
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_5891 | rasdani/github-patches | git_diff | sublimelsp__LSP-1732 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`os.path.relpath` may throw an exception on Windows.
`os.path.relpath` may throw an exception on Windows.
```
Traceback (most recent call last):
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 55, in
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 62, in _handle_response
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 85, in _show_references_in_output_panel
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 107, in _get_relative_path
File "./python3.3/ntpath.py", line 564, in relpath
ValueError: path is on mount 'C:', start on mount '\myserver\myshare'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugin/references.py`
Content:
```
1 from .core.panels import ensure_panel
2 from .core.protocol import Location
3 from .core.protocol import Point
4 from .core.protocol import Request
5 from .core.registry import get_position
6 from .core.registry import LspTextCommand
7 from .core.sessions import Session
8 from .core.settings import PLUGIN_NAME
9 from .core.settings import userprefs
10 from .core.types import ClientConfig
11 from .core.types import PANEL_FILE_REGEX
12 from .core.types import PANEL_LINE_REGEX
13 from .core.typing import Dict, List, Optional, Tuple
14 from .core.views import get_line
15 from .core.views import get_uri_and_position_from_location
16 from .core.views import text_document_position_params
17 from .locationpicker import LocationPicker
18 import functools
19 import linecache
20 import os
21 import sublime
22
23
24 def ensure_references_panel(window: sublime.Window) -> Optional[sublime.View]:
25 return ensure_panel(window, "references", PANEL_FILE_REGEX, PANEL_LINE_REGEX,
26 "Packages/" + PLUGIN_NAME + "/Syntaxes/References.sublime-syntax")
27
28
29 class LspSymbolReferencesCommand(LspTextCommand):
30
31 capability = 'referencesProvider'
32
33 def __init__(self, view: sublime.View) -> None:
34 super().__init__(view)
35 self._picker = None # type: Optional[LocationPicker]
36
37 def run(self, _: sublime.Edit, event: Optional[dict] = None, point: Optional[int] = None) -> None:
38 session = self.best_session(self.capability)
39 file_path = self.view.file_name()
40 pos = get_position(self.view, event, point)
41 if session and file_path and pos is not None:
42 params = text_document_position_params(self.view, pos)
43 params['context'] = {"includeDeclaration": False}
44 request = Request("textDocument/references", params, self.view, progress=True)
45 session.send_request(
46 request,
47 functools.partial(
48 self._handle_response_async,
49 self.view.substr(self.view.word(pos)),
50 session
51 )
52 )
53
54 def _handle_response_async(self, word: str, session: Session, response: Optional[List[Location]]) -> None:
55 sublime.set_timeout(lambda: self._handle_response(word, session, response))
56
57 def _handle_response(self, word: str, session: Session, response: Optional[List[Location]]) -> None:
58 if response:
59 if userprefs().show_references_in_quick_panel:
60 self._show_references_in_quick_panel(session, response)
61 else:
62 self._show_references_in_output_panel(word, session, response)
63 else:
64 window = self.view.window()
65 if window:
66 window.status_message("No references found")
67
68 def _show_references_in_quick_panel(self, session: Session, locations: List[Location]) -> None:
69 self.view.run_command("add_jump_record", {"selection": [(r.a, r.b) for r in self.view.sel()]})
70 LocationPicker(self.view, session, locations, side_by_side=False)
71
72 def _show_references_in_output_panel(self, word: str, session: Session, locations: List[Location]) -> None:
73 window = session.window
74 panel = ensure_references_panel(window)
75 if not panel:
76 return
77 manager = session.manager()
78 if not manager:
79 return
80 base_dir = manager.get_project_path(self.view.file_name() or "")
81 to_render = [] # type: List[str]
82 references_count = 0
83 references_by_file = _group_locations_by_uri(window, session.config, locations)
84 for file, references in references_by_file.items():
85 to_render.append('{}:'.format(_get_relative_path(base_dir, file)))
86 for reference in references:
87 references_count += 1
88 point, line = reference
89 to_render.append('{:>5}:{:<4} {}'.format(point.row + 1, point.col + 1, line))
90 to_render.append("") # add spacing between filenames
91 characters = "\n".join(to_render)
92 panel.settings().set("result_base_dir", base_dir)
93 panel.run_command("lsp_clear_panel")
94 window.run_command("show_panel", {"panel": "output.references"})
95 panel.run_command('append', {
96 'characters': "{} references for '{}'\n\n{}".format(references_count, word, characters),
97 'force': True,
98 'scroll_to_end': False
99 })
100 # highlight all word occurrences
101 regions = panel.find_all(r"\b{}\b".format(word))
102 panel.add_regions('ReferenceHighlight', regions, 'comment', flags=sublime.DRAW_OUTLINED)
103
104
105 def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:
106 if base_dir:
107 return os.path.relpath(file_path, base_dir)
108 else:
109 return file_path
110
111
112 def _group_locations_by_uri(
113 window: sublime.Window,
114 config: ClientConfig,
115 locations: List[Location]
116 ) -> Dict[str, List[Tuple[Point, str]]]:
117 """Return a dictionary that groups locations by the URI it belongs."""
118 grouped_locations = {} # type: Dict[str, List[Tuple[Point, str]]]
119 for location in locations:
120 uri, position = get_uri_and_position_from_location(location)
121 file_path = config.map_server_uri_to_client_path(uri)
122 point = Point.from_lsp(position)
123 # get line of the reference, to showcase its use
124 reference_line = get_line(window, file_path, point.row)
125 if grouped_locations.get(file_path) is None:
126 grouped_locations[file_path] = []
127 grouped_locations[file_path].append((point, reference_line))
128 # we don't want to cache the line, we always want to get fresh data
129 linecache.clearcache()
130 return grouped_locations
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/plugin/references.py b/plugin/references.py
--- a/plugin/references.py
+++ b/plugin/references.py
@@ -104,9 +104,12 @@
def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:
if base_dir:
- return os.path.relpath(file_path, base_dir)
- else:
- return file_path
+ try:
+ return os.path.relpath(file_path, base_dir)
+ except ValueError:
+ # On Windows, ValueError is raised when path and start are on different drives.
+ pass
+ return file_path
def _group_locations_by_uri(
| {"golden_diff": "diff --git a/plugin/references.py b/plugin/references.py\n--- a/plugin/references.py\n+++ b/plugin/references.py\n@@ -104,9 +104,12 @@\n \n def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:\n if base_dir:\n- return os.path.relpath(file_path, base_dir)\n- else:\n- return file_path\n+ try:\n+ return os.path.relpath(file_path, base_dir)\n+ except ValueError:\n+ # On Windows, ValueError is raised when path and start are on different drives.\n+ pass\n+ return file_path\n \n \n def _group_locations_by_uri(\n", "issue": "`os.path.relpath` may throw an exception on Windows.\n`os.path.relpath` may throw an exception on Windows.\r\n\r\n```\r\nTraceback (most recent call last):\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 55, in \r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 62, in _handle_response\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 85, in _show_references_in_output_panel\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 107, in _get_relative_path\r\nFile \"./python3.3/ntpath.py\", line 564, in relpath\r\nValueError: path is on mount 'C:', start on mount '\\myserver\\myshare'\r\n```\n", "before_files": [{"content": "from .core.panels import ensure_panel\nfrom .core.protocol import Location\nfrom .core.protocol import Point\nfrom .core.protocol import Request\nfrom .core.registry import get_position\nfrom .core.registry import LspTextCommand\nfrom .core.sessions import Session\nfrom .core.settings import PLUGIN_NAME\nfrom .core.settings import userprefs\nfrom .core.types import ClientConfig\nfrom .core.types import PANEL_FILE_REGEX\nfrom .core.types import PANEL_LINE_REGEX\nfrom .core.typing import Dict, List, Optional, Tuple\nfrom .core.views import get_line\nfrom .core.views import get_uri_and_position_from_location\nfrom .core.views import text_document_position_params\nfrom .locationpicker import LocationPicker\nimport functools\nimport linecache\nimport os\nimport sublime\n\n\ndef ensure_references_panel(window: sublime.Window) -> Optional[sublime.View]:\n return ensure_panel(window, \"references\", PANEL_FILE_REGEX, PANEL_LINE_REGEX,\n \"Packages/\" + PLUGIN_NAME + \"/Syntaxes/References.sublime-syntax\")\n\n\nclass LspSymbolReferencesCommand(LspTextCommand):\n\n capability = 'referencesProvider'\n\n def __init__(self, view: sublime.View) -> None:\n super().__init__(view)\n self._picker = None # type: Optional[LocationPicker]\n\n def run(self, _: sublime.Edit, event: Optional[dict] = None, point: Optional[int] = None) -> None:\n session = self.best_session(self.capability)\n file_path = self.view.file_name()\n pos = get_position(self.view, event, point)\n if session and file_path and pos is not None:\n params = text_document_position_params(self.view, pos)\n params['context'] = {\"includeDeclaration\": False}\n request = Request(\"textDocument/references\", params, self.view, progress=True)\n session.send_request(\n request,\n functools.partial(\n self._handle_response_async,\n self.view.substr(self.view.word(pos)),\n session\n )\n )\n\n def _handle_response_async(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n sublime.set_timeout(lambda: self._handle_response(word, session, response))\n\n def _handle_response(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n if response:\n if userprefs().show_references_in_quick_panel:\n self._show_references_in_quick_panel(session, response)\n else:\n self._show_references_in_output_panel(word, session, response)\n else:\n window = self.view.window()\n if window:\n window.status_message(\"No references found\")\n\n def _show_references_in_quick_panel(self, session: Session, locations: List[Location]) -> None:\n self.view.run_command(\"add_jump_record\", {\"selection\": [(r.a, r.b) for r in self.view.sel()]})\n LocationPicker(self.view, session, locations, side_by_side=False)\n\n def _show_references_in_output_panel(self, word: str, session: Session, locations: List[Location]) -> None:\n window = session.window\n panel = ensure_references_panel(window)\n if not panel:\n return\n manager = session.manager()\n if not manager:\n return\n base_dir = manager.get_project_path(self.view.file_name() or \"\")\n to_render = [] # type: List[str]\n references_count = 0\n references_by_file = _group_locations_by_uri(window, session.config, locations)\n for file, references in references_by_file.items():\n to_render.append('{}:'.format(_get_relative_path(base_dir, file)))\n for reference in references:\n references_count += 1\n point, line = reference\n to_render.append('{:>5}:{:<4} {}'.format(point.row + 1, point.col + 1, line))\n to_render.append(\"\") # add spacing between filenames\n characters = \"\\n\".join(to_render)\n panel.settings().set(\"result_base_dir\", base_dir)\n panel.run_command(\"lsp_clear_panel\")\n window.run_command(\"show_panel\", {\"panel\": \"output.references\"})\n panel.run_command('append', {\n 'characters': \"{} references for '{}'\\n\\n{}\".format(references_count, word, characters),\n 'force': True,\n 'scroll_to_end': False\n })\n # highlight all word occurrences\n regions = panel.find_all(r\"\\b{}\\b\".format(word))\n panel.add_regions('ReferenceHighlight', regions, 'comment', flags=sublime.DRAW_OUTLINED)\n\n\ndef _get_relative_path(base_dir: Optional[str], file_path: str) -> str:\n if base_dir:\n return os.path.relpath(file_path, base_dir)\n else:\n return file_path\n\n\ndef _group_locations_by_uri(\n window: sublime.Window,\n config: ClientConfig,\n locations: List[Location]\n) -> Dict[str, List[Tuple[Point, str]]]:\n \"\"\"Return a dictionary that groups locations by the URI it belongs.\"\"\"\n grouped_locations = {} # type: Dict[str, List[Tuple[Point, str]]]\n for location in locations:\n uri, position = get_uri_and_position_from_location(location)\n file_path = config.map_server_uri_to_client_path(uri)\n point = Point.from_lsp(position)\n # get line of the reference, to showcase its use\n reference_line = get_line(window, file_path, point.row)\n if grouped_locations.get(file_path) is None:\n grouped_locations[file_path] = []\n grouped_locations[file_path].append((point, reference_line))\n # we don't want to cache the line, we always want to get fresh data\n linecache.clearcache()\n return grouped_locations\n", "path": "plugin/references.py"}], "after_files": [{"content": "from .core.panels import ensure_panel\nfrom .core.protocol import Location\nfrom .core.protocol import Point\nfrom .core.protocol import Request\nfrom .core.registry import get_position\nfrom .core.registry import LspTextCommand\nfrom .core.sessions import Session\nfrom .core.settings import PLUGIN_NAME\nfrom .core.settings import userprefs\nfrom .core.types import ClientConfig\nfrom .core.types import PANEL_FILE_REGEX\nfrom .core.types import PANEL_LINE_REGEX\nfrom .core.typing import Dict, List, Optional, Tuple\nfrom .core.views import get_line\nfrom .core.views import get_uri_and_position_from_location\nfrom .core.views import text_document_position_params\nfrom .locationpicker import LocationPicker\nimport functools\nimport linecache\nimport os\nimport sublime\n\n\ndef ensure_references_panel(window: sublime.Window) -> Optional[sublime.View]:\n return ensure_panel(window, \"references\", PANEL_FILE_REGEX, PANEL_LINE_REGEX,\n \"Packages/\" + PLUGIN_NAME + \"/Syntaxes/References.sublime-syntax\")\n\n\nclass LspSymbolReferencesCommand(LspTextCommand):\n\n capability = 'referencesProvider'\n\n def __init__(self, view: sublime.View) -> None:\n super().__init__(view)\n self._picker = None # type: Optional[LocationPicker]\n\n def run(self, _: sublime.Edit, event: Optional[dict] = None, point: Optional[int] = None) -> None:\n session = self.best_session(self.capability)\n file_path = self.view.file_name()\n pos = get_position(self.view, event, point)\n if session and file_path and pos is not None:\n params = text_document_position_params(self.view, pos)\n params['context'] = {\"includeDeclaration\": False}\n request = Request(\"textDocument/references\", params, self.view, progress=True)\n session.send_request(\n request,\n functools.partial(\n self._handle_response_async,\n self.view.substr(self.view.word(pos)),\n session\n )\n )\n\n def _handle_response_async(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n sublime.set_timeout(lambda: self._handle_response(word, session, response))\n\n def _handle_response(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n if response:\n if userprefs().show_references_in_quick_panel:\n self._show_references_in_quick_panel(session, response)\n else:\n self._show_references_in_output_panel(word, session, response)\n else:\n window = self.view.window()\n if window:\n window.status_message(\"No references found\")\n\n def _show_references_in_quick_panel(self, session: Session, locations: List[Location]) -> None:\n self.view.run_command(\"add_jump_record\", {\"selection\": [(r.a, r.b) for r in self.view.sel()]})\n LocationPicker(self.view, session, locations, side_by_side=False)\n\n def _show_references_in_output_panel(self, word: str, session: Session, locations: List[Location]) -> None:\n window = session.window\n panel = ensure_references_panel(window)\n if not panel:\n return\n manager = session.manager()\n if not manager:\n return\n base_dir = manager.get_project_path(self.view.file_name() or \"\")\n to_render = [] # type: List[str]\n references_count = 0\n references_by_file = _group_locations_by_uri(window, session.config, locations)\n for file, references in references_by_file.items():\n to_render.append('{}:'.format(_get_relative_path(base_dir, file)))\n for reference in references:\n references_count += 1\n point, line = reference\n to_render.append('{:>5}:{:<4} {}'.format(point.row + 1, point.col + 1, line))\n to_render.append(\"\") # add spacing between filenames\n characters = \"\\n\".join(to_render)\n panel.settings().set(\"result_base_dir\", base_dir)\n panel.run_command(\"lsp_clear_panel\")\n window.run_command(\"show_panel\", {\"panel\": \"output.references\"})\n panel.run_command('append', {\n 'characters': \"{} references for '{}'\\n\\n{}\".format(references_count, word, characters),\n 'force': True,\n 'scroll_to_end': False\n })\n # highlight all word occurrences\n regions = panel.find_all(r\"\\b{}\\b\".format(word))\n panel.add_regions('ReferenceHighlight', regions, 'comment', flags=sublime.DRAW_OUTLINED)\n\n\ndef _get_relative_path(base_dir: Optional[str], file_path: str) -> str:\n if base_dir:\n try:\n return os.path.relpath(file_path, base_dir)\n except ValueError:\n # On Windows, ValueError is raised when path and start are on different drives.\n pass\n return file_path\n\n\ndef _group_locations_by_uri(\n window: sublime.Window,\n config: ClientConfig,\n locations: List[Location]\n) -> Dict[str, List[Tuple[Point, str]]]:\n \"\"\"Return a dictionary that groups locations by the URI it belongs.\"\"\"\n grouped_locations = {} # type: Dict[str, List[Tuple[Point, str]]]\n for location in locations:\n uri, position = get_uri_and_position_from_location(location)\n file_path = config.map_server_uri_to_client_path(uri)\n point = Point.from_lsp(position)\n # get line of the reference, to showcase its use\n reference_line = get_line(window, file_path, point.row)\n if grouped_locations.get(file_path) is None:\n grouped_locations[file_path] = []\n grouped_locations[file_path].append((point, reference_line))\n # we don't want to cache the line, we always want to get fresh data\n linecache.clearcache()\n return grouped_locations\n", "path": "plugin/references.py"}]} | 1,973 | 149 |
gh_patches_debug_7263 | rasdani/github-patches | git_diff | iterative__dvc-5753 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
exp show: failing with rich==10.0.0
```console
$ dvc exp show
dvc exp show -v
2021-03-29 11:30:45,071 DEBUG: Check for update is disabled.
