
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_40220
|
rasdani/github-patches
|
git_diff
|
encode__starlette-1715
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Background tasks are cancelled if the client closes connection
### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
When the HTTP client closes the TCP socket immediately after receiving the HTTP response, background tasks are cancelled.
This bug only happens when running the ASGI under uvicorn, and only if at least one HTTP Middleware is defined in the user middleware chain.
### Steps to reproduce the bug
1. Write the following ASGI Starlette application in `repro.py`:
```python
import traceback
import anyio
from starlette.applications import Starlette
from starlette.background import BackgroundTasks
from starlette.middleware import Middleware
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.responses import Response
from starlette.routing import Route
async def passthrough(request, call_next):
return await call_next(request)
async def _sleep(identifier, delay):
print(identifier, "started")
try:
await anyio.sleep(delay)
print(identifier, "completed")
except BaseException:
print(identifier, "error")
traceback.print_exc()
raise
async def response_with_sleeps(request):
background_tasks = BackgroundTasks()
background_tasks.add_task(_sleep, "background task 1", 2)
background_tasks.add_task(_sleep, "background task 2", 2)
return Response(background=background_tasks)
application = Starlette(
middleware=[
Middleware(BaseHTTPMiddleware, dispatch=passthrough),
],
routes=[
Route("/", response_with_sleeps),
],
)
```
2. Run that application using `uvicorn` (either uvloop or regular asyncio will reproduce the issue) on localhost:8000
```bash
uvicorn repro:application --port 8000
```
3. Run the following client script
```python
#!/usr/bin/env python
import socket
connection = socket.create_connection(("localhost", 8000))
connection.sendall(b"GET / HTTP/1.1\r\nHost: localhost\r\n\r\n")
print(connection.recv(10000).decode("utf8"))
connection.close()
```
### Expected behavior
The client script gets the HTTP response, and both background tasks should complete successfully.
The expected behavior will be detectable by the following content in standard output:
```
background task 1 started
background task 1 completed
background task 2 started
background task 2 completed
```
### Actual behavior
Background task 1 is interrupted at the `await` point and background task 2 is never started.
That results in the following content in the output (when running the `repro.py` application):
```
background task 1 started
background task 1 error
Traceback (most recent call last):
File "/Users/jean/PycharmProjects/starlette-bg-cancelled/./repro.py", line 19, in _sleep
await anyio.sleep(delay)
File "/Users/jean/PycharmProjects/starlette-bg-cancelled/venv/lib/python3.9/site-packages/anyio/_core/_eventloop.py", line 69, in sleep
return await get_asynclib().sleep(delay)
File "/usr/local/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/tasks.py", line 654, in sleep
return await future
asyncio.exceptions.CancelledError
```
### Debugging material
_No response_
### Environment
- MacOS 10.14.6 / Python 3.9 / Starlette 0.18.0
### Additional context
* When I remove the `passthrough` middleware, the bug goes away.
* When I run the same application in `hypercorn`, the bug goes away.
* There does not seem to be a difference between using `uvloop` or not.
* If the client script (e.g. with a `time.sleep(10)`) maintains the TCP connection open, the bug goes away.
Shield send "http.response.start" from cancellation (BaseHTTPMiddleware)
Fixes #1634
- Discussion #1527
- Caused by #1157
`await recv_stream.receive()` will raise `anyio.EndOfStream` if request is disconnected, due to:
- `task_group.cancel_scope.cancel()` in `StreamingResponse.__call__.<locals>.wrap` and
- cancellation check in `await checkpoint()` of `MemoryObjectSendStream.send`,
and then `RuntimeError: No response returned.` will be raised in `BaseHTTPMiddleware`.
Let's shield send "http.response.start" from cancellation, since the message is ready to be sent to the receiver.
This is an alternative implementation of #1706 in `BaseHTTPMiddleware` instead of `StreamingResponse`.
We should not force the shielding in `StreamingResponse`, since the cancellation check is an intended feature of `MemoryObjectSendStream`. `BaseHTTPMiddleware`, which uses both, should be responsible for the compatibility.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/middleware/base.py`
Content:
```
1 import typing
2
3 import anyio
4
5 from starlette.requests import Request
6 from starlette.responses import Response, StreamingResponse
7 from starlette.types import ASGIApp, Receive, Scope, Send
8
9 RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]
10 DispatchFunction = typing.Callable[
11 [Request, RequestResponseEndpoint], typing.Awaitable[Response]
12 ]
13
14
15 class BaseHTTPMiddleware:
16 def __init__(
17 self, app: ASGIApp, dispatch: typing.Optional[DispatchFunction] = None
18 ) -> None:
19 self.app = app
20 self.dispatch_func = self.dispatch if dispatch is None else dispatch
21
22 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
23 if scope["type"] != "http":
24 await self.app(scope, receive, send)
25 return
26
27 async def call_next(request: Request) -> Response:
28 app_exc: typing.Optional[Exception] = None
29 send_stream, recv_stream = anyio.create_memory_object_stream()
30
31 async def coro() -> None:
32 nonlocal app_exc
33
34 async with send_stream:
35 try:
36 await self.app(scope, request.receive, send_stream.send)
37 except Exception as exc:
38 app_exc = exc
39
40 task_group.start_soon(coro)
41
42 try:
43 message = await recv_stream.receive()
44 except anyio.EndOfStream:
45 if app_exc is not None:
46 raise app_exc
47 raise RuntimeError("No response returned.")
48
49 assert message["type"] == "http.response.start"
50
51 async def body_stream() -> typing.AsyncGenerator[bytes, None]:
52 async with recv_stream:
53 async for message in recv_stream:
54 assert message["type"] == "http.response.body"
55 body = message.get("body", b"")
56 if body:
57 yield body
58 if not message.get("more_body", False):
59 break
60
61 if app_exc is not None:
62 raise app_exc
63
64 response = StreamingResponse(
65 status_code=message["status"], content=body_stream()
66 )
67 response.raw_headers = message["headers"]
68 return response
69
70 async with anyio.create_task_group() as task_group:
71 request = Request(scope, receive=receive)
72 response = await self.dispatch_func(request, call_next)
73 await response(scope, receive, send)
74 task_group.cancel_scope.cancel()
75
76 async def dispatch(
77 self, request: Request, call_next: RequestResponseEndpoint
78 ) -> Response:
79 raise NotImplementedError() # pragma: no cover
80
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py
--- a/starlette/middleware/base.py
+++ b/starlette/middleware/base.py
@@ -4,12 +4,13 @@
from starlette.requests import Request
from starlette.responses import Response, StreamingResponse
-from starlette.types import ASGIApp, Receive, Scope, Send
+from starlette.types import ASGIApp, Message, Receive, Scope, Send
RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]
DispatchFunction = typing.Callable[
[Request, RequestResponseEndpoint], typing.Awaitable[Response]
]
+T = typing.TypeVar("T")
class BaseHTTPMiddleware:
@@ -24,19 +25,52 @@
await self.app(scope, receive, send)
return
+ response_sent = anyio.Event()
+
async def call_next(request: Request) -> Response:
app_exc: typing.Optional[Exception] = None
send_stream, recv_stream = anyio.create_memory_object_stream()
+ async def receive_or_disconnect() -> Message:
+ if response_sent.is_set():
+ return {"type": "http.disconnect"}
+
+ async with anyio.create_task_group() as task_group:
+
+ async def wrap(func: typing.Callable[[], typing.Awaitable[T]]) -> T:
+ result = await func()
+ task_group.cancel_scope.cancel()
+ return result
+
+ task_group.start_soon(wrap, response_sent.wait)
+ message = await wrap(request.receive)
+
+ if response_sent.is_set():
+ return {"type": "http.disconnect"}
+
+ return message
+
+ async def close_recv_stream_on_response_sent() -> None:
+ await response_sent.wait()
+ recv_stream.close()
+
+ async def send_no_error(message: Message) -> None:
+ try:
+ await send_stream.send(message)
+ except anyio.BrokenResourceError:
+ # recv_stream has been closed, i.e. response_sent has been set.
+ return
+
async def coro() -> None:
nonlocal app_exc
async with send_stream:
try:
- await self.app(scope, request.receive, send_stream.send)
+ await self.app(scope, receive_or_disconnect, send_no_error)
except Exception as exc:
app_exc = exc
+ task_group.start_soon(close_recv_stream_on_response_sent)
task_group.start_soon(coro)
try:
@@ -71,7 +105,7 @@
request = Request(scope, receive=receive)
response = await self.dispatch_func(request, call_next)
await response(scope, receive, send)
- task_group.cancel_scope.cancel()
+ response_sent.set()
async def dispatch(
self, request: Request, call_next: RequestResponseEndpoint
|
{"golden_diff": "diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py\n--- a/starlette/middleware/base.py\n+++ b/starlette/middleware/base.py\n@@ -4,12 +4,13 @@\n \n from starlette.requests import Request\n from starlette.responses import Response, StreamingResponse\n-from starlette.types import ASGIApp, Receive, Scope, Send\n+from starlette.types import ASGIApp, Message, Receive, Scope, Send\n \n RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\n DispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n ]\n+T = typing.TypeVar(\"T\")\n \n \n class BaseHTTPMiddleware:\n@@ -24,19 +25,52 @@\n await self.app(scope, receive, send)\n return\n \n+ response_sent = anyio.Event()\n+\n async def call_next(request: Request) -> Response:\n app_exc: typing.Optional[Exception] = None\n send_stream, recv_stream = anyio.create_memory_object_stream()\n \n+ async def receive_or_disconnect() -> Message:\n+ if response_sent.is_set():\n+ return {\"type\": \"http.disconnect\"}\n+\n+ async with anyio.create_task_group() as task_group:\n+\n+ async def wrap(func: typing.Callable[[], typing.Awaitable[T]]) -> T:\n+ result = await func()\n+ task_group.cancel_scope.cancel()\n+ return result\n+\n+ task_group.start_soon(wrap, response_sent.wait)\n+ message = await wrap(request.receive)\n+\n+ if response_sent.is_set():\n+ return {\"type\": \"http.disconnect\"}\n+\n+ return message\n+\n+ async def close_recv_stream_on_response_sent() -> None:\n+ await response_sent.wait()\n+ recv_stream.close()\n+\n+ async def send_no_error(message: Message) -> None:\n+ try:\n+ await send_stream.send(message)\n+ except anyio.BrokenResourceError:\n+ # recv_stream has been closed, i.e. response_sent has been set.\n+ return\n+\n async def coro() -> None:\n nonlocal app_exc\n \n async with send_stream:\n try:\n- await self.app(scope, request.receive, send_stream.send)\n+ await self.app(scope, receive_or_disconnect, send_no_error)\n except Exception as exc:\n app_exc = exc\n \n+ task_group.start_soon(close_recv_stream_on_response_sent)\n task_group.start_soon(coro)\n \n try:\n@@ -71,7 +105,7 @@\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, call_next)\n await response(scope, receive, send)\n- task_group.cancel_scope.cancel()\n+ response_sent.set()\n \n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n", "issue": "Background tasks are cancelled if the client closes connection\n### Checklist\n\n- [X] The bug is reproducible against the latest release or `master`.\n- [X] There are no similar issues or pull requests to fix it yet.\n\n### Describe the bug\n\nWhen the HTTP client closes the TCP socket immediately after receiving the HTTP response, background tasks are cancelled.\r\n\r\nThis bug only happens when running the ASGI under uvicorn, and only if at least one HTTP Middleware is defined in the user middleware chain.\n\n### Steps to reproduce the bug\n\n1. Write the following ASGI Starlette application in `repro.py`:\r\n```python\r\nimport traceback\r\n\r\nimport anyio\r\nfrom starlette.applications import Starlette\r\nfrom starlette.background import BackgroundTasks\r\nfrom starlette.middleware import Middleware\r\nfrom starlette.middleware.base import BaseHTTPMiddleware\r\nfrom starlette.responses import Response\r\nfrom starlette.routing import Route\r\n\r\n\r\nasync def passthrough(request, call_next):\r\n return await call_next(request)\r\n\r\n\r\nasync def _sleep(identifier, delay):\r\n print(identifier, \"started\")\r\n try:\r\n await anyio.sleep(delay)\r\n print(identifier, \"completed\")\r\n except BaseException:\r\n print(identifier, \"error\")\r\n traceback.print_exc()\r\n raise\r\n\r\n\r\nasync def response_with_sleeps(request):\r\n background_tasks = BackgroundTasks()\r\n background_tasks.add_task(_sleep, \"background task 1\", 2)\r\n background_tasks.add_task(_sleep, \"background task 2\", 2)\r\n return Response(background=background_tasks)\r\n\r\n\r\napplication = Starlette(\r\n middleware=[\r\n Middleware(BaseHTTPMiddleware, dispatch=passthrough),\r\n ],\r\n routes=[\r\n Route(\"/\", response_with_sleeps),\r\n ],\r\n)\r\n```\r\n2. Run that application using `uvicorn` (either uvloop or regular asyncio will reproduce the issue) on localhost:8000\r\n```bash\r\nuvicorn repro:application --port 8000\r\n```\r\n3. Run the following client script\r\n```python\r\n#!/usr/bin/env python\r\nimport socket\r\n\r\nconnection = socket.create_connection((\"localhost\", 8000))\r\nconnection.sendall(b\"GET / HTTP/1.1\\r\\nHost: localhost\\r\\n\\r\\n\")\r\nprint(connection.recv(10000).decode(\"utf8\"))\r\nconnection.close()\r\n```\r\n\n\n### Expected behavior\n\nThe client script gets the HTTP response, and both background tasks should complete successfully.\r\n\r\nThe expected behavior will be detectable by the following content in standard output:\r\n\r\n```\r\nbackground task 1 started\r\nbackground task 1 completed\r\nbackground task 2 started\r\nbackground task 2 completed\r\n```\n\n### Actual behavior\n\nBackground task 1 is interrupted at the `await` point and background task 2 is never started.\r\n\r\nThat results in the following content in the output (when running the `repro.py` application):\r\n```\r\nbackground task 1 started\r\nbackground task 1 error\r\nTraceback (most recent call last):\r\n File \"/Users/jean/PycharmProjects/starlette-bg-cancelled/./repro.py\", line 19, in _sleep\r\n await anyio.sleep(delay)\r\n File \"/Users/jean/PycharmProjects/starlette-bg-cancelled/venv/lib/python3.9/site-packages/anyio/_core/_eventloop.py\", line 69, in sleep\r\n return await get_asynclib().sleep(delay)\r\n File \"/usr/local/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/tasks.py\", line 654, in sleep\r\n return await future\r\nasyncio.exceptions.CancelledError\r\n```\n\n### Debugging material\n\n_No response_\n\n### Environment\n\n- MacOS 10.14.6 / Python 3.9 / Starlette 0.18.0\n\n### Additional context\n\n * When I remove the `passthrough` middleware, the bug goes away.\r\n * When I run the same application in `hypercorn`, the bug goes away.\r\n * There does not seem to be a difference between using `uvloop` or not.\r\n * If the client script (e.g. with a `time.sleep(10)`) maintains the TCP connection open, the bug goes away.\nShield send \"http.response.start\" from cancellation (BaseHTTPMiddleware)\nFixes #1634 \r\n- Discussion #1527 \r\n- Caused by #1157 \r\n\r\n`await recv_stream.receive()` will raise `anyio.EndOfStream` if request is disconnected, due to:\r\n- `task_group.cancel_scope.cancel()` in `StreamingResponse.__call__.<locals>.wrap` and\r\n- cancellation check in `await checkpoint()` of `MemoryObjectSendStream.send`,\r\n\r\nand then `RuntimeError: No response returned.` will be raised in `BaseHTTPMiddleware`.\r\n\r\nLet's shield send \"http.response.start\" from cancellation, since the message is ready to be sent to the receiver.\r\n\r\nThis is an alternative implementation of #1706 in `BaseHTTPMiddleware` instead of `StreamingResponse`.\r\nWe should not force the shielding in `StreamingResponse`, since the cancellation check is an intended feature of `MemoryObjectSendStream`. `BaseHTTPMiddleware`, which uses both, should be responsible for the compatibility.\n", "before_files": [{"content": "import typing\n\nimport anyio\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\n\n\nclass BaseHTTPMiddleware:\n def __init__(\n self, app: ASGIApp, dispatch: typing.Optional[DispatchFunction] = None\n ) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n async def call_next(request: Request) -> Response:\n app_exc: typing.Optional[Exception] = None\n send_stream, recv_stream = anyio.create_memory_object_stream()\n\n async def coro() -> None:\n nonlocal app_exc\n\n async with send_stream:\n try:\n await self.app(scope, request.receive, send_stream.send)\n except Exception as exc:\n app_exc = exc\n\n task_group.start_soon(coro)\n\n try:\n message = await recv_stream.receive()\n except anyio.EndOfStream:\n if app_exc is not None:\n raise app_exc\n raise RuntimeError(\"No response returned.\")\n\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n async with recv_stream:\n async for message in recv_stream:\n assert message[\"type\"] == \"http.response.body\"\n body = message.get(\"body\", b\"\")\n if body:\n yield body\n if not message.get(\"more_body\", False):\n break\n\n if app_exc is not None:\n raise app_exc\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async with anyio.create_task_group() as task_group:\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, call_next)\n await response(scope, receive, send)\n task_group.cancel_scope.cancel()\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}], "after_files": [{"content": "import typing\n\nimport anyio\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Message, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\nT = typing.TypeVar(\"T\")\n\n\nclass BaseHTTPMiddleware:\n def __init__(\n self, app: ASGIApp, dispatch: typing.Optional[DispatchFunction] = None\n ) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n response_sent = anyio.Event()\n\n async def call_next(request: Request) -> Response:\n app_exc: typing.Optional[Exception] = None\n send_stream, recv_stream = anyio.create_memory_object_stream()\n\n async def receive_or_disconnect() -> Message:\n if response_sent.is_set():\n return {\"type\": \"http.disconnect\"}\n\n async with anyio.create_task_group() as task_group:\n\n async def wrap(func: typing.Callable[[], typing.Awaitable[T]]) -> T:\n result = await func()\n task_group.cancel_scope.cancel()\n return result\n\n task_group.start_soon(wrap, response_sent.wait)\n message = await wrap(request.receive)\n\n if response_sent.is_set():\n return {\"type\": \"http.disconnect\"}\n\n return message\n\n async def close_recv_stream_on_response_sent() -> None:\n await response_sent.wait()\n recv_stream.close()\n\n async def send_no_error(message: Message) -> None:\n try:\n await send_stream.send(message)\n except anyio.BrokenResourceError:\n # recv_stream has been closed, i.e. response_sent has been set.\n return\n\n async def coro() -> None:\n nonlocal app_exc\n\n async with send_stream:\n try:\n await self.app(scope, receive_or_disconnect, send_no_error)\n except Exception as exc:\n app_exc = exc\n\n task_group.start_soon(close_recv_stream_on_response_sent)\n task_group.start_soon(coro)\n\n try:\n message = await recv_stream.receive()\n except anyio.EndOfStream:\n if app_exc is not None:\n raise app_exc\n raise RuntimeError(\"No response returned.\")\n\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n async with recv_stream:\n async for message in recv_stream:\n assert message[\"type\"] == \"http.response.body\"\n body = message.get(\"body\", b\"\")\n if body:\n yield body\n if not message.get(\"more_body\", False):\n break\n\n if app_exc is not None:\n raise app_exc\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async with anyio.create_task_group() as task_group:\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, call_next)\n await response(scope, receive, send)\n response_sent.set()\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}]}
| 2,057 | 623 |
gh_patches_debug_7549
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-3463
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`\n` and `,` transposed in notebook generation
**Describe the bug**
Following the tutorial, in the Jupyter notebook, the `ignored_columns` list has commas at the start of the line.
Probably just transpose [here](https://github.com/great-expectations/great_expectations/blob/c49e533c012c275a791fce09df207d2bd7126780/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py#L74-L77) to fix:
```diff
- f' "{column_name}"\n,' for column_name in self.validator.columns()
+ f' "{column_name}",\n' for column_name in self.validator.columns()
```
**To Reproduce**
Steps to reproduce the behavior:
1. Follow the tutorial.
2. In the jupyter notebook, notice the formatting for the `ignored_columns`.
**Expected behavior**
Generated code in notebooks should follow normal formatting conventions.
**Environment (please complete the following information):**
- Operating System: MacOS
- Great Expectations Version:
- superconductive/ge_tutorials @ 5db831a92af51f77dde19723a81a2cea92e2a756
- great-expectations==0.13.35
**Additional context**
Mentioned this when talking with Ortal on September 24: Might already be filed or handled somewhere else.
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py`
Content:
```
1 from typing import Any, Dict, List, Union
2
3 import nbformat
4
5 from great_expectations import DataContext
6 from great_expectations.core.batch import BatchRequest
7 from great_expectations.render.renderer.suite_edit_notebook_renderer import (
8 SuiteEditNotebookRenderer,
9 )
10
11
12 class SuiteProfileNotebookRenderer(SuiteEditNotebookRenderer):
13 def __init__(
14 self,
15 context: DataContext,
16 expectation_suite_name: str,
17 batch_request: Union[str, Dict[str, Union[str, int, Dict[str, Any]]]],
18 ):
19 super().__init__(context=context)
20
21 if batch_request is None:
22 batch_request = {}
23 self.batch_request = batch_request
24
25 self.validator = context.get_validator(
26 batch_request=BatchRequest(**batch_request),
27 expectation_suite_name=expectation_suite_name,
28 )
29
30 self.expectation_suite_name = self.validator.expectation_suite_name
31
32 # noinspection PyMethodOverriding
33 def add_header(self):
34 self.add_markdown_cell(
35 markdown=f"""# Initialize a new Expectation Suite by profiling a batch of your data.
36 This process helps you avoid writing lots of boilerplate when authoring suites by allowing you to select columns and other factors that you care about and letting a profiler write some candidate expectations for you to adjust.
37
38 **Expectation Suite Name**: `{self.expectation_suite_name}`
39 """
40 )
41 self.add_code_cell(
42 code=f"""\
43 import datetime
44
45 import pandas as pd
46
47 import great_expectations as ge
48 import great_expectations.jupyter_ux
49 from great_expectations.core.batch import BatchRequest
50 from great_expectations.profile.user_configurable_profiler import UserConfigurableProfiler
51 from great_expectations.checkpoint import SimpleCheckpoint
52 from great_expectations.exceptions import DataContextError
53
54 context = ge.data_context.DataContext()
55
56 batch_request = {self.batch_request}
57
58 expectation_suite_name = "{self.expectation_suite_name}"
59
60 validator = context.get_validator(
61 batch_request=BatchRequest(**batch_request),
62 expectation_suite_name=expectation_suite_name
63 )
64 column_names = [f'"{{column_name}}"' for column_name in validator.columns()]
65 print(f"Columns: {{', '.join(column_names)}}.")
66 validator.head(n_rows=5, fetch_all=False)
67 """,
68 lint=True,
69 )
70
71 def _add_available_columns_list(self):
72 column_names: List[str]
73 column_name: str
74 column_names = [
75 f' "{column_name}"\n,' for column_name in self.validator.columns()
76 ]
77 code: str = f'ignored_columns = [\n{"".join(column_names)}]'
78 self.add_code_cell(code=code, lint=True)
79
80 def add_footer(self):
81 self.add_markdown_cell(
82 markdown="""# Save & review your new Expectation Suite
83
84 Let's save the draft expectation suite as a JSON file in the
85 `great_expectations/expectations` directory of your project and rebuild the Data
86 Docs site to make it easy to review your new suite."""
87 )
88 code_cell: str = """\
89 print(validator.get_expectation_suite(discard_failed_expectations=False))
90 validator.save_expectation_suite(discard_failed_expectations=False)
91
92 checkpoint_config = {
93 "class_name": "SimpleCheckpoint",
94 "validations": [
95 {
96 "batch_request": batch_request,
97 "expectation_suite_name": expectation_suite_name
98 }
99 ]
100 }
101 checkpoint = SimpleCheckpoint(
102 f"_tmp_checkpoint_{expectation_suite_name}",
103 context,
104 **checkpoint_config
105 )
106 checkpoint_result = checkpoint.run()
107
108 context.build_data_docs()
109
110 validation_result_identifier = checkpoint_result.list_validation_result_identifiers()[0]
111 context.open_data_docs(resource_identifier=validation_result_identifier)
112 """
113 self.add_code_cell(code=code_cell, lint=True)
114 self.add_markdown_cell(
115 markdown=f"""## Next steps
116 After you review this initial Expectation Suite in Data Docs you
117 should edit this suite to make finer grained adjustments to the expectations.
118 This can be done by running `great_expectations suite edit {self.expectation_suite_name}`."""
119 )
120
121 # noinspection PyMethodOverriding
122 def render(self) -> nbformat.NotebookNode:
123 self._notebook = nbformat.v4.new_notebook()
124 self.add_header()
125 self.add_markdown_cell(
126 markdown="""# Select columns
127
128 Select the columns on which you would like to set expectations and those which you would like to ignore.
129
130 Great Expectations will choose which expectations might make sense for a column based on the **data type** and **cardinality** of the data in each selected column.
131
132 Simply comment out columns that are important and should be included. You can select multiple lines and
133 use a jupyter keyboard shortcut to toggle each line: **Linux/Windows**:
134 `Ctrl-/`, **macOS**: `Cmd-/`"""
135 )
136 self._add_available_columns_list()
137 self.add_markdown_cell(
138 markdown="""# Run the data profiler
139
140 The suites generated here are **not meant to be production suites** -- they are **a starting point to build upon**.
141
142 **To get to a production-grade suite, you will definitely want to [edit this
143 suite](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_edit_an_expectation_suite_using_a_disposable_notebook.html?utm_source=notebook&utm_medium=profile_based_expectations)
144 after this initial step gets you started on the path towards what you want.**
145
146 This is highly configurable depending on your goals.
147 You can ignore columns or exclude certain expectations, specify a threshold for creating value set expectations, or even specify semantic types for a given column.
148 You can find more information about [how to configure this profiler, including a list of the expectations that it uses, here.](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_create_an_expectation_suite_with_the_user_configurable_profiler.html)
149
150 """
151 )
152 self._add_profiler_cell()
153 self.add_footer()
154 return self._notebook
155
156 # noinspection PyMethodOverriding
157 def render_to_disk(self, notebook_file_path: str):
158 """
159 Render a notebook to disk from an expectation suite.
160 """
161 self.render()
162 self.write_notebook_to_disk(
163 notebook=self._notebook, notebook_file_path=notebook_file_path
164 )
165
166 def _add_profiler_cell(self):
167 self.add_code_cell(
168 code=f"""\
169 profiler = UserConfigurableProfiler(
170 profile_dataset=validator,
171 excluded_expectations=None,
172 ignored_columns=ignored_columns,
173 not_null_only=False,
174 primary_or_compound_key=False,
175 semantic_types_dict=None,
176 table_expectations_only=False,
177 value_set_threshold="MANY",
178 )
179 suite = profiler.build_suite()""",
180 lint=True,
181 )
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py b/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py
--- a/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py
+++ b/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py
@@ -72,7 +72,7 @@
column_names: List[str]
column_name: str
column_names = [
- f' "{column_name}"\n,' for column_name in self.validator.columns()
+ f' "{column_name}",\n' for column_name in self.validator.columns()
]
code: str = f'ignored_columns = [\n{"".join(column_names)}]'
self.add_code_cell(code=code, lint=True)
|
{"golden_diff": "diff --git a/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py b/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py\n--- a/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py\n+++ b/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py\n@@ -72,7 +72,7 @@\n column_names: List[str]\n column_name: str\n column_names = [\n- f' \"{column_name}\"\\n,' for column_name in self.validator.columns()\n+ f' \"{column_name}\",\\n' for column_name in self.validator.columns()\n ]\n code: str = f'ignored_columns = [\\n{\"\".join(column_names)}]'\n self.add_code_cell(code=code, lint=True)\n", "issue": "`\\n` and `,` transposed in notebook generation\n**Describe the bug**\r\nFollowing the tutorial, in the Jupyter notebook, the `ignored_columns` list has commas at the start of the line.\r\nProbably just transpose [here](https://github.com/great-expectations/great_expectations/blob/c49e533c012c275a791fce09df207d2bd7126780/great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py#L74-L77) to fix:\r\n\r\n```diff\r\n- f' \"{column_name}\"\\n,' for column_name in self.validator.columns()\r\n+ f' \"{column_name}\",\\n' for column_name in self.validator.columns()\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Follow the tutorial.\r\n2. In the jupyter notebook, notice the formatting for the `ignored_columns`.\r\n\r\n**Expected behavior**\r\nGenerated code in notebooks should follow normal formatting conventions.\r\n\r\n**Environment (please complete the following information):**\r\n - Operating System: MacOS\r\n - Great Expectations Version: \r\n - superconductive/ge_tutorials @ 5db831a92af51f77dde19723a81a2cea92e2a756\r\n - great-expectations==0.13.35\r\n\r\n**Additional context**\r\nMentioned this when talking with Ortal on September 24: Might already be filed or handled somewhere else.\r\n\r\n\nUse cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "from typing import Any, Dict, List, Union\n\nimport nbformat\n\nfrom great_expectations import DataContext\nfrom great_expectations.core.batch import BatchRequest\nfrom great_expectations.render.renderer.suite_edit_notebook_renderer import (\n SuiteEditNotebookRenderer,\n)\n\n\nclass SuiteProfileNotebookRenderer(SuiteEditNotebookRenderer):\n def __init__(\n self,\n context: DataContext,\n expectation_suite_name: str,\n batch_request: Union[str, Dict[str, Union[str, int, Dict[str, Any]]]],\n ):\n super().__init__(context=context)\n\n if batch_request is None:\n batch_request = {}\n self.batch_request = batch_request\n\n self.validator = context.get_validator(\n batch_request=BatchRequest(**batch_request),\n expectation_suite_name=expectation_suite_name,\n )\n\n self.expectation_suite_name = self.validator.expectation_suite_name\n\n # noinspection PyMethodOverriding\n def add_header(self):\n self.add_markdown_cell(\n markdown=f\"\"\"# Initialize a new Expectation Suite by profiling a batch of your data.\nThis process helps you avoid writing lots of boilerplate when authoring suites by allowing you to select columns and other factors that you care about and letting a profiler write some candidate expectations for you to adjust.\n\n**Expectation Suite Name**: `{self.expectation_suite_name}`\n\"\"\"\n )\n self.add_code_cell(\n code=f\"\"\"\\\nimport datetime\n\nimport pandas as pd\n\nimport great_expectations as ge\nimport great_expectations.jupyter_ux\nfrom great_expectations.core.batch import BatchRequest\nfrom great_expectations.profile.user_configurable_profiler import UserConfigurableProfiler\nfrom great_expectations.checkpoint import SimpleCheckpoint\nfrom great_expectations.exceptions import DataContextError\n\ncontext = ge.data_context.DataContext()\n\nbatch_request = {self.batch_request}\n\nexpectation_suite_name = \"{self.expectation_suite_name}\"\n\nvalidator = context.get_validator(\n batch_request=BatchRequest(**batch_request),\n expectation_suite_name=expectation_suite_name\n)\ncolumn_names = [f'\"{{column_name}}\"' for column_name in validator.columns()]\nprint(f\"Columns: {{', '.join(column_names)}}.\")\nvalidator.head(n_rows=5, fetch_all=False)\n\"\"\",\n lint=True,\n )\n\n def _add_available_columns_list(self):\n column_names: List[str]\n column_name: str\n column_names = [\n f' \"{column_name}\"\\n,' for column_name in self.validator.columns()\n ]\n code: str = f'ignored_columns = [\\n{\"\".join(column_names)}]'\n self.add_code_cell(code=code, lint=True)\n\n def add_footer(self):\n self.add_markdown_cell(\n markdown=\"\"\"# Save & review your new Expectation Suite\n\nLet's save the draft expectation suite as a JSON file in the\n`great_expectations/expectations` directory of your project and rebuild the Data\n Docs site to make it easy to review your new suite.\"\"\"\n )\n code_cell: str = \"\"\"\\\nprint(validator.get_expectation_suite(discard_failed_expectations=False))\nvalidator.save_expectation_suite(discard_failed_expectations=False)\n\ncheckpoint_config = {\n \"class_name\": \"SimpleCheckpoint\",\n \"validations\": [\n {\n \"batch_request\": batch_request,\n \"expectation_suite_name\": expectation_suite_name\n }\n ]\n}\ncheckpoint = SimpleCheckpoint(\n f\"_tmp_checkpoint_{expectation_suite_name}\",\n context,\n **checkpoint_config\n)\ncheckpoint_result = checkpoint.run()\n\ncontext.build_data_docs()\n\nvalidation_result_identifier = checkpoint_result.list_validation_result_identifiers()[0]\ncontext.open_data_docs(resource_identifier=validation_result_identifier)\n\"\"\"\n self.add_code_cell(code=code_cell, lint=True)\n self.add_markdown_cell(\n markdown=f\"\"\"## Next steps\nAfter you review this initial Expectation Suite in Data Docs you\nshould edit this suite to make finer grained adjustments to the expectations.\nThis can be done by running `great_expectations suite edit {self.expectation_suite_name}`.\"\"\"\n )\n\n # noinspection PyMethodOverriding\n def render(self) -> nbformat.NotebookNode:\n self._notebook = nbformat.v4.new_notebook()\n self.add_header()\n self.add_markdown_cell(\n markdown=\"\"\"# Select columns\n\nSelect the columns on which you would like to set expectations and those which you would like to ignore.\n\nGreat Expectations will choose which expectations might make sense for a column based on the **data type** and **cardinality** of the data in each selected column.\n\nSimply comment out columns that are important and should be included. You can select multiple lines and\nuse a jupyter keyboard shortcut to toggle each line: **Linux/Windows**:\n`Ctrl-/`, **macOS**: `Cmd-/`\"\"\"\n )\n self._add_available_columns_list()\n self.add_markdown_cell(\n markdown=\"\"\"# Run the data profiler\n\nThe suites generated here are **not meant to be production suites** -- they are **a starting point to build upon**.\n\n**To get to a production-grade suite, you will definitely want to [edit this\nsuite](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_edit_an_expectation_suite_using_a_disposable_notebook.html?utm_source=notebook&utm_medium=profile_based_expectations)\nafter this initial step gets you started on the path towards what you want.**\n\nThis is highly configurable depending on your goals.\nYou can ignore columns or exclude certain expectations, specify a threshold for creating value set expectations, or even specify semantic types for a given column.\nYou can find more information about [how to configure this profiler, including a list of the expectations that it uses, here.](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_create_an_expectation_suite_with_the_user_configurable_profiler.html)\n\n\"\"\"\n )\n self._add_profiler_cell()\n self.add_footer()\n return self._notebook\n\n # noinspection PyMethodOverriding\n def render_to_disk(self, notebook_file_path: str):\n \"\"\"\n Render a notebook to disk from an expectation suite.\n \"\"\"\n self.render()\n self.write_notebook_to_disk(\n notebook=self._notebook, notebook_file_path=notebook_file_path\n )\n\n def _add_profiler_cell(self):\n self.add_code_cell(\n code=f\"\"\"\\\nprofiler = UserConfigurableProfiler(\n profile_dataset=validator,\n excluded_expectations=None,\n ignored_columns=ignored_columns,\n not_null_only=False,\n primary_or_compound_key=False,\n semantic_types_dict=None,\n table_expectations_only=False,\n value_set_threshold=\"MANY\",\n)\nsuite = profiler.build_suite()\"\"\",\n lint=True,\n )\n", "path": "great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py"}], "after_files": [{"content": "from typing import Any, Dict, List, Union\n\nimport nbformat\n\nfrom great_expectations import DataContext\nfrom great_expectations.core.batch import BatchRequest\nfrom great_expectations.render.renderer.suite_edit_notebook_renderer import (\n SuiteEditNotebookRenderer,\n)\n\n\nclass SuiteProfileNotebookRenderer(SuiteEditNotebookRenderer):\n def __init__(\n self,\n context: DataContext,\n expectation_suite_name: str,\n batch_request: Union[str, Dict[str, Union[str, int, Dict[str, Any]]]],\n ):\n super().__init__(context=context)\n\n if batch_request is None:\n batch_request = {}\n self.batch_request = batch_request\n\n self.validator = context.get_validator(\n batch_request=BatchRequest(**batch_request),\n expectation_suite_name=expectation_suite_name,\n )\n\n self.expectation_suite_name = self.validator.expectation_suite_name\n\n # noinspection PyMethodOverriding\n def add_header(self):\n self.add_markdown_cell(\n markdown=f\"\"\"# Initialize a new Expectation Suite by profiling a batch of your data.\nThis process helps you avoid writing lots of boilerplate when authoring suites by allowing you to select columns and other factors that you care about and letting a profiler write some candidate expectations for you to adjust.\n\n**Expectation Suite Name**: `{self.expectation_suite_name}`\n\"\"\"\n )\n self.add_code_cell(\n code=f\"\"\"\\\nimport datetime\n\nimport pandas as pd\n\nimport great_expectations as ge\nimport great_expectations.jupyter_ux\nfrom great_expectations.core.batch import BatchRequest\nfrom great_expectations.profile.user_configurable_profiler import UserConfigurableProfiler\nfrom great_expectations.checkpoint import SimpleCheckpoint\nfrom great_expectations.exceptions import DataContextError\n\ncontext = ge.data_context.DataContext()\n\nbatch_request = {self.batch_request}\n\nexpectation_suite_name = \"{self.expectation_suite_name}\"\n\nvalidator = context.get_validator(\n batch_request=BatchRequest(**batch_request),\n expectation_suite_name=expectation_suite_name\n)\ncolumn_names = [f'\"{{column_name}}\"' for column_name in validator.columns()]\nprint(f\"Columns: {{', '.join(column_names)}}.\")\nvalidator.head(n_rows=5, fetch_all=False)\n\"\"\",\n lint=True,\n )\n\n def _add_available_columns_list(self):\n column_names: List[str]\n column_name: str\n column_names = [\n f' \"{column_name}\",\\n' for column_name in self.validator.columns()\n ]\n code: str = f'ignored_columns = [\\n{\"\".join(column_names)}]'\n self.add_code_cell(code=code, lint=True)\n\n def add_footer(self):\n self.add_markdown_cell(\n markdown=\"\"\"# Save & review your new Expectation Suite\n\nLet's save the draft expectation suite as a JSON file in the\n`great_expectations/expectations` directory of your project and rebuild the Data\n Docs site to make it easy to review your new suite.\"\"\"\n )\n code_cell: str = \"\"\"\\\nprint(validator.get_expectation_suite(discard_failed_expectations=False))\nvalidator.save_expectation_suite(discard_failed_expectations=False)\n\ncheckpoint_config = {\n \"class_name\": \"SimpleCheckpoint\",\n \"validations\": [\n {\n \"batch_request\": batch_request,\n \"expectation_suite_name\": expectation_suite_name\n }\n ]\n}\ncheckpoint = SimpleCheckpoint(\n f\"_tmp_checkpoint_{expectation_suite_name}\",\n context,\n **checkpoint_config\n)\ncheckpoint_result = checkpoint.run()\n\ncontext.build_data_docs()\n\nvalidation_result_identifier = checkpoint_result.list_validation_result_identifiers()[0]\ncontext.open_data_docs(resource_identifier=validation_result_identifier)\n\"\"\"\n self.add_code_cell(code=code_cell, lint=True)\n self.add_markdown_cell(\n markdown=f\"\"\"## Next steps\nAfter you review this initial Expectation Suite in Data Docs you\nshould edit this suite to make finer grained adjustments to the expectations.\nThis can be done by running `great_expectations suite edit {self.expectation_suite_name}`.\"\"\"\n )\n\n # noinspection PyMethodOverriding\n def render(self) -> nbformat.NotebookNode:\n self._notebook = nbformat.v4.new_notebook()\n self.add_header()\n self.add_markdown_cell(\n markdown=\"\"\"# Select columns\n\nSelect the columns on which you would like to set expectations and those which you would like to ignore.\n\nGreat Expectations will choose which expectations might make sense for a column based on the **data type** and **cardinality** of the data in each selected column.\n\nSimply comment out columns that are important and should be included. You can select multiple lines and\nuse a jupyter keyboard shortcut to toggle each line: **Linux/Windows**:\n`Ctrl-/`, **macOS**: `Cmd-/`\"\"\"\n )\n self._add_available_columns_list()\n self.add_markdown_cell(\n markdown=\"\"\"# Run the data profiler\n\nThe suites generated here are **not meant to be production suites** -- they are **a starting point to build upon**.\n\n**To get to a production-grade suite, you will definitely want to [edit this\nsuite](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_edit_an_expectation_suite_using_a_disposable_notebook.html?utm_source=notebook&utm_medium=profile_based_expectations)\nafter this initial step gets you started on the path towards what you want.**\n\nThis is highly configurable depending on your goals.\nYou can ignore columns or exclude certain expectations, specify a threshold for creating value set expectations, or even specify semantic types for a given column.\nYou can find more information about [how to configure this profiler, including a list of the expectations that it uses, here.](https://docs.greatexpectations.io/en/latest/guides/how_to_guides/creating_and_editing_expectations/how_to_create_an_expectation_suite_with_the_user_configurable_profiler.html)\n\n\"\"\"\n )\n self._add_profiler_cell()\n self.add_footer()\n return self._notebook\n\n # noinspection PyMethodOverriding\n def render_to_disk(self, notebook_file_path: str):\n \"\"\"\n Render a notebook to disk from an expectation suite.\n \"\"\"\n self.render()\n self.write_notebook_to_disk(\n notebook=self._notebook, notebook_file_path=notebook_file_path\n )\n\n def _add_profiler_cell(self):\n self.add_code_cell(\n code=f\"\"\"\\\nprofiler = UserConfigurableProfiler(\n profile_dataset=validator,\n excluded_expectations=None,\n ignored_columns=ignored_columns,\n not_null_only=False,\n primary_or_compound_key=False,\n semantic_types_dict=None,\n table_expectations_only=False,\n value_set_threshold=\"MANY\",\n)\nsuite = profiler.build_suite()\"\"\",\n lint=True,\n )\n", "path": "great_expectations/render/renderer/v3/suite_profile_notebook_renderer.py"}]}
| 2,512 | 175 |
gh_patches_debug_14974
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Demo world_map.py does not work on python 2
**Problem Description**
urllib.request deprecated in Python 2
**Reproduction Steps:**
Run world_map.py
**Expected behavior:**
Traceback (most recent call last):
File "world_map.py", line 15, in <module>
import urllib.request, urllib.parse, urllib.error
ImportError: No module named request
**OS, Python version:** [Enter OS name and Python version]
OSX, Python 2.7
xref: #385
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/demo/world_map.py`
Content:
```
1 #!/usr/bin/env python
2 """
3 Displays a world map with locations plotted on top. Locations are expected to
4 be tuples of latitude, longitude where West and South are expressed as
5 negative values.
6 - Mousewheel up and down zooms the plot in and out.
7 - Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular
8 region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow
9 and alt-right-arrow moves you forwards and backwards through the "zoom
10 history".
11 """
12
13 # Standard library imports
14 import os.path
15 import urllib.request, urllib.parse, urllib.error
16
17 # Major library imports
18 import numpy
19
20 # ETS imports
21 from chaco.api import Plot, ArrayPlotData, ImageData
22 from chaco.tools.api import ZoomTool
23 from enable.component_editor import ComponentEditor
24 from traits.api import HasTraits, Instance, Str
25 from traitsui.api import Item, View
26
27 class WorldMapPlot(HasTraits):
28
29 ### Public Traits ##########################################################
30
31 # The plot which will be displayed
32 plot = Instance(Plot)
33
34 # The URL which points to the world map image to be downloaded
35 image_url = Str("http://eoimages.gsfc.nasa.gov/ve//2433/land_shallow_topo_2048.jpg")
36
37
38 ### Private Traits #########################################################
39
40 # The path to where the image exists on the filesystem
41 image_path = Str()
42
43 # The view
44 traits_view = View(Item('plot', editor=ComponentEditor(),
45 width=800, height=400, show_label=False),
46 resizable=True)
47
48 #---------------------------------------------------------------------------
49 # Public interface
50 #---------------------------------------------------------------------------
51
52 def __init__(self, **kw):
53 super(WorldMapPlot, self).__init__(**kw)
54
55 self._download_map_image()
56 image = ImageData.fromfile(self.image_path)
57
58 # For now, the locations are hardcoded, though this can be changed
59 # eassily to take command line args, read from a file, or by other
60 # means
61 austin_loc = (30.16, -97.44)
62
63 locations_x = numpy.array([austin_loc[1]])
64 locations_y = numpy.array([austin_loc[0]])
65
66 # transform each of the locations to the image data space, including
67 # moving the origin from bottom left to top left
68 locations_x = (locations_x + 180) * image.data.shape[1]/360
69 locations_y = (locations_y*-1 + 90) * image.data.shape[0]/180
70
71 # Create the plott data, adding the image and the locations
72 plot_data = ArrayPlotData()
73 plot_data.set_data("imagedata", image._data)
74 plot_data.set_data("locations_x", locations_x)
75 plot_data.set_data("locations_y", locations_y)
76
77 # Create the plot with the origin as top left, which matches
78 # how the image data is aligned
79 self.plot = Plot(plot_data, default_origin="top left")
80 self.plot.img_plot('imagedata')
81
82 # Plot the locations as a scatter plot to be overlayed on top
83 # of the map
84 loc_plot = self.plot.plot(('locations_x', 'locations_y'),
85 type='scatter', size=3, color='yellow',
86 marker='dot')[0]
87
88 loc_plot.x_mapper.range.high = image.data.shape[1]
89 loc_plot.x_mapper.range.low = 0
90 loc_plot.y_mapper.range.high = image.data.shape[0]
91 loc_plot.y_mapper.range.low = -0
92
93 # set up any tools, in this case just the zoom tool
94 zoom = ZoomTool(component=self.plot, tool_mode="box", always_on=False)
95 self.plot.overlays.append(zoom)
96
97 #---------------------------------------------------------------------------
98 # Protected interface
99 #---------------------------------------------------------------------------
100
101 def _download_map_image(self):
102 """ Downloads a map from the image_url attribute. This is done
103 primarily to keep the redistributable Chaco package as small
104 as possible
105 """
106 example_dir = os.path.dirname(__file__)
107 self.image_path = os.path.join(example_dir, 'data',
108 os.path.split(self.image_url)[1])
109
110 if not os.path.exists(self.image_path):
111 print("Downloading map image")
112 urllib.request.urlretrieve(self.image_url, self.image_path)
113
114 #===============================================================================
115 # demo object that is used by the demo.py application.
116 #===============================================================================
117 demo = WorldMapPlot()
118
119 if __name__ == "__main__":
120 demo.configure_traits()
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/demo/world_map.py b/examples/demo/world_map.py
--- a/examples/demo/world_map.py
+++ b/examples/demo/world_map.py
@@ -12,7 +12,7 @@
# Standard library imports
import os.path
-import urllib.request, urllib.parse, urllib.error
+from six.moves.urllib import request
# Major library imports
import numpy
@@ -109,7 +109,7 @@
if not os.path.exists(self.image_path):
print("Downloading map image")
- urllib.request.urlretrieve(self.image_url, self.image_path)
+ request.urlretrieve(self.image_url, self.image_path)
#===============================================================================
# demo object that is used by the demo.py application.
|
{"golden_diff": "diff --git a/examples/demo/world_map.py b/examples/demo/world_map.py\n--- a/examples/demo/world_map.py\n+++ b/examples/demo/world_map.py\n@@ -12,7 +12,7 @@\n \n # Standard library imports\n import os.path\n-import urllib.request, urllib.parse, urllib.error\n+from six.moves.urllib import request\n \n # Major library imports\n import numpy\n@@ -109,7 +109,7 @@\n \n if not os.path.exists(self.image_path):\n print(\"Downloading map image\")\n- urllib.request.urlretrieve(self.image_url, self.image_path)\n+ request.urlretrieve(self.image_url, self.image_path)\n \n #===============================================================================\n # demo object that is used by the demo.py application.\n", "issue": "Demo world_map.py does not work on python 2\n**Problem Description**\r\nurllib.request deprecated in Python 2\r\n**Reproduction Steps:**\r\nRun world_map.py\r\n\r\n**Expected behavior:**\r\n\r\nTraceback (most recent call last):\r\n File \"world_map.py\", line 15, in <module>\r\n import urllib.request, urllib.parse, urllib.error\r\nImportError: No module named request\r\n\r\n**OS, Python version:** [Enter OS name and Python version]\r\nOSX, Python 2.7\r\n\r\nxref: #385\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nDisplays a world map with locations plotted on top. Locations are expected to\nbe tuples of latitude, longitude where West and South are expressed as\nnegative values.\n - Mousewheel up and down zooms the plot in and out.\n - Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular\n region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow\n and alt-right-arrow moves you forwards and backwards through the \"zoom\n history\".\n\"\"\"\n\n# Standard library imports\nimport os.path\nimport urllib.request, urllib.parse, urllib.error\n\n# Major library imports\nimport numpy\n\n# ETS imports\nfrom chaco.api import Plot, ArrayPlotData, ImageData\nfrom chaco.tools.api import ZoomTool\nfrom enable.component_editor import ComponentEditor\nfrom traits.api import HasTraits, Instance, Str\nfrom traitsui.api import Item, View\n\nclass WorldMapPlot(HasTraits):\n\n ### Public Traits ##########################################################\n\n # The plot which will be displayed\n plot = Instance(Plot)\n\n # The URL which points to the world map image to be downloaded\n image_url = Str(\"http://eoimages.gsfc.nasa.gov/ve//2433/land_shallow_topo_2048.jpg\")\n\n\n ### Private Traits #########################################################\n\n # The path to where the image exists on the filesystem\n image_path = Str()\n\n # The view\n traits_view = View(Item('plot', editor=ComponentEditor(),\n width=800, height=400, show_label=False),\n resizable=True)\n\n #---------------------------------------------------------------------------\n # Public interface\n #---------------------------------------------------------------------------\n\n def __init__(self, **kw):\n super(WorldMapPlot, self).__init__(**kw)\n\n self._download_map_image()\n image = ImageData.fromfile(self.image_path)\n\n # For now, the locations are hardcoded, though this can be changed\n # eassily to take command line args, read from a file, or by other\n # means\n austin_loc = (30.16, -97.44)\n\n locations_x = numpy.array([austin_loc[1]])\n locations_y = numpy.array([austin_loc[0]])\n\n # transform each of the locations to the image data space, including\n # moving the origin from bottom left to top left\n locations_x = (locations_x + 180) * image.data.shape[1]/360\n locations_y = (locations_y*-1 + 90) * image.data.shape[0]/180\n\n # Create the plott data, adding the image and the locations\n plot_data = ArrayPlotData()\n plot_data.set_data(\"imagedata\", image._data)\n plot_data.set_data(\"locations_x\", locations_x)\n plot_data.set_data(\"locations_y\", locations_y)\n\n # Create the plot with the origin as top left, which matches\n # how the image data is aligned\n self.plot = Plot(plot_data, default_origin=\"top left\")\n self.plot.img_plot('imagedata')\n\n # Plot the locations as a scatter plot to be overlayed on top\n # of the map\n loc_plot = self.plot.plot(('locations_x', 'locations_y'),\n type='scatter', size=3, color='yellow',\n marker='dot')[0]\n\n loc_plot.x_mapper.range.high = image.data.shape[1]\n loc_plot.x_mapper.range.low = 0\n loc_plot.y_mapper.range.high = image.data.shape[0]\n loc_plot.y_mapper.range.low = -0\n\n # set up any tools, in this case just the zoom tool\n zoom = ZoomTool(component=self.plot, tool_mode=\"box\", always_on=False)\n self.plot.overlays.append(zoom)\n\n #---------------------------------------------------------------------------\n # Protected interface\n #---------------------------------------------------------------------------\n\n def _download_map_image(self):\n \"\"\" Downloads a map from the image_url attribute. This is done\n primarily to keep the redistributable Chaco package as small\n as possible\n \"\"\"\n example_dir = os.path.dirname(__file__)\n self.image_path = os.path.join(example_dir, 'data',\n os.path.split(self.image_url)[1])\n\n if not os.path.exists(self.image_path):\n print(\"Downloading map image\")\n urllib.request.urlretrieve(self.image_url, self.image_path)\n\n#===============================================================================\n# demo object that is used by the demo.py application.\n#===============================================================================\ndemo = WorldMapPlot()\n\nif __name__ == \"__main__\":\n demo.configure_traits()\n", "path": "examples/demo/world_map.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nDisplays a world map with locations plotted on top. Locations are expected to\nbe tuples of latitude, longitude where West and South are expressed as\nnegative values.\n - Mousewheel up and down zooms the plot in and out.\n - Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular\n region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow\n and alt-right-arrow moves you forwards and backwards through the \"zoom\n history\".\n\"\"\"\n\n# Standard library imports\nimport os.path\nfrom six.moves.urllib import request\n\n# Major library imports\nimport numpy\n\n# ETS imports\nfrom chaco.api import Plot, ArrayPlotData, ImageData\nfrom chaco.tools.api import ZoomTool\nfrom enable.component_editor import ComponentEditor\nfrom traits.api import HasTraits, Instance, Str\nfrom traitsui.api import Item, View\n\nclass WorldMapPlot(HasTraits):\n\n ### Public Traits ##########################################################\n\n # The plot which will be displayed\n plot = Instance(Plot)\n\n # The URL which points to the world map image to be downloaded\n image_url = Str(\"http://eoimages.gsfc.nasa.gov/ve//2433/land_shallow_topo_2048.jpg\")\n\n\n ### Private Traits #########################################################\n\n # The path to where the image exists on the filesystem\n image_path = Str()\n\n # The view\n traits_view = View(Item('plot', editor=ComponentEditor(),\n width=800, height=400, show_label=False),\n resizable=True)\n\n #---------------------------------------------------------------------------\n # Public interface\n #---------------------------------------------------------------------------\n\n def __init__(self, **kw):\n super(WorldMapPlot, self).__init__(**kw)\n\n self._download_map_image()\n image = ImageData.fromfile(self.image_path)\n\n # For now, the locations are hardcoded, though this can be changed\n # eassily to take command line args, read from a file, or by other\n # means\n austin_loc = (30.16, -97.44)\n\n locations_x = numpy.array([austin_loc[1]])\n locations_y = numpy.array([austin_loc[0]])\n\n # transform each of the locations to the image data space, including\n # moving the origin from bottom left to top left\n locations_x = (locations_x + 180) * image.data.shape[1]/360\n locations_y = (locations_y*-1 + 90) * image.data.shape[0]/180\n\n # Create the plott data, adding the image and the locations\n plot_data = ArrayPlotData()\n plot_data.set_data(\"imagedata\", image._data)\n plot_data.set_data(\"locations_x\", locations_x)\n plot_data.set_data(\"locations_y\", locations_y)\n\n # Create the plot with the origin as top left, which matches\n # how the image data is aligned\n self.plot = Plot(plot_data, default_origin=\"top left\")\n self.plot.img_plot('imagedata')\n\n # Plot the locations as a scatter plot to be overlayed on top\n # of the map\n loc_plot = self.plot.plot(('locations_x', 'locations_y'),\n type='scatter', size=3, color='yellow',\n marker='dot')[0]\n\n loc_plot.x_mapper.range.high = image.data.shape[1]\n loc_plot.x_mapper.range.low = 0\n loc_plot.y_mapper.range.high = image.data.shape[0]\n loc_plot.y_mapper.range.low = -0\n\n # set up any tools, in this case just the zoom tool\n zoom = ZoomTool(component=self.plot, tool_mode=\"box\", always_on=False)\n self.plot.overlays.append(zoom)\n\n #---------------------------------------------------------------------------\n # Protected interface\n #---------------------------------------------------------------------------\n\n def _download_map_image(self):\n \"\"\" Downloads a map from the image_url attribute. This is done\n primarily to keep the redistributable Chaco package as small\n as possible\n \"\"\"\n example_dir = os.path.dirname(__file__)\n self.image_path = os.path.join(example_dir, 'data',\n os.path.split(self.image_url)[1])\n\n if not os.path.exists(self.image_path):\n print(\"Downloading map image\")\n request.urlretrieve(self.image_url, self.image_path)\n\n#===============================================================================\n# demo object that is used by the demo.py application.\n#===============================================================================\ndemo = WorldMapPlot()\n\nif __name__ == \"__main__\":\n demo.configure_traits()\n", "path": "examples/demo/world_map.py"}]}
| 1,631 | 156 |
gh_patches_debug_28762
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-9057
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tune] sync_on_checkpoint ignored when list of experiments passed to tune.run
### What is the problem?
When passing a list of predefined Experiments to tune via the `run` function, the `sync_on_checkpoint` flag is ignored.
**Reason for this behaviour:**
The `make_parser` function takes in `no_sync_on_checkpoint`; it's set to False by default.
https://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L75-L77
The create_trial_from_spec function gets a `sync_on_checkpoint` from the Experiment spec, but that key is never used by the parser. So the following line makes the `sync_on_checkpoint` of the returned `Trial` object `True` by default, thus ignoring the value of `sync_on_checkpoint` in the incoming Experiment spec.
https://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L185
*Ray Version: All versions starting from 0.7.7 when the feature was released.*
### Reproduction (REQUIRED)
```python3
import ray
from ray import tune
from ray.tune import Experiment
def func(config):
pass
sync_true_obj = Experiment("test_sync", func, sync_on_checkpoint=True)
sync_false_obj = Experiment("test_sync", func, sync_on_checkpoint=False)
ls = [sync_true_obj, sync_false_obj]
ray.init(local_mode=True)
analysis = tune.run(ls)
```
To check the error, add the following lines just before the `return Trial(` line in `config_parser.py`
```python3
print(args)
print(args.no_sync_on_checkpoint)
```
https://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L173
- [x] I have verified my script runs in a clean environment and reproduces the issue.
- [x] I have verified the issue also occurs with the [latest wheels](https://docs.ray.io/en/latest/installation.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/tune/config_parser.py`
Content:
```
1 import argparse
2 import json
3 import os
4
5 # For compatibility under py2 to consider unicode as str
6 from six import string_types
7
8 from ray.tune import TuneError
9 from ray.tune.trial import Trial
10 from ray.tune.resources import json_to_resources
11 from ray.tune.logger import _SafeFallbackEncoder
12
13
14 def make_parser(parser_creator=None, **kwargs):
15 """Returns a base argument parser for the ray.tune tool.
16
17 Args:
18 parser_creator: A constructor for the parser class.
19 kwargs: Non-positional args to be passed into the
20 parser class constructor.
21 """
22
23 if parser_creator:
24 parser = parser_creator(**kwargs)
25 else:
26 parser = argparse.ArgumentParser(**kwargs)
27
28 # Note: keep this in sync with rllib/train.py
29 parser.add_argument(
30 "--run",
31 default=None,
32 type=str,
33 help="The algorithm or model to train. This may refer to the name "
34 "of a built-on algorithm (e.g. RLLib's DQN or PPO), or a "
35 "user-defined trainable function or class registered in the "
36 "tune registry.")
37 parser.add_argument(
38 "--stop",
39 default="{}",
40 type=json.loads,
41 help="The stopping criteria, specified in JSON. The keys may be any "
42 "field returned by 'train()' e.g. "
43 "'{\"time_total_s\": 600, \"training_iteration\": 100000}' to stop "
44 "after 600 seconds or 100k iterations, whichever is reached first.")
45 parser.add_argument(
46 "--config",
47 default="{}",
48 type=json.loads,
49 help="Algorithm-specific configuration (e.g. env, hyperparams), "
50 "specified in JSON.")
51 parser.add_argument(
52 "--resources-per-trial",
53 default=None,
54 type=json_to_resources,
55 help="Override the machine resources to allocate per trial, e.g. "
56 "'{\"cpu\": 64, \"gpu\": 8}'. Note that GPUs will not be assigned "
57 "unless you specify them here. For RLlib, you probably want to "
58 "leave this alone and use RLlib configs to control parallelism.")
59 parser.add_argument(
60 "--num-samples",
61 default=1,
62 type=int,
63 help="Number of times to repeat each trial.")
64 parser.add_argument(
65 "--checkpoint-freq",
66 default=0,
67 type=int,
68 help="How many training iterations between checkpoints. "
69 "A value of 0 (default) disables checkpointing.")
70 parser.add_argument(
71 "--checkpoint-at-end",
72 action="store_true",
73 help="Whether to checkpoint at the end of the experiment. "
74 "Default is False.")
75 parser.add_argument(
76 "--no-sync-on-checkpoint",
77 action="store_true",
78 help="Disable sync-down of trial checkpoint, which is enabled by "
79 "default to guarantee recoverability. If set, checkpoint syncing from "
80 "worker to driver is asynchronous. Set this only if synchronous "
81 "checkpointing is too slow and trial restoration failures can be "
82 "tolerated")
83 parser.add_argument(
84 "--keep-checkpoints-num",
85 default=None,
86 type=int,
87 help="Number of best checkpoints to keep. Others get "
88 "deleted. Default (None) keeps all checkpoints.")
89 parser.add_argument(
90 "--checkpoint-score-attr",
91 default="training_iteration",
92 type=str,
93 help="Specifies by which attribute to rank the best checkpoint. "
94 "Default is increasing order. If attribute starts with min- it "
95 "will rank attribute in decreasing order. Example: "
96 "min-validation_loss")
97 parser.add_argument(
98 "--export-formats",
99 default=None,
100 help="List of formats that exported at the end of the experiment. "
101 "Default is None. For RLlib, 'checkpoint' and 'model' are "
102 "supported for TensorFlow policy graphs.")
103 parser.add_argument(
104 "--max-failures",
105 default=3,
106 type=int,
107 help="Try to recover a trial from its last checkpoint at least this "
108 "many times. Only applies if checkpointing is enabled.")
109 parser.add_argument(
110 "--scheduler",
111 default="FIFO",
112 type=str,
113 help="FIFO (default), MedianStopping, AsyncHyperBand, "
114 "HyperBand, or HyperOpt.")
115 parser.add_argument(
116 "--scheduler-config",
117 default="{}",
118 type=json.loads,
119 help="Config options to pass to the scheduler.")
120
121 # Note: this currently only makes sense when running a single trial
122 parser.add_argument(
123 "--restore",
124 default=None,
125 type=str,
126 help="If specified, restore from this checkpoint.")
127
128 return parser
129
130
131 def to_argv(config):
132 """Converts configuration to a command line argument format."""
133 argv = []
134 for k, v in config.items():
135 if "-" in k:
136 raise ValueError("Use '_' instead of '-' in `{}`".format(k))
137 if v is None:
138 continue
139 if not isinstance(v, bool) or v: # for argparse flags
140 argv.append("--{}".format(k.replace("_", "-")))
141 if isinstance(v, string_types):
142 argv.append(v)
143 elif isinstance(v, bool):
144 pass
145 else:
146 argv.append(json.dumps(v, cls=_SafeFallbackEncoder))
147 return argv
148
149
150 def create_trial_from_spec(spec, output_path, parser, **trial_kwargs):
151 """Creates a Trial object from parsing the spec.
152
153 Arguments:
154 spec (dict): A resolved experiment specification. Arguments should
155 The args here should correspond to the command line flags
156 in ray.tune.config_parser.
157 output_path (str); A specific output path within the local_dir.
158 Typically the name of the experiment.
159 parser (ArgumentParser): An argument parser object from
160 make_parser.
161 trial_kwargs: Extra keyword arguments used in instantiating the Trial.
162
163 Returns:
164 A trial object with corresponding parameters to the specification.
165 """
166 try:
167 args, _ = parser.parse_known_args(to_argv(spec))
168 except SystemExit:
169 raise TuneError("Error parsing args, see above message", spec)
170 if "resources_per_trial" in spec:
171 trial_kwargs["resources"] = json_to_resources(
172 spec["resources_per_trial"])
173 return Trial(
174 # Submitting trial via server in py2.7 creates Unicode, which does not
175 # convert to string in a straightforward manner.
176 trainable_name=spec["run"],
177 # json.load leads to str -> unicode in py2.7
178 config=spec.get("config", {}),
179 local_dir=os.path.join(spec["local_dir"], output_path),
180 # json.load leads to str -> unicode in py2.7
181 stopping_criterion=spec.get("stop", {}),
182 remote_checkpoint_dir=spec.get("remote_checkpoint_dir"),
183 checkpoint_freq=args.checkpoint_freq,
184 checkpoint_at_end=args.checkpoint_at_end,
185 sync_on_checkpoint=not args.no_sync_on_checkpoint,
186 keep_checkpoints_num=args.keep_checkpoints_num,
187 checkpoint_score_attr=args.checkpoint_score_attr,
188 export_formats=spec.get("export_formats", []),
189 # str(None) doesn't create None
190 restore_path=spec.get("restore"),
191 trial_name_creator=spec.get("trial_name_creator"),
192 loggers=spec.get("loggers"),
193 # str(None) doesn't create None
194 sync_to_driver_fn=spec.get("sync_to_driver"),
195 max_failures=args.max_failures,
196 **trial_kwargs)
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/ray/tune/config_parser.py b/python/ray/tune/config_parser.py
--- a/python/ray/tune/config_parser.py
+++ b/python/ray/tune/config_parser.py
@@ -73,13 +73,13 @@
help="Whether to checkpoint at the end of the experiment. "
"Default is False.")
parser.add_argument(
- "--no-sync-on-checkpoint",
+ "--sync-on-checkpoint",
action="store_true",
- help="Disable sync-down of trial checkpoint, which is enabled by "
- "default to guarantee recoverability. If set, checkpoint syncing from "
- "worker to driver is asynchronous. Set this only if synchronous "
- "checkpointing is too slow and trial restoration failures can be "
- "tolerated")
+ help="Enable sync-down of trial checkpoint to guarantee "
+ "recoverability. If unset, checkpoint syncing from worker "
+ "to driver is asynchronous, so unset this only if synchronous "
+ "checkpointing is too slow and trial restoration failures "
+ "can be tolerated.")
parser.add_argument(
"--keep-checkpoints-num",
default=None,
@@ -182,7 +182,7 @@
remote_checkpoint_dir=spec.get("remote_checkpoint_dir"),
checkpoint_freq=args.checkpoint_freq,
checkpoint_at_end=args.checkpoint_at_end,
- sync_on_checkpoint=not args.no_sync_on_checkpoint,
+ sync_on_checkpoint=args.sync_on_checkpoint,
keep_checkpoints_num=args.keep_checkpoints_num,
checkpoint_score_attr=args.checkpoint_score_attr,
export_formats=spec.get("export_formats", []),
|
{"golden_diff": "diff --git a/python/ray/tune/config_parser.py b/python/ray/tune/config_parser.py\n--- a/python/ray/tune/config_parser.py\n+++ b/python/ray/tune/config_parser.py\n@@ -73,13 +73,13 @@\n help=\"Whether to checkpoint at the end of the experiment. \"\n \"Default is False.\")\n parser.add_argument(\n- \"--no-sync-on-checkpoint\",\n+ \"--sync-on-checkpoint\",\n action=\"store_true\",\n- help=\"Disable sync-down of trial checkpoint, which is enabled by \"\n- \"default to guarantee recoverability. If set, checkpoint syncing from \"\n- \"worker to driver is asynchronous. Set this only if synchronous \"\n- \"checkpointing is too slow and trial restoration failures can be \"\n- \"tolerated\")\n+ help=\"Enable sync-down of trial checkpoint to guarantee \"\n+ \"recoverability. If unset, checkpoint syncing from worker \"\n+ \"to driver is asynchronous, so unset this only if synchronous \"\n+ \"checkpointing is too slow and trial restoration failures \"\n+ \"can be tolerated.\")\n parser.add_argument(\n \"--keep-checkpoints-num\",\n default=None,\n@@ -182,7 +182,7 @@\n remote_checkpoint_dir=spec.get(\"remote_checkpoint_dir\"),\n checkpoint_freq=args.checkpoint_freq,\n checkpoint_at_end=args.checkpoint_at_end,\n- sync_on_checkpoint=not args.no_sync_on_checkpoint,\n+ sync_on_checkpoint=args.sync_on_checkpoint,\n keep_checkpoints_num=args.keep_checkpoints_num,\n checkpoint_score_attr=args.checkpoint_score_attr,\n export_formats=spec.get(\"export_formats\", []),\n", "issue": "[tune] sync_on_checkpoint ignored when list of experiments passed to tune.run\n### What is the problem?\r\nWhen passing a list of predefined Experiments to tune via the `run` function, the `sync_on_checkpoint` flag is ignored.\r\n\r\n**Reason for this behaviour:**\r\nThe `make_parser` function takes in `no_sync_on_checkpoint`; it's set to False by default.\r\nhttps://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L75-L77\r\n\r\nThe create_trial_from_spec function gets a `sync_on_checkpoint` from the Experiment spec, but that key is never used by the parser. So the following line makes the `sync_on_checkpoint` of the returned `Trial` object `True` by default, thus ignoring the value of `sync_on_checkpoint` in the incoming Experiment spec.\r\nhttps://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L185\r\n\r\n*Ray Version: All versions starting from 0.7.7 when the feature was released.*\r\n\r\n### Reproduction (REQUIRED)\r\n```python3\r\nimport ray\r\nfrom ray import tune\r\nfrom ray.tune import Experiment\r\n\r\ndef func(config):\r\n pass\r\n\r\nsync_true_obj = Experiment(\"test_sync\", func, sync_on_checkpoint=True)\r\nsync_false_obj = Experiment(\"test_sync\", func, sync_on_checkpoint=False)\r\n\r\nls = [sync_true_obj, sync_false_obj]\r\n\r\nray.init(local_mode=True)\r\nanalysis = tune.run(ls)\r\n```\r\nTo check the error, add the following lines just before the `return Trial(` line in `config_parser.py`\r\n```python3\r\nprint(args)\r\nprint(args.no_sync_on_checkpoint)\r\n```\r\nhttps://github.com/ray-project/ray/blob/981f67bfb01725f1e153c881f81082fcba0ac223/python/ray/tune/config_parser.py#L173\r\n\r\n\r\n- [x] I have verified my script runs in a clean environment and reproduces the issue.\r\n- [x] I have verified the issue also occurs with the [latest wheels](https://docs.ray.io/en/latest/installation.html).\r\n\n", "before_files": [{"content": "import argparse\nimport json\nimport os\n\n# For compatibility under py2 to consider unicode as str\nfrom six import string_types\n\nfrom ray.tune import TuneError\nfrom ray.tune.trial import Trial\nfrom ray.tune.resources import json_to_resources\nfrom ray.tune.logger import _SafeFallbackEncoder\n\n\ndef make_parser(parser_creator=None, **kwargs):\n \"\"\"Returns a base argument parser for the ray.tune tool.\n\n Args:\n parser_creator: A constructor for the parser class.\n kwargs: Non-positional args to be passed into the\n parser class constructor.\n \"\"\"\n\n if parser_creator:\n parser = parser_creator(**kwargs)\n else:\n parser = argparse.ArgumentParser(**kwargs)\n\n # Note: keep this in sync with rllib/train.py\n parser.add_argument(\n \"--run\",\n default=None,\n type=str,\n help=\"The algorithm or model to train. This may refer to the name \"\n \"of a built-on algorithm (e.g. RLLib's DQN or PPO), or a \"\n \"user-defined trainable function or class registered in the \"\n \"tune registry.\")\n parser.add_argument(\n \"--stop\",\n default=\"{}\",\n type=json.loads,\n help=\"The stopping criteria, specified in JSON. The keys may be any \"\n \"field returned by 'train()' e.g. \"\n \"'{\\\"time_total_s\\\": 600, \\\"training_iteration\\\": 100000}' to stop \"\n \"after 600 seconds or 100k iterations, whichever is reached first.\")\n parser.add_argument(\n \"--config\",\n default=\"{}\",\n type=json.loads,\n help=\"Algorithm-specific configuration (e.g. env, hyperparams), \"\n \"specified in JSON.\")\n parser.add_argument(\n \"--resources-per-trial\",\n default=None,\n type=json_to_resources,\n help=\"Override the machine resources to allocate per trial, e.g. \"\n \"'{\\\"cpu\\\": 64, \\\"gpu\\\": 8}'. Note that GPUs will not be assigned \"\n \"unless you specify them here. For RLlib, you probably want to \"\n \"leave this alone and use RLlib configs to control parallelism.\")\n parser.add_argument(\n \"--num-samples\",\n default=1,\n type=int,\n help=\"Number of times to repeat each trial.\")\n parser.add_argument(\n \"--checkpoint-freq\",\n default=0,\n type=int,\n help=\"How many training iterations between checkpoints. \"\n \"A value of 0 (default) disables checkpointing.\")\n parser.add_argument(\n \"--checkpoint-at-end\",\n action=\"store_true\",\n help=\"Whether to checkpoint at the end of the experiment. \"\n \"Default is False.\")\n parser.add_argument(\n \"--no-sync-on-checkpoint\",\n action=\"store_true\",\n help=\"Disable sync-down of trial checkpoint, which is enabled by \"\n \"default to guarantee recoverability. If set, checkpoint syncing from \"\n \"worker to driver is asynchronous. Set this only if synchronous \"\n \"checkpointing is too slow and trial restoration failures can be \"\n \"tolerated\")\n parser.add_argument(\n \"--keep-checkpoints-num\",\n default=None,\n type=int,\n help=\"Number of best checkpoints to keep. Others get \"\n \"deleted. Default (None) keeps all checkpoints.\")\n parser.add_argument(\n \"--checkpoint-score-attr\",\n default=\"training_iteration\",\n type=str,\n help=\"Specifies by which attribute to rank the best checkpoint. \"\n \"Default is increasing order. If attribute starts with min- it \"\n \"will rank attribute in decreasing order. Example: \"\n \"min-validation_loss\")\n parser.add_argument(\n \"--export-formats\",\n default=None,\n help=\"List of formats that exported at the end of the experiment. \"\n \"Default is None. For RLlib, 'checkpoint' and 'model' are \"\n \"supported for TensorFlow policy graphs.\")\n parser.add_argument(\n \"--max-failures\",\n default=3,\n type=int,\n help=\"Try to recover a trial from its last checkpoint at least this \"\n \"many times. Only applies if checkpointing is enabled.\")\n parser.add_argument(\n \"--scheduler\",\n default=\"FIFO\",\n type=str,\n help=\"FIFO (default), MedianStopping, AsyncHyperBand, \"\n \"HyperBand, or HyperOpt.\")\n parser.add_argument(\n \"--scheduler-config\",\n default=\"{}\",\n type=json.loads,\n help=\"Config options to pass to the scheduler.\")\n\n # Note: this currently only makes sense when running a single trial\n parser.add_argument(\n \"--restore\",\n default=None,\n type=str,\n help=\"If specified, restore from this checkpoint.\")\n\n return parser\n\n\ndef to_argv(config):\n \"\"\"Converts configuration to a command line argument format.\"\"\"\n argv = []\n for k, v in config.items():\n if \"-\" in k:\n raise ValueError(\"Use '_' instead of '-' in `{}`\".format(k))\n if v is None:\n continue\n if not isinstance(v, bool) or v: # for argparse flags\n argv.append(\"--{}\".format(k.replace(\"_\", \"-\")))\n if isinstance(v, string_types):\n argv.append(v)\n elif isinstance(v, bool):\n pass\n else:\n argv.append(json.dumps(v, cls=_SafeFallbackEncoder))\n return argv\n\n\ndef create_trial_from_spec(spec, output_path, parser, **trial_kwargs):\n \"\"\"Creates a Trial object from parsing the spec.\n\n Arguments:\n spec (dict): A resolved experiment specification. Arguments should\n The args here should correspond to the command line flags\n in ray.tune.config_parser.\n output_path (str); A specific output path within the local_dir.\n Typically the name of the experiment.\n parser (ArgumentParser): An argument parser object from\n make_parser.\n trial_kwargs: Extra keyword arguments used in instantiating the Trial.\n\n Returns:\n A trial object with corresponding parameters to the specification.\n \"\"\"\n try:\n args, _ = parser.parse_known_args(to_argv(spec))\n except SystemExit:\n raise TuneError(\"Error parsing args, see above message\", spec)\n if \"resources_per_trial\" in spec:\n trial_kwargs[\"resources\"] = json_to_resources(\n spec[\"resources_per_trial\"])\n return Trial(\n # Submitting trial via server in py2.7 creates Unicode, which does not\n # convert to string in a straightforward manner.\n trainable_name=spec[\"run\"],\n # json.load leads to str -> unicode in py2.7\n config=spec.get(\"config\", {}),\n local_dir=os.path.join(spec[\"local_dir\"], output_path),\n # json.load leads to str -> unicode in py2.7\n stopping_criterion=spec.get(\"stop\", {}),\n remote_checkpoint_dir=spec.get(\"remote_checkpoint_dir\"),\n checkpoint_freq=args.checkpoint_freq,\n checkpoint_at_end=args.checkpoint_at_end,\n sync_on_checkpoint=not args.no_sync_on_checkpoint,\n keep_checkpoints_num=args.keep_checkpoints_num,\n checkpoint_score_attr=args.checkpoint_score_attr,\n export_formats=spec.get(\"export_formats\", []),\n # str(None) doesn't create None\n restore_path=spec.get(\"restore\"),\n trial_name_creator=spec.get(\"trial_name_creator\"),\n loggers=spec.get(\"loggers\"),\n # str(None) doesn't create None\n sync_to_driver_fn=spec.get(\"sync_to_driver\"),\n max_failures=args.max_failures,\n **trial_kwargs)\n", "path": "python/ray/tune/config_parser.py"}], "after_files": [{"content": "import argparse\nimport json\nimport os\n\n# For compatibility under py2 to consider unicode as str\nfrom six import string_types\n\nfrom ray.tune import TuneError\nfrom ray.tune.trial import Trial\nfrom ray.tune.resources import json_to_resources\nfrom ray.tune.logger import _SafeFallbackEncoder\n\n\ndef make_parser(parser_creator=None, **kwargs):\n \"\"\"Returns a base argument parser for the ray.tune tool.\n\n Args:\n parser_creator: A constructor for the parser class.\n kwargs: Non-positional args to be passed into the\n parser class constructor.\n \"\"\"\n\n if parser_creator:\n parser = parser_creator(**kwargs)\n else:\n parser = argparse.ArgumentParser(**kwargs)\n\n # Note: keep this in sync with rllib/train.py\n parser.add_argument(\n \"--run\",\n default=None,\n type=str,\n help=\"The algorithm or model to train. This may refer to the name \"\n \"of a built-on algorithm (e.g. RLLib's DQN or PPO), or a \"\n \"user-defined trainable function or class registered in the \"\n \"tune registry.\")\n parser.add_argument(\n \"--stop\",\n default=\"{}\",\n type=json.loads,\n help=\"The stopping criteria, specified in JSON. The keys may be any \"\n \"field returned by 'train()' e.g. \"\n \"'{\\\"time_total_s\\\": 600, \\\"training_iteration\\\": 100000}' to stop \"\n \"after 600 seconds or 100k iterations, whichever is reached first.\")\n parser.add_argument(\n \"--config\",\n default=\"{}\",\n type=json.loads,\n help=\"Algorithm-specific configuration (e.g. env, hyperparams), \"\n \"specified in JSON.\")\n parser.add_argument(\n \"--resources-per-trial\",\n default=None,\n type=json_to_resources,\n help=\"Override the machine resources to allocate per trial, e.g. \"\n \"'{\\\"cpu\\\": 64, \\\"gpu\\\": 8}'. Note that GPUs will not be assigned \"\n \"unless you specify them here. For RLlib, you probably want to \"\n \"leave this alone and use RLlib configs to control parallelism.\")\n parser.add_argument(\n \"--num-samples\",\n default=1,\n type=int,\n help=\"Number of times to repeat each trial.\")\n parser.add_argument(\n \"--checkpoint-freq\",\n default=0,\n type=int,\n help=\"How many training iterations between checkpoints. \"\n \"A value of 0 (default) disables checkpointing.\")\n parser.add_argument(\n \"--checkpoint-at-end\",\n action=\"store_true\",\n help=\"Whether to checkpoint at the end of the experiment. \"\n \"Default is False.\")\n parser.add_argument(\n \"--sync-on-checkpoint\",\n action=\"store_true\",\n help=\"Enable sync-down of trial checkpoint to guarantee \"\n \"recoverability. If unset, checkpoint syncing from worker \"\n \"to driver is asynchronous, so unset this only if synchronous \"\n \"checkpointing is too slow and trial restoration failures \"\n \"can be tolerated.\")\n parser.add_argument(\n \"--keep-checkpoints-num\",\n default=None,\n type=int,\n help=\"Number of best checkpoints to keep. Others get \"\n \"deleted. Default (None) keeps all checkpoints.\")\n parser.add_argument(\n \"--checkpoint-score-attr\",\n default=\"training_iteration\",\n type=str,\n help=\"Specifies by which attribute to rank the best checkpoint. \"\n \"Default is increasing order. If attribute starts with min- it \"\n \"will rank attribute in decreasing order. Example: \"\n \"min-validation_loss\")\n parser.add_argument(\n \"--export-formats\",\n default=None,\n help=\"List of formats that exported at the end of the experiment. \"\n \"Default is None. For RLlib, 'checkpoint' and 'model' are \"\n \"supported for TensorFlow policy graphs.\")\n parser.add_argument(\n \"--max-failures\",\n default=3,\n type=int,\n help=\"Try to recover a trial from its last checkpoint at least this \"\n \"many times. Only applies if checkpointing is enabled.\")\n parser.add_argument(\n \"--scheduler\",\n default=\"FIFO\",\n type=str,\n help=\"FIFO (default), MedianStopping, AsyncHyperBand, \"\n \"HyperBand, or HyperOpt.\")\n parser.add_argument(\n \"--scheduler-config\",\n default=\"{}\",\n type=json.loads,\n help=\"Config options to pass to the scheduler.\")\n\n # Note: this currently only makes sense when running a single trial\n parser.add_argument(\n \"--restore\",\n default=None,\n type=str,\n help=\"If specified, restore from this checkpoint.\")\n\n return parser\n\n\ndef to_argv(config):\n \"\"\"Converts configuration to a command line argument format.\"\"\"\n argv = []\n for k, v in config.items():\n if \"-\" in k:\n raise ValueError(\"Use '_' instead of '-' in `{}`\".format(k))\n if v is None:\n continue\n if not isinstance(v, bool) or v: # for argparse flags\n argv.append(\"--{}\".format(k.replace(\"_\", \"-\")))\n if isinstance(v, string_types):\n argv.append(v)\n elif isinstance(v, bool):\n pass\n else:\n argv.append(json.dumps(v, cls=_SafeFallbackEncoder))\n return argv\n\n\ndef create_trial_from_spec(spec, output_path, parser, **trial_kwargs):\n \"\"\"Creates a Trial object from parsing the spec.\n\n Arguments:\n spec (dict): A resolved experiment specification. Arguments should\n The args here should correspond to the command line flags\n in ray.tune.config_parser.\n output_path (str); A specific output path within the local_dir.\n Typically the name of the experiment.\n parser (ArgumentParser): An argument parser object from\n make_parser.\n trial_kwargs: Extra keyword arguments used in instantiating the Trial.\n\n Returns:\n A trial object with corresponding parameters to the specification.\n \"\"\"\n try:\n args, _ = parser.parse_known_args(to_argv(spec))\n except SystemExit:\n raise TuneError(\"Error parsing args, see above message\", spec)\n if \"resources_per_trial\" in spec:\n trial_kwargs[\"resources\"] = json_to_resources(\n spec[\"resources_per_trial\"])\n return Trial(\n # Submitting trial via server in py2.7 creates Unicode, which does not\n # convert to string in a straightforward manner.\n trainable_name=spec[\"run\"],\n # json.load leads to str -> unicode in py2.7\n config=spec.get(\"config\", {}),\n local_dir=os.path.join(spec[\"local_dir\"], output_path),\n # json.load leads to str -> unicode in py2.7\n stopping_criterion=spec.get(\"stop\", {}),\n remote_checkpoint_dir=spec.get(\"remote_checkpoint_dir\"),\n checkpoint_freq=args.checkpoint_freq,\n checkpoint_at_end=args.checkpoint_at_end,\n sync_on_checkpoint=args.sync_on_checkpoint,\n keep_checkpoints_num=args.keep_checkpoints_num,\n checkpoint_score_attr=args.checkpoint_score_attr,\n export_formats=spec.get(\"export_formats\", []),\n # str(None) doesn't create None\n restore_path=spec.get(\"restore\"),\n trial_name_creator=spec.get(\"trial_name_creator\"),\n loggers=spec.get(\"loggers\"),\n # str(None) doesn't create None\n sync_to_driver_fn=spec.get(\"sync_to_driver\"),\n max_failures=args.max_failures,\n **trial_kwargs)\n", "path": "python/ray/tune/config_parser.py"}]}
| 2,884 | 352 |
gh_patches_debug_15353
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-3721
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
REST args in GitLab push notification do not work
This is fundamentally the same problem we had at #3506 (@rodrigc). In Python3, some strings are now byte strings and are not identified properly by Buildbot.
In this case, I have a local gitlab instance with the webhook for push events: `https://mybuildbot/change_hook/gitlab?project=lthmb`.
However, when I test this the Buildbot logs show no `project` parameter set:
```
2017-10-27 18:15:14+0200 [-] injected change Change(revision='2afc1ab3ab28980db47d64714852aa0d586be7f9', who='Paulo Matos <[email protected]>', branch='master', comments="Merge branch 'foobar'\n", when=1506599131, category='push', project='', repository='git@linki:pmatos/lthmb.git', codebase='')
```
I went ahead and printed the request received from gitlab in `www/hooks/gitlab.py` and noticed that `request.args` in `getChanges` are byte strings: `2017-10-27 18:15:14+0200 [-] {b'project': [b'lthmb']}`
I think in Buildbot nine with Py3 we might need string conversion here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/www/hooks/gitlab.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18
19 import json
20 import re
21
22 from dateutil.parser import parse as dateparse
23
24 from twisted.python import log
25
26 from buildbot.util import bytes2unicode
27 from buildbot.www.hooks.base import BaseHookHandler
28
29 _HEADER_EVENT = b'X-Gitlab-Event'
30 _HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'
31
32
33 class GitLabHandler(BaseHookHandler):
34
35 def _process_change(self, payload, user, repo, repo_url, project, event,
36 codebase=None):
37 """
38 Consumes the JSON as a python object and actually starts the build.
39
40 :arguments:
41 payload
42 Python Object that represents the JSON sent by GitLab Service
43 Hook.
44 """
45 changes = []
46 refname = payload['ref']
47
48 # We only care about regular heads or tags
49 match = re.match(r"^refs/(heads|tags)/(.+)$", refname)
50 if not match:
51 log.msg("Ignoring refname `%s': Not a branch" % refname)
52 return changes
53
54 branch = match.group(2)
55 if payload.get('deleted'):
56 log.msg("Branch `%s' deleted, ignoring" % branch)
57 return changes
58
59 for commit in payload['commits']:
60 if not commit.get('distinct', True):
61 log.msg('Commit `%s` is a non-distinct commit, ignoring...' %
62 (commit['id'],))
63 continue
64
65 files = []
66 for kind in ('added', 'modified', 'removed'):
67 files.extend(commit.get(kind, []))
68
69 when_timestamp = dateparse(commit['timestamp'])
70
71 log.msg("New revision: %s" % commit['id'][:8])
72
73 change = {
74 'author': '%s <%s>' % (commit['author']['name'],
75 commit['author']['email']),
76 'files': files,
77 'comments': commit['message'],
78 'revision': commit['id'],
79 'when_timestamp': when_timestamp,
80 'branch': branch,
81 'revlink': commit['url'],
82 'repository': repo_url,
83 'project': project,
84 'category': event,
85 'properties': {
86 'event': event,
87 },
88 }
89
90 if codebase is not None:
91 change['codebase'] = codebase
92
93 changes.append(change)
94
95 return changes
96
97 def _process_merge_request_change(self, payload, project, event, codebase=None):
98 """
99 Consumes the merge_request JSON as a python object and turn it into a buildbot change.
100
101 :arguments:
102 payload
103 Python Object that represents the JSON sent by GitLab Service
104 Hook.
105 """
106 attrs = payload['object_attributes']
107 commit = attrs['last_commit']
108 when_timestamp = dateparse(commit['timestamp'])
109 # @todo provide and document a way to choose between http and ssh url
110 repo_url = attrs['source']['git_http_url']
111 changes = [{
112 'author': '%s <%s>' % (commit['author']['name'],
113 commit['author']['email']),
114 'files': [], # @todo use rest API
115 'comments': "MR#{}: {}\n\n{}".format(attrs['iid'], attrs['title'], attrs['description']),
116 'revision': commit['id'],
117 'when_timestamp': when_timestamp,
118 'branch': attrs['source_branch'],
119 'repository': repo_url,
120 'project': project,
121 'category': event,
122 'revlink': attrs['url'],
123 'properties': {
124 'target_branch': attrs['target_branch'],
125 'target_repository': attrs['target']['git_http_url'],
126 'event': event,
127 },
128 }]
129 if codebase is not None:
130 changes[0]['codebase'] = codebase
131 return changes
132
133 def getChanges(self, request):
134 """
135 Reponds only to POST events and starts the build process
136
137 :arguments:
138 request
139 the http request object
140 """
141 expected_secret = isinstance(self.options, dict) and self.options.get('secret')
142 if expected_secret:
143 received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)
144 received_secret = bytes2unicode(received_secret)
145 if received_secret != expected_secret:
146 raise ValueError("Invalid secret")
147 try:
148 content = request.content.read()
149 payload = json.loads(bytes2unicode(content))
150 except Exception as e:
151 raise ValueError("Error loading JSON: " + str(e))
152 event_type = request.getHeader(_HEADER_EVENT)
153 event_type = bytes2unicode(event_type)
154 # newer version of gitlab have a object_kind parameter,
155 # which allows not to use the http header
156 event_type = payload.get('object_kind', event_type)
157 project = request.args.get('project', [''])[0]
158 codebase = request.args.get('codebase', [None])[0]
159 if event_type in ("push", "tag_push", "Push Hook"):
160 user = payload['user_name']
161 repo = payload['repository']['name']
162 repo_url = payload['repository']['url']
163 changes = self._process_change(
164 payload, user, repo, repo_url, project, event_type, codebase=codebase)
165 elif event_type == 'merge_request':
166 changes = self._process_merge_request_change(
167 payload, project, event_type, codebase=codebase)
168 else:
169 changes = []
170 if changes:
171 log.msg("Received {} changes from {} gitlab event".format(
172 len(changes), event_type))
173 return (changes, 'git')
174
175
176 gitlab = GitLabHandler
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/www/hooks/gitlab.py b/master/buildbot/www/hooks/gitlab.py
--- a/master/buildbot/www/hooks/gitlab.py
+++ b/master/buildbot/www/hooks/gitlab.py
@@ -154,8 +154,10 @@
# newer version of gitlab have a object_kind parameter,
# which allows not to use the http header
event_type = payload.get('object_kind', event_type)
- project = request.args.get('project', [''])[0]
- codebase = request.args.get('codebase', [None])[0]
+ project = request.args.get(b'project', [''])[0]
+ project = bytes2unicode(project)
+ codebase = request.args.get(b'codebase', [None])[0]
+ codebase = bytes2unicode(codebase)
if event_type in ("push", "tag_push", "Push Hook"):
user = payload['user_name']
repo = payload['repository']['name']
|
{"golden_diff": "diff --git a/master/buildbot/www/hooks/gitlab.py b/master/buildbot/www/hooks/gitlab.py\n--- a/master/buildbot/www/hooks/gitlab.py\n+++ b/master/buildbot/www/hooks/gitlab.py\n@@ -154,8 +154,10 @@\n # newer version of gitlab have a object_kind parameter,\n # which allows not to use the http header\n event_type = payload.get('object_kind', event_type)\n- project = request.args.get('project', [''])[0]\n- codebase = request.args.get('codebase', [None])[0]\n+ project = request.args.get(b'project', [''])[0]\n+ project = bytes2unicode(project)\n+ codebase = request.args.get(b'codebase', [None])[0]\n+ codebase = bytes2unicode(codebase)\n if event_type in (\"push\", \"tag_push\", \"Push Hook\"):\n user = payload['user_name']\n repo = payload['repository']['name']\n", "issue": "REST args in GitLab push notification do not work\nThis is fundamentally the same problem we had at #3506 (@rodrigc). In Python3, some strings are now byte strings and are not identified properly by Buildbot.\r\n\r\nIn this case, I have a local gitlab instance with the webhook for push events: `https://mybuildbot/change_hook/gitlab?project=lthmb`.\r\n\r\nHowever, when I test this the Buildbot logs show no `project` parameter set:\r\n```\r\n2017-10-27 18:15:14+0200 [-] injected change Change(revision='2afc1ab3ab28980db47d64714852aa0d586be7f9', who='Paulo Matos <[email protected]>', branch='master', comments=\"Merge branch 'foobar'\\n\", when=1506599131, category='push', project='', repository='git@linki:pmatos/lthmb.git', codebase='')\r\n```\r\nI went ahead and printed the request received from gitlab in `www/hooks/gitlab.py` and noticed that `request.args` in `getChanges` are byte strings: `2017-10-27 18:15:14+0200 [-] {b'project': [b'lthmb']}`\r\n\r\nI think in Buildbot nine with Py3 we might need string conversion here.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport re\n\nfrom dateutil.parser import parse as dateparse\n\nfrom twisted.python import log\n\nfrom buildbot.util import bytes2unicode\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n_HEADER_EVENT = b'X-Gitlab-Event'\n_HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'\n\n\nclass GitLabHandler(BaseHookHandler):\n\n def _process_change(self, payload, user, repo, repo_url, project, event,\n codebase=None):\n \"\"\"\n Consumes the JSON as a python object and actually starts the build.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n changes = []\n refname = payload['ref']\n\n # We only care about regular heads or tags\n match = re.match(r\"^refs/(heads|tags)/(.+)$\", refname)\n if not match:\n log.msg(\"Ignoring refname `%s': Not a branch\" % refname)\n return changes\n\n branch = match.group(2)\n if payload.get('deleted'):\n log.msg(\"Branch `%s' deleted, ignoring\" % branch)\n return changes\n\n for commit in payload['commits']:\n if not commit.get('distinct', True):\n log.msg('Commit `%s` is a non-distinct commit, ignoring...' %\n (commit['id'],))\n continue\n\n files = []\n for kind in ('added', 'modified', 'removed'):\n files.extend(commit.get(kind, []))\n\n when_timestamp = dateparse(commit['timestamp'])\n\n log.msg(\"New revision: %s\" % commit['id'][:8])\n\n change = {\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': files,\n 'comments': commit['message'],\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': branch,\n 'revlink': commit['url'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'properties': {\n 'event': event,\n },\n }\n\n if codebase is not None:\n change['codebase'] = codebase\n\n changes.append(change)\n\n return changes\n\n def _process_merge_request_change(self, payload, project, event, codebase=None):\n \"\"\"\n Consumes the merge_request JSON as a python object and turn it into a buildbot change.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n attrs = payload['object_attributes']\n commit = attrs['last_commit']\n when_timestamp = dateparse(commit['timestamp'])\n # @todo provide and document a way to choose between http and ssh url\n repo_url = attrs['source']['git_http_url']\n changes = [{\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': [], # @todo use rest API\n 'comments': \"MR#{}: {}\\n\\n{}\".format(attrs['iid'], attrs['title'], attrs['description']),\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': attrs['source_branch'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'revlink': attrs['url'],\n 'properties': {\n 'target_branch': attrs['target_branch'],\n 'target_repository': attrs['target']['git_http_url'],\n 'event': event,\n },\n }]\n if codebase is not None:\n changes[0]['codebase'] = codebase\n return changes\n\n def getChanges(self, request):\n \"\"\"\n Reponds only to POST events and starts the build process\n\n :arguments:\n request\n the http request object\n \"\"\"\n expected_secret = isinstance(self.options, dict) and self.options.get('secret')\n if expected_secret:\n received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)\n received_secret = bytes2unicode(received_secret)\n if received_secret != expected_secret:\n raise ValueError(\"Invalid secret\")\n try:\n content = request.content.read()\n payload = json.loads(bytes2unicode(content))\n except Exception as e:\n raise ValueError(\"Error loading JSON: \" + str(e))\n event_type = request.getHeader(_HEADER_EVENT)\n event_type = bytes2unicode(event_type)\n # newer version of gitlab have a object_kind parameter,\n # which allows not to use the http header\n event_type = payload.get('object_kind', event_type)\n project = request.args.get('project', [''])[0]\n codebase = request.args.get('codebase', [None])[0]\n if event_type in (\"push\", \"tag_push\", \"Push Hook\"):\n user = payload['user_name']\n repo = payload['repository']['name']\n repo_url = payload['repository']['url']\n changes = self._process_change(\n payload, user, repo, repo_url, project, event_type, codebase=codebase)\n elif event_type == 'merge_request':\n changes = self._process_merge_request_change(\n payload, project, event_type, codebase=codebase)\n else:\n changes = []\n if changes:\n log.msg(\"Received {} changes from {} gitlab event\".format(\n len(changes), event_type))\n return (changes, 'git')\n\n\ngitlab = GitLabHandler\n", "path": "master/buildbot/www/hooks/gitlab.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport re\n\nfrom dateutil.parser import parse as dateparse\n\nfrom twisted.python import log\n\nfrom buildbot.util import bytes2unicode\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n_HEADER_EVENT = b'X-Gitlab-Event'\n_HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'\n\n\nclass GitLabHandler(BaseHookHandler):\n\n def _process_change(self, payload, user, repo, repo_url, project, event,\n codebase=None):\n \"\"\"\n Consumes the JSON as a python object and actually starts the build.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n changes = []\n refname = payload['ref']\n\n # We only care about regular heads or tags\n match = re.match(r\"^refs/(heads|tags)/(.+)$\", refname)\n if not match:\n log.msg(\"Ignoring refname `%s': Not a branch\" % refname)\n return changes\n\n branch = match.group(2)\n if payload.get('deleted'):\n log.msg(\"Branch `%s' deleted, ignoring\" % branch)\n return changes\n\n for commit in payload['commits']:\n if not commit.get('distinct', True):\n log.msg('Commit `%s` is a non-distinct commit, ignoring...' %\n (commit['id'],))\n continue\n\n files = []\n for kind in ('added', 'modified', 'removed'):\n files.extend(commit.get(kind, []))\n\n when_timestamp = dateparse(commit['timestamp'])\n\n log.msg(\"New revision: %s\" % commit['id'][:8])\n\n change = {\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': files,\n 'comments': commit['message'],\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': branch,\n 'revlink': commit['url'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'properties': {\n 'event': event,\n },\n }\n\n if codebase is not None:\n change['codebase'] = codebase\n\n changes.append(change)\n\n return changes\n\n def _process_merge_request_change(self, payload, project, event, codebase=None):\n \"\"\"\n Consumes the merge_request JSON as a python object and turn it into a buildbot change.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n attrs = payload['object_attributes']\n commit = attrs['last_commit']\n when_timestamp = dateparse(commit['timestamp'])\n # @todo provide and document a way to choose between http and ssh url\n repo_url = attrs['source']['git_http_url']\n changes = [{\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': [], # @todo use rest API\n 'comments': \"MR#{}: {}\\n\\n{}\".format(attrs['iid'], attrs['title'], attrs['description']),\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': attrs['source_branch'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'revlink': attrs['url'],\n 'properties': {\n 'target_branch': attrs['target_branch'],\n 'target_repository': attrs['target']['git_http_url'],\n 'event': event,\n },\n }]\n if codebase is not None:\n changes[0]['codebase'] = codebase\n return changes\n\n def getChanges(self, request):\n \"\"\"\n Reponds only to POST events and starts the build process\n\n :arguments:\n request\n the http request object\n \"\"\"\n expected_secret = isinstance(self.options, dict) and self.options.get('secret')\n if expected_secret:\n received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)\n received_secret = bytes2unicode(received_secret)\n if received_secret != expected_secret:\n raise ValueError(\"Invalid secret\")\n try:\n content = request.content.read()\n payload = json.loads(bytes2unicode(content))\n except Exception as e:\n raise ValueError(\"Error loading JSON: \" + str(e))\n event_type = request.getHeader(_HEADER_EVENT)\n event_type = bytes2unicode(event_type)\n # newer version of gitlab have a object_kind parameter,\n # which allows not to use the http header\n event_type = payload.get('object_kind', event_type)\n project = request.args.get(b'project', [''])[0]\n project = bytes2unicode(project)\n codebase = request.args.get(b'codebase', [None])[0]\n codebase = bytes2unicode(codebase)\n if event_type in (\"push\", \"tag_push\", \"Push Hook\"):\n user = payload['user_name']\n repo = payload['repository']['name']\n repo_url = payload['repository']['url']\n changes = self._process_change(\n payload, user, repo, repo_url, project, event_type, codebase=codebase)\n elif event_type == 'merge_request':\n changes = self._process_merge_request_change(\n payload, project, event_type, codebase=codebase)\n else:\n changes = []\n if changes:\n log.msg(\"Received {} changes from {} gitlab event\".format(\n len(changes), event_type))\n return (changes, 'git')\n\n\ngitlab = GitLabHandler\n", "path": "master/buildbot/www/hooks/gitlab.py"}]}
| 2,389 | 213 |
gh_patches_debug_37650
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-30
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
make_executable_schema resolvers arg should accept dict of dicts or list of dicts of dicts
The `make_executable_schema` utility should optionally take list of dicts of dicts (AKA "resolvers map"), this would allow larger projects to easily split and compose resolvers as needed:
```python
from ariadne import make_executable_schema
from products.graphql import resolvers as products_resolvers
from users.graphql import resolvers as users_resolvers
typedefs = "..."
resolvers = [products_resolvers, users_resolvers]
schema = make_executable_schema(typedefs, resolvers)
```
This task will likely require #13 to be done first, so we are 100% certain that all resolver mappings are dicts.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ariadne/executable_schema.py`
Content:
```
1 from typing import List, Union
2
3 from graphql import GraphQLSchema
4
5 from .build_schema import build_schema_from_type_definitions
6 from .resolvers import add_resolve_functions_to_schema
7
8
9 def make_executable_schema(
10 type_defs: Union[str, List[str]], resolvers: dict
11 ) -> GraphQLSchema:
12 schema = build_schema_from_type_definitions(type_defs)
13 add_resolve_functions_to_schema(schema, resolvers)
14 return schema
15
```
Path: `ariadne/build_schema.py`
Content:
```
1 from typing import List, Union
2
3 from graphql import GraphQLSchema, parse
4 from graphql.language.ast import (
5 Document,
6 ObjectTypeDefinition,
7 OperationTypeDefinition,
8 Name,
9 NamedType,
10 SchemaDefinition,
11 )
12 from graphql.utils.build_ast_schema import build_ast_schema
13
14
15 def build_schema_from_type_definitions(
16 type_defs: Union[str, List[str]]
17 ) -> GraphQLSchema:
18 if isinstance(type_defs, list):
19 type_defs = concatenate_type_defs(type_defs)
20
21 document = parse(type_defs)
22
23 if not document_has_schema(document):
24 schema_definition = build_default_schema(document)
25 document.definitions.append(schema_definition)
26
27 return build_ast_schema(document)
28
29
30 def concatenate_type_defs(type_defs: List[str]) -> str:
31 resolved_type_defs = []
32 for type_def in type_defs:
33 resolved_type_defs.append(type_def.strip())
34 return "\n\n".join(resolved_type_defs)
35
36
37 def build_default_schema(document: Document) -> SchemaDefinition:
38 defined_types = [
39 td.name.value
40 for td in document.definitions
41 if isinstance(td, ObjectTypeDefinition)
42 ]
43 operations = []
44 if "Query" in defined_types:
45 operations.append(
46 OperationTypeDefinition("query", type=NamedType(name=Name("Query")))
47 )
48 if "Mutation" in defined_types:
49 operations.append(
50 OperationTypeDefinition("mutation", type=NamedType(name=Name("Mutation")))
51 )
52 if "Subscription" in defined_types:
53 operations.append(
54 OperationTypeDefinition(
55 "subscription", type=NamedType(name=Name("Subscription"))
56 )
57 )
58 return SchemaDefinition(operation_types=operations, directives=[])
59
60
61 def document_has_schema(document: Document) -> bool:
62 return any(isinstance(td, SchemaDefinition) for td in document.definitions)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ariadne/build_schema.py b/ariadne/build_schema.py
--- a/ariadne/build_schema.py
+++ b/ariadne/build_schema.py
@@ -1,5 +1,3 @@
-from typing import List, Union
-
from graphql import GraphQLSchema, parse
from graphql.language.ast import (
Document,
@@ -12,12 +10,7 @@
from graphql.utils.build_ast_schema import build_ast_schema
-def build_schema_from_type_definitions(
- type_defs: Union[str, List[str]]
-) -> GraphQLSchema:
- if isinstance(type_defs, list):
- type_defs = concatenate_type_defs(type_defs)
-
+def build_schema_from_type_definitions(type_defs: str) -> GraphQLSchema:
document = parse(type_defs)
if not document_has_schema(document):
@@ -27,13 +20,6 @@
return build_ast_schema(document)
-def concatenate_type_defs(type_defs: List[str]) -> str:
- resolved_type_defs = []
- for type_def in type_defs:
- resolved_type_defs.append(type_def.strip())
- return "\n\n".join(resolved_type_defs)
-
-
def build_default_schema(document: Document) -> SchemaDefinition:
defined_types = [
td.name.value
diff --git a/ariadne/executable_schema.py b/ariadne/executable_schema.py
--- a/ariadne/executable_schema.py
+++ b/ariadne/executable_schema.py
@@ -1,4 +1,6 @@
-from typing import List, Union
+from collections import defaultdict
+from itertools import chain
+from typing import Iterator, List, Union
from graphql import GraphQLSchema
@@ -6,9 +8,39 @@
from .resolvers import add_resolve_functions_to_schema
+def decompose_maps(resolvers_maps: List[dict]) -> Iterator[tuple]:
+ def flatten(rm):
+ for key, value in rm.items():
+ for resolver_name, resolver in value.items():
+ yield (key, resolver_name, resolver)
+
+ return chain.from_iterable(flatten(m) for m in resolvers_maps)
+
+
+def merge_resolvers(resolver_list: Iterator[tuple]) -> dict:
+ output = defaultdict(dict) # type: dict
+ for key, resolver_name, resolver in resolver_list:
+ output[key][resolver_name] = resolver
+ return output
+
+
+def join_type_defs(type_defs: List[str]) -> str:
+ return "\n\n".join(t.strip() for t in type_defs)
+
+
def make_executable_schema(
- type_defs: Union[str, List[str]], resolvers: dict
+ type_defs: Union[str, List[str]], resolvers: Union[dict, List[dict]]
) -> GraphQLSchema:
+ if isinstance(type_defs, list):
+ type_defs = join_type_defs(type_defs)
+
schema = build_schema_from_type_definitions(type_defs)
- add_resolve_functions_to_schema(schema, resolvers)
+
+ if isinstance(resolvers, list):
+ add_resolve_functions_to_schema(
+ schema, merge_resolvers(decompose_maps(resolvers))
+ )
+ elif isinstance(resolvers, dict):
+ add_resolve_functions_to_schema(schema, resolvers)
+
return schema
|
{"golden_diff": "diff --git a/ariadne/build_schema.py b/ariadne/build_schema.py\n--- a/ariadne/build_schema.py\n+++ b/ariadne/build_schema.py\n@@ -1,5 +1,3 @@\n-from typing import List, Union\n-\n from graphql import GraphQLSchema, parse\n from graphql.language.ast import (\n Document,\n@@ -12,12 +10,7 @@\n from graphql.utils.build_ast_schema import build_ast_schema\n \n \n-def build_schema_from_type_definitions(\n- type_defs: Union[str, List[str]]\n-) -> GraphQLSchema:\n- if isinstance(type_defs, list):\n- type_defs = concatenate_type_defs(type_defs)\n-\n+def build_schema_from_type_definitions(type_defs: str) -> GraphQLSchema:\n document = parse(type_defs)\n \n if not document_has_schema(document):\n@@ -27,13 +20,6 @@\n return build_ast_schema(document)\n \n \n-def concatenate_type_defs(type_defs: List[str]) -> str:\n- resolved_type_defs = []\n- for type_def in type_defs:\n- resolved_type_defs.append(type_def.strip())\n- return \"\\n\\n\".join(resolved_type_defs)\n-\n-\n def build_default_schema(document: Document) -> SchemaDefinition:\n defined_types = [\n td.name.value\ndiff --git a/ariadne/executable_schema.py b/ariadne/executable_schema.py\n--- a/ariadne/executable_schema.py\n+++ b/ariadne/executable_schema.py\n@@ -1,4 +1,6 @@\n-from typing import List, Union\n+from collections import defaultdict\n+from itertools import chain\n+from typing import Iterator, List, Union\n \n from graphql import GraphQLSchema\n \n@@ -6,9 +8,39 @@\n from .resolvers import add_resolve_functions_to_schema\n \n \n+def decompose_maps(resolvers_maps: List[dict]) -> Iterator[tuple]:\n+ def flatten(rm):\n+ for key, value in rm.items():\n+ for resolver_name, resolver in value.items():\n+ yield (key, resolver_name, resolver)\n+\n+ return chain.from_iterable(flatten(m) for m in resolvers_maps)\n+\n+\n+def merge_resolvers(resolver_list: Iterator[tuple]) -> dict:\n+ output = defaultdict(dict) # type: dict\n+ for key, resolver_name, resolver in resolver_list:\n+ output[key][resolver_name] = resolver\n+ return output\n+\n+\n+def join_type_defs(type_defs: List[str]) -> str:\n+ return \"\\n\\n\".join(t.strip() for t in type_defs)\n+\n+\n def make_executable_schema(\n- type_defs: Union[str, List[str]], resolvers: dict\n+ type_defs: Union[str, List[str]], resolvers: Union[dict, List[dict]]\n ) -> GraphQLSchema:\n+ if isinstance(type_defs, list):\n+ type_defs = join_type_defs(type_defs)\n+\n schema = build_schema_from_type_definitions(type_defs)\n- add_resolve_functions_to_schema(schema, resolvers)\n+\n+ if isinstance(resolvers, list):\n+ add_resolve_functions_to_schema(\n+ schema, merge_resolvers(decompose_maps(resolvers))\n+ )\n+ elif isinstance(resolvers, dict):\n+ add_resolve_functions_to_schema(schema, resolvers)\n+\n return schema\n", "issue": "make_executable_schema resolvers arg should accept dict of dicts or list of dicts of dicts\nThe `make_executable_schema` utility should optionally take list of dicts of dicts (AKA \"resolvers map\"), this would allow larger projects to easily split and compose resolvers as needed:\r\n\r\n```python\r\nfrom ariadne import make_executable_schema\r\n\r\nfrom products.graphql import resolvers as products_resolvers\r\nfrom users.graphql import resolvers as users_resolvers\r\n\r\n\r\ntypedefs = \"...\"\r\nresolvers = [products_resolvers, users_resolvers]\r\n\r\nschema = make_executable_schema(typedefs, resolvers)\r\n```\r\n\r\nThis task will likely require #13 to be done first, so we are 100% certain that all resolver mappings are dicts.\n", "before_files": [{"content": "from typing import List, Union\n\nfrom graphql import GraphQLSchema\n\nfrom .build_schema import build_schema_from_type_definitions\nfrom .resolvers import add_resolve_functions_to_schema\n\n\ndef make_executable_schema(\n type_defs: Union[str, List[str]], resolvers: dict\n) -> GraphQLSchema:\n schema = build_schema_from_type_definitions(type_defs)\n add_resolve_functions_to_schema(schema, resolvers)\n return schema\n", "path": "ariadne/executable_schema.py"}, {"content": "from typing import List, Union\n\nfrom graphql import GraphQLSchema, parse\nfrom graphql.language.ast import (\n Document,\n ObjectTypeDefinition,\n OperationTypeDefinition,\n Name,\n NamedType,\n SchemaDefinition,\n)\nfrom graphql.utils.build_ast_schema import build_ast_schema\n\n\ndef build_schema_from_type_definitions(\n type_defs: Union[str, List[str]]\n) -> GraphQLSchema:\n if isinstance(type_defs, list):\n type_defs = concatenate_type_defs(type_defs)\n\n document = parse(type_defs)\n\n if not document_has_schema(document):\n schema_definition = build_default_schema(document)\n document.definitions.append(schema_definition)\n\n return build_ast_schema(document)\n\n\ndef concatenate_type_defs(type_defs: List[str]) -> str:\n resolved_type_defs = []\n for type_def in type_defs:\n resolved_type_defs.append(type_def.strip())\n return \"\\n\\n\".join(resolved_type_defs)\n\n\ndef build_default_schema(document: Document) -> SchemaDefinition:\n defined_types = [\n td.name.value\n for td in document.definitions\n if isinstance(td, ObjectTypeDefinition)\n ]\n operations = []\n if \"Query\" in defined_types:\n operations.append(\n OperationTypeDefinition(\"query\", type=NamedType(name=Name(\"Query\")))\n )\n if \"Mutation\" in defined_types:\n operations.append(\n OperationTypeDefinition(\"mutation\", type=NamedType(name=Name(\"Mutation\")))\n )\n if \"Subscription\" in defined_types:\n operations.append(\n OperationTypeDefinition(\n \"subscription\", type=NamedType(name=Name(\"Subscription\"))\n )\n )\n return SchemaDefinition(operation_types=operations, directives=[])\n\n\ndef document_has_schema(document: Document) -> bool:\n return any(isinstance(td, SchemaDefinition) for td in document.definitions)\n", "path": "ariadne/build_schema.py"}], "after_files": [{"content": "from collections import defaultdict\nfrom itertools import chain\nfrom typing import Iterator, List, Union\n\nfrom graphql import GraphQLSchema\n\nfrom .build_schema import build_schema_from_type_definitions\nfrom .resolvers import add_resolve_functions_to_schema\n\n\ndef decompose_maps(resolvers_maps: List[dict]) -> Iterator[tuple]:\n def flatten(rm):\n for key, value in rm.items():\n for resolver_name, resolver in value.items():\n yield (key, resolver_name, resolver)\n\n return chain.from_iterable(flatten(m) for m in resolvers_maps)\n\n\ndef merge_resolvers(resolver_list: Iterator[tuple]) -> dict:\n output = defaultdict(dict) # type: dict\n for key, resolver_name, resolver in resolver_list:\n output[key][resolver_name] = resolver\n return output\n\n\ndef join_type_defs(type_defs: List[str]) -> str:\n return \"\\n\\n\".join(t.strip() for t in type_defs)\n\n\ndef make_executable_schema(\n type_defs: Union[str, List[str]], resolvers: Union[dict, List[dict]]\n) -> GraphQLSchema:\n if isinstance(type_defs, list):\n type_defs = join_type_defs(type_defs)\n\n schema = build_schema_from_type_definitions(type_defs)\n\n if isinstance(resolvers, list):\n add_resolve_functions_to_schema(\n schema, merge_resolvers(decompose_maps(resolvers))\n )\n elif isinstance(resolvers, dict):\n add_resolve_functions_to_schema(schema, resolvers)\n\n return schema\n", "path": "ariadne/executable_schema.py"}, {"content": "from graphql import GraphQLSchema, parse\nfrom graphql.language.ast import (\n Document,\n ObjectTypeDefinition,\n OperationTypeDefinition,\n Name,\n NamedType,\n SchemaDefinition,\n)\nfrom graphql.utils.build_ast_schema import build_ast_schema\n\n\ndef build_schema_from_type_definitions(type_defs: str) -> GraphQLSchema:\n document = parse(type_defs)\n\n if not document_has_schema(document):\n schema_definition = build_default_schema(document)\n document.definitions.append(schema_definition)\n\n return build_ast_schema(document)\n\n\ndef build_default_schema(document: Document) -> SchemaDefinition:\n defined_types = [\n td.name.value\n for td in document.definitions\n if isinstance(td, ObjectTypeDefinition)\n ]\n operations = []\n if \"Query\" in defined_types:\n operations.append(\n OperationTypeDefinition(\"query\", type=NamedType(name=Name(\"Query\")))\n )\n if \"Mutation\" in defined_types:\n operations.append(\n OperationTypeDefinition(\"mutation\", type=NamedType(name=Name(\"Mutation\")))\n )\n if \"Subscription\" in defined_types:\n operations.append(\n OperationTypeDefinition(\n \"subscription\", type=NamedType(name=Name(\"Subscription\"))\n )\n )\n return SchemaDefinition(operation_types=operations, directives=[])\n\n\ndef document_has_schema(document: Document) -> bool:\n return any(isinstance(td, SchemaDefinition) for td in document.definitions)\n", "path": "ariadne/build_schema.py"}]}
| 1,041 | 709 |
gh_patches_debug_8225
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-2049
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Crash for Resize augmentation on masks
### Describe the bug
The default `extra_args` added for operating on masks cause the underlying `torch.nn.functional.interpolate` to crash - bad combination of `interpolation` mode Resample.NEAREST and `align_corners=True`. Interpolate wants to not be set (None) when using nearest neighbour interpolation:
```
ValueError: align_corners option can only be set with the interpolating modes: linear | bilinear | bicubic | trilinear
```
### Reproduction steps
```bash
import kornia.augmentation as K
import torch
from kornia.constants import DataKey
img = torch.zeros((3,5,5))
mask = torch.zeros((1,5,5))
data_keys= [DataKey.INPUT, DataKey.MASK]
aug = K.AugmentationSequential(K.Resize(2), data_keys=data_keys)
transformed = aug(img, mask)
```
### Expected behavior
No crashes and correct computation of resize op.
### Environment
```shell
Collecting environment information...
PyTorch version: 1.10.2
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.7.15 (default, Nov 24 2022, 21:12:53) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-4.15.0-196-generic-x86_64-with-debian-buster-sid
Is CUDA available: False
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: NVIDIA TITAN X (Pascal)
GPU 1: NVIDIA TITAN X (Pascal)
GPU 2: NVIDIA TITAN Xp
Nvidia driver version: 520.61.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.10.2
[pip3] torchvision==0.2.2
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] mypy 0.991 pypi_0 pypi
[conda] mypy-extensions 0.4.3 pypi_0 pypi
[conda] numpy 1.21.5 py37h6c91a56_3
[conda] numpy-base 1.21.5 py37ha15fc14_3
[conda] pytorch 1.10.2 cpu_py37hfa7516b_0
[conda] torchvision 0.2.2 py_3 pytorch
```
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kornia/augmentation/_2d/geometric/resize.py`
Content:
```
1 from typing import Any, Dict, Optional, Tuple, Union
2
3 import torch
4
5 from kornia.augmentation import random_generator as rg
6 from kornia.augmentation._2d.geometric.base import GeometricAugmentationBase2D
7 from kornia.constants import Resample
8 from kornia.core import Tensor
9 from kornia.geometry.transform import crop_by_transform_mat, get_perspective_transform, resize
10 from kornia.utils import eye_like
11
12
13 class Resize(GeometricAugmentationBase2D):
14 """Resize to size.
15
16 Args:
17 size: Size (h, w) in pixels of the resized region or just one side.
18 side: Which side to resize, if size is only of type int.
19 resample: Resampling mode.
20 align_corners: interpolation flag.
21 antialias: if True, then image will be filtered with Gaussian before downscaling. No effect for upscaling.
22 keepdim: whether to keep the output shape the same as input (True) or broadcast it
23 to the batch form (False).
24 """
25
26 def __init__(
27 self,
28 size: Union[int, Tuple[int, int]],
29 side: str = "short",
30 resample: Union[str, int, Resample] = Resample.BILINEAR.name,
31 align_corners: bool = True,
32 antialias: bool = False,
33 p: float = 1.0,
34 return_transform: Optional[bool] = None,
35 keepdim: bool = False,
36 ) -> None:
37 super().__init__(p=1.0, return_transform=return_transform, same_on_batch=True, p_batch=p, keepdim=keepdim)
38 self._param_generator = rg.ResizeGenerator(resize_to=size, side=side)
39 self.flags = dict(
40 size=size, side=side, resample=Resample.get(resample), align_corners=align_corners, antialias=antialias
41 )
42
43 def compute_transformation(self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any]) -> Tensor:
44 if params["output_size"] == input.shape[-2:]:
45 return eye_like(3, input)
46
47 transform: Tensor = get_perspective_transform(params["src"], params["dst"])
48 transform = transform.expand(input.shape[0], -1, -1)
49 return transform
50
51 def apply_transform(
52 self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any], transform: Optional[Tensor] = None
53 ) -> Tensor:
54 B, C, _, _ = input.shape
55 out_size = tuple(params["output_size"][0].tolist())
56 out = torch.empty(B, C, *out_size, device=input.device, dtype=input.dtype)
57
58 for i in range(B):
59 x1 = int(params["src"][i, 0, 0])
60 x2 = int(params["src"][i, 1, 0]) + 1
61 y1 = int(params["src"][i, 0, 1])
62 y2 = int(params["src"][i, 3, 1]) + 1
63 out[i] = resize(
64 input[i : i + 1, :, y1:y2, x1:x2],
65 out_size,
66 interpolation=flags["resample"].name.lower(),
67 align_corners=flags["align_corners"],
68 antialias=flags["antialias"],
69 )
70 return out
71
72 def inverse_transform(
73 self,
74 input: Tensor,
75 flags: Dict[str, Any],
76 transform: Optional[Tensor] = None,
77 size: Optional[Tuple[int, int]] = None,
78 ) -> Tensor:
79 if not isinstance(size, tuple):
80 raise TypeError(f'Expected the size be a tuple. Gotcha {type(size)}')
81
82 if not isinstance(transform, Tensor):
83 raise TypeError(f'Expected the transform be a Tensor. Gotcha {type(transform)}')
84
85 return crop_by_transform_mat(
86 input, transform[:, :2, :], size, flags["resample"], flags["padding_mode"], flags["align_corners"]
87 )
88
89
90 class LongestMaxSize(Resize):
91 """Rescale an image so that maximum side is equal to max_size, keeping the aspect ratio of the initial image.
92
93 Args:
94 max_size: maximum size of the image after the transformation.
95 """
96
97 def __init__(
98 self,
99 max_size: int,
100 resample: Union[str, int, Resample] = Resample.BILINEAR.name,
101 align_corners: bool = True,
102 p: float = 1.0,
103 return_transform: Optional[bool] = None,
104 ) -> None:
105 # TODO: Support max_size list input to randomly select from
106 super().__init__(
107 size=max_size,
108 side="long",
109 resample=resample,
110 return_transform=return_transform,
111 align_corners=align_corners,
112 p=p,
113 )
114
115
116 class SmallestMaxSize(Resize):
117 """Rescale an image so that minimum side is equal to max_size, keeping the aspect ratio of the initial image.
118
119 Args:
120 max_size: maximum size of the image after the transformation.
121 """
122
123 def __init__(
124 self,
125 max_size: int,
126 resample: Union[str, int, Resample] = Resample.BILINEAR.name,
127 align_corners: bool = True,
128 p: float = 1.0,
129 return_transform: Optional[bool] = None,
130 ) -> None:
131 # TODO: Support max_size list input to randomly select from
132 super().__init__(
133 size=max_size,
134 side="short",
135 resample=resample,
136 return_transform=return_transform,
137 align_corners=align_corners,
138 p=p,
139 )
140
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kornia/augmentation/_2d/geometric/resize.py b/kornia/augmentation/_2d/geometric/resize.py
--- a/kornia/augmentation/_2d/geometric/resize.py
+++ b/kornia/augmentation/_2d/geometric/resize.py
@@ -64,7 +64,9 @@
input[i : i + 1, :, y1:y2, x1:x2],
out_size,
interpolation=flags["resample"].name.lower(),
- align_corners=flags["align_corners"],
+ align_corners=flags["align_corners"]
+ if flags["resample"] in [Resample.BILINEAR, Resample.BICUBIC]
+ else None,
antialias=flags["antialias"],
)
return out
|
{"golden_diff": "diff --git a/kornia/augmentation/_2d/geometric/resize.py b/kornia/augmentation/_2d/geometric/resize.py\n--- a/kornia/augmentation/_2d/geometric/resize.py\n+++ b/kornia/augmentation/_2d/geometric/resize.py\n@@ -64,7 +64,9 @@\n input[i : i + 1, :, y1:y2, x1:x2],\n out_size,\n interpolation=flags[\"resample\"].name.lower(),\n- align_corners=flags[\"align_corners\"],\n+ align_corners=flags[\"align_corners\"]\n+ if flags[\"resample\"] in [Resample.BILINEAR, Resample.BICUBIC]\n+ else None,\n antialias=flags[\"antialias\"],\n )\n return out\n", "issue": "Crash for Resize augmentation on masks\n### Describe the bug\r\n\r\nThe default `extra_args` added for operating on masks cause the underlying `torch.nn.functional.interpolate` to crash - bad combination of `interpolation` mode Resample.NEAREST and `align_corners=True`. Interpolate wants to not be set (None) when using nearest neighbour interpolation:\r\n\r\n```\r\nValueError: align_corners option can only be set with the interpolating modes: linear | bilinear | bicubic | trilinear\r\n```\r\n \r\n### Reproduction steps\r\n\r\n```bash\r\nimport kornia.augmentation as K\r\nimport torch\r\nfrom kornia.constants import DataKey\r\n\r\nimg = torch.zeros((3,5,5))\r\nmask = torch.zeros((1,5,5))\r\n\r\ndata_keys= [DataKey.INPUT, DataKey.MASK]\r\naug = K.AugmentationSequential(K.Resize(2), data_keys=data_keys)\r\ntransformed = aug(img, mask)\r\n```\r\n\r\n\r\n### Expected behavior\r\n\r\nNo crashes and correct computation of resize op.\r\n\r\n### Environment\r\n\r\n```shell\r\nCollecting environment information...\r\nPyTorch version: 1.10.2\r\nIs debug build: False\r\nCUDA used to build PyTorch: Could not collect\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: Ubuntu 18.04.6 LTS (x86_64)\r\nGCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0\r\nClang version: Could not collect\r\nCMake version: Could not collect\r\nLibc version: glibc-2.17\r\n\r\nPython version: 3.7.15 (default, Nov 24 2022, 21:12:53) [GCC 11.2.0] (64-bit runtime)\r\nPython platform: Linux-4.15.0-196-generic-x86_64-with-debian-buster-sid\r\nIs CUDA available: False\r\nCUDA runtime version: Could not collect\r\nGPU models and configuration:\r\nGPU 0: NVIDIA TITAN X (Pascal)\r\nGPU 1: NVIDIA TITAN X (Pascal)\r\nGPU 2: NVIDIA TITAN Xp\r\n\r\nNvidia driver version: 520.61.05\r\ncuDNN version: Could not collect\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\n\r\nVersions of relevant libraries:\r\n[pip3] mypy==0.991\r\n[pip3] mypy-extensions==0.4.3\r\n[pip3] numpy==1.21.5\r\n[pip3] torch==1.10.2\r\n[pip3] torchvision==0.2.2\r\n[conda] blas 1.0 mkl\r\n[conda] cudatoolkit 10.2.89 hfd86e86_1\r\n[conda] mkl 2021.4.0 h06a4308_640\r\n[conda] mkl-service 2.4.0 py37h7f8727e_0\r\n[conda] mkl_fft 1.3.1 py37hd3c417c_0\r\n[conda] mkl_random 1.2.2 py37h51133e4_0\r\n[conda] mypy 0.991 pypi_0 pypi\r\n[conda] mypy-extensions 0.4.3 pypi_0 pypi\r\n[conda] numpy 1.21.5 py37h6c91a56_3\r\n[conda] numpy-base 1.21.5 py37ha15fc14_3\r\n[conda] pytorch 1.10.2 cpu_py37hfa7516b_0\r\n[conda] torchvision 0.2.2 py_3 pytorch\r\n```\r\n\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "from typing import Any, Dict, Optional, Tuple, Union\n\nimport torch\n\nfrom kornia.augmentation import random_generator as rg\nfrom kornia.augmentation._2d.geometric.base import GeometricAugmentationBase2D\nfrom kornia.constants import Resample\nfrom kornia.core import Tensor\nfrom kornia.geometry.transform import crop_by_transform_mat, get_perspective_transform, resize\nfrom kornia.utils import eye_like\n\n\nclass Resize(GeometricAugmentationBase2D):\n \"\"\"Resize to size.\n\n Args:\n size: Size (h, w) in pixels of the resized region or just one side.\n side: Which side to resize, if size is only of type int.\n resample: Resampling mode.\n align_corners: interpolation flag.\n antialias: if True, then image will be filtered with Gaussian before downscaling. No effect for upscaling.\n keepdim: whether to keep the output shape the same as input (True) or broadcast it\n to the batch form (False).\n \"\"\"\n\n def __init__(\n self,\n size: Union[int, Tuple[int, int]],\n side: str = \"short\",\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n antialias: bool = False,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n keepdim: bool = False,\n ) -> None:\n super().__init__(p=1.0, return_transform=return_transform, same_on_batch=True, p_batch=p, keepdim=keepdim)\n self._param_generator = rg.ResizeGenerator(resize_to=size, side=side)\n self.flags = dict(\n size=size, side=side, resample=Resample.get(resample), align_corners=align_corners, antialias=antialias\n )\n\n def compute_transformation(self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any]) -> Tensor:\n if params[\"output_size\"] == input.shape[-2:]:\n return eye_like(3, input)\n\n transform: Tensor = get_perspective_transform(params[\"src\"], params[\"dst\"])\n transform = transform.expand(input.shape[0], -1, -1)\n return transform\n\n def apply_transform(\n self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any], transform: Optional[Tensor] = None\n ) -> Tensor:\n B, C, _, _ = input.shape\n out_size = tuple(params[\"output_size\"][0].tolist())\n out = torch.empty(B, C, *out_size, device=input.device, dtype=input.dtype)\n\n for i in range(B):\n x1 = int(params[\"src\"][i, 0, 0])\n x2 = int(params[\"src\"][i, 1, 0]) + 1\n y1 = int(params[\"src\"][i, 0, 1])\n y2 = int(params[\"src\"][i, 3, 1]) + 1\n out[i] = resize(\n input[i : i + 1, :, y1:y2, x1:x2],\n out_size,\n interpolation=flags[\"resample\"].name.lower(),\n align_corners=flags[\"align_corners\"],\n antialias=flags[\"antialias\"],\n )\n return out\n\n def inverse_transform(\n self,\n input: Tensor,\n flags: Dict[str, Any],\n transform: Optional[Tensor] = None,\n size: Optional[Tuple[int, int]] = None,\n ) -> Tensor:\n if not isinstance(size, tuple):\n raise TypeError(f'Expected the size be a tuple. Gotcha {type(size)}')\n\n if not isinstance(transform, Tensor):\n raise TypeError(f'Expected the transform be a Tensor. Gotcha {type(transform)}')\n\n return crop_by_transform_mat(\n input, transform[:, :2, :], size, flags[\"resample\"], flags[\"padding_mode\"], flags[\"align_corners\"]\n )\n\n\nclass LongestMaxSize(Resize):\n \"\"\"Rescale an image so that maximum side is equal to max_size, keeping the aspect ratio of the initial image.\n\n Args:\n max_size: maximum size of the image after the transformation.\n \"\"\"\n\n def __init__(\n self,\n max_size: int,\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n ) -> None:\n # TODO: Support max_size list input to randomly select from\n super().__init__(\n size=max_size,\n side=\"long\",\n resample=resample,\n return_transform=return_transform,\n align_corners=align_corners,\n p=p,\n )\n\n\nclass SmallestMaxSize(Resize):\n \"\"\"Rescale an image so that minimum side is equal to max_size, keeping the aspect ratio of the initial image.\n\n Args:\n max_size: maximum size of the image after the transformation.\n \"\"\"\n\n def __init__(\n self,\n max_size: int,\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n ) -> None:\n # TODO: Support max_size list input to randomly select from\n super().__init__(\n size=max_size,\n side=\"short\",\n resample=resample,\n return_transform=return_transform,\n align_corners=align_corners,\n p=p,\n )\n", "path": "kornia/augmentation/_2d/geometric/resize.py"}], "after_files": [{"content": "from typing import Any, Dict, Optional, Tuple, Union\n\nimport torch\n\nfrom kornia.augmentation import random_generator as rg\nfrom kornia.augmentation._2d.geometric.base import GeometricAugmentationBase2D\nfrom kornia.constants import Resample\nfrom kornia.core import Tensor\nfrom kornia.geometry.transform import crop_by_transform_mat, get_perspective_transform, resize\nfrom kornia.utils import eye_like\n\n\nclass Resize(GeometricAugmentationBase2D):\n \"\"\"Resize to size.\n\n Args:\n size: Size (h, w) in pixels of the resized region or just one side.\n side: Which side to resize, if size is only of type int.\n resample: Resampling mode.\n align_corners: interpolation flag.\n antialias: if True, then image will be filtered with Gaussian before downscaling. No effect for upscaling.\n keepdim: whether to keep the output shape the same as input (True) or broadcast it\n to the batch form (False).\n \"\"\"\n\n def __init__(\n self,\n size: Union[int, Tuple[int, int]],\n side: str = \"short\",\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n antialias: bool = False,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n keepdim: bool = False,\n ) -> None:\n super().__init__(p=1.0, return_transform=return_transform, same_on_batch=True, p_batch=p, keepdim=keepdim)\n self._param_generator = rg.ResizeGenerator(resize_to=size, side=side)\n self.flags = dict(\n size=size, side=side, resample=Resample.get(resample), align_corners=align_corners, antialias=antialias\n )\n\n def compute_transformation(self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any]) -> Tensor:\n if params[\"output_size\"] == input.shape[-2:]:\n return eye_like(3, input)\n\n transform: Tensor = get_perspective_transform(params[\"src\"], params[\"dst\"])\n transform = transform.expand(input.shape[0], -1, -1)\n return transform\n\n def apply_transform(\n self, input: Tensor, params: Dict[str, Tensor], flags: Dict[str, Any], transform: Optional[Tensor] = None\n ) -> Tensor:\n B, C, _, _ = input.shape\n out_size = tuple(params[\"output_size\"][0].tolist())\n out = torch.empty(B, C, *out_size, device=input.device, dtype=input.dtype)\n\n for i in range(B):\n x1 = int(params[\"src\"][i, 0, 0])\n x2 = int(params[\"src\"][i, 1, 0]) + 1\n y1 = int(params[\"src\"][i, 0, 1])\n y2 = int(params[\"src\"][i, 3, 1]) + 1\n out[i] = resize(\n input[i : i + 1, :, y1:y2, x1:x2],\n out_size,\n interpolation=flags[\"resample\"].name.lower(),\n align_corners=flags[\"align_corners\"]\n if flags[\"resample\"] in [Resample.BILINEAR, Resample.BICUBIC]\n else None,\n antialias=flags[\"antialias\"],\n )\n return out\n\n def inverse_transform(\n self,\n input: Tensor,\n flags: Dict[str, Any],\n transform: Optional[Tensor] = None,\n size: Optional[Tuple[int, int]] = None,\n ) -> Tensor:\n if not isinstance(size, tuple):\n raise TypeError(f'Expected the size be a tuple. Gotcha {type(size)}')\n\n if not isinstance(transform, Tensor):\n raise TypeError(f'Expected the transform be a Tensor. Gotcha {type(transform)}')\n\n return crop_by_transform_mat(\n input, transform[:, :2, :], size, flags[\"resample\"], flags[\"padding_mode\"], flags[\"align_corners\"]\n )\n\n\nclass LongestMaxSize(Resize):\n \"\"\"Rescale an image so that maximum side is equal to max_size, keeping the aspect ratio of the initial image.\n\n Args:\n max_size: maximum size of the image after the transformation.\n \"\"\"\n\n def __init__(\n self,\n max_size: int,\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n ) -> None:\n # TODO: Support max_size list input to randomly select from\n super().__init__(\n size=max_size,\n side=\"long\",\n resample=resample,\n return_transform=return_transform,\n align_corners=align_corners,\n p=p,\n )\n\n\nclass SmallestMaxSize(Resize):\n \"\"\"Rescale an image so that minimum side is equal to max_size, keeping the aspect ratio of the initial image.\n\n Args:\n max_size: maximum size of the image after the transformation.\n \"\"\"\n\n def __init__(\n self,\n max_size: int,\n resample: Union[str, int, Resample] = Resample.BILINEAR.name,\n align_corners: bool = True,\n p: float = 1.0,\n return_transform: Optional[bool] = None,\n ) -> None:\n # TODO: Support max_size list input to randomly select from\n super().__init__(\n size=max_size,\n side=\"short\",\n resample=resample,\n return_transform=return_transform,\n align_corners=align_corners,\n p=p,\n )\n", "path": "kornia/augmentation/_2d/geometric/resize.py"}]}
| 2,707 | 178 |
gh_patches_debug_18394
|
rasdani/github-patches
|
git_diff
|
vega__altair-1888
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HTML renderer should use uuid in chart divs
Currently, divs are generated via chart counts. This means that if a kernel is restarted in the notebook, new charts may not display correctly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `altair/utils/display.py`
Content:
```
1 import json
2 import pkgutil
3 import textwrap
4 from typing import Callable, Dict
5
6 from jsonschema import validate
7
8 from .plugin_registry import PluginRegistry
9 from .mimebundle import spec_to_mimebundle
10
11
12 # ==============================================================================
13 # Renderer registry
14 # ==============================================================================
15 MimeBundleType = Dict[str, object]
16 RendererType = Callable[..., MimeBundleType]
17
18
19 class RendererRegistry(PluginRegistry[RendererType]):
20 entrypoint_err_messages = {
21 'notebook': textwrap.dedent(
22 """
23 To use the 'notebook' renderer, you must install the vega package
24 and the associated Jupyter extension.
25 See https://altair-viz.github.io/getting_started/installation.html
26 for more information.
27 """),
28 'vegascope': textwrap.dedent(
29 """
30 To use the 'vegascope' renderer, you must install the vegascope
31 package; see http://github.com/diana-hep/vegascope/
32 for more information.
33 """),
34 }
35
36 def set_embed_options(self, defaultStyle=None, renderer=None,
37 width=None, height=None, padding=None,
38 scaleFactor=None, actions=None, **kwargs):
39 """Set options for embeddings of Vega & Vega-Lite charts.
40
41 Options are fully documented at https://github.com/vega/vega-embed.
42 Similar to the `enable()` method, this can be used as either
43 a persistent global switch, or as a temporary local setting using
44 a context manager (i.e. a `with` statement).
45
46 Parameters
47 ----------
48 defaultStyle : bool or string
49 Specify a default stylesheet for embed actions.
50 renderer : string
51 The renderer to use for the view. One of "canvas" (default) or "svg"
52 width : integer
53 The view width in pixels
54 height : integer
55 The view height in pixels
56 padding : integer
57 The view padding in pixels
58 scaleFactor : number
59 The number by which to multiply the width and height (default 1)
60 of an exported PNG or SVG image.
61 actions : bool or dict
62 Determines if action links ("Export as PNG/SVG", "View Source",
63 "View Vega" (only for Vega-Lite), "Open in Vega Editor") are
64 included with the embedded view. If the value is true, all action
65 links will be shown and none if the value is false. This property
66 can take a key-value mapping object that maps keys (export, source,
67 compiled, editor) to boolean values for determining if
68 each action link should be shown.
69 **kwargs :
70 Additional options are passed directly to embed options.
71 """
72 options = {'defaultStyle': defaultStyle, 'renderer': renderer,
73 'width': width, 'height': height, 'padding': padding,
74 'scaleFactor': scaleFactor, 'actions': actions}
75 kwargs.update({key: val for key, val in options.items()
76 if val is not None})
77 return self.enable(None, embed_options=kwargs)
78
79
80 # ==============================================================================
81 # VegaLite v1/v2 renderer logic
82 # ==============================================================================
83
84
85 class Displayable(object):
86 """A base display class for VegaLite v1/v2.
87
88 This class takes a VegaLite v1/v2 spec and does the following:
89
90 1. Optionally validates the spec against a schema.
91 2. Uses the RendererPlugin to grab a renderer and call it when the
92 IPython/Jupyter display method (_repr_mimebundle_) is called.
93
94 The spec passed to this class must be fully schema compliant and already
95 have the data portion of the spec fully processed and ready to serialize.
96 In practice, this means, the data portion of the spec should have been passed
97 through appropriate data model transformers.
98 """
99
100 renderers = None
101 schema_path = ('altair', '')
102
103 def __init__(self, spec, validate=False):
104 # type: (dict, bool) -> None
105 self.spec = spec
106 self.validate = validate
107 self._validate()
108
109 def _validate(self):
110 # type: () -> None
111 """Validate the spec against the schema."""
112 schema_dict = json.loads(pkgutil.get_data(*self.schema_path).decode('utf-8'))
113 validate(self.spec, schema_dict)
114
115 def _repr_mimebundle_(self, include, exclude):
116 """Return a MIME bundle for display in Jupyter frontends."""
117 if self.renderers is not None:
118 return self.renderers.get()(self.spec)
119 else:
120 return {}
121
122
123 def default_renderer_base(spec, mime_type, str_repr, **options):
124 """A default renderer for Vega or VegaLite that works for modern frontends.
125
126 This renderer works with modern frontends (JupyterLab, nteract) that know
127 how to render the custom VegaLite MIME type listed above.
128 """
129 assert isinstance(spec, dict)
130 bundle = {}
131 metadata = {}
132
133 bundle[mime_type] = spec
134 bundle['text/plain'] = str_repr
135 if options:
136 metadata[mime_type] = options
137 return bundle, metadata
138
139
140 def json_renderer_base(spec, str_repr, **options):
141 """A renderer that returns a MIME type of application/json.
142
143 In JupyterLab/nteract this is rendered as a nice JSON tree.
144 """
145 return default_renderer_base(spec, mime_type='application/json',
146 str_repr=str_repr, **options)
147
148
149 class HTMLRenderer(object):
150 """Object to render charts as HTML, with a unique output div each time"""
151 def __init__(self, output_div='altair-viz-{}', **kwargs):
152 self._output_div = output_div
153 self._output_count = 0
154 self.kwargs = kwargs
155
156 @property
157 def output_div(self):
158 self._output_count += 1
159 return self._output_div.format(self._output_count)
160
161 def __call__(self, spec, **metadata):
162 kwargs = self.kwargs.copy()
163 kwargs.update(metadata)
164 return spec_to_mimebundle(spec, format='html',
165 output_div=self.output_div, **kwargs)
166
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/altair/utils/display.py b/altair/utils/display.py
--- a/altair/utils/display.py
+++ b/altair/utils/display.py
@@ -2,6 +2,7 @@
import pkgutil
import textwrap
from typing import Callable, Dict
+import uuid
from jsonschema import validate
@@ -150,13 +151,11 @@
"""Object to render charts as HTML, with a unique output div each time"""
def __init__(self, output_div='altair-viz-{}', **kwargs):
self._output_div = output_div
- self._output_count = 0
self.kwargs = kwargs
@property
def output_div(self):
- self._output_count += 1
- return self._output_div.format(self._output_count)
+ return self._output_div.format(uuid.uuid4().hex)
def __call__(self, spec, **metadata):
kwargs = self.kwargs.copy()
|
{"golden_diff": "diff --git a/altair/utils/display.py b/altair/utils/display.py\n--- a/altair/utils/display.py\n+++ b/altair/utils/display.py\n@@ -2,6 +2,7 @@\n import pkgutil\n import textwrap\n from typing import Callable, Dict\n+import uuid\n \n from jsonschema import validate\n \n@@ -150,13 +151,11 @@\n \"\"\"Object to render charts as HTML, with a unique output div each time\"\"\"\n def __init__(self, output_div='altair-viz-{}', **kwargs):\n self._output_div = output_div\n- self._output_count = 0\n self.kwargs = kwargs\n \n @property\n def output_div(self):\n- self._output_count += 1\n- return self._output_div.format(self._output_count)\n+ return self._output_div.format(uuid.uuid4().hex)\n \n def __call__(self, spec, **metadata):\n kwargs = self.kwargs.copy()\n", "issue": "HTML renderer should use uuid in chart divs\nCurrently, divs are generated via chart counts. This means that if a kernel is restarted in the notebook, new charts may not display correctly.\n", "before_files": [{"content": "import json\nimport pkgutil\nimport textwrap\nfrom typing import Callable, Dict\n\nfrom jsonschema import validate\n\nfrom .plugin_registry import PluginRegistry\nfrom .mimebundle import spec_to_mimebundle\n\n\n# ==============================================================================\n# Renderer registry\n# ==============================================================================\nMimeBundleType = Dict[str, object]\nRendererType = Callable[..., MimeBundleType]\n\n\nclass RendererRegistry(PluginRegistry[RendererType]):\n entrypoint_err_messages = {\n 'notebook': textwrap.dedent(\n \"\"\"\n To use the 'notebook' renderer, you must install the vega package\n and the associated Jupyter extension.\n See https://altair-viz.github.io/getting_started/installation.html\n for more information.\n \"\"\"),\n 'vegascope': textwrap.dedent(\n \"\"\"\n To use the 'vegascope' renderer, you must install the vegascope\n package; see http://github.com/diana-hep/vegascope/\n for more information.\n \"\"\"),\n }\n\n def set_embed_options(self, defaultStyle=None, renderer=None,\n width=None, height=None, padding=None,\n scaleFactor=None, actions=None, **kwargs):\n \"\"\"Set options for embeddings of Vega & Vega-Lite charts.\n\n Options are fully documented at https://github.com/vega/vega-embed.\n Similar to the `enable()` method, this can be used as either\n a persistent global switch, or as a temporary local setting using\n a context manager (i.e. a `with` statement).\n\n Parameters\n ----------\n defaultStyle : bool or string\n Specify a default stylesheet for embed actions.\n renderer : string\n The renderer to use for the view. One of \"canvas\" (default) or \"svg\"\n width : integer\n The view width in pixels\n height : integer\n The view height in pixels\n padding : integer\n The view padding in pixels\n scaleFactor : number\n The number by which to multiply the width and height (default 1)\n of an exported PNG or SVG image.\n actions : bool or dict\n Determines if action links (\"Export as PNG/SVG\", \"View Source\",\n \"View Vega\" (only for Vega-Lite), \"Open in Vega Editor\") are\n included with the embedded view. If the value is true, all action\n links will be shown and none if the value is false. This property\n can take a key-value mapping object that maps keys (export, source,\n compiled, editor) to boolean values for determining if\n each action link should be shown.\n **kwargs :\n Additional options are passed directly to embed options.\n \"\"\"\n options = {'defaultStyle': defaultStyle, 'renderer': renderer,\n 'width': width, 'height': height, 'padding': padding,\n 'scaleFactor': scaleFactor, 'actions': actions}\n kwargs.update({key: val for key, val in options.items()\n if val is not None})\n return self.enable(None, embed_options=kwargs)\n\n\n# ==============================================================================\n# VegaLite v1/v2 renderer logic\n# ==============================================================================\n\n\nclass Displayable(object):\n \"\"\"A base display class for VegaLite v1/v2.\n\n This class takes a VegaLite v1/v2 spec and does the following:\n\n 1. Optionally validates the spec against a schema.\n 2. Uses the RendererPlugin to grab a renderer and call it when the\n IPython/Jupyter display method (_repr_mimebundle_) is called.\n\n The spec passed to this class must be fully schema compliant and already\n have the data portion of the spec fully processed and ready to serialize.\n In practice, this means, the data portion of the spec should have been passed\n through appropriate data model transformers.\n \"\"\"\n\n renderers = None\n schema_path = ('altair', '')\n\n def __init__(self, spec, validate=False):\n # type: (dict, bool) -> None\n self.spec = spec\n self.validate = validate\n self._validate()\n\n def _validate(self):\n # type: () -> None\n \"\"\"Validate the spec against the schema.\"\"\"\n schema_dict = json.loads(pkgutil.get_data(*self.schema_path).decode('utf-8'))\n validate(self.spec, schema_dict)\n\n def _repr_mimebundle_(self, include, exclude):\n \"\"\"Return a MIME bundle for display in Jupyter frontends.\"\"\"\n if self.renderers is not None:\n return self.renderers.get()(self.spec)\n else:\n return {}\n\n\ndef default_renderer_base(spec, mime_type, str_repr, **options):\n \"\"\"A default renderer for Vega or VegaLite that works for modern frontends.\n\n This renderer works with modern frontends (JupyterLab, nteract) that know\n how to render the custom VegaLite MIME type listed above.\n \"\"\"\n assert isinstance(spec, dict)\n bundle = {}\n metadata = {}\n\n bundle[mime_type] = spec\n bundle['text/plain'] = str_repr\n if options:\n metadata[mime_type] = options\n return bundle, metadata\n\n\ndef json_renderer_base(spec, str_repr, **options):\n \"\"\"A renderer that returns a MIME type of application/json.\n\n In JupyterLab/nteract this is rendered as a nice JSON tree.\n \"\"\"\n return default_renderer_base(spec, mime_type='application/json',\n str_repr=str_repr, **options)\n\n\nclass HTMLRenderer(object):\n \"\"\"Object to render charts as HTML, with a unique output div each time\"\"\"\n def __init__(self, output_div='altair-viz-{}', **kwargs):\n self._output_div = output_div\n self._output_count = 0\n self.kwargs = kwargs\n\n @property\n def output_div(self):\n self._output_count += 1\n return self._output_div.format(self._output_count)\n\n def __call__(self, spec, **metadata):\n kwargs = self.kwargs.copy()\n kwargs.update(metadata)\n return spec_to_mimebundle(spec, format='html',\n output_div=self.output_div, **kwargs)\n", "path": "altair/utils/display.py"}], "after_files": [{"content": "import json\nimport pkgutil\nimport textwrap\nfrom typing import Callable, Dict\nimport uuid\n\nfrom jsonschema import validate\n\nfrom .plugin_registry import PluginRegistry\nfrom .mimebundle import spec_to_mimebundle\n\n\n# ==============================================================================\n# Renderer registry\n# ==============================================================================\nMimeBundleType = Dict[str, object]\nRendererType = Callable[..., MimeBundleType]\n\n\nclass RendererRegistry(PluginRegistry[RendererType]):\n entrypoint_err_messages = {\n 'notebook': textwrap.dedent(\n \"\"\"\n To use the 'notebook' renderer, you must install the vega package\n and the associated Jupyter extension.\n See https://altair-viz.github.io/getting_started/installation.html\n for more information.\n \"\"\"),\n 'vegascope': textwrap.dedent(\n \"\"\"\n To use the 'vegascope' renderer, you must install the vegascope\n package; see http://github.com/diana-hep/vegascope/\n for more information.\n \"\"\"),\n }\n\n def set_embed_options(self, defaultStyle=None, renderer=None,\n width=None, height=None, padding=None,\n scaleFactor=None, actions=None, **kwargs):\n \"\"\"Set options for embeddings of Vega & Vega-Lite charts.\n\n Options are fully documented at https://github.com/vega/vega-embed.\n Similar to the `enable()` method, this can be used as either\n a persistent global switch, or as a temporary local setting using\n a context manager (i.e. a `with` statement).\n\n Parameters\n ----------\n defaultStyle : bool or string\n Specify a default stylesheet for embed actions.\n renderer : string\n The renderer to use for the view. One of \"canvas\" (default) or \"svg\"\n width : integer\n The view width in pixels\n height : integer\n The view height in pixels\n padding : integer\n The view padding in pixels\n scaleFactor : number\n The number by which to multiply the width and height (default 1)\n of an exported PNG or SVG image.\n actions : bool or dict\n Determines if action links (\"Export as PNG/SVG\", \"View Source\",\n \"View Vega\" (only for Vega-Lite), \"Open in Vega Editor\") are\n included with the embedded view. If the value is true, all action\n links will be shown and none if the value is false. This property\n can take a key-value mapping object that maps keys (export, source,\n compiled, editor) to boolean values for determining if\n each action link should be shown.\n **kwargs :\n Additional options are passed directly to embed options.\n \"\"\"\n options = {'defaultStyle': defaultStyle, 'renderer': renderer,\n 'width': width, 'height': height, 'padding': padding,\n 'scaleFactor': scaleFactor, 'actions': actions}\n kwargs.update({key: val for key, val in options.items()\n if val is not None})\n return self.enable(None, embed_options=kwargs)\n\n\n# ==============================================================================\n# VegaLite v1/v2 renderer logic\n# ==============================================================================\n\n\nclass Displayable(object):\n \"\"\"A base display class for VegaLite v1/v2.\n\n This class takes a VegaLite v1/v2 spec and does the following:\n\n 1. Optionally validates the spec against a schema.\n 2. Uses the RendererPlugin to grab a renderer and call it when the\n IPython/Jupyter display method (_repr_mimebundle_) is called.\n\n The spec passed to this class must be fully schema compliant and already\n have the data portion of the spec fully processed and ready to serialize.\n In practice, this means, the data portion of the spec should have been passed\n through appropriate data model transformers.\n \"\"\"\n\n renderers = None\n schema_path = ('altair', '')\n\n def __init__(self, spec, validate=False):\n # type: (dict, bool) -> None\n self.spec = spec\n self.validate = validate\n self._validate()\n\n def _validate(self):\n # type: () -> None\n \"\"\"Validate the spec against the schema.\"\"\"\n schema_dict = json.loads(pkgutil.get_data(*self.schema_path).decode('utf-8'))\n validate(self.spec, schema_dict)\n\n def _repr_mimebundle_(self, include, exclude):\n \"\"\"Return a MIME bundle for display in Jupyter frontends.\"\"\"\n if self.renderers is not None:\n return self.renderers.get()(self.spec)\n else:\n return {}\n\n\ndef default_renderer_base(spec, mime_type, str_repr, **options):\n \"\"\"A default renderer for Vega or VegaLite that works for modern frontends.\n\n This renderer works with modern frontends (JupyterLab, nteract) that know\n how to render the custom VegaLite MIME type listed above.\n \"\"\"\n assert isinstance(spec, dict)\n bundle = {}\n metadata = {}\n\n bundle[mime_type] = spec\n bundle['text/plain'] = str_repr\n if options:\n metadata[mime_type] = options\n return bundle, metadata\n\n\ndef json_renderer_base(spec, str_repr, **options):\n \"\"\"A renderer that returns a MIME type of application/json.\n\n In JupyterLab/nteract this is rendered as a nice JSON tree.\n \"\"\"\n return default_renderer_base(spec, mime_type='application/json',\n str_repr=str_repr, **options)\n\n\nclass HTMLRenderer(object):\n \"\"\"Object to render charts as HTML, with a unique output div each time\"\"\"\n def __init__(self, output_div='altair-viz-{}', **kwargs):\n self._output_div = output_div\n self.kwargs = kwargs\n\n @property\n def output_div(self):\n return self._output_div.format(uuid.uuid4().hex)\n\n def __call__(self, spec, **metadata):\n kwargs = self.kwargs.copy()\n kwargs.update(metadata)\n return spec_to_mimebundle(spec, format='html',\n output_div=self.output_div, **kwargs)\n", "path": "altair/utils/display.py"}]}
| 2,001 | 216 |
gh_patches_debug_36406
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-1565
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Deep Sigma Point Processes
Hi,
The DSPPs documentaiton makes it seem like theyare coded up very similarly to the standard Deep GPs, and this does seem true for[ two layers](https://docs.gpytorch.ai/en/stable/examples/05_Deep_Gaussian_Processes/Deep_Sigma_Point_Processes.html).
However, if I try to add a third layer (a second hidden layer) and update the input and output dims and make sure the forward call is correct, the loss function returns a vector rather than a single value (which the optimsier obviously doesn't like).
I'm guessing these losses are meant to be weighted according to the quadrature points. Is this true? Perhpas this could be more clear in the documentation (or alternatively, should this be done automatically in the backend?)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gpytorch/models/deep_gps/dspp.py`
Content:
```
1 import torch
2
3 from gpytorch import settings
4 from gpytorch.distributions import MultitaskMultivariateNormal
5 from gpytorch.lazy import BlockDiagLazyTensor
6
7 from ..approximate_gp import ApproximateGP
8 from .deep_gp import DeepGP, DeepGPLayer
9
10
11 class DSPPLayer(DeepGPLayer):
12 """
13 Represents a layer in a DSPP where inference is performed using the techniques defined in Jankowiak et al., 2020.
14
15 From an end user perspective, the functionality and usage of a DSPPLayer is essentially identical to that of a
16 DeepGPLayer. It is therefore recommended that you review the documentation for DeepGPLayer.
17
18 :param ~gpytorch.variational.VariationalStrategy variational_strategy: Strategy for
19 changing q(u) -> q(f) (see other VI docs)
20 :param int input_dims: Dimensionality of input data expected by each GP
21 :param int output_dims: (default None) Number of GPs in this layer, equivalent to
22 output dimensionality. If set to `None`, then the output dimension will be squashed.
23 :param int num_quad_sites: Number of quadrature sites to use. Also the number of Gaussians in the mixture output
24 by this layer.
25
26 Again, refer to the documentation for DeepGPLayer or our example notebooks for full details on what calling a
27 DSPPLayer module does. The high level overview is that if a tensor `x` is `n x d` then
28
29 >>> hidden_gp2(hidden_gp1(x))
30
31 will return a `num_quad_sites` by `output_dims` set of Gaussians, where for each output dim the first batch dim
32 represents a weighted mixture of `num_quad_sites` Gaussians with weights given by DSPP.quad_weights (see DSPP below)
33 """
34
35 def __init__(self, variational_strategy, input_dims, output_dims, num_quad_sites=3, quad_sites=None):
36 super().__init__(variational_strategy, input_dims, output_dims)
37
38 self.num_quad_sites = num_quad_sites
39
40 # Pass in previous_layer.quad_sites if you want to share quad_sites across layers.
41 if quad_sites is not None:
42 self.quad_sites = quad_sites
43 else:
44 self.quad_sites = torch.nn.Parameter(torch.randn(num_quad_sites, input_dims))
45
46 def __call__(self, inputs, are_samples=False, expand_for_quadgrid=True, **kwargs):
47 if isinstance(inputs, MultitaskMultivariateNormal):
48 # inputs is definitely in the second layer, and mean is n x t
49 mus, sigmas = inputs.mean, inputs.variance.sqrt()
50
51 if expand_for_quadgrid:
52 xi_mus = mus.unsqueeze(0) # 1 x n x t
53 xi_sigmas = sigmas.unsqueeze(0) # 1 x n x t
54 else:
55 xi_mus = mus
56 xi_sigmas = sigmas
57
58 # unsqueeze sigmas to 1 x n x t, locations from [q] to Q^T x 1 x T.
59 # Broadcasted result will be Q^T x N x T
60 qg = self.quad_sites.view([self.num_quad_sites] + [1] * (xi_mus.dim() - 2) + [self.input_dims])
61 xi_sigmas = xi_sigmas * qg
62
63 inputs = xi_mus + xi_sigmas # q^t x n x t
64 if settings.debug.on():
65 if not torch.is_tensor(inputs):
66 raise ValueError(
67 "`inputs` should either be a MultitaskMultivariateNormal or a Tensor, got "
68 f"{inputs.__class__.__Name__}"
69 )
70
71 if inputs.size(-1) != self.input_dims:
72 raise RuntimeError(
73 f"Input shape did not match self.input_dims. Got total feature dims [{inputs.size(-1)}],"
74 f" expected [{self.input_dims}]"
75 )
76
77 # Repeat the input for all possible outputs
78 if self.output_dims is not None:
79 inputs = inputs.unsqueeze(-3)
80 inputs = inputs.expand(*inputs.shape[:-3], self.output_dims, *inputs.shape[-2:])
81 # Now run samples through the GP
82 output = ApproximateGP.__call__(self, inputs, **kwargs)
83
84 if self.num_quad_sites > 0:
85 if self.output_dims is not None and not isinstance(output, MultitaskMultivariateNormal):
86 mean = output.loc.transpose(-1, -2)
87 covar = BlockDiagLazyTensor(output.lazy_covariance_matrix, block_dim=-3)
88 output = MultitaskMultivariateNormal(mean, covar, interleaved=False)
89 else:
90 output = output.loc.transpose(-1, -2) # this layer provides noiseless kernel interpolation
91
92 return output
93
94
95 class DSPP(DeepGP):
96 """
97 A container module to build a DSPP
98 This module should contain :obj:`~gpytorch.models.deep_gps.DSPPLayer`
99 modules, and can also contain other modules as well.
100
101 This Module contains an additional set of parameters, `raw_quad_weights`, that represent the mixture weights for
102 the output distribution.
103 """
104
105 def __init__(self, num_quad_sites):
106 super().__init__()
107 self.num_quad_sites = num_quad_sites
108 self.register_parameter("raw_quad_weights", torch.nn.Parameter(torch.randn(self.num_quad_sites)))
109
110 @property
111 def quad_weights(self):
112 qwd = self.raw_quad_weights
113 return qwd - qwd.logsumexp(dim=-1)
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gpytorch/models/deep_gps/dspp.py b/gpytorch/models/deep_gps/dspp.py
--- a/gpytorch/models/deep_gps/dspp.py
+++ b/gpytorch/models/deep_gps/dspp.py
@@ -43,24 +43,18 @@
else:
self.quad_sites = torch.nn.Parameter(torch.randn(num_quad_sites, input_dims))
- def __call__(self, inputs, are_samples=False, expand_for_quadgrid=True, **kwargs):
+ def __call__(self, inputs, **kwargs):
if isinstance(inputs, MultitaskMultivariateNormal):
- # inputs is definitely in the second layer, and mean is n x t
+ # This is for subsequent layers. We apply quadrature here
+ # Mean, stdv are q x ... x n x t
mus, sigmas = inputs.mean, inputs.variance.sqrt()
+ qg = self.quad_sites.view([self.num_quad_sites] + [1] * (mus.dim() - 2) + [self.input_dims])
+ sigmas = sigmas * qg
+ inputs = mus + sigmas # q^t x n x t
+ deterministic_inputs = False
+ else:
+ deterministic_inputs = True
- if expand_for_quadgrid:
- xi_mus = mus.unsqueeze(0) # 1 x n x t
- xi_sigmas = sigmas.unsqueeze(0) # 1 x n x t
- else:
- xi_mus = mus
- xi_sigmas = sigmas
-
- # unsqueeze sigmas to 1 x n x t, locations from [q] to Q^T x 1 x T.
- # Broadcasted result will be Q^T x N x T
- qg = self.quad_sites.view([self.num_quad_sites] + [1] * (xi_mus.dim() - 2) + [self.input_dims])
- xi_sigmas = xi_sigmas * qg
-
- inputs = xi_mus + xi_sigmas # q^t x n x t
if settings.debug.on():
if not torch.is_tensor(inputs):
raise ValueError(
@@ -78,9 +72,15 @@
if self.output_dims is not None:
inputs = inputs.unsqueeze(-3)
inputs = inputs.expand(*inputs.shape[:-3], self.output_dims, *inputs.shape[-2:])
+
# Now run samples through the GP
output = ApproximateGP.__call__(self, inputs, **kwargs)
+ # If this is the first layer (deterministic inputs), expand the output
+ # This allows quadrature to be applied to future layers
+ if deterministic_inputs:
+ output = output.expand(torch.Size([self.num_quad_sites]) + output.batch_shape)
+
if self.num_quad_sites > 0:
if self.output_dims is not None and not isinstance(output, MultitaskMultivariateNormal):
mean = output.loc.transpose(-1, -2)
|
{"golden_diff": "diff --git a/gpytorch/models/deep_gps/dspp.py b/gpytorch/models/deep_gps/dspp.py\n--- a/gpytorch/models/deep_gps/dspp.py\n+++ b/gpytorch/models/deep_gps/dspp.py\n@@ -43,24 +43,18 @@\n else:\n self.quad_sites = torch.nn.Parameter(torch.randn(num_quad_sites, input_dims))\n \n- def __call__(self, inputs, are_samples=False, expand_for_quadgrid=True, **kwargs):\n+ def __call__(self, inputs, **kwargs):\n if isinstance(inputs, MultitaskMultivariateNormal):\n- # inputs is definitely in the second layer, and mean is n x t\n+ # This is for subsequent layers. We apply quadrature here\n+ # Mean, stdv are q x ... x n x t\n mus, sigmas = inputs.mean, inputs.variance.sqrt()\n+ qg = self.quad_sites.view([self.num_quad_sites] + [1] * (mus.dim() - 2) + [self.input_dims])\n+ sigmas = sigmas * qg\n+ inputs = mus + sigmas # q^t x n x t\n+ deterministic_inputs = False\n+ else:\n+ deterministic_inputs = True\n \n- if expand_for_quadgrid:\n- xi_mus = mus.unsqueeze(0) # 1 x n x t\n- xi_sigmas = sigmas.unsqueeze(0) # 1 x n x t\n- else:\n- xi_mus = mus\n- xi_sigmas = sigmas\n-\n- # unsqueeze sigmas to 1 x n x t, locations from [q] to Q^T x 1 x T.\n- # Broadcasted result will be Q^T x N x T\n- qg = self.quad_sites.view([self.num_quad_sites] + [1] * (xi_mus.dim() - 2) + [self.input_dims])\n- xi_sigmas = xi_sigmas * qg\n-\n- inputs = xi_mus + xi_sigmas # q^t x n x t\n if settings.debug.on():\n if not torch.is_tensor(inputs):\n raise ValueError(\n@@ -78,9 +72,15 @@\n if self.output_dims is not None:\n inputs = inputs.unsqueeze(-3)\n inputs = inputs.expand(*inputs.shape[:-3], self.output_dims, *inputs.shape[-2:])\n+\n # Now run samples through the GP\n output = ApproximateGP.__call__(self, inputs, **kwargs)\n \n+ # If this is the first layer (deterministic inputs), expand the output\n+ # This allows quadrature to be applied to future layers\n+ if deterministic_inputs:\n+ output = output.expand(torch.Size([self.num_quad_sites]) + output.batch_shape)\n+\n if self.num_quad_sites > 0:\n if self.output_dims is not None and not isinstance(output, MultitaskMultivariateNormal):\n mean = output.loc.transpose(-1, -2)\n", "issue": "[Docs] Deep Sigma Point Processes\nHi,\r\n\r\nThe DSPPs documentaiton makes it seem like theyare coded up very similarly to the standard Deep GPs, and this does seem true for[ two layers](https://docs.gpytorch.ai/en/stable/examples/05_Deep_Gaussian_Processes/Deep_Sigma_Point_Processes.html). \r\n\r\nHowever, if I try to add a third layer (a second hidden layer) and update the input and output dims and make sure the forward call is correct, the loss function returns a vector rather than a single value (which the optimsier obviously doesn't like).\r\n\r\nI'm guessing these losses are meant to be weighted according to the quadrature points. Is this true? Perhpas this could be more clear in the documentation (or alternatively, should this be done automatically in the backend?)\n", "before_files": [{"content": "import torch\n\nfrom gpytorch import settings\nfrom gpytorch.distributions import MultitaskMultivariateNormal\nfrom gpytorch.lazy import BlockDiagLazyTensor\n\nfrom ..approximate_gp import ApproximateGP\nfrom .deep_gp import DeepGP, DeepGPLayer\n\n\nclass DSPPLayer(DeepGPLayer):\n \"\"\"\n Represents a layer in a DSPP where inference is performed using the techniques defined in Jankowiak et al., 2020.\n\n From an end user perspective, the functionality and usage of a DSPPLayer is essentially identical to that of a\n DeepGPLayer. It is therefore recommended that you review the documentation for DeepGPLayer.\n\n :param ~gpytorch.variational.VariationalStrategy variational_strategy: Strategy for\n changing q(u) -> q(f) (see other VI docs)\n :param int input_dims: Dimensionality of input data expected by each GP\n :param int output_dims: (default None) Number of GPs in this layer, equivalent to\n output dimensionality. If set to `None`, then the output dimension will be squashed.\n :param int num_quad_sites: Number of quadrature sites to use. Also the number of Gaussians in the mixture output\n by this layer.\n\n Again, refer to the documentation for DeepGPLayer or our example notebooks for full details on what calling a\n DSPPLayer module does. The high level overview is that if a tensor `x` is `n x d` then\n\n >>> hidden_gp2(hidden_gp1(x))\n\n will return a `num_quad_sites` by `output_dims` set of Gaussians, where for each output dim the first batch dim\n represents a weighted mixture of `num_quad_sites` Gaussians with weights given by DSPP.quad_weights (see DSPP below)\n \"\"\"\n\n def __init__(self, variational_strategy, input_dims, output_dims, num_quad_sites=3, quad_sites=None):\n super().__init__(variational_strategy, input_dims, output_dims)\n\n self.num_quad_sites = num_quad_sites\n\n # Pass in previous_layer.quad_sites if you want to share quad_sites across layers.\n if quad_sites is not None:\n self.quad_sites = quad_sites\n else:\n self.quad_sites = torch.nn.Parameter(torch.randn(num_quad_sites, input_dims))\n\n def __call__(self, inputs, are_samples=False, expand_for_quadgrid=True, **kwargs):\n if isinstance(inputs, MultitaskMultivariateNormal):\n # inputs is definitely in the second layer, and mean is n x t\n mus, sigmas = inputs.mean, inputs.variance.sqrt()\n\n if expand_for_quadgrid:\n xi_mus = mus.unsqueeze(0) # 1 x n x t\n xi_sigmas = sigmas.unsqueeze(0) # 1 x n x t\n else:\n xi_mus = mus\n xi_sigmas = sigmas\n\n # unsqueeze sigmas to 1 x n x t, locations from [q] to Q^T x 1 x T.\n # Broadcasted result will be Q^T x N x T\n qg = self.quad_sites.view([self.num_quad_sites] + [1] * (xi_mus.dim() - 2) + [self.input_dims])\n xi_sigmas = xi_sigmas * qg\n\n inputs = xi_mus + xi_sigmas # q^t x n x t\n if settings.debug.on():\n if not torch.is_tensor(inputs):\n raise ValueError(\n \"`inputs` should either be a MultitaskMultivariateNormal or a Tensor, got \"\n f\"{inputs.__class__.__Name__}\"\n )\n\n if inputs.size(-1) != self.input_dims:\n raise RuntimeError(\n f\"Input shape did not match self.input_dims. Got total feature dims [{inputs.size(-1)}],\"\n f\" expected [{self.input_dims}]\"\n )\n\n # Repeat the input for all possible outputs\n if self.output_dims is not None:\n inputs = inputs.unsqueeze(-3)\n inputs = inputs.expand(*inputs.shape[:-3], self.output_dims, *inputs.shape[-2:])\n # Now run samples through the GP\n output = ApproximateGP.__call__(self, inputs, **kwargs)\n\n if self.num_quad_sites > 0:\n if self.output_dims is not None and not isinstance(output, MultitaskMultivariateNormal):\n mean = output.loc.transpose(-1, -2)\n covar = BlockDiagLazyTensor(output.lazy_covariance_matrix, block_dim=-3)\n output = MultitaskMultivariateNormal(mean, covar, interleaved=False)\n else:\n output = output.loc.transpose(-1, -2) # this layer provides noiseless kernel interpolation\n\n return output\n\n\nclass DSPP(DeepGP):\n \"\"\"\n A container module to build a DSPP\n This module should contain :obj:`~gpytorch.models.deep_gps.DSPPLayer`\n modules, and can also contain other modules as well.\n\n This Module contains an additional set of parameters, `raw_quad_weights`, that represent the mixture weights for\n the output distribution.\n \"\"\"\n\n def __init__(self, num_quad_sites):\n super().__init__()\n self.num_quad_sites = num_quad_sites\n self.register_parameter(\"raw_quad_weights\", torch.nn.Parameter(torch.randn(self.num_quad_sites)))\n\n @property\n def quad_weights(self):\n qwd = self.raw_quad_weights\n return qwd - qwd.logsumexp(dim=-1)\n", "path": "gpytorch/models/deep_gps/dspp.py"}], "after_files": [{"content": "import torch\n\nfrom gpytorch import settings\nfrom gpytorch.distributions import MultitaskMultivariateNormal\nfrom gpytorch.lazy import BlockDiagLazyTensor\n\nfrom ..approximate_gp import ApproximateGP\nfrom .deep_gp import DeepGP, DeepGPLayer\n\n\nclass DSPPLayer(DeepGPLayer):\n \"\"\"\n Represents a layer in a DSPP where inference is performed using the techniques defined in Jankowiak et al., 2020.\n\n From an end user perspective, the functionality and usage of a DSPPLayer is essentially identical to that of a\n DeepGPLayer. It is therefore recommended that you review the documentation for DeepGPLayer.\n\n :param ~gpytorch.variational.VariationalStrategy variational_strategy: Strategy for\n changing q(u) -> q(f) (see other VI docs)\n :param int input_dims: Dimensionality of input data expected by each GP\n :param int output_dims: (default None) Number of GPs in this layer, equivalent to\n output dimensionality. If set to `None`, then the output dimension will be squashed.\n :param int num_quad_sites: Number of quadrature sites to use. Also the number of Gaussians in the mixture output\n by this layer.\n\n Again, refer to the documentation for DeepGPLayer or our example notebooks for full details on what calling a\n DSPPLayer module does. The high level overview is that if a tensor `x` is `n x d` then\n\n >>> hidden_gp2(hidden_gp1(x))\n\n will return a `num_quad_sites` by `output_dims` set of Gaussians, where for each output dim the first batch dim\n represents a weighted mixture of `num_quad_sites` Gaussians with weights given by DSPP.quad_weights (see DSPP below)\n \"\"\"\n\n def __init__(self, variational_strategy, input_dims, output_dims, num_quad_sites=3, quad_sites=None):\n super().__init__(variational_strategy, input_dims, output_dims)\n\n self.num_quad_sites = num_quad_sites\n\n # Pass in previous_layer.quad_sites if you want to share quad_sites across layers.\n if quad_sites is not None:\n self.quad_sites = quad_sites\n else:\n self.quad_sites = torch.nn.Parameter(torch.randn(num_quad_sites, input_dims))\n\n def __call__(self, inputs, **kwargs):\n if isinstance(inputs, MultitaskMultivariateNormal):\n # This is for subsequent layers. We apply quadrature here\n # Mean, stdv are q x ... x n x t\n mus, sigmas = inputs.mean, inputs.variance.sqrt()\n qg = self.quad_sites.view([self.num_quad_sites] + [1] * (mus.dim() - 2) + [self.input_dims])\n sigmas = sigmas * qg\n inputs = mus + sigmas # q^t x n x t\n deterministic_inputs = False\n else:\n deterministic_inputs = True\n\n if settings.debug.on():\n if not torch.is_tensor(inputs):\n raise ValueError(\n \"`inputs` should either be a MultitaskMultivariateNormal or a Tensor, got \"\n f\"{inputs.__class__.__Name__}\"\n )\n\n if inputs.size(-1) != self.input_dims:\n raise RuntimeError(\n f\"Input shape did not match self.input_dims. Got total feature dims [{inputs.size(-1)}],\"\n f\" expected [{self.input_dims}]\"\n )\n\n # Repeat the input for all possible outputs\n if self.output_dims is not None:\n inputs = inputs.unsqueeze(-3)\n inputs = inputs.expand(*inputs.shape[:-3], self.output_dims, *inputs.shape[-2:])\n\n # Now run samples through the GP\n output = ApproximateGP.__call__(self, inputs, **kwargs)\n\n # If this is the first layer (deterministic inputs), expand the output\n # This allows quadrature to be applied to future layers\n if deterministic_inputs:\n output = output.expand(torch.Size([self.num_quad_sites]) + output.batch_shape)\n\n if self.num_quad_sites > 0:\n if self.output_dims is not None and not isinstance(output, MultitaskMultivariateNormal):\n mean = output.loc.transpose(-1, -2)\n covar = BlockDiagLazyTensor(output.lazy_covariance_matrix, block_dim=-3)\n output = MultitaskMultivariateNormal(mean, covar, interleaved=False)\n else:\n output = output.loc.transpose(-1, -2) # this layer provides noiseless kernel interpolation\n\n return output\n\n\nclass DSPP(DeepGP):\n \"\"\"\n A container module to build a DSPP\n This module should contain :obj:`~gpytorch.models.deep_gps.DSPPLayer`\n modules, and can also contain other modules as well.\n\n This Module contains an additional set of parameters, `raw_quad_weights`, that represent the mixture weights for\n the output distribution.\n \"\"\"\n\n def __init__(self, num_quad_sites):\n super().__init__()\n self.num_quad_sites = num_quad_sites\n self.register_parameter(\"raw_quad_weights\", torch.nn.Parameter(torch.randn(self.num_quad_sites)))\n\n @property\n def quad_weights(self):\n qwd = self.raw_quad_weights\n return qwd - qwd.logsumexp(dim=-1)\n", "path": "gpytorch/models/deep_gps/dspp.py"}]}
| 1,877 | 671 |
gh_patches_debug_10331
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-2086
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pretrain models for FCN and DeepLabV3
Is it possible to provide the pretrain weight for deeplabv3 and FCN?
right now when i do:
`model = torchvision.models.segmentation.fcn_resnet50(pretrained=True)`
I receive this:
> NotImplementedError: pretrained fcn_resnet50_coco is not supported as of now
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/models/segmentation/segmentation.py`
Content:
```
1 from .._utils import IntermediateLayerGetter
2 from ..utils import load_state_dict_from_url
3 from .. import resnet
4 from .deeplabv3 import DeepLabHead, DeepLabV3
5 from .fcn import FCN, FCNHead
6
7
8 __all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101']
9
10
11 model_urls = {
12 'fcn_resnet50_coco': None,
13 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',
14 'deeplabv3_resnet50_coco': None,
15 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',
16 }
17
18
19 def _segm_resnet(name, backbone_name, num_classes, aux, pretrained_backbone=True):
20 backbone = resnet.__dict__[backbone_name](
21 pretrained=pretrained_backbone,
22 replace_stride_with_dilation=[False, True, True])
23
24 return_layers = {'layer4': 'out'}
25 if aux:
26 return_layers['layer3'] = 'aux'
27 backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
28
29 aux_classifier = None
30 if aux:
31 inplanes = 1024
32 aux_classifier = FCNHead(inplanes, num_classes)
33
34 model_map = {
35 'deeplabv3': (DeepLabHead, DeepLabV3),
36 'fcn': (FCNHead, FCN),
37 }
38 inplanes = 2048
39 classifier = model_map[name][0](inplanes, num_classes)
40 base_model = model_map[name][1]
41
42 model = base_model(backbone, classifier, aux_classifier)
43 return model
44
45
46 def _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):
47 if pretrained:
48 aux_loss = True
49 model = _segm_resnet(arch_type, backbone, num_classes, aux_loss, **kwargs)
50 if pretrained:
51 arch = arch_type + '_' + backbone + '_coco'
52 model_url = model_urls[arch]
53 if model_url is None:
54 raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))
55 else:
56 state_dict = load_state_dict_from_url(model_url, progress=progress)
57 model.load_state_dict(state_dict)
58 return model
59
60
61 def fcn_resnet50(pretrained=False, progress=True,
62 num_classes=21, aux_loss=None, **kwargs):
63 """Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.
64
65 Args:
66 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
67 contains the same classes as Pascal VOC
68 progress (bool): If True, displays a progress bar of the download to stderr
69 """
70 return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)
71
72
73 def fcn_resnet101(pretrained=False, progress=True,
74 num_classes=21, aux_loss=None, **kwargs):
75 """Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.
76
77 Args:
78 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
79 contains the same classes as Pascal VOC
80 progress (bool): If True, displays a progress bar of the download to stderr
81 """
82 return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)
83
84
85 def deeplabv3_resnet50(pretrained=False, progress=True,
86 num_classes=21, aux_loss=None, **kwargs):
87 """Constructs a DeepLabV3 model with a ResNet-50 backbone.
88
89 Args:
90 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
91 contains the same classes as Pascal VOC
92 progress (bool): If True, displays a progress bar of the download to stderr
93 """
94 return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)
95
96
97 def deeplabv3_resnet101(pretrained=False, progress=True,
98 num_classes=21, aux_loss=None, **kwargs):
99 """Constructs a DeepLabV3 model with a ResNet-101 backbone.
100
101 Args:
102 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
103 contains the same classes as Pascal VOC
104 progress (bool): If True, displays a progress bar of the download to stderr
105 """
106 return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/models/segmentation/segmentation.py b/torchvision/models/segmentation/segmentation.py
--- a/torchvision/models/segmentation/segmentation.py
+++ b/torchvision/models/segmentation/segmentation.py
@@ -9,9 +9,9 @@
model_urls = {
- 'fcn_resnet50_coco': None,
+ 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',
'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',
- 'deeplabv3_resnet50_coco': None,
+ 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',
'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',
}
|
{"golden_diff": "diff --git a/torchvision/models/segmentation/segmentation.py b/torchvision/models/segmentation/segmentation.py\n--- a/torchvision/models/segmentation/segmentation.py\n+++ b/torchvision/models/segmentation/segmentation.py\n@@ -9,9 +9,9 @@\n \n \n model_urls = {\n- 'fcn_resnet50_coco': None,\n+ 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',\n 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',\n- 'deeplabv3_resnet50_coco': None,\n+ 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',\n 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',\n }\n", "issue": "pretrain models for FCN and DeepLabV3\nIs it possible to provide the pretrain weight for deeplabv3 and FCN?\r\nright now when i do:\r\n`model = torchvision.models.segmentation.fcn_resnet50(pretrained=True)`\r\nI receive this:\r\n\r\n> NotImplementedError: pretrained fcn_resnet50_coco is not supported as of now\n", "before_files": [{"content": "from .._utils import IntermediateLayerGetter\nfrom ..utils import load_state_dict_from_url\nfrom .. import resnet\nfrom .deeplabv3 import DeepLabHead, DeepLabV3\nfrom .fcn import FCN, FCNHead\n\n\n__all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101']\n\n\nmodel_urls = {\n 'fcn_resnet50_coco': None,\n 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',\n 'deeplabv3_resnet50_coco': None,\n 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',\n}\n\n\ndef _segm_resnet(name, backbone_name, num_classes, aux, pretrained_backbone=True):\n backbone = resnet.__dict__[backbone_name](\n pretrained=pretrained_backbone,\n replace_stride_with_dilation=[False, True, True])\n\n return_layers = {'layer4': 'out'}\n if aux:\n return_layers['layer3'] = 'aux'\n backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)\n\n aux_classifier = None\n if aux:\n inplanes = 1024\n aux_classifier = FCNHead(inplanes, num_classes)\n\n model_map = {\n 'deeplabv3': (DeepLabHead, DeepLabV3),\n 'fcn': (FCNHead, FCN),\n }\n inplanes = 2048\n classifier = model_map[name][0](inplanes, num_classes)\n base_model = model_map[name][1]\n\n model = base_model(backbone, classifier, aux_classifier)\n return model\n\n\ndef _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):\n if pretrained:\n aux_loss = True\n model = _segm_resnet(arch_type, backbone, num_classes, aux_loss, **kwargs)\n if pretrained:\n arch = arch_type + '_' + backbone + '_coco'\n model_url = model_urls[arch]\n if model_url is None:\n raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))\n else:\n state_dict = load_state_dict_from_url(model_url, progress=progress)\n model.load_state_dict(state_dict)\n return model\n\n\ndef fcn_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef fcn_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n", "path": "torchvision/models/segmentation/segmentation.py"}], "after_files": [{"content": "from .._utils import IntermediateLayerGetter\nfrom ..utils import load_state_dict_from_url\nfrom .. import resnet\nfrom .deeplabv3 import DeepLabHead, DeepLabV3\nfrom .fcn import FCN, FCNHead\n\n\n__all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101']\n\n\nmodel_urls = {\n 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',\n 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',\n 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',\n 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',\n}\n\n\ndef _segm_resnet(name, backbone_name, num_classes, aux, pretrained_backbone=True):\n backbone = resnet.__dict__[backbone_name](\n pretrained=pretrained_backbone,\n replace_stride_with_dilation=[False, True, True])\n\n return_layers = {'layer4': 'out'}\n if aux:\n return_layers['layer3'] = 'aux'\n backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)\n\n aux_classifier = None\n if aux:\n inplanes = 1024\n aux_classifier = FCNHead(inplanes, num_classes)\n\n model_map = {\n 'deeplabv3': (DeepLabHead, DeepLabV3),\n 'fcn': (FCNHead, FCN),\n }\n inplanes = 2048\n classifier = model_map[name][0](inplanes, num_classes)\n base_model = model_map[name][1]\n\n model = base_model(backbone, classifier, aux_classifier)\n return model\n\n\ndef _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):\n if pretrained:\n aux_loss = True\n model = _segm_resnet(arch_type, backbone, num_classes, aux_loss, **kwargs)\n if pretrained:\n arch = arch_type + '_' + backbone + '_coco'\n model_url = model_urls[arch]\n if model_url is None:\n raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))\n else:\n state_dict = load_state_dict_from_url(model_url, progress=progress)\n model.load_state_dict(state_dict)\n return model\n\n\ndef fcn_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef fcn_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n \"\"\"\n return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n", "path": "torchvision/models/segmentation/segmentation.py"}]}
| 1,687 | 268 |
gh_patches_debug_7787
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1682
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Firefox cpu usage escalates and then stops responding only when run in qtile
Hi,
When starting firefox (firefox 69.0-1, qtile 0.14.2-2) its cpu usage starts rising to the point were the interface becomes unresponsive, also only parts of firefox interface are drawn, but like after 5 mins the window is not visible at all, may be the screenshots will make things clearer.
screenshots with description:
https://imgur.com/a/V17wJrM
Nothing is there in the logs (I only checked .local/share/qtile/qtile.log), this does not happen with me under i3 or bspwm. I also use optirun with my browsers but it does not matter if I start firefox without it. this bug happens every time I use firefox, and I use a lot of gtk3, gtk2, qt4, qt5, electron apps and it only happens with firefox on qtile only.
I am not sure what other information I can provide.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/widget/keyboardlayout.py`
Content:
```
1 # Copyright (c) 2013 Jacob Mourelos
2 # Copyright (c) 2014 Shepilov Vladislav
3 # Copyright (c) 2014-2015 Sean Vig
4 # Copyright (c) 2014 Tycho Andersen
5 # Copyright (c) 2019 zordsdavini
6 #
7 # Permission is hereby granted, free of charge, to any person obtaining a copy
8 # of this software and associated documentation files (the "Software"), to deal
9 # in the Software without restriction, including without limitation the rights
10 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
11 # copies of the Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice shall be included in
15 # all copies or substantial portions of the Software.
16 #
17 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
18 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
19 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
20 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
21 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
22 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
23 # SOFTWARE.
24
25 import re
26 from subprocess import CalledProcessError
27
28 from libqtile.log_utils import logger
29 from libqtile.widget import base
30
31 kb_layout_regex = re.compile(r'layout:\s+(?P<layout>\w+)')
32 kb_variant_regex = re.compile(r'variant:\s+(?P<variant>\w+)')
33
34
35 class KeyboardLayout(base.InLoopPollText):
36 """Widget for changing and displaying the current keyboard layout
37
38 It requires setxkbmap to be available in the system.
39 """
40 orientations = base.ORIENTATION_HORIZONTAL
41 defaults = [
42 ("update_interval", 1, "Update time in seconds."),
43 ("configured_keyboards", ["us"], "A list of predefined keyboard layouts "
44 "represented as strings. For example: "
45 "['us', 'us colemak', 'es', 'fr']."),
46 ("option", None, "string of setxkbmap option. Ex., 'compose:menu,grp_led:scroll'"),
47 ]
48
49 def __init__(self, **config):
50 base.InLoopPollText.__init__(self, **config)
51 self.add_defaults(KeyboardLayout.defaults)
52
53 def button_press(self, x, y, button):
54 if button == 1:
55 self.next_keyboard()
56
57 def next_keyboard(self):
58 """Set the next layout in the list of configured keyboard layouts as
59 new current layout in use
60
61 If the current keyboard layout is not in the list, it will set as new
62 layout the first one in the list.
63 """
64
65 current_keyboard = self.keyboard
66 if current_keyboard in self.configured_keyboards:
67 # iterate the list circularly
68 next_keyboard = self.configured_keyboards[
69 (self.configured_keyboards.index(current_keyboard) + 1) %
70 len(self.configured_keyboards)]
71 else:
72 next_keyboard = self.configured_keyboards[0]
73
74 self.keyboard = next_keyboard
75
76 self.tick()
77
78 def poll(self):
79 return self.keyboard.upper()
80
81 def get_keyboard_layout(self, setxkbmap_output):
82 match_layout = kb_layout_regex.search(setxkbmap_output)
83 match_variant = kb_variant_regex.search(setxkbmap_output)
84
85 if match_layout is None:
86 return 'ERR'
87
88 kb = match_layout.group('layout')
89 if match_variant:
90 kb += " " + match_variant.group('variant')
91 return kb
92
93 @property
94 def keyboard(self):
95 """Return the currently used keyboard layout as a string
96
97 Examples: "us", "us dvorak". In case of error returns "unknown".
98 """
99 try:
100 command = 'setxkbmap -verbose 10'
101 setxkbmap_output = self.call_process(command.split(' '))
102 keyboard = self.get_keyboard_layout(setxkbmap_output)
103 return str(keyboard)
104 except CalledProcessError as e:
105 logger.error('Can not get the keyboard layout: {0}'.format(e))
106 except OSError as e:
107 logger.error('Please, check that xset is available: {0}'.format(e))
108 return "unknown"
109
110 @keyboard.setter
111 def keyboard(self, keyboard):
112 command = ['setxkbmap']
113 command.extend(keyboard.split(" "))
114 if self.option:
115 command.extend(['-option', self.option])
116 try:
117 self.call_process(command)
118 except CalledProcessError as e:
119 logger.error('Can not change the keyboard layout: {0}'.format(e))
120 except OSError as e:
121 logger.error('Please, check that setxkbmap is available: {0}'.format(e))
122
123 def cmd_next_keyboard(self):
124 """Select next keyboard layout"""
125 self.next_keyboard()
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/widget/keyboardlayout.py b/libqtile/widget/keyboardlayout.py
--- a/libqtile/widget/keyboardlayout.py
+++ b/libqtile/widget/keyboardlayout.py
@@ -97,7 +97,7 @@
Examples: "us", "us dvorak". In case of error returns "unknown".
"""
try:
- command = 'setxkbmap -verbose 10'
+ command = 'setxkbmap -verbose 10 -query'
setxkbmap_output = self.call_process(command.split(' '))
keyboard = self.get_keyboard_layout(setxkbmap_output)
return str(keyboard)
|
{"golden_diff": "diff --git a/libqtile/widget/keyboardlayout.py b/libqtile/widget/keyboardlayout.py\n--- a/libqtile/widget/keyboardlayout.py\n+++ b/libqtile/widget/keyboardlayout.py\n@@ -97,7 +97,7 @@\n Examples: \"us\", \"us dvorak\". In case of error returns \"unknown\".\n \"\"\"\n try:\n- command = 'setxkbmap -verbose 10'\n+ command = 'setxkbmap -verbose 10 -query'\n setxkbmap_output = self.call_process(command.split(' '))\n keyboard = self.get_keyboard_layout(setxkbmap_output)\n return str(keyboard)\n", "issue": "Firefox cpu usage escalates and then stops responding only when run in qtile\nHi, \r\n\r\nWhen starting firefox (firefox 69.0-1, qtile 0.14.2-2) its cpu usage starts rising to the point were the interface becomes unresponsive, also only parts of firefox interface are drawn, but like after 5 mins the window is not visible at all, may be the screenshots will make things clearer. \r\n\r\nscreenshots with description:\r\nhttps://imgur.com/a/V17wJrM\r\n\r\nNothing is there in the logs (I only checked .local/share/qtile/qtile.log), this does not happen with me under i3 or bspwm. I also use optirun with my browsers but it does not matter if I start firefox without it. this bug happens every time I use firefox, and I use a lot of gtk3, gtk2, qt4, qt5, electron apps and it only happens with firefox on qtile only.\r\n\r\nI am not sure what other information I can provide.\r\n\n", "before_files": [{"content": "# Copyright (c) 2013 Jacob Mourelos\n# Copyright (c) 2014 Shepilov Vladislav\n# Copyright (c) 2014-2015 Sean Vig\n# Copyright (c) 2014 Tycho Andersen\n# Copyright (c) 2019 zordsdavini\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport re\nfrom subprocess import CalledProcessError\n\nfrom libqtile.log_utils import logger\nfrom libqtile.widget import base\n\nkb_layout_regex = re.compile(r'layout:\\s+(?P<layout>\\w+)')\nkb_variant_regex = re.compile(r'variant:\\s+(?P<variant>\\w+)')\n\n\nclass KeyboardLayout(base.InLoopPollText):\n \"\"\"Widget for changing and displaying the current keyboard layout\n\n It requires setxkbmap to be available in the system.\n \"\"\"\n orientations = base.ORIENTATION_HORIZONTAL\n defaults = [\n (\"update_interval\", 1, \"Update time in seconds.\"),\n (\"configured_keyboards\", [\"us\"], \"A list of predefined keyboard layouts \"\n \"represented as strings. For example: \"\n \"['us', 'us colemak', 'es', 'fr'].\"),\n (\"option\", None, \"string of setxkbmap option. Ex., 'compose:menu,grp_led:scroll'\"),\n ]\n\n def __init__(self, **config):\n base.InLoopPollText.__init__(self, **config)\n self.add_defaults(KeyboardLayout.defaults)\n\n def button_press(self, x, y, button):\n if button == 1:\n self.next_keyboard()\n\n def next_keyboard(self):\n \"\"\"Set the next layout in the list of configured keyboard layouts as\n new current layout in use\n\n If the current keyboard layout is not in the list, it will set as new\n layout the first one in the list.\n \"\"\"\n\n current_keyboard = self.keyboard\n if current_keyboard in self.configured_keyboards:\n # iterate the list circularly\n next_keyboard = self.configured_keyboards[\n (self.configured_keyboards.index(current_keyboard) + 1) %\n len(self.configured_keyboards)]\n else:\n next_keyboard = self.configured_keyboards[0]\n\n self.keyboard = next_keyboard\n\n self.tick()\n\n def poll(self):\n return self.keyboard.upper()\n\n def get_keyboard_layout(self, setxkbmap_output):\n match_layout = kb_layout_regex.search(setxkbmap_output)\n match_variant = kb_variant_regex.search(setxkbmap_output)\n\n if match_layout is None:\n return 'ERR'\n\n kb = match_layout.group('layout')\n if match_variant:\n kb += \" \" + match_variant.group('variant')\n return kb\n\n @property\n def keyboard(self):\n \"\"\"Return the currently used keyboard layout as a string\n\n Examples: \"us\", \"us dvorak\". In case of error returns \"unknown\".\n \"\"\"\n try:\n command = 'setxkbmap -verbose 10'\n setxkbmap_output = self.call_process(command.split(' '))\n keyboard = self.get_keyboard_layout(setxkbmap_output)\n return str(keyboard)\n except CalledProcessError as e:\n logger.error('Can not get the keyboard layout: {0}'.format(e))\n except OSError as e:\n logger.error('Please, check that xset is available: {0}'.format(e))\n return \"unknown\"\n\n @keyboard.setter\n def keyboard(self, keyboard):\n command = ['setxkbmap']\n command.extend(keyboard.split(\" \"))\n if self.option:\n command.extend(['-option', self.option])\n try:\n self.call_process(command)\n except CalledProcessError as e:\n logger.error('Can not change the keyboard layout: {0}'.format(e))\n except OSError as e:\n logger.error('Please, check that setxkbmap is available: {0}'.format(e))\n\n def cmd_next_keyboard(self):\n \"\"\"Select next keyboard layout\"\"\"\n self.next_keyboard()\n", "path": "libqtile/widget/keyboardlayout.py"}], "after_files": [{"content": "# Copyright (c) 2013 Jacob Mourelos\n# Copyright (c) 2014 Shepilov Vladislav\n# Copyright (c) 2014-2015 Sean Vig\n# Copyright (c) 2014 Tycho Andersen\n# Copyright (c) 2019 zordsdavini\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport re\nfrom subprocess import CalledProcessError\n\nfrom libqtile.log_utils import logger\nfrom libqtile.widget import base\n\nkb_layout_regex = re.compile(r'layout:\\s+(?P<layout>\\w+)')\nkb_variant_regex = re.compile(r'variant:\\s+(?P<variant>\\w+)')\n\n\nclass KeyboardLayout(base.InLoopPollText):\n \"\"\"Widget for changing and displaying the current keyboard layout\n\n It requires setxkbmap to be available in the system.\n \"\"\"\n orientations = base.ORIENTATION_HORIZONTAL\n defaults = [\n (\"update_interval\", 1, \"Update time in seconds.\"),\n (\"configured_keyboards\", [\"us\"], \"A list of predefined keyboard layouts \"\n \"represented as strings. For example: \"\n \"['us', 'us colemak', 'es', 'fr'].\"),\n (\"option\", None, \"string of setxkbmap option. Ex., 'compose:menu,grp_led:scroll'\"),\n ]\n\n def __init__(self, **config):\n base.InLoopPollText.__init__(self, **config)\n self.add_defaults(KeyboardLayout.defaults)\n\n def button_press(self, x, y, button):\n if button == 1:\n self.next_keyboard()\n\n def next_keyboard(self):\n \"\"\"Set the next layout in the list of configured keyboard layouts as\n new current layout in use\n\n If the current keyboard layout is not in the list, it will set as new\n layout the first one in the list.\n \"\"\"\n\n current_keyboard = self.keyboard\n if current_keyboard in self.configured_keyboards:\n # iterate the list circularly\n next_keyboard = self.configured_keyboards[\n (self.configured_keyboards.index(current_keyboard) + 1) %\n len(self.configured_keyboards)]\n else:\n next_keyboard = self.configured_keyboards[0]\n\n self.keyboard = next_keyboard\n\n self.tick()\n\n def poll(self):\n return self.keyboard.upper()\n\n def get_keyboard_layout(self, setxkbmap_output):\n match_layout = kb_layout_regex.search(setxkbmap_output)\n match_variant = kb_variant_regex.search(setxkbmap_output)\n\n if match_layout is None:\n return 'ERR'\n\n kb = match_layout.group('layout')\n if match_variant:\n kb += \" \" + match_variant.group('variant')\n return kb\n\n @property\n def keyboard(self):\n \"\"\"Return the currently used keyboard layout as a string\n\n Examples: \"us\", \"us dvorak\". In case of error returns \"unknown\".\n \"\"\"\n try:\n command = 'setxkbmap -verbose 10 -query'\n setxkbmap_output = self.call_process(command.split(' '))\n keyboard = self.get_keyboard_layout(setxkbmap_output)\n return str(keyboard)\n except CalledProcessError as e:\n logger.error('Can not get the keyboard layout: {0}'.format(e))\n except OSError as e:\n logger.error('Please, check that xset is available: {0}'.format(e))\n return \"unknown\"\n\n @keyboard.setter\n def keyboard(self, keyboard):\n command = ['setxkbmap']\n command.extend(keyboard.split(\" \"))\n if self.option:\n command.extend(['-option', self.option])\n try:\n self.call_process(command)\n except CalledProcessError as e:\n logger.error('Can not change the keyboard layout: {0}'.format(e))\n except OSError as e:\n logger.error('Please, check that setxkbmap is available: {0}'.format(e))\n\n def cmd_next_keyboard(self):\n \"\"\"Select next keyboard layout\"\"\"\n self.next_keyboard()\n", "path": "libqtile/widget/keyboardlayout.py"}]}
| 1,844 | 147 |
gh_patches_debug_15175
|
rasdani/github-patches
|
git_diff
|
dmlc__dgl-4027
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Running error on examples/pytorch/gat/train.py
## 🐛 Bug
When running the cpu version of gat, an error is reported, indicating that cuda is not supported.
## To Reproduce
Steps to reproduce the behavior:
python train.py --dataset=cora --gpu=-1
Traceback (most recent call last):
File "train.py", line 181, in <module>
main(args)
File "train.py", line 110, in main
torch.cuda.synchronize()
File "/opt/homebrew/Caskroom/miniconda/base/envs/dgl/lib/python3.8/site-packages/torch/cuda/__init__.py", line 493, in synchronize
_lazy_init()
File "/opt/homebrew/Caskroom/miniconda/base/envs/dgl/lib/python3.8/site-packages/torch/cuda/__init__.py", line 210, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
## Expected behavior
The example should run successful.
## Environment
- DGL Version (e.g., 1.0): 0.8.1
- Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3):1.11.0
- OS (e.g., Linux): macOS 12.3.1
- How you installed DGL (`conda`, `pip`, source): conda
- Build command you used (if compiling from source):
- Python version: 3.8.13
- CUDA/cuDNN version (if applicable):
- GPU models and configuration (e.g. V100):
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
It seems that the conditional judgment of cuda is missing here (line 110 and 121).
https://github.com/dmlc/dgl/blob/4b87e47f15552cb27ddf8e594769ad0361d06627/examples/pytorch/gat/train.py#L109-L111
https://github.com/dmlc/dgl/blob/4b87e47f15552cb27ddf8e594769ad0361d06627/examples/pytorch/gat/train.py#L120-L122
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/pytorch/gat/train.py`
Content:
```
1 """
2 Graph Attention Networks in DGL using SPMV optimization.
3 Multiple heads are also batched together for faster training.
4 References
5 ----------
6 Paper: https://arxiv.org/abs/1710.10903
7 Author's code: https://github.com/PetarV-/GAT
8 Pytorch implementation: https://github.com/Diego999/pyGAT
9 """
10
11 import argparse
12 import numpy as np
13 import networkx as nx
14 import time
15 import torch
16 import torch.nn.functional as F
17 import dgl
18 from dgl.data import register_data_args
19 from dgl.data import CoraGraphDataset, CiteseerGraphDataset, PubmedGraphDataset
20
21 from gat import GAT
22 from utils import EarlyStopping
23
24
25 def accuracy(logits, labels):
26 _, indices = torch.max(logits, dim=1)
27 correct = torch.sum(indices == labels)
28 return correct.item() * 1.0 / len(labels)
29
30
31 def evaluate(model, features, labels, mask):
32 model.eval()
33 with torch.no_grad():
34 logits = model(features)
35 logits = logits[mask]
36 labels = labels[mask]
37 return accuracy(logits, labels)
38
39
40 def main(args):
41 # load and preprocess dataset
42 if args.dataset == 'cora':
43 data = CoraGraphDataset()
44 elif args.dataset == 'citeseer':
45 data = CiteseerGraphDataset()
46 elif args.dataset == 'pubmed':
47 data = PubmedGraphDataset()
48 else:
49 raise ValueError('Unknown dataset: {}'.format(args.dataset))
50
51 g = data[0]
52 if args.gpu < 0:
53 cuda = False
54 else:
55 cuda = True
56 g = g.int().to(args.gpu)
57
58 features = g.ndata['feat']
59 labels = g.ndata['label']
60 train_mask = g.ndata['train_mask']
61 val_mask = g.ndata['val_mask']
62 test_mask = g.ndata['test_mask']
63 num_feats = features.shape[1]
64 n_classes = data.num_labels
65 n_edges = data.graph.number_of_edges()
66 print("""----Data statistics------'
67 #Edges %d
68 #Classes %d
69 #Train samples %d
70 #Val samples %d
71 #Test samples %d""" %
72 (n_edges, n_classes,
73 train_mask.int().sum().item(),
74 val_mask.int().sum().item(),
75 test_mask.int().sum().item()))
76
77 # add self loop
78 g = dgl.remove_self_loop(g)
79 g = dgl.add_self_loop(g)
80 n_edges = g.number_of_edges()
81 # create model
82 heads = ([args.num_heads] * (args.num_layers-1)) + [args.num_out_heads]
83 model = GAT(g,
84 args.num_layers,
85 num_feats,
86 args.num_hidden,
87 n_classes,
88 heads,
89 F.elu,
90 args.in_drop,
91 args.attn_drop,
92 args.negative_slope,
93 args.residual)
94 print(model)
95 if args.early_stop:
96 stopper = EarlyStopping(patience=100)
97 if cuda:
98 model.cuda()
99 loss_fcn = torch.nn.CrossEntropyLoss()
100
101 # use optimizer
102 optimizer = torch.optim.Adam(
103 model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
104
105 # initialize graph
106 dur = []
107 for epoch in range(args.epochs):
108 model.train()
109 if epoch >= 3:
110 torch.cuda.synchronize()
111 t0 = time.time()
112 # forward
113 logits = model(features)
114 loss = loss_fcn(logits[train_mask], labels[train_mask])
115
116 optimizer.zero_grad()
117 loss.backward()
118 optimizer.step()
119
120 if epoch >= 3:
121 torch.cuda.synchronize()
122 dur.append(time.time() - t0)
123
124 train_acc = accuracy(logits[train_mask], labels[train_mask])
125
126 if args.fastmode:
127 val_acc = accuracy(logits[val_mask], labels[val_mask])
128 else:
129 val_acc = evaluate(model, features, labels, val_mask)
130 if args.early_stop:
131 if stopper.step(val_acc, model):
132 break
133
134 print("Epoch {:05d} | Time(s) {:.4f} | Loss {:.4f} | TrainAcc {:.4f} |"
135 " ValAcc {:.4f} | ETputs(KTEPS) {:.2f}".
136 format(epoch, np.mean(dur), loss.item(), train_acc,
137 val_acc, n_edges / np.mean(dur) / 1000))
138
139 print()
140 if args.early_stop:
141 model.load_state_dict(torch.load('es_checkpoint.pt'))
142 acc = evaluate(model, features, labels, test_mask)
143 print("Test Accuracy {:.4f}".format(acc))
144
145
146 if __name__ == '__main__':
147
148 parser = argparse.ArgumentParser(description='GAT')
149 register_data_args(parser)
150 parser.add_argument("--gpu", type=int, default=-1,
151 help="which GPU to use. Set -1 to use CPU.")
152 parser.add_argument("--epochs", type=int, default=200,
153 help="number of training epochs")
154 parser.add_argument("--num-heads", type=int, default=8,
155 help="number of hidden attention heads")
156 parser.add_argument("--num-out-heads", type=int, default=1,
157 help="number of output attention heads")
158 parser.add_argument("--num-layers", type=int, default=2,
159 help="number of hidden layers")
160 parser.add_argument("--num-hidden", type=int, default=8,
161 help="number of hidden units")
162 parser.add_argument("--residual", action="store_true", default=False,
163 help="use residual connection")
164 parser.add_argument("--in-drop", type=float, default=.6,
165 help="input feature dropout")
166 parser.add_argument("--attn-drop", type=float, default=.6,
167 help="attention dropout")
168 parser.add_argument("--lr", type=float, default=0.005,
169 help="learning rate")
170 parser.add_argument('--weight-decay', type=float, default=5e-4,
171 help="weight decay")
172 parser.add_argument('--negative-slope', type=float, default=0.2,
173 help="the negative slope of leaky relu")
174 parser.add_argument('--early-stop', action='store_true', default=False,
175 help="indicates whether to use early stop or not")
176 parser.add_argument('--fastmode', action="store_true", default=False,
177 help="skip re-evaluate the validation set")
178 args = parser.parse_args()
179 print(args)
180
181 main(args)
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/pytorch/gat/train.py b/examples/pytorch/gat/train.py
--- a/examples/pytorch/gat/train.py
+++ b/examples/pytorch/gat/train.py
@@ -107,7 +107,8 @@
for epoch in range(args.epochs):
model.train()
if epoch >= 3:
- torch.cuda.synchronize()
+ if cuda:
+ torch.cuda.synchronize()
t0 = time.time()
# forward
logits = model(features)
@@ -118,7 +119,8 @@
optimizer.step()
if epoch >= 3:
- torch.cuda.synchronize()
+ if cuda:
+ torch.cuda.synchronize()
dur.append(time.time() - t0)
train_acc = accuracy(logits[train_mask], labels[train_mask])
|
{"golden_diff": "diff --git a/examples/pytorch/gat/train.py b/examples/pytorch/gat/train.py\n--- a/examples/pytorch/gat/train.py\n+++ b/examples/pytorch/gat/train.py\n@@ -107,7 +107,8 @@\n for epoch in range(args.epochs):\n model.train()\n if epoch >= 3:\n- torch.cuda.synchronize()\n+ if cuda:\n+ torch.cuda.synchronize()\n t0 = time.time()\n # forward\n logits = model(features)\n@@ -118,7 +119,8 @@\n optimizer.step()\n \n if epoch >= 3:\n- torch.cuda.synchronize()\n+ if cuda:\n+ torch.cuda.synchronize()\n dur.append(time.time() - t0)\n \n train_acc = accuracy(logits[train_mask], labels[train_mask])\n", "issue": "Running error on examples/pytorch/gat/train.py \n## \ud83d\udc1b Bug\r\n\r\nWhen running the cpu version of gat, an error is reported, indicating that cuda is not supported.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\npython train.py --dataset=cora --gpu=-1\r\n\r\nTraceback (most recent call last):\r\n File \"train.py\", line 181, in <module>\r\n main(args)\r\n File \"train.py\", line 110, in main\r\n torch.cuda.synchronize()\r\n File \"/opt/homebrew/Caskroom/miniconda/base/envs/dgl/lib/python3.8/site-packages/torch/cuda/__init__.py\", line 493, in synchronize\r\n _lazy_init()\r\n File \"/opt/homebrew/Caskroom/miniconda/base/envs/dgl/lib/python3.8/site-packages/torch/cuda/__init__.py\", line 210, in _lazy_init\r\n raise AssertionError(\"Torch not compiled with CUDA enabled\")\r\nAssertionError: Torch not compiled with CUDA enabled\r\n\r\n\r\n## Expected behavior\r\n\r\nThe example should run successful.\r\n\r\n## Environment\r\n\r\n - DGL Version (e.g., 1.0): 0.8.1\r\n - Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3):1.11.0\r\n - OS (e.g., Linux): macOS 12.3.1 \r\n - How you installed DGL (`conda`, `pip`, source): conda\r\n - Build command you used (if compiling from source): \r\n - Python version: 3.8.13\r\n - CUDA/cuDNN version (if applicable):\r\n - GPU models and configuration (e.g. V100):\r\n - Any other relevant information:\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\r\nIt seems that the conditional judgment of cuda is missing here (line 110 and 121).\r\n\r\nhttps://github.com/dmlc/dgl/blob/4b87e47f15552cb27ddf8e594769ad0361d06627/examples/pytorch/gat/train.py#L109-L111\r\n\r\nhttps://github.com/dmlc/dgl/blob/4b87e47f15552cb27ddf8e594769ad0361d06627/examples/pytorch/gat/train.py#L120-L122\r\n\n", "before_files": [{"content": "\"\"\"\nGraph Attention Networks in DGL using SPMV optimization.\nMultiple heads are also batched together for faster training.\nReferences\n----------\nPaper: https://arxiv.org/abs/1710.10903\nAuthor's code: https://github.com/PetarV-/GAT\nPytorch implementation: https://github.com/Diego999/pyGAT\n\"\"\"\n\nimport argparse\nimport numpy as np\nimport networkx as nx\nimport time\nimport torch\nimport torch.nn.functional as F\nimport dgl\nfrom dgl.data import register_data_args\nfrom dgl.data import CoraGraphDataset, CiteseerGraphDataset, PubmedGraphDataset\n\nfrom gat import GAT\nfrom utils import EarlyStopping\n\n\ndef accuracy(logits, labels):\n _, indices = torch.max(logits, dim=1)\n correct = torch.sum(indices == labels)\n return correct.item() * 1.0 / len(labels)\n\n\ndef evaluate(model, features, labels, mask):\n model.eval()\n with torch.no_grad():\n logits = model(features)\n logits = logits[mask]\n labels = labels[mask]\n return accuracy(logits, labels)\n\n\ndef main(args):\n # load and preprocess dataset\n if args.dataset == 'cora':\n data = CoraGraphDataset()\n elif args.dataset == 'citeseer':\n data = CiteseerGraphDataset()\n elif args.dataset == 'pubmed':\n data = PubmedGraphDataset()\n else:\n raise ValueError('Unknown dataset: {}'.format(args.dataset))\n\n g = data[0]\n if args.gpu < 0:\n cuda = False\n else:\n cuda = True\n g = g.int().to(args.gpu)\n\n features = g.ndata['feat']\n labels = g.ndata['label']\n train_mask = g.ndata['train_mask']\n val_mask = g.ndata['val_mask']\n test_mask = g.ndata['test_mask']\n num_feats = features.shape[1]\n n_classes = data.num_labels\n n_edges = data.graph.number_of_edges()\n print(\"\"\"----Data statistics------'\n #Edges %d\n #Classes %d\n #Train samples %d\n #Val samples %d\n #Test samples %d\"\"\" %\n (n_edges, n_classes,\n train_mask.int().sum().item(),\n val_mask.int().sum().item(),\n test_mask.int().sum().item()))\n\n # add self loop\n g = dgl.remove_self_loop(g)\n g = dgl.add_self_loop(g)\n n_edges = g.number_of_edges()\n # create model\n heads = ([args.num_heads] * (args.num_layers-1)) + [args.num_out_heads]\n model = GAT(g,\n args.num_layers,\n num_feats,\n args.num_hidden,\n n_classes,\n heads,\n F.elu,\n args.in_drop,\n args.attn_drop,\n args.negative_slope,\n args.residual)\n print(model)\n if args.early_stop:\n stopper = EarlyStopping(patience=100)\n if cuda:\n model.cuda()\n loss_fcn = torch.nn.CrossEntropyLoss()\n\n # use optimizer\n optimizer = torch.optim.Adam(\n model.parameters(), lr=args.lr, weight_decay=args.weight_decay)\n\n # initialize graph\n dur = []\n for epoch in range(args.epochs):\n model.train()\n if epoch >= 3:\n torch.cuda.synchronize()\n t0 = time.time()\n # forward\n logits = model(features)\n loss = loss_fcn(logits[train_mask], labels[train_mask])\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n if epoch >= 3:\n torch.cuda.synchronize()\n dur.append(time.time() - t0)\n\n train_acc = accuracy(logits[train_mask], labels[train_mask])\n\n if args.fastmode:\n val_acc = accuracy(logits[val_mask], labels[val_mask])\n else:\n val_acc = evaluate(model, features, labels, val_mask)\n if args.early_stop:\n if stopper.step(val_acc, model):\n break\n\n print(\"Epoch {:05d} | Time(s) {:.4f} | Loss {:.4f} | TrainAcc {:.4f} |\"\n \" ValAcc {:.4f} | ETputs(KTEPS) {:.2f}\".\n format(epoch, np.mean(dur), loss.item(), train_acc,\n val_acc, n_edges / np.mean(dur) / 1000))\n\n print()\n if args.early_stop:\n model.load_state_dict(torch.load('es_checkpoint.pt'))\n acc = evaluate(model, features, labels, test_mask)\n print(\"Test Accuracy {:.4f}\".format(acc))\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser(description='GAT')\n register_data_args(parser)\n parser.add_argument(\"--gpu\", type=int, default=-1,\n help=\"which GPU to use. Set -1 to use CPU.\")\n parser.add_argument(\"--epochs\", type=int, default=200,\n help=\"number of training epochs\")\n parser.add_argument(\"--num-heads\", type=int, default=8,\n help=\"number of hidden attention heads\")\n parser.add_argument(\"--num-out-heads\", type=int, default=1,\n help=\"number of output attention heads\")\n parser.add_argument(\"--num-layers\", type=int, default=2,\n help=\"number of hidden layers\")\n parser.add_argument(\"--num-hidden\", type=int, default=8,\n help=\"number of hidden units\")\n parser.add_argument(\"--residual\", action=\"store_true\", default=False,\n help=\"use residual connection\")\n parser.add_argument(\"--in-drop\", type=float, default=.6,\n help=\"input feature dropout\")\n parser.add_argument(\"--attn-drop\", type=float, default=.6,\n help=\"attention dropout\")\n parser.add_argument(\"--lr\", type=float, default=0.005,\n help=\"learning rate\")\n parser.add_argument('--weight-decay', type=float, default=5e-4,\n help=\"weight decay\")\n parser.add_argument('--negative-slope', type=float, default=0.2,\n help=\"the negative slope of leaky relu\")\n parser.add_argument('--early-stop', action='store_true', default=False,\n help=\"indicates whether to use early stop or not\")\n parser.add_argument('--fastmode', action=\"store_true\", default=False,\n help=\"skip re-evaluate the validation set\")\n args = parser.parse_args()\n print(args)\n\n main(args)\n", "path": "examples/pytorch/gat/train.py"}], "after_files": [{"content": "\"\"\"\nGraph Attention Networks in DGL using SPMV optimization.\nMultiple heads are also batched together for faster training.\nReferences\n----------\nPaper: https://arxiv.org/abs/1710.10903\nAuthor's code: https://github.com/PetarV-/GAT\nPytorch implementation: https://github.com/Diego999/pyGAT\n\"\"\"\n\nimport argparse\nimport numpy as np\nimport networkx as nx\nimport time\nimport torch\nimport torch.nn.functional as F\nimport dgl\nfrom dgl.data import register_data_args\nfrom dgl.data import CoraGraphDataset, CiteseerGraphDataset, PubmedGraphDataset\n\nfrom gat import GAT\nfrom utils import EarlyStopping\n\n\ndef accuracy(logits, labels):\n _, indices = torch.max(logits, dim=1)\n correct = torch.sum(indices == labels)\n return correct.item() * 1.0 / len(labels)\n\n\ndef evaluate(model, features, labels, mask):\n model.eval()\n with torch.no_grad():\n logits = model(features)\n logits = logits[mask]\n labels = labels[mask]\n return accuracy(logits, labels)\n\n\ndef main(args):\n # load and preprocess dataset\n if args.dataset == 'cora':\n data = CoraGraphDataset()\n elif args.dataset == 'citeseer':\n data = CiteseerGraphDataset()\n elif args.dataset == 'pubmed':\n data = PubmedGraphDataset()\n else:\n raise ValueError('Unknown dataset: {}'.format(args.dataset))\n\n g = data[0]\n if args.gpu < 0:\n cuda = False\n else:\n cuda = True\n g = g.int().to(args.gpu)\n\n features = g.ndata['feat']\n labels = g.ndata['label']\n train_mask = g.ndata['train_mask']\n val_mask = g.ndata['val_mask']\n test_mask = g.ndata['test_mask']\n num_feats = features.shape[1]\n n_classes = data.num_labels\n n_edges = data.graph.number_of_edges()\n print(\"\"\"----Data statistics------'\n #Edges %d\n #Classes %d\n #Train samples %d\n #Val samples %d\n #Test samples %d\"\"\" %\n (n_edges, n_classes,\n train_mask.int().sum().item(),\n val_mask.int().sum().item(),\n test_mask.int().sum().item()))\n\n # add self loop\n g = dgl.remove_self_loop(g)\n g = dgl.add_self_loop(g)\n n_edges = g.number_of_edges()\n # create model\n heads = ([args.num_heads] * (args.num_layers-1)) + [args.num_out_heads]\n model = GAT(g,\n args.num_layers,\n num_feats,\n args.num_hidden,\n n_classes,\n heads,\n F.elu,\n args.in_drop,\n args.attn_drop,\n args.negative_slope,\n args.residual)\n print(model)\n if args.early_stop:\n stopper = EarlyStopping(patience=100)\n if cuda:\n model.cuda()\n loss_fcn = torch.nn.CrossEntropyLoss()\n\n # use optimizer\n optimizer = torch.optim.Adam(\n model.parameters(), lr=args.lr, weight_decay=args.weight_decay)\n\n # initialize graph\n dur = []\n for epoch in range(args.epochs):\n model.train()\n if epoch >= 3:\n if cuda:\n torch.cuda.synchronize()\n t0 = time.time()\n # forward\n logits = model(features)\n loss = loss_fcn(logits[train_mask], labels[train_mask])\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n if epoch >= 3:\n if cuda:\n torch.cuda.synchronize()\n dur.append(time.time() - t0)\n\n train_acc = accuracy(logits[train_mask], labels[train_mask])\n\n if args.fastmode:\n val_acc = accuracy(logits[val_mask], labels[val_mask])\n else:\n val_acc = evaluate(model, features, labels, val_mask)\n if args.early_stop:\n if stopper.step(val_acc, model):\n break\n\n print(\"Epoch {:05d} | Time(s) {:.4f} | Loss {:.4f} | TrainAcc {:.4f} |\"\n \" ValAcc {:.4f} | ETputs(KTEPS) {:.2f}\".\n format(epoch, np.mean(dur), loss.item(), train_acc,\n val_acc, n_edges / np.mean(dur) / 1000))\n\n print()\n if args.early_stop:\n model.load_state_dict(torch.load('es_checkpoint.pt'))\n acc = evaluate(model, features, labels, test_mask)\n print(\"Test Accuracy {:.4f}\".format(acc))\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser(description='GAT')\n register_data_args(parser)\n parser.add_argument(\"--gpu\", type=int, default=-1,\n help=\"which GPU to use. Set -1 to use CPU.\")\n parser.add_argument(\"--epochs\", type=int, default=200,\n help=\"number of training epochs\")\n parser.add_argument(\"--num-heads\", type=int, default=8,\n help=\"number of hidden attention heads\")\n parser.add_argument(\"--num-out-heads\", type=int, default=1,\n help=\"number of output attention heads\")\n parser.add_argument(\"--num-layers\", type=int, default=2,\n help=\"number of hidden layers\")\n parser.add_argument(\"--num-hidden\", type=int, default=8,\n help=\"number of hidden units\")\n parser.add_argument(\"--residual\", action=\"store_true\", default=False,\n help=\"use residual connection\")\n parser.add_argument(\"--in-drop\", type=float, default=.6,\n help=\"input feature dropout\")\n parser.add_argument(\"--attn-drop\", type=float, default=.6,\n help=\"attention dropout\")\n parser.add_argument(\"--lr\", type=float, default=0.005,\n help=\"learning rate\")\n parser.add_argument('--weight-decay', type=float, default=5e-4,\n help=\"weight decay\")\n parser.add_argument('--negative-slope', type=float, default=0.2,\n help=\"the negative slope of leaky relu\")\n parser.add_argument('--early-stop', action='store_true', default=False,\n help=\"indicates whether to use early stop or not\")\n parser.add_argument('--fastmode', action=\"store_true\", default=False,\n help=\"skip re-evaluate the validation set\")\n args = parser.parse_args()\n print(args)\n\n main(args)\n", "path": "examples/pytorch/gat/train.py"}]}
| 2,668 | 179 |
gh_patches_debug_32327
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-2505
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Challenge runtime statistics are not correct
Looking at the Tiger statistics, for Segmentation and Detection (Final) phase:
Average algorithm job duration for Segmentation and Detection (Final): 25 minutes
Total algorithm job duration for Segmentation and Detection (Final): 4 days
There has been 1 submission to this phase:
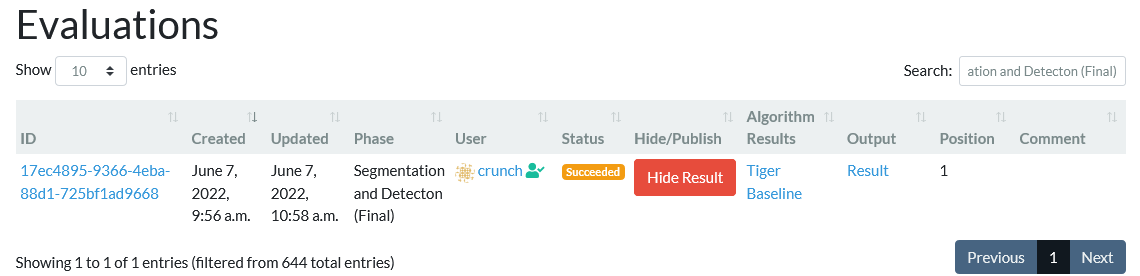
Looking at a couple of those results they seem to take ~30 seconds each, and maybe 50 jobs. I think what is happening is that the algorithm was used for multiple phases, and there are different versions, which are inflating the runtime statistics.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/pages/views.py`
Content:
```
1 from django.contrib import messages
2 from django.contrib.auth.mixins import UserPassesTestMixin
3 from django.db.models import Q
4 from django.http import Http404
5 from django.views.generic import (
6 CreateView,
7 DeleteView,
8 DetailView,
9 ListView,
10 TemplateView,
11 UpdateView,
12 )
13 from guardian.mixins import LoginRequiredMixin
14 from guardian.mixins import (
15 PermissionRequiredMixin as ObjectPermissionRequiredMixin,
16 )
17
18 from grandchallenge.algorithms.models import Job
19 from grandchallenge.core.mixins import UserIsStaffMixin
20 from grandchallenge.evaluation.models import Submission
21 from grandchallenge.evaluation.utils import SubmissionKindChoices
22 from grandchallenge.pages.forms import PageCreateForm, PageUpdateForm
23 from grandchallenge.pages.models import Page
24 from grandchallenge.subdomains.utils import reverse, reverse_lazy
25
26
27 class ChallengeFilteredQuerysetMixin:
28 def get_queryset(self):
29 queryset = super().get_queryset()
30 return queryset.filter(Q(challenge=self.request.challenge))
31
32
33 class ChallengeFormKwargsMixin:
34 def get_form_kwargs(self):
35 kwargs = super().get_form_kwargs()
36 kwargs.update({"challenge": self.request.challenge})
37 return kwargs
38
39
40 class PageCreate(
41 LoginRequiredMixin,
42 ObjectPermissionRequiredMixin,
43 ChallengeFormKwargsMixin,
44 CreateView,
45 ):
46 model = Page
47 form_class = PageCreateForm
48 permission_required = "change_challenge"
49 raise_exception = True
50 login_url = reverse_lazy("account_login")
51
52 def get_permission_object(self):
53 return self.request.challenge
54
55 def form_valid(self, form):
56 form.instance.challenge = self.request.challenge
57 return super().form_valid(form)
58
59
60 class PageList(
61 LoginRequiredMixin,
62 ObjectPermissionRequiredMixin,
63 ChallengeFilteredQuerysetMixin,
64 ListView,
65 ):
66 model = Page
67 permission_required = "change_challenge"
68 raise_exception = True
69 login_url = reverse_lazy("account_login")
70
71 def get_permission_object(self):
72 return self.request.challenge
73
74
75 class PageDetail(
76 UserPassesTestMixin, ChallengeFilteredQuerysetMixin, DetailView
77 ):
78 model = Page
79 raise_exception = True
80 login_url = reverse_lazy("account_login")
81
82 def test_func(self):
83 user = self.request.user
84 page = self.get_object()
85 return page.can_be_viewed_by(user=user)
86
87 def get_context_object_name(self, obj):
88 return "currentpage"
89
90 def get_context_data(self, **kwargs):
91 context = super().get_context_data(**kwargs)
92 context.update(self.object.detail_context)
93 return context
94
95
96 class ChallengeHome(PageDetail):
97 def get_object(self, queryset=None):
98 page = self.request.challenge.page_set.first()
99
100 if page is None:
101 raise Http404("No pages found for this challenge")
102
103 return page
104
105
106 class PageUpdate(
107 LoginRequiredMixin,
108 ObjectPermissionRequiredMixin,
109 ChallengeFilteredQuerysetMixin,
110 ChallengeFormKwargsMixin,
111 UpdateView,
112 ):
113 model = Page
114 form_class = PageUpdateForm
115 permission_required = "change_challenge"
116 raise_exception = True
117 login_url = reverse_lazy("account_login")
118
119 def get_permission_object(self):
120 return self.request.challenge
121
122 def form_valid(self, form):
123 response = super().form_valid(form)
124 self.object.move(form.cleaned_data["move"])
125 return response
126
127
128 class PageDelete(
129 LoginRequiredMixin,
130 ObjectPermissionRequiredMixin,
131 ChallengeFilteredQuerysetMixin,
132 DeleteView,
133 ):
134 model = Page
135 success_message = "Page was successfully deleted"
136 permission_required = "change_challenge"
137 raise_exception = True
138 login_url = reverse_lazy("account_login")
139
140 def get_permission_object(self):
141 return self.request.challenge
142
143 def get_success_url(self):
144 return reverse(
145 "pages:list",
146 kwargs={"challenge_short_name": self.request.challenge.short_name},
147 )
148
149 def delete(self, request, *args, **kwargs):
150 messages.success(self.request, self.success_message)
151 return super().delete(request, *args, **kwargs)
152
153
154 def get_average_job_duration_for_phase(phase):
155 algorithm_images = Submission.objects.filter(
156 phase__pk=phase.pk
157 ).values_list("algorithm_image__pk")
158 jobs = Job.objects.filter(
159 algorithm_image__pk__in=algorithm_images,
160 status=Job.SUCCESS,
161 creator=None,
162 )
163 duration_dict = {
164 "average_duration": jobs.average_duration(),
165 "total_duration": jobs.total_duration(),
166 }
167 return duration_dict
168
169
170 class ChallengeStatistics(LoginRequiredMixin, UserIsStaffMixin, TemplateView):
171 template_name = "pages/challenge_statistics.html"
172
173 def get_context_data(self, **kwargs):
174 context = super().get_context_data()
175 phases = (
176 self.request.challenge.phase_set.filter(
177 submission_kind=SubmissionKindChoices.ALGORITHM
178 )
179 .select_related("archive")
180 .prefetch_related("archive__items__values")
181 .all()
182 )
183 duration_dict = {}
184 for phase in phases:
185 duration_dict[phase.title] = get_average_job_duration_for_phase(
186 phase=phase
187 )
188
189 context.update(
190 {
191 "average_job_durations": duration_dict,
192 }
193 )
194
195 return context
196
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/grandchallenge/pages/views.py b/app/grandchallenge/pages/views.py
--- a/app/grandchallenge/pages/views.py
+++ b/app/grandchallenge/pages/views.py
@@ -17,7 +17,6 @@
from grandchallenge.algorithms.models import Job
from grandchallenge.core.mixins import UserIsStaffMixin
-from grandchallenge.evaluation.models import Submission
from grandchallenge.evaluation.utils import SubmissionKindChoices
from grandchallenge.pages.forms import PageCreateForm, PageUpdateForm
from grandchallenge.pages.models import Page
@@ -152,14 +151,9 @@
def get_average_job_duration_for_phase(phase):
- algorithm_images = Submission.objects.filter(
- phase__pk=phase.pk
- ).values_list("algorithm_image__pk")
jobs = Job.objects.filter(
- algorithm_image__pk__in=algorithm_images,
- status=Job.SUCCESS,
- creator=None,
- )
+ outputs__evaluation_evaluations_as_input__submission__phase=phase,
+ ).distinct()
duration_dict = {
"average_duration": jobs.average_duration(),
"total_duration": jobs.total_duration(),
@@ -172,14 +166,9 @@
def get_context_data(self, **kwargs):
context = super().get_context_data()
- phases = (
- self.request.challenge.phase_set.filter(
- submission_kind=SubmissionKindChoices.ALGORITHM
- )
- .select_related("archive")
- .prefetch_related("archive__items__values")
- .all()
- )
+ phases = self.request.challenge.phase_set.filter(
+ submission_kind=SubmissionKindChoices.ALGORITHM
+ ).all()
duration_dict = {}
for phase in phases:
duration_dict[phase.title] = get_average_job_duration_for_phase(
|
{"golden_diff": "diff --git a/app/grandchallenge/pages/views.py b/app/grandchallenge/pages/views.py\n--- a/app/grandchallenge/pages/views.py\n+++ b/app/grandchallenge/pages/views.py\n@@ -17,7 +17,6 @@\n \n from grandchallenge.algorithms.models import Job\n from grandchallenge.core.mixins import UserIsStaffMixin\n-from grandchallenge.evaluation.models import Submission\n from grandchallenge.evaluation.utils import SubmissionKindChoices\n from grandchallenge.pages.forms import PageCreateForm, PageUpdateForm\n from grandchallenge.pages.models import Page\n@@ -152,14 +151,9 @@\n \n \n def get_average_job_duration_for_phase(phase):\n- algorithm_images = Submission.objects.filter(\n- phase__pk=phase.pk\n- ).values_list(\"algorithm_image__pk\")\n jobs = Job.objects.filter(\n- algorithm_image__pk__in=algorithm_images,\n- status=Job.SUCCESS,\n- creator=None,\n- )\n+ outputs__evaluation_evaluations_as_input__submission__phase=phase,\n+ ).distinct()\n duration_dict = {\n \"average_duration\": jobs.average_duration(),\n \"total_duration\": jobs.total_duration(),\n@@ -172,14 +166,9 @@\n \n def get_context_data(self, **kwargs):\n context = super().get_context_data()\n- phases = (\n- self.request.challenge.phase_set.filter(\n- submission_kind=SubmissionKindChoices.ALGORITHM\n- )\n- .select_related(\"archive\")\n- .prefetch_related(\"archive__items__values\")\n- .all()\n- )\n+ phases = self.request.challenge.phase_set.filter(\n+ submission_kind=SubmissionKindChoices.ALGORITHM\n+ ).all()\n duration_dict = {}\n for phase in phases:\n duration_dict[phase.title] = get_average_job_duration_for_phase(\n", "issue": "Challenge runtime statistics are not correct\nLooking at the Tiger statistics, for Segmentation and Detection (Final) phase:\r\n\r\nAverage algorithm job duration for Segmentation and Detection (Final):\t25 minutes\r\nTotal algorithm job duration for Segmentation and Detection (Final):\t4 days\r\n\r\nThere has been 1 submission to this phase:\r\n\r\n\r\n\r\nLooking at a couple of those results they seem to take ~30 seconds each, and maybe 50 jobs. I think what is happening is that the algorithm was used for multiple phases, and there are different versions, which are inflating the runtime statistics.\r\n\r\n\n", "before_files": [{"content": "from django.contrib import messages\nfrom django.contrib.auth.mixins import UserPassesTestMixin\nfrom django.db.models import Q\nfrom django.http import Http404\nfrom django.views.generic import (\n CreateView,\n DeleteView,\n DetailView,\n ListView,\n TemplateView,\n UpdateView,\n)\nfrom guardian.mixins import LoginRequiredMixin\nfrom guardian.mixins import (\n PermissionRequiredMixin as ObjectPermissionRequiredMixin,\n)\n\nfrom grandchallenge.algorithms.models import Job\nfrom grandchallenge.core.mixins import UserIsStaffMixin\nfrom grandchallenge.evaluation.models import Submission\nfrom grandchallenge.evaluation.utils import SubmissionKindChoices\nfrom grandchallenge.pages.forms import PageCreateForm, PageUpdateForm\nfrom grandchallenge.pages.models import Page\nfrom grandchallenge.subdomains.utils import reverse, reverse_lazy\n\n\nclass ChallengeFilteredQuerysetMixin:\n def get_queryset(self):\n queryset = super().get_queryset()\n return queryset.filter(Q(challenge=self.request.challenge))\n\n\nclass ChallengeFormKwargsMixin:\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs.update({\"challenge\": self.request.challenge})\n return kwargs\n\n\nclass PageCreate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFormKwargsMixin,\n CreateView,\n):\n model = Page\n form_class = PageCreateForm\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def form_valid(self, form):\n form.instance.challenge = self.request.challenge\n return super().form_valid(form)\n\n\nclass PageList(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n ListView,\n):\n model = Page\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n\nclass PageDetail(\n UserPassesTestMixin, ChallengeFilteredQuerysetMixin, DetailView\n):\n model = Page\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def test_func(self):\n user = self.request.user\n page = self.get_object()\n return page.can_be_viewed_by(user=user)\n\n def get_context_object_name(self, obj):\n return \"currentpage\"\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context.update(self.object.detail_context)\n return context\n\n\nclass ChallengeHome(PageDetail):\n def get_object(self, queryset=None):\n page = self.request.challenge.page_set.first()\n\n if page is None:\n raise Http404(\"No pages found for this challenge\")\n\n return page\n\n\nclass PageUpdate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n ChallengeFormKwargsMixin,\n UpdateView,\n):\n model = Page\n form_class = PageUpdateForm\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def form_valid(self, form):\n response = super().form_valid(form)\n self.object.move(form.cleaned_data[\"move\"])\n return response\n\n\nclass PageDelete(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n DeleteView,\n):\n model = Page\n success_message = \"Page was successfully deleted\"\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def get_success_url(self):\n return reverse(\n \"pages:list\",\n kwargs={\"challenge_short_name\": self.request.challenge.short_name},\n )\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super().delete(request, *args, **kwargs)\n\n\ndef get_average_job_duration_for_phase(phase):\n algorithm_images = Submission.objects.filter(\n phase__pk=phase.pk\n ).values_list(\"algorithm_image__pk\")\n jobs = Job.objects.filter(\n algorithm_image__pk__in=algorithm_images,\n status=Job.SUCCESS,\n creator=None,\n )\n duration_dict = {\n \"average_duration\": jobs.average_duration(),\n \"total_duration\": jobs.total_duration(),\n }\n return duration_dict\n\n\nclass ChallengeStatistics(LoginRequiredMixin, UserIsStaffMixin, TemplateView):\n template_name = \"pages/challenge_statistics.html\"\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data()\n phases = (\n self.request.challenge.phase_set.filter(\n submission_kind=SubmissionKindChoices.ALGORITHM\n )\n .select_related(\"archive\")\n .prefetch_related(\"archive__items__values\")\n .all()\n )\n duration_dict = {}\n for phase in phases:\n duration_dict[phase.title] = get_average_job_duration_for_phase(\n phase=phase\n )\n\n context.update(\n {\n \"average_job_durations\": duration_dict,\n }\n )\n\n return context\n", "path": "app/grandchallenge/pages/views.py"}], "after_files": [{"content": "from django.contrib import messages\nfrom django.contrib.auth.mixins import UserPassesTestMixin\nfrom django.db.models import Q\nfrom django.http import Http404\nfrom django.views.generic import (\n CreateView,\n DeleteView,\n DetailView,\n ListView,\n TemplateView,\n UpdateView,\n)\nfrom guardian.mixins import LoginRequiredMixin\nfrom guardian.mixins import (\n PermissionRequiredMixin as ObjectPermissionRequiredMixin,\n)\n\nfrom grandchallenge.algorithms.models import Job\nfrom grandchallenge.core.mixins import UserIsStaffMixin\nfrom grandchallenge.evaluation.utils import SubmissionKindChoices\nfrom grandchallenge.pages.forms import PageCreateForm, PageUpdateForm\nfrom grandchallenge.pages.models import Page\nfrom grandchallenge.subdomains.utils import reverse, reverse_lazy\n\n\nclass ChallengeFilteredQuerysetMixin:\n def get_queryset(self):\n queryset = super().get_queryset()\n return queryset.filter(Q(challenge=self.request.challenge))\n\n\nclass ChallengeFormKwargsMixin:\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs.update({\"challenge\": self.request.challenge})\n return kwargs\n\n\nclass PageCreate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFormKwargsMixin,\n CreateView,\n):\n model = Page\n form_class = PageCreateForm\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def form_valid(self, form):\n form.instance.challenge = self.request.challenge\n return super().form_valid(form)\n\n\nclass PageList(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n ListView,\n):\n model = Page\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n\nclass PageDetail(\n UserPassesTestMixin, ChallengeFilteredQuerysetMixin, DetailView\n):\n model = Page\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def test_func(self):\n user = self.request.user\n page = self.get_object()\n return page.can_be_viewed_by(user=user)\n\n def get_context_object_name(self, obj):\n return \"currentpage\"\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context.update(self.object.detail_context)\n return context\n\n\nclass ChallengeHome(PageDetail):\n def get_object(self, queryset=None):\n page = self.request.challenge.page_set.first()\n\n if page is None:\n raise Http404(\"No pages found for this challenge\")\n\n return page\n\n\nclass PageUpdate(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n ChallengeFormKwargsMixin,\n UpdateView,\n):\n model = Page\n form_class = PageUpdateForm\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def form_valid(self, form):\n response = super().form_valid(form)\n self.object.move(form.cleaned_data[\"move\"])\n return response\n\n\nclass PageDelete(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n ChallengeFilteredQuerysetMixin,\n DeleteView,\n):\n model = Page\n success_message = \"Page was successfully deleted\"\n permission_required = \"change_challenge\"\n raise_exception = True\n login_url = reverse_lazy(\"account_login\")\n\n def get_permission_object(self):\n return self.request.challenge\n\n def get_success_url(self):\n return reverse(\n \"pages:list\",\n kwargs={\"challenge_short_name\": self.request.challenge.short_name},\n )\n\n def delete(self, request, *args, **kwargs):\n messages.success(self.request, self.success_message)\n return super().delete(request, *args, **kwargs)\n\n\ndef get_average_job_duration_for_phase(phase):\n jobs = Job.objects.filter(\n outputs__evaluation_evaluations_as_input__submission__phase=phase,\n ).distinct()\n duration_dict = {\n \"average_duration\": jobs.average_duration(),\n \"total_duration\": jobs.total_duration(),\n }\n return duration_dict\n\n\nclass ChallengeStatistics(LoginRequiredMixin, UserIsStaffMixin, TemplateView):\n template_name = \"pages/challenge_statistics.html\"\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data()\n phases = self.request.challenge.phase_set.filter(\n submission_kind=SubmissionKindChoices.ALGORITHM\n ).all()\n duration_dict = {}\n for phase in phases:\n duration_dict[phase.title] = get_average_job_duration_for_phase(\n phase=phase\n )\n\n context.update(\n {\n \"average_job_durations\": duration_dict,\n }\n )\n\n return context\n", "path": "app/grandchallenge/pages/views.py"}]}
| 2,049 | 395 |
gh_patches_debug_28995
|
rasdani/github-patches
|
git_diff
|
vacanza__python-holidays-1020
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update MANIFEST.in
Clean up and make sure `sdist` contains all needed files.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # python-holidays
2 # ---------------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: dr-prodigy <[email protected]> (c) 2017-2023
8 # ryanss <[email protected]> (c) 2014-2017
9 # Website: https://github.com/dr-prodigy/python-holidays
10 # License: MIT (see LICENSE file)
11
12 import os
13 import subprocess
14 import sys
15 from pathlib import Path
16
17 from setuptools import setup
18
19
20 def generate_mo_files():
21 """Looks up for .po files and generates respective .mo files."""
22 for po_path in Path(os.path.join("holidays", "locale")).rglob("*.po"):
23 po_file = str(po_path)
24 mo_file = po_file.replace(".po", ".mo")
25
26 if os.path.exists(mo_file):
27 os.unlink(mo_file)
28 subprocess.run(
29 (
30 sys.executable,
31 os.path.join("scripts", "l10n", "msgfmt.py"),
32 "-o",
33 mo_file,
34 po_file,
35 ),
36 check=True,
37 )
38
39
40 if __name__ == "__main__":
41 generate_mo_files()
42 setup()
43
```
Path: `scripts/l10n/generate_mo_files.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # python-holidays
4 # ---------------
5 # A fast, efficient Python library for generating country, province and state
6 # specific sets of holidays on the fly. It aims to make determining whether a
7 # specific date is a holiday as fast and flexible as possible.
8 #
9 # Authors: dr-prodigy <[email protected]> (c) 2017-2023
10 # ryanss <[email protected]> (c) 2014-2017
11 # Website: https://github.com/dr-prodigy/python-holidays
12 # License: MIT (see LICENSE file)
13
14 import os
15 import subprocess
16 import sys
17 from pathlib import Path
18
19
20 class MOGenerator:
21 """Creates .mo files for supported country/market entities."""
22
23 def run(self):
24 """Runs the .mo files generation process."""
25 # Delete old files.
26 for mo_file in Path(os.path.join("holidays", "locale")).rglob("*.mo"):
27 os.unlink(str(mo_file))
28
29 # Create new files.
30 for po_path in Path(os.path.join("holidays", "locale")).rglob("*.po"):
31 po_file = str(po_path)
32 mo_file = po_file.replace(".po", ".mo")
33 subprocess.run(
34 (
35 sys.executable,
36 os.path.join("scripts", "l10n", "msgfmt.py"),
37 "-o",
38 mo_file,
39 po_file,
40 ),
41 check=True,
42 )
43
44
45 if __name__ == "__main__":
46 MOGenerator().run()
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/l10n/generate_mo_files.py b/scripts/l10n/generate_mo_files.py
--- a/scripts/l10n/generate_mo_files.py
+++ b/scripts/l10n/generate_mo_files.py
@@ -22,14 +22,12 @@
def run(self):
"""Runs the .mo files generation process."""
- # Delete old files.
- for mo_file in Path(os.path.join("holidays", "locale")).rglob("*.mo"):
- os.unlink(str(mo_file))
-
- # Create new files.
for po_path in Path(os.path.join("holidays", "locale")).rglob("*.po"):
po_file = str(po_path)
mo_file = po_file.replace(".po", ".mo")
+
+ if os.path.exists(mo_file):
+ os.unlink(mo_file)
subprocess.run(
(
sys.executable,
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -9,34 +9,7 @@
# Website: https://github.com/dr-prodigy/python-holidays
# License: MIT (see LICENSE file)
-import os
-import subprocess
-import sys
-from pathlib import Path
-
from setuptools import setup
-
-def generate_mo_files():
- """Looks up for .po files and generates respective .mo files."""
- for po_path in Path(os.path.join("holidays", "locale")).rglob("*.po"):
- po_file = str(po_path)
- mo_file = po_file.replace(".po", ".mo")
-
- if os.path.exists(mo_file):
- os.unlink(mo_file)
- subprocess.run(
- (
- sys.executable,
- os.path.join("scripts", "l10n", "msgfmt.py"),
- "-o",
- mo_file,
- po_file,
- ),
- check=True,
- )
-
-
if __name__ == "__main__":
- generate_mo_files()
setup()
|
{"golden_diff": "diff --git a/scripts/l10n/generate_mo_files.py b/scripts/l10n/generate_mo_files.py\n--- a/scripts/l10n/generate_mo_files.py\n+++ b/scripts/l10n/generate_mo_files.py\n@@ -22,14 +22,12 @@\n \n def run(self):\n \"\"\"Runs the .mo files generation process.\"\"\"\n- # Delete old files.\n- for mo_file in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.mo\"):\n- os.unlink(str(mo_file))\n-\n- # Create new files.\n for po_path in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.po\"):\n po_file = str(po_path)\n mo_file = po_file.replace(\".po\", \".mo\")\n+\n+ if os.path.exists(mo_file):\n+ os.unlink(mo_file)\n subprocess.run(\n (\n sys.executable,\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -9,34 +9,7 @@\n # Website: https://github.com/dr-prodigy/python-holidays\n # License: MIT (see LICENSE file)\n \n-import os\n-import subprocess\n-import sys\n-from pathlib import Path\n-\n from setuptools import setup\n \n-\n-def generate_mo_files():\n- \"\"\"Looks up for .po files and generates respective .mo files.\"\"\"\n- for po_path in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.po\"):\n- po_file = str(po_path)\n- mo_file = po_file.replace(\".po\", \".mo\")\n-\n- if os.path.exists(mo_file):\n- os.unlink(mo_file)\n- subprocess.run(\n- (\n- sys.executable,\n- os.path.join(\"scripts\", \"l10n\", \"msgfmt.py\"),\n- \"-o\",\n- mo_file,\n- po_file,\n- ),\n- check=True,\n- )\n-\n-\n if __name__ == \"__main__\":\n- generate_mo_files()\n setup()\n", "issue": "Update MANIFEST.in\nClean up and make sure `sdist` contains all needed files.\n", "before_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport os\nimport subprocess\nimport sys\nfrom pathlib import Path\n\nfrom setuptools import setup\n\n\ndef generate_mo_files():\n \"\"\"Looks up for .po files and generates respective .mo files.\"\"\"\n for po_path in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.po\"):\n po_file = str(po_path)\n mo_file = po_file.replace(\".po\", \".mo\")\n\n if os.path.exists(mo_file):\n os.unlink(mo_file)\n subprocess.run(\n (\n sys.executable,\n os.path.join(\"scripts\", \"l10n\", \"msgfmt.py\"),\n \"-o\",\n mo_file,\n po_file,\n ),\n check=True,\n )\n\n\nif __name__ == \"__main__\":\n generate_mo_files()\n setup()\n", "path": "setup.py"}, {"content": "#!/usr/bin/env python3\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport os\nimport subprocess\nimport sys\nfrom pathlib import Path\n\n\nclass MOGenerator:\n \"\"\"Creates .mo files for supported country/market entities.\"\"\"\n\n def run(self):\n \"\"\"Runs the .mo files generation process.\"\"\"\n # Delete old files.\n for mo_file in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.mo\"):\n os.unlink(str(mo_file))\n\n # Create new files.\n for po_path in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.po\"):\n po_file = str(po_path)\n mo_file = po_file.replace(\".po\", \".mo\")\n subprocess.run(\n (\n sys.executable,\n os.path.join(\"scripts\", \"l10n\", \"msgfmt.py\"),\n \"-o\",\n mo_file,\n po_file,\n ),\n check=True,\n )\n\n\nif __name__ == \"__main__\":\n MOGenerator().run()\n", "path": "scripts/l10n/generate_mo_files.py"}], "after_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nfrom setuptools import setup\n\nif __name__ == \"__main__\":\n setup()\n", "path": "setup.py"}, {"content": "#!/usr/bin/env python3\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport os\nimport subprocess\nimport sys\nfrom pathlib import Path\n\n\nclass MOGenerator:\n \"\"\"Creates .mo files for supported country/market entities.\"\"\"\n\n def run(self):\n \"\"\"Runs the .mo files generation process.\"\"\"\n for po_path in Path(os.path.join(\"holidays\", \"locale\")).rglob(\"*.po\"):\n po_file = str(po_path)\n mo_file = po_file.replace(\".po\", \".mo\")\n\n if os.path.exists(mo_file):\n os.unlink(mo_file)\n subprocess.run(\n (\n sys.executable,\n os.path.join(\"scripts\", \"l10n\", \"msgfmt.py\"),\n \"-o\",\n mo_file,\n po_file,\n ),\n check=True,\n )\n\n\nif __name__ == \"__main__\":\n MOGenerator().run()\n", "path": "scripts/l10n/generate_mo_files.py"}]}
| 1,128 | 445 |
gh_patches_debug_35484
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-271
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"My sources" panel should appear on homepage
In OldCantus on the homepage when a user is logged in, a list of sources appears in a "My sources" box in the left sidebar. This box replaces the "jump to source" and "what's new" boxes that are visible when a user is not logged in.
