.set_yticks([])\n\n if legend:\n ax.legend()\n\n return ax\n", "path": "arviz/plots/energyplot.py"}], "after_files": [{"content": "\"\"\"Plot energy transition distribution in HMC inference.\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom ..data import convert_to_dataset\nfrom ..stats import bfmi as e_bfmi\nfrom .kdeplot import plot_kde\nfrom .plot_utils import _scale_fig_size\n\n\ndef plot_energy(\n data,\n kind=\"kde\",\n bfmi=True,\n figsize=None,\n legend=True,\n fill_alpha=(1, 0.75),\n fill_color=(\"C0\", \"C5\"),\n bw=4.5,\n textsize=None,\n fill_kwargs=None,\n plot_kwargs=None,\n ax=None,\n):\n \"\"\"Plot energy transition distribution and marginal energy distribution in HMC algorithms.\n\n This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.\n\n Parameters\n ----------\n data : xarray dataset, or object that can be converted (must represent\n `sample_stats` and have an `energy` variable)\n kind : str\n Type of plot to display (kde or histogram)\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n Flag for plotting legend (defaults to True)\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n (no shade) and 1 (opaque). Defaults to (1, .75)\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n Defaults to ('C0', 'C5')\n bw : float\n Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the\n smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule\n of thumb (the default rule used by SciPy). Only works if `kind='kde'`\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` (to control the shade)\n plot_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')\n ax : axes\n Matplotlib axes.\n\n Returns\n -------\n ax : matplotlib axes\n\n Examples\n --------\n Plot a default energy plot\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> data = az.load_arviz_data('centered_eight')\n >>> az.plot_energy(data)\n\n Represent energy plot via histograms\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_energy(data, kind='hist')\n\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n\n if ax is None:\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\n\n if fill_kwargs is None:\n fill_kwargs = {}\n\n if plot_kwargs is None:\n plot_kwargs = {}\n\n figsize, _, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\n\n series = zip(\n fill_alpha,\n fill_color,\n (\"Marginal Energy\", \"Energy transition\"),\n (energy - energy.mean(), np.diff(energy)),\n )\n\n if kind == \"kde\":\n for alpha, color, label, value in series:\n fill_kwargs[\"alpha\"] = alpha\n fill_kwargs[\"color\"] = color\n plot_kwargs.setdefault(\"color\", color)\n plot_kwargs.setdefault(\"alpha\", 0)\n plot_kwargs.setdefault(\"linewidth\", linewidth)\n plot_kde(\n value,\n bw=bw,\n label=label,\n textsize=xt_labelsize,\n plot_kwargs=plot_kwargs,\n fill_kwargs=fill_kwargs,\n ax=ax,\n )\n\n elif kind == \"hist\":\n for alpha, color, label, value in series:\n ax.hist(\n value.flatten(),\n bins=\"auto\",\n density=True,\n alpha=alpha,\n label=label,\n color=color,\n **plot_kwargs\n )\n\n else:\n raise ValueError(\"Plot type {} not recognized.\".format(kind))\n\n if bfmi:\n for idx, val in enumerate(e_bfmi(energy)):\n ax.plot([], label=\"chain {:>2} BFMI = {:.2f}\".format(idx, val), alpha=0)\n\n ax.set_xticks([])\n ax.set_yticks([])\n\n if legend:\n ax.legend()\n\n return ax\n", "path": "arviz/plots/energyplot.py"}]}
| 1,536 | 191 |
gh_patches_debug_16849
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-4514
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
IonQ Job should throw TimeoutError when wait time exceeded
**Description of the issue**
Currently, `Job.results()` throws a `RuntimeError` when the job execution exceeds the `timeout_seconds` wait time. It would be more accurate to throw a `TimeoutError` instead.
see cirq-ionq/cirq_ionq/job.py:
https://github.com/quantumlib/Cirq/blob/7759c05fd71673ca58559307c220b5b779bf5bb6/cirq-ionq/cirq_ionq/job.py#L202
**How to reproduce the issue**
```
import cirq
import cirq.ionq as ionq
API_KEY = 'tomyheart' # Replace with your IonQ API key
service = ionq.Service(api_key=API_KEY,
default_target='simulator')
q0, q1 = cirq.LineQubit.range(2)
circuit = cirq.Circuit(
cirq.X(q0)**0.5, # Square root of X
cirq.CX(q0, q1), # CNOT
cirq.measure(q0, q1, key='b') # Measure both qubits
)
# create a job
job = service.create_job(circuit, repetitions=100)
job.results(timeout_seconds=0.1) # trigger a timeout
```
<details>
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_6204/2129298043.py in <module>
----> 1 job.results(timeout_seconds=0.01)
~/anaconda3/envs/my-env/lib/python3.7/site-packages/cirq_ionq/job.py in results(self, timeout_seconds, polling_seconds)
199 raise RuntimeError(f'Job failed. Error message: {error}')
200 raise RuntimeError(
--> 201 f'Job was not completed successful. Instead had status: {self.status()}'
202 )
203 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
RuntimeError: Job was not completed successful. Instead had status: ready
</details>
**Cirq version**
0.12.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq-ionq/cirq_ionq/job.py`
Content:
```
1 # Copyright 2020 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Represents a job created via the IonQ API."""
15
16 import time
17 from typing import Dict, Sequence, Union, TYPE_CHECKING
18
19 from cirq_ionq import ionq_exceptions, results
20 from cirq._doc import document
21
22 import cirq
23
24 if TYPE_CHECKING:
25 import cirq_ionq
26
27
28 def _little_endian_to_big(value: int, bit_count: int) -> int:
29 return cirq.big_endian_bits_to_int(
30 cirq.big_endian_int_to_bits(value, bit_count=bit_count)[::-1]
31 )
32
33
34 class Job:
35 """A job created on the IonQ API.
36
37 Note that this is mutable, when calls to get status or results are made
38 the job updates itself to the results returned from the API.
39
40 If a job is canceled or deleted, only the job id and the status remain
41 valid.
42 """
43
44 TERMINAL_STATES = ('completed', 'canceled', 'failed', 'deleted')
45 document(
46 TERMINAL_STATES,
47 'States of the IonQ API job from which the job cannot transition. '
48 'Note that deleted can only exist in a return call from a delete '
49 '(subsequent calls will return not found).',
50 )
51
52 NON_TERMINAL_STATES = ('ready', 'submitted', 'running')
53 document(
54 NON_TERMINAL_STATES, 'States of the IonQ API job which can transition to other states.'
55 )
56
57 ALL_STATES = TERMINAL_STATES + NON_TERMINAL_STATES
58 document(ALL_STATES, 'All states that an IonQ API job can exist in.')
59
60 UNSUCCESSFUL_STATES = ('canceled', 'failed', 'deleted')
61 document(
62 UNSUCCESSFUL_STATES,
63 'States of the IonQ API job when it was not successful and so does not have any '
64 'data associated with it beyond an id and a status.',
65 )
66
67 def __init__(self, client: 'cirq_ionq.ionq_client._IonQClient', job_dict: dict):
68 """Construct an IonQJob.
69
70 Users should not call this themselves. If you only know the `job_id`, use `get_job`
71 on `cirq_ionq.Service`.
72
73 Args:
74 client: The client used for calling the API.
75 job_dict: A dict representing the response from a call to get_job on the client.
76 """
77 self._client = client
78 self._job = job_dict
79
80 def _refresh_job(self):
81 """If the last fetched job is not terminal, gets the job from the API."""
82 if self._job['status'] not in self.TERMINAL_STATES:
83 self._job = self._client.get_job(self.job_id())
84
85 def _check_if_unsuccessful(self):
86 if self.status() in self.UNSUCCESSFUL_STATES:
87 raise ionq_exceptions.IonQUnsuccessfulJobException(self.job_id(), self.status())
88
89 def job_id(self) -> str:
90 """Returns the job id (UID) for the job.
91
92 This is the id used for identifying the job by the API.
93 """
94 return self._job['id']
95
96 def status(self) -> str:
97 """Gets the current status of the job.
98
99 This will get a new job if the status of the job previously was determined to not be in
100 a terminal state. A full list of states is given in `cirq_ionq.IonQJob.ALL_STATES`.
101
102 Raises:
103 IonQException: If the API is not able to get the status of the job.
104
105 Returns:
106 The job status.
107 """
108 self._refresh_job()
109 return self._job['status']
110
111 def target(self) -> str:
112 """Returns the target where the job is to be run, or was run.
113
114 Returns:
115 'qpu' or 'simulator' depending on where the job was run or is running.
116
117 Raises:
118 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
119 IonQException: If unable to get the status of the job from the API.
120 """
121 self._check_if_unsuccessful()
122 return self._job['target']
123
124 def name(self) -> str:
125 """Returns the name of the job which was supplied during job creation.
126
127 This is different than the `job_id`.
128
129 Raises:
130 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
131 IonQException: If unable to get the status of the job from the API.
132 """
133 self._check_if_unsuccessful()
134 return self._job['name']
135
136 def num_qubits(self) -> int:
137 """Returns the number of qubits for the job.
138
139 Raises:
140 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
141 IonQException: If unable to get the status of the job from the API.
142 """
143 self._check_if_unsuccessful()
144 return int(self._job['qubits'])
145
146 def repetitions(self) -> int:
147 """Returns the number of repetitions for the job.
148
149 Raises:
150 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
151 IonQException: If unable to get the status of the job from the API.
152 """
153 self._check_if_unsuccessful()
154 return int(self._job['metadata']['shots'])
155
156 def measurement_dict(self) -> Dict[str, Sequence[int]]:
157 """Returns a dictionary of measurement keys to target qubit index."""
158 measurement_dict: Dict[str, Sequence[int]] = {}
159 if 'metadata' in self._job:
160 full_str = ''.join(
161 value
162 for key, value in self._job['metadata'].items()
163 if key.startswith('measurement')
164 )
165 if full_str == '':
166 return measurement_dict
167 for key_value in full_str.split(chr(30)):
168 key, value = key_value.split(chr(31))
169 measurement_dict[key] = [int(t) for t in value.split(',')]
170 return measurement_dict
171
172 # TODO(#3388) Add documentation for Raises.
173 # pylint: disable=missing-raises-doc
174 def results(
175 self, timeout_seconds: int = 7200, polling_seconds: int = 1
176 ) -> Union[results.QPUResult, results.SimulatorResult]:
177 """Polls the IonQ api for results.
178
179 Args:
180 timeout_seconds: The total number of seconds to poll for.
181 polling_seconds: The interval with which to poll.
182
183 Returns:
184 Either a `cirq_ionq.QPUResults` or `cirq_ionq.SimulatorResults` depending on whether
185 the job was running on an actual quantum processor or a simulator.
186
187 Raises:
188 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
189 IonQException: If unable to get the results from the API.
190 """
191 time_waited_seconds = 0
192 while time_waited_seconds < timeout_seconds:
193 # Status does a refresh.
194 if self.status() in self.TERMINAL_STATES:
195 break
196 time.sleep(polling_seconds)
197 time_waited_seconds += polling_seconds
198 if self.status() != 'completed':
199 if 'failure' in self._job and 'error' in self._job['failure']:
200 error = self._job['failure']['error']
201 raise RuntimeError(f'Job failed. Error message: {error}')
202 raise RuntimeError(
203 f'Job was not completed successful. Instead had status: {self.status()}'
204 )
205 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
206 if self.target() == 'qpu':
207 repetitions = self.repetitions()
208 counts = {
209 _little_endian_to_big(int(k), self.num_qubits()): int(repetitions * float(v))
210 for k, v in self._job['data']['histogram'].items()
211 }
212 return results.QPUResult(
213 counts=counts,
214 num_qubits=self.num_qubits(),
215 measurement_dict=self.measurement_dict(),
216 )
217 else:
218 probabilities = {
219 _little_endian_to_big(int(k), self.num_qubits()): float(v)
220 for k, v in self._job['data']['histogram'].items()
221 }
222 return results.SimulatorResult(
223 probabilities=probabilities,
224 num_qubits=self.num_qubits(),
225 measurement_dict=self.measurement_dict(),
226 repetitions=self.repetitions(),
227 )
228
229 # pylint: enable=missing-raises-doc
230 def cancel(self):
231 """Cancel the given job.
232
233 This mutates the job to only have a job id and status `canceled`.
234 """
235 self._job = self._client.cancel_job(job_id=self.job_id())
236
237 def delete(self):
238 """Delete the given job.
239
240 This mutates the job to only have a job id and status `deleted`. Subsequence attempts to
241 get the job with this job id will return not found.
242 """
243 self._job = self._client.delete_job(job_id=self.job_id())
244
245 def __str__(self) -> str:
246 return f'cirq_ionq.Job(job_id={self.job_id()})'
247
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cirq-ionq/cirq_ionq/job.py b/cirq-ionq/cirq_ionq/job.py
--- a/cirq-ionq/cirq_ionq/job.py
+++ b/cirq-ionq/cirq_ionq/job.py
@@ -199,8 +199,10 @@
if 'failure' in self._job and 'error' in self._job['failure']:
error = self._job['failure']['error']
raise RuntimeError(f'Job failed. Error message: {error}')
+ if time_waited_seconds >= timeout_seconds:
+ raise TimeoutError(f'Job timed out after waiting {time_waited_seconds} seconds.')
raise RuntimeError(
- f'Job was not completed successful. Instead had status: {self.status()}'
+ f'Job was not completed successfully. Instead had status: {self.status()}'
)
# IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
if self.target() == 'qpu':
|
{"golden_diff": "diff --git a/cirq-ionq/cirq_ionq/job.py b/cirq-ionq/cirq_ionq/job.py\n--- a/cirq-ionq/cirq_ionq/job.py\n+++ b/cirq-ionq/cirq_ionq/job.py\n@@ -199,8 +199,10 @@\n if 'failure' in self._job and 'error' in self._job['failure']:\n error = self._job['failure']['error']\n raise RuntimeError(f'Job failed. Error message: {error}')\n+ if time_waited_seconds >= timeout_seconds:\n+ raise TimeoutError(f'Job timed out after waiting {time_waited_seconds} seconds.')\n raise RuntimeError(\n- f'Job was not completed successful. Instead had status: {self.status()}'\n+ f'Job was not completed successfully. Instead had status: {self.status()}'\n )\n # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\n if self.target() == 'qpu':\n", "issue": "IonQ Job should throw TimeoutError when wait time exceeded\n**Description of the issue**\r\n\r\nCurrently, `Job.results()` throws a `RuntimeError` when the job execution exceeds the `timeout_seconds` wait time. It would be more accurate to throw a `TimeoutError` instead.\r\n\r\nsee cirq-ionq/cirq_ionq/job.py:\r\n\r\nhttps://github.com/quantumlib/Cirq/blob/7759c05fd71673ca58559307c220b5b779bf5bb6/cirq-ionq/cirq_ionq/job.py#L202\r\n\r\n**How to reproduce the issue**\r\n\r\n```\r\nimport cirq\r\nimport cirq.ionq as ionq\r\n\r\nAPI_KEY = 'tomyheart' # Replace with your IonQ API key\r\n\r\nservice = ionq.Service(api_key=API_KEY, \r\n default_target='simulator')\r\n\r\nq0, q1 = cirq.LineQubit.range(2)\r\ncircuit = cirq.Circuit(\r\n cirq.X(q0)**0.5, # Square root of X\r\n cirq.CX(q0, q1), # CNOT\r\n cirq.measure(q0, q1, key='b') # Measure both qubits\r\n)\r\n\r\n# create a job\r\njob = service.create_job(circuit, repetitions=100)\r\njob.results(timeout_seconds=0.1) # trigger a timeout\r\n```\r\n\r\n<details>\r\n\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n/tmp/ipykernel_6204/2129298043.py in <module>\r\n----> 1 job.results(timeout_seconds=0.01)\r\n\r\n~/anaconda3/envs/my-env/lib/python3.7/site-packages/cirq_ionq/job.py in results(self, timeout_seconds, polling_seconds)\r\n 199 raise RuntimeError(f'Job failed. Error message: {error}')\r\n 200 raise RuntimeError(\r\n--> 201 f'Job was not completed successful. Instead had status: {self.status()}'\r\n 202 )\r\n 203 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\r\n\r\nRuntimeError: Job was not completed successful. Instead had status: ready\r\n\r\n</details>\r\n\r\n**Cirq version**\r\n\r\n0.12.0\n", "before_files": [{"content": "# Copyright 2020 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Represents a job created via the IonQ API.\"\"\"\n\nimport time\nfrom typing import Dict, Sequence, Union, TYPE_CHECKING\n\nfrom cirq_ionq import ionq_exceptions, results\nfrom cirq._doc import document\n\nimport cirq\n\nif TYPE_CHECKING:\n import cirq_ionq\n\n\ndef _little_endian_to_big(value: int, bit_count: int) -> int:\n return cirq.big_endian_bits_to_int(\n cirq.big_endian_int_to_bits(value, bit_count=bit_count)[::-1]\n )\n\n\nclass Job:\n \"\"\"A job created on the IonQ API.\n\n Note that this is mutable, when calls to get status or results are made\n the job updates itself to the results returned from the API.\n\n If a job is canceled or deleted, only the job id and the status remain\n valid.\n \"\"\"\n\n TERMINAL_STATES = ('completed', 'canceled', 'failed', 'deleted')\n document(\n TERMINAL_STATES,\n 'States of the IonQ API job from which the job cannot transition. '\n 'Note that deleted can only exist in a return call from a delete '\n '(subsequent calls will return not found).',\n )\n\n NON_TERMINAL_STATES = ('ready', 'submitted', 'running')\n document(\n NON_TERMINAL_STATES, 'States of the IonQ API job which can transition to other states.'\n )\n\n ALL_STATES = TERMINAL_STATES + NON_TERMINAL_STATES\n document(ALL_STATES, 'All states that an IonQ API job can exist in.')\n\n UNSUCCESSFUL_STATES = ('canceled', 'failed', 'deleted')\n document(\n UNSUCCESSFUL_STATES,\n 'States of the IonQ API job when it was not successful and so does not have any '\n 'data associated with it beyond an id and a status.',\n )\n\n def __init__(self, client: 'cirq_ionq.ionq_client._IonQClient', job_dict: dict):\n \"\"\"Construct an IonQJob.\n\n Users should not call this themselves. If you only know the `job_id`, use `get_job`\n on `cirq_ionq.Service`.\n\n Args:\n client: The client used for calling the API.\n job_dict: A dict representing the response from a call to get_job on the client.\n \"\"\"\n self._client = client\n self._job = job_dict\n\n def _refresh_job(self):\n \"\"\"If the last fetched job is not terminal, gets the job from the API.\"\"\"\n if self._job['status'] not in self.TERMINAL_STATES:\n self._job = self._client.get_job(self.job_id())\n\n def _check_if_unsuccessful(self):\n if self.status() in self.UNSUCCESSFUL_STATES:\n raise ionq_exceptions.IonQUnsuccessfulJobException(self.job_id(), self.status())\n\n def job_id(self) -> str:\n \"\"\"Returns the job id (UID) for the job.\n\n This is the id used for identifying the job by the API.\n \"\"\"\n return self._job['id']\n\n def status(self) -> str:\n \"\"\"Gets the current status of the job.\n\n This will get a new job if the status of the job previously was determined to not be in\n a terminal state. A full list of states is given in `cirq_ionq.IonQJob.ALL_STATES`.\n\n Raises:\n IonQException: If the API is not able to get the status of the job.\n\n Returns:\n The job status.\n \"\"\"\n self._refresh_job()\n return self._job['status']\n\n def target(self) -> str:\n \"\"\"Returns the target where the job is to be run, or was run.\n\n Returns:\n 'qpu' or 'simulator' depending on where the job was run or is running.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['target']\n\n def name(self) -> str:\n \"\"\"Returns the name of the job which was supplied during job creation.\n\n This is different than the `job_id`.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['name']\n\n def num_qubits(self) -> int:\n \"\"\"Returns the number of qubits for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['qubits'])\n\n def repetitions(self) -> int:\n \"\"\"Returns the number of repetitions for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['metadata']['shots'])\n\n def measurement_dict(self) -> Dict[str, Sequence[int]]:\n \"\"\"Returns a dictionary of measurement keys to target qubit index.\"\"\"\n measurement_dict: Dict[str, Sequence[int]] = {}\n if 'metadata' in self._job:\n full_str = ''.join(\n value\n for key, value in self._job['metadata'].items()\n if key.startswith('measurement')\n )\n if full_str == '':\n return measurement_dict\n for key_value in full_str.split(chr(30)):\n key, value = key_value.split(chr(31))\n measurement_dict[key] = [int(t) for t in value.split(',')]\n return measurement_dict\n\n # TODO(#3388) Add documentation for Raises.\n # pylint: disable=missing-raises-doc\n def results(\n self, timeout_seconds: int = 7200, polling_seconds: int = 1\n ) -> Union[results.QPUResult, results.SimulatorResult]:\n \"\"\"Polls the IonQ api for results.\n\n Args:\n timeout_seconds: The total number of seconds to poll for.\n polling_seconds: The interval with which to poll.\n\n Returns:\n Either a `cirq_ionq.QPUResults` or `cirq_ionq.SimulatorResults` depending on whether\n the job was running on an actual quantum processor or a simulator.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the results from the API.\n \"\"\"\n time_waited_seconds = 0\n while time_waited_seconds < timeout_seconds:\n # Status does a refresh.\n if self.status() in self.TERMINAL_STATES:\n break\n time.sleep(polling_seconds)\n time_waited_seconds += polling_seconds\n if self.status() != 'completed':\n if 'failure' in self._job and 'error' in self._job['failure']:\n error = self._job['failure']['error']\n raise RuntimeError(f'Job failed. Error message: {error}')\n raise RuntimeError(\n f'Job was not completed successful. Instead had status: {self.status()}'\n )\n # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\n if self.target() == 'qpu':\n repetitions = self.repetitions()\n counts = {\n _little_endian_to_big(int(k), self.num_qubits()): int(repetitions * float(v))\n for k, v in self._job['data']['histogram'].items()\n }\n return results.QPUResult(\n counts=counts,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n )\n else:\n probabilities = {\n _little_endian_to_big(int(k), self.num_qubits()): float(v)\n for k, v in self._job['data']['histogram'].items()\n }\n return results.SimulatorResult(\n probabilities=probabilities,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n repetitions=self.repetitions(),\n )\n\n # pylint: enable=missing-raises-doc\n def cancel(self):\n \"\"\"Cancel the given job.\n\n This mutates the job to only have a job id and status `canceled`.\n \"\"\"\n self._job = self._client.cancel_job(job_id=self.job_id())\n\n def delete(self):\n \"\"\"Delete the given job.\n\n This mutates the job to only have a job id and status `deleted`. Subsequence attempts to\n get the job with this job id will return not found.\n \"\"\"\n self._job = self._client.delete_job(job_id=self.job_id())\n\n def __str__(self) -> str:\n return f'cirq_ionq.Job(job_id={self.job_id()})'\n", "path": "cirq-ionq/cirq_ionq/job.py"}], "after_files": [{"content": "# Copyright 2020 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Represents a job created via the IonQ API.\"\"\"\n\nimport time\nfrom typing import Dict, Sequence, Union, TYPE_CHECKING\n\nfrom cirq_ionq import ionq_exceptions, results\nfrom cirq._doc import document\n\nimport cirq\n\nif TYPE_CHECKING:\n import cirq_ionq\n\n\ndef _little_endian_to_big(value: int, bit_count: int) -> int:\n return cirq.big_endian_bits_to_int(\n cirq.big_endian_int_to_bits(value, bit_count=bit_count)[::-1]\n )\n\n\nclass Job:\n \"\"\"A job created on the IonQ API.\n\n Note that this is mutable, when calls to get status or results are made\n the job updates itself to the results returned from the API.\n\n If a job is canceled or deleted, only the job id and the status remain\n valid.\n \"\"\"\n\n TERMINAL_STATES = ('completed', 'canceled', 'failed', 'deleted')\n document(\n TERMINAL_STATES,\n 'States of the IonQ API job from which the job cannot transition. '\n 'Note that deleted can only exist in a return call from a delete '\n '(subsequent calls will return not found).',\n )\n\n NON_TERMINAL_STATES = ('ready', 'submitted', 'running')\n document(\n NON_TERMINAL_STATES, 'States of the IonQ API job which can transition to other states.'\n )\n\n ALL_STATES = TERMINAL_STATES + NON_TERMINAL_STATES\n document(ALL_STATES, 'All states that an IonQ API job can exist in.')\n\n UNSUCCESSFUL_STATES = ('canceled', 'failed', 'deleted')\n document(\n UNSUCCESSFUL_STATES,\n 'States of the IonQ API job when it was not successful and so does not have any '\n 'data associated with it beyond an id and a status.',\n )\n\n def __init__(self, client: 'cirq_ionq.ionq_client._IonQClient', job_dict: dict):\n \"\"\"Construct an IonQJob.\n\n Users should not call this themselves. If you only know the `job_id`, use `get_job`\n on `cirq_ionq.Service`.\n\n Args:\n client: The client used for calling the API.\n job_dict: A dict representing the response from a call to get_job on the client.\n \"\"\"\n self._client = client\n self._job = job_dict\n\n def _refresh_job(self):\n \"\"\"If the last fetched job is not terminal, gets the job from the API.\"\"\"\n if self._job['status'] not in self.TERMINAL_STATES:\n self._job = self._client.get_job(self.job_id())\n\n def _check_if_unsuccessful(self):\n if self.status() in self.UNSUCCESSFUL_STATES:\n raise ionq_exceptions.IonQUnsuccessfulJobException(self.job_id(), self.status())\n\n def job_id(self) -> str:\n \"\"\"Returns the job id (UID) for the job.\n\n This is the id used for identifying the job by the API.\n \"\"\"\n return self._job['id']\n\n def status(self) -> str:\n \"\"\"Gets the current status of the job.\n\n This will get a new job if the status of the job previously was determined to not be in\n a terminal state. A full list of states is given in `cirq_ionq.IonQJob.ALL_STATES`.\n\n Raises:\n IonQException: If the API is not able to get the status of the job.\n\n Returns:\n The job status.\n \"\"\"\n self._refresh_job()\n return self._job['status']\n\n def target(self) -> str:\n \"\"\"Returns the target where the job is to be run, or was run.\n\n Returns:\n 'qpu' or 'simulator' depending on where the job was run or is running.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['target']\n\n def name(self) -> str:\n \"\"\"Returns the name of the job which was supplied during job creation.\n\n This is different than the `job_id`.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['name']\n\n def num_qubits(self) -> int:\n \"\"\"Returns the number of qubits for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['qubits'])\n\n def repetitions(self) -> int:\n \"\"\"Returns the number of repetitions for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['metadata']['shots'])\n\n def measurement_dict(self) -> Dict[str, Sequence[int]]:\n \"\"\"Returns a dictionary of measurement keys to target qubit index.\"\"\"\n measurement_dict: Dict[str, Sequence[int]] = {}\n if 'metadata' in self._job:\n full_str = ''.join(\n value\n for key, value in self._job['metadata'].items()\n if key.startswith('measurement')\n )\n if full_str == '':\n return measurement_dict\n for key_value in full_str.split(chr(30)):\n key, value = key_value.split(chr(31))\n measurement_dict[key] = [int(t) for t in value.split(',')]\n return measurement_dict\n\n # TODO(#3388) Add documentation for Raises.\n # pylint: disable=missing-raises-doc\n def results(\n self, timeout_seconds: int = 7200, polling_seconds: int = 1\n ) -> Union[results.QPUResult, results.SimulatorResult]:\n \"\"\"Polls the IonQ api for results.\n\n Args:\n timeout_seconds: The total number of seconds to poll for.\n polling_seconds: The interval with which to poll.\n\n Returns:\n Either a `cirq_ionq.QPUResults` or `cirq_ionq.SimulatorResults` depending on whether\n the job was running on an actual quantum processor or a simulator.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the results from the API.\n \"\"\"\n time_waited_seconds = 0\n while time_waited_seconds < timeout_seconds:\n # Status does a refresh.\n if self.status() in self.TERMINAL_STATES:\n break\n time.sleep(polling_seconds)\n time_waited_seconds += polling_seconds\n if self.status() != 'completed':\n if 'failure' in self._job and 'error' in self._job['failure']:\n error = self._job['failure']['error']\n raise RuntimeError(f'Job failed. Error message: {error}')\n if time_waited_seconds >= timeout_seconds:\n raise TimeoutError(f'Job timed out after waiting {time_waited_seconds} seconds.')\n raise RuntimeError(\n f'Job was not completed successfully. Instead had status: {self.status()}'\n )\n # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\n if self.target() == 'qpu':\n repetitions = self.repetitions()\n counts = {\n _little_endian_to_big(int(k), self.num_qubits()): int(repetitions * float(v))\n for k, v in self._job['data']['histogram'].items()\n }\n return results.QPUResult(\n counts=counts,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n )\n else:\n probabilities = {\n _little_endian_to_big(int(k), self.num_qubits()): float(v)\n for k, v in self._job['data']['histogram'].items()\n }\n return results.SimulatorResult(\n probabilities=probabilities,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n repetitions=self.repetitions(),\n )\n\n # pylint: enable=missing-raises-doc\n def cancel(self):\n \"\"\"Cancel the given job.\n\n This mutates the job to only have a job id and status `canceled`.\n \"\"\"\n self._job = self._client.cancel_job(job_id=self.job_id())\n\n def delete(self):\n \"\"\"Delete the given job.\n\n This mutates the job to only have a job id and status `deleted`. Subsequence attempts to\n get the job with this job id will return not found.\n \"\"\"\n self._job = self._client.delete_job(job_id=self.job_id())\n\n def __str__(self) -> str:\n return f'cirq_ionq.Job(job_id={self.job_id()})'\n", "path": "cirq-ionq/cirq_ionq/job.py"}]}
| 3,525 | 223 |
gh_patches_debug_10892
|
rasdani/github-patches
|
git_diff
|
NVIDIA__TransformerEngine-627
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The version v1.2 has compatibility issues with PyTorch 2.0.1, causing errors during execution.
Hello,
I encountered the following error while using version v1.2 of Transformer Engine:
`no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive). The error message is TypeError: disable() got an unexpected keyword argument 'recursive'.
`
My environment setup is as follows: CUDA 11.8, PyTorch 2.0.1, and Python 3.10. I am experiencing this issue specifically in the context of using MegatronLM at commit fab0bd6 for Large Language Model (LLM) training. The error occurs right at the start of the training.
Possible cause of the issue:
The `disable` function in PyTorch 2.0.1 is defined as `def disable(f)`, and the recursive parameter was introduced only in later versions starting from PyTorch 2.1.0.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `transformer_engine/pytorch/jit.py`
Content:
```
1 # Copyright (c) 2022-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
2 #
3 # See LICENSE for license information.
4
5 """NVFuser functions and JIT utilities"""
6 import os
7 from typing import Callable, Optional, Tuple
8
9 import torch
10
11 jit_fuser = torch.jit.script
12 if torch.__version__ >= "2" and bool(int(os.getenv("NVTE_TORCH_COMPILE", "1"))):
13 jit_fuser = torch.compile
14
15 # See: https://github.com/NVIDIA/TransformerEngine/issues/597
16 dropout_fuser = torch.jit.script
17 if torch.__version__ >= "2.2" and bool(int(os.getenv("NVTE_TORCH_COMPILE", "1"))):
18 dropout_fuser = torch.compile
19
20 # Decorator to disable Torch Dynamo
21 # See: https://github.com/NVIDIA/TransformerEngine/issues/308
22 no_torch_dynamo = lambda recursive=True: lambda func: func
23 if torch.__version__ >= "2":
24 import torch._dynamo
25 no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)
26
27
28 def set_jit_fusion_options() -> None:
29 """Set PyTorch JIT layer fusion options."""
30 # flags required to enable jit fusion kernels
31 TORCH_MAJOR = int(torch.__version__.split(".")[0])
32 TORCH_MINOR = int(torch.__version__.split(".")[1])
33 if (TORCH_MAJOR > 1) or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10):
34 # nvfuser
35 torch._C._jit_set_profiling_executor(True)
36 torch._C._jit_set_profiling_mode(True)
37 torch._C._jit_override_can_fuse_on_cpu(False)
38 torch._C._jit_override_can_fuse_on_gpu(False)
39 torch._C._jit_set_texpr_fuser_enabled(False)
40 torch._C._jit_set_nvfuser_enabled(True)
41 torch._C._debug_set_autodiff_subgraph_inlining(False)
42 else:
43 # legacy pytorch fuser
44 torch._C._jit_set_profiling_mode(False)
45 torch._C._jit_set_profiling_executor(False)
46 torch._C._jit_override_can_fuse_on_cpu(True)
47 torch._C._jit_override_can_fuse_on_gpu(True)
48
49
50 @jit_fuser
51 def bias_gelu_fused_(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
52 """Bias-GeLU fused"""
53 x = inp + bias
54 return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
55
56
57 @jit_fuser
58 def gelu_fused_(inp: torch.Tensor) -> torch.Tensor:
59 """
60 GeLU fused, this is copy of bias_gelu_fused cause jit fusion doesn't allow conditioning.
61 """
62 x = inp
63 return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
64
65
66 # gradient of tanh approximation of gelu
67 # gradient of actual gelu is:
68 # 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)
69 @jit_fuser
70 def bgrad_dgelu_fused_(
71 grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor
72 ) -> Tuple[torch.Tensor, torch.Tensor]:
73 """Bgrad-Dgelu fused"""
74 x = inp + bias
75 tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
76 # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
77 ff = 0.5 * x * (
78 (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)
79 ) + 0.5 * (1 + tanh_out)
80 dgelu = ff * grad_output
81 bgrad = dgelu.sum(dim=0)
82 return bgrad, dgelu
83
84
85 @jit_fuser
86 def dgelu_fused_(
87 grad_output: torch.Tensor, inp: torch.Tensor
88 ) -> torch.Tensor:
89 """
90 Dgelu fused, this is copy of bgrad_dgelu_fused_ cause jit fusion doesn't allow conditioning.
91 """
92 x = inp
93 tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
94 # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
95 ff = 0.5 * x * (
96 (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)
97 ) + 0.5 * (1 + tanh_out)
98 dgelu = ff * grad_output
99 return dgelu
100
101
102 def bias_gelu_fused(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
103 """Disable native AMP for bias_gelu_fused_"""
104 with torch.cuda.amp.autocast(enabled=False):
105 if bias.numel() != 0:
106 return bias_gelu_fused_(inp, bias)
107 return gelu_fused_(inp)
108
109
110 def bgrad_dgelu_fused(
111 grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor
112 ) -> Tuple[Optional[torch.Tensor], torch.Tensor]:
113 """Disable native AMP for `bgrad_dgelu_fused_`"""
114 with torch.cuda.amp.autocast(enabled=False):
115 if bias.numel() != 0:
116 return bgrad_dgelu_fused_(grad_output, inp, bias)
117 return None, dgelu_fused_(grad_output, inp)
118
119
120 def bias_dropout_add(
121 x: torch.Tensor,
122 bias: torch.Tensor,
123 residual: torch.Tensor,
124 prob: float,
125 training: bool,
126 ) -> torch.Tensor:
127 """dropout(inp + bias) + residual"""
128 out = torch.nn.functional.dropout(x + bias, p=prob, training=training)
129 out = residual + out
130 return out
131
132
133 def get_bias_dropout_add(training: bool) -> Callable:
134 """bias_dropout_add based on training or not"""
135
136 def _bias_dropout_add(x, bias, residual, prob):
137 return bias_dropout_add(x, bias, residual, prob, training)
138
139 return _bias_dropout_add
140
141
142 @dropout_fuser
143 def bias_dropout_add_fused_train_(
144 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
145 ) -> torch.Tensor:
146 """Jit fused bias_dropout_add for training"""
147 return bias_dropout_add(x, bias, residual, prob, True)
148
149
150 def bias_dropout_add_fused_train(
151 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
152 ) -> torch.Tensor:
153 """Disable native AMP and enable grad for BDA"""
154 with torch.enable_grad():
155 with torch.cuda.amp.autocast(enabled=False):
156 return bias_dropout_add_fused_train_(x, bias, residual, prob)
157
158
159 @dropout_fuser
160 def bias_dropout_add_fused_inference_(
161 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
162 ) -> torch.Tensor:
163 """Jit fused bias_dropout_add for inference"""
164 return bias_dropout_add(x, bias, residual, prob, False)
165
166
167 def bias_dropout_add_fused_inference(
168 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
169 ) -> torch.Tensor:
170 """Disable native AMP for BDA"""
171 with torch.cuda.amp.autocast(enabled=False):
172 return bias_dropout_add_fused_inference_(x, bias, residual, prob)
173
174
175 def warmup_jit_bias_dropout_add(
176 hidden_size: int, dtype: torch.dtype, seq_length: int, micro_batch_size: int
177 ) -> None:
178 """Compile BDA JIT function before the main training steps"""
179
180 # Save cuda RNG state to ensure warmup does not affect reproducibility.
181 rng_state = torch.cuda.get_rng_state()
182
183 inp = torch.rand(
184 (seq_length, micro_batch_size, hidden_size), dtype=dtype, device="cuda"
185 )
186 residual = torch.rand(
187 (seq_length, micro_batch_size, hidden_size), dtype=dtype, device="cuda"
188 )
189 bias = torch.rand((hidden_size), dtype=dtype, device="cuda")
190 dropout_rate = 0.1
191 # Warmup JIT fusions with the input grad_enable state of both forward
192 # prop and recomputation
193 for input_grad, bias_grad, residual_grad in zip(
194 [False, True], [True, True], [True, True]
195 ):
196 inp.requires_grad = input_grad
197 bias.requires_grad = bias_grad
198 residual.requires_grad = residual_grad
199 for _ in range(5):
200 output = bias_dropout_add_fused_train(inp, bias, residual, dropout_rate)
201 del bias, inp, residual, output
202
203 torch.cuda.empty_cache()
204 torch.cuda.set_rng_state(rng_state)
205
206
207 def warmup_jit_bias_dropout_add_all_dtypes(
208 hidden_size: int, seq_length: int, micro_batch_size: int
209 ) -> None:
210 """Call `warmup_jit_bias_dropout_add` for all training dtypes"""
211 for dtype in [torch.float32, torch.bfloat16, torch.float16]:
212 warmup_jit_bias_dropout_add(hidden_size, dtype, seq_length, micro_batch_size)
213
214
215 def warmup_jit_bias_gelu(
216 ffn_hidden_size_per_partition: int,
217 dtype: torch.dtype,
218 seq_length: int,
219 micro_batch_size: int,
220 ) -> None:
221 """Compile bias-gelu JIT function before the main training steps"""
222
223 # Save cuda RNG state to ensure warmup does not affect reproducibility.
224 rng_state = torch.cuda.get_rng_state()
225
226 bias = torch.rand(ffn_hidden_size_per_partition, dtype=dtype, device="cuda")
227 inp = torch.rand(
228 (seq_length * micro_batch_size, ffn_hidden_size_per_partition),
229 dtype=dtype,
230 device="cuda",
231 )
232 # Warmup JIT fusions with the input grad_enable state of both forward
233 # prop and recomputation
234 for bias_grad, input_grad in zip([True, True], [False, True]):
235 bias.requires_grad, inp.requires_grad = bias_grad, input_grad
236 for _ in range(5):
237 _ = bias_gelu_fused_(inp, bias)
238 _ = gelu_fused_(inp)
239 del bias, inp
240
241 torch.cuda.empty_cache()
242 torch.cuda.set_rng_state(rng_state)
243
244
245 def warmup_jit_bias_gelu_all_dtypes(
246 ffn_hidden_size: int, seq_length: int, micro_batch_size: int
247 ) -> None:
248 """Call `warmup_jit_bias_gelu` for all training dtypes"""
249 for dtype in [torch.float32, torch.bfloat16, torch.float16]:
250 warmup_jit_bias_gelu(ffn_hidden_size, dtype, seq_length, micro_batch_size)
251
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/transformer_engine/pytorch/jit.py b/transformer_engine/pytorch/jit.py
--- a/transformer_engine/pytorch/jit.py
+++ b/transformer_engine/pytorch/jit.py
@@ -22,7 +22,12 @@
no_torch_dynamo = lambda recursive=True: lambda func: func
if torch.__version__ >= "2":
import torch._dynamo
- no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)
+ if torch.__version__ >= "2.1":
+ no_torch_dynamo = lambda recursive=True: lambda f: \
+ torch._dynamo.disable(f, recursive=recursive)
+ else:
+ # no "recursive" option in pyTorch 2.0 - it acts as if recursive was True
+ no_torch_dynamo = lambda recursive=True: torch._dynamo.disable
def set_jit_fusion_options() -> None:
|
{"golden_diff": "diff --git a/transformer_engine/pytorch/jit.py b/transformer_engine/pytorch/jit.py\n--- a/transformer_engine/pytorch/jit.py\n+++ b/transformer_engine/pytorch/jit.py\n@@ -22,7 +22,12 @@\n no_torch_dynamo = lambda recursive=True: lambda func: func\n if torch.__version__ >= \"2\":\n import torch._dynamo\n- no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)\n+ if torch.__version__ >= \"2.1\":\n+ no_torch_dynamo = lambda recursive=True: lambda f: \\\n+ torch._dynamo.disable(f, recursive=recursive)\n+ else:\n+ # no \"recursive\" option in pyTorch 2.0 - it acts as if recursive was True\n+ no_torch_dynamo = lambda recursive=True: torch._dynamo.disable\n \n \n def set_jit_fusion_options() -> None:\n", "issue": "The version v1.2 has compatibility issues with PyTorch 2.0.1, causing errors during execution.\nHello,\r\n\r\nI encountered the following error while using version v1.2 of Transformer Engine: \r\n\r\n`no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive). The error message is TypeError: disable() got an unexpected keyword argument 'recursive'.\r\n`\r\n\r\nMy environment setup is as follows: CUDA 11.8, PyTorch 2.0.1, and Python 3.10. I am experiencing this issue specifically in the context of using MegatronLM at commit fab0bd6 for Large Language Model (LLM) training. The error occurs right at the start of the training.\r\n\r\nPossible cause of the issue:\r\nThe `disable` function in PyTorch 2.0.1 is defined as `def disable(f)`, and the recursive parameter was introduced only in later versions starting from PyTorch 2.1.0.\n", "before_files": [{"content": "# Copyright (c) 2022-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.\n#\n# See LICENSE for license information.\n\n\"\"\"NVFuser functions and JIT utilities\"\"\"\nimport os\nfrom typing import Callable, Optional, Tuple\n\nimport torch\n\njit_fuser = torch.jit.script\nif torch.__version__ >= \"2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n jit_fuser = torch.compile\n\n# See: https://github.com/NVIDIA/TransformerEngine/issues/597\ndropout_fuser = torch.jit.script\nif torch.__version__ >= \"2.2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n dropout_fuser = torch.compile\n\n# Decorator to disable Torch Dynamo\n# See: https://github.com/NVIDIA/TransformerEngine/issues/308\nno_torch_dynamo = lambda recursive=True: lambda func: func\nif torch.__version__ >= \"2\":\n import torch._dynamo\n no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)\n\n\ndef set_jit_fusion_options() -> None:\n \"\"\"Set PyTorch JIT layer fusion options.\"\"\"\n # flags required to enable jit fusion kernels\n TORCH_MAJOR = int(torch.__version__.split(\".\")[0])\n TORCH_MINOR = int(torch.__version__.split(\".\")[1])\n if (TORCH_MAJOR > 1) or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10):\n # nvfuser\n torch._C._jit_set_profiling_executor(True)\n torch._C._jit_set_profiling_mode(True)\n torch._C._jit_override_can_fuse_on_cpu(False)\n torch._C._jit_override_can_fuse_on_gpu(False)\n torch._C._jit_set_texpr_fuser_enabled(False)\n torch._C._jit_set_nvfuser_enabled(True)\n torch._C._debug_set_autodiff_subgraph_inlining(False)\n else:\n # legacy pytorch fuser\n torch._C._jit_set_profiling_mode(False)\n torch._C._jit_set_profiling_executor(False)\n torch._C._jit_override_can_fuse_on_cpu(True)\n torch._C._jit_override_can_fuse_on_gpu(True)\n\n\n@jit_fuser\ndef bias_gelu_fused_(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Bias-GeLU fused\"\"\"\n x = inp + bias\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n@jit_fuser\ndef gelu_fused_(inp: torch.Tensor) -> torch.Tensor:\n \"\"\"\n GeLU fused, this is copy of bias_gelu_fused cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n# gradient of tanh approximation of gelu\n# gradient of actual gelu is:\n# 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)\n@jit_fuser\ndef bgrad_dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"Bgrad-Dgelu fused\"\"\"\n x = inp + bias\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n bgrad = dgelu.sum(dim=0)\n return bgrad, dgelu\n\n\n@jit_fuser\ndef dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor\n) -> torch.Tensor:\n \"\"\"\n Dgelu fused, this is copy of bgrad_dgelu_fused_ cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n return dgelu\n\n\ndef bias_gelu_fused(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Disable native AMP for bias_gelu_fused_\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bias_gelu_fused_(inp, bias)\n return gelu_fused_(inp)\n\n\ndef bgrad_dgelu_fused(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[Optional[torch.Tensor], torch.Tensor]:\n \"\"\"Disable native AMP for `bgrad_dgelu_fused_`\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bgrad_dgelu_fused_(grad_output, inp, bias)\n return None, dgelu_fused_(grad_output, inp)\n\n\ndef bias_dropout_add(\n x: torch.Tensor,\n bias: torch.Tensor,\n residual: torch.Tensor,\n prob: float,\n training: bool,\n) -> torch.Tensor:\n \"\"\"dropout(inp + bias) + residual\"\"\"\n out = torch.nn.functional.dropout(x + bias, p=prob, training=training)\n out = residual + out\n return out\n\n\ndef get_bias_dropout_add(training: bool) -> Callable:\n \"\"\"bias_dropout_add based on training or not\"\"\"\n\n def _bias_dropout_add(x, bias, residual, prob):\n return bias_dropout_add(x, bias, residual, prob, training)\n\n return _bias_dropout_add\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_train_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for training\"\"\"\n return bias_dropout_add(x, bias, residual, prob, True)\n\n\ndef bias_dropout_add_fused_train(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP and enable grad for BDA\"\"\"\n with torch.enable_grad():\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_train_(x, bias, residual, prob)\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_inference_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for inference\"\"\"\n return bias_dropout_add(x, bias, residual, prob, False)\n\n\ndef bias_dropout_add_fused_inference(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP for BDA\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_inference_(x, bias, residual, prob)\n\n\ndef warmup_jit_bias_dropout_add(\n hidden_size: int, dtype: torch.dtype, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Compile BDA JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n inp = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n residual = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n bias = torch.rand((hidden_size), dtype=dtype, device=\"cuda\")\n dropout_rate = 0.1\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for input_grad, bias_grad, residual_grad in zip(\n [False, True], [True, True], [True, True]\n ):\n inp.requires_grad = input_grad\n bias.requires_grad = bias_grad\n residual.requires_grad = residual_grad\n for _ in range(5):\n output = bias_dropout_add_fused_train(inp, bias, residual, dropout_rate)\n del bias, inp, residual, output\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_dropout_add_all_dtypes(\n hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_dropout_add` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_dropout_add(hidden_size, dtype, seq_length, micro_batch_size)\n\n\ndef warmup_jit_bias_gelu(\n ffn_hidden_size_per_partition: int,\n dtype: torch.dtype,\n seq_length: int,\n micro_batch_size: int,\n) -> None:\n \"\"\"Compile bias-gelu JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n bias = torch.rand(ffn_hidden_size_per_partition, dtype=dtype, device=\"cuda\")\n inp = torch.rand(\n (seq_length * micro_batch_size, ffn_hidden_size_per_partition),\n dtype=dtype,\n device=\"cuda\",\n )\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for bias_grad, input_grad in zip([True, True], [False, True]):\n bias.requires_grad, inp.requires_grad = bias_grad, input_grad\n for _ in range(5):\n _ = bias_gelu_fused_(inp, bias)\n _ = gelu_fused_(inp)\n del bias, inp\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_gelu_all_dtypes(\n ffn_hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_gelu` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_gelu(ffn_hidden_size, dtype, seq_length, micro_batch_size)\n", "path": "transformer_engine/pytorch/jit.py"}], "after_files": [{"content": "# Copyright (c) 2022-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.\n#\n# See LICENSE for license information.\n\n\"\"\"NVFuser functions and JIT utilities\"\"\"\nimport os\nfrom typing import Callable, Optional, Tuple\n\nimport torch\n\njit_fuser = torch.jit.script\nif torch.__version__ >= \"2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n jit_fuser = torch.compile\n\n# See: https://github.com/NVIDIA/TransformerEngine/issues/597\ndropout_fuser = torch.jit.script\nif torch.__version__ >= \"2.2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n dropout_fuser = torch.compile\n\n# Decorator to disable Torch Dynamo\n# See: https://github.com/NVIDIA/TransformerEngine/issues/308\nno_torch_dynamo = lambda recursive=True: lambda func: func\nif torch.__version__ >= \"2\":\n import torch._dynamo\n if torch.__version__ >= \"2.1\":\n no_torch_dynamo = lambda recursive=True: lambda f: \\\n torch._dynamo.disable(f, recursive=recursive)\n else:\n # no \"recursive\" option in pyTorch 2.0 - it acts as if recursive was True\n no_torch_dynamo = lambda recursive=True: torch._dynamo.disable\n\n\ndef set_jit_fusion_options() -> None:\n \"\"\"Set PyTorch JIT layer fusion options.\"\"\"\n # flags required to enable jit fusion kernels\n TORCH_MAJOR = int(torch.__version__.split(\".\")[0])\n TORCH_MINOR = int(torch.__version__.split(\".\")[1])\n if (TORCH_MAJOR > 1) or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10):\n # nvfuser\n torch._C._jit_set_profiling_executor(True)\n torch._C._jit_set_profiling_mode(True)\n torch._C._jit_override_can_fuse_on_cpu(False)\n torch._C._jit_override_can_fuse_on_gpu(False)\n torch._C._jit_set_texpr_fuser_enabled(False)\n torch._C._jit_set_nvfuser_enabled(True)\n torch._C._debug_set_autodiff_subgraph_inlining(False)\n else:\n # legacy pytorch fuser\n torch._C._jit_set_profiling_mode(False)\n torch._C._jit_set_profiling_executor(False)\n torch._C._jit_override_can_fuse_on_cpu(True)\n torch._C._jit_override_can_fuse_on_gpu(True)\n\n\n@jit_fuser\ndef bias_gelu_fused_(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Bias-GeLU fused\"\"\"\n x = inp + bias\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n@jit_fuser\ndef gelu_fused_(inp: torch.Tensor) -> torch.Tensor:\n \"\"\"\n GeLU fused, this is copy of bias_gelu_fused cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n# gradient of tanh approximation of gelu\n# gradient of actual gelu is:\n# 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)\n@jit_fuser\ndef bgrad_dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"Bgrad-Dgelu fused\"\"\"\n x = inp + bias\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n bgrad = dgelu.sum(dim=0)\n return bgrad, dgelu\n\n\n@jit_fuser\ndef dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor\n) -> torch.Tensor:\n \"\"\"\n Dgelu fused, this is copy of bgrad_dgelu_fused_ cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n return dgelu\n\n\ndef bias_gelu_fused(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Disable native AMP for bias_gelu_fused_\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bias_gelu_fused_(inp, bias)\n return gelu_fused_(inp)\n\n\ndef bgrad_dgelu_fused(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[Optional[torch.Tensor], torch.Tensor]:\n \"\"\"Disable native AMP for `bgrad_dgelu_fused_`\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bgrad_dgelu_fused_(grad_output, inp, bias)\n return None, dgelu_fused_(grad_output, inp)\n\n\ndef bias_dropout_add(\n x: torch.Tensor,\n bias: torch.Tensor,\n residual: torch.Tensor,\n prob: float,\n training: bool,\n) -> torch.Tensor:\n \"\"\"dropout(inp + bias) + residual\"\"\"\n out = torch.nn.functional.dropout(x + bias, p=prob, training=training)\n out = residual + out\n return out\n\n\ndef get_bias_dropout_add(training: bool) -> Callable:\n \"\"\"bias_dropout_add based on training or not\"\"\"\n\n def _bias_dropout_add(x, bias, residual, prob):\n return bias_dropout_add(x, bias, residual, prob, training)\n\n return _bias_dropout_add\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_train_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for training\"\"\"\n return bias_dropout_add(x, bias, residual, prob, True)\n\n\ndef bias_dropout_add_fused_train(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP and enable grad for BDA\"\"\"\n with torch.enable_grad():\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_train_(x, bias, residual, prob)\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_inference_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for inference\"\"\"\n return bias_dropout_add(x, bias, residual, prob, False)\n\n\ndef bias_dropout_add_fused_inference(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP for BDA\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_inference_(x, bias, residual, prob)\n\n\ndef warmup_jit_bias_dropout_add(\n hidden_size: int, dtype: torch.dtype, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Compile BDA JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n inp = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n residual = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n bias = torch.rand((hidden_size), dtype=dtype, device=\"cuda\")\n dropout_rate = 0.1\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for input_grad, bias_grad, residual_grad in zip(\n [False, True], [True, True], [True, True]\n ):\n inp.requires_grad = input_grad\n bias.requires_grad = bias_grad\n residual.requires_grad = residual_grad\n for _ in range(5):\n output = bias_dropout_add_fused_train(inp, bias, residual, dropout_rate)\n del bias, inp, residual, output\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_dropout_add_all_dtypes(\n hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_dropout_add` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_dropout_add(hidden_size, dtype, seq_length, micro_batch_size)\n\n\ndef warmup_jit_bias_gelu(\n ffn_hidden_size_per_partition: int,\n dtype: torch.dtype,\n seq_length: int,\n micro_batch_size: int,\n) -> None:\n \"\"\"Compile bias-gelu JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n bias = torch.rand(ffn_hidden_size_per_partition, dtype=dtype, device=\"cuda\")\n inp = torch.rand(\n (seq_length * micro_batch_size, ffn_hidden_size_per_partition),\n dtype=dtype,\n device=\"cuda\",\n )\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for bias_grad, input_grad in zip([True, True], [False, True]):\n bias.requires_grad, inp.requires_grad = bias_grad, input_grad\n for _ in range(5):\n _ = bias_gelu_fused_(inp, bias)\n _ = gelu_fused_(inp)\n del bias, inp\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_gelu_all_dtypes(\n ffn_hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_gelu` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_gelu(ffn_hidden_size, dtype, seq_length, micro_batch_size)\n", "path": "transformer_engine/pytorch/jit.py"}]}
| 3,709 | 219 |
gh_patches_debug_5140
|
rasdani/github-patches
|
git_diff
|
abey79__vpype-144
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doesn't have support for outputting a2 to a0 paper sizes
I was hoping to output some large paper sizes to plot.
the error messages were the same for paper sizes a2 to a0
```
Traceback (most recent call last):
File "/usr/local/bin/vpype", line 8, in <module>
sys.exit(cli())
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 74, in main
return super().main(args=preprocess_argument_list(args), **extra)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 1290, in invoke
return _process_result(rv)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 1224, in _process_result
value = ctx.invoke(self.result_callback, value, **ctx.params)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 128, in process_pipeline
execute_processors(processors)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 212, in execute_processors
state = proc(state)
File "/usr/local/lib/python3.8/site-packages/vpype/decorators.py", line 150, in global_processor
state.document = f(state.document, *args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/write.py", line 199, in write
page_size_px = convert_page_size(page_size)
File "/usr/local/lib/python3.8/site-packages/vpype/utils.py", line 154, in convert_page_size
raise ValueError(f"page size '{value}' unknown")
ValueError: page size 'a2' unknown
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vpype/utils.py`
Content:
```
1 import logging
2 import math
3 import re
4 from typing import Callable, Dict, List, Tuple, Union
5
6 import click
7 import numpy as np
8
9 # REMINDER: anything added here must be added to docs/api.rst
10 __all__ = [
11 "UNITS",
12 "ANGLE_UNITS",
13 "PAGE_SIZES",
14 "LengthType",
15 "AngleType",
16 "PageSizeType",
17 "convert_length",
18 "convert_angle",
19 "convert_page_size",
20 "union",
21 # deprecated:
22 "PAGE_FORMATS",
23 "convert",
24 "convert_page_format",
25 "Length",
26 ]
27
28
29 def _mm_to_px(x: float, y: float) -> Tuple[float, float]:
30 return x * 96.0 / 25.4, y * 96.0 / 25.4
31
32
33 UNITS = {
34 "px": 1.0,
35 "in": 96.0,
36 "mm": 96.0 / 25.4,
37 "cm": 96.0 / 2.54,
38 "pc": 16.0,
39 "pt": 96.0 / 72.0,
40 }
41
42 ANGLE_UNITS = {
43 "deg": 1.0,
44 "grad": 9.0 / 10.0, # note: must be before "rad"!
45 "rad": 180.0 / math.pi,
46 "turn": 360.0,
47 }
48
49 # page sizes in pixel
50 PAGE_SIZES = {
51 "tight": _mm_to_px(0, 0),
52 "a6": _mm_to_px(105.0, 148.0),
53 "a5": _mm_to_px(148.0, 210.0),
54 "a4": _mm_to_px(210.0, 297.0),
55 "a3": _mm_to_px(297.0, 420.0),
56 "letter": _mm_to_px(215.9, 279.4),
57 "legal": _mm_to_px(215.9, 355.6),
58 "executive": _mm_to_px(185.15, 266.7),
59 "tabloid": _mm_to_px(279.4, 431.8),
60 }
61
62 # deprecated
63 PAGE_FORMATS = PAGE_SIZES
64
65
66 def _convert_unit(value: Union[str, float], units: Dict[str, float]) -> float:
67 """Converts a string with unit to a value"""
68 if isinstance(value, str):
69 value = value.strip().lower()
70 for unit, factor in units.items():
71 if value.endswith(unit):
72 num = value.strip(unit)
73 return (float(num) if len(num) > 0 else 1.0) * factor
74
75 return float(value)
76
77
78 def convert_length(value: Union[str, float]) -> float:
79 """Convert a length optionally expressed as a string with unit to px value.
80
81 Args:
82 value: value to convert
83
84 Returns:
85 converted value
86
87 Raises:
88 :class:`ValueError`
89 """
90 return _convert_unit(value, UNITS)
91
92
93 def convert(value: Union[str, float]) -> float: # pragma: no cover
94 """Deprecated, use convert_length."""
95 logging.warning(
96 "!!! `vpype.convert()` is deprecated, use `vpype.convert_length()` instead."
97 )
98 return convert_length(value)
99
100
101 def convert_angle(value: Union[str, float]) -> float:
102 """Convert an angle optionally expressed as a string with unit to degrees.
103
104 Args:
105 value: angle to convert
106
107 Returns:
108 converted angle in degree
109
110 Raises:
111 :class:`ValueError`
112 """
113 return _convert_unit(value, ANGLE_UNITS)
114
115
116 def convert_page_size(value: str) -> Tuple[float, float]:
117 """Converts a string with page size to dimension in pixels.
118
119 The input can be either a known page size (see ``vpype write --help`` for a list) or
120 a page size descriptor in the form of "WxH" where both W and H can have units.
121
122 Examples:
123
124 Using a know page size::
125
126 >>> import vpype
127 >>> vpype.convert_page_size("a3")
128 (1122.5196850393702, 1587.4015748031497)
129
130 Using page size descriptor (no units, pixels are assumed)::
131
132 >>> vpype.convert_page_size("100x200")
133 (100.0, 200.0)
134
135 Using page size descriptor (explicit units)::
136
137 >>> vpype.convert_page_size("1inx2in")
138 (96.0, 192.0)
139
140 Args:
141 value: page size descriptor
142
143 Returns:
144 the page size in CSS pixels
145 """
146 if value in PAGE_SIZES:
147 return PAGE_SIZES[value]
148
149 match = re.match(
150 r"^(\d+\.?\d*)({0})?x(\d+\.?\d*)({0})?$".format("|".join(UNITS.keys())), value
151 )
152
153 if not match:
154 raise ValueError(f"page size '{value}' unknown")
155
156 x, x_unit, y, y_unit = match.groups()
157
158 if not x_unit:
159 x_unit = y_unit if y_unit else "px"
160 if not y_unit:
161 y_unit = x_unit
162
163 return float(x) * convert_length(x_unit), float(y) * convert_length(y_unit)
164
165
166 def convert_page_format(value: str) -> Tuple[float, float]: # pragma: no cover
167 """Deprecated, use convert_page_size."""
168 logging.warning(
169 "!!! `vpype.convert_page_format()` is deprecated, use `vpype.convert_page_size()` "
170 "instead."
171 )
172 return convert_page_size(value)
173
174
175 class LengthType(click.ParamType):
176 """:class:`click.ParamType` sub-class to automatically converts a user-provided length
177 string (which may contain units) into a value in CSS pixel units. This class uses
178 :func:`convert_length` internally.
179
180 Example::
181
182 >>> import click
183 >>> import vpype_cli
184 >>> import vpype
185 >>> @vpype_cli.cli.command(group="my commands")
186 ... @click.argument("x", type=vpype.LengthType())
187 ... @click.option("-o", "--option", type=vpype.LengthType(), default="1mm")
188 ... @vpype.generator
189 ... def my_command(x: float, option: float):
190 ... pass
191 """
192
193 name = "length"
194
195 def convert(self, value, param, ctx):
196 try:
197 return convert_length(value)
198 except ValueError:
199 self.fail(f"parameter {value} is an incorrect length")
200
201
202 class Length(LengthType): # pragma: no cover
203 """Deprecated, use LengthType."""
204
205 def __init__(self, *args, **kwargs):
206 super().__init__(*args, **kwargs)
207 logging.warning("!!! `vpype.Length` is deprecated, use `vpype.LengthType` instead.")
208
209
210 class AngleType(click.ParamType):
211 """:class:`click.ParamType` sub-class to automatically converts a user-provided angle
212 string (which may contain units) into a value in degrees. This class uses
213 :func:`convert_angle` internally.
214
215 Example::
216
217 >>> import click
218 >>> import vpype_cli
219 >>> import vpype
220 >>> @vpype_cli.cli.command(group="my commands")
221 ... @click.argument("angle", type=vpype.AngleType())
222 ... @vpype.generator
223 ... def my_command(angle: float):
224 ... pass
225 """
226
227 name = "angle"
228
229 def convert(self, value, param, ctx):
230 try:
231 return convert_angle(value)
232 except ValueError:
233 self.fail(f"parameter {value} is an incorrect angle")
234
235
236 class PageSizeType(click.ParamType):
237 """:class:`click.ParamType` sub-class to automatically converts a user-provided page size
238 string into a tuple of float in CSS pixel units. See :func:`convert_page_size` for
239 information on the page size descriptor syntax.
240
241 Example::
242
243 >>> import click
244 >>> import vpype_cli
245 >>> import vpype
246 >>> @vpype_cli.cli.command(group="my commands")
247 ... @click.argument("fmt", type=vpype.PageSizeType())
248 ... @vpype.generator
249 ... def my_command(fmt: Tuple[float, float]):
250 ... pass
251 """
252
253 name = "PAGESIZE"
254
255 def convert(self, value, param, ctx) -> Tuple[float, float]:
256 try:
257 return convert_page_size(value)
258 except ValueError:
259 self.fail(f"parameter {value} is not a valid page size")
260
261
262 def union(line: np.ndarray, keys: List[Callable[[np.ndarray], bool]]) -> bool:
263 """Returns True if every callables in ``keys`` return True (similar to ``all()``. This
264 function is typically used with :meth:`LineCollection.filter`.
265
266 Args:
267 line: line to test
268 keys: list of callables
269
270 Returns:
271 True if every callables return True
272 """
273 for key in keys:
274 if not key(line):
275 return False
276 return True
277
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vpype/utils.py b/vpype/utils.py
--- a/vpype/utils.py
+++ b/vpype/utils.py
@@ -53,6 +53,9 @@
"a5": _mm_to_px(148.0, 210.0),
"a4": _mm_to_px(210.0, 297.0),
"a3": _mm_to_px(297.0, 420.0),
+ "a2": _mm_to_px(420.0, 594.0),
+ "a1": _mm_to_px(594.0, 841.0),
+ "a0": _mm_to_px(841.0, 1189.0),
"letter": _mm_to_px(215.9, 279.4),
"legal": _mm_to_px(215.9, 355.6),
"executive": _mm_to_px(185.15, 266.7),
|
{"golden_diff": "diff --git a/vpype/utils.py b/vpype/utils.py\n--- a/vpype/utils.py\n+++ b/vpype/utils.py\n@@ -53,6 +53,9 @@\n \"a5\": _mm_to_px(148.0, 210.0),\n \"a4\": _mm_to_px(210.0, 297.0),\n \"a3\": _mm_to_px(297.0, 420.0),\n+ \"a2\": _mm_to_px(420.0, 594.0),\n+ \"a1\": _mm_to_px(594.0, 841.0),\n+ \"a0\": _mm_to_px(841.0, 1189.0),\n \"letter\": _mm_to_px(215.9, 279.4),\n \"legal\": _mm_to_px(215.9, 355.6),\n \"executive\": _mm_to_px(185.15, 266.7),\n", "issue": "Doesn't have support for outputting a2 to a0 paper sizes\nI was hoping to output some large paper sizes to plot.\r\n\r\nthe error messages were the same for paper sizes a2 to a0\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/vpype\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 74, in main\r\n return super().main(args=preprocess_argument_list(args), **extra)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 1290, in invoke\r\n return _process_result(rv)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 1224, in _process_result\r\n value = ctx.invoke(self.result_callback, value, **ctx.params)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 128, in process_pipeline\r\n execute_processors(processors)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 212, in execute_processors\r\n state = proc(state)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype/decorators.py\", line 150, in global_processor\r\n state.document = f(state.document, *args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/write.py\", line 199, in write\r\n page_size_px = convert_page_size(page_size)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype/utils.py\", line 154, in convert_page_size\r\n raise ValueError(f\"page size '{value}' unknown\")\r\nValueError: page size 'a2' unknown\r\n```\n", "before_files": [{"content": "import logging\nimport math\nimport re\nfrom typing import Callable, Dict, List, Tuple, Union\n\nimport click\nimport numpy as np\n\n# REMINDER: anything added here must be added to docs/api.rst\n__all__ = [\n \"UNITS\",\n \"ANGLE_UNITS\",\n \"PAGE_SIZES\",\n \"LengthType\",\n \"AngleType\",\n \"PageSizeType\",\n \"convert_length\",\n \"convert_angle\",\n \"convert_page_size\",\n \"union\",\n # deprecated:\n \"PAGE_FORMATS\",\n \"convert\",\n \"convert_page_format\",\n \"Length\",\n]\n\n\ndef _mm_to_px(x: float, y: float) -> Tuple[float, float]:\n return x * 96.0 / 25.4, y * 96.0 / 25.4\n\n\nUNITS = {\n \"px\": 1.0,\n \"in\": 96.0,\n \"mm\": 96.0 / 25.4,\n \"cm\": 96.0 / 2.54,\n \"pc\": 16.0,\n \"pt\": 96.0 / 72.0,\n}\n\nANGLE_UNITS = {\n \"deg\": 1.0,\n \"grad\": 9.0 / 10.0, # note: must be before \"rad\"!\n \"rad\": 180.0 / math.pi,\n \"turn\": 360.0,\n}\n\n# page sizes in pixel\nPAGE_SIZES = {\n \"tight\": _mm_to_px(0, 0),\n \"a6\": _mm_to_px(105.0, 148.0),\n \"a5\": _mm_to_px(148.0, 210.0),\n \"a4\": _mm_to_px(210.0, 297.0),\n \"a3\": _mm_to_px(297.0, 420.0),\n \"letter\": _mm_to_px(215.9, 279.4),\n \"legal\": _mm_to_px(215.9, 355.6),\n \"executive\": _mm_to_px(185.15, 266.7),\n \"tabloid\": _mm_to_px(279.4, 431.8),\n}\n\n# deprecated\nPAGE_FORMATS = PAGE_SIZES\n\n\ndef _convert_unit(value: Union[str, float], units: Dict[str, float]) -> float:\n \"\"\"Converts a string with unit to a value\"\"\"\n if isinstance(value, str):\n value = value.strip().lower()\n for unit, factor in units.items():\n if value.endswith(unit):\n num = value.strip(unit)\n return (float(num) if len(num) > 0 else 1.0) * factor\n\n return float(value)\n\n\ndef convert_length(value: Union[str, float]) -> float:\n \"\"\"Convert a length optionally expressed as a string with unit to px value.\n\n Args:\n value: value to convert\n\n Returns:\n converted value\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, UNITS)\n\n\ndef convert(value: Union[str, float]) -> float: # pragma: no cover\n \"\"\"Deprecated, use convert_length.\"\"\"\n logging.warning(\n \"!!! `vpype.convert()` is deprecated, use `vpype.convert_length()` instead.\"\n )\n return convert_length(value)\n\n\ndef convert_angle(value: Union[str, float]) -> float:\n \"\"\"Convert an angle optionally expressed as a string with unit to degrees.\n\n Args:\n value: angle to convert\n\n Returns:\n converted angle in degree\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, ANGLE_UNITS)\n\n\ndef convert_page_size(value: str) -> Tuple[float, float]:\n \"\"\"Converts a string with page size to dimension in pixels.\n\n The input can be either a known page size (see ``vpype write --help`` for a list) or\n a page size descriptor in the form of \"WxH\" where both W and H can have units.\n\n Examples:\n\n Using a know page size::\n\n >>> import vpype\n >>> vpype.convert_page_size(\"a3\")\n (1122.5196850393702, 1587.4015748031497)\n\n Using page size descriptor (no units, pixels are assumed)::\n\n >>> vpype.convert_page_size(\"100x200\")\n (100.0, 200.0)\n\n Using page size descriptor (explicit units)::\n\n >>> vpype.convert_page_size(\"1inx2in\")\n (96.0, 192.0)\n\n Args:\n value: page size descriptor\n\n Returns:\n the page size in CSS pixels\n \"\"\"\n if value in PAGE_SIZES:\n return PAGE_SIZES[value]\n\n match = re.match(\n r\"^(\\d+\\.?\\d*)({0})?x(\\d+\\.?\\d*)({0})?$\".format(\"|\".join(UNITS.keys())), value\n )\n\n if not match:\n raise ValueError(f\"page size '{value}' unknown\")\n\n x, x_unit, y, y_unit = match.groups()\n\n if not x_unit:\n x_unit = y_unit if y_unit else \"px\"\n if not y_unit:\n y_unit = x_unit\n\n return float(x) * convert_length(x_unit), float(y) * convert_length(y_unit)\n\n\ndef convert_page_format(value: str) -> Tuple[float, float]: # pragma: no cover\n \"\"\"Deprecated, use convert_page_size.\"\"\"\n logging.warning(\n \"!!! `vpype.convert_page_format()` is deprecated, use `vpype.convert_page_size()` \"\n \"instead.\"\n )\n return convert_page_size(value)\n\n\nclass LengthType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided length\n string (which may contain units) into a value in CSS pixel units. This class uses\n :func:`convert_length` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"x\", type=vpype.LengthType())\n ... @click.option(\"-o\", \"--option\", type=vpype.LengthType(), default=\"1mm\")\n ... @vpype.generator\n ... def my_command(x: float, option: float):\n ... pass\n \"\"\"\n\n name = \"length\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_length(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect length\")\n\n\nclass Length(LengthType): # pragma: no cover\n \"\"\"Deprecated, use LengthType.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n logging.warning(\"!!! `vpype.Length` is deprecated, use `vpype.LengthType` instead.\")\n\n\nclass AngleType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided angle\n string (which may contain units) into a value in degrees. This class uses\n :func:`convert_angle` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"angle\", type=vpype.AngleType())\n ... @vpype.generator\n ... def my_command(angle: float):\n ... pass\n \"\"\"\n\n name = \"angle\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_angle(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect angle\")\n\n\nclass PageSizeType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided page size\n string into a tuple of float in CSS pixel units. See :func:`convert_page_size` for\n information on the page size descriptor syntax.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"fmt\", type=vpype.PageSizeType())\n ... @vpype.generator\n ... def my_command(fmt: Tuple[float, float]):\n ... pass\n \"\"\"\n\n name = \"PAGESIZE\"\n\n def convert(self, value, param, ctx) -> Tuple[float, float]:\n try:\n return convert_page_size(value)\n except ValueError:\n self.fail(f\"parameter {value} is not a valid page size\")\n\n\ndef union(line: np.ndarray, keys: List[Callable[[np.ndarray], bool]]) -> bool:\n \"\"\"Returns True if every callables in ``keys`` return True (similar to ``all()``. This\n function is typically used with :meth:`LineCollection.filter`.\n\n Args:\n line: line to test\n keys: list of callables\n\n Returns:\n True if every callables return True\n \"\"\"\n for key in keys:\n if not key(line):\n return False\n return True\n", "path": "vpype/utils.py"}], "after_files": [{"content": "import logging\nimport math\nimport re\nfrom typing import Callable, Dict, List, Tuple, Union\n\nimport click\nimport numpy as np\n\n# REMINDER: anything added here must be added to docs/api.rst\n__all__ = [\n \"UNITS\",\n \"ANGLE_UNITS\",\n \"PAGE_SIZES\",\n \"LengthType\",\n \"AngleType\",\n \"PageSizeType\",\n \"convert_length\",\n \"convert_angle\",\n \"convert_page_size\",\n \"union\",\n # deprecated:\n \"PAGE_FORMATS\",\n \"convert\",\n \"convert_page_format\",\n \"Length\",\n]\n\n\ndef _mm_to_px(x: float, y: float) -> Tuple[float, float]:\n return x * 96.0 / 25.4, y * 96.0 / 25.4\n\n\nUNITS = {\n \"px\": 1.0,\n \"in\": 96.0,\n \"mm\": 96.0 / 25.4,\n \"cm\": 96.0 / 2.54,\n \"pc\": 16.0,\n \"pt\": 96.0 / 72.0,\n}\n\nANGLE_UNITS = {\n \"deg\": 1.0,\n \"grad\": 9.0 / 10.0, # note: must be before \"rad\"!\n \"rad\": 180.0 / math.pi,\n \"turn\": 360.0,\n}\n\n# page sizes in pixel\nPAGE_SIZES = {\n \"tight\": _mm_to_px(0, 0),\n \"a6\": _mm_to_px(105.0, 148.0),\n \"a5\": _mm_to_px(148.0, 210.0),\n \"a4\": _mm_to_px(210.0, 297.0),\n \"a3\": _mm_to_px(297.0, 420.0),\n \"a2\": _mm_to_px(420.0, 594.0),\n \"a1\": _mm_to_px(594.0, 841.0),\n \"a0\": _mm_to_px(841.0, 1189.0),\n \"letter\": _mm_to_px(215.9, 279.4),\n \"legal\": _mm_to_px(215.9, 355.6),\n \"executive\": _mm_to_px(185.15, 266.7),\n \"tabloid\": _mm_to_px(279.4, 431.8),\n}\n\n# deprecated\nPAGE_FORMATS = PAGE_SIZES\n\n\ndef _convert_unit(value: Union[str, float], units: Dict[str, float]) -> float:\n \"\"\"Converts a string with unit to a value\"\"\"\n if isinstance(value, str):\n value = value.strip().lower()\n for unit, factor in units.items():\n if value.endswith(unit):\n num = value.strip(unit)\n return (float(num) if len(num) > 0 else 1.0) * factor\n\n return float(value)\n\n\ndef convert_length(value: Union[str, float]) -> float:\n \"\"\"Convert a length optionally expressed as a string with unit to px value.\n\n Args:\n value: value to convert\n\n Returns:\n converted value\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, UNITS)\n\n\ndef convert(value: Union[str, float]) -> float: # pragma: no cover\n \"\"\"Deprecated, use convert_length.\"\"\"\n logging.warning(\n \"!!! `vpype.convert()` is deprecated, use `vpype.convert_length()` instead.\"\n )\n return convert_length(value)\n\n\ndef convert_angle(value: Union[str, float]) -> float:\n \"\"\"Convert an angle optionally expressed as a string with unit to degrees.\n\n Args:\n value: angle to convert\n\n Returns:\n converted angle in degree\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, ANGLE_UNITS)\n\n\ndef convert_page_size(value: str) -> Tuple[float, float]:\n \"\"\"Converts a string with page size to dimension in pixels.\n\n The input can be either a known page size (see ``vpype write --help`` for a list) or\n a page size descriptor in the form of \"WxH\" where both W and H can have units.\n\n Examples:\n\n Using a know page size::\n\n >>> import vpype\n >>> vpype.convert_page_size(\"a3\")\n (1122.5196850393702, 1587.4015748031497)\n\n Using page size descriptor (no units, pixels are assumed)::\n\n >>> vpype.convert_page_size(\"100x200\")\n (100.0, 200.0)\n\n Using page size descriptor (explicit units)::\n\n >>> vpype.convert_page_size(\"1inx2in\")\n (96.0, 192.0)\n\n Args:\n value: page size descriptor\n\n Returns:\n the page size in CSS pixels\n \"\"\"\n if value in PAGE_SIZES:\n return PAGE_SIZES[value]\n\n match = re.match(\n r\"^(\\d+\\.?\\d*)({0})?x(\\d+\\.?\\d*)({0})?$\".format(\"|\".join(UNITS.keys())), value\n )\n\n if not match:\n raise ValueError(f\"page size '{value}' unknown\")\n\n x, x_unit, y, y_unit = match.groups()\n\n if not x_unit:\n x_unit = y_unit if y_unit else \"px\"\n if not y_unit:\n y_unit = x_unit\n\n return float(x) * convert_length(x_unit), float(y) * convert_length(y_unit)\n\n\ndef convert_page_format(value: str) -> Tuple[float, float]: # pragma: no cover\n \"\"\"Deprecated, use convert_page_size.\"\"\"\n logging.warning(\n \"!!! `vpype.convert_page_format()` is deprecated, use `vpype.convert_page_size()` \"\n \"instead.\"\n )\n return convert_page_size(value)\n\n\nclass LengthType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided length\n string (which may contain units) into a value in CSS pixel units. This class uses\n :func:`convert_length` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"x\", type=vpype.LengthType())\n ... @click.option(\"-o\", \"--option\", type=vpype.LengthType(), default=\"1mm\")\n ... @vpype.generator\n ... def my_command(x: float, option: float):\n ... pass\n \"\"\"\n\n name = \"length\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_length(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect length\")\n\n\nclass Length(LengthType): # pragma: no cover\n \"\"\"Deprecated, use LengthType.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n logging.warning(\"!!! `vpype.Length` is deprecated, use `vpype.LengthType` instead.\")\n\n\nclass AngleType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided angle\n string (which may contain units) into a value in degrees. This class uses\n :func:`convert_angle` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"angle\", type=vpype.AngleType())\n ... @vpype.generator\n ... def my_command(angle: float):\n ... pass\n \"\"\"\n\n name = \"angle\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_angle(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect angle\")\n\n\nclass PageSizeType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided page size\n string into a tuple of float in CSS pixel units. See :func:`convert_page_size` for\n information on the page size descriptor syntax.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"fmt\", type=vpype.PageSizeType())\n ... @vpype.generator\n ... def my_command(fmt: Tuple[float, float]):\n ... pass\n \"\"\"\n\n name = \"PAGESIZE\"\n\n def convert(self, value, param, ctx) -> Tuple[float, float]:\n try:\n return convert_page_size(value)\n except ValueError:\n self.fail(f\"parameter {value} is not a valid page size\")\n\n\ndef union(line: np.ndarray, keys: List[Callable[[np.ndarray], bool]]) -> bool:\n \"\"\"Returns True if every callables in ``keys`` return True (similar to ``all()``. This\n function is typically used with :meth:`LineCollection.filter`.\n\n Args:\n line: line to test\n keys: list of callables\n\n Returns:\n True if every callables return True\n \"\"\"\n for key in keys:\n if not key(line):\n return False\n return True\n", "path": "vpype/utils.py"}]}
| 3,592 | 254 |
gh_patches_debug_42818
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1807
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rename CompositeHTTPPropagator
[`CompositeHTTPPropagator`](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23) has nothing to do with HTTP so this name is confusing. It should be renamed to probably just `CompositePropagator`, but we need to keep an alias of the old name for backward compatibility.
[Relevant section of spec](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/examples/datadog_exporter/server.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from flask import Flask, request
16
17 from opentelemetry import trace
18 from opentelemetry.exporter.datadog import (
19 DatadogExportSpanProcessor,
20 DatadogSpanExporter,
21 )
22 from opentelemetry.exporter.datadog.propagator import DatadogFormat
23 from opentelemetry.propagate import get_global_textmap, set_global_textmap
24 from opentelemetry.propagators.composite import CompositeHTTPPropagator
25 from opentelemetry.sdk.trace import TracerProvider
26
27 app = Flask(__name__)
28
29 trace.set_tracer_provider(TracerProvider())
30
31 trace.get_tracer_provider().add_span_processor(
32 DatadogExportSpanProcessor(
33 DatadogSpanExporter(
34 agent_url="http://localhost:8126", service="example-server"
35 )
36 )
37 )
38
39 # append Datadog format for propagation to and from Datadog instrumented services
40 global_textmap = get_global_textmap()
41 if isinstance(global_textmap, CompositeHTTPPropagator) and not any(
42 isinstance(p, DatadogFormat) for p in global_textmap._propagators
43 ):
44 set_global_textmap(
45 CompositeHTTPPropagator(
46 global_textmap._propagators + [DatadogFormat()]
47 )
48 )
49 else:
50 set_global_textmap(DatadogFormat())
51
52 tracer = trace.get_tracer(__name__)
53
54
55 @app.route("/server_request")
56 def server_request():
57 param = request.args.get("param")
58 with tracer.start_as_current_span("server-inner"):
59 if param == "error":
60 raise ValueError("forced server error")
61 return "served: {}".format(param)
62
63
64 if __name__ == "__main__":
65 app.run(port=8082)
66
```
Path: `opentelemetry-api/src/opentelemetry/propagate/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 API for propagation of context.
17
18 The propagators for the
19 ``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined
20 via configuration in the ``OTEL_PROPAGATORS`` environment variable. This
21 variable should be set to a comma-separated string of names of values for the
22 ``opentelemetry_propagator`` entry point. For example, setting
23 ``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)
24 would instantiate
25 ``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2
26 propagators, one of type
27 ``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``
28 and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.
29 Notice that these propagator classes are defined as
30 ``opentelemetry_propagator`` entry points in the ``setup.cfg`` file of
31 ``opentelemetry``.
32
33 Example::
34
35 import flask
36 import requests
37 from opentelemetry import propagators
38
39
40 PROPAGATOR = propagators.get_global_textmap()
41
42
43 def get_header_from_flask_request(request, key):
44 return request.headers.get_all(key)
45
46 def set_header_into_requests_request(request: requests.Request,
47 key: str, value: str):
48 request.headers[key] = value
49
50 def example_route():
51 context = PROPAGATOR.extract(
52 get_header_from_flask_request,
53 flask.request
54 )
55 request_to_downstream = requests.Request(
56 "GET", "http://httpbin.org/get"
57 )
58 PROPAGATOR.inject(
59 set_header_into_requests_request,
60 request_to_downstream,
61 context=context
62 )
63 session = requests.Session()
64 session.send(request_to_downstream.prepare())
65
66
67 .. _Propagation API Specification:
68 https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md
69 """
70
71 import typing
72 from logging import getLogger
73 from os import environ
74
75 from pkg_resources import iter_entry_points
76
77 from opentelemetry.context.context import Context
78 from opentelemetry.environment_variables import OTEL_PROPAGATORS
79 from opentelemetry.propagators import composite, textmap
80
81 logger = getLogger(__name__)
82
83
84 def extract(
85 carrier: textmap.CarrierT,
86 context: typing.Optional[Context] = None,
87 getter: textmap.Getter = textmap.default_getter,
88 ) -> Context:
89 """Uses the configured propagator to extract a Context from the carrier.
90
91 Args:
92 getter: an object which contains a get function that can retrieve zero
93 or more values from the carrier and a keys function that can get all the keys
94 from carrier.
95 carrier: and object which contains values that are
96 used to construct a Context. This object
97 must be paired with an appropriate getter
98 which understands how to extract a value from it.
99 context: an optional Context to use. Defaults to current
100 context if not set.
101 """
102 return get_global_textmap().extract(carrier, context, getter=getter)
103
104
105 def inject(
106 carrier: textmap.CarrierT,
107 context: typing.Optional[Context] = None,
108 setter: textmap.Setter = textmap.default_setter,
109 ) -> None:
110 """Uses the configured propagator to inject a Context into the carrier.
111
112 Args:
113 carrier: An object that contains a representation of HTTP
114 headers. Should be paired with setter, which
115 should know how to set header values on the carrier.
116 context: An optional Context to use. Defaults to current
117 context if not set.
118 setter: An optional `Setter` object that can set values
119 on the carrier.
120 """
121 get_global_textmap().inject(carrier, context=context, setter=setter)
122
123
124 try:
125
126 propagators = []
127
128 # Single use variable here to hack black and make lint pass
129 environ_propagators = environ.get(
130 OTEL_PROPAGATORS,
131 "tracecontext,baggage",
132 )
133
134 for propagator in environ_propagators.split(","):
135 propagators.append( # type: ignore
136 next( # type: ignore
137 iter_entry_points("opentelemetry_propagator", propagator)
138 ).load()()
139 )
140
141 except Exception: # pylint: disable=broad-except
142 logger.exception("Failed to load configured propagators")
143 raise
144
145 _HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore
146
147
148 def get_global_textmap() -> textmap.TextMapPropagator:
149 return _HTTP_TEXT_FORMAT
150
151
152 def set_global_textmap(
153 http_text_format: textmap.TextMapPropagator,
154 ) -> None:
155 global _HTTP_TEXT_FORMAT # pylint:disable=global-statement
156 _HTTP_TEXT_FORMAT = http_text_format # type: ignore
157
```
Path: `opentelemetry-api/src/opentelemetry/propagators/composite.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import logging
15 import typing
16
17 from opentelemetry.context.context import Context
18 from opentelemetry.propagators import textmap
19
20 logger = logging.getLogger(__name__)
21
22
23 class CompositeHTTPPropagator(textmap.TextMapPropagator):
24 """CompositeHTTPPropagator provides a mechanism for combining multiple
25 propagators into a single one.
26
27 Args:
28 propagators: the list of propagators to use
29 """
30
31 def __init__(
32 self, propagators: typing.Sequence[textmap.TextMapPropagator]
33 ) -> None:
34 self._propagators = propagators
35
36 def extract(
37 self,
38 carrier: textmap.CarrierT,
39 context: typing.Optional[Context] = None,
40 getter: textmap.Getter = textmap.default_getter,
41 ) -> Context:
42 """Run each of the configured propagators with the given context and carrier.
43 Propagators are run in the order they are configured, if multiple
44 propagators write the same context key, the propagator later in the list
45 will override previous propagators.
46
47 See `opentelemetry.propagators.textmap.TextMapPropagator.extract`
48 """
49 for propagator in self._propagators:
50 context = propagator.extract(carrier, context, getter=getter)
51 return context # type: ignore
52
53 def inject(
54 self,
55 carrier: textmap.CarrierT,
56 context: typing.Optional[Context] = None,
57 setter: textmap.Setter = textmap.default_setter,
58 ) -> None:
59 """Run each of the configured propagators with the given context and carrier.
60 Propagators are run in the order they are configured, if multiple
61 propagators write the same carrier key, the propagator later in the list
62 will override previous propagators.
63
64 See `opentelemetry.propagators.textmap.TextMapPropagator.inject`
65 """
66 for propagator in self._propagators:
67 propagator.inject(carrier, context, setter=setter)
68
69 @property
70 def fields(self) -> typing.Set[str]:
71 """Returns a set with the fields set in `inject`.
72
73 See
74 `opentelemetry.propagators.textmap.TextMapPropagator.fields`
75 """
76 composite_fields = set()
77
78 for propagator in self._propagators:
79 for field in propagator.fields:
80 composite_fields.add(field)
81
82 return composite_fields
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/examples/datadog_exporter/server.py b/docs/examples/datadog_exporter/server.py
--- a/docs/examples/datadog_exporter/server.py
+++ b/docs/examples/datadog_exporter/server.py
@@ -21,7 +21,7 @@
)
from opentelemetry.exporter.datadog.propagator import DatadogFormat
from opentelemetry.propagate import get_global_textmap, set_global_textmap
-from opentelemetry.propagators.composite import CompositeHTTPPropagator
+from opentelemetry.propagators.composite import CompositePropagator
from opentelemetry.sdk.trace import TracerProvider
app = Flask(__name__)
@@ -38,13 +38,11 @@
# append Datadog format for propagation to and from Datadog instrumented services
global_textmap = get_global_textmap()
-if isinstance(global_textmap, CompositeHTTPPropagator) and not any(
+if isinstance(global_textmap, CompositePropagator) and not any(
isinstance(p, DatadogFormat) for p in global_textmap._propagators
):
set_global_textmap(
- CompositeHTTPPropagator(
- global_textmap._propagators + [DatadogFormat()]
- )
+ CompositePropagator(global_textmap._propagators + [DatadogFormat()])
)
else:
set_global_textmap(DatadogFormat())
diff --git a/opentelemetry-api/src/opentelemetry/propagate/__init__.py b/opentelemetry-api/src/opentelemetry/propagate/__init__.py
--- a/opentelemetry-api/src/opentelemetry/propagate/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/propagate/__init__.py
@@ -16,13 +16,13 @@
API for propagation of context.
The propagators for the
-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined
+``opentelemetry.propagators.composite.CompositePropagator`` can be defined
via configuration in the ``OTEL_PROPAGATORS`` environment variable. This
variable should be set to a comma-separated string of names of values for the
``opentelemetry_propagator`` entry point. For example, setting
``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)
would instantiate
-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2
+``opentelemetry.propagators.composite.CompositePropagator`` with 2
propagators, one of type
``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``
and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.
@@ -142,7 +142,7 @@
logger.exception("Failed to load configured propagators")
raise
-_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore
+_HTTP_TEXT_FORMAT = composite.CompositePropagator(propagators) # type: ignore
def get_global_textmap() -> textmap.TextMapPropagator:
diff --git a/opentelemetry-api/src/opentelemetry/propagators/composite.py b/opentelemetry-api/src/opentelemetry/propagators/composite.py
--- a/opentelemetry-api/src/opentelemetry/propagators/composite.py
+++ b/opentelemetry-api/src/opentelemetry/propagators/composite.py
@@ -14,14 +14,16 @@
import logging
import typing
+from deprecated import deprecated
+
from opentelemetry.context.context import Context
from opentelemetry.propagators import textmap
logger = logging.getLogger(__name__)
-class CompositeHTTPPropagator(textmap.TextMapPropagator):
- """CompositeHTTPPropagator provides a mechanism for combining multiple
+class CompositePropagator(textmap.TextMapPropagator):
+ """CompositePropagator provides a mechanism for combining multiple
propagators into a single one.
Args:
@@ -80,3 +82,10 @@
composite_fields.add(field)
return composite_fields
+
+
+@deprecated(version="1.2.0", reason="You should use CompositePropagator") # type: ignore
+class CompositeHTTPPropagator(CompositePropagator):
+ """CompositeHTTPPropagator provides a mechanism for combining multiple
+ propagators into a single one.
+ """
|
{"golden_diff": "diff --git a/docs/examples/datadog_exporter/server.py b/docs/examples/datadog_exporter/server.py\n--- a/docs/examples/datadog_exporter/server.py\n+++ b/docs/examples/datadog_exporter/server.py\n@@ -21,7 +21,7 @@\n )\n from opentelemetry.exporter.datadog.propagator import DatadogFormat\n from opentelemetry.propagate import get_global_textmap, set_global_textmap\n-from opentelemetry.propagators.composite import CompositeHTTPPropagator\n+from opentelemetry.propagators.composite import CompositePropagator\n from opentelemetry.sdk.trace import TracerProvider\n \n app = Flask(__name__)\n@@ -38,13 +38,11 @@\n \n # append Datadog format for propagation to and from Datadog instrumented services\n global_textmap = get_global_textmap()\n-if isinstance(global_textmap, CompositeHTTPPropagator) and not any(\n+if isinstance(global_textmap, CompositePropagator) and not any(\n isinstance(p, DatadogFormat) for p in global_textmap._propagators\n ):\n set_global_textmap(\n- CompositeHTTPPropagator(\n- global_textmap._propagators + [DatadogFormat()]\n- )\n+ CompositePropagator(global_textmap._propagators + [DatadogFormat()])\n )\n else:\n set_global_textmap(DatadogFormat())\ndiff --git a/opentelemetry-api/src/opentelemetry/propagate/__init__.py b/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n@@ -16,13 +16,13 @@\n API for propagation of context.\n \n The propagators for the\n-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined\n+``opentelemetry.propagators.composite.CompositePropagator`` can be defined\n via configuration in the ``OTEL_PROPAGATORS`` environment variable. This\n variable should be set to a comma-separated string of names of values for the\n ``opentelemetry_propagator`` entry point. For example, setting\n ``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)\n would instantiate\n-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2\n+``opentelemetry.propagators.composite.CompositePropagator`` with 2\n propagators, one of type\n ``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``\n and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.\n@@ -142,7 +142,7 @@\n logger.exception(\"Failed to load configured propagators\")\n raise\n \n-_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore\n+_HTTP_TEXT_FORMAT = composite.CompositePropagator(propagators) # type: ignore\n \n \n def get_global_textmap() -> textmap.TextMapPropagator:\ndiff --git a/opentelemetry-api/src/opentelemetry/propagators/composite.py b/opentelemetry-api/src/opentelemetry/propagators/composite.py\n--- a/opentelemetry-api/src/opentelemetry/propagators/composite.py\n+++ b/opentelemetry-api/src/opentelemetry/propagators/composite.py\n@@ -14,14 +14,16 @@\n import logging\n import typing\n \n+from deprecated import deprecated\n+\n from opentelemetry.context.context import Context\n from opentelemetry.propagators import textmap\n \n logger = logging.getLogger(__name__)\n \n \n-class CompositeHTTPPropagator(textmap.TextMapPropagator):\n- \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n+class CompositePropagator(textmap.TextMapPropagator):\n+ \"\"\"CompositePropagator provides a mechanism for combining multiple\n propagators into a single one.\n \n Args:\n@@ -80,3 +82,10 @@\n composite_fields.add(field)\n \n return composite_fields\n+\n+\n+@deprecated(version=\"1.2.0\", reason=\"You should use CompositePropagator\") # type: ignore\n+class CompositeHTTPPropagator(CompositePropagator):\n+ \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n+ propagators into a single one.\n+ \"\"\"\n", "issue": "Rename CompositeHTTPPropagator\n[`CompositeHTTPPropagator`](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23) has nothing to do with HTTP so this name is confusing. It should be renamed to probably just `CompositePropagator`, but we need to keep an alias of the old name for backward compatibility.\r\n\r\n[Relevant section of spec](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23)\r\n\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom flask import Flask, request\n\nfrom opentelemetry import trace\nfrom opentelemetry.exporter.datadog import (\n DatadogExportSpanProcessor,\n DatadogSpanExporter,\n)\nfrom opentelemetry.exporter.datadog.propagator import DatadogFormat\nfrom opentelemetry.propagate import get_global_textmap, set_global_textmap\nfrom opentelemetry.propagators.composite import CompositeHTTPPropagator\nfrom opentelemetry.sdk.trace import TracerProvider\n\napp = Flask(__name__)\n\ntrace.set_tracer_provider(TracerProvider())\n\ntrace.get_tracer_provider().add_span_processor(\n DatadogExportSpanProcessor(\n DatadogSpanExporter(\n agent_url=\"http://localhost:8126\", service=\"example-server\"\n )\n )\n)\n\n# append Datadog format for propagation to and from Datadog instrumented services\nglobal_textmap = get_global_textmap()\nif isinstance(global_textmap, CompositeHTTPPropagator) and not any(\n isinstance(p, DatadogFormat) for p in global_textmap._propagators\n):\n set_global_textmap(\n CompositeHTTPPropagator(\n global_textmap._propagators + [DatadogFormat()]\n )\n )\nelse:\n set_global_textmap(DatadogFormat())\n\ntracer = trace.get_tracer(__name__)\n\n\[email protected](\"/server_request\")\ndef server_request():\n param = request.args.get(\"param\")\n with tracer.start_as_current_span(\"server-inner\"):\n if param == \"error\":\n raise ValueError(\"forced server error\")\n return \"served: {}\".format(param)\n\n\nif __name__ == \"__main__\":\n app.run(port=8082)\n", "path": "docs/examples/datadog_exporter/server.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nAPI for propagation of context.\n\nThe propagators for the\n``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined\nvia configuration in the ``OTEL_PROPAGATORS`` environment variable. This\nvariable should be set to a comma-separated string of names of values for the\n``opentelemetry_propagator`` entry point. For example, setting\n``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)\nwould instantiate\n``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2\npropagators, one of type\n``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``\nand other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.\nNotice that these propagator classes are defined as\n``opentelemetry_propagator`` entry points in the ``setup.cfg`` file of\n``opentelemetry``.\n\nExample::\n\n import flask\n import requests\n from opentelemetry import propagators\n\n\n PROPAGATOR = propagators.get_global_textmap()\n\n\n def get_header_from_flask_request(request, key):\n return request.headers.get_all(key)\n\n def set_header_into_requests_request(request: requests.Request,\n key: str, value: str):\n request.headers[key] = value\n\n def example_route():\n context = PROPAGATOR.extract(\n get_header_from_flask_request,\n flask.request\n )\n request_to_downstream = requests.Request(\n \"GET\", \"http://httpbin.org/get\"\n )\n PROPAGATOR.inject(\n set_header_into_requests_request,\n request_to_downstream,\n context=context\n )\n session = requests.Session()\n session.send(request_to_downstream.prepare())\n\n\n.. _Propagation API Specification:\n https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md\n\"\"\"\n\nimport typing\nfrom logging import getLogger\nfrom os import environ\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.environment_variables import OTEL_PROPAGATORS\nfrom opentelemetry.propagators import composite, textmap\n\nlogger = getLogger(__name__)\n\n\ndef extract(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n) -> Context:\n \"\"\"Uses the configured propagator to extract a Context from the carrier.\n\n Args:\n getter: an object which contains a get function that can retrieve zero\n or more values from the carrier and a keys function that can get all the keys\n from carrier.\n carrier: and object which contains values that are\n used to construct a Context. This object\n must be paired with an appropriate getter\n which understands how to extract a value from it.\n context: an optional Context to use. Defaults to current\n context if not set.\n \"\"\"\n return get_global_textmap().extract(carrier, context, getter=getter)\n\n\ndef inject(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n) -> None:\n \"\"\"Uses the configured propagator to inject a Context into the carrier.\n\n Args:\n carrier: An object that contains a representation of HTTP\n headers. Should be paired with setter, which\n should know how to set header values on the carrier.\n context: An optional Context to use. Defaults to current\n context if not set.\n setter: An optional `Setter` object that can set values\n on the carrier.\n \"\"\"\n get_global_textmap().inject(carrier, context=context, setter=setter)\n\n\ntry:\n\n propagators = []\n\n # Single use variable here to hack black and make lint pass\n environ_propagators = environ.get(\n OTEL_PROPAGATORS,\n \"tracecontext,baggage\",\n )\n\n for propagator in environ_propagators.split(\",\"):\n propagators.append( # type: ignore\n next( # type: ignore\n iter_entry_points(\"opentelemetry_propagator\", propagator)\n ).load()()\n )\n\nexcept Exception: # pylint: disable=broad-except\n logger.exception(\"Failed to load configured propagators\")\n raise\n\n_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore\n\n\ndef get_global_textmap() -> textmap.TextMapPropagator:\n return _HTTP_TEXT_FORMAT\n\n\ndef set_global_textmap(\n http_text_format: textmap.TextMapPropagator,\n) -> None:\n global _HTTP_TEXT_FORMAT # pylint:disable=global-statement\n _HTTP_TEXT_FORMAT = http_text_format # type: ignore\n", "path": "opentelemetry-api/src/opentelemetry/propagate/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport logging\nimport typing\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.propagators import textmap\n\nlogger = logging.getLogger(__name__)\n\n\nclass CompositeHTTPPropagator(textmap.TextMapPropagator):\n \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n propagators into a single one.\n\n Args:\n propagators: the list of propagators to use\n \"\"\"\n\n def __init__(\n self, propagators: typing.Sequence[textmap.TextMapPropagator]\n ) -> None:\n self._propagators = propagators\n\n def extract(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n ) -> Context:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same context key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.extract`\n \"\"\"\n for propagator in self._propagators:\n context = propagator.extract(carrier, context, getter=getter)\n return context # type: ignore\n\n def inject(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n ) -> None:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same carrier key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.inject`\n \"\"\"\n for propagator in self._propagators:\n propagator.inject(carrier, context, setter=setter)\n\n @property\n def fields(self) -> typing.Set[str]:\n \"\"\"Returns a set with the fields set in `inject`.\n\n See\n `opentelemetry.propagators.textmap.TextMapPropagator.fields`\n \"\"\"\n composite_fields = set()\n\n for propagator in self._propagators:\n for field in propagator.fields:\n composite_fields.add(field)\n\n return composite_fields\n", "path": "opentelemetry-api/src/opentelemetry/propagators/composite.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom flask import Flask, request\n\nfrom opentelemetry import trace\nfrom opentelemetry.exporter.datadog import (\n DatadogExportSpanProcessor,\n DatadogSpanExporter,\n)\nfrom opentelemetry.exporter.datadog.propagator import DatadogFormat\nfrom opentelemetry.propagate import get_global_textmap, set_global_textmap\nfrom opentelemetry.propagators.composite import CompositePropagator\nfrom opentelemetry.sdk.trace import TracerProvider\n\napp = Flask(__name__)\n\ntrace.set_tracer_provider(TracerProvider())\n\ntrace.get_tracer_provider().add_span_processor(\n DatadogExportSpanProcessor(\n DatadogSpanExporter(\n agent_url=\"http://localhost:8126\", service=\"example-server\"\n )\n )\n)\n\n# append Datadog format for propagation to and from Datadog instrumented services\nglobal_textmap = get_global_textmap()\nif isinstance(global_textmap, CompositePropagator) and not any(\n isinstance(p, DatadogFormat) for p in global_textmap._propagators\n):\n set_global_textmap(\n CompositePropagator(global_textmap._propagators + [DatadogFormat()])\n )\nelse:\n set_global_textmap(DatadogFormat())\n\ntracer = trace.get_tracer(__name__)\n\n\[email protected](\"/server_request\")\ndef server_request():\n param = request.args.get(\"param\")\n with tracer.start_as_current_span(\"server-inner\"):\n if param == \"error\":\n raise ValueError(\"forced server error\")\n return \"served: {}\".format(param)\n\n\nif __name__ == \"__main__\":\n app.run(port=8082)\n", "path": "docs/examples/datadog_exporter/server.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nAPI for propagation of context.\n\nThe propagators for the\n``opentelemetry.propagators.composite.CompositePropagator`` can be defined\nvia configuration in the ``OTEL_PROPAGATORS`` environment variable. This\nvariable should be set to a comma-separated string of names of values for the\n``opentelemetry_propagator`` entry point. For example, setting\n``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)\nwould instantiate\n``opentelemetry.propagators.composite.CompositePropagator`` with 2\npropagators, one of type\n``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``\nand other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.\nNotice that these propagator classes are defined as\n``opentelemetry_propagator`` entry points in the ``setup.cfg`` file of\n``opentelemetry``.\n\nExample::\n\n import flask\n import requests\n from opentelemetry import propagators\n\n\n PROPAGATOR = propagators.get_global_textmap()\n\n\n def get_header_from_flask_request(request, key):\n return request.headers.get_all(key)\n\n def set_header_into_requests_request(request: requests.Request,\n key: str, value: str):\n request.headers[key] = value\n\n def example_route():\n context = PROPAGATOR.extract(\n get_header_from_flask_request,\n flask.request\n )\n request_to_downstream = requests.Request(\n \"GET\", \"http://httpbin.org/get\"\n )\n PROPAGATOR.inject(\n set_header_into_requests_request,\n request_to_downstream,\n context=context\n )\n session = requests.Session()\n session.send(request_to_downstream.prepare())\n\n\n.. _Propagation API Specification:\n https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md\n\"\"\"\n\nimport typing\nfrom logging import getLogger\nfrom os import environ\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.environment_variables import OTEL_PROPAGATORS\nfrom opentelemetry.propagators import composite, textmap\n\nlogger = getLogger(__name__)\n\n\ndef extract(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n) -> Context:\n \"\"\"Uses the configured propagator to extract a Context from the carrier.\n\n Args:\n getter: an object which contains a get function that can retrieve zero\n or more values from the carrier and a keys function that can get all the keys\n from carrier.\n carrier: and object which contains values that are\n used to construct a Context. This object\n must be paired with an appropriate getter\n which understands how to extract a value from it.\n context: an optional Context to use. Defaults to current\n context if not set.\n \"\"\"\n return get_global_textmap().extract(carrier, context, getter=getter)\n\n\ndef inject(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n) -> None:\n \"\"\"Uses the configured propagator to inject a Context into the carrier.\n\n Args:\n carrier: An object that contains a representation of HTTP\n headers. Should be paired with setter, which\n should know how to set header values on the carrier.\n context: An optional Context to use. Defaults to current\n context if not set.\n setter: An optional `Setter` object that can set values\n on the carrier.\n \"\"\"\n get_global_textmap().inject(carrier, context=context, setter=setter)\n\n\ntry:\n\n propagators = []\n\n # Single use variable here to hack black and make lint pass\n environ_propagators = environ.get(\n OTEL_PROPAGATORS,\n \"tracecontext,baggage\",\n )\n\n for propagator in environ_propagators.split(\",\"):\n propagators.append( # type: ignore\n next( # type: ignore\n iter_entry_points(\"opentelemetry_propagator\", propagator)\n ).load()()\n )\n\nexcept Exception: # pylint: disable=broad-except\n logger.exception(\"Failed to load configured propagators\")\n raise\n\n_HTTP_TEXT_FORMAT = composite.CompositePropagator(propagators) # type: ignore\n\n\ndef get_global_textmap() -> textmap.TextMapPropagator:\n return _HTTP_TEXT_FORMAT\n\n\ndef set_global_textmap(\n http_text_format: textmap.TextMapPropagator,\n) -> None:\n global _HTTP_TEXT_FORMAT # pylint:disable=global-statement\n _HTTP_TEXT_FORMAT = http_text_format # type: ignore\n", "path": "opentelemetry-api/src/opentelemetry/propagate/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport logging\nimport typing\n\nfrom deprecated import deprecated\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.propagators import textmap\n\nlogger = logging.getLogger(__name__)\n\n\nclass CompositePropagator(textmap.TextMapPropagator):\n \"\"\"CompositePropagator provides a mechanism for combining multiple\n propagators into a single one.\n\n Args:\n propagators: the list of propagators to use\n \"\"\"\n\n def __init__(\n self, propagators: typing.Sequence[textmap.TextMapPropagator]\n ) -> None:\n self._propagators = propagators\n\n def extract(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n ) -> Context:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same context key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.extract`\n \"\"\"\n for propagator in self._propagators:\n context = propagator.extract(carrier, context, getter=getter)\n return context # type: ignore\n\n def inject(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n ) -> None:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same carrier key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.inject`\n \"\"\"\n for propagator in self._propagators:\n propagator.inject(carrier, context, setter=setter)\n\n @property\n def fields(self) -> typing.Set[str]:\n \"\"\"Returns a set with the fields set in `inject`.\n\n See\n `opentelemetry.propagators.textmap.TextMapPropagator.fields`\n \"\"\"\n composite_fields = set()\n\n for propagator in self._propagators:\n for field in propagator.fields:\n composite_fields.add(field)\n\n return composite_fields\n\n\n@deprecated(version=\"1.2.0\", reason=\"You should use CompositePropagator\") # type: ignore\nclass CompositeHTTPPropagator(CompositePropagator):\n \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n propagators into a single one.\n \"\"\"\n", "path": "opentelemetry-api/src/opentelemetry/propagators/composite.py"}]}
| 3,486 | 986 |
gh_patches_debug_12018
|
rasdani/github-patches
|
git_diff
|
gwastro__pycbc-2107
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyCBC can't import its own version
It seems that a broken relative import means pycbc can't actually import its own version, from `ldas-pcdev1.ligo.caltech.edu`:
```bash
$ . /cvmfs/oasis.opensciencegrid.org/ligo/sw/pycbc/x86_64_rhel_7/virtualenv/pycbc-v1.9.2/bin/activate
(pycbc-v1.9.2) $ python -c "import pycbc; print(pycbc.pycbc_version)"
none
```
The fix is pretty trivial, I will post a PR shortly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pycbc/__init__.py`
Content:
```
1 # Copyright (C) 2012 Alex Nitz, Josh Willis
2 #
3 # This program is free software; you can redistribute it and/or modify it
4 # under the terms of the GNU General Public License as published by the
5 # Free Software Foundation; either version 3 of the License, or (at your
6 # option) any later version.
7 #
8 # This program is distributed in the hope that it will be useful, but
9 # WITHOUT ANY WARRANTY; without even the implied warranty of
10 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General
11 # Public License for more details.
12 #
13 # You should have received a copy of the GNU General Public License along
14 # with this program; if not, write to the Free Software Foundation, Inc.,
15 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
16
17
18 #
19 # =============================================================================
20 #
21 # Preamble
22 #
23 # =============================================================================
24 #
25 """PyCBC contains a toolkit for CBC gravitational wave analysis
26 """
27 from __future__ import (absolute_import, print_function)
28 import subprocess, os, sys, tempfile
29 import logging
30 import signal
31
32 try:
33 # This will fail when pycbc is imported during the build process,
34 # before version.py has been generated.
35 from version import git_hash
36 from version import version as pycbc_version
37 except:
38 git_hash = 'none'
39 pycbc_version = 'none'
40
41 def init_logging(verbose=False, format='%(asctime)s %(message)s'):
42 """ Common utility for setting up logging in PyCBC.
43
44 Installs a signal handler such that verbosity can be activated at
45 run-time by sending a SIGUSR1 to the process.
46 """
47 def sig_handler(signum, frame):
48 logger = logging.getLogger()
49 log_level = logger.level
50 if log_level == logging.DEBUG:
51 log_level = logging.WARN
52 else:
53 log_level = logging.DEBUG
54 logging.warn('Got signal %d, setting log level to %d',
55 signum, log_level)
56 logger.setLevel(log_level)
57
58 signal.signal(signal.SIGUSR1, sig_handler)
59
60 if verbose:
61 initial_level = logging.DEBUG
62 else:
63 initial_level = logging.WARN
64 logging.getLogger().setLevel(initial_level)
65 logging.basicConfig(format=format, level=initial_level)
66
67
68 # Check for optional components of the PyCBC Package
69 try:
70 # This is a crude check to make sure that the driver is installed
71 try:
72 loaded_modules = subprocess.Popen(['lsmod'], stdout=subprocess.PIPE).communicate()[0]
73 loaded_modules = loaded_modules.decode()
74 if 'nvidia' not in loaded_modules:
75 raise ImportError("nvidia driver may not be installed correctly")
76 except OSError:
77 pass
78
79 # Check that pycuda is installed and can talk to the driver
80 import pycuda.driver as _pycudadrv
81
82 HAVE_CUDA=True
83 except ImportError:
84 HAVE_CUDA=False
85
86 # Check for openmp suppport, currently we pressume it exists, unless on
87 # platforms (mac) that are silly and don't use the standard gcc.
88 if sys.platform == 'darwin':
89 HAVE_OMP = False
90 else:
91 HAVE_OMP = True
92
93 # PyCBC-Specific Constants
94
95 # Set the value we want any aligned memory calls to use
96 # N.B.: *Not* all pycbc memory will be aligned to multiples
97 # of this value
98
99 PYCBC_ALIGNMENT = 32
100
101 # Dynamic range factor: a large constant for rescaling
102 # GW strains. This is 2**69 rounded to 17 sig.fig.
103
104 DYN_RANGE_FAC = 5.9029581035870565e+20
105
106 if os.environ.get("INITIAL_LOG_LEVEL", None):
107 logging.basicConfig(format='%(asctime)s %(message)s',
108 level=int(os.environ["INITIAL_LOG_LEVEL"]))
109
110 # Make sure we use a user specific, machine specific compiled cache location
111 _python_name = "python%d%d_compiled" % tuple(sys.version_info[:2])
112 _tmp_dir = tempfile.gettempdir()
113 _cache_dir_name = repr(os.getuid()) + '_' + _python_name
114 _cache_dir_path = os.path.join(_tmp_dir, _cache_dir_name)
115 # Append the git hash to the cache path. This will ensure that cached
116 # files are correct even in cases where weave currently doesn't realize
117 # that a recompile is needed.
118 # FIXME: It would be better to find a way to trigger a recompile off
119 # of all the arguments to weave.
120 _cache_dir_path = os.path.join(_cache_dir_path, pycbc_version)
121 _cache_dir_path = os.path.join(_cache_dir_path, git_hash)
122 if os.environ.get("NO_TMPDIR", None):
123 if os.environ.get("INITIAL_LOG_LEVEL", 0) >= 10:
124 print("__init__: Skipped creating %s as NO_TEMPDIR is set"
125 % _cache_dir_path, file=sys.stderr)
126 else:
127 try: os.makedirs(_cache_dir_path)
128 except OSError: pass
129 if os.environ.get("INITIAL_LOG_LEVEL", 0) >= 10:
130 print("__init__: Setting weave cache to %s" % _cache_dir_path,
131 file=sys.stderr)
132 os.environ['PYTHONCOMPILED'] = _cache_dir_path
133
134 # Check for MKL capability
135 try:
136 import pycbc.fft.mkl
137 HAVE_MKL=True
138 except ImportError as e:
139 print(e)
140 HAVE_MKL=False
141
142
143 # Check for site-local flags to pass to gcc
144 WEAVE_FLAGS = '-march=native -O3 -w '
145 if 'WEAVE_FLAGS' in os.environ:
146 if '-march=' in os.environ['WEAVE_FLAGS']:
147 WEAVE_FLAGS = os.environ['WEAVE_FLAGS']
148 else:
149 WEAVE_FLAGS += os.environ['WEAVE_FLAGS']
150
151 def multiprocess_cache_dir():
152 import multiprocessing
153 cache_dir = os.path.join(_cache_dir_path, str(id(multiprocessing.current_process())))
154 os.environ['PYTHONCOMPILED'] = cache_dir
155 try: os.makedirs(cache_dir)
156 except OSError: pass
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pycbc/__init__.py b/pycbc/__init__.py
--- a/pycbc/__init__.py
+++ b/pycbc/__init__.py
@@ -32,12 +32,15 @@
try:
# This will fail when pycbc is imported during the build process,
# before version.py has been generated.
- from version import git_hash
- from version import version as pycbc_version
+ from .version import git_hash
+ from .version import version as pycbc_version
except:
git_hash = 'none'
pycbc_version = 'none'
+__version__ = pycbc_version
+
+
def init_logging(verbose=False, format='%(asctime)s %(message)s'):
""" Common utility for setting up logging in PyCBC.
|
{"golden_diff": "diff --git a/pycbc/__init__.py b/pycbc/__init__.py\n--- a/pycbc/__init__.py\n+++ b/pycbc/__init__.py\n@@ -32,12 +32,15 @@\n try:\n # This will fail when pycbc is imported during the build process,\n # before version.py has been generated.\n- from version import git_hash\n- from version import version as pycbc_version\n+ from .version import git_hash\n+ from .version import version as pycbc_version\n except:\n git_hash = 'none'\n pycbc_version = 'none'\n \n+__version__ = pycbc_version\n+\n+\n def init_logging(verbose=False, format='%(asctime)s %(message)s'):\n \"\"\" Common utility for setting up logging in PyCBC.\n", "issue": "PyCBC can't import its own version\nIt seems that a broken relative import means pycbc can't actually import its own version, from `ldas-pcdev1.ligo.caltech.edu`:\r\n\r\n```bash\r\n$ . /cvmfs/oasis.opensciencegrid.org/ligo/sw/pycbc/x86_64_rhel_7/virtualenv/pycbc-v1.9.2/bin/activate\r\n(pycbc-v1.9.2) $ python -c \"import pycbc; print(pycbc.pycbc_version)\"\r\nnone\r\n```\r\n\r\nThe fix is pretty trivial, I will post a PR shortly.\n", "before_files": [{"content": "# Copyright (C) 2012 Alex Nitz, Josh Willis\n#\n# This program is free software; you can redistribute it and/or modify it\n# under the terms of the GNU General Public License as published by the\n# Free Software Foundation; either version 3 of the License, or (at your\n# option) any later version.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n\n#\n# =============================================================================\n#\n# Preamble\n#\n# =============================================================================\n#\n\"\"\"PyCBC contains a toolkit for CBC gravitational wave analysis\n\"\"\"\nfrom __future__ import (absolute_import, print_function)\nimport subprocess, os, sys, tempfile\nimport logging\nimport signal\n\ntry:\n # This will fail when pycbc is imported during the build process,\n # before version.py has been generated.\n from version import git_hash\n from version import version as pycbc_version\nexcept:\n git_hash = 'none'\n pycbc_version = 'none'\n\ndef init_logging(verbose=False, format='%(asctime)s %(message)s'):\n \"\"\" Common utility for setting up logging in PyCBC.\n\n Installs a signal handler such that verbosity can be activated at\n run-time by sending a SIGUSR1 to the process.\n \"\"\"\n def sig_handler(signum, frame):\n logger = logging.getLogger()\n log_level = logger.level\n if log_level == logging.DEBUG:\n log_level = logging.WARN\n else:\n log_level = logging.DEBUG\n logging.warn('Got signal %d, setting log level to %d',\n signum, log_level)\n logger.setLevel(log_level)\n\n signal.signal(signal.SIGUSR1, sig_handler)\n\n if verbose:\n initial_level = logging.DEBUG\n else:\n initial_level = logging.WARN\n logging.getLogger().setLevel(initial_level)\n logging.basicConfig(format=format, level=initial_level)\n\n\n# Check for optional components of the PyCBC Package\ntry:\n # This is a crude check to make sure that the driver is installed\n try:\n loaded_modules = subprocess.Popen(['lsmod'], stdout=subprocess.PIPE).communicate()[0]\n loaded_modules = loaded_modules.decode()\n if 'nvidia' not in loaded_modules:\n raise ImportError(\"nvidia driver may not be installed correctly\")\n except OSError:\n pass\n\n # Check that pycuda is installed and can talk to the driver\n import pycuda.driver as _pycudadrv\n\n HAVE_CUDA=True \nexcept ImportError:\n HAVE_CUDA=False\n \n# Check for openmp suppport, currently we pressume it exists, unless on \n# platforms (mac) that are silly and don't use the standard gcc. \nif sys.platform == 'darwin':\n HAVE_OMP = False\nelse:\n HAVE_OMP = True\n\n# PyCBC-Specific Constants\n\n# Set the value we want any aligned memory calls to use\n# N.B.: *Not* all pycbc memory will be aligned to multiples\n# of this value\n\nPYCBC_ALIGNMENT = 32\n\n# Dynamic range factor: a large constant for rescaling\n# GW strains. This is 2**69 rounded to 17 sig.fig.\n\nDYN_RANGE_FAC = 5.9029581035870565e+20\n\nif os.environ.get(\"INITIAL_LOG_LEVEL\", None):\n logging.basicConfig(format='%(asctime)s %(message)s',\n level=int(os.environ[\"INITIAL_LOG_LEVEL\"]))\n\n# Make sure we use a user specific, machine specific compiled cache location\n_python_name = \"python%d%d_compiled\" % tuple(sys.version_info[:2])\n_tmp_dir = tempfile.gettempdir()\n_cache_dir_name = repr(os.getuid()) + '_' + _python_name\n_cache_dir_path = os.path.join(_tmp_dir, _cache_dir_name)\n# Append the git hash to the cache path. This will ensure that cached \n# files are correct even in cases where weave currently doesn't realize\n# that a recompile is needed.\n# FIXME: It would be better to find a way to trigger a recompile off\n# of all the arguments to weave.\n_cache_dir_path = os.path.join(_cache_dir_path, pycbc_version)\n_cache_dir_path = os.path.join(_cache_dir_path, git_hash)\nif os.environ.get(\"NO_TMPDIR\", None):\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Skipped creating %s as NO_TEMPDIR is set\"\n % _cache_dir_path, file=sys.stderr)\nelse:\n try: os.makedirs(_cache_dir_path)\n except OSError: pass\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Setting weave cache to %s\" % _cache_dir_path,\n file=sys.stderr)\nos.environ['PYTHONCOMPILED'] = _cache_dir_path\n\n# Check for MKL capability\ntry:\n import pycbc.fft.mkl\n HAVE_MKL=True\nexcept ImportError as e:\n print(e)\n HAVE_MKL=False\n \n\n# Check for site-local flags to pass to gcc\nWEAVE_FLAGS = '-march=native -O3 -w '\nif 'WEAVE_FLAGS' in os.environ:\n if '-march=' in os.environ['WEAVE_FLAGS']:\n WEAVE_FLAGS = os.environ['WEAVE_FLAGS']\n else:\n WEAVE_FLAGS += os.environ['WEAVE_FLAGS']\n\ndef multiprocess_cache_dir():\n import multiprocessing\n cache_dir = os.path.join(_cache_dir_path, str(id(multiprocessing.current_process())))\n os.environ['PYTHONCOMPILED'] = cache_dir\n try: os.makedirs(cache_dir)\n except OSError: pass\n", "path": "pycbc/__init__.py"}], "after_files": [{"content": "# Copyright (C) 2012 Alex Nitz, Josh Willis\n#\n# This program is free software; you can redistribute it and/or modify it\n# under the terms of the GNU General Public License as published by the\n# Free Software Foundation; either version 3 of the License, or (at your\n# option) any later version.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n\n#\n# =============================================================================\n#\n# Preamble\n#\n# =============================================================================\n#\n\"\"\"PyCBC contains a toolkit for CBC gravitational wave analysis\n\"\"\"\nfrom __future__ import (absolute_import, print_function)\nimport subprocess, os, sys, tempfile\nimport logging\nimport signal\n\ntry:\n # This will fail when pycbc is imported during the build process,\n # before version.py has been generated.\n from .version import git_hash\n from .version import version as pycbc_version\nexcept:\n git_hash = 'none'\n pycbc_version = 'none'\n\n__version__ = pycbc_version\n\n\ndef init_logging(verbose=False, format='%(asctime)s %(message)s'):\n \"\"\" Common utility for setting up logging in PyCBC.\n\n Installs a signal handler such that verbosity can be activated at\n run-time by sending a SIGUSR1 to the process.\n \"\"\"\n def sig_handler(signum, frame):\n logger = logging.getLogger()\n log_level = logger.level\n if log_level == logging.DEBUG:\n log_level = logging.WARN\n else:\n log_level = logging.DEBUG\n logging.warn('Got signal %d, setting log level to %d',\n signum, log_level)\n logger.setLevel(log_level)\n\n signal.signal(signal.SIGUSR1, sig_handler)\n\n if verbose:\n initial_level = logging.DEBUG\n else:\n initial_level = logging.WARN\n logging.getLogger().setLevel(initial_level)\n logging.basicConfig(format=format, level=initial_level)\n\n\n# Check for optional components of the PyCBC Package\ntry:\n # This is a crude check to make sure that the driver is installed\n try:\n loaded_modules = subprocess.Popen(['lsmod'], stdout=subprocess.PIPE).communicate()[0]\n loaded_modules = loaded_modules.decode()\n if 'nvidia' not in loaded_modules:\n raise ImportError(\"nvidia driver may not be installed correctly\")\n except OSError:\n pass\n\n # Check that pycuda is installed and can talk to the driver\n import pycuda.driver as _pycudadrv\n\n HAVE_CUDA=True \nexcept ImportError:\n HAVE_CUDA=False\n \n# Check for openmp suppport, currently we pressume it exists, unless on \n# platforms (mac) that are silly and don't use the standard gcc. \nif sys.platform == 'darwin':\n HAVE_OMP = False\nelse:\n HAVE_OMP = True\n\n# PyCBC-Specific Constants\n\n# Set the value we want any aligned memory calls to use\n# N.B.: *Not* all pycbc memory will be aligned to multiples\n# of this value\n\nPYCBC_ALIGNMENT = 32\n\n# Dynamic range factor: a large constant for rescaling\n# GW strains. This is 2**69 rounded to 17 sig.fig.\n\nDYN_RANGE_FAC = 5.9029581035870565e+20\n\nif os.environ.get(\"INITIAL_LOG_LEVEL\", None):\n logging.basicConfig(format='%(asctime)s %(message)s',\n level=int(os.environ[\"INITIAL_LOG_LEVEL\"]))\n\n# Make sure we use a user specific, machine specific compiled cache location\n_python_name = \"python%d%d_compiled\" % tuple(sys.version_info[:2])\n_tmp_dir = tempfile.gettempdir()\n_cache_dir_name = repr(os.getuid()) + '_' + _python_name\n_cache_dir_path = os.path.join(_tmp_dir, _cache_dir_name)\n# Append the git hash to the cache path. This will ensure that cached \n# files are correct even in cases where weave currently doesn't realize\n# that a recompile is needed.\n# FIXME: It would be better to find a way to trigger a recompile off\n# of all the arguments to weave.\n_cache_dir_path = os.path.join(_cache_dir_path, pycbc_version)\n_cache_dir_path = os.path.join(_cache_dir_path, git_hash)\nif os.environ.get(\"NO_TMPDIR\", None):\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Skipped creating %s as NO_TEMPDIR is set\"\n % _cache_dir_path, file=sys.stderr)\nelse:\n try: os.makedirs(_cache_dir_path)\n except OSError: pass\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Setting weave cache to %s\" % _cache_dir_path,\n file=sys.stderr)\nos.environ['PYTHONCOMPILED'] = _cache_dir_path\n\n# Check for MKL capability\ntry:\n import pycbc.fft.mkl\n HAVE_MKL=True\nexcept ImportError as e:\n print(e)\n HAVE_MKL=False\n \n\n# Check for site-local flags to pass to gcc\nWEAVE_FLAGS = '-march=native -O3 -w '\nif 'WEAVE_FLAGS' in os.environ:\n if '-march=' in os.environ['WEAVE_FLAGS']:\n WEAVE_FLAGS = os.environ['WEAVE_FLAGS']\n else:\n WEAVE_FLAGS += os.environ['WEAVE_FLAGS']\n\ndef multiprocess_cache_dir():\n import multiprocessing\n cache_dir = os.path.join(_cache_dir_path, str(id(multiprocessing.current_process())))\n os.environ['PYTHONCOMPILED'] = cache_dir\n try: os.makedirs(cache_dir)\n except OSError: pass\n", "path": "pycbc/__init__.py"}]}
| 2,095 | 177 |
gh_patches_debug_8207
|
rasdani/github-patches
|
git_diff
|
nautobot__nautobot-4976
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Install issue 2.0.1 -> collect static fails to create directories
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
This form is only for reporting reproducible bugs. If you need assistance
with Nautobot installation, or if you have a general question, please start a
discussion instead: https://github.com/nautobot/nautobot/discussions
Please describe the environment in which you are running Nautobot. Be sure
that you are running an unmodified instance of the latest stable release
before submitting a bug report, and that any plugins have been disabled.