2021-03-29 11:30:46,006 ERROR: unexpected error - 'int' object has no attribute 'max_width'
------------------------------------------------------------
Traceback (most recent call last):
File "/home/saugat/repos/iterative/dvc/dvc/main.py", line 55, in main
ret = cmd.run()
File "/home/saugat/repos/iterative/dvc/dvc/command/experiments.py", line 411, in run
measurement = table.__rich_measure__(console, SHOW_MAX_WIDTH)
File "/home/saugat/venvs/dvc/env39/lib/python3.9/site-packages/rich/table.py", line 287, in __rich_measure__
max_width = options.max_width
AttributeError: 'int' object has no attribute 'max_width'
------------------------------------------------------------
2021-03-29 11:30:47,022 DEBUG: Version info for developers:
DVC version: 2.0.11+f8c567
---------------------------------
Platform: Python 3.9.2 on Linux-5.11.8-arch1-1-x86_64-with-glibc2.33
Supports: All remotes
Cache types: hardlink, symlink
Cache directory: ext4 on /dev/sda9
Caches: local
Remotes: https
Workspace directory: ext4 on /dev/sda9
Repo: dvc, git
Having any troubles? Hit us up at https://dvc.org/support, we are always happy to help!
```
This is also breaking our linter ([here](https://github.com/iterative/dvc/runs/2214172187?check_suite_focus=true#step:7:250
)) and tests as well due to the change in rich's internal API that we are using:
https://github.com/iterative/dvc/blob/1a25ebe3bd2eda4c3612e408fb503d64490fb56c/dvc/utils/table.py#L59
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/utils/table.py`
Content:
```
1 from dataclasses import dataclass
2 from typing import TYPE_CHECKING, List, cast
3
4 from rich.style import StyleType
5 from rich.table import Column as RichColumn
6 from rich.table import Table as RichTable
7
8 if TYPE_CHECKING:
9 from rich.console import (
10 Console,
11 ConsoleOptions,
12 JustifyMethod,
13 OverflowMethod,
14 RenderableType,
15 )
16
17
18 @dataclass
19 class Column(RichColumn):
20 collapse: bool = False
21
22
23 class Table(RichTable):
24 def add_column( # pylint: disable=arguments-differ
25 self,
26 header: "RenderableType" = "",
27 footer: "RenderableType" = "",
28 *,
29 header_style: StyleType = None,
30 footer_style: StyleType = None,
31 style: StyleType = None,
32 justify: "JustifyMethod" = "left",
33 overflow: "OverflowMethod" = "ellipsis",
34 width: int = None,
35 min_width: int = None,
36 max_width: int = None,
37 ratio: int = None,
38 no_wrap: bool = False,
39 collapse: bool = False,
40 ) -> None:
41 column = Column( # type: ignore[call-arg]
42 _index=len(self.columns),
43 header=header,
44 footer=footer,
45 header_style=header_style or "",
46 footer_style=footer_style or "",
47 style=style or "",
48 justify=justify,
49 overflow=overflow,
50 width=width,
51 min_width=min_width,
52 max_width=max_width,
53 ratio=ratio,
54 no_wrap=no_wrap,
55 collapse=collapse,
56 )
57 self.columns.append(column)
58
59 def _calculate_column_widths(
60 self, console: "Console", options: "ConsoleOptions"
61 ) -> List[int]:
62 """Calculate the widths of each column, including padding, not
63 including borders.
64
65 Adjacent collapsed columns will be removed until there is only a single
66 truncated column remaining.
67 """
68 widths = super()._calculate_column_widths(console, options)
69 last_collapsed = -1
70 columns = cast(List[Column], self.columns)
71 for i in range(len(columns) - 1, -1, -1):
72 if widths[i] == 1 and columns[i].collapse:
73 if last_collapsed >= 0:
74 del widths[last_collapsed]
75 del columns[last_collapsed]
76 if self.box:
77 options.max_width += 1
78 for column in columns[last_collapsed:]:
79 column._index -= 1
80 last_collapsed = i
81 padding = self._get_padding_width(i)
82 if (
83 columns[i].overflow == "ellipsis"
84 and (sum(widths) + padding) <= options.max_width
85 ):
86 # Set content width to 1 (plus padding) if we can fit a
87 # single unicode ellipsis in this column
88 widths[i] = 1 + padding
89 else:
90 last_collapsed = -1
91 return widths
92
93 def _collapse_widths( # type: ignore[override]
94 self, widths: List[int], wrapable: List[bool], max_width: int,
95 ) -> List[int]:
96 """Collapse columns right-to-left if possible to fit table into
97 max_width.
98
99 If table is still too wide after collapsing, rich's automatic overflow
100 handling will be used.
101 """
102 columns = cast(List[Column], self.columns)
103 collapsible = [column.collapse for column in columns]
104 total_width = sum(widths)
105 excess_width = total_width - max_width
106 if any(collapsible):
107 for i in range(len(widths) - 1, -1, -1):
108 if collapsible[i]:
109 total_width -= widths[i]
110 excess_width -= widths[i]
111 widths[i] = 0
112 if excess_width <= 0:
113 break
114 return super()._collapse_widths(widths, wrapable, max_width)
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/dvc/utils/table.py b/dvc/utils/table.py
--- a/dvc/utils/table.py
+++ b/dvc/utils/table.py
@@ -69,7 +69,7 @@
last_collapsed = -1
columns = cast(List[Column], self.columns)
for i in range(len(columns) - 1, -1, -1):
- if widths[i] == 1 and columns[i].collapse:
+ if widths[i] == 0 and columns[i].collapse:
if last_collapsed >= 0:
del widths[last_collapsed]
del columns[last_collapsed]
| {"golden_diff": "diff --git a/dvc/utils/table.py b/dvc/utils/table.py\n--- a/dvc/utils/table.py\n+++ b/dvc/utils/table.py\n@@ -69,7 +69,7 @@\n last_collapsed = -1\n columns = cast(List[Column], self.columns)\n for i in range(len(columns) - 1, -1, -1):\n- if widths[i] == 1 and columns[i].collapse:\n+ if widths[i] == 0 and columns[i].collapse:\n if last_collapsed >= 0:\n del widths[last_collapsed]\n del columns[last_collapsed]\n", "issue": "exp show: failing with rich==10.0.0\n```console\r\n$ dvc exp show\r\ndvc exp show -v\r\n2021-03-29 11:30:45,071 DEBUG: Check for update is disabled.\r\n2021-03-29 11:30:46,006 ERROR: unexpected error - 'int' object has no attribute 'max_width'\r\n------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/home/saugat/repos/iterative/dvc/dvc/main.py\", line 55, in main\r\n ret = cmd.run()\r\n File \"/home/saugat/repos/iterative/dvc/dvc/command/experiments.py\", line 411, in run\r\n measurement = table.__rich_measure__(console, SHOW_MAX_WIDTH)\r\n File \"/home/saugat/venvs/dvc/env39/lib/python3.9/site-packages/rich/table.py\", line 287, in __rich_measure__\r\n max_width = options.max_width\r\nAttributeError: 'int' object has no attribute 'max_width'\r\n------------------------------------------------------------\r\n2021-03-29 11:30:47,022 DEBUG: Version info for developers:\r\nDVC version: 2.0.11+f8c567 \r\n---------------------------------\r\nPlatform: Python 3.9.2 on Linux-5.11.8-arch1-1-x86_64-with-glibc2.33\r\nSupports: All remotes\r\nCache types: hardlink, symlink\r\nCache directory: ext4 on /dev/sda9\r\nCaches: local\r\nRemotes: https\r\nWorkspace directory: ext4 on /dev/sda9\r\nRepo: dvc, git\r\n\r\nHaving any troubles? Hit us up at https://dvc.org/support, we are always happy to help!\r\n```\r\n\r\n\r\nThis is also breaking our linter ([here](https://github.com/iterative/dvc/runs/2214172187?check_suite_focus=true#step:7:250\r\n)) and tests as well due to the change in rich's internal API that we are using:\r\nhttps://github.com/iterative/dvc/blob/1a25ebe3bd2eda4c3612e408fb503d64490fb56c/dvc/utils/table.py#L59\r\n\r\n\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import TYPE_CHECKING, List, cast\n\nfrom rich.style import StyleType\nfrom rich.table import Column as RichColumn\nfrom rich.table import Table as RichTable\n\nif TYPE_CHECKING:\n from rich.console import (\n Console,\n ConsoleOptions,\n JustifyMethod,\n OverflowMethod,\n RenderableType,\n )\n\n\n@dataclass\nclass Column(RichColumn):\n collapse: bool = False\n\n\nclass Table(RichTable):\n def add_column( # pylint: disable=arguments-differ\n self,\n header: \"RenderableType\" = \"\",\n footer: \"RenderableType\" = \"\",\n *,\n header_style: StyleType = None,\n footer_style: StyleType = None,\n style: StyleType = None,\n justify: \"JustifyMethod\" = \"left\",\n overflow: \"OverflowMethod\" = \"ellipsis\",\n width: int = None,\n min_width: int = None,\n max_width: int = None,\n ratio: int = None,\n no_wrap: bool = False,\n collapse: bool = False,\n ) -> None:\n column = Column( # type: ignore[call-arg]\n _index=len(self.columns),\n header=header,\n footer=footer,\n header_style=header_style or \"\",\n footer_style=footer_style or \"\",\n style=style or \"\",\n justify=justify,\n overflow=overflow,\n width=width,\n min_width=min_width,\n max_width=max_width,\n ratio=ratio,\n no_wrap=no_wrap,\n collapse=collapse,\n )\n self.columns.append(column)\n\n def _calculate_column_widths(\n self, console: \"Console\", options: \"ConsoleOptions\"\n ) -> List[int]:\n \"\"\"Calculate the widths of each column, including padding, not\n including borders.\n\n Adjacent collapsed columns will be removed until there is only a single\n truncated column remaining.\n \"\"\"\n widths = super()._calculate_column_widths(console, options)\n last_collapsed = -1\n columns = cast(List[Column], self.columns)\n for i in range(len(columns) - 1, -1, -1):\n if widths[i] == 1 and columns[i].collapse:\n if last_collapsed >= 0:\n del widths[last_collapsed]\n del columns[last_collapsed]\n if self.box:\n options.max_width += 1\n for column in columns[last_collapsed:]:\n column._index -= 1\n last_collapsed = i\n padding = self._get_padding_width(i)\n if (\n columns[i].overflow == \"ellipsis\"\n and (sum(widths) + padding) <= options.max_width\n ):\n # Set content width to 1 (plus padding) if we can fit a\n # single unicode ellipsis in this column\n widths[i] = 1 + padding\n else:\n last_collapsed = -1\n return widths\n\n def _collapse_widths( # type: ignore[override]\n self, widths: List[int], wrapable: List[bool], max_width: int,\n ) -> List[int]:\n \"\"\"Collapse columns right-to-left if possible to fit table into\n max_width.\n\n If table is still too wide after collapsing, rich's automatic overflow\n handling will be used.\n \"\"\"\n columns = cast(List[Column], self.columns)\n collapsible = [column.collapse for column in columns]\n total_width = sum(widths)\n excess_width = total_width - max_width\n if any(collapsible):\n for i in range(len(widths) - 1, -1, -1):\n if collapsible[i]:\n total_width -= widths[i]\n excess_width -= widths[i]\n widths[i] = 0\n if excess_width <= 0:\n break\n return super()._collapse_widths(widths, wrapable, max_width)\n", "path": "dvc/utils/table.py"}], "after_files": [{"content": "from dataclasses import dataclass\nfrom typing import TYPE_CHECKING, List, cast\n\nfrom rich.style import StyleType\nfrom rich.table import Column as RichColumn\nfrom rich.table import Table as RichTable\n\nif TYPE_CHECKING:\n from rich.console import (\n Console,\n ConsoleOptions,\n JustifyMethod,\n OverflowMethod,\n RenderableType,\n )\n\n\n@dataclass\nclass Column(RichColumn):\n collapse: bool = False\n\n\nclass Table(RichTable):\n def add_column( # pylint: disable=arguments-differ\n self,\n header: \"RenderableType\" = \"\",\n footer: \"RenderableType\" = \"\",\n *,\n header_style: StyleType = None,\n footer_style: StyleType = None,\n style: StyleType = None,\n justify: \"JustifyMethod\" = \"left\",\n overflow: \"OverflowMethod\" = \"ellipsis\",\n width: int = None,\n min_width: int = None,\n max_width: int = None,\n ratio: int = None,\n no_wrap: bool = False,\n collapse: bool = False,\n ) -> None:\n column = Column( # type: ignore[call-arg]\n _index=len(self.columns),\n header=header,\n footer=footer,\n header_style=header_style or \"\",\n footer_style=footer_style or \"\",\n style=style or \"\",\n justify=justify,\n overflow=overflow,\n width=width,\n min_width=min_width,\n max_width=max_width,\n ratio=ratio,\n no_wrap=no_wrap,\n collapse=collapse,\n )\n self.columns.append(column)\n\n def _calculate_column_widths(\n self, console: \"Console\", options: \"ConsoleOptions\"\n ) -> List[int]:\n \"\"\"Calculate the widths of each column, including padding, not\n including borders.\n\n Adjacent collapsed columns will be removed until there is only a single\n truncated column remaining.\n \"\"\"\n widths = super()._calculate_column_widths(console, options)\n last_collapsed = -1\n columns = cast(List[Column], self.columns)\n for i in range(len(columns) - 1, -1, -1):\n if widths[i] == 0 and columns[i].collapse:\n if last_collapsed >= 0:\n del widths[last_collapsed]\n del columns[last_collapsed]\n if self.box:\n options.max_width += 1\n for column in columns[last_collapsed:]:\n column._index -= 1\n last_collapsed = i\n padding = self._get_padding_width(i)\n if (\n columns[i].overflow == \"ellipsis\"\n and (sum(widths) + padding) <= options.max_width\n ):\n # Set content width to 1 (plus padding) if we can fit a\n # single unicode ellipsis in this column\n widths[i] = 1 + padding\n else:\n last_collapsed = -1\n return widths\n\n def _collapse_widths( # type: ignore[override]\n self, widths: List[int], wrapable: List[bool], max_width: int,\n ) -> List[int]:\n \"\"\"Collapse columns right-to-left if possible to fit table into\n max_width.\n\n If table is still too wide after collapsing, rich's automatic overflow\n handling will be used.\n \"\"\"\n columns = cast(List[Column], self.columns)\n collapsible = [column.collapse for column in columns]\n total_width = sum(widths)\n excess_width = total_width - max_width\n if any(collapsible):\n for i in range(len(widths) - 1, -1, -1):\n if collapsible[i]:\n total_width -= widths[i]\n excess_width -= widths[i]\n widths[i] = 0\n if excess_width <= 0:\n break\n return super()._collapse_widths(widths, wrapable, max_width)\n", "path": "dvc/utils/table.py"}]} | 1,877 | 134 |
gh_patches_debug_15548 | rasdani/github-patches | git_diff | tensorflow__addons-340 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tfa.seq2seq.sequence_loss can't average over one dimension (batch or timesteps) while summing over the other one
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google Colab
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 2.0.0=beta1
- TensorFlow Addons installed from (source, PyPi): PyPi
- TensorFlow Addons version: 0.4.0
- Python version and type (eg. Anaconda Python, Stock Python as in Mac, or homebrew installed Python etc): Google Colab Python
- Is GPU used? (yes/no): yes
- GPU model (if used): T4
**Describe the bug**
`tfa.seq2seq.sequence_loss` can't average over one dimension (`batch` or `timesteps`) while summing over the other one. It will arbitrarily only execute the averaging and ignore the sum right now.
**Describe the expected behavior**
I think the weights should be associated with the summing operation, and then the averaging should happen irrespective of that.
Concretely, when passing, say `average_across_batch=True` and `sum_over_timesteps=True` (of course, making sure `average_across_timesteps=False` is set), you should expect either of these things:
1. An error stating that this is not implemented (might be the wisest).
2. Return a scalar tensor obtained by either of these two following orders:
a) first computing the *weighted sum* of xents over timesteps (yielding a batchsize-sized tensor of xent-sums), then simply averaging this vector, i.e., summing and dividing by the batchsize. The result, however, is just the both-averaged version times the batchsize, divided by the sum of all weights.
b) first computing the *weighted average* over the batchsize, then summing these averages over all timesteps. The result here is different from 1a and the double-averaged (of course, there is some correlation...)!
I think 1a is the desired behavior (as the loglikelihood of a sequence really is the sum of the individual loglikelihoods and batches do correspond to sequence-length agnostic averages) and I'd be happy to establish it as the standard for this. Either way, doing something other than failing with an error will require an explicit notice in the docs. An error (or warning for backwards-compatibility?) might just be the simplest and safest option.
**Code to reproduce the issue**
```python
tfa.seq2seq.sequence_loss(
logits=tf.random.normal([3, 5, 7]),
targets=tf.zeros([3, 5], dtype=tf.int32),
weights=tf.sequence_mask(lengths=[3, 5, 1], maxlen=5, dtype=tf.float32),
average_across_batch=True,
average_across_timesteps=False,
sum_over_batch=False,
sum_over_timesteps=True,
)
```
...should return a scalar but returns only the batch-averaged tensor.