In NewCantus, the "jump to source" and "what's new" boxes appear whether or not a user is logged in. Behavior on NewCantus should be changed to match that of OldCantus
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/cantusdb_project/main_app/templatetags/helper_tags.py`
Content:
```
1 import calendar
2 from typing import Union, Optional
3 from django.utils.http import urlencode
4 from django import template
5 from main_app.models import Source
6 from articles.models import Article
7 from django.utils.safestring import mark_safe
8
9 register = template.Library()
10
11
12 @register.simple_tag(takes_context=False)
13 def recent_articles():
14 articles = Article.objects.order_by("-date_created")[:5]
15 list_item_template = '<li><a href="{url}">{title}</a><br><small>{date}</small></li>'
16 list_items = [
17 list_item_template.format(
18 url=a.get_absolute_url(),
19 title=a.title,
20 date=a.date_created.strftime("%x"),
21 )
22 for a
23 in articles
24 ]
25 list_items_string = "".join(list_items)
26 recent_articles_string = "<ul>{lis}</ul>".format(lis=list_items_string)
27 return mark_safe(recent_articles_string)
28
29
30 @register.filter(name="month_to_string")
31 def month_to_string(value: Optional[Union[str, int]]) -> Optional[Union[str, int]]:
32 """Converts month number to textual representation, 3 letters (Jan, Mar, etc)"""
33 if type(value) == int and value in range(1, 13):
34 return calendar.month_abbr[value]
35 else:
36 return value
37
38
39 @register.simple_tag(takes_context=True)
40 def url_add_get_params(context, **kwargs):
41 query = context["request"].GET.copy()
42 # accounts for the situations where there may be two paginations in one page
43 if "page" in kwargs:
44 query.pop("page", None)
45 if "page2" in kwargs:
46 query.pop("page2", None)
47 query.update(kwargs)
48 return query.urlencode()
49
50
51 @register.simple_tag(takes_context=False)
52 def source_links():
53 sources = (
54 Source.objects.filter(public=True, visible=True, segment__id=4063)
55 .exclude(siglum=None)
56 .values("siglum", "id")
57 .order_by("siglum")
58 )
59 options = ""
60 # <option value="source1">Source 1</option>
61 # <option value="source2">Source 2</option>
62 # <option value="source3">Source 3</option>
63 for source in sources:
64 option_str = (
65 f"<option value=source/{source['id']}>{source['siglum']}</option>\n"
66 )
67 options += option_str
68
69 return mark_safe(options)
70
71
72
73 @register.filter
74 def classname(obj):
75 """
76 Returns the name of the object's class
77 A use-case is: {% if object|classname == "Notation" %}
78 """
79 return obj.__class__.__name__
80
81 @register.filter
82 def admin_url_name(class_name, action):
83 """
84 Accepts a class name and an action (either "change" or "delete") as arguments.
85 Returns the name of the URL for changing/deleting an object in the admin interface.
86 """
87 class_name = class_name.lower()
88 action = action.lower()
89
90 return f"admin:main_app_{class_name}_{action}"
91
92 @register.filter(name='has_group')
93 def has_group(user, group_name):
94 return user.groups.filter(name=group_name).exists()
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django/cantusdb_project/main_app/templatetags/helper_tags.py b/django/cantusdb_project/main_app/templatetags/helper_tags.py
--- a/django/cantusdb_project/main_app/templatetags/helper_tags.py
+++ b/django/cantusdb_project/main_app/templatetags/helper_tags.py
@@ -5,6 +5,7 @@
from main_app.models import Source
from articles.models import Article
from django.utils.safestring import mark_safe
+from django.urls import reverse
register = template.Library()
@@ -27,6 +28,57 @@
return mark_safe(recent_articles_string)
[email protected]_tag(takes_context=False)
+def my_sources(user):
+ def make_source_detail_link_with_siglum(source):
+ id = source.id
+ siglum = source.rism_siglum
+ url = reverse("source-detail", args=[id])
+ link = '<a href="{}">{}</a>'.format(url, siglum)
+ return link
+ def make_source_detail_link_with_title(source):
+ id = source.id
+ title = source.title
+ url = reverse("source-detail", args=[id])
+ link = '<a href="{}">{}</a>'.format(url, title)
+ return link
+ def make_add_new_chants_link(source):
+ id = source.id
+ url = reverse("chant-create", args=[id])
+ link = '<a href="{}">+ Add new chant</a>'.format(url)
+ return link
+ def make_edit_chants_link(source):
+ id = source.id
+ url = reverse("source-edit-volpiano", args=[id])
+ link = '<a href="{}">Edit chants (Fulltext & Volpiano editor)</a>'.format(url)
+ return link
+ def make_links_for_source(source):
+ link_with_siglum = make_source_detail_link_with_siglum(source)
+ link_with_title = make_source_detail_link_with_title(source)
+ add_new_chants_link = make_add_new_chants_link(source)
+ edit_chants_link = make_edit_chants_link(source)
+ template = """{sigl}<br>
+ <small>
+ <b>{title}</b><br>
+ {add}<br>
+ {edit}<br>
+ </small>
+ """
+ links_string = template.format(
+ sigl=link_with_siglum,
+ title=link_with_title,
+ add=add_new_chants_link,
+ edit=edit_chants_link,
+ )
+ return links_string
+ MAX_SOURCES_TO_DISPLAY = 6
+ sources = list(user.sources_user_can_edit.all())[:MAX_SOURCES_TO_DISPLAY]
+ source_links = [make_links_for_source(source) for source in sources]
+ list_items = ["<li>{}</li>".format(link) for link in source_links]
+ joined_list_items = "".join(list_items)
+ links_ul = "<ul>{}</ul>".format(joined_list_items)
+ return mark_safe(links_ul)
+
@register.filter(name="month_to_string")
def month_to_string(value: Optional[Union[str, int]]) -> Optional[Union[str, int]]:
"""Converts month number to textual representation, 3 letters (Jan, Mar, etc)"""
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/templatetags/helper_tags.py b/django/cantusdb_project/main_app/templatetags/helper_tags.py\n--- a/django/cantusdb_project/main_app/templatetags/helper_tags.py\n+++ b/django/cantusdb_project/main_app/templatetags/helper_tags.py\n@@ -5,6 +5,7 @@\n from main_app.models import Source\n from articles.models import Article\n from django.utils.safestring import mark_safe\n+from django.urls import reverse\n \n register = template.Library()\n \n@@ -27,6 +28,57 @@\n return mark_safe(recent_articles_string)\n \n \[email protected]_tag(takes_context=False)\n+def my_sources(user):\n+ def make_source_detail_link_with_siglum(source):\n+ id = source.id\n+ siglum = source.rism_siglum\n+ url = reverse(\"source-detail\", args=[id])\n+ link = '<a href=\"{}\">{}</a>'.format(url, siglum)\n+ return link\n+ def make_source_detail_link_with_title(source):\n+ id = source.id\n+ title = source.title\n+ url = reverse(\"source-detail\", args=[id])\n+ link = '<a href=\"{}\">{}</a>'.format(url, title) \n+ return link\n+ def make_add_new_chants_link(source):\n+ id = source.id\n+ url = reverse(\"chant-create\", args=[id])\n+ link = '<a href=\"{}\">+ Add new chant</a>'.format(url) \n+ return link\n+ def make_edit_chants_link(source):\n+ id = source.id\n+ url = reverse(\"source-edit-volpiano\", args=[id])\n+ link = '<a href=\"{}\">Edit chants (Fulltext & Volpiano editor)</a>'.format(url) \n+ return link\n+ def make_links_for_source(source):\n+ link_with_siglum = make_source_detail_link_with_siglum(source)\n+ link_with_title = make_source_detail_link_with_title(source)\n+ add_new_chants_link = make_add_new_chants_link(source)\n+ edit_chants_link = make_edit_chants_link(source)\n+ template = \"\"\"{sigl}<br>\n+ <small>\n+ <b>{title}</b><br>\n+ {add}<br>\n+ {edit}<br>\n+ </small>\n+ \"\"\"\n+ links_string = template.format(\n+ sigl=link_with_siglum,\n+ title=link_with_title,\n+ add=add_new_chants_link,\n+ edit=edit_chants_link,\n+ )\n+ return links_string\n+ MAX_SOURCES_TO_DISPLAY = 6\n+ sources = list(user.sources_user_can_edit.all())[:MAX_SOURCES_TO_DISPLAY]\n+ source_links = [make_links_for_source(source) for source in sources]\n+ list_items = [\"<li>{}</li>\".format(link) for link in source_links]\n+ joined_list_items = \"\".join(list_items)\n+ links_ul = \"<ul>{}</ul>\".format(joined_list_items)\n+ return mark_safe(links_ul)\n+\n @register.filter(name=\"month_to_string\")\n def month_to_string(value: Optional[Union[str, int]]) -> Optional[Union[str, int]]:\n \"\"\"Converts month number to textual representation, 3 letters (Jan, Mar, etc)\"\"\"\n", "issue": "\"My sources\" panel should appear on homepage\nIn OldCantus on the homepage when a user is logged in, a list of sources appears in a \"My sources\" box in the left sidebar. This box replaces the \"jump to source\" and \"what's new\" boxes that are visible when a user is not logged in.\r\n\r\nIn NewCantus, the \"jump to source\" and \"what's new\" boxes appear whether or not a user is logged in. Behavior on NewCantus should be changed to match that of OldCantus\n", "before_files": [{"content": "import calendar\nfrom typing import Union, Optional\nfrom django.utils.http import urlencode\nfrom django import template\nfrom main_app.models import Source\nfrom articles.models import Article\nfrom django.utils.safestring import mark_safe\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=False)\ndef recent_articles():\n articles = Article.objects.order_by(\"-date_created\")[:5]\n list_item_template = '<li><a href=\"{url}\">{title}</a><br><small>{date}</small></li>'\n list_items = [\n list_item_template.format(\n url=a.get_absolute_url(),\n title=a.title,\n date=a.date_created.strftime(\"%x\"),\n )\n for a\n in articles\n ]\n list_items_string = \"\".join(list_items)\n recent_articles_string = \"<ul>{lis}</ul>\".format(lis=list_items_string)\n return mark_safe(recent_articles_string)\n\n\[email protected](name=\"month_to_string\")\ndef month_to_string(value: Optional[Union[str, int]]) -> Optional[Union[str, int]]:\n \"\"\"Converts month number to textual representation, 3 letters (Jan, Mar, etc)\"\"\"\n if type(value) == int and value in range(1, 13):\n return calendar.month_abbr[value]\n else:\n return value\n\n\[email protected]_tag(takes_context=True)\ndef url_add_get_params(context, **kwargs):\n query = context[\"request\"].GET.copy()\n # accounts for the situations where there may be two paginations in one page\n if \"page\" in kwargs:\n query.pop(\"page\", None)\n if \"page2\" in kwargs:\n query.pop(\"page2\", None)\n query.update(kwargs)\n return query.urlencode()\n\n\[email protected]_tag(takes_context=False)\ndef source_links():\n sources = (\n Source.objects.filter(public=True, visible=True, segment__id=4063)\n .exclude(siglum=None)\n .values(\"siglum\", \"id\")\n .order_by(\"siglum\")\n )\n options = \"\"\n # <option value=\"source1\">Source 1</option>\n # <option value=\"source2\">Source 2</option>\n # <option value=\"source3\">Source 3</option>\n for source in sources:\n option_str = (\n f\"<option value=source/{source['id']}>{source['siglum']}</option>\\n\"\n )\n options += option_str\n\n return mark_safe(options)\n\n\n\[email protected]\ndef classname(obj):\n \"\"\"\n Returns the name of the object's class\n A use-case is: {% if object|classname == \"Notation\" %}\n \"\"\"\n return obj.__class__.__name__\n\[email protected]\ndef admin_url_name(class_name, action):\n \"\"\"\n Accepts a class name and an action (either \"change\" or \"delete\") as arguments.\n Returns the name of the URL for changing/deleting an object in the admin interface.\n \"\"\"\n class_name = class_name.lower()\n action = action.lower()\n\n return f\"admin:main_app_{class_name}_{action}\"\n\[email protected](name='has_group') \ndef has_group(user, group_name):\n return user.groups.filter(name=group_name).exists() \n", "path": "django/cantusdb_project/main_app/templatetags/helper_tags.py"}], "after_files": [{"content": "import calendar\nfrom typing import Union, Optional\nfrom django.utils.http import urlencode\nfrom django import template\nfrom main_app.models import Source\nfrom articles.models import Article\nfrom django.utils.safestring import mark_safe\nfrom django.urls import reverse\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=False)\ndef recent_articles():\n articles = Article.objects.order_by(\"-date_created\")[:5]\n list_item_template = '<li><a href=\"{url}\">{title}</a><br><small>{date}</small></li>'\n list_items = [\n list_item_template.format(\n url=a.get_absolute_url(),\n title=a.title,\n date=a.date_created.strftime(\"%x\"),\n )\n for a\n in articles\n ]\n list_items_string = \"\".join(list_items)\n recent_articles_string = \"<ul>{lis}</ul>\".format(lis=list_items_string)\n return mark_safe(recent_articles_string)\n\n\[email protected]_tag(takes_context=False)\ndef my_sources(user):\n def make_source_detail_link_with_siglum(source):\n id = source.id\n siglum = source.rism_siglum\n url = reverse(\"source-detail\", args=[id])\n link = '<a href=\"{}\">{}</a>'.format(url, siglum)\n return link\n def make_source_detail_link_with_title(source):\n id = source.id\n title = source.title\n url = reverse(\"source-detail\", args=[id])\n link = '<a href=\"{}\">{}</a>'.format(url, title) \n return link\n def make_add_new_chants_link(source):\n id = source.id\n url = reverse(\"chant-create\", args=[id])\n link = '<a href=\"{}\">+ Add new chant</a>'.format(url) \n return link\n def make_edit_chants_link(source):\n id = source.id\n url = reverse(\"source-edit-volpiano\", args=[id])\n link = '<a href=\"{}\">Edit chants (Fulltext & Volpiano editor)</a>'.format(url) \n return link\n def make_links_for_source(source):\n link_with_siglum = make_source_detail_link_with_siglum(source)\n link_with_title = make_source_detail_link_with_title(source)\n add_new_chants_link = make_add_new_chants_link(source)\n edit_chants_link = make_edit_chants_link(source)\n template = \"\"\"{sigl}<br>\n <small>\n <b>{title}</b><br>\n {add}<br>\n {edit}<br>\n </small>\n \"\"\"\n links_string = template.format(\n sigl=link_with_siglum,\n title=link_with_title,\n add=add_new_chants_link,\n edit=edit_chants_link,\n )\n return links_string\n MAX_SOURCES_TO_DISPLAY = 6\n sources = list(user.sources_user_can_edit.all())[:MAX_SOURCES_TO_DISPLAY]\n source_links = [make_links_for_source(source) for source in sources]\n list_items = [\"<li>{}</li>\".format(link) for link in source_links]\n joined_list_items = \"\".join(list_items)\n links_ul = \"<ul>{}</ul>\".format(joined_list_items)\n return mark_safe(links_ul)\n\[email protected](name=\"month_to_string\")\ndef month_to_string(value: Optional[Union[str, int]]) -> Optional[Union[str, int]]:\n \"\"\"Converts month number to textual representation, 3 letters (Jan, Mar, etc)\"\"\"\n if type(value) == int and value in range(1, 13):\n return calendar.month_abbr[value]\n else:\n return value\n\n\[email protected]_tag(takes_context=True)\ndef url_add_get_params(context, **kwargs):\n query = context[\"request\"].GET.copy()\n # accounts for the situations where there may be two paginations in one page\n if \"page\" in kwargs:\n query.pop(\"page\", None)\n if \"page2\" in kwargs:\n query.pop(\"page2\", None)\n query.update(kwargs)\n return query.urlencode()\n\n\[email protected]_tag(takes_context=False)\ndef source_links():\n sources = (\n Source.objects.filter(public=True, visible=True, segment__id=4063)\n .exclude(siglum=None)\n .values(\"siglum\", \"id\")\n .order_by(\"siglum\")\n )\n options = \"\"\n # <option value=\"source1\">Source 1</option>\n # <option value=\"source2\">Source 2</option>\n # <option value=\"source3\">Source 3</option>\n for source in sources:\n option_str = (\n f\"<option value=source/{source['id']}>{source['siglum']}</option>\\n\"\n )\n options += option_str\n\n return mark_safe(options)\n\n\n\[email protected]\ndef classname(obj):\n \"\"\"\n Returns the name of the object's class\n A use-case is: {% if object|classname == \"Notation\" %}\n \"\"\"\n return obj.__class__.__name__\n\[email protected]\ndef admin_url_name(class_name, action):\n \"\"\"\n Accepts a class name and an action (either \"change\" or \"delete\") as arguments.\n Returns the name of the URL for changing/deleting an object in the admin interface.\n \"\"\"\n class_name = class_name.lower()\n action = action.lower()\n\n return f\"admin:main_app_{class_name}_{action}\"\n\[email protected](name='has_group') \ndef has_group(user, group_name):\n return user.groups.filter(name=group_name).exists() \n", "path": "django/cantusdb_project/main_app/templatetags/helper_tags.py"}]}
| 1,268 | 751 |
gh_patches_debug_24026
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-4627
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
run_target improperly handles command if 'python' is in meson's installation path
My build environment is RHEL 7.6 with the python 3.6 Red Hat software collection enabled in my .bashrc. Meson was installed by running ``pip3.6 install .`` as root in the ``meson-0.49.0/`` folder from a fresh download. (This issue also happens in meson 48.)
I was setting up a custom run_target to run cppcheck with the command
```
run_target('cppcheck', command : ['cppcheck', '--project=' + join_paths(meson.build_root(), 'compile_commands.json')])
```
but noticed that it was failing to run with the following error message:
```
Could not execute command "--project=[build dir]/compile_commands.json". File not found.
FAILED: meson-cppcheck
/opt/rh/rh-python36/root/usr/bin/meson --internal commandrunner [src dir] [build dir] '' /opt/rh/rh-python36/root/usr/bin/meson cppcheck --project=[build dir]/compile_commands.json
ninja: build stopped: subcommand failed
```
I traced the issue for a bit and it the issue appears to be in ``commandrunner.py`` line 61 (ironically the line with the comment "Hack." haha): it looks for the presence of the string ``python`` in the meson path, presumably to catch instances of meson being launched with a ``python3 meson`` call. However it ignores the possibility that python is simply a part of the path to the meson executable. When this happens, the commandrunner script grabs the fifth argument and assumes that it's part of the meson command, which is wrong.
I'm currently working around the issue by inserting an empty argument into the run_target command, like this:
```
run_target('cppcheck', command : ['', 'cppcheck', '--project=' + join_paths(meson.build_root(), 'compile_commands.json')])
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mesonbuild/scripts/commandrunner.py`
Content:
```
1 # Copyright 2014 The Meson development team
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """This program is a wrapper to run external commands. It determines
16 what to run, sets up the environment and executes the command."""
17
18 import sys, os, subprocess, shutil, shlex
19
20 def run_command(source_dir, build_dir, subdir, meson_command, command, arguments):
21 env = {'MESON_SOURCE_ROOT': source_dir,
22 'MESON_BUILD_ROOT': build_dir,
23 'MESON_SUBDIR': subdir,
24 'MESONINTROSPECT': ' '.join([shlex.quote(x) for x in meson_command + ['introspect']]),
25 }
26 cwd = os.path.join(source_dir, subdir)
27 child_env = os.environ.copy()
28 child_env.update(env)
29
30 # Is the command an executable in path?
31 exe = shutil.which(command)
32 if exe is not None:
33 command_array = [exe] + arguments
34 else:# No? Maybe it is a script in the source tree.
35 fullpath = os.path.join(source_dir, subdir, command)
36 command_array = [fullpath] + arguments
37 try:
38 return subprocess.Popen(command_array, env=child_env, cwd=cwd)
39 except FileNotFoundError:
40 print('Could not execute command "%s". File not found.' % command)
41 sys.exit(1)
42 except PermissionError:
43 print('Could not execute command "%s". File not executable.' % command)
44 sys.exit(1)
45 except OSError as err:
46 print('Could not execute command "{}": {}'.format(command, err))
47 sys.exit(1)
48 except subprocess.SubprocessError as err:
49 print('Could not execute command "{}": {}'.format(command, err))
50 sys.exit(1)
51
52
53 def run(args):
54 if len(args) < 4:
55 print('commandrunner.py <source dir> <build dir> <subdir> <command> [arguments]')
56 return 1
57 src_dir = args[0]
58 build_dir = args[1]
59 subdir = args[2]
60 meson_command = args[3]
61 if 'python' in meson_command: # Hack.
62 meson_command = [meson_command, args[4]]
63 command = args[5]
64 arguments = args[6:]
65 else:
66 meson_command = [meson_command]
67 command = args[4]
68 arguments = args[5:]
69 pc = run_command(src_dir, build_dir, subdir, meson_command, command, arguments)
70 pc.wait()
71 return pc.returncode
72
73 if __name__ == '__main__':
74 sys.exit(run(sys.argv[1:]))
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mesonbuild/scripts/commandrunner.py b/mesonbuild/scripts/commandrunner.py
--- a/mesonbuild/scripts/commandrunner.py
+++ b/mesonbuild/scripts/commandrunner.py
@@ -16,6 +16,7 @@
what to run, sets up the environment and executes the command."""
import sys, os, subprocess, shutil, shlex
+import re
def run_command(source_dir, build_dir, subdir, meson_command, command, arguments):
env = {'MESON_SOURCE_ROOT': source_dir,
@@ -49,6 +50,9 @@
print('Could not execute command "{}": {}'.format(command, err))
sys.exit(1)
+def is_python_command(cmdname):
+ end_py_regex = r'python(3|3\.\d+)?(\.exe)?$'
+ return re.search(end_py_regex, cmdname) is not None
def run(args):
if len(args) < 4:
@@ -58,7 +62,7 @@
build_dir = args[1]
subdir = args[2]
meson_command = args[3]
- if 'python' in meson_command: # Hack.
+ if is_python_command(meson_command):
meson_command = [meson_command, args[4]]
command = args[5]
arguments = args[6:]
|
{"golden_diff": "diff --git a/mesonbuild/scripts/commandrunner.py b/mesonbuild/scripts/commandrunner.py\n--- a/mesonbuild/scripts/commandrunner.py\n+++ b/mesonbuild/scripts/commandrunner.py\n@@ -16,6 +16,7 @@\n what to run, sets up the environment and executes the command.\"\"\"\n \n import sys, os, subprocess, shutil, shlex\n+import re\n \n def run_command(source_dir, build_dir, subdir, meson_command, command, arguments):\n env = {'MESON_SOURCE_ROOT': source_dir,\n@@ -49,6 +50,9 @@\n print('Could not execute command \"{}\": {}'.format(command, err))\n sys.exit(1)\n \n+def is_python_command(cmdname):\n+ end_py_regex = r'python(3|3\\.\\d+)?(\\.exe)?$'\n+ return re.search(end_py_regex, cmdname) is not None\n \n def run(args):\n if len(args) < 4:\n@@ -58,7 +62,7 @@\n build_dir = args[1]\n subdir = args[2]\n meson_command = args[3]\n- if 'python' in meson_command: # Hack.\n+ if is_python_command(meson_command):\n meson_command = [meson_command, args[4]]\n command = args[5]\n arguments = args[6:]\n", "issue": "run_target improperly handles command if 'python' is in meson's installation path\nMy build environment is RHEL 7.6 with the python 3.6 Red Hat software collection enabled in my .bashrc. Meson was installed by running ``pip3.6 install .`` as root in the ``meson-0.49.0/`` folder from a fresh download. (This issue also happens in meson 48.)\r\n\r\nI was setting up a custom run_target to run cppcheck with the command\r\n```\r\nrun_target('cppcheck', command : ['cppcheck', '--project=' + join_paths(meson.build_root(), 'compile_commands.json')])\r\n```\r\nbut noticed that it was failing to run with the following error message:\r\n```\r\nCould not execute command \"--project=[build dir]/compile_commands.json\". File not found.\r\nFAILED: meson-cppcheck\r\n/opt/rh/rh-python36/root/usr/bin/meson --internal commandrunner [src dir] [build dir] '' /opt/rh/rh-python36/root/usr/bin/meson cppcheck --project=[build dir]/compile_commands.json\r\nninja: build stopped: subcommand failed\r\n```\r\n\r\nI traced the issue for a bit and it the issue appears to be in ``commandrunner.py`` line 61 (ironically the line with the comment \"Hack.\" haha): it looks for the presence of the string ``python`` in the meson path, presumably to catch instances of meson being launched with a ``python3 meson`` call. However it ignores the possibility that python is simply a part of the path to the meson executable. When this happens, the commandrunner script grabs the fifth argument and assumes that it's part of the meson command, which is wrong.\r\n\r\nI'm currently working around the issue by inserting an empty argument into the run_target command, like this:\r\n```\r\nrun_target('cppcheck', command : ['', 'cppcheck', '--project=' + join_paths(meson.build_root(), 'compile_commands.json')])\r\n```\n", "before_files": [{"content": "# Copyright 2014 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This program is a wrapper to run external commands. It determines\nwhat to run, sets up the environment and executes the command.\"\"\"\n\nimport sys, os, subprocess, shutil, shlex\n\ndef run_command(source_dir, build_dir, subdir, meson_command, command, arguments):\n env = {'MESON_SOURCE_ROOT': source_dir,\n 'MESON_BUILD_ROOT': build_dir,\n 'MESON_SUBDIR': subdir,\n 'MESONINTROSPECT': ' '.join([shlex.quote(x) for x in meson_command + ['introspect']]),\n }\n cwd = os.path.join(source_dir, subdir)\n child_env = os.environ.copy()\n child_env.update(env)\n\n # Is the command an executable in path?\n exe = shutil.which(command)\n if exe is not None:\n command_array = [exe] + arguments\n else:# No? Maybe it is a script in the source tree.\n fullpath = os.path.join(source_dir, subdir, command)\n command_array = [fullpath] + arguments\n try:\n return subprocess.Popen(command_array, env=child_env, cwd=cwd)\n except FileNotFoundError:\n print('Could not execute command \"%s\". File not found.' % command)\n sys.exit(1)\n except PermissionError:\n print('Could not execute command \"%s\". File not executable.' % command)\n sys.exit(1)\n except OSError as err:\n print('Could not execute command \"{}\": {}'.format(command, err))\n sys.exit(1)\n except subprocess.SubprocessError as err:\n print('Could not execute command \"{}\": {}'.format(command, err))\n sys.exit(1)\n\n\ndef run(args):\n if len(args) < 4:\n print('commandrunner.py <source dir> <build dir> <subdir> <command> [arguments]')\n return 1\n src_dir = args[0]\n build_dir = args[1]\n subdir = args[2]\n meson_command = args[3]\n if 'python' in meson_command: # Hack.\n meson_command = [meson_command, args[4]]\n command = args[5]\n arguments = args[6:]\n else:\n meson_command = [meson_command]\n command = args[4]\n arguments = args[5:]\n pc = run_command(src_dir, build_dir, subdir, meson_command, command, arguments)\n pc.wait()\n return pc.returncode\n\nif __name__ == '__main__':\n sys.exit(run(sys.argv[1:]))\n", "path": "mesonbuild/scripts/commandrunner.py"}], "after_files": [{"content": "# Copyright 2014 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This program is a wrapper to run external commands. It determines\nwhat to run, sets up the environment and executes the command.\"\"\"\n\nimport sys, os, subprocess, shutil, shlex\nimport re\n\ndef run_command(source_dir, build_dir, subdir, meson_command, command, arguments):\n env = {'MESON_SOURCE_ROOT': source_dir,\n 'MESON_BUILD_ROOT': build_dir,\n 'MESON_SUBDIR': subdir,\n 'MESONINTROSPECT': ' '.join([shlex.quote(x) for x in meson_command + ['introspect']]),\n }\n cwd = os.path.join(source_dir, subdir)\n child_env = os.environ.copy()\n child_env.update(env)\n\n # Is the command an executable in path?\n exe = shutil.which(command)\n if exe is not None:\n command_array = [exe] + arguments\n else:# No? Maybe it is a script in the source tree.\n fullpath = os.path.join(source_dir, subdir, command)\n command_array = [fullpath] + arguments\n try:\n return subprocess.Popen(command_array, env=child_env, cwd=cwd)\n except FileNotFoundError:\n print('Could not execute command \"%s\". File not found.' % command)\n sys.exit(1)\n except PermissionError:\n print('Could not execute command \"%s\". File not executable.' % command)\n sys.exit(1)\n except OSError as err:\n print('Could not execute command \"{}\": {}'.format(command, err))\n sys.exit(1)\n except subprocess.SubprocessError as err:\n print('Could not execute command \"{}\": {}'.format(command, err))\n sys.exit(1)\n\ndef is_python_command(cmdname):\n end_py_regex = r'python(3|3\\.\\d+)?(\\.exe)?$'\n return re.search(end_py_regex, cmdname) is not None\n\ndef run(args):\n if len(args) < 4:\n print('commandrunner.py <source dir> <build dir> <subdir> <command> [arguments]')\n return 1\n src_dir = args[0]\n build_dir = args[1]\n subdir = args[2]\n meson_command = args[3]\n if is_python_command(meson_command):\n meson_command = [meson_command, args[4]]\n command = args[5]\n arguments = args[6:]\n else:\n meson_command = [meson_command]\n command = args[4]\n arguments = args[5:]\n pc = run_command(src_dir, build_dir, subdir, meson_command, command, arguments)\n pc.wait()\n return pc.returncode\n\nif __name__ == '__main__':\n sys.exit(run(sys.argv[1:]))\n", "path": "mesonbuild/scripts/commandrunner.py"}]}
| 1,512 | 295 |
gh_patches_debug_17173
|
rasdani/github-patches
|
git_diff
|
huggingface__text-generation-inference-860
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
falcon-rw-1b does not work
### System Info
A Nvidia Tesla T4 GPU in Kubernetes running text-generation-inference version 1.0.0 (official image)
### Information
- [ ] Docker
- [X] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
Run
```
text-generation-launcher --model-id tiiuae/falcon-rw-1b --trust-remote-code --revision e4b9872bb803165eb22f0a867d4e6a64d34fce19
```
Once the model is loaded, calling the server gives error:
```
$ curl 127.0.0.1:80/generate_stream -X POST -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' -H 'Content-Type: application/json'
data:{"token":{"id":43398,"text":" chapel","logprob":-4.859375,"special":false},"generated_text":null,"details":null}
data:{"error":"Request failed during generation: Server error: not enough values to unpack (expected 4, got 3)","error_type":"generation"}
```
In the server, there is this error:
```
2023-08-11T21:57:42.634325Z ERROR text_generation_launcher: Method Decode encountered an error.
Traceback (most recent call last):
File "/opt/conda/bin/text-generation-server", line 8, in <module>
sys.exit(app())
File "/opt/conda/lib/python3.9/site-packages/typer/main.py", line 311, in __call__
return get_command(self)(*args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/typer/core.py", line 778, in main
return _main(
File "/opt/conda/lib/python3.9/site-packages/typer/core.py", line 216, in _main
rv = self.invoke(ctx)
File "/opt/conda/lib/python3.9/site-packages/click/core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/opt/conda/lib/python3.9/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/opt/conda/lib/python3.9/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/opt/conda/lib/python3.9/site-packages/typer/main.py", line 683, in wrapper
return callback(**use_params) # type: ignore
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/cli.py", line 78, in serve
server.serve(
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/server.py", line 184, in serve
asyncio.run(
File "/opt/conda/lib/python3.9/asyncio/runners.py", line 44, in run
return loop.run_until_complete(main)
File "/opt/conda/lib/python3.9/asyncio/base_events.py", line 634, in run_until_complete
self.run_forever()
File "/opt/conda/lib/python3.9/asyncio/base_events.py", line 601, in run_forever
self._run_once()
File "/opt/conda/lib/python3.9/asyncio/base_events.py", line 1905, in _run_once
handle._run()
File "/opt/conda/lib/python3.9/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/opt/conda/lib/python3.9/site-packages/grpc_interceptor/server.py", line 159, in invoke_intercept_method
return await self.intercept(
> File "/opt/conda/lib/python3.9/site-packages/text_generation_server/interceptor.py", line 21, in intercept
return await response
File "/opt/conda/lib/python3.9/site-packages/opentelemetry/instrumentation/grpc/_aio_server.py", line 82, in _unary_interceptor
raise error
File "/opt/conda/lib/python3.9/site-packages/opentelemetry/instrumentation/grpc/_aio_server.py", line 73, in _unary_interceptor
return await behavior(request_or_iterator, context)
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/server.py", line 98, in Decode
generations, next_batch = self.model.generate_token(batch)
File "/opt/conda/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/models/causal_lm.py", line 541, in generate_token
logits, past = self.forward(
File "/opt/conda/lib/python3.9/site-packages/text_generation_server/models/rw.py", line 82, in forward
outputs = self.model.forward(
File "/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py", line 900, in forward
transformer_outputs = self.transformer(
File "/opt/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py", line 734, in forward
past_key_values = self._convert_to_rw_cache(past_key_values)
File "/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py", line 622, in _convert_to_rw_cache
batch_size, num_heads, kv_length, head_dim = past_key_value[0][0].shape
ValueError: not enough values to unpack (expected 4, got 3)
```
### Expected behavior
No error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `server/text_generation_server/models/rw.py`
Content:
```
1 import torch
2
3 from transformers import AutoTokenizer, AutoModelForCausalLM
4 from typing import List, Optional, Tuple
5
6 from text_generation_server.models import CausalLM
7
8
9 class RW(CausalLM):
10 def __init__(
11 self,
12 model_id: str,
13 revision: Optional[str] = None,
14 quantize: Optional[str] = None,
15 dtype: Optional[torch.dtype] = None,
16 trust_remote_code: bool = False,
17 ):
18 if torch.cuda.is_available():
19 device = torch.device("cuda")
20 dtype = torch.float16 if dtype is None else dtype
21 else:
22 if quantize:
23 raise ValueError("quantization is not available on CPU")
24
25 device = torch.device("cpu")
26 dtype = torch.float32
27
28 tokenizer = AutoTokenizer.from_pretrained(
29 model_id,
30 revision=revision,
31 padding_side="left",
32 truncation_side="left",
33 trust_remote_code=trust_remote_code,
34 )
35 model = AutoModelForCausalLM.from_pretrained(
36 model_id,
37 revision=revision,
38 torch_dtype=dtype,
39 device_map="auto"
40 if torch.cuda.is_available() and torch.cuda.device_count() > 1
41 else None,
42 load_in_8bit=quantize == "bitsandbytes",
43 trust_remote_code=trust_remote_code,
44 )
45 if torch.cuda.is_available() and torch.cuda.device_count() == 1:
46 model = model.cuda()
47
48 if tokenizer.pad_token_id is None:
49 if model.config.pad_token_id is not None:
50 tokenizer.pad_token_id = model.config.pad_token_id
51 elif model.config.eos_token_id is not None:
52 tokenizer.pad_token_id = model.config.eos_token_id
53 elif tokenizer.eos_token_id is not None:
54 tokenizer.pad_token_id = tokenizer.eos_token_id
55 else:
56 tokenizer.add_special_tokens({"pad_token": "[PAD]"})
57
58 super(CausalLM, self).__init__(
59 model=model,
60 tokenizer=tokenizer,
61 requires_padding=True,
62 dtype=dtype,
63 device=device,
64 )
65
66 def forward(
67 self, input_ids, attention_mask, position_ids, past_key_values: Optional = None
68 ) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:
69 # Model Forward
70 if past_key_values is not None:
71 reshaped_past_key_values = []
72 for layer in past_key_values:
73 past_keys, past_values = layer
74 reshaped_past_key_values.append(
75 (
76 past_keys.view(-1, *past_keys.shape[-2:]),
77 past_values.view(-1, *past_values.shape[-2:]),
78 )
79 )
80 past_key_values = reshaped_past_key_values
81
82 outputs = self.model.forward(
83 input_ids=input_ids,
84 attention_mask=attention_mask,
85 past_key_values=past_key_values,
86 )
87 return outputs.logits, outputs.past_key_values
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/server/text_generation_server/models/rw.py b/server/text_generation_server/models/rw.py
--- a/server/text_generation_server/models/rw.py
+++ b/server/text_generation_server/models/rw.py
@@ -67,18 +67,6 @@
self, input_ids, attention_mask, position_ids, past_key_values: Optional = None
) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:
# Model Forward
- if past_key_values is not None:
- reshaped_past_key_values = []
- for layer in past_key_values:
- past_keys, past_values = layer
- reshaped_past_key_values.append(
- (
- past_keys.view(-1, *past_keys.shape[-2:]),
- past_values.view(-1, *past_values.shape[-2:]),
- )
- )
- past_key_values = reshaped_past_key_values
-
outputs = self.model.forward(
input_ids=input_ids,
attention_mask=attention_mask,
|
{"golden_diff": "diff --git a/server/text_generation_server/models/rw.py b/server/text_generation_server/models/rw.py\n--- a/server/text_generation_server/models/rw.py\n+++ b/server/text_generation_server/models/rw.py\n@@ -67,18 +67,6 @@\n self, input_ids, attention_mask, position_ids, past_key_values: Optional = None\n ) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:\n # Model Forward\n- if past_key_values is not None:\n- reshaped_past_key_values = []\n- for layer in past_key_values:\n- past_keys, past_values = layer\n- reshaped_past_key_values.append(\n- (\n- past_keys.view(-1, *past_keys.shape[-2:]),\n- past_values.view(-1, *past_values.shape[-2:]),\n- )\n- )\n- past_key_values = reshaped_past_key_values\n-\n outputs = self.model.forward(\n input_ids=input_ids,\n attention_mask=attention_mask,\n", "issue": "falcon-rw-1b does not work\n### System Info\n\nA Nvidia Tesla T4 GPU in Kubernetes running text-generation-inference version 1.0.0 (official image)\n\n### Information\n\n- [ ] Docker\n- [X] The CLI directly\n\n### Tasks\n\n- [X] An officially supported command\n- [ ] My own modifications\n\n### Reproduction\n\nRun\r\n```\r\ntext-generation-launcher --model-id tiiuae/falcon-rw-1b --trust-remote-code --revision e4b9872bb803165eb22f0a867d4e6a64d34fce19\r\n```\r\nOnce the model is loaded, calling the server gives error:\r\n```\r\n$ curl 127.0.0.1:80/generate_stream -X POST -d '{\"inputs\":\"What is Deep Learning?\",\"parameters\":{\"max_new_tokens\":20}}' -H 'Content-Type: application/json'\r\ndata:{\"token\":{\"id\":43398,\"text\":\" chapel\",\"logprob\":-4.859375,\"special\":false},\"generated_text\":null,\"details\":null}\r\n\r\ndata:{\"error\":\"Request failed during generation: Server error: not enough values to unpack (expected 4, got 3)\",\"error_type\":\"generation\"}\r\n```\r\nIn the server, there is this error:\r\n```\r\n2023-08-11T21:57:42.634325Z ERROR text_generation_launcher: Method Decode encountered an error.\r\nTraceback (most recent call last):\r\n File \"/opt/conda/bin/text-generation-server\", line 8, in <module>\r\n sys.exit(app())\r\n File \"/opt/conda/lib/python3.9/site-packages/typer/main.py\", line 311, in __call__\r\n return get_command(self)(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.9/site-packages/click/core.py\", line 1130, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.9/site-packages/typer/core.py\", line 778, in main\r\n return _main(\r\n File \"/opt/conda/lib/python3.9/site-packages/typer/core.py\", line 216, in _main\r\n rv = self.invoke(ctx)\r\n File \"/opt/conda/lib/python3.9/site-packages/click/core.py\", line 1657, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/opt/conda/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/opt/conda/lib/python3.9/site-packages/click/core.py\", line 760, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.9/site-packages/typer/main.py\", line 683, in wrapper\r\n return callback(**use_params) # type: ignore\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/cli.py\", line 78, in serve\r\n server.serve(\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/server.py\", line 184, in serve\r\n asyncio.run(\r\n File \"/opt/conda/lib/python3.9/asyncio/runners.py\", line 44, in run\r\n return loop.run_until_complete(main)\r\n File \"/opt/conda/lib/python3.9/asyncio/base_events.py\", line 634, in run_until_complete\r\n self.run_forever()\r\n File \"/opt/conda/lib/python3.9/asyncio/base_events.py\", line 601, in run_forever\r\n self._run_once()\r\n File \"/opt/conda/lib/python3.9/asyncio/base_events.py\", line 1905, in _run_once\r\n handle._run()\r\n File \"/opt/conda/lib/python3.9/asyncio/events.py\", line 80, in _run\r\n self._context.run(self._callback, *self._args)\r\n File \"/opt/conda/lib/python3.9/site-packages/grpc_interceptor/server.py\", line 159, in invoke_intercept_method\r\n return await self.intercept(\r\n> File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/interceptor.py\", line 21, in intercept\r\n return await response\r\n File \"/opt/conda/lib/python3.9/site-packages/opentelemetry/instrumentation/grpc/_aio_server.py\", line 82, in _unary_interceptor\r\n raise error\r\n File \"/opt/conda/lib/python3.9/site-packages/opentelemetry/instrumentation/grpc/_aio_server.py\", line 73, in _unary_interceptor\r\n return await behavior(request_or_iterator, context)\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/server.py\", line 98, in Decode\r\n generations, next_batch = self.model.generate_token(batch)\r\n File \"/opt/conda/lib/python3.9/contextlib.py\", line 79, in inner\r\n return func(*args, **kwds)\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/models/causal_lm.py\", line 541, in generate_token\r\n logits, past = self.forward(\r\n File \"/opt/conda/lib/python3.9/site-packages/text_generation_server/models/rw.py\", line 82, in forward\r\n outputs = self.model.forward(\r\n File \"/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py\", line 900, in forward\r\n transformer_outputs = self.transformer(\r\n File \"/opt/conda/lib/python3.9/site-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py\", line 734, in forward\r\n past_key_values = self._convert_to_rw_cache(past_key_values)\r\n File \"/root/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-rw-1b/e4b9872bb803165eb22f0a867d4e6a64d34fce19/modeling_falcon.py\", line 622, in _convert_to_rw_cache\r\n batch_size, num_heads, kv_length, head_dim = past_key_value[0][0].shape\r\nValueError: not enough values to unpack (expected 4, got 3)\r\n```\r\n\n\n### Expected behavior\n\nNo error\n", "before_files": [{"content": "import torch\n\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\nfrom typing import List, Optional, Tuple\n\nfrom text_generation_server.models import CausalLM\n\n\nclass RW(CausalLM):\n def __init__(\n self,\n model_id: str,\n revision: Optional[str] = None,\n quantize: Optional[str] = None,\n dtype: Optional[torch.dtype] = None,\n trust_remote_code: bool = False,\n ):\n if torch.cuda.is_available():\n device = torch.device(\"cuda\")\n dtype = torch.float16 if dtype is None else dtype\n else:\n if quantize:\n raise ValueError(\"quantization is not available on CPU\")\n\n device = torch.device(\"cpu\")\n dtype = torch.float32\n\n tokenizer = AutoTokenizer.from_pretrained(\n model_id,\n revision=revision,\n padding_side=\"left\",\n truncation_side=\"left\",\n trust_remote_code=trust_remote_code,\n )\n model = AutoModelForCausalLM.from_pretrained(\n model_id,\n revision=revision,\n torch_dtype=dtype,\n device_map=\"auto\"\n if torch.cuda.is_available() and torch.cuda.device_count() > 1\n else None,\n load_in_8bit=quantize == \"bitsandbytes\",\n trust_remote_code=trust_remote_code,\n )\n if torch.cuda.is_available() and torch.cuda.device_count() == 1:\n model = model.cuda()\n\n if tokenizer.pad_token_id is None:\n if model.config.pad_token_id is not None:\n tokenizer.pad_token_id = model.config.pad_token_id\n elif model.config.eos_token_id is not None:\n tokenizer.pad_token_id = model.config.eos_token_id\n elif tokenizer.eos_token_id is not None:\n tokenizer.pad_token_id = tokenizer.eos_token_id\n else:\n tokenizer.add_special_tokens({\"pad_token\": \"[PAD]\"})\n\n super(CausalLM, self).__init__(\n model=model,\n tokenizer=tokenizer,\n requires_padding=True,\n dtype=dtype,\n device=device,\n )\n\n def forward(\n self, input_ids, attention_mask, position_ids, past_key_values: Optional = None\n ) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:\n # Model Forward\n if past_key_values is not None:\n reshaped_past_key_values = []\n for layer in past_key_values:\n past_keys, past_values = layer\n reshaped_past_key_values.append(\n (\n past_keys.view(-1, *past_keys.shape[-2:]),\n past_values.view(-1, *past_values.shape[-2:]),\n )\n )\n past_key_values = reshaped_past_key_values\n\n outputs = self.model.forward(\n input_ids=input_ids,\n attention_mask=attention_mask,\n past_key_values=past_key_values,\n )\n return outputs.logits, outputs.past_key_values\n", "path": "server/text_generation_server/models/rw.py"}], "after_files": [{"content": "import torch\n\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\nfrom typing import List, Optional, Tuple\n\nfrom text_generation_server.models import CausalLM\n\n\nclass RW(CausalLM):\n def __init__(\n self,\n model_id: str,\n revision: Optional[str] = None,\n quantize: Optional[str] = None,\n dtype: Optional[torch.dtype] = None,\n trust_remote_code: bool = False,\n ):\n if torch.cuda.is_available():\n device = torch.device(\"cuda\")\n dtype = torch.float16 if dtype is None else dtype\n else:\n if quantize:\n raise ValueError(\"quantization is not available on CPU\")\n\n device = torch.device(\"cpu\")\n dtype = torch.float32\n\n tokenizer = AutoTokenizer.from_pretrained(\n model_id,\n revision=revision,\n padding_side=\"left\",\n truncation_side=\"left\",\n trust_remote_code=trust_remote_code,\n )\n model = AutoModelForCausalLM.from_pretrained(\n model_id,\n revision=revision,\n torch_dtype=dtype,\n device_map=\"auto\"\n if torch.cuda.is_available() and torch.cuda.device_count() > 1\n else None,\n load_in_8bit=quantize == \"bitsandbytes\",\n trust_remote_code=trust_remote_code,\n )\n if torch.cuda.is_available() and torch.cuda.device_count() == 1:\n model = model.cuda()\n\n if tokenizer.pad_token_id is None:\n if model.config.pad_token_id is not None:\n tokenizer.pad_token_id = model.config.pad_token_id\n elif model.config.eos_token_id is not None:\n tokenizer.pad_token_id = model.config.eos_token_id\n elif tokenizer.eos_token_id is not None:\n tokenizer.pad_token_id = tokenizer.eos_token_id\n else:\n tokenizer.add_special_tokens({\"pad_token\": \"[PAD]\"})\n\n super(CausalLM, self).__init__(\n model=model,\n tokenizer=tokenizer,\n requires_padding=True,\n dtype=dtype,\n device=device,\n )\n\n def forward(\n self, input_ids, attention_mask, position_ids, past_key_values: Optional = None\n ) -> Tuple[torch.Tensor, List[Tuple[torch.Tensor, torch.Tensor]]]:\n # Model Forward\n outputs = self.model.forward(\n input_ids=input_ids,\n attention_mask=attention_mask,\n past_key_values=past_key_values,\n )\n return outputs.logits, outputs.past_key_values\n", "path": "server/text_generation_server/models/rw.py"}]}
| 2,632 | 222 |
gh_patches_debug_61898
|
rasdani/github-patches
|
git_diff
|
opendatacube__datacube-core-534
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pin rasterio >= 1.0.2
There are some issues with rasterio that are fixed with 1.0.2 (See: https://github.com/opendatacube/datacube-core/pull/531#pullrequestreview-143845097).
Files to change:
- setup.py
- requirements.txt
- rtd-environment.yml (this also needs the conda-forge/label/dev channel removed with the change)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 import versioneer
4 from setuptools import setup, find_packages
5 import os
6
7 tests_require = [
8 'compliance-checker',
9 'hypothesis',
10 'mock',
11 'objgraph',
12 'pycodestyle',
13 'pylint',
14 'pytest',
15 'pytest-cov',
16 'pytest-timeout',
17 ]
18
19 extras_require = {
20 'performance': ['ciso8601', 'bottleneck'],
21 'interactive': ['matplotlib', 'fiona'],
22 'distributed': ['distributed', 'dask[distributed]'],
23 'doc': ['Sphinx', 'setuptools'],
24 'replicas': ['paramiko', 'sshtunnel', 'tqdm'],
25 'celery': ['celery>=4', 'redis'],
26 's3': ['boto3', 'SharedArray', 'pathos', 'zstandard'],
27 'test': tests_require,
28 }
29 # An 'all' option, following ipython naming conventions.
30 extras_require['all'] = sorted(set(sum(extras_require.values(), [])))
31
32 extra_plugins = dict(read=[], write=[], index=[])
33
34 if os.name != 'nt':
35 extra_plugins['read'].extend([
36 's3aio = datacube.drivers.s3.driver:reader_driver_init [s3]',
37 's3aio_test = datacube.drivers.s3.driver:reader_test_driver_init [s3]',
38 ])
39 extra_plugins['write'].extend([
40 's3aio = datacube.drivers.s3.driver:writer_driver_init [s3]',
41 's3aio_test = datacube.drivers.s3.driver:writer_test_driver_init [s3]',
42 ])
43
44 extra_plugins['index'].extend([
45 's3aio_index = datacube.drivers.s3aio_index:index_driver_init [s3]',
46 ])
47
48 setup(
49 name='datacube',
50 version=versioneer.get_version(),
51 cmdclass=versioneer.get_cmdclass(),
52 python_requires='>=3.5.2',
53
54 url='https://github.com/opendatacube/datacube-core',
55 author='Open Data Cube',
56 maintainer='Open Data Cube',
57 maintainer_email='',
58 description='An analysis environment for satellite and other earth observation data',
59 long_description=open('README.rst').read(),
60 license='Apache License 2.0',
61 classifiers=[
62 "Development Status :: 4 - Beta",
63 "Intended Audience :: Developers",
64 "Intended Audience :: Science/Research",
65 "License :: OSI Approved :: Apache Software License",
66 "Natural Language :: English",
67 "Operating System :: MacOS :: MacOS X",
68 "Operating System :: POSIX",
69 "Operating System :: POSIX :: BSD",
70 "Operating System :: POSIX :: Linux",
71 "Operating System :: Microsoft :: Windows",
72 "Programming Language :: Python",
73 "Programming Language :: Python :: 3",
74 "Programming Language :: Python :: 3.5",
75 "Programming Language :: Python :: 3.6",
76 "Topic :: Scientific/Engineering :: GIS",
77 "Topic :: Scientific/Engineering :: Information Analysis",
78 ],
79
80 packages=find_packages(
81 exclude=('tests', 'tests.*',
82 'integration_tests', 'integration_tests.*')
83 ),
84 package_data={
85 '': ['*.yaml', '*/*.yaml'],
86 },
87 scripts=[
88 'datacube_apps/scripts/pbs_helpers.sh'
89 ],
90 setup_requires=[
91 'pytest-runner'
92 ],
93 install_requires=[
94 'affine',
95 'cachetools',
96 'click>=5.0',
97 'cloudpickle>=0.4',
98 'dask[array]',
99 'gdal>=1.9',
100 'jsonschema',
101 'netcdf4',
102 'numpy',
103 'psycopg2',
104 'pypeg2',
105 'python-dateutil',
106 'pyyaml',
107 'rasterio~=1.0',
108 'singledispatch',
109 'sqlalchemy',
110 'toolz',
111 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost
112 ],
113 extras_require=extras_require,
114 tests_require=tests_require,
115
116 entry_points={
117 'console_scripts': [
118 'datacube = datacube.scripts.cli_app:cli',
119 'datacube-search = datacube.scripts.search_tool:cli',
120 'datacube-stacker = datacube_apps.stacker:main',
121 'datacube-worker = datacube.execution.worker:main',
122 'datacube-fixer = datacube_apps.stacker:fixer_main',
123 'datacube-ncml = datacube_apps.ncml:ncml_app',
124 'pixeldrill = datacube_apps.pixeldrill:main [interactive]',
125 'movie_generator = datacube_apps.movie_generator:main',
126 'datacube-simple-replica = datacube_apps.simple_replica:replicate [replicas]'
127 ],
128 'datacube.plugins.io.read': [
129 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',
130 *extra_plugins['read'],
131 ],
132 'datacube.plugins.io.write': [
133 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',
134 *extra_plugins['write'],
135 ],
136 'datacube.plugins.index': [
137 'default = datacube.index.index:index_driver_init',
138 *extra_plugins['index'],
139 ],
140 },
141 )
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -104,7 +104,7 @@
'pypeg2',
'python-dateutil',
'pyyaml',
- 'rasterio~=1.0',
+ 'rasterio>=1.0.2', # Multi-band re-project fixed in that version
'singledispatch',
'sqlalchemy',
'toolz',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -104,7 +104,7 @@\n 'pypeg2',\n 'python-dateutil',\n 'pyyaml',\n- 'rasterio~=1.0',\n+ 'rasterio>=1.0.2', # Multi-band re-project fixed in that version\n 'singledispatch',\n 'sqlalchemy',\n 'toolz',\n", "issue": "Pin rasterio >= 1.0.2\nThere are some issues with rasterio that are fixed with 1.0.2 (See: https://github.com/opendatacube/datacube-core/pull/531#pullrequestreview-143845097).\r\n\r\nFiles to change:\r\n- setup.py\r\n- requirements.txt\r\n- rtd-environment.yml (this also needs the conda-forge/label/dev channel removed with the change)\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport versioneer\nfrom setuptools import setup, find_packages\nimport os\n\ntests_require = [\n 'compliance-checker',\n 'hypothesis',\n 'mock',\n 'objgraph',\n 'pycodestyle',\n 'pylint',\n 'pytest',\n 'pytest-cov',\n 'pytest-timeout',\n]\n\nextras_require = {\n 'performance': ['ciso8601', 'bottleneck'],\n 'interactive': ['matplotlib', 'fiona'],\n 'distributed': ['distributed', 'dask[distributed]'],\n 'doc': ['Sphinx', 'setuptools'],\n 'replicas': ['paramiko', 'sshtunnel', 'tqdm'],\n 'celery': ['celery>=4', 'redis'],\n 's3': ['boto3', 'SharedArray', 'pathos', 'zstandard'],\n 'test': tests_require,\n}\n# An 'all' option, following ipython naming conventions.\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\nextra_plugins = dict(read=[], write=[], index=[])\n\nif os.name != 'nt':\n extra_plugins['read'].extend([\n 's3aio = datacube.drivers.s3.driver:reader_driver_init [s3]',\n 's3aio_test = datacube.drivers.s3.driver:reader_test_driver_init [s3]',\n ])\n extra_plugins['write'].extend([\n 's3aio = datacube.drivers.s3.driver:writer_driver_init [s3]',\n 's3aio_test = datacube.drivers.s3.driver:writer_test_driver_init [s3]',\n ])\n\n extra_plugins['index'].extend([\n 's3aio_index = datacube.drivers.s3aio_index:index_driver_init [s3]',\n ])\n\nsetup(\n name='datacube',\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n python_requires='>=3.5.2',\n\n url='https://github.com/opendatacube/datacube-core',\n author='Open Data Cube',\n maintainer='Open Data Cube',\n maintainer_email='',\n description='An analysis environment for satellite and other earth observation data',\n long_description=open('README.rst').read(),\n license='Apache License 2.0',\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Topic :: Scientific/Engineering :: GIS\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n ],\n\n packages=find_packages(\n exclude=('tests', 'tests.*',\n 'integration_tests', 'integration_tests.*')\n ),\n package_data={\n '': ['*.yaml', '*/*.yaml'],\n },\n scripts=[\n 'datacube_apps/scripts/pbs_helpers.sh'\n ],\n setup_requires=[\n 'pytest-runner'\n ],\n install_requires=[\n 'affine',\n 'cachetools',\n 'click>=5.0',\n 'cloudpickle>=0.4',\n 'dask[array]',\n 'gdal>=1.9',\n 'jsonschema',\n 'netcdf4',\n 'numpy',\n 'psycopg2',\n 'pypeg2',\n 'python-dateutil',\n 'pyyaml',\n 'rasterio~=1.0',\n 'singledispatch',\n 'sqlalchemy',\n 'toolz',\n 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost\n ],\n extras_require=extras_require,\n tests_require=tests_require,\n\n entry_points={\n 'console_scripts': [\n 'datacube = datacube.scripts.cli_app:cli',\n 'datacube-search = datacube.scripts.search_tool:cli',\n 'datacube-stacker = datacube_apps.stacker:main',\n 'datacube-worker = datacube.execution.worker:main',\n 'datacube-fixer = datacube_apps.stacker:fixer_main',\n 'datacube-ncml = datacube_apps.ncml:ncml_app',\n 'pixeldrill = datacube_apps.pixeldrill:main [interactive]',\n 'movie_generator = datacube_apps.movie_generator:main',\n 'datacube-simple-replica = datacube_apps.simple_replica:replicate [replicas]'\n ],\n 'datacube.plugins.io.read': [\n 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',\n *extra_plugins['read'],\n ],\n 'datacube.plugins.io.write': [\n 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',\n *extra_plugins['write'],\n ],\n 'datacube.plugins.index': [\n 'default = datacube.index.index:index_driver_init',\n *extra_plugins['index'],\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport versioneer\nfrom setuptools import setup, find_packages\nimport os\n\ntests_require = [\n 'compliance-checker',\n 'hypothesis',\n 'mock',\n 'objgraph',\n 'pycodestyle',\n 'pylint',\n 'pytest',\n 'pytest-cov',\n 'pytest-timeout',\n]\n\nextras_require = {\n 'performance': ['ciso8601', 'bottleneck'],\n 'interactive': ['matplotlib', 'fiona'],\n 'distributed': ['distributed', 'dask[distributed]'],\n 'doc': ['Sphinx', 'setuptools'],\n 'replicas': ['paramiko', 'sshtunnel', 'tqdm'],\n 'celery': ['celery>=4', 'redis'],\n 's3': ['boto3', 'SharedArray', 'pathos', 'zstandard'],\n 'test': tests_require,\n}\n# An 'all' option, following ipython naming conventions.\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\nextra_plugins = dict(read=[], write=[], index=[])\n\nif os.name != 'nt':\n extra_plugins['read'].extend([\n 's3aio = datacube.drivers.s3.driver:reader_driver_init [s3]',\n 's3aio_test = datacube.drivers.s3.driver:reader_test_driver_init [s3]',\n ])\n extra_plugins['write'].extend([\n 's3aio = datacube.drivers.s3.driver:writer_driver_init [s3]',\n 's3aio_test = datacube.drivers.s3.driver:writer_test_driver_init [s3]',\n ])\n\n extra_plugins['index'].extend([\n 's3aio_index = datacube.drivers.s3aio_index:index_driver_init [s3]',\n ])\n\nsetup(\n name='datacube',\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n python_requires='>=3.5.2',\n\n url='https://github.com/opendatacube/datacube-core',\n author='Open Data Cube',\n maintainer='Open Data Cube',\n maintainer_email='',\n description='An analysis environment for satellite and other earth observation data',\n long_description=open('README.rst').read(),\n license='Apache License 2.0',\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Topic :: Scientific/Engineering :: GIS\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n ],\n\n packages=find_packages(\n exclude=('tests', 'tests.*',\n 'integration_tests', 'integration_tests.*')\n ),\n package_data={\n '': ['*.yaml', '*/*.yaml'],\n },\n scripts=[\n 'datacube_apps/scripts/pbs_helpers.sh'\n ],\n setup_requires=[\n 'pytest-runner'\n ],\n install_requires=[\n 'affine',\n 'cachetools',\n 'click>=5.0',\n 'cloudpickle>=0.4',\n 'dask[array]',\n 'gdal>=1.9',\n 'jsonschema',\n 'netcdf4',\n 'numpy',\n 'psycopg2',\n 'pypeg2',\n 'python-dateutil',\n 'pyyaml',\n 'rasterio>=1.0.2', # Multi-band re-project fixed in that version\n 'singledispatch',\n 'sqlalchemy',\n 'toolz',\n 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost\n ],\n extras_require=extras_require,\n tests_require=tests_require,\n\n entry_points={\n 'console_scripts': [\n 'datacube = datacube.scripts.cli_app:cli',\n 'datacube-search = datacube.scripts.search_tool:cli',\n 'datacube-stacker = datacube_apps.stacker:main',\n 'datacube-worker = datacube.execution.worker:main',\n 'datacube-fixer = datacube_apps.stacker:fixer_main',\n 'datacube-ncml = datacube_apps.ncml:ncml_app',\n 'pixeldrill = datacube_apps.pixeldrill:main [interactive]',\n 'movie_generator = datacube_apps.movie_generator:main',\n 'datacube-simple-replica = datacube_apps.simple_replica:replicate [replicas]'\n ],\n 'datacube.plugins.io.read': [\n 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',\n *extra_plugins['read'],\n ],\n 'datacube.plugins.io.write': [\n 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',\n *extra_plugins['write'],\n ],\n 'datacube.plugins.index': [\n 'default = datacube.index.index:index_driver_init',\n *extra_plugins['index'],\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,825 | 104 |
gh_patches_debug_1299
|
rasdani/github-patches
|
git_diff
|
jupyterhub__zero-to-jupyterhub-k8s-403
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow making JupyterLab default thing to launch
Is there a way to make JupyterLab come up by default when new users connect?
Is there a way to get the JupyterHub control panel from JupyterLab?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `images/hub/jupyterhub_config.py`
Content:
```
1 import os
2 import glob
3 from tornado.httpclient import AsyncHTTPClient
4
5 from z2jh import get_config, get_secret
6
7 # Configure JupyterHub to use the curl backend for making HTTP requests,
8 # rather than the pure-python implementations. The default one starts
9 # being too slow to make a large number of requests to the proxy API
10 # at the rate required.
11 AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
12
13 c.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'
14
15 # Connect to a proxy running in a different pod
16 c.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))
17 c.ConfigurableHTTPProxy.should_start = False
18
19 # Do not shut down user pods when hub is restarted
20 c.JupyterHub.cleanup_servers = False
21
22 # Check that the proxy has routes appropriately setup
23 # This isn't the best named setting :D
24 c.JupyterHub.last_activity_interval = 60
25
26 # Max number of servers that can be spawning at any one time
27 c.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')
28
29 active_server_limit = get_config('hub.active-server-limit', None)
30
31 if active_server_limit is not None:
32 c.JupyterHub.active_server_limit = int(active_server_limit)
33
34 c.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']
35 c.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])
36
37 # the hub should listen on all interfaces, so the proxy can access it
38 c.JupyterHub.hub_ip = '0.0.0.0'
39
40 c.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')
41
42 c.KubeSpawner.start_timeout = get_config('singleuser.start-timeout')
43
44 # Use env var for this, since we want hub to restart when this changes
45 c.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']
46
47 c.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})
48
49 c.KubeSpawner.singleuser_uid = get_config('singleuser.uid')
50 c.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')
51
52 service_account_name = get_config('singleuser.service-account-name', None)
53 if service_account_name:
54 c.KubeSpawner.singleuser_service_account = service_account_name
55
56 c.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')
57 # Configure dynamically provisioning pvc
58 storage_type = get_config('singleuser.storage.type')
59 if storage_type == 'dynamic':
60 c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'
61 c.KubeSpawner.user_storage_pvc_ensure = True
62 storage_class = get_config('singleuser.storage.dynamic.storage-class', None)
63 if storage_class:
64 c.KubeSpawner.user_storage_class = storage_class
65 c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']
66 c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')
67
68 # Add volumes to singleuser pods
69 c.KubeSpawner.volumes = [
70 {
71 'name': 'volume-{username}{servername}',
72 'persistentVolumeClaim': {
73 'claimName': 'claim-{username}{servername}'
74 }
75 }
76 ]
77 c.KubeSpawner.volume_mounts = [
78 {
79 'mountPath': get_config('singleuser.storage.home_mount_path'),
80 'name': 'volume-{username}{servername}'
81 }
82 ]
83 elif storage_type == 'static':
84 pvc_claim_name = get_config('singleuser.storage.static.pvc-name')
85 c.KubeSpawner.volumes = [{
86 'name': 'home',
87 'persistentVolumeClaim': {
88 'claimName': pvc_claim_name
89 }
90 }]
91
92 c.KubeSpawner.volume_mounts = [{
93 'mountPath': get_config('singleuser.storage.home_mount_path'),
94 'name': 'home',
95 'subPath': get_config('singleuser.storage.static.sub-path')
96 }]
97
98 c.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))
99 c.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))
100
101 lifecycle_hooks = get_config('singleuser.lifecycle-hooks')
102 if lifecycle_hooks:
103 c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks
104
105 init_containers = get_config('singleuser.init-containers')
106 if init_containers:
107 c.KubeSpawner.singleuser_init_containers = init_containers
108
109 # Gives spawned containers access to the API of the hub
110 c.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']
111 c.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])
112
113 c.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']
114 c.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])
115
116 c.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')
117 c.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')
118 c.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')
119 c.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')
120
121 # Allow switching authenticators easily
122 auth_type = get_config('auth.type')
123 email_domain = 'local'
124
125 if auth_type == 'google':
126 c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'
127 c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')
128 c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')
129 c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')
130 c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')
131 c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')
132 email_domain = get_config('auth.google.hosted-domain')
133 elif auth_type == 'github':
134 c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'
135 c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')
136 c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')
137 c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')
138 elif auth_type == 'cilogon':
139 c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'
140 c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')
141 c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')
142 c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')
143 elif auth_type == 'gitlab':
144 c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'
145 c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')
146 c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')
147 c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')
148 elif auth_type == 'mediawiki':
149 c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'
150 c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')
151 c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')
152 c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')
153 elif auth_type == 'globus':
154 c.JupyterHub.authenticator_class = 'oauthenticator.globus.GlobusOAuthenticator'
155 c.GlobusOAuthenticator.oauth_callback_url = get_config('auth.globus.callback-url')
156 c.GlobusOAuthenticator.client_id = get_config('auth.globus.client-id')
157 c.GlobusOAuthenticator.client_secret = get_config('auth.globus.client-secret')
158 c.GlobusOAuthenticator.identity_provider = get_config('auth.globus.identity-provider', '')
159 elif auth_type == 'hmac':
160 c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'
161 c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))
162 elif auth_type == 'dummy':
163 c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'
164 c.DummyAuthenticator.password = get_config('auth.dummy.password', None)
165 elif auth_type == 'tmp':
166 c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'
167 elif auth_type == 'lti':
168 c.JupyterHub.authenticator_class = 'ltiauthenticator.LTIAuthenticator'
169 c.LTIAuthenticator.consumers = get_config('auth.lti.consumers')
170 elif auth_type == 'custom':
171 # full_class_name looks like "myauthenticator.MyAuthenticator".
172 # To create a docker image with this class availabe, you can just have the
173 # following Dockerifle:
174 # FROM jupyterhub/k8s-hub:v0.4
175 # RUN pip3 install myauthenticator
176 full_class_name = get_config('auth.custom.class-name')
177 c.JupyterHub.authenticator_class = full_class_name
178 auth_class_name = full_class_name.rsplit('.', 1)[-1]
179 auth_config = c[auth_class_name]
180 auth_config.update(get_config('auth.custom.config') or {})
181 else:
182 raise ValueError("Unhandled auth type: %r" % auth_type)
183
184 c.Authenticator.enable_auth_state = get_config('auth.state.enabled', False)
185
186 def generate_user_email(spawner):
187 """
188 Used as the EMAIL environment variable
189 """
190 return '{username}@{domain}'.format(
191 username=spawner.user.name, domain=email_domain
192 )
193
194 def generate_user_name(spawner):
195 """
196 Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables
197 """
198 return spawner.user.name
199
200 c.KubeSpawner.environment = {
201 'EMAIL': generate_user_email,
202 # git requires these committer attributes
203 'GIT_AUTHOR_NAME': generate_user_name,
204 'GIT_COMMITTER_NAME': generate_user_name
205 }
206
207 c.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))
208
209 # Enable admins to access user servers
210 c.JupyterHub.admin_access = get_config('auth.admin.access')
211 c.Authenticator.admin_users = get_config('auth.admin.users', [])
212 c.Authenticator.whitelist = get_config('auth.whitelist.users', [])
213
214 c.JupyterHub.base_url = get_config('hub.base_url')
215
216 c.JupyterHub.services = []
217
218 if get_config('cull.enabled', False):
219 cull_timeout = get_config('cull.timeout')
220 cull_every = get_config('cull.every')
221 cull_cmd = [
222 '/usr/local/bin/cull_idle_servers.py',
223 '--timeout=%s' % cull_timeout,
224 '--cull-every=%s' % cull_every,
225 '--url=http://127.0.0.1:8081' + c.JupyterHub.base_url + 'hub/api'
226 ]
227 if get_config('cull.users'):
228 cull_cmd.append('--cull-users')
229 c.JupyterHub.services.append({
230 'name': 'cull-idle',
231 'admin': True,
232 'command': cull_cmd,
233 })
234
235 for name, service in get_config('hub.services', {}).items():
236 api_token = get_secret('services.token.%s' % name)
237 # jupyterhub.services is a list of dicts, but
238 # in the helm chart it is a dict of dicts for easier merged-config
239 service.setdefault('name', name)
240 if api_token:
241 service['api_token'] = api_token
242 c.JupyterHub.services.append(service)
243
244
245 c.JupyterHub.db_url = get_config('hub.db_url')
246
247 cmd = get_config('singleuser.cmd', None)
248 if cmd:
249 c.Spawner.cmd = cmd
250
251
252 scheduler_strategy = get_config('singleuser.scheduler-strategy', 'spread')
253
254 if scheduler_strategy == 'pack':
255 # FIXME: Support setting affinity directly in KubeSpawner
256 c.KubeSpawner.singleuser_extra_pod_config = {
257 'affinity': {
258 'podAffinity': {
259 'preferredDuringSchedulingIgnoredDuringExecution': [{
260 'weight': 100,
261 'podAffinityTerm': {
262 'labelSelector': {
263 'matchExpressions': [{
264 'key': 'component',
265 'operator': 'In',
266 'values': ['singleuser-server']
267 }]
268 },
269 'topologyKey': 'kubernetes.io/hostname'
270 }
271 }],
272 }
273 }
274 }
275 else:
276 # Set default to {} so subconfigs can easily update it
277 c.KubeSpawner.singleuser_extra_pod_config = {}
278
279 extra_configs = sorted(glob.glob('/etc/jupyterhub/config/hub.extra-config.*.py'))
280 for ec in extra_configs:
281 load_subconfig(ec)
282
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/images/hub/jupyterhub_config.py b/images/hub/jupyterhub_config.py
--- a/images/hub/jupyterhub_config.py
+++ b/images/hub/jupyterhub_config.py
@@ -248,6 +248,9 @@
if cmd:
c.Spawner.cmd = cmd
+default_url = get_config('singleuser.default-url', None)
+if default_url:
+ c.Spawner.default_url = default_url
scheduler_strategy = get_config('singleuser.scheduler-strategy', 'spread')
|
{"golden_diff": "diff --git a/images/hub/jupyterhub_config.py b/images/hub/jupyterhub_config.py\n--- a/images/hub/jupyterhub_config.py\n+++ b/images/hub/jupyterhub_config.py\n@@ -248,6 +248,9 @@\n if cmd:\n c.Spawner.cmd = cmd\n \n+default_url = get_config('singleuser.default-url', None)\n+if default_url:\n+ c.Spawner.default_url = default_url\n \n scheduler_strategy = get_config('singleuser.scheduler-strategy', 'spread')\n", "issue": "Allow making JupyterLab default thing to launch\nIs there a way to make JupyterLab come up by default when new users connect?\r\n\r\nIs there a way to get the JupyterHub control panel from JupyterLab?\n", "before_files": [{"content": "import os\nimport glob\nfrom tornado.httpclient import AsyncHTTPClient\n\nfrom z2jh import get_config, get_secret\n\n# Configure JupyterHub to use the curl backend for making HTTP requests,\n# rather than the pure-python implementations. The default one starts\n# being too slow to make a large number of requests to the proxy API\n# at the rate required.\nAsyncHTTPClient.configure(\"tornado.curl_httpclient.CurlAsyncHTTPClient\")\n\nc.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'\n\n# Connect to a proxy running in a different pod\nc.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))\nc.ConfigurableHTTPProxy.should_start = False\n\n# Do not shut down user pods when hub is restarted\nc.JupyterHub.cleanup_servers = False\n\n# Check that the proxy has routes appropriately setup\n# This isn't the best named setting :D\nc.JupyterHub.last_activity_interval = 60\n\n# Max number of servers that can be spawning at any one time\nc.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')\n\nactive_server_limit = get_config('hub.active-server-limit', None)\n\nif active_server_limit is not None:\n c.JupyterHub.active_server_limit = int(active_server_limit)\n\nc.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']\nc.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])\n\n# the hub should listen on all interfaces, so the proxy can access it\nc.JupyterHub.hub_ip = '0.0.0.0'\n\nc.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')\n\nc.KubeSpawner.start_timeout = get_config('singleuser.start-timeout')\n\n# Use env var for this, since we want hub to restart when this changes\nc.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']\n\nc.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})\n\nc.KubeSpawner.singleuser_uid = get_config('singleuser.uid')\nc.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')\n\nservice_account_name = get_config('singleuser.service-account-name', None)\nif service_account_name:\n c.KubeSpawner.singleuser_service_account = service_account_name\n\nc.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')\n# Configure dynamically provisioning pvc\nstorage_type = get_config('singleuser.storage.type')\nif storage_type == 'dynamic':\n c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'\n c.KubeSpawner.user_storage_pvc_ensure = True\n storage_class = get_config('singleuser.storage.dynamic.storage-class', None)\n if storage_class:\n c.KubeSpawner.user_storage_class = storage_class\n c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']\n c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')\n\n # Add volumes to singleuser pods\n c.KubeSpawner.volumes = [\n {\n 'name': 'volume-{username}{servername}',\n 'persistentVolumeClaim': {\n 'claimName': 'claim-{username}{servername}'\n }\n }\n ]\n c.KubeSpawner.volume_mounts = [\n {\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'volume-{username}{servername}'\n }\n ]\nelif storage_type == 'static':\n pvc_claim_name = get_config('singleuser.storage.static.pvc-name')\n c.KubeSpawner.volumes = [{\n 'name': 'home',\n 'persistentVolumeClaim': {\n 'claimName': pvc_claim_name\n }\n }]\n\n c.KubeSpawner.volume_mounts = [{\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'home',\n 'subPath': get_config('singleuser.storage.static.sub-path')\n }]\n\nc.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))\nc.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))\n\nlifecycle_hooks = get_config('singleuser.lifecycle-hooks')\nif lifecycle_hooks:\n c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks\n\ninit_containers = get_config('singleuser.init-containers')\nif init_containers:\n c.KubeSpawner.singleuser_init_containers = init_containers\n\n# Gives spawned containers access to the API of the hub\nc.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')\nc.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')\nc.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')\nc.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')\n\n# Allow switching authenticators easily\nauth_type = get_config('auth.type')\nemail_domain = 'local'\n\nif auth_type == 'google':\n c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'\n c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')\n c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')\n c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')\n c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')\n c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')\n email_domain = get_config('auth.google.hosted-domain')\nelif auth_type == 'github':\n c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'\n c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')\n c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')\n c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')\nelif auth_type == 'cilogon':\n c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'\n c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')\n c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')\n c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')\nelif auth_type == 'gitlab':\n c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'\n c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')\n c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')\n c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')\nelif auth_type == 'mediawiki':\n c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'\n c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')\n c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')\n c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')\nelif auth_type == 'globus':\n c.JupyterHub.authenticator_class = 'oauthenticator.globus.GlobusOAuthenticator'\n c.GlobusOAuthenticator.oauth_callback_url = get_config('auth.globus.callback-url')\n c.GlobusOAuthenticator.client_id = get_config('auth.globus.client-id')\n c.GlobusOAuthenticator.client_secret = get_config('auth.globus.client-secret')\n c.GlobusOAuthenticator.identity_provider = get_config('auth.globus.identity-provider', '')\nelif auth_type == 'hmac':\n c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'\n c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))\nelif auth_type == 'dummy':\n c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'\n c.DummyAuthenticator.password = get_config('auth.dummy.password', None)\nelif auth_type == 'tmp':\n c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'\nelif auth_type == 'lti':\n c.JupyterHub.authenticator_class = 'ltiauthenticator.LTIAuthenticator'\n c.LTIAuthenticator.consumers = get_config('auth.lti.consumers')\nelif auth_type == 'custom':\n # full_class_name looks like \"myauthenticator.MyAuthenticator\".\n # To create a docker image with this class availabe, you can just have the\n # following Dockerifle:\n # FROM jupyterhub/k8s-hub:v0.4\n # RUN pip3 install myauthenticator\n full_class_name = get_config('auth.custom.class-name')\n c.JupyterHub.authenticator_class = full_class_name\n auth_class_name = full_class_name.rsplit('.', 1)[-1]\n auth_config = c[auth_class_name]\n auth_config.update(get_config('auth.custom.config') or {})\nelse:\n raise ValueError(\"Unhandled auth type: %r\" % auth_type)\n\nc.Authenticator.enable_auth_state = get_config('auth.state.enabled', False)\n\ndef generate_user_email(spawner):\n \"\"\"\n Used as the EMAIL environment variable\n \"\"\"\n return '{username}@{domain}'.format(\n username=spawner.user.name, domain=email_domain\n )\n\ndef generate_user_name(spawner):\n \"\"\"\n Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables\n \"\"\"\n return spawner.user.name\n\nc.KubeSpawner.environment = {\n 'EMAIL': generate_user_email,\n # git requires these committer attributes\n 'GIT_AUTHOR_NAME': generate_user_name,\n 'GIT_COMMITTER_NAME': generate_user_name\n}\n\nc.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))\n\n# Enable admins to access user servers\nc.JupyterHub.admin_access = get_config('auth.admin.access')\nc.Authenticator.admin_users = get_config('auth.admin.users', [])\nc.Authenticator.whitelist = get_config('auth.whitelist.users', [])\n\nc.JupyterHub.base_url = get_config('hub.base_url')\n\nc.JupyterHub.services = []\n\nif get_config('cull.enabled', False):\n cull_timeout = get_config('cull.timeout')\n cull_every = get_config('cull.every')\n cull_cmd = [\n '/usr/local/bin/cull_idle_servers.py',\n '--timeout=%s' % cull_timeout,\n '--cull-every=%s' % cull_every,\n '--url=http://127.0.0.1:8081' + c.JupyterHub.base_url + 'hub/api'\n ]\n if get_config('cull.users'):\n cull_cmd.append('--cull-users')\n c.JupyterHub.services.append({\n 'name': 'cull-idle',\n 'admin': True,\n 'command': cull_cmd,\n })\n\nfor name, service in get_config('hub.services', {}).items():\n api_token = get_secret('services.token.%s' % name)\n # jupyterhub.services is a list of dicts, but\n # in the helm chart it is a dict of dicts for easier merged-config\n service.setdefault('name', name)\n if api_token:\n service['api_token'] = api_token\n c.JupyterHub.services.append(service)\n\n\nc.JupyterHub.db_url = get_config('hub.db_url')\n\ncmd = get_config('singleuser.cmd', None)\nif cmd:\n c.Spawner.cmd = cmd\n\n\nscheduler_strategy = get_config('singleuser.scheduler-strategy', 'spread')\n\nif scheduler_strategy == 'pack':\n # FIXME: Support setting affinity directly in KubeSpawner\n c.KubeSpawner.singleuser_extra_pod_config = {\n 'affinity': {\n 'podAffinity': {\n 'preferredDuringSchedulingIgnoredDuringExecution': [{\n 'weight': 100,\n 'podAffinityTerm': {\n 'labelSelector': {\n 'matchExpressions': [{\n 'key': 'component',\n 'operator': 'In',\n 'values': ['singleuser-server']\n }]\n },\n 'topologyKey': 'kubernetes.io/hostname'\n }\n }],\n }\n }\n }\nelse:\n # Set default to {} so subconfigs can easily update it\n c.KubeSpawner.singleuser_extra_pod_config = {}\n\nextra_configs = sorted(glob.glob('/etc/jupyterhub/config/hub.extra-config.*.py'))\nfor ec in extra_configs:\n load_subconfig(ec)\n", "path": "images/hub/jupyterhub_config.py"}], "after_files": [{"content": "import os\nimport glob\nfrom tornado.httpclient import AsyncHTTPClient\n\nfrom z2jh import get_config, get_secret\n\n# Configure JupyterHub to use the curl backend for making HTTP requests,\n# rather than the pure-python implementations. The default one starts\n# being too slow to make a large number of requests to the proxy API\n# at the rate required.\nAsyncHTTPClient.configure(\"tornado.curl_httpclient.CurlAsyncHTTPClient\")\n\nc.JupyterHub.spawner_class = 'kubespawner.KubeSpawner'\n\n# Connect to a proxy running in a different pod\nc.ConfigurableHTTPProxy.api_url = 'http://{}:{}'.format(os.environ['PROXY_API_SERVICE_HOST'], int(os.environ['PROXY_API_SERVICE_PORT']))\nc.ConfigurableHTTPProxy.should_start = False\n\n# Do not shut down user pods when hub is restarted\nc.JupyterHub.cleanup_servers = False\n\n# Check that the proxy has routes appropriately setup\n# This isn't the best named setting :D\nc.JupyterHub.last_activity_interval = 60\n\n# Max number of servers that can be spawning at any one time\nc.JupyterHub.concurrent_spawn_limit = get_config('hub.concurrent-spawn-limit')\n\nactive_server_limit = get_config('hub.active-server-limit', None)\n\nif active_server_limit is not None:\n c.JupyterHub.active_server_limit = int(active_server_limit)\n\nc.JupyterHub.ip = os.environ['PROXY_PUBLIC_SERVICE_HOST']\nc.JupyterHub.port = int(os.environ['PROXY_PUBLIC_SERVICE_PORT'])\n\n# the hub should listen on all interfaces, so the proxy can access it\nc.JupyterHub.hub_ip = '0.0.0.0'\n\nc.KubeSpawner.namespace = os.environ.get('POD_NAMESPACE', 'default')\n\nc.KubeSpawner.start_timeout = get_config('singleuser.start-timeout')\n\n# Use env var for this, since we want hub to restart when this changes\nc.KubeSpawner.singleuser_image_spec = os.environ['SINGLEUSER_IMAGE']\n\nc.KubeSpawner.singleuser_extra_labels = get_config('singleuser.extra-labels', {})\n\nc.KubeSpawner.singleuser_uid = get_config('singleuser.uid')\nc.KubeSpawner.singleuser_fs_gid = get_config('singleuser.fs-gid')\n\nservice_account_name = get_config('singleuser.service-account-name', None)\nif service_account_name:\n c.KubeSpawner.singleuser_service_account = service_account_name\n\nc.KubeSpawner.singleuser_node_selector = get_config('singleuser.node-selector')\n# Configure dynamically provisioning pvc\nstorage_type = get_config('singleuser.storage.type')\nif storage_type == 'dynamic':\n c.KubeSpawner.pvc_name_template = 'claim-{username}{servername}'\n c.KubeSpawner.user_storage_pvc_ensure = True\n storage_class = get_config('singleuser.storage.dynamic.storage-class', None)\n if storage_class:\n c.KubeSpawner.user_storage_class = storage_class\n c.KubeSpawner.user_storage_access_modes = ['ReadWriteOnce']\n c.KubeSpawner.user_storage_capacity = get_config('singleuser.storage.capacity')\n\n # Add volumes to singleuser pods\n c.KubeSpawner.volumes = [\n {\n 'name': 'volume-{username}{servername}',\n 'persistentVolumeClaim': {\n 'claimName': 'claim-{username}{servername}'\n }\n }\n ]\n c.KubeSpawner.volume_mounts = [\n {\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'volume-{username}{servername}'\n }\n ]\nelif storage_type == 'static':\n pvc_claim_name = get_config('singleuser.storage.static.pvc-name')\n c.KubeSpawner.volumes = [{\n 'name': 'home',\n 'persistentVolumeClaim': {\n 'claimName': pvc_claim_name\n }\n }]\n\n c.KubeSpawner.volume_mounts = [{\n 'mountPath': get_config('singleuser.storage.home_mount_path'),\n 'name': 'home',\n 'subPath': get_config('singleuser.storage.static.sub-path')\n }]\n\nc.KubeSpawner.volumes.extend(get_config('singleuser.storage.extra-volumes', []))\nc.KubeSpawner.volume_mounts.extend(get_config('singleuser.storage.extra-volume-mounts', []))\n\nlifecycle_hooks = get_config('singleuser.lifecycle-hooks')\nif lifecycle_hooks:\n c.KubeSpawner.singleuser_lifecycle_hooks = lifecycle_hooks\n\ninit_containers = get_config('singleuser.init-containers')\nif init_containers:\n c.KubeSpawner.singleuser_init_containers = init_containers\n\n# Gives spawned containers access to the API of the hub\nc.KubeSpawner.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.KubeSpawner.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.JupyterHub.hub_connect_ip = os.environ['HUB_SERVICE_HOST']\nc.JupyterHub.hub_connect_port = int(os.environ['HUB_SERVICE_PORT'])\n\nc.KubeSpawner.mem_limit = get_config('singleuser.memory.limit')\nc.KubeSpawner.mem_guarantee = get_config('singleuser.memory.guarantee')\nc.KubeSpawner.cpu_limit = get_config('singleuser.cpu.limit')\nc.KubeSpawner.cpu_guarantee = get_config('singleuser.cpu.guarantee')\n\n# Allow switching authenticators easily\nauth_type = get_config('auth.type')\nemail_domain = 'local'\n\nif auth_type == 'google':\n c.JupyterHub.authenticator_class = 'oauthenticator.GoogleOAuthenticator'\n c.GoogleOAuthenticator.client_id = get_config('auth.google.client-id')\n c.GoogleOAuthenticator.client_secret = get_config('auth.google.client-secret')\n c.GoogleOAuthenticator.oauth_callback_url = get_config('auth.google.callback-url')\n c.GoogleOAuthenticator.hosted_domain = get_config('auth.google.hosted-domain')\n c.GoogleOAuthenticator.login_service = get_config('auth.google.login-service')\n email_domain = get_config('auth.google.hosted-domain')\nelif auth_type == 'github':\n c.JupyterHub.authenticator_class = 'oauthenticator.GitHubOAuthenticator'\n c.GitHubOAuthenticator.oauth_callback_url = get_config('auth.github.callback-url')\n c.GitHubOAuthenticator.client_id = get_config('auth.github.client-id')\n c.GitHubOAuthenticator.client_secret = get_config('auth.github.client-secret')\nelif auth_type == 'cilogon':\n c.JupyterHub.authenticator_class = 'oauthenticator.CILogonOAuthenticator'\n c.CILogonOAuthenticator.oauth_callback_url = get_config('auth.cilogon.callback-url')\n c.CILogonOAuthenticator.client_id = get_config('auth.cilogon.client-id')\n c.CILogonOAuthenticator.client_secret = get_config('auth.cilogon.client-secret')\nelif auth_type == 'gitlab':\n c.JupyterHub.authenticator_class = 'oauthenticator.gitlab.GitLabOAuthenticator'\n c.GitLabOAuthenticator.oauth_callback_url = get_config('auth.gitlab.callback-url')\n c.GitLabOAuthenticator.client_id = get_config('auth.gitlab.client-id')\n c.GitLabOAuthenticator.client_secret = get_config('auth.gitlab.client-secret')\nelif auth_type == 'mediawiki':\n c.JupyterHub.authenticator_class = 'oauthenticator.mediawiki.MWOAuthenticator'\n c.MWOAuthenticator.client_id = get_config('auth.mediawiki.client-id')\n c.MWOAuthenticator.client_secret = get_config('auth.mediawiki.client-secret')\n c.MWOAuthenticator.index_url = get_config('auth.mediawiki.index-url')\nelif auth_type == 'globus':\n c.JupyterHub.authenticator_class = 'oauthenticator.globus.GlobusOAuthenticator'\n c.GlobusOAuthenticator.oauth_callback_url = get_config('auth.globus.callback-url')\n c.GlobusOAuthenticator.client_id = get_config('auth.globus.client-id')\n c.GlobusOAuthenticator.client_secret = get_config('auth.globus.client-secret')\n c.GlobusOAuthenticator.identity_provider = get_config('auth.globus.identity-provider', '')\nelif auth_type == 'hmac':\n c.JupyterHub.authenticator_class = 'hmacauthenticator.HMACAuthenticator'\n c.HMACAuthenticator.secret_key = bytes.fromhex(get_config('auth.hmac.secret-key'))\nelif auth_type == 'dummy':\n c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'\n c.DummyAuthenticator.password = get_config('auth.dummy.password', None)\nelif auth_type == 'tmp':\n c.JupyterHub.authenticator_class = 'tmpauthenticator.TmpAuthenticator'\nelif auth_type == 'lti':\n c.JupyterHub.authenticator_class = 'ltiauthenticator.LTIAuthenticator'\n c.LTIAuthenticator.consumers = get_config('auth.lti.consumers')\nelif auth_type == 'custom':\n # full_class_name looks like \"myauthenticator.MyAuthenticator\".\n # To create a docker image with this class availabe, you can just have the\n # following Dockerifle:\n # FROM jupyterhub/k8s-hub:v0.4\n # RUN pip3 install myauthenticator\n full_class_name = get_config('auth.custom.class-name')\n c.JupyterHub.authenticator_class = full_class_name\n auth_class_name = full_class_name.rsplit('.', 1)[-1]\n auth_config = c[auth_class_name]\n auth_config.update(get_config('auth.custom.config') or {})\nelse:\n raise ValueError(\"Unhandled auth type: %r\" % auth_type)\n\nc.Authenticator.enable_auth_state = get_config('auth.state.enabled', False)\n\ndef generate_user_email(spawner):\n \"\"\"\n Used as the EMAIL environment variable\n \"\"\"\n return '{username}@{domain}'.format(\n username=spawner.user.name, domain=email_domain\n )\n\ndef generate_user_name(spawner):\n \"\"\"\n Used as GIT_AUTHOR_NAME and GIT_COMMITTER_NAME environment variables\n \"\"\"\n return spawner.user.name\n\nc.KubeSpawner.environment = {\n 'EMAIL': generate_user_email,\n # git requires these committer attributes\n 'GIT_AUTHOR_NAME': generate_user_name,\n 'GIT_COMMITTER_NAME': generate_user_name\n}\n\nc.KubeSpawner.environment.update(get_config('singleuser.extra-env', {}))\n\n# Enable admins to access user servers\nc.JupyterHub.admin_access = get_config('auth.admin.access')\nc.Authenticator.admin_users = get_config('auth.admin.users', [])\nc.Authenticator.whitelist = get_config('auth.whitelist.users', [])\n\nc.JupyterHub.base_url = get_config('hub.base_url')\n\nc.JupyterHub.services = []\n\nif get_config('cull.enabled', False):\n cull_timeout = get_config('cull.timeout')\n cull_every = get_config('cull.every')\n cull_cmd = [\n '/usr/local/bin/cull_idle_servers.py',\n '--timeout=%s' % cull_timeout,\n '--cull-every=%s' % cull_every,\n '--url=http://127.0.0.1:8081' + c.JupyterHub.base_url + 'hub/api'\n ]\n if get_config('cull.users'):\n cull_cmd.append('--cull-users')\n c.JupyterHub.services.append({\n 'name': 'cull-idle',\n 'admin': True,\n 'command': cull_cmd,\n })\n\nfor name, service in get_config('hub.services', {}).items():\n api_token = get_secret('services.token.%s' % name)\n # jupyterhub.services is a list of dicts, but\n # in the helm chart it is a dict of dicts for easier merged-config\n service.setdefault('name', name)\n if api_token:\n service['api_token'] = api_token\n c.JupyterHub.services.append(service)\n\n\nc.JupyterHub.db_url = get_config('hub.db_url')\n\ncmd = get_config('singleuser.cmd', None)\nif cmd:\n c.Spawner.cmd = cmd\n\ndefault_url = get_config('singleuser.default-url', None)\nif default_url:\n c.Spawner.default_url = default_url\n\nscheduler_strategy = get_config('singleuser.scheduler-strategy', 'spread')\n\nif scheduler_strategy == 'pack':\n # FIXME: Support setting affinity directly in KubeSpawner\n c.KubeSpawner.singleuser_extra_pod_config = {\n 'affinity': {\n 'podAffinity': {\n 'preferredDuringSchedulingIgnoredDuringExecution': [{\n 'weight': 100,\n 'podAffinityTerm': {\n 'labelSelector': {\n 'matchExpressions': [{\n 'key': 'component',\n 'operator': 'In',\n 'values': ['singleuser-server']\n }]\n },\n 'topologyKey': 'kubernetes.io/hostname'\n }\n }],\n }\n }\n }\nelse:\n # Set default to {} so subconfigs can easily update it\n c.KubeSpawner.singleuser_extra_pod_config = {}\n\nextra_configs = sorted(glob.glob('/etc/jupyterhub/config/hub.extra-config.*.py'))\nfor ec in extra_configs:\n load_subconfig(ec)\n", "path": "images/hub/jupyterhub_config.py"}]}
| 3,863 | 114 |
gh_patches_debug_7604
|
rasdani/github-patches
|
git_diff
|
robocorp__rpaframework-617
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`RPA.Windows.Get Elements` not copying the `robocorp_click_offset` attribute
Should make available this attribute in all siblings found elements, otherwise the `Click` keyword will fail when using offsets:
<img width="841" alt="Screen Shot 2022-08-26 at 4 48 38 PM" src="https://user-images.githubusercontent.com/709053/187146331-32d1ea86-7da7-4afe-b8ec-ea9b5289db70.png">
<img width="1391" alt="Screen Shot 2022-08-26 at 4 48 20 PM" src="https://user-images.githubusercontent.com/709053/187146342-b6ae653f-0ae7-4870-bdc9-edba1ef83533.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packages/windows/src/RPA/Windows/keywords/locators.py`
Content:
```
1 from typing import List, Optional
2
3 from RPA.core.windows.locators import (
4 Locator,
5 LocatorMethods,
6 WindowsElement,
7 )
8
9 from RPA.Windows.keywords import keyword
10 from RPA.Windows.keywords.context import with_timeout
11
12
13 class LocatorKeywords(LocatorMethods):
14 """Keywords for handling Windows locators"""
15
16 @keyword
17 @with_timeout
18 def get_element(
19 self,
20 locator: Optional[Locator] = None,
21 search_depth: int = 8,
22 root_element: Optional[WindowsElement] = None,
23 timeout: Optional[float] = None, # pylint: disable=unused-argument
24 ) -> WindowsElement:
25 """Get Control element defined by the locator.
26
27 Returned element can be used instead of a locator string for
28 keywords accepting `locator`.
29
30 Keyword ``Get Attribute`` can be used to read element attribute values.
31
32 If `locator` is *None* then returned `element` will be in order of preference:
33
34 1. anchor element if that has been set with `Set Anchor`
35 2. current active window if that has been set with `Control Window`
36 3. final option is the `Desktop`
37
38 :param locator: locator as a string or as an element
39 :param search_depth: how deep the element search will traverse (default 8)
40 :param root_element: can be used to set search root element
41 :param timeout: float value in seconds, see keyword
42 ``Set Global Timeout``
43 :return: WindowsElement object
44
45 Example:
46
47 .. code-block:: robotframework
48
49 ${element} = Get Element name:"RichEdit Control"
50 Set Value ${element} note to myself
51 """
52 # NOTE(cmiN): Timeout is automatically set to `None` in the upper call by the
53 # `with_timeout` decorator, so we alter the behaviour (context timeout
54 # setting) at this level only.
55 return super().get_element(
56 locator=locator,
57 search_depth=search_depth,
58 root_element=root_element,
59 timeout=timeout,
60 )
61
62 @keyword
63 @with_timeout
64 def get_elements(
65 self,
66 locator: Optional[Locator] = None,
67 search_depth: int = 8,
68 root_element: Optional[WindowsElement] = None,
69 timeout: Optional[float] = None, # pylint: disable=unused-argument
70 ) -> List[WindowsElement]:
71 """Get list of elements matching locator.
72
73 :param locator: locator as a string or as an element
74 :param search_depth: how deep the element search will traverse (default 8)
75 :param root_element: can be used to set search root element
76 :param timeout: float value in seconds, see keyword
77 ``Set Global Timeout``
78 :return: list of WindowsElement objects
79
80 Example:
81
82 .. code-block:: robotframework
83
84 Set Anchor id:DataGrid
85 ${elements}= Get Elements type:HeaderItem
86 FOR ${el} IN @{elements}
87 Log To Console ${el.Name}
88 END
89 """
90 elements = []
91 initial_element = element = self.get_element(
92 locator, search_depth, root_element
93 )
94 elements.append(initial_element)
95 while True:
96 next_control = element.item.GetNextSiblingControl()
97 if next_control:
98 element = WindowsElement(next_control, locator)
99 if initial_element.is_sibling(element):
100 elements.append(element)
101 else:
102 break
103 return elements
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packages/windows/src/RPA/Windows/keywords/locators.py b/packages/windows/src/RPA/Windows/keywords/locators.py
--- a/packages/windows/src/RPA/Windows/keywords/locators.py
+++ b/packages/windows/src/RPA/Windows/keywords/locators.py
@@ -97,6 +97,9 @@
if next_control:
element = WindowsElement(next_control, locator)
if initial_element.is_sibling(element):
+ element.item.robocorp_click_offset = (
+ initial_element.item.robocorp_click_offset
+ )
elements.append(element)
else:
break
|
{"golden_diff": "diff --git a/packages/windows/src/RPA/Windows/keywords/locators.py b/packages/windows/src/RPA/Windows/keywords/locators.py\n--- a/packages/windows/src/RPA/Windows/keywords/locators.py\n+++ b/packages/windows/src/RPA/Windows/keywords/locators.py\n@@ -97,6 +97,9 @@\n if next_control:\n element = WindowsElement(next_control, locator)\n if initial_element.is_sibling(element):\n+ element.item.robocorp_click_offset = (\n+ initial_element.item.robocorp_click_offset\n+ )\n elements.append(element)\n else:\n break\n", "issue": "`RPA.Windows.Get Elements` not copying the `robocorp_click_offset` attribute\nShould make available this attribute in all siblings found elements, otherwise the `Click` keyword will fail when using offsets:\r\n\r\n<img width=\"841\" alt=\"Screen Shot 2022-08-26 at 4 48 38 PM\" src=\"https://user-images.githubusercontent.com/709053/187146331-32d1ea86-7da7-4afe-b8ec-ea9b5289db70.png\">\r\n<img width=\"1391\" alt=\"Screen Shot 2022-08-26 at 4 48 20 PM\" src=\"https://user-images.githubusercontent.com/709053/187146342-b6ae653f-0ae7-4870-bdc9-edba1ef83533.png\">\r\n\n", "before_files": [{"content": "from typing import List, Optional\n\nfrom RPA.core.windows.locators import (\n Locator,\n LocatorMethods,\n WindowsElement,\n)\n\nfrom RPA.Windows.keywords import keyword\nfrom RPA.Windows.keywords.context import with_timeout\n\n\nclass LocatorKeywords(LocatorMethods):\n \"\"\"Keywords for handling Windows locators\"\"\"\n\n @keyword\n @with_timeout\n def get_element(\n self,\n locator: Optional[Locator] = None,\n search_depth: int = 8,\n root_element: Optional[WindowsElement] = None,\n timeout: Optional[float] = None, # pylint: disable=unused-argument\n ) -> WindowsElement:\n \"\"\"Get Control element defined by the locator.\n\n Returned element can be used instead of a locator string for\n keywords accepting `locator`.\n\n Keyword ``Get Attribute`` can be used to read element attribute values.\n\n If `locator` is *None* then returned `element` will be in order of preference:\n\n 1. anchor element if that has been set with `Set Anchor`\n 2. current active window if that has been set with `Control Window`\n 3. final option is the `Desktop`\n\n :param locator: locator as a string or as an element\n :param search_depth: how deep the element search will traverse (default 8)\n :param root_element: can be used to set search root element\n :param timeout: float value in seconds, see keyword\n ``Set Global Timeout``\n :return: WindowsElement object\n\n Example:\n\n .. code-block:: robotframework\n\n ${element} = Get Element name:\"RichEdit Control\"\n Set Value ${element} note to myself\n \"\"\"\n # NOTE(cmiN): Timeout is automatically set to `None` in the upper call by the\n # `with_timeout` decorator, so we alter the behaviour (context timeout\n # setting) at this level only.\n return super().get_element(\n locator=locator,\n search_depth=search_depth,\n root_element=root_element,\n timeout=timeout,\n )\n\n @keyword\n @with_timeout\n def get_elements(\n self,\n locator: Optional[Locator] = None,\n search_depth: int = 8,\n root_element: Optional[WindowsElement] = None,\n timeout: Optional[float] = None, # pylint: disable=unused-argument\n ) -> List[WindowsElement]:\n \"\"\"Get list of elements matching locator.\n\n :param locator: locator as a string or as an element\n :param search_depth: how deep the element search will traverse (default 8)\n :param root_element: can be used to set search root element\n :param timeout: float value in seconds, see keyword\n ``Set Global Timeout``\n :return: list of WindowsElement objects\n\n Example:\n\n .. code-block:: robotframework\n\n Set Anchor id:DataGrid\n ${elements}= Get Elements type:HeaderItem\n FOR ${el} IN @{elements}\n Log To Console ${el.Name}\n END\n \"\"\"\n elements = []\n initial_element = element = self.get_element(\n locator, search_depth, root_element\n )\n elements.append(initial_element)\n while True:\n next_control = element.item.GetNextSiblingControl()\n if next_control:\n element = WindowsElement(next_control, locator)\n if initial_element.is_sibling(element):\n elements.append(element)\n else:\n break\n return elements\n", "path": "packages/windows/src/RPA/Windows/keywords/locators.py"}], "after_files": [{"content": "from typing import List, Optional\n\nfrom RPA.core.windows.locators import (\n Locator,\n LocatorMethods,\n WindowsElement,\n)\n\nfrom RPA.Windows.keywords import keyword\nfrom RPA.Windows.keywords.context import with_timeout\n\n\nclass LocatorKeywords(LocatorMethods):\n \"\"\"Keywords for handling Windows locators\"\"\"\n\n @keyword\n @with_timeout\n def get_element(\n self,\n locator: Optional[Locator] = None,\n search_depth: int = 8,\n root_element: Optional[WindowsElement] = None,\n timeout: Optional[float] = None, # pylint: disable=unused-argument\n ) -> WindowsElement:\n \"\"\"Get Control element defined by the locator.\n\n Returned element can be used instead of a locator string for\n keywords accepting `locator`.\n\n Keyword ``Get Attribute`` can be used to read element attribute values.\n\n If `locator` is *None* then returned `element` will be in order of preference:\n\n 1. anchor element if that has been set with `Set Anchor`\n 2. current active window if that has been set with `Control Window`\n 3. final option is the `Desktop`\n\n :param locator: locator as a string or as an element\n :param search_depth: how deep the element search will traverse (default 8)\n :param root_element: can be used to set search root element\n :param timeout: float value in seconds, see keyword\n ``Set Global Timeout``\n :return: WindowsElement object\n\n Example:\n\n .. code-block:: robotframework\n\n ${element} = Get Element name:\"RichEdit Control\"\n Set Value ${element} note to myself\n \"\"\"\n # NOTE(cmiN): Timeout is automatically set to `None` in the upper call by the\n # `with_timeout` decorator, so we alter the behaviour (context timeout\n # setting) at this level only.\n return super().get_element(\n locator=locator,\n search_depth=search_depth,\n root_element=root_element,\n timeout=timeout,\n )\n\n @keyword\n @with_timeout\n def get_elements(\n self,\n locator: Optional[Locator] = None,\n search_depth: int = 8,\n root_element: Optional[WindowsElement] = None,\n timeout: Optional[float] = None, # pylint: disable=unused-argument\n ) -> List[WindowsElement]:\n \"\"\"Get list of elements matching locator.\n\n :param locator: locator as a string or as an element\n :param search_depth: how deep the element search will traverse (default 8)\n :param root_element: can be used to set search root element\n :param timeout: float value in seconds, see keyword\n ``Set Global Timeout``\n :return: list of WindowsElement objects\n\n Example:\n\n .. code-block:: robotframework\n\n Set Anchor id:DataGrid\n ${elements}= Get Elements type:HeaderItem\n FOR ${el} IN @{elements}\n Log To Console ${el.Name}\n END\n \"\"\"\n elements = []\n initial_element = element = self.get_element(\n locator, search_depth, root_element\n )\n elements.append(initial_element)\n while True:\n next_control = element.item.GetNextSiblingControl()\n if next_control:\n element = WindowsElement(next_control, locator)\n if initial_element.is_sibling(element):\n element.item.robocorp_click_offset = (\n initial_element.item.robocorp_click_offset\n )\n elements.append(element)\n else:\n break\n return elements\n", "path": "packages/windows/src/RPA/Windows/keywords/locators.py"}]}
| 1,453 | 137 |
gh_patches_debug_15011
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-1237
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
via lines often result in git conflict
#### What's the problem this feature will solve?
currently when adding and removing packages in multiple github PRs the `# via` line will conflict
#### Describe the solution you'd like
put each `# via` on a new line:
```
six==1.12.0 \
--hash=sha256:3350809f0555b11f552448330d0b52d5f24c91a322ea4a15ef22629740f3761c \
--hash=sha256:d16a0141ec1a18405cd4ce8b4613101da75da0e9a7aec5bdd4fa804d0e0eba73 \
# via automat, bcrypt, cryptography, ecdsa, format-cef, grpcio, patchy, pathlib, prompt-toolkit, protobuf, pyhamcrest
```
instead use:
```
six==1.12.0 \
--hash=sha256:3350809f0555b11f552448330d0b52d5f24c91a322ea4a15ef22629740f3761c \
--hash=sha256:d16a0141ec1a18405cd4ce8b4613101da75da0e9a7aec5bdd4fa804d0e0eba73 \
# via automat
# , bcrypt
# , cryptography
# , ecdsa
# , format-cef
# , grpcio
# , patchy
# , pathlib
# , prompt-toolkit
# , protobuf
# , pyhamcrest
```
<!-- Provide examples of real-world use cases that this would enable and how it solves the problem described above. -->
#### Alternative Solutions
<!-- Have you tried to workaround the problem using pip-tools or other tools? Or a different approach to solving this issue? Please elaborate here. -->
#### Additional context
<!-- Add any other context, links, etc. about the feature here. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `piptools/writer.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import os
4 import re
5 from itertools import chain
6
7 from pip._vendor import six
8
9 from .click import unstyle
10 from .logging import log
11 from .utils import (
12 UNSAFE_PACKAGES,
13 comment,
14 dedup,
15 format_requirement,
16 get_compile_command,
17 key_from_ireq,
18 )
19
20 MESSAGE_UNHASHED_PACKAGE = comment(
21 "# WARNING: pip install will require the following package to be hashed."
22 "\n# Consider using a hashable URL like "
23 "https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip"
24 )
25
26 MESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(
27 "# WARNING: The following packages were not pinned, but pip requires them to be"
28 "\n# pinned when the requirements file includes hashes. "
29 "Consider using the --allow-unsafe flag."
30 )
31
32 MESSAGE_UNSAFE_PACKAGES = comment(
33 "# The following packages are considered to be unsafe in a requirements file:"
34 )
35
36 MESSAGE_UNINSTALLABLE = (
37 "The generated requirements file may be rejected by pip install. "
38 "See # WARNING lines for details."
39 )
40
41
42 strip_comes_from_line_re = re.compile(r" \(line \d+\)$")
43
44
45 def _comes_from_as_string(ireq):
46 if isinstance(ireq.comes_from, six.string_types):
47 return strip_comes_from_line_re.sub("", ireq.comes_from)
48 return key_from_ireq(ireq.comes_from)
49
50
51 class OutputWriter(object):
52 def __init__(
53 self,
54 src_files,
55 dst_file,
56 click_ctx,
57 dry_run,
58 emit_header,
59 emit_index_url,
60 emit_trusted_host,
61 annotate,
62 generate_hashes,
63 default_index_url,
64 index_urls,
65 trusted_hosts,
66 format_control,
67 allow_unsafe,
68 find_links,
69 emit_find_links,
70 ):
71 self.src_files = src_files
72 self.dst_file = dst_file
73 self.click_ctx = click_ctx
74 self.dry_run = dry_run
75 self.emit_header = emit_header
76 self.emit_index_url = emit_index_url
77 self.emit_trusted_host = emit_trusted_host
78 self.annotate = annotate
79 self.generate_hashes = generate_hashes
80 self.default_index_url = default_index_url
81 self.index_urls = index_urls
82 self.trusted_hosts = trusted_hosts
83 self.format_control = format_control
84 self.allow_unsafe = allow_unsafe
85 self.find_links = find_links
86 self.emit_find_links = emit_find_links
87
88 def _sort_key(self, ireq):
89 return (not ireq.editable, str(ireq.req).lower())
90
91 def write_header(self):
92 if self.emit_header:
93 yield comment("#")
94 yield comment("# This file is autogenerated by pip-compile")
95 yield comment("# To update, run:")
96 yield comment("#")
97 compile_command = os.environ.get(
98 "CUSTOM_COMPILE_COMMAND"
99 ) or get_compile_command(self.click_ctx)
100 yield comment("# {}".format(compile_command))
101 yield comment("#")
102
103 def write_index_options(self):
104 if self.emit_index_url:
105 for index, index_url in enumerate(dedup(self.index_urls)):
106 if index_url.rstrip("/") == self.default_index_url:
107 continue
108 flag = "--index-url" if index == 0 else "--extra-index-url"
109 yield "{} {}".format(flag, index_url)
110
111 def write_trusted_hosts(self):
112 if self.emit_trusted_host:
113 for trusted_host in dedup(self.trusted_hosts):
114 yield "--trusted-host {}".format(trusted_host)
115
116 def write_format_controls(self):
117 for nb in dedup(sorted(self.format_control.no_binary)):
118 yield "--no-binary {}".format(nb)
119 for ob in dedup(sorted(self.format_control.only_binary)):
120 yield "--only-binary {}".format(ob)
121
122 def write_find_links(self):
123 if self.emit_find_links:
124 for find_link in dedup(self.find_links):
125 yield "--find-links {}".format(find_link)
126
127 def write_flags(self):
128 emitted = False
129 for line in chain(
130 self.write_index_options(),
131 self.write_find_links(),
132 self.write_trusted_hosts(),
133 self.write_format_controls(),
134 ):
135 emitted = True
136 yield line
137 if emitted:
138 yield ""
139
140 def _iter_lines(self, results, unsafe_requirements=None, markers=None, hashes=None):
141 # default values
142 unsafe_requirements = unsafe_requirements or []
143 markers = markers or {}
144 hashes = hashes or {}
145
146 # Check for unhashed or unpinned packages if at least one package does have
147 # hashes, which will trigger pip install's --require-hashes mode.
148 warn_uninstallable = False
149 has_hashes = hashes and any(hash for hash in hashes.values())
150
151 yielded = False
152
153 for line in self.write_header():
154 yield line
155 yielded = True
156 for line in self.write_flags():
157 yield line
158 yielded = True
159
160 unsafe_requirements = (
161 {r for r in results if r.name in UNSAFE_PACKAGES}
162 if not unsafe_requirements
163 else unsafe_requirements
164 )
165 packages = {r for r in results if r.name not in UNSAFE_PACKAGES}
166
167 if packages:
168 packages = sorted(packages, key=self._sort_key)
169 for ireq in packages:
170 if has_hashes and not hashes.get(ireq):
171 yield MESSAGE_UNHASHED_PACKAGE
172 warn_uninstallable = True
173 line = self._format_requirement(
174 ireq, markers.get(key_from_ireq(ireq)), hashes=hashes
175 )
176 yield line
177 yielded = True
178
179 if unsafe_requirements:
180 unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)
181 yield ""
182 yielded = True
183 if has_hashes and not self.allow_unsafe:
184 yield MESSAGE_UNSAFE_PACKAGES_UNPINNED
185 warn_uninstallable = True
186 else:
187 yield MESSAGE_UNSAFE_PACKAGES
188
189 for ireq in unsafe_requirements:
190 ireq_key = key_from_ireq(ireq)
191 if not self.allow_unsafe:
192 yield comment("# {}".format(ireq_key))
193 else:
194 line = self._format_requirement(
195 ireq, marker=markers.get(ireq_key), hashes=hashes
196 )
197 yield line
198
199 # Yield even when there's no real content, so that blank files are written
200 if not yielded:
201 yield ""
202
203 if warn_uninstallable:
204 log.warning(MESSAGE_UNINSTALLABLE)
205
206 def write(self, results, unsafe_requirements, markers, hashes):
207
208 for line in self._iter_lines(results, unsafe_requirements, markers, hashes):
209 log.info(line)
210 if not self.dry_run:
211 self.dst_file.write(unstyle(line).encode("utf-8"))
212 self.dst_file.write(os.linesep.encode("utf-8"))
213
214 def _format_requirement(self, ireq, marker=None, hashes=None):
215 ireq_hashes = (hashes if hashes is not None else {}).get(ireq)
216
217 line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)
218
219 if not self.annotate:
220 return line
221
222 # Annotate what packages or reqs-ins this package is required by
223 required_by = set()
224 if hasattr(ireq, "_source_ireqs"):
225 required_by |= {
226 _comes_from_as_string(src_ireq)
227 for src_ireq in ireq._source_ireqs
228 if src_ireq.comes_from
229 }
230 elif ireq.comes_from:
231 required_by.add(_comes_from_as_string(ireq))
232 if required_by:
233 annotation = ", ".join(sorted(required_by))
234 line = "{:24}{}{}".format(
235 line,
236 " \\\n " if ireq_hashes else " ",
237 comment("# via " + annotation),
238 )
239 return line
240
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/piptools/writer.py b/piptools/writer.py
--- a/piptools/writer.py
+++ b/piptools/writer.py
@@ -230,10 +230,14 @@
elif ireq.comes_from:
required_by.add(_comes_from_as_string(ireq))
if required_by:
- annotation = ", ".join(sorted(required_by))
- line = "{:24}{}{}".format(
- line,
- " \\\n " if ireq_hashes else " ",
- comment("# via " + annotation),
- )
+ required_by = sorted(required_by)
+ if len(required_by) == 1:
+ source = required_by[0]
+ annotation = " # via " + source
+ else:
+ annotation_lines = [" # via"]
+ for source in required_by:
+ annotation_lines.append(" # " + source)
+ annotation = "\n".join(annotation_lines)
+ line = "{}\n{}".format(line, comment(annotation))
return line
|
{"golden_diff": "diff --git a/piptools/writer.py b/piptools/writer.py\n--- a/piptools/writer.py\n+++ b/piptools/writer.py\n@@ -230,10 +230,14 @@\n elif ireq.comes_from:\n required_by.add(_comes_from_as_string(ireq))\n if required_by:\n- annotation = \", \".join(sorted(required_by))\n- line = \"{:24}{}{}\".format(\n- line,\n- \" \\\\\\n \" if ireq_hashes else \" \",\n- comment(\"# via \" + annotation),\n- )\n+ required_by = sorted(required_by)\n+ if len(required_by) == 1:\n+ source = required_by[0]\n+ annotation = \" # via \" + source\n+ else:\n+ annotation_lines = [\" # via\"]\n+ for source in required_by:\n+ annotation_lines.append(\" # \" + source)\n+ annotation = \"\\n\".join(annotation_lines)\n+ line = \"{}\\n{}\".format(line, comment(annotation))\n return line\n", "issue": "via lines often result in git conflict\n#### What's the problem this feature will solve?\r\ncurrently when adding and removing packages in multiple github PRs the `# via` line will conflict\r\n\r\n#### Describe the solution you'd like\r\nput each `# via` on a new line:\r\n```\r\nsix==1.12.0 \\\r\n --hash=sha256:3350809f0555b11f552448330d0b52d5f24c91a322ea4a15ef22629740f3761c \\\r\n --hash=sha256:d16a0141ec1a18405cd4ce8b4613101da75da0e9a7aec5bdd4fa804d0e0eba73 \\\r\n # via automat, bcrypt, cryptography, ecdsa, format-cef, grpcio, patchy, pathlib, prompt-toolkit, protobuf, pyhamcrest\r\n```\r\ninstead use:\r\n```\r\nsix==1.12.0 \\\r\n --hash=sha256:3350809f0555b11f552448330d0b52d5f24c91a322ea4a15ef22629740f3761c \\\r\n --hash=sha256:d16a0141ec1a18405cd4ce8b4613101da75da0e9a7aec5bdd4fa804d0e0eba73 \\\r\n # via automat\r\n # , bcrypt\r\n # , cryptography\r\n # , ecdsa\r\n # , format-cef\r\n # , grpcio\r\n # , patchy\r\n # , pathlib\r\n # , prompt-toolkit\r\n # , protobuf\r\n # , pyhamcrest\r\n```\r\n<!-- Provide examples of real-world use cases that this would enable and how it solves the problem described above. -->\r\n\r\n#### Alternative Solutions\r\n<!-- Have you tried to workaround the problem using pip-tools or other tools? Or a different approach to solving this issue? Please elaborate here. -->\r\n\r\n#### Additional context\r\n<!-- Add any other context, links, etc. about the feature here. -->\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport os\nimport re\nfrom itertools import chain\n\nfrom pip._vendor import six\n\nfrom .click import unstyle\nfrom .logging import log\nfrom .utils import (\n UNSAFE_PACKAGES,\n comment,\n dedup,\n format_requirement,\n get_compile_command,\n key_from_ireq,\n)\n\nMESSAGE_UNHASHED_PACKAGE = comment(\n \"# WARNING: pip install will require the following package to be hashed.\"\n \"\\n# Consider using a hashable URL like \"\n \"https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip\"\n)\n\nMESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(\n \"# WARNING: The following packages were not pinned, but pip requires them to be\"\n \"\\n# pinned when the requirements file includes hashes. \"\n \"Consider using the --allow-unsafe flag.\"\n)\n\nMESSAGE_UNSAFE_PACKAGES = comment(\n \"# The following packages are considered to be unsafe in a requirements file:\"\n)\n\nMESSAGE_UNINSTALLABLE = (\n \"The generated requirements file may be rejected by pip install. \"\n \"See # WARNING lines for details.\"\n)\n\n\nstrip_comes_from_line_re = re.compile(r\" \\(line \\d+\\)$\")\n\n\ndef _comes_from_as_string(ireq):\n if isinstance(ireq.comes_from, six.string_types):\n return strip_comes_from_line_re.sub(\"\", ireq.comes_from)\n return key_from_ireq(ireq.comes_from)\n\n\nclass OutputWriter(object):\n def __init__(\n self,\n src_files,\n dst_file,\n click_ctx,\n dry_run,\n emit_header,\n emit_index_url,\n emit_trusted_host,\n annotate,\n generate_hashes,\n default_index_url,\n index_urls,\n trusted_hosts,\n format_control,\n allow_unsafe,\n find_links,\n emit_find_links,\n ):\n self.src_files = src_files\n self.dst_file = dst_file\n self.click_ctx = click_ctx\n self.dry_run = dry_run\n self.emit_header = emit_header\n self.emit_index_url = emit_index_url\n self.emit_trusted_host = emit_trusted_host\n self.annotate = annotate\n self.generate_hashes = generate_hashes\n self.default_index_url = default_index_url\n self.index_urls = index_urls\n self.trusted_hosts = trusted_hosts\n self.format_control = format_control\n self.allow_unsafe = allow_unsafe\n self.find_links = find_links\n self.emit_find_links = emit_find_links\n\n def _sort_key(self, ireq):\n return (not ireq.editable, str(ireq.req).lower())\n\n def write_header(self):\n if self.emit_header:\n yield comment(\"#\")\n yield comment(\"# This file is autogenerated by pip-compile\")\n yield comment(\"# To update, run:\")\n yield comment(\"#\")\n compile_command = os.environ.get(\n \"CUSTOM_COMPILE_COMMAND\"\n ) or get_compile_command(self.click_ctx)\n yield comment(\"# {}\".format(compile_command))\n yield comment(\"#\")\n\n def write_index_options(self):\n if self.emit_index_url:\n for index, index_url in enumerate(dedup(self.index_urls)):\n if index_url.rstrip(\"/\") == self.default_index_url:\n continue\n flag = \"--index-url\" if index == 0 else \"--extra-index-url\"\n yield \"{} {}\".format(flag, index_url)\n\n def write_trusted_hosts(self):\n if self.emit_trusted_host:\n for trusted_host in dedup(self.trusted_hosts):\n yield \"--trusted-host {}\".format(trusted_host)\n\n def write_format_controls(self):\n for nb in dedup(sorted(self.format_control.no_binary)):\n yield \"--no-binary {}\".format(nb)\n for ob in dedup(sorted(self.format_control.only_binary)):\n yield \"--only-binary {}\".format(ob)\n\n def write_find_links(self):\n if self.emit_find_links:\n for find_link in dedup(self.find_links):\n yield \"--find-links {}\".format(find_link)\n\n def write_flags(self):\n emitted = False\n for line in chain(\n self.write_index_options(),\n self.write_find_links(),\n self.write_trusted_hosts(),\n self.write_format_controls(),\n ):\n emitted = True\n yield line\n if emitted:\n yield \"\"\n\n def _iter_lines(self, results, unsafe_requirements=None, markers=None, hashes=None):\n # default values\n unsafe_requirements = unsafe_requirements or []\n markers = markers or {}\n hashes = hashes or {}\n\n # Check for unhashed or unpinned packages if at least one package does have\n # hashes, which will trigger pip install's --require-hashes mode.\n warn_uninstallable = False\n has_hashes = hashes and any(hash for hash in hashes.values())\n\n yielded = False\n\n for line in self.write_header():\n yield line\n yielded = True\n for line in self.write_flags():\n yield line\n yielded = True\n\n unsafe_requirements = (\n {r for r in results if r.name in UNSAFE_PACKAGES}\n if not unsafe_requirements\n else unsafe_requirements\n )\n packages = {r for r in results if r.name not in UNSAFE_PACKAGES}\n\n if packages:\n packages = sorted(packages, key=self._sort_key)\n for ireq in packages:\n if has_hashes and not hashes.get(ireq):\n yield MESSAGE_UNHASHED_PACKAGE\n warn_uninstallable = True\n line = self._format_requirement(\n ireq, markers.get(key_from_ireq(ireq)), hashes=hashes\n )\n yield line\n yielded = True\n\n if unsafe_requirements:\n unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)\n yield \"\"\n yielded = True\n if has_hashes and not self.allow_unsafe:\n yield MESSAGE_UNSAFE_PACKAGES_UNPINNED\n warn_uninstallable = True\n else:\n yield MESSAGE_UNSAFE_PACKAGES\n\n for ireq in unsafe_requirements:\n ireq_key = key_from_ireq(ireq)\n if not self.allow_unsafe:\n yield comment(\"# {}\".format(ireq_key))\n else:\n line = self._format_requirement(\n ireq, marker=markers.get(ireq_key), hashes=hashes\n )\n yield line\n\n # Yield even when there's no real content, so that blank files are written\n if not yielded:\n yield \"\"\n\n if warn_uninstallable:\n log.warning(MESSAGE_UNINSTALLABLE)\n\n def write(self, results, unsafe_requirements, markers, hashes):\n\n for line in self._iter_lines(results, unsafe_requirements, markers, hashes):\n log.info(line)\n if not self.dry_run:\n self.dst_file.write(unstyle(line).encode(\"utf-8\"))\n self.dst_file.write(os.linesep.encode(\"utf-8\"))\n\n def _format_requirement(self, ireq, marker=None, hashes=None):\n ireq_hashes = (hashes if hashes is not None else {}).get(ireq)\n\n line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)\n\n if not self.annotate:\n return line\n\n # Annotate what packages or reqs-ins this package is required by\n required_by = set()\n if hasattr(ireq, \"_source_ireqs\"):\n required_by |= {\n _comes_from_as_string(src_ireq)\n for src_ireq in ireq._source_ireqs\n if src_ireq.comes_from\n }\n elif ireq.comes_from:\n required_by.add(_comes_from_as_string(ireq))\n if required_by:\n annotation = \", \".join(sorted(required_by))\n line = \"{:24}{}{}\".format(\n line,\n \" \\\\\\n \" if ireq_hashes else \" \",\n comment(\"# via \" + annotation),\n )\n return line\n", "path": "piptools/writer.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport os\nimport re\nfrom itertools import chain\n\nfrom pip._vendor import six\n\nfrom .click import unstyle\nfrom .logging import log\nfrom .utils import (\n UNSAFE_PACKAGES,\n comment,\n dedup,\n format_requirement,\n get_compile_command,\n key_from_ireq,\n)\n\nMESSAGE_UNHASHED_PACKAGE = comment(\n \"# WARNING: pip install will require the following package to be hashed.\"\n \"\\n# Consider using a hashable URL like \"\n \"https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip\"\n)\n\nMESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(\n \"# WARNING: The following packages were not pinned, but pip requires them to be\"\n \"\\n# pinned when the requirements file includes hashes. \"\n \"Consider using the --allow-unsafe flag.\"\n)\n\nMESSAGE_UNSAFE_PACKAGES = comment(\n \"# The following packages are considered to be unsafe in a requirements file:\"\n)\n\nMESSAGE_UNINSTALLABLE = (\n \"The generated requirements file may be rejected by pip install. \"\n \"See # WARNING lines for details.\"\n)\n\n\nstrip_comes_from_line_re = re.compile(r\" \\(line \\d+\\)$\")\n\n\ndef _comes_from_as_string(ireq):\n if isinstance(ireq.comes_from, six.string_types):\n return strip_comes_from_line_re.sub(\"\", ireq.comes_from)\n return key_from_ireq(ireq.comes_from)\n\n\nclass OutputWriter(object):\n def __init__(\n self,\n src_files,\n dst_file,\n click_ctx,\n dry_run,\n emit_header,\n emit_index_url,\n emit_trusted_host,\n annotate,\n generate_hashes,\n default_index_url,\n index_urls,\n trusted_hosts,\n format_control,\n allow_unsafe,\n find_links,\n emit_find_links,\n ):\n self.src_files = src_files\n self.dst_file = dst_file\n self.click_ctx = click_ctx\n self.dry_run = dry_run\n self.emit_header = emit_header\n self.emit_index_url = emit_index_url\n self.emit_trusted_host = emit_trusted_host\n self.annotate = annotate\n self.generate_hashes = generate_hashes\n self.default_index_url = default_index_url\n self.index_urls = index_urls\n self.trusted_hosts = trusted_hosts\n self.format_control = format_control\n self.allow_unsafe = allow_unsafe\n self.find_links = find_links\n self.emit_find_links = emit_find_links\n\n def _sort_key(self, ireq):\n return (not ireq.editable, str(ireq.req).lower())\n\n def write_header(self):\n if self.emit_header:\n yield comment(\"#\")\n yield comment(\"# This file is autogenerated by pip-compile\")\n yield comment(\"# To update, run:\")\n yield comment(\"#\")\n compile_command = os.environ.get(\n \"CUSTOM_COMPILE_COMMAND\"\n ) or get_compile_command(self.click_ctx)\n yield comment(\"# {}\".format(compile_command))\n yield comment(\"#\")\n\n def write_index_options(self):\n if self.emit_index_url:\n for index, index_url in enumerate(dedup(self.index_urls)):\n if index_url.rstrip(\"/\") == self.default_index_url:\n continue\n flag = \"--index-url\" if index == 0 else \"--extra-index-url\"\n yield \"{} {}\".format(flag, index_url)\n\n def write_trusted_hosts(self):\n if self.emit_trusted_host:\n for trusted_host in dedup(self.trusted_hosts):\n yield \"--trusted-host {}\".format(trusted_host)\n\n def write_format_controls(self):\n for nb in dedup(sorted(self.format_control.no_binary)):\n yield \"--no-binary {}\".format(nb)\n for ob in dedup(sorted(self.format_control.only_binary)):\n yield \"--only-binary {}\".format(ob)\n\n def write_find_links(self):\n if self.emit_find_links:\n for find_link in dedup(self.find_links):\n yield \"--find-links {}\".format(find_link)\n\n def write_flags(self):\n emitted = False\n for line in chain(\n self.write_index_options(),\n self.write_find_links(),\n self.write_trusted_hosts(),\n self.write_format_controls(),\n ):\n emitted = True\n yield line\n if emitted:\n yield \"\"\n\n def _iter_lines(self, results, unsafe_requirements=None, markers=None, hashes=None):\n # default values\n unsafe_requirements = unsafe_requirements or []\n markers = markers or {}\n hashes = hashes or {}\n\n # Check for unhashed or unpinned packages if at least one package does have\n # hashes, which will trigger pip install's --require-hashes mode.\n warn_uninstallable = False\n has_hashes = hashes and any(hash for hash in hashes.values())\n\n yielded = False\n\n for line in self.write_header():\n yield line\n yielded = True\n for line in self.write_flags():\n yield line\n yielded = True\n\n unsafe_requirements = (\n {r for r in results if r.name in UNSAFE_PACKAGES}\n if not unsafe_requirements\n else unsafe_requirements\n )\n packages = {r for r in results if r.name not in UNSAFE_PACKAGES}\n\n if packages:\n packages = sorted(packages, key=self._sort_key)\n for ireq in packages:\n if has_hashes and not hashes.get(ireq):\n yield MESSAGE_UNHASHED_PACKAGE\n warn_uninstallable = True\n line = self._format_requirement(\n ireq, markers.get(key_from_ireq(ireq)), hashes=hashes\n )\n yield line\n yielded = True\n\n if unsafe_requirements:\n unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)\n yield \"\"\n yielded = True\n if has_hashes and not self.allow_unsafe:\n yield MESSAGE_UNSAFE_PACKAGES_UNPINNED\n warn_uninstallable = True\n else:\n yield MESSAGE_UNSAFE_PACKAGES\n\n for ireq in unsafe_requirements:\n ireq_key = key_from_ireq(ireq)\n if not self.allow_unsafe:\n yield comment(\"# {}\".format(ireq_key))\n else:\n line = self._format_requirement(\n ireq, marker=markers.get(ireq_key), hashes=hashes\n )\n yield line\n\n # Yield even when there's no real content, so that blank files are written\n if not yielded:\n yield \"\"\n\n if warn_uninstallable:\n log.warning(MESSAGE_UNINSTALLABLE)\n\n def write(self, results, unsafe_requirements, markers, hashes):\n\n for line in self._iter_lines(results, unsafe_requirements, markers, hashes):\n log.info(line)\n if not self.dry_run:\n self.dst_file.write(unstyle(line).encode(\"utf-8\"))\n self.dst_file.write(os.linesep.encode(\"utf-8\"))\n\n def _format_requirement(self, ireq, marker=None, hashes=None):\n ireq_hashes = (hashes if hashes is not None else {}).get(ireq)\n\n line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)\n\n if not self.annotate:\n return line\n\n # Annotate what packages or reqs-ins this package is required by\n required_by = set()\n if hasattr(ireq, \"_source_ireqs\"):\n required_by |= {\n _comes_from_as_string(src_ireq)\n for src_ireq in ireq._source_ireqs\n if src_ireq.comes_from\n }\n elif ireq.comes_from:\n required_by.add(_comes_from_as_string(ireq))\n if required_by:\n required_by = sorted(required_by)\n if len(required_by) == 1:\n source = required_by[0]\n annotation = \" # via \" + source\n else:\n annotation_lines = [\" # via\"]\n for source in required_by:\n annotation_lines.append(\" # \" + source)\n annotation = \"\\n\".join(annotation_lines)\n line = \"{}\\n{}\".format(line, comment(annotation))\n return line\n", "path": "piptools/writer.py"}]}
| 3,123 | 239 |
gh_patches_debug_39773
|
rasdani/github-patches
|
git_diff
|
WeblateOrg__weblate-7906
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make 404 more useful when possible
### Describe the problem
For example, if you try go to a non-existent language of a component, the page will only suggest to go home or to all projects, while it would be better if it linked to the component, or suggested adding a language that you tried to visit. Example: https://hosted.weblate.org/projects/keepassxc/keepassxc-browser-dev/fil/
### Describe the solution you'd like
Add useful suggestions depending on the context.
### Describe alternatives you've considered
_No response_
### Screenshots
_No response_
### Additional context
https://github.com/WeblateOrg/weblate/blob/1804a951c8ae9199d23099a8ec322134ee5b45bc/weblate/urls.py#L136-L140
https://github.com/WeblateOrg/weblate/blob/329dabf59991ed2ee1b44f331929da41d8031c98/weblate/templates/404.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `weblate/middleware.py`
Content:
```
1 #
2 # Copyright © 2012–2022 Michal Čihař <[email protected]>
3 #
4 # This file is part of Weblate <https://weblate.org/>
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this program. If not, see <https://www.gnu.org/licenses/>.
18 #
19
20 from urllib.parse import urlparse
21
22 from django.conf import settings
23 from django.core.exceptions import ValidationError
24 from django.core.validators import validate_ipv46_address
25 from django.http import Http404, HttpResponsePermanentRedirect
26 from django.urls import is_valid_path, reverse
27 from django.utils.http import escape_leading_slashes
28
29 from weblate.lang.models import Language
30 from weblate.trans.models import Change, Component, Project
31 from weblate.utils.errors import report_error
32 from weblate.utils.site import get_site_url
33
34 CSP_TEMPLATE = (
35 "default-src 'self'; style-src {0}; img-src {1}; script-src {2}; "
36 "connect-src {3}; object-src 'none'; font-src {4};"
37 "frame-src 'none'; frame-ancestors 'none';"
38 )
39
40 # URLs requiring inline javascript
41 INLINE_PATHS = {"social:begin", "djangosaml2idp:saml_login_process"}
42
43
44 class ProxyMiddleware:
45 """Middleware that updates REMOTE_ADDR from proxy.
46
47 Note that this can have security implications and settings have to match your actual
48 proxy setup.
49 """
50
51 def __init__(self, get_response=None):
52 self.get_response = get_response
53
54 def __call__(self, request):
55 # Fake HttpRequest attribute to inject configured
56 # site name into build_absolute_uri
57 request._current_scheme_host = get_site_url()
58
59 # Actual proxy handling
60 proxy = None
61 if settings.IP_BEHIND_REVERSE_PROXY:
62 proxy = request.META.get(settings.IP_PROXY_HEADER)
63 if proxy:
64 # X_FORWARDED_FOR returns client1, proxy1, proxy2,...
65 address = proxy.split(",")[settings.IP_PROXY_OFFSET].strip()
66 try:
67 validate_ipv46_address(address)
68 request.META["REMOTE_ADDR"] = address
69 except ValidationError:
70 report_error(cause="Invalid IP address")
71
72 return self.get_response(request)
73
74
75 class RedirectMiddleware:
76 """
77 Middleware that handles URL redirecting.
78
79 This used for fuzzy lookups of projects, for example case insensitive
80 or after renaming.
81 """
82
83 def __init__(self, get_response=None):
84 self.get_response = get_response
85
86 def __call__(self, request):
87 response = self.get_response(request)
88 # This is based on APPEND_SLASH handling in Django
89 if response.status_code == 404 and self.should_redirect_with_slash(request):
90 new_path = request.get_full_path(force_append_slash=True)
91 # Prevent construction of scheme relative urls.
92 new_path = escape_leading_slashes(new_path)
93 return HttpResponsePermanentRedirect(new_path)
94 return response
95
96 def should_redirect_with_slash(self, request):
97 path = request.path_info
98 # Avoid redirecting non GET requests, these would fail anyway due to
99 # missing parameters.
100 # Redirecting on API removes authentication headers in many cases,
101 # so avoid that as well.
102 if (
103 path.endswith("/")
104 or request.method != "GET"
105 or path.startswith(f"{settings.URL_PREFIX}/api")
106 ):
107 return False
108 urlconf = getattr(request, "urlconf", None)
109 slash_path = f"{path}/"
110 return not is_valid_path(path, urlconf) and is_valid_path(slash_path, urlconf)
111
112 def fixup_language(self, lang):
113 return Language.objects.fuzzy_get(code=lang, strict=True)
114
115 def fixup_project(self, slug, request):
116 try:
117 project = Project.objects.get(slug__iexact=slug)
118 except Project.MultipleObjectsReturned:
119 return None
120 except Project.DoesNotExist:
121 try:
122 project = (
123 Change.objects.filter(
124 action=Change.ACTION_RENAME_PROJECT,
125 old=slug,
126 )
127 .order()[0]
128 .project
129 )
130 except IndexError:
131 return None
132
133 request.user.check_access(project)
134 return project
135
136 def fixup_component(self, slug, request, project):
137 try:
138 component = Component.objects.get(project=project, slug__iexact=slug)
139 except Component.DoesNotExist:
140 try:
141 component = (
142 Change.objects.filter(
143 action=Change.ACTION_RENAME_COMPONENT, old=slug
144 )
145 .order()[0]
146 .component
147 )
148 except IndexError:
149 return None
150
151 request.user.check_access_component(component)
152 return component
153
154 def process_exception(self, request, exception):
155 if not isinstance(exception, Http404):
156 return None
157
158 try:
159 resolver_match = request.resolver_match
160 except AttributeError:
161 return None
162
163 kwargs = dict(resolver_match.kwargs)
164
165 if "lang" in kwargs:
166 language = self.fixup_language(kwargs["lang"])
167 if language is None:
168 return None
169 kwargs["lang"] = language.code
170
171 if "project" in kwargs:
172 project = self.fixup_project(kwargs["project"], request)
173 if project is None:
174 return None
175 kwargs["project"] = project.slug
176
177 if "component" in kwargs:
178 component = self.fixup_component(kwargs["component"], request, project)
179 if component is None:
180 return None
181 kwargs["component"] = component.slug
182
183 if kwargs != resolver_match.kwargs:
184 query = request.META["QUERY_STRING"]
185 if query:
186 query = f"?{query}"
187 return HttpResponsePermanentRedirect(
188 reverse(resolver_match.url_name, kwargs=kwargs) + query
189 )
190
191 return None
192
193
194 class SecurityMiddleware:
195 """Middleware that sets Content-Security-Policy."""
196
197 def __init__(self, get_response=None):
198 self.get_response = get_response
199
200 def __call__(self, request):
201 response = self.get_response(request)
202 # No CSP for debug mode (to allow djdt or error pages)
203 if settings.DEBUG:
204 return response
205
206 style = {"'self'", "'unsafe-inline'"} | set(settings.CSP_STYLE_SRC)
207 script = {"'self'"} | set(settings.CSP_SCRIPT_SRC)
208 image = {"'self'"} | set(settings.CSP_IMG_SRC)
209 connect = {"'self'"} | set(settings.CSP_CONNECT_SRC)
210 font = {"'self'"} | set(settings.CSP_FONT_SRC)
211
212 if request.resolver_match and request.resolver_match.view_name in INLINE_PATHS:
213 script.add("'unsafe-inline'")
214
215 # Support form
216 if request.resolver_match and request.resolver_match.view_name == "manage":
217 script.add("care.weblate.org")
218 connect.add("care.weblate.org")
219 style.add("care.weblate.org")
220
221 # Rollbar client errors reporting
222 if (
223 hasattr(settings, "ROLLBAR")
224 and "client_token" in settings.ROLLBAR
225 and "environment" in settings.ROLLBAR
226 and response.status_code == 500
227 ):
228 script.add("'unsafe-inline'")
229 script.add("cdnjs.cloudflare.com")
230 connect.add("api.rollbar.com")
231
232 # Sentry user feedback
233 if settings.SENTRY_DSN and response.status_code == 500:
234 domain = urlparse(settings.SENTRY_DSN).hostname
235 script.add(domain)
236 script.add("sentry.io")
237 connect.add(domain)
238 connect.add("sentry.io")
239 script.add("'unsafe-inline'")
240 image.add("data:")
241
242 # Matomo (Piwik) analytics
243 if settings.MATOMO_URL:
244 domain = urlparse(settings.MATOMO_URL).hostname
245 script.add(domain)
246 image.add(domain)
247 connect.add(domain)
248
249 # Google Analytics
250 if settings.GOOGLE_ANALYTICS_ID:
251 script.add("'unsafe-inline'")
252 script.add("www.google-analytics.com")
253 image.add("www.google-analytics.com")
254
255 # External media URL
256 if "://" in settings.MEDIA_URL:
257 domain = urlparse(settings.MEDIA_URL).hostname
258 image.add(domain)
259
260 # External static URL
261 if "://" in settings.STATIC_URL:
262 domain = urlparse(settings.STATIC_URL).hostname
263 script.add(domain)
264 image.add(domain)
265 style.add(domain)
266 font.add(domain)
267
268 # CDN for fonts
269 if settings.FONTS_CDN_URL:
270 domain = urlparse(settings.FONTS_CDN_URL).hostname
271 style.add(domain)
272 font.add(domain)
273
274 # When using external image for Auth0 provider, add it here
275 if "://" in settings.SOCIAL_AUTH_AUTH0_IMAGE:
276 domain = urlparse(settings.SOCIAL_AUTH_AUTH0_IMAGE).hostname
277 image.add(domain)
278
279 response["Content-Security-Policy"] = CSP_TEMPLATE.format(
280 " ".join(style),
281 " ".join(image),
282 " ".join(script),
283 " ".join(connect),
284 " ".join(font),
285 )
286 if settings.SENTRY_SECURITY:
287 response["Content-Security-Policy"] += " report-uri {}".format(
288 settings.SENTRY_SECURITY
289 )
290 response["Expect-CT"] = 'max-age=86400, enforce, report-uri="{}"'.format(
291 settings.SENTRY_SECURITY
292 )
293
294 # Opt-out from Google FLoC
295 response["Permissions-Policy"] = "interest-cohort=()"
296
297 return response
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/weblate/middleware.py b/weblate/middleware.py
--- a/weblate/middleware.py
+++ b/weblate/middleware.py
@@ -20,11 +20,14 @@
from urllib.parse import urlparse
from django.conf import settings
+from django.contrib import messages
from django.core.exceptions import ValidationError
from django.core.validators import validate_ipv46_address
from django.http import Http404, HttpResponsePermanentRedirect
+from django.shortcuts import redirect
from django.urls import is_valid_path, reverse
from django.utils.http import escape_leading_slashes
+from django.utils.translation import gettext_lazy as _
from weblate.lang.models import Language
from weblate.trans.models import Change, Component, Project
@@ -151,6 +154,13 @@
request.user.check_access_component(component)
return component
+ def check_existing_translations(self, slug, project):
+ """Check in existing translations for specific language.
+
+ Return False if language translation not present, else True.
+ """
+ return any(lang.name == slug for lang in project.languages)
+
def process_exception(self, request, exception):
if not isinstance(exception, Http404):
return None
@@ -161,12 +171,13 @@
return None
kwargs = dict(resolver_match.kwargs)
-
+ new_lang = None
if "lang" in kwargs:
language = self.fixup_language(kwargs["lang"])
if language is None:
return None
kwargs["lang"] = language.code
+ new_lang = language.name
if "project" in kwargs:
project = self.fixup_project(kwargs["project"], request)
@@ -180,6 +191,24 @@
return None
kwargs["component"] = component.slug
+ if new_lang:
+ existing_trans = self.check_existing_translations(new_lang, project)
+ if not existing_trans:
+ messages.add_message(
+ request,
+ messages.INFO,
+ _(
+ f"{new_lang} translation is currently not available,\
+ but can be added."
+ ),
+ )
+ return redirect(
+ reverse(
+ "component",
+ args=[kwargs["project"], kwargs["component"]],
+ )
+ )
+
if kwargs != resolver_match.kwargs:
query = request.META["QUERY_STRING"]
if query:
|
{"golden_diff": "diff --git a/weblate/middleware.py b/weblate/middleware.py\n--- a/weblate/middleware.py\n+++ b/weblate/middleware.py\n@@ -20,11 +20,14 @@\n from urllib.parse import urlparse\n \n from django.conf import settings\n+from django.contrib import messages\n from django.core.exceptions import ValidationError\n from django.core.validators import validate_ipv46_address\n from django.http import Http404, HttpResponsePermanentRedirect\n+from django.shortcuts import redirect\n from django.urls import is_valid_path, reverse\n from django.utils.http import escape_leading_slashes\n+from django.utils.translation import gettext_lazy as _\n \n from weblate.lang.models import Language\n from weblate.trans.models import Change, Component, Project\n@@ -151,6 +154,13 @@\n request.user.check_access_component(component)\n return component\n \n+ def check_existing_translations(self, slug, project):\n+ \"\"\"Check in existing translations for specific language.\n+\n+ Return False if language translation not present, else True.\n+ \"\"\"\n+ return any(lang.name == slug for lang in project.languages)\n+\n def process_exception(self, request, exception):\n if not isinstance(exception, Http404):\n return None\n@@ -161,12 +171,13 @@\n return None\n \n kwargs = dict(resolver_match.kwargs)\n-\n+ new_lang = None\n if \"lang\" in kwargs:\n language = self.fixup_language(kwargs[\"lang\"])\n if language is None:\n return None\n kwargs[\"lang\"] = language.code\n+ new_lang = language.name\n \n if \"project\" in kwargs:\n project = self.fixup_project(kwargs[\"project\"], request)\n@@ -180,6 +191,24 @@\n return None\n kwargs[\"component\"] = component.slug\n \n+ if new_lang:\n+ existing_trans = self.check_existing_translations(new_lang, project)\n+ if not existing_trans:\n+ messages.add_message(\n+ request,\n+ messages.INFO,\n+ _(\n+ f\"{new_lang} translation is currently not available,\\\n+ but can be added.\"\n+ ),\n+ )\n+ return redirect(\n+ reverse(\n+ \"component\",\n+ args=[kwargs[\"project\"], kwargs[\"component\"]],\n+ )\n+ )\n+\n if kwargs != resolver_match.kwargs:\n query = request.META[\"QUERY_STRING\"]\n if query:\n", "issue": "Make 404 more useful when possible\n### Describe the problem\n\nFor example, if you try go to a non-existent language of a component, the page will only suggest to go home or to all projects, while it would be better if it linked to the component, or suggested adding a language that you tried to visit. Example: https://hosted.weblate.org/projects/keepassxc/keepassxc-browser-dev/fil/\r\n\r\n\r\n\n\n### Describe the solution you'd like\n\nAdd useful suggestions depending on the context.\n\n### Describe alternatives you've considered\n\n_No response_\n\n### Screenshots\n\n_No response_\n\n### Additional context\n\nhttps://github.com/WeblateOrg/weblate/blob/1804a951c8ae9199d23099a8ec322134ee5b45bc/weblate/urls.py#L136-L140\r\n\r\nhttps://github.com/WeblateOrg/weblate/blob/329dabf59991ed2ee1b44f331929da41d8031c98/weblate/templates/404.html\n", "before_files": [{"content": "#\n# Copyright \u00a9 2012\u20132022 Michal \u010ciha\u0159 <[email protected]>\n#\n# This file is part of Weblate <https://weblate.org/>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <https://www.gnu.org/licenses/>.\n#\n\nfrom urllib.parse import urlparse\n\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\nfrom django.core.validators import validate_ipv46_address\nfrom django.http import Http404, HttpResponsePermanentRedirect\nfrom django.urls import is_valid_path, reverse\nfrom django.utils.http import escape_leading_slashes\n\nfrom weblate.lang.models import Language\nfrom weblate.trans.models import Change, Component, Project\nfrom weblate.utils.errors import report_error\nfrom weblate.utils.site import get_site_url\n\nCSP_TEMPLATE = (\n \"default-src 'self'; style-src {0}; img-src {1}; script-src {2}; \"\n \"connect-src {3}; object-src 'none'; font-src {4};\"\n \"frame-src 'none'; frame-ancestors 'none';\"\n)\n\n# URLs requiring inline javascript\nINLINE_PATHS = {\"social:begin\", \"djangosaml2idp:saml_login_process\"}\n\n\nclass ProxyMiddleware:\n \"\"\"Middleware that updates REMOTE_ADDR from proxy.\n\n Note that this can have security implications and settings have to match your actual\n proxy setup.\n \"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n # Fake HttpRequest attribute to inject configured\n # site name into build_absolute_uri\n request._current_scheme_host = get_site_url()\n\n # Actual proxy handling\n proxy = None\n if settings.IP_BEHIND_REVERSE_PROXY:\n proxy = request.META.get(settings.IP_PROXY_HEADER)\n if proxy:\n # X_FORWARDED_FOR returns client1, proxy1, proxy2,...\n address = proxy.split(\",\")[settings.IP_PROXY_OFFSET].strip()\n try:\n validate_ipv46_address(address)\n request.META[\"REMOTE_ADDR\"] = address\n except ValidationError:\n report_error(cause=\"Invalid IP address\")\n\n return self.get_response(request)\n\n\nclass RedirectMiddleware:\n \"\"\"\n Middleware that handles URL redirecting.\n\n This used for fuzzy lookups of projects, for example case insensitive\n or after renaming.\n \"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n response = self.get_response(request)\n # This is based on APPEND_SLASH handling in Django\n if response.status_code == 404 and self.should_redirect_with_slash(request):\n new_path = request.get_full_path(force_append_slash=True)\n # Prevent construction of scheme relative urls.\n new_path = escape_leading_slashes(new_path)\n return HttpResponsePermanentRedirect(new_path)\n return response\n\n def should_redirect_with_slash(self, request):\n path = request.path_info\n # Avoid redirecting non GET requests, these would fail anyway due to\n # missing parameters.\n # Redirecting on API removes authentication headers in many cases,\n # so avoid that as well.\n if (\n path.endswith(\"/\")\n or request.method != \"GET\"\n or path.startswith(f\"{settings.URL_PREFIX}/api\")\n ):\n return False\n urlconf = getattr(request, \"urlconf\", None)\n slash_path = f\"{path}/\"\n return not is_valid_path(path, urlconf) and is_valid_path(slash_path, urlconf)\n\n def fixup_language(self, lang):\n return Language.objects.fuzzy_get(code=lang, strict=True)\n\n def fixup_project(self, slug, request):\n try:\n project = Project.objects.get(slug__iexact=slug)\n except Project.MultipleObjectsReturned:\n return None\n except Project.DoesNotExist:\n try:\n project = (\n Change.objects.filter(\n action=Change.ACTION_RENAME_PROJECT,\n old=slug,\n )\n .order()[0]\n .project\n )\n except IndexError:\n return None\n\n request.user.check_access(project)\n return project\n\n def fixup_component(self, slug, request, project):\n try:\n component = Component.objects.get(project=project, slug__iexact=slug)\n except Component.DoesNotExist:\n try:\n component = (\n Change.objects.filter(\n action=Change.ACTION_RENAME_COMPONENT, old=slug\n )\n .order()[0]\n .component\n )\n except IndexError:\n return None\n\n request.user.check_access_component(component)\n return component\n\n def process_exception(self, request, exception):\n if not isinstance(exception, Http404):\n return None\n\n try:\n resolver_match = request.resolver_match\n except AttributeError:\n return None\n\n kwargs = dict(resolver_match.kwargs)\n\n if \"lang\" in kwargs:\n language = self.fixup_language(kwargs[\"lang\"])\n if language is None:\n return None\n kwargs[\"lang\"] = language.code\n\n if \"project\" in kwargs:\n project = self.fixup_project(kwargs[\"project\"], request)\n if project is None:\n return None\n kwargs[\"project\"] = project.slug\n\n if \"component\" in kwargs:\n component = self.fixup_component(kwargs[\"component\"], request, project)\n if component is None:\n return None\n kwargs[\"component\"] = component.slug\n\n if kwargs != resolver_match.kwargs:\n query = request.META[\"QUERY_STRING\"]\n if query:\n query = f\"?{query}\"\n return HttpResponsePermanentRedirect(\n reverse(resolver_match.url_name, kwargs=kwargs) + query\n )\n\n return None\n\n\nclass SecurityMiddleware:\n \"\"\"Middleware that sets Content-Security-Policy.\"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n response = self.get_response(request)\n # No CSP for debug mode (to allow djdt or error pages)\n if settings.DEBUG:\n return response\n\n style = {\"'self'\", \"'unsafe-inline'\"} | set(settings.CSP_STYLE_SRC)\n script = {\"'self'\"} | set(settings.CSP_SCRIPT_SRC)\n image = {\"'self'\"} | set(settings.CSP_IMG_SRC)\n connect = {\"'self'\"} | set(settings.CSP_CONNECT_SRC)\n font = {\"'self'\"} | set(settings.CSP_FONT_SRC)\n\n if request.resolver_match and request.resolver_match.view_name in INLINE_PATHS:\n script.add(\"'unsafe-inline'\")\n\n # Support form\n if request.resolver_match and request.resolver_match.view_name == \"manage\":\n script.add(\"care.weblate.org\")\n connect.add(\"care.weblate.org\")\n style.add(\"care.weblate.org\")\n\n # Rollbar client errors reporting\n if (\n hasattr(settings, \"ROLLBAR\")\n and \"client_token\" in settings.ROLLBAR\n and \"environment\" in settings.ROLLBAR\n and response.status_code == 500\n ):\n script.add(\"'unsafe-inline'\")\n script.add(\"cdnjs.cloudflare.com\")\n connect.add(\"api.rollbar.com\")\n\n # Sentry user feedback\n if settings.SENTRY_DSN and response.status_code == 500:\n domain = urlparse(settings.SENTRY_DSN).hostname\n script.add(domain)\n script.add(\"sentry.io\")\n connect.add(domain)\n connect.add(\"sentry.io\")\n script.add(\"'unsafe-inline'\")\n image.add(\"data:\")\n\n # Matomo (Piwik) analytics\n if settings.MATOMO_URL:\n domain = urlparse(settings.MATOMO_URL).hostname\n script.add(domain)\n image.add(domain)\n connect.add(domain)\n\n # Google Analytics\n if settings.GOOGLE_ANALYTICS_ID:\n script.add(\"'unsafe-inline'\")\n script.add(\"www.google-analytics.com\")\n image.add(\"www.google-analytics.com\")\n\n # External media URL\n if \"://\" in settings.MEDIA_URL:\n domain = urlparse(settings.MEDIA_URL).hostname\n image.add(domain)\n\n # External static URL\n if \"://\" in settings.STATIC_URL:\n domain = urlparse(settings.STATIC_URL).hostname\n script.add(domain)\n image.add(domain)\n style.add(domain)\n font.add(domain)\n\n # CDN for fonts\n if settings.FONTS_CDN_URL:\n domain = urlparse(settings.FONTS_CDN_URL).hostname\n style.add(domain)\n font.add(domain)\n\n # When using external image for Auth0 provider, add it here\n if \"://\" in settings.SOCIAL_AUTH_AUTH0_IMAGE:\n domain = urlparse(settings.SOCIAL_AUTH_AUTH0_IMAGE).hostname\n image.add(domain)\n\n response[\"Content-Security-Policy\"] = CSP_TEMPLATE.format(\n \" \".join(style),\n \" \".join(image),\n \" \".join(script),\n \" \".join(connect),\n \" \".join(font),\n )\n if settings.SENTRY_SECURITY:\n response[\"Content-Security-Policy\"] += \" report-uri {}\".format(\n settings.SENTRY_SECURITY\n )\n response[\"Expect-CT\"] = 'max-age=86400, enforce, report-uri=\"{}\"'.format(\n settings.SENTRY_SECURITY\n )\n\n # Opt-out from Google FLoC\n response[\"Permissions-Policy\"] = \"interest-cohort=()\"\n\n return response\n", "path": "weblate/middleware.py"}], "after_files": [{"content": "#\n# Copyright \u00a9 2012\u20132022 Michal \u010ciha\u0159 <[email protected]>\n#\n# This file is part of Weblate <https://weblate.org/>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <https://www.gnu.org/licenses/>.\n#\n\nfrom urllib.parse import urlparse\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.core.exceptions import ValidationError\nfrom django.core.validators import validate_ipv46_address\nfrom django.http import Http404, HttpResponsePermanentRedirect\nfrom django.shortcuts import redirect\nfrom django.urls import is_valid_path, reverse\nfrom django.utils.http import escape_leading_slashes\nfrom django.utils.translation import gettext_lazy as _\n\nfrom weblate.lang.models import Language\nfrom weblate.trans.models import Change, Component, Project\nfrom weblate.utils.errors import report_error\nfrom weblate.utils.site import get_site_url\n\nCSP_TEMPLATE = (\n \"default-src 'self'; style-src {0}; img-src {1}; script-src {2}; \"\n \"connect-src {3}; object-src 'none'; font-src {4};\"\n \"frame-src 'none'; frame-ancestors 'none';\"\n)\n\n# URLs requiring inline javascript\nINLINE_PATHS = {\"social:begin\", \"djangosaml2idp:saml_login_process\"}\n\n\nclass ProxyMiddleware:\n \"\"\"Middleware that updates REMOTE_ADDR from proxy.\n\n Note that this can have security implications and settings have to match your actual\n proxy setup.\n \"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n # Fake HttpRequest attribute to inject configured\n # site name into build_absolute_uri\n request._current_scheme_host = get_site_url()\n\n # Actual proxy handling\n proxy = None\n if settings.IP_BEHIND_REVERSE_PROXY:\n proxy = request.META.get(settings.IP_PROXY_HEADER)\n if proxy:\n # X_FORWARDED_FOR returns client1, proxy1, proxy2,...\n address = proxy.split(\",\")[settings.IP_PROXY_OFFSET].strip()\n try:\n validate_ipv46_address(address)\n request.META[\"REMOTE_ADDR\"] = address\n except ValidationError:\n report_error(cause=\"Invalid IP address\")\n\n return self.get_response(request)\n\n\nclass RedirectMiddleware:\n \"\"\"\n Middleware that handles URL redirecting.\n\n This used for fuzzy lookups of projects, for example case insensitive\n or after renaming.\n \"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n response = self.get_response(request)\n # This is based on APPEND_SLASH handling in Django\n if response.status_code == 404 and self.should_redirect_with_slash(request):\n new_path = request.get_full_path(force_append_slash=True)\n # Prevent construction of scheme relative urls.\n new_path = escape_leading_slashes(new_path)\n return HttpResponsePermanentRedirect(new_path)\n return response\n\n def should_redirect_with_slash(self, request):\n path = request.path_info\n # Avoid redirecting non GET requests, these would fail anyway due to\n # missing parameters.\n # Redirecting on API removes authentication headers in many cases,\n # so avoid that as well.\n if (\n path.endswith(\"/\")\n or request.method != \"GET\"\n or path.startswith(f\"{settings.URL_PREFIX}/api\")\n ):\n return False\n urlconf = getattr(request, \"urlconf\", None)\n slash_path = f\"{path}/\"\n return not is_valid_path(path, urlconf) and is_valid_path(slash_path, urlconf)\n\n def fixup_language(self, lang):\n return Language.objects.fuzzy_get(code=lang, strict=True)\n\n def fixup_project(self, slug, request):\n try:\n project = Project.objects.get(slug__iexact=slug)\n except Project.MultipleObjectsReturned:\n return None\n except Project.DoesNotExist:\n try:\n project = (\n Change.objects.filter(\n action=Change.ACTION_RENAME_PROJECT,\n old=slug,\n )\n .order()[0]\n .project\n )\n except IndexError:\n return None\n\n request.user.check_access(project)\n return project\n\n def fixup_component(self, slug, request, project):\n try:\n component = Component.objects.get(project=project, slug__iexact=slug)\n except Component.DoesNotExist:\n try:\n component = (\n Change.objects.filter(\n action=Change.ACTION_RENAME_COMPONENT, old=slug\n )\n .order()[0]\n .component\n )\n except IndexError:\n return None\n\n request.user.check_access_component(component)\n return component\n\n def check_existing_translations(self, slug, project):\n \"\"\"Check in existing translations for specific language.\n\n Return False if language translation not present, else True.\n \"\"\"\n return any(lang.name == slug for lang in project.languages)\n\n def process_exception(self, request, exception):\n if not isinstance(exception, Http404):\n return None\n\n try:\n resolver_match = request.resolver_match\n except AttributeError:\n return None\n\n kwargs = dict(resolver_match.kwargs)\n new_lang = None\n if \"lang\" in kwargs:\n language = self.fixup_language(kwargs[\"lang\"])\n if language is None:\n return None\n kwargs[\"lang\"] = language.code\n new_lang = language.name\n\n if \"project\" in kwargs:\n project = self.fixup_project(kwargs[\"project\"], request)\n if project is None:\n return None\n kwargs[\"project\"] = project.slug\n\n if \"component\" in kwargs:\n component = self.fixup_component(kwargs[\"component\"], request, project)\n if component is None:\n return None\n kwargs[\"component\"] = component.slug\n\n if new_lang:\n existing_trans = self.check_existing_translations(new_lang, project)\n if not existing_trans:\n messages.add_message(\n request,\n messages.INFO,\n _(\n f\"{new_lang} translation is currently not available,\\\n but can be added.\"\n ),\n )\n return redirect(\n reverse(\n \"component\",\n args=[kwargs[\"project\"], kwargs[\"component\"]],\n )\n )\n\n if kwargs != resolver_match.kwargs:\n query = request.META[\"QUERY_STRING\"]\n if query:\n query = f\"?{query}\"\n return HttpResponsePermanentRedirect(\n reverse(resolver_match.url_name, kwargs=kwargs) + query\n )\n\n return None\n\n\nclass SecurityMiddleware:\n \"\"\"Middleware that sets Content-Security-Policy.\"\"\"\n\n def __init__(self, get_response=None):\n self.get_response = get_response\n\n def __call__(self, request):\n response = self.get_response(request)\n # No CSP for debug mode (to allow djdt or error pages)\n if settings.DEBUG:\n return response\n\n style = {\"'self'\", \"'unsafe-inline'\"} | set(settings.CSP_STYLE_SRC)\n script = {\"'self'\"} | set(settings.CSP_SCRIPT_SRC)\n image = {\"'self'\"} | set(settings.CSP_IMG_SRC)\n connect = {\"'self'\"} | set(settings.CSP_CONNECT_SRC)\n font = {\"'self'\"} | set(settings.CSP_FONT_SRC)\n\n if request.resolver_match and request.resolver_match.view_name in INLINE_PATHS:\n script.add(\"'unsafe-inline'\")\n\n # Support form\n if request.resolver_match and request.resolver_match.view_name == \"manage\":\n script.add(\"care.weblate.org\")\n connect.add(\"care.weblate.org\")\n style.add(\"care.weblate.org\")\n\n # Rollbar client errors reporting\n if (\n hasattr(settings, \"ROLLBAR\")\n and \"client_token\" in settings.ROLLBAR\n and \"environment\" in settings.ROLLBAR\n and response.status_code == 500\n ):\n script.add(\"'unsafe-inline'\")\n script.add(\"cdnjs.cloudflare.com\")\n connect.add(\"api.rollbar.com\")\n\n # Sentry user feedback\n if settings.SENTRY_DSN and response.status_code == 500:\n domain = urlparse(settings.SENTRY_DSN).hostname\n script.add(domain)\n script.add(\"sentry.io\")\n connect.add(domain)\n connect.add(\"sentry.io\")\n script.add(\"'unsafe-inline'\")\n image.add(\"data:\")\n\n # Matomo (Piwik) analytics\n if settings.MATOMO_URL:\n domain = urlparse(settings.MATOMO_URL).hostname\n script.add(domain)\n image.add(domain)\n connect.add(domain)\n\n # Google Analytics\n if settings.GOOGLE_ANALYTICS_ID:\n script.add(\"'unsafe-inline'\")\n script.add(\"www.google-analytics.com\")\n image.add(\"www.google-analytics.com\")\n\n # External media URL\n if \"://\" in settings.MEDIA_URL:\n domain = urlparse(settings.MEDIA_URL).hostname\n image.add(domain)\n\n # External static URL\n if \"://\" in settings.STATIC_URL:\n domain = urlparse(settings.STATIC_URL).hostname\n script.add(domain)\n image.add(domain)\n style.add(domain)\n font.add(domain)\n\n # CDN for fonts\n if settings.FONTS_CDN_URL:\n domain = urlparse(settings.FONTS_CDN_URL).hostname\n style.add(domain)\n font.add(domain)\n\n # When using external image for Auth0 provider, add it here\n if \"://\" in settings.SOCIAL_AUTH_AUTH0_IMAGE:\n domain = urlparse(settings.SOCIAL_AUTH_AUTH0_IMAGE).hostname\n image.add(domain)\n\n response[\"Content-Security-Policy\"] = CSP_TEMPLATE.format(\n \" \".join(style),\n \" \".join(image),\n \" \".join(script),\n \" \".join(connect),\n \" \".join(font),\n )\n if settings.SENTRY_SECURITY:\n response[\"Content-Security-Policy\"] += \" report-uri {}\".format(\n settings.SENTRY_SECURITY\n )\n response[\"Expect-CT\"] = 'max-age=86400, enforce, report-uri=\"{}\"'.format(\n settings.SENTRY_SECURITY\n )\n\n # Opt-out from Google FLoC\n response[\"Permissions-Policy\"] = \"interest-cohort=()\"\n\n return response\n", "path": "weblate/middleware.py"}]}
| 3,531 | 529 |
gh_patches_debug_16248
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1754
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Faker returns one value when using multiple locales
* Faker version: 13.11
* OS: Mac OS Monterey
Computer: MacBook Pro (14-inch, 2021)
Brief summary of the issue goes here.
If using multiple locales, faker only makes one choice. This only happens when you select multiple locales
### Steps to reproduce
```
from faker import Faker
fake = Faker(["en_GB", "fr_FR", "en_IN"])
Faker.seed(0)
for _ in range(5):
print(fake.date_time_this_year())
```
### Expected behavior
returns
```
2022-03-16 19:22:23
2022-03-23 16:00:20
2022-01-08 20:40:15
2022-02-20 06:38:22
2022-04-10 06:42:46
```
### Actual behavior
returns
```
2022-03-23 16:00:20
2022-03-23 16:00:20
2022-03-23 16:00:20
2022-03-23 16:00:20
2022-03-23 16:00:20
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/proxy.py`
Content:
```
1 import copy
2 import functools
3 import re
4
5 from collections import OrderedDict
6 from random import Random
7 from typing import Any, Callable, Dict, List, Optional, Pattern, Sequence, Tuple, Union
8
9 from .config import DEFAULT_LOCALE
10 from .exceptions import UniquenessException
11 from .factory import Factory
12 from .generator import Generator, Sentinel, random
13 from .typing import SeedType
14 from .utils.distribution import choices_distribution
15
16 _UNIQUE_ATTEMPTS = 1000
17
18
19 class Faker:
20 """Proxy class capable of supporting multiple locales"""
21
22 cache_pattern: Pattern = re.compile(r"^_cached_\w*_mapping$")
23 generator_attrs = [
24 attr for attr in dir(Generator) if not attr.startswith("__") and attr not in ["seed", "seed_instance", "random"]
25 ]
26
27 def __init__(
28 self,
29 locale: Optional[Union[str, Sequence[str], Dict[str, Union[int, float]]]] = None,
30 providers: Optional[List[str]] = None,
31 generator: Optional[Generator] = None,
32 includes: Optional[List[str]] = None,
33 use_weighting: bool = True,
34 **config: Any,
35 ) -> None:
36 self._factory_map = OrderedDict()
37 self._weights = None
38 self._unique_proxy = UniqueProxy(self)
39
40 if isinstance(locale, str):
41 locales = [locale.replace("-", "_")]
42
43 # This guarantees a FIFO ordering of elements in `locales` based on the final
44 # locale string while discarding duplicates after processing
45 elif isinstance(locale, (list, tuple, set)):
46 locales = []
47 for code in locale:
48 if not isinstance(code, str):
49 raise TypeError('The locale "%s" must be a string.' % str(code))
50 final_locale = code.replace("-", "_")
51 if final_locale not in locales:
52 locales.append(final_locale)
53
54 elif isinstance(locale, OrderedDict):
55 assert all(isinstance(v, (int, float)) for v in locale.values())
56 odict = OrderedDict()
57 for k, v in locale.items():
58 key = k.replace("-", "_")
59 odict[key] = v
60 locales = list(odict.keys())
61 self._weights = list(odict.values())
62
63 else:
64 locales = [DEFAULT_LOCALE]
65
66 for locale in locales:
67 self._factory_map[locale] = Factory.create(
68 locale,
69 providers,
70 generator,
71 includes,
72 use_weighting=use_weighting,
73 **config,
74 )
75
76 self._locales = locales
77 self._factories = list(self._factory_map.values())
78
79 def __dir__(self):
80 attributes = set(super(Faker, self).__dir__())
81 for factory in self.factories:
82 attributes |= {attr for attr in dir(factory) if not attr.startswith("_")}
83 return sorted(attributes)
84
85 def __getitem__(self, locale: str) -> Generator:
86 return self._factory_map[locale.replace("-", "_")]
87
88 def __getattribute__(self, attr: str) -> Any:
89 """
90 Handles the "attribute resolution" behavior for declared members of this proxy class
91
92 The class method `seed` cannot be called from an instance.
93
94 :param attr: attribute name
95 :return: the appropriate attribute
96 """
97 if attr == "seed":
98 msg = "Calling `.seed()` on instances is deprecated. " "Use the class method `Faker.seed()` instead."
99 raise TypeError(msg)
100 else:
101 return super().__getattribute__(attr)
102
103 def __getattr__(self, attr: str) -> Any:
104 """
105 Handles cache access and proxying behavior
106
107 :param attr: attribute name
108 :return: the appropriate attribute
109 """
110 if len(self._factories) == 1:
111 return getattr(self._factories[0], attr)
112 elif attr in self.generator_attrs:
113 msg = "Proxying calls to `%s` is not implemented in multiple locale mode." % attr
114 raise NotImplementedError(msg)
115 elif self.cache_pattern.match(attr):
116 msg = "Cached attribute `%s` does not exist" % attr
117 raise AttributeError(msg)
118 else:
119 factory = self._select_factory(attr)
120 return getattr(factory, attr)
121
122 def __deepcopy__(self, memodict: Dict = {}) -> "Faker":
123 cls = self.__class__
124 result = cls.__new__(cls)
125 result._locales = copy.deepcopy(self._locales)
126 result._factories = copy.deepcopy(self._factories)
127 result._factory_map = copy.deepcopy(self._factory_map)
128 result._weights = copy.deepcopy(self._weights)
129 result._unique_proxy = UniqueProxy(self)
130 result._unique_proxy._seen = {k: {result._unique_proxy._sentinel} for k in self._unique_proxy._seen.keys()}
131 return result
132
133 def __setstate__(self, state: Any) -> None:
134 self.__dict__.update(state)
135
136 @property
137 def unique(self) -> "UniqueProxy":
138 return self._unique_proxy
139
140 def _select_factory(self, method_name: str) -> Factory:
141 """
142 Returns a random factory that supports the provider method
143
144 :param method_name: Name of provider method
145 :return: A factory that supports the provider method
146 """
147
148 factories, weights = self._map_provider_method(method_name)
149
150 if len(factories) == 0:
151 msg = f"No generator object has attribute {method_name!r}"
152 raise AttributeError(msg)
153 elif len(factories) == 1:
154 return factories[0]
155
156 if Generator._global_seed is not Sentinel:
157 random.seed(Generator._global_seed) # type: ignore
158 if weights:
159 factory = self._select_factory_distribution(factories, weights)
160 else:
161 factory = self._select_factory_choice(factories)
162 return factory
163
164 def _select_factory_distribution(self, factories, weights):
165 return choices_distribution(factories, weights, random, length=1)[0]
166
167 def _select_factory_choice(self, factories):
168 return random.choice(factories)
169
170 def _map_provider_method(self, method_name: str) -> Tuple[List[Factory], Optional[List[float]]]:
171 """
172 Creates a 2-tuple of factories and weights for the given provider method name
173
174 The first element of the tuple contains a list of compatible factories.
175 The second element of the tuple contains a list of distribution weights.
176
177 :param method_name: Name of provider method
178 :return: 2-tuple (factories, weights)
179 """
180
181 # Return cached mapping if it exists for given method
182 attr = f"_cached_{method_name}_mapping"
183 if hasattr(self, attr):
184 return getattr(self, attr)
185
186 # Create mapping if it does not exist
187 if self._weights:
188 value = [
189 (factory, weight)
190 for factory, weight in zip(self.factories, self._weights)
191 if hasattr(factory, method_name)
192 ]
193 factories, weights = zip(*value)
194 mapping = list(factories), list(weights)
195 else:
196 value = [factory for factory in self.factories if hasattr(factory, method_name)] # type: ignore
197 mapping = value, None # type: ignore
198
199 # Then cache and return results
200 setattr(self, attr, mapping)
201 return mapping
202
203 @classmethod
204 def seed(cls, seed: Optional[SeedType] = None) -> None:
205 """
206 Hashables the shared `random.Random` object across all factories
207
208 :param seed: seed value
209 """
210 Generator.seed(seed)
211
212 def seed_instance(self, seed: Optional[SeedType] = None) -> None:
213 """
214 Creates and seeds a new `random.Random` object for each factory
215
216 :param seed: seed value
217 """
218 for factory in self._factories:
219 factory.seed_instance(seed)
220
221 def seed_locale(self, locale: str, seed: Optional[SeedType] = None) -> None:
222 """
223 Creates and seeds a new `random.Random` object for the factory of the specified locale
224
225 :param locale: locale string
226 :param seed: seed value
227 """
228 self._factory_map[locale.replace("-", "_")].seed_instance(seed)
229
230 @property
231 def random(self) -> Random:
232 """
233 Proxies `random` getter calls
234
235 In single locale mode, this will be proxied to the `random` getter
236 of the only internal `Generator` object. Subclasses will have to
237 implement desired behavior in multiple locale mode.
238 """
239
240 if len(self._factories) == 1:
241 return self._factories[0].random
242 else:
243 msg = "Proxying `random` getter calls is not implemented in multiple locale mode."
244 raise NotImplementedError(msg)
245
246 @random.setter
247 def random(self, value: Random) -> None:
248 """
249 Proxies `random` setter calls
250
251 In single locale mode, this will be proxied to the `random` setter
252 of the only internal `Generator` object. Subclasses will have to
253 implement desired behavior in multiple locale mode.
254 """
255
256 if len(self._factories) == 1:
257 self._factories[0].random = value
258 else:
259 msg = "Proxying `random` setter calls is not implemented in multiple locale mode."
260 raise NotImplementedError(msg)
261
262 @property
263 def locales(self) -> List[str]:
264 return list(self._locales)
265
266 @property
267 def weights(self) -> Optional[List[Union[int, float]]]:
268 return self._weights
269
270 @property
271 def factories(self) -> List[Generator]:
272 return self._factories
273
274 def items(self) -> List[Tuple[str, Generator]]:
275 return list(self._factory_map.items())
276
277
278 class UniqueProxy:
279 def __init__(self, proxy: Faker):
280 self._proxy = proxy
281 self._seen: Dict = {}
282 self._sentinel = object()
283
284 def clear(self) -> None:
285 self._seen = {}
286
287 def __getattr__(self, name: str) -> Any:
288 obj = getattr(self._proxy, name)
289 if callable(obj):
290 return self._wrap(name, obj)
291 else:
292 raise TypeError("Accessing non-functions through .unique is not supported.")
293
294 def __getstate__(self):
295 # Copy the object's state from self.__dict__ which contains
296 # all our instance attributes. Always use the dict.copy()
297 # method to avoid modifying the original state.
298 state = self.__dict__.copy()
299 return state
300
301 def __setstate__(self, state):
302 self.__dict__.update(state)
303
304 def _wrap(self, name: str, function: Callable) -> Callable:
305 @functools.wraps(function)
306 def wrapper(*args, **kwargs):
307 key = (name, args, tuple(sorted(kwargs.items())))
308
309 generated = self._seen.setdefault(key, {self._sentinel})
310
311 # With use of a sentinel value rather than None, we leave
312 # None open as a valid return value.
313 retval = self._sentinel
314
315 for i in range(_UNIQUE_ATTEMPTS):
316 if retval not in generated:
317 break
318 retval = function(*args, **kwargs)
319 else:
320 raise UniquenessException(f"Got duplicated values after {_UNIQUE_ATTEMPTS:,} iterations.")
321
322 generated.add(retval)
323
324 return retval
325
326 return wrapper
327
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/proxy.py b/faker/proxy.py
--- a/faker/proxy.py
+++ b/faker/proxy.py
@@ -9,7 +9,7 @@
from .config import DEFAULT_LOCALE
from .exceptions import UniquenessException
from .factory import Factory
-from .generator import Generator, Sentinel, random
+from .generator import Generator, random
from .typing import SeedType
from .utils.distribution import choices_distribution
@@ -153,8 +153,6 @@
elif len(factories) == 1:
return factories[0]
- if Generator._global_seed is not Sentinel:
- random.seed(Generator._global_seed) # type: ignore
if weights:
factory = self._select_factory_distribution(factories, weights)
else:
|
{"golden_diff": "diff --git a/faker/proxy.py b/faker/proxy.py\n--- a/faker/proxy.py\n+++ b/faker/proxy.py\n@@ -9,7 +9,7 @@\n from .config import DEFAULT_LOCALE\n from .exceptions import UniquenessException\n from .factory import Factory\n-from .generator import Generator, Sentinel, random\n+from .generator import Generator, random\n from .typing import SeedType\n from .utils.distribution import choices_distribution\n \n@@ -153,8 +153,6 @@\n elif len(factories) == 1:\n return factories[0]\n \n- if Generator._global_seed is not Sentinel:\n- random.seed(Generator._global_seed) # type: ignore\n if weights:\n factory = self._select_factory_distribution(factories, weights)\n else:\n", "issue": "Faker returns one value when using multiple locales\n* Faker version: 13.11\r\n* OS: Mac OS Monterey\r\nComputer: MacBook Pro (14-inch, 2021)\r\n\r\nBrief summary of the issue goes here.\r\nIf using multiple locales, faker only makes one choice. This only happens when you select multiple locales\r\n\r\n### Steps to reproduce\r\n\r\n```\r\nfrom faker import Faker\r\n\r\nfake = Faker([\"en_GB\", \"fr_FR\", \"en_IN\"])\r\nFaker.seed(0)\r\nfor _ in range(5):\r\n print(fake.date_time_this_year())\r\n\r\n```\r\n\r\n### Expected behavior\r\nreturns\r\n```\r\n2022-03-16 19:22:23\r\n2022-03-23 16:00:20\r\n2022-01-08 20:40:15\r\n2022-02-20 06:38:22\r\n2022-04-10 06:42:46\r\n```\r\n\r\n### Actual behavior\r\nreturns\r\n```\r\n2022-03-23 16:00:20\r\n2022-03-23 16:00:20\r\n2022-03-23 16:00:20\r\n2022-03-23 16:00:20\r\n2022-03-23 16:00:20\r\n\r\n```\n", "before_files": [{"content": "import copy\nimport functools\nimport re\n\nfrom collections import OrderedDict\nfrom random import Random\nfrom typing import Any, Callable, Dict, List, Optional, Pattern, Sequence, Tuple, Union\n\nfrom .config import DEFAULT_LOCALE\nfrom .exceptions import UniquenessException\nfrom .factory import Factory\nfrom .generator import Generator, Sentinel, random\nfrom .typing import SeedType\nfrom .utils.distribution import choices_distribution\n\n_UNIQUE_ATTEMPTS = 1000\n\n\nclass Faker:\n \"\"\"Proxy class capable of supporting multiple locales\"\"\"\n\n cache_pattern: Pattern = re.compile(r\"^_cached_\\w*_mapping$\")\n generator_attrs = [\n attr for attr in dir(Generator) if not attr.startswith(\"__\") and attr not in [\"seed\", \"seed_instance\", \"random\"]\n ]\n\n def __init__(\n self,\n locale: Optional[Union[str, Sequence[str], Dict[str, Union[int, float]]]] = None,\n providers: Optional[List[str]] = None,\n generator: Optional[Generator] = None,\n includes: Optional[List[str]] = None,\n use_weighting: bool = True,\n **config: Any,\n ) -> None:\n self._factory_map = OrderedDict()\n self._weights = None\n self._unique_proxy = UniqueProxy(self)\n\n if isinstance(locale, str):\n locales = [locale.replace(\"-\", \"_\")]\n\n # This guarantees a FIFO ordering of elements in `locales` based on the final\n # locale string while discarding duplicates after processing\n elif isinstance(locale, (list, tuple, set)):\n locales = []\n for code in locale:\n if not isinstance(code, str):\n raise TypeError('The locale \"%s\" must be a string.' % str(code))\n final_locale = code.replace(\"-\", \"_\")\n if final_locale not in locales:\n locales.append(final_locale)\n\n elif isinstance(locale, OrderedDict):\n assert all(isinstance(v, (int, float)) for v in locale.values())\n odict = OrderedDict()\n for k, v in locale.items():\n key = k.replace(\"-\", \"_\")\n odict[key] = v\n locales = list(odict.keys())\n self._weights = list(odict.values())\n\n else:\n locales = [DEFAULT_LOCALE]\n\n for locale in locales:\n self._factory_map[locale] = Factory.create(\n locale,\n providers,\n generator,\n includes,\n use_weighting=use_weighting,\n **config,\n )\n\n self._locales = locales\n self._factories = list(self._factory_map.values())\n\n def __dir__(self):\n attributes = set(super(Faker, self).__dir__())\n for factory in self.factories:\n attributes |= {attr for attr in dir(factory) if not attr.startswith(\"_\")}\n return sorted(attributes)\n\n def __getitem__(self, locale: str) -> Generator:\n return self._factory_map[locale.replace(\"-\", \"_\")]\n\n def __getattribute__(self, attr: str) -> Any:\n \"\"\"\n Handles the \"attribute resolution\" behavior for declared members of this proxy class\n\n The class method `seed` cannot be called from an instance.\n\n :param attr: attribute name\n :return: the appropriate attribute\n \"\"\"\n if attr == \"seed\":\n msg = \"Calling `.seed()` on instances is deprecated. \" \"Use the class method `Faker.seed()` instead.\"\n raise TypeError(msg)\n else:\n return super().__getattribute__(attr)\n\n def __getattr__(self, attr: str) -> Any:\n \"\"\"\n Handles cache access and proxying behavior\n\n :param attr: attribute name\n :return: the appropriate attribute\n \"\"\"\n if len(self._factories) == 1:\n return getattr(self._factories[0], attr)\n elif attr in self.generator_attrs:\n msg = \"Proxying calls to `%s` is not implemented in multiple locale mode.\" % attr\n raise NotImplementedError(msg)\n elif self.cache_pattern.match(attr):\n msg = \"Cached attribute `%s` does not exist\" % attr\n raise AttributeError(msg)\n else:\n factory = self._select_factory(attr)\n return getattr(factory, attr)\n\n def __deepcopy__(self, memodict: Dict = {}) -> \"Faker\":\n cls = self.__class__\n result = cls.__new__(cls)\n result._locales = copy.deepcopy(self._locales)\n result._factories = copy.deepcopy(self._factories)\n result._factory_map = copy.deepcopy(self._factory_map)\n result._weights = copy.deepcopy(self._weights)\n result._unique_proxy = UniqueProxy(self)\n result._unique_proxy._seen = {k: {result._unique_proxy._sentinel} for k in self._unique_proxy._seen.keys()}\n return result\n\n def __setstate__(self, state: Any) -> None:\n self.__dict__.update(state)\n\n @property\n def unique(self) -> \"UniqueProxy\":\n return self._unique_proxy\n\n def _select_factory(self, method_name: str) -> Factory:\n \"\"\"\n Returns a random factory that supports the provider method\n\n :param method_name: Name of provider method\n :return: A factory that supports the provider method\n \"\"\"\n\n factories, weights = self._map_provider_method(method_name)\n\n if len(factories) == 0:\n msg = f\"No generator object has attribute {method_name!r}\"\n raise AttributeError(msg)\n elif len(factories) == 1:\n return factories[0]\n\n if Generator._global_seed is not Sentinel:\n random.seed(Generator._global_seed) # type: ignore\n if weights:\n factory = self._select_factory_distribution(factories, weights)\n else:\n factory = self._select_factory_choice(factories)\n return factory\n\n def _select_factory_distribution(self, factories, weights):\n return choices_distribution(factories, weights, random, length=1)[0]\n\n def _select_factory_choice(self, factories):\n return random.choice(factories)\n\n def _map_provider_method(self, method_name: str) -> Tuple[List[Factory], Optional[List[float]]]:\n \"\"\"\n Creates a 2-tuple of factories and weights for the given provider method name\n\n The first element of the tuple contains a list of compatible factories.\n The second element of the tuple contains a list of distribution weights.\n\n :param method_name: Name of provider method\n :return: 2-tuple (factories, weights)\n \"\"\"\n\n # Return cached mapping if it exists for given method\n attr = f\"_cached_{method_name}_mapping\"\n if hasattr(self, attr):\n return getattr(self, attr)\n\n # Create mapping if it does not exist\n if self._weights:\n value = [\n (factory, weight)\n for factory, weight in zip(self.factories, self._weights)\n if hasattr(factory, method_name)\n ]\n factories, weights = zip(*value)\n mapping = list(factories), list(weights)\n else:\n value = [factory for factory in self.factories if hasattr(factory, method_name)] # type: ignore\n mapping = value, None # type: ignore\n\n # Then cache and return results\n setattr(self, attr, mapping)\n return mapping\n\n @classmethod\n def seed(cls, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Hashables the shared `random.Random` object across all factories\n\n :param seed: seed value\n \"\"\"\n Generator.seed(seed)\n\n def seed_instance(self, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Creates and seeds a new `random.Random` object for each factory\n\n :param seed: seed value\n \"\"\"\n for factory in self._factories:\n factory.seed_instance(seed)\n\n def seed_locale(self, locale: str, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Creates and seeds a new `random.Random` object for the factory of the specified locale\n\n :param locale: locale string\n :param seed: seed value\n \"\"\"\n self._factory_map[locale.replace(\"-\", \"_\")].seed_instance(seed)\n\n @property\n def random(self) -> Random:\n \"\"\"\n Proxies `random` getter calls\n\n In single locale mode, this will be proxied to the `random` getter\n of the only internal `Generator` object. Subclasses will have to\n implement desired behavior in multiple locale mode.\n \"\"\"\n\n if len(self._factories) == 1:\n return self._factories[0].random\n else:\n msg = \"Proxying `random` getter calls is not implemented in multiple locale mode.\"\n raise NotImplementedError(msg)\n\n @random.setter\n def random(self, value: Random) -> None:\n \"\"\"\n Proxies `random` setter calls\n\n In single locale mode, this will be proxied to the `random` setter\n of the only internal `Generator` object. Subclasses will have to\n implement desired behavior in multiple locale mode.\n \"\"\"\n\n if len(self._factories) == 1:\n self._factories[0].random = value\n else:\n msg = \"Proxying `random` setter calls is not implemented in multiple locale mode.\"\n raise NotImplementedError(msg)\n\n @property\n def locales(self) -> List[str]:\n return list(self._locales)\n\n @property\n def weights(self) -> Optional[List[Union[int, float]]]:\n return self._weights\n\n @property\n def factories(self) -> List[Generator]:\n return self._factories\n\n def items(self) -> List[Tuple[str, Generator]]:\n return list(self._factory_map.items())\n\n\nclass UniqueProxy:\n def __init__(self, proxy: Faker):\n self._proxy = proxy\n self._seen: Dict = {}\n self._sentinel = object()\n\n def clear(self) -> None:\n self._seen = {}\n\n def __getattr__(self, name: str) -> Any:\n obj = getattr(self._proxy, name)\n if callable(obj):\n return self._wrap(name, obj)\n else:\n raise TypeError(\"Accessing non-functions through .unique is not supported.\")\n\n def __getstate__(self):\n # Copy the object's state from self.__dict__ which contains\n # all our instance attributes. Always use the dict.copy()\n # method to avoid modifying the original state.\n state = self.__dict__.copy()\n return state\n\n def __setstate__(self, state):\n self.__dict__.update(state)\n\n def _wrap(self, name: str, function: Callable) -> Callable:\n @functools.wraps(function)\n def wrapper(*args, **kwargs):\n key = (name, args, tuple(sorted(kwargs.items())))\n\n generated = self._seen.setdefault(key, {self._sentinel})\n\n # With use of a sentinel value rather than None, we leave\n # None open as a valid return value.\n retval = self._sentinel\n\n for i in range(_UNIQUE_ATTEMPTS):\n if retval not in generated:\n break\n retval = function(*args, **kwargs)\n else:\n raise UniquenessException(f\"Got duplicated values after {_UNIQUE_ATTEMPTS:,} iterations.\")\n\n generated.add(retval)\n\n return retval\n\n return wrapper\n", "path": "faker/proxy.py"}], "after_files": [{"content": "import copy\nimport functools\nimport re\n\nfrom collections import OrderedDict\nfrom random import Random\nfrom typing import Any, Callable, Dict, List, Optional, Pattern, Sequence, Tuple, Union\n\nfrom .config import DEFAULT_LOCALE\nfrom .exceptions import UniquenessException\nfrom .factory import Factory\nfrom .generator import Generator, random\nfrom .typing import SeedType\nfrom .utils.distribution import choices_distribution\n\n_UNIQUE_ATTEMPTS = 1000\n\n\nclass Faker:\n \"\"\"Proxy class capable of supporting multiple locales\"\"\"\n\n cache_pattern: Pattern = re.compile(r\"^_cached_\\w*_mapping$\")\n generator_attrs = [\n attr for attr in dir(Generator) if not attr.startswith(\"__\") and attr not in [\"seed\", \"seed_instance\", \"random\"]\n ]\n\n def __init__(\n self,\n locale: Optional[Union[str, Sequence[str], Dict[str, Union[int, float]]]] = None,\n providers: Optional[List[str]] = None,\n generator: Optional[Generator] = None,\n includes: Optional[List[str]] = None,\n use_weighting: bool = True,\n **config: Any,\n ) -> None:\n self._factory_map = OrderedDict()\n self._weights = None\n self._unique_proxy = UniqueProxy(self)\n\n if isinstance(locale, str):\n locales = [locale.replace(\"-\", \"_\")]\n\n # This guarantees a FIFO ordering of elements in `locales` based on the final\n # locale string while discarding duplicates after processing\n elif isinstance(locale, (list, tuple, set)):\n locales = []\n for code in locale:\n if not isinstance(code, str):\n raise TypeError('The locale \"%s\" must be a string.' % str(code))\n final_locale = code.replace(\"-\", \"_\")\n if final_locale not in locales:\n locales.append(final_locale)\n\n elif isinstance(locale, OrderedDict):\n assert all(isinstance(v, (int, float)) for v in locale.values())\n odict = OrderedDict()\n for k, v in locale.items():\n key = k.replace(\"-\", \"_\")\n odict[key] = v\n locales = list(odict.keys())\n self._weights = list(odict.values())\n\n else:\n locales = [DEFAULT_LOCALE]\n\n for locale in locales:\n self._factory_map[locale] = Factory.create(\n locale,\n providers,\n generator,\n includes,\n use_weighting=use_weighting,\n **config,\n )\n\n self._locales = locales\n self._factories = list(self._factory_map.values())\n\n def __dir__(self):\n attributes = set(super(Faker, self).__dir__())\n for factory in self.factories:\n attributes |= {attr for attr in dir(factory) if not attr.startswith(\"_\")}\n return sorted(attributes)\n\n def __getitem__(self, locale: str) -> Generator:\n return self._factory_map[locale.replace(\"-\", \"_\")]\n\n def __getattribute__(self, attr: str) -> Any:\n \"\"\"\n Handles the \"attribute resolution\" behavior for declared members of this proxy class\n\n The class method `seed` cannot be called from an instance.\n\n :param attr: attribute name\n :return: the appropriate attribute\n \"\"\"\n if attr == \"seed\":\n msg = \"Calling `.seed()` on instances is deprecated. \" \"Use the class method `Faker.seed()` instead.\"\n raise TypeError(msg)\n else:\n return super().__getattribute__(attr)\n\n def __getattr__(self, attr: str) -> Any:\n \"\"\"\n Handles cache access and proxying behavior\n\n :param attr: attribute name\n :return: the appropriate attribute\n \"\"\"\n if len(self._factories) == 1:\n return getattr(self._factories[0], attr)\n elif attr in self.generator_attrs:\n msg = \"Proxying calls to `%s` is not implemented in multiple locale mode.\" % attr\n raise NotImplementedError(msg)\n elif self.cache_pattern.match(attr):\n msg = \"Cached attribute `%s` does not exist\" % attr\n raise AttributeError(msg)\n else:\n factory = self._select_factory(attr)\n return getattr(factory, attr)\n\n def __deepcopy__(self, memodict: Dict = {}) -> \"Faker\":\n cls = self.__class__\n result = cls.__new__(cls)\n result._locales = copy.deepcopy(self._locales)\n result._factories = copy.deepcopy(self._factories)\n result._factory_map = copy.deepcopy(self._factory_map)\n result._weights = copy.deepcopy(self._weights)\n result._unique_proxy = UniqueProxy(self)\n result._unique_proxy._seen = {k: {result._unique_proxy._sentinel} for k in self._unique_proxy._seen.keys()}\n return result\n\n def __setstate__(self, state: Any) -> None:\n self.__dict__.update(state)\n\n @property\n def unique(self) -> \"UniqueProxy\":\n return self._unique_proxy\n\n def _select_factory(self, method_name: str) -> Factory:\n \"\"\"\n Returns a random factory that supports the provider method\n\n :param method_name: Name of provider method\n :return: A factory that supports the provider method\n \"\"\"\n\n factories, weights = self._map_provider_method(method_name)\n\n if len(factories) == 0:\n msg = f\"No generator object has attribute {method_name!r}\"\n raise AttributeError(msg)\n elif len(factories) == 1:\n return factories[0]\n\n if weights:\n factory = self._select_factory_distribution(factories, weights)\n else:\n factory = self._select_factory_choice(factories)\n return factory\n\n def _select_factory_distribution(self, factories, weights):\n return choices_distribution(factories, weights, random, length=1)[0]\n\n def _select_factory_choice(self, factories):\n return random.choice(factories)\n\n def _map_provider_method(self, method_name: str) -> Tuple[List[Factory], Optional[List[float]]]:\n \"\"\"\n Creates a 2-tuple of factories and weights for the given provider method name\n\n The first element of the tuple contains a list of compatible factories.\n The second element of the tuple contains a list of distribution weights.\n\n :param method_name: Name of provider method\n :return: 2-tuple (factories, weights)\n \"\"\"\n\n # Return cached mapping if it exists for given method\n attr = f\"_cached_{method_name}_mapping\"\n if hasattr(self, attr):\n return getattr(self, attr)\n\n # Create mapping if it does not exist\n if self._weights:\n value = [\n (factory, weight)\n for factory, weight in zip(self.factories, self._weights)\n if hasattr(factory, method_name)\n ]\n factories, weights = zip(*value)\n mapping = list(factories), list(weights)\n else:\n value = [factory for factory in self.factories if hasattr(factory, method_name)] # type: ignore\n mapping = value, None # type: ignore\n\n # Then cache and return results\n setattr(self, attr, mapping)\n return mapping\n\n @classmethod\n def seed(cls, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Hashables the shared `random.Random` object across all factories\n\n :param seed: seed value\n \"\"\"\n Generator.seed(seed)\n\n def seed_instance(self, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Creates and seeds a new `random.Random` object for each factory\n\n :param seed: seed value\n \"\"\"\n for factory in self._factories:\n factory.seed_instance(seed)\n\n def seed_locale(self, locale: str, seed: Optional[SeedType] = None) -> None:\n \"\"\"\n Creates and seeds a new `random.Random` object for the factory of the specified locale\n\n :param locale: locale string\n :param seed: seed value\n \"\"\"\n self._factory_map[locale.replace(\"-\", \"_\")].seed_instance(seed)\n\n @property\n def random(self) -> Random:\n \"\"\"\n Proxies `random` getter calls\n\n In single locale mode, this will be proxied to the `random` getter\n of the only internal `Generator` object. Subclasses will have to\n implement desired behavior in multiple locale mode.\n \"\"\"\n\n if len(self._factories) == 1:\n return self._factories[0].random\n else:\n msg = \"Proxying `random` getter calls is not implemented in multiple locale mode.\"\n raise NotImplementedError(msg)\n\n @random.setter\n def random(self, value: Random) -> None:\n \"\"\"\n Proxies `random` setter calls\n\n In single locale mode, this will be proxied to the `random` setter\n of the only internal `Generator` object. Subclasses will have to\n implement desired behavior in multiple locale mode.\n \"\"\"\n\n if len(self._factories) == 1:\n self._factories[0].random = value\n else:\n msg = \"Proxying `random` setter calls is not implemented in multiple locale mode.\"\n raise NotImplementedError(msg)\n\n @property\n def locales(self) -> List[str]:\n return list(self._locales)\n\n @property\n def weights(self) -> Optional[List[Union[int, float]]]:\n return self._weights\n\n @property\n def factories(self) -> List[Generator]:\n return self._factories\n\n def items(self) -> List[Tuple[str, Generator]]:\n return list(self._factory_map.items())\n\n\nclass UniqueProxy:\n def __init__(self, proxy: Faker):\n self._proxy = proxy\n self._seen: Dict = {}\n self._sentinel = object()\n\n def clear(self) -> None:\n self._seen = {}\n\n def __getattr__(self, name: str) -> Any:\n obj = getattr(self._proxy, name)\n if callable(obj):\n return self._wrap(name, obj)\n else:\n raise TypeError(\"Accessing non-functions through .unique is not supported.\")\n\n def __getstate__(self):\n # Copy the object's state from self.__dict__ which contains\n # all our instance attributes. Always use the dict.copy()\n # method to avoid modifying the original state.\n state = self.__dict__.copy()\n return state\n\n def __setstate__(self, state):\n self.__dict__.update(state)\n\n def _wrap(self, name: str, function: Callable) -> Callable:\n @functools.wraps(function)\n def wrapper(*args, **kwargs):\n key = (name, args, tuple(sorted(kwargs.items())))\n\n generated = self._seen.setdefault(key, {self._sentinel})\n\n # With use of a sentinel value rather than None, we leave\n # None open as a valid return value.\n retval = self._sentinel\n\n for i in range(_UNIQUE_ATTEMPTS):\n if retval not in generated:\n break\n retval = function(*args, **kwargs)\n else:\n raise UniquenessException(f\"Got duplicated values after {_UNIQUE_ATTEMPTS:,} iterations.\")\n\n generated.add(retval)\n\n return retval\n\n return wrapper\n", "path": "faker/proxy.py"}]}
| 3,947 | 178 |
gh_patches_debug_29378
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5018
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CKV_AWS_338 does not account for 0 (keep forever) & has insufficient error message
**Describe the issue**
CKV_AWS_338 is a check for the number of retention days for a Cloudwatch log group. However, the actual check source code requires not just being specified, but also to be at least 1 year.
1 - The message "Ensure that CloudWatch Log Group specifies retention days" does not reflect the need to not only be specified, but also be of sufficient length (or provide ref to web page providing more detail on the check)
2 - 0 is a valid value and means that logs are always retained and never expire, which should result in passing the "must retain for at least 1 year" rule.
**Examples**
Please share an example code sample (in the IaC of your choice) + the expected outcomes.
**Version (please complete the following information):**
2.3.212
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import Any
4
5 from checkov.common.models.enums import CheckCategories, CheckResult
6 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
7
8
9 class CloudWatchLogGroupRetentionYear(BaseResourceCheck):
10 def __init__(self) -> None:
11 """
12 NIST.800-53.r5 AU-10, NIST.800-53.r5 AU-11, NIST.800-53.r5 AU-6(3), NIST.800-53.r5 AU-6(4),
13 NIST.800-53.r5 CA-7, NIST.800-53.r5 SI-12
14 CloudWatch log groups should be retained for at least 1 year
15 """
16 name = "Ensure that CloudWatch Log Group specifies retention days"
17 id = "CKV_AWS_338"
18 supported_resource = ("aws_cloudwatch_log_group",)
19 categories = (CheckCategories.LOGGING,)
20 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resource)
21
22 def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:
23 retention = conf.get("retention_in_days")
24 if retention and isinstance(retention, list):
25 retention = retention[0]
26 if not isinstance(retention, int):
27 # probably a dependent variable
28 return CheckResult.UNKNOWN
29
30 if retention >= 365:
31 return CheckResult.PASSED
32
33 return CheckResult.FAILED
34
35
36 check = CloudWatchLogGroupRetentionYear()
37
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py b/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py
--- a/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py
+++ b/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py
@@ -3,7 +3,8 @@
from typing import Any
from checkov.common.models.enums import CheckCategories, CheckResult
-from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
+from checkov.terraform.checks.resource.base_resource_check import \
+ BaseResourceCheck
class CloudWatchLogGroupRetentionYear(BaseResourceCheck):
@@ -13,7 +14,7 @@
NIST.800-53.r5 CA-7, NIST.800-53.r5 SI-12
CloudWatch log groups should be retained for at least 1 year
"""
- name = "Ensure that CloudWatch Log Group specifies retention days"
+ name = "Ensure CloudWatch log groups retains logs for at least 1 year"
id = "CKV_AWS_338"
supported_resource = ("aws_cloudwatch_log_group",)
categories = (CheckCategories.LOGGING,)
@@ -26,8 +27,8 @@
if not isinstance(retention, int):
# probably a dependent variable
return CheckResult.UNKNOWN
-
- if retention >= 365:
+ # If you select 0, the events in the log group are always retained and never expire.
+ if retention == 0 or retention >= 365:
return CheckResult.PASSED
return CheckResult.FAILED
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py b/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py\n--- a/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py\n+++ b/checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py\n@@ -3,7 +3,8 @@\n from typing import Any\n \n from checkov.common.models.enums import CheckCategories, CheckResult\n-from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n+from checkov.terraform.checks.resource.base_resource_check import \\\n+ BaseResourceCheck\n \n \n class CloudWatchLogGroupRetentionYear(BaseResourceCheck):\n@@ -13,7 +14,7 @@\n NIST.800-53.r5 CA-7, NIST.800-53.r5 SI-12\n CloudWatch log groups should be retained for at least 1 year\n \"\"\"\n- name = \"Ensure that CloudWatch Log Group specifies retention days\"\n+ name = \"Ensure CloudWatch log groups retains logs for at least 1 year\"\n id = \"CKV_AWS_338\"\n supported_resource = (\"aws_cloudwatch_log_group\",)\n categories = (CheckCategories.LOGGING,)\n@@ -26,8 +27,8 @@\n if not isinstance(retention, int):\n # probably a dependent variable\n return CheckResult.UNKNOWN\n-\n- if retention >= 365:\n+ # If you select 0, the events in the log group are always retained and never expire.\n+ if retention == 0 or retention >= 365:\n return CheckResult.PASSED\n \n return CheckResult.FAILED\n", "issue": "CKV_AWS_338 does not account for 0 (keep forever) & has insufficient error message\n**Describe the issue**\r\nCKV_AWS_338 is a check for the number of retention days for a Cloudwatch log group. However, the actual check source code requires not just being specified, but also to be at least 1 year.\r\n\r\n1 - The message \"Ensure that CloudWatch Log Group specifies retention days\" does not reflect the need to not only be specified, but also be of sufficient length (or provide ref to web page providing more detail on the check)\r\n\r\n2 - 0 is a valid value and means that logs are always retained and never expire, which should result in passing the \"must retain for at least 1 year\" rule.\r\n\r\n**Examples**\r\nPlease share an example code sample (in the IaC of your choice) + the expected outcomes.\r\n\r\n**Version (please complete the following information):**\r\n2.3.212\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass CloudWatchLogGroupRetentionYear(BaseResourceCheck):\n def __init__(self) -> None:\n \"\"\"\n NIST.800-53.r5 AU-10, NIST.800-53.r5 AU-11, NIST.800-53.r5 AU-6(3), NIST.800-53.r5 AU-6(4),\n NIST.800-53.r5 CA-7, NIST.800-53.r5 SI-12\n CloudWatch log groups should be retained for at least 1 year\n \"\"\"\n name = \"Ensure that CloudWatch Log Group specifies retention days\"\n id = \"CKV_AWS_338\"\n supported_resource = (\"aws_cloudwatch_log_group\",)\n categories = (CheckCategories.LOGGING,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resource)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n retention = conf.get(\"retention_in_days\")\n if retention and isinstance(retention, list):\n retention = retention[0]\n if not isinstance(retention, int):\n # probably a dependent variable\n return CheckResult.UNKNOWN\n\n if retention >= 365:\n return CheckResult.PASSED\n\n return CheckResult.FAILED\n\n\ncheck = CloudWatchLogGroupRetentionYear()\n", "path": "checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import \\\n BaseResourceCheck\n\n\nclass CloudWatchLogGroupRetentionYear(BaseResourceCheck):\n def __init__(self) -> None:\n \"\"\"\n NIST.800-53.r5 AU-10, NIST.800-53.r5 AU-11, NIST.800-53.r5 AU-6(3), NIST.800-53.r5 AU-6(4),\n NIST.800-53.r5 CA-7, NIST.800-53.r5 SI-12\n CloudWatch log groups should be retained for at least 1 year\n \"\"\"\n name = \"Ensure CloudWatch log groups retains logs for at least 1 year\"\n id = \"CKV_AWS_338\"\n supported_resource = (\"aws_cloudwatch_log_group\",)\n categories = (CheckCategories.LOGGING,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resource)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n retention = conf.get(\"retention_in_days\")\n if retention and isinstance(retention, list):\n retention = retention[0]\n if not isinstance(retention, int):\n # probably a dependent variable\n return CheckResult.UNKNOWN\n # If you select 0, the events in the log group are always retained and never expire.\n if retention == 0 or retention >= 365:\n return CheckResult.PASSED\n\n return CheckResult.FAILED\n\n\ncheck = CloudWatchLogGroupRetentionYear()\n", "path": "checkov/terraform/checks/resource/aws/CloudWatchLogGroupRetentionYear.py"}]}
| 897 | 379 |
gh_patches_debug_35330
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-1531
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
daemon: address dvc directly
Our daemon is using `sys.executable -m dvc` to launch a new dvc process, but a more proper way would be to address dvc directly, by dynamically computing its location ourselves from `__file__`. See discussion https://github.com/iterative/dvc/issues/1509#issuecomment-457415307 .
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/daemon.py`
Content:
```
1 """Launch `dvc daemon` command in a separate detached process."""
2
3 import os
4 import sys
5 from subprocess import Popen
6
7 import dvc.logger as logger
8 from dvc.utils import is_binary, fix_env
9
10
11 CREATE_NEW_PROCESS_GROUP = 0x00000200
12 DETACHED_PROCESS = 0x00000008
13
14
15 def _spawn_windows(cmd):
16 from subprocess import STARTUPINFO, STARTF_USESHOWWINDOW
17
18 creationflags = CREATE_NEW_PROCESS_GROUP | DETACHED_PROCESS
19
20 startupinfo = STARTUPINFO()
21 startupinfo.dwFlags |= STARTF_USESHOWWINDOW
22
23 Popen(cmd,
24 env=fix_env(),
25 close_fds=True,
26 shell=False,
27 creationflags=creationflags,
28 startupinfo=startupinfo).communicate()
29
30
31 def _spawn_posix(cmd):
32 # NOTE: using os._exit instead of sys.exit, because dvc built
33 # with PyInstaller has trouble with SystemExit exeption and throws
34 # errors such as "[26338] Failed to execute script __main__"
35 try:
36 pid = os.fork()
37 if pid > 0:
38 return
39 except OSError:
40 logger.error("failed at first fork")
41 os._exit(1) # pylint: disable=protected-access
42
43 os.setsid()
44 os.umask(0)
45
46 try:
47 pid = os.fork()
48 if pid > 0:
49 os._exit(0) # pylint: disable=protected-access
50 except OSError:
51 logger.error("failed at second fork")
52 os._exit(1) # pylint: disable=protected-access
53
54 sys.stdin.close()
55 sys.stdout.close()
56 sys.stderr.close()
57
58 Popen(cmd, env=fix_env(), close_fds=True, shell=False).communicate()
59
60 os._exit(0) # pylint: disable=protected-access
61
62
63 def daemon(args):
64 """Launch a `dvc daemon` command in a detached process.
65
66 Args:
67 args (list): list of arguments to append to `dvc daemon` command.
68 """
69 cmd = [sys.executable]
70 if not is_binary():
71 cmd += ['-m', 'dvc']
72 cmd += ['daemon', '-q'] + args
73
74 logger.debug("Trying to spawn '{}'".format(cmd))
75
76 if os.name == 'nt':
77 _spawn_windows(cmd)
78 elif os.name == 'posix':
79 _spawn_posix(cmd)
80 else:
81 raise NotImplementedError
82
83 logger.debug("Spawned '{}'".format(cmd))
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/daemon.py b/dvc/daemon.py
--- a/dvc/daemon.py
+++ b/dvc/daemon.py
@@ -2,6 +2,7 @@
import os
import sys
+import inspect
from subprocess import Popen
import dvc.logger as logger
@@ -12,7 +13,7 @@
DETACHED_PROCESS = 0x00000008
-def _spawn_windows(cmd):
+def _spawn_windows(cmd, env):
from subprocess import STARTUPINFO, STARTF_USESHOWWINDOW
creationflags = CREATE_NEW_PROCESS_GROUP | DETACHED_PROCESS
@@ -21,14 +22,14 @@
startupinfo.dwFlags |= STARTF_USESHOWWINDOW
Popen(cmd,
- env=fix_env(),
+ env=env,
close_fds=True,
shell=False,
creationflags=creationflags,
startupinfo=startupinfo).communicate()
-def _spawn_posix(cmd):
+def _spawn_posix(cmd, env):
# NOTE: using os._exit instead of sys.exit, because dvc built
# with PyInstaller has trouble with SystemExit exeption and throws
# errors such as "[26338] Failed to execute script __main__"
@@ -55,7 +56,7 @@
sys.stdout.close()
sys.stderr.close()
- Popen(cmd, env=fix_env(), close_fds=True, shell=False).communicate()
+ Popen(cmd, env=env, close_fds=True, shell=False).communicate()
os._exit(0) # pylint: disable=protected-access
@@ -71,12 +72,16 @@
cmd += ['-m', 'dvc']
cmd += ['daemon', '-q'] + args
- logger.debug("Trying to spawn '{}'".format(cmd))
+ env = fix_env()
+ file_path = os.path.abspath(inspect.stack()[0][1])
+ env['PYTHONPATH'] = os.path.dirname(os.path.dirname(file_path))
+
+ logger.debug("Trying to spawn '{}' with env '{}'".format(cmd, env))
if os.name == 'nt':
- _spawn_windows(cmd)
+ _spawn_windows(cmd, env)
elif os.name == 'posix':
- _spawn_posix(cmd)
+ _spawn_posix(cmd, env)
else:
raise NotImplementedError
|
{"golden_diff": "diff --git a/dvc/daemon.py b/dvc/daemon.py\n--- a/dvc/daemon.py\n+++ b/dvc/daemon.py\n@@ -2,6 +2,7 @@\n \n import os\n import sys\n+import inspect\n from subprocess import Popen\n \n import dvc.logger as logger\n@@ -12,7 +13,7 @@\n DETACHED_PROCESS = 0x00000008\n \n \n-def _spawn_windows(cmd):\n+def _spawn_windows(cmd, env):\n from subprocess import STARTUPINFO, STARTF_USESHOWWINDOW\n \n creationflags = CREATE_NEW_PROCESS_GROUP | DETACHED_PROCESS\n@@ -21,14 +22,14 @@\n startupinfo.dwFlags |= STARTF_USESHOWWINDOW\n \n Popen(cmd,\n- env=fix_env(),\n+ env=env,\n close_fds=True,\n shell=False,\n creationflags=creationflags,\n startupinfo=startupinfo).communicate()\n \n \n-def _spawn_posix(cmd):\n+def _spawn_posix(cmd, env):\n # NOTE: using os._exit instead of sys.exit, because dvc built\n # with PyInstaller has trouble with SystemExit exeption and throws\n # errors such as \"[26338] Failed to execute script __main__\"\n@@ -55,7 +56,7 @@\n sys.stdout.close()\n sys.stderr.close()\n \n- Popen(cmd, env=fix_env(), close_fds=True, shell=False).communicate()\n+ Popen(cmd, env=env, close_fds=True, shell=False).communicate()\n \n os._exit(0) # pylint: disable=protected-access\n \n@@ -71,12 +72,16 @@\n cmd += ['-m', 'dvc']\n cmd += ['daemon', '-q'] + args\n \n- logger.debug(\"Trying to spawn '{}'\".format(cmd))\n+ env = fix_env()\n+ file_path = os.path.abspath(inspect.stack()[0][1])\n+ env['PYTHONPATH'] = os.path.dirname(os.path.dirname(file_path))\n+\n+ logger.debug(\"Trying to spawn '{}' with env '{}'\".format(cmd, env))\n \n if os.name == 'nt':\n- _spawn_windows(cmd)\n+ _spawn_windows(cmd, env)\n elif os.name == 'posix':\n- _spawn_posix(cmd)\n+ _spawn_posix(cmd, env)\n else:\n raise NotImplementedError\n", "issue": "daemon: address dvc directly\nOur daemon is using `sys.executable -m dvc` to launch a new dvc process, but a more proper way would be to address dvc directly, by dynamically computing its location ourselves from `__file__`. See discussion https://github.com/iterative/dvc/issues/1509#issuecomment-457415307 .\n", "before_files": [{"content": "\"\"\"Launch `dvc daemon` command in a separate detached process.\"\"\"\n\nimport os\nimport sys\nfrom subprocess import Popen\n\nimport dvc.logger as logger\nfrom dvc.utils import is_binary, fix_env\n\n\nCREATE_NEW_PROCESS_GROUP = 0x00000200\nDETACHED_PROCESS = 0x00000008\n\n\ndef _spawn_windows(cmd):\n from subprocess import STARTUPINFO, STARTF_USESHOWWINDOW\n\n creationflags = CREATE_NEW_PROCESS_GROUP | DETACHED_PROCESS\n\n startupinfo = STARTUPINFO()\n startupinfo.dwFlags |= STARTF_USESHOWWINDOW\n\n Popen(cmd,\n env=fix_env(),\n close_fds=True,\n shell=False,\n creationflags=creationflags,\n startupinfo=startupinfo).communicate()\n\n\ndef _spawn_posix(cmd):\n # NOTE: using os._exit instead of sys.exit, because dvc built\n # with PyInstaller has trouble with SystemExit exeption and throws\n # errors such as \"[26338] Failed to execute script __main__\"\n try:\n pid = os.fork()\n if pid > 0:\n return\n except OSError:\n logger.error(\"failed at first fork\")\n os._exit(1) # pylint: disable=protected-access\n\n os.setsid()\n os.umask(0)\n\n try:\n pid = os.fork()\n if pid > 0:\n os._exit(0) # pylint: disable=protected-access\n except OSError:\n logger.error(\"failed at second fork\")\n os._exit(1) # pylint: disable=protected-access\n\n sys.stdin.close()\n sys.stdout.close()\n sys.stderr.close()\n\n Popen(cmd, env=fix_env(), close_fds=True, shell=False).communicate()\n\n os._exit(0) # pylint: disable=protected-access\n\n\ndef daemon(args):\n \"\"\"Launch a `dvc daemon` command in a detached process.\n\n Args:\n args (list): list of arguments to append to `dvc daemon` command.\n \"\"\"\n cmd = [sys.executable]\n if not is_binary():\n cmd += ['-m', 'dvc']\n cmd += ['daemon', '-q'] + args\n\n logger.debug(\"Trying to spawn '{}'\".format(cmd))\n\n if os.name == 'nt':\n _spawn_windows(cmd)\n elif os.name == 'posix':\n _spawn_posix(cmd)\n else:\n raise NotImplementedError\n\n logger.debug(\"Spawned '{}'\".format(cmd))\n", "path": "dvc/daemon.py"}], "after_files": [{"content": "\"\"\"Launch `dvc daemon` command in a separate detached process.\"\"\"\n\nimport os\nimport sys\nimport inspect\nfrom subprocess import Popen\n\nimport dvc.logger as logger\nfrom dvc.utils import is_binary, fix_env\n\n\nCREATE_NEW_PROCESS_GROUP = 0x00000200\nDETACHED_PROCESS = 0x00000008\n\n\ndef _spawn_windows(cmd, env):\n from subprocess import STARTUPINFO, STARTF_USESHOWWINDOW\n\n creationflags = CREATE_NEW_PROCESS_GROUP | DETACHED_PROCESS\n\n startupinfo = STARTUPINFO()\n startupinfo.dwFlags |= STARTF_USESHOWWINDOW\n\n Popen(cmd,\n env=env,\n close_fds=True,\n shell=False,\n creationflags=creationflags,\n startupinfo=startupinfo).communicate()\n\n\ndef _spawn_posix(cmd, env):\n # NOTE: using os._exit instead of sys.exit, because dvc built\n # with PyInstaller has trouble with SystemExit exeption and throws\n # errors such as \"[26338] Failed to execute script __main__\"\n try:\n pid = os.fork()\n if pid > 0:\n return\n except OSError:\n logger.error(\"failed at first fork\")\n os._exit(1) # pylint: disable=protected-access\n\n os.setsid()\n os.umask(0)\n\n try:\n pid = os.fork()\n if pid > 0:\n os._exit(0) # pylint: disable=protected-access\n except OSError:\n logger.error(\"failed at second fork\")\n os._exit(1) # pylint: disable=protected-access\n\n sys.stdin.close()\n sys.stdout.close()\n sys.stderr.close()\n\n Popen(cmd, env=env, close_fds=True, shell=False).communicate()\n\n os._exit(0) # pylint: disable=protected-access\n\n\ndef daemon(args):\n \"\"\"Launch a `dvc daemon` command in a detached process.\n\n Args:\n args (list): list of arguments to append to `dvc daemon` command.\n \"\"\"\n cmd = [sys.executable]\n if not is_binary():\n cmd += ['-m', 'dvc']\n cmd += ['daemon', '-q'] + args\n\n env = fix_env()\n file_path = os.path.abspath(inspect.stack()[0][1])\n env['PYTHONPATH'] = os.path.dirname(os.path.dirname(file_path))\n\n logger.debug(\"Trying to spawn '{}' with env '{}'\".format(cmd, env))\n\n if os.name == 'nt':\n _spawn_windows(cmd, env)\n elif os.name == 'posix':\n _spawn_posix(cmd, env)\n else:\n raise NotImplementedError\n\n logger.debug(\"Spawned '{}'\".format(cmd))\n", "path": "dvc/daemon.py"}]}
| 1,062 | 525 |
gh_patches_debug_4289
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1158
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
rabbitmq_parameter fails when passing dynamically generated json
##### Issue Type:
“Bug Report”
##### Ansible Version:
ansible 1.8.2
configured module search path = None
Tested also on ansible 1.9
ansible 1.9 (devel 8f06ba2bc1) last updated 2015/02/05 11:16:37 (GMT +200)
lib/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:16:50 (GMT +200)
lib/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:01 (GMT +200)
v2/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:17:13 (GMT +200)
v2/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:36 (GMT +200)
configured module search path = None
##### Environment:
OS X 10.9.5 > Ubuntu 14.04
##### Summary:
Passing non-hardcoded json (through templating) to rabbitmq_parameter's "value" argument raises an exception. It works when hardcoding the json though.
##### Steps To Reproduce:
Here's an example playbook with one successful task (the first one), and two failing tasks (the next two) which both raise the same exception (see below). All of them are supposed to do the same thing.
```
- hosts: my-host
tasks:
- set_fact:
upstream_list:
- upstream: "test"
- upstream: "test2"
json_upstreams: '[{"upstream":"test1"},{"upstream":"test2"}]'
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '[{"upstream":"test1"},{"upstream":"test2"}]'
sudo: yes
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '{{ json_upstreams }}'
sudo: yes
- rabbitmq_parameter:
component: federation-upstream-set
name: test-upstream-set
value: '{{ upstream_list|to_json }}'
sudo: yes
```
##### Expected Results:
Set a federation-upstream-set parameter to the default vhost.
##### Actual Results:
The two failing tasks raise the same exception. The output from ansible with -vvvv is as follows:
```
<my-host> ESTABLISH CONNECTION FOR USER: xxxx
<my-host> REMOTE_MODULE rabbitmq_parameter name=test-upstream-set component=federation-upstream-set vhost=/
<my-host> EXEC ssh -C -vvv -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=30m -o ControlPath="xxxx/.ansible/cp/ansible-ssh-%h-%p-%r" -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-k
eyex,hostbased,publickey -o PasswordAuthentication=no -o User=xxxx -o ConnectTimeout=10 my- host /bin/sh -c 'sudo -k && sudo -H -S -p "[sudo via ansible, key=xxxxxx] password: " -u root /bin/sh -c '"'"'echo SUDO-SUCCESS-xxxxxx; LANG=en_US.UTF-8 LC_CTYPE=en_US.UTF-8 /usr/bin/python'"'"''
failed: [my-host] => {"failed": true, "parsed": false}
SUDO-SUCCESS-xxxxxx
OpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec 2011
debug1: Reading configuration data /xxxxx/.ssh/config
debug1: Reading configuration data /etc/ssh_config
debug1: /etc/ssh_config line 20: Applying options for *
debug1: /etc/ssh_config line 102: Applying options for *
debug1: auto-mux: Trying existing master
debug2: fd 3 setting O_NONBLOCK
debug2: mux_client_hello_exchange: master version 4
debug3: mux_client_forwards: request forwardings: 0 local, 0 remote
debug3: mux_client_request_session: entering
debug3: mux_client_request_alive: entering
debug3: mux_client_request_alive: done pid = 58450
debug3: mux_client_request_session: session request sent
debug1: mux_client_request_session: master session id: 2
[sudo via ansible, key=xxxxx] password: Traceback (most recent call last):
File "<stdin>", line 1717, in <module>
File "<stdin>", line 142, in main
File "<stdin>", line 104, in set
File "<stdin>", line 88, in _exec
File "<stdin>", line 1566, in run_command
File "/usr/lib/python2.7/posixpath.py", line 261, in expanduser
if not path.startswith('~'):
AttributeError: 'list' object has no attribute 'startswith'
debug3: mux_client_read_packet: read header failed: Broken pipe
debug2: Received exit status from master 1
```
##### Tentative solution:
From what I've seen while troubleshooting the issue, the problem comes from the rabbitmq_parameter module being passed a list to its "value" argument. It is then passed to AnsibleModule::run_command, which assumes it is a string and passes it through os.path.expanduser.
I've managed to correct this behavior by setting the value to `value if type(value) == str else json.dumps(value)`.
I can submit a more complete patch or pull request if this is indeed a bug and not an issue in my playbook.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `messaging/rabbitmq_parameter.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Chatham Financial <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 DOCUMENTATION = '''
22 ---
23 module: rabbitmq_parameter
24 short_description: Adds or removes parameters to RabbitMQ
25 description:
26 - Manage dynamic, cluster-wide parameters for RabbitMQ
27 version_added: "1.1"
28 author: Chris Hoffman
29 options:
30 component:
31 description:
32 - Name of the component of which the parameter is being set
33 required: true
34 default: null
35 name:
36 description:
37 - Name of the parameter being set
38 required: true
39 default: null
40 value:
41 description:
42 - Value of the parameter, as a JSON term
43 required: false
44 default: null
45 vhost:
46 description:
47 - vhost to apply access privileges.
48 required: false
49 default: /
50 node:
51 description:
52 - erlang node name of the rabbit we wish to configure
53 required: false
54 default: rabbit
55 version_added: "1.2"
56 state:
57 description:
58 - Specify if user is to be added or removed
59 required: false
60 default: present
61 choices: [ 'present', 'absent']
62 '''
63
64 EXAMPLES = """
65 # Set the federation parameter 'local_username' to a value of 'guest' (in quotes)
66 - rabbitmq_parameter: component=federation
67 name=local-username
68 value='"guest"'
69 state=present
70 """
71
72 class RabbitMqParameter(object):
73 def __init__(self, module, component, name, value, vhost, node):
74 self.module = module
75 self.component = component
76 self.name = name
77 self.value = value
78 self.vhost = vhost
79 self.node = node
80
81 self._value = None
82
83 self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)
84
85 def _exec(self, args, run_in_check_mode=False):
86 if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):
87 cmd = [self._rabbitmqctl, '-q', '-n', self.node]
88 rc, out, err = self.module.run_command(cmd + args, check_rc=True)
89 return out.splitlines()
90 return list()
91
92 def get(self):
93 parameters = self._exec(['list_parameters', '-p', self.vhost], True)
94
95 for param_item in parameters:
96 component, name, value = param_item.split('\t')
97
98 if component == self.component and name == self.name:
99 self._value = value
100 return True
101 return False
102
103 def set(self):
104 self._exec(['set_parameter', '-p', self.vhost, self.component, self.name, self.value])
105
106 def delete(self):
107 self._exec(['clear_parameter', '-p', self.vhost, self.component, self.name])
108
109 def has_modifications(self):
110 return self.value != self._value
111
112 def main():
113 arg_spec = dict(
114 component=dict(required=True),
115 name=dict(required=True),
116 value=dict(default=None),
117 vhost=dict(default='/'),
118 state=dict(default='present', choices=['present', 'absent']),
119 node=dict(default='rabbit')
120 )
121 module = AnsibleModule(
122 argument_spec=arg_spec,
123 supports_check_mode=True
124 )
125
126 component = module.params['component']
127 name = module.params['name']
128 value = module.params['value']
129 vhost = module.params['vhost']
130 state = module.params['state']
131 node = module.params['node']
132
133 rabbitmq_parameter = RabbitMqParameter(module, component, name, value, vhost, node)
134
135 changed = False
136 if rabbitmq_parameter.get():
137 if state == 'absent':
138 rabbitmq_parameter.delete()
139 changed = True
140 else:
141 if rabbitmq_parameter.has_modifications():
142 rabbitmq_parameter.set()
143 changed = True
144 elif state == 'present':
145 rabbitmq_parameter.set()
146 changed = True
147
148 module.exit_json(changed=changed, component=component, name=name, vhost=vhost, state=state)
149
150 # import module snippets
151 from ansible.module_utils.basic import *
152 main()
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/messaging/rabbitmq_parameter.py b/messaging/rabbitmq_parameter.py
--- a/messaging/rabbitmq_parameter.py
+++ b/messaging/rabbitmq_parameter.py
@@ -126,6 +126,8 @@
component = module.params['component']
name = module.params['name']
value = module.params['value']
+ if not isinstance(value, str):
+ value = json.dumps(value)
vhost = module.params['vhost']
state = module.params['state']
node = module.params['node']
|
{"golden_diff": "diff --git a/messaging/rabbitmq_parameter.py b/messaging/rabbitmq_parameter.py\n--- a/messaging/rabbitmq_parameter.py\n+++ b/messaging/rabbitmq_parameter.py\n@@ -126,6 +126,8 @@\n component = module.params['component']\n name = module.params['name']\n value = module.params['value']\n+ if not isinstance(value, str):\n+ value = json.dumps(value)\n vhost = module.params['vhost']\n state = module.params['state']\n node = module.params['node']\n", "issue": "rabbitmq_parameter fails when passing dynamically generated json\n##### Issue Type:\n\n\u201cBug Report\u201d\n##### Ansible Version:\n\nansible 1.8.2\n configured module search path = None\n\nTested also on ansible 1.9\nansible 1.9 (devel 8f06ba2bc1) last updated 2015/02/05 11:16:37 (GMT +200)\n lib/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:16:50 (GMT +200)\n lib/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:01 (GMT +200)\n v2/ansible/modules/core: (detached HEAD 600fc15b42) last updated 2015/02/05 11:17:13 (GMT +200)\n v2/ansible/modules/extras: (detached HEAD 77485f6c6a) last updated 2015/02/05 11:17:36 (GMT +200)\n configured module search path = None\n##### Environment:\n\nOS X 10.9.5 > Ubuntu 14.04\n##### Summary:\n\nPassing non-hardcoded json (through templating) to rabbitmq_parameter's \"value\" argument raises an exception. It works when hardcoding the json though.\n##### Steps To Reproduce:\n\nHere's an example playbook with one successful task (the first one), and two failing tasks (the next two) which both raise the same exception (see below). All of them are supposed to do the same thing.\n\n```\n- hosts: my-host\n tasks:\n - set_fact:\n upstream_list:\n - upstream: \"test\"\n - upstream: \"test2\"\n json_upstreams: '[{\"upstream\":\"test1\"},{\"upstream\":\"test2\"}]'\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '[{\"upstream\":\"test1\"},{\"upstream\":\"test2\"}]'\n sudo: yes\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '{{ json_upstreams }}'\n sudo: yes\n\n - rabbitmq_parameter:\n component: federation-upstream-set\n name: test-upstream-set\n value: '{{ upstream_list|to_json }}'\n sudo: yes\n```\n##### Expected Results:\n\nSet a federation-upstream-set parameter to the default vhost.\n##### Actual Results:\n\nThe two failing tasks raise the same exception. The output from ansible with -vvvv is as follows:\n\n```\n<my-host> ESTABLISH CONNECTION FOR USER: xxxx\n<my-host> REMOTE_MODULE rabbitmq_parameter name=test-upstream-set component=federation-upstream-set vhost=/\n<my-host> EXEC ssh -C -vvv -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=30m -o ControlPath=\"xxxx/.ansible/cp/ansible-ssh-%h-%p-%r\" -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-k\neyex,hostbased,publickey -o PasswordAuthentication=no -o User=xxxx -o ConnectTimeout=10 my- host /bin/sh -c 'sudo -k && sudo -H -S -p \"[sudo via ansible, key=xxxxxx] password: \" -u root /bin/sh -c '\"'\"'echo SUDO-SUCCESS-xxxxxx; LANG=en_US.UTF-8 LC_CTYPE=en_US.UTF-8 /usr/bin/python'\"'\"''\nfailed: [my-host] => {\"failed\": true, \"parsed\": false}\nSUDO-SUCCESS-xxxxxx\nOpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec 2011\ndebug1: Reading configuration data /xxxxx/.ssh/config\ndebug1: Reading configuration data /etc/ssh_config\ndebug1: /etc/ssh_config line 20: Applying options for *\ndebug1: /etc/ssh_config line 102: Applying options for *\ndebug1: auto-mux: Trying existing master\ndebug2: fd 3 setting O_NONBLOCK\ndebug2: mux_client_hello_exchange: master version 4\ndebug3: mux_client_forwards: request forwardings: 0 local, 0 remote\ndebug3: mux_client_request_session: entering\ndebug3: mux_client_request_alive: entering\ndebug3: mux_client_request_alive: done pid = 58450\ndebug3: mux_client_request_session: session request sent\ndebug1: mux_client_request_session: master session id: 2\n[sudo via ansible, key=xxxxx] password: Traceback (most recent call last):\n File \"<stdin>\", line 1717, in <module>\n File \"<stdin>\", line 142, in main\n File \"<stdin>\", line 104, in set\n File \"<stdin>\", line 88, in _exec\n File \"<stdin>\", line 1566, in run_command\n File \"/usr/lib/python2.7/posixpath.py\", line 261, in expanduser\n if not path.startswith('~'):\nAttributeError: 'list' object has no attribute 'startswith'\ndebug3: mux_client_read_packet: read header failed: Broken pipe\ndebug2: Received exit status from master 1\n```\n##### Tentative solution:\n\nFrom what I've seen while troubleshooting the issue, the problem comes from the rabbitmq_parameter module being passed a list to its \"value\" argument. It is then passed to AnsibleModule::run_command, which assumes it is a string and passes it through os.path.expanduser.\nI've managed to correct this behavior by setting the value to `value if type(value) == str else json.dumps(value)`.\nI can submit a more complete patch or pull request if this is indeed a bug and not an issue in my playbook.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_parameter\nshort_description: Adds or removes parameters to RabbitMQ\ndescription:\n - Manage dynamic, cluster-wide parameters for RabbitMQ\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n component:\n description:\n - Name of the component of which the parameter is being set\n required: true\n default: null\n name:\n description:\n - Name of the parameter being set\n required: true\n default: null\n value:\n description:\n - Value of the parameter, as a JSON term\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [ 'present', 'absent']\n'''\n\nEXAMPLES = \"\"\"\n# Set the federation parameter 'local_username' to a value of 'guest' (in quotes)\n- rabbitmq_parameter: component=federation\n name=local-username\n value='\"guest\"'\n state=present\n\"\"\"\n\nclass RabbitMqParameter(object):\n def __init__(self, module, component, name, value, vhost, node):\n self.module = module\n self.component = component\n self.name = name\n self.value = value\n self.vhost = vhost\n self.node = node\n\n self._value = None\n\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n parameters = self._exec(['list_parameters', '-p', self.vhost], True)\n\n for param_item in parameters:\n component, name, value = param_item.split('\\t')\n\n if component == self.component and name == self.name:\n self._value = value\n return True\n return False\n\n def set(self):\n self._exec(['set_parameter', '-p', self.vhost, self.component, self.name, self.value])\n\n def delete(self):\n self._exec(['clear_parameter', '-p', self.vhost, self.component, self.name])\n\n def has_modifications(self):\n return self.value != self._value\n\ndef main():\n arg_spec = dict(\n component=dict(required=True),\n name=dict(required=True),\n value=dict(default=None),\n vhost=dict(default='/'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n component = module.params['component']\n name = module.params['name']\n value = module.params['value']\n vhost = module.params['vhost']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_parameter = RabbitMqParameter(module, component, name, value, vhost, node)\n\n changed = False\n if rabbitmq_parameter.get():\n if state == 'absent':\n rabbitmq_parameter.delete()\n changed = True\n else:\n if rabbitmq_parameter.has_modifications():\n rabbitmq_parameter.set()\n changed = True\n elif state == 'present':\n rabbitmq_parameter.set()\n changed = True\n\n module.exit_json(changed=changed, component=component, name=name, vhost=vhost, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_parameter.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_parameter\nshort_description: Adds or removes parameters to RabbitMQ\ndescription:\n - Manage dynamic, cluster-wide parameters for RabbitMQ\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n component:\n description:\n - Name of the component of which the parameter is being set\n required: true\n default: null\n name:\n description:\n - Name of the parameter being set\n required: true\n default: null\n value:\n description:\n - Value of the parameter, as a JSON term\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [ 'present', 'absent']\n'''\n\nEXAMPLES = \"\"\"\n# Set the federation parameter 'local_username' to a value of 'guest' (in quotes)\n- rabbitmq_parameter: component=federation\n name=local-username\n value='\"guest\"'\n state=present\n\"\"\"\n\nclass RabbitMqParameter(object):\n def __init__(self, module, component, name, value, vhost, node):\n self.module = module\n self.component = component\n self.name = name\n self.value = value\n self.vhost = vhost\n self.node = node\n\n self._value = None\n\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n parameters = self._exec(['list_parameters', '-p', self.vhost], True)\n\n for param_item in parameters:\n component, name, value = param_item.split('\\t')\n\n if component == self.component and name == self.name:\n self._value = value\n return True\n return False\n\n def set(self):\n self._exec(['set_parameter', '-p', self.vhost, self.component, self.name, self.value])\n\n def delete(self):\n self._exec(['clear_parameter', '-p', self.vhost, self.component, self.name])\n\n def has_modifications(self):\n return self.value != self._value\n\ndef main():\n arg_spec = dict(\n component=dict(required=True),\n name=dict(required=True),\n value=dict(default=None),\n vhost=dict(default='/'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n component = module.params['component']\n name = module.params['name']\n value = module.params['value']\n if not isinstance(value, str):\n value = json.dumps(value)\n vhost = module.params['vhost']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_parameter = RabbitMqParameter(module, component, name, value, vhost, node)\n\n changed = False\n if rabbitmq_parameter.get():\n if state == 'absent':\n rabbitmq_parameter.delete()\n changed = True\n else:\n if rabbitmq_parameter.has_modifications():\n rabbitmq_parameter.set()\n changed = True\n elif state == 'present':\n rabbitmq_parameter.set()\n changed = True\n\n module.exit_json(changed=changed, component=component, name=name, vhost=vhost, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_parameter.py"}]}
| 3,058 | 121 |
gh_patches_debug_27533
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-5271
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feature Request: Document the task management
### What are you trying to do?
Understand how the task management functions
### Describe the solution you'd like
A technical documentation of how it works.
### Have you consider alternatives?
_No response_
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/management/commands/django_q_probettp.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3
4 # Akvo Reporting is covered by the GNU Affero General Public License.
5 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
6 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
7
8 """
9 Provides a localhost HTTP server to query the local status of the django-q cluster
10 """
11 import logging
12 import signal
13 import socket
14 from http.server import BaseHTTPRequestHandler, HTTPServer
15
16 from django.core.management.base import BaseCommand
17 from django_q.conf import Conf
18 from django_q.status import Stat
19
20 logger = logging.getLogger(__name__)
21
22
23 class Command(BaseCommand):
24 help = __doc__
25
26 def handle(self, *args, **options):
27 server = HTTPServer(("localhost", 8080), DjangoQRequestHandler)
28
29 def handle_end(*_):
30 logger.info("Stopping server")
31 server.shutdown()
32
33 signal.signal(signal.SIGINT, handle_end)
34 signal.signal(signal.SIGTERM, handle_end)
35
36 logger.info("Starting server...")
37 server.serve_forever()
38
39
40 class DjangoQRequestHandler(BaseHTTPRequestHandler):
41
42 def do_GET(self):
43 hostname = socket.gethostname()
44
45 # Find local cluster
46 local_stat = next(iter(stat for stat in Stat.get_all() if stat.host == hostname), None)
47 if local_stat:
48 message = local_stat.status
49 else:
50 message = Conf.STOPPED
51 logger.info(f"Probe response {message}")
52 self.send_response(200)
53 self.end_headers()
54 self.wfile.write(message.encode())
55
56 def log_message(self, format: str, *args) -> None:
57 logger.debug(format, *args)
58
```
Path: `akvo/cache/heartbeat.py`
Content:
```
1 import datetime
2 import logging
3 from threading import Event, Thread
4 from typing import Union
5
6 from django.core.cache import cache
7
8
9 class CacheHeartbeat(Thread):
10 """
11 Thread to update set a cache key with a max life and refresh it as long as the thread is alive
12
13 The thread can be ended by setting the `event_end` flag
14 """
15
16 def __init__(self, cache_key: str, key_timeout: float = 30.0, beat_interval: int = 3):
17 """
18 :param cache_key: The cache key to keep alive
19 :param key_timeout: How long the cache key should live without the heartbeat thread
20 :param beat_interval: How often per timeout the key should "beat"
21 """
22 super().__init__()
23 self.cache_key = cache_key
24 self.event_end = Event()
25 self.key_timeout = key_timeout
26 self.beat_interval = beat_interval
27
28 def run(self) -> None:
29 logger = logging.getLogger("akvo.rsr.CacheHeartBeat")
30 logger.info("Starting cache heartbeat for '%s' with timeout %s", self.cache_key, self.key_timeout)
31 self.event_end.clear()
32 while not self.event_end.is_set():
33 # Refresh the heartbeat
34 self.set_cache_value()
35 self.event_end.wait(self.key_timeout / self.beat_interval)
36
37 cache.delete(self.cache_key)
38 logger.info("Ended cache heartbeat for '%s'", self.cache_key)
39
40 def set_cache_value(self):
41 cache.set(self.cache_key, self.get_calc_value(), self.key_timeout)
42
43 def get_calc_value(self) -> Union[str, int, float]:
44 return datetime.datetime.utcnow().timestamp()
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/cache/heartbeat.py b/akvo/cache/heartbeat.py
--- a/akvo/cache/heartbeat.py
+++ b/akvo/cache/heartbeat.py
@@ -8,7 +8,7 @@
class CacheHeartbeat(Thread):
"""
- Thread to update set a cache key with a max life and refresh it as long as the thread is alive
+ Thread to set a cache key with a max life and refresh it as long as the thread is alive
The thread can be ended by setting the `event_end` flag
"""
@@ -38,7 +38,13 @@
logger.info("Ended cache heartbeat for '%s'", self.cache_key)
def set_cache_value(self):
- cache.set(self.cache_key, self.get_calc_value(), self.key_timeout)
+ """
+ Set the cache key and its value
+ """
+ cache.set(self.cache_key, self.calc_cache_value(), self.key_timeout)
- def get_calc_value(self) -> Union[str, int, float]:
+ def calc_cache_value(self) -> Union[str, int, float]:
+ """
+ Calculate a value to be used when setting the cache key
+ """
return datetime.datetime.utcnow().timestamp()
diff --git a/akvo/rsr/management/commands/django_q_probettp.py b/akvo/rsr/management/commands/django_q_probettp.py
--- a/akvo/rsr/management/commands/django_q_probettp.py
+++ b/akvo/rsr/management/commands/django_q_probettp.py
@@ -38,8 +38,14 @@
class DjangoQRequestHandler(BaseHTTPRequestHandler):
+ """
+ A handler to be used with HTTPServer to get the status of the local django-q cluster
+ """
def do_GET(self):
+ """
+ Handle GET requests to return a simple string indicating the status of the django-q cluster
+ """
hostname = socket.gethostname()
# Find local cluster
|
{"golden_diff": "diff --git a/akvo/cache/heartbeat.py b/akvo/cache/heartbeat.py\n--- a/akvo/cache/heartbeat.py\n+++ b/akvo/cache/heartbeat.py\n@@ -8,7 +8,7 @@\n \n class CacheHeartbeat(Thread):\n \"\"\"\n- Thread to update set a cache key with a max life and refresh it as long as the thread is alive\n+ Thread to set a cache key with a max life and refresh it as long as the thread is alive\n \n The thread can be ended by setting the `event_end` flag\n \"\"\"\n@@ -38,7 +38,13 @@\n logger.info(\"Ended cache heartbeat for '%s'\", self.cache_key)\n \n def set_cache_value(self):\n- cache.set(self.cache_key, self.get_calc_value(), self.key_timeout)\n+ \"\"\"\n+ Set the cache key and its value\n+ \"\"\"\n+ cache.set(self.cache_key, self.calc_cache_value(), self.key_timeout)\n \n- def get_calc_value(self) -> Union[str, int, float]:\n+ def calc_cache_value(self) -> Union[str, int, float]:\n+ \"\"\"\n+ Calculate a value to be used when setting the cache key\n+ \"\"\"\n return datetime.datetime.utcnow().timestamp()\ndiff --git a/akvo/rsr/management/commands/django_q_probettp.py b/akvo/rsr/management/commands/django_q_probettp.py\n--- a/akvo/rsr/management/commands/django_q_probettp.py\n+++ b/akvo/rsr/management/commands/django_q_probettp.py\n@@ -38,8 +38,14 @@\n \n \n class DjangoQRequestHandler(BaseHTTPRequestHandler):\n+ \"\"\"\n+ A handler to be used with HTTPServer to get the status of the local django-q cluster\n+ \"\"\"\n \n def do_GET(self):\n+ \"\"\"\n+ Handle GET requests to return a simple string indicating the status of the django-q cluster\n+ \"\"\"\n hostname = socket.gethostname()\n \n # Find local cluster\n", "issue": "Feature Request: Document the task management\n### What are you trying to do?\n\nUnderstand how the task management functions\n\n### Describe the solution you'd like\n\nA technical documentation of how it works.\n\n### Have you consider alternatives?\n\n_No response_\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\"\"\"\nProvides a localhost HTTP server to query the local status of the django-q cluster\n\"\"\"\nimport logging\nimport signal\nimport socket\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\n\nfrom django.core.management.base import BaseCommand\nfrom django_q.conf import Conf\nfrom django_q.status import Stat\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(BaseCommand):\n help = __doc__\n\n def handle(self, *args, **options):\n server = HTTPServer((\"localhost\", 8080), DjangoQRequestHandler)\n\n def handle_end(*_):\n logger.info(\"Stopping server\")\n server.shutdown()\n\n signal.signal(signal.SIGINT, handle_end)\n signal.signal(signal.SIGTERM, handle_end)\n\n logger.info(\"Starting server...\")\n server.serve_forever()\n\n\nclass DjangoQRequestHandler(BaseHTTPRequestHandler):\n\n def do_GET(self):\n hostname = socket.gethostname()\n\n # Find local cluster\n local_stat = next(iter(stat for stat in Stat.get_all() if stat.host == hostname), None)\n if local_stat:\n message = local_stat.status\n else:\n message = Conf.STOPPED\n logger.info(f\"Probe response {message}\")\n self.send_response(200)\n self.end_headers()\n self.wfile.write(message.encode())\n\n def log_message(self, format: str, *args) -> None:\n logger.debug(format, *args)\n", "path": "akvo/rsr/management/commands/django_q_probettp.py"}, {"content": "import datetime\nimport logging\nfrom threading import Event, Thread\nfrom typing import Union\n\nfrom django.core.cache import cache\n\n\nclass CacheHeartbeat(Thread):\n \"\"\"\n Thread to update set a cache key with a max life and refresh it as long as the thread is alive\n\n The thread can be ended by setting the `event_end` flag\n \"\"\"\n\n def __init__(self, cache_key: str, key_timeout: float = 30.0, beat_interval: int = 3):\n \"\"\"\n :param cache_key: The cache key to keep alive\n :param key_timeout: How long the cache key should live without the heartbeat thread\n :param beat_interval: How often per timeout the key should \"beat\"\n \"\"\"\n super().__init__()\n self.cache_key = cache_key\n self.event_end = Event()\n self.key_timeout = key_timeout\n self.beat_interval = beat_interval\n\n def run(self) -> None:\n logger = logging.getLogger(\"akvo.rsr.CacheHeartBeat\")\n logger.info(\"Starting cache heartbeat for '%s' with timeout %s\", self.cache_key, self.key_timeout)\n self.event_end.clear()\n while not self.event_end.is_set():\n # Refresh the heartbeat\n self.set_cache_value()\n self.event_end.wait(self.key_timeout / self.beat_interval)\n\n cache.delete(self.cache_key)\n logger.info(\"Ended cache heartbeat for '%s'\", self.cache_key)\n\n def set_cache_value(self):\n cache.set(self.cache_key, self.get_calc_value(), self.key_timeout)\n\n def get_calc_value(self) -> Union[str, int, float]:\n return datetime.datetime.utcnow().timestamp()\n", "path": "akvo/cache/heartbeat.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\"\"\"\nProvides a localhost HTTP server to query the local status of the django-q cluster\n\"\"\"\nimport logging\nimport signal\nimport socket\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\n\nfrom django.core.management.base import BaseCommand\nfrom django_q.conf import Conf\nfrom django_q.status import Stat\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(BaseCommand):\n help = __doc__\n\n def handle(self, *args, **options):\n server = HTTPServer((\"localhost\", 8080), DjangoQRequestHandler)\n\n def handle_end(*_):\n logger.info(\"Stopping server\")\n server.shutdown()\n\n signal.signal(signal.SIGINT, handle_end)\n signal.signal(signal.SIGTERM, handle_end)\n\n logger.info(\"Starting server...\")\n server.serve_forever()\n\n\nclass DjangoQRequestHandler(BaseHTTPRequestHandler):\n \"\"\"\n A handler to be used with HTTPServer to get the status of the local django-q cluster\n \"\"\"\n\n def do_GET(self):\n \"\"\"\n Handle GET requests to return a simple string indicating the status of the django-q cluster\n \"\"\"\n hostname = socket.gethostname()\n\n # Find local cluster\n local_stat = next(iter(stat for stat in Stat.get_all() if stat.host == hostname), None)\n if local_stat:\n message = local_stat.status\n else:\n message = Conf.STOPPED\n logger.info(f\"Probe response {message}\")\n self.send_response(200)\n self.end_headers()\n self.wfile.write(message.encode())\n\n def log_message(self, format: str, *args) -> None:\n logger.debug(format, *args)\n", "path": "akvo/rsr/management/commands/django_q_probettp.py"}, {"content": "import datetime\nimport logging\nfrom threading import Event, Thread\nfrom typing import Union\n\nfrom django.core.cache import cache\n\n\nclass CacheHeartbeat(Thread):\n \"\"\"\n Thread to set a cache key with a max life and refresh it as long as the thread is alive\n\n The thread can be ended by setting the `event_end` flag\n \"\"\"\n\n def __init__(self, cache_key: str, key_timeout: float = 30.0, beat_interval: int = 3):\n \"\"\"\n :param cache_key: The cache key to keep alive\n :param key_timeout: How long the cache key should live without the heartbeat thread\n :param beat_interval: How often per timeout the key should \"beat\"\n \"\"\"\n super().__init__()\n self.cache_key = cache_key\n self.event_end = Event()\n self.key_timeout = key_timeout\n self.beat_interval = beat_interval\n\n def run(self) -> None:\n logger = logging.getLogger(\"akvo.rsr.CacheHeartBeat\")\n logger.info(\"Starting cache heartbeat for '%s' with timeout %s\", self.cache_key, self.key_timeout)\n self.event_end.clear()\n while not self.event_end.is_set():\n # Refresh the heartbeat\n self.set_cache_value()\n self.event_end.wait(self.key_timeout / self.beat_interval)\n\n cache.delete(self.cache_key)\n logger.info(\"Ended cache heartbeat for '%s'\", self.cache_key)\n\n def set_cache_value(self):\n \"\"\"\n Set the cache key and its value\n \"\"\"\n cache.set(self.cache_key, self.calc_cache_value(), self.key_timeout)\n\n def calc_cache_value(self) -> Union[str, int, float]:\n \"\"\"\n Calculate a value to be used when setting the cache key\n \"\"\"\n return datetime.datetime.utcnow().timestamp()\n", "path": "akvo/cache/heartbeat.py"}]}
| 1,265 | 442 |
gh_patches_debug_11081
|
rasdani/github-patches
|
git_diff
|
deeppavlov__DeepPavlov-635
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add an environment variable to skip nltk.download()
Add an environment variable to skip nltk.download()
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deeppavlov/models/__init__.py`
Content:
```
1 # Copyright 2017 Neural Networks and Deep Learning lab, MIPT
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import nltk
16
17 from deeppavlov.core.common.prints import RedirectedPrints
18
19
20 with RedirectedPrints():
21 nltk.download('punkt')
22 nltk.download('stopwords')
23 nltk.download('perluniprops')
24 nltk.download('nonbreaking_prefixes')
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deeppavlov/models/__init__.py b/deeppavlov/models/__init__.py
--- a/deeppavlov/models/__init__.py
+++ b/deeppavlov/models/__init__.py
@@ -12,13 +12,14 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
import nltk
from deeppavlov.core.common.prints import RedirectedPrints
-
-with RedirectedPrints():
- nltk.download('punkt')
- nltk.download('stopwords')
- nltk.download('perluniprops')
- nltk.download('nonbreaking_prefixes')
+if not os.environ.get('DP_SKIP_NLTK_DOWNLOAD'):
+ with RedirectedPrints():
+ nltk.download('punkt')
+ nltk.download('stopwords')
+ nltk.download('perluniprops')
+ nltk.download('nonbreaking_prefixes')
|
{"golden_diff": "diff --git a/deeppavlov/models/__init__.py b/deeppavlov/models/__init__.py\n--- a/deeppavlov/models/__init__.py\n+++ b/deeppavlov/models/__init__.py\n@@ -12,13 +12,14 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n+import os\n import nltk\n \n from deeppavlov.core.common.prints import RedirectedPrints\n \n-\n-with RedirectedPrints():\n- nltk.download('punkt')\n- nltk.download('stopwords')\n- nltk.download('perluniprops')\n- nltk.download('nonbreaking_prefixes')\n+if not os.environ.get('DP_SKIP_NLTK_DOWNLOAD'):\n+ with RedirectedPrints():\n+ nltk.download('punkt')\n+ nltk.download('stopwords')\n+ nltk.download('perluniprops')\n+ nltk.download('nonbreaking_prefixes')\n", "issue": "Add an environment variable to skip nltk.download()\n\nAdd an environment variable to skip nltk.download()\n\n", "before_files": [{"content": "# Copyright 2017 Neural Networks and Deep Learning lab, MIPT\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport nltk\n\nfrom deeppavlov.core.common.prints import RedirectedPrints\n\n\nwith RedirectedPrints():\n nltk.download('punkt')\n nltk.download('stopwords')\n nltk.download('perluniprops')\n nltk.download('nonbreaking_prefixes')\n", "path": "deeppavlov/models/__init__.py"}], "after_files": [{"content": "# Copyright 2017 Neural Networks and Deep Learning lab, MIPT\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport nltk\n\nfrom deeppavlov.core.common.prints import RedirectedPrints\n\nif not os.environ.get('DP_SKIP_NLTK_DOWNLOAD'):\n with RedirectedPrints():\n nltk.download('punkt')\n nltk.download('stopwords')\n nltk.download('perluniprops')\n nltk.download('nonbreaking_prefixes')\n", "path": "deeppavlov/models/__init__.py"}]}
| 518 | 206 |
gh_patches_debug_2610
|
rasdani/github-patches
|
git_diff
|
openai__openai-python-1007
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing default value to logprobs in openai.types.chat.chat_completion.Choice
### Confirm this is an issue with the Python library and not an underlying OpenAI API
- [X] This is an issue with the Python library
### Describe the bug
#980 added token `logprobs` to chat completions of type `Optional[ChoiceLogprobs]` in [`openai.types.chat.chat_completion.Choice`](https://github.com/openai/openai-python/blob/3ad4e8bc9d89d7a81586bf598289ff62b0a339b9/src/openai/types/chat/chat_completion.py#L33) and [`openai.types.chat.chat_completion_chunk.Choice`](https://github.com/openai/openai-python/blob/3ad4e8bc9d89d7a81586bf598289ff62b0a339b9/src/openai/types/chat/chat_completion_chunk.py#L97). In the latter, the default value is set to `None`, while in the former it is not set. This causes backward compatibility problems with code written for versions prior to 1.5.0.