-->
### Environment
* Nautobot version (Docker tag too if applicable): 2.0.1
* Python version: 3.10.12
* Database platform, version: postgres
* Middleware(s):none
<!--
Describe in detail the exact steps that someone else can take to reproduce
this bug using the current stable release of Nautobot. Begin with the
creation of any necessary database objects and call out every operation
being performed explicitly. If reporting a bug in the REST API, be sure to
reconstruct the raw HTTP request(s) being made: Don't rely on a client
library such as pynautobot.
-->
### Steps to Reproduce
1. New installation of nautobot
2. Following instructions at https://blog.networktocode.com/post/installing-nautobot/
3. Issue command nautobot-server collectstatic
<!-- What did you expect to happen? -->
### Expected Behavior
Expected directories to be created and static files to be collected
<!-- What happened instead? -->
Error occurred
nautobot@server:~$ nautobot-server collectstatic
16:21:56.992 ERROR nautobot.core.apps :
Error in link construction for Notes: Reverse for 'note_list' not found. 'note_list' is not a valid view function or pattern name.
Traceback (most recent call last):
File "/opt/nautobot/bin/nautobot-server", line 8, in <module>
sys.exit(main())
File "/opt/nautobot/lib/python3.10/site-packages/nautobot/core/cli/__init__.py", line 54, in main
run_app(
File "/opt/nautobot/lib/python3.10/site-packages/nautobot/core/runner/runner.py", line 297, in run_app
management.execute_from_command_line([runner_name, command] + command_args)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py", line 419, in execute_from_command_line
utility.execute()
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py", line 413, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py", line 354, in run_from_argv
self.execute(*args, **cmd_options)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py", line 398, in execute
output = self.handle(*args, **options)
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py", line 187, in handle
collected = self.collect()
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py", line 105, in collect
for path, storage in finder.list(self.ignore_patterns):
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/finders.py", line 130, in list
for path in utils.get_files(storage, ignore_patterns):
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/utils.py", line 23, in get_files
directories, files = storage.listdir(location)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/files/storage.py", line 330, in listdir
for entry in os.scandir(path):
FileNotFoundError: [Errno 2] No such file or directory: '/opt/nautobot/ui/build/static'
As a workaround, I manually created /opt/nautobot/ui/build/static and re-ran collectstatic
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nautobot/core/cli/__init__.py`
Content:
```
1 """
2 Utilities and primitives for the `nautobot-server` CLI command.
3 """
4
5 import os
6
7 from django.core.exceptions import ImproperlyConfigured
8 from django.core.management.utils import get_random_secret_key
9 from jinja2 import BaseLoader, Environment
10
11 from nautobot.core.runner import run_app
12 from nautobot.extras.plugins.utils import load_plugins
13
14
15 # Default file location for the generated config emitted by `init`
16 NAUTOBOT_ROOT = os.getenv("NAUTOBOT_ROOT", os.path.expanduser("~/.nautobot"))
17 DEFAULT_CONFIG_PATH = os.path.join(NAUTOBOT_ROOT, "nautobot_config.py")
18
19 # Default settings to use when building the config
20 DEFAULT_SETTINGS = "nautobot.core.settings"
21
22 # Name of the environment variable used to specify path of config
23 SETTINGS_ENVVAR = "NAUTOBOT_CONFIG"
24
25 # Base directory for this module
26 BASE_DIR = os.path.dirname(__file__)
27
28 # File path of template used to generate config emitted by `init`
29 CONFIG_TEMPLATE = os.path.join(BASE_DIR, "../templates/nautobot_config.py.j2")
30
31 DESCRIPTION = """
32 Nautobot server management utility.
33
34 Type '%(prog)s help' to display a list of included sub-commands.
35
36 Type '%(prog)s init' to generate a new configuration.
37 """
38
39
40 def main():
41 """
42 The main server CLI command that replaces `manage.py` and allows a
43 configuration file to be passed in.
44
45 How this works:
46
47 - Process CLI args
48 - Load default settings
49 - Read config file from path
50 - Overlay config settings on top of default settings
51 - Overlay special/conditional settings (see `_configure_settings`)
52 """
53 run_app(
54 project="nautobot",
55 description=DESCRIPTION,
56 default_config_path=DEFAULT_CONFIG_PATH,
57 default_settings=DEFAULT_SETTINGS,
58 settings_initializer=generate_settings,
59 settings_envvar=SETTINGS_ENVVAR,
60 initializer=_configure_settings, # Called after defaults
61 )
62
63
64 def generate_settings(config_template=CONFIG_TEMPLATE, **kwargs):
65 """
66 This command is ran when `default_config_path` doesn't exist, or `init` is
67 ran and returns a string representing the default data to put into the
68 settings file.
69 """
70 template_vars = {
71 "secret_key": get_random_secret_key(),
72 "installation_metrics_enabled": kwargs.get("installation_metrics_enabled", True),
73 }
74
75 with open(config_template) as fh:
76 environment = Environment(loader=BaseLoader, keep_trailing_newline=True)
77 config = environment.from_string(fh.read())
78
79 return config.render(**template_vars)
80
81
82 def _configure_settings(config):
83 """
84 Callback for processing conditional or special purpose settings.
85
86 Any specially prepared settings will be handled here, such as loading
87 plugins, enabling social auth, etc.
88
89 This is intended to be called by `run_app` and should not be invoked
90 directly.
91
92 :param config:
93 A dictionary of `config_path`, `project`, `settings`
94
95 Example::
96
97 {
98 'project': 'nautobot',
99 'config_path': '/path/to/nautobot_config.py',
100 'settings': <LazySettings "nautobot_config">
101 }
102 """
103
104 settings = config["settings"]
105
106 # Include the config path to the settings to align with builtin
107 # `settings.SETTINGS_MODULE`. Useful for debugging correct config path.
108 settings.SETTINGS_PATH = config["config_path"]
109
110 #
111 # Storage directories
112 #
113 os.makedirs(settings.GIT_ROOT, exist_ok=True)
114 os.makedirs(settings.JOBS_ROOT, exist_ok=True)
115 os.makedirs(settings.MEDIA_ROOT, exist_ok=True)
116 os.makedirs(os.path.join(settings.MEDIA_ROOT, "devicetype-images"), exist_ok=True)
117 os.makedirs(os.path.join(settings.MEDIA_ROOT, "image-attachments"), exist_ok=True)
118 os.makedirs(settings.STATIC_ROOT, exist_ok=True)
119
120 #
121 # Databases
122 #
123
124 # If metrics are enabled and postgres is the backend, set the driver to the
125 # one provided by django-prometheus.
126 if settings.METRICS_ENABLED and "postgres" in settings.DATABASES["default"]["ENGINE"]:
127 settings.DATABASES["default"]["ENGINE"] = "django_prometheus.db.backends.postgresql"
128
129 # Create secondary db connection for job logging. This still writes to the default db, but because it's a separate
130 # connection, it allows allows us to "escape" from transaction.atomic() and ensure that job log entries are saved
131 # to the database even when the rest of the job transaction is rolled back.
132 settings.DATABASES["job_logs"] = settings.DATABASES["default"].copy()
133 # When running unit tests, treat it as a mirror of the default test DB, not a separate test DB of its own
134 settings.DATABASES["job_logs"]["TEST"] = {"MIRROR": "default"}
135
136 #
137 # Media storage
138 #
139
140 if settings.STORAGE_BACKEND is not None:
141 settings.DEFAULT_FILE_STORAGE = settings.STORAGE_BACKEND
142
143 # django-storages
144 if settings.STORAGE_BACKEND.startswith("storages."):
145 try:
146 import storages.utils
147 except ModuleNotFoundError as e:
148 if getattr(e, "name") == "storages":
149 raise ImproperlyConfigured(
150 f"STORAGE_BACKEND is set to {settings.STORAGE_BACKEND} but django-storages is not present. It "
151 f"can be installed by running 'pip install django-storages'."
152 )
153 raise e
154
155 # Monkey-patch django-storages to fetch settings from STORAGE_CONFIG or fall back to settings
156 def _setting(name, default=None):
157 if name in settings.STORAGE_CONFIG:
158 return settings.STORAGE_CONFIG[name]
159 return getattr(settings, name, default)
160
161 storages.utils.setting = _setting
162
163 #
164 # Plugins
165 #
166
167 # Process the plugins and manipulate the specified config settings that are
168 # passed in.
169 load_plugins(settings)
170
171
172 if __name__ == "__main__":
173 main()
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nautobot/core/cli/__init__.py b/nautobot/core/cli/__init__.py
--- a/nautobot/core/cli/__init__.py
+++ b/nautobot/core/cli/__init__.py
@@ -115,6 +115,7 @@
os.makedirs(settings.MEDIA_ROOT, exist_ok=True)
os.makedirs(os.path.join(settings.MEDIA_ROOT, "devicetype-images"), exist_ok=True)
os.makedirs(os.path.join(settings.MEDIA_ROOT, "image-attachments"), exist_ok=True)
+ os.makedirs(os.path.join(settings.NAUTOBOT_UI_DIR, "build", "static"), exist_ok=True)
os.makedirs(settings.STATIC_ROOT, exist_ok=True)
#
|
{"golden_diff": "diff --git a/nautobot/core/cli/__init__.py b/nautobot/core/cli/__init__.py\n--- a/nautobot/core/cli/__init__.py\n+++ b/nautobot/core/cli/__init__.py\n@@ -115,6 +115,7 @@\n os.makedirs(settings.MEDIA_ROOT, exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"devicetype-images\"), exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"image-attachments\"), exist_ok=True)\n+ os.makedirs(os.path.join(settings.NAUTOBOT_UI_DIR, \"build\", \"static\"), exist_ok=True)\n os.makedirs(settings.STATIC_ROOT, exist_ok=True)\n \n #\n", "issue": "Install issue 2.0.1 -> collect static fails to create directories\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n This form is only for reporting reproducible bugs. If you need assistance\r\n with Nautobot installation, or if you have a general question, please start a\r\n discussion instead: https://github.com/nautobot/nautobot/discussions\r\n\r\n Please describe the environment in which you are running Nautobot. Be sure\r\n that you are running an unmodified instance of the latest stable release\r\n before submitting a bug report, and that any plugins have been disabled.\r\n-->\r\n### Environment\r\n* Nautobot version (Docker tag too if applicable): 2.0.1\r\n* Python version: 3.10.12\r\n* Database platform, version: postgres\r\n* Middleware(s):none\r\n\r\n<!--\r\n Describe in detail the exact steps that someone else can take to reproduce\r\n this bug using the current stable release of Nautobot. Begin with the\r\n creation of any necessary database objects and call out every operation\r\n being performed explicitly. If reporting a bug in the REST API, be sure to\r\n reconstruct the raw HTTP request(s) being made: Don't rely on a client\r\n library such as pynautobot.\r\n-->\r\n### Steps to Reproduce\r\n1. New installation of nautobot\r\n2. Following instructions at https://blog.networktocode.com/post/installing-nautobot/\r\n3. Issue command nautobot-server collectstatic\r\n\r\n<!-- What did you expect to happen? -->\r\n### Expected Behavior\r\nExpected directories to be created and static files to be collected\r\n\r\n<!-- What happened instead? -->\r\nError occurred\r\n\r\nnautobot@server:~$ nautobot-server collectstatic\r\n16:21:56.992 ERROR nautobot.core.apps :\r\n Error in link construction for Notes: Reverse for 'note_list' not found. 'note_list' is not a valid view function or pattern name.\r\nTraceback (most recent call last):\r\n File \"/opt/nautobot/bin/nautobot-server\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/opt/nautobot/lib/python3.10/site-packages/nautobot/core/cli/__init__.py\", line 54, in main\r\n run_app(\r\n File \"/opt/nautobot/lib/python3.10/site-packages/nautobot/core/runner/runner.py\", line 297, in run_app\r\n management.execute_from_command_line([runner_name, command] + command_args)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py\", line 419, in execute_from_command_line\r\n utility.execute()\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py\", line 413, in execute\r\n self.fetch_command(subcommand).run_from_argv(self.argv)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py\", line 354, in run_from_argv\r\n self.execute(*args, **cmd_options)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py\", line 398, in execute\r\n output = self.handle(*args, **options)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py\", line 187, in handle\r\n collected = self.collect()\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py\", line 105, in collect\r\n for path, storage in finder.list(self.ignore_patterns):\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/finders.py\", line 130, in list\r\n for path in utils.get_files(storage, ignore_patterns):\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/utils.py\", line 23, in get_files\r\n directories, files = storage.listdir(location)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/files/storage.py\", line 330, in listdir\r\n for entry in os.scandir(path):\r\nFileNotFoundError: [Errno 2] No such file or directory: '/opt/nautobot/ui/build/static'\r\n\r\n\r\n\r\nAs a workaround, I manually created /opt/nautobot/ui/build/static and re-ran collectstatic\n", "before_files": [{"content": "\"\"\"\nUtilities and primitives for the `nautobot-server` CLI command.\n\"\"\"\n\nimport os\n\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.core.management.utils import get_random_secret_key\nfrom jinja2 import BaseLoader, Environment\n\nfrom nautobot.core.runner import run_app\nfrom nautobot.extras.plugins.utils import load_plugins\n\n\n# Default file location for the generated config emitted by `init`\nNAUTOBOT_ROOT = os.getenv(\"NAUTOBOT_ROOT\", os.path.expanduser(\"~/.nautobot\"))\nDEFAULT_CONFIG_PATH = os.path.join(NAUTOBOT_ROOT, \"nautobot_config.py\")\n\n# Default settings to use when building the config\nDEFAULT_SETTINGS = \"nautobot.core.settings\"\n\n# Name of the environment variable used to specify path of config\nSETTINGS_ENVVAR = \"NAUTOBOT_CONFIG\"\n\n# Base directory for this module\nBASE_DIR = os.path.dirname(__file__)\n\n# File path of template used to generate config emitted by `init`\nCONFIG_TEMPLATE = os.path.join(BASE_DIR, \"../templates/nautobot_config.py.j2\")\n\nDESCRIPTION = \"\"\"\nNautobot server management utility.\n\nType '%(prog)s help' to display a list of included sub-commands.\n\nType '%(prog)s init' to generate a new configuration.\n\"\"\"\n\n\ndef main():\n \"\"\"\n The main server CLI command that replaces `manage.py` and allows a\n configuration file to be passed in.\n\n How this works:\n\n - Process CLI args\n - Load default settings\n - Read config file from path\n - Overlay config settings on top of default settings\n - Overlay special/conditional settings (see `_configure_settings`)\n \"\"\"\n run_app(\n project=\"nautobot\",\n description=DESCRIPTION,\n default_config_path=DEFAULT_CONFIG_PATH,\n default_settings=DEFAULT_SETTINGS,\n settings_initializer=generate_settings,\n settings_envvar=SETTINGS_ENVVAR,\n initializer=_configure_settings, # Called after defaults\n )\n\n\ndef generate_settings(config_template=CONFIG_TEMPLATE, **kwargs):\n \"\"\"\n This command is ran when `default_config_path` doesn't exist, or `init` is\n ran and returns a string representing the default data to put into the\n settings file.\n \"\"\"\n template_vars = {\n \"secret_key\": get_random_secret_key(),\n \"installation_metrics_enabled\": kwargs.get(\"installation_metrics_enabled\", True),\n }\n\n with open(config_template) as fh:\n environment = Environment(loader=BaseLoader, keep_trailing_newline=True)\n config = environment.from_string(fh.read())\n\n return config.render(**template_vars)\n\n\ndef _configure_settings(config):\n \"\"\"\n Callback for processing conditional or special purpose settings.\n\n Any specially prepared settings will be handled here, such as loading\n plugins, enabling social auth, etc.\n\n This is intended to be called by `run_app` and should not be invoked\n directly.\n\n :param config:\n A dictionary of `config_path`, `project`, `settings`\n\n Example::\n\n {\n 'project': 'nautobot',\n 'config_path': '/path/to/nautobot_config.py',\n 'settings': <LazySettings \"nautobot_config\">\n }\n \"\"\"\n\n settings = config[\"settings\"]\n\n # Include the config path to the settings to align with builtin\n # `settings.SETTINGS_MODULE`. Useful for debugging correct config path.\n settings.SETTINGS_PATH = config[\"config_path\"]\n\n #\n # Storage directories\n #\n os.makedirs(settings.GIT_ROOT, exist_ok=True)\n os.makedirs(settings.JOBS_ROOT, exist_ok=True)\n os.makedirs(settings.MEDIA_ROOT, exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"devicetype-images\"), exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"image-attachments\"), exist_ok=True)\n os.makedirs(settings.STATIC_ROOT, exist_ok=True)\n\n #\n # Databases\n #\n\n # If metrics are enabled and postgres is the backend, set the driver to the\n # one provided by django-prometheus.\n if settings.METRICS_ENABLED and \"postgres\" in settings.DATABASES[\"default\"][\"ENGINE\"]:\n settings.DATABASES[\"default\"][\"ENGINE\"] = \"django_prometheus.db.backends.postgresql\"\n\n # Create secondary db connection for job logging. This still writes to the default db, but because it's a separate\n # connection, it allows allows us to \"escape\" from transaction.atomic() and ensure that job log entries are saved\n # to the database even when the rest of the job transaction is rolled back.\n settings.DATABASES[\"job_logs\"] = settings.DATABASES[\"default\"].copy()\n # When running unit tests, treat it as a mirror of the default test DB, not a separate test DB of its own\n settings.DATABASES[\"job_logs\"][\"TEST\"] = {\"MIRROR\": \"default\"}\n\n #\n # Media storage\n #\n\n if settings.STORAGE_BACKEND is not None:\n settings.DEFAULT_FILE_STORAGE = settings.STORAGE_BACKEND\n\n # django-storages\n if settings.STORAGE_BACKEND.startswith(\"storages.\"):\n try:\n import storages.utils\n except ModuleNotFoundError as e:\n if getattr(e, \"name\") == \"storages\":\n raise ImproperlyConfigured(\n f\"STORAGE_BACKEND is set to {settings.STORAGE_BACKEND} but django-storages is not present. It \"\n f\"can be installed by running 'pip install django-storages'.\"\n )\n raise e\n\n # Monkey-patch django-storages to fetch settings from STORAGE_CONFIG or fall back to settings\n def _setting(name, default=None):\n if name in settings.STORAGE_CONFIG:\n return settings.STORAGE_CONFIG[name]\n return getattr(settings, name, default)\n\n storages.utils.setting = _setting\n\n #\n # Plugins\n #\n\n # Process the plugins and manipulate the specified config settings that are\n # passed in.\n load_plugins(settings)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "nautobot/core/cli/__init__.py"}], "after_files": [{"content": "\"\"\"\nUtilities and primitives for the `nautobot-server` CLI command.\n\"\"\"\n\nimport os\n\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.core.management.utils import get_random_secret_key\nfrom jinja2 import BaseLoader, Environment\n\nfrom nautobot.core.runner import run_app\nfrom nautobot.extras.plugins.utils import load_plugins\n\n\n# Default file location for the generated config emitted by `init`\nNAUTOBOT_ROOT = os.getenv(\"NAUTOBOT_ROOT\", os.path.expanduser(\"~/.nautobot\"))\nDEFAULT_CONFIG_PATH = os.path.join(NAUTOBOT_ROOT, \"nautobot_config.py\")\n\n# Default settings to use when building the config\nDEFAULT_SETTINGS = \"nautobot.core.settings\"\n\n# Name of the environment variable used to specify path of config\nSETTINGS_ENVVAR = \"NAUTOBOT_CONFIG\"\n\n# Base directory for this module\nBASE_DIR = os.path.dirname(__file__)\n\n# File path of template used to generate config emitted by `init`\nCONFIG_TEMPLATE = os.path.join(BASE_DIR, \"../templates/nautobot_config.py.j2\")\n\nDESCRIPTION = \"\"\"\nNautobot server management utility.\n\nType '%(prog)s help' to display a list of included sub-commands.\n\nType '%(prog)s init' to generate a new configuration.\n\"\"\"\n\n\ndef main():\n \"\"\"\n The main server CLI command that replaces `manage.py` and allows a\n configuration file to be passed in.\n\n How this works:\n\n - Process CLI args\n - Load default settings\n - Read config file from path\n - Overlay config settings on top of default settings\n - Overlay special/conditional settings (see `_configure_settings`)\n \"\"\"\n run_app(\n project=\"nautobot\",\n description=DESCRIPTION,\n default_config_path=DEFAULT_CONFIG_PATH,\n default_settings=DEFAULT_SETTINGS,\n settings_initializer=generate_settings,\n settings_envvar=SETTINGS_ENVVAR,\n initializer=_configure_settings, # Called after defaults\n )\n\n\ndef generate_settings(config_template=CONFIG_TEMPLATE, **kwargs):\n \"\"\"\n This command is ran when `default_config_path` doesn't exist, or `init` is\n ran and returns a string representing the default data to put into the\n settings file.\n \"\"\"\n template_vars = {\n \"secret_key\": get_random_secret_key(),\n \"installation_metrics_enabled\": kwargs.get(\"installation_metrics_enabled\", True),\n }\n\n with open(config_template) as fh:\n environment = Environment(loader=BaseLoader, keep_trailing_newline=True)\n config = environment.from_string(fh.read())\n\n return config.render(**template_vars)\n\n\ndef _configure_settings(config):\n \"\"\"\n Callback for processing conditional or special purpose settings.\n\n Any specially prepared settings will be handled here, such as loading\n plugins, enabling social auth, etc.\n\n This is intended to be called by `run_app` and should not be invoked\n directly.\n\n :param config:\n A dictionary of `config_path`, `project`, `settings`\n\n Example::\n\n {\n 'project': 'nautobot',\n 'config_path': '/path/to/nautobot_config.py',\n 'settings': <LazySettings \"nautobot_config\">\n }\n \"\"\"\n\n settings = config[\"settings\"]\n\n # Include the config path to the settings to align with builtin\n # `settings.SETTINGS_MODULE`. Useful for debugging correct config path.\n settings.SETTINGS_PATH = config[\"config_path\"]\n\n #\n # Storage directories\n #\n os.makedirs(settings.GIT_ROOT, exist_ok=True)\n os.makedirs(settings.JOBS_ROOT, exist_ok=True)\n os.makedirs(settings.MEDIA_ROOT, exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"devicetype-images\"), exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"image-attachments\"), exist_ok=True)\n os.makedirs(os.path.join(settings.NAUTOBOT_UI_DIR, \"build\", \"static\"), exist_ok=True)\n os.makedirs(settings.STATIC_ROOT, exist_ok=True)\n\n #\n # Databases\n #\n\n # If metrics are enabled and postgres is the backend, set the driver to the\n # one provided by django-prometheus.\n if settings.METRICS_ENABLED and \"postgres\" in settings.DATABASES[\"default\"][\"ENGINE\"]:\n settings.DATABASES[\"default\"][\"ENGINE\"] = \"django_prometheus.db.backends.postgresql\"\n\n # Create secondary db connection for job logging. This still writes to the default db, but because it's a separate\n # connection, it allows allows us to \"escape\" from transaction.atomic() and ensure that job log entries are saved\n # to the database even when the rest of the job transaction is rolled back.\n settings.DATABASES[\"job_logs\"] = settings.DATABASES[\"default\"].copy()\n # When running unit tests, treat it as a mirror of the default test DB, not a separate test DB of its own\n settings.DATABASES[\"job_logs\"][\"TEST\"] = {\"MIRROR\": \"default\"}\n\n #\n # Media storage\n #\n\n if settings.STORAGE_BACKEND is not None:\n settings.DEFAULT_FILE_STORAGE = settings.STORAGE_BACKEND\n\n # django-storages\n if settings.STORAGE_BACKEND.startswith(\"storages.\"):\n try:\n import storages.utils\n except ModuleNotFoundError as e:\n if getattr(e, \"name\") == \"storages\":\n raise ImproperlyConfigured(\n f\"STORAGE_BACKEND is set to {settings.STORAGE_BACKEND} but django-storages is not present. It \"\n f\"can be installed by running 'pip install django-storages'.\"\n )\n raise e\n\n # Monkey-patch django-storages to fetch settings from STORAGE_CONFIG or fall back to settings\n def _setting(name, default=None):\n if name in settings.STORAGE_CONFIG:\n return settings.STORAGE_CONFIG[name]\n return getattr(settings, name, default)\n\n storages.utils.setting = _setting\n\n #\n # Plugins\n #\n\n # Process the plugins and manipulate the specified config settings that are\n # passed in.\n load_plugins(settings)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "nautobot/core/cli/__init__.py"}]}
| 2,967 | 151 |
gh_patches_debug_8546
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2567
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Choose more secure configuration defaults
The configuration for SMTP server, privacyIDEA server or LDAP resolvers default to not using TLS and no certificate verification.
Better defaults or additional documentation may reduce the chance of accidental misconfiguration by the admins.
We have the following occurances:
* [x] Config -> SMTP Server: ``Use TLS``, check it by default.
* [x] Config -> privacyIDEA Server ``Verify the certificate``, check it by default
* [x] Config -> SMS Gateways (HTTP Gateway), default ``Check_SSL`` to "yes".
* ~~Config->User->New LDAP server: already defaults to ``verify TLS``.~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `privacyidea/lib/smsprovider/HttpSMSProvider.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # E-mail: [email protected]
4 # Contact: www.privacyidea.org
5 #
6 # 2018-06-15 Pascal Fuks <[email protected]>
7 # Added REGEXP parameter on phone number
8 # 2018-01-10 Cornelius Kölbel <[email protected]>
9 # Fix type cast for timeout
10 # 2016-06-14 Cornelius Kölbel <[email protected]>
11 # Add properties for new SMS provider model
12 # 2016-04-08 Cornelius Kölbel <[email protected]>
13 # Remote "None" as redundant 2nd argument to get
14 # 2016-01-13 Cornelius Kölbel <[email protected]>
15 # omit data object in GET request
16 # omit params in POST request
17 #
18 # privacyIDEA is a fork of LinOTP
19 # May 28, 2014 Cornelius Kölbel
20 # 2015-01-30 Rewrite for migration to flask
21 # Cornelius Kölbel <[email protected]>
22 #
23 #
24 # Copyright (C) LinOTP: 2010 - 2014 LSE Leading Security Experts GmbH
25 #
26 # This program is free software: you can redistribute it and/or
27 # modify it under the terms of the GNU Affero General Public
28 # License, version 3, as published by the Free Software Foundation.
29 #
30 # This program is distributed in the hope that it will be useful,
31 # but WITHOUT ANY WARRANTY; without even the implied warranty of
32 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
33 # GNU Affero General Public License for more details.
34 #
35 # You should have received a copy of the
36 # GNU Affero General Public License
37 # along with this program. If not, see <http://www.gnu.org/licenses/>.
38 #
39 #
40
41 __doc__ = """This is the SMSClass to send SMS via HTTP Gateways
42 It can handle HTTP/HTTPS PUT and GET requests also with Proxy support
43
44 The code is tested in tests/test_lib_smsprovider
45 """
46
47 from privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider, SMSError)
48 from privacyidea.lib import _
49 import requests
50 from six.moves.urllib.parse import urlparse
51 import re
52 import logging
53 log = logging.getLogger(__name__)
54
55
56 class HttpSMSProvider(ISMSProvider):
57
58 @staticmethod
59 def _mangle_phone(phone, config):
60 regexp = config.get("REGEXP")
61 if regexp:
62 try:
63 m = re.match("^/(.*)/(.*)/$", regexp)
64 if m:
65 phone = re.sub(m.group(1), m.group(2), phone)
66 except re.error:
67 log.warning(u"Can not mangle phone number. "
68 u"Please check your REGEXP: {0!s}".format(regexp))
69
70 return phone
71
72 def submit_message(self, phone, message):
73 """
74 send a message to a phone via an http sms gateway
75
76 :param phone: the phone number
77 :param message: the message to submit to the phone
78 :return:
79 """
80 log.debug("submitting message {0!r} to {1!s}".format(message, phone))
81 parameter = {}
82 headers = {}
83 if self.smsgateway:
84 phone = self._mangle_phone(phone, self.smsgateway.option_dict)
85 url = self.smsgateway.option_dict.get("URL")
86 method = self.smsgateway.option_dict.get("HTTP_METHOD", "GET")
87 username = self.smsgateway.option_dict.get("USERNAME")
88 password = self.smsgateway.option_dict.get("PASSWORD")
89 ssl_verify = self.smsgateway.option_dict.get("CHECK_SSL",
90 "yes") == "yes"
91 # FIXME: The Proxy option is deprecated and will be removed a version > 2.21
92 proxy = self.smsgateway.option_dict.get("PROXY")
93 http_proxy = self.smsgateway.option_dict.get('HTTP_PROXY')
94 https_proxy = self.smsgateway.option_dict.get('HTTPS_PROXY')
95 timeout = self.smsgateway.option_dict.get("TIMEOUT") or 3
96 for k, v in self.smsgateway.option_dict.items():
97 if k not in self.parameters().get("parameters"):
98 # This is an additional option
99 parameter[k] = v.format(otp=message, phone=phone)
100 headers = self.smsgateway.header_dict
101 else:
102 phone = self._mangle_phone(phone, self.config)
103 url = self.config.get('URL')
104 method = self.config.get('HTTP_Method', 'GET')
105 username = self.config.get('USERNAME')
106 password = self.config.get('PASSWORD')
107 ssl_verify = self.config.get('CHECK_SSL', True)
108 # FIXME: The Proxy option is deprecated and will be removed a version > 2.21
109 proxy = self.config.get('PROXY')
110 http_proxy = self.config.get('HTTP_PROXY')
111 https_proxy = self.config.get('HTTPS_PROXY')
112 parameter = self._get_parameters(message, phone)
113 timeout = self.config.get("TIMEOUT") or 3
114
115 if url is None:
116 log.warning("can not submit message. URL is missing.")
117 raise SMSError(-1, "No URL specified in the provider config.")
118 basic_auth = None
119
120 # there might be the basic authentication in the request url
121 # like http://user:passw@hostname:port/path
122 if password is None and username is None:
123 parsed_url = urlparse(url)
124 if "@" in parsed_url[1]:
125 puser, server = parsed_url[1].split('@')
126 username, password = puser.split(':')
127
128 if username and password is not None:
129 basic_auth = (username, password)
130
131 proxies = {}
132 if http_proxy:
133 proxies["http"] = http_proxy
134 if https_proxy:
135 proxies["https"] = https_proxy
136 if not proxies and proxy:
137 # No new proxy config but only the old one.
138 protocol = proxy.split(":")[0]
139 proxies = {protocol: proxy}
140
141 # url, parameter, username, password, method
142 requestor = requests.get
143 params = parameter
144 data = {}
145 if method == "POST":
146 requestor = requests.post
147 params = {}
148 data = parameter
149
150 log.debug(u"issuing request with parameters {0!s} headers {1!s} and method {2!s} and"
151 "authentication {3!s} to url {4!s}.".format(params, headers, method,
152 basic_auth, url))
153 # Todo: drop basic auth if Authorization-Header is given?
154 r = requestor(url, params=params, headers=headers,
155 data=data,
156 verify=ssl_verify,
157 auth=basic_auth,
158 timeout=float(timeout),
159 proxies=proxies)
160 log.debug("queued SMS on the HTTP gateway. status code returned: {0!s}".format(
161 r.status_code))
162
163 # We assume, that all gateways return with HTTP Status Code 200,
164 # 201 or 202
165 if r.status_code not in [200, 201, 202]:
166 raise SMSError(r.status_code, "SMS could not be "
167 "sent: %s" % r.status_code)
168 success = self._check_success(r)
169 return success
170
171 def _get_parameters(self, message, phone):
172
173 urldata = {}
174 # transfer the phone key
175 phoneKey = self.config.get('SMS_PHONENUMBER_KEY', "phone")
176 urldata[phoneKey] = phone
177 # transfer the sms key
178 messageKey = self.config.get('SMS_TEXT_KEY', "sms")
179 urldata[messageKey] = message
180 params = self.config.get('PARAMETER', {})
181 urldata.update(params)
182 log.debug("[getParameters] urldata: {0!s}".format(urldata))
183 return urldata
184
185 def _check_success(self, response):
186 """
187 Check the success according to the reply
188 1. if RETURN_SUCCESS is defined
189 2. if RETURN_FAIL is defined
190 :response reply: A response object.
191 """
192 reply = response.text
193 ret = False
194 if self.smsgateway:
195 return_success = self.smsgateway.option_dict.get("RETURN_SUCCESS")
196 return_fail = self.smsgateway.option_dict.get("RETURN_FAIL")
197 else:
198 return_success = self.config.get("RETURN_SUCCESS")
199 return_fail = self.config.get("RETURN_FAIL")
200
201 if return_success:
202 if return_success in reply:
203 log.debug("sending sms success")
204 ret = True
205 else:
206 log.warning("failed to send sms. Reply %s does not match "
207 "the RETURN_SUCCESS definition" % reply)
208 raise SMSError(response.status_code,
209 "We received a none success reply from the "
210 "SMS Gateway: {0!s} ({1!s})".format(reply,
211 return_success))
212
213 elif return_fail:
214 if return_fail in reply:
215 log.warning("sending sms failed. %s was not found "
216 "in %s" % (return_fail, reply))
217 raise SMSError(response.status_code,
218 "We received the predefined error from the "
219 "SMS Gateway.")
220 else:
221 log.debug("sending sms success")
222 ret = True
223 else:
224 ret = True
225 return ret
226
227 @classmethod
228 def parameters(cls):
229 """
230 Return a dictionary, that describes the parameters and options for the
231 SMS provider.
232 Parameters are required keys to values.
233
234 :return: dict
235 """
236 params = {"options_allowed": True,
237 "headers_allowed": True,
238 "parameters": {
239 "URL": {
240 "required": True,
241 "description": _("The base URL of the HTTP Gateway")},
242 "HTTP_METHOD": {
243 "required": True,
244 "description": _("Should the HTTP Gateway be "
245 "connected via an HTTP GET or POST "
246 "request."),
247 "values": ["GET", "POST"]},
248 "RETURN_SUCCESS": {
249 "description": _("Specify a substring, "
250 "that indicates, that the SMS was "
251 "delivered successfully.")},
252 "RETURN_FAIL": {
253 "description": _("Specify a substring, "
254 "that indicates, that the SMS "
255 "failed to be delivered.")},
256 "USERNAME": {
257 "description": _("Username in case of basic "
258 "authentication.")
259 },
260 "PASSWORD": {
261 "description": _("Password in case of basic "
262 "authentication.")
263 },
264 "CHECK_SSL": {
265 "description": _("Should the SSL certificate be "
266 "verified."),
267 "values": ["yes", "no"]
268 },
269 "REGEXP": {
270 "description": _("Regular expression to modify the phone number "
271 "to make it compatible with provider. "
272 "Enter something like '/[\\+/]//' to remove "
273 "pluses and slashes.")
274 },
275 "PROXY": {"description": _("An optional proxy string. DEPRECATED. Do not use "
276 "this anymore. Rather use HTTP_PROXY for http "
277 "connections and HTTPS_PROXY for https "
278 "connection. The PROXY option will be removed in "
279 "future.")},
280 "HTTP_PROXY": {"description": _("Proxy setting for HTTP connections.")},
281 "HTTPS_PROXY": {"description": _("Proxy setting for HTTPS connections.")},
282 "TIMEOUT": {"description": _("The timeout in seconds.")}
283 }
284 }
285 return params
286
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/privacyidea/lib/smsprovider/HttpSMSProvider.py b/privacyidea/lib/smsprovider/HttpSMSProvider.py
--- a/privacyidea/lib/smsprovider/HttpSMSProvider.py
+++ b/privacyidea/lib/smsprovider/HttpSMSProvider.py
@@ -262,6 +262,7 @@
"authentication.")
},
"CHECK_SSL": {
+ "required": True,
"description": _("Should the SSL certificate be "
"verified."),
"values": ["yes", "no"]
|
{"golden_diff": "diff --git a/privacyidea/lib/smsprovider/HttpSMSProvider.py b/privacyidea/lib/smsprovider/HttpSMSProvider.py\n--- a/privacyidea/lib/smsprovider/HttpSMSProvider.py\n+++ b/privacyidea/lib/smsprovider/HttpSMSProvider.py\n@@ -262,6 +262,7 @@\n \"authentication.\")\n },\n \"CHECK_SSL\": {\n+ \"required\": True,\n \"description\": _(\"Should the SSL certificate be \"\n \"verified.\"),\n \"values\": [\"yes\", \"no\"]\n", "issue": "Choose more secure configuration defaults\nThe configuration for SMTP server, privacyIDEA server or LDAP resolvers default to not using TLS and no certificate verification.\r\nBetter defaults or additional documentation may reduce the chance of accidental misconfiguration by the admins.\r\n\r\nWe have the following occurances:\r\n\r\n* [x] Config -> SMTP Server: ``Use TLS``, check it by default.\r\n* [x] Config -> privacyIDEA Server ``Verify the certificate``, check it by default\r\n* [x] Config -> SMS Gateways (HTTP Gateway), default ``Check_SSL`` to \"yes\".\r\n* ~~Config->User->New LDAP server: already defaults to ``verify TLS``.~~\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# E-mail: [email protected]\n# Contact: www.privacyidea.org\n#\n# 2018-06-15 Pascal Fuks <[email protected]>\n# Added REGEXP parameter on phone number\n# 2018-01-10 Cornelius K\u00f6lbel <[email protected]>\n# Fix type cast for timeout\n# 2016-06-14 Cornelius K\u00f6lbel <[email protected]>\n# Add properties for new SMS provider model\n# 2016-04-08 Cornelius K\u00f6lbel <[email protected]>\n# Remote \"None\" as redundant 2nd argument to get\n# 2016-01-13 Cornelius K\u00f6lbel <[email protected]>\n# omit data object in GET request\n# omit params in POST request\n#\n# privacyIDEA is a fork of LinOTP\n# May 28, 2014 Cornelius K\u00f6lbel\n# 2015-01-30 Rewrite for migration to flask\n# Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# Copyright (C) LinOTP: 2010 - 2014 LSE Leading Security Experts GmbH\n#\n# This program is free software: you can redistribute it and/or\n# modify it under the terms of the GNU Affero General Public\n# License, version 3, as published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the\n# GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n\n__doc__ = \"\"\"This is the SMSClass to send SMS via HTTP Gateways\nIt can handle HTTP/HTTPS PUT and GET requests also with Proxy support\n\nThe code is tested in tests/test_lib_smsprovider\n\"\"\"\n\nfrom privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider, SMSError)\nfrom privacyidea.lib import _\nimport requests\nfrom six.moves.urllib.parse import urlparse\nimport re\nimport logging\nlog = logging.getLogger(__name__)\n\n\nclass HttpSMSProvider(ISMSProvider):\n\n @staticmethod\n def _mangle_phone(phone, config):\n regexp = config.get(\"REGEXP\")\n if regexp:\n try:\n m = re.match(\"^/(.*)/(.*)/$\", regexp)\n if m:\n phone = re.sub(m.group(1), m.group(2), phone)\n except re.error:\n log.warning(u\"Can not mangle phone number. \"\n u\"Please check your REGEXP: {0!s}\".format(regexp))\n\n return phone\n\n def submit_message(self, phone, message):\n \"\"\"\n send a message to a phone via an http sms gateway\n\n :param phone: the phone number\n :param message: the message to submit to the phone\n :return:\n \"\"\"\n log.debug(\"submitting message {0!r} to {1!s}\".format(message, phone))\n parameter = {}\n headers = {}\n if self.smsgateway:\n phone = self._mangle_phone(phone, self.smsgateway.option_dict)\n url = self.smsgateway.option_dict.get(\"URL\")\n method = self.smsgateway.option_dict.get(\"HTTP_METHOD\", \"GET\")\n username = self.smsgateway.option_dict.get(\"USERNAME\")\n password = self.smsgateway.option_dict.get(\"PASSWORD\")\n ssl_verify = self.smsgateway.option_dict.get(\"CHECK_SSL\",\n \"yes\") == \"yes\"\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.smsgateway.option_dict.get(\"PROXY\")\n http_proxy = self.smsgateway.option_dict.get('HTTP_PROXY')\n https_proxy = self.smsgateway.option_dict.get('HTTPS_PROXY')\n timeout = self.smsgateway.option_dict.get(\"TIMEOUT\") or 3\n for k, v in self.smsgateway.option_dict.items():\n if k not in self.parameters().get(\"parameters\"):\n # This is an additional option\n parameter[k] = v.format(otp=message, phone=phone)\n headers = self.smsgateway.header_dict\n else:\n phone = self._mangle_phone(phone, self.config)\n url = self.config.get('URL')\n method = self.config.get('HTTP_Method', 'GET')\n username = self.config.get('USERNAME')\n password = self.config.get('PASSWORD')\n ssl_verify = self.config.get('CHECK_SSL', True)\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.config.get('PROXY')\n http_proxy = self.config.get('HTTP_PROXY')\n https_proxy = self.config.get('HTTPS_PROXY')\n parameter = self._get_parameters(message, phone)\n timeout = self.config.get(\"TIMEOUT\") or 3\n\n if url is None:\n log.warning(\"can not submit message. URL is missing.\")\n raise SMSError(-1, \"No URL specified in the provider config.\")\n basic_auth = None\n\n # there might be the basic authentication in the request url\n # like http://user:passw@hostname:port/path\n if password is None and username is None:\n parsed_url = urlparse(url)\n if \"@\" in parsed_url[1]:\n puser, server = parsed_url[1].split('@')\n username, password = puser.split(':')\n\n if username and password is not None:\n basic_auth = (username, password)\n\n proxies = {}\n if http_proxy:\n proxies[\"http\"] = http_proxy\n if https_proxy:\n proxies[\"https\"] = https_proxy\n if not proxies and proxy:\n # No new proxy config but only the old one.\n protocol = proxy.split(\":\")[0]\n proxies = {protocol: proxy}\n\n # url, parameter, username, password, method\n requestor = requests.get\n params = parameter\n data = {}\n if method == \"POST\":\n requestor = requests.post\n params = {}\n data = parameter\n\n log.debug(u\"issuing request with parameters {0!s} headers {1!s} and method {2!s} and\"\n \"authentication {3!s} to url {4!s}.\".format(params, headers, method,\n basic_auth, url))\n # Todo: drop basic auth if Authorization-Header is given?\n r = requestor(url, params=params, headers=headers,\n data=data,\n verify=ssl_verify,\n auth=basic_auth,\n timeout=float(timeout),\n proxies=proxies)\n log.debug(\"queued SMS on the HTTP gateway. status code returned: {0!s}\".format(\n r.status_code))\n\n # We assume, that all gateways return with HTTP Status Code 200,\n # 201 or 202\n if r.status_code not in [200, 201, 202]:\n raise SMSError(r.status_code, \"SMS could not be \"\n \"sent: %s\" % r.status_code)\n success = self._check_success(r)\n return success\n\n def _get_parameters(self, message, phone):\n\n urldata = {}\n # transfer the phone key\n phoneKey = self.config.get('SMS_PHONENUMBER_KEY', \"phone\")\n urldata[phoneKey] = phone\n # transfer the sms key\n messageKey = self.config.get('SMS_TEXT_KEY', \"sms\")\n urldata[messageKey] = message\n params = self.config.get('PARAMETER', {})\n urldata.update(params)\n log.debug(\"[getParameters] urldata: {0!s}\".format(urldata))\n return urldata\n\n def _check_success(self, response):\n \"\"\"\n Check the success according to the reply\n 1. if RETURN_SUCCESS is defined\n 2. if RETURN_FAIL is defined\n :response reply: A response object.\n \"\"\"\n reply = response.text\n ret = False\n if self.smsgateway:\n return_success = self.smsgateway.option_dict.get(\"RETURN_SUCCESS\")\n return_fail = self.smsgateway.option_dict.get(\"RETURN_FAIL\")\n else:\n return_success = self.config.get(\"RETURN_SUCCESS\")\n return_fail = self.config.get(\"RETURN_FAIL\")\n\n if return_success:\n if return_success in reply:\n log.debug(\"sending sms success\")\n ret = True\n else:\n log.warning(\"failed to send sms. Reply %s does not match \"\n \"the RETURN_SUCCESS definition\" % reply)\n raise SMSError(response.status_code,\n \"We received a none success reply from the \"\n \"SMS Gateway: {0!s} ({1!s})\".format(reply,\n return_success))\n\n elif return_fail:\n if return_fail in reply:\n log.warning(\"sending sms failed. %s was not found \"\n \"in %s\" % (return_fail, reply))\n raise SMSError(response.status_code,\n \"We received the predefined error from the \"\n \"SMS Gateway.\")\n else:\n log.debug(\"sending sms success\")\n ret = True\n else:\n ret = True\n return ret\n\n @classmethod\n def parameters(cls):\n \"\"\"\n Return a dictionary, that describes the parameters and options for the\n SMS provider.\n Parameters are required keys to values.\n\n :return: dict\n \"\"\"\n params = {\"options_allowed\": True,\n \"headers_allowed\": True,\n \"parameters\": {\n \"URL\": {\n \"required\": True,\n \"description\": _(\"The base URL of the HTTP Gateway\")},\n \"HTTP_METHOD\": {\n \"required\": True,\n \"description\": _(\"Should the HTTP Gateway be \"\n \"connected via an HTTP GET or POST \"\n \"request.\"),\n \"values\": [\"GET\", \"POST\"]},\n \"RETURN_SUCCESS\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS was \"\n \"delivered successfully.\")},\n \"RETURN_FAIL\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS \"\n \"failed to be delivered.\")},\n \"USERNAME\": {\n \"description\": _(\"Username in case of basic \"\n \"authentication.\")\n },\n \"PASSWORD\": {\n \"description\": _(\"Password in case of basic \"\n \"authentication.\")\n },\n \"CHECK_SSL\": {\n \"description\": _(\"Should the SSL certificate be \"\n \"verified.\"),\n \"values\": [\"yes\", \"no\"]\n },\n \"REGEXP\": {\n \"description\": _(\"Regular expression to modify the phone number \" \n \"to make it compatible with provider. \"\n \"Enter something like '/[\\\\+/]//' to remove \"\n \"pluses and slashes.\")\n },\n \"PROXY\": {\"description\": _(\"An optional proxy string. DEPRECATED. Do not use \"\n \"this anymore. Rather use HTTP_PROXY for http \"\n \"connections and HTTPS_PROXY for https \"\n \"connection. The PROXY option will be removed in \"\n \"future.\")},\n \"HTTP_PROXY\": {\"description\": _(\"Proxy setting for HTTP connections.\")},\n \"HTTPS_PROXY\": {\"description\": _(\"Proxy setting for HTTPS connections.\")},\n \"TIMEOUT\": {\"description\": _(\"The timeout in seconds.\")}\n }\n }\n return params\n", "path": "privacyidea/lib/smsprovider/HttpSMSProvider.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# E-mail: [email protected]\n# Contact: www.privacyidea.org\n#\n# 2018-06-15 Pascal Fuks <[email protected]>\n# Added REGEXP parameter on phone number\n# 2018-01-10 Cornelius K\u00f6lbel <[email protected]>\n# Fix type cast for timeout\n# 2016-06-14 Cornelius K\u00f6lbel <[email protected]>\n# Add properties for new SMS provider model\n# 2016-04-08 Cornelius K\u00f6lbel <[email protected]>\n# Remote \"None\" as redundant 2nd argument to get\n# 2016-01-13 Cornelius K\u00f6lbel <[email protected]>\n# omit data object in GET request\n# omit params in POST request\n#\n# privacyIDEA is a fork of LinOTP\n# May 28, 2014 Cornelius K\u00f6lbel\n# 2015-01-30 Rewrite for migration to flask\n# Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# Copyright (C) LinOTP: 2010 - 2014 LSE Leading Security Experts GmbH\n#\n# This program is free software: you can redistribute it and/or\n# modify it under the terms of the GNU Affero General Public\n# License, version 3, as published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the\n# GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n\n__doc__ = \"\"\"This is the SMSClass to send SMS via HTTP Gateways\nIt can handle HTTP/HTTPS PUT and GET requests also with Proxy support\n\nThe code is tested in tests/test_lib_smsprovider\n\"\"\"\n\nfrom privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider, SMSError)\nfrom privacyidea.lib import _\nimport requests\nfrom six.moves.urllib.parse import urlparse\nimport re\nimport logging\nlog = logging.getLogger(__name__)\n\n\nclass HttpSMSProvider(ISMSProvider):\n\n @staticmethod\n def _mangle_phone(phone, config):\n regexp = config.get(\"REGEXP\")\n if regexp:\n try:\n m = re.match(\"^/(.*)/(.*)/$\", regexp)\n if m:\n phone = re.sub(m.group(1), m.group(2), phone)\n except re.error:\n log.warning(u\"Can not mangle phone number. \"\n u\"Please check your REGEXP: {0!s}\".format(regexp))\n\n return phone\n\n def submit_message(self, phone, message):\n \"\"\"\n send a message to a phone via an http sms gateway\n\n :param phone: the phone number\n :param message: the message to submit to the phone\n :return:\n \"\"\"\n log.debug(\"submitting message {0!r} to {1!s}\".format(message, phone))\n parameter = {}\n headers = {}\n if self.smsgateway:\n phone = self._mangle_phone(phone, self.smsgateway.option_dict)\n url = self.smsgateway.option_dict.get(\"URL\")\n method = self.smsgateway.option_dict.get(\"HTTP_METHOD\", \"GET\")\n username = self.smsgateway.option_dict.get(\"USERNAME\")\n password = self.smsgateway.option_dict.get(\"PASSWORD\")\n ssl_verify = self.smsgateway.option_dict.get(\"CHECK_SSL\",\n \"yes\") == \"yes\"\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.smsgateway.option_dict.get(\"PROXY\")\n http_proxy = self.smsgateway.option_dict.get('HTTP_PROXY')\n https_proxy = self.smsgateway.option_dict.get('HTTPS_PROXY')\n timeout = self.smsgateway.option_dict.get(\"TIMEOUT\") or 3\n for k, v in self.smsgateway.option_dict.items():\n if k not in self.parameters().get(\"parameters\"):\n # This is an additional option\n parameter[k] = v.format(otp=message, phone=phone)\n headers = self.smsgateway.header_dict\n else:\n phone = self._mangle_phone(phone, self.config)\n url = self.config.get('URL')\n method = self.config.get('HTTP_Method', 'GET')\n username = self.config.get('USERNAME')\n password = self.config.get('PASSWORD')\n ssl_verify = self.config.get('CHECK_SSL', True)\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.config.get('PROXY')\n http_proxy = self.config.get('HTTP_PROXY')\n https_proxy = self.config.get('HTTPS_PROXY')\n parameter = self._get_parameters(message, phone)\n timeout = self.config.get(\"TIMEOUT\") or 3\n\n if url is None:\n log.warning(\"can not submit message. URL is missing.\")\n raise SMSError(-1, \"No URL specified in the provider config.\")\n basic_auth = None\n\n # there might be the basic authentication in the request url\n # like http://user:passw@hostname:port/path\n if password is None and username is None:\n parsed_url = urlparse(url)\n if \"@\" in parsed_url[1]:\n puser, server = parsed_url[1].split('@')\n username, password = puser.split(':')\n\n if username and password is not None:\n basic_auth = (username, password)\n\n proxies = {}\n if http_proxy:\n proxies[\"http\"] = http_proxy\n if https_proxy:\n proxies[\"https\"] = https_proxy\n if not proxies and proxy:\n # No new proxy config but only the old one.\n protocol = proxy.split(\":\")[0]\n proxies = {protocol: proxy}\n\n # url, parameter, username, password, method\n requestor = requests.get\n params = parameter\n data = {}\n if method == \"POST\":\n requestor = requests.post\n params = {}\n data = parameter\n\n log.debug(u\"issuing request with parameters {0!s} headers {1!s} and method {2!s} and\"\n \"authentication {3!s} to url {4!s}.\".format(params, headers, method,\n basic_auth, url))\n # Todo: drop basic auth if Authorization-Header is given?\n r = requestor(url, params=params, headers=headers,\n data=data,\n verify=ssl_verify,\n auth=basic_auth,\n timeout=float(timeout),\n proxies=proxies)\n log.debug(\"queued SMS on the HTTP gateway. status code returned: {0!s}\".format(\n r.status_code))\n\n # We assume, that all gateways return with HTTP Status Code 200,\n # 201 or 202\n if r.status_code not in [200, 201, 202]:\n raise SMSError(r.status_code, \"SMS could not be \"\n \"sent: %s\" % r.status_code)\n success = self._check_success(r)\n return success\n\n def _get_parameters(self, message, phone):\n\n urldata = {}\n # transfer the phone key\n phoneKey = self.config.get('SMS_PHONENUMBER_KEY', \"phone\")\n urldata[phoneKey] = phone\n # transfer the sms key\n messageKey = self.config.get('SMS_TEXT_KEY', \"sms\")\n urldata[messageKey] = message\n params = self.config.get('PARAMETER', {})\n urldata.update(params)\n log.debug(\"[getParameters] urldata: {0!s}\".format(urldata))\n return urldata\n\n def _check_success(self, response):\n \"\"\"\n Check the success according to the reply\n 1. if RETURN_SUCCESS is defined\n 2. if RETURN_FAIL is defined\n :response reply: A response object.\n \"\"\"\n reply = response.text\n ret = False\n if self.smsgateway:\n return_success = self.smsgateway.option_dict.get(\"RETURN_SUCCESS\")\n return_fail = self.smsgateway.option_dict.get(\"RETURN_FAIL\")\n else:\n return_success = self.config.get(\"RETURN_SUCCESS\")\n return_fail = self.config.get(\"RETURN_FAIL\")\n\n if return_success:\n if return_success in reply:\n log.debug(\"sending sms success\")\n ret = True\n else:\n log.warning(\"failed to send sms. Reply %s does not match \"\n \"the RETURN_SUCCESS definition\" % reply)\n raise SMSError(response.status_code,\n \"We received a none success reply from the \"\n \"SMS Gateway: {0!s} ({1!s})\".format(reply,\n return_success))\n\n elif return_fail:\n if return_fail in reply:\n log.warning(\"sending sms failed. %s was not found \"\n \"in %s\" % (return_fail, reply))\n raise SMSError(response.status_code,\n \"We received the predefined error from the \"\n \"SMS Gateway.\")\n else:\n log.debug(\"sending sms success\")\n ret = True\n else:\n ret = True\n return ret\n\n @classmethod\n def parameters(cls):\n \"\"\"\n Return a dictionary, that describes the parameters and options for the\n SMS provider.\n Parameters are required keys to values.\n\n :return: dict\n \"\"\"\n params = {\"options_allowed\": True,\n \"headers_allowed\": True,\n \"parameters\": {\n \"URL\": {\n \"required\": True,\n \"description\": _(\"The base URL of the HTTP Gateway\")},\n \"HTTP_METHOD\": {\n \"required\": True,\n \"description\": _(\"Should the HTTP Gateway be \"\n \"connected via an HTTP GET or POST \"\n \"request.\"),\n \"values\": [\"GET\", \"POST\"]},\n \"RETURN_SUCCESS\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS was \"\n \"delivered successfully.\")},\n \"RETURN_FAIL\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS \"\n \"failed to be delivered.\")},\n \"USERNAME\": {\n \"description\": _(\"Username in case of basic \"\n \"authentication.\")\n },\n \"PASSWORD\": {\n \"description\": _(\"Password in case of basic \"\n \"authentication.\")\n },\n \"CHECK_SSL\": {\n \"required\": True,\n \"description\": _(\"Should the SSL certificate be \"\n \"verified.\"),\n \"values\": [\"yes\", \"no\"]\n },\n \"REGEXP\": {\n \"description\": _(\"Regular expression to modify the phone number \" \n \"to make it compatible with provider. \"\n \"Enter something like '/[\\\\+/]//' to remove \"\n \"pluses and slashes.\")\n },\n \"PROXY\": {\"description\": _(\"An optional proxy string. DEPRECATED. Do not use \"\n \"this anymore. Rather use HTTP_PROXY for http \"\n \"connections and HTTPS_PROXY for https \"\n \"connection. The PROXY option will be removed in \"\n \"future.\")},\n \"HTTP_PROXY\": {\"description\": _(\"Proxy setting for HTTP connections.\")},\n \"HTTPS_PROXY\": {\"description\": _(\"Proxy setting for HTTPS connections.\")},\n \"TIMEOUT\": {\"description\": _(\"The timeout in seconds.\")}\n }\n }\n return params\n", "path": "privacyidea/lib/smsprovider/HttpSMSProvider.py"}]}
| 3,695 | 118 |
gh_patches_debug_26757
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-532
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nondeterministic "invalid command 'bdist_wheel'" resulting in "Untranslateable" exception
I just started using pex. About half of the time I run it, it works great. The other half of the time, it fails like this.
```
> pex --python python2.7 abc.zip -v
**** Failed to install enum34-1.0.4. stdout: :: Packaging enum34
**** Failed to install enum34-1.0.4. stderr:
usage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]
or: setup.py --help [cmd1 cmd2 ...]
or: setup.py --help-commands
or: setup.py cmd --help
error: invalid command 'bdist_wheel'
pex: Failed to install package at /tmp/tmppcotrf/enum34-1.0.4: Failed to install /tmp/tmppcotrf/enum34-1.0.4
Traceback (most recent call last):
File "/bin/pex", line 9, in <module>
load_entry_point('pex==1.0.3', 'console_scripts', 'pex')()
File "/usr/lib/python3.3/site-packages/pex/bin/pex.py", line 509, in main
pex_builder = build_pex(reqs, options, resolver_options_builder)
File "/usr/lib/python3.3/site-packages/pex/bin/pex.py", line 471, in build_pex
resolveds = resolver.resolve(resolvables)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 191, in resolve
dist = self.build(package, resolvable.options)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 248, in build
dist = super(CachingResolver, self).build(package, options)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 160, in build
raise Untranslateable('Package %s is not translateable by %s' % (package, translator))
pex.resolver.Untranslateable: Package SourcePackage('file:///home/chris/.pex/build/enum34-1.0.4.zip') is not translateable by ChainedTranslator(WheelTranslator, EggTranslator, SourceTranslator)
```
In the above example it failed on `enum34`, but which dependency it fails on appears random as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/installer.py`
Content:
```
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import, print_function
5
6 import os
7 import sys
8 import tempfile
9
10 from pkg_resources import Distribution, PathMetadata
11
12 from .common import safe_mkdtemp, safe_rmtree
13 from .compatibility import WINDOWS
14 from .executor import Executor
15 from .interpreter import PythonInterpreter
16 from .tracer import TRACER
17 from .version import SETUPTOOLS_REQUIREMENT, WHEEL_REQUIREMENT
18
19 __all__ = (
20 'Installer',
21 'Packager'
22 )
23
24
25 def after_installation(function):
26 def function_wrapper(self, *args, **kw):
27 self._installed = self.run()
28 if not self._installed:
29 raise Installer.InstallFailure('Failed to install %s' % self._source_dir)
30 return function(self, *args, **kw)
31 return function_wrapper
32
33
34 class InstallerBase(object):
35 SETUP_BOOTSTRAP_HEADER = "import sys"
36 SETUP_BOOTSTRAP_MODULE = "sys.path.insert(0, %(path)r); import %(module)s"
37 SETUP_BOOTSTRAP_FOOTER = """
38 __file__ = 'setup.py'
39 sys.argv[0] = 'setup.py'
40 exec(compile(open(__file__, 'rb').read(), __file__, 'exec'))
41 """
42
43 class Error(Exception): pass
44 class InstallFailure(Error): pass
45 class IncapableInterpreter(Error): pass
46
47 def __init__(self, source_dir, strict=True, interpreter=None, install_dir=None):
48 """
49 Create an installer from an unpacked source distribution in source_dir.
50
51 If strict=True, fail if any installation dependencies (e.g. distribute)
52 are missing.
53 """
54 self._source_dir = source_dir
55 self._install_tmp = install_dir or safe_mkdtemp()
56 self._installed = None
57 self._strict = strict
58 self._interpreter = interpreter or PythonInterpreter.get()
59 if not self._interpreter.satisfies(self.capability) and strict:
60 raise self.IncapableInterpreter('Interpreter %s not capable of running %s' % (
61 self._interpreter.binary, self.__class__.__name__))
62
63 def mixins(self):
64 """Return a map from import name to requirement to load into setup script prior to invocation.
65
66 May be subclassed.
67 """
68 return {}
69
70 @property
71 def install_tmp(self):
72 return self._install_tmp
73
74 def _setup_command(self):
75 """the setup command-line to run, to be implemented by subclasses."""
76 raise NotImplementedError
77
78 def _postprocess(self):
79 """a post-processing function to run following setup.py invocation."""
80
81 @property
82 def capability(self):
83 """returns the list of requirements for the interpreter to run this installer."""
84 return list(self.mixins().values())
85
86 @property
87 def bootstrap_script(self):
88 bootstrap_modules = []
89 for module, requirement in self.mixins().items():
90 path = self._interpreter.get_location(requirement)
91 if not path:
92 assert not self._strict # This should be caught by validation
93 continue
94 bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})
95 return '\n'.join(
96 [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])
97
98 def run(self):
99 if self._installed is not None:
100 return self._installed
101
102 with TRACER.timed('Installing %s' % self._install_tmp, V=2):
103 command = [self._interpreter.binary, '-'] + self._setup_command()
104 try:
105 Executor.execute(command,
106 env=self._interpreter.sanitized_environment(),
107 cwd=self._source_dir,
108 stdin_payload=self.bootstrap_script.encode('ascii'))
109 self._installed = True
110 except Executor.NonZeroExit as e:
111 self._installed = False
112 name = os.path.basename(self._source_dir)
113 print('**** Failed to install %s (caused by: %r\n):' % (name, e), file=sys.stderr)
114 print('stdout:\n%s\nstderr:\n%s\n' % (e.stdout, e.stderr), file=sys.stderr)
115 return self._installed
116
117 self._postprocess()
118 return self._installed
119
120 def cleanup(self):
121 safe_rmtree(self._install_tmp)
122
123
124 class Installer(InstallerBase):
125 """Install an unpacked distribution with a setup.py."""
126
127 def __init__(self, source_dir, strict=True, interpreter=None):
128 """
129 Create an installer from an unpacked source distribution in source_dir.
130
131 If strict=True, fail if any installation dependencies (e.g. setuptools)
132 are missing.
133 """
134 super(Installer, self).__init__(source_dir, strict=strict, interpreter=interpreter)
135 self._egg_info = None
136 fd, self._install_record = tempfile.mkstemp()
137 os.close(fd)
138
139 def _setup_command(self):
140 return ['install',
141 '--root=%s' % self._install_tmp,
142 '--prefix=',
143 '--single-version-externally-managed',
144 '--record', self._install_record]
145
146 def _postprocess(self):
147 installed_files = []
148 egg_info = None
149 with open(self._install_record) as fp:
150 installed_files = fp.read().splitlines()
151 for line in installed_files:
152 if line.endswith('.egg-info'):
153 assert line.startswith('/'), 'Expect .egg-info to be within install_tmp!'
154 egg_info = line
155 break
156
157 if not egg_info:
158 self._installed = False
159 return self._installed
160
161 installed_files = [os.path.relpath(fn, egg_info) for fn in installed_files if fn != egg_info]
162
163 self._egg_info = os.path.join(self._install_tmp, egg_info[1:])
164 with open(os.path.join(self._egg_info, 'installed-files.txt'), 'w') as fp:
165 fp.write('\n'.join(installed_files))
166 fp.write('\n')
167
168 return self._installed
169
170 @after_installation
171 def egg_info(self):
172 return self._egg_info
173
174 @after_installation
175 def root(self):
176 egg_info = self.egg_info()
177 assert egg_info
178 return os.path.realpath(os.path.dirname(egg_info))
179
180 @after_installation
181 def distribution(self):
182 base_dir = self.root()
183 egg_info = self.egg_info()
184 metadata = PathMetadata(base_dir, egg_info)
185 return Distribution.from_location(base_dir, os.path.basename(egg_info), metadata=metadata)
186
187
188 class DistributionPackager(InstallerBase):
189 def mixins(self):
190 mixins = super(DistributionPackager, self).mixins().copy()
191 mixins.update(setuptools=SETUPTOOLS_REQUIREMENT)
192 return mixins
193
194 def find_distribution(self):
195 dists = os.listdir(self.install_tmp)
196 if len(dists) == 0:
197 raise self.InstallFailure('No distributions were produced!')
198 elif len(dists) > 1:
199 raise self.InstallFailure('Ambiguous source distributions found: %s' % (' '.join(dists)))
200 else:
201 return os.path.join(self.install_tmp, dists[0])
202
203
204 class Packager(DistributionPackager):
205 """
206 Create a source distribution from an unpacked setup.py-based project.
207 """
208
209 def _setup_command(self):
210 if WINDOWS:
211 return ['sdist', '--formats=zip', '--dist-dir=%s' % self._install_tmp]
212 else:
213 return ['sdist', '--formats=gztar', '--dist-dir=%s' % self._install_tmp]
214
215 @after_installation
216 def sdist(self):
217 return self.find_distribution()
218
219
220 class EggInstaller(DistributionPackager):
221 """
222 Create a source distribution from an unpacked setup.py-based project.
223 """
224
225 def _setup_command(self):
226 return ['bdist_egg', '--dist-dir=%s' % self._install_tmp]
227
228 @after_installation
229 def bdist(self):
230 return self.find_distribution()
231
232
233 class WheelInstaller(DistributionPackager):
234 """
235 Create a source distribution from an unpacked setup.py-based project.
236 """
237 MIXINS = {
238 'setuptools': SETUPTOOLS_REQUIREMENT,
239 'wheel': WHEEL_REQUIREMENT,
240 }
241
242 def mixins(self):
243 mixins = super(WheelInstaller, self).mixins().copy()
244 mixins.update(self.MIXINS)
245 return mixins
246
247 def _setup_command(self):
248 return ['bdist_wheel', '--dist-dir=%s' % self._install_tmp]
249
250 @after_installation
251 def bdist(self):
252 return self.find_distribution()
253
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/installer.py b/pex/installer.py
--- a/pex/installer.py
+++ b/pex/installer.py
@@ -33,7 +33,8 @@
class InstallerBase(object):
SETUP_BOOTSTRAP_HEADER = "import sys"
- SETUP_BOOTSTRAP_MODULE = "sys.path.insert(0, %(path)r); import %(module)s"
+ SETUP_BOOTSTRAP_PYPATH = "sys.path.insert(0, %(path)r)"
+ SETUP_BOOTSTRAP_MODULE = "import %(module)s"
SETUP_BOOTSTRAP_FOOTER = """
__file__ = 'setup.py'
sys.argv[0] = 'setup.py'
@@ -85,15 +86,21 @@
@property
def bootstrap_script(self):
+ bootstrap_sys_paths = []
bootstrap_modules = []
for module, requirement in self.mixins().items():
path = self._interpreter.get_location(requirement)
if not path:
assert not self._strict # This should be caught by validation
continue
- bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})
+ bootstrap_sys_paths.append(self.SETUP_BOOTSTRAP_PYPATH % {'path': path})
+ bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'module': module})
return '\n'.join(
- [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])
+ [self.SETUP_BOOTSTRAP_HEADER] +
+ bootstrap_sys_paths +
+ bootstrap_modules +
+ [self.SETUP_BOOTSTRAP_FOOTER]
+ )
def run(self):
if self._installed is not None:
|
{"golden_diff": "diff --git a/pex/installer.py b/pex/installer.py\n--- a/pex/installer.py\n+++ b/pex/installer.py\n@@ -33,7 +33,8 @@\n \n class InstallerBase(object):\n SETUP_BOOTSTRAP_HEADER = \"import sys\"\n- SETUP_BOOTSTRAP_MODULE = \"sys.path.insert(0, %(path)r); import %(module)s\"\n+ SETUP_BOOTSTRAP_PYPATH = \"sys.path.insert(0, %(path)r)\"\n+ SETUP_BOOTSTRAP_MODULE = \"import %(module)s\"\n SETUP_BOOTSTRAP_FOOTER = \"\"\"\n __file__ = 'setup.py'\n sys.argv[0] = 'setup.py'\n@@ -85,15 +86,21 @@\n \n @property\n def bootstrap_script(self):\n+ bootstrap_sys_paths = []\n bootstrap_modules = []\n for module, requirement in self.mixins().items():\n path = self._interpreter.get_location(requirement)\n if not path:\n assert not self._strict # This should be caught by validation\n continue\n- bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})\n+ bootstrap_sys_paths.append(self.SETUP_BOOTSTRAP_PYPATH % {'path': path})\n+ bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'module': module})\n return '\\n'.join(\n- [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])\n+ [self.SETUP_BOOTSTRAP_HEADER] +\n+ bootstrap_sys_paths +\n+ bootstrap_modules +\n+ [self.SETUP_BOOTSTRAP_FOOTER]\n+ )\n \n def run(self):\n if self._installed is not None:\n", "issue": "Nondeterministic \"invalid command 'bdist_wheel'\" resulting in \"Untranslateable\" exception\nI just started using pex. About half of the time I run it, it works great. The other half of the time, it fails like this.\n\n```\n> pex --python python2.7 abc.zip -v\n**** Failed to install enum34-1.0.4. stdout: :: Packaging enum34\n\n**** Failed to install enum34-1.0.4. stderr:\nusage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]\n or: setup.py --help [cmd1 cmd2 ...]\n or: setup.py --help-commands\n or: setup.py cmd --help\n\nerror: invalid command 'bdist_wheel'\n\npex: Failed to install package at /tmp/tmppcotrf/enum34-1.0.4: Failed to install /tmp/tmppcotrf/enum34-1.0.4\nTraceback (most recent call last):\n File \"/bin/pex\", line 9, in <module>\n load_entry_point('pex==1.0.3', 'console_scripts', 'pex')()\n File \"/usr/lib/python3.3/site-packages/pex/bin/pex.py\", line 509, in main\n pex_builder = build_pex(reqs, options, resolver_options_builder)\n File \"/usr/lib/python3.3/site-packages/pex/bin/pex.py\", line 471, in build_pex\n resolveds = resolver.resolve(resolvables)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 191, in resolve\n dist = self.build(package, resolvable.options)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 248, in build\n dist = super(CachingResolver, self).build(package, options)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 160, in build\n raise Untranslateable('Package %s is not translateable by %s' % (package, translator))\npex.resolver.Untranslateable: Package SourcePackage('file:///home/chris/.pex/build/enum34-1.0.4.zip') is not translateable by ChainedTranslator(WheelTranslator, EggTranslator, SourceTranslator)\n```\n\nIn the above example it failed on `enum34`, but which dependency it fails on appears random as well.\n\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import, print_function\n\nimport os\nimport sys\nimport tempfile\n\nfrom pkg_resources import Distribution, PathMetadata\n\nfrom .common import safe_mkdtemp, safe_rmtree\nfrom .compatibility import WINDOWS\nfrom .executor import Executor\nfrom .interpreter import PythonInterpreter\nfrom .tracer import TRACER\nfrom .version import SETUPTOOLS_REQUIREMENT, WHEEL_REQUIREMENT\n\n__all__ = (\n 'Installer',\n 'Packager'\n)\n\n\ndef after_installation(function):\n def function_wrapper(self, *args, **kw):\n self._installed = self.run()\n if not self._installed:\n raise Installer.InstallFailure('Failed to install %s' % self._source_dir)\n return function(self, *args, **kw)\n return function_wrapper\n\n\nclass InstallerBase(object):\n SETUP_BOOTSTRAP_HEADER = \"import sys\"\n SETUP_BOOTSTRAP_MODULE = \"sys.path.insert(0, %(path)r); import %(module)s\"\n SETUP_BOOTSTRAP_FOOTER = \"\"\"\n__file__ = 'setup.py'\nsys.argv[0] = 'setup.py'\nexec(compile(open(__file__, 'rb').read(), __file__, 'exec'))\n\"\"\"\n\n class Error(Exception): pass\n class InstallFailure(Error): pass\n class IncapableInterpreter(Error): pass\n\n def __init__(self, source_dir, strict=True, interpreter=None, install_dir=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. distribute)\n are missing.\n \"\"\"\n self._source_dir = source_dir\n self._install_tmp = install_dir or safe_mkdtemp()\n self._installed = None\n self._strict = strict\n self._interpreter = interpreter or PythonInterpreter.get()\n if not self._interpreter.satisfies(self.capability) and strict:\n raise self.IncapableInterpreter('Interpreter %s not capable of running %s' % (\n self._interpreter.binary, self.__class__.__name__))\n\n def mixins(self):\n \"\"\"Return a map from import name to requirement to load into setup script prior to invocation.\n\n May be subclassed.\n \"\"\"\n return {}\n\n @property\n def install_tmp(self):\n return self._install_tmp\n\n def _setup_command(self):\n \"\"\"the setup command-line to run, to be implemented by subclasses.\"\"\"\n raise NotImplementedError\n\n def _postprocess(self):\n \"\"\"a post-processing function to run following setup.py invocation.\"\"\"\n\n @property\n def capability(self):\n \"\"\"returns the list of requirements for the interpreter to run this installer.\"\"\"\n return list(self.mixins().values())\n\n @property\n def bootstrap_script(self):\n bootstrap_modules = []\n for module, requirement in self.mixins().items():\n path = self._interpreter.get_location(requirement)\n if not path:\n assert not self._strict # This should be caught by validation\n continue\n bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})\n return '\\n'.join(\n [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])\n\n def run(self):\n if self._installed is not None:\n return self._installed\n\n with TRACER.timed('Installing %s' % self._install_tmp, V=2):\n command = [self._interpreter.binary, '-'] + self._setup_command()\n try:\n Executor.execute(command,\n env=self._interpreter.sanitized_environment(),\n cwd=self._source_dir,\n stdin_payload=self.bootstrap_script.encode('ascii'))\n self._installed = True\n except Executor.NonZeroExit as e:\n self._installed = False\n name = os.path.basename(self._source_dir)\n print('**** Failed to install %s (caused by: %r\\n):' % (name, e), file=sys.stderr)\n print('stdout:\\n%s\\nstderr:\\n%s\\n' % (e.stdout, e.stderr), file=sys.stderr)\n return self._installed\n\n self._postprocess()\n return self._installed\n\n def cleanup(self):\n safe_rmtree(self._install_tmp)\n\n\nclass Installer(InstallerBase):\n \"\"\"Install an unpacked distribution with a setup.py.\"\"\"\n\n def __init__(self, source_dir, strict=True, interpreter=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. setuptools)\n are missing.\n \"\"\"\n super(Installer, self).__init__(source_dir, strict=strict, interpreter=interpreter)\n self._egg_info = None\n fd, self._install_record = tempfile.mkstemp()\n os.close(fd)\n\n def _setup_command(self):\n return ['install',\n '--root=%s' % self._install_tmp,\n '--prefix=',\n '--single-version-externally-managed',\n '--record', self._install_record]\n\n def _postprocess(self):\n installed_files = []\n egg_info = None\n with open(self._install_record) as fp:\n installed_files = fp.read().splitlines()\n for line in installed_files:\n if line.endswith('.egg-info'):\n assert line.startswith('/'), 'Expect .egg-info to be within install_tmp!'\n egg_info = line\n break\n\n if not egg_info:\n self._installed = False\n return self._installed\n\n installed_files = [os.path.relpath(fn, egg_info) for fn in installed_files if fn != egg_info]\n\n self._egg_info = os.path.join(self._install_tmp, egg_info[1:])\n with open(os.path.join(self._egg_info, 'installed-files.txt'), 'w') as fp:\n fp.write('\\n'.join(installed_files))\n fp.write('\\n')\n\n return self._installed\n\n @after_installation\n def egg_info(self):\n return self._egg_info\n\n @after_installation\n def root(self):\n egg_info = self.egg_info()\n assert egg_info\n return os.path.realpath(os.path.dirname(egg_info))\n\n @after_installation\n def distribution(self):\n base_dir = self.root()\n egg_info = self.egg_info()\n metadata = PathMetadata(base_dir, egg_info)\n return Distribution.from_location(base_dir, os.path.basename(egg_info), metadata=metadata)\n\n\nclass DistributionPackager(InstallerBase):\n def mixins(self):\n mixins = super(DistributionPackager, self).mixins().copy()\n mixins.update(setuptools=SETUPTOOLS_REQUIREMENT)\n return mixins\n\n def find_distribution(self):\n dists = os.listdir(self.install_tmp)\n if len(dists) == 0:\n raise self.InstallFailure('No distributions were produced!')\n elif len(dists) > 1:\n raise self.InstallFailure('Ambiguous source distributions found: %s' % (' '.join(dists)))\n else:\n return os.path.join(self.install_tmp, dists[0])\n\n\nclass Packager(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n if WINDOWS:\n return ['sdist', '--formats=zip', '--dist-dir=%s' % self._install_tmp]\n else:\n return ['sdist', '--formats=gztar', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def sdist(self):\n return self.find_distribution()\n\n\nclass EggInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n return ['bdist_egg', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n\n\nclass WheelInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n MIXINS = {\n 'setuptools': SETUPTOOLS_REQUIREMENT,\n 'wheel': WHEEL_REQUIREMENT,\n }\n\n def mixins(self):\n mixins = super(WheelInstaller, self).mixins().copy()\n mixins.update(self.MIXINS)\n return mixins\n\n def _setup_command(self):\n return ['bdist_wheel', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n", "path": "pex/installer.py"}], "after_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import, print_function\n\nimport os\nimport sys\nimport tempfile\n\nfrom pkg_resources import Distribution, PathMetadata\n\nfrom .common import safe_mkdtemp, safe_rmtree\nfrom .compatibility import WINDOWS\nfrom .executor import Executor\nfrom .interpreter import PythonInterpreter\nfrom .tracer import TRACER\nfrom .version import SETUPTOOLS_REQUIREMENT, WHEEL_REQUIREMENT\n\n__all__ = (\n 'Installer',\n 'Packager'\n)\n\n\ndef after_installation(function):\n def function_wrapper(self, *args, **kw):\n self._installed = self.run()\n if not self._installed:\n raise Installer.InstallFailure('Failed to install %s' % self._source_dir)\n return function(self, *args, **kw)\n return function_wrapper\n\n\nclass InstallerBase(object):\n SETUP_BOOTSTRAP_HEADER = \"import sys\"\n SETUP_BOOTSTRAP_PYPATH = \"sys.path.insert(0, %(path)r)\"\n SETUP_BOOTSTRAP_MODULE = \"import %(module)s\"\n SETUP_BOOTSTRAP_FOOTER = \"\"\"\n__file__ = 'setup.py'\nsys.argv[0] = 'setup.py'\nexec(compile(open(__file__, 'rb').read(), __file__, 'exec'))\n\"\"\"\n\n class Error(Exception): pass\n class InstallFailure(Error): pass\n class IncapableInterpreter(Error): pass\n\n def __init__(self, source_dir, strict=True, interpreter=None, install_dir=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. distribute)\n are missing.\n \"\"\"\n self._source_dir = source_dir\n self._install_tmp = install_dir or safe_mkdtemp()\n self._installed = None\n self._strict = strict\n self._interpreter = interpreter or PythonInterpreter.get()\n if not self._interpreter.satisfies(self.capability) and strict:\n raise self.IncapableInterpreter('Interpreter %s not capable of running %s' % (\n self._interpreter.binary, self.__class__.__name__))\n\n def mixins(self):\n \"\"\"Return a map from import name to requirement to load into setup script prior to invocation.\n\n May be subclassed.\n \"\"\"\n return {}\n\n @property\n def install_tmp(self):\n return self._install_tmp\n\n def _setup_command(self):\n \"\"\"the setup command-line to run, to be implemented by subclasses.\"\"\"\n raise NotImplementedError\n\n def _postprocess(self):\n \"\"\"a post-processing function to run following setup.py invocation.\"\"\"\n\n @property\n def capability(self):\n \"\"\"returns the list of requirements for the interpreter to run this installer.\"\"\"\n return list(self.mixins().values())\n\n @property\n def bootstrap_script(self):\n bootstrap_sys_paths = []\n bootstrap_modules = []\n for module, requirement in self.mixins().items():\n path = self._interpreter.get_location(requirement)\n if not path:\n assert not self._strict # This should be caught by validation\n continue\n bootstrap_sys_paths.append(self.SETUP_BOOTSTRAP_PYPATH % {'path': path})\n bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'module': module})\n return '\\n'.join(\n [self.SETUP_BOOTSTRAP_HEADER] +\n bootstrap_sys_paths +\n bootstrap_modules +\n [self.SETUP_BOOTSTRAP_FOOTER]\n )\n\n def run(self):\n if self._installed is not None:\n return self._installed\n\n with TRACER.timed('Installing %s' % self._install_tmp, V=2):\n command = [self._interpreter.binary, '-'] + self._setup_command()\n try:\n Executor.execute(command,\n env=self._interpreter.sanitized_environment(),\n cwd=self._source_dir,\n stdin_payload=self.bootstrap_script.encode('ascii'))\n self._installed = True\n except Executor.NonZeroExit as e:\n self._installed = False\n name = os.path.basename(self._source_dir)\n print('**** Failed to install %s (caused by: %r\\n):' % (name, e), file=sys.stderr)\n print('stdout:\\n%s\\nstderr:\\n%s\\n' % (e.stdout, e.stderr), file=sys.stderr)\n return self._installed\n\n self._postprocess()\n return self._installed\n\n def cleanup(self):\n safe_rmtree(self._install_tmp)\n\n\nclass Installer(InstallerBase):\n \"\"\"Install an unpacked distribution with a setup.py.\"\"\"\n\n def __init__(self, source_dir, strict=True, interpreter=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. setuptools)\n are missing.\n \"\"\"\n super(Installer, self).__init__(source_dir, strict=strict, interpreter=interpreter)\n self._egg_info = None\n fd, self._install_record = tempfile.mkstemp()\n os.close(fd)\n\n def _setup_command(self):\n return ['install',\n '--root=%s' % self._install_tmp,\n '--prefix=',\n '--single-version-externally-managed',\n '--record', self._install_record]\n\n def _postprocess(self):\n installed_files = []\n egg_info = None\n with open(self._install_record) as fp:\n installed_files = fp.read().splitlines()\n for line in installed_files:\n if line.endswith('.egg-info'):\n assert line.startswith('/'), 'Expect .egg-info to be within install_tmp!'\n egg_info = line\n break\n\n if not egg_info:\n self._installed = False\n return self._installed\n\n installed_files = [os.path.relpath(fn, egg_info) for fn in installed_files if fn != egg_info]\n\n self._egg_info = os.path.join(self._install_tmp, egg_info[1:])\n with open(os.path.join(self._egg_info, 'installed-files.txt'), 'w') as fp:\n fp.write('\\n'.join(installed_files))\n fp.write('\\n')\n\n return self._installed\n\n @after_installation\n def egg_info(self):\n return self._egg_info\n\n @after_installation\n def root(self):\n egg_info = self.egg_info()\n assert egg_info\n return os.path.realpath(os.path.dirname(egg_info))\n\n @after_installation\n def distribution(self):\n base_dir = self.root()\n egg_info = self.egg_info()\n metadata = PathMetadata(base_dir, egg_info)\n return Distribution.from_location(base_dir, os.path.basename(egg_info), metadata=metadata)\n\n\nclass DistributionPackager(InstallerBase):\n def mixins(self):\n mixins = super(DistributionPackager, self).mixins().copy()\n mixins.update(setuptools=SETUPTOOLS_REQUIREMENT)\n return mixins\n\n def find_distribution(self):\n dists = os.listdir(self.install_tmp)\n if len(dists) == 0:\n raise self.InstallFailure('No distributions were produced!')\n elif len(dists) > 1:\n raise self.InstallFailure('Ambiguous source distributions found: %s' % (' '.join(dists)))\n else:\n return os.path.join(self.install_tmp, dists[0])\n\n\nclass Packager(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n if WINDOWS:\n return ['sdist', '--formats=zip', '--dist-dir=%s' % self._install_tmp]\n else:\n return ['sdist', '--formats=gztar', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def sdist(self):\n return self.find_distribution()\n\n\nclass EggInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n return ['bdist_egg', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n\n\nclass WheelInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n MIXINS = {\n 'setuptools': SETUPTOOLS_REQUIREMENT,\n 'wheel': WHEEL_REQUIREMENT,\n }\n\n def mixins(self):\n mixins = super(WheelInstaller, self).mixins().copy()\n mixins.update(self.MIXINS)\n return mixins\n\n def _setup_command(self):\n return ['bdist_wheel', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n", "path": "pex/installer.py"}]}
| 3,349 | 380 |
gh_patches_debug_12670
|
rasdani/github-patches
|
git_diff
|
liqd__a4-product-54
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adapt to meinBerlin Changes
- [x] use A4_CATEGORIZABLE ( liqd/a4-meinberlin#893 )
- [x] adapt to project_list_tile templates in user space (liqd/a4-meinberlin#798 liqd/a4-meinberlin#792 liqd/a4-meinberlin#783 ... )
- [x] adapt to project_list_tile templates in dashboard ( liqd/a4-meinberlin#851 ... )
- [x] check if css refactorings should be used in product, too ( liqd/a4-meinberlin#903 liqd/a4-meinberlin#900 liqd/a4-meinberlin#875 liqd/a4-meinberlin#860 liqd/a4-meinberlin#881 liqd/a4-meinberlin#807 liqd/a4-meinberlin#788 ...)
- [x] unifiy admin.pys with meinBerlin
- [x] include 'adhocracy4.rules.apps.RulesConfig', ( liqd/a4-meinberlin#914 )
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `liqd_product/apps/organisations/admin.py`
Content:
```
1 from django.contrib import admin
2
3 from . import models
4
5
6 class OrganisationAdmin(admin.ModelAdmin):
7 raw_id_fields = ('initiators', )
8
9
10 admin.site.register(models.Organisation, OrganisationAdmin)
11
```
Path: `liqd_product/config/settings/base.py`
Content:
```
1 """Django settings for _LIQD_PRODUCT_."""
2
3 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
4 import os
5
6 CONFIG_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
7 PROJECT_DIR = os.path.dirname(CONFIG_DIR)
8 BASE_DIR = os.path.dirname(PROJECT_DIR)
9
10 # Application definition
11
12 INSTALLED_APPS = (
13 'liqd_product.apps.django_overwrites.apps.Config',
14 'django.contrib.sites',
15 'django.contrib.admin',
16 'django.contrib.auth',
17 'django.contrib.contenttypes',
18 'django.contrib.sessions',
19 'django.contrib.messages',
20 'django.contrib.staticfiles',
21 'django.contrib.humanize',
22
23 'widget_tweaks',
24 'rest_framework',
25 'allauth',
26 'allauth.account',
27 'rules.apps.AutodiscoverRulesConfig',
28 'easy_thumbnails',
29 'ckeditor',
30 'ckeditor_uploader',
31 'capture_tag',
32 'background_task',
33
34 # Temporary Compatibility layer for a4-meinberlin
35 'liqd_product.apps.compatibility.apps.Config',
36
37 # General adhocracy 4 components
38 'adhocracy4.actions.apps.ActionsConfig',
39 'adhocracy4.categories.apps.CategoriesConfig',
40 'adhocracy4.comments.apps.CommentsConfig',
41 'adhocracy4.filters.apps.FiltersConfig',
42 'adhocracy4.follows.apps.FollowsConfig',
43 'adhocracy4.forms.apps.FormsConfig',
44 'adhocracy4.images.apps.ImagesConfig',
45 'adhocracy4.maps.apps.MapsConfig',
46 'adhocracy4.modules.apps.ModulesConfig',
47 'adhocracy4.organisations.apps.OrganisationsConfig',
48 'adhocracy4.phases.apps.PhasesConfig',
49 'adhocracy4.projects.apps.ProjectsConfig',
50 'adhocracy4.ratings.apps.RatingsConfig',
51 'adhocracy4.reports.apps.ReportsConfig',
52
53 # General components that define models or helpers
54 'liqd_product.apps.contrib.apps.Config',
55 'liqd_product.apps.organisations.apps.Config',
56 'liqd_product.apps.partners.apps.Config',
57 'liqd_product.apps.users.apps.Config',
58 'meinberlin.apps.contrib.apps.Config',
59 'meinberlin.apps.actions.apps.Config',
60 'meinberlin.apps.moderatorfeedback.apps.Config',
61 'meinberlin.apps.maps.apps.Config',
62
63 # General apps containing views
64 'liqd_product.apps.account.apps.Config',
65 'meinberlin.apps.embed.apps.Config',
66 'meinberlin.apps.exports.apps.Config',
67 'meinberlin.apps.offlineevents.apps.Config',
68 'meinberlin.apps.projects.apps.Config',
69 'meinberlin.apps.dashboard2.apps.Config',
70
71 # Apps defining phases
72 'meinberlin.apps.documents.apps.Config',
73 'meinberlin.apps.ideas.apps.Config',
74 'meinberlin.apps.mapideas.apps.Config',
75 'meinberlin.apps.polls.apps.Config',
76 )
77
78 MIDDLEWARE = (
79 'django.contrib.sessions.middleware.SessionMiddleware',
80 'django.middleware.common.CommonMiddleware',
81 'django.middleware.csrf.CsrfViewMiddleware',
82 'django.contrib.auth.middleware.AuthenticationMiddleware',
83 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
84 'django.contrib.messages.middleware.MessageMiddleware',
85 'django.middleware.clickjacking.XFrameOptionsMiddleware',
86 'django.middleware.security.SecurityMiddleware',
87 'django.middleware.locale.LocaleMiddleware',
88
89 'liqd_product.apps.partners.middleware.PartnerMiddleware',
90 'meinberlin.apps.embed.middleware.AjaxPathMiddleware',
91 )
92
93 SITE_ID = 1
94
95 ROOT_URLCONF = 'liqd_product.config.urls'
96
97 LOCALE_PATHS = [os.path.join(BASE_DIR, 'locale')]
98
99 TEMPLATES = [
100 {
101 'BACKEND': 'django.template.backends.django.DjangoTemplates',
102 'DIRS': [
103 os.path.join(PROJECT_DIR, 'templates'),
104 ],
105 'APP_DIRS': True,
106 'OPTIONS': {
107 'context_processors': [
108 'django.template.context_processors.debug',
109 'django.template.context_processors.request',
110 'django.contrib.auth.context_processors.auth',
111 'django.contrib.messages.context_processors.messages',
112 ],
113 },
114 },
115 ]
116
117 WSGI_APPLICATION = 'liqd_product.config.wsgi.application'
118
119 REVERSE_METHOD = 'liqd_product.apps.partners.urlresolvers.reverse'
120
121
122 # Database
123 # https://docs.djangoproject.com/en/1.8/ref/settings/#databases
124
125 DATABASES = {
126 'default': {
127 'ENGINE': 'django.db.backends.sqlite3',
128 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
129 'TEST': {
130 'NAME': os.path.join(BASE_DIR, 'test_db.sqlite3'),
131 }
132 }
133 }
134
135
136 # Internationalization
137 # https://docs.djangoproject.com/en/1.8/topics/i18n/
138
139 LANGUAGE_CODE = 'en-us'
140
141 TIME_ZONE = 'Europe/Berlin'
142
143 USE_I18N = True
144
145 USE_L10N = True
146
147 USE_TZ = True
148
149
150 # Static files (CSS, JavaScript, Images)
151 # https://docs.djangoproject.com/en/1.8/howto/static-files/
152
153 STATICFILES_DIRS = [
154 os.path.join(PROJECT_DIR, 'static'),
155 ]
156
157 STATIC_ROOT = os.path.join(BASE_DIR, 'static')
158 STATIC_URL = '/static/'
159
160 MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
161 MEDIA_URL = '/media/'
162
163 IMAGE_ALIASES = {
164 '*': {
165 'max_size': 5*10**6,
166 'fileformats': ('image/png', 'image/jpeg', 'image/gif')
167 },
168 'heroimage': {'min_resolution': (1500, 500)},
169 'tileimage': {'min_resolution': (500, 300)},
170 'logo': {'min_resolution': (200, 200), 'aspect_ratio': (1, 1)},
171 'avatar': {'min_resolution': (200, 200)},
172 'idea_image': {'min_resolution': (800, 200)},
173 }
174
175 THUMBNAIL_ALIASES = {
176 '': {
177 'heroimage': {'size': (1500, 500), 'crop': 'smart'},
178 'heroimage_preview': {'size': (880, 220), 'crop': 'smart'},
179 'project_thumbnail': {'size': (520, 330), 'crop': 'smart'},
180 'idea_image': {'size': (800, 0), 'crop': 'scale'},
181 'idea_thumbnail': {'size': (240, 240), 'crop': 'smart'},
182 }
183 }
184
185 ALLOWED_UPLOAD_IMAGES = ('png', 'jpeg', 'gif')
186
187
188 # Authentication
189
190 AUTH_USER_MODEL = 'liqd_product_users.User'
191
192 AUTHENTICATION_BACKENDS = (
193 'rules.permissions.ObjectPermissionBackend',
194 'django.contrib.auth.backends.ModelBackend',
195 'allauth.account.auth_backends.AuthenticationBackend',
196 )
197
198 ACCOUNT_ADAPTER = 'liqd_product.apps.users.adapters.AccountAdapter'
199 ACCOUNT_AUTHENTICATION_METHOD = 'username_email'
200 ACCOUNT_EMAIL_CONFIRMATION_EXPIRE_DAYS = 3
201 ACCOUNT_EMAIL_REQUIRED = True
202 ACCOUNT_EMAIL_VERIFICATION = 'mandatory'
203 ACCOUNT_USERNAME_REQUIRED = True
204 ACCOUNT_LOGIN_ATTEMPTS_LIMIT = 10
205 ACCOUNT_LOGIN_ATTEMPTS_TIMEOUT = 300 # seconds
206 ACCOUNT_LOGIN_ON_EMAIL_CONFIRMATION = True
207 ACCOUNT_LOGIN_ON_PASSWORD_RESET = True
208 ACCOUNT_SIGNUP_FORM_CLASS = 'liqd_product.apps.users.forms.TermsSignupForm'
209 SOCIALACCOUNT_EMAIL_VERIFICATION = 'none'
210
211 LOGIN_URL = 'account_login'
212 LOGIN_REDIRECT_URL = '/'
213
214 EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
215
216
217 # CKEditor
218
219 CKEDITOR_UPLOAD_PATH = "uploads/"
220 CKEDITOR_RESTRICT_BY_USER = 'username'
221 CKEDITOR_ALLOW_NONIMAGE_FILES = True
222
223 CKEDITOR_CONFIGS = {
224 'default': {
225 'width': '100%',
226 'toolbar': 'Custom',
227 'toolbar_Custom': [
228 ['Bold', 'Italic', 'Underline'],
229 ['NumberedList', 'BulletedList'],
230 ['Link', 'Unlink']
231 ]
232 },
233 'image-editor': {
234 'width': '100%',
235 'toolbar': 'Custom',
236 'toolbar_Custom': [
237 ['Bold', 'Italic', 'Underline'],
238 ['Image'],
239 ['NumberedList', 'BulletedList'],
240 ['Link', 'Unlink']
241 ]
242 }
243 }
244
245 BLEACH_LIST = {
246 'default' : {
247 'tags': ['p','strong','em','u','ol','li','ul','a'],
248 'attributes': {
249 'a': ['href', 'rel'],
250 },
251 },
252 'image-editor': {
253 'tags': ['p','strong','em','u','ol','li','ul','a','img'],
254 'attributes': {
255 'a': ['href', 'rel'],
256 'img': ['src', 'alt', 'style']
257 },
258 'styles': [
259 'float',
260 'margin',
261 'padding',
262 'width',
263 'height',
264 'margin-bottom',
265 'margin-top',
266 'margin-left',
267 'margin-right',
268 ],
269 }
270 }
271
272
273 # adhocracy4
274
275 A4_ORGANISATIONS_MODEL = 'liqd_product_organisations.Organisation'
276
277 A4_RATEABLES = (
278 ('a4comments', 'comment'),
279 ('meinberlin_ideas', 'idea'),
280 ('meinberlin_mapideas', 'mapidea'),
281 )
282
283 A4_COMMENTABLES = (
284 ('a4comments', 'comment'),
285 ('meinberlin_ideas', 'idea'),
286 ('meinberlin_documents', 'chapter'),
287 ('meinberlin_documents', 'paragraph'),
288 ('meinberlin_mapideas', 'mapidea'),
289 ('meinberlin_polls', 'poll'),
290 )
291
292 A4_REPORTABLES = (
293 ('a4comments', 'comment'),
294 ('meinberlin_ideas', 'idea'),
295 ('meinberlin_mapideas', 'mapidea'),
296 )
297
298 A4_ACTIONABLES = (
299 ('a4comments', 'comment'),
300 ('meinberlin_ideas', 'idea'),
301 ('meinberlin_mapideas', 'mapidea'),
302 )
303
304 A4_AUTO_FOLLOWABLES = (
305 ('a4comments', 'comment'),
306 ('meinberlin_ideas', 'idea'),
307 ('meinberlin_mapideas', 'mapidea'),
308 )
309
310
311 A4_CATEGORIZABLE = (
312 ('meinberlin_ideas', 'idea'),
313 ('meinberlin_mapideas', 'mapidea'),
314 )
315
316
317 A4_MAP_BASEURL = 'https://{s}.tile.openstreetmap.org/'
318 A4_MAP_ATTRIBUTION = '© <a href="http://openstreetmap.org/copyright">OpenStreetMap</a> contributors'
319 A4_MAP_BOUNDING_BOX = ([[52.3517, 13.8229], [52.6839, 12.9543]])
320
321 A4_DASHBOARD = {
322 'PROJECT_DASHBOARD_CLASS': 'meinberlin.apps.dashboard2.ProjectDashboard',
323 'BLUEPRINTS': 'liqd_product.apps.dashboard.blueprints.blueprints'
324 }
325
326 CONTACT_EMAIL = '[email protected]'
327 EMAIL_DEFAULT_LANGUAGE = 'de'
328
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/liqd_product/apps/organisations/admin.py b/liqd_product/apps/organisations/admin.py
--- a/liqd_product/apps/organisations/admin.py
+++ b/liqd_product/apps/organisations/admin.py
@@ -4,6 +4,7 @@
class OrganisationAdmin(admin.ModelAdmin):
+ search_fields = ('name',)
raw_id_fields = ('initiators', )
diff --git a/liqd_product/config/settings/base.py b/liqd_product/config/settings/base.py
--- a/liqd_product/config/settings/base.py
+++ b/liqd_product/config/settings/base.py
@@ -49,6 +49,7 @@
'adhocracy4.projects.apps.ProjectsConfig',
'adhocracy4.ratings.apps.RatingsConfig',
'adhocracy4.reports.apps.ReportsConfig',
+ 'adhocracy4.rules.apps.RulesConfig',
# General components that define models or helpers
'liqd_product.apps.contrib.apps.Config',
|
{"golden_diff": "diff --git a/liqd_product/apps/organisations/admin.py b/liqd_product/apps/organisations/admin.py\n--- a/liqd_product/apps/organisations/admin.py\n+++ b/liqd_product/apps/organisations/admin.py\n@@ -4,6 +4,7 @@\n \n \n class OrganisationAdmin(admin.ModelAdmin):\n+ search_fields = ('name',)\n raw_id_fields = ('initiators', )\n \n \ndiff --git a/liqd_product/config/settings/base.py b/liqd_product/config/settings/base.py\n--- a/liqd_product/config/settings/base.py\n+++ b/liqd_product/config/settings/base.py\n@@ -49,6 +49,7 @@\n 'adhocracy4.projects.apps.ProjectsConfig',\n 'adhocracy4.ratings.apps.RatingsConfig',\n 'adhocracy4.reports.apps.ReportsConfig',\n+ 'adhocracy4.rules.apps.RulesConfig',\n \n # General components that define models or helpers\n 'liqd_product.apps.contrib.apps.Config',\n", "issue": "Adapt to meinBerlin Changes\n- [x] use A4_CATEGORIZABLE ( liqd/a4-meinberlin#893 )\r\n- [x] adapt to project_list_tile templates in user space (liqd/a4-meinberlin#798 liqd/a4-meinberlin#792 liqd/a4-meinberlin#783 ... )\r\n- [x] adapt to project_list_tile templates in dashboard ( liqd/a4-meinberlin#851 ... )\r\n- [x] check if css refactorings should be used in product, too ( liqd/a4-meinberlin#903 liqd/a4-meinberlin#900 liqd/a4-meinberlin#875 liqd/a4-meinberlin#860 liqd/a4-meinberlin#881 liqd/a4-meinberlin#807 liqd/a4-meinberlin#788 ...)\r\n- [x] unifiy admin.pys with meinBerlin\r\n- [x] include 'adhocracy4.rules.apps.RulesConfig', ( liqd/a4-meinberlin#914 )\n", "before_files": [{"content": "from django.contrib import admin\n\nfrom . import models\n\n\nclass OrganisationAdmin(admin.ModelAdmin):\n raw_id_fields = ('initiators', )\n\n\nadmin.site.register(models.Organisation, OrganisationAdmin)\n", "path": "liqd_product/apps/organisations/admin.py"}, {"content": "\"\"\"Django settings for _LIQD_PRODUCT_.\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nimport os\n\nCONFIG_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nPROJECT_DIR = os.path.dirname(CONFIG_DIR)\nBASE_DIR = os.path.dirname(PROJECT_DIR)\n\n# Application definition\n\nINSTALLED_APPS = (\n 'liqd_product.apps.django_overwrites.apps.Config',\n 'django.contrib.sites',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n\n 'widget_tweaks',\n 'rest_framework',\n 'allauth',\n 'allauth.account',\n 'rules.apps.AutodiscoverRulesConfig',\n 'easy_thumbnails',\n 'ckeditor',\n 'ckeditor_uploader',\n 'capture_tag',\n 'background_task',\n\n # Temporary Compatibility layer for a4-meinberlin\n 'liqd_product.apps.compatibility.apps.Config',\n\n # General adhocracy 4 components\n 'adhocracy4.actions.apps.ActionsConfig',\n 'adhocracy4.categories.apps.CategoriesConfig',\n 'adhocracy4.comments.apps.CommentsConfig',\n 'adhocracy4.filters.apps.FiltersConfig',\n 'adhocracy4.follows.apps.FollowsConfig',\n 'adhocracy4.forms.apps.FormsConfig',\n 'adhocracy4.images.apps.ImagesConfig',\n 'adhocracy4.maps.apps.MapsConfig',\n 'adhocracy4.modules.apps.ModulesConfig',\n 'adhocracy4.organisations.apps.OrganisationsConfig',\n 'adhocracy4.phases.apps.PhasesConfig',\n 'adhocracy4.projects.apps.ProjectsConfig',\n 'adhocracy4.ratings.apps.RatingsConfig',\n 'adhocracy4.reports.apps.ReportsConfig',\n\n # General components that define models or helpers\n 'liqd_product.apps.contrib.apps.Config',\n 'liqd_product.apps.organisations.apps.Config',\n 'liqd_product.apps.partners.apps.Config',\n 'liqd_product.apps.users.apps.Config',\n 'meinberlin.apps.contrib.apps.Config',\n 'meinberlin.apps.actions.apps.Config',\n 'meinberlin.apps.moderatorfeedback.apps.Config',\n 'meinberlin.apps.maps.apps.Config',\n\n # General apps containing views\n 'liqd_product.apps.account.apps.Config',\n 'meinberlin.apps.embed.apps.Config',\n 'meinberlin.apps.exports.apps.Config',\n 'meinberlin.apps.offlineevents.apps.Config',\n 'meinberlin.apps.projects.apps.Config',\n 'meinberlin.apps.dashboard2.apps.Config',\n\n # Apps defining phases\n 'meinberlin.apps.documents.apps.Config',\n 'meinberlin.apps.ideas.apps.Config',\n 'meinberlin.apps.mapideas.apps.Config',\n 'meinberlin.apps.polls.apps.Config',\n)\n\nMIDDLEWARE = (\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.middleware.locale.LocaleMiddleware',\n\n 'liqd_product.apps.partners.middleware.PartnerMiddleware',\n 'meinberlin.apps.embed.middleware.AjaxPathMiddleware',\n)\n\nSITE_ID = 1\n\nROOT_URLCONF = 'liqd_product.config.urls'\n\nLOCALE_PATHS = [os.path.join(BASE_DIR, 'locale')]\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [\n os.path.join(PROJECT_DIR, 'templates'),\n ],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'liqd_product.config.wsgi.application'\n\nREVERSE_METHOD = 'liqd_product.apps.partners.urlresolvers.reverse'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.8/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n 'TEST': {\n 'NAME': os.path.join(BASE_DIR, 'test_db.sqlite3'),\n }\n }\n}\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'Europe/Berlin'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nSTATICFILES_DIRS = [\n os.path.join(PROJECT_DIR, 'static'),\n]\n\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nSTATIC_URL = '/static/'\n\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = '/media/'\n\nIMAGE_ALIASES = {\n '*': {\n 'max_size': 5*10**6,\n 'fileformats': ('image/png', 'image/jpeg', 'image/gif')\n },\n 'heroimage': {'min_resolution': (1500, 500)},\n 'tileimage': {'min_resolution': (500, 300)},\n 'logo': {'min_resolution': (200, 200), 'aspect_ratio': (1, 1)},\n 'avatar': {'min_resolution': (200, 200)},\n 'idea_image': {'min_resolution': (800, 200)},\n}\n\nTHUMBNAIL_ALIASES = {\n '': {\n 'heroimage': {'size': (1500, 500), 'crop': 'smart'},\n 'heroimage_preview': {'size': (880, 220), 'crop': 'smart'},\n 'project_thumbnail': {'size': (520, 330), 'crop': 'smart'},\n 'idea_image': {'size': (800, 0), 'crop': 'scale'},\n 'idea_thumbnail': {'size': (240, 240), 'crop': 'smart'},\n }\n}\n\nALLOWED_UPLOAD_IMAGES = ('png', 'jpeg', 'gif')\n\n\n# Authentication\n\nAUTH_USER_MODEL = 'liqd_product_users.User'\n\nAUTHENTICATION_BACKENDS = (\n 'rules.permissions.ObjectPermissionBackend',\n 'django.contrib.auth.backends.ModelBackend',\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\nACCOUNT_ADAPTER = 'liqd_product.apps.users.adapters.AccountAdapter'\nACCOUNT_AUTHENTICATION_METHOD = 'username_email'\nACCOUNT_EMAIL_CONFIRMATION_EXPIRE_DAYS = 3\nACCOUNT_EMAIL_REQUIRED = True\nACCOUNT_EMAIL_VERIFICATION = 'mandatory'\nACCOUNT_USERNAME_REQUIRED = True\nACCOUNT_LOGIN_ATTEMPTS_LIMIT = 10\nACCOUNT_LOGIN_ATTEMPTS_TIMEOUT = 300 # seconds\nACCOUNT_LOGIN_ON_EMAIL_CONFIRMATION = True\nACCOUNT_LOGIN_ON_PASSWORD_RESET = True\nACCOUNT_SIGNUP_FORM_CLASS = 'liqd_product.apps.users.forms.TermsSignupForm'\nSOCIALACCOUNT_EMAIL_VERIFICATION = 'none'\n\nLOGIN_URL = 'account_login'\nLOGIN_REDIRECT_URL = '/'\n\nEMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\n\n# CKEditor\n\nCKEDITOR_UPLOAD_PATH = \"uploads/\"\nCKEDITOR_RESTRICT_BY_USER = 'username'\nCKEDITOR_ALLOW_NONIMAGE_FILES = True\n\nCKEDITOR_CONFIGS = {\n 'default': {\n 'width': '100%',\n 'toolbar': 'Custom',\n 'toolbar_Custom': [\n ['Bold', 'Italic', 'Underline'],\n ['NumberedList', 'BulletedList'],\n ['Link', 'Unlink']\n ]\n },\n 'image-editor': {\n 'width': '100%',\n 'toolbar': 'Custom',\n 'toolbar_Custom': [\n ['Bold', 'Italic', 'Underline'],\n ['Image'],\n ['NumberedList', 'BulletedList'],\n ['Link', 'Unlink']\n ]\n }\n}\n\nBLEACH_LIST = {\n 'default' : {\n 'tags': ['p','strong','em','u','ol','li','ul','a'],\n 'attributes': {\n 'a': ['href', 'rel'],\n },\n },\n 'image-editor': {\n 'tags': ['p','strong','em','u','ol','li','ul','a','img'],\n 'attributes': {\n 'a': ['href', 'rel'],\n 'img': ['src', 'alt', 'style']\n },\n 'styles': [\n 'float',\n 'margin',\n 'padding',\n 'width',\n 'height',\n 'margin-bottom',\n 'margin-top',\n 'margin-left',\n 'margin-right',\n ],\n }\n}\n\n\n# adhocracy4\n\nA4_ORGANISATIONS_MODEL = 'liqd_product_organisations.Organisation'\n\nA4_RATEABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_COMMENTABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_documents', 'chapter'),\n ('meinberlin_documents', 'paragraph'),\n ('meinberlin_mapideas', 'mapidea'),\n ('meinberlin_polls', 'poll'),\n)\n\nA4_REPORTABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_ACTIONABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_AUTO_FOLLOWABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\n\nA4_CATEGORIZABLE = (\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\n\nA4_MAP_BASEURL = 'https://{s}.tile.openstreetmap.org/'\nA4_MAP_ATTRIBUTION = '© <a href=\"http://openstreetmap.org/copyright\">OpenStreetMap</a> contributors'\nA4_MAP_BOUNDING_BOX = ([[52.3517, 13.8229], [52.6839, 12.9543]])\n\nA4_DASHBOARD = {\n 'PROJECT_DASHBOARD_CLASS': 'meinberlin.apps.dashboard2.ProjectDashboard',\n 'BLUEPRINTS': 'liqd_product.apps.dashboard.blueprints.blueprints'\n}\n\nCONTACT_EMAIL = '[email protected]'\nEMAIL_DEFAULT_LANGUAGE = 'de'\n", "path": "liqd_product/config/settings/base.py"}], "after_files": [{"content": "from django.contrib import admin\n\nfrom . import models\n\n\nclass OrganisationAdmin(admin.ModelAdmin):\n search_fields = ('name',)\n raw_id_fields = ('initiators', )\n\n\nadmin.site.register(models.Organisation, OrganisationAdmin)\n", "path": "liqd_product/apps/organisations/admin.py"}, {"content": "\"\"\"Django settings for _LIQD_PRODUCT_.\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nimport os\n\nCONFIG_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nPROJECT_DIR = os.path.dirname(CONFIG_DIR)\nBASE_DIR = os.path.dirname(PROJECT_DIR)\n\n# Application definition\n\nINSTALLED_APPS = (\n 'liqd_product.apps.django_overwrites.apps.Config',\n 'django.contrib.sites',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n\n 'widget_tweaks',\n 'rest_framework',\n 'allauth',\n 'allauth.account',\n 'rules.apps.AutodiscoverRulesConfig',\n 'easy_thumbnails',\n 'ckeditor',\n 'ckeditor_uploader',\n 'capture_tag',\n 'background_task',\n\n # Temporary Compatibility layer for a4-meinberlin\n 'liqd_product.apps.compatibility.apps.Config',\n\n # General adhocracy 4 components\n 'adhocracy4.actions.apps.ActionsConfig',\n 'adhocracy4.categories.apps.CategoriesConfig',\n 'adhocracy4.comments.apps.CommentsConfig',\n 'adhocracy4.filters.apps.FiltersConfig',\n 'adhocracy4.follows.apps.FollowsConfig',\n 'adhocracy4.forms.apps.FormsConfig',\n 'adhocracy4.images.apps.ImagesConfig',\n 'adhocracy4.maps.apps.MapsConfig',\n 'adhocracy4.modules.apps.ModulesConfig',\n 'adhocracy4.organisations.apps.OrganisationsConfig',\n 'adhocracy4.phases.apps.PhasesConfig',\n 'adhocracy4.projects.apps.ProjectsConfig',\n 'adhocracy4.ratings.apps.RatingsConfig',\n 'adhocracy4.reports.apps.ReportsConfig',\n 'adhocracy4.rules.apps.RulesConfig',\n\n # General components that define models or helpers\n 'liqd_product.apps.contrib.apps.Config',\n 'liqd_product.apps.organisations.apps.Config',\n 'liqd_product.apps.partners.apps.Config',\n 'liqd_product.apps.users.apps.Config',\n 'meinberlin.apps.contrib.apps.Config',\n 'meinberlin.apps.actions.apps.Config',\n 'meinberlin.apps.moderatorfeedback.apps.Config',\n 'meinberlin.apps.maps.apps.Config',\n\n # General apps containing views\n 'liqd_product.apps.account.apps.Config',\n 'meinberlin.apps.embed.apps.Config',\n 'meinberlin.apps.exports.apps.Config',\n 'meinberlin.apps.offlineevents.apps.Config',\n 'meinberlin.apps.projects.apps.Config',\n 'meinberlin.apps.dashboard2.apps.Config',\n\n # Apps defining phases\n 'meinberlin.apps.documents.apps.Config',\n 'meinberlin.apps.ideas.apps.Config',\n 'meinberlin.apps.mapideas.apps.Config',\n 'meinberlin.apps.polls.apps.Config',\n)\n\nMIDDLEWARE = (\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.middleware.locale.LocaleMiddleware',\n\n 'liqd_product.apps.partners.middleware.PartnerMiddleware',\n 'meinberlin.apps.embed.middleware.AjaxPathMiddleware',\n)\n\nSITE_ID = 1\n\nROOT_URLCONF = 'liqd_product.config.urls'\n\nLOCALE_PATHS = [os.path.join(BASE_DIR, 'locale')]\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [\n os.path.join(PROJECT_DIR, 'templates'),\n ],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'liqd_product.config.wsgi.application'\n\nREVERSE_METHOD = 'liqd_product.apps.partners.urlresolvers.reverse'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.8/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n 'TEST': {\n 'NAME': os.path.join(BASE_DIR, 'test_db.sqlite3'),\n }\n }\n}\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'Europe/Berlin'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nSTATICFILES_DIRS = [\n os.path.join(PROJECT_DIR, 'static'),\n]\n\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nSTATIC_URL = '/static/'\n\nMEDIA_ROOT = os.path.join(BASE_DIR, 'media')\nMEDIA_URL = '/media/'\n\nIMAGE_ALIASES = {\n '*': {\n 'max_size': 5*10**6,\n 'fileformats': ('image/png', 'image/jpeg', 'image/gif')\n },\n 'heroimage': {'min_resolution': (1500, 500)},\n 'tileimage': {'min_resolution': (500, 300)},\n 'logo': {'min_resolution': (200, 200), 'aspect_ratio': (1, 1)},\n 'avatar': {'min_resolution': (200, 200)},\n 'idea_image': {'min_resolution': (800, 200)},\n}\n\nTHUMBNAIL_ALIASES = {\n '': {\n 'heroimage': {'size': (1500, 500), 'crop': 'smart'},\n 'heroimage_preview': {'size': (880, 220), 'crop': 'smart'},\n 'project_thumbnail': {'size': (520, 330), 'crop': 'smart'},\n 'idea_image': {'size': (800, 0), 'crop': 'scale'},\n 'idea_thumbnail': {'size': (240, 240), 'crop': 'smart'},\n }\n}\n\nALLOWED_UPLOAD_IMAGES = ('png', 'jpeg', 'gif')\n\n\n# Authentication\n\nAUTH_USER_MODEL = 'liqd_product_users.User'\n\nAUTHENTICATION_BACKENDS = (\n 'rules.permissions.ObjectPermissionBackend',\n 'django.contrib.auth.backends.ModelBackend',\n 'allauth.account.auth_backends.AuthenticationBackend',\n)\n\nACCOUNT_ADAPTER = 'liqd_product.apps.users.adapters.AccountAdapter'\nACCOUNT_AUTHENTICATION_METHOD = 'username_email'\nACCOUNT_EMAIL_CONFIRMATION_EXPIRE_DAYS = 3\nACCOUNT_EMAIL_REQUIRED = True\nACCOUNT_EMAIL_VERIFICATION = 'mandatory'\nACCOUNT_USERNAME_REQUIRED = True\nACCOUNT_LOGIN_ATTEMPTS_LIMIT = 10\nACCOUNT_LOGIN_ATTEMPTS_TIMEOUT = 300 # seconds\nACCOUNT_LOGIN_ON_EMAIL_CONFIRMATION = True\nACCOUNT_LOGIN_ON_PASSWORD_RESET = True\nACCOUNT_SIGNUP_FORM_CLASS = 'liqd_product.apps.users.forms.TermsSignupForm'\nSOCIALACCOUNT_EMAIL_VERIFICATION = 'none'\n\nLOGIN_URL = 'account_login'\nLOGIN_REDIRECT_URL = '/'\n\nEMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\n\n# CKEditor\n\nCKEDITOR_UPLOAD_PATH = \"uploads/\"\nCKEDITOR_RESTRICT_BY_USER = 'username'\nCKEDITOR_ALLOW_NONIMAGE_FILES = True\n\nCKEDITOR_CONFIGS = {\n 'default': {\n 'width': '100%',\n 'toolbar': 'Custom',\n 'toolbar_Custom': [\n ['Bold', 'Italic', 'Underline'],\n ['NumberedList', 'BulletedList'],\n ['Link', 'Unlink']\n ]\n },\n 'image-editor': {\n 'width': '100%',\n 'toolbar': 'Custom',\n 'toolbar_Custom': [\n ['Bold', 'Italic', 'Underline'],\n ['Image'],\n ['NumberedList', 'BulletedList'],\n ['Link', 'Unlink']\n ]\n }\n}\n\nBLEACH_LIST = {\n 'default' : {\n 'tags': ['p','strong','em','u','ol','li','ul','a'],\n 'attributes': {\n 'a': ['href', 'rel'],\n },\n },\n 'image-editor': {\n 'tags': ['p','strong','em','u','ol','li','ul','a','img'],\n 'attributes': {\n 'a': ['href', 'rel'],\n 'img': ['src', 'alt', 'style']\n },\n 'styles': [\n 'float',\n 'margin',\n 'padding',\n 'width',\n 'height',\n 'margin-bottom',\n 'margin-top',\n 'margin-left',\n 'margin-right',\n ],\n }\n}\n\n\n# adhocracy4\n\nA4_ORGANISATIONS_MODEL = 'liqd_product_organisations.Organisation'\n\nA4_RATEABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_COMMENTABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_documents', 'chapter'),\n ('meinberlin_documents', 'paragraph'),\n ('meinberlin_mapideas', 'mapidea'),\n ('meinberlin_polls', 'poll'),\n)\n\nA4_REPORTABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_ACTIONABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\nA4_AUTO_FOLLOWABLES = (\n ('a4comments', 'comment'),\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\n\nA4_CATEGORIZABLE = (\n ('meinberlin_ideas', 'idea'),\n ('meinberlin_mapideas', 'mapidea'),\n)\n\n\nA4_MAP_BASEURL = 'https://{s}.tile.openstreetmap.org/'\nA4_MAP_ATTRIBUTION = '© <a href=\"http://openstreetmap.org/copyright\">OpenStreetMap</a> contributors'\nA4_MAP_BOUNDING_BOX = ([[52.3517, 13.8229], [52.6839, 12.9543]])\n\nA4_DASHBOARD = {\n 'PROJECT_DASHBOARD_CLASS': 'meinberlin.apps.dashboard2.ProjectDashboard',\n 'BLUEPRINTS': 'liqd_product.apps.dashboard.blueprints.blueprints'\n}\n\nCONTACT_EMAIL = '[email protected]'\nEMAIL_DEFAULT_LANGUAGE = 'de'\n", "path": "liqd_product/config/settings/base.py"}]}
| 3,930 | 204 |
gh_patches_debug_18826
|
rasdani/github-patches
|
git_diff
|
LMFDB__lmfdb-4276
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some Dirichlet character pages are failing to load
The page https://www.lmfdb.org/Character/Dirichlet/947/934 is timing out. Some similar pages such as https://www.lmfdb.org/Character/Dirichlet/947/933 and https://www.lmfdb.org/Character/Dirichlet/947/935 work but are slow too load and the knowl for the fixed field does not work. I believe this is due to some of the recent changes that were made #4231 -- @BarinderBanwait can you take a look at this?
Below is the trace back from the page that is failing to load. the failure is inside the call to "zeta_order" on line 156 of https://github.com/LMFDB/lmfdb/blob/master/lmfdb/characters/TinyConrey.py. I don't think that call should be taking any time, but if Sage is doing something silly we should just compute zeta_order directly. I confess it's not clear to me why we are using Sage DirichletGroup and Sage characters at all (it appears they are being used in just 2 places).