**Some more code to play with to test the claims above**
```python
import tensorflow.compat.v2 as tf
import tensorflow_addons as tfa
import numpy as np
import random
case1b = []
dblavg = []
for _ in range(100):
dtype = tf.float32
batchsize = random.randint(2, 10)
maxlen = random.randint(2, 10)
logits = tf.random.normal([batchsize, maxlen, 3])
labels = tf.zeros([batchsize, maxlen], dtype=tf.int32)
lengths = tf.squeeze(tf.random.categorical(tf.zeros([1, maxlen - 1]), batchsize)) + 1
weights = tf.sequence_mask(lengths=lengths, maxlen=maxlen, dtype=tf.float32)
def sl(ab, sb, at, st):
return tfa.seq2seq.sequence_loss(
logits,
labels,
weights,
average_across_batch=ab,
average_across_timesteps=at,
sum_over_batch=sb,
sum_over_timesteps=st,
)
all_b_all_t = sl(ab=False, sb=False, at=False, st=False)
avg_b_avg_t = sl(ab=True, sb=False, at=True, st=False)
sum_b_all_t = sl(ab=False, sb=True, at=False, st=False)
tf.assert_equal(sum_b_all_t, tf.math.divide_no_nan(tf.reduce_sum(all_b_all_t, axis=0), tf.reduce_sum(weights, axis=0)))
weighted = all_b_all_t * weights
first_sum_timesteps = tf.reduce_sum(weighted, axis=1)
then_average_batch = tf.reduce_sum(first_sum_timesteps) / batchsize
first_average_batch = tf.math.divide_no_nan(tf.reduce_sum(weighted, axis=0), tf.reduce_sum(weights, axis=0))
then_sum_timesteps = tf.reduce_sum(first_average_batch)
# Case 1a and 1b are different.
assert not np.isclose(then_average_batch, then_sum_timesteps)
# Case 1a is just the double-averaging up to a constant.
assert np.allclose(then_average_batch * batchsize / tf.reduce_sum(weights), avg_b_avg_t)
# Case 1b is not just the averaging.
assert not np.allclose(then_sum_timesteps / maxlen, avg_b_avg_t)
# They only kind of correlate:
case1b.append(then_sum_timesteps / maxlen)
dblavg.append(avg_b_avg_t)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/seq2seq/loss.py`
Content:
```
1 # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Seq2seq loss operations for use in sequence models."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19 from __future__ import print_function
20
21 import tensorflow as tf
22
23
24 def sequence_loss(logits,
25 targets,
26 weights,
27 average_across_timesteps=True,
28 average_across_batch=True,
29 sum_over_timesteps=False,
30 sum_over_batch=False,
31 softmax_loss_function=None,
32 name=None):
33 """Weighted cross-entropy loss for a sequence of logits.
34
35 Depending on the values of `average_across_timesteps` /
36 `sum_over_timesteps` and `average_across_batch` / `sum_over_batch`, the
37 return Tensor will have rank 0, 1, or 2 as these arguments reduce the
38 cross-entropy at each target, which has shape
39 `[batch_size, sequence_length]`, over their respective dimensions. For
40 example, if `average_across_timesteps` is `True` and `average_across_batch`
41 is `False`, then the return Tensor will have shape `[batch_size]`.
42
43 Note that `average_across_timesteps` and `sum_over_timesteps` cannot be
44 True at same time. Same for `average_across_batch` and `sum_over_batch`.
45
46 The recommended loss reduction in tf 2.0 has been changed to sum_over,
47 instead of weighted average. User are recommend to use `sum_over_timesteps`
48 and `sum_over_batch` for reduction.
49
50 Args:
51 logits: A Tensor of shape
52 `[batch_size, sequence_length, num_decoder_symbols]` and dtype float.
53 The logits correspond to the prediction across all classes at each
54 timestep.
55 targets: A Tensor of shape `[batch_size, sequence_length]` and dtype
56 int. The target represents the true class at each timestep.
57 weights: A Tensor of shape `[batch_size, sequence_length]` and dtype
58 float. `weights` constitutes the weighting of each prediction in the
59 sequence. When using `weights` as masking, set all valid timesteps to 1
60 and all padded timesteps to 0, e.g. a mask returned by
61 `tf.sequence_mask`.
62 average_across_timesteps: If set, sum the cost across the sequence
63 dimension and divide the cost by the total label weight across
64 timesteps.
65 average_across_batch: If set, sum the cost across the batch dimension and
66 divide the returned cost by the batch size.
67 sum_over_timesteps: If set, sum the cost across the sequence dimension
68 and divide the size of the sequence. Note that any element with 0
69 weights will be excluded from size calculation.
70 sum_over_batch: if set, sum the cost across the batch dimension and
71 divide the total cost by the batch size. Not that any element with 0
72 weights will be excluded from size calculation.
73 softmax_loss_function: Function (labels, logits) -> loss-batch
74 to be used instead of the standard softmax (the default if this is
75 None). **Note that to avoid confusion, it is required for the function
76 to accept named arguments.**
77 name: Optional name for this operation, defaults to "sequence_loss".
78
79 Returns:
80 A float Tensor of rank 0, 1, or 2 depending on the
81 `average_across_timesteps` and `average_across_batch` arguments. By
82 default, it has rank 0 (scalar) and is the weighted average cross-entropy
83 (log-perplexity) per symbol.
84
85 Raises:
86 ValueError: logits does not have 3 dimensions or targets does not have 2
87 dimensions or weights does not have 2 dimensions.
88 """
89 if len(logits.get_shape()) != 3:
90 raise ValueError("Logits must be a "
91 "[batch_size x sequence_length x logits] tensor")
92 if len(targets.get_shape()) != 2:
93 raise ValueError(
94 "Targets must be a [batch_size x sequence_length] tensor")
95 if len(weights.get_shape()) != 2:
96 raise ValueError(
97 "Weights must be a [batch_size x sequence_length] tensor")
98 if average_across_timesteps and sum_over_timesteps:
99 raise ValueError(
100 "average_across_timesteps and sum_over_timesteps cannot "
101 "be set to True at same time.")
102 if average_across_batch and sum_over_batch:
103 raise ValueError(
104 "average_across_batch and sum_over_batch cannot be set "
105 "to True at same time.")
106 with tf.name_scope(name or "sequence_loss"):
107 num_classes = tf.shape(input=logits)[2]
108 logits_flat = tf.reshape(logits, [-1, num_classes])
109 targets = tf.reshape(targets, [-1])
110 if softmax_loss_function is None:
111 crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(
112 labels=targets, logits=logits_flat)
113 else:
114 crossent = softmax_loss_function(
115 labels=targets, logits=logits_flat)
116 crossent *= tf.reshape(weights, [-1])
117 if average_across_timesteps and average_across_batch:
118 crossent = tf.reduce_sum(input_tensor=crossent)
119 total_size = tf.reduce_sum(input_tensor=weights)
120 crossent = tf.math.divide_no_nan(crossent, total_size)
121 elif sum_over_timesteps and sum_over_batch:
122 crossent = tf.reduce_sum(input_tensor=crossent)
123 total_count = tf.cast(
124 tf.math.count_nonzero(weights), crossent.dtype)
125 crossent = tf.math.divide_no_nan(crossent, total_count)
126 else:
127 crossent = tf.reshape(crossent, tf.shape(input=logits)[0:2])
128 if average_across_timesteps or average_across_batch:
129 reduce_axis = [0] if average_across_batch else [1]
130 crossent = tf.reduce_sum(
131 input_tensor=crossent, axis=reduce_axis)
132 total_size = tf.reduce_sum(
133 input_tensor=weights, axis=reduce_axis)
134 crossent = tf.math.divide_no_nan(crossent, total_size)
135 elif sum_over_timesteps or sum_over_batch:
136 reduce_axis = [0] if sum_over_batch else [1]
137 crossent = tf.reduce_sum(
138 input_tensor=crossent, axis=reduce_axis)
139 total_count = tf.cast(
140 tf.math.count_nonzero(weights, axis=reduce_axis),
141 dtype=crossent.dtype)
142 crossent = tf.math.divide_no_nan(crossent, total_count)
143 return crossent
144
145
146 class SequenceLoss(tf.keras.losses.Loss):
147 """Weighted cross-entropy loss for a sequence of logits."""
148
149 def __init__(self,
150 average_across_timesteps=False,
151 average_across_batch=False,
152 sum_over_timesteps=True,
153 sum_over_batch=True,
154 softmax_loss_function=None,
155 name=None):
156 super(SequenceLoss, self).__init__(name=name)
157 self.average_across_timesteps = average_across_timesteps
158 self.average_across_batch = average_across_batch
159 self.sum_over_timesteps = sum_over_timesteps
160 self.sum_over_batch = sum_over_batch
161 self.softmax_loss_function = softmax_loss_function
162
163 def __call__(self, y_true, y_pred, sample_weight=None):
164 """Override the parent __call__ to have a customized reduce
165 behavior."""
166 return sequence_loss(
167 y_pred,
168 y_true,
169 sample_weight,
170 average_across_timesteps=self.average_across_timesteps,
171 average_across_batch=self.average_across_batch,
172 sum_over_timesteps=self.sum_over_timesteps,
173 sum_over_batch=self.sum_over_batch,
174 softmax_loss_function=self.softmax_loss_function,
175 name=self.name)
176
177 def call(self, y_true, y_pred):
178 # Skip this method since the __call__ contains real implementation.
179 pass
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tensorflow_addons/seq2seq/loss.py b/tensorflow_addons/seq2seq/loss.py
--- a/tensorflow_addons/seq2seq/loss.py
+++ b/tensorflow_addons/seq2seq/loss.py
@@ -103,6 +103,14 @@
raise ValueError(
"average_across_batch and sum_over_batch cannot be set "
"to True at same time.")
+ if average_across_batch and sum_over_timesteps:
+ raise ValueError(
+ "average_across_batch and sum_over_timesteps cannot be set "
+ "to True at same time because of ambiguous order.")
+ if sum_over_batch and average_across_timesteps:
+ raise ValueError(
+ "sum_over_batch and average_across_timesteps cannot be set "
+ "to True at same time because of ambiguous order.")
with tf.name_scope(name or "sequence_loss"):
num_classes = tf.shape(input=logits)[2]
logits_flat = tf.reshape(logits, [-1, num_classes])
| {"golden_diff": "diff --git a/tensorflow_addons/seq2seq/loss.py b/tensorflow_addons/seq2seq/loss.py\n--- a/tensorflow_addons/seq2seq/loss.py\n+++ b/tensorflow_addons/seq2seq/loss.py\n@@ -103,6 +103,14 @@\n raise ValueError(\n \"average_across_batch and sum_over_batch cannot be set \"\n \"to True at same time.\")\n+ if average_across_batch and sum_over_timesteps:\n+ raise ValueError(\n+ \"average_across_batch and sum_over_timesteps cannot be set \"\n+ \"to True at same time because of ambiguous order.\")\n+ if sum_over_batch and average_across_timesteps:\n+ raise ValueError(\n+ \"sum_over_batch and average_across_timesteps cannot be set \"\n+ \"to True at same time because of ambiguous order.\")\n with tf.name_scope(name or \"sequence_loss\"):\n num_classes = tf.shape(input=logits)[2]\n logits_flat = tf.reshape(logits, [-1, num_classes])\n", "issue": "tfa.seq2seq.sequence_loss can't average over one dimension (batch or timesteps) while summing over the other one\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google Colab\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.0.0=beta1\r\n- TensorFlow Addons installed from (source, PyPi): PyPi\r\n- TensorFlow Addons version: 0.4.0\r\n- Python version and type (eg. Anaconda Python, Stock Python as in Mac, or homebrew installed Python etc): Google Colab Python\r\n- Is GPU used? (yes/no): yes\r\n- GPU model (if used): T4\r\n\r\n**Describe the bug**\r\n\r\n`tfa.seq2seq.sequence_loss` can't average over one dimension (`batch` or `timesteps`) while summing over the other one. It will arbitrarily only execute the averaging and ignore the sum right now.\r\n\r\n**Describe the expected behavior**\r\n\r\nI think the weights should be associated with the summing operation, and then the averaging should happen irrespective of that.\r\nConcretely, when passing, say `average_across_batch=True` and `sum_over_timesteps=True` (of course, making sure `average_across_timesteps=False` is set), you should expect either of these things:\r\n\r\n1. An error stating that this is not implemented (might be the wisest).\r\n2. Return a scalar tensor obtained by either of these two following orders:\r\n a) first computing the *weighted sum* of xents over timesteps (yielding a batchsize-sized tensor of xent-sums), then simply averaging this vector, i.e., summing and dividing by the batchsize. The result, however, is just the both-averaged version times the batchsize, divided by the sum of all weights.\r\n b) first computing the *weighted average* over the batchsize, then summing these averages over all timesteps. The result here is different from 1a and the double-averaged (of course, there is some correlation...)!\r\n\r\nI think 1a is the desired behavior (as the loglikelihood of a sequence really is the sum of the individual loglikelihoods and batches do correspond to sequence-length agnostic averages) and I'd be happy to establish it as the standard for this. Either way, doing something other than failing with an error will require an explicit notice in the docs. An error (or warning for backwards-compatibility?) might just be the simplest and safest option.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\ntfa.seq2seq.sequence_loss(\r\n logits=tf.random.normal([3, 5, 7]),\r\n targets=tf.zeros([3, 5], dtype=tf.int32),\r\n weights=tf.sequence_mask(lengths=[3, 5, 1], maxlen=5, dtype=tf.float32),\r\n average_across_batch=True,\r\n average_across_timesteps=False,\r\n sum_over_batch=False,\r\n sum_over_timesteps=True,\r\n)\r\n```\r\n...should return a scalar but returns only the batch-averaged tensor.\r\n\r\n**Some more code to play with to test the claims above**\r\n\r\n```python\r\nimport tensorflow.compat.v2 as tf\r\nimport tensorflow_addons as tfa\r\nimport numpy as np\r\nimport random\r\n\r\ncase1b = []\r\ndblavg = []\r\n\r\nfor _ in range(100):\r\n dtype = tf.float32\r\n batchsize = random.randint(2, 10)\r\n maxlen = random.randint(2, 10)\r\n logits = tf.random.normal([batchsize, maxlen, 3])\r\n labels = tf.zeros([batchsize, maxlen], dtype=tf.int32)\r\n lengths = tf.squeeze(tf.random.categorical(tf.zeros([1, maxlen - 1]), batchsize)) + 1\r\n weights = tf.sequence_mask(lengths=lengths, maxlen=maxlen, dtype=tf.float32)\r\n\r\n def sl(ab, sb, at, st):\r\n return tfa.seq2seq.sequence_loss(\r\n logits,\r\n labels,\r\n weights,\r\n average_across_batch=ab,\r\n average_across_timesteps=at,\r\n sum_over_batch=sb,\r\n sum_over_timesteps=st,\r\n )\r\n\r\n all_b_all_t = sl(ab=False, sb=False, at=False, st=False)\r\n avg_b_avg_t = sl(ab=True, sb=False, at=True, st=False)\r\n sum_b_all_t = sl(ab=False, sb=True, at=False, st=False)\r\n\r\n tf.assert_equal(sum_b_all_t, tf.math.divide_no_nan(tf.reduce_sum(all_b_all_t, axis=0), tf.reduce_sum(weights, axis=0)))\r\n\r\n weighted = all_b_all_t * weights\r\n\r\n first_sum_timesteps = tf.reduce_sum(weighted, axis=1)\r\n then_average_batch = tf.reduce_sum(first_sum_timesteps) / batchsize\r\n\r\n first_average_batch = tf.math.divide_no_nan(tf.reduce_sum(weighted, axis=0), tf.reduce_sum(weights, axis=0))\r\n then_sum_timesteps = tf.reduce_sum(first_average_batch)\r\n\r\n # Case 1a and 1b are different.\r\n assert not np.isclose(then_average_batch, then_sum_timesteps)\r\n # Case 1a is just the double-averaging up to a constant.\r\n assert np.allclose(then_average_batch * batchsize / tf.reduce_sum(weights), avg_b_avg_t)\r\n # Case 1b is not just the averaging.\r\n assert not np.allclose(then_sum_timesteps / maxlen, avg_b_avg_t)\r\n # They only kind of correlate:\r\n case1b.append(then_sum_timesteps / maxlen)\r\n dblavg.append(avg_b_avg_t)\r\n```\n", "before_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Seq2seq loss operations for use in sequence models.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\n\n\ndef sequence_loss(logits,\n targets,\n weights,\n average_across_timesteps=True,\n average_across_batch=True,\n sum_over_timesteps=False,\n sum_over_batch=False,\n softmax_loss_function=None,\n name=None):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\n\n Depending on the values of `average_across_timesteps` /\n `sum_over_timesteps` and `average_across_batch` / `sum_over_batch`, the\n return Tensor will have rank 0, 1, or 2 as these arguments reduce the\n cross-entropy at each target, which has shape\n `[batch_size, sequence_length]`, over their respective dimensions. For\n example, if `average_across_timesteps` is `True` and `average_across_batch`\n is `False`, then the return Tensor will have shape `[batch_size]`.\n\n Note that `average_across_timesteps` and `sum_over_timesteps` cannot be\n True at same time. Same for `average_across_batch` and `sum_over_batch`.\n\n The recommended loss reduction in tf 2.0 has been changed to sum_over,\n instead of weighted average. User are recommend to use `sum_over_timesteps`\n and `sum_over_batch` for reduction.\n\n Args:\n logits: A Tensor of shape\n `[batch_size, sequence_length, num_decoder_symbols]` and dtype float.\n The logits correspond to the prediction across all classes at each\n timestep.\n targets: A Tensor of shape `[batch_size, sequence_length]` and dtype\n int. The target represents the true class at each timestep.\n weights: A Tensor of shape `[batch_size, sequence_length]` and dtype\n float. `weights` constitutes the weighting of each prediction in the\n sequence. When using `weights` as masking, set all valid timesteps to 1\n and all padded timesteps to 0, e.g. a mask returned by\n `tf.sequence_mask`.\n average_across_timesteps: If set, sum the cost across the sequence\n dimension and divide the cost by the total label weight across\n timesteps.\n average_across_batch: If set, sum the cost across the batch dimension and\n divide the returned cost by the batch size.\n sum_over_timesteps: If set, sum the cost across the sequence dimension\n and divide the size of the sequence. Note that any element with 0\n weights will be excluded from size calculation.\n sum_over_batch: if set, sum the cost across the batch dimension and\n divide the total cost by the batch size. Not that any element with 0\n weights will be excluded from size calculation.