### To Reproduce
Execution of the following code fails:
```python
from openai.types.chat.chat_completion import ChatCompletionMessage, Choice
msg = ChatCompletionMessage(role="assistant", content="")
Choice(
index=0,
finish_reason="stop",
message=msg,
)
```
The output
```
----> 1 Choice(
2 index=0,
3 finish_reason="stop",
4 message=msg,
5 )
File /.venv-3.10/lib/python3.10/site-packages/pydantic/main.py:164, in BaseModel.__init__(__pydantic_self__, **data)
162 # `__tracebackhide__` tells pytest and some other tools to omit this function from tracebacks
163 __tracebackhide__ = True
--> 164 __pydantic_self__.__pydantic_validator__.validate_python(data, self_instance=__pydantic_self__)
ValidationError: 1 validation error for Choice
logprobs
Field required [type=missing, input_value={'index': 0, 'finish_reas...=None, tool_calls=None)}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.5/v/missing
```
Setting `logprobs` to `None` fixes the problem.
```python
from openai.types.chat.chat_completion import ChatCompletionMessage, Choice
msg = ChatCompletionMessage(role="assistant", content="")
Choice(
index=0,
finish_reason="stop",
message=msg,
logprobs=None # added line
)
```
### Code snippets
```Python
see above
```
### OS
Linux
### Python version
Python 3.10.13
### Library version
openai 1.6.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/openai/types/chat/chat_completion.py`
Content:
```
1 # File generated from our OpenAPI spec by Stainless.
2
3 from typing import List, Optional
4 from typing_extensions import Literal
5
6 from ..._models import BaseModel
7 from ..completion_usage import CompletionUsage
8 from .chat_completion_message import ChatCompletionMessage
9 from .chat_completion_token_logprob import ChatCompletionTokenLogprob
10
11 __all__ = ["ChatCompletion", "Choice", "ChoiceLogprobs"]
12
13
14 class ChoiceLogprobs(BaseModel):
15 content: Optional[List[ChatCompletionTokenLogprob]]
16 """A list of message content tokens with log probability information."""
17
18
19 class Choice(BaseModel):
20 finish_reason: Literal["stop", "length", "tool_calls", "content_filter", "function_call"]
21 """The reason the model stopped generating tokens.
22
23 This will be `stop` if the model hit a natural stop point or a provided stop
24 sequence, `length` if the maximum number of tokens specified in the request was
25 reached, `content_filter` if content was omitted due to a flag from our content
26 filters, `tool_calls` if the model called a tool, or `function_call`
27 (deprecated) if the model called a function.
28 """
29
30 index: int
31 """The index of the choice in the list of choices."""
32
33 logprobs: Optional[ChoiceLogprobs]
34 """Log probability information for the choice."""
35
36 message: ChatCompletionMessage
37 """A chat completion message generated by the model."""
38
39
40 class ChatCompletion(BaseModel):
41 id: str
42 """A unique identifier for the chat completion."""
43
44 choices: List[Choice]
45 """A list of chat completion choices.
46
47 Can be more than one if `n` is greater than 1.
48 """
49
50 created: int
51 """The Unix timestamp (in seconds) of when the chat completion was created."""
52
53 model: str
54 """The model used for the chat completion."""
55
56 object: Literal["chat.completion"]
57 """The object type, which is always `chat.completion`."""
58
59 system_fingerprint: Optional[str] = None
60 """This fingerprint represents the backend configuration that the model runs with.
61
62 Can be used in conjunction with the `seed` request parameter to understand when
63 backend changes have been made that might impact determinism.
64 """
65
66 usage: Optional[CompletionUsage] = None
67 """Usage statistics for the completion request."""
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/openai/types/chat/chat_completion.py b/src/openai/types/chat/chat_completion.py
--- a/src/openai/types/chat/chat_completion.py
+++ b/src/openai/types/chat/chat_completion.py
@@ -30,7 +30,7 @@
index: int
"""The index of the choice in the list of choices."""
- logprobs: Optional[ChoiceLogprobs]
+ logprobs: Optional[ChoiceLogprobs] = None
"""Log probability information for the choice."""
message: ChatCompletionMessage
|
{"golden_diff": "diff --git a/src/openai/types/chat/chat_completion.py b/src/openai/types/chat/chat_completion.py\n--- a/src/openai/types/chat/chat_completion.py\n+++ b/src/openai/types/chat/chat_completion.py\n@@ -30,7 +30,7 @@\n index: int\n \"\"\"The index of the choice in the list of choices.\"\"\"\n \n- logprobs: Optional[ChoiceLogprobs]\n+ logprobs: Optional[ChoiceLogprobs] = None\n \"\"\"Log probability information for the choice.\"\"\"\n \n message: ChatCompletionMessage\n", "issue": "Missing default value to logprobs in openai.types.chat.chat_completion.Choice\n### Confirm this is an issue with the Python library and not an underlying OpenAI API\r\n\r\n- [X] This is an issue with the Python library\r\n\r\n### Describe the bug\r\n\r\n#980 added token `logprobs` to chat completions of type `Optional[ChoiceLogprobs]` in [`openai.types.chat.chat_completion.Choice`](https://github.com/openai/openai-python/blob/3ad4e8bc9d89d7a81586bf598289ff62b0a339b9/src/openai/types/chat/chat_completion.py#L33) and [`openai.types.chat.chat_completion_chunk.Choice`](https://github.com/openai/openai-python/blob/3ad4e8bc9d89d7a81586bf598289ff62b0a339b9/src/openai/types/chat/chat_completion_chunk.py#L97). In the latter, the default value is set to `None`, while in the former it is not set. This causes backward compatibility problems with code written for versions prior to 1.5.0.\r\n\r\n\r\n\r\n### To Reproduce\r\n\r\nExecution of the following code fails:\r\n\r\n```python \r\nfrom openai.types.chat.chat_completion import ChatCompletionMessage, Choice\r\n\r\nmsg = ChatCompletionMessage(role=\"assistant\", content=\"\")\r\n\r\nChoice(\r\n index=0,\r\n finish_reason=\"stop\",\r\n message=msg,\r\n)\r\n```\r\nThe output\r\n```\r\n----> 1 Choice(\r\n 2 index=0,\r\n 3 finish_reason=\"stop\",\r\n 4 message=msg,\r\n 5 )\r\n\r\nFile /.venv-3.10/lib/python3.10/site-packages/pydantic/main.py:164, in BaseModel.__init__(__pydantic_self__, **data)\r\n 162 # `__tracebackhide__` tells pytest and some other tools to omit this function from tracebacks\r\n 163 __tracebackhide__ = True\r\n--> 164 __pydantic_self__.__pydantic_validator__.validate_python(data, self_instance=__pydantic_self__)\r\n\r\nValidationError: 1 validation error for Choice\r\nlogprobs\r\n Field required [type=missing, input_value={'index': 0, 'finish_reas...=None, tool_calls=None)}, input_type=dict]\r\n For further information visit https://errors.pydantic.dev/2.5/v/missing\r\n```\r\nSetting `logprobs` to `None` fixes the problem.\r\n```python \r\nfrom openai.types.chat.chat_completion import ChatCompletionMessage, Choice\r\n\r\nmsg = ChatCompletionMessage(role=\"assistant\", content=\"\")\r\n\r\nChoice(\r\n index=0,\r\n finish_reason=\"stop\",\r\n message=msg,\r\n logprobs=None # added line\r\n)\r\n```\r\n\r\n### Code snippets\r\n\r\n```Python\r\nsee above\r\n```\r\n\r\n\r\n### OS\r\n\r\nLinux\r\n\r\n### Python version\r\n\r\nPython 3.10.13\r\n\r\n### Library version\r\n\r\nopenai 1.6.0\n", "before_files": [{"content": "# File generated from our OpenAPI spec by Stainless.\n\nfrom typing import List, Optional\nfrom typing_extensions import Literal\n\nfrom ..._models import BaseModel\nfrom ..completion_usage import CompletionUsage\nfrom .chat_completion_message import ChatCompletionMessage\nfrom .chat_completion_token_logprob import ChatCompletionTokenLogprob\n\n__all__ = [\"ChatCompletion\", \"Choice\", \"ChoiceLogprobs\"]\n\n\nclass ChoiceLogprobs(BaseModel):\n content: Optional[List[ChatCompletionTokenLogprob]]\n \"\"\"A list of message content tokens with log probability information.\"\"\"\n\n\nclass Choice(BaseModel):\n finish_reason: Literal[\"stop\", \"length\", \"tool_calls\", \"content_filter\", \"function_call\"]\n \"\"\"The reason the model stopped generating tokens.\n\n This will be `stop` if the model hit a natural stop point or a provided stop\n sequence, `length` if the maximum number of tokens specified in the request was\n reached, `content_filter` if content was omitted due to a flag from our content\n filters, `tool_calls` if the model called a tool, or `function_call`\n (deprecated) if the model called a function.\n \"\"\"\n\n index: int\n \"\"\"The index of the choice in the list of choices.\"\"\"\n\n logprobs: Optional[ChoiceLogprobs]\n \"\"\"Log probability information for the choice.\"\"\"\n\n message: ChatCompletionMessage\n \"\"\"A chat completion message generated by the model.\"\"\"\n\n\nclass ChatCompletion(BaseModel):\n id: str\n \"\"\"A unique identifier for the chat completion.\"\"\"\n\n choices: List[Choice]\n \"\"\"A list of chat completion choices.\n\n Can be more than one if `n` is greater than 1.\n \"\"\"\n\n created: int\n \"\"\"The Unix timestamp (in seconds) of when the chat completion was created.\"\"\"\n\n model: str\n \"\"\"The model used for the chat completion.\"\"\"\n\n object: Literal[\"chat.completion\"]\n \"\"\"The object type, which is always `chat.completion`.\"\"\"\n\n system_fingerprint: Optional[str] = None\n \"\"\"This fingerprint represents the backend configuration that the model runs with.\n\n Can be used in conjunction with the `seed` request parameter to understand when\n backend changes have been made that might impact determinism.\n \"\"\"\n\n usage: Optional[CompletionUsage] = None\n \"\"\"Usage statistics for the completion request.\"\"\"\n", "path": "src/openai/types/chat/chat_completion.py"}], "after_files": [{"content": "# File generated from our OpenAPI spec by Stainless.\n\nfrom typing import List, Optional\nfrom typing_extensions import Literal\n\nfrom ..._models import BaseModel\nfrom ..completion_usage import CompletionUsage\nfrom .chat_completion_message import ChatCompletionMessage\nfrom .chat_completion_token_logprob import ChatCompletionTokenLogprob\n\n__all__ = [\"ChatCompletion\", \"Choice\", \"ChoiceLogprobs\"]\n\n\nclass ChoiceLogprobs(BaseModel):\n content: Optional[List[ChatCompletionTokenLogprob]]\n \"\"\"A list of message content tokens with log probability information.\"\"\"\n\n\nclass Choice(BaseModel):\n finish_reason: Literal[\"stop\", \"length\", \"tool_calls\", \"content_filter\", \"function_call\"]\n \"\"\"The reason the model stopped generating tokens.\n\n This will be `stop` if the model hit a natural stop point or a provided stop\n sequence, `length` if the maximum number of tokens specified in the request was\n reached, `content_filter` if content was omitted due to a flag from our content\n filters, `tool_calls` if the model called a tool, or `function_call`\n (deprecated) if the model called a function.\n \"\"\"\n\n index: int\n \"\"\"The index of the choice in the list of choices.\"\"\"\n\n logprobs: Optional[ChoiceLogprobs] = None\n \"\"\"Log probability information for the choice.\"\"\"\n\n message: ChatCompletionMessage\n \"\"\"A chat completion message generated by the model.\"\"\"\n\n\nclass ChatCompletion(BaseModel):\n id: str\n \"\"\"A unique identifier for the chat completion.\"\"\"\n\n choices: List[Choice]\n \"\"\"A list of chat completion choices.\n\n Can be more than one if `n` is greater than 1.\n \"\"\"\n\n created: int\n \"\"\"The Unix timestamp (in seconds) of when the chat completion was created.\"\"\"\n\n model: str\n \"\"\"The model used for the chat completion.\"\"\"\n\n object: Literal[\"chat.completion\"]\n \"\"\"The object type, which is always `chat.completion`.\"\"\"\n\n system_fingerprint: Optional[str] = None\n \"\"\"This fingerprint represents the backend configuration that the model runs with.\n\n Can be used in conjunction with the `seed` request parameter to understand when\n backend changes have been made that might impact determinism.\n \"\"\"\n\n usage: Optional[CompletionUsage] = None\n \"\"\"Usage statistics for the completion request.\"\"\"\n", "path": "src/openai/types/chat/chat_completion.py"}]}
| 1,557 | 121 |
gh_patches_debug_23877
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1322
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
docs: Investiage revising author field styling in Zenodo citation
# Description
The current Zendo citation of
https://github.com/scikit-hep/pyhf/blob/3f0c8fc26d13bf2c7740bd2465bc10bbcd5f7746/src/pyhf/data/citation.bib#L1-L7
quotes the author field which can make some BibTeX style files force it to render in a way that is perhaps not desirable

However, if the author field is given to BibTeX with more flexibility (using `and`s and without quotes)
```bibtex
@software{pyhf,
author = {Lukas Heinrich and Matthew Feickert and Giordon Stark},
title = "{pyhf: v0.6.0}",
version = {0.6.0},
doi = {10.5281/zenodo.1169739},
url = {https://github.com/scikit-hep/pyhf},
}
```
the render can be improved

Thoughts on style here @lukasheinrich @kratsg?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pyhf/utils.py`
Content:
```
1 import json
2 import jsonschema
3 import pkg_resources
4 from pathlib import Path
5 import yaml
6 import click
7 import hashlib
8
9 from .exceptions import InvalidSpecification
10
11 SCHEMA_CACHE = {}
12 SCHEMA_BASE = "https://scikit-hep.org/pyhf/schemas/"
13 SCHEMA_VERSION = '1.0.0'
14
15
16 def load_schema(schema_id, version=None):
17 global SCHEMA_CACHE
18 if not version:
19 version = SCHEMA_VERSION
20 try:
21 return SCHEMA_CACHE[f'{SCHEMA_BASE}{Path(version).joinpath(schema_id)}']
22 except KeyError:
23 pass
24
25 path = pkg_resources.resource_filename(
26 __name__, str(Path('schemas').joinpath(version, schema_id))
27 )
28 with open(path) as json_schema:
29 schema = json.load(json_schema)
30 SCHEMA_CACHE[schema['$id']] = schema
31 return SCHEMA_CACHE[schema['$id']]
32
33
34 # load the defs.json as it is included by $ref
35 load_schema('defs.json')
36
37
38 def validate(spec, schema_name, version=None):
39 schema = load_schema(schema_name, version=version)
40 try:
41 resolver = jsonschema.RefResolver(
42 base_uri=f"file://{pkg_resources.resource_filename(__name__, 'schemas/'):s}",
43 referrer=schema_name,
44 store=SCHEMA_CACHE,
45 )
46 validator = jsonschema.Draft6Validator(
47 schema, resolver=resolver, format_checker=None
48 )
49 return validator.validate(spec)
50 except jsonschema.ValidationError as err:
51 raise InvalidSpecification(err, schema_name)
52
53
54 def options_from_eqdelimstring(opts):
55 document = '\n'.join(
56 f"{opt.split('=', 1)[0]}: {opt.split('=', 1)[1]}" for opt in opts
57 )
58 return yaml.full_load(document)
59
60
61 class EqDelimStringParamType(click.ParamType):
62 name = 'equal-delimited option'
63
64 def convert(self, value, param, ctx):
65 try:
66 return options_from_eqdelimstring([value])
67 except IndexError:
68 self.fail(f'{value:s} is not a valid equal-delimited string', param, ctx)
69
70
71 def digest(obj, algorithm='sha256'):
72 """
73 Get the digest for the provided object. Note: object must be JSON-serializable.
74
75 The hashing algorithms supported are in :mod:`hashlib`, part of Python's Standard Libraries.
76
77 Example:
78
79 >>> import pyhf
80 >>> obj = {'a': 2.0, 'b': 3.0, 'c': 1.0}
81 >>> pyhf.utils.digest(obj)
82 'a38f6093800189b79bc22ef677baf90c75705af2cfc7ff594159eca54eaa7928'
83 >>> pyhf.utils.digest(obj, algorithm='md5')
84 '2c0633f242928eb55c3672fed5ba8612'
85 >>> pyhf.utils.digest(obj, algorithm='sha1')
86 '49a27f499e763766c9545b294880df277be6f545'
87
88 Raises:
89 ValueError: If the object is not JSON-serializable or if the algorithm is not supported.
90
91 Args:
92 obj (:obj:`jsonable`): A JSON-serializable object to compute the digest of. Usually a :class:`~pyhf.workspace.Workspace` object.
93 algorithm (:obj:`str`): The hashing algorithm to use.
94
95 Returns:
96 digest (:obj:`str`): The digest for the JSON-serialized object provided and hash algorithm specified.
97 """
98
99 try:
100 stringified = json.dumps(obj, sort_keys=True, ensure_ascii=False).encode('utf8')
101 except TypeError:
102 raise ValueError(
103 "The supplied object is not JSON-serializable for calculating a hash."
104 )
105 try:
106 hash_alg = getattr(hashlib, algorithm)
107 except AttributeError:
108 raise ValueError(
109 f"{algorithm} is not an algorithm provided by Python's hashlib library."
110 )
111 return hash_alg(stringified).hexdigest()
112
113
114 def remove_prefix(text, prefix):
115 """
116 Remove a prefix from the beginning of the provided text.
117
118 Example:
119
120 >>> import pyhf
121 >>> pyhf.utils.remove_prefix("alpha_syst1", "alpha_")
122 'syst1'
123
124 Args:
125 text (:obj:`str`): A provided input to manipulate.
126 prefix (:obj:`str`): A prefix to remove from provided input, if it exists.
127
128 Returns:
129 stripped_text (:obj:`str`): Text with the prefix removed.
130 """
131 # NB: python3.9 can be `return text.removeprefix(prefix)`
132 if text.startswith(prefix):
133 return text[len(prefix) :]
134 return text
135
136
137 def citation(oneline=False):
138 """
139 Get the bibtex citation for pyhf
140
141 Example:
142
143 >>> import pyhf
144 >>> pyhf.utils.citation(True)
145 '@software{pyhf, author = "{Heinrich, Lukas and Feickert, Matthew and Stark, Giordon}", title = "{pyhf: v0.6.0}", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
146
147 Keyword Args:
148 oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.
149
150 Returns:
151 citation (:obj:`str`): The citation for this software
152 """
153 path = Path(
154 pkg_resources.resource_filename(
155 __name__, str(Path('data').joinpath('citation.bib'))
156 )
157 )
158 with path.open() as fp:
159 # remove end-of-file newline if there is one
160 data = fp.read().strip()
161
162 if oneline:
163 data = ''.join(data.splitlines())
164 return data
165
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pyhf/utils.py b/src/pyhf/utils.py
--- a/src/pyhf/utils.py
+++ b/src/pyhf/utils.py
@@ -142,7 +142,7 @@
>>> import pyhf
>>> pyhf.utils.citation(True)
- '@software{pyhf, author = "{Heinrich, Lukas and Feickert, Matthew and Stark, Giordon}", title = "{pyhf: v0.6.0}", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
+ '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = "{pyhf: v0.6.0}", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
Keyword Args:
oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.
|
{"golden_diff": "diff --git a/src/pyhf/utils.py b/src/pyhf/utils.py\n--- a/src/pyhf/utils.py\n+++ b/src/pyhf/utils.py\n@@ -142,7 +142,7 @@\n \n >>> import pyhf\n >>> pyhf.utils.citation(True)\n- '@software{pyhf, author = \"{Heinrich, Lukas and Feickert, Matthew and Stark, Giordon}\", title = \"{pyhf: v0.6.0}\", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'\n+ '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = \"{pyhf: v0.6.0}\", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'\n \n Keyword Args:\n oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.\n", "issue": "docs: Investiage revising author field styling in Zenodo citation\n# Description\r\n\r\nThe current Zendo citation of \r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/3f0c8fc26d13bf2c7740bd2465bc10bbcd5f7746/src/pyhf/data/citation.bib#L1-L7\r\n\r\nquotes the author field which can make some BibTeX style files force it to render in a way that is perhaps not desirable\r\n\r\n\r\n\r\nHowever, if the author field is given to BibTeX with more flexibility (using `and`s and without quotes)\r\n\r\n```bibtex\r\n@software{pyhf,\r\n author = {Lukas Heinrich and Matthew Feickert and Giordon Stark},\r\n title = \"{pyhf: v0.6.0}\",\r\n version = {0.6.0},\r\n doi = {10.5281/zenodo.1169739},\r\n url = {https://github.com/scikit-hep/pyhf},\r\n}\r\n```\r\n\r\nthe render can be improved\r\n\r\n\r\n\r\nThoughts on style here @lukasheinrich @kratsg?\n", "before_files": [{"content": "import json\nimport jsonschema\nimport pkg_resources\nfrom pathlib import Path\nimport yaml\nimport click\nimport hashlib\n\nfrom .exceptions import InvalidSpecification\n\nSCHEMA_CACHE = {}\nSCHEMA_BASE = \"https://scikit-hep.org/pyhf/schemas/\"\nSCHEMA_VERSION = '1.0.0'\n\n\ndef load_schema(schema_id, version=None):\n global SCHEMA_CACHE\n if not version:\n version = SCHEMA_VERSION\n try:\n return SCHEMA_CACHE[f'{SCHEMA_BASE}{Path(version).joinpath(schema_id)}']\n except KeyError:\n pass\n\n path = pkg_resources.resource_filename(\n __name__, str(Path('schemas').joinpath(version, schema_id))\n )\n with open(path) as json_schema:\n schema = json.load(json_schema)\n SCHEMA_CACHE[schema['$id']] = schema\n return SCHEMA_CACHE[schema['$id']]\n\n\n# load the defs.json as it is included by $ref\nload_schema('defs.json')\n\n\ndef validate(spec, schema_name, version=None):\n schema = load_schema(schema_name, version=version)\n try:\n resolver = jsonschema.RefResolver(\n base_uri=f\"file://{pkg_resources.resource_filename(__name__, 'schemas/'):s}\",\n referrer=schema_name,\n store=SCHEMA_CACHE,\n )\n validator = jsonschema.Draft6Validator(\n schema, resolver=resolver, format_checker=None\n )\n return validator.validate(spec)\n except jsonschema.ValidationError as err:\n raise InvalidSpecification(err, schema_name)\n\n\ndef options_from_eqdelimstring(opts):\n document = '\\n'.join(\n f\"{opt.split('=', 1)[0]}: {opt.split('=', 1)[1]}\" for opt in opts\n )\n return yaml.full_load(document)\n\n\nclass EqDelimStringParamType(click.ParamType):\n name = 'equal-delimited option'\n\n def convert(self, value, param, ctx):\n try:\n return options_from_eqdelimstring([value])\n except IndexError:\n self.fail(f'{value:s} is not a valid equal-delimited string', param, ctx)\n\n\ndef digest(obj, algorithm='sha256'):\n \"\"\"\n Get the digest for the provided object. Note: object must be JSON-serializable.\n\n The hashing algorithms supported are in :mod:`hashlib`, part of Python's Standard Libraries.\n\n Example:\n\n >>> import pyhf\n >>> obj = {'a': 2.0, 'b': 3.0, 'c': 1.0}\n >>> pyhf.utils.digest(obj)\n 'a38f6093800189b79bc22ef677baf90c75705af2cfc7ff594159eca54eaa7928'\n >>> pyhf.utils.digest(obj, algorithm='md5')\n '2c0633f242928eb55c3672fed5ba8612'\n >>> pyhf.utils.digest(obj, algorithm='sha1')\n '49a27f499e763766c9545b294880df277be6f545'\n\n Raises:\n ValueError: If the object is not JSON-serializable or if the algorithm is not supported.\n\n Args:\n obj (:obj:`jsonable`): A JSON-serializable object to compute the digest of. Usually a :class:`~pyhf.workspace.Workspace` object.\n algorithm (:obj:`str`): The hashing algorithm to use.\n\n Returns:\n digest (:obj:`str`): The digest for the JSON-serialized object provided and hash algorithm specified.\n \"\"\"\n\n try:\n stringified = json.dumps(obj, sort_keys=True, ensure_ascii=False).encode('utf8')\n except TypeError:\n raise ValueError(\n \"The supplied object is not JSON-serializable for calculating a hash.\"\n )\n try:\n hash_alg = getattr(hashlib, algorithm)\n except AttributeError:\n raise ValueError(\n f\"{algorithm} is not an algorithm provided by Python's hashlib library.\"\n )\n return hash_alg(stringified).hexdigest()\n\n\ndef remove_prefix(text, prefix):\n \"\"\"\n Remove a prefix from the beginning of the provided text.\n\n Example:\n\n >>> import pyhf\n >>> pyhf.utils.remove_prefix(\"alpha_syst1\", \"alpha_\")\n 'syst1'\n\n Args:\n text (:obj:`str`): A provided input to manipulate.\n prefix (:obj:`str`): A prefix to remove from provided input, if it exists.\n\n Returns:\n stripped_text (:obj:`str`): Text with the prefix removed.\n \"\"\"\n # NB: python3.9 can be `return text.removeprefix(prefix)`\n if text.startswith(prefix):\n return text[len(prefix) :]\n return text\n\n\ndef citation(oneline=False):\n \"\"\"\n Get the bibtex citation for pyhf\n\n Example:\n\n >>> import pyhf\n >>> pyhf.utils.citation(True)\n '@software{pyhf, author = \"{Heinrich, Lukas and Feickert, Matthew and Stark, Giordon}\", title = \"{pyhf: v0.6.0}\", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'\n\n Keyword Args:\n oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.\n\n Returns:\n citation (:obj:`str`): The citation for this software\n \"\"\"\n path = Path(\n pkg_resources.resource_filename(\n __name__, str(Path('data').joinpath('citation.bib'))\n )\n )\n with path.open() as fp:\n # remove end-of-file newline if there is one\n data = fp.read().strip()\n\n if oneline:\n data = ''.join(data.splitlines())\n return data\n", "path": "src/pyhf/utils.py"}], "after_files": [{"content": "import json\nimport jsonschema\nimport pkg_resources\nfrom pathlib import Path\nimport yaml\nimport click\nimport hashlib\n\nfrom .exceptions import InvalidSpecification\n\nSCHEMA_CACHE = {}\nSCHEMA_BASE = \"https://scikit-hep.org/pyhf/schemas/\"\nSCHEMA_VERSION = '1.0.0'\n\n\ndef load_schema(schema_id, version=None):\n global SCHEMA_CACHE\n if not version:\n version = SCHEMA_VERSION\n try:\n return SCHEMA_CACHE[f'{SCHEMA_BASE}{Path(version).joinpath(schema_id)}']\n except KeyError:\n pass\n\n path = pkg_resources.resource_filename(\n __name__, str(Path('schemas').joinpath(version, schema_id))\n )\n with open(path) as json_schema:\n schema = json.load(json_schema)\n SCHEMA_CACHE[schema['$id']] = schema\n return SCHEMA_CACHE[schema['$id']]\n\n\n# load the defs.json as it is included by $ref\nload_schema('defs.json')\n\n\ndef validate(spec, schema_name, version=None):\n schema = load_schema(schema_name, version=version)\n try:\n resolver = jsonschema.RefResolver(\n base_uri=f\"file://{pkg_resources.resource_filename(__name__, 'schemas/'):s}\",\n referrer=schema_name,\n store=SCHEMA_CACHE,\n )\n validator = jsonschema.Draft6Validator(\n schema, resolver=resolver, format_checker=None\n )\n return validator.validate(spec)\n except jsonschema.ValidationError as err:\n raise InvalidSpecification(err, schema_name)\n\n\ndef options_from_eqdelimstring(opts):\n document = '\\n'.join(\n f\"{opt.split('=', 1)[0]}: {opt.split('=', 1)[1]}\" for opt in opts\n )\n return yaml.full_load(document)\n\n\nclass EqDelimStringParamType(click.ParamType):\n name = 'equal-delimited option'\n\n def convert(self, value, param, ctx):\n try:\n return options_from_eqdelimstring([value])\n except IndexError:\n self.fail(f'{value:s} is not a valid equal-delimited string', param, ctx)\n\n\ndef digest(obj, algorithm='sha256'):\n \"\"\"\n Get the digest for the provided object. Note: object must be JSON-serializable.\n\n The hashing algorithms supported are in :mod:`hashlib`, part of Python's Standard Libraries.\n\n Example:\n\n >>> import pyhf\n >>> obj = {'a': 2.0, 'b': 3.0, 'c': 1.0}\n >>> pyhf.utils.digest(obj)\n 'a38f6093800189b79bc22ef677baf90c75705af2cfc7ff594159eca54eaa7928'\n >>> pyhf.utils.digest(obj, algorithm='md5')\n '2c0633f242928eb55c3672fed5ba8612'\n >>> pyhf.utils.digest(obj, algorithm='sha1')\n '49a27f499e763766c9545b294880df277be6f545'\n\n Raises:\n ValueError: If the object is not JSON-serializable or if the algorithm is not supported.\n\n Args:\n obj (:obj:`jsonable`): A JSON-serializable object to compute the digest of. Usually a :class:`~pyhf.workspace.Workspace` object.\n algorithm (:obj:`str`): The hashing algorithm to use.\n\n Returns:\n digest (:obj:`str`): The digest for the JSON-serialized object provided and hash algorithm specified.\n \"\"\"\n\n try:\n stringified = json.dumps(obj, sort_keys=True, ensure_ascii=False).encode('utf8')\n except TypeError:\n raise ValueError(\n \"The supplied object is not JSON-serializable for calculating a hash.\"\n )\n try:\n hash_alg = getattr(hashlib, algorithm)\n except AttributeError:\n raise ValueError(\n f\"{algorithm} is not an algorithm provided by Python's hashlib library.\"\n )\n return hash_alg(stringified).hexdigest()\n\n\ndef remove_prefix(text, prefix):\n \"\"\"\n Remove a prefix from the beginning of the provided text.\n\n Example:\n\n >>> import pyhf\n >>> pyhf.utils.remove_prefix(\"alpha_syst1\", \"alpha_\")\n 'syst1'\n\n Args:\n text (:obj:`str`): A provided input to manipulate.\n prefix (:obj:`str`): A prefix to remove from provided input, if it exists.\n\n Returns:\n stripped_text (:obj:`str`): Text with the prefix removed.\n \"\"\"\n # NB: python3.9 can be `return text.removeprefix(prefix)`\n if text.startswith(prefix):\n return text[len(prefix) :]\n return text\n\n\ndef citation(oneline=False):\n \"\"\"\n Get the bibtex citation for pyhf\n\n Example:\n\n >>> import pyhf\n >>> pyhf.utils.citation(True)\n '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = \"{pyhf: v0.6.0}\", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'\n\n Keyword Args:\n oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.\n\n Returns:\n citation (:obj:`str`): The citation for this software\n \"\"\"\n path = Path(\n pkg_resources.resource_filename(\n __name__, str(Path('data').joinpath('citation.bib'))\n )\n )\n with path.open() as fp:\n # remove end-of-file newline if there is one\n data = fp.read().strip()\n\n if oneline:\n data = ''.join(data.splitlines())\n return data\n", "path": "src/pyhf/utils.py"}]}
| 2,494 | 564 |
gh_patches_debug_31945
|
rasdani/github-patches
|
git_diff
|
openai__gym-2365
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Seed and sample behaviour in Tuple space
If I create a Tuple space containing Discrete spaces, fix the seed, and then generate a sample, all elements of the sampled tuple are the same. For example, (0, 0) or (4, 4). Conversely, if I create a MultiDiscrete space, fix the seed, and then generate a sample, elements of the sampled tuple are not necessarily the same. For example, (0, 4) or (1, 3).
This is especially problematic when a Tuple space contains Tuple spaces (i.e. where MultiDiscrete is not an adequate replacement):
```python
from gym.spaces import Tuple, MultiDiscrete, Discrete
my_seed = 0
# Test 1
print("Test 1:")
a1 = Tuple([Tuple([Discrete(5) for _ in range(2)]) for _ in range(2)])
b1 = Tuple([MultiDiscrete([5 for _ in range(2)]) for _ in range(2)])
a1.seed(my_seed)
b1.seed(my_seed)
for _ in range(5):
print(a1.sample(), b1.sample())
# Test 2
print("Test 2:")
a2 = Tuple([Tuple([Discrete(5) for _ in range(2)]) for _ in range(2)])
b2 = Tuple([MultiDiscrete([5 for _ in range(2)]) for _ in range(2)])
for a2_space, b2_space in zip(a2, b2):
my_seed += 1
a2_space.seed(my_seed)
b2_space.seed(my_seed)
for _ in range(5):
print(a2.sample(), b2.sample())
```
```
Test 1:
((0, 0), (0, 0)) (array([0, 4]), array([0, 4]))
((3, 3), (3, 3)) (array([3, 1]), array([3, 1]))
((4, 4), (4, 4)) (array([0, 3]), array([0, 3]))
((3, 3), (3, 3)) (array([1, 3]), array([1, 3]))
((3, 3), (3, 3)) (array([0, 2]), array([0, 2]))
Test 2:
((0, 0), (4, 4)) (array([4, 2]), array([4, 3]))
((4, 4), (0, 0)) (array([0, 0]), array([3, 3]))
((3, 3), (0, 0)) (array([3, 0]), array([4, 2]))
((2, 2), (4, 4)) (array([0, 2]), array([1, 2]))
((4, 4), (1, 1)) (array([3, 2]), array([2, 2]))
```
Is this expected/desirable behaviour for Tuple or am I using it incorrectly? I would have expected Tuple to behave for arbitrary tuples as MultiDiscrete behaves for a single tuple.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gym/spaces/dict.py`
Content:
```
1 from collections import OrderedDict
2 from .space import Space
3
4
5 class Dict(Space):
6 """
7 A dictionary of simpler spaces.
8
9 Example usage:
10 self.observation_space = spaces.Dict({"position": spaces.Discrete(2), "velocity": spaces.Discrete(3)})
11
12 Example usage [nested]:
13 self.nested_observation_space = spaces.Dict({
14 'sensors': spaces.Dict({
15 'position': spaces.Box(low=-100, high=100, shape=(3,)),
16 'velocity': spaces.Box(low=-1, high=1, shape=(3,)),
17 'front_cam': spaces.Tuple((
18 spaces.Box(low=0, high=1, shape=(10, 10, 3)),
19 spaces.Box(low=0, high=1, shape=(10, 10, 3))
20 )),
21 'rear_cam': spaces.Box(low=0, high=1, shape=(10, 10, 3)),
22 }),
23 'ext_controller': spaces.MultiDiscrete((5, 2, 2)),
24 'inner_state':spaces.Dict({
25 'charge': spaces.Discrete(100),
26 'system_checks': spaces.MultiBinary(10),
27 'job_status': spaces.Dict({
28 'task': spaces.Discrete(5),
29 'progress': spaces.Box(low=0, high=100, shape=()),
30 })
31 })
32 })
33 """
34
35 def __init__(self, spaces=None, **spaces_kwargs):
36 assert (spaces is None) or (
37 not spaces_kwargs
38 ), "Use either Dict(spaces=dict(...)) or Dict(foo=x, bar=z)"
39 if spaces is None:
40 spaces = spaces_kwargs
41 if isinstance(spaces, dict) and not isinstance(spaces, OrderedDict):
42 spaces = OrderedDict(sorted(list(spaces.items())))
43 if isinstance(spaces, list):
44 spaces = OrderedDict(spaces)
45 self.spaces = spaces
46 for space in spaces.values():
47 assert isinstance(
48 space, Space
49 ), "Values of the dict should be instances of gym.Space"
50 super(Dict, self).__init__(
51 None, None
52 ) # None for shape and dtype, since it'll require special handling
53
54 def seed(self, seed=None):
55 [space.seed(seed) for space in self.spaces.values()]
56
57 def sample(self):
58 return OrderedDict([(k, space.sample()) for k, space in self.spaces.items()])
59
60 def contains(self, x):
61 if not isinstance(x, dict) or len(x) != len(self.spaces):
62 return False
63 for k, space in self.spaces.items():
64 if k not in x:
65 return False
66 if not space.contains(x[k]):
67 return False
68 return True
69
70 def __getitem__(self, key):
71 return self.spaces[key]
72
73 def __setitem__(self, key, value):
74 self.spaces[key] = value
75
76 def __iter__(self):
77 for key in self.spaces:
78 yield key
79
80 def __len__(self):
81 return len(self.spaces)
82
83 def __contains__(self, item):
84 return self.contains(item)
85
86 def __repr__(self):
87 return (
88 "Dict("
89 + ", ".join([str(k) + ":" + str(s) for k, s in self.spaces.items()])
90 + ")"
91 )
92
93 def to_jsonable(self, sample_n):
94 # serialize as dict-repr of vectors
95 return {
96 key: space.to_jsonable([sample[key] for sample in sample_n])
97 for key, space in self.spaces.items()
98 }
99
100 def from_jsonable(self, sample_n):
101 dict_of_list = {}
102 for key, space in self.spaces.items():
103 dict_of_list[key] = space.from_jsonable(sample_n[key])
104 ret = []
105 for i, _ in enumerate(dict_of_list[key]):
106 entry = {}
107 for key, value in dict_of_list.items():
108 entry[key] = value[i]
109 ret.append(entry)
110 return ret
111
112 def __eq__(self, other):
113 return isinstance(other, Dict) and self.spaces == other.spaces
114
```
Path: `gym/spaces/tuple.py`
Content:
```
1 import numpy as np
2 from .space import Space
3
4
5 class Tuple(Space):
6 """
7 A tuple (i.e., product) of simpler spaces
8
9 Example usage:
10 self.observation_space = spaces.Tuple((spaces.Discrete(2), spaces.Discrete(3)))
11 """
12
13 def __init__(self, spaces):
14 self.spaces = spaces
15 for space in spaces:
16 assert isinstance(
17 space, Space
18 ), "Elements of the tuple must be instances of gym.Space"
19 super(Tuple, self).__init__(None, None)
20
21 def seed(self, seed=None):
22 [space.seed(seed) for space in self.spaces]
23
24 def sample(self):
25 return tuple([space.sample() for space in self.spaces])
26
27 def contains(self, x):
28 if isinstance(x, list):
29 x = tuple(x) # Promote list to tuple for contains check
30 return (
31 isinstance(x, tuple)
32 and len(x) == len(self.spaces)
33 and all(space.contains(part) for (space, part) in zip(self.spaces, x))
34 )
35
36 def __repr__(self):
37 return "Tuple(" + ", ".join([str(s) for s in self.spaces]) + ")"
38
39 def to_jsonable(self, sample_n):
40 # serialize as list-repr of tuple of vectors
41 return [
42 space.to_jsonable([sample[i] for sample in sample_n])
43 for i, space in enumerate(self.spaces)
44 ]
45
46 def from_jsonable(self, sample_n):
47 return [
48 sample
49 for sample in zip(
50 *[
51 space.from_jsonable(sample_n[i])
52 for i, space in enumerate(self.spaces)
53 ]
54 )
55 ]
56
57 def __getitem__(self, index):
58 return self.spaces[index]
59
60 def __len__(self):
61 return len(self.spaces)
62
63 def __eq__(self, other):
64 return isinstance(other, Tuple) and self.spaces == other.spaces
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gym/spaces/dict.py b/gym/spaces/dict.py
--- a/gym/spaces/dict.py
+++ b/gym/spaces/dict.py
@@ -1,4 +1,5 @@
from collections import OrderedDict
+import numpy as np
from .space import Space
@@ -52,7 +53,24 @@
) # None for shape and dtype, since it'll require special handling
def seed(self, seed=None):
- [space.seed(seed) for space in self.spaces.values()]
+ seed = super().seed(seed)
+ try:
+ subseeds = self.np_random.choice(
+ np.iinfo(int).max,
+ size=len(self.spaces),
+ replace=False, # unique subseed for each subspace
+ )
+ except ValueError:
+ subseeds = self.np_random.choice(
+ np.iinfo(int).max,
+ size=len(self.spaces),
+ replace=True, # we get more than INT_MAX subspaces
+ )
+
+ for subspace, subseed in zip(self.spaces.values(), subseeds):
+ seed.append(subspace.seed(int(subseed))[0])
+
+ return seed
def sample(self):
return OrderedDict([(k, space.sample()) for k, space in self.spaces.items()])
diff --git a/gym/spaces/tuple.py b/gym/spaces/tuple.py
--- a/gym/spaces/tuple.py
+++ b/gym/spaces/tuple.py
@@ -19,7 +19,24 @@
super(Tuple, self).__init__(None, None)
def seed(self, seed=None):
- [space.seed(seed) for space in self.spaces]
+ seed = super().seed(seed)
+ try:
+ subseeds = self.np_random.choice(
+ np.iinfo(int).max,
+ size=len(self.spaces),
+ replace=False, # unique subseed for each subspace
+ )
+ except ValueError:
+ subseeds = self.np_random.choice(
+ np.iinfo(int).max,
+ size=len(self.spaces),
+ replace=True, # we get more than INT_MAX subspaces
+ )
+
+ for subspace, subseed in zip(self.spaces, subseeds):
+ seed.append(subspace.seed(int(subseed))[0])
+
+ return seed
def sample(self):
return tuple([space.sample() for space in self.spaces])
|
{"golden_diff": "diff --git a/gym/spaces/dict.py b/gym/spaces/dict.py\n--- a/gym/spaces/dict.py\n+++ b/gym/spaces/dict.py\n@@ -1,4 +1,5 @@\n from collections import OrderedDict\n+import numpy as np\n from .space import Space\n \n \n@@ -52,7 +53,24 @@\n ) # None for shape and dtype, since it'll require special handling\n \n def seed(self, seed=None):\n- [space.seed(seed) for space in self.spaces.values()]\n+ seed = super().seed(seed)\n+ try:\n+ subseeds = self.np_random.choice(\n+ np.iinfo(int).max,\n+ size=len(self.spaces),\n+ replace=False, # unique subseed for each subspace\n+ )\n+ except ValueError:\n+ subseeds = self.np_random.choice(\n+ np.iinfo(int).max,\n+ size=len(self.spaces),\n+ replace=True, # we get more than INT_MAX subspaces\n+ )\n+\n+ for subspace, subseed in zip(self.spaces.values(), subseeds):\n+ seed.append(subspace.seed(int(subseed))[0])\n+\n+ return seed\n \n def sample(self):\n return OrderedDict([(k, space.sample()) for k, space in self.spaces.items()])\ndiff --git a/gym/spaces/tuple.py b/gym/spaces/tuple.py\n--- a/gym/spaces/tuple.py\n+++ b/gym/spaces/tuple.py\n@@ -19,7 +19,24 @@\n super(Tuple, self).__init__(None, None)\n \n def seed(self, seed=None):\n- [space.seed(seed) for space in self.spaces]\n+ seed = super().seed(seed)\n+ try:\n+ subseeds = self.np_random.choice(\n+ np.iinfo(int).max,\n+ size=len(self.spaces),\n+ replace=False, # unique subseed for each subspace\n+ )\n+ except ValueError:\n+ subseeds = self.np_random.choice(\n+ np.iinfo(int).max,\n+ size=len(self.spaces),\n+ replace=True, # we get more than INT_MAX subspaces\n+ )\n+\n+ for subspace, subseed in zip(self.spaces, subseeds):\n+ seed.append(subspace.seed(int(subseed))[0])\n+\n+ return seed\n \n def sample(self):\n return tuple([space.sample() for space in self.spaces])\n", "issue": "Seed and sample behaviour in Tuple space\nIf I create a Tuple space containing Discrete spaces, fix the seed, and then generate a sample, all elements of the sampled tuple are the same. For example, (0, 0) or (4, 4). Conversely, if I create a MultiDiscrete space, fix the seed, and then generate a sample, elements of the sampled tuple are not necessarily the same. For example, (0, 4) or (1, 3).\r\n\r\nThis is especially problematic when a Tuple space contains Tuple spaces (i.e. where MultiDiscrete is not an adequate replacement):\r\n\r\n```python\r\nfrom gym.spaces import Tuple, MultiDiscrete, Discrete\r\n\r\nmy_seed = 0\r\n\r\n# Test 1\r\n\r\nprint(\"Test 1:\")\r\n\r\na1 = Tuple([Tuple([Discrete(5) for _ in range(2)]) for _ in range(2)])\r\nb1 = Tuple([MultiDiscrete([5 for _ in range(2)]) for _ in range(2)])\r\n\r\na1.seed(my_seed)\r\nb1.seed(my_seed)\r\n\r\nfor _ in range(5):\r\n print(a1.sample(), b1.sample())\r\n\r\n# Test 2\r\n\r\nprint(\"Test 2:\")\r\n\r\na2 = Tuple([Tuple([Discrete(5) for _ in range(2)]) for _ in range(2)])\r\nb2 = Tuple([MultiDiscrete([5 for _ in range(2)]) for _ in range(2)])\r\n\r\nfor a2_space, b2_space in zip(a2, b2):\r\n my_seed += 1\r\n a2_space.seed(my_seed)\r\n b2_space.seed(my_seed)\r\n\r\nfor _ in range(5):\r\n print(a2.sample(), b2.sample())\r\n```\r\n```\r\nTest 1:\r\n((0, 0), (0, 0)) (array([0, 4]), array([0, 4]))\r\n((3, 3), (3, 3)) (array([3, 1]), array([3, 1]))\r\n((4, 4), (4, 4)) (array([0, 3]), array([0, 3]))\r\n((3, 3), (3, 3)) (array([1, 3]), array([1, 3]))\r\n((3, 3), (3, 3)) (array([0, 2]), array([0, 2]))\r\nTest 2:\r\n((0, 0), (4, 4)) (array([4, 2]), array([4, 3]))\r\n((4, 4), (0, 0)) (array([0, 0]), array([3, 3]))\r\n((3, 3), (0, 0)) (array([3, 0]), array([4, 2]))\r\n((2, 2), (4, 4)) (array([0, 2]), array([1, 2]))\r\n((4, 4), (1, 1)) (array([3, 2]), array([2, 2]))\r\n```\r\n\r\nIs this expected/desirable behaviour for Tuple or am I using it incorrectly? I would have expected Tuple to behave for arbitrary tuples as MultiDiscrete behaves for a single tuple.\n", "before_files": [{"content": "from collections import OrderedDict\nfrom .space import Space\n\n\nclass Dict(Space):\n \"\"\"\n A dictionary of simpler spaces.\n\n Example usage:\n self.observation_space = spaces.Dict({\"position\": spaces.Discrete(2), \"velocity\": spaces.Discrete(3)})\n\n Example usage [nested]:\n self.nested_observation_space = spaces.Dict({\n 'sensors': spaces.Dict({\n 'position': spaces.Box(low=-100, high=100, shape=(3,)),\n 'velocity': spaces.Box(low=-1, high=1, shape=(3,)),\n 'front_cam': spaces.Tuple((\n spaces.Box(low=0, high=1, shape=(10, 10, 3)),\n spaces.Box(low=0, high=1, shape=(10, 10, 3))\n )),\n 'rear_cam': spaces.Box(low=0, high=1, shape=(10, 10, 3)),\n }),\n 'ext_controller': spaces.MultiDiscrete((5, 2, 2)),\n 'inner_state':spaces.Dict({\n 'charge': spaces.Discrete(100),\n 'system_checks': spaces.MultiBinary(10),\n 'job_status': spaces.Dict({\n 'task': spaces.Discrete(5),\n 'progress': spaces.Box(low=0, high=100, shape=()),\n })\n })\n })\n \"\"\"\n\n def __init__(self, spaces=None, **spaces_kwargs):\n assert (spaces is None) or (\n not spaces_kwargs\n ), \"Use either Dict(spaces=dict(...)) or Dict(foo=x, bar=z)\"\n if spaces is None:\n spaces = spaces_kwargs\n if isinstance(spaces, dict) and not isinstance(spaces, OrderedDict):\n spaces = OrderedDict(sorted(list(spaces.items())))\n if isinstance(spaces, list):\n spaces = OrderedDict(spaces)\n self.spaces = spaces\n for space in spaces.values():\n assert isinstance(\n space, Space\n ), \"Values of the dict should be instances of gym.Space\"\n super(Dict, self).__init__(\n None, None\n ) # None for shape and dtype, since it'll require special handling\n\n def seed(self, seed=None):\n [space.seed(seed) for space in self.spaces.values()]\n\n def sample(self):\n return OrderedDict([(k, space.sample()) for k, space in self.spaces.items()])\n\n def contains(self, x):\n if not isinstance(x, dict) or len(x) != len(self.spaces):\n return False\n for k, space in self.spaces.items():\n if k not in x:\n return False\n if not space.contains(x[k]):\n return False\n return True\n\n def __getitem__(self, key):\n return self.spaces[key]\n\n def __setitem__(self, key, value):\n self.spaces[key] = value\n\n def __iter__(self):\n for key in self.spaces:\n yield key\n\n def __len__(self):\n return len(self.spaces)\n\n def __contains__(self, item):\n return self.contains(item)\n\n def __repr__(self):\n return (\n \"Dict(\"\n + \", \".join([str(k) + \":\" + str(s) for k, s in self.spaces.items()])\n + \")\"\n )\n\n def to_jsonable(self, sample_n):\n # serialize as dict-repr of vectors\n return {\n key: space.to_jsonable([sample[key] for sample in sample_n])\n for key, space in self.spaces.items()\n }\n\n def from_jsonable(self, sample_n):\n dict_of_list = {}\n for key, space in self.spaces.items():\n dict_of_list[key] = space.from_jsonable(sample_n[key])\n ret = []\n for i, _ in enumerate(dict_of_list[key]):\n entry = {}\n for key, value in dict_of_list.items():\n entry[key] = value[i]\n ret.append(entry)\n return ret\n\n def __eq__(self, other):\n return isinstance(other, Dict) and self.spaces == other.spaces\n", "path": "gym/spaces/dict.py"}, {"content": "import numpy as np\nfrom .space import Space\n\n\nclass Tuple(Space):\n \"\"\"\n A tuple (i.e., product) of simpler spaces\n\n Example usage:\n self.observation_space = spaces.Tuple((spaces.Discrete(2), spaces.Discrete(3)))\n \"\"\"\n\n def __init__(self, spaces):\n self.spaces = spaces\n for space in spaces:\n assert isinstance(\n space, Space\n ), \"Elements of the tuple must be instances of gym.Space\"\n super(Tuple, self).__init__(None, None)\n\n def seed(self, seed=None):\n [space.seed(seed) for space in self.spaces]\n\n def sample(self):\n return tuple([space.sample() for space in self.spaces])\n\n def contains(self, x):\n if isinstance(x, list):\n x = tuple(x) # Promote list to tuple for contains check\n return (\n isinstance(x, tuple)\n and len(x) == len(self.spaces)\n and all(space.contains(part) for (space, part) in zip(self.spaces, x))\n )\n\n def __repr__(self):\n return \"Tuple(\" + \", \".join([str(s) for s in self.spaces]) + \")\"\n\n def to_jsonable(self, sample_n):\n # serialize as list-repr of tuple of vectors\n return [\n space.to_jsonable([sample[i] for sample in sample_n])\n for i, space in enumerate(self.spaces)\n ]\n\n def from_jsonable(self, sample_n):\n return [\n sample\n for sample in zip(\n *[\n space.from_jsonable(sample_n[i])\n for i, space in enumerate(self.spaces)\n ]\n )\n ]\n\n def __getitem__(self, index):\n return self.spaces[index]\n\n def __len__(self):\n return len(self.spaces)\n\n def __eq__(self, other):\n return isinstance(other, Tuple) and self.spaces == other.spaces\n", "path": "gym/spaces/tuple.py"}], "after_files": [{"content": "from collections import OrderedDict\nimport numpy as np\nfrom .space import Space\n\n\nclass Dict(Space):\n \"\"\"\n A dictionary of simpler spaces.\n\n Example usage:\n self.observation_space = spaces.Dict({\"position\": spaces.Discrete(2), \"velocity\": spaces.Discrete(3)})\n\n Example usage [nested]:\n self.nested_observation_space = spaces.Dict({\n 'sensors': spaces.Dict({\n 'position': spaces.Box(low=-100, high=100, shape=(3,)),\n 'velocity': spaces.Box(low=-1, high=1, shape=(3,)),\n 'front_cam': spaces.Tuple((\n spaces.Box(low=0, high=1, shape=(10, 10, 3)),\n spaces.Box(low=0, high=1, shape=(10, 10, 3))\n )),\n 'rear_cam': spaces.Box(low=0, high=1, shape=(10, 10, 3)),\n }),\n 'ext_controller': spaces.MultiDiscrete((5, 2, 2)),\n 'inner_state':spaces.Dict({\n 'charge': spaces.Discrete(100),\n 'system_checks': spaces.MultiBinary(10),\n 'job_status': spaces.Dict({\n 'task': spaces.Discrete(5),\n 'progress': spaces.Box(low=0, high=100, shape=()),\n })\n })\n })\n \"\"\"\n\n def __init__(self, spaces=None, **spaces_kwargs):\n assert (spaces is None) or (\n not spaces_kwargs\n ), \"Use either Dict(spaces=dict(...)) or Dict(foo=x, bar=z)\"\n if spaces is None:\n spaces = spaces_kwargs\n if isinstance(spaces, dict) and not isinstance(spaces, OrderedDict):\n spaces = OrderedDict(sorted(list(spaces.items())))\n if isinstance(spaces, list):\n spaces = OrderedDict(spaces)\n self.spaces = spaces\n for space in spaces.values():\n assert isinstance(\n space, Space\n ), \"Values of the dict should be instances of gym.Space\"\n super(Dict, self).__init__(\n None, None\n ) # None for shape and dtype, since it'll require special handling\n\n def seed(self, seed=None):\n seed = super().seed(seed)\n try:\n subseeds = self.np_random.choice(\n np.iinfo(int).max,\n size=len(self.spaces),\n replace=False, # unique subseed for each subspace\n )\n except ValueError:\n subseeds = self.np_random.choice(\n np.iinfo(int).max,\n size=len(self.spaces),\n replace=True, # we get more than INT_MAX subspaces\n )\n\n for subspace, subseed in zip(self.spaces.values(), subseeds):\n seed.append(subspace.seed(int(subseed))[0])\n\n return seed\n\n def sample(self):\n return OrderedDict([(k, space.sample()) for k, space in self.spaces.items()])\n\n def contains(self, x):\n if not isinstance(x, dict) or len(x) != len(self.spaces):\n return False\n for k, space in self.spaces.items():\n if k not in x:\n return False\n if not space.contains(x[k]):\n return False\n return True\n\n def __getitem__(self, key):\n return self.spaces[key]\n\n def __setitem__(self, key, value):\n self.spaces[key] = value\n\n def __iter__(self):\n for key in self.spaces:\n yield key\n\n def __len__(self):\n return len(self.spaces)\n\n def __contains__(self, item):\n return self.contains(item)\n\n def __repr__(self):\n return (\n \"Dict(\"\n + \", \".join([str(k) + \":\" + str(s) for k, s in self.spaces.items()])\n + \")\"\n )\n\n def to_jsonable(self, sample_n):\n # serialize as dict-repr of vectors\n return {\n key: space.to_jsonable([sample[key] for sample in sample_n])\n for key, space in self.spaces.items()\n }\n\n def from_jsonable(self, sample_n):\n dict_of_list = {}\n for key, space in self.spaces.items():\n dict_of_list[key] = space.from_jsonable(sample_n[key])\n ret = []\n for i, _ in enumerate(dict_of_list[key]):\n entry = {}\n for key, value in dict_of_list.items():\n entry[key] = value[i]\n ret.append(entry)\n return ret\n\n def __eq__(self, other):\n return isinstance(other, Dict) and self.spaces == other.spaces\n", "path": "gym/spaces/dict.py"}, {"content": "import numpy as np\nfrom .space import Space\n\n\nclass Tuple(Space):\n \"\"\"\n A tuple (i.e., product) of simpler spaces\n\n Example usage:\n self.observation_space = spaces.Tuple((spaces.Discrete(2), spaces.Discrete(3)))\n \"\"\"\n\n def __init__(self, spaces):\n self.spaces = spaces\n for space in spaces:\n assert isinstance(\n space, Space\n ), \"Elements of the tuple must be instances of gym.Space\"\n super(Tuple, self).__init__(None, None)\n\n def seed(self, seed=None):\n seed = super().seed(seed)\n try:\n subseeds = self.np_random.choice(\n np.iinfo(int).max,\n size=len(self.spaces),\n replace=False, # unique subseed for each subspace\n )\n except ValueError:\n subseeds = self.np_random.choice(\n np.iinfo(int).max,\n size=len(self.spaces),\n replace=True, # we get more than INT_MAX subspaces\n )\n\n for subspace, subseed in zip(self.spaces, subseeds):\n seed.append(subspace.seed(int(subseed))[0])\n\n return seed\n\n def sample(self):\n return tuple([space.sample() for space in self.spaces])\n\n def contains(self, x):\n if isinstance(x, list):\n x = tuple(x) # Promote list to tuple for contains check\n return (\n isinstance(x, tuple)\n and len(x) == len(self.spaces)\n and all(space.contains(part) for (space, part) in zip(self.spaces, x))\n )\n\n def __repr__(self):\n return \"Tuple(\" + \", \".join([str(s) for s in self.spaces]) + \")\"\n\n def to_jsonable(self, sample_n):\n # serialize as list-repr of tuple of vectors\n return [\n space.to_jsonable([sample[i] for sample in sample_n])\n for i, space in enumerate(self.spaces)\n ]\n\n def from_jsonable(self, sample_n):\n return [\n sample\n for sample in zip(\n *[\n space.from_jsonable(sample_n[i])\n for i, space in enumerate(self.spaces)\n ]\n )\n ]\n\n def __getitem__(self, index):\n return self.spaces[index]\n\n def __len__(self):\n return len(self.spaces)\n\n def __eq__(self, other):\n return isinstance(other, Tuple) and self.spaces == other.spaces\n", "path": "gym/spaces/tuple.py"}]}
| 2,654 | 556 |
gh_patches_debug_24203
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2096
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Markdown parsing error in NovoGrad documentation page
The documentation page of NovoGrad has a broken Markdown link shown below:
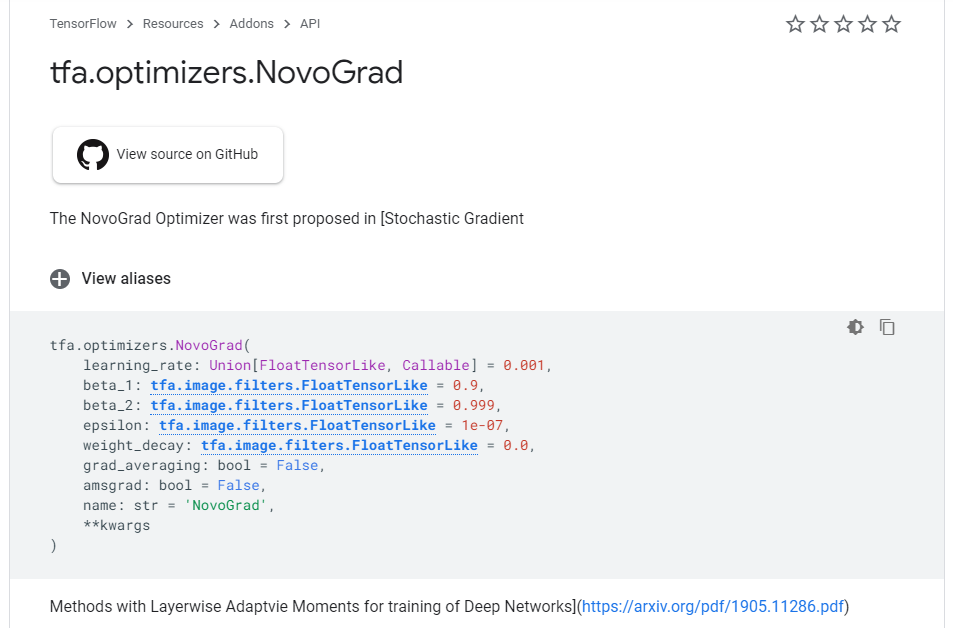
I suspect this is because only the first line of the docstring is used for the first line of the documentation page. In the docstring (shown below), the link spans multiple lines.
https://github.com/tensorflow/addons/blob/5f746971d0d9491716f2f13206299a2c45941b0c/tensorflow_addons/optimizers/novograd.py#L26-L28
The simplest solution would be to edit the docstring so that there is a one-line summary for the first line with a paper link after the newline. One example would be [LAMB's documentation page](https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/LAMB). I will create a PR with this solution.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/optimizers/novograd.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """NovoGrad for TensorFlow."""
16
17 import tensorflow as tf
18 from tensorflow_addons.utils.types import FloatTensorLike
19
20 from typing import Union, Callable
21 from typeguard import typechecked
22
23
24 @tf.keras.utils.register_keras_serializable(package="Addons")
25 class NovoGrad(tf.keras.optimizers.Optimizer):
26 """The NovoGrad Optimizer was first proposed in [Stochastic Gradient
27 Methods with Layerwise Adaptvie Moments for training of Deep
28 Networks](https://arxiv.org/pdf/1905.11286.pdf)
29
30 NovoGrad is a first-order SGD-based algorithm, which computes second
31 moments per layer instead of per weight as in Adam. Compared to Adam,
32 NovoGrad takes less memory, and has been found to be more numerically
33 stable. More specifically we compute (for more information on the
34 computation please refer to this
35 [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html):
36
37 Second order moment = exponential moving average of Layer-wise square
38 of grads:
39 v_t <-- beta_2 * v_{t-1} + (1-beta_2) * (g_t)^2
40 First order moment in one of four modes:
41 1. moment of grads normalized by v_t:
42 m_t <- beta_1 * m_{t-1} + [ g_t / (sqrt(v_t)+epsilon)]
43 2. moment similar to Adam: exponential moving average of grads
44 normalized by v_t (set grad_averaging = True to use this):
45 m_t <- beta_1 * m_{t-1} +
46 [(1 - beta_1) * (g_t / (sqrt(v_t) + epsilon))]
47 3. weight decay adds a w_d term after grads are rescaled by
48 1/sqrt(v_t) (set weight_decay > 0 to use this0:
49 m_t <- beta_1 * m_{t-1} +
50 [(g_t / (sqrt(v_t) + epsilon)) + (w_d * w_{t-1})]
51 4. weight decay + exponential moving average from Adam:
52 m_t <- beta_1 * m_{t-1} +
53 [(1 - beta_1) * ((g_t / (sqrt(v_t + epsilon)) +
54 (w_d * w_{t-1}))]
55 Weight update:
56 w_t <- w_{t-1} - lr_t * m_t
57
58 Example of usage:
59 ```python
60 opt = tfa.optimizers.NovoGrad(
61 lr=1e-3,
62 beta_1=0.9,
63 beta_2=0.999,
64 weight_decay=0.001,
65 grad_averaging=False
66 )
67 ```
68 """
69
70 @typechecked
71 def __init__(
72 self,
73 learning_rate: Union[FloatTensorLike, Callable] = 0.001,
74 beta_1: FloatTensorLike = 0.9,
75 beta_2: FloatTensorLike = 0.999,
76 epsilon: FloatTensorLike = 1e-7,
77 weight_decay: FloatTensorLike = 0.0,
78 grad_averaging: bool = False,
79 amsgrad: bool = False,
80 name: str = "NovoGrad",
81 **kwargs
82 ):
83 r"""Construct a new NovoGrad optimizer.
84
85 Args:
86 learning_rate: A `Tensor` or a floating point value. or a schedule
87 that is a `tf.keras.optimizers.schedules.LearningRateSchedule`
88 The learning rate.
89 beta_1: A float value or a constant float tensor.
90 The exponential decay rate for the 1st moment estimates.
91 beta_2: A float value or a constant float tensor.
92 The exponential decay rate for the 2nd moment estimates.
93 epsilon: A small constant for numerical stability.
94 weight_decay: A floating point value. Weight decay for each param.
95 grad_averaging: determines whether to use Adam style exponential
96 moving averaging for the first order moments.
97 **kwargs: keyword arguments. Allowed to be {`clipnorm`,
98 `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients
99 by norm; `clipvalue` is clip gradients by value, `decay` is
100 included for backward compatibility to allow time inverse
101 decay of learning rate. `lr` is included for backward
102 compatibility, recommended to use `learning_rate` instead.
103 """
104 super().__init__(name, **kwargs)
105 if weight_decay < 0.0:
106 raise ValueError("Weight decay rate cannot be negative")
107 self._set_hyper("learning_rate", kwargs.get("lr", learning_rate))
108 self._set_hyper("decay", self._initial_decay)
109 self._set_hyper("beta_1", beta_1)
110 self._set_hyper("beta_2", beta_2)
111 self._set_hyper("weight_decay", weight_decay)
112 self._set_hyper("grad_averaging", grad_averaging)
113 self.amsgrad = amsgrad
114 self.epsilon = epsilon or tf.keras.backend.epsilon()
115
116 def _create_slots(self, var_list):
117 # Create slots for the first and second moments.
118 # Separate for-loops to respect the ordering of slot variables from v1.
119 for var in var_list:
120 self.add_slot(var=var, slot_name="m", initializer="zeros")
121 for var in var_list:
122 self.add_slot(
123 var=var, slot_name="v", initializer=tf.zeros(shape=[], dtype=var.dtype)
124 )
125 if self.amsgrad:
126 for var in var_list:
127 self.add_slot(var, "vhat")
128
129 def _prepare_local(self, var_device, var_dtype, apply_state):
130 super()._prepare_local(var_device, var_dtype, apply_state)
131 beta_1_t = tf.identity(self._get_hyper("beta_1", var_dtype))
132 beta_2_t = tf.identity(self._get_hyper("beta_2", var_dtype))
133 apply_state[(var_device, var_dtype)].update(
134 dict(
135 epsilon=tf.convert_to_tensor(self.epsilon, var_dtype),
136 beta_1_t=beta_1_t,
137 beta_2_t=beta_2_t,
138 one_minus_beta_2_t=1 - beta_2_t,
139 one_minus_beta_1_t=1 - beta_1_t,
140 )
141 )
142
143 def set_weights(self, weights):
144 params = self.weights
145 # If the weights are generated by Keras V1 optimizer, it includes vhats
146 # even without amsgrad, i.e, V1 optimizer has 3x + 1 variables, while V2
147 # optimizer has 2x + 1 variables. Filter vhats out for compatibility.
148 num_vars = int((len(params) - 1) / 2)
149 if len(weights) == 3 * num_vars + 1:
150 weights = weights[: len(params)]
151 super().set_weights(weights)
152
153 def _resource_apply_dense(self, grad, var, apply_state=None):
154 var_device, var_dtype = var.device, var.dtype.base_dtype
155 coefficients = (apply_state or {}).get(
156 (var_device, var_dtype)
157 ) or self._fallback_apply_state(var_device, var_dtype)
158 weight_decay = self._get_hyper("weight_decay")
159 grad_averaging = self._get_hyper("grad_averaging")
160
161 v = self.get_slot(var, "v")
162 g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))
163 v_t = tf.cond(
164 tf.equal(self.iterations, 0),
165 lambda: g_2,
166 lambda: v * coefficients["beta_2_t"]
167 + g_2 * coefficients["one_minus_beta_2_t"],
168 )
169 v_t = v.assign(v_t, use_locking=self._use_locking)
170
171 if self.amsgrad:
172 vhat = self.get_slot(var, "vhat")
173 vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)
174 grad = grad / (tf.sqrt(vhat_t) + self.epsilon)
175 else:
176 grad = grad / (tf.sqrt(v_t) + self.epsilon)
177 grad = tf.cond(
178 tf.greater(weight_decay, 0), lambda: grad + weight_decay * var, lambda: grad
179 )
180 grad = tf.cond(
181 tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),
182 lambda: grad * coefficients["one_minus_beta_1_t"],
183 lambda: grad,
184 )
185 m = self.get_slot(var, "m")
186 return tf.raw_ops.ResourceApplyKerasMomentum(
187 var=var.handle,
188 accum=m.handle,
189 lr=coefficients["lr_t"],
190 grad=grad,
191 momentum=coefficients["beta_1_t"],
192 use_locking=self._use_locking,
193 use_nesterov=False,
194 )
195
196 def _resource_apply_sparse(self, grad, var, indices, apply_state=None):
197 var_device, var_dtype = var.device, var.dtype.base_dtype
198 coefficients = (apply_state or {}).get(
199 (var_device, var_dtype)
200 ) or self._fallback_apply_state(var_device, var_dtype)
201 weight_decay = self._get_hyper("weight_decay")
202 grad_averaging = self._get_hyper("grad_averaging")
203
204 v = self.get_slot(var, "v")
205 g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))
206 # v is just a scalar and does not need to involve sparse tensors.
207 v_t = tf.cond(
208 tf.equal(self.iterations, 0),
209 lambda: g_2,
210 lambda: v * coefficients["beta_2_t"]
211 + g_2 * coefficients["one_minus_beta_2_t"],
212 )
213 v_t = v.assign(v_t, use_locking=self._use_locking)
214
215 if self.amsgrad:
216 vhat = self.get_slot(var, "vhat")
217 vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)
218 grad = grad / (tf.sqrt(vhat_t) + self.epsilon)
219 else:
220 grad = grad / (tf.sqrt(v_t) + self.epsilon)
221 grad = tf.cond(
222 tf.greater(weight_decay, 0),
223 lambda: grad + weight_decay * tf.gather(var, indices),
224 lambda: grad,
225 )
226 grad = tf.cond(
227 tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),
228 lambda: grad * coefficients["one_minus_beta_1_t"],
229 lambda: grad,
230 )
231 m = self.get_slot(var, "m")
232 return tf.raw_ops.ResourceSparseApplyKerasMomentum(
233 var=var.handle,
234 accum=m.handle,
235 lr=coefficients["lr_t"],
236 grad=grad,
237 indices=indices,
238 momentum=coefficients["beta_1_t"],
239 use_locking=self._use_locking,
240 use_nesterov=False,
241 )
242
243 def get_config(self):
244 config = super().get_config()
245 config.update(
246 {
247 "learning_rate": self._serialize_hyperparameter("learning_rate"),
248 "beta_1": self._serialize_hyperparameter("beta_1"),
249 "beta_2": self._serialize_hyperparameter("beta_2"),
250 "epsilon": self.epsilon,
251 "weight_decay": self._serialize_hyperparameter("weight_decay"),
252 "grad_averaging": self._serialize_hyperparameter("grad_averaging"),
253 }
254 )
255 return config
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_addons/optimizers/novograd.py b/tensorflow_addons/optimizers/novograd.py
--- a/tensorflow_addons/optimizers/novograd.py
+++ b/tensorflow_addons/optimizers/novograd.py
@@ -23,16 +23,16 @@
@tf.keras.utils.register_keras_serializable(package="Addons")
class NovoGrad(tf.keras.optimizers.Optimizer):
- """The NovoGrad Optimizer was first proposed in [Stochastic Gradient
- Methods with Layerwise Adaptvie Moments for training of Deep
- Networks](https://arxiv.org/pdf/1905.11286.pdf)
-
- NovoGrad is a first-order SGD-based algorithm, which computes second
- moments per layer instead of per weight as in Adam. Compared to Adam,
- NovoGrad takes less memory, and has been found to be more numerically
- stable. More specifically we compute (for more information on the
- computation please refer to this
- [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html):
+ """Optimizer that implements NovoGrad.
+
+ The NovoGrad Optimizer was first proposed in [Stochastic Gradient
+ Methods with Layerwise Adaptive Moments for training of Deep
+ Networks](https://arxiv.org/pdf/1905.11286.pdf) NovoGrad is a
+ first-order SGD-based algorithm, which computes second moments per
+ layer instead of per weight as in Adam. Compared to Adam, NovoGrad
+ takes less memory, and has been found to be more numerically stable.
+ (For more information on the computation please refer to this
+ [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html))
Second order moment = exponential moving average of Layer-wise square
of grads:
|
{"golden_diff": "diff --git a/tensorflow_addons/optimizers/novograd.py b/tensorflow_addons/optimizers/novograd.py\n--- a/tensorflow_addons/optimizers/novograd.py\n+++ b/tensorflow_addons/optimizers/novograd.py\n@@ -23,16 +23,16 @@\n \n @tf.keras.utils.register_keras_serializable(package=\"Addons\")\n class NovoGrad(tf.keras.optimizers.Optimizer):\n- \"\"\"The NovoGrad Optimizer was first proposed in [Stochastic Gradient\n- Methods with Layerwise Adaptvie Moments for training of Deep\n- Networks](https://arxiv.org/pdf/1905.11286.pdf)\n-\n- NovoGrad is a first-order SGD-based algorithm, which computes second\n- moments per layer instead of per weight as in Adam. Compared to Adam,\n- NovoGrad takes less memory, and has been found to be more numerically\n- stable. More specifically we compute (for more information on the\n- computation please refer to this\n- [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html):\n+ \"\"\"Optimizer that implements NovoGrad.\n+\n+ The NovoGrad Optimizer was first proposed in [Stochastic Gradient\n+ Methods with Layerwise Adaptive Moments for training of Deep\n+ Networks](https://arxiv.org/pdf/1905.11286.pdf) NovoGrad is a\n+ first-order SGD-based algorithm, which computes second moments per\n+ layer instead of per weight as in Adam. Compared to Adam, NovoGrad\n+ takes less memory, and has been found to be more numerically stable.\n+ (For more information on the computation please refer to this\n+ [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html))\n \n Second order moment = exponential moving average of Layer-wise square\n of grads:\n", "issue": "Markdown parsing error in NovoGrad documentation page\nThe documentation page of NovoGrad has a broken Markdown link shown below:\r\n\r\n\r\n\r\nI suspect this is because only the first line of the docstring is used for the first line of the documentation page. In the docstring (shown below), the link spans multiple lines.\r\n\r\nhttps://github.com/tensorflow/addons/blob/5f746971d0d9491716f2f13206299a2c45941b0c/tensorflow_addons/optimizers/novograd.py#L26-L28\r\n\r\nThe simplest solution would be to edit the docstring so that there is a one-line summary for the first line with a paper link after the newline. One example would be [LAMB's documentation page](https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers/LAMB). I will create a PR with this solution.\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"NovoGrad for TensorFlow.\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils.types import FloatTensorLike\n\nfrom typing import Union, Callable\nfrom typeguard import typechecked\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass NovoGrad(tf.keras.optimizers.Optimizer):\n \"\"\"The NovoGrad Optimizer was first proposed in [Stochastic Gradient\n Methods with Layerwise Adaptvie Moments for training of Deep\n Networks](https://arxiv.org/pdf/1905.11286.pdf)\n\n NovoGrad is a first-order SGD-based algorithm, which computes second\n moments per layer instead of per weight as in Adam. Compared to Adam,\n NovoGrad takes less memory, and has been found to be more numerically\n stable. More specifically we compute (for more information on the\n computation please refer to this\n [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html):\n\n Second order moment = exponential moving average of Layer-wise square\n of grads:\n v_t <-- beta_2 * v_{t-1} + (1-beta_2) * (g_t)^2\n First order moment in one of four modes:\n 1. moment of grads normalized by v_t:\n m_t <- beta_1 * m_{t-1} + [ g_t / (sqrt(v_t)+epsilon)]\n 2. moment similar to Adam: exponential moving average of grads\n normalized by v_t (set grad_averaging = True to use this):\n m_t <- beta_1 * m_{t-1} +\n [(1 - beta_1) * (g_t / (sqrt(v_t) + epsilon))]\n 3. weight decay adds a w_d term after grads are rescaled by\n 1/sqrt(v_t) (set weight_decay > 0 to use this0:\n m_t <- beta_1 * m_{t-1} +\n [(g_t / (sqrt(v_t) + epsilon)) + (w_d * w_{t-1})]\n 4. weight decay + exponential moving average from Adam:\n m_t <- beta_1 * m_{t-1} +\n [(1 - beta_1) * ((g_t / (sqrt(v_t + epsilon)) +\n (w_d * w_{t-1}))]\n Weight update:\n w_t <- w_{t-1} - lr_t * m_t\n\n Example of usage:\n ```python\n opt = tfa.optimizers.NovoGrad(\n lr=1e-3,\n beta_1=0.9,\n beta_2=0.999,\n weight_decay=0.001,\n grad_averaging=False\n )\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n learning_rate: Union[FloatTensorLike, Callable] = 0.001,\n beta_1: FloatTensorLike = 0.9,\n beta_2: FloatTensorLike = 0.999,\n epsilon: FloatTensorLike = 1e-7,\n weight_decay: FloatTensorLike = 0.0,\n grad_averaging: bool = False,\n amsgrad: bool = False,\n name: str = \"NovoGrad\",\n **kwargs\n ):\n r\"\"\"Construct a new NovoGrad optimizer.\n\n Args:\n learning_rate: A `Tensor` or a floating point value. or a schedule\n that is a `tf.keras.optimizers.schedules.LearningRateSchedule`\n The learning rate.\n beta_1: A float value or a constant float tensor.\n The exponential decay rate for the 1st moment estimates.\n beta_2: A float value or a constant float tensor.\n The exponential decay rate for the 2nd moment estimates.\n epsilon: A small constant for numerical stability.\n weight_decay: A floating point value. Weight decay for each param.\n grad_averaging: determines whether to use Adam style exponential\n moving averaging for the first order moments.\n **kwargs: keyword arguments. Allowed to be {`clipnorm`,\n `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients\n by norm; `clipvalue` is clip gradients by value, `decay` is\n included for backward compatibility to allow time inverse\n decay of learning rate. `lr` is included for backward\n compatibility, recommended to use `learning_rate` instead.\n \"\"\"\n super().__init__(name, **kwargs)\n if weight_decay < 0.0:\n raise ValueError(\"Weight decay rate cannot be negative\")\n self._set_hyper(\"learning_rate\", kwargs.get(\"lr\", learning_rate))\n self._set_hyper(\"decay\", self._initial_decay)\n self._set_hyper(\"beta_1\", beta_1)\n self._set_hyper(\"beta_2\", beta_2)\n self._set_hyper(\"weight_decay\", weight_decay)\n self._set_hyper(\"grad_averaging\", grad_averaging)\n self.amsgrad = amsgrad\n self.epsilon = epsilon or tf.keras.backend.epsilon()\n\n def _create_slots(self, var_list):\n # Create slots for the first and second moments.\n # Separate for-loops to respect the ordering of slot variables from v1.\n for var in var_list:\n self.add_slot(var=var, slot_name=\"m\", initializer=\"zeros\")\n for var in var_list:\n self.add_slot(\n var=var, slot_name=\"v\", initializer=tf.zeros(shape=[], dtype=var.dtype)\n )\n if self.amsgrad:\n for var in var_list:\n self.add_slot(var, \"vhat\")\n\n def _prepare_local(self, var_device, var_dtype, apply_state):\n super()._prepare_local(var_device, var_dtype, apply_state)\n beta_1_t = tf.identity(self._get_hyper(\"beta_1\", var_dtype))\n beta_2_t = tf.identity(self._get_hyper(\"beta_2\", var_dtype))\n apply_state[(var_device, var_dtype)].update(\n dict(\n epsilon=tf.convert_to_tensor(self.epsilon, var_dtype),\n beta_1_t=beta_1_t,\n beta_2_t=beta_2_t,\n one_minus_beta_2_t=1 - beta_2_t,\n one_minus_beta_1_t=1 - beta_1_t,\n )\n )\n\n def set_weights(self, weights):\n params = self.weights\n # If the weights are generated by Keras V1 optimizer, it includes vhats\n # even without amsgrad, i.e, V1 optimizer has 3x + 1 variables, while V2\n # optimizer has 2x + 1 variables. Filter vhats out for compatibility.\n num_vars = int((len(params) - 1) / 2)\n if len(weights) == 3 * num_vars + 1:\n weights = weights[: len(params)]\n super().set_weights(weights)\n\n def _resource_apply_dense(self, grad, var, apply_state=None):\n var_device, var_dtype = var.device, var.dtype.base_dtype\n coefficients = (apply_state or {}).get(\n (var_device, var_dtype)\n ) or self._fallback_apply_state(var_device, var_dtype)\n weight_decay = self._get_hyper(\"weight_decay\")\n grad_averaging = self._get_hyper(\"grad_averaging\")\n\n v = self.get_slot(var, \"v\")\n g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))\n v_t = tf.cond(\n tf.equal(self.iterations, 0),\n lambda: g_2,\n lambda: v * coefficients[\"beta_2_t\"]\n + g_2 * coefficients[\"one_minus_beta_2_t\"],\n )\n v_t = v.assign(v_t, use_locking=self._use_locking)\n\n if self.amsgrad:\n vhat = self.get_slot(var, \"vhat\")\n vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)\n grad = grad / (tf.sqrt(vhat_t) + self.epsilon)\n else:\n grad = grad / (tf.sqrt(v_t) + self.epsilon)\n grad = tf.cond(\n tf.greater(weight_decay, 0), lambda: grad + weight_decay * var, lambda: grad\n )\n grad = tf.cond(\n tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),\n lambda: grad * coefficients[\"one_minus_beta_1_t\"],\n lambda: grad,\n )\n m = self.get_slot(var, \"m\")\n return tf.raw_ops.ResourceApplyKerasMomentum(\n var=var.handle,\n accum=m.handle,\n lr=coefficients[\"lr_t\"],\n grad=grad,\n momentum=coefficients[\"beta_1_t\"],\n use_locking=self._use_locking,\n use_nesterov=False,\n )\n\n def _resource_apply_sparse(self, grad, var, indices, apply_state=None):\n var_device, var_dtype = var.device, var.dtype.base_dtype\n coefficients = (apply_state or {}).get(\n (var_device, var_dtype)\n ) or self._fallback_apply_state(var_device, var_dtype)\n weight_decay = self._get_hyper(\"weight_decay\")\n grad_averaging = self._get_hyper(\"grad_averaging\")\n\n v = self.get_slot(var, \"v\")\n g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))\n # v is just a scalar and does not need to involve sparse tensors.\n v_t = tf.cond(\n tf.equal(self.iterations, 0),\n lambda: g_2,\n lambda: v * coefficients[\"beta_2_t\"]\n + g_2 * coefficients[\"one_minus_beta_2_t\"],\n )\n v_t = v.assign(v_t, use_locking=self._use_locking)\n\n if self.amsgrad:\n vhat = self.get_slot(var, \"vhat\")\n vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)\n grad = grad / (tf.sqrt(vhat_t) + self.epsilon)\n else:\n grad = grad / (tf.sqrt(v_t) + self.epsilon)\n grad = tf.cond(\n tf.greater(weight_decay, 0),\n lambda: grad + weight_decay * tf.gather(var, indices),\n lambda: grad,\n )\n grad = tf.cond(\n tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),\n lambda: grad * coefficients[\"one_minus_beta_1_t\"],\n lambda: grad,\n )\n m = self.get_slot(var, \"m\")\n return tf.raw_ops.ResourceSparseApplyKerasMomentum(\n var=var.handle,\n accum=m.handle,\n lr=coefficients[\"lr_t\"],\n grad=grad,\n indices=indices,\n momentum=coefficients[\"beta_1_t\"],\n use_locking=self._use_locking,\n use_nesterov=False,\n )\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"learning_rate\": self._serialize_hyperparameter(\"learning_rate\"),\n \"beta_1\": self._serialize_hyperparameter(\"beta_1\"),\n \"beta_2\": self._serialize_hyperparameter(\"beta_2\"),\n \"epsilon\": self.epsilon,\n \"weight_decay\": self._serialize_hyperparameter(\"weight_decay\"),\n \"grad_averaging\": self._serialize_hyperparameter(\"grad_averaging\"),\n }\n )\n return config\n", "path": "tensorflow_addons/optimizers/novograd.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"NovoGrad for TensorFlow.\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils.types import FloatTensorLike\n\nfrom typing import Union, Callable\nfrom typeguard import typechecked\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass NovoGrad(tf.keras.optimizers.Optimizer):\n \"\"\"Optimizer that implements NovoGrad.\n\n The NovoGrad Optimizer was first proposed in [Stochastic Gradient\n Methods with Layerwise Adaptive Moments for training of Deep\n Networks](https://arxiv.org/pdf/1905.11286.pdf) NovoGrad is a\n first-order SGD-based algorithm, which computes second moments per\n layer instead of per weight as in Adam. Compared to Adam, NovoGrad\n takes less memory, and has been found to be more numerically stable.\n (For more information on the computation please refer to this\n [link](https://nvidia.github.io/OpenSeq2Seq/html/optimizers.html))\n\n Second order moment = exponential moving average of Layer-wise square\n of grads:\n v_t <-- beta_2 * v_{t-1} + (1-beta_2) * (g_t)^2\n First order moment in one of four modes:\n 1. moment of grads normalized by v_t:\n m_t <- beta_1 * m_{t-1} + [ g_t / (sqrt(v_t)+epsilon)]\n 2. moment similar to Adam: exponential moving average of grads\n normalized by v_t (set grad_averaging = True to use this):\n m_t <- beta_1 * m_{t-1} +\n [(1 - beta_1) * (g_t / (sqrt(v_t) + epsilon))]\n 3. weight decay adds a w_d term after grads are rescaled by\n 1/sqrt(v_t) (set weight_decay > 0 to use this0:\n m_t <- beta_1 * m_{t-1} +\n [(g_t / (sqrt(v_t) + epsilon)) + (w_d * w_{t-1})]\n 4. weight decay + exponential moving average from Adam:\n m_t <- beta_1 * m_{t-1} +\n [(1 - beta_1) * ((g_t / (sqrt(v_t + epsilon)) +\n (w_d * w_{t-1}))]\n Weight update:\n w_t <- w_{t-1} - lr_t * m_t\n\n Example of usage:\n ```python\n opt = tfa.optimizers.NovoGrad(\n lr=1e-3,\n beta_1=0.9,\n beta_2=0.999,\n weight_decay=0.001,\n grad_averaging=False\n )\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n learning_rate: Union[FloatTensorLike, Callable] = 0.001,\n beta_1: FloatTensorLike = 0.9,\n beta_2: FloatTensorLike = 0.999,\n epsilon: FloatTensorLike = 1e-7,\n weight_decay: FloatTensorLike = 0.0,\n grad_averaging: bool = False,\n amsgrad: bool = False,\n name: str = \"NovoGrad\",\n **kwargs\n ):\n r\"\"\"Construct a new NovoGrad optimizer.\n\n Args:\n learning_rate: A `Tensor` or a floating point value. or a schedule\n that is a `tf.keras.optimizers.schedules.LearningRateSchedule`\n The learning rate.\n beta_1: A float value or a constant float tensor.\n The exponential decay rate for the 1st moment estimates.\n beta_2: A float value or a constant float tensor.\n The exponential decay rate for the 2nd moment estimates.\n epsilon: A small constant for numerical stability.\n weight_decay: A floating point value. Weight decay for each param.\n grad_averaging: determines whether to use Adam style exponential\n moving averaging for the first order moments.\n **kwargs: keyword arguments. Allowed to be {`clipnorm`,\n `clipvalue`, `lr`, `decay`}. `clipnorm` is clip gradients\n by norm; `clipvalue` is clip gradients by value, `decay` is\n included for backward compatibility to allow time inverse\n decay of learning rate. `lr` is included for backward\n compatibility, recommended to use `learning_rate` instead.\n \"\"\"\n super().__init__(name, **kwargs)\n if weight_decay < 0.0:\n raise ValueError(\"Weight decay rate cannot be negative\")\n self._set_hyper(\"learning_rate\", kwargs.get(\"lr\", learning_rate))\n self._set_hyper(\"decay\", self._initial_decay)\n self._set_hyper(\"beta_1\", beta_1)\n self._set_hyper(\"beta_2\", beta_2)\n self._set_hyper(\"weight_decay\", weight_decay)\n self._set_hyper(\"grad_averaging\", grad_averaging)\n self.amsgrad = amsgrad\n self.epsilon = epsilon or tf.keras.backend.epsilon()\n\n def _create_slots(self, var_list):\n # Create slots for the first and second moments.\n # Separate for-loops to respect the ordering of slot variables from v1.\n for var in var_list:\n self.add_slot(var=var, slot_name=\"m\", initializer=\"zeros\")\n for var in var_list:\n self.add_slot(\n var=var, slot_name=\"v\", initializer=tf.zeros(shape=[], dtype=var.dtype)\n )\n if self.amsgrad:\n for var in var_list:\n self.add_slot(var, \"vhat\")\n\n def _prepare_local(self, var_device, var_dtype, apply_state):\n super()._prepare_local(var_device, var_dtype, apply_state)\n beta_1_t = tf.identity(self._get_hyper(\"beta_1\", var_dtype))\n beta_2_t = tf.identity(self._get_hyper(\"beta_2\", var_dtype))\n apply_state[(var_device, var_dtype)].update(\n dict(\n epsilon=tf.convert_to_tensor(self.epsilon, var_dtype),\n beta_1_t=beta_1_t,\n beta_2_t=beta_2_t,\n one_minus_beta_2_t=1 - beta_2_t,\n one_minus_beta_1_t=1 - beta_1_t,\n )\n )\n\n def set_weights(self, weights):\n params = self.weights\n # If the weights are generated by Keras V1 optimizer, it includes vhats\n # even without amsgrad, i.e, V1 optimizer has 3x + 1 variables, while V2\n # optimizer has 2x + 1 variables. Filter vhats out for compatibility.\n num_vars = int((len(params) - 1) / 2)\n if len(weights) == 3 * num_vars + 1:\n weights = weights[: len(params)]\n super().set_weights(weights)\n\n def _resource_apply_dense(self, grad, var, apply_state=None):\n var_device, var_dtype = var.device, var.dtype.base_dtype\n coefficients = (apply_state or {}).get(\n (var_device, var_dtype)\n ) or self._fallback_apply_state(var_device, var_dtype)\n weight_decay = self._get_hyper(\"weight_decay\")\n grad_averaging = self._get_hyper(\"grad_averaging\")\n\n v = self.get_slot(var, \"v\")\n g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))\n v_t = tf.cond(\n tf.equal(self.iterations, 0),\n lambda: g_2,\n lambda: v * coefficients[\"beta_2_t\"]\n + g_2 * coefficients[\"one_minus_beta_2_t\"],\n )\n v_t = v.assign(v_t, use_locking=self._use_locking)\n\n if self.amsgrad:\n vhat = self.get_slot(var, \"vhat\")\n vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)\n grad = grad / (tf.sqrt(vhat_t) + self.epsilon)\n else:\n grad = grad / (tf.sqrt(v_t) + self.epsilon)\n grad = tf.cond(\n tf.greater(weight_decay, 0), lambda: grad + weight_decay * var, lambda: grad\n )\n grad = tf.cond(\n tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),\n lambda: grad * coefficients[\"one_minus_beta_1_t\"],\n lambda: grad,\n )\n m = self.get_slot(var, \"m\")\n return tf.raw_ops.ResourceApplyKerasMomentum(\n var=var.handle,\n accum=m.handle,\n lr=coefficients[\"lr_t\"],\n grad=grad,\n momentum=coefficients[\"beta_1_t\"],\n use_locking=self._use_locking,\n use_nesterov=False,\n )\n\n def _resource_apply_sparse(self, grad, var, indices, apply_state=None):\n var_device, var_dtype = var.device, var.dtype.base_dtype\n coefficients = (apply_state or {}).get(\n (var_device, var_dtype)\n ) or self._fallback_apply_state(var_device, var_dtype)\n weight_decay = self._get_hyper(\"weight_decay\")\n grad_averaging = self._get_hyper(\"grad_averaging\")\n\n v = self.get_slot(var, \"v\")\n g_2 = tf.reduce_sum(tf.square(tf.cast(grad, tf.float32)))\n # v is just a scalar and does not need to involve sparse tensors.\n v_t = tf.cond(\n tf.equal(self.iterations, 0),\n lambda: g_2,\n lambda: v * coefficients[\"beta_2_t\"]\n + g_2 * coefficients[\"one_minus_beta_2_t\"],\n )\n v_t = v.assign(v_t, use_locking=self._use_locking)\n\n if self.amsgrad:\n vhat = self.get_slot(var, \"vhat\")\n vhat_t = vhat.assign(tf.maximum(vhat, v_t), use_locking=self._use_locking)\n grad = grad / (tf.sqrt(vhat_t) + self.epsilon)\n else:\n grad = grad / (tf.sqrt(v_t) + self.epsilon)\n grad = tf.cond(\n tf.greater(weight_decay, 0),\n lambda: grad + weight_decay * tf.gather(var, indices),\n lambda: grad,\n )\n grad = tf.cond(\n tf.logical_and(grad_averaging, tf.not_equal(self.iterations, 0)),\n lambda: grad * coefficients[\"one_minus_beta_1_t\"],\n lambda: grad,\n )\n m = self.get_slot(var, \"m\")\n return tf.raw_ops.ResourceSparseApplyKerasMomentum(\n var=var.handle,\n accum=m.handle,\n lr=coefficients[\"lr_t\"],\n grad=grad,\n indices=indices,\n momentum=coefficients[\"beta_1_t\"],\n use_locking=self._use_locking,\n use_nesterov=False,\n )\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"learning_rate\": self._serialize_hyperparameter(\"learning_rate\"),\n \"beta_1\": self._serialize_hyperparameter(\"beta_1\"),\n \"beta_2\": self._serialize_hyperparameter(\"beta_2\"),\n \"epsilon\": self.epsilon,\n \"weight_decay\": self._serialize_hyperparameter(\"weight_decay\"),\n \"grad_averaging\": self._serialize_hyperparameter(\"grad_averaging\"),\n }\n )\n return config\n", "path": "tensorflow_addons/optimizers/novograd.py"}]}
| 3,849 | 427 |
gh_patches_debug_27876
|
rasdani/github-patches
|
git_diff
|
zenml-io__zenml-1057
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FEATURE]: Handle over 100 secrets when using the `AWSSecretsManager`
### Contact Details [Optional]
[email protected]
### Describe the feature you'd like
The [`get_all_secret_keys`](https://github.com/zenml-io/zenml/blob/develop/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py#L108) method (found at `src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py`) currently has an inbuilt limit whereby it can only access 100 secrets stored in the `AWSSecretsManager`. This has to do with the fact that the API effectively paginates the results. We currently hard-code the max number of results in the method, but ideally:
- we would be able to handle an arbitrary number of secrets (i.e. greater than 100) stored on AWS
- we would no longer hard-code the magic `100` value
### Is your feature request related to a problem?
_No response_
### How do you solve your current problem with the current status-quo of ZenML?
Currently we limit the number of secrets that you can query from AWS to 100.
### Any other comments?
This is related to #ENG-721 and #ENG-720.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py`
Content:
```
1 # Copyright (c) ZenML GmbH 2022. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at:
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express
12 # or implied. See the License for the specific language governing
13 # permissions and limitations under the License.
14 """Implementation of the AWS Secrets Manager integration."""
15 import json
16 from typing import Any, ClassVar, Dict, List, Optional, cast
17
18 import boto3
19
20 from zenml.exceptions import SecretExistsError
21 from zenml.integrations.aws.flavors.aws_secrets_manager_flavor import (
22 AWSSecretsManagerConfig,
23 validate_aws_secret_name_or_namespace,
24 )
25 from zenml.logger import get_logger
26 from zenml.secret.base_secret import BaseSecretSchema
27 from zenml.secrets_managers.base_secrets_manager import (
28 BaseSecretsManager,
29 SecretsManagerScope,
30 )
31 from zenml.secrets_managers.utils import secret_from_dict, secret_to_dict
32
33 logger = get_logger(__name__)
34
35
36 class AWSSecretsManager(BaseSecretsManager):
37 """Class to interact with the AWS secrets manager."""
38
39 CLIENT: ClassVar[Any] = None
40
41 @property
42 def config(self) -> AWSSecretsManagerConfig:
43 """Returns the `AWSSecretsManagerConfig` config.
44
45 Returns:
46 The configuration.
47 """
48 return cast(AWSSecretsManagerConfig, self._config)
49
50 @classmethod
51 def _ensure_client_connected(cls, region_name: str) -> None:
52 """Ensure that the client is connected to the AWS secrets manager.
53
54 Args:
55 region_name: the AWS region name
56 """
57 if cls.CLIENT is None:
58 # Create a Secrets Manager client
59 session = boto3.session.Session()
60 cls.CLIENT = session.client(
61 service_name="secretsmanager", region_name=region_name
62 )
63
64 def _get_secret_tags(
65 self, secret: BaseSecretSchema
66 ) -> List[Dict[str, str]]:
67 """Return a list of AWS secret tag values for a given secret.
68
69 Args:
70 secret: the secret object
71
72 Returns:
73 A list of AWS secret tag values
74 """
75 metadata = self._get_secret_metadata(secret)
76 return [{"Key": k, "Value": v} for k, v in metadata.items()]
77
78 def _get_secret_scope_filters(
79 self,
80 secret_name: Optional[str] = None,
81 ) -> List[Dict[str, Any]]:
82 """Return a list of AWS filters for the entire scope or just a scoped secret.
83
84 These filters can be used when querying the AWS Secrets Manager
85 for all secrets or for a single secret available in the configured
86 scope. For more information see: https://docs.aws.amazon.com/secretsmanager/latest/userguide/manage_search-secret.html
87
88 Example AWS filters for all secrets in the current (namespace) scope:
89
90 ```python
91 [
92 {
93 "Key: "tag-key",
94 "Values": ["zenml_scope"],
95 },
96 {
97 "Key: "tag-value",
98 "Values": ["namespace"],
99 },
100 {
101 "Key: "tag-key",
102 "Values": ["zenml_namespace"],
103 },
104 {
105 "Key: "tag-value",
106 "Values": ["my_namespace"],
107 },
108 ]
109 ```
110
111 Example AWS filters for a particular secret in the current (namespace)
112 scope:
113
114 ```python
115 [
116 {
117 "Key: "tag-key",
118 "Values": ["zenml_secret_name"],
119 },
120 {
121 "Key: "tag-value",
122 "Values": ["my_secret"],
123 },
124 {
125 "Key: "tag-key",
126 "Values": ["zenml_scope"],
127 },
128 {
129 "Key: "tag-value",
130 "Values": ["namespace"],
131 },
132 {
133 "Key: "tag-key",
134 "Values": ["zenml_namespace"],
135 },
136 {
137 "Key: "tag-value",
138 "Values": ["my_namespace"],
139 },
140 ]
141 ```
142
143 Args:
144 secret_name: Optional secret name to filter for.
145
146 Returns:
147 A list of AWS filters uniquely identifying all secrets
148 or a named secret within the configured scope.
149 """
150 metadata = self._get_secret_scope_metadata(secret_name)
151 filters: List[Dict[str, Any]] = []
152 for k, v in metadata.items():
153 filters.append(
154 {
155 "Key": "tag-key",
156 "Values": [
157 k,
158 ],
159 }
160 )
161 filters.append(
162 {
163 "Key": "tag-value",
164 "Values": [
165 str(v),
166 ],
167 }
168 )
169
170 return filters
171
172 def _list_secrets(self, secret_name: Optional[str] = None) -> List[str]:
173 """List all secrets matching a name.
174
175 This method lists all the secrets in the current scope without loading
176 their contents. An optional secret name can be supplied to filter out
177 all but a single secret identified by name.
178
179 Args:
180 secret_name: Optional secret name to filter for.
181
182 Returns:
183 A list of secret names in the current scope and the optional
184 secret name.
185 """
186 self._ensure_client_connected(self.config.region_name)
187
188 filters: List[Dict[str, Any]] = []
189 prefix: Optional[str] = None
190 if self.config.scope == SecretsManagerScope.NONE:
191 # unscoped (legacy) secrets don't have tags. We want to filter out
192 # non-legacy secrets
193 filters = [
194 {
195 "Key": "tag-key",
196 "Values": [
197 "!zenml_scope",
198 ],
199 },
200 ]
201 if secret_name:
202 prefix = secret_name
203 else:
204 filters = self._get_secret_scope_filters()
205 if secret_name:
206 prefix = self._get_scoped_secret_name(secret_name)
207 else:
208 # add the name prefix to the filters to account for the fact
209 # that AWS does not do exact matching but prefix-matching on the
210 # filters
211 prefix = self._get_scoped_secret_name_prefix()
212
213 if prefix:
214 filters.append(
215 {
216 "Key": "name",
217 "Values": [
218 f"{prefix}",
219 ],
220 }
221 )
222
223 # TODO [ENG-720]: Deal with pagination in the aws secret manager when
224 # listing all secrets
225 # TODO [ENG-721]: take out this magic maxresults number
226 response = self.CLIENT.list_secrets(MaxResults=100, Filters=filters)
227 results = []
228 for secret in response["SecretList"]:
229 name = self._get_unscoped_secret_name(secret["Name"])
230 # keep only the names that are in scope and filter by secret name,
231 # if one was given
232 if name and (not secret_name or secret_name == name):
233 results.append(name)
234
235 return results
236
237 def register_secret(self, secret: BaseSecretSchema) -> None:
238 """Registers a new secret.
239
240 Args:
241 secret: the secret to register
242
243 Raises:
244 SecretExistsError: if the secret already exists
245 """
246 validate_aws_secret_name_or_namespace(secret.name)
247 self._ensure_client_connected(self.config.region_name)
248
249 if self._list_secrets(secret.name):
250 raise SecretExistsError(
251 f"A Secret with the name {secret.name} already exists"
252 )
253
254 secret_value = json.dumps(secret_to_dict(secret, encode=False))
255 kwargs: Dict[str, Any] = {
256 "Name": self._get_scoped_secret_name(secret.name),
257 "SecretString": secret_value,
258 "Tags": self._get_secret_tags(secret),
259 }
260
261 self.CLIENT.create_secret(**kwargs)
262
263 logger.debug("Created AWS secret: %s", kwargs["Name"])
264
265 def get_secret(self, secret_name: str) -> BaseSecretSchema:
266 """Gets a secret.
267
268 Args:
269 secret_name: the name of the secret to get
270
271 Returns:
272 The secret.
273
274 Raises:
275 KeyError: if the secret does not exist
276 """
277 validate_aws_secret_name_or_namespace(secret_name)
278 self._ensure_client_connected(self.config.region_name)
279
280 if not self._list_secrets(secret_name):
281 raise KeyError(f"Can't find the specified secret '{secret_name}'")
282
283 get_secret_value_response = self.CLIENT.get_secret_value(
284 SecretId=self._get_scoped_secret_name(secret_name)
285 )
286 if "SecretString" not in get_secret_value_response:
287 get_secret_value_response = None
288
289 return secret_from_dict(
290 json.loads(get_secret_value_response["SecretString"]),
291 secret_name=secret_name,
292 decode=False,
293 )
294
295 def get_all_secret_keys(self) -> List[str]:
296 """Get all secret keys.
297
298 Returns:
299 A list of all secret keys
300 """
301 return self._list_secrets()
302
303 def update_secret(self, secret: BaseSecretSchema) -> None:
304 """Update an existing secret.
305
306 Args:
307 secret: the secret to update
308
309 Raises:
310 KeyError: if the secret does not exist
311 """
312 validate_aws_secret_name_or_namespace(secret.name)
313 self._ensure_client_connected(self.config.region_name)
314
315 if not self._list_secrets(secret.name):
316 raise KeyError(f"Can't find the specified secret '{secret.name}'")
317
318 secret_value = json.dumps(secret_to_dict(secret))
319
320 kwargs = {
321 "SecretId": self._get_scoped_secret_name(secret.name),
322 "SecretString": secret_value,
323 }
324
325 self.CLIENT.put_secret_value(**kwargs)
326
327 def delete_secret(self, secret_name: str) -> None:
328 """Delete an existing secret.
329
330 Args:
331 secret_name: the name of the secret to delete
332
333 Raises:
334 KeyError: if the secret does not exist
335 """
336 self._ensure_client_connected(self.config.region_name)
337
338 if not self._list_secrets(secret_name):
339 raise KeyError(f"Can't find the specified secret '{secret_name}'")
340
341 self.CLIENT.delete_secret(
342 SecretId=self._get_scoped_secret_name(secret_name),
343 ForceDeleteWithoutRecovery=True,
344 )
345
346 def delete_all_secrets(self) -> None:
347 """Delete all existing secrets.
348
349 This method will force delete all your secrets. You will not be able to
350 recover them once this method is called.
351 """
352 self._ensure_client_connected(self.config.region_name)
353 for secret_name in self._list_secrets():
354 self.CLIENT.delete_secret(
355 SecretId=self._get_scoped_secret_name(secret_name),
356 ForceDeleteWithoutRecovery=True,
357 )
358
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py b/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py
--- a/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py
+++ b/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py
@@ -32,6 +32,9 @@
logger = get_logger(__name__)
+_BOTO_CLIENT_LIST_SECRETS = "list_secrets"
+_PAGINATOR_RESPONSE_SECRETS_LIST_KEY = "SecretList"
+
class AWSSecretsManager(BaseSecretsManager):
"""Class to interact with the AWS secrets manager."""
@@ -220,17 +223,21 @@
}
)
- # TODO [ENG-720]: Deal with pagination in the aws secret manager when
- # listing all secrets
- # TODO [ENG-721]: take out this magic maxresults number
- response = self.CLIENT.list_secrets(MaxResults=100, Filters=filters)
+ paginator = self.CLIENT.get_paginator(_BOTO_CLIENT_LIST_SECRETS)
+ pages = paginator.paginate(
+ Filters=filters,
+ PaginationConfig={
+ "PageSize": 100,
+ },
+ )
results = []
- for secret in response["SecretList"]:
- name = self._get_unscoped_secret_name(secret["Name"])
- # keep only the names that are in scope and filter by secret name,
- # if one was given
- if name and (not secret_name or secret_name == name):
- results.append(name)
+ for page in pages:
+ for secret in page[_PAGINATOR_RESPONSE_SECRETS_LIST_KEY]:
+ name = self._get_unscoped_secret_name(secret["Name"])
+ # keep only the names that are in scope and filter by secret name,
+ # if one was given
+ if name and (not secret_name or secret_name == name):
+ results.append(name)
return results
|
{"golden_diff": "diff --git a/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py b/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py\n--- a/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py\n+++ b/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py\n@@ -32,6 +32,9 @@\n \n logger = get_logger(__name__)\n \n+_BOTO_CLIENT_LIST_SECRETS = \"list_secrets\"\n+_PAGINATOR_RESPONSE_SECRETS_LIST_KEY = \"SecretList\"\n+\n \n class AWSSecretsManager(BaseSecretsManager):\n \"\"\"Class to interact with the AWS secrets manager.\"\"\"\n@@ -220,17 +223,21 @@\n }\n )\n \n- # TODO [ENG-720]: Deal with pagination in the aws secret manager when\n- # listing all secrets\n- # TODO [ENG-721]: take out this magic maxresults number\n- response = self.CLIENT.list_secrets(MaxResults=100, Filters=filters)\n+ paginator = self.CLIENT.get_paginator(_BOTO_CLIENT_LIST_SECRETS)\n+ pages = paginator.paginate(\n+ Filters=filters,\n+ PaginationConfig={\n+ \"PageSize\": 100,\n+ },\n+ )\n results = []\n- for secret in response[\"SecretList\"]:\n- name = self._get_unscoped_secret_name(secret[\"Name\"])\n- # keep only the names that are in scope and filter by secret name,\n- # if one was given\n- if name and (not secret_name or secret_name == name):\n- results.append(name)\n+ for page in pages:\n+ for secret in page[_PAGINATOR_RESPONSE_SECRETS_LIST_KEY]:\n+ name = self._get_unscoped_secret_name(secret[\"Name\"])\n+ # keep only the names that are in scope and filter by secret name,\n+ # if one was given\n+ if name and (not secret_name or secret_name == name):\n+ results.append(name)\n \n return results\n", "issue": "[FEATURE]: Handle over 100 secrets when using the `AWSSecretsManager`\n### Contact Details [Optional]\n\[email protected]\n\n### Describe the feature you'd like\n\nThe [`get_all_secret_keys`](https://github.com/zenml-io/zenml/blob/develop/src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py#L108) method (found at `src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py`) currently has an inbuilt limit whereby it can only access 100 secrets stored in the `AWSSecretsManager`. This has to do with the fact that the API effectively paginates the results. We currently hard-code the max number of results in the method, but ideally:\r\n\r\n- we would be able to handle an arbitrary number of secrets (i.e. greater than 100) stored on AWS\r\n- we would no longer hard-code the magic `100` value\n\n### Is your feature request related to a problem?\n\n_No response_\n\n### How do you solve your current problem with the current status-quo of ZenML?\n\nCurrently we limit the number of secrets that you can query from AWS to 100.\n\n### Any other comments?\n\nThis is related to #ENG-721 and #ENG-720.\n", "before_files": [{"content": "# Copyright (c) ZenML GmbH 2022. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at:\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express\n# or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\"\"\"Implementation of the AWS Secrets Manager integration.\"\"\"\nimport json\nfrom typing import Any, ClassVar, Dict, List, Optional, cast\n\nimport boto3\n\nfrom zenml.exceptions import SecretExistsError\nfrom zenml.integrations.aws.flavors.aws_secrets_manager_flavor import (\n AWSSecretsManagerConfig,\n validate_aws_secret_name_or_namespace,\n)\nfrom zenml.logger import get_logger\nfrom zenml.secret.base_secret import BaseSecretSchema\nfrom zenml.secrets_managers.base_secrets_manager import (\n BaseSecretsManager,\n SecretsManagerScope,\n)\nfrom zenml.secrets_managers.utils import secret_from_dict, secret_to_dict\n\nlogger = get_logger(__name__)\n\n\nclass AWSSecretsManager(BaseSecretsManager):\n \"\"\"Class to interact with the AWS secrets manager.\"\"\"\n\n CLIENT: ClassVar[Any] = None\n\n @property\n def config(self) -> AWSSecretsManagerConfig:\n \"\"\"Returns the `AWSSecretsManagerConfig` config.\n\n Returns:\n The configuration.\n \"\"\"\n return cast(AWSSecretsManagerConfig, self._config)\n\n @classmethod\n def _ensure_client_connected(cls, region_name: str) -> None:\n \"\"\"Ensure that the client is connected to the AWS secrets manager.\n\n Args:\n region_name: the AWS region name\n \"\"\"\n if cls.CLIENT is None:\n # Create a Secrets Manager client\n session = boto3.session.Session()\n cls.CLIENT = session.client(\n service_name=\"secretsmanager\", region_name=region_name\n )\n\n def _get_secret_tags(\n self, secret: BaseSecretSchema\n ) -> List[Dict[str, str]]:\n \"\"\"Return a list of AWS secret tag values for a given secret.\n\n Args:\n secret: the secret object\n\n Returns:\n A list of AWS secret tag values\n \"\"\"\n metadata = self._get_secret_metadata(secret)\n return [{\"Key\": k, \"Value\": v} for k, v in metadata.items()]\n\n def _get_secret_scope_filters(\n self,\n secret_name: Optional[str] = None,\n ) -> List[Dict[str, Any]]:\n \"\"\"Return a list of AWS filters for the entire scope or just a scoped secret.\n\n These filters can be used when querying the AWS Secrets Manager\n for all secrets or for a single secret available in the configured\n scope. For more information see: https://docs.aws.amazon.com/secretsmanager/latest/userguide/manage_search-secret.html\n\n Example AWS filters for all secrets in the current (namespace) scope:\n\n ```python\n [\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_scope\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"namespace\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_namespace\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_namespace\"],\n },\n ]\n ```\n\n Example AWS filters for a particular secret in the current (namespace)\n scope:\n\n ```python\n [\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_secret_name\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_secret\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_scope\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"namespace\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_namespace\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_namespace\"],\n },\n ]\n ```\n\n Args:\n secret_name: Optional secret name to filter for.\n\n Returns:\n A list of AWS filters uniquely identifying all secrets\n or a named secret within the configured scope.\n \"\"\"\n metadata = self._get_secret_scope_metadata(secret_name)\n filters: List[Dict[str, Any]] = []\n for k, v in metadata.items():\n filters.append(\n {\n \"Key\": \"tag-key\",\n \"Values\": [\n k,\n ],\n }\n )\n filters.append(\n {\n \"Key\": \"tag-value\",\n \"Values\": [\n str(v),\n ],\n }\n )\n\n return filters\n\n def _list_secrets(self, secret_name: Optional[str] = None) -> List[str]:\n \"\"\"List all secrets matching a name.\n\n This method lists all the secrets in the current scope without loading\n their contents. An optional secret name can be supplied to filter out\n all but a single secret identified by name.\n\n Args:\n secret_name: Optional secret name to filter for.\n\n Returns:\n A list of secret names in the current scope and the optional\n secret name.\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n\n filters: List[Dict[str, Any]] = []\n prefix: Optional[str] = None\n if self.config.scope == SecretsManagerScope.NONE:\n # unscoped (legacy) secrets don't have tags. We want to filter out\n # non-legacy secrets\n filters = [\n {\n \"Key\": \"tag-key\",\n \"Values\": [\n \"!zenml_scope\",\n ],\n },\n ]\n if secret_name:\n prefix = secret_name\n else:\n filters = self._get_secret_scope_filters()\n if secret_name:\n prefix = self._get_scoped_secret_name(secret_name)\n else:\n # add the name prefix to the filters to account for the fact\n # that AWS does not do exact matching but prefix-matching on the\n # filters\n prefix = self._get_scoped_secret_name_prefix()\n\n if prefix:\n filters.append(\n {\n \"Key\": \"name\",\n \"Values\": [\n f\"{prefix}\",\n ],\n }\n )\n\n # TODO [ENG-720]: Deal with pagination in the aws secret manager when\n # listing all secrets\n # TODO [ENG-721]: take out this magic maxresults number\n response = self.CLIENT.list_secrets(MaxResults=100, Filters=filters)\n results = []\n for secret in response[\"SecretList\"]:\n name = self._get_unscoped_secret_name(secret[\"Name\"])\n # keep only the names that are in scope and filter by secret name,\n # if one was given\n if name and (not secret_name or secret_name == name):\n results.append(name)\n\n return results\n\n def register_secret(self, secret: BaseSecretSchema) -> None:\n \"\"\"Registers a new secret.\n\n Args:\n secret: the secret to register\n\n Raises:\n SecretExistsError: if the secret already exists\n \"\"\"\n validate_aws_secret_name_or_namespace(secret.name)\n self._ensure_client_connected(self.config.region_name)\n\n if self._list_secrets(secret.name):\n raise SecretExistsError(\n f\"A Secret with the name {secret.name} already exists\"\n )\n\n secret_value = json.dumps(secret_to_dict(secret, encode=False))\n kwargs: Dict[str, Any] = {\n \"Name\": self._get_scoped_secret_name(secret.name),\n \"SecretString\": secret_value,\n \"Tags\": self._get_secret_tags(secret),\n }\n\n self.CLIENT.create_secret(**kwargs)\n\n logger.debug(\"Created AWS secret: %s\", kwargs[\"Name\"])\n\n def get_secret(self, secret_name: str) -> BaseSecretSchema:\n \"\"\"Gets a secret.\n\n Args:\n secret_name: the name of the secret to get\n\n Returns:\n The secret.\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n validate_aws_secret_name_or_namespace(secret_name)\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret_name):\n raise KeyError(f\"Can't find the specified secret '{secret_name}'\")\n\n get_secret_value_response = self.CLIENT.get_secret_value(\n SecretId=self._get_scoped_secret_name(secret_name)\n )\n if \"SecretString\" not in get_secret_value_response:\n get_secret_value_response = None\n\n return secret_from_dict(\n json.loads(get_secret_value_response[\"SecretString\"]),\n secret_name=secret_name,\n decode=False,\n )\n\n def get_all_secret_keys(self) -> List[str]:\n \"\"\"Get all secret keys.\n\n Returns:\n A list of all secret keys\n \"\"\"\n return self._list_secrets()\n\n def update_secret(self, secret: BaseSecretSchema) -> None:\n \"\"\"Update an existing secret.\n\n Args:\n secret: the secret to update\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n validate_aws_secret_name_or_namespace(secret.name)\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret.name):\n raise KeyError(f\"Can't find the specified secret '{secret.name}'\")\n\n secret_value = json.dumps(secret_to_dict(secret))\n\n kwargs = {\n \"SecretId\": self._get_scoped_secret_name(secret.name),\n \"SecretString\": secret_value,\n }\n\n self.CLIENT.put_secret_value(**kwargs)\n\n def delete_secret(self, secret_name: str) -> None:\n \"\"\"Delete an existing secret.\n\n Args:\n secret_name: the name of the secret to delete\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret_name):\n raise KeyError(f\"Can't find the specified secret '{secret_name}'\")\n\n self.CLIENT.delete_secret(\n SecretId=self._get_scoped_secret_name(secret_name),\n ForceDeleteWithoutRecovery=True,\n )\n\n def delete_all_secrets(self) -> None:\n \"\"\"Delete all existing secrets.\n\n This method will force delete all your secrets. You will not be able to\n recover them once this method is called.\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n for secret_name in self._list_secrets():\n self.CLIENT.delete_secret(\n SecretId=self._get_scoped_secret_name(secret_name),\n ForceDeleteWithoutRecovery=True,\n )\n", "path": "src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py"}], "after_files": [{"content": "# Copyright (c) ZenML GmbH 2022. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at:\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express\n# or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\"\"\"Implementation of the AWS Secrets Manager integration.\"\"\"\nimport json\nfrom typing import Any, ClassVar, Dict, List, Optional, cast\n\nimport boto3\n\nfrom zenml.exceptions import SecretExistsError\nfrom zenml.integrations.aws.flavors.aws_secrets_manager_flavor import (\n AWSSecretsManagerConfig,\n validate_aws_secret_name_or_namespace,\n)\nfrom zenml.logger import get_logger\nfrom zenml.secret.base_secret import BaseSecretSchema\nfrom zenml.secrets_managers.base_secrets_manager import (\n BaseSecretsManager,\n SecretsManagerScope,\n)\nfrom zenml.secrets_managers.utils import secret_from_dict, secret_to_dict\n\nlogger = get_logger(__name__)\n\n_BOTO_CLIENT_LIST_SECRETS = \"list_secrets\"\n_PAGINATOR_RESPONSE_SECRETS_LIST_KEY = \"SecretList\"\n\n\nclass AWSSecretsManager(BaseSecretsManager):\n \"\"\"Class to interact with the AWS secrets manager.\"\"\"\n\n CLIENT: ClassVar[Any] = None\n\n @property\n def config(self) -> AWSSecretsManagerConfig:\n \"\"\"Returns the `AWSSecretsManagerConfig` config.\n\n Returns:\n The configuration.\n \"\"\"\n return cast(AWSSecretsManagerConfig, self._config)\n\n @classmethod\n def _ensure_client_connected(cls, region_name: str) -> None:\n \"\"\"Ensure that the client is connected to the AWS secrets manager.\n\n Args:\n region_name: the AWS region name\n \"\"\"\n if cls.CLIENT is None:\n # Create a Secrets Manager client\n session = boto3.session.Session()\n cls.CLIENT = session.client(\n service_name=\"secretsmanager\", region_name=region_name\n )\n\n def _get_secret_tags(\n self, secret: BaseSecretSchema\n ) -> List[Dict[str, str]]:\n \"\"\"Return a list of AWS secret tag values for a given secret.\n\n Args:\n secret: the secret object\n\n Returns:\n A list of AWS secret tag values\n \"\"\"\n metadata = self._get_secret_metadata(secret)\n return [{\"Key\": k, \"Value\": v} for k, v in metadata.items()]\n\n def _get_secret_scope_filters(\n self,\n secret_name: Optional[str] = None,\n ) -> List[Dict[str, Any]]:\n \"\"\"Return a list of AWS filters for the entire scope or just a scoped secret.\n\n These filters can be used when querying the AWS Secrets Manager\n for all secrets or for a single secret available in the configured\n scope. For more information see: https://docs.aws.amazon.com/secretsmanager/latest/userguide/manage_search-secret.html\n\n Example AWS filters for all secrets in the current (namespace) scope:\n\n ```python\n [\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_scope\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"namespace\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_namespace\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_namespace\"],\n },\n ]\n ```\n\n Example AWS filters for a particular secret in the current (namespace)\n scope:\n\n ```python\n [\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_secret_name\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_secret\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_scope\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"namespace\"],\n },\n {\n \"Key: \"tag-key\",\n \"Values\": [\"zenml_namespace\"],\n },\n {\n \"Key: \"tag-value\",\n \"Values\": [\"my_namespace\"],\n },\n ]\n ```\n\n Args:\n secret_name: Optional secret name to filter for.\n\n Returns:\n A list of AWS filters uniquely identifying all secrets\n or a named secret within the configured scope.\n \"\"\"\n metadata = self._get_secret_scope_metadata(secret_name)\n filters: List[Dict[str, Any]] = []\n for k, v in metadata.items():\n filters.append(\n {\n \"Key\": \"tag-key\",\n \"Values\": [\n k,\n ],\n }\n )\n filters.append(\n {\n \"Key\": \"tag-value\",\n \"Values\": [\n str(v),\n ],\n }\n )\n\n return filters\n\n def _list_secrets(self, secret_name: Optional[str] = None) -> List[str]:\n \"\"\"List all secrets matching a name.\n\n This method lists all the secrets in the current scope without loading\n their contents. An optional secret name can be supplied to filter out\n all but a single secret identified by name.\n\n Args:\n secret_name: Optional secret name to filter for.\n\n Returns:\n A list of secret names in the current scope and the optional\n secret name.\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n\n filters: List[Dict[str, Any]] = []\n prefix: Optional[str] = None\n if self.config.scope == SecretsManagerScope.NONE:\n # unscoped (legacy) secrets don't have tags. We want to filter out\n # non-legacy secrets\n filters = [\n {\n \"Key\": \"tag-key\",\n \"Values\": [\n \"!zenml_scope\",\n ],\n },\n ]\n if secret_name:\n prefix = secret_name\n else:\n filters = self._get_secret_scope_filters()\n if secret_name:\n prefix = self._get_scoped_secret_name(secret_name)\n else:\n # add the name prefix to the filters to account for the fact\n # that AWS does not do exact matching but prefix-matching on the\n # filters\n prefix = self._get_scoped_secret_name_prefix()\n\n if prefix:\n filters.append(\n {\n \"Key\": \"name\",\n \"Values\": [\n f\"{prefix}\",\n ],\n }\n )\n\n paginator = self.CLIENT.get_paginator(_BOTO_CLIENT_LIST_SECRETS)\n pages = paginator.paginate(\n Filters=filters,\n PaginationConfig={\n \"PageSize\": 100,\n },\n )\n results = []\n for page in pages:\n for secret in page[_PAGINATOR_RESPONSE_SECRETS_LIST_KEY]:\n name = self._get_unscoped_secret_name(secret[\"Name\"])\n # keep only the names that are in scope and filter by secret name,\n # if one was given\n if name and (not secret_name or secret_name == name):\n results.append(name)\n\n return results\n\n def register_secret(self, secret: BaseSecretSchema) -> None:\n \"\"\"Registers a new secret.\n\n Args:\n secret: the secret to register\n\n Raises:\n SecretExistsError: if the secret already exists\n \"\"\"\n validate_aws_secret_name_or_namespace(secret.name)\n self._ensure_client_connected(self.config.region_name)\n\n if self._list_secrets(secret.name):\n raise SecretExistsError(\n f\"A Secret with the name {secret.name} already exists\"\n )\n\n secret_value = json.dumps(secret_to_dict(secret, encode=False))\n kwargs: Dict[str, Any] = {\n \"Name\": self._get_scoped_secret_name(secret.name),\n \"SecretString\": secret_value,\n \"Tags\": self._get_secret_tags(secret),\n }\n\n self.CLIENT.create_secret(**kwargs)\n\n logger.debug(\"Created AWS secret: %s\", kwargs[\"Name\"])\n\n def get_secret(self, secret_name: str) -> BaseSecretSchema:\n \"\"\"Gets a secret.\n\n Args:\n secret_name: the name of the secret to get\n\n Returns:\n The secret.\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n validate_aws_secret_name_or_namespace(secret_name)\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret_name):\n raise KeyError(f\"Can't find the specified secret '{secret_name}'\")\n\n get_secret_value_response = self.CLIENT.get_secret_value(\n SecretId=self._get_scoped_secret_name(secret_name)\n )\n if \"SecretString\" not in get_secret_value_response:\n get_secret_value_response = None\n\n return secret_from_dict(\n json.loads(get_secret_value_response[\"SecretString\"]),\n secret_name=secret_name,\n decode=False,\n )\n\n def get_all_secret_keys(self) -> List[str]:\n \"\"\"Get all secret keys.\n\n Returns:\n A list of all secret keys\n \"\"\"\n return self._list_secrets()\n\n def update_secret(self, secret: BaseSecretSchema) -> None:\n \"\"\"Update an existing secret.\n\n Args:\n secret: the secret to update\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n validate_aws_secret_name_or_namespace(secret.name)\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret.name):\n raise KeyError(f\"Can't find the specified secret '{secret.name}'\")\n\n secret_value = json.dumps(secret_to_dict(secret))\n\n kwargs = {\n \"SecretId\": self._get_scoped_secret_name(secret.name),\n \"SecretString\": secret_value,\n }\n\n self.CLIENT.put_secret_value(**kwargs)\n\n def delete_secret(self, secret_name: str) -> None:\n \"\"\"Delete an existing secret.\n\n Args:\n secret_name: the name of the secret to delete\n\n Raises:\n KeyError: if the secret does not exist\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n\n if not self._list_secrets(secret_name):\n raise KeyError(f\"Can't find the specified secret '{secret_name}'\")\n\n self.CLIENT.delete_secret(\n SecretId=self._get_scoped_secret_name(secret_name),\n ForceDeleteWithoutRecovery=True,\n )\n\n def delete_all_secrets(self) -> None:\n \"\"\"Delete all existing secrets.\n\n This method will force delete all your secrets. You will not be able to\n recover them once this method is called.\n \"\"\"\n self._ensure_client_connected(self.config.region_name)\n for secret_name in self._list_secrets():\n self.CLIENT.delete_secret(\n SecretId=self._get_scoped_secret_name(secret_name),\n ForceDeleteWithoutRecovery=True,\n )\n", "path": "src/zenml/integrations/aws/secrets_managers/aws_secrets_manager.py"}]}
| 3,879 | 463 |
gh_patches_debug_13241
|
rasdani/github-patches
|
git_diff
|
pypa__pip-12173
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
23.2: Unable to add zsh completion as documented
### Description
Attempting to follow the steps in the [documentation for adding zsh shell completion](https://pip.pypa.io/en/stable/user_guide/#command-completion) raises an error regarding the use of `compadd` outside of a completion function. This seems to be new with 23.2 and added in https://github.com/pypa/pip/pull/11417.
### Expected behavior
As in previous versions, following the documented steps should successfully add completion for pip.
### pip version
23.2
### Python version
3.11.4
### OS
macOS 12.6.8
### How to Reproduce
As documented:
1. Execute `python -m pip completion --zsh >> ~/.zprofile` or add eval "`pip completion --zsh`" to `.zprofile` or `.zshrc`
2. Start a new shell
### Output
From startup:
```
/dev/fd/16:compadd:4: can only be called from completion function
```
### Code of Conduct
- [X] I agree to follow the [PSF Code of Conduct](https://www.python.org/psf/conduct/).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pip/_internal/commands/completion.py`
Content:
```
1 import sys
2 import textwrap
3 from optparse import Values
4 from typing import List
5
6 from pip._internal.cli.base_command import Command
7 from pip._internal.cli.status_codes import SUCCESS
8 from pip._internal.utils.misc import get_prog
9
10 BASE_COMPLETION = """
11 # pip {shell} completion start{script}# pip {shell} completion end
12 """
13
14 COMPLETION_SCRIPTS = {
15 "bash": """
16 _pip_completion()
17 {{
18 COMPREPLY=( $( COMP_WORDS="${{COMP_WORDS[*]}}" \\
19 COMP_CWORD=$COMP_CWORD \\
20 PIP_AUTO_COMPLETE=1 $1 2>/dev/null ) )
21 }}
22 complete -o default -F _pip_completion {prog}
23 """,
24 "zsh": """
25 #compdef -P pip[0-9.]#
26 compadd $( COMP_WORDS="$words[*]" \\
27 COMP_CWORD=$((CURRENT-1)) \\
28 PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )
29 """,
30 "fish": """
31 function __fish_complete_pip
32 set -lx COMP_WORDS (commandline -o) ""
33 set -lx COMP_CWORD ( \\
34 math (contains -i -- (commandline -t) $COMP_WORDS)-1 \\
35 )
36 set -lx PIP_AUTO_COMPLETE 1
37 string split \\ -- (eval $COMP_WORDS[1])
38 end
39 complete -fa "(__fish_complete_pip)" -c {prog}
40 """,
41 "powershell": """
42 if ((Test-Path Function:\\TabExpansion) -and -not `
43 (Test-Path Function:\\_pip_completeBackup)) {{
44 Rename-Item Function:\\TabExpansion _pip_completeBackup
45 }}
46 function TabExpansion($line, $lastWord) {{
47 $lastBlock = [regex]::Split($line, '[|;]')[-1].TrimStart()
48 if ($lastBlock.StartsWith("{prog} ")) {{
49 $Env:COMP_WORDS=$lastBlock
50 $Env:COMP_CWORD=$lastBlock.Split().Length - 1
51 $Env:PIP_AUTO_COMPLETE=1
52 (& {prog}).Split()
53 Remove-Item Env:COMP_WORDS
54 Remove-Item Env:COMP_CWORD
55 Remove-Item Env:PIP_AUTO_COMPLETE
56 }}
57 elseif (Test-Path Function:\\_pip_completeBackup) {{
58 # Fall back on existing tab expansion
59 _pip_completeBackup $line $lastWord
60 }}
61 }}
62 """,
63 }
64
65
66 class CompletionCommand(Command):
67 """A helper command to be used for command completion."""
68
69 ignore_require_venv = True
70
71 def add_options(self) -> None:
72 self.cmd_opts.add_option(
73 "--bash",
74 "-b",
75 action="store_const",
76 const="bash",
77 dest="shell",
78 help="Emit completion code for bash",
79 )
80 self.cmd_opts.add_option(
81 "--zsh",
82 "-z",
83 action="store_const",
84 const="zsh",
85 dest="shell",
86 help="Emit completion code for zsh",
87 )
88 self.cmd_opts.add_option(
89 "--fish",
90 "-f",
91 action="store_const",
92 const="fish",
93 dest="shell",
94 help="Emit completion code for fish",
95 )
96 self.cmd_opts.add_option(
97 "--powershell",
98 "-p",
99 action="store_const",
100 const="powershell",
101 dest="shell",
102 help="Emit completion code for powershell",
103 )
104
105 self.parser.insert_option_group(0, self.cmd_opts)
106
107 def run(self, options: Values, args: List[str]) -> int:
108 """Prints the completion code of the given shell"""
109 shells = COMPLETION_SCRIPTS.keys()
110 shell_options = ["--" + shell for shell in sorted(shells)]
111 if options.shell in shells:
112 script = textwrap.dedent(
113 COMPLETION_SCRIPTS.get(options.shell, "").format(prog=get_prog())
114 )
115 print(BASE_COMPLETION.format(script=script, shell=options.shell))
116 return SUCCESS
117 else:
118 sys.stderr.write(
119 "ERROR: You must pass {}\n".format(" or ".join(shell_options))
120 )
121 return SUCCESS
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/pip/_internal/commands/completion.py b/src/pip/_internal/commands/completion.py
--- a/src/pip/_internal/commands/completion.py
+++ b/src/pip/_internal/commands/completion.py
@@ -23,9 +23,18 @@
""",
"zsh": """
#compdef -P pip[0-9.]#
- compadd $( COMP_WORDS="$words[*]" \\
- COMP_CWORD=$((CURRENT-1)) \\
- PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )
+ __pip() {{
+ compadd $( COMP_WORDS="$words[*]" \\
+ COMP_CWORD=$((CURRENT-1)) \\
+ PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )
+ }}
+ if [[ $zsh_eval_context[-1] == loadautofunc ]]; then
+ # autoload from fpath, call function directly
+ __pip "$@"
+ else
+ # eval/source/. command, register function for later
+ compdef __pip -P 'pip[0-9.]#'
+ fi
""",
"fish": """
function __fish_complete_pip
|
{"golden_diff": "diff --git a/src/pip/_internal/commands/completion.py b/src/pip/_internal/commands/completion.py\n--- a/src/pip/_internal/commands/completion.py\n+++ b/src/pip/_internal/commands/completion.py\n@@ -23,9 +23,18 @@\n \"\"\",\n \"zsh\": \"\"\"\n #compdef -P pip[0-9.]#\n- compadd $( COMP_WORDS=\"$words[*]\" \\\\\n- COMP_CWORD=$((CURRENT-1)) \\\\\n- PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )\n+ __pip() {{\n+ compadd $( COMP_WORDS=\"$words[*]\" \\\\\n+ COMP_CWORD=$((CURRENT-1)) \\\\\n+ PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )\n+ }}\n+ if [[ $zsh_eval_context[-1] == loadautofunc ]]; then\n+ # autoload from fpath, call function directly\n+ __pip \"$@\"\n+ else\n+ # eval/source/. command, register function for later\n+ compdef __pip -P 'pip[0-9.]#'\n+ fi\n \"\"\",\n \"fish\": \"\"\"\n function __fish_complete_pip\n", "issue": "23.2: Unable to add zsh completion as documented\n### Description\r\n\r\nAttempting to follow the steps in the [documentation for adding zsh shell completion](https://pip.pypa.io/en/stable/user_guide/#command-completion) raises an error regarding the use of `compadd` outside of a completion function. This seems to be new with 23.2 and added in https://github.com/pypa/pip/pull/11417.\r\n\r\n### Expected behavior\r\n\r\nAs in previous versions, following the documented steps should successfully add completion for pip.\r\n\r\n### pip version\r\n\r\n23.2\r\n\r\n### Python version\r\n\r\n3.11.4\r\n\r\n### OS\r\n\r\nmacOS 12.6.8\r\n\r\n### How to Reproduce\r\n\r\nAs documented:\r\n1. Execute `python -m pip completion --zsh >> ~/.zprofile` or add eval \"`pip completion --zsh`\" to `.zprofile` or `.zshrc`\r\n2. Start a new shell\r\n\r\n### Output\r\n\r\nFrom startup:\r\n```\r\n/dev/fd/16:compadd:4: can only be called from completion function\r\n```\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow the [PSF Code of Conduct](https://www.python.org/psf/conduct/).\n", "before_files": [{"content": "import sys\nimport textwrap\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.utils.misc import get_prog\n\nBASE_COMPLETION = \"\"\"\n# pip {shell} completion start{script}# pip {shell} completion end\n\"\"\"\n\nCOMPLETION_SCRIPTS = {\n \"bash\": \"\"\"\n _pip_completion()\n {{\n COMPREPLY=( $( COMP_WORDS=\"${{COMP_WORDS[*]}}\" \\\\\n COMP_CWORD=$COMP_CWORD \\\\\n PIP_AUTO_COMPLETE=1 $1 2>/dev/null ) )\n }}\n complete -o default -F _pip_completion {prog}\n \"\"\",\n \"zsh\": \"\"\"\n #compdef -P pip[0-9.]#\n compadd $( COMP_WORDS=\"$words[*]\" \\\\\n COMP_CWORD=$((CURRENT-1)) \\\\\n PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )\n \"\"\",\n \"fish\": \"\"\"\n function __fish_complete_pip\n set -lx COMP_WORDS (commandline -o) \"\"\n set -lx COMP_CWORD ( \\\\\n math (contains -i -- (commandline -t) $COMP_WORDS)-1 \\\\\n )\n set -lx PIP_AUTO_COMPLETE 1\n string split \\\\ -- (eval $COMP_WORDS[1])\n end\n complete -fa \"(__fish_complete_pip)\" -c {prog}\n \"\"\",\n \"powershell\": \"\"\"\n if ((Test-Path Function:\\\\TabExpansion) -and -not `\n (Test-Path Function:\\\\_pip_completeBackup)) {{\n Rename-Item Function:\\\\TabExpansion _pip_completeBackup\n }}\n function TabExpansion($line, $lastWord) {{\n $lastBlock = [regex]::Split($line, '[|;]')[-1].TrimStart()\n if ($lastBlock.StartsWith(\"{prog} \")) {{\n $Env:COMP_WORDS=$lastBlock\n $Env:COMP_CWORD=$lastBlock.Split().Length - 1\n $Env:PIP_AUTO_COMPLETE=1\n (& {prog}).Split()\n Remove-Item Env:COMP_WORDS\n Remove-Item Env:COMP_CWORD\n Remove-Item Env:PIP_AUTO_COMPLETE\n }}\n elseif (Test-Path Function:\\\\_pip_completeBackup) {{\n # Fall back on existing tab expansion\n _pip_completeBackup $line $lastWord\n }}\n }}\n \"\"\",\n}\n\n\nclass CompletionCommand(Command):\n \"\"\"A helper command to be used for command completion.\"\"\"\n\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"--bash\",\n \"-b\",\n action=\"store_const\",\n const=\"bash\",\n dest=\"shell\",\n help=\"Emit completion code for bash\",\n )\n self.cmd_opts.add_option(\n \"--zsh\",\n \"-z\",\n action=\"store_const\",\n const=\"zsh\",\n dest=\"shell\",\n help=\"Emit completion code for zsh\",\n )\n self.cmd_opts.add_option(\n \"--fish\",\n \"-f\",\n action=\"store_const\",\n const=\"fish\",\n dest=\"shell\",\n help=\"Emit completion code for fish\",\n )\n self.cmd_opts.add_option(\n \"--powershell\",\n \"-p\",\n action=\"store_const\",\n const=\"powershell\",\n dest=\"shell\",\n help=\"Emit completion code for powershell\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n \"\"\"Prints the completion code of the given shell\"\"\"\n shells = COMPLETION_SCRIPTS.keys()\n shell_options = [\"--\" + shell for shell in sorted(shells)]\n if options.shell in shells:\n script = textwrap.dedent(\n COMPLETION_SCRIPTS.get(options.shell, \"\").format(prog=get_prog())\n )\n print(BASE_COMPLETION.format(script=script, shell=options.shell))\n return SUCCESS\n else:\n sys.stderr.write(\n \"ERROR: You must pass {}\\n\".format(\" or \".join(shell_options))\n )\n return SUCCESS\n", "path": "src/pip/_internal/commands/completion.py"}], "after_files": [{"content": "import sys\nimport textwrap\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.utils.misc import get_prog\n\nBASE_COMPLETION = \"\"\"\n# pip {shell} completion start{script}# pip {shell} completion end\n\"\"\"\n\nCOMPLETION_SCRIPTS = {\n \"bash\": \"\"\"\n _pip_completion()\n {{\n COMPREPLY=( $( COMP_WORDS=\"${{COMP_WORDS[*]}}\" \\\\\n COMP_CWORD=$COMP_CWORD \\\\\n PIP_AUTO_COMPLETE=1 $1 2>/dev/null ) )\n }}\n complete -o default -F _pip_completion {prog}\n \"\"\",\n \"zsh\": \"\"\"\n #compdef -P pip[0-9.]#\n __pip() {{\n compadd $( COMP_WORDS=\"$words[*]\" \\\\\n COMP_CWORD=$((CURRENT-1)) \\\\\n PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null )\n }}\n if [[ $zsh_eval_context[-1] == loadautofunc ]]; then\n # autoload from fpath, call function directly\n __pip \"$@\"\n else\n # eval/source/. command, register function for later\n compdef __pip -P 'pip[0-9.]#'\n fi\n \"\"\",\n \"fish\": \"\"\"\n function __fish_complete_pip\n set -lx COMP_WORDS (commandline -o) \"\"\n set -lx COMP_CWORD ( \\\\\n math (contains -i -- (commandline -t) $COMP_WORDS)-1 \\\\\n )\n set -lx PIP_AUTO_COMPLETE 1\n string split \\\\ -- (eval $COMP_WORDS[1])\n end\n complete -fa \"(__fish_complete_pip)\" -c {prog}\n \"\"\",\n \"powershell\": \"\"\"\n if ((Test-Path Function:\\\\TabExpansion) -and -not `\n (Test-Path Function:\\\\_pip_completeBackup)) {{\n Rename-Item Function:\\\\TabExpansion _pip_completeBackup\n }}\n function TabExpansion($line, $lastWord) {{\n $lastBlock = [regex]::Split($line, '[|;]')[-1].TrimStart()\n if ($lastBlock.StartsWith(\"{prog} \")) {{\n $Env:COMP_WORDS=$lastBlock\n $Env:COMP_CWORD=$lastBlock.Split().Length - 1\n $Env:PIP_AUTO_COMPLETE=1\n (& {prog}).Split()\n Remove-Item Env:COMP_WORDS\n Remove-Item Env:COMP_CWORD\n Remove-Item Env:PIP_AUTO_COMPLETE\n }}\n elseif (Test-Path Function:\\\\_pip_completeBackup) {{\n # Fall back on existing tab expansion\n _pip_completeBackup $line $lastWord\n }}\n }}\n \"\"\",\n}\n\n\nclass CompletionCommand(Command):\n \"\"\"A helper command to be used for command completion.\"\"\"\n\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"--bash\",\n \"-b\",\n action=\"store_const\",\n const=\"bash\",\n dest=\"shell\",\n help=\"Emit completion code for bash\",\n )\n self.cmd_opts.add_option(\n \"--zsh\",\n \"-z\",\n action=\"store_const\",\n const=\"zsh\",\n dest=\"shell\",\n help=\"Emit completion code for zsh\",\n )\n self.cmd_opts.add_option(\n \"--fish\",\n \"-f\",\n action=\"store_const\",\n const=\"fish\",\n dest=\"shell\",\n help=\"Emit completion code for fish\",\n )\n self.cmd_opts.add_option(\n \"--powershell\",\n \"-p\",\n action=\"store_const\",\n const=\"powershell\",\n dest=\"shell\",\n help=\"Emit completion code for powershell\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n \"\"\"Prints the completion code of the given shell\"\"\"\n shells = COMPLETION_SCRIPTS.keys()\n shell_options = [\"--\" + shell for shell in sorted(shells)]\n if options.shell in shells:\n script = textwrap.dedent(\n COMPLETION_SCRIPTS.get(options.shell, \"\").format(prog=get_prog())\n )\n print(BASE_COMPLETION.format(script=script, shell=options.shell))\n return SUCCESS\n else:\n sys.stderr.write(\n \"ERROR: You must pass {}\\n\".format(\" or \".join(shell_options))\n )\n return SUCCESS\n", "path": "src/pip/_internal/commands/completion.py"}]}
| 1,696 | 273 |
gh_patches_debug_27686
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-861
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
COMPLETIONS_MENU_ROWS not working
Hello
My value for `COMPLETIONS_MENU_ROWS` is 5 (default). But it does not seem to work. My terminal grow until the bottom of the window and when it has reached the last line then I don't get completions anymore.
I use gnome-terminal on Ubuntu 14.04
Thank you for your help !
EDIT: I installed HEAD from the git repo. I still have the problem
EDIT2+3: I also have the problem with xtrem and Terminator (It seems Terminal independant)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xonsh/ptk/completer.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Completer implementation to use with prompt_toolkit."""
3 import os
4 import builtins
5
6 from prompt_toolkit.layout.dimension import LayoutDimension
7 from prompt_toolkit.completion import Completer, Completion
8
9
10 class PromptToolkitCompleter(Completer):
11 """Simple prompt_toolkit Completer object.
12
13 It just redirects requests to normal Xonsh completer.
14 """
15
16 def __init__(self, completer, ctx):
17 """Takes instance of xonsh.completer.Completer and dict with context."""
18 self.completer = completer
19 self.ctx = ctx
20
21 def get_completions(self, document, complete_event):
22 """Returns a generator for list of completions."""
23
24 # Only generate completions when the user hits tab.
25 if complete_event.completion_requested:
26 line = document.current_line.lstrip()
27 endidx = document.cursor_position_col
28 begidx = line[:endidx].rfind(' ') + 1 if line[:endidx].rfind(' ') >= 0 else 0
29 prefix = line[begidx:endidx]
30 completions, l = self.completer.complete(prefix,
31 line,
32 begidx,
33 endidx,
34 self.ctx)
35 if len(completions) <= 1:
36 pass
37 elif len(os.path.commonprefix(completions)) <= len(prefix):
38 self.reserve_space()
39 for comp in completions:
40 yield Completion(comp, -l)
41
42 def reserve_space(self):
43 cli = builtins.__xonsh_shell__.shell.prompter.cli
44 #TODO remove after next prompt_toolkit release
45 try:
46 #old layout to be removed at next ptk release
47 window = cli.application.layout.children[1].children[1].content
48 except AttributeError:
49 #new layout to become default
50 window = cli.application.layout.children[1].content
51 if window and window.render_info:
52 h = window.render_info.content_height
53 r = builtins.__xonsh_env__.get('COMPLETIONS_MENU_ROWS')
54 size = h + r
55 def comp_height(cli):
56 # If there is an autocompletion menu to be shown, make sure that o
57 # layout has at least a minimal height in order to display it.
58 if not cli.is_done:
59 return LayoutDimension(min=size)
60 else:
61 return LayoutDimension()
62 window._height = comp_height
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xonsh/ptk/completer.py b/xonsh/ptk/completer.py
--- a/xonsh/ptk/completer.py
+++ b/xonsh/ptk/completer.py
@@ -2,6 +2,7 @@
"""Completer implementation to use with prompt_toolkit."""
import os
import builtins
+import xonsh.shell
from prompt_toolkit.layout.dimension import LayoutDimension
from prompt_toolkit.completion import Completer, Completion
@@ -41,13 +42,18 @@
def reserve_space(self):
cli = builtins.__xonsh_shell__.shell.prompter.cli
- #TODO remove after next prompt_toolkit release
- try:
- #old layout to be removed at next ptk release
- window = cli.application.layout.children[1].children[1].content
- except AttributeError:
- #new layout to become default
- window = cli.application.layout.children[1].content
+ if xonsh.shell.prompt_toolkit_version().startswith("1.0"):
+ # This is the layout for ptk 1.0
+ window = cli.application.layout.children[0].content.children[1]
+ else:
+ #TODO remove after next prompt_toolkit release
+ try:
+ #old layout to be removed at next ptk release
+ window = cli.application.layout.children[1].children[1].content
+ except AttributeError:
+ #new layout to become default
+ window = cli.application.layout.children[1].content
+
if window and window.render_info:
h = window.render_info.content_height
r = builtins.__xonsh_env__.get('COMPLETIONS_MENU_ROWS')
|
{"golden_diff": "diff --git a/xonsh/ptk/completer.py b/xonsh/ptk/completer.py\n--- a/xonsh/ptk/completer.py\n+++ b/xonsh/ptk/completer.py\n@@ -2,6 +2,7 @@\n \"\"\"Completer implementation to use with prompt_toolkit.\"\"\"\n import os\n import builtins\n+import xonsh.shell\n \n from prompt_toolkit.layout.dimension import LayoutDimension\n from prompt_toolkit.completion import Completer, Completion\n@@ -41,13 +42,18 @@\n \n def reserve_space(self):\n cli = builtins.__xonsh_shell__.shell.prompter.cli\n- #TODO remove after next prompt_toolkit release\n- try:\n- #old layout to be removed at next ptk release\n- window = cli.application.layout.children[1].children[1].content\n- except AttributeError:\n- #new layout to become default\n- window = cli.application.layout.children[1].content\n+ if xonsh.shell.prompt_toolkit_version().startswith(\"1.0\"):\n+ # This is the layout for ptk 1.0\n+ window = cli.application.layout.children[0].content.children[1]\n+ else:\n+ #TODO remove after next prompt_toolkit release\n+ try:\n+ #old layout to be removed at next ptk release\n+ window = cli.application.layout.children[1].children[1].content\n+ except AttributeError:\n+ #new layout to become default\n+ window = cli.application.layout.children[1].content\n+\n if window and window.render_info:\n h = window.render_info.content_height\n r = builtins.__xonsh_env__.get('COMPLETIONS_MENU_ROWS')\n", "issue": "COMPLETIONS_MENU_ROWS not working\nHello\n\nMy value for `COMPLETIONS_MENU_ROWS` is 5 (default). But it does not seem to work. My terminal grow until the bottom of the window and when it has reached the last line then I don't get completions anymore.\n\nI use gnome-terminal on Ubuntu 14.04\n\nThank you for your help !\n\nEDIT: I installed HEAD from the git repo. I still have the problem\n\nEDIT2+3: I also have the problem with xtrem and Terminator (It seems Terminal independant)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Completer implementation to use with prompt_toolkit.\"\"\"\nimport os\nimport builtins\n\nfrom prompt_toolkit.layout.dimension import LayoutDimension\nfrom prompt_toolkit.completion import Completer, Completion\n\n\nclass PromptToolkitCompleter(Completer):\n \"\"\"Simple prompt_toolkit Completer object.\n\n It just redirects requests to normal Xonsh completer.\n \"\"\"\n\n def __init__(self, completer, ctx):\n \"\"\"Takes instance of xonsh.completer.Completer and dict with context.\"\"\"\n self.completer = completer\n self.ctx = ctx\n\n def get_completions(self, document, complete_event):\n \"\"\"Returns a generator for list of completions.\"\"\"\n\n # Only generate completions when the user hits tab.\n if complete_event.completion_requested:\n line = document.current_line.lstrip()\n endidx = document.cursor_position_col\n begidx = line[:endidx].rfind(' ') + 1 if line[:endidx].rfind(' ') >= 0 else 0\n prefix = line[begidx:endidx]\n completions, l = self.completer.complete(prefix,\n line,\n begidx,\n endidx,\n self.ctx)\n if len(completions) <= 1:\n pass\n elif len(os.path.commonprefix(completions)) <= len(prefix):\n self.reserve_space()\n for comp in completions:\n yield Completion(comp, -l)\n\n def reserve_space(self):\n cli = builtins.__xonsh_shell__.shell.prompter.cli\n #TODO remove after next prompt_toolkit release\n try:\n #old layout to be removed at next ptk release\n window = cli.application.layout.children[1].children[1].content\n except AttributeError:\n #new layout to become default\n window = cli.application.layout.children[1].content\n if window and window.render_info:\n h = window.render_info.content_height\n r = builtins.__xonsh_env__.get('COMPLETIONS_MENU_ROWS')\n size = h + r\n def comp_height(cli):\n # If there is an autocompletion menu to be shown, make sure that o\n # layout has at least a minimal height in order to display it.\n if not cli.is_done:\n return LayoutDimension(min=size)\n else:\n return LayoutDimension()\n window._height = comp_height\n", "path": "xonsh/ptk/completer.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Completer implementation to use with prompt_toolkit.\"\"\"\nimport os\nimport builtins\nimport xonsh.shell\n\nfrom prompt_toolkit.layout.dimension import LayoutDimension\nfrom prompt_toolkit.completion import Completer, Completion\n\n\nclass PromptToolkitCompleter(Completer):\n \"\"\"Simple prompt_toolkit Completer object.\n\n It just redirects requests to normal Xonsh completer.\n \"\"\"\n\n def __init__(self, completer, ctx):\n \"\"\"Takes instance of xonsh.completer.Completer and dict with context.\"\"\"\n self.completer = completer\n self.ctx = ctx\n\n def get_completions(self, document, complete_event):\n \"\"\"Returns a generator for list of completions.\"\"\"\n\n # Only generate completions when the user hits tab.\n if complete_event.completion_requested:\n line = document.current_line.lstrip()\n endidx = document.cursor_position_col\n begidx = line[:endidx].rfind(' ') + 1 if line[:endidx].rfind(' ') >= 0 else 0\n prefix = line[begidx:endidx]\n completions, l = self.completer.complete(prefix,\n line,\n begidx,\n endidx,\n self.ctx)\n if len(completions) <= 1:\n pass\n elif len(os.path.commonprefix(completions)) <= len(prefix):\n self.reserve_space()\n for comp in completions:\n yield Completion(comp, -l)\n\n def reserve_space(self):\n cli = builtins.__xonsh_shell__.shell.prompter.cli\n if xonsh.shell.prompt_toolkit_version().startswith(\"1.0\"):\n # This is the layout for ptk 1.0\n window = cli.application.layout.children[0].content.children[1]\n else:\n #TODO remove after next prompt_toolkit release\n try:\n #old layout to be removed at next ptk release\n window = cli.application.layout.children[1].children[1].content\n except AttributeError:\n #new layout to become default\n window = cli.application.layout.children[1].content\n\n if window and window.render_info:\n h = window.render_info.content_height\n r = builtins.__xonsh_env__.get('COMPLETIONS_MENU_ROWS')\n size = h + r\n def comp_height(cli):\n # If there is an autocompletion menu to be shown, make sure that o\n # layout has at least a minimal height in order to display it.\n if not cli.is_done:\n return LayoutDimension(min=size)\n else:\n return LayoutDimension()\n window._height = comp_height\n", "path": "xonsh/ptk/completer.py"}]}
| 1,020 | 383 |
gh_patches_debug_17138
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-133
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MIN_TRADE_REQUIREMENT_NOT_MET
"stake_amount": 0.0005
Traceback (most recent call last):
File "./freqtrade/main.py", line 70, in _process
trade = create_trade(float(_CONF['stake_amount']))
File "./freqtrade/main.py", line 213, in create_trade
order_id = exchange.buy(pair, buy_limit, amount)
File "/vagrant/freqtrade/freqtrade/exchange/__init__.py", line 100, in buy
return _API.buy(pair, rate, amount)
File "/vagrant/freqtrade/freqtrade/exchange/bittrex.py", line 53, in buy
amount=amount))
RuntimeError: MIN_TRADE_REQUIREMENT_NOT_MET params=(BTC_CLUB, 0.00067, 0.7444029850746269)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/main.py`
Content:
```
1 #!/usr/bin/env python3
2 import copy
3 import json
4 import logging
5 import sys
6 import time
7 import traceback
8 from datetime import datetime
9 from typing import Dict, Optional, List
10
11 import requests
12 from cachetools import cached, TTLCache
13
14 from freqtrade import __version__, exchange, persistence, rpc, DependencyException, \
15 OperationalException
16 from freqtrade.analyze import get_signal, SignalType
17 from freqtrade.misc import State, get_state, update_state, parse_args, throttle, \
18 load_config
19 from freqtrade.persistence import Trade
20
21 logger = logging.getLogger('freqtrade')
22
23 _CONF = {}
24
25
26 def refresh_whitelist(whitelist: Optional[List[str]] = None) -> None:
27 """
28 Check wallet health and remove pair from whitelist if necessary
29 :param whitelist: a new whitelist (optional)
30 :return: None
31 """
32 whitelist = whitelist or _CONF['exchange']['pair_whitelist']
33
34 sanitized_whitelist = []
35 health = exchange.get_wallet_health()
36 for status in health:
37 pair = '{}_{}'.format(_CONF['stake_currency'], status['Currency'])
38 if pair not in whitelist:
39 continue
40 if status['IsActive']:
41 sanitized_whitelist.append(pair)
42 else:
43 logger.info(
44 'Ignoring %s from whitelist (reason: %s).',
45 pair, status.get('Notice') or 'wallet is not active'
46 )
47 if _CONF['exchange']['pair_whitelist'] != sanitized_whitelist:
48 logger.debug('Using refreshed pair whitelist: %s ...', sanitized_whitelist)
49 _CONF['exchange']['pair_whitelist'] = sanitized_whitelist
50
51
52 def _process(dynamic_whitelist: Optional[bool] = False) -> bool:
53 """
54 Queries the persistence layer for open trades and handles them,
55 otherwise a new trade is created.
56 :param: dynamic_whitelist: True is a dynamic whitelist should be generated (optional)
57 :return: True if a trade has been created or closed, False otherwise
58 """
59 state_changed = False
60 try:
61 # Refresh whitelist based on wallet maintenance
62 refresh_whitelist(
63 gen_pair_whitelist(_CONF['stake_currency']) if dynamic_whitelist else None
64 )
65 # Query trades from persistence layer
66 trades = Trade.query.filter(Trade.is_open.is_(True)).all()
67 if len(trades) < _CONF['max_open_trades']:
68 try:
69 # Create entity and execute trade
70 state_changed = create_trade(float(_CONF['stake_amount']))
71 if not state_changed:
72 logger.info(
73 'Checked all whitelisted currencies. '
74 'Found no suitable entry positions for buying. Will keep looking ...'
75 )
76 except DependencyException as e:
77 logger.warning('Unable to create trade: %s', e)
78
79 for trade in trades:
80 # Get order details for actual price per unit
81 if trade.open_order_id:
82 # Update trade with order values
83 logger.info('Got open order for %s', trade)
84 trade.update(exchange.get_order(trade.open_order_id))
85
86 if trade.is_open and trade.open_order_id is None:
87 # Check if we can sell our current pair
88 state_changed = handle_trade(trade) or state_changed
89
90 Trade.session.flush()
91 except (requests.exceptions.RequestException, json.JSONDecodeError) as error:
92 logger.warning(
93 'Got %s in _process(), retrying in 30 seconds...',
94 error
95 )
96 time.sleep(30)
97 except OperationalException:
98 rpc.send_msg('*Status:* Got OperationalException:\n```\n{traceback}```{hint}'.format(
99 traceback=traceback.format_exc(),
100 hint='Issue `/start` if you think it is safe to restart.'
101 ))
102 logger.exception('Got OperationalException. Stopping trader ...')
103 update_state(State.STOPPED)
104 return state_changed
105
106
107 def execute_sell(trade: Trade, limit: float) -> None:
108 """
109 Executes a limit sell for the given trade and limit
110 :param trade: Trade instance
111 :param limit: limit rate for the sell order
112 :return: None
113 """
114 # Execute sell and update trade record
115 order_id = exchange.sell(str(trade.pair), limit, trade.amount)
116 trade.open_order_id = order_id
117
118 fmt_exp_profit = round(trade.calc_profit(limit) * 100, 2)
119 rpc.send_msg('*{}:* Selling [{}]({}) with limit `{:.8f} (profit: ~{:.2f}%)`'.format(
120 trade.exchange,
121 trade.pair.replace('_', '/'),
122 exchange.get_pair_detail_url(trade.pair),
123 limit,
124 fmt_exp_profit
125 ))
126 Trade.session.flush()
127
128
129 def min_roi_reached(trade: Trade, current_rate: float, current_time: datetime) -> bool:
130 """
131 Based an earlier trade and current price and ROI configuration, decides whether bot should sell
132 :return True if bot should sell at current rate
133 """
134 current_profit = trade.calc_profit(current_rate)
135 if 'stoploss' in _CONF and current_profit < float(_CONF['stoploss']):
136 logger.debug('Stop loss hit.')
137 return True
138
139 # Check if time matches and current rate is above threshold
140 time_diff = (current_time - trade.open_date).total_seconds() / 60
141 for duration, threshold in sorted(_CONF['minimal_roi'].items()):
142 if time_diff > float(duration) and current_profit > threshold:
143 return True
144
145 logger.debug('Threshold not reached. (cur_profit: %1.2f%%)', current_profit * 100.0)
146 return False
147
148
149 def handle_trade(trade: Trade) -> bool:
150 """
151 Sells the current pair if the threshold is reached and updates the trade record.
152 :return: True if trade has been sold, False otherwise
153 """
154 if not trade.is_open:
155 raise ValueError('attempt to handle closed trade: {}'.format(trade))
156
157 logger.debug('Handling %s ...', trade)
158 current_rate = exchange.get_ticker(trade.pair)['bid']
159 if min_roi_reached(trade, current_rate, datetime.utcnow()) or get_signal(trade.pair, SignalType.SELL):
160 execute_sell(trade, current_rate)
161 return True
162 return False
163
164
165 def get_target_bid(ticker: Dict[str, float]) -> float:
166 """ Calculates bid target between current ask price and last price """
167 if ticker['ask'] < ticker['last']:
168 return ticker['ask']
169 balance = _CONF['bid_strategy']['ask_last_balance']
170 return ticker['ask'] + balance * (ticker['last'] - ticker['ask'])
171
172
173 def create_trade(stake_amount: float) -> bool:
174 """
175 Checks the implemented trading indicator(s) for a randomly picked pair,
176 if one pair triggers the buy_signal a new trade record gets created
177 :param stake_amount: amount of btc to spend
178 :return: True if a trade object has been created and persisted, False otherwise
179 """
180 logger.info(
181 'Checking buy signals to create a new trade with stake_amount: %f ...',
182 stake_amount
183 )
184 whitelist = copy.deepcopy(_CONF['exchange']['pair_whitelist'])
185 # Check if stake_amount is fulfilled
186 if exchange.get_balance(_CONF['stake_currency']) < stake_amount:
187 raise DependencyException(
188 'stake amount is not fulfilled (currency={})'.format(_CONF['stake_currency'])
189 )
190
191 # Remove currently opened and latest pairs from whitelist
192 for trade in Trade.query.filter(Trade.is_open.is_(True)).all():
193 if trade.pair in whitelist:
194 whitelist.remove(trade.pair)
195 logger.debug('Ignoring %s in pair whitelist', trade.pair)
196 if not whitelist:
197 raise DependencyException('No pair in whitelist')
198
199 # Pick pair based on StochRSI buy signals
200 for _pair in whitelist:
201 if get_signal(_pair, SignalType.BUY):
202 pair = _pair
203 break
204 else:
205 return False
206
207 # Calculate amount and subtract fee
208 fee = exchange.get_fee()
209 buy_limit = get_target_bid(exchange.get_ticker(pair))
210 amount = (1 - fee) * stake_amount / buy_limit
211
212 order_id = exchange.buy(pair, buy_limit, amount)
213 # Create trade entity and return
214 rpc.send_msg('*{}:* Buying [{}]({}) with limit `{:.8f}`'.format(
215 exchange.get_name().upper(),
216 pair.replace('_', '/'),
217 exchange.get_pair_detail_url(pair),
218 buy_limit
219 ))
220 # Fee is applied twice because we make a LIMIT_BUY and LIMIT_SELL
221 trade = Trade(
222 pair=pair,
223 stake_amount=stake_amount,
224 amount=amount,
225 fee=fee * 2,
226 open_rate=buy_limit,
227 open_date=datetime.utcnow(),
228 exchange=exchange.get_name().upper(),
229 open_order_id=order_id
230 )
231 Trade.session.add(trade)
232 Trade.session.flush()
233 return True
234
235
236 def init(config: dict, db_url: Optional[str] = None) -> None:
237 """
238 Initializes all modules and updates the config
239 :param config: config as dict
240 :param db_url: database connector string for sqlalchemy (Optional)
241 :return: None
242 """
243 # Initialize all modules
244 rpc.init(config)
245 persistence.init(config, db_url)
246 exchange.init(config)
247
248 # Set initial application state
249 initial_state = config.get('initial_state')
250 if initial_state:
251 update_state(State[initial_state.upper()])
252 else:
253 update_state(State.STOPPED)
254
255
256 @cached(TTLCache(maxsize=1, ttl=1800))
257 def gen_pair_whitelist(base_currency: str, topn: int = 20, key: str = 'BaseVolume') -> List[str]:
258 """
259 Updates the whitelist with with a dynamically generated list
260 :param base_currency: base currency as str
261 :param topn: maximum number of returned results
262 :param key: sort key (defaults to 'BaseVolume')
263 :return: List of pairs
264 """
265 summaries = sorted(
266 (s for s in exchange.get_market_summaries() if s['MarketName'].startswith(base_currency)),
267 key=lambda s: s.get(key) or 0.0,
268 reverse=True
269 )
270 return [s['MarketName'].replace('-', '_') for s in summaries[:topn]]
271
272
273 def cleanup() -> None:
274 """
275 Cleanup the application state und finish all pending tasks
276 :return: None
277 """
278 rpc.send_msg('*Status:* `Stopping trader...`')
279 logger.info('Stopping trader and cleaning up modules...')
280 update_state(State.STOPPED)
281 persistence.cleanup()
282 rpc.cleanup()
283 exit(0)
284
285
286 def main() -> None:
287 """
288 Loads and validates the config and handles the main loop
289 :return: None
290 """
291 global _CONF
292 args = parse_args(sys.argv[1:])
293 if not args:
294 exit(0)
295
296 # Initialize logger
297 logging.basicConfig(
298 level=args.loglevel,
299 format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
300 )
301
302 logger.info(
303 'Starting freqtrade %s (loglevel=%s)',
304 __version__,
305 logging.getLevelName(args.loglevel)
306 )
307
308 # Load and validate configuration
309 _CONF = load_config(args.config)
310
311 # Initialize all modules and start main loop
312 if args.dynamic_whitelist:
313 logger.info('Using dynamically generated whitelist. (--dynamic-whitelist detected)')
314
315 try:
316 init(_CONF)
317 old_state = None
318 while True:
319 new_state = get_state()
320 # Log state transition
321 if new_state != old_state:
322 rpc.send_msg('*Status:* `{}`'.format(new_state.name.lower()))
323 logger.info('Changing state to: %s', new_state.name)
324
325 if new_state == State.STOPPED:
326 time.sleep(1)
327 elif new_state == State.RUNNING:
328 throttle(
329 _process,
330 min_secs=_CONF['internals'].get('process_throttle_secs', 10),
331 dynamic_whitelist=args.dynamic_whitelist,
332 )
333 old_state = new_state
334 except KeyboardInterrupt:
335 logger.info('Got SIGINT, aborting ...')
336 except BaseException:
337 logger.exception('Got fatal exception!')
338 finally:
339 cleanup()
340
341
342 if __name__ == '__main__':
343 main()
344
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/freqtrade/main.py b/freqtrade/main.py
--- a/freqtrade/main.py
+++ b/freqtrade/main.py
@@ -204,10 +204,9 @@
else:
return False
- # Calculate amount and subtract fee
- fee = exchange.get_fee()
+ # Calculate amount
buy_limit = get_target_bid(exchange.get_ticker(pair))
- amount = (1 - fee) * stake_amount / buy_limit
+ amount = stake_amount / buy_limit
order_id = exchange.buy(pair, buy_limit, amount)
# Create trade entity and return
@@ -222,7 +221,7 @@
pair=pair,
stake_amount=stake_amount,
amount=amount,
- fee=fee * 2,
+ fee=exchange.get_fee() * 2,
open_rate=buy_limit,
open_date=datetime.utcnow(),
exchange=exchange.get_name().upper(),
|
{"golden_diff": "diff --git a/freqtrade/main.py b/freqtrade/main.py\n--- a/freqtrade/main.py\n+++ b/freqtrade/main.py\n@@ -204,10 +204,9 @@\n else:\n return False\n \n- # Calculate amount and subtract fee\n- fee = exchange.get_fee()\n+ # Calculate amount\n buy_limit = get_target_bid(exchange.get_ticker(pair))\n- amount = (1 - fee) * stake_amount / buy_limit\n+ amount = stake_amount / buy_limit\n \n order_id = exchange.buy(pair, buy_limit, amount)\n # Create trade entity and return\n@@ -222,7 +221,7 @@\n pair=pair,\n stake_amount=stake_amount,\n amount=amount,\n- fee=fee * 2,\n+ fee=exchange.get_fee() * 2,\n open_rate=buy_limit,\n open_date=datetime.utcnow(),\n exchange=exchange.get_name().upper(),\n", "issue": "MIN_TRADE_REQUIREMENT_NOT_MET\n\"stake_amount\": 0.0005\r\n\r\nTraceback (most recent call last):\r\n File \"./freqtrade/main.py\", line 70, in _process\r\n trade = create_trade(float(_CONF['stake_amount']))\r\n File \"./freqtrade/main.py\", line 213, in create_trade\r\n order_id = exchange.buy(pair, buy_limit, amount)\r\n File \"/vagrant/freqtrade/freqtrade/exchange/__init__.py\", line 100, in buy\r\n return _API.buy(pair, rate, amount)\r\n File \"/vagrant/freqtrade/freqtrade/exchange/bittrex.py\", line 53, in buy\r\n amount=amount))\r\nRuntimeError: MIN_TRADE_REQUIREMENT_NOT_MET params=(BTC_CLUB, 0.00067, 0.7444029850746269)\n", "before_files": [{"content": "#!/usr/bin/env python3\nimport copy\nimport json\nimport logging\nimport sys\nimport time\nimport traceback\nfrom datetime import datetime\nfrom typing import Dict, Optional, List\n\nimport requests\nfrom cachetools import cached, TTLCache\n\nfrom freqtrade import __version__, exchange, persistence, rpc, DependencyException, \\\n OperationalException\nfrom freqtrade.analyze import get_signal, SignalType\nfrom freqtrade.misc import State, get_state, update_state, parse_args, throttle, \\\n load_config\nfrom freqtrade.persistence import Trade\n\nlogger = logging.getLogger('freqtrade')\n\n_CONF = {}\n\n\ndef refresh_whitelist(whitelist: Optional[List[str]] = None) -> None:\n \"\"\"\n Check wallet health and remove pair from whitelist if necessary\n :param whitelist: a new whitelist (optional)\n :return: None\n \"\"\"\n whitelist = whitelist or _CONF['exchange']['pair_whitelist']\n\n sanitized_whitelist = []\n health = exchange.get_wallet_health()\n for status in health:\n pair = '{}_{}'.format(_CONF['stake_currency'], status['Currency'])\n if pair not in whitelist:\n continue\n if status['IsActive']:\n sanitized_whitelist.append(pair)\n else:\n logger.info(\n 'Ignoring %s from whitelist (reason: %s).',\n pair, status.get('Notice') or 'wallet is not active'\n )\n if _CONF['exchange']['pair_whitelist'] != sanitized_whitelist:\n logger.debug('Using refreshed pair whitelist: %s ...', sanitized_whitelist)\n _CONF['exchange']['pair_whitelist'] = sanitized_whitelist\n\n\ndef _process(dynamic_whitelist: Optional[bool] = False) -> bool:\n \"\"\"\n Queries the persistence layer for open trades and handles them,\n otherwise a new trade is created.\n :param: dynamic_whitelist: True is a dynamic whitelist should be generated (optional)\n :return: True if a trade has been created or closed, False otherwise\n \"\"\"\n state_changed = False\n try:\n # Refresh whitelist based on wallet maintenance\n refresh_whitelist(\n gen_pair_whitelist(_CONF['stake_currency']) if dynamic_whitelist else None\n )\n # Query trades from persistence layer\n trades = Trade.query.filter(Trade.is_open.is_(True)).all()\n if len(trades) < _CONF['max_open_trades']:\n try:\n # Create entity and execute trade\n state_changed = create_trade(float(_CONF['stake_amount']))\n if not state_changed:\n logger.info(\n 'Checked all whitelisted currencies. '\n 'Found no suitable entry positions for buying. Will keep looking ...'\n )\n except DependencyException as e:\n logger.warning('Unable to create trade: %s', e)\n\n for trade in trades:\n # Get order details for actual price per unit\n if trade.open_order_id:\n # Update trade with order values\n logger.info('Got open order for %s', trade)\n trade.update(exchange.get_order(trade.open_order_id))\n\n if trade.is_open and trade.open_order_id is None:\n # Check if we can sell our current pair\n state_changed = handle_trade(trade) or state_changed\n\n Trade.session.flush()\n except (requests.exceptions.RequestException, json.JSONDecodeError) as error:\n logger.warning(\n 'Got %s in _process(), retrying in 30 seconds...',\n error\n )\n time.sleep(30)\n except OperationalException:\n rpc.send_msg('*Status:* Got OperationalException:\\n```\\n{traceback}```{hint}'.format(\n traceback=traceback.format_exc(),\n hint='Issue `/start` if you think it is safe to restart.'\n ))\n logger.exception('Got OperationalException. Stopping trader ...')\n update_state(State.STOPPED)\n return state_changed\n\n\ndef execute_sell(trade: Trade, limit: float) -> None:\n \"\"\"\n Executes a limit sell for the given trade and limit\n :param trade: Trade instance\n :param limit: limit rate for the sell order\n :return: None\n \"\"\"\n # Execute sell and update trade record\n order_id = exchange.sell(str(trade.pair), limit, trade.amount)\n trade.open_order_id = order_id\n\n fmt_exp_profit = round(trade.calc_profit(limit) * 100, 2)\n rpc.send_msg('*{}:* Selling [{}]({}) with limit `{:.8f} (profit: ~{:.2f}%)`'.format(\n trade.exchange,\n trade.pair.replace('_', '/'),\n exchange.get_pair_detail_url(trade.pair),\n limit,\n fmt_exp_profit\n ))\n Trade.session.flush()\n\n\ndef min_roi_reached(trade: Trade, current_rate: float, current_time: datetime) -> bool:\n \"\"\"\n Based an earlier trade and current price and ROI configuration, decides whether bot should sell\n :return True if bot should sell at current rate\n \"\"\"\n current_profit = trade.calc_profit(current_rate)\n if 'stoploss' in _CONF and current_profit < float(_CONF['stoploss']):\n logger.debug('Stop loss hit.')\n return True\n\n # Check if time matches and current rate is above threshold\n time_diff = (current_time - trade.open_date).total_seconds() / 60\n for duration, threshold in sorted(_CONF['minimal_roi'].items()):\n if time_diff > float(duration) and current_profit > threshold:\n return True\n\n logger.debug('Threshold not reached. (cur_profit: %1.2f%%)', current_profit * 100.0)\n return False\n\n\ndef handle_trade(trade: Trade) -> bool:\n \"\"\"\n Sells the current pair if the threshold is reached and updates the trade record.\n :return: True if trade has been sold, False otherwise\n \"\"\"\n if not trade.is_open:\n raise ValueError('attempt to handle closed trade: {}'.format(trade))\n\n logger.debug('Handling %s ...', trade)\n current_rate = exchange.get_ticker(trade.pair)['bid']\n if min_roi_reached(trade, current_rate, datetime.utcnow()) or get_signal(trade.pair, SignalType.SELL):\n execute_sell(trade, current_rate)\n return True\n return False\n\n\ndef get_target_bid(ticker: Dict[str, float]) -> float:\n \"\"\" Calculates bid target between current ask price and last price \"\"\"\n if ticker['ask'] < ticker['last']:\n return ticker['ask']\n balance = _CONF['bid_strategy']['ask_last_balance']\n return ticker['ask'] + balance * (ticker['last'] - ticker['ask'])\n\n\ndef create_trade(stake_amount: float) -> bool:\n \"\"\"\n Checks the implemented trading indicator(s) for a randomly picked pair,\n if one pair triggers the buy_signal a new trade record gets created\n :param stake_amount: amount of btc to spend\n :return: True if a trade object has been created and persisted, False otherwise\n \"\"\"\n logger.info(\n 'Checking buy signals to create a new trade with stake_amount: %f ...',\n stake_amount\n )\n whitelist = copy.deepcopy(_CONF['exchange']['pair_whitelist'])\n # Check if stake_amount is fulfilled\n if exchange.get_balance(_CONF['stake_currency']) < stake_amount:\n raise DependencyException(\n 'stake amount is not fulfilled (currency={})'.format(_CONF['stake_currency'])\n )\n\n # Remove currently opened and latest pairs from whitelist\n for trade in Trade.query.filter(Trade.is_open.is_(True)).all():\n if trade.pair in whitelist:\n whitelist.remove(trade.pair)\n logger.debug('Ignoring %s in pair whitelist', trade.pair)\n if not whitelist:\n raise DependencyException('No pair in whitelist')\n\n # Pick pair based on StochRSI buy signals\n for _pair in whitelist:\n if get_signal(_pair, SignalType.BUY):\n pair = _pair\n break\n else:\n return False\n\n # Calculate amount and subtract fee\n fee = exchange.get_fee()\n buy_limit = get_target_bid(exchange.get_ticker(pair))\n amount = (1 - fee) * stake_amount / buy_limit\n\n order_id = exchange.buy(pair, buy_limit, amount)\n # Create trade entity and return\n rpc.send_msg('*{}:* Buying [{}]({}) with limit `{:.8f}`'.format(\n exchange.get_name().upper(),\n pair.replace('_', '/'),\n exchange.get_pair_detail_url(pair),\n buy_limit\n ))\n # Fee is applied twice because we make a LIMIT_BUY and LIMIT_SELL\n trade = Trade(\n pair=pair,\n stake_amount=stake_amount,\n amount=amount,\n fee=fee * 2,\n open_rate=buy_limit,\n open_date=datetime.utcnow(),\n exchange=exchange.get_name().upper(),\n open_order_id=order_id\n )\n Trade.session.add(trade)\n Trade.session.flush()\n return True\n\n\ndef init(config: dict, db_url: Optional[str] = None) -> None:\n \"\"\"\n Initializes all modules and updates the config\n :param config: config as dict\n :param db_url: database connector string for sqlalchemy (Optional)\n :return: None\n \"\"\"\n # Initialize all modules\n rpc.init(config)\n persistence.init(config, db_url)\n exchange.init(config)\n\n # Set initial application state\n initial_state = config.get('initial_state')\n if initial_state:\n update_state(State[initial_state.upper()])\n else:\n update_state(State.STOPPED)\n\n\n@cached(TTLCache(maxsize=1, ttl=1800))\ndef gen_pair_whitelist(base_currency: str, topn: int = 20, key: str = 'BaseVolume') -> List[str]:\n \"\"\"\n Updates the whitelist with with a dynamically generated list\n :param base_currency: base currency as str\n :param topn: maximum number of returned results\n :param key: sort key (defaults to 'BaseVolume')\n :return: List of pairs\n \"\"\"\n summaries = sorted(\n (s for s in exchange.get_market_summaries() if s['MarketName'].startswith(base_currency)),\n key=lambda s: s.get(key) or 0.0,\n reverse=True\n )\n return [s['MarketName'].replace('-', '_') for s in summaries[:topn]]\n\n\ndef cleanup() -> None:\n \"\"\"\n Cleanup the application state und finish all pending tasks\n :return: None\n \"\"\"\n rpc.send_msg('*Status:* `Stopping trader...`')\n logger.info('Stopping trader and cleaning up modules...')\n update_state(State.STOPPED)\n persistence.cleanup()\n rpc.cleanup()\n exit(0)\n\n\ndef main() -> None:\n \"\"\"\n Loads and validates the config and handles the main loop\n :return: None\n \"\"\"\n global _CONF\n args = parse_args(sys.argv[1:])\n if not args:\n exit(0)\n\n # Initialize logger\n logging.basicConfig(\n level=args.loglevel,\n format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',\n )\n\n logger.info(\n 'Starting freqtrade %s (loglevel=%s)',\n __version__,\n logging.getLevelName(args.loglevel)\n )\n\n # Load and validate configuration\n _CONF = load_config(args.config)\n\n # Initialize all modules and start main loop\n if args.dynamic_whitelist:\n logger.info('Using dynamically generated whitelist. (--dynamic-whitelist detected)')\n\n try:\n init(_CONF)\n old_state = None\n while True:\n new_state = get_state()\n # Log state transition\n if new_state != old_state:\n rpc.send_msg('*Status:* `{}`'.format(new_state.name.lower()))\n logger.info('Changing state to: %s', new_state.name)\n\n if new_state == State.STOPPED:\n time.sleep(1)\n elif new_state == State.RUNNING:\n throttle(\n _process,\n min_secs=_CONF['internals'].get('process_throttle_secs', 10),\n dynamic_whitelist=args.dynamic_whitelist,\n )\n old_state = new_state\n except KeyboardInterrupt:\n logger.info('Got SIGINT, aborting ...')\n except BaseException:\n logger.exception('Got fatal exception!')\n finally:\n cleanup()\n\n\nif __name__ == '__main__':\n main()\n", "path": "freqtrade/main.py"}], "after_files": [{"content": "#!/usr/bin/env python3\nimport copy\nimport json\nimport logging\nimport sys\nimport time\nimport traceback\nfrom datetime import datetime\nfrom typing import Dict, Optional, List\n\nimport requests\nfrom cachetools import cached, TTLCache\n\nfrom freqtrade import __version__, exchange, persistence, rpc, DependencyException, \\\n OperationalException\nfrom freqtrade.analyze import get_signal, SignalType\nfrom freqtrade.misc import State, get_state, update_state, parse_args, throttle, \\\n load_config\nfrom freqtrade.persistence import Trade\n\nlogger = logging.getLogger('freqtrade')\n\n_CONF = {}\n\n\ndef refresh_whitelist(whitelist: Optional[List[str]] = None) -> None:\n \"\"\"\n Check wallet health and remove pair from whitelist if necessary\n :param whitelist: a new whitelist (optional)\n :return: None\n \"\"\"\n whitelist = whitelist or _CONF['exchange']['pair_whitelist']\n\n sanitized_whitelist = []\n health = exchange.get_wallet_health()\n for status in health:\n pair = '{}_{}'.format(_CONF['stake_currency'], status['Currency'])\n if pair not in whitelist:\n continue\n if status['IsActive']:\n sanitized_whitelist.append(pair)\n else:\n logger.info(\n 'Ignoring %s from whitelist (reason: %s).',\n pair, status.get('Notice') or 'wallet is not active'\n )\n if _CONF['exchange']['pair_whitelist'] != sanitized_whitelist:\n logger.debug('Using refreshed pair whitelist: %s ...', sanitized_whitelist)\n _CONF['exchange']['pair_whitelist'] = sanitized_whitelist\n\n\ndef _process(dynamic_whitelist: Optional[bool] = False) -> bool:\n \"\"\"\n Queries the persistence layer for open trades and handles them,\n otherwise a new trade is created.\n :param: dynamic_whitelist: True is a dynamic whitelist should be generated (optional)\n :return: True if a trade has been created or closed, False otherwise\n \"\"\"\n state_changed = False\n try:\n # Refresh whitelist based on wallet maintenance\n refresh_whitelist(\n gen_pair_whitelist(_CONF['stake_currency']) if dynamic_whitelist else None\n )\n # Query trades from persistence layer\n trades = Trade.query.filter(Trade.is_open.is_(True)).all()\n if len(trades) < _CONF['max_open_trades']:\n try:\n # Create entity and execute trade\n state_changed = create_trade(float(_CONF['stake_amount']))\n if not state_changed:\n logger.info(\n 'Checked all whitelisted currencies. '\n 'Found no suitable entry positions for buying. Will keep looking ...'\n )\n except DependencyException as e:\n logger.warning('Unable to create trade: %s', e)\n\n for trade in trades:\n # Get order details for actual price per unit\n if trade.open_order_id:\n # Update trade with order values\n logger.info('Got open order for %s', trade)\n trade.update(exchange.get_order(trade.open_order_id))\n\n if trade.is_open and trade.open_order_id is None:\n # Check if we can sell our current pair\n state_changed = handle_trade(trade) or state_changed\n\n Trade.session.flush()\n except (requests.exceptions.RequestException, json.JSONDecodeError) as error:\n logger.warning(\n 'Got %s in _process(), retrying in 30 seconds...',\n error\n )\n time.sleep(30)\n except OperationalException:\n rpc.send_msg('*Status:* Got OperationalException:\\n```\\n{traceback}```{hint}'.format(\n traceback=traceback.format_exc(),\n hint='Issue `/start` if you think it is safe to restart.'\n ))\n logger.exception('Got OperationalException. Stopping trader ...')\n update_state(State.STOPPED)\n return state_changed\n\n\ndef execute_sell(trade: Trade, limit: float) -> None:\n \"\"\"\n Executes a limit sell for the given trade and limit\n :param trade: Trade instance\n :param limit: limit rate for the sell order\n :return: None\n \"\"\"\n # Execute sell and update trade record\n order_id = exchange.sell(str(trade.pair), limit, trade.amount)\n trade.open_order_id = order_id\n\n fmt_exp_profit = round(trade.calc_profit(limit) * 100, 2)\n rpc.send_msg('*{}:* Selling [{}]({}) with limit `{:.8f} (profit: ~{:.2f}%)`'.format(\n trade.exchange,\n trade.pair.replace('_', '/'),\n exchange.get_pair_detail_url(trade.pair),\n limit,\n fmt_exp_profit\n ))\n Trade.session.flush()\n\n\ndef min_roi_reached(trade: Trade, current_rate: float, current_time: datetime) -> bool:\n \"\"\"\n Based an earlier trade and current price and ROI configuration, decides whether bot should sell\n :return True if bot should sell at current rate\n \"\"\"\n current_profit = trade.calc_profit(current_rate)\n if 'stoploss' in _CONF and current_profit < float(_CONF['stoploss']):\n logger.debug('Stop loss hit.')\n return True\n\n # Check if time matches and current rate is above threshold\n time_diff = (current_time - trade.open_date).total_seconds() / 60\n for duration, threshold in sorted(_CONF['minimal_roi'].items()):\n if time_diff > float(duration) and current_profit > threshold:\n return True\n\n logger.debug('Threshold not reached. (cur_profit: %1.2f%%)', current_profit * 100.0)\n return False\n\n\ndef handle_trade(trade: Trade) -> bool:\n \"\"\"\n Sells the current pair if the threshold is reached and updates the trade record.\n :return: True if trade has been sold, False otherwise\n \"\"\"\n if not trade.is_open:\n raise ValueError('attempt to handle closed trade: {}'.format(trade))\n\n logger.debug('Handling %s ...', trade)\n current_rate = exchange.get_ticker(trade.pair)['bid']\n if min_roi_reached(trade, current_rate, datetime.utcnow()) or get_signal(trade.pair, SignalType.SELL):\n execute_sell(trade, current_rate)\n return True\n return False\n\n\ndef get_target_bid(ticker: Dict[str, float]) -> float:\n \"\"\" Calculates bid target between current ask price and last price \"\"\"\n if ticker['ask'] < ticker['last']:\n return ticker['ask']\n balance = _CONF['bid_strategy']['ask_last_balance']\n return ticker['ask'] + balance * (ticker['last'] - ticker['ask'])\n\n\ndef create_trade(stake_amount: float) -> bool:\n \"\"\"\n Checks the implemented trading indicator(s) for a randomly picked pair,\n if one pair triggers the buy_signal a new trade record gets created\n :param stake_amount: amount of btc to spend\n :return: True if a trade object has been created and persisted, False otherwise\n \"\"\"\n logger.info(\n 'Checking buy signals to create a new trade with stake_amount: %f ...',\n stake_amount\n )\n whitelist = copy.deepcopy(_CONF['exchange']['pair_whitelist'])\n # Check if stake_amount is fulfilled\n if exchange.get_balance(_CONF['stake_currency']) < stake_amount:\n raise DependencyException(\n 'stake amount is not fulfilled (currency={})'.format(_CONF['stake_currency'])\n )\n\n # Remove currently opened and latest pairs from whitelist\n for trade in Trade.query.filter(Trade.is_open.is_(True)).all():\n if trade.pair in whitelist:\n whitelist.remove(trade.pair)\n logger.debug('Ignoring %s in pair whitelist', trade.pair)\n if not whitelist:\n raise DependencyException('No pair in whitelist')\n\n # Pick pair based on StochRSI buy signals\n for _pair in whitelist:\n if get_signal(_pair, SignalType.BUY):\n pair = _pair\n break\n else:\n return False\n\n # Calculate amount\n buy_limit = get_target_bid(exchange.get_ticker(pair))\n amount = stake_amount / buy_limit\n\n order_id = exchange.buy(pair, buy_limit, amount)\n # Create trade entity and return\n rpc.send_msg('*{}:* Buying [{}]({}) with limit `{:.8f}`'.format(\n exchange.get_name().upper(),\n pair.replace('_', '/'),\n exchange.get_pair_detail_url(pair),\n buy_limit\n ))\n # Fee is applied twice because we make a LIMIT_BUY and LIMIT_SELL\n trade = Trade(\n pair=pair,\n stake_amount=stake_amount,\n amount=amount,\n fee=exchange.get_fee() * 2,\n open_rate=buy_limit,\n open_date=datetime.utcnow(),\n exchange=exchange.get_name().upper(),\n open_order_id=order_id\n )\n Trade.session.add(trade)\n Trade.session.flush()\n return True\n\n\ndef init(config: dict, db_url: Optional[str] = None) -> None:\n \"\"\"\n Initializes all modules and updates the config\n :param config: config as dict\n :param db_url: database connector string for sqlalchemy (Optional)\n :return: None\n \"\"\"\n # Initialize all modules\n rpc.init(config)\n persistence.init(config, db_url)\n exchange.init(config)\n\n # Set initial application state\n initial_state = config.get('initial_state')\n if initial_state:\n update_state(State[initial_state.upper()])\n else:\n update_state(State.STOPPED)\n\n\n@cached(TTLCache(maxsize=1, ttl=1800))\ndef gen_pair_whitelist(base_currency: str, topn: int = 20, key: str = 'BaseVolume') -> List[str]:\n \"\"\"\n Updates the whitelist with with a dynamically generated list\n :param base_currency: base currency as str\n :param topn: maximum number of returned results\n :param key: sort key (defaults to 'BaseVolume')\n :return: List of pairs\n \"\"\"\n summaries = sorted(\n (s for s in exchange.get_market_summaries() if s['MarketName'].startswith(base_currency)),\n key=lambda s: s.get(key) or 0.0,\n reverse=True\n )\n return [s['MarketName'].replace('-', '_') for s in summaries[:topn]]\n\n\ndef cleanup() -> None:\n \"\"\"\n Cleanup the application state und finish all pending tasks\n :return: None\n \"\"\"\n rpc.send_msg('*Status:* `Stopping trader...`')\n logger.info('Stopping trader and cleaning up modules...')\n update_state(State.STOPPED)\n persistence.cleanup()\n rpc.cleanup()\n exit(0)\n\n\ndef main() -> None:\n \"\"\"\n Loads and validates the config and handles the main loop\n :return: None\n \"\"\"\n global _CONF\n args = parse_args(sys.argv[1:])\n if not args:\n exit(0)\n\n # Initialize logger\n logging.basicConfig(\n level=args.loglevel,\n format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',\n )\n\n logger.info(\n 'Starting freqtrade %s (loglevel=%s)',\n __version__,\n logging.getLevelName(args.loglevel)\n )\n\n # Load and validate configuration\n _CONF = load_config(args.config)\n\n # Initialize all modules and start main loop\n if args.dynamic_whitelist:\n logger.info('Using dynamically generated whitelist. (--dynamic-whitelist detected)')\n\n try:\n init(_CONF)\n old_state = None\n while True:\n new_state = get_state()\n # Log state transition\n if new_state != old_state:\n rpc.send_msg('*Status:* `{}`'.format(new_state.name.lower()))\n logger.info('Changing state to: %s', new_state.name)\n\n if new_state == State.STOPPED:\n time.sleep(1)\n elif new_state == State.RUNNING:\n throttle(\n _process,\n min_secs=_CONF['internals'].get('process_throttle_secs', 10),\n dynamic_whitelist=args.dynamic_whitelist,\n )\n old_state = new_state\n except KeyboardInterrupt:\n logger.info('Got SIGINT, aborting ...')\n except BaseException:\n logger.exception('Got fatal exception!')\n finally:\n cleanup()\n\n\nif __name__ == '__main__':\n main()\n", "path": "freqtrade/main.py"}]}
| 4,069 | 213 |
gh_patches_debug_5538
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-3710
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
testing 4293: change wording for template
**URL:** module template in dashboard
**user:** initiator
**expected behaviour:** correct template description
**behaviour:** needs to be adapted
**important screensize:**
**device & browser:**
**Comment/Question:**
change wording from:
Die Teilnehmenden können auf eine oder mehrere Fragen mit vordefinierten Antwortmöglichkeiten antworten und die Umfrage kommentieren.
to
Die Teilnehmenden können auf offene und Multiple-Choice-Fragen antworten und die Umfrage kommentieren.
Participants can answer to open and multiple choice questions and comment on the poll.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/dashboard/blueprints.py`
Content:
```
1 from django.utils.translation import ugettext_lazy as _
2
3 from adhocracy4.dashboard.blueprints import ProjectBlueprint
4 from adhocracy4.polls import phases as poll_phases
5 from meinberlin.apps.budgeting import phases as budgeting_phases
6 from meinberlin.apps.documents import phases as documents_phases
7 from meinberlin.apps.ideas import phases as ideas_phases
8 from meinberlin.apps.kiezkasse import phases as kiezkasse_phases
9 from meinberlin.apps.livequestions import phases as livequestion_phases
10 from meinberlin.apps.mapideas import phases as mapideas_phases
11 from meinberlin.apps.maptopicprio import phases as maptopicprio_phases
12 from meinberlin.apps.topicprio import phases as topicprio_phases
13
14 blueprints = [
15 ('brainstorming',
16 ProjectBlueprint(
17 title=_('Brainstorming'),
18 description=_(
19 'Participants can submit their own ideas and discuss the ideas '
20 'of others.'
21 ),
22 content=[
23 ideas_phases.CollectPhase(),
24 ],
25 image='images/brainstorming.svg',
26 settings_model=None,
27 )),
28 ('map-brainstorming',
29 ProjectBlueprint(
30 title=_('Spatial Brainstorming'),
31 description=_(
32 'Participants can submit their own ideas and locate them on a '
33 'map. They can also discuss the ideas of others.'
34 ),
35 content=[
36 mapideas_phases.CollectPhase(),
37 ],
38 image='images/map-brainstorming.svg',
39 settings_model=('a4maps', 'AreaSettings'),
40 )),
41 ('idea-collection',
42 ProjectBlueprint(
43 title=_('Idea Collection'),
44 description=_(
45 'Participants can submit their own ideas and discuss and rate '
46 '(pro/contra) the ideas of others.'
47 ),
48 content=[
49 ideas_phases.CollectFeedbackPhase(),
50 ],
51 image='images/agenda-setting.svg',
52 settings_model=None,
53 )),
54 ('map-idea-collection',
55 ProjectBlueprint(
56 title=_('Spatial Idea Collection'),
57 description=_(
58 'Participants can submit their own ideas and locate them on a '
59 'map. They can also discuss and rate (pro/contra) the ideas of '
60 'others.'
61 ),
62 content=[
63 mapideas_phases.CollectFeedbackPhase(),
64 ],
65 image='images/map-idea-collection.svg',
66 settings_model=('a4maps', 'AreaSettings'),
67 )),
68 ('participatory-budgeting',
69 ProjectBlueprint(
70 title=_('Participatory budgeting (1 phase)'),
71 description=_(
72 'Participants can submit their own proposals, mark them on a '
73 'map, and add a budget. The proposals of others can be discussed '
74 'and rated (pro/contra).'
75 ),
76 content=[
77 budgeting_phases.RequestPhase()
78 ],
79 image='images/participatory-budgeting-1.svg',
80 settings_model=('a4maps', 'AreaSettings'),
81 )),
82 ('participatory-budgeting-2-phases',
83 ProjectBlueprint(
84 title=_('Participatory budgeting (2 phase)'),
85 description=_(
86 'In a first phase, participants can submit their own proposals, '
87 'mark them on a map, and add a budget. The proposals of others '
88 'can be discussed and in a second phase rated (pro/contra).'
89 ),
90 content=[
91 budgeting_phases.CollectPhase(),
92 budgeting_phases.RatingPhase(),
93 ],
94 image='images/participatory-budgeting-2.svg',
95 settings_model=('a4maps', 'AreaSettings'),
96 )),
97 ('kiezkasse',
98 ProjectBlueprint(
99 title=_('Kiezkasse'),
100 description=_(
101 'Participants can submit their own proposals, mark them on a '
102 'map, and add a budget. They can express their interest in '
103 'participating in the proposals’s implementation. The proposals '
104 'of others can be discussed and rated (pro/contra).'
105 ),
106 content=[
107 kiezkasse_phases.RequestFeedbackPhase(),
108 ],
109 image='images/kiezkasse.svg',
110 settings_model=('a4maps', 'AreaSettings'),
111 )),
112 ('prioritization',
113 ProjectBlueprint(
114 title=_('Prioritization'),
115 description=_(
116 'Participants can discuss and rate (pro/contra) previously added '
117 'ideas and topics. Participants cannot add ideas or topics.'
118 ),
119 content=[
120 topicprio_phases.PrioritizePhase(),
121 ],
122 image='images/priorization.svg',
123 settings_model=None,
124 )),
125 ('map-topic-prioritization',
126 ProjectBlueprint(
127 title=_('Spatial Prioritization'),
128 description=_(
129 'Participants can discuss and rate (pro/contra) ideas and topics '
130 'previously added to a map. Participants cannot add ideas or '
131 'topics.'
132 ),
133 content=[
134 maptopicprio_phases.PrioritizePhase(),
135 ],
136 image='images/place-priotization.svg',
137 settings_model=('a4maps', 'AreaSettings'),
138 )),
139 ('text-review',
140 ProjectBlueprint(
141 title=_('Text Review'),
142 description=_(
143 'Participants can discuss the paragraphs of a text that you '
144 'added beforehand.'
145 ),
146 content=[
147 documents_phases.CommentPhase(),
148 ],
149 image='images/text-review.svg',
150 settings_model=None,
151 )),
152 ('poll',
153 ProjectBlueprint(
154 title=_('Poll'),
155 description=_(
156 'Participants can answer one or more questions with predefined '
157 'choices and comment on the poll.'
158 ),
159 content=[
160 poll_phases.VotingPhase(),
161 ],
162 image='images/poll.svg',
163 settings_model=None,
164 )),
165 ('interactive-event',
166 ProjectBlueprint(
167 title=_('Interactive Event'),
168 description=_(
169 'The participants of an event can ask their questions online. '
170 'Other participants can support the question. The moderator can '
171 'sort the questions by support or affiliation.'
172 ),
173 content=[
174 livequestion_phases.IssuePhase(),
175 ],
176 image='images/interactive-event.svg',
177 settings_model=None,
178 )),
179 ]
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/dashboard/blueprints.py b/meinberlin/apps/dashboard/blueprints.py
--- a/meinberlin/apps/dashboard/blueprints.py
+++ b/meinberlin/apps/dashboard/blueprints.py
@@ -153,8 +153,8 @@
ProjectBlueprint(
title=_('Poll'),
description=_(
- 'Participants can answer one or more questions with predefined '
- 'choices and comment on the poll.'
+ 'Participants can answer open and multiple choice questions '
+ 'and can comment on the poll'
),
content=[
poll_phases.VotingPhase(),
|
{"golden_diff": "diff --git a/meinberlin/apps/dashboard/blueprints.py b/meinberlin/apps/dashboard/blueprints.py\n--- a/meinberlin/apps/dashboard/blueprints.py\n+++ b/meinberlin/apps/dashboard/blueprints.py\n@@ -153,8 +153,8 @@\n ProjectBlueprint(\n title=_('Poll'),\n description=_(\n- 'Participants can answer one or more questions with predefined '\n- 'choices and comment on the poll.'\n+ 'Participants can answer open and multiple choice questions '\n+ 'and can comment on the poll'\n ),\n content=[\n poll_phases.VotingPhase(),\n", "issue": "testing 4293: change wording for template\n**URL:** module template in dashboard\r\n**user:** initiator\r\n**expected behaviour:** correct template description\r\n**behaviour:** needs to be adapted\r\n**important screensize:**\r\n**device & browser:** \r\n**Comment/Question:** \r\n\r\nchange wording from:\r\nDie Teilnehmenden k\u00f6nnen auf eine oder mehrere Fragen mit vordefinierten Antwortm\u00f6glichkeiten antworten und die Umfrage kommentieren.\r\n\r\nto \r\nDie Teilnehmenden k\u00f6nnen auf offene und Multiple-Choice-Fragen antworten und die Umfrage kommentieren.\r\n\r\nParticipants can answer to open and multiple choice questions and comment on the poll. \r\n\r\n\r\n\n", "before_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4.dashboard.blueprints import ProjectBlueprint\nfrom adhocracy4.polls import phases as poll_phases\nfrom meinberlin.apps.budgeting import phases as budgeting_phases\nfrom meinberlin.apps.documents import phases as documents_phases\nfrom meinberlin.apps.ideas import phases as ideas_phases\nfrom meinberlin.apps.kiezkasse import phases as kiezkasse_phases\nfrom meinberlin.apps.livequestions import phases as livequestion_phases\nfrom meinberlin.apps.mapideas import phases as mapideas_phases\nfrom meinberlin.apps.maptopicprio import phases as maptopicprio_phases\nfrom meinberlin.apps.topicprio import phases as topicprio_phases\n\nblueprints = [\n ('brainstorming',\n ProjectBlueprint(\n title=_('Brainstorming'),\n description=_(\n 'Participants can submit their own ideas and discuss the ideas '\n 'of others.'\n ),\n content=[\n ideas_phases.CollectPhase(),\n ],\n image='images/brainstorming.svg',\n settings_model=None,\n )),\n ('map-brainstorming',\n ProjectBlueprint(\n title=_('Spatial Brainstorming'),\n description=_(\n 'Participants can submit their own ideas and locate them on a '\n 'map. They can also discuss the ideas of others.'\n ),\n content=[\n mapideas_phases.CollectPhase(),\n ],\n image='images/map-brainstorming.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('idea-collection',\n ProjectBlueprint(\n title=_('Idea Collection'),\n description=_(\n 'Participants can submit their own ideas and discuss and rate '\n '(pro/contra) the ideas of others.'\n ),\n content=[\n ideas_phases.CollectFeedbackPhase(),\n ],\n image='images/agenda-setting.svg',\n settings_model=None,\n )),\n ('map-idea-collection',\n ProjectBlueprint(\n title=_('Spatial Idea Collection'),\n description=_(\n 'Participants can submit their own ideas and locate them on a '\n 'map. They can also discuss and rate (pro/contra) the ideas of '\n 'others.'\n ),\n content=[\n mapideas_phases.CollectFeedbackPhase(),\n ],\n image='images/map-idea-collection.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('participatory-budgeting',\n ProjectBlueprint(\n title=_('Participatory budgeting (1 phase)'),\n description=_(\n 'Participants can submit their own proposals, mark them on a '\n 'map, and add a budget. The proposals of others can be discussed '\n 'and rated (pro/contra).'\n ),\n content=[\n budgeting_phases.RequestPhase()\n ],\n image='images/participatory-budgeting-1.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('participatory-budgeting-2-phases',\n ProjectBlueprint(\n title=_('Participatory budgeting (2 phase)'),\n description=_(\n 'In a first phase, participants can submit their own proposals, '\n 'mark them on a map, and add a budget. The proposals of others '\n 'can be discussed and in a second phase rated (pro/contra).'\n ),\n content=[\n budgeting_phases.CollectPhase(),\n budgeting_phases.RatingPhase(),\n ],\n image='images/participatory-budgeting-2.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('kiezkasse',\n ProjectBlueprint(\n title=_('Kiezkasse'),\n description=_(\n 'Participants can submit their own proposals, mark them on a '\n 'map, and add a budget. They can express their interest in '\n 'participating in the proposals\u2019s implementation. The proposals '\n 'of others can be discussed and rated (pro/contra).'\n ),\n content=[\n kiezkasse_phases.RequestFeedbackPhase(),\n ],\n image='images/kiezkasse.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('prioritization',\n ProjectBlueprint(\n title=_('Prioritization'),\n description=_(\n 'Participants can discuss and rate (pro/contra) previously added '\n 'ideas and topics. Participants cannot add ideas or topics.'\n ),\n content=[\n topicprio_phases.PrioritizePhase(),\n ],\n image='images/priorization.svg',\n settings_model=None,\n )),\n ('map-topic-prioritization',\n ProjectBlueprint(\n title=_('Spatial Prioritization'),\n description=_(\n 'Participants can discuss and rate (pro/contra) ideas and topics '\n 'previously added to a map. Participants cannot add ideas or '\n 'topics.'\n ),\n content=[\n maptopicprio_phases.PrioritizePhase(),\n ],\n image='images/place-priotization.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('text-review',\n ProjectBlueprint(\n title=_('Text Review'),\n description=_(\n 'Participants can discuss the paragraphs of a text that you '\n 'added beforehand.'\n ),\n content=[\n documents_phases.CommentPhase(),\n ],\n image='images/text-review.svg',\n settings_model=None,\n )),\n ('poll',\n ProjectBlueprint(\n title=_('Poll'),\n description=_(\n 'Participants can answer one or more questions with predefined '\n 'choices and comment on the poll.'\n ),\n content=[\n poll_phases.VotingPhase(),\n ],\n image='images/poll.svg',\n settings_model=None,\n )),\n ('interactive-event',\n ProjectBlueprint(\n title=_('Interactive Event'),\n description=_(\n 'The participants of an event can ask their questions online. '\n 'Other participants can support the question. The moderator can '\n 'sort the questions by support or affiliation.'\n ),\n content=[\n livequestion_phases.IssuePhase(),\n ],\n image='images/interactive-event.svg',\n settings_model=None,\n )),\n]\n", "path": "meinberlin/apps/dashboard/blueprints.py"}], "after_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4.dashboard.blueprints import ProjectBlueprint\nfrom adhocracy4.polls import phases as poll_phases\nfrom meinberlin.apps.budgeting import phases as budgeting_phases\nfrom meinberlin.apps.documents import phases as documents_phases\nfrom meinberlin.apps.ideas import phases as ideas_phases\nfrom meinberlin.apps.kiezkasse import phases as kiezkasse_phases\nfrom meinberlin.apps.livequestions import phases as livequestion_phases\nfrom meinberlin.apps.mapideas import phases as mapideas_phases\nfrom meinberlin.apps.maptopicprio import phases as maptopicprio_phases\nfrom meinberlin.apps.topicprio import phases as topicprio_phases\n\nblueprints = [\n ('brainstorming',\n ProjectBlueprint(\n title=_('Brainstorming'),\n description=_(\n 'Participants can submit their own ideas and discuss the ideas '\n 'of others.'\n ),\n content=[\n ideas_phases.CollectPhase(),\n ],\n image='images/brainstorming.svg',\n settings_model=None,\n )),\n ('map-brainstorming',\n ProjectBlueprint(\n title=_('Spatial Brainstorming'),\n description=_(\n 'Participants can submit their own ideas and locate them on a '\n 'map. They can also discuss the ideas of others.'\n ),\n content=[\n mapideas_phases.CollectPhase(),\n ],\n image='images/map-brainstorming.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('idea-collection',\n ProjectBlueprint(\n title=_('Idea Collection'),\n description=_(\n 'Participants can submit their own ideas and discuss and rate '\n '(pro/contra) the ideas of others.'\n ),\n content=[\n ideas_phases.CollectFeedbackPhase(),\n ],\n image='images/agenda-setting.svg',\n settings_model=None,\n )),\n ('map-idea-collection',\n ProjectBlueprint(\n title=_('Spatial Idea Collection'),\n description=_(\n 'Participants can submit their own ideas and locate them on a '\n 'map. They can also discuss and rate (pro/contra) the ideas of '\n 'others.'\n ),\n content=[\n mapideas_phases.CollectFeedbackPhase(),\n ],\n image='images/map-idea-collection.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('participatory-budgeting',\n ProjectBlueprint(\n title=_('Participatory budgeting (1 phase)'),\n description=_(\n 'Participants can submit their own proposals, mark them on a '\n 'map, and add a budget. The proposals of others can be discussed '\n 'and rated (pro/contra).'\n ),\n content=[\n budgeting_phases.RequestPhase()\n ],\n image='images/participatory-budgeting-1.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('participatory-budgeting-2-phases',\n ProjectBlueprint(\n title=_('Participatory budgeting (2 phase)'),\n description=_(\n 'In a first phase, participants can submit their own proposals, '\n 'mark them on a map, and add a budget. The proposals of others '\n 'can be discussed and in a second phase rated (pro/contra).'\n ),\n content=[\n budgeting_phases.CollectPhase(),\n budgeting_phases.RatingPhase(),\n ],\n image='images/participatory-budgeting-2.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('kiezkasse',\n ProjectBlueprint(\n title=_('Kiezkasse'),\n description=_(\n 'Participants can submit their own proposals, mark them on a '\n 'map, and add a budget. They can express their interest in '\n 'participating in the proposals\u2019s implementation. The proposals '\n 'of others can be discussed and rated (pro/contra).'\n ),\n content=[\n kiezkasse_phases.RequestFeedbackPhase(),\n ],\n image='images/kiezkasse.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('prioritization',\n ProjectBlueprint(\n title=_('Prioritization'),\n description=_(\n 'Participants can discuss and rate (pro/contra) previously added '\n 'ideas and topics. Participants cannot add ideas or topics.'\n ),\n content=[\n topicprio_phases.PrioritizePhase(),\n ],\n image='images/priorization.svg',\n settings_model=None,\n )),\n ('map-topic-prioritization',\n ProjectBlueprint(\n title=_('Spatial Prioritization'),\n description=_(\n 'Participants can discuss and rate (pro/contra) ideas and topics '\n 'previously added to a map. Participants cannot add ideas or '\n 'topics.'\n ),\n content=[\n maptopicprio_phases.PrioritizePhase(),\n ],\n image='images/place-priotization.svg',\n settings_model=('a4maps', 'AreaSettings'),\n )),\n ('text-review',\n ProjectBlueprint(\n title=_('Text Review'),\n description=_(\n 'Participants can discuss the paragraphs of a text that you '\n 'added beforehand.'\n ),\n content=[\n documents_phases.CommentPhase(),\n ],\n image='images/text-review.svg',\n settings_model=None,\n )),\n ('poll',\n ProjectBlueprint(\n title=_('Poll'),\n description=_(\n 'Participants can answer open and multiple choice questions '\n 'and can comment on the poll'\n ),\n content=[\n poll_phases.VotingPhase(),\n ],\n image='images/poll.svg',\n settings_model=None,\n )),\n ('interactive-event',\n ProjectBlueprint(\n title=_('Interactive Event'),\n description=_(\n 'The participants of an event can ask their questions online. '\n 'Other participants can support the question. The moderator can '\n 'sort the questions by support or affiliation.'\n ),\n content=[\n livequestion_phases.IssuePhase(),\n ],\n image='images/interactive-event.svg',\n settings_model=None,\n )),\n]\n", "path": "meinberlin/apps/dashboard/blueprints.py"}]}
| 2,120 | 133 |
gh_patches_debug_9657
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1187
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
assert scope["type"] == "http"`on websocket connection
`
...lib/python3.9/site-packages/elasticapm/contrib/starlette/__init__.py", line 135, in __call__
assert scope["type"] == "http"
AssertionError
`
**To Reproduce**
```py
import uvicorn
from elasticapm.contrib.starlette import make_apm_client, ElasticAPM
from fastapi import FastAPI, WebSocket
apm = make_apm_client({'SERVICE_NAME': 'test', 'SERVER_URL': 'http://0.0.0.0:8200'})
app = FastAPI()
app.add_middleware(ElasticAPM, client=apm)
@app.websocket('/ws/')
async def websocket_endpoint(
websocket: WebSocket,
):
await websocket.accept()
if __name__ == '__main__':
uvicorn.run(app, host='0.0.0.0', port=18000)
```
run in Chrome console
```js
socket = new WebSocket('ws://127.0.0.1:18000/ws/');
```
**Environment (please complete the following information)**
- OS: MacOs
- Python version: 3.9
- Framework and version: FastAPI
- APM Server version: 3.6.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/contrib/starlette/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 from __future__ import absolute_import
33
34 import asyncio
35 import functools
36 from typing import Dict, Optional
37
38 import starlette
39 from starlette.requests import Request
40 from starlette.routing import Match, Mount
41 from starlette.types import ASGIApp, Message
42
43 import elasticapm
44 import elasticapm.instrumentation.control
45 from elasticapm.base import Client
46 from elasticapm.conf import constants
47 from elasticapm.contrib.asyncio.traces import set_context
48 from elasticapm.contrib.starlette.utils import get_body, get_data_from_request, get_data_from_response
49 from elasticapm.utils.disttracing import TraceParent
50 from elasticapm.utils.logging import get_logger
51
52 logger = get_logger("elasticapm.errors.client")
53
54
55 def make_apm_client(config: Optional[Dict] = None, client_cls=Client, **defaults) -> Client:
56 """Builds ElasticAPM client.
57
58 Args:
59 config (dict): Dictionary of Client configuration. All keys must be uppercase. See `elasticapm.conf.Config`.
60 client_cls (Client): Must be Client or its child.
61 **defaults: Additional parameters for Client. See `elasticapm.base.Client`
62
63 Returns:
64 Client
65 """
66 if "framework_name" not in defaults:
67 defaults["framework_name"] = "starlette"
68 defaults["framework_version"] = starlette.__version__
69
70 return client_cls(config, **defaults)
71
72
73 class ElasticAPM:
74 """
75 Starlette / FastAPI middleware for Elastic APM capturing.
76
77 >>> apm = make_apm_client({
78 >>> 'SERVICE_NAME': 'myapp',
79 >>> 'DEBUG': True,
80 >>> 'SERVER_URL': 'http://localhost:8200',
81 >>> 'CAPTURE_HEADERS': True,
82 >>> 'CAPTURE_BODY': 'all'
83 >>> })
84
85 >>> app.add_middleware(ElasticAPM, client=apm)
86
87 Pass an arbitrary APP_NAME and SECRET_TOKEN::
88
89 >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')
90
91 Pass an explicit client (don't pass in additional options in this case)::
92
93 >>> elasticapm = ElasticAPM(app, client=client)
94
95 Capture an exception::
96
97 >>> try:
98 >>> 1 / 0
99 >>> except ZeroDivisionError:
100 >>> elasticapm.capture_exception()
101
102 Capture a message::
103
104 >>> elasticapm.capture_message('hello, world!')
105 """
106
107 def __init__(self, app: ASGIApp, client: Optional[Client], **kwargs):
108 """
109
110 Args:
111 app (ASGIApp): Starlette app
112 client (Client): ElasticAPM Client
113 """
114 if client:
115 self.client = client
116 else:
117 self.client = make_apm_client(**kwargs)
118
119 if self.client.config.instrument and self.client.config.enabled:
120 elasticapm.instrumentation.control.instrument()
121
122 # If we ever make this a general-use ASGI middleware we should use
123 # `asgiref.conpatibility.guarantee_single_callable(app)` here
124 self.app = app
125
126 async def __call__(self, scope, receive, send):
127 """
128 Args:
129 scope: ASGI scope dictionary
130 receive: receive awaitable callable
131 send: send awaitable callable
132 """
133 # we only handle the http scope, raise an exception for anything else
134 # see https://www.uvicorn.org/#the-asgi-interface
135 assert scope["type"] == "http"
136
137 @functools.wraps(send)
138 async def wrapped_send(message):
139 if message.get("type") == "http.response.start":
140 await set_context(
141 lambda: get_data_from_response(message, self.client.config, constants.TRANSACTION), "response"
142 )
143 result = "HTTP {}xx".format(message["status"] // 100)
144 elasticapm.set_transaction_result(result, override=False)
145 await send(message)
146
147 # When we consume the body from receive, we replace the streaming
148 # mechanism with a mocked version -- this workaround came from
149 # https://github.com/encode/starlette/issues/495#issuecomment-513138055
150 body = b""
151 while True:
152 message = await receive()
153 if not message:
154 break
155 if message["type"] == "http.request":
156 b = message.get("body", b"")
157 if b:
158 body += b
159 if not message.get("more_body", False):
160 break
161 if message["type"] == "http.disconnect":
162 break
163
164 async def _receive() -> Message:
165 await asyncio.sleep(0)
166 return {"type": "http.request", "body": body}
167
168 request = Request(scope, receive=_receive)
169 await self._request_started(request)
170
171 try:
172 await self.app(scope, _receive, wrapped_send)
173 elasticapm.set_transaction_outcome(constants.OUTCOME.SUCCESS, override=False)
174 except Exception:
175 await self.capture_exception(
176 context={"request": await get_data_from_request(request, self.client.config, constants.ERROR)}
177 )
178 elasticapm.set_transaction_result("HTTP 5xx", override=False)
179 elasticapm.set_transaction_outcome(constants.OUTCOME.FAILURE, override=False)
180 elasticapm.set_context({"status_code": 500}, "response")
181
182 raise
183 finally:
184 self.client.end_transaction()
185
186 async def capture_exception(self, *args, **kwargs):
187 """Captures your exception.
188
189 Args:
190 *args:
191 **kwargs:
192 """
193 self.client.capture_exception(*args, **kwargs)
194
195 async def capture_message(self, *args, **kwargs):
196 """Captures your message.
197
198 Args:
199 *args: Whatever
200 **kwargs: Whatever
201 """
202 self.client.capture_message(*args, **kwargs)
203
204 async def _request_started(self, request: Request):
205 """Captures the begin of the request processing to APM.
206
207 Args:
208 request (Request)
209 """
210 # When we consume the body, we replace the streaming mechanism with
211 # a mocked version -- this workaround came from
212 # https://github.com/encode/starlette/issues/495#issuecomment-513138055
213 # and we call the workaround here to make sure that regardless of
214 # `capture_body` settings, we will have access to the body if we need it.
215 if self.client.config.capture_body != "off":
216 await get_body(request)
217
218 if not self.client.should_ignore_url(request.url.path):
219 trace_parent = TraceParent.from_headers(dict(request.headers))
220 self.client.begin_transaction("request", trace_parent=trace_parent)
221
222 await set_context(
223 lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), "request"
224 )
225 transaction_name = self.get_route_name(request) or request.url.path
226 elasticapm.set_transaction_name("{} {}".format(request.method, transaction_name), override=False)
227
228 def get_route_name(self, request: Request) -> str:
229 app = request.app
230 scope = request.scope
231 routes = app.routes
232 route_name = self._get_route_name(scope, routes)
233
234 # Starlette magically redirects requests if the path matches a route name with a trailing slash
235 # appended or removed. To not spam the transaction names list, we do the same here and put these
236 # redirects all in the same "redirect trailing slashes" transaction name
237 if not route_name and app.router.redirect_slashes and scope["path"] != "/":
238 redirect_scope = dict(scope)
239 if scope["path"].endswith("/"):
240 redirect_scope["path"] = scope["path"][:-1]
241 trim = True
242 else:
243 redirect_scope["path"] = scope["path"] + "/"
244 trim = False
245
246 route_name = self._get_route_name(redirect_scope, routes)
247 if route_name is not None:
248 route_name = route_name + "/" if trim else route_name[:-1]
249 return route_name
250
251 def _get_route_name(self, scope, routes, route_name=None):
252 for route in routes:
253 match, child_scope = route.matches(scope)
254 if match == Match.FULL:
255 route_name = route.path
256 child_scope = {**scope, **child_scope}
257 if isinstance(route, Mount) and route.routes:
258 child_route_name = self._get_route_name(child_scope, route.routes, route_name)
259 if child_route_name is None:
260 route_name = None
261 else:
262 route_name += child_route_name
263 return route_name
264 elif match == Match.PARTIAL and route_name is None:
265 route_name = route.path
266
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/contrib/starlette/__init__.py b/elasticapm/contrib/starlette/__init__.py
--- a/elasticapm/contrib/starlette/__init__.py
+++ b/elasticapm/contrib/starlette/__init__.py
@@ -130,9 +130,10 @@
receive: receive awaitable callable
send: send awaitable callable
"""
- # we only handle the http scope, raise an exception for anything else
- # see https://www.uvicorn.org/#the-asgi-interface
- assert scope["type"] == "http"
+ # we only handle the http scope, skip anything else.
+ if scope["type"] != "http":
+ await self.app(scope, receive, send)
+ return
@functools.wraps(send)
async def wrapped_send(message):
|
{"golden_diff": "diff --git a/elasticapm/contrib/starlette/__init__.py b/elasticapm/contrib/starlette/__init__.py\n--- a/elasticapm/contrib/starlette/__init__.py\n+++ b/elasticapm/contrib/starlette/__init__.py\n@@ -130,9 +130,10 @@\n receive: receive awaitable callable\n send: send awaitable callable\n \"\"\"\n- # we only handle the http scope, raise an exception for anything else\n- # see https://www.uvicorn.org/#the-asgi-interface\n- assert scope[\"type\"] == \"http\"\n+ # we only handle the http scope, skip anything else.\n+ if scope[\"type\"] != \"http\":\n+ await self.app(scope, receive, send)\n+ return\n \n @functools.wraps(send)\n async def wrapped_send(message):\n", "issue": "assert scope[\"type\"] == \"http\"`on websocket connection \n`\r\n ...lib/python3.9/site-packages/elasticapm/contrib/starlette/__init__.py\", line 135, in __call__\r\n assert scope[\"type\"] == \"http\"\r\nAssertionError\r\n`\r\n\r\n**To Reproduce**\r\n\r\n```py\r\nimport uvicorn\r\nfrom elasticapm.contrib.starlette import make_apm_client, ElasticAPM\r\nfrom fastapi import FastAPI, WebSocket\r\n\r\napm = make_apm_client({'SERVICE_NAME': 'test', 'SERVER_URL': 'http://0.0.0.0:8200'})\r\napp = FastAPI()\r\napp.add_middleware(ElasticAPM, client=apm)\r\n\r\n\r\[email protected]('/ws/')\r\nasync def websocket_endpoint(\r\n websocket: WebSocket,\r\n):\r\n await websocket.accept()\r\n\r\n\r\nif __name__ == '__main__':\r\n uvicorn.run(app, host='0.0.0.0', port=18000)\r\n\r\n```\r\n\r\nrun in Chrome console\r\n```js\r\nsocket = new WebSocket('ws://127.0.0.1:18000/ws/');\r\n```\r\n\r\n**Environment (please complete the following information)**\r\n- OS: MacOs\r\n- Python version: 3.9\r\n- Framework and version: FastAPI\r\n- APM Server version: 3.6.1\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom __future__ import absolute_import\n\nimport asyncio\nimport functools\nfrom typing import Dict, Optional\n\nimport starlette\nfrom starlette.requests import Request\nfrom starlette.routing import Match, Mount\nfrom starlette.types import ASGIApp, Message\n\nimport elasticapm\nimport elasticapm.instrumentation.control\nfrom elasticapm.base import Client\nfrom elasticapm.conf import constants\nfrom elasticapm.contrib.asyncio.traces import set_context\nfrom elasticapm.contrib.starlette.utils import get_body, get_data_from_request, get_data_from_response\nfrom elasticapm.utils.disttracing import TraceParent\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.errors.client\")\n\n\ndef make_apm_client(config: Optional[Dict] = None, client_cls=Client, **defaults) -> Client:\n \"\"\"Builds ElasticAPM client.\n\n Args:\n config (dict): Dictionary of Client configuration. All keys must be uppercase. See `elasticapm.conf.Config`.\n client_cls (Client): Must be Client or its child.\n **defaults: Additional parameters for Client. See `elasticapm.base.Client`\n\n Returns:\n Client\n \"\"\"\n if \"framework_name\" not in defaults:\n defaults[\"framework_name\"] = \"starlette\"\n defaults[\"framework_version\"] = starlette.__version__\n\n return client_cls(config, **defaults)\n\n\nclass ElasticAPM:\n \"\"\"\n Starlette / FastAPI middleware for Elastic APM capturing.\n\n >>> apm = make_apm_client({\n >>> 'SERVICE_NAME': 'myapp',\n >>> 'DEBUG': True,\n >>> 'SERVER_URL': 'http://localhost:8200',\n >>> 'CAPTURE_HEADERS': True,\n >>> 'CAPTURE_BODY': 'all'\n >>> })\n\n >>> app.add_middleware(ElasticAPM, client=apm)\n\n Pass an arbitrary APP_NAME and SECRET_TOKEN::\n\n >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')\n\n Pass an explicit client (don't pass in additional options in this case)::\n\n >>> elasticapm = ElasticAPM(app, client=client)\n\n Capture an exception::\n\n >>> try:\n >>> 1 / 0\n >>> except ZeroDivisionError:\n >>> elasticapm.capture_exception()\n\n Capture a message::\n\n >>> elasticapm.capture_message('hello, world!')\n \"\"\"\n\n def __init__(self, app: ASGIApp, client: Optional[Client], **kwargs):\n \"\"\"\n\n Args:\n app (ASGIApp): Starlette app\n client (Client): ElasticAPM Client\n \"\"\"\n if client:\n self.client = client\n else:\n self.client = make_apm_client(**kwargs)\n\n if self.client.config.instrument and self.client.config.enabled:\n elasticapm.instrumentation.control.instrument()\n\n # If we ever make this a general-use ASGI middleware we should use\n # `asgiref.conpatibility.guarantee_single_callable(app)` here\n self.app = app\n\n async def __call__(self, scope, receive, send):\n \"\"\"\n Args:\n scope: ASGI scope dictionary\n receive: receive awaitable callable\n send: send awaitable callable\n \"\"\"\n # we only handle the http scope, raise an exception for anything else\n # see https://www.uvicorn.org/#the-asgi-interface\n assert scope[\"type\"] == \"http\"\n\n @functools.wraps(send)\n async def wrapped_send(message):\n if message.get(\"type\") == \"http.response.start\":\n await set_context(\n lambda: get_data_from_response(message, self.client.config, constants.TRANSACTION), \"response\"\n )\n result = \"HTTP {}xx\".format(message[\"status\"] // 100)\n elasticapm.set_transaction_result(result, override=False)\n await send(message)\n\n # When we consume the body from receive, we replace the streaming\n # mechanism with a mocked version -- this workaround came from\n # https://github.com/encode/starlette/issues/495#issuecomment-513138055\n body = b\"\"\n while True:\n message = await receive()\n if not message:\n break\n if message[\"type\"] == \"http.request\":\n b = message.get(\"body\", b\"\")\n if b:\n body += b\n if not message.get(\"more_body\", False):\n break\n if message[\"type\"] == \"http.disconnect\":\n break\n\n async def _receive() -> Message:\n await asyncio.sleep(0)\n return {\"type\": \"http.request\", \"body\": body}\n\n request = Request(scope, receive=_receive)\n await self._request_started(request)\n\n try:\n await self.app(scope, _receive, wrapped_send)\n elasticapm.set_transaction_outcome(constants.OUTCOME.SUCCESS, override=False)\n except Exception:\n await self.capture_exception(\n context={\"request\": await get_data_from_request(request, self.client.config, constants.ERROR)}\n )\n elasticapm.set_transaction_result(\"HTTP 5xx\", override=False)\n elasticapm.set_transaction_outcome(constants.OUTCOME.FAILURE, override=False)\n elasticapm.set_context({\"status_code\": 500}, \"response\")\n\n raise\n finally:\n self.client.end_transaction()\n\n async def capture_exception(self, *args, **kwargs):\n \"\"\"Captures your exception.\n\n Args:\n *args:\n **kwargs:\n \"\"\"\n self.client.capture_exception(*args, **kwargs)\n\n async def capture_message(self, *args, **kwargs):\n \"\"\"Captures your message.\n\n Args:\n *args: Whatever\n **kwargs: Whatever\n \"\"\"\n self.client.capture_message(*args, **kwargs)\n\n async def _request_started(self, request: Request):\n \"\"\"Captures the begin of the request processing to APM.\n\n Args:\n request (Request)\n \"\"\"\n # When we consume the body, we replace the streaming mechanism with\n # a mocked version -- this workaround came from\n # https://github.com/encode/starlette/issues/495#issuecomment-513138055\n # and we call the workaround here to make sure that regardless of\n # `capture_body` settings, we will have access to the body if we need it.\n if self.client.config.capture_body != \"off\":\n await get_body(request)\n\n if not self.client.should_ignore_url(request.url.path):\n trace_parent = TraceParent.from_headers(dict(request.headers))\n self.client.begin_transaction(\"request\", trace_parent=trace_parent)\n\n await set_context(\n lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), \"request\"\n )\n transaction_name = self.get_route_name(request) or request.url.path\n elasticapm.set_transaction_name(\"{} {}\".format(request.method, transaction_name), override=False)\n\n def get_route_name(self, request: Request) -> str:\n app = request.app\n scope = request.scope\n routes = app.routes\n route_name = self._get_route_name(scope, routes)\n\n # Starlette magically redirects requests if the path matches a route name with a trailing slash\n # appended or removed. To not spam the transaction names list, we do the same here and put these\n # redirects all in the same \"redirect trailing slashes\" transaction name\n if not route_name and app.router.redirect_slashes and scope[\"path\"] != \"/\":\n redirect_scope = dict(scope)\n if scope[\"path\"].endswith(\"/\"):\n redirect_scope[\"path\"] = scope[\"path\"][:-1]\n trim = True\n else:\n redirect_scope[\"path\"] = scope[\"path\"] + \"/\"\n trim = False\n\n route_name = self._get_route_name(redirect_scope, routes)\n if route_name is not None:\n route_name = route_name + \"/\" if trim else route_name[:-1]\n return route_name\n\n def _get_route_name(self, scope, routes, route_name=None):\n for route in routes:\n match, child_scope = route.matches(scope)\n if match == Match.FULL:\n route_name = route.path\n child_scope = {**scope, **child_scope}\n if isinstance(route, Mount) and route.routes:\n child_route_name = self._get_route_name(child_scope, route.routes, route_name)\n if child_route_name is None:\n route_name = None\n else:\n route_name += child_route_name\n return route_name\n elif match == Match.PARTIAL and route_name is None:\n route_name = route.path\n", "path": "elasticapm/contrib/starlette/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom __future__ import absolute_import\n\nimport asyncio\nimport functools\nfrom typing import Dict, Optional\n\nimport starlette\nfrom starlette.requests import Request\nfrom starlette.routing import Match, Mount\nfrom starlette.types import ASGIApp, Message\n\nimport elasticapm\nimport elasticapm.instrumentation.control\nfrom elasticapm.base import Client\nfrom elasticapm.conf import constants\nfrom elasticapm.contrib.asyncio.traces import set_context\nfrom elasticapm.contrib.starlette.utils import get_body, get_data_from_request, get_data_from_response\nfrom elasticapm.utils.disttracing import TraceParent\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.errors.client\")\n\n\ndef make_apm_client(config: Optional[Dict] = None, client_cls=Client, **defaults) -> Client:\n \"\"\"Builds ElasticAPM client.\n\n Args:\n config (dict): Dictionary of Client configuration. All keys must be uppercase. See `elasticapm.conf.Config`.\n client_cls (Client): Must be Client or its child.\n **defaults: Additional parameters for Client. See `elasticapm.base.Client`\n\n Returns:\n Client\n \"\"\"\n if \"framework_name\" not in defaults:\n defaults[\"framework_name\"] = \"starlette\"\n defaults[\"framework_version\"] = starlette.__version__\n\n return client_cls(config, **defaults)\n\n\nclass ElasticAPM:\n \"\"\"\n Starlette / FastAPI middleware for Elastic APM capturing.\n\n >>> apm = make_apm_client({\n >>> 'SERVICE_NAME': 'myapp',\n >>> 'DEBUG': True,\n >>> 'SERVER_URL': 'http://localhost:8200',\n >>> 'CAPTURE_HEADERS': True,\n >>> 'CAPTURE_BODY': 'all'\n >>> })\n\n >>> app.add_middleware(ElasticAPM, client=apm)\n\n Pass an arbitrary APP_NAME and SECRET_TOKEN::\n\n >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')\n\n Pass an explicit client (don't pass in additional options in this case)::\n\n >>> elasticapm = ElasticAPM(app, client=client)\n\n Capture an exception::\n\n >>> try:\n >>> 1 / 0\n >>> except ZeroDivisionError:\n >>> elasticapm.capture_exception()\n\n Capture a message::\n\n >>> elasticapm.capture_message('hello, world!')\n \"\"\"\n\n def __init__(self, app: ASGIApp, client: Optional[Client], **kwargs):\n \"\"\"\n\n Args:\n app (ASGIApp): Starlette app\n client (Client): ElasticAPM Client\n \"\"\"\n if client:\n self.client = client\n else:\n self.client = make_apm_client(**kwargs)\n\n if self.client.config.instrument and self.client.config.enabled:\n elasticapm.instrumentation.control.instrument()\n\n # If we ever make this a general-use ASGI middleware we should use\n # `asgiref.conpatibility.guarantee_single_callable(app)` here\n self.app = app\n\n async def __call__(self, scope, receive, send):\n \"\"\"\n Args:\n scope: ASGI scope dictionary\n receive: receive awaitable callable\n send: send awaitable callable\n \"\"\"\n # we only handle the http scope, skip anything else.\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n @functools.wraps(send)\n async def wrapped_send(message):\n if message.get(\"type\") == \"http.response.start\":\n await set_context(\n lambda: get_data_from_response(message, self.client.config, constants.TRANSACTION), \"response\"\n )\n result = \"HTTP {}xx\".format(message[\"status\"] // 100)\n elasticapm.set_transaction_result(result, override=False)\n await send(message)\n\n # When we consume the body from receive, we replace the streaming\n # mechanism with a mocked version -- this workaround came from\n # https://github.com/encode/starlette/issues/495#issuecomment-513138055\n body = b\"\"\n while True:\n message = await receive()\n if not message:\n break\n if message[\"type\"] == \"http.request\":\n b = message.get(\"body\", b\"\")\n if b:\n body += b\n if not message.get(\"more_body\", False):\n break\n if message[\"type\"] == \"http.disconnect\":\n break\n\n async def _receive() -> Message:\n await asyncio.sleep(0)\n return {\"type\": \"http.request\", \"body\": body}\n\n request = Request(scope, receive=_receive)\n await self._request_started(request)\n\n try:\n await self.app(scope, _receive, wrapped_send)\n elasticapm.set_transaction_outcome(constants.OUTCOME.SUCCESS, override=False)\n except Exception:\n await self.capture_exception(\n context={\"request\": await get_data_from_request(request, self.client.config, constants.ERROR)}\n )\n elasticapm.set_transaction_result(\"HTTP 5xx\", override=False)\n elasticapm.set_transaction_outcome(constants.OUTCOME.FAILURE, override=False)\n elasticapm.set_context({\"status_code\": 500}, \"response\")\n\n raise\n finally:\n self.client.end_transaction()\n\n async def capture_exception(self, *args, **kwargs):\n \"\"\"Captures your exception.\n\n Args:\n *args:\n **kwargs:\n \"\"\"\n self.client.capture_exception(*args, **kwargs)\n\n async def capture_message(self, *args, **kwargs):\n \"\"\"Captures your message.\n\n Args:\n *args: Whatever\n **kwargs: Whatever\n \"\"\"\n self.client.capture_message(*args, **kwargs)\n\n async def _request_started(self, request: Request):\n \"\"\"Captures the begin of the request processing to APM.\n\n Args:\n request (Request)\n \"\"\"\n # When we consume the body, we replace the streaming mechanism with\n # a mocked version -- this workaround came from\n # https://github.com/encode/starlette/issues/495#issuecomment-513138055\n # and we call the workaround here to make sure that regardless of\n # `capture_body` settings, we will have access to the body if we need it.\n if self.client.config.capture_body != \"off\":\n await get_body(request)\n\n if not self.client.should_ignore_url(request.url.path):\n trace_parent = TraceParent.from_headers(dict(request.headers))\n self.client.begin_transaction(\"request\", trace_parent=trace_parent)\n\n await set_context(\n lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), \"request\"\n )\n transaction_name = self.get_route_name(request) or request.url.path\n elasticapm.set_transaction_name(\"{} {}\".format(request.method, transaction_name), override=False)\n\n def get_route_name(self, request: Request) -> str:\n app = request.app\n scope = request.scope\n routes = app.routes\n route_name = self._get_route_name(scope, routes)\n\n # Starlette magically redirects requests if the path matches a route name with a trailing slash\n # appended or removed. To not spam the transaction names list, we do the same here and put these\n # redirects all in the same \"redirect trailing slashes\" transaction name\n if not route_name and app.router.redirect_slashes and scope[\"path\"] != \"/\":\n redirect_scope = dict(scope)\n if scope[\"path\"].endswith(\"/\"):\n redirect_scope[\"path\"] = scope[\"path\"][:-1]\n trim = True\n else:\n redirect_scope[\"path\"] = scope[\"path\"] + \"/\"\n trim = False\n\n route_name = self._get_route_name(redirect_scope, routes)\n if route_name is not None:\n route_name = route_name + \"/\" if trim else route_name[:-1]\n return route_name\n\n def _get_route_name(self, scope, routes, route_name=None):\n for route in routes:\n match, child_scope = route.matches(scope)\n if match == Match.FULL:\n route_name = route.path\n child_scope = {**scope, **child_scope}\n if isinstance(route, Mount) and route.routes:\n child_route_name = self._get_route_name(child_scope, route.routes, route_name)\n if child_route_name is None:\n route_name = None\n else:\n route_name += child_route_name\n return route_name\n elif match == Match.PARTIAL and route_name is None:\n route_name = route.path\n", "path": "elasticapm/contrib/starlette/__init__.py"}]}
| 3,472 | 194 |
gh_patches_debug_12683
|
rasdani/github-patches
|
git_diff
|
celery__celery-6524
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
celery_worker pytest fixture timeouts since celery 5.0.3
Since the 5.0.3 release of celery, the `celery_worker` pytest fixture leads to a timeout when performing ping check.
The issue can be reproduced using this simple test file:
```python
pytest_plugins = ["celery.contrib.pytest"]
def test_create_task(celery_app, celery_worker):
@celery_app.task
def mul(x, y):
return x * y
assert mul.delay(4, 4).get(timeout=10) == 16
```
Below is the pytest output:
```
$ pytest -sv test_celery_worker.py
============================================================================================== test session starts ===============================================================================================
platform linux -- Python 3.7.3, pytest-6.1.2, py-1.9.0, pluggy-0.13.1 -- /home/anlambert/.virtualenvs/swh/bin/python3
cachedir: .pytest_cache
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/anlambert/tmp/.hypothesis/examples')
rootdir: /home/anlambert/tmp
plugins: postgresql-2.5.2, asyncio-0.14.0, mock-3.3.1, cov-2.10.1, django-4.1.0, requests-mock-1.8.0, hypothesis-5.41.3, forked-1.3.0, swh.core-0.9.2.dev4+g6f9779f, flask-1.1.0, xdist-2.1.0, dash-1.17.0, swh.journal-0.5.2.dev1+g12b31a2
collected 1 item
test_celery_worker.py::test_create_task ERROR
===================================================================================================== ERRORS =====================================================================================================
_______________________________________________________________________________________ ERROR at setup of test_create_task _______________________________________________________________________________________
request = <SubRequest 'celery_worker' for <Function test_create_task>>, celery_app = <Celery celery.tests at 0x7f99b4b91d30>, celery_includes = (), celery_worker_pool = 'solo', celery_worker_parameters = {}
@pytest.fixture()
def celery_worker(request,
celery_app,
celery_includes,
celery_worker_pool,
celery_worker_parameters):
# type: (Any, Celery, Sequence[str], str, Any) -> WorkController
"""Fixture: Start worker in a thread, stop it when the test returns."""
if not NO_WORKER:
for module in celery_includes:
celery_app.loader.import_task_module(module)
with worker.start_worker(celery_app,
pool=celery_worker_pool,
> **celery_worker_parameters) as w:
../dev/celery/celery/contrib/pytest.py:196:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/lib/python3.7/contextlib.py:112: in __enter__
return next(self.gen)
../dev/celery/celery/contrib/testing/worker.py:82: in start_worker
assert ping.delay().get(timeout=ping_task_timeout) == 'pong'
../dev/celery/celery/result.py:230: in get
on_message=on_message,
../dev/celery/celery/backends/base.py:655: in wait_for_pending
no_ack=no_ack,
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <celery.backends.cache.CacheBackend object at 0x7f99b411fb00>, task_id = '98b047a2-2027-453c-a317-eb31f44a2547', timeout = 10.0, interval = 0.5, no_ack = True, on_interval = <promise@0x7f99b4a2adf0>
def wait_for(self, task_id,
timeout=None, interval=0.5, no_ack=True, on_interval=None):
"""Wait for task and return its result.
If the task raises an exception, this exception
will be re-raised by :func:`wait_for`.
Raises:
celery.exceptions.TimeoutError:
If `timeout` is not :const:`None`, and the operation
takes longer than `timeout` seconds.
"""
self._ensure_not_eager()
time_elapsed = 0.0
while 1:
meta = self.get_task_meta(task_id)
if meta['status'] in states.READY_STATES:
return meta
if on_interval:
on_interval()
# avoid hammering the CPU checking status.
time.sleep(interval)
time_elapsed += interval
if timeout and time_elapsed >= timeout:
> raise TimeoutError('The operation timed out.')
E celery.exceptions.TimeoutError: The operation timed out.
../dev/celery/celery/backends/base.py:687: TimeoutError
============================================================================================ short test summary info =============================================================================================
ERROR test_celery_worker.py::test_create_task - celery.exceptions.TimeoutError: The operation timed out.
=============================================================================================== 1 error in 10.41s ================================================================================================
```
After a quick `git bisect` session, I managed to identify the commit that introduced the issue: https://github.com/celery/celery/commit/e2031688284484d5b5a57ba29cd9cae2d9a81e39
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `celery/backends/cache.py`
Content:
```
1 """Memcached and in-memory cache result backend."""
2 from kombu.utils.encoding import bytes_to_str, ensure_bytes
3 from kombu.utils.objects import cached_property
4
5 from celery.exceptions import ImproperlyConfigured
6 from celery.utils.functional import LRUCache
7
8 from .base import KeyValueStoreBackend
9
10 __all__ = ('CacheBackend',)
11
12 _imp = [None]
13
14 REQUIRES_BACKEND = """\
15 The Memcached backend requires either pylibmc or python-memcached.\
16 """
17
18 UNKNOWN_BACKEND = """\
19 The cache backend {0!r} is unknown,
20 Please use one of the following backends instead: {1}\
21 """
22
23
24 def import_best_memcache():
25 if _imp[0] is None:
26 is_pylibmc, memcache_key_t = False, bytes_to_str
27 try:
28 import pylibmc as memcache
29 is_pylibmc = True
30 except ImportError:
31 try:
32 import memcache # noqa
33 except ImportError:
34 raise ImproperlyConfigured(REQUIRES_BACKEND)
35 _imp[0] = (is_pylibmc, memcache, memcache_key_t)
36 return _imp[0]
37
38
39 def get_best_memcache(*args, **kwargs):
40 # pylint: disable=unpacking-non-sequence
41 # This is most definitely a sequence, but pylint thinks it's not.
42 is_pylibmc, memcache, key_t = import_best_memcache()
43 Client = _Client = memcache.Client
44
45 if not is_pylibmc:
46 def Client(*args, **kwargs): # noqa
47 kwargs.pop('behaviors', None)
48 return _Client(*args, **kwargs)
49
50 return Client, key_t
51
52
53 class DummyClient:
54
55 def __init__(self, *args, **kwargs):
56 self.cache = LRUCache(limit=5000)
57
58 def get(self, key, *args, **kwargs):
59 return self.cache.get(key)
60
61 def get_multi(self, keys):
62 cache = self.cache
63 return {k: cache[k] for k in keys if k in cache}
64
65 def set(self, key, value, *args, **kwargs):
66 self.cache[key] = value
67
68 def delete(self, key, *args, **kwargs):
69 self.cache.pop(key, None)
70
71 def incr(self, key, delta=1):
72 return self.cache.incr(key, delta)
73
74 def touch(self, key, expire):
75 pass
76
77
78 backends = {
79 'memcache': get_best_memcache,
80 'memcached': get_best_memcache,
81 'pylibmc': get_best_memcache,
82 'memory': lambda: (DummyClient, ensure_bytes),
83 }
84
85
86 class CacheBackend(KeyValueStoreBackend):
87 """Cache result backend."""
88
89 servers = None
90 supports_autoexpire = True
91 supports_native_join = True
92 implements_incr = True
93
94 def __init__(self, app, expires=None, backend=None,
95 options=None, url=None, **kwargs):
96 options = {} if not options else options
97 super().__init__(app, **kwargs)
98 self.url = url
99
100 self.options = dict(self.app.conf.cache_backend_options,
101 **options)
102
103 self.backend = url or backend or self.app.conf.cache_backend
104 if self.backend:
105 self.backend, _, servers = self.backend.partition('://')
106 self.servers = servers.rstrip('/').split(';')
107 self.expires = self.prepare_expires(expires, type=int)
108 try:
109 self.Client, self.key_t = backends[self.backend]()
110 except KeyError:
111 raise ImproperlyConfigured(UNKNOWN_BACKEND.format(
112 self.backend, ', '.join(backends)))
113 self._encode_prefixes() # rencode the keyprefixes
114
115 def get(self, key):
116 return self.client.get(key)
117
118 def mget(self, keys):
119 return self.client.get_multi(keys)
120
121 def set(self, key, value):
122 return self.client.set(key, value, self.expires)
123
124 def delete(self, key):
125 return self.client.delete(key)
126
127 def _apply_chord_incr(self, header_result, body, **kwargs):
128 chord_key = self.get_key_for_chord(header_result.id)
129 self.client.set(chord_key, 0, time=self.expires)
130 return super()._apply_chord_incr(
131 header_result, body, **kwargs)
132
133 def incr(self, key):
134 return self.client.incr(key)
135
136 def expire(self, key, value):
137 return self.client.touch(key, value)
138
139 @cached_property
140 def client(self):
141 return self.Client(self.servers, **self.options)
142
143 def __reduce__(self, args=(), kwargs=None):
144 kwargs = {} if not kwargs else kwargs
145 servers = ';'.join(self.servers)
146 backend = f'{self.backend}://{servers}/'
147 kwargs.update(
148 {'backend': backend,
149 'expires': self.expires,
150 'options': self.options})
151 return super().__reduce__(args, kwargs)
152
153 def as_uri(self, *args, **kwargs):
154 """Return the backend as an URI.