```
Traceback (most recent call last):
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1952, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1821, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py", line 367, in render_Dirichletwebpage
webchar = make_webchar(args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py", line 313, in make_webchar
return WebDBDirichletCharacter(**args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 925, in __init__
WebDBDirichlet.__init__(self, **kwargs)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 568, in __init__
self._compute()
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 575, in _compute
self._populate_from_db()
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 589, in _populate_from_db
self._set_generators_and_genvalues(values_data)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 615, in _set_generators_and_genvalues
self._genvalues_for_code = get_sage_genvalues(self.modulus, self.order, vals, self.chi.sage_zeta_order(self.order))
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/TinyConrey.py", line 156, in sage_zeta_order
return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
File "sage/misc/cachefunc.pyx", line 2310, in sage.misc.cachefunc.CachedMethodCallerNoArgs.__call__ (build/cythonized/sage/misc/cachefunc.c:12712)
self.cache = f(self._instance)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/sage/modular/dirichlet.py", line 2880, in zeta_order
order = self.zeta().multiplicative_order()
File "sage/rings/number_field/number_field_element.pyx", line 3229, in sage.rings.number_field.number_field_element.NumberFieldElement.multiplicative_order (build/cythonized/sage/rings/number_field/number_field_element.cpp:27976)
elif not (self.is_integral() and self.norm().is_one()):
File "sage/rings/number_field/number_field_element.pyx", line 3576, in sage.rings.number_field.number_field_element.NumberFieldElement.is_integral (build/cythonized/sage/rings/number_field/number_field_element.cpp:30234)
return all(a in ZZ for a in self.absolute_minpoly())
File "sage/rings/number_field/number_field_element.pyx", line 3576, in genexpr (build/cythonized/sage/rings/number_field/number_field_element.cpp:30109)
return all(a in ZZ for a in self.absolute_minpoly())
File "sage/rings/number_field/number_field_element.pyx", line 4488, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.absolute_minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37507)
return self.minpoly(var)
File "sage/rings/number_field/number_field_element.pyx", line 4576, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:38144)
return self.charpoly(var, algorithm).radical() # square free part of charpoly
File "sage/rings/number_field/number_field_element.pyx", line 4543, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.charpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37945)
return R(self.matrix().charpoly())
File "sage/matrix/matrix_rational_dense.pyx", line 1034, in sage.matrix.matrix_rational_dense.Matrix_rational_dense.charpoly (build/cythonized/sage/matrix/matrix_rational_dense.c:10660)
f = A.charpoly(var, algorithm=algorithm)
File "sage/matrix/matrix_integer_dense.pyx", line 1336, in sage.matrix.matrix_integer_dense.Matrix_integer_dense.charpoly (build/cythonized/sage/matrix/matrix_integer_dense.c:12941)
sig_on()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lmfdb/characters/TinyConrey.py`
Content:
```
1 from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,
2 DirichletGroup, CyclotomicField, euler_phi)
3 from sage.misc.cachefunc import cached_method
4 from sage.modular.dirichlet import DirichletCharacter
5
6 def symbol_numerator(cond, parity):
7 # Reference: Sect. 9.3, Montgomery, Hugh L; Vaughan, Robert C. (2007).
8 # Multiplicative number theory. I. Classical theory. Cambridge Studies in
9 # Advanced Mathematics 97
10 #
11 # Let F = Q(\sqrt(d)) with d a non zero squarefree integer then a real
12 # Dirichlet character \chi(n) can be represented as a Kronecker symbol
13 # (m / n) where { m = d if # d = 1 mod 4 else m = 4d if d = 2,3 (mod) 4 }
14 # and m is the discriminant of F. The conductor of \chi is |m|.
15 #
16 # symbol_numerator returns the appropriate Kronecker symbol depending on
17 # the conductor of \chi.
18 m = cond
19 if cond % 2 == 1:
20 if cond % 4 == 3:
21 m = -cond
22 elif cond % 8 == 4:
23 # Fixed cond % 16 == 4 and cond % 16 == 12 were switched in the
24 # previous version of the code.
25 #
26 # Let d be a non zero squarefree integer. If d = 2,3 (mod) 4 and if
27 # cond = 4d = 4 ( 4n + 2) or 4 (4n + 3) = 16 n + 8 or 16n + 12 then we
28 # set m = cond. On the other hand if d = 1 (mod) 4 and cond = 4d = 4
29 # (4n +1) = 16n + 4 then we set m = -cond.
30 if cond % 16 == 4:
31 m = -cond
32 elif cond % 16 == 8:
33 if parity == 1:
34 m = -cond
35 else:
36 return None
37 return m
38
39
40 def kronecker_symbol(m):
41 if m:
42 return r'\(\displaystyle\left(\frac{%s}{\bullet}\right)\)' % (m)
43 else:
44 return None
45
46 ###############################################################################
47 ## Conrey character with no call to Jonathan's code
48 ## in order to handle big moduli
49 ##
50
51 def get_sage_genvalues(modulus, order, genvalues, zeta_order):
52 """
53 Helper method for computing correct genvalues when constructing
54 the sage character
55 """
56 phi_mod = euler_phi(modulus)
57 exponent_factor = phi_mod / order
58 genvalues_exponent = [x * exponent_factor for x in genvalues]
59 return [x * zeta_order / phi_mod for x in genvalues_exponent]
60
61
62 class PariConreyGroup(object):
63
64 def __init__(self, modulus):
65 self.modulus = int(modulus)
66 self.G = Pari("znstar({},1)".format(modulus))
67
68 def gens(self):
69 return Integers(self.modulus).unit_gens()
70
71 def invariants(self):
72 return pari("znstar({},1).cyc".format(self.modulus))
73
74
75 class ConreyCharacter(object):
76 """
77 tiny implementation on Conrey index only
78 """
79
80 def __init__(self, modulus, number):
81 assert gcd(modulus, number)==1
82 self.modulus = Integer(modulus)
83 self.number = Integer(number)
84 self.G = Pari("znstar({},1)".format(modulus))
85 self.chi_pari = pari("znconreylog(%s,%d)"%(self.G,self.number))
86 self.chi_0 = None
87 self.indlabel = None
88
89 @property
90 def texname(self):
91 from lmfdb.characters.web_character import WebDirichlet
92 return WebDirichlet.char2tex(self.modulus, self.number)
93
94 @cached_method
95 def modfactor(self):
96 return self.modulus.factor()
97
98 @cached_method
99 def conductor(self):
100 B = pari("znconreyconductor(%s,%s,&chi0)"%(self.G, self.chi_pari))
101 if B.type() == 't_INT':
102 # means chi is primitive
103 self.chi_0 = self.chi_pari
104 self.indlabel = self.number
105 return int(B)
106 else:
107 self.chi_0 = pari("chi0")
108 G_0 = Pari("znstar({},1)".format(B))
109 self.indlabel = int(pari("znconreyexp(%s,%s)"%(G_0,self.chi_0)))
110 return int(B[0])
111
112 def is_primitive(self):
113 return self.conductor() == self.modulus
114
115 @cached_method
116 def parity(self):
117 number = self.number
118 par = 0
119 for p,e in self.modfactor():
120 if p == 2:
121 if number % 4 == 3:
122 par = 1 - par
123 else:
124 phi2 = (p-1)/Integer(2) * p **(e-1)
125 if Mod(number, p ** e)**phi2 != 1:
126 par = 1 - par
127 return par
128
129 def is_odd(self):
130 return self.parity() == 1
131
132 def is_even(self):
133 return self.parity() == 0
134
135 @cached_method
136 def multiplicative_order(self):
137 return Mod(self.number, self.modulus).multiplicative_order()
138
139 @property
140 def order(self):
141 return self.multiplicative_order()
142
143 @cached_method
144 def kronecker_symbol(self):
145 c = self.conductor()
146 p = self.parity()
147 return kronecker_symbol(symbol_numerator(c, p))
148
149 def conreyangle(self,x):
150 return Rational(pari("chareval(%s,znconreylog(%s,%d),%d)"%(self.G,self.G,self.number,x)))
151
152 def gauss_sum_numerical(self, a):
153 return pari("znchargauss(%s,%s,a=%d)"%(self.G,self.chi_pari,a))
154
155 def sage_zeta_order(self, order):
156 return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
157
158 def sage_character(self, order, genvalues):
159 H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))
160 M = H._module
161 order_corrected_genvalues = get_sage_genvalues(self.modulus, order, genvalues, H.zeta_order())
162 return DirichletCharacter(H,M(order_corrected_genvalues))
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lmfdb/characters/TinyConrey.py b/lmfdb/characters/TinyConrey.py
--- a/lmfdb/characters/TinyConrey.py
+++ b/lmfdb/characters/TinyConrey.py
@@ -1,5 +1,5 @@
from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,
- DirichletGroup, CyclotomicField, euler_phi)
+ DirichletGroup, CyclotomicField, euler_phi, lcm)
from sage.misc.cachefunc import cached_method
from sage.modular.dirichlet import DirichletCharacter
@@ -153,7 +153,7 @@
return pari("znchargauss(%s,%s,a=%d)"%(self.G,self.chi_pari,a))
def sage_zeta_order(self, order):
- return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
+ return 1 if self.modulus <= 2 else lcm(2,order)
def sage_character(self, order, genvalues):
H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))
|
{"golden_diff": "diff --git a/lmfdb/characters/TinyConrey.py b/lmfdb/characters/TinyConrey.py\n--- a/lmfdb/characters/TinyConrey.py\n+++ b/lmfdb/characters/TinyConrey.py\n@@ -1,5 +1,5 @@\n from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,\n- DirichletGroup, CyclotomicField, euler_phi)\n+ DirichletGroup, CyclotomicField, euler_phi, lcm)\n from sage.misc.cachefunc import cached_method\n from sage.modular.dirichlet import DirichletCharacter\n \n@@ -153,7 +153,7 @@\n return pari(\"znchargauss(%s,%s,a=%d)\"%(self.G,self.chi_pari,a))\n \n def sage_zeta_order(self, order):\n- return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\n+ return 1 if self.modulus <= 2 else lcm(2,order)\n \n def sage_character(self, order, genvalues):\n H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))\n", "issue": "Some Dirichlet character pages are failing to load\nThe page https://www.lmfdb.org/Character/Dirichlet/947/934 is timing out. Some similar pages such as https://www.lmfdb.org/Character/Dirichlet/947/933 and https://www.lmfdb.org/Character/Dirichlet/947/935 work but are slow too load and the knowl for the fixed field does not work. I believe this is due to some of the recent changes that were made #4231 -- @BarinderBanwait can you take a look at this?\r\n\r\nBelow is the trace back from the page that is failing to load. the failure is inside the call to \"zeta_order\" on line 156 of https://github.com/LMFDB/lmfdb/blob/master/lmfdb/characters/TinyConrey.py. I don't think that call should be taking any time, but if Sage is doing something silly we should just compute zeta_order directly. I confess it's not clear to me why we are using Sage DirichletGroup and Sage characters at all (it appears they are being used in just 2 places).\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 2447, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1952, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1821, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/_compat.py\", line 39, in reraise\r\n raise value\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1950, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1936, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py\", line 367, in render_Dirichletwebpage\r\n webchar = make_webchar(args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py\", line 313, in make_webchar\r\n return WebDBDirichletCharacter(**args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 925, in __init__\r\n WebDBDirichlet.__init__(self, **kwargs)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 568, in __init__\r\n self._compute()\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 575, in _compute\r\n self._populate_from_db()\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 589, in _populate_from_db\r\n self._set_generators_and_genvalues(values_data)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 615, in _set_generators_and_genvalues\r\n self._genvalues_for_code = get_sage_genvalues(self.modulus, self.order, vals, self.chi.sage_zeta_order(self.order))\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/TinyConrey.py\", line 156, in sage_zeta_order\r\n return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\r\n File \"sage/misc/cachefunc.pyx\", line 2310, in sage.misc.cachefunc.CachedMethodCallerNoArgs.__call__ (build/cythonized/sage/misc/cachefunc.c:12712)\r\n self.cache = f(self._instance)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/sage/modular/dirichlet.py\", line 2880, in zeta_order\r\n order = self.zeta().multiplicative_order()\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3229, in sage.rings.number_field.number_field_element.NumberFieldElement.multiplicative_order (build/cythonized/sage/rings/number_field/number_field_element.cpp:27976)\r\n elif not (self.is_integral() and self.norm().is_one()):\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3576, in sage.rings.number_field.number_field_element.NumberFieldElement.is_integral (build/cythonized/sage/rings/number_field/number_field_element.cpp:30234)\r\n return all(a in ZZ for a in self.absolute_minpoly())\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3576, in genexpr (build/cythonized/sage/rings/number_field/number_field_element.cpp:30109)\r\n return all(a in ZZ for a in self.absolute_minpoly())\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4488, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.absolute_minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37507)\r\n return self.minpoly(var)\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4576, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:38144)\r\n return self.charpoly(var, algorithm).radical() # square free part of charpoly\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4543, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.charpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37945)\r\n return R(self.matrix().charpoly())\r\n File \"sage/matrix/matrix_rational_dense.pyx\", line 1034, in sage.matrix.matrix_rational_dense.Matrix_rational_dense.charpoly (build/cythonized/sage/matrix/matrix_rational_dense.c:10660)\r\n f = A.charpoly(var, algorithm=algorithm)\r\n File \"sage/matrix/matrix_integer_dense.pyx\", line 1336, in sage.matrix.matrix_integer_dense.Matrix_integer_dense.charpoly (build/cythonized/sage/matrix/matrix_integer_dense.c:12941)\r\n sig_on()\r\n```\n", "before_files": [{"content": "from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,\n DirichletGroup, CyclotomicField, euler_phi)\nfrom sage.misc.cachefunc import cached_method\nfrom sage.modular.dirichlet import DirichletCharacter\n\ndef symbol_numerator(cond, parity):\n # Reference: Sect. 9.3, Montgomery, Hugh L; Vaughan, Robert C. (2007).\n # Multiplicative number theory. I. Classical theory. Cambridge Studies in\n # Advanced Mathematics 97\n #\n # Let F = Q(\\sqrt(d)) with d a non zero squarefree integer then a real\n # Dirichlet character \\chi(n) can be represented as a Kronecker symbol\n # (m / n) where { m = d if # d = 1 mod 4 else m = 4d if d = 2,3 (mod) 4 }\n # and m is the discriminant of F. The conductor of \\chi is |m|.\n #\n # symbol_numerator returns the appropriate Kronecker symbol depending on\n # the conductor of \\chi.\n m = cond\n if cond % 2 == 1:\n if cond % 4 == 3:\n m = -cond\n elif cond % 8 == 4:\n # Fixed cond % 16 == 4 and cond % 16 == 12 were switched in the\n # previous version of the code.\n #\n # Let d be a non zero squarefree integer. If d = 2,3 (mod) 4 and if\n # cond = 4d = 4 ( 4n + 2) or 4 (4n + 3) = 16 n + 8 or 16n + 12 then we\n # set m = cond. On the other hand if d = 1 (mod) 4 and cond = 4d = 4\n # (4n +1) = 16n + 4 then we set m = -cond.\n if cond % 16 == 4:\n m = -cond\n elif cond % 16 == 8:\n if parity == 1:\n m = -cond\n else:\n return None\n return m\n\n\ndef kronecker_symbol(m):\n if m:\n return r'\\(\\displaystyle\\left(\\frac{%s}{\\bullet}\\right)\\)' % (m)\n else:\n return None\n\n###############################################################################\n## Conrey character with no call to Jonathan's code\n## in order to handle big moduli\n##\n\ndef get_sage_genvalues(modulus, order, genvalues, zeta_order):\n \"\"\"\n Helper method for computing correct genvalues when constructing\n the sage character\n \"\"\"\n phi_mod = euler_phi(modulus)\n exponent_factor = phi_mod / order\n genvalues_exponent = [x * exponent_factor for x in genvalues]\n return [x * zeta_order / phi_mod for x in genvalues_exponent]\n\n\nclass PariConreyGroup(object):\n\n def __init__(self, modulus):\n self.modulus = int(modulus)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n\n def gens(self):\n return Integers(self.modulus).unit_gens()\n\n def invariants(self):\n return pari(\"znstar({},1).cyc\".format(self.modulus))\n\n\nclass ConreyCharacter(object):\n \"\"\"\n tiny implementation on Conrey index only\n \"\"\"\n\n def __init__(self, modulus, number):\n assert gcd(modulus, number)==1\n self.modulus = Integer(modulus)\n self.number = Integer(number)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n self.chi_pari = pari(\"znconreylog(%s,%d)\"%(self.G,self.number))\n self.chi_0 = None\n self.indlabel = None\n\n @property\n def texname(self):\n from lmfdb.characters.web_character import WebDirichlet\n return WebDirichlet.char2tex(self.modulus, self.number)\n\n @cached_method\n def modfactor(self):\n return self.modulus.factor()\n\n @cached_method\n def conductor(self):\n B = pari(\"znconreyconductor(%s,%s,&chi0)\"%(self.G, self.chi_pari))\n if B.type() == 't_INT':\n # means chi is primitive\n self.chi_0 = self.chi_pari\n self.indlabel = self.number\n return int(B)\n else:\n self.chi_0 = pari(\"chi0\")\n G_0 = Pari(\"znstar({},1)\".format(B))\n self.indlabel = int(pari(\"znconreyexp(%s,%s)\"%(G_0,self.chi_0)))\n return int(B[0])\n\n def is_primitive(self):\n return self.conductor() == self.modulus\n\n @cached_method\n def parity(self):\n number = self.number\n par = 0\n for p,e in self.modfactor():\n if p == 2:\n if number % 4 == 3:\n par = 1 - par\n else:\n phi2 = (p-1)/Integer(2) * p **(e-1)\n if Mod(number, p ** e)**phi2 != 1:\n par = 1 - par\n return par\n\n def is_odd(self):\n return self.parity() == 1\n\n def is_even(self):\n return self.parity() == 0\n\n @cached_method\n def multiplicative_order(self):\n return Mod(self.number, self.modulus).multiplicative_order()\n\n @property\n def order(self):\n return self.multiplicative_order()\n\n @cached_method\n def kronecker_symbol(self):\n c = self.conductor()\n p = self.parity()\n return kronecker_symbol(symbol_numerator(c, p))\n\n def conreyangle(self,x):\n return Rational(pari(\"chareval(%s,znconreylog(%s,%d),%d)\"%(self.G,self.G,self.number,x)))\n\n def gauss_sum_numerical(self, a):\n return pari(\"znchargauss(%s,%s,a=%d)\"%(self.G,self.chi_pari,a))\n\n def sage_zeta_order(self, order):\n return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\n\n def sage_character(self, order, genvalues):\n H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))\n M = H._module\n order_corrected_genvalues = get_sage_genvalues(self.modulus, order, genvalues, H.zeta_order())\n return DirichletCharacter(H,M(order_corrected_genvalues))\n", "path": "lmfdb/characters/TinyConrey.py"}], "after_files": [{"content": "from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,\n DirichletGroup, CyclotomicField, euler_phi, lcm)\nfrom sage.misc.cachefunc import cached_method\nfrom sage.modular.dirichlet import DirichletCharacter\n\ndef symbol_numerator(cond, parity):\n # Reference: Sect. 9.3, Montgomery, Hugh L; Vaughan, Robert C. (2007).\n # Multiplicative number theory. I. Classical theory. Cambridge Studies in\n # Advanced Mathematics 97\n #\n # Let F = Q(\\sqrt(d)) with d a non zero squarefree integer then a real\n # Dirichlet character \\chi(n) can be represented as a Kronecker symbol\n # (m / n) where { m = d if # d = 1 mod 4 else m = 4d if d = 2,3 (mod) 4 }\n # and m is the discriminant of F. The conductor of \\chi is |m|.\n #\n # symbol_numerator returns the appropriate Kronecker symbol depending on\n # the conductor of \\chi.\n m = cond\n if cond % 2 == 1:\n if cond % 4 == 3:\n m = -cond\n elif cond % 8 == 4:\n # Fixed cond % 16 == 4 and cond % 16 == 12 were switched in the\n # previous version of the code.\n #\n # Let d be a non zero squarefree integer. If d = 2,3 (mod) 4 and if\n # cond = 4d = 4 ( 4n + 2) or 4 (4n + 3) = 16 n + 8 or 16n + 12 then we\n # set m = cond. On the other hand if d = 1 (mod) 4 and cond = 4d = 4\n # (4n +1) = 16n + 4 then we set m = -cond.\n if cond % 16 == 4:\n m = -cond\n elif cond % 16 == 8:\n if parity == 1:\n m = -cond\n else:\n return None\n return m\n\n\ndef kronecker_symbol(m):\n if m:\n return r'\\(\\displaystyle\\left(\\frac{%s}{\\bullet}\\right)\\)' % (m)\n else:\n return None\n\n###############################################################################\n## Conrey character with no call to Jonathan's code\n## in order to handle big moduli\n##\n\ndef get_sage_genvalues(modulus, order, genvalues, zeta_order):\n \"\"\"\n Helper method for computing correct genvalues when constructing\n the sage character\n \"\"\"\n phi_mod = euler_phi(modulus)\n exponent_factor = phi_mod / order\n genvalues_exponent = [x * exponent_factor for x in genvalues]\n return [x * zeta_order / phi_mod for x in genvalues_exponent]\n\n\nclass PariConreyGroup(object):\n\n def __init__(self, modulus):\n self.modulus = int(modulus)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n\n def gens(self):\n return Integers(self.modulus).unit_gens()\n\n def invariants(self):\n return pari(\"znstar({},1).cyc\".format(self.modulus))\n\n\nclass ConreyCharacter(object):\n \"\"\"\n tiny implementation on Conrey index only\n \"\"\"\n\n def __init__(self, modulus, number):\n assert gcd(modulus, number)==1\n self.modulus = Integer(modulus)\n self.number = Integer(number)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n self.chi_pari = pari(\"znconreylog(%s,%d)\"%(self.G,self.number))\n self.chi_0 = None\n self.indlabel = None\n\n @property\n def texname(self):\n from lmfdb.characters.web_character import WebDirichlet\n return WebDirichlet.char2tex(self.modulus, self.number)\n\n @cached_method\n def modfactor(self):\n return self.modulus.factor()\n\n @cached_method\n def conductor(self):\n B = pari(\"znconreyconductor(%s,%s,&chi0)\"%(self.G, self.chi_pari))\n if B.type() == 't_INT':\n # means chi is primitive\n self.chi_0 = self.chi_pari\n self.indlabel = self.number\n return int(B)\n else:\n self.chi_0 = pari(\"chi0\")\n G_0 = Pari(\"znstar({},1)\".format(B))\n self.indlabel = int(pari(\"znconreyexp(%s,%s)\"%(G_0,self.chi_0)))\n return int(B[0])\n\n def is_primitive(self):\n return self.conductor() == self.modulus\n\n @cached_method\n def parity(self):\n number = self.number\n par = 0\n for p,e in self.modfactor():\n if p == 2:\n if number % 4 == 3:\n par = 1 - par\n else:\n phi2 = (p-1)/Integer(2) * p **(e-1)\n if Mod(number, p ** e)**phi2 != 1:\n par = 1 - par\n return par\n\n def is_odd(self):\n return self.parity() == 1\n\n def is_even(self):\n return self.parity() == 0\n\n @cached_method\n def multiplicative_order(self):\n return Mod(self.number, self.modulus).multiplicative_order()\n\n @property\n def order(self):\n return self.multiplicative_order()\n\n @cached_method\n def kronecker_symbol(self):\n c = self.conductor()\n p = self.parity()\n return kronecker_symbol(symbol_numerator(c, p))\n\n def conreyangle(self,x):\n return Rational(pari(\"chareval(%s,znconreylog(%s,%d),%d)\"%(self.G,self.G,self.number,x)))\n\n def gauss_sum_numerical(self, a):\n return pari(\"znchargauss(%s,%s,a=%d)\"%(self.G,self.chi_pari,a))\n\n def sage_zeta_order(self, order):\n return 1 if self.modulus <= 2 else lcm(2,order)\n\n def sage_character(self, order, genvalues):\n H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))\n M = H._module\n order_corrected_genvalues = get_sage_genvalues(self.modulus, order, genvalues, H.zeta_order())\n return DirichletCharacter(H,M(order_corrected_genvalues))\n", "path": "lmfdb/characters/TinyConrey.py"}]}
| 3,779 | 264 |
gh_patches_debug_14517
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-862
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make interactive visualizations default for Jupyter
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. -->
### What is the expected enhancement?
The interactive visualizations contributed in PR #765 are much better than the static ones, and should be default when the environment is a Jupyter notebook. This is related to Epic #707 for providing better jupyter tools.
Several issues must be solved first:
- These visualizations need internet connection. Can we eliminate that?
- The interface of the static and interactive visualizations are all the same, except for `plot_histogram` vs `iplot_histogram`. These should be made similar for consistency. But the interactive visualization is able to plot multiple histograms in one plot.
- How "heavy" is it to run these interactive visualizations? I hear my laptop fan.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/tools/visualization/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2018, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 """Main QISKit visualization methods."""
9
10 from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\
11 latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme
12 from ._state_visualization import plot_state
13 from ._counts_visualization import plot_histogram
14
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/tools/visualization/__init__.py b/qiskit/tools/visualization/__init__.py
--- a/qiskit/tools/visualization/__init__.py
+++ b/qiskit/tools/visualization/__init__.py
@@ -7,7 +7,18 @@
"""Main QISKit visualization methods."""
+import sys
+
from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\
latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme
-from ._state_visualization import plot_state
from ._counts_visualization import plot_histogram
+
+if ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):
+ import requests
+ if requests.get(
+ 'https://qvisualization.mybluemix.net/').status_code == 200:
+ from .interactive._iplot_state import iplot_state as plot_state
+ else:
+ from ._state_visualization import plot_state
+else:
+ from ._state_visualization import plot_state
|
{"golden_diff": "diff --git a/qiskit/tools/visualization/__init__.py b/qiskit/tools/visualization/__init__.py\n--- a/qiskit/tools/visualization/__init__.py\n+++ b/qiskit/tools/visualization/__init__.py\n@@ -7,7 +7,18 @@\n \n \"\"\"Main QISKit visualization methods.\"\"\"\n \n+import sys\n+\n from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\\\n latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme\n-from ._state_visualization import plot_state\n from ._counts_visualization import plot_histogram\n+\n+if ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n+ import requests\n+ if requests.get(\n+ 'https://qvisualization.mybluemix.net/').status_code == 200:\n+ from .interactive._iplot_state import iplot_state as plot_state\n+ else:\n+ from ._state_visualization import plot_state\n+else:\n+ from ._state_visualization import plot_state\n", "issue": "Make interactive visualizations default for Jupyter\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues to confirm this idea does not exist. -->\r\n\r\n### What is the expected enhancement?\r\nThe interactive visualizations contributed in PR #765 are much better than the static ones, and should be default when the environment is a Jupyter notebook. This is related to Epic #707 for providing better jupyter tools.\r\n\r\nSeveral issues must be solved first:\r\n- These visualizations need internet connection. Can we eliminate that?\r\n- The interface of the static and interactive visualizations are all the same, except for `plot_histogram` vs `iplot_histogram`. These should be made similar for consistency. But the interactive visualization is able to plot multiple histograms in one plot.\r\n- How \"heavy\" is it to run these interactive visualizations? I hear my laptop fan.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"Main QISKit visualization methods.\"\"\"\n\nfrom ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\\\n latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme\nfrom ._state_visualization import plot_state\nfrom ._counts_visualization import plot_histogram\n", "path": "qiskit/tools/visualization/__init__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"Main QISKit visualization methods.\"\"\"\n\nimport sys\n\nfrom ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\\\n latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme\nfrom ._counts_visualization import plot_histogram\n\nif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n import requests\n if requests.get(\n 'https://qvisualization.mybluemix.net/').status_code == 200:\n from .interactive._iplot_state import iplot_state as plot_state\n else:\n from ._state_visualization import plot_state\nelse:\n from ._state_visualization import plot_state\n", "path": "qiskit/tools/visualization/__init__.py"}]}
| 593 | 230 |
gh_patches_debug_50209
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2286
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`venv create` no longer includes `--sources-directory` contents when all files are nested
It seems like there was a regression from 2.1.148 -> 2.1.149 with the behaviour of `venv create` with a `--pex-repository` that was created with `--sources-directory`: those sources aren't included in the final venv.
Reproducer:
```shell
cd $(mktemp -d)
# create our dummy file
mkdir -p source_files/foo
touch source_files/foo/bar.py # NB.1
# touch source_files/qux.py # NB.2
for version in v2.1.148 v2.1.149; do
curl -s -L https://github.com/pantsbuild/pex/releases/download/$version/pex > pex-$version
chmod +x pex-$version
# NB.3
./pex-$version --output-file=repository-$version.pex --sources-directory=source_files
# NB.4
PEX_SCRIPT=pex3 ./pex-$version venv create --dest-dir=dest-$version --pex-repository=repository-$version.pex --layout=flat
# what was included?
tree dest-$version
done
```
Running that shows that the contents of the `dest-...` directory depends on the version, without the `bar.py` file when using v2.1.149, but should be the same:
```
dest-v2.1.148
└── foo
└── bar.py
1 directory, 1 file
dest-v2.1.149
0 directories, 0 files
```
Ablative studies:
- uncommenting `NB.2` line (to have two files) passes ✅ (both versions have both `foo/bar.py` and `qux.py`)
- _replacing_ the `NB.1` with `NB.2` (to just `qux.py` at the top level) passes ✅
- _always_ using v2.1.148 on line `NB.3` (create the pex) and v2.1.149 on line `NB.4` (create the venv) passes ✅
- v2.1.149 for `NB.3` and v2.1.148 for `NB.4` fails ❌
- I think third-party dependencies work okay, but haven't confirmed in this reduced setting
- This reproduces without `--layout`, but the output is simpler with `--layout=flat`
(First observed in https://github.com/pantsbuild/pants/pull/20149.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/util.py`
Content:
```
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import
5
6 import contextlib
7 import hashlib
8 import importlib
9 import os
10 import shutil
11 import tempfile
12 from hashlib import sha1
13 from site import makepath # type: ignore[attr-defined]
14
15 from pex import hashing
16 from pex.common import is_pyc_dir, is_pyc_file, safe_mkdir, safe_mkdtemp
17 from pex.compatibility import ( # type: ignore[attr-defined] # `exec_function` is defined dynamically
18 PY2,
19 exec_function,
20 )
21 from pex.orderedset import OrderedSet
22 from pex.typing import TYPE_CHECKING
23
24 if TYPE_CHECKING:
25 from typing import IO, Any, Callable, Iterator, Optional, Text
26
27 from pex.hashing import Hasher
28
29
30 class DistributionHelper(object):
31 # TODO(#584: This appears unused, but clients might still use it. We cannot remove until we
32 # have a deprecation policy.
33 @classmethod
34 def access_zipped_assets(cls, static_module_name, static_path, dir_location=None):
35 # type: (str, str, Optional[str]) -> str
36 """Create a copy of static resource files as we can't serve them from within the pex file.
37
38 :param static_module_name: Module name containing module to cache in a tempdir
39 :param static_path: Module name, for example 'serverset'
40 :param dir_location: create a new temporary directory inside, or None to have one created
41 :returns temp_dir: Temporary directory with the zipped assets inside
42 """
43 if dir_location is None:
44 temp_dir = safe_mkdtemp()
45 else:
46 temp_dir = dir_location
47
48 module = importlib.import_module(static_module_name)
49 # N.B.: This handles namespace packages new and old.
50 paths = OrderedSet(os.path.realpath(d) for d in getattr(module, "__path__", []))
51 if module.__file__:
52 # And this handles old-style __init__.py packages.
53 paths.add(os.path.realpath(module.__file__))
54
55 safe_mkdir(temp_dir)
56 for path in paths:
57 resource_dir = os.path.realpath(os.path.join(path, static_path))
58 if os.path.isdir(resource_dir):
59 for root, dirs, files in os.walk(resource_dir):
60 for d in dirs:
61 safe_mkdir(
62 os.path.join(
63 temp_dir, os.path.relpath(os.path.join(root, d), resource_dir)
64 )
65 )
66 for f in files:
67 src = os.path.join(root, f)
68 shutil.copy(src, os.path.join(temp_dir, os.path.relpath(src, resource_dir)))
69 return temp_dir
70
71
72 class CacheHelper(object):
73 @classmethod
74 def hash(cls, path, digest=None, hasher=sha1):
75 # type: (Text, Optional[Hasher], Callable[[], Hasher]) -> str
76 """Return the digest of a single file in a memory-efficient manner."""
77 if digest is None:
78 digest = hasher()
79 hashing.file_hash(path, digest)
80 return digest.hexdigest()
81
82 @classmethod
83 def pex_code_hash(cls, directory):
84 # type: (str) -> str
85 """Return a reproducible hash of the contents of a loose PEX; excluding all `.pyc` files."""
86 digest = hashlib.sha1()
87 hashing.dir_hash(
88 directory=directory,
89 digest=digest,
90 dir_filter=is_pyc_dir,
91 file_filter=lambda file_path: not is_pyc_file(file_path)
92 and not file_path.startswith("."),
93 )
94 return digest.hexdigest()
95
96 @classmethod
97 def dir_hash(cls, directory, digest=None, hasher=sha1):
98 # type: (str, Optional[Hasher], Callable[[], Hasher]) -> str
99 """Return a reproducible hash of the contents of a directory; excluding all `.pyc` files."""
100 if digest is None:
101 digest = hasher()
102 hashing.dir_hash(
103 directory=directory,
104 digest=digest,
105 dir_filter=lambda d: not is_pyc_dir(d),
106 file_filter=lambda f: not is_pyc_file(f),
107 )
108 return digest.hexdigest()
109
110 @classmethod
111 def zip_hash(
112 cls,
113 zip_path, # type: str
114 relpath=None, # type: Optional[str]
115 ):
116 # type: (...) -> str
117 """Return a reproducible hash of the contents of a zip; excluding all `.pyc` files."""
118 digest = hashlib.sha1()
119 hashing.zip_hash(
120 zip_path=zip_path,
121 digest=digest,
122 relpath=relpath,
123 dir_filter=lambda d: not is_pyc_dir(d),
124 file_filter=lambda f: not is_pyc_file(f),
125 )
126 return digest.hexdigest()
127
128
129 @contextlib.contextmanager
130 def named_temporary_file(**kwargs):
131 # type: (**Any) -> Iterator[IO]
132 """Due to a bug in python (https://bugs.python.org/issue14243), we need this to be able to use
133 the temporary file without deleting it."""
134 assert "delete" not in kwargs
135 kwargs["delete"] = False
136 fp = tempfile.NamedTemporaryFile(**kwargs)
137 try:
138 with fp:
139 yield fp
140 finally:
141 os.remove(fp.name)
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/util.py b/pex/util.py
--- a/pex/util.py
+++ b/pex/util.py
@@ -87,7 +87,7 @@
hashing.dir_hash(
directory=directory,
digest=digest,
- dir_filter=is_pyc_dir,
+ dir_filter=lambda d: not is_pyc_dir(d),
file_filter=lambda file_path: not is_pyc_file(file_path)
and not file_path.startswith("."),
)
|
{"golden_diff": "diff --git a/pex/util.py b/pex/util.py\n--- a/pex/util.py\n+++ b/pex/util.py\n@@ -87,7 +87,7 @@\n hashing.dir_hash(\n directory=directory,\n digest=digest,\n- dir_filter=is_pyc_dir,\n+ dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda file_path: not is_pyc_file(file_path)\n and not file_path.startswith(\".\"),\n )\n", "issue": "`venv create` no longer includes `--sources-directory` contents when all files are nested\nIt seems like there was a regression from 2.1.148 -> 2.1.149 with the behaviour of `venv create` with a `--pex-repository` that was created with `--sources-directory`: those sources aren't included in the final venv.\r\n\r\nReproducer:\r\n\r\n```shell\r\ncd $(mktemp -d)\r\n\r\n# create our dummy file\r\nmkdir -p source_files/foo\r\ntouch source_files/foo/bar.py # NB.1\r\n# touch source_files/qux.py # NB.2\r\n\r\nfor version in v2.1.148 v2.1.149; do\r\n curl -s -L https://github.com/pantsbuild/pex/releases/download/$version/pex > pex-$version\r\n chmod +x pex-$version\r\n\r\n # NB.3\r\n ./pex-$version --output-file=repository-$version.pex --sources-directory=source_files\r\n\r\n # NB.4\r\n PEX_SCRIPT=pex3 ./pex-$version venv create --dest-dir=dest-$version --pex-repository=repository-$version.pex --layout=flat\r\n\r\n # what was included?\r\n tree dest-$version\r\ndone\r\n```\r\n\r\nRunning that shows that the contents of the `dest-...` directory depends on the version, without the `bar.py` file when using v2.1.149, but should be the same:\r\n\r\n```\r\ndest-v2.1.148\r\n\u2514\u2500\u2500 foo\r\n \u2514\u2500\u2500 bar.py\r\n\r\n1 directory, 1 file\r\ndest-v2.1.149\r\n\r\n0 directories, 0 files\r\n```\r\n\r\nAblative studies:\r\n\r\n- uncommenting `NB.2` line (to have two files) passes \u2705 (both versions have both `foo/bar.py` and `qux.py`)\r\n- _replacing_ the `NB.1` with `NB.2` (to just `qux.py` at the top level) passes \u2705 \r\n- _always_ using v2.1.148 on line `NB.3` (create the pex) and v2.1.149 on line `NB.4` (create the venv) passes \u2705 \r\n- v2.1.149 for `NB.3` and v2.1.148 for `NB.4` fails \u274c \r\n- I think third-party dependencies work okay, but haven't confirmed in this reduced setting\r\n- This reproduces without `--layout`, but the output is simpler with `--layout=flat`\r\n\r\n(First observed in https://github.com/pantsbuild/pants/pull/20149.)\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import\n\nimport contextlib\nimport hashlib\nimport importlib\nimport os\nimport shutil\nimport tempfile\nfrom hashlib import sha1\nfrom site import makepath # type: ignore[attr-defined]\n\nfrom pex import hashing\nfrom pex.common import is_pyc_dir, is_pyc_file, safe_mkdir, safe_mkdtemp\nfrom pex.compatibility import ( # type: ignore[attr-defined] # `exec_function` is defined dynamically\n PY2,\n exec_function,\n)\nfrom pex.orderedset import OrderedSet\nfrom pex.typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from typing import IO, Any, Callable, Iterator, Optional, Text\n\n from pex.hashing import Hasher\n\n\nclass DistributionHelper(object):\n # TODO(#584: This appears unused, but clients might still use it. We cannot remove until we\n # have a deprecation policy.\n @classmethod\n def access_zipped_assets(cls, static_module_name, static_path, dir_location=None):\n # type: (str, str, Optional[str]) -> str\n \"\"\"Create a copy of static resource files as we can't serve them from within the pex file.\n\n :param static_module_name: Module name containing module to cache in a tempdir\n :param static_path: Module name, for example 'serverset'\n :param dir_location: create a new temporary directory inside, or None to have one created\n :returns temp_dir: Temporary directory with the zipped assets inside\n \"\"\"\n if dir_location is None:\n temp_dir = safe_mkdtemp()\n else:\n temp_dir = dir_location\n\n module = importlib.import_module(static_module_name)\n # N.B.: This handles namespace packages new and old.\n paths = OrderedSet(os.path.realpath(d) for d in getattr(module, \"__path__\", []))\n if module.__file__:\n # And this handles old-style __init__.py packages.\n paths.add(os.path.realpath(module.__file__))\n\n safe_mkdir(temp_dir)\n for path in paths:\n resource_dir = os.path.realpath(os.path.join(path, static_path))\n if os.path.isdir(resource_dir):\n for root, dirs, files in os.walk(resource_dir):\n for d in dirs:\n safe_mkdir(\n os.path.join(\n temp_dir, os.path.relpath(os.path.join(root, d), resource_dir)\n )\n )\n for f in files:\n src = os.path.join(root, f)\n shutil.copy(src, os.path.join(temp_dir, os.path.relpath(src, resource_dir)))\n return temp_dir\n\n\nclass CacheHelper(object):\n @classmethod\n def hash(cls, path, digest=None, hasher=sha1):\n # type: (Text, Optional[Hasher], Callable[[], Hasher]) -> str\n \"\"\"Return the digest of a single file in a memory-efficient manner.\"\"\"\n if digest is None:\n digest = hasher()\n hashing.file_hash(path, digest)\n return digest.hexdigest()\n\n @classmethod\n def pex_code_hash(cls, directory):\n # type: (str) -> str\n \"\"\"Return a reproducible hash of the contents of a loose PEX; excluding all `.pyc` files.\"\"\"\n digest = hashlib.sha1()\n hashing.dir_hash(\n directory=directory,\n digest=digest,\n dir_filter=is_pyc_dir,\n file_filter=lambda file_path: not is_pyc_file(file_path)\n and not file_path.startswith(\".\"),\n )\n return digest.hexdigest()\n\n @classmethod\n def dir_hash(cls, directory, digest=None, hasher=sha1):\n # type: (str, Optional[Hasher], Callable[[], Hasher]) -> str\n \"\"\"Return a reproducible hash of the contents of a directory; excluding all `.pyc` files.\"\"\"\n if digest is None:\n digest = hasher()\n hashing.dir_hash(\n directory=directory,\n digest=digest,\n dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda f: not is_pyc_file(f),\n )\n return digest.hexdigest()\n\n @classmethod\n def zip_hash(\n cls,\n zip_path, # type: str\n relpath=None, # type: Optional[str]\n ):\n # type: (...) -> str\n \"\"\"Return a reproducible hash of the contents of a zip; excluding all `.pyc` files.\"\"\"\n digest = hashlib.sha1()\n hashing.zip_hash(\n zip_path=zip_path,\n digest=digest,\n relpath=relpath,\n dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda f: not is_pyc_file(f),\n )\n return digest.hexdigest()\n\n\[email protected]\ndef named_temporary_file(**kwargs):\n # type: (**Any) -> Iterator[IO]\n \"\"\"Due to a bug in python (https://bugs.python.org/issue14243), we need this to be able to use\n the temporary file without deleting it.\"\"\"\n assert \"delete\" not in kwargs\n kwargs[\"delete\"] = False\n fp = tempfile.NamedTemporaryFile(**kwargs)\n try:\n with fp:\n yield fp\n finally:\n os.remove(fp.name)\n", "path": "pex/util.py"}], "after_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import\n\nimport contextlib\nimport hashlib\nimport importlib\nimport os\nimport shutil\nimport tempfile\nfrom hashlib import sha1\nfrom site import makepath # type: ignore[attr-defined]\n\nfrom pex import hashing\nfrom pex.common import is_pyc_dir, is_pyc_file, safe_mkdir, safe_mkdtemp\nfrom pex.compatibility import ( # type: ignore[attr-defined] # `exec_function` is defined dynamically\n PY2,\n exec_function,\n)\nfrom pex.orderedset import OrderedSet\nfrom pex.typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from typing import IO, Any, Callable, Iterator, Optional, Text\n\n from pex.hashing import Hasher\n\n\nclass DistributionHelper(object):\n # TODO(#584: This appears unused, but clients might still use it. We cannot remove until we\n # have a deprecation policy.\n @classmethod\n def access_zipped_assets(cls, static_module_name, static_path, dir_location=None):\n # type: (str, str, Optional[str]) -> str\n \"\"\"Create a copy of static resource files as we can't serve them from within the pex file.\n\n :param static_module_name: Module name containing module to cache in a tempdir\n :param static_path: Module name, for example 'serverset'\n :param dir_location: create a new temporary directory inside, or None to have one created\n :returns temp_dir: Temporary directory with the zipped assets inside\n \"\"\"\n if dir_location is None:\n temp_dir = safe_mkdtemp()\n else:\n temp_dir = dir_location\n\n module = importlib.import_module(static_module_name)\n # N.B.: This handles namespace packages new and old.\n paths = OrderedSet(os.path.realpath(d) for d in getattr(module, \"__path__\", []))\n if module.__file__:\n # And this handles old-style __init__.py packages.\n paths.add(os.path.realpath(module.__file__))\n\n safe_mkdir(temp_dir)\n for path in paths:\n resource_dir = os.path.realpath(os.path.join(path, static_path))\n if os.path.isdir(resource_dir):\n for root, dirs, files in os.walk(resource_dir):\n for d in dirs:\n safe_mkdir(\n os.path.join(\n temp_dir, os.path.relpath(os.path.join(root, d), resource_dir)\n )\n )\n for f in files:\n src = os.path.join(root, f)\n shutil.copy(src, os.path.join(temp_dir, os.path.relpath(src, resource_dir)))\n return temp_dir\n\n\nclass CacheHelper(object):\n @classmethod\n def hash(cls, path, digest=None, hasher=sha1):\n # type: (Text, Optional[Hasher], Callable[[], Hasher]) -> str\n \"\"\"Return the digest of a single file in a memory-efficient manner.\"\"\"\n if digest is None:\n digest = hasher()\n hashing.file_hash(path, digest)\n return digest.hexdigest()\n\n @classmethod\n def pex_code_hash(cls, directory):\n # type: (str) -> str\n \"\"\"Return a reproducible hash of the contents of a loose PEX; excluding all `.pyc` files.\"\"\"\n digest = hashlib.sha1()\n hashing.dir_hash(\n directory=directory,\n digest=digest,\n dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda file_path: not is_pyc_file(file_path)\n and not file_path.startswith(\".\"),\n )\n return digest.hexdigest()\n\n @classmethod\n def dir_hash(cls, directory, digest=None, hasher=sha1):\n # type: (str, Optional[Hasher], Callable[[], Hasher]) -> str\n \"\"\"Return a reproducible hash of the contents of a directory; excluding all `.pyc` files.\"\"\"\n if digest is None:\n digest = hasher()\n hashing.dir_hash(\n directory=directory,\n digest=digest,\n dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda f: not is_pyc_file(f),\n )\n return digest.hexdigest()\n\n @classmethod\n def zip_hash(\n cls,\n zip_path, # type: str\n relpath=None, # type: Optional[str]\n ):\n # type: (...) -> str\n \"\"\"Return a reproducible hash of the contents of a zip; excluding all `.pyc` files.\"\"\"\n digest = hashlib.sha1()\n hashing.zip_hash(\n zip_path=zip_path,\n digest=digest,\n relpath=relpath,\n dir_filter=lambda d: not is_pyc_dir(d),\n file_filter=lambda f: not is_pyc_file(f),\n )\n return digest.hexdigest()\n\n\[email protected]\ndef named_temporary_file(**kwargs):\n # type: (**Any) -> Iterator[IO]\n \"\"\"Due to a bug in python (https://bugs.python.org/issue14243), we need this to be able to use\n the temporary file without deleting it.\"\"\"\n assert \"delete\" not in kwargs\n kwargs[\"delete\"] = False\n fp = tempfile.NamedTemporaryFile(**kwargs)\n try:\n with fp:\n yield fp\n finally:\n os.remove(fp.name)\n", "path": "pex/util.py"}]}
| 2,337 | 103 |
gh_patches_debug_28189
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-4718
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API Definitions for available-ips and available-prefixes are incorrect
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
Please indicate the nature of the change by placing an X in one of the
boxes below.
-->
### Change Type
[ ] Addition
[x] Correction
[ ] Deprecation
[ ] Cleanup (formatting, typos, etc.)
### Area
[ ] Installation instructions
[ ] Configuration parameters
[ ] Functionality/features
[x] REST API
[ ] Administration/development
[ ] Other
<!-- Describe the proposed change(s). -->
### Proposed Changes
I'm writing a ipam project with go-netbox(https://github.com/kobayashi/go-netbox for v2.8), which generate the client from swagger. And I'm using the prefix/available-ips api to create unused ip address. I notice that the api documents in http://netbox/api/docs/ has difference with actually code:
* The request model should be IPAddress rather than WritablePrefix
_ref: https://github.com/netbox-community/netbox/blob/v2.8.3/netbox/ipam/api/views.py#L211_
* The return code should be 201 rather than 200
_ref: https://github.com/netbox-community/netbox/blob/v2.8.3/netbox/ipam/api/views.py#L218_
These mismatches make go-netbox client unable to work correctly. I would appreciate if this can be fixed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/ipam/api/views.py`
Content:
```
1 from django.conf import settings
2 from django.db.models import Count
3 from django.shortcuts import get_object_or_404
4 from django_pglocks import advisory_lock
5 from drf_yasg.utils import swagger_auto_schema
6 from rest_framework import status
7 from rest_framework.decorators import action
8 from rest_framework.exceptions import PermissionDenied
9 from rest_framework.response import Response
10
11 from extras.api.views import CustomFieldModelViewSet
12 from ipam import filters
13 from ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF
14 from utilities.api import ModelViewSet
15 from utilities.constants import ADVISORY_LOCK_KEYS
16 from utilities.utils import get_subquery
17 from . import serializers
18
19
20 #
21 # VRFs
22 #
23
24 class VRFViewSet(CustomFieldModelViewSet):
25 queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(
26 ipaddress_count=get_subquery(IPAddress, 'vrf'),
27 prefix_count=get_subquery(Prefix, 'vrf')
28 )
29 serializer_class = serializers.VRFSerializer
30 filterset_class = filters.VRFFilterSet
31
32
33 #
34 # RIRs
35 #
36
37 class RIRViewSet(ModelViewSet):
38 queryset = RIR.objects.annotate(
39 aggregate_count=Count('aggregates')
40 )
41 serializer_class = serializers.RIRSerializer
42 filterset_class = filters.RIRFilterSet
43
44
45 #
46 # Aggregates
47 #
48
49 class AggregateViewSet(CustomFieldModelViewSet):
50 queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')
51 serializer_class = serializers.AggregateSerializer
52 filterset_class = filters.AggregateFilterSet
53
54
55 #
56 # Roles
57 #
58
59 class RoleViewSet(ModelViewSet):
60 queryset = Role.objects.annotate(
61 prefix_count=get_subquery(Prefix, 'role'),
62 vlan_count=get_subquery(VLAN, 'role')
63 )
64 serializer_class = serializers.RoleSerializer
65 filterset_class = filters.RoleFilterSet
66
67
68 #
69 # Prefixes
70 #
71
72 class PrefixViewSet(CustomFieldModelViewSet):
73 queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')
74 serializer_class = serializers.PrefixSerializer
75 filterset_class = filters.PrefixFilterSet
76
77 @swagger_auto_schema(
78 methods=['get', 'post'],
79 responses={
80 200: serializers.AvailablePrefixSerializer(many=True),
81 }
82 )
83 @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])
84 @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])
85 def available_prefixes(self, request, pk=None):
86 """
87 A convenience method for returning available child prefixes within a parent.
88
89 The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being
90 invoked in parallel, which results in a race condition where multiple insertions can occur.
91 """
92 prefix = get_object_or_404(Prefix, pk=pk)
93 available_prefixes = prefix.get_available_prefixes()
94
95 if request.method == 'POST':
96
97 # Permissions check
98 if not request.user.has_perm('ipam.add_prefix'):
99 raise PermissionDenied()
100
101 # Validate Requested Prefixes' length
102 serializer = serializers.PrefixLengthSerializer(
103 data=request.data if isinstance(request.data, list) else [request.data],
104 many=True,
105 context={
106 'request': request,
107 'prefix': prefix,
108 }
109 )
110 if not serializer.is_valid():
111 return Response(
112 serializer.errors,
113 status=status.HTTP_400_BAD_REQUEST
114 )
115
116 requested_prefixes = serializer.validated_data
117 # Allocate prefixes to the requested objects based on availability within the parent
118 for i, requested_prefix in enumerate(requested_prefixes):
119
120 # Find the first available prefix equal to or larger than the requested size
121 for available_prefix in available_prefixes.iter_cidrs():
122 if requested_prefix['prefix_length'] >= available_prefix.prefixlen:
123 allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])
124 requested_prefix['prefix'] = allocated_prefix
125 requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None
126 break
127 else:
128 return Response(
129 {
130 "detail": "Insufficient space is available to accommodate the requested prefix size(s)"
131 },
132 status=status.HTTP_204_NO_CONTENT
133 )
134
135 # Remove the allocated prefix from the list of available prefixes
136 available_prefixes.remove(allocated_prefix)
137
138 # Initialize the serializer with a list or a single object depending on what was requested
139 context = {'request': request}
140 if isinstance(request.data, list):
141 serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)
142 else:
143 serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)
144
145 # Create the new Prefix(es)
146 if serializer.is_valid():
147 serializer.save()
148 return Response(serializer.data, status=status.HTTP_201_CREATED)
149
150 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
151
152 else:
153
154 serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={
155 'request': request,
156 'vrf': prefix.vrf,
157 })
158
159 return Response(serializer.data)
160
161 @swagger_auto_schema(
162 methods=['get', 'post'],
163 responses={
164 200: serializers.AvailableIPSerializer(many=True),
165 }
166 )
167 @action(detail=True, url_path='available-ips', methods=['get', 'post'])
168 @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])
169 def available_ips(self, request, pk=None):
170 """
171 A convenience method for returning available IP addresses within a prefix. By default, the number of IPs
172 returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,
173 however results will not be paginated.
174
175 The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being
176 invoked in parallel, which results in a race condition where multiple insertions can occur.
177 """
178 prefix = get_object_or_404(Prefix, pk=pk)
179
180 # Create the next available IP within the prefix
181 if request.method == 'POST':
182
183 # Permissions check
184 if not request.user.has_perm('ipam.add_ipaddress'):
185 raise PermissionDenied()
186
187 # Normalize to a list of objects
188 requested_ips = request.data if isinstance(request.data, list) else [request.data]
189
190 # Determine if the requested number of IPs is available
191 available_ips = prefix.get_available_ips()
192 if available_ips.size < len(requested_ips):
193 return Response(
194 {
195 "detail": "An insufficient number of IP addresses are available within the prefix {} ({} "
196 "requested, {} available)".format(prefix, len(requested_ips), len(available_ips))
197 },
198 status=status.HTTP_204_NO_CONTENT
199 )
200
201 # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix
202 available_ips = iter(available_ips)
203 prefix_length = prefix.prefix.prefixlen
204 for requested_ip in requested_ips:
205 requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)
206 requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None
207
208 # Initialize the serializer with a list or a single object depending on what was requested
209 context = {'request': request}
210 if isinstance(request.data, list):
211 serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)
212 else:
213 serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)
214
215 # Create the new IP address(es)
216 if serializer.is_valid():
217 serializer.save()
218 return Response(serializer.data, status=status.HTTP_201_CREATED)
219
220 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
221
222 # Determine the maximum number of IPs to return
223 else:
224 try:
225 limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))
226 except ValueError:
227 limit = settings.PAGINATE_COUNT
228 if settings.MAX_PAGE_SIZE:
229 limit = min(limit, settings.MAX_PAGE_SIZE)
230
231 # Calculate available IPs within the prefix
232 ip_list = []
233 for index, ip in enumerate(prefix.get_available_ips(), start=1):
234 ip_list.append(ip)
235 if index == limit:
236 break
237 serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={
238 'request': request,
239 'prefix': prefix.prefix,
240 'vrf': prefix.vrf,
241 })
242
243 return Response(serializer.data)
244
245
246 #
247 # IP addresses
248 #
249
250 class IPAddressViewSet(CustomFieldModelViewSet):
251 queryset = IPAddress.objects.prefetch_related(
252 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',
253 'nat_outside', 'tags',
254 )
255 serializer_class = serializers.IPAddressSerializer
256 filterset_class = filters.IPAddressFilterSet
257
258
259 #
260 # VLAN groups
261 #
262
263 class VLANGroupViewSet(ModelViewSet):
264 queryset = VLANGroup.objects.prefetch_related('site').annotate(
265 vlan_count=Count('vlans')
266 )
267 serializer_class = serializers.VLANGroupSerializer
268 filterset_class = filters.VLANGroupFilterSet
269
270
271 #
272 # VLANs
273 #
274
275 class VLANViewSet(CustomFieldModelViewSet):
276 queryset = VLAN.objects.prefetch_related(
277 'site', 'group', 'tenant', 'role', 'tags'
278 ).annotate(
279 prefix_count=get_subquery(Prefix, 'vlan')
280 )
281 serializer_class = serializers.VLANSerializer
282 filterset_class = filters.VLANFilterSet
283
284
285 #
286 # Services
287 #
288
289 class ServiceViewSet(ModelViewSet):
290 queryset = Service.objects.prefetch_related('device').prefetch_related('tags')
291 serializer_class = serializers.ServiceSerializer
292 filterset_class = filters.ServiceFilterSet
293
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netbox/ipam/api/views.py b/netbox/ipam/api/views.py
--- a/netbox/ipam/api/views.py
+++ b/netbox/ipam/api/views.py
@@ -74,12 +74,8 @@
serializer_class = serializers.PrefixSerializer
filterset_class = filters.PrefixFilterSet
- @swagger_auto_schema(
- methods=['get', 'post'],
- responses={
- 200: serializers.AvailablePrefixSerializer(many=True),
- }
- )
+ @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})
+ @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})
@action(detail=True, url_path='available-prefixes', methods=['get', 'post'])
@advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])
def available_prefixes(self, request, pk=None):
@@ -158,12 +154,9 @@
return Response(serializer.data)
- @swagger_auto_schema(
- methods=['get', 'post'],
- responses={
- 200: serializers.AvailableIPSerializer(many=True),
- }
- )
+ @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})
+ @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},
+ request_body=serializers.AvailableIPSerializer(many=False))
@action(detail=True, url_path='available-ips', methods=['get', 'post'])
@advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])
def available_ips(self, request, pk=None):
|
{"golden_diff": "diff --git a/netbox/ipam/api/views.py b/netbox/ipam/api/views.py\n--- a/netbox/ipam/api/views.py\n+++ b/netbox/ipam/api/views.py\n@@ -74,12 +74,8 @@\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n \n- @swagger_auto_schema(\n- methods=['get', 'post'],\n- responses={\n- 200: serializers.AvailablePrefixSerializer(many=True),\n- }\n- )\n+ @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})\n+ @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])\n def available_prefixes(self, request, pk=None):\n@@ -158,12 +154,9 @@\n \n return Response(serializer.data)\n \n- @swagger_auto_schema(\n- methods=['get', 'post'],\n- responses={\n- 200: serializers.AvailableIPSerializer(many=True),\n- }\n- )\n+ @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})\n+ @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},\n+ request_body=serializers.AvailableIPSerializer(many=False))\n @action(detail=True, url_path='available-ips', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])\n def available_ips(self, request, pk=None):\n", "issue": "API Definitions for available-ips and available-prefixes are incorrect\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n Please indicate the nature of the change by placing an X in one of the\r\n boxes below.\r\n-->\r\n### Change Type\r\n[ ] Addition\r\n[x] Correction\r\n[ ] Deprecation\r\n[ ] Cleanup (formatting, typos, etc.)\r\n\r\n### Area\r\n[ ] Installation instructions\r\n[ ] Configuration parameters\r\n[ ] Functionality/features\r\n[x] REST API\r\n[ ] Administration/development\r\n[ ] Other\r\n\r\n<!-- Describe the proposed change(s). -->\r\n### Proposed Changes\r\nI'm writing a ipam project with go-netbox(https://github.com/kobayashi/go-netbox for v2.8), which generate the client from swagger. And I'm using the prefix/available-ips api to create unused ip address. I notice that the api documents in http://netbox/api/docs/ has difference with actually code:\r\n* The request model should be IPAddress rather than WritablePrefix\r\n _ref: https://github.com/netbox-community/netbox/blob/v2.8.3/netbox/ipam/api/views.py#L211_\r\n* The return code should be 201 rather than 200\r\n _ref: https://github.com/netbox-community/netbox/blob/v2.8.3/netbox/ipam/api/views.py#L218_\r\n\r\nThese mismatches make go-netbox client unable to work correctly. I would appreciate if this can be fixed.\n", "before_files": [{"content": "from django.conf import settings\nfrom django.db.models import Count\nfrom django.shortcuts import get_object_or_404\nfrom django_pglocks import advisory_lock\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework import status\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.response import Response\n\nfrom extras.api.views import CustomFieldModelViewSet\nfrom ipam import filters\nfrom ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF\nfrom utilities.api import ModelViewSet\nfrom utilities.constants import ADVISORY_LOCK_KEYS\nfrom utilities.utils import get_subquery\nfrom . import serializers\n\n\n#\n# VRFs\n#\n\nclass VRFViewSet(CustomFieldModelViewSet):\n queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(\n ipaddress_count=get_subquery(IPAddress, 'vrf'),\n prefix_count=get_subquery(Prefix, 'vrf')\n )\n serializer_class = serializers.VRFSerializer\n filterset_class = filters.VRFFilterSet\n\n\n#\n# RIRs\n#\n\nclass RIRViewSet(ModelViewSet):\n queryset = RIR.objects.annotate(\n aggregate_count=Count('aggregates')\n )\n serializer_class = serializers.RIRSerializer\n filterset_class = filters.RIRFilterSet\n\n\n#\n# Aggregates\n#\n\nclass AggregateViewSet(CustomFieldModelViewSet):\n queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')\n serializer_class = serializers.AggregateSerializer\n filterset_class = filters.AggregateFilterSet\n\n\n#\n# Roles\n#\n\nclass RoleViewSet(ModelViewSet):\n queryset = Role.objects.annotate(\n prefix_count=get_subquery(Prefix, 'role'),\n vlan_count=get_subquery(VLAN, 'role')\n )\n serializer_class = serializers.RoleSerializer\n filterset_class = filters.RoleFilterSet\n\n\n#\n# Prefixes\n#\n\nclass PrefixViewSet(CustomFieldModelViewSet):\n queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n\n @swagger_auto_schema(\n methods=['get', 'post'],\n responses={\n 200: serializers.AvailablePrefixSerializer(many=True),\n }\n )\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])\n def available_prefixes(self, request, pk=None):\n \"\"\"\n A convenience method for returning available child prefixes within a parent.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n available_prefixes = prefix.get_available_prefixes()\n\n if request.method == 'POST':\n\n # Permissions check\n if not request.user.has_perm('ipam.add_prefix'):\n raise PermissionDenied()\n\n # Validate Requested Prefixes' length\n serializer = serializers.PrefixLengthSerializer(\n data=request.data if isinstance(request.data, list) else [request.data],\n many=True,\n context={\n 'request': request,\n 'prefix': prefix,\n }\n )\n if not serializer.is_valid():\n return Response(\n serializer.errors,\n status=status.HTTP_400_BAD_REQUEST\n )\n\n requested_prefixes = serializer.validated_data\n # Allocate prefixes to the requested objects based on availability within the parent\n for i, requested_prefix in enumerate(requested_prefixes):\n\n # Find the first available prefix equal to or larger than the requested size\n for available_prefix in available_prefixes.iter_cidrs():\n if requested_prefix['prefix_length'] >= available_prefix.prefixlen:\n allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])\n requested_prefix['prefix'] = allocated_prefix\n requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None\n break\n else:\n return Response(\n {\n \"detail\": \"Insufficient space is available to accommodate the requested prefix size(s)\"\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Remove the allocated prefix from the list of available prefixes\n available_prefixes.remove(allocated_prefix)\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)\n else:\n serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)\n\n # Create the new Prefix(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n else:\n\n serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={\n 'request': request,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n @swagger_auto_schema(\n methods=['get', 'post'],\n responses={\n 200: serializers.AvailableIPSerializer(many=True),\n }\n )\n @action(detail=True, url_path='available-ips', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])\n def available_ips(self, request, pk=None):\n \"\"\"\n A convenience method for returning available IP addresses within a prefix. By default, the number of IPs\n returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,\n however results will not be paginated.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n\n # Create the next available IP within the prefix\n if request.method == 'POST':\n\n # Permissions check\n if not request.user.has_perm('ipam.add_ipaddress'):\n raise PermissionDenied()\n\n # Normalize to a list of objects\n requested_ips = request.data if isinstance(request.data, list) else [request.data]\n\n # Determine if the requested number of IPs is available\n available_ips = prefix.get_available_ips()\n if available_ips.size < len(requested_ips):\n return Response(\n {\n \"detail\": \"An insufficient number of IP addresses are available within the prefix {} ({} \"\n \"requested, {} available)\".format(prefix, len(requested_ips), len(available_ips))\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix\n available_ips = iter(available_ips)\n prefix_length = prefix.prefix.prefixlen\n for requested_ip in requested_ips:\n requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)\n requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)\n else:\n serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)\n\n # Create the new IP address(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n # Determine the maximum number of IPs to return\n else:\n try:\n limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))\n except ValueError:\n limit = settings.PAGINATE_COUNT\n if settings.MAX_PAGE_SIZE:\n limit = min(limit, settings.MAX_PAGE_SIZE)\n\n # Calculate available IPs within the prefix\n ip_list = []\n for index, ip in enumerate(prefix.get_available_ips(), start=1):\n ip_list.append(ip)\n if index == limit:\n break\n serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={\n 'request': request,\n 'prefix': prefix.prefix,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n\n#\n# IP addresses\n#\n\nclass IPAddressViewSet(CustomFieldModelViewSet):\n queryset = IPAddress.objects.prefetch_related(\n 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',\n 'nat_outside', 'tags',\n )\n serializer_class = serializers.IPAddressSerializer\n filterset_class = filters.IPAddressFilterSet\n\n\n#\n# VLAN groups\n#\n\nclass VLANGroupViewSet(ModelViewSet):\n queryset = VLANGroup.objects.prefetch_related('site').annotate(\n vlan_count=Count('vlans')\n )\n serializer_class = serializers.VLANGroupSerializer\n filterset_class = filters.VLANGroupFilterSet\n\n\n#\n# VLANs\n#\n\nclass VLANViewSet(CustomFieldModelViewSet):\n queryset = VLAN.objects.prefetch_related(\n 'site', 'group', 'tenant', 'role', 'tags'\n ).annotate(\n prefix_count=get_subquery(Prefix, 'vlan')\n )\n serializer_class = serializers.VLANSerializer\n filterset_class = filters.VLANFilterSet\n\n\n#\n# Services\n#\n\nclass ServiceViewSet(ModelViewSet):\n queryset = Service.objects.prefetch_related('device').prefetch_related('tags')\n serializer_class = serializers.ServiceSerializer\n filterset_class = filters.ServiceFilterSet\n", "path": "netbox/ipam/api/views.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.db.models import Count\nfrom django.shortcuts import get_object_or_404\nfrom django_pglocks import advisory_lock\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework import status\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.response import Response\n\nfrom extras.api.views import CustomFieldModelViewSet\nfrom ipam import filters\nfrom ipam.models import Aggregate, IPAddress, Prefix, RIR, Role, Service, VLAN, VLANGroup, VRF\nfrom utilities.api import ModelViewSet\nfrom utilities.constants import ADVISORY_LOCK_KEYS\nfrom utilities.utils import get_subquery\nfrom . import serializers\n\n\n#\n# VRFs\n#\n\nclass VRFViewSet(CustomFieldModelViewSet):\n queryset = VRF.objects.prefetch_related('tenant').prefetch_related('tags').annotate(\n ipaddress_count=get_subquery(IPAddress, 'vrf'),\n prefix_count=get_subquery(Prefix, 'vrf')\n )\n serializer_class = serializers.VRFSerializer\n filterset_class = filters.VRFFilterSet\n\n\n#\n# RIRs\n#\n\nclass RIRViewSet(ModelViewSet):\n queryset = RIR.objects.annotate(\n aggregate_count=Count('aggregates')\n )\n serializer_class = serializers.RIRSerializer\n filterset_class = filters.RIRFilterSet\n\n\n#\n# Aggregates\n#\n\nclass AggregateViewSet(CustomFieldModelViewSet):\n queryset = Aggregate.objects.prefetch_related('rir').prefetch_related('tags')\n serializer_class = serializers.AggregateSerializer\n filterset_class = filters.AggregateFilterSet\n\n\n#\n# Roles\n#\n\nclass RoleViewSet(ModelViewSet):\n queryset = Role.objects.annotate(\n prefix_count=get_subquery(Prefix, 'role'),\n vlan_count=get_subquery(VLAN, 'role')\n )\n serializer_class = serializers.RoleSerializer\n filterset_class = filters.RoleFilterSet\n\n\n#\n# Prefixes\n#\n\nclass PrefixViewSet(CustomFieldModelViewSet):\n queryset = Prefix.objects.prefetch_related('site', 'vrf__tenant', 'tenant', 'vlan', 'role', 'tags')\n serializer_class = serializers.PrefixSerializer\n filterset_class = filters.PrefixFilterSet\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailablePrefixSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailablePrefixSerializer(many=True)})\n @action(detail=True, url_path='available-prefixes', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-prefixes'])\n def available_prefixes(self, request, pk=None):\n \"\"\"\n A convenience method for returning available child prefixes within a parent.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n available_prefixes = prefix.get_available_prefixes()\n\n if request.method == 'POST':\n\n # Permissions check\n if not request.user.has_perm('ipam.add_prefix'):\n raise PermissionDenied()\n\n # Validate Requested Prefixes' length\n serializer = serializers.PrefixLengthSerializer(\n data=request.data if isinstance(request.data, list) else [request.data],\n many=True,\n context={\n 'request': request,\n 'prefix': prefix,\n }\n )\n if not serializer.is_valid():\n return Response(\n serializer.errors,\n status=status.HTTP_400_BAD_REQUEST\n )\n\n requested_prefixes = serializer.validated_data\n # Allocate prefixes to the requested objects based on availability within the parent\n for i, requested_prefix in enumerate(requested_prefixes):\n\n # Find the first available prefix equal to or larger than the requested size\n for available_prefix in available_prefixes.iter_cidrs():\n if requested_prefix['prefix_length'] >= available_prefix.prefixlen:\n allocated_prefix = '{}/{}'.format(available_prefix.network, requested_prefix['prefix_length'])\n requested_prefix['prefix'] = allocated_prefix\n requested_prefix['vrf'] = prefix.vrf.pk if prefix.vrf else None\n break\n else:\n return Response(\n {\n \"detail\": \"Insufficient space is available to accommodate the requested prefix size(s)\"\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Remove the allocated prefix from the list of available prefixes\n available_prefixes.remove(allocated_prefix)\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.PrefixSerializer(data=requested_prefixes, many=True, context=context)\n else:\n serializer = serializers.PrefixSerializer(data=requested_prefixes[0], context=context)\n\n # Create the new Prefix(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n else:\n\n serializer = serializers.AvailablePrefixSerializer(available_prefixes.iter_cidrs(), many=True, context={\n 'request': request,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n @swagger_auto_schema(method='get', responses={200: serializers.AvailableIPSerializer(many=True)})\n @swagger_auto_schema(method='post', responses={201: serializers.AvailableIPSerializer(many=True)},\n request_body=serializers.AvailableIPSerializer(many=False))\n @action(detail=True, url_path='available-ips', methods=['get', 'post'])\n @advisory_lock(ADVISORY_LOCK_KEYS['available-ips'])\n def available_ips(self, request, pk=None):\n \"\"\"\n A convenience method for returning available IP addresses within a prefix. By default, the number of IPs\n returned will be equivalent to PAGINATE_COUNT. An arbitrary limit (up to MAX_PAGE_SIZE, if set) may be passed,\n however results will not be paginated.\n\n The advisory lock decorator uses a PostgreSQL advisory lock to prevent this API from being\n invoked in parallel, which results in a race condition where multiple insertions can occur.\n \"\"\"\n prefix = get_object_or_404(Prefix, pk=pk)\n\n # Create the next available IP within the prefix\n if request.method == 'POST':\n\n # Permissions check\n if not request.user.has_perm('ipam.add_ipaddress'):\n raise PermissionDenied()\n\n # Normalize to a list of objects\n requested_ips = request.data if isinstance(request.data, list) else [request.data]\n\n # Determine if the requested number of IPs is available\n available_ips = prefix.get_available_ips()\n if available_ips.size < len(requested_ips):\n return Response(\n {\n \"detail\": \"An insufficient number of IP addresses are available within the prefix {} ({} \"\n \"requested, {} available)\".format(prefix, len(requested_ips), len(available_ips))\n },\n status=status.HTTP_204_NO_CONTENT\n )\n\n # Assign addresses from the list of available IPs and copy VRF assignment from the parent prefix\n available_ips = iter(available_ips)\n prefix_length = prefix.prefix.prefixlen\n for requested_ip in requested_ips:\n requested_ip['address'] = '{}/{}'.format(next(available_ips), prefix_length)\n requested_ip['vrf'] = prefix.vrf.pk if prefix.vrf else None\n\n # Initialize the serializer with a list or a single object depending on what was requested\n context = {'request': request}\n if isinstance(request.data, list):\n serializer = serializers.IPAddressSerializer(data=requested_ips, many=True, context=context)\n else:\n serializer = serializers.IPAddressSerializer(data=requested_ips[0], context=context)\n\n # Create the new IP address(es)\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n # Determine the maximum number of IPs to return\n else:\n try:\n limit = int(request.query_params.get('limit', settings.PAGINATE_COUNT))\n except ValueError:\n limit = settings.PAGINATE_COUNT\n if settings.MAX_PAGE_SIZE:\n limit = min(limit, settings.MAX_PAGE_SIZE)\n\n # Calculate available IPs within the prefix\n ip_list = []\n for index, ip in enumerate(prefix.get_available_ips(), start=1):\n ip_list.append(ip)\n if index == limit:\n break\n serializer = serializers.AvailableIPSerializer(ip_list, many=True, context={\n 'request': request,\n 'prefix': prefix.prefix,\n 'vrf': prefix.vrf,\n })\n\n return Response(serializer.data)\n\n\n#\n# IP addresses\n#\n\nclass IPAddressViewSet(CustomFieldModelViewSet):\n queryset = IPAddress.objects.prefetch_related(\n 'vrf__tenant', 'tenant', 'nat_inside', 'interface__device__device_type', 'interface__virtual_machine',\n 'nat_outside', 'tags',\n )\n serializer_class = serializers.IPAddressSerializer\n filterset_class = filters.IPAddressFilterSet\n\n\n#\n# VLAN groups\n#\n\nclass VLANGroupViewSet(ModelViewSet):\n queryset = VLANGroup.objects.prefetch_related('site').annotate(\n vlan_count=Count('vlans')\n )\n serializer_class = serializers.VLANGroupSerializer\n filterset_class = filters.VLANGroupFilterSet\n\n\n#\n# VLANs\n#\n\nclass VLANViewSet(CustomFieldModelViewSet):\n queryset = VLAN.objects.prefetch_related(\n 'site', 'group', 'tenant', 'role', 'tags'\n ).annotate(\n prefix_count=get_subquery(Prefix, 'vlan')\n )\n serializer_class = serializers.VLANSerializer\n filterset_class = filters.VLANFilterSet\n\n\n#\n# Services\n#\n\nclass ServiceViewSet(ModelViewSet):\n queryset = Service.objects.prefetch_related('device').prefetch_related('tags')\n serializer_class = serializers.ServiceSerializer\n filterset_class = filters.ServiceFilterSet\n", "path": "netbox/ipam/api/views.py"}]}
| 3,512 | 392 |
gh_patches_debug_40882
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-3193
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clean up and Document the io.image enhancements
PR #3024 introduced a few enhancements on the `io.image` methods used for reading JPEG and PNG images. The code changes were merged but there are a few nice-to-have improvements missing.
More specifically:
- [x] Provide better error messages for [JPEG](https://github.com/pytorch/vision/pull/3024#discussion_r527066925) and [PNG](https://github.com/pytorch/vision/pull/3024#discussion_r527093866) when a specific `ImageReadMode` value is not supported.
- [x] Ensure that `image_read_mode.h` has a new line at the [end of the file](https://github.com/pytorch/vision/pull/3024#discussion_r526710809).
- [x] [Replace](https://github.com/pytorch/vision/pull/3024#discussion_r527065253) the old `#define` with the newer `constexpr` expression at `image_read_mode.h`.
- [x] [Move the documentation](https://github.com/pytorch/vision/pull/3024#discussion_r527095264) of `ImageReadMode` values from the methods to the enum.
**Note:** `constexpr` might cause problems on Windows. If that's the case, try using const instead.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/io/image.py`
Content:
```
1 import torch
2
3 import os
4 import os.path as osp
5 import importlib.machinery
6
7 from enum import Enum
8
9 _HAS_IMAGE_OPT = False
10
11 try:
12 lib_dir = osp.abspath(osp.join(osp.dirname(__file__), ".."))
13
14 loader_details = (
15 importlib.machinery.ExtensionFileLoader,
16 importlib.machinery.EXTENSION_SUFFIXES
17 )
18
19 extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]
20 ext_specs = extfinder.find_spec("image")
21
22 if os.name == 'nt':
23 # Load the image extension using LoadLibraryExW
24 import ctypes
25 import sys
26
27 kernel32 = ctypes.WinDLL('kernel32.dll', use_last_error=True)
28 with_load_library_flags = hasattr(kernel32, 'AddDllDirectory')
29 prev_error_mode = kernel32.SetErrorMode(0x0001)
30
31 kernel32.LoadLibraryW.restype = ctypes.c_void_p
32 if with_load_library_flags:
33 kernel32.LoadLibraryExW.restype = ctypes.c_void_p
34
35 if ext_specs is not None:
36 res = kernel32.LoadLibraryExW(ext_specs.origin, None, 0x00001100)
37 if res is None:
38 err = ctypes.WinError(ctypes.get_last_error())
39 err.strerror += (f' Error loading "{ext_specs.origin}" or any or '
40 'its dependencies.')
41 raise err
42
43 kernel32.SetErrorMode(prev_error_mode)
44
45 if ext_specs is not None:
46 torch.ops.load_library(ext_specs.origin)
47 _HAS_IMAGE_OPT = True
48 except (ImportError, OSError):
49 pass
50
51
52 class ImageReadMode(Enum):
53 UNCHANGED = 0
54 GRAY = 1
55 GRAY_ALPHA = 2
56 RGB = 3
57 RGB_ALPHA = 4
58
59
60 def read_file(path: str) -> torch.Tensor:
61 """
62 Reads and outputs the bytes contents of a file as a uint8 Tensor
63 with one dimension.
64
65 Arguments:
66 path (str): the path to the file to be read
67
68 Returns:
69 data (Tensor)
70 """
71 data = torch.ops.image.read_file(path)
72 return data
73
74
75 def write_file(filename: str, data: torch.Tensor) -> None:
76 """
77 Writes the contents of a uint8 tensor with one dimension to a
78 file.
79
80 Arguments:
81 filename (str): the path to the file to be written
82 data (Tensor): the contents to be written to the output file
83 """
84 torch.ops.image.write_file(filename, data)
85
86
87 def decode_png(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:
88 """
89 Decodes a PNG image into a 3 dimensional RGB Tensor.
90 Optionally converts the image to the desired format.
91 The values of the output tensor are uint8 between 0 and 255.
92
93 Arguments:
94 input (Tensor[1]): a one dimensional uint8 tensor containing
95 the raw bytes of the PNG image.
96 mode (ImageReadMode): the read mode used for optionally
97 converting the image. Use `ImageReadMode.UNCHANGED` for loading
98 the image as-is, `ImageReadMode.GRAY` for converting to grayscale,
99 `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,
100 `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for
101 RGB with transparency. Default: `ImageReadMode.UNCHANGED`
102
103 Returns:
104 output (Tensor[image_channels, image_height, image_width])
105 """
106 output = torch.ops.image.decode_png(input, mode.value)
107 return output
108
109
110 def encode_png(input: torch.Tensor, compression_level: int = 6) -> torch.Tensor:
111 """
112 Takes an input tensor in CHW layout and returns a buffer with the contents
113 of its corresponding PNG file.
114
115 Parameters
116 ----------
117 input: Tensor[channels, image_height, image_width]
118 int8 image tensor of `c` channels, where `c` must 3 or 1.
119 compression_level: int
120 Compression factor for the resulting file, it must be a number
121 between 0 and 9. Default: 6
122
123 Returns
124 -------
125 output: Tensor[1]
126 A one dimensional int8 tensor that contains the raw bytes of the
127 PNG file.
128 """
129 output = torch.ops.image.encode_png(input, compression_level)
130 return output
131
132
133 def write_png(input: torch.Tensor, filename: str, compression_level: int = 6):
134 """
135 Takes an input tensor in CHW layout (or HW in the case of grayscale images)
136 and saves it in a PNG file.
137
138 Parameters
139 ----------
140 input: Tensor[channels, image_height, image_width]
141 int8 image tensor of `c` channels, where `c` must be 1 or 3.
142 filename: str
143 Path to save the image.
144 compression_level: int
145 Compression factor for the resulting file, it must be a number
146 between 0 and 9. Default: 6
147 """
148 output = encode_png(input, compression_level)
149 write_file(filename, output)
150
151
152 def decode_jpeg(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:
153 """
154 Decodes a JPEG image into a 3 dimensional RGB Tensor.
155 Optionally converts the image to the desired format.
156 The values of the output tensor are uint8 between 0 and 255.
157
158 Arguments:
159 input (Tensor[1]): a one dimensional uint8 tensor containing
160 the raw bytes of the JPEG image.
161 mode (ImageReadMode): the read mode used for optionally
162 converting the image. Use `ImageReadMode.UNCHANGED` for loading
163 the image as-is, `ImageReadMode.GRAY` for converting to grayscale
164 and `ImageReadMode.RGB` for RGB. Default: `ImageReadMode.UNCHANGED`
165
166 Returns:
167 output (Tensor[image_channels, image_height, image_width])
168 """
169 output = torch.ops.image.decode_jpeg(input, mode.value)
170 return output
171
172
173 def encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:
174 """
175 Takes an input tensor in CHW layout and returns a buffer with the contents
176 of its corresponding JPEG file.
177
178 Parameters
179 ----------
180 input: Tensor[channels, image_height, image_width])
181 int8 image tensor of `c` channels, where `c` must be 1 or 3.
182 quality: int
183 Quality of the resulting JPEG file, it must be a number between
184 1 and 100. Default: 75
185
186 Returns
187 -------
188 output: Tensor[1]
189 A one dimensional int8 tensor that contains the raw bytes of the
190 JPEG file.
191 """
192 if quality < 1 or quality > 100:
193 raise ValueError('Image quality should be a positive number '
194 'between 1 and 100')
195
196 output = torch.ops.image.encode_jpeg(input, quality)
197 return output
198
199
200 def write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):
201 """
202 Takes an input tensor in CHW layout and saves it in a JPEG file.
203
204 Parameters
205 ----------
206 input: Tensor[channels, image_height, image_width]
207 int8 image tensor of `c` channels, where `c` must be 1 or 3.
208 filename: str
209 Path to save the image.
210 quality: int
211 Quality of the resulting JPEG file, it must be a number
212 between 1 and 100. Default: 75
213 """
214 output = encode_jpeg(input, quality)
215 write_file(filename, output)
216
217
218 def decode_image(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:
219 """
220 Detects whether an image is a JPEG or PNG and performs the appropriate
221 operation to decode the image into a 3 dimensional RGB Tensor.
222
223 Optionally converts the image to the desired format.
224 The values of the output tensor are uint8 between 0 and 255.
225
226 Parameters
227 ----------
228 input: Tensor
229 a one dimensional uint8 tensor containing the raw bytes of the
230 PNG or JPEG image.
231 mode: ImageReadMode
232 the read mode used for optionally converting the image. JPEG
233 and PNG images have different permitted values. The default
234 value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.
235 See `decode_jpeg()` and `decode_png()` for more information.
236 Default: `ImageReadMode.UNCHANGED`
237
238 Returns
239 -------
240 output: Tensor[image_channels, image_height, image_width]
241 """
242 output = torch.ops.image.decode_image(input, mode.value)
243 return output
244
245
246 def read_image(path: str, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:
247 """
248 Reads a JPEG or PNG image into a 3 dimensional RGB Tensor.
249 Optionally converts the image to the desired format.
250 The values of the output tensor are uint8 between 0 and 255.
251
252 Parameters
253 ----------
254 path: str
255 path of the JPEG or PNG image.
256 mode: ImageReadMode
257 the read mode used for optionally converting the image. JPEG
258 and PNG images have different permitted values. The default
259 value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.
260 See `decode_jpeg()` and `decode_png()` for more information.
261 Default: `ImageReadMode.UNCHANGED`
262
263 Returns
264 -------
265 output: Tensor[image_channels, image_height, image_width]
266 """
267 data = read_file(path)
268 return decode_image(data, mode)
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/io/image.py b/torchvision/io/image.py
--- a/torchvision/io/image.py
+++ b/torchvision/io/image.py
@@ -50,6 +50,15 @@
class ImageReadMode(Enum):
+ """
+ Support for various modes while reading images.
+
+ Use `ImageReadMode.UNCHANGED` for loading the image as-is,
+ `ImageReadMode.GRAY` for converting to grayscale,
+ `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,
+ `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for
+ RGB with transparency.
+ """
UNCHANGED = 0
GRAY = 1
GRAY_ALPHA = 2
@@ -94,11 +103,9 @@
input (Tensor[1]): a one dimensional uint8 tensor containing
the raw bytes of the PNG image.
mode (ImageReadMode): the read mode used for optionally
- converting the image. Use `ImageReadMode.UNCHANGED` for loading
- the image as-is, `ImageReadMode.GRAY` for converting to grayscale,
- `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,
- `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for
- RGB with transparency. Default: `ImageReadMode.UNCHANGED`
+ converting the image. Default: `ImageReadMode.UNCHANGED`.
+ See `ImageReadMode` class for more information on various
+ available modes.
Returns:
output (Tensor[image_channels, image_height, image_width])
@@ -159,9 +166,9 @@
input (Tensor[1]): a one dimensional uint8 tensor containing
the raw bytes of the JPEG image.
mode (ImageReadMode): the read mode used for optionally
- converting the image. Use `ImageReadMode.UNCHANGED` for loading
- the image as-is, `ImageReadMode.GRAY` for converting to grayscale
- and `ImageReadMode.RGB` for RGB. Default: `ImageReadMode.UNCHANGED`
+ converting the image. Default: `ImageReadMode.UNCHANGED`.
+ See `ImageReadMode` class for more information on various
+ available modes.
Returns:
output (Tensor[image_channels, image_height, image_width])
@@ -229,11 +236,10 @@
a one dimensional uint8 tensor containing the raw bytes of the
PNG or JPEG image.
mode: ImageReadMode
- the read mode used for optionally converting the image. JPEG
- and PNG images have different permitted values. The default
- value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.
- See `decode_jpeg()` and `decode_png()` for more information.
- Default: `ImageReadMode.UNCHANGED`
+ the read mode used for optionally converting the image.
+ Default: `ImageReadMode.UNCHANGED`.
+ See `ImageReadMode` class for more information on various
+ available modes.
Returns
-------
@@ -254,11 +260,10 @@
path: str
path of the JPEG or PNG image.
mode: ImageReadMode
- the read mode used for optionally converting the image. JPEG
- and PNG images have different permitted values. The default
- value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.
- See `decode_jpeg()` and `decode_png()` for more information.
- Default: `ImageReadMode.UNCHANGED`
+ the read mode used for optionally converting the image.
+ Default: `ImageReadMode.UNCHANGED`.
+ See `ImageReadMode` class for more information on various
+ available modes.
Returns
-------
|
{"golden_diff": "diff --git a/torchvision/io/image.py b/torchvision/io/image.py\n--- a/torchvision/io/image.py\n+++ b/torchvision/io/image.py\n@@ -50,6 +50,15 @@\n \n \n class ImageReadMode(Enum):\n+ \"\"\"\n+ Support for various modes while reading images.\n+\n+ Use `ImageReadMode.UNCHANGED` for loading the image as-is,\n+ `ImageReadMode.GRAY` for converting to grayscale,\n+ `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,\n+ `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for\n+ RGB with transparency.\n+ \"\"\"\n UNCHANGED = 0\n GRAY = 1\n GRAY_ALPHA = 2\n@@ -94,11 +103,9 @@\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the PNG image.\n mode (ImageReadMode): the read mode used for optionally\n- converting the image. Use `ImageReadMode.UNCHANGED` for loading\n- the image as-is, `ImageReadMode.GRAY` for converting to grayscale,\n- `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,\n- `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for\n- RGB with transparency. Default: `ImageReadMode.UNCHANGED`\n+ converting the image. Default: `ImageReadMode.UNCHANGED`.\n+ See `ImageReadMode` class for more information on various\n+ available modes.\n \n Returns:\n output (Tensor[image_channels, image_height, image_width])\n@@ -159,9 +166,9 @@\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the JPEG image.\n mode (ImageReadMode): the read mode used for optionally\n- converting the image. Use `ImageReadMode.UNCHANGED` for loading\n- the image as-is, `ImageReadMode.GRAY` for converting to grayscale\n- and `ImageReadMode.RGB` for RGB. Default: `ImageReadMode.UNCHANGED`\n+ converting the image. Default: `ImageReadMode.UNCHANGED`.\n+ See `ImageReadMode` class for more information on various\n+ available modes.\n \n Returns:\n output (Tensor[image_channels, image_height, image_width])\n@@ -229,11 +236,10 @@\n a one dimensional uint8 tensor containing the raw bytes of the\n PNG or JPEG image.\n mode: ImageReadMode\n- the read mode used for optionally converting the image. JPEG\n- and PNG images have different permitted values. The default\n- value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.\n- See `decode_jpeg()` and `decode_png()` for more information.\n- Default: `ImageReadMode.UNCHANGED`\n+ the read mode used for optionally converting the image.\n+ Default: `ImageReadMode.UNCHANGED`.\n+ See `ImageReadMode` class for more information on various\n+ available modes.\n \n Returns\n -------\n@@ -254,11 +260,10 @@\n path: str\n path of the JPEG or PNG image.\n mode: ImageReadMode\n- the read mode used for optionally converting the image. JPEG\n- and PNG images have different permitted values. The default\n- value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.\n- See `decode_jpeg()` and `decode_png()` for more information.\n- Default: `ImageReadMode.UNCHANGED`\n+ the read mode used for optionally converting the image.\n+ Default: `ImageReadMode.UNCHANGED`.\n+ See `ImageReadMode` class for more information on various\n+ available modes.\n \n Returns\n -------\n", "issue": "Clean up and Document the io.image enhancements\nPR #3024 introduced a few enhancements on the `io.image` methods used for reading JPEG and PNG images. The code changes were merged but there are a few nice-to-have improvements missing.\r\n\r\nMore specifically:\r\n- [x] Provide better error messages for [JPEG](https://github.com/pytorch/vision/pull/3024#discussion_r527066925) and [PNG](https://github.com/pytorch/vision/pull/3024#discussion_r527093866) when a specific `ImageReadMode` value is not supported.\r\n- [x] Ensure that `image_read_mode.h` has a new line at the [end of the file](https://github.com/pytorch/vision/pull/3024#discussion_r526710809).\r\n- [x] [Replace](https://github.com/pytorch/vision/pull/3024#discussion_r527065253) the old `#define` with the newer `constexpr` expression at `image_read_mode.h`.\r\n- [x] [Move the documentation](https://github.com/pytorch/vision/pull/3024#discussion_r527095264) of `ImageReadMode` values from the methods to the enum.\r\n\r\n**Note:** `constexpr` might cause problems on Windows. If that's the case, try using const instead.\n", "before_files": [{"content": "import torch\n\nimport os\nimport os.path as osp\nimport importlib.machinery\n\nfrom enum import Enum\n\n_HAS_IMAGE_OPT = False\n\ntry:\n lib_dir = osp.abspath(osp.join(osp.dirname(__file__), \"..\"))\n\n loader_details = (\n importlib.machinery.ExtensionFileLoader,\n importlib.machinery.EXTENSION_SUFFIXES\n )\n\n extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]\n ext_specs = extfinder.find_spec(\"image\")\n\n if os.name == 'nt':\n # Load the image extension using LoadLibraryExW\n import ctypes\n import sys\n\n kernel32 = ctypes.WinDLL('kernel32.dll', use_last_error=True)\n with_load_library_flags = hasattr(kernel32, 'AddDllDirectory')\n prev_error_mode = kernel32.SetErrorMode(0x0001)\n\n kernel32.LoadLibraryW.restype = ctypes.c_void_p\n if with_load_library_flags:\n kernel32.LoadLibraryExW.restype = ctypes.c_void_p\n\n if ext_specs is not None:\n res = kernel32.LoadLibraryExW(ext_specs.origin, None, 0x00001100)\n if res is None:\n err = ctypes.WinError(ctypes.get_last_error())\n err.strerror += (f' Error loading \"{ext_specs.origin}\" or any or '\n 'its dependencies.')\n raise err\n\n kernel32.SetErrorMode(prev_error_mode)\n\n if ext_specs is not None:\n torch.ops.load_library(ext_specs.origin)\n _HAS_IMAGE_OPT = True\nexcept (ImportError, OSError):\n pass\n\n\nclass ImageReadMode(Enum):\n UNCHANGED = 0\n GRAY = 1\n GRAY_ALPHA = 2\n RGB = 3\n RGB_ALPHA = 4\n\n\ndef read_file(path: str) -> torch.Tensor:\n \"\"\"\n Reads and outputs the bytes contents of a file as a uint8 Tensor\n with one dimension.\n\n Arguments:\n path (str): the path to the file to be read\n\n Returns:\n data (Tensor)\n \"\"\"\n data = torch.ops.image.read_file(path)\n return data\n\n\ndef write_file(filename: str, data: torch.Tensor) -> None:\n \"\"\"\n Writes the contents of a uint8 tensor with one dimension to a\n file.\n\n Arguments:\n filename (str): the path to the file to be written\n data (Tensor): the contents to be written to the output file\n \"\"\"\n torch.ops.image.write_file(filename, data)\n\n\ndef decode_png(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Decodes a PNG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the PNG image.\n mode (ImageReadMode): the read mode used for optionally\n converting the image. Use `ImageReadMode.UNCHANGED` for loading\n the image as-is, `ImageReadMode.GRAY` for converting to grayscale,\n `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,\n `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for\n RGB with transparency. Default: `ImageReadMode.UNCHANGED`\n\n Returns:\n output (Tensor[image_channels, image_height, image_width])\n \"\"\"\n output = torch.ops.image.decode_png(input, mode.value)\n return output\n\n\ndef encode_png(input: torch.Tensor, compression_level: int = 6) -> torch.Tensor:\n \"\"\"\n Takes an input tensor in CHW layout and returns a buffer with the contents\n of its corresponding PNG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must 3 or 1.\n compression_level: int\n Compression factor for the resulting file, it must be a number\n between 0 and 9. Default: 6\n\n Returns\n -------\n output: Tensor[1]\n A one dimensional int8 tensor that contains the raw bytes of the\n PNG file.\n \"\"\"\n output = torch.ops.image.encode_png(input, compression_level)\n return output\n\n\ndef write_png(input: torch.Tensor, filename: str, compression_level: int = 6):\n \"\"\"\n Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n and saves it in a PNG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n filename: str\n Path to save the image.\n compression_level: int\n Compression factor for the resulting file, it must be a number\n between 0 and 9. Default: 6\n \"\"\"\n output = encode_png(input, compression_level)\n write_file(filename, output)\n\n\ndef decode_jpeg(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Decodes a JPEG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the JPEG image.\n mode (ImageReadMode): the read mode used for optionally\n converting the image. Use `ImageReadMode.UNCHANGED` for loading\n the image as-is, `ImageReadMode.GRAY` for converting to grayscale\n and `ImageReadMode.RGB` for RGB. Default: `ImageReadMode.UNCHANGED`\n\n Returns:\n output (Tensor[image_channels, image_height, image_width])\n \"\"\"\n output = torch.ops.image.decode_jpeg(input, mode.value)\n return output\n\n\ndef encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:\n \"\"\"\n Takes an input tensor in CHW layout and returns a buffer with the contents\n of its corresponding JPEG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width])\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n quality: int\n Quality of the resulting JPEG file, it must be a number between\n 1 and 100. Default: 75\n\n Returns\n -------\n output: Tensor[1]\n A one dimensional int8 tensor that contains the raw bytes of the\n JPEG file.\n \"\"\"\n if quality < 1 or quality > 100:\n raise ValueError('Image quality should be a positive number '\n 'between 1 and 100')\n\n output = torch.ops.image.encode_jpeg(input, quality)\n return output\n\n\ndef write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):\n \"\"\"\n Takes an input tensor in CHW layout and saves it in a JPEG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n filename: str\n Path to save the image.\n quality: int\n Quality of the resulting JPEG file, it must be a number\n between 1 and 100. Default: 75\n \"\"\"\n output = encode_jpeg(input, quality)\n write_file(filename, output)\n\n\ndef decode_image(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Detects whether an image is a JPEG or PNG and performs the appropriate\n operation to decode the image into a 3 dimensional RGB Tensor.\n\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Parameters\n ----------\n input: Tensor\n a one dimensional uint8 tensor containing the raw bytes of the\n PNG or JPEG image.\n mode: ImageReadMode\n the read mode used for optionally converting the image. JPEG\n and PNG images have different permitted values. The default\n value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.\n See `decode_jpeg()` and `decode_png()` for more information.\n Default: `ImageReadMode.UNCHANGED`\n\n Returns\n -------\n output: Tensor[image_channels, image_height, image_width]\n \"\"\"\n output = torch.ops.image.decode_image(input, mode.value)\n return output\n\n\ndef read_image(path: str, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Reads a JPEG or PNG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Parameters\n ----------\n path: str\n path of the JPEG or PNG image.\n mode: ImageReadMode\n the read mode used for optionally converting the image. JPEG\n and PNG images have different permitted values. The default\n value is `ImageReadMode.UNCHANGED` and it keeps the image as-is.\n See `decode_jpeg()` and `decode_png()` for more information.\n Default: `ImageReadMode.UNCHANGED`\n\n Returns\n -------\n output: Tensor[image_channels, image_height, image_width]\n \"\"\"\n data = read_file(path)\n return decode_image(data, mode)\n", "path": "torchvision/io/image.py"}], "after_files": [{"content": "import torch\n\nimport os\nimport os.path as osp\nimport importlib.machinery\n\nfrom enum import Enum\n\n_HAS_IMAGE_OPT = False\n\ntry:\n lib_dir = osp.abspath(osp.join(osp.dirname(__file__), \"..\"))\n\n loader_details = (\n importlib.machinery.ExtensionFileLoader,\n importlib.machinery.EXTENSION_SUFFIXES\n )\n\n extfinder = importlib.machinery.FileFinder(lib_dir, loader_details) # type: ignore[arg-type]\n ext_specs = extfinder.find_spec(\"image\")\n\n if os.name == 'nt':\n # Load the image extension using LoadLibraryExW\n import ctypes\n import sys\n\n kernel32 = ctypes.WinDLL('kernel32.dll', use_last_error=True)\n with_load_library_flags = hasattr(kernel32, 'AddDllDirectory')\n prev_error_mode = kernel32.SetErrorMode(0x0001)\n\n kernel32.LoadLibraryW.restype = ctypes.c_void_p\n if with_load_library_flags:\n kernel32.LoadLibraryExW.restype = ctypes.c_void_p\n\n if ext_specs is not None:\n res = kernel32.LoadLibraryExW(ext_specs.origin, None, 0x00001100)\n if res is None:\n err = ctypes.WinError(ctypes.get_last_error())\n err.strerror += (f' Error loading \"{ext_specs.origin}\" or any or '\n 'its dependencies.')\n raise err\n\n kernel32.SetErrorMode(prev_error_mode)\n\n if ext_specs is not None:\n torch.ops.load_library(ext_specs.origin)\n _HAS_IMAGE_OPT = True\nexcept (ImportError, OSError):\n pass\n\n\nclass ImageReadMode(Enum):\n \"\"\"\n Support for various modes while reading images.\n\n Use `ImageReadMode.UNCHANGED` for loading the image as-is,\n `ImageReadMode.GRAY` for converting to grayscale,\n `ImageReadMode.GRAY_ALPHA` for grayscale with transparency,\n `ImageReadMode.RGB` for RGB and `ImageReadMode.RGB_ALPHA` for\n RGB with transparency.\n \"\"\"\n UNCHANGED = 0\n GRAY = 1\n GRAY_ALPHA = 2\n RGB = 3\n RGB_ALPHA = 4\n\n\ndef read_file(path: str) -> torch.Tensor:\n \"\"\"\n Reads and outputs the bytes contents of a file as a uint8 Tensor\n with one dimension.\n\n Arguments:\n path (str): the path to the file to be read\n\n Returns:\n data (Tensor)\n \"\"\"\n data = torch.ops.image.read_file(path)\n return data\n\n\ndef write_file(filename: str, data: torch.Tensor) -> None:\n \"\"\"\n Writes the contents of a uint8 tensor with one dimension to a\n file.\n\n Arguments:\n filename (str): the path to the file to be written\n data (Tensor): the contents to be written to the output file\n \"\"\"\n torch.ops.image.write_file(filename, data)\n\n\ndef decode_png(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Decodes a PNG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the PNG image.\n mode (ImageReadMode): the read mode used for optionally\n converting the image. Default: `ImageReadMode.UNCHANGED`.\n See `ImageReadMode` class for more information on various\n available modes.\n\n Returns:\n output (Tensor[image_channels, image_height, image_width])\n \"\"\"\n output = torch.ops.image.decode_png(input, mode.value)\n return output\n\n\ndef encode_png(input: torch.Tensor, compression_level: int = 6) -> torch.Tensor:\n \"\"\"\n Takes an input tensor in CHW layout and returns a buffer with the contents\n of its corresponding PNG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must 3 or 1.\n compression_level: int\n Compression factor for the resulting file, it must be a number\n between 0 and 9. Default: 6\n\n Returns\n -------\n output: Tensor[1]\n A one dimensional int8 tensor that contains the raw bytes of the\n PNG file.\n \"\"\"\n output = torch.ops.image.encode_png(input, compression_level)\n return output\n\n\ndef write_png(input: torch.Tensor, filename: str, compression_level: int = 6):\n \"\"\"\n Takes an input tensor in CHW layout (or HW in the case of grayscale images)\n and saves it in a PNG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n filename: str\n Path to save the image.\n compression_level: int\n Compression factor for the resulting file, it must be a number\n between 0 and 9. Default: 6\n \"\"\"\n output = encode_png(input, compression_level)\n write_file(filename, output)\n\n\ndef decode_jpeg(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Decodes a JPEG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Arguments:\n input (Tensor[1]): a one dimensional uint8 tensor containing\n the raw bytes of the JPEG image.\n mode (ImageReadMode): the read mode used for optionally\n converting the image. Default: `ImageReadMode.UNCHANGED`.\n See `ImageReadMode` class for more information on various\n available modes.\n\n Returns:\n output (Tensor[image_channels, image_height, image_width])\n \"\"\"\n output = torch.ops.image.decode_jpeg(input, mode.value)\n return output\n\n\ndef encode_jpeg(input: torch.Tensor, quality: int = 75) -> torch.Tensor:\n \"\"\"\n Takes an input tensor in CHW layout and returns a buffer with the contents\n of its corresponding JPEG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width])\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n quality: int\n Quality of the resulting JPEG file, it must be a number between\n 1 and 100. Default: 75\n\n Returns\n -------\n output: Tensor[1]\n A one dimensional int8 tensor that contains the raw bytes of the\n JPEG file.\n \"\"\"\n if quality < 1 or quality > 100:\n raise ValueError('Image quality should be a positive number '\n 'between 1 and 100')\n\n output = torch.ops.image.encode_jpeg(input, quality)\n return output\n\n\ndef write_jpeg(input: torch.Tensor, filename: str, quality: int = 75):\n \"\"\"\n Takes an input tensor in CHW layout and saves it in a JPEG file.\n\n Parameters\n ----------\n input: Tensor[channels, image_height, image_width]\n int8 image tensor of `c` channels, where `c` must be 1 or 3.\n filename: str\n Path to save the image.\n quality: int\n Quality of the resulting JPEG file, it must be a number\n between 1 and 100. Default: 75\n \"\"\"\n output = encode_jpeg(input, quality)\n write_file(filename, output)\n\n\ndef decode_image(input: torch.Tensor, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Detects whether an image is a JPEG or PNG and performs the appropriate\n operation to decode the image into a 3 dimensional RGB Tensor.\n\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Parameters\n ----------\n input: Tensor\n a one dimensional uint8 tensor containing the raw bytes of the\n PNG or JPEG image.\n mode: ImageReadMode\n the read mode used for optionally converting the image.\n Default: `ImageReadMode.UNCHANGED`.\n See `ImageReadMode` class for more information on various\n available modes.\n\n Returns\n -------\n output: Tensor[image_channels, image_height, image_width]\n \"\"\"\n output = torch.ops.image.decode_image(input, mode.value)\n return output\n\n\ndef read_image(path: str, mode: ImageReadMode = ImageReadMode.UNCHANGED) -> torch.Tensor:\n \"\"\"\n Reads a JPEG or PNG image into a 3 dimensional RGB Tensor.\n Optionally converts the image to the desired format.\n The values of the output tensor are uint8 between 0 and 255.\n\n Parameters\n ----------\n path: str\n path of the JPEG or PNG image.\n mode: ImageReadMode\n the read mode used for optionally converting the image.\n Default: `ImageReadMode.UNCHANGED`.\n See `ImageReadMode` class for more information on various\n available modes.\n\n Returns\n -------\n output: Tensor[image_channels, image_height, image_width]\n \"\"\"\n data = read_file(path)\n return decode_image(data, mode)\n", "path": "torchvision/io/image.py"}]}
| 3,433 | 858 |
gh_patches_debug_30925
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-1970
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ocr_recognition 评估、预测错误
1、ocr_recognition CTC model eval.py有函数缺少参数:
<img width="909" alt="e8ec154b99d031a872f8f222e1088e92" src="https://user-images.githubusercontent.com/46314656/53880163-453f1e00-404b-11e9-85c7-8dd84fe81020.png">
2、预测时CTC和attention模型的报错:
<img width="987" alt="93b4cc1a5a0309688355e42a33bddad7" src="https://user-images.githubusercontent.com/46314656/53880294-9e0eb680-404b-11e9-9619-47c6bdaff889.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PaddleCV/ocr_recognition/data_reader.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4 import os
5 import cv2
6 import tarfile
7 import numpy as np
8 from PIL import Image
9 from os import path
10 from paddle.dataset.image import load_image
11 import paddle
12
13 SOS = 0
14 EOS = 1
15 NUM_CLASSES = 95
16 DATA_SHAPE = [1, 48, 512]
17
18 DATA_MD5 = "7256b1d5420d8c3e74815196e58cdad5"
19 DATA_URL = "http://paddle-ocr-data.bj.bcebos.com/data.tar.gz"
20 CACHE_DIR_NAME = "ctc_data"
21 SAVED_FILE_NAME = "data.tar.gz"
22 DATA_DIR_NAME = "data"
23 TRAIN_DATA_DIR_NAME = "train_images"
24 TEST_DATA_DIR_NAME = "test_images"
25 TRAIN_LIST_FILE_NAME = "train.list"
26 TEST_LIST_FILE_NAME = "test.list"
27
28
29 class DataGenerator(object):
30 def __init__(self, model="crnn_ctc"):
31 self.model = model
32
33 def train_reader(self,
34 img_root_dir,
35 img_label_list,
36 batchsize,
37 cycle,
38 shuffle=True):
39 '''
40 Reader interface for training.
41
42 :param img_root_dir: The root path of the image for training.
43 :type img_root_dir: str
44
45 :param img_label_list: The path of the <image_name, label> file for training.
46 :type img_label_list: str
47
48 :param cycle: If number of iterations is greater than dataset_size / batch_size
49 it reiterates dataset over as many times as necessary.
50 :type cycle: bool
51
52 '''
53
54 img_label_lines = []
55 to_file = "tmp.txt"
56 if not shuffle:
57 cmd = "cat " + img_label_list + " | awk '{print $1,$2,$3,$4;}' > " + to_file
58 elif batchsize == 1:
59 cmd = "cat " + img_label_list + " | awk '{print $1,$2,$3,$4;}' | shuf > " + to_file
60 else:
61 #cmd1: partial shuffle
62 cmd = "cat " + img_label_list + " | awk '{printf(\"%04d%.4f %s\\n\", $1, rand(), $0)}' | sort | sed 1,$((1 + RANDOM % 100))d | "
63 #cmd2: batch merge and shuffle
64 cmd += "awk '{printf $2\" \"$3\" \"$4\" \"$5\" \"; if(NR % " + str(
65 batchsize) + " == 0) print \"\";}' | shuf | "
66 #cmd3: batch split
67 cmd += "awk '{if(NF == " + str(
68 batchsize
69 ) + " * 4) {for(i = 0; i < " + str(
70 batchsize
71 ) + "; i++) print $(4*i+1)\" \"$(4*i+2)\" \"$(4*i+3)\" \"$(4*i+4);}}' > " + to_file
72 os.system(cmd)
73 print("finish batch shuffle")
74 img_label_lines = open(to_file, 'r').readlines()
75
76 def reader():
77 sizes = len(img_label_lines) // batchsize
78 if sizes == 0:
79 raise ValueError('Batch size is bigger than the dataset size.')
80 while True:
81 for i in range(sizes):
82 result = []
83 sz = [0, 0]
84 for j in range(batchsize):
85 line = img_label_lines[i * batchsize + j]
86 # h, w, img_name, labels
87 items = line.split(' ')
88
89 label = [int(c) for c in items[-1].split(',')]
90 img = Image.open(os.path.join(img_root_dir, items[
91 2])).convert('L') #zhuanhuidu
92 if j == 0:
93 sz = img.size
94 img = img.resize((sz[0], sz[1]))
95 img = np.array(img) - 127.5
96 img = img[np.newaxis, ...]
97 if self.model == "crnn_ctc":
98 result.append([img, label])
99 else:
100 result.append([img, [SOS] + label, label + [EOS]])
101 yield result
102 if not cycle:
103 break
104
105 return reader
106
107 def test_reader(self, img_root_dir, img_label_list):
108 '''
109 Reader interface for inference.
110
111 :param img_root_dir: The root path of the images for training.
112 :type img_root_dir: str
113
114 :param img_label_list: The path of the <image_name, label> file for testing.
115 :type img_label_list: str
116 '''
117
118 def reader():
119 for line in open(img_label_list):
120 # h, w, img_name, labels
121 items = line.split(' ')
122
123 label = [int(c) for c in items[-1].split(',')]
124 img = Image.open(os.path.join(img_root_dir, items[2])).convert(
125 'L')
126 img = np.array(img) - 127.5
127 img = img[np.newaxis, ...]
128 if self.model == "crnn_ctc":
129 yield img, label
130 else:
131 yield img, [SOS] + label, label + [EOS]
132
133 return reader
134
135 def infer_reader(self, img_root_dir=None, img_label_list=None, cycle=False):
136 '''A reader interface for inference.
137
138 :param img_root_dir: The root path of the images for training.
139 :type img_root_dir: str
140
141 :param img_label_list: The path of the <image_name, label> file for
142 inference. It should be the path of <image_path> file if img_root_dir
143 was None. If img_label_list was set to None, it will read image path
144 from stdin.
145 :type img_root_dir: str
146
147 :param cycle: If number of iterations is greater than dataset_size /
148 batch_size it reiterates dataset over as many times as necessary.
149 :type cycle: bool
150 '''
151
152 def reader():
153 def yield_img_and_label(lines):
154 for line in lines:
155 if img_root_dir is not None:
156 # h, w, img_name, labels
157 img_name = line.split(' ')[2]
158 img_path = os.path.join(img_root_dir, img_name)
159 else:
160 img_path = line.strip("\t\n\r")
161 img = Image.open(img_path).convert('L')
162 img = np.array(img) - 127.5
163 img = img[np.newaxis, ...]
164 label = [int(c) for c in line.split(' ')[3].split(',')]
165 yield img, label
166
167 if img_label_list is not None:
168 lines = []
169 with open(img_label_list) as f:
170 lines = f.readlines()
171 for img, label in yield_img_and_label(lines):
172 yield img, label
173 while cycle:
174 for img, label in yield_img_and_label(lines):
175 yield img, label
176 else:
177 while True:
178 img_path = raw_input("Please input the path of image: ")
179 img = Image.open(img_path).convert('L')
180 img = np.array(img) - 127.5
181 img = img[np.newaxis, ...]
182 yield img, [[0]]
183
184 return reader
185
186
187 def num_classes():
188 '''Get classes number of this dataset.
189 '''
190 return NUM_CLASSES
191
192
193 def data_shape():
194 '''Get image shape of this dataset. It is a dummy shape for this dataset.
195 '''
196 return DATA_SHAPE
197
198
199 def train(batch_size,
200 train_images_dir=None,
201 train_list_file=None,
202 cycle=False,
203 model="crnn_ctc"):
204 generator = DataGenerator(model)
205 if train_images_dir is None:
206 data_dir = download_data()
207 train_images_dir = path.join(data_dir, TRAIN_DATA_DIR_NAME)
208 if train_list_file is None:
209 train_list_file = path.join(data_dir, TRAIN_LIST_FILE_NAME)
210 shuffle = True
211 if 'ce_mode' in os.environ:
212 shuffle = False
213 return generator.train_reader(
214 train_images_dir, train_list_file, batch_size, cycle, shuffle=shuffle)
215
216
217 def test(batch_size=1,
218 test_images_dir=None,
219 test_list_file=None,
220 model="crnn_ctc"):
221 generator = DataGenerator(model)
222 if test_images_dir is None:
223 data_dir = download_data()
224 test_images_dir = path.join(data_dir, TEST_DATA_DIR_NAME)
225 if test_list_file is None:
226 test_list_file = path.join(data_dir, TEST_LIST_FILE_NAME)
227 return paddle.batch(
228 generator.test_reader(test_images_dir, test_list_file), batch_size)
229
230
231 def inference(batch_size=1,
232 infer_images_dir=None,
233 infer_list_file=None,
234 cycle=False,
235 model="crnn_ctc"):
236 generator = DataGenerator(model)
237 return paddle.batch(
238 generator.infer_reader(infer_images_dir, infer_list_file, cycle),
239 batch_size)
240
241
242 def download_data():
243 '''Download train and test data.
244 '''
245 tar_file = paddle.dataset.common.download(
246 DATA_URL, CACHE_DIR_NAME, DATA_MD5, save_name=SAVED_FILE_NAME)
247 data_dir = path.join(path.dirname(tar_file), DATA_DIR_NAME)
248 if not path.isdir(data_dir):
249 t = tarfile.open(tar_file, "r:gz")
250 t.extractall(path=path.dirname(tar_file))
251 t.close()
252 return data_dir
253
```
Path: `PaddleCV/ocr_recognition/eval.py`
Content:
```
1 import paddle.fluid as fluid
2 from utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data
3 from attention_model import attention_eval
4 from crnn_ctc_model import ctc_eval
5 import data_reader
6 import argparse
7 import functools
8 import os
9
10 parser = argparse.ArgumentParser(description=__doc__)
11 add_arg = functools.partial(add_arguments, argparser=parser)
12 # yapf: disable
13 add_arg('model', str, "crnn_ctc", "Which type of network to be used. 'crnn_ctc' or 'attention'")
14 add_arg('model_path', str, "", "The model path to be used for inference.")
15 add_arg('input_images_dir', str, None, "The directory of images.")
16 add_arg('input_images_list', str, None, "The list file of images.")
17 add_arg('use_gpu', bool, True, "Whether use GPU to eval.")