\n softmax_loss_function: Function (labels, logits) -> loss-batch\n to be used instead of the standard softmax (the default if this is\n None). **Note that to avoid confusion, it is required for the function\n to accept named arguments.**\n name: Optional name for this operation, defaults to \"sequence_loss\".\n\n Returns:\n A float Tensor of rank 0, 1, or 2 depending on the\n `average_across_timesteps` and `average_across_batch` arguments. By\n default, it has rank 0 (scalar) and is the weighted average cross-entropy\n (log-perplexity) per symbol.\n\n Raises:\n ValueError: logits does not have 3 dimensions or targets does not have 2\n dimensions or weights does not have 2 dimensions.\n \"\"\"\n if len(logits.get_shape()) != 3:\n raise ValueError(\"Logits must be a \"\n \"[batch_size x sequence_length x logits] tensor\")\n if len(targets.get_shape()) != 2:\n raise ValueError(\n \"Targets must be a [batch_size x sequence_length] tensor\")\n if len(weights.get_shape()) != 2:\n raise ValueError(\n \"Weights must be a [batch_size x sequence_length] tensor\")\n if average_across_timesteps and sum_over_timesteps:\n raise ValueError(\n \"average_across_timesteps and sum_over_timesteps cannot \"\n \"be set to True at same time.\")\n if average_across_batch and sum_over_batch:\n raise ValueError(\n \"average_across_batch and sum_over_batch cannot be set \"\n \"to True at same time.\")\n with tf.name_scope(name or \"sequence_loss\"):\n num_classes = tf.shape(input=logits)[2]\n logits_flat = tf.reshape(logits, [-1, num_classes])\n targets = tf.reshape(targets, [-1])\n if softmax_loss_function is None:\n crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(\n labels=targets, logits=logits_flat)\n else:\n crossent = softmax_loss_function(\n labels=targets, logits=logits_flat)\n crossent *= tf.reshape(weights, [-1])\n if average_across_timesteps and average_across_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_size = tf.reduce_sum(input_tensor=weights)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps and sum_over_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_count = tf.cast(\n tf.math.count_nonzero(weights), crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n else:\n crossent = tf.reshape(crossent, tf.shape(input=logits)[0:2])\n if average_across_timesteps or average_across_batch:\n reduce_axis = [0] if average_across_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_size = tf.reduce_sum(\n input_tensor=weights, axis=reduce_axis)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps or sum_over_batch:\n reduce_axis = [0] if sum_over_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_count = tf.cast(\n tf.math.count_nonzero(weights, axis=reduce_axis),\n dtype=crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n return crossent\n\n\nclass SequenceLoss(tf.keras.losses.Loss):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\"\"\"\n\n def __init__(self,\n average_across_timesteps=False,\n average_across_batch=False,\n sum_over_timesteps=True,\n sum_over_batch=True,\n softmax_loss_function=None,\n name=None):\n super(SequenceLoss, self).__init__(name=name)\n self.average_across_timesteps = average_across_timesteps\n self.average_across_batch = average_across_batch\n self.sum_over_timesteps = sum_over_timesteps\n self.sum_over_batch = sum_over_batch\n self.softmax_loss_function = softmax_loss_function\n\n def __call__(self, y_true, y_pred, sample_weight=None):\n \"\"\"Override the parent __call__ to have a customized reduce\n behavior.\"\"\"\n return sequence_loss(\n y_pred,\n y_true,\n sample_weight,\n average_across_timesteps=self.average_across_timesteps,\n average_across_batch=self.average_across_batch,\n sum_over_timesteps=self.sum_over_timesteps,\n sum_over_batch=self.sum_over_batch,\n softmax_loss_function=self.softmax_loss_function,\n name=self.name)\n\n def call(self, y_true, y_pred):\n # Skip this method since the __call__ contains real implementation.\n pass\n", "path": "tensorflow_addons/seq2seq/loss.py"}], "after_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Seq2seq loss operations for use in sequence models.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\n\n\ndef sequence_loss(logits,\n targets,\n weights,\n average_across_timesteps=True,\n average_across_batch=True,\n sum_over_timesteps=False,\n sum_over_batch=False,\n softmax_loss_function=None,\n name=None):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\n\n Depending on the values of `average_across_timesteps` /\n `sum_over_timesteps` and `average_across_batch` / `sum_over_batch`, the\n return Tensor will have rank 0, 1, or 2 as these arguments reduce the\n cross-entropy at each target, which has shape\n `[batch_size, sequence_length]`, over their respective dimensions. For\n example, if `average_across_timesteps` is `True` and `average_across_batch`\n is `False`, then the return Tensor will have shape `[batch_size]`.\n\n Note that `average_across_timesteps` and `sum_over_timesteps` cannot be\n True at same time. Same for `average_across_batch` and `sum_over_batch`.\n\n The recommended loss reduction in tf 2.0 has been changed to sum_over,\n instead of weighted average. User are recommend to use `sum_over_timesteps`\n and `sum_over_batch` for reduction.\n\n Args:\n logits: A Tensor of shape\n `[batch_size, sequence_length, num_decoder_symbols]` and dtype float.\n The logits correspond to the prediction across all classes at each\n timestep.\n targets: A Tensor of shape `[batch_size, sequence_length]` and dtype\n int. The target represents the true class at each timestep.\n weights: A Tensor of shape `[batch_size, sequence_length]` and dtype\n float. `weights` constitutes the weighting of each prediction in the\n sequence. When using `weights` as masking, set all valid timesteps to 1\n and all padded timesteps to 0, e.g. a mask returned by\n `tf.sequence_mask`.\n average_across_timesteps: If set, sum the cost across the sequence\n dimension and divide the cost by the total label weight across\n timesteps.\n average_across_batch: If set, sum the cost across the batch dimension and\n divide the returned cost by the batch size.\n sum_over_timesteps: If set, sum the cost across the sequence dimension\n and divide the size of the sequence. Note that any element with 0\n weights will be excluded from size calculation.\n sum_over_batch: if set, sum the cost across the batch dimension and\n divide the total cost by the batch size. Not that any element with 0\n weights will be excluded from size calculation.\n softmax_loss_function: Function (labels, logits) -> loss-batch\n to be used instead of the standard softmax (the default if this is\n None). **Note that to avoid confusion, it is required for the function\n to accept named arguments.**\n name: Optional name for this operation, defaults to \"sequence_loss\".\n\n Returns:\n A float Tensor of rank 0, 1, or 2 depending on the\n `average_across_timesteps` and `average_across_batch` arguments. By\n default, it has rank 0 (scalar) and is the weighted average cross-entropy\n (log-perplexity) per symbol.\n\n Raises:\n ValueError: logits does not have 3 dimensions or targets does not have 2\n dimensions or weights does not have 2 dimensions.\n \"\"\"\n if len(logits.get_shape()) != 3:\n raise ValueError(\"Logits must be a \"\n \"[batch_size x sequence_length x logits] tensor\")\n if len(targets.get_shape()) != 2:\n raise ValueError(\n \"Targets must be a [batch_size x sequence_length] tensor\")\n if len(weights.get_shape()) != 2:\n raise ValueError(\n \"Weights must be a [batch_size x sequence_length] tensor\")\n if average_across_timesteps and sum_over_timesteps:\n raise ValueError(\n \"average_across_timesteps and sum_over_timesteps cannot \"\n \"be set to True at same time.\")\n if average_across_batch and sum_over_batch:\n raise ValueError(\n \"average_across_batch and sum_over_batch cannot be set \"\n \"to True at same time.\")\n if average_across_batch and sum_over_timesteps:\n raise ValueError(\n \"average_across_batch and sum_over_timesteps cannot be set \"\n \"to True at same time because of ambiguous order.\")\n if sum_over_batch and average_across_timesteps:\n raise ValueError(\n \"sum_over_batch and average_across_timesteps cannot be set \"\n \"to True at same time because of ambiguous order.\")\n with tf.name_scope(name or \"sequence_loss\"):\n num_classes = tf.shape(input=logits)[2]\n logits_flat = tf.reshape(logits, [-1, num_classes])\n targets = tf.reshape(targets, [-1])\n if softmax_loss_function is None:\n crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(\n labels=targets, logits=logits_flat)\n else:\n crossent = softmax_loss_function(\n labels=targets, logits=logits_flat)\n crossent *= tf.reshape(weights, [-1])\n if average_across_timesteps and average_across_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_size = tf.reduce_sum(input_tensor=weights)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps and sum_over_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_count = tf.cast(\n tf.math.count_nonzero(weights), crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n else:\n crossent = tf.reshape(crossent, tf.shape(input=logits)[0:2])\n if average_across_timesteps or average_across_batch:\n reduce_axis = [0] if average_across_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_size = tf.reduce_sum(\n input_tensor=weights, axis=reduce_axis)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps or sum_over_batch:\n reduce_axis = [0] if sum_over_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_count = tf.cast(\n tf.math.count_nonzero(weights, axis=reduce_axis),\n dtype=crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n return crossent\n\n\nclass SequenceLoss(tf.keras.losses.Loss):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\"\"\"\n\n def __init__(self,\n average_across_timesteps=False,\n average_across_batch=False,\n sum_over_timesteps=True,\n sum_over_batch=True,\n softmax_loss_function=None,\n name=None):\n super(SequenceLoss, self).__init__(name=name)\n self.average_across_timesteps = average_across_timesteps\n self.average_across_batch = average_across_batch\n self.sum_over_timesteps = sum_over_timesteps\n self.sum_over_batch = sum_over_batch\n self.softmax_loss_function = softmax_loss_function\n\n def __call__(self, y_true, y_pred, sample_weight=None):\n \"\"\"Override the parent __call__ to have a customized reduce\n behavior.\"\"\"\n return sequence_loss(\n y_pred,\n y_true,\n sample_weight,\n average_across_timesteps=self.average_across_timesteps,\n average_across_batch=self.average_across_batch,\n sum_over_timesteps=self.sum_over_timesteps,\n sum_over_batch=self.sum_over_batch,\n softmax_loss_function=self.softmax_loss_function,\n name=self.name)\n\n def call(self, y_true, y_pred):\n # Skip this method since the __call__ contains real implementation.\n pass\n", "path": "tensorflow_addons/seq2seq/loss.py"}]} | 3,719 | 232 |
gh_patches_debug_10799 | rasdani/github-patches | git_diff | optuna__optuna-1680 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use function annotation syntax for Type Hints.
After dropping Python 2.7 support at #710, we can define type hints with function annotation syntax.
~~Do you have a plan to update the coding style guideline?~~
https://github.com/optuna/optuna/wiki/Coding-Style-Conventions
## Progress
- [x] `optuna/integration/sklearn.py` (#1735)
- [x] `optuna/study.py` - assigned to harpy
## Note to the questioner
We still cannot use variable annotation syntax introduced by [PEP 526](https://www.python.org/dev/peps/pep-0526/) because we supports Python 3.5.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `optuna/pruners/_nop.py`
Content:
```
1 from optuna.pruners import BasePruner
2 from optuna import type_checking
3
4 if type_checking.TYPE_CHECKING:
5 from optuna.study import Study # NOQA
6 from optuna.trial import FrozenTrial # NOQA
7
8
9 class NopPruner(BasePruner):
10 """Pruner which never prunes trials.
11
12 Example:
13
14 .. testcode::
15
16 import numpy as np
17 from sklearn.datasets import load_iris
18 from sklearn.linear_model import SGDClassifier
19 from sklearn.model_selection import train_test_split
20
21 import optuna
22
23 X, y = load_iris(return_X_y=True)
24 X_train, X_valid, y_train, y_valid = train_test_split(X, y)
25 classes = np.unique(y)
26
27 def objective(trial):
28 alpha = trial.suggest_uniform('alpha', 0.0, 1.0)
29 clf = SGDClassifier(alpha=alpha)
30 n_train_iter = 100
31
32 for step in range(n_train_iter):
33 clf.partial_fit(X_train, y_train, classes=classes)
34
35 intermediate_value = clf.score(X_valid, y_valid)
36 trial.report(intermediate_value, step)
37
38 if trial.should_prune():
39 assert False, "should_prune() should always return False with this pruner."
40 raise optuna.TrialPruned()
41
42 return clf.score(X_valid, y_valid)
43
44 study = optuna.create_study(direction='maximize',
45 pruner=optuna.pruners.NopPruner())
46 study.optimize(objective, n_trials=20)
47 """
48
49 def prune(self, study, trial):
50 # type: (Study, FrozenTrial) -> bool
51
52 return False
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/optuna/pruners/_nop.py b/optuna/pruners/_nop.py
--- a/optuna/pruners/_nop.py
+++ b/optuna/pruners/_nop.py
@@ -1,9 +1,5 @@
+import optuna
from optuna.pruners import BasePruner
-from optuna import type_checking
-
-if type_checking.TYPE_CHECKING:
- from optuna.study import Study # NOQA
- from optuna.trial import FrozenTrial # NOQA
class NopPruner(BasePruner):
@@ -46,7 +42,6 @@
study.optimize(objective, n_trials=20)
"""
- def prune(self, study, trial):
- # type: (Study, FrozenTrial) -> bool
+ def prune(self, study: "optuna.study.Study", trial: "optuna.trial.FrozenTrial") -> bool:
return False
| {"golden_diff": "diff --git a/optuna/pruners/_nop.py b/optuna/pruners/_nop.py\n--- a/optuna/pruners/_nop.py\n+++ b/optuna/pruners/_nop.py\n@@ -1,9 +1,5 @@\n+import optuna\n from optuna.pruners import BasePruner\n-from optuna import type_checking\n-\n-if type_checking.TYPE_CHECKING:\n- from optuna.study import Study # NOQA\n- from optuna.trial import FrozenTrial # NOQA\n \n \n class NopPruner(BasePruner):\n@@ -46,7 +42,6 @@\n study.optimize(objective, n_trials=20)\n \"\"\"\n \n- def prune(self, study, trial):\n- # type: (Study, FrozenTrial) -> bool\n+ def prune(self, study: \"optuna.study.Study\", trial: \"optuna.trial.FrozenTrial\") -> bool:\n \n return False\n", "issue": "Use function annotation syntax for Type Hints.\nAfter dropping Python 2.7 support at #710, we can define type hints with function annotation syntax. \r\n~~Do you have a plan to update the coding style guideline?~~\r\nhttps://github.com/optuna/optuna/wiki/Coding-Style-Conventions\r\n\r\n## Progress\r\n\r\n- [x] `optuna/integration/sklearn.py` (#1735)\r\n- [x] `optuna/study.py` - assigned to harpy\r\n\r\n## Note to the questioner\r\n\r\nWe still cannot use variable annotation syntax introduced by [PEP 526](https://www.python.org/dev/peps/pep-0526/) because we supports Python 3.5.\n", "before_files": [{"content": "from optuna.pruners import BasePruner\nfrom optuna import type_checking\n\nif type_checking.TYPE_CHECKING:\n from optuna.study import Study # NOQA\n from optuna.trial import FrozenTrial # NOQA\n\n\nclass NopPruner(BasePruner):\n \"\"\"Pruner which never prunes trials.\n\n Example:\n\n .. testcode::\n\n import numpy as np\n from sklearn.datasets import load_iris\n from sklearn.linear_model import SGDClassifier\n from sklearn.model_selection import train_test_split\n\n import optuna\n\n X, y = load_iris(return_X_y=True)\n X_train, X_valid, y_train, y_valid = train_test_split(X, y)\n classes = np.unique(y)\n\n def objective(trial):\n alpha = trial.suggest_uniform('alpha', 0.0, 1.0)\n clf = SGDClassifier(alpha=alpha)\n n_train_iter = 100\n\n for step in range(n_train_iter):\n clf.partial_fit(X_train, y_train, classes=classes)\n\n intermediate_value = clf.score(X_valid, y_valid)\n trial.report(intermediate_value, step)\n\n if trial.should_prune():\n assert False, \"should_prune() should always return False with this pruner.\"\n raise optuna.TrialPruned()\n\n return clf.score(X_valid, y_valid)\n\n study = optuna.create_study(direction='maximize',\n pruner=optuna.pruners.NopPruner())\n study.optimize(objective, n_trials=20)\n \"\"\"\n\n def prune(self, study, trial):\n # type: (Study, FrozenTrial) -> bool\n\n return False\n", "path": "optuna/pruners/_nop.py"}], "after_files": [{"content": "import optuna\nfrom optuna.pruners import BasePruner\n\n\nclass NopPruner(BasePruner):\n \"\"\"Pruner which never prunes trials.\n\n Example:\n\n .. testcode::\n\n import numpy as np\n from sklearn.datasets import load_iris\n from sklearn.linear_model import SGDClassifier\n from sklearn.model_selection import train_test_split\n\n import optuna\n\n X, y = load_iris(return_X_y=True)\n X_train, X_valid, y_train, y_valid = train_test_split(X, y)\n classes = np.unique(y)\n\n def objective(trial):\n alpha = trial.suggest_uniform('alpha', 0.0, 1.0)\n clf = SGDClassifier(alpha=alpha)\n n_train_iter = 100\n\n for step in range(n_train_iter):\n clf.partial_fit(X_train, y_train, classes=classes)\n\n intermediate_value = clf.score(X_valid, y_valid)\n trial.report(intermediate_value, step)\n\n if trial.should_prune():\n assert False, \"should_prune() should always return False with this pruner.\"\n raise optuna.TrialPruned()\n\n return clf.score(X_valid, y_valid)\n\n study = optuna.create_study(direction='maximize',\n pruner=optuna.pruners.NopPruner())\n study.optimize(objective, n_trials=20)\n \"\"\"\n\n def prune(self, study: \"optuna.study.Study\", trial: \"optuna.trial.FrozenTrial\") -> bool:\n\n return False\n", "path": "optuna/pruners/_nop.py"}]} | 889 | 210 |
gh_patches_debug_15760 | rasdani/github-patches | git_diff | iterative__dvc-1052 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dvc status error with S3 output
DVC version 0.17.1, installed with pip.