155
156 This properly handles the case of multiple servers.
157 """
158 servers = ';'.join(self.servers)
159 return f'{self.backend}://{servers}/'
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/celery/backends/cache.py b/celery/backends/cache.py
--- a/celery/backends/cache.py
+++ b/celery/backends/cache.py
@@ -20,6 +20,10 @@
Please use one of the following backends instead: {1}\
"""
+# Global shared in-memory cache for in-memory cache client
+# This is to share cache between threads
+_DUMMY_CLIENT_CACHE = LRUCache(limit=5000)
+
def import_best_memcache():
if _imp[0] is None:
@@ -53,7 +57,7 @@
class DummyClient:
def __init__(self, *args, **kwargs):
- self.cache = LRUCache(limit=5000)
+ self.cache = _DUMMY_CLIENT_CACHE
def get(self, key, *args, **kwargs):
return self.cache.get(key)
|
{"golden_diff": "diff --git a/celery/backends/cache.py b/celery/backends/cache.py\n--- a/celery/backends/cache.py\n+++ b/celery/backends/cache.py\n@@ -20,6 +20,10 @@\n Please use one of the following backends instead: {1}\\\n \"\"\"\n \n+# Global shared in-memory cache for in-memory cache client\n+# This is to share cache between threads\n+_DUMMY_CLIENT_CACHE = LRUCache(limit=5000)\n+\n \n def import_best_memcache():\n if _imp[0] is None:\n@@ -53,7 +57,7 @@\n class DummyClient:\n \n def __init__(self, *args, **kwargs):\n- self.cache = LRUCache(limit=5000)\n+ self.cache = _DUMMY_CLIENT_CACHE\n \n def get(self, key, *args, **kwargs):\n return self.cache.get(key)\n", "issue": "celery_worker pytest fixture timeouts since celery 5.0.3\nSince the 5.0.3 release of celery, the `celery_worker` pytest fixture leads to a timeout when performing ping check.\r\n\r\nThe issue can be reproduced using this simple test file:\r\n```python\r\npytest_plugins = [\"celery.contrib.pytest\"]\r\n\r\ndef test_create_task(celery_app, celery_worker):\r\n @celery_app.task\r\n def mul(x, y):\r\n return x * y\r\n\r\n assert mul.delay(4, 4).get(timeout=10) == 16\r\n```\r\n\r\nBelow is the pytest output:\r\n```\r\n$ pytest -sv test_celery_worker.py \r\n============================================================================================== test session starts ===============================================================================================\r\nplatform linux -- Python 3.7.3, pytest-6.1.2, py-1.9.0, pluggy-0.13.1 -- /home/anlambert/.virtualenvs/swh/bin/python3\r\ncachedir: .pytest_cache\r\nhypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/anlambert/tmp/.hypothesis/examples')\r\nrootdir: /home/anlambert/tmp\r\nplugins: postgresql-2.5.2, asyncio-0.14.0, mock-3.3.1, cov-2.10.1, django-4.1.0, requests-mock-1.8.0, hypothesis-5.41.3, forked-1.3.0, swh.core-0.9.2.dev4+g6f9779f, flask-1.1.0, xdist-2.1.0, dash-1.17.0, swh.journal-0.5.2.dev1+g12b31a2\r\ncollected 1 item \r\n\r\ntest_celery_worker.py::test_create_task ERROR\r\n\r\n===================================================================================================== ERRORS =====================================================================================================\r\n_______________________________________________________________________________________ ERROR at setup of test_create_task _______________________________________________________________________________________\r\n\r\nrequest = <SubRequest 'celery_worker' for <Function test_create_task>>, celery_app = <Celery celery.tests at 0x7f99b4b91d30>, celery_includes = (), celery_worker_pool = 'solo', celery_worker_parameters = {}\r\n\r\n @pytest.fixture()\r\n def celery_worker(request,\r\n celery_app,\r\n celery_includes,\r\n celery_worker_pool,\r\n celery_worker_parameters):\r\n # type: (Any, Celery, Sequence[str], str, Any) -> WorkController\r\n \"\"\"Fixture: Start worker in a thread, stop it when the test returns.\"\"\"\r\n if not NO_WORKER:\r\n for module in celery_includes:\r\n celery_app.loader.import_task_module(module)\r\n with worker.start_worker(celery_app,\r\n pool=celery_worker_pool,\r\n> **celery_worker_parameters) as w:\r\n\r\n../dev/celery/celery/contrib/pytest.py:196: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n/usr/lib/python3.7/contextlib.py:112: in __enter__\r\n return next(self.gen)\r\n../dev/celery/celery/contrib/testing/worker.py:82: in start_worker\r\n assert ping.delay().get(timeout=ping_task_timeout) == 'pong'\r\n../dev/celery/celery/result.py:230: in get\r\n on_message=on_message,\r\n../dev/celery/celery/backends/base.py:655: in wait_for_pending\r\n no_ack=no_ack,\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n\r\nself = <celery.backends.cache.CacheBackend object at 0x7f99b411fb00>, task_id = '98b047a2-2027-453c-a317-eb31f44a2547', timeout = 10.0, interval = 0.5, no_ack = True, on_interval = <promise@0x7f99b4a2adf0>\r\n\r\n def wait_for(self, task_id,\r\n timeout=None, interval=0.5, no_ack=True, on_interval=None):\r\n \"\"\"Wait for task and return its result.\r\n \r\n If the task raises an exception, this exception\r\n will be re-raised by :func:`wait_for`.\r\n \r\n Raises:\r\n celery.exceptions.TimeoutError:\r\n If `timeout` is not :const:`None`, and the operation\r\n takes longer than `timeout` seconds.\r\n \"\"\"\r\n self._ensure_not_eager()\r\n \r\n time_elapsed = 0.0\r\n \r\n while 1:\r\n meta = self.get_task_meta(task_id)\r\n if meta['status'] in states.READY_STATES:\r\n return meta\r\n if on_interval:\r\n on_interval()\r\n # avoid hammering the CPU checking status.\r\n time.sleep(interval)\r\n time_elapsed += interval\r\n if timeout and time_elapsed >= timeout:\r\n> raise TimeoutError('The operation timed out.')\r\nE celery.exceptions.TimeoutError: The operation timed out.\r\n\r\n../dev/celery/celery/backends/base.py:687: TimeoutError\r\n============================================================================================ short test summary info =============================================================================================\r\nERROR test_celery_worker.py::test_create_task - celery.exceptions.TimeoutError: The operation timed out.\r\n=============================================================================================== 1 error in 10.41s ================================================================================================\r\n```\r\nAfter a quick `git bisect` session, I managed to identify the commit that introduced the issue: https://github.com/celery/celery/commit/e2031688284484d5b5a57ba29cd9cae2d9a81e39\n", "before_files": [{"content": "\"\"\"Memcached and in-memory cache result backend.\"\"\"\nfrom kombu.utils.encoding import bytes_to_str, ensure_bytes\nfrom kombu.utils.objects import cached_property\n\nfrom celery.exceptions import ImproperlyConfigured\nfrom celery.utils.functional import LRUCache\n\nfrom .base import KeyValueStoreBackend\n\n__all__ = ('CacheBackend',)\n\n_imp = [None]\n\nREQUIRES_BACKEND = \"\"\"\\\nThe Memcached backend requires either pylibmc or python-memcached.\\\n\"\"\"\n\nUNKNOWN_BACKEND = \"\"\"\\\nThe cache backend {0!r} is unknown,\nPlease use one of the following backends instead: {1}\\\n\"\"\"\n\n\ndef import_best_memcache():\n if _imp[0] is None:\n is_pylibmc, memcache_key_t = False, bytes_to_str\n try:\n import pylibmc as memcache\n is_pylibmc = True\n except ImportError:\n try:\n import memcache # noqa\n except ImportError:\n raise ImproperlyConfigured(REQUIRES_BACKEND)\n _imp[0] = (is_pylibmc, memcache, memcache_key_t)\n return _imp[0]\n\n\ndef get_best_memcache(*args, **kwargs):\n # pylint: disable=unpacking-non-sequence\n # This is most definitely a sequence, but pylint thinks it's not.\n is_pylibmc, memcache, key_t = import_best_memcache()\n Client = _Client = memcache.Client\n\n if not is_pylibmc:\n def Client(*args, **kwargs): # noqa\n kwargs.pop('behaviors', None)\n return _Client(*args, **kwargs)\n\n return Client, key_t\n\n\nclass DummyClient:\n\n def __init__(self, *args, **kwargs):\n self.cache = LRUCache(limit=5000)\n\n def get(self, key, *args, **kwargs):\n return self.cache.get(key)\n\n def get_multi(self, keys):\n cache = self.cache\n return {k: cache[k] for k in keys if k in cache}\n\n def set(self, key, value, *args, **kwargs):\n self.cache[key] = value\n\n def delete(self, key, *args, **kwargs):\n self.cache.pop(key, None)\n\n def incr(self, key, delta=1):\n return self.cache.incr(key, delta)\n\n def touch(self, key, expire):\n pass\n\n\nbackends = {\n 'memcache': get_best_memcache,\n 'memcached': get_best_memcache,\n 'pylibmc': get_best_memcache,\n 'memory': lambda: (DummyClient, ensure_bytes),\n}\n\n\nclass CacheBackend(KeyValueStoreBackend):\n \"\"\"Cache result backend.\"\"\"\n\n servers = None\n supports_autoexpire = True\n supports_native_join = True\n implements_incr = True\n\n def __init__(self, app, expires=None, backend=None,\n options=None, url=None, **kwargs):\n options = {} if not options else options\n super().__init__(app, **kwargs)\n self.url = url\n\n self.options = dict(self.app.conf.cache_backend_options,\n **options)\n\n self.backend = url or backend or self.app.conf.cache_backend\n if self.backend:\n self.backend, _, servers = self.backend.partition('://')\n self.servers = servers.rstrip('/').split(';')\n self.expires = self.prepare_expires(expires, type=int)\n try:\n self.Client, self.key_t = backends[self.backend]()\n except KeyError:\n raise ImproperlyConfigured(UNKNOWN_BACKEND.format(\n self.backend, ', '.join(backends)))\n self._encode_prefixes() # rencode the keyprefixes\n\n def get(self, key):\n return self.client.get(key)\n\n def mget(self, keys):\n return self.client.get_multi(keys)\n\n def set(self, key, value):\n return self.client.set(key, value, self.expires)\n\n def delete(self, key):\n return self.client.delete(key)\n\n def _apply_chord_incr(self, header_result, body, **kwargs):\n chord_key = self.get_key_for_chord(header_result.id)\n self.client.set(chord_key, 0, time=self.expires)\n return super()._apply_chord_incr(\n header_result, body, **kwargs)\n\n def incr(self, key):\n return self.client.incr(key)\n\n def expire(self, key, value):\n return self.client.touch(key, value)\n\n @cached_property\n def client(self):\n return self.Client(self.servers, **self.options)\n\n def __reduce__(self, args=(), kwargs=None):\n kwargs = {} if not kwargs else kwargs\n servers = ';'.join(self.servers)\n backend = f'{self.backend}://{servers}/'\n kwargs.update(\n {'backend': backend,\n 'expires': self.expires,\n 'options': self.options})\n return super().__reduce__(args, kwargs)\n\n def as_uri(self, *args, **kwargs):\n \"\"\"Return the backend as an URI.\n\n This properly handles the case of multiple servers.\n \"\"\"\n servers = ';'.join(self.servers)\n return f'{self.backend}://{servers}/'\n", "path": "celery/backends/cache.py"}], "after_files": [{"content": "\"\"\"Memcached and in-memory cache result backend.\"\"\"\nfrom kombu.utils.encoding import bytes_to_str, ensure_bytes\nfrom kombu.utils.objects import cached_property\n\nfrom celery.exceptions import ImproperlyConfigured\nfrom celery.utils.functional import LRUCache\n\nfrom .base import KeyValueStoreBackend\n\n__all__ = ('CacheBackend',)\n\n_imp = [None]\n\nREQUIRES_BACKEND = \"\"\"\\\nThe Memcached backend requires either pylibmc or python-memcached.\\\n\"\"\"\n\nUNKNOWN_BACKEND = \"\"\"\\\nThe cache backend {0!r} is unknown,\nPlease use one of the following backends instead: {1}\\\n\"\"\"\n\n# Global shared in-memory cache for in-memory cache client\n# This is to share cache between threads\n_DUMMY_CLIENT_CACHE = LRUCache(limit=5000)\n\n\ndef import_best_memcache():\n if _imp[0] is None:\n is_pylibmc, memcache_key_t = False, bytes_to_str\n try:\n import pylibmc as memcache\n is_pylibmc = True\n except ImportError:\n try:\n import memcache # noqa\n except ImportError:\n raise ImproperlyConfigured(REQUIRES_BACKEND)\n _imp[0] = (is_pylibmc, memcache, memcache_key_t)\n return _imp[0]\n\n\ndef get_best_memcache(*args, **kwargs):\n # pylint: disable=unpacking-non-sequence\n # This is most definitely a sequence, but pylint thinks it's not.\n is_pylibmc, memcache, key_t = import_best_memcache()\n Client = _Client = memcache.Client\n\n if not is_pylibmc:\n def Client(*args, **kwargs): # noqa\n kwargs.pop('behaviors', None)\n return _Client(*args, **kwargs)\n\n return Client, key_t\n\n\nclass DummyClient:\n\n def __init__(self, *args, **kwargs):\n self.cache = _DUMMY_CLIENT_CACHE\n\n def get(self, key, *args, **kwargs):\n return self.cache.get(key)\n\n def get_multi(self, keys):\n cache = self.cache\n return {k: cache[k] for k in keys if k in cache}\n\n def set(self, key, value, *args, **kwargs):\n self.cache[key] = value\n\n def delete(self, key, *args, **kwargs):\n self.cache.pop(key, None)\n\n def incr(self, key, delta=1):\n return self.cache.incr(key, delta)\n\n def touch(self, key, expire):\n pass\n\n\nbackends = {\n 'memcache': get_best_memcache,\n 'memcached': get_best_memcache,\n 'pylibmc': get_best_memcache,\n 'memory': lambda: (DummyClient, ensure_bytes),\n}\n\n\nclass CacheBackend(KeyValueStoreBackend):\n \"\"\"Cache result backend.\"\"\"\n\n servers = None\n supports_autoexpire = True\n supports_native_join = True\n implements_incr = True\n\n def __init__(self, app, expires=None, backend=None,\n options=None, url=None, **kwargs):\n options = {} if not options else options\n super().__init__(app, **kwargs)\n self.url = url\n\n self.options = dict(self.app.conf.cache_backend_options,\n **options)\n\n self.backend = url or backend or self.app.conf.cache_backend\n if self.backend:\n self.backend, _, servers = self.backend.partition('://')\n self.servers = servers.rstrip('/').split(';')\n self.expires = self.prepare_expires(expires, type=int)\n try:\n self.Client, self.key_t = backends[self.backend]()\n except KeyError:\n raise ImproperlyConfigured(UNKNOWN_BACKEND.format(\n self.backend, ', '.join(backends)))\n self._encode_prefixes() # rencode the keyprefixes\n\n def get(self, key):\n return self.client.get(key)\n\n def mget(self, keys):\n return self.client.get_multi(keys)\n\n def set(self, key, value):\n return self.client.set(key, value, self.expires)\n\n def delete(self, key):\n return self.client.delete(key)\n\n def _apply_chord_incr(self, header_result, body, **kwargs):\n chord_key = self.get_key_for_chord(header_result.id)\n self.client.set(chord_key, 0, time=self.expires)\n return super()._apply_chord_incr(\n header_result, body, **kwargs)\n\n def incr(self, key):\n return self.client.incr(key)\n\n def expire(self, key, value):\n return self.client.touch(key, value)\n\n @cached_property\n def client(self):\n return self.Client(self.servers, **self.options)\n\n def __reduce__(self, args=(), kwargs=None):\n kwargs = {} if not kwargs else kwargs\n servers = ';'.join(self.servers)\n backend = f'{self.backend}://{servers}/'\n kwargs.update(\n {'backend': backend,\n 'expires': self.expires,\n 'options': self.options})\n return super().__reduce__(args, kwargs)\n\n def as_uri(self, *args, **kwargs):\n \"\"\"Return the backend as an URI.\n\n This properly handles the case of multiple servers.\n \"\"\"\n servers = ';'.join(self.servers)\n return f'{self.backend}://{servers}/'\n", "path": "celery/backends/cache.py"}]}
| 3,190 | 200 |
gh_patches_debug_37069
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-8674
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
There is a missing check for the "associativity" of the operators in the stacks/infix_to_postfix_conversion.py file.
### Repository commit
11582943a555ae3b6a22938df6d3645b0327562e
### Python version (python --version)
Python 3.10.6
### Dependencies version (pip freeze)
astroid==2.11.3
bcc==0.18.0
black==22.3.0
blinker==1.4
Brlapi==0.8.3
certifi==2020.6.20
chardet==4.0.0
### Expected behavior
Hi, In the [data_structures/stacks/infix_to_postfix_conversion.py](https://github.com/TheAlgorithms/Python/blob/master/data_structures/stacks/infix_to_postfix_conversion.py) file, when we pass `"2^3^2"` argument to the `infix_to_postfix` function, it should return `'2 3 2 ^ ^'` back. This results in number `512` which is the correct calculation.
### Actual behavior
Currently `infix_to_postfix("2^3^2")` returns `'2 3 ^ 2 ^'` which is wrong. If we calculate it, it returns number `64`.
The reason behind this is that currently we don't have any check for the "associativity" of the operators. In particular `^` operator causes problem here. It has `Right-To-Left` associativity.
There is a missing check for the "associativity" of the operators in the stacks/infix_to_postfix_conversion.py file.
### Repository commit
11582943a555ae3b6a22938df6d3645b0327562e
### Python version (python --version)
Python 3.10.6
### Dependencies version (pip freeze)
astroid==2.11.3
bcc==0.18.0
black==22.3.0
blinker==1.4
Brlapi==0.8.3
certifi==2020.6.20
chardet==4.0.0
### Expected behavior
Hi, In the [data_structures/stacks/infix_to_postfix_conversion.py](https://github.com/TheAlgorithms/Python/blob/master/data_structures/stacks/infix_to_postfix_conversion.py) file, when we pass `"2^3^2"` argument to the `infix_to_postfix` function, it should return `'2 3 2 ^ ^'` back. This results in number `512` which is the correct calculation.
### Actual behavior
Currently `infix_to_postfix("2^3^2")` returns `'2 3 ^ 2 ^'` which is wrong. If we calculate it, it returns number `64`.
The reason behind this is that currently we don't have any check for the "associativity" of the operators. In particular `^` operator causes problem here. It has `Right-To-Left` associativity.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `data_structures/stacks/infix_to_postfix_conversion.py`
Content:
```
1 """
2 https://en.wikipedia.org/wiki/Infix_notation
3 https://en.wikipedia.org/wiki/Reverse_Polish_notation
4 https://en.wikipedia.org/wiki/Shunting-yard_algorithm
5 """
6
7 from .balanced_parentheses import balanced_parentheses
8 from .stack import Stack
9
10
11 def precedence(char: str) -> int:
12 """
13 Return integer value representing an operator's precedence, or
14 order of operation.
15 https://en.wikipedia.org/wiki/Order_of_operations
16 """
17 return {"+": 1, "-": 1, "*": 2, "/": 2, "^": 3}.get(char, -1)
18
19
20 def infix_to_postfix(expression_str: str) -> str:
21 """
22 >>> infix_to_postfix("(1*(2+3)+4))")
23 Traceback (most recent call last):
24 ...
25 ValueError: Mismatched parentheses
26 >>> infix_to_postfix("")
27 ''
28 >>> infix_to_postfix("3+2")
29 '3 2 +'
30 >>> infix_to_postfix("(3+4)*5-6")
31 '3 4 + 5 * 6 -'
32 >>> infix_to_postfix("(1+2)*3/4-5")
33 '1 2 + 3 * 4 / 5 -'
34 >>> infix_to_postfix("a+b*c+(d*e+f)*g")
35 'a b c * + d e * f + g * +'
36 >>> infix_to_postfix("x^y/(5*z)+2")
37 'x y ^ 5 z * / 2 +'
38 """
39 if not balanced_parentheses(expression_str):
40 raise ValueError("Mismatched parentheses")
41 stack: Stack[str] = Stack()
42 postfix = []
43 for char in expression_str:
44 if char.isalpha() or char.isdigit():
45 postfix.append(char)
46 elif char == "(":
47 stack.push(char)
48 elif char == ")":
49 while not stack.is_empty() and stack.peek() != "(":
50 postfix.append(stack.pop())
51 stack.pop()
52 else:
53 while not stack.is_empty() and precedence(char) <= precedence(stack.peek()):
54 postfix.append(stack.pop())
55 stack.push(char)
56 while not stack.is_empty():
57 postfix.append(stack.pop())
58 return " ".join(postfix)
59
60
61 if __name__ == "__main__":
62 from doctest import testmod
63
64 testmod()
65 expression = "a+b*(c^d-e)^(f+g*h)-i"
66
67 print("Infix to Postfix Notation demonstration:\n")
68 print("Infix notation: " + expression)
69 print("Postfix notation: " + infix_to_postfix(expression))
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/data_structures/stacks/infix_to_postfix_conversion.py b/data_structures/stacks/infix_to_postfix_conversion.py
--- a/data_structures/stacks/infix_to_postfix_conversion.py
+++ b/data_structures/stacks/infix_to_postfix_conversion.py
@@ -4,9 +4,26 @@
https://en.wikipedia.org/wiki/Shunting-yard_algorithm
"""
+from typing import Literal
+
from .balanced_parentheses import balanced_parentheses
from .stack import Stack
+PRECEDENCES: dict[str, int] = {
+ "+": 1,
+ "-": 1,
+ "*": 2,
+ "/": 2,
+ "^": 3,
+}
+ASSOCIATIVITIES: dict[str, Literal["LR", "RL"]] = {
+ "+": "LR",
+ "-": "LR",
+ "*": "LR",
+ "/": "LR",
+ "^": "RL",
+}
+
def precedence(char: str) -> int:
"""
@@ -14,7 +31,15 @@
order of operation.
https://en.wikipedia.org/wiki/Order_of_operations
"""
- return {"+": 1, "-": 1, "*": 2, "/": 2, "^": 3}.get(char, -1)
+ return PRECEDENCES.get(char, -1)
+
+
+def associativity(char: str) -> Literal["LR", "RL"]:
+ """
+ Return the associativity of the operator `char`.
+ https://en.wikipedia.org/wiki/Operator_associativity
+ """
+ return ASSOCIATIVITIES[char]
def infix_to_postfix(expression_str: str) -> str:
@@ -35,6 +60,8 @@
'a b c * + d e * f + g * +'
>>> infix_to_postfix("x^y/(5*z)+2")
'x y ^ 5 z * / 2 +'
+ >>> infix_to_postfix("2^3^2")
+ '2 3 2 ^ ^'
"""
if not balanced_parentheses(expression_str):
raise ValueError("Mismatched parentheses")
@@ -50,9 +77,26 @@
postfix.append(stack.pop())
stack.pop()
else:
- while not stack.is_empty() and precedence(char) <= precedence(stack.peek()):
+ while True:
+ if stack.is_empty():
+ stack.push(char)
+ break
+
+ char_precedence = precedence(char)
+ tos_precedence = precedence(stack.peek())
+
+ if char_precedence > tos_precedence:
+ stack.push(char)
+ break
+ if char_precedence < tos_precedence:
+ postfix.append(stack.pop())
+ continue
+ # Precedences are equal
+ if associativity(char) == "RL":
+ stack.push(char)
+ break
postfix.append(stack.pop())
- stack.push(char)
+
while not stack.is_empty():
postfix.append(stack.pop())
return " ".join(postfix)
|
{"golden_diff": "diff --git a/data_structures/stacks/infix_to_postfix_conversion.py b/data_structures/stacks/infix_to_postfix_conversion.py\n--- a/data_structures/stacks/infix_to_postfix_conversion.py\n+++ b/data_structures/stacks/infix_to_postfix_conversion.py\n@@ -4,9 +4,26 @@\n https://en.wikipedia.org/wiki/Shunting-yard_algorithm\n \"\"\"\n \n+from typing import Literal\n+\n from .balanced_parentheses import balanced_parentheses\n from .stack import Stack\n \n+PRECEDENCES: dict[str, int] = {\n+ \"+\": 1,\n+ \"-\": 1,\n+ \"*\": 2,\n+ \"/\": 2,\n+ \"^\": 3,\n+}\n+ASSOCIATIVITIES: dict[str, Literal[\"LR\", \"RL\"]] = {\n+ \"+\": \"LR\",\n+ \"-\": \"LR\",\n+ \"*\": \"LR\",\n+ \"/\": \"LR\",\n+ \"^\": \"RL\",\n+}\n+\n \n def precedence(char: str) -> int:\n \"\"\"\n@@ -14,7 +31,15 @@\n order of operation.\n https://en.wikipedia.org/wiki/Order_of_operations\n \"\"\"\n- return {\"+\": 1, \"-\": 1, \"*\": 2, \"/\": 2, \"^\": 3}.get(char, -1)\n+ return PRECEDENCES.get(char, -1)\n+\n+\n+def associativity(char: str) -> Literal[\"LR\", \"RL\"]:\n+ \"\"\"\n+ Return the associativity of the operator `char`.\n+ https://en.wikipedia.org/wiki/Operator_associativity\n+ \"\"\"\n+ return ASSOCIATIVITIES[char]\n \n \n def infix_to_postfix(expression_str: str) -> str:\n@@ -35,6 +60,8 @@\n 'a b c * + d e * f + g * +'\n >>> infix_to_postfix(\"x^y/(5*z)+2\")\n 'x y ^ 5 z * / 2 +'\n+ >>> infix_to_postfix(\"2^3^2\")\n+ '2 3 2 ^ ^'\n \"\"\"\n if not balanced_parentheses(expression_str):\n raise ValueError(\"Mismatched parentheses\")\n@@ -50,9 +77,26 @@\n postfix.append(stack.pop())\n stack.pop()\n else:\n- while not stack.is_empty() and precedence(char) <= precedence(stack.peek()):\n+ while True:\n+ if stack.is_empty():\n+ stack.push(char)\n+ break\n+\n+ char_precedence = precedence(char)\n+ tos_precedence = precedence(stack.peek())\n+\n+ if char_precedence > tos_precedence:\n+ stack.push(char)\n+ break\n+ if char_precedence < tos_precedence:\n+ postfix.append(stack.pop())\n+ continue\n+ # Precedences are equal\n+ if associativity(char) == \"RL\":\n+ stack.push(char)\n+ break\n postfix.append(stack.pop())\n- stack.push(char)\n+\n while not stack.is_empty():\n postfix.append(stack.pop())\n return \" \".join(postfix)\n", "issue": "There is a missing check for the \"associativity\" of the operators in the stacks/infix_to_postfix_conversion.py file.\n### Repository commit\r\n\r\n11582943a555ae3b6a22938df6d3645b0327562e\r\n\r\n### Python version (python --version)\r\n\r\nPython 3.10.6\r\n\r\n### Dependencies version (pip freeze)\r\n\r\nastroid==2.11.3\r\nbcc==0.18.0\r\nblack==22.3.0\r\nblinker==1.4\r\nBrlapi==0.8.3\r\ncertifi==2020.6.20\r\nchardet==4.0.0\r\n\r\n\r\n### Expected behavior\r\n\r\nHi, In the [data_structures/stacks/infix_to_postfix_conversion.py](https://github.com/TheAlgorithms/Python/blob/master/data_structures/stacks/infix_to_postfix_conversion.py) file, when we pass `\"2^3^2\"` argument to the `infix_to_postfix` function, it should return `'2 3 2 ^ ^'` back. This results in number `512` which is the correct calculation.\r\n\r\n### Actual behavior\r\n\r\nCurrently `infix_to_postfix(\"2^3^2\")` returns `'2 3 ^ 2 ^'` which is wrong. If we calculate it, it returns number `64`.\r\n\r\nThe reason behind this is that currently we don't have any check for the \"associativity\" of the operators. In particular `^` operator causes problem here. It has `Right-To-Left` associativity. \nThere is a missing check for the \"associativity\" of the operators in the stacks/infix_to_postfix_conversion.py file.\n### Repository commit\r\n\r\n11582943a555ae3b6a22938df6d3645b0327562e\r\n\r\n### Python version (python --version)\r\n\r\nPython 3.10.6\r\n\r\n### Dependencies version (pip freeze)\r\n\r\nastroid==2.11.3\r\nbcc==0.18.0\r\nblack==22.3.0\r\nblinker==1.4\r\nBrlapi==0.8.3\r\ncertifi==2020.6.20\r\nchardet==4.0.0\r\n\r\n\r\n### Expected behavior\r\n\r\nHi, In the [data_structures/stacks/infix_to_postfix_conversion.py](https://github.com/TheAlgorithms/Python/blob/master/data_structures/stacks/infix_to_postfix_conversion.py) file, when we pass `\"2^3^2\"` argument to the `infix_to_postfix` function, it should return `'2 3 2 ^ ^'` back. This results in number `512` which is the correct calculation.\r\n\r\n### Actual behavior\r\n\r\nCurrently `infix_to_postfix(\"2^3^2\")` returns `'2 3 ^ 2 ^'` which is wrong. If we calculate it, it returns number `64`.\r\n\r\nThe reason behind this is that currently we don't have any check for the \"associativity\" of the operators. In particular `^` operator causes problem here. It has `Right-To-Left` associativity. \n", "before_files": [{"content": "\"\"\"\nhttps://en.wikipedia.org/wiki/Infix_notation\nhttps://en.wikipedia.org/wiki/Reverse_Polish_notation\nhttps://en.wikipedia.org/wiki/Shunting-yard_algorithm\n\"\"\"\n\nfrom .balanced_parentheses import balanced_parentheses\nfrom .stack import Stack\n\n\ndef precedence(char: str) -> int:\n \"\"\"\n Return integer value representing an operator's precedence, or\n order of operation.\n https://en.wikipedia.org/wiki/Order_of_operations\n \"\"\"\n return {\"+\": 1, \"-\": 1, \"*\": 2, \"/\": 2, \"^\": 3}.get(char, -1)\n\n\ndef infix_to_postfix(expression_str: str) -> str:\n \"\"\"\n >>> infix_to_postfix(\"(1*(2+3)+4))\")\n Traceback (most recent call last):\n ...\n ValueError: Mismatched parentheses\n >>> infix_to_postfix(\"\")\n ''\n >>> infix_to_postfix(\"3+2\")\n '3 2 +'\n >>> infix_to_postfix(\"(3+4)*5-6\")\n '3 4 + 5 * 6 -'\n >>> infix_to_postfix(\"(1+2)*3/4-5\")\n '1 2 + 3 * 4 / 5 -'\n >>> infix_to_postfix(\"a+b*c+(d*e+f)*g\")\n 'a b c * + d e * f + g * +'\n >>> infix_to_postfix(\"x^y/(5*z)+2\")\n 'x y ^ 5 z * / 2 +'\n \"\"\"\n if not balanced_parentheses(expression_str):\n raise ValueError(\"Mismatched parentheses\")\n stack: Stack[str] = Stack()\n postfix = []\n for char in expression_str:\n if char.isalpha() or char.isdigit():\n postfix.append(char)\n elif char == \"(\":\n stack.push(char)\n elif char == \")\":\n while not stack.is_empty() and stack.peek() != \"(\":\n postfix.append(stack.pop())\n stack.pop()\n else:\n while not stack.is_empty() and precedence(char) <= precedence(stack.peek()):\n postfix.append(stack.pop())\n stack.push(char)\n while not stack.is_empty():\n postfix.append(stack.pop())\n return \" \".join(postfix)\n\n\nif __name__ == \"__main__\":\n from doctest import testmod\n\n testmod()\n expression = \"a+b*(c^d-e)^(f+g*h)-i\"\n\n print(\"Infix to Postfix Notation demonstration:\\n\")\n print(\"Infix notation: \" + expression)\n print(\"Postfix notation: \" + infix_to_postfix(expression))\n", "path": "data_structures/stacks/infix_to_postfix_conversion.py"}], "after_files": [{"content": "\"\"\"\nhttps://en.wikipedia.org/wiki/Infix_notation\nhttps://en.wikipedia.org/wiki/Reverse_Polish_notation\nhttps://en.wikipedia.org/wiki/Shunting-yard_algorithm\n\"\"\"\n\nfrom typing import Literal\n\nfrom .balanced_parentheses import balanced_parentheses\nfrom .stack import Stack\n\nPRECEDENCES: dict[str, int] = {\n \"+\": 1,\n \"-\": 1,\n \"*\": 2,\n \"/\": 2,\n \"^\": 3,\n}\nASSOCIATIVITIES: dict[str, Literal[\"LR\", \"RL\"]] = {\n \"+\": \"LR\",\n \"-\": \"LR\",\n \"*\": \"LR\",\n \"/\": \"LR\",\n \"^\": \"RL\",\n}\n\n\ndef precedence(char: str) -> int:\n \"\"\"\n Return integer value representing an operator's precedence, or\n order of operation.\n https://en.wikipedia.org/wiki/Order_of_operations\n \"\"\"\n return PRECEDENCES.get(char, -1)\n\n\ndef associativity(char: str) -> Literal[\"LR\", \"RL\"]:\n \"\"\"\n Return the associativity of the operator `char`.\n https://en.wikipedia.org/wiki/Operator_associativity\n \"\"\"\n return ASSOCIATIVITIES[char]\n\n\ndef infix_to_postfix(expression_str: str) -> str:\n \"\"\"\n >>> infix_to_postfix(\"(1*(2+3)+4))\")\n Traceback (most recent call last):\n ...\n ValueError: Mismatched parentheses\n >>> infix_to_postfix(\"\")\n ''\n >>> infix_to_postfix(\"3+2\")\n '3 2 +'\n >>> infix_to_postfix(\"(3+4)*5-6\")\n '3 4 + 5 * 6 -'\n >>> infix_to_postfix(\"(1+2)*3/4-5\")\n '1 2 + 3 * 4 / 5 -'\n >>> infix_to_postfix(\"a+b*c+(d*e+f)*g\")\n 'a b c * + d e * f + g * +'\n >>> infix_to_postfix(\"x^y/(5*z)+2\")\n 'x y ^ 5 z * / 2 +'\n >>> infix_to_postfix(\"2^3^2\")\n '2 3 2 ^ ^'\n \"\"\"\n if not balanced_parentheses(expression_str):\n raise ValueError(\"Mismatched parentheses\")\n stack: Stack[str] = Stack()\n postfix = []\n for char in expression_str:\n if char.isalpha() or char.isdigit():\n postfix.append(char)\n elif char == \"(\":\n stack.push(char)\n elif char == \")\":\n while not stack.is_empty() and stack.peek() != \"(\":\n postfix.append(stack.pop())\n stack.pop()\n else:\n while True:\n if stack.is_empty():\n stack.push(char)\n break\n\n char_precedence = precedence(char)\n tos_precedence = precedence(stack.peek())\n\n if char_precedence > tos_precedence:\n stack.push(char)\n break\n if char_precedence < tos_precedence:\n postfix.append(stack.pop())\n continue\n # Precedences are equal\n if associativity(char) == \"RL\":\n stack.push(char)\n break\n postfix.append(stack.pop())\n\n while not stack.is_empty():\n postfix.append(stack.pop())\n return \" \".join(postfix)\n\n\nif __name__ == \"__main__\":\n from doctest import testmod\n\n testmod()\n expression = \"a+b*(c^d-e)^(f+g*h)-i\"\n\n print(\"Infix to Postfix Notation demonstration:\\n\")\n print(\"Infix notation: \" + expression)\n print(\"Postfix notation: \" + infix_to_postfix(expression))\n", "path": "data_structures/stacks/infix_to_postfix_conversion.py"}]}
| 1,677 | 687 |
gh_patches_debug_24866
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-914
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update Example Launcher Plugin mention restoring the singletons
The singletons should be restored when performing multi-process launching.
something
```python
# In the launcher's launch:
state = Singleton.get_state()
# In the remote process
Singleton.set_state(state)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 from pathlib import Path
4 from typing import Optional, Sequence
5
6 from hydra.core.config_loader import ConfigLoader
7 from hydra.core.config_search_path import ConfigSearchPath
8 from hydra.core.hydra_config import HydraConfig
9 from hydra.core.utils import (
10 JobReturn,
11 configure_log,
12 filter_overrides,
13 run_job,
14 setup_globals,
15 )
16 from hydra.plugins.launcher import Launcher
17 from hydra.plugins.search_path_plugin import SearchPathPlugin
18 from hydra.types import TaskFunction
19 from omegaconf import DictConfig, open_dict
20
21 # IMPORTANT:
22 # If your plugin imports any module that takes more than a fraction of a second to import,
23 # Import the module lazily (typically inside launch()).
24 # Installed plugins are imported during Hydra initialization and plugins that are slow to import plugins will slow
25 # the startup of ALL hydra applications.
26 # Another approach is to place heavy includes in a file prefixed by _, such as _core.py:
27 # Hydra will not look for plugin in such files and will not import them during plugin discovery.
28
29
30 log = logging.getLogger(__name__)
31
32
33 class ExampleLauncherSearchPathPlugin(SearchPathPlugin):
34 """
35 This plugin is allowing configuration files provided by the ExampleLauncher plugin to be discovered
36 and used once the ExampleLauncher plugin is installed
37 """
38
39 def manipulate_search_path(self, search_path: ConfigSearchPath) -> None:
40 # Appends the search path for this plugin to the end of the search path
41 search_path.append(
42 "hydra-example-launcher", "pkg://hydra_plugins.example_launcher_plugin.conf"
43 )
44
45
46 class ExampleLauncher(Launcher):
47 def __init__(self, foo: str, bar: str) -> None:
48 self.config: Optional[DictConfig] = None
49 self.config_loader: Optional[ConfigLoader] = None
50 self.task_function: Optional[TaskFunction] = None
51
52 # foo and var are coming from the the plugin's configuration
53 self.foo = foo
54 self.bar = bar
55
56 def setup(
57 self,
58 config: DictConfig,
59 config_loader: ConfigLoader,
60 task_function: TaskFunction,
61 ) -> None:
62 self.config = config
63 self.config_loader = config_loader
64 self.task_function = task_function
65
66 def launch(
67 self, job_overrides: Sequence[Sequence[str]], initial_job_idx: int
68 ) -> Sequence[JobReturn]:
69 """
70 :param job_overrides: a List of List<String>, where each inner list is the arguments for one job run.
71 :param initial_job_idx: Initial job idx in batch.
72 :return: an array of return values from run_job with indexes corresponding to the input list indexes.
73 """
74 setup_globals()
75 assert self.config is not None
76 assert self.config_loader is not None
77 assert self.task_function is not None
78
79 configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)
80 sweep_dir = Path(str(self.config.hydra.sweep.dir))
81 sweep_dir.mkdir(parents=True, exist_ok=True)
82 log.info(
83 f"Example Launcher(foo={self.foo}, bar={self.bar}) is launching {len(job_overrides)} jobs locally"
84 )
85 log.info(f"Sweep output dir : {sweep_dir}")
86 runs = []
87
88 for idx, overrides in enumerate(job_overrides):
89 idx = initial_job_idx + idx
90 lst = " ".join(filter_overrides(overrides))
91 log.info(f"\t#{idx} : {lst}")
92 sweep_config = self.config_loader.load_sweep_config(
93 self.config, list(overrides)
94 )
95 with open_dict(sweep_config):
96 # This typically coming from the underlying scheduler (SLURM_JOB_ID for instance)
97 # In that case, it will not be available here because we are still in the main process.
98 # but instead should be populated remotely before calling the task_function.
99 sweep_config.hydra.job.id = f"job_id_for_{idx}"
100 sweep_config.hydra.job.num = idx
101 HydraConfig.instance().set_config(sweep_config)
102
103 ret = run_job(
104 config=sweep_config,
105 task_function=self.task_function,
106 job_dir_key="hydra.sweep.dir",
107 job_subdir_key="hydra.sweep.subdir",
108 )
109 runs.append(ret)
110 # reconfigure the logging subsystem for Hydra as the run_job call configured it for the Job.
111 # This is needed for launchers that calls run_job in the same process and not spawn a new one.
112 configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)
113 return runs
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py b/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py
--- a/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py
+++ b/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py
@@ -6,6 +6,7 @@
from hydra.core.config_loader import ConfigLoader
from hydra.core.config_search_path import ConfigSearchPath
from hydra.core.hydra_config import HydraConfig
+from hydra.core.singleton import Singleton
from hydra.core.utils import (
JobReturn,
configure_log,
@@ -100,6 +101,17 @@
sweep_config.hydra.job.num = idx
HydraConfig.instance().set_config(sweep_config)
+ # If your launcher is executing code in a different process, it is important to restore
+ # the singleton state in the new process.
+ # To do this, you will likely need to serialize the singleton state along with the other
+ # parameters passed to the child process.
+
+ # happening on launcher process
+ state = Singleton.get_state()
+
+ # happening on the spawned process
+ Singleton.set_state(state)
+
ret = run_job(
config=sweep_config,
task_function=self.task_function,
|
{"golden_diff": "diff --git a/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py b/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py\n--- a/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py\n+++ b/plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py\n@@ -6,6 +6,7 @@\n from hydra.core.config_loader import ConfigLoader\n from hydra.core.config_search_path import ConfigSearchPath\n from hydra.core.hydra_config import HydraConfig\n+from hydra.core.singleton import Singleton\n from hydra.core.utils import (\n JobReturn,\n configure_log,\n@@ -100,6 +101,17 @@\n sweep_config.hydra.job.num = idx\n HydraConfig.instance().set_config(sweep_config)\n \n+ # If your launcher is executing code in a different process, it is important to restore\n+ # the singleton state in the new process.\n+ # To do this, you will likely need to serialize the singleton state along with the other\n+ # parameters passed to the child process.\n+\n+ # happening on launcher process\n+ state = Singleton.get_state()\n+\n+ # happening on the spawned process\n+ Singleton.set_state(state)\n+\n ret = run_job(\n config=sweep_config,\n task_function=self.task_function,\n", "issue": "Update Example Launcher Plugin mention restoring the singletons\nThe singletons should be restored when performing multi-process launching.\r\nsomething \r\n\r\n```python\r\n# In the launcher's launch:\r\nstate = Singleton.get_state()\r\n\r\n# In the remote process\r\nSingleton.set_state(state)\r\n```\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nfrom pathlib import Path\nfrom typing import Optional, Sequence\n\nfrom hydra.core.config_loader import ConfigLoader\nfrom hydra.core.config_search_path import ConfigSearchPath\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.utils import (\n JobReturn,\n configure_log,\n filter_overrides,\n run_job,\n setup_globals,\n)\nfrom hydra.plugins.launcher import Launcher\nfrom hydra.plugins.search_path_plugin import SearchPathPlugin\nfrom hydra.types import TaskFunction\nfrom omegaconf import DictConfig, open_dict\n\n# IMPORTANT:\n# If your plugin imports any module that takes more than a fraction of a second to import,\n# Import the module lazily (typically inside launch()).\n# Installed plugins are imported during Hydra initialization and plugins that are slow to import plugins will slow\n# the startup of ALL hydra applications.\n# Another approach is to place heavy includes in a file prefixed by _, such as _core.py:\n# Hydra will not look for plugin in such files and will not import them during plugin discovery.\n\n\nlog = logging.getLogger(__name__)\n\n\nclass ExampleLauncherSearchPathPlugin(SearchPathPlugin):\n \"\"\"\n This plugin is allowing configuration files provided by the ExampleLauncher plugin to be discovered\n and used once the ExampleLauncher plugin is installed\n \"\"\"\n\n def manipulate_search_path(self, search_path: ConfigSearchPath) -> None:\n # Appends the search path for this plugin to the end of the search path\n search_path.append(\n \"hydra-example-launcher\", \"pkg://hydra_plugins.example_launcher_plugin.conf\"\n )\n\n\nclass ExampleLauncher(Launcher):\n def __init__(self, foo: str, bar: str) -> None:\n self.config: Optional[DictConfig] = None\n self.config_loader: Optional[ConfigLoader] = None\n self.task_function: Optional[TaskFunction] = None\n\n # foo and var are coming from the the plugin's configuration\n self.foo = foo\n self.bar = bar\n\n def setup(\n self,\n config: DictConfig,\n config_loader: ConfigLoader,\n task_function: TaskFunction,\n ) -> None:\n self.config = config\n self.config_loader = config_loader\n self.task_function = task_function\n\n def launch(\n self, job_overrides: Sequence[Sequence[str]], initial_job_idx: int\n ) -> Sequence[JobReturn]:\n \"\"\"\n :param job_overrides: a List of List<String>, where each inner list is the arguments for one job run.\n :param initial_job_idx: Initial job idx in batch.\n :return: an array of return values from run_job with indexes corresponding to the input list indexes.\n \"\"\"\n setup_globals()\n assert self.config is not None\n assert self.config_loader is not None\n assert self.task_function is not None\n\n configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)\n sweep_dir = Path(str(self.config.hydra.sweep.dir))\n sweep_dir.mkdir(parents=True, exist_ok=True)\n log.info(\n f\"Example Launcher(foo={self.foo}, bar={self.bar}) is launching {len(job_overrides)} jobs locally\"\n )\n log.info(f\"Sweep output dir : {sweep_dir}\")\n runs = []\n\n for idx, overrides in enumerate(job_overrides):\n idx = initial_job_idx + idx\n lst = \" \".join(filter_overrides(overrides))\n log.info(f\"\\t#{idx} : {lst}\")\n sweep_config = self.config_loader.load_sweep_config(\n self.config, list(overrides)\n )\n with open_dict(sweep_config):\n # This typically coming from the underlying scheduler (SLURM_JOB_ID for instance)\n # In that case, it will not be available here because we are still in the main process.\n # but instead should be populated remotely before calling the task_function.\n sweep_config.hydra.job.id = f\"job_id_for_{idx}\"\n sweep_config.hydra.job.num = idx\n HydraConfig.instance().set_config(sweep_config)\n\n ret = run_job(\n config=sweep_config,\n task_function=self.task_function,\n job_dir_key=\"hydra.sweep.dir\",\n job_subdir_key=\"hydra.sweep.subdir\",\n )\n runs.append(ret)\n # reconfigure the logging subsystem for Hydra as the run_job call configured it for the Job.\n # This is needed for launchers that calls run_job in the same process and not spawn a new one.\n configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)\n return runs\n", "path": "plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nfrom pathlib import Path\nfrom typing import Optional, Sequence\n\nfrom hydra.core.config_loader import ConfigLoader\nfrom hydra.core.config_search_path import ConfigSearchPath\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.singleton import Singleton\nfrom hydra.core.utils import (\n JobReturn,\n configure_log,\n filter_overrides,\n run_job,\n setup_globals,\n)\nfrom hydra.plugins.launcher import Launcher\nfrom hydra.plugins.search_path_plugin import SearchPathPlugin\nfrom hydra.types import TaskFunction\nfrom omegaconf import DictConfig, open_dict\n\n# IMPORTANT:\n# If your plugin imports any module that takes more than a fraction of a second to import,\n# Import the module lazily (typically inside launch()).\n# Installed plugins are imported during Hydra initialization and plugins that are slow to import plugins will slow\n# the startup of ALL hydra applications.\n# Another approach is to place heavy includes in a file prefixed by _, such as _core.py:\n# Hydra will not look for plugin in such files and will not import them during plugin discovery.\n\n\nlog = logging.getLogger(__name__)\n\n\nclass ExampleLauncherSearchPathPlugin(SearchPathPlugin):\n \"\"\"\n This plugin is allowing configuration files provided by the ExampleLauncher plugin to be discovered\n and used once the ExampleLauncher plugin is installed\n \"\"\"\n\n def manipulate_search_path(self, search_path: ConfigSearchPath) -> None:\n # Appends the search path for this plugin to the end of the search path\n search_path.append(\n \"hydra-example-launcher\", \"pkg://hydra_plugins.example_launcher_plugin.conf\"\n )\n\n\nclass ExampleLauncher(Launcher):\n def __init__(self, foo: str, bar: str) -> None:\n self.config: Optional[DictConfig] = None\n self.config_loader: Optional[ConfigLoader] = None\n self.task_function: Optional[TaskFunction] = None\n\n # foo and var are coming from the the plugin's configuration\n self.foo = foo\n self.bar = bar\n\n def setup(\n self,\n config: DictConfig,\n config_loader: ConfigLoader,\n task_function: TaskFunction,\n ) -> None:\n self.config = config\n self.config_loader = config_loader\n self.task_function = task_function\n\n def launch(\n self, job_overrides: Sequence[Sequence[str]], initial_job_idx: int\n ) -> Sequence[JobReturn]:\n \"\"\"\n :param job_overrides: a List of List<String>, where each inner list is the arguments for one job run.\n :param initial_job_idx: Initial job idx in batch.\n :return: an array of return values from run_job with indexes corresponding to the input list indexes.\n \"\"\"\n setup_globals()\n assert self.config is not None\n assert self.config_loader is not None\n assert self.task_function is not None\n\n configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)\n sweep_dir = Path(str(self.config.hydra.sweep.dir))\n sweep_dir.mkdir(parents=True, exist_ok=True)\n log.info(\n f\"Example Launcher(foo={self.foo}, bar={self.bar}) is launching {len(job_overrides)} jobs locally\"\n )\n log.info(f\"Sweep output dir : {sweep_dir}\")\n runs = []\n\n for idx, overrides in enumerate(job_overrides):\n idx = initial_job_idx + idx\n lst = \" \".join(filter_overrides(overrides))\n log.info(f\"\\t#{idx} : {lst}\")\n sweep_config = self.config_loader.load_sweep_config(\n self.config, list(overrides)\n )\n with open_dict(sweep_config):\n # This typically coming from the underlying scheduler (SLURM_JOB_ID for instance)\n # In that case, it will not be available here because we are still in the main process.\n # but instead should be populated remotely before calling the task_function.\n sweep_config.hydra.job.id = f\"job_id_for_{idx}\"\n sweep_config.hydra.job.num = idx\n HydraConfig.instance().set_config(sweep_config)\n\n # If your launcher is executing code in a different process, it is important to restore\n # the singleton state in the new process.\n # To do this, you will likely need to serialize the singleton state along with the other\n # parameters passed to the child process.\n\n # happening on launcher process\n state = Singleton.get_state()\n\n # happening on the spawned process\n Singleton.set_state(state)\n\n ret = run_job(\n config=sweep_config,\n task_function=self.task_function,\n job_dir_key=\"hydra.sweep.dir\",\n job_subdir_key=\"hydra.sweep.subdir\",\n )\n runs.append(ret)\n # reconfigure the logging subsystem for Hydra as the run_job call configured it for the Job.\n # This is needed for launchers that calls run_job in the same process and not spawn a new one.\n configure_log(self.config.hydra.hydra_logging, self.config.hydra.verbose)\n return runs\n", "path": "plugins/examples/example_launcher_plugin/hydra_plugins/example_launcher_plugin/example_launcher.py"}]}
| 1,553 | 292 |
gh_patches_debug_8906
|
rasdani/github-patches
|
git_diff
|
apache__tvm-5150
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG][TUTORIAL] Tutorial for quantization need update
Dear community,
I've noticed that the [stock tutorial for quantization](https://github.com/apache/incubator-tvm/blob/master/tutorials/frontend/deploy_quantized.py) fails if the following call is changed from local scales to global scales:
```
...
mod = quantize(mod, params, data_aware=True) # -> fails with data_aware=False
...
ValueError: Unknown calibrate mode global
```
The fix is straight forward:
```
- with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):
---
+ with relay.quantize.qconfig(calibrate_mode='global_scale', global_scale=8.0):
```
I would like to kindly ask @vinx13 to update the tutorial. Thank you very much in advance & best regards!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tutorials/frontend/deploy_quantized.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 """
18 Deploy a Quantized Model on Cuda
19 ================================
20 **Author**: `Wuwei Lin <https://github.com/vinx13>`_
21
22 This article is an introductory tutorial of automatic quantization with TVM.
23 Automatic quantization is one of the quantization modes in TVM. More details on
24 the quantization story in TVM can be found
25 `here <https://discuss.tvm.ai/t/quantization-story/3920>`_.
26 In this tutorial, we will import a GluonCV pre-trained model on ImageNet to
27 Relay, quantize the Relay model and then perform the inference.
28 """
29
30 import tvm
31 from tvm import te
32 from tvm import relay
33 import mxnet as mx
34 from tvm.contrib.download import download_testdata
35 from mxnet import gluon
36 import logging
37 import os
38
39 batch_size = 1
40 model_name = "resnet18_v1"
41 target = 'cuda'
42 ctx = tvm.context(target)
43
44 ###############################################################################
45 # Prepare the Dataset
46 # -------------------
47 # We will demonstrate how to prepare the calibration dataset for quantization.
48 # We first download the validation set of ImageNet and pre-process the dataset.
49 calibration_rec = download_testdata(
50 'http://data.mxnet.io.s3-website-us-west-1.amazonaws.com/data/val_256_q90.rec',
51 'val_256_q90.rec')
52
53 def get_val_data(num_workers=4):
54 mean_rgb = [123.68, 116.779, 103.939]
55 std_rgb = [58.393, 57.12, 57.375]
56
57 def batch_fn(batch):
58 return batch.data[0].asnumpy(), batch.label[0].asnumpy()
59
60 img_size = 299 if model_name == 'inceptionv3' else 224
61 val_data = mx.io.ImageRecordIter(
62 path_imgrec=calibration_rec,
63 preprocess_threads=num_workers,
64 shuffle=False,
65 batch_size=batch_size,
66 resize=256,
67 data_shape=(3, img_size, img_size),
68 mean_r=mean_rgb[0],
69 mean_g=mean_rgb[1],
70 mean_b=mean_rgb[2],
71 std_r=std_rgb[0],
72 std_g=std_rgb[1],
73 std_b=std_rgb[2],
74 )
75 return val_data, batch_fn
76
77
78 ###############################################################################
79 # The calibration dataset should be an iterable object. We define the
80 # calibration dataset as a generator object in Python. In this tutorial, we
81 # only use a few samples for calibration.
82
83 calibration_samples = 10
84
85 def calibrate_dataset():
86 val_data, batch_fn = get_val_data()
87 val_data.reset()
88 for i, batch in enumerate(val_data):
89 if i * batch_size >= calibration_samples:
90 break
91 data, _ = batch_fn(batch)
92 yield {'data': data}
93
94
95 ###############################################################################
96 # Import the model
97 # ----------------
98 # We use the Relay MxNet frontend to import a model from the Gluon model zoo.
99 def get_model():
100 gluon_model = gluon.model_zoo.vision.get_model(model_name, pretrained=True)
101 img_size = 299 if model_name == 'inceptionv3' else 224
102 data_shape = (batch_size, 3, img_size, img_size)
103 mod, params = relay.frontend.from_mxnet(gluon_model, {"data": data_shape})
104 return mod, params
105
106
107 ###############################################################################
108 # Quantize the Model
109 # ------------------
110 # In quantization, we need to find the scale for each weight and intermediate
111 # feature map tensor of each layer.
112 #
113 # For weights, the scales are directly calculated based on the value of the
114 # weights. Two modes are supported: `power2` and `max`. Both modes find the
115 # maximum value within the weight tensor first. In `power2` mode, the maximum
116 # is rounded down to power of two. If the scales of both weights and
117 # intermediate feature maps are power of two, we can leverage bit shifting for
118 # multiplications. This make it computationally more efficient. In `max` mode,
119 # the maximum is used as the scale. Without rounding, `max` mode might have
120 # better accuracy in some cases. When the scales are not powers of two, fixed
121 # point multiplications will be used.
122 #
123 # For intermediate feature maps, we can find the scales with data-aware
124 # quantization. Data-aware quantization takes a calibration dataset as the
125 # input argument. Scales are calculated by minimizing the KL divergence between
126 # distribution of activation before and after quantization.
127 # Alternatively, we can also use pre-defined global scales. This saves the time
128 # for calibration. But the accuracy might be impacted.
129
130 def quantize(mod, params, data_aware):
131 if data_aware:
132 with relay.quantize.qconfig(calibrate_mode='kl_divergence', weight_scale='max'):
133 mod = relay.quantize.quantize(mod, params, dataset=calibrate_dataset())
134 else:
135 with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):
136 mod = relay.quantize.quantize(mod, params)
137 return mod
138
139
140 ###############################################################################
141 # Run Inference
142 # -------------
143 # We create a Relay VM to build and execute the model.
144 def run_inference(mod):
145 executor = relay.create_executor('vm', mod, ctx, target)
146 val_data, batch_fn = get_val_data()
147 for i, batch in enumerate(val_data):
148 data, label = batch_fn(batch)
149 prediction = executor.evaluate()(data)
150 if i > 10: # only run inference on a few samples in this tutorial
151 break
152
153 def main():
154 mod, params = get_model()
155 mod = quantize(mod, params, data_aware=True)
156 run_inference(mod)
157
158 if __name__ == '__main__':
159 main()
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tutorials/frontend/deploy_quantized.py b/tutorials/frontend/deploy_quantized.py
--- a/tutorials/frontend/deploy_quantized.py
+++ b/tutorials/frontend/deploy_quantized.py
@@ -132,7 +132,7 @@
with relay.quantize.qconfig(calibrate_mode='kl_divergence', weight_scale='max'):
mod = relay.quantize.quantize(mod, params, dataset=calibrate_dataset())
else:
- with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):
+ with relay.quantize.qconfig(calibrate_mode='global_scale', global_scale=8.0):
mod = relay.quantize.quantize(mod, params)
return mod
|
{"golden_diff": "diff --git a/tutorials/frontend/deploy_quantized.py b/tutorials/frontend/deploy_quantized.py\n--- a/tutorials/frontend/deploy_quantized.py\n+++ b/tutorials/frontend/deploy_quantized.py\n@@ -132,7 +132,7 @@\n with relay.quantize.qconfig(calibrate_mode='kl_divergence', weight_scale='max'):\n mod = relay.quantize.quantize(mod, params, dataset=calibrate_dataset())\n else:\n- with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):\n+ with relay.quantize.qconfig(calibrate_mode='global_scale', global_scale=8.0):\n mod = relay.quantize.quantize(mod, params)\n return mod\n", "issue": " [BUG][TUTORIAL] Tutorial for quantization need update\nDear community,\r\nI've noticed that the [stock tutorial for quantization](https://github.com/apache/incubator-tvm/blob/master/tutorials/frontend/deploy_quantized.py) fails if the following call is changed from local scales to global scales:\r\n\r\n```\r\n...\r\nmod = quantize(mod, params, data_aware=True) # -> fails with data_aware=False \r\n...\r\n\r\nValueError: Unknown calibrate mode global\r\n```\r\n\r\nThe fix is straight forward:\r\n\r\n```\r\n- with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):\r\n---\r\n+ with relay.quantize.qconfig(calibrate_mode='global_scale', global_scale=8.0):\r\n```\r\n\r\nI would like to kindly ask @vinx13 to update the tutorial. Thank you very much in advance & best regards!\r\n\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"\nDeploy a Quantized Model on Cuda\n================================\n**Author**: `Wuwei Lin <https://github.com/vinx13>`_\n\nThis article is an introductory tutorial of automatic quantization with TVM.\nAutomatic quantization is one of the quantization modes in TVM. More details on\nthe quantization story in TVM can be found\n`here <https://discuss.tvm.ai/t/quantization-story/3920>`_.\nIn this tutorial, we will import a GluonCV pre-trained model on ImageNet to\nRelay, quantize the Relay model and then perform the inference.\n\"\"\"\n\nimport tvm\nfrom tvm import te\nfrom tvm import relay\nimport mxnet as mx\nfrom tvm.contrib.download import download_testdata\nfrom mxnet import gluon\nimport logging\nimport os\n\nbatch_size = 1\nmodel_name = \"resnet18_v1\"\ntarget = 'cuda'\nctx = tvm.context(target)\n\n###############################################################################\n# Prepare the Dataset\n# -------------------\n# We will demonstrate how to prepare the calibration dataset for quantization.\n# We first download the validation set of ImageNet and pre-process the dataset.\ncalibration_rec = download_testdata(\n 'http://data.mxnet.io.s3-website-us-west-1.amazonaws.com/data/val_256_q90.rec',\n 'val_256_q90.rec')\n\ndef get_val_data(num_workers=4):\n mean_rgb = [123.68, 116.779, 103.939]\n std_rgb = [58.393, 57.12, 57.375]\n\n def batch_fn(batch):\n return batch.data[0].asnumpy(), batch.label[0].asnumpy()\n\n img_size = 299 if model_name == 'inceptionv3' else 224\n val_data = mx.io.ImageRecordIter(\n path_imgrec=calibration_rec,\n preprocess_threads=num_workers,\n shuffle=False,\n batch_size=batch_size,\n resize=256,\n data_shape=(3, img_size, img_size),\n mean_r=mean_rgb[0],\n mean_g=mean_rgb[1],\n mean_b=mean_rgb[2],\n std_r=std_rgb[0],\n std_g=std_rgb[1],\n std_b=std_rgb[2],\n )\n return val_data, batch_fn\n\n\n###############################################################################\n# The calibration dataset should be an iterable object. We define the\n# calibration dataset as a generator object in Python. In this tutorial, we\n# only use a few samples for calibration.\n\ncalibration_samples = 10\n\ndef calibrate_dataset():\n val_data, batch_fn = get_val_data()\n val_data.reset()\n for i, batch in enumerate(val_data):\n if i * batch_size >= calibration_samples:\n break\n data, _ = batch_fn(batch)\n yield {'data': data}\n\n\n###############################################################################\n# Import the model\n# ----------------\n# We use the Relay MxNet frontend to import a model from the Gluon model zoo.\ndef get_model():\n gluon_model = gluon.model_zoo.vision.get_model(model_name, pretrained=True)\n img_size = 299 if model_name == 'inceptionv3' else 224\n data_shape = (batch_size, 3, img_size, img_size)\n mod, params = relay.frontend.from_mxnet(gluon_model, {\"data\": data_shape})\n return mod, params\n\n\n###############################################################################\n# Quantize the Model\n# ------------------\n# In quantization, we need to find the scale for each weight and intermediate\n# feature map tensor of each layer.\n#\n# For weights, the scales are directly calculated based on the value of the\n# weights. Two modes are supported: `power2` and `max`. Both modes find the\n# maximum value within the weight tensor first. In `power2` mode, the maximum\n# is rounded down to power of two. If the scales of both weights and\n# intermediate feature maps are power of two, we can leverage bit shifting for\n# multiplications. This make it computationally more efficient. In `max` mode,\n# the maximum is used as the scale. Without rounding, `max` mode might have\n# better accuracy in some cases. When the scales are not powers of two, fixed\n# point multiplications will be used.\n#\n# For intermediate feature maps, we can find the scales with data-aware\n# quantization. Data-aware quantization takes a calibration dataset as the\n# input argument. Scales are calculated by minimizing the KL divergence between\n# distribution of activation before and after quantization.\n# Alternatively, we can also use pre-defined global scales. This saves the time\n# for calibration. But the accuracy might be impacted.\n\ndef quantize(mod, params, data_aware):\n if data_aware:\n with relay.quantize.qconfig(calibrate_mode='kl_divergence', weight_scale='max'):\n mod = relay.quantize.quantize(mod, params, dataset=calibrate_dataset())\n else:\n with relay.quantize.qconfig(calibrate_mode='global', global_scale=8.0):\n mod = relay.quantize.quantize(mod, params)\n return mod\n\n\n###############################################################################\n# Run Inference\n# -------------\n# We create a Relay VM to build and execute the model.\ndef run_inference(mod):\n executor = relay.create_executor('vm', mod, ctx, target)\n val_data, batch_fn = get_val_data()\n for i, batch in enumerate(val_data):\n data, label = batch_fn(batch)\n prediction = executor.evaluate()(data)\n if i > 10: # only run inference on a few samples in this tutorial\n break\n\ndef main():\n mod, params = get_model()\n mod = quantize(mod, params, data_aware=True)\n run_inference(mod)\n\nif __name__ == '__main__':\n main()\n", "path": "tutorials/frontend/deploy_quantized.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"\nDeploy a Quantized Model on Cuda\n================================\n**Author**: `Wuwei Lin <https://github.com/vinx13>`_\n\nThis article is an introductory tutorial of automatic quantization with TVM.\nAutomatic quantization is one of the quantization modes in TVM. More details on\nthe quantization story in TVM can be found\n`here <https://discuss.tvm.ai/t/quantization-story/3920>`_.\nIn this tutorial, we will import a GluonCV pre-trained model on ImageNet to\nRelay, quantize the Relay model and then perform the inference.\n\"\"\"\n\nimport tvm\nfrom tvm import te\nfrom tvm import relay\nimport mxnet as mx\nfrom tvm.contrib.download import download_testdata\nfrom mxnet import gluon\nimport logging\nimport os\n\nbatch_size = 1\nmodel_name = \"resnet18_v1\"\ntarget = 'cuda'\nctx = tvm.context(target)\n\n###############################################################################\n# Prepare the Dataset\n# -------------------\n# We will demonstrate how to prepare the calibration dataset for quantization.\n# We first download the validation set of ImageNet and pre-process the dataset.\ncalibration_rec = download_testdata(\n 'http://data.mxnet.io.s3-website-us-west-1.amazonaws.com/data/val_256_q90.rec',\n 'val_256_q90.rec')\n\ndef get_val_data(num_workers=4):\n mean_rgb = [123.68, 116.779, 103.939]\n std_rgb = [58.393, 57.12, 57.375]\n\n def batch_fn(batch):\n return batch.data[0].asnumpy(), batch.label[0].asnumpy()\n\n img_size = 299 if model_name == 'inceptionv3' else 224\n val_data = mx.io.ImageRecordIter(\n path_imgrec=calibration_rec,\n preprocess_threads=num_workers,\n shuffle=False,\n batch_size=batch_size,\n resize=256,\n data_shape=(3, img_size, img_size),\n mean_r=mean_rgb[0],\n mean_g=mean_rgb[1],\n mean_b=mean_rgb[2],\n std_r=std_rgb[0],\n std_g=std_rgb[1],\n std_b=std_rgb[2],\n )\n return val_data, batch_fn\n\n\n###############################################################################\n# The calibration dataset should be an iterable object. We define the\n# calibration dataset as a generator object in Python. In this tutorial, we\n# only use a few samples for calibration.\n\ncalibration_samples = 10\n\ndef calibrate_dataset():\n val_data, batch_fn = get_val_data()\n val_data.reset()\n for i, batch in enumerate(val_data):\n if i * batch_size >= calibration_samples:\n break\n data, _ = batch_fn(batch)\n yield {'data': data}\n\n\n###############################################################################\n# Import the model\n# ----------------\n# We use the Relay MxNet frontend to import a model from the Gluon model zoo.\ndef get_model():\n gluon_model = gluon.model_zoo.vision.get_model(model_name, pretrained=True)\n img_size = 299 if model_name == 'inceptionv3' else 224\n data_shape = (batch_size, 3, img_size, img_size)\n mod, params = relay.frontend.from_mxnet(gluon_model, {\"data\": data_shape})\n return mod, params\n\n\n###############################################################################\n# Quantize the Model\n# ------------------\n# In quantization, we need to find the scale for each weight and intermediate\n# feature map tensor of each layer.\n#\n# For weights, the scales are directly calculated based on the value of the\n# weights. Two modes are supported: `power2` and `max`. Both modes find the\n# maximum value within the weight tensor first. In `power2` mode, the maximum\n# is rounded down to power of two. If the scales of both weights and\n# intermediate feature maps are power of two, we can leverage bit shifting for\n# multiplications. This make it computationally more efficient. In `max` mode,\n# the maximum is used as the scale. Without rounding, `max` mode might have\n# better accuracy in some cases. When the scales are not powers of two, fixed\n# point multiplications will be used.\n#\n# For intermediate feature maps, we can find the scales with data-aware\n# quantization. Data-aware quantization takes a calibration dataset as the\n# input argument. Scales are calculated by minimizing the KL divergence between\n# distribution of activation before and after quantization.\n# Alternatively, we can also use pre-defined global scales. This saves the time\n# for calibration. But the accuracy might be impacted.\n\ndef quantize(mod, params, data_aware):\n if data_aware:\n with relay.quantize.qconfig(calibrate_mode='kl_divergence', weight_scale='max'):\n mod = relay.quantize.quantize(mod, params, dataset=calibrate_dataset())\n else:\n with relay.quantize.qconfig(calibrate_mode='global_scale', global_scale=8.0):\n mod = relay.quantize.quantize(mod, params)\n return mod\n\n\n###############################################################################\n# Run Inference\n# -------------\n# We create a Relay VM to build and execute the model.\ndef run_inference(mod):\n executor = relay.create_executor('vm', mod, ctx, target)\n val_data, batch_fn = get_val_data()\n for i, batch in enumerate(val_data):\n data, label = batch_fn(batch)\n prediction = executor.evaluate()(data)\n if i > 10: # only run inference on a few samples in this tutorial\n break\n\ndef main():\n mod, params = get_model()\n mod = quantize(mod, params, data_aware=True)\n run_inference(mod)\n\nif __name__ == '__main__':\n main()\n", "path": "tutorials/frontend/deploy_quantized.py"}]}
| 2,286 | 159 |
gh_patches_debug_19176
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-4097
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Buildbot schedules build when a GitLab merge request is deleted
My master installation is running 28958cffbdf703e29b76fb24344848bd65e8ea8a.
In the Buildbot configuration a "gitlab" change hook is registered and triggered by a GitLab configured "Merge Requests Event".
Currently builds are triggering when a merge request is created, updated or deleted.
Build should not be scheduled when a merge request is deleted.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/www/hooks/gitlab.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18
19 import json
20 import re
21
22 from dateutil.parser import parse as dateparse
23
24 from twisted.python import log
25
26 from buildbot.util import bytes2unicode
27 from buildbot.www.hooks.base import BaseHookHandler
28
29 _HEADER_EVENT = b'X-Gitlab-Event'
30 _HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'
31
32
33 class GitLabHandler(BaseHookHandler):
34
35 def _process_change(self, payload, user, repo, repo_url, project, event,
36 codebase=None):
37 """
38 Consumes the JSON as a python object and actually starts the build.
39
40 :arguments:
41 payload
42 Python Object that represents the JSON sent by GitLab Service
43 Hook.
44 """
45 changes = []
46 refname = payload['ref']
47
48 # We only care about regular heads or tags
49 match = re.match(r"^refs/(heads|tags)/(.+)$", refname)
50 if not match:
51 log.msg("Ignoring refname `%s': Not a branch" % refname)
52 return changes
53
54 branch = match.group(2)
55 if payload.get('deleted'):
56 log.msg("Branch `%s' deleted, ignoring" % branch)
57 return changes
58
59 for commit in payload['commits']:
60 if not commit.get('distinct', True):
61 log.msg('Commit `%s` is a non-distinct commit, ignoring...' %
62 (commit['id'],))
63 continue
64
65 files = []
66 for kind in ('added', 'modified', 'removed'):
67 files.extend(commit.get(kind, []))
68
69 when_timestamp = dateparse(commit['timestamp'])
70
71 log.msg("New revision: %s" % commit['id'][:8])
72
73 change = {
74 'author': '%s <%s>' % (commit['author']['name'],
75 commit['author']['email']),
76 'files': files,
77 'comments': commit['message'],
78 'revision': commit['id'],
79 'when_timestamp': when_timestamp,
80 'branch': branch,
81 'revlink': commit['url'],
82 'repository': repo_url,
83 'project': project,
84 'category': event,
85 'properties': {
86 'event': event,
87 },
88 }
89
90 if codebase is not None:
91 change['codebase'] = codebase
92
93 changes.append(change)
94
95 return changes
96
97 def _process_merge_request_change(self, payload, project, event, codebase=None):
98 """
99 Consumes the merge_request JSON as a python object and turn it into a buildbot change.
100
101 :arguments:
102 payload
103 Python Object that represents the JSON sent by GitLab Service
104 Hook.
105 """
106 attrs = payload['object_attributes']
107 commit = attrs['last_commit']
108 when_timestamp = dateparse(commit['timestamp'])
109 # @todo provide and document a way to choose between http and ssh url
110 repo_url = attrs['source']['git_http_url']
111 changes = [{
112 'author': '%s <%s>' % (commit['author']['name'],
113 commit['author']['email']),
114 'files': [], # @todo use rest API
115 'comments': "MR#{}: {}\n\n{}".format(attrs['iid'], attrs['title'], attrs['description']),
116 'revision': commit['id'],
117 'when_timestamp': when_timestamp,
118 'branch': attrs['source_branch'],
119 'repository': repo_url,
120 'project': project,
121 'category': event,
122 'revlink': attrs['url'],
123 'properties': {
124 'target_branch': attrs['target_branch'],
125 'target_repository': attrs['target']['git_http_url'],
126 'event': event,
127 },
128 }]
129 if codebase is not None:
130 changes[0]['codebase'] = codebase
131 return changes
132
133 def getChanges(self, request):
134 """
135 Reponds only to POST events and starts the build process
136
137 :arguments:
138 request
139 the http request object
140 """
141 expected_secret = isinstance(self.options, dict) and self.options.get('secret')
142 if expected_secret:
143 received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)
144 received_secret = bytes2unicode(received_secret)
145 if received_secret != expected_secret:
146 raise ValueError("Invalid secret")
147 try:
148 content = request.content.read()
149 payload = json.loads(bytes2unicode(content))
150 except Exception as e:
151 raise ValueError("Error loading JSON: " + str(e))
152 event_type = request.getHeader(_HEADER_EVENT)
153 event_type = bytes2unicode(event_type)
154 # newer version of gitlab have a object_kind parameter,
155 # which allows not to use the http header
156 event_type = payload.get('object_kind', event_type)
157 project = request.args.get(b'project', [''])[0]
158 project = bytes2unicode(project)
159 codebase = request.args.get(b'codebase', [None])[0]
160 codebase = bytes2unicode(codebase)
161 if event_type in ("push", "tag_push", "Push Hook"):
162 user = payload['user_name']
163 repo = payload['repository']['name']
164 repo_url = payload['repository']['url']
165 changes = self._process_change(
166 payload, user, repo, repo_url, project, event_type, codebase=codebase)
167 elif event_type == 'merge_request':
168 changes = self._process_merge_request_change(
169 payload, project, event_type, codebase=codebase)
170 else:
171 changes = []
172 if changes:
173 log.msg("Received {} changes from {} gitlab event".format(
174 len(changes), event_type))
175 return (changes, 'git')
176
177
178 gitlab = GitLabHandler
179
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/www/hooks/gitlab.py b/master/buildbot/www/hooks/gitlab.py
--- a/master/buildbot/www/hooks/gitlab.py
+++ b/master/buildbot/www/hooks/gitlab.py
@@ -108,6 +108,17 @@
when_timestamp = dateparse(commit['timestamp'])
# @todo provide and document a way to choose between http and ssh url
repo_url = attrs['source']['git_http_url']
+
+ # Filter out uninteresting events
+ state = attrs['state']
+ if re.match('^(closed|merged|approved)$', state):
+ log.msg("GitLab MR#{}: Ignoring because state is {}".format(attrs['iid'], state))
+ return []
+ action = attrs['action']
+ if not re.match('^(open|reopen)$', action) and not (action == "update" and "oldrev" in attrs):
+ log.msg("GitLab MR#{}: Ignoring because action {} was not open or reopen or an update that added code".format(attrs['iid'], action))
+ return []
+
changes = [{
'author': '%s <%s>' % (commit['author']['name'],
commit['author']['email']),
|
{"golden_diff": "diff --git a/master/buildbot/www/hooks/gitlab.py b/master/buildbot/www/hooks/gitlab.py\n--- a/master/buildbot/www/hooks/gitlab.py\n+++ b/master/buildbot/www/hooks/gitlab.py\n@@ -108,6 +108,17 @@\n when_timestamp = dateparse(commit['timestamp'])\n # @todo provide and document a way to choose between http and ssh url\n repo_url = attrs['source']['git_http_url']\n+\n+ # Filter out uninteresting events\n+ state = attrs['state']\n+ if re.match('^(closed|merged|approved)$', state):\n+ log.msg(\"GitLab MR#{}: Ignoring because state is {}\".format(attrs['iid'], state))\n+ return []\n+ action = attrs['action']\n+ if not re.match('^(open|reopen)$', action) and not (action == \"update\" and \"oldrev\" in attrs):\n+ log.msg(\"GitLab MR#{}: Ignoring because action {} was not open or reopen or an update that added code\".format(attrs['iid'], action))\n+ return []\n+\n changes = [{\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n", "issue": "Buildbot schedules build when a GitLab merge request is deleted\nMy master installation is running 28958cffbdf703e29b76fb24344848bd65e8ea8a.\r\nIn the Buildbot configuration a \"gitlab\" change hook is registered and triggered by a GitLab configured \"Merge Requests Event\".\r\n\r\nCurrently builds are triggering when a merge request is created, updated or deleted.\r\nBuild should not be scheduled when a merge request is deleted.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport re\n\nfrom dateutil.parser import parse as dateparse\n\nfrom twisted.python import log\n\nfrom buildbot.util import bytes2unicode\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n_HEADER_EVENT = b'X-Gitlab-Event'\n_HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'\n\n\nclass GitLabHandler(BaseHookHandler):\n\n def _process_change(self, payload, user, repo, repo_url, project, event,\n codebase=None):\n \"\"\"\n Consumes the JSON as a python object and actually starts the build.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n changes = []\n refname = payload['ref']\n\n # We only care about regular heads or tags\n match = re.match(r\"^refs/(heads|tags)/(.+)$\", refname)\n if not match:\n log.msg(\"Ignoring refname `%s': Not a branch\" % refname)\n return changes\n\n branch = match.group(2)\n if payload.get('deleted'):\n log.msg(\"Branch `%s' deleted, ignoring\" % branch)\n return changes\n\n for commit in payload['commits']:\n if not commit.get('distinct', True):\n log.msg('Commit `%s` is a non-distinct commit, ignoring...' %\n (commit['id'],))\n continue\n\n files = []\n for kind in ('added', 'modified', 'removed'):\n files.extend(commit.get(kind, []))\n\n when_timestamp = dateparse(commit['timestamp'])\n\n log.msg(\"New revision: %s\" % commit['id'][:8])\n\n change = {\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': files,\n 'comments': commit['message'],\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': branch,\n 'revlink': commit['url'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'properties': {\n 'event': event,\n },\n }\n\n if codebase is not None:\n change['codebase'] = codebase\n\n changes.append(change)\n\n return changes\n\n def _process_merge_request_change(self, payload, project, event, codebase=None):\n \"\"\"\n Consumes the merge_request JSON as a python object and turn it into a buildbot change.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n attrs = payload['object_attributes']\n commit = attrs['last_commit']\n when_timestamp = dateparse(commit['timestamp'])\n # @todo provide and document a way to choose between http and ssh url\n repo_url = attrs['source']['git_http_url']\n changes = [{\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': [], # @todo use rest API\n 'comments': \"MR#{}: {}\\n\\n{}\".format(attrs['iid'], attrs['title'], attrs['description']),\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': attrs['source_branch'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'revlink': attrs['url'],\n 'properties': {\n 'target_branch': attrs['target_branch'],\n 'target_repository': attrs['target']['git_http_url'],\n 'event': event,\n },\n }]\n if codebase is not None:\n changes[0]['codebase'] = codebase\n return changes\n\n def getChanges(self, request):\n \"\"\"\n Reponds only to POST events and starts the build process\n\n :arguments:\n request\n the http request object\n \"\"\"\n expected_secret = isinstance(self.options, dict) and self.options.get('secret')\n if expected_secret:\n received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)\n received_secret = bytes2unicode(received_secret)\n if received_secret != expected_secret:\n raise ValueError(\"Invalid secret\")\n try:\n content = request.content.read()\n payload = json.loads(bytes2unicode(content))\n except Exception as e:\n raise ValueError(\"Error loading JSON: \" + str(e))\n event_type = request.getHeader(_HEADER_EVENT)\n event_type = bytes2unicode(event_type)\n # newer version of gitlab have a object_kind parameter,\n # which allows not to use the http header\n event_type = payload.get('object_kind', event_type)\n project = request.args.get(b'project', [''])[0]\n project = bytes2unicode(project)\n codebase = request.args.get(b'codebase', [None])[0]\n codebase = bytes2unicode(codebase)\n if event_type in (\"push\", \"tag_push\", \"Push Hook\"):\n user = payload['user_name']\n repo = payload['repository']['name']\n repo_url = payload['repository']['url']\n changes = self._process_change(\n payload, user, repo, repo_url, project, event_type, codebase=codebase)\n elif event_type == 'merge_request':\n changes = self._process_merge_request_change(\n payload, project, event_type, codebase=codebase)\n else:\n changes = []\n if changes:\n log.msg(\"Received {} changes from {} gitlab event\".format(\n len(changes), event_type))\n return (changes, 'git')\n\n\ngitlab = GitLabHandler\n", "path": "master/buildbot/www/hooks/gitlab.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport re\n\nfrom dateutil.parser import parse as dateparse\n\nfrom twisted.python import log\n\nfrom buildbot.util import bytes2unicode\nfrom buildbot.www.hooks.base import BaseHookHandler\n\n_HEADER_EVENT = b'X-Gitlab-Event'\n_HEADER_GITLAB_TOKEN = b'X-Gitlab-Token'\n\n\nclass GitLabHandler(BaseHookHandler):\n\n def _process_change(self, payload, user, repo, repo_url, project, event,\n codebase=None):\n \"\"\"\n Consumes the JSON as a python object and actually starts the build.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n changes = []\n refname = payload['ref']\n\n # We only care about regular heads or tags\n match = re.match(r\"^refs/(heads|tags)/(.+)$\", refname)\n if not match:\n log.msg(\"Ignoring refname `%s': Not a branch\" % refname)\n return changes\n\n branch = match.group(2)\n if payload.get('deleted'):\n log.msg(\"Branch `%s' deleted, ignoring\" % branch)\n return changes\n\n for commit in payload['commits']:\n if not commit.get('distinct', True):\n log.msg('Commit `%s` is a non-distinct commit, ignoring...' %\n (commit['id'],))\n continue\n\n files = []\n for kind in ('added', 'modified', 'removed'):\n files.extend(commit.get(kind, []))\n\n when_timestamp = dateparse(commit['timestamp'])\n\n log.msg(\"New revision: %s\" % commit['id'][:8])\n\n change = {\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': files,\n 'comments': commit['message'],\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': branch,\n 'revlink': commit['url'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'properties': {\n 'event': event,\n },\n }\n\n if codebase is not None:\n change['codebase'] = codebase\n\n changes.append(change)\n\n return changes\n\n def _process_merge_request_change(self, payload, project, event, codebase=None):\n \"\"\"\n Consumes the merge_request JSON as a python object and turn it into a buildbot change.\n\n :arguments:\n payload\n Python Object that represents the JSON sent by GitLab Service\n Hook.\n \"\"\"\n attrs = payload['object_attributes']\n commit = attrs['last_commit']\n when_timestamp = dateparse(commit['timestamp'])\n # @todo provide and document a way to choose between http and ssh url\n repo_url = attrs['source']['git_http_url']\n\n # Filter out uninteresting events\n state = attrs['state']\n if re.match('^(closed|merged|approved)$', state):\n log.msg(\"GitLab MR#{}: Ignoring because state is {}\".format(attrs['iid'], state))\n return []\n action = attrs['action']\n if not re.match('^(open|reopen)$', action) and not (action == \"update\" and \"oldrev\" in attrs):\n log.msg(\"GitLab MR#{}: Ignoring because action {} was not open or reopen or an update that added code\".format(attrs['iid'], action))\n return []\n\n changes = [{\n 'author': '%s <%s>' % (commit['author']['name'],\n commit['author']['email']),\n 'files': [], # @todo use rest API\n 'comments': \"MR#{}: {}\\n\\n{}\".format(attrs['iid'], attrs['title'], attrs['description']),\n 'revision': commit['id'],\n 'when_timestamp': when_timestamp,\n 'branch': attrs['source_branch'],\n 'repository': repo_url,\n 'project': project,\n 'category': event,\n 'revlink': attrs['url'],\n 'properties': {\n 'target_branch': attrs['target_branch'],\n 'target_repository': attrs['target']['git_http_url'],\n 'event': event,\n },\n }]\n if codebase is not None:\n changes[0]['codebase'] = codebase\n return changes\n\n def getChanges(self, request):\n \"\"\"\n Reponds only to POST events and starts the build process\n\n :arguments:\n request\n the http request object\n \"\"\"\n expected_secret = isinstance(self.options, dict) and self.options.get('secret')\n if expected_secret:\n received_secret = request.getHeader(_HEADER_GITLAB_TOKEN)\n received_secret = bytes2unicode(received_secret)\n if received_secret != expected_secret:\n raise ValueError(\"Invalid secret\")\n try:\n content = request.content.read()\n payload = json.loads(bytes2unicode(content))\n except Exception as e:\n raise ValueError(\"Error loading JSON: \" + str(e))\n event_type = request.getHeader(_HEADER_EVENT)\n event_type = bytes2unicode(event_type)\n # newer version of gitlab have a object_kind parameter,\n # which allows not to use the http header\n event_type = payload.get('object_kind', event_type)\n project = request.args.get(b'project', [''])[0]\n project = bytes2unicode(project)\n codebase = request.args.get(b'codebase', [None])[0]\n codebase = bytes2unicode(codebase)\n if event_type in (\"push\", \"tag_push\", \"Push Hook\"):\n user = payload['user_name']\n repo = payload['repository']['name']\n repo_url = payload['repository']['url']\n changes = self._process_change(\n payload, user, repo, repo_url, project, event_type, codebase=codebase)\n elif event_type == 'merge_request':\n changes = self._process_merge_request_change(\n payload, project, event_type, codebase=codebase)\n else:\n changes = []\n if changes:\n log.msg(\"Received {} changes from {} gitlab event\".format(\n len(changes), event_type))\n return (changes, 'git')\n\n\ngitlab = GitLabHandler\n", "path": "master/buildbot/www/hooks/gitlab.py"}]}
| 2,195 | 267 |
gh_patches_debug_14684
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-4988
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add clear instructions for authorization code / token
I was following [this official example](https://colab.research.google.com/github/kubeflow/website/blob/master/content/en/docs/pipelines/sdk/python-function-components.ipynb) to submit a pipeline via Jupyter or Python script
I filled in the client id and credentials [following these instructions](https://www.kubeflow.org/docs/gke/pipelines/authentication-sdk/#connecting-to-kubeflow-pipelines-in-a-full-kubeflow-deployment), but when I try to [compile the pipeline](https://www.kubeflow.org/docs/pipelines/sdk/build-component/#compile-the-pipeline) with
```
dsl-compile --py [path/to/python/file] --output [path/to/output/tar.gz]
```
The resulting prompt doesn't make it evident that the url can be copy pasted into the browser, to get the Authorization code, and I got stuck on it for a while. Looking back it's kind of an Occam's razor thing, but it could have saved a lot of time with even simple instructions "copy paste this url"

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/kfp/_auth.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import os
17 import google.auth
18 import google.auth.app_engine
19 import google.auth.compute_engine.credentials
20 import google.auth.iam
21 from google.auth.transport.requests import Request
22 import google.oauth2.credentials
23 import google.oauth2.service_account
24 import requests_toolbelt.adapters.appengine
25 from webbrowser import open_new_tab
26 import requests
27 import json
28
29 IAM_SCOPE = 'https://www.googleapis.com/auth/iam'
30 OAUTH_TOKEN_URI = 'https://www.googleapis.com/oauth2/v4/token'
31 LOCAL_KFP_CREDENTIAL = os.path.expanduser('~/.config/kfp/credentials.json')
32
33 def get_gcp_access_token():
34 """Get and return GCP access token for the current Application Default
35 Credentials. If not set, returns None. For more information, see
36 https://cloud.google.com/sdk/gcloud/reference/auth/application-default/print-access-token
37 """
38 token = None
39 try:
40 creds, project = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
41 if not creds.valid:
42 auth_req = Request()
43 creds.refresh(auth_req)
44 if creds.valid:
45 token = creds.token
46 except Exception as e:
47 logging.warning('Failed to get GCP access token: %s', e)
48 return token
49
50 def get_auth_token(client_id, other_client_id, other_client_secret):
51 """Gets auth token from default service account or user account."""
52 if os.path.exists(LOCAL_KFP_CREDENTIAL):
53 # fetch IAP auth token using the locally stored credentials.
54 with open(LOCAL_KFP_CREDENTIAL, 'r') as f:
55 credentials = json.load(f)
56 if client_id in credentials:
57 return id_token_from_refresh_token(credentials[client_id]['other_client_id'],
58 credentials[client_id]['other_client_secret'],
59 credentials[client_id]['refresh_token'],
60 client_id)
61 if other_client_id is None or other_client_secret is None:
62 # fetch IAP auth token: service accounts
63 token = get_auth_token_from_sa(client_id)
64 else:
65 # fetch IAP auth token: user account
66 # Obtain the ID token for provided Client ID with user accounts.
67 # Flow: get authorization code -> exchange for refresh token -> obtain and return ID token
68 refresh_token = get_refresh_token_from_client_id(other_client_id, other_client_secret)
69 credentials = {}
70 if os.path.exists(LOCAL_KFP_CREDENTIAL):
71 with open(LOCAL_KFP_CREDENTIAL, 'r') as f:
72 credentials = json.load(f)
73 credentials[client_id] = {}
74 credentials[client_id]['other_client_id'] = other_client_id
75 credentials[client_id]['other_client_secret'] = other_client_secret
76 credentials[client_id]['refresh_token'] = refresh_token
77 #TODO: handle the case when the refresh_token expires.
78 # which only happens if the refresh_token is not used once for six months.
79 if not os.path.exists(os.path.dirname(LOCAL_KFP_CREDENTIAL)):
80 os.makedirs(os.path.dirname(LOCAL_KFP_CREDENTIAL))
81 with open(LOCAL_KFP_CREDENTIAL, 'w') as f:
82 json.dump(credentials, f)
83 token = id_token_from_refresh_token(other_client_id, other_client_secret, refresh_token, client_id)
84 return token
85
86 def get_auth_token_from_sa(client_id):
87 """Gets auth token from default service account.
88
89 If no service account credential is found, returns None.
90 """
91 service_account_credentials = get_service_account_credentials(client_id)
92 if service_account_credentials:
93 return get_google_open_id_connect_token(service_account_credentials)
94 return None
95
96 def get_service_account_credentials(client_id):
97 # Figure out what environment we're running in and get some preliminary
98 # information about the service account.
99 bootstrap_credentials, _ = google.auth.default(
100 scopes=[IAM_SCOPE])
101 if isinstance(bootstrap_credentials,
102 google.oauth2.credentials.Credentials):
103 logging.info('Found OAuth2 credentials and skip SA auth.')
104 return None
105 elif isinstance(bootstrap_credentials,
106 google.auth.app_engine.Credentials):
107 requests_toolbelt.adapters.appengine.monkeypatch()
108
109 # For service account's using the Compute Engine metadata service,
110 # service_account_email isn't available until refresh is called.
111 bootstrap_credentials.refresh(Request())
112 signer_email = bootstrap_credentials.service_account_email
113 if isinstance(bootstrap_credentials,
114 google.auth.compute_engine.credentials.Credentials):
115 # Since the Compute Engine metadata service doesn't expose the service
116 # account key, we use the IAM signBlob API to sign instead.
117 # In order for this to work:
118 #
119 # 1. Your VM needs the https://www.googleapis.com/auth/iam scope.
120 # You can specify this specific scope when creating a VM
121 # through the API or gcloud. When using Cloud Console,
122 # you'll need to specify the "full access to all Cloud APIs"
123 # scope. A VM's scopes can only be specified at creation time.
124 #
125 # 2. The VM's default service account needs the "Service Account Actor"
126 # role. This can be found under the "Project" category in Cloud
127 # Console, or roles/iam.serviceAccountActor in gcloud.
128 signer = google.auth.iam.Signer(
129 Request(), bootstrap_credentials, signer_email)
130 else:
131 # A Signer object can sign a JWT using the service account's key.
132 signer = bootstrap_credentials.signer
133
134 # Construct OAuth 2.0 service account credentials using the signer
135 # and email acquired from the bootstrap credentials.
136 return google.oauth2.service_account.Credentials(
137 signer, signer_email, token_uri=OAUTH_TOKEN_URI, additional_claims={
138 'target_audience': client_id
139 })
140
141 def get_google_open_id_connect_token(service_account_credentials):
142 """Get an OpenID Connect token issued by Google for the service account.
143 This function:
144 1. Generates a JWT signed with the service account's private key
145 containing a special "target_audience" claim.
146 2. Sends it to the OAUTH_TOKEN_URI endpoint. Because the JWT in #1
147 has a target_audience claim, that endpoint will respond with
148 an OpenID Connect token for the service account -- in other words,
149 a JWT signed by *Google*. The aud claim in this JWT will be
150 set to the value from the target_audience claim in #1.
151 For more information, see
152 https://developers.google.com/identity/protocols/OAuth2ServiceAccount .
153 The HTTP/REST example on that page describes the JWT structure and
154 demonstrates how to call the token endpoint. (The example on that page
155 shows how to get an OAuth2 access token; this code is using a
156 modified version of it to get an OpenID Connect token.)
157 """
158
159 service_account_jwt = (
160 service_account_credentials._make_authorization_grant_assertion())
161 request = google.auth.transport.requests.Request()
162 body = {
163 'assertion': service_account_jwt,
164 'grant_type': google.oauth2._client._JWT_GRANT_TYPE,
165 }
166 token_response = google.oauth2._client._token_endpoint_request(
167 request, OAUTH_TOKEN_URI, body)
168 return token_response['id_token']
169
170 def get_refresh_token_from_client_id(client_id, client_secret):
171 """Obtain the ID token for provided Client ID with user accounts.
172 Flow: get authorization code -> exchange for refresh token -> obtain and return ID token
173 """
174 auth_code = get_auth_code(client_id)
175 return get_refresh_token_from_code(auth_code, client_id, client_secret)
176
177 def get_auth_code(client_id):
178 auth_url = "https://accounts.google.com/o/oauth2/v2/auth?client_id=%s&response_type=code&scope=openid%%20email&access_type=offline&redirect_uri=urn:ietf:wg:oauth:2.0:oob"%client_id
179 print(auth_url)
180 open_new_tab(auth_url)
181 return input("Authorization code: ")
182
183 def get_refresh_token_from_code(auth_code, client_id, client_secret):
184 payload = {"code": auth_code, "client_id": client_id, "client_secret": client_secret,
185 "redirect_uri": "urn:ietf:wg:oauth:2.0:oob", "grant_type": "authorization_code"}
186 res = requests.post(OAUTH_TOKEN_URI, data=payload)
187 return (str(json.loads(res.text)[u"refresh_token"]))
188
189 def id_token_from_refresh_token(client_id, client_secret, refresh_token, audience):
190 payload = {"client_id": client_id, "client_secret": client_secret,
191 "refresh_token": refresh_token, "grant_type": "refresh_token",
192 "audience": audience}
193 res = requests.post(OAUTH_TOKEN_URI, data=payload)
194 return (str(json.loads(res.text)[u"id_token"]))
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sdk/python/kfp/_auth.py b/sdk/python/kfp/_auth.py
--- a/sdk/python/kfp/_auth.py
+++ b/sdk/python/kfp/_auth.py
@@ -178,7 +178,7 @@
auth_url = "https://accounts.google.com/o/oauth2/v2/auth?client_id=%s&response_type=code&scope=openid%%20email&access_type=offline&redirect_uri=urn:ietf:wg:oauth:2.0:oob"%client_id
print(auth_url)
open_new_tab(auth_url)
- return input("Authorization code: ")
+ return input("If there's no browser window prompt, please direct to the URL above, then copy and paste the authorization code here: ")
def get_refresh_token_from_code(auth_code, client_id, client_secret):
payload = {"code": auth_code, "client_id": client_id, "client_secret": client_secret,
|
{"golden_diff": "diff --git a/sdk/python/kfp/_auth.py b/sdk/python/kfp/_auth.py\n--- a/sdk/python/kfp/_auth.py\n+++ b/sdk/python/kfp/_auth.py\n@@ -178,7 +178,7 @@\n auth_url = \"https://accounts.google.com/o/oauth2/v2/auth?client_id=%s&response_type=code&scope=openid%%20email&access_type=offline&redirect_uri=urn:ietf:wg:oauth:2.0:oob\"%client_id\n print(auth_url)\n open_new_tab(auth_url)\n- return input(\"Authorization code: \")\n+ return input(\"If there's no browser window prompt, please direct to the URL above, then copy and paste the authorization code here: \")\n \n def get_refresh_token_from_code(auth_code, client_id, client_secret):\n payload = {\"code\": auth_code, \"client_id\": client_id, \"client_secret\": client_secret,\n", "issue": "Add clear instructions for authorization code / token\nI was following [this official example](https://colab.research.google.com/github/kubeflow/website/blob/master/content/en/docs/pipelines/sdk/python-function-components.ipynb) to submit a pipeline via Jupyter or Python script\r\n\r\nI filled in the client id and credentials [following these instructions](https://www.kubeflow.org/docs/gke/pipelines/authentication-sdk/#connecting-to-kubeflow-pipelines-in-a-full-kubeflow-deployment), but when I try to [compile the pipeline](https://www.kubeflow.org/docs/pipelines/sdk/build-component/#compile-the-pipeline) with\r\n```\r\ndsl-compile --py [path/to/python/file] --output [path/to/output/tar.gz]\r\n```\r\nThe resulting prompt doesn't make it evident that the url can be copy pasted into the browser, to get the Authorization code, and I got stuck on it for a while. Looking back it's kind of an Occam's razor thing, but it could have saved a lot of time with even simple instructions \"copy paste this url\"\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nimport google.auth\nimport google.auth.app_engine\nimport google.auth.compute_engine.credentials\nimport google.auth.iam\nfrom google.auth.transport.requests import Request\nimport google.oauth2.credentials\nimport google.oauth2.service_account\nimport requests_toolbelt.adapters.appengine\nfrom webbrowser import open_new_tab\nimport requests\nimport json\n\nIAM_SCOPE = 'https://www.googleapis.com/auth/iam'\nOAUTH_TOKEN_URI = 'https://www.googleapis.com/oauth2/v4/token'\nLOCAL_KFP_CREDENTIAL = os.path.expanduser('~/.config/kfp/credentials.json')\n\ndef get_gcp_access_token():\n \"\"\"Get and return GCP access token for the current Application Default\n Credentials. If not set, returns None. For more information, see\n https://cloud.google.com/sdk/gcloud/reference/auth/application-default/print-access-token\n \"\"\"\n token = None\n try:\n creds, project = google.auth.default(scopes=[\"https://www.googleapis.com/auth/cloud-platform\"])\n if not creds.valid:\n auth_req = Request()\n creds.refresh(auth_req)\n if creds.valid:\n token = creds.token\n except Exception as e:\n logging.warning('Failed to get GCP access token: %s', e)\n return token\n\ndef get_auth_token(client_id, other_client_id, other_client_secret):\n \"\"\"Gets auth token from default service account or user account.\"\"\"\n if os.path.exists(LOCAL_KFP_CREDENTIAL):\n # fetch IAP auth token using the locally stored credentials.\n with open(LOCAL_KFP_CREDENTIAL, 'r') as f:\n credentials = json.load(f)\n if client_id in credentials:\n return id_token_from_refresh_token(credentials[client_id]['other_client_id'],\n credentials[client_id]['other_client_secret'],\n credentials[client_id]['refresh_token'],\n client_id)\n if other_client_id is None or other_client_secret is None:\n # fetch IAP auth token: service accounts\n token = get_auth_token_from_sa(client_id)\n else:\n # fetch IAP auth token: user account\n # Obtain the ID token for provided Client ID with user accounts.\n # Flow: get authorization code -> exchange for refresh token -> obtain and return ID token\n refresh_token = get_refresh_token_from_client_id(other_client_id, other_client_secret)\n credentials = {}\n if os.path.exists(LOCAL_KFP_CREDENTIAL):\n with open(LOCAL_KFP_CREDENTIAL, 'r') as f:\n credentials = json.load(f)\n credentials[client_id] = {}\n credentials[client_id]['other_client_id'] = other_client_id\n credentials[client_id]['other_client_secret'] = other_client_secret\n credentials[client_id]['refresh_token'] = refresh_token\n #TODO: handle the case when the refresh_token expires.\n # which only happens if the refresh_token is not used once for six months.\n if not os.path.exists(os.path.dirname(LOCAL_KFP_CREDENTIAL)):\n os.makedirs(os.path.dirname(LOCAL_KFP_CREDENTIAL))\n with open(LOCAL_KFP_CREDENTIAL, 'w') as f:\n json.dump(credentials, f)\n token = id_token_from_refresh_token(other_client_id, other_client_secret, refresh_token, client_id)\n return token\n\ndef get_auth_token_from_sa(client_id):\n \"\"\"Gets auth token from default service account.\n\n If no service account credential is found, returns None.\n \"\"\"\n service_account_credentials = get_service_account_credentials(client_id)\n if service_account_credentials:\n return get_google_open_id_connect_token(service_account_credentials)\n return None\n\ndef get_service_account_credentials(client_id):\n # Figure out what environment we're running in and get some preliminary\n # information about the service account.\n bootstrap_credentials, _ = google.auth.default(\n scopes=[IAM_SCOPE])\n if isinstance(bootstrap_credentials,\n google.oauth2.credentials.Credentials):\n logging.info('Found OAuth2 credentials and skip SA auth.')\n return None\n elif isinstance(bootstrap_credentials,\n google.auth.app_engine.Credentials):\n requests_toolbelt.adapters.appengine.monkeypatch()\n\n # For service account's using the Compute Engine metadata service,\n # service_account_email isn't available until refresh is called.\n bootstrap_credentials.refresh(Request())\n signer_email = bootstrap_credentials.service_account_email\n if isinstance(bootstrap_credentials,\n google.auth.compute_engine.credentials.Credentials):\n # Since the Compute Engine metadata service doesn't expose the service\n # account key, we use the IAM signBlob API to sign instead.\n # In order for this to work:\n #\n # 1. Your VM needs the https://www.googleapis.com/auth/iam scope.\n # You can specify this specific scope when creating a VM\n # through the API or gcloud. When using Cloud Console,\n # you'll need to specify the \"full access to all Cloud APIs\"\n # scope. A VM's scopes can only be specified at creation time.\n #\n # 2. The VM's default service account needs the \"Service Account Actor\"\n # role. This can be found under the \"Project\" category in Cloud\n # Console, or roles/iam.serviceAccountActor in gcloud.\n signer = google.auth.iam.Signer(\n Request(), bootstrap_credentials, signer_email)\n else:\n # A Signer object can sign a JWT using the service account's key.\n signer = bootstrap_credentials.signer\n\n # Construct OAuth 2.0 service account credentials using the signer\n # and email acquired from the bootstrap credentials.\n return google.oauth2.service_account.Credentials(\n signer, signer_email, token_uri=OAUTH_TOKEN_URI, additional_claims={\n 'target_audience': client_id\n })\n\ndef get_google_open_id_connect_token(service_account_credentials):\n \"\"\"Get an OpenID Connect token issued by Google for the service account.\n This function:\n 1. Generates a JWT signed with the service account's private key\n containing a special \"target_audience\" claim.\n 2. Sends it to the OAUTH_TOKEN_URI endpoint. Because the JWT in #1\n has a target_audience claim, that endpoint will respond with\n an OpenID Connect token for the service account -- in other words,\n a JWT signed by *Google*. The aud claim in this JWT will be\n set to the value from the target_audience claim in #1.\n For more information, see\n https://developers.google.com/identity/protocols/OAuth2ServiceAccount .\n The HTTP/REST example on that page describes the JWT structure and\n demonstrates how to call the token endpoint. (The example on that page\n shows how to get an OAuth2 access token; this code is using a\n modified version of it to get an OpenID Connect token.)\n \"\"\"\n\n service_account_jwt = (\n service_account_credentials._make_authorization_grant_assertion())\n request = google.auth.transport.requests.Request()\n body = {\n 'assertion': service_account_jwt,\n 'grant_type': google.oauth2._client._JWT_GRANT_TYPE,\n }\n token_response = google.oauth2._client._token_endpoint_request(\n request, OAUTH_TOKEN_URI, body)\n return token_response['id_token']\n\ndef get_refresh_token_from_client_id(client_id, client_secret):\n \"\"\"Obtain the ID token for provided Client ID with user accounts.\n Flow: get authorization code -> exchange for refresh token -> obtain and return ID token\n \"\"\"\n auth_code = get_auth_code(client_id)\n return get_refresh_token_from_code(auth_code, client_id, client_secret)\n\ndef get_auth_code(client_id):\n auth_url = \"https://accounts.google.com/o/oauth2/v2/auth?client_id=%s&response_type=code&scope=openid%%20email&access_type=offline&redirect_uri=urn:ietf:wg:oauth:2.0:oob\"%client_id\n print(auth_url)\n open_new_tab(auth_url)\n return input(\"Authorization code: \")\n\ndef get_refresh_token_from_code(auth_code, client_id, client_secret):\n payload = {\"code\": auth_code, \"client_id\": client_id, \"client_secret\": client_secret,\n \"redirect_uri\": \"urn:ietf:wg:oauth:2.0:oob\", \"grant_type\": \"authorization_code\"}\n res = requests.post(OAUTH_TOKEN_URI, data=payload)\n return (str(json.loads(res.text)[u\"refresh_token\"]))\n\ndef id_token_from_refresh_token(client_id, client_secret, refresh_token, audience):\n payload = {\"client_id\": client_id, \"client_secret\": client_secret,\n \"refresh_token\": refresh_token, \"grant_type\": \"refresh_token\",\n \"audience\": audience}\n res = requests.post(OAUTH_TOKEN_URI, data=payload)\n return (str(json.loads(res.text)[u\"id_token\"]))\n", "path": "sdk/python/kfp/_auth.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nimport google.auth\nimport google.auth.app_engine\nimport google.auth.compute_engine.credentials\nimport google.auth.iam\nfrom google.auth.transport.requests import Request\nimport google.oauth2.credentials\nimport google.oauth2.service_account\nimport requests_toolbelt.adapters.appengine\nfrom webbrowser import open_new_tab\nimport requests\nimport json\n\nIAM_SCOPE = 'https://www.googleapis.com/auth/iam'\nOAUTH_TOKEN_URI = 'https://www.googleapis.com/oauth2/v4/token'\nLOCAL_KFP_CREDENTIAL = os.path.expanduser('~/.config/kfp/credentials.json')\n\ndef get_gcp_access_token():\n \"\"\"Get and return GCP access token for the current Application Default\n Credentials. If not set, returns None. For more information, see\n https://cloud.google.com/sdk/gcloud/reference/auth/application-default/print-access-token\n \"\"\"\n token = None\n try:\n creds, project = google.auth.default(scopes=[\"https://www.googleapis.com/auth/cloud-platform\"])\n if not creds.valid:\n auth_req = Request()\n creds.refresh(auth_req)\n if creds.valid:\n token = creds.token\n except Exception as e:\n logging.warning('Failed to get GCP access token: %s', e)\n return token\n\ndef get_auth_token(client_id, other_client_id, other_client_secret):\n \"\"\"Gets auth token from default service account or user account.\"\"\"\n if os.path.exists(LOCAL_KFP_CREDENTIAL):\n # fetch IAP auth token using the locally stored credentials.\n with open(LOCAL_KFP_CREDENTIAL, 'r') as f:\n credentials = json.load(f)\n if client_id in credentials:\n return id_token_from_refresh_token(credentials[client_id]['other_client_id'],\n credentials[client_id]['other_client_secret'],\n credentials[client_id]['refresh_token'],\n client_id)\n if other_client_id is None or other_client_secret is None:\n # fetch IAP auth token: service accounts\n token = get_auth_token_from_sa(client_id)\n else:\n # fetch IAP auth token: user account\n # Obtain the ID token for provided Client ID with user accounts.\n # Flow: get authorization code -> exchange for refresh token -> obtain and return ID token\n refresh_token = get_refresh_token_from_client_id(other_client_id, other_client_secret)\n credentials = {}\n if os.path.exists(LOCAL_KFP_CREDENTIAL):\n with open(LOCAL_KFP_CREDENTIAL, 'r') as f:\n credentials = json.load(f)\n credentials[client_id] = {}\n credentials[client_id]['other_client_id'] = other_client_id\n credentials[client_id]['other_client_secret'] = other_client_secret\n credentials[client_id]['refresh_token'] = refresh_token\n #TODO: handle the case when the refresh_token expires.\n # which only happens if the refresh_token is not used once for six months.\n if not os.path.exists(os.path.dirname(LOCAL_KFP_CREDENTIAL)):\n os.makedirs(os.path.dirname(LOCAL_KFP_CREDENTIAL))\n with open(LOCAL_KFP_CREDENTIAL, 'w') as f:\n json.dump(credentials, f)\n token = id_token_from_refresh_token(other_client_id, other_client_secret, refresh_token, client_id)\n return token\n\ndef get_auth_token_from_sa(client_id):\n \"\"\"Gets auth token from default service account.\n\n If no service account credential is found, returns None.\n \"\"\"\n service_account_credentials = get_service_account_credentials(client_id)\n if service_account_credentials:\n return get_google_open_id_connect_token(service_account_credentials)\n return None\n\ndef get_service_account_credentials(client_id):\n # Figure out what environment we're running in and get some preliminary\n # information about the service account.\n bootstrap_credentials, _ = google.auth.default(\n scopes=[IAM_SCOPE])\n if isinstance(bootstrap_credentials,\n google.oauth2.credentials.Credentials):\n logging.info('Found OAuth2 credentials and skip SA auth.')\n return None\n elif isinstance(bootstrap_credentials,\n google.auth.app_engine.Credentials):\n requests_toolbelt.adapters.appengine.monkeypatch()\n\n # For service account's using the Compute Engine metadata service,\n # service_account_email isn't available until refresh is called.\n bootstrap_credentials.refresh(Request())\n signer_email = bootstrap_credentials.service_account_email\n if isinstance(bootstrap_credentials,\n google.auth.compute_engine.credentials.Credentials):\n # Since the Compute Engine metadata service doesn't expose the service\n # account key, we use the IAM signBlob API to sign instead.\n # In order for this to work:\n #\n # 1. Your VM needs the https://www.googleapis.com/auth/iam scope.\n # You can specify this specific scope when creating a VM\n # through the API or gcloud. When using Cloud Console,\n # you'll need to specify the \"full access to all Cloud APIs\"\n # scope. A VM's scopes can only be specified at creation time.\n #\n # 2. The VM's default service account needs the \"Service Account Actor\"\n # role. This can be found under the \"Project\" category in Cloud\n # Console, or roles/iam.serviceAccountActor in gcloud.\n signer = google.auth.iam.Signer(\n Request(), bootstrap_credentials, signer_email)\n else:\n # A Signer object can sign a JWT using the service account's key.\n signer = bootstrap_credentials.signer\n\n # Construct OAuth 2.0 service account credentials using the signer\n # and email acquired from the bootstrap credentials.\n return google.oauth2.service_account.Credentials(\n signer, signer_email, token_uri=OAUTH_TOKEN_URI, additional_claims={\n 'target_audience': client_id\n })\n\ndef get_google_open_id_connect_token(service_account_credentials):\n \"\"\"Get an OpenID Connect token issued by Google for the service account.\n This function:\n 1. Generates a JWT signed with the service account's private key\n containing a special \"target_audience\" claim.\n 2. Sends it to the OAUTH_TOKEN_URI endpoint. Because the JWT in #1\n has a target_audience claim, that endpoint will respond with\n an OpenID Connect token for the service account -- in other words,\n a JWT signed by *Google*. The aud claim in this JWT will be\n set to the value from the target_audience claim in #1.\n For more information, see\n https://developers.google.com/identity/protocols/OAuth2ServiceAccount .\n The HTTP/REST example on that page describes the JWT structure and\n demonstrates how to call the token endpoint. (The example on that page\n shows how to get an OAuth2 access token; this code is using a\n modified version of it to get an OpenID Connect token.)\n \"\"\"\n\n service_account_jwt = (\n service_account_credentials._make_authorization_grant_assertion())\n request = google.auth.transport.requests.Request()\n body = {\n 'assertion': service_account_jwt,\n 'grant_type': google.oauth2._client._JWT_GRANT_TYPE,\n }\n token_response = google.oauth2._client._token_endpoint_request(\n request, OAUTH_TOKEN_URI, body)\n return token_response['id_token']\n\ndef get_refresh_token_from_client_id(client_id, client_secret):\n \"\"\"Obtain the ID token for provided Client ID with user accounts.\n Flow: get authorization code -> exchange for refresh token -> obtain and return ID token\n \"\"\"\n auth_code = get_auth_code(client_id)\n return get_refresh_token_from_code(auth_code, client_id, client_secret)\n\ndef get_auth_code(client_id):\n auth_url = \"https://accounts.google.com/o/oauth2/v2/auth?client_id=%s&response_type=code&scope=openid%%20email&access_type=offline&redirect_uri=urn:ietf:wg:oauth:2.0:oob\"%client_id\n print(auth_url)\n open_new_tab(auth_url)\n return input(\"If there's no browser window prompt, please direct to the URL above, then copy and paste the authorization code here: \")\n\ndef get_refresh_token_from_code(auth_code, client_id, client_secret):\n payload = {\"code\": auth_code, \"client_id\": client_id, \"client_secret\": client_secret,\n \"redirect_uri\": \"urn:ietf:wg:oauth:2.0:oob\", \"grant_type\": \"authorization_code\"}\n res = requests.post(OAUTH_TOKEN_URI, data=payload)\n return (str(json.loads(res.text)[u\"refresh_token\"]))\n\ndef id_token_from_refresh_token(client_id, client_secret, refresh_token, audience):\n payload = {\"client_id\": client_id, \"client_secret\": client_secret,\n \"refresh_token\": refresh_token, \"grant_type\": \"refresh_token\",\n \"audience\": audience}\n res = requests.post(OAUTH_TOKEN_URI, data=payload)\n return (str(json.loads(res.text)[u\"id_token\"]))\n", "path": "sdk/python/kfp/_auth.py"}]}
| 3,063 | 204 |
gh_patches_debug_30573
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1357
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
StreamField EmbedBlock renders the url only
Given the following setup:
```
class EmbedOnImage(StructBlock):
embed = EmbedBlock()
background_image = ImageChooserBlock(required=False)
class Meta:
template = 'streamfield_blocks/embed_on_image.html'
```
`{{ self.embed }}` outputs the embed url only in `streamfield_blocks/embed_on_image.html`.
And `EmbedBlock.render_basic` is never called: https://github.com/torchbox/wagtail/blob/master/wagtail/wagtailembeds/blocks.py#L8
Also, if I apply the embed filter too: `{{ self.embed|embed }}` then it outputs nothing because the embed filter won't call `embed_to_frontend_html` either, which would use the correct template to render it: https://github.com/torchbox/wagtail/blob/master/wagtail/wagtailembeds/templatetags/wagtailembeds_tags.py#L14
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailembeds/blocks.py`
Content:
```
1 from wagtail.wagtailcore import blocks
2
3 from wagtail.wagtailembeds.format import embed_to_frontend_html
4
5
6 class EmbedBlock(blocks.URLBlock):
7 def render_basic(self, value):
8 return embed_to_frontend_html(value)
9
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailembeds/blocks.py b/wagtail/wagtailembeds/blocks.py
--- a/wagtail/wagtailembeds/blocks.py
+++ b/wagtail/wagtailembeds/blocks.py
@@ -1,8 +1,62 @@
+from django.utils.encoding import python_2_unicode_compatible
+
from wagtail.wagtailcore import blocks
from wagtail.wagtailembeds.format import embed_to_frontend_html
+@python_2_unicode_compatible
+class EmbedValue(object):
+ """
+ Native value of an EmbedBlock. Should, at minimum, have a 'url' property
+ and render as the embed HTML when rendered in a template.
+ NB We don't use a wagtailembeds.model.Embed object for this, because
+ we want to be able to do {{ value.url|embed:max_width=500 }} without
+ doing a redundant fetch of the embed at the default width.
+ """
+ def __init__(self, url):
+ self.url = url
+
+ def __str__(self):
+ return embed_to_frontend_html(self.url)
+
+
class EmbedBlock(blocks.URLBlock):
- def render_basic(self, value):
- return embed_to_frontend_html(value)
+ def get_default(self):
+ # Allow specifying the default for an EmbedBlock as either an EmbedValue or a string (or None).
+ if not self.meta.default:
+ return None
+ elif isinstance(self.meta.default, EmbedValue):
+ return self.meta.default
+ else:
+ # assume default has been passed as a string
+ return EmbedValue(self.meta.default)
+
+ def to_python(self, value):
+ # The JSON representation of an EmbedBlock's value is a URL string;
+ # this should be converted to an EmbedValue (or None).
+ if not value:
+ return None
+ else:
+ return EmbedValue(value)
+
+ def get_prep_value(self, value):
+ # serialisable value should be a URL string
+ if value is None:
+ return ''
+ else:
+ return value.url
+
+ def value_for_form(self, value):
+ # the value to be handled by the URLField is a plain URL string (or the empty string)
+ if value is None:
+ return ''
+ else:
+ return value.url
+
+ def value_from_form(self, value):
+ # convert the value returned from the form (a URL string) to an EmbedValue (or None)
+ if not value:
+ return None
+ else:
+ return EmbedValue(value)
|
{"golden_diff": "diff --git a/wagtail/wagtailembeds/blocks.py b/wagtail/wagtailembeds/blocks.py\n--- a/wagtail/wagtailembeds/blocks.py\n+++ b/wagtail/wagtailembeds/blocks.py\n@@ -1,8 +1,62 @@\n+from django.utils.encoding import python_2_unicode_compatible\n+\n from wagtail.wagtailcore import blocks\n \n from wagtail.wagtailembeds.format import embed_to_frontend_html\n \n \n+@python_2_unicode_compatible\n+class EmbedValue(object):\n+ \"\"\"\n+ Native value of an EmbedBlock. Should, at minimum, have a 'url' property\n+ and render as the embed HTML when rendered in a template.\n+ NB We don't use a wagtailembeds.model.Embed object for this, because\n+ we want to be able to do {{ value.url|embed:max_width=500 }} without\n+ doing a redundant fetch of the embed at the default width.\n+ \"\"\"\n+ def __init__(self, url):\n+ self.url = url\n+\n+ def __str__(self):\n+ return embed_to_frontend_html(self.url)\n+\n+\n class EmbedBlock(blocks.URLBlock):\n- def render_basic(self, value):\n- return embed_to_frontend_html(value)\n+ def get_default(self):\n+ # Allow specifying the default for an EmbedBlock as either an EmbedValue or a string (or None).\n+ if not self.meta.default:\n+ return None\n+ elif isinstance(self.meta.default, EmbedValue):\n+ return self.meta.default\n+ else:\n+ # assume default has been passed as a string\n+ return EmbedValue(self.meta.default)\n+\n+ def to_python(self, value):\n+ # The JSON representation of an EmbedBlock's value is a URL string;\n+ # this should be converted to an EmbedValue (or None).\n+ if not value:\n+ return None\n+ else:\n+ return EmbedValue(value)\n+\n+ def get_prep_value(self, value):\n+ # serialisable value should be a URL string\n+ if value is None:\n+ return ''\n+ else:\n+ return value.url\n+\n+ def value_for_form(self, value):\n+ # the value to be handled by the URLField is a plain URL string (or the empty string)\n+ if value is None:\n+ return ''\n+ else:\n+ return value.url\n+\n+ def value_from_form(self, value):\n+ # convert the value returned from the form (a URL string) to an EmbedValue (or None)\n+ if not value:\n+ return None\n+ else:\n+ return EmbedValue(value)\n", "issue": "StreamField EmbedBlock renders the url only\nGiven the following setup:\n\n```\nclass EmbedOnImage(StructBlock):\n embed = EmbedBlock()\n background_image = ImageChooserBlock(required=False)\n\n class Meta:\n template = 'streamfield_blocks/embed_on_image.html'\n```\n\n`{{ self.embed }}` outputs the embed url only in `streamfield_blocks/embed_on_image.html`.\n\nAnd `EmbedBlock.render_basic` is never called: https://github.com/torchbox/wagtail/blob/master/wagtail/wagtailembeds/blocks.py#L8\n\nAlso, if I apply the embed filter too: `{{ self.embed|embed }}` then it outputs nothing because the embed filter won't call `embed_to_frontend_html` either, which would use the correct template to render it: https://github.com/torchbox/wagtail/blob/master/wagtail/wagtailembeds/templatetags/wagtailembeds_tags.py#L14\n\n", "before_files": [{"content": "from wagtail.wagtailcore import blocks\n\nfrom wagtail.wagtailembeds.format import embed_to_frontend_html\n\n\nclass EmbedBlock(blocks.URLBlock):\n def render_basic(self, value):\n return embed_to_frontend_html(value)\n", "path": "wagtail/wagtailembeds/blocks.py"}], "after_files": [{"content": "from django.utils.encoding import python_2_unicode_compatible\n\nfrom wagtail.wagtailcore import blocks\n\nfrom wagtail.wagtailembeds.format import embed_to_frontend_html\n\n\n@python_2_unicode_compatible\nclass EmbedValue(object):\n \"\"\"\n Native value of an EmbedBlock. Should, at minimum, have a 'url' property\n and render as the embed HTML when rendered in a template.\n NB We don't use a wagtailembeds.model.Embed object for this, because\n we want to be able to do {{ value.url|embed:max_width=500 }} without\n doing a redundant fetch of the embed at the default width.\n \"\"\"\n def __init__(self, url):\n self.url = url\n\n def __str__(self):\n return embed_to_frontend_html(self.url)\n\n\nclass EmbedBlock(blocks.URLBlock):\n def get_default(self):\n # Allow specifying the default for an EmbedBlock as either an EmbedValue or a string (or None).\n if not self.meta.default:\n return None\n elif isinstance(self.meta.default, EmbedValue):\n return self.meta.default\n else:\n # assume default has been passed as a string\n return EmbedValue(self.meta.default)\n\n def to_python(self, value):\n # The JSON representation of an EmbedBlock's value is a URL string;\n # this should be converted to an EmbedValue (or None).\n if not value:\n return None\n else:\n return EmbedValue(value)\n\n def get_prep_value(self, value):\n # serialisable value should be a URL string\n if value is None:\n return ''\n else:\n return value.url\n\n def value_for_form(self, value):\n # the value to be handled by the URLField is a plain URL string (or the empty string)\n if value is None:\n return ''\n else:\n return value.url\n\n def value_from_form(self, value):\n # convert the value returned from the form (a URL string) to an EmbedValue (or None)\n if not value:\n return None\n else:\n return EmbedValue(value)\n", "path": "wagtail/wagtailembeds/blocks.py"}]}
| 536 | 600 |
gh_patches_debug_30740
|
rasdani/github-patches
|
git_diff
|
translate__translate-3520
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add traits and variants support in l20nfile
L20n traits allow storing value variants and additional information for a unit. We need to add such support when parsing `.ftl` and convert resources.
```
file-menu =
[xul/label] File
[xul/accesskey] F
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `translate/storage/l20n.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2016 Zuza Software Foundation
4 #
5 # This file is part of translate.
6 #
7 # translate is free software; you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation; either version 2 of the License, or
10 # (at your option) any later version.
11 #
12 # translate is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with this program; if not, see <http://www.gnu.org/licenses/>.
19
20 from __future__ import absolute_import
21
22 from codecs import iterencode
23
24 from l20n.format.parser import FTLParser as L20nParser
25 from l20n.format.serializer import FTLSerializer as L20nSerializer
26
27 from translate.storage import base
28
29
30 class l20nunit(base.TranslationUnit):
31 """Single L20n Entity"""
32
33 def __init__(self, source='', id='', comment=''):
34 super(l20nunit, self).__init__(source)
35 self.id = id
36 self.value = source
37 self.comment = comment
38
39 # Note that source and target are equivalent for monolingual units
40 def getsource(self):
41 return self.value
42
43 def setsource(self, source):
44 self.value = source
45
46 source = property(getsource, setsource)
47
48 def gettarget(self):
49 return self.value
50
51 def settarget(self, target):
52 self.value = target
53
54 target = property(gettarget, settarget)
55
56 def getid(self):
57 return self.id
58
59 def setid(self, new_id):
60 self.id = new_id
61
62 def getoutput(self):
63 return u"%s = %s\n" % (self.id, self.value)
64
65
66 class l20nfile(base.TranslationStore):
67 UnitClass = l20nunit
68 encoding = 'utf8'
69
70 def __init__(self, inputfile=None):
71 super(l20nfile, self).__init__(unitclass=self.UnitClass)
72 self.filename = getattr(inputfile, 'name', '')
73 if inputfile is not None:
74 l20nsrc = inputfile.read()
75 self.parse(l20nsrc)
76 self.makeindex()
77
78 def parse(self, l20nsrc):
79 text, encoding = self.detect_encoding(
80 l20nsrc, default_encodings=[self.encoding])
81 if not text:
82 raise IOError("Cannot detect encoding for %s." % (self.filename or
83 "given string"))
84 l20nsrc = text
85
86 parser = L20nParser()
87 ast, errors = parser.parseResource(l20nsrc)
88
89 for entry in ast['body']:
90 if entry['type'] == 'Entity':
91 translation = L20nSerializer().dumpPattern(entry['value'])
92 comment = ''
93 if entry['comment']:
94 comment = entry['comment']['content']
95
96 newl20n = l20nunit(
97 source=translation,
98 id=entry['id']['name'],
99 comment=comment
100 )
101 self.addunit(newl20n)
102
103 def serialize(self, out):
104 """Write the units back to file."""
105 # Thanks to iterencode, a possible BOM is written only once
106 for chunk in iterencode((unit.getoutput() for unit in self.units), self.encoding):
107 out.write(chunk)
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/translate/storage/l20n.py b/translate/storage/l20n.py
--- a/translate/storage/l20n.py
+++ b/translate/storage/l20n.py
@@ -27,6 +27,17 @@
from translate.storage import base
+def dump_l20n_entity_value(entity):
+ serializer = L20nSerializer()
+ value = serializer.dumpPattern(entity['value'])
+
+ if len(entity['traits']):
+ traits = serializer.dumpMembers(entity['traits'], 2)
+ return u'{}\n{}'.format(value, traits)
+
+ return value
+
+
class l20nunit(base.TranslationUnit):
"""Single L20n Entity"""
@@ -75,6 +86,19 @@
self.parse(l20nsrc)
self.makeindex()
+ def parse_entity(self, entity):
+ translation = dump_l20n_entity_value(entity)
+ comment = ''
+ if entity['comment']:
+ comment = entity['comment']['content']
+
+ newl20n = l20nunit(
+ source=translation,
+ id=entity['id']['name'],
+ comment=comment
+ )
+ self.addunit(newl20n)
+
def parse(self, l20nsrc):
text, encoding = self.detect_encoding(
l20nsrc, default_encodings=[self.encoding])
@@ -88,17 +112,7 @@
for entry in ast['body']:
if entry['type'] == 'Entity':
- translation = L20nSerializer().dumpPattern(entry['value'])
- comment = ''
- if entry['comment']:
- comment = entry['comment']['content']
-
- newl20n = l20nunit(
- source=translation,
- id=entry['id']['name'],
- comment=comment
- )
- self.addunit(newl20n)
+ self.parse_entity(entry)
def serialize(self, out):
"""Write the units back to file."""
|
{"golden_diff": "diff --git a/translate/storage/l20n.py b/translate/storage/l20n.py\n--- a/translate/storage/l20n.py\n+++ b/translate/storage/l20n.py\n@@ -27,6 +27,17 @@\n from translate.storage import base\n \n \n+def dump_l20n_entity_value(entity):\n+ serializer = L20nSerializer()\n+ value = serializer.dumpPattern(entity['value'])\n+\n+ if len(entity['traits']):\n+ traits = serializer.dumpMembers(entity['traits'], 2)\n+ return u'{}\\n{}'.format(value, traits)\n+\n+ return value\n+\n+\n class l20nunit(base.TranslationUnit):\n \"\"\"Single L20n Entity\"\"\"\n \n@@ -75,6 +86,19 @@\n self.parse(l20nsrc)\n self.makeindex()\n \n+ def parse_entity(self, entity):\n+ translation = dump_l20n_entity_value(entity)\n+ comment = ''\n+ if entity['comment']:\n+ comment = entity['comment']['content']\n+\n+ newl20n = l20nunit(\n+ source=translation,\n+ id=entity['id']['name'],\n+ comment=comment\n+ )\n+ self.addunit(newl20n)\n+\n def parse(self, l20nsrc):\n text, encoding = self.detect_encoding(\n l20nsrc, default_encodings=[self.encoding])\n@@ -88,17 +112,7 @@\n \n for entry in ast['body']:\n if entry['type'] == 'Entity':\n- translation = L20nSerializer().dumpPattern(entry['value'])\n- comment = ''\n- if entry['comment']:\n- comment = entry['comment']['content']\n-\n- newl20n = l20nunit(\n- source=translation,\n- id=entry['id']['name'],\n- comment=comment\n- )\n- self.addunit(newl20n)\n+ self.parse_entity(entry)\n \n def serialize(self, out):\n \"\"\"Write the units back to file.\"\"\"\n", "issue": "Add traits and variants support in l20nfile\nL20n traits allow storing value variants and additional information for a unit. We need to add such support when parsing `.ftl` and convert resources.\r\n\r\n```\r\nfile-menu =\r\n [xul/label] File\r\n [xul/accesskey] F\r\n```\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2016 Zuza Software Foundation\n#\n# This file is part of translate.\n#\n# translate is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import absolute_import\n\nfrom codecs import iterencode\n\nfrom l20n.format.parser import FTLParser as L20nParser\nfrom l20n.format.serializer import FTLSerializer as L20nSerializer\n\nfrom translate.storage import base\n\n\nclass l20nunit(base.TranslationUnit):\n \"\"\"Single L20n Entity\"\"\"\n\n def __init__(self, source='', id='', comment=''):\n super(l20nunit, self).__init__(source)\n self.id = id\n self.value = source\n self.comment = comment\n\n # Note that source and target are equivalent for monolingual units\n def getsource(self):\n return self.value\n\n def setsource(self, source):\n self.value = source\n\n source = property(getsource, setsource)\n\n def gettarget(self):\n return self.value\n\n def settarget(self, target):\n self.value = target\n\n target = property(gettarget, settarget)\n\n def getid(self):\n return self.id\n\n def setid(self, new_id):\n self.id = new_id\n\n def getoutput(self):\n return u\"%s = %s\\n\" % (self.id, self.value)\n\n\nclass l20nfile(base.TranslationStore):\n UnitClass = l20nunit\n encoding = 'utf8'\n\n def __init__(self, inputfile=None):\n super(l20nfile, self).__init__(unitclass=self.UnitClass)\n self.filename = getattr(inputfile, 'name', '')\n if inputfile is not None:\n l20nsrc = inputfile.read()\n self.parse(l20nsrc)\n self.makeindex()\n\n def parse(self, l20nsrc):\n text, encoding = self.detect_encoding(\n l20nsrc, default_encodings=[self.encoding])\n if not text:\n raise IOError(\"Cannot detect encoding for %s.\" % (self.filename or\n \"given string\"))\n l20nsrc = text\n\n parser = L20nParser()\n ast, errors = parser.parseResource(l20nsrc)\n\n for entry in ast['body']:\n if entry['type'] == 'Entity':\n translation = L20nSerializer().dumpPattern(entry['value'])\n comment = ''\n if entry['comment']:\n comment = entry['comment']['content']\n\n newl20n = l20nunit(\n source=translation,\n id=entry['id']['name'],\n comment=comment\n )\n self.addunit(newl20n)\n\n def serialize(self, out):\n \"\"\"Write the units back to file.\"\"\"\n # Thanks to iterencode, a possible BOM is written only once\n for chunk in iterencode((unit.getoutput() for unit in self.units), self.encoding):\n out.write(chunk)\n", "path": "translate/storage/l20n.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2016 Zuza Software Foundation\n#\n# This file is part of translate.\n#\n# translate is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\nfrom __future__ import absolute_import\n\nfrom codecs import iterencode\n\nfrom l20n.format.parser import FTLParser as L20nParser\nfrom l20n.format.serializer import FTLSerializer as L20nSerializer\n\nfrom translate.storage import base\n\n\ndef dump_l20n_entity_value(entity):\n serializer = L20nSerializer()\n value = serializer.dumpPattern(entity['value'])\n\n if len(entity['traits']):\n traits = serializer.dumpMembers(entity['traits'], 2)\n return u'{}\\n{}'.format(value, traits)\n\n return value\n\n\nclass l20nunit(base.TranslationUnit):\n \"\"\"Single L20n Entity\"\"\"\n\n def __init__(self, source='', id='', comment=''):\n super(l20nunit, self).__init__(source)\n self.id = id\n self.value = source\n self.comment = comment\n\n # Note that source and target are equivalent for monolingual units\n def getsource(self):\n return self.value\n\n def setsource(self, source):\n self.value = source\n\n source = property(getsource, setsource)\n\n def gettarget(self):\n return self.value\n\n def settarget(self, target):\n self.value = target\n\n target = property(gettarget, settarget)\n\n def getid(self):\n return self.id\n\n def setid(self, new_id):\n self.id = new_id\n\n def getoutput(self):\n return u\"%s = %s\\n\" % (self.id, self.value)\n\n\nclass l20nfile(base.TranslationStore):\n UnitClass = l20nunit\n encoding = 'utf8'\n\n def __init__(self, inputfile=None):\n super(l20nfile, self).__init__(unitclass=self.UnitClass)\n self.filename = getattr(inputfile, 'name', '')\n if inputfile is not None:\n l20nsrc = inputfile.read()\n self.parse(l20nsrc)\n self.makeindex()\n\n def parse_entity(self, entity):\n translation = dump_l20n_entity_value(entity)\n comment = ''\n if entity['comment']:\n comment = entity['comment']['content']\n\n newl20n = l20nunit(\n source=translation,\n id=entity['id']['name'],\n comment=comment\n )\n self.addunit(newl20n)\n\n def parse(self, l20nsrc):\n text, encoding = self.detect_encoding(\n l20nsrc, default_encodings=[self.encoding])\n if not text:\n raise IOError(\"Cannot detect encoding for %s.\" % (self.filename or\n \"given string\"))\n l20nsrc = text\n\n parser = L20nParser()\n ast, errors = parser.parseResource(l20nsrc)\n\n for entry in ast['body']:\n if entry['type'] == 'Entity':\n self.parse_entity(entry)\n\n def serialize(self, out):\n \"\"\"Write the units back to file.\"\"\"\n # Thanks to iterencode, a possible BOM is written only once\n for chunk in iterencode((unit.getoutput() for unit in self.units), self.encoding):\n out.write(chunk)\n", "path": "translate/storage/l20n.py"}]}
| 1,346 | 465 |
gh_patches_debug_53194
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-1208
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fixed availabale typo
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/changes/hgpoller.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 import os
17 import time
18
19 from twisted.internet import defer
20 from twisted.internet import utils
21 from twisted.python import log
22
23 from buildbot import config
24 from buildbot.changes import base
25 from buildbot.util import ascii2unicode
26 from buildbot.util import deferredLocked
27
28
29 class HgPoller(base.PollingChangeSource):
30
31 """This source will poll a remote hg repo for changes and submit
32 them to the change master."""
33
34 compare_attrs = ("repourl", "branch", "workdir",
35 "pollInterval", "hgpoller", "usetimestamps",
36 "category", "project", "pollAtLaunch")
37
38 db_class_name = 'HgPoller'
39
40 def __init__(self, repourl, branch='default',
41 workdir=None, pollInterval=10 * 60,
42 hgbin='hg', usetimestamps=True,
43 category=None, project='', pollinterval=-2,
44 encoding='utf-8', name=None, pollAtLaunch=False):
45
46 # for backward compatibility; the parameter used to be spelled with 'i'
47 if pollinterval != -2:
48 pollInterval = pollinterval
49
50 if name is None:
51 name = repourl
52
53 self.repourl = repourl
54 self.branch = branch
55 base.PollingChangeSource.__init__(
56 self, name=name, pollInterval=pollInterval, pollAtLaunch=pollAtLaunch)
57 self.encoding = encoding
58 self.lastChange = time.time()
59 self.lastPoll = time.time()
60 self.hgbin = hgbin
61 self.workdir = workdir
62 self.usetimestamps = usetimestamps
63 self.category = category
64 self.project = project
65 self.commitInfo = {}
66 self.initLock = defer.DeferredLock()
67
68 if self.workdir is None:
69 config.error("workdir is mandatory for now in HgPoller")
70
71 def describe(self):
72 status = ""
73 if not self.master:
74 status = "[STOPPED - check log]"
75 return ("HgPoller watching the remote Mercurial repository %r, "
76 "branch: %r, in workdir %r %s") % (self.repourl, self.branch,
77 self.workdir, status)
78
79 @deferredLocked('initLock')
80 def poll(self):
81 d = self._getChanges()
82 d.addCallback(self._processChanges)
83 d.addErrback(self._processChangesFailure)
84 return d
85
86 def _absWorkdir(self):
87 workdir = self.workdir
88 if os.path.isabs(workdir):
89 return workdir
90 return os.path.join(self.master.basedir, workdir)
91
92 def _getRevDetails(self, rev):
93 """Return a deferred for (date, author, files, comments) of given rev.
94
95 Deferred will be in error if rev is unknown.
96 """
97 args = ['log', '-r', rev, os.linesep.join((
98 '--template={date|hgdate}',
99 '{author}',
100 "{files % '{file}" + os.pathsep + "'}",
101 '{desc|strip}'))]
102 # Mercurial fails with status 255 if rev is unknown
103 d = utils.getProcessOutput(self.hgbin, args, path=self._absWorkdir(),
104 env=os.environ, errortoo=False)
105
106 def process(output):
107 # all file names are on one line
108 date, author, files, comments = output.decode(self.encoding, "replace").split(
109 os.linesep, 3)
110
111 if not self.usetimestamps:
112 stamp = None
113 else:
114 try:
115 stamp = float(date.split()[0])
116 except:
117 log.msg('hgpoller: caught exception converting output %r '
118 'to timestamp' % date)
119 raise
120 return stamp, author.strip(), files.split(os.pathsep)[:-1], comments.strip()
121
122 d.addCallback(process)
123 return d
124
125 def _isRepositoryReady(self):
126 """Easy to patch in tests."""
127 return os.path.exists(os.path.join(self._absWorkdir(), '.hg'))
128
129 def _initRepository(self):
130 """Have mercurial init the workdir as a repository (hg init) if needed.
131
132 hg init will also create all needed intermediate directories.
133 """
134 if self._isRepositoryReady():
135 return defer.succeed(None)
136 log.msg('hgpoller: initializing working dir from %s' % self.repourl)
137 d = utils.getProcessOutputAndValue(self.hgbin,
138 ['init', self._absWorkdir()],
139 env=os.environ)
140 d.addCallback(self._convertNonZeroToFailure)
141 d.addErrback(self._stopOnFailure)
142 d.addCallback(lambda _: log.msg(
143 "hgpoller: finished initializing working dir %r" % self.workdir))
144 return d
145
146 def _getChanges(self):
147 self.lastPoll = time.time()
148
149 d = self._initRepository()
150 d.addCallback(lambda _: log.msg(
151 "hgpoller: polling hg repo at %s" % self.repourl))
152
153 # get a deferred object that performs the fetch
154 args = ['pull', '-b', self.branch, self.repourl]
155
156 # This command always produces data on stderr, but we actually do not
157 # care about the stderr or stdout from this command.
158 # We set errortoo=True to avoid an errback from the deferred.
159 # The callback which will be added to this
160 # deferred will not use the response.
161 d.addCallback(lambda _: utils.getProcessOutput(
162 self.hgbin, args, path=self._absWorkdir(),
163 env=os.environ, errortoo=True))
164
165 return d
166
167 def _getStateObjectId(self):
168 """Return a deferred for object id in state db.
169
170 Being unique among pollers, workdir is used with branch as instance
171 name for db.
172 """
173 return self.master.db.state.getObjectId(
174 '#'.join((self.workdir, self.branch)), self.db_class_name)
175
176 def _getCurrentRev(self):
177 """Return a deferred for object id in state db and current numeric rev.
178
179 If never has been set, current rev is None.
180 """
181 d = self._getStateObjectId()
182
183 def oid_cb(oid):
184 d = self.master.db.state.getState(oid, 'current_rev', None)
185
186 def addOid(cur):
187 if cur is not None:
188 return oid, int(cur)
189 return oid, cur
190 d.addCallback(addOid)
191 return d
192 d.addCallback(oid_cb)
193 return d
194
195 def _setCurrentRev(self, rev, oid=None):
196 """Return a deferred to set current revision in persistent state.
197
198 oid is self's id for state db. It can be passed to avoid a db lookup."""
199 if oid is None:
200 d = self._getStateObjectId()
201 else:
202 d = defer.succeed(oid)
203
204 def set_in_state(obj_id):
205 return self.master.db.state.setState(obj_id, 'current_rev', rev)
206 d.addCallback(set_in_state)
207
208 return d
209
210 def _getHead(self):
211 """Return a deferred for branch head revision or None.
212
213 We'll get an error if there is no head for this branch, which is
214 proabably a good thing, since it's probably a mispelling
215 (if really buildbotting a branch that does not have any changeset
216 yet, one shouldn't be surprised to get errors)
217 """
218 d = utils.getProcessOutput(self.hgbin,
219 ['heads', self.branch, '--template={rev}' + os.linesep],
220 path=self._absWorkdir(), env=os.environ, errortoo=False)
221
222 def no_head_err(exc):
223 log.err("hgpoller: could not find branch %r in repository %r" % (
224 self.branch, self.repourl))
225 d.addErrback(no_head_err)
226
227 def results(heads):
228 if not heads:
229 return
230
231 if len(heads.split()) > 1:
232 log.err(("hgpoller: caught several heads in branch %r "
233 "from repository %r. Staying at previous revision"
234 "You should wait until the situation is normal again "
235 "due to a merge or directly strip if remote repo "
236 "gets stripped later.") % (self.branch, self.repourl))
237 return
238
239 # in case of whole reconstruction, are we sure that we'll get the
240 # same node -> rev assignations ?
241 return int(heads.strip())
242
243 d.addCallback(results)
244 return d
245
246 @defer.inlineCallbacks
247 def _processChanges(self, unused_output):
248 """Send info about pulled changes to the master and record current.
249
250 GitPoller does the recording by moving the working dir to the head
251 of the branch.
252 We don't update the tree (unnecessary treatment and waste of space)
253 instead, we simply store the current rev number in a file.
254 Recall that hg rev numbers are local and incremental.
255 """
256 oid, current = yield self._getCurrentRev()
257 # hg log on a range of revisions is never empty
258 # also, if a numeric revision does not exist, a node may match.
259 # Therefore, we have to check explicitely that branch head > current.
260 head = yield self._getHead()
261 if head <= current:
262 return
263 if current is None:
264 # we could have used current = -1 convention as well (as hg does)
265 revrange = '%d:%d' % (head, head)
266 else:
267 revrange = '%d:%s' % (current + 1, head)
268
269 # two passes for hg log makes parsing simpler (comments is multi-lines)
270 revListArgs = ['log', '-b', self.branch, '-r', revrange,
271 r'--template={rev}:{node}\n']
272 results = yield utils.getProcessOutput(self.hgbin, revListArgs,
273 path=self._absWorkdir(), env=os.environ, errortoo=False)
274
275 revNodeList = [rn.split(':', 1) for rn in results.strip().split()]
276
277 log.msg('hgpoller: processing %d changes: %r in %r'
278 % (len(revNodeList), revNodeList, self._absWorkdir()))
279 for rev, node in revNodeList:
280 timestamp, author, files, comments = yield self._getRevDetails(
281 node)
282 yield self.master.data.updates.addChange(
283 author=author,
284 revision=unicode(node),
285 files=files,
286 comments=comments,
287 when_timestamp=int(timestamp),
288 branch=ascii2unicode(self.branch),
289 category=ascii2unicode(self.category),
290 project=ascii2unicode(self.project),
291 repository=ascii2unicode(self.repourl),
292 src=u'hg')
293 # writing after addChange so that a rev is never missed,
294 # but at once to avoid impact from later errors
295 yield self._setCurrentRev(rev, oid=oid)
296
297 def _processChangesFailure(self, f):
298 log.msg('hgpoller: repo poll failed')
299 log.err(f)
300 # eat the failure to continue along the deferred chain - we still want to catch up
301 return None
302
303 def _convertNonZeroToFailure(self, res):
304 "utility method to handle the result of getProcessOutputAndValue"
305 (stdout, stderr, code) = res
306 if code != 0:
307 raise EnvironmentError('command failed with exit code %d: %s' % (code, stderr))
308 return (stdout, stderr, code)
309
310 def _stopOnFailure(self, f):
311 "utility method to stop the service when a failure occurs"
312 if self.running:
313 d = defer.maybeDeferred(lambda: self.stopService())
314 d.addErrback(log.err, 'while stopping broken HgPoller service')
315 return f
316
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/changes/hgpoller.py b/master/buildbot/changes/hgpoller.py
--- a/master/buildbot/changes/hgpoller.py
+++ b/master/buildbot/changes/hgpoller.py
@@ -48,7 +48,7 @@
pollInterval = pollinterval
if name is None:
- name = repourl
+ name = "%s[%s]" % (repourl, branch)
self.repourl = repourl
self.branch = branch
|
{"golden_diff": "diff --git a/master/buildbot/changes/hgpoller.py b/master/buildbot/changes/hgpoller.py\n--- a/master/buildbot/changes/hgpoller.py\n+++ b/master/buildbot/changes/hgpoller.py\n@@ -48,7 +48,7 @@\n pollInterval = pollinterval\n \n if name is None:\n- name = repourl\n+ name = \"%s[%s]\" % (repourl, branch)\n \n self.repourl = repourl\n self.branch = branch\n", "issue": "fixed availabale typo\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport os\nimport time\n\nfrom twisted.internet import defer\nfrom twisted.internet import utils\nfrom twisted.python import log\n\nfrom buildbot import config\nfrom buildbot.changes import base\nfrom buildbot.util import ascii2unicode\nfrom buildbot.util import deferredLocked\n\n\nclass HgPoller(base.PollingChangeSource):\n\n \"\"\"This source will poll a remote hg repo for changes and submit\n them to the change master.\"\"\"\n\n compare_attrs = (\"repourl\", \"branch\", \"workdir\",\n \"pollInterval\", \"hgpoller\", \"usetimestamps\",\n \"category\", \"project\", \"pollAtLaunch\")\n\n db_class_name = 'HgPoller'\n\n def __init__(self, repourl, branch='default',\n workdir=None, pollInterval=10 * 60,\n hgbin='hg', usetimestamps=True,\n category=None, project='', pollinterval=-2,\n encoding='utf-8', name=None, pollAtLaunch=False):\n\n # for backward compatibility; the parameter used to be spelled with 'i'\n if pollinterval != -2:\n pollInterval = pollinterval\n\n if name is None:\n name = repourl\n\n self.repourl = repourl\n self.branch = branch\n base.PollingChangeSource.__init__(\n self, name=name, pollInterval=pollInterval, pollAtLaunch=pollAtLaunch)\n self.encoding = encoding\n self.lastChange = time.time()\n self.lastPoll = time.time()\n self.hgbin = hgbin\n self.workdir = workdir\n self.usetimestamps = usetimestamps\n self.category = category\n self.project = project\n self.commitInfo = {}\n self.initLock = defer.DeferredLock()\n\n if self.workdir is None:\n config.error(\"workdir is mandatory for now in HgPoller\")\n\n def describe(self):\n status = \"\"\n if not self.master:\n status = \"[STOPPED - check log]\"\n return (\"HgPoller watching the remote Mercurial repository %r, \"\n \"branch: %r, in workdir %r %s\") % (self.repourl, self.branch,\n self.workdir, status)\n\n @deferredLocked('initLock')\n def poll(self):\n d = self._getChanges()\n d.addCallback(self._processChanges)\n d.addErrback(self._processChangesFailure)\n return d\n\n def _absWorkdir(self):\n workdir = self.workdir\n if os.path.isabs(workdir):\n return workdir\n return os.path.join(self.master.basedir, workdir)\n\n def _getRevDetails(self, rev):\n \"\"\"Return a deferred for (date, author, files, comments) of given rev.\n\n Deferred will be in error if rev is unknown.\n \"\"\"\n args = ['log', '-r', rev, os.linesep.join((\n '--template={date|hgdate}',\n '{author}',\n \"{files % '{file}\" + os.pathsep + \"'}\",\n '{desc|strip}'))]\n # Mercurial fails with status 255 if rev is unknown\n d = utils.getProcessOutput(self.hgbin, args, path=self._absWorkdir(),\n env=os.environ, errortoo=False)\n\n def process(output):\n # all file names are on one line\n date, author, files, comments = output.decode(self.encoding, \"replace\").split(\n os.linesep, 3)\n\n if not self.usetimestamps:\n stamp = None\n else:\n try:\n stamp = float(date.split()[0])\n except:\n log.msg('hgpoller: caught exception converting output %r '\n 'to timestamp' % date)\n raise\n return stamp, author.strip(), files.split(os.pathsep)[:-1], comments.strip()\n\n d.addCallback(process)\n return d\n\n def _isRepositoryReady(self):\n \"\"\"Easy to patch in tests.\"\"\"\n return os.path.exists(os.path.join(self._absWorkdir(), '.hg'))\n\n def _initRepository(self):\n \"\"\"Have mercurial init the workdir as a repository (hg init) if needed.\n\n hg init will also create all needed intermediate directories.\n \"\"\"\n if self._isRepositoryReady():\n return defer.succeed(None)\n log.msg('hgpoller: initializing working dir from %s' % self.repourl)\n d = utils.getProcessOutputAndValue(self.hgbin,\n ['init', self._absWorkdir()],\n env=os.environ)\n d.addCallback(self._convertNonZeroToFailure)\n d.addErrback(self._stopOnFailure)\n d.addCallback(lambda _: log.msg(\n \"hgpoller: finished initializing working dir %r\" % self.workdir))\n return d\n\n def _getChanges(self):\n self.lastPoll = time.time()\n\n d = self._initRepository()\n d.addCallback(lambda _: log.msg(\n \"hgpoller: polling hg repo at %s\" % self.repourl))\n\n # get a deferred object that performs the fetch\n args = ['pull', '-b', self.branch, self.repourl]\n\n # This command always produces data on stderr, but we actually do not\n # care about the stderr or stdout from this command.\n # We set errortoo=True to avoid an errback from the deferred.\n # The callback which will be added to this\n # deferred will not use the response.\n d.addCallback(lambda _: utils.getProcessOutput(\n self.hgbin, args, path=self._absWorkdir(),\n env=os.environ, errortoo=True))\n\n return d\n\n def _getStateObjectId(self):\n \"\"\"Return a deferred for object id in state db.\n\n Being unique among pollers, workdir is used with branch as instance\n name for db.\n \"\"\"\n return self.master.db.state.getObjectId(\n '#'.join((self.workdir, self.branch)), self.db_class_name)\n\n def _getCurrentRev(self):\n \"\"\"Return a deferred for object id in state db and current numeric rev.\n\n If never has been set, current rev is None.\n \"\"\"\n d = self._getStateObjectId()\n\n def oid_cb(oid):\n d = self.master.db.state.getState(oid, 'current_rev', None)\n\n def addOid(cur):\n if cur is not None:\n return oid, int(cur)\n return oid, cur\n d.addCallback(addOid)\n return d\n d.addCallback(oid_cb)\n return d\n\n def _setCurrentRev(self, rev, oid=None):\n \"\"\"Return a deferred to set current revision in persistent state.\n\n oid is self's id for state db. It can be passed to avoid a db lookup.\"\"\"\n if oid is None:\n d = self._getStateObjectId()\n else:\n d = defer.succeed(oid)\n\n def set_in_state(obj_id):\n return self.master.db.state.setState(obj_id, 'current_rev', rev)\n d.addCallback(set_in_state)\n\n return d\n\n def _getHead(self):\n \"\"\"Return a deferred for branch head revision or None.\n\n We'll get an error if there is no head for this branch, which is\n proabably a good thing, since it's probably a mispelling\n (if really buildbotting a branch that does not have any changeset\n yet, one shouldn't be surprised to get errors)\n \"\"\"\n d = utils.getProcessOutput(self.hgbin,\n ['heads', self.branch, '--template={rev}' + os.linesep],\n path=self._absWorkdir(), env=os.environ, errortoo=False)\n\n def no_head_err(exc):\n log.err(\"hgpoller: could not find branch %r in repository %r\" % (\n self.branch, self.repourl))\n d.addErrback(no_head_err)\n\n def results(heads):\n if not heads:\n return\n\n if len(heads.split()) > 1:\n log.err((\"hgpoller: caught several heads in branch %r \"\n \"from repository %r. Staying at previous revision\"\n \"You should wait until the situation is normal again \"\n \"due to a merge or directly strip if remote repo \"\n \"gets stripped later.\") % (self.branch, self.repourl))\n return\n\n # in case of whole reconstruction, are we sure that we'll get the\n # same node -> rev assignations ?\n return int(heads.strip())\n\n d.addCallback(results)\n return d\n\n @defer.inlineCallbacks\n def _processChanges(self, unused_output):\n \"\"\"Send info about pulled changes to the master and record current.\n\n GitPoller does the recording by moving the working dir to the head\n of the branch.\n We don't update the tree (unnecessary treatment and waste of space)\n instead, we simply store the current rev number in a file.\n Recall that hg rev numbers are local and incremental.\n \"\"\"\n oid, current = yield self._getCurrentRev()\n # hg log on a range of revisions is never empty\n # also, if a numeric revision does not exist, a node may match.\n # Therefore, we have to check explicitely that branch head > current.\n head = yield self._getHead()\n if head <= current:\n return\n if current is None:\n # we could have used current = -1 convention as well (as hg does)\n revrange = '%d:%d' % (head, head)\n else:\n revrange = '%d:%s' % (current + 1, head)\n\n # two passes for hg log makes parsing simpler (comments is multi-lines)\n revListArgs = ['log', '-b', self.branch, '-r', revrange,\n r'--template={rev}:{node}\\n']\n results = yield utils.getProcessOutput(self.hgbin, revListArgs,\n path=self._absWorkdir(), env=os.environ, errortoo=False)\n\n revNodeList = [rn.split(':', 1) for rn in results.strip().split()]\n\n log.msg('hgpoller: processing %d changes: %r in %r'\n % (len(revNodeList), revNodeList, self._absWorkdir()))\n for rev, node in revNodeList:\n timestamp, author, files, comments = yield self._getRevDetails(\n node)\n yield self.master.data.updates.addChange(\n author=author,\n revision=unicode(node),\n files=files,\n comments=comments,\n when_timestamp=int(timestamp),\n branch=ascii2unicode(self.branch),\n category=ascii2unicode(self.category),\n project=ascii2unicode(self.project),\n repository=ascii2unicode(self.repourl),\n src=u'hg')\n # writing after addChange so that a rev is never missed,\n # but at once to avoid impact from later errors\n yield self._setCurrentRev(rev, oid=oid)\n\n def _processChangesFailure(self, f):\n log.msg('hgpoller: repo poll failed')\n log.err(f)\n # eat the failure to continue along the deferred chain - we still want to catch up\n return None\n\n def _convertNonZeroToFailure(self, res):\n \"utility method to handle the result of getProcessOutputAndValue\"\n (stdout, stderr, code) = res\n if code != 0:\n raise EnvironmentError('command failed with exit code %d: %s' % (code, stderr))\n return (stdout, stderr, code)\n\n def _stopOnFailure(self, f):\n \"utility method to stop the service when a failure occurs\"\n if self.running:\n d = defer.maybeDeferred(lambda: self.stopService())\n d.addErrback(log.err, 'while stopping broken HgPoller service')\n return f\n", "path": "master/buildbot/changes/hgpoller.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport os\nimport time\n\nfrom twisted.internet import defer\nfrom twisted.internet import utils\nfrom twisted.python import log\n\nfrom buildbot import config\nfrom buildbot.changes import base\nfrom buildbot.util import ascii2unicode\nfrom buildbot.util import deferredLocked\n\n\nclass HgPoller(base.PollingChangeSource):\n\n \"\"\"This source will poll a remote hg repo for changes and submit\n them to the change master.\"\"\"\n\n compare_attrs = (\"repourl\", \"branch\", \"workdir\",\n \"pollInterval\", \"hgpoller\", \"usetimestamps\",\n \"category\", \"project\", \"pollAtLaunch\")\n\n db_class_name = 'HgPoller'\n\n def __init__(self, repourl, branch='default',\n workdir=None, pollInterval=10 * 60,\n hgbin='hg', usetimestamps=True,\n category=None, project='', pollinterval=-2,\n encoding='utf-8', name=None, pollAtLaunch=False):\n\n # for backward compatibility; the parameter used to be spelled with 'i'\n if pollinterval != -2:\n pollInterval = pollinterval\n\n if name is None:\n name = \"%s[%s]\" % (repourl, branch)\n\n self.repourl = repourl\n self.branch = branch\n base.PollingChangeSource.__init__(\n self, name=name, pollInterval=pollInterval, pollAtLaunch=pollAtLaunch)\n self.encoding = encoding\n self.lastChange = time.time()\n self.lastPoll = time.time()\n self.hgbin = hgbin\n self.workdir = workdir\n self.usetimestamps = usetimestamps\n self.category = category\n self.project = project\n self.commitInfo = {}\n self.initLock = defer.DeferredLock()\n\n if self.workdir is None:\n config.error(\"workdir is mandatory for now in HgPoller\")\n\n def describe(self):\n status = \"\"\n if not self.master:\n status = \"[STOPPED - check log]\"\n return (\"HgPoller watching the remote Mercurial repository %r, \"\n \"branch: %r, in workdir %r %s\") % (self.repourl, self.branch,\n self.workdir, status)\n\n @deferredLocked('initLock')\n def poll(self):\n d = self._getChanges()\n d.addCallback(self._processChanges)\n d.addErrback(self._processChangesFailure)\n return d\n\n def _absWorkdir(self):\n workdir = self.workdir\n if os.path.isabs(workdir):\n return workdir\n return os.path.join(self.master.basedir, workdir)\n\n def _getRevDetails(self, rev):\n \"\"\"Return a deferred for (date, author, files, comments) of given rev.\n\n Deferred will be in error if rev is unknown.\n \"\"\"\n args = ['log', '-r', rev, os.linesep.join((\n '--template={date|hgdate}',\n '{author}',\n \"{files % '{file}\" + os.pathsep + \"'}\",\n '{desc|strip}'))]\n # Mercurial fails with status 255 if rev is unknown\n d = utils.getProcessOutput(self.hgbin, args, path=self._absWorkdir(),\n env=os.environ, errortoo=False)\n\n def process(output):\n # all file names are on one line\n date, author, files, comments = output.decode(self.encoding, \"replace\").split(\n os.linesep, 3)\n\n if not self.usetimestamps:\n stamp = None\n else:\n try:\n stamp = float(date.split()[0])\n except:\n log.msg('hgpoller: caught exception converting output %r '\n 'to timestamp' % date)\n raise\n return stamp, author.strip(), files.split(os.pathsep)[:-1], comments.strip()\n\n d.addCallback(process)\n return d\n\n def _isRepositoryReady(self):\n \"\"\"Easy to patch in tests.\"\"\"\n return os.path.exists(os.path.join(self._absWorkdir(), '.hg'))\n\n def _initRepository(self):\n \"\"\"Have mercurial init the workdir as a repository (hg init) if needed.\n\n hg init will also create all needed intermediate directories.\n \"\"\"\n if self._isRepositoryReady():\n return defer.succeed(None)\n log.msg('hgpoller: initializing working dir from %s' % self.repourl)\n d = utils.getProcessOutputAndValue(self.hgbin,\n ['init', self._absWorkdir()],\n env=os.environ)\n d.addCallback(self._convertNonZeroToFailure)\n d.addErrback(self._stopOnFailure)\n d.addCallback(lambda _: log.msg(\n \"hgpoller: finished initializing working dir %r\" % self.workdir))\n return d\n\n def _getChanges(self):\n self.lastPoll = time.time()\n\n d = self._initRepository()\n d.addCallback(lambda _: log.msg(\n \"hgpoller: polling hg repo at %s\" % self.repourl))\n\n # get a deferred object that performs the fetch\n args = ['pull', '-b', self.branch, self.repourl]\n\n # This command always produces data on stderr, but we actually do not\n # care about the stderr or stdout from this command.\n # We set errortoo=True to avoid an errback from the deferred.\n # The callback which will be added to this\n # deferred will not use the response.\n d.addCallback(lambda _: utils.getProcessOutput(\n self.hgbin, args, path=self._absWorkdir(),\n env=os.environ, errortoo=True))\n\n return d\n\n def _getStateObjectId(self):\n \"\"\"Return a deferred for object id in state db.\n\n Being unique among pollers, workdir is used with branch as instance\n name for db.\n \"\"\"\n return self.master.db.state.getObjectId(\n '#'.join((self.workdir, self.branch)), self.db_class_name)\n\n def _getCurrentRev(self):\n \"\"\"Return a deferred for object id in state db and current numeric rev.\n\n If never has been set, current rev is None.\n \"\"\"\n d = self._getStateObjectId()\n\n def oid_cb(oid):\n d = self.master.db.state.getState(oid, 'current_rev', None)\n\n def addOid(cur):\n if cur is not None:\n return oid, int(cur)\n return oid, cur\n d.addCallback(addOid)\n return d\n d.addCallback(oid_cb)\n return d\n\n def _setCurrentRev(self, rev, oid=None):\n \"\"\"Return a deferred to set current revision in persistent state.\n\n oid is self's id for state db. It can be passed to avoid a db lookup.\"\"\"\n if oid is None:\n d = self._getStateObjectId()\n else:\n d = defer.succeed(oid)\n\n def set_in_state(obj_id):\n return self.master.db.state.setState(obj_id, 'current_rev', rev)\n d.addCallback(set_in_state)\n\n return d\n\n def _getHead(self):\n \"\"\"Return a deferred for branch head revision or None.\n\n We'll get an error if there is no head for this branch, which is\n proabably a good thing, since it's probably a mispelling\n (if really buildbotting a branch that does not have any changeset\n yet, one shouldn't be surprised to get errors)\n \"\"\"\n d = utils.getProcessOutput(self.hgbin,\n ['heads', self.branch, '--template={rev}' + os.linesep],\n path=self._absWorkdir(), env=os.environ, errortoo=False)\n\n def no_head_err(exc):\n log.err(\"hgpoller: could not find branch %r in repository %r\" % (\n self.branch, self.repourl))\n d.addErrback(no_head_err)\n\n def results(heads):\n if not heads:\n return\n\n if len(heads.split()) > 1:\n log.err((\"hgpoller: caught several heads in branch %r \"\n \"from repository %r. Staying at previous revision\"\n \"You should wait until the situation is normal again \"\n \"due to a merge or directly strip if remote repo \"\n \"gets stripped later.\") % (self.branch, self.repourl))\n return\n\n # in case of whole reconstruction, are we sure that we'll get the\n # same node -> rev assignations ?\n return int(heads.strip())\n\n d.addCallback(results)\n return d\n\n @defer.inlineCallbacks\n def _processChanges(self, unused_output):\n \"\"\"Send info about pulled changes to the master and record current.\n\n GitPoller does the recording by moving the working dir to the head\n of the branch.\n We don't update the tree (unnecessary treatment and waste of space)\n instead, we simply store the current rev number in a file.\n Recall that hg rev numbers are local and incremental.\n \"\"\"\n oid, current = yield self._getCurrentRev()\n # hg log on a range of revisions is never empty\n # also, if a numeric revision does not exist, a node may match.\n # Therefore, we have to check explicitely that branch head > current.\n head = yield self._getHead()\n if head <= current:\n return\n if current is None:\n # we could have used current = -1 convention as well (as hg does)\n revrange = '%d:%d' % (head, head)\n else:\n revrange = '%d:%s' % (current + 1, head)\n\n # two passes for hg log makes parsing simpler (comments is multi-lines)\n revListArgs = ['log', '-b', self.branch, '-r', revrange,\n r'--template={rev}:{node}\\n']\n results = yield utils.getProcessOutput(self.hgbin, revListArgs,\n path=self._absWorkdir(), env=os.environ, errortoo=False)\n\n revNodeList = [rn.split(':', 1) for rn in results.strip().split()]\n\n log.msg('hgpoller: processing %d changes: %r in %r'\n % (len(revNodeList), revNodeList, self._absWorkdir()))\n for rev, node in revNodeList:\n timestamp, author, files, comments = yield self._getRevDetails(\n node)\n yield self.master.data.updates.addChange(\n author=author,\n revision=unicode(node),\n files=files,\n comments=comments,\n when_timestamp=int(timestamp),\n branch=ascii2unicode(self.branch),\n category=ascii2unicode(self.category),\n project=ascii2unicode(self.project),\n repository=ascii2unicode(self.repourl),\n src=u'hg')\n # writing after addChange so that a rev is never missed,\n # but at once to avoid impact from later errors\n yield self._setCurrentRev(rev, oid=oid)\n\n def _processChangesFailure(self, f):\n log.msg('hgpoller: repo poll failed')\n log.err(f)\n # eat the failure to continue along the deferred chain - we still want to catch up\n return None\n\n def _convertNonZeroToFailure(self, res):\n \"utility method to handle the result of getProcessOutputAndValue\"\n (stdout, stderr, code) = res\n if code != 0:\n raise EnvironmentError('command failed with exit code %d: %s' % (code, stderr))\n return (stdout, stderr, code)\n\n def _stopOnFailure(self, f):\n \"utility method to stop the service when a failure occurs\"\n if self.running:\n d = defer.maybeDeferred(lambda: self.stopService())\n d.addErrback(log.err, 'while stopping broken HgPoller service')\n return f\n", "path": "master/buildbot/changes/hgpoller.py"}]}
| 3,866 | 115 |
gh_patches_debug_26716
|
rasdani/github-patches
|
git_diff
|
facebookresearch__xformers-207
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
blocksparse gives RuntimeError: CUDA: Error- illegal address when increase the block size
# 🐛 Bug
I'm not sure whether this is a bug or simply a restriction of triton. But when I follow you doc here https://github.com/facebookresearch/xformers/blob/main/HOWTO.md#blocksparseattention
The sample works fine but it does not work when I increase the block size.
## Command
## To Reproduce
Steps to reproduce the behavior:
Simply replacing your hyperparameter like this
BATCH = 1
HEADS = 16
SEQ = 8192
EMB = 64 * HEADS
BLOCK_SIZE = 512
DROPOUT = 0.1
should reproduce the error "RuntimeError: CUDA: Error- illegal address"
- PyTorch Version (e.g., 1.0): 1.10.2
- OS (e.g., Linux): Ubuntu 18.04
- How you installed PyTorch (`conda`, `pip`, source): pip
- Build command you used (if compiling from source):
- Python version: 3.8
- CUDA/cuDNN version: 11.6
- GPU models and configuration: A100
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `xformers/components/attention/blocksparse.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6
7 import logging
8 import math
9 from dataclasses import dataclass
10 from typing import Optional
11
12 import torch
13
14 from xformers import _is_triton_available
15 from xformers.components.attention import Attention, AttentionConfig, register_attention
16 from xformers.components.attention.utils import bool_mask_to_additive
17
18 _mask_type_warning = True
19
20 if _is_triton_available:
21 from triton.ops.blocksparse import matmul as blocksparse_matmul # type: ignore
22 from triton.ops.blocksparse import softmax as blocksparse_softmax # type: ignore
23
24 from xformers.triton.softmax import MaskType
25 from xformers.triton.utils import gpu_capabilities_older_than_70
26
27 # Blocksparse requires Tensor cores
28 if gpu_capabilities_older_than_70():
29 logging.warning(
30 "Blocksparse is not available: the current GPU does not expose Tensor cores"
31 )
32 _is_triton_available = False
33
34
35 if _is_triton_available:
36
37 @dataclass
38 class BlockSparseAttentionConfig(AttentionConfig):
39 layout: torch.Tensor # The dimensions of the random features
40 block_size: int
41 dropout: float
42 num_heads: int
43
44 @register_attention("blocksparse", BlockSparseAttentionConfig)
45 class BlockSparseAttention(Attention):
46 r"""
47 Thin wrap over the Triton blocksparse computations. The sparsity pattern is determined through the layout.
48
49 .. warning: the layout is assumed to have the dimensions [heads, seq, seq].
50 If some dimensions are missing, we assume that the same layout is to be used across heads.
51
52 .. warning: for now, the sequence (context) length has to be a power of two. This constraint could
53 be relaxed in the future.
54
55 .. note: it is possible to pass a specific per batch mask in the forward call,
56 but this will not lead to any speed up.
57 Any constant sparsity pattern is better passed through the layout parameter.
58 """
59
60 def __init__(
61 self,
62 layout: torch.Tensor,
63 block_size: int = 16,
64 dropout: float = 0.0,
65 num_heads: int = 1, # optional, used to adapt the layout if in need
66 *args,
67 **kwargs,
68 ):
69 if layout.dim() == 2:
70 logging.warning(
71 "The layout passed is lacking a head dimension and a batch dimension"
72 )
73 logging.warning(
74 "Now assuming that the same layout is to be used across all heads"
75 )
76 layout = layout.unsqueeze(0).expand(num_heads, -1, -1)
77 logging.warning(f"New layout dimensions: {layout.shape}")
78
79 assert block_size >= 16, "Minimum block size is 16, for now at least"
80
81 super().__init__()
82 self.attn_drop = torch.nn.Dropout(dropout, inplace=False)
83
84 # Pure blocksparse data
85 self.layout = layout
86 self.block_size = block_size
87
88 # blocksparse operators
89 self.sparse_dot_sdd = blocksparse_matmul(
90 self.layout,
91 self.block_size,
92 "sdd",
93 trans_a=False,
94 trans_b=True,
95 )
96 self.sparse_dot_dsd = blocksparse_matmul(
97 self.layout,
98 self.block_size,
99 "dsd",
100 trans_a=False,
101 trans_b=False,
102 )
103 self.sparse_softmax = blocksparse_softmax(self.layout, self.block_size)
104
105 # make sure that the head dimension is not folded down with the batch
106 self.requires_head_dimension = True
107
108 # key padding mask and attention mask must be passed in separately
109 self.requires_separate_masks = True
110
111 self.requires_same_k_q_dimensions = True
112
113 def update_mask_type(self, mask: torch.Tensor):
114 global _mask_type_warning
115 if _mask_type_warning:
116 logging.warning(
117 "Mask has to be additive. Fixing that but this slows things down"
118 )
119 mask = bool_mask_to_additive(mask)
120
121 def forward(
122 self,
123 q: torch.Tensor,
124 k: torch.Tensor,
125 v: torch.Tensor,
126 att_mask: Optional[torch.Tensor] = None,
127 key_padding_mask: Optional[torch.Tensor] = None,
128 scale: float = 1.0,
129 *args,
130 **kwargs,
131 ) -> torch.Tensor:
132 r"""
133 att_mask A 2D attention mask. The dtype must be the same as q. An additive mask is expected,
134 meaning float values using "-inf" to mask values.
135 key_padding_mask A mask with size (batch size x sequence length). The dtype must be the same as q.
136 An additive mask is expected, meaning float values using "-inf" to mask values
137 """
138
139 # NOTE:
140 # The attention mask will be taken into account when computing the softmax
141 # meaning that non-masked values which are present in the initial blocksparse layout will be computed.
142 # If blocks are to be constantly masked, better perf would thus be reached by signalling them out in the
143 # initial attention setup
144
145 if att_mask is not None and att_mask.dtype == torch.bool:
146 self.update_mask_type(att_mask)
147 if key_padding_mask is not None and key_padding_mask.dtype == torch.bool:
148 self.update_mask_type(key_padding_mask)
149
150 assert (
151 att_mask is None or att_mask.dim() == 2
152 ), "The attention mask is constant across heads, expected dimensions are [seq x seq]"
153
154 assert (
155 q.shape[-2] == k.shape[-2]
156 ), "Blocksparse requires the same dimensions for K and Q for now"
157
158 assert (
159 q.shape[-2] == self.layout.shape[-2] * self.block_size
160 ), "Actual sequence size and layout are inconsistent"
161 assert (
162 k.shape[-2] == self.layout.shape[-2] * self.block_size
163 ), "Actual sequence size and layout are inconsistent"
164
165 assert math.log(
166 q.shape[-2], 2
167 ).is_integer(), (
168 "For now blocksparse only works on power-of-two sequence lengths"
169 )
170
171 # Blocksparse only works on fp16
172 q_dtype = q.dtype
173 q, k, v = q.half(), k.half(), v.half()
174
175 if att_mask is not None:
176 att_mask = att_mask.half()
177
178 if key_padding_mask is not None:
179 key_padding_mask = key_padding_mask.half()
180
181 # Self-attend: (B, nh, S, hs) x (B, nh, hs, S) -> (B, nh, S, S)
182 # When the computations are block sparse, the matrix types change along the way:
183 # - (sparse) attention matrix = (dense) Kt * (dense) Q
184 q = q / math.sqrt(q.size(-1))
185 sparse_att_mat = self.sparse_dot_sdd(q, k)
186
187 # - softmax on the sparse attention matrix
188 sparse_att_mat = self.sparse_softmax(
189 sparse_att_mat,
190 scale=scale,
191 key_padding_mask=key_padding_mask,
192 attn_mask=att_mask,
193 key_padding_mask_mode=MaskType.ADD,
194 attn_mask_mode=MaskType.ADD,
195 )
196
197 sparse_att_mat = self.attn_drop(sparse_att_mat)
198
199 # - then (dense) attention is (sparse) attention matrix * dense (value)
200 a = self.sparse_dot_dsd(sparse_att_mat, v)
201 return a.to(q_dtype)
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/xformers/components/attention/blocksparse.py b/xformers/components/attention/blocksparse.py
--- a/xformers/components/attention/blocksparse.py
+++ b/xformers/components/attention/blocksparse.py
@@ -52,6 +52,9 @@
.. warning: for now, the sequence (context) length has to be a power of two. This constraint could
be relaxed in the future.
+ .. warning: the block size has to be picked from [16, 32, 64]. Some speed is gained from bigger blocks.
+ It is of course possible to reproduce coarser patterns given these primitives, as the user sees fit.
+
.. note: it is possible to pass a specific per batch mask in the forward call,
but this will not lead to any speed up.
Any constant sparsity pattern is better passed through the layout parameter.
@@ -76,7 +79,11 @@
layout = layout.unsqueeze(0).expand(num_heads, -1, -1)
logging.warning(f"New layout dimensions: {layout.shape}")
- assert block_size >= 16, "Minimum block size is 16, for now at least"
+ assert block_size in (
+ 16,
+ 32,
+ 64,
+ ), "Only block sizes in [16, 32, 64] are supported"
super().__init__()
self.attn_drop = torch.nn.Dropout(dropout, inplace=False)
|
{"golden_diff": "diff --git a/xformers/components/attention/blocksparse.py b/xformers/components/attention/blocksparse.py\n--- a/xformers/components/attention/blocksparse.py\n+++ b/xformers/components/attention/blocksparse.py\n@@ -52,6 +52,9 @@\n .. warning: for now, the sequence (context) length has to be a power of two. This constraint could\n be relaxed in the future.\n \n+ .. warning: the block size has to be picked from [16, 32, 64]. Some speed is gained from bigger blocks.\n+ It is of course possible to reproduce coarser patterns given these primitives, as the user sees fit.\n+\n .. note: it is possible to pass a specific per batch mask in the forward call,\n but this will not lead to any speed up.\n Any constant sparsity pattern is better passed through the layout parameter.\n@@ -76,7 +79,11 @@\n layout = layout.unsqueeze(0).expand(num_heads, -1, -1)\n logging.warning(f\"New layout dimensions: {layout.shape}\")\n \n- assert block_size >= 16, \"Minimum block size is 16, for now at least\"\n+ assert block_size in (\n+ 16,\n+ 32,\n+ 64,\n+ ), \"Only block sizes in [16, 32, 64] are supported\"\n \n super().__init__()\n self.attn_drop = torch.nn.Dropout(dropout, inplace=False)\n", "issue": "blocksparse gives RuntimeError: CUDA: Error- illegal address when increase the block size\n# \ud83d\udc1b Bug\r\n\r\nI'm not sure whether this is a bug or simply a restriction of triton. But when I follow you doc here https://github.com/facebookresearch/xformers/blob/main/HOWTO.md#blocksparseattention\r\n\r\nThe sample works fine but it does not work when I increase the block size. \r\n\r\n## Command\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\nSimply replacing your hyperparameter like this \r\nBATCH = 1\r\nHEADS = 16\r\nSEQ = 8192\r\nEMB = 64 * HEADS\r\nBLOCK_SIZE = 512\r\nDROPOUT = 0.1\r\nshould reproduce the error \"RuntimeError: CUDA: Error- illegal address\"\r\n\r\n\r\n- PyTorch Version (e.g., 1.0): 1.10.2\r\n- OS (e.g., Linux): Ubuntu 18.04\r\n- How you installed PyTorch (`conda`, `pip`, source): pip\r\n- Build command you used (if compiling from source):\r\n- Python version: 3.8\r\n- CUDA/cuDNN version: 11.6\r\n- GPU models and configuration: A100\r\n- Any other relevant information:\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n\nimport logging\nimport math\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport torch\n\nfrom xformers import _is_triton_available\nfrom xformers.components.attention import Attention, AttentionConfig, register_attention\nfrom xformers.components.attention.utils import bool_mask_to_additive\n\n_mask_type_warning = True\n\nif _is_triton_available:\n from triton.ops.blocksparse import matmul as blocksparse_matmul # type: ignore\n from triton.ops.blocksparse import softmax as blocksparse_softmax # type: ignore\n\n from xformers.triton.softmax import MaskType\n from xformers.triton.utils import gpu_capabilities_older_than_70\n\n # Blocksparse requires Tensor cores\n if gpu_capabilities_older_than_70():\n logging.warning(\n \"Blocksparse is not available: the current GPU does not expose Tensor cores\"\n )\n _is_triton_available = False\n\n\nif _is_triton_available:\n\n @dataclass\n class BlockSparseAttentionConfig(AttentionConfig):\n layout: torch.Tensor # The dimensions of the random features\n block_size: int\n dropout: float\n num_heads: int\n\n @register_attention(\"blocksparse\", BlockSparseAttentionConfig)\n class BlockSparseAttention(Attention):\n r\"\"\"\n Thin wrap over the Triton blocksparse computations. The sparsity pattern is determined through the layout.\n\n .. warning: the layout is assumed to have the dimensions [heads, seq, seq].\n If some dimensions are missing, we assume that the same layout is to be used across heads.\n\n .. warning: for now, the sequence (context) length has to be a power of two. This constraint could\n be relaxed in the future.\n\n .. note: it is possible to pass a specific per batch mask in the forward call,\n but this will not lead to any speed up.\n Any constant sparsity pattern is better passed through the layout parameter.\n \"\"\"\n\n def __init__(\n self,\n layout: torch.Tensor,\n block_size: int = 16,\n dropout: float = 0.0,\n num_heads: int = 1, # optional, used to adapt the layout if in need\n *args,\n **kwargs,\n ):\n if layout.dim() == 2:\n logging.warning(\n \"The layout passed is lacking a head dimension and a batch dimension\"\n )\n logging.warning(\n \"Now assuming that the same layout is to be used across all heads\"\n )\n layout = layout.unsqueeze(0).expand(num_heads, -1, -1)\n logging.warning(f\"New layout dimensions: {layout.shape}\")\n\n assert block_size >= 16, \"Minimum block size is 16, for now at least\"\n\n super().__init__()\n self.attn_drop = torch.nn.Dropout(dropout, inplace=False)\n\n # Pure blocksparse data\n self.layout = layout\n self.block_size = block_size\n\n # blocksparse operators\n self.sparse_dot_sdd = blocksparse_matmul(\n self.layout,\n self.block_size,\n \"sdd\",\n trans_a=False,\n trans_b=True,\n )\n self.sparse_dot_dsd = blocksparse_matmul(\n self.layout,\n self.block_size,\n \"dsd\",\n trans_a=False,\n trans_b=False,\n )\n self.sparse_softmax = blocksparse_softmax(self.layout, self.block_size)\n\n # make sure that the head dimension is not folded down with the batch\n self.requires_head_dimension = True\n\n # key padding mask and attention mask must be passed in separately\n self.requires_separate_masks = True\n\n self.requires_same_k_q_dimensions = True\n\n def update_mask_type(self, mask: torch.Tensor):\n global _mask_type_warning\n if _mask_type_warning:\n logging.warning(\n \"Mask has to be additive. Fixing that but this slows things down\"\n )\n mask = bool_mask_to_additive(mask)\n\n def forward(\n self,\n q: torch.Tensor,\n k: torch.Tensor,\n v: torch.Tensor,\n att_mask: Optional[torch.Tensor] = None,\n key_padding_mask: Optional[torch.Tensor] = None,\n scale: float = 1.0,\n *args,\n **kwargs,\n ) -> torch.Tensor:\n r\"\"\"\n att_mask A 2D attention mask. The dtype must be the same as q. An additive mask is expected,\n meaning float values using \"-inf\" to mask values.\n key_padding_mask A mask with size (batch size x sequence length). The dtype must be the same as q.\n An additive mask is expected, meaning float values using \"-inf\" to mask values\n \"\"\"\n\n # NOTE:\n # The attention mask will be taken into account when computing the softmax\n # meaning that non-masked values which are present in the initial blocksparse layout will be computed.\n # If blocks are to be constantly masked, better perf would thus be reached by signalling them out in the\n # initial attention setup\n\n if att_mask is not None and att_mask.dtype == torch.bool:\n self.update_mask_type(att_mask)\n if key_padding_mask is not None and key_padding_mask.dtype == torch.bool:\n self.update_mask_type(key_padding_mask)\n\n assert (\n att_mask is None or att_mask.dim() == 2\n ), \"The attention mask is constant across heads, expected dimensions are [seq x seq]\"\n\n assert (\n q.shape[-2] == k.shape[-2]\n ), \"Blocksparse requires the same dimensions for K and Q for now\"\n\n assert (\n q.shape[-2] == self.layout.shape[-2] * self.block_size\n ), \"Actual sequence size and layout are inconsistent\"\n assert (\n k.shape[-2] == self.layout.shape[-2] * self.block_size\n ), \"Actual sequence size and layout are inconsistent\"\n\n assert math.log(\n q.shape[-2], 2\n ).is_integer(), (\n \"For now blocksparse only works on power-of-two sequence lengths\"\n )\n\n # Blocksparse only works on fp16\n q_dtype = q.dtype\n q, k, v = q.half(), k.half(), v.half()\n\n if att_mask is not None:\n att_mask = att_mask.half()\n\n if key_padding_mask is not None:\n key_padding_mask = key_padding_mask.half()\n\n # Self-attend: (B, nh, S, hs) x (B, nh, hs, S) -> (B, nh, S, S)\n # When the computations are block sparse, the matrix types change along the way:\n # - (sparse) attention matrix = (dense) Kt * (dense) Q\n q = q / math.sqrt(q.size(-1))\n sparse_att_mat = self.sparse_dot_sdd(q, k)\n\n # - softmax on the sparse attention matrix\n sparse_att_mat = self.sparse_softmax(\n sparse_att_mat,\n scale=scale,\n key_padding_mask=key_padding_mask,\n attn_mask=att_mask,\n key_padding_mask_mode=MaskType.ADD,\n attn_mask_mode=MaskType.ADD,\n )\n\n sparse_att_mat = self.attn_drop(sparse_att_mat)\n\n # - then (dense) attention is (sparse) attention matrix * dense (value)\n a = self.sparse_dot_dsd(sparse_att_mat, v)\n return a.to(q_dtype)\n", "path": "xformers/components/attention/blocksparse.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n\nimport logging\nimport math\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport torch\n\nfrom xformers import _is_triton_available\nfrom xformers.components.attention import Attention, AttentionConfig, register_attention\nfrom xformers.components.attention.utils import bool_mask_to_additive\n\n_mask_type_warning = True\n\nif _is_triton_available:\n from triton.ops.blocksparse import matmul as blocksparse_matmul # type: ignore\n from triton.ops.blocksparse import softmax as blocksparse_softmax # type: ignore\n\n from xformers.triton.softmax import MaskType\n from xformers.triton.utils import gpu_capabilities_older_than_70\n\n # Blocksparse requires Tensor cores\n if gpu_capabilities_older_than_70():\n logging.warning(\n \"Blocksparse is not available: the current GPU does not expose Tensor cores\"\n )\n _is_triton_available = False\n\n\nif _is_triton_available:\n\n @dataclass\n class BlockSparseAttentionConfig(AttentionConfig):\n layout: torch.Tensor # The dimensions of the random features\n block_size: int\n dropout: float\n num_heads: int\n\n @register_attention(\"blocksparse\", BlockSparseAttentionConfig)\n class BlockSparseAttention(Attention):\n r\"\"\"\n Thin wrap over the Triton blocksparse computations. The sparsity pattern is determined through the layout.\n\n .. warning: the layout is assumed to have the dimensions [heads, seq, seq].\n If some dimensions are missing, we assume that the same layout is to be used across heads.\n\n .. warning: for now, the sequence (context) length has to be a power of two. This constraint could\n be relaxed in the future.\n\n .. warning: the block size has to be picked from [16, 32, 64]. Some speed is gained from bigger blocks.\n It is of course possible to reproduce coarser patterns given these primitives, as the user sees fit.\n\n .. note: it is possible to pass a specific per batch mask in the forward call,\n but this will not lead to any speed up.\n Any constant sparsity pattern is better passed through the layout parameter.\n \"\"\"\n\n def __init__(\n self,\n layout: torch.Tensor,\n block_size: int = 16,\n dropout: float = 0.0,\n num_heads: int = 1, # optional, used to adapt the layout if in need\n *args,\n **kwargs,\n ):\n if layout.dim() == 2:\n logging.warning(\n \"The layout passed is lacking a head dimension and a batch dimension\"\n )\n logging.warning(\n \"Now assuming that the same layout is to be used across all heads\"\n )\n layout = layout.unsqueeze(0).expand(num_heads, -1, -1)\n logging.warning(f\"New layout dimensions: {layout.shape}\")\n\n assert block_size in (\n 16,\n 32,\n 64,\n ), \"Only block sizes in [16, 32, 64] are supported\"\n\n super().__init__()\n self.attn_drop = torch.nn.Dropout(dropout, inplace=False)\n\n # Pure blocksparse data\n self.layout = layout\n self.block_size = block_size\n\n # blocksparse operators\n self.sparse_dot_sdd = blocksparse_matmul(\n self.layout,\n self.block_size,\n \"sdd\",\n trans_a=False,\n trans_b=True,\n )\n self.sparse_dot_dsd = blocksparse_matmul(\n self.layout,\n self.block_size,\n \"dsd\",\n trans_a=False,\n trans_b=False,\n )\n self.sparse_softmax = blocksparse_softmax(self.layout, self.block_size)\n\n # make sure that the head dimension is not folded down with the batch\n self.requires_head_dimension = True\n\n # key padding mask and attention mask must be passed in separately\n self.requires_separate_masks = True\n\n self.requires_same_k_q_dimensions = True\n\n def update_mask_type(self, mask: torch.Tensor):\n global _mask_type_warning\n if _mask_type_warning:\n logging.warning(\n \"Mask has to be additive. Fixing that but this slows things down\"\n )\n mask = bool_mask_to_additive(mask)\n\n def forward(\n self,\n q: torch.Tensor,\n k: torch.Tensor,\n v: torch.Tensor,\n att_mask: Optional[torch.Tensor] = None,\n key_padding_mask: Optional[torch.Tensor] = None,\n scale: float = 1.0,\n *args,\n **kwargs,\n ) -> torch.Tensor:\n r\"\"\"\n att_mask A 2D attention mask. The dtype must be the same as q. An additive mask is expected,\n meaning float values using \"-inf\" to mask values.\n key_padding_mask A mask with size (batch size x sequence length). The dtype must be the same as q.\n An additive mask is expected, meaning float values using \"-inf\" to mask values\n \"\"\"\n\n # NOTE:\n # The attention mask will be taken into account when computing the softmax\n # meaning that non-masked values which are present in the initial blocksparse layout will be computed.\n # If blocks are to be constantly masked, better perf would thus be reached by signalling them out in the\n # initial attention setup\n\n if att_mask is not None and att_mask.dtype == torch.bool:\n self.update_mask_type(att_mask)\n if key_padding_mask is not None and key_padding_mask.dtype == torch.bool:\n self.update_mask_type(key_padding_mask)\n\n assert (\n att_mask is None or att_mask.dim() == 2\n ), \"The attention mask is constant across heads, expected dimensions are [seq x seq]\"\n\n assert (\n q.shape[-2] == k.shape[-2]\n ), \"Blocksparse requires the same dimensions for K and Q for now\"\n\n assert (\n q.shape[-2] == self.layout.shape[-2] * self.block_size\n ), \"Actual sequence size and layout are inconsistent\"\n assert (\n k.shape[-2] == self.layout.shape[-2] * self.block_size\n ), \"Actual sequence size and layout are inconsistent\"\n\n assert math.log(\n q.shape[-2], 2\n ).is_integer(), (\n \"For now blocksparse only works on power-of-two sequence lengths\"\n )\n\n # Blocksparse only works on fp16\n q_dtype = q.dtype\n q, k, v = q.half(), k.half(), v.half()\n\n if att_mask is not None:\n att_mask = att_mask.half()\n\n if key_padding_mask is not None:\n key_padding_mask = key_padding_mask.half()\n\n # Self-attend: (B, nh, S, hs) x (B, nh, hs, S) -> (B, nh, S, S)\n # When the computations are block sparse, the matrix types change along the way:\n # - (sparse) attention matrix = (dense) Kt * (dense) Q\n q = q / math.sqrt(q.size(-1))\n sparse_att_mat = self.sparse_dot_sdd(q, k)\n\n # - softmax on the sparse attention matrix\n sparse_att_mat = self.sparse_softmax(\n sparse_att_mat,\n scale=scale,\n key_padding_mask=key_padding_mask,\n attn_mask=att_mask,\n key_padding_mask_mode=MaskType.ADD,\n attn_mask_mode=MaskType.ADD,\n )\n\n sparse_att_mat = self.attn_drop(sparse_att_mat)\n\n # - then (dense) attention is (sparse) attention matrix * dense (value)\n a = self.sparse_dot_dsd(sparse_att_mat, v)\n return a.to(q_dtype)\n", "path": "xformers/components/attention/blocksparse.py"}]}
| 2,713 | 335 |
gh_patches_debug_7268
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-165
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
output/hydra.yaml is wrong
hydra.yaml in output directory is malformed (not rooted at hydra.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hydra/plugins/common/utils.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 import copy
4 import logging
5 import os
6 import re
7 import sys
8 from time import strftime, localtime
9
10 import six
11 from omegaconf import OmegaConf, DictConfig
12
13 # pylint: disable=C0103
14 log = logging.getLogger(__name__)
15
16
17 def configure_log(log_config, verbose=None):
18 if log_config is not None:
19 conf = log_config.to_container(resolve=True)
20 logging.config.dictConfig(conf)
21 else:
22 # default logging to stdout
23 root = logging.getLogger()
24 root.setLevel(logging.INFO)
25 handler = logging.StreamHandler(sys.stdout)
26 formatter = logging.Formatter(
27 "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
28 )
29 handler.setFormatter(formatter)
30 root.addHandler(handler)
31
32 if verbose is not None:
33 if verbose == "root":
34 logging.getLogger().setLevel(logging.DEBUG)
35 for logger in verbose.split(","):
36 logging.getLogger(logger).setLevel(logging.DEBUG)
37
38
39 def save_config(cfg, filename):
40 with open(os.path.join(filename), "w") as file:
41 file.write(cfg.pretty())
42
43
44 def get_overrides_dirname(lst, exclude_keys=[]):
45 lst = [x for x in lst if x not in exclude_keys]
46 lst.sort()
47 return re.sub(pattern="[=]", repl="=", string=",".join(lst))
48
49
50 def filter_overrides(overrides):
51 """
52 :param overrides: overrides list
53 :return: returning a new overrides list with all the keys starting with hydra. fitlered.
54 """
55 return [x for x in overrides if not x.startswith("hydra.")]
56
57
58 def run_job(config, task_function, verbose, job_dir_key, job_subdir_key):
59 old_cwd = os.getcwd()
60 working_dir = str(config.select(job_dir_key))
61 if job_subdir_key is not None:
62 # evaluate job_subdir_key lazily.
63 # this is running on the client side in sweep and contains things such as job:id which
64 # are only available there.
65 subdir = str(config.select(job_subdir_key))
66 working_dir = os.path.join(working_dir, subdir)
67 try:
68 ret = JobReturn()
69 ret.working_dir = working_dir
70 task_cfg = copy.deepcopy(config)
71 hydra_cfg = task_cfg["hydra"]
72 del task_cfg["hydra"]
73 ret.cfg = task_cfg
74 ret.hydra_cfg = copy.deepcopy(HydraConfig())
75 ret.overrides = config.hydra.overrides.task.to_container()
76 if not os.path.exists(working_dir):
77 os.makedirs(working_dir)
78 os.chdir(working_dir)
79 configure_log(config.hydra.job_logging, verbose)
80
81 save_config(task_cfg, "config.yaml")
82 save_config(hydra_cfg, "hydra.yaml")
83 save_config(config.hydra.overrides.task, "overrides.yaml")
84 ret.return_value = task_function(task_cfg)
85 ret.task_name = JobRuntime().get("name")
86 return ret
87 finally:
88 os.chdir(old_cwd)
89
90
91 def get_valid_filename(s):
92 s = str(s).strip().replace(" ", "_")
93 return re.sub(r"(?u)[^-\w.]", "", s)
94
95
96 def setup_globals():
97 try:
98 OmegaConf.register_resolver(
99 "now", lambda pattern: strftime(pattern, localtime())
100 )
101
102 def job_error(x):
103 raise Exception(
104 "job:{} is no longer available. use hydra.job.{}".format(x, x)
105 )
106
107 OmegaConf.register_resolver("job", job_error)
108
109 except AssertionError:
110 # calling it again in no_workers mode will throw. safe to ignore.
111 pass
112
113
114 class JobReturn:
115 def __init__(self):
116 self.overrides = None
117 self.return_value = None
118 self.cfg = None
119 self.hydra_cfg = None
120 self.working_dir = None
121 self.task_name = None
122
123
124 class Singleton(type):
125 _instances = {}
126
127 def __call__(cls, *args, **kwargs):
128 if cls not in cls._instances:
129 cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
130 return cls._instances[cls]
131
132 @staticmethod
133 def get_state():
134 return Singleton._instances
135
136 @staticmethod
137 def set_state(instances):
138 Singleton._instances = instances
139
140
141 @six.add_metaclass(Singleton)
142 class JobRuntime:
143 def __init__(self):
144 self.conf = OmegaConf.create()
145 self.set("name", "UNKNOWN_NAME")
146
147 def get(self, key):
148 ret = self.conf.select(key)
149 if ret is None:
150 raise KeyError("Key not found in {}: {}".format(type(self).__name__, key))
151 return ret
152
153 def set(self, key, value):
154 log.debug("Setting {}:{}={}".format(type(self).__name__, key, value))
155 self.conf[key] = value
156
157
158 @six.add_metaclass(Singleton)
159 class HydraConfig(DictConfig):
160 def __init__(self):
161 super(HydraConfig, self).__init__(content={})
162 self.hydra = None
163
164 def set_config(self, cfg):
165 try:
166 OmegaConf.set_readonly(self, False)
167 self.hydra = copy.deepcopy(cfg.hydra)
168 finally:
169 OmegaConf.set_readonly(self, True)
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hydra/plugins/common/utils.py b/hydra/plugins/common/utils.py
--- a/hydra/plugins/common/utils.py
+++ b/hydra/plugins/common/utils.py
@@ -68,7 +68,8 @@
ret = JobReturn()
ret.working_dir = working_dir
task_cfg = copy.deepcopy(config)
- hydra_cfg = task_cfg["hydra"]
+ # TODO: update this after https://github.com/omry/omegaconf/issues/42 is resolved
+ hydra_cfg = OmegaConf.create({"hydra": task_cfg["hydra"]});
del task_cfg["hydra"]
ret.cfg = task_cfg
ret.hydra_cfg = copy.deepcopy(HydraConfig())
|
{"golden_diff": "diff --git a/hydra/plugins/common/utils.py b/hydra/plugins/common/utils.py\n--- a/hydra/plugins/common/utils.py\n+++ b/hydra/plugins/common/utils.py\n@@ -68,7 +68,8 @@\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n- hydra_cfg = task_cfg[\"hydra\"]\n+ # TODO: update this after https://github.com/omry/omegaconf/issues/42 is resolved\n+ hydra_cfg = OmegaConf.create({\"hydra\": task_cfg[\"hydra\"]});\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = copy.deepcopy(HydraConfig())\n", "issue": "output/hydra.yaml is wrong\nhydra.yaml in output directory is malformed (not rooted at hydra.)\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nfrom time import strftime, localtime\n\nimport six\nfrom omegaconf import OmegaConf, DictConfig\n\n# pylint: disable=C0103\nlog = logging.getLogger(__name__)\n\n\ndef configure_log(log_config, verbose=None):\n if log_config is not None:\n conf = log_config.to_container(resolve=True)\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n if verbose is not None:\n if verbose == \"root\":\n logging.getLogger().setLevel(logging.DEBUG)\n for logger in verbose.split(\",\"):\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef save_config(cfg, filename):\n with open(os.path.join(filename), \"w\") as file:\n file.write(cfg.pretty())\n\n\ndef get_overrides_dirname(lst, exclude_keys=[]):\n lst = [x for x in lst if x not in exclude_keys]\n lst.sort()\n return re.sub(pattern=\"[=]\", repl=\"=\", string=\",\".join(lst))\n\n\ndef filter_overrides(overrides):\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. fitlered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef run_job(config, task_function, verbose, job_dir_key, job_subdir_key):\n old_cwd = os.getcwd()\n working_dir = str(config.select(job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(config.select(job_subdir_key))\n working_dir = os.path.join(working_dir, subdir)\n try:\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n hydra_cfg = task_cfg[\"hydra\"]\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = copy.deepcopy(HydraConfig())\n ret.overrides = config.hydra.overrides.task.to_container()\n if not os.path.exists(working_dir):\n os.makedirs(working_dir)\n os.chdir(working_dir)\n configure_log(config.hydra.job_logging, verbose)\n\n save_config(task_cfg, \"config.yaml\")\n save_config(hydra_cfg, \"hydra.yaml\")\n save_config(config.hydra.overrides.task, \"overrides.yaml\")\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime().get(\"name\")\n return ret\n finally:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s):\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals():\n try:\n OmegaConf.register_resolver(\n \"now\", lambda pattern: strftime(pattern, localtime())\n )\n\n def job_error(x):\n raise Exception(\n \"job:{} is no longer available. use hydra.job.{}\".format(x, x)\n )\n\n OmegaConf.register_resolver(\"job\", job_error)\n\n except AssertionError:\n # calling it again in no_workers mode will throw. safe to ignore.\n pass\n\n\nclass JobReturn:\n def __init__(self):\n self.overrides = None\n self.return_value = None\n self.cfg = None\n self.hydra_cfg = None\n self.working_dir = None\n self.task_name = None\n\n\nclass Singleton(type):\n _instances = {}\n\n def __call__(cls, *args, **kwargs):\n if cls not in cls._instances:\n cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)\n return cls._instances[cls]\n\n @staticmethod\n def get_state():\n return Singleton._instances\n\n @staticmethod\n def set_state(instances):\n Singleton._instances = instances\n\n\[email protected]_metaclass(Singleton)\nclass JobRuntime:\n def __init__(self):\n self.conf = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key):\n ret = self.conf.select(key)\n if ret is None:\n raise KeyError(\"Key not found in {}: {}\".format(type(self).__name__, key))\n return ret\n\n def set(self, key, value):\n log.debug(\"Setting {}:{}={}\".format(type(self).__name__, key, value))\n self.conf[key] = value\n\n\[email protected]_metaclass(Singleton)\nclass HydraConfig(DictConfig):\n def __init__(self):\n super(HydraConfig, self).__init__(content={})\n self.hydra = None\n\n def set_config(self, cfg):\n try:\n OmegaConf.set_readonly(self, False)\n self.hydra = copy.deepcopy(cfg.hydra)\n finally:\n OmegaConf.set_readonly(self, True)\n", "path": "hydra/plugins/common/utils.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nfrom time import strftime, localtime\n\nimport six\nfrom omegaconf import OmegaConf, DictConfig\n\n# pylint: disable=C0103\nlog = logging.getLogger(__name__)\n\n\ndef configure_log(log_config, verbose=None):\n if log_config is not None:\n conf = log_config.to_container(resolve=True)\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n if verbose is not None:\n if verbose == \"root\":\n logging.getLogger().setLevel(logging.DEBUG)\n for logger in verbose.split(\",\"):\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef save_config(cfg, filename):\n with open(os.path.join(filename), \"w\") as file:\n file.write(cfg.pretty())\n\n\ndef get_overrides_dirname(lst, exclude_keys=[]):\n lst = [x for x in lst if x not in exclude_keys]\n lst.sort()\n return re.sub(pattern=\"[=]\", repl=\"=\", string=\",\".join(lst))\n\n\ndef filter_overrides(overrides):\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. fitlered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef run_job(config, task_function, verbose, job_dir_key, job_subdir_key):\n old_cwd = os.getcwd()\n working_dir = str(config.select(job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(config.select(job_subdir_key))\n working_dir = os.path.join(working_dir, subdir)\n try:\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n # TODO: update this after https://github.com/omry/omegaconf/issues/42 is resolved\n hydra_cfg = OmegaConf.create({\"hydra\": task_cfg[\"hydra\"]});\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = copy.deepcopy(HydraConfig())\n ret.overrides = config.hydra.overrides.task.to_container()\n if not os.path.exists(working_dir):\n os.makedirs(working_dir)\n os.chdir(working_dir)\n configure_log(config.hydra.job_logging, verbose)\n\n save_config(task_cfg, \"config.yaml\")\n save_config(hydra_cfg, \"hydra.yaml\")\n save_config(config.hydra.overrides.task, \"overrides.yaml\")\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime().get(\"name\")\n return ret\n finally:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s):\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals():\n try:\n OmegaConf.register_resolver(\n \"now\", lambda pattern: strftime(pattern, localtime())\n )\n\n def job_error(x):\n raise Exception(\n \"job:{} is no longer available. use hydra.job.{}\".format(x, x)\n )\n\n OmegaConf.register_resolver(\"job\", job_error)\n\n except AssertionError:\n # calling it again in no_workers mode will throw. safe to ignore.\n pass\n\n\nclass JobReturn:\n def __init__(self):\n self.overrides = None\n self.return_value = None\n self.cfg = None\n self.hydra_cfg = None\n self.working_dir = None\n self.task_name = None\n\n\nclass Singleton(type):\n _instances = {}\n\n def __call__(cls, *args, **kwargs):\n if cls not in cls._instances:\n cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)\n return cls._instances[cls]\n\n @staticmethod\n def get_state():\n return Singleton._instances\n\n @staticmethod\n def set_state(instances):\n Singleton._instances = instances\n\n\[email protected]_metaclass(Singleton)\nclass JobRuntime:\n def __init__(self):\n self.conf = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key):\n ret = self.conf.select(key)\n if ret is None:\n raise KeyError(\"Key not found in {}: {}\".format(type(self).__name__, key))\n return ret\n\n def set(self, key, value):\n log.debug(\"Setting {}:{}={}\".format(type(self).__name__, key, value))\n self.conf[key] = value\n\n\[email protected]_metaclass(Singleton)\nclass HydraConfig(DictConfig):\n def __init__(self):\n super(HydraConfig, self).__init__(content={})\n self.hydra = None\n\n def set_config(self, cfg):\n try:\n OmegaConf.set_readonly(self, False)\n self.hydra = copy.deepcopy(cfg.hydra)\n finally:\n OmegaConf.set_readonly(self, True)\n", "path": "hydra/plugins/common/utils.py"}]}
| 1,844 | 160 |
gh_patches_debug_19703
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-5349
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't install new certificates with certbot-apache under Gentoo since version 0.20.0
It seems that version 0.20.0 has a major architecture revision from 0.19.0, in particular regarding OS specific overrides. But the Gentoo overrides have a flaw when trying to install a new certificate : at one point it tries to run "apache2ctl -t -D DUMP_MODULES", which is no good at all under Gentoo because apache2ctl is a dummy script redirecting to /etc/init.d/apache2. It generates this error :
`Error in checking parameter list: /etc/init.d/apache2: invalid option -- 't'`
## My operating system is (include version):
Gentoo
## I installed Certbot with (certbot-auto, OS package manager, pip, etc):
OS package manager (emerge) with testing (~amd64) flag
## I ran this command and it produced this output:
```
certbot -d test.example.com
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Plugins selected: Authenticator apache, Installer apache
Obtaining a new certificate
Performing the following challenges:
tls-sni-01 challenge for test.example.com
Waiting for verification...
Cleaning up challenges
Error in checking parameter list: /etc/init.d/apache2: invalid option -- 't'
Apache is unable to check whether or not the module is loaded because Apache is misconfigured.
```
## Certbot's behavior differed from what I expected because:
Certbot did not install the certificate because it failed to run apache2ctl -t -D DUMP_MODULES
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `certbot-apache/certbot_apache/override_gentoo.py`
Content:
```
1 """ Distribution specific override class for Gentoo Linux """
2 import pkg_resources
3
4 import zope.interface
5
6 from certbot import interfaces
7
8 from certbot_apache import apache_util
9 from certbot_apache import configurator
10 from certbot_apache import parser
11
12 @zope.interface.provider(interfaces.IPluginFactory)
13 class GentooConfigurator(configurator.ApacheConfigurator):
14 """Gentoo specific ApacheConfigurator override class"""
15
16 OS_DEFAULTS = dict(
17 server_root="/etc/apache2",
18 vhost_root="/etc/apache2/vhosts.d",
19 vhost_files="*.conf",
20 logs_root="/var/log/apache2",
21 version_cmd=['/usr/sbin/apache2', '-v'],
22 apache_cmd="apache2ctl",
23 restart_cmd=['apache2ctl', 'graceful'],
24 conftest_cmd=['apache2ctl', 'configtest'],
25 enmod=None,
26 dismod=None,
27 le_vhost_ext="-le-ssl.conf",
28 handle_mods=False,
29 handle_sites=False,
30 challenge_location="/etc/apache2/vhosts.d",
31 MOD_SSL_CONF_SRC=pkg_resources.resource_filename(
32 "certbot_apache", "options-ssl-apache.conf")
33 )
34
35 def get_parser(self):
36 """Initializes the ApacheParser"""
37 return GentooParser(
38 self.aug, self.conf("server-root"), self.conf("vhost-root"),
39 self.version, configurator=self)
40
41
42 class GentooParser(parser.ApacheParser):
43 """Gentoo specific ApacheParser override class"""
44 def __init__(self, *args, **kwargs):
45 # Gentoo specific configuration file for Apache2
46 self.apacheconfig_filep = "/etc/conf.d/apache2"
47 super(GentooParser, self).__init__(*args, **kwargs)
48
49 def update_runtime_variables(self):
50 """ Override for update_runtime_variables for custom parsing """
51 self.parse_sysconfig_var()
52
53 def parse_sysconfig_var(self):
54 """ Parses Apache CLI options from Gentoo configuration file """
55 defines = apache_util.parse_define_file(self.apacheconfig_filep,
56 "APACHE2_OPTS")
57 for k in defines.keys():
58 self.variables[k] = defines[k]
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/certbot-apache/certbot_apache/override_gentoo.py b/certbot-apache/certbot_apache/override_gentoo.py
--- a/certbot-apache/certbot_apache/override_gentoo.py
+++ b/certbot-apache/certbot_apache/override_gentoo.py
@@ -49,6 +49,7 @@
def update_runtime_variables(self):
""" Override for update_runtime_variables for custom parsing """
self.parse_sysconfig_var()
+ self.update_modules()
def parse_sysconfig_var(self):
""" Parses Apache CLI options from Gentoo configuration file """
@@ -56,3 +57,10 @@
"APACHE2_OPTS")
for k in defines.keys():
self.variables[k] = defines[k]
+
+ def update_modules(self):
+ """Get loaded modules from httpd process, and add them to DOM"""
+ mod_cmd = [self.configurator.constant("apache_cmd"), "modules"]
+ matches = self.parse_from_subprocess(mod_cmd, r"(.*)_module")
+ for mod in matches:
+ self.add_mod(mod.strip())
|
{"golden_diff": "diff --git a/certbot-apache/certbot_apache/override_gentoo.py b/certbot-apache/certbot_apache/override_gentoo.py\n--- a/certbot-apache/certbot_apache/override_gentoo.py\n+++ b/certbot-apache/certbot_apache/override_gentoo.py\n@@ -49,6 +49,7 @@\n def update_runtime_variables(self):\n \"\"\" Override for update_runtime_variables for custom parsing \"\"\"\n self.parse_sysconfig_var()\n+ self.update_modules()\n \n def parse_sysconfig_var(self):\n \"\"\" Parses Apache CLI options from Gentoo configuration file \"\"\"\n@@ -56,3 +57,10 @@\n \"APACHE2_OPTS\")\n for k in defines.keys():\n self.variables[k] = defines[k]\n+\n+ def update_modules(self):\n+ \"\"\"Get loaded modules from httpd process, and add them to DOM\"\"\"\n+ mod_cmd = [self.configurator.constant(\"apache_cmd\"), \"modules\"]\n+ matches = self.parse_from_subprocess(mod_cmd, r\"(.*)_module\")\n+ for mod in matches:\n+ self.add_mod(mod.strip())\n", "issue": "Can't install new certificates with certbot-apache under Gentoo since version 0.20.0\nIt seems that version 0.20.0 has a major architecture revision from 0.19.0, in particular regarding OS specific overrides. But the Gentoo overrides have a flaw when trying to install a new certificate : at one point it tries to run \"apache2ctl -t -D DUMP_MODULES\", which is no good at all under Gentoo because apache2ctl is a dummy script redirecting to /etc/init.d/apache2. It generates this error :\r\n\r\n`Error in checking parameter list: /etc/init.d/apache2: invalid option -- 't'`\r\n\r\n## My operating system is (include version):\r\nGentoo\r\n\r\n## I installed Certbot with (certbot-auto, OS package manager, pip, etc):\r\nOS package manager (emerge) with testing (~amd64) flag\r\n\r\n## I ran this command and it produced this output:\r\n```\r\ncertbot -d test.example.com\r\nSaving debug log to /var/log/letsencrypt/letsencrypt.log\r\nPlugins selected: Authenticator apache, Installer apache\r\nObtaining a new certificate\r\nPerforming the following challenges:\r\ntls-sni-01 challenge for test.example.com\r\nWaiting for verification...\r\nCleaning up challenges\r\nError in checking parameter list: /etc/init.d/apache2: invalid option -- 't'\r\n\r\nApache is unable to check whether or not the module is loaded because Apache is misconfigured.\r\n```\r\n\r\n## Certbot's behavior differed from what I expected because:\r\nCertbot did not install the certificate because it failed to run apache2ctl -t -D DUMP_MODULES\n", "before_files": [{"content": "\"\"\" Distribution specific override class for Gentoo Linux \"\"\"\nimport pkg_resources\n\nimport zope.interface\n\nfrom certbot import interfaces\n\nfrom certbot_apache import apache_util\nfrom certbot_apache import configurator\nfrom certbot_apache import parser\n\[email protected](interfaces.IPluginFactory)\nclass GentooConfigurator(configurator.ApacheConfigurator):\n \"\"\"Gentoo specific ApacheConfigurator override class\"\"\"\n\n OS_DEFAULTS = dict(\n server_root=\"/etc/apache2\",\n vhost_root=\"/etc/apache2/vhosts.d\",\n vhost_files=\"*.conf\",\n logs_root=\"/var/log/apache2\",\n version_cmd=['/usr/sbin/apache2', '-v'],\n apache_cmd=\"apache2ctl\",\n restart_cmd=['apache2ctl', 'graceful'],\n conftest_cmd=['apache2ctl', 'configtest'],\n enmod=None,\n dismod=None,\n le_vhost_ext=\"-le-ssl.conf\",\n handle_mods=False,\n handle_sites=False,\n challenge_location=\"/etc/apache2/vhosts.d\",\n MOD_SSL_CONF_SRC=pkg_resources.resource_filename(\n \"certbot_apache\", \"options-ssl-apache.conf\")\n )\n\n def get_parser(self):\n \"\"\"Initializes the ApacheParser\"\"\"\n return GentooParser(\n self.aug, self.conf(\"server-root\"), self.conf(\"vhost-root\"),\n self.version, configurator=self)\n\n\nclass GentooParser(parser.ApacheParser):\n \"\"\"Gentoo specific ApacheParser override class\"\"\"\n def __init__(self, *args, **kwargs):\n # Gentoo specific configuration file for Apache2\n self.apacheconfig_filep = \"/etc/conf.d/apache2\"\n super(GentooParser, self).__init__(*args, **kwargs)\n\n def update_runtime_variables(self):\n \"\"\" Override for update_runtime_variables for custom parsing \"\"\"\n self.parse_sysconfig_var()\n\n def parse_sysconfig_var(self):\n \"\"\" Parses Apache CLI options from Gentoo configuration file \"\"\"\n defines = apache_util.parse_define_file(self.apacheconfig_filep,\n \"APACHE2_OPTS\")\n for k in defines.keys():\n self.variables[k] = defines[k]\n", "path": "certbot-apache/certbot_apache/override_gentoo.py"}], "after_files": [{"content": "\"\"\" Distribution specific override class for Gentoo Linux \"\"\"\nimport pkg_resources\n\nimport zope.interface\n\nfrom certbot import interfaces\n\nfrom certbot_apache import apache_util\nfrom certbot_apache import configurator\nfrom certbot_apache import parser\n\[email protected](interfaces.IPluginFactory)\nclass GentooConfigurator(configurator.ApacheConfigurator):\n \"\"\"Gentoo specific ApacheConfigurator override class\"\"\"\n\n OS_DEFAULTS = dict(\n server_root=\"/etc/apache2\",\n vhost_root=\"/etc/apache2/vhosts.d\",\n vhost_files=\"*.conf\",\n logs_root=\"/var/log/apache2\",\n version_cmd=['/usr/sbin/apache2', '-v'],\n apache_cmd=\"apache2ctl\",\n restart_cmd=['apache2ctl', 'graceful'],\n conftest_cmd=['apache2ctl', 'configtest'],\n enmod=None,\n dismod=None,\n le_vhost_ext=\"-le-ssl.conf\",\n handle_mods=False,\n handle_sites=False,\n challenge_location=\"/etc/apache2/vhosts.d\",\n MOD_SSL_CONF_SRC=pkg_resources.resource_filename(\n \"certbot_apache\", \"options-ssl-apache.conf\")\n )\n\n def get_parser(self):\n \"\"\"Initializes the ApacheParser\"\"\"\n return GentooParser(\n self.aug, self.conf(\"server-root\"), self.conf(\"vhost-root\"),\n self.version, configurator=self)\n\n\nclass GentooParser(parser.ApacheParser):\n \"\"\"Gentoo specific ApacheParser override class\"\"\"\n def __init__(self, *args, **kwargs):\n # Gentoo specific configuration file for Apache2\n self.apacheconfig_filep = \"/etc/conf.d/apache2\"\n super(GentooParser, self).__init__(*args, **kwargs)\n\n def update_runtime_variables(self):\n \"\"\" Override for update_runtime_variables for custom parsing \"\"\"\n self.parse_sysconfig_var()\n self.update_modules()\n\n def parse_sysconfig_var(self):\n \"\"\" Parses Apache CLI options from Gentoo configuration file \"\"\"\n defines = apache_util.parse_define_file(self.apacheconfig_filep,\n \"APACHE2_OPTS\")\n for k in defines.keys():\n self.variables[k] = defines[k]\n\n def update_modules(self):\n \"\"\"Get loaded modules from httpd process, and add them to DOM\"\"\"\n mod_cmd = [self.configurator.constant(\"apache_cmd\"), \"modules\"]\n matches = self.parse_from_subprocess(mod_cmd, r\"(.*)_module\")\n for mod in matches:\n self.add_mod(mod.strip())\n", "path": "certbot-apache/certbot_apache/override_gentoo.py"}]}
| 1,185 | 251 |
gh_patches_debug_40058
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-452
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Recover 'doing' tasks from preempted workers
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticdl/python/elasticdl/master/k8s_worker_manager.py`
Content:
```
1 import logging
2 import os
3 import time
4
5 from collections import Counter
6 from elasticdl.master import k8s
7
8
9 class WorkerTracker(object):
10 def __init__(self):
11 # pod name to phase mapping
12 # phase: Pending/Running/Succeeded/Failed/Unknown
13 # Pending: worker pod not started yet
14 # Running: worker pod is running
15 # Succeeded: worker pod finishes all jobs and terminates with no issue.
16 # Failed: worker pod is killed for some reason
17 # Unknown: unkown
18 self._pods_phase = {}
19
20 def get_counters(self):
21 return Counter(self._pods_phase.values())
22
23 def event_cb(self, event):
24 pod_name = event["object"].metadata.name
25 self._pods_phase[pod_name] = event["object"].status.phase
26 if event["type"] == "DELETED":
27 del self._pods_phase[pod_name]
28
29
30 class WorkerManager(object):
31 def __init__(self, command, args, num_worker=1, cpu_request="1000m", cpu_limit="1000m",
32 memory_request="4096Mi", memory_limit="4096Mi", pod_priority=None, **kwargs):
33 self._logger = logging.getLogger("WorkerManager")
34 self._command = command
35 self._args = args
36 self._num_worker = num_worker
37 self._cpu_request = cpu_request
38 self._cpu_limit = cpu_limit
39 self._memory_request = memory_request
40 self._memory_limit = memory_limit
41 self._pod_priority = pod_priority
42 self._worker_tracker = WorkerTracker()
43 self._k8s_client = k8s.Client(
44 event_callback=self._worker_tracker.event_cb, **kwargs
45 )
46
47 def start_workers(self, restart_policy="OnFailure"):
48 for i in range(self._num_worker):
49 self._logger.warning("Starting worker: %d" % i)
50 self._add_worker(i, restart_policy=restart_policy)
51
52 def remove_workers(self):
53 for i in range(self._num_worker):
54 pod_name = self._k8s_client.get_pod_name(i)
55 if pod_name in self._worker_tracker._pods_phase:
56 self._logger.warning("Deleting worker: %d", i)
57 self._delete_worker(i)
58
59 def _add_worker(self, worker_id, restart_policy):
60 self._k8s_client.create_worker(
61 worker_id,
62 self._cpu_request,
63 self._cpu_limit,
64 self._memory_request,
65 self._memory_limit,
66 self._pod_priority,
67 command=self._command,
68 args=self._args + ["--worker_id", str(worker_id)],
69 restart_policy=restart_policy,
70 )
71
72 def _delete_worker(self, worker_id):
73 self._k8s_client.delete_worker(worker_id)
74
75 def get_counters(self):
76 return self._worker_tracker.get_counters()
77
```
Path: `elasticdl/python/elasticdl/master/task_queue.py`
Content:
```
1 """TaskQueue Implementation"""
2
3 import logging
4 import random
5 import threading
6
7
8 class _Task(object):
9 """Internal representation of a task"""
10
11 def __init__(self, *, file_name, start, end):
12 self.file_name = file_name
13 self.start = start
14 self.end = end
15
16
17 class _TaskQueue(object):
18 """Creates and dispatches Tasks. Keep track of a Task's lifecycle."""
19
20 def __init__(self, shards, record_per_task, num_epoch):
21 """
22 shards: a dictionary from RecordIO file name to number of records
23 """
24 self._logger = logging.getLogger("TaskQueue")
25 self._lock = threading.Lock()
26
27 self._num_epoch = num_epoch
28 self._epoch = 0
29 self._shards = shards
30 self._record_per_task = record_per_task
31
32 self._todo = []
33 # dictionary from task id to Task.
34 self._doing = {}
35 self._task_id = 0
36
37 self._create_tasks()
38
39 def _create_tasks(self):
40 for name, num_records in self._shards.items():
41 for start in range(0, num_records, self._record_per_task):
42 self._todo.append(
43 _Task(
44 file_name=name,
45 start=start,
46 end=min(start + self._record_per_task, num_records),
47 )
48 )
49 random.shuffle(self._todo)
50
51 def get(self, worker_id):
52 """Return next (task_id, Task) tuple"""
53
54 with self._lock:
55 if not self._todo and self._epoch < self._num_epoch - 1:
56 # Start a new epoch
57 self._create_tasks()
58 self._epoch += 1
59 self._logger.warning("Starting epoch %d" % self._epoch)
60
61 if not self._todo:
62 # No more tasks
63 return -1, None
64
65 self._task_id += 1
66 task = self._todo.pop()
67 # TODO: Handle timeout of tasks.
68 self._doing[self._task_id] = (worker_id, task)
69
70 return self._task_id, task
71
72 def report(self, task_id, success):
73 """Report if the task is successful or not"""
74
75 with self._lock:
76 _, task = self._doing.pop(task_id, (-1, None))
77 if not task:
78 self._logger.warning("Unknown task_id: %d" % task_id)
79 elif not success:
80 # TODO: keep count of retries.
81 self._todo.append(task)
82
83 def finished(self):
84 """Return if all tasks are done"""
85 return not self._todo and not self._doing
86
```
Path: `elasticdl/python/elasticdl/master/main.py`
Content:
```
1 import logging
2 import time
3 import argparse
4 import os
5
6 import grpc
7 import tensorflow as tf
8
9 tf.enable_eager_execution()
10
11 from concurrent import futures
12 from recordio import File
13 from elasticdl.proto import master_pb2_grpc
14 from elasticdl.master.servicer import MasterServicer
15 from elasticdl.master.task_queue import _TaskQueue
16 from elasticdl.master.k8s_worker_manager import WorkerManager
17 from elasticdl.common.model_helper import load_user_model, build_model
18
19
20 def _make_task_queue(data_dir, record_per_task, num_epoch):
21 f_records = {}
22 for f in os.listdir(data_dir):
23 p = os.path.join(data_dir, f)
24 with File(p, "r") as rio:
25 f_records[p] = rio.count()
26 return _TaskQueue(f_records, record_per_task, num_epoch)
27
28
29 def _parse_args():
30 parser = argparse.ArgumentParser(description="ElasticDL Master")
31 parser.add_argument(
32 "--model_file",
33 help="Full file path of user defined neural model",
34 required=True,
35 )
36 parser.add_argument(
37 "--train_data_dir",
38 help="Training data directory. Files should be in RecordIO format",
39 required=True,
40 )
41 parser.add_argument("--record_per_task", type=int, required=True)
42 parser.add_argument("--num_epoch", type=int, required=True)
43 parser.add_argument(
44 "--grads_to_wait",
45 type=int,
46 help="Number of gradients to wait before updating model",
47 required=True,
48 )
49 parser.add_argument(
50 "--minibatch_size",
51 type=int,
52 help="Minibatch size used by workers to compute gradients",
53 required=True,
54 )
55 parser.add_argument(
56 "--num_worker",
57 type=int,
58 help="the number of workers used in training",
59 default=0,
60 )
61 parser.add_argument(
62 "--worker_cpu_request",
63 help="the minimal cpu required by worker in training",
64 default="1000m",
65 )
66 parser.add_argument(
67 "--worker_cpu_limit",
68 help="the maximal cpu used by worker in training",
69 default="1000m",
70 )
71 parser.add_argument(
72 "--worker_memory_request",
73 help="the minimal memory required by worker in training",
74 default="4096Mi",
75 )
76 parser.add_argument(
77 "--worker_memory_limit",
78 help="the maximal memory used by worker in training",
79 default="4096Mi",
80 )
81 parser.add_argument(
82 "--worker_pod_priority",
83 help="the requested priority of worker pod")
84 parser.add_argument(
85 "--worker_image", help="docker image for worker", default=None
86 )
87 parser.add_argument("--job_name", help="job name", required=True)
88 parser.add_argument(
89 "--codec_type",
90 default="bytes",
91 choices=["tf_example", "bytes"],
92 help="Type of codec(tf_example or bytes)",
93 )
94 return parser.parse_args()
95
96
97 def main():
98 # TODO: pass port via flags.
99 PORT = 50001
100 logger = logging.getLogger("master")
101 args = _parse_args()
102 task_q = _make_task_queue(
103 args.train_data_dir, args.record_per_task, args.num_epoch
104 )
105 model_module = load_user_model(args.model_file)
106 model_inst = model_module.model
107 build_model(model_inst, model_module.feature_columns())
108 optimizer = model_module.optimizer()
109
110 server = grpc.server(futures.ThreadPoolExecutor(max_workers=64))
111 master_pb2_grpc.add_MasterServicer_to_server(
112 MasterServicer(
113 logger,
114 args.grads_to_wait,
115 args.minibatch_size,
116 optimizer,
117 task_q,
118 init_var=model_inst.trainable_variables,
119 ),
120 server,
121 )
122 server.add_insecure_port("[::]:{}".format(PORT))
123 server.start()
124 logger.warning("Server started at port: %d", PORT)
125
126 if args.num_worker:
127 master_addr = "%s:%d" % (os.getenv("MY_POD_IP", "localhost"), PORT)
128 worker_command = ["python"]
129 worker_args = [
130 "-m",
131 "elasticdl.worker.main",
132 "--model_file",
133 args.model_file,
134 "--master_addr",
135 master_addr,
136 "--codec_type",
137 args.codec_type
138 ]
139
140 worker_manager = WorkerManager(
141 job_name=args.job_name,
142 worker_image=args.worker_image,
143 command=worker_command,
144 args=worker_args,
145 namespace="default",
146 num_worker=args.num_worker,
147 cpu_request=args.worker_cpu_request,
148 cpu_limit=args.worker_cpu_limit,
149 memory_request=args.worker_memory_request,
150 memory_limit=args.worker_memory_limit,
151 pod_priority=args.worker_pod_priority,
152 )
153 worker_manager.start_workers(restart_policy="Never")
154
155 try:
156 while True:
157 if task_q.finished():
158 break
159 time.sleep(30)
160 except KeyboardInterrupt:
161 logger.warning("Server stopping")
162
163 if args.num_worker:
164 # TODO: worker_manager.remove_workers supports synchronized call
165 worker_manager.remove_workers()
166
167 server.stop(0)
168
169
170 if __name__ == "__main__":
171 logging.basicConfig()
172 main()
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticdl/python/elasticdl/master/k8s_worker_manager.py b/elasticdl/python/elasticdl/master/k8s_worker_manager.py
--- a/elasticdl/python/elasticdl/master/k8s_worker_manager.py
+++ b/elasticdl/python/elasticdl/master/k8s_worker_manager.py
@@ -6,8 +6,8 @@
from elasticdl.master import k8s
-class WorkerTracker(object):
- def __init__(self):
+class _WorkerTracker(object):
+ def __init__(self, task_q):
# pod name to phase mapping
# phase: Pending/Running/Succeeded/Failed/Unknown
# Pending: worker pod not started yet
@@ -16,6 +16,7 @@
# Failed: worker pod is killed for some reason
# Unknown: unkown
self._pods_phase = {}
+ self._task_q = task_q
def get_counters(self):
return Counter(self._pods_phase.values())
@@ -25,10 +26,15 @@
self._pods_phase[pod_name] = event["object"].status.phase
if event["type"] == "DELETED":
del self._pods_phase[pod_name]
+ self._task_q.recover_tasks(
+ # TODO: move worker_id and pod name mapping to a separate class
+ int(pod_name.rsplit("-", 1)[1])
+ )
+
class WorkerManager(object):
- def __init__(self, command, args, num_worker=1, cpu_request="1000m", cpu_limit="1000m",
+ def __init__(self, task_q, command, args, num_worker=1, cpu_request="1000m", cpu_limit="1000m",
memory_request="4096Mi", memory_limit="4096Mi", pod_priority=None, **kwargs):
self._logger = logging.getLogger("WorkerManager")
self._command = command
@@ -39,7 +45,7 @@
self._memory_request = memory_request
self._memory_limit = memory_limit
self._pod_priority = pod_priority
- self._worker_tracker = WorkerTracker()
+ self._worker_tracker = _WorkerTracker(task_q)
self._k8s_client = k8s.Client(
event_callback=self._worker_tracker.event_cb, **kwargs
)
diff --git a/elasticdl/python/elasticdl/master/main.py b/elasticdl/python/elasticdl/master/main.py
--- a/elasticdl/python/elasticdl/master/main.py
+++ b/elasticdl/python/elasticdl/master/main.py
@@ -138,6 +138,7 @@
]
worker_manager = WorkerManager(
+ task_q,
job_name=args.job_name,
worker_image=args.worker_image,
command=worker_command,
diff --git a/elasticdl/python/elasticdl/master/task_queue.py b/elasticdl/python/elasticdl/master/task_queue.py
--- a/elasticdl/python/elasticdl/master/task_queue.py
+++ b/elasticdl/python/elasticdl/master/task_queue.py
@@ -83,3 +83,10 @@
def finished(self):
"""Return if all tasks are done"""
return not self._todo and not self._doing
+
+ def recover_tasks(self, worker_id):
+ """Recover doing tasks for a dead worker"""
+
+ with self._lock:
+ tasks = [task for wid, task in self._doing if wid == worker_id]
+ self._todo.extend(tasks)
|
{"golden_diff": "diff --git a/elasticdl/python/elasticdl/master/k8s_worker_manager.py b/elasticdl/python/elasticdl/master/k8s_worker_manager.py\n--- a/elasticdl/python/elasticdl/master/k8s_worker_manager.py\n+++ b/elasticdl/python/elasticdl/master/k8s_worker_manager.py\n@@ -6,8 +6,8 @@\n from elasticdl.master import k8s\n \n \n-class WorkerTracker(object):\n- def __init__(self):\n+class _WorkerTracker(object):\n+ def __init__(self, task_q):\n # pod name to phase mapping\n # phase: Pending/Running/Succeeded/Failed/Unknown\n # Pending: worker pod not started yet\n@@ -16,6 +16,7 @@\n # Failed: worker pod is killed for some reason\n # Unknown: unkown\n self._pods_phase = {}\n+ self._task_q = task_q\n \n def get_counters(self):\n return Counter(self._pods_phase.values())\n@@ -25,10 +26,15 @@\n self._pods_phase[pod_name] = event[\"object\"].status.phase\n if event[\"type\"] == \"DELETED\":\n del self._pods_phase[pod_name]\n+ self._task_q.recover_tasks(\n+ # TODO: move worker_id and pod name mapping to a separate class \n+ int(pod_name.rsplit(\"-\", 1)[1])\n+ )\n+\n \n \n class WorkerManager(object):\n- def __init__(self, command, args, num_worker=1, cpu_request=\"1000m\", cpu_limit=\"1000m\",\n+ def __init__(self, task_q, command, args, num_worker=1, cpu_request=\"1000m\", cpu_limit=\"1000m\",\n memory_request=\"4096Mi\", memory_limit=\"4096Mi\", pod_priority=None, **kwargs):\n self._logger = logging.getLogger(\"WorkerManager\")\n self._command = command\n@@ -39,7 +45,7 @@\n self._memory_request = memory_request\n self._memory_limit = memory_limit\n self._pod_priority = pod_priority\n- self._worker_tracker = WorkerTracker()\n+ self._worker_tracker = _WorkerTracker(task_q)\n self._k8s_client = k8s.Client(\n event_callback=self._worker_tracker.event_cb, **kwargs\n )\ndiff --git a/elasticdl/python/elasticdl/master/main.py b/elasticdl/python/elasticdl/master/main.py\n--- a/elasticdl/python/elasticdl/master/main.py\n+++ b/elasticdl/python/elasticdl/master/main.py\n@@ -138,6 +138,7 @@\n ]\n \n worker_manager = WorkerManager(\n+ task_q,\n job_name=args.job_name,\n worker_image=args.worker_image,\n command=worker_command,\ndiff --git a/elasticdl/python/elasticdl/master/task_queue.py b/elasticdl/python/elasticdl/master/task_queue.py\n--- a/elasticdl/python/elasticdl/master/task_queue.py\n+++ b/elasticdl/python/elasticdl/master/task_queue.py\n@@ -83,3 +83,10 @@\n def finished(self):\n \"\"\"Return if all tasks are done\"\"\"\n return not self._todo and not self._doing\n+\n+ def recover_tasks(self, worker_id):\n+ \"\"\"Recover doing tasks for a dead worker\"\"\"\n+\n+ with self._lock:\n+ tasks = [task for wid, task in self._doing if wid == worker_id]\n+ self._todo.extend(tasks)\n", "issue": "Recover 'doing' tasks from preempted workers\n\n", "before_files": [{"content": "import logging\nimport os\nimport time\n\nfrom collections import Counter\nfrom elasticdl.master import k8s\n\n\nclass WorkerTracker(object):\n def __init__(self):\n # pod name to phase mapping\n # phase: Pending/Running/Succeeded/Failed/Unknown\n # Pending: worker pod not started yet\n # Running: worker pod is running\n # Succeeded: worker pod finishes all jobs and terminates with no issue.\n # Failed: worker pod is killed for some reason\n # Unknown: unkown\n self._pods_phase = {}\n\n def get_counters(self):\n return Counter(self._pods_phase.values())\n\n def event_cb(self, event):\n pod_name = event[\"object\"].metadata.name\n self._pods_phase[pod_name] = event[\"object\"].status.phase\n if event[\"type\"] == \"DELETED\":\n del self._pods_phase[pod_name]\n\n\nclass WorkerManager(object):\n def __init__(self, command, args, num_worker=1, cpu_request=\"1000m\", cpu_limit=\"1000m\",\n memory_request=\"4096Mi\", memory_limit=\"4096Mi\", pod_priority=None, **kwargs):\n self._logger = logging.getLogger(\"WorkerManager\")\n self._command = command\n self._args = args\n self._num_worker = num_worker\n self._cpu_request = cpu_request \n self._cpu_limit = cpu_limit\n self._memory_request = memory_request\n self._memory_limit = memory_limit\n self._pod_priority = pod_priority\n self._worker_tracker = WorkerTracker()\n self._k8s_client = k8s.Client(\n event_callback=self._worker_tracker.event_cb, **kwargs\n )\n\n def start_workers(self, restart_policy=\"OnFailure\"):\n for i in range(self._num_worker):\n self._logger.warning(\"Starting worker: %d\" % i)\n self._add_worker(i, restart_policy=restart_policy)\n\n def remove_workers(self):\n for i in range(self._num_worker):\n pod_name = self._k8s_client.get_pod_name(i)\n if pod_name in self._worker_tracker._pods_phase:\n self._logger.warning(\"Deleting worker: %d\", i)\n self._delete_worker(i)\n\n def _add_worker(self, worker_id, restart_policy):\n self._k8s_client.create_worker(\n worker_id,\n self._cpu_request,\n self._cpu_limit,\n self._memory_request,\n self._memory_limit,\n self._pod_priority,\n command=self._command,\n args=self._args + [\"--worker_id\", str(worker_id)],\n restart_policy=restart_policy,\n )\n\n def _delete_worker(self, worker_id):\n self._k8s_client.delete_worker(worker_id)\n\n def get_counters(self):\n return self._worker_tracker.get_counters()\n", "path": "elasticdl/python/elasticdl/master/k8s_worker_manager.py"}, {"content": "\"\"\"TaskQueue Implementation\"\"\"\n\nimport logging\nimport random\nimport threading\n\n\nclass _Task(object):\n \"\"\"Internal representation of a task\"\"\"\n\n def __init__(self, *, file_name, start, end):\n self.file_name = file_name\n self.start = start\n self.end = end\n\n\nclass _TaskQueue(object):\n \"\"\"Creates and dispatches Tasks. Keep track of a Task's lifecycle.\"\"\"\n\n def __init__(self, shards, record_per_task, num_epoch):\n \"\"\"\n shards: a dictionary from RecordIO file name to number of records\n \"\"\"\n self._logger = logging.getLogger(\"TaskQueue\")\n self._lock = threading.Lock()\n\n self._num_epoch = num_epoch\n self._epoch = 0\n self._shards = shards\n self._record_per_task = record_per_task\n\n self._todo = []\n # dictionary from task id to Task.\n self._doing = {}\n self._task_id = 0\n\n self._create_tasks()\n\n def _create_tasks(self):\n for name, num_records in self._shards.items():\n for start in range(0, num_records, self._record_per_task):\n self._todo.append(\n _Task(\n file_name=name,\n start=start,\n end=min(start + self._record_per_task, num_records),\n )\n )\n random.shuffle(self._todo)\n\n def get(self, worker_id):\n \"\"\"Return next (task_id, Task) tuple\"\"\"\n\n with self._lock:\n if not self._todo and self._epoch < self._num_epoch - 1:\n # Start a new epoch\n self._create_tasks()\n self._epoch += 1\n self._logger.warning(\"Starting epoch %d\" % self._epoch)\n\n if not self._todo:\n # No more tasks\n return -1, None\n\n self._task_id += 1\n task = self._todo.pop()\n # TODO: Handle timeout of tasks.\n self._doing[self._task_id] = (worker_id, task)\n\n return self._task_id, task\n\n def report(self, task_id, success):\n \"\"\"Report if the task is successful or not\"\"\"\n\n with self._lock:\n _, task = self._doing.pop(task_id, (-1, None))\n if not task:\n self._logger.warning(\"Unknown task_id: %d\" % task_id)\n elif not success:\n # TODO: keep count of retries.\n self._todo.append(task)\n\n def finished(self):\n \"\"\"Return if all tasks are done\"\"\"\n return not self._todo and not self._doing\n", "path": "elasticdl/python/elasticdl/master/task_queue.py"}, {"content": "import logging\nimport time\nimport argparse\nimport os\n\nimport grpc\nimport tensorflow as tf\n\ntf.enable_eager_execution()\n\nfrom concurrent import futures\nfrom recordio import File\nfrom elasticdl.proto import master_pb2_grpc\nfrom elasticdl.master.servicer import MasterServicer\nfrom elasticdl.master.task_queue import _TaskQueue\nfrom elasticdl.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.common.model_helper import load_user_model, build_model\n\n\ndef _make_task_queue(data_dir, record_per_task, num_epoch):\n f_records = {}\n for f in os.listdir(data_dir):\n p = os.path.join(data_dir, f)\n with File(p, \"r\") as rio:\n f_records[p] = rio.count()\n return _TaskQueue(f_records, record_per_task, num_epoch)\n\n\ndef _parse_args():\n parser = argparse.ArgumentParser(description=\"ElasticDL Master\")\n parser.add_argument(\n \"--model_file\",\n help=\"Full file path of user defined neural model\",\n required=True,\n )\n parser.add_argument(\n \"--train_data_dir\",\n help=\"Training data directory. Files should be in RecordIO format\",\n required=True,\n )\n parser.add_argument(\"--record_per_task\", type=int, required=True)\n parser.add_argument(\"--num_epoch\", type=int, required=True)\n parser.add_argument(\n \"--grads_to_wait\",\n type=int,\n help=\"Number of gradients to wait before updating model\",\n required=True,\n )\n parser.add_argument(\n \"--minibatch_size\",\n type=int,\n help=\"Minibatch size used by workers to compute gradients\",\n required=True,\n )\n parser.add_argument(\n \"--num_worker\",\n type=int,\n help=\"the number of workers used in training\",\n default=0,\n )\n parser.add_argument(\n \"--worker_cpu_request\",\n help=\"the minimal cpu required by worker in training\",\n default=\"1000m\",\n )\n parser.add_argument(\n \"--worker_cpu_limit\",\n help=\"the maximal cpu used by worker in training\",\n default=\"1000m\",\n )\n parser.add_argument(\n \"--worker_memory_request\",\n help=\"the minimal memory required by worker in training\",\n default=\"4096Mi\",\n )\n parser.add_argument(\n \"--worker_memory_limit\",\n help=\"the maximal memory used by worker in training\",\n default=\"4096Mi\",\n )\n parser.add_argument(\n \"--worker_pod_priority\",\n help=\"the requested priority of worker pod\")\n parser.add_argument(\n \"--worker_image\", help=\"docker image for worker\", default=None\n )\n parser.add_argument(\"--job_name\", help=\"job name\", required=True)\n parser.add_argument(\n \"--codec_type\",\n default=\"bytes\",\n choices=[\"tf_example\", \"bytes\"],\n help=\"Type of codec(tf_example or bytes)\",\n )\n return parser.parse_args()\n\n\ndef main():\n # TODO: pass port via flags.\n PORT = 50001\n logger = logging.getLogger(\"master\")\n args = _parse_args()\n task_q = _make_task_queue(\n args.train_data_dir, args.record_per_task, args.num_epoch\n )\n model_module = load_user_model(args.model_file)\n model_inst = model_module.model\n build_model(model_inst, model_module.feature_columns())\n optimizer = model_module.optimizer()\n\n server = grpc.server(futures.ThreadPoolExecutor(max_workers=64))\n master_pb2_grpc.add_MasterServicer_to_server(\n MasterServicer(\n logger,\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_q,\n init_var=model_inst.trainable_variables,\n ),\n server,\n )\n server.add_insecure_port(\"[::]:{}\".format(PORT))\n server.start()\n logger.warning(\"Server started at port: %d\", PORT)\n\n if args.num_worker:\n master_addr = \"%s:%d\" % (os.getenv(\"MY_POD_IP\", \"localhost\"), PORT)\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.worker.main\",\n \"--model_file\",\n args.model_file,\n \"--master_addr\",\n master_addr,\n \"--codec_type\",\n args.codec_type\n ]\n\n worker_manager = WorkerManager(\n job_name=args.job_name,\n worker_image=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=\"default\",\n num_worker=args.num_worker,\n cpu_request=args.worker_cpu_request,\n cpu_limit=args.worker_cpu_limit,\n memory_request=args.worker_memory_request,\n memory_limit=args.worker_memory_limit,\n pod_priority=args.worker_pod_priority,\n )\n worker_manager.start_workers(restart_policy=\"Never\")\n\n try:\n while True:\n if task_q.finished():\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if args.num_worker:\n # TODO: worker_manager.remove_workers supports synchronized call\n worker_manager.remove_workers()\n\n server.stop(0)\n\n\nif __name__ == \"__main__\":\n logging.basicConfig()\n main()\n", "path": "elasticdl/python/elasticdl/master/main.py"}], "after_files": [{"content": "import logging\nimport os\nimport time\n\nfrom collections import Counter\nfrom elasticdl.master import k8s\n\n\nclass _WorkerTracker(object):\n def __init__(self, task_q):\n # pod name to phase mapping\n # phase: Pending/Running/Succeeded/Failed/Unknown\n # Pending: worker pod not started yet\n # Running: worker pod is running\n # Succeeded: worker pod finishes all jobs and terminates with no issue.\n # Failed: worker pod is killed for some reason\n # Unknown: unkown\n self._pods_phase = {}\n self._task_q = task_q\n\n def get_counters(self):\n return Counter(self._pods_phase.values())\n\n def event_cb(self, event):\n pod_name = event[\"object\"].metadata.name\n self._pods_phase[pod_name] = event[\"object\"].status.phase\n if event[\"type\"] == \"DELETED\":\n del self._pods_phase[pod_name]\n self._task_q.recover_tasks(\n # TODO: move worker_id and pod name mapping to a separate class \n int(pod_name.rsplit(\"-\", 1)[1])\n )\n\n\n\nclass WorkerManager(object):\n def __init__(self, task_q, command, args, num_worker=1, cpu_request=\"1000m\", cpu_limit=\"1000m\",\n memory_request=\"4096Mi\", memory_limit=\"4096Mi\", pod_priority=None, **kwargs):\n self._logger = logging.getLogger(\"WorkerManager\")\n self._command = command\n self._args = args\n self._num_worker = num_worker\n self._cpu_request = cpu_request \n self._cpu_limit = cpu_limit\n self._memory_request = memory_request\n self._memory_limit = memory_limit\n self._pod_priority = pod_priority\n self._worker_tracker = _WorkerTracker(task_q)\n self._k8s_client = k8s.Client(\n event_callback=self._worker_tracker.event_cb, **kwargs\n )\n\n def start_workers(self, restart_policy=\"OnFailure\"):\n for i in range(self._num_worker):\n self._logger.warning(\"Starting worker: %d\" % i)\n self._add_worker(i, restart_policy=restart_policy)\n\n def remove_workers(self):\n for i in range(self._num_worker):\n pod_name = self._k8s_client.get_pod_name(i)\n if pod_name in self._worker_tracker._pods_phase:\n self._logger.warning(\"Deleting worker: %d\", i)\n self._delete_worker(i)\n\n def _add_worker(self, worker_id, restart_policy):\n self._k8s_client.create_worker(\n worker_id,\n self._cpu_request,\n self._cpu_limit,\n self._memory_request,\n self._memory_limit,\n self._pod_priority,\n command=self._command,\n args=self._args + [\"--worker_id\", str(worker_id)],\n restart_policy=restart_policy,\n )\n\n def _delete_worker(self, worker_id):\n self._k8s_client.delete_worker(worker_id)\n\n def get_counters(self):\n return self._worker_tracker.get_counters()\n", "path": "elasticdl/python/elasticdl/master/k8s_worker_manager.py"}, {"content": "\"\"\"TaskQueue Implementation\"\"\"\n\nimport logging\nimport random\nimport threading\n\n\nclass _Task(object):\n \"\"\"Internal representation of a task\"\"\"\n\n def __init__(self, *, file_name, start, end):\n self.file_name = file_name\n self.start = start\n self.end = end\n\n\nclass _TaskQueue(object):\n \"\"\"Creates and dispatches Tasks. Keep track of a Task's lifecycle.\"\"\"\n\n def __init__(self, shards, record_per_task, num_epoch):\n \"\"\"\n shards: a dictionary from RecordIO file name to number of records\n \"\"\"\n self._logger = logging.getLogger(\"TaskQueue\")\n self._lock = threading.Lock()\n\n self._num_epoch = num_epoch\n self._epoch = 0\n self._shards = shards\n self._record_per_task = record_per_task\n\n self._todo = []\n # dictionary from task id to Task.\n self._doing = {}\n self._task_id = 0\n\n self._create_tasks()\n\n def _create_tasks(self):\n for name, num_records in self._shards.items():\n for start in range(0, num_records, self._record_per_task):\n self._todo.append(\n _Task(\n file_name=name,\n start=start,\n end=min(start + self._record_per_task, num_records),\n )\n )\n random.shuffle(self._todo)\n\n def get(self, worker_id):\n \"\"\"Return next (task_id, Task) tuple\"\"\"\n\n with self._lock:\n if not self._todo and self._epoch < self._num_epoch - 1:\n # Start a new epoch\n self._create_tasks()\n self._epoch += 1\n self._logger.warning(\"Starting epoch %d\" % self._epoch)\n\n if not self._todo:\n # No more tasks\n return -1, None\n\n self._task_id += 1\n task = self._todo.pop()\n # TODO: Handle timeout of tasks.\n self._doing[self._task_id] = (worker_id, task)\n\n return self._task_id, task\n\n def report(self, task_id, success):\n \"\"\"Report if the task is successful or not\"\"\"\n\n with self._lock:\n _, task = self._doing.pop(task_id, (-1, None))\n if not task:\n self._logger.warning(\"Unknown task_id: %d\" % task_id)\n elif not success:\n # TODO: keep count of retries.\n self._todo.append(task)\n\n def finished(self):\n \"\"\"Return if all tasks are done\"\"\"\n return not self._todo and not self._doing\n\n def recover_tasks(self, worker_id):\n \"\"\"Recover doing tasks for a dead worker\"\"\"\n\n with self._lock:\n tasks = [task for wid, task in self._doing if wid == worker_id]\n self._todo.extend(tasks)\n", "path": "elasticdl/python/elasticdl/master/task_queue.py"}, {"content": "import logging\nimport time\nimport argparse\nimport os\n\nimport grpc\nimport tensorflow as tf\n\ntf.enable_eager_execution()\n\nfrom concurrent import futures\nfrom recordio import File\nfrom elasticdl.proto import master_pb2_grpc\nfrom elasticdl.master.servicer import MasterServicer\nfrom elasticdl.master.task_queue import _TaskQueue\nfrom elasticdl.master.k8s_worker_manager import WorkerManager\nfrom elasticdl.common.model_helper import load_user_model, build_model\n\n\ndef _make_task_queue(data_dir, record_per_task, num_epoch):\n f_records = {}\n for f in os.listdir(data_dir):\n p = os.path.join(data_dir, f)\n with File(p, \"r\") as rio:\n f_records[p] = rio.count()\n return _TaskQueue(f_records, record_per_task, num_epoch)\n\n\ndef _parse_args():\n parser = argparse.ArgumentParser(description=\"ElasticDL Master\")\n parser.add_argument(\n \"--model_file\",\n help=\"Full file path of user defined neural model\",\n required=True,\n )\n parser.add_argument(\n \"--train_data_dir\",\n help=\"Training data directory. Files should be in RecordIO format\",\n required=True,\n )\n parser.add_argument(\"--record_per_task\", type=int, required=True)\n parser.add_argument(\"--num_epoch\", type=int, required=True)\n parser.add_argument(\n \"--grads_to_wait\",\n type=int,\n help=\"Number of gradients to wait before updating model\",\n required=True,\n )\n parser.add_argument(\n \"--minibatch_size\",\n type=int,\n help=\"Minibatch size used by workers to compute gradients\",\n required=True,\n )\n parser.add_argument(\n \"--num_worker\",\n type=int,\n help=\"the number of workers used in training\",\n default=0,\n )\n parser.add_argument(\n \"--worker_cpu_request\",\n help=\"the minimal cpu required by worker in training\",\n default=\"1000m\",\n )\n parser.add_argument(\n \"--worker_cpu_limit\",\n help=\"the maximal cpu used by worker in training\",\n default=\"1000m\",\n )\n parser.add_argument(\n \"--worker_memory_request\",\n help=\"the minimal memory required by worker in training\",\n default=\"4096Mi\",\n )\n parser.add_argument(\n \"--worker_memory_limit\",\n help=\"the maximal memory used by worker in training\",\n default=\"4096Mi\",\n )\n parser.add_argument(\n \"--worker_pod_priority\",\n help=\"the requested priority of worker pod\")\n parser.add_argument(\n \"--worker_image\", help=\"docker image for worker\", default=None\n )\n parser.add_argument(\"--job_name\", help=\"job name\", required=True)\n parser.add_argument(\n \"--codec_type\",\n default=\"bytes\",\n choices=[\"tf_example\", \"bytes\"],\n help=\"Type of codec(tf_example or bytes)\",\n )\n return parser.parse_args()\n\n\ndef main():\n # TODO: pass port via flags.\n PORT = 50001\n logger = logging.getLogger(\"master\")\n args = _parse_args()\n task_q = _make_task_queue(\n args.train_data_dir, args.record_per_task, args.num_epoch\n )\n model_module = load_user_model(args.model_file)\n model_inst = model_module.model\n build_model(model_inst, model_module.feature_columns())\n optimizer = model_module.optimizer()\n\n server = grpc.server(futures.ThreadPoolExecutor(max_workers=64))\n master_pb2_grpc.add_MasterServicer_to_server(\n MasterServicer(\n logger,\n args.grads_to_wait,\n args.minibatch_size,\n optimizer,\n task_q,\n init_var=model_inst.trainable_variables,\n ),\n server,\n )\n server.add_insecure_port(\"[::]:{}\".format(PORT))\n server.start()\n logger.warning(\"Server started at port: %d\", PORT)\n\n if args.num_worker:\n master_addr = \"%s:%d\" % (os.getenv(\"MY_POD_IP\", \"localhost\"), PORT)\n worker_command = [\"python\"]\n worker_args = [\n \"-m\",\n \"elasticdl.worker.main\",\n \"--model_file\",\n args.model_file,\n \"--master_addr\",\n master_addr,\n \"--codec_type\",\n args.codec_type\n ]\n\n worker_manager = WorkerManager(\n task_q,\n job_name=args.job_name,\n worker_image=args.worker_image,\n command=worker_command,\n args=worker_args,\n namespace=\"default\",\n num_worker=args.num_worker,\n cpu_request=args.worker_cpu_request,\n cpu_limit=args.worker_cpu_limit,\n memory_request=args.worker_memory_request,\n memory_limit=args.worker_memory_limit,\n pod_priority=args.worker_pod_priority,\n )\n worker_manager.start_workers(restart_policy=\"Never\")\n\n try:\n while True:\n if task_q.finished():\n break\n time.sleep(30)\n except KeyboardInterrupt:\n logger.warning(\"Server stopping\")\n\n if args.num_worker:\n # TODO: worker_manager.remove_workers supports synchronized call\n worker_manager.remove_workers()\n\n server.stop(0)\n\n\nif __name__ == \"__main__\":\n logging.basicConfig()\n main()\n", "path": "elasticdl/python/elasticdl/master/main.py"}]}
| 3,346 | 786 |
gh_patches_debug_2097
|
rasdani/github-patches
|
git_diff
|
sosreport__sos-1100
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[rabbitmq] does not elide password in /etc/rabbitmq.config
Hi,
Sosreport as in sos-3.2-36.eo7ost.1.noarch includes in `/etc/rabbitmq/rabbitmq.conf` `default_user` and `default_pass` without being hidden.
Regards,
Pablo
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sos/plugins/rabbitmq.py`
Content:
```
1 # This program is free software; you can redistribute it and/or modify
2 # it under the terms of the GNU General Public License as published by
3 # the Free Software Foundation; either version 2 of the License, or
4 # (at your option) any later version.