18 # yapf: enable
19
20
21 def evaluate(args):
22 """OCR inference"""
23
24 if args.model == "crnn_ctc":
25 eval = ctc_eval
26 get_feeder_data = get_ctc_feeder_data
27 else:
28 eval = attention_eval
29 get_feeder_data = get_attention_feeder_data
30
31 num_classes = data_reader.num_classes()
32 data_shape = data_reader.data_shape()
33 # define network
34 evaluator, cost = eval(data_shape, num_classes)
35
36 # data reader
37 test_reader = data_reader.test(
38 test_images_dir=args.input_images_dir,
39 test_list_file=args.input_images_list,
40 model=args.model)
41
42 # prepare environment
43 place = fluid.CPUPlace()
44 if args.use_gpu:
45 place = fluid.CUDAPlace(0)
46
47 exe = fluid.Executor(place)
48 exe.run(fluid.default_startup_program())
49
50 # load init model
51 model_dir = args.model_path
52 model_file_name = None
53 if not os.path.isdir(args.model_path):
54 model_dir = os.path.dirname(args.model_path)
55 model_file_name = os.path.basename(args.model_path)
56 fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)
57 print("Init model from: %s." % args.model_path)
58
59 evaluator.reset(exe)
60 count = 0
61 for data in test_reader():
62 count += 1
63 exe.run(fluid.default_main_program(), feed=get_feeder_data(data, place))
64 avg_distance, avg_seq_error = evaluator.eval(exe)
65 print("Read %d samples; avg_distance: %s; avg_seq_error: %s" % (
66 count, avg_distance, avg_seq_error))
67
68
69 def main():
70 args = parser.parse_args()
71 print_arguments(args)
72 evaluate(args)
73
74
75 if __name__ == "__main__":
76 main()
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PaddleCV/ocr_recognition/data_reader.py b/PaddleCV/ocr_recognition/data_reader.py
--- a/PaddleCV/ocr_recognition/data_reader.py
+++ b/PaddleCV/ocr_recognition/data_reader.py
@@ -10,6 +10,11 @@
from paddle.dataset.image import load_image
import paddle
+try:
+ input = raw_input
+except NameError:
+ pass
+
SOS = 0
EOS = 1
NUM_CLASSES = 95
@@ -175,7 +180,7 @@
yield img, label
else:
while True:
- img_path = raw_input("Please input the path of image: ")
+ img_path = input("Please input the path of image: ")
img = Image.open(img_path).convert('L')
img = np.array(img) - 127.5
img = img[np.newaxis, ...]
diff --git a/PaddleCV/ocr_recognition/eval.py b/PaddleCV/ocr_recognition/eval.py
--- a/PaddleCV/ocr_recognition/eval.py
+++ b/PaddleCV/ocr_recognition/eval.py
@@ -31,7 +31,8 @@
num_classes = data_reader.num_classes()
data_shape = data_reader.data_shape()
# define network
- evaluator, cost = eval(data_shape, num_classes)
+ evaluator, cost = eval(
+ data_shape, num_classes, use_cudnn=True if args.use_gpu else False)
# data reader
test_reader = data_reader.test(
@@ -62,8 +63,8 @@
count += 1
exe.run(fluid.default_main_program(), feed=get_feeder_data(data, place))
avg_distance, avg_seq_error = evaluator.eval(exe)
- print("Read %d samples; avg_distance: %s; avg_seq_error: %s" % (
- count, avg_distance, avg_seq_error))
+ print("Read %d samples; avg_distance: %s; avg_seq_error: %s" %
+ (count, avg_distance, avg_seq_error))
def main():
|
{"golden_diff": "diff --git a/PaddleCV/ocr_recognition/data_reader.py b/PaddleCV/ocr_recognition/data_reader.py\n--- a/PaddleCV/ocr_recognition/data_reader.py\n+++ b/PaddleCV/ocr_recognition/data_reader.py\n@@ -10,6 +10,11 @@\n from paddle.dataset.image import load_image\n import paddle\n \n+try:\n+ input = raw_input\n+except NameError:\n+ pass\n+\n SOS = 0\n EOS = 1\n NUM_CLASSES = 95\n@@ -175,7 +180,7 @@\n yield img, label\n else:\n while True:\n- img_path = raw_input(\"Please input the path of image: \")\n+ img_path = input(\"Please input the path of image: \")\n img = Image.open(img_path).convert('L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\ndiff --git a/PaddleCV/ocr_recognition/eval.py b/PaddleCV/ocr_recognition/eval.py\n--- a/PaddleCV/ocr_recognition/eval.py\n+++ b/PaddleCV/ocr_recognition/eval.py\n@@ -31,7 +31,8 @@\n num_classes = data_reader.num_classes()\n data_shape = data_reader.data_shape()\n # define network\n- evaluator, cost = eval(data_shape, num_classes)\n+ evaluator, cost = eval(\n+ data_shape, num_classes, use_cudnn=True if args.use_gpu else False)\n \n # data reader\n test_reader = data_reader.test(\n@@ -62,8 +63,8 @@\n count += 1\n exe.run(fluid.default_main_program(), feed=get_feeder_data(data, place))\n avg_distance, avg_seq_error = evaluator.eval(exe)\n- print(\"Read %d samples; avg_distance: %s; avg_seq_error: %s\" % (\n- count, avg_distance, avg_seq_error))\n+ print(\"Read %d samples; avg_distance: %s; avg_seq_error: %s\" %\n+ (count, avg_distance, avg_seq_error))\n \n \n def main():\n", "issue": "ocr_recognition \u8bc4\u4f30\u3001\u9884\u6d4b\u9519\u8bef\n1\u3001ocr_recognition CTC model eval.py\u6709\u51fd\u6570\u7f3a\u5c11\u53c2\u6570\uff1a\r\n<img width=\"909\" alt=\"e8ec154b99d031a872f8f222e1088e92\" src=\"https://user-images.githubusercontent.com/46314656/53880163-453f1e00-404b-11e9-85c7-8dd84fe81020.png\">\r\n2\u3001\u9884\u6d4b\u65f6CTC\u548cattention\u6a21\u578b\u7684\u62a5\u9519\uff1a\r\n<img width=\"987\" alt=\"93b4cc1a5a0309688355e42a33bddad7\" src=\"https://user-images.githubusercontent.com/46314656/53880294-9e0eb680-404b-11e9-9619-47c6bdaff889.png\">\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nimport os\nimport cv2\nimport tarfile\nimport numpy as np\nfrom PIL import Image\nfrom os import path\nfrom paddle.dataset.image import load_image\nimport paddle\n\nSOS = 0\nEOS = 1\nNUM_CLASSES = 95\nDATA_SHAPE = [1, 48, 512]\n\nDATA_MD5 = \"7256b1d5420d8c3e74815196e58cdad5\"\nDATA_URL = \"http://paddle-ocr-data.bj.bcebos.com/data.tar.gz\"\nCACHE_DIR_NAME = \"ctc_data\"\nSAVED_FILE_NAME = \"data.tar.gz\"\nDATA_DIR_NAME = \"data\"\nTRAIN_DATA_DIR_NAME = \"train_images\"\nTEST_DATA_DIR_NAME = \"test_images\"\nTRAIN_LIST_FILE_NAME = \"train.list\"\nTEST_LIST_FILE_NAME = \"test.list\"\n\n\nclass DataGenerator(object):\n def __init__(self, model=\"crnn_ctc\"):\n self.model = model\n\n def train_reader(self,\n img_root_dir,\n img_label_list,\n batchsize,\n cycle,\n shuffle=True):\n '''\n Reader interface for training.\n\n :param img_root_dir: The root path of the image for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for training.\n :type img_label_list: str\n\n :param cycle: If number of iterations is greater than dataset_size / batch_size\n it reiterates dataset over as many times as necessary.\n :type cycle: bool\n \n '''\n\n img_label_lines = []\n to_file = \"tmp.txt\"\n if not shuffle:\n cmd = \"cat \" + img_label_list + \" | awk '{print $1,$2,$3,$4;}' > \" + to_file\n elif batchsize == 1:\n cmd = \"cat \" + img_label_list + \" | awk '{print $1,$2,$3,$4;}' | shuf > \" + to_file\n else:\n #cmd1: partial shuffle\n cmd = \"cat \" + img_label_list + \" | awk '{printf(\\\"%04d%.4f %s\\\\n\\\", $1, rand(), $0)}' | sort | sed 1,$((1 + RANDOM % 100))d | \"\n #cmd2: batch merge and shuffle\n cmd += \"awk '{printf $2\\\" \\\"$3\\\" \\\"$4\\\" \\\"$5\\\" \\\"; if(NR % \" + str(\n batchsize) + \" == 0) print \\\"\\\";}' | shuf | \"\n #cmd3: batch split\n cmd += \"awk '{if(NF == \" + str(\n batchsize\n ) + \" * 4) {for(i = 0; i < \" + str(\n batchsize\n ) + \"; i++) print $(4*i+1)\\\" \\\"$(4*i+2)\\\" \\\"$(4*i+3)\\\" \\\"$(4*i+4);}}' > \" + to_file\n os.system(cmd)\n print(\"finish batch shuffle\")\n img_label_lines = open(to_file, 'r').readlines()\n\n def reader():\n sizes = len(img_label_lines) // batchsize\n if sizes == 0:\n raise ValueError('Batch size is bigger than the dataset size.')\n while True:\n for i in range(sizes):\n result = []\n sz = [0, 0]\n for j in range(batchsize):\n line = img_label_lines[i * batchsize + j]\n # h, w, img_name, labels\n items = line.split(' ')\n\n label = [int(c) for c in items[-1].split(',')]\n img = Image.open(os.path.join(img_root_dir, items[\n 2])).convert('L') #zhuanhuidu\n if j == 0:\n sz = img.size\n img = img.resize((sz[0], sz[1]))\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n if self.model == \"crnn_ctc\":\n result.append([img, label])\n else:\n result.append([img, [SOS] + label, label + [EOS]])\n yield result\n if not cycle:\n break\n\n return reader\n\n def test_reader(self, img_root_dir, img_label_list):\n '''\n Reader interface for inference.\n\n :param img_root_dir: The root path of the images for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for testing.\n :type img_label_list: str\n '''\n\n def reader():\n for line in open(img_label_list):\n # h, w, img_name, labels\n items = line.split(' ')\n\n label = [int(c) for c in items[-1].split(',')]\n img = Image.open(os.path.join(img_root_dir, items[2])).convert(\n 'L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n if self.model == \"crnn_ctc\":\n yield img, label\n else:\n yield img, [SOS] + label, label + [EOS]\n\n return reader\n\n def infer_reader(self, img_root_dir=None, img_label_list=None, cycle=False):\n '''A reader interface for inference.\n\n :param img_root_dir: The root path of the images for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for\n inference. It should be the path of <image_path> file if img_root_dir\n was None. If img_label_list was set to None, it will read image path\n from stdin.\n :type img_root_dir: str\n \n :param cycle: If number of iterations is greater than dataset_size /\n batch_size it reiterates dataset over as many times as necessary.\n :type cycle: bool\n '''\n\n def reader():\n def yield_img_and_label(lines):\n for line in lines:\n if img_root_dir is not None:\n # h, w, img_name, labels\n img_name = line.split(' ')[2]\n img_path = os.path.join(img_root_dir, img_name)\n else:\n img_path = line.strip(\"\\t\\n\\r\")\n img = Image.open(img_path).convert('L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n label = [int(c) for c in line.split(' ')[3].split(',')]\n yield img, label\n\n if img_label_list is not None:\n lines = []\n with open(img_label_list) as f:\n lines = f.readlines()\n for img, label in yield_img_and_label(lines):\n yield img, label\n while cycle:\n for img, label in yield_img_and_label(lines):\n yield img, label\n else:\n while True:\n img_path = raw_input(\"Please input the path of image: \")\n img = Image.open(img_path).convert('L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n yield img, [[0]]\n\n return reader\n\n\ndef num_classes():\n '''Get classes number of this dataset.\n '''\n return NUM_CLASSES\n\n\ndef data_shape():\n '''Get image shape of this dataset. It is a dummy shape for this dataset.\n '''\n return DATA_SHAPE\n\n\ndef train(batch_size,\n train_images_dir=None,\n train_list_file=None,\n cycle=False,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n if train_images_dir is None:\n data_dir = download_data()\n train_images_dir = path.join(data_dir, TRAIN_DATA_DIR_NAME)\n if train_list_file is None:\n train_list_file = path.join(data_dir, TRAIN_LIST_FILE_NAME)\n shuffle = True\n if 'ce_mode' in os.environ:\n shuffle = False\n return generator.train_reader(\n train_images_dir, train_list_file, batch_size, cycle, shuffle=shuffle)\n\n\ndef test(batch_size=1,\n test_images_dir=None,\n test_list_file=None,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n if test_images_dir is None:\n data_dir = download_data()\n test_images_dir = path.join(data_dir, TEST_DATA_DIR_NAME)\n if test_list_file is None:\n test_list_file = path.join(data_dir, TEST_LIST_FILE_NAME)\n return paddle.batch(\n generator.test_reader(test_images_dir, test_list_file), batch_size)\n\n\ndef inference(batch_size=1,\n infer_images_dir=None,\n infer_list_file=None,\n cycle=False,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n return paddle.batch(\n generator.infer_reader(infer_images_dir, infer_list_file, cycle),\n batch_size)\n\n\ndef download_data():\n '''Download train and test data.\n '''\n tar_file = paddle.dataset.common.download(\n DATA_URL, CACHE_DIR_NAME, DATA_MD5, save_name=SAVED_FILE_NAME)\n data_dir = path.join(path.dirname(tar_file), DATA_DIR_NAME)\n if not path.isdir(data_dir):\n t = tarfile.open(tar_file, \"r:gz\")\n t.extractall(path=path.dirname(tar_file))\n t.close()\n return data_dir\n", "path": "PaddleCV/ocr_recognition/data_reader.py"}, {"content": "import paddle.fluid as fluid\nfrom utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data\nfrom attention_model import attention_eval\nfrom crnn_ctc_model import ctc_eval\nimport data_reader\nimport argparse\nimport functools\nimport os\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('model', str, \"crnn_ctc\", \"Which type of network to be used. 'crnn_ctc' or 'attention'\")\nadd_arg('model_path', str, \"\", \"The model path to be used for inference.\")\nadd_arg('input_images_dir', str, None, \"The directory of images.\")\nadd_arg('input_images_list', str, None, \"The list file of images.\")\nadd_arg('use_gpu', bool, True, \"Whether use GPU to eval.\")\n# yapf: enable\n\n\ndef evaluate(args):\n \"\"\"OCR inference\"\"\"\n\n if args.model == \"crnn_ctc\":\n eval = ctc_eval\n get_feeder_data = get_ctc_feeder_data\n else:\n eval = attention_eval\n get_feeder_data = get_attention_feeder_data\n\n num_classes = data_reader.num_classes()\n data_shape = data_reader.data_shape()\n # define network\n evaluator, cost = eval(data_shape, num_classes)\n\n # data reader\n test_reader = data_reader.test(\n test_images_dir=args.input_images_dir,\n test_list_file=args.input_images_list,\n model=args.model)\n\n # prepare environment\n place = fluid.CPUPlace()\n if args.use_gpu:\n place = fluid.CUDAPlace(0)\n\n exe = fluid.Executor(place)\n exe.run(fluid.default_startup_program())\n\n # load init model\n model_dir = args.model_path\n model_file_name = None\n if not os.path.isdir(args.model_path):\n model_dir = os.path.dirname(args.model_path)\n model_file_name = os.path.basename(args.model_path)\n fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)\n print(\"Init model from: %s.\" % args.model_path)\n\n evaluator.reset(exe)\n count = 0\n for data in test_reader():\n count += 1\n exe.run(fluid.default_main_program(), feed=get_feeder_data(data, place))\n avg_distance, avg_seq_error = evaluator.eval(exe)\n print(\"Read %d samples; avg_distance: %s; avg_seq_error: %s\" % (\n count, avg_distance, avg_seq_error))\n\n\ndef main():\n args = parser.parse_args()\n print_arguments(args)\n evaluate(args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "PaddleCV/ocr_recognition/eval.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nimport os\nimport cv2\nimport tarfile\nimport numpy as np\nfrom PIL import Image\nfrom os import path\nfrom paddle.dataset.image import load_image\nimport paddle\n\ntry:\n input = raw_input\nexcept NameError:\n pass\n\nSOS = 0\nEOS = 1\nNUM_CLASSES = 95\nDATA_SHAPE = [1, 48, 512]\n\nDATA_MD5 = \"7256b1d5420d8c3e74815196e58cdad5\"\nDATA_URL = \"http://paddle-ocr-data.bj.bcebos.com/data.tar.gz\"\nCACHE_DIR_NAME = \"ctc_data\"\nSAVED_FILE_NAME = \"data.tar.gz\"\nDATA_DIR_NAME = \"data\"\nTRAIN_DATA_DIR_NAME = \"train_images\"\nTEST_DATA_DIR_NAME = \"test_images\"\nTRAIN_LIST_FILE_NAME = \"train.list\"\nTEST_LIST_FILE_NAME = \"test.list\"\n\n\nclass DataGenerator(object):\n def __init__(self, model=\"crnn_ctc\"):\n self.model = model\n\n def train_reader(self,\n img_root_dir,\n img_label_list,\n batchsize,\n cycle,\n shuffle=True):\n '''\n Reader interface for training.\n\n :param img_root_dir: The root path of the image for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for training.\n :type img_label_list: str\n\n :param cycle: If number of iterations is greater than dataset_size / batch_size\n it reiterates dataset over as many times as necessary.\n :type cycle: bool\n \n '''\n\n img_label_lines = []\n to_file = \"tmp.txt\"\n if not shuffle:\n cmd = \"cat \" + img_label_list + \" | awk '{print $1,$2,$3,$4;}' > \" + to_file\n elif batchsize == 1:\n cmd = \"cat \" + img_label_list + \" | awk '{print $1,$2,$3,$4;}' | shuf > \" + to_file\n else:\n #cmd1: partial shuffle\n cmd = \"cat \" + img_label_list + \" | awk '{printf(\\\"%04d%.4f %s\\\\n\\\", $1, rand(), $0)}' | sort | sed 1,$((1 + RANDOM % 100))d | \"\n #cmd2: batch merge and shuffle\n cmd += \"awk '{printf $2\\\" \\\"$3\\\" \\\"$4\\\" \\\"$5\\\" \\\"; if(NR % \" + str(\n batchsize) + \" == 0) print \\\"\\\";}' | shuf | \"\n #cmd3: batch split\n cmd += \"awk '{if(NF == \" + str(\n batchsize\n ) + \" * 4) {for(i = 0; i < \" + str(\n batchsize\n ) + \"; i++) print $(4*i+1)\\\" \\\"$(4*i+2)\\\" \\\"$(4*i+3)\\\" \\\"$(4*i+4);}}' > \" + to_file\n os.system(cmd)\n print(\"finish batch shuffle\")\n img_label_lines = open(to_file, 'r').readlines()\n\n def reader():\n sizes = len(img_label_lines) // batchsize\n if sizes == 0:\n raise ValueError('Batch size is bigger than the dataset size.')\n while True:\n for i in range(sizes):\n result = []\n sz = [0, 0]\n for j in range(batchsize):\n line = img_label_lines[i * batchsize + j]\n # h, w, img_name, labels\n items = line.split(' ')\n\n label = [int(c) for c in items[-1].split(',')]\n img = Image.open(os.path.join(img_root_dir, items[\n 2])).convert('L') #zhuanhuidu\n if j == 0:\n sz = img.size\n img = img.resize((sz[0], sz[1]))\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n if self.model == \"crnn_ctc\":\n result.append([img, label])\n else:\n result.append([img, [SOS] + label, label + [EOS]])\n yield result\n if not cycle:\n break\n\n return reader\n\n def test_reader(self, img_root_dir, img_label_list):\n '''\n Reader interface for inference.\n\n :param img_root_dir: The root path of the images for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for testing.\n :type img_label_list: str\n '''\n\n def reader():\n for line in open(img_label_list):\n # h, w, img_name, labels\n items = line.split(' ')\n\n label = [int(c) for c in items[-1].split(',')]\n img = Image.open(os.path.join(img_root_dir, items[2])).convert(\n 'L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n if self.model == \"crnn_ctc\":\n yield img, label\n else:\n yield img, [SOS] + label, label + [EOS]\n\n return reader\n\n def infer_reader(self, img_root_dir=None, img_label_list=None, cycle=False):\n '''A reader interface for inference.\n\n :param img_root_dir: The root path of the images for training.\n :type img_root_dir: str\n\n :param img_label_list: The path of the <image_name, label> file for\n inference. It should be the path of <image_path> file if img_root_dir\n was None. If img_label_list was set to None, it will read image path\n from stdin.\n :type img_root_dir: str\n \n :param cycle: If number of iterations is greater than dataset_size /\n batch_size it reiterates dataset over as many times as necessary.\n :type cycle: bool\n '''\n\n def reader():\n def yield_img_and_label(lines):\n for line in lines:\n if img_root_dir is not None:\n # h, w, img_name, labels\n img_name = line.split(' ')[2]\n img_path = os.path.join(img_root_dir, img_name)\n else:\n img_path = line.strip(\"\\t\\n\\r\")\n img = Image.open(img_path).convert('L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n label = [int(c) for c in line.split(' ')[3].split(',')]\n yield img, label\n\n if img_label_list is not None:\n lines = []\n with open(img_label_list) as f:\n lines = f.readlines()\n for img, label in yield_img_and_label(lines):\n yield img, label\n while cycle:\n for img, label in yield_img_and_label(lines):\n yield img, label\n else:\n while True:\n img_path = input(\"Please input the path of image: \")\n img = Image.open(img_path).convert('L')\n img = np.array(img) - 127.5\n img = img[np.newaxis, ...]\n yield img, [[0]]\n\n return reader\n\n\ndef num_classes():\n '''Get classes number of this dataset.\n '''\n return NUM_CLASSES\n\n\ndef data_shape():\n '''Get image shape of this dataset. It is a dummy shape for this dataset.\n '''\n return DATA_SHAPE\n\n\ndef train(batch_size,\n train_images_dir=None,\n train_list_file=None,\n cycle=False,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n if train_images_dir is None:\n data_dir = download_data()\n train_images_dir = path.join(data_dir, TRAIN_DATA_DIR_NAME)\n if train_list_file is None:\n train_list_file = path.join(data_dir, TRAIN_LIST_FILE_NAME)\n shuffle = True\n if 'ce_mode' in os.environ:\n shuffle = False\n return generator.train_reader(\n train_images_dir, train_list_file, batch_size, cycle, shuffle=shuffle)\n\n\ndef test(batch_size=1,\n test_images_dir=None,\n test_list_file=None,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n if test_images_dir is None:\n data_dir = download_data()\n test_images_dir = path.join(data_dir, TEST_DATA_DIR_NAME)\n if test_list_file is None:\n test_list_file = path.join(data_dir, TEST_LIST_FILE_NAME)\n return paddle.batch(\n generator.test_reader(test_images_dir, test_list_file), batch_size)\n\n\ndef inference(batch_size=1,\n infer_images_dir=None,\n infer_list_file=None,\n cycle=False,\n model=\"crnn_ctc\"):\n generator = DataGenerator(model)\n return paddle.batch(\n generator.infer_reader(infer_images_dir, infer_list_file, cycle),\n batch_size)\n\n\ndef download_data():\n '''Download train and test data.\n '''\n tar_file = paddle.dataset.common.download(\n DATA_URL, CACHE_DIR_NAME, DATA_MD5, save_name=SAVED_FILE_NAME)\n data_dir = path.join(path.dirname(tar_file), DATA_DIR_NAME)\n if not path.isdir(data_dir):\n t = tarfile.open(tar_file, \"r:gz\")\n t.extractall(path=path.dirname(tar_file))\n t.close()\n return data_dir\n", "path": "PaddleCV/ocr_recognition/data_reader.py"}, {"content": "import paddle.fluid as fluid\nfrom utility import add_arguments, print_arguments, to_lodtensor, get_ctc_feeder_data, get_attention_feeder_data\nfrom attention_model import attention_eval\nfrom crnn_ctc_model import ctc_eval\nimport data_reader\nimport argparse\nimport functools\nimport os\n\nparser = argparse.ArgumentParser(description=__doc__)\nadd_arg = functools.partial(add_arguments, argparser=parser)\n# yapf: disable\nadd_arg('model', str, \"crnn_ctc\", \"Which type of network to be used. 'crnn_ctc' or 'attention'\")\nadd_arg('model_path', str, \"\", \"The model path to be used for inference.\")\nadd_arg('input_images_dir', str, None, \"The directory of images.\")\nadd_arg('input_images_list', str, None, \"The list file of images.\")\nadd_arg('use_gpu', bool, True, \"Whether use GPU to eval.\")\n# yapf: enable\n\n\ndef evaluate(args):\n \"\"\"OCR inference\"\"\"\n\n if args.model == \"crnn_ctc\":\n eval = ctc_eval\n get_feeder_data = get_ctc_feeder_data\n else:\n eval = attention_eval\n get_feeder_data = get_attention_feeder_data\n\n num_classes = data_reader.num_classes()\n data_shape = data_reader.data_shape()\n # define network\n evaluator, cost = eval(\n data_shape, num_classes, use_cudnn=True if args.use_gpu else False)\n\n # data reader\n test_reader = data_reader.test(\n test_images_dir=args.input_images_dir,\n test_list_file=args.input_images_list,\n model=args.model)\n\n # prepare environment\n place = fluid.CPUPlace()\n if args.use_gpu:\n place = fluid.CUDAPlace(0)\n\n exe = fluid.Executor(place)\n exe.run(fluid.default_startup_program())\n\n # load init model\n model_dir = args.model_path\n model_file_name = None\n if not os.path.isdir(args.model_path):\n model_dir = os.path.dirname(args.model_path)\n model_file_name = os.path.basename(args.model_path)\n fluid.io.load_params(exe, dirname=model_dir, filename=model_file_name)\n print(\"Init model from: %s.\" % args.model_path)\n\n evaluator.reset(exe)\n count = 0\n for data in test_reader():\n count += 1\n exe.run(fluid.default_main_program(), feed=get_feeder_data(data, place))\n avg_distance, avg_seq_error = evaluator.eval(exe)\n print(\"Read %d samples; avg_distance: %s; avg_seq_error: %s\" %\n (count, avg_distance, avg_seq_error))\n\n\ndef main():\n args = parser.parse_args()\n print_arguments(args)\n evaluate(args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "PaddleCV/ocr_recognition/eval.py"}]}
| 4,044 | 472 |
gh_patches_debug_6597
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-2196
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot preview artifacts in UI when uploaded to remote machine via FTP
### System information
- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**:
No
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
Linux Ubuntu 18.04
- **MLflow installed from (source or binary)**:
installed via from pypi via pip
- **MLflow version (run ``mlflow --version``)**:
0.9.1
- **Python version**:
3.6.7
- **npm version (if running the dev UI):
- **Exact command to reproduce**:
Server runs with:
```
mlflow server --backend-store-uri ./mlruns --default-artifact-root ./artifacts -h 0.0.0.0 -p 5020
```
within a folder holding a `mlruns` and a `artifacts` folder
### Describe the problem
I am running the server on a remote machine.
On the local machine which uploads via the tracking API the
tracking uri is set to: `http://path.to.server:port`
and artifact uri to: `ftp://anonymous:@path.to.server/artifacts`
uploading the tracking information and artifacts work fine and everything shows in the ui:
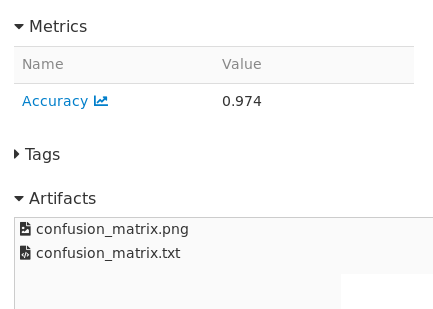
However when I try to click one of the artifacts I always get the message that something went wrong:

Previewing the artifacts work when I store them locally on my machine but as soon as I transfer them via FTP and then try to preview them from the remote machine I get the error shown above.
### Source code / logs
-
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mlflow/store/artifact/ftp_artifact_repo.py`
Content:
```
1 import os
2 import ftplib
3 from ftplib import FTP
4 from contextlib import contextmanager
5
6 import posixpath
7 from six.moves import urllib
8
9 from mlflow.entities.file_info import FileInfo
10 from mlflow.store.artifact.artifact_repo import ArtifactRepository
11 from mlflow.utils.file_utils import relative_path_to_artifact_path
12 from mlflow.exceptions import MlflowException
13
14
15 class FTPArtifactRepository(ArtifactRepository):
16 """Stores artifacts as files in a remote directory, via ftp."""
17
18 def __init__(self, artifact_uri):
19 self.uri = artifact_uri
20 parsed = urllib.parse.urlparse(artifact_uri)
21 self.config = {
22 'host': parsed.hostname,
23 'port': 21 if parsed.port is None else parsed.port,
24 'username': parsed.username,
25 'password': parsed.password
26 }
27 self.path = parsed.path
28
29 if self.config['host'] is None:
30 self.config['host'] = 'localhost'
31
32 super(FTPArtifactRepository, self).__init__(artifact_uri)
33
34 @contextmanager
35 def get_ftp_client(self):
36 ftp = FTP()
37 ftp.connect(self.config['host'], self.config['port'])
38 ftp.login(self.config['username'], self.config['password'])
39 yield ftp
40 ftp.close()
41
42 @staticmethod
43 def _is_dir(ftp, full_file_path):
44 try:
45 ftp.cwd(full_file_path)
46 return True
47 except ftplib.error_perm:
48 return False
49
50 @staticmethod
51 def _mkdir(ftp, artifact_dir):
52 try:
53 if not FTPArtifactRepository._is_dir(ftp, artifact_dir):
54 ftp.mkd(artifact_dir)
55 except ftplib.error_perm:
56 head, _ = posixpath.split(artifact_dir)
57 FTPArtifactRepository._mkdir(ftp, head)
58 FTPArtifactRepository._mkdir(ftp, artifact_dir)
59
60 @staticmethod
61 def _size(ftp, full_file_path):
62 ftp.voidcmd('TYPE I')
63 size = ftp.size(full_file_path)
64 ftp.voidcmd('TYPE A')
65 return size
66
67 def log_artifact(self, local_file, artifact_path=None):
68 with self.get_ftp_client() as ftp:
69 artifact_dir = posixpath.join(self.path, artifact_path) \
70 if artifact_path else self.path
71 self._mkdir(ftp, artifact_dir)
72 with open(local_file, 'rb') as f:
73 ftp.cwd(artifact_dir)
74 ftp.storbinary('STOR ' + os.path.basename(local_file), f)
75
76 def log_artifacts(self, local_dir, artifact_path=None):
77 dest_path = posixpath.join(self.path, artifact_path) \
78 if artifact_path else self.path
79
80 dest_path = posixpath.join(
81 dest_path, os.path.split(local_dir)[1])
82 dest_path_re = os.path.split(local_dir)[1]
83 if artifact_path:
84 dest_path_re = posixpath.join(
85 artifact_path, os.path.split(local_dir)[1])
86
87 local_dir = os.path.abspath(local_dir)
88 for (root, _, filenames) in os.walk(local_dir):
89 upload_path = dest_path
90 if root != local_dir:
91 rel_path = os.path.relpath(root, local_dir)
92 rel_path = relative_path_to_artifact_path(rel_path)
93 upload_path = posixpath.join(dest_path_re, rel_path)
94 if not filenames:
95 with self.get_ftp_client() as ftp:
96 self._mkdir(ftp, posixpath.join(self.path, upload_path))
97 for f in filenames:
98 if os.path.isfile(os.path.join(root, f)):
99 self.log_artifact(os.path.join(root, f), upload_path)
100
101 def _is_directory(self, artifact_path):
102 artifact_dir = self.path
103 list_dir = posixpath.join(artifact_dir, artifact_path) if artifact_path else artifact_dir
104 with self.get_ftp_client() as ftp:
105 return self._is_dir(ftp, list_dir)
106
107 def list_artifacts(self, path=None):
108 with self.get_ftp_client() as ftp:
109 artifact_dir = self.path
110 list_dir = posixpath.join(artifact_dir, path) if path else artifact_dir
111 if not self._is_dir(ftp, list_dir):
112 return []
113 artifact_files = ftp.nlst(list_dir)
114 infos = []
115 for file_name in artifact_files:
116 file_path = (file_name if path is None
117 else posixpath.join(path, file_name))
118 full_file_path = posixpath.join(list_dir, file_name)
119 if self._is_dir(ftp, full_file_path):
120 infos.append(FileInfo(file_path, True, None))
121 else:
122 size = self._size(ftp, full_file_path)
123 infos.append(FileInfo(file_path, False, size))
124 return infos
125
126 def _download_file(self, remote_file_path, local_path):
127 remote_full_path = posixpath.join(self.path, remote_file_path) \
128 if remote_file_path else self.path
129 with self.get_ftp_client() as ftp:
130 with open(local_path, 'wb') as f:
131 ftp.retrbinary('RETR ' + remote_full_path, f.write)
132
133 def delete_artifacts(self, artifact_path=None):
134 raise MlflowException('Not implemented yet')
135
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mlflow/store/artifact/ftp_artifact_repo.py b/mlflow/store/artifact/ftp_artifact_repo.py
--- a/mlflow/store/artifact/ftp_artifact_repo.py
+++ b/mlflow/store/artifact/ftp_artifact_repo.py
@@ -111,6 +111,7 @@
if not self._is_dir(ftp, list_dir):
return []
artifact_files = ftp.nlst(list_dir)
+ artifact_files = list(filter(lambda x: x != "." and x != "..", artifact_files))
infos = []
for file_name in artifact_files:
file_path = (file_name if path is None
|
{"golden_diff": "diff --git a/mlflow/store/artifact/ftp_artifact_repo.py b/mlflow/store/artifact/ftp_artifact_repo.py\n--- a/mlflow/store/artifact/ftp_artifact_repo.py\n+++ b/mlflow/store/artifact/ftp_artifact_repo.py\n@@ -111,6 +111,7 @@\n if not self._is_dir(ftp, list_dir):\n return []\n artifact_files = ftp.nlst(list_dir)\n+ artifact_files = list(filter(lambda x: x != \".\" and x != \"..\", artifact_files))\n infos = []\n for file_name in artifact_files:\n file_path = (file_name if path is None\n", "issue": "Cannot preview artifacts in UI when uploaded to remote machine via FTP\n### System information\r\n- **Have I written custom code (as opposed to using a stock example script provided in MLflow)**:\r\nNo\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:\r\nLinux Ubuntu 18.04\r\n- **MLflow installed from (source or binary)**: \r\ninstalled via from pypi via pip\r\n- **MLflow version (run ``mlflow --version``)**:\r\n0.9.1\r\n- **Python version**: \r\n3.6.7\r\n- **npm version (if running the dev UI):\r\n- **Exact command to reproduce**:\r\nServer runs with:\r\n```\r\nmlflow server --backend-store-uri ./mlruns --default-artifact-root ./artifacts -h 0.0.0.0 -p 5020\r\n```\r\nwithin a folder holding a `mlruns` and a `artifacts` folder\r\n\r\n### Describe the problem\r\nI am running the server on a remote machine.\r\nOn the local machine which uploads via the tracking API the\r\ntracking uri is set to: `http://path.to.server:port`\r\nand artifact uri to: `ftp://anonymous:@path.to.server/artifacts`\r\n\r\nuploading the tracking information and artifacts work fine and everything shows in the ui:\r\n\r\n\r\nHowever when I try to click one of the artifacts I always get the message that something went wrong:\r\n\r\n\r\nPreviewing the artifacts work when I store them locally on my machine but as soon as I transfer them via FTP and then try to preview them from the remote machine I get the error shown above.\r\n\r\n\r\n### Source code / logs\r\n-\r\n\n", "before_files": [{"content": "import os\nimport ftplib\nfrom ftplib import FTP\nfrom contextlib import contextmanager\n\nimport posixpath\nfrom six.moves import urllib\n\nfrom mlflow.entities.file_info import FileInfo\nfrom mlflow.store.artifact.artifact_repo import ArtifactRepository\nfrom mlflow.utils.file_utils import relative_path_to_artifact_path\nfrom mlflow.exceptions import MlflowException\n\n\nclass FTPArtifactRepository(ArtifactRepository):\n \"\"\"Stores artifacts as files in a remote directory, via ftp.\"\"\"\n\n def __init__(self, artifact_uri):\n self.uri = artifact_uri\n parsed = urllib.parse.urlparse(artifact_uri)\n self.config = {\n 'host': parsed.hostname,\n 'port': 21 if parsed.port is None else parsed.port,\n 'username': parsed.username,\n 'password': parsed.password\n }\n self.path = parsed.path\n\n if self.config['host'] is None:\n self.config['host'] = 'localhost'\n\n super(FTPArtifactRepository, self).__init__(artifact_uri)\n\n @contextmanager\n def get_ftp_client(self):\n ftp = FTP()\n ftp.connect(self.config['host'], self.config['port'])\n ftp.login(self.config['username'], self.config['password'])\n yield ftp\n ftp.close()\n\n @staticmethod\n def _is_dir(ftp, full_file_path):\n try:\n ftp.cwd(full_file_path)\n return True\n except ftplib.error_perm:\n return False\n\n @staticmethod\n def _mkdir(ftp, artifact_dir):\n try:\n if not FTPArtifactRepository._is_dir(ftp, artifact_dir):\n ftp.mkd(artifact_dir)\n except ftplib.error_perm:\n head, _ = posixpath.split(artifact_dir)\n FTPArtifactRepository._mkdir(ftp, head)\n FTPArtifactRepository._mkdir(ftp, artifact_dir)\n\n @staticmethod\n def _size(ftp, full_file_path):\n ftp.voidcmd('TYPE I')\n size = ftp.size(full_file_path)\n ftp.voidcmd('TYPE A')\n return size\n\n def log_artifact(self, local_file, artifact_path=None):\n with self.get_ftp_client() as ftp:\n artifact_dir = posixpath.join(self.path, artifact_path) \\\n if artifact_path else self.path\n self._mkdir(ftp, artifact_dir)\n with open(local_file, 'rb') as f:\n ftp.cwd(artifact_dir)\n ftp.storbinary('STOR ' + os.path.basename(local_file), f)\n\n def log_artifacts(self, local_dir, artifact_path=None):\n dest_path = posixpath.join(self.path, artifact_path) \\\n if artifact_path else self.path\n\n dest_path = posixpath.join(\n dest_path, os.path.split(local_dir)[1])\n dest_path_re = os.path.split(local_dir)[1]\n if artifact_path:\n dest_path_re = posixpath.join(\n artifact_path, os.path.split(local_dir)[1])\n\n local_dir = os.path.abspath(local_dir)\n for (root, _, filenames) in os.walk(local_dir):\n upload_path = dest_path\n if root != local_dir:\n rel_path = os.path.relpath(root, local_dir)\n rel_path = relative_path_to_artifact_path(rel_path)\n upload_path = posixpath.join(dest_path_re, rel_path)\n if not filenames:\n with self.get_ftp_client() as ftp:\n self._mkdir(ftp, posixpath.join(self.path, upload_path))\n for f in filenames:\n if os.path.isfile(os.path.join(root, f)):\n self.log_artifact(os.path.join(root, f), upload_path)\n\n def _is_directory(self, artifact_path):\n artifact_dir = self.path\n list_dir = posixpath.join(artifact_dir, artifact_path) if artifact_path else artifact_dir\n with self.get_ftp_client() as ftp:\n return self._is_dir(ftp, list_dir)\n\n def list_artifacts(self, path=None):\n with self.get_ftp_client() as ftp:\n artifact_dir = self.path\n list_dir = posixpath.join(artifact_dir, path) if path else artifact_dir\n if not self._is_dir(ftp, list_dir):\n return []\n artifact_files = ftp.nlst(list_dir)\n infos = []\n for file_name in artifact_files:\n file_path = (file_name if path is None\n else posixpath.join(path, file_name))\n full_file_path = posixpath.join(list_dir, file_name)\n if self._is_dir(ftp, full_file_path):\n infos.append(FileInfo(file_path, True, None))\n else:\n size = self._size(ftp, full_file_path)\n infos.append(FileInfo(file_path, False, size))\n return infos\n\n def _download_file(self, remote_file_path, local_path):\n remote_full_path = posixpath.join(self.path, remote_file_path) \\\n if remote_file_path else self.path\n with self.get_ftp_client() as ftp:\n with open(local_path, 'wb') as f:\n ftp.retrbinary('RETR ' + remote_full_path, f.write)\n\n def delete_artifacts(self, artifact_path=None):\n raise MlflowException('Not implemented yet')\n", "path": "mlflow/store/artifact/ftp_artifact_repo.py"}], "after_files": [{"content": "import os\nimport ftplib\nfrom ftplib import FTP\nfrom contextlib import contextmanager\n\nimport posixpath\nfrom six.moves import urllib\n\nfrom mlflow.entities.file_info import FileInfo\nfrom mlflow.store.artifact.artifact_repo import ArtifactRepository\nfrom mlflow.utils.file_utils import relative_path_to_artifact_path\nfrom mlflow.exceptions import MlflowException\n\n\nclass FTPArtifactRepository(ArtifactRepository):\n \"\"\"Stores artifacts as files in a remote directory, via ftp.\"\"\"\n\n def __init__(self, artifact_uri):\n self.uri = artifact_uri\n parsed = urllib.parse.urlparse(artifact_uri)\n self.config = {\n 'host': parsed.hostname,\n 'port': 21 if parsed.port is None else parsed.port,\n 'username': parsed.username,\n 'password': parsed.password\n }\n self.path = parsed.path\n\n if self.config['host'] is None:\n self.config['host'] = 'localhost'\n\n super(FTPArtifactRepository, self).__init__(artifact_uri)\n\n @contextmanager\n def get_ftp_client(self):\n ftp = FTP()\n ftp.connect(self.config['host'], self.config['port'])\n ftp.login(self.config['username'], self.config['password'])\n yield ftp\n ftp.close()\n\n @staticmethod\n def _is_dir(ftp, full_file_path):\n try:\n ftp.cwd(full_file_path)\n return True\n except ftplib.error_perm:\n return False\n\n @staticmethod\n def _mkdir(ftp, artifact_dir):\n try:\n if not FTPArtifactRepository._is_dir(ftp, artifact_dir):\n ftp.mkd(artifact_dir)\n except ftplib.error_perm:\n head, _ = posixpath.split(artifact_dir)\n FTPArtifactRepository._mkdir(ftp, head)\n FTPArtifactRepository._mkdir(ftp, artifact_dir)\n\n @staticmethod\n def _size(ftp, full_file_path):\n ftp.voidcmd('TYPE I')\n size = ftp.size(full_file_path)\n ftp.voidcmd('TYPE A')\n return size\n\n def log_artifact(self, local_file, artifact_path=None):\n with self.get_ftp_client() as ftp:\n artifact_dir = posixpath.join(self.path, artifact_path) \\\n if artifact_path else self.path\n self._mkdir(ftp, artifact_dir)\n with open(local_file, 'rb') as f:\n ftp.cwd(artifact_dir)\n ftp.storbinary('STOR ' + os.path.basename(local_file), f)\n\n def log_artifacts(self, local_dir, artifact_path=None):\n dest_path = posixpath.join(self.path, artifact_path) \\\n if artifact_path else self.path\n\n dest_path = posixpath.join(\n dest_path, os.path.split(local_dir)[1])\n dest_path_re = os.path.split(local_dir)[1]\n if artifact_path:\n dest_path_re = posixpath.join(\n artifact_path, os.path.split(local_dir)[1])\n\n local_dir = os.path.abspath(local_dir)\n for (root, _, filenames) in os.walk(local_dir):\n upload_path = dest_path\n if root != local_dir:\n rel_path = os.path.relpath(root, local_dir)\n rel_path = relative_path_to_artifact_path(rel_path)\n upload_path = posixpath.join(dest_path_re, rel_path)\n if not filenames:\n with self.get_ftp_client() as ftp:\n self._mkdir(ftp, posixpath.join(self.path, upload_path))\n for f in filenames:\n if os.path.isfile(os.path.join(root, f)):\n self.log_artifact(os.path.join(root, f), upload_path)\n\n def _is_directory(self, artifact_path):\n artifact_dir = self.path\n list_dir = posixpath.join(artifact_dir, artifact_path) if artifact_path else artifact_dir\n with self.get_ftp_client() as ftp:\n return self._is_dir(ftp, list_dir)\n\n def list_artifacts(self, path=None):\n with self.get_ftp_client() as ftp:\n artifact_dir = self.path\n list_dir = posixpath.join(artifact_dir, path) if path else artifact_dir\n if not self._is_dir(ftp, list_dir):\n return []\n artifact_files = ftp.nlst(list_dir)\n artifact_files = list(filter(lambda x: x != \".\" and x != \"..\", artifact_files))\n infos = []\n for file_name in artifact_files:\n file_path = (file_name if path is None\n else posixpath.join(path, file_name))\n full_file_path = posixpath.join(list_dir, file_name)\n if self._is_dir(ftp, full_file_path):\n infos.append(FileInfo(file_path, True, None))\n else:\n size = self._size(ftp, full_file_path)\n infos.append(FileInfo(file_path, False, size))\n return infos\n\n def _download_file(self, remote_file_path, local_path):\n remote_full_path = posixpath.join(self.path, remote_file_path) \\\n if remote_file_path else self.path\n with self.get_ftp_client() as ftp:\n with open(local_path, 'wb') as f:\n ftp.retrbinary('RETR ' + remote_full_path, f.write)\n\n def delete_artifacts(self, artifact_path=None):\n raise MlflowException('Not implemented yet')\n", "path": "mlflow/store/artifact/ftp_artifact_repo.py"}]}
| 2,160 | 141 |
gh_patches_debug_6388
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-259
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Translations for v0.2.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ephios/user_management/consequences.py`
Content:
```
1 import functools
2 import operator
3 from datetime import datetime
4
5 import django.dispatch
6 from django.contrib.auth import get_user_model
7 from django.contrib.auth.models import Group
8 from django.db.models import OuterRef, Q, Subquery
9 from django.db.models.fields.json import KeyTransform
10 from django.utils.formats import date_format
11 from django.utils.translation import gettext_lazy as _
12 from guardian.shortcuts import get_objects_for_user
13
14 from ephios.event_management.models import Event, Shift
15 from ephios.user_management.models import (
16 Consequence,
17 Qualification,
18 QualificationGrant,
19 UserProfile,
20 WorkingHours,
21 )
22
23 register_consequence_handlers = django.dispatch.Signal()
24
25
26 def all_consequence_handlers():
27 for _, handlers in register_consequence_handlers.send(None):
28 yield from (h() for h in handlers)
29
30
31 def consequence_handler_from_slug(slug):
32 for handler in all_consequence_handlers():
33 if handler.slug == slug:
34 return handler
35 raise ValueError(_("Consequence Handler '{slug}' was not found.").format(slug=slug))
36
37
38 def editable_consequences(user):
39 handlers = list(all_consequence_handlers())
40 qs = Consequence.objects.filter(
41 functools.reduce(
42 operator.or_,
43 (handler.editable_by_filter(user) for handler in handlers),
44 Q(),
45 )
46 ).distinct()
47 for handler in handlers:
48 qs = handler.annotate_queryset(qs)
49 return qs
50
51
52 class ConsequenceError(Exception):
53 pass
54
55
56 class BaseConsequenceHandler:
57 @property
58 def slug(self):
59 raise NotImplementedError
60
61 @classmethod
62 def execute(cls, consequence):
63 """
64 Gets a consequence and tries to execute whatever it is the consequence wants to happen.
65 """
66 raise NotImplementedError
67
68 @classmethod
69 def render(cls, consequence):
70 """
71 Return html describing the action to be done as a consequence of what.
72 Return None if you cannot handle this consequence.
73 """
74 raise NotImplementedError
75
76 @classmethod
77 def editable_by_filter(cls, user: UserProfile):
78 """
79 Return a Q object to filter consequence objects of this type that can be confirmed by the given user.
80 """
81 raise NotImplementedError
82
83 @classmethod
84 def annotate_queryset(cls, qs):
85 """
86 Annotate a queryset of heterogeneous consequences to avoid needing additional queries for rendering a consequence.
87 Does no annotations by default.
88 """
89 return qs
90
91
92 class WorkingHoursConsequenceHandler(BaseConsequenceHandler):
93 slug = "ephios.grant_working_hours"
94
95 @classmethod
96 def create(
97 cls,
98 user: UserProfile,
99 when: datetime,
100 hours: float,
101 reason: str,
102 ):
103 return Consequence.objects.create(
104 slug=cls.slug,
105 user=user,
106 data=dict(hours=hours, date=when, reason=reason),
107 )
108
109 @classmethod
110 def execute(cls, consequence):
111 WorkingHours.objects.create(
112 user=consequence.user,
113 date=consequence.data["date"],
114 hours=consequence.data["hours"],
115 reason=consequence.data.get("reason"),
116 )
117
118 @classmethod
119 def render(cls, consequence):
120 return _("{user} logs {hours:.1f} hours on {date} for {reason}").format(
121 user=consequence.user.get_full_name(),
122 hours=consequence.data.get("hours"),
123 reason=consequence.data.get("reason"),
124 date=date_format(consequence.data.get("date")),
125 )
126
127 @classmethod
128 def editable_by_filter(cls, user):
129 return Q(
130 slug=cls.slug,
131 user__groups__in=get_objects_for_user(
132 user, "decide_workinghours_for_group", klass=Group
133 ),
134 )
135
136
137 class QualificationConsequenceHandler(BaseConsequenceHandler):
138 slug = "ephios.grant_qualification"
139
140 @classmethod
141 def create(
142 cls,
143 user: UserProfile,
144 qualification: Qualification,
145 expires: datetime = None,
146 shift: Shift = None,
147 ):
148 return Consequence.objects.create(
149 slug=cls.slug,
150 user=user,
151 data=dict(
152 qualification_id=qualification.id,
153 event_id=None if shift is None else shift.event_id,
154 expires=expires,
155 ),
156 )
157
158 @classmethod
159 def execute(cls, consequence):
160 qg, created = QualificationGrant.objects.get_or_create(
161 defaults=dict(
162 expires=consequence.data["expires"],
163 ),
164 user=consequence.user,
165 qualification_id=consequence.data["qualification_id"],
166 )
167 if not created:
168 qg.expires = max(
169 qg.expires, consequence.data["expires"], key=lambda dt: dt or datetime.max
170 )
171 qg.save()
172
173 @classmethod
174 def render(cls, consequence):
175 # Get all the strings we need from the annotations, or fetch them from DB as backup
176 try: # try the annotation
177 event_title = consequence.event_title
178 except AttributeError:
179 if event_id := consequence.data["event_id"]: # fetch from DB as backup
180 event_title = Event.objects.get(id=event_id).title
181 else: # no event has been associated
182 event_title = None
183
184 try:
185 qualification_title = consequence.qualification_title
186 except AttributeError:
187 qualification_title = Qualification.objects.get(
188 id=consequence.data["qualification_id"]
189 ).title
190
191 if expires := consequence.data.get("expires"):
192 expires = date_format(expires)
193
194 user = consequence.user.get_full_name()
195
196 # build string based on available data
197
198 if event_title:
199 s = _("{user} acquires '{qualification}' after participating in {event}.").format(
200 user=user, qualification=qualification_title, event=event_title
201 )
202 else:
203 s = _("{user} acquires '{qualification}'.").format(
204 user=user,
205 qualification=qualification_title,
206 )
207
208 if expires:
209 s += " " + _("(valid until {expires_str})").format(expires_str=expires)
210 return s
211
212 @classmethod
213 def editable_by_filter(cls, user: UserProfile):
214 # Qualifications can be granted by people who...
215 return Q(slug=cls.slug,) & (
216 Q( # are responsible for the event the consequence originated from, if applicable
217 data__event_id__isnull=False,
218 data__event_id__in=get_objects_for_user(user, perms="change_event", klass=Event),
219 )
220 | Q( # can edit the affected user anyway
221 user__in=get_objects_for_user(
222 user, perms="user_management.change_userprofile", klass=get_user_model()
223 )
224 )
225 )
226
227 @classmethod
228 def annotate_queryset(cls, qs):
229 return qs.annotate(
230 qualification_id=KeyTransform("qualification_id", "data"),
231 event_id=KeyTransform("event_id", "data"),
232 ).annotate(
233 qualification_title=Subquery(
234 Qualification.objects.filter(id=OuterRef("qualification_id")).values("title")[:1]
235 ),
236 event_title=Subquery(Event.objects.filter(id=OuterRef("event_id")).values("title")[:1]),
237 )
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ephios/user_management/consequences.py b/ephios/user_management/consequences.py
--- a/ephios/user_management/consequences.py
+++ b/ephios/user_management/consequences.py
@@ -117,7 +117,7 @@
@classmethod
def render(cls, consequence):
- return _("{user} logs {hours:.1f} hours on {date} for {reason}").format(
+ return _("{user} logs {hours:.1f} hours on {date}. Reason: {reason}").format(
user=consequence.user.get_full_name(),
hours=consequence.data.get("hours"),
reason=consequence.data.get("reason"),
|
{"golden_diff": "diff --git a/ephios/user_management/consequences.py b/ephios/user_management/consequences.py\n--- a/ephios/user_management/consequences.py\n+++ b/ephios/user_management/consequences.py\n@@ -117,7 +117,7 @@\n \n @classmethod\n def render(cls, consequence):\n- return _(\"{user} logs {hours:.1f} hours on {date} for {reason}\").format(\n+ return _(\"{user} logs {hours:.1f} hours on {date}. Reason: {reason}\").format(\n user=consequence.user.get_full_name(),\n hours=consequence.data.get(\"hours\"),\n reason=consequence.data.get(\"reason\"),\n", "issue": "Translations for v0.2.0\n\n", "before_files": [{"content": "import functools\nimport operator\nfrom datetime import datetime\n\nimport django.dispatch\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group\nfrom django.db.models import OuterRef, Q, Subquery\nfrom django.db.models.fields.json import KeyTransform\nfrom django.utils.formats import date_format\nfrom django.utils.translation import gettext_lazy as _\nfrom guardian.shortcuts import get_objects_for_user\n\nfrom ephios.event_management.models import Event, Shift\nfrom ephios.user_management.models import (\n Consequence,\n Qualification,\n QualificationGrant,\n UserProfile,\n WorkingHours,\n)\n\nregister_consequence_handlers = django.dispatch.Signal()\n\n\ndef all_consequence_handlers():\n for _, handlers in register_consequence_handlers.send(None):\n yield from (h() for h in handlers)\n\n\ndef consequence_handler_from_slug(slug):\n for handler in all_consequence_handlers():\n if handler.slug == slug:\n return handler\n raise ValueError(_(\"Consequence Handler '{slug}' was not found.\").format(slug=slug))\n\n\ndef editable_consequences(user):\n handlers = list(all_consequence_handlers())\n qs = Consequence.objects.filter(\n functools.reduce(\n operator.or_,\n (handler.editable_by_filter(user) for handler in handlers),\n Q(),\n )\n ).distinct()\n for handler in handlers:\n qs = handler.annotate_queryset(qs)\n return qs\n\n\nclass ConsequenceError(Exception):\n pass\n\n\nclass BaseConsequenceHandler:\n @property\n def slug(self):\n raise NotImplementedError\n\n @classmethod\n def execute(cls, consequence):\n \"\"\"\n Gets a consequence and tries to execute whatever it is the consequence wants to happen.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def render(cls, consequence):\n \"\"\"\n Return html describing the action to be done as a consequence of what.\n Return None if you cannot handle this consequence.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def editable_by_filter(cls, user: UserProfile):\n \"\"\"\n Return a Q object to filter consequence objects of this type that can be confirmed by the given user.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def annotate_queryset(cls, qs):\n \"\"\"\n Annotate a queryset of heterogeneous consequences to avoid needing additional queries for rendering a consequence.\n Does no annotations by default.\n \"\"\"\n return qs\n\n\nclass WorkingHoursConsequenceHandler(BaseConsequenceHandler):\n slug = \"ephios.grant_working_hours\"\n\n @classmethod\n def create(\n cls,\n user: UserProfile,\n when: datetime,\n hours: float,\n reason: str,\n ):\n return Consequence.objects.create(\n slug=cls.slug,\n user=user,\n data=dict(hours=hours, date=when, reason=reason),\n )\n\n @classmethod\n def execute(cls, consequence):\n WorkingHours.objects.create(\n user=consequence.user,\n date=consequence.data[\"date\"],\n hours=consequence.data[\"hours\"],\n reason=consequence.data.get(\"reason\"),\n )\n\n @classmethod\n def render(cls, consequence):\n return _(\"{user} logs {hours:.1f} hours on {date} for {reason}\").format(\n user=consequence.user.get_full_name(),\n hours=consequence.data.get(\"hours\"),\n reason=consequence.data.get(\"reason\"),\n date=date_format(consequence.data.get(\"date\")),\n )\n\n @classmethod\n def editable_by_filter(cls, user):\n return Q(\n slug=cls.slug,\n user__groups__in=get_objects_for_user(\n user, \"decide_workinghours_for_group\", klass=Group\n ),\n )\n\n\nclass QualificationConsequenceHandler(BaseConsequenceHandler):\n slug = \"ephios.grant_qualification\"\n\n @classmethod\n def create(\n cls,\n user: UserProfile,\n qualification: Qualification,\n expires: datetime = None,\n shift: Shift = None,\n ):\n return Consequence.objects.create(\n slug=cls.slug,\n user=user,\n data=dict(\n qualification_id=qualification.id,\n event_id=None if shift is None else shift.event_id,\n expires=expires,\n ),\n )\n\n @classmethod\n def execute(cls, consequence):\n qg, created = QualificationGrant.objects.get_or_create(\n defaults=dict(\n expires=consequence.data[\"expires\"],\n ),\n user=consequence.user,\n qualification_id=consequence.data[\"qualification_id\"],\n )\n if not created:\n qg.expires = max(\n qg.expires, consequence.data[\"expires\"], key=lambda dt: dt or datetime.max\n )\n qg.save()\n\n @classmethod\n def render(cls, consequence):\n # Get all the strings we need from the annotations, or fetch them from DB as backup\n try: # try the annotation\n event_title = consequence.event_title\n except AttributeError:\n if event_id := consequence.data[\"event_id\"]: # fetch from DB as backup\n event_title = Event.objects.get(id=event_id).title\n else: # no event has been associated\n event_title = None\n\n try:\n qualification_title = consequence.qualification_title\n except AttributeError:\n qualification_title = Qualification.objects.get(\n id=consequence.data[\"qualification_id\"]\n ).title\n\n if expires := consequence.data.get(\"expires\"):\n expires = date_format(expires)\n\n user = consequence.user.get_full_name()\n\n # build string based on available data\n\n if event_title:\n s = _(\"{user} acquires '{qualification}' after participating in {event}.\").format(\n user=user, qualification=qualification_title, event=event_title\n )\n else:\n s = _(\"{user} acquires '{qualification}'.\").format(\n user=user,\n qualification=qualification_title,\n )\n\n if expires:\n s += \" \" + _(\"(valid until {expires_str})\").format(expires_str=expires)\n return s\n\n @classmethod\n def editable_by_filter(cls, user: UserProfile):\n # Qualifications can be granted by people who...\n return Q(slug=cls.slug,) & (\n Q( # are responsible for the event the consequence originated from, if applicable\n data__event_id__isnull=False,\n data__event_id__in=get_objects_for_user(user, perms=\"change_event\", klass=Event),\n )\n | Q( # can edit the affected user anyway\n user__in=get_objects_for_user(\n user, perms=\"user_management.change_userprofile\", klass=get_user_model()\n )\n )\n )\n\n @classmethod\n def annotate_queryset(cls, qs):\n return qs.annotate(\n qualification_id=KeyTransform(\"qualification_id\", \"data\"),\n event_id=KeyTransform(\"event_id\", \"data\"),\n ).annotate(\n qualification_title=Subquery(\n Qualification.objects.filter(id=OuterRef(\"qualification_id\")).values(\"title\")[:1]\n ),\n event_title=Subquery(Event.objects.filter(id=OuterRef(\"event_id\")).values(\"title\")[:1]),\n )\n", "path": "ephios/user_management/consequences.py"}], "after_files": [{"content": "import functools\nimport operator\nfrom datetime import datetime\n\nimport django.dispatch\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group\nfrom django.db.models import OuterRef, Q, Subquery\nfrom django.db.models.fields.json import KeyTransform\nfrom django.utils.formats import date_format\nfrom django.utils.translation import gettext_lazy as _\nfrom guardian.shortcuts import get_objects_for_user\n\nfrom ephios.event_management.models import Event, Shift\nfrom ephios.user_management.models import (\n Consequence,\n Qualification,\n QualificationGrant,\n UserProfile,\n WorkingHours,\n)\n\nregister_consequence_handlers = django.dispatch.Signal()\n\n\ndef all_consequence_handlers():\n for _, handlers in register_consequence_handlers.send(None):\n yield from (h() for h in handlers)\n\n\ndef consequence_handler_from_slug(slug):\n for handler in all_consequence_handlers():\n if handler.slug == slug:\n return handler\n raise ValueError(_(\"Consequence Handler '{slug}' was not found.\").format(slug=slug))\n\n\ndef editable_consequences(user):\n handlers = list(all_consequence_handlers())\n qs = Consequence.objects.filter(\n functools.reduce(\n operator.or_,\n (handler.editable_by_filter(user) for handler in handlers),\n Q(),\n )\n ).distinct()\n for handler in handlers:\n qs = handler.annotate_queryset(qs)\n return qs\n\n\nclass ConsequenceError(Exception):\n pass\n\n\nclass BaseConsequenceHandler:\n @property\n def slug(self):\n raise NotImplementedError\n\n @classmethod\n def execute(cls, consequence):\n \"\"\"\n Gets a consequence and tries to execute whatever it is the consequence wants to happen.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def render(cls, consequence):\n \"\"\"\n Return html describing the action to be done as a consequence of what.\n Return None if you cannot handle this consequence.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def editable_by_filter(cls, user: UserProfile):\n \"\"\"\n Return a Q object to filter consequence objects of this type that can be confirmed by the given user.\n \"\"\"\n raise NotImplementedError\n\n @classmethod\n def annotate_queryset(cls, qs):\n \"\"\"\n Annotate a queryset of heterogeneous consequences to avoid needing additional queries for rendering a consequence.\n Does no annotations by default.\n \"\"\"\n return qs\n\n\nclass WorkingHoursConsequenceHandler(BaseConsequenceHandler):\n slug = \"ephios.grant_working_hours\"\n\n @classmethod\n def create(\n cls,\n user: UserProfile,\n when: datetime,\n hours: float,\n reason: str,\n ):\n return Consequence.objects.create(\n slug=cls.slug,\n user=user,\n data=dict(hours=hours, date=when, reason=reason),\n )\n\n @classmethod\n def execute(cls, consequence):\n WorkingHours.objects.create(\n user=consequence.user,\n date=consequence.data[\"date\"],\n hours=consequence.data[\"hours\"],\n reason=consequence.data.get(\"reason\"),\n )\n\n @classmethod\n def render(cls, consequence):\n return _(\"{user} logs {hours:.1f} hours on {date}. Reason: {reason}\").format(\n user=consequence.user.get_full_name(),\n hours=consequence.data.get(\"hours\"),\n reason=consequence.data.get(\"reason\"),\n date=date_format(consequence.data.get(\"date\")),\n )\n\n @classmethod\n def editable_by_filter(cls, user):\n return Q(\n slug=cls.slug,\n user__groups__in=get_objects_for_user(\n user, \"decide_workinghours_for_group\", klass=Group\n ),\n )\n\n\nclass QualificationConsequenceHandler(BaseConsequenceHandler):\n slug = \"ephios.grant_qualification\"\n\n @classmethod\n def create(\n cls,\n user: UserProfile,\n qualification: Qualification,\n expires: datetime = None,\n shift: Shift = None,\n ):\n return Consequence.objects.create(\n slug=cls.slug,\n user=user,\n data=dict(\n qualification_id=qualification.id,\n event_id=None if shift is None else shift.event_id,\n expires=expires,\n ),\n )\n\n @classmethod\n def execute(cls, consequence):\n qg, created = QualificationGrant.objects.get_or_create(\n defaults=dict(\n expires=consequence.data[\"expires\"],\n ),\n user=consequence.user,\n qualification_id=consequence.data[\"qualification_id\"],\n )\n if not created:\n qg.expires = max(\n qg.expires, consequence.data[\"expires\"], key=lambda dt: dt or datetime.max\n )\n qg.save()\n\n @classmethod\n def render(cls, consequence):\n # Get all the strings we need from the annotations, or fetch them from DB as backup\n try: # try the annotation\n event_title = consequence.event_title\n except AttributeError:\n if event_id := consequence.data[\"event_id\"]: # fetch from DB as backup\n event_title = Event.objects.get(id=event_id).title\n else: # no event has been associated\n event_title = None\n\n try:\n qualification_title = consequence.qualification_title\n except AttributeError:\n qualification_title = Qualification.objects.get(\n id=consequence.data[\"qualification_id\"]\n ).title\n\n if expires := consequence.data.get(\"expires\"):\n expires = date_format(expires)\n\n user = consequence.user.get_full_name()\n\n # build string based on available data\n\n if event_title:\n s = _(\"{user} acquires '{qualification}' after participating in {event}.\").format(\n user=user, qualification=qualification_title, event=event_title\n )\n else:\n s = _(\"{user} acquires '{qualification}'.\").format(\n user=user,\n qualification=qualification_title,\n )\n\n if expires:\n s += \" \" + _(\"(valid until {expires_str})\").format(expires_str=expires)\n return s\n\n @classmethod\n def editable_by_filter(cls, user: UserProfile):\n # Qualifications can be granted by people who...\n return Q(slug=cls.slug,) & (\n Q( # are responsible for the event the consequence originated from, if applicable\n data__event_id__isnull=False,\n data__event_id__in=get_objects_for_user(user, perms=\"change_event\", klass=Event),\n )\n | Q( # can edit the affected user anyway\n user__in=get_objects_for_user(\n user, perms=\"user_management.change_userprofile\", klass=get_user_model()\n )\n )\n )\n\n @classmethod\n def annotate_queryset(cls, qs):\n return qs.annotate(\n qualification_id=KeyTransform(\"qualification_id\", \"data\"),\n event_id=KeyTransform(\"event_id\", \"data\"),\n ).annotate(\n qualification_title=Subquery(\n Qualification.objects.filter(id=OuterRef(\"qualification_id\")).values(\"title\")[:1]\n ),\n event_title=Subquery(Event.objects.filter(id=OuterRef(\"event_id\")).values(\"title\")[:1]),\n )\n", "path": "ephios/user_management/consequences.py"}]}
| 2,385 | 153 |
gh_patches_debug_58539
|
rasdani/github-patches
|
git_diff
|
ansible__molecule-4038
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
created: true is ignored in state.yml
# Issue Type
- Bug report
# Molecule and Ansible details
```
ansible --version && molecule --version
ansible [core 2.15.3]
config file = None
configured module search path = ['/home/manu/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/lib/python3.11/site-packages/ansible
ansible collection location = /home/manu/.ansible/collections:/usr/share/ansible/collections
executable location = /home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/bin/ansible
python version = 3.11.5 (main, Aug 28 2023, 20:02:58) [GCC 13.2.1 20230801] (/home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/bin/python)
jinja version = 3.1.2
libyaml = True
molecule 6.0.2 using python 3.11
ansible:2.15.3
default:6.0.2 from molecule
molecule-qemu:0.5.3 from molecule_qemu
```
Molecule installation method: source
Ansible installation method: pip
# Desired Behavior
In molecule v5, the `create` step was automatically skipped when `created: true` in `<XDG_CACHE_HOME>/molecule//<scenario>/state.yml` with the message `WARNING Skipping, instances already created.`. This is the desired behavior.
Here an example with a simple hello_world role after a `molecule create` execution. The molecule-qemu plugin is used here.
```
❯ molecule converge
INFO default scenario test matrix: dependency, create, prepare, converge
INFO Performing prerun with role_name_check=0...
INFO Set ANSIBLE_LIBRARY=/home/manu/.cache/ansible-compat/35072c/modules:/home/manu/.ansible/plugins/modules:/usr/share/ansible/plugins/modules
INFO Set ANSIBLE_COLLECTIONS_PATH=/home/manu/.cache/ansible-compat/35072c/collections:/home/manu/.ansible/collections:/usr/share/ansible/collections
INFO Set ANSIBLE_ROLES_PATH=/home/manu/.cache/ansible-compat/35072c/roles:/home/manu/.ansible/roles:/usr/share/ansible/roles:/etc/ansible/roles
INFO Running default > dependency
WARNING Skipping, missing the requirements file.
WARNING Skipping, missing the requirements file.
INFO Running default > create
WARNING Skipping, instances already created.
INFO Running default > prepare
WARNING Skipping, prepare playbook not configured.
INFO Running default > converge
PLAY [all] *********************************************************************
TASK [hello_world : Hello world] ***********************************************
ok: [test-hello-world] => {
"msg": "Hello, world!"
}
PLAY RECAP *********************************************************************
test-hello-world : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
# Actual Behaviour
Since molecule v6, the `WARNING Skipping, instances already created.` message is no longer displayed and the create step is executed each time the `molecule converge` is called.
Here an example with the same role, with the same conditions except that molecule version is 6.0.2.
```
INFO default scenario test matrix: dependency, create, prepare, converge
INFO Performing prerun with role_name_check=0...
INFO Running default > dependency
WARNING Skipping, missing the requirements file.
WARNING Skipping, missing the requirements file.
INFO Running default > create
PLAY [Create] ******************************************************************
TASK [Gather only necessary facts] *********************************************
ok: [localhost]
TASK [Register VMs data] *******************************************************
ok: [localhost] => (item=test-hello-world)
TASK [Prepare VMs data] ********************************************************
ok: [localhost]
...
TASK [Dump VMs config] *********************************************************
ok: [localhost]
PLAY RECAP *********************************************************************
localhost : ok=31 changed=0 unreachable=0 failed=0 skipped=5 rescued=0 ignored=0
INFO Running default > prepare
WARNING Skipping, prepare playbook not configured.
INFO Running default > converge
PLAY [all] *********************************************************************
TASK [hello_world : Hello world] ***********************************************
ok: [test-hello-world] => {
"msg": "Hello, world!"
}
PLAY RECAP *********************************************************************
test-hello-world : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/molecule/command/create.py`
Content:
```
1 # Copyright (c) 2015-2018 Cisco Systems, Inc.
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a copy
4 # of this software and associated documentation files (the "Software"), to
5 # deal in the Software without restriction, including without limitation the
6 # rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
7 # sell copies of the Software, and to permit persons to whom the Software is
8 # furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
16 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20 """Create Command Module."""
21
22 import logging
23
24 import click
25
26 from molecule.api import drivers
27 from molecule.command import base
28 from molecule.config import DEFAULT_DRIVER
29
30 LOG = logging.getLogger(__name__)
31
32
33 class Create(base.Base):
34 """Create Command Class."""
35
36 def execute(self, action_args=None):
37 """Execute the actions necessary to perform a `molecule create` and \
38 returns None.
39
40 :return: None
41 """
42 self._config.state.change_state("driver", self._config.driver.name)
43
44 self._config.provisioner.create()
45
46 self._config.state.change_state("created", True)
47
48
49 @base.click_command_ex()
50 @click.pass_context
51 @click.option(
52 "--scenario-name",
53 "-s",
54 default=base.MOLECULE_DEFAULT_SCENARIO_NAME,
55 help=f"Name of the scenario to target. ({base.MOLECULE_DEFAULT_SCENARIO_NAME})",
56 )
57 @click.option(
58 "--driver-name",
59 "-d",
60 type=click.Choice([str(s) for s in drivers()]),
61 help=f"Name of driver to use. ({DEFAULT_DRIVER})",
62 )
63 def create(ctx, scenario_name, driver_name): # pragma: no cover
64 """Use the provisioner to start the instances."""
65 args = ctx.obj.get("args")
66 subcommand = base._get_subcommand(__name__)
67 command_args = {"subcommand": subcommand, "driver_name": driver_name}
68
69 base.execute_cmdline_scenarios(scenario_name, args, command_args)
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/molecule/command/create.py b/src/molecule/command/create.py
--- a/src/molecule/command/create.py
+++ b/src/molecule/command/create.py
@@ -41,6 +41,11 @@
"""
self._config.state.change_state("driver", self._config.driver.name)
+ if self._config.state.created:
+ msg = "Skipping, instances already created."
+ LOG.warning(msg)
+ return
+
self._config.provisioner.create()
self._config.state.change_state("created", True)
|
{"golden_diff": "diff --git a/src/molecule/command/create.py b/src/molecule/command/create.py\n--- a/src/molecule/command/create.py\n+++ b/src/molecule/command/create.py\n@@ -41,6 +41,11 @@\n \"\"\"\n self._config.state.change_state(\"driver\", self._config.driver.name)\n \n+ if self._config.state.created:\n+ msg = \"Skipping, instances already created.\"\n+ LOG.warning(msg)\n+ return\n+\n self._config.provisioner.create()\n \n self._config.state.change_state(\"created\", True)\n", "issue": "created: true is ignored in state.yml\n# Issue Type\r\n\r\n- Bug report\r\n\r\n# Molecule and Ansible details\r\n\r\n```\r\nansible --version && molecule --version\r\nansible [core 2.15.3]\r\n config file = None\r\n configured module search path = ['/home/manu/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/lib/python3.11/site-packages/ansible\r\n ansible collection location = /home/manu/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/bin/ansible\r\n python version = 3.11.5 (main, Aug 28 2023, 20:02:58) [GCC 13.2.1 20230801] (/home/manu/.local/share/virtualenvs/molecule-test-IsY3eZIi/bin/python)\r\n jinja version = 3.1.2\r\n libyaml = True\r\nmolecule 6.0.2 using python 3.11\r\n ansible:2.15.3\r\n default:6.0.2 from molecule\r\n molecule-qemu:0.5.3 from molecule_qemu\r\n```\r\n\r\nMolecule installation method: source\r\nAnsible installation method: pip\r\n\r\n# Desired Behavior\r\n\r\nIn molecule v5, the `create` step was automatically skipped when `created: true` in `<XDG_CACHE_HOME>/molecule//<scenario>/state.yml` with the message `WARNING Skipping, instances already created.`. This is the desired behavior.\r\n\r\nHere an example with a simple hello_world role after a `molecule create` execution. The molecule-qemu plugin is used here.\r\n```\r\n\u276f molecule converge\r\nINFO default scenario test matrix: dependency, create, prepare, converge\r\nINFO Performing prerun with role_name_check=0...\r\nINFO Set ANSIBLE_LIBRARY=/home/manu/.cache/ansible-compat/35072c/modules:/home/manu/.ansible/plugins/modules:/usr/share/ansible/plugins/modules\r\nINFO Set ANSIBLE_COLLECTIONS_PATH=/home/manu/.cache/ansible-compat/35072c/collections:/home/manu/.ansible/collections:/usr/share/ansible/collections\r\nINFO Set ANSIBLE_ROLES_PATH=/home/manu/.cache/ansible-compat/35072c/roles:/home/manu/.ansible/roles:/usr/share/ansible/roles:/etc/ansible/roles\r\nINFO Running default > dependency\r\nWARNING Skipping, missing the requirements file.\r\nWARNING Skipping, missing the requirements file.\r\nINFO Running default > create\r\nWARNING Skipping, instances already created.\r\nINFO Running default > prepare\r\nWARNING Skipping, prepare playbook not configured.\r\nINFO Running default > converge\r\n\r\nPLAY [all] *********************************************************************\r\n\r\nTASK [hello_world : Hello world] ***********************************************\r\nok: [test-hello-world] => {\r\n \"msg\": \"Hello, world!\"\r\n}\r\n\r\nPLAY RECAP *********************************************************************\r\ntest-hello-world : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\n```\r\n\r\n# Actual Behaviour\r\n\r\nSince molecule v6, the `WARNING Skipping, instances already created.` message is no longer displayed and the create step is executed each time the `molecule converge` is called.\r\n\r\nHere an example with the same role, with the same conditions except that molecule version is 6.0.2.\r\n```\r\nINFO default scenario test matrix: dependency, create, prepare, converge\r\nINFO Performing prerun with role_name_check=0...\r\nINFO Running default > dependency\r\nWARNING Skipping, missing the requirements file.\r\nWARNING Skipping, missing the requirements file.\r\nINFO Running default > create\r\n\r\nPLAY [Create] ******************************************************************\r\n\r\nTASK [Gather only necessary facts] *********************************************\r\nok: [localhost]\r\n\r\nTASK [Register VMs data] *******************************************************\r\nok: [localhost] => (item=test-hello-world)\r\n\r\nTASK [Prepare VMs data] ********************************************************\r\nok: [localhost]\r\n...\r\nTASK [Dump VMs config] *********************************************************\r\nok: [localhost]\r\n\r\nPLAY RECAP *********************************************************************\r\nlocalhost : ok=31 changed=0 unreachable=0 failed=0 skipped=5 rescued=0 ignored=0\r\n\r\nINFO Running default > prepare\r\nWARNING Skipping, prepare playbook not configured.\r\nINFO Running default > converge\r\n\r\nPLAY [all] *********************************************************************\r\n\r\nTASK [hello_world : Hello world] ***********************************************\r\nok: [test-hello-world] => {\r\n \"msg\": \"Hello, world!\"\r\n}\r\n\r\nPLAY RECAP *********************************************************************\r\ntest-hello-world : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0\r\n```\n", "before_files": [{"content": "# Copyright (c) 2015-2018 Cisco Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to\n# deal in the Software without restriction, including without limitation the\n# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n# sell copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\"\"\"Create Command Module.\"\"\"\n\nimport logging\n\nimport click\n\nfrom molecule.api import drivers\nfrom molecule.command import base\nfrom molecule.config import DEFAULT_DRIVER\n\nLOG = logging.getLogger(__name__)\n\n\nclass Create(base.Base):\n \"\"\"Create Command Class.\"\"\"\n\n def execute(self, action_args=None):\n \"\"\"Execute the actions necessary to perform a `molecule create` and \\\n returns None.\n\n :return: None\n \"\"\"\n self._config.state.change_state(\"driver\", self._config.driver.name)\n\n self._config.provisioner.create()\n\n self._config.state.change_state(\"created\", True)\n\n\[email protected]_command_ex()\[email protected]_context\[email protected](\n \"--scenario-name\",\n \"-s\",\n default=base.MOLECULE_DEFAULT_SCENARIO_NAME,\n help=f\"Name of the scenario to target. ({base.MOLECULE_DEFAULT_SCENARIO_NAME})\",\n)\[email protected](\n \"--driver-name\",\n \"-d\",\n type=click.Choice([str(s) for s in drivers()]),\n help=f\"Name of driver to use. ({DEFAULT_DRIVER})\",\n)\ndef create(ctx, scenario_name, driver_name): # pragma: no cover\n \"\"\"Use the provisioner to start the instances.\"\"\"\n args = ctx.obj.get(\"args\")\n subcommand = base._get_subcommand(__name__)\n command_args = {\"subcommand\": subcommand, \"driver_name\": driver_name}\n\n base.execute_cmdline_scenarios(scenario_name, args, command_args)\n", "path": "src/molecule/command/create.py"}], "after_files": [{"content": "# Copyright (c) 2015-2018 Cisco Systems, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to\n# deal in the Software without restriction, including without limitation the\n# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n# sell copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\"\"\"Create Command Module.\"\"\"\n\nimport logging\n\nimport click\n\nfrom molecule.api import drivers\nfrom molecule.command import base\nfrom molecule.config import DEFAULT_DRIVER\n\nLOG = logging.getLogger(__name__)\n\n\nclass Create(base.Base):\n \"\"\"Create Command Class.\"\"\"\n\n def execute(self, action_args=None):\n \"\"\"Execute the actions necessary to perform a `molecule create` and \\\n returns None.\n\n :return: None\n \"\"\"\n self._config.state.change_state(\"driver\", self._config.driver.name)\n\n if self._config.state.created:\n msg = \"Skipping, instances already created.\"\n LOG.warning(msg)\n return\n\n self._config.provisioner.create()\n\n self._config.state.change_state(\"created\", True)\n\n\[email protected]_command_ex()\[email protected]_context\[email protected](\n \"--scenario-name\",\n \"-s\",\n default=base.MOLECULE_DEFAULT_SCENARIO_NAME,\n help=f\"Name of the scenario to target. ({base.MOLECULE_DEFAULT_SCENARIO_NAME})\",\n)\[email protected](\n \"--driver-name\",\n \"-d\",\n type=click.Choice([str(s) for s in drivers()]),\n help=f\"Name of driver to use. ({DEFAULT_DRIVER})\",\n)\ndef create(ctx, scenario_name, driver_name): # pragma: no cover\n \"\"\"Use the provisioner to start the instances.\"\"\"\n args = ctx.obj.get(\"args\")\n subcommand = base._get_subcommand(__name__)\n command_args = {\"subcommand\": subcommand, \"driver_name\": driver_name}\n\n base.execute_cmdline_scenarios(scenario_name, args, command_args)\n", "path": "src/molecule/command/create.py"}]}
| 2,034 | 121 |
gh_patches_debug_3440
|
rasdani/github-patches
|
git_diff
|
spack__spack-21932
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
shell test kcov suggestion does not work
### Steps to reproduce the issue
```console
$ ./share/spack/qa/run-shell-tests
ERROR: kcov is required to run this script.
To install with Spack, run:
$ spack install kcov
Then add the bin directory to your PATH.
$ spack load kcov
$ ./share/spack/qa/run-shell-tests
ERROR: kcov is required to run this script.
To install with Spack, run:
$ spack install kcov
Then add the bin directory to your PATH.
```
Seems like there is no kcov binary:
```
$ kcov
Command 'kcov' not found, but can be installed with:
sudo apt install kcov
```
* **Spack:** 0.16.0-1501-e8eb76c198
* **Python:** 3.8.7
* **Platform:** linux-ubuntu20.04-zen2
* **Concretizer:** clingo
### Additional information
- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform
- [x] I have searched the issues of this repo and believe this is not a duplicate
- [x] I have run the failing commands in debug mode and reported the output
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/kcov/package.py`
Content:
```
1 # Copyright 2013-2021 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class Kcov(CMakePackage):
10 """Code coverage tool for compiled programs, Python and Bash which uses
11 debugging information to collect and report data without special
12 compilation options"""
13
14 homepage = "http://simonkagstrom.github.io/kcov/index.html"
15 url = "https://github.com/SimonKagstrom/kcov/archive/38.tar.gz"
16
17 version('38', sha256='b37af60d81a9b1e3b140f9473bdcb7975af12040feb24cc666f9bb2bb0be68b4')
18
19 depends_on('[email protected]:', type='build')
20 depends_on('zlib')
21 depends_on('curl')
22
23 def cmake_args(self):
24 # Necessary at least on macOS, fixes linking error to LLDB
25 # https://github.com/Homebrew/homebrew-core/blob/master/Formula/kcov.rb
26 return ['-DSPECIFY_RPATH=ON']
27
28 @run_after('install')
29 @on_package_attributes(run_tests=True)
30 def test_install(self):
31 # The help message exits with an exit code of 1
32 kcov = Executable(self.prefix.bin.kcov)
33 kcov('-h', ignore_errors=1)
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/kcov/package.py b/var/spack/repos/builtin/packages/kcov/package.py
--- a/var/spack/repos/builtin/packages/kcov/package.py
+++ b/var/spack/repos/builtin/packages/kcov/package.py
@@ -19,6 +19,8 @@
depends_on('[email protected]:', type='build')
depends_on('zlib')
depends_on('curl')
+ depends_on('elfutils')
+ depends_on('binutils +libiberty', type='link')
def cmake_args(self):
# Necessary at least on macOS, fixes linking error to LLDB
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/kcov/package.py b/var/spack/repos/builtin/packages/kcov/package.py\n--- a/var/spack/repos/builtin/packages/kcov/package.py\n+++ b/var/spack/repos/builtin/packages/kcov/package.py\n@@ -19,6 +19,8 @@\n depends_on('[email protected]:', type='build')\n depends_on('zlib')\n depends_on('curl')\n+ depends_on('elfutils')\n+ depends_on('binutils +libiberty', type='link')\n \n def cmake_args(self):\n # Necessary at least on macOS, fixes linking error to LLDB\n", "issue": "shell test kcov suggestion does not work\n### Steps to reproduce the issue\r\n\r\n```console\r\n$ ./share/spack/qa/run-shell-tests \r\nERROR: kcov is required to run this script.\r\n\r\nTo install with Spack, run:\r\n $ spack install kcov\r\nThen add the bin directory to your PATH.\r\n$ spack load kcov\r\n$ ./share/spack/qa/run-shell-tests \r\nERROR: kcov is required to run this script.\r\n\r\nTo install with Spack, run:\r\n $ spack install kcov\r\nThen add the bin directory to your PATH.\r\n```\r\n\r\nSeems like there is no kcov binary:\r\n\r\n```\r\n$ kcov\r\n\r\nCommand 'kcov' not found, but can be installed with:\r\n\r\nsudo apt install kcov\r\n```\r\n\r\n* **Spack:** 0.16.0-1501-e8eb76c198\r\n* **Python:** 3.8.7\r\n* **Platform:** linux-ubuntu20.04-zen2\r\n* **Concretizer:** clingo\r\n\r\n### Additional information\r\n\r\n- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform\r\n- [x] I have searched the issues of this repo and believe this is not a duplicate\r\n- [x] I have run the failing commands in debug mode and reported the output\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Kcov(CMakePackage):\n \"\"\"Code coverage tool for compiled programs, Python and Bash which uses\n debugging information to collect and report data without special\n compilation options\"\"\"\n\n homepage = \"http://simonkagstrom.github.io/kcov/index.html\"\n url = \"https://github.com/SimonKagstrom/kcov/archive/38.tar.gz\"\n\n version('38', sha256='b37af60d81a9b1e3b140f9473bdcb7975af12040feb24cc666f9bb2bb0be68b4')\n\n depends_on('[email protected]:', type='build')\n depends_on('zlib')\n depends_on('curl')\n\n def cmake_args(self):\n # Necessary at least on macOS, fixes linking error to LLDB\n # https://github.com/Homebrew/homebrew-core/blob/master/Formula/kcov.rb\n return ['-DSPECIFY_RPATH=ON']\n\n @run_after('install')\n @on_package_attributes(run_tests=True)\n def test_install(self):\n # The help message exits with an exit code of 1\n kcov = Executable(self.prefix.bin.kcov)\n kcov('-h', ignore_errors=1)\n", "path": "var/spack/repos/builtin/packages/kcov/package.py"}], "after_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Kcov(CMakePackage):\n \"\"\"Code coverage tool for compiled programs, Python and Bash which uses\n debugging information to collect and report data without special\n compilation options\"\"\"\n\n homepage = \"http://simonkagstrom.github.io/kcov/index.html\"\n url = \"https://github.com/SimonKagstrom/kcov/archive/38.tar.gz\"\n\n version('38', sha256='b37af60d81a9b1e3b140f9473bdcb7975af12040feb24cc666f9bb2bb0be68b4')\n\n depends_on('[email protected]:', type='build')\n depends_on('zlib')\n depends_on('curl')\n depends_on('elfutils')\n depends_on('binutils +libiberty', type='link')\n\n def cmake_args(self):\n # Necessary at least on macOS, fixes linking error to LLDB\n # https://github.com/Homebrew/homebrew-core/blob/master/Formula/kcov.rb\n return ['-DSPECIFY_RPATH=ON']\n\n @run_after('install')\n @on_package_attributes(run_tests=True)\n def test_install(self):\n # The help message exits with an exit code of 1\n kcov = Executable(self.prefix.bin.kcov)\n kcov('-h', ignore_errors=1)\n", "path": "var/spack/repos/builtin/packages/kcov/package.py"}]}
| 965 | 144 |
gh_patches_debug_23351
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-671
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
subprocess.CalledProcessError: Command '['/usr/local/bin/checksec', '--file', '/tmp/xxx']' returned non-zero exit status 2.
```
pwndbg> checksec
Traceback (most recent call last):
File "/root/pwndbg/pwndbg/commands/__init__.py", line 109, in __call__
return self.function(*args, **kwargs)
File "/root/pwndbg/pwndbg/commands/__init__.py", line 189, in _OnlyWithFile
return function(*a, **kw)
File "/root/pwndbg/pwndbg/commands/checksec.py", line 16, in checksec
print(pwndbg.wrappers.checksec.get_raw_out())
File "/root/pwndbg/pwndbg/commands/__init__.py", line 189, in _OnlyWithFile
return function(*a, **kw)
File "/root/pwndbg/pwndbg/wrappers/__init__.py", line 28, in _OnlyWithCommand
return function(*a, **kw)
File "/root/pwndbg/pwndbg/memoize.py", line 48, in __call__
value = self.func(*args, **kwargs)
File "/root/pwndbg/pwndbg/wrappers/checksec.py", line 20, in get_raw_out
return pwndbg.wrappers.call_cmd(cmd)
File "/root/pwndbg/pwndbg/wrappers/__init__.py", line 35, in call_cmd
return subprocess.check_output(cmd, stderr=STDOUT).decode('utf-8')
File "/usr/lib/python3.7/subprocess.py", line 395, in check_output
**kwargs).stdout
File "/usr/lib/python3.7/subprocess.py", line 487, in run
output=stdout, stderr=stderr)
subprocess.CalledProcessError: Command '['/usr/local/bin/checksec', '--file', '/tmp/forgot']' returned non-zero exit status 2.
```
when checksec running in python3 pwntools environment, raise a failure. Here's the reason:
```
root@kali:/tmp# checksec --file forgot
usage: checksec [-h] elf [elf ...]
checksec: error: unrecognized arguments: --file
```
So modify pwndbg/pwndbg/wrappers/checksec.py: 19 with:
`cmd = [get_raw_out.cmd_path, local_path]`
Then it will be solved
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/wrappers/checksec.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import absolute_import
4 from __future__ import division
5 from __future__ import print_function
6 from __future__ import unicode_literals
7
8 import pwndbg.commands
9 import pwndbg.memoize
10 import pwndbg.wrappers
11
12 cmd_name = "checksec"
13
14 @pwndbg.wrappers.OnlyWithCommand(cmd_name)
15 @pwndbg.memoize.reset_on_objfile
16 def get_raw_out():
17
18 local_path = pwndbg.file.get_file(pwndbg.proc.exe)
19 cmd = [get_raw_out.cmd_path, "--file", local_path]
20 return pwndbg.wrappers.call_cmd(cmd)
21
22 @pwndbg.wrappers.OnlyWithCommand(cmd_name)
23 def relro_status():
24 relro = "No RELRO"
25 out = get_raw_out()
26
27 if "Full RELRO" in out:
28 relro = "Full RELRO"
29 elif "Partial RELRO" in out:
30 relro = "Partial RELRO"
31
32 return relro
33
34 @pwndbg.wrappers.OnlyWithCommand(cmd_name)
35 def pie_status():
36 pie = "No PIE"
37 out = get_raw_out()
38
39 if "PIE enabled" in out:
40 pie = "PIE enabled"
41
42 return pie
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwndbg/wrappers/checksec.py b/pwndbg/wrappers/checksec.py
--- a/pwndbg/wrappers/checksec.py
+++ b/pwndbg/wrappers/checksec.py
@@ -5,6 +5,10 @@
from __future__ import print_function
from __future__ import unicode_literals
+import subprocess
+from re import search
+from subprocess import STDOUT
+
import pwndbg.commands
import pwndbg.memoize
import pwndbg.wrappers
@@ -14,10 +18,17 @@
@pwndbg.wrappers.OnlyWithCommand(cmd_name)
@pwndbg.memoize.reset_on_objfile
def get_raw_out():
-
local_path = pwndbg.file.get_file(pwndbg.proc.exe)
- cmd = [get_raw_out.cmd_path, "--file", local_path]
- return pwndbg.wrappers.call_cmd(cmd)
+ try:
+ version_output = subprocess.check_output([get_raw_out.cmd_path, "--version"], stderr=STDOUT).decode('utf-8')
+ match = search('checksec v([\\w.]+),', version_output)
+ if match:
+ version = tuple(map(int, (match.group(1).split("."))))
+ if version >= (2, 0):
+ return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, "--file=" + local_path])
+ except Exception:
+ pass
+ return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, "--file", local_path])
@pwndbg.wrappers.OnlyWithCommand(cmd_name)
def relro_status():
|
{"golden_diff": "diff --git a/pwndbg/wrappers/checksec.py b/pwndbg/wrappers/checksec.py\n--- a/pwndbg/wrappers/checksec.py\n+++ b/pwndbg/wrappers/checksec.py\n@@ -5,6 +5,10 @@\n from __future__ import print_function\n from __future__ import unicode_literals\n \n+import subprocess\n+from re import search\n+from subprocess import STDOUT\n+\n import pwndbg.commands\n import pwndbg.memoize\n import pwndbg.wrappers\n@@ -14,10 +18,17 @@\n @pwndbg.wrappers.OnlyWithCommand(cmd_name)\n @pwndbg.memoize.reset_on_objfile\n def get_raw_out():\n-\n local_path = pwndbg.file.get_file(pwndbg.proc.exe)\n- cmd = [get_raw_out.cmd_path, \"--file\", local_path]\n- return pwndbg.wrappers.call_cmd(cmd)\n+ try:\n+ version_output = subprocess.check_output([get_raw_out.cmd_path, \"--version\"], stderr=STDOUT).decode('utf-8')\n+ match = search('checksec v([\\\\w.]+),', version_output)\n+ if match:\n+ version = tuple(map(int, (match.group(1).split(\".\"))))\n+ if version >= (2, 0):\n+ return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, \"--file=\" + local_path])\n+ except Exception:\n+ pass\n+ return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, \"--file\", local_path])\n \n @pwndbg.wrappers.OnlyWithCommand(cmd_name)\n def relro_status():\n", "issue": "subprocess.CalledProcessError: Command '['/usr/local/bin/checksec', '--file', '/tmp/xxx']' returned non-zero exit status 2.\n```\r\npwndbg> checksec \r\nTraceback (most recent call last):\r\n File \"/root/pwndbg/pwndbg/commands/__init__.py\", line 109, in __call__\r\n return self.function(*args, **kwargs)\r\n File \"/root/pwndbg/pwndbg/commands/__init__.py\", line 189, in _OnlyWithFile\r\n return function(*a, **kw)\r\n File \"/root/pwndbg/pwndbg/commands/checksec.py\", line 16, in checksec\r\n print(pwndbg.wrappers.checksec.get_raw_out())\r\n File \"/root/pwndbg/pwndbg/commands/__init__.py\", line 189, in _OnlyWithFile\r\n return function(*a, **kw)\r\n File \"/root/pwndbg/pwndbg/wrappers/__init__.py\", line 28, in _OnlyWithCommand\r\n return function(*a, **kw)\r\n File \"/root/pwndbg/pwndbg/memoize.py\", line 48, in __call__\r\n value = self.func(*args, **kwargs)\r\n File \"/root/pwndbg/pwndbg/wrappers/checksec.py\", line 20, in get_raw_out\r\n return pwndbg.wrappers.call_cmd(cmd)\r\n File \"/root/pwndbg/pwndbg/wrappers/__init__.py\", line 35, in call_cmd\r\n return subprocess.check_output(cmd, stderr=STDOUT).decode('utf-8')\r\n File \"/usr/lib/python3.7/subprocess.py\", line 395, in check_output\r\n **kwargs).stdout\r\n File \"/usr/lib/python3.7/subprocess.py\", line 487, in run\r\n output=stdout, stderr=stderr)\r\nsubprocess.CalledProcessError: Command '['/usr/local/bin/checksec', '--file', '/tmp/forgot']' returned non-zero exit status 2.\r\n```\r\n\r\nwhen checksec running in python3 pwntools environment, raise a failure. Here's the reason:\r\n```\r\nroot@kali:/tmp# checksec --file forgot\r\nusage: checksec [-h] elf [elf ...]\r\nchecksec: error: unrecognized arguments: --file\r\n```\r\n\r\n\r\nSo modify pwndbg/pwndbg/wrappers/checksec.py: 19 with:\r\n`cmd = [get_raw_out.cmd_path, local_path]`\r\n\r\nThen it will be solved\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport pwndbg.commands\nimport pwndbg.memoize\nimport pwndbg.wrappers\n\ncmd_name = \"checksec\"\n\[email protected](cmd_name)\[email protected]_on_objfile\ndef get_raw_out():\n\n local_path = pwndbg.file.get_file(pwndbg.proc.exe)\n cmd = [get_raw_out.cmd_path, \"--file\", local_path]\n return pwndbg.wrappers.call_cmd(cmd)\n\[email protected](cmd_name)\ndef relro_status():\n relro = \"No RELRO\"\n out = get_raw_out()\n\n if \"Full RELRO\" in out:\n relro = \"Full RELRO\"\n elif \"Partial RELRO\" in out:\n relro = \"Partial RELRO\"\n\n return relro\n\[email protected](cmd_name)\ndef pie_status():\n pie = \"No PIE\"\n out = get_raw_out()\n\n if \"PIE enabled\" in out:\n pie = \"PIE enabled\"\n\n return pie\n", "path": "pwndbg/wrappers/checksec.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport subprocess\nfrom re import search\nfrom subprocess import STDOUT\n\nimport pwndbg.commands\nimport pwndbg.memoize\nimport pwndbg.wrappers\n\ncmd_name = \"checksec\"\n\[email protected](cmd_name)\[email protected]_on_objfile\ndef get_raw_out():\n local_path = pwndbg.file.get_file(pwndbg.proc.exe)\n try:\n version_output = subprocess.check_output([get_raw_out.cmd_path, \"--version\"], stderr=STDOUT).decode('utf-8')\n match = search('checksec v([\\\\w.]+),', version_output)\n if match:\n version = tuple(map(int, (match.group(1).split(\".\"))))\n if version >= (2, 0):\n return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, \"--file=\" + local_path])\n except Exception:\n pass\n return pwndbg.wrappers.call_cmd([get_raw_out.cmd_path, \"--file\", local_path])\n\[email protected](cmd_name)\ndef relro_status():\n relro = \"No RELRO\"\n out = get_raw_out()\n\n if \"Full RELRO\" in out:\n relro = \"Full RELRO\"\n elif \"Partial RELRO\" in out:\n relro = \"Partial RELRO\"\n\n return relro\n\[email protected](cmd_name)\ndef pie_status():\n pie = \"No PIE\"\n out = get_raw_out()\n\n if \"PIE enabled\" in out:\n pie = \"PIE enabled\"\n\n return pie\n", "path": "pwndbg/wrappers/checksec.py"}]}
| 1,178 | 360 |
gh_patches_debug_43335
|
rasdani/github-patches
|
git_diff
|
google__mobly-437
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Propagate stderr from adb commands
The current mobly adb proxy does not propagate stderr if ret code is zero.
We thought this was ok since Android has fixed return code issues in M.
But turns out many China manufacturers did not fix this in China devices.
In order to better support China devices and potentially other devices of the same ret code problem, we need to surface stderr.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mobly/controllers/android_device_lib/adb.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from builtins import str
16 from past.builtins import basestring
17
18 import logging
19 import pipes
20 import psutil
21 import subprocess
22 import threading
23
24 # Command to use for running ADB commands.
25 ADB = 'adb'
26
27 # adb gets confused if we try to manage bound ports in parallel, so anything to
28 # do with port forwarding must happen under this lock.
29 ADB_PORT_LOCK = threading.Lock()
30
31 # Qualified class name of the default instrumentation test runner.
32 DEFAULT_INSTRUMENTATION_RUNNER = 'com.android.common.support.test.runner.AndroidJUnitRunner'
33
34
35 class Error(Exception):
36 """Base error type for adb proxy module."""
37
38
39 class AdbError(Error):
40 """Raised when an adb command encounters an error.
41
42 Args:
43 cmd: list of strings, the adb command executed.
44 stdout: byte string, the raw stdout of the command.
45 stderr: byte string, the raw stderr of the command.
46 ret_code: int, the return code of the command.
47 """
48
49 def __init__(self, cmd, stdout, stderr, ret_code):
50 self.cmd = cmd
51 self.stdout = stdout
52 self.stderr = stderr
53 self.ret_code = ret_code
54
55 def __str__(self):
56 return ('Error executing adb cmd "%s". ret: %d, stdout: %s, stderr: %s'
57 ) % (cli_cmd_to_string(self.cmd), self.ret_code, self.stdout,
58 self.stderr)
59
60
61 class AdbTimeoutError(Error):
62 """Raised when an command did not complete within expected time.
63
64 Args:
65 cmd: list of strings, the adb command that timed out
66 timeout: float, the number of seconds passed before timing out.
67 """
68
69 def __init__(self, cmd, timeout):
70 self.cmd = cmd
71 self.timeout = timeout
72
73 def __str__(self):
74 return 'Timed out executing command "%s" after %ss.' % (
75 cli_cmd_to_string(self.cmd), self.timeout)
76
77
78 def list_occupied_adb_ports():
79 """Lists all the host ports occupied by adb forward.
80
81 This is useful because adb will silently override the binding if an attempt
82 to bind to a port already used by adb was made, instead of throwing binding
83 error. So one should always check what ports adb is using before trying to
84 bind to a port with adb.
85
86 Returns:
87 A list of integers representing occupied host ports.
88 """
89 out = AdbProxy().forward('--list')
90 clean_lines = str(out, 'utf-8').strip().split('\n')
91 used_ports = []
92 for line in clean_lines:
93 tokens = line.split(' tcp:')
94 if len(tokens) != 3:
95 continue
96 used_ports.append(int(tokens[1]))
97 return used_ports
98
99
100 def cli_cmd_to_string(args):
101 """Converts a cmd arg list to string.
102
103 Args:
104 args: list of strings, the arguments of a command.
105
106 Returns:
107 String representation of the command.
108 """
109 if isinstance(args, basestring):
110 # Return directly if it's already a string.
111 return args
112 return ' '.join([pipes.quote(arg) for arg in args])
113
114
115 class AdbProxy(object):
116 """Proxy class for ADB.
117
118 For syntactic reasons, the '-' in adb commands need to be replaced with
119 '_'. Can directly execute adb commands on an object:
120 >> adb = AdbProxy(<serial>)
121 >> adb.start_server()
122 >> adb.devices() # will return the console output of "adb devices".
123
124 By default, command args are expected to be an iterable which is passed
125 directly to subprocess.Popen():
126 >> adb.shell(['echo', 'a', 'b'])
127
128 This way of launching commands is recommended by the subprocess
129 documentation to avoid shell injection vulnerabilities and avoid having to
130 deal with multiple layers of shell quoting and different shell environments
131 between different OSes.
132
133 If you really want to run the command through the system shell, this is
134 possible by supplying shell=True, but try to avoid this if possible:
135 >> adb.shell('cat /foo > /tmp/file', shell=True)
136 """
137
138 def __init__(self, serial=''):
139 self.serial = serial
140
141 def _exec_cmd(self, args, shell, timeout):
142 """Executes adb commands.
143
144 Args:
145 args: string or list of strings, program arguments.
146 See subprocess.Popen() documentation.
147 shell: bool, True to run this command through the system shell,
148 False to invoke it directly. See subprocess.Popen() docs.
149 timeout: float, the number of seconds to wait before timing out.
150 If not specified, no timeout takes effect.
151
152 Returns:
153 The output of the adb command run if exit code is 0.
154
155 Raises:
156 AdbError: The adb command exit code is not 0.
157 AdbTimeoutError: The adb command timed out.
158 """
159 proc = subprocess.Popen(
160 args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=shell)
161 process = psutil.Process(proc.pid)
162 if timeout and timeout <= 0:
163 raise Error('Timeout is not a positive value: %s' % timeout)
164 if timeout and timeout > 0:
165 try:
166 process.wait(timeout=timeout)
167 except psutil.TimeoutExpired:
168 process.terminate()
169 raise AdbTimeoutError(cmd=args, timeout=timeout)
170
171 (out, err) = proc.communicate()
172 ret = proc.returncode
173 logging.debug('cmd: %s, stdout: %s, stderr: %s, ret: %s',
174 cli_cmd_to_string(args), out, err, ret)
175 if ret == 0:
176 return out
177 else:
178 raise AdbError(cmd=args, stdout=out, stderr=err, ret_code=ret)
179
180 def _exec_adb_cmd(self, name, args, shell, timeout):
181 if shell:
182 # Add quotes around "adb" in case the ADB path contains spaces. This
183 # is pretty common on Windows (e.g. Program Files).
184 if self.serial:
185 adb_cmd = '"%s" -s "%s" %s %s' % (ADB, self.serial, name, args)
186 else:
187 adb_cmd = '"%s" %s %s' % (ADB, name, args)
188 else:
189 adb_cmd = [ADB]
190 if self.serial:
191 adb_cmd.extend(['-s', self.serial])
192 adb_cmd.append(name)
193 if args:
194 if isinstance(args, basestring):
195 adb_cmd.append(args)
196 else:
197 adb_cmd.extend(args)
198 return self._exec_cmd(adb_cmd, shell=shell, timeout=timeout)
199
200 def getprop(self, prop_name):
201 """Get a property of the device.
202
203 This is a convenience wrapper for "adb shell getprop xxx".
204
205 Args:
206 prop_name: A string that is the name of the property to get.
207
208 Returns:
209 A string that is the value of the property, or None if the property
210 doesn't exist.
211 """
212 return self.shell('getprop %s' % prop_name).decode('utf-8').strip()
213
214 def has_shell_command(self, command):
215 """Checks to see if a given check command exists on the device.
216
217 Args:
218 command: A string that is the name of the command to check.
219
220 Returns:
221 A boolean that is True if the command exists and False otherwise.
222 """
223 try:
224 output = self.shell(['command', '-v',
225 command]).decode('utf-8').strip()
226 return command in output
227 except AdbError:
228 # If the command doesn't exist, then 'command -v' can return
229 # an exit code > 1.
230 return False
231
232 def forward(self, args=None, shell=False):
233 with ADB_PORT_LOCK:
234 return self._exec_adb_cmd('forward', args, shell, timeout=None)
235
236 def instrument(self, package, options=None, runner=None):
237 """Runs an instrumentation command on the device.
238
239 This is a convenience wrapper to avoid parameter formatting.
240
241 Example:
242 device.instrument(
243 'com.my.package.test',
244 options = {
245 'class': 'com.my.package.test.TestSuite',
246 },
247 )
248
249 Args:
250 package: string, the package of the instrumentation tests.
251 options: dict, the instrumentation options including the test
252 class.
253 runner: string, the test runner name, which defaults to
254 DEFAULT_INSTRUMENTATION_RUNNER.
255
256 Returns:
257 The output of instrumentation command.
258 """
259 if runner is None:
260 runner = DEFAULT_INSTRUMENTATION_RUNNER
261 if options is None:
262 options = {}
263
264 options_list = []
265 for option_key, option_value in options.items():
266 options_list.append('-e %s %s' % (option_key, option_value))
267 options_string = ' '.join(options_list)
268
269 instrumentation_command = 'am instrument -r -w %s %s/%s' % (
270 options_string, package, runner)
271 logging.info('AndroidDevice|%s: Executing adb shell %s', self.serial,
272 instrumentation_command)
273 return self.shell(instrumentation_command)
274
275 def __getattr__(self, name):
276 def adb_call(args=None, shell=False, timeout=None):
277 """Wrapper for an ADB command.
278
279 Args:
280 args: string or list of strings, arguments to the adb command.
281 See subprocess.Proc() documentation.
282 shell: bool, True to run this command through the system shell,
283 False to invoke it directly. See subprocess.Proc() docs.
284 timeout: float, the number of seconds to wait before timing out.
285 If not specified, no timeout takes effect.
286
287 Returns:
288 The output of the adb command run if exit code is 0.
289 """
290 args = args or ''
291 clean_name = name.replace('_', '-')
292 return self._exec_adb_cmd(
293 clean_name, args, shell=shell, timeout=timeout)
294
295 return adb_call
296
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mobly/controllers/android_device_lib/adb.py b/mobly/controllers/android_device_lib/adb.py
--- a/mobly/controllers/android_device_lib/adb.py
+++ b/mobly/controllers/android_device_lib/adb.py
@@ -138,7 +138,7 @@
def __init__(self, serial=''):
self.serial = serial
- def _exec_cmd(self, args, shell, timeout):
+ def _exec_cmd(self, args, shell, timeout, stderr):
"""Executes adb commands.
Args:
@@ -148,6 +148,8 @@
False to invoke it directly. See subprocess.Popen() docs.
timeout: float, the number of seconds to wait before timing out.
If not specified, no timeout takes effect.
+ stderr: a Byte stream, like io.BytesIO, stderr of the command will
+ be written to this object if provided.
Returns:
The output of the adb command run if exit code is 0.
@@ -169,6 +171,8 @@
raise AdbTimeoutError(cmd=args, timeout=timeout)
(out, err) = proc.communicate()
+ if stderr:
+ stderr.write(err)
ret = proc.returncode
logging.debug('cmd: %s, stdout: %s, stderr: %s, ret: %s',
cli_cmd_to_string(args), out, err, ret)
@@ -177,7 +181,7 @@
else:
raise AdbError(cmd=args, stdout=out, stderr=err, ret_code=ret)
- def _exec_adb_cmd(self, name, args, shell, timeout):
+ def _exec_adb_cmd(self, name, args, shell, timeout, stderr):
if shell:
# Add quotes around "adb" in case the ADB path contains spaces. This
# is pretty common on Windows (e.g. Program Files).
@@ -195,7 +199,9 @@
adb_cmd.append(args)
else:
adb_cmd.extend(args)
- return self._exec_cmd(adb_cmd, shell=shell, timeout=timeout)
+ out = self._exec_cmd(
+ adb_cmd, shell=shell, timeout=timeout, stderr=stderr)
+ return out
def getprop(self, prop_name):
"""Get a property of the device.
@@ -273,7 +279,7 @@
return self.shell(instrumentation_command)
def __getattr__(self, name):
- def adb_call(args=None, shell=False, timeout=None):
+ def adb_call(args=None, shell=False, timeout=None, stderr=None):
"""Wrapper for an ADB command.
Args:
@@ -283,6 +289,8 @@
False to invoke it directly. See subprocess.Proc() docs.
timeout: float, the number of seconds to wait before timing out.
If not specified, no timeout takes effect.
+ stderr: a Byte stream, like io.BytesIO, stderr of the command
+ will be written to this object if provided.
Returns:
The output of the adb command run if exit code is 0.
@@ -290,6 +298,6 @@
args = args or ''
clean_name = name.replace('_', '-')
return self._exec_adb_cmd(
- clean_name, args, shell=shell, timeout=timeout)
+ clean_name, args, shell=shell, timeout=timeout, stderr=stderr)
return adb_call
|
{"golden_diff": "diff --git a/mobly/controllers/android_device_lib/adb.py b/mobly/controllers/android_device_lib/adb.py\n--- a/mobly/controllers/android_device_lib/adb.py\n+++ b/mobly/controllers/android_device_lib/adb.py\n@@ -138,7 +138,7 @@\n def __init__(self, serial=''):\n self.serial = serial\n \n- def _exec_cmd(self, args, shell, timeout):\n+ def _exec_cmd(self, args, shell, timeout, stderr):\n \"\"\"Executes adb commands.\n \n Args:\n@@ -148,6 +148,8 @@\n False to invoke it directly. See subprocess.Popen() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n+ stderr: a Byte stream, like io.BytesIO, stderr of the command will\n+ be written to this object if provided.\n \n Returns:\n The output of the adb command run if exit code is 0.\n@@ -169,6 +171,8 @@\n raise AdbTimeoutError(cmd=args, timeout=timeout)\n \n (out, err) = proc.communicate()\n+ if stderr:\n+ stderr.write(err)\n ret = proc.returncode\n logging.debug('cmd: %s, stdout: %s, stderr: %s, ret: %s',\n cli_cmd_to_string(args), out, err, ret)\n@@ -177,7 +181,7 @@\n else:\n raise AdbError(cmd=args, stdout=out, stderr=err, ret_code=ret)\n \n- def _exec_adb_cmd(self, name, args, shell, timeout):\n+ def _exec_adb_cmd(self, name, args, shell, timeout, stderr):\n if shell:\n # Add quotes around \"adb\" in case the ADB path contains spaces. This\n # is pretty common on Windows (e.g. Program Files).\n@@ -195,7 +199,9 @@\n adb_cmd.append(args)\n else:\n adb_cmd.extend(args)\n- return self._exec_cmd(adb_cmd, shell=shell, timeout=timeout)\n+ out = self._exec_cmd(\n+ adb_cmd, shell=shell, timeout=timeout, stderr=stderr)\n+ return out\n \n def getprop(self, prop_name):\n \"\"\"Get a property of the device.\n@@ -273,7 +279,7 @@\n return self.shell(instrumentation_command)\n \n def __getattr__(self, name):\n- def adb_call(args=None, shell=False, timeout=None):\n+ def adb_call(args=None, shell=False, timeout=None, stderr=None):\n \"\"\"Wrapper for an ADB command.\n \n Args:\n@@ -283,6 +289,8 @@\n False to invoke it directly. See subprocess.Proc() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n+ stderr: a Byte stream, like io.BytesIO, stderr of the command\n+ will be written to this object if provided.\n \n Returns:\n The output of the adb command run if exit code is 0.\n@@ -290,6 +298,6 @@\n args = args or ''\n clean_name = name.replace('_', '-')\n return self._exec_adb_cmd(\n- clean_name, args, shell=shell, timeout=timeout)\n+ clean_name, args, shell=shell, timeout=timeout, stderr=stderr)\n \n return adb_call\n", "issue": "Propagate stderr from adb commands\nThe current mobly adb proxy does not propagate stderr if ret code is zero.\r\nWe thought this was ok since Android has fixed return code issues in M.\r\n\r\nBut turns out many China manufacturers did not fix this in China devices.\r\nIn order to better support China devices and potentially other devices of the same ret code problem, we need to surface stderr.\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom builtins import str\nfrom past.builtins import basestring\n\nimport logging\nimport pipes\nimport psutil\nimport subprocess\nimport threading\n\n# Command to use for running ADB commands.\nADB = 'adb'\n\n# adb gets confused if we try to manage bound ports in parallel, so anything to\n# do with port forwarding must happen under this lock.\nADB_PORT_LOCK = threading.Lock()\n\n# Qualified class name of the default instrumentation test runner.\nDEFAULT_INSTRUMENTATION_RUNNER = 'com.android.common.support.test.runner.AndroidJUnitRunner'\n\n\nclass Error(Exception):\n \"\"\"Base error type for adb proxy module.\"\"\"\n\n\nclass AdbError(Error):\n \"\"\"Raised when an adb command encounters an error.\n\n Args:\n cmd: list of strings, the adb command executed.\n stdout: byte string, the raw stdout of the command.\n stderr: byte string, the raw stderr of the command.\n ret_code: int, the return code of the command.\n \"\"\"\n\n def __init__(self, cmd, stdout, stderr, ret_code):\n self.cmd = cmd\n self.stdout = stdout\n self.stderr = stderr\n self.ret_code = ret_code\n\n def __str__(self):\n return ('Error executing adb cmd \"%s\". ret: %d, stdout: %s, stderr: %s'\n ) % (cli_cmd_to_string(self.cmd), self.ret_code, self.stdout,\n self.stderr)\n\n\nclass AdbTimeoutError(Error):\n \"\"\"Raised when an command did not complete within expected time.\n\n Args:\n cmd: list of strings, the adb command that timed out\n timeout: float, the number of seconds passed before timing out.\n \"\"\"\n\n def __init__(self, cmd, timeout):\n self.cmd = cmd\n self.timeout = timeout\n\n def __str__(self):\n return 'Timed out executing command \"%s\" after %ss.' % (\n cli_cmd_to_string(self.cmd), self.timeout)\n\n\ndef list_occupied_adb_ports():\n \"\"\"Lists all the host ports occupied by adb forward.\n\n This is useful because adb will silently override the binding if an attempt\n to bind to a port already used by adb was made, instead of throwing binding\n error. So one should always check what ports adb is using before trying to\n bind to a port with adb.\n\n Returns:\n A list of integers representing occupied host ports.\n \"\"\"\n out = AdbProxy().forward('--list')\n clean_lines = str(out, 'utf-8').strip().split('\\n')\n used_ports = []\n for line in clean_lines:\n tokens = line.split(' tcp:')\n if len(tokens) != 3:\n continue\n used_ports.append(int(tokens[1]))\n return used_ports\n\n\ndef cli_cmd_to_string(args):\n \"\"\"Converts a cmd arg list to string.\n\n Args:\n args: list of strings, the arguments of a command.\n\n Returns:\n String representation of the command.\n \"\"\"\n if isinstance(args, basestring):\n # Return directly if it's already a string.\n return args\n return ' '.join([pipes.quote(arg) for arg in args])\n\n\nclass AdbProxy(object):\n \"\"\"Proxy class for ADB.\n\n For syntactic reasons, the '-' in adb commands need to be replaced with\n '_'. Can directly execute adb commands on an object:\n >> adb = AdbProxy(<serial>)\n >> adb.start_server()\n >> adb.devices() # will return the console output of \"adb devices\".\n\n By default, command args are expected to be an iterable which is passed\n directly to subprocess.Popen():\n >> adb.shell(['echo', 'a', 'b'])\n\n This way of launching commands is recommended by the subprocess\n documentation to avoid shell injection vulnerabilities and avoid having to\n deal with multiple layers of shell quoting and different shell environments\n between different OSes.\n\n If you really want to run the command through the system shell, this is\n possible by supplying shell=True, but try to avoid this if possible:\n >> adb.shell('cat /foo > /tmp/file', shell=True)\n \"\"\"\n\n def __init__(self, serial=''):\n self.serial = serial\n\n def _exec_cmd(self, args, shell, timeout):\n \"\"\"Executes adb commands.\n\n Args:\n args: string or list of strings, program arguments.\n See subprocess.Popen() documentation.\n shell: bool, True to run this command through the system shell,\n False to invoke it directly. See subprocess.Popen() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n\n Returns:\n The output of the adb command run if exit code is 0.\n\n Raises:\n AdbError: The adb command exit code is not 0.\n AdbTimeoutError: The adb command timed out.\n \"\"\"\n proc = subprocess.Popen(\n args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=shell)\n process = psutil.Process(proc.pid)\n if timeout and timeout <= 0:\n raise Error('Timeout is not a positive value: %s' % timeout)\n if timeout and timeout > 0:\n try:\n process.wait(timeout=timeout)\n except psutil.TimeoutExpired:\n process.terminate()\n raise AdbTimeoutError(cmd=args, timeout=timeout)\n\n (out, err) = proc.communicate()\n ret = proc.returncode\n logging.debug('cmd: %s, stdout: %s, stderr: %s, ret: %s',\n cli_cmd_to_string(args), out, err, ret)\n if ret == 0:\n return out\n else:\n raise AdbError(cmd=args, stdout=out, stderr=err, ret_code=ret)\n\n def _exec_adb_cmd(self, name, args, shell, timeout):\n if shell:\n # Add quotes around \"adb\" in case the ADB path contains spaces. This\n # is pretty common on Windows (e.g. Program Files).\n if self.serial:\n adb_cmd = '\"%s\" -s \"%s\" %s %s' % (ADB, self.serial, name, args)\n else:\n adb_cmd = '\"%s\" %s %s' % (ADB, name, args)\n else:\n adb_cmd = [ADB]\n if self.serial:\n adb_cmd.extend(['-s', self.serial])\n adb_cmd.append(name)\n if args:\n if isinstance(args, basestring):\n adb_cmd.append(args)\n else:\n adb_cmd.extend(args)\n return self._exec_cmd(adb_cmd, shell=shell, timeout=timeout)\n\n def getprop(self, prop_name):\n \"\"\"Get a property of the device.\n\n This is a convenience wrapper for \"adb shell getprop xxx\".\n\n Args:\n prop_name: A string that is the name of the property to get.\n\n Returns:\n A string that is the value of the property, or None if the property\n doesn't exist.\n \"\"\"\n return self.shell('getprop %s' % prop_name).decode('utf-8').strip()\n\n def has_shell_command(self, command):\n \"\"\"Checks to see if a given check command exists on the device.\n\n Args:\n command: A string that is the name of the command to check.\n\n Returns:\n A boolean that is True if the command exists and False otherwise.\n \"\"\"\n try:\n output = self.shell(['command', '-v',\n command]).decode('utf-8').strip()\n return command in output\n except AdbError:\n # If the command doesn't exist, then 'command -v' can return\n # an exit code > 1.\n return False\n\n def forward(self, args=None, shell=False):\n with ADB_PORT_LOCK:\n return self._exec_adb_cmd('forward', args, shell, timeout=None)\n\n def instrument(self, package, options=None, runner=None):\n \"\"\"Runs an instrumentation command on the device.\n\n This is a convenience wrapper to avoid parameter formatting.\n\n Example:\n device.instrument(\n 'com.my.package.test',\n options = {\n 'class': 'com.my.package.test.TestSuite',\n },\n )\n\n Args:\n package: string, the package of the instrumentation tests.\n options: dict, the instrumentation options including the test\n class.\n runner: string, the test runner name, which defaults to\n DEFAULT_INSTRUMENTATION_RUNNER.\n\n Returns:\n The output of instrumentation command.\n \"\"\"\n if runner is None:\n runner = DEFAULT_INSTRUMENTATION_RUNNER\n if options is None:\n options = {}\n\n options_list = []\n for option_key, option_value in options.items():\n options_list.append('-e %s %s' % (option_key, option_value))\n options_string = ' '.join(options_list)\n\n instrumentation_command = 'am instrument -r -w %s %s/%s' % (\n options_string, package, runner)\n logging.info('AndroidDevice|%s: Executing adb shell %s', self.serial,\n instrumentation_command)\n return self.shell(instrumentation_command)\n\n def __getattr__(self, name):\n def adb_call(args=None, shell=False, timeout=None):\n \"\"\"Wrapper for an ADB command.\n\n Args:\n args: string or list of strings, arguments to the adb command.\n See subprocess.Proc() documentation.\n shell: bool, True to run this command through the system shell,\n False to invoke it directly. See subprocess.Proc() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n\n Returns:\n The output of the adb command run if exit code is 0.\n \"\"\"\n args = args or ''\n clean_name = name.replace('_', '-')\n return self._exec_adb_cmd(\n clean_name, args, shell=shell, timeout=timeout)\n\n return adb_call\n", "path": "mobly/controllers/android_device_lib/adb.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom builtins import str\nfrom past.builtins import basestring\n\nimport logging\nimport pipes\nimport psutil\nimport subprocess\nimport threading\n\n# Command to use for running ADB commands.\nADB = 'adb'\n\n# adb gets confused if we try to manage bound ports in parallel, so anything to\n# do with port forwarding must happen under this lock.\nADB_PORT_LOCK = threading.Lock()\n\n# Qualified class name of the default instrumentation test runner.\nDEFAULT_INSTRUMENTATION_RUNNER = 'com.android.common.support.test.runner.AndroidJUnitRunner'\n\n\nclass Error(Exception):\n \"\"\"Base error type for adb proxy module.\"\"\"\n\n\nclass AdbError(Error):\n \"\"\"Raised when an adb command encounters an error.\n\n Args:\n cmd: list of strings, the adb command executed.\n stdout: byte string, the raw stdout of the command.\n stderr: byte string, the raw stderr of the command.\n ret_code: int, the return code of the command.\n \"\"\"\n\n def __init__(self, cmd, stdout, stderr, ret_code):\n self.cmd = cmd\n self.stdout = stdout\n self.stderr = stderr\n self.ret_code = ret_code\n\n def __str__(self):\n return ('Error executing adb cmd \"%s\". ret: %d, stdout: %s, stderr: %s'\n ) % (cli_cmd_to_string(self.cmd), self.ret_code, self.stdout,\n self.stderr)\n\n\nclass AdbTimeoutError(Error):\n \"\"\"Raised when an command did not complete within expected time.\n\n Args:\n cmd: list of strings, the adb command that timed out\n timeout: float, the number of seconds passed before timing out.\n \"\"\"\n\n def __init__(self, cmd, timeout):\n self.cmd = cmd\n self.timeout = timeout\n\n def __str__(self):\n return 'Timed out executing command \"%s\" after %ss.' % (\n cli_cmd_to_string(self.cmd), self.timeout)\n\n\ndef list_occupied_adb_ports():\n \"\"\"Lists all the host ports occupied by adb forward.\n\n This is useful because adb will silently override the binding if an attempt\n to bind to a port already used by adb was made, instead of throwing binding\n error. So one should always check what ports adb is using before trying to\n bind to a port with adb.\n\n Returns:\n A list of integers representing occupied host ports.\n \"\"\"\n out = AdbProxy().forward('--list')\n clean_lines = str(out, 'utf-8').strip().split('\\n')\n used_ports = []\n for line in clean_lines:\n tokens = line.split(' tcp:')\n if len(tokens) != 3:\n continue\n used_ports.append(int(tokens[1]))\n return used_ports\n\n\ndef cli_cmd_to_string(args):\n \"\"\"Converts a cmd arg list to string.\n\n Args:\n args: list of strings, the arguments of a command.\n\n Returns:\n String representation of the command.\n \"\"\"\n if isinstance(args, basestring):\n # Return directly if it's already a string.\n return args\n return ' '.join([pipes.quote(arg) for arg in args])\n\n\nclass AdbProxy(object):\n \"\"\"Proxy class for ADB.\n\n For syntactic reasons, the '-' in adb commands need to be replaced with\n '_'. Can directly execute adb commands on an object:\n >> adb = AdbProxy(<serial>)\n >> adb.start_server()\n >> adb.devices() # will return the console output of \"adb devices\".\n\n By default, command args are expected to be an iterable which is passed\n directly to subprocess.Popen():\n >> adb.shell(['echo', 'a', 'b'])\n\n This way of launching commands is recommended by the subprocess\n documentation to avoid shell injection vulnerabilities and avoid having to\n deal with multiple layers of shell quoting and different shell environments\n between different OSes.\n\n If you really want to run the command through the system shell, this is\n possible by supplying shell=True, but try to avoid this if possible:\n >> adb.shell('cat /foo > /tmp/file', shell=True)\n \"\"\"\n\n def __init__(self, serial=''):\n self.serial = serial\n\n def _exec_cmd(self, args, shell, timeout, stderr):\n \"\"\"Executes adb commands.\n\n Args:\n args: string or list of strings, program arguments.\n See subprocess.Popen() documentation.\n shell: bool, True to run this command through the system shell,\n False to invoke it directly. See subprocess.Popen() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n stderr: a Byte stream, like io.BytesIO, stderr of the command will\n be written to this object if provided.\n\n Returns:\n The output of the adb command run if exit code is 0.\n\n Raises:\n AdbError: The adb command exit code is not 0.\n AdbTimeoutError: The adb command timed out.\n \"\"\"\n proc = subprocess.Popen(\n args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=shell)\n process = psutil.Process(proc.pid)\n if timeout and timeout <= 0:\n raise Error('Timeout is not a positive value: %s' % timeout)\n if timeout and timeout > 0:\n try:\n process.wait(timeout=timeout)\n except psutil.TimeoutExpired:\n process.terminate()\n raise AdbTimeoutError(cmd=args, timeout=timeout)\n\n (out, err) = proc.communicate()\n if stderr:\n stderr.write(err)\n ret = proc.returncode\n logging.debug('cmd: %s, stdout: %s, stderr: %s, ret: %s',\n cli_cmd_to_string(args), out, err, ret)\n if ret == 0:\n return out\n else:\n raise AdbError(cmd=args, stdout=out, stderr=err, ret_code=ret)\n\n def _exec_adb_cmd(self, name, args, shell, timeout, stderr):\n if shell:\n # Add quotes around \"adb\" in case the ADB path contains spaces. This\n # is pretty common on Windows (e.g. Program Files).\n if self.serial:\n adb_cmd = '\"%s\" -s \"%s\" %s %s' % (ADB, self.serial, name, args)\n else:\n adb_cmd = '\"%s\" %s %s' % (ADB, name, args)\n else:\n adb_cmd = [ADB]\n if self.serial:\n adb_cmd.extend(['-s', self.serial])\n adb_cmd.append(name)\n if args:\n if isinstance(args, basestring):\n adb_cmd.append(args)\n else:\n adb_cmd.extend(args)\n out = self._exec_cmd(\n adb_cmd, shell=shell, timeout=timeout, stderr=stderr)\n return out\n\n def getprop(self, prop_name):\n \"\"\"Get a property of the device.\n\n This is a convenience wrapper for \"adb shell getprop xxx\".\n\n Args:\n prop_name: A string that is the name of the property to get.\n\n Returns:\n A string that is the value of the property, or None if the property\n doesn't exist.\n \"\"\"\n return self.shell('getprop %s' % prop_name).decode('utf-8').strip()\n\n def has_shell_command(self, command):\n \"\"\"Checks to see if a given check command exists on the device.\n\n Args:\n command: A string that is the name of the command to check.\n\n Returns:\n A boolean that is True if the command exists and False otherwise.\n \"\"\"\n try:\n output = self.shell(['command', '-v',\n command]).decode('utf-8').strip()\n return command in output\n except AdbError:\n # If the command doesn't exist, then 'command -v' can return\n # an exit code > 1.\n return False\n\n def forward(self, args=None, shell=False):\n with ADB_PORT_LOCK:\n return self._exec_adb_cmd('forward', args, shell, timeout=None)\n\n def instrument(self, package, options=None, runner=None):\n \"\"\"Runs an instrumentation command on the device.\n\n This is a convenience wrapper to avoid parameter formatting.\n\n Example:\n device.instrument(\n 'com.my.package.test',\n options = {\n 'class': 'com.my.package.test.TestSuite',\n },\n )\n\n Args:\n package: string, the package of the instrumentation tests.\n options: dict, the instrumentation options including the test\n class.\n runner: string, the test runner name, which defaults to\n DEFAULT_INSTRUMENTATION_RUNNER.\n\n Returns:\n The output of instrumentation command.\n \"\"\"\n if runner is None:\n runner = DEFAULT_INSTRUMENTATION_RUNNER\n if options is None:\n options = {}\n\n options_list = []\n for option_key, option_value in options.items():\n options_list.append('-e %s %s' % (option_key, option_value))\n options_string = ' '.join(options_list)\n\n instrumentation_command = 'am instrument -r -w %s %s/%s' % (\n options_string, package, runner)\n logging.info('AndroidDevice|%s: Executing adb shell %s', self.serial,\n instrumentation_command)\n return self.shell(instrumentation_command)\n\n def __getattr__(self, name):\n def adb_call(args=None, shell=False, timeout=None, stderr=None):\n \"\"\"Wrapper for an ADB command.\n\n Args:\n args: string or list of strings, arguments to the adb command.\n See subprocess.Proc() documentation.\n shell: bool, True to run this command through the system shell,\n False to invoke it directly. See subprocess.Proc() docs.\n timeout: float, the number of seconds to wait before timing out.\n If not specified, no timeout takes effect.\n stderr: a Byte stream, like io.BytesIO, stderr of the command\n will be written to this object if provided.\n\n Returns:\n The output of the adb command run if exit code is 0.\n \"\"\"\n args = args or ''\n clean_name = name.replace('_', '-')\n return self._exec_adb_cmd(\n clean_name, args, shell=shell, timeout=timeout, stderr=stderr)\n\n return adb_call\n", "path": "mobly/controllers/android_device_lib/adb.py"}]}
| 3,409 | 781 |
gh_patches_debug_30288
|
rasdani/github-patches
|
git_diff
|
OCA__social-687
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[14.0] mail_debrand: TypeError: cannot use a string pattern on a bytes-like object
This error occurs in the app email marketing(mass_mailing) by clicking on "Test" in the Mailings tab
File "/opt/odoo/odoo/addons/base/models/ir_http.py", line 237, in _dispatch
result = request.dispatch()
File "/opt/odoo/odoo/http.py", line 683, in dispatch
result = self._call_function(**self.params)
File "/opt/odoo/odoo/http.py", line 359, in _call_function
return checked_call(self.db, *args, **kwargs)
File "/opt/odoo/odoo/service/model.py", line 94, in wrapper
return f(dbname, *args, **kwargs)
File "/opt/odoo/odoo/http.py", line 347, in checked_call
result = self.endpoint(*a, **kw)
File "/opt/odoo/odoo/http.py", line 912, in __call__
return self.method(*args, **kw)
File "/opt/odoo/odoo/http.py", line 531, in response_wrap
response = f(*args, **kw)
File "/opt/odoo/odoo/addons/web/controllers/main.py", line 1368, in call_button
action = self._call_kw(model, method, args, kwargs)
File "/opt/odoo/odoo/addons/web/controllers/main.py", line 1356, in _call_kw
return call_kw(request.env[model], method, args, kwargs)
File "/opt/odoo/odoo/api.py", line 396, in call_kw
result = _call_kw_multi(method, model, args, kwargs)
File "/opt/odoo/odoo/api.py", line 383, in _call_kw_multi
result = method(recs, *args, **kwargs)
File "/opt/odoo/odoo/addons/mass_mailing/wizard/mailing_mailing_test.py", line 54, in send_mail_test
mail = self.env['mail.mail'].sudo().create(mail_values)
File "<decorator-gen-210>", line 2, in create
File "/opt/odoo/odoo/api.py", line 344, in _model_create_multi
return create(self, [arg])
File "/opt/odoo/odoo/addons/mass_mailing/models/mail_mail.py", line 21, in create
mails = super(MailMail, self).create(values_list)
File "<decorator-gen-155>", line 2, in create
File "/opt/odoo/odoo/api.py", line 345, in _model_create_multi
return create(self, arg)
File "/opt/odoo/custom-addons/mail_debrand/models/mail_render_mixinANDmail_mail.py", line 98, in create
values_list[index]["body_html"] = self.env[
File "/opt/odoo/custom-addons/mail_debrand/models/mail_render_mixinANDmail_mail.py", line 18, in remove_href_odoo
has_odoo_link = re.search(r"<a\s(.*)odoo\.com", value, flags=re.IGNORECASE)
File "/usr/lib/python3.8/re.py", line 201, in search
return _compile(pattern, flags).search(string)
Exception
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/opt/odoo/odoo/http.py", line 639, in _handle_exception
return super(JsonRequest, self)._handle_exception(exception)
File "/opt/odoo/odoo/http.py", line 315, in _handle_exception
raise exception.with_traceback(None) from new_cause
TypeError: cannot use a string pattern on a bytes-like object
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mail_debrand/models/mail_render_mixinANDmail_mail.py`
Content:
```
1 # Copyright 2019 O4SB - Graeme Gellatly
2 # Copyright 2019 Tecnativa - Ernesto Tejeda
3 # Copyright 2020 Onestein - Andrea Stirpe
4 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
5 import re
6
7 from lxml import etree, html
8
9 from odoo import api, models
10
11
12 class MailRenderMixin(models.AbstractModel):
13 _inherit = "mail.render.mixin"
14
15 def remove_href_odoo(self, value, remove_parent=True, remove_before=False):
16 if len(value) < 20:
17 return value
18 has_odoo_link = re.search(r"<a\s(.*)odoo\.com", value, flags=re.IGNORECASE)
19 if has_odoo_link:
20 tree = etree.HTML(
21 value
22 ) # html with brlken links tree = etree.fromstring(value) just xml
23 odoo_achors = tree.xpath('//a[contains(@href,"odoo.com")]')
24 for elem in odoo_achors:
25 parent = elem.getparent()
26 previous = elem.getprevious()
27
28 if remove_before and not remove_parent and previous:
29 # remove 'using' that is before <a and after </span>
30 bytes_text = etree.tostring(
31 previous, pretty_print=True, method="html"
32 )
33 only_what_is_in_tags = bytes_text[: bytes_text.rfind(b">") + 1]
34 data_formatted = html.fromstring(only_what_is_in_tags)
35 parent.replace(previous, data_formatted)
36 if len(parent.getparent()) and remove_parent:
37 # anchor <a href odoo has a parent powered by that must be removed
38 parent.getparent().remove(parent)
39 else:
40 if parent.tag == "td": # also here can be powerd by
41 parent.getparent().remove(parent)
42 else:
43 parent.remove(elem)
44 value = etree.tostring(tree, pretty_print=True, method="html")
45 # etree can return bytes; ensure we get a proper string
46 if type(value) is bytes:
47 value = value.decode()
48 return re.sub("[^(<)(</)]odoo", "", value, flags=re.IGNORECASE)
49
50 @api.model
51 def _render_template(
52 self,
53 template_src,
54 model,
55 res_ids,
56 engine="jinja",
57 add_context=None,
58 post_process=False,
59 ):
60 """replace anything that is with odoo in templates
61 if is a <a that contains odoo will delete it completly
62 original:
63 Render the given string on records designed by model / res_ids using
64 the given rendering engine. Currently only jinja is supported.