Running `dvc status` shows
```
Failed to obtain data status: 'OutputS3' object has no attribute 'rel_path'
```
and nothing else (e.g. files that are not output to S3)
My .dvc/config:
```
['remote "data"']
url = s3://xxxxx/data
[core]
remote = data
['remote "s3cache"']
url = s3://xxxxx/cache
[cache]
s3 = s3cache
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/dependency/base.py`
Content:
```
1 import re
2
3 from dvc.exceptions import DvcException
4
5
6 class DependencyError(DvcException):
7 def __init__(self, path, msg):
8 msg = 'Dependency \'{}\' error: {}'
9 super(DependencyError, self).__init__(msg.format(path, msg))
10
11
12 class DependencyDoesNotExistError(DependencyError):
13 def __init__(self, path):
14 msg = 'does not exist'
15 super(DependencyDoesNotExistError, self).__init__(path, msg)
16
17
18 class DependencyIsNotFileOrDirError(DependencyError):
19 def __init__(self, path):
20 msg = 'not a file or directory'
21 super(DependencyIsNotFileOrDirError, self).__init__(path, msg)
22
23
24 class DependencyBase(object):
25 REGEX = None
26
27 PARAM_PATH = 'path'
28
29 def __init__(self, stage, path):
30 self.stage = stage
31 self.project = stage.project
32 self.path = path
33
34 @classmethod
35 def match(cls, url):
36 return re.match(cls.REGEX, url)
37
38 def group(self, name):
39 match = self.match(self.path)
40 if not match:
41 return None
42 return match.group(name)
43
44 @classmethod
45 def supported(cls, url):
46 return cls.match(url) is not None
47
48 @property
49 def sep(self):
50 return '/'
51
52 @property
53 def exists(self):
54 return self.remote.exists([self.path_info])
55
56 def changed(self):
57 raise NotImplementedError
58
59 def status(self):
60 if self.changed():
61 # FIXME better msgs
62 return {self.rel_path: 'changed'}
63 return {}
64
65 def save(self):
66 raise NotImplementedError
67
68 def dumpd(self):
69 return {self.PARAM_PATH: self.path}
70
71 def download(self, to_info):
72 self.remote.download([self.path_info], [to_info])
73
```
Path: `dvc/config.py`
Content:
```
1 """
2 DVC config objects.
3 """
4 import os
5 import configobj
6 from schema import Schema, Optional, And, Use, Regex
7
8 from dvc.exceptions import DvcException
9
10
11 class ConfigError(DvcException):
12 """ DVC config exception """
13 def __init__(self, ex=None):
14 super(ConfigError, self).__init__('Config file error', ex)
15
16
17 def supported_url(url):
18 from dvc.remote import supported_url as supported
19 return supported(url)
20
21
22 def supported_cache_type(types):
23 if isinstance(types, str):
24 types = [t.strip() for t in types.split(',')]
25 for t in types:
26 if t not in ['reflink', 'hardlink', 'symlink', 'copy']:
27 return False
28 return True
29
30
31 def supported_loglevel(level):
32 return level in ['info', 'debug', 'warning', 'error']
33
34
35 def supported_cloud(cloud):
36 return cloud in ['aws', 'gcp', 'local', '']
37
38
39 def is_bool(val):
40 return val.lower() in ['true', 'false']
41
42
43 def to_bool(val):
44 return val.lower() == 'true'
45
46
47 class Config(object):
48 CONFIG = 'config'
49 CONFIG_LOCAL = 'config.local'
50
51 SECTION_CORE = 'core'
52 SECTION_CORE_LOGLEVEL = 'loglevel'
53 SECTION_CORE_LOGLEVEL_SCHEMA = And(Use(str.lower), supported_loglevel)
54 SECTION_CORE_REMOTE = 'remote'
55 SECTION_CORE_INTERACTIVE_SCHEMA = And(str, is_bool, Use(to_bool))
56 SECTION_CORE_INTERACTIVE = 'interactive'
57
58 SECTION_CACHE = 'cache'
59 SECTION_CACHE_DIR = 'dir'
60 SECTION_CACHE_TYPE = 'type'
61 SECTION_CACHE_TYPE_SCHEMA = supported_cache_type
62 SECTION_CACHE_LOCAL = 'local'
63 SECTION_CACHE_S3 = 's3'
64 SECTION_CACHE_GS = 'gs'
65 SECTION_CACHE_SSH = 'ssh'
66 SECTION_CACHE_HDFS = 'hdfs'
67 SECTION_CACHE_AZURE = 'azure'
68 SECTION_CACHE_SCHEMA = {
69 Optional(SECTION_CACHE_LOCAL): str,
70 Optional(SECTION_CACHE_S3): str,
71 Optional(SECTION_CACHE_GS): str,
72 Optional(SECTION_CACHE_HDFS): str,
73 Optional(SECTION_CACHE_SSH): str,
74 Optional(SECTION_CACHE_AZURE): str,
75
76 # backward compatibility
77 Optional(SECTION_CACHE_DIR, default='cache'): str,
78 Optional(SECTION_CACHE_TYPE, default=None): SECTION_CACHE_TYPE_SCHEMA,
79 }
80
81 # backward compatibility
82 SECTION_CORE_CLOUD = 'cloud'
83 SECTION_CORE_CLOUD_SCHEMA = And(Use(str.lower), supported_cloud)
84 SECTION_CORE_STORAGEPATH = 'storagepath'
85
86 SECTION_CORE_SCHEMA = {
87 Optional(SECTION_CORE_LOGLEVEL,
88 default='info'): And(str, Use(str.lower),
89 SECTION_CORE_LOGLEVEL_SCHEMA),
90 Optional(SECTION_CORE_REMOTE, default=''): And(str, Use(str.lower)),
91 Optional(SECTION_CORE_INTERACTIVE,
92 default=False): SECTION_CORE_INTERACTIVE_SCHEMA,
93
94 # backward compatibility
95 Optional(SECTION_CORE_CLOUD, default=''): SECTION_CORE_CLOUD_SCHEMA,
96 Optional(SECTION_CORE_STORAGEPATH, default=''): str,
97 }
98
99 # backward compatibility
100 SECTION_AWS = 'aws'
101 SECTION_AWS_STORAGEPATH = 'storagepath'
102 SECTION_AWS_CREDENTIALPATH = 'credentialpath'
103 SECTION_AWS_ENDPOINT_URL = 'endpointurl'
104 SECTION_AWS_REGION = 'region'
105 SECTION_AWS_PROFILE = 'profile'
106 SECTION_AWS_SCHEMA = {
107 SECTION_AWS_STORAGEPATH: str,
108 Optional(SECTION_AWS_REGION): str,
109 Optional(SECTION_AWS_PROFILE, default='default'): str,
110 Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,
111 Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,
112 }
113
114 # backward compatibility
115 SECTION_GCP = 'gcp'
116 SECTION_GCP_STORAGEPATH = SECTION_AWS_STORAGEPATH
117 SECTION_GCP_PROJECTNAME = 'projectname'
118 SECTION_GCP_SCHEMA = {
119 SECTION_GCP_STORAGEPATH: str,
120 Optional(SECTION_GCP_PROJECTNAME): str,
121 }
122
123 # backward compatibility
124 SECTION_LOCAL = 'local'
125 SECTION_LOCAL_STORAGEPATH = SECTION_AWS_STORAGEPATH
126 SECTION_LOCAL_SCHEMA = {
127 SECTION_LOCAL_STORAGEPATH: str,
128 }
129
130 SECTION_REMOTE_REGEX = r'^\s*remote\s*"(?P<name>.*)"\s*$'
131 SECTION_REMOTE_FMT = 'remote "{}"'
132 SECTION_REMOTE_URL = 'url'
133 SECTION_REMOTE_USER = 'user'
134 SECTION_REMOTE_SCHEMA = {
135 SECTION_REMOTE_URL: And(supported_url, error="Unsupported URL"),
136 Optional(SECTION_AWS_REGION): str,
137 Optional(SECTION_AWS_PROFILE, default='default'): str,
138 Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,
139 Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,
140 Optional(SECTION_GCP_PROJECTNAME): str,
141 Optional(SECTION_CACHE_TYPE): SECTION_CACHE_TYPE_SCHEMA,
142 Optional(SECTION_REMOTE_USER): str,
143 }
144
145 SCHEMA = {
146 Optional(SECTION_CORE, default={}): SECTION_CORE_SCHEMA,
147 Optional(Regex(SECTION_REMOTE_REGEX)): SECTION_REMOTE_SCHEMA,
148 Optional(SECTION_CACHE, default={}): SECTION_CACHE_SCHEMA,
149
150 # backward compatibility
151 Optional(SECTION_AWS, default={}): SECTION_AWS_SCHEMA,
152 Optional(SECTION_GCP, default={}): SECTION_GCP_SCHEMA,
153 Optional(SECTION_LOCAL, default={}): SECTION_LOCAL_SCHEMA,
154 }
155
156 def __init__(self, dvc_dir):
157 self.dvc_dir = os.path.abspath(os.path.realpath(dvc_dir))
158 self.config_file = os.path.join(dvc_dir, self.CONFIG)
159 self.config_local_file = os.path.join(dvc_dir, self.CONFIG_LOCAL)
160
161 try:
162 self._config = configobj.ConfigObj(self.config_file)
163 local = configobj.ConfigObj(self.config_local_file)
164
165 # NOTE: schema doesn't support ConfigObj.Section validation, so we
166 # need to convert our config to dict before passing it to
167 self._config = self._lower(self._config)
168 local = self._lower(local)
169 self._config.update(local)
170
171 self._config = Schema(self.SCHEMA).validate(self._config)
172
173 # NOTE: now converting back to ConfigObj
174 self._config = configobj.ConfigObj(self._config,
175 write_empty_values=True)
176 self._config.filename = self.config_file
177 except Exception as ex:
178 raise ConfigError(ex)
179
180 @staticmethod
181 def _lower(config):
182 new_config = {}
183 for s_key, s_value in config.items():
184 new_s = {}
185 for key, value in s_value.items():
186 new_s[key.lower()] = value
187 new_config[s_key.lower()] = new_s
188 return new_config
189
190 @staticmethod
191 def init(dvc_dir):
192 config_file = os.path.join(dvc_dir, Config.CONFIG)
193 open(config_file, 'w+').close()
194 return Config(dvc_dir)
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/dvc/config.py b/dvc/config.py
--- a/dvc/config.py
+++ b/dvc/config.py
@@ -10,8 +10,9 @@
class ConfigError(DvcException):
""" DVC config exception """
- def __init__(self, ex=None):
- super(ConfigError, self).__init__('Config file error', ex)
+ def __init__(self, msg, ex=None):
+ super(ConfigError, self).__init__('Config file error: {}'.format(msg),
+ ex)
def supported_url(url):
diff --git a/dvc/dependency/base.py b/dvc/dependency/base.py
--- a/dvc/dependency/base.py
+++ b/dvc/dependency/base.py
@@ -59,7 +59,11 @@
def status(self):
if self.changed():
# FIXME better msgs
- return {self.rel_path: 'changed'}
+ if self.path_info['scheme'] == 'local':
+ p = self.rel_path
+ else:
+ p = self.path
+ return {p: 'changed'}
return {}
def save(self):
| {"golden_diff": "diff --git a/dvc/config.py b/dvc/config.py\n--- a/dvc/config.py\n+++ b/dvc/config.py\n@@ -10,8 +10,9 @@\n \n class ConfigError(DvcException):\n \"\"\" DVC config exception \"\"\"\n- def __init__(self, ex=None):\n- super(ConfigError, self).__init__('Config file error', ex)\n+ def __init__(self, msg, ex=None):\n+ super(ConfigError, self).__init__('Config file error: {}'.format(msg),\n+ ex)\n \n \n def supported_url(url):\ndiff --git a/dvc/dependency/base.py b/dvc/dependency/base.py\n--- a/dvc/dependency/base.py\n+++ b/dvc/dependency/base.py\n@@ -59,7 +59,11 @@\n def status(self):\n if self.changed():\n # FIXME better msgs\n- return {self.rel_path: 'changed'}\n+ if self.path_info['scheme'] == 'local':\n+ p = self.rel_path\n+ else:\n+ p = self.path\n+ return {p: 'changed'}\n return {}\n \n def save(self):\n", "issue": "dvc status error with S3 output\nDVC version 0.17.1, installed with pip.\r\n\r\nRunning `dvc status` shows\r\n```\r\nFailed to obtain data status: 'OutputS3' object has no attribute 'rel_path'\r\n```\r\nand nothing else (e.g. files that are not output to S3)\r\n\r\nMy .dvc/config:\r\n```\r\n['remote \"data\"']\r\nurl = s3://xxxxx/data\r\n[core]\r\nremote = data\r\n['remote \"s3cache\"']\r\nurl = s3://xxxxx/cache\r\n[cache]\r\ns3 = s3cache\r\n```\n", "before_files": [{"content": "import re\n\nfrom dvc.exceptions import DvcException\n\n\nclass DependencyError(DvcException):\n def __init__(self, path, msg):\n msg = 'Dependency \\'{}\\' error: {}'\n super(DependencyError, self).__init__(msg.format(path, msg))\n\n\nclass DependencyDoesNotExistError(DependencyError):\n def __init__(self, path):\n msg = 'does not exist'\n super(DependencyDoesNotExistError, self).__init__(path, msg)\n\n\nclass DependencyIsNotFileOrDirError(DependencyError):\n def __init__(self, path):\n msg = 'not a file or directory'\n super(DependencyIsNotFileOrDirError, self).__init__(path, msg)\n\n\nclass DependencyBase(object):\n REGEX = None\n\n PARAM_PATH = 'path'\n\n def __init__(self, stage, path):\n self.stage = stage\n self.project = stage.project\n self.path = path\n\n @classmethod\n def match(cls, url):\n return re.match(cls.REGEX, url)\n\n def group(self, name):\n match = self.match(self.path)\n if not match:\n return None\n return match.group(name)\n\n @classmethod\n def supported(cls, url):\n return cls.match(url) is not None\n\n @property\n def sep(self):\n return '/'\n\n @property\n def exists(self):\n return self.remote.exists([self.path_info])\n\n def changed(self):\n raise NotImplementedError\n\n def status(self):\n if self.changed():\n # FIXME better msgs\n return {self.rel_path: 'changed'}\n return {}\n\n def save(self):\n raise NotImplementedError\n\n def dumpd(self):\n return {self.PARAM_PATH: self.path}\n\n def download(self, to_info):\n self.remote.download([self.path_info], [to_info])\n", "path": "dvc/dependency/base.py"}, {"content": "\"\"\"\nDVC config objects.\n\"\"\"\nimport os\nimport configobj\nfrom schema import Schema, Optional, And, Use, Regex\n\nfrom dvc.exceptions import DvcException\n\n\nclass ConfigError(DvcException):\n \"\"\" DVC config exception \"\"\"\n def __init__(self, ex=None):\n super(ConfigError, self).