5
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10
11 # You should have received a copy of the GNU General Public License along
12 # with this program; if not, write to the Free Software Foundation, Inc.,
13 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
14
15 from sos.plugins import Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin
16
17
18 class RabbitMQ(Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin):
19 """RabbitMQ messaging service
20 """
21 plugin_name = 'rabbitmq'
22 profiles = ('services',)
23 var_puppet_gen = "/var/lib/config-data/puppet-generated/rabbitmq"
24 files = (
25 '/etc/rabbitmq/rabbitmq.conf',
26 var_puppet_gen + '/etc/rabbitmq/rabbitmq.config'
27 )
28 packages = ('rabbitmq-server',)
29
30 def setup(self):
31 container_status = self.get_command_output(
32 "docker ps -a --format='{{ .Names }}'")
33
34 in_container = False
35 container_names = []
36 if container_status['status'] == 0:
37 for line in container_status['output'].splitlines():
38 if line.startswith("rabbitmq"):
39 in_container = True
40 container_names.append(line)
41
42 if in_container:
43 for container in container_names:
44 self.add_cmd_output('docker logs {0}'.format(container))
45 self.add_cmd_output(
46 'docker exec -t {0} rabbitmqctl report'
47 .format(container)
48 )
49 else:
50 self.add_cmd_output("rabbitmqctl report")
51
52 self.add_copy_spec([
53 "/etc/rabbitmq/*",
54 self.var_puppet_gen + "/etc/rabbitmq/*",
55 self.var_puppet_gen + "/etc/security/limits.d/",
56 self.var_puppet_gen + "/etc/systemd/"
57 ])
58 self.add_copy_spec([
59 "/var/log/rabbitmq/*",
60 "/var/log/containers/rabbitmq/*"
61 ], sizelimit=self.get_option('log_size'))
62
63
64 # vim: set et ts=4 sw=4 :
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sos/plugins/rabbitmq.py b/sos/plugins/rabbitmq.py
--- a/sos/plugins/rabbitmq.py
+++ b/sos/plugins/rabbitmq.py
@@ -60,5 +60,8 @@
"/var/log/containers/rabbitmq/*"
], sizelimit=self.get_option('log_size'))
+ def postproc(self):
+ self.do_file_sub("/etc/rabbitmq/rabbitmq.conf",
+ r"(\s*default_pass\s*,\s*)\S+", r"\1<<***>>},")
# vim: set et ts=4 sw=4 :
|
{"golden_diff": "diff --git a/sos/plugins/rabbitmq.py b/sos/plugins/rabbitmq.py\n--- a/sos/plugins/rabbitmq.py\n+++ b/sos/plugins/rabbitmq.py\n@@ -60,5 +60,8 @@\n \"/var/log/containers/rabbitmq/*\"\n ], sizelimit=self.get_option('log_size'))\n \n+ def postproc(self):\n+ self.do_file_sub(\"/etc/rabbitmq/rabbitmq.conf\",\n+ r\"(\\s*default_pass\\s*,\\s*)\\S+\", r\"\\1<<***>>},\")\n \n # vim: set et ts=4 sw=4 :\n", "issue": "[rabbitmq] does not elide password in /etc/rabbitmq.config\nHi,\nSosreport as in sos-3.2-36.eo7ost.1.noarch includes in `/etc/rabbitmq/rabbitmq.conf` `default_user` and `default_pass` without being hidden.\n\nRegards,\nPablo\n\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nfrom sos.plugins import Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin\n\n\nclass RabbitMQ(Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin):\n \"\"\"RabbitMQ messaging service\n \"\"\"\n plugin_name = 'rabbitmq'\n profiles = ('services',)\n var_puppet_gen = \"/var/lib/config-data/puppet-generated/rabbitmq\"\n files = (\n '/etc/rabbitmq/rabbitmq.conf',\n var_puppet_gen + '/etc/rabbitmq/rabbitmq.config'\n )\n packages = ('rabbitmq-server',)\n\n def setup(self):\n container_status = self.get_command_output(\n \"docker ps -a --format='{{ .Names }}'\")\n\n in_container = False\n container_names = []\n if container_status['status'] == 0:\n for line in container_status['output'].splitlines():\n if line.startswith(\"rabbitmq\"):\n in_container = True\n container_names.append(line)\n\n if in_container:\n for container in container_names:\n self.add_cmd_output('docker logs {0}'.format(container))\n self.add_cmd_output(\n 'docker exec -t {0} rabbitmqctl report'\n .format(container)\n )\n else:\n self.add_cmd_output(\"rabbitmqctl report\")\n\n self.add_copy_spec([\n \"/etc/rabbitmq/*\",\n self.var_puppet_gen + \"/etc/rabbitmq/*\",\n self.var_puppet_gen + \"/etc/security/limits.d/\",\n self.var_puppet_gen + \"/etc/systemd/\"\n ])\n self.add_copy_spec([\n \"/var/log/rabbitmq/*\",\n \"/var/log/containers/rabbitmq/*\"\n ], sizelimit=self.get_option('log_size'))\n\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/plugins/rabbitmq.py"}], "after_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nfrom sos.plugins import Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin\n\n\nclass RabbitMQ(Plugin, RedHatPlugin, DebianPlugin, UbuntuPlugin):\n \"\"\"RabbitMQ messaging service\n \"\"\"\n plugin_name = 'rabbitmq'\n profiles = ('services',)\n var_puppet_gen = \"/var/lib/config-data/puppet-generated/rabbitmq\"\n files = (\n '/etc/rabbitmq/rabbitmq.conf',\n var_puppet_gen + '/etc/rabbitmq/rabbitmq.config'\n )\n packages = ('rabbitmq-server',)\n\n def setup(self):\n container_status = self.get_command_output(\n \"docker ps -a --format='{{ .Names }}'\")\n\n in_container = False\n container_names = []\n if container_status['status'] == 0:\n for line in container_status['output'].splitlines():\n if line.startswith(\"rabbitmq\"):\n in_container = True\n container_names.append(line)\n\n if in_container:\n for container in container_names:\n self.add_cmd_output('docker logs {0}'.format(container))\n self.add_cmd_output(\n 'docker exec -t {0} rabbitmqctl report'\n .format(container)\n )\n else:\n self.add_cmd_output(\"rabbitmqctl report\")\n\n self.add_copy_spec([\n \"/etc/rabbitmq/*\",\n self.var_puppet_gen + \"/etc/rabbitmq/*\",\n self.var_puppet_gen + \"/etc/security/limits.d/\",\n self.var_puppet_gen + \"/etc/systemd/\"\n ])\n self.add_copy_spec([\n \"/var/log/rabbitmq/*\",\n \"/var/log/containers/rabbitmq/*\"\n ], sizelimit=self.get_option('log_size'))\n\n def postproc(self):\n self.do_file_sub(\"/etc/rabbitmq/rabbitmq.conf\",\n r\"(\\s*default_pass\\s*,\\s*)\\S+\", r\"\\1<<***>>},\")\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/plugins/rabbitmq.py"}]}
| 996 | 137 |
gh_patches_debug_11108
|
rasdani/github-patches
|
git_diff
|
ultrabug__py3status-2091
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
After i3wm reload on first click error happens: JSONDecodeError: Expecting value: line 1 column 2 (char 1) [happens with custom module]
**Describe the bug**
Error after reloading i3wm first click fails with error:
```
2022-01-17 21:03:22 WARNING Event failed.
2022-01-17 21:03:22 INFO Traceback
JSONDecodeError: Expecting value: line 1 column 2 (char 1)
File "/home/valdur/arendus/py3status-valdur55/py3status/events.py", line 281, in run
event = loads(event_str)
File "/usr/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.8/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
2022-01-17 21:03:22 ERROR Event failed. Please try to fix this and reload i3wm (Mod+Shift+R)
```
Without debugger values are:
(self.io, sys.stdin, line)
(<_io.BufferedReader name=5>, <_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>, b'[')
With debugger loaded:
(<_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>, <_pydev_bundle.pydev_stdin.DebugConsoleStdIn object at 0x7fd05220ef70>, '')
Pydevd modifies **sys.stdin** and puts original one as **sys.stdin.original_stdin**
**Your py3status version**
3.40
**To Reproduce**
Steps to reproduce the behavior along with your py3status configuration (filter out any private values):
1. Add module . (https://gist.github.com/valdur55/6879f298095b8c54883eb01f8392ba55) and install pydevd module (IDE not needed)
I am using it for connecting to IDE remote debugger session so I can use module panel and do debug actions on IDE.
2. Enable module by adding order += pydev_debug
3. Run py3status in panel
4. Click on module/panes and see error notification.
**Expected behavior**
Error should not appear.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py3status/events.py`
Content:
```
1 import select
2 import sys
3
4 from threading import Thread
5 from subprocess import Popen, PIPE
6 from json import loads
7 from shlex import quote as shell_quote
8
9 from py3status.profiling import profile
10
11
12 class IOPoller:
13 """
14 This class implements a predictive and timing-out I/O reader
15 using select and the poll() mechanism for greater compatibility.
16 """
17
18 def __init__(self, io, eventmask=select.POLLIN):
19 """
20 Our default is to read (POLLIN) the specified 'io' file descriptor.
21 """
22 self.io = io
23 self.poller = select.poll()
24 self.poller.register(io, eventmask)
25
26 def readline(self, timeout=500):
27 """
28 Try to read our I/O for 'timeout' milliseconds, return None otherwise.
29 This makes calling and reading I/O non blocking !
30 """
31 poll_result = self.poller.poll(timeout)
32 if poll_result:
33 line = self.io.readline().strip()
34 if self.io == sys.stdin and line == "[":
35 # skip first event line wrt issue #19
36 line = self.io.readline().strip()
37 try:
38 # python3 compatibility code
39 line = line.decode()
40 except (AttributeError, UnicodeDecodeError):
41 pass
42 return line
43 else:
44 return None
45
46
47 class EventTask:
48 """
49 A simple task that can be run by the scheduler.
50 """
51
52 def __init__(self, module_name, event, default_event, events_thread):
53 self.events_thread = events_thread
54 self.module_full_name = module_name
55 self.default_event = default_event
56 self.event = event
57
58 def run(self):
59 self.events_thread.process_event(
60 self.module_full_name, self.event, self.default_event
61 )
62
63
64 class EventClickTask:
65 """
66 A task to run an external on_click event
67 """
68
69 def __init__(self, module_name, event, events_thread, command):
70 self.events_thread = events_thread
71 self.module_name = module_name
72 self.command = command
73 self.event = event
74
75 def run(self):
76 self.events_thread.on_click_dispatcher(
77 self.module_name, self.event, self.command
78 )
79
80
81 class Events(Thread):
82 """
83 This class is responsible for dispatching event JSONs sent by the i3bar.
84 """
85
86 def __init__(self, py3_wrapper):
87 """
88 We need to poll stdin to receive i3bar messages.
89 """
90 Thread.__init__(self)
91 self.config = py3_wrapper.config
92 self.error = None
93 self.py3_config = py3_wrapper.config["py3_config"]
94 self.modules = py3_wrapper.modules
95 self.on_click = self.py3_config["on_click"]
96 self.output_modules = py3_wrapper.output_modules
97 self.poller_inp = IOPoller(sys.stdin)
98 self.py3_wrapper = py3_wrapper
99
100 def get_module_text(self, module_name, event):
101 """
102 Get the full text for the module as well as the partial text if the
103 module is a composite. Partial text is the text for just the single
104 section of a composite.
105 """
106 index = event.get("index")
107 module_info = self.py3_wrapper.output_modules.get(module_name)
108 output = module_info["module"].get_latest()
109 full_text = "".join(out["full_text"] for out in output)
110
111 partial = None
112 if index is not None:
113 if isinstance(index, int):
114 partial = output[index]
115 else:
116 for item in output:
117 if item.get("index") == index:
118 partial = item
119 break
120 if partial:
121 partial_text = partial["full_text"]
122 else:
123 partial_text = full_text
124 return full_text, partial_text
125
126 def on_click_dispatcher(self, module_name, event, command):
127 """
128 Dispatch on_click config parameters to either:
129 - Our own methods for special py3status commands (listed below)
130 - The i3-msg program which is part of i3wm
131 """
132 if command is None:
133 return
134 elif command == "refresh_all":
135 self.py3_wrapper.refresh_modules()
136 elif command == "refresh":
137 self.py3_wrapper.refresh_modules(module_name)
138 else:
139 # In commands we are able to use substitutions for the text output
140 # of a module
141 if "$OUTPUT" in command or "$OUTPUT_PART" in command:
142 full_text, partial_text = self.get_module_text(module_name, event)
143 command = command.replace("$OUTPUT_PART", shell_quote(partial_text))
144 command = command.replace("$OUTPUT", shell_quote(full_text))
145
146 # this is a i3 message
147 self.wm_msg(module_name, command)
148 # to make the bar more responsive to users we ask for a refresh
149 # of the module or of i3status if the module is an i3status one
150 self.py3_wrapper.refresh_modules(module_name)
151
152 def wm_msg(self, module_name, command):
153 """
154 Execute the message with i3-msg or swaymsg and log its output.
155 """
156 wm_msg = self.config["wm"]["msg"]
157 pipe = Popen([wm_msg, command], stdout=PIPE)
158 self.py3_wrapper.log(
159 '{} module="{}" command="{}" stdout={}'.format(
160 wm_msg, module_name, command, pipe.stdout.read()
161 )
162 )
163
164 def process_event(self, module_name, event, default_event=False):
165 """
166 Process the event for the named module.
167 Events may have been declared in i3status.conf, modules may have
168 on_click() functions. There is a default middle click event etc.
169 """
170
171 # get the module that the event is for
172 module_info = self.output_modules.get(module_name)
173
174 # if module is a py3status one call it.
175 if module_info["type"] == "py3status":
176 module = module_info["module"]
177 module.click_event(event)
178 if self.config["debug"]:
179 self.py3_wrapper.log(f"dispatching event {event}")
180
181 # to make the bar more responsive to users we refresh the module
182 # unless the on_click event called py3.prevent_refresh()
183 if not module.prevent_refresh:
184 self.py3_wrapper.refresh_modules(module_name)
185 default_event = False
186
187 if default_event:
188 # default button 2 action is to clear this method's cache
189 if self.config["debug"]:
190 self.py3_wrapper.log(f"dispatching default event {event}")
191 self.py3_wrapper.refresh_modules(module_name)
192
193 # find container that holds the module and call its onclick
194 module_groups = self.py3_config[".module_groups"]
195 containers = module_groups.get(module_name, [])
196 for container in containers:
197 self.process_event(container, event)
198
199 def dispatch_event(self, event):
200 """
201 Takes an event dict. Logs the event if needed and cleans up the dict
202 such as setting the index needed for composits.
203 """
204 if self.config["debug"]:
205 self.py3_wrapper.log(f"received event {event}")
206
207 # usage variables
208 event["index"] = event.get("index", "")
209 instance = event.get("instance", "")
210 name = event.get("name", "")
211
212 # composites have an index which is passed to i3bar with
213 # the instance. We need to separate this out here and
214 # clean up the event. If index
215 # is an integer type then cast it as such.
216 if " " in instance:
217 instance, index = instance.split(" ", 1)
218 try:
219 index = int(index)
220 except ValueError:
221 pass
222 event["index"] = index
223 event["instance"] = instance
224
225 if self.config["debug"]:
226 self.py3_wrapper.log(
227 'trying to dispatch event to module "{}"'.format(
228 f"{name} {instance}".strip()
229 )
230 )
231
232 # guess the module config name
233 module_name = f"{name} {instance}".strip()
234
235 default_event = False
236 module_info = self.output_modules.get(module_name)
237 module = module_info["module"]
238 # execute any configured i3-msg command
239 # we do not do this for containers
240 # modules that have failed do not execute their config on_click
241 if module.allow_config_clicks:
242 button = event.get("button", 0)
243 on_click = self.on_click.get(module_name, {}).get(str(button))
244 if on_click:
245 task = EventClickTask(module_name, event, self, on_click)
246 self.py3_wrapper.timeout_queue_add(task)
247 # otherwise setup default action on button 2 press
248 elif button == 2:
249 default_event = True
250
251 # do the work
252 task = EventTask(module_name, event, default_event, self)
253 self.py3_wrapper.timeout_queue_add(task)
254
255 @profile
256 def run(self):
257 """
258 Wait for an i3bar JSON event, then find the right module to dispatch
259 the message to based on the 'name' and 'instance' of the event.
260
261 In case the module does NOT support click_events, the default
262 implementation is to clear the module's cache
263 when the MIDDLE button (2) is pressed on it.
264
265 Example event:
266 {'y': 13, 'x': 1737, 'button': 1, 'name': 'empty', 'instance': 'first'}
267 """
268 try:
269 while self.py3_wrapper.running:
270 event_str = self.poller_inp.readline()
271 if not event_str:
272 continue
273 try:
274 # remove leading comma if present
275 if event_str[0] == ",":
276 event_str = event_str[1:]
277 event = loads(event_str)
278 self.dispatch_event(event)
279 except Exception:
280 self.py3_wrapper.report_exception("Event failed")
281 except: # noqa e722
282 err = "Events thread died, click events are disabled."
283 self.py3_wrapper.report_exception(err, notify_user=False)
284 self.py3_wrapper.notify_user(err, level="warning")
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py3status/events.py b/py3status/events.py
--- a/py3status/events.py
+++ b/py3status/events.py
@@ -31,7 +31,11 @@
poll_result = self.poller.poll(timeout)
if poll_result:
line = self.io.readline().strip()
- if self.io == sys.stdin and line == "[":
+ # When using pydev.deugger sys.stdin gets overwritten and placed into sys.stdin.original_stdin issue #2090
+ if (
+ self.io == getattr(sys.stdin, "original_stdin", sys.stdin)
+ and line == "["
+ ):
# skip first event line wrt issue #19
line = self.io.readline().strip()
try:
|
{"golden_diff": "diff --git a/py3status/events.py b/py3status/events.py\n--- a/py3status/events.py\n+++ b/py3status/events.py\n@@ -31,7 +31,11 @@\n poll_result = self.poller.poll(timeout)\n if poll_result:\n line = self.io.readline().strip()\n- if self.io == sys.stdin and line == \"[\":\n+ # When using pydev.deugger sys.stdin gets overwritten and placed into sys.stdin.original_stdin issue #2090\n+ if (\n+ self.io == getattr(sys.stdin, \"original_stdin\", sys.stdin)\n+ and line == \"[\"\n+ ):\n # skip first event line wrt issue #19\n line = self.io.readline().strip()\n try:\n", "issue": "After i3wm reload on first click error happens: JSONDecodeError: Expecting value: line 1 column 2 (char 1) [happens with custom module]\n**Describe the bug**\r\nError after reloading i3wm first click fails with error:\r\n\r\n```\r\n2022-01-17 21:03:22 WARNING Event failed.\r\n2022-01-17 21:03:22 INFO Traceback\r\nJSONDecodeError: Expecting value: line 1 column 2 (char 1)\r\n File \"/home/valdur/arendus/py3status-valdur55/py3status/events.py\", line 281, in run\r\n event = loads(event_str)\r\n File \"/usr/lib/python3.8/json/__init__.py\", line 357, in loads\r\n return _default_decoder.decode(s)\r\n File \"/usr/lib/python3.8/json/decoder.py\", line 337, in decode\r\n obj, end = self.raw_decode(s, idx=_w(s, 0).end())\r\n File \"/usr/lib/python3.8/json/decoder.py\", line 355, in raw_decode\r\n raise JSONDecodeError(\"Expecting value\", s, err.value) from None\r\n2022-01-17 21:03:22 ERROR Event failed. Please try to fix this and reload i3wm (Mod+Shift+R)\r\n```\r\nWithout debugger values are:\r\n(self.io, sys.stdin, line)\r\n(<_io.BufferedReader name=5>, <_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>, b'[')\r\n\r\nWith debugger loaded:\r\n(<_io.TextIOWrapper name='<stdin>' mode='r' encoding='utf-8'>, <_pydev_bundle.pydev_stdin.DebugConsoleStdIn object at 0x7fd05220ef70>, '')\r\n\r\nPydevd modifies **sys.stdin** and puts original one as **sys.stdin.original_stdin**\r\n\r\n**Your py3status version**\r\n3.40\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior along with your py3status configuration (filter out any private values):\r\n1. Add module . (https://gist.github.com/valdur55/6879f298095b8c54883eb01f8392ba55) and install pydevd module (IDE not needed)\r\n I am using it for connecting to IDE remote debugger session so I can use module panel and do debug actions on IDE.\r\n2. Enable module by adding order += pydev_debug\r\n3. Run py3status in panel\r\n4. Click on module/panes and see error notification.\r\n\r\n**Expected behavior**\r\nError should not appear.\r\n\r\n\n", "before_files": [{"content": "import select\nimport sys\n\nfrom threading import Thread\nfrom subprocess import Popen, PIPE\nfrom json import loads\nfrom shlex import quote as shell_quote\n\nfrom py3status.profiling import profile\n\n\nclass IOPoller:\n \"\"\"\n This class implements a predictive and timing-out I/O reader\n using select and the poll() mechanism for greater compatibility.\n \"\"\"\n\n def __init__(self, io, eventmask=select.POLLIN):\n \"\"\"\n Our default is to read (POLLIN) the specified 'io' file descriptor.\n \"\"\"\n self.io = io\n self.poller = select.poll()\n self.poller.register(io, eventmask)\n\n def readline(self, timeout=500):\n \"\"\"\n Try to read our I/O for 'timeout' milliseconds, return None otherwise.\n This makes calling and reading I/O non blocking !\n \"\"\"\n poll_result = self.poller.poll(timeout)\n if poll_result:\n line = self.io.readline().strip()\n if self.io == sys.stdin and line == \"[\":\n # skip first event line wrt issue #19\n line = self.io.readline().strip()\n try:\n # python3 compatibility code\n line = line.decode()\n except (AttributeError, UnicodeDecodeError):\n pass\n return line\n else:\n return None\n\n\nclass EventTask:\n \"\"\"\n A simple task that can be run by the scheduler.\n \"\"\"\n\n def __init__(self, module_name, event, default_event, events_thread):\n self.events_thread = events_thread\n self.module_full_name = module_name\n self.default_event = default_event\n self.event = event\n\n def run(self):\n self.events_thread.process_event(\n self.module_full_name, self.event, self.default_event\n )\n\n\nclass EventClickTask:\n \"\"\"\n A task to run an external on_click event\n \"\"\"\n\n def __init__(self, module_name, event, events_thread, command):\n self.events_thread = events_thread\n self.module_name = module_name\n self.command = command\n self.event = event\n\n def run(self):\n self.events_thread.on_click_dispatcher(\n self.module_name, self.event, self.command\n )\n\n\nclass Events(Thread):\n \"\"\"\n This class is responsible for dispatching event JSONs sent by the i3bar.\n \"\"\"\n\n def __init__(self, py3_wrapper):\n \"\"\"\n We need to poll stdin to receive i3bar messages.\n \"\"\"\n Thread.__init__(self)\n self.config = py3_wrapper.config\n self.error = None\n self.py3_config = py3_wrapper.config[\"py3_config\"]\n self.modules = py3_wrapper.modules\n self.on_click = self.py3_config[\"on_click\"]\n self.output_modules = py3_wrapper.output_modules\n self.poller_inp = IOPoller(sys.stdin)\n self.py3_wrapper = py3_wrapper\n\n def get_module_text(self, module_name, event):\n \"\"\"\n Get the full text for the module as well as the partial text if the\n module is a composite. Partial text is the text for just the single\n section of a composite.\n \"\"\"\n index = event.get(\"index\")\n module_info = self.py3_wrapper.output_modules.get(module_name)\n output = module_info[\"module\"].get_latest()\n full_text = \"\".join(out[\"full_text\"] for out in output)\n\n partial = None\n if index is not None:\n if isinstance(index, int):\n partial = output[index]\n else:\n for item in output:\n if item.get(\"index\") == index:\n partial = item\n break\n if partial:\n partial_text = partial[\"full_text\"]\n else:\n partial_text = full_text\n return full_text, partial_text\n\n def on_click_dispatcher(self, module_name, event, command):\n \"\"\"\n Dispatch on_click config parameters to either:\n - Our own methods for special py3status commands (listed below)\n - The i3-msg program which is part of i3wm\n \"\"\"\n if command is None:\n return\n elif command == \"refresh_all\":\n self.py3_wrapper.refresh_modules()\n elif command == \"refresh\":\n self.py3_wrapper.refresh_modules(module_name)\n else:\n # In commands we are able to use substitutions for the text output\n # of a module\n if \"$OUTPUT\" in command or \"$OUTPUT_PART\" in command:\n full_text, partial_text = self.get_module_text(module_name, event)\n command = command.replace(\"$OUTPUT_PART\", shell_quote(partial_text))\n command = command.replace(\"$OUTPUT\", shell_quote(full_text))\n\n # this is a i3 message\n self.wm_msg(module_name, command)\n # to make the bar more responsive to users we ask for a refresh\n # of the module or of i3status if the module is an i3status one\n self.py3_wrapper.refresh_modules(module_name)\n\n def wm_msg(self, module_name, command):\n \"\"\"\n Execute the message with i3-msg or swaymsg and log its output.\n \"\"\"\n wm_msg = self.config[\"wm\"][\"msg\"]\n pipe = Popen([wm_msg, command], stdout=PIPE)\n self.py3_wrapper.log(\n '{} module=\"{}\" command=\"{}\" stdout={}'.format(\n wm_msg, module_name, command, pipe.stdout.read()\n )\n )\n\n def process_event(self, module_name, event, default_event=False):\n \"\"\"\n Process the event for the named module.\n Events may have been declared in i3status.conf, modules may have\n on_click() functions. There is a default middle click event etc.\n \"\"\"\n\n # get the module that the event is for\n module_info = self.output_modules.get(module_name)\n\n # if module is a py3status one call it.\n if module_info[\"type\"] == \"py3status\":\n module = module_info[\"module\"]\n module.click_event(event)\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"dispatching event {event}\")\n\n # to make the bar more responsive to users we refresh the module\n # unless the on_click event called py3.prevent_refresh()\n if not module.prevent_refresh:\n self.py3_wrapper.refresh_modules(module_name)\n default_event = False\n\n if default_event:\n # default button 2 action is to clear this method's cache\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"dispatching default event {event}\")\n self.py3_wrapper.refresh_modules(module_name)\n\n # find container that holds the module and call its onclick\n module_groups = self.py3_config[\".module_groups\"]\n containers = module_groups.get(module_name, [])\n for container in containers:\n self.process_event(container, event)\n\n def dispatch_event(self, event):\n \"\"\"\n Takes an event dict. Logs the event if needed and cleans up the dict\n such as setting the index needed for composits.\n \"\"\"\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"received event {event}\")\n\n # usage variables\n event[\"index\"] = event.get(\"index\", \"\")\n instance = event.get(\"instance\", \"\")\n name = event.get(\"name\", \"\")\n\n # composites have an index which is passed to i3bar with\n # the instance. We need to separate this out here and\n # clean up the event. If index\n # is an integer type then cast it as such.\n if \" \" in instance:\n instance, index = instance.split(\" \", 1)\n try:\n index = int(index)\n except ValueError:\n pass\n event[\"index\"] = index\n event[\"instance\"] = instance\n\n if self.config[\"debug\"]:\n self.py3_wrapper.log(\n 'trying to dispatch event to module \"{}\"'.format(\n f\"{name} {instance}\".strip()\n )\n )\n\n # guess the module config name\n module_name = f\"{name} {instance}\".strip()\n\n default_event = False\n module_info = self.output_modules.get(module_name)\n module = module_info[\"module\"]\n # execute any configured i3-msg command\n # we do not do this for containers\n # modules that have failed do not execute their config on_click\n if module.allow_config_clicks:\n button = event.get(\"button\", 0)\n on_click = self.on_click.get(module_name, {}).get(str(button))\n if on_click:\n task = EventClickTask(module_name, event, self, on_click)\n self.py3_wrapper.timeout_queue_add(task)\n # otherwise setup default action on button 2 press\n elif button == 2:\n default_event = True\n\n # do the work\n task = EventTask(module_name, event, default_event, self)\n self.py3_wrapper.timeout_queue_add(task)\n\n @profile\n def run(self):\n \"\"\"\n Wait for an i3bar JSON event, then find the right module to dispatch\n the message to based on the 'name' and 'instance' of the event.\n\n In case the module does NOT support click_events, the default\n implementation is to clear the module's cache\n when the MIDDLE button (2) is pressed on it.\n\n Example event:\n {'y': 13, 'x': 1737, 'button': 1, 'name': 'empty', 'instance': 'first'}\n \"\"\"\n try:\n while self.py3_wrapper.running:\n event_str = self.poller_inp.readline()\n if not event_str:\n continue\n try:\n # remove leading comma if present\n if event_str[0] == \",\":\n event_str = event_str[1:]\n event = loads(event_str)\n self.dispatch_event(event)\n except Exception:\n self.py3_wrapper.report_exception(\"Event failed\")\n except: # noqa e722\n err = \"Events thread died, click events are disabled.\"\n self.py3_wrapper.report_exception(err, notify_user=False)\n self.py3_wrapper.notify_user(err, level=\"warning\")\n", "path": "py3status/events.py"}], "after_files": [{"content": "import select\nimport sys\n\nfrom threading import Thread\nfrom subprocess import Popen, PIPE\nfrom json import loads\nfrom shlex import quote as shell_quote\n\nfrom py3status.profiling import profile\n\n\nclass IOPoller:\n \"\"\"\n This class implements a predictive and timing-out I/O reader\n using select and the poll() mechanism for greater compatibility.\n \"\"\"\n\n def __init__(self, io, eventmask=select.POLLIN):\n \"\"\"\n Our default is to read (POLLIN) the specified 'io' file descriptor.\n \"\"\"\n self.io = io\n self.poller = select.poll()\n self.poller.register(io, eventmask)\n\n def readline(self, timeout=500):\n \"\"\"\n Try to read our I/O for 'timeout' milliseconds, return None otherwise.\n This makes calling and reading I/O non blocking !\n \"\"\"\n poll_result = self.poller.poll(timeout)\n if poll_result:\n line = self.io.readline().strip()\n # When using pydev.deugger sys.stdin gets overwritten and placed into sys.stdin.original_stdin issue #2090\n if (\n self.io == getattr(sys.stdin, \"original_stdin\", sys.stdin)\n and line == \"[\"\n ):\n # skip first event line wrt issue #19\n line = self.io.readline().strip()\n try:\n # python3 compatibility code\n line = line.decode()\n except (AttributeError, UnicodeDecodeError):\n pass\n return line\n else:\n return None\n\n\nclass EventTask:\n \"\"\"\n A simple task that can be run by the scheduler.\n \"\"\"\n\n def __init__(self, module_name, event, default_event, events_thread):\n self.events_thread = events_thread\n self.module_full_name = module_name\n self.default_event = default_event\n self.event = event\n\n def run(self):\n self.events_thread.process_event(\n self.module_full_name, self.event, self.default_event\n )\n\n\nclass EventClickTask:\n \"\"\"\n A task to run an external on_click event\n \"\"\"\n\n def __init__(self, module_name, event, events_thread, command):\n self.events_thread = events_thread\n self.module_name = module_name\n self.command = command\n self.event = event\n\n def run(self):\n self.events_thread.on_click_dispatcher(\n self.module_name, self.event, self.command\n )\n\n\nclass Events(Thread):\n \"\"\"\n This class is responsible for dispatching event JSONs sent by the i3bar.\n \"\"\"\n\n def __init__(self, py3_wrapper):\n \"\"\"\n We need to poll stdin to receive i3bar messages.\n \"\"\"\n Thread.__init__(self)\n self.config = py3_wrapper.config\n self.error = None\n self.py3_config = py3_wrapper.config[\"py3_config\"]\n self.modules = py3_wrapper.modules\n self.on_click = self.py3_config[\"on_click\"]\n self.output_modules = py3_wrapper.output_modules\n self.poller_inp = IOPoller(sys.stdin)\n self.py3_wrapper = py3_wrapper\n\n def get_module_text(self, module_name, event):\n \"\"\"\n Get the full text for the module as well as the partial text if the\n module is a composite. Partial text is the text for just the single\n section of a composite.\n \"\"\"\n index = event.get(\"index\")\n module_info = self.py3_wrapper.output_modules.get(module_name)\n output = module_info[\"module\"].get_latest()\n full_text = \"\".join(out[\"full_text\"] for out in output)\n\n partial = None\n if index is not None:\n if isinstance(index, int):\n partial = output[index]\n else:\n for item in output:\n if item.get(\"index\") == index:\n partial = item\n break\n if partial:\n partial_text = partial[\"full_text\"]\n else:\n partial_text = full_text\n return full_text, partial_text\n\n def on_click_dispatcher(self, module_name, event, command):\n \"\"\"\n Dispatch on_click config parameters to either:\n - Our own methods for special py3status commands (listed below)\n - The i3-msg program which is part of i3wm\n \"\"\"\n if command is None:\n return\n elif command == \"refresh_all\":\n self.py3_wrapper.refresh_modules()\n elif command == \"refresh\":\n self.py3_wrapper.refresh_modules(module_name)\n else:\n # In commands we are able to use substitutions for the text output\n # of a module\n if \"$OUTPUT\" in command or \"$OUTPUT_PART\" in command:\n full_text, partial_text = self.get_module_text(module_name, event)\n command = command.replace(\"$OUTPUT_PART\", shell_quote(partial_text))\n command = command.replace(\"$OUTPUT\", shell_quote(full_text))\n\n # this is a i3 message\n self.wm_msg(module_name, command)\n # to make the bar more responsive to users we ask for a refresh\n # of the module or of i3status if the module is an i3status one\n self.py3_wrapper.refresh_modules(module_name)\n\n def wm_msg(self, module_name, command):\n \"\"\"\n Execute the message with i3-msg or swaymsg and log its output.\n \"\"\"\n wm_msg = self.config[\"wm\"][\"msg\"]\n pipe = Popen([wm_msg, command], stdout=PIPE)\n self.py3_wrapper.log(\n '{} module=\"{}\" command=\"{}\" stdout={}'.format(\n wm_msg, module_name, command, pipe.stdout.read()\n )\n )\n\n def process_event(self, module_name, event, default_event=False):\n \"\"\"\n Process the event for the named module.\n Events may have been declared in i3status.conf, modules may have\n on_click() functions. There is a default middle click event etc.\n \"\"\"\n\n # get the module that the event is for\n module_info = self.output_modules.get(module_name)\n\n # if module is a py3status one call it.\n if module_info[\"type\"] == \"py3status\":\n module = module_info[\"module\"]\n module.click_event(event)\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"dispatching event {event}\")\n\n # to make the bar more responsive to users we refresh the module\n # unless the on_click event called py3.prevent_refresh()\n if not module.prevent_refresh:\n self.py3_wrapper.refresh_modules(module_name)\n default_event = False\n\n if default_event:\n # default button 2 action is to clear this method's cache\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"dispatching default event {event}\")\n self.py3_wrapper.refresh_modules(module_name)\n\n # find container that holds the module and call its onclick\n module_groups = self.py3_config[\".module_groups\"]\n containers = module_groups.get(module_name, [])\n for container in containers:\n self.process_event(container, event)\n\n def dispatch_event(self, event):\n \"\"\"\n Takes an event dict. Logs the event if needed and cleans up the dict\n such as setting the index needed for composits.\n \"\"\"\n if self.config[\"debug\"]:\n self.py3_wrapper.log(f\"received event {event}\")\n\n # usage variables\n event[\"index\"] = event.get(\"index\", \"\")\n instance = event.get(\"instance\", \"\")\n name = event.get(\"name\", \"\")\n\n # composites have an index which is passed to i3bar with\n # the instance. We need to separate this out here and\n # clean up the event. If index\n # is an integer type then cast it as such.\n if \" \" in instance:\n instance, index = instance.split(\" \", 1)\n try:\n index = int(index)\n except ValueError:\n pass\n event[\"index\"] = index\n event[\"instance\"] = instance\n\n if self.config[\"debug\"]:\n self.py3_wrapper.log(\n 'trying to dispatch event to module \"{}\"'.format(\n f\"{name} {instance}\".strip()\n )\n )\n\n # guess the module config name\n module_name = f\"{name} {instance}\".strip()\n\n default_event = False\n module_info = self.output_modules.get(module_name)\n module = module_info[\"module\"]\n # execute any configured i3-msg command\n # we do not do this for containers\n # modules that have failed do not execute their config on_click\n if module.allow_config_clicks:\n button = event.get(\"button\", 0)\n on_click = self.on_click.get(module_name, {}).get(str(button))\n if on_click:\n task = EventClickTask(module_name, event, self, on_click)\n self.py3_wrapper.timeout_queue_add(task)\n # otherwise setup default action on button 2 press\n elif button == 2:\n default_event = True\n\n # do the work\n task = EventTask(module_name, event, default_event, self)\n self.py3_wrapper.timeout_queue_add(task)\n\n @profile\n def run(self):\n \"\"\"\n Wait for an i3bar JSON event, then find the right module to dispatch\n the message to based on the 'name' and 'instance' of the event.\n\n In case the module does NOT support click_events, the default\n implementation is to clear the module's cache\n when the MIDDLE button (2) is pressed on it.\n\n Example event:\n {'y': 13, 'x': 1737, 'button': 1, 'name': 'empty', 'instance': 'first'}\n \"\"\"\n try:\n while self.py3_wrapper.running:\n event_str = self.poller_inp.readline()\n if not event_str:\n continue\n try:\n # remove leading comma if present\n if event_str[0] == \",\":\n event_str = event_str[1:]\n event = loads(event_str)\n self.dispatch_event(event)\n except Exception:\n self.py3_wrapper.report_exception(\"Event failed\")\n except: # noqa e722\n err = \"Events thread died, click events are disabled.\"\n self.py3_wrapper.report_exception(err, notify_user=False)\n self.py3_wrapper.notify_user(err, level=\"warning\")\n", "path": "py3status/events.py"}]}
| 3,802 | 167 |
gh_patches_debug_19429
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1861
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DroppedSpan has no attribute 'transaction' error in grpc/client_interceptor.py
We are experiencing the following error using automatic instrumentation of gRPC requests for transactions with more than 500 spans: `AttributeError: 'DroppedSpan' object has no attribute 'transaction'`. The error occurs at the following line
https://github.com/elastic/apm-agent-python/blob/479a69d61f728ec24de5fb7504c02dcbfe4f4c8a/elasticapm/contrib/grpc/client_interceptor.py#L197
**To Reproduce**
1. Start a transaction
2. Produce more spans than the transaction_max_spans
3. Call a gRPC endpoint
**Environment (please complete the following information)**
- agent version: 6.15.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/contrib/grpc/client_interceptor.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2022, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from typing import Optional
32
33 import grpc
34 from grpc._interceptor import _ClientCallDetails
35
36 import elasticapm
37 from elasticapm.conf import constants
38 from elasticapm.traces import Span
39 from elasticapm.utils import default_ports
40
41
42 class _ClientInterceptor(
43 grpc.UnaryUnaryClientInterceptor,
44 # grpc.UnaryStreamClientInterceptor,
45 # grpc.StreamUnaryClientInterceptor,
46 # grpc.StreamStreamClientInterceptor,
47 ):
48 def __init__(self, host: Optional[str], port: Optional[str], secure: bool):
49 self.host: str = host
50 self.port: str = port
51 self.secure: bool = secure
52 schema = "https" if secure else "http"
53 resource = f"{schema}://{host}"
54 if port and int(port) != default_ports[schema]:
55 resource += f":{port}"
56
57 self._context = {
58 "http": {
59 "url": resource,
60 },
61 "destination": {
62 "address": host,
63 "port": port,
64 },
65 }
66
67 def intercept_unary_unary(self, continuation, client_call_details, request):
68 """Intercepts a unary-unary invocation asynchronously.
69
70 Args:
71 continuation: A function that proceeds with the invocation by
72 executing the next interceptor in chain or invoking the
73 actual RPC on the underlying Channel. It is the interceptor's
74 responsibility to call it if it decides to move the RPC forward.
75 The interceptor can use
76 `response_future = continuation(client_call_details, request)`
77 to continue with the RPC. `continuation` returns an object that is
78 both a Call for the RPC and a Future. In the event of RPC
79 completion, the return Call-Future's result value will be
80 the response message of the RPC. Should the event terminate
81 with non-OK status, the returned Call-Future's exception value
82 will be an RpcError.
83 client_call_details: A ClientCallDetails object describing the
84 outgoing RPC.
85 request: The request value for the RPC.
86
87 Returns:
88 An object that is both a Call for the RPC and a Future.
89 In the event of RPC completion, the return Call-Future's
90 result value will be the response message of the RPC.
91 Should the event terminate with non-OK status, the returned
92 Call-Future's exception value will be an RpcError.
93 """
94 with elasticapm.capture_span(
95 client_call_details.method, span_type="external", span_subtype="grpc", extra=self._context.copy(), leaf=True
96 ) as span:
97 if not span:
98 return continuation(client_call_details, request)
99 client_call_details = self.attach_traceparent(client_call_details, span)
100 try:
101 response = continuation(client_call_details, request)
102 except grpc.RpcError:
103 span.set_failure()
104 raise
105
106 return response
107
108 # TODO: instrument other types of requests once the spec is ready
109
110 # def intercept_unary_stream(self, continuation, client_call_details,
111 # request):
112 # """Intercepts a unary-stream invocation.
113 #
114 # Args:
115 # continuation: A function that proceeds with the invocation by
116 # executing the next interceptor in chain or invoking the
117 # actual RPC on the underlying Channel. It is the interceptor's
118 # responsibility to call it if it decides to move the RPC forward.
119 # The interceptor can use
120 # `response_iterator = continuation(client_call_details, request)`
121 # to continue with the RPC. `continuation` returns an object that is
122 # both a Call for the RPC and an iterator for response values.
123 # Drawing response values from the returned Call-iterator may
124 # raise RpcError indicating termination of the RPC with non-OK
125 # status.
126 # client_call_details: A ClientCallDetails object describing the
127 # outgoing RPC.
128 # request: The request value for the RPC.
129 #
130 # Returns:
131 # An object that is both a Call for the RPC and an iterator of
132 # response values. Drawing response values from the returned
133 # Call-iterator may raise RpcError indicating termination of
134 # the RPC with non-OK status. This object *should* also fulfill the
135 # Future interface, though it may not.
136 # """
137 # response_iterator = continuation(client_call_details, request)
138 # return response_iterator
139 #
140 # def intercept_stream_unary(self, continuation, client_call_details,
141 # request_iterator):
142 # """Intercepts a stream-unary invocation asynchronously.
143 #
144 # Args:
145 # continuation: A function that proceeds with the invocation by
146 # executing the next interceptor in chain or invoking the
147 # actual RPC on the underlying Channel. It is the interceptor's
148 # responsibility to call it if it decides to move the RPC forward.
149 # The interceptor can use
150 # `response_future = continuation(client_call_details, request_iterator)`
151 # to continue with the RPC. `continuation` returns an object that is
152 # both a Call for the RPC and a Future. In the event of RPC completion,
153 # the return Call-Future's result value will be the response message
154 # of the RPC. Should the event terminate with non-OK status, the
155 # returned Call-Future's exception value will be an RpcError.
156 # client_call_details: A ClientCallDetails object describing the
157 # outgoing RPC.
158 # request_iterator: An iterator that yields request values for the RPC.
159 #
160 # Returns:
161 # An object that is both a Call for the RPC and a Future.
162 # In the event of RPC completion, the return Call-Future's
163 # result value will be the response message of the RPC.
164 # Should the event terminate with non-OK status, the returned
165 # Call-Future's exception value will be an RpcError.
166 # """
167 #
168 # def intercept_stream_stream(self, continuation, client_call_details,
169 # request_iterator):
170 # """Intercepts a stream-stream invocation.
171 #
172 # Args:
173 # continuation: A function that proceeds with the invocation by
174 # executing the next interceptor in chain or invoking the
175 # actual RPC on the underlying Channel. It is the interceptor's
176 # responsibility to call it if it decides to move the RPC forward.
177 # The interceptor can use
178 # `response_iterator = continuation(client_call_details, request_iterator)`
179 # to continue with the RPC. `continuation` returns an object that is
180 # both a Call for the RPC and an iterator for response values.
181 # Drawing response values from the returned Call-iterator may
182 # raise RpcError indicating termination of the RPC with non-OK
183 # status.
184 # client_call_details: A ClientCallDetails object describing the
185 # outgoing RPC.
186 # request_iterator: An iterator that yields request values for the RPC.
187 #
188 # Returns:
189 # An object that is both a Call for the RPC and an iterator of
190 # response values. Drawing response values from the returned
191 # Call-iterator may raise RpcError indicating termination of
192 # the RPC with non-OK status. This object *should* also fulfill the
193 # Future interface, though it may not.
194 # """
195
196 def attach_traceparent(self, client_call_details: _ClientCallDetails, span: Span):
197 if not span.transaction:
198 return client_call_details
199 meta = list(client_call_details.metadata) if client_call_details.metadata else []
200 if constants.TRACEPARENT_HEADER_NAME not in meta:
201 traceparent = span.transaction.trace_parent.copy_from(span_id=span.id)
202 meta.extend(
203 (
204 (constants.TRACEPARENT_HEADER_NAME, traceparent.to_string()),
205 (constants.TRACESTATE_HEADER_NAME, traceparent.tracestate),
206 )
207 )
208 return client_call_details._replace(metadata=meta)
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/contrib/grpc/client_interceptor.py b/elasticapm/contrib/grpc/client_interceptor.py
--- a/elasticapm/contrib/grpc/client_interceptor.py
+++ b/elasticapm/contrib/grpc/client_interceptor.py
@@ -35,7 +35,7 @@
import elasticapm
from elasticapm.conf import constants
-from elasticapm.traces import Span
+from elasticapm.traces import DroppedSpan, SpanType
from elasticapm.utils import default_ports
@@ -193,8 +193,8 @@
# Future interface, though it may not.
# """
- def attach_traceparent(self, client_call_details: _ClientCallDetails, span: Span):
- if not span.transaction:
+ def attach_traceparent(self, client_call_details: _ClientCallDetails, span: SpanType) -> _ClientCallDetails:
+ if isinstance(span, DroppedSpan) or not span.transaction:
return client_call_details
meta = list(client_call_details.metadata) if client_call_details.metadata else []
if constants.TRACEPARENT_HEADER_NAME not in meta:
|
{"golden_diff": "diff --git a/elasticapm/contrib/grpc/client_interceptor.py b/elasticapm/contrib/grpc/client_interceptor.py\n--- a/elasticapm/contrib/grpc/client_interceptor.py\n+++ b/elasticapm/contrib/grpc/client_interceptor.py\n@@ -35,7 +35,7 @@\n \n import elasticapm\n from elasticapm.conf import constants\n-from elasticapm.traces import Span\n+from elasticapm.traces import DroppedSpan, SpanType\n from elasticapm.utils import default_ports\n \n \n@@ -193,8 +193,8 @@\n # Future interface, though it may not.\n # \"\"\"\n \n- def attach_traceparent(self, client_call_details: _ClientCallDetails, span: Span):\n- if not span.transaction:\n+ def attach_traceparent(self, client_call_details: _ClientCallDetails, span: SpanType) -> _ClientCallDetails:\n+ if isinstance(span, DroppedSpan) or not span.transaction:\n return client_call_details\n meta = list(client_call_details.metadata) if client_call_details.metadata else []\n if constants.TRACEPARENT_HEADER_NAME not in meta:\n", "issue": "DroppedSpan has no attribute 'transaction' error in grpc/client_interceptor.py\nWe are experiencing the following error using automatic instrumentation of gRPC requests for transactions with more than 500 spans: `AttributeError: 'DroppedSpan' object has no attribute 'transaction'`. The error occurs at the following line\r\nhttps://github.com/elastic/apm-agent-python/blob/479a69d61f728ec24de5fb7504c02dcbfe4f4c8a/elasticapm/contrib/grpc/client_interceptor.py#L197\r\n**To Reproduce**\r\n\r\n1. Start a transaction\r\n2. Produce more spans than the transaction_max_spans\r\n3. Call a gRPC endpoint\r\n\r\n**Environment (please complete the following information)**\r\n- agent version: 6.15.1\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2022, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom typing import Optional\n\nimport grpc\nfrom grpc._interceptor import _ClientCallDetails\n\nimport elasticapm\nfrom elasticapm.conf import constants\nfrom elasticapm.traces import Span\nfrom elasticapm.utils import default_ports\n\n\nclass _ClientInterceptor(\n grpc.UnaryUnaryClientInterceptor,\n # grpc.UnaryStreamClientInterceptor,\n # grpc.StreamUnaryClientInterceptor,\n # grpc.StreamStreamClientInterceptor,\n):\n def __init__(self, host: Optional[str], port: Optional[str], secure: bool):\n self.host: str = host\n self.port: str = port\n self.secure: bool = secure\n schema = \"https\" if secure else \"http\"\n resource = f\"{schema}://{host}\"\n if port and int(port) != default_ports[schema]:\n resource += f\":{port}\"\n\n self._context = {\n \"http\": {\n \"url\": resource,\n },\n \"destination\": {\n \"address\": host,\n \"port\": port,\n },\n }\n\n def intercept_unary_unary(self, continuation, client_call_details, request):\n \"\"\"Intercepts a unary-unary invocation asynchronously.\n\n Args:\n continuation: A function that proceeds with the invocation by\n executing the next interceptor in chain or invoking the\n actual RPC on the underlying Channel. It is the interceptor's\n responsibility to call it if it decides to move the RPC forward.\n The interceptor can use\n `response_future = continuation(client_call_details, request)`\n to continue with the RPC. `continuation` returns an object that is\n both a Call for the RPC and a Future. In the event of RPC\n completion, the return Call-Future's result value will be\n the response message of the RPC. Should the event terminate\n with non-OK status, the returned Call-Future's exception value\n will be an RpcError.\n client_call_details: A ClientCallDetails object describing the\n outgoing RPC.\n request: The request value for the RPC.\n\n Returns:\n An object that is both a Call for the RPC and a Future.\n In the event of RPC completion, the return Call-Future's\n result value will be the response message of the RPC.\n Should the event terminate with non-OK status, the returned\n Call-Future's exception value will be an RpcError.\n \"\"\"\n with elasticapm.capture_span(\n client_call_details.method, span_type=\"external\", span_subtype=\"grpc\", extra=self._context.copy(), leaf=True\n ) as span:\n if not span:\n return continuation(client_call_details, request)\n client_call_details = self.attach_traceparent(client_call_details, span)\n try:\n response = continuation(client_call_details, request)\n except grpc.RpcError:\n span.set_failure()\n raise\n\n return response\n\n # TODO: instrument other types of requests once the spec is ready\n\n # def intercept_unary_stream(self, continuation, client_call_details,\n # request):\n # \"\"\"Intercepts a unary-stream invocation.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_iterator = continuation(client_call_details, request)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and an iterator for response values.\n # Drawing response values from the returned Call-iterator may\n # raise RpcError indicating termination of the RPC with non-OK\n # status.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request: The request value for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and an iterator of\n # response values. Drawing response values from the returned\n # Call-iterator may raise RpcError indicating termination of\n # the RPC with non-OK status. This object *should* also fulfill the\n # Future interface, though it may not.\n # \"\"\"\n # response_iterator = continuation(client_call_details, request)\n # return response_iterator\n #\n # def intercept_stream_unary(self, continuation, client_call_details,\n # request_iterator):\n # \"\"\"Intercepts a stream-unary invocation asynchronously.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_future = continuation(client_call_details, request_iterator)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and a Future. In the event of RPC completion,\n # the return Call-Future's result value will be the response message\n # of the RPC. Should the event terminate with non-OK status, the\n # returned Call-Future's exception value will be an RpcError.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request_iterator: An iterator that yields request values for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and a Future.\n # In the event of RPC completion, the return Call-Future's\n # result value will be the response message of the RPC.\n # Should the event terminate with non-OK status, the returned\n # Call-Future's exception value will be an RpcError.\n # \"\"\"\n #\n # def intercept_stream_stream(self, continuation, client_call_details,\n # request_iterator):\n # \"\"\"Intercepts a stream-stream invocation.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_iterator = continuation(client_call_details, request_iterator)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and an iterator for response values.\n # Drawing response values from the returned Call-iterator may\n # raise RpcError indicating termination of the RPC with non-OK\n # status.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request_iterator: An iterator that yields request values for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and an iterator of\n # response values. Drawing response values from the returned\n # Call-iterator may raise RpcError indicating termination of\n # the RPC with non-OK status. This object *should* also fulfill the\n # Future interface, though it may not.\n # \"\"\"\n\n def attach_traceparent(self, client_call_details: _ClientCallDetails, span: Span):\n if not span.transaction:\n return client_call_details\n meta = list(client_call_details.metadata) if client_call_details.metadata else []\n if constants.TRACEPARENT_HEADER_NAME not in meta:\n traceparent = span.transaction.trace_parent.copy_from(span_id=span.id)\n meta.extend(\n (\n (constants.TRACEPARENT_HEADER_NAME, traceparent.to_string()),\n (constants.TRACESTATE_HEADER_NAME, traceparent.tracestate),\n )\n )\n return client_call_details._replace(metadata=meta)\n", "path": "elasticapm/contrib/grpc/client_interceptor.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2022, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom typing import Optional\n\nimport grpc\nfrom grpc._interceptor import _ClientCallDetails\n\nimport elasticapm\nfrom elasticapm.conf import constants\nfrom elasticapm.traces import DroppedSpan, SpanType\nfrom elasticapm.utils import default_ports\n\n\nclass _ClientInterceptor(\n grpc.UnaryUnaryClientInterceptor,\n # grpc.UnaryStreamClientInterceptor,\n # grpc.StreamUnaryClientInterceptor,\n # grpc.StreamStreamClientInterceptor,\n):\n def __init__(self, host: Optional[str], port: Optional[str], secure: bool):\n self.host: str = host\n self.port: str = port\n self.secure: bool = secure\n schema = \"https\" if secure else \"http\"\n resource = f\"{schema}://{host}\"\n if port and int(port) != default_ports[schema]:\n resource += f\":{port}\"\n\n self._context = {\n \"http\": {\n \"url\": resource,\n },\n \"destination\": {\n \"address\": host,\n \"port\": port,\n },\n }\n\n def intercept_unary_unary(self, continuation, client_call_details, request):\n \"\"\"Intercepts a unary-unary invocation asynchronously.\n\n Args:\n continuation: A function that proceeds with the invocation by\n executing the next interceptor in chain or invoking the\n actual RPC on the underlying Channel. It is the interceptor's\n responsibility to call it if it decides to move the RPC forward.\n The interceptor can use\n `response_future = continuation(client_call_details, request)`\n to continue with the RPC. `continuation` returns an object that is\n both a Call for the RPC and a Future. In the event of RPC\n completion, the return Call-Future's result value will be\n the response message of the RPC. Should the event terminate\n with non-OK status, the returned Call-Future's exception value\n will be an RpcError.\n client_call_details: A ClientCallDetails object describing the\n outgoing RPC.\n request: The request value for the RPC.\n\n Returns:\n An object that is both a Call for the RPC and a Future.\n In the event of RPC completion, the return Call-Future's\n result value will be the response message of the RPC.\n Should the event terminate with non-OK status, the returned\n Call-Future's exception value will be an RpcError.\n \"\"\"\n with elasticapm.capture_span(\n client_call_details.method, span_type=\"external\", span_subtype=\"grpc\", extra=self._context.copy(), leaf=True\n ) as span:\n if not span:\n return continuation(client_call_details, request)\n client_call_details = self.attach_traceparent(client_call_details, span)\n try:\n response = continuation(client_call_details, request)\n except grpc.RpcError:\n span.set_failure()\n raise\n\n return response\n\n # TODO: instrument other types of requests once the spec is ready\n\n # def intercept_unary_stream(self, continuation, client_call_details,\n # request):\n # \"\"\"Intercepts a unary-stream invocation.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_iterator = continuation(client_call_details, request)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and an iterator for response values.\n # Drawing response values from the returned Call-iterator may\n # raise RpcError indicating termination of the RPC with non-OK\n # status.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request: The request value for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and an iterator of\n # response values. Drawing response values from the returned\n # Call-iterator may raise RpcError indicating termination of\n # the RPC with non-OK status. This object *should* also fulfill the\n # Future interface, though it may not.\n # \"\"\"\n # response_iterator = continuation(client_call_details, request)\n # return response_iterator\n #\n # def intercept_stream_unary(self, continuation, client_call_details,\n # request_iterator):\n # \"\"\"Intercepts a stream-unary invocation asynchronously.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_future = continuation(client_call_details, request_iterator)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and a Future. In the event of RPC completion,\n # the return Call-Future's result value will be the response message\n # of the RPC. Should the event terminate with non-OK status, the\n # returned Call-Future's exception value will be an RpcError.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request_iterator: An iterator that yields request values for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and a Future.\n # In the event of RPC completion, the return Call-Future's\n # result value will be the response message of the RPC.\n # Should the event terminate with non-OK status, the returned\n # Call-Future's exception value will be an RpcError.\n # \"\"\"\n #\n # def intercept_stream_stream(self, continuation, client_call_details,\n # request_iterator):\n # \"\"\"Intercepts a stream-stream invocation.\n #\n # Args:\n # continuation: A function that proceeds with the invocation by\n # executing the next interceptor in chain or invoking the\n # actual RPC on the underlying Channel. It is the interceptor's\n # responsibility to call it if it decides to move the RPC forward.\n # The interceptor can use\n # `response_iterator = continuation(client_call_details, request_iterator)`\n # to continue with the RPC. `continuation` returns an object that is\n # both a Call for the RPC and an iterator for response values.\n # Drawing response values from the returned Call-iterator may\n # raise RpcError indicating termination of the RPC with non-OK\n # status.\n # client_call_details: A ClientCallDetails object describing the\n # outgoing RPC.\n # request_iterator: An iterator that yields request values for the RPC.\n #\n # Returns:\n # An object that is both a Call for the RPC and an iterator of\n # response values. Drawing response values from the returned\n # Call-iterator may raise RpcError indicating termination of\n # the RPC with non-OK status. This object *should* also fulfill the\n # Future interface, though it may not.\n # \"\"\"\n\n def attach_traceparent(self, client_call_details: _ClientCallDetails, span: SpanType) -> _ClientCallDetails:\n if isinstance(span, DroppedSpan) or not span.transaction:\n return client_call_details\n meta = list(client_call_details.metadata) if client_call_details.metadata else []\n if constants.TRACEPARENT_HEADER_NAME not in meta:\n traceparent = span.transaction.trace_parent.copy_from(span_id=span.id)\n meta.extend(\n (\n (constants.TRACEPARENT_HEADER_NAME, traceparent.to_string()),\n (constants.TRACESTATE_HEADER_NAME, traceparent.tracestate),\n )\n )\n return client_call_details._replace(metadata=meta)\n", "path": "elasticapm/contrib/grpc/client_interceptor.py"}]}
| 3,052 | 252 |
gh_patches_debug_62860
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-7774
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[request] sigslot/1.2.1
### Package Details
* Package Name/Version: **sigslot/1.2.1**
* Changelog: **https://github.com/palacaze/sigslot/releases/tag/v1.2.1**
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/sigslot/all/conanfile.py`
Content:
```
1 import os
2
3 from conans import ConanFile, tools
4 from conans.errors import ConanInvalidConfiguration
5
6
7 class SigslotConan(ConanFile):
8 name = "sigslot"
9 description = "Sigslot is a header-only, thread safe implementation of signal-slots for C++."
10 topics = ("signal", "slot", "c++14", "header-only")
11 url = "https://github.com/conan-io/conan-center-index"
12 homepage = "https://github.com/palacaze/sigslot"
13 license = "MIT"
14 settings = "compiler", "os"
15 no_copy_source = True
16
17 @property
18 def _source_subfolder(self):
19 return "source_subfolder"
20
21 def configure(self):
22 minimal_cpp_standard = "14"
23 if self.settings.compiler.cppstd:
24 tools.check_min_cppstd(self, minimal_cpp_standard)
25 minimal_version = {
26 "gcc": "5",
27 "clang": "3.4",
28 "apple-clang": "10",
29 "Visual Studio": "15" # 14 is not supported by the library
30 }
31 compiler = str(self.settings.compiler)
32 if compiler not in minimal_version:
33 self.output.warn(
34 "%s recipe lacks information about the %s compiler standard version support" % (self.name, compiler))
35 self.output.warn(
36 "%s requires a compiler that supports at least C++%s" % (self.name, minimal_cpp_standard))
37 return
38 version = tools.Version(self.settings.compiler.version)
39 if version < minimal_version[compiler]:
40 raise ConanInvalidConfiguration("%s requires a compiler that supports at least C++%s" % (self.name, minimal_cpp_standard))
41
42 def source(self):
43 tools.get(**self.conan_data["sources"][self.version])
44 extracted_dir = "sigslot-" + self.version
45 os.rename(extracted_dir, self._source_subfolder)
46
47 def package(self):
48 self.copy(pattern="LICENSE", src=self._source_subfolder, dst="licenses")
49 self.copy(pattern="signal.hpp", src=os.path.join(self._source_subfolder, "include", "sigslot"), dst=os.path.join("include", "sigslot"))
50
51 def package_id(self):
52 self.info.header_only()
53
54 def package_info(self):
55 self.cpp_info.filenames["cmake_find_package"] = "PalSigslot"
56 self.cpp_info.filenames["cmake_find_package_multi"] = "PalSigslot"
57 self.cpp_info.names["cmake_find_package"] = "Pal"
58 self.cpp_info.names["cmake_find_package_multi"] = "Pal"
59
60 self.cpp_info.components["_sigslot"].libs = []
61 self.cpp_info.components["_sigslot"].names["cmake_find_package"] = "Sigslot"
62 self.cpp_info.components["_sigslot"].names["cmake_find_package_multi"] = "Sigslot"
63
64 if self.settings.os == "Linux":
65 self.cpp_info.components["_sigslot"].system_libs.append("pthread")
66 if self.settings.os == "Windows":
67 if self.settings.compiler in ("Visual Studio", "clang"):
68 self.cpp_info.components["_sigslot"].exelinkflags.append('/OPT:NOICF')
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/sigslot/all/conanfile.py b/recipes/sigslot/all/conanfile.py
--- a/recipes/sigslot/all/conanfile.py
+++ b/recipes/sigslot/all/conanfile.py
@@ -65,4 +65,4 @@
self.cpp_info.components["_sigslot"].system_libs.append("pthread")
if self.settings.os == "Windows":
if self.settings.compiler in ("Visual Studio", "clang"):
- self.cpp_info.components["_sigslot"].exelinkflags.append('/OPT:NOICF')
+ self.cpp_info.components["_sigslot"].exelinkflags.append('-OPT:NOICF')
|
{"golden_diff": "diff --git a/recipes/sigslot/all/conanfile.py b/recipes/sigslot/all/conanfile.py\n--- a/recipes/sigslot/all/conanfile.py\n+++ b/recipes/sigslot/all/conanfile.py\n@@ -65,4 +65,4 @@\n self.cpp_info.components[\"_sigslot\"].system_libs.append(\"pthread\")\n if self.settings.os == \"Windows\":\n if self.settings.compiler in (\"Visual Studio\", \"clang\"):\n- self.cpp_info.components[\"_sigslot\"].exelinkflags.append('/OPT:NOICF')\n+ self.cpp_info.components[\"_sigslot\"].exelinkflags.append('-OPT:NOICF')\n", "issue": "[request] sigslot/1.2.1\n### Package Details\r\n * Package Name/Version: **sigslot/1.2.1**\r\n * Changelog: **https://github.com/palacaze/sigslot/releases/tag/v1.2.1**\r\n\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\r\n\n", "before_files": [{"content": "import os\n\nfrom conans import ConanFile, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass SigslotConan(ConanFile):\n name = \"sigslot\"\n description = \"Sigslot is a header-only, thread safe implementation of signal-slots for C++.\"\n topics = (\"signal\", \"slot\", \"c++14\", \"header-only\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/palacaze/sigslot\"\n license = \"MIT\"\n settings = \"compiler\", \"os\"\n no_copy_source = True\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n minimal_cpp_standard = \"14\"\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, minimal_cpp_standard)\n minimal_version = {\n \"gcc\": \"5\",\n \"clang\": \"3.4\",\n \"apple-clang\": \"10\",\n \"Visual Studio\": \"15\" # 14 is not supported by the library\n }\n compiler = str(self.settings.compiler)\n if compiler not in minimal_version:\n self.output.warn(\n \"%s recipe lacks information about the %s compiler standard version support\" % (self.name, compiler))\n self.output.warn(\n \"%s requires a compiler that supports at least C++%s\" % (self.name, minimal_cpp_standard))\n return\n version = tools.Version(self.settings.compiler.version)\n if version < minimal_version[compiler]:\n raise ConanInvalidConfiguration(\"%s requires a compiler that supports at least C++%s\" % (self.name, minimal_cpp_standard))\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = \"sigslot-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def package(self):\n self.copy(pattern=\"LICENSE\", src=self._source_subfolder, dst=\"licenses\")\n self.copy(pattern=\"signal.hpp\", src=os.path.join(self._source_subfolder, \"include\", \"sigslot\"), dst=os.path.join(\"include\", \"sigslot\"))\n\n def package_id(self):\n self.info.header_only()\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"PalSigslot\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"PalSigslot\"\n self.cpp_info.names[\"cmake_find_package\"] = \"Pal\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Pal\"\n\n self.cpp_info.components[\"_sigslot\"].libs = []\n self.cpp_info.components[\"_sigslot\"].names[\"cmake_find_package\"] = \"Sigslot\"\n self.cpp_info.components[\"_sigslot\"].names[\"cmake_find_package_multi\"] = \"Sigslot\"\n\n if self.settings.os == \"Linux\":\n self.cpp_info.components[\"_sigslot\"].system_libs.append(\"pthread\")\n if self.settings.os == \"Windows\":\n if self.settings.compiler in (\"Visual Studio\", \"clang\"):\n self.cpp_info.components[\"_sigslot\"].exelinkflags.append('/OPT:NOICF')\n", "path": "recipes/sigslot/all/conanfile.py"}], "after_files": [{"content": "import os\n\nfrom conans import ConanFile, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass SigslotConan(ConanFile):\n name = \"sigslot\"\n description = \"Sigslot is a header-only, thread safe implementation of signal-slots for C++.\"\n topics = (\"signal\", \"slot\", \"c++14\", \"header-only\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/palacaze/sigslot\"\n license = \"MIT\"\n settings = \"compiler\", \"os\"\n no_copy_source = True\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n minimal_cpp_standard = \"14\"\n if self.settings.compiler.cppstd:\n tools.check_min_cppstd(self, minimal_cpp_standard)\n minimal_version = {\n \"gcc\": \"5\",\n \"clang\": \"3.4\",\n \"apple-clang\": \"10\",\n \"Visual Studio\": \"15\" # 14 is not supported by the library\n }\n compiler = str(self.settings.compiler)\n if compiler not in minimal_version:\n self.output.warn(\n \"%s recipe lacks information about the %s compiler standard version support\" % (self.name, compiler))\n self.output.warn(\n \"%s requires a compiler that supports at least C++%s\" % (self.name, minimal_cpp_standard))\n return\n version = tools.Version(self.settings.compiler.version)\n if version < minimal_version[compiler]:\n raise ConanInvalidConfiguration(\"%s requires a compiler that supports at least C++%s\" % (self.name, minimal_cpp_standard))\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = \"sigslot-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n\n def package(self):\n self.copy(pattern=\"LICENSE\", src=self._source_subfolder, dst=\"licenses\")\n self.copy(pattern=\"signal.hpp\", src=os.path.join(self._source_subfolder, \"include\", \"sigslot\"), dst=os.path.join(\"include\", \"sigslot\"))\n\n def package_id(self):\n self.info.header_only()\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"PalSigslot\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"PalSigslot\"\n self.cpp_info.names[\"cmake_find_package\"] = \"Pal\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Pal\"\n\n self.cpp_info.components[\"_sigslot\"].libs = []\n self.cpp_info.components[\"_sigslot\"].names[\"cmake_find_package\"] = \"Sigslot\"\n self.cpp_info.components[\"_sigslot\"].names[\"cmake_find_package_multi\"] = \"Sigslot\"\n\n if self.settings.os == \"Linux\":\n self.cpp_info.components[\"_sigslot\"].system_libs.append(\"pthread\")\n if self.settings.os == \"Windows\":\n if self.settings.compiler in (\"Visual Studio\", \"clang\"):\n self.cpp_info.components[\"_sigslot\"].exelinkflags.append('-OPT:NOICF')\n", "path": "recipes/sigslot/all/conanfile.py"}]}
| 1,162 | 144 |
gh_patches_debug_24057
|
rasdani/github-patches
|
git_diff
|
astronomer__astro-sdk-1188
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CI: `example_load_file.py` isnt running
**Describe the bug**
The `python-sdk/example_dags/example_load_file.py` example DAG in not running in our CI tests
**Version**
* Astro: [e.g. 0.6.0]
* OS: [eg. Debian]
**To Reproduce**
Steps to reproduce the behavior:
1. Write the DAG '...'
2. Create connection '....'
3. Run using '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Additional context**
Add any other context about the problem here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python-sdk/example_dags/example_load_file.py`
Content:
```
1 import os
2 import pathlib
3 from datetime import datetime, timedelta
4
5 import sqlalchemy
6 from airflow.models import DAG
7
8 from astro import sql as aql
9 from astro.constants import FileType
10 from astro.files import File
11 from astro.table import Metadata, Table
12
13 # To create IAM role with needed permissions,
14 # refer: https://www.dataliftoff.com/iam-roles-for-loading-data-from-s3-into-redshift/
15 REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN = os.getenv("REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN")
16
17 CWD = pathlib.Path(__file__).parent
18 default_args = {
19 "owner": "airflow",
20 "retries": 1,
21 "retry_delay": 0,
22 }
23 data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" # URL for Iris data API
24
25 dag = DAG(
26 dag_id="example_load_file",
27 start_date=datetime(2019, 1, 1),
28 max_active_runs=3,
29 schedule_interval=timedelta(minutes=30),
30 default_args=default_args,
31 )
32
33
34 with dag:
35 # [START load_file_example_1]
36 my_homes_table = aql.load_file(
37 input_file=File(path="s3://astro-sdk/sample.csv"),
38 output_table=Table(
39 conn_id="postgres_conn",
40 ),
41 )
42 # [END load_file_example_1]
43
44 # [START load_file_example_2]
45 dataframe = aql.load_file(
46 input_file=File(path="s3://astro-sdk/sample.csv"),
47 )
48 # [END load_file_example_2]
49
50 # [START load_file_example_3]
51 sample_table = aql.load_file(
52 input_file=File(path="s3://astro-sdk/sample.ndjson"),
53 output_table=Table(
54 conn_id="postgres_conn",
55 ),
56 ndjson_normalize_sep="__",
57 )
58 # [END load_file_example_3]
59
60 # [START load_file_example_4]
61 new_table = aql.load_file(
62 input_file=File(path="s3://astro-sdk/sample.csv"),
63 output_table=Table(
64 conn_id="postgres_conn",
65 ),
66 if_exists="replace",
67 )
68 # [END load_file_example_4]
69
70 # [START load_file_example_5]
71 custom_schema_table = aql.load_file(
72 input_file=File(path="s3://astro-sdk/sample.csv"),
73 output_table=Table(
74 conn_id="postgres_conn",
75 columns=[
76 sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
77 sqlalchemy.Column("name", sqlalchemy.String(60), nullable=False, key="name"),
78 ],
79 ),
80 )
81 # [END load_file_example_5]
82
83 # [START load_file_example_6]
84 dataframe = aql.load_file(
85 input_file=File(path="s3://astro-sdk/sample.csv"),
86 columns_names_capitalization="upper",
87 )
88 # [END load_file_example_6]
89
90 # [START load_file_example_7]
91 aql.load_file(
92 input_file=File("s3://tmp9/homes_main.csv", conn_id="aws_conn"),
93 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
94 use_native_support=False,
95 )
96 # [END load_file_example_7]
97
98 # [START load_file_example_8]
99 aql.load_file(
100 input_file=File("s3://tmp9/homes_main.csv", conn_id="aws_conn"),
101 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
102 use_native_support=True,
103 native_support_kwargs={
104 "ignore_unknown_values": True,
105 "allow_jagged_rows": True,
106 "skip_leading_rows": "1",
107 },
108 )
109 # [END load_file_example_8]
110
111 # [START load_file_example_9]
112 aql.load_file(
113 input_file=File("s3://tmp9/homes_main.csv", conn_id="aws_conn"),
114 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
115 use_native_support=True,
116 native_support_kwargs={
117 "ignore_unknown_values": True,
118 "allow_jagged_rows": True,
119 "skip_leading_rows": "1",
120 },
121 enable_native_fallback=False,
122 )
123 # [END load_file_example_9]
124
125 # [START load_file_example_10]
126 my_homes_table = aql.load_file(
127 input_file=File(path=str(CWD.parent) + "/tests/data/homes*", filetype=FileType.CSV),
128 output_table=Table(
129 conn_id="postgres_conn",
130 ),
131 )
132 # [END load_file_example_10]
133
134 # [START load_file_example_11]
135 aql.load_file(
136 input_file=File("s3://astro-sdk/sample_pattern", conn_id="aws_conn", filetype=FileType.CSV),
137 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
138 use_native_support=False,
139 )
140 # [END load_file_example_11]
141
142 # [START load_file_example_12]
143 aql.load_file(
144 input_file=File(
145 "gs://astro-sdk/workspace/sample_pattern",
146 conn_id="bigquery",
147 filetype=FileType.CSV,
148 ),
149 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
150 use_native_support=False,
151 )
152 # [END load_file_example_12]
153
154 # [START load_file_example_13]
155 aql.load_file(
156 input_file=File(
157 "s3://astro-sdk/sample_pattern",
158 conn_id="aws_conn",
159 filetype=FileType.CSV,
160 ),
161 output_table=Table(conn_id="redshift_conn", metadata=Metadata(schema="astro")),
162 use_native_support=False,
163 )
164 # [END load_file_example_13]
165
166 # [START load_file_example_14]
167 aql.load_file(
168 input_file=File(
169 "gs://astro-sdk/workspace/sample_pattern",
170 conn_id="bigquery",
171 filetype=FileType.CSV,
172 ),
173 output_table=Table(conn_id="redshift_conn", metadata=Metadata(schema="astro")),
174 use_native_support=False,
175 )
176 # [END load_file_example_14]
177
178 # [START load_file_example_15]
179 aql.load_file(
180 input_file=File(path=str(CWD.parent) + "/tests/data/homes*", filetype=FileType.CSV),
181 output_table=Table(
182 conn_id="postgres_conn",
183 ),
184 )
185 # [END load_file_example_15]
186
187 # [START load_file_example_16]
188 aql.load_file(
189 input_file=File("s3://tmp9/homes_main.csv", conn_id="aws_conn"),
190 output_table=Table(conn_id="redshift_conn", metadata=Metadata(schema="astro")),
191 use_native_support=True,
192 native_support_kwargs={
193 "IGNOREHEADER": 1,
194 "REGION": "us-west-2",
195 "IAM_ROLE": REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN,
196 },
197 )
198 # [END load_file_example_16]
199
200 # [START load_file_example_17]
201 aql.load_file(
202 input_file=File(
203 "gs://astro-sdk/workspace/sample_pattern",
204 conn_id="bigquery",
205 filetype=FileType.CSV,
206 ),
207 output_table=Table(conn_id="bigquery", metadata=Metadata(schema="astro")),
208 use_native_support=True,
209 native_support_kwargs={
210 "ignore_unknown_values": True,
211 "allow_jagged_rows": True,
212 "skip_leading_rows": "1",
213 },
214 enable_native_fallback=True,
215 )
216 # [END load_file_example_17]
217
218 # [START load_file_example_18]
219 dataframe = aql.load_file(input_file=File(path=data_url, filetype=FileType.CSV))
220 # [END load_file_example_18]
221
222 aql.cleanup()
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python-sdk/example_dags/example_load_file.py b/python-sdk/example_dags/example_load_file.py
--- a/python-sdk/example_dags/example_load_file.py
+++ b/python-sdk/example_dags/example_load_file.py
@@ -142,7 +142,7 @@
# [START load_file_example_12]
aql.load_file(
input_file=File(
- "gs://astro-sdk/workspace/sample_pattern",
+ "gs://astro-sdk/workspace/sample_pattern.csv",
conn_id="bigquery",
filetype=FileType.CSV,
),
@@ -166,7 +166,7 @@
# [START load_file_example_14]
aql.load_file(
input_file=File(
- "gs://astro-sdk/workspace/sample_pattern",
+ "gs://astro-sdk/workspace/sample_pattern.csv",
conn_id="bigquery",
filetype=FileType.CSV,
),
@@ -200,7 +200,7 @@
# [START load_file_example_17]
aql.load_file(
input_file=File(
- "gs://astro-sdk/workspace/sample_pattern",
+ "gs://astro-sdk/workspace/sample_pattern.csv",
conn_id="bigquery",
filetype=FileType.CSV,
),
|
{"golden_diff": "diff --git a/python-sdk/example_dags/example_load_file.py b/python-sdk/example_dags/example_load_file.py\n--- a/python-sdk/example_dags/example_load_file.py\n+++ b/python-sdk/example_dags/example_load_file.py\n@@ -142,7 +142,7 @@\n # [START load_file_example_12]\n aql.load_file(\n input_file=File(\n- \"gs://astro-sdk/workspace/sample_pattern\",\n+ \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n@@ -166,7 +166,7 @@\n # [START load_file_example_14]\n aql.load_file(\n input_file=File(\n- \"gs://astro-sdk/workspace/sample_pattern\",\n+ \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n@@ -200,7 +200,7 @@\n # [START load_file_example_17]\n aql.load_file(\n input_file=File(\n- \"gs://astro-sdk/workspace/sample_pattern\",\n+ \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n", "issue": "CI: `example_load_file.py` isnt running\n**Describe the bug**\r\n The `python-sdk/example_dags/example_load_file.py` example DAG in not running in our CI tests\r\n\r\n**Version**\r\n* Astro: [e.g. 0.6.0]\r\n* OS: [eg. Debian]\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Write the DAG '...'\r\n2. Create connection '....'\r\n3. Run using '....'\r\n4. See error\r\n\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "import os\nimport pathlib\nfrom datetime import datetime, timedelta\n\nimport sqlalchemy\nfrom airflow.models import DAG\n\nfrom astro import sql as aql\nfrom astro.constants import FileType\nfrom astro.files import File\nfrom astro.table import Metadata, Table\n\n# To create IAM role with needed permissions,\n# refer: https://www.dataliftoff.com/iam-roles-for-loading-data-from-s3-into-redshift/\nREDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN = os.getenv(\"REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN\")\n\nCWD = pathlib.Path(__file__).parent\ndefault_args = {\n \"owner\": \"airflow\",\n \"retries\": 1,\n \"retry_delay\": 0,\n}\ndata_url = \"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data\" # URL for Iris data API\n\ndag = DAG(\n dag_id=\"example_load_file\",\n start_date=datetime(2019, 1, 1),\n max_active_runs=3,\n schedule_interval=timedelta(minutes=30),\n default_args=default_args,\n)\n\n\nwith dag:\n # [START load_file_example_1]\n my_homes_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_1]\n\n # [START load_file_example_2]\n dataframe = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n )\n # [END load_file_example_2]\n\n # [START load_file_example_3]\n sample_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.ndjson\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n ndjson_normalize_sep=\"__\",\n )\n # [END load_file_example_3]\n\n # [START load_file_example_4]\n new_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n if_exists=\"replace\",\n )\n # [END load_file_example_4]\n\n # [START load_file_example_5]\n custom_schema_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n columns=[\n sqlalchemy.Column(\"id\", sqlalchemy.Integer, primary_key=True),\n sqlalchemy.Column(\"name\", sqlalchemy.String(60), nullable=False, key=\"name\"),\n ],\n ),\n )\n # [END load_file_example_5]\n\n # [START load_file_example_6]\n dataframe = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n columns_names_capitalization=\"upper\",\n )\n # [END load_file_example_6]\n\n # [START load_file_example_7]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_7]\n\n # [START load_file_example_8]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n )\n # [END load_file_example_8]\n\n # [START load_file_example_9]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n enable_native_fallback=False,\n )\n # [END load_file_example_9]\n\n # [START load_file_example_10]\n my_homes_table = aql.load_file(\n input_file=File(path=str(CWD.parent) + \"/tests/data/homes*\", filetype=FileType.CSV),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_10]\n\n # [START load_file_example_11]\n aql.load_file(\n input_file=File(\"s3://astro-sdk/sample_pattern\", conn_id=\"aws_conn\", filetype=FileType.CSV),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_11]\n\n # [START load_file_example_12]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_12]\n\n # [START load_file_example_13]\n aql.load_file(\n input_file=File(\n \"s3://astro-sdk/sample_pattern\",\n conn_id=\"aws_conn\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_13]\n\n # [START load_file_example_14]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_14]\n\n # [START load_file_example_15]\n aql.load_file(\n input_file=File(path=str(CWD.parent) + \"/tests/data/homes*\", filetype=FileType.CSV),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_15]\n\n # [START load_file_example_16]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"IGNOREHEADER\": 1,\n \"REGION\": \"us-west-2\",\n \"IAM_ROLE\": REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN,\n },\n )\n # [END load_file_example_16]\n\n # [START load_file_example_17]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n enable_native_fallback=True,\n )\n # [END load_file_example_17]\n\n # [START load_file_example_18]\n dataframe = aql.load_file(input_file=File(path=data_url, filetype=FileType.CSV))\n # [END load_file_example_18]\n\n aql.cleanup()\n", "path": "python-sdk/example_dags/example_load_file.py"}], "after_files": [{"content": "import os\nimport pathlib\nfrom datetime import datetime, timedelta\n\nimport sqlalchemy\nfrom airflow.models import DAG\n\nfrom astro import sql as aql\nfrom astro.constants import FileType\nfrom astro.files import File\nfrom astro.table import Metadata, Table\n\n# To create IAM role with needed permissions,\n# refer: https://www.dataliftoff.com/iam-roles-for-loading-data-from-s3-into-redshift/\nREDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN = os.getenv(\"REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN\")\n\nCWD = pathlib.Path(__file__).parent\ndefault_args = {\n \"owner\": \"airflow\",\n \"retries\": 1,\n \"retry_delay\": 0,\n}\ndata_url = \"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data\" # URL for Iris data API\n\ndag = DAG(\n dag_id=\"example_load_file\",\n start_date=datetime(2019, 1, 1),\n max_active_runs=3,\n schedule_interval=timedelta(minutes=30),\n default_args=default_args,\n)\n\n\nwith dag:\n # [START load_file_example_1]\n my_homes_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_1]\n\n # [START load_file_example_2]\n dataframe = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n )\n # [END load_file_example_2]\n\n # [START load_file_example_3]\n sample_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.ndjson\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n ndjson_normalize_sep=\"__\",\n )\n # [END load_file_example_3]\n\n # [START load_file_example_4]\n new_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n if_exists=\"replace\",\n )\n # [END load_file_example_4]\n\n # [START load_file_example_5]\n custom_schema_table = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n output_table=Table(\n conn_id=\"postgres_conn\",\n columns=[\n sqlalchemy.Column(\"id\", sqlalchemy.Integer, primary_key=True),\n sqlalchemy.Column(\"name\", sqlalchemy.String(60), nullable=False, key=\"name\"),\n ],\n ),\n )\n # [END load_file_example_5]\n\n # [START load_file_example_6]\n dataframe = aql.load_file(\n input_file=File(path=\"s3://astro-sdk/sample.csv\"),\n columns_names_capitalization=\"upper\",\n )\n # [END load_file_example_6]\n\n # [START load_file_example_7]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_7]\n\n # [START load_file_example_8]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n )\n # [END load_file_example_8]\n\n # [START load_file_example_9]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n enable_native_fallback=False,\n )\n # [END load_file_example_9]\n\n # [START load_file_example_10]\n my_homes_table = aql.load_file(\n input_file=File(path=str(CWD.parent) + \"/tests/data/homes*\", filetype=FileType.CSV),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_10]\n\n # [START load_file_example_11]\n aql.load_file(\n input_file=File(\"s3://astro-sdk/sample_pattern\", conn_id=\"aws_conn\", filetype=FileType.CSV),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_11]\n\n # [START load_file_example_12]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_12]\n\n # [START load_file_example_13]\n aql.load_file(\n input_file=File(\n \"s3://astro-sdk/sample_pattern\",\n conn_id=\"aws_conn\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_13]\n\n # [START load_file_example_14]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=False,\n )\n # [END load_file_example_14]\n\n # [START load_file_example_15]\n aql.load_file(\n input_file=File(path=str(CWD.parent) + \"/tests/data/homes*\", filetype=FileType.CSV),\n output_table=Table(\n conn_id=\"postgres_conn\",\n ),\n )\n # [END load_file_example_15]\n\n # [START load_file_example_16]\n aql.load_file(\n input_file=File(\"s3://tmp9/homes_main.csv\", conn_id=\"aws_conn\"),\n output_table=Table(conn_id=\"redshift_conn\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"IGNOREHEADER\": 1,\n \"REGION\": \"us-west-2\",\n \"IAM_ROLE\": REDSHIFT_NATIVE_LOAD_IAM_ROLE_ARN,\n },\n )\n # [END load_file_example_16]\n\n # [START load_file_example_17]\n aql.load_file(\n input_file=File(\n \"gs://astro-sdk/workspace/sample_pattern.csv\",\n conn_id=\"bigquery\",\n filetype=FileType.CSV,\n ),\n output_table=Table(conn_id=\"bigquery\", metadata=Metadata(schema=\"astro\")),\n use_native_support=True,\n native_support_kwargs={\n \"ignore_unknown_values\": True,\n \"allow_jagged_rows\": True,\n \"skip_leading_rows\": \"1\",\n },\n enable_native_fallback=True,\n )\n # [END load_file_example_17]\n\n # [START load_file_example_18]\n dataframe = aql.load_file(input_file=File(path=data_url, filetype=FileType.CSV))\n # [END load_file_example_18]\n\n aql.cleanup()\n", "path": "python-sdk/example_dags/example_load_file.py"}]}
| 2,706 | 276 |
gh_patches_debug_7494
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2590
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E0001: Error DisableExecuteApiEndpoint works only within 'DefinitionBody' property
### CloudFormation Lint Version
0.73.1
### What operating system are you using?
Ubuntu
### Describe the bug
I want to disable the execute api endpoint in my RestAPI using SAM. This works as expected in deployment by adding the ` DisableExecuteApiEndpoint: True` property on `Properties` for a `AWS::Serverless::Api` type (see reproduction template).
However cfn-lint gives this error message running:
```
$ cfn-lint -t template.yaml
E0001 Error transforming template: Resource with id [ApiGatewayRestApi] is invalid. DisableExecuteApiEndpoint works only within 'DefinitionBody' property.
template2.yaml:1:1
```
### Expected behavior
No E0001 lint error when using DisableExecuteApiEndpoint on a SAM `AWS::Serverless::Api`
### Reproduction template
```yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
ApiGatewayRestApi:
Type: AWS::Serverless::Api
Properties:
OpenApiVersion: "3.0.3"
DisableExecuteApiEndpoint: True
StageName: default
EndpointConfiguration:
Type: REGIONAL
Function:
Type: AWS::Serverless::Function
Properties:
Handler: index.handler
Runtime: nodejs16.x
InlineCode: |
exports.handler = async (event) => ++event;
Events:
Notify:
Type: Api
Properties:
Method: POST
Path: /
RestApiId: !Ref ApiGatewayRestApi
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/transform.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import logging
6 import os
7
8 import samtranslator
9 from samtranslator.parser import parser
10 from samtranslator.public.exceptions import InvalidDocumentException
11 from samtranslator.sdk import resource
12 from samtranslator.translator.translator import Translator
13
14 from cfnlint.data import Serverless
15 from cfnlint.helpers import convert_dict, format_json_string, load_resource
16 from cfnlint.rules import Match, TransformError
17
18 LOGGER = logging.getLogger("cfnlint")
19
20 samtranslator_logger = logging.getLogger("samtranslator")
21 samtranslator_logger.setLevel(logging.CRITICAL)
22
23
24 # Override SAM validation as cfn-lint does thoese
25 # checks already
26 # pylint: disable=unused-argument
27 def valid_override(self):
28 return resource.SamResourceType.has_value(self.type)
29
30
31 # pylint: disable=redefined-outer-name
32 resource.SamResource.valid = valid_override
33
34
35 class Transform:
36 """
37 Application Serverless Module tranform Wrapper.
38 Based on code from AWS SAM CLI:
39 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py
40 """
41
42 def __init__(self, filename, template, region):
43 """
44 Initialize Transform class
45 """
46 self._filename = filename
47 self._template = template
48 self._region = region
49 self._parameters = {}
50
51 self._managed_policy_map = self.load_managed_policies()
52 self._sam_parser = parser.Parser()
53
54 def template(self):
55 """Get the template"""
56 return self._template
57
58 def load_managed_policies(self):
59 """
60 Load the ManagedPolicies locally, based on the AWS-CLI:
61 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json
62 """
63 return load_resource(Serverless, "ManagedPolicies.json")
64
65 def _replace_local_codeuri(self):
66 """
67 Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in
68 AWS::Serverless::Api to a fake S3 Uri. This is to support running the
69 SAM Translator with valid values for these fields. If this is not done,
70 the template is invalid in the eyes of SAM Translator (the translator
71 does not support local paths)
72 """
73
74 all_resources = self._template.get("Resources", {})
75
76 template_globals = self._template.get("Globals", {})
77 auto_publish_alias = template_globals.get("Function", {}).get(
78 "AutoPublishAlias"
79 )
80 if isinstance(auto_publish_alias, dict):
81 if len(auto_publish_alias) == 1:
82 for k, v in auto_publish_alias.items():
83 if k == "Ref":
84 if v in self._template.get("Parameters"):
85 self._parameters[v] = "Alias"
86
87 for _, resource in all_resources.items():
88 resource_type = resource.get("Type")
89 resource_dict = resource.get("Properties")
90
91 if resource_type == "AWS::Serverless::Function":
92 if resource_dict.get("PackageType") == "Image":
93 Transform._update_to_s3_uri("ImageUri", resource_dict)
94 else:
95 Transform._update_to_s3_uri("CodeUri", resource_dict)
96 auto_publish_alias = resource_dict.get("AutoPublishAlias")
97 if isinstance(auto_publish_alias, dict):
98 if len(auto_publish_alias) == 1:
99 for k, v in auto_publish_alias.items():
100 if k == "Ref":
101 if v in self._template.get("Parameters"):
102 self._parameters[v] = "Alias"
103 if resource_type in ["AWS::Serverless::LayerVersion"]:
104 if resource_dict.get("ContentUri"):
105 Transform._update_to_s3_uri("ContentUri", resource_dict)
106 if resource_type == "AWS::Serverless::Application":
107 if resource_dict.get("Location"):
108 if isinstance(resource_dict.get("Location"), dict):
109 resource_dict["Location"] = ""
110 Transform._update_to_s3_uri("Location", resource_dict)
111 if resource_type == "AWS::Serverless::Api":
112 if (
113 "DefinitionBody" not in resource_dict
114 and "Auth" not in resource_dict
115 and "Cors" not in resource_dict
116 ):
117 Transform._update_to_s3_uri("DefinitionUri", resource_dict)
118 else:
119 resource_dict["DefinitionBody"] = ""
120 if resource_type == "AWS::Serverless::StateMachine" and resource_dict.get(
121 "DefinitionUri"
122 ):
123 Transform._update_to_s3_uri("DefinitionUri", resource_dict)
124
125 def transform_template(self):
126 """
127 Transform the Template using the Serverless Application Model.
128 """
129 matches = []
130
131 try:
132 # Output the SAM Translator version in debug mode
133 LOGGER.info("SAM Translator: %s", samtranslator.__version__)
134
135 sam_translator = Translator(
136 managed_policy_map=self._managed_policy_map, sam_parser=self._sam_parser
137 )
138
139 self._replace_local_codeuri()
140
141 # Tell SAM to use the region we're linting in, this has to be
142 # controlled using the default AWS mechanisms, see also:
143 # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py
144 LOGGER.info("Setting AWS_DEFAULT_REGION to %s", self._region)
145 os.environ["AWS_DEFAULT_REGION"] = self._region
146
147 self._template = convert_dict(
148 sam_translator.translate(
149 sam_template=self._template, parameter_values=self._parameters
150 )
151 )
152
153 LOGGER.info(
154 "Transformed template: \n%s", format_json_string(self._template)
155 )
156 except InvalidDocumentException as e:
157 message = "Error transforming template: {0}"
158 for cause in e.causes:
159 matches.append(
160 Match(
161 1,
162 1,
163 1,
164 1,
165 self._filename,
166 TransformError(),
167 message.format(cause.message),
168 )
169 )
170 except Exception as e: # pylint: disable=W0703
171 LOGGER.debug("Error transforming template: %s", str(e))
172 LOGGER.debug("Stack trace: %s", e, exc_info=True)
173 message = "Error transforming template: {0}"
174 matches.append(
175 Match(
176 1, 1, 1, 1, self._filename, TransformError(), message.format(str(e))
177 )
178 )
179
180 return matches
181
182 @staticmethod
183 def is_s3_uri(uri):
184 """
185 Checks the uri and determines if it is a valid S3 Uri
186 Parameters
187 ----------
188 uri str, required
189 Uri to check
190 Returns
191 -------
192 bool
193 Returns True if the uri given is an S3 uri, otherwise False
194 """
195 return isinstance(uri, str) and uri.startswith("s3://")
196
197 @staticmethod
198 def _update_to_s3_uri(
199 property_key, resource_property_dict, s3_uri_value="s3://bucket/value"
200 ):
201 """
202 Updates the 'property_key' in the 'resource_property_dict' to the
203 value of 's3_uri_value'
204 Note: The function will mutate the resource_property_dict that is pass
205 in Parameters
206 ----------
207 property_key str, required
208 Key in the resource_property_dict
209 resource_property_dict dict, required
210 Property dictionary of a Resource in the template to replace
211 s3_uri_value str, optional
212 Value to update the value of the property_key to
213 """
214 uri_property = resource_property_dict.get(property_key, ".")
215
216 # ignore if dict or already an S3 Uri
217 if isinstance(uri_property, dict):
218 if len(uri_property) == 1:
219 for k in uri_property.keys():
220 if k == "Ref":
221 resource_property_dict[property_key] = s3_uri_value
222 return
223 if Transform.is_s3_uri(uri_property):
224 return
225
226 resource_property_dict[property_key] = s3_uri_value
227
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py
--- a/src/cfnlint/transform.py
+++ b/src/cfnlint/transform.py
@@ -113,6 +113,7 @@
"DefinitionBody" not in resource_dict
and "Auth" not in resource_dict
and "Cors" not in resource_dict
+ and "DisableExecuteApiEndpoint" not in resource_dict
):
Transform._update_to_s3_uri("DefinitionUri", resource_dict)
else:
|
{"golden_diff": "diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py\n--- a/src/cfnlint/transform.py\n+++ b/src/cfnlint/transform.py\n@@ -113,6 +113,7 @@\n \"DefinitionBody\" not in resource_dict\n and \"Auth\" not in resource_dict\n and \"Cors\" not in resource_dict\n+ and \"DisableExecuteApiEndpoint\" not in resource_dict\n ):\n Transform._update_to_s3_uri(\"DefinitionUri\", resource_dict)\n else:\n", "issue": "E0001: Error DisableExecuteApiEndpoint works only within 'DefinitionBody' property\n### CloudFormation Lint Version\n\n0.73.1\n\n### What operating system are you using?\n\nUbuntu\n\n### Describe the bug\n\nI want to disable the execute api endpoint in my RestAPI using SAM. This works as expected in deployment by adding the ` DisableExecuteApiEndpoint: True` property on `Properties` for a `AWS::Serverless::Api` type (see reproduction template). \r\n\r\nHowever cfn-lint gives this error message running:\r\n\r\n```\r\n$ cfn-lint -t template.yaml\r\n\r\nE0001 Error transforming template: Resource with id [ApiGatewayRestApi] is invalid. DisableExecuteApiEndpoint works only within 'DefinitionBody' property.\r\ntemplate2.yaml:1:1\r\n```\n\n### Expected behavior\n\nNo E0001 lint error when using DisableExecuteApiEndpoint on a SAM `AWS::Serverless::Api`\n\n### Reproduction template\n\n```yaml\r\nAWSTemplateFormatVersion: '2010-09-09'\r\nTransform: AWS::Serverless-2016-10-31\r\n\r\nResources:\r\n ApiGatewayRestApi:\r\n Type: AWS::Serverless::Api\r\n Properties:\r\n OpenApiVersion: \"3.0.3\"\r\n DisableExecuteApiEndpoint: True\r\n StageName: default\r\n EndpointConfiguration:\r\n Type: REGIONAL\r\n\r\n Function:\r\n Type: AWS::Serverless::Function\r\n Properties:\r\n Handler: index.handler\r\n Runtime: nodejs16.x\r\n InlineCode: |\r\n exports.handler = async (event) => ++event;\r\n Events:\r\n Notify:\r\n Type: Api\r\n Properties:\r\n Method: POST\r\n Path: /\r\n RestApiId: !Ref ApiGatewayRestApi\r\n```\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport logging\nimport os\n\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.public.exceptions import InvalidDocumentException\nfrom samtranslator.sdk import resource\nfrom samtranslator.translator.translator import Translator\n\nfrom cfnlint.data import Serverless\nfrom cfnlint.helpers import convert_dict, format_json_string, load_resource\nfrom cfnlint.rules import Match, TransformError\n\nLOGGER = logging.getLogger(\"cfnlint\")\n\nsamtranslator_logger = logging.getLogger(\"samtranslator\")\nsamtranslator_logger.setLevel(logging.CRITICAL)\n\n\n# Override SAM validation as cfn-lint does thoese\n# checks already\n# pylint: disable=unused-argument\ndef valid_override(self):\n return resource.SamResourceType.has_value(self.type)\n\n\n# pylint: disable=redefined-outer-name\nresource.SamResource.valid = valid_override\n\n\nclass Transform:\n \"\"\"\n Application Serverless Module tranform Wrapper.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resource(Serverless, \"ManagedPolicies.json\")\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this is not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get(\"Resources\", {})\n\n template_globals = self._template.get(\"Globals\", {})\n auto_publish_alias = template_globals.get(\"Function\", {}).get(\n \"AutoPublishAlias\"\n )\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == \"Ref\":\n if v in self._template.get(\"Parameters\"):\n self._parameters[v] = \"Alias\"\n\n for _, resource in all_resources.items():\n resource_type = resource.get(\"Type\")\n resource_dict = resource.get(\"Properties\")\n\n if resource_type == \"AWS::Serverless::Function\":\n if resource_dict.get(\"PackageType\") == \"Image\":\n Transform._update_to_s3_uri(\"ImageUri\", resource_dict)\n else:\n Transform._update_to_s3_uri(\"CodeUri\", resource_dict)\n auto_publish_alias = resource_dict.get(\"AutoPublishAlias\")\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == \"Ref\":\n if v in self._template.get(\"Parameters\"):\n self._parameters[v] = \"Alias\"\n if resource_type in [\"AWS::Serverless::LayerVersion\"]:\n if resource_dict.get(\"ContentUri\"):\n Transform._update_to_s3_uri(\"ContentUri\", resource_dict)\n if resource_type == \"AWS::Serverless::Application\":\n if resource_dict.get(\"Location\"):\n if isinstance(resource_dict.get(\"Location\"), dict):\n resource_dict[\"Location\"] = \"\"\n Transform._update_to_s3_uri(\"Location\", resource_dict)\n if resource_type == \"AWS::Serverless::Api\":\n if (\n \"DefinitionBody\" not in resource_dict\n and \"Auth\" not in resource_dict\n and \"Cors\" not in resource_dict\n ):\n Transform._update_to_s3_uri(\"DefinitionUri\", resource_dict)\n else:\n resource_dict[\"DefinitionBody\"] = \"\"\n if resource_type == \"AWS::Serverless::StateMachine\" and resource_dict.get(\n \"DefinitionUri\"\n ):\n Transform._update_to_s3_uri(\"DefinitionUri\", resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info(\"SAM Translator: %s\", samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map, sam_parser=self._sam_parser\n )\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info(\"Setting AWS_DEFAULT_REGION to %s\", self._region)\n os.environ[\"AWS_DEFAULT_REGION\"] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(\n sam_template=self._template, parameter_values=self._parameters\n )\n )\n\n LOGGER.info(\n \"Transformed template: \\n%s\", format_json_string(self._template)\n )\n except InvalidDocumentException as e:\n message = \"Error transforming template: {0}\"\n for cause in e.causes:\n matches.append(\n Match(\n 1,\n 1,\n 1,\n 1,\n self._filename,\n TransformError(),\n message.format(cause.message),\n )\n )\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug(\"Error transforming template: %s\", str(e))\n LOGGER.debug(\"Stack trace: %s\", e, exc_info=True)\n message = \"Error transforming template: {0}\"\n matches.append(\n Match(\n 1, 1, 1, 1, self._filename, TransformError(), message.format(str(e))\n )\n )\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, str) and uri.startswith(\"s3://\")\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict, s3_uri_value=\"s3://bucket/value\"\n ):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, \".\")\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict):\n if len(uri_property) == 1:\n for k in uri_property.keys():\n if k == \"Ref\":\n resource_property_dict[property_key] = s3_uri_value\n return\n if Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport logging\nimport os\n\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.public.exceptions import InvalidDocumentException\nfrom samtranslator.sdk import resource\nfrom samtranslator.translator.translator import Translator\n\nfrom cfnlint.data import Serverless\nfrom cfnlint.helpers import convert_dict, format_json_string, load_resource\nfrom cfnlint.rules import Match, TransformError\n\nLOGGER = logging.getLogger(\"cfnlint\")\n\nsamtranslator_logger = logging.getLogger(\"samtranslator\")\nsamtranslator_logger.setLevel(logging.CRITICAL)\n\n\n# Override SAM validation as cfn-lint does thoese\n# checks already\n# pylint: disable=unused-argument\ndef valid_override(self):\n return resource.SamResourceType.has_value(self.type)\n\n\n# pylint: disable=redefined-outer-name\nresource.SamResource.valid = valid_override\n\n\nclass Transform:\n \"\"\"\n Application Serverless Module tranform Wrapper.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resource(Serverless, \"ManagedPolicies.json\")\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this is not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get(\"Resources\", {})\n\n template_globals = self._template.get(\"Globals\", {})\n auto_publish_alias = template_globals.get(\"Function\", {}).get(\n \"AutoPublishAlias\"\n )\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == \"Ref\":\n if v in self._template.get(\"Parameters\"):\n self._parameters[v] = \"Alias\"\n\n for _, resource in all_resources.items():\n resource_type = resource.get(\"Type\")\n resource_dict = resource.get(\"Properties\")\n\n if resource_type == \"AWS::Serverless::Function\":\n if resource_dict.get(\"PackageType\") == \"Image\":\n Transform._update_to_s3_uri(\"ImageUri\", resource_dict)\n else:\n Transform._update_to_s3_uri(\"CodeUri\", resource_dict)\n auto_publish_alias = resource_dict.get(\"AutoPublishAlias\")\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == \"Ref\":\n if v in self._template.get(\"Parameters\"):\n self._parameters[v] = \"Alias\"\n if resource_type in [\"AWS::Serverless::LayerVersion\"]:\n if resource_dict.get(\"ContentUri\"):\n Transform._update_to_s3_uri(\"ContentUri\", resource_dict)\n if resource_type == \"AWS::Serverless::Application\":\n if resource_dict.get(\"Location\"):\n if isinstance(resource_dict.get(\"Location\"), dict):\n resource_dict[\"Location\"] = \"\"\n Transform._update_to_s3_uri(\"Location\", resource_dict)\n if resource_type == \"AWS::Serverless::Api\":\n if (\n \"DefinitionBody\" not in resource_dict\n and \"Auth\" not in resource_dict\n and \"Cors\" not in resource_dict\n and \"DisableExecuteApiEndpoint\" not in resource_dict\n ):\n Transform._update_to_s3_uri(\"DefinitionUri\", resource_dict)\n else:\n resource_dict[\"DefinitionBody\"] = \"\"\n if resource_type == \"AWS::Serverless::StateMachine\" and resource_dict.get(\n \"DefinitionUri\"\n ):\n Transform._update_to_s3_uri(\"DefinitionUri\", resource_dict)\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info(\"SAM Translator: %s\", samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map, sam_parser=self._sam_parser\n )\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info(\"Setting AWS_DEFAULT_REGION to %s\", self._region)\n os.environ[\"AWS_DEFAULT_REGION\"] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(\n sam_template=self._template, parameter_values=self._parameters\n )\n )\n\n LOGGER.info(\n \"Transformed template: \\n%s\", format_json_string(self._template)\n )\n except InvalidDocumentException as e:\n message = \"Error transforming template: {0}\"\n for cause in e.causes:\n matches.append(\n Match(\n 1,\n 1,\n 1,\n 1,\n self._filename,\n TransformError(),\n message.format(cause.message),\n )\n )\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug(\"Error transforming template: %s\", str(e))\n LOGGER.debug(\"Stack trace: %s\", e, exc_info=True)\n message = \"Error transforming template: {0}\"\n matches.append(\n Match(\n 1, 1, 1, 1, self._filename, TransformError(), message.format(str(e))\n )\n )\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, str) and uri.startswith(\"s3://\")\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict, s3_uri_value=\"s3://bucket/value\"\n ):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, \".\")\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict):\n if len(uri_property) == 1:\n for k in uri_property.keys():\n if k == \"Ref\":\n resource_property_dict[property_key] = s3_uri_value\n return\n if Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}]}
| 2,939 | 118 |
gh_patches_debug_4307
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleOCR-9099
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
paddleocr中gen_lable.py对icdar2015数据转换有误

我用gen_lable.py转换的数据是这样子的,我感觉好像是错误的
不应该是:ch4_training_images/img_1.jpg [{"transcription": "Genaxis Theatre", "points": [[377, 117], [463, 117], [465, 130], [378, 130]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ppocr/postprocess/east_postprocess.py`
Content:
```
1 # Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from __future__ import absolute_import
16 from __future__ import division
17 from __future__ import print_function
18
19 import numpy as np
20 from .locality_aware_nms import nms_locality
21 import cv2
22 import paddle
23
24 import os
25 from ppocr.utils.utility import check_install
26 import sys
27
28
29 class EASTPostProcess(object):
30 """
31 The post process for EAST.
32 """
33
34 def __init__(self,
35 score_thresh=0.8,
36 cover_thresh=0.1,
37 nms_thresh=0.2,
38 **kwargs):
39
40 self.score_thresh = score_thresh
41 self.cover_thresh = cover_thresh
42 self.nms_thresh = nms_thresh
43
44 def restore_rectangle_quad(self, origin, geometry):
45 """
46 Restore rectangle from quadrangle.
47 """
48 # quad
49 origin_concat = np.concatenate(
50 (origin, origin, origin, origin), axis=1) # (n, 8)
51 pred_quads = origin_concat - geometry
52 pred_quads = pred_quads.reshape((-1, 4, 2)) # (n, 4, 2)
53 return pred_quads
54
55 def detect(self,
56 score_map,
57 geo_map,
58 score_thresh=0.8,
59 cover_thresh=0.1,
60 nms_thresh=0.2):
61 """
62 restore text boxes from score map and geo map
63 """
64
65 score_map = score_map[0]
66 geo_map = np.swapaxes(geo_map, 1, 0)
67 geo_map = np.swapaxes(geo_map, 1, 2)
68 # filter the score map
69 xy_text = np.argwhere(score_map > score_thresh)
70 if len(xy_text) == 0:
71 return []
72 # sort the text boxes via the y axis
73 xy_text = xy_text[np.argsort(xy_text[:, 0])]
74 #restore quad proposals
75 text_box_restored = self.restore_rectangle_quad(
76 xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :])
77 boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)
78 boxes[:, :8] = text_box_restored.reshape((-1, 8))
79 boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
80
81 try:
82 check_install('lanms', 'lanms-nova')
83 import lanms
84 except:
85 print(
86 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'
87 )
88 boxes = nms_locality(boxes.astype(np.float64), nms_thresh)
89 if boxes.shape[0] == 0:
90 return []
91 # Here we filter some low score boxes by the average score map,
92 # this is different from the orginal paper.
93 for i, box in enumerate(boxes):
94 mask = np.zeros_like(score_map, dtype=np.uint8)
95 cv2.fillPoly(mask, box[:8].reshape(
96 (-1, 4, 2)).astype(np.int32) // 4, 1)
97 boxes[i, 8] = cv2.mean(score_map, mask)[0]
98 boxes = boxes[boxes[:, 8] > cover_thresh]
99 return boxes
100
101 def sort_poly(self, p):
102 """
103 Sort polygons.
104 """
105 min_axis = np.argmin(np.sum(p, axis=1))
106 p = p[[min_axis, (min_axis + 1) % 4,\
107 (min_axis + 2) % 4, (min_axis + 3) % 4]]
108 if abs(p[0, 0] - p[1, 0]) > abs(p[0, 1] - p[1, 1]):
109 return p
110 else:
111 return p[[0, 3, 2, 1]]
112
113 def __call__(self, outs_dict, shape_list):
114 score_list = outs_dict['f_score']
115 geo_list = outs_dict['f_geo']
116 if isinstance(score_list, paddle.Tensor):
117 score_list = score_list.numpy()
118 geo_list = geo_list.numpy()
119 img_num = len(shape_list)
120 dt_boxes_list = []
121 for ino in range(img_num):
122 score = score_list[ino]
123 geo = geo_list[ino]
124 boxes = self.detect(
125 score_map=score,
126 geo_map=geo,
127 score_thresh=self.score_thresh,
128 cover_thresh=self.cover_thresh,
129 nms_thresh=self.nms_thresh)
130 boxes_norm = []
131 if len(boxes) > 0:
132 h, w = score.shape[1:]
133 src_h, src_w, ratio_h, ratio_w = shape_list[ino]
134 boxes = boxes[:, :8].reshape((-1, 4, 2))
135 boxes[:, :, 0] /= ratio_w
136 boxes[:, :, 1] /= ratio_h
137 for i_box, box in enumerate(boxes):
138 box = self.sort_poly(box.astype(np.int32))
139 if np.linalg.norm(box[0] - box[1]) < 5 \
140 or np.linalg.norm(box[3] - box[0]) < 5:
141 continue
142 boxes_norm.append(box)
143 dt_boxes_list.append({'points': np.array(boxes_norm)})
144 return dt_boxes_list
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ppocr/postprocess/east_postprocess.py b/ppocr/postprocess/east_postprocess.py
--- a/ppocr/postprocess/east_postprocess.py
+++ b/ppocr/postprocess/east_postprocess.py
@@ -81,6 +81,7 @@
try:
check_install('lanms', 'lanms-nova')
import lanms
+ boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)
except:
print(
'You should install lanms by pip3 install lanms-nova to speed up nms_locality'
|
{"golden_diff": "diff --git a/ppocr/postprocess/east_postprocess.py b/ppocr/postprocess/east_postprocess.py\n--- a/ppocr/postprocess/east_postprocess.py\n+++ b/ppocr/postprocess/east_postprocess.py\n@@ -81,6 +81,7 @@\n try:\n check_install('lanms', 'lanms-nova')\n import lanms\n+ boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)\n except:\n print(\n 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'\n", "issue": "paddleocr\u4e2dgen_lable.py\u5bf9icdar2015\u6570\u636e\u8f6c\u6362\u6709\u8bef\n\r\n\r\n\u6211\u7528gen_lable.py\u8f6c\u6362\u7684\u6570\u636e\u662f\u8fd9\u6837\u5b50\u7684\uff0c\u6211\u611f\u89c9\u597d\u50cf\u662f\u9519\u8bef\u7684\r\n\r\n\u4e0d\u5e94\u8be5\u662f\uff1ach4_training_images/img_1.jpg\t[{\"transcription\": \"Genaxis Theatre\", \"points\": [[377, 117], [463, 117], [465, 130], [378, 130]\n", "before_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport numpy as np\nfrom .locality_aware_nms import nms_locality\nimport cv2\nimport paddle\n\nimport os\nfrom ppocr.utils.utility import check_install\nimport sys\n\n\nclass EASTPostProcess(object):\n \"\"\"\n The post process for EAST.\n \"\"\"\n\n def __init__(self,\n score_thresh=0.8,\n cover_thresh=0.1,\n nms_thresh=0.2,\n **kwargs):\n\n self.score_thresh = score_thresh\n self.cover_thresh = cover_thresh\n self.nms_thresh = nms_thresh\n\n def restore_rectangle_quad(self, origin, geometry):\n \"\"\"\n Restore rectangle from quadrangle.\n \"\"\"\n # quad\n origin_concat = np.concatenate(\n (origin, origin, origin, origin), axis=1) # (n, 8)\n pred_quads = origin_concat - geometry\n pred_quads = pred_quads.reshape((-1, 4, 2)) # (n, 4, 2)\n return pred_quads\n\n def detect(self,\n score_map,\n geo_map,\n score_thresh=0.8,\n cover_thresh=0.1,\n nms_thresh=0.2):\n \"\"\"\n restore text boxes from score map and geo map\n \"\"\"\n\n score_map = score_map[0]\n geo_map = np.swapaxes(geo_map, 1, 0)\n geo_map = np.swapaxes(geo_map, 1, 2)\n # filter the score map\n xy_text = np.argwhere(score_map > score_thresh)\n if len(xy_text) == 0:\n return []\n # sort the text boxes via the y axis\n xy_text = xy_text[np.argsort(xy_text[:, 0])]\n #restore quad proposals\n text_box_restored = self.restore_rectangle_quad(\n xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :])\n boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)\n boxes[:, :8] = text_box_restored.reshape((-1, 8))\n boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]\n\n try:\n check_install('lanms', 'lanms-nova')\n import lanms\n except:\n print(\n 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'\n )\n boxes = nms_locality(boxes.astype(np.float64), nms_thresh)\n if boxes.shape[0] == 0:\n return []\n # Here we filter some low score boxes by the average score map, \n # this is different from the orginal paper.\n for i, box in enumerate(boxes):\n mask = np.zeros_like(score_map, dtype=np.uint8)\n cv2.fillPoly(mask, box[:8].reshape(\n (-1, 4, 2)).astype(np.int32) // 4, 1)\n boxes[i, 8] = cv2.mean(score_map, mask)[0]\n boxes = boxes[boxes[:, 8] > cover_thresh]\n return boxes\n\n def sort_poly(self, p):\n \"\"\"\n Sort polygons.\n \"\"\"\n min_axis = np.argmin(np.sum(p, axis=1))\n p = p[[min_axis, (min_axis + 1) % 4,\\\n (min_axis + 2) % 4, (min_axis + 3) % 4]]\n if abs(p[0, 0] - p[1, 0]) > abs(p[0, 1] - p[1, 1]):\n return p\n else:\n return p[[0, 3, 2, 1]]\n\n def __call__(self, outs_dict, shape_list):\n score_list = outs_dict['f_score']\n geo_list = outs_dict['f_geo']\n if isinstance(score_list, paddle.Tensor):\n score_list = score_list.numpy()\n geo_list = geo_list.numpy()\n img_num = len(shape_list)\n dt_boxes_list = []\n for ino in range(img_num):\n score = score_list[ino]\n geo = geo_list[ino]\n boxes = self.detect(\n score_map=score,\n geo_map=geo,\n score_thresh=self.score_thresh,\n cover_thresh=self.cover_thresh,\n nms_thresh=self.nms_thresh)\n boxes_norm = []\n if len(boxes) > 0:\n h, w = score.shape[1:]\n src_h, src_w, ratio_h, ratio_w = shape_list[ino]\n boxes = boxes[:, :8].reshape((-1, 4, 2))\n boxes[:, :, 0] /= ratio_w\n boxes[:, :, 1] /= ratio_h\n for i_box, box in enumerate(boxes):\n box = self.sort_poly(box.astype(np.int32))\n if np.linalg.norm(box[0] - box[1]) < 5 \\\n or np.linalg.norm(box[3] - box[0]) < 5:\n continue\n boxes_norm.append(box)\n dt_boxes_list.append({'points': np.array(boxes_norm)})\n return dt_boxes_list\n", "path": "ppocr/postprocess/east_postprocess.py"}], "after_files": [{"content": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport numpy as np\nfrom .locality_aware_nms import nms_locality\nimport cv2\nimport paddle\n\nimport os\nfrom ppocr.utils.utility import check_install\nimport sys\n\n\nclass EASTPostProcess(object):\n \"\"\"\n The post process for EAST.\n \"\"\"\n\n def __init__(self,\n score_thresh=0.8,\n cover_thresh=0.1,\n nms_thresh=0.2,\n **kwargs):\n\n self.score_thresh = score_thresh\n self.cover_thresh = cover_thresh\n self.nms_thresh = nms_thresh\n\n def restore_rectangle_quad(self, origin, geometry):\n \"\"\"\n Restore rectangle from quadrangle.\n \"\"\"\n # quad\n origin_concat = np.concatenate(\n (origin, origin, origin, origin), axis=1) # (n, 8)\n pred_quads = origin_concat - geometry\n pred_quads = pred_quads.reshape((-1, 4, 2)) # (n, 4, 2)\n return pred_quads\n\n def detect(self,\n score_map,\n geo_map,\n score_thresh=0.8,\n cover_thresh=0.1,\n nms_thresh=0.2):\n \"\"\"\n restore text boxes from score map and geo map\n \"\"\"\n\n score_map = score_map[0]\n geo_map = np.swapaxes(geo_map, 1, 0)\n geo_map = np.swapaxes(geo_map, 1, 2)\n # filter the score map\n xy_text = np.argwhere(score_map > score_thresh)\n if len(xy_text) == 0:\n return []\n # sort the text boxes via the y axis\n xy_text = xy_text[np.argsort(xy_text[:, 0])]\n #restore quad proposals\n text_box_restored = self.restore_rectangle_quad(\n xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :])\n boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)\n boxes[:, :8] = text_box_restored.reshape((-1, 8))\n boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]\n\n try:\n check_install('lanms', 'lanms-nova')\n import lanms\n boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)\n except:\n print(\n 'You should install lanms by pip3 install lanms-nova to speed up nms_locality'\n )\n boxes = nms_locality(boxes.astype(np.float64), nms_thresh)\n if boxes.shape[0] == 0:\n return []\n # Here we filter some low score boxes by the average score map, \n # this is different from the orginal paper.\n for i, box in enumerate(boxes):\n mask = np.zeros_like(score_map, dtype=np.uint8)\n cv2.fillPoly(mask, box[:8].reshape(\n (-1, 4, 2)).astype(np.int32) // 4, 1)\n boxes[i, 8] = cv2.mean(score_map, mask)[0]\n boxes = boxes[boxes[:, 8] > cover_thresh]\n return boxes\n\n def sort_poly(self, p):\n \"\"\"\n Sort polygons.\n \"\"\"\n min_axis = np.argmin(np.sum(p, axis=1))\n p = p[[min_axis, (min_axis + 1) % 4,\\\n (min_axis + 2) % 4, (min_axis + 3) % 4]]\n if abs(p[0, 0] - p[1, 0]) > abs(p[0, 1] - p[1, 1]):\n return p\n else:\n return p[[0, 3, 2, 1]]\n\n def __call__(self, outs_dict, shape_list):\n score_list = outs_dict['f_score']\n geo_list = outs_dict['f_geo']\n if isinstance(score_list, paddle.Tensor):\n score_list = score_list.numpy()\n geo_list = geo_list.numpy()\n img_num = len(shape_list)\n dt_boxes_list = []\n for ino in range(img_num):\n score = score_list[ino]\n geo = geo_list[ino]\n boxes = self.detect(\n score_map=score,\n geo_map=geo,\n score_thresh=self.score_thresh,\n cover_thresh=self.cover_thresh,\n nms_thresh=self.nms_thresh)\n boxes_norm = []\n if len(boxes) > 0:\n h, w = score.shape[1:]\n src_h, src_w, ratio_h, ratio_w = shape_list[ino]\n boxes = boxes[:, :8].reshape((-1, 4, 2))\n boxes[:, :, 0] /= ratio_w\n boxes[:, :, 1] /= ratio_h\n for i_box, box in enumerate(boxes):\n box = self.sort_poly(box.astype(np.int32))\n if np.linalg.norm(box[0] - box[1]) < 5 \\\n or np.linalg.norm(box[3] - box[0]) < 5:\n continue\n boxes_norm.append(box)\n dt_boxes_list.append({'points': np.array(boxes_norm)})\n return dt_boxes_list\n", "path": "ppocr/postprocess/east_postprocess.py"}]}
| 2,064 | 129 |
gh_patches_debug_21462
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4422
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove Trusty-specific logic from application code and dev env
## Description
Some platform-specific logic was added to handle the upgrade from Trusty to Xenial and should be removed:
- Source Interface Submission disable logic: https://github.com/freedomofpress/securedrop/pull/4325
- Admin Interface alert for end-of-life OS: https://github.com/freedomofpress/securedrop/pull/4055
There is also some Trusty-specific logic in the development environment:
- [Docker images](https://github.com/freedomofpress/securedrop/tree/develop/securedrop/dockerfiles/trusty)
- [CI targets](https://github.com/freedomofpress/securedrop/blob/develop/.circleci/config.yml#L59
- The use of `BASE_OS` in Makefile targets
- Upgrade testing scenarios and boxes
Since Trusty will no longer be supported after 0.12.2, we should remove this logic to improve the maintainability of the codebase and reduce the risk of errors.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `molecule/vagrant-packager/package.py`
Content:
```
1 #!/usr/bin/env python3
2 #
3 #
4 #
5 #
6 import hashlib
7 import json
8 import os
9 from os.path import join
10 import re
11 import shutil
12 import subprocess
13 import tarfile
14 import xml.etree.ElementTree as ET
15
16
17 # Current script is symlinked into adjacent scenario, for Trusty compatibility.
18 # Look up "name" for scenario from real path (relative to symlink), but store
19 # all artifacts in primary scenario (via realpath).
20 SCENARIO_NAME = os.path.basename(os.path.dirname(os.path.abspath(__file__)))
21 SCENARIO_PATH = os.path.dirname(os.path.realpath(__file__))
22 BOX_BUILD_DIR = join(SCENARIO_PATH, "build")
23 BOX_METADATA_DIR = join(SCENARIO_PATH, "box_files")
24 EPHEMERAL_DIRS = {}
25 TARGET_VERSION_FILE = os.path.join(SCENARIO_PATH, os.path.pardir, "shared", "stable.ver")
26
27
28 class LibVirtPackager(object):
29
30 def __init__(self, vm):
31 # type: (str) -> None
32 self.cli_prefix = "virsh --connect qemu:///system {}"
33 self.vm_name = vm
34
35 def _get_virsh_xml(self, cmd):
36 # type: (str) -> ET.Element
37 virsh_cmd_str = self.cli_prefix.format(cmd)
38 cmd_output = subprocess.check_output(virsh_cmd_str.split())
39 return ET.fromstring(cmd_output)
40
41 def vm_xml(self):
42 # type: () -> ET.Element
43 """ Get XML definition for virtual machine domain
44 """
45 return self._get_virsh_xml("dumpxml "+self.vm_name)
46
47 def default_image_location(self):
48 # type: () -> str
49 """
50 Get full system path to the default system pool dir
51 """
52 pool = self._get_virsh_xml("pool-dumpxml default")
53
54 return pool.findall('./target/path')[0].text
55
56 def image_rebase(self, img_location):
57 # type: (str) -> None
58 """ If an image has a backing store, merge the backing store into the
59 target image file
60 """
61 if self.default_image_location() in img_location:
62 raise UserWarning("To prevent catastrophy, will not"
63 " run on image in the default pool. Copy it"
64 " first to someplace else")
65
66 img_info = subprocess.check_output(["qemu-img", "info", img_location])
67 rebase_cmd = """qemu-img rebase -b "" {}""".format(img_location)
68
69 if "backing file:" in img_info.decode('utf-8'):
70 print("Running rebase now..")
71 subprocess.check_call(rebase_cmd, shell=True)
72 else:
73 print("No rebase necessary")
74
75 def image_store_path(self):
76 # type: () -> str
77 """ Get location of VM's first storage disk file """
78 vm_xml = self.vm_xml()
79 return vm_xml.findall('./devices/disk/source')[0].attrib['file']
80
81 def image_sparsify(self, src, dest, tmp_dir, inplace):
82 # type: (str, str, str, bool) -> None
83 """ Remove blank-space from the image. Note that setting inplace to
84 false will get you better bang for your buck but can make system
85 unstable. Pushed IO to the max on my machine and caused it to crash
86 """
87 img_info = subprocess.check_output(["qemu-img", "info", src])
88
89 if "backing file:" in img_info.decode('utf-8'):
90 raise UserWarning("Cannot sparsify image w/ backing "
91 "store. Please rebase first.")
92
93 if inplace:
94 subprocess.check_call(["virt-sparsify",
95 "--in-place",
96 src])
97 shutil.move(src, dest)
98 else:
99 subprocess.check_call(["virt-sparsify", "--tmp",
100 tmp_dir,
101 src,
102 dest])
103
104 def sysprep(self, img_location):
105 # type: (str) -> None
106 """ Run the virt-sysprep tool over the image to prep the log for
107 re-dist. Removes things like logs and user history files
108 """
109 sysprep_cmd = ("virt-sysprep --no-logfile --operations "
110 "defaults,-ssh-userdir,-ssh-hostkeys,-logfiles -a " +
111 img_location)
112 subprocess.check_call(sysprep_cmd.split())
113
114 def vagrant_metadata(self, img_location):
115 # type: (str) -> dict
116 """ Produce dictionary of necessary vagrant key/values """
117 json = {}
118
119 info_output = subprocess.check_output(["qemu-img", "info",
120 img_location]).decode('utf-8')
121 json['virtual_size'] = int((re.search("virtual size: (?P<size>\d+)G",
122 info_output)).group("size"))
123
124 json['format'] = (re.search("file format: (?P<format>\w+)",
125 info_output)).group("format")
126 json['provider'] = 'libvirt'
127
128 return json
129
130
131 def main():
132 with open(TARGET_VERSION_FILE, 'r') as f:
133 TARGET_VERSION = f.read().strip()
134
135 # Default to Xenial as base OS, but detect if script was invoked from the
136 # Trusty-specific scenario, and use Trusty if so.
137 TARGET_PLATFORM = os.environ.get("SECUREDROP_TARGET_PLATFORM", "xenial")
138
139 for srv in ["app-staging", "mon-staging"]:
140
141 for temp_dir in ["build", "tmp"]:
142 try:
143 ephemeral_path = join(SCENARIO_PATH, ".molecule",
144 temp_dir)
145 EPHEMERAL_DIRS[temp_dir] = ephemeral_path
146
147 os.makedirs(os.path.join(SCENARIO_PATH, ".molecule", temp_dir))
148 except OSError:
149 pass
150
151 vm = LibVirtPackager("{}_{}".format(SCENARIO_NAME, srv))
152
153 tmp_img_file = join(EPHEMERAL_DIRS["tmp"], "wip.img")
154 packaged_img_file = join(EPHEMERAL_DIRS["build"], "box.img")
155
156 print("Copying VM image store locally")
157 subprocess.check_output(["sudo", "cp",
158 vm.image_store_path(), # source
159 tmp_img_file # dest
160 ])
161
162 print("Changing file ownership")
163 subprocess.check_output(["sudo", "chown", os.environ['USER'],
164 tmp_img_file])
165
166 # Run a sysprep on it
167 print("Run an image sysprep")
168 vm.sysprep(tmp_img_file)
169
170 print("Rebase Image")
171 vm.image_rebase(tmp_img_file)
172
173 # Sparsify the image file
174 print("Run sparsi-fication on the image")
175 vm.image_sparsify(src=tmp_img_file,
176 dest=packaged_img_file,
177 tmp_dir=EPHEMERAL_DIRS['tmp'],
178 inplace=True)
179
180 # Write out metadata file
181 with open(join(EPHEMERAL_DIRS['build'], 'metadata.json'),
182 'w') as mdata:
183 json.dump(
184 vm.vagrant_metadata(packaged_img_file),
185 mdata)
186
187 # Copy in appropriate vagrant file to build dir
188 shutil.copyfile(join(BOX_METADATA_DIR, "Vagrantfile."+srv),
189 join(EPHEMERAL_DIRS['build'], 'Vagrantfile'))
190
191 print("Creating tar file")
192 box_file = join(BOX_BUILD_DIR, "{}-{}_{}.box".format(srv, TARGET_PLATFORM, TARGET_VERSION))
193 with tarfile.open(box_file, "w|gz") as tar:
194 for boxfile in ["box.img", "Vagrantfile", "metadata.json"]:
195 tar.add(join(EPHEMERAL_DIRS["build"], boxfile),
196 arcname=boxfile)
197
198 print("Box created at {}".format(box_file))
199
200 print("Updating box metadata")
201 update_box_metadata(srv, box_file, TARGET_PLATFORM, TARGET_VERSION)
202
203 print("Clean-up tmp space")
204 shutil.rmtree(EPHEMERAL_DIRS['tmp'])
205
206
207 def sha256_checksum(filepath):
208 """
209 Returns a SHA256 checksum for a given filepath.
210 """
211 checksum = hashlib.sha256()
212 with open(filepath, 'rb') as f:
213 # Read by chunks, to avoid slurping the entire file into memory.
214 # Box files range from 500MB to 1.5GB.
215 for block in iter(lambda: f.read(checksum.block_size), b''):
216 checksum.update(block)
217 return checksum.hexdigest()
218
219
220 def update_box_metadata(server_name, box_file, platform, version):
221 """
222 Updates the JSON file of Vagrant box metadata, including remote URL,
223 version number, and SHA256 checksum.
224 """
225 # Strip off "staging" suffix from box names
226 server_name_short = re.sub('\-staging$', '', server_name)
227 json_file_basename = "{}_{}_metadata.json".format(server_name_short, platform)
228 json_file = os.path.join(BOX_METADATA_DIR, json_file_basename)
229
230 # Read in current JSON metadata, so we can append the new info to it.
231 with open(json_file, "r") as f:
232 metadata_config = json.loads(f.read())
233
234 base_url = "https://dev-bin.ops.securedrop.org/vagrant"
235 box_name = os.path.basename(box_file)
236 box_url = "{}/{}".format(base_url, box_name)
237 box_checksum = sha256_checksum(box_file)
238 box_config = dict(
239 name="libvirt",
240 url=box_url,
241 checksum_type="sha256",
242 checksum=box_checksum,
243 )
244 # Creating list of dicts to adhere to JSON format of Vagrant box metadata
245 providers_list = []
246 providers_list.append(box_config)
247 version_config = dict(
248 version=version,
249 providers=providers_list,
250 )
251 box_versions = metadata_config['versions']
252 box_versions.append(version_config)
253 metadata_config['versions'] = box_versions
254
255 # Write out final, modified data. Does not validate for uniqueness,
256 # so repeated runs on the same version will duplicate version info,
257 # which'll likely break the box fetching. Target file is version-controlled,
258 # though, so easy enough to correct in the event of a mistake.
259 with open(json_file, "w") as f:
260 f.write(json.dumps(metadata_config, indent=2, sort_keys=True))
261
262
263 if __name__ == "__main__":
264 main()
265
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/molecule/vagrant-packager/package.py b/molecule/vagrant-packager/package.py
--- a/molecule/vagrant-packager/package.py
+++ b/molecule/vagrant-packager/package.py
@@ -14,9 +14,6 @@
import xml.etree.ElementTree as ET
-# Current script is symlinked into adjacent scenario, for Trusty compatibility.
-# Look up "name" for scenario from real path (relative to symlink), but store
-# all artifacts in primary scenario (via realpath).
SCENARIO_NAME = os.path.basename(os.path.dirname(os.path.abspath(__file__)))
SCENARIO_PATH = os.path.dirname(os.path.realpath(__file__))
BOX_BUILD_DIR = join(SCENARIO_PATH, "build")
@@ -132,8 +129,7 @@
with open(TARGET_VERSION_FILE, 'r') as f:
TARGET_VERSION = f.read().strip()
- # Default to Xenial as base OS, but detect if script was invoked from the
- # Trusty-specific scenario, and use Trusty if so.
+ # Default to Xenial as base OS.
TARGET_PLATFORM = os.environ.get("SECUREDROP_TARGET_PLATFORM", "xenial")
for srv in ["app-staging", "mon-staging"]:
|
{"golden_diff": "diff --git a/molecule/vagrant-packager/package.py b/molecule/vagrant-packager/package.py\n--- a/molecule/vagrant-packager/package.py\n+++ b/molecule/vagrant-packager/package.py\n@@ -14,9 +14,6 @@\n import xml.etree.ElementTree as ET\n \n \n-# Current script is symlinked into adjacent scenario, for Trusty compatibility.\n-# Look up \"name\" for scenario from real path (relative to symlink), but store\n-# all artifacts in primary scenario (via realpath).\n SCENARIO_NAME = os.path.basename(os.path.dirname(os.path.abspath(__file__)))\n SCENARIO_PATH = os.path.dirname(os.path.realpath(__file__))\n BOX_BUILD_DIR = join(SCENARIO_PATH, \"build\")\n@@ -132,8 +129,7 @@\n with open(TARGET_VERSION_FILE, 'r') as f:\n TARGET_VERSION = f.read().strip()\n \n- # Default to Xenial as base OS, but detect if script was invoked from the\n- # Trusty-specific scenario, and use Trusty if so.\n+ # Default to Xenial as base OS.\n TARGET_PLATFORM = os.environ.get(\"SECUREDROP_TARGET_PLATFORM\", \"xenial\")\n \n for srv in [\"app-staging\", \"mon-staging\"]:\n", "issue": "Remove Trusty-specific logic from application code and dev env\n## Description\r\n\r\nSome platform-specific logic was added to handle the upgrade from Trusty to Xenial and should be removed:\r\n- Source Interface Submission disable logic: https://github.com/freedomofpress/securedrop/pull/4325\r\n- Admin Interface alert for end-of-life OS: https://github.com/freedomofpress/securedrop/pull/4055\r\n\r\nThere is also some Trusty-specific logic in the development environment: \r\n- [Docker images](https://github.com/freedomofpress/securedrop/tree/develop/securedrop/dockerfiles/trusty)\r\n- [CI targets](https://github.com/freedomofpress/securedrop/blob/develop/.circleci/config.yml#L59\r\n- The use of `BASE_OS` in Makefile targets\r\n- Upgrade testing scenarios and boxes\r\n\r\nSince Trusty will no longer be supported after 0.12.2, we should remove this logic to improve the maintainability of the codebase and reduce the risk of errors.\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n#\n#\n#\nimport hashlib\nimport json\nimport os\nfrom os.path import join\nimport re\nimport shutil\nimport subprocess\nimport tarfile\nimport xml.etree.ElementTree as ET\n\n\n# Current script is symlinked into adjacent scenario, for Trusty compatibility.\n# Look up \"name\" for scenario from real path (relative to symlink), but store\n# all artifacts in primary scenario (via realpath).\nSCENARIO_NAME = os.path.basename(os.path.dirname(os.path.abspath(__file__)))\nSCENARIO_PATH = os.path.dirname(os.path.realpath(__file__))\nBOX_BUILD_DIR = join(SCENARIO_PATH, \"build\")\nBOX_METADATA_DIR = join(SCENARIO_PATH, \"box_files\")\nEPHEMERAL_DIRS = {}\nTARGET_VERSION_FILE = os.path.join(SCENARIO_PATH, os.path.pardir, \"shared\", \"stable.ver\")\n\n\nclass LibVirtPackager(object):\n\n def __init__(self, vm):\n # type: (str) -> None\n self.cli_prefix = \"virsh --connect qemu:///system {}\"\n self.vm_name = vm\n\n def _get_virsh_xml(self, cmd):\n # type: (str) -> ET.Element\n virsh_cmd_str = self.cli_prefix.format(cmd)\n cmd_output = subprocess.check_output(virsh_cmd_str.split())\n return ET.fromstring(cmd_output)\n\n def vm_xml(self):\n # type: () -> ET.Element\n \"\"\" Get XML definition for virtual machine domain\n \"\"\"\n return self._get_virsh_xml(\"dumpxml \"+self.vm_name)\n\n def default_image_location(self):\n # type: () -> str\n \"\"\"\n Get full system path to the default system pool dir\n \"\"\"\n pool = self._get_virsh_xml(\"pool-dumpxml default\")\n\n return pool.findall('./target/path')[0].text\n\n def image_rebase(self, img_location):\n # type: (str) -> None\n \"\"\" If an image has a backing store, merge the backing store into the\n target image file\n \"\"\"\n if self.default_image_location() in img_location:\n raise UserWarning(\"To prevent catastrophy, will not\"\n \" run on image in the default pool. Copy it\"\n \" first to someplace else\")\n\n img_info = subprocess.check_output([\"qemu-img\", \"info\", img_location])\n rebase_cmd = \"\"\"qemu-img rebase -b \"\" {}\"\"\".format(img_location)\n\n if \"backing file:\" in img_info.decode('utf-8'):\n print(\"Running rebase now..\")\n subprocess.check_call(rebase_cmd, shell=True)\n else:\n print(\"No rebase necessary\")\n\n def image_store_path(self):\n # type: () -> str\n \"\"\" Get location of VM's first storage disk file \"\"\"\n vm_xml = self.vm_xml()\n return vm_xml.findall('./devices/disk/source')[0].attrib['file']\n\n def image_sparsify(self, src, dest, tmp_dir, inplace):\n # type: (str, str, str, bool) -> None\n \"\"\" Remove blank-space from the image. Note that setting inplace to\n false will get you better bang for your buck but can make system\n unstable. Pushed IO to the max on my machine and caused it to crash\n \"\"\"\n img_info = subprocess.check_output([\"qemu-img\", \"info\", src])\n\n if \"backing file:\" in img_info.decode('utf-8'):\n raise UserWarning(\"Cannot sparsify image w/ backing \"\n \"store. Please rebase first.\")\n\n if inplace:\n subprocess.check_call([\"virt-sparsify\",\n \"--in-place\",\n src])\n shutil.move(src, dest)\n else:\n subprocess.check_call([\"virt-sparsify\", \"--tmp\",\n tmp_dir,\n src,\n dest])\n\n def sysprep(self, img_location):\n # type: (str) -> None\n \"\"\" Run the virt-sysprep tool over the image to prep the log for\n re-dist. Removes things like logs and user history files\n \"\"\"\n sysprep_cmd = (\"virt-sysprep --no-logfile --operations \"\n \"defaults,-ssh-userdir,-ssh-hostkeys,-logfiles -a \" +\n img_location)\n subprocess.check_call(sysprep_cmd.split())\n\n def vagrant_metadata(self, img_location):\n # type: (str) -> dict\n \"\"\" Produce dictionary of necessary vagrant key/values \"\"\"\n json = {}\n\n info_output = subprocess.check_output([\"qemu-img\", \"info\",\n img_location]).decode('utf-8')\n json['virtual_size'] = int((re.search(\"virtual size: (?P<size>\\d+)G\",\n info_output)).group(\"size\"))\n\n json['format'] = (re.search(\"file format: (?P<format>\\w+)\",\n info_output)).group(\"format\")\n json['provider'] = 'libvirt'\n\n return json\n\n\ndef main():\n with open(TARGET_VERSION_FILE, 'r') as f:\n TARGET_VERSION = f.read().strip()\n\n # Default to Xenial as base OS, but detect if script was invoked from the\n # Trusty-specific scenario, and use Trusty if so.\n TARGET_PLATFORM = os.environ.get(\"SECUREDROP_TARGET_PLATFORM\", \"xenial\")\n\n for srv in [\"app-staging\", \"mon-staging\"]:\n\n for temp_dir in [\"build\", \"tmp\"]:\n try:\n ephemeral_path = join(SCENARIO_PATH, \".molecule\",\n temp_dir)\n EPHEMERAL_DIRS[temp_dir] = ephemeral_path\n\n os.makedirs(os.path.join(SCENARIO_PATH, \".molecule\", temp_dir))\n except OSError:\n pass\n\n vm = LibVirtPackager(\"{}_{}\".format(SCENARIO_NAME, srv))\n\n tmp_img_file = join(EPHEMERAL_DIRS[\"tmp\"], \"wip.img\")\n packaged_img_file = join(EPHEMERAL_DIRS[\"build\"], \"box.img\")\n\n print(\"Copying VM image store locally\")\n subprocess.check_output([\"sudo\", \"cp\",\n vm.image_store_path(), # source\n tmp_img_file # dest\n ])\n\n print(\"Changing file ownership\")\n subprocess.check_output([\"sudo\", \"chown\", os.environ['USER'],\n tmp_img_file])\n\n # Run a sysprep on it\n print(\"Run an image sysprep\")\n vm.sysprep(tmp_img_file)\n\n print(\"Rebase Image\")\n vm.image_rebase(tmp_img_file)\n\n # Sparsify the image file\n print(\"Run sparsi-fication on the image\")\n vm.image_sparsify(src=tmp_img_file,\n dest=packaged_img_file,\n tmp_dir=EPHEMERAL_DIRS['tmp'],\n inplace=True)\n\n # Write out metadata file\n with open(join(EPHEMERAL_DIRS['build'], 'metadata.json'),\n 'w') as mdata:\n json.dump(\n vm.vagrant_metadata(packaged_img_file),\n mdata)\n\n # Copy in appropriate vagrant file to build dir\n shutil.copyfile(join(BOX_METADATA_DIR, \"Vagrantfile.\"+srv),\n join(EPHEMERAL_DIRS['build'], 'Vagrantfile'))\n\n print(\"Creating tar file\")\n box_file = join(BOX_BUILD_DIR, \"{}-{}_{}.box\".format(srv, TARGET_PLATFORM, TARGET_VERSION))\n with tarfile.open(box_file, \"w|gz\") as tar:\n for boxfile in [\"box.img\", \"Vagrantfile\", \"metadata.json\"]:\n tar.add(join(EPHEMERAL_DIRS[\"build\"], boxfile),\n arcname=boxfile)\n\n print(\"Box created at {}\".format(box_file))\n\n print(\"Updating box metadata\")\n update_box_metadata(srv, box_file, TARGET_PLATFORM, TARGET_VERSION)\n\n print(\"Clean-up tmp space\")\n shutil.rmtree(EPHEMERAL_DIRS['tmp'])\n\n\ndef sha256_checksum(filepath):\n \"\"\"\n Returns a SHA256 checksum for a given filepath.\n \"\"\"\n checksum = hashlib.sha256()\n with open(filepath, 'rb') as f:\n # Read by chunks, to avoid slurping the entire file into memory.\n # Box files range from 500MB to 1.5GB.\n for block in iter(lambda: f.read(checksum.block_size), b''):\n checksum.update(block)\n return checksum.hexdigest()\n\n\ndef update_box_metadata(server_name, box_file, platform, version):\n \"\"\"\n Updates the JSON file of Vagrant box metadata, including remote URL,\n version number, and SHA256 checksum.\n \"\"\"\n # Strip off \"staging\" suffix from box names\n server_name_short = re.sub('\\-staging$', '', server_name)\n json_file_basename = \"{}_{}_metadata.json\".format(server_name_short, platform)\n json_file = os.path.join(BOX_METADATA_DIR, json_file_basename)\n\n # Read in current JSON metadata, so we can append the new info to it.\n with open(json_file, \"r\") as f:\n metadata_config = json.loads(f.read())\n\n base_url = \"https://dev-bin.ops.securedrop.org/vagrant\"\n box_name = os.path.basename(box_file)\n box_url = \"{}/{}\".format(base_url, box_name)\n box_checksum = sha256_checksum(box_file)\n box_config = dict(\n name=\"libvirt\",\n url=box_url,\n checksum_type=\"sha256\",\n checksum=box_checksum,\n )\n # Creating list of dicts to adhere to JSON format of Vagrant box metadata\n providers_list = []\n providers_list.append(box_config)\n version_config = dict(\n version=version,\n providers=providers_list,\n )\n box_versions = metadata_config['versions']\n box_versions.append(version_config)\n metadata_config['versions'] = box_versions\n\n # Write out final, modified data. Does not validate for uniqueness,\n # so repeated runs on the same version will duplicate version info,\n # which'll likely break the box fetching. Target file is version-controlled,\n # though, so easy enough to correct in the event of a mistake.\n with open(json_file, \"w\") as f:\n f.write(json.dumps(metadata_config, indent=2, sort_keys=True))\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "molecule/vagrant-packager/package.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n#\n#\n#\n#\nimport hashlib\nimport json\nimport os\nfrom os.path import join\nimport re\nimport shutil\nimport subprocess\nimport tarfile\nimport xml.etree.ElementTree as ET\n\n\nSCENARIO_NAME = os.path.basename(os.path.dirname(os.path.abspath(__file__)))\nSCENARIO_PATH = os.path.dirname(os.path.realpath(__file__))\nBOX_BUILD_DIR = join(SCENARIO_PATH, \"build\")\nBOX_METADATA_DIR = join(SCENARIO_PATH, \"box_files\")\nEPHEMERAL_DIRS = {}\nTARGET_VERSION_FILE = os.path.join(SCENARIO_PATH, os.path.pardir, \"shared\", \"stable.ver\")\n\n\nclass LibVirtPackager(object):\n\n def __init__(self, vm):\n # type: (str) -> None\n self.cli_prefix = \"virsh --connect qemu:///system {}\"\n self.vm_name = vm\n\n def _get_virsh_xml(self, cmd):\n # type: (str) -> ET.Element\n virsh_cmd_str = self.cli_prefix.format(cmd)\n cmd_output = subprocess.check_output(virsh_cmd_str.split())\n return ET.fromstring(cmd_output)\n\n def vm_xml(self):\n # type: () -> ET.Element\n \"\"\" Get XML definition for virtual machine domain\n \"\"\"\n return self._get_virsh_xml(\"dumpxml \"+self.vm_name)\n\n def default_image_location(self):\n # type: () -> str\n \"\"\"\n Get full system path to the default system pool dir\n \"\"\"\n pool = self._get_virsh_xml(\"pool-dumpxml default\")\n\n return pool.findall('./target/path')[0].text\n\n def image_rebase(self, img_location):\n # type: (str) -> None\n \"\"\" If an image has a backing store, merge the backing store into the\n target image file\n \"\"\"\n if self.default_image_location() in img_location:\n raise UserWarning(\"To prevent catastrophy, will not\"\n \" run on image in the default pool. Copy it\"\n \" first to someplace else\")\n\n img_info = subprocess.check_output([\"qemu-img\", \"info\", img_location])\n rebase_cmd = \"\"\"qemu-img rebase -b \"\" {}\"\"\".format(img_location)\n\n if \"backing file:\" in img_info.decode('utf-8'):\n print(\"Running rebase now..\")\n subprocess.check_call(rebase_cmd, shell=True)\n else:\n print(\"No rebase necessary\")\n\n def image_store_path(self):\n # type: () -> str\n \"\"\" Get location of VM's first storage disk file \"\"\"\n vm_xml = self.vm_xml()\n return vm_xml.findall('./devices/disk/source')[0].attrib['file']\n\n def image_sparsify(self, src, dest, tmp_dir, inplace):\n # type: (str, str, str, bool) -> None\n \"\"\" Remove blank-space from the image. Note that setting inplace to\n false will get you better bang for your buck but can make system\n unstable. Pushed IO to the max on my machine and caused it to crash\n \"\"\"\n img_info = subprocess.check_output([\"qemu-img\", \"info\", src])\n\n if \"backing file:\" in img_info.decode('utf-8'):\n raise UserWarning(\"Cannot sparsify image w/ backing \"\n \"store. Please rebase first.\")\n\n if inplace:\n subprocess.check_call([\"virt-sparsify\",\n \"--in-place\",\n src])\n shutil.move(src, dest)\n else:\n subprocess.check_call([\"virt-sparsify\", \"--tmp\",\n tmp_dir,\n src,\n dest])\n\n def sysprep(self, img_location):\n # type: (str) -> None\n \"\"\" Run the virt-sysprep tool over the image to prep the log for\n re-dist. Removes things like logs and user history files\n \"\"\"\n sysprep_cmd = (\"virt-sysprep --no-logfile --operations \"\n \"defaults,-ssh-userdir,-ssh-hostkeys,-logfiles -a \" +\n img_location)\n subprocess.check_call(sysprep_cmd.split())\n\n def vagrant_metadata(self, img_location):\n # type: (str) -> dict\n \"\"\" Produce dictionary of necessary vagrant key/values \"\"\"\n json = {}\n\n info_output = subprocess.check_output([\"qemu-img\", \"info\",\n img_location]).decode('utf-8')\n json['virtual_size'] = int((re.search(\"virtual size: (?P<size>\\d+)G\",\n info_output)).group(\"size\"))\n\n json['format'] = (re.search(\"file format: (?P<format>\\w+)\",\n info_output)).group(\"format\")\n json['provider'] = 'libvirt'\n\n return json\n\n\ndef main():\n with open(TARGET_VERSION_FILE, 'r') as f:\n TARGET_VERSION = f.read().strip()\n\n # Default to Xenial as base OS.\n TARGET_PLATFORM = os.environ.get(\"SECUREDROP_TARGET_PLATFORM\", \"xenial\")\n\n for srv in [\"app-staging\", \"mon-staging\"]:\n\n for temp_dir in [\"build\", \"tmp\"]:\n try:\n ephemeral_path = join(SCENARIO_PATH, \".molecule\",\n temp_dir)\n EPHEMERAL_DIRS[temp_dir] = ephemeral_path\n\n os.makedirs(os.path.join(SCENARIO_PATH, \".molecule\", temp_dir))\n except OSError:\n pass\n\n vm = LibVirtPackager(\"{}_{}\".format(SCENARIO_NAME, srv))\n\n tmp_img_file = join(EPHEMERAL_DIRS[\"tmp\"], \"wip.img\")\n packaged_img_file = join(EPHEMERAL_DIRS[\"build\"], \"box.img\")\n\n print(\"Copying VM image store locally\")\n subprocess.check_output([\"sudo\", \"cp\",\n vm.image_store_path(), # source\n tmp_img_file # dest\n ])\n\n print(\"Changing file ownership\")\n subprocess.check_output([\"sudo\", \"chown\", os.environ['USER'],\n tmp_img_file])\n\n # Run a sysprep on it\n print(\"Run an image sysprep\")\n vm.sysprep(tmp_img_file)\n\n print(\"Rebase Image\")\n vm.image_rebase(tmp_img_file)\n\n # Sparsify the image file\n print(\"Run sparsi-fication on the image\")\n vm.image_sparsify(src=tmp_img_file,\n dest=packaged_img_file,\n tmp_dir=EPHEMERAL_DIRS['tmp'],\n inplace=True)\n\n # Write out metadata file\n with open(join(EPHEMERAL_DIRS['build'], 'metadata.json'),\n 'w') as mdata:\n json.dump(\n vm.vagrant_metadata(packaged_img_file),\n mdata)\n\n # Copy in appropriate vagrant file to build dir\n shutil.copyfile(join(BOX_METADATA_DIR, \"Vagrantfile.\"+srv),\n join(EPHEMERAL_DIRS['build'], 'Vagrantfile'))\n\n print(\"Creating tar file\")\n box_file = join(BOX_BUILD_DIR, \"{}-{}_{}.box\".format(srv, TARGET_PLATFORM, TARGET_VERSION))\n with tarfile.open(box_file, \"w|gz\") as tar:\n for boxfile in [\"box.img\", \"Vagrantfile\", \"metadata.json\"]:\n tar.add(join(EPHEMERAL_DIRS[\"build\"], boxfile),\n arcname=boxfile)\n\n print(\"Box created at {}\".format(box_file))\n\n print(\"Updating box metadata\")\n update_box_metadata(srv, box_file, TARGET_PLATFORM, TARGET_VERSION)\n\n print(\"Clean-up tmp space\")\n shutil.rmtree(EPHEMERAL_DIRS['tmp'])\n\n\ndef sha256_checksum(filepath):\n \"\"\"\n Returns a SHA256 checksum for a given filepath.\n \"\"\"\n checksum = hashlib.sha256()\n with open(filepath, 'rb') as f:\n # Read by chunks, to avoid slurping the entire file into memory.\n # Box files range from 500MB to 1.5GB.\n for block in iter(lambda: f.read(checksum.block_size), b''):\n checksum.update(block)\n return checksum.hexdigest()\n\n\ndef update_box_metadata(server_name, box_file, platform, version):\n \"\"\"\n Updates the JSON file of Vagrant box metadata, including remote URL,\n version number, and SHA256 checksum.\n \"\"\"\n # Strip off \"staging\" suffix from box names\n server_name_short = re.sub('\\-staging$', '', server_name)\n json_file_basename = \"{}_{}_metadata.json\".format(server_name_short, platform)\n json_file = os.path.join(BOX_METADATA_DIR, json_file_basename)\n\n # Read in current JSON metadata, so we can append the new info to it.\n with open(json_file, \"r\") as f:\n metadata_config = json.loads(f.read())\n\n base_url = \"https://dev-bin.ops.securedrop.org/vagrant\"\n box_name = os.path.basename(box_file)\n box_url = \"{}/{}\".format(base_url, box_name)\n box_checksum = sha256_checksum(box_file)\n box_config = dict(\n name=\"libvirt\",\n url=box_url,\n checksum_type=\"sha256\",\n checksum=box_checksum,\n )\n # Creating list of dicts to adhere to JSON format of Vagrant box metadata\n providers_list = []\n providers_list.append(box_config)\n version_config = dict(\n version=version,\n providers=providers_list,\n )\n box_versions = metadata_config['versions']\n box_versions.append(version_config)\n metadata_config['versions'] = box_versions\n\n # Write out final, modified data. Does not validate for uniqueness,\n # so repeated runs on the same version will duplicate version info,\n # which'll likely break the box fetching. Target file is version-controlled,\n # though, so easy enough to correct in the event of a mistake.\n with open(json_file, \"w\") as f:\n f.write(json.dumps(metadata_config, indent=2, sort_keys=True))\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "molecule/vagrant-packager/package.py"}]}
| 3,403 | 273 |
gh_patches_debug_11690
|
rasdani/github-patches
|
git_diff
|
searxng__searxng-3369
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove ask engine
Reasons:
1. User Tracking via query parameters.
Example Query: [!ask best museums in Köln](https://searx.be/search?q=%21ask+best+museums+in+K%C3%B6ln&category_none=&language=auto&time_range=&safesearch=0&theme=simple)
Notice the ```euid=some_id``` at the end for most urls.
2. Very bad results - Something must have changed.
Example Query: [!ask "yt-dlp"](https://searx.be/search?q=%21ask+%22yt-dlp%22&category_none=&language=auto&time_range=&safesearch=0&theme=simple)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/engines/ask.py`
Content:
```
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 """Ask.com"""
3
4 from urllib.parse import urlencode
5 import dateutil
6 from lxml import html
7 from searx import utils
8
9 # Metadata
10 about = {
11 "website": "https://www.ask.com/",
12 "wikidata_id": 'Q847564',
13 "official_api_documentation": None,
14 "use_official_api": False,
15 "require_api_key": False,
16 "results": "HTML",
17 }
18
19 # Engine Configuration
20 categories = ['general']
21 paging = True
22
23 # Base URL
24 base_url = "https://www.ask.com/web"
25
26
27 def request(query, params):
28
29 query_params = {
30 "q": query,
31 "page": params["pageno"],
32 }
33
34 params["url"] = f"{base_url}?{urlencode(query_params)}"
35 return params
36
37
38 def response(resp):
39
40 start_tag = 'window.MESON.initialState = {'
41 end_tag = '}};'
42
43 dom = html.fromstring(resp.text)
44 script = utils.eval_xpath_getindex(dom, '//script', 0, default=None).text
45
46 pos = script.index(start_tag) + len(start_tag) - 1
47 script = script[pos:]
48 pos = script.index(end_tag) + len(end_tag) - 1
49 script = script[:pos]
50
51 json_resp = utils.js_variable_to_python(script)
52
53 results = []
54
55 for item in json_resp['search']['webResults']['results']:
56
57 pubdate_original = item.get('pubdate_original')
58 if pubdate_original:
59 pubdate_original = dateutil.parser.parse(pubdate_original)
60 metadata = [item.get(field) for field in ['category_l1', 'catsy'] if item.get(field)]
61
62 results.append(
63 {
64 "url": item['url'],
65 "title": item['title'],
66 "content": item['abstract'],
67 "publishedDate": pubdate_original,
68 # "img_src": item.get('image_url') or None, # these are not thumbs / to large
69 "metadata": ' | '.join(metadata),
70 }
71 )
72
73 return results
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/searx/engines/ask.py b/searx/engines/ask.py
--- a/searx/engines/ask.py
+++ b/searx/engines/ask.py
@@ -19,6 +19,7 @@
# Engine Configuration
categories = ['general']
paging = True
+max_page = 5
# Base URL
base_url = "https://www.ask.com/web"
@@ -61,7 +62,7 @@
results.append(
{
- "url": item['url'],
+ "url": item['url'].split('&ueid')[0],
"title": item['title'],
"content": item['abstract'],
"publishedDate": pubdate_original,
|
{"golden_diff": "diff --git a/searx/engines/ask.py b/searx/engines/ask.py\n--- a/searx/engines/ask.py\n+++ b/searx/engines/ask.py\n@@ -19,6 +19,7 @@\n # Engine Configuration\n categories = ['general']\n paging = True\n+max_page = 5\n \n # Base URL\n base_url = \"https://www.ask.com/web\"\n@@ -61,7 +62,7 @@\n \n results.append(\n {\n- \"url\": item['url'],\n+ \"url\": item['url'].split('&ueid')[0],\n \"title\": item['title'],\n \"content\": item['abstract'],\n \"publishedDate\": pubdate_original,\n", "issue": "remove ask engine\nReasons:\r\n\r\n1. User Tracking via query parameters.\r\n\r\n Example Query: [!ask best museums in K\u00f6ln](https://searx.be/search?q=%21ask+best+museums+in+K%C3%B6ln&category_none=&language=auto&time_range=&safesearch=0&theme=simple)\r\n\r\n Notice the ```euid=some_id``` at the end for most urls.\r\n\r\n2. Very bad results - Something must have changed.\r\n\r\n Example Query: [!ask \"yt-dlp\"](https://searx.be/search?q=%21ask+%22yt-dlp%22&category_none=&language=auto&time_range=&safesearch=0&theme=simple)\r\n\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n\"\"\"Ask.com\"\"\"\n\nfrom urllib.parse import urlencode\nimport dateutil\nfrom lxml import html\nfrom searx import utils\n\n# Metadata\nabout = {\n \"website\": \"https://www.ask.com/\",\n \"wikidata_id\": 'Q847564',\n \"official_api_documentation\": None,\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": \"HTML\",\n}\n\n# Engine Configuration\ncategories = ['general']\npaging = True\n\n# Base URL\nbase_url = \"https://www.ask.com/web\"\n\n\ndef request(query, params):\n\n query_params = {\n \"q\": query,\n \"page\": params[\"pageno\"],\n }\n\n params[\"url\"] = f\"{base_url}?{urlencode(query_params)}\"\n return params\n\n\ndef response(resp):\n\n start_tag = 'window.MESON.initialState = {'\n end_tag = '}};'\n\n dom = html.fromstring(resp.text)\n script = utils.eval_xpath_getindex(dom, '//script', 0, default=None).text\n\n pos = script.index(start_tag) + len(start_tag) - 1\n script = script[pos:]\n pos = script.index(end_tag) + len(end_tag) - 1\n script = script[:pos]\n\n json_resp = utils.js_variable_to_python(script)\n\n results = []\n\n for item in json_resp['search']['webResults']['results']:\n\n pubdate_original = item.get('pubdate_original')\n if pubdate_original:\n pubdate_original = dateutil.parser.parse(pubdate_original)\n metadata = [item.get(field) for field in ['category_l1', 'catsy'] if item.get(field)]\n\n results.append(\n {\n \"url\": item['url'],\n \"title\": item['title'],\n \"content\": item['abstract'],\n \"publishedDate\": pubdate_original,\n # \"img_src\": item.get('image_url') or None, # these are not thumbs / to large\n \"metadata\": ' | '.join(metadata),\n }\n )\n\n return results\n", "path": "searx/engines/ask.py"}], "after_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n\"\"\"Ask.com\"\"\"\n\nfrom urllib.parse import urlencode\nimport dateutil\nfrom lxml import html\nfrom searx import utils\n\n# Metadata\nabout = {\n \"website\": \"https://www.ask.com/\",\n \"wikidata_id\": 'Q847564',\n \"official_api_documentation\": None,\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": \"HTML\",\n}\n\n# Engine Configuration\ncategories = ['general']\npaging = True\nmax_page = 5\n\n# Base URL\nbase_url = \"https://www.ask.com/web\"\n\n\ndef request(query, params):\n\n query_params = {\n \"q\": query,\n \"page\": params[\"pageno\"],\n }\n\n params[\"url\"] = f\"{base_url}?{urlencode(query_params)}\"\n return params\n\n\ndef response(resp):\n\n start_tag = 'window.MESON.initialState = {'\n end_tag = '}};'\n\n dom = html.fromstring(resp.text)\n script = utils.eval_xpath_getindex(dom, '//script', 0, default=None).text\n\n pos = script.index(start_tag) + len(start_tag) - 1\n script = script[pos:]\n pos = script.index(end_tag) + len(end_tag) - 1\n script = script[:pos]\n\n json_resp = utils.js_variable_to_python(script)\n\n results = []\n\n for item in json_resp['search']['webResults']['results']:\n\n pubdate_original = item.get('pubdate_original')\n if pubdate_original:\n pubdate_original = dateutil.parser.parse(pubdate_original)\n metadata = [item.get(field) for field in ['category_l1', 'catsy'] if item.get(field)]\n\n results.append(\n {\n \"url\": item['url'].split('&ueid')[0],\n \"title\": item['title'],\n \"content\": item['abstract'],\n \"publishedDate\": pubdate_original,\n # \"img_src\": item.get('image_url') or None, # these are not thumbs / to large\n \"metadata\": ' | '.join(metadata),\n }\n )\n\n return results\n", "path": "searx/engines/ask.py"}]}
| 1,032 | 164 |
gh_patches_debug_28065
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-5013
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Problem with hook-_tkinter.py using Python3.7 on MacOS
My application builds and runs perfectly on the same machine using Python3.6 (venv). But with Python 3.7 (installed from python.org) the following occurs:
```
14638 INFO: Excluding import 'tkinter'
14639 INFO: Import to be excluded not found: 'FixTk'
14639 INFO: Loading module hook "hook-xml.etree.cElementTree.py"...
14640 INFO: Loading module hook "hook-_tkinter.py"...
14642 ERROR: Tcl/Tk improperly installed on this system.
```
Then when I try and run the app:
```
Traceback (most recent call last):
File "PyInstaller/loader/rthooks/pyi_rth__tkinter.py", line 28, in <module>
FileNotFoundError: Tcl data directory "/var/folders/nl/2wxh3z313l129zpzq2f8ww5m0000gn/T/_MEILUmJRc/tcl" not found.
[2195] Failed to execute script pyi_rth__tkinter
```
I suspect it is to do with the fact that Python3.7 comes with Tcl/Tk 8.6 built in and the hook script isn't properly aware of this but I don't know enough about how it all works to be able to make any contribution.
As my application doesn't actually use tkinter I can work round it using `--exclude-module tkinter` but the problem's there for those who do neeed it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PyInstaller/hooks/hook-_tkinter.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013-2020, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12
13 import os
14 import sys
15 import locale
16
17 from PyInstaller.compat import is_win, is_darwin, is_unix, is_venv, \
18 base_prefix, open_file, text_read_mode
19 from PyInstaller.compat import modname_tkinter
20 from PyInstaller.depend.bindepend import selectImports, getImports
21 from PyInstaller.building.datastruct import Tree
22 from PyInstaller.utils.hooks import exec_statement, logger
23
24
25 def _handle_broken_tcl_tk():
26 """
27 When freezing from a Windows venv, overwrite the values of the standard
28 `${TCL_LIBRARY}`, `${TK_LIBRARY}`, and `${TIX_LIBRARY}` environment
29 variables.
30
31 This is a workaround for broken Tcl/Tk detection in Windows virtual
32 environments. Older versions of `virtualenv` set such variables erroneously,
33 preventing PyInstaller from properly detecting Tcl/Tk. This issue has been
34 noted for `virtualenv` under Python 2.4 and Windows 7.
35
36 See Also
37 -------
38 https://github.com/pypa/virtualenv/issues/93
39 """
40 if is_win and is_venv:
41 basedir = os.path.join(base_prefix, 'tcl')
42 files = os.listdir(basedir)
43
44 # Detect Tcl/Tk paths.
45 for f in files:
46 abs_path = os.path.join(basedir, f)
47 if f.startswith('tcl') and os.path.isdir(abs_path):
48 os.environ['TCL_LIBRARY'] = abs_path
49 elif f.startswith('tk') and os.path.isdir(abs_path):
50 os.environ['TK_LIBRARY'] = abs_path
51 elif f.startswith('tix') and os.path.isdir(abs_path):
52 os.environ['TIX_LIBRARY'] = abs_path
53
54
55 def _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree):
56 """
57 If the current Tcl installation is a Teapot-distributed version of ActiveTcl
58 *and* the current platform is OS X, log a non-fatal warning that the
59 resulting executable will (probably) fail to run on non-host systems.
60
61 PyInstaller does *not* freeze all ActiveTcl dependencies -- including
62 Teapot, which is typically ignorable. Since Teapot is *not* ignorable in
63 this case, this function warns of impending failure.
64
65 See Also
66 -------
67 https://github.com/pyinstaller/pyinstaller/issues/621
68 """
69 from macholib import util
70
71 # System libraries do not experience this problem.
72 if util.in_system_path(tcl_root):
73 return
74
75 # Absolute path of the "init.tcl" script.
76 try:
77 init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]
78 # If such script could not be found, silently return.
79 except IndexError:
80 return
81
82 mentions_activetcl = False
83 mentions_teapot = False
84 # TCL/TK reads files using the `system encoding <https://www.tcl.tk/doc/howto/i18n.html#system_encoding>`_.
85 with open_file(init_resource, text_read_mode,
86 encoding=locale.getpreferredencoding()) as init_file:
87 for line in init_file.readlines():
88 line = line.strip().lower()
89 if line.startswith('#'):
90 continue
91 if 'activetcl' in line:
92 mentions_activetcl = True
93 if 'teapot' in line:
94 mentions_teapot = True
95 if mentions_activetcl and mentions_teapot:
96 break
97
98 if mentions_activetcl and mentions_teapot:
99 logger.warning(
100 """
101 You appear to be using an ActiveTcl build of Tcl/Tk, which PyInstaller has
102 difficulty freezing. To fix this, comment out all references to "teapot" in:
103
104 %s
105
106 See https://github.com/pyinstaller/pyinstaller/issues/621 for more information.
107 """ % init_resource)
108
109
110 def _find_tcl_tk_darwin_frameworks(binaries):
111 """
112 Get an OS X-specific 2-tuple of the absolute paths of the top-level
113 external data directories for both Tcl and Tk, respectively.
114
115 Under OS X, Tcl and Tk are installed as Frameworks requiring special care.
116
117 Returns
118 -------
119 list
120 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose
121 second element is the value of `${TK_LIBRARY}`.
122 """
123 tcl_root = tk_root = None
124 for nm, fnm in binaries:
125 if nm == 'Tcl':
126 tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')
127 elif nm == 'Tk':
128 tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')
129 return tcl_root, tk_root
130
131
132 def _find_tcl_tk_dir():
133 """
134 Get a platform-agnostic 2-tuple of the absolute paths of the top-level
135 external data directories for both Tcl and Tk, respectively.
136
137 Returns
138 -------
139 list
140 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose
141 second element is the value of `${TK_LIBRARY}`.
142 """
143 # Python code to get path to TCL_LIBRARY.
144 tcl_root = exec_statement(
145 'from %s import Tcl; print(Tcl().eval("info library"))' % modname_tkinter)
146 tk_version = exec_statement(
147 'from _tkinter import TK_VERSION; print(TK_VERSION)')
148
149 # TK_LIBRARY is in the same prefix as Tcl.
150 tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)
151 return tcl_root, tk_root
152
153
154 def _find_tcl_tk(hook_api):
155 """
156 Get a platform-specific 2-tuple of the absolute paths of the top-level
157 external data directories for both Tcl and Tk, respectively.
158
159 Returns
160 -------
161 list
162 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose
163 second element is the value of `${TK_LIBRARY}`.
164 """
165 bins = selectImports(hook_api.__file__)
166
167 if is_darwin:
168 # _tkinter depends on system Tcl/Tk frameworks.
169 # For example this is the case of Python from homebrew.
170 if not bins:
171 # 'hook_api.binaries' can't be used because on Mac OS X _tkinter.so
172 # might depend on system Tcl/Tk frameworks and these are not
173 # included in 'hook_api.binaries'.
174 bins = getImports(hook_api.__file__)
175 # Reformat data structure from
176 # set(['lib1', 'lib2', 'lib3'])
177 # to
178 # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]
179 mapping = {}
180 for l in bins:
181 mapping[os.path.basename(l)] = l
182 bins = [
183 ('Tcl', mapping['Tcl']),
184 ('Tk', mapping['Tk']),
185 ]
186
187 # _tkinter depends on Tcl/Tk compiled as frameworks.
188 path_to_tcl = bins[0][1]
189 if 'Library/Frameworks' in path_to_tcl:
190 tcl_tk = _find_tcl_tk_darwin_frameworks(bins)
191 # Tcl/Tk compiled as on Linux other Unixes.
192 # For example this is the case of Tcl/Tk from macports.
193 else:
194 tcl_tk = _find_tcl_tk_dir()
195
196 else:
197 tcl_tk = _find_tcl_tk_dir()
198
199 return tcl_tk
200
201
202 def _collect_tcl_tk_files(hook_api):
203 """
204 Get a list of TOC-style 3-tuples describing all external Tcl/Tk data files.
205
206 Returns
207 -------
208 Tree
209 Such list.
210 """
211 # Workaround for broken Tcl/Tk detection in virtualenv on Windows.
212 _handle_broken_tcl_tk()
213
214 tcl_root, tk_root = _find_tcl_tk(hook_api)
215
216 # TODO Shouldn't these be fatal exceptions?
217 if not tcl_root:
218 logger.error('Tcl/Tk improperly installed on this system.')
219 return []
220 if not os.path.isdir(tcl_root):
221 logger.error('Tcl data directory "%s" not found.', tcl_root)
222 return []
223 if not os.path.isdir(tk_root):
224 logger.error('Tk data directory "%s" not found.', tk_root)
225 return []
226
227 tcltree = Tree(
228 tcl_root, prefix='tcl', excludes=['demos', '*.lib', 'tclConfig.sh'])
229 tktree = Tree(
230 tk_root, prefix='tk', excludes=['demos', '*.lib', 'tkConfig.sh'])
231
232 # If the current Tcl installation is a Teapot-distributed version of
233 # ActiveTcl and the current platform is OS X, warn that this is bad.
234 if is_darwin:
235 _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree)
236
237 return (tcltree + tktree)
238
239
240 def hook(hook_api):
241 # Use a hook-function to get the module's attr:`__file__` easily.
242 """
243 Freeze all external Tcl/Tk data files if this is a supported platform *or*
244 log a non-fatal error otherwise.
245 """
246 if is_win or is_darwin or is_unix:
247 # _collect_tcl_tk_files(hook_api) returns a Tree (which is okay),
248 # so we need to store it into `hook_api.datas` to prevent
249 # `building.imphook.format_binaries_and_datas` from crashing
250 # with "too many values to unpack".
251 hook_api.add_datas(_collect_tcl_tk_files(hook_api))
252 else:
253 logger.error("... skipping Tcl/Tk handling on unsupported platform %s", sys.platform)
254
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PyInstaller/hooks/hook-_tkinter.py b/PyInstaller/hooks/hook-_tkinter.py
--- a/PyInstaller/hooks/hook-_tkinter.py
+++ b/PyInstaller/hooks/hook-_tkinter.py
@@ -107,12 +107,13 @@
""" % init_resource)
-def _find_tcl_tk_darwin_frameworks(binaries):
+def _find_tcl_tk_darwin_system_frameworks(binaries):
"""
Get an OS X-specific 2-tuple of the absolute paths of the top-level
external data directories for both Tcl and Tk, respectively.
- Under OS X, Tcl and Tk are installed as Frameworks requiring special care.
+ This function finds the OS X system installation of Tcl and Tk.
+ System OS X Tcl and Tk are installed as Frameworks requiring special care.
Returns
-------
@@ -186,10 +187,15 @@
# _tkinter depends on Tcl/Tk compiled as frameworks.
path_to_tcl = bins[0][1]
- if 'Library/Frameworks' in path_to_tcl:
- tcl_tk = _find_tcl_tk_darwin_frameworks(bins)
+ # OS X system installation of Tcl/Tk.
+ # [/System]/Library/Frameworks/Tcl.framework/Resources/Scripts/Tcl
+ if 'Library/Frameworks/Tcl.framework' in path_to_tcl:
+ tcl_tk = _find_tcl_tk_darwin_system_frameworks(bins)
# Tcl/Tk compiled as on Linux other Unixes.
- # For example this is the case of Tcl/Tk from macports.
+ # This is the case of Tcl/Tk from macports and Tck/Tk built into
+ # python.org OS X python distributions.
+ # python.org built-in tcl/tk is located at
+ # /Library/Frameworks/Python.framework/Versions/3.x/lib/libtcl8.6.dylib
else:
tcl_tk = _find_tcl_tk_dir()
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-_tkinter.py b/PyInstaller/hooks/hook-_tkinter.py\n--- a/PyInstaller/hooks/hook-_tkinter.py\n+++ b/PyInstaller/hooks/hook-_tkinter.py\n@@ -107,12 +107,13 @@\n \"\"\" % init_resource)\n \n \n-def _find_tcl_tk_darwin_frameworks(binaries):\n+def _find_tcl_tk_darwin_system_frameworks(binaries):\n \"\"\"\n Get an OS X-specific 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n \n- Under OS X, Tcl and Tk are installed as Frameworks requiring special care.\n+ This function finds the OS X system installation of Tcl and Tk.\n+ System OS X Tcl and Tk are installed as Frameworks requiring special care.\n \n Returns\n -------\n@@ -186,10 +187,15 @@\n \n # _tkinter depends on Tcl/Tk compiled as frameworks.\n path_to_tcl = bins[0][1]\n- if 'Library/Frameworks' in path_to_tcl:\n- tcl_tk = _find_tcl_tk_darwin_frameworks(bins)\n+ # OS X system installation of Tcl/Tk.\n+ # [/System]/Library/Frameworks/Tcl.framework/Resources/Scripts/Tcl\n+ if 'Library/Frameworks/Tcl.framework' in path_to_tcl:\n+ tcl_tk = _find_tcl_tk_darwin_system_frameworks(bins)\n # Tcl/Tk compiled as on Linux other Unixes.\n- # For example this is the case of Tcl/Tk from macports.\n+ # This is the case of Tcl/Tk from macports and Tck/Tk built into\n+ # python.org OS X python distributions.\n+ # python.org built-in tcl/tk is located at\n+ # /Library/Frameworks/Python.framework/Versions/3.x/lib/libtcl8.6.dylib\n else:\n tcl_tk = _find_tcl_tk_dir()\n", "issue": "Problem with hook-_tkinter.py using Python3.7 on MacOS\nMy application builds and runs perfectly on the same machine using Python3.6 (venv). But with Python 3.7 (installed from python.org) the following occurs:\r\n\r\n```\r\n14638 INFO: Excluding import 'tkinter'\r\n14639 INFO: Import to be excluded not found: 'FixTk'\r\n14639 INFO: Loading module hook \"hook-xml.etree.cElementTree.py\"...\r\n14640 INFO: Loading module hook \"hook-_tkinter.py\"...\r\n14642 ERROR: Tcl/Tk improperly installed on this system.\r\n```\r\n\r\nThen when I try and run the app:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"PyInstaller/loader/rthooks/pyi_rth__tkinter.py\", line 28, in <module>\r\nFileNotFoundError: Tcl data directory \"/var/folders/nl/2wxh3z313l129zpzq2f8ww5m0000gn/T/_MEILUmJRc/tcl\" not found.\r\n[2195] Failed to execute script pyi_rth__tkinter\r\n```\r\n\r\nI suspect it is to do with the fact that Python3.7 comes with Tcl/Tk 8.6 built in and the hook script isn't properly aware of this but I don't know enough about how it all works to be able to make any contribution.\r\nAs my application doesn't actually use tkinter I can work round it using `--exclude-module tkinter` but the problem's there for those who do neeed it.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2020, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\n\nimport os\nimport sys\nimport locale\n\nfrom PyInstaller.compat import is_win, is_darwin, is_unix, is_venv, \\\n base_prefix, open_file, text_read_mode\nfrom PyInstaller.compat import modname_tkinter\nfrom PyInstaller.depend.bindepend import selectImports, getImports\nfrom PyInstaller.building.datastruct import Tree\nfrom PyInstaller.utils.hooks import exec_statement, logger\n\n\ndef _handle_broken_tcl_tk():\n \"\"\"\n When freezing from a Windows venv, overwrite the values of the standard\n `${TCL_LIBRARY}`, `${TK_LIBRARY}`, and `${TIX_LIBRARY}` environment\n variables.\n\n This is a workaround for broken Tcl/Tk detection in Windows virtual\n environments. Older versions of `virtualenv` set such variables erroneously,\n preventing PyInstaller from properly detecting Tcl/Tk. This issue has been\n noted for `virtualenv` under Python 2.4 and Windows 7.\n\n See Also\n -------\n https://github.com/pypa/virtualenv/issues/93\n \"\"\"\n if is_win and is_venv:\n basedir = os.path.join(base_prefix, 'tcl')\n files = os.listdir(basedir)\n\n # Detect Tcl/Tk paths.\n for f in files:\n abs_path = os.path.join(basedir, f)\n if f.startswith('tcl') and os.path.isdir(abs_path):\n os.environ['TCL_LIBRARY'] = abs_path\n elif f.startswith('tk') and os.path.isdir(abs_path):\n os.environ['TK_LIBRARY'] = abs_path\n elif f.startswith('tix') and os.path.isdir(abs_path):\n os.environ['TIX_LIBRARY'] = abs_path\n\n\ndef _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree):\n \"\"\"\n If the current Tcl installation is a Teapot-distributed version of ActiveTcl\n *and* the current platform is OS X, log a non-fatal warning that the\n resulting executable will (probably) fail to run on non-host systems.\n\n PyInstaller does *not* freeze all ActiveTcl dependencies -- including\n Teapot, which is typically ignorable. Since Teapot is *not* ignorable in\n this case, this function warns of impending failure.\n\n See Also\n -------\n https://github.com/pyinstaller/pyinstaller/issues/621\n \"\"\"\n from macholib import util\n\n # System libraries do not experience this problem.\n if util.in_system_path(tcl_root):\n return\n\n # Absolute path of the \"init.tcl\" script.\n try:\n init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]\n # If such script could not be found, silently return.\n except IndexError:\n return\n\n mentions_activetcl = False\n mentions_teapot = False\n # TCL/TK reads files using the `system encoding <https://www.tcl.tk/doc/howto/i18n.html#system_encoding>`_.\n with open_file(init_resource, text_read_mode,\n encoding=locale.getpreferredencoding()) as init_file:\n for line in init_file.readlines():\n line = line.strip().lower()\n if line.startswith('#'):\n continue\n if 'activetcl' in line:\n mentions_activetcl = True\n if 'teapot' in line:\n mentions_teapot = True\n if mentions_activetcl and mentions_teapot:\n break\n\n if mentions_activetcl and mentions_teapot:\n logger.warning(\n \"\"\"\nYou appear to be using an ActiveTcl build of Tcl/Tk, which PyInstaller has\ndifficulty freezing. To fix this, comment out all references to \"teapot\" in:\n\n %s\n\nSee https://github.com/pyinstaller/pyinstaller/issues/621 for more information.\n \"\"\" % init_resource)\n\n\ndef _find_tcl_tk_darwin_frameworks(binaries):\n \"\"\"\n Get an OS X-specific 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n Under OS X, Tcl and Tk are installed as Frameworks requiring special care.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n tcl_root = tk_root = None\n for nm, fnm in binaries:\n if nm == 'Tcl':\n tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n elif nm == 'Tk':\n tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n return tcl_root, tk_root\n\n\ndef _find_tcl_tk_dir():\n \"\"\"\n Get a platform-agnostic 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n # Python code to get path to TCL_LIBRARY.\n tcl_root = exec_statement(\n 'from %s import Tcl; print(Tcl().eval(\"info library\"))' % modname_tkinter)\n tk_version = exec_statement(\n 'from _tkinter import TK_VERSION; print(TK_VERSION)')\n\n # TK_LIBRARY is in the same prefix as Tcl.\n tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)\n return tcl_root, tk_root\n\n\ndef _find_tcl_tk(hook_api):\n \"\"\"\n Get a platform-specific 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n bins = selectImports(hook_api.__file__)\n\n if is_darwin:\n # _tkinter depends on system Tcl/Tk frameworks.\n # For example this is the case of Python from homebrew.\n if not bins:\n # 'hook_api.binaries' can't be used because on Mac OS X _tkinter.so\n # might depend on system Tcl/Tk frameworks and these are not\n # included in 'hook_api.binaries'.\n bins = getImports(hook_api.__file__)\n # Reformat data structure from\n # set(['lib1', 'lib2', 'lib3'])\n # to\n # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]\n mapping = {}\n for l in bins:\n mapping[os.path.basename(l)] = l\n bins = [\n ('Tcl', mapping['Tcl']),\n ('Tk', mapping['Tk']),\n ]\n\n # _tkinter depends on Tcl/Tk compiled as frameworks.\n path_to_tcl = bins[0][1]\n if 'Library/Frameworks' in path_to_tcl:\n tcl_tk = _find_tcl_tk_darwin_frameworks(bins)\n # Tcl/Tk compiled as on Linux other Unixes.\n # For example this is the case of Tcl/Tk from macports.\n else:\n tcl_tk = _find_tcl_tk_dir()\n\n else:\n tcl_tk = _find_tcl_tk_dir()\n\n return tcl_tk\n\n\ndef _collect_tcl_tk_files(hook_api):\n \"\"\"\n Get a list of TOC-style 3-tuples describing all external Tcl/Tk data files.\n\n Returns\n -------\n Tree\n Such list.\n \"\"\"\n # Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n _handle_broken_tcl_tk()\n\n tcl_root, tk_root = _find_tcl_tk(hook_api)\n\n # TODO Shouldn't these be fatal exceptions?\n if not tcl_root:\n logger.error('Tcl/Tk improperly installed on this system.')\n return []\n if not os.path.isdir(tcl_root):\n logger.error('Tcl data directory \"%s\" not found.', tcl_root)\n return []\n if not os.path.isdir(tk_root):\n logger.error('Tk data directory \"%s\" not found.', tk_root)\n return []\n\n tcltree = Tree(\n tcl_root, prefix='tcl', excludes=['demos', '*.lib', 'tclConfig.sh'])\n tktree = Tree(\n tk_root, prefix='tk', excludes=['demos', '*.lib', 'tkConfig.sh'])\n\n # If the current Tcl installation is a Teapot-distributed version of\n # ActiveTcl and the current platform is OS X, warn that this is bad.\n if is_darwin:\n _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree)\n\n return (tcltree + tktree)\n\n\ndef hook(hook_api):\n # Use a hook-function to get the module's attr:`__file__` easily.\n \"\"\"\n Freeze all external Tcl/Tk data files if this is a supported platform *or*\n log a non-fatal error otherwise.\n \"\"\"\n if is_win or is_darwin or is_unix:\n # _collect_tcl_tk_files(hook_api) returns a Tree (which is okay),\n # so we need to store it into `hook_api.datas` to prevent\n # `building.imphook.format_binaries_and_datas` from crashing\n # with \"too many values to unpack\".\n hook_api.add_datas(_collect_tcl_tk_files(hook_api))\n else:\n logger.error(\"... skipping Tcl/Tk handling on unsupported platform %s\", sys.platform)\n", "path": "PyInstaller/hooks/hook-_tkinter.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2020, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\n\nimport os\nimport sys\nimport locale\n\nfrom PyInstaller.compat import is_win, is_darwin, is_unix, is_venv, \\\n base_prefix, open_file, text_read_mode\nfrom PyInstaller.compat import modname_tkinter\nfrom PyInstaller.depend.bindepend import selectImports, getImports\nfrom PyInstaller.building.datastruct import Tree\nfrom PyInstaller.utils.hooks import exec_statement, logger\n\n\ndef _handle_broken_tcl_tk():\n \"\"\"\n When freezing from a Windows venv, overwrite the values of the standard\n `${TCL_LIBRARY}`, `${TK_LIBRARY}`, and `${TIX_LIBRARY}` environment\n variables.\n\n This is a workaround for broken Tcl/Tk detection in Windows virtual\n environments. Older versions of `virtualenv` set such variables erroneously,\n preventing PyInstaller from properly detecting Tcl/Tk. This issue has been\n noted for `virtualenv` under Python 2.4 and Windows 7.\n\n See Also\n -------\n https://github.com/pypa/virtualenv/issues/93\n \"\"\"\n if is_win and is_venv:\n basedir = os.path.join(base_prefix, 'tcl')\n files = os.listdir(basedir)\n\n # Detect Tcl/Tk paths.\n for f in files:\n abs_path = os.path.join(basedir, f)\n if f.startswith('tcl') and os.path.isdir(abs_path):\n os.environ['TCL_LIBRARY'] = abs_path\n elif f.startswith('tk') and os.path.isdir(abs_path):\n os.environ['TK_LIBRARY'] = abs_path\n elif f.startswith('tix') and os.path.isdir(abs_path):\n os.environ['TIX_LIBRARY'] = abs_path\n\n\ndef _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree):\n \"\"\"\n If the current Tcl installation is a Teapot-distributed version of ActiveTcl\n *and* the current platform is OS X, log a non-fatal warning that the\n resulting executable will (probably) fail to run on non-host systems.\n\n PyInstaller does *not* freeze all ActiveTcl dependencies -- including\n Teapot, which is typically ignorable. Since Teapot is *not* ignorable in\n this case, this function warns of impending failure.\n\n See Also\n -------\n https://github.com/pyinstaller/pyinstaller/issues/621\n \"\"\"\n from macholib import util\n\n # System libraries do not experience this problem.\n if util.in_system_path(tcl_root):\n return\n\n # Absolute path of the \"init.tcl\" script.\n try:\n init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]\n # If such script could not be found, silently return.\n except IndexError:\n return\n\n mentions_activetcl = False\n mentions_teapot = False\n # TCL/TK reads files using the `system encoding <https://www.tcl.tk/doc/howto/i18n.html#system_encoding>`_.\n with open_file(init_resource, text_read_mode,\n encoding=locale.getpreferredencoding()) as init_file:\n for line in init_file.readlines():\n line = line.strip().lower()\n if line.startswith('#'):\n continue\n if 'activetcl' in line:\n mentions_activetcl = True\n if 'teapot' in line:\n mentions_teapot = True\n if mentions_activetcl and mentions_teapot:\n break\n\n if mentions_activetcl and mentions_teapot:\n logger.warning(\n \"\"\"\nYou appear to be using an ActiveTcl build of Tcl/Tk, which PyInstaller has\ndifficulty freezing. To fix this, comment out all references to \"teapot\" in:\n\n %s\n\nSee https://github.com/pyinstaller/pyinstaller/issues/621 for more information.\n \"\"\" % init_resource)\n\n\ndef _find_tcl_tk_darwin_system_frameworks(binaries):\n \"\"\"\n Get an OS X-specific 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n This function finds the OS X system installation of Tcl and Tk.\n System OS X Tcl and Tk are installed as Frameworks requiring special care.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n tcl_root = tk_root = None\n for nm, fnm in binaries:\n if nm == 'Tcl':\n tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n elif nm == 'Tk':\n tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n return tcl_root, tk_root\n\n\ndef _find_tcl_tk_dir():\n \"\"\"\n Get a platform-agnostic 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n # Python code to get path to TCL_LIBRARY.\n tcl_root = exec_statement(\n 'from %s import Tcl; print(Tcl().eval(\"info library\"))' % modname_tkinter)\n tk_version = exec_statement(\n 'from _tkinter import TK_VERSION; print(TK_VERSION)')\n\n # TK_LIBRARY is in the same prefix as Tcl.\n tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)\n return tcl_root, tk_root\n\n\ndef _find_tcl_tk(hook_api):\n \"\"\"\n Get a platform-specific 2-tuple of the absolute paths of the top-level\n external data directories for both Tcl and Tk, respectively.\n\n Returns\n -------\n list\n 2-tuple whose first element is the value of `${TCL_LIBRARY}` and whose\n second element is the value of `${TK_LIBRARY}`.\n \"\"\"\n bins = selectImports(hook_api.__file__)\n\n if is_darwin:\n # _tkinter depends on system Tcl/Tk frameworks.\n # For example this is the case of Python from homebrew.\n if not bins:\n # 'hook_api.binaries' can't be used because on Mac OS X _tkinter.so\n # might depend on system Tcl/Tk frameworks and these are not\n # included in 'hook_api.binaries'.\n bins = getImports(hook_api.__file__)\n # Reformat data structure from\n # set(['lib1', 'lib2', 'lib3'])\n # to\n # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]\n mapping = {}\n for l in bins:\n mapping[os.path.basename(l)] = l\n bins = [\n ('Tcl', mapping['Tcl']),\n ('Tk', mapping['Tk']),\n ]\n\n # _tkinter depends on Tcl/Tk compiled as frameworks.\n path_to_tcl = bins[0][1]\n # OS X system installation of Tcl/Tk.\n # [/System]/Library/Frameworks/Tcl.framework/Resources/Scripts/Tcl\n if 'Library/Frameworks/Tcl.framework' in path_to_tcl:\n tcl_tk = _find_tcl_tk_darwin_system_frameworks(bins)\n # Tcl/Tk compiled as on Linux other Unixes.\n # This is the case of Tcl/Tk from macports and Tck/Tk built into\n # python.org OS X python distributions.\n # python.org built-in tcl/tk is located at\n # /Library/Frameworks/Python.framework/Versions/3.x/lib/libtcl8.6.dylib\n else:\n tcl_tk = _find_tcl_tk_dir()\n\n else:\n tcl_tk = _find_tcl_tk_dir()\n\n return tcl_tk\n\n\ndef _collect_tcl_tk_files(hook_api):\n \"\"\"\n Get a list of TOC-style 3-tuples describing all external Tcl/Tk data files.\n\n Returns\n -------\n Tree\n Such list.\n \"\"\"\n # Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n _handle_broken_tcl_tk()\n\n tcl_root, tk_root = _find_tcl_tk(hook_api)\n\n # TODO Shouldn't these be fatal exceptions?\n if not tcl_root:\n logger.error('Tcl/Tk improperly installed on this system.')\n return []\n if not os.path.isdir(tcl_root):\n logger.error('Tcl data directory \"%s\" not found.', tcl_root)\n return []\n if not os.path.isdir(tk_root):\n logger.error('Tk data directory \"%s\" not found.', tk_root)\n return []\n\n tcltree = Tree(\n tcl_root, prefix='tcl', excludes=['demos', '*.lib', 'tclConfig.sh'])\n tktree = Tree(\n tk_root, prefix='tk', excludes=['demos', '*.lib', 'tkConfig.sh'])\n\n # If the current Tcl installation is a Teapot-distributed version of\n # ActiveTcl and the current platform is OS X, warn that this is bad.\n if is_darwin:\n _warn_if_activetcl_or_teapot_installed(tcl_root, tcltree)\n\n return (tcltree + tktree)\n\n\ndef hook(hook_api):\n # Use a hook-function to get the module's attr:`__file__` easily.\n \"\"\"\n Freeze all external Tcl/Tk data files if this is a supported platform *or*\n log a non-fatal error otherwise.\n \"\"\"\n if is_win or is_darwin or is_unix:\n # _collect_tcl_tk_files(hook_api) returns a Tree (which is okay),\n # so we need to store it into `hook_api.datas` to prevent\n # `building.imphook.format_binaries_and_datas` from crashing\n # with \"too many values to unpack\".\n hook_api.add_datas(_collect_tcl_tk_files(hook_api))\n else:\n logger.error(\"... skipping Tcl/Tk handling on unsupported platform %s\", sys.platform)\n", "path": "PyInstaller/hooks/hook-_tkinter.py"}]}
| 3,521 | 462 |
gh_patches_debug_11039
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-23799
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PostgreSQL - permission denied for schema public
<!--
Welcome to the Frappe Framework issue tracker! Before creating an issue, please heed the following:
1. This tracker should only be used to report bugs and request features / enhancements to Frappe
- For questions and general support, use https://stackoverflow.com/questions/tagged/frappe
- For documentation issues, refer to https://frappeframework.com/docs/user/en or the developer cheetsheet https://github.com/frappe/frappe/wiki/Developer-Cheatsheet
2. Use the search function before creating a new issue. Duplicates will be closed and directed to
the original discussion.
3. When making a bug report, make sure you provide all required information. The easier it is for
maintainers to reproduce, the faster it'll be fixed.
4. If you think you know what the reason for the bug is, share it with us. Maybe put in a PR 😉
-->
## Description of the issue
When PostgreSQL version 15 or greater is used, the `bench new-site` command files with insufficient permission error from PostgreSQL. This is due to the change introduced, where `PostgreSQL 15 also revokes the CREATE permission from all users except a database owner from the public (or default) schema.`
## Context information (for bug reports)
**Output of `bench version`**
```
5.19.0
```
## Steps to reproduce the issue
1. Configure Frappe to use PostgreSQL version which is 15 or greater (16.1 in my case)
2. Attempt to perform `bench new-site` (Ex: ERPNext)
### Observed result
Error from Postgres:
```
ERROR: permission denied for schema public at character 14
```
Error from Frappe:
```
psql:/home/frappe/frappe-bench/apps/frappe/frappe/database/postgres/framework_postgres.sql:72: ERROR: permission denied for schema public
```
### Expected result
Installation should proceed without any errors
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `frappe/database/postgres/setup_db.py`
Content:
```
1 import os
2
3 import frappe
4 from frappe import _
5
6
7 def setup_database():
8 root_conn = get_root_connection(frappe.flags.root_login, frappe.flags.root_password)
9 root_conn.commit()
10 root_conn.sql("end")
11 root_conn.sql(f"DROP DATABASE IF EXISTS `{frappe.conf.db_name}`")
12 root_conn.sql(f"DROP USER IF EXISTS {frappe.conf.db_name}")
13 root_conn.sql(f"CREATE DATABASE `{frappe.conf.db_name}`")
14 root_conn.sql(f"CREATE user {frappe.conf.db_name} password '{frappe.conf.db_password}'")
15 root_conn.sql("GRANT ALL PRIVILEGES ON DATABASE `{0}` TO {0}".format(frappe.conf.db_name))
16 root_conn.close()
17
18
19 def bootstrap_database(db_name, verbose, source_sql=None):
20 frappe.connect(db_name=db_name)
21 import_db_from_sql(source_sql, verbose)
22 frappe.connect(db_name=db_name)
23
24 if "tabDefaultValue" not in frappe.db.get_tables():
25 import sys
26
27 from click import secho
28
29 secho(
30 "Table 'tabDefaultValue' missing in the restored site. "
31 "This may be due to incorrect permissions or the result of a restore from a bad backup file. "
32 "Database not installed correctly.",
33 fg="red",
34 )
35 sys.exit(1)
36
37
38 def import_db_from_sql(source_sql=None, verbose=False):
39 import shlex
40 from shutil import which
41
42 from frappe.database import get_command
43 from frappe.utils import execute_in_shell
44
45 # bootstrap db
46 if not source_sql:
47 source_sql = os.path.join(os.path.dirname(__file__), "framework_postgres.sql")
48
49 pv = which("pv")
50
51 command = []
52
53 if pv:
54 command.extend([pv, source_sql, "|"])
55 source = []
56 print("Restoring Database file...")
57 else:
58 source = ["-f", source_sql]
59
60 bin, args, bin_name = get_command(
61 host=frappe.conf.db_host,
62 port=frappe.conf.db_port,
63 user=frappe.conf.db_name,
64 password=frappe.conf.db_password,
65 db_name=frappe.conf.db_name,
66 )
67
68 if not bin:
69 frappe.throw(
70 _("{} not found in PATH! This is required to restore the database.").format(bin_name),
71 exc=frappe.ExecutableNotFound,
72 )
73 command.append(bin)
74 command.append(shlex.join(args))
75 command.extend(source)
76 execute_in_shell(" ".join(command), check_exit_code=True, verbose=verbose)
77 frappe.cache.delete_keys("") # Delete all keys associated with this site.
78
79
80 def get_root_connection(root_login=None, root_password=None):
81 if not frappe.local.flags.root_connection:
82 if not root_login:
83 root_login = frappe.conf.get("root_login") or None
84
85 if not root_login:
86 root_login = input("Enter postgres super user: ")
87
88 if not root_password:
89 root_password = frappe.conf.get("root_password") or None
90
91 if not root_password:
92 from getpass import getpass
93
94 root_password = getpass("Postgres super user password: ")
95
96 frappe.local.flags.root_connection = frappe.database.get_db(
97 host=frappe.conf.db_host,
98 port=frappe.conf.db_port,
99 user=root_login,
100 password=root_password,
101 )
102
103 return frappe.local.flags.root_connection
104
105
106 def drop_user_and_database(db_name, root_login, root_password):
107 root_conn = get_root_connection(
108 frappe.flags.root_login or root_login, frappe.flags.root_password or root_password
109 )
110 root_conn.commit()
111 root_conn.sql(
112 "SELECT pg_terminate_backend (pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = %s",
113 (db_name,),
114 )
115 root_conn.sql("end")
116 root_conn.sql(f"DROP DATABASE IF EXISTS {db_name}")
117 root_conn.sql(f"DROP USER IF EXISTS {db_name}")
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/frappe/database/postgres/setup_db.py b/frappe/database/postgres/setup_db.py
--- a/frappe/database/postgres/setup_db.py
+++ b/frappe/database/postgres/setup_db.py
@@ -13,6 +13,9 @@
root_conn.sql(f"CREATE DATABASE `{frappe.conf.db_name}`")
root_conn.sql(f"CREATE user {frappe.conf.db_name} password '{frappe.conf.db_password}'")
root_conn.sql("GRANT ALL PRIVILEGES ON DATABASE `{0}` TO {0}".format(frappe.conf.db_name))
+ psql_version = root_conn.sql(f"SELECT VERSION()", as_dict=True)
+ if psql_version and psql_version[0].get("version", "PostgreSQL 14").split()[1] >= "15":
+ root_conn.sql("ALTER DATABASE `{0}` OWNER TO {0}".format(frappe.conf.db_name))
root_conn.close()
|
{"golden_diff": "diff --git a/frappe/database/postgres/setup_db.py b/frappe/database/postgres/setup_db.py\n--- a/frappe/database/postgres/setup_db.py\n+++ b/frappe/database/postgres/setup_db.py\n@@ -13,6 +13,9 @@\n \troot_conn.sql(f\"CREATE DATABASE `{frappe.conf.db_name}`\")\n \troot_conn.sql(f\"CREATE user {frappe.conf.db_name} password '{frappe.conf.db_password}'\")\n \troot_conn.sql(\"GRANT ALL PRIVILEGES ON DATABASE `{0}` TO {0}\".format(frappe.conf.db_name))\n+\tpsql_version = root_conn.sql(f\"SELECT VERSION()\", as_dict=True)\n+\tif psql_version and psql_version[0].get(\"version\", \"PostgreSQL 14\").split()[1] >= \"15\":\n+\t\troot_conn.sql(\"ALTER DATABASE `{0}` OWNER TO {0}\".format(frappe.conf.db_name))\n \troot_conn.close()\n", "issue": "PostgreSQL - permission denied for schema public\n<!--\r\nWelcome to the Frappe Framework issue tracker! Before creating an issue, please heed the following:\r\n\r\n1. This tracker should only be used to report bugs and request features / enhancements to Frappe\r\n - For questions and general support, use https://stackoverflow.com/questions/tagged/frappe\r\n - For documentation issues, refer to https://frappeframework.com/docs/user/en or the developer cheetsheet https://github.com/frappe/frappe/wiki/Developer-Cheatsheet\r\n2. Use the search function before creating a new issue. Duplicates will be closed and directed to\r\n the original discussion.\r\n3. When making a bug report, make sure you provide all required information. The easier it is for\r\n maintainers to reproduce, the faster it'll be fixed.\r\n4. If you think you know what the reason for the bug is, share it with us. Maybe put in a PR \ud83d\ude09\r\n-->\r\n\r\n## Description of the issue\r\nWhen PostgreSQL version 15 or greater is used, the `bench new-site` command files with insufficient permission error from PostgreSQL. This is due to the change introduced, where `PostgreSQL 15 also revokes the CREATE permission from all users except a database owner from the public (or default) schema.`\r\n\r\n## Context information (for bug reports)\r\n\r\n**Output of `bench version`**\r\n```\r\n5.19.0\r\n```\r\n\r\n## Steps to reproduce the issue\r\n\r\n1. Configure Frappe to use PostgreSQL version which is 15 or greater (16.1 in my case)\r\n2. Attempt to perform `bench new-site` (Ex: ERPNext)\r\n\r\n### Observed result\r\nError from Postgres:\r\n```\r\nERROR: permission denied for schema public at character 14\r\n```\r\n\r\nError from Frappe:\r\n```\r\npsql:/home/frappe/frappe-bench/apps/frappe/frappe/database/postgres/framework_postgres.sql:72: ERROR: permission denied for schema public\r\n```\r\n\r\n### Expected result\r\nInstallation should proceed without any errors\r\n\r\n\r\n\n", "before_files": [{"content": "import os\n\nimport frappe\nfrom frappe import _\n\n\ndef setup_database():\n\troot_conn = get_root_connection(frappe.flags.root_login, frappe.flags.root_password)\n\troot_conn.commit()\n\troot_conn.sql(\"end\")\n\troot_conn.sql(f\"DROP DATABASE IF EXISTS `{frappe.conf.db_name}`\")\n\troot_conn.sql(f\"DROP USER IF EXISTS {frappe.conf.db_name}\")\n\troot_conn.sql(f\"CREATE DATABASE `{frappe.conf.db_name}`\")\n\troot_conn.sql(f\"CREATE user {frappe.conf.db_name} password '{frappe.conf.db_password}'\")\n\troot_conn.sql(\"GRANT ALL PRIVILEGES ON DATABASE `{0}` TO {0}\".format(frappe.conf.db_name))\n\troot_conn.close()\n\n\ndef bootstrap_database(db_name, verbose, source_sql=None):\n\tfrappe.connect(db_name=db_name)\n\timport_db_from_sql(source_sql, verbose)\n\tfrappe.connect(db_name=db_name)\n\n\tif \"tabDefaultValue\" not in frappe.db.get_tables():\n\t\timport sys\n\n\t\tfrom click import secho\n\n\t\tsecho(\n\t\t\t\"Table 'tabDefaultValue' missing in the restored site. \"\n\t\t\t\"This may be due to incorrect permissions or the result of a restore from a bad backup file. \"\n\t\t\t\"Database not installed correctly.\",\n\t\t\tfg=\"red\",\n\t\t)\n\t\tsys.exit(1)\n\n\ndef import_db_from_sql(source_sql=None, verbose=False):\n\timport shlex\n\tfrom shutil import which\n\n\tfrom frappe.database import get_command\n\tfrom frappe.utils import execute_in_shell\n\n\t# bootstrap db\n\tif not source_sql:\n\t\tsource_sql = os.path.join(os.path.dirname(__file__), \"framework_postgres.sql\")\n\n\tpv = which(\"pv\")\n\n\tcommand = []\n\n\tif pv:\n\t\tcommand.extend([pv, source_sql, \"|\"])\n\t\tsource = []\n\t\tprint(\"Restoring Database file...\")\n\telse:\n\t\tsource = [\"-f\", source_sql]\n\n\tbin, args, bin_name = get_command(\n\t\thost=frappe.conf.db_host,\n\t\tport=frappe.conf.db_port,\n\t\tuser=frappe.conf.db_name,\n\t\tpassword=frappe.conf.db_password,\n\t\tdb_name=frappe.conf.db_name,\n\t)\n\n\tif not bin:\n\t\tfrappe.throw(\n\t\t\t_(\"{} not found in PATH! This is required to restore the database.\").format(bin_name),\n\t\t\texc=frappe.ExecutableNotFound,\n\t\t)\n\tcommand.append(bin)\n\tcommand.append(shlex.join(args))\n\tcommand.extend(source)\n\texecute_in_shell(\" \".join(command), check_exit_code=True, verbose=verbose)\n\tfrappe.cache.delete_keys(\"\") # Delete all keys associated with this site.\n\n\ndef get_root_connection(root_login=None, root_password=None):\n\tif not frappe.local.flags.root_connection:\n\t\tif not root_login:\n\t\t\troot_login = frappe.conf.get(\"root_login\") or None\n\n\t\tif not root_login:\n\t\t\troot_login = input(\"Enter postgres super user: \")\n\n\t\tif not root_password:\n\t\t\troot_password = frappe.conf.get(\"root_password\") or None\n\n\t\tif not root_password:\n\t\t\tfrom getpass import getpass\n\n\t\t\troot_password = getpass(\"Postgres super user password: \")\n\n\t\tfrappe.local.flags.root_connection = frappe.database.get_db(\n\t\t\thost=frappe.conf.db_host,\n\t\t\tport=frappe.conf.db_port,\n\t\t\tuser=root_login,\n\t\t\tpassword=root_password,\n\t\t)\n\n\treturn frappe.local.flags.root_connection\n\n\ndef drop_user_and_database(db_name, root_login, root_password):\n\troot_conn = get_root_connection(\n\t\tfrappe.flags.root_login or root_login, frappe.flags.root_password or root_password\n\t)\n\troot_conn.commit()\n\troot_conn.sql(\n\t\t\"SELECT pg_terminate_backend (pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = %s\",\n\t\t(db_name,),\n\t)\n\troot_conn.sql(\"end\")\n\troot_conn.sql(f\"DROP DATABASE IF EXISTS {db_name}\")\n\troot_conn.sql(f\"DROP USER IF EXISTS {db_name}\")\n", "path": "frappe/database/postgres/setup_db.py"}], "after_files": [{"content": "import os\n\nimport frappe\nfrom frappe import _\n\n\ndef setup_database():\n\troot_conn = get_root_connection(frappe.flags.root_login, frappe.flags.root_password)\n\troot_conn.commit()\n\troot_conn.sql(\"end\")\n\troot_conn.sql(f\"DROP DATABASE IF EXISTS `{frappe.conf.db_name}`\")\n\troot_conn.sql(f\"DROP USER IF EXISTS {frappe.conf.db_name}\")\n\troot_conn.sql(f\"CREATE DATABASE `{frappe.conf.db_name}`\")\n\troot_conn.sql(f\"CREATE user {frappe.conf.db_name} password '{frappe.conf.db_password}'\")\n\troot_conn.sql(\"GRANT ALL PRIVILEGES ON DATABASE `{0}` TO {0}\".format(frappe.conf.db_name))\n\tpsql_version = root_conn.sql(f\"SELECT VERSION()\", as_dict=True)\n\tif psql_version and psql_version[0].get(\"version\", \"PostgreSQL 14\").split()[1] >= \"15\":\n\t\troot_conn.sql(\"ALTER DATABASE `{0}` OWNER TO {0}\".format(frappe.conf.db_name))\n\troot_conn.close()\n\n\ndef bootstrap_database(db_name, verbose, source_sql=None):\n\tfrappe.connect(db_name=db_name)\n\timport_db_from_sql(source_sql, verbose)\n\tfrappe.connect(db_name=db_name)\n\n\tif \"tabDefaultValue\" not in frappe.db.get_tables():\n\t\timport sys\n\n\t\tfrom click import secho\n\n\t\tsecho(\n\t\t\t\"Table 'tabDefaultValue' missing in the restored site. \"\n\t\t\t\"This may be due to incorrect permissions or the result of a restore from a bad backup file. \"\n\t\t\t\"Database not installed correctly.\",\n\t\t\tfg=\"red\",\n\t\t)\n\t\tsys.exit(1)\n\n\ndef import_db_from_sql(source_sql=None, verbose=False):\n\timport shlex\n\tfrom shutil import which\n\n\tfrom frappe.database import get_command\n\tfrom frappe.utils import execute_in_shell\n\n\t# bootstrap db\n\tif not source_sql:\n\t\tsource_sql = os.path.join(os.path.dirname(__file__), \"framework_postgres.sql\")\n\n\tpv = which(\"pv\")\n\n\tcommand = []\n\n\tif pv:\n\t\tcommand.extend([pv, source_sql, \"|\"])\n\t\tsource = []\n\t\tprint(\"Restoring Database file...\")\n\telse:\n\t\tsource = [\"-f\", source_sql]\n\n\tbin, args, bin_name = get_command(\n\t\thost=frappe.conf.db_host,\n\t\tport=frappe.conf.db_port,\n\t\tuser=frappe.conf.db_name,\n\t\tpassword=frappe.conf.db_password,\n\t\tdb_name=frappe.conf.db_name,\n\t)\n\n\tif not bin:\n\t\tfrappe.throw(\n\t\t\t_(\"{} not found in PATH! This is required to restore the database.\").format(bin_name),\n\t\t\texc=frappe.ExecutableNotFound,\n\t\t)\n\tcommand.append(bin)\n\tcommand.append(shlex.join(args))\n\tcommand.extend(source)\n\texecute_in_shell(\" \".join(command), check_exit_code=True, verbose=verbose)\n\tfrappe.cache.delete_keys(\"\") # Delete all keys associated with this site.\n\n\ndef get_root_connection(root_login=None, root_password=None):\n\tif not frappe.local.flags.root_connection:\n\t\tif not root_login:\n\t\t\troot_login = frappe.conf.get(\"root_login\") or None\n\n\t\tif not root_login:\n\t\t\troot_login = input(\"Enter postgres super user: \")\n\n\t\tif not root_password:\n\t\t\troot_password = frappe.conf.get(\"root_password\") or None\n\n\t\tif not root_password:\n\t\t\tfrom getpass import getpass\n\n\t\t\troot_password = getpass(\"Postgres super user password: \")\n\n\t\tfrappe.local.flags.root_connection = frappe.database.get_db(\n\t\t\thost=frappe.conf.db_host,\n\t\t\tport=frappe.conf.db_port,\n\t\t\tuser=root_login,\n\t\t\tpassword=root_password,\n\t\t)\n\n\treturn frappe.local.flags.root_connection\n\n\ndef drop_user_and_database(db_name, root_login, root_password):\n\troot_conn = get_root_connection(\n\t\tfrappe.flags.root_login or root_login, frappe.flags.root_password or root_password\n\t)\n\troot_conn.commit()\n\troot_conn.sql(\n\t\t\"SELECT pg_terminate_backend (pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = %s\",\n\t\t(db_name,),\n\t)\n\troot_conn.sql(\"end\")\n\troot_conn.sql(f\"DROP DATABASE IF EXISTS {db_name}\")\n\troot_conn.sql(f\"DROP USER IF EXISTS {db_name}\")\n", "path": "frappe/database/postgres/setup_db.py"}]}
| 1,827 | 202 |
gh_patches_debug_28722
|
rasdani/github-patches
|
git_diff
|
OpenCTI-Platform__connectors-401
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[AbuseIPdb] Crash on listing "Korea (Republic of)" entity
## Description
The AbuseIPDB enrichment connector stops gathering data as soon as there is an entity of "Korea (Republic of)" is found.
## Actual Output
Example listing:
```
connector-abuseipdb_1 | 2021-05-20T13:07:59.843767030Z INFO:root:Listing Stix-Domain-Objects with filters [{"key": "name", "values": ["Korea (Republic of)"]}].
connector-abuseipdb_1 | 2021-05-20T13:07:59.859596474Z INFO:root:Listing Stix-Domain-Objects with filters [{"key": "aliases", "values": ["Korea (Republic of)"]}].
connector-abuseipdb_1 | 2021-05-20T13:07:59.959406389Z ERROR:root:Error in message processing, reporting error to API
connector-abuseipdb_1 | 2021-05-20T13:07:59.959533538Z Traceback (most recent call last):
connector-abuseipdb_1 | 2021-05-20T13:07:59.959542290Z File "/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py", line 145, in _data_handler
connector-abuseipdb_1 | 2021-05-20T13:07:59.959548366Z message = self.callback(json_data["event"])
connector-abuseipdb_1 | 2021-05-20T13:07:59.959553788Z File "/opt/opencti-connector-abuseipdb/abuseipdb.py", line 108, in _process_message
connector-abuseipdb_1 | 2021-05-20T13:07:59.959559549Z toId=country["id"],
connector-abuseipdb_1 | 2021-05-20T13:07:59.959564881Z TypeError: 'NoneType' object is not subscriptable
```
## Additional information
The error above has been using IP address 143.198.132.45
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `abuseipdb/src/abuseipdb.py`
Content:
```
1 import yaml
2 import os
3 import requests
4
5 from pycti import OpenCTIConnectorHelper, get_config_variable
6
7
8 class AbuseIPDBConnector:
9 def __init__(self):
10 # Instantiate the connector helper from config
11 config_file_path = os.path.dirname(os.path.abspath(__file__)) + "/config.yml"
12 config = (
13 yaml.load(open(config_file_path), Loader=yaml.FullLoader)
14 if os.path.isfile(config_file_path)
15 else {}
16 )
17 self.helper = OpenCTIConnectorHelper(config)
18 self.api_key = get_config_variable(
19 "ABUSEIPDB_API_KEY", ["abuseipdb", "api_key"], config
20 )
21 self.max_tlp = get_config_variable(
22 "ABUSEIPDB_MAX_TLP", ["abuseipdb", "max_tlp"], config
23 )
24 self.whitelist_label = self.helper.api.label.create(
25 value="whitelist", color="#4caf50"
26 )
27
28 @staticmethod
29 def extract_abuse_ipdb_category(category_number):
30 # Reference: https://www.abuseipdb.com/categories
31 mapping = {
32 "3": "Fraud Orders",
33 "4": "DDOS Attack",
34 "5": "FTP Brute-Force",
35 "6": "Ping of Death",
36 "7": "Phishing",
37 "8": "Fraud VOIP",
38 "9": "Open Proxy",
39 "10": "Web Spam",
40 "11": "Email Spam",
41 "12": "Blog Spam",
42 "13": "VPN IP",
43 "14": "Port Scan",
44 "15": "Hacking",
45 "16": "SQL Injection",
46 "17": "Spoofing",
47 "18": "Brute Force",
48 "19": "Bad Web Bot",
49 "20": "Exploited Host",
50 "21": "Web App Attack",
51 "22": "SSH",
52 "23": "IoT Targeted",
53 }
54 return mapping.get(str(category_number), "unknown category")
55
56 def _process_message(self, data):
57 entity_id = data["entity_id"]
58 observable = self.helper.api.stix_cyber_observable.read(id=entity_id)
59 # Extract TLP
60 tlp = "TLP:WHITE"
61 for marking_definition in observable["objectMarking"]:
62 if marking_definition["definition_type"] == "TLP":
63 tlp = marking_definition["definition"]
64
65 if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):
66 raise ValueError(
67 "Do not send any data, TLP of the observable is greater than MAX TLP"
68 )
69 # Extract IP from entity data
70 observable_id = observable["standard_id"]
71 observable_value = observable["value"]
72 url = "https://api.abuseipdb.com/api/v2/check"
73 headers = {
74 "Accept": "application/json",
75 "Content-Type": "application/x-www-form-urlencoded",
76 "Key": "%s" % self.api_key,
77 }
78 params = {"maxAgeInDays": 365, "verbose": "True", "ipAddress": observable_value}
79 r = requests.get(url, headers=headers, params=params)
80 r.raise_for_status()
81 data = r.json()
82 data = data["data"]
83 self.helper.api.stix_cyber_observable.update_field(
84 id=observable_id,
85 key="x_opencti_score",
86 value=str(data["abuseConfidenceScore"]),
87 )
88 if data["isWhitelisted"]:
89 external_reference = self.helper.api.external_reference.create(
90 source_name="AbuseIPDB (whitelist)",
91 url="https://www.abuseipdb.com/check/" + observable_value,
92 description="This IP address is from within our whitelist.",
93 )
94 self.helper.api.stix_cyber_observable.add_external_reference(
95 id=observable_id, external_reference_id=external_reference["id"]
96 )
97 self.helper.api.stix_cyber_observable.add_label(
98 id=observable_id, label_id=self.whitelist_label["id"]
99 )
100 return "IP found in AbuseIPDB WHITELIST."
101 if len(data["reports"]) > 0:
102 for report in data["reports"]:
103 country = self.helper.api.stix_domain_object.get_by_stix_id_or_name(
104 name=report["reporterCountryName"]
105 )
106 self.helper.api.stix_sighting_relationship.create(
107 fromId=observable_id,
108 toId=country["id"],
109 count=1,
110 first_seen=report["reportedAt"],
111 last_seen=report["reportedAt"],
112 )
113 for category in report["categories"]:
114 category_text = self.extract_abuse_ipdb_category(category)
115 label = self.helper.api.label.create(value=category_text)
116 self.helper.api.stix_cyber_observable.add_label(
117 id=observable_id, label_id=label["id"]
118 )
119 return "IP found in AbuseIPDB with reports, knowledge attached."
120
121 # Start the main loop
122 def start(self):
123 self.helper.listen(self._process_message)
124
125
126 if __name__ == "__main__":
127 abuseIPDBInstance = AbuseIPDBConnector()
128 abuseIPDBInstance.start()
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/abuseipdb/src/abuseipdb.py b/abuseipdb/src/abuseipdb.py
--- a/abuseipdb/src/abuseipdb.py
+++ b/abuseipdb/src/abuseipdb.py
@@ -100,16 +100,27 @@
return "IP found in AbuseIPDB WHITELIST."
if len(data["reports"]) > 0:
for report in data["reports"]:
- country = self.helper.api.stix_domain_object.get_by_stix_id_or_name(
- name=report["reporterCountryName"]
- )
- self.helper.api.stix_sighting_relationship.create(
- fromId=observable_id,
- toId=country["id"],
- count=1,
- first_seen=report["reportedAt"],
- last_seen=report["reportedAt"],
+ country = self.helper.api.location.read(
+ filters=[
+ {
+ "key": "x_opencti_aliases",
+ "values": [report["reporterCountryCode"]],
+ }
+ ],
+ getAll=True,
)
+ if country is None:
+ self.helper.log_warning(
+ f"No country found with Alpha 2 code {report['reporterCountryCode']}"
+ )
+ else:
+ self.helper.api.stix_sighting_relationship.create(
+ fromId=observable_id,
+ toId=country["id"],
+ count=1,
+ first_seen=report["reportedAt"],
+ last_seen=report["reportedAt"],
+ )
for category in report["categories"]:
category_text = self.extract_abuse_ipdb_category(category)
label = self.helper.api.label.create(value=category_text)
|
{"golden_diff": "diff --git a/abuseipdb/src/abuseipdb.py b/abuseipdb/src/abuseipdb.py\n--- a/abuseipdb/src/abuseipdb.py\n+++ b/abuseipdb/src/abuseipdb.py\n@@ -100,16 +100,27 @@\n return \"IP found in AbuseIPDB WHITELIST.\"\n if len(data[\"reports\"]) > 0:\n for report in data[\"reports\"]:\n- country = self.helper.api.stix_domain_object.get_by_stix_id_or_name(\n- name=report[\"reporterCountryName\"]\n- )\n- self.helper.api.stix_sighting_relationship.create(\n- fromId=observable_id,\n- toId=country[\"id\"],\n- count=1,\n- first_seen=report[\"reportedAt\"],\n- last_seen=report[\"reportedAt\"],\n+ country = self.helper.api.location.read(\n+ filters=[\n+ {\n+ \"key\": \"x_opencti_aliases\",\n+ \"values\": [report[\"reporterCountryCode\"]],\n+ }\n+ ],\n+ getAll=True,\n )\n+ if country is None:\n+ self.helper.log_warning(\n+ f\"No country found with Alpha 2 code {report['reporterCountryCode']}\"\n+ )\n+ else:\n+ self.helper.api.stix_sighting_relationship.create(\n+ fromId=observable_id,\n+ toId=country[\"id\"],\n+ count=1,\n+ first_seen=report[\"reportedAt\"],\n+ last_seen=report[\"reportedAt\"],\n+ )\n for category in report[\"categories\"]:\n category_text = self.extract_abuse_ipdb_category(category)\n label = self.helper.api.label.create(value=category_text)\n", "issue": "[AbuseIPdb] Crash on listing \"Korea (Republic of)\" entity\n## Description\r\n\r\nThe AbuseIPDB enrichment connector stops gathering data as soon as there is an entity of \"Korea (Republic of)\" is found. \r\n\r\n## Actual Output\r\n\r\nExample listing:\r\n```\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.843767030Z INFO:root:Listing Stix-Domain-Objects with filters [{\"key\": \"name\", \"values\": [\"Korea (Republic of)\"]}].\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.859596474Z INFO:root:Listing Stix-Domain-Objects with filters [{\"key\": \"aliases\", \"values\": [\"Korea (Republic of)\"]}].\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959406389Z ERROR:root:Error in message processing, reporting error to API\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959533538Z Traceback (most recent call last):\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959542290Z File \"/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py\", line 145, in _data_handler\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959548366Z message = self.callback(json_data[\"event\"])\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959553788Z File \"/opt/opencti-connector-abuseipdb/abuseipdb.py\", line 108, in _process_message\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959559549Z toId=country[\"id\"],\r\nconnector-abuseipdb_1 | 2021-05-20T13:07:59.959564881Z TypeError: 'NoneType' object is not subscriptable\r\n\r\n``` \r\n## Additional information\r\n\r\nThe error above has been using IP address 143.198.132.45\n", "before_files": [{"content": "import yaml\nimport os\nimport requests\n\nfrom pycti import OpenCTIConnectorHelper, get_config_variable\n\n\nclass AbuseIPDBConnector:\n def __init__(self):\n # Instantiate the connector helper from config\n config_file_path = os.path.dirname(os.path.abspath(__file__)) + \"/config.yml\"\n config = (\n yaml.load(open(config_file_path), Loader=yaml.FullLoader)\n if os.path.isfile(config_file_path)\n else {}\n )\n self.helper = OpenCTIConnectorHelper(config)\n self.api_key = get_config_variable(\n \"ABUSEIPDB_API_KEY\", [\"abuseipdb\", \"api_key\"], config\n )\n self.max_tlp = get_config_variable(\n \"ABUSEIPDB_MAX_TLP\", [\"abuseipdb\", \"max_tlp\"], config\n )\n self.whitelist_label = self.helper.api.label.create(\n value=\"whitelist\", color=\"#4caf50\"\n )\n\n @staticmethod\n def extract_abuse_ipdb_category(category_number):\n # Reference: https://www.abuseipdb.com/categories\n mapping = {\n \"3\": \"Fraud Orders\",\n \"4\": \"DDOS Attack\",\n \"5\": \"FTP Brute-Force\",\n \"6\": \"Ping of Death\",\n \"7\": \"Phishing\",\n \"8\": \"Fraud VOIP\",\n \"9\": \"Open Proxy\",\n \"10\": \"Web Spam\",\n \"11\": \"Email Spam\",\n \"12\": \"Blog Spam\",\n \"13\": \"VPN IP\",\n \"14\": \"Port Scan\",\n \"15\": \"Hacking\",\n \"16\": \"SQL Injection\",\n \"17\": \"Spoofing\",\n \"18\": \"Brute Force\",\n \"19\": \"Bad Web Bot\",\n \"20\": \"Exploited Host\",\n \"21\": \"Web App Attack\",\n \"22\": \"SSH\",\n \"23\": \"IoT Targeted\",\n }\n return mapping.get(str(category_number), \"unknown category\")\n\n def _process_message(self, data):\n entity_id = data[\"entity_id\"]\n observable = self.helper.api.stix_cyber_observable.read(id=entity_id)\n # Extract TLP\n tlp = \"TLP:WHITE\"\n for marking_definition in observable[\"objectMarking\"]:\n if marking_definition[\"definition_type\"] == \"TLP\":\n tlp = marking_definition[\"definition\"]\n\n if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):\n raise ValueError(\n \"Do not send any data, TLP of the observable is greater than MAX TLP\"\n )\n # Extract IP from entity data\n observable_id = observable[\"standard_id\"]\n observable_value = observable[\"value\"]\n url = \"https://api.abuseipdb.com/api/v2/check\"\n headers = {\n \"Accept\": \"application/json\",\n \"Content-Type\": \"application/x-www-form-urlencoded\",\n \"Key\": \"%s\" % self.api_key,\n }\n params = {\"maxAgeInDays\": 365, \"verbose\": \"True\", \"ipAddress\": observable_value}\n r = requests.get(url, headers=headers, params=params)\n r.raise_for_status()\n data = r.json()\n data = data[\"data\"]\n self.helper.api.stix_cyber_observable.update_field(\n id=observable_id,\n key=\"x_opencti_score\",\n value=str(data[\"abuseConfidenceScore\"]),\n )\n if data[\"isWhitelisted\"]:\n external_reference = self.helper.api.external_reference.create(\n source_name=\"AbuseIPDB (whitelist)\",\n url=\"https://www.abuseipdb.com/check/\" + observable_value,\n description=\"This IP address is from within our whitelist.\",\n )\n self.helper.api.stix_cyber_observable.add_external_reference(\n id=observable_id, external_reference_id=external_reference[\"id\"]\n )\n self.helper.api.stix_cyber_observable.add_label(\n id=observable_id, label_id=self.whitelist_label[\"id\"]\n )\n return \"IP found in AbuseIPDB WHITELIST.\"\n if len(data[\"reports\"]) > 0:\n for report in data[\"reports\"]:\n country = self.helper.api.stix_domain_object.get_by_stix_id_or_name(\n name=report[\"reporterCountryName\"]\n )\n self.helper.api.stix_sighting_relationship.create(\n fromId=observable_id,\n toId=country[\"id\"],\n count=1,\n first_seen=report[\"reportedAt\"],\n last_seen=report[\"reportedAt\"],\n )\n for category in report[\"categories\"]:\n category_text = self.extract_abuse_ipdb_category(category)\n label = self.helper.api.label.create(value=category_text)\n self.helper.api.stix_cyber_observable.add_label(\n id=observable_id, label_id=label[\"id\"]\n )\n return \"IP found in AbuseIPDB with reports, knowledge attached.\"\n\n # Start the main loop\n def start(self):\n self.helper.listen(self._process_message)\n\n\nif __name__ == \"__main__\":\n abuseIPDBInstance = AbuseIPDBConnector()\n abuseIPDBInstance.start()\n", "path": "abuseipdb/src/abuseipdb.py"}], "after_files": [{"content": "import yaml\nimport os\nimport requests\n\nfrom pycti import OpenCTIConnectorHelper, get_config_variable\n\n\nclass AbuseIPDBConnector:\n def __init__(self):\n # Instantiate the connector helper from config\n config_file_path = os.path.dirname(os.path.abspath(__file__)) + \"/config.yml\"\n config = (\n yaml.load(open(config_file_path), Loader=yaml.FullLoader)\n if os.path.isfile(config_file_path)\n else {}\n )\n self.helper = OpenCTIConnectorHelper(config)\n self.api_key = get_config_variable(\n \"ABUSEIPDB_API_KEY\", [\"abuseipdb\", \"api_key\"], config\n )\n self.max_tlp = get_config_variable(\n \"ABUSEIPDB_MAX_TLP\", [\"abuseipdb\", \"max_tlp\"], config\n )\n self.whitelist_label = self.helper.api.label.create(\n value=\"whitelist\", color=\"#4caf50\"\n )\n\n @staticmethod\n def extract_abuse_ipdb_category(category_number):\n # Reference: https://www.abuseipdb.com/categories\n mapping = {\n \"3\": \"Fraud Orders\",\n \"4\": \"DDOS Attack\",\n \"5\": \"FTP Brute-Force\",\n \"6\": \"Ping of Death\",\n \"7\": \"Phishing\",\n \"8\": \"Fraud VOIP\",\n \"9\": \"Open Proxy\",\n \"10\": \"Web Spam\",\n \"11\": \"Email Spam\",\n \"12\": \"Blog Spam\",\n \"13\": \"VPN IP\",\n \"14\": \"Port Scan\",\n \"15\": \"Hacking\",\n \"16\": \"SQL Injection\",\n \"17\": \"Spoofing\",\n \"18\": \"Brute Force\",\n \"19\": \"Bad Web Bot\",\n \"20\": \"Exploited Host\",\n \"21\": \"Web App Attack\",\n \"22\": \"SSH\",\n \"23\": \"IoT Targeted\",\n }\n return mapping.get(str(category_number), \"unknown category\")\n\n def _process_message(self, data):\n entity_id = data[\"entity_id\"]\n observable = self.helper.api.stix_cyber_observable.read(id=entity_id)\n # Extract TLP\n tlp = \"TLP:WHITE\"\n for marking_definition in observable[\"objectMarking\"]:\n if marking_definition[\"definition_type\"] == \"TLP\":\n tlp = marking_definition[\"definition\"]\n\n if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):\n raise ValueError(\n \"Do not send any data, TLP of the observable is greater than MAX TLP\"\n )\n # Extract IP from entity data\n observable_id = observable[\"standard_id\"]\n observable_value = observable[\"value\"]\n url = \"https://api.abuseipdb.com/api/v2/check\"\n headers = {\n \"Accept\": \"application/json\",\n \"Content-Type\": \"application/x-www-form-urlencoded\",\n \"Key\": \"%s\" % self.api_key,\n }\n params = {\"maxAgeInDays\": 365, \"verbose\": \"True\", \"ipAddress\": observable_value}\n r = requests.get(url, headers=headers, params=params)\n r.raise_for_status()\n data = r.json()\n data = data[\"data\"]\n self.helper.api.stix_cyber_observable.update_field(\n id=observable_id,\n key=\"x_opencti_score\",\n value=str(data[\"abuseConfidenceScore\"]),\n )\n if data[\"isWhitelisted\"]:\n external_reference = self.helper.api.external_reference.create(\n source_name=\"AbuseIPDB (whitelist)\",\n url=\"https://www.abuseipdb.com/check/\" + observable_value,\n description=\"This IP address is from within our whitelist.\",\n )\n self.helper.api.stix_cyber_observable.add_external_reference(\n id=observable_id, external_reference_id=external_reference[\"id\"]\n )\n self.helper.api.stix_cyber_observable.add_label(\n id=observable_id, label_id=self.whitelist_label[\"id\"]\n )\n return \"IP found in AbuseIPDB WHITELIST.\"\n if len(data[\"reports\"]) > 0:\n for report in data[\"reports\"]:\n country = self.helper.api.location.read(\n filters=[\n {\n \"key\": \"x_opencti_aliases\",\n \"values\": [report[\"reporterCountryCode\"]],\n }\n ],\n getAll=True,\n )\n if country is None:\n self.helper.log_warning(\n f\"No country found with Alpha 2 code {report['reporterCountryCode']}\"\n )\n else:\n self.helper.api.stix_sighting_relationship.create(\n fromId=observable_id,\n toId=country[\"id\"],\n count=1,\n first_seen=report[\"reportedAt\"],\n last_seen=report[\"reportedAt\"],\n )\n for category in report[\"categories\"]:\n category_text = self.extract_abuse_ipdb_category(category)\n label = self.helper.api.label.create(value=category_text)\n self.helper.api.stix_cyber_observable.add_label(\n id=observable_id, label_id=label[\"id\"]\n )\n return \"IP found in AbuseIPDB with reports, knowledge attached.\"\n\n # Start the main loop\n def start(self):\n self.helper.listen(self._process_message)\n\n\nif __name__ == \"__main__\":\n abuseIPDBInstance = AbuseIPDBConnector()\n abuseIPDBInstance.start()\n", "path": "abuseipdb/src/abuseipdb.py"}]}
| 2,307 | 385 |
gh_patches_debug_20236
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1235
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Generic input type broken from 0.69.0 onward
Generic input types were working correctly until version `0.68.4` but after `0.69.0` it's throwing a type error.
here's a test for it
```python
def test_generic_input():
E = TypeVar('E')
@strawberry.input
class EnumInput(Generic[E]):
value: E
@strawberry.enum
class Make(Enum):
FORD = 'ford'
TOYOTA = 'toyota'
HONDA = 'honda'
@strawberry.type
class Car:
make: Make
@strawberry.type
class Query:
@strawberry.field
def cars(self, make: Optional[EnumInput[Make]] = None) -> List[Car]:
return []
schema = strawberry.Schema(query=Query)
query = '''
query CarsList {
cars(make: {value: FORD}) {
__typename
}
}
'''
result = schema.execute_sync(query)
assert result.errors is None
```
output error
```
self = <GraphQLObjectType 'Query'>
@cached_property
def fields(self) -> GraphQLFieldMap:
"""Get provided fields, wrapping them as GraphQLFields if needed."""
try:
fields = resolve_thunk(self._fields)
except Exception as error:
> raise TypeError(f"{self.name} fields cannot be resolved. {error}")
E TypeError: Query fields cannot be resolved. 'EnumDefinition' object has no attribute '__name__'
.venv/lib/python3.9/site-packages/graphql/type/definition.py:769: TypeError
```
Generic input type broken from 0.69.0 onward
Generic input types were working correctly until version `0.68.4` but after `0.69.0` it's throwing a type error.
here's a test for it
```python
def test_generic_input():
E = TypeVar('E')
@strawberry.input
class EnumInput(Generic[E]):
value: E
@strawberry.enum
class Make(Enum):
FORD = 'ford'
TOYOTA = 'toyota'
HONDA = 'honda'
@strawberry.type
class Car:
make: Make
@strawberry.type
class Query:
@strawberry.field
def cars(self, make: Optional[EnumInput[Make]] = None) -> List[Car]:
return []
schema = strawberry.Schema(query=Query)
query = '''
query CarsList {
cars(make: {value: FORD}) {
__typename
}
}
'''
result = schema.execute_sync(query)
assert result.errors is None
```
output error
```
self = <GraphQLObjectType 'Query'>
@cached_property
def fields(self) -> GraphQLFieldMap:
"""Get provided fields, wrapping them as GraphQLFields if needed."""
try:
fields = resolve_thunk(self._fields)
except Exception as error:
> raise TypeError(f"{self.name} fields cannot be resolved. {error}")
E TypeError: Query fields cannot be resolved. 'EnumDefinition' object has no attribute '__name__'
.venv/lib/python3.9/site-packages/graphql/type/definition.py:769: TypeError
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/types/types.py`
Content:
```
1 from __future__ import annotations
2
3 import dataclasses
4 from typing import (
5 TYPE_CHECKING,
6 Iterable,
7 List,
8 Mapping,
9 Optional,
10 Type,
11 TypeVar,
12 Union,
13 )
14
15 from strawberry.type import StrawberryType, StrawberryTypeVar
16 from strawberry.utils.str_converters import capitalize_first
17 from strawberry.utils.typing import is_generic as is_type_generic
18
19
20 if TYPE_CHECKING:
21 from strawberry.field import StrawberryField
22
23
24 @dataclasses.dataclass
25 class FederationTypeParams:
26 keys: List[str] = dataclasses.field(default_factory=list)
27 extend: bool = False
28
29
30 @dataclasses.dataclass(eq=False)
31 class TypeDefinition(StrawberryType):
32 name: str
33 is_input: bool
34 is_interface: bool
35 origin: Type
36 description: Optional[str]
37 federation: FederationTypeParams
38 interfaces: List["TypeDefinition"]
39
40 _fields: List["StrawberryField"]
41
42 concrete_of: Optional["TypeDefinition"] = None
43 """Concrete implementations of Generic TypeDefinitions fill this in"""
44 type_var_map: Mapping[TypeVar, Union[StrawberryType, type]] = dataclasses.field(
45 default_factory=dict
46 )
47
48 # TODO: remove wrapped cls when we "merge" this with `StrawberryObject`
49 def resolve_generic(self, wrapped_cls: type) -> type:
50 from strawberry.annotation import StrawberryAnnotation
51
52 passed_types = wrapped_cls.__args__ # type: ignore
53 params = wrapped_cls.__origin__.__parameters__ # type: ignore
54
55 # Make sure all passed_types are turned into StrawberryTypes
56 resolved_types = []
57 for passed_type in passed_types:
58 resolved_type = StrawberryAnnotation(passed_type).resolve()
59 resolved_types.append(resolved_type)
60
61 type_var_map = dict(zip(params, resolved_types))
62
63 return self.copy_with(type_var_map)
64
65 # TODO: Return a StrawberryObject
66 def copy_with(
67 self, type_var_map: Mapping[TypeVar, Union[StrawberryType, type]]
68 ) -> type:
69 name = self.get_name_from_types(type_var_map.values())
70
71 fields = []
72 for field in self.fields:
73 # TODO: Logic unnecessary with StrawberryObject
74 field_type = field.type
75 if hasattr(field_type, "_type_definition"):
76 field_type = field_type._type_definition # type: ignore
77
78 # TODO: All types should end up being StrawberryTypes
79 # The first check is here as a symptom of strawberry.ID being a
80 # Scalar, but not a StrawberryType
81 if isinstance(field_type, StrawberryType) and field_type.is_generic:
82 field = field.copy_with(type_var_map)
83
84 fields.append(field)
85
86 new_type_definition = TypeDefinition(
87 name=name,
88 is_input=self.is_input,
89 origin=self.origin,
90 is_interface=self.is_interface,
91 federation=self.federation,
92 interfaces=self.interfaces,
93 description=self.description,
94 _fields=fields,
95 concrete_of=self,
96 type_var_map=type_var_map,
97 )
98
99 new_type = type(
100 new_type_definition.name,
101 (self.origin,),
102 {"_type_definition": new_type_definition},
103 )
104
105 new_type_definition.origin = new_type
106
107 return new_type
108
109 def get_field(self, python_name: str) -> Optional["StrawberryField"]:
110 return next(
111 (field for field in self.fields if field.python_name == python_name), None
112 )
113
114 def get_name_from_types(self, types: Iterable[Union[StrawberryType, type]]) -> str:
115 from strawberry.union import StrawberryUnion
116
117 names: List[str] = []
118
119 for type_ in types:
120 if isinstance(type_, StrawberryUnion):
121 name = type_.name
122 elif hasattr(type_, "_type_definition"):
123 field_type = type_._type_definition # type: ignore
124
125 name = capitalize_first(field_type.name)
126 else:
127 name = capitalize_first(type_.__name__) # type: ignore
128
129 names.append(name)
130
131 return "".join(names) + self.name
132
133 @property
134 def fields(self) -> List["StrawberryField"]:
135 # TODO: rename _fields to fields and remove this property
136 return self._fields
137
138 @property
139 def is_generic(self) -> bool:
140 return is_type_generic(self.origin)
141
142 @property
143 def type_params(self) -> List[TypeVar]:
144 type_params: List[TypeVar] = []
145 for field in self.fields:
146 type_params.extend(field.type_params)
147
148 return type_params
149
150 def is_implemented_by(self, root: Union[type, dict]) -> bool:
151 # TODO: Accept StrawberryObject instead
152 # TODO: Support dicts
153 if isinstance(root, dict):
154 raise NotImplementedError()
155
156 type_definition = root._type_definition # type: ignore
157
158 if type_definition is self:
159 # No generics involved. Exact type match
160 return True
161
162 if type_definition is not self.concrete_of:
163 # Either completely different type, or concrete type of a different generic
164 return False
165
166 # Check the mapping of all fields' TypeVars
167 for generic_field in type_definition.fields:
168 generic_field_type = generic_field.type
169 if not isinstance(generic_field_type, StrawberryTypeVar):
170 continue
171
172 # For each TypeVar found, get the expected type from the copy's type map
173 expected_concrete_type = self.type_var_map.get(generic_field_type.type_var)
174 if expected_concrete_type is None:
175 # TODO: Should this return False?
176 continue
177
178 # Check if the expected type matches the type found on the type_map
179 real_concrete_type = type(getattr(root, generic_field.name))
180 if real_concrete_type is not expected_concrete_type:
181 return False
182
183 # All field mappings succeeded. This is a match
184 return True
185
186
187 @dataclasses.dataclass
188 class FederationFieldParams:
189 provides: List[str] = dataclasses.field(default_factory=list)
190 requires: List[str] = dataclasses.field(default_factory=list)
191 external: bool = False
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/types/types.py b/strawberry/types/types.py
--- a/strawberry/types/types.py
+++ b/strawberry/types/types.py
@@ -12,6 +12,8 @@
Union,
)
+from strawberry.enum import EnumDefinition
+from strawberry.lazy_type import LazyType
from strawberry.type import StrawberryType, StrawberryTypeVar
from strawberry.utils.str_converters import capitalize_first
from strawberry.utils.typing import is_generic as is_type_generic
@@ -117,7 +119,11 @@
names: List[str] = []
for type_ in types:
- if isinstance(type_, StrawberryUnion):
+ if isinstance(type_, LazyType):
+ name = type_.type_name
+ elif isinstance(type_, EnumDefinition):
+ name = type_.name
+ elif isinstance(type_, StrawberryUnion):
name = type_.name
elif hasattr(type_, "_type_definition"):
field_type = type_._type_definition # type: ignore
|
{"golden_diff": "diff --git a/strawberry/types/types.py b/strawberry/types/types.py\n--- a/strawberry/types/types.py\n+++ b/strawberry/types/types.py\n@@ -12,6 +12,8 @@\n Union,\n )\n \n+from strawberry.enum import EnumDefinition\n+from strawberry.lazy_type import LazyType\n from strawberry.type import StrawberryType, StrawberryTypeVar\n from strawberry.utils.str_converters import capitalize_first\n from strawberry.utils.typing import is_generic as is_type_generic\n@@ -117,7 +119,11 @@\n names: List[str] = []\n \n for type_ in types:\n- if isinstance(type_, StrawberryUnion):\n+ if isinstance(type_, LazyType):\n+ name = type_.type_name\n+ elif isinstance(type_, EnumDefinition):\n+ name = type_.name\n+ elif isinstance(type_, StrawberryUnion):\n name = type_.name\n elif hasattr(type_, \"_type_definition\"):\n field_type = type_._type_definition # type: ignore\n", "issue": "Generic input type broken from 0.69.0 onward\nGeneric input types were working correctly until version `0.68.4` but after `0.69.0` it's throwing a type error.\r\nhere's a test for it\r\n```python\r\ndef test_generic_input():\r\n E = TypeVar('E')\r\n\r\n @strawberry.input\r\n class EnumInput(Generic[E]):\r\n value: E\r\n\r\n @strawberry.enum\r\n class Make(Enum):\r\n FORD = 'ford'\r\n TOYOTA = 'toyota'\r\n HONDA = 'honda'\r\n\r\n @strawberry.type\r\n class Car:\r\n make: Make\r\n\r\n @strawberry.type\r\n class Query:\r\n @strawberry.field\r\n def cars(self, make: Optional[EnumInput[Make]] = None) -> List[Car]:\r\n return []\r\n\r\n schema = strawberry.Schema(query=Query)\r\n query = '''\r\n query CarsList {\r\n cars(make: {value: FORD}) {\r\n __typename\r\n }\r\n }\r\n '''\r\n result = schema.execute_sync(query)\r\n assert result.errors is None\r\n```\r\noutput error\r\n```\r\nself = <GraphQLObjectType 'Query'>\r\n\r\n @cached_property\r\n def fields(self) -> GraphQLFieldMap:\r\n \"\"\"Get provided fields, wrapping them as GraphQLFields if needed.\"\"\"\r\n try:\r\n fields = resolve_thunk(self._fields)\r\n except Exception as error:\r\n> raise TypeError(f\"{self.name} fields cannot be resolved. {error}\")\r\nE TypeError: Query fields cannot be resolved. 'EnumDefinition' object has no attribute '__name__'\r\n\r\n.venv/lib/python3.9/site-packages/graphql/type/definition.py:769: TypeError\r\n```\r\n\nGeneric input type broken from 0.69.0 onward\nGeneric input types were working correctly until version `0.68.4` but after `0.69.0` it's throwing a type error.\r\nhere's a test for it\r\n```python\r\ndef test_generic_input():\r\n E = TypeVar('E')\r\n\r\n @strawberry.input\r\n class EnumInput(Generic[E]):\r\n value: E\r\n\r\n @strawberry.enum\r\n class Make(Enum):\r\n FORD = 'ford'\r\n TOYOTA = 'toyota'\r\n HONDA = 'honda'\r\n\r\n @strawberry.type\r\n class Car:\r\n make: Make\r\n\r\n @strawberry.type\r\n class Query:\r\n @strawberry.field\r\n def cars(self, make: Optional[EnumInput[Make]] = None) -> List[Car]:\r\n return []\r\n\r\n schema = strawberry.Schema(query=Query)\r\n query = '''\r\n query CarsList {\r\n cars(make: {value: FORD}) {\r\n __typename\r\n }\r\n }\r\n '''\r\n result = schema.execute_sync(query)\r\n assert result.errors is None\r\n```\r\noutput error\r\n```\r\nself = <GraphQLObjectType 'Query'>\r\n\r\n @cached_property\r\n def fields(self) -> GraphQLFieldMap:\r\n \"\"\"Get provided fields, wrapping them as GraphQLFields if needed.\"\"\"\r\n try:\r\n fields = resolve_thunk(self._fields)\r\n except Exception as error:\r\n> raise TypeError(f\"{self.name} fields cannot be resolved. {error}\")\r\nE TypeError: Query fields cannot be resolved. 'EnumDefinition' object has no attribute '__name__'\r\n\r\n.venv/lib/python3.9/site-packages/graphql/type/definition.py:769: TypeError\r\n```\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport dataclasses\nfrom typing import (\n TYPE_CHECKING,\n Iterable,\n List,\n Mapping,\n Optional,\n Type,\n TypeVar,\n Union,\n)\n\nfrom strawberry.type import StrawberryType, StrawberryTypeVar\nfrom strawberry.utils.str_converters import capitalize_first\nfrom strawberry.utils.typing import is_generic as is_type_generic\n\n\nif TYPE_CHECKING:\n from strawberry.field import StrawberryField\n\n\[email protected]\nclass FederationTypeParams:\n keys: List[str] = dataclasses.field(default_factory=list)\n extend: bool = False\n\n\[email protected](eq=False)\nclass TypeDefinition(StrawberryType):\n name: str\n is_input: bool\n is_interface: bool\n origin: Type\n description: Optional[str]\n federation: FederationTypeParams\n interfaces: List[\"TypeDefinition\"]\n\n _fields: List[\"StrawberryField\"]\n\n concrete_of: Optional[\"TypeDefinition\"] = None\n \"\"\"Concrete implementations of Generic TypeDefinitions fill this in\"\"\"\n type_var_map: Mapping[TypeVar, Union[StrawberryType, type]] = dataclasses.field(\n default_factory=dict\n )\n\n # TODO: remove wrapped cls when we \"merge\" this with `StrawberryObject`\n def resolve_generic(self, wrapped_cls: type) -> type:\n from strawberry.annotation import StrawberryAnnotation\n\n passed_types = wrapped_cls.__args__ # type: ignore\n params = wrapped_cls.__origin__.__parameters__ # type: ignore\n\n # Make sure all passed_types are turned into StrawberryTypes\n resolved_types = []\n for passed_type in passed_types:\n resolved_type = StrawberryAnnotation(passed_type).resolve()\n resolved_types.append(resolved_type)\n\n type_var_map = dict(zip(params, resolved_types))\n\n return self.copy_with(type_var_map)\n\n # TODO: Return a StrawberryObject\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, type]]\n ) -> type:\n name = self.get_name_from_types(type_var_map.values())\n\n fields = []\n for field in self.fields:\n # TODO: Logic unnecessary with StrawberryObject\n field_type = field.type\n if hasattr(field_type, \"_type_definition\"):\n field_type = field_type._type_definition # type: ignore\n\n # TODO: All types should end up being StrawberryTypes\n # The first check is here as a symptom of strawberry.ID being a\n # Scalar, but not a StrawberryType\n if isinstance(field_type, StrawberryType) and field_type.is_generic:\n field = field.copy_with(type_var_map)\n\n fields.append(field)\n\n new_type_definition = TypeDefinition(\n name=name,\n is_input=self.is_input,\n origin=self.origin,\n is_interface=self.is_interface,\n federation=self.federation,\n interfaces=self.interfaces,\n description=self.description,\n _fields=fields,\n concrete_of=self,\n type_var_map=type_var_map,\n )\n\n new_type = type(\n new_type_definition.name,\n (self.origin,),\n {\"_type_definition\": new_type_definition},\n )\n\n new_type_definition.origin = new_type\n\n return new_type\n\n def get_field(self, python_name: str) -> Optional[\"StrawberryField\"]:\n return next(\n (field for field in self.fields if field.python_name == python_name), None\n )\n\n def get_name_from_types(self, types: Iterable[Union[StrawberryType, type]]) -> str:\n from strawberry.union import StrawberryUnion\n\n names: List[str] = []\n\n for type_ in types:\n if isinstance(type_, StrawberryUnion):\n name = type_.name\n elif hasattr(type_, \"_type_definition\"):\n field_type = type_._type_definition # type: ignore\n\n name = capitalize_first(field_type.name)\n else:\n name = capitalize_first(type_.__name__) # type: ignore\n\n names.append(name)\n\n return \"\".join(names) + self.name\n\n @property\n def fields(self) -> List[\"StrawberryField\"]:\n # TODO: rename _fields to fields and remove this property\n return self._fields\n\n @property\n def is_generic(self) -> bool:\n return is_type_generic(self.origin)\n\n @property\n def type_params(self) -> List[TypeVar]:\n type_params: List[TypeVar] = []\n for field in self.fields:\n type_params.extend(field.type_params)\n\n return type_params\n\n def is_implemented_by(self, root: Union[type, dict]) -> bool:\n # TODO: Accept StrawberryObject instead\n # TODO: Support dicts\n if isinstance(root, dict):\n raise NotImplementedError()\n\n type_definition = root._type_definition # type: ignore\n\n if type_definition is self:\n # No generics involved. Exact type match\n return True\n\n if type_definition is not self.concrete_of:\n # Either completely different type, or concrete type of a different generic\n return False\n\n # Check the mapping of all fields' TypeVars\n for generic_field in type_definition.fields:\n generic_field_type = generic_field.type\n if not isinstance(generic_field_type, StrawberryTypeVar):\n continue\n\n # For each TypeVar found, get the expected type from the copy's type map\n expected_concrete_type = self.type_var_map.get(generic_field_type.type_var)\n if expected_concrete_type is None:\n # TODO: Should this return False?\n continue\n\n # Check if the expected type matches the type found on the type_map\n real_concrete_type = type(getattr(root, generic_field.name))\n if real_concrete_type is not expected_concrete_type:\n return False\n\n # All field mappings succeeded. This is a match\n return True\n\n\[email protected]\nclass FederationFieldParams:\n provides: List[str] = dataclasses.field(default_factory=list)\n requires: List[str] = dataclasses.field(default_factory=list)\n external: bool = False\n", "path": "strawberry/types/types.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport dataclasses\nfrom typing import (\n TYPE_CHECKING,\n Iterable,\n List,\n Mapping,\n Optional,\n Type,\n TypeVar,\n Union,\n)\n\nfrom strawberry.enum import EnumDefinition\nfrom strawberry.lazy_type import LazyType\nfrom strawberry.type import StrawberryType, StrawberryTypeVar\nfrom strawberry.utils.str_converters import capitalize_first\nfrom strawberry.utils.typing import is_generic as is_type_generic\n\n\nif TYPE_CHECKING:\n from strawberry.field import StrawberryField\n\n\[email protected]\nclass FederationTypeParams:\n keys: List[str] = dataclasses.field(default_factory=list)\n extend: bool = False\n\n\[email protected](eq=False)\nclass TypeDefinition(StrawberryType):\n name: str\n is_input: bool\n is_interface: bool\n origin: Type\n description: Optional[str]\n federation: FederationTypeParams\n interfaces: List[\"TypeDefinition\"]\n\n _fields: List[\"StrawberryField\"]\n\n concrete_of: Optional[\"TypeDefinition\"] = None\n \"\"\"Concrete implementations of Generic TypeDefinitions fill this in\"\"\"\n type_var_map: Mapping[TypeVar, Union[StrawberryType, type]] = dataclasses.field(\n default_factory=dict\n )\n\n # TODO: remove wrapped cls when we \"merge\" this with `StrawberryObject`\n def resolve_generic(self, wrapped_cls: type) -> type:\n from strawberry.annotation import StrawberryAnnotation\n\n passed_types = wrapped_cls.__args__ # type: ignore\n params = wrapped_cls.__origin__.__parameters__ # type: ignore\n\n # Make sure all passed_types are turned into StrawberryTypes\n resolved_types = []\n for passed_type in passed_types:\n resolved_type = StrawberryAnnotation(passed_type).resolve()\n resolved_types.append(resolved_type)\n\n type_var_map = dict(zip(params, resolved_types))\n\n return self.copy_with(type_var_map)\n\n # TODO: Return a StrawberryObject\n def copy_with(\n self, type_var_map: Mapping[TypeVar, Union[StrawberryType, type]]\n ) -> type:\n name = self.get_name_from_types(type_var_map.values())\n\n fields = []\n for field in self.fields:\n # TODO: Logic unnecessary with StrawberryObject\n field_type = field.type\n if hasattr(field_type, \"_type_definition\"):\n field_type = field_type._type_definition # type: ignore\n\n # TODO: All types should end up being StrawberryTypes\n # The first check is here as a symptom of strawberry.ID being a\n # Scalar, but not a StrawberryType\n if isinstance(field_type, StrawberryType) and field_type.is_generic:\n field = field.copy_with(type_var_map)\n\n fields.append(field)\n\n new_type_definition = TypeDefinition(\n name=name,\n is_input=self.is_input,\n origin=self.origin,\n is_interface=self.is_interface,\n federation=self.federation,\n interfaces=self.interfaces,\n description=self.description,\n _fields=fields,\n concrete_of=self,\n type_var_map=type_var_map,\n )\n\n new_type = type(\n new_type_definition.name,\n (self.origin,),\n {\"_type_definition\": new_type_definition},\n )\n\n new_type_definition.origin = new_type\n\n return new_type\n\n def get_field(self, python_name: str) -> Optional[\"StrawberryField\"]:\n return next(\n (field for field in self.fields if field.python_name == python_name), None\n )\n\n def get_name_from_types(self, types: Iterable[Union[StrawberryType, type]]) -> str:\n from strawberry.union import StrawberryUnion\n\n names: List[str] = []\n\n for type_ in types:\n if isinstance(type_, LazyType):\n name = type_.type_name\n elif isinstance(type_, EnumDefinition):\n name = type_.name\n elif isinstance(type_, StrawberryUnion):\n name = type_.name\n elif hasattr(type_, \"_type_definition\"):\n field_type = type_._type_definition # type: ignore\n\n name = capitalize_first(field_type.name)\n else:\n name = capitalize_first(type_.__name__) # type: ignore\n\n names.append(name)\n\n return \"\".join(names) + self.name\n\n @property\n def fields(self) -> List[\"StrawberryField\"]:\n # TODO: rename _fields to fields and remove this property\n return self._fields\n\n @property\n def is_generic(self) -> bool:\n return is_type_generic(self.origin)\n\n @property\n def type_params(self) -> List[TypeVar]:\n type_params: List[TypeVar] = []\n for field in self.fields:\n type_params.extend(field.type_params)\n\n return type_params\n\n def is_implemented_by(self, root: Union[type, dict]) -> bool:\n # TODO: Accept StrawberryObject instead\n # TODO: Support dicts\n if isinstance(root, dict):\n raise NotImplementedError()\n\n type_definition = root._type_definition # type: ignore\n\n if type_definition is self:\n # No generics involved. Exact type match\n return True\n\n if type_definition is not self.concrete_of:\n # Either completely different type, or concrete type of a different generic\n return False\n\n # Check the mapping of all fields' TypeVars\n for generic_field in type_definition.fields:\n generic_field_type = generic_field.type\n if not isinstance(generic_field_type, StrawberryTypeVar):\n continue\n\n # For each TypeVar found, get the expected type from the copy's type map\n expected_concrete_type = self.type_var_map.get(generic_field_type.type_var)\n if expected_concrete_type is None:\n # TODO: Should this return False?\n continue\n\n # Check if the expected type matches the type found on the type_map\n real_concrete_type = type(getattr(root, generic_field.name))\n if real_concrete_type is not expected_concrete_type:\n return False\n\n # All field mappings succeeded. This is a match\n return True\n\n\[email protected]\nclass FederationFieldParams:\n provides: List[str] = dataclasses.field(default_factory=list)\n requires: List[str] = dataclasses.field(default_factory=list)\n external: bool = False\n", "path": "strawberry/types/types.py"}]}
| 2,786 | 223 |
gh_patches_debug_12011
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-11971
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] EndeavourOS not among list of distros listed for pacman support
### Environment Details (include every applicable attribute)
* Operating System+version: EndeavourOS 2022.06.23
* Compiler+version: Clang 14.0.6
* Conan version: 1.51.3
* Python version: 3.10.6
### Steps to reproduce (Include if Applicable)
In a python interpreter
```bash
>>> from conans import tools
>>> tools.os_info.with_pacman
False
>>>tools.os_info.is_linux
True
>>> tools.os_info.linux_distro
'endeavouros'
```
We need to add `endeavouros` to this [line](https://github.com/conan-io/conan/blob/develop/conans/client/tools/oss.py#L220)
### Logs (Executed commands with output) (Include/Attach if Applicable)
As a result of the above, OpenGL recipe doesn't know how to install itself, xorg/system also fails to install some dependencies as well
```log
opengl/system: Package installed 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9
opengl/system: Downloaded package revision 0
xorg/system: Retrieving package 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 from remote 'conancenter'
Downloading conanmanifest.txt completed [0.06k]
Downloading conaninfo.txt completed [0.16k]
Downloading conan_package.tgz completed [0.06k]
Decompressing conan_package.tgz completed [0.00k]
xorg/system: Package installed 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9
xorg/system: Downloaded package revision 0
opengl/system: WARN: Don't know how to install OpenGL for your distro.