65
66 :param str template_src: template text to render (jinja) or (qweb)
67 this could be cleaned but hey, we are in a rush
68 :param str model: model name of records on which we want to perform rendering
69 :param list res_ids: list of ids of records (all belonging to same model)
70 :param string engine: jinja
71 :param post_process: perform rendered str / html post processing (see
72 ``_render_template_postprocess``)
73
74 :return dict: {res_id: string of rendered template based on record}"""
75 orginal_rendered = super()._render_template(
76 template_src,
77 model,
78 res_ids,
79 engine="jinja",
80 add_context=None,
81 post_process=False,
82 )
83
84 for key in res_ids:
85 orginal_rendered[key] = self.remove_href_odoo(orginal_rendered[key])
86
87 return orginal_rendered
88
89
90 class MailMail(models.AbstractModel):
91 _inherit = "mail.mail"
92
93 # in messages from objects is adding using Odoo that we are going to remove
94
95 @api.model_create_multi
96 def create(self, values_list):
97 for index, _value in enumerate(values_list):
98 values_list[index]["body_html"] = self.env[
99 "mail.render.mixin"
100 ].remove_href_odoo(
101 values_list[index]["body_html"], remove_parent=0, remove_before=1
102 )
103
104 return super().create(values_list)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mail_debrand/models/mail_render_mixinANDmail_mail.py b/mail_debrand/models/mail_render_mixinANDmail_mail.py
--- a/mail_debrand/models/mail_render_mixinANDmail_mail.py
+++ b/mail_debrand/models/mail_render_mixinANDmail_mail.py
@@ -15,11 +15,14 @@
def remove_href_odoo(self, value, remove_parent=True, remove_before=False):
if len(value) < 20:
return value
+ # value can be bytes type; ensure we get a proper string
+ if type(value) is bytes:
+ value = value.decode()
has_odoo_link = re.search(r"<a\s(.*)odoo\.com", value, flags=re.IGNORECASE)
if has_odoo_link:
tree = etree.HTML(
value
- ) # html with brlken links tree = etree.fromstring(value) just xml
+ ) # html with broken links tree = etree.fromstring(value) just xml
odoo_achors = tree.xpath('//a[contains(@href,"odoo.com")]')
for elem in odoo_achors:
parent = elem.getparent()
@@ -33,7 +36,7 @@
only_what_is_in_tags = bytes_text[: bytes_text.rfind(b">") + 1]
data_formatted = html.fromstring(only_what_is_in_tags)
parent.replace(previous, data_formatted)
- if len(parent.getparent()) and remove_parent:
+ if remove_parent and len(parent.getparent()):
# anchor <a href odoo has a parent powered by that must be removed
parent.getparent().remove(parent)
else:
|
{"golden_diff": "diff --git a/mail_debrand/models/mail_render_mixinANDmail_mail.py b/mail_debrand/models/mail_render_mixinANDmail_mail.py\n--- a/mail_debrand/models/mail_render_mixinANDmail_mail.py\n+++ b/mail_debrand/models/mail_render_mixinANDmail_mail.py\n@@ -15,11 +15,14 @@\n def remove_href_odoo(self, value, remove_parent=True, remove_before=False):\n if len(value) < 20:\n return value\n+ # value can be bytes type; ensure we get a proper string\n+ if type(value) is bytes:\n+ value = value.decode()\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\n if has_odoo_link:\n tree = etree.HTML(\n value\n- ) # html with brlken links tree = etree.fromstring(value) just xml\n+ ) # html with broken links tree = etree.fromstring(value) just xml\n odoo_achors = tree.xpath('//a[contains(@href,\"odoo.com\")]')\n for elem in odoo_achors:\n parent = elem.getparent()\n@@ -33,7 +36,7 @@\n only_what_is_in_tags = bytes_text[: bytes_text.rfind(b\">\") + 1]\n data_formatted = html.fromstring(only_what_is_in_tags)\n parent.replace(previous, data_formatted)\n- if len(parent.getparent()) and remove_parent:\n+ if remove_parent and len(parent.getparent()):\n # anchor <a href odoo has a parent powered by that must be removed\n parent.getparent().remove(parent)\n else:\n", "issue": "[14.0] mail_debrand: TypeError: cannot use a string pattern on a bytes-like object\nThis error occurs in the app email marketing(mass_mailing) by clicking on \"Test\" in the Mailings tab\r\n\r\n File \"/opt/odoo/odoo/addons/base/models/ir_http.py\", line 237, in _dispatch\r\n result = request.dispatch()\r\n File \"/opt/odoo/odoo/http.py\", line 683, in dispatch\r\n result = self._call_function(**self.params)\r\n File \"/opt/odoo/odoo/http.py\", line 359, in _call_function\r\n return checked_call(self.db, *args, **kwargs)\r\n File \"/opt/odoo/odoo/service/model.py\", line 94, in wrapper\r\n return f(dbname, *args, **kwargs)\r\n File \"/opt/odoo/odoo/http.py\", line 347, in checked_call\r\n result = self.endpoint(*a, **kw)\r\n File \"/opt/odoo/odoo/http.py\", line 912, in __call__\r\n return self.method(*args, **kw)\r\n File \"/opt/odoo/odoo/http.py\", line 531, in response_wrap\r\n response = f(*args, **kw)\r\n File \"/opt/odoo/odoo/addons/web/controllers/main.py\", line 1368, in call_button\r\n action = self._call_kw(model, method, args, kwargs)\r\n File \"/opt/odoo/odoo/addons/web/controllers/main.py\", line 1356, in _call_kw\r\n return call_kw(request.env[model], method, args, kwargs)\r\n File \"/opt/odoo/odoo/api.py\", line 396, in call_kw\r\n result = _call_kw_multi(method, model, args, kwargs)\r\n File \"/opt/odoo/odoo/api.py\", line 383, in _call_kw_multi\r\n result = method(recs, *args, **kwargs)\r\n File \"/opt/odoo/odoo/addons/mass_mailing/wizard/mailing_mailing_test.py\", line 54, in send_mail_test\r\n mail = self.env['mail.mail'].sudo().create(mail_values)\r\n File \"<decorator-gen-210>\", line 2, in create\r\n File \"/opt/odoo/odoo/api.py\", line 344, in _model_create_multi\r\n return create(self, [arg])\r\n File \"/opt/odoo/odoo/addons/mass_mailing/models/mail_mail.py\", line 21, in create\r\n mails = super(MailMail, self).create(values_list)\r\n File \"<decorator-gen-155>\", line 2, in create\r\n File \"/opt/odoo/odoo/api.py\", line 345, in _model_create_multi\r\n return create(self, arg)\r\n File \"/opt/odoo/custom-addons/mail_debrand/models/mail_render_mixinANDmail_mail.py\", line 98, in create\r\n values_list[index][\"body_html\"] = self.env[\r\n File \"/opt/odoo/custom-addons/mail_debrand/models/mail_render_mixinANDmail_mail.py\", line 18, in remove_href_odoo\r\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\r\n File \"/usr/lib/python3.8/re.py\", line 201, in search\r\n return _compile(pattern, flags).search(string)\r\nException\r\n \r\nThe above exception was the direct cause of the following exception:\r\n \r\nTraceback (most recent call last):\r\n File \"/opt/odoo/odoo/http.py\", line 639, in _handle_exception\r\n return super(JsonRequest, self)._handle_exception(exception)\r\n File \"/opt/odoo/odoo/http.py\", line 315, in _handle_exception\r\n raise exception.with_traceback(None) from new_cause\r\nTypeError: cannot use a string pattern on a bytes-like object\n", "before_files": [{"content": "# Copyright 2019 O4SB - Graeme Gellatly\n# Copyright 2019 Tecnativa - Ernesto Tejeda\n# Copyright 2020 Onestein - Andrea Stirpe\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\nimport re\n\nfrom lxml import etree, html\n\nfrom odoo import api, models\n\n\nclass MailRenderMixin(models.AbstractModel):\n _inherit = \"mail.render.mixin\"\n\n def remove_href_odoo(self, value, remove_parent=True, remove_before=False):\n if len(value) < 20:\n return value\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\n if has_odoo_link:\n tree = etree.HTML(\n value\n ) # html with brlken links tree = etree.fromstring(value) just xml\n odoo_achors = tree.xpath('//a[contains(@href,\"odoo.com\")]')\n for elem in odoo_achors:\n parent = elem.getparent()\n previous = elem.getprevious()\n\n if remove_before and not remove_parent and previous:\n # remove 'using' that is before <a and after </span>\n bytes_text = etree.tostring(\n previous, pretty_print=True, method=\"html\"\n )\n only_what_is_in_tags = bytes_text[: bytes_text.rfind(b\">\") + 1]\n data_formatted = html.fromstring(only_what_is_in_tags)\n parent.replace(previous, data_formatted)\n if len(parent.getparent()) and remove_parent:\n # anchor <a href odoo has a parent powered by that must be removed\n parent.getparent().remove(parent)\n else:\n if parent.tag == \"td\": # also here can be powerd by\n parent.getparent().remove(parent)\n else:\n parent.remove(elem)\n value = etree.tostring(tree, pretty_print=True, method=\"html\")\n # etree can return bytes; ensure we get a proper string\n if type(value) is bytes:\n value = value.decode()\n return re.sub(\"[^(<)(</)]odoo\", \"\", value, flags=re.IGNORECASE)\n\n @api.model\n def _render_template(\n self,\n template_src,\n model,\n res_ids,\n engine=\"jinja\",\n add_context=None,\n post_process=False,\n ):\n \"\"\"replace anything that is with odoo in templates\n if is a <a that contains odoo will delete it completly\n original:\n Render the given string on records designed by model / res_ids using\n the given rendering engine. Currently only jinja is supported.\n\n :param str template_src: template text to render (jinja) or (qweb)\n this could be cleaned but hey, we are in a rush\n :param str model: model name of records on which we want to perform rendering\n :param list res_ids: list of ids of records (all belonging to same model)\n :param string engine: jinja\n :param post_process: perform rendered str / html post processing (see\n ``_render_template_postprocess``)\n\n :return dict: {res_id: string of rendered template based on record}\"\"\"\n orginal_rendered = super()._render_template(\n template_src,\n model,\n res_ids,\n engine=\"jinja\",\n add_context=None,\n post_process=False,\n )\n\n for key in res_ids:\n orginal_rendered[key] = self.remove_href_odoo(orginal_rendered[key])\n\n return orginal_rendered\n\n\nclass MailMail(models.AbstractModel):\n _inherit = \"mail.mail\"\n\n # in messages from objects is adding using Odoo that we are going to remove\n\n @api.model_create_multi\n def create(self, values_list):\n for index, _value in enumerate(values_list):\n values_list[index][\"body_html\"] = self.env[\n \"mail.render.mixin\"\n ].remove_href_odoo(\n values_list[index][\"body_html\"], remove_parent=0, remove_before=1\n )\n\n return super().create(values_list)\n", "path": "mail_debrand/models/mail_render_mixinANDmail_mail.py"}], "after_files": [{"content": "# Copyright 2019 O4SB - Graeme Gellatly\n# Copyright 2019 Tecnativa - Ernesto Tejeda\n# Copyright 2020 Onestein - Andrea Stirpe\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\nimport re\n\nfrom lxml import etree, html\n\nfrom odoo import api, models\n\n\nclass MailRenderMixin(models.AbstractModel):\n _inherit = \"mail.render.mixin\"\n\n def remove_href_odoo(self, value, remove_parent=True, remove_before=False):\n if len(value) < 20:\n return value\n # value can be bytes type; ensure we get a proper string\n if type(value) is bytes:\n value = value.decode()\n has_odoo_link = re.search(r\"<a\\s(.*)odoo\\.com\", value, flags=re.IGNORECASE)\n if has_odoo_link:\n tree = etree.HTML(\n value\n ) # html with broken links tree = etree.fromstring(value) just xml\n odoo_achors = tree.xpath('//a[contains(@href,\"odoo.com\")]')\n for elem in odoo_achors:\n parent = elem.getparent()\n previous = elem.getprevious()\n\n if remove_before and not remove_parent and previous:\n # remove 'using' that is before <a and after </span>\n bytes_text = etree.tostring(\n previous, pretty_print=True, method=\"html\"\n )\n only_what_is_in_tags = bytes_text[: bytes_text.rfind(b\">\") + 1]\n data_formatted = html.fromstring(only_what_is_in_tags)\n parent.replace(previous, data_formatted)\n if remove_parent and len(parent.getparent()):\n # anchor <a href odoo has a parent powered by that must be removed\n parent.getparent().remove(parent)\n else:\n if parent.tag == \"td\": # also here can be powerd by\n parent.getparent().remove(parent)\n else:\n parent.remove(elem)\n value = etree.tostring(tree, pretty_print=True, method=\"html\")\n # etree can return bytes; ensure we get a proper string\n if type(value) is bytes:\n value = value.decode()\n return re.sub(\"[^(<)(</)]odoo\", \"\", value, flags=re.IGNORECASE)\n\n @api.model\n def _render_template(\n self,\n template_src,\n model,\n res_ids,\n engine=\"jinja\",\n add_context=None,\n post_process=False,\n ):\n \"\"\"replace anything that is with odoo in templates\n if is a <a that contains odoo will delete it completly\n original:\n Render the given string on records designed by model / res_ids using\n the given rendering engine. Currently only jinja is supported.\n\n :param str template_src: template text to render (jinja) or (qweb)\n this could be cleaned but hey, we are in a rush\n :param str model: model name of records on which we want to perform rendering\n :param list res_ids: list of ids of records (all belonging to same model)\n :param string engine: jinja\n :param post_process: perform rendered str / html post processing (see\n ``_render_template_postprocess``)\n\n :return dict: {res_id: string of rendered template based on record}\"\"\"\n orginal_rendered = super()._render_template(\n template_src,\n model,\n res_ids,\n engine=\"jinja\",\n add_context=None,\n post_process=False,\n )\n\n for key in res_ids:\n orginal_rendered[key] = self.remove_href_odoo(orginal_rendered[key])\n\n return orginal_rendered\n\n\nclass MailMail(models.AbstractModel):\n _inherit = \"mail.mail\"\n\n # in messages from objects is adding using Odoo that we are going to remove\n\n @api.model_create_multi\n def create(self, values_list):\n for index, _value in enumerate(values_list):\n values_list[index][\"body_html\"] = self.env[\n \"mail.render.mixin\"\n ].remove_href_odoo(\n values_list[index][\"body_html\"], remove_parent=0, remove_before=1\n )\n\n return super().create(values_list)\n", "path": "mail_debrand/models/mail_render_mixinANDmail_mail.py"}]}
| 2,262 | 368 |
gh_patches_debug_24957
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-10297
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] dbus/1.12.20: cannot connect to system bus on linux
# dbus/1.12.20 cannot connect to the system bus on linux
The system bus socket in improperly configured (see log) when dbus/1.12.20 is built. This makes any connection attempt to the system bus impossible.
### Package and Environment Details
* Package Name/Version: **dbus/1.12.20**
* Operating System+version: **Linux Ubuntu 20.04**
* Compiler+version: **GCC 9**
* Docker image: **n/a**
* Conan version: **conan 1.46.2**
* Python version: **Python 3.8.10**
### Conan profile
```
Configuration for profile default:
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=9
compiler.libcxx=libstdc++11
build_type=Release
[options]
[conf]
[build_requires]
[env]
```
### Steps to reproduce
Minimal Example:
conanfile.txt:
```
[requires]
dbus/1.12.20
qt/5.15.2
[options]
qt:shared=True
qt:with_dbus=True
[generators]
CMakeDeps
CMakeToolchain
VirtualRunEnv
```
CMakeLists.txt:
```cmake
cmake_minimum_required(VERSION 3.15)
project(dbus-test)
find_package(Qt5 REQUIRED COMPONENTS DBus)
add_executable(dbus-test main.cpp)
target_link_libraries(dbus-test Qt5::DBus)
```
main.cpp:
```cpp
#include <iostream>
#include <QCoreApplication>
#include <QDBusConnection>
#include <QDBusError>
int main(int argc, char**argv) {
QDBusConnection connection = QDBusConnection::systemBus();
std::cout << "Is connected? " << connection.isConnected()
<< "\nError: \"" << connection.lastError().message().toStdString() << "\"\n";
return 0;
}
```
1. run `mkdir build && cd build && conan install .. --build=missing`
2. run `cmake -DCMAKE_TOOLCHAIN_FILE=conan_toolchain.cmake ..`
3. run `make`
4. run `source conanrun.sh`
5. run `./dbus-test`
Expected output:
```
Is connected? 1
Error: ""
```
Actual output:
```
Is connected? 0
Error: "Socket name too long
"
```
**Note** that running `dbus-test` outside of the conan runenv will produce the expected behavior, as the system dbus library is used (as seen by `ldd dbus-test`).
### Logs (Include/Attach if Applicable)
[log.txt](https://github.com/conan-io/conan-center-index/files/8470511/log.txt)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/dbus/1.x.x/conanfile.py`
Content:
```
1 from conans import AutoToolsBuildEnvironment, ConanFile, tools, CMake
2 import os
3 import shutil
4 import textwrap
5
6 required_conan_version = ">=1.43.0"
7
8
9 class DbusConan(ConanFile):
10 name = "dbus"
11 license = ("AFL-2.1", "GPL-2.0-or-later")
12 url = "https://github.com/conan-io/conan-center-index"
13 homepage = "https://www.freedesktop.org/wiki/Software/dbus"
14 description = "D-Bus is a simple system for interprocess communication and coordination."
15 topics = ("dbus")
16
17 settings = "os", "arch", "compiler", "build_type"
18 options = {
19 "with_x11": [True, False],
20 "with_glib": [True, False],
21 }
22 default_options = {
23 "with_x11": False,
24 "with_glib": False,
25 }
26
27 generators = "pkg_config", "cmake", "cmake_find_package"
28 _autotools = None
29 _cmake = None
30
31 @property
32 def _source_subfolder(self):
33 return "source_subfolder"
34
35 @property
36 def _build_subfolder(self):
37 return "build_subfolder"
38
39 def config_options(self):
40 if self.settings.os not in ("Linux", "FreeBSD"):
41 del self.options.with_x11
42
43 def configure(self):
44 del self.settings.compiler.libcxx
45 del self.settings.compiler.cppstd
46
47 def requirements(self):
48 self.requires("expat/2.4.6")
49 if self.options.with_glib:
50 self.requires("glib/2.70.1")
51 if self.options.get_safe("with_x11"):
52 self.requires("xorg/system")
53
54 def source(self):
55 tools.get(**self.conan_data["sources"][self.version], strip_root=True, destination=self._source_subfolder)
56
57 def _configure_autotools(self):
58 if not self._autotools:
59 self._autotools = AutoToolsBuildEnvironment(self)
60
61 args = []
62 args.append("--disable-tests")
63 args.append("--disable-doxygen-docs")
64 args.append("--disable-xml-docs")
65
66 args.append("--with-x=%s" % ("yes" if self.options.get_safe("with_x11", False) else "no"))
67 args.append("--%s-x11-autolaunch" % ("enable" if self.options.get_safe("with_x11", False) else "disable"))
68 args.append("--disable-asserts")
69 args.append("--disable-checks")
70
71 args.append("--with-systemdsystemunitdir=%s" % os.path.join(self.package_folder, "lib", "systemd", "system"))
72 args.append("--with-systemduserunitdir=%s" % os.path.join(self.package_folder, "lib", "systemd", "user"))
73
74 args.append("--disable-launchd")
75 args.append("--disable-systemd")
76
77 self._autotools.configure(args=args, configure_dir=self._source_subfolder)
78 return self._autotools
79
80 def _configure_cmake(self):
81 if not self._cmake:
82 self._cmake = CMake(self)
83
84 self._cmake.definitions["DBUS_BUILD_TESTS"] = False
85 self._cmake.definitions["DBUS_ENABLE_DOXYGEN_DOCS"] = False
86 self._cmake.definitions["DBUS_ENABLE_XML_DOCS"] = False
87
88 self._cmake.definitions["DBUS_BUILD_X11"] = self.options.get_safe("with_x11", False)
89 self._cmake.definitions["DBUS_WITH_GLIB"] = self.options.with_glib
90 self._cmake.definitions["DBUS_DISABLE_ASSERT"] = False
91 self._cmake.definitions["DBUS_DISABLE_CHECKS"] = False
92
93 path_to_cmake_lists = os.path.join(self._source_subfolder, "cmake")
94
95 self._cmake.configure(source_folder=path_to_cmake_lists,
96 build_folder=self._build_subfolder)
97 return self._cmake
98
99 def build(self):
100 tools.replace_in_file(os.path.join(self._source_subfolder, "cmake", "CMakeLists.txt"),
101 "project(dbus)",
102 "project(dbus)\ninclude(../../conanbuildinfo.cmake)\nconan_basic_setup()")
103 if self.settings.os == "Windows":
104 cmake = self._configure_cmake()
105 cmake.build()
106 else:
107 autotools = self._configure_autotools()
108 autotools.make()
109
110 def package(self):
111 self.copy(pattern="COPYING", dst="licenses",
112 src=self._source_subfolder)
113 if self.settings.os == "Windows":
114 cmake = self._configure_cmake()
115 cmake.install()
116 else:
117 autotools = self._configure_autotools()
118 autotools.install()
119
120 tools.rmdir(os.path.join(self.package_folder, "share", "doc"))
121 for i in ["var", "share", "etc"]:
122 shutil.move(os.path.join(self.package_folder, i), os.path.join(self.package_folder, "res", i))
123
124 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
125 tools.rmdir(os.path.join(self.package_folder, "lib", "pkgconfig"))
126 tools.rmdir(os.path.join(self.package_folder, "lib", "systemd"))
127 tools.remove_files_by_mask(self.package_folder, "*.la")
128
129 # TODO: to remove in conan v2 once cmake_find_package_* generators removed
130 self._create_cmake_module_alias_targets(
131 os.path.join(self.package_folder, self._module_file_rel_path),
132 {"dbus-1": "dbus-1::dbus-1"}
133 )
134
135 @staticmethod
136 def _create_cmake_module_alias_targets(module_file, targets):
137 content = ""
138 for alias, aliased in targets.items():
139 content += textwrap.dedent("""\
140 if(TARGET {aliased} AND NOT TARGET {alias})
141 add_library({alias} INTERFACE IMPORTED)
142 set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})
143 endif()
144 """.format(alias=alias, aliased=aliased))
145 tools.save(module_file, content)
146
147 @property
148 def _module_file_rel_path(self):
149 return os.path.join("lib", "cmake", "conan-official-{}-targets.cmake".format(self.name))
150
151 def package_info(self):
152 self.cpp_info.set_property("cmake_file_name", "DBus1")
153 self.cpp_info.set_property("cmake_target_name", "dbus-1")
154 self.cpp_info.set_property("pkg_config_name", "dbus-1")
155 self.cpp_info.includedirs.extend([
156 os.path.join("include", "dbus-1.0"),
157 os.path.join("lib", "dbus-1.0", "include"),
158 ])
159 self.cpp_info.libs = ["dbus-1"]
160
161 # TODO: to remove in conan v2 once cmake_find_package_* & pkg_config generators removed
162 self.cpp_info.filenames["cmake_find_package"] = "DBus1"
163 self.cpp_info.filenames["cmake_find_package_multi"] = "DBus1"
164 self.cpp_info.names["cmake_find_package"] = "dbus-1"
165 self.cpp_info.names["cmake_find_package_multi"] = "dbus-1"
166 self.cpp_info.build_modules["cmake_find_package"] = [self._module_file_rel_path]
167 self.cpp_info.build_modules["cmake_find_package_multi"] = [self._module_file_rel_path]
168 self.cpp_info.names["pkg_config"] = "dbus-1"
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/dbus/1.x.x/conanfile.py b/recipes/dbus/1.x.x/conanfile.py
--- a/recipes/dbus/1.x.x/conanfile.py
+++ b/recipes/dbus/1.x.x/conanfile.py
@@ -16,10 +16,14 @@
settings = "os", "arch", "compiler", "build_type"
options = {
+ "system_socket": "ANY",
+ "system_pid_file": "ANY",
"with_x11": [True, False],
"with_glib": [True, False],
}
default_options = {
+ "system_socket": "",
+ "system_pid_file": "",
"with_x11": False,
"with_glib": False,
}
@@ -71,6 +75,11 @@
args.append("--with-systemdsystemunitdir=%s" % os.path.join(self.package_folder, "lib", "systemd", "system"))
args.append("--with-systemduserunitdir=%s" % os.path.join(self.package_folder, "lib", "systemd", "user"))
+ if str(self.options.system_socket) is not "":
+ args.append("--with-system-socket=%s" % self.options.system_socket)
+ if str(self.options.system_pid_file) is not "":
+ args.append("--with-system-pid-file=%s" % self.options.system_pid_file)
+
args.append("--disable-launchd")
args.append("--disable-systemd")
|
{"golden_diff": "diff --git a/recipes/dbus/1.x.x/conanfile.py b/recipes/dbus/1.x.x/conanfile.py\n--- a/recipes/dbus/1.x.x/conanfile.py\n+++ b/recipes/dbus/1.x.x/conanfile.py\n@@ -16,10 +16,14 @@\n \n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n+ \"system_socket\": \"ANY\",\n+ \"system_pid_file\": \"ANY\",\n \"with_x11\": [True, False],\n \"with_glib\": [True, False],\n }\n default_options = {\n+ \"system_socket\": \"\",\n+ \"system_pid_file\": \"\",\n \"with_x11\": False,\n \"with_glib\": False,\n }\n@@ -71,6 +75,11 @@\n args.append(\"--with-systemdsystemunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"system\"))\n args.append(\"--with-systemduserunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"user\"))\n \n+ if str(self.options.system_socket) is not \"\":\n+ args.append(\"--with-system-socket=%s\" % self.options.system_socket)\n+ if str(self.options.system_pid_file) is not \"\":\n+ args.append(\"--with-system-pid-file=%s\" % self.options.system_pid_file)\n+\n args.append(\"--disable-launchd\")\n args.append(\"--disable-systemd\")\n", "issue": "[package] dbus/1.12.20: cannot connect to system bus on linux\n# dbus/1.12.20 cannot connect to the system bus on linux\r\nThe system bus socket in improperly configured (see log) when dbus/1.12.20 is built. This makes any connection attempt to the system bus impossible.\r\n\r\n### Package and Environment Details\r\n * Package Name/Version: **dbus/1.12.20**\r\n * Operating System+version: **Linux Ubuntu 20.04**\r\n * Compiler+version: **GCC 9**\r\n * Docker image: **n/a**\r\n * Conan version: **conan 1.46.2**\r\n * Python version: **Python 3.8.10**\r\n\r\n\r\n### Conan profile\r\n```\r\nConfiguration for profile default:\r\n\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=9\r\ncompiler.libcxx=libstdc++11\r\nbuild_type=Release\r\n[options]\r\n[conf]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n\r\n### Steps to reproduce\r\nMinimal Example:\r\n\r\nconanfile.txt:\r\n```\r\n[requires]\r\ndbus/1.12.20\r\nqt/5.15.2\r\n\r\n[options]\r\nqt:shared=True\r\nqt:with_dbus=True\r\n\r\n[generators]\r\nCMakeDeps\r\nCMakeToolchain\r\nVirtualRunEnv\r\n```\r\n\r\nCMakeLists.txt:\r\n```cmake\r\ncmake_minimum_required(VERSION 3.15)\r\nproject(dbus-test)\r\n\r\nfind_package(Qt5 REQUIRED COMPONENTS DBus)\r\nadd_executable(dbus-test main.cpp)\r\ntarget_link_libraries(dbus-test Qt5::DBus)\r\n```\r\n\r\nmain.cpp:\r\n```cpp\r\n#include <iostream>\r\n\r\n#include <QCoreApplication>\r\n#include <QDBusConnection>\r\n#include <QDBusError>\r\n\r\nint main(int argc, char**argv) {\r\n QDBusConnection connection = QDBusConnection::systemBus();\r\n\r\n std::cout << \"Is connected? \" << connection.isConnected()\r\n << \"\\nError: \\\"\" << connection.lastError().message().toStdString() << \"\\\"\\n\";\r\n\r\n return 0;\r\n}\r\n```\r\n\r\n1. run `mkdir build && cd build && conan install .. --build=missing`\r\n2. run `cmake -DCMAKE_TOOLCHAIN_FILE=conan_toolchain.cmake ..`\r\n3. run `make`\r\n4. run `source conanrun.sh`\r\n5. run `./dbus-test`\r\n\r\nExpected output:\r\n```\r\nIs connected? 1\r\nError: \"\"\r\n```\r\nActual output:\r\n```\r\nIs connected? 0\r\nError: \"Socket name too long\r\n\"\r\n```\r\n\r\n**Note** that running `dbus-test` outside of the conan runenv will produce the expected behavior, as the system dbus library is used (as seen by `ldd dbus-test`).\r\n\r\n### Logs (Include/Attach if Applicable)\r\n[log.txt](https://github.com/conan-io/conan-center-index/files/8470511/log.txt)\r\n\r\n\r\n\n", "before_files": [{"content": "from conans import AutoToolsBuildEnvironment, ConanFile, tools, CMake\nimport os\nimport shutil\nimport textwrap\n\nrequired_conan_version = \">=1.43.0\"\n\n\nclass DbusConan(ConanFile):\n name = \"dbus\"\n license = (\"AFL-2.1\", \"GPL-2.0-or-later\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://www.freedesktop.org/wiki/Software/dbus\"\n description = \"D-Bus is a simple system for interprocess communication and coordination.\"\n topics = (\"dbus\")\n\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"with_x11\": [True, False],\n \"with_glib\": [True, False],\n }\n default_options = {\n \"with_x11\": False,\n \"with_glib\": False,\n }\n\n generators = \"pkg_config\", \"cmake\", \"cmake_find_package\"\n _autotools = None\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def config_options(self):\n if self.settings.os not in (\"Linux\", \"FreeBSD\"):\n del self.options.with_x11\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def requirements(self):\n self.requires(\"expat/2.4.6\")\n if self.options.with_glib:\n self.requires(\"glib/2.70.1\")\n if self.options.get_safe(\"with_x11\"):\n self.requires(\"xorg/system\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version], strip_root=True, destination=self._source_subfolder)\n\n def _configure_autotools(self):\n if not self._autotools:\n self._autotools = AutoToolsBuildEnvironment(self)\n\n args = []\n args.append(\"--disable-tests\")\n args.append(\"--disable-doxygen-docs\")\n args.append(\"--disable-xml-docs\")\n\n args.append(\"--with-x=%s\" % (\"yes\" if self.options.get_safe(\"with_x11\", False) else \"no\"))\n args.append(\"--%s-x11-autolaunch\" % (\"enable\" if self.options.get_safe(\"with_x11\", False) else \"disable\"))\n args.append(\"--disable-asserts\")\n args.append(\"--disable-checks\")\n\n args.append(\"--with-systemdsystemunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"system\"))\n args.append(\"--with-systemduserunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"user\"))\n\n args.append(\"--disable-launchd\")\n args.append(\"--disable-systemd\")\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder)\n return self._autotools\n\n def _configure_cmake(self):\n if not self._cmake:\n self._cmake = CMake(self)\n\n self._cmake.definitions[\"DBUS_BUILD_TESTS\"] = False\n self._cmake.definitions[\"DBUS_ENABLE_DOXYGEN_DOCS\"] = False\n self._cmake.definitions[\"DBUS_ENABLE_XML_DOCS\"] = False\n\n self._cmake.definitions[\"DBUS_BUILD_X11\"] = self.options.get_safe(\"with_x11\", False)\n self._cmake.definitions[\"DBUS_WITH_GLIB\"] = self.options.with_glib\n self._cmake.definitions[\"DBUS_DISABLE_ASSERT\"] = False\n self._cmake.definitions[\"DBUS_DISABLE_CHECKS\"] = False\n\n path_to_cmake_lists = os.path.join(self._source_subfolder, \"cmake\")\n\n self._cmake.configure(source_folder=path_to_cmake_lists,\n build_folder=self._build_subfolder)\n return self._cmake\n\n def build(self):\n tools.replace_in_file(os.path.join(self._source_subfolder, \"cmake\", \"CMakeLists.txt\"),\n \"project(dbus)\",\n \"project(dbus)\\ninclude(../../conanbuildinfo.cmake)\\nconan_basic_setup()\")\n if self.settings.os == \"Windows\":\n cmake = self._configure_cmake()\n cmake.build()\n else:\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"COPYING\", dst=\"licenses\",\n src=self._source_subfolder)\n if self.settings.os == \"Windows\":\n cmake = self._configure_cmake()\n cmake.install()\n else:\n autotools = self._configure_autotools()\n autotools.install()\n\n tools.rmdir(os.path.join(self.package_folder, \"share\", \"doc\"))\n for i in [\"var\", \"share\", \"etc\"]:\n shutil.move(os.path.join(self.package_folder, i), os.path.join(self.package_folder, \"res\", i))\n\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"systemd\"))\n tools.remove_files_by_mask(self.package_folder, \"*.la\")\n\n # TODO: to remove in conan v2 once cmake_find_package_* generators removed\n self._create_cmake_module_alias_targets(\n os.path.join(self.package_folder, self._module_file_rel_path),\n {\"dbus-1\": \"dbus-1::dbus-1\"}\n )\n\n @staticmethod\n def _create_cmake_module_alias_targets(module_file, targets):\n content = \"\"\n for alias, aliased in targets.items():\n content += textwrap.dedent(\"\"\"\\\n if(TARGET {aliased} AND NOT TARGET {alias})\n add_library({alias} INTERFACE IMPORTED)\n set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})\n endif()\n \"\"\".format(alias=alias, aliased=aliased))\n tools.save(module_file, content)\n\n @property\n def _module_file_rel_path(self):\n return os.path.join(\"lib\", \"cmake\", \"conan-official-{}-targets.cmake\".format(self.name))\n\n def package_info(self):\n self.cpp_info.set_property(\"cmake_file_name\", \"DBus1\")\n self.cpp_info.set_property(\"cmake_target_name\", \"dbus-1\")\n self.cpp_info.set_property(\"pkg_config_name\", \"dbus-1\")\n self.cpp_info.includedirs.extend([\n os.path.join(\"include\", \"dbus-1.0\"),\n os.path.join(\"lib\", \"dbus-1.0\", \"include\"),\n ])\n self.cpp_info.libs = [\"dbus-1\"]\n\n # TODO: to remove in conan v2 once cmake_find_package_* & pkg_config generators removed\n self.cpp_info.filenames[\"cmake_find_package\"] = \"DBus1\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"DBus1\"\n self.cpp_info.names[\"cmake_find_package\"] = \"dbus-1\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"dbus-1\"\n self.cpp_info.build_modules[\"cmake_find_package\"] = [self._module_file_rel_path]\n self.cpp_info.build_modules[\"cmake_find_package_multi\"] = [self._module_file_rel_path]\n self.cpp_info.names[\"pkg_config\"] = \"dbus-1\"\n", "path": "recipes/dbus/1.x.x/conanfile.py"}], "after_files": [{"content": "from conans import AutoToolsBuildEnvironment, ConanFile, tools, CMake\nimport os\nimport shutil\nimport textwrap\n\nrequired_conan_version = \">=1.43.0\"\n\n\nclass DbusConan(ConanFile):\n name = \"dbus\"\n license = (\"AFL-2.1\", \"GPL-2.0-or-later\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://www.freedesktop.org/wiki/Software/dbus\"\n description = \"D-Bus is a simple system for interprocess communication and coordination.\"\n topics = (\"dbus\")\n\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"system_socket\": \"ANY\",\n \"system_pid_file\": \"ANY\",\n \"with_x11\": [True, False],\n \"with_glib\": [True, False],\n }\n default_options = {\n \"system_socket\": \"\",\n \"system_pid_file\": \"\",\n \"with_x11\": False,\n \"with_glib\": False,\n }\n\n generators = \"pkg_config\", \"cmake\", \"cmake_find_package\"\n _autotools = None\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def config_options(self):\n if self.settings.os not in (\"Linux\", \"FreeBSD\"):\n del self.options.with_x11\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def requirements(self):\n self.requires(\"expat/2.4.6\")\n if self.options.with_glib:\n self.requires(\"glib/2.70.1\")\n if self.options.get_safe(\"with_x11\"):\n self.requires(\"xorg/system\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version], strip_root=True, destination=self._source_subfolder)\n\n def _configure_autotools(self):\n if not self._autotools:\n self._autotools = AutoToolsBuildEnvironment(self)\n\n args = []\n args.append(\"--disable-tests\")\n args.append(\"--disable-doxygen-docs\")\n args.append(\"--disable-xml-docs\")\n\n args.append(\"--with-x=%s\" % (\"yes\" if self.options.get_safe(\"with_x11\", False) else \"no\"))\n args.append(\"--%s-x11-autolaunch\" % (\"enable\" if self.options.get_safe(\"with_x11\", False) else \"disable\"))\n args.append(\"--disable-asserts\")\n args.append(\"--disable-checks\")\n\n args.append(\"--with-systemdsystemunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"system\"))\n args.append(\"--with-systemduserunitdir=%s\" % os.path.join(self.package_folder, \"lib\", \"systemd\", \"user\"))\n\n if str(self.options.system_socket) is not \"\":\n args.append(\"--with-system-socket=%s\" % self.options.system_socket)\n if str(self.options.system_pid_file) is not \"\":\n args.append(\"--with-system-pid-file=%s\" % self.options.system_pid_file)\n\n args.append(\"--disable-launchd\")\n args.append(\"--disable-systemd\")\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder)\n return self._autotools\n\n def _configure_cmake(self):\n if not self._cmake:\n self._cmake = CMake(self)\n\n self._cmake.definitions[\"DBUS_BUILD_TESTS\"] = False\n self._cmake.definitions[\"DBUS_ENABLE_DOXYGEN_DOCS\"] = False\n self._cmake.definitions[\"DBUS_ENABLE_XML_DOCS\"] = False\n\n self._cmake.definitions[\"DBUS_BUILD_X11\"] = self.options.get_safe(\"with_x11\", False)\n self._cmake.definitions[\"DBUS_WITH_GLIB\"] = self.options.with_glib\n self._cmake.definitions[\"DBUS_DISABLE_ASSERT\"] = False\n self._cmake.definitions[\"DBUS_DISABLE_CHECKS\"] = False\n\n path_to_cmake_lists = os.path.join(self._source_subfolder, \"cmake\")\n\n self._cmake.configure(source_folder=path_to_cmake_lists,\n build_folder=self._build_subfolder)\n return self._cmake\n\n def build(self):\n tools.replace_in_file(os.path.join(self._source_subfolder, \"cmake\", \"CMakeLists.txt\"),\n \"project(dbus)\",\n \"project(dbus)\\ninclude(../../conanbuildinfo.cmake)\\nconan_basic_setup()\")\n if self.settings.os == \"Windows\":\n cmake = self._configure_cmake()\n cmake.build()\n else:\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"COPYING\", dst=\"licenses\",\n src=self._source_subfolder)\n if self.settings.os == \"Windows\":\n cmake = self._configure_cmake()\n cmake.install()\n else:\n autotools = self._configure_autotools()\n autotools.install()\n\n tools.rmdir(os.path.join(self.package_folder, \"share\", \"doc\"))\n for i in [\"var\", \"share\", \"etc\"]:\n shutil.move(os.path.join(self.package_folder, i), os.path.join(self.package_folder, \"res\", i))\n\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"pkgconfig\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"systemd\"))\n tools.remove_files_by_mask(self.package_folder, \"*.la\")\n\n # TODO: to remove in conan v2 once cmake_find_package_* generators removed\n self._create_cmake_module_alias_targets(\n os.path.join(self.package_folder, self._module_file_rel_path),\n {\"dbus-1\": \"dbus-1::dbus-1\"}\n )\n\n @staticmethod\n def _create_cmake_module_alias_targets(module_file, targets):\n content = \"\"\n for alias, aliased in targets.items():\n content += textwrap.dedent(\"\"\"\\\n if(TARGET {aliased} AND NOT TARGET {alias})\n add_library({alias} INTERFACE IMPORTED)\n set_property(TARGET {alias} PROPERTY INTERFACE_LINK_LIBRARIES {aliased})\n endif()\n \"\"\".format(alias=alias, aliased=aliased))\n tools.save(module_file, content)\n\n @property\n def _module_file_rel_path(self):\n return os.path.join(\"lib\", \"cmake\", \"conan-official-{}-targets.cmake\".format(self.name))\n\n def package_info(self):\n self.cpp_info.set_property(\"cmake_file_name\", \"DBus1\")\n self.cpp_info.set_property(\"cmake_target_name\", \"dbus-1\")\n self.cpp_info.set_property(\"pkg_config_name\", \"dbus-1\")\n self.cpp_info.includedirs.extend([\n os.path.join(\"include\", \"dbus-1.0\"),\n os.path.join(\"lib\", \"dbus-1.0\", \"include\"),\n ])\n self.cpp_info.libs = [\"dbus-1\"]\n\n # TODO: to remove in conan v2 once cmake_find_package_* & pkg_config generators removed\n self.cpp_info.filenames[\"cmake_find_package\"] = \"DBus1\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"DBus1\"\n self.cpp_info.names[\"cmake_find_package\"] = \"dbus-1\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"dbus-1\"\n self.cpp_info.build_modules[\"cmake_find_package\"] = [self._module_file_rel_path]\n self.cpp_info.build_modules[\"cmake_find_package_multi\"] = [self._module_file_rel_path]\n self.cpp_info.names[\"pkg_config\"] = \"dbus-1\"\n", "path": "recipes/dbus/1.x.x/conanfile.py"}]}
| 2,981 | 334 |
gh_patches_debug_3919
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-3381
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FoVBackgroundMaker parameter error not accessible
After the running the `FoVBackgroundMaker`, the error on the fitted parameters is not accessible.
**To reproduce**
Try `print(dataset.background_model.spectral_model.norm.error)` inside the `Data Reduction Loop` in `analysis_2` notebook. It is always `0`
**Reason**
It seems that the error is available at this stage,
https://github.com/gammapy/gammapy/blob/df3db33e34233369512d57cca5341a7b645802d6/gammapy/makers/background/fov.py#L180
but the info is lost outside the `with models.restore_status` block, eg: in line 187.
I did not understand why, though.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gammapy/makers/background/fov.py`
Content:
```
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 """FoV background estimation."""
3 import logging
4 import numpy as np
5 from gammapy.maps import Map
6 from gammapy.modeling import Fit
7 from gammapy.modeling.models import FoVBackgroundModel, Model
8 from ..core import Maker
9
10
11 __all__ = ["FoVBackgroundMaker"]
12
13 log = logging.getLogger(__name__)
14
15
16 class FoVBackgroundMaker(Maker):
17 """Normalize template background on the whole field-of-view.
18
19 The dataset background model can be simply scaled (method="scale") or fitted (method="fit")
20 on the dataset counts.
21
22 The normalization is performed outside the exclusion mask that is passed on init.
23
24 If a SkyModel is set on the input dataset and method is 'fit', it' parameters
25 are frozen during the fov normalization fit.
26
27 If the requirement (greater than) of either min_counts or min_npred_background is not satisfied,
28 the background will not be normalised
29
30 Parameters
31 ----------
32 method : str in ['fit', 'scale']
33 the normalization method to be applied. Default 'scale'.
34 exclusion_mask : `~gammapy.maps.WcsNDMap`
35 Exclusion mask
36 spectral_model : SpectralModel or str
37 Reference norm spectral model to use for the `FoVBackgroundModel`, if none is defined
38 on the dataset. By default, use pl-norm.
39 min_counts : int
40 Minimum number of counts required outside the exclusion region
41 min_npred_background : float
42 Minimum number of predicted background counts required outside the exclusion region
43 """
44
45 tag = "FoVBackgroundMaker"
46 available_methods = ["fit", "scale"]
47
48 def __init__(
49 self,
50 method="scale",
51 exclusion_mask=None,
52 spectral_model="pl-norm",
53 min_counts=0,
54 min_npred_background=0,
55 ):
56 self.method = method
57 self.exclusion_mask = exclusion_mask
58 self.min_counts = min_counts
59 self.min_npred_background = min_npred_background
60
61 if isinstance(spectral_model, str):
62 spectral_model = Model.create(tag=spectral_model, model_type="spectral")
63
64 if not spectral_model.is_norm_spectral_model:
65 raise ValueError("Spectral model must be a norm spectral model")
66
67 self.default_spectral_model = spectral_model
68
69 @property
70 def method(self):
71 """Method"""
72 return self._method
73
74 @method.setter
75 def method(self, value):
76 """Method setter"""
77 if value not in self.available_methods:
78 raise ValueError(
79 f"Not a valid method for FoVBackgroundMaker: {value}."
80 f" Choose from {self.available_methods}"
81 )
82
83 self._method = value
84
85 def make_default_fov_background_model(self, dataset):
86 """Add fov background model to the model definition
87
88 Parameters
89 ----------
90 dataset : `~gammapy.datasets.MapDataset`
91 Input map dataset.
92
93 Returns
94 -------
95 dataset : `~gammapy.datasets.MapDataset`
96 Map dataset including background model
97
98 """
99 bkg_model = FoVBackgroundModel(
100 dataset_name=dataset.name, spectral_model=self.default_spectral_model.copy()
101 )
102
103 if dataset.models is None:
104 dataset.models = bkg_model
105 else:
106 dataset.models = dataset.models + bkg_model
107
108 return dataset
109
110 def make_exclusion_mask(self, dataset):
111 """Project input exclusion mask to dataset geom
112
113 Parameters
114 ----------
115 dataset : `~gammapy.datasets.MapDataset`
116 Input map dataset.
117
118 Returns
119 -------
120 mask : `~gammapy.maps.WcsNDMap`
121 Projected exclusion mask
122 """
123 geom = dataset._geom
124 if self.exclusion_mask:
125 mask = self.exclusion_mask.interp_to_geom(geom=geom)
126 else:
127 mask = Map.from_geom(geom=geom, data=1, dtype=bool)
128 return mask
129
130 def run(self, dataset, observation=None):
131 """Run FoV background maker.
132
133 Fit the background model norm
134
135 Parameters
136 ----------
137 dataset : `~gammapy.datasets.MapDataset`
138 Input map dataset.
139
140 """
141 mask_fit = dataset.mask_fit
142
143 dataset.mask_fit = self.make_exclusion_mask(dataset)
144
145 if dataset.background_model is None:
146 dataset = self.make_default_fov_background_model(dataset)
147
148 if self.method == "fit":
149 dataset = self.make_background_fit(dataset)
150 else:
151 # always scale the background first
152 dataset = self.make_background_scale(dataset)
153
154 dataset.mask_fit = mask_fit
155 return dataset
156
157 @staticmethod
158 def make_background_fit(dataset):
159 """Fit the FoV background model on the dataset counts data
160
161 Parameters
162 ----------
163 dataset : `~gammapy.datasets.MapDataset`
164 Input dataset.
165
166 Returns
167 -------
168 dataset : `~gammapy.datasets.MapDataset`
169 Map dataset with fitted background model
170 """
171 # freeze all model components not related to background model
172
173 models = dataset.models
174
175 with models.restore_status(restore_values=False):
176 models.select(tag="sky-model").freeze()
177
178 fit = Fit([dataset])
179 fit_result = fit.run()
180 if not fit_result.success:
181 log.warning(
182 f"FoVBackgroundMaker failed. Fit did not converge for {dataset.name}. "
183 f"Setting mask to False."
184 )
185 dataset.mask_safe.data[...] = False
186
187 return dataset
188
189 def make_background_scale(self, dataset):
190 """Fit the FoV background model on the dataset counts data
191
192 Parameters
193 ----------
194 dataset : `~gammapy.datasets.MapDataset`
195 Input dataset.
196
197 Returns
198 -------
199 dataset : `~gammapy.datasets.MapDataset`
200 Map dataset with scaled background model
201
202 """
203 mask = dataset.mask
204 count_tot = dataset.counts.data[mask].sum()
205 bkg_tot = dataset.npred_background().data[mask].sum()
206
207 if count_tot <= self.min_counts:
208 log.warning(
209 f"FoVBackgroundMaker failed. Only {int(count_tot)} counts outside exclusion mask for {dataset.name}. "
210 f"Setting mask to False."
211 )
212 dataset.mask_safe.data[...] = False
213 elif bkg_tot <= self.min_npred_background:
214 log.warning(
215 f"FoVBackgroundMaker failed. Only {int(bkg_tot)} background counts outside exclusion mask for {dataset.name}. "
216 f"Setting mask to False."
217 )
218 dataset.mask_safe.data[...] = False
219 else:
220 value = count_tot / bkg_tot
221 err = np.sqrt(count_tot) / bkg_tot
222 dataset.models[f"{dataset.name}-bkg"].spectral_model.norm.value = value
223 dataset.models[f"{dataset.name}-bkg"].spectral_model.norm.error = err
224
225 return dataset
226
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gammapy/makers/background/fov.py b/gammapy/makers/background/fov.py
--- a/gammapy/makers/background/fov.py
+++ b/gammapy/makers/background/fov.py
@@ -170,7 +170,7 @@
"""
# freeze all model components not related to background model
- models = dataset.models
+ models = dataset.models.select(tag="sky-model")
with models.restore_status(restore_values=False):
models.select(tag="sky-model").freeze()
|
{"golden_diff": "diff --git a/gammapy/makers/background/fov.py b/gammapy/makers/background/fov.py\n--- a/gammapy/makers/background/fov.py\n+++ b/gammapy/makers/background/fov.py\n@@ -170,7 +170,7 @@\n \"\"\"\n # freeze all model components not related to background model\n \n- models = dataset.models\n+ models = dataset.models.select(tag=\"sky-model\")\n \n with models.restore_status(restore_values=False):\n models.select(tag=\"sky-model\").freeze()\n", "issue": "FoVBackgroundMaker parameter error not accessible\nAfter the running the `FoVBackgroundMaker`, the error on the fitted parameters is not accessible.\r\n\r\n**To reproduce**\r\nTry `print(dataset.background_model.spectral_model.norm.error)` inside the `Data Reduction Loop` in `analysis_2` notebook. It is always `0`\r\n\r\n**Reason**\r\nIt seems that the error is available at this stage, \r\nhttps://github.com/gammapy/gammapy/blob/df3db33e34233369512d57cca5341a7b645802d6/gammapy/makers/background/fov.py#L180\r\n\r\nbut the info is lost outside the `with models.restore_status` block, eg: in line 187.\r\nI did not understand why, though.\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\"\"\"FoV background estimation.\"\"\"\nimport logging\nimport numpy as np\nfrom gammapy.maps import Map\nfrom gammapy.modeling import Fit\nfrom gammapy.modeling.models import FoVBackgroundModel, Model\nfrom ..core import Maker\n\n\n__all__ = [\"FoVBackgroundMaker\"]\n\nlog = logging.getLogger(__name__)\n\n\nclass FoVBackgroundMaker(Maker):\n \"\"\"Normalize template background on the whole field-of-view.\n\n The dataset background model can be simply scaled (method=\"scale\") or fitted (method=\"fit\")\n on the dataset counts.\n\n The normalization is performed outside the exclusion mask that is passed on init.\n\n If a SkyModel is set on the input dataset and method is 'fit', it' parameters\n are frozen during the fov normalization fit.\n\n If the requirement (greater than) of either min_counts or min_npred_background is not satisfied,\n the background will not be normalised\n\n Parameters\n ----------\n method : str in ['fit', 'scale']\n the normalization method to be applied. Default 'scale'.\n exclusion_mask : `~gammapy.maps.WcsNDMap`\n Exclusion mask\n spectral_model : SpectralModel or str\n Reference norm spectral model to use for the `FoVBackgroundModel`, if none is defined\n on the dataset. By default, use pl-norm.\n min_counts : int\n Minimum number of counts required outside the exclusion region\n min_npred_background : float\n Minimum number of predicted background counts required outside the exclusion region\n \"\"\"\n\n tag = \"FoVBackgroundMaker\"\n available_methods = [\"fit\", \"scale\"]\n\n def __init__(\n self,\n method=\"scale\",\n exclusion_mask=None,\n spectral_model=\"pl-norm\",\n min_counts=0,\n min_npred_background=0,\n ):\n self.method = method\n self.exclusion_mask = exclusion_mask\n self.min_counts = min_counts\n self.min_npred_background = min_npred_background\n\n if isinstance(spectral_model, str):\n spectral_model = Model.create(tag=spectral_model, model_type=\"spectral\")\n\n if not spectral_model.is_norm_spectral_model:\n raise ValueError(\"Spectral model must be a norm spectral model\")\n\n self.default_spectral_model = spectral_model\n\n @property\n def method(self):\n \"\"\"Method\"\"\"\n return self._method\n\n @method.setter\n def method(self, value):\n \"\"\"Method setter\"\"\"\n if value not in self.available_methods:\n raise ValueError(\n f\"Not a valid method for FoVBackgroundMaker: {value}.\"\n f\" Choose from {self.available_methods}\"\n )\n\n self._method = value\n\n def make_default_fov_background_model(self, dataset):\n \"\"\"Add fov background model to the model definition\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset including background model\n\n \"\"\"\n bkg_model = FoVBackgroundModel(\n dataset_name=dataset.name, spectral_model=self.default_spectral_model.copy()\n )\n\n if dataset.models is None:\n dataset.models = bkg_model\n else:\n dataset.models = dataset.models + bkg_model\n\n return dataset\n\n def make_exclusion_mask(self, dataset):\n \"\"\"Project input exclusion mask to dataset geom\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n Returns\n -------\n mask : `~gammapy.maps.WcsNDMap`\n Projected exclusion mask\n \"\"\"\n geom = dataset._geom\n if self.exclusion_mask:\n mask = self.exclusion_mask.interp_to_geom(geom=geom)\n else:\n mask = Map.from_geom(geom=geom, data=1, dtype=bool)\n return mask\n\n def run(self, dataset, observation=None):\n \"\"\"Run FoV background maker.\n\n Fit the background model norm\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n \"\"\"\n mask_fit = dataset.mask_fit\n\n dataset.mask_fit = self.make_exclusion_mask(dataset)\n\n if dataset.background_model is None:\n dataset = self.make_default_fov_background_model(dataset)\n\n if self.method == \"fit\":\n dataset = self.make_background_fit(dataset)\n else:\n # always scale the background first\n dataset = self.make_background_scale(dataset)\n\n dataset.mask_fit = mask_fit\n return dataset\n\n @staticmethod\n def make_background_fit(dataset):\n \"\"\"Fit the FoV background model on the dataset counts data\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset with fitted background model\n \"\"\"\n # freeze all model components not related to background model\n\n models = dataset.models\n\n with models.restore_status(restore_values=False):\n models.select(tag=\"sky-model\").freeze()\n\n fit = Fit([dataset])\n fit_result = fit.run()\n if not fit_result.success:\n log.warning(\n f\"FoVBackgroundMaker failed. Fit did not converge for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n\n return dataset\n\n def make_background_scale(self, dataset):\n \"\"\"Fit the FoV background model on the dataset counts data\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset with scaled background model\n\n \"\"\"\n mask = dataset.mask\n count_tot = dataset.counts.data[mask].sum()\n bkg_tot = dataset.npred_background().data[mask].sum()\n\n if count_tot <= self.min_counts:\n log.warning(\n f\"FoVBackgroundMaker failed. Only {int(count_tot)} counts outside exclusion mask for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n elif bkg_tot <= self.min_npred_background:\n log.warning(\n f\"FoVBackgroundMaker failed. Only {int(bkg_tot)} background counts outside exclusion mask for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n else:\n value = count_tot / bkg_tot\n err = np.sqrt(count_tot) / bkg_tot\n dataset.models[f\"{dataset.name}-bkg\"].spectral_model.norm.value = value\n dataset.models[f\"{dataset.name}-bkg\"].spectral_model.norm.error = err\n\n return dataset\n", "path": "gammapy/makers/background/fov.py"}], "after_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\"\"\"FoV background estimation.\"\"\"\nimport logging\nimport numpy as np\nfrom gammapy.maps import Map\nfrom gammapy.modeling import Fit\nfrom gammapy.modeling.models import FoVBackgroundModel, Model\nfrom ..core import Maker\n\n\n__all__ = [\"FoVBackgroundMaker\"]\n\nlog = logging.getLogger(__name__)\n\n\nclass FoVBackgroundMaker(Maker):\n \"\"\"Normalize template background on the whole field-of-view.\n\n The dataset background model can be simply scaled (method=\"scale\") or fitted (method=\"fit\")\n on the dataset counts.\n\n The normalization is performed outside the exclusion mask that is passed on init.\n\n If a SkyModel is set on the input dataset and method is 'fit', it' parameters\n are frozen during the fov normalization fit.\n\n If the requirement (greater than) of either min_counts or min_npred_background is not satisfied,\n the background will not be normalised\n\n Parameters\n ----------\n method : str in ['fit', 'scale']\n the normalization method to be applied. Default 'scale'.\n exclusion_mask : `~gammapy.maps.WcsNDMap`\n Exclusion mask\n spectral_model : SpectralModel or str\n Reference norm spectral model to use for the `FoVBackgroundModel`, if none is defined\n on the dataset. By default, use pl-norm.\n min_counts : int\n Minimum number of counts required outside the exclusion region\n min_npred_background : float\n Minimum number of predicted background counts required outside the exclusion region\n \"\"\"\n\n tag = \"FoVBackgroundMaker\"\n available_methods = [\"fit\", \"scale\"]\n\n def __init__(\n self,\n method=\"scale\",\n exclusion_mask=None,\n spectral_model=\"pl-norm\",\n min_counts=0,\n min_npred_background=0,\n ):\n self.method = method\n self.exclusion_mask = exclusion_mask\n self.min_counts = min_counts\n self.min_npred_background = min_npred_background\n\n if isinstance(spectral_model, str):\n spectral_model = Model.create(tag=spectral_model, model_type=\"spectral\")\n\n if not spectral_model.is_norm_spectral_model:\n raise ValueError(\"Spectral model must be a norm spectral model\")\n\n self.default_spectral_model = spectral_model\n\n @property\n def method(self):\n \"\"\"Method\"\"\"\n return self._method\n\n @method.setter\n def method(self, value):\n \"\"\"Method setter\"\"\"\n if value not in self.available_methods:\n raise ValueError(\n f\"Not a valid method for FoVBackgroundMaker: {value}.\"\n f\" Choose from {self.available_methods}\"\n )\n\n self._method = value\n\n def make_default_fov_background_model(self, dataset):\n \"\"\"Add fov background model to the model definition\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset including background model\n\n \"\"\"\n bkg_model = FoVBackgroundModel(\n dataset_name=dataset.name, spectral_model=self.default_spectral_model.copy()\n )\n\n if dataset.models is None:\n dataset.models = bkg_model\n else:\n dataset.models = dataset.models + bkg_model\n\n return dataset\n\n def make_exclusion_mask(self, dataset):\n \"\"\"Project input exclusion mask to dataset geom\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n Returns\n -------\n mask : `~gammapy.maps.WcsNDMap`\n Projected exclusion mask\n \"\"\"\n geom = dataset._geom\n if self.exclusion_mask:\n mask = self.exclusion_mask.interp_to_geom(geom=geom)\n else:\n mask = Map.from_geom(geom=geom, data=1, dtype=bool)\n return mask\n\n def run(self, dataset, observation=None):\n \"\"\"Run FoV background maker.\n\n Fit the background model norm\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input map dataset.\n\n \"\"\"\n mask_fit = dataset.mask_fit\n\n dataset.mask_fit = self.make_exclusion_mask(dataset)\n\n if dataset.background_model is None:\n dataset = self.make_default_fov_background_model(dataset)\n\n if self.method == \"fit\":\n dataset = self.make_background_fit(dataset)\n else:\n # always scale the background first\n dataset = self.make_background_scale(dataset)\n\n dataset.mask_fit = mask_fit\n return dataset\n\n @staticmethod\n def make_background_fit(dataset):\n \"\"\"Fit the FoV background model on the dataset counts data\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset with fitted background model\n \"\"\"\n # freeze all model components not related to background model\n\n models = dataset.models.select(tag=\"sky-model\")\n\n with models.restore_status(restore_values=False):\n models.select(tag=\"sky-model\").freeze()\n\n fit = Fit([dataset])\n fit_result = fit.run()\n if not fit_result.success:\n log.warning(\n f\"FoVBackgroundMaker failed. Fit did not converge for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n\n return dataset\n\n def make_background_scale(self, dataset):\n \"\"\"Fit the FoV background model on the dataset counts data\n\n Parameters\n ----------\n dataset : `~gammapy.datasets.MapDataset`\n Input dataset.\n\n Returns\n -------\n dataset : `~gammapy.datasets.MapDataset`\n Map dataset with scaled background model\n\n \"\"\"\n mask = dataset.mask\n count_tot = dataset.counts.data[mask].sum()\n bkg_tot = dataset.npred_background().data[mask].sum()\n\n if count_tot <= self.min_counts:\n log.warning(\n f\"FoVBackgroundMaker failed. Only {int(count_tot)} counts outside exclusion mask for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n elif bkg_tot <= self.min_npred_background:\n log.warning(\n f\"FoVBackgroundMaker failed. Only {int(bkg_tot)} background counts outside exclusion mask for {dataset.name}. \"\n f\"Setting mask to False.\"\n )\n dataset.mask_safe.data[...] = False\n else:\n value = count_tot / bkg_tot\n err = np.sqrt(count_tot) / bkg_tot\n dataset.models[f\"{dataset.name}-bkg\"].spectral_model.norm.value = value\n dataset.models[f\"{dataset.name}-bkg\"].spectral_model.norm.error = err\n\n return dataset\n", "path": "gammapy/makers/background/fov.py"}]}
| 2,507 | 120 |
gh_patches_debug_60955
|
rasdani/github-patches
|
git_diff
|
voicepaw__so-vits-svc-fork-1155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ensure proper sorting by name for output files
### Is your feature request related to a problem? Please describe.
To enhance readability and ensure proper sorting by name, the numeric part of output file names should have a fixed width. This can be achieved by adding leading zeros to the numeric part, with four digits likely being sufficient.
### Describe alternatives you've considered
I don't have any.
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
### Are you willing to resolve this issue by submitting a Pull Request?
- [X] Yes, I have the time, and I know how to start.
- [ ] Yes, I have the time, but I don't know how to start. I would need guidance.
- [ ] No, I don't have the time, although I believe I could do it if I had the time...
- [ ] No, I don't have the time and I wouldn't even know how to start.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py`
Content:
```
1 from __future__ import annotations
2
3 from collections import defaultdict
4 from logging import getLogger
5 from pathlib import Path
6
7 import librosa
8 import soundfile as sf
9 import torch
10 from joblib import Parallel, delayed
11 from pyannote.audio import Pipeline
12 from tqdm import tqdm
13 from tqdm_joblib import tqdm_joblib
14
15 LOG = getLogger(__name__)
16
17
18 def _process_one(
19 input_path: Path,
20 output_dir: Path,
21 sr: int,
22 *,
23 min_speakers: int = 1,
24 max_speakers: int = 1,
25 huggingface_token: str | None = None,
26 ) -> None:
27 try:
28 audio, sr = librosa.load(input_path, sr=sr, mono=True)
29 except Exception as e:
30 LOG.warning(f"Failed to read {input_path}: {e}")
31 return
32 pipeline = Pipeline.from_pretrained(
33 "pyannote/speaker-diarization", use_auth_token=huggingface_token
34 )
35 if pipeline is None:
36 raise ValueError("Failed to load pipeline")
37 pipeline = pipeline.to(torch.device("cuda"))
38 LOG.info(f"Processing {input_path}. This may take a while...")
39 diarization = pipeline(
40 input_path, min_speakers=min_speakers, max_speakers=max_speakers
41 )
42
43 LOG.info(f"Found {len(diarization)} tracks, writing to {output_dir}")
44 speaker_count = defaultdict(int)
45
46 output_dir.mkdir(parents=True, exist_ok=True)
47 for segment, track, speaker in tqdm(
48 list(diarization.itertracks(yield_label=True)), desc=f"Writing {input_path}"
49 ):
50 if segment.end - segment.start < 1:
51 continue
52 speaker_count[speaker] += 1
53 audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]
54 sf.write(
55 (output_dir / f"{speaker}_{speaker_count[speaker]}.wav"),
56 audio_cut,
57 sr,
58 )
59
60 LOG.info(f"Speaker count: {speaker_count}")
61
62
63 def preprocess_speaker_diarization(
64 input_dir: Path | str,
65 output_dir: Path | str,
66 sr: int,
67 *,
68 min_speakers: int = 1,
69 max_speakers: int = 1,
70 huggingface_token: str | None = None,
71 n_jobs: int = -1,
72 ) -> None:
73 if huggingface_token is not None and not huggingface_token.startswith("hf_"):
74 LOG.warning("Huggingface token probably should start with hf_")
75 if not torch.cuda.is_available():
76 LOG.warning("CUDA is not available. This will be extremely slow.")
77 input_dir = Path(input_dir)
78 output_dir = Path(output_dir)
79 input_dir.mkdir(parents=True, exist_ok=True)
80 output_dir.mkdir(parents=True, exist_ok=True)
81 input_paths = list(input_dir.rglob("*.*"))
82 with tqdm_joblib(desc="Preprocessing speaker diarization", total=len(input_paths)):
83 Parallel(n_jobs=n_jobs)(
84 delayed(_process_one)(
85 input_path,
86 output_dir / input_path.relative_to(input_dir).parent / input_path.stem,
87 sr,
88 max_speakers=max_speakers,
89 min_speakers=min_speakers,
90 huggingface_token=huggingface_token,
91 )
92 for input_path in input_paths
93 )
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
--- a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
+++ b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
@@ -52,7 +52,7 @@
speaker_count[speaker] += 1
audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]
sf.write(
- (output_dir / f"{speaker}_{speaker_count[speaker]}.wav"),
+ (output_dir / f"{speaker}_{speaker_count[speaker]:04d}.wav"),
audio_cut,
sr,
)
|
{"golden_diff": "diff --git a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py\n--- a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py\n+++ b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py\n@@ -52,7 +52,7 @@\n speaker_count[speaker] += 1\n audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]\n sf.write(\n- (output_dir / f\"{speaker}_{speaker_count[speaker]}.wav\"),\n+ (output_dir / f\"{speaker}_{speaker_count[speaker]:04d}.wav\"),\n audio_cut,\n sr,\n )\n", "issue": "Ensure proper sorting by name for output files\n### Is your feature request related to a problem? Please describe.\n\nTo enhance readability and ensure proper sorting by name, the numeric part of output file names should have a fixed width. This can be achieved by adding leading zeros to the numeric part, with four digits likely being sufficient.\n\n### Describe alternatives you've considered\n\nI don't have any.\n\n### Additional context\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n\n### Are you willing to resolve this issue by submitting a Pull Request?\n\n- [X] Yes, I have the time, and I know how to start.\n- [ ] Yes, I have the time, but I don't know how to start. I would need guidance.\n- [ ] No, I don't have the time, although I believe I could do it if I had the time...\n- [ ] No, I don't have the time and I wouldn't even know how to start.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom collections import defaultdict\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport librosa\nimport soundfile as sf\nimport torch\nfrom joblib import Parallel, delayed\nfrom pyannote.audio import Pipeline\nfrom tqdm import tqdm\nfrom tqdm_joblib import tqdm_joblib\n\nLOG = getLogger(__name__)\n\n\ndef _process_one(\n input_path: Path,\n output_dir: Path,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n) -> None:\n try:\n audio, sr = librosa.load(input_path, sr=sr, mono=True)\n except Exception as e:\n LOG.warning(f\"Failed to read {input_path}: {e}\")\n return\n pipeline = Pipeline.from_pretrained(\n \"pyannote/speaker-diarization\", use_auth_token=huggingface_token\n )\n if pipeline is None:\n raise ValueError(\"Failed to load pipeline\")\n pipeline = pipeline.to(torch.device(\"cuda\"))\n LOG.info(f\"Processing {input_path}. This may take a while...\")\n diarization = pipeline(\n input_path, min_speakers=min_speakers, max_speakers=max_speakers\n )\n\n LOG.info(f\"Found {len(diarization)} tracks, writing to {output_dir}\")\n speaker_count = defaultdict(int)\n\n output_dir.mkdir(parents=True, exist_ok=True)\n for segment, track, speaker in tqdm(\n list(diarization.itertracks(yield_label=True)), desc=f\"Writing {input_path}\"\n ):\n if segment.end - segment.start < 1:\n continue\n speaker_count[speaker] += 1\n audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]\n sf.write(\n (output_dir / f\"{speaker}_{speaker_count[speaker]}.wav\"),\n audio_cut,\n sr,\n )\n\n LOG.info(f\"Speaker count: {speaker_count}\")\n\n\ndef preprocess_speaker_diarization(\n input_dir: Path | str,\n output_dir: Path | str,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n n_jobs: int = -1,\n) -> None:\n if huggingface_token is not None and not huggingface_token.startswith(\"hf_\"):\n LOG.warning(\"Huggingface token probably should start with hf_\")\n if not torch.cuda.is_available():\n LOG.warning(\"CUDA is not available. This will be extremely slow.\")\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n input_dir.mkdir(parents=True, exist_ok=True)\n output_dir.mkdir(parents=True, exist_ok=True)\n input_paths = list(input_dir.rglob(\"*.*\"))\n with tqdm_joblib(desc=\"Preprocessing speaker diarization\", total=len(input_paths)):\n Parallel(n_jobs=n_jobs)(\n delayed(_process_one)(\n input_path,\n output_dir / input_path.relative_to(input_dir).parent / input_path.stem,\n sr,\n max_speakers=max_speakers,\n min_speakers=min_speakers,\n huggingface_token=huggingface_token,\n )\n for input_path in input_paths\n )\n", "path": "src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom collections import defaultdict\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport librosa\nimport soundfile as sf\nimport torch\nfrom joblib import Parallel, delayed\nfrom pyannote.audio import Pipeline\nfrom tqdm import tqdm\nfrom tqdm_joblib import tqdm_joblib\n\nLOG = getLogger(__name__)\n\n\ndef _process_one(\n input_path: Path,\n output_dir: Path,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n) -> None:\n try:\n audio, sr = librosa.load(input_path, sr=sr, mono=True)\n except Exception as e:\n LOG.warning(f\"Failed to read {input_path}: {e}\")\n return\n pipeline = Pipeline.from_pretrained(\n \"pyannote/speaker-diarization\", use_auth_token=huggingface_token\n )\n if pipeline is None:\n raise ValueError(\"Failed to load pipeline\")\n pipeline = pipeline.to(torch.device(\"cuda\"))\n LOG.info(f\"Processing {input_path}. This may take a while...\")\n diarization = pipeline(\n input_path, min_speakers=min_speakers, max_speakers=max_speakers\n )\n\n LOG.info(f\"Found {len(diarization)} tracks, writing to {output_dir}\")\n speaker_count = defaultdict(int)\n\n output_dir.mkdir(parents=True, exist_ok=True)\n for segment, track, speaker in tqdm(\n list(diarization.itertracks(yield_label=True)), desc=f\"Writing {input_path}\"\n ):\n if segment.end - segment.start < 1:\n continue\n speaker_count[speaker] += 1\n audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]\n sf.write(\n (output_dir / f\"{speaker}_{speaker_count[speaker]:04d}.wav\"),\n audio_cut,\n sr,\n )\n\n LOG.info(f\"Speaker count: {speaker_count}\")\n\n\ndef preprocess_speaker_diarization(\n input_dir: Path | str,\n output_dir: Path | str,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n n_jobs: int = -1,\n) -> None:\n if huggingface_token is not None and not huggingface_token.startswith(\"hf_\"):\n LOG.warning(\"Huggingface token probably should start with hf_\")\n if not torch.cuda.is_available():\n LOG.warning(\"CUDA is not available. This will be extremely slow.\")\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n input_dir.mkdir(parents=True, exist_ok=True)\n output_dir.mkdir(parents=True, exist_ok=True)\n input_paths = list(input_dir.rglob(\"*.*\"))\n with tqdm_joblib(desc=\"Preprocessing speaker diarization\", total=len(input_paths)):\n Parallel(n_jobs=n_jobs)(\n delayed(_process_one)(\n input_path,\n output_dir / input_path.relative_to(input_dir).parent / input_path.stem,\n sr,\n max_speakers=max_speakers,\n min_speakers=min_speakers,\n huggingface_token=huggingface_token,\n )\n for input_path in input_paths\n )\n", "path": "src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py"}]}
| 1,388 | 176 |
gh_patches_debug_12304
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-635
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Switching from signup method with requested state to one w/o breaks disposition
```
2021-12-03 14:39:00,166 DEBG 'uwsgi' stderr output:
Traceback (most recent call last):
File "/home/juhsp/.local/lib/python3.8/site-packages/django/core/handlers/exception.py", line 47, in inner
2021-12-03 14:39:00,167 DEBG 'uwsgi' stderr output:
response = get_response(request)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/core/handlers/base.py", line 181, in _get_response
2021-12-03 14:39:00,168 DEBG 'uwsgi' stderr output:
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/views/generic/base.py", line 70, in view
2021-12-03 14:39:00,168 DEBG 'uwsgi' stderr output:
return self.dispatch(request, *args, **kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py", line 118, in dispatch
2021-12-03 14:39:00,169 DEBG 'uwsgi' stderr output:
return super().dispatch(request, *args, **kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/contrib/auth/mixins.py", line 104, in dispatch
2021-12-03 14:39:00,169 DEBG 'uwsgi' stderr output:
return super().dispatch(request, *args, **kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/views/generic/base.py", line 98, in dispatch
return handler(request, *args, **kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py", line 224, in post
2021-12-03 14:39:00,170 DEBG 'uwsgi' stderr output:
if not formset.is_valid():
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 321, in is_valid
2021-12-03 14:39:00,171 DEBG 'uwsgi' stderr output:
self.errors
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 304, in errors
2021-12-03 14:39:00,171 DEBG 'uwsgi' stderr output:
self.full_clean()
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 355, in full_clean
2021-12-03 14:39:00,172 DEBG 'uwsgi' stderr output:
for i, form in enumerate(self.forms):
File "/home/juhsp/.local/lib/python3.8/site-packages/django/utils/functional.py", line 48, in __get__
2021-12-03 14:39:00,172 DEBG 'uwsgi' stderr output:
res = instance.__dict__[self.name] = self.func(instance)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 155, in forms
return [
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 156, in <listcomp>
2021-12-03 14:39:00,175 DEBG 'uwsgi' stderr output:
self._construct_form(i, **self.get_form_kwargs(i))
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/models.py", line 632, in _construct_form
form = super()._construct_form(i, **kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py", line 193, in _construct_form
form = self.form(**defaults)
File "/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py", line 31, in __init__
super().__init__(**kwargs)
File "/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/methods.py", line 141, in __init__
instance = kwargs["instance"]
KeyError: 'instance'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ephios/core/signup/disposition.py`
Content:
```
1 from django import forms
2 from django.http import Http404
3 from django.shortcuts import redirect
4 from django.utils.translation import gettext_lazy as _
5 from django.views import View
6 from django.views.generic import TemplateView
7 from django.views.generic.base import TemplateResponseMixin
8 from django.views.generic.detail import SingleObjectMixin
9 from django_select2.forms import ModelSelect2Widget
10
11 from ephios.core.models import (
12 AbstractParticipation,
13 LocalParticipation,
14 Qualification,
15 Shift,
16 UserProfile,
17 )
18 from ephios.core.services.notifications.types import (
19 ParticipationConfirmedNotification,
20 ParticipationCustomizationNotification,
21 ParticipationRejectedNotification,
22 )
23 from ephios.core.signup.methods import BaseParticipationForm
24 from ephios.extra.mixins import CustomPermissionRequiredMixin
25
26
27 class BaseDispositionParticipationForm(BaseParticipationForm):
28 disposition_participation_template = "core/disposition/fragment_participation.html"
29
30 def __init__(self, **kwargs):
31 super().__init__(**kwargs)
32 self.can_delete = self.instance.state == AbstractParticipation.States.GETTING_DISPATCHED
33 self.fields["comment"].disabled = True
34 try:
35 self.shift = self.instance.shift
36 except AttributeError as e:
37 raise ValueError(f"{type(self)} must be initialized with an instance.") from e
38
39 class Meta(BaseParticipationForm.Meta):
40 fields = ["state", "individual_start_time", "individual_end_time", "comment"]
41 widgets = dict(state=forms.HiddenInput(attrs={"class": "state-input"}))
42
43
44 class DispositionBaseModelFormset(forms.BaseModelFormSet):
45 """
46 To allow us to dynamically add server-side rendered forms to a formset
47 we patch a way to change the starting index.
48 """
49
50 def __init__(self, *args, start_index=0, **kwargs):
51 self._start_index = start_index
52 super().__init__(*args, **kwargs)
53
54 def add_prefix(self, index):
55 return f"{self.prefix}-{self._start_index + index}"
56
57 def save_existing(self, form, instance, commit=True):
58 """Existing participation state overwrites the getting dispatched state."""
59 if form.instance.state == AbstractParticipation.States.GETTING_DISPATCHED:
60 form.instance.state = AbstractParticipation.objects.get(id=form.instance.id).state
61 return form.save(commit=commit)
62
63
64 def get_disposition_formset(form):
65 return forms.modelformset_factory(
66 model=AbstractParticipation,
67 formset=DispositionBaseModelFormset,
68 form=form,
69 extra=0,
70 can_order=False,
71 can_delete=True,
72 )
73
74
75 def addable_users(shift):
76 """
77 Return queryset of user objects that can be added to the shift.
78 This also includes users that already have a participation, as that might have gotten removed in JS.
79
80 This also includes users that can normally not see the event. The permission will be added accordingly.
81 If needed, this method could be moved to signup methods.
82 """
83 return UserProfile.objects.all()
84
85
86 class AddUserForm(forms.Form):
87 user = forms.ModelChoiceField(
88 widget=ModelSelect2Widget(
89 model=UserProfile,
90 search_fields=["first_name__icontains", "last_name__icontains"],
91 attrs={
92 "form": "add-user-form",
93 "data-placeholder": _("search"),
94 "data-tags": "true",
95 "data-token-separators": [],
96 },
97 ),
98 queryset=UserProfile.objects.none(), # set using __init__
99 )
100 new_index = forms.IntegerField(widget=forms.HiddenInput)
101
102 def __init__(self, user_queryset, *args, **kwargs):
103 super().__init__(*args, **kwargs)
104 self.fields["user"].queryset = user_queryset
105
106
107 class DispositionBaseViewMixin(CustomPermissionRequiredMixin, SingleObjectMixin):
108 permission_required = "core.change_event"
109 model = Shift
110
111 def setup(self, request, *args, **kwargs):
112 super().setup(request, *args, **kwargs)
113 self.object: Shift = self.get_object()
114
115 def dispatch(self, request, *args, **kwargs):
116 if self.object.signup_method.disposition_participation_form_class is None:
117 raise Http404(_("This signup method does not support disposition."))
118 return super().dispatch(request, *args, **kwargs)
119
120 def get_permission_object(self):
121 return self.object.event
122
123
124 class AddUserView(DispositionBaseViewMixin, TemplateResponseMixin, View):
125 def get_template_names(self):
126 return [
127 self.object.signup_method.disposition_participation_form_class.disposition_participation_template
128 ]
129
130 def post(self, request, *args, **kwargs):
131 shift = self.object
132 form = AddUserForm(
133 data=request.POST,
134 user_queryset=addable_users(shift),
135 )
136 if form.is_valid():
137 user: UserProfile = form.cleaned_data["user"]
138 instance = shift.signup_method.get_participation_for(user.as_participant())
139 instance.state = AbstractParticipation.States.GETTING_DISPATCHED
140 instance.save()
141
142 DispositionParticipationFormset = get_disposition_formset(
143 self.object.signup_method.disposition_participation_form_class
144 )
145 formset = DispositionParticipationFormset(
146 queryset=AbstractParticipation.objects.filter(pk=instance.pk),
147 prefix="participations",
148 start_index=form.cleaned_data["new_index"],
149 )
150 form = next(filter(lambda form: form.instance.id == instance.id, formset))
151 return self.render_to_response({"form": form, "shift": shift})
152 raise Http404()
153
154
155 class AddPlaceholderParticipantView(DispositionBaseViewMixin, TemplateResponseMixin, View):
156 def get_template_names(self):
157 return [
158 self.object.signup_method.disposition_participation_form_class.disposition_participation_template
159 ]
160
161 def post(self, request, *args, **kwargs):
162 shift = self.object
163 from ephios.core.signup.participants import PlaceholderParticipant
164
165 participant = PlaceholderParticipant(
166 first_name=request.POST["first_name"],
167 last_name=request.POST["last_name"],
168 qualifications=Qualification.objects.none(),
169 email=None,
170 date_of_birth=None,
171 )
172 instance = shift.signup_method.get_participation_for(participant)
173 instance.state = AbstractParticipation.States.GETTING_DISPATCHED
174 instance.save()
175
176 DispositionParticipationFormset = get_disposition_formset(
177 self.object.signup_method.disposition_participation_form_class
178 )
179 formset = DispositionParticipationFormset(
180 queryset=AbstractParticipation.objects.filter(pk=instance.pk),
181 prefix="participations",
182 start_index=int(request.POST["new_index"]),
183 )
184 form = next(filter(lambda form: form.instance.id == instance.id, formset))
185 return self.render_to_response({"form": form, "shift": shift})
186
187
188 class DispositionView(DispositionBaseViewMixin, TemplateView):
189 template_name = "core/disposition/disposition.html"
190
191 def get_formset(self):
192 DispositionParticipationFormset = get_disposition_formset(
193 self.object.signup_method.disposition_participation_form_class
194 )
195 formset = DispositionParticipationFormset(
196 self.request.POST or None,
197 queryset=self.object.participations.all(),
198 prefix="participations",
199 )
200 return formset
201
202 def _send_participant_notifications(self, formset):
203 for participation, changed_fields in formset.changed_objects:
204 if (
205 participation.get_real_instance_class() != LocalParticipation
206 or participation.user != self.request.user
207 ):
208 if "state" in changed_fields:
209 # send state updates
210 if participation.state == AbstractParticipation.States.CONFIRMED:
211 ParticipationConfirmedNotification.send(participation)
212 elif participation.state == AbstractParticipation.States.RESPONSIBLE_REJECTED:
213 ParticipationRejectedNotification.send(participation)
214 elif participation.state == AbstractParticipation.States.CONFIRMED:
215 form: BaseParticipationForm = next(
216 filter(lambda f, p=participation: f.instance == p, formset.forms)
217 )
218 if claims := form.get_customization_notification_info():
219 # If state didn't change, but confirmed participation was customized, notify about that.
220 ParticipationCustomizationNotification.send(participation, claims)
221
222 def post(self, request, *args, **kwargs):
223 formset = self.get_formset()
224 if not formset.is_valid():
225 return self.get(request, *args, **kwargs, formset=formset)
226
227 formset.save()
228 self._send_participant_notifications(formset)
229
230 self.object.participations.filter(
231 state=AbstractParticipation.States.GETTING_DISPATCHED
232 ).non_polymorphic().delete()
233 return redirect(self.object.event.get_absolute_url())
234
235 def get_context_data(self, **kwargs):
236 kwargs.setdefault("formset", self.get_formset())
237 kwargs.setdefault("states", AbstractParticipation.States)
238 kwargs.setdefault(
239 "participant_template",
240 self.object.signup_method.disposition_participation_form_class.disposition_participation_template,
241 )
242 kwargs.setdefault(
243 "add_user_form",
244 AddUserForm(user_queryset=addable_users(self.object)),
245 )
246 return super().get_context_data(**kwargs)
247
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ephios/core/signup/disposition.py b/ephios/core/signup/disposition.py
--- a/ephios/core/signup/disposition.py
+++ b/ephios/core/signup/disposition.py
@@ -239,6 +239,13 @@
"participant_template",
self.object.signup_method.disposition_participation_form_class.disposition_participation_template,
)
+ kwargs.setdefault(
+ "render_requested_state",
+ self.object.signup_method.uses_requested_state
+ or self.object.participations.filter(
+ state=AbstractParticipation.States.REQUESTED
+ ).exists(),
+ )
kwargs.setdefault(
"add_user_form",
AddUserForm(user_queryset=addable_users(self.object)),
|
{"golden_diff": "diff --git a/ephios/core/signup/disposition.py b/ephios/core/signup/disposition.py\n--- a/ephios/core/signup/disposition.py\n+++ b/ephios/core/signup/disposition.py\n@@ -239,6 +239,13 @@\n \"participant_template\",\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template,\n )\n+ kwargs.setdefault(\n+ \"render_requested_state\",\n+ self.object.signup_method.uses_requested_state\n+ or self.object.participations.filter(\n+ state=AbstractParticipation.States.REQUESTED\n+ ).exists(),\n+ )\n kwargs.setdefault(\n \"add_user_form\",\n AddUserForm(user_queryset=addable_users(self.object)),\n", "issue": "Switching from signup method with requested state to one w/o breaks disposition\n```\r\n\r\n2021-12-03 14:39:00,166 DEBG 'uwsgi' stderr output:\r\nTraceback (most recent call last):\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/core/handlers/exception.py\", line 47, in inner\r\n\r\n2021-12-03 14:39:00,167 DEBG 'uwsgi' stderr output:\r\n response = get_response(request)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/core/handlers/base.py\", line 181, in _get_response\r\n\r\n2021-12-03 14:39:00,168 DEBG 'uwsgi' stderr output:\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/views/generic/base.py\", line 70, in view\r\n\r\n2021-12-03 14:39:00,168 DEBG 'uwsgi' stderr output:\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py\", line 118, in dispatch\r\n\r\n2021-12-03 14:39:00,169 DEBG 'uwsgi' stderr output:\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/contrib/auth/mixins.py\", line 104, in dispatch\r\n\r\n2021-12-03 14:39:00,169 DEBG 'uwsgi' stderr output:\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/views/generic/base.py\", line 98, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py\", line 224, in post\r\n\r\n2021-12-03 14:39:00,170 DEBG 'uwsgi' stderr output:\r\n if not formset.is_valid():\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 321, in is_valid\r\n\r\n2021-12-03 14:39:00,171 DEBG 'uwsgi' stderr output:\r\n self.errors\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 304, in errors\r\n\r\n2021-12-03 14:39:00,171 DEBG 'uwsgi' stderr output:\r\n self.full_clean()\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 355, in full_clean\r\n\r\n2021-12-03 14:39:00,172 DEBG 'uwsgi' stderr output:\r\n for i, form in enumerate(self.forms):\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/utils/functional.py\", line 48, in __get__\r\n\r\n2021-12-03 14:39:00,172 DEBG 'uwsgi' stderr output:\r\n res = instance.__dict__[self.name] = self.func(instance)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 155, in forms\r\n return [\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 156, in <listcomp>\r\n\r\n2021-12-03 14:39:00,175 DEBG 'uwsgi' stderr output:\r\n self._construct_form(i, **self.get_form_kwargs(i))\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/models.py\", line 632, in _construct_form\r\n form = super()._construct_form(i, **kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/django/forms/formsets.py\", line 193, in _construct_form\r\n form = self.form(**defaults)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/disposition.py\", line 31, in __init__\r\n super().__init__(**kwargs)\r\n File \"/home/juhsp/.local/lib/python3.8/site-packages/ephios/core/signup/methods.py\", line 141, in __init__\r\n instance = kwargs[\"instance\"]\r\nKeyError: 'instance'\r\n\r\n```\n", "before_files": [{"content": "from django import forms\nfrom django.http import Http404\nfrom django.shortcuts import redirect\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\nfrom django.views.generic import TemplateView\nfrom django.views.generic.base import TemplateResponseMixin\nfrom django.views.generic.detail import SingleObjectMixin\nfrom django_select2.forms import ModelSelect2Widget\n\nfrom ephios.core.models import (\n AbstractParticipation,\n LocalParticipation,\n Qualification,\n Shift,\n UserProfile,\n)\nfrom ephios.core.services.notifications.types import (\n ParticipationConfirmedNotification,\n ParticipationCustomizationNotification,\n ParticipationRejectedNotification,\n)\nfrom ephios.core.signup.methods import BaseParticipationForm\nfrom ephios.extra.mixins import CustomPermissionRequiredMixin\n\n\nclass BaseDispositionParticipationForm(BaseParticipationForm):\n disposition_participation_template = \"core/disposition/fragment_participation.html\"\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.can_delete = self.instance.state == AbstractParticipation.States.GETTING_DISPATCHED\n self.fields[\"comment\"].disabled = True\n try:\n self.shift = self.instance.shift\n except AttributeError as e:\n raise ValueError(f\"{type(self)} must be initialized with an instance.\") from e\n\n class Meta(BaseParticipationForm.Meta):\n fields = [\"state\", \"individual_start_time\", \"individual_end_time\", \"comment\"]\n widgets = dict(state=forms.HiddenInput(attrs={\"class\": \"state-input\"}))\n\n\nclass DispositionBaseModelFormset(forms.BaseModelFormSet):\n \"\"\"\n To allow us to dynamically add server-side rendered forms to a formset\n we patch a way to change the starting index.\n \"\"\"\n\n def __init__(self, *args, start_index=0, **kwargs):\n self._start_index = start_index\n super().__init__(*args, **kwargs)\n\n def add_prefix(self, index):\n return f\"{self.prefix}-{self._start_index + index}\"\n\n def save_existing(self, form, instance, commit=True):\n \"\"\"Existing participation state overwrites the getting dispatched state.\"\"\"\n if form.instance.state == AbstractParticipation.States.GETTING_DISPATCHED:\n form.instance.state = AbstractParticipation.objects.get(id=form.instance.id).state\n return form.save(commit=commit)\n\n\ndef get_disposition_formset(form):\n return forms.modelformset_factory(\n model=AbstractParticipation,\n formset=DispositionBaseModelFormset,\n form=form,\n extra=0,\n can_order=False,\n can_delete=True,\n )\n\n\ndef addable_users(shift):\n \"\"\"\n Return queryset of user objects that can be added to the shift.\n This also includes users that already have a participation, as that might have gotten removed in JS.\n\n This also includes users that can normally not see the event. The permission will be added accordingly.\n If needed, this method could be moved to signup methods.\n \"\"\"\n return UserProfile.objects.all()\n\n\nclass AddUserForm(forms.Form):\n user = forms.ModelChoiceField(\n widget=ModelSelect2Widget(\n model=UserProfile,\n search_fields=[\"first_name__icontains\", \"last_name__icontains\"],\n attrs={\n \"form\": \"add-user-form\",\n \"data-placeholder\": _(\"search\"),\n \"data-tags\": \"true\",\n \"data-token-separators\": [],\n },\n ),\n queryset=UserProfile.objects.none(), # set using __init__\n )\n new_index = forms.IntegerField(widget=forms.HiddenInput)\n\n def __init__(self, user_queryset, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"user\"].queryset = user_queryset\n\n\nclass DispositionBaseViewMixin(CustomPermissionRequiredMixin, SingleObjectMixin):\n permission_required = \"core.change_event\"\n model = Shift\n\n def setup(self, request, *args, **kwargs):\n super().setup(request, *args, **kwargs)\n self.object: Shift = self.get_object()\n\n def dispatch(self, request, *args, **kwargs):\n if self.object.signup_method.disposition_participation_form_class is None:\n raise Http404(_(\"This signup method does not support disposition.\"))\n return super().dispatch(request, *args, **kwargs)\n\n def get_permission_object(self):\n return self.object.event\n\n\nclass AddUserView(DispositionBaseViewMixin, TemplateResponseMixin, View):\n def get_template_names(self):\n return [\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template\n ]\n\n def post(self, request, *args, **kwargs):\n shift = self.object\n form = AddUserForm(\n data=request.POST,\n user_queryset=addable_users(shift),\n )\n if form.is_valid():\n user: UserProfile = form.cleaned_data[\"user\"]\n instance = shift.signup_method.get_participation_for(user.as_participant())\n instance.state = AbstractParticipation.States.GETTING_DISPATCHED\n instance.save()\n\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n queryset=AbstractParticipation.objects.filter(pk=instance.pk),\n prefix=\"participations\",\n start_index=form.cleaned_data[\"new_index\"],\n )\n form = next(filter(lambda form: form.instance.id == instance.id, formset))\n return self.render_to_response({\"form\": form, \"shift\": shift})\n raise Http404()\n\n\nclass AddPlaceholderParticipantView(DispositionBaseViewMixin, TemplateResponseMixin, View):\n def get_template_names(self):\n return [\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template\n ]\n\n def post(self, request, *args, **kwargs):\n shift = self.object\n from ephios.core.signup.participants import PlaceholderParticipant\n\n participant = PlaceholderParticipant(\n first_name=request.POST[\"first_name\"],\n last_name=request.POST[\"last_name\"],\n qualifications=Qualification.objects.none(),\n email=None,\n date_of_birth=None,\n )\n instance = shift.signup_method.get_participation_for(participant)\n instance.state = AbstractParticipation.States.GETTING_DISPATCHED\n instance.save()\n\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n queryset=AbstractParticipation.objects.filter(pk=instance.pk),\n prefix=\"participations\",\n start_index=int(request.POST[\"new_index\"]),\n )\n form = next(filter(lambda form: form.instance.id == instance.id, formset))\n return self.render_to_response({\"form\": form, \"shift\": shift})\n\n\nclass DispositionView(DispositionBaseViewMixin, TemplateView):\n template_name = \"core/disposition/disposition.html\"\n\n def get_formset(self):\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n self.request.POST or None,\n queryset=self.object.participations.all(),\n prefix=\"participations\",\n )\n return formset\n\n def _send_participant_notifications(self, formset):\n for participation, changed_fields in formset.changed_objects:\n if (\n participation.get_real_instance_class() != LocalParticipation\n or participation.user != self.request.user\n ):\n if \"state\" in changed_fields:\n # send state updates\n if participation.state == AbstractParticipation.States.CONFIRMED:\n ParticipationConfirmedNotification.send(participation)\n elif participation.state == AbstractParticipation.States.RESPONSIBLE_REJECTED:\n ParticipationRejectedNotification.send(participation)\n elif participation.state == AbstractParticipation.States.CONFIRMED:\n form: BaseParticipationForm = next(\n filter(lambda f, p=participation: f.instance == p, formset.forms)\n )\n if claims := form.get_customization_notification_info():\n # If state didn't change, but confirmed participation was customized, notify about that.\n ParticipationCustomizationNotification.send(participation, claims)\n\n def post(self, request, *args, **kwargs):\n formset = self.get_formset()\n if not formset.is_valid():\n return self.get(request, *args, **kwargs, formset=formset)\n\n formset.save()\n self._send_participant_notifications(formset)\n\n self.object.participations.filter(\n state=AbstractParticipation.States.GETTING_DISPATCHED\n ).non_polymorphic().delete()\n return redirect(self.object.event.get_absolute_url())\n\n def get_context_data(self, **kwargs):\n kwargs.setdefault(\"formset\", self.get_formset())\n kwargs.setdefault(\"states\", AbstractParticipation.States)\n kwargs.setdefault(\n \"participant_template\",\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template,\n )\n kwargs.setdefault(\n \"add_user_form\",\n AddUserForm(user_queryset=addable_users(self.object)),\n )\n return super().get_context_data(**kwargs)\n", "path": "ephios/core/signup/disposition.py"}], "after_files": [{"content": "from django import forms\nfrom django.http import Http404\nfrom django.shortcuts import redirect\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\nfrom django.views.generic import TemplateView\nfrom django.views.generic.base import TemplateResponseMixin\nfrom django.views.generic.detail import SingleObjectMixin\nfrom django_select2.forms import ModelSelect2Widget\n\nfrom ephios.core.models import (\n AbstractParticipation,\n LocalParticipation,\n Qualification,\n Shift,\n UserProfile,\n)\nfrom ephios.core.services.notifications.types import (\n ParticipationConfirmedNotification,\n ParticipationCustomizationNotification,\n ParticipationRejectedNotification,\n)\nfrom ephios.core.signup.methods import BaseParticipationForm\nfrom ephios.extra.mixins import CustomPermissionRequiredMixin\n\n\nclass BaseDispositionParticipationForm(BaseParticipationForm):\n disposition_participation_template = \"core/disposition/fragment_participation.html\"\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.can_delete = self.instance.state == AbstractParticipation.States.GETTING_DISPATCHED\n self.fields[\"comment\"].disabled = True\n try:\n self.shift = self.instance.shift\n except AttributeError as e:\n raise ValueError(f\"{type(self)} must be initialized with an instance.\") from e\n\n class Meta(BaseParticipationForm.Meta):\n fields = [\"state\", \"individual_start_time\", \"individual_end_time\", \"comment\"]\n widgets = dict(state=forms.HiddenInput(attrs={\"class\": \"state-input\"}))\n\n\nclass DispositionBaseModelFormset(forms.BaseModelFormSet):\n \"\"\"\n To allow us to dynamically add server-side rendered forms to a formset\n we patch a way to change the starting index.\n \"\"\"\n\n def __init__(self, *args, start_index=0, **kwargs):\n self._start_index = start_index\n super().__init__(*args, **kwargs)\n\n def add_prefix(self, index):\n return f\"{self.prefix}-{self._start_index + index}\"\n\n def save_existing(self, form, instance, commit=True):\n \"\"\"Existing participation state overwrites the getting dispatched state.\"\"\"\n if form.instance.state == AbstractParticipation.States.GETTING_DISPATCHED:\n form.instance.state = AbstractParticipation.objects.get(id=form.instance.id).state\n return form.save(commit=commit)\n\n\ndef get_disposition_formset(form):\n return forms.modelformset_factory(\n model=AbstractParticipation,\n formset=DispositionBaseModelFormset,\n form=form,\n extra=0,\n can_order=False,\n can_delete=True,\n )\n\n\ndef addable_users(shift):\n \"\"\"\n Return queryset of user objects that can be added to the shift.\n This also includes users that already have a participation, as that might have gotten removed in JS.\n\n This also includes users that can normally not see the event. The permission will be added accordingly.\n If needed, this method could be moved to signup methods.\n \"\"\"\n return UserProfile.objects.all()\n\n\nclass AddUserForm(forms.Form):\n user = forms.ModelChoiceField(\n widget=ModelSelect2Widget(\n model=UserProfile,\n search_fields=[\"first_name__icontains\", \"last_name__icontains\"],\n attrs={\n \"form\": \"add-user-form\",\n \"data-placeholder\": _(\"search\"),\n \"data-tags\": \"true\",\n \"data-token-separators\": [],\n },\n ),\n queryset=UserProfile.objects.none(), # set using __init__\n )\n new_index = forms.IntegerField(widget=forms.HiddenInput)\n\n def __init__(self, user_queryset, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"user\"].queryset = user_queryset\n\n\nclass DispositionBaseViewMixin(CustomPermissionRequiredMixin, SingleObjectMixin):\n permission_required = \"core.change_event\"\n model = Shift\n\n def setup(self, request, *args, **kwargs):\n super().setup(request, *args, **kwargs)\n self.object: Shift = self.get_object()\n\n def dispatch(self, request, *args, **kwargs):\n if self.object.signup_method.disposition_participation_form_class is None:\n raise Http404(_(\"This signup method does not support disposition.\"))\n return super().dispatch(request, *args, **kwargs)\n\n def get_permission_object(self):\n return self.object.event\n\n\nclass AddUserView(DispositionBaseViewMixin, TemplateResponseMixin, View):\n def get_template_names(self):\n return [\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template\n ]\n\n def post(self, request, *args, **kwargs):\n shift = self.object\n form = AddUserForm(\n data=request.POST,\n user_queryset=addable_users(shift),\n )\n if form.is_valid():\n user: UserProfile = form.cleaned_data[\"user\"]\n instance = shift.signup_method.get_participation_for(user.as_participant())\n instance.state = AbstractParticipation.States.GETTING_DISPATCHED\n instance.save()\n\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n queryset=AbstractParticipation.objects.filter(pk=instance.pk),\n prefix=\"participations\",\n start_index=form.cleaned_data[\"new_index\"],\n )\n form = next(filter(lambda form: form.instance.id == instance.id, formset))\n return self.render_to_response({\"form\": form, \"shift\": shift})\n raise Http404()\n\n\nclass AddPlaceholderParticipantView(DispositionBaseViewMixin, TemplateResponseMixin, View):\n def get_template_names(self):\n return [\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template\n ]\n\n def post(self, request, *args, **kwargs):\n shift = self.object\n from ephios.core.signup.participants import PlaceholderParticipant\n\n participant = PlaceholderParticipant(\n first_name=request.POST[\"first_name\"],\n last_name=request.POST[\"last_name\"],\n qualifications=Qualification.objects.none(),\n email=None,\n date_of_birth=None,\n )\n instance = shift.signup_method.get_participation_for(participant)\n instance.state = AbstractParticipation.States.GETTING_DISPATCHED\n instance.save()\n\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n queryset=AbstractParticipation.objects.filter(pk=instance.pk),\n prefix=\"participations\",\n start_index=int(request.POST[\"new_index\"]),\n )\n form = next(filter(lambda form: form.instance.id == instance.id, formset))\n return self.render_to_response({\"form\": form, \"shift\": shift})\n\n\nclass DispositionView(DispositionBaseViewMixin, TemplateView):\n template_name = \"core/disposition/disposition.html\"\n\n def get_formset(self):\n DispositionParticipationFormset = get_disposition_formset(\n self.object.signup_method.disposition_participation_form_class\n )\n formset = DispositionParticipationFormset(\n self.request.POST or None,\n queryset=self.object.participations.all(),\n prefix=\"participations\",\n )\n return formset\n\n def _send_participant_notifications(self, formset):\n for participation, changed_fields in formset.changed_objects:\n if (\n participation.get_real_instance_class() != LocalParticipation\n or participation.user != self.request.user\n ):\n if \"state\" in changed_fields:\n # send state updates\n if participation.state == AbstractParticipation.States.CONFIRMED:\n ParticipationConfirmedNotification.send(participation)\n elif participation.state == AbstractParticipation.States.RESPONSIBLE_REJECTED:\n ParticipationRejectedNotification.send(participation)\n elif participation.state == AbstractParticipation.States.CONFIRMED:\n form: BaseParticipationForm = next(\n filter(lambda f, p=participation: f.instance == p, formset.forms)\n )\n if claims := form.get_customization_notification_info():\n # If state didn't change, but confirmed participation was customized, notify about that.\n ParticipationCustomizationNotification.send(participation, claims)\n\n def post(self, request, *args, **kwargs):\n formset = self.get_formset()\n if not formset.is_valid():\n return self.get(request, *args, **kwargs, formset=formset)\n\n formset.save()\n self._send_participant_notifications(formset)\n\n self.object.participations.filter(\n state=AbstractParticipation.States.GETTING_DISPATCHED\n ).non_polymorphic().delete()\n return redirect(self.object.event.get_absolute_url())\n\n def get_context_data(self, **kwargs):\n kwargs.setdefault(\"formset\", self.get_formset())\n kwargs.setdefault(\"states\", AbstractParticipation.States)\n kwargs.setdefault(\n \"participant_template\",\n self.object.signup_method.disposition_participation_form_class.disposition_participation_template,\n )\n kwargs.setdefault(\n \"render_requested_state\",\n self.object.signup_method.uses_requested_state\n or self.object.participations.filter(\n state=AbstractParticipation.States.REQUESTED\n ).exists(),\n )\n kwargs.setdefault(\n \"add_user_form\",\n AddUserForm(user_queryset=addable_users(self.object)),\n )\n return super().get_context_data(**kwargs)\n", "path": "ephios/core/signup/disposition.py"}]}
| 3,989 | 158 |
gh_patches_debug_30960
|
rasdani/github-patches
|
git_diff
|
spack__spack-7852
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PMIx build fails on aarch64
PMIx up through version 2.1.0 has a bug in its test code that causes problems on strict alignment architectures like aarch64. (The issue is explained in this commit: pmix/pmix@3a8bc4503a04158e3be072c92eb0253c6c77e534) The fix is included in the 2.1.1 release. The issue is exacerbated by building with optimizations turned on (which Spack does by default); it doesn't seem to happen when compiling with ```-O0```.
Since the issue is in test code, the work-around is to just not build that code.
### Expected Result
The install should work.
### Actual Result
The install fails attempting to link pmix_test.
### Steps to reproduce the issue
On an aarch64 machine:
```console
$ spack install -j 56 pmix %[email protected]
```
### Information on your system
1. HPE (pre-production) Apache servers (w/ Cavium ThunderX2 CPU's)
1. RHEL 7.4
1. GCC 7.3.0 (built by Spack) and GCC 4.8.5 (RHEL 7 default version)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/pmix/package.py`
Content:
```
1 ##############################################################################
2 # Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/spack/spack
10 # Please also see the NOTICE and LICENSE files for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25
26 from spack import *
27
28
29 class Pmix(AutotoolsPackage):
30 """The Process Management Interface (PMI) has been used for quite some time
31 as a means of exchanging wireup information needed for interprocess
32 communication. Two versions (PMI-1 and PMI-2) have been released as part
33 of the MPICH effort. While PMI-2 demonstrates better scaling properties
34 than its PMI-1 predecessor, attaining rapid launch and wireup of the
35 roughly 1M processes executing across 100k nodes expected for exascale
36 operations remains challenging. PMI Exascale (PMIx) represents an
37 attempt to resolve these questions by providing an extended version
38 of the PMI definitions specifically designed to support clusters up
39 to and including exascale sizes. The overall objective of the project
40 is not to branch the existing definitions - in fact, PMIx fully
41 supports both of the existing PMI-1 and PMI-2 APIs - but rather to
42 (a) augment and extend those APIs to eliminate some current restrictions
43 that impact scalability, (b) establish a standards-like body for
44 maintaining the definitions, and (c) provide a reference implementation
45 of the PMIx standard that demonstrates the desired level of
46 scalability."""
47
48 homepage = "https://pmix.github.io/pmix"
49 url = "https://github.com/pmix/pmix/releases/download/v2.0.1/pmix-2.0.1.tar.bz2"
50
51 version('2.1.0', 'fc97513b601d78fe7c6bb20c6a21df3c')
52 version('2.0.2', 'e3ed1deed87c84f9b43da2621c6ad689')
53 version('2.0.1', 'ba3193b485843516e6b4e8641e443b1e')
54 version('2.0.0', '3e047c2ea0ba8ee9925ed92b205fd92e')
55 version('1.2.4', '242a812e206e7c5948f1f5c9688eb2a7')
56 version('1.2.3', '102b1cc650018b62348b45d572b158e9')
57 version('1.2.2', 'd85c8fd437bd88f984549425ad369e9f')
58 version('1.2.1', 'f090f524681c52001ea2db3b0285596f')
59 version('1.2.0', '6a42472d5a32e1c31ce5da19d50fc21a')
60
61 depends_on('libevent')
62
63 def configure_args(self):
64 spec = self.spec
65 config_args = [
66 '--enable-shared',
67 '--enable-static'
68 ]
69
70 # external libevent support (needed to keep Open MPI happy)
71 config_args.append(
72 '--with-libevent={0}'.format(spec['libevent'].prefix))
73
74 return config_args
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/pmix/package.py b/var/spack/repos/builtin/packages/pmix/package.py
--- a/var/spack/repos/builtin/packages/pmix/package.py
+++ b/var/spack/repos/builtin/packages/pmix/package.py
@@ -24,6 +24,7 @@
##############################################################################
from spack import *
+import spack.architecture
class Pmix(AutotoolsPackage):
@@ -48,6 +49,7 @@
homepage = "https://pmix.github.io/pmix"
url = "https://github.com/pmix/pmix/releases/download/v2.0.1/pmix-2.0.1.tar.bz2"
+ version('2.1.1', 'f9f109421661b757245d5e0bd44a38b3')
version('2.1.0', 'fc97513b601d78fe7c6bb20c6a21df3c')
version('2.0.2', 'e3ed1deed87c84f9b43da2621c6ad689')
version('2.0.1', 'ba3193b485843516e6b4e8641e443b1e')
@@ -61,6 +63,7 @@
depends_on('libevent')
def configure_args(self):
+
spec = self.spec
config_args = [
'--enable-shared',
@@ -71,4 +74,11 @@
config_args.append(
'--with-libevent={0}'.format(spec['libevent'].prefix))
+ # Versions < 2.1.1 have a bug in the test code that *sometimes*
+ # causes problems on strict alignment architectures such as
+ # aarch64. Work-around is to just not build the test code.
+ if 'aarch64' in spack.architecture.sys_type() and \
+ self.spec.version < Version('2.1.1'):
+ config_args.append('--without-tests-examples')
+
return config_args
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/pmix/package.py b/var/spack/repos/builtin/packages/pmix/package.py\n--- a/var/spack/repos/builtin/packages/pmix/package.py\n+++ b/var/spack/repos/builtin/packages/pmix/package.py\n@@ -24,6 +24,7 @@\n ##############################################################################\n \n from spack import *\n+import spack.architecture\n \n \n class Pmix(AutotoolsPackage):\n@@ -48,6 +49,7 @@\n homepage = \"https://pmix.github.io/pmix\"\n url = \"https://github.com/pmix/pmix/releases/download/v2.0.1/pmix-2.0.1.tar.bz2\"\n \n+ version('2.1.1', 'f9f109421661b757245d5e0bd44a38b3')\n version('2.1.0', 'fc97513b601d78fe7c6bb20c6a21df3c')\n version('2.0.2', 'e3ed1deed87c84f9b43da2621c6ad689')\n version('2.0.1', 'ba3193b485843516e6b4e8641e443b1e')\n@@ -61,6 +63,7 @@\n depends_on('libevent')\n \n def configure_args(self):\n+\n spec = self.spec\n config_args = [\n '--enable-shared',\n@@ -71,4 +74,11 @@\n config_args.append(\n '--with-libevent={0}'.format(spec['libevent'].prefix))\n \n+ # Versions < 2.1.1 have a bug in the test code that *sometimes*\n+ # causes problems on strict alignment architectures such as\n+ # aarch64. Work-around is to just not build the test code.\n+ if 'aarch64' in spack.architecture.sys_type() and \\\n+ self.spec.version < Version('2.1.1'):\n+ config_args.append('--without-tests-examples')\n+\n return config_args\n", "issue": "PMIx build fails on aarch64\n\r\nPMIx up through version 2.1.0 has a bug in its test code that causes problems on strict alignment architectures like aarch64. (The issue is explained in this commit: pmix/pmix@3a8bc4503a04158e3be072c92eb0253c6c77e534) The fix is included in the 2.1.1 release. The issue is exacerbated by building with optimizations turned on (which Spack does by default); it doesn't seem to happen when compiling with ```-O0```.\r\n\r\nSince the issue is in test code, the work-around is to just not build that code.\r\n### Expected Result\r\n\r\nThe install should work.\r\n\r\n### Actual Result\r\n\r\nThe install fails attempting to link pmix_test.\r\n\r\n### Steps to reproduce the issue\r\n\r\nOn an aarch64 machine:\r\n```console\r\n$ spack install -j 56 pmix %[email protected]\r\n```\r\n\r\n### Information on your system\r\n\r\n1. HPE (pre-production) Apache servers (w/ Cavium ThunderX2 CPU's)\r\n1. RHEL 7.4\r\n1. GCC 7.3.0 (built by Spack) and GCC 4.8.5 (RHEL 7 default version)\r\n\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/spack/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\n\nfrom spack import *\n\n\nclass Pmix(AutotoolsPackage):\n \"\"\"The Process Management Interface (PMI) has been used for quite some time\n as a means of exchanging wireup information needed for interprocess\n communication. Two versions (PMI-1 and PMI-2) have been released as part\n of the MPICH effort. While PMI-2 demonstrates better scaling properties\n than its PMI-1 predecessor, attaining rapid launch and wireup of the\n roughly 1M processes executing across 100k nodes expected for exascale\n operations remains challenging. PMI Exascale (PMIx) represents an\n attempt to resolve these questions by providing an extended version\n of the PMI definitions specifically designed to support clusters up\n to and including exascale sizes. The overall objective of the project\n is not to branch the existing definitions - in fact, PMIx fully\n supports both of the existing PMI-1 and PMI-2 APIs - but rather to\n (a) augment and extend those APIs to eliminate some current restrictions\n that impact scalability, (b) establish a standards-like body for\n maintaining the definitions, and (c) provide a reference implementation\n of the PMIx standard that demonstrates the desired level of\n scalability.\"\"\"\n\n homepage = \"https://pmix.github.io/pmix\"\n url = \"https://github.com/pmix/pmix/releases/download/v2.0.1/pmix-2.0.1.tar.bz2\"\n\n version('2.1.0', 'fc97513b601d78fe7c6bb20c6a21df3c')\n version('2.0.2', 'e3ed1deed87c84f9b43da2621c6ad689')\n version('2.0.1', 'ba3193b485843516e6b4e8641e443b1e')\n version('2.0.0', '3e047c2ea0ba8ee9925ed92b205fd92e')\n version('1.2.4', '242a812e206e7c5948f1f5c9688eb2a7')\n version('1.2.3', '102b1cc650018b62348b45d572b158e9')\n version('1.2.2', 'd85c8fd437bd88f984549425ad369e9f')\n version('1.2.1', 'f090f524681c52001ea2db3b0285596f')\n version('1.2.0', '6a42472d5a32e1c31ce5da19d50fc21a')\n\n depends_on('libevent')\n\n def configure_args(self):\n spec = self.spec\n config_args = [\n '--enable-shared',\n '--enable-static'\n ]\n\n # external libevent support (needed to keep Open MPI happy)\n config_args.append(\n '--with-libevent={0}'.format(spec['libevent'].prefix))\n\n return config_args\n", "path": "var/spack/repos/builtin/packages/pmix/package.py"}], "after_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/spack/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\n\nfrom spack import *\nimport spack.architecture\n\n\nclass Pmix(AutotoolsPackage):\n \"\"\"The Process Management Interface (PMI) has been used for quite some time\n as a means of exchanging wireup information needed for interprocess\n communication. Two versions (PMI-1 and PMI-2) have been released as part\n of the MPICH effort. While PMI-2 demonstrates better scaling properties\n than its PMI-1 predecessor, attaining rapid launch and wireup of the\n roughly 1M processes executing across 100k nodes expected for exascale\n operations remains challenging. PMI Exascale (PMIx) represents an\n attempt to resolve these questions by providing an extended version\n of the PMI definitions specifically designed to support clusters up\n to and including exascale sizes. The overall objective of the project\n is not to branch the existing definitions - in fact, PMIx fully\n supports both of the existing PMI-1 and PMI-2 APIs - but rather to\n (a) augment and extend those APIs to eliminate some current restrictions\n that impact scalability, (b) establish a standards-like body for\n maintaining the definitions, and (c) provide a reference implementation\n of the PMIx standard that demonstrates the desired level of\n scalability.\"\"\"\n\n homepage = \"https://pmix.github.io/pmix\"\n url = \"https://github.com/pmix/pmix/releases/download/v2.0.1/pmix-2.0.1.tar.bz2\"\n\n version('2.1.1', 'f9f109421661b757245d5e0bd44a38b3')\n version('2.1.0', 'fc97513b601d78fe7c6bb20c6a21df3c')\n version('2.0.2', 'e3ed1deed87c84f9b43da2621c6ad689')\n version('2.0.1', 'ba3193b485843516e6b4e8641e443b1e')\n version('2.0.0', '3e047c2ea0ba8ee9925ed92b205fd92e')\n version('1.2.4', '242a812e206e7c5948f1f5c9688eb2a7')\n version('1.2.3', '102b1cc650018b62348b45d572b158e9')\n version('1.2.2', 'd85c8fd437bd88f984549425ad369e9f')\n version('1.2.1', 'f090f524681c52001ea2db3b0285596f')\n version('1.2.0', '6a42472d5a32e1c31ce5da19d50fc21a')\n\n depends_on('libevent')\n\n def configure_args(self):\n\n spec = self.spec\n config_args = [\n '--enable-shared',\n '--enable-static'\n ]\n\n # external libevent support (needed to keep Open MPI happy)\n config_args.append(\n '--with-libevent={0}'.format(spec['libevent'].prefix))\n\n # Versions < 2.1.1 have a bug in the test code that *sometimes*\n # causes problems on strict alignment architectures such as\n # aarch64. Work-around is to just not build the test code.\n if 'aarch64' in spack.architecture.sys_type() and \\\n self.spec.version < Version('2.1.1'):\n config_args.append('--without-tests-examples')\n\n return config_args\n", "path": "var/spack/repos/builtin/packages/pmix/package.py"}]}
| 1,769 | 500 |
gh_patches_debug_2385
|
rasdani/github-patches
|
git_diff
|
ansible__awx-13645
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Websocket not working at non-root path
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
### Summary
Changes from #11342 and #652 are not full
### AWX version
21.0.0
### Select the relevant components
- [X] UI
- [ ] API
- [ ] Docs
### Installation method
kubernetes
### Modifications
no
### Ansible version
_No response_
### Operating system
_No response_
### Web browser
_No response_
### Steps to reproduce
Deploy AWX with custom `ingress_path: /awx`
### Expected results
websocket should work
### Actual results
`2022-05-17 08:46:41,031 ERROR [-] daphne.ws_protocol [Failure instance: Traceback: <class 'ValueError'>: No route found for path 'awx/websocket/'.
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/autobahn/websocket/protocol.py:2841:processHandshake
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/txaio/tx.py:366:as_future
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/ws_protocol.py:72:onConnect
--- <exception caught here> ---
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/server.py:201:create_application
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:54:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:47:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:145:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:169:__init__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/middleware.py:31:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:150:__call__
]
2022-05-17 08:46:41,031 ERROR [Failure instance: Traceback: <class 'ValueError'>: No route found for path 'awx/websocket/'.
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/autobahn/websocket/protocol.py:2841:processHandshake
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/txaio/tx.py:366:as_future
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/ws_protocol.py:72:onConnect
--- <exception caught here> ---
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/server.py:201:create_application
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:54:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:47:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:145:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:169:__init__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/middleware.py:31:__call__
/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:150:__call__`
### Additional information
It seems that issue is in https://github.com/ansible/awx/blob/48b016802c517ff04d1cff4c43e64f17bb77a7a8/awx/main/routing.py
```
websocket_urlpatterns = [
re_path(r'websocket/$', consumers.EventConsumer),
re_path(r'websocket/broadcast/$', consumers.BroadcastConsumer),
]
```
From https://docs.djangoproject.com/en/4.0/ref/urls/:
When a route ends with $ the whole requested URL, matching against path_info, must match the regular expression pattern (re.fullmatch() is used).
Replacing with
```
websocket_urlpatterns = [
re_path(r'websocket/', consumers.EventConsumer),
re_path(r'websocket/broadcast/', consumers.BroadcastConsumer),
]
```
solves the issue
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awx/main/routing.py`
Content:
```
1 import redis
2 import logging
3
4 from django.conf import settings
5 from django.urls import re_path
6
7 from channels.auth import AuthMiddlewareStack
8 from channels.routing import ProtocolTypeRouter, URLRouter
9
10 from . import consumers
11
12
13 logger = logging.getLogger('awx.main.routing')
14
15
16 class AWXProtocolTypeRouter(ProtocolTypeRouter):
17 def __init__(self, *args, **kwargs):
18 try:
19 r = redis.Redis.from_url(settings.BROKER_URL)
20 for k in r.scan_iter('asgi:*', 500):
21 logger.debug(f"cleaning up Redis key {k}")
22 r.delete(k)
23 except redis.exceptions.RedisError as e:
24 logger.warning("encountered an error communicating with redis.")