__init__('Config file error', ex)\n\n\ndef supported_url(url):\n from dvc.remote import supported_url as supported\n return supported(url)\n\n\ndef supported_cache_type(types):\n if isinstance(types, str):\n types = [t.strip() for t in types.split(',')]\n for t in types:\n if t not in ['reflink', 'hardlink', 'symlink', 'copy']:\n return False\n return True\n\n\ndef supported_loglevel(level):\n return level in ['info', 'debug', 'warning', 'error']\n\n\ndef supported_cloud(cloud):\n return cloud in ['aws', 'gcp', 'local', '']\n\n\ndef is_bool(val):\n return val.lower() in ['true', 'false']\n\n\ndef to_bool(val):\n return val.lower() == 'true'\n\n\nclass Config(object):\n CONFIG = 'config'\n CONFIG_LOCAL = 'config.local'\n\n SECTION_CORE = 'core'\n SECTION_CORE_LOGLEVEL = 'loglevel'\n SECTION_CORE_LOGLEVEL_SCHEMA = And(Use(str.lower), supported_loglevel)\n SECTION_CORE_REMOTE = 'remote'\n SECTION_CORE_INTERACTIVE_SCHEMA = And(str, is_bool, Use(to_bool))\n SECTION_CORE_INTERACTIVE = 'interactive'\n\n SECTION_CACHE = 'cache'\n SECTION_CACHE_DIR = 'dir'\n SECTION_CACHE_TYPE = 'type'\n SECTION_CACHE_TYPE_SCHEMA = supported_cache_type\n SECTION_CACHE_LOCAL = 'local'\n SECTION_CACHE_S3 = 's3'\n SECTION_CACHE_GS = 'gs'\n SECTION_CACHE_SSH = 'ssh'\n SECTION_CACHE_HDFS = 'hdfs'\n SECTION_CACHE_AZURE = 'azure'\n SECTION_CACHE_SCHEMA = {\n Optional(SECTION_CACHE_LOCAL): str,\n Optional(SECTION_CACHE_S3): str,\n Optional(SECTION_CACHE_GS): str,\n Optional(SECTION_CACHE_HDFS): str,\n Optional(SECTION_CACHE_SSH): str,\n Optional(SECTION_CACHE_AZURE): str,\n\n # backward compatibility\n Optional(SECTION_CACHE_DIR, default='cache'): str,\n Optional(SECTION_CACHE_TYPE, default=None): SECTION_CACHE_TYPE_SCHEMA,\n }\n\n # backward compatibility\n SECTION_CORE_CLOUD = 'cloud'\n SECTION_CORE_CLOUD_SCHEMA = And(Use(str.lower), supported_cloud)\n SECTION_CORE_STORAGEPATH = 'storagepath'\n\n SECTION_CORE_SCHEMA = {\n Optional(SECTION_CORE_LOGLEVEL,\n default='info'): And(str, Use(str.lower),\n SECTION_CORE_LOGLEVEL_SCHEMA),\n Optional(SECTION_CORE_REMOTE, default=''): And(str, Use(str.lower)),\n Optional(SECTION_CORE_INTERACTIVE,\n default=False): SECTION_CORE_INTERACTIVE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_CORE_CLOUD, default=''): SECTION_CORE_CLOUD_SCHEMA,\n Optional(SECTION_CORE_STORAGEPATH, default=''): str,\n }\n\n # backward compatibility\n SECTION_AWS = 'aws'\n SECTION_AWS_STORAGEPATH = 'storagepath'\n SECTION_AWS_CREDENTIALPATH = 'credentialpath'\n SECTION_AWS_ENDPOINT_URL = 'endpointurl'\n SECTION_AWS_REGION = 'region'\n SECTION_AWS_PROFILE = 'profile'\n SECTION_AWS_SCHEMA = {\n SECTION_AWS_STORAGEPATH: str,\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n }\n\n # backward compatibility\n SECTION_GCP = 'gcp'\n SECTION_GCP_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_GCP_PROJECTNAME = 'projectname'\n SECTION_GCP_SCHEMA = {\n SECTION_GCP_STORAGEPATH: str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n }\n\n # backward compatibility\n SECTION_LOCAL = 'local'\n SECTION_LOCAL_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_LOCAL_SCHEMA = {\n SECTION_LOCAL_STORAGEPATH: str,\n }\n\n SECTION_REMOTE_REGEX = r'^\\s*remote\\s*\"(?P<name>.*)\"\\s*$'\n SECTION_REMOTE_FMT = 'remote \"{}\"'\n SECTION_REMOTE_URL = 'url'\n SECTION_REMOTE_USER = 'user'\n SECTION_REMOTE_SCHEMA = {\n SECTION_REMOTE_URL: And(supported_url, error=\"Unsupported URL\"),\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n Optional(SECTION_CACHE_TYPE): SECTION_CACHE_TYPE_SCHEMA,\n Optional(SECTION_REMOTE_USER): str,\n }\n\n SCHEMA = {\n Optional(SECTION_CORE, default={}): SECTION_CORE_SCHEMA,\n Optional(Regex(SECTION_REMOTE_REGEX)): SECTION_REMOTE_SCHEMA,\n Optional(SECTION_CACHE, default={}): SECTION_CACHE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_AWS, default={}): SECTION_AWS_SCHEMA,\n Optional(SECTION_GCP, default={}): SECTION_GCP_SCHEMA,\n Optional(SECTION_LOCAL, default={}): SECTION_LOCAL_SCHEMA,\n }\n\n def __init__(self, dvc_dir):\n self.dvc_dir = os.path.abspath(os.path.realpath(dvc_dir))\n self.config_file = os.path.join(dvc_dir, self.CONFIG)\n self.config_local_file = os.path.join(dvc_dir, self.CONFIG_LOCAL)\n\n try:\n self._config = configobj.ConfigObj(self.config_file)\n local = configobj.ConfigObj(self.config_local_file)\n\n # NOTE: schema doesn't support ConfigObj.Section validation, so we\n # need to convert our config to dict before passing it to\n self._config = self._lower(self._config)\n local = self._lower(local)\n self._config.update(local)\n\n self._config = Schema(self.SCHEMA).validate(self._config)\n\n # NOTE: now converting back to ConfigObj\n self._config = configobj.ConfigObj(self._config,\n write_empty_values=True)\n self._config.filename = self.config_file\n except Exception as ex:\n raise ConfigError(ex)\n\n @staticmethod\n def _lower(config):\n new_config = {}\n for s_key, s_value in config.items():\n new_s = {}\n for key, value in s_value.items():\n new_s[key.lower()] = value\n new_config[s_key.lower()] = new_s\n return new_config\n\n @staticmethod\n def init(dvc_dir):\n config_file = os.path.join(dvc_dir, Config.CONFIG)\n open(config_file, 'w+').close()\n return Config(dvc_dir)\n", "path": "dvc/config.py"}], "after_files": [{"content": "import re\n\nfrom dvc.exceptions import DvcException\n\n\nclass DependencyError(DvcException):\n def __init__(self, path, msg):\n msg = 'Dependency \\'{}\\' error: {}'\n super(DependencyError, self).__init__(msg.format(path, msg))\n\n\nclass DependencyDoesNotExistError(DependencyError):\n def __init__(self, path):\n msg = 'does not exist'\n super(DependencyDoesNotExistError, self).__init__(path, msg)\n\n\nclass DependencyIsNotFileOrDirError(DependencyError):\n def __init__(self, path):\n msg = 'not a file or directory'\n super(DependencyIsNotFileOrDirError, self).__init__(path, msg)\n\n\nclass DependencyBase(object):\n REGEX = None\n\n PARAM_PATH = 'path'\n\n def __init__(self, stage, path):\n self.stage = stage\n self.project = stage.project\n self.path = path\n\n @classmethod\n def match(cls, url):\n return re.match(cls.REGEX, url)\n\n def group(self, name):\n match = self.match(self.path)\n if not match:\n return None\n return match.group(name)\n\n @classmethod\n def supported(cls, url):\n return cls.match(url) is not None\n\n @property\n def sep(self):\n return '/'\n\n @property\n def exists(self):\n return self.remote.exists([self.path_info])\n\n def changed(self):\n raise NotImplementedError\n\n def status(self):\n if self.changed():\n # FIXME better msgs\n if self.path_info['scheme'] == 'local':\n p = self.rel_path\n else:\n p = self.path\n return {p: 'changed'}\n return {}\n\n def save(self):\n raise NotImplementedError\n\n def dumpd(self):\n return {self.PARAM_PATH: self.path}\n\n def download(self, to_info):\n self.remote.download([self.path_info], [to_info])\n", "path": "dvc/dependency/base.py"}, {"content": "\"\"\"\nDVC config objects.\n\"\"\"\nimport os\nimport configobj\nfrom schema import Schema, Optional, And, Use, Regex\n\nfrom dvc.exceptions import DvcException\n\n\nclass ConfigError(DvcException):\n \"\"\" DVC config exception \"\"\"\n def __init__(self, msg, ex=None):\n super(ConfigError, self).__init__('Config file error: {}'.format(msg),\n ex)\n\n\ndef supported_url(url):\n from dvc.remote import supported_url as supported\n return supported(url)\n\n\ndef supported_cache_type(types):\n if isinstance(types, str):\n types = [t.strip() for t in types.split(',')]\n for t in types:\n if t not in ['reflink', 'hardlink', 'symlink', 'copy']:\n return False\n return True\n\n\ndef supported_loglevel(level):\n return level in ['info', 'debug', 'warning', 'error']\n\n\ndef supported_cloud(cloud):\n return cloud in ['aws', 'gcp', 'local', '']\n\n\ndef is_bool(val):\n return val.lower() in ['true', 'false']\n\n\ndef to_bool(val):\n return val.lower() == 'true'\n\n\nclass Config(object):\n CONFIG = 'config'\n CONFIG_LOCAL = 'config.local'\n\n SECTION_CORE = 'core'\n SECTION_CORE_LOGLEVEL = 'loglevel'\n SECTION_CORE_LOGLEVEL_SCHEMA = And(Use(str.lower), supported_loglevel)\n SECTION_CORE_REMOTE = 'remote'\n SECTION_CORE_INTERACTIVE_SCHEMA = And(str, is_bool, Use(to_bool))\n SECTION_CORE_INTERACTIVE = 'interactive'\n\n SECTION_CACHE = 'cache'\n SECTION_CACHE_DIR = 'dir'\n SECTION_CACHE_TYPE = 'type'\n SECTION_CACHE_TYPE_SCHEMA = supported_cache_type\n SECTION_CACHE_LOCAL = 'local'\n SECTION_CACHE_S3 = 's3'\n SECTION_CACHE_GS = 'gs'\n SECTION_CACHE_SSH = 'ssh'\n SECTION_CACHE_HDFS = 'hdfs'\n SECTION_CACHE_AZURE = 'azure'\n SECTION_CACHE_SCHEMA = {\n Optional(SECTION_CACHE_LOCAL): str,\n Optional(SECTION_CACHE_S3): str,\n Optional(SECTION_CACHE_GS): str,\n Optional(SECTION_CACHE_HDFS): str,\n Optional(SECTION_CACHE_SSH): str,\n Optional(SECTION_CACHE_AZURE): str,\n\n # backward compatibility\n Optional(SECTION_CACHE_DIR, default='cache'): str,\n Optional(SECTION_CACHE_TYPE, default=None): SECTION_CACHE_TYPE_SCHEMA,\n }\n\n # backward compatibility\n SECTION_CORE_CLOUD = 'cloud'\n SECTION_CORE_CLOUD_SCHEMA = And(Use(str.lower), supported_cloud)\n SECTION_CORE_STORAGEPATH = 'storagepath'\n\n SECTION_CORE_SCHEMA = {\n Optional(SECTION_CORE_LOGLEVEL,\n default='info'): And(str, Use(str.lower),\n SECTION_CORE_LOGLEVEL_SCHEMA),\n Optional(SECTION_CORE_REMOTE, default=''): And(str, Use(str.lower)),\n Optional(SECTION_CORE_INTERACTIVE,\n default=False): SECTION_CORE_INTERACTIVE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_CORE_CLOUD, default=''): SECTION_CORE_CLOUD_SCHEMA,\n Optional(SECTION_CORE_STORAGEPATH, default=''): str,\n }\n\n # backward compatibility\n SECTION_AWS = 'aws'\n SECTION_AWS_STORAGEPATH = 'storagepath'\n SECTION_AWS_CREDENTIALPATH = 'credentialpath'\n SECTION_AWS_ENDPOINT_URL = 'endpointurl'\n SECTION_AWS_REGION = 'region'\n SECTION_AWS_PROFILE = 'profile'\n SECTION_AWS_SCHEMA = {\n SECTION_AWS_STORAGEPATH: str,\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n }\n\n # backward compatibility\n SECTION_GCP = 'gcp'\n SECTION_GCP_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_GCP_PROJECTNAME = 'projectname'\n SECTION_GCP_SCHEMA = {\n SECTION_GCP_STORAGEPATH: str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n }\n\n # backward compatibility\n SECTION_LOCAL = 'local'\n SECTION_LOCAL_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_LOCAL_SCHEMA = {\n SECTION_LOCAL_STORAGEPATH: str,\n }\n\n SECTION_REMOTE_REGEX = r'^\\s*remote\\s*\"(?P<name>.*)\"\\s*$'\n SECTION_REMOTE_FMT = 'remote \"{}\"'\n SECTION_REMOTE_URL = 'url'\n SECTION_REMOTE_USER = 'user'\n SECTION_REMOTE_SCHEMA = {\n SECTION_REMOTE_URL: And(supported_url, error=\"Unsupported URL\"),\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n Optional(SECTION_CACHE_TYPE): SECTION_CACHE_TYPE_SCHEMA,\n Optional(SECTION_REMOTE_USER): str,\n }\n\n SCHEMA = {\n Optional(SECTION_CORE, default={}): SECTION_CORE_SCHEMA,\n Optional(Regex(SECTION_REMOTE_REGEX)): SECTION_REMOTE_SCHEMA,\n Optional(SECTION_CACHE, default={}): SECTION_CACHE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_AWS, default={}): SECTION_AWS_SCHEMA,\n Optional(SECTION_GCP, default={}): SECTION_GCP_SCHEMA,\n Optional(SECTION_LOCAL, default={}): SECTION_LOCAL_SCHEMA,\n }\n\n def __init__(self, dvc_dir):\n self.dvc_dir = os.path.abspath(os.path.realpath(dvc_dir))\n self.config_file = os.path.join(dvc_dir, self.CONFIG)\n self.config_local_file = os.path.join(dvc_dir, self.CONFIG_LOCAL)\n\n try:\n self._config = configobj.ConfigObj(self.config_file)\n local = configobj.ConfigObj(self.config_local_file)\n\n # NOTE: schema doesn't support ConfigObj.Section validation, so we\n # need to convert our config to dict before passing it to\n self._config = self._lower(self._config)\n local = self._lower(local)\n self._config.update(local)\n\n self._config = Schema(self.SCHEMA).validate(self._config)\n\n # NOTE: now converting back to ConfigObj\n self._config = configobj.ConfigObj(self._config,\n write_empty_values=True)\n self._config.filename = self.config_file\n except Exception as ex:\n raise ConfigError(ex)\n\n @staticmethod\n def _lower(config):\n new_config = {}\n for s_key, s_value in config.items():\n new_s = {}\n for key, value in s_value.items():\n new_s[key.lower()] = value\n new_config[s_key.lower()] = new_s\n return new_config\n\n @staticmethod\n def init(dvc_dir):\n config_file = os.path.join(dvc_dir, Config.CONFIG)\n open(config_file, 'w+').close()\n return Config(dvc_dir)\n", "path": "dvc/config.py"}]} | 2,928 | 249 |
gh_patches_debug_14763 | rasdani/github-patches | git_diff | pantsbuild__pants-20300 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`terraform_deployment` cannot load vars files if the root `terraform_module` is not in the same dir
**Describe the bug**
root/BUILD:
```
terraform_deployment(root_module="//mod0:mod0", var_files=["a.tfvars"])
```
root/a.tfvars:
```
var0 = "hihello"
```
mod/BUILD:
```
terraform_module()
```
mod/main.tf:
```
resource "null_resource" "dep" {}
```
running `pants experimental-deploy //root:root` yields:
```
Engine traceback:
in select
..
in pants.core.goals.deploy.run_deploy
`experimental-deploy` goal
Traceback (most recent call last):
File "/home/lilatomic/vnd/pants/src/python/pants/core/goals/deploy.py", line 176, in run_deploy
deploy_processes = await MultiGet(
File "/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py", line 374, in MultiGet
return await _MultiGet(tuple(__arg0))
File "/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py", line 172, in __await__
result = yield self.gets
ValueError: 'root/a.tfvars' is not in the subpath of 'mod0' OR one path is relative and the other is absolute.
```
**Pants version**
2.18+
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/backend/terraform/utils.py`
Content:
```
1 # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3 import shlex
4 from pathlib import PurePath
5
6
7 def terraform_arg(name: str, value: str) -> str:
8 """Format a Terraform arg."""
9 return f"{name}={shlex.quote(value)}"
10
11
12 def terraform_relpath(chdir: str, target: str) -> str:
13 """Compute the relative path of a target file to the Terraform deployment root."""