ERROR: xorg/system: Error in package_info() method, line 79
pkg_config.fill_cpp_info(
ConanException: pkg-config command ['pkg-config', '--print-provides', 'xvmc', '--print-errors'] failed with error: Command 'pkg-config --print-provides xvmc --print-errors' returned non-zero exit status 1.
Package xvmc was not found in the pkg-config search path.
Perhaps you should add the directory containing `xvmc.pc'
to the PKG_CONFIG_PATH environment variable
Package 'xvmc', required by 'virtual:world', not found
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conan/tools/system/package_manager.py`
Content:
```
1 import platform
2
3 from conans.client.graph.graph import CONTEXT_BUILD
4 from conans.errors import ConanException
5
6
7 class _SystemPackageManagerTool(object):
8 mode_check = "check"
9 mode_install = "install"
10 tool_name = None
11 install_command = ""
12 update_command = ""
13 check_command = ""
14 accepted_install_codes = [0]
15 accepted_update_codes = [0]
16 accepted_check_codes = [0, 1]
17
18 def __init__(self, conanfile):
19 self._conanfile = conanfile
20 self._active_tool = self._conanfile.conf.get("tools.system.package_manager:tool", default=self.get_default_tool())
21 self._sudo = self._conanfile.conf.get("tools.system.package_manager:sudo", default=False, check_type=bool)
22 self._sudo_askpass = self._conanfile.conf.get("tools.system.package_manager:sudo_askpass", default=False, check_type=bool)
23 self._mode = self._conanfile.conf.get("tools.system.package_manager:mode", default=self.mode_check)
24 self._arch = self._conanfile.settings_build.get_safe('arch') \
25 if self._conanfile.context == CONTEXT_BUILD else self._conanfile.settings.get_safe('arch')
26 self._arch_names = {}
27 self._arch_separator = ""
28
29 def get_default_tool(self):
30 os_name = platform.system()
31 if os_name in ["Linux", "FreeBSD"]:
32 import distro
33 os_name = distro.id() or os_name
34 elif os_name == "Windows" and self._conanfile.conf.get("tools.microsoft.bash:subsystem") == "msys2":
35 os_name = "msys2"
36 manager_mapping = {"apt-get": ["Linux", "ubuntu", "debian", "raspbian"],
37 "yum": ["pidora", "scientific", "xenserver", "amazon", "oracle", "amzn",
38 "almalinux", "rocky"],
39 "dnf": ["fedora", "rhel", "centos", "mageia"],
40 "brew": ["Darwin"],
41 "pacman": ["arch", "manjaro", "msys2"],
42 "choco": ["Windows"],
43 "zypper": ["opensuse", "sles"],
44 "pkg": ["freebsd"],
45 "pkgutil": ["Solaris"]}
46 # first check exact match of name
47 for tool, distros in manager_mapping.items():
48 if os_name in distros:
49 return tool
50 # in case we did not detect any exact match, check
51 # if the name is contained inside the returned distro name
52 # like for opensuse, that can have opensuse-version names
53 for tool, distros in manager_mapping.items():
54 for d in distros:
55 if d in os_name:
56 return tool
57
58 def get_package_name(self, package):
59 # TODO: should we only add the arch if cross-building?
60 if self._arch in self._arch_names:
61 return "{}{}{}".format(package, self._arch_separator,
62 self._arch_names.get(self._arch))
63 return package
64
65 @property
66 def sudo_str(self):
67 sudo = "sudo " if self._sudo else ""
68 askpass = "-A " if self._sudo and self._sudo_askpass else ""
69 return "{}{}".format(sudo, askpass)
70
71 def run(self, method, *args, **kwargs):
72 if self._active_tool == self.__class__.tool_name:
73 return method(*args, **kwargs)
74
75 def _conanfile_run(self, command, accepted_returns):
76 ret = self._conanfile.run(command, ignore_errors=True)
77 if ret not in accepted_returns:
78 raise ConanException("Command '%s' failed" % command)
79 return ret
80
81 def install_substitutes(self, *args, **kwargs):
82 return self.run(self._install_substitutes, *args, **kwargs)
83
84 def install(self, *args, **kwargs):
85 return self.run(self._install, *args, **kwargs)
86
87 def update(self, *args, **kwargs):
88 return self.run(self._update, *args, **kwargs)
89
90 def check(self, *args, **kwargs):
91 return self.run(self._check, *args, **kwargs)
92
93 def _install_substitutes(self, *packages_substitutes, update=False, check=True, **kwargs):
94 errors = []
95 for packages in packages_substitutes:
96 try:
97 return self.install(packages, update, check, **kwargs)
98 except ConanException as e:
99 errors.append(e)
100
101 for error in errors:
102 self._conanfile.output.warn(str(error))
103 raise ConanException("None of the installs for the package substitutes succeeded.")
104
105 def _install(self, packages, update=False, check=True, **kwargs):
106 if check:
107 packages = self.check(packages)
108
109 if self._mode == self.mode_check and packages:
110 raise ConanException("System requirements: '{0}' are missing but can't install "
111 "because tools.system.package_manager:mode is '{1}'."
112 "Please update packages manually or set "
113 "'tools.system.package_manager:mode' "
114 "to '{2}' in the [conf] section of the profile, "
115 "or in the command line using "
116 "'-c tools.system.package_manager:mode={2}'".format(", ".join(packages),
117 self.mode_check,
118 self.mode_install))
119 elif packages:
120 if update:
121 self.update()
122
123 packages_arch = [self.get_package_name(package) for package in packages]
124 if packages_arch:
125 command = self.install_command.format(sudo=self.sudo_str,
126 tool=self.tool_name,
127 packages=" ".join(packages_arch),
128 **kwargs)
129 return self._conanfile_run(command, self.accepted_install_codes)
130 else:
131 self._conanfile.output.info("System requirements: {} already "
132 "installed".format(" ".join(packages)))
133
134 def _update(self):
135 # we just update the package manager database in case we are in 'install mode'
136 # in case we are in check mode just ignore
137 if self._mode == self.mode_install:
138 command = self.update_command.format(sudo=self.sudo_str, tool=self.tool_name)
139 return self._conanfile_run(command, self.accepted_update_codes)
140
141 def _check(self, packages):
142 missing = [pkg for pkg in packages if self.check_package(self.get_package_name(pkg)) != 0]
143 return missing
144
145 def check_package(self, package):
146 command = self.check_command.format(tool=self.tool_name,
147 package=package)
148 return self._conanfile_run(command, self.accepted_check_codes)
149
150
151 class Apt(_SystemPackageManagerTool):
152 # TODO: apt? apt-get?
153 tool_name = "apt-get"
154 install_command = "{sudo}{tool} install -y {recommends}{packages}"
155 update_command = "{sudo}{tool} update"
156 check_command = "dpkg-query -W -f='${{Status}}' {package} | grep -q \"ok installed\""
157
158 def __init__(self, conanfile, arch_names=None):
159 super(Apt, self).__init__(conanfile)
160 self._arch_names = {"x86_64": "amd64",
161 "x86": "i386",
162 "ppc32": "powerpc",
163 "ppc64le": "ppc64el",
164 "armv7": "arm",
165 "armv7hf": "armhf",
166 "armv8": "arm64",
167 "s390x": "s390x"} if arch_names is None else arch_names
168
169 self._arch_separator = ":"
170
171 def install(self, packages, update=False, check=False, recommends=False):
172 recommends_str = '' if recommends else '--no-install-recommends '
173 return super(Apt, self).install(packages, update=update, check=check,
174 recommends=recommends_str)
175
176
177 class Yum(_SystemPackageManagerTool):
178 tool_name = "yum"
179 install_command = "{sudo}{tool} install -y {packages}"
180 update_command = "{sudo}{tool} check-update -y"
181 check_command = "rpm -q {package}"
182 accepted_update_codes = [0, 100]
183
184 def __init__(self, conanfile, arch_names=None):
185 super(Yum, self).__init__(conanfile)
186 self._arch_names = {"x86_64": "x86_64",
187 "x86": "i?86",
188 "ppc32": "powerpc",
189 "ppc64le": "ppc64le",
190 "armv7": "armv7",
191 "armv7hf": "armv7hl",
192 "armv8": "aarch64",
193 "s390x": "s390x"} if arch_names is None else arch_names
194 self._arch_separator = "."
195
196
197 class Dnf(Yum):
198 tool_name = "dnf"
199
200
201 class Brew(_SystemPackageManagerTool):
202 tool_name = "brew"
203 install_command = "{sudo}{tool} install {packages}"
204 update_command = "{sudo}{tool} update"
205 check_command = 'test -n "$({tool} ls --versions {package})"'
206
207
208 class Pkg(_SystemPackageManagerTool):
209 tool_name = "pkg"
210 install_command = "{sudo}{tool} install -y {packages}"
211 update_command = "{sudo}{tool} update"
212 check_command = "{tool} info {package}"
213
214
215 class PkgUtil(_SystemPackageManagerTool):
216 tool_name = "pkgutil"
217 install_command = "{sudo}{tool} --install --yes {packages}"
218 update_command = "{sudo}{tool} --catalog"
219 check_command = 'test -n "`{tool} --list {package}`"'
220
221
222 class Chocolatey(_SystemPackageManagerTool):
223 tool_name = "choco"
224 install_command = "{tool} install --yes {packages}"
225 update_command = "{tool} outdated"
226 check_command = '{tool} search --local-only --exact {package} | ' \
227 'findstr /c:"1 packages installed."'
228
229
230 class PacMan(_SystemPackageManagerTool):
231 tool_name = "pacman"
232 install_command = "{sudo}{tool} -S --noconfirm {packages}"
233 update_command = "{sudo}{tool} -Syyu --noconfirm"
234 check_command = "{tool} -Qi {package}"
235
236 def __init__(self, conanfile, arch_names=None):
237 super(PacMan, self).__init__(conanfile)
238 self._arch_names = {"x86": "lib32"} if arch_names is None else arch_names
239 self._arch_separator = "-"
240
241
242 class Zypper(_SystemPackageManagerTool):
243 tool_name = "zypper"
244 install_command = "{sudo}{tool} --non-interactive in {packages}"
245 update_command = "{sudo}{tool} --non-interactive ref"
246 check_command = "rpm -q {package}"
247
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conan/tools/system/package_manager.py b/conan/tools/system/package_manager.py
--- a/conan/tools/system/package_manager.py
+++ b/conan/tools/system/package_manager.py
@@ -38,7 +38,7 @@
"almalinux", "rocky"],
"dnf": ["fedora", "rhel", "centos", "mageia"],
"brew": ["Darwin"],
- "pacman": ["arch", "manjaro", "msys2"],
+ "pacman": ["arch", "manjaro", "msys2", "endeavouros"],
"choco": ["Windows"],
"zypper": ["opensuse", "sles"],
"pkg": ["freebsd"],
|
{"golden_diff": "diff --git a/conan/tools/system/package_manager.py b/conan/tools/system/package_manager.py\n--- a/conan/tools/system/package_manager.py\n+++ b/conan/tools/system/package_manager.py\n@@ -38,7 +38,7 @@\n \"almalinux\", \"rocky\"],\n \"dnf\": [\"fedora\", \"rhel\", \"centos\", \"mageia\"],\n \"brew\": [\"Darwin\"],\n- \"pacman\": [\"arch\", \"manjaro\", \"msys2\"],\n+ \"pacman\": [\"arch\", \"manjaro\", \"msys2\", \"endeavouros\"],\n \"choco\": [\"Windows\"],\n \"zypper\": [\"opensuse\", \"sles\"],\n \"pkg\": [\"freebsd\"],\n", "issue": "[bug] EndeavourOS not among list of distros listed for pacman support\n### Environment Details (include every applicable attribute)\r\n * Operating System+version: EndeavourOS 2022.06.23\r\n * Compiler+version: Clang 14.0.6\r\n * Conan version: 1.51.3\r\n * Python version: 3.10.6\r\n\r\n### Steps to reproduce (Include if Applicable)\r\nIn a python interpreter\r\n```bash\r\n>>> from conans import tools\r\n>>> tools.os_info.with_pacman\r\nFalse\r\n>>>tools.os_info.is_linux\r\nTrue\r\n>>> tools.os_info.linux_distro\r\n'endeavouros'\r\n```\r\n\r\nWe need to add `endeavouros` to this [line](https://github.com/conan-io/conan/blob/develop/conans/client/tools/oss.py#L220)\r\n\r\n### Logs (Executed commands with output) (Include/Attach if Applicable)\r\nAs a result of the above, OpenGL recipe doesn't know how to install itself, xorg/system also fails to install some dependencies as well\r\n\r\n```log\r\nopengl/system: Package installed 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9\r\nopengl/system: Downloaded package revision 0\r\nxorg/system: Retrieving package 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 from remote 'conancenter' \r\nDownloading conanmanifest.txt completed [0.06k] \r\nDownloading conaninfo.txt completed [0.16k] \r\nDownloading conan_package.tgz completed [0.06k] \r\nDecompressing conan_package.tgz completed [0.00k] \r\nxorg/system: Package installed 5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9\r\nxorg/system: Downloaded package revision 0\r\nopengl/system: WARN: Don't know how to install OpenGL for your distro.\r\nERROR: xorg/system: Error in package_info() method, line 79\r\n pkg_config.fill_cpp_info(\r\n ConanException: pkg-config command ['pkg-config', '--print-provides', 'xvmc', '--print-errors'] failed with error: Command 'pkg-config --print-provides xvmc --print-errors' returned non-zero exit status 1.\r\nPackage xvmc was not found in the pkg-config search path.\r\nPerhaps you should add the directory containing `xvmc.pc'\r\nto the PKG_CONFIG_PATH environment variable\r\nPackage 'xvmc', required by 'virtual:world', not found\r\n```\r\n\n", "before_files": [{"content": "import platform\n\nfrom conans.client.graph.graph import CONTEXT_BUILD\nfrom conans.errors import ConanException\n\n\nclass _SystemPackageManagerTool(object):\n mode_check = \"check\"\n mode_install = \"install\"\n tool_name = None\n install_command = \"\"\n update_command = \"\"\n check_command = \"\"\n accepted_install_codes = [0]\n accepted_update_codes = [0]\n accepted_check_codes = [0, 1]\n\n def __init__(self, conanfile):\n self._conanfile = conanfile\n self._active_tool = self._conanfile.conf.get(\"tools.system.package_manager:tool\", default=self.get_default_tool())\n self._sudo = self._conanfile.conf.get(\"tools.system.package_manager:sudo\", default=False, check_type=bool)\n self._sudo_askpass = self._conanfile.conf.get(\"tools.system.package_manager:sudo_askpass\", default=False, check_type=bool)\n self._mode = self._conanfile.conf.get(\"tools.system.package_manager:mode\", default=self.mode_check)\n self._arch = self._conanfile.settings_build.get_safe('arch') \\\n if self._conanfile.context == CONTEXT_BUILD else self._conanfile.settings.get_safe('arch')\n self._arch_names = {}\n self._arch_separator = \"\"\n\n def get_default_tool(self):\n os_name = platform.system()\n if os_name in [\"Linux\", \"FreeBSD\"]:\n import distro\n os_name = distro.id() or os_name\n elif os_name == \"Windows\" and self._conanfile.conf.get(\"tools.microsoft.bash:subsystem\") == \"msys2\":\n os_name = \"msys2\"\n manager_mapping = {\"apt-get\": [\"Linux\", \"ubuntu\", \"debian\", \"raspbian\"],\n \"yum\": [\"pidora\", \"scientific\", \"xenserver\", \"amazon\", \"oracle\", \"amzn\",\n \"almalinux\", \"rocky\"],\n \"dnf\": [\"fedora\", \"rhel\", \"centos\", \"mageia\"],\n \"brew\": [\"Darwin\"],\n \"pacman\": [\"arch\", \"manjaro\", \"msys2\"],\n \"choco\": [\"Windows\"],\n \"zypper\": [\"opensuse\", \"sles\"],\n \"pkg\": [\"freebsd\"],\n \"pkgutil\": [\"Solaris\"]}\n # first check exact match of name\n for tool, distros in manager_mapping.items():\n if os_name in distros:\n return tool\n # in case we did not detect any exact match, check\n # if the name is contained inside the returned distro name\n # like for opensuse, that can have opensuse-version names\n for tool, distros in manager_mapping.items():\n for d in distros:\n if d in os_name:\n return tool\n\n def get_package_name(self, package):\n # TODO: should we only add the arch if cross-building?\n if self._arch in self._arch_names:\n return \"{}{}{}\".format(package, self._arch_separator,\n self._arch_names.get(self._arch))\n return package\n\n @property\n def sudo_str(self):\n sudo = \"sudo \" if self._sudo else \"\"\n askpass = \"-A \" if self._sudo and self._sudo_askpass else \"\"\n return \"{}{}\".format(sudo, askpass)\n\n def run(self, method, *args, **kwargs):\n if self._active_tool == self.__class__.tool_name:\n return method(*args, **kwargs)\n\n def _conanfile_run(self, command, accepted_returns):\n ret = self._conanfile.run(command, ignore_errors=True)\n if ret not in accepted_returns:\n raise ConanException(\"Command '%s' failed\" % command)\n return ret\n\n def install_substitutes(self, *args, **kwargs):\n return self.run(self._install_substitutes, *args, **kwargs)\n\n def install(self, *args, **kwargs):\n return self.run(self._install, *args, **kwargs)\n\n def update(self, *args, **kwargs):\n return self.run(self._update, *args, **kwargs)\n\n def check(self, *args, **kwargs):\n return self.run(self._check, *args, **kwargs)\n\n def _install_substitutes(self, *packages_substitutes, update=False, check=True, **kwargs):\n errors = []\n for packages in packages_substitutes:\n try:\n return self.install(packages, update, check, **kwargs)\n except ConanException as e:\n errors.append(e)\n\n for error in errors:\n self._conanfile.output.warn(str(error))\n raise ConanException(\"None of the installs for the package substitutes succeeded.\")\n\n def _install(self, packages, update=False, check=True, **kwargs):\n if check:\n packages = self.check(packages)\n\n if self._mode == self.mode_check and packages:\n raise ConanException(\"System requirements: '{0}' are missing but can't install \"\n \"because tools.system.package_manager:mode is '{1}'.\"\n \"Please update packages manually or set \"\n \"'tools.system.package_manager:mode' \"\n \"to '{2}' in the [conf] section of the profile, \"\n \"or in the command line using \"\n \"'-c tools.system.package_manager:mode={2}'\".format(\", \".join(packages),\n self.mode_check,\n self.mode_install))\n elif packages:\n if update:\n self.update()\n\n packages_arch = [self.get_package_name(package) for package in packages]\n if packages_arch:\n command = self.install_command.format(sudo=self.sudo_str,\n tool=self.tool_name,\n packages=\" \".join(packages_arch),\n **kwargs)\n return self._conanfile_run(command, self.accepted_install_codes)\n else:\n self._conanfile.output.info(\"System requirements: {} already \"\n \"installed\".format(\" \".join(packages)))\n\n def _update(self):\n # we just update the package manager database in case we are in 'install mode'\n # in case we are in check mode just ignore\n if self._mode == self.mode_install:\n command = self.update_command.format(sudo=self.sudo_str, tool=self.tool_name)\n return self._conanfile_run(command, self.accepted_update_codes)\n\n def _check(self, packages):\n missing = [pkg for pkg in packages if self.check_package(self.get_package_name(pkg)) != 0]\n return missing\n\n def check_package(self, package):\n command = self.check_command.format(tool=self.tool_name,\n package=package)\n return self._conanfile_run(command, self.accepted_check_codes)\n\n\nclass Apt(_SystemPackageManagerTool):\n # TODO: apt? apt-get?\n tool_name = \"apt-get\"\n install_command = \"{sudo}{tool} install -y {recommends}{packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = \"dpkg-query -W -f='${{Status}}' {package} | grep -q \\\"ok installed\\\"\"\n\n def __init__(self, conanfile, arch_names=None):\n super(Apt, self).__init__(conanfile)\n self._arch_names = {\"x86_64\": \"amd64\",\n \"x86\": \"i386\",\n \"ppc32\": \"powerpc\",\n \"ppc64le\": \"ppc64el\",\n \"armv7\": \"arm\",\n \"armv7hf\": \"armhf\",\n \"armv8\": \"arm64\",\n \"s390x\": \"s390x\"} if arch_names is None else arch_names\n\n self._arch_separator = \":\"\n\n def install(self, packages, update=False, check=False, recommends=False):\n recommends_str = '' if recommends else '--no-install-recommends '\n return super(Apt, self).install(packages, update=update, check=check,\n recommends=recommends_str)\n\n\nclass Yum(_SystemPackageManagerTool):\n tool_name = \"yum\"\n install_command = \"{sudo}{tool} install -y {packages}\"\n update_command = \"{sudo}{tool} check-update -y\"\n check_command = \"rpm -q {package}\"\n accepted_update_codes = [0, 100]\n\n def __init__(self, conanfile, arch_names=None):\n super(Yum, self).__init__(conanfile)\n self._arch_names = {\"x86_64\": \"x86_64\",\n \"x86\": \"i?86\",\n \"ppc32\": \"powerpc\",\n \"ppc64le\": \"ppc64le\",\n \"armv7\": \"armv7\",\n \"armv7hf\": \"armv7hl\",\n \"armv8\": \"aarch64\",\n \"s390x\": \"s390x\"} if arch_names is None else arch_names\n self._arch_separator = \".\"\n\n\nclass Dnf(Yum):\n tool_name = \"dnf\"\n\n\nclass Brew(_SystemPackageManagerTool):\n tool_name = \"brew\"\n install_command = \"{sudo}{tool} install {packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = 'test -n \"$({tool} ls --versions {package})\"'\n\n\nclass Pkg(_SystemPackageManagerTool):\n tool_name = \"pkg\"\n install_command = \"{sudo}{tool} install -y {packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = \"{tool} info {package}\"\n\n\nclass PkgUtil(_SystemPackageManagerTool):\n tool_name = \"pkgutil\"\n install_command = \"{sudo}{tool} --install --yes {packages}\"\n update_command = \"{sudo}{tool} --catalog\"\n check_command = 'test -n \"`{tool} --list {package}`\"'\n\n\nclass Chocolatey(_SystemPackageManagerTool):\n tool_name = \"choco\"\n install_command = \"{tool} install --yes {packages}\"\n update_command = \"{tool} outdated\"\n check_command = '{tool} search --local-only --exact {package} | ' \\\n 'findstr /c:\"1 packages installed.\"'\n\n\nclass PacMan(_SystemPackageManagerTool):\n tool_name = \"pacman\"\n install_command = \"{sudo}{tool} -S --noconfirm {packages}\"\n update_command = \"{sudo}{tool} -Syyu --noconfirm\"\n check_command = \"{tool} -Qi {package}\"\n\n def __init__(self, conanfile, arch_names=None):\n super(PacMan, self).__init__(conanfile)\n self._arch_names = {\"x86\": \"lib32\"} if arch_names is None else arch_names\n self._arch_separator = \"-\"\n\n\nclass Zypper(_SystemPackageManagerTool):\n tool_name = \"zypper\"\n install_command = \"{sudo}{tool} --non-interactive in {packages}\"\n update_command = \"{sudo}{tool} --non-interactive ref\"\n check_command = \"rpm -q {package}\"\n", "path": "conan/tools/system/package_manager.py"}], "after_files": [{"content": "import platform\n\nfrom conans.client.graph.graph import CONTEXT_BUILD\nfrom conans.errors import ConanException\n\n\nclass _SystemPackageManagerTool(object):\n mode_check = \"check\"\n mode_install = \"install\"\n tool_name = None\n install_command = \"\"\n update_command = \"\"\n check_command = \"\"\n accepted_install_codes = [0]\n accepted_update_codes = [0]\n accepted_check_codes = [0, 1]\n\n def __init__(self, conanfile):\n self._conanfile = conanfile\n self._active_tool = self._conanfile.conf.get(\"tools.system.package_manager:tool\", default=self.get_default_tool())\n self._sudo = self._conanfile.conf.get(\"tools.system.package_manager:sudo\", default=False, check_type=bool)\n self._sudo_askpass = self._conanfile.conf.get(\"tools.system.package_manager:sudo_askpass\", default=False, check_type=bool)\n self._mode = self._conanfile.conf.get(\"tools.system.package_manager:mode\", default=self.mode_check)\n self._arch = self._conanfile.settings_build.get_safe('arch') \\\n if self._conanfile.context == CONTEXT_BUILD else self._conanfile.settings.get_safe('arch')\n self._arch_names = {}\n self._arch_separator = \"\"\n\n def get_default_tool(self):\n os_name = platform.system()\n if os_name in [\"Linux\", \"FreeBSD\"]:\n import distro\n os_name = distro.id() or os_name\n elif os_name == \"Windows\" and self._conanfile.conf.get(\"tools.microsoft.bash:subsystem\") == \"msys2\":\n os_name = \"msys2\"\n manager_mapping = {\"apt-get\": [\"Linux\", \"ubuntu\", \"debian\", \"raspbian\"],\n \"yum\": [\"pidora\", \"scientific\", \"xenserver\", \"amazon\", \"oracle\", \"amzn\",\n \"almalinux\", \"rocky\"],\n \"dnf\": [\"fedora\", \"rhel\", \"centos\", \"mageia\"],\n \"brew\": [\"Darwin\"],\n \"pacman\": [\"arch\", \"manjaro\", \"msys2\", \"endeavouros\"],\n \"choco\": [\"Windows\"],\n \"zypper\": [\"opensuse\", \"sles\"],\n \"pkg\": [\"freebsd\"],\n \"pkgutil\": [\"Solaris\"]}\n # first check exact match of name\n for tool, distros in manager_mapping.items():\n if os_name in distros:\n return tool\n # in case we did not detect any exact match, check\n # if the name is contained inside the returned distro name\n # like for opensuse, that can have opensuse-version names\n for tool, distros in manager_mapping.items():\n for d in distros:\n if d in os_name:\n return tool\n\n def get_package_name(self, package):\n # TODO: should we only add the arch if cross-building?\n if self._arch in self._arch_names:\n return \"{}{}{}\".format(package, self._arch_separator,\n self._arch_names.get(self._arch))\n return package\n\n @property\n def sudo_str(self):\n sudo = \"sudo \" if self._sudo else \"\"\n askpass = \"-A \" if self._sudo and self._sudo_askpass else \"\"\n return \"{}{}\".format(sudo, askpass)\n\n def run(self, method, *args, **kwargs):\n if self._active_tool == self.__class__.tool_name:\n return method(*args, **kwargs)\n\n def _conanfile_run(self, command, accepted_returns):\n ret = self._conanfile.run(command, ignore_errors=True)\n if ret not in accepted_returns:\n raise ConanException(\"Command '%s' failed\" % command)\n return ret\n\n def install_substitutes(self, *args, **kwargs):\n return self.run(self._install_substitutes, *args, **kwargs)\n\n def install(self, *args, **kwargs):\n return self.run(self._install, *args, **kwargs)\n\n def update(self, *args, **kwargs):\n return self.run(self._update, *args, **kwargs)\n\n def check(self, *args, **kwargs):\n return self.run(self._check, *args, **kwargs)\n\n def _install_substitutes(self, *packages_substitutes, update=False, check=True, **kwargs):\n errors = []\n for packages in packages_substitutes:\n try:\n return self.install(packages, update, check, **kwargs)\n except ConanException as e:\n errors.append(e)\n\n for error in errors:\n self._conanfile.output.warn(str(error))\n raise ConanException(\"None of the installs for the package substitutes succeeded.\")\n\n def _install(self, packages, update=False, check=True, **kwargs):\n if check:\n packages = self.check(packages)\n\n if self._mode == self.mode_check and packages:\n raise ConanException(\"System requirements: '{0}' are missing but can't install \"\n \"because tools.system.package_manager:mode is '{1}'.\"\n \"Please update packages manually or set \"\n \"'tools.system.package_manager:mode' \"\n \"to '{2}' in the [conf] section of the profile, \"\n \"or in the command line using \"\n \"'-c tools.system.package_manager:mode={2}'\".format(\", \".join(packages),\n self.mode_check,\n self.mode_install))\n elif packages:\n if update:\n self.update()\n\n packages_arch = [self.get_package_name(package) for package in packages]\n if packages_arch:\n command = self.install_command.format(sudo=self.sudo_str,\n tool=self.tool_name,\n packages=\" \".join(packages_arch),\n **kwargs)\n return self._conanfile_run(command, self.accepted_install_codes)\n else:\n self._conanfile.output.info(\"System requirements: {} already \"\n \"installed\".format(\" \".join(packages)))\n\n def _update(self):\n # we just update the package manager database in case we are in 'install mode'\n # in case we are in check mode just ignore\n if self._mode == self.mode_install:\n command = self.update_command.format(sudo=self.sudo_str, tool=self.tool_name)\n return self._conanfile_run(command, self.accepted_update_codes)\n\n def _check(self, packages):\n missing = [pkg for pkg in packages if self.check_package(self.get_package_name(pkg)) != 0]\n return missing\n\n def check_package(self, package):\n command = self.check_command.format(tool=self.tool_name,\n package=package)\n return self._conanfile_run(command, self.accepted_check_codes)\n\n\nclass Apt(_SystemPackageManagerTool):\n # TODO: apt? apt-get?\n tool_name = \"apt-get\"\n install_command = \"{sudo}{tool} install -y {recommends}{packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = \"dpkg-query -W -f='${{Status}}' {package} | grep -q \\\"ok installed\\\"\"\n\n def __init__(self, conanfile, arch_names=None):\n super(Apt, self).__init__(conanfile)\n self._arch_names = {\"x86_64\": \"amd64\",\n \"x86\": \"i386\",\n \"ppc32\": \"powerpc\",\n \"ppc64le\": \"ppc64el\",\n \"armv7\": \"arm\",\n \"armv7hf\": \"armhf\",\n \"armv8\": \"arm64\",\n \"s390x\": \"s390x\"} if arch_names is None else arch_names\n\n self._arch_separator = \":\"\n\n def install(self, packages, update=False, check=False, recommends=False):\n recommends_str = '' if recommends else '--no-install-recommends '\n return super(Apt, self).install(packages, update=update, check=check,\n recommends=recommends_str)\n\n\nclass Yum(_SystemPackageManagerTool):\n tool_name = \"yum\"\n install_command = \"{sudo}{tool} install -y {packages}\"\n update_command = \"{sudo}{tool} check-update -y\"\n check_command = \"rpm -q {package}\"\n accepted_update_codes = [0, 100]\n\n def __init__(self, conanfile, arch_names=None):\n super(Yum, self).__init__(conanfile)\n self._arch_names = {\"x86_64\": \"x86_64\",\n \"x86\": \"i?86\",\n \"ppc32\": \"powerpc\",\n \"ppc64le\": \"ppc64le\",\n \"armv7\": \"armv7\",\n \"armv7hf\": \"armv7hl\",\n \"armv8\": \"aarch64\",\n \"s390x\": \"s390x\"} if arch_names is None else arch_names\n self._arch_separator = \".\"\n\n\nclass Dnf(Yum):\n tool_name = \"dnf\"\n\n\nclass Brew(_SystemPackageManagerTool):\n tool_name = \"brew\"\n install_command = \"{sudo}{tool} install {packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = 'test -n \"$({tool} ls --versions {package})\"'\n\n\nclass Pkg(_SystemPackageManagerTool):\n tool_name = \"pkg\"\n install_command = \"{sudo}{tool} install -y {packages}\"\n update_command = \"{sudo}{tool} update\"\n check_command = \"{tool} info {package}\"\n\n\nclass PkgUtil(_SystemPackageManagerTool):\n tool_name = \"pkgutil\"\n install_command = \"{sudo}{tool} --install --yes {packages}\"\n update_command = \"{sudo}{tool} --catalog\"\n check_command = 'test -n \"`{tool} --list {package}`\"'\n\n\nclass Chocolatey(_SystemPackageManagerTool):\n tool_name = \"choco\"\n install_command = \"{tool} install --yes {packages}\"\n update_command = \"{tool} outdated\"\n check_command = '{tool} search --local-only --exact {package} | ' \\\n 'findstr /c:\"1 packages installed.\"'\n\n\nclass PacMan(_SystemPackageManagerTool):\n tool_name = \"pacman\"\n install_command = \"{sudo}{tool} -S --noconfirm {packages}\"\n update_command = \"{sudo}{tool} -Syyu --noconfirm\"\n check_command = \"{tool} -Qi {package}\"\n\n def __init__(self, conanfile, arch_names=None):\n super(PacMan, self).__init__(conanfile)\n self._arch_names = {\"x86\": \"lib32\"} if arch_names is None else arch_names\n self._arch_separator = \"-\"\n\n\nclass Zypper(_SystemPackageManagerTool):\n tool_name = \"zypper\"\n install_command = \"{sudo}{tool} --non-interactive in {packages}\"\n update_command = \"{sudo}{tool} --non-interactive ref\"\n check_command = \"rpm -q {package}\"\n", "path": "conan/tools/system/package_manager.py"}]}
| 3,933 | 164 |
gh_patches_debug_3277
|
rasdani/github-patches
|
git_diff
|
spack__spack-11755
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Installing rclone leaves a go folder outside spack root
Spack version: commit a45c4ef33de (if no change on relevant part, it is basically the head).
OS distribution: Ubuntu server 18.04.
After `spack install rclone`, there is a folder named go outside spack installation root as `~/go/` (the spack root is `~/spack/`). I have no idea about go lang, but it seems to be the go packages directory, denoted as `$GOPATH`.
I wonder whether it is necessary to leave something outside spack root or should it be simple to move such GOPATH within spack root by hacking some repos (such as go or rclone).
BTW,
```bash
module show go-1.11.5-gcc-7.4.0-gm
--------------------------------------------------------------------------------------------------------------------------------
/home/ubuntu/spack/share/spack/modules/linux-ubuntu18.04-x86_64/go-1.11.5-gcc-7.4.0-gm:
--------------------------------------------------------------------------------------------------------------------------------
whatis("The golang compiler and build environment ")
prepend_path("PATH","/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/bin")
prepend_path("LD_LIBRARY_PATH","/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/lib")
prepend_path("LIBRARY_PATH","/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/lib")
prepend_path("CMAKE_PREFIX_PATH","/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/")
help([[The golang compiler and build environment
]])
```
The auto generated module file for go by spack has no modification on `$GOPATH`.
Correct me if I have any misunderstanding on go or its way of doing things, since literally I know nothing about it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/rclone/package.py`
Content:
```
1 # Copyright 2013-2019 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class Rclone(Package):
10 """Rclone is a command line program to sync files and directories
11 to and from various cloud storage providers"""
12
13 homepage = "http://rclone.org"
14 url = "https://github.com/ncw/rclone/releases/download/v1.43/rclone-v1.43.tar.gz"
15
16 version('1.43', sha256='d30527b00cecb4e5e7188dddb78e5cec62d67cf2422dab82190db58512b5a4e3')
17
18 depends_on("go", type='build')
19
20 def install(self, spec, prefix):
21 go('build')
22 mkdirp(prefix.bin)
23 install('rclone', prefix.bin)
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/rclone/package.py b/var/spack/repos/builtin/packages/rclone/package.py
--- a/var/spack/repos/builtin/packages/rclone/package.py
+++ b/var/spack/repos/builtin/packages/rclone/package.py
@@ -17,6 +17,10 @@
depends_on("go", type='build')
+ def setup_environment(self, spack_env, run_env):
+ # Point GOPATH at the top of the staging dir for the build step.
+ spack_env.prepend_path('GOPATH', self.stage.path)
+
def install(self, spec, prefix):
go('build')
mkdirp(prefix.bin)
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/rclone/package.py b/var/spack/repos/builtin/packages/rclone/package.py\n--- a/var/spack/repos/builtin/packages/rclone/package.py\n+++ b/var/spack/repos/builtin/packages/rclone/package.py\n@@ -17,6 +17,10 @@\n \n depends_on(\"go\", type='build')\n \n+ def setup_environment(self, spack_env, run_env):\n+ # Point GOPATH at the top of the staging dir for the build step.\n+ spack_env.prepend_path('GOPATH', self.stage.path)\n+\n def install(self, spec, prefix):\n go('build')\n mkdirp(prefix.bin)\n", "issue": "Installing rclone leaves a go folder outside spack root\nSpack version: commit a45c4ef33de (if no change on relevant part, it is basically the head).\r\nOS distribution: Ubuntu server 18.04.\r\n\r\nAfter `spack install rclone`, there is a folder named go outside spack installation root as `~/go/` (the spack root is `~/spack/`). I have no idea about go lang, but it seems to be the go packages directory, denoted as `$GOPATH`.\r\n\r\nI wonder whether it is necessary to leave something outside spack root or should it be simple to move such GOPATH within spack root by hacking some repos (such as go or rclone).\r\n\r\nBTW, \r\n```bash\r\nmodule show go-1.11.5-gcc-7.4.0-gm\r\n--------------------------------------------------------------------------------------------------------------------------------\r\n /home/ubuntu/spack/share/spack/modules/linux-ubuntu18.04-x86_64/go-1.11.5-gcc-7.4.0-gm:\r\n--------------------------------------------------------------------------------------------------------------------------------\r\nwhatis(\"The golang compiler and build environment \")\r\nprepend_path(\"PATH\",\"/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/bin\")\r\nprepend_path(\"LD_LIBRARY_PATH\",\"/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/lib\")\r\nprepend_path(\"LIBRARY_PATH\",\"/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/lib\")\r\nprepend_path(\"CMAKE_PREFIX_PATH\",\"/home/ubuntu/spack/opt/spack/linux-ubuntu18.04-x86_64/gcc-7.4.0/go-1.11.5-gmcvqdwr6az4hxbicr375if5fttk6sna/\")\r\nhelp([[The golang compiler and build environment\r\n]])\r\n```\r\nThe auto generated module file for go by spack has no modification on `$GOPATH`.\r\n\r\nCorrect me if I have any misunderstanding on go or its way of doing things, since literally I know nothing about it.\n", "before_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Rclone(Package):\n \"\"\"Rclone is a command line program to sync files and directories\n to and from various cloud storage providers\"\"\"\n\n homepage = \"http://rclone.org\"\n url = \"https://github.com/ncw/rclone/releases/download/v1.43/rclone-v1.43.tar.gz\"\n\n version('1.43', sha256='d30527b00cecb4e5e7188dddb78e5cec62d67cf2422dab82190db58512b5a4e3')\n\n depends_on(\"go\", type='build')\n\n def install(self, spec, prefix):\n go('build')\n mkdirp(prefix.bin)\n install('rclone', prefix.bin)\n", "path": "var/spack/repos/builtin/packages/rclone/package.py"}], "after_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass Rclone(Package):\n \"\"\"Rclone is a command line program to sync files and directories\n to and from various cloud storage providers\"\"\"\n\n homepage = \"http://rclone.org\"\n url = \"https://github.com/ncw/rclone/releases/download/v1.43/rclone-v1.43.tar.gz\"\n\n version('1.43', sha256='d30527b00cecb4e5e7188dddb78e5cec62d67cf2422dab82190db58512b5a4e3')\n\n depends_on(\"go\", type='build')\n\n def setup_environment(self, spack_env, run_env):\n # Point GOPATH at the top of the staging dir for the build step.\n spack_env.prepend_path('GOPATH', self.stage.path)\n\n def install(self, spec, prefix):\n go('build')\n mkdirp(prefix.bin)\n install('rclone', prefix.bin)\n", "path": "var/spack/repos/builtin/packages/rclone/package.py"}]}
| 1,118 | 149 |
gh_patches_debug_49610
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-4656
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
3.0 - `source_channel` no longer working for Mistral workflows
##### SUMMARY
In ST2 3.0, Mistral workflows no longer able to identify `source_channel` that alias was called from.
##### ISSUE TYPE
- Bug Report
##### STACKSTORM VERSION
`st2 3.0.0, on Python 2.7.12`
##### OS / ENVIRONMENT / INSTALL METHOD
one-liner, on Ubuntu 16.04.
System upgraded from 2.10.4 to 3.0.0.
##### STEPS TO REPRODUCE
Create a Mistral workflow that uses `source_channel`, and call it via a Chat alias.
Mistral workflow [here](https://github.com/StackStorm/st2_demos/blob/master/actions/workflows/multicap.yaml#L20).
Alias [here](https://github.com/StackStorm/st2_demos/blob/master/aliases/multicap.yaml).
Key lines:
```yaml
input:
channel: "<% env().get('__actions').get('st2.action').st2_context.parent.source_channel %>"
message: "Setting up environment and starting captures now...{~}"
on-success:
```
##### EXPECTED RESULTS
Workflow should post back to the original channel with my message
> Setting up environment and starting captures now...
##### ACTUAL RESULTS
Workflow fails, because it can't get the value of source_channel. Error similar to
```
"Failed to run task [error=Can not evaluate YAQL expression [expression=env().get('__actions').get('st2.action').st2_context.parent.source_channel, error=u'source_channel', data={}], wf=st2_demos.multicap.main, task=notify_slack]:
```
This stems from https://github.com/StackStorm/st2/pull/4609/files#diff-f2911a69b88d56311f8945335e9457b7L148, which is part of PR #4609. If I add that removed line back to `aliasexecution.py`, it works as expected.
Looks like this data may be available in the `notify` dict.
/cc @blag @m4dcoder @emptywee
3.0 - `source_channel` no longer working for Mistral workflows
##### SUMMARY
In ST2 3.0, Mistral workflows no longer able to identify `source_channel` that alias was called from.
##### ISSUE TYPE
- Bug Report
##### STACKSTORM VERSION
`st2 3.0.0, on Python 2.7.12`
##### OS / ENVIRONMENT / INSTALL METHOD
one-liner, on Ubuntu 16.04.
System upgraded from 2.10.4 to 3.0.0.
##### STEPS TO REPRODUCE
Create a Mistral workflow that uses `source_channel`, and call it via a Chat alias.
Mistral workflow [here](https://github.com/StackStorm/st2_demos/blob/master/actions/workflows/multicap.yaml#L20).
Alias [here](https://github.com/StackStorm/st2_demos/blob/master/aliases/multicap.yaml).
Key lines:
```yaml
input:
channel: "<% env().get('__actions').get('st2.action').st2_context.parent.source_channel %>"
message: "Setting up environment and starting captures now...{~}"
on-success:
```
##### EXPECTED RESULTS
Workflow should post back to the original channel with my message
> Setting up environment and starting captures now...
##### ACTUAL RESULTS
Workflow fails, because it can't get the value of source_channel. Error similar to
```
"Failed to run task [error=Can not evaluate YAQL expression [expression=env().get('__actions').get('st2.action').st2_context.parent.source_channel, error=u'source_channel', data={}], wf=st2_demos.multicap.main, task=notify_slack]:
```
This stems from https://github.com/StackStorm/st2/pull/4609/files#diff-f2911a69b88d56311f8945335e9457b7L148, which is part of PR #4609. If I add that removed line back to `aliasexecution.py`, it works as expected.
Looks like this data may be available in the `notify` dict.
/cc @blag @m4dcoder @emptywee
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `st2api/st2api/controllers/v1/aliasexecution.py`
Content:
```
1 # Copyright 2019 Extreme Networks, Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import six
16 import jsonschema
17 from jinja2.exceptions import UndefinedError
18 from oslo_config import cfg
19
20 from st2api.controllers.base import BaseRestControllerMixin
21 from st2common import log as logging
22 from st2common.exceptions.actionalias import ActionAliasAmbiguityException
23 from st2common.exceptions.db import StackStormDBObjectNotFoundError
24 from st2common.models.api.action import ActionAliasAPI
25 from st2common.models.api.action import AliasMatchAndExecuteInputAPI
26 from st2common.models.api.auth import get_system_username
27 from st2common.models.api.execution import ActionExecutionAPI
28 from st2common.models.db.auth import UserDB
29 from st2common.models.db.liveaction import LiveActionDB
30 from st2common.models.db.notification import NotificationSchema, NotificationSubSchema
31 from st2common.models.utils import action_param_utils
32 from st2common.models.utils.action_alias_utils import extract_parameters_for_action_alias_db
33 from st2common.persistence.actionalias import ActionAlias
34 from st2common.services import action as action_service
35 from st2common.util import action_db as action_utils
36 from st2common.util import reference
37 from st2common.util.actionalias_matching import get_matching_alias
38 from st2common.util.jinja import render_values as render
39 from st2common.rbac.types import PermissionType
40 from st2common.rbac.backends import get_rbac_backend
41 from st2common.router import abort
42 from st2common.router import Response
43
44 http_client = six.moves.http_client
45
46 LOG = logging.getLogger(__name__)
47
48 CAST_OVERRIDES = {
49 'array': (lambda cs_x: [v.strip() for v in cs_x.split(',')])
50 }
51
52
53 class ActionAliasExecutionController(BaseRestControllerMixin):
54 def match_and_execute(self, input_api, requester_user, show_secrets=False):
55 """
56 Try to find a matching alias and if one is found, schedule a new
57 execution by parsing parameters from the provided command against
58 the matched alias.
59
60 Handles requests:
61 POST /aliasexecution/match_and_execute
62 """
63 command = input_api.command
64
65 try:
66 format_ = get_matching_alias(command=command)
67 except ActionAliasAmbiguityException as e:
68 LOG.exception('Command "%s" matched (%s) patterns.', e.command, len(e.matches))
69 return abort(http_client.BAD_REQUEST, six.text_type(e))
70
71 action_alias_db = format_['alias']
72 representation = format_['representation']
73
74 params = {
75 'name': action_alias_db.name,
76 'format': representation,
77 'command': command,
78 'user': input_api.user,
79 'source_channel': input_api.source_channel,
80 }
81
82 # Add in any additional parameters provided by the user
83 if input_api.notification_channel:
84 params['notification_channel'] = input_api.notification_channel
85
86 if input_api.notification_route:
87 params['notification_route'] = input_api.notification_route
88
89 alias_execution_api = AliasMatchAndExecuteInputAPI(**params)
90 results = self._post(
91 payload=alias_execution_api,
92 requester_user=requester_user,
93 show_secrets=show_secrets,
94 match_multiple=format_['match_multiple'])
95 return Response(json={'results': results}, status=http_client.CREATED)
96
97 def _post(self, payload, requester_user, show_secrets=False, match_multiple=False):
98 action_alias_name = payload.name if payload else None
99
100 if not action_alias_name:
101 abort(http_client.BAD_REQUEST, 'Alias execution "name" is required')
102 return
103
104 if not requester_user:
105 requester_user = UserDB(cfg.CONF.system_user.user)
106
107 format_str = payload.format or ''
108 command = payload.command or ''
109
110 try:
111 action_alias_db = ActionAlias.get_by_name(action_alias_name)
112 except ValueError:
113 action_alias_db = None
114
115 if not action_alias_db:
116 msg = 'Unable to identify action alias with name "%s".' % (action_alias_name)
117 abort(http_client.NOT_FOUND, msg)
118 return
119
120 if not action_alias_db.enabled:
121 msg = 'Action alias with name "%s" is disabled.' % (action_alias_name)
122 abort(http_client.BAD_REQUEST, msg)
123 return
124
125 if match_multiple:
126 multiple_execution_parameters = extract_parameters_for_action_alias_db(
127 action_alias_db=action_alias_db,
128 format_str=format_str,
129 param_stream=command,
130 match_multiple=match_multiple)
131 else:
132 multiple_execution_parameters = [
133 extract_parameters_for_action_alias_db(
134 action_alias_db=action_alias_db,
135 format_str=format_str,
136 param_stream=command,
137 match_multiple=match_multiple)
138 ]
139
140 notify = self._get_notify_field(payload)
141
142 context = {
143 'action_alias_ref': reference.get_ref_from_model(action_alias_db),
144 'api_user': payload.user,
145 'user': requester_user.name,
146 }
147
148 results = []
149 for execution_parameters in multiple_execution_parameters:
150 execution = self._schedule_execution(action_alias_db=action_alias_db,
151 params=execution_parameters,
152 notify=notify,
153 context=context,
154 show_secrets=show_secrets,
155 requester_user=requester_user)
156
157 result = {
158 'execution': execution,
159 'actionalias': ActionAliasAPI.from_model(action_alias_db)
160 }
161
162 if action_alias_db.ack:
163 try:
164 if 'format' in action_alias_db.ack:
165 message = render({'alias': action_alias_db.ack['format']}, result)['alias']
166
167 result.update({
168 'message': message
169 })
170 except UndefinedError as e:
171 result.update({
172 'message': ('Cannot render "format" in field "ack" for alias. ' +
173 six.text_type(e))
174 })
175
176 try:
177 if 'extra' in action_alias_db.ack:
178 result.update({
179 'extra': render(action_alias_db.ack['extra'], result)
180 })
181 except UndefinedError as e:
182 result.update({
183 'extra': ('Cannot render "extra" in field "ack" for alias. ' +
184 six.text_type(e))
185 })
186
187 results.append(result)
188
189 return results
190
191 def post(self, payload, requester_user, show_secrets=False):
192 results = self._post(payload, requester_user, show_secrets, match_multiple=False)
193 return Response(json=results[0], status=http_client.CREATED)
194
195 def _tokenize_alias_execution(self, alias_execution):
196 tokens = alias_execution.strip().split(' ', 1)
197 return (tokens[0], tokens[1] if len(tokens) > 1 else None)
198
199 def _get_notify_field(self, payload):
200 on_complete = NotificationSubSchema()
201 route = (getattr(payload, 'notification_route', None) or
202 getattr(payload, 'notification_channel', None))
203 on_complete.routes = [route]
204 on_complete.data = {
205 'user': payload.user,
206 'source_channel': payload.source_channel,
207 'source_context': getattr(payload, 'source_context', None),
208 }
209 notify = NotificationSchema()
210 notify.on_complete = on_complete
211 return notify
212
213 def _schedule_execution(self, action_alias_db, params, notify, context, requester_user,
214 show_secrets):
215 action_ref = action_alias_db.action_ref
216 action_db = action_utils.get_action_by_ref(action_ref)
217
218 if not action_db:
219 raise StackStormDBObjectNotFoundError('Action with ref "%s" not found ' % (action_ref))
220
221 rbac_utils = get_rbac_backend().get_utils_class()
222 permission_type = PermissionType.ACTION_EXECUTE
223 rbac_utils.assert_user_has_resource_db_permission(user_db=requester_user,
224 resource_db=action_db,
225 permission_type=permission_type)
226
227 try:
228 # prior to shipping off the params cast them to the right type.
229 params = action_param_utils.cast_params(action_ref=action_alias_db.action_ref,
230 params=params,
231 cast_overrides=CAST_OVERRIDES)
232 if not context:
233 context = {
234 'action_alias_ref': reference.get_ref_from_model(action_alias_db),
235 'user': get_system_username()
236 }
237 liveaction = LiveActionDB(action=action_alias_db.action_ref, context=context,
238 parameters=params, notify=notify)
239 _, action_execution_db = action_service.request(liveaction)
240 mask_secrets = self._get_mask_secrets(requester_user, show_secrets=show_secrets)
241 return ActionExecutionAPI.from_model(action_execution_db, mask_secrets=mask_secrets)
242 except ValueError as e:
243 LOG.exception('Unable to execute action.')
244 abort(http_client.BAD_REQUEST, six.text_type(e))
245 except jsonschema.ValidationError as e:
246 LOG.exception('Unable to execute action. Parameter validation failed.')
247 abort(http_client.BAD_REQUEST, six.text_type(e))
248 except Exception as e:
249 LOG.exception('Unable to execute action. Unexpected error encountered.')
250 abort(http_client.INTERNAL_SERVER_ERROR, six.text_type(e))
251
252
253 action_alias_execution_controller = ActionAliasExecutionController()
254
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/st2api/st2api/controllers/v1/aliasexecution.py b/st2api/st2api/controllers/v1/aliasexecution.py
--- a/st2api/st2api/controllers/v1/aliasexecution.py
+++ b/st2api/st2api/controllers/v1/aliasexecution.py
@@ -143,6 +143,7 @@
'action_alias_ref': reference.get_ref_from_model(action_alias_db),
'api_user': payload.user,
'user': requester_user.name,
+ 'source_channel': payload.source_channel,
}
results = []
|
{"golden_diff": "diff --git a/st2api/st2api/controllers/v1/aliasexecution.py b/st2api/st2api/controllers/v1/aliasexecution.py\n--- a/st2api/st2api/controllers/v1/aliasexecution.py\n+++ b/st2api/st2api/controllers/v1/aliasexecution.py\n@@ -143,6 +143,7 @@\n 'action_alias_ref': reference.get_ref_from_model(action_alias_db),\n 'api_user': payload.user,\n 'user': requester_user.name,\n+ 'source_channel': payload.source_channel,\n }\n \n results = []\n", "issue": "3.0 - `source_channel` no longer working for Mistral workflows\n##### SUMMARY\r\n\r\nIn ST2 3.0, Mistral workflows no longer able to identify `source_channel` that alias was called from. \r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### STACKSTORM VERSION\r\n\r\n`st2 3.0.0, on Python 2.7.12`\r\n\r\n##### OS / ENVIRONMENT / INSTALL METHOD\r\n\r\none-liner, on Ubuntu 16.04. \r\n\r\nSystem upgraded from 2.10.4 to 3.0.0.\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\nCreate a Mistral workflow that uses `source_channel`, and call it via a Chat alias.\r\n\r\nMistral workflow [here](https://github.com/StackStorm/st2_demos/blob/master/actions/workflows/multicap.yaml#L20).\r\n\r\nAlias [here](https://github.com/StackStorm/st2_demos/blob/master/aliases/multicap.yaml).\r\n\r\nKey lines:\r\n```yaml\r\ninput:\r\n channel: \"<% env().get('__actions').get('st2.action').st2_context.parent.source_channel %>\"\r\n message: \"Setting up environment and starting captures now...{~}\"\r\non-success:\r\n```\r\n\r\n##### EXPECTED RESULTS\r\n\r\nWorkflow should post back to the original channel with my message \r\n\r\n> Setting up environment and starting captures now...\r\n\r\n##### ACTUAL RESULTS\r\n\r\nWorkflow fails, because it can't get the value of source_channel. Error similar to\r\n\r\n```\r\n\"Failed to run task [error=Can not evaluate YAQL expression [expression=env().get('__actions').get('st2.action').st2_context.parent.source_channel, error=u'source_channel', data={}], wf=st2_demos.multicap.main, task=notify_slack]:\r\n```\r\n\r\nThis stems from https://github.com/StackStorm/st2/pull/4609/files#diff-f2911a69b88d56311f8945335e9457b7L148, which is part of PR #4609. If I add that removed line back to `aliasexecution.py`, it works as expected.\r\n\r\nLooks like this data may be available in the `notify` dict.\r\n\r\n/cc @blag @m4dcoder @emptywee \n3.0 - `source_channel` no longer working for Mistral workflows\n##### SUMMARY\r\n\r\nIn ST2 3.0, Mistral workflows no longer able to identify `source_channel` that alias was called from. \r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### STACKSTORM VERSION\r\n\r\n`st2 3.0.0, on Python 2.7.12`\r\n\r\n##### OS / ENVIRONMENT / INSTALL METHOD\r\n\r\none-liner, on Ubuntu 16.04. \r\n\r\nSystem upgraded from 2.10.4 to 3.0.0.\r\n\r\n##### STEPS TO REPRODUCE\r\n\r\nCreate a Mistral workflow that uses `source_channel`, and call it via a Chat alias.\r\n\r\nMistral workflow [here](https://github.com/StackStorm/st2_demos/blob/master/actions/workflows/multicap.yaml#L20).\r\n\r\nAlias [here](https://github.com/StackStorm/st2_demos/blob/master/aliases/multicap.yaml).\r\n\r\nKey lines:\r\n```yaml\r\ninput:\r\n channel: \"<% env().get('__actions').get('st2.action').st2_context.parent.source_channel %>\"\r\n message: \"Setting up environment and starting captures now...{~}\"\r\non-success:\r\n```\r\n\r\n##### EXPECTED RESULTS\r\n\r\nWorkflow should post back to the original channel with my message \r\n\r\n> Setting up environment and starting captures now...\r\n\r\n##### ACTUAL RESULTS\r\n\r\nWorkflow fails, because it can't get the value of source_channel. Error similar to\r\n\r\n```\r\n\"Failed to run task [error=Can not evaluate YAQL expression [expression=env().get('__actions').get('st2.action').st2_context.parent.source_channel, error=u'source_channel', data={}], wf=st2_demos.multicap.main, task=notify_slack]:\r\n```\r\n\r\nThis stems from https://github.com/StackStorm/st2/pull/4609/files#diff-f2911a69b88d56311f8945335e9457b7L148, which is part of PR #4609. If I add that removed line back to `aliasexecution.py`, it works as expected.\r\n\r\nLooks like this data may be available in the `notify` dict.\r\n\r\n/cc @blag @m4dcoder @emptywee \n", "before_files": [{"content": "# Copyright 2019 Extreme Networks, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport six\nimport jsonschema\nfrom jinja2.exceptions import UndefinedError\nfrom oslo_config import cfg\n\nfrom st2api.controllers.base import BaseRestControllerMixin\nfrom st2common import log as logging\nfrom st2common.exceptions.actionalias import ActionAliasAmbiguityException\nfrom st2common.exceptions.db import StackStormDBObjectNotFoundError\nfrom st2common.models.api.action import ActionAliasAPI\nfrom st2common.models.api.action import AliasMatchAndExecuteInputAPI\nfrom st2common.models.api.auth import get_system_username\nfrom st2common.models.api.execution import ActionExecutionAPI\nfrom st2common.models.db.auth import UserDB\nfrom st2common.models.db.liveaction import LiveActionDB\nfrom st2common.models.db.notification import NotificationSchema, NotificationSubSchema\nfrom st2common.models.utils import action_param_utils\nfrom st2common.models.utils.action_alias_utils import extract_parameters_for_action_alias_db\nfrom st2common.persistence.actionalias import ActionAlias\nfrom st2common.services import action as action_service\nfrom st2common.util import action_db as action_utils\nfrom st2common.util import reference\nfrom st2common.util.actionalias_matching import get_matching_alias\nfrom st2common.util.jinja import render_values as render\nfrom st2common.rbac.types import PermissionType\nfrom st2common.rbac.backends import get_rbac_backend\nfrom st2common.router import abort\nfrom st2common.router import Response\n\nhttp_client = six.moves.http_client\n\nLOG = logging.getLogger(__name__)\n\nCAST_OVERRIDES = {\n 'array': (lambda cs_x: [v.strip() for v in cs_x.split(',')])\n}\n\n\nclass ActionAliasExecutionController(BaseRestControllerMixin):\n def match_and_execute(self, input_api, requester_user, show_secrets=False):\n \"\"\"\n Try to find a matching alias and if one is found, schedule a new\n execution by parsing parameters from the provided command against\n the matched alias.\n\n Handles requests:\n POST /aliasexecution/match_and_execute\n \"\"\"\n command = input_api.command\n\n try:\n format_ = get_matching_alias(command=command)\n except ActionAliasAmbiguityException as e:\n LOG.exception('Command \"%s\" matched (%s) patterns.', e.command, len(e.matches))\n return abort(http_client.BAD_REQUEST, six.text_type(e))\n\n action_alias_db = format_['alias']\n representation = format_['representation']\n\n params = {\n 'name': action_alias_db.name,\n 'format': representation,\n 'command': command,\n 'user': input_api.user,\n 'source_channel': input_api.source_channel,\n }\n\n # Add in any additional parameters provided by the user\n if input_api.notification_channel:\n params['notification_channel'] = input_api.notification_channel\n\n if input_api.notification_route:\n params['notification_route'] = input_api.notification_route\n\n alias_execution_api = AliasMatchAndExecuteInputAPI(**params)\n results = self._post(\n payload=alias_execution_api,\n requester_user=requester_user,\n show_secrets=show_secrets,\n match_multiple=format_['match_multiple'])\n return Response(json={'results': results}, status=http_client.CREATED)\n\n def _post(self, payload, requester_user, show_secrets=False, match_multiple=False):\n action_alias_name = payload.name if payload else None\n\n if not action_alias_name:\n abort(http_client.BAD_REQUEST, 'Alias execution \"name\" is required')\n return\n\n if not requester_user:\n requester_user = UserDB(cfg.CONF.system_user.user)\n\n format_str = payload.format or ''\n command = payload.command or ''\n\n try:\n action_alias_db = ActionAlias.get_by_name(action_alias_name)\n except ValueError:\n action_alias_db = None\n\n if not action_alias_db:\n msg = 'Unable to identify action alias with name \"%s\".' % (action_alias_name)\n abort(http_client.NOT_FOUND, msg)\n return\n\n if not action_alias_db.enabled:\n msg = 'Action alias with name \"%s\" is disabled.' % (action_alias_name)\n abort(http_client.BAD_REQUEST, msg)\n return\n\n if match_multiple:\n multiple_execution_parameters = extract_parameters_for_action_alias_db(\n action_alias_db=action_alias_db,\n format_str=format_str,\n param_stream=command,\n match_multiple=match_multiple)\n else:\n multiple_execution_parameters = [\n extract_parameters_for_action_alias_db(\n action_alias_db=action_alias_db,\n format_str=format_str,\n param_stream=command,\n match_multiple=match_multiple)\n ]\n\n notify = self._get_notify_field(payload)\n\n context = {\n 'action_alias_ref': reference.get_ref_from_model(action_alias_db),\n 'api_user': payload.user,\n 'user': requester_user.name,\n }\n\n results = []\n for execution_parameters in multiple_execution_parameters:\n execution = self._schedule_execution(action_alias_db=action_alias_db,\n params=execution_parameters,\n notify=notify,\n context=context,\n show_secrets=show_secrets,\n requester_user=requester_user)\n\n result = {\n 'execution': execution,\n 'actionalias': ActionAliasAPI.from_model(action_alias_db)\n }\n\n if action_alias_db.ack:\n try:\n if 'format' in action_alias_db.ack:\n message = render({'alias': action_alias_db.ack['format']}, result)['alias']\n\n result.update({\n 'message': message\n })\n except UndefinedError as e:\n result.update({\n 'message': ('Cannot render \"format\" in field \"ack\" for alias. ' +\n six.text_type(e))\n })\n\n try:\n if 'extra' in action_alias_db.ack:\n result.update({\n 'extra': render(action_alias_db.ack['extra'], result)\n })\n except UndefinedError as e:\n result.update({\n 'extra': ('Cannot render \"extra\" in field \"ack\" for alias. ' +\n six.text_type(e))\n })\n\n results.append(result)\n\n return results\n\n def post(self, payload, requester_user, show_secrets=False):\n results = self._post(payload, requester_user, show_secrets, match_multiple=False)\n return Response(json=results[0], status=http_client.CREATED)\n\n def _tokenize_alias_execution(self, alias_execution):\n tokens = alias_execution.strip().split(' ', 1)\n return (tokens[0], tokens[1] if len(tokens) > 1 else None)\n\n def _get_notify_field(self, payload):\n on_complete = NotificationSubSchema()\n route = (getattr(payload, 'notification_route', None) or\n getattr(payload, 'notification_channel', None))\n on_complete.routes = [route]\n on_complete.data = {\n 'user': payload.user,\n 'source_channel': payload.source_channel,\n 'source_context': getattr(payload, 'source_context', None),\n }\n notify = NotificationSchema()\n notify.on_complete = on_complete\n return notify\n\n def _schedule_execution(self, action_alias_db, params, notify, context, requester_user,\n show_secrets):\n action_ref = action_alias_db.action_ref\n action_db = action_utils.get_action_by_ref(action_ref)\n\n if not action_db:\n raise StackStormDBObjectNotFoundError('Action with ref \"%s\" not found ' % (action_ref))\n\n rbac_utils = get_rbac_backend().get_utils_class()\n permission_type = PermissionType.ACTION_EXECUTE\n rbac_utils.assert_user_has_resource_db_permission(user_db=requester_user,\n resource_db=action_db,\n permission_type=permission_type)\n\n try:\n # prior to shipping off the params cast them to the right type.\n params = action_param_utils.cast_params(action_ref=action_alias_db.action_ref,\n params=params,\n cast_overrides=CAST_OVERRIDES)\n if not context:\n context = {\n 'action_alias_ref': reference.get_ref_from_model(action_alias_db),\n 'user': get_system_username()\n }\n liveaction = LiveActionDB(action=action_alias_db.action_ref, context=context,\n parameters=params, notify=notify)\n _, action_execution_db = action_service.request(liveaction)\n mask_secrets = self._get_mask_secrets(requester_user, show_secrets=show_secrets)\n return ActionExecutionAPI.from_model(action_execution_db, mask_secrets=mask_secrets)\n except ValueError as e:\n LOG.exception('Unable to execute action.')\n abort(http_client.BAD_REQUEST, six.text_type(e))\n except jsonschema.ValidationError as e:\n LOG.exception('Unable to execute action. Parameter validation failed.')\n abort(http_client.BAD_REQUEST, six.text_type(e))\n except Exception as e:\n LOG.exception('Unable to execute action. Unexpected error encountered.')\n abort(http_client.INTERNAL_SERVER_ERROR, six.text_type(e))\n\n\naction_alias_execution_controller = ActionAliasExecutionController()\n", "path": "st2api/st2api/controllers/v1/aliasexecution.py"}], "after_files": [{"content": "# Copyright 2019 Extreme Networks, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport six\nimport jsonschema\nfrom jinja2.exceptions import UndefinedError\nfrom oslo_config import cfg\n\nfrom st2api.controllers.base import BaseRestControllerMixin\nfrom st2common import log as logging\nfrom st2common.exceptions.actionalias import ActionAliasAmbiguityException\nfrom st2common.exceptions.db import StackStormDBObjectNotFoundError\nfrom st2common.models.api.action import ActionAliasAPI\nfrom st2common.models.api.action import AliasMatchAndExecuteInputAPI\nfrom st2common.models.api.auth import get_system_username\nfrom st2common.models.api.execution import ActionExecutionAPI\nfrom st2common.models.db.auth import UserDB\nfrom st2common.models.db.liveaction import LiveActionDB\nfrom st2common.models.db.notification import NotificationSchema, NotificationSubSchema\nfrom st2common.models.utils import action_param_utils\nfrom st2common.models.utils.action_alias_utils import extract_parameters_for_action_alias_db\nfrom st2common.persistence.actionalias import ActionAlias\nfrom st2common.services import action as action_service\nfrom st2common.util import action_db as action_utils\nfrom st2common.util import reference\nfrom st2common.util.actionalias_matching import get_matching_alias\nfrom st2common.util.jinja import render_values as render\nfrom st2common.rbac.types import PermissionType\nfrom st2common.rbac.backends import get_rbac_backend\nfrom st2common.router import abort\nfrom st2common.router import Response\n\nhttp_client = six.moves.http_client\n\nLOG = logging.getLogger(__name__)\n\nCAST_OVERRIDES = {\n 'array': (lambda cs_x: [v.strip() for v in cs_x.split(',')])\n}\n\n\nclass ActionAliasExecutionController(BaseRestControllerMixin):\n def match_and_execute(self, input_api, requester_user, show_secrets=False):\n \"\"\"\n Try to find a matching alias and if one is found, schedule a new\n execution by parsing parameters from the provided command against\n the matched alias.\n\n Handles requests:\n POST /aliasexecution/match_and_execute\n \"\"\"\n command = input_api.command\n\n try:\n format_ = get_matching_alias(command=command)\n except ActionAliasAmbiguityException as e:\n LOG.exception('Command \"%s\" matched (%s) patterns.', e.command, len(e.matches))\n return abort(http_client.BAD_REQUEST, six.text_type(e))\n\n action_alias_db = format_['alias']\n representation = format_['representation']\n\n params = {\n 'name': action_alias_db.name,\n 'format': representation,\n 'command': command,\n 'user': input_api.user,\n 'source_channel': input_api.source_channel,\n }\n\n # Add in any additional parameters provided by the user\n if input_api.notification_channel:\n params['notification_channel'] = input_api.notification_channel\n\n if input_api.notification_route:\n params['notification_route'] = input_api.notification_route\n\n alias_execution_api = AliasMatchAndExecuteInputAPI(**params)\n results = self._post(\n payload=alias_execution_api,\n requester_user=requester_user,\n show_secrets=show_secrets,\n match_multiple=format_['match_multiple'])\n return Response(json={'results': results}, status=http_client.CREATED)\n\n def _post(self, payload, requester_user, show_secrets=False, match_multiple=False):\n action_alias_name = payload.name if payload else None\n\n if not action_alias_name:\n abort(http_client.BAD_REQUEST, 'Alias execution \"name\" is required')\n return\n\n if not requester_user:\n requester_user = UserDB(cfg.CONF.system_user.user)\n\n format_str = payload.format or ''\n command = payload.command or ''\n\n try:\n action_alias_db = ActionAlias.get_by_name(action_alias_name)\n except ValueError:\n action_alias_db = None\n\n if not action_alias_db:\n msg = 'Unable to identify action alias with name \"%s\".' % (action_alias_name)\n abort(http_client.NOT_FOUND, msg)\n return\n\n if not action_alias_db.enabled:\n msg = 'Action alias with name \"%s\" is disabled.' % (action_alias_name)\n abort(http_client.BAD_REQUEST, msg)\n return\n\n if match_multiple:\n multiple_execution_parameters = extract_parameters_for_action_alias_db(\n action_alias_db=action_alias_db,\n format_str=format_str,\n param_stream=command,\n match_multiple=match_multiple)\n else:\n multiple_execution_parameters = [\n extract_parameters_for_action_alias_db(\n action_alias_db=action_alias_db,\n format_str=format_str,\n param_stream=command,\n match_multiple=match_multiple)\n ]\n\n notify = self._get_notify_field(payload)\n\n context = {\n 'action_alias_ref': reference.get_ref_from_model(action_alias_db),\n 'api_user': payload.user,\n 'user': requester_user.name,\n 'source_channel': payload.source_channel,\n }\n\n results = []\n for execution_parameters in multiple_execution_parameters:\n execution = self._schedule_execution(action_alias_db=action_alias_db,\n params=execution_parameters,\n notify=notify,\n context=context,\n show_secrets=show_secrets,\n requester_user=requester_user)\n\n result = {\n 'execution': execution,\n 'actionalias': ActionAliasAPI.from_model(action_alias_db)\n }\n\n if action_alias_db.ack:\n try:\n if 'format' in action_alias_db.ack:\n message = render({'alias': action_alias_db.ack['format']}, result)['alias']\n\n result.update({\n 'message': message\n })\n except UndefinedError as e:\n result.update({\n 'message': ('Cannot render \"format\" in field \"ack\" for alias. ' +\n six.text_type(e))\n })\n\n try:\n if 'extra' in action_alias_db.ack:\n result.update({\n 'extra': render(action_alias_db.ack['extra'], result)\n })\n except UndefinedError as e:\n result.update({\n 'extra': ('Cannot render \"extra\" in field \"ack\" for alias. ' +\n six.text_type(e))\n })\n\n results.append(result)\n\n return results\n\n def post(self, payload, requester_user, show_secrets=False):\n results = self._post(payload, requester_user, show_secrets, match_multiple=False)\n return Response(json=results[0], status=http_client.CREATED)\n\n def _tokenize_alias_execution(self, alias_execution):\n tokens = alias_execution.strip().split(' ', 1)\n return (tokens[0], tokens[1] if len(tokens) > 1 else None)\n\n def _get_notify_field(self, payload):\n on_complete = NotificationSubSchema()\n route = (getattr(payload, 'notification_route', None) or\n getattr(payload, 'notification_channel', None))\n on_complete.routes = [route]\n on_complete.data = {\n 'user': payload.user,\n 'source_channel': payload.source_channel,\n 'source_context': getattr(payload, 'source_context', None),\n }\n notify = NotificationSchema()\n notify.on_complete = on_complete\n return notify\n\n def _schedule_execution(self, action_alias_db, params, notify, context, requester_user,\n show_secrets):\n action_ref = action_alias_db.action_ref\n action_db = action_utils.get_action_by_ref(action_ref)\n\n if not action_db:\n raise StackStormDBObjectNotFoundError('Action with ref \"%s\" not found ' % (action_ref))\n\n rbac_utils = get_rbac_backend().get_utils_class()\n permission_type = PermissionType.ACTION_EXECUTE\n rbac_utils.assert_user_has_resource_db_permission(user_db=requester_user,\n resource_db=action_db,\n permission_type=permission_type)\n\n try:\n # prior to shipping off the params cast them to the right type.\n params = action_param_utils.cast_params(action_ref=action_alias_db.action_ref,\n params=params,\n cast_overrides=CAST_OVERRIDES)\n if not context:\n context = {\n 'action_alias_ref': reference.get_ref_from_model(action_alias_db),\n 'user': get_system_username()\n }\n liveaction = LiveActionDB(action=action_alias_db.action_ref, context=context,\n parameters=params, notify=notify)\n _, action_execution_db = action_service.request(liveaction)\n mask_secrets = self._get_mask_secrets(requester_user, show_secrets=show_secrets)\n return ActionExecutionAPI.from_model(action_execution_db, mask_secrets=mask_secrets)\n except ValueError as e:\n LOG.exception('Unable to execute action.')\n abort(http_client.BAD_REQUEST, six.text_type(e))\n except jsonschema.ValidationError as e:\n LOG.exception('Unable to execute action. Parameter validation failed.')\n abort(http_client.BAD_REQUEST, six.text_type(e))\n except Exception as e:\n LOG.exception('Unable to execute action. Unexpected error encountered.')\n abort(http_client.INTERNAL_SERVER_ERROR, six.text_type(e))\n\n\naction_alias_execution_controller = ActionAliasExecutionController()\n", "path": "st2api/st2api/controllers/v1/aliasexecution.py"}]}
| 3,938 | 126 |
gh_patches_debug_22919
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-959
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
make docs recipe is failing
`make docs` recipe is failing due to an invalid reference on `docs/core/resource.rst`. It produces just a warning, but `sphinx-build` is set with `-W` flag to treat it as an error.
```
> make docs
.venv/bin/sphinx-build -a -W -n -b html -d docs/_build/doctrees docs docs/_build/html
Running Sphinx v1.4.8
loading pickled environment... not yet created
loading intersphinx inventory from https://colander.readthedocs.io/en/latest/objects.inv...
loading intersphinx inventory from https://pyramid.readthedocs.io/en/latest/objects.inv...
loading intersphinx inventory from https://cornice.readthedocs.io/en/latest/objects.inv...
building [mo]: all of 0 po files
building [html]: all source files
updating environment: 73 added, 0 changed, 0 removed
reading sources... [100%] tutorials/write-plugin
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
preparing documents... done
writing output... [100%] tutorials/write-plugin
Warning, treated as error:
kinto/docs/core/resource.rst:30: WARNING: py:class reference target not found: ResourceSchema
Makefile:130: recipe for target 'docs' failed
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Kinto documentation build configuration file, created by
4 # sphinx-quickstart on Mon Feb 2 15:08:06 2015.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import os
16 import sys
17
18 __HERE__ = os.path.dirname(os.path.abspath(__file__))
19
20 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
21
22 if not on_rtd: # only import and set the theme if we're building docs locally
23 import sphinx_rtd_theme
24 html_theme = 'sphinx_rtd_theme'
25 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
26
27 # otherwise, readthedocs.io uses their theme by default, so no need to specify
28 # it
29
30 # If extensions (or modules to document with autodoc) are in another directory,
31 # add these directories to sys.path here. If the directory is relative to the
32 # documentation root, use os.path.abspath to make it absolute, like shown here.
33 sys.path.insert(0, os.path.abspath(os.path.join('..')))
34
35 # -- General configuration ------------------------------------------------
36
37 # If your documentation needs a minimal Sphinx version, state it here.
38 # needs_sphinx = '1.0'
39
40 # Add any Sphinx extension module names here, as strings. They can be
41 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
42 # ones.
43 extensions = [
44 'sphinx.ext.autodoc',
45 'sphinxcontrib.httpdomain',
46 'sphinx.ext.extlinks',
47 'sphinx.ext.intersphinx',
48 ]
49
50 # Add any paths that contain templates here, relative to this directory.
51 templates_path = ['_templates']
52 html_additional_pages = {
53 'index': 'indexcontent.html',
54 }
55
56
57 # The suffix of source filenames.
58 source_suffix = '.rst'
59
60 # The encoding of source files.
61 # source_encoding = 'utf-8-sig'
62
63 # The master toctree document.
64 master_doc = 'index'
65
66 # General information about the project.
67 project = u'Kinto'
68 copyright = u'2015-2016 — Mozilla Services'
69
70 # The version info for the project you're documenting, acts as replacement for
71 # |version| and |release|, also used in various other places throughout the
72 # built documents.
73 #
74 # The short X.Y version.
75 version = '5.0'
76 # The full version, including alpha/beta/rc tags.
77 release = '5.0.0'
78
79 # List of patterns, relative to source directory, that match files and
80 # directories to ignore when looking for source files.
81 exclude_patterns = ['_build']
82
83 # The name of the Pygments (syntax highlighting) style to use.
84 pygments_style = 'sphinx'
85
86 # Add any paths that contain custom static files (such as style sheets) here,
87 # relative to this directory. They are copied after the builtin static files,
88 # so a file named "default.css" will overwrite the builtin "default.css".
89 html_static_path = ['_static']
90
91 # Output file base name for HTML help builder.
92 htmlhelp_basename = 'Kintodoc'
93
94
95 # -- Options for autodoc --------------------------------------------------
96
97 autodoc_member_order = 'bysource'
98 # Enable nitpicky mode - which ensures that all references in the docs
99 # resolve.
100 nitpicky = True
101 nitpick_ignore = [
102 ('py:obj', 'bool'),
103 ('py:obj', 'Exception'),
104 ('py:obj', 'int'),
105 ('py:obj', 'str'),
106 ('py:obj', 'dict'),
107 ('py:obj', 'list'),
108 ('py:obj', 'tuple'),
109 ('py:obj', 'float'),
110 ('py:obj', 'cornice.Service'),
111 # Member autodoc fails with those:
112 # kinto.core.resource.schema
113 ('py:class', 'Integer'),
114 ('py:class', 'String'),
115 # kinto.core.resource
116 ('py:class', 'ViewSet'),
117 ('py:class', 'ShareableViewSet'),
118 ('py:class', 'Model'),
119 ('py:class', 'ShareableModel'),
120 ]
121
122
123 # -- Options of extlinks --------------------------------------------------
124
125 extlinks = {
126 'github': ('https://github.com/%s/', ''),
127 'rtd': ('https://%s.readthedocs.io', ''),
128 'blog': ('http://www.servicedenuages.fr/%s', '')
129 }
130
131
132 # -- Substitutions
133
134 rst_epilog = """
135 .. |status-200| replace:: ``200 OK``
136 .. |status-201| replace:: ``201 Created``
137 .. |status-304| replace:: ``304 Not Modified``
138 .. |status-400| replace:: ``400 Bad Request``
139 .. |status-401| replace:: ``401 Unauthorized``
140 .. |status-403| replace:: ``403 Forbidden``
141 .. |status-404| replace:: ``404 Not Found``
142 .. |status-405| replace:: ``405 Method Not Allowed``
143 .. |status-406| replace:: ``406 Not Acceptable``
144 .. |status-409| replace:: ``409 Conflict``
145 .. |status-410| replace:: ``410 Gone``
146 .. |status-412| replace:: ``412 Precondition Failed``
147 .. |status-415| replace:: ``415 Unsupported Media Type``
148 .. |status-503| replace:: ``503 Service Unavailable``
149 """
150
151 # --
152
153 def setup(app):
154 # path relative to _static
155 app.add_stylesheet('theme_overrides.css')
156 app.add_javascript('piwik.js')
157
158
159 # -- Options for intersphinx --------------------------------------------------
160
161 intersphinx_mapping = {
162 'colander': ('https://colander.readthedocs.io/en/latest/', None),
163 'cornice': ('https://cornice.readthedocs.io/en/latest/', None),
164 'pyramid': ('https://pyramid.readthedocs.io/en/latest/', None)
165 }
166
167 # -- Options for LaTeX output ---------------------------------------------
168
169 latex_elements = {}
170
171 # Grouping the document tree into LaTeX files. List of tuples
172 # (source start file, target name, title,
173 # author, documentclass [howto, manual, or own class]).
174 latex_documents = [
175 ('index', 'Kinto.tex', u'Kinto Documentation',
176 u'Mozilla Services — Da French Team', 'manual'),
177 ]
178
179
180 # -- Options for manual page output ---------------------------------------
181
182 # One entry per manual page. List of tuples
183 # (source start file, name, description, authors, manual section).
184 man_pages = [
185 ('index', 'kinto', u'Kinto Documentation',
186 [u'Mozilla Services — Da French Team'], 1)
187 ]
188
189
190 # -- Options for Texinfo output -------------------------------------------
191
192 # Grouping the document tree into Texinfo files. List of tuples
193 # (source start file, target name, title, author,
194 # dir menu entry, description, category)
195 texinfo_documents = [
196 ('index', 'Kinto', u'Kinto Documentation',
197 u'Mozilla Services — Da French Team', 'Kinto',
198 'A remote storage service with syncing and sharing abilities.',
199 'Miscellaneous'),
200 ]
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -97,26 +97,28 @@
autodoc_member_order = 'bysource'
# Enable nitpicky mode - which ensures that all references in the docs
# resolve.
+# See: http://stackoverflow.com/a/30624034/186202
nitpicky = True
nitpick_ignore = [
- ('py:obj', 'bool'),
('py:obj', 'Exception'),
- ('py:obj', 'int'),
- ('py:obj', 'str'),
+ ('py:obj', 'bool'),
('py:obj', 'dict'),
+ ('py:obj', 'float'),
+ ('py:obj', 'int'),
('py:obj', 'list'),
+ ('py:obj', 'str'),
('py:obj', 'tuple'),
- ('py:obj', 'float'),
('py:obj', 'cornice.Service'),
# Member autodoc fails with those:
# kinto.core.resource.schema
('py:class', 'Integer'),
('py:class', 'String'),
# kinto.core.resource
- ('py:class', 'ViewSet'),
- ('py:class', 'ShareableViewSet'),
('py:class', 'Model'),
+ ('py:class', 'ResourceSchema'),
('py:class', 'ShareableModel'),
+ ('py:class', 'ShareableViewSet'),
+ ('py:class', 'ViewSet'),
]
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -97,26 +97,28 @@\n autodoc_member_order = 'bysource'\n # Enable nitpicky mode - which ensures that all references in the docs\n # resolve.\n+# See: http://stackoverflow.com/a/30624034/186202\n nitpicky = True\n nitpick_ignore = [\n- ('py:obj', 'bool'),\n ('py:obj', 'Exception'),\n- ('py:obj', 'int'),\n- ('py:obj', 'str'),\n+ ('py:obj', 'bool'),\n ('py:obj', 'dict'),\n+ ('py:obj', 'float'),\n+ ('py:obj', 'int'),\n ('py:obj', 'list'),\n+ ('py:obj', 'str'),\n ('py:obj', 'tuple'),\n- ('py:obj', 'float'),\n ('py:obj', 'cornice.Service'),\n # Member autodoc fails with those:\n # kinto.core.resource.schema\n ('py:class', 'Integer'),\n ('py:class', 'String'),\n # kinto.core.resource\n- ('py:class', 'ViewSet'),\n- ('py:class', 'ShareableViewSet'),\n ('py:class', 'Model'),\n+ ('py:class', 'ResourceSchema'),\n ('py:class', 'ShareableModel'),\n+ ('py:class', 'ShareableViewSet'),\n+ ('py:class', 'ViewSet'),\n ]\n", "issue": "make docs recipe is failing\n`make docs` recipe is failing due to an invalid reference on `docs/core/resource.rst`. It produces just a warning, but `sphinx-build` is set with `-W` flag to treat it as an error. \r\n\r\n```\r\n> make docs \r\n.venv/bin/sphinx-build -a -W -n -b html -d docs/_build/doctrees docs docs/_build/html\r\nRunning Sphinx v1.4.8\r\nloading pickled environment... not yet created\r\nloading intersphinx inventory from https://colander.readthedocs.io/en/latest/objects.inv...\r\nloading intersphinx inventory from https://pyramid.readthedocs.io/en/latest/objects.inv...\r\nloading intersphinx inventory from https://cornice.readthedocs.io/en/latest/objects.inv...\r\nbuilding [mo]: all of 0 po files\r\nbuilding [html]: all source files\r\nupdating environment: 73 added, 0 changed, 0 removed\r\nreading sources... [100%] tutorials/write-plugin \r\nlooking for now-outdated files... none found\r\npickling environment... done\r\nchecking consistency... done\r\npreparing documents... done\r\nwriting output... [100%] tutorials/write-plugin \r\n\r\nWarning, treated as error:\r\nkinto/docs/core/resource.rst:30: WARNING: py:class reference target not found: ResourceSchema\r\n\r\nMakefile:130: recipe for target 'docs' failed\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Kinto documentation build configuration file, created by\n# sphinx-quickstart on Mon Feb 2 15:08:06 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\n\n__HERE__ = os.path.dirname(os.path.abspath(__file__))\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# otherwise, readthedocs.io uses their theme by default, so no need to specify\n# it\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath(os.path.join('..')))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinxcontrib.httpdomain',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.intersphinx',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\nhtml_additional_pages = {\n 'index': 'indexcontent.html',\n}\n\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Kinto'\ncopyright = u'2015-2016 \u2014 Mozilla Services'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '5.0'\n# The full version, including alpha/beta/rc tags.\nrelease = '5.0.0'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Kintodoc'\n\n\n# -- Options for autodoc --------------------------------------------------\n\nautodoc_member_order = 'bysource'\n# Enable nitpicky mode - which ensures that all references in the docs\n# resolve.\nnitpicky = True\nnitpick_ignore = [\n ('py:obj', 'bool'),\n ('py:obj', 'Exception'),\n ('py:obj', 'int'),\n ('py:obj', 'str'),\n ('py:obj', 'dict'),\n ('py:obj', 'list'),\n ('py:obj', 'tuple'),\n ('py:obj', 'float'),\n ('py:obj', 'cornice.Service'),\n # Member autodoc fails with those:\n # kinto.core.resource.schema\n ('py:class', 'Integer'),\n ('py:class', 'String'),\n # kinto.core.resource\n ('py:class', 'ViewSet'),\n ('py:class', 'ShareableViewSet'),\n ('py:class', 'Model'),\n ('py:class', 'ShareableModel'),\n]\n\n\n# -- Options of extlinks --------------------------------------------------\n\nextlinks = {\n 'github': ('https://github.com/%s/', ''),\n 'rtd': ('https://%s.readthedocs.io', ''),\n 'blog': ('http://www.servicedenuages.fr/%s', '')\n}\n\n\n# -- Substitutions\n\nrst_epilog = \"\"\"\n.. |status-200| replace:: ``200 OK``\n.. |status-201| replace:: ``201 Created``\n.. |status-304| replace:: ``304 Not Modified``\n.. |status-400| replace:: ``400 Bad Request``\n.. |status-401| replace:: ``401 Unauthorized``\n.. |status-403| replace:: ``403 Forbidden``\n.. |status-404| replace:: ``404 Not Found``\n.. |status-405| replace:: ``405 Method Not Allowed``\n.. |status-406| replace:: ``406 Not Acceptable``\n.. |status-409| replace:: ``409 Conflict``\n.. |status-410| replace:: ``410 Gone``\n.. |status-412| replace:: ``412 Precondition Failed``\n.. |status-415| replace:: ``415 Unsupported Media Type``\n.. |status-503| replace:: ``503 Service Unavailable``\n\"\"\"\n\n# --\n\ndef setup(app):\n # path relative to _static\n app.add_stylesheet('theme_overrides.css')\n app.add_javascript('piwik.js')\n\n\n# -- Options for intersphinx --------------------------------------------------\n\nintersphinx_mapping = {\n 'colander': ('https://colander.readthedocs.io/en/latest/', None),\n 'cornice': ('https://cornice.readthedocs.io/en/latest/', None),\n 'pyramid': ('https://pyramid.readthedocs.io/en/latest/', None)\n}\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n ('index', 'Kinto.tex', u'Kinto Documentation',\n u'Mozilla Services \u2014 Da French Team', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'kinto', u'Kinto Documentation',\n [u'Mozilla Services \u2014 Da French Team'], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Kinto', u'Kinto Documentation',\n u'Mozilla Services \u2014 Da French Team', 'Kinto',\n 'A remote storage service with syncing and sharing abilities.',\n 'Miscellaneous'),\n]\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Kinto documentation build configuration file, created by\n# sphinx-quickstart on Mon Feb 2 15:08:06 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\n\n__HERE__ = os.path.dirname(os.path.abspath(__file__))\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# otherwise, readthedocs.io uses their theme by default, so no need to specify\n# it\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath(os.path.join('..')))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinxcontrib.httpdomain',\n 'sphinx.ext.extlinks',\n 'sphinx.ext.intersphinx',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\nhtml_additional_pages = {\n 'index': 'indexcontent.html',\n}\n\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Kinto'\ncopyright = u'2015-2016 \u2014 Mozilla Services'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '5.0'\n# The full version, including alpha/beta/rc tags.\nrelease = '5.0.0'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Kintodoc'\n\n\n# -- Options for autodoc --------------------------------------------------\n\nautodoc_member_order = 'bysource'\n# Enable nitpicky mode - which ensures that all references in the docs\n# resolve.\n# See: http://stackoverflow.com/a/30624034/186202\nnitpicky = True\nnitpick_ignore = [\n ('py:obj', 'Exception'),\n ('py:obj', 'bool'),\n ('py:obj', 'dict'),\n ('py:obj', 'float'),\n ('py:obj', 'int'),\n ('py:obj', 'list'),\n ('py:obj', 'str'),\n ('py:obj', 'tuple'),\n ('py:obj', 'cornice.Service'),\n # Member autodoc fails with those:\n # kinto.core.resource.schema\n ('py:class', 'Integer'),\n ('py:class', 'String'),\n # kinto.core.resource\n ('py:class', 'Model'),\n ('py:class', 'ResourceSchema'),\n ('py:class', 'ShareableModel'),\n ('py:class', 'ShareableViewSet'),\n ('py:class', 'ViewSet'),\n]\n\n\n# -- Options of extlinks --------------------------------------------------\n\nextlinks = {\n 'github': ('https://github.com/%s/', ''),\n 'rtd': ('https://%s.readthedocs.io', ''),\n 'blog': ('http://www.servicedenuages.fr/%s', '')\n}\n\n\n# -- Substitutions\n\nrst_epilog = \"\"\"\n.. |status-200| replace:: ``200 OK``\n.. |status-201| replace:: ``201 Created``\n.. |status-304| replace:: ``304 Not Modified``\n.. |status-400| replace:: ``400 Bad Request``\n.. |status-401| replace:: ``401 Unauthorized``\n.. |status-403| replace:: ``403 Forbidden``\n.. |status-404| replace:: ``404 Not Found``\n.. |status-405| replace:: ``405 Method Not Allowed``\n.. |status-406| replace:: ``406 Not Acceptable``\n.. |status-409| replace:: ``409 Conflict``\n.. |status-410| replace:: ``410 Gone``\n.. |status-412| replace:: ``412 Precondition Failed``\n.. |status-415| replace:: ``415 Unsupported Media Type``\n.. |status-503| replace:: ``503 Service Unavailable``\n\"\"\"\n\n# --\n\ndef setup(app):\n # path relative to _static\n app.add_stylesheet('theme_overrides.css')\n app.add_javascript('piwik.js')\n\n\n# -- Options for intersphinx --------------------------------------------------\n\nintersphinx_mapping = {\n 'colander': ('https://colander.readthedocs.io/en/latest/', None),\n 'cornice': ('https://cornice.readthedocs.io/en/latest/', None),\n 'pyramid': ('https://pyramid.readthedocs.io/en/latest/', None)\n}\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n ('index', 'Kinto.tex', u'Kinto Documentation',\n u'Mozilla Services \u2014 Da French Team', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'kinto', u'Kinto Documentation',\n [u'Mozilla Services \u2014 Da French Team'], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Kinto', u'Kinto Documentation',\n u'Mozilla Services \u2014 Da French Team', 'Kinto',\n 'A remote storage service with syncing and sharing abilities.',\n 'Miscellaneous'),\n]\n", "path": "docs/conf.py"}]}
| 2,683 | 341 |
gh_patches_debug_30001
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-5722
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[plugin] Regression: Webhook Test Button
Somehow during transfer to the new plugin architecture, the webhook plugin's Test button has disappeared.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/api/endpoints/project_plugin_details.py`
Content:
```
1 from __future__ import absolute_import
2
3 import six
4
5 from django import forms
6 from django.core.urlresolvers import reverse
7 from rest_framework import serializers
8 from rest_framework.response import Response
9
10 from sentry.exceptions import PluginError, PluginIdentityRequired
11 from sentry.plugins import plugins
12 from sentry.api.bases.project import ProjectEndpoint
13 from sentry.api.exceptions import ResourceDoesNotExist
14 from sentry.api.serializers import serialize
15 from sentry.api.serializers.models.plugin import (
16 PluginSerializer, PluginWithConfigSerializer, serialize_field
17 )
18 from sentry.signals import plugin_enabled
19
20 ERR_ALWAYS_ENABLED = 'This plugin is always enabled.'
21 ERR_FIELD_REQUIRED = 'This field is required.'
22
23 OK_UPDATED = 'Successfully updated configuration.'
24
25
26 class ProjectPluginDetailsEndpoint(ProjectEndpoint):
27 def _get_plugin(self, plugin_id):
28 try:
29 return plugins.get(plugin_id)
30 except KeyError:
31 raise ResourceDoesNotExist
32
33 def get(self, request, project, plugin_id):
34 plugin = self._get_plugin(plugin_id)
35
36 try:
37 context = serialize(plugin, request.user, PluginWithConfigSerializer(project))
38 except PluginIdentityRequired as e:
39 context = serialize(plugin, request.user, PluginSerializer(project))
40 context['config_error'] = e.message
41 context['auth_url'] = reverse('socialauth_associate', args=[plugin.slug])
42
43 return Response(context)
44
45 def post(self, request, project, plugin_id):
46 """
47 Enable plugin
48 """
49 plugin = self._get_plugin(plugin_id)
50
51 if not plugin.can_disable:
52 return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)
53
54 plugin.enable(project)
55
56 return Response(status=201)
57
58 def delete(self, request, project, plugin_id):
59 """
60 Disable plugin
61 """
62 plugin = self._get_plugin(plugin_id)
63
64 if not plugin.can_disable:
65 return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)
66
67 plugin.disable(project)
68
69 return Response(status=204)
70
71 def put(self, request, project, plugin_id):
72 plugin = self._get_plugin(plugin_id)
73
74 config = [
75 serialize_field(project, plugin, c)
76 for c in plugin.get_config(
77 project=project,
78 user=request.user,
79 )
80 ]
81
82 cleaned = {}
83 errors = {}
84 for field in config:
85 key = field['name']
86 value = request.DATA.get(key)
87
88 if field.get('required') and not value:
89 errors[key] = ERR_FIELD_REQUIRED
90
91 try:
92 value = plugin.validate_config_field(
93 project=project,
94 name=key,
95 value=value,
96 actor=request.user,
97 )
98 except (forms.ValidationError, serializers.ValidationError, PluginError) as e:
99 errors[key] = e.message
100
101 if not errors.get(key):
102 cleaned[key] = value
103
104 if not errors:
105 try:
106 cleaned = plugin.validate_config(
107 project=project,
108 config=cleaned,
109 actor=request.user,
110 )
111 except PluginError as e:
112 errors['__all__'] = e.message
113
114 if errors:
115 return Response(
116 {
117 'errors': errors,
118 }, status=400
119 )
120
121 for key, value in six.iteritems(cleaned):
122 if value is None:
123 plugin.unset_option(
124 project=project,
125 key=key,
126 )
127 else:
128 plugin.set_option(
129 project=project,
130 key=key,
131 value=value,
132 )
133
134 context = serialize(plugin, request.user, PluginWithConfigSerializer(project))
135
136 plugin_enabled.send(plugin=plugin, project=project, user=request.user, sender=self)
137
138 return Response(context)
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/sentry/api/endpoints/project_plugin_details.py b/src/sentry/api/endpoints/project_plugin_details.py
--- a/src/sentry/api/endpoints/project_plugin_details.py
+++ b/src/sentry/api/endpoints/project_plugin_details.py
@@ -1,11 +1,13 @@
from __future__ import absolute_import
+import logging
import six
from django import forms
from django.core.urlresolvers import reverse
from rest_framework import serializers
from rest_framework.response import Response
+from requests.exceptions import HTTPError
from sentry.exceptions import PluginError, PluginIdentityRequired
from sentry.plugins import plugins
@@ -44,10 +46,26 @@
def post(self, request, project, plugin_id):
"""
- Enable plugin
+ Enable plugin or Test plugin
"""
plugin = self._get_plugin(plugin_id)
+ if request.DATA.get('test') and plugin.is_testable():
+ try:
+ test_results = plugin.test_configuration(project)
+ except Exception as exc:
+ if isinstance(exc, HTTPError):
+ test_results = '%s\n%s' % (exc, exc.response.text[:256])
+ elif hasattr(exc, 'read') and callable(exc.read):
+ test_results = '%s\n%s' % (exc, exc.read()[:256])
+ else:
+ logging.exception('Plugin(%s) raised an error during test',
+ plugin_id)
+ test_results = 'There was an internal error with the Plugin'
+ if not test_results:
+ test_results = 'No errors returned'
+ return Response({'detail': test_results}, status=200)
+
if not plugin.can_disable:
return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)
|
{"golden_diff": "diff --git a/src/sentry/api/endpoints/project_plugin_details.py b/src/sentry/api/endpoints/project_plugin_details.py\n--- a/src/sentry/api/endpoints/project_plugin_details.py\n+++ b/src/sentry/api/endpoints/project_plugin_details.py\n@@ -1,11 +1,13 @@\n from __future__ import absolute_import\n \n+import logging\n import six\n \n from django import forms\n from django.core.urlresolvers import reverse\n from rest_framework import serializers\n from rest_framework.response import Response\n+from requests.exceptions import HTTPError\n \n from sentry.exceptions import PluginError, PluginIdentityRequired\n from sentry.plugins import plugins\n@@ -44,10 +46,26 @@\n \n def post(self, request, project, plugin_id):\n \"\"\"\n- Enable plugin\n+ Enable plugin or Test plugin\n \"\"\"\n plugin = self._get_plugin(plugin_id)\n \n+ if request.DATA.get('test') and plugin.is_testable():\n+ try:\n+ test_results = plugin.test_configuration(project)\n+ except Exception as exc:\n+ if isinstance(exc, HTTPError):\n+ test_results = '%s\\n%s' % (exc, exc.response.text[:256])\n+ elif hasattr(exc, 'read') and callable(exc.read):\n+ test_results = '%s\\n%s' % (exc, exc.read()[:256])\n+ else:\n+ logging.exception('Plugin(%s) raised an error during test',\n+ plugin_id)\n+ test_results = 'There was an internal error with the Plugin'\n+ if not test_results:\n+ test_results = 'No errors returned'\n+ return Response({'detail': test_results}, status=200)\n+\n if not plugin.can_disable:\n return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)\n", "issue": "[plugin] Regression: Webhook Test Button\nSomehow during transfer to the new plugin architecture, the webhook plugin's Test button has disappeared.\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport six\n\nfrom django import forms\nfrom django.core.urlresolvers import reverse\nfrom rest_framework import serializers\nfrom rest_framework.response import Response\n\nfrom sentry.exceptions import PluginError, PluginIdentityRequired\nfrom sentry.plugins import plugins\nfrom sentry.api.bases.project import ProjectEndpoint\nfrom sentry.api.exceptions import ResourceDoesNotExist\nfrom sentry.api.serializers import serialize\nfrom sentry.api.serializers.models.plugin import (\n PluginSerializer, PluginWithConfigSerializer, serialize_field\n)\nfrom sentry.signals import plugin_enabled\n\nERR_ALWAYS_ENABLED = 'This plugin is always enabled.'\nERR_FIELD_REQUIRED = 'This field is required.'\n\nOK_UPDATED = 'Successfully updated configuration.'\n\n\nclass ProjectPluginDetailsEndpoint(ProjectEndpoint):\n def _get_plugin(self, plugin_id):\n try:\n return plugins.get(plugin_id)\n except KeyError:\n raise ResourceDoesNotExist\n\n def get(self, request, project, plugin_id):\n plugin = self._get_plugin(plugin_id)\n\n try:\n context = serialize(plugin, request.user, PluginWithConfigSerializer(project))\n except PluginIdentityRequired as e:\n context = serialize(plugin, request.user, PluginSerializer(project))\n context['config_error'] = e.message\n context['auth_url'] = reverse('socialauth_associate', args=[plugin.slug])\n\n return Response(context)\n\n def post(self, request, project, plugin_id):\n \"\"\"\n Enable plugin\n \"\"\"\n plugin = self._get_plugin(plugin_id)\n\n if not plugin.can_disable:\n return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)\n\n plugin.enable(project)\n\n return Response(status=201)\n\n def delete(self, request, project, plugin_id):\n \"\"\"\n Disable plugin\n \"\"\"\n plugin = self._get_plugin(plugin_id)\n\n if not plugin.can_disable:\n return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)\n\n plugin.disable(project)\n\n return Response(status=204)\n\n def put(self, request, project, plugin_id):\n plugin = self._get_plugin(plugin_id)\n\n config = [\n serialize_field(project, plugin, c)\n for c in plugin.get_config(\n project=project,\n user=request.user,\n )\n ]\n\n cleaned = {}\n errors = {}\n for field in config:\n key = field['name']\n value = request.DATA.get(key)\n\n if field.get('required') and not value:\n errors[key] = ERR_FIELD_REQUIRED\n\n try:\n value = plugin.validate_config_field(\n project=project,\n name=key,\n value=value,\n actor=request.user,\n )\n except (forms.ValidationError, serializers.ValidationError, PluginError) as e:\n errors[key] = e.message\n\n if not errors.get(key):\n cleaned[key] = value\n\n if not errors:\n try:\n cleaned = plugin.validate_config(\n project=project,\n config=cleaned,\n actor=request.user,\n )\n except PluginError as e:\n errors['__all__'] = e.message\n\n if errors:\n return Response(\n {\n 'errors': errors,\n }, status=400\n )\n\n for key, value in six.iteritems(cleaned):\n if value is None:\n plugin.unset_option(\n project=project,\n key=key,\n )\n else:\n plugin.set_option(\n project=project,\n key=key,\n value=value,\n )\n\n context = serialize(plugin, request.user, PluginWithConfigSerializer(project))\n\n plugin_enabled.send(plugin=plugin, project=project, user=request.user, sender=self)\n\n return Response(context)\n", "path": "src/sentry/api/endpoints/project_plugin_details.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport logging\nimport six\n\nfrom django import forms\nfrom django.core.urlresolvers import reverse\nfrom rest_framework import serializers\nfrom rest_framework.response import Response\nfrom requests.exceptions import HTTPError\n\nfrom sentry.exceptions import PluginError, PluginIdentityRequired\nfrom sentry.plugins import plugins\nfrom sentry.api.bases.project import ProjectEndpoint\nfrom sentry.api.exceptions import ResourceDoesNotExist\nfrom sentry.api.serializers import serialize\nfrom sentry.api.serializers.models.plugin import (\n PluginSerializer, PluginWithConfigSerializer, serialize_field\n)\nfrom sentry.signals import plugin_enabled\n\nERR_ALWAYS_ENABLED = 'This plugin is always enabled.'\nERR_FIELD_REQUIRED = 'This field is required.'\n\nOK_UPDATED = 'Successfully updated configuration.'\n\n\nclass ProjectPluginDetailsEndpoint(ProjectEndpoint):\n def _get_plugin(self, plugin_id):\n try:\n return plugins.get(plugin_id)\n except KeyError:\n raise ResourceDoesNotExist\n\n def get(self, request, project, plugin_id):\n plugin = self._get_plugin(plugin_id)\n\n try:\n context = serialize(plugin, request.user, PluginWithConfigSerializer(project))\n except PluginIdentityRequired as e:\n context = serialize(plugin, request.user, PluginSerializer(project))\n context['config_error'] = e.message\n context['auth_url'] = reverse('socialauth_associate', args=[plugin.slug])\n\n return Response(context)\n\n def post(self, request, project, plugin_id):\n \"\"\"\n Enable plugin or Test plugin\n \"\"\"\n plugin = self._get_plugin(plugin_id)\n\n if request.DATA.get('test') and plugin.is_testable():\n try:\n test_results = plugin.test_configuration(project)\n except Exception as exc:\n if isinstance(exc, HTTPError):\n test_results = '%s\\n%s' % (exc, exc.response.text[:256])\n elif hasattr(exc, 'read') and callable(exc.read):\n test_results = '%s\\n%s' % (exc, exc.read()[:256])\n else:\n logging.exception('Plugin(%s) raised an error during test',\n plugin_id)\n test_results = 'There was an internal error with the Plugin'\n if not test_results:\n test_results = 'No errors returned'\n return Response({'detail': test_results}, status=200)\n\n if not plugin.can_disable:\n return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)\n\n plugin.enable(project)\n\n return Response(status=201)\n\n def delete(self, request, project, plugin_id):\n \"\"\"\n Disable plugin\n \"\"\"\n plugin = self._get_plugin(plugin_id)\n\n if not plugin.can_disable:\n return Response({'detail': ERR_ALWAYS_ENABLED}, status=400)\n\n plugin.disable(project)\n\n return Response(status=204)\n\n def put(self, request, project, plugin_id):\n plugin = self._get_plugin(plugin_id)\n\n config = [\n serialize_field(project, plugin, c)\n for c in plugin.get_config(\n project=project,\n user=request.user,\n )\n ]\n\n cleaned = {}\n errors = {}\n for field in config:\n key = field['name']\n value = request.DATA.get(key)\n\n if field.get('required') and not value:\n errors[key] = ERR_FIELD_REQUIRED\n\n try:\n value = plugin.validate_config_field(\n project=project,\n name=key,\n value=value,\n actor=request.user,\n )\n except (forms.ValidationError, serializers.ValidationError, PluginError) as e:\n errors[key] = e.message\n\n if not errors.get(key):\n cleaned[key] = value\n\n if not errors:\n try:\n cleaned = plugin.validate_config(\n project=project,\n config=cleaned,\n actor=request.user,\n )\n except PluginError as e:\n errors['__all__'] = e.message\n\n if errors:\n return Response(\n {\n 'errors': errors,\n }, status=400\n )\n\n for key, value in six.iteritems(cleaned):\n if value is None:\n plugin.unset_option(\n project=project,\n key=key,\n )\n else:\n plugin.set_option(\n project=project,\n key=key,\n value=value,\n )\n\n context = serialize(plugin, request.user, PluginWithConfigSerializer(project))\n\n plugin_enabled.send(plugin=plugin, project=project, user=request.user, sender=self)\n\n return Response(context)\n", "path": "src/sentry/api/endpoints/project_plugin_details.py"}]}
| 1,392 | 387 |
gh_patches_debug_15019
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1305
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Certwatcher does not work with symlinks (on Kubernetes)
I need to recheck this, but I just had this issue... Will report in 3 Months
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/nginx/certwatcher.py`
Content:
```
1 #!/usr/bin/python3
2 """
3 Certificate watcher which reloads nginx or reconfigures it, depending on what
4 happens to externally supplied certificates. Only executed by start.py in case
5 of TLS_FLAVOR=[mail, cert]
6 """
7
8 from os.path import exists, split as path_split
9 from os import system
10 import time
11 from watchdog.observers import Observer
12 from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \
13 FileCreatedEvent, FileModifiedEvent, FileMovedEvent
14
15 class ChangeHandler(FileSystemEventHandler):
16 "watchdog-handler listening on any event, executing the correct configuration/reload steps"
17 @staticmethod
18 def reload_nginx():
19 "merely reload nginx without re-configuring everything"
20 if exists("/var/run/nginx.pid"):
21 print("Reloading a running nginx")
22 system("nginx -s reload")
23
24 @staticmethod
25 def reexec_config():
26 "execute a reconfiguration of the system, which also reloads"
27 print("Reconfiguring system")
28 system("/config.py")
29
30 def on_any_event(self, event):
31 "event-listener checking if the affected files are the cert-files we're interested in"
32 if event.is_directory:
33 return
34
35 filename = path_split(event.src_path)[-1]
36 if isinstance(event, FileMovedEvent):
37 filename = path_split(event.dest_path)[-1]
38
39 if filename in ['cert.pem', 'key.pem']:
40 # all cases except for FileModified need re-configure
41 if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):
42 ChangeHandler.reexec_config()
43 # file modification needs only a nginx reload without config.py
44 elif isinstance(event, FileModifiedEvent):
45 ChangeHandler.reload_nginx()
46 # cert files have been moved away, re-configure
47 elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:
48 ChangeHandler.reexec_config()
49
50
51 if __name__ == '__main__':
52 observer = Observer()
53 handler = ChangeHandler()
54 observer.schedule(handler, "/certs", recursive=False)
55 observer.start()
56
57 try:
58 while True:
59 time.sleep(1)
60 except KeyboardInterrupt:
61 observer.stop()
62
63 observer.join()
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/nginx/certwatcher.py b/core/nginx/certwatcher.py
--- a/core/nginx/certwatcher.py
+++ b/core/nginx/certwatcher.py
@@ -8,7 +8,7 @@
from os.path import exists, split as path_split
from os import system
import time
-from watchdog.observers import Observer
+from watchdog.observers.polling import PollingObserver
from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \
FileCreatedEvent, FileModifiedEvent, FileMovedEvent
@@ -49,7 +49,7 @@
if __name__ == '__main__':
- observer = Observer()
+ observer = PollingObserver()
handler = ChangeHandler()
observer.schedule(handler, "/certs", recursive=False)
observer.start()
|
{"golden_diff": "diff --git a/core/nginx/certwatcher.py b/core/nginx/certwatcher.py\n--- a/core/nginx/certwatcher.py\n+++ b/core/nginx/certwatcher.py\n@@ -8,7 +8,7 @@\n from os.path import exists, split as path_split\n from os import system\n import time\n-from watchdog.observers import Observer\n+from watchdog.observers.polling import PollingObserver\n from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n FileCreatedEvent, FileModifiedEvent, FileMovedEvent\n \n@@ -49,7 +49,7 @@\n \n \n if __name__ == '__main__':\n- observer = Observer()\n+ observer = PollingObserver()\n handler = ChangeHandler()\n observer.schedule(handler, \"/certs\", recursive=False)\n observer.start()\n", "issue": "Certwatcher does not work with symlinks (on Kubernetes)\nI need to recheck this, but I just had this issue... Will report in 3 Months\n", "before_files": [{"content": "#!/usr/bin/python3\n\"\"\"\nCertificate watcher which reloads nginx or reconfigures it, depending on what\nhappens to externally supplied certificates. Only executed by start.py in case\nof TLS_FLAVOR=[mail, cert]\n\"\"\"\n\nfrom os.path import exists, split as path_split\nfrom os import system\nimport time\nfrom watchdog.observers import Observer\nfrom watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n FileCreatedEvent, FileModifiedEvent, FileMovedEvent\n\nclass ChangeHandler(FileSystemEventHandler):\n \"watchdog-handler listening on any event, executing the correct configuration/reload steps\"\n @staticmethod\n def reload_nginx():\n \"merely reload nginx without re-configuring everything\"\n if exists(\"/var/run/nginx.pid\"):\n print(\"Reloading a running nginx\")\n system(\"nginx -s reload\")\n\n @staticmethod\n def reexec_config():\n \"execute a reconfiguration of the system, which also reloads\"\n print(\"Reconfiguring system\")\n system(\"/config.py\")\n\n def on_any_event(self, event):\n \"event-listener checking if the affected files are the cert-files we're interested in\"\n if event.is_directory:\n return\n\n filename = path_split(event.src_path)[-1]\n if isinstance(event, FileMovedEvent):\n filename = path_split(event.dest_path)[-1]\n\n if filename in ['cert.pem', 'key.pem']:\n # all cases except for FileModified need re-configure\n if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):\n ChangeHandler.reexec_config()\n # file modification needs only a nginx reload without config.py\n elif isinstance(event, FileModifiedEvent):\n ChangeHandler.reload_nginx()\n # cert files have been moved away, re-configure\n elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:\n ChangeHandler.reexec_config()\n\n\nif __name__ == '__main__':\n observer = Observer()\n handler = ChangeHandler()\n observer.schedule(handler, \"/certs\", recursive=False)\n observer.start()\n\n try:\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n observer.stop()\n\n observer.join()\n", "path": "core/nginx/certwatcher.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\"\"\"\nCertificate watcher which reloads nginx or reconfigures it, depending on what\nhappens to externally supplied certificates. Only executed by start.py in case\nof TLS_FLAVOR=[mail, cert]\n\"\"\"\n\nfrom os.path import exists, split as path_split\nfrom os import system\nimport time\nfrom watchdog.observers.polling import PollingObserver\nfrom watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n FileCreatedEvent, FileModifiedEvent, FileMovedEvent\n\nclass ChangeHandler(FileSystemEventHandler):\n \"watchdog-handler listening on any event, executing the correct configuration/reload steps\"\n @staticmethod\n def reload_nginx():\n \"merely reload nginx without re-configuring everything\"\n if exists(\"/var/run/nginx.pid\"):\n print(\"Reloading a running nginx\")\n system(\"nginx -s reload\")\n\n @staticmethod\n def reexec_config():\n \"execute a reconfiguration of the system, which also reloads\"\n print(\"Reconfiguring system\")\n system(\"/config.py\")\n\n def on_any_event(self, event):\n \"event-listener checking if the affected files are the cert-files we're interested in\"\n if event.is_directory:\n return\n\n filename = path_split(event.src_path)[-1]\n if isinstance(event, FileMovedEvent):\n filename = path_split(event.dest_path)[-1]\n\n if filename in ['cert.pem', 'key.pem']:\n # all cases except for FileModified need re-configure\n if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):\n ChangeHandler.reexec_config()\n # file modification needs only a nginx reload without config.py\n elif isinstance(event, FileModifiedEvent):\n ChangeHandler.reload_nginx()\n # cert files have been moved away, re-configure\n elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:\n ChangeHandler.reexec_config()\n\n\nif __name__ == '__main__':\n observer = PollingObserver()\n handler = ChangeHandler()\n observer.schedule(handler, \"/certs\", recursive=False)\n observer.start()\n\n try:\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n observer.stop()\n\n observer.join()\n", "path": "core/nginx/certwatcher.py"}]}
| 891 | 170 |
gh_patches_debug_4511
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-704
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Xiaomi Mijia Light Sensor (GZCGQ01LM) in ZHA not detecting battery level anymore (it did in previous versions lower than 2020.12.7)
Hai The original call is from ( lustreking aka Steve Small) , I (yfands) can confirm Steve's findings indeed no battery level.
Steve posted his issue [here ](https://community.home-assistant.io/t/xiaomi-mijia-zha-not-detecting-battery-level/257827)but no answer there, so iam trying it here. In his original call there are 2 pictures one when all was well and the second picture after the update to 2020.12.7, the one that is not working any more, the difference is the class the device was assigned to.
The Problem
A while ago I got a Xiaomi Mijia Light Sensor (GZCGQ01LM), and it worked well for me, so I eventually ordered 2 more. Before I got them, I updated to the current version of HA (2020.12.7), as well as migrated HA to a new RPi.
When I tried to add them, ZHA found the illuminance entity, but not the battery entity, which my previous sensor had.
In ZHA I see the new sensors listed as Xiaomi, while the previous sensor’s manufacturer was listed as lumi. The model for both is lumi.sen_ill.mgl01
Under the zigbee info for the new ones it says “Power Source: Mains” which is obviously incorrect!
Here are the zigbee details of the good and bad ones, (see his original link).. The configuration below is from me (yfands), so to be short in ZHA found the illuminance entity, but not the battery entity anymore!
## System Health
version | 2020.12.2
-- | --
installation_type | Home Assistant OS
dev | false
hassio | true
docker | true
virtualenv | false
python_version | 3.8.6
os_name | Linux
os_version | 5.4.79-v8
arch | aarch64
timezone | Europe/Amsterdam
<details><summary>Home Assistant Community Store</summary>
GitHub API | ok
-- | --
Github API Calls Remaining | 4646
Installed Version | 1.9.0
Stage | running
Available Repositories | 711
Installed Repositories | 29
</details>
<details><summary>Home Assistant Cloud</summary>
logged_in | false
-- | --
can_reach_cert_server | ok
can_reach_cloud_auth | ok
can_reach_cloud | ok
</details>
<details><summary>Home Assistant Supervisor</summary>
host_os | Home Assistant OS 5.9
-- | --
update_channel | stable
supervisor_version | 2020.12.7
docker_version | 19.03.13
disk_total | 27.2 GB
disk_used | 5.5 GB
healthy | true
supported | true
board | rpi4-64
supervisor_api | ok
version_api | ok
installed_addons | File editor (5.2.0), Samba share (9.3.0), Terminal & SSH (8.10.0), Mosquitto broker (5.1), Node-RED (7.2.11)
</details>
<details><summary>Lovelace</summary>
dashboards | 1
-- | --
mode | storage
views | 10
resources | 20
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/xiaomi/aqara/illumination.py`
Content:
```
1 """Quirk for lumi.sen_ill.mgl01 illumination sensor."""
2 import logging
3
4 from zigpy.profiles import zha
5 from zigpy.zcl.clusters.general import Basic, Identify
6 from zigpy.zcl.clusters.measurement import IlluminanceMeasurement
7 from zigpy.zdo.types import NodeDescriptor
8
9 from .. import LUMI, BasicCluster, XiaomiCustomDevice
10 from ... import PowerConfigurationCluster
11 from ...const import (
12 DEVICE_TYPE,
13 ENDPOINTS,
14 INPUT_CLUSTERS,
15 MODELS_INFO,
16 NODE_DESCRIPTOR,
17 OUTPUT_CLUSTERS,
18 PROFILE_ID,
19 )
20
21 _LOGGER = logging.getLogger(__name__)
22
23
24 class Illumination(XiaomiCustomDevice):
25 """Aqara LUMI lumi.sen_ill.mgl01."""
26
27 signature = {
28 # <SimpleDescriptor endpoint=1 profile=260 device_type=262
29 # device_version=1
30 # input_clusters=[0, 1024, 3, 1]
31 # output_clusters=[3]>
32 MODELS_INFO: [(LUMI, "lumi.sen_ill.mgl01")],
33 ENDPOINTS: {
34 1: {
35 PROFILE_ID: zha.PROFILE_ID,
36 DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,
37 INPUT_CLUSTERS: [
38 Basic.cluster_id,
39 Identify.cluster_id,
40 IlluminanceMeasurement.cluster_id,
41 PowerConfigurationCluster.cluster_id,
42 ],
43 OUTPUT_CLUSTERS: [Identify.cluster_id],
44 }
45 },
46 }
47
48 replacement = {
49 NODE_DESCRIPTOR: NodeDescriptor(
50 0x02, 0x40, 0x80, 0x115F, 0x7F, 0x0064, 0x2C00, 0x0064, 0x00
51 ),
52 ENDPOINTS: {
53 1: {
54 PROFILE_ID: zha.PROFILE_ID,
55 DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,
56 INPUT_CLUSTERS: [
57 BasicCluster,
58 Identify.cluster_id,
59 IlluminanceMeasurement.cluster_id,
60 PowerConfigurationCluster,
61 ],
62 OUTPUT_CLUSTERS: [Identify.cluster_id],
63 }
64 },
65 }
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/xiaomi/aqara/illumination.py b/zhaquirks/xiaomi/aqara/illumination.py
--- a/zhaquirks/xiaomi/aqara/illumination.py
+++ b/zhaquirks/xiaomi/aqara/illumination.py
@@ -29,7 +29,7 @@
# device_version=1
# input_clusters=[0, 1024, 3, 1]
# output_clusters=[3]>
- MODELS_INFO: [(LUMI, "lumi.sen_ill.mgl01")],
+ MODELS_INFO: [(LUMI, "lumi.sen_ill.mgl01"), ("XIAOMI", "lumi.sen_ill.mgl01")],
ENDPOINTS: {
1: {
PROFILE_ID: zha.PROFILE_ID,
|
{"golden_diff": "diff --git a/zhaquirks/xiaomi/aqara/illumination.py b/zhaquirks/xiaomi/aqara/illumination.py\n--- a/zhaquirks/xiaomi/aqara/illumination.py\n+++ b/zhaquirks/xiaomi/aqara/illumination.py\n@@ -29,7 +29,7 @@\n # device_version=1\n # input_clusters=[0, 1024, 3, 1]\n # output_clusters=[3]>\n- MODELS_INFO: [(LUMI, \"lumi.sen_ill.mgl01\")],\n+ MODELS_INFO: [(LUMI, \"lumi.sen_ill.mgl01\"), (\"XIAOMI\", \"lumi.sen_ill.mgl01\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n", "issue": "Xiaomi Mijia Light Sensor (GZCGQ01LM) in ZHA not detecting battery level anymore (it did in previous versions lower than 2020.12.7)\nHai The original call is from ( lustreking aka Steve Small) , I (yfands) can confirm Steve's findings indeed no battery level.\r\nSteve posted his issue [here ](https://community.home-assistant.io/t/xiaomi-mijia-zha-not-detecting-battery-level/257827)but no answer there, so iam trying it here. In his original call there are 2 pictures one when all was well and the second picture after the update to 2020.12.7, the one that is not working any more, the difference is the class the device was assigned to.\r\n\r\nThe Problem\r\nA while ago I got a Xiaomi Mijia Light Sensor (GZCGQ01LM), and it worked well for me, so I eventually ordered 2 more. Before I got them, I updated to the current version of HA (2020.12.7), as well as migrated HA to a new RPi.\r\n\r\nWhen I tried to add them, ZHA found the illuminance entity, but not the battery entity, which my previous sensor had.\r\n\r\nIn ZHA I see the new sensors listed as Xiaomi, while the previous sensor\u2019s manufacturer was listed as lumi. The model for both is lumi.sen_ill.mgl01\r\n\r\nUnder the zigbee info for the new ones it says \u201cPower Source: Mains\u201d which is obviously incorrect!\r\nHere are the zigbee details of the good and bad ones, (see his original link).. The configuration below is from me (yfands), so to be short in ZHA found the illuminance entity, but not the battery entity anymore!\r\n\r\n## System Health\r\n\r\nversion | 2020.12.2\r\n-- | --\r\ninstallation_type | Home Assistant OS\r\ndev | false\r\nhassio | true\r\ndocker | true\r\nvirtualenv | false\r\npython_version | 3.8.6\r\nos_name | Linux\r\nos_version | 5.4.79-v8\r\narch | aarch64\r\ntimezone | Europe/Amsterdam\r\n\r\n<details><summary>Home Assistant Community Store</summary>\r\n\r\nGitHub API | ok\r\n-- | --\r\nGithub API Calls Remaining | 4646\r\nInstalled Version | 1.9.0\r\nStage | running\r\nAvailable Repositories | 711\r\nInstalled Repositories | 29\r\n\r\n</details>\r\n\r\n<details><summary>Home Assistant Cloud</summary>\r\n\r\nlogged_in | false\r\n-- | --\r\ncan_reach_cert_server | ok\r\ncan_reach_cloud_auth | ok\r\ncan_reach_cloud | ok\r\n\r\n</details>\r\n\r\n<details><summary>Home Assistant Supervisor</summary>\r\n\r\nhost_os | Home Assistant OS 5.9\r\n-- | --\r\nupdate_channel | stable\r\nsupervisor_version | 2020.12.7\r\ndocker_version | 19.03.13\r\ndisk_total | 27.2 GB\r\ndisk_used | 5.5 GB\r\nhealthy | true\r\nsupported | true\r\nboard | rpi4-64\r\nsupervisor_api | ok\r\nversion_api | ok\r\ninstalled_addons | File editor (5.2.0), Samba share (9.3.0), Terminal & SSH (8.10.0), Mosquitto broker (5.1), Node-RED (7.2.11)\r\n\r\n</details>\r\n\r\n<details><summary>Lovelace</summary>\r\n\r\ndashboards | 1\r\n-- | --\r\nmode | storage\r\nviews | 10\r\nresources | 20\r\n\r\n</details>\r\n\n", "before_files": [{"content": "\"\"\"Quirk for lumi.sen_ill.mgl01 illumination sensor.\"\"\"\nimport logging\n\nfrom zigpy.profiles import zha\nfrom zigpy.zcl.clusters.general import Basic, Identify\nfrom zigpy.zcl.clusters.measurement import IlluminanceMeasurement\nfrom zigpy.zdo.types import NodeDescriptor\n\nfrom .. import LUMI, BasicCluster, XiaomiCustomDevice\nfrom ... import PowerConfigurationCluster\nfrom ...const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n NODE_DESCRIPTOR,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Illumination(XiaomiCustomDevice):\n \"\"\"Aqara LUMI lumi.sen_ill.mgl01.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=262\n # device_version=1\n # input_clusters=[0, 1024, 3, 1]\n # output_clusters=[3]>\n MODELS_INFO: [(LUMI, \"lumi.sen_ill.mgl01\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n IlluminanceMeasurement.cluster_id,\n PowerConfigurationCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n }\n },\n }\n\n replacement = {\n NODE_DESCRIPTOR: NodeDescriptor(\n 0x02, 0x40, 0x80, 0x115F, 0x7F, 0x0064, 0x2C00, 0x0064, 0x00\n ),\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,\n INPUT_CLUSTERS: [\n BasicCluster,\n Identify.cluster_id,\n IlluminanceMeasurement.cluster_id,\n PowerConfigurationCluster,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n }\n },\n }\n", "path": "zhaquirks/xiaomi/aqara/illumination.py"}], "after_files": [{"content": "\"\"\"Quirk for lumi.sen_ill.mgl01 illumination sensor.\"\"\"\nimport logging\n\nfrom zigpy.profiles import zha\nfrom zigpy.zcl.clusters.general import Basic, Identify\nfrom zigpy.zcl.clusters.measurement import IlluminanceMeasurement\nfrom zigpy.zdo.types import NodeDescriptor\n\nfrom .. import LUMI, BasicCluster, XiaomiCustomDevice\nfrom ... import PowerConfigurationCluster\nfrom ...const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n NODE_DESCRIPTOR,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass Illumination(XiaomiCustomDevice):\n \"\"\"Aqara LUMI lumi.sen_ill.mgl01.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=262\n # device_version=1\n # input_clusters=[0, 1024, 3, 1]\n # output_clusters=[3]>\n MODELS_INFO: [(LUMI, \"lumi.sen_ill.mgl01\"), (\"XIAOMI\", \"lumi.sen_ill.mgl01\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n IlluminanceMeasurement.cluster_id,\n PowerConfigurationCluster.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n }\n },\n }\n\n replacement = {\n NODE_DESCRIPTOR: NodeDescriptor(\n 0x02, 0x40, 0x80, 0x115F, 0x7F, 0x0064, 0x2C00, 0x0064, 0x00\n ),\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LIGHT_SENSOR,\n INPUT_CLUSTERS: [\n BasicCluster,\n Identify.cluster_id,\n IlluminanceMeasurement.cluster_id,\n PowerConfigurationCluster,\n ],\n OUTPUT_CLUSTERS: [Identify.cluster_id],\n }\n },\n }\n", "path": "zhaquirks/xiaomi/aqara/illumination.py"}]}
| 1,678 | 199 |
gh_patches_debug_27430
|
rasdani/github-patches
|
git_diff
|
python-gitlab__python-gitlab-2678
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Snippets requires deprecated fields
## Description of the problem, including code/CLI snippet
in `project.snippets.create()` the required attributes were deprecated
```shell
AttributeError: Missing attributes: file_name, content
```
filename and content were deprecated in `files:file_path` and `files:content`
https://docs.gitlab.com/ee/api/snippets.html#create-new-snippet
## Specifications
- python-gitlab version: 3.15.0
- API version you are using (v3/v4): v4
- Gitlab server version (or gitlab.com): 15.11
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gitlab/v4/objects/snippets.py`
Content:
```
1 from typing import Any, Callable, cast, Iterator, List, Optional, TYPE_CHECKING, Union
2
3 import requests
4
5 from gitlab import cli
6 from gitlab import exceptions as exc
7 from gitlab import utils
8 from gitlab.base import RESTManager, RESTObject, RESTObjectList
9 from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin, UserAgentDetailMixin
10 from gitlab.types import RequiredOptional
11
12 from .award_emojis import ProjectSnippetAwardEmojiManager # noqa: F401
13 from .discussions import ProjectSnippetDiscussionManager # noqa: F401
14 from .notes import ProjectSnippetNoteManager # noqa: F401
15
16 __all__ = [
17 "Snippet",
18 "SnippetManager",
19 "ProjectSnippet",
20 "ProjectSnippetManager",
21 ]
22
23
24 class Snippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):
25 _repr_attr = "title"
26
27 @cli.register_custom_action("Snippet")
28 @exc.on_http_error(exc.GitlabGetError)
29 def content(
30 self,
31 streamed: bool = False,
32 action: Optional[Callable[..., Any]] = None,
33 chunk_size: int = 1024,
34 *,
35 iterator: bool = False,
36 **kwargs: Any,
37 ) -> Optional[Union[bytes, Iterator[Any]]]:
38 """Return the content of a snippet.
39
40 Args:
41 streamed: If True the data will be processed by chunks of
42 `chunk_size` and each chunk is passed to `action` for
43 treatment.
44 iterator: If True directly return the underlying response
45 iterator
46 action: Callable responsible of dealing with chunk of
47 data
48 chunk_size: Size of each chunk
49 **kwargs: Extra options to send to the server (e.g. sudo)
50
51 Raises:
52 GitlabAuthenticationError: If authentication is not correct
53 GitlabGetError: If the content could not be retrieved
54
55 Returns:
56 The snippet content
57 """
58 path = f"/snippets/{self.encoded_id}/raw"
59 result = self.manager.gitlab.http_get(
60 path, streamed=streamed, raw=True, **kwargs
61 )
62 if TYPE_CHECKING:
63 assert isinstance(result, requests.Response)
64 return utils.response_content(
65 result, streamed, action, chunk_size, iterator=iterator
66 )
67
68
69 class SnippetManager(CRUDMixin, RESTManager):
70 _path = "/snippets"
71 _obj_cls = Snippet
72 _create_attrs = RequiredOptional(
73 required=("title", "file_name", "content"), optional=("lifetime", "visibility")
74 )
75 _update_attrs = RequiredOptional(
76 optional=("title", "file_name", "content", "visibility")
77 )
78
79 @cli.register_custom_action("SnippetManager")
80 def public(self, **kwargs: Any) -> Union[RESTObjectList, List[RESTObject]]:
81 """List all the public snippets.
82
83 Args:
84 all: If True the returned object will be a list
85 **kwargs: Extra options to send to the server (e.g. sudo)
86
87 Raises:
88 GitlabListError: If the list could not be retrieved
89
90 Returns:
91 A generator for the snippets list
92 """
93 return self.list(path="/snippets/public", **kwargs)
94
95 def get(self, id: Union[str, int], lazy: bool = False, **kwargs: Any) -> Snippet:
96 return cast(Snippet, super().get(id=id, lazy=lazy, **kwargs))
97
98
99 class ProjectSnippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):
100 _url = "/projects/{project_id}/snippets"
101 _repr_attr = "title"
102
103 awardemojis: ProjectSnippetAwardEmojiManager
104 discussions: ProjectSnippetDiscussionManager
105 notes: ProjectSnippetNoteManager
106
107 @cli.register_custom_action("ProjectSnippet")
108 @exc.on_http_error(exc.GitlabGetError)
109 def content(
110 self,
111 streamed: bool = False,
112 action: Optional[Callable[..., Any]] = None,
113 chunk_size: int = 1024,
114 *,
115 iterator: bool = False,
116 **kwargs: Any,
117 ) -> Optional[Union[bytes, Iterator[Any]]]:
118 """Return the content of a snippet.
119
120 Args:
121 streamed: If True the data will be processed by chunks of
122 `chunk_size` and each chunk is passed to `action` for
123 treatment.
124 iterator: If True directly return the underlying response
125 iterator
126 action: Callable responsible of dealing with chunk of
127 data
128 chunk_size: Size of each chunk
129 **kwargs: Extra options to send to the server (e.g. sudo)
130
131 Raises:
132 GitlabAuthenticationError: If authentication is not correct
133 GitlabGetError: If the content could not be retrieved
134
135 Returns:
136 The snippet content
137 """
138 path = f"{self.manager.path}/{self.encoded_id}/raw"
139 result = self.manager.gitlab.http_get(
140 path, streamed=streamed, raw=True, **kwargs
141 )
142 if TYPE_CHECKING:
143 assert isinstance(result, requests.Response)
144 return utils.response_content(
145 result, streamed, action, chunk_size, iterator=iterator
146 )
147
148
149 class ProjectSnippetManager(CRUDMixin, RESTManager):
150 _path = "/projects/{project_id}/snippets"
151 _obj_cls = ProjectSnippet
152 _from_parent_attrs = {"project_id": "id"}
153 _create_attrs = RequiredOptional(
154 required=("title", "file_name", "content", "visibility"),
155 optional=("description",),
156 )
157 _update_attrs = RequiredOptional(
158 optional=("title", "file_name", "content", "visibility", "description"),
159 )
160
161 def get(
162 self, id: Union[str, int], lazy: bool = False, **kwargs: Any
163 ) -> ProjectSnippet:
164 return cast(ProjectSnippet, super().get(id=id, lazy=lazy, **kwargs))
165
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gitlab/v4/objects/snippets.py b/gitlab/v4/objects/snippets.py
--- a/gitlab/v4/objects/snippets.py
+++ b/gitlab/v4/objects/snippets.py
@@ -70,10 +70,23 @@
_path = "/snippets"
_obj_cls = Snippet
_create_attrs = RequiredOptional(
- required=("title", "file_name", "content"), optional=("lifetime", "visibility")
+ required=("title",),
+ exclusive=("files", "file_name"),
+ optional=(
+ "description",
+ "content",
+ "visibility",
+ ),
)
_update_attrs = RequiredOptional(
- optional=("title", "file_name", "content", "visibility")
+ optional=(
+ "title",
+ "files",
+ "file_name",
+ "content",
+ "visibility",
+ "description",
+ ),
)
@cli.register_custom_action("SnippetManager")
@@ -151,11 +164,22 @@
_obj_cls = ProjectSnippet
_from_parent_attrs = {"project_id": "id"}
_create_attrs = RequiredOptional(
- required=("title", "file_name", "content", "visibility"),
- optional=("description",),
+ required=("title", "visibility"),
+ exclusive=("files", "file_name"),
+ optional=(
+ "description",
+ "content",
+ ),
)
_update_attrs = RequiredOptional(
- optional=("title", "file_name", "content", "visibility", "description"),
+ optional=(
+ "title",
+ "files",
+ "file_name",
+ "content",
+ "visibility",
+ "description",
+ ),
)
def get(
|
{"golden_diff": "diff --git a/gitlab/v4/objects/snippets.py b/gitlab/v4/objects/snippets.py\n--- a/gitlab/v4/objects/snippets.py\n+++ b/gitlab/v4/objects/snippets.py\n@@ -70,10 +70,23 @@\n _path = \"/snippets\"\n _obj_cls = Snippet\n _create_attrs = RequiredOptional(\n- required=(\"title\", \"file_name\", \"content\"), optional=(\"lifetime\", \"visibility\")\n+ required=(\"title\",),\n+ exclusive=(\"files\", \"file_name\"),\n+ optional=(\n+ \"description\",\n+ \"content\",\n+ \"visibility\",\n+ ),\n )\n _update_attrs = RequiredOptional(\n- optional=(\"title\", \"file_name\", \"content\", \"visibility\")\n+ optional=(\n+ \"title\",\n+ \"files\",\n+ \"file_name\",\n+ \"content\",\n+ \"visibility\",\n+ \"description\",\n+ ),\n )\n \n @cli.register_custom_action(\"SnippetManager\")\n@@ -151,11 +164,22 @@\n _obj_cls = ProjectSnippet\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n- required=(\"title\", \"file_name\", \"content\", \"visibility\"),\n- optional=(\"description\",),\n+ required=(\"title\", \"visibility\"),\n+ exclusive=(\"files\", \"file_name\"),\n+ optional=(\n+ \"description\",\n+ \"content\",\n+ ),\n )\n _update_attrs = RequiredOptional(\n- optional=(\"title\", \"file_name\", \"content\", \"visibility\", \"description\"),\n+ optional=(\n+ \"title\",\n+ \"files\",\n+ \"file_name\",\n+ \"content\",\n+ \"visibility\",\n+ \"description\",\n+ ),\n )\n \n def get(\n", "issue": "Snippets requires deprecated fields \n## Description of the problem, including code/CLI snippet\r\n\r\nin `project.snippets.create()` the required attributes were deprecated\r\n```shell\r\nAttributeError: Missing attributes: file_name, content\r\n```\r\nfilename and content were deprecated in `files:file_path` and `files:content`\r\n\r\nhttps://docs.gitlab.com/ee/api/snippets.html#create-new-snippet\r\n\r\n\r\n## Specifications\r\n\r\n - python-gitlab version: 3.15.0 \r\n - API version you are using (v3/v4): v4\r\n - Gitlab server version (or gitlab.com): 15.11\r\n\n", "before_files": [{"content": "from typing import Any, Callable, cast, Iterator, List, Optional, TYPE_CHECKING, Union\n\nimport requests\n\nfrom gitlab import cli\nfrom gitlab import exceptions as exc\nfrom gitlab import utils\nfrom gitlab.base import RESTManager, RESTObject, RESTObjectList\nfrom gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin, UserAgentDetailMixin\nfrom gitlab.types import RequiredOptional\n\nfrom .award_emojis import ProjectSnippetAwardEmojiManager # noqa: F401\nfrom .discussions import ProjectSnippetDiscussionManager # noqa: F401\nfrom .notes import ProjectSnippetNoteManager # noqa: F401\n\n__all__ = [\n \"Snippet\",\n \"SnippetManager\",\n \"ProjectSnippet\",\n \"ProjectSnippetManager\",\n]\n\n\nclass Snippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):\n _repr_attr = \"title\"\n\n @cli.register_custom_action(\"Snippet\")\n @exc.on_http_error(exc.GitlabGetError)\n def content(\n self,\n streamed: bool = False,\n action: Optional[Callable[..., Any]] = None,\n chunk_size: int = 1024,\n *,\n iterator: bool = False,\n **kwargs: Any,\n ) -> Optional[Union[bytes, Iterator[Any]]]:\n \"\"\"Return the content of a snippet.\n\n Args:\n streamed: If True the data will be processed by chunks of\n `chunk_size` and each chunk is passed to `action` for\n treatment.\n iterator: If True directly return the underlying response\n iterator\n action: Callable responsible of dealing with chunk of\n data\n chunk_size: Size of each chunk\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabGetError: If the content could not be retrieved\n\n Returns:\n The snippet content\n \"\"\"\n path = f\"/snippets/{self.encoded_id}/raw\"\n result = self.manager.gitlab.http_get(\n path, streamed=streamed, raw=True, **kwargs\n )\n if TYPE_CHECKING:\n assert isinstance(result, requests.Response)\n return utils.response_content(\n result, streamed, action, chunk_size, iterator=iterator\n )\n\n\nclass SnippetManager(CRUDMixin, RESTManager):\n _path = \"/snippets\"\n _obj_cls = Snippet\n _create_attrs = RequiredOptional(\n required=(\"title\", \"file_name\", \"content\"), optional=(\"lifetime\", \"visibility\")\n )\n _update_attrs = RequiredOptional(\n optional=(\"title\", \"file_name\", \"content\", \"visibility\")\n )\n\n @cli.register_custom_action(\"SnippetManager\")\n def public(self, **kwargs: Any) -> Union[RESTObjectList, List[RESTObject]]:\n \"\"\"List all the public snippets.\n\n Args:\n all: If True the returned object will be a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabListError: If the list could not be retrieved\n\n Returns:\n A generator for the snippets list\n \"\"\"\n return self.list(path=\"/snippets/public\", **kwargs)\n\n def get(self, id: Union[str, int], lazy: bool = False, **kwargs: Any) -> Snippet:\n return cast(Snippet, super().get(id=id, lazy=lazy, **kwargs))\n\n\nclass ProjectSnippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):\n _url = \"/projects/{project_id}/snippets\"\n _repr_attr = \"title\"\n\n awardemojis: ProjectSnippetAwardEmojiManager\n discussions: ProjectSnippetDiscussionManager\n notes: ProjectSnippetNoteManager\n\n @cli.register_custom_action(\"ProjectSnippet\")\n @exc.on_http_error(exc.GitlabGetError)\n def content(\n self,\n streamed: bool = False,\n action: Optional[Callable[..., Any]] = None,\n chunk_size: int = 1024,\n *,\n iterator: bool = False,\n **kwargs: Any,\n ) -> Optional[Union[bytes, Iterator[Any]]]:\n \"\"\"Return the content of a snippet.\n\n Args:\n streamed: If True the data will be processed by chunks of\n `chunk_size` and each chunk is passed to `action` for\n treatment.\n iterator: If True directly return the underlying response\n iterator\n action: Callable responsible of dealing with chunk of\n data\n chunk_size: Size of each chunk\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabGetError: If the content could not be retrieved\n\n Returns:\n The snippet content\n \"\"\"\n path = f\"{self.manager.path}/{self.encoded_id}/raw\"\n result = self.manager.gitlab.http_get(\n path, streamed=streamed, raw=True, **kwargs\n )\n if TYPE_CHECKING:\n assert isinstance(result, requests.Response)\n return utils.response_content(\n result, streamed, action, chunk_size, iterator=iterator\n )\n\n\nclass ProjectSnippetManager(CRUDMixin, RESTManager):\n _path = \"/projects/{project_id}/snippets\"\n _obj_cls = ProjectSnippet\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"title\", \"file_name\", \"content\", \"visibility\"),\n optional=(\"description\",),\n )\n _update_attrs = RequiredOptional(\n optional=(\"title\", \"file_name\", \"content\", \"visibility\", \"description\"),\n )\n\n def get(\n self, id: Union[str, int], lazy: bool = False, **kwargs: Any\n ) -> ProjectSnippet:\n return cast(ProjectSnippet, super().get(id=id, lazy=lazy, **kwargs))\n", "path": "gitlab/v4/objects/snippets.py"}], "after_files": [{"content": "from typing import Any, Callable, cast, Iterator, List, Optional, TYPE_CHECKING, Union\n\nimport requests\n\nfrom gitlab import cli\nfrom gitlab import exceptions as exc\nfrom gitlab import utils\nfrom gitlab.base import RESTManager, RESTObject, RESTObjectList\nfrom gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin, UserAgentDetailMixin\nfrom gitlab.types import RequiredOptional\n\nfrom .award_emojis import ProjectSnippetAwardEmojiManager # noqa: F401\nfrom .discussions import ProjectSnippetDiscussionManager # noqa: F401\nfrom .notes import ProjectSnippetNoteManager # noqa: F401\n\n__all__ = [\n \"Snippet\",\n \"SnippetManager\",\n \"ProjectSnippet\",\n \"ProjectSnippetManager\",\n]\n\n\nclass Snippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):\n _repr_attr = \"title\"\n\n @cli.register_custom_action(\"Snippet\")\n @exc.on_http_error(exc.GitlabGetError)\n def content(\n self,\n streamed: bool = False,\n action: Optional[Callable[..., Any]] = None,\n chunk_size: int = 1024,\n *,\n iterator: bool = False,\n **kwargs: Any,\n ) -> Optional[Union[bytes, Iterator[Any]]]:\n \"\"\"Return the content of a snippet.\n\n Args:\n streamed: If True the data will be processed by chunks of\n `chunk_size` and each chunk is passed to `action` for\n treatment.\n iterator: If True directly return the underlying response\n iterator\n action: Callable responsible of dealing with chunk of\n data\n chunk_size: Size of each chunk\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabGetError: If the content could not be retrieved\n\n Returns:\n The snippet content\n \"\"\"\n path = f\"/snippets/{self.encoded_id}/raw\"\n result = self.manager.gitlab.http_get(\n path, streamed=streamed, raw=True, **kwargs\n )\n if TYPE_CHECKING:\n assert isinstance(result, requests.Response)\n return utils.response_content(\n result, streamed, action, chunk_size, iterator=iterator\n )\n\n\nclass SnippetManager(CRUDMixin, RESTManager):\n _path = \"/snippets\"\n _obj_cls = Snippet\n _create_attrs = RequiredOptional(\n required=(\"title\",),\n exclusive=(\"files\", \"file_name\"),\n optional=(\n \"description\",\n \"content\",\n \"visibility\",\n ),\n )\n _update_attrs = RequiredOptional(\n optional=(\n \"title\",\n \"files\",\n \"file_name\",\n \"content\",\n \"visibility\",\n \"description\",\n ),\n )\n\n @cli.register_custom_action(\"SnippetManager\")\n def public(self, **kwargs: Any) -> Union[RESTObjectList, List[RESTObject]]:\n \"\"\"List all the public snippets.\n\n Args:\n all: If True the returned object will be a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabListError: If the list could not be retrieved\n\n Returns:\n A generator for the snippets list\n \"\"\"\n return self.list(path=\"/snippets/public\", **kwargs)\n\n def get(self, id: Union[str, int], lazy: bool = False, **kwargs: Any) -> Snippet:\n return cast(Snippet, super().get(id=id, lazy=lazy, **kwargs))\n\n\nclass ProjectSnippet(UserAgentDetailMixin, SaveMixin, ObjectDeleteMixin, RESTObject):\n _url = \"/projects/{project_id}/snippets\"\n _repr_attr = \"title\"\n\n awardemojis: ProjectSnippetAwardEmojiManager\n discussions: ProjectSnippetDiscussionManager\n notes: ProjectSnippetNoteManager\n\n @cli.register_custom_action(\"ProjectSnippet\")\n @exc.on_http_error(exc.GitlabGetError)\n def content(\n self,\n streamed: bool = False,\n action: Optional[Callable[..., Any]] = None,\n chunk_size: int = 1024,\n *,\n iterator: bool = False,\n **kwargs: Any,\n ) -> Optional[Union[bytes, Iterator[Any]]]:\n \"\"\"Return the content of a snippet.\n\n Args:\n streamed: If True the data will be processed by chunks of\n `chunk_size` and each chunk is passed to `action` for\n treatment.\n iterator: If True directly return the underlying response\n iterator\n action: Callable responsible of dealing with chunk of\n data\n chunk_size: Size of each chunk\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabGetError: If the content could not be retrieved\n\n Returns:\n The snippet content\n \"\"\"\n path = f\"{self.manager.path}/{self.encoded_id}/raw\"\n result = self.manager.gitlab.http_get(\n path, streamed=streamed, raw=True, **kwargs\n )\n if TYPE_CHECKING:\n assert isinstance(result, requests.Response)\n return utils.response_content(\n result, streamed, action, chunk_size, iterator=iterator\n )\n\n\nclass ProjectSnippetManager(CRUDMixin, RESTManager):\n _path = \"/projects/{project_id}/snippets\"\n _obj_cls = ProjectSnippet\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"title\", \"visibility\"),\n exclusive=(\"files\", \"file_name\"),\n optional=(\n \"description\",\n \"content\",\n ),\n )\n _update_attrs = RequiredOptional(\n optional=(\n \"title\",\n \"files\",\n \"file_name\",\n \"content\",\n \"visibility\",\n \"description\",\n ),\n )\n\n def get(\n self, id: Union[str, int], lazy: bool = False, **kwargs: Any\n ) -> ProjectSnippet:\n return cast(ProjectSnippet, super().get(id=id, lazy=lazy, **kwargs))\n", "path": "gitlab/v4/objects/snippets.py"}]}
| 2,084 | 400 |
gh_patches_debug_661
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2055
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.122
On the docket:
+ [x] Support the latest Pip releases: 22.3.1 & 23.0 #2056
+ [x] Lock sdists with prepare-metadata-for-build-wheel. #2053
+ [x] Fix `execute_parallel` "leaking" a thread. #2052
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.121"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.121"
+__version__ = "2.1.122"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.121\"\n+__version__ = \"2.1.122\"\n", "issue": "Release 2.1.122\nOn the docket:\r\n+ [x] Support the latest Pip releases: 22.3.1 & 23.0 #2056\r\n+ [x] Lock sdists with prepare-metadata-for-build-wheel. #2053\r\n+ [x] Fix `execute_parallel` \"leaking\" a thread. #2052\r\n\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.121\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.122\"\n", "path": "pex/version.py"}]}
| 395 | 98 |
gh_patches_debug_16138
|
rasdani/github-patches
|
git_diff
|
uccser__cs-unplugged-718
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Workaround Crowdin bug where integer yaml keys are not preserved
When downloading in-context localisation files, integer keys in YAML files are not preserved. This is only an issue in the file `topics/content/en/programming-challenges-structure-difficulties.yaml`, which uses the difficulty number as the key.
As a work around, we can use the string value of the integer as the key, i.e. `"0"` instead of `0`
Workaround Crowdin bug where integer yaml keys are not preserved
When downloading in-context localisation files, integer keys in YAML files are not preserved. This is only an issue in the file `topics/content/en/programming-challenges-structure-difficulties.yaml`, which uses the difficulty number as the key.
As a work around, we can use the string value of the integer as the key, i.e. `"0"` instead of `0`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py`
Content:
```
1 """Custom loader for loading structure of programming challenges."""
2
3 import os
4 from django.db import transaction
5 from utils.errors.MissingRequiredFieldError import MissingRequiredFieldError
6 from utils.TranslatableModelLoader import TranslatableModelLoader
7 from topics.models import ProgrammingChallengeLanguage, ProgrammingChallengeDifficulty
8
9
10 class ProgrammingChallengesStructureLoader(TranslatableModelLoader):
11 """Custom loader for loading structure of programming challenges."""
12
13 @transaction.atomic
14 def load(self):
15 """Load the content for structure of programming challenges.
16
17 Raises:
18 MissingRequiredFieldError: when no object can be found with the matching
19 attribute.
20 """
21 structure = self.load_yaml_file(self.structure_file_path)
22
23 prog_languages = structure.get("languages", None)
24 difficulty_levels = structure.get("difficulties", None)
25 if None in [prog_languages, difficulty_levels]:
26 raise MissingRequiredFieldError(
27 self.structure_file_path,
28 ["lanugages", "difficulties"],
29 "Programming Challenge Structure"
30 )
31
32 # Add "-languages" to the structure filename
33 prog_languages_translation_filename = "{}-languages.yaml".format(
34 os.path.splitext(self.structure_filename)[0]
35 )
36 prog_languages_translations = self.get_yaml_translations(
37 prog_languages_translation_filename,
38 required_slugs=prog_languages.keys(),
39 required_fields=["name"]
40 )
41
42 for (prog_language, prog_language_data) in prog_languages.items():
43
44 if prog_language_data is None:
45 raise MissingRequiredFieldError(
46 self.structure_file_path,
47 ["number"],
48 "Programming Challenge Language"
49 )
50
51 # Check for required fields
52 prog_language_number = prog_language_data.get("number", None)
53 if prog_language_number is None:
54 raise MissingRequiredFieldError(
55 self.structure_file_path,
56 ["number"],
57 "Programming Challenge Language"
58 )
59
60 # Check if icon is given
61 if "icon" in prog_language_data:
62 prog_language_icon = prog_language_data["icon"]
63 else:
64 prog_language_icon = None
65
66 new_prog_language = ProgrammingChallengeLanguage(
67 slug=prog_language,
68 number=prog_language_number,
69 icon=prog_language_icon
70 )
71
72 translations = prog_languages_translations.get(prog_language, dict())
73 self.populate_translations(new_prog_language, translations)
74 self.mark_translation_availability(new_prog_language, required_fields=["name"])
75 new_prog_language.save()
76
77 self.log("Added programming language: {}".format(new_prog_language.__str__()))
78
79 # Add "-languages" to the structure filename
80 difficulties_translation_filename = "{}-difficulties.yaml".format(
81 os.path.splitext(self.structure_filename)[0]
82 )
83 difficulties_translations = self.get_yaml_translations(
84 difficulties_translation_filename,
85 required_slugs=difficulty_levels,
86 required_fields=["name"],
87 )
88
89 for difficulty in difficulty_levels:
90
91 new_difficulty = ProgrammingChallengeDifficulty(
92 level=int(difficulty),
93 )
94
95 translations = difficulties_translations.get(difficulty, dict())
96 self.populate_translations(new_difficulty, translations)
97 self.mark_translation_availability(new_difficulty, required_fields=["name"])
98 new_difficulty.save()
99
100 self.log("Added programming difficulty level: {}".format(new_difficulty.__str__()))
101
102 self.log("")
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py b/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py
--- a/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py
+++ b/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py
@@ -86,13 +86,13 @@
required_fields=["name"],
)
- for difficulty in difficulty_levels:
+ for level, difficulty_slug in enumerate(difficulty_levels):
new_difficulty = ProgrammingChallengeDifficulty(
- level=int(difficulty),
+ level=level,
)
- translations = difficulties_translations.get(difficulty, dict())
+ translations = difficulties_translations.get(difficulty_slug, dict())
self.populate_translations(new_difficulty, translations)
self.mark_translation_availability(new_difficulty, required_fields=["name"])
new_difficulty.save()
|
{"golden_diff": "diff --git a/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py b/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py\n--- a/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py\n+++ b/csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py\n@@ -86,13 +86,13 @@\n required_fields=[\"name\"],\n )\n \n- for difficulty in difficulty_levels:\n+ for level, difficulty_slug in enumerate(difficulty_levels):\n \n new_difficulty = ProgrammingChallengeDifficulty(\n- level=int(difficulty),\n+ level=level,\n )\n \n- translations = difficulties_translations.get(difficulty, dict())\n+ translations = difficulties_translations.get(difficulty_slug, dict())\n self.populate_translations(new_difficulty, translations)\n self.mark_translation_availability(new_difficulty, required_fields=[\"name\"])\n new_difficulty.save()\n", "issue": "Workaround Crowdin bug where integer yaml keys are not preserved\nWhen downloading in-context localisation files, integer keys in YAML files are not preserved. This is only an issue in the file `topics/content/en/programming-challenges-structure-difficulties.yaml`, which uses the difficulty number as the key.\r\n\r\nAs a work around, we can use the string value of the integer as the key, i.e. `\"0\"` instead of `0`\nWorkaround Crowdin bug where integer yaml keys are not preserved\nWhen downloading in-context localisation files, integer keys in YAML files are not preserved. This is only an issue in the file `topics/content/en/programming-challenges-structure-difficulties.yaml`, which uses the difficulty number as the key.\r\n\r\nAs a work around, we can use the string value of the integer as the key, i.e. `\"0\"` instead of `0`\n", "before_files": [{"content": "\"\"\"Custom loader for loading structure of programming challenges.\"\"\"\n\nimport os\nfrom django.db import transaction\nfrom utils.errors.MissingRequiredFieldError import MissingRequiredFieldError\nfrom utils.TranslatableModelLoader import TranslatableModelLoader\nfrom topics.models import ProgrammingChallengeLanguage, ProgrammingChallengeDifficulty\n\n\nclass ProgrammingChallengesStructureLoader(TranslatableModelLoader):\n \"\"\"Custom loader for loading structure of programming challenges.\"\"\"\n\n @transaction.atomic\n def load(self):\n \"\"\"Load the content for structure of programming challenges.\n\n Raises:\n MissingRequiredFieldError: when no object can be found with the matching\n attribute.\n \"\"\"\n structure = self.load_yaml_file(self.structure_file_path)\n\n prog_languages = structure.get(\"languages\", None)\n difficulty_levels = structure.get(\"difficulties\", None)\n if None in [prog_languages, difficulty_levels]:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"lanugages\", \"difficulties\"],\n \"Programming Challenge Structure\"\n )\n\n # Add \"-languages\" to the structure filename\n prog_languages_translation_filename = \"{}-languages.yaml\".format(\n os.path.splitext(self.structure_filename)[0]\n )\n prog_languages_translations = self.get_yaml_translations(\n prog_languages_translation_filename,\n required_slugs=prog_languages.keys(),\n required_fields=[\"name\"]\n )\n\n for (prog_language, prog_language_data) in prog_languages.items():\n\n if prog_language_data is None:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"number\"],\n \"Programming Challenge Language\"\n )\n\n # Check for required fields\n prog_language_number = prog_language_data.get(\"number\", None)\n if prog_language_number is None:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"number\"],\n \"Programming Challenge Language\"\n )\n\n # Check if icon is given\n if \"icon\" in prog_language_data:\n prog_language_icon = prog_language_data[\"icon\"]\n else:\n prog_language_icon = None\n\n new_prog_language = ProgrammingChallengeLanguage(\n slug=prog_language,\n number=prog_language_number,\n icon=prog_language_icon\n )\n\n translations = prog_languages_translations.get(prog_language, dict())\n self.populate_translations(new_prog_language, translations)\n self.mark_translation_availability(new_prog_language, required_fields=[\"name\"])\n new_prog_language.save()\n\n self.log(\"Added programming language: {}\".format(new_prog_language.__str__()))\n\n # Add \"-languages\" to the structure filename\n difficulties_translation_filename = \"{}-difficulties.yaml\".format(\n os.path.splitext(self.structure_filename)[0]\n )\n difficulties_translations = self.get_yaml_translations(\n difficulties_translation_filename,\n required_slugs=difficulty_levels,\n required_fields=[\"name\"],\n )\n\n for difficulty in difficulty_levels:\n\n new_difficulty = ProgrammingChallengeDifficulty(\n level=int(difficulty),\n )\n\n translations = difficulties_translations.get(difficulty, dict())\n self.populate_translations(new_difficulty, translations)\n self.mark_translation_availability(new_difficulty, required_fields=[\"name\"])\n new_difficulty.save()\n\n self.log(\"Added programming difficulty level: {}\".format(new_difficulty.__str__()))\n\n self.log(\"\")\n", "path": "csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py"}], "after_files": [{"content": "\"\"\"Custom loader for loading structure of programming challenges.\"\"\"\n\nimport os\nfrom django.db import transaction\nfrom utils.errors.MissingRequiredFieldError import MissingRequiredFieldError\nfrom utils.TranslatableModelLoader import TranslatableModelLoader\nfrom topics.models import ProgrammingChallengeLanguage, ProgrammingChallengeDifficulty\n\n\nclass ProgrammingChallengesStructureLoader(TranslatableModelLoader):\n \"\"\"Custom loader for loading structure of programming challenges.\"\"\"\n\n @transaction.atomic\n def load(self):\n \"\"\"Load the content for structure of programming challenges.\n\n Raises:\n MissingRequiredFieldError: when no object can be found with the matching\n attribute.\n \"\"\"\n structure = self.load_yaml_file(self.structure_file_path)\n\n prog_languages = structure.get(\"languages\", None)\n difficulty_levels = structure.get(\"difficulties\", None)\n if None in [prog_languages, difficulty_levels]:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"lanugages\", \"difficulties\"],\n \"Programming Challenge Structure\"\n )\n\n # Add \"-languages\" to the structure filename\n prog_languages_translation_filename = \"{}-languages.yaml\".format(\n os.path.splitext(self.structure_filename)[0]\n )\n prog_languages_translations = self.get_yaml_translations(\n prog_languages_translation_filename,\n required_slugs=prog_languages.keys(),\n required_fields=[\"name\"]\n )\n\n for (prog_language, prog_language_data) in prog_languages.items():\n\n if prog_language_data is None:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"number\"],\n \"Programming Challenge Language\"\n )\n\n # Check for required fields\n prog_language_number = prog_language_data.get(\"number\", None)\n if prog_language_number is None:\n raise MissingRequiredFieldError(\n self.structure_file_path,\n [\"number\"],\n \"Programming Challenge Language\"\n )\n\n # Check if icon is given\n if \"icon\" in prog_language_data:\n prog_language_icon = prog_language_data[\"icon\"]\n else:\n prog_language_icon = None\n\n new_prog_language = ProgrammingChallengeLanguage(\n slug=prog_language,\n number=prog_language_number,\n icon=prog_language_icon\n )\n\n translations = prog_languages_translations.get(prog_language, dict())\n self.populate_translations(new_prog_language, translations)\n self.mark_translation_availability(new_prog_language, required_fields=[\"name\"])\n new_prog_language.save()\n\n self.log(\"Added programming language: {}\".format(new_prog_language.__str__()))\n\n # Add \"-languages\" to the structure filename\n difficulties_translation_filename = \"{}-difficulties.yaml\".format(\n os.path.splitext(self.structure_filename)[0]\n )\n difficulties_translations = self.get_yaml_translations(\n difficulties_translation_filename,\n required_slugs=difficulty_levels,\n required_fields=[\"name\"],\n )\n\n for level, difficulty_slug in enumerate(difficulty_levels):\n\n new_difficulty = ProgrammingChallengeDifficulty(\n level=level,\n )\n\n translations = difficulties_translations.get(difficulty_slug, dict())\n self.populate_translations(new_difficulty, translations)\n self.mark_translation_availability(new_difficulty, required_fields=[\"name\"])\n new_difficulty.save()\n\n self.log(\"Added programming difficulty level: {}\".format(new_difficulty.__str__()))\n\n self.log(\"\")\n", "path": "csunplugged/topics/management/commands/_ProgrammingChallengesStructureLoader.py"}]}
| 1,343 | 205 |
gh_patches_debug_12753
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-2056
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add custom properties for UTM code information
We are proposing to use UTM codes in query strings for various Benefits outreach campaigns. Read more about UTM codes in this article from Hubspot: https://blog.hubspot.com/marketing/what-are-utm-tracking-codes-ht
We need to implement these properties into the Amplitude analytics tracking to be able to later gauge campaign effectiveness.
The proposal is to add them as `event_properties` and `user_properties` in the `viewed page` event. This is likely the first event that a user following a tracked URL will generate. And having the properties on both the event and the user makes later analysis in Amplitude more flexible.
## Acceptance Criteria
<!-- Remember to consider edge cases -->
- [x] The [`viewed page` event](https://github.com/cal-itp/benefits/blob/dev/benefits/core/analytics.py#L90) is modified to capture UTM code information
- [x] Custom `event_properties` are added for each of the UTM codes:
- [ ] `utm_campaign`
- [ ] `utm_source`
- [ ] `utm_medium`
- [ ] `utm_content`
- [ ] `utm_id`
- [x] Custom `user_properties` are added for each of the UTM codes:
- [ ] `utm_campaign`
- [ ] `utm_source`
- [ ] `utm_medium`
- [ ] `utm_content`
- [ ] `utm_id`
## Additional context
UTM code information comes from the query string, accessible via the Django [`request.GET`](https://docs.djangoproject.com/en/5.0/ref/request-response/#django.http.HttpRequest.GET) attribute, an instance of [`QueryDict`](https://docs.djangoproject.com/en/5.0/ref/request-response/#django.http.QueryDict).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/core/analytics.py`
Content:
```
1 """
2 The core application: analytics implementation.
3 """
4
5 import itertools
6 import json
7 import logging
8 import re
9 import time
10 import uuid
11
12 from django.conf import settings
13 import requests
14
15 from benefits import VERSION
16 from benefits.core.models import EligibilityType
17 from . import session
18
19
20 logger = logging.getLogger(__name__)
21
22
23 class Event:
24 """Base analytics event of a given type, including attributes from request's session."""
25
26 _counter = itertools.count()
27 _domain_re = re.compile(r"^(?:https?:\/\/)?(?:[^@\n]+@)?(?:www\.)?([^:\/\n?]+)", re.IGNORECASE)
28
29 def __init__(self, request, event_type, **kwargs):
30 self.app_version = VERSION
31 # device_id is generated based on the user_id, and both are set explicitly (per session)
32 self.device_id = session.did(request)
33 self.event_properties = {}
34 self.event_type = str(event_type).lower()
35 self.insert_id = str(uuid.uuid4())
36 self.language = session.language(request)
37 # Amplitude tracks sessions using the start time as the session_id
38 self.session_id = session.start(request)
39 self.time = int(time.time() * 1000)
40 # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous
41 # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.
42 self.user_id = session.uid(request)
43 self.user_properties = {}
44 self.__dict__.update(kwargs)
45
46 agency = session.agency(request)
47 agency_name = agency.long_name if agency else None
48 verifier = session.verifier(request)
49 verifier_name = verifier.name if verifier else None
50 eligibility_types = session.eligibility(request)
51 eligibility_types = EligibilityType.get_names(eligibility_types) if eligibility_types else None
52
53 self.update_event_properties(
54 path=request.path,
55 transit_agency=agency_name,
56 eligibility_types=eligibility_types,
57 eligibility_verifier=verifier_name,
58 )
59
60 uagent = request.headers.get("user-agent")
61
62 ref = request.headers.get("referer")
63 match = Event._domain_re.match(ref) if ref else None
64 refdom = match.group(1) if match else None
65
66 self.update_user_properties(
67 referrer=ref,
68 referring_domain=refdom,
69 user_agent=uagent,
70 transit_agency=agency_name,
71 eligibility_types=eligibility_types,
72 eligibility_verifier=verifier_name,
73 )
74
75 # event is initialized, consume next counter
76 self.event_id = next(Event._counter)
77
78 def __str__(self):
79 return json.dumps(self.__dict__)
80
81 def update_event_properties(self, **kwargs):
82 """Merge kwargs into the self.event_properties dict."""
83 self.event_properties.update(kwargs)
84
85 def update_user_properties(self, **kwargs):
86 """Merge kwargs into the self.user_properties dict."""
87 self.user_properties.update(kwargs)
88
89
90 class ViewedPageEvent(Event):
91 """Analytics event representing a single page view."""
92
93 def __init__(self, request):
94 super().__init__(request, "viewed page")
95
96
97 class ChangedLanguageEvent(Event):
98 """Analytics event representing a change in the app's language."""
99
100 def __init__(self, request, new_lang):
101 super().__init__(request, "changed language")
102 self.update_event_properties(language=new_lang)
103
104
105 class Client:
106 """Analytics API client"""
107
108 def __init__(self, api_key):
109 self.api_key = api_key
110 self.headers = {"Accept": "*/*", "Content-type": "application/json"}
111 self.url = "https://api2.amplitude.com/2/httpapi"
112 logger.debug(f"Initialize Client for {self.url}")
113
114 def _payload(self, events):
115 if not isinstance(events, list):
116 events = [events]
117 return {"api_key": self.api_key, "events": [e.__dict__ for e in events]}
118
119 def send(self, event):
120 """Send an analytics event."""
121 if not isinstance(event, Event):
122 raise ValueError("event must be an Event instance")
123
124 if not self.api_key:
125 logger.warning(f"api_key is not configured, cannot send event: {event}")
126 return
127
128 try:
129 payload = self._payload(event)
130 logger.debug(f"Sending event payload: {payload}")
131
132 r = requests.post(
133 self.url,
134 headers=self.headers,
135 json=payload,
136 timeout=settings.REQUESTS_TIMEOUT,
137 )
138 if r.status_code == 200:
139 logger.debug(f"Event sent successfully: {r.json()}")
140 elif r.status_code == 400:
141 logger.error(f"Event request was invalid: {r.json()}")
142 elif r.status_code == 413:
143 logger.error(f"Event payload was too large: {r.json()}")
144 elif r.status_code == 429:
145 logger.error(f"Event contained too many requests for some users: {r.json()}")
146 else:
147 logger.error(f"Failed to send event: {r.json()}")
148
149 except Exception:
150 logger.error(f"Failed to send event: {event}")
151
152
153 client = Client(settings.ANALYTICS_KEY)
154
155
156 def send_event(event):
157 """Send an analytics event."""
158 if isinstance(event, Event):
159 client.send(event)
160 else:
161 raise ValueError("event must be an Event instance")
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benefits/core/analytics.py b/benefits/core/analytics.py
--- a/benefits/core/analytics.py
+++ b/benefits/core/analytics.py
@@ -92,6 +92,18 @@
def __init__(self, request):
super().__init__(request, "viewed page")
+ # Add UTM codes
+ utm_campaign = request.GET.get("utm_campaign")
+ utm_source = request.GET.get("utm_source")
+ utm_medium = request.GET.get("utm_medium")
+ utm_content = request.GET.get("utm_content")
+ utm_id = request.GET.get("utm_id")
+ self.update_event_properties(
+ utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id
+ )
+ self.update_user_properties(
+ utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id
+ )
class ChangedLanguageEvent(Event):
|
{"golden_diff": "diff --git a/benefits/core/analytics.py b/benefits/core/analytics.py\n--- a/benefits/core/analytics.py\n+++ b/benefits/core/analytics.py\n@@ -92,6 +92,18 @@\n \n def __init__(self, request):\n super().__init__(request, \"viewed page\")\n+ # Add UTM codes\n+ utm_campaign = request.GET.get(\"utm_campaign\")\n+ utm_source = request.GET.get(\"utm_source\")\n+ utm_medium = request.GET.get(\"utm_medium\")\n+ utm_content = request.GET.get(\"utm_content\")\n+ utm_id = request.GET.get(\"utm_id\")\n+ self.update_event_properties(\n+ utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id\n+ )\n+ self.update_user_properties(\n+ utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id\n+ )\n \n \n class ChangedLanguageEvent(Event):\n", "issue": "Add custom properties for UTM code information\nWe are proposing to use UTM codes in query strings for various Benefits outreach campaigns. Read more about UTM codes in this article from Hubspot: https://blog.hubspot.com/marketing/what-are-utm-tracking-codes-ht\r\n\r\nWe need to implement these properties into the Amplitude analytics tracking to be able to later gauge campaign effectiveness.\r\n\r\nThe proposal is to add them as `event_properties` and `user_properties` in the `viewed page` event. This is likely the first event that a user following a tracked URL will generate. And having the properties on both the event and the user makes later analysis in Amplitude more flexible.\r\n\r\n## Acceptance Criteria\r\n\r\n<!-- Remember to consider edge cases -->\r\n\r\n- [x] The [`viewed page` event](https://github.com/cal-itp/benefits/blob/dev/benefits/core/analytics.py#L90) is modified to capture UTM code information\r\n- [x] Custom `event_properties` are added for each of the UTM codes:\r\n - [ ] `utm_campaign`\r\n - [ ] `utm_source`\r\n - [ ] `utm_medium`\r\n - [ ] `utm_content`\r\n - [ ] `utm_id`\r\n- [x] Custom `user_properties` are added for each of the UTM codes:\r\n - [ ] `utm_campaign`\r\n - [ ] `utm_source`\r\n - [ ] `utm_medium`\r\n - [ ] `utm_content`\r\n - [ ] `utm_id`\r\n\r\n## Additional context\r\n\r\nUTM code information comes from the query string, accessible via the Django [`request.GET`](https://docs.djangoproject.com/en/5.0/ref/request-response/#django.http.HttpRequest.GET) attribute, an instance of [`QueryDict`](https://docs.djangoproject.com/en/5.0/ref/request-response/#django.http.QueryDict).\r\n\n", "before_files": [{"content": "\"\"\"\nThe core application: analytics implementation.\n\"\"\"\n\nimport itertools\nimport json\nimport logging\nimport re\nimport time\nimport uuid\n\nfrom django.conf import settings\nimport requests\n\nfrom benefits import VERSION\nfrom benefits.core.models import EligibilityType\nfrom . import session\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Event:\n \"\"\"Base analytics event of a given type, including attributes from request's session.\"\"\"\n\n _counter = itertools.count()\n _domain_re = re.compile(r\"^(?:https?:\\/\\/)?(?:[^@\\n]+@)?(?:www\\.)?([^:\\/\\n?]+)\", re.IGNORECASE)\n\n def __init__(self, request, event_type, **kwargs):\n self.app_version = VERSION\n # device_id is generated based on the user_id, and both are set explicitly (per session)\n self.device_id = session.did(request)\n self.event_properties = {}\n self.event_type = str(event_type).lower()\n self.insert_id = str(uuid.uuid4())\n self.language = session.language(request)\n # Amplitude tracks sessions using the start time as the session_id\n self.session_id = session.start(request)\n self.time = int(time.time() * 1000)\n # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous\n # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.\n self.user_id = session.uid(request)\n self.user_properties = {}\n self.__dict__.update(kwargs)\n\n agency = session.agency(request)\n agency_name = agency.long_name if agency else None\n verifier = session.verifier(request)\n verifier_name = verifier.name if verifier else None\n eligibility_types = session.eligibility(request)\n eligibility_types = EligibilityType.get_names(eligibility_types) if eligibility_types else None\n\n self.update_event_properties(\n path=request.path,\n transit_agency=agency_name,\n eligibility_types=eligibility_types,\n eligibility_verifier=verifier_name,\n )\n\n uagent = request.headers.get(\"user-agent\")\n\n ref = request.headers.get(\"referer\")\n match = Event._domain_re.match(ref) if ref else None\n refdom = match.group(1) if match else None\n\n self.update_user_properties(\n referrer=ref,\n referring_domain=refdom,\n user_agent=uagent,\n transit_agency=agency_name,\n eligibility_types=eligibility_types,\n eligibility_verifier=verifier_name,\n )\n\n # event is initialized, consume next counter\n self.event_id = next(Event._counter)\n\n def __str__(self):\n return json.dumps(self.__dict__)\n\n def update_event_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.event_properties dict.\"\"\"\n self.event_properties.update(kwargs)\n\n def update_user_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.user_properties dict.\"\"\"\n self.user_properties.update(kwargs)\n\n\nclass ViewedPageEvent(Event):\n \"\"\"Analytics event representing a single page view.\"\"\"\n\n def __init__(self, request):\n super().__init__(request, \"viewed page\")\n\n\nclass ChangedLanguageEvent(Event):\n \"\"\"Analytics event representing a change in the app's language.\"\"\"\n\n def __init__(self, request, new_lang):\n super().__init__(request, \"changed language\")\n self.update_event_properties(language=new_lang)\n\n\nclass Client:\n \"\"\"Analytics API client\"\"\"\n\n def __init__(self, api_key):\n self.api_key = api_key\n self.headers = {\"Accept\": \"*/*\", \"Content-type\": \"application/json\"}\n self.url = \"https://api2.amplitude.com/2/httpapi\"\n logger.debug(f\"Initialize Client for {self.url}\")\n\n def _payload(self, events):\n if not isinstance(events, list):\n events = [events]\n return {\"api_key\": self.api_key, \"events\": [e.__dict__ for e in events]}\n\n def send(self, event):\n \"\"\"Send an analytics event.\"\"\"\n if not isinstance(event, Event):\n raise ValueError(\"event must be an Event instance\")\n\n if not self.api_key:\n logger.warning(f\"api_key is not configured, cannot send event: {event}\")\n return\n\n try:\n payload = self._payload(event)\n logger.debug(f\"Sending event payload: {payload}\")\n\n r = requests.post(\n self.url,\n headers=self.headers,\n json=payload,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n if r.status_code == 200:\n logger.debug(f\"Event sent successfully: {r.json()}\")\n elif r.status_code == 400:\n logger.error(f\"Event request was invalid: {r.json()}\")\n elif r.status_code == 413:\n logger.error(f\"Event payload was too large: {r.json()}\")\n elif r.status_code == 429:\n logger.error(f\"Event contained too many requests for some users: {r.json()}\")\n else:\n logger.error(f\"Failed to send event: {r.json()}\")\n\n except Exception:\n logger.error(f\"Failed to send event: {event}\")\n\n\nclient = Client(settings.ANALYTICS_KEY)\n\n\ndef send_event(event):\n \"\"\"Send an analytics event.\"\"\"\n if isinstance(event, Event):\n client.send(event)\n else:\n raise ValueError(\"event must be an Event instance\")\n", "path": "benefits/core/analytics.py"}], "after_files": [{"content": "\"\"\"\nThe core application: analytics implementation.\n\"\"\"\n\nimport itertools\nimport json\nimport logging\nimport re\nimport time\nimport uuid\n\nfrom django.conf import settings\nimport requests\n\nfrom benefits import VERSION\nfrom benefits.core.models import EligibilityType\nfrom . import session\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Event:\n \"\"\"Base analytics event of a given type, including attributes from request's session.\"\"\"\n\n _counter = itertools.count()\n _domain_re = re.compile(r\"^(?:https?:\\/\\/)?(?:[^@\\n]+@)?(?:www\\.)?([^:\\/\\n?]+)\", re.IGNORECASE)\n\n def __init__(self, request, event_type, **kwargs):\n self.app_version = VERSION\n # device_id is generated based on the user_id, and both are set explicitly (per session)\n self.device_id = session.did(request)\n self.event_properties = {}\n self.event_type = str(event_type).lower()\n self.insert_id = str(uuid.uuid4())\n self.language = session.language(request)\n # Amplitude tracks sessions using the start time as the session_id\n self.session_id = session.start(request)\n self.time = int(time.time() * 1000)\n # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous\n # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.\n self.user_id = session.uid(request)\n self.user_properties = {}\n self.__dict__.update(kwargs)\n\n agency = session.agency(request)\n agency_name = agency.long_name if agency else None\n verifier = session.verifier(request)\n verifier_name = verifier.name if verifier else None\n eligibility_types = session.eligibility(request)\n eligibility_types = EligibilityType.get_names(eligibility_types) if eligibility_types else None\n\n self.update_event_properties(\n path=request.path,\n transit_agency=agency_name,\n eligibility_types=eligibility_types,\n eligibility_verifier=verifier_name,\n )\n\n uagent = request.headers.get(\"user-agent\")\n\n ref = request.headers.get(\"referer\")\n match = Event._domain_re.match(ref) if ref else None\n refdom = match.group(1) if match else None\n\n self.update_user_properties(\n referrer=ref,\n referring_domain=refdom,\n user_agent=uagent,\n transit_agency=agency_name,\n eligibility_types=eligibility_types,\n eligibility_verifier=verifier_name,\n )\n\n # event is initialized, consume next counter\n self.event_id = next(Event._counter)\n\n def __str__(self):\n return json.dumps(self.__dict__)\n\n def update_event_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.event_properties dict.\"\"\"\n self.event_properties.update(kwargs)\n\n def update_user_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.user_properties dict.\"\"\"\n self.user_properties.update(kwargs)\n\n\nclass ViewedPageEvent(Event):\n \"\"\"Analytics event representing a single page view.\"\"\"\n\n def __init__(self, request):\n super().__init__(request, \"viewed page\")\n # Add UTM codes\n utm_campaign = request.GET.get(\"utm_campaign\")\n utm_source = request.GET.get(\"utm_source\")\n utm_medium = request.GET.get(\"utm_medium\")\n utm_content = request.GET.get(\"utm_content\")\n utm_id = request.GET.get(\"utm_id\")\n self.update_event_properties(\n utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id\n )\n self.update_user_properties(\n utm_campaign=utm_campaign, utm_source=utm_source, utm_medium=utm_medium, utm_content=utm_content, utm_id=utm_id\n )\n\n\nclass ChangedLanguageEvent(Event):\n \"\"\"Analytics event representing a change in the app's language.\"\"\"\n\n def __init__(self, request, new_lang):\n super().__init__(request, \"changed language\")\n self.update_event_properties(language=new_lang)\n\n\nclass Client:\n \"\"\"Analytics API client\"\"\"\n\n def __init__(self, api_key):\n self.api_key = api_key\n self.headers = {\"Accept\": \"*/*\", \"Content-type\": \"application/json\"}\n self.url = \"https://api2.amplitude.com/2/httpapi\"\n logger.debug(f\"Initialize Client for {self.url}\")\n\n def _payload(self, events):\n if not isinstance(events, list):\n events = [events]\n return {\"api_key\": self.api_key, \"events\": [e.__dict__ for e in events]}\n\n def send(self, event):\n \"\"\"Send an analytics event.\"\"\"\n if not isinstance(event, Event):\n raise ValueError(\"event must be an Event instance\")\n\n if not self.api_key:\n logger.warning(f\"api_key is not configured, cannot send event: {event}\")\n return\n\n try:\n payload = self._payload(event)\n logger.debug(f\"Sending event payload: {payload}\")\n\n r = requests.post(\n self.url,\n headers=self.headers,\n json=payload,\n timeout=settings.REQUESTS_TIMEOUT,\n )\n if r.status_code == 200:\n logger.debug(f\"Event sent successfully: {r.json()}\")\n elif r.status_code == 400:\n logger.error(f\"Event request was invalid: {r.json()}\")\n elif r.status_code == 413:\n logger.error(f\"Event payload was too large: {r.json()}\")\n elif r.status_code == 429:\n logger.error(f\"Event contained too many requests for some users: {r.json()}\")\n else:\n logger.error(f\"Failed to send event: {r.json()}\")\n\n except Exception:\n logger.error(f\"Failed to send event: {event}\")\n\n\nclient = Client(settings.ANALYTICS_KEY)\n\n\ndef send_event(event):\n \"\"\"Send an analytics event.\"\"\"\n if isinstance(event, Event):\n client.send(event)\n else:\n raise ValueError(\"event must be an Event instance\")\n", "path": "benefits/core/analytics.py"}]}
| 2,201 | 249 |
gh_patches_debug_24775
|
rasdani/github-patches
|
git_diff
|
dj-stripe__dj-stripe-838
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Djstripe is suppressing backtraces that would otherwise be shown by the logging framework
Example logging config:
```
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'verbose': {
'format': '%(levelname)s %(asctime)s %(module)s %(process)d %(thread)d %(message)s'
},
},
'handlers': {
'file': {
'level': 'ERROR',
'class': 'logging.FileHandler',
'filename': os.path.join(BASE_DIR, 'logs/django.log'),
'formatter': 'verbose',
},
'mail_admins': {
'level': 'ERROR',
'class': 'django.utils.log.AdminEmailHandler',
'formatter': 'verbose',
},
},
'loggers': {
'django': {
'handlers': ['file', 'mail_admins'],
'level': 'ERROR',
'propagate': True,
},
},
}
```
Normally it would print an error and a backtrace, but it can't because djstripe is explicitly returning a 500 rather than raising the exception again!
I initially suggested that return line in https://github.com/dj-stripe/dj-stripe/blob/master/djstripe/views.py#L39 should be replaced with `raise trigger.exception`. Though I now realised that it's actually just a string as it's being processed in https://github.com/dj-stripe/dj-stripe/blob/master/djstripe/models/webhooks.py#L101
The correct solution would actually to remove the "return trigger.exception" from views.py, and reraise the exception in the code block I linked to in L101. Serializing it is fine, but also raise it again. Let django handle it.
Thoughts?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `djstripe/views.py`
Content:
```
1 """
2 dj-stripe - Views related to the djstripe app.
3 """
4 import logging
5
6 from django.http import HttpResponse, HttpResponseBadRequest, HttpResponseServerError
7 from django.utils.decorators import method_decorator
8 from django.views.decorators.csrf import csrf_exempt
9 from django.views.generic import View
10
11 from .models import WebhookEventTrigger
12
13 logger = logging.getLogger(__name__)
14
15
16 @method_decorator(csrf_exempt, name="dispatch")
17 class ProcessWebhookView(View):
18 """
19 A Stripe Webhook handler view.
20
21 This will create a WebhookEventTrigger instance, verify it,
22 then attempt to process it.
23
24 If the webhook cannot be verified, returns HTTP 400.
25
26 If an exception happens during processing, returns HTTP 500.
27 """
28
29 def post(self, request):
30 if "HTTP_STRIPE_SIGNATURE" not in request.META:
31 # Do not even attempt to process/store the event if there is
32 # no signature in the headers so we avoid overfilling the db.
33 return HttpResponseBadRequest()
34
35 trigger = WebhookEventTrigger.from_request(request)
36
37 if trigger.exception:
38 # An exception happened, return 500
39 return HttpResponseServerError()
40
41 if trigger.is_test_event:
42 # Since we don't do signature verification, we have to skip trigger.valid
43 return HttpResponse("Test webhook successfully received!")
44
45 if not trigger.valid:
46 # Webhook Event did not validate, return 400
47 return HttpResponseBadRequest()
48
49 return HttpResponse(str(trigger.id))
50
```
Path: `djstripe/models/webhooks.py`
Content:
```
1 import json
2 import warnings
3 from traceback import format_exc
4
5 import stripe
6 from django.db import models
7 from django.utils.functional import cached_property
8
9 from .. import settings as djstripe_settings
10 from .. import webhooks
11 from ..context_managers import stripe_temporary_api_version
12 from ..fields import JSONField
13 from ..signals import webhook_processing_error
14 from ..utils import fix_django_headers
15 from .base import logger
16 from .core import Event
17
18
19 def _get_version():
20 from .. import __version__
21
22 return __version__
23
24
25 class WebhookEventTrigger(models.Model):
26 """
27 An instance of a request that reached the server endpoint for Stripe webhooks.
28
29 Webhook Events are initially **UNTRUSTED**, as it is possible for any web entity to
30 post any data to our webhook url. Data posted may be valid Stripe information, garbage, or even malicious.
31 The 'valid' flag in this model monitors this.
32 """
33
34 id = models.BigAutoField(primary_key=True)
35 remote_ip = models.GenericIPAddressField(help_text="IP address of the request client.")
36 headers = JSONField()
37 body = models.TextField(blank=True)
38 valid = models.BooleanField(
39 default=False, help_text="Whether or not the webhook event has passed validation"
40 )
41 processed = models.BooleanField(
42 default=False,
43 help_text="Whether or not the webhook event has been successfully processed",
44 )
45 exception = models.CharField(max_length=128, blank=True)
46 traceback = models.TextField(
47 blank=True, help_text="Traceback if an exception was thrown during processing"
48 )
49 event = models.ForeignKey(
50 "Event",
51 on_delete=models.SET_NULL,
52 null=True,
53 blank=True,
54 help_text="Event object contained in the (valid) Webhook",
55 )
56 djstripe_version = models.CharField(
57 max_length=32,
58 default=_get_version, # Needs to be a callable, otherwise it's a db default.
59 help_text="The version of dj-stripe when the webhook was received",
60 )
61 created = models.DateTimeField(auto_now_add=True)
62 updated = models.DateTimeField(auto_now=True)
63
64 @classmethod
65 def from_request(cls, request):
66 """
67 Create, validate and process a WebhookEventTrigger given a Django
68 request object.
69
70 The process is three-fold:
71 1. Create a WebhookEventTrigger object from a Django request.
72 2. Validate the WebhookEventTrigger as a Stripe event using the API.
73 3. If valid, process it into an Event object (and child resource).
74 """
75
76 headers = fix_django_headers(request.META)
77 assert headers
78 try:
79 body = request.body.decode(request.encoding or "utf-8")
80 except Exception:
81 body = "(error decoding body)"
82
83 ip = request.META.get("REMOTE_ADDR")
84 if ip is None:
85 warnings.warn(
86 "Could not determine remote IP (missing REMOTE_ADDR). "
87 "This is likely an issue with your wsgi/server setup."
88 )
89 ip = "0.0.0.0"
90 obj = cls.objects.create(headers=headers, body=body, remote_ip=ip)
91
92 try:
93 obj.valid = obj.validate()
94 if obj.valid:
95 if djstripe_settings.WEBHOOK_EVENT_CALLBACK:
96 # If WEBHOOK_EVENT_CALLBACK, pass it for processing
97 djstripe_settings.WEBHOOK_EVENT_CALLBACK(obj)
98 else:
99 # Process the item (do not save it, it'll get saved below)
100 obj.process(save=False)
101 except Exception as e:
102 max_length = WebhookEventTrigger._meta.get_field("exception").max_length
103 obj.exception = str(e)[:max_length]
104 obj.traceback = format_exc()
105
106 # Send the exception as the webhook_processing_error signal
107 webhook_processing_error.send(
108 sender=WebhookEventTrigger, exception=e, data=getattr(e, "http_body", "")
109 )
110 finally:
111 obj.save()
112
113 return obj
114
115 @cached_property
116 def json_body(self):
117 try:
118 return json.loads(self.body)
119 except ValueError:
120 return {}
121
122 @property
123 def is_test_event(self):
124 return self.json_body.get("id") == webhooks.TEST_EVENT_ID
125
126 def validate(self, api_key=None):
127 """
128 The original contents of the Event message must be confirmed by
129 refetching it and comparing the fetched data with the original data.
130
131 This function makes an API call to Stripe to redownload the Event data
132 and returns whether or not it matches the WebhookEventTrigger data.
133 """
134
135 local_data = self.json_body
136 if "id" not in local_data or "livemode" not in local_data:
137 return False
138
139 if self.is_test_event:
140 logger.info("Test webhook received: {}".format(local_data))
141 return False
142
143 if djstripe_settings.WEBHOOK_VALIDATION is None:
144 # validation disabled
145 return True
146 elif (
147 djstripe_settings.WEBHOOK_VALIDATION == "verify_signature"
148 and djstripe_settings.WEBHOOK_SECRET
149 ):
150 try:
151 stripe.WebhookSignature.verify_header(
152 self.body,
153 self.headers.get("stripe-signature"),
154 djstripe_settings.WEBHOOK_SECRET,
155 djstripe_settings.WEBHOOK_TOLERANCE,
156 )
157 except stripe.error.SignatureVerificationError:
158 return False
159 else:
160 return True
161
162 livemode = local_data["livemode"]
163 api_key = api_key or djstripe_settings.get_default_api_key(livemode)
164
165 # Retrieve the event using the api_version specified in itself
166 with stripe_temporary_api_version(local_data["api_version"], validate=False):
167 remote_data = Event.stripe_class.retrieve(id=local_data["id"], api_key=api_key)
168
169 return local_data["data"] == remote_data["data"]
170
171 def process(self, save=True):
172 # Reset traceback and exception in case of reprocessing
173 self.exception = ""
174 self.traceback = ""
175
176 self.event = Event.process(self.json_body)
177 self.processed = True
178 if save:
179 self.save()
180
181 return self.event
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/djstripe/models/webhooks.py b/djstripe/models/webhooks.py
--- a/djstripe/models/webhooks.py
+++ b/djstripe/models/webhooks.py
@@ -107,6 +107,9 @@
webhook_processing_error.send(
sender=WebhookEventTrigger, exception=e, data=getattr(e, "http_body", "")
)
+
+ # re-raise the exception so Django sees it
+ raise e
finally:
obj.save()
diff --git a/djstripe/views.py b/djstripe/views.py
--- a/djstripe/views.py
+++ b/djstripe/views.py
@@ -3,7 +3,7 @@
"""
import logging
-from django.http import HttpResponse, HttpResponseBadRequest, HttpResponseServerError
+from django.http import HttpResponse, HttpResponseBadRequest
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt
from django.views.generic import View
@@ -34,10 +34,6 @@
trigger = WebhookEventTrigger.from_request(request)
- if trigger.exception:
- # An exception happened, return 500
- return HttpResponseServerError()
-
if trigger.is_test_event:
# Since we don't do signature verification, we have to skip trigger.valid
return HttpResponse("Test webhook successfully received!")
|
{"golden_diff": "diff --git a/djstripe/models/webhooks.py b/djstripe/models/webhooks.py\n--- a/djstripe/models/webhooks.py\n+++ b/djstripe/models/webhooks.py\n@@ -107,6 +107,9 @@\n \t\t\twebhook_processing_error.send(\n \t\t\t\tsender=WebhookEventTrigger, exception=e, data=getattr(e, \"http_body\", \"\")\n \t\t\t)\n+\n+\t\t\t# re-raise the exception so Django sees it\n+\t\t\traise e\n \t\tfinally:\n \t\t\tobj.save()\n \ndiff --git a/djstripe/views.py b/djstripe/views.py\n--- a/djstripe/views.py\n+++ b/djstripe/views.py\n@@ -3,7 +3,7 @@\n \"\"\"\n import logging\n \n-from django.http import HttpResponse, HttpResponseBadRequest, HttpResponseServerError\n+from django.http import HttpResponse, HttpResponseBadRequest\n from django.utils.decorators import method_decorator\n from django.views.decorators.csrf import csrf_exempt\n from django.views.generic import View\n@@ -34,10 +34,6 @@\n \n \t\ttrigger = WebhookEventTrigger.from_request(request)\n \n-\t\tif trigger.exception:\n-\t\t\t# An exception happened, return 500\n-\t\t\treturn HttpResponseServerError()\n-\n \t\tif trigger.is_test_event:\n \t\t\t# Since we don't do signature verification, we have to skip trigger.valid\n \t\t\treturn HttpResponse(\"Test webhook successfully received!\")\n", "issue": "Djstripe is suppressing backtraces that would otherwise be shown by the logging framework\nExample logging config:\r\n\r\n```\r\nLOGGING = {\r\n 'version': 1,\r\n 'disable_existing_loggers': False,\r\n 'formatters': {\r\n 'verbose': {\r\n 'format': '%(levelname)s %(asctime)s %(module)s %(process)d %(thread)d %(message)s'\r\n },\r\n },\r\n 'handlers': {\r\n 'file': {\r\n 'level': 'ERROR',\r\n 'class': 'logging.FileHandler',\r\n 'filename': os.path.join(BASE_DIR, 'logs/django.log'),\r\n 'formatter': 'verbose',\r\n },\r\n 'mail_admins': {\r\n 'level': 'ERROR',\r\n 'class': 'django.utils.log.AdminEmailHandler',\r\n 'formatter': 'verbose',\r\n },\r\n },\r\n 'loggers': {\r\n 'django': {\r\n 'handlers': ['file', 'mail_admins'],\r\n 'level': 'ERROR',\r\n 'propagate': True,\r\n },\r\n },\r\n}\r\n```\r\n\r\nNormally it would print an error and a backtrace, but it can't because djstripe is explicitly returning a 500 rather than raising the exception again!\r\n\r\nI initially suggested that return line in https://github.com/dj-stripe/dj-stripe/blob/master/djstripe/views.py#L39 should be replaced with `raise trigger.exception`. Though I now realised that it's actually just a string as it's being processed in https://github.com/dj-stripe/dj-stripe/blob/master/djstripe/models/webhooks.py#L101\r\nThe correct solution would actually to remove the \"return trigger.exception\" from views.py, and reraise the exception in the code block I linked to in L101. Serializing it is fine, but also raise it again. Let django handle it.\r\n\r\nThoughts?\n", "before_files": [{"content": "\"\"\"\ndj-stripe - Views related to the djstripe app.\n\"\"\"\nimport logging\n\nfrom django.http import HttpResponse, HttpResponseBadRequest, HttpResponseServerError\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.generic import View\n\nfrom .models import WebhookEventTrigger\n\nlogger = logging.getLogger(__name__)\n\n\n@method_decorator(csrf_exempt, name=\"dispatch\")\nclass ProcessWebhookView(View):\n\t\"\"\"\n\tA Stripe Webhook handler view.\n\n\tThis will create a WebhookEventTrigger instance, verify it,\n\tthen attempt to process it.\n\n\tIf the webhook cannot be verified, returns HTTP 400.\n\n\tIf an exception happens during processing, returns HTTP 500.\n\t\"\"\"\n\n\tdef post(self, request):\n\t\tif \"HTTP_STRIPE_SIGNATURE\" not in request.META:\n\t\t\t# Do not even attempt to process/store the event if there is\n\t\t\t# no signature in the headers so we avoid overfilling the db.\n\t\t\treturn HttpResponseBadRequest()\n\n\t\ttrigger = WebhookEventTrigger.from_request(request)\n\n\t\tif trigger.exception:\n\t\t\t# An exception happened, return 500\n\t\t\treturn HttpResponseServerError()\n\n\t\tif trigger.is_test_event:\n\t\t\t# Since we don't do signature verification, we have to skip trigger.valid\n\t\t\treturn HttpResponse(\"Test webhook successfully received!\")\n\n\t\tif not trigger.valid:\n\t\t\t# Webhook Event did not validate, return 400\n\t\t\treturn HttpResponseBadRequest()\n\n\t\treturn HttpResponse(str(trigger.id))\n", "path": "djstripe/views.py"}, {"content": "import json\nimport warnings\nfrom traceback import format_exc\n\nimport stripe\nfrom django.db import models\nfrom django.utils.functional import cached_property\n\nfrom .. import settings as djstripe_settings\nfrom .. import webhooks\nfrom ..context_managers import stripe_temporary_api_version\nfrom ..fields import JSONField\nfrom ..signals import webhook_processing_error\nfrom ..utils import fix_django_headers\nfrom .base import logger\nfrom .core import Event\n\n\ndef _get_version():\n\tfrom .. import __version__\n\n\treturn __version__\n\n\nclass WebhookEventTrigger(models.Model):\n\t\"\"\"\n\tAn instance of a request that reached the server endpoint for Stripe webhooks.\n\n\tWebhook Events are initially **UNTRUSTED**, as it is possible for any web entity to\n\tpost any data to our webhook url. Data posted may be valid Stripe information, garbage, or even malicious.\n\tThe 'valid' flag in this model monitors this.\n\t\"\"\"\n\n\tid = models.BigAutoField(primary_key=True)\n\tremote_ip = models.GenericIPAddressField(help_text=\"IP address of the request client.\")\n\theaders = JSONField()\n\tbody = models.TextField(blank=True)\n\tvalid = models.BooleanField(\n\t\tdefault=False, help_text=\"Whether or not the webhook event has passed validation\"\n\t)\n\tprocessed = models.BooleanField(\n\t\tdefault=False,\n\t\thelp_text=\"Whether or not the webhook event has been successfully processed\",\n\t)\n\texception = models.CharField(max_length=128, blank=True)\n\ttraceback = models.TextField(\n\t\tblank=True, help_text=\"Traceback if an exception was thrown during processing\"\n\t)\n\tevent = models.ForeignKey(\n\t\t\"Event\",\n\t\ton_delete=models.SET_NULL,\n\t\tnull=True,\n\t\tblank=True,\n\t\thelp_text=\"Event object contained in the (valid) Webhook\",\n\t)\n\tdjstripe_version = models.CharField(\n\t\tmax_length=32,\n\t\tdefault=_get_version, # Needs to be a callable, otherwise it's a db default.\n\t\thelp_text=\"The version of dj-stripe when the webhook was received\",\n\t)\n\tcreated = models.DateTimeField(auto_now_add=True)\n\tupdated = models.DateTimeField(auto_now=True)\n\n\t@classmethod\n\tdef from_request(cls, request):\n\t\t\"\"\"\n\t\tCreate, validate and process a WebhookEventTrigger given a Django\n\t\trequest object.\n\n\t\tThe process is three-fold:\n\t\t1. Create a WebhookEventTrigger object from a Django request.\n\t\t2. Validate the WebhookEventTrigger as a Stripe event using the API.\n\t\t3. If valid, process it into an Event object (and child resource).\n\t\t\"\"\"\n\n\t\theaders = fix_django_headers(request.META)\n\t\tassert headers\n\t\ttry:\n\t\t\tbody = request.body.decode(request.encoding or \"utf-8\")\n\t\texcept Exception:\n\t\t\tbody = \"(error decoding body)\"\n\n\t\tip = request.META.get(\"REMOTE_ADDR\")\n\t\tif ip is None:\n\t\t\twarnings.warn(\n\t\t\t\t\"Could not determine remote IP (missing REMOTE_ADDR). \"\n\t\t\t\t\"This is likely an issue with your wsgi/server setup.\"\n\t\t\t)\n\t\t\tip = \"0.0.0.0\"\n\t\tobj = cls.objects.create(headers=headers, body=body, remote_ip=ip)\n\n\t\ttry:\n\t\t\tobj.valid = obj.validate()\n\t\t\tif obj.valid:\n\t\t\t\tif djstripe_settings.WEBHOOK_EVENT_CALLBACK:\n\t\t\t\t\t# If WEBHOOK_EVENT_CALLBACK, pass it for processing\n\t\t\t\t\tdjstripe_settings.WEBHOOK_EVENT_CALLBACK(obj)\n\t\t\t\telse:\n\t\t\t\t\t# Process the item (do not save it, it'll get saved below)\n\t\t\t\t\tobj.process(save=False)\n\t\texcept Exception as e:\n\t\t\tmax_length = WebhookEventTrigger._meta.get_field(\"exception\").max_length\n\t\t\tobj.exception = str(e)[:max_length]\n\t\t\tobj.traceback = format_exc()\n\n\t\t\t# Send the exception as the webhook_processing_error signal\n\t\t\twebhook_processing_error.send(\n\t\t\t\tsender=WebhookEventTrigger, exception=e, data=getattr(e, \"http_body\", \"\")\n\t\t\t)\n\t\tfinally:\n\t\t\tobj.save()\n\n\t\treturn obj\n\n\t@cached_property\n\tdef json_body(self):\n\t\ttry:\n\t\t\treturn json.loads(self.body)\n\t\texcept ValueError:\n\t\t\treturn {}\n\n\t@property\n\tdef is_test_event(self):\n\t\treturn self.json_body.get(\"id\") == webhooks.TEST_EVENT_ID\n\n\tdef validate(self, api_key=None):\n\t\t\"\"\"\n\t\tThe original contents of the Event message must be confirmed by\n\t\trefetching it and comparing the fetched data with the original data.\n\n\t\tThis function makes an API call to Stripe to redownload the Event data\n\t\tand returns whether or not it matches the WebhookEventTrigger data.\n\t\t\"\"\"\n\n\t\tlocal_data = self.json_body\n\t\tif \"id\" not in local_data or \"livemode\" not in local_data:\n\t\t\treturn False\n\n\t\tif self.is_test_event:\n\t\t\tlogger.info(\"Test webhook received: {}\".format(local_data))\n\t\t\treturn False\n\n\t\tif djstripe_settings.WEBHOOK_VALIDATION is None:\n\t\t\t# validation disabled\n\t\t\treturn True\n\t\telif (\n\t\t\tdjstripe_settings.WEBHOOK_VALIDATION == \"verify_signature\"\n\t\t\tand djstripe_settings.WEBHOOK_SECRET\n\t\t):\n\t\t\ttry:\n\t\t\t\tstripe.WebhookSignature.verify_header(\n\t\t\t\t\tself.body,\n\t\t\t\t\tself.headers.get(\"stripe-signature\"),\n\t\t\t\t\tdjstripe_settings.WEBHOOK_SECRET,\n\t\t\t\t\tdjstripe_settings.WEBHOOK_TOLERANCE,\n\t\t\t\t)\n\t\t\texcept stripe.error.SignatureVerificationError:\n\t\t\t\treturn False\n\t\t\telse:\n\t\t\t\treturn True\n\n\t\tlivemode = local_data[\"livemode\"]\n\t\tapi_key = api_key or djstripe_settings.get_default_api_key(livemode)\n\n\t\t# Retrieve the event using the api_version specified in itself\n\t\twith stripe_temporary_api_version(local_data[\"api_version\"], validate=False):\n\t\t\tremote_data = Event.stripe_class.retrieve(id=local_data[\"id\"], api_key=api_key)\n\n\t\treturn local_data[\"data\"] == remote_data[\"data\"]\n\n\tdef process(self, save=True):\n\t\t# Reset traceback and exception in case of reprocessing\n\t\tself.exception = \"\"\n\t\tself.traceback = \"\"\n\n\t\tself.event = Event.process(self.json_body)\n\t\tself.processed = True\n\t\tif save:\n\t\t\tself.save()\n\n\t\treturn self.event\n", "path": "djstripe/models/webhooks.py"}], "after_files": [{"content": "\"\"\"\ndj-stripe - Views related to the djstripe app.\n\"\"\"\nimport logging\n\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.generic import View\n\nfrom .models import WebhookEventTrigger\n\nlogger = logging.getLogger(__name__)\n\n\n@method_decorator(csrf_exempt, name=\"dispatch\")\nclass ProcessWebhookView(View):\n\t\"\"\"\n\tA Stripe Webhook handler view.\n\n\tThis will create a WebhookEventTrigger instance, verify it,\n\tthen attempt to process it.\n\n\tIf the webhook cannot be verified, returns HTTP 400.\n\n\tIf an exception happens during processing, returns HTTP 500.\n\t\"\"\"\n\n\tdef post(self, request):\n\t\tif \"HTTP_STRIPE_SIGNATURE\" not in request.META:\n\t\t\t# Do not even attempt to process/store the event if there is\n\t\t\t# no signature in the headers so we avoid overfilling the db.\n\t\t\treturn HttpResponseBadRequest()\n\n\t\ttrigger = WebhookEventTrigger.from_request(request)\n\n\t\tif trigger.is_test_event:\n\t\t\t# Since we don't do signature verification, we have to skip trigger.valid\n\t\t\treturn HttpResponse(\"Test webhook successfully received!\")\n\n\t\tif not trigger.valid:\n\t\t\t# Webhook Event did not validate, return 400\n\t\t\treturn HttpResponseBadRequest()\n\n\t\treturn HttpResponse(str(trigger.id))\n", "path": "djstripe/views.py"}, {"content": "import json\nimport warnings\nfrom traceback import format_exc\n\nimport stripe\nfrom django.db import models\nfrom django.utils.functional import cached_property\n\nfrom .. import settings as djstripe_settings\nfrom .. import webhooks\nfrom ..context_managers import stripe_temporary_api_version\nfrom ..fields import JSONField\nfrom ..signals import webhook_processing_error\nfrom ..utils import fix_django_headers\nfrom .base import logger\nfrom .core import Event\n\n\ndef _get_version():\n\tfrom .. import __version__\n\n\treturn __version__\n\n\nclass WebhookEventTrigger(models.Model):\n\t\"\"\"\n\tAn instance of a request that reached the server endpoint for Stripe webhooks.\n\n\tWebhook Events are initially **UNTRUSTED**, as it is possible for any web entity to\n\tpost any data to our webhook url. Data posted may be valid Stripe information, garbage, or even malicious.\n\tThe 'valid' flag in this model monitors this.\n\t\"\"\"\n\n\tid = models.BigAutoField(primary_key=True)\n\tremote_ip = models.GenericIPAddressField(help_text=\"IP address of the request client.\")\n\theaders = JSONField()\n\tbody = models.TextField(blank=True)\n\tvalid = models.BooleanField(\n\t\tdefault=False, help_text=\"Whether or not the webhook event has passed validation\"\n\t)\n\tprocessed = models.BooleanField(\n\t\tdefault=False,\n\t\thelp_text=\"Whether or not the webhook event has been successfully processed\",\n\t)\n\texception = models.CharField(max_length=128, blank=True)\n\ttraceback = models.TextField(\n\t\tblank=True, help_text=\"Traceback if an exception was thrown during processing\"\n\t)\n\tevent = models.ForeignKey(\n\t\t\"Event\",\n\t\ton_delete=models.SET_NULL,\n\t\tnull=True,\n\t\tblank=True,\n\t\thelp_text=\"Event object contained in the (valid) Webhook\",\n\t)\n\tdjstripe_version = models.CharField(\n\t\tmax_length=32,\n\t\tdefault=_get_version, # Needs to be a callable, otherwise it's a db default.\n\t\thelp_text=\"The version of dj-stripe when the webhook was received\",\n\t)\n\tcreated = models.DateTimeField(auto_now_add=True)\n\tupdated = models.DateTimeField(auto_now=True)\n\n\t@classmethod\n\tdef from_request(cls, request):\n\t\t\"\"\"\n\t\tCreate, validate and process a WebhookEventTrigger given a Django\n\t\trequest object.\n\n\t\tThe process is three-fold:\n\t\t1. Create a WebhookEventTrigger object from a Django request.\n\t\t2. Validate the WebhookEventTrigger as a Stripe event using the API.\n\t\t3. If valid, process it into an Event object (and child resource).\n\t\t\"\"\"\n\n\t\theaders = fix_django_headers(request.META)\n\t\tassert headers\n\t\ttry:\n\t\t\tbody = request.body.decode(request.encoding or \"utf-8\")\n\t\texcept Exception:\n\t\t\tbody = \"(error decoding body)\"\n\n\t\tip = request.META.get(\"REMOTE_ADDR\")\n\t\tif ip is None:\n\t\t\twarnings.warn(\n\t\t\t\t\"Could not determine remote IP (missing REMOTE_ADDR). \"\n\t\t\t\t\"This is likely an issue with your wsgi/server setup.\"\n\t\t\t)\n\t\t\tip = \"0.0.0.0\"\n\t\tobj = cls.objects.create(headers=headers, body=body, remote_ip=ip)\n\n\t\ttry:\n\t\t\tobj.valid = obj.validate()\n\t\t\tif obj.valid:\n\t\t\t\tif djstripe_settings.WEBHOOK_EVENT_CALLBACK:\n\t\t\t\t\t# If WEBHOOK_EVENT_CALLBACK, pass it for processing\n\t\t\t\t\tdjstripe_settings.WEBHOOK_EVENT_CALLBACK(obj)\n\t\t\t\telse:\n\t\t\t\t\t# Process the item (do not save it, it'll get saved below)\n\t\t\t\t\tobj.process(save=False)\n\t\texcept Exception as e:\n\t\t\tmax_length = WebhookEventTrigger._meta.get_field(\"exception\").max_length\n\t\t\tobj.exception = str(e)[:max_length]\n\t\t\tobj.traceback = format_exc()\n\n\t\t\t# Send the exception as the webhook_processing_error signal\n\t\t\twebhook_processing_error.send(\n\t\t\t\tsender=WebhookEventTrigger, exception=e, data=getattr(e, \"http_body\", \"\")\n\t\t\t)\n\n\t\t\t# re-raise the exception so Django sees it\n\t\t\traise e\n\t\tfinally:\n\t\t\tobj.save()\n\n\t\treturn obj\n\n\t@cached_property\n\tdef json_body(self):\n\t\ttry:\n\t\t\treturn json.loads(self.body)\n\t\texcept ValueError:\n\t\t\treturn {}\n\n\t@property\n\tdef is_test_event(self):\n\t\treturn self.json_body.get(\"id\") == webhooks.TEST_EVENT_ID\n\n\tdef validate(self, api_key=None):\n\t\t\"\"\"\n\t\tThe original contents of the Event message must be confirmed by\n\t\trefetching it and comparing the fetched data with the original data.\n\n\t\tThis function makes an API call to Stripe to redownload the Event data\n\t\tand returns whether or not it matches the WebhookEventTrigger data.\n\t\t\"\"\"\n\n\t\tlocal_data = self.json_body\n\t\tif \"id\" not in local_data or \"livemode\" not in local_data:\n\t\t\treturn False\n\n\t\tif self.is_test_event:\n\t\t\tlogger.info(\"Test webhook received: {}\".format(local_data))\n\t\t\treturn False\n\n\t\tif djstripe_settings.WEBHOOK_VALIDATION is None:\n\t\t\t# validation disabled\n\t\t\treturn True\n\t\telif (\n\t\t\tdjstripe_settings.WEBHOOK_VALIDATION == \"verify_signature\"\n\t\t\tand djstripe_settings.WEBHOOK_SECRET\n\t\t):\n\t\t\ttry:\n\t\t\t\tstripe.WebhookSignature.verify_header(\n\t\t\t\t\tself.body,\n\t\t\t\t\tself.headers.get(\"stripe-signature\"),\n\t\t\t\t\tdjstripe_settings.WEBHOOK_SECRET,\n\t\t\t\t\tdjstripe_settings.WEBHOOK_TOLERANCE,\n\t\t\t\t)\n\t\t\texcept stripe.error.SignatureVerificationError:\n\t\t\t\treturn False\n\t\t\telse:\n\t\t\t\treturn True\n\n\t\tlivemode = local_data[\"livemode\"]\n\t\tapi_key = api_key or djstripe_settings.get_default_api_key(livemode)\n\n\t\t# Retrieve the event using the api_version specified in itself\n\t\twith stripe_temporary_api_version(local_data[\"api_version\"], validate=False):\n\t\t\tremote_data = Event.stripe_class.retrieve(id=local_data[\"id\"], api_key=api_key)\n\n\t\treturn local_data[\"data\"] == remote_data[\"data\"]\n\n\tdef process(self, save=True):\n\t\t# Reset traceback and exception in case of reprocessing\n\t\tself.exception = \"\"\n\t\tself.traceback = \"\"\n\n\t\tself.event = Event.process(self.json_body)\n\t\tself.processed = True\n\t\tif save:\n\t\t\tself.save()\n\n\t\treturn self.event\n", "path": "djstripe/models/webhooks.py"}]}
| 2,881 | 293 |
gh_patches_debug_35415
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-3099
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TypeError: '<' not supported between instances of 'NoneType' and 'str'
### Infos
We're using DD to monitor our systems. From time to time we see the following errors popping up in our Sentry environment.
Maybe related to #3019?
### Which version of dd-trace-py are you using?
0.56.0
### Which version of pip are you using?
latest
### What is the result that you get?
```
TypeError: '<' not supported between instances of 'NoneType' and 'str'
File "ddtrace/profiling/scheduler.py", line 53, in flush
exp.export(events, start, self._last_export)
File "ddtrace/profiling/exporter/http.py", line 150, in export
profile = super(PprofHTTPExporter, self).export(events, start_time_ns, end_time_ns)
File "ddtrace/profiling/exporter/pprof.pyx", line 630, in ddtrace.profiling.exporter.pprof.PprofExporter.export
File "ddtrace/profiling/exporter/pprof.pyx", line 314, in ddtrace.profiling.exporter.pprof._PprofConverter._build_profile
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/profiling/event.py`
Content:
```
1 import typing
2
3 import attr
4
5 from ddtrace import span as ddspan
6 from ddtrace.internal import compat
7
8
9 _T = typing.TypeVar("_T")
10
11 # (filename, line number, function name)
12 FrameType = typing.Tuple[str, int, typing.Optional[str]]
13 StackTraceType = typing.List[FrameType]
14
15
16 def event_class(
17 klass, # type: typing.Type[_T]
18 ):
19 # type: (...) -> typing.Type[_T]
20 return attr.s(slots=True)(klass)
21
22
23 @event_class
24 class Event(object):
25 """An event happening at a point in time."""
26
27 timestamp = attr.ib(factory=compat.time_ns)
28
29 @property
30 def name(self):
31 # type: (...) -> str
32 """Name of the event."""
33 return self.__class__.__name__
34
35
36 @event_class
37 class TimedEvent(Event):
38 """An event that has a duration."""
39
40 duration = attr.ib(default=None)
41
42
43 @event_class
44 class SampleEvent(Event):
45 """An event representing a sample gathered from the system."""
46
47 sampling_period = attr.ib(default=None)
48
49
50 @event_class
51 class StackBasedEvent(SampleEvent):
52 thread_id = attr.ib(default=None, type=typing.Optional[int])
53 thread_name = attr.ib(default=None, type=typing.Optional[str])
54 thread_native_id = attr.ib(default=None, type=typing.Optional[int])
55 task_id = attr.ib(default=None, type=typing.Optional[int])
56 task_name = attr.ib(default=None, type=typing.Optional[str])
57 frames = attr.ib(default=None, type=StackTraceType)
58 nframes = attr.ib(default=0, type=int)
59 local_root_span_id = attr.ib(default=None, type=typing.Optional[int])
60 span_id = attr.ib(default=None, type=typing.Optional[int])
61 trace_type = attr.ib(default=None, type=typing.Optional[str])
62 trace_resource_container = attr.ib(default=None, type=typing.List[str])
63
64 def set_trace_info(
65 self,
66 span, # type: typing.Optional[ddspan.Span]
67 endpoint_collection_enabled, # type: bool
68 ):
69 # type: (...) -> None
70 if span:
71 self.span_id = span.span_id
72 if span._local_root is not None:
73 self.local_root_span_id = span._local_root.span_id
74 self.trace_type = span._local_root._span_type
75 if endpoint_collection_enabled:
76 self.trace_resource_container = span._local_root._resource
77
```
Path: `ddtrace/profiling/collector/threading.py`
Content:
```
1 from __future__ import absolute_import
2
3 import os.path
4 import sys
5 import threading
6 import typing
7
8 import attr
9
10 from ddtrace.internal import compat
11 from ddtrace.internal import nogevent
12 from ddtrace.internal.utils import attr as attr_utils
13 from ddtrace.internal.utils import formats
14 from ddtrace.profiling import collector
15 from ddtrace.profiling import event
16 from ddtrace.profiling.collector import _task
17 from ddtrace.profiling.collector import _threading
18 from ddtrace.profiling.collector import _traceback
19 from ddtrace.vendor import wrapt
20
21
22 @event.event_class
23 class LockEventBase(event.StackBasedEvent):
24 """Base Lock event."""
25
26 lock_name = attr.ib(default="<unknown lock name>", type=str)
27 sampling_pct = attr.ib(default=0, type=int)
28
29
30 @event.event_class
31 class LockAcquireEvent(LockEventBase):
32 """A lock has been acquired."""
33
34 wait_time_ns = attr.ib(default=0, type=int)
35
36
37 @event.event_class
38 class LockReleaseEvent(LockEventBase):
39 """A lock has been released."""
40
41 locked_for_ns = attr.ib(default=0, type=int)
42
43
44 def _current_thread():
45 # type: (...) -> typing.Tuple[int, str]
46 thread_id = nogevent.thread_get_ident()
47 return thread_id, _threading.get_thread_name(thread_id)
48
49
50 # We need to know if wrapt is compiled in C or not. If it's not using the C module, then the wrappers function will
51 # appear in the stack trace and we need to hide it.
52 if os.environ.get("WRAPT_DISABLE_EXTENSIONS"):
53 WRAPT_C_EXT = False
54 else:
55 try:
56 import ddtrace.vendor.wrapt._wrappers as _w # noqa: F401
57 except ImportError:
58 WRAPT_C_EXT = False
59 else:
60 WRAPT_C_EXT = True
61 del _w
62
63
64 class _ProfiledLock(wrapt.ObjectProxy):
65 def __init__(self, wrapped, recorder, tracer, max_nframes, capture_sampler, endpoint_collection_enabled):
66 wrapt.ObjectProxy.__init__(self, wrapped)
67 self._self_recorder = recorder
68 self._self_tracer = tracer
69 self._self_max_nframes = max_nframes
70 self._self_capture_sampler = capture_sampler
71 self._self_endpoint_collection_enabled = endpoint_collection_enabled
72 frame = sys._getframe(2 if WRAPT_C_EXT else 3)
73 code = frame.f_code
74 self._self_name = "%s:%d" % (os.path.basename(code.co_filename), frame.f_lineno)
75
76 def acquire(self, *args, **kwargs):
77 if not self._self_capture_sampler.capture():
78 return self.__wrapped__.acquire(*args, **kwargs)
79
80 start = compat.monotonic_ns()
81 try:
82 return self.__wrapped__.acquire(*args, **kwargs)
83 finally:
84 try:
85 end = self._self_acquired_at = compat.monotonic_ns()
86 thread_id, thread_name = _current_thread()
87 task_id, task_name, task_frame = _task.get_task(thread_id)
88
89 if task_frame is None:
90 frame = sys._getframe(1)
91 else:
92 frame = task_frame
93
94 frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)
95
96 event = LockAcquireEvent(
97 lock_name=self._self_name,
98 frames=frames,
99 nframes=nframes,
100 thread_id=thread_id,
101 thread_name=thread_name,
102 task_id=task_id,
103 task_name=task_name,
104 wait_time_ns=end - start,
105 sampling_pct=self._self_capture_sampler.capture_pct,
106 )
107
108 if self._self_tracer is not None:
109 event.set_trace_info(self._self_tracer.current_span(), self._self_endpoint_collection_enabled)
110
111 self._self_recorder.push_event(event)
112 except Exception:
113 pass
114
115 def release(
116 self,
117 *args, # type: typing.Any
118 **kwargs # type: typing.Any
119 ):
120 # type: (...) -> None
121 try:
122 return self.__wrapped__.release(*args, **kwargs)
123 finally:
124 try:
125 if hasattr(self, "_self_acquired_at"):
126 try:
127 end = compat.monotonic_ns()
128 thread_id, thread_name = _current_thread()
129 task_id, task_name, task_frame = _task.get_task(thread_id)
130
131 if task_frame is None:
132 frame = sys._getframe(1)
133 else:
134 frame = task_frame
135
136 frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)
137
138 event = LockReleaseEvent( # type: ignore[call-arg]
139 lock_name=self._self_name,
140 frames=frames,
141 nframes=nframes,
142 thread_id=thread_id,
143 thread_name=thread_name,
144 task_id=task_id,
145 task_name=task_name,
146 locked_for_ns=end - self._self_acquired_at,
147 sampling_pct=self._self_capture_sampler.capture_pct,
148 )
149
150 if self._self_tracer is not None:
151 event.set_trace_info(
152 self._self_tracer.current_span(), self._self_endpoint_collection_enabled
153 )
154
155 self._self_recorder.push_event(event)
156 finally:
157 del self._self_acquired_at
158 except Exception:
159 pass
160
161 acquire_lock = acquire
162
163
164 class FunctionWrapper(wrapt.FunctionWrapper):
165 # Override the __get__ method: whatever happens, _allocate_lock is always considered by Python like a "static"
166 # method, even when used as a class attribute. Python never tried to "bind" it to a method, because it sees it is a
167 # builtin function. Override default wrapt behavior here that tries to detect bound method.
168 def __get__(self, instance, owner=None):
169 return self
170
171
172 @attr.s
173 class LockCollector(collector.CaptureSamplerCollector):
174 """Record lock usage."""
175
176 nframes = attr.ib(factory=attr_utils.from_env("DD_PROFILING_MAX_FRAMES", 64, int))
177 endpoint_collection_enabled = attr.ib(
178 factory=attr_utils.from_env("DD_PROFILING_ENDPOINT_COLLECTION_ENABLED", True, formats.asbool)
179 )
180
181 tracer = attr.ib(default=None)
182
183 def _start_service(self): # type: ignore[override]
184 # type: (...) -> None
185 """Start collecting `threading.Lock` usage."""
186 self.patch()
187 super(LockCollector, self)._start_service()
188
189 def _stop_service(self): # type: ignore[override]
190 # type: (...) -> None
191 """Stop collecting `threading.Lock` usage."""
192 super(LockCollector, self)._stop_service()
193 self.unpatch()
194
195 def patch(self):
196 # type: (...) -> None
197 """Patch the threading module for tracking lock allocation."""
198 # We only patch the lock from the `threading` module.
199 # Nobody should use locks from `_thread`; if they do so, then it's deliberate and we don't profile.
200 self.original = threading.Lock
201
202 def _allocate_lock(wrapped, instance, args, kwargs):
203 lock = wrapped(*args, **kwargs)
204 return _ProfiledLock(
205 lock, self.recorder, self.tracer, self.nframes, self._capture_sampler, self.endpoint_collection_enabled
206 )
207
208 threading.Lock = FunctionWrapper(self.original, _allocate_lock) # type: ignore[misc]
209
210 def unpatch(self):
211 # type: (...) -> None
212 """Unpatch the threading module for tracking lock allocation."""
213 threading.Lock = self.original # type: ignore[misc]
214
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/profiling/collector/threading.py b/ddtrace/profiling/collector/threading.py
--- a/ddtrace/profiling/collector/threading.py
+++ b/ddtrace/profiling/collector/threading.py
@@ -7,6 +7,7 @@
import attr
+import ddtrace
from ddtrace.internal import compat
from ddtrace.internal import nogevent
from ddtrace.internal.utils import attr as attr_utils
@@ -19,6 +20,10 @@
from ddtrace.vendor import wrapt
+if typing.TYPE_CHECKING:
+ from ddtrace.profiling import recorder as ddrecorder
+
+
@event.event_class
class LockEventBase(event.StackBasedEvent):
"""Base Lock event."""
@@ -62,7 +67,16 @@
class _ProfiledLock(wrapt.ObjectProxy):
- def __init__(self, wrapped, recorder, tracer, max_nframes, capture_sampler, endpoint_collection_enabled):
+ def __init__(
+ self,
+ wrapped, # type: threading.Lock
+ recorder, # type: ddrecorder.Recorder
+ tracer, # type: ddtrace.Tracer
+ max_nframes, # type: int
+ capture_sampler, # type: collector.CaptureSampler
+ endpoint_collection_enabled, # type: bool
+ ):
+ # type: (...) -> None
wrapt.ObjectProxy.__init__(self, wrapped)
self._self_recorder = recorder
self._self_tracer = tracer
@@ -71,7 +85,10 @@
self._self_endpoint_collection_enabled = endpoint_collection_enabled
frame = sys._getframe(2 if WRAPT_C_EXT else 3)
code = frame.f_code
- self._self_name = "%s:%d" % (os.path.basename(code.co_filename), frame.f_lineno)
+ self._self_name = "%s:%d" % (
+ os.path.basename(code.co_filename),
+ 0 if frame.f_lineno is None else frame.f_lineno,
+ )
def acquire(self, *args, **kwargs):
if not self._self_capture_sampler.capture():
diff --git a/ddtrace/profiling/event.py b/ddtrace/profiling/event.py
--- a/ddtrace/profiling/event.py
+++ b/ddtrace/profiling/event.py
@@ -9,7 +9,7 @@
_T = typing.TypeVar("_T")
# (filename, line number, function name)
-FrameType = typing.Tuple[str, int, typing.Optional[str]]
+FrameType = typing.Tuple[str, int, str]
StackTraceType = typing.List[FrameType]
|
{"golden_diff": "diff --git a/ddtrace/profiling/collector/threading.py b/ddtrace/profiling/collector/threading.py\n--- a/ddtrace/profiling/collector/threading.py\n+++ b/ddtrace/profiling/collector/threading.py\n@@ -7,6 +7,7 @@\n \n import attr\n \n+import ddtrace\n from ddtrace.internal import compat\n from ddtrace.internal import nogevent\n from ddtrace.internal.utils import attr as attr_utils\n@@ -19,6 +20,10 @@\n from ddtrace.vendor import wrapt\n \n \n+if typing.TYPE_CHECKING:\n+ from ddtrace.profiling import recorder as ddrecorder\n+\n+\n @event.event_class\n class LockEventBase(event.StackBasedEvent):\n \"\"\"Base Lock event.\"\"\"\n@@ -62,7 +67,16 @@\n \n \n class _ProfiledLock(wrapt.ObjectProxy):\n- def __init__(self, wrapped, recorder, tracer, max_nframes, capture_sampler, endpoint_collection_enabled):\n+ def __init__(\n+ self,\n+ wrapped, # type: threading.Lock\n+ recorder, # type: ddrecorder.Recorder\n+ tracer, # type: ddtrace.Tracer\n+ max_nframes, # type: int\n+ capture_sampler, # type: collector.CaptureSampler\n+ endpoint_collection_enabled, # type: bool\n+ ):\n+ # type: (...) -> None\n wrapt.ObjectProxy.__init__(self, wrapped)\n self._self_recorder = recorder\n self._self_tracer = tracer\n@@ -71,7 +85,10 @@\n self._self_endpoint_collection_enabled = endpoint_collection_enabled\n frame = sys._getframe(2 if WRAPT_C_EXT else 3)\n code = frame.f_code\n- self._self_name = \"%s:%d\" % (os.path.basename(code.co_filename), frame.f_lineno)\n+ self._self_name = \"%s:%d\" % (\n+ os.path.basename(code.co_filename),\n+ 0 if frame.f_lineno is None else frame.f_lineno,\n+ )\n \n def acquire(self, *args, **kwargs):\n if not self._self_capture_sampler.capture():\ndiff --git a/ddtrace/profiling/event.py b/ddtrace/profiling/event.py\n--- a/ddtrace/profiling/event.py\n+++ b/ddtrace/profiling/event.py\n@@ -9,7 +9,7 @@\n _T = typing.TypeVar(\"_T\")\n \n # (filename, line number, function name)\n-FrameType = typing.Tuple[str, int, typing.Optional[str]]\n+FrameType = typing.Tuple[str, int, str]\n StackTraceType = typing.List[FrameType]\n", "issue": "TypeError: '<' not supported between instances of 'NoneType' and 'str'\n### Infos\r\nWe're using DD to monitor our systems. From time to time we see the following errors popping up in our Sentry environment.\r\n\r\nMaybe related to #3019?\r\n\r\n### Which version of dd-trace-py are you using?\r\n0.56.0\r\n\r\n### Which version of pip are you using?\r\nlatest\r\n\r\n### What is the result that you get?\r\n``` \r\nTypeError: '<' not supported between instances of 'NoneType' and 'str'\r\n File \"ddtrace/profiling/scheduler.py\", line 53, in flush\r\n exp.export(events, start, self._last_export)\r\n File \"ddtrace/profiling/exporter/http.py\", line 150, in export\r\n profile = super(PprofHTTPExporter, self).export(events, start_time_ns, end_time_ns)\r\n File \"ddtrace/profiling/exporter/pprof.pyx\", line 630, in ddtrace.profiling.exporter.pprof.PprofExporter.export\r\n File \"ddtrace/profiling/exporter/pprof.pyx\", line 314, in ddtrace.profiling.exporter.pprof._PprofConverter._build_profile\r\n```\n", "before_files": [{"content": "import typing\n\nimport attr\n\nfrom ddtrace import span as ddspan\nfrom ddtrace.internal import compat\n\n\n_T = typing.TypeVar(\"_T\")\n\n# (filename, line number, function name)\nFrameType = typing.Tuple[str, int, typing.Optional[str]]\nStackTraceType = typing.List[FrameType]\n\n\ndef event_class(\n klass, # type: typing.Type[_T]\n):\n # type: (...) -> typing.Type[_T]\n return attr.s(slots=True)(klass)\n\n\n@event_class\nclass Event(object):\n \"\"\"An event happening at a point in time.\"\"\"\n\n timestamp = attr.ib(factory=compat.time_ns)\n\n @property\n def name(self):\n # type: (...) -> str\n \"\"\"Name of the event.\"\"\"\n return self.__class__.__name__\n\n\n@event_class\nclass TimedEvent(Event):\n \"\"\"An event that has a duration.\"\"\"\n\n duration = attr.ib(default=None)\n\n\n@event_class\nclass SampleEvent(Event):\n \"\"\"An event representing a sample gathered from the system.\"\"\"\n\n sampling_period = attr.ib(default=None)\n\n\n@event_class\nclass StackBasedEvent(SampleEvent):\n thread_id = attr.ib(default=None, type=typing.Optional[int])\n thread_name = attr.ib(default=None, type=typing.Optional[str])\n thread_native_id = attr.ib(default=None, type=typing.Optional[int])\n task_id = attr.ib(default=None, type=typing.Optional[int])\n task_name = attr.ib(default=None, type=typing.Optional[str])\n frames = attr.ib(default=None, type=StackTraceType)\n nframes = attr.ib(default=0, type=int)\n local_root_span_id = attr.ib(default=None, type=typing.Optional[int])\n span_id = attr.ib(default=None, type=typing.Optional[int])\n trace_type = attr.ib(default=None, type=typing.Optional[str])\n trace_resource_container = attr.ib(default=None, type=typing.List[str])\n\n def set_trace_info(\n self,\n span, # type: typing.Optional[ddspan.Span]\n endpoint_collection_enabled, # type: bool\n ):\n # type: (...) -> None\n if span:\n self.span_id = span.span_id\n if span._local_root is not None:\n self.local_root_span_id = span._local_root.span_id\n self.trace_type = span._local_root._span_type\n if endpoint_collection_enabled:\n self.trace_resource_container = span._local_root._resource\n", "path": "ddtrace/profiling/event.py"}, {"content": "from __future__ import absolute_import\n\nimport os.path\nimport sys\nimport threading\nimport typing\n\nimport attr\n\nfrom ddtrace.internal import compat\nfrom ddtrace.internal import nogevent\nfrom ddtrace.internal.utils import attr as attr_utils\nfrom ddtrace.internal.utils import formats\nfrom ddtrace.profiling import collector\nfrom ddtrace.profiling import event\nfrom ddtrace.profiling.collector import _task\nfrom ddtrace.profiling.collector import _threading\nfrom ddtrace.profiling.collector import _traceback\nfrom ddtrace.vendor import wrapt\n\n\[email protected]_class\nclass LockEventBase(event.StackBasedEvent):\n \"\"\"Base Lock event.\"\"\"\n\n lock_name = attr.ib(default=\"<unknown lock name>\", type=str)\n sampling_pct = attr.ib(default=0, type=int)\n\n\[email protected]_class\nclass LockAcquireEvent(LockEventBase):\n \"\"\"A lock has been acquired.\"\"\"\n\n wait_time_ns = attr.ib(default=0, type=int)\n\n\[email protected]_class\nclass LockReleaseEvent(LockEventBase):\n \"\"\"A lock has been released.\"\"\"\n\n locked_for_ns = attr.ib(default=0, type=int)\n\n\ndef _current_thread():\n # type: (...) -> typing.Tuple[int, str]\n thread_id = nogevent.thread_get_ident()\n return thread_id, _threading.get_thread_name(thread_id)\n\n\n# We need to know if wrapt is compiled in C or not. If it's not using the C module, then the wrappers function will\n# appear in the stack trace and we need to hide it.\nif os.environ.get(\"WRAPT_DISABLE_EXTENSIONS\"):\n WRAPT_C_EXT = False\nelse:\n try:\n import ddtrace.vendor.wrapt._wrappers as _w # noqa: F401\n except ImportError:\n WRAPT_C_EXT = False\n else:\n WRAPT_C_EXT = True\n del _w\n\n\nclass _ProfiledLock(wrapt.ObjectProxy):\n def __init__(self, wrapped, recorder, tracer, max_nframes, capture_sampler, endpoint_collection_enabled):\n wrapt.ObjectProxy.__init__(self, wrapped)\n self._self_recorder = recorder\n self._self_tracer = tracer\n self._self_max_nframes = max_nframes\n self._self_capture_sampler = capture_sampler\n self._self_endpoint_collection_enabled = endpoint_collection_enabled\n frame = sys._getframe(2 if WRAPT_C_EXT else 3)\n code = frame.f_code\n self._self_name = \"%s:%d\" % (os.path.basename(code.co_filename), frame.f_lineno)\n\n def acquire(self, *args, **kwargs):\n if not self._self_capture_sampler.capture():\n return self.__wrapped__.acquire(*args, **kwargs)\n\n start = compat.monotonic_ns()\n try:\n return self.__wrapped__.acquire(*args, **kwargs)\n finally:\n try:\n end = self._self_acquired_at = compat.monotonic_ns()\n thread_id, thread_name = _current_thread()\n task_id, task_name, task_frame = _task.get_task(thread_id)\n\n if task_frame is None:\n frame = sys._getframe(1)\n else:\n frame = task_frame\n\n frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)\n\n event = LockAcquireEvent(\n lock_name=self._self_name,\n frames=frames,\n nframes=nframes,\n thread_id=thread_id,\n thread_name=thread_name,\n task_id=task_id,\n task_name=task_name,\n wait_time_ns=end - start,\n sampling_pct=self._self_capture_sampler.capture_pct,\n )\n\n if self._self_tracer is not None:\n event.set_trace_info(self._self_tracer.current_span(), self._self_endpoint_collection_enabled)\n\n self._self_recorder.push_event(event)\n except Exception:\n pass\n\n def release(\n self,\n *args, # type: typing.Any\n **kwargs # type: typing.Any\n ):\n # type: (...) -> None\n try:\n return self.__wrapped__.release(*args, **kwargs)\n finally:\n try:\n if hasattr(self, \"_self_acquired_at\"):\n try:\n end = compat.monotonic_ns()\n thread_id, thread_name = _current_thread()\n task_id, task_name, task_frame = _task.get_task(thread_id)\n\n if task_frame is None:\n frame = sys._getframe(1)\n else:\n frame = task_frame\n\n frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)\n\n event = LockReleaseEvent( # type: ignore[call-arg]\n lock_name=self._self_name,\n frames=frames,\n nframes=nframes,\n thread_id=thread_id,\n thread_name=thread_name,\n task_id=task_id,\n task_name=task_name,\n locked_for_ns=end - self._self_acquired_at,\n sampling_pct=self._self_capture_sampler.capture_pct,\n )\n\n if self._self_tracer is not None:\n event.set_trace_info(\n self._self_tracer.current_span(), self._self_endpoint_collection_enabled\n )\n\n self._self_recorder.push_event(event)\n finally:\n del self._self_acquired_at\n except Exception:\n pass\n\n acquire_lock = acquire\n\n\nclass FunctionWrapper(wrapt.FunctionWrapper):\n # Override the __get__ method: whatever happens, _allocate_lock is always considered by Python like a \"static\"\n # method, even when used as a class attribute. Python never tried to \"bind\" it to a method, because it sees it is a\n # builtin function. Override default wrapt behavior here that tries to detect bound method.\n def __get__(self, instance, owner=None):\n return self\n\n\[email protected]\nclass LockCollector(collector.CaptureSamplerCollector):\n \"\"\"Record lock usage.\"\"\"\n\n nframes = attr.ib(factory=attr_utils.from_env(\"DD_PROFILING_MAX_FRAMES\", 64, int))\n endpoint_collection_enabled = attr.ib(\n factory=attr_utils.from_env(\"DD_PROFILING_ENDPOINT_COLLECTION_ENABLED\", True, formats.asbool)\n )\n\n tracer = attr.ib(default=None)\n\n def _start_service(self): # type: ignore[override]\n # type: (...) -> None\n \"\"\"Start collecting `threading.Lock` usage.\"\"\"\n self.patch()\n super(LockCollector, self)._start_service()\n\n def _stop_service(self): # type: ignore[override]\n # type: (...) -> None\n \"\"\"Stop collecting `threading.Lock` usage.\"\"\"\n super(LockCollector, self)._stop_service()\n self.unpatch()\n\n def patch(self):\n # type: (...) -> None\n \"\"\"Patch the threading module for tracking lock allocation.\"\"\"\n # We only patch the lock from the `threading` module.\n # Nobody should use locks from `_thread`; if they do so, then it's deliberate and we don't profile.\n self.original = threading.Lock\n\n def _allocate_lock(wrapped, instance, args, kwargs):\n lock = wrapped(*args, **kwargs)\n return _ProfiledLock(\n lock, self.recorder, self.tracer, self.nframes, self._capture_sampler, self.endpoint_collection_enabled\n )\n\n threading.Lock = FunctionWrapper(self.original, _allocate_lock) # type: ignore[misc]\n\n def unpatch(self):\n # type: (...) -> None\n \"\"\"Unpatch the threading module for tracking lock allocation.\"\"\"\n threading.Lock = self.original # type: ignore[misc]\n", "path": "ddtrace/profiling/collector/threading.py"}], "after_files": [{"content": "import typing\n\nimport attr\n\nfrom ddtrace import span as ddspan\nfrom ddtrace.internal import compat\n\n\n_T = typing.TypeVar(\"_T\")\n\n# (filename, line number, function name)\nFrameType = typing.Tuple[str, int, str]\nStackTraceType = typing.List[FrameType]\n\n\ndef event_class(\n klass, # type: typing.Type[_T]\n):\n # type: (...) -> typing.Type[_T]\n return attr.s(slots=True)(klass)\n\n\n@event_class\nclass Event(object):\n \"\"\"An event happening at a point in time.\"\"\"\n\n timestamp = attr.ib(factory=compat.time_ns)\n\n @property\n def name(self):\n # type: (...) -> str\n \"\"\"Name of the event.\"\"\"\n return self.__class__.__name__\n\n\n@event_class\nclass TimedEvent(Event):\n \"\"\"An event that has a duration.\"\"\"\n\n duration = attr.ib(default=None)\n\n\n@event_class\nclass SampleEvent(Event):\n \"\"\"An event representing a sample gathered from the system.\"\"\"\n\n sampling_period = attr.ib(default=None)\n\n\n@event_class\nclass StackBasedEvent(SampleEvent):\n thread_id = attr.ib(default=None, type=typing.Optional[int])\n thread_name = attr.ib(default=None, type=typing.Optional[str])\n thread_native_id = attr.ib(default=None, type=typing.Optional[int])\n task_id = attr.ib(default=None, type=typing.Optional[int])\n task_name = attr.ib(default=None, type=typing.Optional[str])\n frames = attr.ib(default=None, type=StackTraceType)\n nframes = attr.ib(default=0, type=int)\n local_root_span_id = attr.ib(default=None, type=typing.Optional[int])\n span_id = attr.ib(default=None, type=typing.Optional[int])\n trace_type = attr.ib(default=None, type=typing.Optional[str])\n trace_resource_container = attr.ib(default=None, type=typing.List[str])\n\n def set_trace_info(\n self,\n span, # type: typing.Optional[ddspan.Span]\n endpoint_collection_enabled, # type: bool\n ):\n # type: (...) -> None\n if span:\n self.span_id = span.span_id\n if span._local_root is not None:\n self.local_root_span_id = span._local_root.span_id\n self.trace_type = span._local_root._span_type\n if endpoint_collection_enabled:\n self.trace_resource_container = span._local_root._resource\n", "path": "ddtrace/profiling/event.py"}, {"content": "from __future__ import absolute_import\n\nimport os.path\nimport sys\nimport threading\nimport typing\n\nimport attr\n\nimport ddtrace\nfrom ddtrace.internal import compat\nfrom ddtrace.internal import nogevent\nfrom ddtrace.internal.utils import attr as attr_utils\nfrom ddtrace.internal.utils import formats\nfrom ddtrace.profiling import collector\nfrom ddtrace.profiling import event\nfrom ddtrace.profiling.collector import _task\nfrom ddtrace.profiling.collector import _threading\nfrom ddtrace.profiling.collector import _traceback\nfrom ddtrace.vendor import wrapt\n\n\nif typing.TYPE_CHECKING:\n from ddtrace.profiling import recorder as ddrecorder\n\n\[email protected]_class\nclass LockEventBase(event.StackBasedEvent):\n \"\"\"Base Lock event.\"\"\"\n\n lock_name = attr.ib(default=\"<unknown lock name>\", type=str)\n sampling_pct = attr.ib(default=0, type=int)\n\n\[email protected]_class\nclass LockAcquireEvent(LockEventBase):\n \"\"\"A lock has been acquired.\"\"\"\n\n wait_time_ns = attr.ib(default=0, type=int)\n\n\[email protected]_class\nclass LockReleaseEvent(LockEventBase):\n \"\"\"A lock has been released.\"\"\"\n\n locked_for_ns = attr.ib(default=0, type=int)\n\n\ndef _current_thread():\n # type: (...) -> typing.Tuple[int, str]\n thread_id = nogevent.thread_get_ident()\n return thread_id, _threading.get_thread_name(thread_id)\n\n\n# We need to know if wrapt is compiled in C or not. If it's not using the C module, then the wrappers function will\n# appear in the stack trace and we need to hide it.\nif os.environ.get(\"WRAPT_DISABLE_EXTENSIONS\"):\n WRAPT_C_EXT = False\nelse:\n try:\n import ddtrace.vendor.wrapt._wrappers as _w # noqa: F401\n except ImportError:\n WRAPT_C_EXT = False\n else:\n WRAPT_C_EXT = True\n del _w\n\n\nclass _ProfiledLock(wrapt.ObjectProxy):\n def __init__(\n self,\n wrapped, # type: threading.Lock\n recorder, # type: ddrecorder.Recorder\n tracer, # type: ddtrace.Tracer\n max_nframes, # type: int\n capture_sampler, # type: collector.CaptureSampler\n endpoint_collection_enabled, # type: bool\n ):\n # type: (...) -> None\n wrapt.ObjectProxy.__init__(self, wrapped)\n self._self_recorder = recorder\n self._self_tracer = tracer\n self._self_max_nframes = max_nframes\n self._self_capture_sampler = capture_sampler\n self._self_endpoint_collection_enabled = endpoint_collection_enabled\n frame = sys._getframe(2 if WRAPT_C_EXT else 3)\n code = frame.f_code\n self._self_name = \"%s:%d\" % (\n os.path.basename(code.co_filename),\n 0 if frame.f_lineno is None else frame.f_lineno,\n )\n\n def acquire(self, *args, **kwargs):\n if not self._self_capture_sampler.capture():\n return self.__wrapped__.acquire(*args, **kwargs)\n\n start = compat.monotonic_ns()\n try:\n return self.__wrapped__.acquire(*args, **kwargs)\n finally:\n try:\n end = self._self_acquired_at = compat.monotonic_ns()\n thread_id, thread_name = _current_thread()\n task_id, task_name, task_frame = _task.get_task(thread_id)\n\n if task_frame is None:\n frame = sys._getframe(1)\n else:\n frame = task_frame\n\n frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)\n\n event = LockAcquireEvent(\n lock_name=self._self_name,\n frames=frames,\n nframes=nframes,\n thread_id=thread_id,\n thread_name=thread_name,\n task_id=task_id,\n task_name=task_name,\n wait_time_ns=end - start,\n sampling_pct=self._self_capture_sampler.capture_pct,\n )\n\n if self._self_tracer is not None:\n event.set_trace_info(self._self_tracer.current_span(), self._self_endpoint_collection_enabled)\n\n self._self_recorder.push_event(event)\n except Exception:\n pass\n\n def release(\n self,\n *args, # type: typing.Any\n **kwargs # type: typing.Any\n ):\n # type: (...) -> None\n try:\n return self.__wrapped__.release(*args, **kwargs)\n finally:\n try:\n if hasattr(self, \"_self_acquired_at\"):\n try:\n end = compat.monotonic_ns()\n thread_id, thread_name = _current_thread()\n task_id, task_name, task_frame = _task.get_task(thread_id)\n\n if task_frame is None:\n frame = sys._getframe(1)\n else:\n frame = task_frame\n\n frames, nframes = _traceback.pyframe_to_frames(frame, self._self_max_nframes)\n\n event = LockReleaseEvent( # type: ignore[call-arg]\n lock_name=self._self_name,\n frames=frames,\n nframes=nframes,\n thread_id=thread_id,\n thread_name=thread_name,\n task_id=task_id,\n task_name=task_name,\n locked_for_ns=end - self._self_acquired_at,\n sampling_pct=self._self_capture_sampler.capture_pct,\n )\n\n if self._self_tracer is not None:\n event.set_trace_info(\n self._self_tracer.current_span(), self._self_endpoint_collection_enabled\n )\n\n self._self_recorder.push_event(event)\n finally:\n del self._self_acquired_at\n except Exception:\n pass\n\n acquire_lock = acquire\n\n\nclass FunctionWrapper(wrapt.FunctionWrapper):\n # Override the __get__ method: whatever happens, _allocate_lock is always considered by Python like a \"static\"\n # method, even when used as a class attribute. Python never tried to \"bind\" it to a method, because it sees it is a\n # builtin function. Override default wrapt behavior here that tries to detect bound method.\n def __get__(self, instance, owner=None):\n return self\n\n\[email protected]\nclass LockCollector(collector.CaptureSamplerCollector):\n \"\"\"Record lock usage.\"\"\"\n\n nframes = attr.ib(factory=attr_utils.from_env(\"DD_PROFILING_MAX_FRAMES\", 64, int))\n endpoint_collection_enabled = attr.ib(\n factory=attr_utils.from_env(\"DD_PROFILING_ENDPOINT_COLLECTION_ENABLED\", True, formats.asbool)\n )\n\n tracer = attr.ib(default=None)\n\n def _start_service(self): # type: ignore[override]\n # type: (...) -> None\n \"\"\"Start collecting `threading.Lock` usage.\"\"\"\n self.patch()\n super(LockCollector, self)._start_service()\n\n def _stop_service(self): # type: ignore[override]\n # type: (...) -> None\n \"\"\"Stop collecting `threading.Lock` usage.\"\"\"\n super(LockCollector, self)._stop_service()\n self.unpatch()\n\n def patch(self):\n # type: (...) -> None\n \"\"\"Patch the threading module for tracking lock allocation.\"\"\"\n # We only patch the lock from the `threading` module.\n # Nobody should use locks from `_thread`; if they do so, then it's deliberate and we don't profile.\n self.original = threading.Lock\n\n def _allocate_lock(wrapped, instance, args, kwargs):\n lock = wrapped(*args, **kwargs)\n return _ProfiledLock(\n lock, self.recorder, self.tracer, self.nframes, self._capture_sampler, self.endpoint_collection_enabled\n )\n\n threading.Lock = FunctionWrapper(self.original, _allocate_lock) # type: ignore[misc]\n\n def unpatch(self):\n # type: (...) -> None\n \"\"\"Unpatch the threading module for tracking lock allocation.\"\"\"\n threading.Lock = self.original # type: ignore[misc]\n", "path": "ddtrace/profiling/collector/threading.py"}]}
| 3,423 | 586 |
gh_patches_debug_13951
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-1831
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Issue with Event Importing
Importing Event with Copyright information in event.json fails.