25 raise e
26 super().__init__(*args, **kwargs)
27
28
29 websocket_urlpatterns = [
30 re_path(r'websocket/', consumers.EventConsumer.as_asgi()),
31 re_path(r'websocket/broadcast/', consumers.BroadcastConsumer.as_asgi()),
32 ]
33
34 application = AWXProtocolTypeRouter(
35 {
36 'websocket': AuthMiddlewareStack(URLRouter(websocket_urlpatterns)),
37 }
38 )
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awx/main/routing.py b/awx/main/routing.py
--- a/awx/main/routing.py
+++ b/awx/main/routing.py
@@ -27,8 +27,8 @@
websocket_urlpatterns = [
- re_path(r'websocket/', consumers.EventConsumer.as_asgi()),
- re_path(r'websocket/broadcast/', consumers.BroadcastConsumer.as_asgi()),
+ re_path(r'websocket/$', consumers.EventConsumer.as_asgi()),
+ re_path(r'websocket/broadcast/$', consumers.BroadcastConsumer.as_asgi()),
]
application = AWXProtocolTypeRouter(
|
{"golden_diff": "diff --git a/awx/main/routing.py b/awx/main/routing.py\n--- a/awx/main/routing.py\n+++ b/awx/main/routing.py\n@@ -27,8 +27,8 @@\n \n \n websocket_urlpatterns = [\n- re_path(r'websocket/', consumers.EventConsumer.as_asgi()),\n- re_path(r'websocket/broadcast/', consumers.BroadcastConsumer.as_asgi()),\n+ re_path(r'websocket/$', consumers.EventConsumer.as_asgi()),\n+ re_path(r'websocket/broadcast/$', consumers.BroadcastConsumer.as_asgi()),\n ]\n \n application = AWXProtocolTypeRouter(\n", "issue": "Websocket not working at non-root path\n### Please confirm the following\n\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\n\n### Summary\n\nChanges from #11342 and #652 are not full\n\n### AWX version\n\n21.0.0\n\n### Select the relevant components\n\n- [X] UI\n- [ ] API\n- [ ] Docs\n\n### Installation method\n\nkubernetes\n\n### Modifications\n\nno\n\n### Ansible version\n\n_No response_\n\n### Operating system\n\n_No response_\n\n### Web browser\n\n_No response_\n\n### Steps to reproduce\n\nDeploy AWX with custom `ingress_path: /awx`\n\n### Expected results\n\nwebsocket should work\n\n### Actual results\n\n`2022-05-17 08:46:41,031 ERROR [-] daphne.ws_protocol [Failure instance: Traceback: <class 'ValueError'>: No route found for path 'awx/websocket/'.\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/autobahn/websocket/protocol.py:2841:processHandshake\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/txaio/tx.py:366:as_future\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/ws_protocol.py:72:onConnect\r\n--- <exception caught here> ---\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/server.py:201:create_application\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:54:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:47:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:145:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:169:__init__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/middleware.py:31:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:150:__call__\r\n]\r\n2022-05-17 08:46:41,031 ERROR [Failure instance: Traceback: <class 'ValueError'>: No route found for path 'awx/websocket/'.\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/autobahn/websocket/protocol.py:2841:processHandshake\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/txaio/tx.py:366:as_future\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/ws_protocol.py:72:onConnect\r\n--- <exception caught here> ---\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/twisted/internet/defer.py:151:maybeDeferred\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/daphne/server.py:201:create_application\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:54:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:47:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:145:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/sessions.py:169:__init__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/middleware.py:31:__call__\r\n/var/lib/awx/venv/awx/lib64/python3.9/site-packages/channels/routing.py:150:__call__`\n\n### Additional information\n\nIt seems that issue is in https://github.com/ansible/awx/blob/48b016802c517ff04d1cff4c43e64f17bb77a7a8/awx/main/routing.py\r\n\r\n```\r\nwebsocket_urlpatterns = [\r\n re_path(r'websocket/$', consumers.EventConsumer),\r\n re_path(r'websocket/broadcast/$', consumers.BroadcastConsumer),\r\n]\r\n```\r\nFrom https://docs.djangoproject.com/en/4.0/ref/urls/:\r\n\r\nWhen a route ends with $ the whole requested URL, matching against path_info, must match the regular expression pattern (re.fullmatch() is used).\r\n\r\nReplacing with\r\n\r\n```\r\nwebsocket_urlpatterns = [\r\n re_path(r'websocket/', consumers.EventConsumer),\r\n re_path(r'websocket/broadcast/', consumers.BroadcastConsumer),\r\n]\r\n```\r\n\r\nsolves the issue\n", "before_files": [{"content": "import redis\nimport logging\n\nfrom django.conf import settings\nfrom django.urls import re_path\n\nfrom channels.auth import AuthMiddlewareStack\nfrom channels.routing import ProtocolTypeRouter, URLRouter\n\nfrom . import consumers\n\n\nlogger = logging.getLogger('awx.main.routing')\n\n\nclass AWXProtocolTypeRouter(ProtocolTypeRouter):\n def __init__(self, *args, **kwargs):\n try:\n r = redis.Redis.from_url(settings.BROKER_URL)\n for k in r.scan_iter('asgi:*', 500):\n logger.debug(f\"cleaning up Redis key {k}\")\n r.delete(k)\n except redis.exceptions.RedisError as e:\n logger.warning(\"encountered an error communicating with redis.\")\n raise e\n super().__init__(*args, **kwargs)\n\n\nwebsocket_urlpatterns = [\n re_path(r'websocket/', consumers.EventConsumer.as_asgi()),\n re_path(r'websocket/broadcast/', consumers.BroadcastConsumer.as_asgi()),\n]\n\napplication = AWXProtocolTypeRouter(\n {\n 'websocket': AuthMiddlewareStack(URLRouter(websocket_urlpatterns)),\n }\n)\n", "path": "awx/main/routing.py"}], "after_files": [{"content": "import redis\nimport logging\n\nfrom django.conf import settings\nfrom django.urls import re_path\n\nfrom channels.auth import AuthMiddlewareStack\nfrom channels.routing import ProtocolTypeRouter, URLRouter\n\nfrom . import consumers\n\n\nlogger = logging.getLogger('awx.main.routing')\n\n\nclass AWXProtocolTypeRouter(ProtocolTypeRouter):\n def __init__(self, *args, **kwargs):\n try:\n r = redis.Redis.from_url(settings.BROKER_URL)\n for k in r.scan_iter('asgi:*', 500):\n logger.debug(f\"cleaning up Redis key {k}\")\n r.delete(k)\n except redis.exceptions.RedisError as e:\n logger.warning(\"encountered an error communicating with redis.\")\n raise e\n super().__init__(*args, **kwargs)\n\n\nwebsocket_urlpatterns = [\n re_path(r'websocket/$', consumers.EventConsumer.as_asgi()),\n re_path(r'websocket/broadcast/$', consumers.BroadcastConsumer.as_asgi()),\n]\n\napplication = AWXProtocolTypeRouter(\n {\n 'websocket': AuthMiddlewareStack(URLRouter(websocket_urlpatterns)),\n }\n)\n", "path": "awx/main/routing.py"}]}
| 1,911 | 132 |
gh_patches_debug_38974
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-18020
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DocType Layout Fields table does not populate
## Description of the issue
When selecting a Document Type in a DocType Layout document the Fields table does not populate. The document must be saved twice in order to populate the fields, because the first save resulting in an error message. Obviously this would lead people (like myself) to believe the DocType Layout feature is non-functional.
Here is an image demonstrating the problems:

## Context information (for bug reports)
**Output of `bench version`**
```
ERPNext: v13.22.0 (version-13)
Frappe Framework: v13.22.0 (version-13)
```
## Steps to reproduce the issue
1. Add a new DocType Layout document
2. Enter a value in Document Type
### Observed result
- Fields table does not populate.
### Expected result
Something more like this
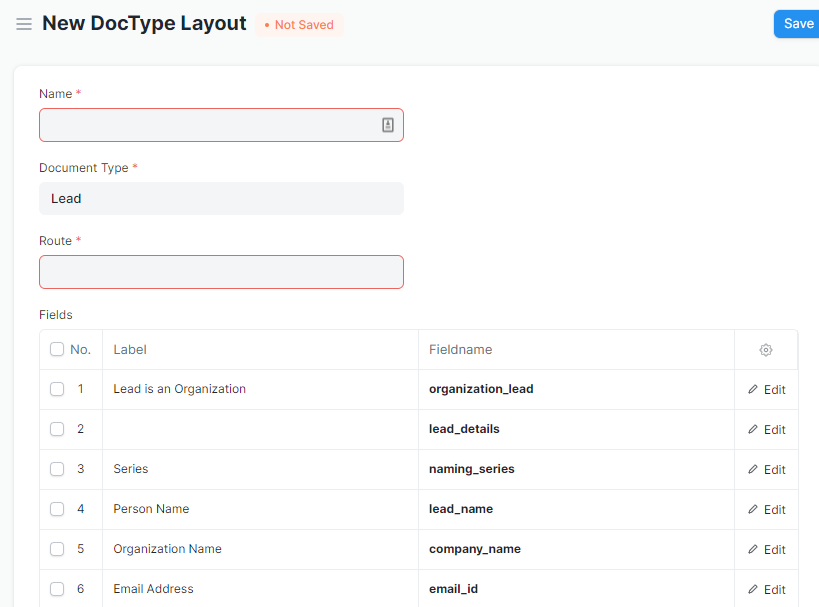
## Additional information
From what I can tell, there are two issues at play:
1. The document_type field expects no rows to exist (but a blank row is auto-generated)
2. The method neglects to refresh the Fields table
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frappe/custom/doctype/doctype_layout/doctype_layout.py`
Content:
```
1 # Copyright (c) 2020, Frappe Technologies and contributors
2 # License: MIT. See LICENSE
3
4 from frappe.desk.utils import slug
5 from frappe.model.document import Document
6
7
8 class DocTypeLayout(Document):
9 def validate(self):
10 if not self.route:
11 self.route = slug(self.name)
12
```
Path: `frappe/custom/doctype/custom_field/custom_field.py`
Content:
```
1 # Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
2 # License: MIT. See LICENSE
3
4 import json
5
6 import frappe
7 from frappe import _
8 from frappe.model import core_doctypes_list
9 from frappe.model.docfield import supports_translation
10 from frappe.model.document import Document
11 from frappe.query_builder.functions import IfNull
12 from frappe.utils import cstr
13
14
15 class CustomField(Document):
16 def autoname(self):
17 self.set_fieldname()
18 self.name = self.dt + "-" + self.fieldname
19
20 def set_fieldname(self):
21 if not self.fieldname:
22 label = self.label
23 if not label:
24 if self.fieldtype in ["Section Break", "Column Break", "Tab Break"]:
25 label = self.fieldtype + "_" + str(self.idx)
26 else:
27 frappe.throw(_("Label is mandatory"))
28
29 # remove special characters from fieldname
30 self.fieldname = "".join(
31 filter(lambda x: x.isdigit() or x.isalpha() or "_", cstr(label).replace(" ", "_"))
32 )
33
34 # fieldnames should be lowercase
35 self.fieldname = self.fieldname.lower()
36
37 def before_insert(self):
38 self.set_fieldname()
39
40 def validate(self):
41 # these imports have been added to avoid cyclical import, should fix in future
42 from frappe.core.doctype.doctype.doctype import check_fieldname_conflicts
43 from frappe.custom.doctype.customize_form.customize_form import CustomizeForm
44
45 # don't always get meta to improve performance
46 # setting idx is just an improvement, not a requirement
47 if self.is_new() or self.insert_after == "append":
48 meta = frappe.get_meta(self.dt, cached=False)
49 fieldnames = [df.fieldname for df in meta.get("fields")]
50
51 if self.is_new() and self.fieldname in fieldnames:
52 frappe.throw(
53 _("A field with the name {0} already exists in {1}").format(
54 frappe.bold(self.fieldname), self.dt
55 )
56 )
57
58 if self.insert_after == "append":
59 self.insert_after = fieldnames[-1]
60
61 if self.insert_after and self.insert_after in fieldnames:
62 self.idx = fieldnames.index(self.insert_after) + 1
63
64 if (
65 not self.is_virtual
66 and (doc_before_save := self.get_doc_before_save())
67 and (old_fieldtype := doc_before_save.fieldtype) != self.fieldtype
68 and not CustomizeForm.allow_fieldtype_change(old_fieldtype, self.fieldtype)
69 ):
70 frappe.throw(
71 _("Fieldtype cannot be changed from {0} to {1}").format(old_fieldtype, self.fieldtype)
72 )
73
74 if not self.fieldname:
75 frappe.throw(_("Fieldname not set for Custom Field"))
76
77 if self.get("translatable", 0) and not supports_translation(self.fieldtype):
78 self.translatable = 0
79
80 check_fieldname_conflicts(self)
81
82 def on_update(self):
83 # validate field
84 if not self.flags.ignore_validate:
85 from frappe.core.doctype.doctype.doctype import validate_fields_for_doctype
86
87 validate_fields_for_doctype(self.dt)
88
89 # clear cache and update the schema
90 if not frappe.flags.in_create_custom_fields:
91 frappe.clear_cache(doctype=self.dt)
92 frappe.db.updatedb(self.dt)
93
94 def on_trash(self):
95 # check if Admin owned field
96 if self.owner == "Administrator" and frappe.session.user != "Administrator":
97 frappe.throw(
98 _(
99 "Custom Field {0} is created by the Administrator and can only be deleted through the Administrator account."
100 ).format(frappe.bold(self.label))
101 )
102
103 # delete property setter entries
104 frappe.db.delete("Property Setter", {"doc_type": self.dt, "field_name": self.fieldname})
105 frappe.clear_cache(doctype=self.dt)
106
107 def validate_insert_after(self, meta):
108 if not meta.get_field(self.insert_after):
109 frappe.throw(
110 _(
111 "Insert After field '{0}' mentioned in Custom Field '{1}', with label '{2}', does not exist"
112 ).format(self.insert_after, self.name, self.label),
113 frappe.DoesNotExistError,
114 )
115
116 if self.fieldname == self.insert_after:
117 frappe.throw(_("Insert After cannot be set as {0}").format(meta.get_label(self.insert_after)))
118
119
120 @frappe.whitelist()
121 def get_fields_label(doctype=None):
122 meta = frappe.get_meta(doctype)
123
124 if doctype in core_doctypes_list:
125 return frappe.msgprint(_("Custom Fields cannot be added to core DocTypes."))
126
127 if meta.custom:
128 return frappe.msgprint(_("Custom Fields can only be added to a standard DocType."))
129
130 return [
131 {"value": df.fieldname or "", "label": _(df.label or "")}
132 for df in frappe.get_meta(doctype).get("fields")
133 ]
134
135
136 def create_custom_field_if_values_exist(doctype, df):
137 df = frappe._dict(df)
138 if df.fieldname in frappe.db.get_table_columns(doctype) and frappe.db.count(
139 dt=doctype, filters=IfNull(df.fieldname, "") != ""
140 ):
141 create_custom_field(doctype, df)
142
143
144 def create_custom_field(doctype, df, ignore_validate=False, is_system_generated=True):
145 df = frappe._dict(df)
146 if not df.fieldname and df.label:
147 df.fieldname = frappe.scrub(df.label)
148 if not frappe.db.get_value("Custom Field", {"dt": doctype, "fieldname": df.fieldname}):
149 custom_field = frappe.get_doc(
150 {
151 "doctype": "Custom Field",
152 "dt": doctype,
153 "permlevel": 0,
154 "fieldtype": "Data",
155 "hidden": 0,
156 "is_system_generated": is_system_generated,
157 }
158 )
159 custom_field.update(df)
160 custom_field.flags.ignore_validate = ignore_validate
161 custom_field.insert()
162 return custom_field
163
164
165 def create_custom_fields(custom_fields, ignore_validate=False, update=True):
166 """Add / update multiple custom fields
167
168 :param custom_fields: example `{'Sales Invoice': [dict(fieldname='test')]}`"""
169
170 try:
171 frappe.flags.in_create_custom_fields = True
172 doctypes_to_update = set()
173
174 if frappe.flags.in_setup_wizard:
175 ignore_validate = True
176
177 for doctypes, fields in custom_fields.items():
178 if isinstance(fields, dict):
179 # only one field
180 fields = [fields]
181
182 if isinstance(doctypes, str):
183 # only one doctype
184 doctypes = (doctypes,)
185
186 for doctype in doctypes:
187 doctypes_to_update.add(doctype)
188
189 for df in fields:
190 field = frappe.db.get_value("Custom Field", {"dt": doctype, "fieldname": df["fieldname"]})
191 if not field:
192 try:
193 df = df.copy()
194 df["owner"] = "Administrator"
195 create_custom_field(doctype, df, ignore_validate=ignore_validate)
196
197 except frappe.exceptions.DuplicateEntryError:
198 pass
199
200 elif update:
201 custom_field = frappe.get_doc("Custom Field", field)
202 custom_field.flags.ignore_validate = ignore_validate
203 custom_field.update(df)
204 custom_field.save()
205
206 for doctype in doctypes_to_update:
207 frappe.clear_cache(doctype=doctype)
208 frappe.db.updatedb(doctype)
209
210 finally:
211 frappe.flags.in_create_custom_fields = False
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frappe/custom/doctype/custom_field/custom_field.py b/frappe/custom/doctype/custom_field/custom_field.py
--- a/frappe/custom/doctype/custom_field/custom_field.py
+++ b/frappe/custom/doctype/custom_field/custom_field.py
@@ -102,6 +102,20 @@
# delete property setter entries
frappe.db.delete("Property Setter", {"doc_type": self.dt, "field_name": self.fieldname})
+
+ # update doctype layouts
+ doctype_layouts = frappe.get_all(
+ "DocType Layout", filters={"document_type": self.dt}, pluck="name"
+ )
+
+ for layout in doctype_layouts:
+ layout_doc = frappe.get_doc("DocType Layout", layout)
+ for field in layout_doc.fields:
+ if field.fieldname == self.fieldname:
+ layout_doc.remove(field)
+ layout_doc.save()
+ break
+
frappe.clear_cache(doctype=self.dt)
def validate_insert_after(self, meta):
diff --git a/frappe/custom/doctype/doctype_layout/doctype_layout.py b/frappe/custom/doctype/doctype_layout/doctype_layout.py
--- a/frappe/custom/doctype/doctype_layout/doctype_layout.py
+++ b/frappe/custom/doctype/doctype_layout/doctype_layout.py
@@ -1,11 +1,77 @@
# Copyright (c) 2020, Frappe Technologies and contributors
# License: MIT. See LICENSE
+from typing import TYPE_CHECKING
+
+import frappe
from frappe.desk.utils import slug
from frappe.model.document import Document
+if TYPE_CHECKING:
+ from frappe.core.doctype.docfield.docfield import DocField
+
class DocTypeLayout(Document):
def validate(self):
if not self.route:
self.route = slug(self.name)
+
+ @frappe.whitelist()
+ def sync_fields(self):
+ doctype_fields = frappe.get_meta(self.document_type).fields
+
+ if self.is_new():
+ added_fields = [field.fieldname for field in doctype_fields]
+ removed_fields = []
+ else:
+ doctype_fieldnames = {field.fieldname for field in doctype_fields}
+ layout_fieldnames = {field.fieldname for field in self.fields}
+ added_fields = list(doctype_fieldnames - layout_fieldnames)
+ removed_fields = list(layout_fieldnames - doctype_fieldnames)
+
+ if not (added_fields or removed_fields):
+ return
+
+ added = self.add_fields(added_fields, doctype_fields)
+ removed = self.remove_fields(removed_fields)
+
+ for index, field in enumerate(self.fields):
+ field.idx = index + 1
+
+ return {"added": added, "removed": removed}
+
+ def add_fields(self, added_fields: list[str], doctype_fields: list["DocField"]) -> list[dict]:
+ added = []
+ for field in added_fields:
+ field_details = next((f for f in doctype_fields if f.fieldname == field), None)
+ if not field_details:
+ continue
+
+ # remove 'doctype' data from the DocField to allow adding it to the layout
+ row = self.append("fields", field_details.as_dict(no_default_fields=True))
+ row_data = row.as_dict()
+
+ if field_details.get("insert_after"):
+ insert_after = next(
+ (f for f in self.fields if f.fieldname == field_details.insert_after),
+ None,
+ )
+
+ # initialize new row to just after the insert_after field
+ if insert_after:
+ self.fields.insert(insert_after.idx, row)
+ self.fields.pop()
+
+ row_data = {"idx": insert_after.idx + 1, "fieldname": row.fieldname, "label": row.label}
+
+ added.append(row_data)
+ return added
+
+ def remove_fields(self, removed_fields: list[str]) -> list[dict]:
+ removed = []
+ for field in removed_fields:
+ field_details = next((f for f in self.fields if f.fieldname == field), None)
+ if field_details:
+ self.remove(field_details)
+ removed.append(field_details.as_dict())
+ return removed
|
{"golden_diff": "diff --git a/frappe/custom/doctype/custom_field/custom_field.py b/frappe/custom/doctype/custom_field/custom_field.py\n--- a/frappe/custom/doctype/custom_field/custom_field.py\n+++ b/frappe/custom/doctype/custom_field/custom_field.py\n@@ -102,6 +102,20 @@\n \n \t\t# delete property setter entries\n \t\tfrappe.db.delete(\"Property Setter\", {\"doc_type\": self.dt, \"field_name\": self.fieldname})\n+\n+\t\t# update doctype layouts\n+\t\tdoctype_layouts = frappe.get_all(\n+\t\t\t\"DocType Layout\", filters={\"document_type\": self.dt}, pluck=\"name\"\n+\t\t)\n+\n+\t\tfor layout in doctype_layouts:\n+\t\t\tlayout_doc = frappe.get_doc(\"DocType Layout\", layout)\n+\t\t\tfor field in layout_doc.fields:\n+\t\t\t\tif field.fieldname == self.fieldname:\n+\t\t\t\t\tlayout_doc.remove(field)\n+\t\t\t\t\tlayout_doc.save()\n+\t\t\t\t\tbreak\n+\n \t\tfrappe.clear_cache(doctype=self.dt)\n \n \tdef validate_insert_after(self, meta):\ndiff --git a/frappe/custom/doctype/doctype_layout/doctype_layout.py b/frappe/custom/doctype/doctype_layout/doctype_layout.py\n--- a/frappe/custom/doctype/doctype_layout/doctype_layout.py\n+++ b/frappe/custom/doctype/doctype_layout/doctype_layout.py\n@@ -1,11 +1,77 @@\n # Copyright (c) 2020, Frappe Technologies and contributors\n # License: MIT. See LICENSE\n \n+from typing import TYPE_CHECKING\n+\n+import frappe\n from frappe.desk.utils import slug\n from frappe.model.document import Document\n \n+if TYPE_CHECKING:\n+\tfrom frappe.core.doctype.docfield.docfield import DocField\n+\n \n class DocTypeLayout(Document):\n \tdef validate(self):\n \t\tif not self.route:\n \t\t\tself.route = slug(self.name)\n+\n+\[email protected]()\n+\tdef sync_fields(self):\n+\t\tdoctype_fields = frappe.get_meta(self.document_type).fields\n+\n+\t\tif self.is_new():\n+\t\t\tadded_fields = [field.fieldname for field in doctype_fields]\n+\t\t\tremoved_fields = []\n+\t\telse:\n+\t\t\tdoctype_fieldnames = {field.fieldname for field in doctype_fields}\n+\t\t\tlayout_fieldnames = {field.fieldname for field in self.fields}\n+\t\t\tadded_fields = list(doctype_fieldnames - layout_fieldnames)\n+\t\t\tremoved_fields = list(layout_fieldnames - doctype_fieldnames)\n+\n+\t\tif not (added_fields or removed_fields):\n+\t\t\treturn\n+\n+\t\tadded = self.add_fields(added_fields, doctype_fields)\n+\t\tremoved = self.remove_fields(removed_fields)\n+\n+\t\tfor index, field in enumerate(self.fields):\n+\t\t\tfield.idx = index + 1\n+\n+\t\treturn {\"added\": added, \"removed\": removed}\n+\n+\tdef add_fields(self, added_fields: list[str], doctype_fields: list[\"DocField\"]) -> list[dict]:\n+\t\tadded = []\n+\t\tfor field in added_fields:\n+\t\t\tfield_details = next((f for f in doctype_fields if f.fieldname == field), None)\n+\t\t\tif not field_details:\n+\t\t\t\tcontinue\n+\n+\t\t\t# remove 'doctype' data from the DocField to allow adding it to the layout\n+\t\t\trow = self.append(\"fields\", field_details.as_dict(no_default_fields=True))\n+\t\t\trow_data = row.as_dict()\n+\n+\t\t\tif field_details.get(\"insert_after\"):\n+\t\t\t\tinsert_after = next(\n+\t\t\t\t\t(f for f in self.fields if f.fieldname == field_details.insert_after),\n+\t\t\t\t\tNone,\n+\t\t\t\t)\n+\n+\t\t\t\t# initialize new row to just after the insert_after field\n+\t\t\t\tif insert_after:\n+\t\t\t\t\tself.fields.insert(insert_after.idx, row)\n+\t\t\t\t\tself.fields.pop()\n+\n+\t\t\t\t\trow_data = {\"idx\": insert_after.idx + 1, \"fieldname\": row.fieldname, \"label\": row.label}\n+\n+\t\t\tadded.append(row_data)\n+\t\treturn added\n+\n+\tdef remove_fields(self, removed_fields: list[str]) -> list[dict]:\n+\t\tremoved = []\n+\t\tfor field in removed_fields:\n+\t\t\tfield_details = next((f for f in self.fields if f.fieldname == field), None)\n+\t\t\tif field_details:\n+\t\t\t\tself.remove(field_details)\n+\t\t\t\tremoved.append(field_details.as_dict())\n+\t\treturn removed\n", "issue": "DocType Layout Fields table does not populate\n## Description of the issue\r\nWhen selecting a Document Type in a DocType Layout document the Fields table does not populate. The document must be saved twice in order to populate the fields, because the first save resulting in an error message. Obviously this would lead people (like myself) to believe the DocType Layout feature is non-functional.\r\n\r\nHere is an image demonstrating the problems:\r\n\r\n\r\n## Context information (for bug reports)\r\n\r\n**Output of `bench version`**\r\n```\r\nERPNext: v13.22.0 (version-13)\r\nFrappe Framework: v13.22.0 (version-13)\r\n```\r\n\r\n## Steps to reproduce the issue\r\n\r\n1. Add a new DocType Layout document\r\n2. Enter a value in Document Type\r\n\r\n### Observed result\r\n\r\n- Fields table does not populate.\r\n\r\n### Expected result\r\n\r\nSomething more like this\r\n\r\n\r\n## Additional information\r\n\r\nFrom what I can tell, there are two issues at play:\r\n\r\n1. The document_type field expects no rows to exist (but a blank row is auto-generated)\r\n2. The method neglects to refresh the Fields table\n", "before_files": [{"content": "# Copyright (c) 2020, Frappe Technologies and contributors\n# License: MIT. See LICENSE\n\nfrom frappe.desk.utils import slug\nfrom frappe.model.document import Document\n\n\nclass DocTypeLayout(Document):\n\tdef validate(self):\n\t\tif not self.route:\n\t\t\tself.route = slug(self.name)\n", "path": "frappe/custom/doctype/doctype_layout/doctype_layout.py"}, {"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# License: MIT. See LICENSE\n\nimport json\n\nimport frappe\nfrom frappe import _\nfrom frappe.model import core_doctypes_list\nfrom frappe.model.docfield import supports_translation\nfrom frappe.model.document import Document\nfrom frappe.query_builder.functions import IfNull\nfrom frappe.utils import cstr\n\n\nclass CustomField(Document):\n\tdef autoname(self):\n\t\tself.set_fieldname()\n\t\tself.name = self.dt + \"-\" + self.fieldname\n\n\tdef set_fieldname(self):\n\t\tif not self.fieldname:\n\t\t\tlabel = self.label\n\t\t\tif not label:\n\t\t\t\tif self.fieldtype in [\"Section Break\", \"Column Break\", \"Tab Break\"]:\n\t\t\t\t\tlabel = self.fieldtype + \"_\" + str(self.idx)\n\t\t\t\telse:\n\t\t\t\t\tfrappe.throw(_(\"Label is mandatory\"))\n\n\t\t\t# remove special characters from fieldname\n\t\t\tself.fieldname = \"\".join(\n\t\t\t\tfilter(lambda x: x.isdigit() or x.isalpha() or \"_\", cstr(label).replace(\" \", \"_\"))\n\t\t\t)\n\n\t\t# fieldnames should be lowercase\n\t\tself.fieldname = self.fieldname.lower()\n\n\tdef before_insert(self):\n\t\tself.set_fieldname()\n\n\tdef validate(self):\n\t\t# these imports have been added to avoid cyclical import, should fix in future\n\t\tfrom frappe.core.doctype.doctype.doctype import check_fieldname_conflicts\n\t\tfrom frappe.custom.doctype.customize_form.customize_form import CustomizeForm\n\n\t\t# don't always get meta to improve performance\n\t\t# setting idx is just an improvement, not a requirement\n\t\tif self.is_new() or self.insert_after == \"append\":\n\t\t\tmeta = frappe.get_meta(self.dt, cached=False)\n\t\t\tfieldnames = [df.fieldname for df in meta.get(\"fields\")]\n\n\t\t\tif self.is_new() and self.fieldname in fieldnames:\n\t\t\t\tfrappe.throw(\n\t\t\t\t\t_(\"A field with the name {0} already exists in {1}\").format(\n\t\t\t\t\t\tfrappe.bold(self.fieldname), self.dt\n\t\t\t\t\t)\n\t\t\t\t)\n\n\t\t\tif self.insert_after == \"append\":\n\t\t\t\tself.insert_after = fieldnames[-1]\n\n\t\t\tif self.insert_after and self.insert_after in fieldnames:\n\t\t\t\tself.idx = fieldnames.index(self.insert_after) + 1\n\n\t\tif (\n\t\t\tnot self.is_virtual\n\t\t\tand (doc_before_save := self.get_doc_before_save())\n\t\t\tand (old_fieldtype := doc_before_save.fieldtype) != self.fieldtype\n\t\t\tand not CustomizeForm.allow_fieldtype_change(old_fieldtype, self.fieldtype)\n\t\t):\n\t\t\tfrappe.throw(\n\t\t\t\t_(\"Fieldtype cannot be changed from {0} to {1}\").format(old_fieldtype, self.fieldtype)\n\t\t\t)\n\n\t\tif not self.fieldname:\n\t\t\tfrappe.throw(_(\"Fieldname not set for Custom Field\"))\n\n\t\tif self.get(\"translatable\", 0) and not supports_translation(self.fieldtype):\n\t\t\tself.translatable = 0\n\n\t\tcheck_fieldname_conflicts(self)\n\n\tdef on_update(self):\n\t\t# validate field\n\t\tif not self.flags.ignore_validate:\n\t\t\tfrom frappe.core.doctype.doctype.doctype import validate_fields_for_doctype\n\n\t\t\tvalidate_fields_for_doctype(self.dt)\n\n\t\t# clear cache and update the schema\n\t\tif not frappe.flags.in_create_custom_fields:\n\t\t\tfrappe.clear_cache(doctype=self.dt)\n\t\t\tfrappe.db.updatedb(self.dt)\n\n\tdef on_trash(self):\n\t\t# check if Admin owned field\n\t\tif self.owner == \"Administrator\" and frappe.session.user != \"Administrator\":\n\t\t\tfrappe.throw(\n\t\t\t\t_(\n\t\t\t\t\t\"Custom Field {0} is created by the Administrator and can only be deleted through the Administrator account.\"\n\t\t\t\t).format(frappe.bold(self.label))\n\t\t\t)\n\n\t\t# delete property setter entries\n\t\tfrappe.db.delete(\"Property Setter\", {\"doc_type\": self.dt, \"field_name\": self.fieldname})\n\t\tfrappe.clear_cache(doctype=self.dt)\n\n\tdef validate_insert_after(self, meta):\n\t\tif not meta.get_field(self.insert_after):\n\t\t\tfrappe.throw(\n\t\t\t\t_(\n\t\t\t\t\t\"Insert After field '{0}' mentioned in Custom Field '{1}', with label '{2}', does not exist\"\n\t\t\t\t).format(self.insert_after, self.name, self.label),\n\t\t\t\tfrappe.DoesNotExistError,\n\t\t\t)\n\n\t\tif self.fieldname == self.insert_after:\n\t\t\tfrappe.throw(_(\"Insert After cannot be set as {0}\").format(meta.get_label(self.insert_after)))\n\n\[email protected]()\ndef get_fields_label(doctype=None):\n\tmeta = frappe.get_meta(doctype)\n\n\tif doctype in core_doctypes_list:\n\t\treturn frappe.msgprint(_(\"Custom Fields cannot be added to core DocTypes.\"))\n\n\tif meta.custom:\n\t\treturn frappe.msgprint(_(\"Custom Fields can only be added to a standard DocType.\"))\n\n\treturn [\n\t\t{\"value\": df.fieldname or \"\", \"label\": _(df.label or \"\")}\n\t\tfor df in frappe.get_meta(doctype).get(\"fields\")\n\t]\n\n\ndef create_custom_field_if_values_exist(doctype, df):\n\tdf = frappe._dict(df)\n\tif df.fieldname in frappe.db.get_table_columns(doctype) and frappe.db.count(\n\t\tdt=doctype, filters=IfNull(df.fieldname, \"\") != \"\"\n\t):\n\t\tcreate_custom_field(doctype, df)\n\n\ndef create_custom_field(doctype, df, ignore_validate=False, is_system_generated=True):\n\tdf = frappe._dict(df)\n\tif not df.fieldname and df.label:\n\t\tdf.fieldname = frappe.scrub(df.label)\n\tif not frappe.db.get_value(\"Custom Field\", {\"dt\": doctype, \"fieldname\": df.fieldname}):\n\t\tcustom_field = frappe.get_doc(\n\t\t\t{\n\t\t\t\t\"doctype\": \"Custom Field\",\n\t\t\t\t\"dt\": doctype,\n\t\t\t\t\"permlevel\": 0,\n\t\t\t\t\"fieldtype\": \"Data\",\n\t\t\t\t\"hidden\": 0,\n\t\t\t\t\"is_system_generated\": is_system_generated,\n\t\t\t}\n\t\t)\n\t\tcustom_field.update(df)\n\t\tcustom_field.flags.ignore_validate = ignore_validate\n\t\tcustom_field.insert()\n\t\treturn custom_field\n\n\ndef create_custom_fields(custom_fields, ignore_validate=False, update=True):\n\t\"\"\"Add / update multiple custom fields\n\n\t:param custom_fields: example `{'Sales Invoice': [dict(fieldname='test')]}`\"\"\"\n\n\ttry:\n\t\tfrappe.flags.in_create_custom_fields = True\n\t\tdoctypes_to_update = set()\n\n\t\tif frappe.flags.in_setup_wizard:\n\t\t\tignore_validate = True\n\n\t\tfor doctypes, fields in custom_fields.items():\n\t\t\tif isinstance(fields, dict):\n\t\t\t\t# only one field\n\t\t\t\tfields = [fields]\n\n\t\t\tif isinstance(doctypes, str):\n\t\t\t\t# only one doctype\n\t\t\t\tdoctypes = (doctypes,)\n\n\t\t\tfor doctype in doctypes:\n\t\t\t\tdoctypes_to_update.add(doctype)\n\n\t\t\t\tfor df in fields:\n\t\t\t\t\tfield = frappe.db.get_value(\"Custom Field\", {\"dt\": doctype, \"fieldname\": df[\"fieldname\"]})\n\t\t\t\t\tif not field:\n\t\t\t\t\t\ttry:\n\t\t\t\t\t\t\tdf = df.copy()\n\t\t\t\t\t\t\tdf[\"owner\"] = \"Administrator\"\n\t\t\t\t\t\t\tcreate_custom_field(doctype, df, ignore_validate=ignore_validate)\n\n\t\t\t\t\t\texcept frappe.exceptions.DuplicateEntryError:\n\t\t\t\t\t\t\tpass\n\n\t\t\t\t\telif update:\n\t\t\t\t\t\tcustom_field = frappe.get_doc(\"Custom Field\", field)\n\t\t\t\t\t\tcustom_field.flags.ignore_validate = ignore_validate\n\t\t\t\t\t\tcustom_field.update(df)\n\t\t\t\t\t\tcustom_field.save()\n\n\t\tfor doctype in doctypes_to_update:\n\t\t\tfrappe.clear_cache(doctype=doctype)\n\t\t\tfrappe.db.updatedb(doctype)\n\n\tfinally:\n\t\tfrappe.flags.in_create_custom_fields = False\n", "path": "frappe/custom/doctype/custom_field/custom_field.py"}], "after_files": [{"content": "# Copyright (c) 2020, Frappe Technologies and contributors\n# License: MIT. See LICENSE\n\nfrom typing import TYPE_CHECKING\n\nimport frappe\nfrom frappe.desk.utils import slug\nfrom frappe.model.document import Document\n\nif TYPE_CHECKING:\n\tfrom frappe.core.doctype.docfield.docfield import DocField\n\n\nclass DocTypeLayout(Document):\n\tdef validate(self):\n\t\tif not self.route:\n\t\t\tself.route = slug(self.name)\n\n\[email protected]()\n\tdef sync_fields(self):\n\t\tdoctype_fields = frappe.get_meta(self.document_type).fields\n\n\t\tif self.is_new():\n\t\t\tadded_fields = [field.fieldname for field in doctype_fields]\n\t\t\tremoved_fields = []\n\t\telse:\n\t\t\tdoctype_fieldnames = {field.fieldname for field in doctype_fields}\n\t\t\tlayout_fieldnames = {field.fieldname for field in self.fields}\n\t\t\tadded_fields = list(doctype_fieldnames - layout_fieldnames)\n\t\t\tremoved_fields = list(layout_fieldnames - doctype_fieldnames)\n\n\t\tif not (added_fields or removed_fields):\n\t\t\treturn\n\n\t\tadded = self.add_fields(added_fields, doctype_fields)\n\t\tremoved = self.remove_fields(removed_fields)\n\n\t\tfor index, field in enumerate(self.fields):\n\t\t\tfield.idx = index + 1\n\n\t\treturn {\"added\": added, \"removed\": removed}\n\n\tdef add_fields(self, added_fields: list[str], doctype_fields: list[\"DocField\"]) -> list[dict]:\n\t\tadded = []\n\t\tfor field in added_fields:\n\t\t\tfield_details = next((f for f in doctype_fields if f.fieldname == field), None)\n\t\t\tif not field_details:\n\t\t\t\tcontinue\n\n\t\t\t# remove 'doctype' data from the DocField to allow adding it to the layout\n\t\t\trow = self.append(\"fields\", field_details.as_dict(no_default_fields=True))\n\t\t\trow_data = row.as_dict()\n\n\t\t\tif field_details.get(\"insert_after\"):\n\t\t\t\tinsert_after = next(\n\t\t\t\t\t(f for f in self.fields if f.fieldname == field_details.insert_after),\n\t\t\t\t\tNone,\n\t\t\t\t)\n\n\t\t\t\t# initialize new row to just after the insert_after field\n\t\t\t\tif insert_after:\n\t\t\t\t\tself.fields.insert(insert_after.idx, row)\n\t\t\t\t\tself.fields.pop()\n\n\t\t\t\t\trow_data = {\"idx\": insert_after.idx + 1, \"fieldname\": row.fieldname, \"label\": row.label}\n\n\t\t\tadded.append(row_data)\n\t\treturn added\n\n\tdef remove_fields(self, removed_fields: list[str]) -> list[dict]:\n\t\tremoved = []\n\t\tfor field in removed_fields:\n\t\t\tfield_details = next((f for f in self.fields if f.fieldname == field), None)\n\t\t\tif field_details:\n\t\t\t\tself.remove(field_details)\n\t\t\t\tremoved.append(field_details.as_dict())\n\t\treturn removed\n", "path": "frappe/custom/doctype/doctype_layout/doctype_layout.py"}, {"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# License: MIT. See LICENSE\n\nimport json\n\nimport frappe\nfrom frappe import _\nfrom frappe.model import core_doctypes_list\nfrom frappe.model.docfield import supports_translation\nfrom frappe.model.document import Document\nfrom frappe.query_builder.functions import IfNull\nfrom frappe.utils import cstr\n\n\nclass CustomField(Document):\n\tdef autoname(self):\n\t\tself.set_fieldname()\n\t\tself.name = self.dt + \"-\" + self.fieldname\n\n\tdef set_fieldname(self):\n\t\tif not self.fieldname:\n\t\t\tlabel = self.label\n\t\t\tif not label:\n\t\t\t\tif self.fieldtype in [\"Section Break\", \"Column Break\", \"Tab Break\"]:\n\t\t\t\t\tlabel = self.fieldtype + \"_\" + str(self.idx)\n\t\t\t\telse:\n\t\t\t\t\tfrappe.throw(_(\"Label is mandatory\"))\n\n\t\t\t# remove special characters from fieldname\n\t\t\tself.fieldname = \"\".join(\n\t\t\t\tfilter(lambda x: x.isdigit() or x.isalpha() or \"_\", cstr(label).replace(\" \", \"_\"))\n\t\t\t)\n\n\t\t# fieldnames should be lowercase\n\t\tself.fieldname = self.fieldname.lower()\n\n\tdef before_insert(self):\n\t\tself.set_fieldname()\n\n\tdef validate(self):\n\t\t# these imports have been added to avoid cyclical import, should fix in future\n\t\tfrom frappe.core.doctype.doctype.doctype import check_fieldname_conflicts\n\t\tfrom frappe.custom.doctype.customize_form.customize_form import CustomizeForm\n\n\t\t# don't always get meta to improve performance\n\t\t# setting idx is just an improvement, not a requirement\n\t\tif self.is_new() or self.insert_after == \"append\":\n\t\t\tmeta = frappe.get_meta(self.dt, cached=False)\n\t\t\tfieldnames = [df.fieldname for df in meta.get(\"fields\")]\n\n\t\t\tif self.is_new() and self.fieldname in fieldnames:\n\t\t\t\tfrappe.throw(\n\t\t\t\t\t_(\"A field with the name {0} already exists in {1}\").format(\n\t\t\t\t\t\tfrappe.bold(self.fieldname), self.dt\n\t\t\t\t\t)\n\t\t\t\t)\n\n\t\t\tif self.insert_after == \"append\":\n\t\t\t\tself.insert_after = fieldnames[-1]\n\n\t\t\tif self.insert_after and self.insert_after in fieldnames:\n\t\t\t\tself.idx = fieldnames.index(self.insert_after) + 1\n\n\t\tif (\n\t\t\tnot self.is_virtual\n\t\t\tand (doc_before_save := self.get_doc_before_save())\n\t\t\tand (old_fieldtype := doc_before_save.fieldtype) != self.fieldtype\n\t\t\tand not CustomizeForm.allow_fieldtype_change(old_fieldtype, self.fieldtype)\n\t\t):\n\t\t\tfrappe.throw(\n\t\t\t\t_(\"Fieldtype cannot be changed from {0} to {1}\").format(old_fieldtype, self.fieldtype)\n\t\t\t)\n\n\t\tif not self.fieldname:\n\t\t\tfrappe.throw(_(\"Fieldname not set for Custom Field\"))\n\n\t\tif self.get(\"translatable\", 0) and not supports_translation(self.fieldtype):\n\t\t\tself.translatable = 0\n\n\t\tcheck_fieldname_conflicts(self)\n\n\tdef on_update(self):\n\t\t# validate field\n\t\tif not self.flags.ignore_validate:\n\t\t\tfrom frappe.core.doctype.doctype.doctype import validate_fields_for_doctype\n\n\t\t\tvalidate_fields_for_doctype(self.dt)\n\n\t\t# clear cache and update the schema\n\t\tif not frappe.flags.in_create_custom_fields:\n\t\t\tfrappe.clear_cache(doctype=self.dt)\n\t\t\tfrappe.db.updatedb(self.dt)\n\n\tdef on_trash(self):\n\t\t# check if Admin owned field\n\t\tif self.owner == \"Administrator\" and frappe.session.user != \"Administrator\":\n\t\t\tfrappe.throw(\n\t\t\t\t_(\n\t\t\t\t\t\"Custom Field {0} is created by the Administrator and can only be deleted through the Administrator account.\"\n\t\t\t\t).format(frappe.bold(self.label))\n\t\t\t)\n\n\t\t# delete property setter entries\n\t\tfrappe.db.delete(\"Property Setter\", {\"doc_type\": self.dt, \"field_name\": self.fieldname})\n\n\t\t# update doctype layouts\n\t\tdoctype_layouts = frappe.get_all(\n\t\t\t\"DocType Layout\", filters={\"document_type\": self.dt}, pluck=\"name\"\n\t\t)\n\n\t\tfor layout in doctype_layouts:\n\t\t\tlayout_doc = frappe.get_doc(\"DocType Layout\", layout)\n\t\t\tfor field in layout_doc.fields:\n\t\t\t\tif field.fieldname == self.fieldname:\n\t\t\t\t\tlayout_doc.remove(field)\n\t\t\t\t\tlayout_doc.save()\n\t\t\t\t\tbreak\n\n\t\tfrappe.clear_cache(doctype=self.dt)\n\n\tdef validate_insert_after(self, meta):\n\t\tif not meta.get_field(self.insert_after):\n\t\t\tfrappe.throw(\n\t\t\t\t_(\n\t\t\t\t\t\"Insert After field '{0}' mentioned in Custom Field '{1}', with label '{2}', does not exist\"\n\t\t\t\t).format(self.insert_after, self.name, self.label),\n\t\t\t\tfrappe.DoesNotExistError,\n\t\t\t)\n\n\t\tif self.fieldname == self.insert_after:\n\t\t\tfrappe.throw(_(\"Insert After cannot be set as {0}\").format(meta.get_label(self.insert_after)))\n\n\[email protected]()\ndef get_fields_label(doctype=None):\n\tmeta = frappe.get_meta(doctype)\n\n\tif doctype in core_doctypes_list:\n\t\treturn frappe.msgprint(_(\"Custom Fields cannot be added to core DocTypes.\"))\n\n\tif meta.custom:\n\t\treturn frappe.msgprint(_(\"Custom Fields can only be added to a standard DocType.\"))\n\n\treturn [\n\t\t{\"value\": df.fieldname or \"\", \"label\": _(df.label or \"\")}\n\t\tfor df in frappe.get_meta(doctype).get(\"fields\")\n\t]\n\n\ndef create_custom_field_if_values_exist(doctype, df):\n\tdf = frappe._dict(df)\n\tif df.fieldname in frappe.db.get_table_columns(doctype) and frappe.db.count(\n\t\tdt=doctype, filters=IfNull(df.fieldname, \"\") != \"\"\n\t):\n\t\tcreate_custom_field(doctype, df)\n\n\ndef create_custom_field(doctype, df, ignore_validate=False, is_system_generated=True):\n\tdf = frappe._dict(df)\n\tif not df.fieldname and df.label:\n\t\tdf.fieldname = frappe.scrub(df.label)\n\tif not frappe.db.get_value(\"Custom Field\", {\"dt\": doctype, \"fieldname\": df.fieldname}):\n\t\tcustom_field = frappe.get_doc(\n\t\t\t{\n\t\t\t\t\"doctype\": \"Custom Field\",\n\t\t\t\t\"dt\": doctype,\n\t\t\t\t\"permlevel\": 0,\n\t\t\t\t\"fieldtype\": \"Data\",\n\t\t\t\t\"hidden\": 0,\n\t\t\t\t\"is_system_generated\": is_system_generated,\n\t\t\t}\n\t\t)\n\t\tcustom_field.update(df)\n\t\tcustom_field.flags.ignore_validate = ignore_validate\n\t\tcustom_field.insert()\n\t\treturn custom_field\n\n\ndef create_custom_fields(custom_fields, ignore_validate=False, update=True):\n\t\"\"\"Add / update multiple custom fields\n\n\t:param custom_fields: example `{'Sales Invoice': [dict(fieldname='test')]}`\"\"\"\n\n\ttry:\n\t\tfrappe.flags.in_create_custom_fields = True\n\t\tdoctypes_to_update = set()\n\n\t\tif frappe.flags.in_setup_wizard:\n\t\t\tignore_validate = True\n\n\t\tfor doctypes, fields in custom_fields.items():\n\t\t\tif isinstance(fields, dict):\n\t\t\t\t# only one field\n\t\t\t\tfields = [fields]\n\n\t\t\tif isinstance(doctypes, str):\n\t\t\t\t# only one doctype\n\t\t\t\tdoctypes = (doctypes,)\n\n\t\t\tfor doctype in doctypes:\n\t\t\t\tdoctypes_to_update.add(doctype)\n\n\t\t\t\tfor df in fields:\n\t\t\t\t\tfield = frappe.db.get_value(\"Custom Field\", {\"dt\": doctype, \"fieldname\": df[\"fieldname\"]})\n\t\t\t\t\tif not field:\n\t\t\t\t\t\ttry:\n\t\t\t\t\t\t\tdf = df.copy()\n\t\t\t\t\t\t\tdf[\"owner\"] = \"Administrator\"\n\t\t\t\t\t\t\tcreate_custom_field(doctype, df, ignore_validate=ignore_validate)\n\n\t\t\t\t\t\texcept frappe.exceptions.DuplicateEntryError:\n\t\t\t\t\t\t\tpass\n\n\t\t\t\t\telif update:\n\t\t\t\t\t\tcustom_field = frappe.get_doc(\"Custom Field\", field)\n\t\t\t\t\t\tcustom_field.flags.ignore_validate = ignore_validate\n\t\t\t\t\t\tcustom_field.update(df)\n\t\t\t\t\t\tcustom_field.save()\n\n\t\tfor doctype in doctypes_to_update:\n\t\t\tfrappe.clear_cache(doctype=doctype)\n\t\t\tfrappe.db.updatedb(doctype)\n\n\tfinally:\n\t\tfrappe.flags.in_create_custom_fields = False\n", "path": "frappe/custom/doctype/custom_field/custom_field.py"}]}
| 2,977 | 957 |
gh_patches_debug_40221
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-797
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Using http for webhdfs not possible when kerberos is enabled
The hdfs_connect function has no option to choose http or https protocol when connecting to webhdfs.
We are running CDH 5.5 with kerberos but without ssl enabled for webhdfs.
Could you maybe add an option to signal the use of http when using kerberos?
code snippet.
the hdfs_connect function code in ibis/ibis/**init**.py always uses https when auth_mechanism in ['GSSAPI', 'LDAP']
example:
def hdfs_connect(host='localhost', port=50070, protocol='webhdfs',
auth_mechanism='NOSASL', verify=True, use_https=True, **kwds):
if auth_mechanism in ['GSSAPI', 'LDAP']:
try:
import requests_kerberos
except ImportError:
raise IbisError(
"Unable to import requests-kerberos, which is required for "
"Kerberos HDFS support. Install it by executing `pip install "
"requests-kerberos` or `pip install hdfs[kerberos]`.")
from hdfs.ext.kerberos import KerberosClient
if use_https:
url = 'https://{0}:{1}'.format(host, port) # use SSL
else:
url = 'http://{0}:{1}'.format(host, port) # no SSL
kwds.setdefault('mutual_auth', 'OPTIONAL')
hdfs_client = KerberosClient(url, *_kwds)
else:
from hdfs.client import InsecureClient
url = 'http://{0}:{1}'.format(host, port)
hdfs_client = InsecureClient(url, *_kwds)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ibis/impala/api.py`
Content:
```
1 # Copyright 2015 Cloudera Inc
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Unless required by applicable law or agreed to in writing, software
9 # distributed under the License is distributed on an "AS IS" BASIS,
10 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from ibis.impala.client import (ImpalaConnection, # noqa
15 ImpalaClient,
16 ImpalaDatabase,
17 ImpalaTable)
18 from ibis.impala.udf import * # noqa
19 from ibis.impala.madlib import MADLibAPI # noqa
20 from ibis.config import options
21 import ibis.common as com
22
23
24 def compile(expr):
25 """
26 Force compilation of expression as though it were an expression depending
27 on Impala. Note you can also call expr.compile()
28
29 Returns
30 -------
31 compiled : string
32 """
33 from .compiler import to_sql
34 return to_sql(expr)
35
36
37 def verify(expr):
38 """
39 Determine if expression can be successfully translated to execute on Impala
40 """
41 try:
42 compile(expr)
43 return True
44 except com.TranslationError:
45 return False
46
47
48 def connect(host='localhost', port=21050, database='default', timeout=45,
49 use_ssl=False, ca_cert=None, user=None, password=None,
50 auth_mechanism='NOSASL', kerberos_service_name='impala',
51 pool_size=8, hdfs_client=None):
52 """
53 Create an ImpalaClient for use with Ibis.
54
55 Parameters
56 ----------
57 host : string, Host name of the impalad or HiveServer2 in Hive
58 port : int, Defaults to 21050 (Impala's HiveServer2)
59 database : string, Default database when obtaining new cursors
60 timeout : int, Connection timeout (seconds) when communicating with
61 HiveServer2
62 use_ssl : boolean, Use SSL when connecting to HiveServer2
63 ca_cert : string, Local path to 3rd party CA certificate or copy of server
64 certificate for self-signed certificates. If SSL is enabled, but this
65 argument is None, then certificate validation is skipped.
66 user : string, LDAP user to authenticate
67 password : string, LDAP password to authenticate
68 auth_mechanism : string, {'NOSASL' <- default, 'PLAIN', 'GSSAPI', 'LDAP'}.
69 Use NOSASL for non-secured Impala connections. Use PLAIN for
70 non-secured Hive clusters. Use LDAP for LDAP authenticated
71 connections. Use GSSAPI for Kerberos-secured clusters.
72 kerberos_service_name : string, Specify particular impalad service
73 principal.
74
75 Examples
76 --------
77 >>> hdfs = ibis.hdfs_connect(**hdfs_params)
78 >>> client = ibis.impala.connect(hdfs_client=hdfs, **impala_params)
79
80 Returns
81 -------
82 con : ImpalaClient
83 """
84 params = {
85 'host': host,
86 'port': port,
87 'database': database,
88 'timeout': timeout,
89 'use_ssl': use_ssl,
90 'ca_cert': ca_cert,
91 'user': user,
92 'password': password,
93 'auth_mechanism': auth_mechanism,
94 'kerberos_service_name': kerberos_service_name
95 }
96
97 con = ImpalaConnection(pool_size=pool_size, **params)
98 client = ImpalaClient(con, hdfs_client=hdfs_client)
99
100 if options.default_backend is None:
101 options.default_backend = client
102
103 return client
104
```
Path: `ibis/__init__.py`
Content:
```
1 # Copyright 2014 Cloudera Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 # flake8: noqa
17
18 __version__ = '0.5.0'
19
20 from ibis.filesystems import HDFS, WebHDFS
21 from ibis.common import IbisError
22
23 import ibis.expr.api as api
24 import ibis.expr.types as ir
25
26 # __all__ is defined
27 from ibis.expr.api import *
28
29 import ibis.impala.api as impala
30 import ibis.sql.sqlite.api as sqlite
31
32 import ibis.config_init
33 from ibis.config import options
34 import ibis.util as util
35
36
37 # Deprecated
38 impala_connect = util.deprecate(impala.connect,
39 'impala_connect is deprecated, use'
40 ' ibis.impala.connect instead')
41
42
43 def make_client(db, hdfs_client=None):
44 """
45 Create an Ibis client from a database connection and optional additional
46 connections (like HDFS)
47
48 Parameters
49 ----------
50 db : Connection
51 e.g. produced by ibis.impala.connect
52 hdfs_client : ibis HDFS client
53
54 Examples
55 --------
56 >>> con = ibis.impala.connect(**impala_params)
57 >>> hdfs = ibis.hdfs_connect(**hdfs_params)
58 >>> client = ibis.make_client(con, hdfs_client=hdfs)
59
60 Returns
61 -------
62 client : IbisClient
63 """
64 db._hdfs = hdfs_client
65 return db
66
67 make_client = util.deprecate(
68 make_client, ('make_client is deprecated. '
69 'Use ibis.impala.connect '
70 ' with hdfs_client=hdfs_client'))
71
72
73 def hdfs_connect(host='localhost', port=50070, protocol='webhdfs',
74 auth_mechanism='NOSASL', verify=True, **kwds):
75 """
76 Connect to HDFS
77
78 Parameters
79 ----------
80 host : string, Host name of the HDFS NameNode
81 port : int, NameNode's WebHDFS port (default 50070)
82 protocol : {'webhdfs'}
83 auth_mechanism : string, Set to NOSASL or PLAIN for non-secure clusters.
84 Set to GSSAPI or LDAP for Kerberos-secured clusters.
85 verify : boolean, Set to False to turn off verifying SSL certificates.
86 (default True)
87
88 Other keywords are forwarded to hdfs library classes
89
90 Returns
91 -------
92 client : WebHDFS
93 """
94 import requests
95 session = kwds.setdefault('session', requests.Session())
96 session.verify = verify
97 if auth_mechanism in ['GSSAPI', 'LDAP']:
98 try:
99 import requests_kerberos
100 except ImportError:
101 raise IbisError(
102 "Unable to import requests-kerberos, which is required for "
103 "Kerberos HDFS support. Install it by executing `pip install "
104 "requests-kerberos` or `pip install hdfs[kerberos]`.")
105 from hdfs.ext.kerberos import KerberosClient
106 url = 'https://{0}:{1}'.format(host, port) # note SSL
107 kwds.setdefault('mutual_auth', 'OPTIONAL')
108 hdfs_client = KerberosClient(url, **kwds)
109 else:
110 from hdfs.client import InsecureClient
111 url = 'http://{0}:{1}'.format(host, port)
112 hdfs_client = InsecureClient(url, **kwds)
113 return WebHDFS(hdfs_client)
114
115 def test(impala=False):
116 import pytest
117 import ibis
118 import os
119
120 ibis_dir, _ = os.path.split(ibis.__file__)
121
122 args = ['--pyargs', ibis_dir]
123 if impala:
124 args.append('--impala')
125 pytest.main(args)
126
127 from ._version import get_versions
128 __version__ = get_versions()['version']
129 del get_versions
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ibis/__init__.py b/ibis/__init__.py
--- a/ibis/__init__.py
+++ b/ibis/__init__.py
@@ -71,7 +71,8 @@
def hdfs_connect(host='localhost', port=50070, protocol='webhdfs',
- auth_mechanism='NOSASL', verify=True, **kwds):
+ use_https='default', auth_mechanism='NOSASL',
+ verify=True, **kwds):
"""
Connect to HDFS
@@ -80,6 +81,9 @@
host : string, Host name of the HDFS NameNode
port : int, NameNode's WebHDFS port (default 50070)
protocol : {'webhdfs'}
+ use_https : boolean, default 'default'
+ Connect to WebHDFS with HTTPS, otherwise plain HTTP. For secure
+ authentication, the default for this is True, otherwise False
auth_mechanism : string, Set to NOSASL or PLAIN for non-secure clusters.
Set to GSSAPI or LDAP for Kerberos-secured clusters.
verify : boolean, Set to False to turn off verifying SSL certificates.
@@ -95,6 +99,10 @@
session = kwds.setdefault('session', requests.Session())
session.verify = verify
if auth_mechanism in ['GSSAPI', 'LDAP']:
+ if use_https == 'default':
+ prefix = 'https'
+ else:
+ prefix = 'https' if use_https else 'http'
try:
import requests_kerberos
except ImportError:
@@ -103,12 +111,17 @@
"Kerberos HDFS support. Install it by executing `pip install "
"requests-kerberos` or `pip install hdfs[kerberos]`.")
from hdfs.ext.kerberos import KerberosClient
- url = 'https://{0}:{1}'.format(host, port) # note SSL
+ # note SSL
+ url = '{0}://{1}:{2}'.format(prefix, host, port)
kwds.setdefault('mutual_auth', 'OPTIONAL')
hdfs_client = KerberosClient(url, **kwds)
else:
+ if use_https == 'default':
+ prefix = 'http'
+ else:
+ prefix = 'https' if use_https else 'http'
from hdfs.client import InsecureClient
- url = 'http://{0}:{1}'.format(host, port)
+ url = '{0}://{1}:{2}'.format(prefix, host, port)
hdfs_client = InsecureClient(url, **kwds)
return WebHDFS(hdfs_client)
diff --git a/ibis/impala/api.py b/ibis/impala/api.py
--- a/ibis/impala/api.py
+++ b/ibis/impala/api.py
@@ -46,9 +46,9 @@
def connect(host='localhost', port=21050, database='default', timeout=45,
- use_ssl=False, ca_cert=None, user=None, password=None,
- auth_mechanism='NOSASL', kerberos_service_name='impala',
- pool_size=8, hdfs_client=None):
+ use_ssl=False, ca_cert=None, user=None,
+ password=None, auth_mechanism='NOSASL',
+ kerberos_service_name='impala', pool_size=8, hdfs_client=None):
"""
Create an ImpalaClient for use with Ibis.
|
{"golden_diff": "diff --git a/ibis/__init__.py b/ibis/__init__.py\n--- a/ibis/__init__.py\n+++ b/ibis/__init__.py\n@@ -71,7 +71,8 @@\n \n \n def hdfs_connect(host='localhost', port=50070, protocol='webhdfs',\n- auth_mechanism='NOSASL', verify=True, **kwds):\n+ use_https='default', auth_mechanism='NOSASL',\n+ verify=True, **kwds):\n \"\"\"\n Connect to HDFS\n \n@@ -80,6 +81,9 @@\n host : string, Host name of the HDFS NameNode\n port : int, NameNode's WebHDFS port (default 50070)\n protocol : {'webhdfs'}\n+ use_https : boolean, default 'default'\n+ Connect to WebHDFS with HTTPS, otherwise plain HTTP. For secure\n+ authentication, the default for this is True, otherwise False\n auth_mechanism : string, Set to NOSASL or PLAIN for non-secure clusters.\n Set to GSSAPI or LDAP for Kerberos-secured clusters.\n verify : boolean, Set to False to turn off verifying SSL certificates.\n@@ -95,6 +99,10 @@\n session = kwds.setdefault('session', requests.Session())\n session.verify = verify\n if auth_mechanism in ['GSSAPI', 'LDAP']:\n+ if use_https == 'default':\n+ prefix = 'https'\n+ else:\n+ prefix = 'https' if use_https else 'http'\n try:\n import requests_kerberos\n except ImportError:\n@@ -103,12 +111,17 @@\n \"Kerberos HDFS support. Install it by executing `pip install \"\n \"requests-kerberos` or `pip install hdfs[kerberos]`.\")\n from hdfs.ext.kerberos import KerberosClient\n- url = 'https://{0}:{1}'.format(host, port) # note SSL\n+ # note SSL\n+ url = '{0}://{1}:{2}'.format(prefix, host, port)\n kwds.setdefault('mutual_auth', 'OPTIONAL')\n hdfs_client = KerberosClient(url, **kwds)\n else:\n+ if use_https == 'default':\n+ prefix = 'http'\n+ else:\n+ prefix = 'https' if use_https else 'http'\n from hdfs.client import InsecureClient\n- url = 'http://{0}:{1}'.format(host, port)\n+ url = '{0}://{1}:{2}'.format(prefix, host, port)\n hdfs_client = InsecureClient(url, **kwds)\n return WebHDFS(hdfs_client)\n \ndiff --git a/ibis/impala/api.py b/ibis/impala/api.py\n--- a/ibis/impala/api.py\n+++ b/ibis/impala/api.py\n@@ -46,9 +46,9 @@\n \n \n def connect(host='localhost', port=21050, database='default', timeout=45,\n- use_ssl=False, ca_cert=None, user=None, password=None,\n- auth_mechanism='NOSASL', kerberos_service_name='impala',\n- pool_size=8, hdfs_client=None):\n+ use_ssl=False, ca_cert=None, user=None,\n+ password=None, auth_mechanism='NOSASL',\n+ kerberos_service_name='impala', pool_size=8, hdfs_client=None):\n \"\"\"\n Create an ImpalaClient for use with Ibis.\n", "issue": "Using http for webhdfs not possible when kerberos is enabled \nThe hdfs_connect function has no option to choose http or https protocol when connecting to webhdfs.\nWe are running CDH 5.5 with kerberos but without ssl enabled for webhdfs.\n\nCould you maybe add an option to signal the use of http when using kerberos?\n\ncode snippet.\n\nthe hdfs_connect function code in ibis/ibis/**init**.py always uses https when auth_mechanism in ['GSSAPI', 'LDAP']\n\nexample:\n\ndef hdfs_connect(host='localhost', port=50070, protocol='webhdfs',\n auth_mechanism='NOSASL', verify=True, use_https=True, **kwds):\n\nif auth_mechanism in ['GSSAPI', 'LDAP']:\n try:\n import requests_kerberos\n except ImportError:\n raise IbisError(\n \"Unable to import requests-kerberos, which is required for \"\n \"Kerberos HDFS support. Install it by executing `pip install \"\n \"requests-kerberos` or `pip install hdfs[kerberos]`.\")\n from hdfs.ext.kerberos import KerberosClient\n if use_https:\n url = 'https://{0}:{1}'.format(host, port) # use SSL\n else:\n url = 'http://{0}:{1}'.format(host, port) # no SSL\n kwds.setdefault('mutual_auth', 'OPTIONAL')\n hdfs_client = KerberosClient(url, *_kwds)\n else:\n from hdfs.client import InsecureClient\n url = 'http://{0}:{1}'.format(host, port)\n hdfs_client = InsecureClient(url, *_kwds)\n\n", "before_files": [{"content": "# Copyright 2015 Cloudera Inc\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom ibis.impala.client import (ImpalaConnection, # noqa\n ImpalaClient,\n ImpalaDatabase,\n ImpalaTable)\nfrom ibis.impala.udf import * # noqa\nfrom ibis.impala.madlib import MADLibAPI # noqa\nfrom ibis.config import options\nimport ibis.common as com\n\n\ndef compile(expr):\n \"\"\"\n Force compilation of expression as though it were an expression depending\n on Impala. Note you can also call expr.compile()\n\n Returns\n -------\n compiled : string\n \"\"\"\n from .compiler import to_sql\n return to_sql(expr)\n\n\ndef verify(expr):\n \"\"\"\n Determine if expression can be successfully translated to execute on Impala\n \"\"\"\n try:\n compile(expr)\n return True\n except com.TranslationError:\n return False\n\n\ndef connect(host='localhost', port=21050, database='default', timeout=45,\n use_ssl=False, ca_cert=None, user=None, password=None,\n auth_mechanism='NOSASL', kerberos_service_name='impala',\n pool_size=8, hdfs_client=None):\n \"\"\"\n Create an ImpalaClient for use with Ibis.\n\n Parameters\n ----------\n host : string, Host name of the impalad or HiveServer2 in Hive\n port : int, Defaults to 21050 (Impala's HiveServer2)\n database : string, Default database when obtaining new cursors\n timeout : int, Connection timeout (seconds) when communicating with\n HiveServer2\n use_ssl : boolean, Use SSL when connecting to HiveServer2\n ca_cert : string, Local path to 3rd party CA certificate or copy of server\n certificate for self-signed certificates. If SSL is enabled, but this\n argument is None, then certificate validation is skipped.\n user : string, LDAP user to authenticate\n password : string, LDAP password to authenticate\n auth_mechanism : string, {'NOSASL' <- default, 'PLAIN', 'GSSAPI', 'LDAP'}.\n Use NOSASL for non-secured Impala connections. Use PLAIN for\n non-secured Hive clusters. Use LDAP for LDAP authenticated\n connections. Use GSSAPI for Kerberos-secured clusters.\n kerberos_service_name : string, Specify particular impalad service\n principal.\n\n Examples\n --------\n >>> hdfs = ibis.hdfs_connect(**hdfs_params)\n >>> client = ibis.impala.connect(hdfs_client=hdfs, **impala_params)\n\n Returns\n -------\n con : ImpalaClient\n \"\"\"\n params = {\n 'host': host,\n 'port': port,\n 'database': database,\n 'timeout': timeout,\n 'use_ssl': use_ssl,\n 'ca_cert': ca_cert,\n 'user': user,\n 'password': password,\n 'auth_mechanism': auth_mechanism,\n 'kerberos_service_name': kerberos_service_name\n }\n\n con = ImpalaConnection(pool_size=pool_size, **params)\n client = ImpalaClient(con, hdfs_client=hdfs_client)\n\n if options.default_backend is None:\n options.default_backend = client\n\n return client\n", "path": "ibis/impala/api.py"}, {"content": "# Copyright 2014 Cloudera Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n# flake8: noqa\n\n__version__ = '0.5.0'\n\nfrom ibis.filesystems import HDFS, WebHDFS\nfrom ibis.common import IbisError\n\nimport ibis.expr.api as api\nimport ibis.expr.types as ir\n\n# __all__ is defined\nfrom ibis.expr.api import *\n\nimport ibis.impala.api as impala\nimport ibis.sql.sqlite.api as sqlite\n\nimport ibis.config_init\nfrom ibis.config import options\nimport ibis.util as util\n\n\n# Deprecated\nimpala_connect = util.deprecate(impala.connect,\n 'impala_connect is deprecated, use'\n ' ibis.impala.connect instead')\n\n\ndef make_client(db, hdfs_client=None):\n \"\"\"\n Create an Ibis client from a database connection and optional additional\n connections (like HDFS)\n\n Parameters\n ----------\n db : Connection\n e.g. produced by ibis.impala.connect\n hdfs_client : ibis HDFS client\n\n Examples\n --------\n >>> con = ibis.impala.connect(**impala_params)\n >>> hdfs = ibis.hdfs_connect(**hdfs_params)\n >>> client = ibis.make_client(con, hdfs_client=hdfs)\n\n Returns\n -------\n client : IbisClient\n \"\"\"\n db._hdfs = hdfs_client\n return db\n\nmake_client = util.deprecate(\n make_client, ('make_client is deprecated. '\n 'Use ibis.impala.connect '\n ' with hdfs_client=hdfs_client'))\n\n\ndef hdfs_connect(host='localhost', port=50070, protocol='webhdfs',\n auth_mechanism='NOSASL', verify=True, **kwds):\n \"\"\"\n Connect to HDFS\n\n Parameters\n ----------\n host : string, Host name of the HDFS NameNode\n port : int, NameNode's WebHDFS port (default 50070)\n protocol : {'webhdfs'}\n auth_mechanism : string, Set to NOSASL or PLAIN for non-secure clusters.\n Set to GSSAPI or LDAP for Kerberos-secured clusters.\n verify : boolean, Set to False to turn off verifying SSL certificates.\n (default True)\n\n Other keywords are forwarded to hdfs library classes\n\n Returns\n -------\n client : WebHDFS\n \"\"\"\n import requests\n session = kwds.setdefault('session', requests.Session())\n session.verify = verify\n if auth_mechanism in ['GSSAPI', 'LDAP']:\n try:\n import requests_kerberos\n except ImportError:\n raise IbisError(\n \"Unable to import requests-kerberos, which is required for \"\n \"Kerberos HDFS support. Install it by executing `pip install \"\n \"requests-kerberos` or `pip install hdfs[kerberos]`.\")\n from hdfs.ext.kerberos import KerberosClient\n url = 'https://{0}:{1}'.format(host, port) # note SSL\n kwds.setdefault('mutual_auth', 'OPTIONAL')\n hdfs_client = KerberosClient(url, **kwds)\n else:\n from hdfs.client import InsecureClient\n url = 'http://{0}:{1}'.format(host, port)\n hdfs_client = InsecureClient(url, **kwds)\n return WebHDFS(hdfs_client)\n\ndef test(impala=False):\n import pytest\n import ibis\n import os\n\n ibis_dir, _ = os.path.split(ibis.__file__)\n\n args = ['--pyargs', ibis_dir]\n if impala:\n args.append('--impala')\n pytest.main(args)\n\nfrom ._version import get_versions\n__version__ = get_versions()['version']\ndel get_versions\n", "path": "ibis/__init__.py"}], "after_files": [{"content": "# Copyright 2015 Cloudera Inc\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom ibis.impala.client import (ImpalaConnection, # noqa\n ImpalaClient,\n ImpalaDatabase,\n ImpalaTable)\nfrom ibis.impala.udf import * # noqa\nfrom ibis.impala.madlib import MADLibAPI # noqa\nfrom ibis.config import options\nimport ibis.common as com\n\n\ndef compile(expr):\n \"\"\"\n Force compilation of expression as though it were an expression depending\n on Impala. Note you can also call expr.compile()\n\n Returns\n -------\n compiled : string\n \"\"\"\n from .compiler import to_sql\n return to_sql(expr)\n\n\ndef verify(expr):\n \"\"\"\n Determine if expression can be successfully translated to execute on Impala\n \"\"\"\n try:\n compile(expr)\n return True\n except com.TranslationError:\n return False\n\n\ndef connect(host='localhost', port=21050, database='default', timeout=45,\n use_ssl=False, ca_cert=None, user=None,\n password=None, auth_mechanism='NOSASL',\n kerberos_service_name='impala', pool_size=8, hdfs_client=None):\n \"\"\"\n Create an ImpalaClient for use with Ibis.\n\n Parameters\n ----------\n host : string, Host name of the impalad or HiveServer2 in Hive\n port : int, Defaults to 21050 (Impala's HiveServer2)\n database : string, Default database when obtaining new cursors\n timeout : int, Connection timeout (seconds) when communicating with\n HiveServer2\n use_ssl : boolean, Use SSL when connecting to HiveServer2\n ca_cert : string, Local path to 3rd party CA certificate or copy of server\n certificate for self-signed certificates. If SSL is enabled, but this\n argument is None, then certificate validation is skipped.\n user : string, LDAP user to authenticate\n password : string, LDAP password to authenticate\n auth_mechanism : string, {'NOSASL' <- default, 'PLAIN', 'GSSAPI', 'LDAP'}.\n Use NOSASL for non-secured Impala connections. Use PLAIN for\n non-secured Hive clusters. Use LDAP for LDAP authenticated\n connections. Use GSSAPI for Kerberos-secured clusters.\n kerberos_service_name : string, Specify particular impalad service\n principal.\n\n Examples\n --------\n >>> hdfs = ibis.hdfs_connect(**hdfs_params)\n >>> client = ibis.impala.connect(hdfs_client=hdfs, **impala_params)\n\n Returns\n -------\n con : ImpalaClient\n \"\"\"\n params = {\n 'host': host,\n 'port': port,\n 'database': database,\n 'timeout': timeout,\n 'use_ssl': use_ssl,\n 'ca_cert': ca_cert,\n 'user': user,\n 'password': password,\n 'auth_mechanism': auth_mechanism,\n 'kerberos_service_name': kerberos_service_name\n }\n\n con = ImpalaConnection(pool_size=pool_size, **params)\n client = ImpalaClient(con, hdfs_client=hdfs_client)\n\n if options.default_backend is None:\n options.default_backend = client\n\n return client\n", "path": "ibis/impala/api.py"}, {"content": "# Copyright 2014 Cloudera Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n# flake8: noqa\n\n__version__ = '0.5.0'\n\nfrom ibis.filesystems import HDFS, WebHDFS\nfrom ibis.common import IbisError\n\nimport ibis.expr.api as api\nimport ibis.expr.types as ir\n\n# __all__ is defined\nfrom ibis.expr.api import *\n\nimport ibis.impala.api as impala\nimport ibis.sql.sqlite.api as sqlite\n\nimport ibis.config_init\nfrom ibis.config import options\nimport ibis.util as util\n\n\n# Deprecated\nimpala_connect = util.deprecate(impala.connect,\n 'impala_connect is deprecated, use'\n ' ibis.impala.connect instead')\n\n\ndef make_client(db, hdfs_client=None):\n \"\"\"\n Create an Ibis client from a database connection and optional additional\n connections (like HDFS)\n\n Parameters\n ----------\n db : Connection\n e.g. produced by ibis.impala.connect\n hdfs_client : ibis HDFS client\n\n Examples\n --------\n >>> con = ibis.impala.connect(**impala_params)\n >>> hdfs = ibis.hdfs_connect(**hdfs_params)\n >>> client = ibis.make_client(con, hdfs_client=hdfs)\n\n Returns\n -------\n client : IbisClient\n \"\"\"\n db._hdfs = hdfs_client\n return db\n\nmake_client = util.deprecate(\n make_client, ('make_client is deprecated. '\n 'Use ibis.impala.connect '\n ' with hdfs_client=hdfs_client'))\n\n\ndef hdfs_connect(host='localhost', port=50070, protocol='webhdfs',\n use_https='default', auth_mechanism='NOSASL',\n verify=True, **kwds):\n \"\"\"\n Connect to HDFS\n\n Parameters\n ----------\n host : string, Host name of the HDFS NameNode\n port : int, NameNode's WebHDFS port (default 50070)\n protocol : {'webhdfs'}\n use_https : boolean, default 'default'\n Connect to WebHDFS with HTTPS, otherwise plain HTTP. For secure\n authentication, the default for this is True, otherwise False\n auth_mechanism : string, Set to NOSASL or PLAIN for non-secure clusters.\n Set to GSSAPI or LDAP for Kerberos-secured clusters.\n verify : boolean, Set to False to turn off verifying SSL certificates.\n (default True)\n\n Other keywords are forwarded to hdfs library classes\n\n Returns\n -------\n client : WebHDFS\n \"\"\"\n import requests\n session = kwds.setdefault('session', requests.Session())\n session.verify = verify\n if auth_mechanism in ['GSSAPI', 'LDAP']:\n if use_https == 'default':\n prefix = 'https'\n else:\n prefix = 'https' if use_https else 'http'\n try:\n import requests_kerberos\n except ImportError:\n raise IbisError(\n \"Unable to import requests-kerberos, which is required for \"\n \"Kerberos HDFS support. Install it by executing `pip install \"\n \"requests-kerberos` or `pip install hdfs[kerberos]`.\")\n from hdfs.ext.kerberos import KerberosClient\n # note SSL\n url = '{0}://{1}:{2}'.format(prefix, host, port)\n kwds.setdefault('mutual_auth', 'OPTIONAL')\n hdfs_client = KerberosClient(url, **kwds)\n else:\n if use_https == 'default':\n prefix = 'http'\n else:\n prefix = 'https' if use_https else 'http'\n from hdfs.client import InsecureClient\n url = '{0}://{1}:{2}'.format(prefix, host, port)\n hdfs_client = InsecureClient(url, **kwds)\n return WebHDFS(hdfs_client)\n\ndef test(impala=False):\n import pytest\n import ibis\n import os\n\n ibis_dir, _ = os.path.split(ibis.__file__)\n\n args = ['--pyargs', ibis_dir]\n if impala:\n args.append('--impala')\n pytest.main(args)\n\nfrom ._version import get_versions\n__version__ = get_versions()['version']\ndel get_versions\n", "path": "ibis/__init__.py"}]}
| 2,937 | 805 |
gh_patches_debug_32245
|
rasdani/github-patches
|
git_diff
|
AlexsLemonade__refinebio-2216
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Engagement bot summary doesn't seem to be working
### Context
https://github.com/AlexsLemonade/refinebio/issues/2140
### Problem or idea
Tested today and reported no downloads in the last 7 days.
> **EngagementBot**
> There were no downloads in the last 7 days.
However there were a few that should have been counted:
```
data_refinery=> select id, created_at from data_refinery_common_dataset where is_processed='t' and email_address is not NULL order by created_at desc limit 10;
id | created_at
--------------------------------------+-------------------------------
381e86b9-aea2-4d9a-8a61-338b111fe54d | 2020-03-29 13:06:28.954778+00
eb726da7-8006-46c4-95ba-8a3bcecbd6f1 | 2020-03-26 02:26:35.196333+00
099e7b58-dce6-4d5c-a4b6-f4d049dad866 | 2020-03-25 16:19:14.656207+00
c4c086ef-6963-4fd8-b4e2-a7cf09c9eb68 | 2020-03-25 16:18:03.158765+00
0716857b-211f-484c-9e2b-3e447dd5cdaf | 2020-03-25 15:34:20.155269+00
2e7c1e1c-138b-43b1-9463-0113c64e7edb | 2020-03-25 15:19:23.577922+00
4a2ac1ef-4e9e-4945-bdf8-00d595f99c4c | 2020-03-25 15:18:21.49652+00
bbb30f4e-7b5f-4595-a47d-25f8d72e4a7c | 2020-03-25 15:03:55.391917+00
eff9cbe4-c4f5-43a6-b004-6cd36f10ea15 | 2020-03-24 22:41:51.185922+00
```
### Solution or next step
Investigate why these downloads are not being reported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `api/data_refinery_api/management/commands/post_downloads_summary.py`
Content:
```
1 import datetime
2
3 from django.conf import settings
4 from django.core.management.base import BaseCommand
5 from django.utils import timezone
6
7 import requests
8
9 from data_refinery_common.models import DatasetAnnotation
10
11
12 class Command(BaseCommand):
13 help = "Post downloads summary to slack"
14
15 def add_arguments(self, parser):
16 parser.add_argument(
17 "--days",
18 type=int,
19 default=7, # default to a week
20 help=("Number of days in the past for which to build the stats"),
21 )
22 parser.add_argument(
23 "--channel",
24 type=str,
25 default="ccdl-general",
26 help=("Optional parameter to choose the channel where the message will be posted."),
27 )
28
29 def handle(self, *args, **options):
30 days = options["days"]
31 start_time = timezone.now() - datetime.timedelta(days=-days)
32
33 annotation_queryset = DatasetAnnotation.objects.filter(
34 created_at__gt=start_time
35 ).prefetch_related("dataset")
36 annotations = [
37 annotation
38 for annotation in annotation_queryset
39 if annotation.data["start"] and should_display_email(annotation.dataset.email_address)
40 ]
41
42 unique_users = list(set(annotation.dataset.email_address for annotation in annotations))
43 unique_ips = list(set(annotation.data["ip"] for annotation in annotations))
44
45 if unique_users:
46 fallback_text = "In the last {0} days, {1} users downloaded datasets from {2} locations.".format(
47 days, len(unique_users), len(unique_ips)
48 )
49 else:
50 fallback_text = "There were no downloads in the last {0} days.".format(days)
51
52 new_users = ""
53 returning_users = ""
54 for email in unique_users:
55 user_annotations = annotation_queryset.filter(dataset__email_address=email)
56 total_downloads = user_annotations.count()
57 unique_locations = list(set(annotation.data["ip"] for annotation in user_annotations))
58 locations = ", ".join(get_ip_location(ip) for ip in unique_locations)
59 is_new_user = DatasetAnnotation.objects.filter(
60 created_at__lt=start_time, dataset__email_address=email
61 )
62 text = "{0} | {1} downloads from {2}\n".format(email, total_downloads, locations)
63 if is_new_user:
64 new_users += text
65 else:
66 returning_users += text
67
68 blocks = [
69 {
70 "type": "section",
71 "text": {"type": "plain_text", "emoji": True, "text": fallback_text},
72 }
73 ]
74 if new_users:
75 blocks.append(
76 {
77 "type": "section",
78 "text": {"type": "mrkdwn", "text": "*New users* \n" + new_users,},
79 }
80 )
81 if returning_users:
82 blocks.append(
83 {
84 "type": "section",
85 "text": {"type": "mrkdwn", "text": "*Returning users* \n" + returning_users,},
86 }
87 )
88
89 # Post to slack
90 requests.post(
91 settings.ENGAGEMENTBOT_WEBHOOK,
92 json={
93 "username": "EngagementBot",
94 "icon_emoji": ":halal:",
95 "channel": "#" + options["channel"],
96 "text": fallback_text,
97 "blocks": blocks,
98 },
99 headers={"Content-Type": "application/json"},
100 timeout=10,
101 )
102
103
104 def should_display_email(email: str) -> bool:
105 """ Returns true if the given email is not associated with the CCDL suers """
106 if not email:
107 return False
108
109 return not (
110 email.startswith("cansav09")
111 or email.startswith("arielsvn")
112 or email.startswith("jaclyn.n.taroni")
113 or email.startswith("kurt.wheeler")
114 or email.startswith("greenescientist")
115 or "@alexslemonade.org" not in email
116 or email.startswith("miserlou")
117 or email.startswith("d.prasad")
118 or email is ("[email protected]")
119 or email is ("[email protected]")
120 )
121
122
123 def get_ip_location(remote_ip):
124 try:
125 city = requests.get("https://ipapi.co/" + remote_ip + "/json/", timeout=10).json()["city"]
126 except Exception:
127 city = remote_ip
128 return city
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/api/data_refinery_api/management/commands/post_downloads_summary.py b/api/data_refinery_api/management/commands/post_downloads_summary.py
--- a/api/data_refinery_api/management/commands/post_downloads_summary.py
+++ b/api/data_refinery_api/management/commands/post_downloads_summary.py
@@ -28,7 +28,7 @@
def handle(self, *args, **options):
days = options["days"]
- start_time = timezone.now() - datetime.timedelta(days=-days)
+ start_time = timezone.now() - datetime.timedelta(days=days)
annotation_queryset = DatasetAnnotation.objects.filter(
created_at__gt=start_time
@@ -105,16 +105,15 @@
""" Returns true if the given email is not associated with the CCDL suers """
if not email:
return False
-
return not (
email.startswith("cansav09")
or email.startswith("arielsvn")
or email.startswith("jaclyn.n.taroni")
or email.startswith("kurt.wheeler")
or email.startswith("greenescientist")
- or "@alexslemonade.org" not in email
or email.startswith("miserlou")
or email.startswith("d.prasad")
+ or email.endswith("@alexslemonade.org")
or email is ("[email protected]")
or email is ("[email protected]")
)
@@ -122,7 +121,7 @@
def get_ip_location(remote_ip):
try:
- city = requests.get("https://ipapi.co/" + remote_ip + "/json/", timeout=10).json()["city"]
+ data = requests.get("https://ipapi.co/" + remote_ip + "/json/", timeout=10).json()
+ return "{0}, {1}".format(data["city"], data["country_name"])
except Exception:
- city = remote_ip
- return city
+ return remote_ip
|
{"golden_diff": "diff --git a/api/data_refinery_api/management/commands/post_downloads_summary.py b/api/data_refinery_api/management/commands/post_downloads_summary.py\n--- a/api/data_refinery_api/management/commands/post_downloads_summary.py\n+++ b/api/data_refinery_api/management/commands/post_downloads_summary.py\n@@ -28,7 +28,7 @@\n \n def handle(self, *args, **options):\n days = options[\"days\"]\n- start_time = timezone.now() - datetime.timedelta(days=-days)\n+ start_time = timezone.now() - datetime.timedelta(days=days)\n \n annotation_queryset = DatasetAnnotation.objects.filter(\n created_at__gt=start_time\n@@ -105,16 +105,15 @@\n \"\"\" Returns true if the given email is not associated with the CCDL suers \"\"\"\n if not email:\n return False\n-\n return not (\n email.startswith(\"cansav09\")\n or email.startswith(\"arielsvn\")\n or email.startswith(\"jaclyn.n.taroni\")\n or email.startswith(\"kurt.wheeler\")\n or email.startswith(\"greenescientist\")\n- or \"@alexslemonade.org\" not in email\n or email.startswith(\"miserlou\")\n or email.startswith(\"d.prasad\")\n+ or email.endswith(\"@alexslemonade.org\")\n or email is (\"[email protected]\")\n or email is (\"[email protected]\")\n )\n@@ -122,7 +121,7 @@\n \n def get_ip_location(remote_ip):\n try:\n- city = requests.get(\"https://ipapi.co/\" + remote_ip + \"/json/\", timeout=10).json()[\"city\"]\n+ data = requests.get(\"https://ipapi.co/\" + remote_ip + \"/json/\", timeout=10).json()\n+ return \"{0}, {1}\".format(data[\"city\"], data[\"country_name\"])\n except Exception:\n- city = remote_ip\n- return city\n+ return remote_ip\n", "issue": "Engagement bot summary doesn't seem to be working\n### Context\r\n\r\nhttps://github.com/AlexsLemonade/refinebio/issues/2140\r\n\r\n### Problem or idea\r\n\r\nTested today and reported no downloads in the last 7 days.\r\n\r\n> **EngagementBot**\r\n> There were no downloads in the last 7 days.\r\n\r\nHowever there were a few that should have been counted:\r\n\r\n```\r\ndata_refinery=> select id, created_at from data_refinery_common_dataset where is_processed='t' and email_address is not NULL order by created_at desc limit 10;\r\n id | created_at \r\n--------------------------------------+-------------------------------\r\n 381e86b9-aea2-4d9a-8a61-338b111fe54d | 2020-03-29 13:06:28.954778+00\r\n eb726da7-8006-46c4-95ba-8a3bcecbd6f1 | 2020-03-26 02:26:35.196333+00\r\n 099e7b58-dce6-4d5c-a4b6-f4d049dad866 | 2020-03-25 16:19:14.656207+00\r\n c4c086ef-6963-4fd8-b4e2-a7cf09c9eb68 | 2020-03-25 16:18:03.158765+00\r\n 0716857b-211f-484c-9e2b-3e447dd5cdaf | 2020-03-25 15:34:20.155269+00\r\n 2e7c1e1c-138b-43b1-9463-0113c64e7edb | 2020-03-25 15:19:23.577922+00\r\n 4a2ac1ef-4e9e-4945-bdf8-00d595f99c4c | 2020-03-25 15:18:21.49652+00\r\n bbb30f4e-7b5f-4595-a47d-25f8d72e4a7c | 2020-03-25 15:03:55.391917+00\r\n eff9cbe4-c4f5-43a6-b004-6cd36f10ea15 | 2020-03-24 22:41:51.185922+00\r\n```\r\n\r\n### Solution or next step\r\n\r\nInvestigate why these downloads are not being reported.\r\n\n", "before_files": [{"content": "import datetime\n\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom django.utils import timezone\n\nimport requests\n\nfrom data_refinery_common.models import DatasetAnnotation\n\n\nclass Command(BaseCommand):\n help = \"Post downloads summary to slack\"\n\n def add_arguments(self, parser):\n parser.add_argument(\n \"--days\",\n type=int,\n default=7, # default to a week\n help=(\"Number of days in the past for which to build the stats\"),\n )\n parser.add_argument(\n \"--channel\",\n type=str,\n default=\"ccdl-general\",\n help=(\"Optional parameter to choose the channel where the message will be posted.\"),\n )\n\n def handle(self, *args, **options):\n days = options[\"days\"]\n start_time = timezone.now() - datetime.timedelta(days=-days)\n\n annotation_queryset = DatasetAnnotation.objects.filter(\n created_at__gt=start_time\n ).prefetch_related(\"dataset\")\n annotations = [\n annotation\n for annotation in annotation_queryset\n if annotation.data[\"start\"] and should_display_email(annotation.dataset.email_address)\n ]\n\n unique_users = list(set(annotation.dataset.email_address for annotation in annotations))\n unique_ips = list(set(annotation.data[\"ip\"] for annotation in annotations))\n\n if unique_users:\n fallback_text = \"In the last {0} days, {1} users downloaded datasets from {2} locations.\".format(\n days, len(unique_users), len(unique_ips)\n )\n else:\n fallback_text = \"There were no downloads in the last {0} days.\".format(days)\n\n new_users = \"\"\n returning_users = \"\"\n for email in unique_users:\n user_annotations = annotation_queryset.filter(dataset__email_address=email)\n total_downloads = user_annotations.count()\n unique_locations = list(set(annotation.data[\"ip\"] for annotation in user_annotations))\n locations = \", \".join(get_ip_location(ip) for ip in unique_locations)\n is_new_user = DatasetAnnotation.objects.filter(\n created_at__lt=start_time, dataset__email_address=email\n )\n text = \"{0} | {1} downloads from {2}\\n\".format(email, total_downloads, locations)\n if is_new_user:\n new_users += text\n else:\n returning_users += text\n\n blocks = [\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"plain_text\", \"emoji\": True, \"text\": fallback_text},\n }\n ]\n if new_users:\n blocks.append(\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"mrkdwn\", \"text\": \"*New users* \\n\" + new_users,},\n }\n )\n if returning_users:\n blocks.append(\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"mrkdwn\", \"text\": \"*Returning users* \\n\" + returning_users,},\n }\n )\n\n # Post to slack\n requests.post(\n settings.ENGAGEMENTBOT_WEBHOOK,\n json={\n \"username\": \"EngagementBot\",\n \"icon_emoji\": \":halal:\",\n \"channel\": \"#\" + options[\"channel\"],\n \"text\": fallback_text,\n \"blocks\": blocks,\n },\n headers={\"Content-Type\": \"application/json\"},\n timeout=10,\n )\n\n\ndef should_display_email(email: str) -> bool:\n \"\"\" Returns true if the given email is not associated with the CCDL suers \"\"\"\n if not email:\n return False\n\n return not (\n email.startswith(\"cansav09\")\n or email.startswith(\"arielsvn\")\n or email.startswith(\"jaclyn.n.taroni\")\n or email.startswith(\"kurt.wheeler\")\n or email.startswith(\"greenescientist\")\n or \"@alexslemonade.org\" not in email\n or email.startswith(\"miserlou\")\n or email.startswith(\"d.prasad\")\n or email is (\"[email protected]\")\n or email is (\"[email protected]\")\n )\n\n\ndef get_ip_location(remote_ip):\n try:\n city = requests.get(\"https://ipapi.co/\" + remote_ip + \"/json/\", timeout=10).json()[\"city\"]\n except Exception:\n city = remote_ip\n return city\n", "path": "api/data_refinery_api/management/commands/post_downloads_summary.py"}], "after_files": [{"content": "import datetime\n\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom django.utils import timezone\n\nimport requests\n\nfrom data_refinery_common.models import DatasetAnnotation\n\n\nclass Command(BaseCommand):\n help = \"Post downloads summary to slack\"\n\n def add_arguments(self, parser):\n parser.add_argument(\n \"--days\",\n type=int,\n default=7, # default to a week\n help=(\"Number of days in the past for which to build the stats\"),\n )\n parser.add_argument(\n \"--channel\",\n type=str,\n default=\"ccdl-general\",\n help=(\"Optional parameter to choose the channel where the message will be posted.\"),\n )\n\n def handle(self, *args, **options):\n days = options[\"days\"]\n start_time = timezone.now() - datetime.timedelta(days=days)\n\n annotation_queryset = DatasetAnnotation.objects.filter(\n created_at__gt=start_time\n ).prefetch_related(\"dataset\")\n annotations = [\n annotation\n for annotation in annotation_queryset\n if annotation.data[\"start\"] and should_display_email(annotation.dataset.email_address)\n ]\n\n unique_users = list(set(annotation.dataset.email_address for annotation in annotations))\n unique_ips = list(set(annotation.data[\"ip\"] for annotation in annotations))\n\n if unique_users:\n fallback_text = \"In the last {0} days, {1} users downloaded datasets from {2} locations.\".format(\n days, len(unique_users), len(unique_ips)\n )\n else:\n fallback_text = \"There were no downloads in the last {0} days.\".format(days)\n\n new_users = \"\"\n returning_users = \"\"\n for email in unique_users:\n user_annotations = annotation_queryset.filter(dataset__email_address=email)\n total_downloads = user_annotations.count()\n unique_locations = list(set(annotation.data[\"ip\"] for annotation in user_annotations))\n locations = \", \".join(get_ip_location(ip) for ip in unique_locations)\n is_new_user = DatasetAnnotation.objects.filter(\n created_at__lt=start_time, dataset__email_address=email\n )\n text = \"{0} | {1} downloads from {2}\\n\".format(email, total_downloads, locations)\n if is_new_user:\n new_users += text\n else:\n returning_users += text\n\n blocks = [\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"plain_text\", \"emoji\": True, \"text\": fallback_text},\n }\n ]\n if new_users:\n blocks.append(\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"mrkdwn\", \"text\": \"*New users* \\n\" + new_users,},\n }\n )\n if returning_users:\n blocks.append(\n {\n \"type\": \"section\",\n \"text\": {\"type\": \"mrkdwn\", \"text\": \"*Returning users* \\n\" + returning_users,},\n }\n )\n\n # Post to slack\n requests.post(\n settings.ENGAGEMENTBOT_WEBHOOK,\n json={\n \"username\": \"EngagementBot\",\n \"icon_emoji\": \":halal:\",\n \"channel\": \"#\" + options[\"channel\"],\n \"text\": fallback_text,\n \"blocks\": blocks,\n },\n headers={\"Content-Type\": \"application/json\"},\n timeout=10,\n )\n\n\ndef should_display_email(email: str) -> bool:\n \"\"\" Returns true if the given email is not associated with the CCDL suers \"\"\"\n if not email:\n return False\n return not (\n email.startswith(\"cansav09\")\n or email.startswith(\"arielsvn\")\n or email.startswith(\"jaclyn.n.taroni\")\n or email.startswith(\"kurt.wheeler\")\n or email.startswith(\"greenescientist\")\n or email.startswith(\"miserlou\")\n or email.startswith(\"d.prasad\")\n or email.endswith(\"@alexslemonade.org\")\n or email is (\"[email protected]\")\n or email is (\"[email protected]\")\n )\n\n\ndef get_ip_location(remote_ip):\n try:\n data = requests.get(\"https://ipapi.co/\" + remote_ip + \"/json/\", timeout=10).json()\n return \"{0}, {1}\".format(data[\"city\"], data[\"country_name\"])\n except Exception:\n return remote_ip\n", "path": "api/data_refinery_api/management/commands/post_downloads_summary.py"}]}
| 2,197 | 445 |
gh_patches_debug_29866
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-829
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issue Building vllm Wheel: Unsupported GPU Architecture 'compute_89'
I'm trying to build the vllm package from source (pip install vllm), but I'm encountering an error related to CUDA and GPU architecture. I am using RTX 4090. Here are the crucial parts of the log:
```
Building wheels for collected packages: vllm
Building wheel for vllm (pyproject.toml) ... error
error: subprocess-exited-with-error
...
building 'vllm.cache_ops' extension
Emitting ninja build file ...
...
/usr/local/cuda/bin/nvcc -I/tmp/pip-build-env-... (other flags and paths)
nvcc fatal : Unsupported gpu architecture 'compute_89'
```
Here is my compute cluster:
---
6790722
Age:15 min.[Remaining](https://vast.ai/faq#Instances):1d 19h71.69.80.64:44536-44750North Carolina, US1x RTX 409081.8 TFLOPS
m:9663host:39244verified0.3/24.6 GB
3506.9 GB/s
ROME2D16
PCIE 4.0, 8x12.5 GB/s
AMD EPYC 7662 64-Core Processor
25.6/256 cpu
4/52 GB
nvme
4972 MB/s6.9/21.0 GB
516.4 Mbps514.0 MbpsMax CUDA: 12.2
GPU: 0% 35C , CPU: 4% Status: success, running pytorch/pytorch_2.0.1-cuda11.7-cudnn8-devel/jupyter
$0.263/hr
Current State : running Next State : running
Docker Image: pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
Image Runtype : jupyter_direc ssh_direc ssh_proxy
Environment :
{
"JUPYTER_DIR": "/"
}
Docker Args:
Onstart: env | grep _ >> /etc/environment; echo 'starting up'
---
It seems that the nvcc compiler doesn't support the 'compute_89' GPU architecture. I'm using CUDA version 11.7 on a RTX 4090.
Has anyone encountered this issue before? Any suggestions on how to resolve it?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import io
2 import os
3 import re
4 import subprocess
5 from typing import List, Set
6
7 from packaging.version import parse, Version
8 import setuptools
9 import torch
10 from torch.utils.cpp_extension import BuildExtension, CUDAExtension, CUDA_HOME
11
12 ROOT_DIR = os.path.dirname(__file__)
13
14 # Compiler flags.
15 CXX_FLAGS = ["-g", "-O2", "-std=c++17"]
16 # TODO(woosuk): Should we use -O3?
17 NVCC_FLAGS = ["-O2", "-std=c++17"]
18
19 ABI = 1 if torch._C._GLIBCXX_USE_CXX11_ABI else 0
20 CXX_FLAGS += [f"-D_GLIBCXX_USE_CXX11_ABI={ABI}"]
21 NVCC_FLAGS += [f"-D_GLIBCXX_USE_CXX11_ABI={ABI}"]
22
23 if CUDA_HOME is None:
24 raise RuntimeError(
25 f"Cannot find CUDA_HOME. CUDA must be available in order to build the package.")
26
27
28 def get_nvcc_cuda_version(cuda_dir: str) -> Version:
29 """Get the CUDA version from nvcc.
30
31 Adapted from https://github.com/NVIDIA/apex/blob/8b7a1ff183741dd8f9b87e7bafd04cfde99cea28/setup.py
32 """
33 nvcc_output = subprocess.check_output([cuda_dir + "/bin/nvcc", "-V"],
34 universal_newlines=True)
35 output = nvcc_output.split()
36 release_idx = output.index("release") + 1
37 nvcc_cuda_version = parse(output[release_idx].split(",")[0])
38 return nvcc_cuda_version
39
40
41 # Collect the compute capabilities of all available GPUs.
42 device_count = torch.cuda.device_count()
43 compute_capabilities: Set[int] = set()
44 for i in range(device_count):
45 major, minor = torch.cuda.get_device_capability(i)
46 if major < 7:
47 raise RuntimeError(
48 "GPUs with compute capability less than 7.0 are not supported.")
49 compute_capabilities.add(major * 10 + minor)
50
51 # Validate the NVCC CUDA version.
52 nvcc_cuda_version = get_nvcc_cuda_version(CUDA_HOME)
53 if nvcc_cuda_version < Version("11.0"):
54 raise RuntimeError("CUDA 11.0 or higher is required to build the package.")
55 if 86 in compute_capabilities and nvcc_cuda_version < Version("11.1"):
56 raise RuntimeError(
57 "CUDA 11.1 or higher is required for GPUs with compute capability 8.6.")
58 if 90 in compute_capabilities and nvcc_cuda_version < Version("11.8"):
59 raise RuntimeError(
60 "CUDA 11.8 or higher is required for GPUs with compute capability 9.0.")
61
62 # If no GPU is available, add all supported compute capabilities.
63 if not compute_capabilities:
64 compute_capabilities = {70, 75, 80}
65 if nvcc_cuda_version >= Version("11.1"):
66 compute_capabilities.add(86)
67 if nvcc_cuda_version >= Version("11.8"):
68 compute_capabilities.add(90)
69
70 # Add target compute capabilities to NVCC flags.
71 for capability in compute_capabilities:
72 NVCC_FLAGS += ["-gencode", f"arch=compute_{capability},code=sm_{capability}"]
73
74 # Use NVCC threads to parallelize the build.
75 if nvcc_cuda_version >= Version("11.2"):
76 num_threads = min(os.cpu_count(), 8)
77 NVCC_FLAGS += ["--threads", str(num_threads)]
78
79 ext_modules = []
80
81 # Cache operations.
82 cache_extension = CUDAExtension(
83 name="vllm.cache_ops",
84 sources=["csrc/cache.cpp", "csrc/cache_kernels.cu"],
85 extra_compile_args={"cxx": CXX_FLAGS, "nvcc": NVCC_FLAGS},
86 )
87 ext_modules.append(cache_extension)
88
89 # Attention kernels.
90 attention_extension = CUDAExtension(
91 name="vllm.attention_ops",
92 sources=["csrc/attention.cpp", "csrc/attention/attention_kernels.cu"],
93 extra_compile_args={"cxx": CXX_FLAGS, "nvcc": NVCC_FLAGS},
94 )
95 ext_modules.append(attention_extension)
96
97 # Positional encoding kernels.
98 positional_encoding_extension = CUDAExtension(
99 name="vllm.pos_encoding_ops",
100 sources=["csrc/pos_encoding.cpp", "csrc/pos_encoding_kernels.cu"],
101 extra_compile_args={"cxx": CXX_FLAGS, "nvcc": NVCC_FLAGS},
102 )
103 ext_modules.append(positional_encoding_extension)
104
105 # Layer normalization kernels.
106 layernorm_extension = CUDAExtension(
107 name="vllm.layernorm_ops",
108 sources=["csrc/layernorm.cpp", "csrc/layernorm_kernels.cu"],
109 extra_compile_args={"cxx": CXX_FLAGS, "nvcc": NVCC_FLAGS},
110 )
111 ext_modules.append(layernorm_extension)
112
113 # Activation kernels.
114 activation_extension = CUDAExtension(
115 name="vllm.activation_ops",
116 sources=["csrc/activation.cpp", "csrc/activation_kernels.cu"],
117 extra_compile_args={"cxx": CXX_FLAGS, "nvcc": NVCC_FLAGS},
118 )
119 ext_modules.append(activation_extension)
120
121
122 def get_path(*filepath) -> str:
123 return os.path.join(ROOT_DIR, *filepath)
124
125
126 def find_version(filepath: str):
127 """Extract version information from the given filepath.
128
129 Adapted from https://github.com/ray-project/ray/blob/0b190ee1160eeca9796bc091e07eaebf4c85b511/python/setup.py
130 """
131 with open(filepath) as fp:
132 version_match = re.search(
133 r"^__version__ = ['\"]([^'\"]*)['\"]", fp.read(), re.M)
134 if version_match:
135 return version_match.group(1)
136 raise RuntimeError("Unable to find version string.")
137
138
139 def read_readme() -> str:
140 """Read the README file."""
141 return io.open(get_path("README.md"), "r", encoding="utf-8").read()
142
143
144 def get_requirements() -> List[str]:
145 """Get Python package dependencies from requirements.txt."""
146 with open(get_path("requirements.txt")) as f:
147 requirements = f.read().strip().split("\n")
148 return requirements
149
150
151 setuptools.setup(
152 name="vllm",
153 version=find_version(get_path("vllm", "__init__.py")),
154 author="vLLM Team",
155 license="Apache 2.0",
156 description="A high-throughput and memory-efficient inference and serving engine for LLMs",
157 long_description=read_readme(),
158 long_description_content_type="text/markdown",
159 url="https://github.com/vllm-project/vllm",
160 project_urls={
161 "Homepage": "https://github.com/vllm-project/vllm",
162 "Documentation": "https://vllm.readthedocs.io/en/latest/",
163 },
164 classifiers=[
165 "Programming Language :: Python :: 3.8",
166 "Programming Language :: Python :: 3.9",
167 "Programming Language :: Python :: 3.10",
168 "License :: OSI Approved :: Apache Software License",
169 "Topic :: Scientific/Engineering :: Artificial Intelligence",
170 ],
171 packages=setuptools.find_packages(
172 exclude=("assets", "benchmarks", "csrc", "docs", "examples", "tests")),
173 python_requires=">=3.8",
174 install_requires=get_requirements(),
175 ext_modules=ext_modules,
176 cmdclass={"build_ext": BuildExtension},
177 )
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -22,7 +22,7 @@
if CUDA_HOME is None:
raise RuntimeError(
- f"Cannot find CUDA_HOME. CUDA must be available in order to build the package.")
+ f"Cannot find CUDA_HOME. CUDA must be available to build the package.")
def get_nvcc_cuda_version(cuda_dir: str) -> Version:
@@ -55,6 +55,14 @@
if 86 in compute_capabilities and nvcc_cuda_version < Version("11.1"):
raise RuntimeError(
"CUDA 11.1 or higher is required for GPUs with compute capability 8.6.")
+if 89 in compute_capabilities and nvcc_cuda_version < Version("11.8"):
+ # CUDA 11.8 is required to generate the code targeting compute capability 8.9.
+ # However, GPUs with compute capability 8.9 can also run the code generated by
+ # the previous versions of CUDA 11 and targeting compute capability 8.0.
+ # Therefore, if CUDA 11.8 is not available, we target compute capability 8.0
+ # instead of 8.9.
+ compute_capabilities.remove(89)
+ compute_capabilities.add(80)
if 90 in compute_capabilities and nvcc_cuda_version < Version("11.8"):
raise RuntimeError(
"CUDA 11.8 or higher is required for GPUs with compute capability 9.0.")
@@ -65,6 +73,7 @@
if nvcc_cuda_version >= Version("11.1"):
compute_capabilities.add(86)
if nvcc_cuda_version >= Version("11.8"):
+ compute_capabilities.add(89)
compute_capabilities.add(90)
# Add target compute capabilities to NVCC flags.
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -22,7 +22,7 @@\n \n if CUDA_HOME is None:\n raise RuntimeError(\n- f\"Cannot find CUDA_HOME. CUDA must be available in order to build the package.\")\n+ f\"Cannot find CUDA_HOME. CUDA must be available to build the package.\")\n \n \n def get_nvcc_cuda_version(cuda_dir: str) -> Version:\n@@ -55,6 +55,14 @@\n if 86 in compute_capabilities and nvcc_cuda_version < Version(\"11.1\"):\n raise RuntimeError(\n \"CUDA 11.1 or higher is required for GPUs with compute capability 8.6.\")\n+if 89 in compute_capabilities and nvcc_cuda_version < Version(\"11.8\"):\n+ # CUDA 11.8 is required to generate the code targeting compute capability 8.9.\n+ # However, GPUs with compute capability 8.9 can also run the code generated by\n+ # the previous versions of CUDA 11 and targeting compute capability 8.0.\n+ # Therefore, if CUDA 11.8 is not available, we target compute capability 8.0\n+ # instead of 8.9.\n+ compute_capabilities.remove(89)\n+ compute_capabilities.add(80)\n if 90 in compute_capabilities and nvcc_cuda_version < Version(\"11.8\"):\n raise RuntimeError(\n \"CUDA 11.8 or higher is required for GPUs with compute capability 9.0.\")\n@@ -65,6 +73,7 @@\n if nvcc_cuda_version >= Version(\"11.1\"):\n compute_capabilities.add(86)\n if nvcc_cuda_version >= Version(\"11.8\"):\n+ compute_capabilities.add(89)\n compute_capabilities.add(90)\n \n # Add target compute capabilities to NVCC flags.\n", "issue": " Issue Building vllm Wheel: Unsupported GPU Architecture 'compute_89'\nI'm trying to build the vllm package from source (pip install vllm), but I'm encountering an error related to CUDA and GPU architecture. I am using RTX 4090. Here are the crucial parts of the log:\r\n\r\n\r\n```\r\nBuilding wheels for collected packages: vllm\r\nBuilding wheel for vllm (pyproject.toml) ... error\r\nerror: subprocess-exited-with-error\r\n\r\n...\r\n\r\nbuilding 'vllm.cache_ops' extension\r\nEmitting ninja build file ...\r\n\r\n...\r\n\r\n/usr/local/cuda/bin/nvcc -I/tmp/pip-build-env-... (other flags and paths)\r\nnvcc fatal : Unsupported gpu architecture 'compute_89'\r\n```\r\n\r\nHere is my compute cluster:\r\n---\r\n6790722\r\nAge:15 min.[Remaining](https://vast.ai/faq#Instances):1d 19h71.69.80.64:44536-44750North Carolina, US1x RTX 409081.8 TFLOPS\r\nm:9663host:39244verified0.3/24.6 GB\r\n3506.9 GB/s\r\nROME2D16\r\nPCIE 4.0, 8x12.5 GB/s\r\nAMD EPYC 7662 64-Core Processor\r\n25.6/256 cpu\r\n4/52 GB\r\nnvme\r\n4972 MB/s6.9/21.0 GB\r\n516.4 Mbps514.0 MbpsMax CUDA: 12.2\r\n \r\nGPU: 0% 35C , CPU: 4% Status: success, running pytorch/pytorch_2.0.1-cuda11.7-cudnn8-devel/jupyter\r\n$0.263/hr \r\nCurrent State : running Next State : running\r\nDocker Image: pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel\r\n\r\nImage Runtype : jupyter_direc ssh_direc ssh_proxy\r\n\r\nEnvironment :\r\n{\r\n \"JUPYTER_DIR\": \"/\"\r\n}\r\n\r\nDocker Args:\r\n\r\nOnstart: env | grep _ >> /etc/environment; echo 'starting up'\r\n\r\n\r\n---\r\n\r\nIt seems that the nvcc compiler doesn't support the 'compute_89' GPU architecture. I'm using CUDA version 11.7 on a RTX 4090.\r\n\r\nHas anyone encountered this issue before? Any suggestions on how to resolve it?\n", "before_files": [{"content": "import io\nimport os\nimport re\nimport subprocess\nfrom typing import List, Set\n\nfrom packaging.version import parse, Version\nimport setuptools\nimport torch\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension, CUDA_HOME\n\nROOT_DIR = os.path.dirname(__file__)\n\n# Compiler flags.\nCXX_FLAGS = [\"-g\", \"-O2\", \"-std=c++17\"]\n# TODO(woosuk): Should we use -O3?\nNVCC_FLAGS = [\"-O2\", \"-std=c++17\"]\n\nABI = 1 if torch._C._GLIBCXX_USE_CXX11_ABI else 0\nCXX_FLAGS += [f\"-D_GLIBCXX_USE_CXX11_ABI={ABI}\"]\nNVCC_FLAGS += [f\"-D_GLIBCXX_USE_CXX11_ABI={ABI}\"]\n\nif CUDA_HOME is None:\n raise RuntimeError(\n f\"Cannot find CUDA_HOME. CUDA must be available in order to build the package.\")\n\n\ndef get_nvcc_cuda_version(cuda_dir: str) -> Version:\n \"\"\"Get the CUDA version from nvcc.\n\n Adapted from https://github.com/NVIDIA/apex/blob/8b7a1ff183741dd8f9b87e7bafd04cfde99cea28/setup.py\n \"\"\"\n nvcc_output = subprocess.check_output([cuda_dir + \"/bin/nvcc\", \"-V\"],\n universal_newlines=True)\n output = nvcc_output.split()\n release_idx = output.index(\"release\") + 1\n nvcc_cuda_version = parse(output[release_idx].split(\",\")[0])\n return nvcc_cuda_version\n\n\n# Collect the compute capabilities of all available GPUs.\ndevice_count = torch.cuda.device_count()\ncompute_capabilities: Set[int] = set()\nfor i in range(device_count):\n major, minor = torch.cuda.get_device_capability(i)\n if major < 7:\n raise RuntimeError(\n \"GPUs with compute capability less than 7.0 are not supported.\")\n compute_capabilities.add(major * 10 + minor)\n\n# Validate the NVCC CUDA version.\nnvcc_cuda_version = get_nvcc_cuda_version(CUDA_HOME)\nif nvcc_cuda_version < Version(\"11.0\"):\n raise RuntimeError(\"CUDA 11.0 or higher is required to build the package.\")\nif 86 in compute_capabilities and nvcc_cuda_version < Version(\"11.1\"):\n raise RuntimeError(\n \"CUDA 11.1 or higher is required for GPUs with compute capability 8.6.\")\nif 90 in compute_capabilities and nvcc_cuda_version < Version(\"11.8\"):\n raise RuntimeError(\n \"CUDA 11.8 or higher is required for GPUs with compute capability 9.0.\")\n\n# If no GPU is available, add all supported compute capabilities.\nif not compute_capabilities:\n compute_capabilities = {70, 75, 80}\n if nvcc_cuda_version >= Version(\"11.1\"):\n compute_capabilities.add(86)\n if nvcc_cuda_version >= Version(\"11.8\"):\n compute_capabilities.add(90)\n\n# Add target compute capabilities to NVCC flags.\nfor capability in compute_capabilities:\n NVCC_FLAGS += [\"-gencode\", f\"arch=compute_{capability},code=sm_{capability}\"]\n\n# Use NVCC threads to parallelize the build.\nif nvcc_cuda_version >= Version(\"11.2\"):\n num_threads = min(os.cpu_count(), 8)\n NVCC_FLAGS += [\"--threads\", str(num_threads)]\n\next_modules = []\n\n# Cache operations.\ncache_extension = CUDAExtension(\n name=\"vllm.cache_ops\",\n sources=[\"csrc/cache.cpp\", \"csrc/cache_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(cache_extension)\n\n# Attention kernels.\nattention_extension = CUDAExtension(\n name=\"vllm.attention_ops\",\n sources=[\"csrc/attention.cpp\", \"csrc/attention/attention_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(attention_extension)\n\n# Positional encoding kernels.\npositional_encoding_extension = CUDAExtension(\n name=\"vllm.pos_encoding_ops\",\n sources=[\"csrc/pos_encoding.cpp\", \"csrc/pos_encoding_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(positional_encoding_extension)\n\n# Layer normalization kernels.\nlayernorm_extension = CUDAExtension(\n name=\"vllm.layernorm_ops\",\n sources=[\"csrc/layernorm.cpp\", \"csrc/layernorm_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(layernorm_extension)\n\n# Activation kernels.\nactivation_extension = CUDAExtension(\n name=\"vllm.activation_ops\",\n sources=[\"csrc/activation.cpp\", \"csrc/activation_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(activation_extension)\n\n\ndef get_path(*filepath) -> str:\n return os.path.join(ROOT_DIR, *filepath)\n\n\ndef find_version(filepath: str):\n \"\"\"Extract version information from the given filepath.\n\n Adapted from https://github.com/ray-project/ray/blob/0b190ee1160eeca9796bc091e07eaebf4c85b511/python/setup.py\n \"\"\"\n with open(filepath) as fp:\n version_match = re.search(\n r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\", fp.read(), re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\ndef read_readme() -> str:\n \"\"\"Read the README file.\"\"\"\n return io.open(get_path(\"README.md\"), \"r\", encoding=\"utf-8\").read()\n\n\ndef get_requirements() -> List[str]:\n \"\"\"Get Python package dependencies from requirements.txt.\"\"\"\n with open(get_path(\"requirements.txt\")) as f:\n requirements = f.read().strip().split(\"\\n\")\n return requirements\n\n\nsetuptools.setup(\n name=\"vllm\",\n version=find_version(get_path(\"vllm\", \"__init__.py\")),\n author=\"vLLM Team\",\n license=\"Apache 2.0\",\n description=\"A high-throughput and memory-efficient inference and serving engine for LLMs\",\n long_description=read_readme(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/vllm-project/vllm\",\n project_urls={\n \"Homepage\": \"https://github.com/vllm-project/vllm\",\n \"Documentation\": \"https://vllm.readthedocs.io/en/latest/\",\n },\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n packages=setuptools.find_packages(\n exclude=(\"assets\", \"benchmarks\", \"csrc\", \"docs\", \"examples\", \"tests\")),\n python_requires=\">=3.8\",\n install_requires=get_requirements(),\n ext_modules=ext_modules,\n cmdclass={\"build_ext\": BuildExtension},\n)\n", "path": "setup.py"}], "after_files": [{"content": "import io\nimport os\nimport re\nimport subprocess\nfrom typing import List, Set\n\nfrom packaging.version import parse, Version\nimport setuptools\nimport torch\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension, CUDA_HOME\n\nROOT_DIR = os.path.dirname(__file__)\n\n# Compiler flags.\nCXX_FLAGS = [\"-g\", \"-O2\", \"-std=c++17\"]\n# TODO(woosuk): Should we use -O3?\nNVCC_FLAGS = [\"-O2\", \"-std=c++17\"]\n\nABI = 1 if torch._C._GLIBCXX_USE_CXX11_ABI else 0\nCXX_FLAGS += [f\"-D_GLIBCXX_USE_CXX11_ABI={ABI}\"]\nNVCC_FLAGS += [f\"-D_GLIBCXX_USE_CXX11_ABI={ABI}\"]\n\nif CUDA_HOME is None:\n raise RuntimeError(\n f\"Cannot find CUDA_HOME. CUDA must be available to build the package.\")\n\n\ndef get_nvcc_cuda_version(cuda_dir: str) -> Version:\n \"\"\"Get the CUDA version from nvcc.\n\n Adapted from https://github.com/NVIDIA/apex/blob/8b7a1ff183741dd8f9b87e7bafd04cfde99cea28/setup.py\n \"\"\"\n nvcc_output = subprocess.check_output([cuda_dir + \"/bin/nvcc\", \"-V\"],\n universal_newlines=True)\n output = nvcc_output.split()\n release_idx = output.index(\"release\") + 1\n nvcc_cuda_version = parse(output[release_idx].split(\",\")[0])\n return nvcc_cuda_version\n\n\n# Collect the compute capabilities of all available GPUs.\ndevice_count = torch.cuda.device_count()\ncompute_capabilities: Set[int] = set()\nfor i in range(device_count):\n major, minor = torch.cuda.get_device_capability(i)\n if major < 7:\n raise RuntimeError(\n \"GPUs with compute capability less than 7.0 are not supported.\")\n compute_capabilities.add(major * 10 + minor)\n\n# Validate the NVCC CUDA version.\nnvcc_cuda_version = get_nvcc_cuda_version(CUDA_HOME)\nif nvcc_cuda_version < Version(\"11.0\"):\n raise RuntimeError(\"CUDA 11.0 or higher is required to build the package.\")\nif 86 in compute_capabilities and nvcc_cuda_version < Version(\"11.1\"):\n raise RuntimeError(\n \"CUDA 11.1 or higher is required for GPUs with compute capability 8.6.\")\nif 89 in compute_capabilities and nvcc_cuda_version < Version(\"11.8\"):\n # CUDA 11.8 is required to generate the code targeting compute capability 8.9.\n # However, GPUs with compute capability 8.9 can also run the code generated by\n # the previous versions of CUDA 11 and targeting compute capability 8.0.\n # Therefore, if CUDA 11.8 is not available, we target compute capability 8.0\n # instead of 8.9.\n compute_capabilities.remove(89)\n compute_capabilities.add(80)\nif 90 in compute_capabilities and nvcc_cuda_version < Version(\"11.8\"):\n raise RuntimeError(\n \"CUDA 11.8 or higher is required for GPUs with compute capability 9.0.\")\n\n# If no GPU is available, add all supported compute capabilities.\nif not compute_capabilities:\n compute_capabilities = {70, 75, 80}\n if nvcc_cuda_version >= Version(\"11.1\"):\n compute_capabilities.add(86)\n if nvcc_cuda_version >= Version(\"11.8\"):\n compute_capabilities.add(89)\n compute_capabilities.add(90)\n\n# Add target compute capabilities to NVCC flags.\nfor capability in compute_capabilities:\n NVCC_FLAGS += [\"-gencode\", f\"arch=compute_{capability},code=sm_{capability}\"]\n\n# Use NVCC threads to parallelize the build.\nif nvcc_cuda_version >= Version(\"11.2\"):\n num_threads = min(os.cpu_count(), 8)\n NVCC_FLAGS += [\"--threads\", str(num_threads)]\n\next_modules = []\n\n# Cache operations.\ncache_extension = CUDAExtension(\n name=\"vllm.cache_ops\",\n sources=[\"csrc/cache.cpp\", \"csrc/cache_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(cache_extension)\n\n# Attention kernels.\nattention_extension = CUDAExtension(\n name=\"vllm.attention_ops\",\n sources=[\"csrc/attention.cpp\", \"csrc/attention/attention_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(attention_extension)\n\n# Positional encoding kernels.\npositional_encoding_extension = CUDAExtension(\n name=\"vllm.pos_encoding_ops\",\n sources=[\"csrc/pos_encoding.cpp\", \"csrc/pos_encoding_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(positional_encoding_extension)\n\n# Layer normalization kernels.\nlayernorm_extension = CUDAExtension(\n name=\"vllm.layernorm_ops\",\n sources=[\"csrc/layernorm.cpp\", \"csrc/layernorm_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(layernorm_extension)\n\n# Activation kernels.\nactivation_extension = CUDAExtension(\n name=\"vllm.activation_ops\",\n sources=[\"csrc/activation.cpp\", \"csrc/activation_kernels.cu\"],\n extra_compile_args={\"cxx\": CXX_FLAGS, \"nvcc\": NVCC_FLAGS},\n)\next_modules.append(activation_extension)\n\n\ndef get_path(*filepath) -> str:\n return os.path.join(ROOT_DIR, *filepath)\n\n\ndef find_version(filepath: str):\n \"\"\"Extract version information from the given filepath.\n\n Adapted from https://github.com/ray-project/ray/blob/0b190ee1160eeca9796bc091e07eaebf4c85b511/python/setup.py\n \"\"\"\n with open(filepath) as fp:\n version_match = re.search(\n r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\", fp.read(), re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\ndef read_readme() -> str:\n \"\"\"Read the README file.\"\"\"\n return io.open(get_path(\"README.md\"), \"r\", encoding=\"utf-8\").read()\n\n\ndef get_requirements() -> List[str]:\n \"\"\"Get Python package dependencies from requirements.txt.\"\"\"\n with open(get_path(\"requirements.txt\")) as f:\n requirements = f.read().strip().split(\"\\n\")\n return requirements\n\n\nsetuptools.setup(\n name=\"vllm\",\n version=find_version(get_path(\"vllm\", \"__init__.py\")),\n author=\"vLLM Team\",\n license=\"Apache 2.0\",\n description=\"A high-throughput and memory-efficient inference and serving engine for LLMs\",\n long_description=read_readme(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/vllm-project/vllm\",\n project_urls={\n \"Homepage\": \"https://github.com/vllm-project/vllm\",\n \"Documentation\": \"https://vllm.readthedocs.io/en/latest/\",\n },\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n packages=setuptools.find_packages(\n exclude=(\"assets\", \"benchmarks\", \"csrc\", \"docs\", \"examples\", \"tests\")),\n python_requires=\">=3.8\",\n install_requires=get_requirements(),\n ext_modules=ext_modules,\n cmdclass={\"build_ext\": BuildExtension},\n)\n", "path": "setup.py"}]}
| 2,881 | 415 |
gh_patches_debug_6308
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-2583
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Env value of TOIL_DOCKER_REGISTRY is not honored in the docker image
When a docker image is build with a custom `TOIL_DOCKER_REGISTRY`, the built docker image still looks at `quay.io/ucsc_cgl` for pulling related images (e.g. `mtail`, `grafana`, etc). The fix is to put the actual registry in `version_template.py`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `version_template.py`
Content:
```
1 # Copyright (C) 2015-2018 Regents of the University of California
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """This script is a template for src/toil/version.py. Running it without arguments echoes all
16 globals, i.e. module attributes. Constant assignments will be echoed verbatim while callables
17 will be invoked and their result echoed as an assignment using the function name as the left-hand
18 side and the return value of the function as right-hand side. To prevent a module attribute from
19 being echoed, start or end the attribute name with an underscore. To print the value of a single
20 symbol, pass the name of that attribute to the script as a command line argument. You can also
21 import the expand_ function and invoke it directly with either no or exactly one argument."""