14 return PurePath(target).relative_to(chdir).as_posix()
15
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/python/pants/backend/terraform/utils.py b/src/python/pants/backend/terraform/utils.py
--- a/src/python/pants/backend/terraform/utils.py
+++ b/src/python/pants/backend/terraform/utils.py
@@ -1,7 +1,7 @@
# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
+import os.path
import shlex
-from pathlib import PurePath
def terraform_arg(name: str, value: str) -> str:
@@ -11,4 +11,4 @@
def terraform_relpath(chdir: str, target: str) -> str:
"""Compute the relative path of a target file to the Terraform deployment root."""
- return PurePath(target).relative_to(chdir).as_posix()
+ return os.path.relpath(target, start=chdir)
| {"golden_diff": "diff --git a/src/python/pants/backend/terraform/utils.py b/src/python/pants/backend/terraform/utils.py\n--- a/src/python/pants/backend/terraform/utils.py\n+++ b/src/python/pants/backend/terraform/utils.py\n@@ -1,7 +1,7 @@\n # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n+import os.path\n import shlex\n-from pathlib import PurePath\n \n \n def terraform_arg(name: str, value: str) -> str:\n@@ -11,4 +11,4 @@\n \n def terraform_relpath(chdir: str, target: str) -> str:\n \"\"\"Compute the relative path of a target file to the Terraform deployment root.\"\"\"\n- return PurePath(target).relative_to(chdir).as_posix()\n+ return os.path.relpath(target, start=chdir)\n", "issue": "`terraform_deployment` cannot load vars files if the root `terraform_module` is not in the same dir\n**Describe the bug**\r\n\r\nroot/BUILD:\r\n```\r\nterraform_deployment(root_module=\"//mod0:mod0\", var_files=[\"a.tfvars\"])\r\n```\r\nroot/a.tfvars:\r\n```\r\nvar0 = \"hihello\"\r\n```\r\nmod/BUILD:\r\n```\r\nterraform_module()\r\n```\r\nmod/main.tf:\r\n```\r\nresource \"null_resource\" \"dep\" {}\r\n```\r\n\r\nrunning `pants experimental-deploy //root:root` yields:\r\n```\r\nEngine traceback:\r\n in select\r\n ..\r\n in pants.core.goals.deploy.run_deploy\r\n `experimental-deploy` goal\r\n\r\nTraceback (most recent call last):\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/core/goals/deploy.py\", line 176, in run_deploy\r\n deploy_processes = await MultiGet(\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py\", line 374, in MultiGet\r\n return await _MultiGet(tuple(__arg0))\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py\", line 172, in __await__\r\n result = yield self.gets\r\nValueError: 'root/a.tfvars' is not in the subpath of 'mod0' OR one path is relative and the other is absolute.\r\n```\r\n\r\n**Pants version**\r\n2.18+\r\n\n", "before_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nimport shlex\nfrom pathlib import PurePath\n\n\ndef terraform_arg(name: str, value: str) -> str:\n \"\"\"Format a Terraform arg.\"\"\"\n return f\"{name}={shlex.quote(value)}\"\n\n\ndef terraform_relpath(chdir: str, target: str) -> str:\n \"\"\"Compute the relative path of a target file to the Terraform deployment root.\"\"\"\n return PurePath(target).relative_to(chdir).as_posix()\n", "path": "src/python/pants/backend/terraform/utils.py"}], "after_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nimport os.path\nimport shlex\n\n\ndef terraform_arg(name: str, value: str) -> str:\n \"\"\"Format a Terraform arg.\"\"\"\n return f\"{name}={shlex.quote(value)}\"\n\n\ndef terraform_relpath(chdir: str, target: str) -> str:\n \"\"\"Compute the relative path of a target file to the Terraform deployment root.\"\"\"\n return os.path.relpath(target, start=chdir)\n", "path": "src/python/pants/backend/terraform/utils.py"}]} | 729 | 197 |
gh_patches_debug_35794 | rasdani/github-patches | git_diff | microsoft__hi-ml-430 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clean up console logging for runner
Starting the runner prints out "sys.path at container level" twice.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py`
Content:
```
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5 from enum import Enum
6 from pathlib import Path
7 from typing import Any
8 import sys
9
10 from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
11 from SSL.utils import SSLTrainingType
12 from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex
13 from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
14
15 current_file = Path(__file__)
16 print(f"Running container from {current_file}")
17 print(f"Sys path container level {sys.path}")
18
19
20 class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
21 TCGA_CRCK = "CRCKTilesDataset"
22
23
24 class CRCK_SimCLR(HistoSSLContainer):
25 """
26 Config to train SSL model on CRCK tiles dataset.
27 Augmentation can be configured by using a configuration yml file or by specifying the set of transformations
28 in the _get_transforms method.
29 It has been tested locally and on AML on the full training dataset (93408 tiles).
30 """
31 SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.TCGA_CRCK.value:
32 TcgaCrck_TilesDatasetWithReturnIndex})
33
34 def __init__(self, **kwargs: Any) -> None:
35 # if not running in Azure ML, you may want to override certain properties on the command line, such as:
36 # --is_debug_model = True
37 # --num_workers = 0
38 # --max_epochs = 2
39
40 super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,
41 linear_head_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,
42 azure_datasets=["TCGA-CRCk"],
43 random_seed=1,
44 num_workers=8,
45 is_debug_model=False,
46 model_checkpoint_save_interval=50,
47 model_checkpoints_save_last_k=3,
48 model_monitor_metric='ssl_online_evaluator/val/AreaUnderRocCurve',
49 model_monitor_mode='max',
50 max_epochs=50,
51 ssl_training_batch_size=48, # GPU memory is at 70% with batch_size=32, 2GPUs
52 ssl_encoder=EncoderName.resnet50,
53 ssl_training_type=SSLTrainingType.SimCLR,
54 use_balanced_binary_loss_for_linear_head=True,
55 ssl_augmentation_config=None, # Change to path_augmentation to use the config
56 linear_head_augmentation_config=None, # Change to path_augmentation to use the config
57 drop_last=False,
58 **kwargs)
59
```
Path: `hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py`
Content:
```
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5 from enum import Enum
6 from pathlib import Path
7 from typing import Any
8 import sys
9
10 from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
11 from SSL.utils import SSLTrainingType
12 from health_azure.utils import is_running_in_azure_ml
13 from histopathology.datasets.panda_tiles_dataset import PandaTilesDatasetWithReturnIndex
14 from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
15 from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID
16
17
18 current_file = Path(__file__)
19 print(f"Running container from {current_file}")
20 print(f"Sys path container level {sys.path}")
21
22
23 class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
24 PANDA = "PandaTilesDataset"
25
26
27 class PANDA_SimCLR(HistoSSLContainer):
28 """
29 Config to train SSL model on Panda tiles dataset.
30 Augmentation can be configured by using a configuration yml file or by specifying the set of transformations
31 in the _get_transforms method.
32 It has been tested on a toy local dataset (2 slides) and on AML on (~25 slides).
33 """
34 SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.PANDA.value: PandaTilesDatasetWithReturnIndex})
35
36 def __init__(self, **kwargs: Any) -> None:
37 super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.PANDA,
38 linear_head_dataset_name=SSLDatasetNameHiml.PANDA,
39 azure_datasets=[PANDA_TILES_DATASET_ID],
40 random_seed=1,
41 num_workers=5,
42 is_debug_model=False,
43 model_checkpoint_save_interval=50,
44 model_checkpoints_save_last_k=3,
45 model_monitor_metric='ssl_online_evaluator/val/AccuracyAtThreshold05',
46 model_monitor_mode='max',
47 max_epochs=200,
48 ssl_training_batch_size=128,
49 ssl_encoder=EncoderName.resnet50,
50 ssl_training_type=SSLTrainingType.SimCLR,
51 use_balanced_binary_loss_for_linear_head=True,
52 ssl_augmentation_config=None, # Change to path_augmentation to use the config
53 linear_head_augmentation_config=None, # Change to path_augmentation to use the config
54 drop_last=False,
55 **kwargs)
56 self.pl_check_val_every_n_epoch = 10
57 PandaTilesDatasetWithReturnIndex.occupancy_threshold = 0
58 PandaTilesDatasetWithReturnIndex.random_subset_fraction = 1
59 if not is_running_in_azure_ml():
60 self.is_debug_model = True
61 self.num_workers = 0
62 self.max_epochs = 2
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
--- a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
@@ -3,19 +3,13 @@
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
from enum import Enum
-from pathlib import Path
from typing import Any
-import sys
from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
from SSL.utils import SSLTrainingType
from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex
from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
-current_file = Path(__file__)
-print(f"Running container from {current_file}")
-print(f"Sys path container level {sys.path}")
-
class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
TCGA_CRCK = "CRCKTilesDataset"
diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
--- a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
@@ -3,9 +3,7 @@
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
from enum import Enum
-from pathlib import Path
from typing import Any
-import sys
from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
from SSL.utils import SSLTrainingType
@@ -15,11 +13,6 @@
from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID
-current_file = Path(__file__)
-print(f"Running container from {current_file}")
-print(f"Sys path container level {sys.path}")
-
-
class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
PANDA = "PandaTilesDataset"
| {"golden_diff": "diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n--- a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n@@ -3,19 +3,13 @@\n # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n # ------------------------------------------------------------------------------------------\n from enum import Enum\n-from pathlib import Path\n from typing import Any\n-import sys\n \n from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\n from SSL.utils import SSLTrainingType\n from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex\n from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\n \n-current_file = Path(__file__)\n-print(f\"Running container from {current_file}\")\n-print(f\"Sys path container level {sys.path}\")\n-\n \n class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n TCGA_CRCK = \"CRCKTilesDataset\"\ndiff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n--- a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n@@ -3,9 +3,7 @@\n # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n # ------------------------------------------------------------------------------------------\n from enum import Enum\n-from pathlib import Path\n from typing import Any\n-import sys\n \n from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\n from SSL.utils import SSLTrainingType\n@@ -15,11 +13,6 @@\n from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID\n \n \n-current_file = Path(__file__)\n-print(f\"Running container from {current_file}\")\n-print(f\"Sys path container level {sys.path}\")\n-\n-\n class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n PANDA = \"PandaTilesDataset\"\n", "issue": "Clean up console logging for runner\nStarting the runner prints out \"sys.path at container level\" twice.\n", "before_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any\nimport sys\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\n\ncurrent_file = Path(__file__)\nprint(f\"Running container from {current_file}\")\nprint(f\"Sys path container level {sys.path}\")\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n TCGA_CRCK = \"CRCKTilesDataset\"\n\n\nclass CRCK_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on CRCK tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested locally and on AML on the full training dataset (93408 tiles).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.TCGA_CRCK.value:\n TcgaCrck_TilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n # if not running in Azure ML, you may want to override certain properties on the command line, such as:\n # --is_debug_model = True\n # --num_workers = 0\n # --max_epochs = 2\n\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n linear_head_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n azure_datasets=[\"TCGA-CRCk\"],\n random_seed=1,\n num_workers=8,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AreaUnderRocCurve',\n model_monitor_mode='max',\n max_epochs=50,\n ssl_training_batch_size=48, # GPU memory is at 70% with batch_size=32, 2GPUs\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py"}, {"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any\nimport sys\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom health_azure.utils import is_running_in_azure_ml\nfrom histopathology.datasets.panda_tiles_dataset import PandaTilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\nfrom histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID\n\n\ncurrent_file = Path(__file__)\nprint(f\"Running container from {current_file}\")\nprint(f\"Sys path container level {sys.path}\")\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n PANDA = \"PandaTilesDataset\"\n\n\nclass PANDA_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on Panda tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested on a toy local dataset (2 slides) and on AML on (~25 slides).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.PANDA.value: PandaTilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.PANDA,\n linear_head_dataset_name=SSLDatasetNameHiml.PANDA,\n azure_datasets=[PANDA_TILES_DATASET_ID],\n random_seed=1,\n num_workers=5,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AccuracyAtThreshold05',\n model_monitor_mode='max',\n max_epochs=200,\n ssl_training_batch_size=128,\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n self.pl_check_val_every_n_epoch = 10\n PandaTilesDatasetWithReturnIndex.occupancy_threshold = 0\n PandaTilesDatasetWithReturnIndex.random_subset_fraction = 1\n if not is_running_in_azure_ml():\n self.is_debug_model = True\n self.num_workers = 0\n self.max_epochs = 2\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py"}], "after_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom typing import Any\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n TCGA_CRCK = \"CRCKTilesDataset\"\n\n\nclass CRCK_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on CRCK tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested locally and on AML on the full training dataset (93408 tiles).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.TCGA_CRCK.value:\n TcgaCrck_TilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n # if not running in Azure ML, you may want to override certain properties on the command line, such as:\n # --is_debug_model = True\n # --num_workers = 0\n # --max_epochs = 2\n\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n linear_head_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n azure_datasets=[\"TCGA-CRCk\"],\n random_seed=1,\n num_workers=8,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AreaUnderRocCurve',\n model_monitor_mode='max',\n max_epochs=50,\n ssl_training_batch_size=48, # GPU memory is at 70% with batch_size=32, 2GPUs\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py"}, {"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom typing import Any\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom health_azure.utils import is_running_in_azure_ml\nfrom histopathology.datasets.panda_tiles_dataset import PandaTilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\nfrom histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n PANDA = \"PandaTilesDataset\"\n\n\nclass PANDA_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on Panda tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested on a toy local dataset (2 slides) and on AML on (~25 slides).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.PANDA.value: PandaTilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.PANDA,\n linear_head_dataset_name=SSLDatasetNameHiml.PANDA,\n azure_datasets=[PANDA_TILES_DATASET_ID],\n random_seed=1,\n num_workers=5,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AccuracyAtThreshold05',\n model_monitor_mode='max',\n max_epochs=200,\n ssl_training_batch_size=128,\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n self.pl_check_val_every_n_epoch = 10\n PandaTilesDatasetWithReturnIndex.occupancy_threshold = 0\n PandaTilesDatasetWithReturnIndex.random_subset_fraction = 1\n if not is_running_in_azure_ml():\n self.is_debug_model = True\n self.num_workers = 0\n self.max_epochs = 2\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py"}]} | 1,808 | 582 |
gh_patches_debug_26356 | rasdani/github-patches | git_diff | pypi__warehouse-6193 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
2FA: Enrolling a TouchID sensor as a webauthn security key fails (Chrome, Mac)
<!--
NOTE: This issue should be for problems with PyPI itself, including:
* pypi.org
* test.pypi.org
* files.pythonhosted.org
This issue should NOT be for a project installed from PyPI. If you are
having an issue with a specific package, you should reach out to the
maintainers of that project directly instead.
Furthermore, this issue should NOT be for any non-PyPI properties (like
python.org, docs.python.org, etc.)
-->
**Describe the bug**
I'm trying to enroll a TouchID sensor as a webauthn device. PyPI and Chrome do let me select the sensor, and I do get prompted for a touch, but then PyPI throws an error: "Registration rejected. Error: Self attestation is not permitted.."
**Expected behavior**
I expect to be able to enroll a TouchID sensor.
**To Reproduce**
- PyPI --> Account Settings
- Click "Add 2FA With Security Key"
- Type a key name, click "Provision Key"
- Chrome prompts to choose between a USB security key and a built-in sensor. Choose "Built-in sensor"
- MacOS prompts to hit the TouchID sensor. Do so.
- Chrome prompts, "Allow this site to see your security key?" Click "Allow"
- PyPI displays an error: "Registration rejected. Error: Self attestation is not permitted.."
**My Platform**
- MacOS 10.14.5
- MacBook Air (2018 edition, with TouchID)
- Chrome "75.0.3770.100 (Official Build) (64-bit)"
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/utils/webauthn.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import base64
14 import os
15
16 import webauthn as pywebauthn
17
18 from webauthn.webauthn import (
19 AuthenticationRejectedException as _AuthenticationRejectedException,
20 RegistrationRejectedException as _RegistrationRejectedException,
21 )
22
23
24 class AuthenticationRejectedException(Exception):
25 pass
26
27
28 class RegistrationRejectedException(Exception):
29 pass
30
31
32 WebAuthnCredential = pywebauthn.WebAuthnCredential
33
34
35 def _get_webauthn_users(user, *, icon_url, rp_id):
36 """
37 Returns a webauthn.WebAuthnUser instance corresponding
38 to the given user model, with properties suitable for
39 usage within the webauthn API.
40 """
41 return [
42 pywebauthn.WebAuthnUser(
43 str(user.id),
44 user.username,
45 user.name,
46 icon_url,
47 credential.credential_id,
48 credential.public_key,
49 credential.sign_count,
50 rp_id,
51 )
52 for credential in user.webauthn
53 ]
54
55
56 def _webauthn_b64decode(encoded):
57 padding = "=" * (len(encoded) % 4)
58 return base64.urlsafe_b64decode(encoded + padding)
59
60
61 def _webauthn_b64encode(source):
62 return base64.urlsafe_b64encode(source).rstrip(b"=")
63
64
65 def generate_webauthn_challenge():
66 """
67 Returns a random challenge suitable for use within
68 Webauthn's credential and configuration option objects.
69
70 See: https://w3c.github.io/webauthn/#cryptographic-challenges
71 """
72 # NOTE: Webauthn recommends at least 16 bytes of entropy,
73 # we go with 32 because it doesn't cost us anything.
74 return _webauthn_b64encode(os.urandom(32)).decode()
75
76
77 def get_credential_options(user, *, challenge, rp_name, rp_id, icon_url):
78 """
79 Returns a dictionary of options for credential creation
80 on the client side.