The issue is because of CopyrightDAO which has no real value of version_key defined.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/helpers/utils.py`
Content:
```
1 import json
2 from hashlib import md5
3
4 from flask import request
5 from flask.ext.restplus import Resource as RestplusResource
6 from flask_restplus import Model, fields, reqparse
7
8 from .helpers import get_object_list, get_object_or_404, get_object_in_event, \
9 create_model, validate_payload, delete_model, update_model, \
10 handle_extra_payload, get_paginated_list
11 from app.models.event import Event as EventModel
12 from app.helpers.data import update_version
13
14 from .error_docs import (
15 notfound_error_model,
16 notauthorized_error_model,
17 validation_error_model,
18 invalidservice_error_model,
19 )
20
21 DEFAULT_PAGE_START = 1
22 DEFAULT_PAGE_LIMIT = 20
23
24 POST_RESPONSES = {
25 400: ('Validation error', validation_error_model),
26 401: ('Authentication failure', notauthorized_error_model),
27 404: ('Event does not exist', notfound_error_model),
28 201: 'Resource created successfully'
29 }
30
31 PUT_RESPONSES = {
32 400: ('Validation Error', validation_error_model),
33 401: ('Authentication failure', notauthorized_error_model),
34 404: ('Object/Event not found', notfound_error_model)
35 }
36
37 SERVICE_RESPONSES = {
38 404: ('Service not found', notfound_error_model),
39 400: ('Service does not belong to event', invalidservice_error_model),
40 }
41
42 # Parameters for a paginated response
43 PAGE_PARAMS = {
44 'start': {
45 'description': 'Serial number to start from',
46 'type': int,
47 'default': DEFAULT_PAGE_START
48 },
49 'limit': {
50 'description': 'Limit on the number of results',
51 'type': int,
52 'default': DEFAULT_PAGE_LIMIT
53 },
54 }
55
56 # Base Api Model for a paginated response
57 PAGINATED_MODEL = Model('PaginatedModel', {
58 'start': fields.Integer,
59 'limit': fields.Integer,
60 'count': fields.Integer,
61 'next': fields.String,
62 'previous': fields.String
63 })
64
65
66 # Custom Resource Class
67 class Resource(RestplusResource):
68 def dispatch_request(self, *args, **kwargs):
69 resp = super(Resource, self).dispatch_request(*args, **kwargs)
70
71 # ETag checking.
72 if request.method == 'GET':
73 old_etag = request.headers.get('If-None-Match', '')
74 # Generate hash
75 data = json.dumps(resp)
76 new_etag = md5(data).hexdigest()
77
78 if new_etag == old_etag:
79 # Resource has not changed
80 return '', 304
81 else:
82 # Resource has changed, send new ETag value
83 return resp, 200, {'ETag': new_etag}
84 elif request.method == 'POST':
85 # Grab just the response data
86 # Exclude status code and headers
87 resp_data = resp[0]
88
89 data = json.dumps(resp_data)
90 etag = md5(data).hexdigest()
91
92 # Add ETag to response headers
93 resp[2].update({'ETag': etag})
94
95 return resp
96
97
98 # Base class for Paginated Resource
99 class PaginatedResourceBase():
100 """
101 Paginated Resource Helper class
102 This includes basic properties used in the class
103 """
104 parser = reqparse.RequestParser()
105 parser.add_argument('start', type=int, default=DEFAULT_PAGE_START)
106 parser.add_argument('limit', type=int, default=DEFAULT_PAGE_LIMIT)
107
108
109 # DAO for Models
110 class BaseDAO:
111 """
112 DAO for a basic independent model
113 """
114 version_key = 'base_ver'
115
116 def __init__(self, model, post_api_model=None, put_api_model=None):
117 self.model = model
118 self.post_api_model = post_api_model
119 self.put_api_model = put_api_model if put_api_model else post_api_model
120
121 def get(self, id_):
122 return get_object_or_404(self.model, id_)
123
124 def list(self, **kwargs):
125 return get_object_list(self.model, **kwargs)
126
127 def paginated_list(self, url=None, args={}, **kwargs):
128 return get_paginated_list(self.model, url=url, args=args, **kwargs)
129
130 def create(self, data, validate=True):
131 if validate:
132 data = self.validate(data, self.post_api_model)
133 item = create_model(self.model, data)
134 self.update_version(item.id)
135 return item
136
137 def update(self, id_, data, validate=True):
138 if validate:
139 data = self.validate_put(data, self.put_api_model)
140 item = update_model(self.model, id_, data)
141 self.update_version(id_)
142 return item
143
144 def delete(self, id_):
145 item = delete_model(self.model, id_)
146 self.update_version(id_)
147 return item
148
149 def validate(self, data, model=None, check_required=True):
150 if not model:
151 model = self.post_api_model
152 if model:
153 data = handle_extra_payload(data, model)
154 validate_payload(data, model, check_required=check_required)
155 return data
156
157 def validate_put(self, data, model=None):
158 """
159 Abstraction over validate with check_required set to False
160 """
161 return self.validate(data, model=model, check_required=False)
162
163 def update_version(self, event_id):
164 """
165 Update version of the component of the event
166 """
167 update_version(event_id, False, self.version_key)
168
169 # Helper functions
170 def _del(self, data, fields):
171 """
172 Safe delete fields from payload
173 """
174 data_copy = data.copy()
175 for field in fields:
176 if field in data:
177 del data_copy[field]
178 return data_copy
179
180
181 # DAO for Service Models
182 class ServiceDAO(BaseDAO):
183 """
184 Data Access Object for service models like microlocations,
185 speakers and so.
186 """
187 def get(self, event_id, sid):
188 return get_object_in_event(self.model, sid, event_id)
189
190 def list(self, event_id, **kwargs):
191 # Check if an event with `event_id` exists
192 get_object_or_404(EventModel, event_id)
193 return get_object_list(self.model, event_id=event_id, **kwargs)
194
195 def paginated_list(self, url=None, args={}, **kwargs):
196 return get_paginated_list(self.model, url=url, args=args, **kwargs)
197
198 def create(self, event_id, data, url, validate=True):
199 if validate:
200 data = self.validate(data)
201 item = create_model(self.model, data, event_id=event_id)
202 self.update_version(event_id)
203 # Return created resource with a 201 status code and its Location
204 # (url) in the header.
205 resource_location = url + '/' + str(item.id)
206 return item, 201, {'Location': resource_location}
207
208 def update(self, event_id, service_id, data, validate=True):
209 if validate:
210 data = self.validate_put(data)
211 item = update_model(self.model, service_id, data, event_id)
212 self.update_version(event_id)
213 return item
214
215 def delete(self, event_id, service_id):
216 item = delete_model(self.model, service_id, event_id=event_id)
217 self.update_version(event_id)
218 return item
219
220 # store task results in case of testing
221 # state and info
222 TASK_RESULTS = {}
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/helpers/utils.py b/app/api/helpers/utils.py
--- a/app/api/helpers/utils.py
+++ b/app/api/helpers/utils.py
@@ -111,7 +111,7 @@
"""
DAO for a basic independent model
"""
- version_key = 'base_ver'
+ version_key = None
def __init__(self, model, post_api_model=None, put_api_model=None):
self.model = model
@@ -164,7 +164,8 @@
"""
Update version of the component of the event
"""
- update_version(event_id, False, self.version_key)
+ if self.version_key:
+ update_version(event_id, False, self.version_key)
# Helper functions
def _del(self, data, fields):
|
{"golden_diff": "diff --git a/app/api/helpers/utils.py b/app/api/helpers/utils.py\n--- a/app/api/helpers/utils.py\n+++ b/app/api/helpers/utils.py\n@@ -111,7 +111,7 @@\n \"\"\"\n DAO for a basic independent model\n \"\"\"\n- version_key = 'base_ver'\n+ version_key = None\n \n def __init__(self, model, post_api_model=None, put_api_model=None):\n self.model = model\n@@ -164,7 +164,8 @@\n \"\"\"\n Update version of the component of the event\n \"\"\"\n- update_version(event_id, False, self.version_key)\n+ if self.version_key:\n+ update_version(event_id, False, self.version_key)\n \n # Helper functions\n def _del(self, data, fields):\n", "issue": "Issue with Event Importing\nImporting Event with Copyright information in event.json fails.\n\nThe issue is because of CopyrightDAO which has no real value of version_key defined. \n\n", "before_files": [{"content": "import json\nfrom hashlib import md5\n\nfrom flask import request\nfrom flask.ext.restplus import Resource as RestplusResource\nfrom flask_restplus import Model, fields, reqparse\n\nfrom .helpers import get_object_list, get_object_or_404, get_object_in_event, \\\n create_model, validate_payload, delete_model, update_model, \\\n handle_extra_payload, get_paginated_list\nfrom app.models.event import Event as EventModel\nfrom app.helpers.data import update_version\n\nfrom .error_docs import (\n notfound_error_model,\n notauthorized_error_model,\n validation_error_model,\n invalidservice_error_model,\n)\n\nDEFAULT_PAGE_START = 1\nDEFAULT_PAGE_LIMIT = 20\n\nPOST_RESPONSES = {\n 400: ('Validation error', validation_error_model),\n 401: ('Authentication failure', notauthorized_error_model),\n 404: ('Event does not exist', notfound_error_model),\n 201: 'Resource created successfully'\n}\n\nPUT_RESPONSES = {\n 400: ('Validation Error', validation_error_model),\n 401: ('Authentication failure', notauthorized_error_model),\n 404: ('Object/Event not found', notfound_error_model)\n}\n\nSERVICE_RESPONSES = {\n 404: ('Service not found', notfound_error_model),\n 400: ('Service does not belong to event', invalidservice_error_model),\n}\n\n# Parameters for a paginated response\nPAGE_PARAMS = {\n 'start': {\n 'description': 'Serial number to start from',\n 'type': int,\n 'default': DEFAULT_PAGE_START\n },\n 'limit': {\n 'description': 'Limit on the number of results',\n 'type': int,\n 'default': DEFAULT_PAGE_LIMIT\n },\n}\n\n# Base Api Model for a paginated response\nPAGINATED_MODEL = Model('PaginatedModel', {\n 'start': fields.Integer,\n 'limit': fields.Integer,\n 'count': fields.Integer,\n 'next': fields.String,\n 'previous': fields.String\n})\n\n\n# Custom Resource Class\nclass Resource(RestplusResource):\n def dispatch_request(self, *args, **kwargs):\n resp = super(Resource, self).dispatch_request(*args, **kwargs)\n\n # ETag checking.\n if request.method == 'GET':\n old_etag = request.headers.get('If-None-Match', '')\n # Generate hash\n data = json.dumps(resp)\n new_etag = md5(data).hexdigest()\n\n if new_etag == old_etag:\n # Resource has not changed\n return '', 304\n else:\n # Resource has changed, send new ETag value\n return resp, 200, {'ETag': new_etag}\n elif request.method == 'POST':\n # Grab just the response data\n # Exclude status code and headers\n resp_data = resp[0]\n\n data = json.dumps(resp_data)\n etag = md5(data).hexdigest()\n\n # Add ETag to response headers\n resp[2].update({'ETag': etag})\n\n return resp\n\n\n# Base class for Paginated Resource\nclass PaginatedResourceBase():\n \"\"\"\n Paginated Resource Helper class\n This includes basic properties used in the class\n \"\"\"\n parser = reqparse.RequestParser()\n parser.add_argument('start', type=int, default=DEFAULT_PAGE_START)\n parser.add_argument('limit', type=int, default=DEFAULT_PAGE_LIMIT)\n\n\n# DAO for Models\nclass BaseDAO:\n \"\"\"\n DAO for a basic independent model\n \"\"\"\n version_key = 'base_ver'\n\n def __init__(self, model, post_api_model=None, put_api_model=None):\n self.model = model\n self.post_api_model = post_api_model\n self.put_api_model = put_api_model if put_api_model else post_api_model\n\n def get(self, id_):\n return get_object_or_404(self.model, id_)\n\n def list(self, **kwargs):\n return get_object_list(self.model, **kwargs)\n\n def paginated_list(self, url=None, args={}, **kwargs):\n return get_paginated_list(self.model, url=url, args=args, **kwargs)\n\n def create(self, data, validate=True):\n if validate:\n data = self.validate(data, self.post_api_model)\n item = create_model(self.model, data)\n self.update_version(item.id)\n return item\n\n def update(self, id_, data, validate=True):\n if validate:\n data = self.validate_put(data, self.put_api_model)\n item = update_model(self.model, id_, data)\n self.update_version(id_)\n return item\n\n def delete(self, id_):\n item = delete_model(self.model, id_)\n self.update_version(id_)\n return item\n\n def validate(self, data, model=None, check_required=True):\n if not model:\n model = self.post_api_model\n if model:\n data = handle_extra_payload(data, model)\n validate_payload(data, model, check_required=check_required)\n return data\n\n def validate_put(self, data, model=None):\n \"\"\"\n Abstraction over validate with check_required set to False\n \"\"\"\n return self.validate(data, model=model, check_required=False)\n\n def update_version(self, event_id):\n \"\"\"\n Update version of the component of the event\n \"\"\"\n update_version(event_id, False, self.version_key)\n\n # Helper functions\n def _del(self, data, fields):\n \"\"\"\n Safe delete fields from payload\n \"\"\"\n data_copy = data.copy()\n for field in fields:\n if field in data:\n del data_copy[field]\n return data_copy\n\n\n# DAO for Service Models\nclass ServiceDAO(BaseDAO):\n \"\"\"\n Data Access Object for service models like microlocations,\n speakers and so.\n \"\"\"\n def get(self, event_id, sid):\n return get_object_in_event(self.model, sid, event_id)\n\n def list(self, event_id, **kwargs):\n # Check if an event with `event_id` exists\n get_object_or_404(EventModel, event_id)\n return get_object_list(self.model, event_id=event_id, **kwargs)\n\n def paginated_list(self, url=None, args={}, **kwargs):\n return get_paginated_list(self.model, url=url, args=args, **kwargs)\n\n def create(self, event_id, data, url, validate=True):\n if validate:\n data = self.validate(data)\n item = create_model(self.model, data, event_id=event_id)\n self.update_version(event_id)\n # Return created resource with a 201 status code and its Location\n # (url) in the header.\n resource_location = url + '/' + str(item.id)\n return item, 201, {'Location': resource_location}\n\n def update(self, event_id, service_id, data, validate=True):\n if validate:\n data = self.validate_put(data)\n item = update_model(self.model, service_id, data, event_id)\n self.update_version(event_id)\n return item\n\n def delete(self, event_id, service_id):\n item = delete_model(self.model, service_id, event_id=event_id)\n self.update_version(event_id)\n return item\n\n# store task results in case of testing\n# state and info\nTASK_RESULTS = {}\n", "path": "app/api/helpers/utils.py"}], "after_files": [{"content": "import json\nfrom hashlib import md5\n\nfrom flask import request\nfrom flask.ext.restplus import Resource as RestplusResource\nfrom flask_restplus import Model, fields, reqparse\n\nfrom .helpers import get_object_list, get_object_or_404, get_object_in_event, \\\n create_model, validate_payload, delete_model, update_model, \\\n handle_extra_payload, get_paginated_list\nfrom app.models.event import Event as EventModel\nfrom app.helpers.data import update_version\n\nfrom .error_docs import (\n notfound_error_model,\n notauthorized_error_model,\n validation_error_model,\n invalidservice_error_model,\n)\n\nDEFAULT_PAGE_START = 1\nDEFAULT_PAGE_LIMIT = 20\n\nPOST_RESPONSES = {\n 400: ('Validation error', validation_error_model),\n 401: ('Authentication failure', notauthorized_error_model),\n 404: ('Event does not exist', notfound_error_model),\n 201: 'Resource created successfully'\n}\n\nPUT_RESPONSES = {\n 400: ('Validation Error', validation_error_model),\n 401: ('Authentication failure', notauthorized_error_model),\n 404: ('Object/Event not found', notfound_error_model)\n}\n\nSERVICE_RESPONSES = {\n 404: ('Service not found', notfound_error_model),\n 400: ('Service does not belong to event', invalidservice_error_model),\n}\n\n# Parameters for a paginated response\nPAGE_PARAMS = {\n 'start': {\n 'description': 'Serial number to start from',\n 'type': int,\n 'default': DEFAULT_PAGE_START\n },\n 'limit': {\n 'description': 'Limit on the number of results',\n 'type': int,\n 'default': DEFAULT_PAGE_LIMIT\n },\n}\n\n# Base Api Model for a paginated response\nPAGINATED_MODEL = Model('PaginatedModel', {\n 'start': fields.Integer,\n 'limit': fields.Integer,\n 'count': fields.Integer,\n 'next': fields.String,\n 'previous': fields.String\n})\n\n\n# Custom Resource Class\nclass Resource(RestplusResource):\n def dispatch_request(self, *args, **kwargs):\n resp = super(Resource, self).dispatch_request(*args, **kwargs)\n\n # ETag checking.\n if request.method == 'GET':\n old_etag = request.headers.get('If-None-Match', '')\n # Generate hash\n data = json.dumps(resp)\n new_etag = md5(data).hexdigest()\n\n if new_etag == old_etag:\n # Resource has not changed\n return '', 304\n else:\n # Resource has changed, send new ETag value\n return resp, 200, {'ETag': new_etag}\n elif request.method == 'POST':\n # Grab just the response data\n # Exclude status code and headers\n resp_data = resp[0]\n\n data = json.dumps(resp_data)\n etag = md5(data).hexdigest()\n\n # Add ETag to response headers\n resp[2].update({'ETag': etag})\n\n return resp\n\n\n# Base class for Paginated Resource\nclass PaginatedResourceBase():\n \"\"\"\n Paginated Resource Helper class\n This includes basic properties used in the class\n \"\"\"\n parser = reqparse.RequestParser()\n parser.add_argument('start', type=int, default=DEFAULT_PAGE_START)\n parser.add_argument('limit', type=int, default=DEFAULT_PAGE_LIMIT)\n\n\n# DAO for Models\nclass BaseDAO:\n \"\"\"\n DAO for a basic independent model\n \"\"\"\n version_key = None\n\n def __init__(self, model, post_api_model=None, put_api_model=None):\n self.model = model\n self.post_api_model = post_api_model\n self.put_api_model = put_api_model if put_api_model else post_api_model\n\n def get(self, id_):\n return get_object_or_404(self.model, id_)\n\n def list(self, **kwargs):\n return get_object_list(self.model, **kwargs)\n\n def paginated_list(self, url=None, args={}, **kwargs):\n return get_paginated_list(self.model, url=url, args=args, **kwargs)\n\n def create(self, data, validate=True):\n if validate:\n data = self.validate(data, self.post_api_model)\n item = create_model(self.model, data)\n self.update_version(item.id)\n return item\n\n def update(self, id_, data, validate=True):\n if validate:\n data = self.validate_put(data, self.put_api_model)\n item = update_model(self.model, id_, data)\n self.update_version(id_)\n return item\n\n def delete(self, id_):\n item = delete_model(self.model, id_)\n self.update_version(id_)\n return item\n\n def validate(self, data, model=None, check_required=True):\n if not model:\n model = self.post_api_model\n if model:\n data = handle_extra_payload(data, model)\n validate_payload(data, model, check_required=check_required)\n return data\n\n def validate_put(self, data, model=None):\n \"\"\"\n Abstraction over validate with check_required set to False\n \"\"\"\n return self.validate(data, model=model, check_required=False)\n\n def update_version(self, event_id):\n \"\"\"\n Update version of the component of the event\n \"\"\"\n if self.version_key:\n update_version(event_id, False, self.version_key)\n\n # Helper functions\n def _del(self, data, fields):\n \"\"\"\n Safe delete fields from payload\n \"\"\"\n data_copy = data.copy()\n for field in fields:\n if field in data:\n del data_copy[field]\n return data_copy\n\n\n# DAO for Service Models\nclass ServiceDAO(BaseDAO):\n \"\"\"\n Data Access Object for service models like microlocations,\n speakers and so.\n \"\"\"\n def get(self, event_id, sid):\n return get_object_in_event(self.model, sid, event_id)\n\n def list(self, event_id, **kwargs):\n # Check if an event with `event_id` exists\n get_object_or_404(EventModel, event_id)\n return get_object_list(self.model, event_id=event_id, **kwargs)\n\n def paginated_list(self, url=None, args={}, **kwargs):\n return get_paginated_list(self.model, url=url, args=args, **kwargs)\n\n def create(self, event_id, data, url, validate=True):\n if validate:\n data = self.validate(data)\n item = create_model(self.model, data, event_id=event_id)\n self.update_version(event_id)\n # Return created resource with a 201 status code and its Location\n # (url) in the header.\n resource_location = url + '/' + str(item.id)\n return item, 201, {'Location': resource_location}\n\n def update(self, event_id, service_id, data, validate=True):\n if validate:\n data = self.validate_put(data)\n item = update_model(self.model, service_id, data, event_id)\n self.update_version(event_id)\n return item\n\n def delete(self, event_id, service_id):\n item = delete_model(self.model, service_id, event_id=event_id)\n self.update_version(event_id)\n return item\n\n# store task results in case of testing\n# state and info\nTASK_RESULTS = {}\n", "path": "app/api/helpers/utils.py"}]}
| 2,462 | 176 |
gh_patches_debug_43261
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-930
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Type annotation check doesn't work for type aliases
# Bug report
<!--
Hi, thanks for submitting a bug. We appreciate that.
But, we will need some information about what's wrong to help you.
-->
## What's wrong
Type annotation check doesn't work if type aliases are used. For example, this code
```
type_alias = Literal[None]
def my_func(arg: type_alias):
pass
```
passes flake8 checks without raising `WPS701` error, while this code
```
def my_func(arg: Literal[None]):
pass
```
makes flake8 complain: "WPS701 Found useless `Literal[None]` typing annotation".
## How is that should be
Type annotation errors should be raised whether type aliases are used or not.
## System information
wemake-python-styleguide: 0.12.5
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wemake_python_styleguide/violations/annotations.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """
4 These checks help to prevent incorrect usage of Python 3 typing annotations.
5
6 While they maybe of a great help in writing clear
7 and concise code, they still can be abused.
8
9 Once again, these rules are highly subjective. But, we love them.
10
11 .. currentmodule:: wemake_python_styleguide.violations.annotations
12
13 Summary
14 -------
15
16 .. autosummary::
17 :nosignatures:
18
19 LiteralNoneViolation
20 NestedAnnotationsViolation
21 UnionNestedInOptionalViolation
22
23 Annotation checks
24 ------------------
25
26 .. autoclass:: LiteralNoneViolation
27 .. autoclass:: NestedAnnotationsViolation
28 .. autoclass:: UnionNestedInOptionalViolation
29
30 """
31
32 from typing_extensions import final
33
34 from wemake_python_styleguide.violations.base import ASTViolation
35
36
37 @final
38 class LiteralNoneViolation(ASTViolation):
39 """
40 Forbids to use ``Literal[None]`` typing annotation.
41
42 Reasoning:
43 Literal[None] is just the same as None.
44 There's no need to use the first version.
45 It is not type related, it is a consistency rule.
46
47 Solution:
48 Replace ``Literal[None]`` with ``None``.
49
50 Example::
51
52 # Correct:
53 def func(empty: None):
54 '''Empty function.'''
55
56 # Wrong:
57 def func(empty: Literal[None]):
58 '''Empty function.'''
59
60 .. versionadded:: 0.13.0
61
62 """
63
64 code = 700
65 error_template = 'Found useless `Literal[None]` typing annotation'
66
67
68 @final
69 class NestedAnnotationsViolation(ASTViolation):
70 """
71 Forbids use of nested Literal and Union Annotation.
72
73 Reasoning:
74 There is no need to nest certain annotations of the same type.
75 They are exactly equivalent to the flattened version.
76 Use the flattened version for consistency.
77
78 Solution:
79 Flatten consecutively nested ``typing.Literal`` and ``typing.Union``.
80
81 Example::
82
83 # Correct:
84 Literal[1, 2, 3, "foo", 5, None]
85 Union[int, str, float]
86
87 # Wrong:
88 Literal[Literal[Literal[1, 2, 3], "foo"], 5, None]
89 Union[Union[int, str], float]
90
91 .. versionadded:: 0.13.0
92
93 """
94
95 error_template = 'Found redundant nested typing annotation'
96 code = 701
97
98
99 @final
100 class UnionNestedInOptionalViolation(ASTViolation):
101 """
102 Forbids to use ``Optional[Union[int, str]]`` annotation.
103
104 Reasoning:
105 Optional[Union[int, str]] equals to Union[int, str, None].
106 Use Union[int, str, None] version for consistency.
107
108 Solution:
109 Replace ``Optional[Union[int, str]]`` with ``Union[int, str, None]``.
110
111 Example::
112
113 # Correct:
114 Union[int, str, None]
115
116 # Wrong:
117 Optional[Union[int, str]]
118
119 .. versionadded:: 0.13.0
120
121 """
122
123 error_template = 'Found typing annotation with `Union` nested in `Optional`'
124 code = 702
125
```
Path: `wemake_python_styleguide/visitors/ast/annotations.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import ast
4 from typing import ClassVar, FrozenSet, Optional
5
6 from typing_extensions import final
7
8 from wemake_python_styleguide.logic import source
9 from wemake_python_styleguide.types import AnyFunctionDef
10 from wemake_python_styleguide.violations.annotations import (
11 LiteralNoneViolation,
12 NestedAnnotationsViolation,
13 UnionNestedInOptionalViolation,
14 )
15 from wemake_python_styleguide.violations.consistency import (
16 MultilineFunctionAnnotationViolation,
17 )
18 from wemake_python_styleguide.visitors.base import BaseNodeVisitor
19 from wemake_python_styleguide.visitors.decorators import alias
20
21
22 @alias('visit_any_function', (
23 'visit_FunctionDef',
24 'visit_AsyncFunctionDef',
25 ))
26 class _GenericAnnotationVisitor(BaseNodeVisitor):
27 """Base class for all annotations visitors."""
28
29 _possible_prefixes: ClassVar[FrozenSet[str]] = frozenset((
30 'typing.',
31 'typing_extensions.',
32 ))
33
34 @final
35 def visit_AnnAssign(self, node: ast.AnnAssign) -> None:
36 """
37 Checks for assigned value annotation.
38
39 Raises:
40 LiteralNoneAnnotation
41
42 """
43 self._check_annotation(node.annotation)
44 self.generic_visit(node)
45
46 @final
47 def visit_any_function(self, node: AnyFunctionDef) -> None:
48 """
49 Checks return type annotations.
50
51 Raises:
52 LiteralNoneAnnotation
53
54 """
55 self._check_annotation(node.returns)
56 self.generic_visit(node)
57
58 @final
59 def visit_arg(self, node: ast.arg) -> None:
60 """
61 Checks arguments annotations.
62
63 Raises:
64 LiteralNoneAnnotation
65
66 """
67 self._check_annotation(node.annotation)
68 self.generic_visit(node)
69
70 @final
71 def _get_annotation(self, node: ast.AST) -> str:
72 """Smartly turns annotation node to string."""
73 full_annotation = source.node_to_string(node)
74 for prefix in self._possible_prefixes:
75 full_annotation = full_annotation.replace(prefix, '')
76 return full_annotation
77
78 def _check_annotation(self, annotation: Optional[ast.expr]) -> None:
79 """The only method that need to me implemented in child visitors."""
80
81
82 @final
83 class SemanticAnnotationVisitor(_GenericAnnotationVisitor):
84 """Ensures that nested annotations are used correctly."""
85
86 _flat_types: ClassVar[FrozenSet[str]] = frozenset((
87 'Literal',
88 'Union',
89 'Annotated',
90 ))
91
92 def _check_annotation(self, annotation: Optional[ast.expr]) -> None:
93 if not annotation:
94 return
95
96 self._check_nested_annotations(annotation)
97 self._check_literal_none(annotation)
98 self._check_union_nested_in_optional(annotation)
99
100 def _check_nested_annotations(self, annotation: ast.expr) -> None:
101 annotation_string = self._get_annotation(annotation)
102 for flat_type in self._flat_types:
103 if annotation_string.count(flat_type) > 1:
104 self.add_violation(NestedAnnotationsViolation(annotation))
105
106 def _check_literal_none(self, annotation: ast.expr) -> None:
107 annotation_string = self._get_annotation(annotation)
108 if 'Literal[None]' in annotation_string:
109 self.add_violation(LiteralNoneViolation(annotation))
110
111 def _check_union_nested_in_optional(self, annotation: ast.expr) -> None:
112 annotation_string = self._get_annotation(annotation)
113 if 'Optional[Union[' in annotation_string:
114 self.add_violation(UnionNestedInOptionalViolation(annotation))
115
116
117 @final
118 @alias('visit_any_function', (
119 'visit_FunctionDef',
120 'visit_AsyncFunctionDef',
121 ))
122 class WrongAnnotationVisitor(BaseNodeVisitor):
123 """Ensures that annotations are used correctly."""
124
125 def visit_any_function(self, node: AnyFunctionDef) -> None:
126 """
127 Checks return type annotations.
128
129 Raises:
130 MultilineFunctionAnnotationViolation
131 LiteralNoneAnnotation
132
133 """
134 self._check_return_annotation(node)
135 self.generic_visit(node)
136
137 def visit_arg(self, node: ast.arg) -> None:
138 """
139 Checks arguments annotations.
140
141 Raises:
142 MultilineFunctionAnnotationViolation
143 LiteralNoneAnnotation
144
145 """
146 self._check_arg_annotation(node)
147 self.generic_visit(node)
148
149 def _check_arg_annotation(self, node: ast.arg) -> None:
150 for sub_node in ast.walk(node):
151 lineno = getattr(sub_node, 'lineno', None)
152 if lineno and lineno != node.lineno:
153 self.add_violation(MultilineFunctionAnnotationViolation(node))
154 return
155
156 def _check_return_annotation(self, node: AnyFunctionDef) -> None:
157 if not node.returns:
158 return
159
160 for sub_node in ast.walk(node.returns):
161 lineno = getattr(sub_node, 'lineno', None)
162 if lineno and lineno != node.returns.lineno:
163 self.add_violation(MultilineFunctionAnnotationViolation(node))
164 return
165
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wemake_python_styleguide/violations/annotations.py b/wemake_python_styleguide/violations/annotations.py
--- a/wemake_python_styleguide/violations/annotations.py
+++ b/wemake_python_styleguide/violations/annotations.py
@@ -54,6 +54,8 @@
'''Empty function.'''
# Wrong:
+ NONE_ALIAS = Literal[None]
+
def func(empty: Literal[None]):
'''Empty function.'''
diff --git a/wemake_python_styleguide/visitors/ast/annotations.py b/wemake_python_styleguide/visitors/ast/annotations.py
--- a/wemake_python_styleguide/visitors/ast/annotations.py
+++ b/wemake_python_styleguide/visitors/ast/annotations.py
@@ -1,7 +1,9 @@
# -*- coding: utf-8 -*-
import ast
-from typing import ClassVar, FrozenSet, Optional
+import re
+from typing import ClassVar, FrozenSet, Union
+from typing.re import Pattern
from typing_extensions import final
@@ -31,6 +33,11 @@
'typing_extensions.',
))
+ def visit_Assign(self, node: ast.Assign) -> None:
+ """Checks assignment patterns."""
+ self._check_annotation(node)
+ self.generic_visit(node)
+
@final
def visit_AnnAssign(self, node: ast.AnnAssign) -> None:
"""
@@ -75,7 +82,9 @@
full_annotation = full_annotation.replace(prefix, '')
return full_annotation
- def _check_annotation(self, annotation: Optional[ast.expr]) -> None:
+ def _check_annotation(
+ self, annotation: Union[ast.expr, ast.Assign, None],
+ ) -> None:
"""The only method that need to me implemented in child visitors."""
@@ -83,13 +92,17 @@
class SemanticAnnotationVisitor(_GenericAnnotationVisitor):
"""Ensures that nested annotations are used correctly."""
- _flat_types: ClassVar[FrozenSet[str]] = frozenset((
- 'Literal',
- 'Union',
- 'Annotated',
+ # matches nested annotation like Literal[Literal[]],
+ # but not neighbors like Literal[], Literal[]
+ _flat_types: ClassVar[FrozenSet[Pattern]] = frozenset((
+ re.compile(r'^.*Literal\[[^\]]*Literal'),
+ re.compile(r'^.*Union\[[^\]]*Union'),
+ re.compile(r'^.*Annotated\[[^\]]*Annotated'),
))
- def _check_annotation(self, annotation: Optional[ast.expr]) -> None:
+ def _check_annotation(
+ self, annotation: Union[ast.expr, ast.Assign, None],
+ ) -> None:
if not annotation:
return
@@ -97,18 +110,28 @@
self._check_literal_none(annotation)
self._check_union_nested_in_optional(annotation)
- def _check_nested_annotations(self, annotation: ast.expr) -> None:
+ def _check_nested_annotations(
+ self, annotation: Union[ast.expr, ast.Assign],
+ ) -> None:
annotation_string = self._get_annotation(annotation)
for flat_type in self._flat_types:
- if annotation_string.count(flat_type) > 1:
+ if flat_type.search(annotation_string):
self.add_violation(NestedAnnotationsViolation(annotation))
- def _check_literal_none(self, annotation: ast.expr) -> None:
+ def _check_literal_none(
+ self, annotation: Union[ast.expr, ast.Assign],
+ ) -> None:
annotation_string = self._get_annotation(annotation)
- if 'Literal[None]' in annotation_string:
+ assign_string = (
+ isinstance(annotation, ast.Assign) and
+ isinstance(annotation.value, ast.Str)
+ )
+ if not assign_string and 'Literal[None]' in annotation_string:
self.add_violation(LiteralNoneViolation(annotation))
- def _check_union_nested_in_optional(self, annotation: ast.expr) -> None:
+ def _check_union_nested_in_optional(
+ self, annotation: Union[ast.expr, ast.Assign],
+ ) -> None:
annotation_string = self._get_annotation(annotation)
if 'Optional[Union[' in annotation_string:
self.add_violation(UnionNestedInOptionalViolation(annotation))
|
{"golden_diff": "diff --git a/wemake_python_styleguide/violations/annotations.py b/wemake_python_styleguide/violations/annotations.py\n--- a/wemake_python_styleguide/violations/annotations.py\n+++ b/wemake_python_styleguide/violations/annotations.py\n@@ -54,6 +54,8 @@\n '''Empty function.'''\n \n # Wrong:\n+ NONE_ALIAS = Literal[None]\n+\n def func(empty: Literal[None]):\n '''Empty function.'''\n \ndiff --git a/wemake_python_styleguide/visitors/ast/annotations.py b/wemake_python_styleguide/visitors/ast/annotations.py\n--- a/wemake_python_styleguide/visitors/ast/annotations.py\n+++ b/wemake_python_styleguide/visitors/ast/annotations.py\n@@ -1,7 +1,9 @@\n # -*- coding: utf-8 -*-\n \n import ast\n-from typing import ClassVar, FrozenSet, Optional\n+import re\n+from typing import ClassVar, FrozenSet, Union\n+from typing.re import Pattern\n \n from typing_extensions import final\n \n@@ -31,6 +33,11 @@\n 'typing_extensions.',\n ))\n \n+ def visit_Assign(self, node: ast.Assign) -> None:\n+ \"\"\"Checks assignment patterns.\"\"\"\n+ self._check_annotation(node)\n+ self.generic_visit(node)\n+\n @final\n def visit_AnnAssign(self, node: ast.AnnAssign) -> None:\n \"\"\"\n@@ -75,7 +82,9 @@\n full_annotation = full_annotation.replace(prefix, '')\n return full_annotation\n \n- def _check_annotation(self, annotation: Optional[ast.expr]) -> None:\n+ def _check_annotation(\n+ self, annotation: Union[ast.expr, ast.Assign, None],\n+ ) -> None:\n \"\"\"The only method that need to me implemented in child visitors.\"\"\"\n \n \n@@ -83,13 +92,17 @@\n class SemanticAnnotationVisitor(_GenericAnnotationVisitor):\n \"\"\"Ensures that nested annotations are used correctly.\"\"\"\n \n- _flat_types: ClassVar[FrozenSet[str]] = frozenset((\n- 'Literal',\n- 'Union',\n- 'Annotated',\n+ # matches nested annotation like Literal[Literal[]],\n+ # but not neighbors like Literal[], Literal[]\n+ _flat_types: ClassVar[FrozenSet[Pattern]] = frozenset((\n+ re.compile(r'^.*Literal\\[[^\\]]*Literal'),\n+ re.compile(r'^.*Union\\[[^\\]]*Union'),\n+ re.compile(r'^.*Annotated\\[[^\\]]*Annotated'),\n ))\n \n- def _check_annotation(self, annotation: Optional[ast.expr]) -> None:\n+ def _check_annotation(\n+ self, annotation: Union[ast.expr, ast.Assign, None],\n+ ) -> None:\n if not annotation:\n return\n \n@@ -97,18 +110,28 @@\n self._check_literal_none(annotation)\n self._check_union_nested_in_optional(annotation)\n \n- def _check_nested_annotations(self, annotation: ast.expr) -> None:\n+ def _check_nested_annotations(\n+ self, annotation: Union[ast.expr, ast.Assign],\n+ ) -> None:\n annotation_string = self._get_annotation(annotation)\n for flat_type in self._flat_types:\n- if annotation_string.count(flat_type) > 1:\n+ if flat_type.search(annotation_string):\n self.add_violation(NestedAnnotationsViolation(annotation))\n \n- def _check_literal_none(self, annotation: ast.expr) -> None:\n+ def _check_literal_none(\n+ self, annotation: Union[ast.expr, ast.Assign],\n+ ) -> None:\n annotation_string = self._get_annotation(annotation)\n- if 'Literal[None]' in annotation_string:\n+ assign_string = (\n+ isinstance(annotation, ast.Assign) and\n+ isinstance(annotation.value, ast.Str)\n+ )\n+ if not assign_string and 'Literal[None]' in annotation_string:\n self.add_violation(LiteralNoneViolation(annotation))\n \n- def _check_union_nested_in_optional(self, annotation: ast.expr) -> None:\n+ def _check_union_nested_in_optional(\n+ self, annotation: Union[ast.expr, ast.Assign],\n+ ) -> None:\n annotation_string = self._get_annotation(annotation)\n if 'Optional[Union[' in annotation_string:\n self.add_violation(UnionNestedInOptionalViolation(annotation))\n", "issue": "Type annotation check doesn't work for type aliases\n# Bug report\r\n\r\n<!--\r\nHi, thanks for submitting a bug. We appreciate that.\r\n\r\nBut, we will need some information about what's wrong to help you.\r\n-->\r\n\r\n## What's wrong\r\nType annotation check doesn't work if type aliases are used. For example, this code\r\n```\r\ntype_alias = Literal[None]\r\n\r\ndef my_func(arg: type_alias):\r\n pass\r\n```\r\npasses flake8 checks without raising `WPS701` error, while this code\r\n```\r\ndef my_func(arg: Literal[None]):\r\n pass\r\n```\r\nmakes flake8 complain: \"WPS701 Found useless `Literal[None]` typing annotation\".\r\n## How is that should be\r\nType annotation errors should be raised whether type aliases are used or not.\r\n\r\n## System information\r\nwemake-python-styleguide: 0.12.5\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nThese checks help to prevent incorrect usage of Python 3 typing annotations.\n\nWhile they maybe of a great help in writing clear\nand concise code, they still can be abused.\n\nOnce again, these rules are highly subjective. But, we love them.\n\n.. currentmodule:: wemake_python_styleguide.violations.annotations\n\nSummary\n-------\n\n.. autosummary::\n :nosignatures:\n\n LiteralNoneViolation\n NestedAnnotationsViolation\n UnionNestedInOptionalViolation\n\nAnnotation checks\n------------------\n\n.. autoclass:: LiteralNoneViolation\n.. autoclass:: NestedAnnotationsViolation\n.. autoclass:: UnionNestedInOptionalViolation\n\n\"\"\"\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.violations.base import ASTViolation\n\n\n@final\nclass LiteralNoneViolation(ASTViolation):\n \"\"\"\n Forbids to use ``Literal[None]`` typing annotation.\n\n Reasoning:\n Literal[None] is just the same as None.\n There's no need to use the first version.\n It is not type related, it is a consistency rule.\n\n Solution:\n Replace ``Literal[None]`` with ``None``.\n\n Example::\n\n # Correct:\n def func(empty: None):\n '''Empty function.'''\n\n # Wrong:\n def func(empty: Literal[None]):\n '''Empty function.'''\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n code = 700\n error_template = 'Found useless `Literal[None]` typing annotation'\n\n\n@final\nclass NestedAnnotationsViolation(ASTViolation):\n \"\"\"\n Forbids use of nested Literal and Union Annotation.\n\n Reasoning:\n There is no need to nest certain annotations of the same type.\n They are exactly equivalent to the flattened version.\n Use the flattened version for consistency.\n\n Solution:\n Flatten consecutively nested ``typing.Literal`` and ``typing.Union``.\n\n Example::\n\n # Correct:\n Literal[1, 2, 3, \"foo\", 5, None]\n Union[int, str, float]\n\n # Wrong:\n Literal[Literal[Literal[1, 2, 3], \"foo\"], 5, None]\n Union[Union[int, str], float]\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n error_template = 'Found redundant nested typing annotation'\n code = 701\n\n\n@final\nclass UnionNestedInOptionalViolation(ASTViolation):\n \"\"\"\n Forbids to use ``Optional[Union[int, str]]`` annotation.\n\n Reasoning:\n Optional[Union[int, str]] equals to Union[int, str, None].\n Use Union[int, str, None] version for consistency.\n\n Solution:\n Replace ``Optional[Union[int, str]]`` with ``Union[int, str, None]``.\n\n Example::\n\n # Correct:\n Union[int, str, None]\n\n # Wrong:\n Optional[Union[int, str]]\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n error_template = 'Found typing annotation with `Union` nested in `Optional`'\n code = 702\n", "path": "wemake_python_styleguide/violations/annotations.py"}, {"content": "# -*- coding: utf-8 -*-\n\nimport ast\nfrom typing import ClassVar, FrozenSet, Optional\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.logic import source\nfrom wemake_python_styleguide.types import AnyFunctionDef\nfrom wemake_python_styleguide.violations.annotations import (\n LiteralNoneViolation,\n NestedAnnotationsViolation,\n UnionNestedInOptionalViolation,\n)\nfrom wemake_python_styleguide.violations.consistency import (\n MultilineFunctionAnnotationViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseNodeVisitor\nfrom wemake_python_styleguide.visitors.decorators import alias\n\n\n@alias('visit_any_function', (\n 'visit_FunctionDef',\n 'visit_AsyncFunctionDef',\n))\nclass _GenericAnnotationVisitor(BaseNodeVisitor):\n \"\"\"Base class for all annotations visitors.\"\"\"\n\n _possible_prefixes: ClassVar[FrozenSet[str]] = frozenset((\n 'typing.',\n 'typing_extensions.',\n ))\n\n @final\n def visit_AnnAssign(self, node: ast.AnnAssign) -> None:\n \"\"\"\n Checks for assigned value annotation.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.annotation)\n self.generic_visit(node)\n\n @final\n def visit_any_function(self, node: AnyFunctionDef) -> None:\n \"\"\"\n Checks return type annotations.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.returns)\n self.generic_visit(node)\n\n @final\n def visit_arg(self, node: ast.arg) -> None:\n \"\"\"\n Checks arguments annotations.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.annotation)\n self.generic_visit(node)\n\n @final\n def _get_annotation(self, node: ast.AST) -> str:\n \"\"\"Smartly turns annotation node to string.\"\"\"\n full_annotation = source.node_to_string(node)\n for prefix in self._possible_prefixes:\n full_annotation = full_annotation.replace(prefix, '')\n return full_annotation\n\n def _check_annotation(self, annotation: Optional[ast.expr]) -> None:\n \"\"\"The only method that need to me implemented in child visitors.\"\"\"\n\n\n@final\nclass SemanticAnnotationVisitor(_GenericAnnotationVisitor):\n \"\"\"Ensures that nested annotations are used correctly.\"\"\"\n\n _flat_types: ClassVar[FrozenSet[str]] = frozenset((\n 'Literal',\n 'Union',\n 'Annotated',\n ))\n\n def _check_annotation(self, annotation: Optional[ast.expr]) -> None:\n if not annotation:\n return\n\n self._check_nested_annotations(annotation)\n self._check_literal_none(annotation)\n self._check_union_nested_in_optional(annotation)\n\n def _check_nested_annotations(self, annotation: ast.expr) -> None:\n annotation_string = self._get_annotation(annotation)\n for flat_type in self._flat_types:\n if annotation_string.count(flat_type) > 1:\n self.add_violation(NestedAnnotationsViolation(annotation))\n\n def _check_literal_none(self, annotation: ast.expr) -> None:\n annotation_string = self._get_annotation(annotation)\n if 'Literal[None]' in annotation_string:\n self.add_violation(LiteralNoneViolation(annotation))\n\n def _check_union_nested_in_optional(self, annotation: ast.expr) -> None:\n annotation_string = self._get_annotation(annotation)\n if 'Optional[Union[' in annotation_string:\n self.add_violation(UnionNestedInOptionalViolation(annotation))\n\n\n@final\n@alias('visit_any_function', (\n 'visit_FunctionDef',\n 'visit_AsyncFunctionDef',\n))\nclass WrongAnnotationVisitor(BaseNodeVisitor):\n \"\"\"Ensures that annotations are used correctly.\"\"\"\n\n def visit_any_function(self, node: AnyFunctionDef) -> None:\n \"\"\"\n Checks return type annotations.\n\n Raises:\n MultilineFunctionAnnotationViolation\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_return_annotation(node)\n self.generic_visit(node)\n\n def visit_arg(self, node: ast.arg) -> None:\n \"\"\"\n Checks arguments annotations.\n\n Raises:\n MultilineFunctionAnnotationViolation\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_arg_annotation(node)\n self.generic_visit(node)\n\n def _check_arg_annotation(self, node: ast.arg) -> None:\n for sub_node in ast.walk(node):\n lineno = getattr(sub_node, 'lineno', None)\n if lineno and lineno != node.lineno:\n self.add_violation(MultilineFunctionAnnotationViolation(node))\n return\n\n def _check_return_annotation(self, node: AnyFunctionDef) -> None:\n if not node.returns:\n return\n\n for sub_node in ast.walk(node.returns):\n lineno = getattr(sub_node, 'lineno', None)\n if lineno and lineno != node.returns.lineno:\n self.add_violation(MultilineFunctionAnnotationViolation(node))\n return\n", "path": "wemake_python_styleguide/visitors/ast/annotations.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nThese checks help to prevent incorrect usage of Python 3 typing annotations.\n\nWhile they maybe of a great help in writing clear\nand concise code, they still can be abused.\n\nOnce again, these rules are highly subjective. But, we love them.\n\n.. currentmodule:: wemake_python_styleguide.violations.annotations\n\nSummary\n-------\n\n.. autosummary::\n :nosignatures:\n\n LiteralNoneViolation\n NestedAnnotationsViolation\n UnionNestedInOptionalViolation\n\nAnnotation checks\n------------------\n\n.. autoclass:: LiteralNoneViolation\n.. autoclass:: NestedAnnotationsViolation\n.. autoclass:: UnionNestedInOptionalViolation\n\n\"\"\"\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.violations.base import ASTViolation\n\n\n@final\nclass LiteralNoneViolation(ASTViolation):\n \"\"\"\n Forbids to use ``Literal[None]`` typing annotation.\n\n Reasoning:\n Literal[None] is just the same as None.\n There's no need to use the first version.\n It is not type related, it is a consistency rule.\n\n Solution:\n Replace ``Literal[None]`` with ``None``.\n\n Example::\n\n # Correct:\n def func(empty: None):\n '''Empty function.'''\n\n # Wrong:\n NONE_ALIAS = Literal[None]\n\n def func(empty: Literal[None]):\n '''Empty function.'''\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n code = 700\n error_template = 'Found useless `Literal[None]` typing annotation'\n\n\n@final\nclass NestedAnnotationsViolation(ASTViolation):\n \"\"\"\n Forbids use of nested Literal and Union Annotation.\n\n Reasoning:\n There is no need to nest certain annotations of the same type.\n They are exactly equivalent to the flattened version.\n Use the flattened version for consistency.\n\n Solution:\n Flatten consecutively nested ``typing.Literal`` and ``typing.Union``.\n\n Example::\n\n # Correct:\n Literal[1, 2, 3, \"foo\", 5, None]\n Union[int, str, float]\n\n # Wrong:\n Literal[Literal[Literal[1, 2, 3], \"foo\"], 5, None]\n Union[Union[int, str], float]\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n error_template = 'Found redundant nested typing annotation'\n code = 701\n\n\n@final\nclass UnionNestedInOptionalViolation(ASTViolation):\n \"\"\"\n Forbids to use ``Optional[Union[int, str]]`` annotation.\n\n Reasoning:\n Optional[Union[int, str]] equals to Union[int, str, None].\n Use Union[int, str, None] version for consistency.\n\n Solution:\n Replace ``Optional[Union[int, str]]`` with ``Union[int, str, None]``.\n\n Example::\n\n # Correct:\n Union[int, str, None]\n\n # Wrong:\n Optional[Union[int, str]]\n\n .. versionadded:: 0.13.0\n\n \"\"\"\n\n error_template = 'Found typing annotation with `Union` nested in `Optional`'\n code = 702\n", "path": "wemake_python_styleguide/violations/annotations.py"}, {"content": "# -*- coding: utf-8 -*-\n\nimport ast\nimport re\nfrom typing import ClassVar, FrozenSet, Union\nfrom typing.re import Pattern\n\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide.logic import source\nfrom wemake_python_styleguide.types import AnyFunctionDef\nfrom wemake_python_styleguide.violations.annotations import (\n LiteralNoneViolation,\n NestedAnnotationsViolation,\n UnionNestedInOptionalViolation,\n)\nfrom wemake_python_styleguide.violations.consistency import (\n MultilineFunctionAnnotationViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseNodeVisitor\nfrom wemake_python_styleguide.visitors.decorators import alias\n\n\n@alias('visit_any_function', (\n 'visit_FunctionDef',\n 'visit_AsyncFunctionDef',\n))\nclass _GenericAnnotationVisitor(BaseNodeVisitor):\n \"\"\"Base class for all annotations visitors.\"\"\"\n\n _possible_prefixes: ClassVar[FrozenSet[str]] = frozenset((\n 'typing.',\n 'typing_extensions.',\n ))\n\n def visit_Assign(self, node: ast.Assign) -> None:\n \"\"\"Checks assignment patterns.\"\"\"\n self._check_annotation(node)\n self.generic_visit(node)\n\n @final\n def visit_AnnAssign(self, node: ast.AnnAssign) -> None:\n \"\"\"\n Checks for assigned value annotation.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.annotation)\n self.generic_visit(node)\n\n @final\n def visit_any_function(self, node: AnyFunctionDef) -> None:\n \"\"\"\n Checks return type annotations.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.returns)\n self.generic_visit(node)\n\n @final\n def visit_arg(self, node: ast.arg) -> None:\n \"\"\"\n Checks arguments annotations.\n\n Raises:\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_annotation(node.annotation)\n self.generic_visit(node)\n\n @final\n def _get_annotation(self, node: ast.AST) -> str:\n \"\"\"Smartly turns annotation node to string.\"\"\"\n full_annotation = source.node_to_string(node)\n for prefix in self._possible_prefixes:\n full_annotation = full_annotation.replace(prefix, '')\n return full_annotation\n\n def _check_annotation(\n self, annotation: Union[ast.expr, ast.Assign, None],\n ) -> None:\n \"\"\"The only method that need to me implemented in child visitors.\"\"\"\n\n\n@final\nclass SemanticAnnotationVisitor(_GenericAnnotationVisitor):\n \"\"\"Ensures that nested annotations are used correctly.\"\"\"\n\n # matches nested annotation like Literal[Literal[]],\n # but not neighbors like Literal[], Literal[]\n _flat_types: ClassVar[FrozenSet[Pattern]] = frozenset((\n re.compile(r'^.*Literal\\[[^\\]]*Literal'),\n re.compile(r'^.*Union\\[[^\\]]*Union'),\n re.compile(r'^.*Annotated\\[[^\\]]*Annotated'),\n ))\n\n def _check_annotation(\n self, annotation: Union[ast.expr, ast.Assign, None],\n ) -> None:\n if not annotation:\n return\n\n self._check_nested_annotations(annotation)\n self._check_literal_none(annotation)\n self._check_union_nested_in_optional(annotation)\n\n def _check_nested_annotations(\n self, annotation: Union[ast.expr, ast.Assign],\n ) -> None:\n annotation_string = self._get_annotation(annotation)\n for flat_type in self._flat_types:\n if flat_type.search(annotation_string):\n self.add_violation(NestedAnnotationsViolation(annotation))\n\n def _check_literal_none(\n self, annotation: Union[ast.expr, ast.Assign],\n ) -> None:\n annotation_string = self._get_annotation(annotation)\n assign_string = (\n isinstance(annotation, ast.Assign) and\n isinstance(annotation.value, ast.Str)\n )\n if not assign_string and 'Literal[None]' in annotation_string:\n self.add_violation(LiteralNoneViolation(annotation))\n\n def _check_union_nested_in_optional(\n self, annotation: Union[ast.expr, ast.Assign],\n ) -> None:\n annotation_string = self._get_annotation(annotation)\n if 'Optional[Union[' in annotation_string:\n self.add_violation(UnionNestedInOptionalViolation(annotation))\n\n\n@final\n@alias('visit_any_function', (\n 'visit_FunctionDef',\n 'visit_AsyncFunctionDef',\n))\nclass WrongAnnotationVisitor(BaseNodeVisitor):\n \"\"\"Ensures that annotations are used correctly.\"\"\"\n\n def visit_any_function(self, node: AnyFunctionDef) -> None:\n \"\"\"\n Checks return type annotations.\n\n Raises:\n MultilineFunctionAnnotationViolation\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_return_annotation(node)\n self.generic_visit(node)\n\n def visit_arg(self, node: ast.arg) -> None:\n \"\"\"\n Checks arguments annotations.\n\n Raises:\n MultilineFunctionAnnotationViolation\n LiteralNoneAnnotation\n\n \"\"\"\n self._check_arg_annotation(node)\n self.generic_visit(node)\n\n def _check_arg_annotation(self, node: ast.arg) -> None:\n for sub_node in ast.walk(node):\n lineno = getattr(sub_node, 'lineno', None)\n if lineno and lineno != node.lineno:\n self.add_violation(MultilineFunctionAnnotationViolation(node))\n return\n\n def _check_return_annotation(self, node: AnyFunctionDef) -> None:\n if not node.returns:\n return\n\n for sub_node in ast.walk(node.returns):\n lineno = getattr(sub_node, 'lineno', None)\n if lineno and lineno != node.returns.lineno:\n self.add_violation(MultilineFunctionAnnotationViolation(node))\n return\n", "path": "wemake_python_styleguide/visitors/ast/annotations.py"}]}
| 2,896 | 969 |
gh_patches_debug_26514
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-108
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test all code brought in from the prototype
**Problem**
<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->
The code brought over from the prototype in PRs #57 , #60, #75, #79, #85 is not yet fully tested
**Proposed solution**
<!-- A clear and concise description of your proposed solution or feature. -->
Write tests covering all code from those PRs which is not yet covered.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `db/tables.py`
Content:
```
1 from sqlalchemy import (
2 Column, String, Table, MetaData, func, select, ForeignKey, literal, exists
3 )
4
5 from db import columns, constants, schemas
6
7
8 def create_string_column_table(name, schema, column_names, engine):
9 """
10 This method creates a Postgres table in the specified schema, with all
11 columns being String type.
12 """
13 columns_ = [Column(column_name, String) for column_name in column_names]
14 table = create_mathesar_table(name, schema, columns_, engine)
15 return table
16
17
18 def create_mathesar_table(name, schema, columns_, engine, metadata=None):
19 """
20 This method creates a Postgres table in the specified schema using the
21 given name and column list. It adds internal mathesar columns to the
22 table.
23 """
24 columns_ = columns.init_mathesar_table_column_list_with_defaults(columns_)
25 schemas.create_schema(schema, engine)
26 # We need this so that we can create multiple mathesar tables in the
27 # same MetaData, enabling them to reference each other in the
28 # SQLAlchemy context (e.g., for creating a ForeignKey relationship)
29 if metadata is None:
30 metadata = MetaData(bind=engine, schema=schema)
31 # This reflection step lets us notice any "table already exists"
32 # errors before sending error-generating requests to the DB.
33 metadata.reflect()
34 table = Table(
35 name,
36 metadata,
37 *columns_,
38 schema=schema,
39 )
40 table.create(engine)
41 return table
42
43
44 def extract_columns_from_table(
45 old_table_name,
46 extracted_column_names,
47 extracted_table_name,
48 remainder_table_name,
49 schema,
50 engine,
51 drop_original_table=False,
52 ):
53 old_table = reflect_table(old_table_name, schema, engine)
54 old_columns = (
55 columns.MathesarColumn.from_column(col) for col in old_table.columns
56 )
57 old_non_default_columns = [
58 col for col in old_columns if not col.is_default
59 ]
60 extracted_columns, remainder_columns = _split_column_list(
61 old_non_default_columns, extracted_column_names,
62 )
63 with engine.begin() as conn:
64 extracted_table, remainder_table, remainder_fk = _create_split_tables(
65 extracted_table_name,
66 extracted_columns,
67 remainder_table_name,
68 remainder_columns,
69 schema,
70 engine,
71 )
72 split_ins = _create_split_insert_stmt(
73 old_table,
74 extracted_table,
75 extracted_columns,
76 remainder_table,
77 remainder_columns,
78 remainder_fk,
79 )
80 conn.execute(split_ins)
81 if drop_original_table:
82 old_table.drop()
83
84 return extracted_table, remainder_table, remainder_fk
85
86
87 def _split_column_list(columns_, extracted_column_names):
88 extracted_columns = [
89 col for col in columns_ if col.name in extracted_column_names
90 ]
91 remainder_columns = [
92 col for col in columns_ if col.name not in extracted_column_names
93 ]
94 return extracted_columns, remainder_columns
95
96
97 def _create_split_tables(
98 extracted_table_name,
99 extracted_columns,
100 remainder_table_name,
101 remainder_columns,
102 schema,
103 engine,
104 ):
105 extracted_table = create_mathesar_table(
106 extracted_table_name,
107 schema,
108 extracted_columns,
109 engine,
110 )
111 remainder_fk_column = Column(
112 f"{extracted_table.name}_{constants.ID}",
113 columns.ID_TYPE,
114 ForeignKey(f"{extracted_table.name}.{constants.ID}"),
115 nullable=False,
116 )
117 remainder_table = create_mathesar_table(
118 remainder_table_name,
119 schema,
120 [remainder_fk_column] + remainder_columns,
121 engine,
122 metadata=extracted_table.metadata
123 )
124 return extracted_table, remainder_table, remainder_fk_column.name
125
126
127 def _create_split_insert_stmt(
128 old_table,
129 extracted_table,
130 extracted_columns,
131 remainder_table,
132 remainder_columns,
133 remainder_fk_name,
134 ):
135 SPLIT_ID = "f{constants.MATHESAR_PREFIX}_split_column_alias"
136 extracted_column_names = [col.name for col in extracted_columns]
137 remainder_column_names = [col.name for col in remainder_columns]
138 split_cte = select(
139 [
140 old_table,
141 func.dense_rank().over(order_by=extracted_columns).label(SPLIT_ID)
142 ]
143 ).cte()
144 cte_extraction_columns = (
145 [split_cte.columns[SPLIT_ID]]
146 + [split_cte.columns[n] for n in extracted_column_names]
147 )
148 cte_remainder_columns = (
149 [split_cte.columns[SPLIT_ID]]
150 + [split_cte.columns[n] for n in remainder_column_names]
151 )
152 extract_sel = select(
153 cte_extraction_columns,
154 distinct=True
155 )
156 extract_ins_cte = (
157 extracted_table
158 .insert()
159 .from_select([constants.ID] + extracted_column_names, extract_sel)
160 .returning(literal(1))
161 .cte()
162 )
163 remainder_sel = select(
164 cte_remainder_columns,
165 distinct=True
166 ).where(exists(extract_ins_cte.select()))
167
168 split_ins = (
169 remainder_table
170 .insert()
171 .from_select(
172 [remainder_fk_name] + remainder_column_names,
173 remainder_sel
174 )
175 )
176 return split_ins
177
178
179 def merge_tables(
180 table_name_one,
181 table_name_two,
182 merged_table_name,
183 schema,
184 engine,
185 drop_original_tables=False,
186 ):
187 """
188 This specifically undoes the `extract_columns_from_table` (up to
189 unique rows). It may not work in other contexts (yet).
190 """
191 table_one = reflect_table(table_name_one, schema, engine)
192 table_two = reflect_table(
193 table_name_two, schema, engine, metadata=table_one.metadata
194 )
195 merge_join = table_one.join(table_two)
196 referencing_columns = [
197 col for col in [merge_join.onclause.left, merge_join.onclause.right]
198 if col.foreign_keys
199 ]
200 merged_columns_all = [
201 columns.MathesarColumn.from_column(col)
202 for col in list(table_one.columns) + list(table_two.columns)
203 if col not in referencing_columns
204 ]
205 merged_columns = [col for col in merged_columns_all if not col.is_default]
206 with engine.begin() as conn:
207 merged_table = create_mathesar_table(
208 merged_table_name, schema, merged_columns, engine,
209 )
210 insert_stmt = merged_table.insert().from_select(
211 [col.name for col in merged_columns],
212 select(merged_columns, distinct=True).select_from(merge_join)
213 )
214 conn.execute(insert_stmt)
215
216 if drop_original_tables:
217 if table_one.foreign_keys:
218 table_one.drop(bind=engine)
219 table_two.drop(bind=engine)
220 else:
221 table_two.drop(bind=engine)
222 table_one.drop(bind=engine)
223
224 return merged_table
225
226
227 def move_column_between_related_tables(
228 source_table_name,
229 target_table_name,
230 column_names,
231 schema,
232 engine,
233 ):
234 TEMP_MERGED_TABLE_NAME = f"{constants.MATHESAR_PREFIX}_temp_merge_table"
235 source_table = reflect_table(source_table_name, schema, engine)
236 target_table = reflect_table(
237 target_table_name, schema, engine, metadata=source_table.metadata
238 )
239 relationship = _find_table_relationship(source_table, target_table)
240 moving_columns = [source_table.columns[n] for n in column_names]
241 assert _check_columns(relationship, source_table, moving_columns)
242 ext_args = _get_column_moving_extraction_args(
243 relationship,
244 target_table,
245 target_table_name,
246 source_table,
247 source_table_name,
248 moving_columns,
249 column_names,
250 )
251 (extracted_table_name, remainder_table_name, extraction_columns) = ext_args
252 merge_tables(
253 source_table_name,
254 target_table_name,
255 TEMP_MERGED_TABLE_NAME,
256 schema,
257 engine,
258 drop_original_tables=True,
259 )
260 extracted_table, remainder_table, _ = extract_columns_from_table(
261 TEMP_MERGED_TABLE_NAME,
262 [c.name for c in extraction_columns],
263 extracted_table_name,
264 remainder_table_name,
265 schema,
266 engine,
267 drop_original_table=True,
268 )
269 return extracted_table, remainder_table
270
271
272 def _find_table_relationship(table_one, table_two):
273 """
274 This function takes two tables, and returns a dict defining the direction
275 of the foreign key constraint relating the tables (if one exists)
276 """
277 one_referencing_two = [
278 fkey_constraint for fkey_constraint in table_one.foreign_key_constraints
279 if fkey_constraint.referred_table == table_two
280 ]
281 two_referencing_one = [
282 fkey_constraint for fkey_constraint in table_two.foreign_key_constraints
283 if fkey_constraint.referred_table == table_one
284 ]
285 if one_referencing_two and not two_referencing_one:
286 relationship = {"referencing": table_one, "referenced": table_two}
287 elif two_referencing_one and not one_referencing_two:
288 relationship = {"referencing": table_two, "referenced": table_one}
289 else:
290 relationship = None
291 return relationship
292
293
294 def _check_columns(relationship, source_table, moving_columns):
295 return (
296 relationship is not None
297 and all([not c.foreign_keys for c in moving_columns])
298 )
299
300
301 def _get_column_moving_extraction_args(
302 relationship,
303 target_table,
304 target_table_name,
305 source_table,
306 source_table_name,
307 moving_columns,
308 column_names,
309 ):
310 if relationship["referenced"] == target_table:
311 extracted_table_name = target_table_name
312 remainder_table_name = source_table_name
313 extraction_columns = [
314 col for col in target_table.columns
315 if not columns.MathesarColumn.from_column(col).is_default
316 ] + moving_columns
317 else:
318 extracted_table_name = source_table_name
319 remainder_table_name = target_table_name
320 extraction_columns = [
321 col for col in target_table.columns
322 if not columns.MathesarColumn.from_column(col).is_default
323 and col not in column_names
324 ]
325 return extracted_table_name, remainder_table_name, extraction_columns
326
327
328 def reflect_table(name, schema, engine, metadata=None):
329 if metadata is None:
330 metadata = MetaData(bind=engine)
331 return Table(name, metadata, schema=schema, autoload_with=engine)
332
333
334 def get_count(table, engine):
335 query = select([func.count()]).select_from(table)
336 with engine.begin() as conn:
337 return conn.execute(query).scalar()
338
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/db/tables.py b/db/tables.py
--- a/db/tables.py
+++ b/db/tables.py
@@ -132,7 +132,7 @@
remainder_columns,
remainder_fk_name,
):
- SPLIT_ID = "f{constants.MATHESAR_PREFIX}_split_column_alias"
+ SPLIT_ID = f"{constants.MATHESAR_PREFIX}_split_column_alias"
extracted_column_names = [col.name for col in extracted_columns]
remainder_column_names = [col.name for col in remainder_columns]
split_cte = select(
@@ -224,7 +224,7 @@
return merged_table
-def move_column_between_related_tables(
+def move_columns_between_related_tables(
source_table_name,
target_table_name,
column_names,
@@ -318,9 +318,9 @@
extracted_table_name = source_table_name
remainder_table_name = target_table_name
extraction_columns = [
- col for col in target_table.columns
+ col for col in source_table.columns
if not columns.MathesarColumn.from_column(col).is_default
- and col not in column_names
+ and col.name not in column_names
]
return extracted_table_name, remainder_table_name, extraction_columns
|
{"golden_diff": "diff --git a/db/tables.py b/db/tables.py\n--- a/db/tables.py\n+++ b/db/tables.py\n@@ -132,7 +132,7 @@\n remainder_columns,\n remainder_fk_name,\n ):\n- SPLIT_ID = \"f{constants.MATHESAR_PREFIX}_split_column_alias\"\n+ SPLIT_ID = f\"{constants.MATHESAR_PREFIX}_split_column_alias\"\n extracted_column_names = [col.name for col in extracted_columns]\n remainder_column_names = [col.name for col in remainder_columns]\n split_cte = select(\n@@ -224,7 +224,7 @@\n return merged_table\n \n \n-def move_column_between_related_tables(\n+def move_columns_between_related_tables(\n source_table_name,\n target_table_name,\n column_names,\n@@ -318,9 +318,9 @@\n extracted_table_name = source_table_name\n remainder_table_name = target_table_name\n extraction_columns = [\n- col for col in target_table.columns\n+ col for col in source_table.columns\n if not columns.MathesarColumn.from_column(col).is_default\n- and col not in column_names\n+ and col.name not in column_names\n ]\n return extracted_table_name, remainder_table_name, extraction_columns\n", "issue": "Test all code brought in from the prototype\n**Problem**\r\n<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->\r\nThe code brought over from the prototype in PRs #57 , #60, #75, #79, #85 is not yet fully tested\r\n\r\n**Proposed solution**\r\n<!-- A clear and concise description of your proposed solution or feature. -->\r\n\r\nWrite tests covering all code from those PRs which is not yet covered.\r\n\n", "before_files": [{"content": "from sqlalchemy import (\n Column, String, Table, MetaData, func, select, ForeignKey, literal, exists\n)\n\nfrom db import columns, constants, schemas\n\n\ndef create_string_column_table(name, schema, column_names, engine):\n \"\"\"\n This method creates a Postgres table in the specified schema, with all\n columns being String type.\n \"\"\"\n columns_ = [Column(column_name, String) for column_name in column_names]\n table = create_mathesar_table(name, schema, columns_, engine)\n return table\n\n\ndef create_mathesar_table(name, schema, columns_, engine, metadata=None):\n \"\"\"\n This method creates a Postgres table in the specified schema using the\n given name and column list. It adds internal mathesar columns to the\n table.\n \"\"\"\n columns_ = columns.init_mathesar_table_column_list_with_defaults(columns_)\n schemas.create_schema(schema, engine)\n # We need this so that we can create multiple mathesar tables in the\n # same MetaData, enabling them to reference each other in the\n # SQLAlchemy context (e.g., for creating a ForeignKey relationship)\n if metadata is None:\n metadata = MetaData(bind=engine, schema=schema)\n # This reflection step lets us notice any \"table already exists\"\n # errors before sending error-generating requests to the DB.\n metadata.reflect()\n table = Table(\n name,\n metadata,\n *columns_,\n schema=schema,\n )\n table.create(engine)\n return table\n\n\ndef extract_columns_from_table(\n old_table_name,\n extracted_column_names,\n extracted_table_name,\n remainder_table_name,\n schema,\n engine,\n drop_original_table=False,\n):\n old_table = reflect_table(old_table_name, schema, engine)\n old_columns = (\n columns.MathesarColumn.from_column(col) for col in old_table.columns\n )\n old_non_default_columns = [\n col for col in old_columns if not col.is_default\n ]\n extracted_columns, remainder_columns = _split_column_list(\n old_non_default_columns, extracted_column_names,\n )\n with engine.begin() as conn:\n extracted_table, remainder_table, remainder_fk = _create_split_tables(\n extracted_table_name,\n extracted_columns,\n remainder_table_name,\n remainder_columns,\n schema,\n engine,\n )\n split_ins = _create_split_insert_stmt(\n old_table,\n extracted_table,\n extracted_columns,\n remainder_table,\n remainder_columns,\n remainder_fk,\n )\n conn.execute(split_ins)\n if drop_original_table:\n old_table.drop()\n\n return extracted_table, remainder_table, remainder_fk\n\n\ndef _split_column_list(columns_, extracted_column_names):\n extracted_columns = [\n col for col in columns_ if col.name in extracted_column_names\n ]\n remainder_columns = [\n col for col in columns_ if col.name not in extracted_column_names\n ]\n return extracted_columns, remainder_columns\n\n\ndef _create_split_tables(\n extracted_table_name,\n extracted_columns,\n remainder_table_name,\n remainder_columns,\n schema,\n engine,\n):\n extracted_table = create_mathesar_table(\n extracted_table_name,\n schema,\n extracted_columns,\n engine,\n )\n remainder_fk_column = Column(\n f\"{extracted_table.name}_{constants.ID}\",\n columns.ID_TYPE,\n ForeignKey(f\"{extracted_table.name}.{constants.ID}\"),\n nullable=False,\n )\n remainder_table = create_mathesar_table(\n remainder_table_name,\n schema,\n [remainder_fk_column] + remainder_columns,\n engine,\n metadata=extracted_table.metadata\n )\n return extracted_table, remainder_table, remainder_fk_column.name\n\n\ndef _create_split_insert_stmt(\n old_table,\n extracted_table,\n extracted_columns,\n remainder_table,\n remainder_columns,\n remainder_fk_name,\n):\n SPLIT_ID = \"f{constants.MATHESAR_PREFIX}_split_column_alias\"\n extracted_column_names = [col.name for col in extracted_columns]\n remainder_column_names = [col.name for col in remainder_columns]\n split_cte = select(\n [\n old_table,\n func.dense_rank().over(order_by=extracted_columns).label(SPLIT_ID)\n ]\n ).cte()\n cte_extraction_columns = (\n [split_cte.columns[SPLIT_ID]]\n + [split_cte.columns[n] for n in extracted_column_names]\n )\n cte_remainder_columns = (\n [split_cte.columns[SPLIT_ID]]\n + [split_cte.columns[n] for n in remainder_column_names]\n )\n extract_sel = select(\n cte_extraction_columns,\n distinct=True\n )\n extract_ins_cte = (\n extracted_table\n .insert()\n .from_select([constants.ID] + extracted_column_names, extract_sel)\n .returning(literal(1))\n .cte()\n )\n remainder_sel = select(\n cte_remainder_columns,\n distinct=True\n ).where(exists(extract_ins_cte.select()))\n\n split_ins = (\n remainder_table\n .insert()\n .from_select(\n [remainder_fk_name] + remainder_column_names,\n remainder_sel\n )\n )\n return split_ins\n\n\ndef merge_tables(\n table_name_one,\n table_name_two,\n merged_table_name,\n schema,\n engine,\n drop_original_tables=False,\n):\n \"\"\"\n This specifically undoes the `extract_columns_from_table` (up to\n unique rows). It may not work in other contexts (yet).\n \"\"\"\n table_one = reflect_table(table_name_one, schema, engine)\n table_two = reflect_table(\n table_name_two, schema, engine, metadata=table_one.metadata\n )\n merge_join = table_one.join(table_two)\n referencing_columns = [\n col for col in [merge_join.onclause.left, merge_join.onclause.right]\n if col.foreign_keys\n ]\n merged_columns_all = [\n columns.MathesarColumn.from_column(col)\n for col in list(table_one.columns) + list(table_two.columns)\n if col not in referencing_columns\n ]\n merged_columns = [col for col in merged_columns_all if not col.is_default]\n with engine.begin() as conn:\n merged_table = create_mathesar_table(\n merged_table_name, schema, merged_columns, engine,\n )\n insert_stmt = merged_table.insert().from_select(\n [col.name for col in merged_columns],\n select(merged_columns, distinct=True).select_from(merge_join)\n )\n conn.execute(insert_stmt)\n\n if drop_original_tables:\n if table_one.foreign_keys:\n table_one.drop(bind=engine)\n table_two.drop(bind=engine)\n else:\n table_two.drop(bind=engine)\n table_one.drop(bind=engine)\n\n return merged_table\n\n\ndef move_column_between_related_tables(\n source_table_name,\n target_table_name,\n column_names,\n schema,\n engine,\n):\n TEMP_MERGED_TABLE_NAME = f\"{constants.MATHESAR_PREFIX}_temp_merge_table\"\n source_table = reflect_table(source_table_name, schema, engine)\n target_table = reflect_table(\n target_table_name, schema, engine, metadata=source_table.metadata\n )\n relationship = _find_table_relationship(source_table, target_table)\n moving_columns = [source_table.columns[n] for n in column_names]\n assert _check_columns(relationship, source_table, moving_columns)\n ext_args = _get_column_moving_extraction_args(\n relationship,\n target_table,\n target_table_name,\n source_table,\n source_table_name,\n moving_columns,\n column_names,\n )\n (extracted_table_name, remainder_table_name, extraction_columns) = ext_args\n merge_tables(\n source_table_name,\n target_table_name,\n TEMP_MERGED_TABLE_NAME,\n schema,\n engine,\n drop_original_tables=True,\n )\n extracted_table, remainder_table, _ = extract_columns_from_table(\n TEMP_MERGED_TABLE_NAME,\n [c.name for c in extraction_columns],\n extracted_table_name,\n remainder_table_name,\n schema,\n engine,\n drop_original_table=True,\n )\n return extracted_table, remainder_table\n\n\ndef _find_table_relationship(table_one, table_two):\n \"\"\"\n This function takes two tables, and returns a dict defining the direction\n of the foreign key constraint relating the tables (if one exists)\n \"\"\"\n one_referencing_two = [\n fkey_constraint for fkey_constraint in table_one.foreign_key_constraints\n if fkey_constraint.referred_table == table_two\n ]\n two_referencing_one = [\n fkey_constraint for fkey_constraint in table_two.foreign_key_constraints\n if fkey_constraint.referred_table == table_one\n ]\n if one_referencing_two and not two_referencing_one:\n relationship = {\"referencing\": table_one, \"referenced\": table_two}\n elif two_referencing_one and not one_referencing_two:\n relationship = {\"referencing\": table_two, \"referenced\": table_one}\n else:\n relationship = None\n return relationship\n\n\ndef _check_columns(relationship, source_table, moving_columns):\n return (\n relationship is not None\n and all([not c.foreign_keys for c in moving_columns])\n )\n\n\ndef _get_column_moving_extraction_args(\n relationship,\n target_table,\n target_table_name,\n source_table,\n source_table_name,\n moving_columns,\n column_names,\n):\n if relationship[\"referenced\"] == target_table:\n extracted_table_name = target_table_name\n remainder_table_name = source_table_name\n extraction_columns = [\n col for col in target_table.columns\n if not columns.MathesarColumn.from_column(col).is_default\n ] + moving_columns\n else:\n extracted_table_name = source_table_name\n remainder_table_name = target_table_name\n extraction_columns = [\n col for col in target_table.columns\n if not columns.MathesarColumn.from_column(col).is_default\n and col not in column_names\n ]\n return extracted_table_name, remainder_table_name, extraction_columns\n\n\ndef reflect_table(name, schema, engine, metadata=None):\n if metadata is None:\n metadata = MetaData(bind=engine)\n return Table(name, metadata, schema=schema, autoload_with=engine)\n\n\ndef get_count(table, engine):\n query = select([func.count()]).select_from(table)\n with engine.begin() as conn:\n return conn.execute(query).scalar()\n", "path": "db/tables.py"}], "after_files": [{"content": "from sqlalchemy import (\n Column, String, Table, MetaData, func, select, ForeignKey, literal, exists\n)\n\nfrom db import columns, constants, schemas\n\n\ndef create_string_column_table(name, schema, column_names, engine):\n \"\"\"\n This method creates a Postgres table in the specified schema, with all\n columns being String type.\n \"\"\"\n columns_ = [Column(column_name, String) for column_name in column_names]\n table = create_mathesar_table(name, schema, columns_, engine)\n return table\n\n\ndef create_mathesar_table(name, schema, columns_, engine, metadata=None):\n \"\"\"\n This method creates a Postgres table in the specified schema using the\n given name and column list. It adds internal mathesar columns to the\n table.\n \"\"\"\n columns_ = columns.init_mathesar_table_column_list_with_defaults(columns_)\n schemas.create_schema(schema, engine)\n # We need this so that we can create multiple mathesar tables in the\n # same MetaData, enabling them to reference each other in the\n # SQLAlchemy context (e.g., for creating a ForeignKey relationship)\n if metadata is None:\n metadata = MetaData(bind=engine, schema=schema)\n # This reflection step lets us notice any \"table already exists\"\n # errors before sending error-generating requests to the DB.\n metadata.reflect()\n table = Table(\n name,\n metadata,\n *columns_,\n schema=schema,\n )\n table.create(engine)\n return table\n\n\ndef extract_columns_from_table(\n old_table_name,\n extracted_column_names,\n extracted_table_name,\n remainder_table_name,\n schema,\n engine,\n drop_original_table=False,\n):\n old_table = reflect_table(old_table_name, schema, engine)\n old_columns = (\n columns.MathesarColumn.from_column(col) for col in old_table.columns\n )\n old_non_default_columns = [\n col for col in old_columns if not col.is_default\n ]\n extracted_columns, remainder_columns = _split_column_list(\n old_non_default_columns, extracted_column_names,\n )\n with engine.begin() as conn:\n extracted_table, remainder_table, remainder_fk = _create_split_tables(\n extracted_table_name,\n extracted_columns,\n remainder_table_name,\n remainder_columns,\n schema,\n engine,\n )\n split_ins = _create_split_insert_stmt(\n old_table,\n extracted_table,\n extracted_columns,\n remainder_table,\n remainder_columns,\n remainder_fk,\n )\n conn.execute(split_ins)\n if drop_original_table:\n old_table.drop()\n\n return extracted_table, remainder_table, remainder_fk\n\n\ndef _split_column_list(columns_, extracted_column_names):\n extracted_columns = [\n col for col in columns_ if col.name in extracted_column_names\n ]\n remainder_columns = [\n col for col in columns_ if col.name not in extracted_column_names\n ]\n return extracted_columns, remainder_columns\n\n\ndef _create_split_tables(\n extracted_table_name,\n extracted_columns,\n remainder_table_name,\n remainder_columns,\n schema,\n engine,\n):\n extracted_table = create_mathesar_table(\n extracted_table_name,\n schema,\n extracted_columns,\n engine,\n )\n remainder_fk_column = Column(\n f\"{extracted_table.name}_{constants.ID}\",\n columns.ID_TYPE,\n ForeignKey(f\"{extracted_table.name}.{constants.ID}\"),\n nullable=False,\n )\n remainder_table = create_mathesar_table(\n remainder_table_name,\n schema,\n [remainder_fk_column] + remainder_columns,\n engine,\n metadata=extracted_table.metadata\n )\n return extracted_table, remainder_table, remainder_fk_column.name\n\n\ndef _create_split_insert_stmt(\n old_table,\n extracted_table,\n extracted_columns,\n remainder_table,\n remainder_columns,\n remainder_fk_name,\n):\n SPLIT_ID = f\"{constants.MATHESAR_PREFIX}_split_column_alias\"\n extracted_column_names = [col.name for col in extracted_columns]\n remainder_column_names = [col.name for col in remainder_columns]\n split_cte = select(\n [\n old_table,\n func.dense_rank().over(order_by=extracted_columns).label(SPLIT_ID)\n ]\n ).cte()\n cte_extraction_columns = (\n [split_cte.columns[SPLIT_ID]]\n + [split_cte.columns[n] for n in extracted_column_names]\n )\n cte_remainder_columns = (\n [split_cte.columns[SPLIT_ID]]\n + [split_cte.columns[n] for n in remainder_column_names]\n )\n extract_sel = select(\n cte_extraction_columns,\n distinct=True\n )\n extract_ins_cte = (\n extracted_table\n .insert()\n .from_select([constants.ID] + extracted_column_names, extract_sel)\n .returning(literal(1))\n .cte()\n )\n remainder_sel = select(\n cte_remainder_columns,\n distinct=True\n ).where(exists(extract_ins_cte.select()))\n\n split_ins = (\n remainder_table\n .insert()\n .from_select(\n [remainder_fk_name] + remainder_column_names,\n remainder_sel\n )\n )\n return split_ins\n\n\ndef merge_tables(\n table_name_one,\n table_name_two,\n merged_table_name,\n schema,\n engine,\n drop_original_tables=False,\n):\n \"\"\"\n This specifically undoes the `extract_columns_from_table` (up to\n unique rows). It may not work in other contexts (yet).\n \"\"\"\n table_one = reflect_table(table_name_one, schema, engine)\n table_two = reflect_table(\n table_name_two, schema, engine, metadata=table_one.metadata\n )\n merge_join = table_one.join(table_two)\n referencing_columns = [\n col for col in [merge_join.onclause.left, merge_join.onclause.right]\n if col.foreign_keys\n ]\n merged_columns_all = [\n columns.MathesarColumn.from_column(col)\n for col in list(table_one.columns) + list(table_two.columns)\n if col not in referencing_columns\n ]\n merged_columns = [col for col in merged_columns_all if not col.is_default]\n with engine.begin() as conn:\n merged_table = create_mathesar_table(\n merged_table_name, schema, merged_columns, engine,\n )\n insert_stmt = merged_table.insert().from_select(\n [col.name for col in merged_columns],\n select(merged_columns, distinct=True).select_from(merge_join)\n )\n conn.execute(insert_stmt)\n\n if drop_original_tables:\n if table_one.foreign_keys:\n table_one.drop(bind=engine)\n table_two.drop(bind=engine)\n else:\n table_two.drop(bind=engine)\n table_one.drop(bind=engine)\n\n return merged_table\n\n\ndef move_columns_between_related_tables(\n source_table_name,\n target_table_name,\n column_names,\n schema,\n engine,\n):\n TEMP_MERGED_TABLE_NAME = f\"{constants.MATHESAR_PREFIX}_temp_merge_table\"\n source_table = reflect_table(source_table_name, schema, engine)\n target_table = reflect_table(\n target_table_name, schema, engine, metadata=source_table.metadata\n )\n relationship = _find_table_relationship(source_table, target_table)\n moving_columns = [source_table.columns[n] for n in column_names]\n assert _check_columns(relationship, source_table, moving_columns)\n ext_args = _get_column_moving_extraction_args(\n relationship,\n target_table,\n target_table_name,\n source_table,\n source_table_name,\n moving_columns,\n column_names,\n )\n (extracted_table_name, remainder_table_name, extraction_columns) = ext_args\n merge_tables(\n source_table_name,\n target_table_name,\n TEMP_MERGED_TABLE_NAME,\n schema,\n engine,\n drop_original_tables=True,\n )\n extracted_table, remainder_table, _ = extract_columns_from_table(\n TEMP_MERGED_TABLE_NAME,\n [c.name for c in extraction_columns],\n extracted_table_name,\n remainder_table_name,\n schema,\n engine,\n drop_original_table=True,\n )\n return extracted_table, remainder_table\n\n\ndef _find_table_relationship(table_one, table_two):\n \"\"\"\n This function takes two tables, and returns a dict defining the direction\n of the foreign key constraint relating the tables (if one exists)\n \"\"\"\n one_referencing_two = [\n fkey_constraint for fkey_constraint in table_one.foreign_key_constraints\n if fkey_constraint.referred_table == table_two\n ]\n two_referencing_one = [\n fkey_constraint for fkey_constraint in table_two.foreign_key_constraints\n if fkey_constraint.referred_table == table_one\n ]\n if one_referencing_two and not two_referencing_one:\n relationship = {\"referencing\": table_one, \"referenced\": table_two}\n elif two_referencing_one and not one_referencing_two:\n relationship = {\"referencing\": table_two, \"referenced\": table_one}\n else:\n relationship = None\n return relationship\n\n\ndef _check_columns(relationship, source_table, moving_columns):\n return (\n relationship is not None\n and all([not c.foreign_keys for c in moving_columns])\n )\n\n\ndef _get_column_moving_extraction_args(\n relationship,\n target_table,\n target_table_name,\n source_table,\n source_table_name,\n moving_columns,\n column_names,\n):\n if relationship[\"referenced\"] == target_table:\n extracted_table_name = target_table_name\n remainder_table_name = source_table_name\n extraction_columns = [\n col for col in target_table.columns\n if not columns.MathesarColumn.from_column(col).is_default\n ] + moving_columns\n else:\n extracted_table_name = source_table_name\n remainder_table_name = target_table_name\n extraction_columns = [\n col for col in source_table.columns\n if not columns.MathesarColumn.from_column(col).is_default\n and col.name not in column_names\n ]\n return extracted_table_name, remainder_table_name, extraction_columns\n\n\ndef reflect_table(name, schema, engine, metadata=None):\n if metadata is None:\n metadata = MetaData(bind=engine)\n return Table(name, metadata, schema=schema, autoload_with=engine)\n\n\ndef get_count(table, engine):\n query = select([func.count()]).select_from(table)\n with engine.begin() as conn:\n return conn.execute(query).scalar()\n", "path": "db/tables.py"}]}
| 3,498 | 280 |
gh_patches_debug_15782
|
rasdani/github-patches
|
git_diff
|
keras-team__autokeras-1399
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Adding types information on the API surface.
Adding types on the public API surface would allow us to do some runtime type checking later on and would allow user's IDE to have more info for static analysis.
The functions/signatures to type are the ones listed here https://github.com/keras-team/autokeras/blob/master/autokeras/__init__.py
For the context, see #856 where I add some type information on a ImageClassifier.
This issue can be considered easy to solve (good first issue), it's just long to do because the public API surface is big.
I'll do it but some help is welcome :) make sure to make small pull requests.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `autokeras/utils/io_utils.py`
Content:
```
1 # Copyright 2020 The AutoKeras Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import json
16
17 import numpy as np
18 import tensorflow as tf
19 from tensorflow.python.keras.preprocessing import dataset_utils
20
21 WHITELIST_FORMATS = (".bmp", ".gif", ".jpeg", ".jpg", ".png")
22
23
24 def save_json(path, obj):
25 obj = json.dumps(obj)
26 with tf.io.gfile.GFile(path, "w") as f:
27 f.write(obj)
28
29
30 def load_json(path):
31 with tf.io.gfile.GFile(path, "r") as f:
32 obj = f.read()
33 return json.loads(obj)
34
35
36 def get_training_or_validation_split(samples, labels, validation_split, subset):
37 """Potentially restict samples & labels to a training or validation split.
38
39 # Arguments
40 samples: List of elements.
41 labels: List of corresponding labels.
42 validation_split: Float, fraction of data to reserve for validation.
43 subset: Subset of the data to return.
44 Either "training", "validation", or None.
45 If None, we return all of the data.
46
47 # Returns
48 tuple (samples, labels), potentially restricted to the specified subset.
49 """
50 if not validation_split:
51 return samples, labels
52
53 num_val_samples = int(validation_split * len(samples))
54 if subset == "training":
55 print("Using %d files for training." % (len(samples) - num_val_samples,))
56 samples = samples[:-num_val_samples]
57 labels = labels[:-num_val_samples]
58 elif subset == "validation":
59 print("Using %d files for validation." % (num_val_samples,))
60 samples = samples[-num_val_samples:]
61 labels = labels[-num_val_samples:]
62 else:
63 raise ValueError(
64 '`subset` must be either "training" '
65 'or "validation", received: %s' % (subset,)
66 )
67 return samples, labels
68
69
70 def text_dataset_from_directory(
71 directory,
72 batch_size=32,
73 max_length=None,
74 shuffle=True,
75 seed=None,
76 validation_split=None,
77 subset=None,
78 ):
79 """Generates a `tf.data.Dataset` from text files in a directory.
80
81 If your directory structure is:
82
83 ```
84 main_directory/
85 ...class_a/
86 ......a_text_1.txt
87 ......a_text_2.txt
88 ...class_b/
89 ......b_text_1.txt
90 ......b_text_2.txt
91 ```
92
93 Then calling `text_dataset_from_directory(main_directory)`
94 will return a `tf.data.Dataset` that yields batches of texts from
95 the subdirectories `class_a` and `class_b`, together with labels
96 'class_a' and 'class_b'.
97
98 Only `.txt` files are supported at this time.
99
100 # Arguments
101 directory: Directory where the data is located.
102 If `labels` is "inferred", it should contain
103 subdirectories, each containing text files for a class.
104 Otherwise, the directory structure is ignored.
105 batch_size: Size of the batches of data. Defaults to 32.
106 max_length: Maximum size of a text string. Texts longer than this will
107 be truncated to `max_length`.
108 shuffle: Whether to shuffle the data. Default: True.
109 If set to False, sorts the data in alphanumeric order.
110 seed: Optional random seed for shuffling and transformations.
111 validation_split: Optional float between 0 and 1,
112 fraction of data to reserve for validation.
113 subset: One of "training" or "validation".
114 Only used if `validation_split` is set.
115
116 # Returns
117 A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,
118 where both has shape `(batch_size,)` and type of tf.string.
119 """
120 if seed is None:
121 seed = np.random.randint(1e6)
122 file_paths, labels, class_names = dataset_utils.index_directory(
123 directory, "inferred", formats=(".txt",), shuffle=shuffle, seed=seed
124 )
125
126 file_paths, labels = get_training_or_validation_split(
127 file_paths, labels, validation_split, subset
128 )
129
130 strings = tf.data.Dataset.from_tensor_slices(file_paths)
131 strings = strings.map(tf.io.read_file)
132 if max_length is not None:
133 strings = strings.map(lambda x: tf.strings.substr(x, 0, max_length))
134
135 labels = np.array(class_names)[np.array(labels)]
136 labels = tf.data.Dataset.from_tensor_slices(labels)
137
138 dataset = tf.data.Dataset.zip((strings, labels))
139 dataset = dataset.batch(batch_size)
140 return dataset
141
142
143 def image_dataset_from_directory(
144 directory,
145 batch_size=32,
146 color_mode="rgb",
147 image_size=(256, 256),
148 interpolation="bilinear",
149 shuffle=True,
150 seed=None,
151 validation_split=None,
152 subset=None,
153 ):
154 """Generates a `tf.data.Dataset` from image files in a directory.
155 If your directory structure is:
156
157 ```
158 main_directory/
159 ...class_a/
160 ......a_image_1.jpg
161 ......a_image_2.jpg
162 ...class_b/
163 ......b_image_1.jpg
164 ......b_image_2.jpg
165 ```
166
167 Then calling `image_dataset_from_directory(main_directory)`
168 will return a `tf.data.Dataset` that yields batches of images from
169 the subdirectories `class_a` and `class_b`, together with labels
170 'class_a' and 'class_b'.
171
172 Supported image formats: jpeg, png, bmp, gif.
173 Animated gifs are truncated to the first frame.
174
175 # Arguments
176 directory: Directory where the data is located.
177 If `labels` is "inferred", it should contain
178 subdirectories, each containing images for a class.
179 Otherwise, the directory structure is ignored.
180 batch_size: Size of the batches of data. Default: 32.
181 color_mode: One of "grayscale", "rgb", "rgba". Default: "rgb".
182 Whether the images will be converted to
183 have 1, 3, or 4 channels.
184 image_size: Size to resize images to after they are read from disk.
185 Defaults to `(256, 256)`.
186 Since the pipeline processes batches of images that must all have
187 the same size, this must be provided.
188 interpolation: String, the interpolation method used when resizing images.
189 Defaults to `bilinear`. Supports `bilinear`, `nearest`, `bicubic`,
190 `area`, `lanczos3`, `lanczos5`, `gaussian`, `mitchellcubic`.
191 shuffle: Whether to shuffle the data. Default: True.
192 If set to False, sorts the data in alphanumeric order.
193 seed: Optional random seed for shuffling and transformations.
194 validation_split: Optional float between 0 and 1,
195 fraction of data to reserve for validation.
196 subset: One of "training" or "validation".
197 Only used if `validation_split` is set.
198
199 # Returns
200 A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,
201 where `images` has shape `(batch_size, image_size[0], image_size[1],
202 num_channels)` where `labels` has shape `(batch_size,)` and type of
203 tf.string.
204 - if `color_mode` is `grayscale`, there's 1 channel in the image
205 tensors.
206 - if `color_mode` is `rgb`, there are 3 channel in the image tensors.
207 - if `color_mode` is `rgba`, there are 4 channel in the image tensors.
208 """
209 if color_mode == "rgb":
210 num_channels = 3
211 elif color_mode == "rgba":
212 num_channels = 4
213 elif color_mode == "grayscale":
214 num_channels = 1
215 else:
216 raise ValueError(
217 '`color_mode` must be one of {"rbg", "rgba", "grayscale"}. '
218 "Received: %s" % (color_mode,)
219 )
220
221 if seed is None:
222 seed = np.random.randint(1e6)
223 image_paths, labels, class_names = dataset_utils.index_directory(
224 directory, "inferred", formats=WHITELIST_FORMATS, shuffle=shuffle, seed=seed
225 )
226
227 image_paths, labels = get_training_or_validation_split(
228 image_paths, labels, validation_split, subset
229 )
230
231 images = tf.data.Dataset.from_tensor_slices(image_paths)
232 images = images.map(
233 lambda img: path_to_image(img, num_channels, image_size, interpolation)
234 )
235
236 labels = np.array(class_names)[np.array(labels)]
237 labels = tf.data.Dataset.from_tensor_slices(labels)
238
239 dataset = tf.data.Dataset.zip((images, labels))
240 dataset = dataset.batch(batch_size)
241 return dataset
242
243
244 def path_to_image(image, num_channels, image_size, interpolation):
245 image = tf.io.read_file(image)
246 image = tf.io.decode_image(image, channels=num_channels, expand_animations=False)
247 image = tf.image.resize(image, image_size, method=interpolation)
248 image.set_shape((image_size[0], image_size[1], num_channels))
249 return image
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/autokeras/utils/io_utils.py b/autokeras/utils/io_utils.py
--- a/autokeras/utils/io_utils.py
+++ b/autokeras/utils/io_utils.py
@@ -13,6 +13,7 @@
# limitations under the License.
import json
+from typing import Optional
import numpy as np
import tensorflow as tf
@@ -68,14 +69,14 @@
def text_dataset_from_directory(
- directory,
- batch_size=32,
- max_length=None,
- shuffle=True,
- seed=None,
- validation_split=None,
- subset=None,
-):
+ directory: str,
+ batch_size: int = 32,
+ max_length: Optional[int] = None,
+ shuffle: bool = True,
+ seed: Optional[int] = None,
+ validation_split: Optional[float] = None,
+ subset: Optional[str] = None,
+) -> tf.data.Dataset:
"""Generates a `tf.data.Dataset` from text files in a directory.
If your directory structure is:
|
{"golden_diff": "diff --git a/autokeras/utils/io_utils.py b/autokeras/utils/io_utils.py\n--- a/autokeras/utils/io_utils.py\n+++ b/autokeras/utils/io_utils.py\n@@ -13,6 +13,7 @@\n # limitations under the License.\n \n import json\n+from typing import Optional\n \n import numpy as np\n import tensorflow as tf\n@@ -68,14 +69,14 @@\n \n \n def text_dataset_from_directory(\n- directory,\n- batch_size=32,\n- max_length=None,\n- shuffle=True,\n- seed=None,\n- validation_split=None,\n- subset=None,\n-):\n+ directory: str,\n+ batch_size: int = 32,\n+ max_length: Optional[int] = None,\n+ shuffle: bool = True,\n+ seed: Optional[int] = None,\n+ validation_split: Optional[float] = None,\n+ subset: Optional[str] = None,\n+) -> tf.data.Dataset:\n \"\"\"Generates a `tf.data.Dataset` from text files in a directory.\n \n If your directory structure is:\n", "issue": "Adding types information on the API surface.\nAdding types on the public API surface would allow us to do some runtime type checking later on and would allow user's IDE to have more info for static analysis. \r\n\r\nThe functions/signatures to type are the ones listed here https://github.com/keras-team/autokeras/blob/master/autokeras/__init__.py\r\n\r\nFor the context, see #856 where I add some type information on a ImageClassifier.\r\n\r\nThis issue can be considered easy to solve (good first issue), it's just long to do because the public API surface is big.\r\n\r\nI'll do it but some help is welcome :) make sure to make small pull requests.\n", "before_files": [{"content": "# Copyright 2020 The AutoKeras Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.keras.preprocessing import dataset_utils\n\nWHITELIST_FORMATS = (\".bmp\", \".gif\", \".jpeg\", \".jpg\", \".png\")\n\n\ndef save_json(path, obj):\n obj = json.dumps(obj)\n with tf.io.gfile.GFile(path, \"w\") as f:\n f.write(obj)\n\n\ndef load_json(path):\n with tf.io.gfile.GFile(path, \"r\") as f:\n obj = f.read()\n return json.loads(obj)\n\n\ndef get_training_or_validation_split(samples, labels, validation_split, subset):\n \"\"\"Potentially restict samples & labels to a training or validation split.\n\n # Arguments\n samples: List of elements.\n labels: List of corresponding labels.\n validation_split: Float, fraction of data to reserve for validation.\n subset: Subset of the data to return.\n Either \"training\", \"validation\", or None.\n If None, we return all of the data.\n\n # Returns\n tuple (samples, labels), potentially restricted to the specified subset.\n \"\"\"\n if not validation_split:\n return samples, labels\n\n num_val_samples = int(validation_split * len(samples))\n if subset == \"training\":\n print(\"Using %d files for training.\" % (len(samples) - num_val_samples,))\n samples = samples[:-num_val_samples]\n labels = labels[:-num_val_samples]\n elif subset == \"validation\":\n print(\"Using %d files for validation.\" % (num_val_samples,))\n samples = samples[-num_val_samples:]\n labels = labels[-num_val_samples:]\n else:\n raise ValueError(\n '`subset` must be either \"training\" '\n 'or \"validation\", received: %s' % (subset,)\n )\n return samples, labels\n\n\ndef text_dataset_from_directory(\n directory,\n batch_size=32,\n max_length=None,\n shuffle=True,\n seed=None,\n validation_split=None,\n subset=None,\n):\n \"\"\"Generates a `tf.data.Dataset` from text files in a directory.\n\n If your directory structure is:\n\n ```\n main_directory/\n ...class_a/\n ......a_text_1.txt\n ......a_text_2.txt\n ...class_b/\n ......b_text_1.txt\n ......b_text_2.txt\n ```\n\n Then calling `text_dataset_from_directory(main_directory)`\n will return a `tf.data.Dataset` that yields batches of texts from\n the subdirectories `class_a` and `class_b`, together with labels\n 'class_a' and 'class_b'.\n\n Only `.txt` files are supported at this time.\n\n # Arguments\n directory: Directory where the data is located.\n If `labels` is \"inferred\", it should contain\n subdirectories, each containing text files for a class.\n Otherwise, the directory structure is ignored.\n batch_size: Size of the batches of data. Defaults to 32.\n max_length: Maximum size of a text string. Texts longer than this will\n be truncated to `max_length`.\n shuffle: Whether to shuffle the data. Default: True.\n If set to False, sorts the data in alphanumeric order.\n seed: Optional random seed for shuffling and transformations.\n validation_split: Optional float between 0 and 1,\n fraction of data to reserve for validation.\n subset: One of \"training\" or \"validation\".\n Only used if `validation_split` is set.\n\n # Returns\n A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,\n where both has shape `(batch_size,)` and type of tf.string.\n \"\"\"\n if seed is None:\n seed = np.random.randint(1e6)\n file_paths, labels, class_names = dataset_utils.index_directory(\n directory, \"inferred\", formats=(\".txt\",), shuffle=shuffle, seed=seed\n )\n\n file_paths, labels = get_training_or_validation_split(\n file_paths, labels, validation_split, subset\n )\n\n strings = tf.data.Dataset.from_tensor_slices(file_paths)\n strings = strings.map(tf.io.read_file)\n if max_length is not None:\n strings = strings.map(lambda x: tf.strings.substr(x, 0, max_length))\n\n labels = np.array(class_names)[np.array(labels)]\n labels = tf.data.Dataset.from_tensor_slices(labels)\n\n dataset = tf.data.Dataset.zip((strings, labels))\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef image_dataset_from_directory(\n directory,\n batch_size=32,\n color_mode=\"rgb\",\n image_size=(256, 256),\n interpolation=\"bilinear\",\n shuffle=True,\n seed=None,\n validation_split=None,\n subset=None,\n):\n \"\"\"Generates a `tf.data.Dataset` from image files in a directory.\n If your directory structure is:\n\n ```\n main_directory/\n ...class_a/\n ......a_image_1.jpg\n ......a_image_2.jpg\n ...class_b/\n ......b_image_1.jpg\n ......b_image_2.jpg\n ```\n\n Then calling `image_dataset_from_directory(main_directory)`\n will return a `tf.data.Dataset` that yields batches of images from\n the subdirectories `class_a` and `class_b`, together with labels\n 'class_a' and 'class_b'.\n\n Supported image formats: jpeg, png, bmp, gif.\n Animated gifs are truncated to the first frame.\n\n # Arguments\n directory: Directory where the data is located.\n If `labels` is \"inferred\", it should contain\n subdirectories, each containing images for a class.\n Otherwise, the directory structure is ignored.\n batch_size: Size of the batches of data. Default: 32.\n color_mode: One of \"grayscale\", \"rgb\", \"rgba\". Default: \"rgb\".\n Whether the images will be converted to\n have 1, 3, or 4 channels.\n image_size: Size to resize images to after they are read from disk.\n Defaults to `(256, 256)`.\n Since the pipeline processes batches of images that must all have\n the same size, this must be provided.\n interpolation: String, the interpolation method used when resizing images.\n Defaults to `bilinear`. Supports `bilinear`, `nearest`, `bicubic`,\n `area`, `lanczos3`, `lanczos5`, `gaussian`, `mitchellcubic`.\n shuffle: Whether to shuffle the data. Default: True.\n If set to False, sorts the data in alphanumeric order.\n seed: Optional random seed for shuffling and transformations.\n validation_split: Optional float between 0 and 1,\n fraction of data to reserve for validation.\n subset: One of \"training\" or \"validation\".\n Only used if `validation_split` is set.\n\n # Returns\n A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,\n where `images` has shape `(batch_size, image_size[0], image_size[1],\n num_channels)` where `labels` has shape `(batch_size,)` and type of\n tf.string.\n - if `color_mode` is `grayscale`, there's 1 channel in the image\n tensors.\n - if `color_mode` is `rgb`, there are 3 channel in the image tensors.\n - if `color_mode` is `rgba`, there are 4 channel in the image tensors.\n \"\"\"\n if color_mode == \"rgb\":\n num_channels = 3\n elif color_mode == \"rgba\":\n num_channels = 4\n elif color_mode == \"grayscale\":\n num_channels = 1\n else:\n raise ValueError(\n '`color_mode` must be one of {\"rbg\", \"rgba\", \"grayscale\"}. '\n \"Received: %s\" % (color_mode,)\n )\n\n if seed is None:\n seed = np.random.randint(1e6)\n image_paths, labels, class_names = dataset_utils.index_directory(\n directory, \"inferred\", formats=WHITELIST_FORMATS, shuffle=shuffle, seed=seed\n )\n\n image_paths, labels = get_training_or_validation_split(\n image_paths, labels, validation_split, subset\n )\n\n images = tf.data.Dataset.from_tensor_slices(image_paths)\n images = images.map(\n lambda img: path_to_image(img, num_channels, image_size, interpolation)\n )\n\n labels = np.array(class_names)[np.array(labels)]\n labels = tf.data.Dataset.from_tensor_slices(labels)\n\n dataset = tf.data.Dataset.zip((images, labels))\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef path_to_image(image, num_channels, image_size, interpolation):\n image = tf.io.read_file(image)\n image = tf.io.decode_image(image, channels=num_channels, expand_animations=False)\n image = tf.image.resize(image, image_size, method=interpolation)\n image.set_shape((image_size[0], image_size[1], num_channels))\n return image\n", "path": "autokeras/utils/io_utils.py"}], "after_files": [{"content": "# Copyright 2020 The AutoKeras Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nfrom typing import Optional\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.keras.preprocessing import dataset_utils\n\nWHITELIST_FORMATS = (\".bmp\", \".gif\", \".jpeg\", \".jpg\", \".png\")\n\n\ndef save_json(path, obj):\n obj = json.dumps(obj)\n with tf.io.gfile.GFile(path, \"w\") as f:\n f.write(obj)\n\n\ndef load_json(path):\n with tf.io.gfile.GFile(path, \"r\") as f:\n obj = f.read()\n return json.loads(obj)\n\n\ndef get_training_or_validation_split(samples, labels, validation_split, subset):\n \"\"\"Potentially restict samples & labels to a training or validation split.\n\n # Arguments\n samples: List of elements.\n labels: List of corresponding labels.\n validation_split: Float, fraction of data to reserve for validation.\n subset: Subset of the data to return.\n Either \"training\", \"validation\", or None.\n If None, we return all of the data.\n\n # Returns\n tuple (samples, labels), potentially restricted to the specified subset.\n \"\"\"\n if not validation_split:\n return samples, labels\n\n num_val_samples = int(validation_split * len(samples))\n if subset == \"training\":\n print(\"Using %d files for training.\" % (len(samples) - num_val_samples,))\n samples = samples[:-num_val_samples]\n labels = labels[:-num_val_samples]\n elif subset == \"validation\":\n print(\"Using %d files for validation.\" % (num_val_samples,))\n samples = samples[-num_val_samples:]\n labels = labels[-num_val_samples:]\n else:\n raise ValueError(\n '`subset` must be either \"training\" '\n 'or \"validation\", received: %s' % (subset,)\n )\n return samples, labels\n\n\ndef text_dataset_from_directory(\n directory: str,\n batch_size: int = 32,\n max_length: Optional[int] = None,\n shuffle: bool = True,\n seed: Optional[int] = None,\n validation_split: Optional[float] = None,\n subset: Optional[str] = None,\n) -> tf.data.Dataset:\n \"\"\"Generates a `tf.data.Dataset` from text files in a directory.\n\n If your directory structure is:\n\n ```\n main_directory/\n ...class_a/\n ......a_text_1.txt\n ......a_text_2.txt\n ...class_b/\n ......b_text_1.txt\n ......b_text_2.txt\n ```\n\n Then calling `text_dataset_from_directory(main_directory)`\n will return a `tf.data.Dataset` that yields batches of texts from\n the subdirectories `class_a` and `class_b`, together with labels\n 'class_a' and 'class_b'.\n\n Only `.txt` files are supported at this time.\n\n # Arguments\n directory: Directory where the data is located.\n If `labels` is \"inferred\", it should contain\n subdirectories, each containing text files for a class.\n Otherwise, the directory structure is ignored.\n batch_size: Size of the batches of data. Defaults to 32.\n max_length: Maximum size of a text string. Texts longer than this will\n be truncated to `max_length`.\n shuffle: Whether to shuffle the data. Default: True.\n If set to False, sorts the data in alphanumeric order.\n seed: Optional random seed for shuffling and transformations.\n validation_split: Optional float between 0 and 1,\n fraction of data to reserve for validation.\n subset: One of \"training\" or \"validation\".\n Only used if `validation_split` is set.\n\n # Returns\n A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,\n where both has shape `(batch_size,)` and type of tf.string.\n \"\"\"\n if seed is None:\n seed = np.random.randint(1e6)\n file_paths, labels, class_names = dataset_utils.index_directory(\n directory, \"inferred\", formats=(\".txt\",), shuffle=shuffle, seed=seed\n )\n\n file_paths, labels = get_training_or_validation_split(\n file_paths, labels, validation_split, subset\n )\n\n strings = tf.data.Dataset.from_tensor_slices(file_paths)\n strings = strings.map(tf.io.read_file)\n if max_length is not None:\n strings = strings.map(lambda x: tf.strings.substr(x, 0, max_length))\n\n labels = np.array(class_names)[np.array(labels)]\n labels = tf.data.Dataset.from_tensor_slices(labels)\n\n dataset = tf.data.Dataset.zip((strings, labels))\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef image_dataset_from_directory(\n directory,\n batch_size=32,\n color_mode=\"rgb\",\n image_size=(256, 256),\n interpolation=\"bilinear\",\n shuffle=True,\n seed=None,\n validation_split=None,\n subset=None,\n):\n \"\"\"Generates a `tf.data.Dataset` from image files in a directory.\n If your directory structure is:\n\n ```\n main_directory/\n ...class_a/\n ......a_image_1.jpg\n ......a_image_2.jpg\n ...class_b/\n ......b_image_1.jpg\n ......b_image_2.jpg\n ```\n\n Then calling `image_dataset_from_directory(main_directory)`\n will return a `tf.data.Dataset` that yields batches of images from\n the subdirectories `class_a` and `class_b`, together with labels\n 'class_a' and 'class_b'.\n\n Supported image formats: jpeg, png, bmp, gif.\n Animated gifs are truncated to the first frame.\n\n # Arguments\n directory: Directory where the data is located.\n If `labels` is \"inferred\", it should contain\n subdirectories, each containing images for a class.\n Otherwise, the directory structure is ignored.\n batch_size: Size of the batches of data. Default: 32.\n color_mode: One of \"grayscale\", \"rgb\", \"rgba\". Default: \"rgb\".\n Whether the images will be converted to\n have 1, 3, or 4 channels.\n image_size: Size to resize images to after they are read from disk.\n Defaults to `(256, 256)`.\n Since the pipeline processes batches of images that must all have\n the same size, this must be provided.\n interpolation: String, the interpolation method used when resizing images.\n Defaults to `bilinear`. Supports `bilinear`, `nearest`, `bicubic`,\n `area`, `lanczos3`, `lanczos5`, `gaussian`, `mitchellcubic`.\n shuffle: Whether to shuffle the data. Default: True.\n If set to False, sorts the data in alphanumeric order.\n seed: Optional random seed for shuffling and transformations.\n validation_split: Optional float between 0 and 1,\n fraction of data to reserve for validation.\n subset: One of \"training\" or \"validation\".\n Only used if `validation_split` is set.\n\n # Returns\n A `tf.data.Dataset` object, which yields a tuple `(texts, labels)`,\n where `images` has shape `(batch_size, image_size[0], image_size[1],\n num_channels)` where `labels` has shape `(batch_size,)` and type of\n tf.string.\n - if `color_mode` is `grayscale`, there's 1 channel in the image\n tensors.\n - if `color_mode` is `rgb`, there are 3 channel in the image tensors.\n - if `color_mode` is `rgba`, there are 4 channel in the image tensors.\n \"\"\"\n if color_mode == \"rgb\":\n num_channels = 3\n elif color_mode == \"rgba\":\n num_channels = 4\n elif color_mode == \"grayscale\":\n num_channels = 1\n else:\n raise ValueError(\n '`color_mode` must be one of {\"rbg\", \"rgba\", \"grayscale\"}. '\n \"Received: %s\" % (color_mode,)\n )\n\n if seed is None:\n seed = np.random.randint(1e6)\n image_paths, labels, class_names = dataset_utils.index_directory(\n directory, \"inferred\", formats=WHITELIST_FORMATS, shuffle=shuffle, seed=seed\n )\n\n image_paths, labels = get_training_or_validation_split(\n image_paths, labels, validation_split, subset\n )\n\n images = tf.data.Dataset.from_tensor_slices(image_paths)\n images = images.map(\n lambda img: path_to_image(img, num_channels, image_size, interpolation)\n )\n\n labels = np.array(class_names)[np.array(labels)]\n labels = tf.data.Dataset.from_tensor_slices(labels)\n\n dataset = tf.data.Dataset.zip((images, labels))\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef path_to_image(image, num_channels, image_size, interpolation):\n image = tf.io.read_file(image)\n image = tf.io.decode_image(image, channels=num_channels, expand_animations=False)\n image = tf.image.resize(image, image_size, method=interpolation)\n image.set_shape((image_size[0], image_size[1], num_channels))\n return image\n", "path": "autokeras/utils/io_utils.py"}]}
| 3,146 | 242 |
gh_patches_debug_1183
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-2235
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
VBoxForm broken
Added a `float:left` to fix `sliders.py` which broke stock app example worse.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/plotting/file/slider.py`
Content:
```
1
2 from bokeh.io import vform
3 from bokeh.plotting import figure, hplot, output_file, show, vplot, ColumnDataSource
4 from bokeh.models.actions import Callback
5 from bokeh.models.widgets import Slider
6
7 import numpy as np
8
9 x = np.linspace(0, 10, 500)
10 y = np.sin(x)
11
12 source = ColumnDataSource(data=dict(x=x, y=y))
13
14
15 plot = figure(y_range=(-10, 10), plot_width=400, plot_height=400)
16 plot.line('x', 'y', source=source, line_width=3, line_alpha=0.6)
17
18 callback = Callback(args=dict(source=source), code="""
19 var data = source.get('data');
20 var A = amp.get('value')
21 var k = freq.get('value')
22 var phi = phase.get('value')
23 var B = offset.get('value')
24 x = data['x']
25 y = data['y']
26 for (i = 0; i < x.length; i++) {
27 y[i] = B + A*Math.sin(k*x[i]+phi);
28 }
29 source.trigger('change');
30 """)
31
32 amp_slider = Slider(start=0.1, end=10, value=1, step=.1, title="Amplitude", callback=callback)
33 callback.args["amp"] = amp_slider
34
35 freq_slider = Slider(start=0.1, end=10, value=1, step=.1, title="Frequency", callback=callback)
36 callback.args["freq"] = freq_slider
37
38 phase_slider = Slider(start=0, end=6.4, value=0, step=.1, title="Phase", callback=callback)
39 callback.args["phase"] = phase_slider
40
41 offset_slider = Slider(start=-5, end=5, value=0, step=.1, title="Offset", callback=callback)
42 callback.args["offset"] = offset_slider
43
44 layout = hplot(
45 vform(amp_slider, freq_slider, phase_slider, offset_slider),
46 plot
47 )
48
49 output_file("slider.html")
50
51 show(layout)
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/plotting/file/slider.py b/examples/plotting/file/slider.py
--- a/examples/plotting/file/slider.py
+++ b/examples/plotting/file/slider.py
@@ -42,8 +42,8 @@
callback.args["offset"] = offset_slider
layout = hplot(
+ plot,
vform(amp_slider, freq_slider, phase_slider, offset_slider),
- plot
)
output_file("slider.html")
|
{"golden_diff": "diff --git a/examples/plotting/file/slider.py b/examples/plotting/file/slider.py\n--- a/examples/plotting/file/slider.py\n+++ b/examples/plotting/file/slider.py\n@@ -42,8 +42,8 @@\n callback.args[\"offset\"] = offset_slider\n \n layout = hplot(\n+ plot,\n vform(amp_slider, freq_slider, phase_slider, offset_slider),\n- plot\n )\n \n output_file(\"slider.html\")\n", "issue": "VBoxForm broken\nAdded a `float:left` to fix `sliders.py` which broke stock app example worse. \n\n", "before_files": [{"content": "\nfrom bokeh.io import vform\nfrom bokeh.plotting import figure, hplot, output_file, show, vplot, ColumnDataSource\nfrom bokeh.models.actions import Callback\nfrom bokeh.models.widgets import Slider\n\nimport numpy as np\n\nx = np.linspace(0, 10, 500)\ny = np.sin(x)\n\nsource = ColumnDataSource(data=dict(x=x, y=y))\n\n\nplot = figure(y_range=(-10, 10), plot_width=400, plot_height=400)\nplot.line('x', 'y', source=source, line_width=3, line_alpha=0.6)\n\ncallback = Callback(args=dict(source=source), code=\"\"\"\n var data = source.get('data');\n var A = amp.get('value')\n var k = freq.get('value')\n var phi = phase.get('value')\n var B = offset.get('value')\n x = data['x']\n y = data['y']\n for (i = 0; i < x.length; i++) {\n y[i] = B + A*Math.sin(k*x[i]+phi);\n }\n source.trigger('change');\n\"\"\")\n\namp_slider = Slider(start=0.1, end=10, value=1, step=.1, title=\"Amplitude\", callback=callback)\ncallback.args[\"amp\"] = amp_slider\n\nfreq_slider = Slider(start=0.1, end=10, value=1, step=.1, title=\"Frequency\", callback=callback)\ncallback.args[\"freq\"] = freq_slider\n\nphase_slider = Slider(start=0, end=6.4, value=0, step=.1, title=\"Phase\", callback=callback)\ncallback.args[\"phase\"] = phase_slider\n\noffset_slider = Slider(start=-5, end=5, value=0, step=.1, title=\"Offset\", callback=callback)\ncallback.args[\"offset\"] = offset_slider\n\nlayout = hplot(\n vform(amp_slider, freq_slider, phase_slider, offset_slider),\n plot\n)\n\noutput_file(\"slider.html\")\n\nshow(layout)\n", "path": "examples/plotting/file/slider.py"}], "after_files": [{"content": "\nfrom bokeh.io import vform\nfrom bokeh.plotting import figure, hplot, output_file, show, vplot, ColumnDataSource\nfrom bokeh.models.actions import Callback\nfrom bokeh.models.widgets import Slider\n\nimport numpy as np\n\nx = np.linspace(0, 10, 500)\ny = np.sin(x)\n\nsource = ColumnDataSource(data=dict(x=x, y=y))\n\n\nplot = figure(y_range=(-10, 10), plot_width=400, plot_height=400)\nplot.line('x', 'y', source=source, line_width=3, line_alpha=0.6)\n\ncallback = Callback(args=dict(source=source), code=\"\"\"\n var data = source.get('data');\n var A = amp.get('value')\n var k = freq.get('value')\n var phi = phase.get('value')\n var B = offset.get('value')\n x = data['x']\n y = data['y']\n for (i = 0; i < x.length; i++) {\n y[i] = B + A*Math.sin(k*x[i]+phi);\n }\n source.trigger('change');\n\"\"\")\n\namp_slider = Slider(start=0.1, end=10, value=1, step=.1, title=\"Amplitude\", callback=callback)\ncallback.args[\"amp\"] = amp_slider\n\nfreq_slider = Slider(start=0.1, end=10, value=1, step=.1, title=\"Frequency\", callback=callback)\ncallback.args[\"freq\"] = freq_slider\n\nphase_slider = Slider(start=0, end=6.4, value=0, step=.1, title=\"Phase\", callback=callback)\ncallback.args[\"phase\"] = phase_slider\n\noffset_slider = Slider(start=-5, end=5, value=0, step=.1, title=\"Offset\", callback=callback)\ncallback.args[\"offset\"] = offset_slider\n\nlayout = hplot(\n plot,\n vform(amp_slider, freq_slider, phase_slider, offset_slider),\n)\n\noutput_file(\"slider.html\")\n\nshow(layout)\n", "path": "examples/plotting/file/slider.py"}]}
| 836 | 98 |
gh_patches_debug_22318
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-7092
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
user-provided matplotlib backend names list causes TypeError: unhashable type: 'list'
## Description of the issue
* Output of `pyinstaller --version`: ```5.4.1```
* Version of Python: 3.7.9
* Platform: Windows 10
When implementing the matplotliib backend hook configuration example in the docs:
```
a = Analysis(
["my-matplotlib-app.py"],
...,
hooksconfig={
"matplotlib": {
#"backends": "auto", # auto-detect; the default behavior
# "backends": "all", # collect all backends
# "backends": "TkAgg", # collect a specific backend
"backends": ["TkAgg", "Qt5Agg"], # collect multiple backends
},
},
...,
)
```
I get the following exception:
```
File "C:\Users\...\lib\site-packages\PyInstaller\hooks\hook-matplotlib.backends.py", line 192, in hook
logger.info("Matplotlib backend selection method: %s", _method_names.get(backends_method, 'user-provided name(s)'))
TypeError: unhashable type: 'list'
```
I think perhaps this is just an issue with the logger.info call?
I'm very inexperienced with GitHub sorry, otherwise I would try to submit a PR.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PyInstaller/hooks/hook-matplotlib.backends.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013-2022, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 from PyInstaller.compat import is_darwin
13 from PyInstaller.utils.hooks import logger, get_hook_config
14 from PyInstaller import isolated
15
16
17 @isolated.decorate
18 def _get_configured_default_backend():
19 """
20 Return the configured default matplotlib backend name, if available as matplotlib.rcParams['backend'] (or overridden
21 by MPLBACKEND environment variable. If the value of matplotlib.rcParams['backend'] corresponds to the auto-sentinel
22 object, returns None
23 """
24 import matplotlib
25 # matplotlib.rcParams overrides the __getitem__ implementation and attempts to determine and load the default
26 # backend using pyplot.switch_backend(). Therefore, use dict.__getitem__().
27 val = dict.__getitem__(matplotlib.rcParams, 'backend')
28 if isinstance(val, str):
29 return val
30 return None
31
32
33 @isolated.decorate
34 def _list_available_mpl_backends():
35 """
36 Returns the names of all available matplotlib backends.
37 """
38 import matplotlib
39 return matplotlib.rcsetup.all_backends
40
41
42 @isolated.decorate
43 def _check_mpl_backend_importable(module_name):
44 """
45 Attempts to import the given module name (matplotlib backend module).
46
47 Exceptions are propagated to caller.
48 """
49 __import__(module_name)
50
51
52 # Bytecode scanning
53 def _recursive_scan_code_objects_for_mpl_use(co):
54 """
55 Recursively scan the bytecode for occurrences of matplotlib.use() or mpl.use() calls with const arguments, and
56 collect those arguments into list of used matplotlib backend names.
57 """
58
59 from PyInstaller.depend.bytecode import any_alias, recursive_function_calls
60
61 mpl_use_names = {
62 *any_alias("matplotlib.use"),
63 *any_alias("mpl.use"), # matplotlib is commonly aliased as mpl
64 }
65
66 backends = []
67 for calls in recursive_function_calls(co).values():
68 for name, args in calls:
69 # matplotlib.use(backend) or matplotlib.use(backend, force)
70 # We support only literal arguments. Similarly, kwargs are
71 # not supported.
72 if not len(args) in {1, 2} or not isinstance(args[0], str):
73 continue
74 if name in mpl_use_names:
75 backends.append(args[0])
76
77 return backends
78
79
80 def _backend_module_name(name):
81 """
82 Converts matplotlib backend name to its corresponding module name.
83
84 Equivalent to matplotlib.cbook._backend_module_name().
85 """
86 if name.startswith("module://"):
87 return name[9:]
88 return f"matplotlib.backends.backend_{name.lower()}"
89
90
91 def _autodetect_used_backends(hook_api):
92 """
93 Returns a list of automatically-discovered matplotlib backends in use, or the name of the default matplotlib
94 backend. Implements the 'auto' backend selection method.
95 """
96 # Scan the code for matplotlib.use()
97 modulegraph = hook_api.analysis.graph
98 mpl_code_objs = modulegraph.get_code_using("matplotlib")
99 used_backends = []
100 for name, co in mpl_code_objs.items():
101 used_backends += _recursive_scan_code_objects_for_mpl_use(co)
102
103 if used_backends:
104 return used_backends
105
106 # Determine the default matplotlib backend.
107 #
108 # Ideally, this would be done by calling ``matplotlib.get_backend()``. However, that function tries to switch to the
109 # default backend (calling ``matplotlib.pyplot.switch_backend()``), which seems to occasionally fail on our linux CI
110 # with an error and, on other occasions, returns the headless Agg backend instead of the GUI one (even with display
111 # server running). Furthermore, using ``matplotlib.get_backend()`` returns headless 'Agg' when display server is
112 # unavailable, which is not ideal for automated builds.
113 #
114 # Therefore, we try to emulate ``matplotlib.get_backend()`` ourselves. First, we try to obtain the configured
115 # default backend from settings (rcparams and/or MPLBACKEND environment variable). If that is unavailable, we try to
116 # find the first importable GUI-based backend, using the same list as matplotlib.pyplot.switch_backend() uses for
117 # automatic backend selection. The difference is that we only test whether the backend module is importable, without
118 # trying to switch to it.
119 default_backend = _get_configured_default_backend() # isolated sub-process
120 if default_backend:
121 logger.info("Found configured default matplotlib backend: %s", default_backend)
122 return [default_backend]
123
124 candidates = ["Qt5Agg", "Gtk3Agg", "TkAgg", "WxAgg"]
125 if is_darwin:
126 candidates = ["MacOSX"] + candidates
127 logger.info("Trying determine the default backend as first importable candidate from the list: %r", candidates)
128
129 for candidate in candidates:
130 try:
131 module_name = _backend_module_name(candidate)
132 _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.
133 except Exception:
134 continue
135 return [candidate]
136
137 # Fall back to headless Agg backend
138 logger.info("None of the backend candidates could be imported; falling back to headless Agg!")
139 return ['Agg']
140
141
142 def _collect_all_importable_backends(hook_api):
143 """
144 Returns a list of all importable matplotlib backends. Implements the 'all' backend selection method.
145 """
146 # List of the human-readable names of all available backends.
147 backend_names = _list_available_mpl_backends() # NOTE: retrieved in an isolated sub-process.
148 logger.info("All available matplotlib backends: %r", backend_names)
149
150 # Try to import the module(s).
151 importable_backends = []
152
153 # List of backends to exclude; Qt4 is not supported by PyInstaller anymore.
154 exclude_backends = {'Qt4Agg', 'Qt4Cairo'}
155
156 # Ignore "CocoaAgg" on OSes other than Mac OS; attempting to import it on other OSes halts the current
157 # (sub)process without printing output or raising exceptions, preventing reliable detection. Apply the
158 # same logic for the (newer) "MacOSX" backend.
159 if not is_darwin:
160 exclude_backends |= {'CocoaAgg', 'MacOSX'}
161
162 # For safety, attempt to import each backend in an isolated sub-process.
163 for backend_name in backend_names:
164 if backend_name in exclude_backends:
165 logger.info(' Matplotlib backend %r: excluded', backend_name)
166 continue
167
168 try:
169 module_name = _backend_module_name(backend_name)
170 _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.
171 except Exception:
172 # Backend is not importable, for whatever reason.
173 logger.info(' Matplotlib backend %r: ignored due to import error', backend_name)
174 continue
175
176 logger.info(' Matplotlib backend %r: added', backend_name)
177 importable_backends.append(backend_name)
178
179 return importable_backends
180
181
182 def hook(hook_api):
183 # Backend collection setting
184 backends_method = get_hook_config(hook_api, 'matplotlib', 'backends')
185 if backends_method is None:
186 backends_method = 'auto' # default method
187
188 _method_names = {
189 'auto': 'automatic discovery of used backends',
190 'all': 'collection of all importable backends',
191 }
192 logger.info("Matplotlib backend selection method: %s", _method_names.get(backends_method, 'user-provided name(s)'))
193
194 # Select backend(s)
195 if backends_method == 'auto':
196 backend_names = _autodetect_used_backends(hook_api)
197 elif backends_method == 'all':
198 backend_names = _collect_all_importable_backends(hook_api)
199 else:
200 if isinstance(backends_method, str):
201 backend_names = [backends_method]
202 else:
203 assert isinstance(backends_method, list), "User-provided backend name(s) must be either a string or a list!"
204 backend_names = backends_method
205
206 logger.info("Selected matplotlib backends: %r", backend_names)
207
208 # Set module names as hiddenimports
209 module_names = [_backend_module_name(backend) for backend in backend_names] # backend name -> module name
210 hook_api.add_imports(*module_names)
211
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PyInstaller/hooks/hook-matplotlib.backends.py b/PyInstaller/hooks/hook-matplotlib.backends.py
--- a/PyInstaller/hooks/hook-matplotlib.backends.py
+++ b/PyInstaller/hooks/hook-matplotlib.backends.py
@@ -185,18 +185,15 @@
if backends_method is None:
backends_method = 'auto' # default method
- _method_names = {
- 'auto': 'automatic discovery of used backends',
- 'all': 'collection of all importable backends',
- }
- logger.info("Matplotlib backend selection method: %s", _method_names.get(backends_method, 'user-provided name(s)'))
-
# Select backend(s)
if backends_method == 'auto':
+ logger.info("Matplotlib backend selection method: automatic discovery of used backends")
backend_names = _autodetect_used_backends(hook_api)
elif backends_method == 'all':
+ logger.info("Matplotlib backend selection method: collection of all importable backends")
backend_names = _collect_all_importable_backends(hook_api)
else:
+ logger.info("Matplotlib backend selection method: user-provided name(s)")
if isinstance(backends_method, str):
backend_names = [backends_method]
else:
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-matplotlib.backends.py b/PyInstaller/hooks/hook-matplotlib.backends.py\n--- a/PyInstaller/hooks/hook-matplotlib.backends.py\n+++ b/PyInstaller/hooks/hook-matplotlib.backends.py\n@@ -185,18 +185,15 @@\n if backends_method is None:\n backends_method = 'auto' # default method\n \n- _method_names = {\n- 'auto': 'automatic discovery of used backends',\n- 'all': 'collection of all importable backends',\n- }\n- logger.info(\"Matplotlib backend selection method: %s\", _method_names.get(backends_method, 'user-provided name(s)'))\n-\n # Select backend(s)\n if backends_method == 'auto':\n+ logger.info(\"Matplotlib backend selection method: automatic discovery of used backends\")\n backend_names = _autodetect_used_backends(hook_api)\n elif backends_method == 'all':\n+ logger.info(\"Matplotlib backend selection method: collection of all importable backends\")\n backend_names = _collect_all_importable_backends(hook_api)\n else:\n+ logger.info(\"Matplotlib backend selection method: user-provided name(s)\")\n if isinstance(backends_method, str):\n backend_names = [backends_method]\n else:\n", "issue": "user-provided matplotlib backend names list causes TypeError: unhashable type: 'list'\n## Description of the issue\r\n\r\n* Output of `pyinstaller --version`: ```5.4.1```\r\n* Version of Python: 3.7.9\r\n* Platform: Windows 10\r\n\r\nWhen implementing the matplotliib backend hook configuration example in the docs:\r\n\r\n```\r\na = Analysis(\r\n [\"my-matplotlib-app.py\"],\r\n ...,\r\n hooksconfig={\r\n \"matplotlib\": {\r\n #\"backends\": \"auto\", # auto-detect; the default behavior\r\n # \"backends\": \"all\", # collect all backends\r\n # \"backends\": \"TkAgg\", # collect a specific backend\r\n \"backends\": [\"TkAgg\", \"Qt5Agg\"], # collect multiple backends\r\n },\r\n },\r\n ...,\r\n)\r\n```\r\n\r\nI get the following exception:\r\n\r\n```\r\n File \"C:\\Users\\...\\lib\\site-packages\\PyInstaller\\hooks\\hook-matplotlib.backends.py\", line 192, in hook\r\n logger.info(\"Matplotlib backend selection method: %s\", _method_names.get(backends_method, 'user-provided name(s)'))\r\nTypeError: unhashable type: 'list'\r\n\r\n```\r\nI think perhaps this is just an issue with the logger.info call?\r\n\r\nI'm very inexperienced with GitHub sorry, otherwise I would try to submit a PR.\r\n\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2022, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller.compat import is_darwin\nfrom PyInstaller.utils.hooks import logger, get_hook_config\nfrom PyInstaller import isolated\n\n\[email protected]\ndef _get_configured_default_backend():\n \"\"\"\n Return the configured default matplotlib backend name, if available as matplotlib.rcParams['backend'] (or overridden\n by MPLBACKEND environment variable. If the value of matplotlib.rcParams['backend'] corresponds to the auto-sentinel\n object, returns None\n \"\"\"\n import matplotlib\n # matplotlib.rcParams overrides the __getitem__ implementation and attempts to determine and load the default\n # backend using pyplot.switch_backend(). Therefore, use dict.__getitem__().\n val = dict.__getitem__(matplotlib.rcParams, 'backend')\n if isinstance(val, str):\n return val\n return None\n\n\[email protected]\ndef _list_available_mpl_backends():\n \"\"\"\n Returns the names of all available matplotlib backends.\n \"\"\"\n import matplotlib\n return matplotlib.rcsetup.all_backends\n\n\[email protected]\ndef _check_mpl_backend_importable(module_name):\n \"\"\"\n Attempts to import the given module name (matplotlib backend module).\n\n Exceptions are propagated to caller.\n \"\"\"\n __import__(module_name)\n\n\n# Bytecode scanning\ndef _recursive_scan_code_objects_for_mpl_use(co):\n \"\"\"\n Recursively scan the bytecode for occurrences of matplotlib.use() or mpl.use() calls with const arguments, and\n collect those arguments into list of used matplotlib backend names.\n \"\"\"\n\n from PyInstaller.depend.bytecode import any_alias, recursive_function_calls\n\n mpl_use_names = {\n *any_alias(\"matplotlib.use\"),\n *any_alias(\"mpl.use\"), # matplotlib is commonly aliased as mpl\n }\n\n backends = []\n for calls in recursive_function_calls(co).values():\n for name, args in calls:\n # matplotlib.use(backend) or matplotlib.use(backend, force)\n # We support only literal arguments. Similarly, kwargs are\n # not supported.\n if not len(args) in {1, 2} or not isinstance(args[0], str):\n continue\n if name in mpl_use_names:\n backends.append(args[0])\n\n return backends\n\n\ndef _backend_module_name(name):\n \"\"\"\n Converts matplotlib backend name to its corresponding module name.\n\n Equivalent to matplotlib.cbook._backend_module_name().\n \"\"\"\n if name.startswith(\"module://\"):\n return name[9:]\n return f\"matplotlib.backends.backend_{name.lower()}\"\n\n\ndef _autodetect_used_backends(hook_api):\n \"\"\"\n Returns a list of automatically-discovered matplotlib backends in use, or the name of the default matplotlib\n backend. Implements the 'auto' backend selection method.\n \"\"\"\n # Scan the code for matplotlib.use()\n modulegraph = hook_api.analysis.graph\n mpl_code_objs = modulegraph.get_code_using(\"matplotlib\")\n used_backends = []\n for name, co in mpl_code_objs.items():\n used_backends += _recursive_scan_code_objects_for_mpl_use(co)\n\n if used_backends:\n return used_backends\n\n # Determine the default matplotlib backend.\n #\n # Ideally, this would be done by calling ``matplotlib.get_backend()``. However, that function tries to switch to the\n # default backend (calling ``matplotlib.pyplot.switch_backend()``), which seems to occasionally fail on our linux CI\n # with an error and, on other occasions, returns the headless Agg backend instead of the GUI one (even with display\n # server running). Furthermore, using ``matplotlib.get_backend()`` returns headless 'Agg' when display server is\n # unavailable, which is not ideal for automated builds.\n #\n # Therefore, we try to emulate ``matplotlib.get_backend()`` ourselves. First, we try to obtain the configured\n # default backend from settings (rcparams and/or MPLBACKEND environment variable). If that is unavailable, we try to\n # find the first importable GUI-based backend, using the same list as matplotlib.pyplot.switch_backend() uses for\n # automatic backend selection. The difference is that we only test whether the backend module is importable, without\n # trying to switch to it.\n default_backend = _get_configured_default_backend() # isolated sub-process\n if default_backend:\n logger.info(\"Found configured default matplotlib backend: %s\", default_backend)\n return [default_backend]\n\n candidates = [\"Qt5Agg\", \"Gtk3Agg\", \"TkAgg\", \"WxAgg\"]\n if is_darwin:\n candidates = [\"MacOSX\"] + candidates\n logger.info(\"Trying determine the default backend as first importable candidate from the list: %r\", candidates)\n\n for candidate in candidates:\n try:\n module_name = _backend_module_name(candidate)\n _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.\n except Exception:\n continue\n return [candidate]\n\n # Fall back to headless Agg backend\n logger.info(\"None of the backend candidates could be imported; falling back to headless Agg!\")\n return ['Agg']\n\n\ndef _collect_all_importable_backends(hook_api):\n \"\"\"\n Returns a list of all importable matplotlib backends. Implements the 'all' backend selection method.\n \"\"\"\n # List of the human-readable names of all available backends.\n backend_names = _list_available_mpl_backends() # NOTE: retrieved in an isolated sub-process.\n logger.info(\"All available matplotlib backends: %r\", backend_names)\n\n # Try to import the module(s).\n importable_backends = []\n\n # List of backends to exclude; Qt4 is not supported by PyInstaller anymore.\n exclude_backends = {'Qt4Agg', 'Qt4Cairo'}\n\n # Ignore \"CocoaAgg\" on OSes other than Mac OS; attempting to import it on other OSes halts the current\n # (sub)process without printing output or raising exceptions, preventing reliable detection. Apply the\n # same logic for the (newer) \"MacOSX\" backend.\n if not is_darwin:\n exclude_backends |= {'CocoaAgg', 'MacOSX'}\n\n # For safety, attempt to import each backend in an isolated sub-process.\n for backend_name in backend_names:\n if backend_name in exclude_backends:\n logger.info(' Matplotlib backend %r: excluded', backend_name)\n continue\n\n try:\n module_name = _backend_module_name(backend_name)\n _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.\n except Exception:\n # Backend is not importable, for whatever reason.\n logger.info(' Matplotlib backend %r: ignored due to import error', backend_name)\n continue\n\n logger.info(' Matplotlib backend %r: added', backend_name)\n importable_backends.append(backend_name)\n\n return importable_backends\n\n\ndef hook(hook_api):\n # Backend collection setting\n backends_method = get_hook_config(hook_api, 'matplotlib', 'backends')\n if backends_method is None:\n backends_method = 'auto' # default method\n\n _method_names = {\n 'auto': 'automatic discovery of used backends',\n 'all': 'collection of all importable backends',\n }\n logger.info(\"Matplotlib backend selection method: %s\", _method_names.get(backends_method, 'user-provided name(s)'))\n\n # Select backend(s)\n if backends_method == 'auto':\n backend_names = _autodetect_used_backends(hook_api)\n elif backends_method == 'all':\n backend_names = _collect_all_importable_backends(hook_api)\n else:\n if isinstance(backends_method, str):\n backend_names = [backends_method]\n else:\n assert isinstance(backends_method, list), \"User-provided backend name(s) must be either a string or a list!\"\n backend_names = backends_method\n\n logger.info(\"Selected matplotlib backends: %r\", backend_names)\n\n # Set module names as hiddenimports\n module_names = [_backend_module_name(backend) for backend in backend_names] # backend name -> module name\n hook_api.add_imports(*module_names)\n", "path": "PyInstaller/hooks/hook-matplotlib.backends.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2022, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller.compat import is_darwin\nfrom PyInstaller.utils.hooks import logger, get_hook_config\nfrom PyInstaller import isolated\n\n\[email protected]\ndef _get_configured_default_backend():\n \"\"\"\n Return the configured default matplotlib backend name, if available as matplotlib.rcParams['backend'] (or overridden\n by MPLBACKEND environment variable. If the value of matplotlib.rcParams['backend'] corresponds to the auto-sentinel\n object, returns None\n \"\"\"\n import matplotlib\n # matplotlib.rcParams overrides the __getitem__ implementation and attempts to determine and load the default\n # backend using pyplot.switch_backend(). Therefore, use dict.__getitem__().\n val = dict.__getitem__(matplotlib.rcParams, 'backend')\n if isinstance(val, str):\n return val\n return None\n\n\[email protected]\ndef _list_available_mpl_backends():\n \"\"\"\n Returns the names of all available matplotlib backends.\n \"\"\"\n import matplotlib\n return matplotlib.rcsetup.all_backends\n\n\[email protected]\ndef _check_mpl_backend_importable(module_name):\n \"\"\"\n Attempts to import the given module name (matplotlib backend module).\n\n Exceptions are propagated to caller.\n \"\"\"\n __import__(module_name)\n\n\n# Bytecode scanning\ndef _recursive_scan_code_objects_for_mpl_use(co):\n \"\"\"\n Recursively scan the bytecode for occurrences of matplotlib.use() or mpl.use() calls with const arguments, and\n collect those arguments into list of used matplotlib backend names.\n \"\"\"\n\n from PyInstaller.depend.bytecode import any_alias, recursive_function_calls\n\n mpl_use_names = {\n *any_alias(\"matplotlib.use\"),\n *any_alias(\"mpl.use\"), # matplotlib is commonly aliased as mpl\n }\n\n backends = []\n for calls in recursive_function_calls(co).values():\n for name, args in calls:\n # matplotlib.use(backend) or matplotlib.use(backend, force)\n # We support only literal arguments. Similarly, kwargs are\n # not supported.\n if not len(args) in {1, 2} or not isinstance(args[0], str):\n continue\n if name in mpl_use_names:\n backends.append(args[0])\n\n return backends\n\n\ndef _backend_module_name(name):\n \"\"\"\n Converts matplotlib backend name to its corresponding module name.\n\n Equivalent to matplotlib.cbook._backend_module_name().\n \"\"\"\n if name.startswith(\"module://\"):\n return name[9:]\n return f\"matplotlib.backends.backend_{name.lower()}\"\n\n\ndef _autodetect_used_backends(hook_api):\n \"\"\"\n Returns a list of automatically-discovered matplotlib backends in use, or the name of the default matplotlib\n backend. Implements the 'auto' backend selection method.\n \"\"\"\n # Scan the code for matplotlib.use()\n modulegraph = hook_api.analysis.graph\n mpl_code_objs = modulegraph.get_code_using(\"matplotlib\")\n used_backends = []\n for name, co in mpl_code_objs.items():\n used_backends += _recursive_scan_code_objects_for_mpl_use(co)\n\n if used_backends:\n return used_backends\n\n # Determine the default matplotlib backend.\n #\n # Ideally, this would be done by calling ``matplotlib.get_backend()``. However, that function tries to switch to the\n # default backend (calling ``matplotlib.pyplot.switch_backend()``), which seems to occasionally fail on our linux CI\n # with an error and, on other occasions, returns the headless Agg backend instead of the GUI one (even with display\n # server running). Furthermore, using ``matplotlib.get_backend()`` returns headless 'Agg' when display server is\n # unavailable, which is not ideal for automated builds.\n #\n # Therefore, we try to emulate ``matplotlib.get_backend()`` ourselves. First, we try to obtain the configured\n # default backend from settings (rcparams and/or MPLBACKEND environment variable). If that is unavailable, we try to\n # find the first importable GUI-based backend, using the same list as matplotlib.pyplot.switch_backend() uses for\n # automatic backend selection. The difference is that we only test whether the backend module is importable, without\n # trying to switch to it.\n default_backend = _get_configured_default_backend() # isolated sub-process\n if default_backend:\n logger.info(\"Found configured default matplotlib backend: %s\", default_backend)\n return [default_backend]\n\n candidates = [\"Qt5Agg\", \"Gtk3Agg\", \"TkAgg\", \"WxAgg\"]\n if is_darwin:\n candidates = [\"MacOSX\"] + candidates\n logger.info(\"Trying determine the default backend as first importable candidate from the list: %r\", candidates)\n\n for candidate in candidates:\n try:\n module_name = _backend_module_name(candidate)\n _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.\n except Exception:\n continue\n return [candidate]\n\n # Fall back to headless Agg backend\n logger.info(\"None of the backend candidates could be imported; falling back to headless Agg!\")\n return ['Agg']\n\n\ndef _collect_all_importable_backends(hook_api):\n \"\"\"\n Returns a list of all importable matplotlib backends. Implements the 'all' backend selection method.\n \"\"\"\n # List of the human-readable names of all available backends.\n backend_names = _list_available_mpl_backends() # NOTE: retrieved in an isolated sub-process.\n logger.info(\"All available matplotlib backends: %r\", backend_names)\n\n # Try to import the module(s).\n importable_backends = []\n\n # List of backends to exclude; Qt4 is not supported by PyInstaller anymore.\n exclude_backends = {'Qt4Agg', 'Qt4Cairo'}\n\n # Ignore \"CocoaAgg\" on OSes other than Mac OS; attempting to import it on other OSes halts the current\n # (sub)process without printing output or raising exceptions, preventing reliable detection. Apply the\n # same logic for the (newer) \"MacOSX\" backend.\n if not is_darwin:\n exclude_backends |= {'CocoaAgg', 'MacOSX'}\n\n # For safety, attempt to import each backend in an isolated sub-process.\n for backend_name in backend_names:\n if backend_name in exclude_backends:\n logger.info(' Matplotlib backend %r: excluded', backend_name)\n continue\n\n try:\n module_name = _backend_module_name(backend_name)\n _check_mpl_backend_importable(module_name) # NOTE: uses an isolated sub-process.\n except Exception:\n # Backend is not importable, for whatever reason.\n logger.info(' Matplotlib backend %r: ignored due to import error', backend_name)\n continue\n\n logger.info(' Matplotlib backend %r: added', backend_name)\n importable_backends.append(backend_name)\n\n return importable_backends\n\n\ndef hook(hook_api):\n # Backend collection setting\n backends_method = get_hook_config(hook_api, 'matplotlib', 'backends')\n if backends_method is None:\n backends_method = 'auto' # default method\n\n # Select backend(s)\n if backends_method == 'auto':\n logger.info(\"Matplotlib backend selection method: automatic discovery of used backends\")\n backend_names = _autodetect_used_backends(hook_api)\n elif backends_method == 'all':\n logger.info(\"Matplotlib backend selection method: collection of all importable backends\")\n backend_names = _collect_all_importable_backends(hook_api)\n else:\n logger.info(\"Matplotlib backend selection method: user-provided name(s)\")\n if isinstance(backends_method, str):\n backend_names = [backends_method]\n else:\n assert isinstance(backends_method, list), \"User-provided backend name(s) must be either a string or a list!\"\n backend_names = backends_method\n\n logger.info(\"Selected matplotlib backends: %r\", backend_names)\n\n # Set module names as hiddenimports\n module_names = [_backend_module_name(backend) for backend in backend_names] # backend name -> module name\n hook_api.add_imports(*module_names)\n", "path": "PyInstaller/hooks/hook-matplotlib.backends.py"}]}
| 2,988 | 293 |
gh_patches_debug_37739
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1232
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Widgeted progress bar remains visible after suite run
**Describe the bug**
When running the full suite on Kaggle, the 3 progress bars of "Ingesting batches" disappear after completion, but the "Computing single dataset checks" remains visible.
**To Reproduce**
View this notebook:
https://www.kaggle.com/code/itay94/notebook1b0b03205f
**Screenshots**
If applicable, add screenshots to help explain your problem.

**Environment (please complete the following information):**
- OS: Kaggle
- Python Version: Kaggle kernel
- Deepchecks Version: 0.6.0
**Additional context**
Add any other context about the problem here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/vision/suite.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module for base vision abstractions."""
12 # pylint: disable=broad-except,not-callable
13 import logging
14 from typing import Tuple, Mapping, Optional, Union, Dict, List
15 from collections import OrderedDict
16
17 import torch
18 from torch import nn
19 from ignite.metrics import Metric
20
21 from deepchecks.core.check_result import CheckFailure, CheckResult
22 from deepchecks.core.checks import DatasetKind
23 from deepchecks.core.suite import BaseSuite, SuiteResult
24 from deepchecks.core.display_suite import ProgressBar
25 from deepchecks.core.errors import DeepchecksNotSupportedError
26 from deepchecks.vision.base_checks import ModelOnlyCheck, SingleDatasetCheck, TrainTestCheck
27 from deepchecks.vision.context import Context
28 from deepchecks.vision.vision_data import VisionData
29 from deepchecks.vision.batch_wrapper import Batch
30
31
32 __all__ = ['Suite']
33
34
35 logger = logging.getLogger('deepchecks')
36
37
38 class Suite(BaseSuite):
39 """Tabular suite to run checks of types: TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck."""
40
41 @classmethod
42 def supported_checks(cls) -> Tuple:
43 """Return tuple of supported check types of this suite."""
44 return TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck
45
46 def run(
47 self,
48 train_dataset: Optional[VisionData] = None,
49 test_dataset: Optional[VisionData] = None,
50 model: nn.Module = None,
51 scorers: Mapping[str, Metric] = None,
52 scorers_per_class: Mapping[str, Metric] = None,
53 device: Union[str, torch.device, None] = 'cpu',
54 random_state: int = 42,
55 n_samples: Optional[int] = 10_000,
56 ) -> SuiteResult:
57 """Run all checks.
58
59 Parameters
60 ----------
61 train_dataset: Optional[VisionData] , default None
62 object, representing data an estimator was fitted on
63 test_dataset : Optional[VisionData] , default None
64 object, representing data an estimator predicts on
65 model : nn.Module , default None
66 A scikit-learn-compatible fitted estimator instance
67 scorers : Mapping[str, Metric] , default None
68 dict of scorers names to scorer sklearn_name/function
69 scorers_per_class : Mapping[str, Metric], default None
70 dict of scorers for classification without averaging of the classes
71 See <a href=
72 "https://scikit-learn.org/stable/modules/model_evaluation.html#from-binary-to-multiclass-and-multilabel">
73 scikit-learn docs</a>
74 device : Union[str, torch.device], default: None
75 processing unit for use
76 random_state : int
77 A seed to set for pseudo-random functions
78 n_samples : int, default: 10,000
79 number of samples to draw from the dataset.
80 Returns
81 -------
82 SuiteResult
83 All results by all initialized checks
84 """
85 all_pbars = []
86 progress_bar = ProgressBar('Validating Input', 1, unit='')
87 all_pbars.append(progress_bar)
88 context = Context(
89 train_dataset,
90 test_dataset,
91 model,
92 scorers=scorers,
93 scorers_per_class=scorers_per_class,
94 device=device,
95 random_state=random_state,
96 n_samples=n_samples
97 )
98 progress_bar.inc_progress()
99
100 results: Dict[
101 Union[str, int],
102 Union[CheckResult, CheckFailure]
103 ] = OrderedDict({})
104
105 run_train_test_checks = train_dataset is not None and test_dataset is not None
106 non_single_checks = {k: check for k, check in self.checks.items() if not isinstance(check, SingleDatasetCheck)}
107
108 # Initialize here all the checks that are not single dataset, since those are initialized inside the update loop
109 for index, check in non_single_checks.items():
110 try:
111 check.initialize_run(context)
112 except Exception as exp:
113 results[index] = CheckFailure(check, exp)
114
115 if train_dataset is not None:
116 self._update_loop(
117 context=context,
118 run_train_test_checks=run_train_test_checks,
119 results=results,
120 dataset_kind=DatasetKind.TRAIN,
121 progress_bars=all_pbars
122 )
123
124 if test_dataset is not None:
125 self._update_loop(
126 context=context,
127 run_train_test_checks=run_train_test_checks,
128 results=results,
129 dataset_kind=DatasetKind.TEST,
130 progress_bars=all_pbars
131 )
132
133 # Need to compute only on not SingleDatasetCheck, since they computed inside the loop
134 if non_single_checks:
135 progress_bar = ProgressBar('Computing Checks', len(non_single_checks), unit='Check')
136 all_pbars.append(progress_bar)
137 for check_idx, check in non_single_checks.items():
138 progress_bar.set_text(check.name())
139 try:
140 # if check index in results we had failure
141 if check_idx not in results:
142 result = check.finalize_check_result(check.compute(context))
143 results[check_idx] = result
144 except Exception as exp:
145 results[check_idx] = CheckFailure(check, exp)
146 progress_bar.inc_progress()
147
148 # The results are ordered as they ran instead of in the order they were defined, therefore sort by key
149 sorted_result_values = [value for name, value in sorted(results.items(), key=lambda pair: str(pair[0]))]
150
151 # Close all progress bars
152 for pbar in all_pbars:
153 pbar.close()
154
155 footnote = context.get_is_sampled_footnote()
156 extra_info = [footnote] if footnote else []
157 return SuiteResult(self.name, sorted_result_values, extra_info)
158
159 def _update_loop(
160 self,
161 context: Context,
162 run_train_test_checks: bool,
163 results: Dict[Union[str, int], Union[CheckResult, CheckFailure]],
164 dataset_kind: DatasetKind,
165 progress_bars: List
166 ):
167 type_suffix = ' - Test Dataset' if dataset_kind == DatasetKind.TEST else ' - Train Dataset'
168 vision_data = context.get_data_by_kind(dataset_kind)
169 n_batches = len(vision_data)
170 single_dataset_checks = {k: check for k, check in self.checks.items() if isinstance(check, SingleDatasetCheck)}
171
172 # SingleDatasetChecks have different handling, need to initialize them here (to have them ready for different
173 # dataset kind)
174 for idx, check in single_dataset_checks.items():
175 try:
176 check.initialize_run(context, dataset_kind=dataset_kind)
177 except Exception as exp:
178 results[idx] = CheckFailure(check, exp, type_suffix)
179
180 # Init cache of vision_data
181 vision_data.init_cache()
182
183 progress_bar = ProgressBar('Ingesting Batches' + type_suffix, n_batches, unit='Batch')
184 progress_bars.append(progress_bar)
185
186 # Run on all the batches
187 batch_start_index = 0
188 for batch_id, batch in enumerate(vision_data):
189 progress_bar.set_text(f'{100 * batch_id / (1. * n_batches):.0f}%')
190 batch = Batch(batch, context, dataset_kind, batch_start_index)
191 vision_data.update_cache(batch)
192 for check_idx, check in self.checks.items():
193 # If index in results the check already failed before
194 if check_idx in results:
195 continue
196 try:
197 if isinstance(check, TrainTestCheck):
198 if run_train_test_checks is True:
199 check.update(context, batch, dataset_kind=dataset_kind)
200 else:
201 msg = 'Check is irrelevant if not supplied with both train and test datasets'
202 results[check_idx] = self._get_unsupported_failure(check, msg)
203 elif isinstance(check, SingleDatasetCheck):
204 check.update(context, batch, dataset_kind=dataset_kind)
205 elif isinstance(check, ModelOnlyCheck):
206 pass
207 else:
208 raise TypeError(f'Don\'t know how to handle type {check.__class__.__name__} in suite.')
209 except Exception as exp:
210 results[check_idx] = CheckFailure(check, exp, type_suffix)
211
212 batch_start_index += len(batch)
213 progress_bar.inc_progress()
214
215 # SingleDatasetChecks have different handling. If we had failure in them need to add suffix to the index of
216 # the results, else need to compute it.
217 if single_dataset_checks:
218 progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix, len(single_dataset_checks),
219 unit='Check')
220 progress_bars.append(progress_bar)
221 for idx, check in single_dataset_checks.items():
222 progress_bar.set_text(check.name())
223 index_of_kind = str(idx) + type_suffix
224 # If index in results we had a failure
225 if idx in results:
226 results[index_of_kind] = results.pop(idx)
227 continue
228 try:
229 result = check.compute(context, dataset_kind=dataset_kind)
230 result = check.finalize_check_result(result)
231 # Update header with dataset type only if both train and test ran
232 if run_train_test_checks:
233 result.header = result.get_header() + type_suffix
234 results[index_of_kind] = result
235 except Exception as exp:
236 results[index_of_kind] = CheckFailure(check, exp, type_suffix)
237 progress_bar.inc_progress()
238
239 @classmethod
240 def _get_unsupported_failure(cls, check, msg):
241 return CheckFailure(check, DeepchecksNotSupportedError(msg))
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/vision/suite.py b/deepchecks/vision/suite.py
--- a/deepchecks/vision/suite.py
+++ b/deepchecks/vision/suite.py
@@ -185,8 +185,7 @@
# Run on all the batches
batch_start_index = 0
- for batch_id, batch in enumerate(vision_data):
- progress_bar.set_text(f'{100 * batch_id / (1. * n_batches):.0f}%')
+ for batch in vision_data:
batch = Batch(batch, context, dataset_kind, batch_start_index)
vision_data.update_cache(batch)
for check_idx, check in self.checks.items():
@@ -215,7 +214,8 @@
# SingleDatasetChecks have different handling. If we had failure in them need to add suffix to the index of
# the results, else need to compute it.
if single_dataset_checks:
- progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix, len(single_dataset_checks),
+ progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix,
+ len(single_dataset_checks),
unit='Check')
progress_bars.append(progress_bar)
for idx, check in single_dataset_checks.items():
@@ -224,16 +224,16 @@
# If index in results we had a failure
if idx in results:
results[index_of_kind] = results.pop(idx)
- continue
- try:
- result = check.compute(context, dataset_kind=dataset_kind)
- result = check.finalize_check_result(result)
- # Update header with dataset type only if both train and test ran
- if run_train_test_checks:
- result.header = result.get_header() + type_suffix
- results[index_of_kind] = result
- except Exception as exp:
- results[index_of_kind] = CheckFailure(check, exp, type_suffix)
+ else:
+ try:
+ result = check.compute(context, dataset_kind=dataset_kind)
+ result = check.finalize_check_result(result)
+ # Update header with dataset type only if both train and test ran
+ if run_train_test_checks:
+ result.header = result.get_header() + type_suffix
+ results[index_of_kind] = result
+ except Exception as exp:
+ results[index_of_kind] = CheckFailure(check, exp, type_suffix)
progress_bar.inc_progress()
@classmethod
|
{"golden_diff": "diff --git a/deepchecks/vision/suite.py b/deepchecks/vision/suite.py\n--- a/deepchecks/vision/suite.py\n+++ b/deepchecks/vision/suite.py\n@@ -185,8 +185,7 @@\n \n # Run on all the batches\n batch_start_index = 0\n- for batch_id, batch in enumerate(vision_data):\n- progress_bar.set_text(f'{100 * batch_id / (1. * n_batches):.0f}%')\n+ for batch in vision_data:\n batch = Batch(batch, context, dataset_kind, batch_start_index)\n vision_data.update_cache(batch)\n for check_idx, check in self.checks.items():\n@@ -215,7 +214,8 @@\n # SingleDatasetChecks have different handling. If we had failure in them need to add suffix to the index of\n # the results, else need to compute it.\n if single_dataset_checks:\n- progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix, len(single_dataset_checks),\n+ progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix,\n+ len(single_dataset_checks),\n unit='Check')\n progress_bars.append(progress_bar)\n for idx, check in single_dataset_checks.items():\n@@ -224,16 +224,16 @@\n # If index in results we had a failure\n if idx in results:\n results[index_of_kind] = results.pop(idx)\n- continue\n- try:\n- result = check.compute(context, dataset_kind=dataset_kind)\n- result = check.finalize_check_result(result)\n- # Update header with dataset type only if both train and test ran\n- if run_train_test_checks:\n- result.header = result.get_header() + type_suffix\n- results[index_of_kind] = result\n- except Exception as exp:\n- results[index_of_kind] = CheckFailure(check, exp, type_suffix)\n+ else:\n+ try:\n+ result = check.compute(context, dataset_kind=dataset_kind)\n+ result = check.finalize_check_result(result)\n+ # Update header with dataset type only if both train and test ran\n+ if run_train_test_checks:\n+ result.header = result.get_header() + type_suffix\n+ results[index_of_kind] = result\n+ except Exception as exp:\n+ results[index_of_kind] = CheckFailure(check, exp, type_suffix)\n progress_bar.inc_progress()\n \n @classmethod\n", "issue": "[BUG] Widgeted progress bar remains visible after suite run\n**Describe the bug**\r\nWhen running the full suite on Kaggle, the 3 progress bars of \"Ingesting batches\" disappear after completion, but the \"Computing single dataset checks\" remains visible.\r\n\r\n**To Reproduce**\r\nView this notebook:\r\nhttps://www.kaggle.com/code/itay94/notebook1b0b03205f\r\n\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n\r\n**Environment (please complete the following information):**\r\n - OS: Kaggle\r\n - Python Version: Kaggle kernel\r\n - Deepchecks Version: 0.6.0\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module for base vision abstractions.\"\"\"\n# pylint: disable=broad-except,not-callable\nimport logging\nfrom typing import Tuple, Mapping, Optional, Union, Dict, List\nfrom collections import OrderedDict\n\nimport torch\nfrom torch import nn\nfrom ignite.metrics import Metric\n\nfrom deepchecks.core.check_result import CheckFailure, CheckResult\nfrom deepchecks.core.checks import DatasetKind\nfrom deepchecks.core.suite import BaseSuite, SuiteResult\nfrom deepchecks.core.display_suite import ProgressBar\nfrom deepchecks.core.errors import DeepchecksNotSupportedError\nfrom deepchecks.vision.base_checks import ModelOnlyCheck, SingleDatasetCheck, TrainTestCheck\nfrom deepchecks.vision.context import Context\nfrom deepchecks.vision.vision_data import VisionData\nfrom deepchecks.vision.batch_wrapper import Batch\n\n\n__all__ = ['Suite']\n\n\nlogger = logging.getLogger('deepchecks')\n\n\nclass Suite(BaseSuite):\n \"\"\"Tabular suite to run checks of types: TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck.\"\"\"\n\n @classmethod\n def supported_checks(cls) -> Tuple:\n \"\"\"Return tuple of supported check types of this suite.\"\"\"\n return TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck\n\n def run(\n self,\n train_dataset: Optional[VisionData] = None,\n test_dataset: Optional[VisionData] = None,\n model: nn.Module = None,\n scorers: Mapping[str, Metric] = None,\n scorers_per_class: Mapping[str, Metric] = None,\n device: Union[str, torch.device, None] = 'cpu',\n random_state: int = 42,\n n_samples: Optional[int] = 10_000,\n ) -> SuiteResult:\n \"\"\"Run all checks.\n\n Parameters\n ----------\n train_dataset: Optional[VisionData] , default None\n object, representing data an estimator was fitted on\n test_dataset : Optional[VisionData] , default None\n object, representing data an estimator predicts on\n model : nn.Module , default None\n A scikit-learn-compatible fitted estimator instance\n scorers : Mapping[str, Metric] , default None\n dict of scorers names to scorer sklearn_name/function\n scorers_per_class : Mapping[str, Metric], default None\n dict of scorers for classification without averaging of the classes\n See <a href=\n \"https://scikit-learn.org/stable/modules/model_evaluation.html#from-binary-to-multiclass-and-multilabel\">\n scikit-learn docs</a>\n device : Union[str, torch.device], default: None\n processing unit for use\n random_state : int\n A seed to set for pseudo-random functions\n n_samples : int, default: 10,000\n number of samples to draw from the dataset.\n Returns\n -------\n SuiteResult\n All results by all initialized checks\n \"\"\"\n all_pbars = []\n progress_bar = ProgressBar('Validating Input', 1, unit='')\n all_pbars.append(progress_bar)\n context = Context(\n train_dataset,\n test_dataset,\n model,\n scorers=scorers,\n scorers_per_class=scorers_per_class,\n device=device,\n random_state=random_state,\n n_samples=n_samples\n )\n progress_bar.inc_progress()\n\n results: Dict[\n Union[str, int],\n Union[CheckResult, CheckFailure]\n ] = OrderedDict({})\n\n run_train_test_checks = train_dataset is not None and test_dataset is not None\n non_single_checks = {k: check for k, check in self.checks.items() if not isinstance(check, SingleDatasetCheck)}\n\n # Initialize here all the checks that are not single dataset, since those are initialized inside the update loop\n for index, check in non_single_checks.items():\n try:\n check.initialize_run(context)\n except Exception as exp:\n results[index] = CheckFailure(check, exp)\n\n if train_dataset is not None:\n self._update_loop(\n context=context,\n run_train_test_checks=run_train_test_checks,\n results=results,\n dataset_kind=DatasetKind.TRAIN,\n progress_bars=all_pbars\n )\n\n if test_dataset is not None:\n self._update_loop(\n context=context,\n run_train_test_checks=run_train_test_checks,\n results=results,\n dataset_kind=DatasetKind.TEST,\n progress_bars=all_pbars\n )\n\n # Need to compute only on not SingleDatasetCheck, since they computed inside the loop\n if non_single_checks:\n progress_bar = ProgressBar('Computing Checks', len(non_single_checks), unit='Check')\n all_pbars.append(progress_bar)\n for check_idx, check in non_single_checks.items():\n progress_bar.set_text(check.name())\n try:\n # if check index in results we had failure\n if check_idx not in results:\n result = check.finalize_check_result(check.compute(context))\n results[check_idx] = result\n except Exception as exp:\n results[check_idx] = CheckFailure(check, exp)\n progress_bar.inc_progress()\n\n # The results are ordered as they ran instead of in the order they were defined, therefore sort by key\n sorted_result_values = [value for name, value in sorted(results.items(), key=lambda pair: str(pair[0]))]\n\n # Close all progress bars\n for pbar in all_pbars:\n pbar.close()\n\n footnote = context.get_is_sampled_footnote()\n extra_info = [footnote] if footnote else []\n return SuiteResult(self.name, sorted_result_values, extra_info)\n\n def _update_loop(\n self,\n context: Context,\n run_train_test_checks: bool,\n results: Dict[Union[str, int], Union[CheckResult, CheckFailure]],\n dataset_kind: DatasetKind,\n progress_bars: List\n ):\n type_suffix = ' - Test Dataset' if dataset_kind == DatasetKind.TEST else ' - Train Dataset'\n vision_data = context.get_data_by_kind(dataset_kind)\n n_batches = len(vision_data)\n single_dataset_checks = {k: check for k, check in self.checks.items() if isinstance(check, SingleDatasetCheck)}\n\n # SingleDatasetChecks have different handling, need to initialize them here (to have them ready for different\n # dataset kind)\n for idx, check in single_dataset_checks.items():\n try:\n check.initialize_run(context, dataset_kind=dataset_kind)\n except Exception as exp:\n results[idx] = CheckFailure(check, exp, type_suffix)\n\n # Init cache of vision_data\n vision_data.init_cache()\n\n progress_bar = ProgressBar('Ingesting Batches' + type_suffix, n_batches, unit='Batch')\n progress_bars.append(progress_bar)\n\n # Run on all the batches\n batch_start_index = 0\n for batch_id, batch in enumerate(vision_data):\n progress_bar.set_text(f'{100 * batch_id / (1. * n_batches):.0f}%')\n batch = Batch(batch, context, dataset_kind, batch_start_index)\n vision_data.update_cache(batch)\n for check_idx, check in self.checks.items():\n # If index in results the check already failed before\n if check_idx in results:\n continue\n try:\n if isinstance(check, TrainTestCheck):\n if run_train_test_checks is True:\n check.update(context, batch, dataset_kind=dataset_kind)\n else:\n msg = 'Check is irrelevant if not supplied with both train and test datasets'\n results[check_idx] = self._get_unsupported_failure(check, msg)\n elif isinstance(check, SingleDatasetCheck):\n check.update(context, batch, dataset_kind=dataset_kind)\n elif isinstance(check, ModelOnlyCheck):\n pass\n else:\n raise TypeError(f'Don\\'t know how to handle type {check.__class__.__name__} in suite.')\n except Exception as exp:\n results[check_idx] = CheckFailure(check, exp, type_suffix)\n\n batch_start_index += len(batch)\n progress_bar.inc_progress()\n\n # SingleDatasetChecks have different handling. If we had failure in them need to add suffix to the index of\n # the results, else need to compute it.\n if single_dataset_checks:\n progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix, len(single_dataset_checks),\n unit='Check')\n progress_bars.append(progress_bar)\n for idx, check in single_dataset_checks.items():\n progress_bar.set_text(check.name())\n index_of_kind = str(idx) + type_suffix\n # If index in results we had a failure\n if idx in results:\n results[index_of_kind] = results.pop(idx)\n continue\n try:\n result = check.compute(context, dataset_kind=dataset_kind)\n result = check.finalize_check_result(result)\n # Update header with dataset type only if both train and test ran\n if run_train_test_checks:\n result.header = result.get_header() + type_suffix\n results[index_of_kind] = result\n except Exception as exp:\n results[index_of_kind] = CheckFailure(check, exp, type_suffix)\n progress_bar.inc_progress()\n\n @classmethod\n def _get_unsupported_failure(cls, check, msg):\n return CheckFailure(check, DeepchecksNotSupportedError(msg))\n", "path": "deepchecks/vision/suite.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module for base vision abstractions.\"\"\"\n# pylint: disable=broad-except,not-callable\nimport logging\nfrom typing import Tuple, Mapping, Optional, Union, Dict, List\nfrom collections import OrderedDict\n\nimport torch\nfrom torch import nn\nfrom ignite.metrics import Metric\n\nfrom deepchecks.core.check_result import CheckFailure, CheckResult\nfrom deepchecks.core.checks import DatasetKind\nfrom deepchecks.core.suite import BaseSuite, SuiteResult\nfrom deepchecks.core.display_suite import ProgressBar\nfrom deepchecks.core.errors import DeepchecksNotSupportedError\nfrom deepchecks.vision.base_checks import ModelOnlyCheck, SingleDatasetCheck, TrainTestCheck\nfrom deepchecks.vision.context import Context\nfrom deepchecks.vision.vision_data import VisionData\nfrom deepchecks.vision.batch_wrapper import Batch\n\n\n__all__ = ['Suite']\n\n\nlogger = logging.getLogger('deepchecks')\n\n\nclass Suite(BaseSuite):\n \"\"\"Tabular suite to run checks of types: TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck.\"\"\"\n\n @classmethod\n def supported_checks(cls) -> Tuple:\n \"\"\"Return tuple of supported check types of this suite.\"\"\"\n return TrainTestCheck, SingleDatasetCheck, ModelOnlyCheck\n\n def run(\n self,\n train_dataset: Optional[VisionData] = None,\n test_dataset: Optional[VisionData] = None,\n model: nn.Module = None,\n scorers: Mapping[str, Metric] = None,\n scorers_per_class: Mapping[str, Metric] = None,\n device: Union[str, torch.device, None] = 'cpu',\n random_state: int = 42,\n n_samples: Optional[int] = 10_000,\n ) -> SuiteResult:\n \"\"\"Run all checks.\n\n Parameters\n ----------\n train_dataset: Optional[VisionData] , default None\n object, representing data an estimator was fitted on\n test_dataset : Optional[VisionData] , default None\n object, representing data an estimator predicts on\n model : nn.Module , default None\n A scikit-learn-compatible fitted estimator instance\n scorers : Mapping[str, Metric] , default None\n dict of scorers names to scorer sklearn_name/function\n scorers_per_class : Mapping[str, Metric], default None\n dict of scorers for classification without averaging of the classes\n See <a href=\n \"https://scikit-learn.org/stable/modules/model_evaluation.html#from-binary-to-multiclass-and-multilabel\">\n scikit-learn docs</a>\n device : Union[str, torch.device], default: None\n processing unit for use\n random_state : int\n A seed to set for pseudo-random functions\n n_samples : int, default: 10,000\n number of samples to draw from the dataset.\n Returns\n -------\n SuiteResult\n All results by all initialized checks\n \"\"\"\n all_pbars = []\n progress_bar = ProgressBar('Validating Input', 1, unit='')\n all_pbars.append(progress_bar)\n context = Context(\n train_dataset,\n test_dataset,\n model,\n scorers=scorers,\n scorers_per_class=scorers_per_class,\n device=device,\n random_state=random_state,\n n_samples=n_samples\n )\n progress_bar.inc_progress()\n\n results: Dict[\n Union[str, int],\n Union[CheckResult, CheckFailure]\n ] = OrderedDict({})\n\n run_train_test_checks = train_dataset is not None and test_dataset is not None\n non_single_checks = {k: check for k, check in self.checks.items() if not isinstance(check, SingleDatasetCheck)}\n\n # Initialize here all the checks that are not single dataset, since those are initialized inside the update loop\n for index, check in non_single_checks.items():\n try:\n check.initialize_run(context)\n except Exception as exp:\n results[index] = CheckFailure(check, exp)\n\n if train_dataset is not None:\n self._update_loop(\n context=context,\n run_train_test_checks=run_train_test_checks,\n results=results,\n dataset_kind=DatasetKind.TRAIN,\n progress_bars=all_pbars\n )\n\n if test_dataset is not None:\n self._update_loop(\n context=context,\n run_train_test_checks=run_train_test_checks,\n results=results,\n dataset_kind=DatasetKind.TEST,\n progress_bars=all_pbars\n )\n\n # Need to compute only on not SingleDatasetCheck, since they computed inside the loop\n if non_single_checks:\n progress_bar = ProgressBar('Computing Checks', len(non_single_checks), unit='Check')\n all_pbars.append(progress_bar)\n for check_idx, check in non_single_checks.items():\n progress_bar.set_text(check.name())\n try:\n # if check index in results we had failure\n if check_idx not in results:\n result = check.finalize_check_result(check.compute(context))\n results[check_idx] = result\n except Exception as exp:\n results[check_idx] = CheckFailure(check, exp)\n progress_bar.inc_progress()\n\n # The results are ordered as they ran instead of in the order they were defined, therefore sort by key\n sorted_result_values = [value for name, value in sorted(results.items(), key=lambda pair: str(pair[0]))]\n\n # Close all progress bars\n for pbar in all_pbars:\n pbar.close()\n\n footnote = context.get_is_sampled_footnote()\n extra_info = [footnote] if footnote else []\n return SuiteResult(self.name, sorted_result_values, extra_info)\n\n def _update_loop(\n self,\n context: Context,\n run_train_test_checks: bool,\n results: Dict[Union[str, int], Union[CheckResult, CheckFailure]],\n dataset_kind: DatasetKind,\n progress_bars: List\n ):\n type_suffix = ' - Test Dataset' if dataset_kind == DatasetKind.TEST else ' - Train Dataset'\n vision_data = context.get_data_by_kind(dataset_kind)\n n_batches = len(vision_data)\n single_dataset_checks = {k: check for k, check in self.checks.items() if isinstance(check, SingleDatasetCheck)}\n\n # SingleDatasetChecks have different handling, need to initialize them here (to have them ready for different\n # dataset kind)\n for idx, check in single_dataset_checks.items():\n try:\n check.initialize_run(context, dataset_kind=dataset_kind)\n except Exception as exp:\n results[idx] = CheckFailure(check, exp, type_suffix)\n\n # Init cache of vision_data\n vision_data.init_cache()\n\n progress_bar = ProgressBar('Ingesting Batches' + type_suffix, n_batches, unit='Batch')\n progress_bars.append(progress_bar)\n\n # Run on all the batches\n batch_start_index = 0\n for batch in vision_data:\n batch = Batch(batch, context, dataset_kind, batch_start_index)\n vision_data.update_cache(batch)\n for check_idx, check in self.checks.items():\n # If index in results the check already failed before\n if check_idx in results:\n continue\n try:\n if isinstance(check, TrainTestCheck):\n if run_train_test_checks is True:\n check.update(context, batch, dataset_kind=dataset_kind)\n else:\n msg = 'Check is irrelevant if not supplied with both train and test datasets'\n results[check_idx] = self._get_unsupported_failure(check, msg)\n elif isinstance(check, SingleDatasetCheck):\n check.update(context, batch, dataset_kind=dataset_kind)\n elif isinstance(check, ModelOnlyCheck):\n pass\n else:\n raise TypeError(f'Don\\'t know how to handle type {check.__class__.__name__} in suite.')\n except Exception as exp:\n results[check_idx] = CheckFailure(check, exp, type_suffix)\n\n batch_start_index += len(batch)\n progress_bar.inc_progress()\n\n # SingleDatasetChecks have different handling. If we had failure in them need to add suffix to the index of\n # the results, else need to compute it.\n if single_dataset_checks:\n progress_bar = ProgressBar('Computing Single Dataset Checks' + type_suffix,\n len(single_dataset_checks),\n unit='Check')\n progress_bars.append(progress_bar)\n for idx, check in single_dataset_checks.items():\n progress_bar.set_text(check.name())\n index_of_kind = str(idx) + type_suffix\n # If index in results we had a failure\n if idx in results:\n results[index_of_kind] = results.pop(idx)\n else:\n try:\n result = check.compute(context, dataset_kind=dataset_kind)\n result = check.finalize_check_result(result)\n # Update header with dataset type only if both train and test ran\n if run_train_test_checks:\n result.header = result.get_header() + type_suffix\n results[index_of_kind] = result\n except Exception as exp:\n results[index_of_kind] = CheckFailure(check, exp, type_suffix)\n progress_bar.inc_progress()\n\n @classmethod\n def _get_unsupported_failure(cls, check, msg):\n return CheckFailure(check, DeepchecksNotSupportedError(msg))\n", "path": "deepchecks/vision/suite.py"}]}
| 3,190 | 545 |
gh_patches_debug_2661
|
rasdani/github-patches
|
git_diff
|
cowrie__cowrie-920
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
output_localsyslog exceptions.KeyError: 'isError'
After pulling the most recent version of cowrie to some of my honeypots, I get this error when a new connection I enabled [output_localsyslog] with configuration below:
```
[output_localsyslog]
enabled = true
facility = LOCAL5
format = text
```
The log error shows this:
```
2018-10-11T18:29:01.778300+0000 [twisted.logger._observer#critical] Temporarily disabling observer LegacyLogObserverWrapper(<bound method Output.emit of <cowrie.output.localsyslog.Output object at 0xb55ae7b0>>) due to exception: [Failure instance: Traceback: <type 'exceptions.KeyError'>: 'isError'
/opt/cowrie/src/cowrie/core/checkers.py:110:checkUserPass
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/threadable.py:53:sync
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/log.py:286:msg
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py:154:publishToNewObserver
--- <exception caught here> ---
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_observer.py:131:__call__
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py:93:__call__
/opt/cowrie/src/cowrie/core/output.py:209:emit
/opt/cowrie/src/cowrie/output/localsyslog.py:65:write
/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/syslog.py:76:emit
]
Traceback (most recent call last):
File "/opt/cowrie/src/cowrie/core/checkers.py", line 110, in checkUserPass
password=thepassword)
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/threadable.py", line 53, in sync
return function(self, *args, **kwargs)
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/log.py", line 286, in msg
_publishNew(self._publishPublisher, actualEventDict, textFromEventDict)
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py", line 154, in publishToNewObserver
observer(eventDict)
--- <exception caught here> ---
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_observer.py", line 131, in __call__
observer(event)
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py", line 93, in __call__
self.legacyObserver(event)
File "/opt/cowrie/src/cowrie/core/output.py", line 209, in emit
self.write(ev)
File "/opt/cowrie/src/cowrie/output/localsyslog.py", line 65, in write
self.syslog.emit(logentry)
File "/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/syslog.py", line 76, in emit
if eventDict['isError']:
exceptions.KeyError: 'isError'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cowrie/output/localsyslog.py`
Content:
```
1 # Copyright (c) 2015 Michel Oosterhof <[email protected]>
2 # All rights reserved.
3 #
4 # Redistribution and use in source and binary forms, with or without
5 # modification, are permitted provided that the following conditions
6 # are met:
7 #
8 # 1. Redistributions of source code must retain the above copyright
9 # notice, this list of conditions and the following disclaimer.
10 # 2. Redistributions in binary form must reproduce the above copyright
11 # notice, this list of conditions and the following disclaimer in the
12 # documentation and/or other materials provided with the distribution.
13 # 3. The names of the author(s) may not be used to endorse or promote
14 # products derived from this software without specific prior written
15 # permission.
16 #
17 # THIS SOFTWARE IS PROVIDED BY THE AUTHORS ``AS IS'' AND ANY EXPRESS OR
18 # IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
19 # OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
20 # IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY DIRECT, INDIRECT,
21 # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
22 # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
23 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED
24 # AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
25 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
26 # OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
27 # SUCH DAMAGE.
28
29 from __future__ import absolute_import, division
30
31 import syslog
32
33 import twisted.python.syslog
34
35 import cowrie.core.cef
36 import cowrie.core.output
37 from cowrie.core.config import CONFIG
38
39
40 class Output(cowrie.core.output.Output):
41
42 def __init__(self):
43 facilityString = CONFIG.get('output_localsyslog', 'facility')
44 self.format = CONFIG.get('output_localsyslog', 'format')
45 self.facility = vars(syslog)['LOG_' + facilityString]
46 self.syslog = twisted.python.syslog.SyslogObserver(prefix='cowrie', facility=self.facility)
47 cowrie.core.output.Output.__init__(self)
48
49 def start(self):
50 pass
51
52 def stop(self):
53 pass
54
55 def write(self, logentry):
56 if self.format == 'cef':
57 self.syslog.emit({
58 'message': cowrie.core.cef.formatCef(logentry),
59 'isError': False,
60 'system': 'cowrie'
61 })
62 else:
63 # message appears with additional spaces if message key is defined
64 logentry['message'] = [logentry['message']]
65 self.syslog.emit(logentry)
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cowrie/output/localsyslog.py b/src/cowrie/output/localsyslog.py
--- a/src/cowrie/output/localsyslog.py
+++ b/src/cowrie/output/localsyslog.py
@@ -53,6 +53,9 @@
pass
def write(self, logentry):
+ if 'isError' not in logentry:
+ logentry['isError'] = False
+
if self.format == 'cef':
self.syslog.emit({
'message': cowrie.core.cef.formatCef(logentry),
|
{"golden_diff": "diff --git a/src/cowrie/output/localsyslog.py b/src/cowrie/output/localsyslog.py\n--- a/src/cowrie/output/localsyslog.py\n+++ b/src/cowrie/output/localsyslog.py\n@@ -53,6 +53,9 @@\n pass\n \n def write(self, logentry):\n+ if 'isError' not in logentry:\n+ logentry['isError'] = False\n+\n if self.format == 'cef':\n self.syslog.emit({\n 'message': cowrie.core.cef.formatCef(logentry),\n", "issue": "output_localsyslog exceptions.KeyError: 'isError'\nAfter pulling the most recent version of cowrie to some of my honeypots, I get this error when a new connection I enabled [output_localsyslog] with configuration below:\r\n```\r\n[output_localsyslog]\r\nenabled = true\r\nfacility = LOCAL5\r\nformat = text\r\n```\r\nThe log error shows this:\r\n```\r\n2018-10-11T18:29:01.778300+0000 [twisted.logger._observer#critical] Temporarily disabling observer LegacyLogObserverWrapper(<bound method Output.emit of <cowrie.output.localsyslog.Output object at 0xb55ae7b0>>) due to exception: [Failure instance: Traceback: <type 'exceptions.KeyError'>: 'isError'\r\n\t/opt/cowrie/src/cowrie/core/checkers.py:110:checkUserPass\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/threadable.py:53:sync\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/log.py:286:msg\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py:154:publishToNewObserver\r\n\t--- <exception caught here> ---\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_observer.py:131:__call__\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py:93:__call__\r\n\t/opt/cowrie/src/cowrie/core/output.py:209:emit\r\n\t/opt/cowrie/src/cowrie/output/localsyslog.py:65:write\r\n\t/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/syslog.py:76:emit\r\n\t]\r\n\tTraceback (most recent call last):\r\n\t File \"/opt/cowrie/src/cowrie/core/checkers.py\", line 110, in checkUserPass\r\n\t password=thepassword)\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/threadable.py\", line 53, in sync\r\n\t return function(self, *args, **kwargs)\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/log.py\", line 286, in msg\r\n\t _publishNew(self._publishPublisher, actualEventDict, textFromEventDict)\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py\", line 154, in publishToNewObserver\r\n\t observer(eventDict)\r\n\t--- <exception caught here> ---\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_observer.py\", line 131, in __call__\r\n\t observer(event)\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/logger/_legacy.py\", line 93, in __call__\r\n\t self.legacyObserver(event)\r\n\t File \"/opt/cowrie/src/cowrie/core/output.py\", line 209, in emit\r\n\t self.write(ev)\r\n\t File \"/opt/cowrie/src/cowrie/output/localsyslog.py\", line 65, in write\r\n\t self.syslog.emit(logentry)\r\n\t File \"/opt/cowrie/cowrie-env/local/lib/python2.7/site-packages/twisted/python/syslog.py\", line 76, in emit\r\n\t if eventDict['isError']:\r\n\texceptions.KeyError: 'isError'\r\n```\n", "before_files": [{"content": "# Copyright (c) 2015 Michel Oosterhof <[email protected]>\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# 1. Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# 3. The names of the author(s) may not be used to endorse or promote\n# products derived from this software without specific prior written\n# permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE AUTHORS ``AS IS'' AND ANY EXPRESS OR\n# IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES\n# OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.\n# IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED\n# AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY\n# OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\n# SUCH DAMAGE.\n\nfrom __future__ import absolute_import, division\n\nimport syslog\n\nimport twisted.python.syslog\n\nimport cowrie.core.cef\nimport cowrie.core.output\nfrom cowrie.core.config import CONFIG\n\n\nclass Output(cowrie.core.output.Output):\n\n def __init__(self):\n facilityString = CONFIG.get('output_localsyslog', 'facility')\n self.format = CONFIG.get('output_localsyslog', 'format')\n self.facility = vars(syslog)['LOG_' + facilityString]\n self.syslog = twisted.python.syslog.SyslogObserver(prefix='cowrie', facility=self.facility)\n cowrie.core.output.Output.__init__(self)\n\n def start(self):\n pass\n\n def stop(self):\n pass\n\n def write(self, logentry):\n if self.format == 'cef':\n self.syslog.emit({\n 'message': cowrie.core.cef.formatCef(logentry),\n 'isError': False,\n 'system': 'cowrie'\n })\n else:\n # message appears with additional spaces if message key is defined\n logentry['message'] = [logentry['message']]\n self.syslog.emit(logentry)\n", "path": "src/cowrie/output/localsyslog.py"}], "after_files": [{"content": "# Copyright (c) 2015 Michel Oosterhof <[email protected]>\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# 1. Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# 3. The names of the author(s) may not be used to endorse or promote\n# products derived from this software without specific prior written\n# permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE AUTHORS ``AS IS'' AND ANY EXPRESS OR\n# IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES\n# OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.\n# IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED\n# AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY\n# OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\n# SUCH DAMAGE.\n\nfrom __future__ import absolute_import, division\n\nimport syslog\n\nimport twisted.python.syslog\n\nimport cowrie.core.cef\nimport cowrie.core.output\nfrom cowrie.core.config import CONFIG\n\n\nclass Output(cowrie.core.output.Output):\n\n def __init__(self):\n facilityString = CONFIG.get('output_localsyslog', 'facility')\n self.format = CONFIG.get('output_localsyslog', 'format')\n self.facility = vars(syslog)['LOG_' + facilityString]\n self.syslog = twisted.python.syslog.SyslogObserver(prefix='cowrie', facility=self.facility)\n cowrie.core.output.Output.__init__(self)\n\n def start(self):\n pass\n\n def stop(self):\n pass\n\n def write(self, logentry):\n if 'isError' not in logentry:\n logentry['isError'] = False\n\n if self.format == 'cef':\n self.syslog.emit({\n 'message': cowrie.core.cef.formatCef(logentry),\n 'isError': False,\n 'system': 'cowrie'\n })\n else:\n # message appears with additional spaces if message key is defined\n logentry['message'] = [logentry['message']]\n self.syslog.emit(logentry)\n", "path": "src/cowrie/output/localsyslog.py"}]}
| 1,788 | 128 |
gh_patches_debug_42416
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3233
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py`
Content:
```
1 import warnings
2 from typing import Optional, Union
3
4 import torch
5 import torch.distributed as dist
6 import torch.nn as nn
7 import torch.optim as optim
8 from chatgpt.models.base import Actor
9 from chatgpt.models.lora import LoraLinear
10 from torch.optim import Optimizer
11
12 from transformers.modeling_utils import PreTrainedModel
13 from transformers.tokenization_utils_base import PreTrainedTokenizerBase
14
15 import colossalai
16 from colossalai.nn.optimizer import CPUAdam, HybridAdam
17 from colossalai.nn.parallel import ZeroDDP, zero_model_wrapper, zero_optim_wrapper
18 from colossalai.nn.parallel.utils import get_static_torch_model
19 from colossalai.tensor import ProcessGroup, ShardSpec
20 from colossalai.utils import get_current_device
21 from colossalai.utils.model.colo_init_context import ColoInitContext
22
23 from .base import Strategy
24 from .ddp import DDPStrategy
25
26
27 class ColossalAIStrategy(DDPStrategy):
28 """
29 The strategy for training with ColossalAI.
30
31 Args:
32 stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
33 seed(int): The seed for the random number generator.
34 shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
35 This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.
36 placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')
37 If it is “cpu”, parameters, gradients and optimizer states will be offloaded to CPU,
38 If it is “cuda”, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.
39 pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.
40 force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.
41 search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.
42 hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.
43 min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.
44 gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.
45 reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.
46 overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.
47 initial_scale(float): The initial scale for the optimizer.
48 growth_factor(float): The growth factor for the optimizer.
49 backoff_factor(float): The backoff factor for the optimizer.
50 growth_interval(int): The growth interval for the optimizer.
51 hysteresis(int): The hysteresis for the optimizer.
52 min_scale(float): The minimum scale for the optimizer.
53 max_scale(float): The maximum scale for the optimizer.
54 max_norm(float): The maximum norm for the optimizer.
55 norm_type(float): The norm type for the optimizer.
56
57 """
58
59 def __init__(
60 self,
61 stage: int = 3,
62 seed: int = 42,
63 shard_init: bool = False, # only for stage 3
64 placement_policy: str = 'cuda',
65 pin_memory: bool = True, # only for stage 3
66 force_outputs_fp32: bool = False, # only for stage 3
67 search_range_mb: int = 32, # only for stage 3
68 hidden_dim: Optional[int] = None, # only for stage 3
69 min_chunk_size_mb: float = 32, # only for stage 3
70 gpu_margin_mem_ratio: float = 0.0, # only for stage 3
71 reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2
72 overlap_communication: bool = True, # only for stage 1&2
73 initial_scale: float = 2**16,
74 growth_factor: float = 2,
75 backoff_factor: float = 0.5,
76 growth_interval: int = 1000,
77 hysteresis: int = 2,
78 min_scale: float = 1,
79 max_scale: float = 2**32,
80 max_norm: float = 0.0,
81 norm_type: float = 2.0) -> None:
82 super().__init__(seed)
83 assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
84 self.stage = stage
85 # TODO(ver217): support shard_init when using from_pretrained()
86 if shard_init:
87 warnings.warn(
88 f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'
89 )
90 self.shard_init = shard_init
91 self.gemini_config = dict(device=get_current_device(),
92 placement_policy=placement_policy,
93 pin_memory=pin_memory,
94 force_outputs_fp32=force_outputs_fp32,
95 strict_ddp_mode=shard_init,
96 search_range_mb=search_range_mb,
97 hidden_dim=hidden_dim,
98 min_chunk_size_mb=min_chunk_size_mb)
99 if stage == 3:
100 self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)
101 else:
102 self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,
103 overlap_communication=overlap_communication,
104 cpu_offload=(placement_policy == 'cpu'))
105 self.optim_kwargs = dict(initial_scale=initial_scale,
106 growth_factor=growth_factor,
107 backoff_factor=backoff_factor,
108 growth_interval=growth_interval,
109 hysteresis=hysteresis,
110 min_scale=min_scale,
111 max_scale=max_scale,
112 max_norm=max_norm,
113 norm_type=norm_type)
114
115 def setup_distributed(self) -> None:
116 colossalai.launch_from_torch({}, seed=self.seed)
117
118 def model_init_context(self):
119 if self.stage == 3:
120 world_size = dist.get_world_size()
121 shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None
122 default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None
123 return ColoInitContext(device=get_current_device(),
124 dtype=torch.half,
125 default_pg=shard_pg,
126 default_dist_spec=default_dist_spec)
127 return super().model_init_context()
128
129 def setup_model(self, model: nn.Module) -> nn.Module:
130 return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
131
132 def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
133 assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'
134 return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)
135
136 def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
137 optimizer.backward(loss)
138
139 def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
140 optimizer.step()
141
142 @staticmethod
143 def _unwrap_actor(actor: Actor) -> nn.Module:
144 model: Union[nn.Module, ZeroDDP] = Strategy._unwrap_actor(actor)
145 if isinstance(model, ZeroDDP):
146 return model.module
147 return model
148
149 def save_model(self, model: nn.Module, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None:
150 unwrapped_model = self._unwrap_model(model)
151 # TODO : better way to get torch model from gemini model
152 # to get torch model from gemini model
153 if isinstance(unwrapped_model, ZeroDDP):
154 state_dict = unwrapped_model.state_dict()
155 unwrapped_model = get_static_torch_model(unwrapped_model)
156 if only_rank0 and dist.get_rank() != 0:
157 return
158 unwrapped_model.load_state_dict(state_dict)
159 # merge lora_weights into weights
160 for module in unwrapped_model.modules():
161 if isinstance(module, LoraLinear):
162 module.merge_weights=True
163 module.eval()
164 # get state_dict and save
165
166 if not isinstance(self.model, PreTrainedModel):
167 state_dict = unwrapped_model.state_dict()
168 if only_rank0 and dist.get_rank() != 0:
169 return
170 torch.save(state_dict, path)
171 else:
172 self.model.save_pretrained(path)
173 if tokenizer is not None:
174 tokenizer.save_pretrained(path)
175
176 def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:
177 if only_rank0:
178 raise RuntimeError(
179 f'Optimizer states are sharded when using ColossalAIStrategy. Only rank0 is not supported.')
180 torch.save(optimizer.state_dict(), path)
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
--- a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
+++ b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py
@@ -27,6 +27,7 @@
Args:
stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
+ precision(str): The precision to use. Choose in ('fp32', 'fp16'). Stage 3 only supports fp16.
seed(int): The seed for the random number generator.
shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.
@@ -56,6 +57,7 @@
def __init__(
self,
stage: int = 3,
+ precision: str = 'fp16',
seed: int = 42,
shard_init: bool = False, # only for stage 3
placement_policy: str = 'cuda',
@@ -78,12 +80,17 @@
norm_type: float = 2.0) -> None:
super().__init__(seed)
assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
+ assert precision in ('fp32', 'fp16'), f'Unsupported precision "{precision}"'
self.stage = stage
# TODO(ver217): support shard_init when using from_pretrained()
if shard_init:
warnings.warn(
f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'
)
+ if stage == 3 and precision == 'fp32':
+ warnings.warn(f'Stage 3 only supports fp16. Precision is set to fp16.')
+ precision = 'fp16'
+ self.precision = precision
self.shard_init = shard_init
self.gemini_config = dict(device=get_current_device(),
placement_policy=placement_policy,
@@ -124,7 +131,10 @@
return super().model_init_context()
def setup_model(self, model: nn.Module) -> nn.Module:
- return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
+ model = zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
+ if self.stage != 3 and self.precision == 'fp16':
+ model = model.half()
+ return model
def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'
@@ -156,7 +166,7 @@
# merge lora_weights into weights
for module in unwrapped_model.modules():
if isinstance(module, LoraLinear):
- module.merge_weights=True
+ module.merge_weights = True
module.eval()
# get state_dict and save
state_dict = unwrapped_model.state_dict()
|
{"golden_diff": "diff --git a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n--- a/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n+++ b/applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py\n@@ -27,6 +27,7 @@\n \n Args:\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n+ precision(str): The precision to use. Choose in ('fp32', 'fp16'). Stage 3 only supports fp16.\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.\n@@ -56,6 +57,7 @@\n def __init__(\n self,\n stage: int = 3,\n+ precision: str = 'fp16',\n seed: int = 42,\n shard_init: bool = False, # only for stage 3\n placement_policy: str = 'cuda',\n@@ -78,12 +80,17 @@\n norm_type: float = 2.0) -> None:\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n+ assert precision in ('fp32', 'fp16'), f'Unsupported precision \"{precision}\"'\n self.stage = stage\n # TODO(ver217): support shard_init when using from_pretrained()\n if shard_init:\n warnings.warn(\n f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'\n )\n+ if stage == 3 and precision == 'fp32':\n+ warnings.warn(f'Stage 3 only supports fp16. Precision is set to fp16.')\n+ precision = 'fp16'\n+ self.precision = precision\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n@@ -124,7 +131,10 @@\n return super().model_init_context()\n \n def setup_model(self, model: nn.Module) -> nn.Module:\n- return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n+ model = zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n+ if self.stage != 3 and self.precision == 'fp16':\n+ model = model.half()\n+ return model\n \n def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:\n assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'\n@@ -156,7 +166,7 @@\n # merge lora_weights into weights\n for module in unwrapped_model.modules():\n if isinstance(module, LoraLinear):\n- module.merge_weights=True\n+ module.merge_weights = True\n module.eval()\n # get state_dict and save\n state_dict = unwrapped_model.state_dict()\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import warnings\nfrom typing import Optional, Union\n\nimport torch\nimport torch.distributed as dist\nimport torch.nn as nn\nimport torch.optim as optim\nfrom chatgpt.models.base import Actor\nfrom chatgpt.models.lora import LoraLinear\nfrom torch.optim import Optimizer\n\nfrom transformers.modeling_utils import PreTrainedModel\nfrom transformers.tokenization_utils_base import PreTrainedTokenizerBase\n\nimport colossalai\nfrom colossalai.nn.optimizer import CPUAdam, HybridAdam\nfrom colossalai.nn.parallel import ZeroDDP, zero_model_wrapper, zero_optim_wrapper\nfrom colossalai.nn.parallel.utils import get_static_torch_model\nfrom colossalai.tensor import ProcessGroup, ShardSpec\nfrom colossalai.utils import get_current_device\nfrom colossalai.utils.model.colo_init_context import ColoInitContext\n\nfrom .base import Strategy\nfrom .ddp import DDPStrategy\n\n\nclass ColossalAIStrategy(DDPStrategy):\n \"\"\"\n The strategy for training with ColossalAI.\n\n Args:\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.\n placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')\n If it is \u201ccpu\u201d, parameters, gradients and optimizer states will be offloaded to CPU,\n If it is \u201ccuda\u201d, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.\n pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.\n force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.\n search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.\n hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.\n min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.\n gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.\n reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.\n overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.\n initial_scale(float): The initial scale for the optimizer.\n growth_factor(float): The growth factor for the optimizer.\n backoff_factor(float): The backoff factor for the optimizer.\n growth_interval(int): The growth interval for the optimizer.\n hysteresis(int): The hysteresis for the optimizer.\n min_scale(float): The minimum scale for the optimizer.\n max_scale(float): The maximum scale for the optimizer.\n max_norm(float): The maximum norm for the optimizer.\n norm_type(float): The norm type for the optimizer.\n\n \"\"\"\n\n def __init__(\n self,\n stage: int = 3,\n seed: int = 42,\n shard_init: bool = False, # only for stage 3\n placement_policy: str = 'cuda',\n pin_memory: bool = True, # only for stage 3\n force_outputs_fp32: bool = False, # only for stage 3\n search_range_mb: int = 32, # only for stage 3\n hidden_dim: Optional[int] = None, # only for stage 3\n min_chunk_size_mb: float = 32, # only for stage 3\n gpu_margin_mem_ratio: float = 0.0, # only for stage 3\n reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2\n overlap_communication: bool = True, # only for stage 1&2\n initial_scale: float = 2**16,\n growth_factor: float = 2,\n backoff_factor: float = 0.5,\n growth_interval: int = 1000,\n hysteresis: int = 2,\n min_scale: float = 1,\n max_scale: float = 2**32,\n max_norm: float = 0.0,\n norm_type: float = 2.0) -> None:\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n self.stage = stage\n # TODO(ver217): support shard_init when using from_pretrained()\n if shard_init:\n warnings.warn(\n f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'\n )\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n pin_memory=pin_memory,\n force_outputs_fp32=force_outputs_fp32,\n strict_ddp_mode=shard_init,\n search_range_mb=search_range_mb,\n hidden_dim=hidden_dim,\n min_chunk_size_mb=min_chunk_size_mb)\n if stage == 3:\n self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)\n else:\n self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,\n overlap_communication=overlap_communication,\n cpu_offload=(placement_policy == 'cpu'))\n self.optim_kwargs = dict(initial_scale=initial_scale,\n growth_factor=growth_factor,\n backoff_factor=backoff_factor,\n growth_interval=growth_interval,\n hysteresis=hysteresis,\n min_scale=min_scale,\n max_scale=max_scale,\n max_norm=max_norm,\n norm_type=norm_type)\n\n def setup_distributed(self) -> None:\n colossalai.launch_from_torch({}, seed=self.seed)\n\n def model_init_context(self):\n if self.stage == 3:\n world_size = dist.get_world_size()\n shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None\n default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None\n return ColoInitContext(device=get_current_device(),\n dtype=torch.half,\n default_pg=shard_pg,\n default_dist_spec=default_dist_spec)\n return super().model_init_context()\n\n def setup_model(self, model: nn.Module) -> nn.Module:\n return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n\n def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:\n assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'\n return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)\n\n def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.backward(loss)\n\n def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.step()\n\n @staticmethod\n def _unwrap_actor(actor: Actor) -> nn.Module:\n model: Union[nn.Module, ZeroDDP] = Strategy._unwrap_actor(actor)\n if isinstance(model, ZeroDDP):\n return model.module\n return model\n\n def save_model(self, model: nn.Module, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None:\n unwrapped_model = self._unwrap_model(model)\n # TODO : better way to get torch model from gemini model\n # to get torch model from gemini model\n if isinstance(unwrapped_model, ZeroDDP):\n state_dict = unwrapped_model.state_dict()\n unwrapped_model = get_static_torch_model(unwrapped_model)\n if only_rank0 and dist.get_rank() != 0:\n return\n unwrapped_model.load_state_dict(state_dict)\n # merge lora_weights into weights\n for module in unwrapped_model.modules():\n if isinstance(module, LoraLinear):\n module.merge_weights=True\n module.eval()\n # get state_dict and save\n\n if not isinstance(self.model, PreTrainedModel):\n state_dict = unwrapped_model.state_dict()\n if only_rank0 and dist.get_rank() != 0:\n return\n torch.save(state_dict, path)\n else:\n self.model.save_pretrained(path)\n if tokenizer is not None:\n tokenizer.save_pretrained(path)\n\n def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:\n if only_rank0:\n raise RuntimeError(\n f'Optimizer states are sharded when using ColossalAIStrategy. Only rank0 is not supported.')\n torch.save(optimizer.state_dict(), path)\n", "path": "applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py"}], "after_files": [{"content": "import warnings\nfrom typing import Optional, Union\n\nimport torch\nimport torch.distributed as dist\nimport torch.nn as nn\nimport torch.optim as optim\nfrom chatgpt.models.base import Actor\nfrom chatgpt.models.lora import LoraLinear\nfrom torch.optim import Optimizer\n\nimport colossalai\nfrom colossalai.nn.optimizer import CPUAdam, HybridAdam\nfrom colossalai.nn.parallel import ZeroDDP, zero_model_wrapper, zero_optim_wrapper\nfrom colossalai.nn.parallel.utils import get_static_torch_model\nfrom colossalai.tensor import ProcessGroup, ShardSpec\nfrom colossalai.utils import get_current_device\nfrom colossalai.utils.model.colo_init_context import ColoInitContext\n\nfrom .base import Strategy\nfrom .ddp import DDPStrategy\n\n\nclass ColossalAIStrategy(DDPStrategy):\n \"\"\"\n The strategy for training with ColossalAI.\n\n Args:\n stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)\n precision(str): The precision to use. Choose in ('fp32', 'fp16'). Stage 3 only supports fp16.\n seed(int): The seed for the random number generator.\n shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.\n This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.\n placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')\n If it is \u201ccpu\u201d, parameters, gradients and optimizer states will be offloaded to CPU,\n If it is \u201ccuda\u201d, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.\n pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.\n force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.\n search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.\n hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.\n min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.\n gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.\n reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.\n overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.\n initial_scale(float): The initial scale for the optimizer.\n growth_factor(float): The growth factor for the optimizer.\n backoff_factor(float): The backoff factor for the optimizer.\n growth_interval(int): The growth interval for the optimizer.\n hysteresis(int): The hysteresis for the optimizer.\n min_scale(float): The minimum scale for the optimizer.\n max_scale(float): The maximum scale for the optimizer.\n max_norm(float): The maximum norm for the optimizer.\n norm_type(float): The norm type for the optimizer.\n\n \"\"\"\n\n def __init__(\n self,\n stage: int = 3,\n precision: str = 'fp16',\n seed: int = 42,\n shard_init: bool = False, # only for stage 3\n placement_policy: str = 'cuda',\n pin_memory: bool = True, # only for stage 3\n force_outputs_fp32: bool = False, # only for stage 3\n search_range_mb: int = 32, # only for stage 3\n hidden_dim: Optional[int] = None, # only for stage 3\n min_chunk_size_mb: float = 32, # only for stage 3\n gpu_margin_mem_ratio: float = 0.0, # only for stage 3\n reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2\n overlap_communication: bool = True, # only for stage 1&2\n initial_scale: float = 2**16,\n growth_factor: float = 2,\n backoff_factor: float = 0.5,\n growth_interval: int = 1000,\n hysteresis: int = 2,\n min_scale: float = 1,\n max_scale: float = 2**32,\n max_norm: float = 0.0,\n norm_type: float = 2.0) -> None:\n super().__init__(seed)\n assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy \"{placement_policy}\"'\n assert precision in ('fp32', 'fp16'), f'Unsupported precision \"{precision}\"'\n self.stage = stage\n # TODO(ver217): support shard_init when using from_pretrained()\n if shard_init:\n warnings.warn(\n f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'\n )\n if stage == 3 and precision == 'fp32':\n warnings.warn(f'Stage 3 only supports fp16. Precision is set to fp16.')\n precision = 'fp16'\n self.precision = precision\n self.shard_init = shard_init\n self.gemini_config = dict(device=get_current_device(),\n placement_policy=placement_policy,\n pin_memory=pin_memory,\n force_outputs_fp32=force_outputs_fp32,\n strict_ddp_mode=shard_init,\n search_range_mb=search_range_mb,\n hidden_dim=hidden_dim,\n min_chunk_size_mb=min_chunk_size_mb)\n if stage == 3:\n self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)\n else:\n self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,\n overlap_communication=overlap_communication,\n cpu_offload=(placement_policy == 'cpu'))\n self.optim_kwargs = dict(initial_scale=initial_scale,\n growth_factor=growth_factor,\n backoff_factor=backoff_factor,\n growth_interval=growth_interval,\n hysteresis=hysteresis,\n min_scale=min_scale,\n max_scale=max_scale,\n max_norm=max_norm,\n norm_type=norm_type)\n\n def setup_distributed(self) -> None:\n colossalai.launch_from_torch({}, seed=self.seed)\n\n def model_init_context(self):\n if self.stage == 3:\n world_size = dist.get_world_size()\n shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None\n default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None\n return ColoInitContext(device=get_current_device(),\n dtype=torch.half,\n default_pg=shard_pg,\n default_dist_spec=default_dist_spec)\n return super().model_init_context()\n\n def setup_model(self, model: nn.Module) -> nn.Module:\n model = zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)\n if self.stage != 3 and self.precision == 'fp16':\n model = model.half()\n return model\n\n def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:\n assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'\n return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)\n\n def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.backward(loss)\n\n def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:\n optimizer.step()\n\n @staticmethod\n def _unwrap_actor(actor: Actor) -> nn.Module:\n model: Union[nn.Module, ZeroDDP] = Strategy._unwrap_actor(actor)\n if isinstance(model, ZeroDDP):\n return model.module\n return model\n\n def save_model(self, model: nn.Module, path: str, only_rank0: bool = False) -> None:\n unwrapped_model = self._unwrap_model(model)\n # TODO : better way to get torch model from gemini model\n # to get torch model from gemini model\n if isinstance(unwrapped_model, ZeroDDP):\n state_dict = unwrapped_model.state_dict()\n unwrapped_model = get_static_torch_model(unwrapped_model)\n if only_rank0 and dist.get_rank() != 0:\n return\n unwrapped_model.load_state_dict(state_dict)\n # merge lora_weights into weights\n for module in unwrapped_model.modules():\n if isinstance(module, LoraLinear):\n module.merge_weights = True\n module.eval()\n # get state_dict and save\n state_dict = unwrapped_model.state_dict()\n if only_rank0 and dist.get_rank() != 0:\n return\n torch.save(state_dict, path)\n\n def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:\n if only_rank0:\n raise RuntimeError(\n f'Optimizer states are sharded when using ColossalAIStrategy. Only rank0 is not supported.')\n torch.save(optimizer.state_dict(), path)\n", "path": "applications/ChatGPT/chatgpt/trainer/strategies/colossalai.py"}]}
| 2,694 | 747 |
gh_patches_debug_20716
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2365
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Arbitrary rst substitutions
Since we have transforms now, it should be easy to do something generic, like this:
`|bzr-revno|` that would be replaced by the output of `bzr revno` using a configuration like
``` py
def bzr_revno():
return subprocess.check_output(["bzr", "revno"])
RST_SUBSTITUTIONS = {
'bzr_revno': bzr_revno
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/compile/rest/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2016 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """reStructuredText compiler for Nikola."""
28
29 from __future__ import unicode_literals
30 import io
31 import os
32
33 import docutils.core
34 import docutils.nodes
35 import docutils.utils
36 import docutils.io
37 import docutils.readers.standalone
38 import docutils.writers.html4css1
39 import docutils.parsers.rst.directives
40
41 from nikola.plugin_categories import PageCompiler
42 from nikola.utils import unicode_str, get_logger, makedirs, write_metadata, STDERR_HANDLER
43 from nikola.shortcodes import apply_shortcodes
44
45
46 class CompileRest(PageCompiler):
47 """Compile reStructuredText into HTML."""
48
49 name = "rest"
50 friendly_name = "reStructuredText"
51 demote_headers = True
52 logger = None
53
54 def _read_extra_deps(self, post):
55 """Read contents of .dep file and returns them as a list."""
56 dep_path = post.base_path + '.dep'
57 if os.path.isfile(dep_path):
58 with io.open(dep_path, 'r+', encoding='utf8') as depf:
59 deps = [l.strip() for l in depf.readlines()]
60 return deps
61 return []
62
63 def register_extra_dependencies(self, post):
64 """Add dependency to post object to check .dep file."""
65 post.add_dependency(lambda: self._read_extra_deps(post), 'fragment')
66
67 def compile_html_string(self, data, source_path=None, is_two_file=True):
68 """Compile reST into HTML strings."""
69 # If errors occur, this will be added to the line number reported by
70 # docutils so the line number matches the actual line number (off by
71 # 7 with default metadata, could be more or less depending on the post).
72 add_ln = 0
73 if not is_two_file:
74 m_data, data = self.split_metadata(data)
75 add_ln = len(m_data.splitlines()) + 1
76
77 default_template_path = os.path.join(os.path.dirname(__file__), 'template.txt')
78 output, error_level, deps = rst2html(
79 data, settings_overrides={
80 'initial_header_level': 1,
81 'record_dependencies': True,
82 'stylesheet_path': None,
83 'link_stylesheet': True,
84 'syntax_highlight': 'short',
85 'math_output': 'mathjax',
86 'template': default_template_path,
87 }, logger=self.logger, source_path=source_path, l_add_ln=add_ln, transforms=self.site.rst_transforms)
88 if not isinstance(output, unicode_str):
89 # To prevent some weird bugs here or there.
90 # Original issue: empty files. `output` became a bytestring.
91 output = output.decode('utf-8')
92 return output, error_level, deps
93
94 def compile_html(self, source, dest, is_two_file=True):
95 """Compile source file into HTML and save as dest."""
96 makedirs(os.path.dirname(dest))
97 error_level = 100
98 with io.open(dest, "w+", encoding="utf8") as out_file:
99 with io.open(source, "r", encoding="utf8") as in_file:
100 data = in_file.read()
101 output, error_level, deps = self.compile_html_string(data, source, is_two_file)
102 output = apply_shortcodes(output, self.site.shortcode_registry, self.site, source)
103 out_file.write(output)
104 deps_path = dest + '.dep'
105 if deps.list:
106 deps.list = [p for p in deps.list if p != dest] # Don't depend on yourself (#1671)
107 with io.open(deps_path, "w+", encoding="utf8") as deps_file:
108 deps_file.write('\n'.join(deps.list))
109 else:
110 if os.path.isfile(deps_path):
111 os.unlink(deps_path)
112 if error_level < 3:
113 return True
114 else:
115 return False
116
117 def create_post(self, path, **kw):
118 """Create a new post."""
119 content = kw.pop('content', None)
120 onefile = kw.pop('onefile', False)
121 # is_page is not used by create_post as of now.
122 kw.pop('is_page', False)
123 metadata = {}
124 metadata.update(self.default_metadata)
125 metadata.update(kw)
126 makedirs(os.path.dirname(path))
127 if not content.endswith('\n'):
128 content += '\n'
129 with io.open(path, "w+", encoding="utf8") as fd:
130 if onefile:
131 fd.write(write_metadata(metadata))
132 fd.write('\n')
133 fd.write(content)
134
135 def set_site(self, site):
136 """Set Nikola site."""
137 super(CompileRest, self).set_site(site)
138 self.config_dependencies = []
139 for plugin_info in self.get_compiler_extensions():
140 self.config_dependencies.append(plugin_info.name)
141 plugin_info.plugin_object.short_help = plugin_info.description
142
143 self.logger = get_logger('compile_rest', STDERR_HANDLER)
144 if not site.debug:
145 self.logger.level = 4
146
147
148 def get_observer(settings):
149 """Return an observer for the docutils Reporter."""
150 def observer(msg):
151 """Report docutils/rest messages to a Nikola user.
152
153 Error code mapping:
154
155 +------+---------+------+----------+
156 | dNUM | dNAME | lNUM | lNAME | d = docutils, l = logbook
157 +------+---------+------+----------+
158 | 0 | DEBUG | 1 | DEBUG |
159 | 1 | INFO | 2 | INFO |
160 | 2 | WARNING | 4 | WARNING |
161 | 3 | ERROR | 5 | ERROR |
162 | 4 | SEVERE | 6 | CRITICAL |
163 +------+---------+------+----------+
164 """
165 errormap = {0: 1, 1: 2, 2: 4, 3: 5, 4: 6}
166 text = docutils.nodes.Element.astext(msg)
167 line = msg['line'] + settings['add_ln'] if 'line' in msg else 0
168 out = '[{source}{colon}{line}] {text}'.format(
169 source=settings['source'], colon=(':' if line else ''),
170 line=line, text=text)
171 settings['logger'].log(errormap[msg['level']], out)
172
173 return observer
174
175
176 class NikolaReader(docutils.readers.standalone.Reader):
177 """Nikola-specific docutils reader."""
178
179 def __init__(self, *args, **kwargs):
180 """Initialize the reader."""
181 self.transforms = kwargs.pop('transforms', [])
182 docutils.readers.standalone.Reader.__init__(self, *args, **kwargs)
183
184 def get_transforms(self):
185 """Get docutils transforms."""
186 return docutils.readers.standalone.Reader(self).get_transforms() + self.transforms
187
188 def new_document(self):
189 """Create and return a new empty document tree (root node)."""
190 document = docutils.utils.new_document(self.source.source_path, self.settings)
191 document.reporter.stream = False
192 document.reporter.attach_observer(get_observer(self.l_settings))
193 return document
194
195
196 def add_node(node, visit_function=None, depart_function=None):
197 """Register a Docutils node class.
198
199 This function is completely optional. It is a same concept as
200 `Sphinx add_node function <http://sphinx-doc.org/extdev/appapi.html#sphinx.application.Sphinx.add_node>`_.
201
202 For example::
203
204 class Plugin(RestExtension):
205
206 name = "rest_math"
207
208 def set_site(self, site):
209 self.site = site
210 directives.register_directive('math', MathDirective)
211 add_node(MathBlock, visit_Math, depart_Math)
212 return super(Plugin, self).set_site(site)
213
214 class MathDirective(Directive):
215 def run(self):
216 node = MathBlock()
217 return [node]
218
219 class Math(docutils.nodes.Element): pass
220
221 def visit_Math(self, node):
222 self.body.append(self.starttag(node, 'math'))
223
224 def depart_Math(self, node):
225 self.body.append('</math>')
226
227 For full example, you can refer to `Microdata plugin <https://plugins.getnikola.com/#microdata>`_
228 """
229 docutils.nodes._add_node_class_names([node.__name__])
230 if visit_function:
231 setattr(docutils.writers.html4css1.HTMLTranslator, 'visit_' + node.__name__, visit_function)
232 if depart_function:
233 setattr(docutils.writers.html4css1.HTMLTranslator, 'depart_' + node.__name__, depart_function)
234
235
236 def rst2html(source, source_path=None, source_class=docutils.io.StringInput,
237 destination_path=None, reader=None,
238 parser=None, parser_name='restructuredtext', writer=None,
239 writer_name='html', settings=None, settings_spec=None,
240 settings_overrides=None, config_section=None,
241 enable_exit_status=None, logger=None, l_add_ln=0, transforms=None):
242 """Set up & run a ``Publisher``, and return a dictionary of document parts.
243
244 Dictionary keys are the names of parts, and values are Unicode strings;
245 encoding is up to the client. For programmatic use with string I/O.
246
247 For encoded string input, be sure to set the 'input_encoding' setting to
248 the desired encoding. Set it to 'unicode' for unencoded Unicode string
249 input. Here's how::
250
251 publish_parts(..., settings_overrides={'input_encoding': 'unicode'})
252
253 Parameters: see `publish_programmatically`.
254
255 WARNING: `reader` should be None (or NikolaReader()) if you want Nikola to report
256 reStructuredText syntax errors.
257 """
258 if reader is None:
259 reader = NikolaReader(transforms=transforms)
260 # For our custom logging, we have special needs and special settings we
261 # specify here.
262 # logger a logger from Nikola
263 # source source filename (docutils gets a string)
264 # add_ln amount of metadata lines (see comment in compile_html above)
265 reader.l_settings = {'logger': logger, 'source': source_path,
266 'add_ln': l_add_ln}
267
268 pub = docutils.core.Publisher(reader, parser, writer, settings=settings,
269 source_class=source_class,
270 destination_class=docutils.io.StringOutput)
271 pub.set_components(None, parser_name, writer_name)
272 pub.process_programmatic_settings(
273 settings_spec, settings_overrides, config_section)
274 pub.set_source(source, None)
275 pub.settings._nikola_source_path = source_path
276 pub.set_destination(None, destination_path)
277 pub.publish(enable_exit_status=enable_exit_status)
278
279 return pub.writer.parts['docinfo'] + pub.writer.parts['fragment'], pub.document.reporter.max_level, pub.settings.record_dependencies
280
281 # Alignment helpers for extensions
282 _align_options_base = ('left', 'center', 'right')
283
284
285 def _align_choice(argument):
286 return docutils.parsers.rst.directives.choice(argument, _align_options_base + ("none", ""))
287
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/compile/rest/__init__.py b/nikola/plugins/compile/rest/__init__.py
--- a/nikola/plugins/compile/rest/__init__.py
+++ b/nikola/plugins/compile/rest/__init__.py
@@ -37,6 +37,7 @@
import docutils.readers.standalone
import docutils.writers.html4css1
import docutils.parsers.rst.directives
+from docutils.parsers.rst import roles
from nikola.plugin_categories import PageCompiler
from nikola.utils import unicode_str, get_logger, makedirs, write_metadata, STDERR_HANDLER
@@ -193,6 +194,16 @@
return document
+def shortcode_role(name, rawtext, text, lineno, inliner,
+ options={}, content=[]):
+ """A shortcode role that passes through raw inline HTML."""
+ return [docutils.nodes.raw('', text, format='html')], []
+
+roles.register_canonical_role('raw-html', shortcode_role)
+roles.register_canonical_role('html', shortcode_role)
+roles.register_canonical_role('sc', shortcode_role)
+
+
def add_node(node, visit_function=None, depart_function=None):
"""Register a Docutils node class.
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/__init__.py b/nikola/plugins/compile/rest/__init__.py\n--- a/nikola/plugins/compile/rest/__init__.py\n+++ b/nikola/plugins/compile/rest/__init__.py\n@@ -37,6 +37,7 @@\n import docutils.readers.standalone\n import docutils.writers.html4css1\n import docutils.parsers.rst.directives\n+from docutils.parsers.rst import roles\n \n from nikola.plugin_categories import PageCompiler\n from nikola.utils import unicode_str, get_logger, makedirs, write_metadata, STDERR_HANDLER\n@@ -193,6 +194,16 @@\n return document\n \n \n+def shortcode_role(name, rawtext, text, lineno, inliner,\n+ options={}, content=[]):\n+ \"\"\"A shortcode role that passes through raw inline HTML.\"\"\"\n+ return [docutils.nodes.raw('', text, format='html')], []\n+\n+roles.register_canonical_role('raw-html', shortcode_role)\n+roles.register_canonical_role('html', shortcode_role)\n+roles.register_canonical_role('sc', shortcode_role)\n+\n+\n def add_node(node, visit_function=None, depart_function=None):\n \"\"\"Register a Docutils node class.\n", "issue": "Arbitrary rst substitutions\nSince we have transforms now, it should be easy to do something generic, like this:\n\n`|bzr-revno|` that would be replaced by the output of `bzr revno` using a configuration like\n\n``` py\ndef bzr_revno():\n return subprocess.check_output([\"bzr\", \"revno\"])\n\nRST_SUBSTITUTIONS = {\n 'bzr_revno': bzr_revno\n}\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2016 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"reStructuredText compiler for Nikola.\"\"\"\n\nfrom __future__ import unicode_literals\nimport io\nimport os\n\nimport docutils.core\nimport docutils.nodes\nimport docutils.utils\nimport docutils.io\nimport docutils.readers.standalone\nimport docutils.writers.html4css1\nimport docutils.parsers.rst.directives\n\nfrom nikola.plugin_categories import PageCompiler\nfrom nikola.utils import unicode_str, get_logger, makedirs, write_metadata, STDERR_HANDLER\nfrom nikola.shortcodes import apply_shortcodes\n\n\nclass CompileRest(PageCompiler):\n \"\"\"Compile reStructuredText into HTML.\"\"\"\n\n name = \"rest\"\n friendly_name = \"reStructuredText\"\n demote_headers = True\n logger = None\n\n def _read_extra_deps(self, post):\n \"\"\"Read contents of .dep file and returns them as a list.\"\"\"\n dep_path = post.base_path + '.dep'\n if os.path.isfile(dep_path):\n with io.open(dep_path, 'r+', encoding='utf8') as depf:\n deps = [l.strip() for l in depf.readlines()]\n return deps\n return []\n\n def register_extra_dependencies(self, post):\n \"\"\"Add dependency to post object to check .dep file.\"\"\"\n post.add_dependency(lambda: self._read_extra_deps(post), 'fragment')\n\n def compile_html_string(self, data, source_path=None, is_two_file=True):\n \"\"\"Compile reST into HTML strings.\"\"\"\n # If errors occur, this will be added to the line number reported by\n # docutils so the line number matches the actual line number (off by\n # 7 with default metadata, could be more or less depending on the post).\n add_ln = 0\n if not is_two_file:\n m_data, data = self.split_metadata(data)\n add_ln = len(m_data.splitlines()) + 1\n\n default_template_path = os.path.join(os.path.dirname(__file__), 'template.txt')\n output, error_level, deps = rst2html(\n data, settings_overrides={\n 'initial_header_level': 1,\n 'record_dependencies': True,\n 'stylesheet_path': None,\n 'link_stylesheet': True,\n 'syntax_highlight': 'short',\n 'math_output': 'mathjax',\n 'template': default_template_path,\n }, logger=self.logger, source_path=source_path, l_add_ln=add_ln, transforms=self.site.rst_transforms)\n if not isinstance(output, unicode_str):\n # To prevent some weird bugs here or there.\n # Original issue: empty files. `output` became a bytestring.\n output = output.decode('utf-8')\n return output, error_level, deps\n\n def compile_html(self, source, dest, is_two_file=True):\n \"\"\"Compile source file into HTML and save as dest.\"\"\"\n makedirs(os.path.dirname(dest))\n error_level = 100\n with io.open(dest, \"w+\", encoding=\"utf8\") as out_file:\n with io.open(source, \"r\", encoding=\"utf8\") as in_file:\n data = in_file.read()\n output, error_level, deps = self.compile_html_string(data, source, is_two_file)\n output = apply_shortcodes(output, self.site.shortcode_registry, self.site, source)\n out_file.write(output)\n deps_path = dest + '.dep'\n if deps.list:\n deps.list = [p for p in deps.list if p != dest] # Don't depend on yourself (#1671)\n with io.open(deps_path, \"w+\", encoding=\"utf8\") as deps_file:\n deps_file.write('\\n'.join(deps.list))\n else:\n if os.path.isfile(deps_path):\n os.unlink(deps_path)\n if error_level < 3:\n return True\n else:\n return False\n\n def create_post(self, path, **kw):\n \"\"\"Create a new post.\"\"\"\n content = kw.pop('content', None)\n onefile = kw.pop('onefile', False)\n # is_page is not used by create_post as of now.\n kw.pop('is_page', False)\n metadata = {}\n metadata.update(self.default_metadata)\n metadata.update(kw)\n makedirs(os.path.dirname(path))\n if not content.endswith('\\n'):\n content += '\\n'\n with io.open(path, \"w+\", encoding=\"utf8\") as fd:\n if onefile:\n fd.write(write_metadata(metadata))\n fd.write('\\n')\n fd.write(content)\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n super(CompileRest, self).set_site(site)\n self.config_dependencies = []\n for plugin_info in self.get_compiler_extensions():\n self.config_dependencies.append(plugin_info.name)\n plugin_info.plugin_object.short_help = plugin_info.description\n\n self.logger = get_logger('compile_rest', STDERR_HANDLER)\n if not site.debug:\n self.logger.level = 4\n\n\ndef get_observer(settings):\n \"\"\"Return an observer for the docutils Reporter.\"\"\"\n def observer(msg):\n \"\"\"Report docutils/rest messages to a Nikola user.\n\n Error code mapping:\n\n +------+---------+------+----------+\n | dNUM | dNAME | lNUM | lNAME | d = docutils, l = logbook\n +------+---------+------+----------+\n | 0 | DEBUG | 1 | DEBUG |\n | 1 | INFO | 2 | INFO |\n | 2 | WARNING | 4 | WARNING |\n | 3 | ERROR | 5 | ERROR |\n | 4 | SEVERE | 6 | CRITICAL |\n +------+---------+------+----------+\n \"\"\"\n errormap = {0: 1, 1: 2, 2: 4, 3: 5, 4: 6}\n text = docutils.nodes.Element.astext(msg)\n line = msg['line'] + settings['add_ln'] if 'line' in msg else 0\n out = '[{source}{colon}{line}] {text}'.format(\n source=settings['source'], colon=(':' if line else ''),\n line=line, text=text)\n settings['logger'].log(errormap[msg['level']], out)\n\n return observer\n\n\nclass NikolaReader(docutils.readers.standalone.Reader):\n \"\"\"Nikola-specific docutils reader.\"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Initialize the reader.\"\"\"\n self.transforms = kwargs.pop('transforms', [])\n docutils.readers.standalone.Reader.__init__(self, *args, **kwargs)\n\n def get_transforms(self):\n \"\"\"Get docutils transforms.\"\"\"\n return docutils.readers.standalone.Reader(self).get_transforms() + self.transforms\n\n def new_document(self):\n \"\"\"Create and return a new empty document tree (root node).\"\"\"\n document = docutils.utils.new_document(self.source.source_path, self.settings)\n document.reporter.stream = False\n document.reporter.attach_observer(get_observer(self.l_settings))\n return document\n\n\ndef add_node(node, visit_function=None, depart_function=None):\n \"\"\"Register a Docutils node class.\n\n This function is completely optional. It is a same concept as\n `Sphinx add_node function <http://sphinx-doc.org/extdev/appapi.html#sphinx.application.Sphinx.add_node>`_.\n\n For example::\n\n class Plugin(RestExtension):\n\n name = \"rest_math\"\n\n def set_site(self, site):\n self.site = site\n directives.register_directive('math', MathDirective)\n add_node(MathBlock, visit_Math, depart_Math)\n return super(Plugin, self).set_site(site)\n\n class MathDirective(Directive):\n def run(self):\n node = MathBlock()\n return [node]\n\n class Math(docutils.nodes.Element): pass\n\n def visit_Math(self, node):\n self.body.append(self.starttag(node, 'math'))\n\n def depart_Math(self, node):\n self.body.append('</math>')\n\n For full example, you can refer to `Microdata plugin <https://plugins.getnikola.com/#microdata>`_\n \"\"\"\n docutils.nodes._add_node_class_names([node.__name__])\n if visit_function:\n setattr(docutils.writers.html4css1.HTMLTranslator, 'visit_' + node.__name__, visit_function)\n if depart_function:\n setattr(docutils.writers.html4css1.HTMLTranslator, 'depart_' + node.__name__, depart_function)\n\n\ndef rst2html(source, source_path=None, source_class=docutils.io.StringInput,\n destination_path=None, reader=None,\n parser=None, parser_name='restructuredtext', writer=None,\n writer_name='html', settings=None, settings_spec=None,\n settings_overrides=None, config_section=None,\n enable_exit_status=None, logger=None, l_add_ln=0, transforms=None):\n \"\"\"Set up & run a ``Publisher``, and return a dictionary of document parts.\n\n Dictionary keys are the names of parts, and values are Unicode strings;\n encoding is up to the client. For programmatic use with string I/O.\n\n For encoded string input, be sure to set the 'input_encoding' setting to\n the desired encoding. Set it to 'unicode' for unencoded Unicode string\n input. Here's how::\n\n publish_parts(..., settings_overrides={'input_encoding': 'unicode'})\n\n Parameters: see `publish_programmatically`.\n\n WARNING: `reader` should be None (or NikolaReader()) if you want Nikola to report\n reStructuredText syntax errors.\n \"\"\"\n if reader is None:\n reader = NikolaReader(transforms=transforms)\n # For our custom logging, we have special needs and special settings we\n # specify here.\n # logger a logger from Nikola\n # source source filename (docutils gets a string)\n # add_ln amount of metadata lines (see comment in compile_html above)\n reader.l_settings = {'logger': logger, 'source': source_path,\n 'add_ln': l_add_ln}\n\n pub = docutils.core.Publisher(reader, parser, writer, settings=settings,\n source_class=source_class,\n destination_class=docutils.io.StringOutput)\n pub.set_components(None, parser_name, writer_name)\n pub.process_programmatic_settings(\n settings_spec, settings_overrides, config_section)\n pub.set_source(source, None)\n pub.settings._nikola_source_path = source_path\n pub.set_destination(None, destination_path)\n pub.publish(enable_exit_status=enable_exit_status)\n\n return pub.writer.parts['docinfo'] + pub.writer.parts['fragment'], pub.document.reporter.max_level, pub.settings.record_dependencies\n\n# Alignment helpers for extensions\n_align_options_base = ('left', 'center', 'right')\n\n\ndef _align_choice(argument):\n return docutils.parsers.rst.directives.choice(argument, _align_options_base + (\"none\", \"\"))\n", "path": "nikola/plugins/compile/rest/__init__.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2016 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"reStructuredText compiler for Nikola.\"\"\"\n\nfrom __future__ import unicode_literals\nimport io\nimport os\n\nimport docutils.core\nimport docutils.nodes\nimport docutils.utils\nimport docutils.io\nimport docutils.readers.standalone\nimport docutils.writers.html4css1\nimport docutils.parsers.rst.directives\nfrom docutils.parsers.rst import roles\n\nfrom nikola.plugin_categories import PageCompiler\nfrom nikola.utils import unicode_str, get_logger, makedirs, write_metadata, STDERR_HANDLER\nfrom nikola.shortcodes import apply_shortcodes\n\n\nclass CompileRest(PageCompiler):\n \"\"\"Compile reStructuredText into HTML.\"\"\"\n\n name = \"rest\"\n friendly_name = \"reStructuredText\"\n demote_headers = True\n logger = None\n\n def _read_extra_deps(self, post):\n \"\"\"Read contents of .dep file and returns them as a list.\"\"\"\n dep_path = post.base_path + '.dep'\n if os.path.isfile(dep_path):\n with io.open(dep_path, 'r+', encoding='utf8') as depf:\n deps = [l.strip() for l in depf.readlines()]\n return deps\n return []\n\n def register_extra_dependencies(self, post):\n \"\"\"Add dependency to post object to check .dep file.\"\"\"\n post.add_dependency(lambda: self._read_extra_deps(post), 'fragment')\n\n def compile_html_string(self, data, source_path=None, is_two_file=True):\n \"\"\"Compile reST into HTML strings.\"\"\"\n # If errors occur, this will be added to the line number reported by\n # docutils so the line number matches the actual line number (off by\n # 7 with default metadata, could be more or less depending on the post).\n add_ln = 0\n if not is_two_file:\n m_data, data = self.split_metadata(data)\n add_ln = len(m_data.splitlines()) + 1\n\n default_template_path = os.path.join(os.path.dirname(__file__), 'template.txt')\n output, error_level, deps = rst2html(\n data, settings_overrides={\n 'initial_header_level': 1,\n 'record_dependencies': True,\n 'stylesheet_path': None,\n 'link_stylesheet': True,\n 'syntax_highlight': 'short',\n 'math_output': 'mathjax',\n 'template': default_template_path,\n }, logger=self.logger, source_path=source_path, l_add_ln=add_ln, transforms=self.site.rst_transforms)\n if not isinstance(output, unicode_str):\n # To prevent some weird bugs here or there.\n # Original issue: empty files. `output` became a bytestring.\n output = output.decode('utf-8')\n return output, error_level, deps\n\n def compile_html(self, source, dest, is_two_file=True):\n \"\"\"Compile source file into HTML and save as dest.\"\"\"\n makedirs(os.path.dirname(dest))\n error_level = 100\n with io.open(dest, \"w+\", encoding=\"utf8\") as out_file:\n with io.open(source, \"r\", encoding=\"utf8\") as in_file:\n data = in_file.read()\n output, error_level, deps = self.compile_html_string(data, source, is_two_file)\n output = apply_shortcodes(output, self.site.shortcode_registry, self.site, source)\n out_file.write(output)\n deps_path = dest + '.dep'\n if deps.list:\n deps.list = [p for p in deps.list if p != dest] # Don't depend on yourself (#1671)\n with io.open(deps_path, \"w+\", encoding=\"utf8\") as deps_file:\n deps_file.write('\\n'.join(deps.list))\n else:\n if os.path.isfile(deps_path):\n os.unlink(deps_path)\n if error_level < 3:\n return True\n else:\n return False\n\n def create_post(self, path, **kw):\n \"\"\"Create a new post.\"\"\"\n content = kw.pop('content', None)\n onefile = kw.pop('onefile', False)\n # is_page is not used by create_post as of now.\n kw.pop('is_page', False)\n metadata = {}\n metadata.update(self.default_metadata)\n metadata.update(kw)\n makedirs(os.path.dirname(path))\n if not content.endswith('\\n'):\n content += '\\n'\n with io.open(path, \"w+\", encoding=\"utf8\") as fd:\n if onefile:\n fd.write(write_metadata(metadata))\n fd.write('\\n')\n fd.write(content)\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n super(CompileRest, self).set_site(site)\n self.config_dependencies = []\n for plugin_info in self.get_compiler_extensions():\n self.config_dependencies.append(plugin_info.name)\n plugin_info.plugin_object.short_help = plugin_info.description\n\n self.logger = get_logger('compile_rest', STDERR_HANDLER)\n if not site.debug:\n self.logger.level = 4\n\n\ndef get_observer(settings):\n \"\"\"Return an observer for the docutils Reporter.\"\"\"\n def observer(msg):\n \"\"\"Report docutils/rest messages to a Nikola user.\n\n Error code mapping:\n\n +------+---------+------+----------+\n | dNUM | dNAME | lNUM | lNAME | d = docutils, l = logbook\n +------+---------+------+----------+\n | 0 | DEBUG | 1 | DEBUG |\n | 1 | INFO | 2 | INFO |\n | 2 | WARNING | 4 | WARNING |\n | 3 | ERROR | 5 | ERROR |\n | 4 | SEVERE | 6 | CRITICAL |\n +------+---------+------+----------+\n \"\"\"\n errormap = {0: 1, 1: 2, 2: 4, 3: 5, 4: 6}\n text = docutils.nodes.Element.astext(msg)\n line = msg['line'] + settings['add_ln'] if 'line' in msg else 0\n out = '[{source}{colon}{line}] {text}'.format(\n source=settings['source'], colon=(':' if line else ''),\n line=line, text=text)\n settings['logger'].log(errormap[msg['level']], out)\n\n return observer\n\n\nclass NikolaReader(docutils.readers.standalone.Reader):\n \"\"\"Nikola-specific docutils reader.\"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Initialize the reader.\"\"\"\n self.transforms = kwargs.pop('transforms', [])\n docutils.readers.standalone.Reader.__init__(self, *args, **kwargs)\n\n def get_transforms(self):\n \"\"\"Get docutils transforms.\"\"\"\n return docutils.readers.standalone.Reader(self).get_transforms() + self.transforms\n\n def new_document(self):\n \"\"\"Create and return a new empty document tree (root node).\"\"\"\n document = docutils.utils.new_document(self.source.source_path, self.settings)\n document.reporter.stream = False\n document.reporter.attach_observer(get_observer(self.l_settings))\n return document\n\n\ndef shortcode_role(name, rawtext, text, lineno, inliner,\n options={}, content=[]):\n \"\"\"A shortcode role that passes through raw inline HTML.\"\"\"\n return [docutils.nodes.raw('', text, format='html')], []\n\nroles.register_canonical_role('raw-html', shortcode_role)\nroles.register_canonical_role('html', shortcode_role)\nroles.register_canonical_role('sc', shortcode_role)\n\n\ndef add_node(node, visit_function=None, depart_function=None):\n \"\"\"Register a Docutils node class.\n\n This function is completely optional. It is a same concept as\n `Sphinx add_node function <http://sphinx-doc.org/extdev/appapi.html#sphinx.application.Sphinx.add_node>`_.\n\n For example::\n\n class Plugin(RestExtension):\n\n name = \"rest_math\"\n\n def set_site(self, site):\n self.site = site\n directives.register_directive('math', MathDirective)\n add_node(MathBlock, visit_Math, depart_Math)\n return super(Plugin, self).set_site(site)\n\n class MathDirective(Directive):\n def run(self):\n node = MathBlock()\n return [node]\n\n class Math(docutils.nodes.Element): pass\n\n def visit_Math(self, node):\n self.body.append(self.starttag(node, 'math'))\n\n def depart_Math(self, node):\n self.body.append('</math>')\n\n For full example, you can refer to `Microdata plugin <https://plugins.getnikola.com/#microdata>`_\n \"\"\"\n docutils.nodes._add_node_class_names([node.__name__])\n if visit_function:\n setattr(docutils.writers.html4css1.HTMLTranslator, 'visit_' + node.__name__, visit_function)\n if depart_function:\n setattr(docutils.writers.html4css1.HTMLTranslator, 'depart_' + node.__name__, depart_function)\n\n\ndef rst2html(source, source_path=None, source_class=docutils.io.StringInput,\n destination_path=None, reader=None,\n parser=None, parser_name='restructuredtext', writer=None,\n writer_name='html', settings=None, settings_spec=None,\n settings_overrides=None, config_section=None,\n enable_exit_status=None, logger=None, l_add_ln=0, transforms=None):\n \"\"\"Set up & run a ``Publisher``, and return a dictionary of document parts.\n\n Dictionary keys are the names of parts, and values are Unicode strings;\n encoding is up to the client. For programmatic use with string I/O.\n\n For encoded string input, be sure to set the 'input_encoding' setting to\n the desired encoding. Set it to 'unicode' for unencoded Unicode string\n input. Here's how::\n\n publish_parts(..., settings_overrides={'input_encoding': 'unicode'})\n\n Parameters: see `publish_programmatically`.\n\n WARNING: `reader` should be None (or NikolaReader()) if you want Nikola to report\n reStructuredText syntax errors.\n \"\"\"\n if reader is None:\n reader = NikolaReader(transforms=transforms)\n # For our custom logging, we have special needs and special settings we\n # specify here.\n # logger a logger from Nikola\n # source source filename (docutils gets a string)\n # add_ln amount of metadata lines (see comment in compile_html above)\n reader.l_settings = {'logger': logger, 'source': source_path,\n 'add_ln': l_add_ln}\n\n pub = docutils.core.Publisher(reader, parser, writer, settings=settings,\n source_class=source_class,\n destination_class=docutils.io.StringOutput)\n pub.set_components(None, parser_name, writer_name)\n pub.process_programmatic_settings(\n settings_spec, settings_overrides, config_section)\n pub.set_source(source, None)\n pub.settings._nikola_source_path = source_path\n pub.set_destination(None, destination_path)\n pub.publish(enable_exit_status=enable_exit_status)\n\n return pub.writer.parts['docinfo'] + pub.writer.parts['fragment'], pub.document.reporter.max_level, pub.settings.record_dependencies\n\n# Alignment helpers for extensions\n_align_options_base = ('left', 'center', 'right')\n\n\ndef _align_choice(argument):\n return docutils.parsers.rst.directives.choice(argument, _align_options_base + (\"none\", \"\"))\n", "path": "nikola/plugins/compile/rest/__init__.py"}]}
| 3,739 | 269 |
gh_patches_debug_4834
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-724
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Broken UTs on `main` branch
### Describe the bug
Seeing failures in these 2 UTs on main branch
```
Run pipenv run coverage run -m pytest --cov=./src --cov-report=xml
F....................................................................... [ 25%]
........................................................................ [ 50%]
........................................................................ [ 76%]
.................................................................... [100%]
=================================== FAILURES ===================================
__________________________ TestRunAssemble.test_main ___________________________
self = <tests.test_run_assemble.TestRunAssemble testMethod=test_main>
mock_copy = <MagicMock name='copy2' id='140398777086032'>
mock_temp = <MagicMock name='TemporaryDirectory' id='140398777095120'>
mock_recorder = <MagicMock name='BundleRecorder' id='140398777104272'>
mock_bundles = <MagicMock name='Bundles' id='140398777121680'>
mocks = (<MagicMock name='getcwd' id='140398777147472'>, <MagicMock name='makedirs' id='140398777161040'>, <MagicMock name='chdir' id='140398777178384'>)
mock_bundle = <MagicMock name='Bundles.create()' id='140398776678672'>
@patch("os.chdir")
@patch("os.makedirs")
@patch("os.getcwd", return_value="curdir")
@patch("argparse._sys.argv", ["run_assemble.py", BUILD_MANIFEST])
@patch("run_assemble.Bundles", return_value=MagicMock())
@patch("run_assemble.BundleRecorder", return_value=MagicMock())
@patch("tempfile.TemporaryDirectory")
@patch("shutil.copy2")
def test_main(self, mock_copy, mock_temp, mock_recorder, mock_bundles, *mocks):
mock_temp.return_value.__enter__.return_value = tempfile.gettempdir()
mock_bundle = MagicMock(archive_path="path")
mock_bundles.create.return_value = mock_bundle
> main()
tests/test_run_assemble.py:47:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
src/run_assemble.py:48: in main
exit(1)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = Use exit() or Ctrl-D (i.e. EOF) to exit, code = 1
def __call__(self, code=None):
# Shells like IDLE catch the SystemExit, but listen when their
# stdin wrapper is closed.
try:
sys.stdin.close()
except:
pass
> raise SystemExit(code)
E SystemExit: 1
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/_sitebuiltins.py:26: SystemExit
------------------------------ Captured log call -------------------------------
ERROR root:run_assemble.py:46 No installation script found at path: /home/runner/work/opensearch-build/opensearch-build/release/tar/linux/opensearch-tar-install.sh
---------- coverage: platform linux, python 3.7.12-final-0 -----------
Coverage XML written to file coverage.xml
=========================== short test summary info ============================
FAILED tests/test_run_assemble.py::TestRunAssemble::test_main - SystemExit: 1
1 failed, 283 passed in 31.93s
Error: Process completed with exit code 1.
```
### To reproduce
Run ut coverage analysis on repo `opensearch-build`, branch `main`
```
pipenv run coverage run -m pytest --cov=./src --cov-report=xml
```
### Expected behavior
No UT failures
### Screenshots
If applicable, add screenshots to help explain your problem.
### Host / Environment
_No response_
### Additional context
_No response_
### Relevant log output
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/run_assemble.py`
Content:
```
1 #!/usr/bin/env python
2
3 # SPDX-License-Identifier: Apache-2.0
4 #
5 # The OpenSearch Contributors require contributions made to
6 # this file be licensed under the Apache-2.0 license or a
7 # compatible open source license.
8
9 import argparse
10 import logging
11 import os
12 import shutil
13 import sys
14 import tempfile
15
16 from assemble_workflow.bundle_recorder import BundleRecorder
17 from assemble_workflow.bundles import Bundles
18 from manifests.build_manifest import BuildManifest
19 from system import console
20
21
22 def main():
23 parser = argparse.ArgumentParser(description="Assemble an OpenSearch Bundle")
24 parser.add_argument("manifest", type=argparse.FileType("r"), help="Manifest file.")
25 parser.add_argument(
26 "-v",
27 "--verbose",
28 help="Show more verbose output.",
29 action="store_const",
30 default=logging.INFO,
31 const=logging.DEBUG,
32 dest="logging_level",
33 )
34 args = parser.parse_args()
35
36 console.configure(level=args.logging_level)
37
38 tarball_installation_script = os.path.realpath(
39 os.path.join(
40 os.path.dirname(os.path.abspath(__file__)),
41 "../release/tar/linux/opensearch-tar-install.sh",
42 )
43 )
44 if not os.path.isfile(tarball_installation_script):
45 logging.error(
46 f"No installation script found at path: {tarball_installation_script}"
47 )
48 exit(1)
49
50 build_manifest = BuildManifest.from_file(args.manifest)
51 build = build_manifest.build
52 artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))
53 output_dir = os.path.join(os.getcwd(), "bundle")
54 os.makedirs(output_dir, exist_ok=True)
55
56 with tempfile.TemporaryDirectory() as work_dir:
57 logging.info(
58 f"Bundling {build.name} ({build.architecture}) into {output_dir} ..."
59 )
60
61 os.chdir(work_dir)
62
63 bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)
64
65 bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)
66
67 bundle.install_plugins()
68 logging.info(f"Installed plugins: {bundle.installed_plugins}")
69
70 # Copy the tar installation script into the bundle
71 shutil.copy2(
72 tarball_installation_script,
73 os.path.join(
74 bundle.archive_path, os.path.basename(tarball_installation_script)
75 ),
76 )
77
78 # Save a copy of the manifest inside of the tar
79 bundle_recorder.write_manifest(bundle.archive_path)
80 bundle.build_tar(output_dir)
81
82 bundle_recorder.write_manifest(output_dir)
83
84 logging.info("Done.")