22
23 # Note to maintainers:
24 #
25 # - don't import at module level unless you want the imported value to be included in the output
26 # - only import from the Python standard run-time library (you can't have any dependencies)
27
28
29 baseVersion = '3.20.0a1'
30 cgcloudVersion = '1.6.0a1.dev393'
31 dockerRegistry = 'quay.io/ucsc_cgl'
32 dockerName = 'toil'
33
34
35 def version():
36 """
37 A version identifier that includes the full-legth commit SHA1 and an optional suffix to
38 indicate that the working copy is dirty.
39 """
40 return _version()
41
42
43 def shortVersion():
44 """
45 A version identifier that includes the abbreviated commit SHA1 and an optional suffix to
46 indicate that the working copy is dirty.
47 """
48 return _version(shorten=True)
49
50
51 def _version(shorten=False):
52 return '-'.join(filter(None, [distVersion(),
53 currentCommit()[:7 if shorten else None],
54 ('dirty' if dirty() else None)]))
55
56
57 def distVersion():
58 """
59 The distribution version identifying a published release on PyPI.
60 """
61 from pkg_resources import parse_version
62 build_number = buildNumber()
63 parsedBaseVersion = parse_version(baseVersion)
64 if isinstance(parsedBaseVersion, tuple):
65 raise RuntimeError("Setuptools version 8.0 or newer required. Update by running "
66 "'pip install setuptools --upgrade'")
67
68 if build_number is not None and parsedBaseVersion.is_prerelease:
69 return baseVersion + '.dev' + build_number
70 else:
71 return baseVersion
72
73
74 def dockerTag():
75 """
76 The primary tag of the Docker image for the appliance. This uniquely identifies the appliance
77 image.
78 """
79 return version()
80
81
82 def dockerShortTag():
83 """
84 A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for
85 convenience.
86 """
87 return shortVersion()
88
89
90 def dockerMinimalTag():
91 """
92 A minimal tag with which to tag the appliance image for convenience. Does not include
93 information about the git commit or working copy dirtyness.
94 """
95 return distVersion()
96
97
98 def buildNumber():
99 """
100 The Jenkins build number, if defined, else None.
101 """
102 import os
103 return os.getenv('BUILD_NUMBER')
104
105
106 def currentCommit():
107 from subprocess import check_output
108 try:
109 output = check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).decode('utf-8').split()[0]
110 except:
111 # Return this we are not in a git environment.
112 return '000'
113 if isinstance(output, bytes):
114 return output.decode('utf-8')
115 return str(output)
116
117
118 def dirty():
119 from subprocess import call
120 try:
121 return 0 != call('(git diff --exit-code '
122 '&& git diff --cached --exit-code) > /dev/null', shell=True)
123 except:
124 return False # In case the git call fails.
125
126
127 def expand_(name=None):
128 variables = {k: v for k, v in globals().items()
129 if not k.startswith('_') and not k.endswith('_')}
130
131 def resolve(k):
132 v = variables[k]
133 if callable(v):
134 v = v()
135 return v
136
137 if name is None:
138 return ''.join("%s = %s\n" % (k, repr(resolve(k))) for k, v in variables.items())
139 else:
140 return resolve(name)
141
142
143 def _main():
144 import sys
145 sys.stdout.write(expand_(*sys.argv[1:]))
146
147
148 if __name__ == '__main__':
149 _main()
150
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/version_template.py b/version_template.py
--- a/version_template.py
+++ b/version_template.py
@@ -28,7 +28,6 @@
baseVersion = '3.20.0a1'
cgcloudVersion = '1.6.0a1.dev393'
-dockerRegistry = 'quay.io/ucsc_cgl'
dockerName = 'toil'
@@ -115,6 +114,11 @@
return str(output)
+def dockerRegistry():
+ import os
+ return os.getenv('TOIL_DOCKER_REGISTRY', 'quay.io/ucsc_cgl')
+
+
def dirty():
from subprocess import call
try:
|
{"golden_diff": "diff --git a/version_template.py b/version_template.py\n--- a/version_template.py\n+++ b/version_template.py\n@@ -28,7 +28,6 @@\n \n baseVersion = '3.20.0a1'\n cgcloudVersion = '1.6.0a1.dev393'\n-dockerRegistry = 'quay.io/ucsc_cgl'\n dockerName = 'toil'\n \n \n@@ -115,6 +114,11 @@\n return str(output)\n \n \n+def dockerRegistry():\n+ import os\n+ return os.getenv('TOIL_DOCKER_REGISTRY', 'quay.io/ucsc_cgl')\n+\n+\n def dirty():\n from subprocess import call\n try:\n", "issue": "Env value of TOIL_DOCKER_REGISTRY is not honored in the docker image\nWhen a docker image is build with a custom `TOIL_DOCKER_REGISTRY`, the built docker image still looks at `quay.io/ucsc_cgl` for pulling related images (e.g. `mtail`, `grafana`, etc). The fix is to put the actual registry in `version_template.py`.\n", "before_files": [{"content": "# Copyright (C) 2015-2018 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is a template for src/toil/version.py. Running it without arguments echoes all\nglobals, i.e. module attributes. Constant assignments will be echoed verbatim while callables\nwill be invoked and their result echoed as an assignment using the function name as the left-hand\nside and the return value of the function as right-hand side. To prevent a module attribute from\nbeing echoed, start or end the attribute name with an underscore. To print the value of a single\nsymbol, pass the name of that attribute to the script as a command line argument. You can also\nimport the expand_ function and invoke it directly with either no or exactly one argument.\"\"\"\n\n# Note to maintainers:\n#\n# - don't import at module level unless you want the imported value to be included in the output\n# - only import from the Python standard run-time library (you can't have any dependencies)\n\n\nbaseVersion = '3.20.0a1'\ncgcloudVersion = '1.6.0a1.dev393'\ndockerRegistry = 'quay.io/ucsc_cgl'\ndockerName = 'toil'\n\n\ndef version():\n \"\"\"\n A version identifier that includes the full-legth commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version()\n\n\ndef shortVersion():\n \"\"\"\n A version identifier that includes the abbreviated commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version(shorten=True)\n\n\ndef _version(shorten=False):\n return '-'.join(filter(None, [distVersion(),\n currentCommit()[:7 if shorten else None],\n ('dirty' if dirty() else None)]))\n\n\ndef distVersion():\n \"\"\"\n The distribution version identifying a published release on PyPI.\n \"\"\"\n from pkg_resources import parse_version\n build_number = buildNumber()\n parsedBaseVersion = parse_version(baseVersion)\n if isinstance(parsedBaseVersion, tuple):\n raise RuntimeError(\"Setuptools version 8.0 or newer required. Update by running \"\n \"'pip install setuptools --upgrade'\")\n\n if build_number is not None and parsedBaseVersion.is_prerelease:\n return baseVersion + '.dev' + build_number\n else:\n return baseVersion\n\n\ndef dockerTag():\n \"\"\"\n The primary tag of the Docker image for the appliance. This uniquely identifies the appliance\n image.\n \"\"\"\n return version()\n\n\ndef dockerShortTag():\n \"\"\"\n A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for\n convenience.\n \"\"\"\n return shortVersion()\n\n\ndef dockerMinimalTag():\n \"\"\"\n A minimal tag with which to tag the appliance image for convenience. Does not include\n information about the git commit or working copy dirtyness.\n \"\"\"\n return distVersion()\n\n\ndef buildNumber():\n \"\"\"\n The Jenkins build number, if defined, else None.\n \"\"\"\n import os\n return os.getenv('BUILD_NUMBER')\n\n\ndef currentCommit():\n from subprocess import check_output\n try:\n output = check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).decode('utf-8').split()[0]\n except:\n # Return this we are not in a git environment.\n return '000'\n if isinstance(output, bytes):\n return output.decode('utf-8')\n return str(output)\n\n\ndef dirty():\n from subprocess import call\n try:\n return 0 != call('(git diff --exit-code '\n '&& git diff --cached --exit-code) > /dev/null', shell=True)\n except:\n return False # In case the git call fails.\n\n\ndef expand_(name=None):\n variables = {k: v for k, v in globals().items()\n if not k.startswith('_') and not k.endswith('_')}\n\n def resolve(k):\n v = variables[k]\n if callable(v):\n v = v()\n return v\n\n if name is None:\n return ''.join(\"%s = %s\\n\" % (k, repr(resolve(k))) for k, v in variables.items())\n else:\n return resolve(name)\n\n\ndef _main():\n import sys\n sys.stdout.write(expand_(*sys.argv[1:]))\n\n\nif __name__ == '__main__':\n _main()\n", "path": "version_template.py"}], "after_files": [{"content": "# Copyright (C) 2015-2018 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is a template for src/toil/version.py. Running it without arguments echoes all\nglobals, i.e. module attributes. Constant assignments will be echoed verbatim while callables\nwill be invoked and their result echoed as an assignment using the function name as the left-hand\nside and the return value of the function as right-hand side. To prevent a module attribute from\nbeing echoed, start or end the attribute name with an underscore. To print the value of a single\nsymbol, pass the name of that attribute to the script as a command line argument. You can also\nimport the expand_ function and invoke it directly with either no or exactly one argument.\"\"\"\n\n# Note to maintainers:\n#\n# - don't import at module level unless you want the imported value to be included in the output\n# - only import from the Python standard run-time library (you can't have any dependencies)\n\n\nbaseVersion = '3.20.0a1'\ncgcloudVersion = '1.6.0a1.dev393'\ndockerName = 'toil'\n\n\ndef version():\n \"\"\"\n A version identifier that includes the full-legth commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version()\n\n\ndef shortVersion():\n \"\"\"\n A version identifier that includes the abbreviated commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version(shorten=True)\n\n\ndef _version(shorten=False):\n return '-'.join(filter(None, [distVersion(),\n currentCommit()[:7 if shorten else None],\n ('dirty' if dirty() else None)]))\n\n\ndef distVersion():\n \"\"\"\n The distribution version identifying a published release on PyPI.\n \"\"\"\n from pkg_resources import parse_version\n build_number = buildNumber()\n parsedBaseVersion = parse_version(baseVersion)\n if isinstance(parsedBaseVersion, tuple):\n raise RuntimeError(\"Setuptools version 8.0 or newer required. Update by running \"\n \"'pip install setuptools --upgrade'\")\n\n if build_number is not None and parsedBaseVersion.is_prerelease:\n return baseVersion + '.dev' + build_number\n else:\n return baseVersion\n\n\ndef dockerTag():\n \"\"\"\n The primary tag of the Docker image for the appliance. This uniquely identifies the appliance\n image.\n \"\"\"\n return version()\n\n\ndef dockerShortTag():\n \"\"\"\n A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for\n convenience.\n \"\"\"\n return shortVersion()\n\n\ndef dockerMinimalTag():\n \"\"\"\n A minimal tag with which to tag the appliance image for convenience. Does not include\n information about the git commit or working copy dirtyness.\n \"\"\"\n return distVersion()\n\n\ndef buildNumber():\n \"\"\"\n The Jenkins build number, if defined, else None.\n \"\"\"\n import os\n return os.getenv('BUILD_NUMBER')\n\n\ndef currentCommit():\n from subprocess import check_output\n try:\n output = check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).decode('utf-8').split()[0]\n except:\n # Return this we are not in a git environment.\n return '000'\n if isinstance(output, bytes):\n return output.decode('utf-8')\n return str(output)\n\n\ndef dockerRegistry():\n import os\n return os.getenv('TOIL_DOCKER_REGISTRY', 'quay.io/ucsc_cgl')\n\n\ndef dirty():\n from subprocess import call\n try:\n return 0 != call('(git diff --exit-code '\n '&& git diff --cached --exit-code) > /dev/null', shell=True)\n except:\n return False # In case the git call fails.\n\n\ndef expand_(name=None):\n variables = {k: v for k, v in globals().items()\n if not k.startswith('_') and not k.endswith('_')}\n\n def resolve(k):\n v = variables[k]\n if callable(v):\n v = v()\n return v\n\n if name is None:\n return ''.join(\"%s = %s\\n\" % (k, repr(resolve(k))) for k, v in variables.items())\n else:\n return resolve(name)\n\n\ndef _main():\n import sys\n sys.stdout.write(expand_(*sys.argv[1:]))\n\n\nif __name__ == '__main__':\n _main()\n", "path": "version_template.py"}]}
| 1,766 | 157 |
gh_patches_debug_21900
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-928
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Get rid of pack prices multiplication
PO said that 1C stock now is giving already multiplied prices
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shopelectro/management/commands/_update_catalog/update_pack.py`
Content:
```
1 """
2 Update Product.in_pack and prices.
3
4 The update_catalog command always resets product prices to per unit format, so:
5 1. Parse in pack quantity from Tag.name and save it to Product.in_pack
6 2. Multiply product prices by in_pack value and save.
7 """
8 import logging
9
10 from django.conf import settings
11 from django.db import models, transaction
12
13 from catalog.models_expressions import Substring
14
15 from shopelectro.exception import UpdateCatalogException
16 from shopelectro.models import TagQuerySet, TagGroup
17
18 logger = logging.getLogger(__name__)
19 PRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']
20
21
22 def find_pack_group() -> TagGroup:
23 try:
24 pack_group = TagGroup.objects.get_pack()
25 except TagGroup.DoesNotExist as error:
26 raise UpdateCatalogException(
27 'Update the PACK_GROUP_UUID django settings variable to set the new relevant UUID. '
28 + str(error)
29 )
30 if settings.PACK_GROUP_NAME.lower() not in pack_group.name.lower():
31 raise UpdateCatalogException(
32 'The pack group name isn\'t matched with the set name:'
33 f' Pack group name: {pack_group.name}\n'
34 f' Set name: {settings.PACK_GROUP_NAME}\n'
35 'Update the PACK_GROUP_NAME django settings variable to set the new relevant name.'
36 )
37
38 return pack_group
39
40
41 def update_in_packs(packs: TagQuerySet):
42 """Parse and save in pack quantity values."""
43 packs = (
44 packs
45 .annotate(
46 in_pack_str=Substring(
47 models.F('name'),
48 models.Value('[0-9]+\+?[0-9]*')))
49 .exclude(in_pack_str__exact='')
50 )
51
52 for pack in packs:
53 in_pack = sum(map(int, pack.in_pack_str.split('+')))
54 pack.products.all().update(in_pack=max(in_pack, 1))
55
56
57 def update_prices(packs: TagQuerySet):
58 """Multiply product prices on in pack quantity."""
59 fields_to_update = {}
60 for price in PRICES:
61 fields_to_update[price] = models.F(price) * models.F('in_pack')
62
63 with transaction.atomic():
64 packs.products().update(**fields_to_update)
65
66
67 def main(*args, **kwargs):
68 packs = find_pack_group().tags.all().prefetch_related('products')
69 update_in_packs(packs)
70 update_prices(packs)
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shopelectro/management/commands/_update_catalog/update_pack.py b/shopelectro/management/commands/_update_catalog/update_pack.py
--- a/shopelectro/management/commands/_update_catalog/update_pack.py
+++ b/shopelectro/management/commands/_update_catalog/update_pack.py
@@ -8,10 +8,9 @@
import logging
from django.conf import settings
-from django.db import models, transaction
+from django.db import models
from catalog.models_expressions import Substring
-
from shopelectro.exception import UpdateCatalogException
from shopelectro.models import TagQuerySet, TagGroup
@@ -54,17 +53,6 @@
pack.products.all().update(in_pack=max(in_pack, 1))
-def update_prices(packs: TagQuerySet):
- """Multiply product prices on in pack quantity."""
- fields_to_update = {}
- for price in PRICES:
- fields_to_update[price] = models.F(price) * models.F('in_pack')
-
- with transaction.atomic():
- packs.products().update(**fields_to_update)
-
-
def main(*args, **kwargs):
packs = find_pack_group().tags.all().prefetch_related('products')
update_in_packs(packs)
- update_prices(packs)
|
{"golden_diff": "diff --git a/shopelectro/management/commands/_update_catalog/update_pack.py b/shopelectro/management/commands/_update_catalog/update_pack.py\n--- a/shopelectro/management/commands/_update_catalog/update_pack.py\n+++ b/shopelectro/management/commands/_update_catalog/update_pack.py\n@@ -8,10 +8,9 @@\n import logging\n \n from django.conf import settings\n-from django.db import models, transaction\n+from django.db import models\n \n from catalog.models_expressions import Substring\n-\n from shopelectro.exception import UpdateCatalogException\n from shopelectro.models import TagQuerySet, TagGroup\n \n@@ -54,17 +53,6 @@\n pack.products.all().update(in_pack=max(in_pack, 1))\n \n \n-def update_prices(packs: TagQuerySet):\n- \"\"\"Multiply product prices on in pack quantity.\"\"\"\n- fields_to_update = {}\n- for price in PRICES:\n- fields_to_update[price] = models.F(price) * models.F('in_pack')\n-\n- with transaction.atomic():\n- packs.products().update(**fields_to_update)\n-\n-\n def main(*args, **kwargs):\n packs = find_pack_group().tags.all().prefetch_related('products')\n update_in_packs(packs)\n- update_prices(packs)\n", "issue": "Get rid of pack prices multiplication\nPO said that 1C stock now is giving already multiplied prices\n", "before_files": [{"content": "\"\"\"\nUpdate Product.in_pack and prices.\n\nThe update_catalog command always resets product prices to per unit format, so:\n1. Parse in pack quantity from Tag.name and save it to Product.in_pack\n2. Multiply product prices by in_pack value and save.\n\"\"\"\nimport logging\n\nfrom django.conf import settings\nfrom django.db import models, transaction\n\nfrom catalog.models_expressions import Substring\n\nfrom shopelectro.exception import UpdateCatalogException\nfrom shopelectro.models import TagQuerySet, TagGroup\n\nlogger = logging.getLogger(__name__)\nPRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']\n\n\ndef find_pack_group() -> TagGroup:\n try:\n pack_group = TagGroup.objects.get_pack()\n except TagGroup.DoesNotExist as error:\n raise UpdateCatalogException(\n 'Update the PACK_GROUP_UUID django settings variable to set the new relevant UUID. '\n + str(error)\n )\n if settings.PACK_GROUP_NAME.lower() not in pack_group.name.lower():\n raise UpdateCatalogException(\n 'The pack group name isn\\'t matched with the set name:'\n f' Pack group name: {pack_group.name}\\n'\n f' Set name: {settings.PACK_GROUP_NAME}\\n'\n 'Update the PACK_GROUP_NAME django settings variable to set the new relevant name.'\n )\n\n return pack_group\n\n\ndef update_in_packs(packs: TagQuerySet):\n \"\"\"Parse and save in pack quantity values.\"\"\"\n packs = (\n packs\n .annotate(\n in_pack_str=Substring(\n models.F('name'),\n models.Value('[0-9]+\\+?[0-9]*')))\n .exclude(in_pack_str__exact='')\n )\n\n for pack in packs:\n in_pack = sum(map(int, pack.in_pack_str.split('+')))\n pack.products.all().update(in_pack=max(in_pack, 1))\n\n\ndef update_prices(packs: TagQuerySet):\n \"\"\"Multiply product prices on in pack quantity.\"\"\"\n fields_to_update = {}\n for price in PRICES:\n fields_to_update[price] = models.F(price) * models.F('in_pack')\n\n with transaction.atomic():\n packs.products().update(**fields_to_update)\n\n\ndef main(*args, **kwargs):\n packs = find_pack_group().tags.all().prefetch_related('products')\n update_in_packs(packs)\n update_prices(packs)\n", "path": "shopelectro/management/commands/_update_catalog/update_pack.py"}], "after_files": [{"content": "\"\"\"\nUpdate Product.in_pack and prices.\n\nThe update_catalog command always resets product prices to per unit format, so:\n1. Parse in pack quantity from Tag.name and save it to Product.in_pack\n2. Multiply product prices by in_pack value and save.\n\"\"\"\nimport logging\n\nfrom django.conf import settings\nfrom django.db import models\n\nfrom catalog.models_expressions import Substring\nfrom shopelectro.exception import UpdateCatalogException\nfrom shopelectro.models import TagQuerySet, TagGroup\n\nlogger = logging.getLogger(__name__)\nPRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']\n\n\ndef find_pack_group() -> TagGroup:\n try:\n pack_group = TagGroup.objects.get_pack()\n except TagGroup.DoesNotExist as error:\n raise UpdateCatalogException(\n 'Update the PACK_GROUP_UUID django settings variable to set the new relevant UUID. '\n + str(error)\n )\n if settings.PACK_GROUP_NAME.lower() not in pack_group.name.lower():\n raise UpdateCatalogException(\n 'The pack group name isn\\'t matched with the set name:'\n f' Pack group name: {pack_group.name}\\n'\n f' Set name: {settings.PACK_GROUP_NAME}\\n'\n 'Update the PACK_GROUP_NAME django settings variable to set the new relevant name.'\n )\n\n return pack_group\n\n\ndef update_in_packs(packs: TagQuerySet):\n \"\"\"Parse and save in pack quantity values.\"\"\"\n packs = (\n packs\n .annotate(\n in_pack_str=Substring(\n models.F('name'),\n models.Value('[0-9]+\\+?[0-9]*')))\n .exclude(in_pack_str__exact='')\n )\n\n for pack in packs:\n in_pack = sum(map(int, pack.in_pack_str.split('+')))\n pack.products.all().update(in_pack=max(in_pack, 1))\n\n\ndef main(*args, **kwargs):\n packs = find_pack_group().tags.all().prefetch_related('products')\n update_in_packs(packs)\n", "path": "shopelectro/management/commands/_update_catalog/update_pack.py"}]}
| 940 | 282 |
gh_patches_debug_17573
|
rasdani/github-patches
|
git_diff
|
huggingface__accelerate-2388
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python 3.12 distutils deprecation error
### System Info
```Shell
accelerate 0.26.1, Windows 11, Python 3.12.1
```
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)
- [X] My own task or dataset (give details below)
### Reproduction
To reproduce behaviour:
1. In Python 3.12 install latest accelerate with
` pip3 install accelerate --upgrade `
2. Try to initialise accelerate with:
```python
from accelerate import Accelerator
accelerator = Accelerator()
```
This results in the error caused by https://github.com/huggingface/accelerate/blob/f88661b5d9f4977b5a1555a92e64ef3cd359cbc9/src/accelerate/utils/environment.py#L19

The fundamental issue is deprecation of distutils as part of https://peps.python.org/pep-0632/
### Expected behavior
Accelerate should not depend on deprecated package and be compatible with Python 3.12+
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/accelerate/utils/environment.py`
Content:
```
1 # Copyright 2022 The HuggingFace Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import platform
17 import subprocess
18 import sys
19 from distutils import spawn
20 from typing import Dict
21
22 import torch
23
24
25 def str_to_bool(value) -> int:
26 """
27 Converts a string representation of truth to `True` (1) or `False` (0).
28
29 True values are `y`, `yes`, `t`, `true`, `on`, and `1`; False value are `n`, `no`, `f`, `false`, `off`, and `0`;
30 """
31 value = value.lower()
32 if value in ("y", "yes", "t", "true", "on", "1"):
33 return 1
34 elif value in ("n", "no", "f", "false", "off", "0"):
35 return 0
36 else:
37 raise ValueError(f"invalid truth value {value}")
38
39
40 def get_int_from_env(env_keys, default):
41 """Returns the first positive env value found in the `env_keys` list or the default."""
42 for e in env_keys:
43 val = int(os.environ.get(e, -1))
44 if val >= 0:
45 return val
46 return default
47
48
49 def parse_flag_from_env(key, default=False):
50 """Returns truthy value for `key` from the env if available else the default."""
51 value = os.environ.get(key, str(default))
52 return str_to_bool(value) == 1 # As its name indicates `str_to_bool` actually returns an int...
53
54
55 def parse_choice_from_env(key, default="no"):
56 value = os.environ.get(key, str(default))
57 return value
58
59
60 def are_libraries_initialized(*library_names: str) -> Dict[str, bool]:
61 """
62 Checks if any of `library_names` are imported in the environment. Will return results as a `key:bool` pair.
63 """
64 return [lib_name for lib_name in library_names if lib_name in sys.modules.keys()]
65
66
67 def get_gpu_info():
68 """
69 Gets GPU count and names using `nvidia-smi` instead of torch to not initialize CUDA.
70
71 Largely based on the `gputil` library.
72 """
73 if platform.system() == "Windows":
74 # If platform is Windows and nvidia-smi can't be found in path
75 # try from systemd rive with default installation path
76 command = spawn.find_executable("nvidia-smi")
77 if command is None:
78 command = "%s\\Program Files\\NVIDIA Corporation\\NVSMI\\nvidia-smi.exe" % os.environ["systemdrive"]
79 else:
80 command = "nvidia-smi"
81 # Returns as list of `n` GPUs and their names
82 output = subprocess.check_output(
83 [command, "--query-gpu=count,name", "--format=csv,noheader"], universal_newlines=True
84 )
85 output = output.strip()
86 gpus = output.split(os.linesep)
87 # Get names from output
88 gpu_count = len(gpus)
89 gpu_names = [gpu.split(",")[1].strip() for gpu in gpus]
90 return gpu_names, gpu_count
91
92
93 def check_cuda_p2p_ib_support():
94 """
95 Checks if the devices being used have issues with P2P and IB communications, namely any consumer GPU hardware after
96 the 3090.
97
98 Noteably uses `nvidia-smi` instead of torch to not initialize CUDA.
99 """
100 try:
101 device_names, device_count = get_gpu_info()
102 # As new consumer GPUs get released, add them to `unsupported_devices``
103 unsupported_devices = {"RTX 40"}
104 if device_count > 1:
105 if any(
106 unsupported_device in device_name
107 for device_name in device_names
108 for unsupported_device in unsupported_devices
109 ):
110 return False
111 except Exception:
112 pass
113 return True
114
115
116 def check_fp8_capability():
117 """
118 Checks if all the current GPUs available support FP8.
119
120 Notably must initialize `torch.cuda` to check.
121 """
122 cuda_device_capacity = torch.cuda.get_device_capability()
123 return cuda_device_capacity >= (8, 9)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/accelerate/utils/environment.py b/src/accelerate/utils/environment.py
--- a/src/accelerate/utils/environment.py
+++ b/src/accelerate/utils/environment.py
@@ -16,7 +16,7 @@
import platform
import subprocess
import sys
-from distutils import spawn
+from shutil import which
from typing import Dict
import torch
@@ -72,8 +72,8 @@
"""
if platform.system() == "Windows":
# If platform is Windows and nvidia-smi can't be found in path
- # try from systemd rive with default installation path
- command = spawn.find_executable("nvidia-smi")
+ # try from systemd drive with default installation path
+ command = which("nvidia-smi")
if command is None:
command = "%s\\Program Files\\NVIDIA Corporation\\NVSMI\\nvidia-smi.exe" % os.environ["systemdrive"]
else:
|
{"golden_diff": "diff --git a/src/accelerate/utils/environment.py b/src/accelerate/utils/environment.py\n--- a/src/accelerate/utils/environment.py\n+++ b/src/accelerate/utils/environment.py\n@@ -16,7 +16,7 @@\n import platform\n import subprocess\n import sys\n-from distutils import spawn\n+from shutil import which\n from typing import Dict\n \n import torch\n@@ -72,8 +72,8 @@\n \"\"\"\n if platform.system() == \"Windows\":\n # If platform is Windows and nvidia-smi can't be found in path\n- # try from systemd rive with default installation path\n- command = spawn.find_executable(\"nvidia-smi\")\n+ # try from systemd drive with default installation path\n+ command = which(\"nvidia-smi\")\n if command is None:\n command = \"%s\\\\Program Files\\\\NVIDIA Corporation\\\\NVSMI\\\\nvidia-smi.exe\" % os.environ[\"systemdrive\"]\n else:\n", "issue": "Python 3.12 distutils deprecation error\n### System Info\n\n```Shell\naccelerate 0.26.1, Windows 11, Python 3.12.1\n```\n\n\n### Information\n\n- [ ] The official example scripts\n- [x] My own modified scripts\n\n### Tasks\n\n- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)\n- [X] My own task or dataset (give details below)\n\n### Reproduction\n\nTo reproduce behaviour:\r\n1. In Python 3.12 install latest accelerate with\r\n` pip3 install accelerate --upgrade `\r\n2. Try to initialise accelerate with:\r\n```python\r\nfrom accelerate import Accelerator\r\naccelerator = Accelerator()\r\n```\r\n\r\nThis results in the error caused by https://github.com/huggingface/accelerate/blob/f88661b5d9f4977b5a1555a92e64ef3cd359cbc9/src/accelerate/utils/environment.py#L19\r\n\r\n\r\nThe fundamental issue is deprecation of distutils as part of https://peps.python.org/pep-0632/\n\n### Expected behavior\n\nAccelerate should not depend on deprecated package and be compatible with Python 3.12+\n", "before_files": [{"content": "# Copyright 2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport platform\nimport subprocess\nimport sys\nfrom distutils import spawn\nfrom typing import Dict\n\nimport torch\n\n\ndef str_to_bool(value) -> int:\n \"\"\"\n Converts a string representation of truth to `True` (1) or `False` (0).\n\n True values are `y`, `yes`, `t`, `true`, `on`, and `1`; False value are `n`, `no`, `f`, `false`, `off`, and `0`;\n \"\"\"\n value = value.lower()\n if value in (\"y\", \"yes\", \"t\", \"true\", \"on\", \"1\"):\n return 1\n elif value in (\"n\", \"no\", \"f\", \"false\", \"off\", \"0\"):\n return 0\n else:\n raise ValueError(f\"invalid truth value {value}\")\n\n\ndef get_int_from_env(env_keys, default):\n \"\"\"Returns the first positive env value found in the `env_keys` list or the default.\"\"\"\n for e in env_keys:\n val = int(os.environ.get(e, -1))\n if val >= 0:\n return val\n return default\n\n\ndef parse_flag_from_env(key, default=False):\n \"\"\"Returns truthy value for `key` from the env if available else the default.\"\"\"\n value = os.environ.get(key, str(default))\n return str_to_bool(value) == 1 # As its name indicates `str_to_bool` actually returns an int...\n\n\ndef parse_choice_from_env(key, default=\"no\"):\n value = os.environ.get(key, str(default))\n return value\n\n\ndef are_libraries_initialized(*library_names: str) -> Dict[str, bool]:\n \"\"\"\n Checks if any of `library_names` are imported in the environment. Will return results as a `key:bool` pair.\n \"\"\"\n return [lib_name for lib_name in library_names if lib_name in sys.modules.keys()]\n\n\ndef get_gpu_info():\n \"\"\"\n Gets GPU count and names using `nvidia-smi` instead of torch to not initialize CUDA.\n\n Largely based on the `gputil` library.\n \"\"\"\n if platform.system() == \"Windows\":\n # If platform is Windows and nvidia-smi can't be found in path\n # try from systemd rive with default installation path\n command = spawn.find_executable(\"nvidia-smi\")\n if command is None:\n command = \"%s\\\\Program Files\\\\NVIDIA Corporation\\\\NVSMI\\\\nvidia-smi.exe\" % os.environ[\"systemdrive\"]\n else:\n command = \"nvidia-smi\"\n # Returns as list of `n` GPUs and their names\n output = subprocess.check_output(\n [command, \"--query-gpu=count,name\", \"--format=csv,noheader\"], universal_newlines=True\n )\n output = output.strip()\n gpus = output.split(os.linesep)\n # Get names from output\n gpu_count = len(gpus)\n gpu_names = [gpu.split(\",\")[1].strip() for gpu in gpus]\n return gpu_names, gpu_count\n\n\ndef check_cuda_p2p_ib_support():\n \"\"\"\n Checks if the devices being used have issues with P2P and IB communications, namely any consumer GPU hardware after\n the 3090.\n\n Noteably uses `nvidia-smi` instead of torch to not initialize CUDA.\n \"\"\"\n try:\n device_names, device_count = get_gpu_info()\n # As new consumer GPUs get released, add them to `unsupported_devices``\n unsupported_devices = {\"RTX 40\"}\n if device_count > 1:\n if any(\n unsupported_device in device_name\n for device_name in device_names\n for unsupported_device in unsupported_devices\n ):\n return False\n except Exception:\n pass\n return True\n\n\ndef check_fp8_capability():\n \"\"\"\n Checks if all the current GPUs available support FP8.\n\n Notably must initialize `torch.cuda` to check.\n \"\"\"\n cuda_device_capacity = torch.cuda.get_device_capability()\n return cuda_device_capacity >= (8, 9)\n", "path": "src/accelerate/utils/environment.py"}], "after_files": [{"content": "# Copyright 2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport platform\nimport subprocess\nimport sys\nfrom shutil import which\nfrom typing import Dict\n\nimport torch\n\n\ndef str_to_bool(value) -> int:\n \"\"\"\n Converts a string representation of truth to `True` (1) or `False` (0).\n\n True values are `y`, `yes`, `t`, `true`, `on`, and `1`; False value are `n`, `no`, `f`, `false`, `off`, and `0`;\n \"\"\"\n value = value.lower()\n if value in (\"y\", \"yes\", \"t\", \"true\", \"on\", \"1\"):\n return 1\n elif value in (\"n\", \"no\", \"f\", \"false\", \"off\", \"0\"):\n return 0\n else:\n raise ValueError(f\"invalid truth value {value}\")\n\n\ndef get_int_from_env(env_keys, default):\n \"\"\"Returns the first positive env value found in the `env_keys` list or the default.\"\"\"\n for e in env_keys:\n val = int(os.environ.get(e, -1))\n if val >= 0:\n return val\n return default\n\n\ndef parse_flag_from_env(key, default=False):\n \"\"\"Returns truthy value for `key` from the env if available else the default.\"\"\"\n value = os.environ.get(key, str(default))\n return str_to_bool(value) == 1 # As its name indicates `str_to_bool` actually returns an int...\n\n\ndef parse_choice_from_env(key, default=\"no\"):\n value = os.environ.get(key, str(default))\n return value\n\n\ndef are_libraries_initialized(*library_names: str) -> Dict[str, bool]:\n \"\"\"\n Checks if any of `library_names` are imported in the environment. Will return results as a `key:bool` pair.\n \"\"\"\n return [lib_name for lib_name in library_names if lib_name in sys.modules.keys()]\n\n\ndef get_gpu_info():\n \"\"\"\n Gets GPU count and names using `nvidia-smi` instead of torch to not initialize CUDA.\n\n Largely based on the `gputil` library.\n \"\"\"\n if platform.system() == \"Windows\":\n # If platform is Windows and nvidia-smi can't be found in path\n # try from systemd drive with default installation path\n command = which(\"nvidia-smi\")\n if command is None:\n command = \"%s\\\\Program Files\\\\NVIDIA Corporation\\\\NVSMI\\\\nvidia-smi.exe\" % os.environ[\"systemdrive\"]\n else:\n command = \"nvidia-smi\"\n # Returns as list of `n` GPUs and their names\n output = subprocess.check_output(\n [command, \"--query-gpu=count,name\", \"--format=csv,noheader\"], universal_newlines=True\n )\n output = output.strip()\n gpus = output.split(os.linesep)\n # Get names from output\n gpu_count = len(gpus)\n gpu_names = [gpu.split(\",\")[1].strip() for gpu in gpus]\n return gpu_names, gpu_count\n\n\ndef check_cuda_p2p_ib_support():\n \"\"\"\n Checks if the devices being used have issues with P2P and IB communications, namely any consumer GPU hardware after\n the 3090.\n\n Noteably uses `nvidia-smi` instead of torch to not initialize CUDA.\n \"\"\"\n try:\n device_names, device_count = get_gpu_info()\n # As new consumer GPUs get released, add them to `unsupported_devices``\n unsupported_devices = {\"RTX 40\"}\n if device_count > 1:\n if any(\n unsupported_device in device_name\n for device_name in device_names\n for unsupported_device in unsupported_devices\n ):\n return False\n except Exception:\n pass\n return True\n\n\ndef check_fp8_capability():\n \"\"\"\n Checks if all the current GPUs available support FP8.\n\n Notably must initialize `torch.cuda` to check.\n \"\"\"\n cuda_device_capacity = torch.cuda.get_device_capability()\n return cuda_device_capacity >= (8, 9)\n", "path": "src/accelerate/utils/environment.py"}]}
| 1,909 | 211 |
gh_patches_debug_40301
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5543
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/shardformer/shard/shard_config.py`
Content:
```
1 from dataclasses import dataclass, field
2 from typing import Any, Dict, Optional
3
4 import torch.distributed as dist
5 from torch.distributed import ProcessGroup
6
7 from colossalai.pipeline.stage_manager import PipelineStageManager
8
9 __all__ = ["ShardConfig"]
10
11
12 @dataclass
13 class ShardConfig:
14 r"""
15 The config for sharding the huggingface model
16
17 Args:
18 tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.
19 pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.
20 enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.
21 enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.
22 enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.
23 enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.
24 enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.
25 enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.
26 enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.
27 """
28 tensor_parallel_process_group: Optional[ProcessGroup] = None
29 pipeline_stage_manager: Optional[PipelineStageManager] = None
30 enable_tensor_parallelism: bool = True
31 enable_fused_normalization: bool = False
32 enable_flash_attention: bool = False
33 enable_jit_fused: bool = False
34 enable_all_optimization: bool = False
35 enable_sequence_parallelism: bool = False
36 enable_sequence_overlap: bool = False
37 parallel_output = True
38 extra_kwargs: Dict[str, Any] = field(default_factory=dict)
39 # pipeline_parallel_size: int
40 # data_parallel_size: int
41 # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
42
43 @property
44 def tensor_parallel_size(self):
45 return self._tensor_parallel_size
46
47 def __post_init__(self):
48 if not self.enable_tensor_parallelism and self.enable_sequence_parallelism:
49 raise ValueError(
50 "enable_sequence_parallelism can only be set to True when enable_tensor_parallelism is True"
51 )
52 if not self.enable_sequence_parallelism and self.enable_sequence_overlap:
53 raise ValueError("enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True")
54 if not self.enable_tensor_parallelism:
55 self._tensor_parallel_size = 1
56 else:
57 # get the parallel size
58 self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)
59 # turn on all optimization if all_optimization is set to True
60 if self.enable_all_optimization:
61 self._turn_on_all_optimization()
62
63 def _turn_on_all_optimization(self):
64 """
65 Turn on all optimization.
66 """
67 # you can add all the optimization flag here
68 self.enable_fused_normalization = True
69 self.enable_flash_attention = True
70 self.enable_jit_fused = True
71 self.enable_sequence_parallelism = True
72 self.enable_sequence_overlap = True
73
74 def _infer(self):
75 """
76 Set default params for inference.
77 """
78 # assert self.pipeline_stage_manager is None, "pipeline parallelism is not supported in inference for now"
79
```
Path: `colossalai/inference/modeling/policy/nopadding_llama.py`
Content:
```
1 from functools import partial
2
3 from torch.nn import Parameter
4 from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm
5
6 from colossalai.inference.modeling.models.nopadding_llama import (
7 NopadLlamaAttention,
8 NopadLlamaMLP,
9 llama_causal_lm_forward,
10 llama_decoder_layer_forward,
11 llama_model_forward,
12 llama_rmsnorm_forward,
13 )
14 from colossalai.inference.utils import init_to_get_rotary
15 from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
16
17 # import colossalai
18 from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
19
20
21 class NoPaddingLlamaModelInferPolicy(LlamaForCausalLMPolicy):
22 def __init__(self) -> None:
23 super().__init__()
24
25 def module_policy(self):
26 policy = super().module_policy()
27
28 decoder_attribute_replacement = {
29 "lm_head.weight": Parameter(self.model.lm_head.weight.transpose(0, 1), requires_grad=False),
30 }
31 policy[LlamaForCausalLM] = ModulePolicyDescription(
32 attribute_replacement=decoder_attribute_replacement,
33 )
34
35 policy[LlamaDecoderLayer] = ModulePolicyDescription(
36 sub_module_replacement=[
37 SubModuleReplacementDescription(
38 suffix="mlp",
39 target_module=NopadLlamaMLP,
40 ),
41 SubModuleReplacementDescription(
42 suffix="self_attn",
43 target_module=NopadLlamaAttention,
44 ),
45 ]
46 )
47
48 self.shard_config._infer()
49
50 infer_forward = llama_causal_lm_forward
51 method_replacement = {"forward": partial(infer_forward)}
52 self.append_or_create_method_replacement(
53 description=method_replacement, policy=policy, target_key=LlamaForCausalLM
54 )
55
56 infer_forward = llama_model_forward
57 method_replacement = {"forward": partial(infer_forward)}
58 self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
59
60 infer_forward = llama_decoder_layer_forward
61 method_replacement = {"forward": partial(infer_forward)}
62 self.append_or_create_method_replacement(
63 description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
64 )
65
66 infer_forward = llama_rmsnorm_forward
67 method_replacement = {"forward": partial(infer_forward)}
68 self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaRMSNorm)
69
70 return policy
71
72 def postprocess(self):
73 init_to_get_rotary(self.model.model)
74 return self.model
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/inference/modeling/policy/nopadding_llama.py b/colossalai/inference/modeling/policy/nopadding_llama.py
--- a/colossalai/inference/modeling/policy/nopadding_llama.py
+++ b/colossalai/inference/modeling/policy/nopadding_llama.py
@@ -1,5 +1,3 @@
-from functools import partial
-
from torch.nn import Parameter
from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm
@@ -13,8 +11,6 @@
)
from colossalai.inference.utils import init_to_get_rotary
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
-
-# import colossalai
from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
@@ -45,27 +41,18 @@
]
)
- self.shard_config._infer()
-
- infer_forward = llama_causal_lm_forward
- method_replacement = {"forward": partial(infer_forward)}
self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LlamaForCausalLM
+ description={"forward": llama_causal_lm_forward}, policy=policy, target_key=LlamaForCausalLM
)
-
- infer_forward = llama_model_forward
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
-
- infer_forward = llama_decoder_layer_forward
- method_replacement = {"forward": partial(infer_forward)}
self.append_or_create_method_replacement(
- description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
+ description={"forward": llama_model_forward}, policy=policy, target_key=LlamaModel
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_decoder_layer_forward}, policy=policy, target_key=LlamaDecoderLayer
+ )
+ self.append_or_create_method_replacement(
+ description={"forward": llama_rmsnorm_forward}, policy=policy, target_key=LlamaRMSNorm
)
-
- infer_forward = llama_rmsnorm_forward
- method_replacement = {"forward": partial(infer_forward)}
- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaRMSNorm)
return policy
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -36,8 +36,6 @@
enable_sequence_overlap: bool = False
parallel_output = True
extra_kwargs: Dict[str, Any] = field(default_factory=dict)
- # pipeline_parallel_size: int
- # data_parallel_size: int
# tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']
@property
@@ -70,9 +68,3 @@
self.enable_jit_fused = True
self.enable_sequence_parallelism = True
self.enable_sequence_overlap = True
-
- def _infer(self):
- """
- Set default params for inference.
- """
- # assert self.pipeline_stage_manager is None, "pipeline parallelism is not supported in inference for now"
|
{"golden_diff": "diff --git a/colossalai/inference/modeling/policy/nopadding_llama.py b/colossalai/inference/modeling/policy/nopadding_llama.py\n--- a/colossalai/inference/modeling/policy/nopadding_llama.py\n+++ b/colossalai/inference/modeling/policy/nopadding_llama.py\n@@ -1,5 +1,3 @@\n-from functools import partial\n-\n from torch.nn import Parameter\n from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm\n \n@@ -13,8 +11,6 @@\n )\n from colossalai.inference.utils import init_to_get_rotary\n from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription\n-\n-# import colossalai\n from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy\n \n \n@@ -45,27 +41,18 @@\n ]\n )\n \n- self.shard_config._infer()\n-\n- infer_forward = llama_causal_lm_forward\n- method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(\n- description=method_replacement, policy=policy, target_key=LlamaForCausalLM\n+ description={\"forward\": llama_causal_lm_forward}, policy=policy, target_key=LlamaForCausalLM\n )\n-\n- infer_forward = llama_model_forward\n- method_replacement = {\"forward\": partial(infer_forward)}\n- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)\n-\n- infer_forward = llama_decoder_layer_forward\n- method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(\n- description=method_replacement, policy=policy, target_key=LlamaDecoderLayer\n+ description={\"forward\": llama_model_forward}, policy=policy, target_key=LlamaModel\n+ )\n+ self.append_or_create_method_replacement(\n+ description={\"forward\": llama_decoder_layer_forward}, policy=policy, target_key=LlamaDecoderLayer\n+ )\n+ self.append_or_create_method_replacement(\n+ description={\"forward\": llama_rmsnorm_forward}, policy=policy, target_key=LlamaRMSNorm\n )\n-\n- infer_forward = llama_rmsnorm_forward\n- method_replacement = {\"forward\": partial(infer_forward)}\n- self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaRMSNorm)\n \n return policy\n \ndiff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py\n--- a/colossalai/shardformer/shard/shard_config.py\n+++ b/colossalai/shardformer/shard/shard_config.py\n@@ -36,8 +36,6 @@\n enable_sequence_overlap: bool = False\n parallel_output = True\n extra_kwargs: Dict[str, Any] = field(default_factory=dict)\n- # pipeline_parallel_size: int\n- # data_parallel_size: int\n # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']\n \n @property\n@@ -70,9 +68,3 @@\n self.enable_jit_fused = True\n self.enable_sequence_parallelism = True\n self.enable_sequence_overlap = True\n-\n- def _infer(self):\n- \"\"\"\n- Set default params for inference.\n- \"\"\"\n- # assert self.pipeline_stage_manager is None, \"pipeline parallelism is not supported in inference for now\"\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Any, Dict, Optional\n\nimport torch.distributed as dist\nfrom torch.distributed import ProcessGroup\n\nfrom colossalai.pipeline.stage_manager import PipelineStageManager\n\n__all__ = [\"ShardConfig\"]\n\n\n@dataclass\nclass ShardConfig:\n r\"\"\"\n The config for sharding the huggingface model\n\n Args:\n tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.\n pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.\n enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.\n enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.\n enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.\n enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.\n enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.\n enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.\n enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.\n \"\"\"\n tensor_parallel_process_group: Optional[ProcessGroup] = None\n pipeline_stage_manager: Optional[PipelineStageManager] = None\n enable_tensor_parallelism: bool = True\n enable_fused_normalization: bool = False\n enable_flash_attention: bool = False\n enable_jit_fused: bool = False\n enable_all_optimization: bool = False\n enable_sequence_parallelism: bool = False\n enable_sequence_overlap: bool = False\n parallel_output = True\n extra_kwargs: Dict[str, Any] = field(default_factory=dict)\n # pipeline_parallel_size: int\n # data_parallel_size: int\n # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']\n\n @property\n def tensor_parallel_size(self):\n return self._tensor_parallel_size\n\n def __post_init__(self):\n if not self.enable_tensor_parallelism and self.enable_sequence_parallelism:\n raise ValueError(\n \"enable_sequence_parallelism can only be set to True when enable_tensor_parallelism is True\"\n )\n if not self.enable_sequence_parallelism and self.enable_sequence_overlap:\n raise ValueError(\"enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True\")\n if not self.enable_tensor_parallelism:\n self._tensor_parallel_size = 1\n else:\n # get the parallel size\n self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)\n # turn on all optimization if all_optimization is set to True\n if self.enable_all_optimization:\n self._turn_on_all_optimization()\n\n def _turn_on_all_optimization(self):\n \"\"\"\n Turn on all optimization.\n \"\"\"\n # you can add all the optimization flag here\n self.enable_fused_normalization = True\n self.enable_flash_attention = True\n self.enable_jit_fused = True\n self.enable_sequence_parallelism = True\n self.enable_sequence_overlap = True\n\n def _infer(self):\n \"\"\"\n Set default params for inference.\n \"\"\"\n # assert self.pipeline_stage_manager is None, \"pipeline parallelism is not supported in inference for now\"\n", "path": "colossalai/shardformer/shard/shard_config.py"}, {"content": "from functools import partial\n\nfrom torch.nn import Parameter\nfrom transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm\n\nfrom colossalai.inference.modeling.models.nopadding_llama import (\n NopadLlamaAttention,\n NopadLlamaMLP,\n llama_causal_lm_forward,\n llama_decoder_layer_forward,\n llama_model_forward,\n llama_rmsnorm_forward,\n)\nfrom colossalai.inference.utils import init_to_get_rotary\nfrom colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription\n\n# import colossalai\nfrom colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy\n\n\nclass NoPaddingLlamaModelInferPolicy(LlamaForCausalLMPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n policy = super().module_policy()\n\n decoder_attribute_replacement = {\n \"lm_head.weight\": Parameter(self.model.lm_head.weight.transpose(0, 1), requires_grad=False),\n }\n policy[LlamaForCausalLM] = ModulePolicyDescription(\n attribute_replacement=decoder_attribute_replacement,\n )\n\n policy[LlamaDecoderLayer] = ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"mlp\",\n target_module=NopadLlamaMLP,\n ),\n SubModuleReplacementDescription(\n suffix=\"self_attn\",\n target_module=NopadLlamaAttention,\n ),\n ]\n )\n\n self.shard_config._infer()\n\n infer_forward = llama_causal_lm_forward\n method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(\n description=method_replacement, policy=policy, target_key=LlamaForCausalLM\n )\n\n infer_forward = llama_model_forward\n method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)\n\n infer_forward = llama_decoder_layer_forward\n method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(\n description=method_replacement, policy=policy, target_key=LlamaDecoderLayer\n )\n\n infer_forward = llama_rmsnorm_forward\n method_replacement = {\"forward\": partial(infer_forward)}\n self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaRMSNorm)\n\n return policy\n\n def postprocess(self):\n init_to_get_rotary(self.model.model)\n return self.model\n", "path": "colossalai/inference/modeling/policy/nopadding_llama.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Any, Dict, Optional\n\nimport torch.distributed as dist\nfrom torch.distributed import ProcessGroup\n\nfrom colossalai.pipeline.stage_manager import PipelineStageManager\n\n__all__ = [\"ShardConfig\"]\n\n\n@dataclass\nclass ShardConfig:\n r\"\"\"\n The config for sharding the huggingface model\n\n Args:\n tensor_parallel_process_group (Optional[ProcessGroup]): The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group.\n pipeline_stage_manager (Optional[PipelineStageManager]): If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism.\n enable_tensor_parallelism (bool): Whether to use tensor parallelism. Defaults to True.\n enable_fused_normalization (bool): Whether to use fused layernorm. Defaults to False.\n enable_flash_attention (bool, optional): Whether to switch on flash attention. Defaults to False.\n enable_jit_fused (bool, optional): Whether to switch on JIT fused operators. Defaults to False.\n enable_sequence_parallelism (bool): Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False.\n enable_sequence_overlap (bool): Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used when enable_sequence_parallelism is True. Defaults to False.\n enable_all_optimization (bool): Whether to turn on all optimization tools including 'fused normalization', 'flash attention', 'JIT fused operators', 'sequence parallelism' and 'sequence overlap'. Defaults to False.\n \"\"\"\n tensor_parallel_process_group: Optional[ProcessGroup] = None\n pipeline_stage_manager: Optional[PipelineStageManager] = None\n enable_tensor_parallelism: bool = True\n enable_fused_normalization: bool = False\n enable_flash_attention: bool = False\n enable_jit_fused: bool = False\n enable_all_optimization: bool = False\n enable_sequence_parallelism: bool = False\n enable_sequence_overlap: bool = False\n parallel_output = True\n extra_kwargs: Dict[str, Any] = field(default_factory=dict)\n # tensor_parallel_mode: Literal['1d', '2d', '2.5d', '3d']\n\n @property\n def tensor_parallel_size(self):\n return self._tensor_parallel_size\n\n def __post_init__(self):\n if not self.enable_tensor_parallelism and self.enable_sequence_parallelism:\n raise ValueError(\n \"enable_sequence_parallelism can only be set to True when enable_tensor_parallelism is True\"\n )\n if not self.enable_sequence_parallelism and self.enable_sequence_overlap:\n raise ValueError(\"enable_sequence_overlap can only be set to True when enable_sequence_parallelism is True\")\n if not self.enable_tensor_parallelism:\n self._tensor_parallel_size = 1\n else:\n # get the parallel size\n self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)\n # turn on all optimization if all_optimization is set to True\n if self.enable_all_optimization:\n self._turn_on_all_optimization()\n\n def _turn_on_all_optimization(self):\n \"\"\"\n Turn on all optimization.\n \"\"\"\n # you can add all the optimization flag here\n self.enable_fused_normalization = True\n self.enable_flash_attention = True\n self.enable_jit_fused = True\n self.enable_sequence_parallelism = True\n self.enable_sequence_overlap = True\n", "path": "colossalai/shardformer/shard/shard_config.py"}, {"content": "from torch.nn import Parameter\nfrom transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaForCausalLM, LlamaModel, LlamaRMSNorm\n\nfrom colossalai.inference.modeling.models.nopadding_llama import (\n NopadLlamaAttention,\n NopadLlamaMLP,\n llama_causal_lm_forward,\n llama_decoder_layer_forward,\n llama_model_forward,\n llama_rmsnorm_forward,\n)\nfrom colossalai.inference.utils import init_to_get_rotary\nfrom colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription\nfrom colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy\n\n\nclass NoPaddingLlamaModelInferPolicy(LlamaForCausalLMPolicy):\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n policy = super().module_policy()\n\n decoder_attribute_replacement = {\n \"lm_head.weight\": Parameter(self.model.lm_head.weight.transpose(0, 1), requires_grad=False),\n }\n policy[LlamaForCausalLM] = ModulePolicyDescription(\n attribute_replacement=decoder_attribute_replacement,\n )\n\n policy[LlamaDecoderLayer] = ModulePolicyDescription(\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"mlp\",\n target_module=NopadLlamaMLP,\n ),\n SubModuleReplacementDescription(\n suffix=\"self_attn\",\n target_module=NopadLlamaAttention,\n ),\n ]\n )\n\n self.append_or_create_method_replacement(\n description={\"forward\": llama_causal_lm_forward}, policy=policy, target_key=LlamaForCausalLM\n )\n self.append_or_create_method_replacement(\n description={\"forward\": llama_model_forward}, policy=policy, target_key=LlamaModel\n )\n self.append_or_create_method_replacement(\n description={\"forward\": llama_decoder_layer_forward}, policy=policy, target_key=LlamaDecoderLayer\n )\n self.append_or_create_method_replacement(\n description={\"forward\": llama_rmsnorm_forward}, policy=policy, target_key=LlamaRMSNorm\n )\n\n return policy\n\n def postprocess(self):\n init_to_get_rotary(self.model.model)\n return self.model\n", "path": "colossalai/inference/modeling/policy/nopadding_llama.py"}]}
| 2,025 | 807 |
gh_patches_debug_13885
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3039
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove orphans: Repository matching query does not exist.
**Version**
```
$ rpm -qa | grep tfm-rubygem-pulp
tfm-rubygem-pulp_certguard_client-1.5.0-1.el7.noarch
tfm-rubygem-pulp_ansible_client-0.13.1-1.el7.noarch
tfm-rubygem-pulp_deb_client-2.18.0-1.el7.noarch
tfm-rubygem-pulp_rpm_client-3.17.4-1.el7.noarch
tfm-rubygem-pulp_python_client-3.6.0-1.el7.noarch
tfm-rubygem-pulp_ostree_client-2.0.0-0.1.a1.el7.noarch
tfm-rubygem-pulpcore_client-3.18.5-1.el7.noarch
tfm-rubygem-pulp_container_client-2.10.3-1.el7.noarch
tfm-rubygem-pulp_file_client-1.10.0-1.el7.noarch
$ rpm -qa | grep katello-4
tfm-rubygem-katello-4.5.0-1.el7.noarch
katello-4.5.0-1.el7.noarch
```
**Describe the bug**
Running `foreman-rake katello:delete_orphaned_content RAILS_ENV=production` creates two tasks.
One of the tasks gets stuck in _paused_ with the following error: `Repository matching query does not exist.`
**To Reproduce**
- Run
`foreman-rake katello:delete_orphaned_content RAILS_ENV=production`.
- After a few minutes run
`hammer --no-headers --output json task list --order 'started_at DESC' --search 'state = "paused"'`
**Expected behavior**
We expected both tasks to run successfully.
**Additional context**
We had to manually apply this patch: https://github.com/pulp/pulp_rpm/pull/2619 - before that, we had his same issue: https://github.com/pulp/pulp_rpm/issues/2459 .
```
$ hammer --no-headers --output json task list --order 'started_at DESC' --search 'state = "paused" '
[
{
"ID": "a8aae19c-7c62-4a60-ab12-935687e3723e",
"Action": "Remove orphans ",
"State": "paused",
"Result": "error",
"Started at": "2022-07-21 15:29:02 UTC",
"Ended at": null,
"Duration": "00:02:29.56437",
"Owner": "foreman_admin",
"Task errors": [
"Repository matching query does not exist."
]
}
]
```
```
$ http_pulp /pulp/api/v3/tasks/e7df82c7-cb38-4fac-a28a-edd8842b3b69/
HTTP/1.1 200 OK
Access-Control-Expose-Headers: Correlation-ID
Allow: GET, PATCH, DELETE, HEAD, OPTIONS
Connection: Keep-Alive
Content-Length: 3335
Content-Type: application/json
Correlation-ID: e1f2e082da6e401196007424799a05b5
Date: Thu, 21 Jul 2022 17:10:58 GMT
Keep-Alive: timeout=15, max=100
Referrer-Policy: same-origin
Server: gunicorn
Vary: Accept,Cookie
Via: 1.1 updates.eurotux.com
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
{
"child_tasks": [],
"created_resources": [],
"error": {
"description": "Repository matching query does not exist.",
"traceback": " File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulpcore/tasking/pulpcore_worker.py\", line 410, in _perform_task\n result = func(*args, **kwargs)\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulpcore/app/tasks/orphan.py\", line 66, in orphan_cleanup\n c.delete()\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\", line 746, in delete\n deleted, _rows_count = collector.delete()\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/deletion.py\", line 435, in delete\n signals.post_delete.send(\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\", line 180, in send\n return [\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\", line 181, in <listcomp>\n (receiver, receiver(signal=self, sender=sender, **named))\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulp_rpm/app/models/distribution.py\", line 340, in cleanup_subrepos\n Variant.objects.filter(repository=subrepo).delete()\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\", line 746, in delete\n deleted, _rows_count = collector.delete()\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/deletion.py\", line 435, in delete\n signals.post_delete.send(\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\", line 180, in send\n return [\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\", line 181, in <listcomp>\n (receiver, receiver(signal=self, sender=sender, **named))\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulp_rpm/app/models/distribution.py\", line 338, in cleanup_subrepos\n subrepo = instance.repository\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/fields/related_descriptors.py\", line 187, in __get__\n rel_obj = self.get_object(instance)\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/fields/related_descriptors.py\", line 154, in get_object\n return qs.get(self.field.get_reverse_related_filter(instance))\n File \"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\", line 435, in get\n raise self.model.DoesNotExist(\n"
},
"finished_at": "2022-07-21T15:30:11.075104Z",
"logging_cid": "ac4070d63c764578bb854f97873ba88a",
"name": "pulpcore.app.tasks.orphan.orphan_cleanup",
"parent_task": null,
"progress_reports": [
{
"code": "clean-up.content",
"done": 2000,
"message": "Clean up orphan Content",
"state": "running",
"suffix": null,
"total": 17098
}
],
"pulp_created": "2022-07-21T15:29:58.868921Z",
"pulp_href": "/pulp/api/v3/tasks/e7df82c7-cb38-4fac-a28a-edd8842b3b69/",
"reserved_resources_record": [],
"started_at": "2022-07-21T15:29:59.335110Z",
"state": "failed",
"task_group": null,
"worker": "/pulp/api/v3/workers/6ff07070-3e14-49b3-b508-a0c300683f28/"
}
```
edit: related to https://community.theforeman.org/t/delete-orphaned-content-fails/29494/6
https://bugzilla.redhat.com/show_bug.cgi?id=2115881
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/views/orphans.py`
Content:
```
1 from drf_spectacular.utils import extend_schema
2 from rest_framework.views import APIView
3
4 from pulpcore.app.loggers import deprecation_logger
5 from pulpcore.app.response import OperationPostponedResponse
6 from pulpcore.app.serializers import AsyncOperationResponseSerializer
7 from pulpcore.app.tasks import orphan_cleanup
8 from pulpcore.tasking.tasks import dispatch
9
10
11 class OrphansView(APIView):
12 @extend_schema(
13 description="DEPRECATED! Trigger an asynchronous task that deletes all "
14 "orphaned content and artifacts. Use the `POST /pulp/api/v3/orphans/cleanup/` call "
15 "instead.",
16 summary="Delete orphans",
17 responses={202: AsyncOperationResponseSerializer},
18 )
19 def delete(self, request, format=None):
20 """
21 Cleans up all the Content and Artifact orphans in the system
22 """
23 deprecation_logger.warning(
24 "The `DELETE /pulp/api/v3/orphans/` call is deprecated. Use"
25 "`POST /pulp/api/v3/orphans/cleanup/` instead."
26 )
27
28 task = dispatch(orphan_cleanup)
29
30 return OperationPostponedResponse(task, request)
31
```
Path: `pulpcore/app/viewsets/orphans.py`
Content:
```
1 from drf_spectacular.utils import extend_schema
2 from rest_framework.viewsets import ViewSet
3
4 from pulpcore.app.response import OperationPostponedResponse
5 from pulpcore.app.serializers import AsyncOperationResponseSerializer, OrphansCleanupSerializer
6 from pulpcore.app.tasks import orphan_cleanup
7 from pulpcore.tasking.tasks import dispatch
8
9
10 class OrphansCleanupViewset(ViewSet):
11 serializer_class = OrphansCleanupSerializer
12
13 @extend_schema(
14 description="Trigger an asynchronous orphan cleanup operation.",
15 responses={202: AsyncOperationResponseSerializer},
16 )
17 def cleanup(self, request):
18 """
19 Triggers an asynchronous orphan cleanup operation.
20 """
21 serializer = OrphansCleanupSerializer(data=request.data)
22 serializer.is_valid(raise_exception=True)
23
24 content_pks = serializer.validated_data.get("content_hrefs", None)
25 orphan_protection_time = serializer.validated_data.get("orphan_protection_time")
26
27 task = dispatch(
28 orphan_cleanup,
29 kwargs={"content_pks": content_pks, "orphan_protection_time": orphan_protection_time},
30 )
31
32 return OperationPostponedResponse(task, request)
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/views/orphans.py b/pulpcore/app/views/orphans.py
--- a/pulpcore/app/views/orphans.py
+++ b/pulpcore/app/views/orphans.py
@@ -25,6 +25,6 @@
"`POST /pulp/api/v3/orphans/cleanup/` instead."
)
- task = dispatch(orphan_cleanup)
+ task = dispatch(orphan_cleanup, exclusive_resources=["/pulp/api/v3/orphans/cleanup/"])
return OperationPostponedResponse(task, request)
diff --git a/pulpcore/app/viewsets/orphans.py b/pulpcore/app/viewsets/orphans.py
--- a/pulpcore/app/viewsets/orphans.py
+++ b/pulpcore/app/viewsets/orphans.py
@@ -26,6 +26,7 @@
task = dispatch(
orphan_cleanup,
+ exclusive_resources=["/pulp/api/v3/orphans/cleanup/"],
kwargs={"content_pks": content_pks, "orphan_protection_time": orphan_protection_time},
)
|
{"golden_diff": "diff --git a/pulpcore/app/views/orphans.py b/pulpcore/app/views/orphans.py\n--- a/pulpcore/app/views/orphans.py\n+++ b/pulpcore/app/views/orphans.py\n@@ -25,6 +25,6 @@\n \"`POST /pulp/api/v3/orphans/cleanup/` instead.\"\n )\n \n- task = dispatch(orphan_cleanup)\n+ task = dispatch(orphan_cleanup, exclusive_resources=[\"/pulp/api/v3/orphans/cleanup/\"])\n \n return OperationPostponedResponse(task, request)\ndiff --git a/pulpcore/app/viewsets/orphans.py b/pulpcore/app/viewsets/orphans.py\n--- a/pulpcore/app/viewsets/orphans.py\n+++ b/pulpcore/app/viewsets/orphans.py\n@@ -26,6 +26,7 @@\n \n task = dispatch(\n orphan_cleanup,\n+ exclusive_resources=[\"/pulp/api/v3/orphans/cleanup/\"],\n kwargs={\"content_pks\": content_pks, \"orphan_protection_time\": orphan_protection_time},\n )\n", "issue": "Remove orphans: Repository matching query does not exist.\n**Version**\r\n```\r\n$ rpm -qa | grep tfm-rubygem-pulp\r\ntfm-rubygem-pulp_certguard_client-1.5.0-1.el7.noarch\r\ntfm-rubygem-pulp_ansible_client-0.13.1-1.el7.noarch\r\ntfm-rubygem-pulp_deb_client-2.18.0-1.el7.noarch\r\ntfm-rubygem-pulp_rpm_client-3.17.4-1.el7.noarch\r\ntfm-rubygem-pulp_python_client-3.6.0-1.el7.noarch\r\ntfm-rubygem-pulp_ostree_client-2.0.0-0.1.a1.el7.noarch\r\ntfm-rubygem-pulpcore_client-3.18.5-1.el7.noarch\r\ntfm-rubygem-pulp_container_client-2.10.3-1.el7.noarch\r\ntfm-rubygem-pulp_file_client-1.10.0-1.el7.noarch\r\n\r\n$ rpm -qa | grep katello-4\r\ntfm-rubygem-katello-4.5.0-1.el7.noarch\r\nkatello-4.5.0-1.el7.noarch\r\n```\r\n\r\n**Describe the bug**\r\nRunning `foreman-rake katello:delete_orphaned_content RAILS_ENV=production` creates two tasks.\r\nOne of the tasks gets stuck in _paused_ with the following error: `Repository matching query does not exist.`\r\n\r\n\r\n**To Reproduce**\r\n\r\n- Run \r\n `foreman-rake katello:delete_orphaned_content RAILS_ENV=production`.\r\n\r\n- After a few minutes run \r\n `hammer --no-headers --output json task list --order 'started_at DESC' --search 'state = \"paused\"'`\r\n\r\n**Expected behavior**\r\nWe expected both tasks to run successfully.\r\n\r\n**Additional context**\r\nWe had to manually apply this patch: https://github.com/pulp/pulp_rpm/pull/2619 - before that, we had his same issue: https://github.com/pulp/pulp_rpm/issues/2459 .\r\n\r\n```\r\n$ hammer --no-headers --output json task list --order 'started_at DESC' --search 'state = \"paused\" '\r\n[\r\n {\r\n \"ID\": \"a8aae19c-7c62-4a60-ab12-935687e3723e\",\r\n \"Action\": \"Remove orphans \",\r\n \"State\": \"paused\",\r\n \"Result\": \"error\",\r\n \"Started at\": \"2022-07-21 15:29:02 UTC\",\r\n \"Ended at\": null,\r\n \"Duration\": \"00:02:29.56437\",\r\n \"Owner\": \"foreman_admin\",\r\n \"Task errors\": [\r\n \"Repository matching query does not exist.\"\r\n ]\r\n }\r\n]\r\n```\r\n```\r\n$ http_pulp /pulp/api/v3/tasks/e7df82c7-cb38-4fac-a28a-edd8842b3b69/\r\nHTTP/1.1 200 OK\r\nAccess-Control-Expose-Headers: Correlation-ID\r\nAllow: GET, PATCH, DELETE, HEAD, OPTIONS\r\nConnection: Keep-Alive\r\nContent-Length: 3335\r\nContent-Type: application/json\r\nCorrelation-ID: e1f2e082da6e401196007424799a05b5\r\nDate: Thu, 21 Jul 2022 17:10:58 GMT\r\nKeep-Alive: timeout=15, max=100\r\nReferrer-Policy: same-origin\r\nServer: gunicorn\r\nVary: Accept,Cookie\r\nVia: 1.1 updates.eurotux.com\r\nX-Content-Type-Options: nosniff\r\nX-Frame-Options: DENY\r\n\r\n{\r\n \"child_tasks\": [],\r\n \"created_resources\": [],\r\n \"error\": {\r\n \"description\": \"Repository matching query does not exist.\",\r\n \"traceback\": \" File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulpcore/tasking/pulpcore_worker.py\\\", line 410, in _perform_task\\n result = func(*args, **kwargs)\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulpcore/app/tasks/orphan.py\\\", line 66, in orphan_cleanup\\n c.delete()\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\\\", line 746, in delete\\n deleted, _rows_count = collector.delete()\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/deletion.py\\\", line 435, in delete\\n signals.post_delete.send(\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\\\", line 180, in send\\n return [\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\\\", line 181, in <listcomp>\\n (receiver, receiver(signal=self, sender=sender, **named))\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulp_rpm/app/models/distribution.py\\\", line 340, in cleanup_subrepos\\n Variant.objects.filter(repository=subrepo).delete()\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\\\", line 746, in delete\\n deleted, _rows_count = collector.delete()\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/deletion.py\\\", line 435, in delete\\n signals.post_delete.send(\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\\\", line 180, in send\\n return [\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/dispatch/dispatcher.py\\\", line 181, in <listcomp>\\n (receiver, receiver(signal=self, sender=sender, **named))\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/pulp_rpm/app/models/distribution.py\\\", line 338, in cleanup_subrepos\\n subrepo = instance.repository\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/fields/related_descriptors.py\\\", line 187, in __get__\\n rel_obj = self.get_object(instance)\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/fields/related_descriptors.py\\\", line 154, in get_object\\n return qs.get(self.field.get_reverse_related_filter(instance))\\n File \\\"/opt/theforeman/tfm-pulpcore/root/usr/lib/python3.8/site-packages/django/db/models/query.py\\\", line 435, in get\\n raise self.model.DoesNotExist(\\n\"\r\n },\r\n \"finished_at\": \"2022-07-21T15:30:11.075104Z\",\r\n \"logging_cid\": \"ac4070d63c764578bb854f97873ba88a\",\r\n \"name\": \"pulpcore.app.tasks.orphan.orphan_cleanup\",\r\n \"parent_task\": null,\r\n \"progress_reports\": [\r\n {\r\n \"code\": \"clean-up.content\",\r\n \"done\": 2000,\r\n \"message\": \"Clean up orphan Content\",\r\n \"state\": \"running\",\r\n \"suffix\": null,\r\n \"total\": 17098\r\n }\r\n ],\r\n \"pulp_created\": \"2022-07-21T15:29:58.868921Z\",\r\n \"pulp_href\": \"/pulp/api/v3/tasks/e7df82c7-cb38-4fac-a28a-edd8842b3b69/\",\r\n \"reserved_resources_record\": [],\r\n \"started_at\": \"2022-07-21T15:29:59.335110Z\",\r\n \"state\": \"failed\",\r\n \"task_group\": null,\r\n \"worker\": \"/pulp/api/v3/workers/6ff07070-3e14-49b3-b508-a0c300683f28/\"\r\n}\r\n```\r\n\r\nedit: related to https://community.theforeman.org/t/delete-orphaned-content-fails/29494/6\r\n\r\nhttps://bugzilla.redhat.com/show_bug.cgi?id=2115881\r\n\r\n\n", "before_files": [{"content": "from drf_spectacular.utils import extend_schema\nfrom rest_framework.views import APIView\n\nfrom pulpcore.app.loggers import deprecation_logger\nfrom pulpcore.app.response import OperationPostponedResponse\nfrom pulpcore.app.serializers import AsyncOperationResponseSerializer\nfrom pulpcore.app.tasks import orphan_cleanup\nfrom pulpcore.tasking.tasks import dispatch\n\n\nclass OrphansView(APIView):\n @extend_schema(\n description=\"DEPRECATED! Trigger an asynchronous task that deletes all \"\n \"orphaned content and artifacts. Use the `POST /pulp/api/v3/orphans/cleanup/` call \"\n \"instead.\",\n summary=\"Delete orphans\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def delete(self, request, format=None):\n \"\"\"\n Cleans up all the Content and Artifact orphans in the system\n \"\"\"\n deprecation_logger.warning(\n \"The `DELETE /pulp/api/v3/orphans/` call is deprecated. Use\"\n \"`POST /pulp/api/v3/orphans/cleanup/` instead.\"\n )\n\n task = dispatch(orphan_cleanup)\n\n return OperationPostponedResponse(task, request)\n", "path": "pulpcore/app/views/orphans.py"}, {"content": "from drf_spectacular.utils import extend_schema\nfrom rest_framework.viewsets import ViewSet\n\nfrom pulpcore.app.response import OperationPostponedResponse\nfrom pulpcore.app.serializers import AsyncOperationResponseSerializer, OrphansCleanupSerializer\nfrom pulpcore.app.tasks import orphan_cleanup\nfrom pulpcore.tasking.tasks import dispatch\n\n\nclass OrphansCleanupViewset(ViewSet):\n serializer_class = OrphansCleanupSerializer\n\n @extend_schema(\n description=\"Trigger an asynchronous orphan cleanup operation.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def cleanup(self, request):\n \"\"\"\n Triggers an asynchronous orphan cleanup operation.\n \"\"\"\n serializer = OrphansCleanupSerializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n content_pks = serializer.validated_data.get(\"content_hrefs\", None)\n orphan_protection_time = serializer.validated_data.get(\"orphan_protection_time\")\n\n task = dispatch(\n orphan_cleanup,\n kwargs={\"content_pks\": content_pks, \"orphan_protection_time\": orphan_protection_time},\n )\n\n return OperationPostponedResponse(task, request)\n", "path": "pulpcore/app/viewsets/orphans.py"}], "after_files": [{"content": "from drf_spectacular.utils import extend_schema\nfrom rest_framework.views import APIView\n\nfrom pulpcore.app.loggers import deprecation_logger\nfrom pulpcore.app.response import OperationPostponedResponse\nfrom pulpcore.app.serializers import AsyncOperationResponseSerializer\nfrom pulpcore.app.tasks import orphan_cleanup\nfrom pulpcore.tasking.tasks import dispatch\n\n\nclass OrphansView(APIView):\n @extend_schema(\n description=\"DEPRECATED! Trigger an asynchronous task that deletes all \"\n \"orphaned content and artifacts. Use the `POST /pulp/api/v3/orphans/cleanup/` call \"\n \"instead.\",\n summary=\"Delete orphans\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def delete(self, request, format=None):\n \"\"\"\n Cleans up all the Content and Artifact orphans in the system\n \"\"\"\n deprecation_logger.warning(\n \"The `DELETE /pulp/api/v3/orphans/` call is deprecated. Use\"\n \"`POST /pulp/api/v3/orphans/cleanup/` instead.\"\n )\n\n task = dispatch(orphan_cleanup, exclusive_resources=[\"/pulp/api/v3/orphans/cleanup/\"])\n\n return OperationPostponedResponse(task, request)\n", "path": "pulpcore/app/views/orphans.py"}, {"content": "from drf_spectacular.utils import extend_schema\nfrom rest_framework.viewsets import ViewSet\n\nfrom pulpcore.app.response import OperationPostponedResponse\nfrom pulpcore.app.serializers import AsyncOperationResponseSerializer, OrphansCleanupSerializer\nfrom pulpcore.app.tasks import orphan_cleanup\nfrom pulpcore.tasking.tasks import dispatch\n\n\nclass OrphansCleanupViewset(ViewSet):\n serializer_class = OrphansCleanupSerializer\n\n @extend_schema(\n description=\"Trigger an asynchronous orphan cleanup operation.\",\n responses={202: AsyncOperationResponseSerializer},\n )\n def cleanup(self, request):\n \"\"\"\n Triggers an asynchronous orphan cleanup operation.\n \"\"\"\n serializer = OrphansCleanupSerializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n content_pks = serializer.validated_data.get(\"content_hrefs\", None)\n orphan_protection_time = serializer.validated_data.get(\"orphan_protection_time\")\n\n task = dispatch(\n orphan_cleanup,\n exclusive_resources=[\"/pulp/api/v3/orphans/cleanup/\"],\n kwargs={\"content_pks\": content_pks, \"orphan_protection_time\": orphan_protection_time},\n )\n\n return OperationPostponedResponse(task, request)\n", "path": "pulpcore/app/viewsets/orphans.py"}]}
| 2,962 | 233 |
gh_patches_debug_2586
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__numpyro-737
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possible error in the validation of a Categorical distribution
I am getting an error when I try to run the following code. The code just sample from a categorical distribution using the defined probabilities.
```python
import numpyro
import numpyro.distributions as dist
import jax.numpy as jnp
numpyro.enable_validation(True)
def model():
probs = jnp.array([0.5, 0.5, 0.])
c = numpyro.sample('c', dist.Categorical(probs=probs))
return c
with numpyro.handlers.seed(rng_seed=54):
print(model())
```
```
ValueError Traceback (most recent call last)
<ipython-input-1-fc7fe60e083b> in <module>
10
11 with numpyro.handlers.seed(rng_seed=54):
---> 12 print(model())
<ipython-input-1-fc7fe60e083b> in model()
6 def model():
7 probs = jnp.array([0.5, 0.5, 0.])
----> 8 c = numpyro.sample('c', dist.Categorical(probs=probs))
9 return c
10
~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/discrete.py in Categorical(probs, logits, validate_args)
348 def Categorical(probs=None, logits=None, validate_args=None):
349 if probs is not None:
--> 350 return CategoricalProbs(probs, validate_args=validate_args)
351 elif logits is not None:
352 return CategoricalLogits(logits, validate_args=validate_args)
~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/discrete.py in __init__(self, probs, validate_args)
265 raise ValueError("`probs` parameter must be at least one-dimensional.")
266 self.probs = probs
--> 267 super(CategoricalProbs, self).__init__(batch_shape=jnp.shape(self.probs)[:-1],
268 validate_args=validate_args)
269
~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/distribution.py in __init__(self, batch_shape, event_shape, validate_args)
142 if not_jax_tracer(is_valid):
143 if not is_valid:
--> 144 raise ValueError("The parameter {} has invalid values".format(param))
145 super(Distribution, self).__init__()
146
ValueError: The parameter probs has invalid values
```
I think the problem is caused by the validation because If I restart my kernel and comment the line ```numpyro.enable_validation(True)``` the code will run without problem. It will print 0 in my case.
If I write a similar code in Pyro with the validation enabled, I do not get an error.
```python
import torch
import pyro
import pyro.distributions as dist
pyro.enable_validation(True)
pyro.set_rng_seed(54)
def model():
probs = torch.tensor([0.5, 0.5, 0.])
c = pyro.sample('c', dist.Categorical(probs=probs))
return c
print(model())
```
I am using Python 3.8.5, Pyro 1.4.0 and NumPyro 0.3.0 with Ubuntu. Happy to help with what I can.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numpyro/distributions/constraints.py`
Content:
```
1 # Copyright Contributors to the Pyro project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 # The implementation follows the design in PyTorch: torch.distributions.constraints.py
5 #
6 # Copyright (c) 2016- Facebook, Inc (Adam Paszke)
7 # Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
8 # Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
9 # Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
10 # Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
11 # Copyright (c) 2011-2013 NYU (Clement Farabet)
12 # Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
13 # Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
14 # Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
15 #
16 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
17 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
18 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
19 # ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
20 # LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
21 # CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
22 # SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
23 # INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
24 # CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
25 # ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
26 # POSSIBILITY OF SUCH DAMAGE.
27
28
29 __all__ = [
30 'boolean',
31 'corr_cholesky',
32 'corr_matrix',
33 'dependent',
34 'greater_than',
35 'integer_interval',
36 'integer_greater_than',
37 'interval',
38 'is_dependent',
39 'less_than',
40 'lower_cholesky',
41 'multinomial',
42 'nonnegative_integer',
43 'positive',
44 'positive_definite',
45 'positive_integer',
46 'real',
47 'real_vector',
48 'simplex',
49 'unit_interval',
50 'Constraint',
51 ]
52
53 import jax.numpy as jnp
54
55
56 class Constraint(object):
57 """
58 Abstract base class for constraints.
59
60 A constraint object represents a region over which a variable is valid,
61 e.g. within which a variable can be optimized.
62 """
63
64 def __call__(self, x):
65 raise NotImplementedError
66
67 def check(self, value):
68 """
69 Returns a byte tensor of `sample_shape + batch_shape` indicating
70 whether each event in value satisfies this constraint.
71 """
72 return self(value)
73
74
75 class _Boolean(Constraint):
76 def __call__(self, x):
77 return (x == 0) | (x == 1)
78
79
80 class _CorrCholesky(Constraint):
81 def __call__(self, x):
82 tril = jnp.tril(x)
83 lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)
84 positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)
85 x_norm = jnp.linalg.norm(x, axis=-1)
86 unit_norm_row = jnp.all((x_norm <= 1) & (x_norm > 1 - 1e-6), axis=-1)
87 return lower_triangular & positive_diagonal & unit_norm_row
88
89
90 class _CorrMatrix(Constraint):
91 def __call__(self, x):
92 # check for symmetric
93 symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)
94 # check for the smallest eigenvalue is positive
95 positive = jnp.linalg.eigh(x)[0][..., 0] > 0
96 # check for diagonal equal to 1
97 unit_variance = jnp.all(jnp.abs(jnp.diagonal(x, axis1=-2, axis2=-1) - 1) < 1e-6, axis=-1)
98 return symmetric & positive & unit_variance
99
100
101 class _Dependent(Constraint):
102 def __call__(self, x):
103 raise ValueError('Cannot determine validity of dependent constraint')
104
105
106 def is_dependent(constraint):
107 return isinstance(constraint, _Dependent)
108
109
110 class _GreaterThan(Constraint):
111 def __init__(self, lower_bound):
112 self.lower_bound = lower_bound
113
114 def __call__(self, x):
115 return x > self.lower_bound
116
117
118 class _LessThan(Constraint):
119 def __init__(self, upper_bound):
120 self.upper_bound = upper_bound
121
122 def __call__(self, x):
123 return x < self.upper_bound
124
125
126 class _IntegerInterval(Constraint):
127 def __init__(self, lower_bound, upper_bound):
128 self.lower_bound = lower_bound
129 self.upper_bound = upper_bound
130
131 def __call__(self, x):
132 return (x >= self.lower_bound) & (x <= self.upper_bound) & (x == jnp.floor(x))
133
134
135 class _IntegerGreaterThan(Constraint):
136 def __init__(self, lower_bound):
137 self.lower_bound = lower_bound
138
139 def __call__(self, x):
140 return (x % 1 == 0) & (x >= self.lower_bound)
141
142
143 class _Interval(Constraint):
144 def __init__(self, lower_bound, upper_bound):
145 self.lower_bound = lower_bound
146 self.upper_bound = upper_bound
147
148 def __call__(self, x):
149 return (x > self.lower_bound) & (x < self.upper_bound)
150
151
152 class _LowerCholesky(Constraint):
153 def __call__(self, x):
154 tril = jnp.tril(x)
155 lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)
156 positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)
157 return lower_triangular & positive_diagonal
158
159
160 class _Multinomial(Constraint):
161 def __init__(self, upper_bound):
162 self.upper_bound = upper_bound
163
164 def __call__(self, x):
165 return jnp.all(x >= 0, axis=-1) & (jnp.sum(x, -1) == self.upper_bound)
166
167
168 class _OrderedVector(Constraint):
169 def __call__(self, x):
170 return jnp.all(x[..., 1:] > x[..., :-1], axis=-1)
171
172
173 class _PositiveDefinite(Constraint):
174 def __call__(self, x):
175 # check for symmetric
176 symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)
177 # check for the smallest eigenvalue is positive
178 positive = jnp.linalg.eigh(x)[0][..., 0] > 0
179 return symmetric & positive
180
181
182 class _Real(Constraint):
183 def __call__(self, x):
184 return jnp.isfinite(x)
185
186
187 class _RealVector(Constraint):
188 def __call__(self, x):
189 return jnp.all(jnp.isfinite(x), axis=-1)
190
191
192 class _Simplex(Constraint):
193 def __call__(self, x):
194 x_sum = jnp.sum(x, axis=-1)
195 return jnp.all(x > 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)
196
197
198 # TODO: Make types consistent
199
200 boolean = _Boolean()
201 corr_cholesky = _CorrCholesky()
202 corr_matrix = _CorrMatrix()
203 dependent = _Dependent()
204 greater_than = _GreaterThan
205 less_than = _LessThan
206 integer_interval = _IntegerInterval
207 integer_greater_than = _IntegerGreaterThan
208 interval = _Interval
209 lower_cholesky = _LowerCholesky()
210 multinomial = _Multinomial
211 nonnegative_integer = _IntegerGreaterThan(0)
212 ordered_vector = _OrderedVector()
213 positive = _GreaterThan(0.)
214 positive_definite = _PositiveDefinite()
215 positive_integer = _IntegerGreaterThan(1)
216 real = _Real()
217 real_vector = _RealVector()
218 simplex = _Simplex()
219 unit_interval = _Interval(0., 1.)
220
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numpyro/distributions/constraints.py b/numpyro/distributions/constraints.py
--- a/numpyro/distributions/constraints.py
+++ b/numpyro/distributions/constraints.py
@@ -192,7 +192,7 @@
class _Simplex(Constraint):
def __call__(self, x):
x_sum = jnp.sum(x, axis=-1)
- return jnp.all(x > 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)
+ return jnp.all(x >= 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)
# TODO: Make types consistent
|
{"golden_diff": "diff --git a/numpyro/distributions/constraints.py b/numpyro/distributions/constraints.py\n--- a/numpyro/distributions/constraints.py\n+++ b/numpyro/distributions/constraints.py\n@@ -192,7 +192,7 @@\n class _Simplex(Constraint):\n def __call__(self, x):\n x_sum = jnp.sum(x, axis=-1)\n- return jnp.all(x > 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)\n+ return jnp.all(x >= 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)\n \n \n # TODO: Make types consistent\n", "issue": "Possible error in the validation of a Categorical distribution\nI am getting an error when I try to run the following code. The code just sample from a categorical distribution using the defined probabilities. \r\n\r\n```python\r\nimport numpyro\r\nimport numpyro.distributions as dist\r\nimport jax.numpy as jnp\r\nnumpyro.enable_validation(True)\r\n\r\n\r\ndef model():\r\n probs = jnp.array([0.5, 0.5, 0.])\r\n c = numpyro.sample('c', dist.Categorical(probs=probs))\r\n return c\r\n\r\nwith numpyro.handlers.seed(rng_seed=54):\r\n print(model())\r\n```\r\n\r\n```\r\nValueError Traceback (most recent call last)\r\n<ipython-input-1-fc7fe60e083b> in <module>\r\n 10 \r\n 11 with numpyro.handlers.seed(rng_seed=54):\r\n---> 12 print(model())\r\n\r\n<ipython-input-1-fc7fe60e083b> in model()\r\n 6 def model():\r\n 7 probs = jnp.array([0.5, 0.5, 0.])\r\n----> 8 c = numpyro.sample('c', dist.Categorical(probs=probs))\r\n 9 return c\r\n 10 \r\n\r\n~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/discrete.py in Categorical(probs, logits, validate_args)\r\n 348 def Categorical(probs=None, logits=None, validate_args=None):\r\n 349 if probs is not None:\r\n--> 350 return CategoricalProbs(probs, validate_args=validate_args)\r\n 351 elif logits is not None:\r\n 352 return CategoricalLogits(logits, validate_args=validate_args)\r\n\r\n~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/discrete.py in __init__(self, probs, validate_args)\r\n 265 raise ValueError(\"`probs` parameter must be at least one-dimensional.\")\r\n 266 self.probs = probs\r\n--> 267 super(CategoricalProbs, self).__init__(batch_shape=jnp.shape(self.probs)[:-1],\r\n 268 validate_args=validate_args)\r\n 269 \r\n\r\n~/miniconda3/envs/numpyro_test/lib/python3.8/site-packages/numpyro/distributions/distribution.py in __init__(self, batch_shape, event_shape, validate_args)\r\n 142 if not_jax_tracer(is_valid):\r\n 143 if not is_valid:\r\n--> 144 raise ValueError(\"The parameter {} has invalid values\".format(param))\r\n 145 super(Distribution, self).__init__()\r\n 146 \r\n\r\nValueError: The parameter probs has invalid values\r\n```\r\n\r\nI think the problem is caused by the validation because If I restart my kernel and comment the line ```numpyro.enable_validation(True)``` the code will run without problem. It will print 0 in my case.\r\n\r\n\r\nIf I write a similar code in Pyro with the validation enabled, I do not get an error.\r\n\r\n```python\r\nimport torch\r\nimport pyro\r\nimport pyro.distributions as dist\r\npyro.enable_validation(True)\r\npyro.set_rng_seed(54)\r\n\r\ndef model():\r\n probs = torch.tensor([0.5, 0.5, 0.])\r\n c = pyro.sample('c', dist.Categorical(probs=probs))\r\n return c\r\n\r\nprint(model())\r\n```\r\n\r\nI am using Python 3.8.5, Pyro 1.4.0 and NumPyro 0.3.0 with Ubuntu. Happy to help with what I can.\n", "before_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n# The implementation follows the design in PyTorch: torch.distributions.constraints.py\n#\n# Copyright (c) 2016- Facebook, Inc (Adam Paszke)\n# Copyright (c) 2014- Facebook, Inc (Soumith Chintala)\n# Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)\n# Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)\n# Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)\n# Copyright (c) 2011-2013 NYU (Clement Farabet)\n# Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)\n# Copyright (c) 2006 Idiap Research Institute (Samy Bengio)\n# Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE\n# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR\n# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF\n# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS\n# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN\n# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)\n# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\n__all__ = [\n 'boolean',\n 'corr_cholesky',\n 'corr_matrix',\n 'dependent',\n 'greater_than',\n 'integer_interval',\n 'integer_greater_than',\n 'interval',\n 'is_dependent',\n 'less_than',\n 'lower_cholesky',\n 'multinomial',\n 'nonnegative_integer',\n 'positive',\n 'positive_definite',\n 'positive_integer',\n 'real',\n 'real_vector',\n 'simplex',\n 'unit_interval',\n 'Constraint',\n]\n\nimport jax.numpy as jnp\n\n\nclass Constraint(object):\n \"\"\"\n Abstract base class for constraints.\n\n A constraint object represents a region over which a variable is valid,\n e.g. within which a variable can be optimized.\n \"\"\"\n\n def __call__(self, x):\n raise NotImplementedError\n\n def check(self, value):\n \"\"\"\n Returns a byte tensor of `sample_shape + batch_shape` indicating\n whether each event in value satisfies this constraint.\n \"\"\"\n return self(value)\n\n\nclass _Boolean(Constraint):\n def __call__(self, x):\n return (x == 0) | (x == 1)\n\n\nclass _CorrCholesky(Constraint):\n def __call__(self, x):\n tril = jnp.tril(x)\n lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)\n positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)\n x_norm = jnp.linalg.norm(x, axis=-1)\n unit_norm_row = jnp.all((x_norm <= 1) & (x_norm > 1 - 1e-6), axis=-1)\n return lower_triangular & positive_diagonal & unit_norm_row\n\n\nclass _CorrMatrix(Constraint):\n def __call__(self, x):\n # check for symmetric\n symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)\n # check for the smallest eigenvalue is positive\n positive = jnp.linalg.eigh(x)[0][..., 0] > 0\n # check for diagonal equal to 1\n unit_variance = jnp.all(jnp.abs(jnp.diagonal(x, axis1=-2, axis2=-1) - 1) < 1e-6, axis=-1)\n return symmetric & positive & unit_variance\n\n\nclass _Dependent(Constraint):\n def __call__(self, x):\n raise ValueError('Cannot determine validity of dependent constraint')\n\n\ndef is_dependent(constraint):\n return isinstance(constraint, _Dependent)\n\n\nclass _GreaterThan(Constraint):\n def __init__(self, lower_bound):\n self.lower_bound = lower_bound\n\n def __call__(self, x):\n return x > self.lower_bound\n\n\nclass _LessThan(Constraint):\n def __init__(self, upper_bound):\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return x < self.upper_bound\n\n\nclass _IntegerInterval(Constraint):\n def __init__(self, lower_bound, upper_bound):\n self.lower_bound = lower_bound\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return (x >= self.lower_bound) & (x <= self.upper_bound) & (x == jnp.floor(x))\n\n\nclass _IntegerGreaterThan(Constraint):\n def __init__(self, lower_bound):\n self.lower_bound = lower_bound\n\n def __call__(self, x):\n return (x % 1 == 0) & (x >= self.lower_bound)\n\n\nclass _Interval(Constraint):\n def __init__(self, lower_bound, upper_bound):\n self.lower_bound = lower_bound\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return (x > self.lower_bound) & (x < self.upper_bound)\n\n\nclass _LowerCholesky(Constraint):\n def __call__(self, x):\n tril = jnp.tril(x)\n lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)\n positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)\n return lower_triangular & positive_diagonal\n\n\nclass _Multinomial(Constraint):\n def __init__(self, upper_bound):\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return jnp.all(x >= 0, axis=-1) & (jnp.sum(x, -1) == self.upper_bound)\n\n\nclass _OrderedVector(Constraint):\n def __call__(self, x):\n return jnp.all(x[..., 1:] > x[..., :-1], axis=-1)\n\n\nclass _PositiveDefinite(Constraint):\n def __call__(self, x):\n # check for symmetric\n symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)\n # check for the smallest eigenvalue is positive\n positive = jnp.linalg.eigh(x)[0][..., 0] > 0\n return symmetric & positive\n\n\nclass _Real(Constraint):\n def __call__(self, x):\n return jnp.isfinite(x)\n\n\nclass _RealVector(Constraint):\n def __call__(self, x):\n return jnp.all(jnp.isfinite(x), axis=-1)\n\n\nclass _Simplex(Constraint):\n def __call__(self, x):\n x_sum = jnp.sum(x, axis=-1)\n return jnp.all(x > 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)\n\n\n# TODO: Make types consistent\n\nboolean = _Boolean()\ncorr_cholesky = _CorrCholesky()\ncorr_matrix = _CorrMatrix()\ndependent = _Dependent()\ngreater_than = _GreaterThan\nless_than = _LessThan\ninteger_interval = _IntegerInterval\ninteger_greater_than = _IntegerGreaterThan\ninterval = _Interval\nlower_cholesky = _LowerCholesky()\nmultinomial = _Multinomial\nnonnegative_integer = _IntegerGreaterThan(0)\nordered_vector = _OrderedVector()\npositive = _GreaterThan(0.)\npositive_definite = _PositiveDefinite()\npositive_integer = _IntegerGreaterThan(1)\nreal = _Real()\nreal_vector = _RealVector()\nsimplex = _Simplex()\nunit_interval = _Interval(0., 1.)\n", "path": "numpyro/distributions/constraints.py"}], "after_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n# The implementation follows the design in PyTorch: torch.distributions.constraints.py\n#\n# Copyright (c) 2016- Facebook, Inc (Adam Paszke)\n# Copyright (c) 2014- Facebook, Inc (Soumith Chintala)\n# Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)\n# Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)\n# Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)\n# Copyright (c) 2011-2013 NYU (Clement Farabet)\n# Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)\n# Copyright (c) 2006 Idiap Research Institute (Samy Bengio)\n# Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE\n# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR\n# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF\n# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS\n# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN\n# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)\n# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\n__all__ = [\n 'boolean',\n 'corr_cholesky',\n 'corr_matrix',\n 'dependent',\n 'greater_than',\n 'integer_interval',\n 'integer_greater_than',\n 'interval',\n 'is_dependent',\n 'less_than',\n 'lower_cholesky',\n 'multinomial',\n 'nonnegative_integer',\n 'positive',\n 'positive_definite',\n 'positive_integer',\n 'real',\n 'real_vector',\n 'simplex',\n 'unit_interval',\n 'Constraint',\n]\n\nimport jax.numpy as jnp\n\n\nclass Constraint(object):\n \"\"\"\n Abstract base class for constraints.\n\n A constraint object represents a region over which a variable is valid,\n e.g. within which a variable can be optimized.\n \"\"\"\n\n def __call__(self, x):\n raise NotImplementedError\n\n def check(self, value):\n \"\"\"\n Returns a byte tensor of `sample_shape + batch_shape` indicating\n whether each event in value satisfies this constraint.\n \"\"\"\n return self(value)\n\n\nclass _Boolean(Constraint):\n def __call__(self, x):\n return (x == 0) | (x == 1)\n\n\nclass _CorrCholesky(Constraint):\n def __call__(self, x):\n tril = jnp.tril(x)\n lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)\n positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)\n x_norm = jnp.linalg.norm(x, axis=-1)\n unit_norm_row = jnp.all((x_norm <= 1) & (x_norm > 1 - 1e-6), axis=-1)\n return lower_triangular & positive_diagonal & unit_norm_row\n\n\nclass _CorrMatrix(Constraint):\n def __call__(self, x):\n # check for symmetric\n symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)\n # check for the smallest eigenvalue is positive\n positive = jnp.linalg.eigh(x)[0][..., 0] > 0\n # check for diagonal equal to 1\n unit_variance = jnp.all(jnp.abs(jnp.diagonal(x, axis1=-2, axis2=-1) - 1) < 1e-6, axis=-1)\n return symmetric & positive & unit_variance\n\n\nclass _Dependent(Constraint):\n def __call__(self, x):\n raise ValueError('Cannot determine validity of dependent constraint')\n\n\ndef is_dependent(constraint):\n return isinstance(constraint, _Dependent)\n\n\nclass _GreaterThan(Constraint):\n def __init__(self, lower_bound):\n self.lower_bound = lower_bound\n\n def __call__(self, x):\n return x > self.lower_bound\n\n\nclass _LessThan(Constraint):\n def __init__(self, upper_bound):\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return x < self.upper_bound\n\n\nclass _IntegerInterval(Constraint):\n def __init__(self, lower_bound, upper_bound):\n self.lower_bound = lower_bound\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return (x >= self.lower_bound) & (x <= self.upper_bound) & (x == jnp.floor(x))\n\n\nclass _IntegerGreaterThan(Constraint):\n def __init__(self, lower_bound):\n self.lower_bound = lower_bound\n\n def __call__(self, x):\n return (x % 1 == 0) & (x >= self.lower_bound)\n\n\nclass _Interval(Constraint):\n def __init__(self, lower_bound, upper_bound):\n self.lower_bound = lower_bound\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return (x > self.lower_bound) & (x < self.upper_bound)\n\n\nclass _LowerCholesky(Constraint):\n def __call__(self, x):\n tril = jnp.tril(x)\n lower_triangular = jnp.all(jnp.reshape(tril == x, x.shape[:-2] + (-1,)), axis=-1)\n positive_diagonal = jnp.all(jnp.diagonal(x, axis1=-2, axis2=-1) > 0, axis=-1)\n return lower_triangular & positive_diagonal\n\n\nclass _Multinomial(Constraint):\n def __init__(self, upper_bound):\n self.upper_bound = upper_bound\n\n def __call__(self, x):\n return jnp.all(x >= 0, axis=-1) & (jnp.sum(x, -1) == self.upper_bound)\n\n\nclass _OrderedVector(Constraint):\n def __call__(self, x):\n return jnp.all(x[..., 1:] > x[..., :-1], axis=-1)\n\n\nclass _PositiveDefinite(Constraint):\n def __call__(self, x):\n # check for symmetric\n symmetric = jnp.all(jnp.all(x == jnp.swapaxes(x, -2, -1), axis=-1), axis=-1)\n # check for the smallest eigenvalue is positive\n positive = jnp.linalg.eigh(x)[0][..., 0] > 0\n return symmetric & positive\n\n\nclass _Real(Constraint):\n def __call__(self, x):\n return jnp.isfinite(x)\n\n\nclass _RealVector(Constraint):\n def __call__(self, x):\n return jnp.all(jnp.isfinite(x), axis=-1)\n\n\nclass _Simplex(Constraint):\n def __call__(self, x):\n x_sum = jnp.sum(x, axis=-1)\n return jnp.all(x >= 0, axis=-1) & (x_sum < 1 + 1e-6) & (x_sum > 1 - 1e-6)\n\n\n# TODO: Make types consistent\n\nboolean = _Boolean()\ncorr_cholesky = _CorrCholesky()\ncorr_matrix = _CorrMatrix()\ndependent = _Dependent()\ngreater_than = _GreaterThan\nless_than = _LessThan\ninteger_interval = _IntegerInterval\ninteger_greater_than = _IntegerGreaterThan\ninterval = _Interval\nlower_cholesky = _LowerCholesky()\nmultinomial = _Multinomial\nnonnegative_integer = _IntegerGreaterThan(0)\nordered_vector = _OrderedVector()\npositive = _GreaterThan(0.)\npositive_definite = _PositiveDefinite()\npositive_integer = _IntegerGreaterThan(1)\nreal = _Real()\nreal_vector = _RealVector()\nsimplex = _Simplex()\nunit_interval = _Interval(0., 1.)\n", "path": "numpyro/distributions/constraints.py"}]}
| 3,569 | 181 |
gh_patches_debug_6604
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-tf-222
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
assert_state_is_compatible() cannot detect dimension difference between encoder_state and decoder_zero_state when encoder and decoder dimensions are not the same in NMTSmall model
I just followed the instructions on the page [http://opennmt.net/OpenNMT-tf/quickstart.html](http://opennmt.net/OpenNMT-tf/quickstart.html) and played around a little bit with the NMTSmall model by setting a different `num_units` value to the `UnidirectionalRNNEncoder`, say `256`, which is different from the `512` for the `AttentionalRNNDecoder`.
This line
https://github.com/OpenNMT/OpenNMT-tf/blob/ae0ada93a652c02793de3b481e20315716ea4f23/opennmt/layers/bridge.py#L56
in the `CopyBridge` did not throw any error, even though the `encoder_state` and `decoder_zero_state` do not have the same dimensions, `256` vs `512`.
It probably natual for someone to think of using the `DenseBridge` when dimensions are set differently. However, the `CopyBridge` should be throwing some errors in such misusage cases here, instead of letting one to figure out that with some error message as follows
`ValueError: Dimensions must be equal, but are 1280 and 1536 for 'seq2seq/parallel_0/seq2seq/decoder_1/decoder/while/BasicDecoderStep/decoder/attention_wrapper/attention_wrapper/multi_rnn_cell/cell_0/lstm_cell/MatMul' (op: 'MatMul') with input shapes: [?,1280], [1536,2048].`
Can anyone please explain why the
https://github.com/OpenNMT/OpenNMT-tf/blob/ae0ada93a652c02793de3b481e20315716ea4f23/opennmt/layers/bridge.py#L28
passed without an issue?
Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opennmt/layers/bridge.py`
Content:
```
1 """Define bridges: logic of passing the encoder state to the decoder."""
2
3 import abc
4 import six
5
6 import tensorflow as tf
7
8
9 def assert_state_is_compatible(expected_state, state):
10 """Asserts that states are compatible.
11
12 Args:
13 expected_state: The reference state.
14 state: The state that must be compatible with :obj:`expected_state`.
15
16 Raises:
17 ValueError: if the states are incompatible.
18 """
19 # Check structure compatibility.
20 tf.contrib.framework.nest.assert_same_structure(expected_state, state)
21
22 # Check shape compatibility.
23 expected_state_flat = tf.contrib.framework.nest.flatten(expected_state)
24 state_flat = tf.contrib.framework.nest.flatten(state)
25
26 for x, y in zip(expected_state_flat, state_flat):
27 if tf.contrib.framework.is_tensor(x):
28 tf.contrib.framework.with_same_shape(x, y)
29
30
31 @six.add_metaclass(abc.ABCMeta)
32 class Bridge(object):
33 """Base class for bridges."""
34
35 def __call__(self, encoder_state, decoder_zero_state):
36 """Returns the initial decoder state.
37
38 Args:
39 encoder_state: The encoder state.
40 decoder_zero_state: The default decoder state.
41
42 Returns:
43 The decoder initial state.
44 """
45 return self._build(encoder_state, decoder_zero_state)
46
47 @abc.abstractmethod
48 def _build(self, encoder_state, decoder_zero_state):
49 raise NotImplementedError()
50
51
52 class CopyBridge(Bridge):
53 """A bridge that passes the encoder state as is."""
54
55 def _build(self, encoder_state, decoder_zero_state):
56 assert_state_is_compatible(decoder_zero_state, encoder_state)
57 return encoder_state
58
59
60 class ZeroBridge(Bridge):
61 """A bridge that does not pass information from the encoder."""
62
63 def _build(self, encoder_state, decoder_zero_state):
64 # Simply return the default decoder state.
65 return decoder_zero_state
66
67
68 class DenseBridge(Bridge):
69 """A bridge that applies a parameterized linear transformation from the
70 encoder state to the decoder state size.
71 """
72
73 def __init__(self, activation=None):
74 """Initializes the bridge.
75
76 Args:
77 activation: Activation function (a callable).
78 Set it to ``None`` to maintain a linear activation.
79 """
80 self.activation = activation
81
82 def _build(self, encoder_state, decoder_zero_state):
83 # Flattened states.
84 encoder_state_flat = tf.contrib.framework.nest.flatten(encoder_state)
85 decoder_state_flat = tf.contrib.framework.nest.flatten(decoder_zero_state)
86
87 # View encoder state as a single tensor.
88 encoder_state_concat = tf.concat(encoder_state_flat, 1)
89
90 # Extract decoder state sizes.
91 decoder_state_size = []
92 for tensor in decoder_state_flat:
93 decoder_state_size.append(tensor.get_shape().as_list()[-1])
94
95 decoder_total_size = sum(decoder_state_size)
96
97 # Apply linear transformation.
98 transformed = tf.layers.dense(
99 encoder_state_concat,
100 decoder_total_size,
101 activation=self.activation)
102
103 # Split resulting tensor to match the decoder state size.
104 splitted = tf.split(transformed, decoder_state_size, axis=1)
105
106 # Pack as the origial decoder state.
107 return tf.contrib.framework.nest.pack_sequence_as(decoder_zero_state, splitted)
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opennmt/layers/bridge.py b/opennmt/layers/bridge.py
--- a/opennmt/layers/bridge.py
+++ b/opennmt/layers/bridge.py
@@ -25,7 +25,11 @@
for x, y in zip(expected_state_flat, state_flat):
if tf.contrib.framework.is_tensor(x):
- tf.contrib.framework.with_same_shape(x, y)
+ expected_depth = x.get_shape().as_list()[-1]
+ depth = y.get_shape().as_list()[-1]
+ if depth != expected_depth:
+ raise ValueError("Tensor %s in state has shape %s which is incompatible "
+ "with the target shape %s" % (y.name, y.shape, x.shape))
@six.add_metaclass(abc.ABCMeta)
|
{"golden_diff": "diff --git a/opennmt/layers/bridge.py b/opennmt/layers/bridge.py\n--- a/opennmt/layers/bridge.py\n+++ b/opennmt/layers/bridge.py\n@@ -25,7 +25,11 @@\n \n for x, y in zip(expected_state_flat, state_flat):\n if tf.contrib.framework.is_tensor(x):\n- tf.contrib.framework.with_same_shape(x, y)\n+ expected_depth = x.get_shape().as_list()[-1]\n+ depth = y.get_shape().as_list()[-1]\n+ if depth != expected_depth:\n+ raise ValueError(\"Tensor %s in state has shape %s which is incompatible \"\n+ \"with the target shape %s\" % (y.name, y.shape, x.shape))\n \n \n @six.add_metaclass(abc.ABCMeta)\n", "issue": "assert_state_is_compatible() cannot detect dimension difference between encoder_state and decoder_zero_state when encoder and decoder dimensions are not the same in NMTSmall model\nI just followed the instructions on the page [http://opennmt.net/OpenNMT-tf/quickstart.html](http://opennmt.net/OpenNMT-tf/quickstart.html) and played around a little bit with the NMTSmall model by setting a different `num_units` value to the `UnidirectionalRNNEncoder`, say `256`, which is different from the `512` for the `AttentionalRNNDecoder`. \r\n\r\nThis line\r\n\r\nhttps://github.com/OpenNMT/OpenNMT-tf/blob/ae0ada93a652c02793de3b481e20315716ea4f23/opennmt/layers/bridge.py#L56\r\n\r\nin the `CopyBridge` did not throw any error, even though the `encoder_state` and `decoder_zero_state` do not have the same dimensions, `256` vs `512`.\r\n\r\nIt probably natual for someone to think of using the `DenseBridge` when dimensions are set differently. However, the `CopyBridge` should be throwing some errors in such misusage cases here, instead of letting one to figure out that with some error message as follows\r\n\r\n`ValueError: Dimensions must be equal, but are 1280 and 1536 for 'seq2seq/parallel_0/seq2seq/decoder_1/decoder/while/BasicDecoderStep/decoder/attention_wrapper/attention_wrapper/multi_rnn_cell/cell_0/lstm_cell/MatMul' (op: 'MatMul') with input shapes: [?,1280], [1536,2048].`\r\n\r\nCan anyone please explain why the \r\nhttps://github.com/OpenNMT/OpenNMT-tf/blob/ae0ada93a652c02793de3b481e20315716ea4f23/opennmt/layers/bridge.py#L28\r\npassed without an issue?\r\n\r\nThanks!\n", "before_files": [{"content": "\"\"\"Define bridges: logic of passing the encoder state to the decoder.\"\"\"\n\nimport abc\nimport six\n\nimport tensorflow as tf\n\n\ndef assert_state_is_compatible(expected_state, state):\n \"\"\"Asserts that states are compatible.\n\n Args:\n expected_state: The reference state.\n state: The state that must be compatible with :obj:`expected_state`.\n\n Raises:\n ValueError: if the states are incompatible.\n \"\"\"\n # Check structure compatibility.\n tf.contrib.framework.nest.assert_same_structure(expected_state, state)\n\n # Check shape compatibility.\n expected_state_flat = tf.contrib.framework.nest.flatten(expected_state)\n state_flat = tf.contrib.framework.nest.flatten(state)\n\n for x, y in zip(expected_state_flat, state_flat):\n if tf.contrib.framework.is_tensor(x):\n tf.contrib.framework.with_same_shape(x, y)\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass Bridge(object):\n \"\"\"Base class for bridges.\"\"\"\n\n def __call__(self, encoder_state, decoder_zero_state):\n \"\"\"Returns the initial decoder state.\n\n Args:\n encoder_state: The encoder state.\n decoder_zero_state: The default decoder state.\n\n Returns:\n The decoder initial state.\n \"\"\"\n return self._build(encoder_state, decoder_zero_state)\n\n @abc.abstractmethod\n def _build(self, encoder_state, decoder_zero_state):\n raise NotImplementedError()\n\n\nclass CopyBridge(Bridge):\n \"\"\"A bridge that passes the encoder state as is.\"\"\"\n\n def _build(self, encoder_state, decoder_zero_state):\n assert_state_is_compatible(decoder_zero_state, encoder_state)\n return encoder_state\n\n\nclass ZeroBridge(Bridge):\n \"\"\"A bridge that does not pass information from the encoder.\"\"\"\n\n def _build(self, encoder_state, decoder_zero_state):\n # Simply return the default decoder state.\n return decoder_zero_state\n\n\nclass DenseBridge(Bridge):\n \"\"\"A bridge that applies a parameterized linear transformation from the\n encoder state to the decoder state size.\n \"\"\"\n\n def __init__(self, activation=None):\n \"\"\"Initializes the bridge.\n\n Args:\n activation: Activation function (a callable).\n Set it to ``None`` to maintain a linear activation.\n \"\"\"\n self.activation = activation\n\n def _build(self, encoder_state, decoder_zero_state):\n # Flattened states.\n encoder_state_flat = tf.contrib.framework.nest.flatten(encoder_state)\n decoder_state_flat = tf.contrib.framework.nest.flatten(decoder_zero_state)\n\n # View encoder state as a single tensor.\n encoder_state_concat = tf.concat(encoder_state_flat, 1)\n\n # Extract decoder state sizes.\n decoder_state_size = []\n for tensor in decoder_state_flat:\n decoder_state_size.append(tensor.get_shape().as_list()[-1])\n\n decoder_total_size = sum(decoder_state_size)\n\n # Apply linear transformation.\n transformed = tf.layers.dense(\n encoder_state_concat,\n decoder_total_size,\n activation=self.activation)\n\n # Split resulting tensor to match the decoder state size.\n splitted = tf.split(transformed, decoder_state_size, axis=1)\n\n # Pack as the origial decoder state.\n return tf.contrib.framework.nest.pack_sequence_as(decoder_zero_state, splitted)\n", "path": "opennmt/layers/bridge.py"}], "after_files": [{"content": "\"\"\"Define bridges: logic of passing the encoder state to the decoder.\"\"\"\n\nimport abc\nimport six\n\nimport tensorflow as tf\n\n\ndef assert_state_is_compatible(expected_state, state):\n \"\"\"Asserts that states are compatible.\n\n Args:\n expected_state: The reference state.\n state: The state that must be compatible with :obj:`expected_state`.\n\n Raises:\n ValueError: if the states are incompatible.\n \"\"\"\n # Check structure compatibility.\n tf.contrib.framework.nest.assert_same_structure(expected_state, state)\n\n # Check shape compatibility.\n expected_state_flat = tf.contrib.framework.nest.flatten(expected_state)\n state_flat = tf.contrib.framework.nest.flatten(state)\n\n for x, y in zip(expected_state_flat, state_flat):\n if tf.contrib.framework.is_tensor(x):\n expected_depth = x.get_shape().as_list()[-1]\n depth = y.get_shape().as_list()[-1]\n if depth != expected_depth:\n raise ValueError(\"Tensor %s in state has shape %s which is incompatible \"\n \"with the target shape %s\" % (y.name, y.shape, x.shape))\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass Bridge(object):\n \"\"\"Base class for bridges.\"\"\"\n\n def __call__(self, encoder_state, decoder_zero_state):\n \"\"\"Returns the initial decoder state.\n\n Args:\n encoder_state: The encoder state.\n decoder_zero_state: The default decoder state.\n\n Returns:\n The decoder initial state.\n \"\"\"\n return self._build(encoder_state, decoder_zero_state)\n\n @abc.abstractmethod\n def _build(self, encoder_state, decoder_zero_state):\n raise NotImplementedError()\n\n\nclass CopyBridge(Bridge):\n \"\"\"A bridge that passes the encoder state as is.\"\"\"\n\n def _build(self, encoder_state, decoder_zero_state):\n assert_state_is_compatible(decoder_zero_state, encoder_state)\n return encoder_state\n\n\nclass ZeroBridge(Bridge):\n \"\"\"A bridge that does not pass information from the encoder.\"\"\"\n\n def _build(self, encoder_state, decoder_zero_state):\n # Simply return the default decoder state.\n return decoder_zero_state\n\n\nclass DenseBridge(Bridge):\n \"\"\"A bridge that applies a parameterized linear transformation from the\n encoder state to the decoder state size.\n \"\"\"\n\n def __init__(self, activation=None):\n \"\"\"Initializes the bridge.\n\n Args:\n activation: Activation function (a callable).\n Set it to ``None`` to maintain a linear activation.\n \"\"\"\n self.activation = activation\n\n def _build(self, encoder_state, decoder_zero_state):\n # Flattened states.\n encoder_state_flat = tf.contrib.framework.nest.flatten(encoder_state)\n decoder_state_flat = tf.contrib.framework.nest.flatten(decoder_zero_state)\n\n # View encoder state as a single tensor.\n encoder_state_concat = tf.concat(encoder_state_flat, 1)\n\n # Extract decoder state sizes.\n decoder_state_size = []\n for tensor in decoder_state_flat:\n decoder_state_size.append(tensor.get_shape().as_list()[-1])\n\n decoder_total_size = sum(decoder_state_size)\n\n # Apply linear transformation.\n transformed = tf.layers.dense(\n encoder_state_concat,\n decoder_total_size,\n activation=self.activation)\n\n # Split resulting tensor to match the decoder state size.\n splitted = tf.split(transformed, decoder_state_size, axis=1)\n\n # Pack as the origial decoder state.\n return tf.contrib.framework.nest.pack_sequence_as(decoder_zero_state, splitted)\n", "path": "opennmt/layers/bridge.py"}]}
| 1,647 | 181 |
gh_patches_debug_17593
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-5122
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add DCGAN example Duet Notebooks
## Description
Add two notebook's which reflect the DCGAN example split into DO (Data Owner) and DS (Data Scientist):
https://github.com/pytorch/examples/blob/master/dcgan/
## Definition of Done
The partially runnable DCGAN example notebooks should be in the examples/duet/dcgan folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.
Add Super Resolution Example Duet Notebooks
## Description
Add two notebook's which reflect the Super Resolution example split into DO (Data Owner) and DS (Data Scientist):
https://github.com/pytorch/examples/blob/master/super_resolution/
## Definition of Done
The partially runnable Super Resolution example notebooks should be in the examples/duet/super_resolution folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.
Add DCGAN example Duet Notebooks
## Description
Add two notebook's which reflect the DCGAN example split into DO (Data Owner) and DS (Data Scientist):
https://github.com/pytorch/examples/blob/master/dcgan/
## Definition of Done
The partially runnable DCGAN example notebooks should be in the examples/duet/dcgan folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/syft/lib/torch/__init__.py`
Content:
```
1 # stdlib
2 from typing import Any
3 from typing import Dict
4 from typing import Union
5
6 # third party
7 from packaging import version
8 import torch
9
10 # syft relative
11 from . import device # noqa: 401
12 from . import parameter # noqa: 401
13 from . import uppercase_tensor # noqa: 401
14 from ...ast.globals import Globals
15 from ...logger import critical
16 from .allowlist import allowlist
17
18 TORCH_VERSION = version.parse(torch.__version__.split("+")[0])
19
20
21 def get_return_type(support_dict: Union[str, Dict[str, str]]) -> str:
22 if isinstance(support_dict, str):
23 return support_dict
24 else:
25 return support_dict["return_type"]
26
27
28 def version_supported(support_dict: Union[str, Dict[str, str]]) -> bool:
29 if isinstance(support_dict, str):
30 return True
31 else:
32 # if we are on either side of the min or max versions we don't support this op
33 if "min_version" in support_dict and TORCH_VERSION < version.parse(
34 support_dict["min_version"]
35 ):
36 return False
37 if "max_version" in support_dict and TORCH_VERSION > version.parse(
38 support_dict["max_version"]
39 ):
40 return False
41 return True
42
43
44 def create_torch_ast(client: Any = None) -> Globals:
45 ast = Globals(client)
46
47 # most methods work in all versions and have a single return type
48 # for the more complicated ones we pass a dict with keys like return_type and
49 # min_version
50 for method, return_type_name_or_dict in allowlist.items():
51 if version_supported(support_dict=return_type_name_or_dict):
52 return_type = get_return_type(support_dict=return_type_name_or_dict)
53 if return_type == "unknown":
54 # this allows us to import them for testing
55 continue
56 ast.add_path(
57 path=method, framework_reference=torch, return_type_name=return_type
58 )
59 # add all the torch.nn.Parameter hooks
60 if method.startswith("torch.Tensor."):
61 method = method.replace("torch.Tensor.", "torch.nn.Parameter.")