85
86
87 if __name__ == "__main__":
88 sys.exit(main())
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/run_assemble.py b/src/run_assemble.py
--- a/src/run_assemble.py
+++ b/src/run_assemble.py
@@ -38,7 +38,7 @@
tarball_installation_script = os.path.realpath(
os.path.join(
os.path.dirname(os.path.abspath(__file__)),
- "../release/tar/linux/opensearch-tar-install.sh",
+ "../scripts/legacy/tar/linux/opensearch-tar-install.sh",
)
)
if not os.path.isfile(tarball_installation_script):
|
{"golden_diff": "diff --git a/src/run_assemble.py b/src/run_assemble.py\n--- a/src/run_assemble.py\n+++ b/src/run_assemble.py\n@@ -38,7 +38,7 @@\n tarball_installation_script = os.path.realpath(\n os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n- \"../release/tar/linux/opensearch-tar-install.sh\",\n+ \"../scripts/legacy/tar/linux/opensearch-tar-install.sh\",\n )\n )\n if not os.path.isfile(tarball_installation_script):\n", "issue": "[Bug]: Broken UTs on `main` branch\n### Describe the bug\r\n\r\nSeeing failures in these 2 UTs on main branch \r\n\r\n```\r\nRun pipenv run coverage run -m pytest --cov=./src --cov-report=xml\r\nF....................................................................... [ 25%]\r\n........................................................................ [ 50%]\r\n........................................................................ [ 76%]\r\n.................................................................... [100%]\r\n=================================== FAILURES ===================================\r\n__________________________ TestRunAssemble.test_main ___________________________\r\n\r\nself = <tests.test_run_assemble.TestRunAssemble testMethod=test_main>\r\nmock_copy = <MagicMock name='copy2' id='140398777086032'>\r\nmock_temp = <MagicMock name='TemporaryDirectory' id='140398777095120'>\r\nmock_recorder = <MagicMock name='BundleRecorder' id='140398777104272'>\r\nmock_bundles = <MagicMock name='Bundles' id='140398777121680'>\r\nmocks = (<MagicMock name='getcwd' id='140398777147472'>, <MagicMock name='makedirs' id='140398777161040'>, <MagicMock name='chdir' id='140398777178384'>)\r\nmock_bundle = <MagicMock name='Bundles.create()' id='140398776678672'>\r\n\r\n @patch(\"os.chdir\")\r\n @patch(\"os.makedirs\")\r\n @patch(\"os.getcwd\", return_value=\"curdir\")\r\n @patch(\"argparse._sys.argv\", [\"run_assemble.py\", BUILD_MANIFEST])\r\n @patch(\"run_assemble.Bundles\", return_value=MagicMock())\r\n @patch(\"run_assemble.BundleRecorder\", return_value=MagicMock())\r\n @patch(\"tempfile.TemporaryDirectory\")\r\n @patch(\"shutil.copy2\")\r\n def test_main(self, mock_copy, mock_temp, mock_recorder, mock_bundles, *mocks):\r\n mock_temp.return_value.__enter__.return_value = tempfile.gettempdir()\r\n mock_bundle = MagicMock(archive_path=\"path\")\r\n mock_bundles.create.return_value = mock_bundle\r\n \r\n> main()\r\n\r\ntests/test_run_assemble.py:47: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\nsrc/run_assemble.py:48: in main\r\n exit(1)\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n\r\nself = Use exit() or Ctrl-D (i.e. EOF) to exit, code = 1\r\n\r\n def __call__(self, code=None):\r\n # Shells like IDLE catch the SystemExit, but listen when their\r\n # stdin wrapper is closed.\r\n try:\r\n sys.stdin.close()\r\n except:\r\n pass\r\n> raise SystemExit(code)\r\nE SystemExit: 1\r\n\r\n/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/_sitebuiltins.py:26: SystemExit\r\n------------------------------ Captured log call -------------------------------\r\nERROR root:run_assemble.py:46 No installation script found at path: /home/runner/work/opensearch-build/opensearch-build/release/tar/linux/opensearch-tar-install.sh\r\n\r\n---------- coverage: platform linux, python 3.7.12-final-0 -----------\r\nCoverage XML written to file coverage.xml\r\n\r\n=========================== short test summary info ============================\r\nFAILED tests/test_run_assemble.py::TestRunAssemble::test_main - SystemExit: 1\r\n1 failed, 283 passed in 31.93s\r\nError: Process completed with exit code 1.\r\n```\r\n\r\n### To reproduce\r\n\r\nRun ut coverage analysis on repo `opensearch-build`, branch `main`\r\n\r\n```\r\npipenv run coverage run -m pytest --cov=./src --cov-report=xml\r\n```\r\n\r\n### Expected behavior\r\n\r\nNo UT failures\r\n\r\n### Screenshots\r\n\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n### Host / Environment\r\n\r\n_No response_\r\n\r\n### Additional context\r\n\r\n_No response_\r\n\r\n### Relevant log output\r\n\r\n_No response_\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport argparse\nimport logging\nimport os\nimport shutil\nimport sys\nimport tempfile\n\nfrom assemble_workflow.bundle_recorder import BundleRecorder\nfrom assemble_workflow.bundles import Bundles\nfrom manifests.build_manifest import BuildManifest\nfrom system import console\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Assemble an OpenSearch Bundle\")\n parser.add_argument(\"manifest\", type=argparse.FileType(\"r\"), help=\"Manifest file.\")\n parser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"Show more verbose output.\",\n action=\"store_const\",\n default=logging.INFO,\n const=logging.DEBUG,\n dest=\"logging_level\",\n )\n args = parser.parse_args()\n\n console.configure(level=args.logging_level)\n\n tarball_installation_script = os.path.realpath(\n os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n \"../release/tar/linux/opensearch-tar-install.sh\",\n )\n )\n if not os.path.isfile(tarball_installation_script):\n logging.error(\n f\"No installation script found at path: {tarball_installation_script}\"\n )\n exit(1)\n\n build_manifest = BuildManifest.from_file(args.manifest)\n build = build_manifest.build\n artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))\n output_dir = os.path.join(os.getcwd(), \"bundle\")\n os.makedirs(output_dir, exist_ok=True)\n\n with tempfile.TemporaryDirectory() as work_dir:\n logging.info(\n f\"Bundling {build.name} ({build.architecture}) into {output_dir} ...\"\n )\n\n os.chdir(work_dir)\n\n bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)\n\n bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)\n\n bundle.install_plugins()\n logging.info(f\"Installed plugins: {bundle.installed_plugins}\")\n\n # Copy the tar installation script into the bundle\n shutil.copy2(\n tarball_installation_script,\n os.path.join(\n bundle.archive_path, os.path.basename(tarball_installation_script)\n ),\n )\n\n # Save a copy of the manifest inside of the tar\n bundle_recorder.write_manifest(bundle.archive_path)\n bundle.build_tar(output_dir)\n\n bundle_recorder.write_manifest(output_dir)\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_assemble.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport argparse\nimport logging\nimport os\nimport shutil\nimport sys\nimport tempfile\n\nfrom assemble_workflow.bundle_recorder import BundleRecorder\nfrom assemble_workflow.bundles import Bundles\nfrom manifests.build_manifest import BuildManifest\nfrom system import console\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Assemble an OpenSearch Bundle\")\n parser.add_argument(\"manifest\", type=argparse.FileType(\"r\"), help=\"Manifest file.\")\n parser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"Show more verbose output.\",\n action=\"store_const\",\n default=logging.INFO,\n const=logging.DEBUG,\n dest=\"logging_level\",\n )\n args = parser.parse_args()\n\n console.configure(level=args.logging_level)\n\n tarball_installation_script = os.path.realpath(\n os.path.join(\n os.path.dirname(os.path.abspath(__file__)),\n \"../scripts/legacy/tar/linux/opensearch-tar-install.sh\",\n )\n )\n if not os.path.isfile(tarball_installation_script):\n logging.error(\n f\"No installation script found at path: {tarball_installation_script}\"\n )\n exit(1)\n\n build_manifest = BuildManifest.from_file(args.manifest)\n build = build_manifest.build\n artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))\n output_dir = os.path.join(os.getcwd(), \"bundle\")\n os.makedirs(output_dir, exist_ok=True)\n\n with tempfile.TemporaryDirectory() as work_dir:\n logging.info(\n f\"Bundling {build.name} ({build.architecture}) into {output_dir} ...\"\n )\n\n os.chdir(work_dir)\n\n bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)\n\n bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)\n\n bundle.install_plugins()\n logging.info(f\"Installed plugins: {bundle.installed_plugins}\")\n\n # Copy the tar installation script into the bundle\n shutil.copy2(\n tarball_installation_script,\n os.path.join(\n bundle.archive_path, os.path.basename(tarball_installation_script)\n ),\n )\n\n # Save a copy of the manifest inside of the tar\n bundle_recorder.write_manifest(bundle.archive_path)\n bundle.build_tar(output_dir)\n\n bundle_recorder.write_manifest(output_dir)\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_assemble.py"}]}
| 1,960 | 120 |
gh_patches_debug_13605
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-958
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a log statement to masher when reusing cached updateinfo, and change generating statement to info
Basically, in https://github.com/fedora-infra/bodhi/blob/2.2.0/bodhi/server/metadata.py#L79-L81 change
```
self._load_cached_updateinfo()
else:
log.debug("Generating new updateinfo.xml")
```
to
```
log.info('Restoring cached updateinfo.xml')
self._load_cached_updateinfo()
else:
log.info("Generating new updateinfo.xml")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bodhi/server/metadata.py`
Content:
```
1 # This program is free software; you can redistribute it and/or modify
2 # it under the terms of the GNU General Public License as published by
3 # the Free Software Foundation; either version 2 of the License, or
4 # (at your option) any later version.
5 #
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10 #
11 # You should have received a copy of the GNU General Public License along
12 # with this program; if not, write to the Free Software Foundation, Inc.,
13 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
14
15 __version__ = '2.0'
16
17 import os
18 import logging
19 import shutil
20 import tempfile
21
22 from urlgrabber.grabber import urlgrab
23 from kitchen.text.converters import to_bytes
24
25 import createrepo_c as cr
26
27 from bodhi.server.config import config
28 from bodhi.server.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion
29 from bodhi.server.buildsys import get_session
30
31 log = logging.getLogger(__name__)
32
33
34 class ExtendedMetadata(object):
35 """This class represents the updateinfo.xml yum metadata.
36
37 It is generated during push time by the bodhi masher based on koji tags
38 and is injected into the yum repodata using the `modifyrepo_c` tool,
39 which is included in the `createrepo_c` package.
40
41 """
42 def __init__(self, release, request, db, path):
43 self.repo = path
44 log.debug('repo = %r' % self.repo)
45 self.request = request
46 if request is UpdateRequest.stable:
47 self.tag = release.stable_tag
48 else:
49 self.tag = release.testing_tag
50 self.repo_path = os.path.join(self.repo, self.tag)
51
52 self.db = db
53 self.updates = set()
54 self.builds = {}
55 self.missing_ids = []
56 self._from = config.get('bodhi_email')
57 self.koji = get_session()
58 self._fetch_updates()
59
60 self.uinfo = cr.UpdateInfo()
61
62 self.hash_type = cr.SHA256
63 self.comp_type = cr.XZ
64
65 if release.id_prefix == u'FEDORA-EPEL':
66 # yum on py2.4 doesn't support sha256 (#1080373)
67 if 'el5' in self.repo or '5E' in self.repo:
68 self.hash_type = cr.SHA1
69 self.comp_type = cr.GZ
70 else:
71 # FIXME: I'm not sure which versions of RHEL support xz metadata
72 # compression, so use the lowest common denominator for now.
73 self.comp_type = cr.BZ2
74
75 # Load from the cache if it exists
76 self.cached_repodata = os.path.join(self.repo, '..', self.tag +
77 '.repocache', 'repodata/')
78 if os.path.isdir(self.cached_repodata):
79 self._load_cached_updateinfo()
80 else:
81 log.debug("Generating new updateinfo.xml")
82 self.uinfo = cr.UpdateInfo()
83 for update in self.updates:
84 if update.alias:
85 self.add_update(update)
86 else:
87 self.missing_ids.append(update.title)
88
89 if self.missing_ids:
90 log.error("%d updates with missing ID: %r" % (
91 len(self.missing_ids), self.missing_ids))
92
93 def _load_cached_updateinfo(self):
94 """
95 Load the cached updateinfo.xml from '../{tag}.repocache/repodata'
96 """
97 seen_ids = set()
98 from_cache = set()
99 existing_ids = set()
100
101 # Parse the updateinfo out of the repomd
102 updateinfo = None
103 repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')
104 repomd = cr.Repomd()
105 cr.xml_parse_repomd(repomd_xml, repomd)
106 for record in repomd.records:
107 if record.type == 'updateinfo':
108 updateinfo = os.path.join(os.path.dirname(
109 os.path.dirname(self.cached_repodata)),
110 record.location_href)
111 break
112
113 assert updateinfo, 'Unable to find updateinfo'
114
115 # Load the metadata with createrepo_c
116 log.info('Loading cached updateinfo: %s', updateinfo)
117 uinfo = cr.UpdateInfo(updateinfo)
118
119 # Determine which updates are present in the cache
120 for update in uinfo.updates:
121 existing_ids.add(update.id)
122
123 # Generate metadata for any new builds
124 for update in self.updates:
125 seen_ids.add(update.alias)
126 if not update.alias:
127 self.missing_ids.append(update.title)
128 continue
129 if update.alias in existing_ids:
130 notice = None
131 for value in uinfo.updates:
132 if value.title == update.title:
133 notice = value
134 break
135 if not notice:
136 log.warn('%s ID in cache but notice cannot be found', update.title)
137 self.add_update(update)
138 continue
139 if notice.updated_date:
140 if notice.updated_date < update.date_modified:
141 log.debug('Update modified, generating new notice: %s' % update.title)
142 self.add_update(update)
143 else:
144 log.debug('Loading updated %s from cache' % update.title)
145 from_cache.add(update.alias)
146 elif update.date_modified:
147 log.debug('Update modified, generating new notice: %s' % update.title)
148 self.add_update(update)
149 else:
150 log.debug('Loading %s from cache' % update.title)
151 from_cache.add(update.alias)
152 else:
153 log.debug('Adding new update notice: %s' % update.title)
154 self.add_update(update)
155
156 # Add all relevant notices from the cache to this document
157 for notice in uinfo.updates:
158 if notice.id in from_cache:
159 log.debug('Keeping existing notice: %s', notice.title)
160 self.uinfo.append(notice)
161 else:
162 # Keep all security notices in the stable repo
163 if self.request is not UpdateRequest.testing:
164 if notice.type == 'security':
165 if notice.id not in seen_ids:
166 log.debug('Keeping existing security notice: %s',
167 notice.title)
168 self.uinfo.append(notice)
169 else:
170 log.debug('%s already added?', notice.title)
171 else:
172 log.debug('Purging cached stable notice %s', notice.title)
173 else:
174 log.debug('Purging cached testing update %s', notice.title)
175
176 def _fetch_updates(self):
177 """Based on our given koji tag, populate a list of Update objects"""
178 log.debug("Fetching builds tagged with '%s'" % self.tag)
179 kojiBuilds = self.koji.listTagged(self.tag, latest=True)
180 nonexistent = []
181 log.debug("%d builds found" % len(kojiBuilds))
182 for build in kojiBuilds:
183 self.builds[build['nvr']] = build
184 build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()
185 if build_obj:
186 if build_obj.update:
187 self.updates.add(build_obj.update)
188 else:
189 log.warn('%s does not have a corresponding update' % build['nvr'])
190 else:
191 nonexistent.append(build['nvr'])
192 if nonexistent:
193 log.warning("Couldn't find the following koji builds tagged as "
194 "%s in bodhi: %s" % (self.tag, nonexistent))
195
196 def add_update(self, update):
197 """Generate the extended metadata for a given update"""
198 rec = cr.UpdateRecord()
199 rec.version = __version__
200 rec.fromstr = config.get('bodhi_email')
201 rec.status = update.status.value
202 rec.type = update.type.value
203 rec.id = to_bytes(update.alias)
204 rec.title = to_bytes(update.title)
205 rec.summary = to_bytes('%s %s update' % (update.get_title(),
206 update.type.value))
207 rec.description = to_bytes(update.notes)
208 rec.release = to_bytes(update.release.long_name)
209 rec.rights = config.get('updateinfo_rights')
210
211 if update.date_pushed:
212 rec.issued_date = update.date_pushed
213 if update.date_modified:
214 rec.updated_date = update.date_modified
215
216 col = cr.UpdateCollection()
217 col.name = to_bytes(update.release.long_name)
218 col.shortname = to_bytes(update.release.name)
219
220 for build in update.builds:
221 try:
222 kojiBuild = self.builds[build.nvr]
223 except:
224 kojiBuild = self.koji.getBuild(build.nvr)
225
226 rpms = self.koji.listBuildRPMs(kojiBuild['id'])
227 for rpm in rpms:
228 pkg = cr.UpdateCollectionPackage()
229 pkg.name = rpm['name']
230 pkg.version = rpm['version']
231 pkg.release = rpm['release']
232 if rpm['epoch'] is not None:
233 pkg.epoch = str(rpm['epoch'])
234 else:
235 pkg.epoch = '0'
236 pkg.arch = rpm['arch']
237
238 # TODO: how do we handle UpdateSuggestion.logout, etc?
239 pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot
240
241 filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])
242 pkg.filename = filename
243
244 # Build the URL
245 if rpm['arch'] == 'src':
246 arch = 'SRPMS'
247 elif rpm['arch'] in ('noarch', 'i686'):
248 arch = 'i386'
249 else:
250 arch = rpm['arch']
251
252 pkg.src = os.path.join(config.get('file_url'), update.status is
253 UpdateStatus.testing and 'testing' or '',
254 str(update.release.version), arch, filename[0], filename)
255
256 col.append(pkg)
257
258 rec.append_collection(col)
259
260 # Create references for each bug
261 for bug in update.bugs:
262 ref = cr.UpdateReference()
263 ref.type = 'bugzilla'
264 ref.id = to_bytes(bug.bug_id)
265 ref.href = to_bytes(bug.url)
266 ref.title = to_bytes(bug.title)
267 rec.append_reference(ref)
268
269 # Create references for each CVE
270 for cve in update.cves:
271 ref = cr.UpdateReference()
272 ref.type = 'cve'
273 ref.id = to_bytes(cve.cve_id)
274 ref.href = to_bytes(cve.url)
275 rec.append_reference(ref)
276
277 self.uinfo.append(rec)
278
279 def insert_updateinfo(self):
280 fd, name = tempfile.mkstemp()
281 os.write(fd, self.uinfo.xml_dump())
282 os.close(fd)
283 self.modifyrepo(name)
284 os.unlink(name)
285
286 def modifyrepo(self, filename):
287 """Inject a file into the repodata for each architecture"""
288 for arch in os.listdir(self.repo_path):
289 repodata = os.path.join(self.repo_path, arch, 'repodata')
290 log.info('Inserting %s into %s', filename, repodata)
291 uinfo_xml = os.path.join(repodata, 'updateinfo.xml')
292 shutil.copyfile(filename, uinfo_xml)
293 repomd_xml = os.path.join(repodata, 'repomd.xml')
294 repomd = cr.Repomd(repomd_xml)
295 uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)
296 uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)
297 uinfo_rec_comp.rename_file()
298 uinfo_rec_comp.type = 'updateinfo'
299 repomd.set_record(uinfo_rec_comp)
300 with file(repomd_xml, 'w') as repomd_file:
301 repomd_file.write(repomd.xml_dump())
302 os.unlink(uinfo_xml)
303
304 def insert_pkgtags(self):
305 """Download and inject the pkgtags sqlite from fedora-tagger"""
306 if config.get('pkgtags_url'):
307 try:
308 tags_url = config.get('pkgtags_url')
309 tempdir = tempfile.mkdtemp('bodhi')
310 local_tags = os.path.join(tempdir, 'pkgtags.sqlite')
311 log.info('Downloading %s' % tags_url)
312 urlgrab(tags_url, filename=local_tags)
313 self.modifyrepo(local_tags)
314 except:
315 log.exception("There was a problem injecting pkgtags")
316 finally:
317 shutil.rmtree(tempdir)
318
319 def cache_repodata(self):
320 arch = os.listdir(self.repo_path)[0] # Take the first arch
321 repodata = os.path.join(self.repo_path, arch, 'repodata')
322 if not os.path.isdir(repodata):
323 log.warning('Cannot find repodata to cache: %s' % repodata)
324 return
325 cache = self.cached_repodata
326 if os.path.isdir(cache):
327 shutil.rmtree(cache)
328 shutil.copytree(repodata, cache)
329 log.info('%s cached to %s' % (repodata, cache))
330
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bodhi/server/metadata.py b/bodhi/server/metadata.py
--- a/bodhi/server/metadata.py
+++ b/bodhi/server/metadata.py
@@ -76,9 +76,10 @@
self.cached_repodata = os.path.join(self.repo, '..', self.tag +
'.repocache', 'repodata/')
if os.path.isdir(self.cached_repodata):
+ log.info('Loading cached updateinfo.xml')
self._load_cached_updateinfo()
else:
- log.debug("Generating new updateinfo.xml")
+ log.info("Generating new updateinfo.xml")
self.uinfo = cr.UpdateInfo()
for update in self.updates:
if update.alias:
|
{"golden_diff": "diff --git a/bodhi/server/metadata.py b/bodhi/server/metadata.py\n--- a/bodhi/server/metadata.py\n+++ b/bodhi/server/metadata.py\n@@ -76,9 +76,10 @@\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n '.repocache', 'repodata/')\n if os.path.isdir(self.cached_repodata):\n+ log.info('Loading cached updateinfo.xml')\n self._load_cached_updateinfo()\n else:\n- log.debug(\"Generating new updateinfo.xml\")\n+ log.info(\"Generating new updateinfo.xml\")\n self.uinfo = cr.UpdateInfo()\n for update in self.updates:\n if update.alias:\n", "issue": "Add a log statement to masher when reusing cached updateinfo, and change generating statement to info\nBasically, in https://github.com/fedora-infra/bodhi/blob/2.2.0/bodhi/server/metadata.py#L79-L81 change\n\n```\n self._load_cached_updateinfo()\nelse:\n log.debug(\"Generating new updateinfo.xml\")\n```\n\nto\n\n```\n log.info('Restoring cached updateinfo.xml')\n self._load_cached_updateinfo()\nelse:\n log.info(\"Generating new updateinfo.xml\")\n```\n\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n__version__ = '2.0'\n\nimport os\nimport logging\nimport shutil\nimport tempfile\n\nfrom urlgrabber.grabber import urlgrab\nfrom kitchen.text.converters import to_bytes\n\nimport createrepo_c as cr\n\nfrom bodhi.server.config import config\nfrom bodhi.server.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion\nfrom bodhi.server.buildsys import get_session\n\nlog = logging.getLogger(__name__)\n\n\nclass ExtendedMetadata(object):\n \"\"\"This class represents the updateinfo.xml yum metadata.\n\n It is generated during push time by the bodhi masher based on koji tags\n and is injected into the yum repodata using the `modifyrepo_c` tool,\n which is included in the `createrepo_c` package.\n\n \"\"\"\n def __init__(self, release, request, db, path):\n self.repo = path\n log.debug('repo = %r' % self.repo)\n self.request = request\n if request is UpdateRequest.stable:\n self.tag = release.stable_tag\n else:\n self.tag = release.testing_tag\n self.repo_path = os.path.join(self.repo, self.tag)\n\n self.db = db\n self.updates = set()\n self.builds = {}\n self.missing_ids = []\n self._from = config.get('bodhi_email')\n self.koji = get_session()\n self._fetch_updates()\n\n self.uinfo = cr.UpdateInfo()\n\n self.hash_type = cr.SHA256\n self.comp_type = cr.XZ\n\n if release.id_prefix == u'FEDORA-EPEL':\n # yum on py2.4 doesn't support sha256 (#1080373)\n if 'el5' in self.repo or '5E' in self.repo:\n self.hash_type = cr.SHA1\n self.comp_type = cr.GZ\n else:\n # FIXME: I'm not sure which versions of RHEL support xz metadata\n # compression, so use the lowest common denominator for now.\n self.comp_type = cr.BZ2\n\n # Load from the cache if it exists\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n '.repocache', 'repodata/')\n if os.path.isdir(self.cached_repodata):\n self._load_cached_updateinfo()\n else:\n log.debug(\"Generating new updateinfo.xml\")\n self.uinfo = cr.UpdateInfo()\n for update in self.updates:\n if update.alias:\n self.add_update(update)\n else:\n self.missing_ids.append(update.title)\n\n if self.missing_ids:\n log.error(\"%d updates with missing ID: %r\" % (\n len(self.missing_ids), self.missing_ids))\n\n def _load_cached_updateinfo(self):\n \"\"\"\n Load the cached updateinfo.xml from '../{tag}.repocache/repodata'\n \"\"\"\n seen_ids = set()\n from_cache = set()\n existing_ids = set()\n\n # Parse the updateinfo out of the repomd\n updateinfo = None\n repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')\n repomd = cr.Repomd()\n cr.xml_parse_repomd(repomd_xml, repomd)\n for record in repomd.records:\n if record.type == 'updateinfo':\n updateinfo = os.path.join(os.path.dirname(\n os.path.dirname(self.cached_repodata)),\n record.location_href)\n break\n\n assert updateinfo, 'Unable to find updateinfo'\n\n # Load the metadata with createrepo_c\n log.info('Loading cached updateinfo: %s', updateinfo)\n uinfo = cr.UpdateInfo(updateinfo)\n\n # Determine which updates are present in the cache\n for update in uinfo.updates:\n existing_ids.add(update.id)\n\n # Generate metadata for any new builds\n for update in self.updates:\n seen_ids.add(update.alias)\n if not update.alias:\n self.missing_ids.append(update.title)\n continue\n if update.alias in existing_ids:\n notice = None\n for value in uinfo.updates:\n if value.title == update.title:\n notice = value\n break\n if not notice:\n log.warn('%s ID in cache but notice cannot be found', update.title)\n self.add_update(update)\n continue\n if notice.updated_date:\n if notice.updated_date < update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading updated %s from cache' % update.title)\n from_cache.add(update.alias)\n elif update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading %s from cache' % update.title)\n from_cache.add(update.alias)\n else:\n log.debug('Adding new update notice: %s' % update.title)\n self.add_update(update)\n\n # Add all relevant notices from the cache to this document\n for notice in uinfo.updates:\n if notice.id in from_cache:\n log.debug('Keeping existing notice: %s', notice.title)\n self.uinfo.append(notice)\n else:\n # Keep all security notices in the stable repo\n if self.request is not UpdateRequest.testing:\n if notice.type == 'security':\n if notice.id not in seen_ids:\n log.debug('Keeping existing security notice: %s',\n notice.title)\n self.uinfo.append(notice)\n else:\n log.debug('%s already added?', notice.title)\n else:\n log.debug('Purging cached stable notice %s', notice.title)\n else:\n log.debug('Purging cached testing update %s', notice.title)\n\n def _fetch_updates(self):\n \"\"\"Based on our given koji tag, populate a list of Update objects\"\"\"\n log.debug(\"Fetching builds tagged with '%s'\" % self.tag)\n kojiBuilds = self.koji.listTagged(self.tag, latest=True)\n nonexistent = []\n log.debug(\"%d builds found\" % len(kojiBuilds))\n for build in kojiBuilds:\n self.builds[build['nvr']] = build\n build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()\n if build_obj:\n if build_obj.update:\n self.updates.add(build_obj.update)\n else:\n log.warn('%s does not have a corresponding update' % build['nvr'])\n else:\n nonexistent.append(build['nvr'])\n if nonexistent:\n log.warning(\"Couldn't find the following koji builds tagged as \"\n \"%s in bodhi: %s\" % (self.tag, nonexistent))\n\n def add_update(self, update):\n \"\"\"Generate the extended metadata for a given update\"\"\"\n rec = cr.UpdateRecord()\n rec.version = __version__\n rec.fromstr = config.get('bodhi_email')\n rec.status = update.status.value\n rec.type = update.type.value\n rec.id = to_bytes(update.alias)\n rec.title = to_bytes(update.title)\n rec.summary = to_bytes('%s %s update' % (update.get_title(),\n update.type.value))\n rec.description = to_bytes(update.notes)\n rec.release = to_bytes(update.release.long_name)\n rec.rights = config.get('updateinfo_rights')\n\n if update.date_pushed:\n rec.issued_date = update.date_pushed\n if update.date_modified:\n rec.updated_date = update.date_modified\n\n col = cr.UpdateCollection()\n col.name = to_bytes(update.release.long_name)\n col.shortname = to_bytes(update.release.name)\n\n for build in update.builds:\n try:\n kojiBuild = self.builds[build.nvr]\n except:\n kojiBuild = self.koji.getBuild(build.nvr)\n\n rpms = self.koji.listBuildRPMs(kojiBuild['id'])\n for rpm in rpms:\n pkg = cr.UpdateCollectionPackage()\n pkg.name = rpm['name']\n pkg.version = rpm['version']\n pkg.release = rpm['release']\n if rpm['epoch'] is not None:\n pkg.epoch = str(rpm['epoch'])\n else:\n pkg.epoch = '0'\n pkg.arch = rpm['arch']\n\n # TODO: how do we handle UpdateSuggestion.logout, etc?\n pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot\n\n filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])\n pkg.filename = filename\n\n # Build the URL\n if rpm['arch'] == 'src':\n arch = 'SRPMS'\n elif rpm['arch'] in ('noarch', 'i686'):\n arch = 'i386'\n else:\n arch = rpm['arch']\n\n pkg.src = os.path.join(config.get('file_url'), update.status is\n UpdateStatus.testing and 'testing' or '',\n str(update.release.version), arch, filename[0], filename)\n\n col.append(pkg)\n\n rec.append_collection(col)\n\n # Create references for each bug\n for bug in update.bugs:\n ref = cr.UpdateReference()\n ref.type = 'bugzilla'\n ref.id = to_bytes(bug.bug_id)\n ref.href = to_bytes(bug.url)\n ref.title = to_bytes(bug.title)\n rec.append_reference(ref)\n\n # Create references for each CVE\n for cve in update.cves:\n ref = cr.UpdateReference()\n ref.type = 'cve'\n ref.id = to_bytes(cve.cve_id)\n ref.href = to_bytes(cve.url)\n rec.append_reference(ref)\n\n self.uinfo.append(rec)\n\n def insert_updateinfo(self):\n fd, name = tempfile.mkstemp()\n os.write(fd, self.uinfo.xml_dump())\n os.close(fd)\n self.modifyrepo(name)\n os.unlink(name)\n\n def modifyrepo(self, filename):\n \"\"\"Inject a file into the repodata for each architecture\"\"\"\n for arch in os.listdir(self.repo_path):\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n log.info('Inserting %s into %s', filename, repodata)\n uinfo_xml = os.path.join(repodata, 'updateinfo.xml')\n shutil.copyfile(filename, uinfo_xml)\n repomd_xml = os.path.join(repodata, 'repomd.xml')\n repomd = cr.Repomd(repomd_xml)\n uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)\n uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)\n uinfo_rec_comp.rename_file()\n uinfo_rec_comp.type = 'updateinfo'\n repomd.set_record(uinfo_rec_comp)\n with file(repomd_xml, 'w') as repomd_file:\n repomd_file.write(repomd.xml_dump())\n os.unlink(uinfo_xml)\n\n def insert_pkgtags(self):\n \"\"\"Download and inject the pkgtags sqlite from fedora-tagger\"\"\"\n if config.get('pkgtags_url'):\n try:\n tags_url = config.get('pkgtags_url')\n tempdir = tempfile.mkdtemp('bodhi')\n local_tags = os.path.join(tempdir, 'pkgtags.sqlite')\n log.info('Downloading %s' % tags_url)\n urlgrab(tags_url, filename=local_tags)\n self.modifyrepo(local_tags)\n except:\n log.exception(\"There was a problem injecting pkgtags\")\n finally:\n shutil.rmtree(tempdir)\n\n def cache_repodata(self):\n arch = os.listdir(self.repo_path)[0] # Take the first arch\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n if not os.path.isdir(repodata):\n log.warning('Cannot find repodata to cache: %s' % repodata)\n return\n cache = self.cached_repodata\n if os.path.isdir(cache):\n shutil.rmtree(cache)\n shutil.copytree(repodata, cache)\n log.info('%s cached to %s' % (repodata, cache))\n", "path": "bodhi/server/metadata.py"}], "after_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\n__version__ = '2.0'\n\nimport os\nimport logging\nimport shutil\nimport tempfile\n\nfrom urlgrabber.grabber import urlgrab\nfrom kitchen.text.converters import to_bytes\n\nimport createrepo_c as cr\n\nfrom bodhi.server.config import config\nfrom bodhi.server.models import Build, UpdateStatus, UpdateRequest, UpdateSuggestion\nfrom bodhi.server.buildsys import get_session\n\nlog = logging.getLogger(__name__)\n\n\nclass ExtendedMetadata(object):\n \"\"\"This class represents the updateinfo.xml yum metadata.\n\n It is generated during push time by the bodhi masher based on koji tags\n and is injected into the yum repodata using the `modifyrepo_c` tool,\n which is included in the `createrepo_c` package.\n\n \"\"\"\n def __init__(self, release, request, db, path):\n self.repo = path\n log.debug('repo = %r' % self.repo)\n self.request = request\n if request is UpdateRequest.stable:\n self.tag = release.stable_tag\n else:\n self.tag = release.testing_tag\n self.repo_path = os.path.join(self.repo, self.tag)\n\n self.db = db\n self.updates = set()\n self.builds = {}\n self.missing_ids = []\n self._from = config.get('bodhi_email')\n self.koji = get_session()\n self._fetch_updates()\n\n self.uinfo = cr.UpdateInfo()\n\n self.hash_type = cr.SHA256\n self.comp_type = cr.XZ\n\n if release.id_prefix == u'FEDORA-EPEL':\n # yum on py2.4 doesn't support sha256 (#1080373)\n if 'el5' in self.repo or '5E' in self.repo:\n self.hash_type = cr.SHA1\n self.comp_type = cr.GZ\n else:\n # FIXME: I'm not sure which versions of RHEL support xz metadata\n # compression, so use the lowest common denominator for now.\n self.comp_type = cr.BZ2\n\n # Load from the cache if it exists\n self.cached_repodata = os.path.join(self.repo, '..', self.tag +\n '.repocache', 'repodata/')\n if os.path.isdir(self.cached_repodata):\n log.info('Loading cached updateinfo.xml')\n self._load_cached_updateinfo()\n else:\n log.info(\"Generating new updateinfo.xml\")\n self.uinfo = cr.UpdateInfo()\n for update in self.updates:\n if update.alias:\n self.add_update(update)\n else:\n self.missing_ids.append(update.title)\n\n if self.missing_ids:\n log.error(\"%d updates with missing ID: %r\" % (\n len(self.missing_ids), self.missing_ids))\n\n def _load_cached_updateinfo(self):\n \"\"\"\n Load the cached updateinfo.xml from '../{tag}.repocache/repodata'\n \"\"\"\n seen_ids = set()\n from_cache = set()\n existing_ids = set()\n\n # Parse the updateinfo out of the repomd\n updateinfo = None\n repomd_xml = os.path.join(self.cached_repodata, 'repomd.xml')\n repomd = cr.Repomd()\n cr.xml_parse_repomd(repomd_xml, repomd)\n for record in repomd.records:\n if record.type == 'updateinfo':\n updateinfo = os.path.join(os.path.dirname(\n os.path.dirname(self.cached_repodata)),\n record.location_href)\n break\n\n assert updateinfo, 'Unable to find updateinfo'\n\n # Load the metadata with createrepo_c\n log.info('Loading cached updateinfo: %s', updateinfo)\n uinfo = cr.UpdateInfo(updateinfo)\n\n # Determine which updates are present in the cache\n for update in uinfo.updates:\n existing_ids.add(update.id)\n\n # Generate metadata for any new builds\n for update in self.updates:\n seen_ids.add(update.alias)\n if not update.alias:\n self.missing_ids.append(update.title)\n continue\n if update.alias in existing_ids:\n notice = None\n for value in uinfo.updates:\n if value.title == update.title:\n notice = value\n break\n if not notice:\n log.warn('%s ID in cache but notice cannot be found', update.title)\n self.add_update(update)\n continue\n if notice.updated_date:\n if notice.updated_date < update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading updated %s from cache' % update.title)\n from_cache.add(update.alias)\n elif update.date_modified:\n log.debug('Update modified, generating new notice: %s' % update.title)\n self.add_update(update)\n else:\n log.debug('Loading %s from cache' % update.title)\n from_cache.add(update.alias)\n else:\n log.debug('Adding new update notice: %s' % update.title)\n self.add_update(update)\n\n # Add all relevant notices from the cache to this document\n for notice in uinfo.updates:\n if notice.id in from_cache:\n log.debug('Keeping existing notice: %s', notice.title)\n self.uinfo.append(notice)\n else:\n # Keep all security notices in the stable repo\n if self.request is not UpdateRequest.testing:\n if notice.type == 'security':\n if notice.id not in seen_ids:\n log.debug('Keeping existing security notice: %s',\n notice.title)\n self.uinfo.append(notice)\n else:\n log.debug('%s already added?', notice.title)\n else:\n log.debug('Purging cached stable notice %s', notice.title)\n else:\n log.debug('Purging cached testing update %s', notice.title)\n\n def _fetch_updates(self):\n \"\"\"Based on our given koji tag, populate a list of Update objects\"\"\"\n log.debug(\"Fetching builds tagged with '%s'\" % self.tag)\n kojiBuilds = self.koji.listTagged(self.tag, latest=True)\n nonexistent = []\n log.debug(\"%d builds found\" % len(kojiBuilds))\n for build in kojiBuilds:\n self.builds[build['nvr']] = build\n build_obj = self.db.query(Build).filter_by(nvr=unicode(build['nvr'])).first()\n if build_obj:\n if build_obj.update:\n self.updates.add(build_obj.update)\n else:\n log.warn('%s does not have a corresponding update' % build['nvr'])\n else:\n nonexistent.append(build['nvr'])\n if nonexistent:\n log.warning(\"Couldn't find the following koji builds tagged as \"\n \"%s in bodhi: %s\" % (self.tag, nonexistent))\n\n def add_update(self, update):\n \"\"\"Generate the extended metadata for a given update\"\"\"\n rec = cr.UpdateRecord()\n rec.version = __version__\n rec.fromstr = config.get('bodhi_email')\n rec.status = update.status.value\n rec.type = update.type.value\n rec.id = to_bytes(update.alias)\n rec.title = to_bytes(update.title)\n rec.summary = to_bytes('%s %s update' % (update.get_title(),\n update.type.value))\n rec.description = to_bytes(update.notes)\n rec.release = to_bytes(update.release.long_name)\n rec.rights = config.get('updateinfo_rights')\n\n if update.date_pushed:\n rec.issued_date = update.date_pushed\n if update.date_modified:\n rec.updated_date = update.date_modified\n\n col = cr.UpdateCollection()\n col.name = to_bytes(update.release.long_name)\n col.shortname = to_bytes(update.release.name)\n\n for build in update.builds:\n try:\n kojiBuild = self.builds[build.nvr]\n except:\n kojiBuild = self.koji.getBuild(build.nvr)\n\n rpms = self.koji.listBuildRPMs(kojiBuild['id'])\n for rpm in rpms:\n pkg = cr.UpdateCollectionPackage()\n pkg.name = rpm['name']\n pkg.version = rpm['version']\n pkg.release = rpm['release']\n if rpm['epoch'] is not None:\n pkg.epoch = str(rpm['epoch'])\n else:\n pkg.epoch = '0'\n pkg.arch = rpm['arch']\n\n # TODO: how do we handle UpdateSuggestion.logout, etc?\n pkg.reboot_suggested = update.suggest is UpdateSuggestion.reboot\n\n filename = '%s.%s.rpm' % (rpm['nvr'], rpm['arch'])\n pkg.filename = filename\n\n # Build the URL\n if rpm['arch'] == 'src':\n arch = 'SRPMS'\n elif rpm['arch'] in ('noarch', 'i686'):\n arch = 'i386'\n else:\n arch = rpm['arch']\n\n pkg.src = os.path.join(config.get('file_url'), update.status is\n UpdateStatus.testing and 'testing' or '',\n str(update.release.version), arch, filename[0], filename)\n\n col.append(pkg)\n\n rec.append_collection(col)\n\n # Create references for each bug\n for bug in update.bugs:\n ref = cr.UpdateReference()\n ref.type = 'bugzilla'\n ref.id = to_bytes(bug.bug_id)\n ref.href = to_bytes(bug.url)\n ref.title = to_bytes(bug.title)\n rec.append_reference(ref)\n\n # Create references for each CVE\n for cve in update.cves:\n ref = cr.UpdateReference()\n ref.type = 'cve'\n ref.id = to_bytes(cve.cve_id)\n ref.href = to_bytes(cve.url)\n rec.append_reference(ref)\n\n self.uinfo.append(rec)\n\n def insert_updateinfo(self):\n fd, name = tempfile.mkstemp()\n os.write(fd, self.uinfo.xml_dump())\n os.close(fd)\n self.modifyrepo(name)\n os.unlink(name)\n\n def modifyrepo(self, filename):\n \"\"\"Inject a file into the repodata for each architecture\"\"\"\n for arch in os.listdir(self.repo_path):\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n log.info('Inserting %s into %s', filename, repodata)\n uinfo_xml = os.path.join(repodata, 'updateinfo.xml')\n shutil.copyfile(filename, uinfo_xml)\n repomd_xml = os.path.join(repodata, 'repomd.xml')\n repomd = cr.Repomd(repomd_xml)\n uinfo_rec = cr.RepomdRecord('updateinfo', uinfo_xml)\n uinfo_rec_comp = uinfo_rec.compress_and_fill(self.hash_type, self.comp_type)\n uinfo_rec_comp.rename_file()\n uinfo_rec_comp.type = 'updateinfo'\n repomd.set_record(uinfo_rec_comp)\n with file(repomd_xml, 'w') as repomd_file:\n repomd_file.write(repomd.xml_dump())\n os.unlink(uinfo_xml)\n\n def insert_pkgtags(self):\n \"\"\"Download and inject the pkgtags sqlite from fedora-tagger\"\"\"\n if config.get('pkgtags_url'):\n try:\n tags_url = config.get('pkgtags_url')\n tempdir = tempfile.mkdtemp('bodhi')\n local_tags = os.path.join(tempdir, 'pkgtags.sqlite')\n log.info('Downloading %s' % tags_url)\n urlgrab(tags_url, filename=local_tags)\n self.modifyrepo(local_tags)\n except:\n log.exception(\"There was a problem injecting pkgtags\")\n finally:\n shutil.rmtree(tempdir)\n\n def cache_repodata(self):\n arch = os.listdir(self.repo_path)[0] # Take the first arch\n repodata = os.path.join(self.repo_path, arch, 'repodata')\n if not os.path.isdir(repodata):\n log.warning('Cannot find repodata to cache: %s' % repodata)\n return\n cache = self.cached_repodata\n if os.path.isdir(cache):\n shutil.rmtree(cache)\n shutil.copytree(repodata, cache)\n log.info('%s cached to %s' % (repodata, cache))\n", "path": "bodhi/server/metadata.py"}]}
| 4,092 | 156 |
gh_patches_debug_21852
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-7315
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Site history report n+1s
While checking Scout APM for a client project with lots of different authors and overall activity, I've noticed that the site history report has a few N+1s.

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/admin/views/reports/audit_logging.py`
Content:
```
1 import datetime
2
3 import django_filters
4
5 from django import forms
6 from django.db.models import Q, Subquery
7 from django.utils.encoding import force_str
8 from django.utils.translation import gettext_lazy as _
9
10 from wagtail.admin.filters import DateRangePickerWidget, WagtailFilterSet
11 from wagtail.core.log_actions import page_log_action_registry
12 from wagtail.core.models import Page, PageLogEntry, UserPagePermissionsProxy
13
14 from .base import ReportView
15
16
17 class SiteHistoryReportFilterSet(WagtailFilterSet):
18 action = django_filters.ChoiceFilter(choices=page_log_action_registry.get_choices)
19 hide_commenting_actions = django_filters.BooleanFilter(
20 label=_('Hide commenting actions'),
21 method='filter_hide_commenting_actions',
22 widget=forms.CheckboxInput,
23 )
24 timestamp = django_filters.DateFromToRangeFilter(label=_('Date'), widget=DateRangePickerWidget)
25 label = django_filters.CharFilter(label=_('Title'), lookup_expr='icontains')
26 user = django_filters.ModelChoiceFilter(
27 field_name='user', queryset=lambda request: PageLogEntry.objects.all().get_users()
28 )
29
30 def filter_hide_commenting_actions(self, queryset, name, value):
31 if value:
32 queryset = queryset.exclude(
33 action__startswith='wagtail.comments'
34 )
35 return queryset
36
37 class Meta:
38 model = PageLogEntry
39 fields = ['label', 'action', 'user', 'timestamp', 'hide_commenting_actions']
40
41
42 class LogEntriesView(ReportView):
43 template_name = 'wagtailadmin/reports/site_history.html'
44 title = _('Site history')
45 header_icon = 'history'
46 filterset_class = SiteHistoryReportFilterSet
47
48 export_headings = {
49 "object_id": _("ID"),
50 "title": _("Title"),
51 "object_verbose_name": _("Type"),
52 "action": _("Action type"),
53 "timestamp": _("Date/Time")
54 }
55 list_export = [
56 "object_id",
57 "label",
58 "object_verbose_name",
59 "action",
60 "timestamp"
61 ]
62
63 def __init__(self, **kwargs):
64 super().__init__(**kwargs)
65
66 self.custom_field_preprocess['action'] = {
67 self.FORMAT_CSV: self.get_action_label,
68 self.FORMAT_XLSX: self.get_action_label
69 }
70
71 def get_filename(self):
72 return "audit-log-{}".format(
73 datetime.datetime.today().strftime("%Y-%m-%d")
74 )
75
76 def get_queryset(self):
77 q = Q(
78 page__in=UserPagePermissionsProxy(self.request.user).explorable_pages().values_list('pk', flat=True)
79 )
80
81 root_page_permissions = Page.get_first_root_node().permissions_for_user(self.request.user)
82 if (
83 self.request.user.is_superuser
84 or root_page_permissions.can_add_subpage() or root_page_permissions.can_edit()
85 ):
86 # Include deleted entries
87 q = q | Q(page_id__in=Subquery(
88 PageLogEntry.objects.filter(deleted=True).values('page_id')
89 ))
90
91 return PageLogEntry.objects.filter(q)
92
93 def get_action_label(self, action):
94 from wagtail.core.log_actions import page_log_action_registry
95 return force_str(page_log_action_registry.get_action_label(action))
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/admin/views/reports/audit_logging.py b/wagtail/admin/views/reports/audit_logging.py
--- a/wagtail/admin/views/reports/audit_logging.py
+++ b/wagtail/admin/views/reports/audit_logging.py
@@ -74,9 +74,7 @@
)
def get_queryset(self):
- q = Q(
- page__in=UserPagePermissionsProxy(self.request.user).explorable_pages().values_list('pk', flat=True)
- )
+ q = Q(page__in=UserPagePermissionsProxy(self.request.user).explorable_pages())
root_page_permissions = Page.get_first_root_node().permissions_for_user(self.request.user)
if (
@@ -88,7 +86,11 @@
PageLogEntry.objects.filter(deleted=True).values('page_id')
))
- return PageLogEntry.objects.filter(q)
+ # Using prefech_related() on page, as select_related() generates an INNER JOIN,
+ # which filters out entries for deleted pages
+ return PageLogEntry.objects.filter(q).select_related(
+ 'user', 'user__wagtail_userprofile'
+ ).prefetch_related('page')
def get_action_label(self, action):
from wagtail.core.log_actions import page_log_action_registry
|
{"golden_diff": "diff --git a/wagtail/admin/views/reports/audit_logging.py b/wagtail/admin/views/reports/audit_logging.py\n--- a/wagtail/admin/views/reports/audit_logging.py\n+++ b/wagtail/admin/views/reports/audit_logging.py\n@@ -74,9 +74,7 @@\n )\n \n def get_queryset(self):\n- q = Q(\n- page__in=UserPagePermissionsProxy(self.request.user).explorable_pages().values_list('pk', flat=True)\n- )\n+ q = Q(page__in=UserPagePermissionsProxy(self.request.user).explorable_pages())\n \n root_page_permissions = Page.get_first_root_node().permissions_for_user(self.request.user)\n if (\n@@ -88,7 +86,11 @@\n PageLogEntry.objects.filter(deleted=True).values('page_id')\n ))\n \n- return PageLogEntry.objects.filter(q)\n+ # Using prefech_related() on page, as select_related() generates an INNER JOIN,\n+ # which filters out entries for deleted pages\n+ return PageLogEntry.objects.filter(q).select_related(\n+ 'user', 'user__wagtail_userprofile'\n+ ).prefetch_related('page')\n \n def get_action_label(self, action):\n from wagtail.core.log_actions import page_log_action_registry\n", "issue": "Site history report n+1s\nWhile checking Scout APM for a client project with lots of different authors and overall activity, I've noticed that the site history report has a few N+1s.\r\n\r\n\r\n\n", "before_files": [{"content": "import datetime\n\nimport django_filters\n\nfrom django import forms\nfrom django.db.models import Q, Subquery\nfrom django.utils.encoding import force_str\nfrom django.utils.translation import gettext_lazy as _\n\nfrom wagtail.admin.filters import DateRangePickerWidget, WagtailFilterSet\nfrom wagtail.core.log_actions import page_log_action_registry\nfrom wagtail.core.models import Page, PageLogEntry, UserPagePermissionsProxy\n\nfrom .base import ReportView\n\n\nclass SiteHistoryReportFilterSet(WagtailFilterSet):\n action = django_filters.ChoiceFilter(choices=page_log_action_registry.get_choices)\n hide_commenting_actions = django_filters.BooleanFilter(\n label=_('Hide commenting actions'),\n method='filter_hide_commenting_actions',\n widget=forms.CheckboxInput,\n )\n timestamp = django_filters.DateFromToRangeFilter(label=_('Date'), widget=DateRangePickerWidget)\n label = django_filters.CharFilter(label=_('Title'), lookup_expr='icontains')\n user = django_filters.ModelChoiceFilter(\n field_name='user', queryset=lambda request: PageLogEntry.objects.all().get_users()\n )\n\n def filter_hide_commenting_actions(self, queryset, name, value):\n if value:\n queryset = queryset.exclude(\n action__startswith='wagtail.comments'\n )\n return queryset\n\n class Meta:\n model = PageLogEntry\n fields = ['label', 'action', 'user', 'timestamp', 'hide_commenting_actions']\n\n\nclass LogEntriesView(ReportView):\n template_name = 'wagtailadmin/reports/site_history.html'\n title = _('Site history')\n header_icon = 'history'\n filterset_class = SiteHistoryReportFilterSet\n\n export_headings = {\n \"object_id\": _(\"ID\"),\n \"title\": _(\"Title\"),\n \"object_verbose_name\": _(\"Type\"),\n \"action\": _(\"Action type\"),\n \"timestamp\": _(\"Date/Time\")\n }\n list_export = [\n \"object_id\",\n \"label\",\n \"object_verbose_name\",\n \"action\",\n \"timestamp\"\n ]\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n\n self.custom_field_preprocess['action'] = {\n self.FORMAT_CSV: self.get_action_label,\n self.FORMAT_XLSX: self.get_action_label\n }\n\n def get_filename(self):\n return \"audit-log-{}\".format(\n datetime.datetime.today().strftime(\"%Y-%m-%d\")\n )\n\n def get_queryset(self):\n q = Q(\n page__in=UserPagePermissionsProxy(self.request.user).explorable_pages().values_list('pk', flat=True)\n )\n\n root_page_permissions = Page.get_first_root_node().permissions_for_user(self.request.user)\n if (\n self.request.user.is_superuser\n or root_page_permissions.can_add_subpage() or root_page_permissions.can_edit()\n ):\n # Include deleted entries\n q = q | Q(page_id__in=Subquery(\n PageLogEntry.objects.filter(deleted=True).values('page_id')\n ))\n\n return PageLogEntry.objects.filter(q)\n\n def get_action_label(self, action):\n from wagtail.core.log_actions import page_log_action_registry\n return force_str(page_log_action_registry.get_action_label(action))\n", "path": "wagtail/admin/views/reports/audit_logging.py"}], "after_files": [{"content": "import datetime\n\nimport django_filters\n\nfrom django import forms\nfrom django.db.models import Q, Subquery\nfrom django.utils.encoding import force_str\nfrom django.utils.translation import gettext_lazy as _\n\nfrom wagtail.admin.filters import DateRangePickerWidget, WagtailFilterSet\nfrom wagtail.core.log_actions import page_log_action_registry\nfrom wagtail.core.models import Page, PageLogEntry, UserPagePermissionsProxy\n\nfrom .base import ReportView\n\n\nclass SiteHistoryReportFilterSet(WagtailFilterSet):\n action = django_filters.ChoiceFilter(choices=page_log_action_registry.get_choices)\n hide_commenting_actions = django_filters.BooleanFilter(\n label=_('Hide commenting actions'),\n method='filter_hide_commenting_actions',\n widget=forms.CheckboxInput,\n )\n timestamp = django_filters.DateFromToRangeFilter(label=_('Date'), widget=DateRangePickerWidget)\n label = django_filters.CharFilter(label=_('Title'), lookup_expr='icontains')\n user = django_filters.ModelChoiceFilter(\n field_name='user', queryset=lambda request: PageLogEntry.objects.all().get_users()\n )\n\n def filter_hide_commenting_actions(self, queryset, name, value):\n if value:\n queryset = queryset.exclude(\n action__startswith='wagtail.comments'\n )\n return queryset\n\n class Meta:\n model = PageLogEntry\n fields = ['label', 'action', 'user', 'timestamp', 'hide_commenting_actions']\n\n\nclass LogEntriesView(ReportView):\n template_name = 'wagtailadmin/reports/site_history.html'\n title = _('Site history')\n header_icon = 'history'\n filterset_class = SiteHistoryReportFilterSet\n\n export_headings = {\n \"object_id\": _(\"ID\"),\n \"title\": _(\"Title\"),\n \"object_verbose_name\": _(\"Type\"),\n \"action\": _(\"Action type\"),\n \"timestamp\": _(\"Date/Time\")\n }\n list_export = [\n \"object_id\",\n \"label\",\n \"object_verbose_name\",\n \"action\",\n \"timestamp\"\n ]\n\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n\n self.custom_field_preprocess['action'] = {\n self.FORMAT_CSV: self.get_action_label,\n self.FORMAT_XLSX: self.get_action_label\n }\n\n def get_filename(self):\n return \"audit-log-{}\".format(\n datetime.datetime.today().strftime(\"%Y-%m-%d\")\n )\n\n def get_queryset(self):\n q = Q(page__in=UserPagePermissionsProxy(self.request.user).explorable_pages())\n\n root_page_permissions = Page.get_first_root_node().permissions_for_user(self.request.user)\n if (\n self.request.user.is_superuser\n or root_page_permissions.can_add_subpage() or root_page_permissions.can_edit()\n ):\n # Include deleted entries\n q = q | Q(page_id__in=Subquery(\n PageLogEntry.objects.filter(deleted=True).values('page_id')\n ))\n\n # Using prefech_related() on page, as select_related() generates an INNER JOIN,\n # which filters out entries for deleted pages\n return PageLogEntry.objects.filter(q).select_related(\n 'user', 'user__wagtail_userprofile'\n ).prefetch_related('page')\n\n def get_action_label(self, action):\n from wagtail.core.log_actions import page_log_action_registry\n return force_str(page_log_action_registry.get_action_label(action))\n", "path": "wagtail/admin/views/reports/audit_logging.py"}]}
| 1,251 | 285 |
gh_patches_debug_25226
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-1397
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Install roboto mono
## Abstract
We should install the mono version of our main font in order to increase legibility and proper alignment of content in certain scenarios.
## Specification
https://www.npmjs.com/package/typeface-roboto-mono install, require it where we require roboto, use it in classes where a mono font is required to line things up properly in data tables / cards / etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rotkehlchen/chain/ethereum/transactions.py`
Content:
```
1 import logging
2 from collections import defaultdict
3 from typing import Dict, List, Optional
4
5 from rotkehlchen.db.dbhandler import DBHandler
6 from rotkehlchen.db.ranges import DBQueryRanges
7 from rotkehlchen.errors import RemoteError
8 from rotkehlchen.externalapis.etherscan import Etherscan
9 from rotkehlchen.logging import RotkehlchenLogsAdapter
10 from rotkehlchen.typing import ChecksumEthAddress, EthereumTransaction, Timestamp
11 from rotkehlchen.user_messages import MessagesAggregator
12 from rotkehlchen.utils.interfaces import LockableQueryObject, protect_with_lock
13
14 logger = logging.getLogger(__name__)
15 log = RotkehlchenLogsAdapter(logger)
16
17 FREE_ETH_TX_LIMIT = 500
18
19
20 class EthTransactions(LockableQueryObject):
21
22 def __init__(
23 self,
24 database: DBHandler,
25 etherscan: Etherscan,
26 msg_aggregator: MessagesAggregator,
27 ) -> None:
28 super().__init__()
29 self.database = database
30 self.etherscan = etherscan
31 self.msg_aggregator = msg_aggregator
32 self.tx_per_address: Dict[ChecksumEthAddress, int] = defaultdict(int)
33
34 def _single_address_query_transactions(
35 self,
36 address: ChecksumEthAddress,
37 start_ts: Timestamp,
38 end_ts: Timestamp,
39 with_limit: bool,
40 ) -> List[EthereumTransaction]:
41 self.tx_per_address[address] = 0
42 transactions = self.database.get_ethereum_transactions(
43 from_ts=start_ts,
44 to_ts=end_ts,
45 address=address,
46 )
47 ranges = DBQueryRanges(self.database)
48 ranges_to_query = ranges.get_location_query_ranges(
49 location_string=f'ethtxs_{address}',
50 start_ts=start_ts,
51 end_ts=end_ts,
52 )
53 new_transactions = []
54 for query_start_ts, query_end_ts in ranges_to_query:
55 for internal in (False, True):
56 try:
57 new_transactions.extend(self.etherscan.get_transactions(
58 account=address,
59 internal=internal,
60 from_ts=query_start_ts,
61 to_ts=query_end_ts,
62 ))
63 except RemoteError as e:
64 self.msg_aggregator.add_error(
65 f'Got error "{str(e)}" while querying ethereum transactions '
66 f'from Etherscan. Transactions not added to the DB '
67 f'from_ts: {query_start_ts} '
68 f'to_ts: {query_end_ts} '
69 f'internal: {internal}',
70 )
71
72 # add new transactions to the DB
73 if new_transactions != []:
74 self.database.add_ethereum_transactions(new_transactions, from_etherscan=True)
75 # and also set the last queried timestamps for the address
76 ranges.update_used_query_range(
77 location_string=f'ethtxs_{address}',
78 start_ts=start_ts,
79 end_ts=end_ts,
80 ranges_to_query=ranges_to_query,
81 )
82 # finally append them to the already returned DB transactions
83 transactions.extend(new_transactions)
84
85 if with_limit:
86 transactions_queried_so_far = sum(x for _, x in self.tx_per_address.items())
87 remaining_num_tx = FREE_ETH_TX_LIMIT - transactions_queried_so_far
88 returning_tx_length = min(remaining_num_tx, len(transactions))
89 # Note down how many we got for this address
90 self.tx_per_address[address] = returning_tx_length
91 return transactions[:returning_tx_length]
92
93 return transactions
94
95 @protect_with_lock()
96 def query(
97 self,
98 address: Optional[ChecksumEthAddress],
99 from_ts: Timestamp,
100 to_ts: Timestamp,
101 with_limit: bool = False,
102 recent_first: bool = False,
103 ) -> List[EthereumTransaction]:
104 """Queries for all transactions (normal AND internal) of all ethereum accounts.
105 Returns a list of all transactions of all accounts sorted by time.
106
107 If `with_limit` is true then the api limit is applied
108
109 if `recent_first` is true then the transactions are returned with the most
110 recent first on the list
111
112 May raise:
113 - RemoteError if etherscan is used and there is a problem with reaching it or
114 with parsing the response.
115 """
116 transactions: List[EthereumTransaction] = []
117
118 if address is not None:
119 accounts = [address]
120 else:
121 accounts = self.database.get_blockchain_accounts().eth
122
123 for address in accounts:
124 transactions.extend(self._single_address_query_transactions(
125 address=address,
126 start_ts=from_ts,
127 end_ts=to_ts,
128 with_limit=with_limit,
129 ))
130
131 transactions.sort(key=lambda tx: tx.timestamp, reverse=recent_first)
132 return transactions
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rotkehlchen/chain/ethereum/transactions.py b/rotkehlchen/chain/ethereum/transactions.py
--- a/rotkehlchen/chain/ethereum/transactions.py
+++ b/rotkehlchen/chain/ethereum/transactions.py
@@ -72,6 +72,15 @@
# add new transactions to the DB
if new_transactions != []:
self.database.add_ethereum_transactions(new_transactions, from_etherscan=True)
+ # And since at least for now the increasingly negative nonce for the internal
+ # transactions happens only in the DB writing, requery the entire batch from
+ # the DB to get the updated transactions
+ transactions = self.database.get_ethereum_transactions(
+ from_ts=start_ts,
+ to_ts=end_ts,
+ address=address,
+ )
+
# and also set the last queried timestamps for the address
ranges.update_used_query_range(
location_string=f'ethtxs_{address}',
@@ -79,8 +88,6 @@
end_ts=end_ts,
ranges_to_query=ranges_to_query,
)
- # finally append them to the already returned DB transactions
- transactions.extend(new_transactions)
if with_limit:
transactions_queried_so_far = sum(x for _, x in self.tx_per_address.items())
|
{"golden_diff": "diff --git a/rotkehlchen/chain/ethereum/transactions.py b/rotkehlchen/chain/ethereum/transactions.py\n--- a/rotkehlchen/chain/ethereum/transactions.py\n+++ b/rotkehlchen/chain/ethereum/transactions.py\n@@ -72,6 +72,15 @@\n # add new transactions to the DB\n if new_transactions != []:\n self.database.add_ethereum_transactions(new_transactions, from_etherscan=True)\n+ # And since at least for now the increasingly negative nonce for the internal\n+ # transactions happens only in the DB writing, requery the entire batch from\n+ # the DB to get the updated transactions\n+ transactions = self.database.get_ethereum_transactions(\n+ from_ts=start_ts,\n+ to_ts=end_ts,\n+ address=address,\n+ )\n+\n # and also set the last queried timestamps for the address\n ranges.update_used_query_range(\n location_string=f'ethtxs_{address}',\n@@ -79,8 +88,6 @@\n end_ts=end_ts,\n ranges_to_query=ranges_to_query,\n )\n- # finally append them to the already returned DB transactions\n- transactions.extend(new_transactions)\n \n if with_limit:\n transactions_queried_so_far = sum(x for _, x in self.tx_per_address.items())\n", "issue": "Install roboto mono\n## Abstract\r\n\r\nWe should install the mono version of our main font in order to increase legibility and proper alignment of content in certain scenarios.\r\n\r\n## Specification\r\n\r\nhttps://www.npmjs.com/package/typeface-roboto-mono install, require it where we require roboto, use it in classes where a mono font is required to line things up properly in data tables / cards / etc.\n", "before_files": [{"content": "import logging\nfrom collections import defaultdict\nfrom typing import Dict, List, Optional\n\nfrom rotkehlchen.db.dbhandler import DBHandler\nfrom rotkehlchen.db.ranges import DBQueryRanges\nfrom rotkehlchen.errors import RemoteError\nfrom rotkehlchen.externalapis.etherscan import Etherscan\nfrom rotkehlchen.logging import RotkehlchenLogsAdapter\nfrom rotkehlchen.typing import ChecksumEthAddress, EthereumTransaction, Timestamp\nfrom rotkehlchen.user_messages import MessagesAggregator\nfrom rotkehlchen.utils.interfaces import LockableQueryObject, protect_with_lock\n\nlogger = logging.getLogger(__name__)\nlog = RotkehlchenLogsAdapter(logger)\n\nFREE_ETH_TX_LIMIT = 500\n\n\nclass EthTransactions(LockableQueryObject):\n\n def __init__(\n self,\n database: DBHandler,\n etherscan: Etherscan,\n msg_aggregator: MessagesAggregator,\n ) -> None:\n super().__init__()\n self.database = database\n self.etherscan = etherscan\n self.msg_aggregator = msg_aggregator\n self.tx_per_address: Dict[ChecksumEthAddress, int] = defaultdict(int)\n\n def _single_address_query_transactions(\n self,\n address: ChecksumEthAddress,\n start_ts: Timestamp,\n end_ts: Timestamp,\n with_limit: bool,\n ) -> List[EthereumTransaction]:\n self.tx_per_address[address] = 0\n transactions = self.database.get_ethereum_transactions(\n from_ts=start_ts,\n to_ts=end_ts,\n address=address,\n )\n ranges = DBQueryRanges(self.database)\n ranges_to_query = ranges.get_location_query_ranges(\n location_string=f'ethtxs_{address}',\n start_ts=start_ts,\n end_ts=end_ts,\n )\n new_transactions = []\n for query_start_ts, query_end_ts in ranges_to_query:\n for internal in (False, True):\n try:\n new_transactions.extend(self.etherscan.get_transactions(\n account=address,\n internal=internal,\n from_ts=query_start_ts,\n to_ts=query_end_ts,\n ))\n except RemoteError as e:\n self.msg_aggregator.add_error(\n f'Got error \"{str(e)}\" while querying ethereum transactions '\n f'from Etherscan. Transactions not added to the DB '\n f'from_ts: {query_start_ts} '\n f'to_ts: {query_end_ts} '\n f'internal: {internal}',\n )\n\n # add new transactions to the DB\n if new_transactions != []:\n self.database.add_ethereum_transactions(new_transactions, from_etherscan=True)\n # and also set the last queried timestamps for the address\n ranges.update_used_query_range(\n location_string=f'ethtxs_{address}',\n start_ts=start_ts,\n end_ts=end_ts,\n ranges_to_query=ranges_to_query,\n )\n # finally append them to the already returned DB transactions\n transactions.extend(new_transactions)\n\n if with_limit:\n transactions_queried_so_far = sum(x for _, x in self.tx_per_address.items())\n remaining_num_tx = FREE_ETH_TX_LIMIT - transactions_queried_so_far\n returning_tx_length = min(remaining_num_tx, len(transactions))\n # Note down how many we got for this address\n self.tx_per_address[address] = returning_tx_length\n return transactions[:returning_tx_length]\n\n return transactions\n\n @protect_with_lock()\n def query(\n self,\n address: Optional[ChecksumEthAddress],\n from_ts: Timestamp,\n to_ts: Timestamp,\n with_limit: bool = False,\n recent_first: bool = False,\n ) -> List[EthereumTransaction]:\n \"\"\"Queries for all transactions (normal AND internal) of all ethereum accounts.\n Returns a list of all transactions of all accounts sorted by time.\n\n If `with_limit` is true then the api limit is applied\n\n if `recent_first` is true then the transactions are returned with the most\n recent first on the list\n\n May raise:\n - RemoteError if etherscan is used and there is a problem with reaching it or\n with parsing the response.\n \"\"\"\n transactions: List[EthereumTransaction] = []\n\n if address is not None:\n accounts = [address]\n else:\n accounts = self.database.get_blockchain_accounts().eth\n\n for address in accounts:\n transactions.extend(self._single_address_query_transactions(\n address=address,\n start_ts=from_ts,\n end_ts=to_ts,\n with_limit=with_limit,\n ))\n\n transactions.sort(key=lambda tx: tx.timestamp, reverse=recent_first)\n return transactions\n", "path": "rotkehlchen/chain/ethereum/transactions.py"}], "after_files": [{"content": "import logging\nfrom collections import defaultdict\nfrom typing import Dict, List, Optional\n\nfrom rotkehlchen.db.dbhandler import DBHandler\nfrom rotkehlchen.db.ranges import DBQueryRanges\nfrom rotkehlchen.errors import RemoteError\nfrom rotkehlchen.externalapis.etherscan import Etherscan\nfrom rotkehlchen.logging import RotkehlchenLogsAdapter\nfrom rotkehlchen.typing import ChecksumEthAddress, EthereumTransaction, Timestamp\nfrom rotkehlchen.user_messages import MessagesAggregator\nfrom rotkehlchen.utils.interfaces import LockableQueryObject, protect_with_lock\n\nlogger = logging.getLogger(__name__)\nlog = RotkehlchenLogsAdapter(logger)\n\nFREE_ETH_TX_LIMIT = 500\n\n\nclass EthTransactions(LockableQueryObject):\n\n def __init__(\n self,\n database: DBHandler,\n etherscan: Etherscan,\n msg_aggregator: MessagesAggregator,\n ) -> None:\n super().__init__()\n self.database = database\n self.etherscan = etherscan\n self.msg_aggregator = msg_aggregator\n self.tx_per_address: Dict[ChecksumEthAddress, int] = defaultdict(int)\n\n def _single_address_query_transactions(\n self,\n address: ChecksumEthAddress,\n start_ts: Timestamp,\n end_ts: Timestamp,\n with_limit: bool,\n ) -> List[EthereumTransaction]:\n self.tx_per_address[address] = 0\n transactions = self.database.get_ethereum_transactions(\n from_ts=start_ts,\n to_ts=end_ts,\n address=address,\n )\n ranges = DBQueryRanges(self.database)\n ranges_to_query = ranges.get_location_query_ranges(\n location_string=f'ethtxs_{address}',\n start_ts=start_ts,\n end_ts=end_ts,\n )\n new_transactions = []\n for query_start_ts, query_end_ts in ranges_to_query:\n for internal in (False, True):\n try:\n new_transactions.extend(self.etherscan.get_transactions(\n account=address,\n internal=internal,\n from_ts=query_start_ts,\n to_ts=query_end_ts,\n ))\n except RemoteError as e:\n self.msg_aggregator.add_error(\n f'Got error \"{str(e)}\" while querying ethereum transactions '\n f'from Etherscan. Transactions not added to the DB '\n f'from_ts: {query_start_ts} '\n f'to_ts: {query_end_ts} '\n f'internal: {internal}',\n )\n\n # add new transactions to the DB\n if new_transactions != []:\n self.database.add_ethereum_transactions(new_transactions, from_etherscan=True)\n # And since at least for now the increasingly negative nonce for the internal\n # transactions happens only in the DB writing, requery the entire batch from\n # the DB to get the updated transactions\n transactions = self.database.get_ethereum_transactions(\n from_ts=start_ts,\n to_ts=end_ts,\n address=address,\n )\n\n # and also set the last queried timestamps for the address\n ranges.update_used_query_range(\n location_string=f'ethtxs_{address}',\n start_ts=start_ts,\n end_ts=end_ts,\n ranges_to_query=ranges_to_query,\n )\n\n if with_limit:\n transactions_queried_so_far = sum(x for _, x in self.tx_per_address.items())\n remaining_num_tx = FREE_ETH_TX_LIMIT - transactions_queried_so_far\n returning_tx_length = min(remaining_num_tx, len(transactions))\n # Note down how many we got for this address\n self.tx_per_address[address] = returning_tx_length\n return transactions[:returning_tx_length]\n\n return transactions\n\n @protect_with_lock()\n def query(\n self,\n address: Optional[ChecksumEthAddress],\n from_ts: Timestamp,\n to_ts: Timestamp,\n with_limit: bool = False,\n recent_first: bool = False,\n ) -> List[EthereumTransaction]:\n \"\"\"Queries for all transactions (normal AND internal) of all ethereum accounts.\n Returns a list of all transactions of all accounts sorted by time.\n\n If `with_limit` is true then the api limit is applied\n\n if `recent_first` is true then the transactions are returned with the most\n recent first on the list\n\n May raise:\n - RemoteError if etherscan is used and there is a problem with reaching it or\n with parsing the response.\n \"\"\"\n transactions: List[EthereumTransaction] = []\n\n if address is not None:\n accounts = [address]\n else:\n accounts = self.database.get_blockchain_accounts().eth\n\n for address in accounts:\n transactions.extend(self._single_address_query_transactions(\n address=address,\n start_ts=from_ts,\n end_ts=to_ts,\n with_limit=with_limit,\n ))\n\n transactions.sort(key=lambda tx: tx.timestamp, reverse=recent_first)\n return transactions\n", "path": "rotkehlchen/chain/ethereum/transactions.py"}]}
| 1,643 | 291 |
gh_patches_debug_28393
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-966
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Outside of an Sub error for arn:aws:s3:::${transfer:HomeBucket}
*cfn-lint version: 0.21.5*
*Description of issue.*
When defining a scope down policy for AWS SFTP transfer, cfn-lint gives error **E1029 Found an embedded parameter outside of an "Fn::Sub"** on things like `arn:aws:s3:::${transfer:HomeBucket}`. Is there anyway to exclude those?
```yaml
SftpScopeDownPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: Policy for restricting SFTP users to have access to only their home directory
ManagedPolicyName: sftp-scope-down-policy
PolicyDocument:
Version: "2012-10-17"
Statement:
-
Sid: AllowListingOfUserFolder
Effect: Allow
Action:
- s3:ListBucket
Resource: arn:aws:s3:::${transfer:HomeBucket}
Condition:
StringLike:
s3:prefix:
- '${transfer:HomeFolder}'
- '${transfer:HomeFolder}/*'
-
Sid: HomeDirectoryObjectAccess
Effect: Allow
Action:
- s3:GetObject
- s3:GetObjectVersion
- s3:PutObject
- s3:DeleteObject
- s3:DeleteObjectVersion
- s3:GetObjectACL
Resource: arn:aws:s3:::${transfer:HomeDirectory}*
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/functions/SubNeeded.py`
Content:
```
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 from cfnlint import CloudFormationLintRule
19 from cfnlint import RuleMatch
20
21 class SubNeeded(CloudFormationLintRule):
22 """Check if a substitution string exists without a substitution function"""
23 id = 'E1029'
24 shortdesc = 'Sub is required if a variable is used in a string'
25 description = 'If a substitution variable exists in a string but isn\'t wrapped with the Fn::Sub function the deployment will fail.'
26 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'
27 tags = ['functions', 'sub']
28
29 # Free-form text properties to exclude from this rule
30 # content is part of AWS::CloudFormation::Init
31 excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init', 'CloudWatchAlarmDefinition']
32 api_excludes = ['Uri', 'Body']
33
34 # IAM Policy has special variables that don't require !Sub, Check for these
35 # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html
36 # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html
37 # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html
38 resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}', '${aws:TokenIssueTime}', '${aws:principaltype}',
39 '${aws:SecureTransport}', '${aws:SourceIp}', '${aws:UserAgent}', '${aws:userid}',
40 '${aws:username}', '${ec2:SourceInstanceARN}',
41 '${iot:Connection.Thing.ThingName}', '${iot:Connection.Thing.ThingTypeName}',
42 '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}']
43
44 def _match_values(self, searchRegex, cfnelem, path):
45 """Recursively search for values matching the searchRegex"""
46 values = []
47 if isinstance(cfnelem, dict):
48 for key in cfnelem:
49 pathprop = path[:]
50 pathprop.append(key)
51 values.extend(self._match_values(searchRegex, cfnelem[key], pathprop))
52 elif isinstance(cfnelem, list):
53 for index, item in enumerate(cfnelem):
54 pathprop = path[:]
55 pathprop.append(index)
56 values.extend(self._match_values(searchRegex, item, pathprop))
57 else:
58 # Leaf node
59 if isinstance(cfnelem, str) and re.match(searchRegex, cfnelem):
60 # Get all variables as seperate paths
61 regex = re.compile(r'(\$\{.*?\.?.*?})')
62 for variable in re.findall(regex, cfnelem):
63 values.append(path + [variable])
64
65 return values
66
67 def match_values(self, searchRegex, cfn):
68 """
69 Search for values in all parts of the templates that match the searchRegex
70 """
71 results = []
72 results.extend(self._match_values(searchRegex, cfn.template, []))
73 # Globals are removed during a transform. They need to be checked manually
74 results.extend(self._match_values(searchRegex, cfn.template.get('Globals', {}), []))
75 return results
76
77 def _api_exceptions(self, value):
78 """ Key value exceptions """
79 parameter_search = re.compile(r'^\$\{stageVariables\..*\}$')
80 return re.match(parameter_search, value)
81
82 def match(self, cfn):
83 """Basic Rule Matching"""
84
85 matches = []
86
87 # Generic regex to match a string containing at least one ${parameter}
88 parameter_search = re.compile(r'^.*(\$\{.*\}.*(\$\{.*\}.*)*)$')
89
90 # Get a list of paths to every leaf node string containing at least one ${parameter}
91 parameter_string_paths = self.match_values(parameter_search, cfn)
92
93 # We want to search all of the paths to check if each one contains an 'Fn::Sub'
94 for parameter_string_path in parameter_string_paths:
95
96 # Exxclude the special IAM variables
97 variable = parameter_string_path[-1]
98
99 if 'Resource' in parameter_string_path:
100 if variable in self.resource_excludes:
101 continue
102
103 # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)
104 if variable.startswith('${!'):
105 continue
106
107 found_sub = False
108 # Does the path contain an 'Fn::Sub'?
109 for step in parameter_string_path:
110 if step in self.api_excludes:
111 if self._api_exceptions(parameter_string_path[-1]):
112 found_sub = True
113 elif step == 'Fn::Sub' or step in self.excludes:
114 found_sub = True
115
116 # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly
117 if not found_sub:
118 # Remove the last item (the variable) to prevent multiple errors on 1 line errors
119 path = parameter_string_path[:-1]
120 message = 'Found an embedded parameter outside of an "Fn::Sub" at {}'.format('/'.join(map(str, path)))
121 matches.append(RuleMatch(path, message))
122
123 return matches
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py
--- a/src/cfnlint/rules/functions/SubNeeded.py
+++ b/src/cfnlint/rules/functions/SubNeeded.py
@@ -35,11 +35,13 @@
# https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html
# https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html
# https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html
+ # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down
resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}', '${aws:TokenIssueTime}', '${aws:principaltype}',
'${aws:SecureTransport}', '${aws:SourceIp}', '${aws:UserAgent}', '${aws:userid}',
'${aws:username}', '${ec2:SourceInstanceARN}',
'${iot:Connection.Thing.ThingName}', '${iot:Connection.Thing.ThingTypeName}',
- '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}']
+ '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}', '${transfer:HomeBucket}',
+ '${transfer:HomeDirectory}', '${transfer:HomeFolder}', '${transfer:UserName}']
def _match_values(self, searchRegex, cfnelem, path):
"""Recursively search for values matching the searchRegex"""
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py\n--- a/src/cfnlint/rules/functions/SubNeeded.py\n+++ b/src/cfnlint/rules/functions/SubNeeded.py\n@@ -35,11 +35,13 @@\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html\n+ # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down\n resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}', '${aws:TokenIssueTime}', '${aws:principaltype}',\n '${aws:SecureTransport}', '${aws:SourceIp}', '${aws:UserAgent}', '${aws:userid}',\n '${aws:username}', '${ec2:SourceInstanceARN}',\n '${iot:Connection.Thing.ThingName}', '${iot:Connection.Thing.ThingTypeName}',\n- '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}']\n+ '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}', '${transfer:HomeBucket}',\n+ '${transfer:HomeDirectory}', '${transfer:HomeFolder}', '${transfer:UserName}']\n \n def _match_values(self, searchRegex, cfnelem, path):\n \"\"\"Recursively search for values matching the searchRegex\"\"\"\n", "issue": "Outside of an Sub error for arn:aws:s3:::${transfer:HomeBucket}\n*cfn-lint version: 0.21.5*\r\n\r\n*Description of issue.*\r\nWhen defining a scope down policy for AWS SFTP transfer, cfn-lint gives error **E1029 Found an embedded parameter outside of an \"Fn::Sub\"** on things like `arn:aws:s3:::${transfer:HomeBucket}`. Is there anyway to exclude those?\r\n\r\n```yaml\r\n SftpScopeDownPolicy:\r\n Type: AWS::IAM::ManagedPolicy\r\n Properties:\r\n Description: Policy for restricting SFTP users to have access to only their home directory\r\n ManagedPolicyName: sftp-scope-down-policy\r\n PolicyDocument:\r\n Version: \"2012-10-17\"\r\n Statement:\r\n -\r\n Sid: AllowListingOfUserFolder\r\n Effect: Allow\r\n Action:\r\n - s3:ListBucket\r\n Resource: arn:aws:s3:::${transfer:HomeBucket}\r\n Condition:\r\n StringLike:\r\n s3:prefix:\r\n - '${transfer:HomeFolder}'\r\n - '${transfer:HomeFolder}/*'\r\n -\r\n Sid: HomeDirectoryObjectAccess\r\n Effect: Allow\r\n Action:\r\n - s3:GetObject\r\n - s3:GetObjectVersion\r\n - s3:PutObject\r\n - s3:DeleteObject\r\n - s3:DeleteObjectVersion\r\n - s3:GetObjectACL\r\n Resource: arn:aws:s3:::${transfer:HomeDirectory}*\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nclass SubNeeded(CloudFormationLintRule):\n \"\"\"Check if a substitution string exists without a substitution function\"\"\"\n id = 'E1029'\n shortdesc = 'Sub is required if a variable is used in a string'\n description = 'If a substitution variable exists in a string but isn\\'t wrapped with the Fn::Sub function the deployment will fail.'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n # Free-form text properties to exclude from this rule\n # content is part of AWS::CloudFormation::Init\n excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init', 'CloudWatchAlarmDefinition']\n api_excludes = ['Uri', 'Body']\n\n # IAM Policy has special variables that don't require !Sub, Check for these\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html\n resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}', '${aws:TokenIssueTime}', '${aws:principaltype}',\n '${aws:SecureTransport}', '${aws:SourceIp}', '${aws:UserAgent}', '${aws:userid}',\n '${aws:username}', '${ec2:SourceInstanceARN}',\n '${iot:Connection.Thing.ThingName}', '${iot:Connection.Thing.ThingTypeName}',\n '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}']\n\n def _match_values(self, searchRegex, cfnelem, path):\n \"\"\"Recursively search for values matching the searchRegex\"\"\"\n values = []\n if isinstance(cfnelem, dict):\n for key in cfnelem:\n pathprop = path[:]\n pathprop.append(key)\n values.extend(self._match_values(searchRegex, cfnelem[key], pathprop))\n elif isinstance(cfnelem, list):\n for index, item in enumerate(cfnelem):\n pathprop = path[:]\n pathprop.append(index)\n values.extend(self._match_values(searchRegex, item, pathprop))\n else:\n # Leaf node\n if isinstance(cfnelem, str) and re.match(searchRegex, cfnelem):\n # Get all variables as seperate paths\n regex = re.compile(r'(\\$\\{.*?\\.?.*?})')\n for variable in re.findall(regex, cfnelem):\n values.append(path + [variable])\n\n return values\n\n def match_values(self, searchRegex, cfn):\n \"\"\"\n Search for values in all parts of the templates that match the searchRegex\n \"\"\"\n results = []\n results.extend(self._match_values(searchRegex, cfn.template, []))\n # Globals are removed during a transform. They need to be checked manually\n results.extend(self._match_values(searchRegex, cfn.template.get('Globals', {}), []))\n return results\n\n def _api_exceptions(self, value):\n \"\"\" Key value exceptions \"\"\"\n parameter_search = re.compile(r'^\\$\\{stageVariables\\..*\\}$')\n return re.match(parameter_search, value)\n\n def match(self, cfn):\n \"\"\"Basic Rule Matching\"\"\"\n\n matches = []\n\n # Generic regex to match a string containing at least one ${parameter}\n parameter_search = re.compile(r'^.*(\\$\\{.*\\}.*(\\$\\{.*\\}.*)*)$')\n\n # Get a list of paths to every leaf node string containing at least one ${parameter}\n parameter_string_paths = self.match_values(parameter_search, cfn)\n\n # We want to search all of the paths to check if each one contains an 'Fn::Sub'\n for parameter_string_path in parameter_string_paths:\n\n # Exxclude the special IAM variables\n variable = parameter_string_path[-1]\n\n if 'Resource' in parameter_string_path:\n if variable in self.resource_excludes:\n continue\n\n # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)\n if variable.startswith('${!'):\n continue\n\n found_sub = False\n # Does the path contain an 'Fn::Sub'?\n for step in parameter_string_path:\n if step in self.api_excludes:\n if self._api_exceptions(parameter_string_path[-1]):\n found_sub = True\n elif step == 'Fn::Sub' or step in self.excludes:\n found_sub = True\n\n # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly\n if not found_sub:\n # Remove the last item (the variable) to prevent multiple errors on 1 line errors\n path = parameter_string_path[:-1]\n message = 'Found an embedded parameter outside of an \"Fn::Sub\" at {}'.format('/'.join(map(str, path)))\n matches.append(RuleMatch(path, message))\n\n return matches\n", "path": "src/cfnlint/rules/functions/SubNeeded.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nclass SubNeeded(CloudFormationLintRule):\n \"\"\"Check if a substitution string exists without a substitution function\"\"\"\n id = 'E1029'\n shortdesc = 'Sub is required if a variable is used in a string'\n description = 'If a substitution variable exists in a string but isn\\'t wrapped with the Fn::Sub function the deployment will fail.'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n # Free-form text properties to exclude from this rule\n # content is part of AWS::CloudFormation::Init\n excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init', 'CloudWatchAlarmDefinition']\n api_excludes = ['Uri', 'Body']\n\n # IAM Policy has special variables that don't require !Sub, Check for these\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html\n # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down\n resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}', '${aws:TokenIssueTime}', '${aws:principaltype}',\n '${aws:SecureTransport}', '${aws:SourceIp}', '${aws:UserAgent}', '${aws:userid}',\n '${aws:username}', '${ec2:SourceInstanceARN}',\n '${iot:Connection.Thing.ThingName}', '${iot:Connection.Thing.ThingTypeName}',\n '${iot:Connection.Thing.IsAttached}', '${iot:ClientId}', '${transfer:HomeBucket}',\n '${transfer:HomeDirectory}', '${transfer:HomeFolder}', '${transfer:UserName}']\n\n def _match_values(self, searchRegex, cfnelem, path):\n \"\"\"Recursively search for values matching the searchRegex\"\"\"\n values = []\n if isinstance(cfnelem, dict):\n for key in cfnelem:\n pathprop = path[:]\n pathprop.append(key)\n values.extend(self._match_values(searchRegex, cfnelem[key], pathprop))\n elif isinstance(cfnelem, list):\n for index, item in enumerate(cfnelem):\n pathprop = path[:]\n pathprop.append(index)\n values.extend(self._match_values(searchRegex, item, pathprop))\n else:\n # Leaf node\n if isinstance(cfnelem, str) and re.match(searchRegex, cfnelem):\n # Get all variables as seperate paths\n regex = re.compile(r'(\\$\\{.*?\\.?.*?})')\n for variable in re.findall(regex, cfnelem):\n values.append(path + [variable])\n\n return values\n\n def match_values(self, searchRegex, cfn):\n \"\"\"\n Search for values in all parts of the templates that match the searchRegex\n \"\"\"\n results = []\n results.extend(self._match_values(searchRegex, cfn.template, []))\n # Globals are removed during a transform. They need to be checked manually\n results.extend(self._match_values(searchRegex, cfn.template.get('Globals', {}), []))\n return results\n\n def _api_exceptions(self, value):\n \"\"\" Key value exceptions \"\"\"\n parameter_search = re.compile(r'^\\$\\{stageVariables\\..*\\}$')\n return re.match(parameter_search, value)\n\n def match(self, cfn):\n \"\"\"Basic Rule Matching\"\"\"\n\n matches = []\n\n # Generic regex to match a string containing at least one ${parameter}\n parameter_search = re.compile(r'^.*(\\$\\{.*\\}.*(\\$\\{.*\\}.*)*)$')\n\n # Get a list of paths to every leaf node string containing at least one ${parameter}\n parameter_string_paths = self.match_values(parameter_search, cfn)\n\n # We want to search all of the paths to check if each one contains an 'Fn::Sub'\n for parameter_string_path in parameter_string_paths:\n\n # Exxclude the special IAM variables\n variable = parameter_string_path[-1]\n\n if 'Resource' in parameter_string_path:\n if variable in self.resource_excludes:\n continue\n\n # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)\n if variable.startswith('${!'):\n continue\n\n found_sub = False\n # Does the path contain an 'Fn::Sub'?\n for step in parameter_string_path:\n if step in self.api_excludes:\n if self._api_exceptions(parameter_string_path[-1]):\n found_sub = True\n elif step == 'Fn::Sub' or step in self.excludes:\n found_sub = True\n\n # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly\n if not found_sub:\n # Remove the last item (the variable) to prevent multiple errors on 1 line errors\n path = parameter_string_path[:-1]\n message = 'Found an embedded parameter outside of an \"Fn::Sub\" at {}'.format('/'.join(map(str, path)))\n matches.append(RuleMatch(path, message))\n\n return matches\n", "path": "src/cfnlint/rules/functions/SubNeeded.py"}]}
| 2,194 | 326 |
gh_patches_debug_7850
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5436
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.mitele: 403 Client Error: Missing hdnts for url
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
The channel "Boing" on Mitele is not working with the plugin anymore...
### Debug log
```text
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.3
[cli][debug] Streamlink: 5.5.1
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.5.7
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.2
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.17
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.29.0
[cli][debug] urllib3: 1.26.15
[cli][debug] websocket-client: 1.5.1
[cli][debug] Arguments:
[cli][debug] url=https://www.mitele.es/directo/boing/
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --locale=es_ES
[cli][debug] --player-external-http=True
[cli][debug] --player-external-http-port=339
[cli][debug] --hls-audio-select=['*']
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files\Streamlink\ffmpeg\ffmpeg.exe
[cli][debug] --ffmpeg-copyts=True
[cli][debug] --http-proxy=http://AsTJems3WD4V4HgrSTWWkJm9:[email protected]:8080/
[cli][info] Found matching plugin mitele for URL https://www.mitele.es/directo/boing/
[utils.l10n][debug] Language code: es_ES
error: Unable to open URL: https://livek.mediaset.es/orilinear31/live/linear31/playlist/playlist.isml/ctv.m3u8 (403 Client Error: Missing hdnts for url: https://livek.mediaset.es/orilinear31/live/linear31/playlist/playlist.isml/ctv.m3u8)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/mitele.py`
Content:
```
1 """
2 $description Spanish live TV channels from Mediaset Group, including Boing, Cuatro, Divinity, Energy, FDF and Telecinco.
3 $url mitele.es
4 $type live
5 $region Spain
6 """
7
8 import logging
9 import re
10
11 from streamlink.plugin import Plugin, pluginmatcher
12 from streamlink.plugin.api import validate
13 from streamlink.stream.hls import HLSStream
14 from streamlink.utils.parse import parse_qsd
15 from streamlink.utils.url import update_qsd
16
17
18 log = logging.getLogger(__name__)
19
20
21 @pluginmatcher(re.compile(
22 r"https?://(?:www\.)?mitele\.es/directo/(?P<channel>[\w-]+)",
23 ))
24 class Mitele(Plugin):
25 URL_CARONTE = "https://caronte.mediaset.es/delivery/channel/mmc/{channel}/mtweb"
26 URL_GBX = "https://mab.mediaset.es/1.0.0/get"
27
28 TOKEN_ERRORS = {
29 4038: "User has no privileges",
30 }
31
32 def _get_streams(self):
33 channel = self.match.group("channel")
34
35 pdata = self.session.http.get(
36 self.URL_CARONTE.format(channel=channel),
37 acceptable_status=(200, 403, 404),
38 schema=validate.Schema(
39 validate.parse_json(),
40 validate.any(
41 {"code": int},
42 {
43 "cerbero": validate.url(),
44 "bbx": str,
45 "dls": validate.all(
46 [{
47 "drm": bool,
48 "format": str,
49 "stream": validate.all(
50 validate.transform(str.strip),
51 validate.url(),
52 ),
53 "lid": validate.all(
54 int,
55 validate.transform(str),
56 ),
57 validate.optional("assetKey"): str,
58 }],
59 validate.filter(lambda obj: obj["format"] == "hls"),
60 ),
61 },
62 ),
63 ),
64 )
65 if "code" in pdata:
66 log.error(f"Error getting pdata: {pdata['code']}")
67 return
68
69 gbx = self.session.http.get(
70 self.URL_GBX,
71 params={
72 "oid": "mtmw",
73 "eid": f"/api/mtmw/v2/gbx/mtweb/live/mmc/{channel}",
74 },
75 schema=validate.Schema(
76 validate.parse_json(),
77 {"gbx": str},
78 validate.get("gbx"),
79 ),
80 )
81
82 tokens = self.session.http.post(
83 pdata["cerbero"],
84 acceptable_status=(200, 403, 404),
85 json={
86 "bbx": pdata["bbx"],
87 "gbx": gbx,
88 },
89 headers={"origin": "https://www.mitele.es"},
90 schema=validate.Schema(
91 validate.parse_json(),
92 validate.any(
93 {"code": int},
94 validate.all(
95 {"tokens": {str: {"cdn": str}}},
96 validate.get("tokens"),
97 ),
98 ),
99 ),
100 )
101 if "code" in tokens:
102 tokenerrors = self.TOKEN_ERRORS.get(tokens["code"], "unknown error")
103 log.error(f"Could not get stream tokens: {tokens['code']} ({tokenerrors})")
104 return
105
106 urls = set()
107 for stream in pdata["dls"]:
108 if stream["drm"]:
109 log.warning("Stream may be protected by DRM")
110 continue
111 cdn_token = tokens.get(stream["lid"], {}).get("cdn", "")
112 qsd = parse_qsd(cdn_token)
113 urls.add(update_qsd(stream["stream"], qsd, quote_via=lambda string, *_, **__: string))
114
115 for url in urls:
116 yield from HLSStream.parse_variant_playlist(
117 self.session,
118 url,
119 headers={"Origin": "https://www.mitele.es"},
120 name_fmt="{pixels}_{bitrate}",
121 ).items()
122
123
124 __plugin__ = Mitele
125
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/mitele.py b/src/streamlink/plugins/mitele.py
--- a/src/streamlink/plugins/mitele.py
+++ b/src/streamlink/plugins/mitele.py
@@ -109,6 +109,8 @@
log.warning("Stream may be protected by DRM")
continue
cdn_token = tokens.get(stream["lid"], {}).get("cdn", "")
+ if not cdn_token:
+ continue
qsd = parse_qsd(cdn_token)
urls.add(update_qsd(stream["stream"], qsd, quote_via=lambda string, *_, **__: string))
|
{"golden_diff": "diff --git a/src/streamlink/plugins/mitele.py b/src/streamlink/plugins/mitele.py\n--- a/src/streamlink/plugins/mitele.py\n+++ b/src/streamlink/plugins/mitele.py\n@@ -109,6 +109,8 @@\n log.warning(\"Stream may be protected by DRM\")\n continue\n cdn_token = tokens.get(stream[\"lid\"], {}).get(\"cdn\", \"\")\n+ if not cdn_token:\n+ continue\n qsd = parse_qsd(cdn_token)\n urls.add(update_qsd(stream[\"stream\"], qsd, quote_via=lambda string, *_, **__: string))\n", "issue": "plugins.mitele: 403 Client Error: Missing hdnts for url\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nThe channel \"Boing\" on Mitele is not working with the plugin anymore...\n\n### Debug log\n\n```text\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.3\r\n[cli][debug] Streamlink: 5.5.1\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.5.7\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.2\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.17\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.29.0\r\n[cli][debug] urllib3: 1.26.15\r\n[cli][debug] websocket-client: 1.5.1\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.mitele.es/directo/boing/\r\n[cli][debug] stream=['best']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --locale=es_ES\r\n[cli][debug] --player-external-http=True\r\n[cli][debug] --player-external-http-port=339\r\n[cli][debug] --hls-audio-select=['*']\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\Program Files\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][debug] --ffmpeg-copyts=True\r\n[cli][debug] --http-proxy=http://AsTJems3WD4V4HgrSTWWkJm9:[email protected]:8080/\r\n[cli][info] Found matching plugin mitele for URL https://www.mitele.es/directo/boing/\r\n[utils.l10n][debug] Language code: es_ES\r\nerror: Unable to open URL: https://livek.mediaset.es/orilinear31/live/linear31/playlist/playlist.isml/ctv.m3u8 (403 Client Error: Missing hdnts for url: https://livek.mediaset.es/orilinear31/live/linear31/playlist/playlist.isml/ctv.m3u8)\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Spanish live TV channels from Mediaset Group, including Boing, Cuatro, Divinity, Energy, FDF and Telecinco.\n$url mitele.es\n$type live\n$region Spain\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.parse import parse_qsd\nfrom streamlink.utils.url import update_qsd\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?mitele\\.es/directo/(?P<channel>[\\w-]+)\",\n))\nclass Mitele(Plugin):\n URL_CARONTE = \"https://caronte.mediaset.es/delivery/channel/mmc/{channel}/mtweb\"\n URL_GBX = \"https://mab.mediaset.es/1.0.0/get\"\n\n TOKEN_ERRORS = {\n 4038: \"User has no privileges\",\n }\n\n def _get_streams(self):\n channel = self.match.group(\"channel\")\n\n pdata = self.session.http.get(\n self.URL_CARONTE.format(channel=channel),\n acceptable_status=(200, 403, 404),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\"code\": int},\n {\n \"cerbero\": validate.url(),\n \"bbx\": str,\n \"dls\": validate.all(\n [{\n \"drm\": bool,\n \"format\": str,\n \"stream\": validate.all(\n validate.transform(str.strip),\n validate.url(),\n ),\n \"lid\": validate.all(\n int,\n validate.transform(str),\n ),\n validate.optional(\"assetKey\"): str,\n }],\n validate.filter(lambda obj: obj[\"format\"] == \"hls\"),\n ),\n },\n ),\n ),\n )\n if \"code\" in pdata:\n log.error(f\"Error getting pdata: {pdata['code']}\")\n return\n\n gbx = self.session.http.get(\n self.URL_GBX,\n params={\n \"oid\": \"mtmw\",\n \"eid\": f\"/api/mtmw/v2/gbx/mtweb/live/mmc/{channel}\",\n },\n schema=validate.Schema(\n validate.parse_json(),\n {\"gbx\": str},\n validate.get(\"gbx\"),\n ),\n )\n\n tokens = self.session.http.post(\n pdata[\"cerbero\"],\n acceptable_status=(200, 403, 404),\n json={\n \"bbx\": pdata[\"bbx\"],\n \"gbx\": gbx,\n },\n headers={\"origin\": \"https://www.mitele.es\"},\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\"code\": int},\n validate.all(\n {\"tokens\": {str: {\"cdn\": str}}},\n validate.get(\"tokens\"),\n ),\n ),\n ),\n )\n if \"code\" in tokens:\n tokenerrors = self.TOKEN_ERRORS.get(tokens[\"code\"], \"unknown error\")\n log.error(f\"Could not get stream tokens: {tokens['code']} ({tokenerrors})\")\n return\n\n urls = set()\n for stream in pdata[\"dls\"]:\n if stream[\"drm\"]:\n log.warning(\"Stream may be protected by DRM\")\n continue\n cdn_token = tokens.get(stream[\"lid\"], {}).get(\"cdn\", \"\")\n qsd = parse_qsd(cdn_token)\n urls.add(update_qsd(stream[\"stream\"], qsd, quote_via=lambda string, *_, **__: string))\n\n for url in urls:\n yield from HLSStream.parse_variant_playlist(\n self.session,\n url,\n headers={\"Origin\": \"https://www.mitele.es\"},\n name_fmt=\"{pixels}_{bitrate}\",\n ).items()\n\n\n__plugin__ = Mitele\n", "path": "src/streamlink/plugins/mitele.py"}], "after_files": [{"content": "\"\"\"\n$description Spanish live TV channels from Mediaset Group, including Boing, Cuatro, Divinity, Energy, FDF and Telecinco.\n$url mitele.es\n$type live\n$region Spain\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.parse import parse_qsd\nfrom streamlink.utils.url import update_qsd\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?mitele\\.es/directo/(?P<channel>[\\w-]+)\",\n))\nclass Mitele(Plugin):\n URL_CARONTE = \"https://caronte.mediaset.es/delivery/channel/mmc/{channel}/mtweb\"\n URL_GBX = \"https://mab.mediaset.es/1.0.0/get\"\n\n TOKEN_ERRORS = {\n 4038: \"User has no privileges\",\n }\n\n def _get_streams(self):\n channel = self.match.group(\"channel\")\n\n pdata = self.session.http.get(\n self.URL_CARONTE.format(channel=channel),\n acceptable_status=(200, 403, 404),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\"code\": int},\n {\n \"cerbero\": validate.url(),\n \"bbx\": str,\n \"dls\": validate.all(\n [{\n \"drm\": bool,\n \"format\": str,\n \"stream\": validate.all(\n validate.transform(str.strip),\n validate.url(),\n ),\n \"lid\": validate.all(\n int,\n validate.transform(str),\n ),\n validate.optional(\"assetKey\"): str,\n }],\n validate.filter(lambda obj: obj[\"format\"] == \"hls\"),\n ),\n },\n ),\n ),\n )\n if \"code\" in pdata:\n log.error(f\"Error getting pdata: {pdata['code']}\")\n return\n\n gbx = self.session.http.get(\n self.URL_GBX,\n params={\n \"oid\": \"mtmw\",\n \"eid\": f\"/api/mtmw/v2/gbx/mtweb/live/mmc/{channel}\",\n },\n schema=validate.Schema(\n validate.parse_json(),\n {\"gbx\": str},\n validate.get(\"gbx\"),\n ),\n )\n\n tokens = self.session.http.post(\n pdata[\"cerbero\"],\n acceptable_status=(200, 403, 404),\n json={\n \"bbx\": pdata[\"bbx\"],\n \"gbx\": gbx,\n },\n headers={\"origin\": \"https://www.mitele.es\"},\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\"code\": int},\n validate.all(\n {\"tokens\": {str: {\"cdn\": str}}},\n validate.get(\"tokens\"),\n ),\n ),\n ),\n )\n if \"code\" in tokens:\n tokenerrors = self.TOKEN_ERRORS.get(tokens[\"code\"], \"unknown error\")\n log.error(f\"Could not get stream tokens: {tokens['code']} ({tokenerrors})\")\n return\n\n urls = set()\n for stream in pdata[\"dls\"]:\n if stream[\"drm\"]:\n log.warning(\"Stream may be protected by DRM\")\n continue\n cdn_token = tokens.get(stream[\"lid\"], {}).get(\"cdn\", \"\")\n if not cdn_token:\n continue\n qsd = parse_qsd(cdn_token)\n urls.add(update_qsd(stream[\"stream\"], qsd, quote_via=lambda string, *_, **__: string))\n\n for url in urls:\n yield from HLSStream.parse_variant_playlist(\n self.session,\n url,\n headers={\"Origin\": \"https://www.mitele.es\"},\n name_fmt=\"{pixels}_{bitrate}\",\n ).items()\n\n\n__plugin__ = Mitele\n", "path": "src/streamlink/plugins/mitele.py"}]}
| 2,072 | 136 |
gh_patches_debug_28356
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-3658
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CurrentLayoutIcon failing wiith custom layout names
### The issue:
Qtile version: 0.21.0
Relevant logs:
```
2022-06-25 11:37:44,763 ERROR libqtile currentlayout.py:draw():L146 No icon for layout shiftytile
2022-06-25 11:37:47,899 ERROR libqtile currentlayout.py:draw():L146 No icon for layout monadtile
```
(EDIT: My browser ate the rest of this issue. Rewriting.)
I have a couple of tile layouts with custom names and parameters:
```python
layout.Tile(name='monadtile',
add_on_top=False,
shift_windows=False,
margin_on_single=False,
border_on_single=False,
expand=True,
ratio=0.47,
**layout_theme),
layout.Columns(**layout_theme),
layout.Tile(name='shiftytile',
add_on_top=True,
shift_windows=True,
margin_on_single=False,
expand=False,
**layout_theme),
```
The correspondiing widget config is
```python
widget.CurrentLayoutIcon(
custom_icon_paths = [os.path.expanduser("~/.config/qtile/icons")],
foreground = colors[0],
background = pair.cols[0],
padding = 0,
scale = 0.6
),
```
I have icons named `layout-monadtile.png` and `layout-shiftytile.png` in `~/.config/qtile/icons`. They don't show up, and I get the above messages in qtile.log.
The problem is the following. The widget (`libqtile/widget/currentlayout.py`) obtains a list of layout names using
```python
def _get_layout_names(self):
"""
Returns the list of lowercased strings for each available layout name.
"""
return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]
```
I logged it to see what it finds:
``` python
logger.warn(",".join([layout.__class__.__name__.lower() for layout in qtile.config.layouts]))
```
And it finds this:
``` python
2022-06-25 12:20:05,007 WARNING libqtile groups.py:layout_names_test():L51 tile,columns,tile
```
and not `monadtile,columns,shiftytile`. I changed `_get_layout_names` to
```python
def _get_layout_names(self):
"""
Returns the list of lowercased strings for each available layout name.
"""
return [layout.name.lower() for layout in self.qtile.config.layouts]
```
and the icons for all layouts (including the custom `monadtile` and `shiftytile`) now show up. However I'm guessing there's a reason to use `layout.__class__.__name__` instead of `layout.name`. Any ideas?
### Required:
- [X] I have searched past issues to see if this bug has already been reported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/widget/currentlayout.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2011 Florian Mounier
3 # Copyright (c) 2011 Kenji_Takahashi
4 # Copyright (c) 2012 roger
5 # Copyright (c) 2012, 2014 Tycho Andersen
6 # Copyright (c) 2012 Maximilian Köhl
7 # Copyright (c) 2013 Craig Barnes
8 # Copyright (c) 2014 Sean Vig
9 # Copyright (c) 2014 Adi Sieker
10 #
11 # Permission is hereby granted, free of charge, to any person obtaining a copy
12 # of this software and associated documentation files (the "Software"), to deal
13 # in the Software without restriction, including without limitation the rights
14 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
15 # copies of the Software, and to permit persons to whom the Software is
16 # furnished to do so, subject to the following conditions:
17 #
18 # The above copyright notice and this permission notice shall be included in
19 # all copies or substantial portions of the Software.
20 #
21 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
22 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
23 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
24 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
25 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
26 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
27 # SOFTWARE.
28 import os
29
30 import cairocffi
31
32 from libqtile import bar, hook
33 from libqtile.log_utils import logger
34 from libqtile.widget import base
35
36
37 class CurrentLayout(base._TextBox):
38 """
39 Display the name of the current layout of the current group of the screen,
40 the bar containing the widget, is on.
41 """
42
43 def __init__(self, width=bar.CALCULATED, **config):
44 base._TextBox.__init__(self, "", width, **config)
45
46 def _configure(self, qtile, bar):
47 base._TextBox._configure(self, qtile, bar)
48 layout_id = self.bar.screen.group.current_layout
49 self.text = self.bar.screen.group.layouts[layout_id].name
50 self.setup_hooks()
51
52 self.add_callbacks(
53 {
54 "Button1": qtile.cmd_next_layout,
55 "Button2": qtile.cmd_prev_layout,
56 }
57 )
58
59 def setup_hooks(self):
60 def hook_response(layout, group):
61 if group.screen is not None and group.screen == self.bar.screen:
62 self.text = layout.name
63 self.bar.draw()
64
65 hook.subscribe.layout_change(hook_response)
66
67
68 class CurrentLayoutIcon(base._TextBox):
69 """
70 Display the icon representing the current layout of the
71 current group of the screen on which the bar containing the widget is.
72
73 If you are using custom layouts, a default icon with question mark
74 will be displayed for them. If you want to use custom icon for your own
75 layout, for example, `FooGrid`, then create a file named
76 "layout-foogrid.png" and place it in `~/.icons` directory. You can as well
77 use other directories, but then you need to specify those directories
78 in `custom_icon_paths` argument for this plugin.
79
80 The order of icon search is:
81
82 - dirs in `custom_icon_paths` config argument
83 - `~/.icons`
84 - built-in qtile icons
85 """
86
87 orientations = base.ORIENTATION_HORIZONTAL
88
89 defaults = [
90 ("scale", 1, "Scale factor relative to the bar height. " "Defaults to 1"),
91 (
92 "custom_icon_paths",
93 [],
94 "List of folders where to search icons before"
95 "using built-in icons or icons in ~/.icons dir. "
96 "This can also be used to provide"
97 "missing icons for custom layouts. "
98 "Defaults to empty list.",
99 ),
100 ]
101
102 def __init__(self, **config):
103 base._TextBox.__init__(self, "", **config)
104 self.add_defaults(CurrentLayoutIcon.defaults)
105 self.scale = 1.0 / self.scale
106
107 self.length_type = bar.STATIC
108 self.length = 0
109
110 def _configure(self, qtile, bar):
111 base._TextBox._configure(self, qtile, bar)
112 layout_id = self.bar.screen.group.current_layout
113 self.text = self.bar.screen.group.layouts[layout_id].name
114 self.current_layout = self.text
115 self.icons_loaded = False
116 self.icon_paths = []
117 self.surfaces = {}
118 self._update_icon_paths()
119 self._setup_images()
120 self._setup_hooks()
121
122 self.add_callbacks(
123 {
124 "Button1": qtile.cmd_next_layout,
125 "Button2": qtile.cmd_prev_layout,
126 }
127 )
128
129 def _setup_hooks(self):
130 """
131 Listens for layout change and performs a redraw when it occurs.
132 """
133
134 def hook_response(layout, group):
135 if group.screen is not None and group.screen == self.bar.screen:
136 self.current_layout = layout.name
137 self.bar.draw()
138
139 hook.subscribe.layout_change(hook_response)
140
141 def draw(self):
142 if self.icons_loaded:
143 try:
144 surface = self.surfaces[self.current_layout]
145 except KeyError:
146 logger.error("No icon for layout %s", self.current_layout)
147 else:
148 self.drawer.clear(self.background or self.bar.background)
149 self.drawer.ctx.set_source(surface)
150 self.drawer.ctx.paint()
151 self.drawer.draw(offsetx=self.offset, offsety=self.offsety, width=self.length)
152 else:
153 # Fallback to text
154 self.text = self.current_layout[0].upper()
155 base._TextBox.draw(self)
156
157 def _get_layout_names(self):
158 """
159 Returns the list of lowercased strings for each available layout name.
160 """
161 return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]
162
163 def _update_icon_paths(self):
164 self.icon_paths = []
165
166 # We allow user to override icon search path
167 self.icon_paths.extend(self.custom_icon_paths)
168
169 # We also look in ~/.icons/ and ~/.local/share/icons
170 self.icon_paths.append(os.path.expanduser("~/.icons"))
171 self.icon_paths.append(os.path.expanduser("~/.local/share/icons"))
172
173 # Default icons are in libqtile/resources/layout-icons.
174 # If using default config without any custom icons,
175 # this path will be used.
176 root = os.sep.join(os.path.abspath(__file__).split(os.sep)[:-2])
177 self.icon_paths.append(os.path.join(root, "resources", "layout-icons"))
178
179 def find_icon_file_path(self, layout_name):
180 icon_filename = "layout-{}.png".format(layout_name)
181 for icon_path in self.icon_paths:
182 icon_file_path = os.path.join(icon_path, icon_filename)
183 if os.path.isfile(icon_file_path):
184 return icon_file_path
185
186 def _setup_images(self):
187 """
188 Loads layout icons.
189 """
190 for layout_name in self._get_layout_names():
191 icon_file_path = self.find_icon_file_path(layout_name)
192 if icon_file_path is None:
193 logger.warning('No icon found for layout "%s"', layout_name)
194 icon_file_path = self.find_icon_file_path("unknown")
195
196 try:
197 img = cairocffi.ImageSurface.create_from_png(icon_file_path)
198 except (cairocffi.Error, IOError) as e:
199 # Icon file is guaranteed to exist at this point.
200 # If this exception happens, it means the icon file contains
201 # an invalid image or is not readable.
202 self.icons_loaded = False
203 logger.exception(
204 'Failed to load icon from file "%s", error was: %s', icon_file_path, e.message
205 )
206 return
207
208 input_width = img.get_width()
209 input_height = img.get_height()
210
211 sp = input_height / (self.bar.height - 1)
212
213 width = input_width / sp
214 if width > self.length:
215 self.length = int(width) + self.actual_padding * 2
216
217 imgpat = cairocffi.SurfacePattern(img)
218
219 scaler = cairocffi.Matrix()
220
221 scaler.scale(sp, sp)
222 scaler.scale(self.scale, self.scale)
223 factor = (1 - 1 / self.scale) / 2
224 scaler.translate(-width * factor, -width * factor)
225 scaler.translate(self.actual_padding * -1, 0)
226 imgpat.set_matrix(scaler)
227
228 imgpat.set_filter(cairocffi.FILTER_BEST)
229 self.surfaces[layout_name] = imgpat
230
231 self.icons_loaded = True
232
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/widget/currentlayout.py b/libqtile/widget/currentlayout.py
--- a/libqtile/widget/currentlayout.py
+++ b/libqtile/widget/currentlayout.py
@@ -156,9 +156,12 @@
def _get_layout_names(self):
"""
- Returns the list of lowercased strings for each available layout name.
+ Returns a list of tuples of lowercased layout name and class name strings for each available layout.
"""
- return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]
+ return [
+ (layout.name, layout.__class__.__name__.lower())
+ for layout in self.qtile.config.layouts
+ ]
def _update_icon_paths(self):
self.icon_paths = []
@@ -187,9 +190,18 @@
"""
Loads layout icons.
"""
- for layout_name in self._get_layout_names():
- icon_file_path = self.find_icon_file_path(layout_name)
- if icon_file_path is None:
+ for names in self._get_layout_names():
+ layout_name = names[0]
+ # Python doesn't have an ordered set but we can use a dictionary instead
+ # First key is the layout's name (which may have been set by the user),
+ # the second is the class name. If these are the same (i.e. the user hasn't
+ # set a name) then there is only one key in the dictionary.
+ layouts = dict.fromkeys(names)
+ for layout in layouts.keys():
+ icon_file_path = self.find_icon_file_path(layout)
+ if icon_file_path:
+ break
+ else:
logger.warning('No icon found for layout "%s"', layout_name)
icon_file_path = self.find_icon_file_path("unknown")
|
{"golden_diff": "diff --git a/libqtile/widget/currentlayout.py b/libqtile/widget/currentlayout.py\n--- a/libqtile/widget/currentlayout.py\n+++ b/libqtile/widget/currentlayout.py\n@@ -156,9 +156,12 @@\n \n def _get_layout_names(self):\n \"\"\"\n- Returns the list of lowercased strings for each available layout name.\n+ Returns a list of tuples of lowercased layout name and class name strings for each available layout.\n \"\"\"\n- return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]\n+ return [\n+ (layout.name, layout.__class__.__name__.lower())\n+ for layout in self.qtile.config.layouts\n+ ]\n \n def _update_icon_paths(self):\n self.icon_paths = []\n@@ -187,9 +190,18 @@\n \"\"\"\n Loads layout icons.\n \"\"\"\n- for layout_name in self._get_layout_names():\n- icon_file_path = self.find_icon_file_path(layout_name)\n- if icon_file_path is None:\n+ for names in self._get_layout_names():\n+ layout_name = names[0]\n+ # Python doesn't have an ordered set but we can use a dictionary instead\n+ # First key is the layout's name (which may have been set by the user),\n+ # the second is the class name. If these are the same (i.e. the user hasn't\n+ # set a name) then there is only one key in the dictionary.\n+ layouts = dict.fromkeys(names)\n+ for layout in layouts.keys():\n+ icon_file_path = self.find_icon_file_path(layout)\n+ if icon_file_path:\n+ break\n+ else:\n logger.warning('No icon found for layout \"%s\"', layout_name)\n icon_file_path = self.find_icon_file_path(\"unknown\")\n", "issue": "CurrentLayoutIcon failing wiith custom layout names\n### The issue:\r\n\r\nQtile version: 0.21.0\r\n\r\nRelevant logs:\r\n```\r\n2022-06-25 11:37:44,763 ERROR libqtile currentlayout.py:draw():L146 No icon for layout shiftytile\r\n2022-06-25 11:37:47,899 ERROR libqtile currentlayout.py:draw():L146 No icon for layout monadtile\r\n```\r\n\r\n(EDIT: My browser ate the rest of this issue. Rewriting.)\r\n\r\nI have a couple of tile layouts with custom names and parameters:\r\n```python\r\n layout.Tile(name='monadtile',\r\n add_on_top=False,\r\n shift_windows=False,\r\n margin_on_single=False,\r\n border_on_single=False,\r\n expand=True,\r\n ratio=0.47,\r\n **layout_theme),\r\n layout.Columns(**layout_theme),\r\n layout.Tile(name='shiftytile',\r\n add_on_top=True,\r\n shift_windows=True,\r\n margin_on_single=False,\r\n expand=False,\r\n **layout_theme),\r\n```\r\n\r\nThe correspondiing widget config is\r\n```python\r\n widget.CurrentLayoutIcon(\r\n custom_icon_paths = [os.path.expanduser(\"~/.config/qtile/icons\")],\r\n foreground = colors[0],\r\n background = pair.cols[0],\r\n padding = 0,\r\n scale = 0.6\r\n ),\r\n```\r\n\r\nI have icons named `layout-monadtile.png` and `layout-shiftytile.png` in `~/.config/qtile/icons`. They don't show up, and I get the above messages in qtile.log.\r\n\r\nThe problem is the following. The widget (`libqtile/widget/currentlayout.py`) obtains a list of layout names using \r\n```python\r\n def _get_layout_names(self):\r\n \"\"\"\r\n Returns the list of lowercased strings for each available layout name.\r\n \"\"\"\r\n return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]\r\n```\r\n\r\nI logged it to see what it finds:\r\n``` python\r\nlogger.warn(\",\".join([layout.__class__.__name__.lower() for layout in qtile.config.layouts]))\r\n```\r\n\r\nAnd it finds this:\r\n``` python\r\n2022-06-25 12:20:05,007 WARNING libqtile groups.py:layout_names_test():L51 tile,columns,tile\r\n```\r\n\r\nand not `monadtile,columns,shiftytile`. I changed `_get_layout_names` to\r\n```python\r\n def _get_layout_names(self):\r\n \"\"\"\r\n Returns the list of lowercased strings for each available layout name.\r\n \"\"\"\r\n return [layout.name.lower() for layout in self.qtile.config.layouts]\r\n \r\n```\r\n\r\nand the icons for all layouts (including the custom `monadtile` and `shiftytile`) now show up. However I'm guessing there's a reason to use `layout.__class__.__name__` instead of `layout.name`. Any ideas?\r\n\r\n\r\n### Required:\r\n\r\n- [X] I have searched past issues to see if this bug has already been reported.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2011 Florian Mounier\n# Copyright (c) 2011 Kenji_Takahashi\n# Copyright (c) 2012 roger\n# Copyright (c) 2012, 2014 Tycho Andersen\n# Copyright (c) 2012 Maximilian K\u00f6hl\n# Copyright (c) 2013 Craig Barnes\n# Copyright (c) 2014 Sean Vig\n# Copyright (c) 2014 Adi Sieker\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport os\n\nimport cairocffi\n\nfrom libqtile import bar, hook\nfrom libqtile.log_utils import logger\nfrom libqtile.widget import base\n\n\nclass CurrentLayout(base._TextBox):\n \"\"\"\n Display the name of the current layout of the current group of the screen,\n the bar containing the widget, is on.\n \"\"\"\n\n def __init__(self, width=bar.CALCULATED, **config):\n base._TextBox.__init__(self, \"\", width, **config)\n\n def _configure(self, qtile, bar):\n base._TextBox._configure(self, qtile, bar)\n layout_id = self.bar.screen.group.current_layout\n self.text = self.bar.screen.group.layouts[layout_id].name\n self.setup_hooks()\n\n self.add_callbacks(\n {\n \"Button1\": qtile.cmd_next_layout,\n \"Button2\": qtile.cmd_prev_layout,\n }\n )\n\n def setup_hooks(self):\n def hook_response(layout, group):\n if group.screen is not None and group.screen == self.bar.screen:\n self.text = layout.name\n self.bar.draw()\n\n hook.subscribe.layout_change(hook_response)\n\n\nclass CurrentLayoutIcon(base._TextBox):\n \"\"\"\n Display the icon representing the current layout of the\n current group of the screen on which the bar containing the widget is.\n\n If you are using custom layouts, a default icon with question mark\n will be displayed for them. If you want to use custom icon for your own\n layout, for example, `FooGrid`, then create a file named\n \"layout-foogrid.png\" and place it in `~/.icons` directory. You can as well\n use other directories, but then you need to specify those directories\n in `custom_icon_paths` argument for this plugin.\n\n The order of icon search is:\n\n - dirs in `custom_icon_paths` config argument\n - `~/.icons`\n - built-in qtile icons\n \"\"\"\n\n orientations = base.ORIENTATION_HORIZONTAL\n\n defaults = [\n (\"scale\", 1, \"Scale factor relative to the bar height. \" \"Defaults to 1\"),\n (\n \"custom_icon_paths\",\n [],\n \"List of folders where to search icons before\"\n \"using built-in icons or icons in ~/.icons dir. \"\n \"This can also be used to provide\"\n \"missing icons for custom layouts. \"\n \"Defaults to empty list.\",\n ),\n ]\n\n def __init__(self, **config):\n base._TextBox.__init__(self, \"\", **config)\n self.add_defaults(CurrentLayoutIcon.defaults)\n self.scale = 1.0 / self.scale\n\n self.length_type = bar.STATIC\n self.length = 0\n\n def _configure(self, qtile, bar):\n base._TextBox._configure(self, qtile, bar)\n layout_id = self.bar.screen.group.current_layout\n self.text = self.bar.screen.group.layouts[layout_id].name\n self.current_layout = self.text\n self.icons_loaded = False\n self.icon_paths = []\n self.surfaces = {}\n self._update_icon_paths()\n self._setup_images()\n self._setup_hooks()\n\n self.add_callbacks(\n {\n \"Button1\": qtile.cmd_next_layout,\n \"Button2\": qtile.cmd_prev_layout,\n }\n )\n\n def _setup_hooks(self):\n \"\"\"\n Listens for layout change and performs a redraw when it occurs.\n \"\"\"\n\n def hook_response(layout, group):\n if group.screen is not None and group.screen == self.bar.screen:\n self.current_layout = layout.name\n self.bar.draw()\n\n hook.subscribe.layout_change(hook_response)\n\n def draw(self):\n if self.icons_loaded:\n try:\n surface = self.surfaces[self.current_layout]\n except KeyError:\n logger.error(\"No icon for layout %s\", self.current_layout)\n else:\n self.drawer.clear(self.background or self.bar.background)\n self.drawer.ctx.set_source(surface)\n self.drawer.ctx.paint()\n self.drawer.draw(offsetx=self.offset, offsety=self.offsety, width=self.length)\n else:\n # Fallback to text\n self.text = self.current_layout[0].upper()\n base._TextBox.draw(self)\n\n def _get_layout_names(self):\n \"\"\"\n Returns the list of lowercased strings for each available layout name.\n \"\"\"\n return [layout.__class__.__name__.lower() for layout in self.qtile.config.layouts]\n\n def _update_icon_paths(self):\n self.icon_paths = []\n\n # We allow user to override icon search path\n self.icon_paths.extend(self.custom_icon_paths)\n\n # We also look in ~/.icons/ and ~/.local/share/icons\n self.icon_paths.append(os.path.expanduser(\"~/.icons\"))\n self.icon_paths.append(os.path.expanduser(\"~/.local/share/icons\"))\n\n # Default icons are in libqtile/resources/layout-icons.\n # If using default config without any custom icons,\n # this path will be used.\n root = os.sep.join(os.path.abspath(__file__).split(os.sep)[:-2])\n self.icon_paths.append(os.path.join(root, \"resources\", \"layout-icons\"))\n\n def find_icon_file_path(self, layout_name):\n icon_filename = \"layout-{}.png\".format(layout_name)\n for icon_path in self.icon_paths:\n icon_file_path = os.path.join(icon_path, icon_filename)\n if os.path.isfile(icon_file_path):\n return icon_file_path\n\n def _setup_images(self):\n \"\"\"\n Loads layout icons.\n \"\"\"\n for layout_name in self._get_layout_names():\n icon_file_path = self.find_icon_file_path(layout_name)\n if icon_file_path is None:\n logger.warning('No icon found for layout \"%s\"', layout_name)\n icon_file_path = self.find_icon_file_path(\"unknown\")\n\n try:\n img = cairocffi.ImageSurface.create_from_png(icon_file_path)\n except (cairocffi.Error, IOError) as e:\n # Icon file is guaranteed to exist at this point.\n # If this exception happens, it means the icon file contains\n # an invalid image or is not readable.\n self.icons_loaded = False\n logger.exception(\n 'Failed to load icon from file \"%s\", error was: %s', icon_file_path, e.message\n )\n return\n\n input_width = img.get_width()\n input_height = img.get_height()\n\n sp = input_height / (self.bar.height - 1)\n\n width = input_width / sp\n if width > self.length:\n self.length = int(width) + self.actual_padding * 2\n\n imgpat = cairocffi.SurfacePattern(img)\n\n scaler = cairocffi.Matrix()\n\n scaler.scale(sp, sp)\n scaler.scale(self.scale, self.scale)\n factor = (1 - 1 / self.scale) / 2\n scaler.translate(-width * factor, -width * factor)\n scaler.translate(self.actual_padding * -1, 0)\n imgpat.set_matrix(scaler)\n\n imgpat.set_filter(cairocffi.FILTER_BEST)\n self.surfaces[layout_name] = imgpat\n\n self.icons_loaded = True\n", "path": "libqtile/widget/currentlayout.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2011 Florian Mounier\n# Copyright (c) 2011 Kenji_Takahashi\n# Copyright (c) 2012 roger\n# Copyright (c) 2012, 2014 Tycho Andersen\n# Copyright (c) 2012 Maximilian K\u00f6hl\n# Copyright (c) 2013 Craig Barnes\n# Copyright (c) 2014 Sean Vig\n# Copyright (c) 2014 Adi Sieker\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport os\n\nimport cairocffi\n\nfrom libqtile import bar, hook\nfrom libqtile.log_utils import logger\nfrom libqtile.widget import base\n\n\nclass CurrentLayout(base._TextBox):\n \"\"\"\n Display the name of the current layout of the current group of the screen,\n the bar containing the widget, is on.\n \"\"\"\n\n def __init__(self, width=bar.CALCULATED, **config):\n base._TextBox.__init__(self, \"\", width, **config)\n\n def _configure(self, qtile, bar):\n base._TextBox._configure(self, qtile, bar)\n layout_id = self.bar.screen.group.current_layout\n self.text = self.bar.screen.group.layouts[layout_id].name\n self.setup_hooks()\n\n self.add_callbacks(\n {\n \"Button1\": qtile.cmd_next_layout,\n \"Button2\": qtile.cmd_prev_layout,\n }\n )\n\n def setup_hooks(self):\n def hook_response(layout, group):\n if group.screen is not None and group.screen == self.bar.screen:\n self.text = layout.name\n self.bar.draw()\n\n hook.subscribe.layout_change(hook_response)\n\n\nclass CurrentLayoutIcon(base._TextBox):\n \"\"\"\n Display the icon representing the current layout of the\n current group of the screen on which the bar containing the widget is.\n\n If you are using custom layouts, a default icon with question mark\n will be displayed for them. If you want to use custom icon for your own\n layout, for example, `FooGrid`, then create a file named\n \"layout-foogrid.png\" and place it in `~/.icons` directory. You can as well\n use other directories, but then you need to specify those directories\n in `custom_icon_paths` argument for this plugin.\n\n The order of icon search is:\n\n - dirs in `custom_icon_paths` config argument\n - `~/.icons`\n - built-in qtile icons\n \"\"\"\n\n orientations = base.ORIENTATION_HORIZONTAL\n\n defaults = [\n (\"scale\", 1, \"Scale factor relative to the bar height. \" \"Defaults to 1\"),\n (\n \"custom_icon_paths\",\n [],\n \"List of folders where to search icons before\"\n \"using built-in icons or icons in ~/.icons dir. \"\n \"This can also be used to provide\"\n \"missing icons for custom layouts. \"\n \"Defaults to empty list.\",\n ),\n ]\n\n def __init__(self, **config):\n base._TextBox.__init__(self, \"\", **config)\n self.add_defaults(CurrentLayoutIcon.defaults)\n self.scale = 1.0 / self.scale\n\n self.length_type = bar.STATIC\n self.length = 0\n\n def _configure(self, qtile, bar):\n base._TextBox._configure(self, qtile, bar)\n layout_id = self.bar.screen.group.current_layout\n self.text = self.bar.screen.group.layouts[layout_id].name\n self.current_layout = self.text\n self.icons_loaded = False\n self.icon_paths = []\n self.surfaces = {}\n self._update_icon_paths()\n self._setup_images()\n self._setup_hooks()\n\n self.add_callbacks(\n {\n \"Button1\": qtile.cmd_next_layout,\n \"Button2\": qtile.cmd_prev_layout,\n }\n )\n\n def _setup_hooks(self):\n \"\"\"\n Listens for layout change and performs a redraw when it occurs.\n \"\"\"\n\n def hook_response(layout, group):\n if group.screen is not None and group.screen == self.bar.screen:\n self.current_layout = layout.name\n self.bar.draw()\n\n hook.subscribe.layout_change(hook_response)\n\n def draw(self):\n if self.icons_loaded:\n try:\n surface = self.surfaces[self.current_layout]\n except KeyError:\n logger.error(\"No icon for layout %s\", self.current_layout)\n else:\n self.drawer.clear(self.background or self.bar.background)\n self.drawer.ctx.set_source(surface)\n self.drawer.ctx.paint()\n self.drawer.draw(offsetx=self.offset, offsety=self.offsety, width=self.length)\n else:\n # Fallback to text\n self.text = self.current_layout[0].upper()\n base._TextBox.draw(self)\n\n def _get_layout_names(self):\n \"\"\"\n Returns a list of tuples of lowercased layout name and class name strings for each available layout.\n \"\"\"\n return [\n (layout.name, layout.__class__.__name__.lower())\n for layout in self.qtile.config.layouts\n ]\n\n def _update_icon_paths(self):\n self.icon_paths = []\n\n # We allow user to override icon search path\n self.icon_paths.extend(self.custom_icon_paths)\n\n # We also look in ~/.icons/ and ~/.local/share/icons\n self.icon_paths.append(os.path.expanduser(\"~/.icons\"))\n self.icon_paths.append(os.path.expanduser(\"~/.local/share/icons\"))\n\n # Default icons are in libqtile/resources/layout-icons.\n # If using default config without any custom icons,\n # this path will be used.\n root = os.sep.join(os.path.abspath(__file__).split(os.sep)[:-2])\n self.icon_paths.append(os.path.join(root, \"resources\", \"layout-icons\"))\n\n def find_icon_file_path(self, layout_name):\n icon_filename = \"layout-{}.png\".format(layout_name)\n for icon_path in self.icon_paths:\n icon_file_path = os.path.join(icon_path, icon_filename)\n if os.path.isfile(icon_file_path):\n return icon_file_path\n\n def _setup_images(self):\n \"\"\"\n Loads layout icons.\n \"\"\"\n for names in self._get_layout_names():\n layout_name = names[0]\n # Python doesn't have an ordered set but we can use a dictionary instead\n # First key is the layout's name (which may have been set by the user),\n # the second is the class name. If these are the same (i.e. the user hasn't\n # set a name) then there is only one key in the dictionary.\n layouts = dict.fromkeys(names)\n for layout in layouts.keys():\n icon_file_path = self.find_icon_file_path(layout)\n if icon_file_path:\n break\n else:\n logger.warning('No icon found for layout \"%s\"', layout_name)\n icon_file_path = self.find_icon_file_path(\"unknown\")\n\n try:\n img = cairocffi.ImageSurface.create_from_png(icon_file_path)\n except (cairocffi.Error, IOError) as e:\n # Icon file is guaranteed to exist at this point.\n # If this exception happens, it means the icon file contains\n # an invalid image or is not readable.\n self.icons_loaded = False\n logger.exception(\n 'Failed to load icon from file \"%s\", error was: %s', icon_file_path, e.message\n )\n return\n\n input_width = img.get_width()\n input_height = img.get_height()\n\n sp = input_height / (self.bar.height - 1)\n\n width = input_width / sp\n if width > self.length:\n self.length = int(width) + self.actual_padding * 2\n\n imgpat = cairocffi.SurfacePattern(img)\n\n scaler = cairocffi.Matrix()\n\n scaler.scale(sp, sp)\n scaler.scale(self.scale, self.scale)\n factor = (1 - 1 / self.scale) / 2\n scaler.translate(-width * factor, -width * factor)\n scaler.translate(self.actual_padding * -1, 0)\n imgpat.set_matrix(scaler)\n\n imgpat.set_filter(cairocffi.FILTER_BEST)\n self.surfaces[layout_name] = imgpat\n\n self.icons_loaded = True\n", "path": "libqtile/widget/currentlayout.py"}]}
| 3,427 | 403 |
gh_patches_debug_24292
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-395
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add flash message when there are no replies on a sumission
The current flow if there are no replies on a submission make it look like I am just back on the submit flow.
It would be great to work this flow out a bit better in the future.
For now, if we could add a flash message to give an indication of the flow that would be great.
Suggested flash message: "There are no replies as yet on this submission. You can submit more documents under this code name below."
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `securedrop/source.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import os
3 from datetime import datetime
4 import uuid
5 from functools import wraps
6 import zipfile
7 from cStringIO import StringIO
8 import subprocess
9
10 import logging
11 # This module's logger is explicitly labeled so the correct logger is used,
12 # even when this is run from the command line (e.g. during development)
13 log = logging.getLogger('source')
14
15 from flask import (Flask, request, render_template, session, redirect, url_for,
16 flash, abort, g, send_file)
17 from flask_wtf.csrf import CsrfProtect
18
19 from sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound
20
21 import config
22 import version
23 import crypto_util
24 import store
25 import background
26 import util
27 from db import db_session, Source, Submission
28
29 app = Flask(__name__, template_folder=config.SOURCE_TEMPLATES_DIR)
30 app.config.from_object(config.FlaskConfig)
31 CsrfProtect(app)
32
33 app.jinja_env.globals['version'] = version.__version__
34 if getattr(config, 'CUSTOM_HEADER_IMAGE', None):
35 app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE
36 app.jinja_env.globals['use_custom_header_image'] = True
37 else:
38 app.jinja_env.globals['header_image'] = 'securedrop.png'
39 app.jinja_env.globals['use_custom_header_image'] = False
40
41
42 @app.teardown_appcontext
43 def shutdown_session(exception=None):
44 """Automatically remove database sessions at the end of the request, or
45 when the application shuts down"""
46 db_session.remove()
47
48
49 def logged_in():
50 if 'logged_in' in session:
51 return True
52
53
54 def login_required(f):
55 @wraps(f)
56 def decorated_function(*args, **kwargs):
57 if not logged_in():
58 return redirect(url_for('login'))
59 return f(*args, **kwargs)
60 return decorated_function
61
62
63 def ignore_static(f):
64 """Only executes the wrapped function if we're not loading a static resource."""
65 @wraps(f)
66 def decorated_function(*args, **kwargs):
67 if request.path.startswith('/static'):
68 return # don't execute the decorated function
69 return f(*args, **kwargs)
70 return decorated_function
71
72
73 @app.before_request
74 @ignore_static
75 def setup_g():
76 """Store commonly used values in Flask's special g object"""
77 # ignore_static here because `crypto_util.hash_codename` is scrypt (very
78 # time consuming), and we don't need to waste time running if we're just
79 # serving a static resource that won't need to access these common values.
80 if logged_in():
81 g.codename = session['codename']
82 g.sid = crypto_util.hash_codename(g.codename)
83 try:
84 g.source = Source.query.filter(Source.filesystem_id == g.sid).one()
85 except MultipleResultsFound as e:
86 app.logger.error("Found multiple Sources when one was expected: %s" % (e,))
87 abort(500)
88 except NoResultFound as e:
89 app.logger.error("Found no Sources when one was expected: %s" % (e,))
90 del session['logged_in']
91 del session['codename']
92 return redirect(url_for('index'))
93 g.loc = store.path(g.sid)
94
95
96 @app.before_request
97 @ignore_static
98 def check_tor2web():
99 # ignore_static here so we only flash a single message warning about Tor2Web,
100 # corresponding to the intial page load.
101 if 'X-tor2web' in request.headers:
102 flash('<strong>WARNING:</strong> You appear to be using Tor2Web. '
103 'This <strong>does not</strong> provide anonymity. '
104 '<a href="/tor2web-warning">Why is this dangerous?</a>',
105 "banner-warning")
106
107
108 @app.route('/')
109 def index():
110 return render_template('index.html')
111
112
113 @app.route('/generate', methods=('GET', 'POST'))
114 def generate():
115 number_words = 8
116 if request.method == 'POST':
117 number_words = int(request.form['number-words'])
118 if number_words not in range(7, 11):
119 abort(403)
120 session['codename'] = crypto_util.genrandomid(number_words)
121 session.pop('logged_in', None)
122 # TODO: make sure this codename isn't a repeat
123 return render_template('generate.html', codename=session['codename'])
124
125
126 @app.route('/create', methods=['POST'])
127 def create():
128 sid = crypto_util.hash_codename(session['codename'])
129
130 source = Source(sid, crypto_util.display_id())
131 db_session.add(source)
132 db_session.commit()
133
134 if os.path.exists(store.path(sid)):
135 # if this happens, we're not using very secure crypto
136 log.warning("Got a duplicate ID '%s'" % sid)
137 else:
138 os.mkdir(store.path(sid))
139
140 session['logged_in'] = True
141 return redirect(url_for('lookup'))
142
143
144 @app.route('/lookup', methods=('GET',))
145 @login_required
146 def lookup():
147 replies = []
148 for fn in os.listdir(g.loc):
149 if fn.endswith('-reply.gpg'):
150 try:
151 msg = crypto_util.decrypt(g.codename,
152 file(store.path(g.sid, fn)).read()).decode("utf-8")
153 except UnicodeDecodeError:
154 app.logger.error("Could not decode reply %s" % fn)
155 else:
156 d = datetime.fromtimestamp(os.stat(store.path(g.sid, fn)).st_mtime)
157 date = util.format_time(d)
158 replies.append(dict(id=fn, date=date, msg=msg))
159
160 def async_genkey(sid, codename):
161 with app.app_context():
162 background.execute(lambda: crypto_util.genkeypair(sid, codename))
163
164 # Generate a keypair to encrypt replies from the journalist
165 # Only do this if the journalist has flagged the source as one
166 # that they would like to reply to. (Issue #140.)
167 if not crypto_util.getkey(g.sid) and g.source.flagged:
168 async_genkey(g.sid, g.codename)
169
170 return render_template('lookup.html', codename=g.codename, msgs=replies,
171 flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))
172
173
174 def normalize_timestamps(sid):
175 """
176 Update the timestamps on all of the source's submissions to match that of
177 the latest submission. This minimizes metadata that could be useful to
178 investigators. See #301.
179 """
180 sub_paths = [ store.path(sid, submission.filename)
181 for submission in g.source.submissions ]
182 if len(sub_paths) > 1:
183 args = ["touch"]
184 args.extend(sub_paths[:-1])
185 rc = subprocess.call(args)
186 if rc != 0:
187 app.logger.warning("Couldn't normalize submission timestamps (touch exited with %d)" % rc)
188
189
190 @app.route('/submit', methods=('POST',))
191 @login_required
192 def submit():
193 msg = request.form['msg']
194 fh = request.files['fh']
195 strip_metadata = True if 'notclean' in request.form else False
196
197 fnames = []
198 journalist_filename = g.source.journalist_filename()
199
200 if msg:
201 g.source.interaction_count += 1
202 fnames.append(store.save_message_submission(g.sid, g.source.interaction_count,
203 journalist_filename, msg))
204 flash("Thanks! We received your message.", "notification")
205 if fh:
206 g.source.interaction_count += 1
207 fnames.append(store.save_file_submission(g.sid, g.source.interaction_count,
208 journalist_filename, fh.filename, fh.stream, fh.content_type, strip_metadata))
209 flash("Thanks! We received your document '%s'."
210 % fh.filename or '[unnamed]', "notification")
211
212 for fname in fnames:
213 submission = Submission(g.source, fname)
214 db_session.add(submission)
215
216 if g.source.pending:
217 g.source.pending = False
218
219 # Generate a keypair now, if there's enough entropy (issue #303)
220 entropy_avail = int(open('/proc/sys/kernel/random/entropy_avail').read())
221 if entropy_avail >= 2400:
222 crypto_util.genkeypair(g.sid, g.codename)
223
224 g.source.last_updated = datetime.now()
225 db_session.commit()
226 normalize_timestamps(g.sid)
227
228 return redirect(url_for('lookup'))
229
230
231 @app.route('/delete', methods=('POST',))
232 @login_required
233 def delete():
234 msgid = request.form['msgid']
235 assert '/' not in msgid
236 potential_files = os.listdir(g.loc)
237 if msgid not in potential_files:
238 abort(404) # TODO are the checks necessary?
239 store.secure_unlink(store.path(g.sid, msgid))
240 flash("Reply deleted.", "notification")
241
242 return redirect(url_for('lookup'))
243
244
245 def valid_codename(codename):
246 return os.path.exists(store.path(crypto_util.hash_codename(codename)))
247
248 @app.route('/login', methods=('GET', 'POST'))
249 def login():
250 if request.method == 'POST':
251 codename = request.form['codename']
252 if valid_codename(codename):
253 session.update(codename=codename, logged_in=True)
254 return redirect(url_for('lookup'))
255 else:
256 flash("Sorry, that is not a recognized codename.", "error")
257 return render_template('login.html')
258
259
260 @app.route('/howto-disable-js')
261 def howto_disable_js():
262 return render_template("howto-disable-js.html")
263
264
265 @app.route('/tor2web-warning')
266 def tor2web_warning():
267 return render_template("tor2web-warning.html")
268
269
270 @app.route('/journalist-key')
271 def download_journalist_pubkey():
272 journalist_pubkey = crypto_util.gpg.export_keys(config.JOURNALIST_KEY)
273 return send_file(StringIO(journalist_pubkey),
274 mimetype="application/pgp-keys",
275 attachment_filename=config.JOURNALIST_KEY + ".asc",
276 as_attachment=True)
277
278
279 @app.route('/why-journalist-key')
280 def why_download_journalist_pubkey():
281 return render_template("why-journalist-key.html")
282
283
284 _REDIRECT_URL_WHITELIST = ["http://tor2web.org/",
285 "https://www.torproject.org/download.html.en",
286 "https://tails.boum.org/",
287 "http://www.wired.com/threatlevel/2013/09/freedom-hosting-fbi/",
288 "http://www.theguardian.com/world/interactive/2013/oct/04/egotistical-giraffe-nsa-tor-document",
289 "https://addons.mozilla.org/en-US/firefox/addon/noscript/",
290 "http://noscript.net"]
291
292
293 @app.route('/redirect/<path:redirect_url>')
294 def redirect_hack(redirect_url):
295 # A hack to avoid referer leakage when a user clicks on an external link.
296 # TODO: Most likely will want to share this between source.py and
297 # journalist.py in the future.
298 if redirect_url not in _REDIRECT_URL_WHITELIST:
299 return 'Redirect not allowed'
300 else:
301 return render_template("redirect.html", redirect_url=redirect_url)
302
303
304 @app.errorhandler(404)
305 def page_not_found(error):
306 return render_template('notfound.html'), 404
307
308 @app.errorhandler(500)
309 def internal_error(error):
310 return render_template('error.html'), 500
311
312 if __name__ == "__main__":
313 # TODO make sure debug is not on in production
314 app.run(debug=True, host='0.0.0.0', port=8080)
315
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/securedrop/source.py b/securedrop/source.py
--- a/securedrop/source.py
+++ b/securedrop/source.py
@@ -167,7 +167,12 @@
if not crypto_util.getkey(g.sid) and g.source.flagged:
async_genkey(g.sid, g.codename)
- return render_template('lookup.html', codename=g.codename, msgs=replies,
+ # if this was a redirect from the login page, flash a message if there are
+ # no replies to clarify "check for replies" flow (#393)
+ if request.args.get('from_login') == '1' and len(replies) == 0:
+ flash("There are no replies at this time. You can submit more documents from this code name below.", "notification")
+
+ return render_template('lookup.html', codename=g.codename, replies=replies,
flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))
@@ -251,7 +256,7 @@
codename = request.form['codename']
if valid_codename(codename):
session.update(codename=codename, logged_in=True)
- return redirect(url_for('lookup'))
+ return redirect(url_for('lookup', from_login='1'))
else:
flash("Sorry, that is not a recognized codename.", "error")
return render_template('login.html')
|
{"golden_diff": "diff --git a/securedrop/source.py b/securedrop/source.py\n--- a/securedrop/source.py\n+++ b/securedrop/source.py\n@@ -167,7 +167,12 @@\n if not crypto_util.getkey(g.sid) and g.source.flagged:\n async_genkey(g.sid, g.codename)\n \n- return render_template('lookup.html', codename=g.codename, msgs=replies,\n+ # if this was a redirect from the login page, flash a message if there are\n+ # no replies to clarify \"check for replies\" flow (#393)\n+ if request.args.get('from_login') == '1' and len(replies) == 0:\n+ flash(\"There are no replies at this time. You can submit more documents from this code name below.\", \"notification\")\n+\n+ return render_template('lookup.html', codename=g.codename, replies=replies,\n flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))\n \n \n@@ -251,7 +256,7 @@\n codename = request.form['codename']\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n- return redirect(url_for('lookup'))\n+ return redirect(url_for('lookup', from_login='1'))\n else:\n flash(\"Sorry, that is not a recognized codename.\", \"error\")\n return render_template('login.html')\n", "issue": "Add flash message when there are no replies on a sumission\nThe current flow if there are no replies on a submission make it look like I am just back on the submit flow.\n\nIt would be great to work this flow out a bit better in the future.\n\nFor now, if we could add a flash message to give an indication of the flow that would be great.\n\nSuggested flash message: \"There are no replies as yet on this submission. You can submit more documents under this code name below.\"\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nfrom datetime import datetime\nimport uuid\nfrom functools import wraps\nimport zipfile\nfrom cStringIO import StringIO\nimport subprocess\n\nimport logging\n# This module's logger is explicitly labeled so the correct logger is used,\n# even when this is run from the command line (e.g. during development)\nlog = logging.getLogger('source')\n\nfrom flask import (Flask, request, render_template, session, redirect, url_for,\n flash, abort, g, send_file)\nfrom flask_wtf.csrf import CsrfProtect\n\nfrom sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound\n\nimport config\nimport version\nimport crypto_util\nimport store\nimport background\nimport util\nfrom db import db_session, Source, Submission\n\napp = Flask(__name__, template_folder=config.SOURCE_TEMPLATES_DIR)\napp.config.from_object(config.FlaskConfig)\nCsrfProtect(app)\n\napp.jinja_env.globals['version'] = version.__version__\nif getattr(config, 'CUSTOM_HEADER_IMAGE', None):\n app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE\n app.jinja_env.globals['use_custom_header_image'] = True\nelse:\n app.jinja_env.globals['header_image'] = 'securedrop.png'\n app.jinja_env.globals['use_custom_header_image'] = False\n\n\[email protected]_appcontext\ndef shutdown_session(exception=None):\n \"\"\"Automatically remove database sessions at the end of the request, or\n when the application shuts down\"\"\"\n db_session.remove()\n\n\ndef logged_in():\n if 'logged_in' in session:\n return True\n\n\ndef login_required(f):\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not logged_in():\n return redirect(url_for('login'))\n return f(*args, **kwargs)\n return decorated_function\n\n\ndef ignore_static(f):\n \"\"\"Only executes the wrapped function if we're not loading a static resource.\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if request.path.startswith('/static'):\n return # don't execute the decorated function\n return f(*args, **kwargs)\n return decorated_function\n\n\[email protected]_request\n@ignore_static\ndef setup_g():\n \"\"\"Store commonly used values in Flask's special g object\"\"\"\n # ignore_static here because `crypto_util.hash_codename` is scrypt (very\n # time consuming), and we don't need to waste time running if we're just\n # serving a static resource that won't need to access these common values.\n if logged_in():\n g.codename = session['codename']\n g.sid = crypto_util.hash_codename(g.codename)\n try:\n g.source = Source.query.filter(Source.filesystem_id == g.sid).one()\n except MultipleResultsFound as e:\n app.logger.error(\"Found multiple Sources when one was expected: %s\" % (e,))\n abort(500)\n except NoResultFound as e:\n app.logger.error(\"Found no Sources when one was expected: %s\" % (e,))\n del session['logged_in']\n del session['codename']\n return redirect(url_for('index'))\n g.loc = store.path(g.sid)\n\n\[email protected]_request\n@ignore_static\ndef check_tor2web():\n # ignore_static here so we only flash a single message warning about Tor2Web,\n # corresponding to the intial page load.\n if 'X-tor2web' in request.headers:\n flash('<strong>WARNING:</strong> You appear to be using Tor2Web. '\n 'This <strong>does not</strong> provide anonymity. '\n '<a href=\"/tor2web-warning\">Why is this dangerous?</a>',\n \"banner-warning\")\n\n\[email protected]('/')\ndef index():\n return render_template('index.html')\n\n\[email protected]('/generate', methods=('GET', 'POST'))\ndef generate():\n number_words = 8\n if request.method == 'POST':\n number_words = int(request.form['number-words'])\n if number_words not in range(7, 11):\n abort(403)\n session['codename'] = crypto_util.genrandomid(number_words)\n session.pop('logged_in', None)\n # TODO: make sure this codename isn't a repeat\n return render_template('generate.html', codename=session['codename'])\n\n\[email protected]('/create', methods=['POST'])\ndef create():\n sid = crypto_util.hash_codename(session['codename'])\n\n source = Source(sid, crypto_util.display_id())\n db_session.add(source)\n db_session.commit()\n\n if os.path.exists(store.path(sid)):\n # if this happens, we're not using very secure crypto\n log.warning(\"Got a duplicate ID '%s'\" % sid)\n else:\n os.mkdir(store.path(sid))\n\n session['logged_in'] = True\n return redirect(url_for('lookup'))\n\n\[email protected]('/lookup', methods=('GET',))\n@login_required\ndef lookup():\n replies = []\n for fn in os.listdir(g.loc):\n if fn.endswith('-reply.gpg'):\n try:\n msg = crypto_util.decrypt(g.codename,\n file(store.path(g.sid, fn)).read()).decode(\"utf-8\")\n except UnicodeDecodeError:\n app.logger.error(\"Could not decode reply %s\" % fn)\n else:\n d = datetime.fromtimestamp(os.stat(store.path(g.sid, fn)).st_mtime)\n date = util.format_time(d)\n replies.append(dict(id=fn, date=date, msg=msg))\n\n def async_genkey(sid, codename):\n with app.app_context():\n background.execute(lambda: crypto_util.genkeypair(sid, codename))\n\n # Generate a keypair to encrypt replies from the journalist\n # Only do this if the journalist has flagged the source as one\n # that they would like to reply to. (Issue #140.)\n if not crypto_util.getkey(g.sid) and g.source.flagged:\n async_genkey(g.sid, g.codename)\n\n return render_template('lookup.html', codename=g.codename, msgs=replies,\n flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))\n\n\ndef normalize_timestamps(sid):\n \"\"\"\n Update the timestamps on all of the source's submissions to match that of\n the latest submission. This minimizes metadata that could be useful to\n investigators. See #301.\n \"\"\"\n sub_paths = [ store.path(sid, submission.filename)\n for submission in g.source.submissions ]\n if len(sub_paths) > 1:\n args = [\"touch\"]\n args.extend(sub_paths[:-1])\n rc = subprocess.call(args)\n if rc != 0:\n app.logger.warning(\"Couldn't normalize submission timestamps (touch exited with %d)\" % rc)\n\n\[email protected]('/submit', methods=('POST',))\n@login_required\ndef submit():\n msg = request.form['msg']\n fh = request.files['fh']\n strip_metadata = True if 'notclean' in request.form else False\n\n fnames = []\n journalist_filename = g.source.journalist_filename()\n\n if msg:\n g.source.interaction_count += 1\n fnames.append(store.save_message_submission(g.sid, g.source.interaction_count,\n journalist_filename, msg))\n flash(\"Thanks! We received your message.\", \"notification\")\n if fh:\n g.source.interaction_count += 1\n fnames.append(store.save_file_submission(g.sid, g.source.interaction_count,\n journalist_filename, fh.filename, fh.stream, fh.content_type, strip_metadata))\n flash(\"Thanks! We received your document '%s'.\"\n % fh.filename or '[unnamed]', \"notification\")\n\n for fname in fnames:\n submission = Submission(g.source, fname)\n db_session.add(submission)\n\n if g.source.pending:\n g.source.pending = False\n\n # Generate a keypair now, if there's enough entropy (issue #303)\n entropy_avail = int(open('/proc/sys/kernel/random/entropy_avail').read())\n if entropy_avail >= 2400:\n crypto_util.genkeypair(g.sid, g.codename)\n\n g.source.last_updated = datetime.now()\n db_session.commit()\n normalize_timestamps(g.sid)\n\n return redirect(url_for('lookup'))\n\n\[email protected]('/delete', methods=('POST',))\n@login_required\ndef delete():\n msgid = request.form['msgid']\n assert '/' not in msgid\n potential_files = os.listdir(g.loc)\n if msgid not in potential_files:\n abort(404) # TODO are the checks necessary?\n store.secure_unlink(store.path(g.sid, msgid))\n flash(\"Reply deleted.\", \"notification\")\n\n return redirect(url_for('lookup'))\n\n\ndef valid_codename(codename):\n return os.path.exists(store.path(crypto_util.hash_codename(codename)))\n\[email protected]('/login', methods=('GET', 'POST'))\ndef login():\n if request.method == 'POST':\n codename = request.form['codename']\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n return redirect(url_for('lookup'))\n else:\n flash(\"Sorry, that is not a recognized codename.\", \"error\")\n return render_template('login.html')\n\n\[email protected]('/howto-disable-js')\ndef howto_disable_js():\n return render_template(\"howto-disable-js.html\")\n\n\[email protected]('/tor2web-warning')\ndef tor2web_warning():\n return render_template(\"tor2web-warning.html\")\n\n\[email protected]('/journalist-key')\ndef download_journalist_pubkey():\n journalist_pubkey = crypto_util.gpg.export_keys(config.JOURNALIST_KEY)\n return send_file(StringIO(journalist_pubkey),\n mimetype=\"application/pgp-keys\",\n attachment_filename=config.JOURNALIST_KEY + \".asc\",\n as_attachment=True)\n\n\[email protected]('/why-journalist-key')\ndef why_download_journalist_pubkey():\n return render_template(\"why-journalist-key.html\")\n\n\n_REDIRECT_URL_WHITELIST = [\"http://tor2web.org/\",\n \"https://www.torproject.org/download.html.en\",\n \"https://tails.boum.org/\",\n \"http://www.wired.com/threatlevel/2013/09/freedom-hosting-fbi/\",\n \"http://www.theguardian.com/world/interactive/2013/oct/04/egotistical-giraffe-nsa-tor-document\",\n \"https://addons.mozilla.org/en-US/firefox/addon/noscript/\",\n \"http://noscript.net\"]\n\n\[email protected]('/redirect/<path:redirect_url>')\ndef redirect_hack(redirect_url):\n # A hack to avoid referer leakage when a user clicks on an external link.\n # TODO: Most likely will want to share this between source.py and\n # journalist.py in the future.\n if redirect_url not in _REDIRECT_URL_WHITELIST:\n return 'Redirect not allowed'\n else:\n return render_template(\"redirect.html\", redirect_url=redirect_url)\n\n\[email protected](404)\ndef page_not_found(error):\n return render_template('notfound.html'), 404\n\[email protected](500)\ndef internal_error(error):\n return render_template('error.html'), 500\n\nif __name__ == \"__main__\":\n # TODO make sure debug is not on in production\n app.run(debug=True, host='0.0.0.0', port=8080)\n", "path": "securedrop/source.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nfrom datetime import datetime\nimport uuid\nfrom functools import wraps\nimport zipfile\nfrom cStringIO import StringIO\nimport subprocess\n\nimport logging\n# This module's logger is explicitly labeled so the correct logger is used,\n# even when this is run from the command line (e.g. during development)\nlog = logging.getLogger('source')\n\nfrom flask import (Flask, request, render_template, session, redirect, url_for,\n flash, abort, g, send_file)\nfrom flask_wtf.csrf import CsrfProtect\n\nfrom sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound\n\nimport config\nimport version\nimport crypto_util\nimport store\nimport background\nimport util\nfrom db import db_session, Source, Submission\n\napp = Flask(__name__, template_folder=config.SOURCE_TEMPLATES_DIR)\napp.config.from_object(config.FlaskConfig)\nCsrfProtect(app)\n\napp.jinja_env.globals['version'] = version.__version__\nif getattr(config, 'CUSTOM_HEADER_IMAGE', None):\n app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE\n app.jinja_env.globals['use_custom_header_image'] = True\nelse:\n app.jinja_env.globals['header_image'] = 'securedrop.png'\n app.jinja_env.globals['use_custom_header_image'] = False\n\n\[email protected]_appcontext\ndef shutdown_session(exception=None):\n \"\"\"Automatically remove database sessions at the end of the request, or\n when the application shuts down\"\"\"\n db_session.remove()\n\n\ndef logged_in():\n if 'logged_in' in session:\n return True\n\n\ndef login_required(f):\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not logged_in():\n return redirect(url_for('login'))\n return f(*args, **kwargs)\n return decorated_function\n\n\ndef ignore_static(f):\n \"\"\"Only executes the wrapped function if we're not loading a static resource.\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if request.path.startswith('/static'):\n return # don't execute the decorated function\n return f(*args, **kwargs)\n return decorated_function\n\n\[email protected]_request\n@ignore_static\ndef setup_g():\n \"\"\"Store commonly used values in Flask's special g object\"\"\"\n # ignore_static here because `crypto_util.hash_codename` is scrypt (very\n # time consuming), and we don't need to waste time running if we're just\n # serving a static resource that won't need to access these common values.\n if logged_in():\n g.codename = session['codename']\n g.sid = crypto_util.hash_codename(g.codename)\n try:\n g.source = Source.query.filter(Source.filesystem_id == g.sid).one()\n except MultipleResultsFound as e:\n app.logger.error(\"Found multiple Sources when one was expected: %s\" % (e,))\n abort(500)\n except NoResultFound as e:\n app.logger.error(\"Found no Sources when one was expected: %s\" % (e,))\n del session['logged_in']\n del session['codename']\n return redirect(url_for('index'))\n g.loc = store.path(g.sid)\n\n\[email protected]_request\n@ignore_static\ndef check_tor2web():\n # ignore_static here so we only flash a single message warning about Tor2Web,\n # corresponding to the intial page load.\n if 'X-tor2web' in request.headers:\n flash('<strong>WARNING:</strong> You appear to be using Tor2Web. '\n 'This <strong>does not</strong> provide anonymity. '\n '<a href=\"/tor2web-warning\">Why is this dangerous?</a>',\n \"banner-warning\")\n\n\[email protected]('/')\ndef index():\n return render_template('index.html')\n\n\[email protected]('/generate', methods=('GET', 'POST'))\ndef generate():\n number_words = 8\n if request.method == 'POST':\n number_words = int(request.form['number-words'])\n if number_words not in range(7, 11):\n abort(403)\n session['codename'] = crypto_util.genrandomid(number_words)\n session.pop('logged_in', None)\n # TODO: make sure this codename isn't a repeat\n return render_template('generate.html', codename=session['codename'])\n\n\[email protected]('/create', methods=['POST'])\ndef create():\n sid = crypto_util.hash_codename(session['codename'])\n\n source = Source(sid, crypto_util.display_id())\n db_session.add(source)\n db_session.commit()\n\n if os.path.exists(store.path(sid)):\n # if this happens, we're not using very secure crypto\n log.warning(\"Got a duplicate ID '%s'\" % sid)\n else:\n os.mkdir(store.path(sid))\n\n session['logged_in'] = True\n return redirect(url_for('lookup'))\n\n\[email protected]('/lookup', methods=('GET',))\n@login_required\ndef lookup():\n replies = []\n for fn in os.listdir(g.loc):\n if fn.endswith('-reply.gpg'):\n try:\n msg = crypto_util.decrypt(g.codename,\n file(store.path(g.sid, fn)).read()).decode(\"utf-8\")\n except UnicodeDecodeError:\n app.logger.error(\"Could not decode reply %s\" % fn)\n else:\n d = datetime.fromtimestamp(os.stat(store.path(g.sid, fn)).st_mtime)\n date = util.format_time(d)\n replies.append(dict(id=fn, date=date, msg=msg))\n\n def async_genkey(sid, codename):\n with app.app_context():\n background.execute(lambda: crypto_util.genkeypair(sid, codename))\n\n # Generate a keypair to encrypt replies from the journalist\n # Only do this if the journalist has flagged the source as one\n # that they would like to reply to. (Issue #140.)\n if not crypto_util.getkey(g.sid) and g.source.flagged:\n async_genkey(g.sid, g.codename)\n\n # if this was a redirect from the login page, flash a message if there are\n # no replies to clarify \"check for replies\" flow (#393)\n if request.args.get('from_login') == '1' and len(replies) == 0:\n flash(\"There are no replies at this time. You can submit more documents from this code name below.\", \"notification\")\n\n return render_template('lookup.html', codename=g.codename, replies=replies,\n flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))\n\n\ndef normalize_timestamps(sid):\n \"\"\"\n Update the timestamps on all of the source's submissions to match that of\n the latest submission. This minimizes metadata that could be useful to\n investigators. See #301.\n \"\"\"\n sub_paths = [ store.path(sid, submission.filename)\n for submission in g.source.submissions ]\n if len(sub_paths) > 1:\n args = [\"touch\"]\n args.extend(sub_paths[:-1])\n rc = subprocess.call(args)\n if rc != 0:\n app.logger.warning(\"Couldn't normalize submission timestamps (touch exited with %d)\" % rc)\n\n\[email protected]('/submit', methods=('POST',))\n@login_required\ndef submit():\n msg = request.form['msg']\n fh = request.files['fh']\n strip_metadata = True if 'notclean' in request.form else False\n\n fnames = []\n journalist_filename = g.source.journalist_filename()\n\n if msg:\n g.source.interaction_count += 1\n fnames.append(store.save_message_submission(g.sid, g.source.interaction_count,\n journalist_filename, msg))\n flash(\"Thanks! We received your message.\", \"notification\")\n if fh:\n g.source.interaction_count += 1\n fnames.append(store.save_file_submission(g.sid, g.source.interaction_count,\n journalist_filename, fh.filename, fh.stream, fh.content_type, strip_metadata))\n flash(\"Thanks! We received your document '%s'.\"\n % fh.filename or '[unnamed]', \"notification\")\n\n for fname in fnames:\n submission = Submission(g.source, fname)\n db_session.add(submission)\n\n if g.source.pending:\n g.source.pending = False\n\n # Generate a keypair now, if there's enough entropy (issue #303)\n entropy_avail = int(open('/proc/sys/kernel/random/entropy_avail').read())\n if entropy_avail >= 2400:\n crypto_util.genkeypair(g.sid, g.codename)\n\n g.source.last_updated = datetime.now()\n db_session.commit()\n normalize_timestamps(g.sid)\n\n return redirect(url_for('lookup'))\n\n\[email protected]('/delete', methods=('POST',))\n@login_required\ndef delete():\n msgid = request.form['msgid']\n assert '/' not in msgid\n potential_files = os.listdir(g.loc)\n if msgid not in potential_files:\n abort(404) # TODO are the checks necessary?\n store.secure_unlink(store.path(g.sid, msgid))\n flash(\"Reply deleted.\", \"notification\")\n\n return redirect(url_for('lookup'))\n\n\ndef valid_codename(codename):\n return os.path.exists(store.path(crypto_util.hash_codename(codename)))\n\[email protected]('/login', methods=('GET', 'POST'))\ndef login():\n if request.method == 'POST':\n codename = request.form['codename']\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n return redirect(url_for('lookup', from_login='1'))\n else:\n flash(\"Sorry, that is not a recognized codename.\", \"error\")\n return render_template('login.html')\n\n\[email protected]('/howto-disable-js')\ndef howto_disable_js():\n return render_template(\"howto-disable-js.html\")\n\n\[email protected]('/tor2web-warning')\ndef tor2web_warning():\n return render_template(\"tor2web-warning.html\")\n\n\[email protected]('/journalist-key')\ndef download_journalist_pubkey():\n journalist_pubkey = crypto_util.gpg.export_keys(config.JOURNALIST_KEY)\n return send_file(StringIO(journalist_pubkey),\n mimetype=\"application/pgp-keys\",\n attachment_filename=config.JOURNALIST_KEY + \".asc\",\n as_attachment=True)\n\n\[email protected]('/why-journalist-key')\ndef why_download_journalist_pubkey():\n return render_template(\"why-journalist-key.html\")\n\n\n_REDIRECT_URL_WHITELIST = [\"http://tor2web.org/\",\n \"https://www.torproject.org/download.html.en\",\n \"https://tails.boum.org/\",\n \"http://www.wired.com/threatlevel/2013/09/freedom-hosting-fbi/\",\n \"http://www.theguardian.com/world/interactive/2013/oct/04/egotistical-giraffe-nsa-tor-document\",\n \"https://addons.mozilla.org/en-US/firefox/addon/noscript/\",\n \"http://noscript.net\"]\n\n\[email protected]('/redirect/<path:redirect_url>')\ndef redirect_hack(redirect_url):\n # A hack to avoid referer leakage when a user clicks on an external link.\n # TODO: Most likely will want to share this between source.py and\n # journalist.py in the future.\n if redirect_url not in _REDIRECT_URL_WHITELIST:\n return 'Redirect not allowed'\n else:\n return render_template(\"redirect.html\", redirect_url=redirect_url)\n\n\[email protected](404)\ndef page_not_found(error):\n return render_template('notfound.html'), 404\n\[email protected](500)\ndef internal_error(error):\n return render_template('error.html'), 500\n\nif __name__ == \"__main__\":\n # TODO make sure debug is not on in production\n app.run(debug=True, host='0.0.0.0', port=8080)\n", "path": "securedrop/source.py"}]}
| 3,710 | 316 |
gh_patches_debug_17132
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-299
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't attempt to start on Windows (until supported)
As of right now, we error out when attempting to start on a Microsoft Windows system.
We should detect that the OS is not supported, and not start at all (and log that fact).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/core/__init__.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5 from os import getpid
6
7 from scout_apm.core.config import ScoutConfig
8 from scout_apm.core.context import AgentContext
9 from scout_apm.core.core_agent_manager import CoreAgentManager
10 from scout_apm.core.instrument_manager import InstrumentManager
11 from scout_apm.core.metadata import AppMetadata
12
13 try:
14 from scout_apm.core import objtrace
15 except ImportError:
16 objtrace = None
17
18 logger = logging.getLogger(__name__)
19
20
21 def install(*args, **kwargs):
22 if "config" in kwargs:
23 ScoutConfig().set(**kwargs["config"])
24 context = AgentContext.build(config=ScoutConfig())
25
26 if not context.config.value("monitor"):
27 logger.info(
28 "APM Not Launching on PID: %s - Configuration 'monitor' is not true",
29 getpid(),
30 )
31 return False
32
33 InstrumentManager().install_all()
34
35 if objtrace is not None:
36 objtrace.enable()
37
38 logger.debug("APM Launching on PID: %s", getpid())
39 launched = CoreAgentManager().launch()
40
41 AppMetadata.report()
42 if launched:
43 AgentContext.socket().stop()
44
45 return True
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/scout_apm/core/__init__.py b/src/scout_apm/core/__init__.py
--- a/src/scout_apm/core/__init__.py
+++ b/src/scout_apm/core/__init__.py
@@ -2,6 +2,7 @@
from __future__ import absolute_import, division, print_function, unicode_literals
import logging
+import sys
from os import getpid
from scout_apm.core.config import ScoutConfig
@@ -23,6 +24,10 @@
ScoutConfig().set(**kwargs["config"])
context = AgentContext.build(config=ScoutConfig())
+ if sys.platform == "win32":
+ logger.info("APM Not Launching on PID: %s - Windows is not supported", getpid())
+ return False
+
if not context.config.value("monitor"):
logger.info(
"APM Not Launching on PID: %s - Configuration 'monitor' is not true",
|
{"golden_diff": "diff --git a/src/scout_apm/core/__init__.py b/src/scout_apm/core/__init__.py\n--- a/src/scout_apm/core/__init__.py\n+++ b/src/scout_apm/core/__init__.py\n@@ -2,6 +2,7 @@\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n import logging\n+import sys\n from os import getpid\n \n from scout_apm.core.config import ScoutConfig\n@@ -23,6 +24,10 @@\n ScoutConfig().set(**kwargs[\"config\"])\n context = AgentContext.build(config=ScoutConfig())\n \n+ if sys.platform == \"win32\":\n+ logger.info(\"APM Not Launching on PID: %s - Windows is not supported\", getpid())\n+ return False\n+\n if not context.config.value(\"monitor\"):\n logger.info(\n \"APM Not Launching on PID: %s - Configuration 'monitor' is not true\",\n", "issue": "Don't attempt to start on Windows (until supported)\nAs of right now, we error out when attempting to start on a Microsoft Windows system.\r\n\r\nWe should detect that the OS is not supported, and not start at all (and log that fact).\r\n\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nfrom os import getpid\n\nfrom scout_apm.core.config import ScoutConfig\nfrom scout_apm.core.context import AgentContext\nfrom scout_apm.core.core_agent_manager import CoreAgentManager\nfrom scout_apm.core.instrument_manager import InstrumentManager\nfrom scout_apm.core.metadata import AppMetadata\n\ntry:\n from scout_apm.core import objtrace\nexcept ImportError:\n objtrace = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef install(*args, **kwargs):\n if \"config\" in kwargs:\n ScoutConfig().set(**kwargs[\"config\"])\n context = AgentContext.build(config=ScoutConfig())\n\n if not context.config.value(\"monitor\"):\n logger.info(\n \"APM Not Launching on PID: %s - Configuration 'monitor' is not true\",\n getpid(),\n )\n return False\n\n InstrumentManager().install_all()\n\n if objtrace is not None:\n objtrace.enable()\n\n logger.debug(\"APM Launching on PID: %s\", getpid())\n launched = CoreAgentManager().launch()\n\n AppMetadata.report()\n if launched:\n AgentContext.socket().stop()\n\n return True\n", "path": "src/scout_apm/core/__init__.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nimport sys\nfrom os import getpid\n\nfrom scout_apm.core.config import ScoutConfig\nfrom scout_apm.core.context import AgentContext\nfrom scout_apm.core.core_agent_manager import CoreAgentManager\nfrom scout_apm.core.instrument_manager import InstrumentManager\nfrom scout_apm.core.metadata import AppMetadata\n\ntry:\n from scout_apm.core import objtrace\nexcept ImportError:\n objtrace = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef install(*args, **kwargs):\n if \"config\" in kwargs:\n ScoutConfig().set(**kwargs[\"config\"])\n context = AgentContext.build(config=ScoutConfig())\n\n if sys.platform == \"win32\":\n logger.info(\"APM Not Launching on PID: %s - Windows is not supported\", getpid())\n return False\n\n if not context.config.value(\"monitor\"):\n logger.info(\n \"APM Not Launching on PID: %s - Configuration 'monitor' is not true\",\n getpid(),\n )\n return False\n\n InstrumentManager().install_all()\n\n if objtrace is not None:\n objtrace.enable()\n\n logger.debug(\"APM Launching on PID: %s\", getpid())\n launched = CoreAgentManager().launch()\n\n AppMetadata.report()\n if launched:\n AgentContext.socket().stop()\n\n return True\n", "path": "src/scout_apm/core/__init__.py"}]}
| 669 | 210 |
gh_patches_debug_42605
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-2335
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] swig/4.0.1: wrong bison used in windows with MinGW
<!--
Please don't forget to update the issue title.
Include all applicable information to help us reproduce your problem.
-->
### Package and Environment Details
* Package Name/Version: **swig/4.0.1**
* Operating System+version: **Windows 10*
* Compiler+version: **GCC 8 (MinGW)**
* Conan version: **conan 1.27.1**
* Python version: **Python 3.7.4**
### Conan profile
```
[settings]
os=Windows
os_build=Windows
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=8
build_type=Release
compiler.exception=seh
compiler.libcxx=libstdc++11
compiler.threads=posix
[options]
[build_requires]
mingw_installer/1.0@conan/stable
[env]
```
### Steps to reproduce (Include if Applicable)
`conan install -pr=mingw-w64 --build=missing swig/4.0.1@`
Build fails because swig tries to use winflexbison/2.5.22.
### Logs from winflexbison
```
......
-- Conan: Using cmake global configuration
-- Conan: Adjusting default RPATHs Conan policies
-- Conan: Adjusting language standard
-- Conan setting CPP STANDARD: 14 WITH EXTENSIONS OFF
-- Conan: Compiler GCC>=5, checking major version 8.1
-- Conan: Checking correct version: 8.1
-- Conan: C++ stdlib: libstdc++11
CMake Error at source_subfolder/CMakeLists.txt:6 (message):
Visual Studio Build supported only
```
See here:
https://github.com/conan-io/conan-center-index/issues/1967
### Root cause
In the conanfile.py of swig, the build requirements are wrong:
```python
def build_requirements(self):
if tools.os_info.is_windows and not tools.get_env("CONAN_BASH_PATH") \
and tools.os_info.detect_windows_subsystem() != "msys2":
self.build_requires("msys2/20190524")
if tools.os_info.is_windows: // Bad!
self.build_requires("winflexbison/2.5.22")
else:
self.build_requires("bison/3.5.3")
self.build_requires("automake/1.16.2")
```
`winflexbison` only works with Visual Studio. So `bison` should be used instead.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/swig/all/conanfile.py`
Content:
```
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 from contextlib import contextmanager
3 import os
4
5
6 class SwigConan(ConanFile):
7 name = "swig"
8 description = "SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages."
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "http://www.swig.org"
11 license = "GPL-3.0-or-later"
12 topics = ("conan", "swig", "python", "java", "wrapper")
13 exports_sources = "patches/**"
14 settings = "os", "arch", "compiler", "build_type"
15
16 _autotools = None
17
18 @property
19 def _source_subfolder(self):
20 return "source_subfolder"
21
22 def configure(self):
23 del self.settings.compiler.libcxx
24 del self.settings.compiler.cppstd
25
26 def build_requirements(self):
27 if tools.os_info.is_windows and not tools.get_env("CONAN_BASH_PATH") \
28 and tools.os_info.detect_windows_subsystem() != "msys2":
29 self.build_requires("msys2/20190524")
30 if tools.os_info.is_windows:
31 self.build_requires("winflexbison/2.5.22")
32 else:
33 self.build_requires("bison/3.5.3")
34 self.build_requires("automake/1.16.2")
35
36 def requirements(self):
37 self.requires("pcre/8.41")
38
39 def source(self):
40 tools.get(**self.conan_data["sources"][self.version])
41 os.rename("swig-rel-{}".format(self.version), self._source_subfolder)
42
43 @contextmanager
44 def _build_context(self):
45 if self.settings.compiler == "Visual Studio":
46 with tools.vcvars(self.settings):
47 env = {
48 "CC": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
49 "CXX": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
50 "AR": "{} link".format(self.deps_user_info["automake"].ar_lib),
51 "LD": "link",
52 }
53 with tools.environment_append(env):
54 yield
55 else:
56 yield
57
58 def _configure_autotools(self):
59 if self._autotools:
60 return self._autotools
61
62 self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)
63 deps_libpaths = self._autotools.library_paths
64 deps_libs = self._autotools.libs
65 deps_defines = self._autotools.defines
66 if self.settings.os == "Windows" and self.settings.compiler != "Visual Studio":
67 self._autotools.link_flags.append("-static")
68
69 libargs = list("-L\"{}\"".format(p) for p in deps_libpaths) + list("-l\"{}\"".format(l) for l in deps_libs)
70 args = [
71 "PCRE_LIBS={}".format(" ".join(libargs)),
72 "PCRE_CPPFLAGS={}".format(" ".join("-D{}".format(define) for define in deps_defines)),
73 "--host={}".format(self.settings.arch),
74 "--with-swiglibdir={}".format(self._swiglibdir),
75 ]
76 if self.settings.compiler == "Visual Studio":
77 self.output.warn("Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.")
78 args.append("--disable-ccache")
79 self._autotools.flags.append("-FS")
80
81 self._autotools.libs = []
82 self._autotools.library_paths = []
83
84 self._autotools.configure(args=args, configure_dir=self._source_subfolder)
85 return self._autotools
86
87 def _patch_sources(self):
88 for patch in self.conan_data["patches"][self.version]:
89 tools.patch(**patch)
90
91 def build(self):
92 self._patch_sources()
93 with tools.chdir(os.path.join(self._source_subfolder)):
94 self.run("./autogen.sh", win_bash=tools.os_info.is_windows)
95 with self._build_context():
96 autotools = self._configure_autotools()
97 autotools.make()
98
99 def package(self):
100 self.copy(pattern="LICENSE*", dst="licenses", src=self._source_subfolder)
101 self.copy(pattern="COPYRIGHT", dst="licenses", src=self._source_subfolder)
102 with self._build_context():
103 autotools = self._configure_autotools()
104 autotools.install()
105
106 if self.settings.compiler != "Visual Studio":
107 with tools.chdir(os.path.join(self.package_folder, "bin")):
108 strip = tools.get_env("STRIP") or tools.which("strip")
109 ext = ".exe" if tools.os_info.is_windows else ""
110 if strip:
111 self.run("{} swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
112 self.run("{} ccache-swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
113
114 @property
115 def _swiglibdir(self):
116 return os.path.join(self.package_folder, "bin", "swiglib").replace("\\", "/")
117
118 def package_info(self):
119 # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE
120 # self.cpp_info.names["cmake_find_package"] = "SWIG"
121 # self.cpp_info.names["cmake_find_package_multi"] = "SWIG"
122
123 bindir = os.path.join(self.package_folder, "bin")
124 self.output.info("Appending PATH environment variable: {}".format(bindir))
125 self.env_info.PATH.append(bindir)
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/swig/all/conanfile.py b/recipes/swig/all/conanfile.py
--- a/recipes/swig/all/conanfile.py
+++ b/recipes/swig/all/conanfile.py
@@ -27,10 +27,10 @@
if tools.os_info.is_windows and not tools.get_env("CONAN_BASH_PATH") \
and tools.os_info.detect_windows_subsystem() != "msys2":
self.build_requires("msys2/20190524")
- if tools.os_info.is_windows:
+ if self.settings.compiler == "Visual Studio":
self.build_requires("winflexbison/2.5.22")
else:
- self.build_requires("bison/3.5.3")
+ self.build_requires("bison/3.7.1")
self.build_requires("automake/1.16.2")
def requirements(self):
@@ -42,18 +42,22 @@
@contextmanager
def _build_context(self):
+ env = {}
+ if self.settings.compiler != "Visual Studio":
+ env["YACC"] = self.deps_user_info["bison"].YACC
if self.settings.compiler == "Visual Studio":
with tools.vcvars(self.settings):
- env = {
+ env.update({
"CC": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
"CXX": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
"AR": "{} link".format(self.deps_user_info["automake"].ar_lib),
"LD": "link",
- }
+ })
with tools.environment_append(env):
yield
else:
- yield
+ with tools.environment_append(env):
+ yield
def _configure_autotools(self):
if self._autotools:
@@ -73,15 +77,21 @@
"--host={}".format(self.settings.arch),
"--with-swiglibdir={}".format(self._swiglibdir),
]
+
+ host, build = None, None
+
if self.settings.compiler == "Visual Studio":
self.output.warn("Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.")
args.append("--disable-ccache")
self._autotools.flags.append("-FS")
+ # MSVC canonical names aren't understood
+ host, build = False, False
self._autotools.libs = []
self._autotools.library_paths = []
- self._autotools.configure(args=args, configure_dir=self._source_subfolder)
+ self._autotools.configure(args=args, configure_dir=self._source_subfolder,
+ host=host, build=build)
return self._autotools
def _patch_sources(self):
@@ -105,7 +115,7 @@
if self.settings.compiler != "Visual Studio":
with tools.chdir(os.path.join(self.package_folder, "bin")):
- strip = tools.get_env("STRIP") or tools.which("strip")
+ strip = (tools.get_env("STRIP") or tools.which("strip")).replace("\\", "/")
ext = ".exe" if tools.os_info.is_windows else ""
if strip:
self.run("{} swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
|
{"golden_diff": "diff --git a/recipes/swig/all/conanfile.py b/recipes/swig/all/conanfile.py\n--- a/recipes/swig/all/conanfile.py\n+++ b/recipes/swig/all/conanfile.py\n@@ -27,10 +27,10 @@\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\n self.build_requires(\"msys2/20190524\")\n- if tools.os_info.is_windows:\n+ if self.settings.compiler == \"Visual Studio\":\n self.build_requires(\"winflexbison/2.5.22\")\n else:\n- self.build_requires(\"bison/3.5.3\")\n+ self.build_requires(\"bison/3.7.1\")\n self.build_requires(\"automake/1.16.2\")\n \n def requirements(self):\n@@ -42,18 +42,22 @@\n \n @contextmanager\n def _build_context(self):\n+ env = {}\n+ if self.settings.compiler != \"Visual Studio\":\n+ env[\"YACC\"] = self.deps_user_info[\"bison\"].YACC\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n- env = {\n+ env.update({\n \"CC\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"CXX\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"AR\": \"{} link\".format(self.deps_user_info[\"automake\"].ar_lib),\n \"LD\": \"link\",\n- }\n+ })\n with tools.environment_append(env):\n yield\n else:\n- yield\n+ with tools.environment_append(env):\n+ yield\n \n def _configure_autotools(self):\n if self._autotools:\n@@ -73,15 +77,21 @@\n \"--host={}\".format(self.settings.arch),\n \"--with-swiglibdir={}\".format(self._swiglibdir),\n ]\n+\n+ host, build = None, None\n+\n if self.settings.compiler == \"Visual Studio\":\n self.output.warn(\"Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.\")\n args.append(\"--disable-ccache\")\n self._autotools.flags.append(\"-FS\")\n+ # MSVC canonical names aren't understood\n+ host, build = False, False\n \n self._autotools.libs = []\n self._autotools.library_paths = []\n \n- self._autotools.configure(args=args, configure_dir=self._source_subfolder)\n+ self._autotools.configure(args=args, configure_dir=self._source_subfolder,\n+ host=host, build=build)\n return self._autotools\n \n def _patch_sources(self):\n@@ -105,7 +115,7 @@\n \n if self.settings.compiler != \"Visual Studio\":\n with tools.chdir(os.path.join(self.package_folder, \"bin\")):\n- strip = tools.get_env(\"STRIP\") or tools.which(\"strip\")\n+ strip = (tools.get_env(\"STRIP\") or tools.which(\"strip\")).replace(\"\\\\\", \"/\")\n ext = \".exe\" if tools.os_info.is_windows else \"\"\n if strip:\n self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n", "issue": "[package] swig/4.0.1: wrong bison used in windows with MinGW\n<!-- \r\n Please don't forget to update the issue title.\r\n Include all applicable information to help us reproduce your problem.\r\n-->\r\n\r\n### Package and Environment Details\r\n * Package Name/Version: **swig/4.0.1**\r\n * Operating System+version: **Windows 10*\r\n * Compiler+version: **GCC 8 (MinGW)**\r\n * Conan version: **conan 1.27.1**\r\n * Python version: **Python 3.7.4**\r\n\r\n\r\n### Conan profile\r\n```\r\n[settings]\r\nos=Windows\r\nos_build=Windows\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=8\r\nbuild_type=Release\r\ncompiler.exception=seh\r\ncompiler.libcxx=libstdc++11\r\ncompiler.threads=posix\r\n[options]\r\n[build_requires]\r\nmingw_installer/1.0@conan/stable\r\n[env]\r\n\r\n```\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n\r\n`conan install -pr=mingw-w64 --build=missing swig/4.0.1@`\r\n\r\nBuild fails because swig tries to use winflexbison/2.5.22.\r\n\r\n\r\n### Logs from winflexbison\r\n```\r\n......\r\n-- Conan: Using cmake global configuration\r\n-- Conan: Adjusting default RPATHs Conan policies\r\n-- Conan: Adjusting language standard\r\n-- Conan setting CPP STANDARD: 14 WITH EXTENSIONS OFF\r\n-- Conan: Compiler GCC>=5, checking major version 8.1\r\n-- Conan: Checking correct version: 8.1\r\n-- Conan: C++ stdlib: libstdc++11\r\nCMake Error at source_subfolder/CMakeLists.txt:6 (message):\r\n Visual Studio Build supported only\r\n```\r\n\r\nSee here:\r\nhttps://github.com/conan-io/conan-center-index/issues/1967\r\n\r\n### Root cause\r\n\r\nIn the conanfile.py of swig, the build requirements are wrong:\r\n\r\n```python\r\n def build_requirements(self):\r\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\r\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\r\n self.build_requires(\"msys2/20190524\")\r\n if tools.os_info.is_windows: // Bad!\r\n self.build_requires(\"winflexbison/2.5.22\")\r\n else:\r\n self.build_requires(\"bison/3.5.3\")\r\n self.build_requires(\"automake/1.16.2\")\r\n```\r\n\r\n`winflexbison` only works with Visual Studio. So `bison` should be used instead.\r\n\r\n\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport os\n\n\nclass SwigConan(ConanFile):\n name = \"swig\"\n description = \"SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"http://www.swig.org\"\n license = \"GPL-3.0-or-later\"\n topics = (\"conan\", \"swig\", \"python\", \"java\", \"wrapper\")\n exports_sources = \"patches/**\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def build_requirements(self):\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\n self.build_requires(\"msys2/20190524\")\n if tools.os_info.is_windows:\n self.build_requires(\"winflexbison/2.5.22\")\n else:\n self.build_requires(\"bison/3.5.3\")\n self.build_requires(\"automake/1.16.2\")\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"swig-rel-{}\".format(self.version), self._source_subfolder)\n\n @contextmanager\n def _build_context(self):\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n env = {\n \"CC\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"CXX\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"AR\": \"{} link\".format(self.deps_user_info[\"automake\"].ar_lib),\n \"LD\": \"link\",\n }\n with tools.environment_append(env):\n yield\n else:\n yield\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n deps_libpaths = self._autotools.library_paths\n deps_libs = self._autotools.libs\n deps_defines = self._autotools.defines\n if self.settings.os == \"Windows\" and self.settings.compiler != \"Visual Studio\":\n self._autotools.link_flags.append(\"-static\")\n\n libargs = list(\"-L\\\"{}\\\"\".format(p) for p in deps_libpaths) + list(\"-l\\\"{}\\\"\".format(l) for l in deps_libs)\n args = [\n \"PCRE_LIBS={}\".format(\" \".join(libargs)),\n \"PCRE_CPPFLAGS={}\".format(\" \".join(\"-D{}\".format(define) for define in deps_defines)),\n \"--host={}\".format(self.settings.arch),\n \"--with-swiglibdir={}\".format(self._swiglibdir),\n ]\n if self.settings.compiler == \"Visual Studio\":\n self.output.warn(\"Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.\")\n args.append(\"--disable-ccache\")\n self._autotools.flags.append(\"-FS\")\n\n self._autotools.libs = []\n self._autotools.library_paths = []\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder)\n return self._autotools\n\n def _patch_sources(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n with tools.chdir(os.path.join(self._source_subfolder)):\n self.run(\"./autogen.sh\", win_bash=tools.os_info.is_windows)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(pattern=\"COPYRIGHT\", dst=\"licenses\", src=self._source_subfolder)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n\n if self.settings.compiler != \"Visual Studio\":\n with tools.chdir(os.path.join(self.package_folder, \"bin\")):\n strip = tools.get_env(\"STRIP\") or tools.which(\"strip\")\n ext = \".exe\" if tools.os_info.is_windows else \"\"\n if strip:\n self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n self.run(\"{} ccache-swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n\n @property\n def _swiglibdir(self):\n return os.path.join(self.package_folder, \"bin\", \"swiglib\").replace(\"\\\\\", \"/\")\n\n def package_info(self):\n # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE\n # self.cpp_info.names[\"cmake_find_package\"] = \"SWIG\"\n # self.cpp_info.names[\"cmake_find_package_multi\"] = \"SWIG\"\n\n bindir = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bindir))\n self.env_info.PATH.append(bindir)\n", "path": "recipes/swig/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport os\n\n\nclass SwigConan(ConanFile):\n name = \"swig\"\n description = \"SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"http://www.swig.org\"\n license = \"GPL-3.0-or-later\"\n topics = (\"conan\", \"swig\", \"python\", \"java\", \"wrapper\")\n exports_sources = \"patches/**\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def build_requirements(self):\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\n self.build_requires(\"msys2/20190524\")\n if self.settings.compiler == \"Visual Studio\":\n self.build_requires(\"winflexbison/2.5.22\")\n else:\n self.build_requires(\"bison/3.7.1\")\n self.build_requires(\"automake/1.16.2\")\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"swig-rel-{}\".format(self.version), self._source_subfolder)\n\n @contextmanager\n def _build_context(self):\n env = {}\n if self.settings.compiler != \"Visual Studio\":\n env[\"YACC\"] = self.deps_user_info[\"bison\"].YACC\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n env.update({\n \"CC\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"CXX\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"AR\": \"{} link\".format(self.deps_user_info[\"automake\"].ar_lib),\n \"LD\": \"link\",\n })\n with tools.environment_append(env):\n yield\n else:\n with tools.environment_append(env):\n yield\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n deps_libpaths = self._autotools.library_paths\n deps_libs = self._autotools.libs\n deps_defines = self._autotools.defines\n if self.settings.os == \"Windows\" and self.settings.compiler != \"Visual Studio\":\n self._autotools.link_flags.append(\"-static\")\n\n libargs = list(\"-L\\\"{}\\\"\".format(p) for p in deps_libpaths) + list(\"-l\\\"{}\\\"\".format(l) for l in deps_libs)\n args = [\n \"PCRE_LIBS={}\".format(\" \".join(libargs)),\n \"PCRE_CPPFLAGS={}\".format(\" \".join(\"-D{}\".format(define) for define in deps_defines)),\n \"--host={}\".format(self.settings.arch),\n \"--with-swiglibdir={}\".format(self._swiglibdir),\n ]\n\n host, build = None, None\n\n if self.settings.compiler == \"Visual Studio\":\n self.output.warn(\"Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.\")\n args.append(\"--disable-ccache\")\n self._autotools.flags.append(\"-FS\")\n # MSVC canonical names aren't understood\n host, build = False, False\n\n self._autotools.libs = []\n self._autotools.library_paths = []\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder,\n host=host, build=build)\n return self._autotools\n\n def _patch_sources(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n with tools.chdir(os.path.join(self._source_subfolder)):\n self.run(\"./autogen.sh\", win_bash=tools.os_info.is_windows)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(pattern=\"COPYRIGHT\", dst=\"licenses\", src=self._source_subfolder)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n\n if self.settings.compiler != \"Visual Studio\":\n with tools.chdir(os.path.join(self.package_folder, \"bin\")):\n strip = (tools.get_env(\"STRIP\") or tools.which(\"strip\")).replace(\"\\\\\", \"/\")\n ext = \".exe\" if tools.os_info.is_windows else \"\"\n if strip:\n self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n self.run(\"{} ccache-swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n\n @property\n def _swiglibdir(self):\n return os.path.join(self.package_folder, \"bin\", \"swiglib\").replace(\"\\\\\", \"/\")\n\n def package_info(self):\n # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE\n # self.cpp_info.names[\"cmake_find_package\"] = \"SWIG\"\n # self.cpp_info.names[\"cmake_find_package_multi\"] = \"SWIG\"\n\n bindir = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bindir))\n self.env_info.PATH.append(bindir)\n", "path": "recipes/swig/all/conanfile.py"}]}
| 2,394 | 766 |
gh_patches_debug_18254
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-2470
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Watchdog error on install (Mac)
I've tried to install it in a MAC using PIP and PIP3 and I get the same error:
Command "/usr/local/opt/python/bin/python3.7 -u -c "import setuptools, tokenize;__file__='/private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-install-3cscl6kq/watchdog/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-record-qr49cvd0/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-install-3cscl6kq/watchdog/
I'm using:
macOS Mojave 10.14.5
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/setup.py`
Content:
```
1 import os
2 import platform
3 import setuptools
4 import subprocess
5 import sys
6
7 from setuptools.command.install import install
8
9 try:
10 from pipenv.project import Project
11 from pipenv.utils import convert_deps_to_pip
12 except:
13 exit_msg = (
14 "pipenv is required to package Streamlit. Please install pipenv and try again"
15 )
16 sys.exit(exit_msg)
17
18 VERSION = "0.72.0" # PEP-440
19
20 NAME = "streamlit"
21
22 DESCRIPTION = "The fastest way to build data apps in Python"
23
24 LONG_DESCRIPTION = (
25 "Streamlit's open-source app framework is the easiest way "
26 "for data scientists and machine learning engineers to "
27 "create beautiful, performant apps in only a few hours! "
28 "All in pure Python. All for free."
29 )
30
31 pipfile = Project(chdir=False).parsed_pipfile
32
33 packages = pipfile["packages"].copy()
34 requirements = convert_deps_to_pip(packages, r=False)
35
36 # Check whether xcode tools are available before making watchdog a
37 # dependency (only if the current system is a Mac).
38 if platform.system() == "Darwin":
39 has_xcode = subprocess.call(["xcode-select", "--version"], shell=False) == 0
40 has_gcc = subprocess.call(["gcc", "--version"], shell=False) == 0
41
42 if not (has_xcode and has_gcc):
43 try:
44 requirements.remove("watchdog")
45 except ValueError:
46 pass
47
48
49 class VerifyVersionCommand(install):
50 """Custom command to verify that the git tag matches our version"""
51
52 description = "verify that the git tag matches our version"
53
54 def run(self):
55 tag = os.getenv("CIRCLE_TAG")
56
57 if tag != VERSION:
58 info = "Git tag: {0} does not match the version of this app: {1}".format(
59 tag, VERSION
60 )
61 sys.exit(info)
62
63
64 setuptools.setup(
65 name=NAME,
66 version=VERSION,
67 description=DESCRIPTION,
68 long_description=LONG_DESCRIPTION,
69 url="https://streamlit.io",
70 author="Streamlit Inc",
71 author_email="[email protected]",
72 python_requires=">=3.6",
73 license="Apache 2",
74 packages=setuptools.find_packages(exclude=["tests", "tests.*"]),
75 # Requirements
76 install_requires=requirements,
77 zip_safe=False, # install source files not egg
78 include_package_data=True, # copy html and friends
79 entry_points={"console_scripts": ["streamlit = streamlit.cli:main"]},
80 # For Windows so that streamlit * commands work ie.
81 # - streamlit version
82 # - streamlit hello
83 scripts=["bin/streamlit.cmd"],
84 cmdclass={
85 "verify": VerifyVersionCommand,
86 },
87 )
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/setup.py b/lib/setup.py
--- a/lib/setup.py
+++ b/lib/setup.py
@@ -1,7 +1,5 @@
import os
-import platform
import setuptools
-import subprocess
import sys
from setuptools.command.install import install
@@ -33,18 +31,6 @@
packages = pipfile["packages"].copy()
requirements = convert_deps_to_pip(packages, r=False)
-# Check whether xcode tools are available before making watchdog a
-# dependency (only if the current system is a Mac).
-if platform.system() == "Darwin":
- has_xcode = subprocess.call(["xcode-select", "--version"], shell=False) == 0
- has_gcc = subprocess.call(["gcc", "--version"], shell=False) == 0
-
- if not (has_xcode and has_gcc):
- try:
- requirements.remove("watchdog")
- except ValueError:
- pass
-
class VerifyVersionCommand(install):
"""Custom command to verify that the git tag matches our version"""
|
{"golden_diff": "diff --git a/lib/setup.py b/lib/setup.py\n--- a/lib/setup.py\n+++ b/lib/setup.py\n@@ -1,7 +1,5 @@\n import os\n-import platform\n import setuptools\n-import subprocess\n import sys\n \n from setuptools.command.install import install\n@@ -33,18 +31,6 @@\n packages = pipfile[\"packages\"].copy()\n requirements = convert_deps_to_pip(packages, r=False)\n \n-# Check whether xcode tools are available before making watchdog a\n-# dependency (only if the current system is a Mac).\n-if platform.system() == \"Darwin\":\n- has_xcode = subprocess.call([\"xcode-select\", \"--version\"], shell=False) == 0\n- has_gcc = subprocess.call([\"gcc\", \"--version\"], shell=False) == 0\n-\n- if not (has_xcode and has_gcc):\n- try:\n- requirements.remove(\"watchdog\")\n- except ValueError:\n- pass\n-\n \n class VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n", "issue": "Watchdog error on install (Mac)\nI've tried to install it in a MAC using PIP and PIP3 and I get the same error:\r\n\r\nCommand \"/usr/local/opt/python/bin/python3.7 -u -c \"import setuptools, tokenize;__file__='/private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-install-3cscl6kq/watchdog/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\\r\\n', '\\n');f.close();exec(compile(code, __file__, 'exec'))\" install --record /private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-record-qr49cvd0/install-record.txt --single-version-externally-managed --compile\" failed with error code 1 in /private/var/folders/0s/rkvsfhzn2930_3902mpks9lm0000gn/T/pip-install-3cscl6kq/watchdog/\r\n\r\nI'm using: \r\nmacOS Mojave 10.14.5\r\n\n", "before_files": [{"content": "import os\nimport platform\nimport setuptools\nimport subprocess\nimport sys\n\nfrom setuptools.command.install import install\n\ntry:\n from pipenv.project import Project\n from pipenv.utils import convert_deps_to_pip\nexcept:\n exit_msg = (\n \"pipenv is required to package Streamlit. Please install pipenv and try again\"\n )\n sys.exit(exit_msg)\n\nVERSION = \"0.72.0\" # PEP-440\n\nNAME = \"streamlit\"\n\nDESCRIPTION = \"The fastest way to build data apps in Python\"\n\nLONG_DESCRIPTION = (\n \"Streamlit's open-source app framework is the easiest way \"\n \"for data scientists and machine learning engineers to \"\n \"create beautiful, performant apps in only a few hours! \"\n \"All in pure Python. All for free.\"\n)\n\npipfile = Project(chdir=False).parsed_pipfile\n\npackages = pipfile[\"packages\"].copy()\nrequirements = convert_deps_to_pip(packages, r=False)\n\n# Check whether xcode tools are available before making watchdog a\n# dependency (only if the current system is a Mac).\nif platform.system() == \"Darwin\":\n has_xcode = subprocess.call([\"xcode-select\", \"--version\"], shell=False) == 0\n has_gcc = subprocess.call([\"gcc\", \"--version\"], shell=False) == 0\n\n if not (has_xcode and has_gcc):\n try:\n requirements.remove(\"watchdog\")\n except ValueError:\n pass\n\n\nclass VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n\n description = \"verify that the git tag matches our version\"\n\n def run(self):\n tag = os.getenv(\"CIRCLE_TAG\")\n\n if tag != VERSION:\n info = \"Git tag: {0} does not match the version of this app: {1}\".format(\n tag, VERSION\n )\n sys.exit(info)\n\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=\"https://streamlit.io\",\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n python_requires=\">=3.6\",\n license=\"Apache 2\",\n packages=setuptools.find_packages(exclude=[\"tests\", \"tests.*\"]),\n # Requirements\n install_requires=requirements,\n zip_safe=False, # install source files not egg\n include_package_data=True, # copy html and friends\n entry_points={\"console_scripts\": [\"streamlit = streamlit.cli:main\"]},\n # For Windows so that streamlit * commands work ie.\n # - streamlit version\n # - streamlit hello\n scripts=[\"bin/streamlit.cmd\"],\n cmdclass={\n \"verify\": VerifyVersionCommand,\n },\n)\n", "path": "lib/setup.py"}], "after_files": [{"content": "import os\nimport setuptools\nimport sys\n\nfrom setuptools.command.install import install\n\ntry:\n from pipenv.project import Project\n from pipenv.utils import convert_deps_to_pip\nexcept:\n exit_msg = (\n \"pipenv is required to package Streamlit. Please install pipenv and try again\"\n )\n sys.exit(exit_msg)\n\nVERSION = \"0.72.0\" # PEP-440\n\nNAME = \"streamlit\"\n\nDESCRIPTION = \"The fastest way to build data apps in Python\"\n\nLONG_DESCRIPTION = (\n \"Streamlit's open-source app framework is the easiest way \"\n \"for data scientists and machine learning engineers to \"\n \"create beautiful, performant apps in only a few hours! \"\n \"All in pure Python. All for free.\"\n)\n\npipfile = Project(chdir=False).parsed_pipfile\n\npackages = pipfile[\"packages\"].copy()\nrequirements = convert_deps_to_pip(packages, r=False)\n\n\nclass VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n\n description = \"verify that the git tag matches our version\"\n\n def run(self):\n tag = os.getenv(\"CIRCLE_TAG\")\n\n if tag != VERSION:\n info = \"Git tag: {0} does not match the version of this app: {1}\".format(\n tag, VERSION\n )\n sys.exit(info)\n\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=\"https://streamlit.io\",\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n python_requires=\">=3.6\",\n license=\"Apache 2\",\n packages=setuptools.find_packages(exclude=[\"tests\", \"tests.*\"]),\n # Requirements\n install_requires=requirements,\n zip_safe=False, # install source files not egg\n include_package_data=True, # copy html and friends\n entry_points={\"console_scripts\": [\"streamlit = streamlit.cli:main\"]},\n # For Windows so that streamlit * commands work ie.\n # - streamlit version\n # - streamlit hello\n scripts=[\"bin/streamlit.cmd\"],\n cmdclass={\n \"verify\": VerifyVersionCommand,\n },\n)\n", "path": "lib/setup.py"}]}
| 1,302 | 230 |
gh_patches_debug_7071
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-614
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Uncaught exception from pyOpenSSL's shutdown call
See https://github.com/pypa/pip/issues/2753 for more details
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `urllib3/contrib/pyopenssl.py`
Content:
```
1 '''SSL with SNI_-support for Python 2. Follow these instructions if you would
2 like to verify SSL certificates in Python 2. Note, the default libraries do
3 *not* do certificate checking; you need to do additional work to validate
4 certificates yourself.
5
6 This needs the following packages installed:
7
8 * pyOpenSSL (tested with 0.13)
9 * ndg-httpsclient (tested with 0.3.2)
10 * pyasn1 (tested with 0.1.6)
11
12 You can install them with the following command:
13
14 pip install pyopenssl ndg-httpsclient pyasn1
15
16 To activate certificate checking, call
17 :func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code
18 before you begin making HTTP requests. This can be done in a ``sitecustomize``
19 module, or at any other time before your application begins using ``urllib3``,
20 like this::
21
22 try:
23 import urllib3.contrib.pyopenssl
24 urllib3.contrib.pyopenssl.inject_into_urllib3()
25 except ImportError:
26 pass
27
28 Now you can use :mod:`urllib3` as you normally would, and it will support SNI
29 when the required modules are installed.
30
31 Activating this module also has the positive side effect of disabling SSL/TLS
32 compression in Python 2 (see `CRIME attack`_).
33
34 If you want to configure the default list of supported cipher suites, you can
35 set the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.
36
37 Module Variables
38 ----------------
39
40 :var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.
41
42 .. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication
43 .. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)
44
45 '''
46
47 try:
48 from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT
49 from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName
50 except SyntaxError as e:
51 raise ImportError(e)
52
53 import OpenSSL.SSL
54 from pyasn1.codec.der import decoder as der_decoder
55 from pyasn1.type import univ, constraint
56 from socket import _fileobject, timeout
57 import ssl
58 import select
59
60 from .. import connection
61 from .. import util
62
63 __all__ = ['inject_into_urllib3', 'extract_from_urllib3']
64
65 # SNI only *really* works if we can read the subjectAltName of certificates.
66 HAS_SNI = SUBJ_ALT_NAME_SUPPORT
67
68 # Map from urllib3 to PyOpenSSL compatible parameter-values.
69 _openssl_versions = {
70 ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,
71 ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,
72 }
73
74 try:
75 _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})
76 except AttributeError:
77 pass
78
79 _openssl_verify = {
80 ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,
81 ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,
82 ssl.CERT_REQUIRED: OpenSSL.SSL.VERIFY_PEER
83 + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,
84 }
85
86 DEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS
87
88
89 orig_util_HAS_SNI = util.HAS_SNI
90 orig_connection_ssl_wrap_socket = connection.ssl_wrap_socket
91
92
93 def inject_into_urllib3():
94 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'
95
96 connection.ssl_wrap_socket = ssl_wrap_socket
97 util.HAS_SNI = HAS_SNI
98
99
100 def extract_from_urllib3():
101 'Undo monkey-patching by :func:`inject_into_urllib3`.'
102
103 connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket
104 util.HAS_SNI = orig_util_HAS_SNI
105
106
107 ### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.
108 class SubjectAltName(BaseSubjectAltName):
109 '''ASN.1 implementation for subjectAltNames support'''
110
111 # There is no limit to how many SAN certificates a certificate may have,
112 # however this needs to have some limit so we'll set an arbitrarily high
113 # limit.
114 sizeSpec = univ.SequenceOf.sizeSpec + \
115 constraint.ValueSizeConstraint(1, 1024)
116
117
118 ### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.
119 def get_subj_alt_name(peer_cert):
120 # Search through extensions
121 dns_name = []
122 if not SUBJ_ALT_NAME_SUPPORT:
123 return dns_name
124
125 general_names = SubjectAltName()
126 for i in range(peer_cert.get_extension_count()):
127 ext = peer_cert.get_extension(i)
128 ext_name = ext.get_short_name()
129 if ext_name != 'subjectAltName':
130 continue
131
132 # PyOpenSSL returns extension data in ASN.1 encoded form
133 ext_dat = ext.get_data()
134 decoded_dat = der_decoder.decode(ext_dat,
135 asn1Spec=general_names)
136
137 for name in decoded_dat:
138 if not isinstance(name, SubjectAltName):
139 continue
140 for entry in range(len(name)):
141 component = name.getComponentByPosition(entry)
142 if component.getName() != 'dNSName':
143 continue
144 dns_name.append(str(component.getComponent()))
145
146 return dns_name
147
148
149 class WrappedSocket(object):
150 '''API-compatibility wrapper for Python OpenSSL's Connection-class.
151
152 Note: _makefile_refs, _drop() and _reuse() are needed for the garbage
153 collector of pypy.
154 '''
155
156 def __init__(self, connection, socket, suppress_ragged_eofs=True):
157 self.connection = connection
158 self.socket = socket
159 self.suppress_ragged_eofs = suppress_ragged_eofs
160 self._makefile_refs = 0
161
162 def fileno(self):
163 return self.socket.fileno()
164
165 def makefile(self, mode, bufsize=-1):
166 self._makefile_refs += 1
167 return _fileobject(self, mode, bufsize, close=True)
168
169 def recv(self, *args, **kwargs):
170 try:
171 data = self.connection.recv(*args, **kwargs)
172 except OpenSSL.SSL.SysCallError as e:
173 if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):
174 return b''
175 else:
176 raise
177 except OpenSSL.SSL.ZeroReturnError as e:
178 if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
179 return b''
180 else:
181 raise
182 except OpenSSL.SSL.WantReadError:
183 rd, wd, ed = select.select(
184 [self.socket], [], [], self.socket.gettimeout())
185 if not rd:
186 raise timeout('The read operation timed out')
187 else:
188 return self.recv(*args, **kwargs)
189 else:
190 return data
191
192 def settimeout(self, timeout):
193 return self.socket.settimeout(timeout)
194
195 def _send_until_done(self, data):
196 while True:
197 try:
198 return self.connection.send(data)
199 except OpenSSL.SSL.WantWriteError:
200 _, wlist, _ = select.select([], [self.socket], [],
201 self.socket.gettimeout())
202 if not wlist:
203 raise timeout()
204 continue
205
206 def sendall(self, data):
207 while len(data):
208 sent = self._send_until_done(data)
209 data = data[sent:]
210
211 def close(self):
212 if self._makefile_refs < 1:
213 return self.connection.shutdown()
214 else:
215 self._makefile_refs -= 1
216
217 def getpeercert(self, binary_form=False):
218 x509 = self.connection.get_peer_certificate()
219
220 if not x509:
221 return x509
222
223 if binary_form:
224 return OpenSSL.crypto.dump_certificate(
225 OpenSSL.crypto.FILETYPE_ASN1,
226 x509)
227
228 return {
229 'subject': (
230 (('commonName', x509.get_subject().CN),),
231 ),
232 'subjectAltName': [
233 ('DNS', value)
234 for value in get_subj_alt_name(x509)
235 ]
236 }
237
238 def _reuse(self):
239 self._makefile_refs += 1
240
241 def _drop(self):
242 if self._makefile_refs < 1:
243 self.close()
244 else:
245 self._makefile_refs -= 1
246
247
248 def _verify_callback(cnx, x509, err_no, err_depth, return_code):
249 return err_no == 0
250
251
252 def ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,
253 ca_certs=None, server_hostname=None,
254 ssl_version=None):
255 ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])
256 if certfile:
257 keyfile = keyfile or certfile # Match behaviour of the normal python ssl library
258 ctx.use_certificate_file(certfile)
259 if keyfile:
260 ctx.use_privatekey_file(keyfile)
261 if cert_reqs != ssl.CERT_NONE:
262 ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)
263 if ca_certs:
264 try:
265 ctx.load_verify_locations(ca_certs, None)
266 except OpenSSL.SSL.Error as e:
267 raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)
268 else:
269 ctx.set_default_verify_paths()
270
271 # Disable TLS compression to migitate CRIME attack (issue #309)
272 OP_NO_COMPRESSION = 0x20000
273 ctx.set_options(OP_NO_COMPRESSION)
274
275 # Set list of supported ciphersuites.
276 ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)
277
278 cnx = OpenSSL.SSL.Connection(ctx, sock)
279 cnx.set_tlsext_host_name(server_hostname)
280 cnx.set_connect_state()
281 while True:
282 try:
283 cnx.do_handshake()
284 except OpenSSL.SSL.WantReadError:
285 rd, _, _ = select.select([sock], [], [], sock.gettimeout())
286 if not rd:
287 raise timeout('select timed out')
288 continue
289 except OpenSSL.SSL.Error as e:
290 raise ssl.SSLError('bad handshake', e)
291 break
292
293 return WrappedSocket(cnx, sock)
294
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/urllib3/contrib/pyopenssl.py b/urllib3/contrib/pyopenssl.py
--- a/urllib3/contrib/pyopenssl.py
+++ b/urllib3/contrib/pyopenssl.py
@@ -208,9 +208,13 @@
sent = self._send_until_done(data)
data = data[sent:]
+ def shutdown(self):
+ # FIXME rethrow compatible exceptions should we ever use this
+ self.connection.shutdown()
+
def close(self):
if self._makefile_refs < 1:
- return self.connection.shutdown()
+ return self.connection.close()
else:
self._makefile_refs -= 1
|
{"golden_diff": "diff --git a/urllib3/contrib/pyopenssl.py b/urllib3/contrib/pyopenssl.py\n--- a/urllib3/contrib/pyopenssl.py\n+++ b/urllib3/contrib/pyopenssl.py\n@@ -208,9 +208,13 @@\n sent = self._send_until_done(data)\n data = data[sent:]\n \n+ def shutdown(self):\n+ # FIXME rethrow compatible exceptions should we ever use this\n+ self.connection.shutdown()\n+\n def close(self):\n if self._makefile_refs < 1:\n- return self.connection.shutdown()\n+ return self.connection.close()\n else:\n self._makefile_refs -= 1\n", "issue": "Uncaught exception from pyOpenSSL's shutdown call\nSee https://github.com/pypa/pip/issues/2753 for more details\n\n", "before_files": [{"content": "'''SSL with SNI_-support for Python 2. Follow these instructions if you would\nlike to verify SSL certificates in Python 2. Note, the default libraries do\n*not* do certificate checking; you need to do additional work to validate\ncertificates yourself.\n\nThis needs the following packages installed:\n\n* pyOpenSSL (tested with 0.13)\n* ndg-httpsclient (tested with 0.3.2)\n* pyasn1 (tested with 0.1.6)\n\nYou can install them with the following command:\n\n pip install pyopenssl ndg-httpsclient pyasn1\n\nTo activate certificate checking, call\n:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code\nbefore you begin making HTTP requests. This can be done in a ``sitecustomize``\nmodule, or at any other time before your application begins using ``urllib3``,\nlike this::\n\n try:\n import urllib3.contrib.pyopenssl\n urllib3.contrib.pyopenssl.inject_into_urllib3()\n except ImportError:\n pass\n\nNow you can use :mod:`urllib3` as you normally would, and it will support SNI\nwhen the required modules are installed.\n\nActivating this module also has the positive side effect of disabling SSL/TLS\ncompression in Python 2 (see `CRIME attack`_).\n\nIf you want to configure the default list of supported cipher suites, you can\nset the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.\n\nModule Variables\n----------------\n\n:var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.\n\n.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication\n.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)\n\n'''\n\ntry:\n from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT\n from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName\nexcept SyntaxError as e:\n raise ImportError(e)\n\nimport OpenSSL.SSL\nfrom pyasn1.codec.der import decoder as der_decoder\nfrom pyasn1.type import univ, constraint\nfrom socket import _fileobject, timeout\nimport ssl\nimport select\n\nfrom .. import connection\nfrom .. import util\n\n__all__ = ['inject_into_urllib3', 'extract_from_urllib3']\n\n# SNI only *really* works if we can read the subjectAltName of certificates.\nHAS_SNI = SUBJ_ALT_NAME_SUPPORT\n\n# Map from urllib3 to PyOpenSSL compatible parameter-values.\n_openssl_versions = {\n ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,\n ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,\n}\n\ntry:\n _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})\nexcept AttributeError:\n pass\n\n_openssl_verify = {\n ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,\n ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,\n ssl.CERT_REQUIRED: OpenSSL.SSL.VERIFY_PEER\n + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,\n}\n\nDEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS\n\n\norig_util_HAS_SNI = util.HAS_SNI\norig_connection_ssl_wrap_socket = connection.ssl_wrap_socket\n\n\ndef inject_into_urllib3():\n 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'\n\n connection.ssl_wrap_socket = ssl_wrap_socket\n util.HAS_SNI = HAS_SNI\n\n\ndef extract_from_urllib3():\n 'Undo monkey-patching by :func:`inject_into_urllib3`.'\n\n connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket\n util.HAS_SNI = orig_util_HAS_SNI\n\n\n### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\nclass SubjectAltName(BaseSubjectAltName):\n '''ASN.1 implementation for subjectAltNames support'''\n\n # There is no limit to how many SAN certificates a certificate may have,\n # however this needs to have some limit so we'll set an arbitrarily high\n # limit.\n sizeSpec = univ.SequenceOf.sizeSpec + \\\n constraint.ValueSizeConstraint(1, 1024)\n\n\n### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\ndef get_subj_alt_name(peer_cert):\n # Search through extensions\n dns_name = []\n if not SUBJ_ALT_NAME_SUPPORT:\n return dns_name\n\n general_names = SubjectAltName()\n for i in range(peer_cert.get_extension_count()):\n ext = peer_cert.get_extension(i)\n ext_name = ext.get_short_name()\n if ext_name != 'subjectAltName':\n continue\n\n # PyOpenSSL returns extension data in ASN.1 encoded form\n ext_dat = ext.get_data()\n decoded_dat = der_decoder.decode(ext_dat,\n asn1Spec=general_names)\n\n for name in decoded_dat:\n if not isinstance(name, SubjectAltName):\n continue\n for entry in range(len(name)):\n component = name.getComponentByPosition(entry)\n if component.getName() != 'dNSName':\n continue\n dns_name.append(str(component.getComponent()))\n\n return dns_name\n\n\nclass WrappedSocket(object):\n '''API-compatibility wrapper for Python OpenSSL's Connection-class.\n\n Note: _makefile_refs, _drop() and _reuse() are needed for the garbage\n collector of pypy.\n '''\n\n def __init__(self, connection, socket, suppress_ragged_eofs=True):\n self.connection = connection\n self.socket = socket\n self.suppress_ragged_eofs = suppress_ragged_eofs\n self._makefile_refs = 0\n\n def fileno(self):\n return self.socket.fileno()\n\n def makefile(self, mode, bufsize=-1):\n self._makefile_refs += 1\n return _fileobject(self, mode, bufsize, close=True)\n\n def recv(self, *args, **kwargs):\n try:\n data = self.connection.recv(*args, **kwargs)\n except OpenSSL.SSL.SysCallError as e:\n if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):\n return b''\n else:\n raise\n except OpenSSL.SSL.ZeroReturnError as e:\n if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:\n return b''\n else:\n raise\n except OpenSSL.SSL.WantReadError:\n rd, wd, ed = select.select(\n [self.socket], [], [], self.socket.gettimeout())\n if not rd:\n raise timeout('The read operation timed out')\n else:\n return self.recv(*args, **kwargs)\n else:\n return data\n\n def settimeout(self, timeout):\n return self.socket.settimeout(timeout)\n\n def _send_until_done(self, data):\n while True:\n try:\n return self.connection.send(data)\n except OpenSSL.SSL.WantWriteError:\n _, wlist, _ = select.select([], [self.socket], [],\n self.socket.gettimeout())\n if not wlist:\n raise timeout()\n continue\n\n def sendall(self, data):\n while len(data):\n sent = self._send_until_done(data)\n data = data[sent:]\n\n def close(self):\n if self._makefile_refs < 1:\n return self.connection.shutdown()\n else:\n self._makefile_refs -= 1\n\n def getpeercert(self, binary_form=False):\n x509 = self.connection.get_peer_certificate()\n\n if not x509:\n return x509\n\n if binary_form:\n return OpenSSL.crypto.dump_certificate(\n OpenSSL.crypto.FILETYPE_ASN1,\n x509)\n\n return {\n 'subject': (\n (('commonName', x509.get_subject().CN),),\n ),\n 'subjectAltName': [\n ('DNS', value)\n for value in get_subj_alt_name(x509)\n ]\n }\n\n def _reuse(self):\n self._makefile_refs += 1\n\n def _drop(self):\n if self._makefile_refs < 1:\n self.close()\n else:\n self._makefile_refs -= 1\n\n\ndef _verify_callback(cnx, x509, err_no, err_depth, return_code):\n return err_no == 0\n\n\ndef ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,\n ca_certs=None, server_hostname=None,\n ssl_version=None):\n ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])\n if certfile:\n keyfile = keyfile or certfile # Match behaviour of the normal python ssl library\n ctx.use_certificate_file(certfile)\n if keyfile:\n ctx.use_privatekey_file(keyfile)\n if cert_reqs != ssl.CERT_NONE:\n ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)\n if ca_certs:\n try:\n ctx.load_verify_locations(ca_certs, None)\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)\n else:\n ctx.set_default_verify_paths()\n\n # Disable TLS compression to migitate CRIME attack (issue #309)\n OP_NO_COMPRESSION = 0x20000\n ctx.set_options(OP_NO_COMPRESSION)\n\n # Set list of supported ciphersuites.\n ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)\n\n cnx = OpenSSL.SSL.Connection(ctx, sock)\n cnx.set_tlsext_host_name(server_hostname)\n cnx.set_connect_state()\n while True:\n try:\n cnx.do_handshake()\n except OpenSSL.SSL.WantReadError:\n rd, _, _ = select.select([sock], [], [], sock.gettimeout())\n if not rd:\n raise timeout('select timed out')\n continue\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad handshake', e)\n break\n\n return WrappedSocket(cnx, sock)\n", "path": "urllib3/contrib/pyopenssl.py"}], "after_files": [{"content": "'''SSL with SNI_-support for Python 2. Follow these instructions if you would\nlike to verify SSL certificates in Python 2. Note, the default libraries do\n*not* do certificate checking; you need to do additional work to validate\ncertificates yourself.\n\nThis needs the following packages installed:\n\n* pyOpenSSL (tested with 0.13)\n* ndg-httpsclient (tested with 0.3.2)\n* pyasn1 (tested with 0.1.6)\n\nYou can install them with the following command:\n\n pip install pyopenssl ndg-httpsclient pyasn1\n\nTo activate certificate checking, call\n:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code\nbefore you begin making HTTP requests. This can be done in a ``sitecustomize``\nmodule, or at any other time before your application begins using ``urllib3``,\nlike this::\n\n try:\n import urllib3.contrib.pyopenssl\n urllib3.contrib.pyopenssl.inject_into_urllib3()\n except ImportError:\n pass\n\nNow you can use :mod:`urllib3` as you normally would, and it will support SNI\nwhen the required modules are installed.\n\nActivating this module also has the positive side effect of disabling SSL/TLS\ncompression in Python 2 (see `CRIME attack`_).\n\nIf you want to configure the default list of supported cipher suites, you can\nset the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.\n\nModule Variables\n----------------\n\n:var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.\n\n.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication\n.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)\n\n'''\n\ntry:\n from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT\n from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName\nexcept SyntaxError as e:\n raise ImportError(e)\n\nimport OpenSSL.SSL\nfrom pyasn1.codec.der import decoder as der_decoder\nfrom pyasn1.type import univ, constraint\nfrom socket import _fileobject, timeout\nimport ssl\nimport select\n\nfrom .. import connection\nfrom .. import util\n\n__all__ = ['inject_into_urllib3', 'extract_from_urllib3']\n\n# SNI only *really* works if we can read the subjectAltName of certificates.\nHAS_SNI = SUBJ_ALT_NAME_SUPPORT\n\n# Map from urllib3 to PyOpenSSL compatible parameter-values.\n_openssl_versions = {\n ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,\n ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,\n}\n\ntry:\n _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})\nexcept AttributeError:\n pass\n\n_openssl_verify = {\n ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,\n ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,\n ssl.CERT_REQUIRED: OpenSSL.SSL.VERIFY_PEER\n + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,\n}\n\nDEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS\n\n\norig_util_HAS_SNI = util.HAS_SNI\norig_connection_ssl_wrap_socket = connection.ssl_wrap_socket\n\n\ndef inject_into_urllib3():\n 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'\n\n connection.ssl_wrap_socket = ssl_wrap_socket\n util.HAS_SNI = HAS_SNI\n\n\ndef extract_from_urllib3():\n 'Undo monkey-patching by :func:`inject_into_urllib3`.'\n\n connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket\n util.HAS_SNI = orig_util_HAS_SNI\n\n\n### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\nclass SubjectAltName(BaseSubjectAltName):\n '''ASN.1 implementation for subjectAltNames support'''\n\n # There is no limit to how many SAN certificates a certificate may have,\n # however this needs to have some limit so we'll set an arbitrarily high\n # limit.\n sizeSpec = univ.SequenceOf.sizeSpec + \\\n constraint.ValueSizeConstraint(1, 1024)\n\n\n### Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\ndef get_subj_alt_name(peer_cert):\n # Search through extensions\n dns_name = []\n if not SUBJ_ALT_NAME_SUPPORT:\n return dns_name\n\n general_names = SubjectAltName()\n for i in range(peer_cert.get_extension_count()):\n ext = peer_cert.get_extension(i)\n ext_name = ext.get_short_name()\n if ext_name != 'subjectAltName':\n continue\n\n # PyOpenSSL returns extension data in ASN.1 encoded form\n ext_dat = ext.get_data()\n decoded_dat = der_decoder.decode(ext_dat,\n asn1Spec=general_names)\n\n for name in decoded_dat:\n if not isinstance(name, SubjectAltName):\n continue\n for entry in range(len(name)):\n component = name.getComponentByPosition(entry)\n if component.getName() != 'dNSName':\n continue\n dns_name.append(str(component.getComponent()))\n\n return dns_name\n\n\nclass WrappedSocket(object):\n '''API-compatibility wrapper for Python OpenSSL's Connection-class.\n\n Note: _makefile_refs, _drop() and _reuse() are needed for the garbage\n collector of pypy.\n '''\n\n def __init__(self, connection, socket, suppress_ragged_eofs=True):\n self.connection = connection\n self.socket = socket\n self.suppress_ragged_eofs = suppress_ragged_eofs\n self._makefile_refs = 0\n\n def fileno(self):\n return self.socket.fileno()\n\n def makefile(self, mode, bufsize=-1):\n self._makefile_refs += 1\n return _fileobject(self, mode, bufsize, close=True)\n\n def recv(self, *args, **kwargs):\n try:\n data = self.connection.recv(*args, **kwargs)\n except OpenSSL.SSL.SysCallError as e:\n if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):\n return b''\n else:\n raise\n except OpenSSL.SSL.ZeroReturnError as e:\n if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:\n return b''\n else:\n raise\n except OpenSSL.SSL.WantReadError:\n rd, wd, ed = select.select(\n [self.socket], [], [], self.socket.gettimeout())\n if not rd:\n raise timeout('The read operation timed out')\n else:\n return self.recv(*args, **kwargs)\n else:\n return data\n\n def settimeout(self, timeout):\n return self.socket.settimeout(timeout)\n\n def _send_until_done(self, data):\n while True:\n try:\n return self.connection.send(data)\n except OpenSSL.SSL.WantWriteError:\n _, wlist, _ = select.select([], [self.socket], [],\n self.socket.gettimeout())\n if not wlist:\n raise timeout()\n continue\n\n def sendall(self, data):\n while len(data):\n sent = self._send_until_done(data)\n data = data[sent:]\n\n def shutdown(self):\n # FIXME rethrow compatible exceptions should we ever use this\n self.connection.shutdown()\n\n def close(self):\n if self._makefile_refs < 1:\n return self.connection.close()\n else:\n self._makefile_refs -= 1\n\n def getpeercert(self, binary_form=False):\n x509 = self.connection.get_peer_certificate()\n\n if not x509:\n return x509\n\n if binary_form:\n return OpenSSL.crypto.dump_certificate(\n OpenSSL.crypto.FILETYPE_ASN1,\n x509)\n\n return {\n 'subject': (\n (('commonName', x509.get_subject().CN),),\n ),\n 'subjectAltName': [\n ('DNS', value)\n for value in get_subj_alt_name(x509)\n ]\n }\n\n def _reuse(self):\n self._makefile_refs += 1\n\n def _drop(self):\n if self._makefile_refs < 1:\n self.close()\n else:\n self._makefile_refs -= 1\n\n\ndef _verify_callback(cnx, x509, err_no, err_depth, return_code):\n return err_no == 0\n\n\ndef ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,\n ca_certs=None, server_hostname=None,\n ssl_version=None):\n ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])\n if certfile:\n keyfile = keyfile or certfile # Match behaviour of the normal python ssl library\n ctx.use_certificate_file(certfile)\n if keyfile:\n ctx.use_privatekey_file(keyfile)\n if cert_reqs != ssl.CERT_NONE:\n ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)\n if ca_certs:\n try:\n ctx.load_verify_locations(ca_certs, None)\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)\n else:\n ctx.set_default_verify_paths()\n\n # Disable TLS compression to migitate CRIME attack (issue #309)\n OP_NO_COMPRESSION = 0x20000\n ctx.set_options(OP_NO_COMPRESSION)\n\n # Set list of supported ciphersuites.\n ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)\n\n cnx = OpenSSL.SSL.Connection(ctx, sock)\n cnx.set_tlsext_host_name(server_hostname)\n cnx.set_connect_state()\n while True:\n try:\n cnx.do_handshake()\n except OpenSSL.SSL.WantReadError:\n rd, _, _ = select.select([sock], [], [], sock.gettimeout())\n if not rd:\n raise timeout('select timed out')\n continue\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad handshake', e)\n break\n\n return WrappedSocket(cnx, sock)\n", "path": "urllib3/contrib/pyopenssl.py"}]}
| 3,282 | 151 |
gh_patches_debug_10627
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-2601
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
importadded: ValueError on trying to import a large library
After migrating my music to a new drive, I'm trying to update the beets library. I've first run `beet update` so beets flushes out the old files, and I'm now running `beet import -AC .` to import the new files. Along the way, I've seen this error show up a couple times, though it is inconsistent in when it shows:
```
Traceback (most recent call last):
File "/usr/local/bin/beet", line 9, in <module>
load_entry_point('beets==1.3.17', 'console_scripts', 'beet')()
File "/usr/local/lib/python2.7/dist-packages/beets/ui/__init__.py", line 1236, in main
_raw_main(args)
File "/usr/local/lib/python2.7/dist-packages/beets/ui/__init__.py", line 1226, in _raw_main
subcommand.func(lib, suboptions, subargs)
File "/usr/local/lib/python2.7/dist-packages/beets/ui/commands.py", line 966, in import_func
import_files(lib, paths, query)
File "/usr/local/lib/python2.7/dist-packages/beets/ui/commands.py", line 943, in import_files
session.run()
File "/usr/local/lib/python2.7/dist-packages/beets/importer.py", line 321, in run
pl.run_parallel(QUEUE_SIZE)
File "/usr/local/lib/python2.7/dist-packages/beets/util/pipeline.py", line 348, in run
self.coro.send(msg)
File "/usr/local/lib/python2.7/dist-packages/beets/util/pipeline.py", line 161, in coro
task = func(*(args + (task,)))
File "/usr/local/lib/python2.7/dist-packages/beets/importer.py", line 1401, in manipulate_files
task.finalize(session)
File "/usr/local/lib/python2.7/dist-packages/beets/importer.py", line 544, in finalize
self._emit_imported(session.lib)
File "/usr/local/lib/python2.7/dist-packages/beets/importer.py", line 570, in _emit_imported
plugins.send('album_imported', lib=lib, album=self.album)
File "/usr/local/lib/python2.7/dist-packages/beets/plugins.py", line 459, in send
result = handler(**arguments)
File "/usr/local/lib/python2.7/dist-packages/beets/plugins.py", line 124, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/beetsplug/importadded.py", line 106, in update_album_times
album.added = min(album_mtimes)
ValueError: min() arg is an empty sequence
```
I'm currently running beets 1.3.17, and my configuration is listed below:
```
importfeeds:
dir: /media/Backup/Music
relative_to:
formats: m3u m3u_multi
absolute_path: no
m3u_name: imported.m3u
web:
host: 0.0.0.0
cors: '*'
convert:
max_bitrate: 192
command: ffmpeg -i $source -map_metadata 0 $dest
extension: mp3
never_convert_lossy_files: no
format: mp3
dest:
auto: no
threads: 4
copy_album_art: no
tmpdir:
paths: {}
pretend: no
quiet: no
formats:
alac:
command: ffmpeg -i $source -y -vn -acodec alac $dest
extension: m4a
aac:
command: ffmpeg -i $source -y -vn -acodec libfaac -aq 100 $dest
extension: m4a
opus: ffmpeg -i $source -y -vn -acodec libopus -ab 96k $dest
mp3: ffmpeg -i $source -y -vn -aq 2 $dest
flac: ffmpeg -i $source -y -vn -acodec flac $dest
ogg: ffmpeg -i $source -y -vn -acodec libvorbis -aq 2 $dest
wma: ffmpeg -i $source -y -vn -acodec wmav2 -vn $dest
embed: yes
per_disc_numbering: yes
fetchart:
auto: no
minwidth: 0
sources:
- coverart
- itunes
- amazon
- albumart
cautious: no
google_engine: 001442825323518660753:hrh5ch1gjzm
maxwidth: 0
google_key: REDACTED
cover_names:
- cover
- front
- art
- album
- folder
remote_priority: no
enforce_ratio: no
embedart:
auto: no
compare_threshold: 0
ifempty: no
remove_art_file: no
maxwidth: 0
replaygain:
backend: gstreamer
targetlevel: 89
auto: yes
overwrite: no
library: ~/.config/beets/library.db
plugins: duplicates importfeeds importadded replaygain embedart fetchart convert edit
directory: /media/Backup/Music
edit:
itemfields: track title artist album
albumfields: album albumartist
ignore_fields: id path
importadded:
preserve_mtimes: no
duplicates:
count: no
full: no
format: ''
keys: []
move: ''
tag: ''
path: no
copy: ''
tiebreak: {}
album: no
strict: no
checksum: ''
merge: no
delete: no
```
I've since disabled the `importadded` plugin so I can just import all my files, but is there a way to fix this in the future? This is running off of an NTFS filesystem, so I don't know if a `stat` command or similar isn't coming back correctly, but I haven't had issues with this in the past.
Let me know if there's any way I can assist.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `beetsplug/importadded.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Populate an item's `added` and `mtime` fields by using the file
4 modification time (mtime) of the item's source file before import.
5
6 Reimported albums and items are skipped.
7 """
8 from __future__ import division, absolute_import, print_function
9
10 import os
11
12 from beets import util
13 from beets import importer
14 from beets.plugins import BeetsPlugin
15
16
17 class ImportAddedPlugin(BeetsPlugin):
18 def __init__(self):
19 super(ImportAddedPlugin, self).__init__()
20 self.config.add({
21 'preserve_mtimes': False,
22 'preserve_write_mtimes': False,
23 })
24
25 # item.id for new items that were reimported
26 self.reimported_item_ids = None
27 # album.path for old albums that were replaced by a reimported album
28 self.replaced_album_paths = None
29 # item path in the library to the mtime of the source file
30 self.item_mtime = dict()
31
32 register = self.register_listener
33 register('import_task_start', self.check_config)
34 register('import_task_start', self.record_if_inplace)
35 register('import_task_files', self.record_reimported)
36 register('before_item_moved', self.record_import_mtime)
37 register('item_copied', self.record_import_mtime)
38 register('item_linked', self.record_import_mtime)
39 register('item_hardlinked', self.record_import_mtime)
40 register('album_imported', self.update_album_times)
41 register('item_imported', self.update_item_times)
42 register('after_write', self.update_after_write_time)
43
44 def check_config(self, task, session):
45 self.config['preserve_mtimes'].get(bool)
46
47 def reimported_item(self, item):
48 return item.id in self.reimported_item_ids
49
50 def reimported_album(self, album):
51 return album.path in self.replaced_album_paths
52
53 def record_if_inplace(self, task, session):
54 if not (session.config['copy'] or session.config['move'] or
55 session.config['link'] or session.config['hardlink']):
56 self._log.debug(u"In place import detected, recording mtimes from "
57 u"source paths")
58 items = [task.item] \
59 if isinstance(task, importer.SingletonImportTask) \
60 else task.items
61 for item in items:
62 self.record_import_mtime(item, item.path, item.path)
63
64 def record_reimported(self, task, session):
65 self.reimported_item_ids = set(item.id for item, replaced_items
66 in task.replaced_items.items()
67 if replaced_items)
68 self.replaced_album_paths = set(task.replaced_albums.keys())
69
70 def write_file_mtime(self, path, mtime):
71 """Write the given mtime to the destination path.
72 """
73 stat = os.stat(util.syspath(path))
74 os.utime(util.syspath(path), (stat.st_atime, mtime))
75
76 def write_item_mtime(self, item, mtime):
77 """Write the given mtime to an item's `mtime` field and to the mtime
78 of the item's file.
79 """
80 # The file's mtime on disk must be in sync with the item's mtime
81 self.write_file_mtime(util.syspath(item.path), mtime)
82 item.mtime = mtime
83
84 def record_import_mtime(self, item, source, destination):
85 """Record the file mtime of an item's path before its import.
86 """
87 mtime = os.stat(util.syspath(source)).st_mtime
88 self.item_mtime[destination] = mtime
89 self._log.debug(u"Recorded mtime {0} for item '{1}' imported from "
90 u"'{2}'", mtime, util.displayable_path(destination),
91 util.displayable_path(source))
92
93 def update_album_times(self, lib, album):
94 if self.reimported_album(album):
95 self._log.debug(u"Album '{0}' is reimported, skipping import of "
96 u"added dates for the album and its items.",
97 util.displayable_path(album.path))
98 return
99
100 album_mtimes = []
101 for item in album.items():
102 mtime = self.item_mtime.pop(item.path, None)
103 if mtime:
104 album_mtimes.append(mtime)
105 if self.config['preserve_mtimes'].get(bool):
106 self.write_item_mtime(item, mtime)
107 item.store()
108 album.added = min(album_mtimes)
109 self._log.debug(u"Import of album '{0}', selected album.added={1} "
110 u"from item file mtimes.", album.album, album.added)
111 album.store()
112
113 def update_item_times(self, lib, item):
114 if self.reimported_item(item):
115 self._log.debug(u"Item '{0}' is reimported, skipping import of "
116 u"added date.", util.displayable_path(item.path))
117 return
118 mtime = self.item_mtime.pop(item.path, None)
119 if mtime:
120 item.added = mtime
121 if self.config['preserve_mtimes'].get(bool):
122 self.write_item_mtime(item, mtime)
123 self._log.debug(u"Import of item '{0}', selected item.added={1}",
124 util.displayable_path(item.path), item.added)
125 item.store()
126
127 def update_after_write_time(self, item):
128 """Update the mtime of the item's file with the item.added value
129 after each write of the item if `preserve_write_mtimes` is enabled.
130 """
131 if item.added:
132 if self.config['preserve_write_mtimes'].get(bool):
133 self.write_item_mtime(item, item.added)
134 self._log.debug(u"Write of item '{0}', selected item.added={1}",
135 util.displayable_path(item.path), item.added)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/beetsplug/importadded.py b/beetsplug/importadded.py
--- a/beetsplug/importadded.py
+++ b/beetsplug/importadded.py
@@ -30,8 +30,8 @@
self.item_mtime = dict()
register = self.register_listener
- register('import_task_start', self.check_config)
- register('import_task_start', self.record_if_inplace)
+ register('import_task_created', self.check_config)
+ register('import_task_created', self.record_if_inplace)
register('import_task_files', self.record_reimported)
register('before_item_moved', self.record_import_mtime)
register('item_copied', self.record_import_mtime)
|
{"golden_diff": "diff --git a/beetsplug/importadded.py b/beetsplug/importadded.py\n--- a/beetsplug/importadded.py\n+++ b/beetsplug/importadded.py\n@@ -30,8 +30,8 @@\n self.item_mtime = dict()\n \n register = self.register_listener\n- register('import_task_start', self.check_config)\n- register('import_task_start', self.record_if_inplace)\n+ register('import_task_created', self.check_config)\n+ register('import_task_created', self.record_if_inplace)\n register('import_task_files', self.record_reimported)\n register('before_item_moved', self.record_import_mtime)\n register('item_copied', self.record_import_mtime)\n", "issue": "importadded: ValueError on trying to import a large library\nAfter migrating my music to a new drive, I'm trying to update the beets library. I've first run `beet update` so beets flushes out the old files, and I'm now running `beet import -AC .` to import the new files. Along the way, I've seen this error show up a couple times, though it is inconsistent in when it shows:\n\n```\nTraceback (most recent call last):\n File \"/usr/local/bin/beet\", line 9, in <module>\n load_entry_point('beets==1.3.17', 'console_scripts', 'beet')()\n File \"/usr/local/lib/python2.7/dist-packages/beets/ui/__init__.py\", line 1236, in main\n _raw_main(args)\n File \"/usr/local/lib/python2.7/dist-packages/beets/ui/__init__.py\", line 1226, in _raw_main\n subcommand.func(lib, suboptions, subargs)\n File \"/usr/local/lib/python2.7/dist-packages/beets/ui/commands.py\", line 966, in import_func\n import_files(lib, paths, query)\n File \"/usr/local/lib/python2.7/dist-packages/beets/ui/commands.py\", line 943, in import_files\n session.run()\n File \"/usr/local/lib/python2.7/dist-packages/beets/importer.py\", line 321, in run\n pl.run_parallel(QUEUE_SIZE)\n File \"/usr/local/lib/python2.7/dist-packages/beets/util/pipeline.py\", line 348, in run\n self.coro.send(msg)\n File \"/usr/local/lib/python2.7/dist-packages/beets/util/pipeline.py\", line 161, in coro\n task = func(*(args + (task,)))\n File \"/usr/local/lib/python2.7/dist-packages/beets/importer.py\", line 1401, in manipulate_files\n task.finalize(session)\n File \"/usr/local/lib/python2.7/dist-packages/beets/importer.py\", line 544, in finalize\n self._emit_imported(session.lib)\n File \"/usr/local/lib/python2.7/dist-packages/beets/importer.py\", line 570, in _emit_imported\n plugins.send('album_imported', lib=lib, album=self.album)\n File \"/usr/local/lib/python2.7/dist-packages/beets/plugins.py\", line 459, in send\n result = handler(**arguments)\n File \"/usr/local/lib/python2.7/dist-packages/beets/plugins.py\", line 124, in wrapper\n return func(*args, **kwargs)\n File \"/usr/local/lib/python2.7/dist-packages/beetsplug/importadded.py\", line 106, in update_album_times\n album.added = min(album_mtimes)\nValueError: min() arg is an empty sequence\n```\n\nI'm currently running beets 1.3.17, and my configuration is listed below:\n\n```\nimportfeeds:\n dir: /media/Backup/Music\n relative_to:\n formats: m3u m3u_multi\n absolute_path: no\n m3u_name: imported.m3u\nweb:\n host: 0.0.0.0\n cors: '*'\nconvert:\n max_bitrate: 192\n command: ffmpeg -i $source -map_metadata 0 $dest\n extension: mp3\n never_convert_lossy_files: no\n format: mp3\n dest:\n auto: no\n threads: 4\n copy_album_art: no\n tmpdir:\n\n paths: {}\n pretend: no\n quiet: no\n formats:\n alac:\n command: ffmpeg -i $source -y -vn -acodec alac $dest\n extension: m4a\n aac:\n command: ffmpeg -i $source -y -vn -acodec libfaac -aq 100 $dest\n extension: m4a\n opus: ffmpeg -i $source -y -vn -acodec libopus -ab 96k $dest\n mp3: ffmpeg -i $source -y -vn -aq 2 $dest\n flac: ffmpeg -i $source -y -vn -acodec flac $dest\n ogg: ffmpeg -i $source -y -vn -acodec libvorbis -aq 2 $dest\n wma: ffmpeg -i $source -y -vn -acodec wmav2 -vn $dest\n embed: yes\nper_disc_numbering: yes\nfetchart:\n auto: no\n minwidth: 0\n sources:\n - coverart\n - itunes\n - amazon\n - albumart\n cautious: no\n google_engine: 001442825323518660753:hrh5ch1gjzm\n maxwidth: 0\n google_key: REDACTED\n cover_names:\n - cover\n - front\n - art\n - album\n - folder\n remote_priority: no\n enforce_ratio: no\nembedart:\n auto: no\n compare_threshold: 0\n ifempty: no\n remove_art_file: no\n maxwidth: 0\nreplaygain:\n backend: gstreamer\n targetlevel: 89\n auto: yes\n overwrite: no\nlibrary: ~/.config/beets/library.db\n\nplugins: duplicates importfeeds importadded replaygain embedart fetchart convert edit\ndirectory: /media/Backup/Music\nedit:\n itemfields: track title artist album\n albumfields: album albumartist\n ignore_fields: id path\nimportadded:\n preserve_mtimes: no\nduplicates:\n count: no\n full: no\n format: ''\n keys: []\n move: ''\n tag: ''\n path: no\n copy: ''\n tiebreak: {}\n album: no\n strict: no\n checksum: ''\n merge: no\n delete: no\n```\n\nI've since disabled the `importadded` plugin so I can just import all my files, but is there a way to fix this in the future? This is running off of an NTFS filesystem, so I don't know if a `stat` command or similar isn't coming back correctly, but I haven't had issues with this in the past.\n\nLet me know if there's any way I can assist.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Populate an item's `added` and `mtime` fields by using the file\nmodification time (mtime) of the item's source file before import.\n\nReimported albums and items are skipped.\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nimport os\n\nfrom beets import util\nfrom beets import importer\nfrom beets.plugins import BeetsPlugin\n\n\nclass ImportAddedPlugin(BeetsPlugin):\n def __init__(self):\n super(ImportAddedPlugin, self).__init__()\n self.config.add({\n 'preserve_mtimes': False,\n 'preserve_write_mtimes': False,\n })\n\n # item.id for new items that were reimported\n self.reimported_item_ids = None\n # album.path for old albums that were replaced by a reimported album\n self.replaced_album_paths = None\n # item path in the library to the mtime of the source file\n self.item_mtime = dict()\n\n register = self.register_listener\n register('import_task_start', self.check_config)\n register('import_task_start', self.record_if_inplace)\n register('import_task_files', self.record_reimported)\n register('before_item_moved', self.record_import_mtime)\n register('item_copied', self.record_import_mtime)\n register('item_linked', self.record_import_mtime)\n register('item_hardlinked', self.record_import_mtime)\n register('album_imported', self.update_album_times)\n register('item_imported', self.update_item_times)\n register('after_write', self.update_after_write_time)\n\n def check_config(self, task, session):\n self.config['preserve_mtimes'].get(bool)\n\n def reimported_item(self, item):\n return item.id in self.reimported_item_ids\n\n def reimported_album(self, album):\n return album.path in self.replaced_album_paths\n\n def record_if_inplace(self, task, session):\n if not (session.config['copy'] or session.config['move'] or\n session.config['link'] or session.config['hardlink']):\n self._log.debug(u\"In place import detected, recording mtimes from \"\n u\"source paths\")\n items = [task.item] \\\n if isinstance(task, importer.SingletonImportTask) \\\n else task.items\n for item in items:\n self.record_import_mtime(item, item.path, item.path)\n\n def record_reimported(self, task, session):\n self.reimported_item_ids = set(item.id for item, replaced_items\n in task.replaced_items.items()\n if replaced_items)\n self.replaced_album_paths = set(task.replaced_albums.keys())\n\n def write_file_mtime(self, path, mtime):\n \"\"\"Write the given mtime to the destination path.\n \"\"\"\n stat = os.stat(util.syspath(path))\n os.utime(util.syspath(path), (stat.st_atime, mtime))\n\n def write_item_mtime(self, item, mtime):\n \"\"\"Write the given mtime to an item's `mtime` field and to the mtime\n of the item's file.\n \"\"\"\n # The file's mtime on disk must be in sync with the item's mtime\n self.write_file_mtime(util.syspath(item.path), mtime)\n item.mtime = mtime\n\n def record_import_mtime(self, item, source, destination):\n \"\"\"Record the file mtime of an item's path before its import.\n \"\"\"\n mtime = os.stat(util.syspath(source)).st_mtime\n self.item_mtime[destination] = mtime\n self._log.debug(u\"Recorded mtime {0} for item '{1}' imported from \"\n u\"'{2}'\", mtime, util.displayable_path(destination),\n util.displayable_path(source))\n\n def update_album_times(self, lib, album):\n if self.reimported_album(album):\n self._log.debug(u\"Album '{0}' is reimported, skipping import of \"\n u\"added dates for the album and its items.\",\n util.displayable_path(album.path))\n return\n\n album_mtimes = []\n for item in album.items():\n mtime = self.item_mtime.pop(item.path, None)\n if mtime:\n album_mtimes.append(mtime)\n if self.config['preserve_mtimes'].get(bool):\n self.write_item_mtime(item, mtime)\n item.store()\n album.added = min(album_mtimes)\n self._log.debug(u\"Import of album '{0}', selected album.added={1} \"\n u\"from item file mtimes.\", album.album, album.added)\n album.store()\n\n def update_item_times(self, lib, item):\n if self.reimported_item(item):\n self._log.debug(u\"Item '{0}' is reimported, skipping import of \"\n u\"added date.\", util.displayable_path(item.path))\n return\n mtime = self.item_mtime.pop(item.path, None)\n if mtime:\n item.added = mtime\n if self.config['preserve_mtimes'].get(bool):\n self.write_item_mtime(item, mtime)\n self._log.debug(u\"Import of item '{0}', selected item.added={1}\",\n util.displayable_path(item.path), item.added)\n item.store()\n\n def update_after_write_time(self, item):\n \"\"\"Update the mtime of the item's file with the item.added value\n after each write of the item if `preserve_write_mtimes` is enabled.\n \"\"\"\n if item.added:\n if self.config['preserve_write_mtimes'].get(bool):\n self.write_item_mtime(item, item.added)\n self._log.debug(u\"Write of item '{0}', selected item.added={1}\",\n util.displayable_path(item.path), item.added)\n", "path": "beetsplug/importadded.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Populate an item's `added` and `mtime` fields by using the file\nmodification time (mtime) of the item's source file before import.\n\nReimported albums and items are skipped.\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nimport os\n\nfrom beets import util\nfrom beets import importer\nfrom beets.plugins import BeetsPlugin\n\n\nclass ImportAddedPlugin(BeetsPlugin):\n def __init__(self):\n super(ImportAddedPlugin, self).__init__()\n self.config.add({\n 'preserve_mtimes': False,\n 'preserve_write_mtimes': False,\n })\n\n # item.id for new items that were reimported\n self.reimported_item_ids = None\n # album.path for old albums that were replaced by a reimported album\n self.replaced_album_paths = None\n # item path in the library to the mtime of the source file\n self.item_mtime = dict()\n\n register = self.register_listener\n register('import_task_created', self.check_config)\n register('import_task_created', self.record_if_inplace)\n register('import_task_files', self.record_reimported)\n register('before_item_moved', self.record_import_mtime)\n register('item_copied', self.record_import_mtime)\n register('item_linked', self.record_import_mtime)\n register('item_hardlinked', self.record_import_mtime)\n register('album_imported', self.update_album_times)\n register('item_imported', self.update_item_times)\n register('after_write', self.update_after_write_time)\n\n def check_config(self, task, session):\n self.config['preserve_mtimes'].get(bool)\n\n def reimported_item(self, item):\n return item.id in self.reimported_item_ids\n\n def reimported_album(self, album):\n return album.path in self.replaced_album_paths\n\n def record_if_inplace(self, task, session):\n if not (session.config['copy'] or session.config['move'] or\n session.config['link'] or session.config['hardlink']):\n self._log.debug(u\"In place import detected, recording mtimes from \"\n u\"source paths\")\n items = [task.item] \\\n if isinstance(task, importer.SingletonImportTask) \\\n else task.items\n for item in items:\n self.record_import_mtime(item, item.path, item.path)\n\n def record_reimported(self, task, session):\n self.reimported_item_ids = set(item.id for item, replaced_items\n in task.replaced_items.items()\n if replaced_items)\n self.replaced_album_paths = set(task.replaced_albums.keys())\n\n def write_file_mtime(self, path, mtime):\n \"\"\"Write the given mtime to the destination path.\n \"\"\"\n stat = os.stat(util.syspath(path))\n os.utime(util.syspath(path), (stat.st_atime, mtime))\n\n def write_item_mtime(self, item, mtime):\n \"\"\"Write the given mtime to an item's `mtime` field and to the mtime\n of the item's file.\n \"\"\"\n # The file's mtime on disk must be in sync with the item's mtime\n self.write_file_mtime(util.syspath(item.path), mtime)\n item.mtime = mtime\n\n def record_import_mtime(self, item, source, destination):\n \"\"\"Record the file mtime of an item's path before its import.\n \"\"\"\n mtime = os.stat(util.syspath(source)).st_mtime\n self.item_mtime[destination] = mtime\n self._log.debug(u\"Recorded mtime {0} for item '{1}' imported from \"\n u\"'{2}'\", mtime, util.displayable_path(destination),\n util.displayable_path(source))\n\n def update_album_times(self, lib, album):\n if self.reimported_album(album):\n self._log.debug(u\"Album '{0}' is reimported, skipping import of \"\n u\"added dates for the album and its items.\",\n util.displayable_path(album.path))\n return\n\n album_mtimes = []\n for item in album.items():\n mtime = self.item_mtime.pop(item.path, None)\n if mtime:\n album_mtimes.append(mtime)\n if self.config['preserve_mtimes'].get(bool):\n self.write_item_mtime(item, mtime)\n item.store()\n album.added = min(album_mtimes)\n self._log.debug(u\"Import of album '{0}', selected album.added={1} \"\n u\"from item file mtimes.\", album.album, album.added)\n album.store()\n\n def update_item_times(self, lib, item):\n if self.reimported_item(item):\n self._log.debug(u\"Item '{0}' is reimported, skipping import of \"\n u\"added date.\", util.displayable_path(item.path))\n return\n mtime = self.item_mtime.pop(item.path, None)\n if mtime:\n item.added = mtime\n if self.config['preserve_mtimes'].get(bool):\n self.write_item_mtime(item, mtime)\n self._log.debug(u\"Import of item '{0}', selected item.added={1}\",\n util.displayable_path(item.path), item.added)\n item.store()\n\n def update_after_write_time(self, item):\n \"\"\"Update the mtime of the item's file with the item.added value\n after each write of the item if `preserve_write_mtimes` is enabled.\n \"\"\"\n if item.added:\n if self.config['preserve_write_mtimes'].get(bool):\n self.write_item_mtime(item, item.added)\n self._log.debug(u\"Write of item '{0}', selected item.added={1}\",\n util.displayable_path(item.path), item.added)\n", "path": "beetsplug/importadded.py"}]}
| 3,256 | 154 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.