62 return_type = return_type.replace("torch.Tensor", "torch.nn.Parameter")
63 ast.add_path(
64 path=method, framework_reference=torch, return_type_name=return_type
65 )
66 else:
67 critical(f"Skipping {method} not supported in {TORCH_VERSION}")
68
69 for klass in ast.classes:
70 klass.create_pointer_class()
71 klass.create_send_method()
72 klass.create_storable_object_attr_convenience_methods()
73 return ast
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/syft/lib/torch/__init__.py b/src/syft/lib/torch/__init__.py
--- a/src/syft/lib/torch/__init__.py
+++ b/src/syft/lib/torch/__init__.py
@@ -12,7 +12,7 @@
from . import parameter # noqa: 401
from . import uppercase_tensor # noqa: 401
from ...ast.globals import Globals
-from ...logger import critical
+from ...logger import info
from .allowlist import allowlist
TORCH_VERSION = version.parse(torch.__version__.split("+")[0])
@@ -64,7 +64,7 @@
path=method, framework_reference=torch, return_type_name=return_type
)
else:
- critical(f"Skipping {method} not supported in {TORCH_VERSION}")
+ info(f"Skipping {method} not supported in {TORCH_VERSION}")
for klass in ast.classes:
klass.create_pointer_class()
|
{"golden_diff": "diff --git a/src/syft/lib/torch/__init__.py b/src/syft/lib/torch/__init__.py\n--- a/src/syft/lib/torch/__init__.py\n+++ b/src/syft/lib/torch/__init__.py\n@@ -12,7 +12,7 @@\n from . import parameter # noqa: 401\n from . import uppercase_tensor # noqa: 401\n from ...ast.globals import Globals\n-from ...logger import critical\n+from ...logger import info\n from .allowlist import allowlist\n \n TORCH_VERSION = version.parse(torch.__version__.split(\"+\")[0])\n@@ -64,7 +64,7 @@\n path=method, framework_reference=torch, return_type_name=return_type\n )\n else:\n- critical(f\"Skipping {method} not supported in {TORCH_VERSION}\")\n+ info(f\"Skipping {method} not supported in {TORCH_VERSION}\")\n \n for klass in ast.classes:\n klass.create_pointer_class()\n", "issue": "Add DCGAN example Duet Notebooks\n## Description\r\nAdd two notebook's which reflect the DCGAN example split into DO (Data Owner) and DS (Data Scientist):\r\nhttps://github.com/pytorch/examples/blob/master/dcgan/\r\n\r\n## Definition of Done\r\nThe partially runnable DCGAN example notebooks should be in the examples/duet/dcgan folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.\nAdd Super Resolution Example Duet Notebooks\n## Description\r\nAdd two notebook's which reflect the Super Resolution example split into DO (Data Owner) and DS (Data Scientist):\r\nhttps://github.com/pytorch/examples/blob/master/super_resolution/\r\n\r\n## Definition of Done\r\nThe partially runnable Super Resolution example notebooks should be in the examples/duet/super_resolution folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.\nAdd DCGAN example Duet Notebooks\n## Description\r\nAdd two notebook's which reflect the DCGAN example split into DO (Data Owner) and DS (Data Scientist):\r\nhttps://github.com/pytorch/examples/blob/master/dcgan/\r\n\r\n## Definition of Done\r\nThe partially runnable DCGAN example notebooks should be in the examples/duet/dcgan folder and a README.md should be added in the parent examples/duet directory with a link to the original example and our notebook.\n", "before_files": [{"content": "# stdlib\nfrom typing import Any\nfrom typing import Dict\nfrom typing import Union\n\n# third party\nfrom packaging import version\nimport torch\n\n# syft relative\nfrom . import device # noqa: 401\nfrom . import parameter # noqa: 401\nfrom . import uppercase_tensor # noqa: 401\nfrom ...ast.globals import Globals\nfrom ...logger import critical\nfrom .allowlist import allowlist\n\nTORCH_VERSION = version.parse(torch.__version__.split(\"+\")[0])\n\n\ndef get_return_type(support_dict: Union[str, Dict[str, str]]) -> str:\n if isinstance(support_dict, str):\n return support_dict\n else:\n return support_dict[\"return_type\"]\n\n\ndef version_supported(support_dict: Union[str, Dict[str, str]]) -> bool:\n if isinstance(support_dict, str):\n return True\n else:\n # if we are on either side of the min or max versions we don't support this op\n if \"min_version\" in support_dict and TORCH_VERSION < version.parse(\n support_dict[\"min_version\"]\n ):\n return False\n if \"max_version\" in support_dict and TORCH_VERSION > version.parse(\n support_dict[\"max_version\"]\n ):\n return False\n return True\n\n\ndef create_torch_ast(client: Any = None) -> Globals:\n ast = Globals(client)\n\n # most methods work in all versions and have a single return type\n # for the more complicated ones we pass a dict with keys like return_type and\n # min_version\n for method, return_type_name_or_dict in allowlist.items():\n if version_supported(support_dict=return_type_name_or_dict):\n return_type = get_return_type(support_dict=return_type_name_or_dict)\n if return_type == \"unknown\":\n # this allows us to import them for testing\n continue\n ast.add_path(\n path=method, framework_reference=torch, return_type_name=return_type\n )\n # add all the torch.nn.Parameter hooks\n if method.startswith(\"torch.Tensor.\"):\n method = method.replace(\"torch.Tensor.\", \"torch.nn.Parameter.\")\n return_type = return_type.replace(\"torch.Tensor\", \"torch.nn.Parameter\")\n ast.add_path(\n path=method, framework_reference=torch, return_type_name=return_type\n )\n else:\n critical(f\"Skipping {method} not supported in {TORCH_VERSION}\")\n\n for klass in ast.classes:\n klass.create_pointer_class()\n klass.create_send_method()\n klass.create_storable_object_attr_convenience_methods()\n return ast\n", "path": "src/syft/lib/torch/__init__.py"}], "after_files": [{"content": "# stdlib\nfrom typing import Any\nfrom typing import Dict\nfrom typing import Union\n\n# third party\nfrom packaging import version\nimport torch\n\n# syft relative\nfrom . import device # noqa: 401\nfrom . import parameter # noqa: 401\nfrom . import uppercase_tensor # noqa: 401\nfrom ...ast.globals import Globals\nfrom ...logger import info\nfrom .allowlist import allowlist\n\nTORCH_VERSION = version.parse(torch.__version__.split(\"+\")[0])\n\n\ndef get_return_type(support_dict: Union[str, Dict[str, str]]) -> str:\n if isinstance(support_dict, str):\n return support_dict\n else:\n return support_dict[\"return_type\"]\n\n\ndef version_supported(support_dict: Union[str, Dict[str, str]]) -> bool:\n if isinstance(support_dict, str):\n return True\n else:\n # if we are on either side of the min or max versions we don't support this op\n if \"min_version\" in support_dict and TORCH_VERSION < version.parse(\n support_dict[\"min_version\"]\n ):\n return False\n if \"max_version\" in support_dict and TORCH_VERSION > version.parse(\n support_dict[\"max_version\"]\n ):\n return False\n return True\n\n\ndef create_torch_ast(client: Any = None) -> Globals:\n ast = Globals(client)\n\n # most methods work in all versions and have a single return type\n # for the more complicated ones we pass a dict with keys like return_type and\n # min_version\n for method, return_type_name_or_dict in allowlist.items():\n if version_supported(support_dict=return_type_name_or_dict):\n return_type = get_return_type(support_dict=return_type_name_or_dict)\n if return_type == \"unknown\":\n # this allows us to import them for testing\n continue\n ast.add_path(\n path=method, framework_reference=torch, return_type_name=return_type\n )\n # add all the torch.nn.Parameter hooks\n if method.startswith(\"torch.Tensor.\"):\n method = method.replace(\"torch.Tensor.\", \"torch.nn.Parameter.\")\n return_type = return_type.replace(\"torch.Tensor\", \"torch.nn.Parameter\")\n ast.add_path(\n path=method, framework_reference=torch, return_type_name=return_type\n )\n else:\n info(f\"Skipping {method} not supported in {TORCH_VERSION}\")\n\n for klass in ast.classes:\n klass.create_pointer_class()\n klass.create_send_method()\n klass.create_storable_object_attr_convenience_methods()\n return ast\n", "path": "src/syft/lib/torch/__init__.py"}]}
| 1,264 | 220 |
gh_patches_debug_26137
|
rasdani/github-patches
|
git_diff
|
liberapay__liberapay.com-327
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tweaking the take throttling algorithm
We're trying to use liberapay for our catalyst community in Lille, that's why we got 100€ (https://liberapay.com/collectifcatalyst/) by week for our local community. We need people to take this money faster than starting with 1€ (and 2€ / 4 / 8 next week) as people are giving a lot of time now. Is that possible ? Could we get multiple way to distribute money in a team depending on how the project go (for example for a faster project, starting with 1€ is difficult).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `liberapay/models/_mixin_team.py`
Content:
```
1 """Teams are groups of participants.
2 """
3 from __future__ import division, print_function, unicode_literals
4
5 from collections import OrderedDict
6 from decimal import Decimal, ROUND_UP
7 from statistics import median
8
9 from liberapay.constants import D_CENT, D_UNIT, D_ZERO
10
11
12 class MemberLimitReached(Exception): pass
13
14
15 class InactiveParticipantAdded(Exception): pass
16
17
18 class MixinTeam(object):
19
20 def invite(self, invitee, inviter):
21 assert self.kind == 'group'
22 with self.db.get_cursor() as c:
23 n_id = invitee.notify(
24 'team_invite',
25 team=self.username,
26 team_url=self.url(),
27 inviter=inviter.username,
28 )
29 payload = dict(invitee=invitee.id, notification_id=n_id)
30 self.add_event(c, 'invite', payload, inviter.id)
31
32 def add_member(self, member, cursor=None):
33 """Add a member to this team.
34 """
35 if len(self.get_current_takes()) == 149:
36 raise MemberLimitReached
37 if member.status != 'active':
38 raise InactiveParticipantAdded
39 self.set_take_for(member, D_ZERO, self, cursor=cursor)
40
41 def remove_all_members(self, cursor=None):
42 (cursor or self.db).run("""
43 INSERT INTO takes (ctime, member, team, amount, recorder) (
44 SELECT ctime, member, %(id)s, NULL, %(id)s
45 FROM current_takes
46 WHERE team=%(id)s
47 );
48 """, dict(id=self.id))
49
50 def member_of(self, team):
51 """Given a Participant object, return a boolean.
52 """
53 assert team.kind == 'group'
54 return self.db.one("""
55 SELECT true
56 FROM current_takes
57 WHERE team=%s AND member=%s
58 """, (team.id, self.id), default=False)
59
60 def get_takes_last_week(self):
61 """Get the users' nominal takes last week. Used in throttling.
62 """
63 assert self.kind == 'group'
64 takes = {t.member: t.amount for t in self.db.all("""
65
66 SELECT DISTINCT ON (member) member, amount, mtime
67 FROM takes
68 WHERE team=%s
69 AND mtime < (
70 SELECT ts_start
71 FROM paydays
72 WHERE ts_end > ts_start
73 ORDER BY ts_start DESC LIMIT 1
74 )
75 ORDER BY member, mtime DESC
76
77 """, (self.id,)) if t.amount}
78 takes['_relative_min'] = median(takes.values() or (0,)) ** Decimal('0.7')
79 return takes
80
81 def get_take_for(self, member):
82 """Return the nominal take for this member, or None.
83 """
84 return self.db.one(
85 "SELECT amount FROM current_takes WHERE member = %s AND team = %s",
86 (member.id, self.id)
87 )
88
89 def compute_max_this_week(self, member_id, last_week):
90 """2x the member's take last week, or a minimum based on last week's
91 median take, or current income divided by the number of members if takes
92 were zero last week, or 1.
93 """
94 return max(
95 last_week.get(member_id, 0) * 2,
96 last_week['_relative_min'] or self.receiving / self.nmembers,
97 D_UNIT
98 )
99
100 def set_take_for(self, member, take, recorder, check_max=True, cursor=None):
101 """Sets member's take from the team pool.
102 """
103 assert self.kind == 'group'
104
105 if recorder.id != self.id:
106 cur_take = self.get_take_for(member)
107 if cur_take is None:
108 return None
109
110 if not isinstance(take, (None.__class__, Decimal)):
111 take = Decimal(take)
112
113 if take and check_max and take > 1:
114 last_week = self.get_takes_last_week()
115 max_this_week = self.compute_max_this_week(member.id, last_week)
116 if take > max_this_week:
117 take = max_this_week
118
119 with self.db.get_cursor(cursor) as cursor:
120 # Lock to avoid race conditions
121 cursor.run("LOCK TABLE takes IN EXCLUSIVE MODE")
122 # Compute the current takes
123 old_takes = self.compute_actual_takes(cursor)
124 # Insert the new take
125 cursor.run("""
126
127 INSERT INTO takes (ctime, member, team, amount, recorder)
128 VALUES ( COALESCE (( SELECT ctime
129 FROM takes
130 WHERE member=%(member)s
131 AND team=%(team)s
132 LIMIT 1
133 ), CURRENT_TIMESTAMP)
134 , %(member)s
135 , %(team)s
136 , %(amount)s
137 , %(recorder)s
138 )
139
140 """, dict(member=member.id, team=self.id, amount=take,
141 recorder=recorder.id))
142 # Compute the new takes
143 new_takes = self.compute_actual_takes(cursor)
144 # Update receiving amounts in the participants table
145 self.update_taking(old_takes, new_takes, cursor, member)
146 # Update is_funded on member's tips
147 member.update_giving(cursor)
148
149 return take
150
151 def update_taking(self, old_takes, new_takes, cursor=None, member=None):
152 """Update `taking` amounts based on the difference between `old_takes`
153 and `new_takes`.
154 """
155 for p_id in set(old_takes.keys()).union(new_takes.keys()):
156 old = old_takes.get(p_id, {}).get('actual_amount', D_ZERO)
157 new = new_takes.get(p_id, {}).get('actual_amount', D_ZERO)
158 diff = new - old
159 if diff != 0:
160 (cursor or self.db).run("""
161 UPDATE participants
162 SET taking = (taking + %(diff)s)
163 , receiving = (receiving + %(diff)s)
164 WHERE id=%(p_id)s
165 """, dict(p_id=p_id, diff=diff))
166 if member and p_id == member.id:
167 r = (cursor or self.db).one(
168 "SELECT taking, receiving FROM participants WHERE id = %s",
169 (p_id,)
170 )
171 member.set_attributes(**r._asdict())
172
173 def get_current_takes(self, cursor=None):
174 """Return a list of member takes for a team.
175 """
176 assert self.kind == 'group'
177 TAKES = """
178 SELECT p.id AS member_id, p.username AS member_name, p.avatar_url
179 , (p.mangopay_user_id IS NOT NULL) AS is_identified
180 , t.amount, t.ctime, t.mtime
181 FROM current_takes t
182 JOIN participants p ON p.id = member
183 WHERE t.team=%(team)s
184 ORDER BY p.username
185 """
186 records = (cursor or self.db).all(TAKES, dict(team=self.id))
187 return [r._asdict() for r in records]
188
189 def compute_actual_takes(self, cursor=None):
190 """Get the takes, compute the actual amounts, and return an OrderedDict.
191 """
192 actual_takes = OrderedDict()
193 nominal_takes = self.get_current_takes(cursor=cursor)
194 balance = self.receiving
195 total_takes = sum(t['amount'] for t in nominal_takes if t['is_identified'])
196 ratio = min(balance / total_takes, 1) if total_takes else 0
197 for take in nominal_takes:
198 nominal = take['nominal_take'] = take.pop('amount')
199 actual = take['actual_amount'] = min(
200 (nominal * ratio).quantize(D_CENT, rounding=ROUND_UP),
201 balance
202 ) if take['is_identified'] else D_ZERO
203 balance -= actual
204 actual_takes[take['member_id']] = take
205 actual_takes.leftover = balance
206 return actual_takes
207
208 @property
209 def nmembers(self):
210 assert self.kind == 'group'
211 return self.db.one("""
212 SELECT COUNT(*)
213 FROM current_takes
214 WHERE team=%s
215 """, (self.id,))
216
217 def get_members(self):
218 """Return an OrderedDict of member dicts.
219 """
220 takes = self.compute_actual_takes()
221 last_week = self.get_takes_last_week()
222 members = OrderedDict()
223 members.leftover = takes.leftover
224 for take in takes.values():
225 member = {}
226 m_id = member['id'] = take['member_id']
227 member['username'] = take['member_name']
228 member['nominal_take'] = take['nominal_take']
229 member['actual_amount'] = take['actual_amount']
230 member['last_week'] = last_week.get(m_id, D_ZERO)
231 member['max_this_week'] = self.compute_max_this_week(m_id, last_week)
232 members[member['id']] = member
233 return members
234
235 @property
236 def closed_by(self):
237 assert self.status == 'closed'
238 return self.db.one("""
239 SELECT member
240 FROM takes
241 WHERE team = %s
242 ORDER BY mtime DESC
243 LIMIT 1
244 """, (self.id,))
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/liberapay/models/_mixin_team.py b/liberapay/models/_mixin_team.py
--- a/liberapay/models/_mixin_team.py
+++ b/liberapay/models/_mixin_team.py
@@ -75,7 +75,6 @@
ORDER BY member, mtime DESC
""", (self.id,)) if t.amount}
- takes['_relative_min'] = median(takes.values() or (0,)) ** Decimal('0.7')
return takes
def get_take_for(self, member):
@@ -87,13 +86,20 @@
)
def compute_max_this_week(self, member_id, last_week):
- """2x the member's take last week, or a minimum based on last week's
- median take, or current income divided by the number of members if takes
- were zero last week, or 1.
+ """2x the member's take last week, or the member's take last week + a
+ proportional share of the leftover, or a minimum based on last week's
+ median take, or 1.
"""
+ sum_last_week = sum(last_week.values())
+ initial_leftover = self.receiving - sum_last_week
+ nonzero_last_week = [a for a in last_week.values() if a]
+ member_last_week = last_week.get(member_id, 0)
+ leftover_share = member_last_week / (sum_last_week or Decimal('inf'))
+ leftover_share = max(leftover_share, D_UNIT / self.nmembers)
return max(
- last_week.get(member_id, 0) * 2,
- last_week['_relative_min'] or self.receiving / self.nmembers,
+ member_last_week * 2,
+ member_last_week + initial_leftover * leftover_share,
+ median(nonzero_last_week or (0,)),
D_UNIT
)
|
{"golden_diff": "diff --git a/liberapay/models/_mixin_team.py b/liberapay/models/_mixin_team.py\n--- a/liberapay/models/_mixin_team.py\n+++ b/liberapay/models/_mixin_team.py\n@@ -75,7 +75,6 @@\n ORDER BY member, mtime DESC\n \n \"\"\", (self.id,)) if t.amount}\n- takes['_relative_min'] = median(takes.values() or (0,)) ** Decimal('0.7')\n return takes\n \n def get_take_for(self, member):\n@@ -87,13 +86,20 @@\n )\n \n def compute_max_this_week(self, member_id, last_week):\n- \"\"\"2x the member's take last week, or a minimum based on last week's\n- median take, or current income divided by the number of members if takes\n- were zero last week, or 1.\n+ \"\"\"2x the member's take last week, or the member's take last week + a\n+ proportional share of the leftover, or a minimum based on last week's\n+ median take, or 1.\n \"\"\"\n+ sum_last_week = sum(last_week.values())\n+ initial_leftover = self.receiving - sum_last_week\n+ nonzero_last_week = [a for a in last_week.values() if a]\n+ member_last_week = last_week.get(member_id, 0)\n+ leftover_share = member_last_week / (sum_last_week or Decimal('inf'))\n+ leftover_share = max(leftover_share, D_UNIT / self.nmembers)\n return max(\n- last_week.get(member_id, 0) * 2,\n- last_week['_relative_min'] or self.receiving / self.nmembers,\n+ member_last_week * 2,\n+ member_last_week + initial_leftover * leftover_share,\n+ median(nonzero_last_week or (0,)),\n D_UNIT\n )\n", "issue": "Tweaking the take throttling algorithm\n We're trying to use liberapay for our catalyst community in Lille, that's why we got 100\u20ac (https://liberapay.com/collectifcatalyst/) by week for our local community. We need people to take this money faster than starting with 1\u20ac (and 2\u20ac / 4 / 8 next week) as people are giving a lot of time now. Is that possible ? Could we get multiple way to distribute money in a team depending on how the project go (for example for a faster project, starting with 1\u20ac is difficult).\n\n", "before_files": [{"content": "\"\"\"Teams are groups of participants.\n\"\"\"\nfrom __future__ import division, print_function, unicode_literals\n\nfrom collections import OrderedDict\nfrom decimal import Decimal, ROUND_UP\nfrom statistics import median\n\nfrom liberapay.constants import D_CENT, D_UNIT, D_ZERO\n\n\nclass MemberLimitReached(Exception): pass\n\n\nclass InactiveParticipantAdded(Exception): pass\n\n\nclass MixinTeam(object):\n\n def invite(self, invitee, inviter):\n assert self.kind == 'group'\n with self.db.get_cursor() as c:\n n_id = invitee.notify(\n 'team_invite',\n team=self.username,\n team_url=self.url(),\n inviter=inviter.username,\n )\n payload = dict(invitee=invitee.id, notification_id=n_id)\n self.add_event(c, 'invite', payload, inviter.id)\n\n def add_member(self, member, cursor=None):\n \"\"\"Add a member to this team.\n \"\"\"\n if len(self.get_current_takes()) == 149:\n raise MemberLimitReached\n if member.status != 'active':\n raise InactiveParticipantAdded\n self.set_take_for(member, D_ZERO, self, cursor=cursor)\n\n def remove_all_members(self, cursor=None):\n (cursor or self.db).run(\"\"\"\n INSERT INTO takes (ctime, member, team, amount, recorder) (\n SELECT ctime, member, %(id)s, NULL, %(id)s\n FROM current_takes\n WHERE team=%(id)s\n );\n \"\"\", dict(id=self.id))\n\n def member_of(self, team):\n \"\"\"Given a Participant object, return a boolean.\n \"\"\"\n assert team.kind == 'group'\n return self.db.one(\"\"\"\n SELECT true\n FROM current_takes\n WHERE team=%s AND member=%s\n \"\"\", (team.id, self.id), default=False)\n\n def get_takes_last_week(self):\n \"\"\"Get the users' nominal takes last week. Used in throttling.\n \"\"\"\n assert self.kind == 'group'\n takes = {t.member: t.amount for t in self.db.all(\"\"\"\n\n SELECT DISTINCT ON (member) member, amount, mtime\n FROM takes\n WHERE team=%s\n AND mtime < (\n SELECT ts_start\n FROM paydays\n WHERE ts_end > ts_start\n ORDER BY ts_start DESC LIMIT 1\n )\n ORDER BY member, mtime DESC\n\n \"\"\", (self.id,)) if t.amount}\n takes['_relative_min'] = median(takes.values() or (0,)) ** Decimal('0.7')\n return takes\n\n def get_take_for(self, member):\n \"\"\"Return the nominal take for this member, or None.\n \"\"\"\n return self.db.one(\n \"SELECT amount FROM current_takes WHERE member = %s AND team = %s\",\n (member.id, self.id)\n )\n\n def compute_max_this_week(self, member_id, last_week):\n \"\"\"2x the member's take last week, or a minimum based on last week's\n median take, or current income divided by the number of members if takes\n were zero last week, or 1.\n \"\"\"\n return max(\n last_week.get(member_id, 0) * 2,\n last_week['_relative_min'] or self.receiving / self.nmembers,\n D_UNIT\n )\n\n def set_take_for(self, member, take, recorder, check_max=True, cursor=None):\n \"\"\"Sets member's take from the team pool.\n \"\"\"\n assert self.kind == 'group'\n\n if recorder.id != self.id:\n cur_take = self.get_take_for(member)\n if cur_take is None:\n return None\n\n if not isinstance(take, (None.__class__, Decimal)):\n take = Decimal(take)\n\n if take and check_max and take > 1:\n last_week = self.get_takes_last_week()\n max_this_week = self.compute_max_this_week(member.id, last_week)\n if take > max_this_week:\n take = max_this_week\n\n with self.db.get_cursor(cursor) as cursor:\n # Lock to avoid race conditions\n cursor.run(\"LOCK TABLE takes IN EXCLUSIVE MODE\")\n # Compute the current takes\n old_takes = self.compute_actual_takes(cursor)\n # Insert the new take\n cursor.run(\"\"\"\n\n INSERT INTO takes (ctime, member, team, amount, recorder)\n VALUES ( COALESCE (( SELECT ctime\n FROM takes\n WHERE member=%(member)s\n AND team=%(team)s\n LIMIT 1\n ), CURRENT_TIMESTAMP)\n , %(member)s\n , %(team)s\n , %(amount)s\n , %(recorder)s\n )\n\n \"\"\", dict(member=member.id, team=self.id, amount=take,\n recorder=recorder.id))\n # Compute the new takes\n new_takes = self.compute_actual_takes(cursor)\n # Update receiving amounts in the participants table\n self.update_taking(old_takes, new_takes, cursor, member)\n # Update is_funded on member's tips\n member.update_giving(cursor)\n\n return take\n\n def update_taking(self, old_takes, new_takes, cursor=None, member=None):\n \"\"\"Update `taking` amounts based on the difference between `old_takes`\n and `new_takes`.\n \"\"\"\n for p_id in set(old_takes.keys()).union(new_takes.keys()):\n old = old_takes.get(p_id, {}).get('actual_amount', D_ZERO)\n new = new_takes.get(p_id, {}).get('actual_amount', D_ZERO)\n diff = new - old\n if diff != 0:\n (cursor or self.db).run(\"\"\"\n UPDATE participants\n SET taking = (taking + %(diff)s)\n , receiving = (receiving + %(diff)s)\n WHERE id=%(p_id)s\n \"\"\", dict(p_id=p_id, diff=diff))\n if member and p_id == member.id:\n r = (cursor or self.db).one(\n \"SELECT taking, receiving FROM participants WHERE id = %s\",\n (p_id,)\n )\n member.set_attributes(**r._asdict())\n\n def get_current_takes(self, cursor=None):\n \"\"\"Return a list of member takes for a team.\n \"\"\"\n assert self.kind == 'group'\n TAKES = \"\"\"\n SELECT p.id AS member_id, p.username AS member_name, p.avatar_url\n , (p.mangopay_user_id IS NOT NULL) AS is_identified\n , t.amount, t.ctime, t.mtime\n FROM current_takes t\n JOIN participants p ON p.id = member\n WHERE t.team=%(team)s\n ORDER BY p.username\n \"\"\"\n records = (cursor or self.db).all(TAKES, dict(team=self.id))\n return [r._asdict() for r in records]\n\n def compute_actual_takes(self, cursor=None):\n \"\"\"Get the takes, compute the actual amounts, and return an OrderedDict.\n \"\"\"\n actual_takes = OrderedDict()\n nominal_takes = self.get_current_takes(cursor=cursor)\n balance = self.receiving\n total_takes = sum(t['amount'] for t in nominal_takes if t['is_identified'])\n ratio = min(balance / total_takes, 1) if total_takes else 0\n for take in nominal_takes:\n nominal = take['nominal_take'] = take.pop('amount')\n actual = take['actual_amount'] = min(\n (nominal * ratio).quantize(D_CENT, rounding=ROUND_UP),\n balance\n ) if take['is_identified'] else D_ZERO\n balance -= actual\n actual_takes[take['member_id']] = take\n actual_takes.leftover = balance\n return actual_takes\n\n @property\n def nmembers(self):\n assert self.kind == 'group'\n return self.db.one(\"\"\"\n SELECT COUNT(*)\n FROM current_takes\n WHERE team=%s\n \"\"\", (self.id,))\n\n def get_members(self):\n \"\"\"Return an OrderedDict of member dicts.\n \"\"\"\n takes = self.compute_actual_takes()\n last_week = self.get_takes_last_week()\n members = OrderedDict()\n members.leftover = takes.leftover\n for take in takes.values():\n member = {}\n m_id = member['id'] = take['member_id']\n member['username'] = take['member_name']\n member['nominal_take'] = take['nominal_take']\n member['actual_amount'] = take['actual_amount']\n member['last_week'] = last_week.get(m_id, D_ZERO)\n member['max_this_week'] = self.compute_max_this_week(m_id, last_week)\n members[member['id']] = member\n return members\n\n @property\n def closed_by(self):\n assert self.status == 'closed'\n return self.db.one(\"\"\"\n SELECT member\n FROM takes\n WHERE team = %s\n ORDER BY mtime DESC\n LIMIT 1\n \"\"\", (self.id,))\n", "path": "liberapay/models/_mixin_team.py"}], "after_files": [{"content": "\"\"\"Teams are groups of participants.\n\"\"\"\nfrom __future__ import division, print_function, unicode_literals\n\nfrom collections import OrderedDict\nfrom decimal import Decimal, ROUND_UP\nfrom statistics import median\n\nfrom liberapay.constants import D_CENT, D_UNIT, D_ZERO\n\n\nclass MemberLimitReached(Exception): pass\n\n\nclass InactiveParticipantAdded(Exception): pass\n\n\nclass MixinTeam(object):\n\n def invite(self, invitee, inviter):\n assert self.kind == 'group'\n with self.db.get_cursor() as c:\n n_id = invitee.notify(\n 'team_invite',\n team=self.username,\n team_url=self.url(),\n inviter=inviter.username,\n )\n payload = dict(invitee=invitee.id, notification_id=n_id)\n self.add_event(c, 'invite', payload, inviter.id)\n\n def add_member(self, member, cursor=None):\n \"\"\"Add a member to this team.\n \"\"\"\n if len(self.get_current_takes()) == 149:\n raise MemberLimitReached\n if member.status != 'active':\n raise InactiveParticipantAdded\n self.set_take_for(member, D_ZERO, self, cursor=cursor)\n\n def remove_all_members(self, cursor=None):\n (cursor or self.db).run(\"\"\"\n INSERT INTO takes (ctime, member, team, amount, recorder) (\n SELECT ctime, member, %(id)s, NULL, %(id)s\n FROM current_takes\n WHERE team=%(id)s\n );\n \"\"\", dict(id=self.id))\n\n def member_of(self, team):\n \"\"\"Given a Participant object, return a boolean.\n \"\"\"\n assert team.kind == 'group'\n return self.db.one(\"\"\"\n SELECT true\n FROM current_takes\n WHERE team=%s AND member=%s\n \"\"\", (team.id, self.id), default=False)\n\n def get_takes_last_week(self):\n \"\"\"Get the users' nominal takes last week. Used in throttling.\n \"\"\"\n assert self.kind == 'group'\n takes = {t.member: t.amount for t in self.db.all(\"\"\"\n\n SELECT DISTINCT ON (member) member, amount, mtime\n FROM takes\n WHERE team=%s\n AND mtime < (\n SELECT ts_start\n FROM paydays\n WHERE ts_end > ts_start\n ORDER BY ts_start DESC LIMIT 1\n )\n ORDER BY member, mtime DESC\n\n \"\"\", (self.id,)) if t.amount}\n return takes\n\n def get_take_for(self, member):\n \"\"\"Return the nominal take for this member, or None.\n \"\"\"\n return self.db.one(\n \"SELECT amount FROM current_takes WHERE member = %s AND team = %s\",\n (member.id, self.id)\n )\n\n def compute_max_this_week(self, member_id, last_week):\n \"\"\"2x the member's take last week, or the member's take last week + a\n proportional share of the leftover, or a minimum based on last week's\n median take, or 1.\n \"\"\"\n sum_last_week = sum(last_week.values())\n initial_leftover = self.receiving - sum_last_week\n nonzero_last_week = [a for a in last_week.values() if a]\n member_last_week = last_week.get(member_id, 0)\n leftover_share = member_last_week / (sum_last_week or Decimal('inf'))\n leftover_share = max(leftover_share, D_UNIT / self.nmembers)\n return max(\n member_last_week * 2,\n member_last_week + initial_leftover * leftover_share,\n median(nonzero_last_week or (0,)),\n D_UNIT\n )\n\n def set_take_for(self, member, take, recorder, check_max=True, cursor=None):\n \"\"\"Sets member's take from the team pool.\n \"\"\"\n assert self.kind == 'group'\n\n if recorder.id != self.id:\n cur_take = self.get_take_for(member)\n if cur_take is None:\n return None\n\n if not isinstance(take, (None.__class__, Decimal)):\n take = Decimal(take)\n\n if take and check_max and take > 1:\n last_week = self.get_takes_last_week()\n max_this_week = self.compute_max_this_week(member.id, last_week)\n if take > max_this_week:\n take = max_this_week\n\n with self.db.get_cursor(cursor) as cursor:\n # Lock to avoid race conditions\n cursor.run(\"LOCK TABLE takes IN EXCLUSIVE MODE\")\n # Compute the current takes\n old_takes = self.compute_actual_takes(cursor)\n # Insert the new take\n cursor.run(\"\"\"\n\n INSERT INTO takes (ctime, member, team, amount, recorder)\n VALUES ( COALESCE (( SELECT ctime\n FROM takes\n WHERE member=%(member)s\n AND team=%(team)s\n LIMIT 1\n ), CURRENT_TIMESTAMP)\n , %(member)s\n , %(team)s\n , %(amount)s\n , %(recorder)s\n )\n\n \"\"\", dict(member=member.id, team=self.id, amount=take,\n recorder=recorder.id))\n # Compute the new takes\n new_takes = self.compute_actual_takes(cursor)\n # Update receiving amounts in the participants table\n self.update_taking(old_takes, new_takes, cursor, member)\n # Update is_funded on member's tips\n member.update_giving(cursor)\n\n return take\n\n def update_taking(self, old_takes, new_takes, cursor=None, member=None):\n \"\"\"Update `taking` amounts based on the difference between `old_takes`\n and `new_takes`.\n \"\"\"\n for p_id in set(old_takes.keys()).union(new_takes.keys()):\n old = old_takes.get(p_id, {}).get('actual_amount', D_ZERO)\n new = new_takes.get(p_id, {}).get('actual_amount', D_ZERO)\n diff = new - old\n if diff != 0:\n (cursor or self.db).run(\"\"\"\n UPDATE participants\n SET taking = (taking + %(diff)s)\n , receiving = (receiving + %(diff)s)\n WHERE id=%(p_id)s\n \"\"\", dict(p_id=p_id, diff=diff))\n if member and p_id == member.id:\n r = (cursor or self.db).one(\n \"SELECT taking, receiving FROM participants WHERE id = %s\",\n (p_id,)\n )\n member.set_attributes(**r._asdict())\n\n def get_current_takes(self, cursor=None):\n \"\"\"Return a list of member takes for a team.\n \"\"\"\n assert self.kind == 'group'\n TAKES = \"\"\"\n SELECT p.id AS member_id, p.username AS member_name, p.avatar_url\n , (p.mangopay_user_id IS NOT NULL) AS is_identified\n , t.amount, t.ctime, t.mtime\n FROM current_takes t\n JOIN participants p ON p.id = member\n WHERE t.team=%(team)s\n ORDER BY p.username\n \"\"\"\n records = (cursor or self.db).all(TAKES, dict(team=self.id))\n return [r._asdict() for r in records]\n\n def compute_actual_takes(self, cursor=None):\n \"\"\"Get the takes, compute the actual amounts, and return an OrderedDict.\n \"\"\"\n actual_takes = OrderedDict()\n nominal_takes = self.get_current_takes(cursor=cursor)\n balance = self.receiving\n total_takes = sum(t['amount'] for t in nominal_takes if t['is_identified'])\n ratio = min(balance / total_takes, 1) if total_takes else 0\n for take in nominal_takes:\n nominal = take['nominal_take'] = take.pop('amount')\n actual = take['actual_amount'] = min(\n (nominal * ratio).quantize(D_CENT, rounding=ROUND_UP),\n balance\n ) if take['is_identified'] else D_ZERO\n balance -= actual\n actual_takes[take['member_id']] = take\n actual_takes.leftover = balance\n return actual_takes\n\n @property\n def nmembers(self):\n assert self.kind == 'group'\n return self.db.one(\"\"\"\n SELECT COUNT(*)\n FROM current_takes\n WHERE team=%s\n \"\"\", (self.id,))\n\n def get_members(self):\n \"\"\"Return an OrderedDict of member dicts.\n \"\"\"\n takes = self.compute_actual_takes()\n last_week = self.get_takes_last_week()\n members = OrderedDict()\n members.leftover = takes.leftover\n for take in takes.values():\n member = {}\n m_id = member['id'] = take['member_id']\n member['username'] = take['member_name']\n member['nominal_take'] = take['nominal_take']\n member['actual_amount'] = take['actual_amount']\n member['last_week'] = last_week.get(m_id, D_ZERO)\n member['max_this_week'] = self.compute_max_this_week(m_id, last_week)\n members[member['id']] = member\n return members\n\n @property\n def closed_by(self):\n assert self.status == 'closed'\n return self.db.one(\"\"\"\n SELECT member\n FROM takes\n WHERE team = %s\n ORDER BY mtime DESC\n LIMIT 1\n \"\"\", (self.id,))\n", "path": "liberapay/models/_mixin_team.py"}]}
| 2,998 | 422 |
gh_patches_debug_57997
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-569
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Device Support Request] CentraLite Contact Sensor-A
**TL;DR**: The battery entity for the `CentraLite Contact Sensor-A` always reports `Unavailable`. It's very similar in signature to the CentraLite 3320-L sensor, so I'm hoping it just needs a device-specific quirk.
**Is your feature request related to a problem? Please describe.**
I have some Sylvania SMART+ Door/Window sensors that are detected as `CentraLite Contact Sensor-A`. They do not have a device-specific quirk; the ZHA Network Card reports them using zha.device.Device.
The open/close and temp entities currently work fine in HA, but the battery level entity always shows `Unavailable`. There is battery information available in the UI via the entity: battery size is reported as `Other`, battery quantity is reported as `1` and battery voltage is reported as a float like `2.7` or `2.6`.
I also have some other sensors that are very similar both in terms of device signature and physical attributes. They are Lowes Iris Window/Door sensors and are detected as `Centralite 3320-L`. These use the quirk zhaquirks.centralite.ias.CentraLiteIASSensor.
The only differences in the device signatures for these two devices (other than the detected model, of course) are:
- The manufacturer_code entry in the node descriptor is different - I’m assuming this is how the different device model is detected.
- On the Contact Sensor-A Endpoint 2 has an extra in cluster with id 0x0001
- The Contact Sensor-A uses the default Zigbee device quirk, but the 3320-L uses a CentraLite-specific one.
**Describe the solution you'd like**
I'd like for the battery entity in HA to show the remaining percentage, similar to the entities for all my other sensor batteries.
**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**
```
{
"node_descriptor": "NodeDescriptor(byte1=2, byte2=64, mac_capability_flags=128, manufacturer_code=4174, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=0, maximum_outgoing_transfer_size=82, descriptor_capability_field=0)",
"endpoints": {
"1": {
"profile_id": 260,
"device_type": "0x0402",
"in_clusters": [
"0x0000",
"0x0001",
"0x0003",
"0x0020",
"0x0402",
"0x0500",
"0x0b05"
],
"out_clusters": [
"0x0019"
]
},
"2": {
"profile_id": 49887,
"device_type": "0x000c",
"in_clusters": [
"0x0000",
"0x0001",
"0x0003",
"0x0b05",
"0xfc0f"
],
"out_clusters": [
"0x0003"
]
}
},
"manufacturer": "CentraLite",
"model": "Contact Sensor-A",
"class": "zigpy.device.Device"
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/centralite/ias.py`
Content:
```
1 """Device handler for centralite ias sensors."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomDevice
4 from zigpy.zcl.clusters.general import Basic, BinaryInput, Identify, Ota, PollControl
5 from zigpy.zcl.clusters.measurement import TemperatureMeasurement
6 from zigpy.zcl.clusters.security import IasZone
7
8 from zhaquirks import PowerConfigurationCluster
9
10 from . import CENTRALITE
11 from ..const import (
12 DEVICE_TYPE,
13 ENDPOINTS,
14 INPUT_CLUSTERS,
15 MODELS_INFO,
16 OUTPUT_CLUSTERS,
17 PROFILE_ID,
18 )
19
20 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
21 MANUFACTURER_SPECIFIC_CLUSTER_ID = 0xFC0F # decimal = 64527
22 MANUFACTURER_SPECIFIC_PROFILE_ID = 0xC2DF # decimal = 49887
23
24
25 class CentraLiteIASSensor(CustomDevice):
26 """Custom device representing centralite ias sensors."""
27
28 signature = {
29 # <SimpleDescriptor endpoint=1 profile=260 device_type=1026
30 # device_version=0
31 # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]
32 # output_clusters=[25]>
33 MODELS_INFO: [
34 (CENTRALITE, "3300-S"),
35 (CENTRALITE, "3315-G"),
36 (CENTRALITE, "3315-L"),
37 (CENTRALITE, "3315-S"),
38 (CENTRALITE, "3315-Seu"),
39 (CENTRALITE, "3315"),
40 (CENTRALITE, "3320-L"),
41 ],
42 ENDPOINTS: {
43 1: {
44 PROFILE_ID: zha.PROFILE_ID,
45 DEVICE_TYPE: zha.DeviceType.IAS_ZONE,
46 INPUT_CLUSTERS: [
47 Basic.cluster_id,
48 PowerConfigurationCluster.cluster_id,
49 Identify.cluster_id,
50 PollControl.cluster_id,
51 TemperatureMeasurement.cluster_id,
52 IasZone.cluster_id,
53 DIAGNOSTICS_CLUSTER_ID,
54 ],
55 OUTPUT_CLUSTERS: [Ota.cluster_id],
56 },
57 # <SimpleDescriptor endpoint=2 profile=49887 device_type=12
58 # device_version=0
59 # input_clusters=[0, 1, 3, 2821, 64527]
60 # output_clusters=[3]>
61 2: {
62 PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,
63 DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,
64 INPUT_CLUSTERS: [
65 Basic.cluster_id,
66 PowerConfigurationCluster.cluster_id,
67 Identify.cluster_id,
68 DIAGNOSTICS_CLUSTER_ID,
69 MANUFACTURER_SPECIFIC_CLUSTER_ID,
70 ],
71 OUTPUT_CLUSTERS: [Identify.cluster_id],
72 },
73 },
74 }
75
76 replacement = {
77 ENDPOINTS: {
78 1: {
79 INPUT_CLUSTERS: [
80 Basic.cluster_id,
81 PowerConfigurationCluster,
82 Identify.cluster_id,
83 PollControl.cluster_id,
84 TemperatureMeasurement.cluster_id,
85 IasZone.cluster_id,
86 DIAGNOSTICS_CLUSTER_ID,
87 ],
88 OUTPUT_CLUSTERS: [Ota.cluster_id],
89 },
90 2: {
91 INPUT_CLUSTERS: [
92 Basic.cluster_id,
93 Identify.cluster_id,
94 DIAGNOSTICS_CLUSTER_ID,
95 MANUFACTURER_SPECIFIC_CLUSTER_ID,
96 ],
97 OUTPUT_CLUSTERS: [Identify.cluster_id],
98 },
99 }
100 }
101
102
103 class CentraLiteIASSensorV2(CustomDevice):
104 """Custom device representing centralite ias sensors."""
105
106 signature = {
107 # <SimpleDescriptor endpoint=1 profile=260 device_type=1026
108 # device_version=0
109 # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]
110 # output_clusters=[25]>
111 MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],
112 ENDPOINTS: {
113 1: CentraLiteIASSensor.signature[ENDPOINTS][1],
114 # <SimpleDescriptor endpoint=2 profile=49887 device_type=12
115 # device_version=0
116 # input_clusters=[0, 1, 3, 15, 2821, 64527]
117 # output_clusters=[3]>
118 2: {
119 PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,
120 DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,
121 INPUT_CLUSTERS: [
122 Basic.cluster_id,
123 BinaryInput.cluster_id,
124 PowerConfigurationCluster.cluster_id,
125 Identify.cluster_id,
126 DIAGNOSTICS_CLUSTER_ID,
127 MANUFACTURER_SPECIFIC_CLUSTER_ID,
128 ],
129 OUTPUT_CLUSTERS: [Identify.cluster_id],
130 },
131 },
132 }
133
134 replacement = CentraLiteIASSensor.replacement
135
136
137 class CentraLiteIASSensorV3(CustomDevice):
138 """Custom device representing centralite ias sensors."""
139
140 signature = {
141 # <SimpleDescriptor endpoint=1 profile=260 device_type=1026
142 # device_version=0
143 # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]
144 # output_clusters=[25]>
145 MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],
146 ENDPOINTS: {
147 1: CentraLiteIASSensor.signature[ENDPOINTS][1],
148 # <SimpleDescriptor endpoint=2 profile=49887 device_type=12
149 # device_version=0
150 # input_clusters=[0, 1, 3, 15, 2821]
151 # output_clusters=[3]>
152 2: {
153 PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,
154 DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,
155 INPUT_CLUSTERS: [
156 Basic.cluster_id,
157 BinaryInput.cluster_id,
158 PowerConfigurationCluster.cluster_id,
159 Identify.cluster_id,
160 DIAGNOSTICS_CLUSTER_ID,
161 ],
162 OUTPUT_CLUSTERS: [Identify.cluster_id],
163 },
164 },
165 }
166
167 replacement = CentraLiteIASSensor.replacement
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/centralite/ias.py b/zhaquirks/centralite/ias.py
--- a/zhaquirks/centralite/ias.py
+++ b/zhaquirks/centralite/ias.py
@@ -38,6 +38,7 @@
(CENTRALITE, "3315-Seu"),
(CENTRALITE, "3315"),
(CENTRALITE, "3320-L"),
+ (CENTRALITE, "Contact Sensor-A"),
],
ENDPOINTS: {
1: {
|
{"golden_diff": "diff --git a/zhaquirks/centralite/ias.py b/zhaquirks/centralite/ias.py\n--- a/zhaquirks/centralite/ias.py\n+++ b/zhaquirks/centralite/ias.py\n@@ -38,6 +38,7 @@\n (CENTRALITE, \"3315-Seu\"),\n (CENTRALITE, \"3315\"),\n (CENTRALITE, \"3320-L\"),\n+ (CENTRALITE, \"Contact Sensor-A\"),\n ],\n ENDPOINTS: {\n 1: {\n", "issue": "[Device Support Request] CentraLite Contact Sensor-A\n**TL;DR**: The battery entity for the `CentraLite Contact Sensor-A` always reports `Unavailable`. It's very similar in signature to the CentraLite 3320-L sensor, so I'm hoping it just needs a device-specific quirk.\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nI have some Sylvania SMART+ Door/Window sensors that are detected as `CentraLite Contact Sensor-A`. They do not have a device-specific quirk; the ZHA Network Card reports them using zha.device.Device.\r\n\r\nThe open/close and temp entities currently work fine in HA, but the battery level entity always shows `Unavailable`. There is battery information available in the UI via the entity: battery size is reported as `Other`, battery quantity is reported as `1` and battery voltage is reported as a float like `2.7` or `2.6`.\r\n\r\nI also have some other sensors that are very similar both in terms of device signature and physical attributes. They are Lowes Iris Window/Door sensors and are detected as `Centralite 3320-L`. These use the quirk zhaquirks.centralite.ias.CentraLiteIASSensor.\r\n\r\nThe only differences in the device signatures for these two devices (other than the detected model, of course) are: \r\n\r\n- The manufacturer_code entry in the node descriptor is different - I\u2019m assuming this is how the different device model is detected.\r\n- On the Contact Sensor-A Endpoint 2 has an extra in cluster with id 0x0001\r\n- The Contact Sensor-A uses the default Zigbee device quirk, but the 3320-L uses a CentraLite-specific one.\r\n\r\n\r\n\r\n**Describe the solution you'd like**\r\nI'd like for the battery entity in HA to show the remaining percentage, similar to the entities for all my other sensor batteries.\r\n\r\n**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"NodeDescriptor(byte1=2, byte2=64, mac_capability_flags=128, manufacturer_code=4174, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=0, maximum_outgoing_transfer_size=82, descriptor_capability_field=0)\",\r\n \"endpoints\": {\r\n \"1\": {\r\n \"profile_id\": 260,\r\n \"device_type\": \"0x0402\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0001\",\r\n \"0x0003\",\r\n \"0x0020\",\r\n \"0x0402\",\r\n \"0x0500\",\r\n \"0x0b05\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0019\"\r\n ]\r\n },\r\n \"2\": {\r\n \"profile_id\": 49887,\r\n \"device_type\": \"0x000c\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0001\",\r\n \"0x0003\",\r\n \"0x0b05\",\r\n \"0xfc0f\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0003\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"CentraLite\",\r\n \"model\": \"Contact Sensor-A\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Device handler for centralite ias sensors.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import Basic, BinaryInput, Identify, Ota, PollControl\nfrom zigpy.zcl.clusters.measurement import TemperatureMeasurement\nfrom zigpy.zcl.clusters.security import IasZone\n\nfrom zhaquirks import PowerConfigurationCluster\n\nfrom . import CENTRALITE\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nMANUFACTURER_SPECIFIC_CLUSTER_ID = 0xFC0F # decimal = 64527\nMANUFACTURER_SPECIFIC_PROFILE_ID = 0xC2DF # decimal = 49887\n\n\nclass CentraLiteIASSensor(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: [\n (CENTRALITE, \"3300-S\"),\n (CENTRALITE, \"3315-G\"),\n (CENTRALITE, \"3315-L\"),\n (CENTRALITE, \"3315-S\"),\n (CENTRALITE, \"3315-Seu\"),\n (CENTRALITE, \"3315\"),\n (CENTRALITE, \"3320-L\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.IAS_ZONE,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n IasZone.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 2821, 64527]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster,\n Identify.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n IasZone.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n 2: {\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n }\n }\n\n\nclass CentraLiteIASSensorV2(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],\n ENDPOINTS: {\n 1: CentraLiteIASSensor.signature[ENDPOINTS][1],\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 2821, 64527]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n BinaryInput.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = CentraLiteIASSensor.replacement\n\n\nclass CentraLiteIASSensorV3(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],\n ENDPOINTS: {\n 1: CentraLiteIASSensor.signature[ENDPOINTS][1],\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 2821]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n BinaryInput.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = CentraLiteIASSensor.replacement\n", "path": "zhaquirks/centralite/ias.py"}], "after_files": [{"content": "\"\"\"Device handler for centralite ias sensors.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import Basic, BinaryInput, Identify, Ota, PollControl\nfrom zigpy.zcl.clusters.measurement import TemperatureMeasurement\nfrom zigpy.zcl.clusters.security import IasZone\n\nfrom zhaquirks import PowerConfigurationCluster\n\nfrom . import CENTRALITE\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nMANUFACTURER_SPECIFIC_CLUSTER_ID = 0xFC0F # decimal = 64527\nMANUFACTURER_SPECIFIC_PROFILE_ID = 0xC2DF # decimal = 49887\n\n\nclass CentraLiteIASSensor(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: [\n (CENTRALITE, \"3300-S\"),\n (CENTRALITE, \"3315-G\"),\n (CENTRALITE, \"3315-L\"),\n (CENTRALITE, \"3315-S\"),\n (CENTRALITE, \"3315-Seu\"),\n (CENTRALITE, \"3315\"),\n (CENTRALITE, \"3320-L\"),\n (CENTRALITE, \"Contact Sensor-A\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.IAS_ZONE,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n IasZone.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 2821, 64527]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfigurationCluster,\n Identify.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n IasZone.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n 2: {\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n }\n }\n\n\nclass CentraLiteIASSensorV2(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],\n ENDPOINTS: {\n 1: CentraLiteIASSensor.signature[ENDPOINTS][1],\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 2821, 64527]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n BinaryInput.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = CentraLiteIASSensor.replacement\n\n\nclass CentraLiteIASSensorV3(CustomDevice):\n \"\"\"Custom device representing centralite ias sensors.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=1026\n # device_version=0\n # input_clusters=[0, 1, 3, 32, 1026, 1280, 2821]\n # output_clusters=[25]>\n MODELS_INFO: CentraLiteIASSensor.signature[MODELS_INFO],\n ENDPOINTS: {\n 1: CentraLiteIASSensor.signature[ENDPOINTS][1],\n # <SimpleDescriptor endpoint=2 profile=49887 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 2821]\n # output_clusters=[3]>\n 2: {\n PROFILE_ID: MANUFACTURER_SPECIFIC_PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n BinaryInput.cluster_id,\n PowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n },\n },\n }\n\n replacement = CentraLiteIASSensor.replacement\n", "path": "zhaquirks/centralite/ias.py"}]}
| 2,888 | 127 |
gh_patches_debug_11307
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-15802
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
asin
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/math.py`
Content:
```
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes
4 from ivy.functional.frontends.paddle.func_wrapper import (
5 to_ivy_arrays_and_back,
6 )
7
8
9 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
10 @to_ivy_arrays_and_back
11 def sin(x, name=None):
12 return ivy.sin(x)
13
14
15 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
16 @to_ivy_arrays_and_back
17 def cos(x, name=None):
18 return ivy.cos(x)
19
20
21 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
22 @to_ivy_arrays_and_back
23 def acos(x, name=None):
24 return ivy.acos(x)
25
26
27 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
28 @to_ivy_arrays_and_back
29 def cosh(x, name=None):
30 return ivy.cosh(x)
31
32
33 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
34 @to_ivy_arrays_and_back
35 def tanh(x, name=None):
36 return ivy.tanh(x)
37
38
39 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
40 @to_ivy_arrays_and_back
41 def acosh(x, name=None):
42 return ivy.acosh(x)
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/math.py b/ivy/functional/frontends/paddle/tensor/math.py
--- a/ivy/functional/frontends/paddle/tensor/math.py
+++ b/ivy/functional/frontends/paddle/tensor/math.py
@@ -1,6 +1,6 @@
# global
import ivy
-from ivy.func_wrapper import with_unsupported_dtypes
+from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
from ivy.functional.frontends.paddle.func_wrapper import (
to_ivy_arrays_and_back,
)
@@ -40,3 +40,9 @@
@to_ivy_arrays_and_back
def acosh(x, name=None):
return ivy.acosh(x)
+
+
+@with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
+@to_ivy_arrays_and_back
+def asin(x, name=None):
+ return ivy.asin(x)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/math.py b/ivy/functional/frontends/paddle/tensor/math.py\n--- a/ivy/functional/frontends/paddle/tensor/math.py\n+++ b/ivy/functional/frontends/paddle/tensor/math.py\n@@ -1,6 +1,6 @@\n # global\n import ivy\n-from ivy.func_wrapper import with_unsupported_dtypes\n+from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\n from ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n )\n@@ -40,3 +40,9 @@\n @to_ivy_arrays_and_back\n def acosh(x, name=None):\n return ivy.acosh(x)\n+\n+\n+@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def asin(x, name=None):\n+ return ivy.asin(x)\n", "issue": "asin\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sin(x, name=None):\n return ivy.sin(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cos(x, name=None):\n return ivy.cos(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acos(x, name=None):\n return ivy.acos(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cosh(x, name=None):\n return ivy.cosh(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef tanh(x, name=None):\n return ivy.tanh(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acosh(x, name=None):\n return ivy.acosh(x)\n", "path": "ivy/functional/frontends/paddle/tensor/math.py"}], "after_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef sin(x, name=None):\n return ivy.sin(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cos(x, name=None):\n return ivy.cos(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acos(x, name=None):\n return ivy.acos(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cosh(x, name=None):\n return ivy.cosh(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef tanh(x, name=None):\n return ivy.tanh(x)\n\n\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef acosh(x, name=None):\n return ivy.acosh(x)\n\n\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef asin(x, name=None):\n return ivy.asin(x)\n", "path": "ivy/functional/frontends/paddle/tensor/math.py"}]}
| 721 | 223 |
gh_patches_debug_26207
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-663
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Refactor idea to use a4 comments and ratings queryset
https://github.com/liqd/adhocracy4/pull/20
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/ideas/models.py`
Content:
```
1 from autoslug import AutoSlugField
2 from ckeditor.fields import RichTextField
3 from django.contrib.contenttypes.fields import GenericRelation
4 from django.db import models
5
6 from adhocracy4 import transforms
7 from adhocracy4.comments import models as comment_models
8 from adhocracy4.images import fields
9 from adhocracy4.modules import models as module_models
10 from adhocracy4.ratings import models as rating_models
11
12
13 class IdeaQuerySet(models.QuerySet):
14
15 def _rate_value_condition(self, value):
16 return models.Case(
17 models.When(ratings__value=value, then=models.F('ratings__id')),
18 output_field=models.IntegerField()
19 )
20
21 def annotate_positive_rating_count(self):
22 return self.annotate(
23 positive_rating_count=models.Count(
24 self._rate_value_condition(1),
25 distinct=True # needed to combine with other count annotations
26 )
27 )
28
29 def annotate_negative_rating_count(self):
30 return self.annotate(
31 negative_rating_count=models.Count(
32 self._rate_value_condition(-1),
33 distinct=True # needed to combine with other count annotations
34 )
35 )
36
37 def annotate_comment_count(self):
38 return self.annotate(
39 comment_count=models.Count(
40 'comments',
41 distinct=True # needed to combine with other count annotations
42 )
43 )
44
45
46 class Idea(module_models.Item):
47 slug = AutoSlugField(populate_from='name', unique=True)
48 name = models.CharField(max_length=120)
49 description = RichTextField()
50 image = fields.ConfiguredImageField(
51 'idea_image',
52 upload_to='ideas/images',
53 blank=True,
54 )
55 ratings = GenericRelation(rating_models.Rating,
56 related_query_name='idea',
57 object_id_field='object_pk')
58 comments = GenericRelation(comment_models.Comment,
59 related_query_name='idea',
60 object_id_field='object_pk')
61
62 objects = IdeaQuerySet.as_manager()
63
64 def __str__(self):
65 return self.name
66
67 def save(self, *args, **kwargs):
68 self.description = transforms.clean_html_field(
69 self.description)
70 super(Idea, self).save(*args, **kwargs)
71
72 def get_absolute_url(self):
73 from django.core.urlresolvers import reverse
74 return reverse('idea-detail', args=[str(self.slug)])
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/ideas/models.py b/euth/ideas/models.py
--- a/euth/ideas/models.py
+++ b/euth/ideas/models.py
@@ -6,41 +6,13 @@
from adhocracy4 import transforms
from adhocracy4.comments import models as comment_models
from adhocracy4.images import fields
+from adhocracy4.models import query
from adhocracy4.modules import models as module_models
from adhocracy4.ratings import models as rating_models
-class IdeaQuerySet(models.QuerySet):
-
- def _rate_value_condition(self, value):
- return models.Case(
- models.When(ratings__value=value, then=models.F('ratings__id')),
- output_field=models.IntegerField()
- )
-
- def annotate_positive_rating_count(self):
- return self.annotate(
- positive_rating_count=models.Count(
- self._rate_value_condition(1),
- distinct=True # needed to combine with other count annotations
- )
- )
-
- def annotate_negative_rating_count(self):
- return self.annotate(
- negative_rating_count=models.Count(
- self._rate_value_condition(-1),
- distinct=True # needed to combine with other count annotations
- )
- )
-
- def annotate_comment_count(self):
- return self.annotate(
- comment_count=models.Count(
- 'comments',
- distinct=True # needed to combine with other count annotations
- )
- )
+class IdeaQuerySet(query.RateableQuerySet, query.CommentableQuerySet):
+ pass
class Idea(module_models.Item):
|
{"golden_diff": "diff --git a/euth/ideas/models.py b/euth/ideas/models.py\n--- a/euth/ideas/models.py\n+++ b/euth/ideas/models.py\n@@ -6,41 +6,13 @@\n from adhocracy4 import transforms\n from adhocracy4.comments import models as comment_models\n from adhocracy4.images import fields\n+from adhocracy4.models import query\n from adhocracy4.modules import models as module_models\n from adhocracy4.ratings import models as rating_models\n \n \n-class IdeaQuerySet(models.QuerySet):\n-\n- def _rate_value_condition(self, value):\n- return models.Case(\n- models.When(ratings__value=value, then=models.F('ratings__id')),\n- output_field=models.IntegerField()\n- )\n-\n- def annotate_positive_rating_count(self):\n- return self.annotate(\n- positive_rating_count=models.Count(\n- self._rate_value_condition(1),\n- distinct=True # needed to combine with other count annotations\n- )\n- )\n-\n- def annotate_negative_rating_count(self):\n- return self.annotate(\n- negative_rating_count=models.Count(\n- self._rate_value_condition(-1),\n- distinct=True # needed to combine with other count annotations\n- )\n- )\n-\n- def annotate_comment_count(self):\n- return self.annotate(\n- comment_count=models.Count(\n- 'comments',\n- distinct=True # needed to combine with other count annotations\n- )\n- )\n+class IdeaQuerySet(query.RateableQuerySet, query.CommentableQuerySet):\n+ pass\n \n \n class Idea(module_models.Item):\n", "issue": "Refactor idea to use a4 comments and ratings queryset\nhttps://github.com/liqd/adhocracy4/pull/20\n", "before_files": [{"content": "from autoslug import AutoSlugField\nfrom ckeditor.fields import RichTextField\nfrom django.contrib.contenttypes.fields import GenericRelation\nfrom django.db import models\n\nfrom adhocracy4 import transforms\nfrom adhocracy4.comments import models as comment_models\nfrom adhocracy4.images import fields\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.ratings import models as rating_models\n\n\nclass IdeaQuerySet(models.QuerySet):\n\n def _rate_value_condition(self, value):\n return models.Case(\n models.When(ratings__value=value, then=models.F('ratings__id')),\n output_field=models.IntegerField()\n )\n\n def annotate_positive_rating_count(self):\n return self.annotate(\n positive_rating_count=models.Count(\n self._rate_value_condition(1),\n distinct=True # needed to combine with other count annotations\n )\n )\n\n def annotate_negative_rating_count(self):\n return self.annotate(\n negative_rating_count=models.Count(\n self._rate_value_condition(-1),\n distinct=True # needed to combine with other count annotations\n )\n )\n\n def annotate_comment_count(self):\n return self.annotate(\n comment_count=models.Count(\n 'comments',\n distinct=True # needed to combine with other count annotations\n )\n )\n\n\nclass Idea(module_models.Item):\n slug = AutoSlugField(populate_from='name', unique=True)\n name = models.CharField(max_length=120)\n description = RichTextField()\n image = fields.ConfiguredImageField(\n 'idea_image',\n upload_to='ideas/images',\n blank=True,\n )\n ratings = GenericRelation(rating_models.Rating,\n related_query_name='idea',\n object_id_field='object_pk')\n comments = GenericRelation(comment_models.Comment,\n related_query_name='idea',\n object_id_field='object_pk')\n\n objects = IdeaQuerySet.as_manager()\n\n def __str__(self):\n return self.name\n\n def save(self, *args, **kwargs):\n self.description = transforms.clean_html_field(\n self.description)\n super(Idea, self).save(*args, **kwargs)\n\n def get_absolute_url(self):\n from django.core.urlresolvers import reverse\n return reverse('idea-detail', args=[str(self.slug)])\n", "path": "euth/ideas/models.py"}], "after_files": [{"content": "from autoslug import AutoSlugField\nfrom ckeditor.fields import RichTextField\nfrom django.contrib.contenttypes.fields import GenericRelation\nfrom django.db import models\n\nfrom adhocracy4 import transforms\nfrom adhocracy4.comments import models as comment_models\nfrom adhocracy4.images import fields\nfrom adhocracy4.models import query\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.ratings import models as rating_models\n\n\nclass IdeaQuerySet(query.RateableQuerySet, query.CommentableQuerySet):\n pass\n\n\nclass Idea(module_models.Item):\n slug = AutoSlugField(populate_from='name', unique=True)\n name = models.CharField(max_length=120)\n description = RichTextField()\n image = fields.ConfiguredImageField(\n 'idea_image',\n upload_to='ideas/images',\n blank=True,\n )\n ratings = GenericRelation(rating_models.Rating,\n related_query_name='idea',\n object_id_field='object_pk')\n comments = GenericRelation(comment_models.Comment,\n related_query_name='idea',\n object_id_field='object_pk')\n\n objects = IdeaQuerySet.as_manager()\n\n def __str__(self):\n return self.name\n\n def save(self, *args, **kwargs):\n self.description = transforms.clean_html_field(\n self.description)\n super(Idea, self).save(*args, **kwargs)\n\n def get_absolute_url(self):\n from django.core.urlresolvers import reverse\n return reverse('idea-detail', args=[str(self.slug)])\n", "path": "euth/ideas/models.py"}]}
| 913 | 352 |
gh_patches_debug_13963
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-254
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Modify stale files warning to ignore .htaccess, .gitignore and .git
I am not sure if this is the same as issue #167 or not, or if there a better workaround than the setup I am using.
I have the mkdocs project in one folder, and I am building to a sibling folder ( `site_dir: ../site` )
My site dir contains its own git repo, and .htaccess and .gitignore, which I want to keep there, but I get that stale warning.
This causes two issues:
1. Someone may actually run this clean command and delete files I want to keep
2. I cannot run `--clean`
Perhaps the behavior of that warning (and of `--clean`) should be changed to accommodate such scenario?
If it cannot be solved automatically, then perhaps by a directive in the config? `build_ignore: [file, folder]`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/utils.py`
Content:
```
1 # coding: utf-8
2
3 """
4 Standalone file utils.
5
6 Nothing in this module should have an knowledge of config or the layout
7 and structure of the site and pages in the site.
8 """
9
10 import os
11 import shutil
12
13 from mkdocs.compat import urlparse
14
15
16 def copy_file(source_path, output_path):
17 """
18 Copy source_path to output_path, making sure any parent directories exist.
19 """
20 output_dir = os.path.dirname(output_path)
21 if not os.path.exists(output_dir):
22 os.makedirs(output_dir)
23 shutil.copy(source_path, output_path)
24
25
26 def write_file(content, output_path):
27 """
28 Write content to output_path, making sure any parent directories exist.
29 """
30 output_dir = os.path.dirname(output_path)
31 if not os.path.exists(output_dir):
32 os.makedirs(output_dir)
33 open(output_path, 'wb').write(content)
34
35
36 def clean_directory(directory):
37 """
38 Remove the content of a directory recursively but not the directory itself.
39 """
40 if os.path.exists(directory):
41 for entry in os.listdir(directory):
42 path = os.path.join(directory, entry)
43 if os.path.isdir(path):
44 shutil.rmtree(path, True)
45 else:
46 os.unlink(path)
47
48
49 def copy_media_files(from_dir, to_dir):
50 """
51 Recursively copy all files except markdown and HTML into another directory.
52 """
53 for (source_dir, dirnames, filenames) in os.walk(from_dir):
54 relative_path = os.path.relpath(source_dir, from_dir)
55 output_dir = os.path.normpath(os.path.join(to_dir, relative_path))
56
57 for filename in filenames:
58 if not is_markdown_file(filename) and not is_html_file(filename):
59 source_path = os.path.join(source_dir, filename)
60 output_path = os.path.join(output_dir, filename)
61 copy_file(source_path, output_path)
62
63
64 def get_html_path(path):
65 """
66 Map a source file path to an output html path.
67
68 Paths like 'index.md' will be converted to 'index.html'
69 Paths like 'about.md' will be converted to 'about/index.html'
70 Paths like 'api-guide/core.md' will be converted to 'api-guide/core/index.html'
71 """
72 path = os.path.splitext(path)[0]
73 if os.path.basename(path) == 'index':
74 return path + '.html'
75 return "/".join((path, 'index.html'))
76
77
78 def get_url_path(path, use_directory_urls=True):
79 """
80 Map a source file path to an output html path.
81
82 Paths like 'index.md' will be converted to '/'
83 Paths like 'about.md' will be converted to '/about/'
84 Paths like 'api-guide/core.md' will be converted to '/api-guide/core/'
85
86 If `use_directory_urls` is `False`, returned URLs will include the a trailing
87 `index.html` rather than just returning the directory path.
88 """
89 path = get_html_path(path)
90 url = '/' + path.replace(os.path.sep, '/')
91 if use_directory_urls:
92 return url[:-len('index.html')]
93 return url
94
95
96 def is_homepage(path):
97 return os.path.splitext(path)[0] == 'index'
98
99
100 def is_markdown_file(path):
101 """
102 Return True if the given file path is a Markdown file.
103
104 http://superuser.com/questions/249436/file-extension-for-markdown-files
105 """
106 ext = os.path.splitext(path)[1].lower()
107 return ext in [
108 '.markdown',
109 '.mdown',
110 '.mkdn',
111 '.mkd',
112 '.md',
113 ]
114
115
116 def is_css_file(path):
117 """
118 Return True if the given file path is a CSS file.
119 """
120 ext = os.path.splitext(path)[1].lower()
121 return ext in [
122 '.css',
123 ]
124
125
126 def is_javascript_file(path):
127 """
128 Return True if the given file path is a Javascript file.
129 """
130 ext = os.path.splitext(path)[1].lower()
131 return ext in [
132 '.js',
133 '.javascript'
134 ]
135
136
137 def is_html_file(path):
138 """
139 Return True if the given file path is an HTML file.
140 """
141 ext = os.path.splitext(path)[1].lower()
142 return ext in [
143 '.html',
144 '.htm',
145 ]
146
147
148 def create_media_urls(nav, url_list):
149 """
150 Return a list of URLs that have been processed correctly for inclusion in a page.
151 """
152 final_urls = []
153 for url in url_list:
154 # Allow links to fully qualified URL's
155 parsed = urlparse(url)
156 if parsed.netloc:
157 final_urls.append(url)
158 else:
159 relative_url = '%s/%s' % (nav.url_context.make_relative('/'), url)
160 final_urls.append(relative_url)
161 return final_urls
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/utils.py b/mkdocs/utils.py
--- a/mkdocs/utils.py
+++ b/mkdocs/utils.py
@@ -54,6 +54,13 @@
relative_path = os.path.relpath(source_dir, from_dir)
output_dir = os.path.normpath(os.path.join(to_dir, relative_path))
+ # Filter filenames starting with a '.'
+ filenames = [f for f in filenames if not f.startswith('.')]
+
+ # Filter the dirnames that start with a '.' and update the list in
+ # place to prevent us walking these.
+ dirnames[:] = [d for d in dirnames if not d.startswith('.')]
+
for filename in filenames:
if not is_markdown_file(filename) and not is_html_file(filename):
source_path = os.path.join(source_dir, filename)
|
{"golden_diff": "diff --git a/mkdocs/utils.py b/mkdocs/utils.py\n--- a/mkdocs/utils.py\n+++ b/mkdocs/utils.py\n@@ -54,6 +54,13 @@\n relative_path = os.path.relpath(source_dir, from_dir)\n output_dir = os.path.normpath(os.path.join(to_dir, relative_path))\n \n+ # Filter filenames starting with a '.'\n+ filenames = [f for f in filenames if not f.startswith('.')]\n+\n+ # Filter the dirnames that start with a '.' and update the list in\n+ # place to prevent us walking these.\n+ dirnames[:] = [d for d in dirnames if not d.startswith('.')]\n+\n for filename in filenames:\n if not is_markdown_file(filename) and not is_html_file(filename):\n source_path = os.path.join(source_dir, filename)\n", "issue": "Modify stale files warning to ignore .htaccess, .gitignore and .git\nI am not sure if this is the same as issue #167 or not, or if there a better workaround than the setup I am using.\n\nI have the mkdocs project in one folder, and I am building to a sibling folder ( `site_dir: ../site` )\nMy site dir contains its own git repo, and .htaccess and .gitignore, which I want to keep there, but I get that stale warning.\n\nThis causes two issues:\n1. Someone may actually run this clean command and delete files I want to keep\n2. I cannot run `--clean`\n\nPerhaps the behavior of that warning (and of `--clean`) should be changed to accommodate such scenario? \n\nIf it cannot be solved automatically, then perhaps by a directive in the config? `build_ignore: [file, folder]`\n\n", "before_files": [{"content": "# coding: utf-8\n\n\"\"\"\nStandalone file utils.\n\nNothing in this module should have an knowledge of config or the layout\nand structure of the site and pages in the site.\n\"\"\"\n\nimport os\nimport shutil\n\nfrom mkdocs.compat import urlparse\n\n\ndef copy_file(source_path, output_path):\n \"\"\"\n Copy source_path to output_path, making sure any parent directories exist.\n \"\"\"\n output_dir = os.path.dirname(output_path)\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n shutil.copy(source_path, output_path)\n\n\ndef write_file(content, output_path):\n \"\"\"\n Write content to output_path, making sure any parent directories exist.\n \"\"\"\n output_dir = os.path.dirname(output_path)\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n open(output_path, 'wb').write(content)\n\n\ndef clean_directory(directory):\n \"\"\"\n Remove the content of a directory recursively but not the directory itself.\n \"\"\"\n if os.path.exists(directory):\n for entry in os.listdir(directory):\n path = os.path.join(directory, entry)\n if os.path.isdir(path):\n shutil.rmtree(path, True)\n else:\n os.unlink(path)\n\n\ndef copy_media_files(from_dir, to_dir):\n \"\"\"\n Recursively copy all files except markdown and HTML into another directory.\n \"\"\"\n for (source_dir, dirnames, filenames) in os.walk(from_dir):\n relative_path = os.path.relpath(source_dir, from_dir)\n output_dir = os.path.normpath(os.path.join(to_dir, relative_path))\n\n for filename in filenames:\n if not is_markdown_file(filename) and not is_html_file(filename):\n source_path = os.path.join(source_dir, filename)\n output_path = os.path.join(output_dir, filename)\n copy_file(source_path, output_path)\n\n\ndef get_html_path(path):\n \"\"\"\n Map a source file path to an output html path.\n\n Paths like 'index.md' will be converted to 'index.html'\n Paths like 'about.md' will be converted to 'about/index.html'\n Paths like 'api-guide/core.md' will be converted to 'api-guide/core/index.html'\n \"\"\"\n path = os.path.splitext(path)[0]\n if os.path.basename(path) == 'index':\n return path + '.html'\n return \"/\".join((path, 'index.html'))\n\n\ndef get_url_path(path, use_directory_urls=True):\n \"\"\"\n Map a source file path to an output html path.\n\n Paths like 'index.md' will be converted to '/'\n Paths like 'about.md' will be converted to '/about/'\n Paths like 'api-guide/core.md' will be converted to '/api-guide/core/'\n\n If `use_directory_urls` is `False`, returned URLs will include the a trailing\n `index.html` rather than just returning the directory path.\n \"\"\"\n path = get_html_path(path)\n url = '/' + path.replace(os.path.sep, '/')\n if use_directory_urls:\n return url[:-len('index.html')]\n return url\n\n\ndef is_homepage(path):\n return os.path.splitext(path)[0] == 'index'\n\n\ndef is_markdown_file(path):\n \"\"\"\n Return True if the given file path is a Markdown file.\n\n http://superuser.com/questions/249436/file-extension-for-markdown-files\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.markdown',\n '.mdown',\n '.mkdn',\n '.mkd',\n '.md',\n ]\n\n\ndef is_css_file(path):\n \"\"\"\n Return True if the given file path is a CSS file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.css',\n ]\n\n\ndef is_javascript_file(path):\n \"\"\"\n Return True if the given file path is a Javascript file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.js',\n '.javascript'\n ]\n\n\ndef is_html_file(path):\n \"\"\"\n Return True if the given file path is an HTML file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.html',\n '.htm',\n ]\n\n\ndef create_media_urls(nav, url_list):\n \"\"\"\n Return a list of URLs that have been processed correctly for inclusion in a page.\n \"\"\"\n final_urls = []\n for url in url_list:\n # Allow links to fully qualified URL's\n parsed = urlparse(url)\n if parsed.netloc:\n final_urls.append(url)\n else:\n relative_url = '%s/%s' % (nav.url_context.make_relative('/'), url)\n final_urls.append(relative_url)\n return final_urls\n", "path": "mkdocs/utils.py"}], "after_files": [{"content": "# coding: utf-8\n\n\"\"\"\nStandalone file utils.\n\nNothing in this module should have an knowledge of config or the layout\nand structure of the site and pages in the site.\n\"\"\"\n\nimport os\nimport shutil\n\nfrom mkdocs.compat import urlparse\n\n\ndef copy_file(source_path, output_path):\n \"\"\"\n Copy source_path to output_path, making sure any parent directories exist.\n \"\"\"\n output_dir = os.path.dirname(output_path)\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n shutil.copy(source_path, output_path)\n\n\ndef write_file(content, output_path):\n \"\"\"\n Write content to output_path, making sure any parent directories exist.\n \"\"\"\n output_dir = os.path.dirname(output_path)\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n open(output_path, 'wb').write(content)\n\n\ndef clean_directory(directory):\n \"\"\"\n Remove the content of a directory recursively but not the directory itself.\n \"\"\"\n if os.path.exists(directory):\n for entry in os.listdir(directory):\n path = os.path.join(directory, entry)\n if os.path.isdir(path):\n shutil.rmtree(path, True)\n else:\n os.unlink(path)\n\n\ndef copy_media_files(from_dir, to_dir):\n \"\"\"\n Recursively copy all files except markdown and HTML into another directory.\n \"\"\"\n for (source_dir, dirnames, filenames) in os.walk(from_dir):\n relative_path = os.path.relpath(source_dir, from_dir)\n output_dir = os.path.normpath(os.path.join(to_dir, relative_path))\n\n # Filter filenames starting with a '.'\n filenames = [f for f in filenames if not f.startswith('.')]\n\n # Filter the dirnames that start with a '.' and update the list in\n # place to prevent us walking these.\n dirnames[:] = [d for d in dirnames if not d.startswith('.')]\n\n for filename in filenames:\n if not is_markdown_file(filename) and not is_html_file(filename):\n source_path = os.path.join(source_dir, filename)\n output_path = os.path.join(output_dir, filename)\n copy_file(source_path, output_path)\n\n\ndef get_html_path(path):\n \"\"\"\n Map a source file path to an output html path.\n\n Paths like 'index.md' will be converted to 'index.html'\n Paths like 'about.md' will be converted to 'about/index.html'\n Paths like 'api-guide/core.md' will be converted to 'api-guide/core/index.html'\n \"\"\"\n path = os.path.splitext(path)[0]\n if os.path.basename(path) == 'index':\n return path + '.html'\n return \"/\".join((path, 'index.html'))\n\n\ndef get_url_path(path, use_directory_urls=True):\n \"\"\"\n Map a source file path to an output html path.\n\n Paths like 'index.md' will be converted to '/'\n Paths like 'about.md' will be converted to '/about/'\n Paths like 'api-guide/core.md' will be converted to '/api-guide/core/'\n\n If `use_directory_urls` is `False`, returned URLs will include the a trailing\n `index.html` rather than just returning the directory path.\n \"\"\"\n path = get_html_path(path)\n url = '/' + path.replace(os.path.sep, '/')\n if use_directory_urls:\n return url[:-len('index.html')]\n return url\n\n\ndef is_homepage(path):\n return os.path.splitext(path)[0] == 'index'\n\n\ndef is_markdown_file(path):\n \"\"\"\n Return True if the given file path is a Markdown file.\n\n http://superuser.com/questions/249436/file-extension-for-markdown-files\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.markdown',\n '.mdown',\n '.mkdn',\n '.mkd',\n '.md',\n ]\n\n\ndef is_css_file(path):\n \"\"\"\n Return True if the given file path is a CSS file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.css',\n ]\n\n\ndef is_javascript_file(path):\n \"\"\"\n Return True if the given file path is a Javascript file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.js',\n '.javascript'\n ]\n\n\ndef is_html_file(path):\n \"\"\"\n Return True if the given file path is an HTML file.\n \"\"\"\n ext = os.path.splitext(path)[1].lower()\n return ext in [\n '.html',\n '.htm',\n ]\n\n\ndef create_media_urls(nav, url_list):\n \"\"\"\n Return a list of URLs that have been processed correctly for inclusion in a page.\n \"\"\"\n final_urls = []\n for url in url_list:\n # Allow links to fully qualified URL's\n parsed = urlparse(url)\n if parsed.netloc:\n final_urls.append(url)\n else:\n relative_url = '%s/%s' % (nav.url_context.make_relative('/'), url)\n final_urls.append(relative_url)\n return final_urls\n", "path": "mkdocs/utils.py"}]}
| 1,846 | 186 |
gh_patches_debug_13000
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-1432
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ExampleApp Syntax Highlighter broken in PyQt5
### Short description
Since merge of #1302, the syntax highlighter in the ExampleApp is broken (CC @j9ac9k ).
### Code to reproduce
```bash
cd pyqtgraph\examples
python3 .
```
### Expected behavior
Syntax highlighter should work
### Real behavior
Following error:
```
Traceback (most recent call last):
File "/home/b2/Documents/synced/pyqtgraph/examples/ExampleApp.py", line 298, in highlightBlock
format = self.styles[format]
AttributeError: 'PythonHighlighter' object has no attribute 'styles'
```
### Tested environment(s)
* PyQtGraph version: 7e57e07068fc8a62e9ae3b68e5556b11b6ef1841 and newer
* Qt Python binding: yQt5 5.15.1 Qt 5.15.1
* Python version: Python 3.8.5
* NumPy version: 1.19.2
* Operating system: Linux 5.8.16-2-MANJARO
* Installation method: Run in folder (see above)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/__main__.py`
Content:
```
1 import sys, os
2 import pyqtgraph as pg
3 from pyqtgraph.Qt import QtCore, QtGui
4
5
6
7 if __name__ == '__main__':
8 if __package__ is None or __package__ == "":
9 parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
10 sys.path.insert(0, parent_dir)
11 import examples
12 __package__ = "examples"
13
14 from .ExampleApp import main as run
15 run()
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/__main__.py b/examples/__main__.py
--- a/examples/__main__.py
+++ b/examples/__main__.py
@@ -1,15 +1,16 @@
import sys, os
+
+# Set up path to contain pyqtgraph module when run without installation
+if __name__ == "__main__" and (__package__ is None or __package__==''):
+ parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+ sys.path.insert(0, parent_dir)
+ import examples
+ __package__ = "examples"
+
import pyqtgraph as pg
from pyqtgraph.Qt import QtCore, QtGui
-
if __name__ == '__main__':
- if __package__ is None or __package__ == "":
- parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
- sys.path.insert(0, parent_dir)
- import examples
- __package__ = "examples"
-
from .ExampleApp import main as run
run()
|
{"golden_diff": "diff --git a/examples/__main__.py b/examples/__main__.py\n--- a/examples/__main__.py\n+++ b/examples/__main__.py\n@@ -1,15 +1,16 @@\n import sys, os\n+\n+# Set up path to contain pyqtgraph module when run without installation\n+if __name__ == \"__main__\" and (__package__ is None or __package__==''):\n+ parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n+ sys.path.insert(0, parent_dir)\n+ import examples\n+ __package__ = \"examples\"\n+\n import pyqtgraph as pg\n from pyqtgraph.Qt import QtCore, QtGui\n \n \n-\n if __name__ == '__main__':\n- if __package__ is None or __package__ == \"\":\n- parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n- sys.path.insert(0, parent_dir)\n- import examples\n- __package__ = \"examples\"\n-\n from .ExampleApp import main as run\n run()\n", "issue": "ExampleApp Syntax Highlighter broken in PyQt5\n### Short description\r\nSince merge of #1302, the syntax highlighter in the ExampleApp is broken (CC @j9ac9k ).\r\n\r\n### Code to reproduce\r\n```bash\r\ncd pyqtgraph\\examples\r\npython3 .\r\n```\r\n\r\n### Expected behavior\r\nSyntax highlighter should work\r\n\r\n### Real behavior\r\nFollowing error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/b2/Documents/synced/pyqtgraph/examples/ExampleApp.py\", line 298, in highlightBlock\r\n format = self.styles[format]\r\nAttributeError: 'PythonHighlighter' object has no attribute 'styles'\r\n```\r\n\r\n### Tested environment(s)\r\n\r\n * PyQtGraph version: 7e57e07068fc8a62e9ae3b68e5556b11b6ef1841 and newer\r\n * Qt Python binding: yQt5 5.15.1 Qt 5.15.1\r\n * Python version: Python 3.8.5\r\n * NumPy version: 1.19.2\r\n * Operating system: Linux 5.8.16-2-MANJARO\r\n * Installation method: Run in folder (see above)\n", "before_files": [{"content": "import sys, os\nimport pyqtgraph as pg\nfrom pyqtgraph.Qt import QtCore, QtGui\n\n\n\nif __name__ == '__main__':\n if __package__ is None or __package__ == \"\":\n parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n sys.path.insert(0, parent_dir)\n import examples\n __package__ = \"examples\"\n\n from .ExampleApp import main as run\n run()\n", "path": "examples/__main__.py"}], "after_files": [{"content": "import sys, os\n\n# Set up path to contain pyqtgraph module when run without installation\nif __name__ == \"__main__\" and (__package__ is None or __package__==''):\n parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n sys.path.insert(0, parent_dir)\n import examples\n __package__ = \"examples\"\n\nimport pyqtgraph as pg\nfrom pyqtgraph.Qt import QtCore, QtGui\n\n\nif __name__ == '__main__':\n from .ExampleApp import main as run\n run()\n", "path": "examples/__main__.py"}]}
| 657 | 229 |
gh_patches_debug_25299
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-2674
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Problem trying to install
Use this to open other questions or issues, and provide context here.
Hi, I'm kinda new to this, when I was trying to install it, I got the following error:
File "setup.py", line 30
version=f'0.1.{DATE}{BUILD}',
^
SyntaxError: invalid syntax
I used the command:
git clone https://github.com/facebookresearch/ParlAI.git
cd ParlAI; python setup.py develop
Any Idea why?
Thank you.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7
8 import datetime
9 import sys
10
11 from setuptools import setup, find_packages
12
13 BUILD = '' # if multiple in one day, use "dev0", "dev1", ...
14 DATE = datetime.date.today().isoformat().replace('-', '')
15
16 if sys.version_info < (3, 6):
17 sys.exit('Sorry, Python >=3.6 is required for ParlAI.')
18
19 with open('README.md', encoding="utf8") as f:
20 # strip the header and badges etc
21 readme = f.read().split('--------------------')[-1]
22
23 with open('requirements.txt') as f:
24 reqs = f.read()
25
26
27 if __name__ == '__main__':
28 setup(
29 name='parlai',
30 version=f'0.1.{DATE}{BUILD}',
31 description='Unified platform for dialogue research.',
32 long_description=readme,
33 long_description_content_type='text/markdown',
34 url='http://parl.ai/',
35 python_requires='>=3.6',
36 scripts=['bin/parlai'],
37 packages=find_packages(
38 exclude=('data', 'docs', 'examples', 'tests', 'parlai_internal',)
39 ),
40 install_requires=reqs.strip().split('\n'),
41 include_package_data=True,
42 entry_points={"flake8.extension": ["PAI = parlai.utils.flake8:ParlAIChecker"]},
43 classifiers=[
44 "Programming Language :: Python :: 3",
45 "License :: OSI Approved :: MIT License",
46 "Topic :: Scientific/Engineering :: Artificial Intelligence",
47 "Natural Language :: English",
48 ],
49 )
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -10,7 +10,7 @@
from setuptools import setup, find_packages
-BUILD = '' # if multiple in one day, use "dev0", "dev1", ...
+BUILD = '' # test by setting to ".dev0" if multiple in one day, use ".dev1", ...
DATE = datetime.date.today().isoformat().replace('-', '')
if sys.version_info < (3, 6):
@@ -27,7 +27,7 @@
if __name__ == '__main__':
setup(
name='parlai',
- version=f'0.1.{DATE}{BUILD}',
+ version='0.1.{DATE}{BUILD}'.format(DATE=DATE, BUILD=BUILD),
description='Unified platform for dialogue research.',
long_description=readme,
long_description_content_type='text/markdown',
@@ -39,6 +39,7 @@
),
install_requires=reqs.strip().split('\n'),
include_package_data=True,
+ package_data={'': ['*.txt', '*.md']},
entry_points={"flake8.extension": ["PAI = parlai.utils.flake8:ParlAIChecker"]},
classifiers=[
"Programming Language :: Python :: 3",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -10,7 +10,7 @@\n \n from setuptools import setup, find_packages\n \n-BUILD = '' # if multiple in one day, use \"dev0\", \"dev1\", ...\n+BUILD = '' # test by setting to \".dev0\" if multiple in one day, use \".dev1\", ...\n DATE = datetime.date.today().isoformat().replace('-', '')\n \n if sys.version_info < (3, 6):\n@@ -27,7 +27,7 @@\n if __name__ == '__main__':\n setup(\n name='parlai',\n- version=f'0.1.{DATE}{BUILD}',\n+ version='0.1.{DATE}{BUILD}'.format(DATE=DATE, BUILD=BUILD),\n description='Unified platform for dialogue research.',\n long_description=readme,\n long_description_content_type='text/markdown',\n@@ -39,6 +39,7 @@\n ),\n install_requires=reqs.strip().split('\\n'),\n include_package_data=True,\n+ package_data={'': ['*.txt', '*.md']},\n entry_points={\"flake8.extension\": [\"PAI = parlai.utils.flake8:ParlAIChecker\"]},\n classifiers=[\n \"Programming Language :: Python :: 3\",\n", "issue": "Problem trying to install \nUse this to open other questions or issues, and provide context here.\r\nHi, I'm kinda new to this, when I was trying to install it, I got the following error: \r\n\r\n File \"setup.py\", line 30\r\n version=f'0.1.{DATE}{BUILD}',\r\n ^\r\nSyntaxError: invalid syntax\r\n\r\nI used the command: \r\n\r\ngit clone https://github.com/facebookresearch/ParlAI.git\r\ncd ParlAI; python setup.py develop\r\n\r\nAny Idea why?\r\n\r\nThank you. \n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\nimport datetime\nimport sys\n\nfrom setuptools import setup, find_packages\n\nBUILD = '' # if multiple in one day, use \"dev0\", \"dev1\", ...\nDATE = datetime.date.today().isoformat().replace('-', '')\n\nif sys.version_info < (3, 6):\n sys.exit('Sorry, Python >=3.6 is required for ParlAI.')\n\nwith open('README.md', encoding=\"utf8\") as f:\n # strip the header and badges etc\n readme = f.read().split('--------------------')[-1]\n\nwith open('requirements.txt') as f:\n reqs = f.read()\n\n\nif __name__ == '__main__':\n setup(\n name='parlai',\n version=f'0.1.{DATE}{BUILD}',\n description='Unified platform for dialogue research.',\n long_description=readme,\n long_description_content_type='text/markdown',\n url='http://parl.ai/',\n python_requires='>=3.6',\n scripts=['bin/parlai'],\n packages=find_packages(\n exclude=('data', 'docs', 'examples', 'tests', 'parlai_internal',)\n ),\n install_requires=reqs.strip().split('\\n'),\n include_package_data=True,\n entry_points={\"flake8.extension\": [\"PAI = parlai.utils.flake8:ParlAIChecker\"]},\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: MIT License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Natural Language :: English\",\n ],\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\nimport datetime\nimport sys\n\nfrom setuptools import setup, find_packages\n\nBUILD = '' # test by setting to \".dev0\" if multiple in one day, use \".dev1\", ...\nDATE = datetime.date.today().isoformat().replace('-', '')\n\nif sys.version_info < (3, 6):\n sys.exit('Sorry, Python >=3.6 is required for ParlAI.')\n\nwith open('README.md', encoding=\"utf8\") as f:\n # strip the header and badges etc\n readme = f.read().split('--------------------')[-1]\n\nwith open('requirements.txt') as f:\n reqs = f.read()\n\n\nif __name__ == '__main__':\n setup(\n name='parlai',\n version='0.1.{DATE}{BUILD}'.format(DATE=DATE, BUILD=BUILD),\n description='Unified platform for dialogue research.',\n long_description=readme,\n long_description_content_type='text/markdown',\n url='http://parl.ai/',\n python_requires='>=3.6',\n scripts=['bin/parlai'],\n packages=find_packages(\n exclude=('data', 'docs', 'examples', 'tests', 'parlai_internal',)\n ),\n install_requires=reqs.strip().split('\\n'),\n include_package_data=True,\n package_data={'': ['*.txt', '*.md']},\n entry_points={\"flake8.extension\": [\"PAI = parlai.utils.flake8:ParlAIChecker\"]},\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: MIT License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Natural Language :: English\",\n ],\n )\n", "path": "setup.py"}]}
| 842 | 287 |
gh_patches_debug_61
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-5919
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Plotting styling guides are gone
As discussed on Discourse the styling gallery notebooks for Plotly, Altair, Seaborn and Matplotlib have gone missing with Panel 1.0 release.
Please re-add. Thx.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `panel/models/echarts.py`
Content:
```
1 """
2 Defines custom bokeh model to render ECharts plots.
3 """
4 from bokeh.core.properties import (
5 Any, Dict, Enum, List, Nullable, String,
6 )
7 from bokeh.events import ModelEvent
8 from bokeh.models import LayoutDOM
9
10 from ..config import config
11 from ..io.resources import bundled_files
12 from ..util import classproperty
13
14
15 class EChartsEvent(ModelEvent):
16
17 event_name = 'echarts_event'
18
19 def __init__(self, model, type=None, data=None, query=None):
20 self.type = type
21 self.data = data
22 self.query = query
23 super().__init__(model=model)
24
25
26 class ECharts(LayoutDOM):
27 """
28 A Bokeh model that wraps around an ECharts plot and renders it
29 inside a Bokeh.
30 """
31
32 __javascript_raw__ = [
33 f"{config.npm_cdn}/[email protected]/dist/echarts.min.js",
34 f"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js"
35 ]
36
37 @classproperty
38 def __javascript__(cls):
39 return bundled_files(cls)
40
41 @classproperty
42 def __js_skip__(cls):
43 return {
44 'echarts': cls.__javascript__[:1]
45 }
46
47 __js_require__ = {
48 'paths': {
49 "echarts": f"{config.npm_cdn}/[email protected]/dist/echarts.min",
50 "echarts-gl": f"{config.npm_cdn}/[email protected]/dist/echarts-gl.min"
51 },
52 'exports': {}
53 }
54
55 data = Nullable(Dict(String, Any))
56
57 options = Nullable(Dict(String, Any))
58
59 event_config = Dict(String, Any)
60
61 js_events = Dict(String, List(Any))
62
63 renderer = Enum("canvas", "svg")
64
65 theme = Enum("default", "light", "dark")
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/panel/models/echarts.py b/panel/models/echarts.py
--- a/panel/models/echarts.py
+++ b/panel/models/echarts.py
@@ -62,4 +62,4 @@
renderer = Enum("canvas", "svg")
- theme = Enum("default", "light", "dark")
+ theme = String("default")
|
{"golden_diff": "diff --git a/panel/models/echarts.py b/panel/models/echarts.py\n--- a/panel/models/echarts.py\n+++ b/panel/models/echarts.py\n@@ -62,4 +62,4 @@\n \n renderer = Enum(\"canvas\", \"svg\")\n \n- theme = Enum(\"default\", \"light\", \"dark\")\n+ theme = String(\"default\")\n", "issue": "Plotting styling guides are gone\nAs discussed on Discourse the styling gallery notebooks for Plotly, Altair, Seaborn and Matplotlib have gone missing with Panel 1.0 release.\r\n\r\nPlease re-add. Thx.\n", "before_files": [{"content": "\"\"\"\nDefines custom bokeh model to render ECharts plots.\n\"\"\"\nfrom bokeh.core.properties import (\n Any, Dict, Enum, List, Nullable, String,\n)\nfrom bokeh.events import ModelEvent\nfrom bokeh.models import LayoutDOM\n\nfrom ..config import config\nfrom ..io.resources import bundled_files\nfrom ..util import classproperty\n\n\nclass EChartsEvent(ModelEvent):\n\n event_name = 'echarts_event'\n\n def __init__(self, model, type=None, data=None, query=None):\n self.type = type\n self.data = data\n self.query = query\n super().__init__(model=model)\n\n\nclass ECharts(LayoutDOM):\n \"\"\"\n A Bokeh model that wraps around an ECharts plot and renders it\n inside a Bokeh.\n \"\"\"\n\n __javascript_raw__ = [\n f\"{config.npm_cdn}/[email protected]/dist/echarts.min.js\",\n f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js\"\n ]\n\n @classproperty\n def __javascript__(cls):\n return bundled_files(cls)\n\n @classproperty\n def __js_skip__(cls):\n return {\n 'echarts': cls.__javascript__[:1]\n }\n\n __js_require__ = {\n 'paths': {\n \"echarts\": f\"{config.npm_cdn}/[email protected]/dist/echarts.min\",\n \"echarts-gl\": f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min\"\n },\n 'exports': {}\n }\n\n data = Nullable(Dict(String, Any))\n\n options = Nullable(Dict(String, Any))\n\n event_config = Dict(String, Any)\n\n js_events = Dict(String, List(Any))\n\n renderer = Enum(\"canvas\", \"svg\")\n\n theme = Enum(\"default\", \"light\", \"dark\")\n", "path": "panel/models/echarts.py"}], "after_files": [{"content": "\"\"\"\nDefines custom bokeh model to render ECharts plots.\n\"\"\"\nfrom bokeh.core.properties import (\n Any, Dict, Enum, List, Nullable, String,\n)\nfrom bokeh.events import ModelEvent\nfrom bokeh.models import LayoutDOM\n\nfrom ..config import config\nfrom ..io.resources import bundled_files\nfrom ..util import classproperty\n\n\nclass EChartsEvent(ModelEvent):\n\n event_name = 'echarts_event'\n\n def __init__(self, model, type=None, data=None, query=None):\n self.type = type\n self.data = data\n self.query = query\n super().__init__(model=model)\n\n\nclass ECharts(LayoutDOM):\n \"\"\"\n A Bokeh model that wraps around an ECharts plot and renders it\n inside a Bokeh.\n \"\"\"\n\n __javascript_raw__ = [\n f\"{config.npm_cdn}/[email protected]/dist/echarts.min.js\",\n f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js\"\n ]\n\n @classproperty\n def __javascript__(cls):\n return bundled_files(cls)\n\n @classproperty\n def __js_skip__(cls):\n return {\n 'echarts': cls.__javascript__[:1]\n }\n\n __js_require__ = {\n 'paths': {\n \"echarts\": f\"{config.npm_cdn}/[email protected]/dist/echarts.min\",\n \"echarts-gl\": f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min\"\n },\n 'exports': {}\n }\n\n data = Nullable(Dict(String, Any))\n\n options = Nullable(Dict(String, Any))\n\n event_config = Dict(String, Any)\n\n js_events = Dict(String, List(Any))\n\n renderer = Enum(\"canvas\", \"svg\")\n\n theme = String(\"default\")\n", "path": "panel/models/echarts.py"}]}
| 859 | 86 |
gh_patches_debug_600
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1319
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.39
On the docket:
+ [x] Running opvault 0.4.9 pex leads to infinite recursion in setup tools #1316
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.38"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.38"
+__version__ = "2.1.39"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.38\"\n+__version__ = \"2.1.39\"\n", "issue": "Release 2.1.39\nOn the docket:\r\n+ [x] Running opvault 0.4.9 pex leads to infinite recursion in setup tools #1316\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.38\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.39\"\n", "path": "pex/version.py"}]}
| 349 | 96 |
gh_patches_debug_21533
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-464
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
there is duplicated code in EvaP
while browsing the code, i ran across a lot of structurally very similar blocks of code.
this is a reminder for me to search for these code parts, collect a few, and find the cause and solutions for them.
examples:
- [x] https://github.com/fsr-itse/EvaP/commit/ca4b28a6054944859ec4447fff95fc36095a2ffb.
- [x] the contributor course view/template vs the fsr course view/template.
- [x] student_index and contributor_index (html and view)
- [ ] fsr_import and user_import
- [x] the multiselect initialization inside the script blocks exists multiple times in different files. one can find it by searching for select[multiple='multiple']
- [x] https://github.com/janno42/EvaP/blob/reward_points/evap/fsr/templates/fsr_reward_point_redemption_event_delete.html
- [x] search for $(".twipsify") and $("input[data-datepicker='datepicker']:not([readonly='True'])")
- [x] sortable and apply_ordering functions
- [x] if ($.fn.button.noConflict != undefined)
- [x] $('#id_degree').combobox() and similar
- [x] fsr_course_preview.html, fsr_questionnaire_view.html, contributor_course_preview.html
- [x] javascript-code of the sortable forms: [contributor/staff]_course_form.html (or rather, evap_course_edit_js.html), staff_faq_index.html and staff_faq_section.html
- [x] all the leave.js occurrences
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/evaluation/management/commands/merge_users.py`
Content:
```
1 from django.core.management.base import BaseCommand
2
3 from evap.evaluation.models import UserProfile
4 from evap.evaluation.merge import merge_model_objects
5
6
7 class Command(BaseCommand):
8 args = '<user ID 1> <user ID 2>'
9 help = 'Merge two users'
10
11 def handle(self, *args, **options):
12 try:
13 user1 = UserProfile.objects.get(pk=int(args[0]))
14 user2 = UserProfile.objects.get(pk=int(args[1]))
15
16 print("Merging user '{1}' into user '{0}'".format(user1, user2))
17 merge_model_objects(user1, user2)
18 except Exception:
19 import traceback
20 traceback.print_exc()
21
```
Path: `evap/staff/templatetags/staff_templatetags.py`
Content:
```
1 from django.template import Library
2
3 from evap.evaluation.models import Semester
4
5 register = Library()
6
7
8 @register.inclusion_tag("staff_semester_menu.html")
9 def include_staff_semester_menu():
10 return dict(semesters=Semester.objects.all()[:5])
11
12 @register.inclusion_tag('staff_course_selection_list.html')
13 def include_staff_course_selection_list(course_forms, btn_label, empty_msg):
14 return {
15 'course_forms': course_forms,
16 'btn_label': btn_label,
17 'empty_msg': empty_msg
18 }
19
20 @register.inclusion_tag('staff_user_labels.html')
21 def include_staff_user_labels(user):
22 return dict(user=user)
23
```
Path: `evap/evaluation/templatetags/evaluation_templatetags.py`
Content:
```
1 from django.template import Library
2 from evap.evaluation.models import Semester
3
4 register = Library()
5
6
7 @register.inclusion_tag("user_list_with_links.html")
8 def include_user_list_with_links(users):
9 return dict(users=users)
10
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/evap/evaluation/management/commands/merge_users.py b/evap/evaluation/management/commands/merge_users.py
--- a/evap/evaluation/management/commands/merge_users.py
+++ b/evap/evaluation/management/commands/merge_users.py
@@ -5,8 +5,8 @@
class Command(BaseCommand):
- args = '<user ID 1> <user ID 2>'
- help = 'Merge two users'
+ args = '<primary user ID> <duplicate user ID>'
+ help = 'Merges duplicate user into primary user'
def handle(self, *args, **options):
try:
diff --git a/evap/evaluation/templatetags/evaluation_templatetags.py b/evap/evaluation/templatetags/evaluation_templatetags.py
--- a/evap/evaluation/templatetags/evaluation_templatetags.py
+++ b/evap/evaluation/templatetags/evaluation_templatetags.py
@@ -7,3 +7,9 @@
@register.inclusion_tag("user_list_with_links.html")
def include_user_list_with_links(users):
return dict(users=users)
+
+
[email protected]_tag("sortable_form_js.html")
+def include_sortable_form_js():
+ return dict()
+
diff --git a/evap/staff/templatetags/staff_templatetags.py b/evap/staff/templatetags/staff_templatetags.py
--- a/evap/staff/templatetags/staff_templatetags.py
+++ b/evap/staff/templatetags/staff_templatetags.py
@@ -20,3 +20,7 @@
@register.inclusion_tag('staff_user_labels.html')
def include_staff_user_labels(user):
return dict(user=user)
+
[email protected]_tag("staff_questionnaire_index_list.html")
+def include_staff_questionnaire_index_list(questionnaires, headline):
+ return dict(questionnaires=questionnaires, headline=headline)
|
{"golden_diff": "diff --git a/evap/evaluation/management/commands/merge_users.py b/evap/evaluation/management/commands/merge_users.py\n--- a/evap/evaluation/management/commands/merge_users.py\n+++ b/evap/evaluation/management/commands/merge_users.py\n@@ -5,8 +5,8 @@\n \n \n class Command(BaseCommand):\n- args = '<user ID 1> <user ID 2>'\n- help = 'Merge two users'\n+ args = '<primary user ID> <duplicate user ID>'\n+ help = 'Merges duplicate user into primary user'\n \n def handle(self, *args, **options):\n try:\ndiff --git a/evap/evaluation/templatetags/evaluation_templatetags.py b/evap/evaluation/templatetags/evaluation_templatetags.py\n--- a/evap/evaluation/templatetags/evaluation_templatetags.py\n+++ b/evap/evaluation/templatetags/evaluation_templatetags.py\n@@ -7,3 +7,9 @@\n @register.inclusion_tag(\"user_list_with_links.html\")\n def include_user_list_with_links(users):\n return dict(users=users)\n+\n+\[email protected]_tag(\"sortable_form_js.html\")\n+def include_sortable_form_js():\n+ return dict()\n+\ndiff --git a/evap/staff/templatetags/staff_templatetags.py b/evap/staff/templatetags/staff_templatetags.py\n--- a/evap/staff/templatetags/staff_templatetags.py\n+++ b/evap/staff/templatetags/staff_templatetags.py\n@@ -20,3 +20,7 @@\n @register.inclusion_tag('staff_user_labels.html')\n def include_staff_user_labels(user):\n return dict(user=user)\n+\[email protected]_tag(\"staff_questionnaire_index_list.html\")\n+def include_staff_questionnaire_index_list(questionnaires, headline):\n+ return dict(questionnaires=questionnaires, headline=headline)\n", "issue": "there is duplicated code in EvaP\nwhile browsing the code, i ran across a lot of structurally very similar blocks of code. \n\nthis is a reminder for me to search for these code parts, collect a few, and find the cause and solutions for them.\n\nexamples: \n- [x] https://github.com/fsr-itse/EvaP/commit/ca4b28a6054944859ec4447fff95fc36095a2ffb.\n- [x] the contributor course view/template vs the fsr course view/template.\n- [x] student_index and contributor_index (html and view)\n- [ ] fsr_import and user_import\n- [x] the multiselect initialization inside the script blocks exists multiple times in different files. one can find it by searching for select[multiple='multiple']\n- [x] https://github.com/janno42/EvaP/blob/reward_points/evap/fsr/templates/fsr_reward_point_redemption_event_delete.html\n- [x] search for $(\".twipsify\") and $(\"input[data-datepicker='datepicker']:not([readonly='True'])\")\n- [x] sortable and apply_ordering functions\n- [x] if ($.fn.button.noConflict != undefined)\n- [x] $('#id_degree').combobox() and similar\n- [x] fsr_course_preview.html, fsr_questionnaire_view.html, contributor_course_preview.html\n- [x] javascript-code of the sortable forms: [contributor/staff]_course_form.html (or rather, evap_course_edit_js.html), staff_faq_index.html and staff_faq_section.html\n- [x] all the leave.js occurrences\n\n", "before_files": [{"content": "from django.core.management.base import BaseCommand\n\nfrom evap.evaluation.models import UserProfile\nfrom evap.evaluation.merge import merge_model_objects\n\n\nclass Command(BaseCommand):\n args = '<user ID 1> <user ID 2>'\n help = 'Merge two users'\n\n def handle(self, *args, **options):\n try:\n user1 = UserProfile.objects.get(pk=int(args[0]))\n user2 = UserProfile.objects.get(pk=int(args[1]))\n\n print(\"Merging user '{1}' into user '{0}'\".format(user1, user2))\n merge_model_objects(user1, user2)\n except Exception:\n import traceback\n traceback.print_exc()\n", "path": "evap/evaluation/management/commands/merge_users.py"}, {"content": "from django.template import Library\n\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"staff_semester_menu.html\")\ndef include_staff_semester_menu():\n return dict(semesters=Semester.objects.all()[:5])\n\[email protected]_tag('staff_course_selection_list.html')\ndef include_staff_course_selection_list(course_forms, btn_label, empty_msg):\n return {\n 'course_forms': course_forms,\n 'btn_label': btn_label,\n 'empty_msg': empty_msg\n }\n\[email protected]_tag('staff_user_labels.html')\ndef include_staff_user_labels(user):\n return dict(user=user)\n", "path": "evap/staff/templatetags/staff_templatetags.py"}, {"content": "from django.template import Library\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"user_list_with_links.html\")\ndef include_user_list_with_links(users):\n return dict(users=users)\n", "path": "evap/evaluation/templatetags/evaluation_templatetags.py"}], "after_files": [{"content": "from django.core.management.base import BaseCommand\n\nfrom evap.evaluation.models import UserProfile\nfrom evap.evaluation.merge import merge_model_objects\n\n\nclass Command(BaseCommand):\n args = '<primary user ID> <duplicate user ID>'\n help = 'Merges duplicate user into primary user'\n\n def handle(self, *args, **options):\n try:\n user1 = UserProfile.objects.get(pk=int(args[0]))\n user2 = UserProfile.objects.get(pk=int(args[1]))\n\n print(\"Merging user '{1}' into user '{0}'\".format(user1, user2))\n merge_model_objects(user1, user2)\n except Exception:\n import traceback\n traceback.print_exc()\n", "path": "evap/evaluation/management/commands/merge_users.py"}, {"content": "from django.template import Library\n\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"staff_semester_menu.html\")\ndef include_staff_semester_menu():\n return dict(semesters=Semester.objects.all()[:5])\n\[email protected]_tag('staff_course_selection_list.html')\ndef include_staff_course_selection_list(course_forms, btn_label, empty_msg):\n return {\n 'course_forms': course_forms,\n 'btn_label': btn_label,\n 'empty_msg': empty_msg\n }\n\[email protected]_tag('staff_user_labels.html')\ndef include_staff_user_labels(user):\n return dict(user=user)\n\[email protected]_tag(\"staff_questionnaire_index_list.html\")\ndef include_staff_questionnaire_index_list(questionnaires, headline):\n return dict(questionnaires=questionnaires, headline=headline)\n", "path": "evap/staff/templatetags/staff_templatetags.py"}, {"content": "from django.template import Library\nfrom evap.evaluation.models import Semester\n\nregister = Library()\n\n\[email protected]_tag(\"user_list_with_links.html\")\ndef include_user_list_with_links(users):\n return dict(users=users)\n\n\[email protected]_tag(\"sortable_form_js.html\")\ndef include_sortable_form_js():\n return dict()\n\n", "path": "evap/evaluation/templatetags/evaluation_templatetags.py"}]}
| 1,095 | 459 |
gh_patches_debug_1903
|
rasdani/github-patches
|
git_diff
|
systemd__mkosi-1956
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Meta] declare a policy about adding new distributions
Before people start creating issues asking to support their favorite distribution, I think that mkosi should declare its policy regarding new distributions support.
The policy should state in which terms (if any) you will be willing to support a new distributions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkosi/distributions/__init__.py`
Content:
```
1 # SPDX-License-Identifier: LGPL-2.1+
2
3 import enum
4 import importlib
5 import re
6 from collections.abc import Sequence
7 from typing import TYPE_CHECKING, Optional, cast
8
9 from mkosi.architecture import Architecture
10 from mkosi.util import StrEnum, read_os_release
11
12 if TYPE_CHECKING:
13 from mkosi.state import MkosiState
14
15
16 class PackageType(StrEnum):
17 none = enum.auto()
18 rpm = enum.auto()
19 deb = enum.auto()
20 pkg = enum.auto()
21 ebuild = enum.auto()
22
23
24 class DistributionInstaller:
25 @classmethod
26 def pretty_name(cls) -> str:
27 raise NotImplementedError
28
29 @classmethod
30 def setup(cls, state: "MkosiState") -> None:
31 raise NotImplementedError
32
33 @classmethod
34 def install(cls, state: "MkosiState") -> None:
35 raise NotImplementedError
36
37 @classmethod
38 def install_packages(cls, state: "MkosiState", packages: Sequence[str]) -> None:
39 raise NotImplementedError
40
41 @classmethod
42 def remove_packages(cls, state: "MkosiState", packages: Sequence[str]) -> None:
43 raise NotImplementedError
44
45 @classmethod
46 def filesystem(cls) -> str:
47 return "ext4"
48
49 @staticmethod
50 def architecture(arch: Architecture) -> str:
51 return str(arch)
52
53 @classmethod
54 def package_type(cls) -> PackageType:
55 return PackageType.none
56
57 @classmethod
58 def default_release(cls) -> str:
59 return ""
60
61 @classmethod
62 def default_tools_tree_distribution(cls) -> Optional["Distribution"]:
63 return None
64
65 @classmethod
66 def tools_tree_repositories(cls) -> list[str]:
67 return []
68
69 @classmethod
70 def tools_tree_packages(cls) -> list[str]:
71 return []
72
73
74 class Distribution(StrEnum):
75 fedora = enum.auto()
76 debian = enum.auto()
77 ubuntu = enum.auto()
78 arch = enum.auto()
79 opensuse = enum.auto()
80 mageia = enum.auto()
81 centos = enum.auto()
82 rhel_ubi = enum.auto()
83 openmandriva = enum.auto()
84 rocky = enum.auto()
85 alma = enum.auto()
86 gentoo = enum.auto()
87 custom = enum.auto()
88
89 def is_centos_variant(self) -> bool:
90 return self in (Distribution.centos, Distribution.alma, Distribution.rocky)
91
92 def is_dnf_distribution(self) -> bool:
93 return self in (
94 Distribution.fedora,
95 Distribution.mageia,
96 Distribution.centos,
97 Distribution.rhel_ubi,
98 Distribution.openmandriva,
99 Distribution.rocky,
100 Distribution.alma,
101 )
102
103 def is_apt_distribution(self) -> bool:
104 return self in (Distribution.debian, Distribution.ubuntu)
105
106 def setup(self, state: "MkosiState") -> None:
107 return self.installer().setup(state)
108
109 def install(self, state: "MkosiState") -> None:
110 return self.installer().install(state)
111
112 def install_packages(self, state: "MkosiState", packages: Sequence[str]) -> None:
113 return self.installer().install_packages(state, packages)
114
115 def remove_packages(self, state: "MkosiState", packages: Sequence[str]) -> None:
116 return self.installer().remove_packages(state, packages)
117
118 def filesystem(self) -> str:
119 return self.installer().filesystem()
120
121 def architecture(self, arch: Architecture) -> str:
122 return self.installer().architecture(arch)
123
124 def package_type(self) -> PackageType:
125 return self.installer().package_type()
126
127 def default_release(self) -> str:
128 return self.installer().default_release()
129
130 def default_tools_tree_distribution(self) -> Optional["Distribution"]:
131 return self.installer().default_tools_tree_distribution()
132
133 def tools_tree_repositories(self) -> list[str]:
134 return self.installer().tools_tree_repositories()
135
136 def tools_tree_packages(self) -> list[str]:
137 return self.installer().tools_tree_packages()
138
139 def installer(self) -> type[DistributionInstaller]:
140 modname = str(self).replace('-', '_')
141 mod = importlib.import_module(f"mkosi.distributions.{modname}")
142 installer = getattr(mod, "Installer")
143 assert issubclass(installer, DistributionInstaller)
144 return cast(type[DistributionInstaller], installer)
145
146
147 def detect_distribution() -> tuple[Optional[Distribution], Optional[str]]:
148 try:
149 os_release = read_os_release()
150 except FileNotFoundError:
151 return None, None
152
153 dist_id = os_release.get("ID", "linux")
154 dist_id_like = os_release.get("ID_LIKE", "").split()
155 version = os_release.get("VERSION", None)
156 version_id = os_release.get("VERSION_ID", None)
157 version_codename = os_release.get("VERSION_CODENAME", None)
158 extracted_codename = None
159
160 if version:
161 # extract Debian release codename
162 m = re.search(r"\((.*?)\)", version)
163 if m:
164 extracted_codename = m.group(1)
165
166 d: Optional[Distribution] = None
167 for the_id in [dist_id, *dist_id_like]:
168 d = Distribution.__members__.get(the_id, None)
169 if d is not None:
170 break
171
172 if d in {Distribution.debian, Distribution.ubuntu} and (version_codename or extracted_codename):
173 version_id = version_codename or extracted_codename
174
175 return d, version_id
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkosi/distributions/__init__.py b/mkosi/distributions/__init__.py
--- a/mkosi/distributions/__init__.py
+++ b/mkosi/distributions/__init__.py
@@ -72,6 +72,8 @@
class Distribution(StrEnum):
+ # Please consult docs/distribution-policy.md and contact one
+ # of the mkosi maintainers before implementing a new distribution.
fedora = enum.auto()
debian = enum.auto()
ubuntu = enum.auto()
|
{"golden_diff": "diff --git a/mkosi/distributions/__init__.py b/mkosi/distributions/__init__.py\n--- a/mkosi/distributions/__init__.py\n+++ b/mkosi/distributions/__init__.py\n@@ -72,6 +72,8 @@\n \n \n class Distribution(StrEnum):\n+ # Please consult docs/distribution-policy.md and contact one\n+ # of the mkosi maintainers before implementing a new distribution.\n fedora = enum.auto()\n debian = enum.auto()\n ubuntu = enum.auto()\n", "issue": "[Meta] declare a policy about adding new distributions\nBefore people start creating issues asking to support their favorite distribution, I think that mkosi should declare its policy regarding new distributions support.\r\n\r\nThe policy should state in which terms (if any) you will be willing to support a new distributions.\n", "before_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\n\nimport enum\nimport importlib\nimport re\nfrom collections.abc import Sequence\nfrom typing import TYPE_CHECKING, Optional, cast\n\nfrom mkosi.architecture import Architecture\nfrom mkosi.util import StrEnum, read_os_release\n\nif TYPE_CHECKING:\n from mkosi.state import MkosiState\n\n\nclass PackageType(StrEnum):\n none = enum.auto()\n rpm = enum.auto()\n deb = enum.auto()\n pkg = enum.auto()\n ebuild = enum.auto()\n\n\nclass DistributionInstaller:\n @classmethod\n def pretty_name(cls) -> str:\n raise NotImplementedError\n\n @classmethod\n def setup(cls, state: \"MkosiState\") -> None:\n raise NotImplementedError\n\n @classmethod\n def install(cls, state: \"MkosiState\") -> None:\n raise NotImplementedError\n\n @classmethod\n def install_packages(cls, state: \"MkosiState\", packages: Sequence[str]) -> None:\n raise NotImplementedError\n\n @classmethod\n def remove_packages(cls, state: \"MkosiState\", packages: Sequence[str]) -> None:\n raise NotImplementedError\n\n @classmethod\n def filesystem(cls) -> str:\n return \"ext4\"\n\n @staticmethod\n def architecture(arch: Architecture) -> str:\n return str(arch)\n\n @classmethod\n def package_type(cls) -> PackageType:\n return PackageType.none\n\n @classmethod\n def default_release(cls) -> str:\n return \"\"\n\n @classmethod\n def default_tools_tree_distribution(cls) -> Optional[\"Distribution\"]:\n return None\n\n @classmethod\n def tools_tree_repositories(cls) -> list[str]:\n return []\n\n @classmethod\n def tools_tree_packages(cls) -> list[str]:\n return []\n\n\nclass Distribution(StrEnum):\n fedora = enum.auto()\n debian = enum.auto()\n ubuntu = enum.auto()\n arch = enum.auto()\n opensuse = enum.auto()\n mageia = enum.auto()\n centos = enum.auto()\n rhel_ubi = enum.auto()\n openmandriva = enum.auto()\n rocky = enum.auto()\n alma = enum.auto()\n gentoo = enum.auto()\n custom = enum.auto()\n\n def is_centos_variant(self) -> bool:\n return self in (Distribution.centos, Distribution.alma, Distribution.rocky)\n\n def is_dnf_distribution(self) -> bool:\n return self in (\n Distribution.fedora,\n Distribution.mageia,\n Distribution.centos,\n Distribution.rhel_ubi,\n Distribution.openmandriva,\n Distribution.rocky,\n Distribution.alma,\n )\n\n def is_apt_distribution(self) -> bool:\n return self in (Distribution.debian, Distribution.ubuntu)\n\n def setup(self, state: \"MkosiState\") -> None:\n return self.installer().setup(state)\n\n def install(self, state: \"MkosiState\") -> None:\n return self.installer().install(state)\n\n def install_packages(self, state: \"MkosiState\", packages: Sequence[str]) -> None:\n return self.installer().install_packages(state, packages)\n\n def remove_packages(self, state: \"MkosiState\", packages: Sequence[str]) -> None:\n return self.installer().remove_packages(state, packages)\n\n def filesystem(self) -> str:\n return self.installer().filesystem()\n\n def architecture(self, arch: Architecture) -> str:\n return self.installer().architecture(arch)\n\n def package_type(self) -> PackageType:\n return self.installer().package_type()\n\n def default_release(self) -> str:\n return self.installer().default_release()\n\n def default_tools_tree_distribution(self) -> Optional[\"Distribution\"]:\n return self.installer().default_tools_tree_distribution()\n\n def tools_tree_repositories(self) -> list[str]:\n return self.installer().tools_tree_repositories()\n\n def tools_tree_packages(self) -> list[str]:\n return self.installer().tools_tree_packages()\n\n def installer(self) -> type[DistributionInstaller]:\n modname = str(self).replace('-', '_')\n mod = importlib.import_module(f\"mkosi.distributions.{modname}\")\n installer = getattr(mod, \"Installer\")\n assert issubclass(installer, DistributionInstaller)\n return cast(type[DistributionInstaller], installer)\n\n\ndef detect_distribution() -> tuple[Optional[Distribution], Optional[str]]:\n try:\n os_release = read_os_release()\n except FileNotFoundError:\n return None, None\n\n dist_id = os_release.get(\"ID\", \"linux\")\n dist_id_like = os_release.get(\"ID_LIKE\", \"\").split()\n version = os_release.get(\"VERSION\", None)\n version_id = os_release.get(\"VERSION_ID\", None)\n version_codename = os_release.get(\"VERSION_CODENAME\", None)\n extracted_codename = None\n\n if version:\n # extract Debian release codename\n m = re.search(r\"\\((.*?)\\)\", version)\n if m:\n extracted_codename = m.group(1)\n\n d: Optional[Distribution] = None\n for the_id in [dist_id, *dist_id_like]:\n d = Distribution.__members__.get(the_id, None)\n if d is not None:\n break\n\n if d in {Distribution.debian, Distribution.ubuntu} and (version_codename or extracted_codename):\n version_id = version_codename or extracted_codename\n\n return d, version_id\n", "path": "mkosi/distributions/__init__.py"}], "after_files": [{"content": "# SPDX-License-Identifier: LGPL-2.1+\n\nimport enum\nimport importlib\nimport re\nfrom collections.abc import Sequence\nfrom typing import TYPE_CHECKING, Optional, cast\n\nfrom mkosi.architecture import Architecture\nfrom mkosi.util import StrEnum, read_os_release\n\nif TYPE_CHECKING:\n from mkosi.state import MkosiState\n\n\nclass PackageType(StrEnum):\n none = enum.auto()\n rpm = enum.auto()\n deb = enum.auto()\n pkg = enum.auto()\n ebuild = enum.auto()\n\n\nclass DistributionInstaller:\n @classmethod\n def pretty_name(cls) -> str:\n raise NotImplementedError\n\n @classmethod\n def setup(cls, state: \"MkosiState\") -> None:\n raise NotImplementedError\n\n @classmethod\n def install(cls, state: \"MkosiState\") -> None:\n raise NotImplementedError\n\n @classmethod\n def install_packages(cls, state: \"MkosiState\", packages: Sequence[str]) -> None:\n raise NotImplementedError\n\n @classmethod\n def remove_packages(cls, state: \"MkosiState\", packages: Sequence[str]) -> None:\n raise NotImplementedError\n\n @classmethod\n def filesystem(cls) -> str:\n return \"ext4\"\n\n @staticmethod\n def architecture(arch: Architecture) -> str:\n return str(arch)\n\n @classmethod\n def package_type(cls) -> PackageType:\n return PackageType.none\n\n @classmethod\n def default_release(cls) -> str:\n return \"\"\n\n @classmethod\n def default_tools_tree_distribution(cls) -> Optional[\"Distribution\"]:\n return None\n\n @classmethod\n def tools_tree_repositories(cls) -> list[str]:\n return []\n\n @classmethod\n def tools_tree_packages(cls) -> list[str]:\n return []\n\n\nclass Distribution(StrEnum):\n # Please consult docs/distribution-policy.md and contact one\n # of the mkosi maintainers before implementing a new distribution.\n fedora = enum.auto()\n debian = enum.auto()\n ubuntu = enum.auto()\n arch = enum.auto()\n opensuse = enum.auto()\n mageia = enum.auto()\n centos = enum.auto()\n rhel_ubi = enum.auto()\n openmandriva = enum.auto()\n rocky = enum.auto()\n alma = enum.auto()\n gentoo = enum.auto()\n custom = enum.auto()\n\n def is_centos_variant(self) -> bool:\n return self in (Distribution.centos, Distribution.alma, Distribution.rocky)\n\n def is_dnf_distribution(self) -> bool:\n return self in (\n Distribution.fedora,\n Distribution.mageia,\n Distribution.centos,\n Distribution.rhel_ubi,\n Distribution.openmandriva,\n Distribution.rocky,\n Distribution.alma,\n )\n\n def is_apt_distribution(self) -> bool:\n return self in (Distribution.debian, Distribution.ubuntu)\n\n def setup(self, state: \"MkosiState\") -> None:\n return self.installer().setup(state)\n\n def install(self, state: \"MkosiState\") -> None:\n return self.installer().install(state)\n\n def install_packages(self, state: \"MkosiState\", packages: Sequence[str]) -> None:\n return self.installer().install_packages(state, packages)\n\n def remove_packages(self, state: \"MkosiState\", packages: Sequence[str]) -> None:\n return self.installer().remove_packages(state, packages)\n\n def filesystem(self) -> str:\n return self.installer().filesystem()\n\n def architecture(self, arch: Architecture) -> str:\n return self.installer().architecture(arch)\n\n def package_type(self) -> PackageType:\n return self.installer().package_type()\n\n def default_release(self) -> str:\n return self.installer().default_release()\n\n def default_tools_tree_distribution(self) -> Optional[\"Distribution\"]:\n return self.installer().default_tools_tree_distribution()\n\n def tools_tree_repositories(self) -> list[str]:\n return self.installer().tools_tree_repositories()\n\n def tools_tree_packages(self) -> list[str]:\n return self.installer().tools_tree_packages()\n\n def installer(self) -> type[DistributionInstaller]:\n modname = str(self).replace('-', '_')\n mod = importlib.import_module(f\"mkosi.distributions.{modname}\")\n installer = getattr(mod, \"Installer\")\n assert issubclass(installer, DistributionInstaller)\n return cast(type[DistributionInstaller], installer)\n\n\ndef detect_distribution() -> tuple[Optional[Distribution], Optional[str]]:\n try:\n os_release = read_os_release()\n except FileNotFoundError:\n return None, None\n\n dist_id = os_release.get(\"ID\", \"linux\")\n dist_id_like = os_release.get(\"ID_LIKE\", \"\").split()\n version = os_release.get(\"VERSION\", None)\n version_id = os_release.get(\"VERSION_ID\", None)\n version_codename = os_release.get(\"VERSION_CODENAME\", None)\n extracted_codename = None\n\n if version:\n # extract Debian release codename\n m = re.search(r\"\\((.*?)\\)\", version)\n if m:\n extracted_codename = m.group(1)\n\n d: Optional[Distribution] = None\n for the_id in [dist_id, *dist_id_like]:\n d = Distribution.__members__.get(the_id, None)\n if d is not None:\n break\n\n if d in {Distribution.debian, Distribution.ubuntu} and (version_codename or extracted_codename):\n version_id = version_codename or extracted_codename\n\n return d, version_id\n", "path": "mkosi/distributions/__init__.py"}]}
| 1,943 | 117 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.