81 """
82 options = pywebauthn.WebAuthnMakeCredentialOptions(
83 challenge, rp_name, rp_id, str(user.id), user.username, user.name, icon_url
84 )
85
86 return options.registration_dict
87
88
89 def get_assertion_options(user, *, challenge, icon_url, rp_id):
90 """
91 Returns a dictionary of options for assertion retrieval
92 on the client side.
93 """
94 options = pywebauthn.WebAuthnAssertionOptions(
95 _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id), challenge
96 )
97
98 return options.assertion_dict
99
100
101 def verify_registration_response(response, challenge, *, rp_id, origin):
102 """
103 Validates the challenge and attestation information
104 sent from the client during device registration.
105
106 Returns a WebAuthnCredential on success.
107 Raises RegistrationRejectedException on failire.
108 """
109 # NOTE: We re-encode the challenge below, because our
110 # response's clientData.challenge is encoded twice:
111 # first for the entire clientData payload, and then again
112 # for the individual challenge.
113 response = pywebauthn.WebAuthnRegistrationResponse(
114 rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()
115 )
116 try:
117 return response.verify()
118 except _RegistrationRejectedException as e:
119 raise RegistrationRejectedException(str(e))
120
121
122 def verify_assertion_response(assertion, *, challenge, user, origin, icon_url, rp_id):
123 """
124 Validates the challenge and assertion information
125 sent from the client during authentication.
126
127 Returns an updated signage count on success.
128 Raises AuthenticationRejectedException on failure.
129 """
130 webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)
131 cred_ids = [cred.credential_id for cred in webauthn_users]
132
133 for webauthn_user in webauthn_users:
134 response = pywebauthn.WebAuthnAssertionResponse(
135 webauthn_user,
136 assertion,
137 _webauthn_b64encode(challenge.encode()).decode(),
138 origin,
139 allow_credentials=cred_ids,
140 )
141 try:
142 return (webauthn_user.credential_id, response.verify())
143 except _AuthenticationRejectedException:
144 pass
145
146 # If we exit the loop, then we've failed to verify the assertion against
147 # any of the user's WebAuthn credentials. Fail.
148 raise AuthenticationRejectedException("Invalid WebAuthn credential")
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py
--- a/warehouse/utils/webauthn.py
+++ b/warehouse/utils/webauthn.py
@@ -110,8 +110,9 @@
# response's clientData.challenge is encoded twice:
# first for the entire clientData payload, and then again
# for the individual challenge.
+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
response = pywebauthn.WebAuthnRegistrationResponse(
- rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()
+ rp_id, origin, response, encoded_challenge, self_attestation_permitted=True
)
try:
return response.verify()
@@ -129,12 +130,13 @@
"""
webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)
cred_ids = [cred.credential_id for cred in webauthn_users]
+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
for webauthn_user in webauthn_users:
response = pywebauthn.WebAuthnAssertionResponse(
webauthn_user,
assertion,
- _webauthn_b64encode(challenge.encode()).decode(),
+ encoded_challenge,
origin,
allow_credentials=cred_ids,
)
| {"golden_diff": "diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py\n--- a/warehouse/utils/webauthn.py\n+++ b/warehouse/utils/webauthn.py\n@@ -110,8 +110,9 @@\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n response = pywebauthn.WebAuthnRegistrationResponse(\n- rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()\n+ rp_id, origin, response, encoded_challenge, self_attestation_permitted=True\n )\n try:\n return response.verify()\n@@ -129,12 +130,13 @@\n \"\"\"\n webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n \n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n- _webauthn_b64encode(challenge.encode()).decode(),\n+ encoded_challenge,\n origin,\n allow_credentials=cred_ids,\n )\n", "issue": "2FA: Enrolling a TouchID sensor as a webauthn security key fails (Chrome, Mac)\n<!--\r\n NOTE: This issue should be for problems with PyPI itself, including:\r\n * pypi.org\r\n * test.pypi.org\r\n * files.pythonhosted.org\r\n\r\n This issue should NOT be for a project installed from PyPI. If you are\r\n having an issue with a specific package, you should reach out to the\r\n maintainers of that project directly instead.\r\n\r\n Furthermore, this issue should NOT be for any non-PyPI properties (like\r\n python.org, docs.python.org, etc.)\r\n-->\r\n\r\n**Describe the bug**\r\nI'm trying to enroll a TouchID sensor as a webauthn device. PyPI and Chrome do let me select the sensor, and I do get prompted for a touch, but then PyPI throws an error: \"Registration rejected. Error: Self attestation is not permitted..\"\r\n\r\n**Expected behavior**\r\nI expect to be able to enroll a TouchID sensor. \r\n\r\n**To Reproduce**\r\n- PyPI --> Account Settings\r\n- Click \"Add 2FA With Security Key\"\r\n- Type a key name, click \"Provision Key\"\r\n- Chrome prompts to choose between a USB security key and a built-in sensor. Choose \"Built-in sensor\"\r\n- MacOS prompts to hit the TouchID sensor. Do so.\r\n- Chrome prompts, \"Allow this site to see your security key?\" Click \"Allow\"\r\n- PyPI displays an error: \"Registration rejected. Error: Self attestation is not permitted..\"\r\n\r\n**My Platform**\r\n- MacOS 10.14.5\r\n- MacBook Air (2018 edition, with TouchID)\r\n- Chrome \"75.0.3770.100 (Official Build) (64-bit)\"\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport base64\nimport os\n\nimport webauthn as pywebauthn\n\nfrom webauthn.webauthn import (\n AuthenticationRejectedException as _AuthenticationRejectedException,\n RegistrationRejectedException as _RegistrationRejectedException,\n)\n\n\nclass AuthenticationRejectedException(Exception):\n pass\n\n\nclass RegistrationRejectedException(Exception):\n pass\n\n\nWebAuthnCredential = pywebauthn.WebAuthnCredential\n\n\ndef _get_webauthn_users(user, *, icon_url, rp_id):\n \"\"\"\n Returns a webauthn.WebAuthnUser instance corresponding\n to the given user model, with properties suitable for\n usage within the webauthn API.\n \"\"\"\n return [\n pywebauthn.WebAuthnUser(\n str(user.id),\n user.username,\n user.name,\n icon_url,\n credential.credential_id,\n credential.public_key,\n credential.sign_count,\n rp_id,\n )\n for credential in user.webauthn\n ]\n\n\ndef _webauthn_b64decode(encoded):\n padding = \"=\" * (len(encoded) % 4)\n return base64.urlsafe_b64decode(encoded + padding)\n\n\ndef _webauthn_b64encode(source):\n return base64.urlsafe_b64encode(source).rstrip(b\"=\")\n\n\ndef generate_webauthn_challenge():\n \"\"\"\n Returns a random challenge suitable for use within\n Webauthn's credential and configuration option objects.\n\n See: https://w3c.github.io/webauthn/#cryptographic-challenges\n \"\"\"\n # NOTE: Webauthn recommends at least 16 bytes of entropy,\n # we go with 32 because it doesn't cost us anything.\n return _webauthn_b64encode(os.urandom(32)).decode()\n\n\ndef get_credential_options(user, *, challenge, rp_name, rp_id, icon_url):\n \"\"\"\n Returns a dictionary of options for credential creation\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnMakeCredentialOptions(\n challenge, rp_name, rp_id, str(user.id), user.username, user.name, icon_url\n )\n\n return options.registration_dict\n\n\ndef get_assertion_options(user, *, challenge, icon_url, rp_id):\n \"\"\"\n Returns a dictionary of options for assertion retrieval\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnAssertionOptions(\n _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id), challenge\n )\n\n return options.assertion_dict\n\n\ndef verify_registration_response(response, challenge, *, rp_id, origin):\n \"\"\"\n Validates the challenge and attestation information\n sent from the client during device registration.\n\n Returns a WebAuthnCredential on success.\n Raises RegistrationRejectedException on failire.\n \"\"\"\n # NOTE: We re-encode the challenge below, because our\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n response = pywebauthn.WebAuthnRegistrationResponse(\n rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()\n )\n try:\n return response.verify()\n except _RegistrationRejectedException as e:\n raise RegistrationRejectedException(str(e))\n\n\ndef verify_assertion_response(assertion, *, challenge, user, origin, icon_url, rp_id):\n \"\"\"\n Validates the challenge and assertion information\n sent from the client during authentication.\n\n Returns an updated signage count on success.\n Raises AuthenticationRejectedException on failure.\n \"\"\"\n webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n\n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n _webauthn_b64encode(challenge.encode()).decode(),\n origin,\n allow_credentials=cred_ids,\n )\n try:\n return (webauthn_user.credential_id, response.verify())\n except _AuthenticationRejectedException:\n pass\n\n # If we exit the loop, then we've failed to verify the assertion against\n # any of the user's WebAuthn credentials. Fail.\n raise AuthenticationRejectedException(\"Invalid WebAuthn credential\")\n", "path": "warehouse/utils/webauthn.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport base64\nimport os\n\nimport webauthn as pywebauthn\n\nfrom webauthn.webauthn import (\n AuthenticationRejectedException as _AuthenticationRejectedException,\n RegistrationRejectedException as _RegistrationRejectedException,\n)\n\n\nclass AuthenticationRejectedException(Exception):\n pass\n\n\nclass RegistrationRejectedException(Exception):\n pass\n\n\nWebAuthnCredential = pywebauthn.WebAuthnCredential\n\n\ndef _get_webauthn_users(user, *, icon_url, rp_id):\n \"\"\"\n Returns a webauthn.WebAuthnUser instance corresponding\n to the given user model, with properties suitable for\n usage within the webauthn API.\n \"\"\"\n return [\n pywebauthn.WebAuthnUser(\n str(user.id),\n user.username,\n user.name,\n icon_url,\n credential.credential_id,\n credential.public_key,\n credential.sign_count,\n rp_id,\n )\n for credential in user.webauthn\n ]\n\n\ndef _webauthn_b64decode(encoded):\n padding = \"=\" * (len(encoded) % 4)\n return base64.urlsafe_b64decode(encoded + padding)\n\n\ndef _webauthn_b64encode(source):\n return base64.urlsafe_b64encode(source).rstrip(b\"=\")\n\n\ndef generate_webauthn_challenge():\n \"\"\"\n Returns a random challenge suitable for use within\n Webauthn's credential and configuration option objects.\n\n See: https://w3c.github.io/webauthn/#cryptographic-challenges\n \"\"\"\n # NOTE: Webauthn recommends at least 16 bytes of entropy,\n # we go with 32 because it doesn't cost us anything.\n return _webauthn_b64encode(os.urandom(32)).decode()\n\n\ndef get_credential_options(user, *, challenge, rp_name, rp_id, icon_url):\n \"\"\"\n Returns a dictionary of options for credential creation\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnMakeCredentialOptions(\n challenge, rp_name, rp_id, str(user.id), user.username, user.name, icon_url\n )\n\n return options.registration_dict\n\n\ndef get_assertion_options(user, *, challenge, icon_url, rp_id):\n \"\"\"\n Returns a dictionary of options for assertion retrieval\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnAssertionOptions(\n _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id), challenge\n )\n\n return options.assertion_dict\n\n\ndef verify_registration_response(response, challenge, *, rp_id, origin):\n \"\"\"\n Validates the challenge and attestation information\n sent from the client during device registration.\n\n Returns a WebAuthnCredential on success.\n Raises RegistrationRejectedException on failire.\n \"\"\"\n # NOTE: We re-encode the challenge below, because our\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n response = pywebauthn.WebAuthnRegistrationResponse(\n rp_id, origin, response, encoded_challenge, self_attestation_permitted=True\n )\n try:\n return response.verify()\n except _RegistrationRejectedException as e:\n raise RegistrationRejectedException(str(e))\n\n\ndef verify_assertion_response(assertion, *, challenge, user, origin, icon_url, rp_id):\n \"\"\"\n Validates the challenge and assertion information\n sent from the client during authentication.\n\n Returns an updated signage count on success.\n Raises AuthenticationRejectedException on failure.\n \"\"\"\n webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n\n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n encoded_challenge,\n origin,\n allow_credentials=cred_ids,\n )\n try:\n return (webauthn_user.credential_id, response.verify())\n except _AuthenticationRejectedException:\n pass\n\n # If we exit the loop, then we've failed to verify the assertion against\n # any of the user's WebAuthn credentials. Fail.\n raise AuthenticationRejectedException(\"Invalid WebAuthn credential\")\n", "path": "warehouse/utils/webauthn.py"}]} | 2,059 | 319 |
gh_patches_debug_12773 | rasdani/github-patches | git_diff | Nitrate__Nitrate-649 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade db image to newer version
Upgrade following images:
- MySQL 8.0.20
- PostgreSQL 12.2
- MariaDB 10.4.12
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `contrib/travis-ci/testrunner.py`
Content:
```
1 #!/usr/bin/env python3
2 #
3 # Nitrate is a test case management system.
4 # Copyright (C) 2019 Nitrate Team
5 #
6 # This program is free software; you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation; either version 2 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License along
17 # with this program; if not, write to the Free Software Foundation, Inc.,
18 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
19
20 import argparse
21 import logging
22 import os
23 import re
24 import subprocess
25
26 from typing import Dict, List
27
28 logging.basicConfig(level=logging.DEBUG)
29 log = logging.getLogger(__name__)
30
31 DB_CONTAINER_NAME = 'nitrate-test-db'
32 TEST_DB_NAME = 'nitrate'
33 TEST_BOX_IMAGE = 'quay.io/nitrate/testbox:latest'
34 VALID_NITRATE_DB_NAMES = ['mysql', 'mariadb', 'postgres', 'sqlite']
35 # Since this script was written originally to work inside Travis-CI, using
36 # Python version 3.6 and 3.7 would be much easier to match the value of
37 # environment variable TRAVIS_PYTHON_VERSION.
38 VALID_PYTHON_VERSIONS = ['3.6', '3.7']
39 DB_CONTAINER_INFO = {
40 'mysql': {
41 'db_engine': 'mysql',
42 'db_image': 'mysql:5.7',
43 },
44 'mariadb': {
45 'db_engine': 'mysql',
46 'db_image': 'mariadb:10.2.21',
47 },
48 'sqlite': {
49 'db_engine': 'sqlite',
50 'db_image': '',
51 },
52 'postgres': {
53 'db_engine': 'pgsql',
54 'db_image': 'postgres:10.6',
55 },
56 }
57
58
59 def validate_django_ver(value):
60 regex = r'^django(>|>=|<|<=)[0-9]+\.[0-9]+,(>|>=|<|<=)[0-9]+\.[0-9]+$'
61 if not re.match(regex, value):
62 raise argparse.ArgumentTypeError(
63 f"Invalid django version specifier '{value}'.")
64 return value
65
66
67 def validate_project_dir(value):
68 if os.path.exists(value):
69 return value
70 return argparse.ArgumentTypeError(
71 'Invalid project root directory. It might not exist.')
72
73
74 def docker_run(image,
75 rm: bool = False,
76 detach: bool = False,
77 interactive: bool = False,
78 tty: bool = False,
79 name: str = None,
80 link: str = None,
81 volumes: List[str] = None,
82 envs: Dict[str, str] = None,
83 cmd_args: List[str] = None
84 ) -> None:
85 cmd = ['docker', 'run']
86 if rm:
87 cmd.append('--rm')
88 if detach:
89 cmd.append('--detach')
90 if interactive:
91 cmd.append('-i')
92 if tty:
93 cmd.append('-t')
94 if name:
95 cmd.append('--name')
96 cmd.append(name)
97 if link:
98 cmd.append('--link')
99 cmd.append(link)
100 if volumes:
101 for item in volumes:
102 cmd.append('--volume')
103 cmd.append(item)
104 if envs:
105 for var_name, var_value in envs.items():
106 cmd.append('--env')
107 cmd.append(f'{var_name}={var_value}')
108 cmd.append(image)
109 if cmd_args:
110 cmd.extend(cmd_args)
111
112 log.debug('Run: %r', cmd)
113 subprocess.check_call(cmd)
114
115
116 def docker_ps(all_: bool = False,
117 filter_: List[str] = None,
118 quiet: bool = False) -> str:
119 cmd = ['docker', 'ps']
120 if all_:
121 cmd.append('--all')
122 if filter_:
123 for item in filter_:
124 cmd.append('--filter')
125 cmd.append(item)
126 if quiet:
127 cmd.append('--quiet')
128
129 log.debug('Run: %r', cmd)
130 return subprocess.check_output(cmd, universal_newlines=True)
131
132
133 def docker_stop(name: str) -> None:
134 cmd = ['docker', 'stop', name]
135 log.debug('Run: %r', cmd)
136 subprocess.check_call(cmd)
137
138
139 def stop_container(name: str) -> None:
140 c_hash = docker_ps(all_=True, filter_=[f'name={name}'], quiet=True)
141 if c_hash:
142 docker_stop(name)
143
144
145 def main():
146 parser = argparse.ArgumentParser(
147 description='Run tests matrix inside containers. This is particularly '
148 'useful for running tests in Travis-CI.'
149 )
150 parser.add_argument(
151 '--python-ver',
152 choices=VALID_PYTHON_VERSIONS,
153 default='3.7',
154 help='Specify Python version')
155 parser.add_argument(
156 '--django-ver',
157 type=validate_django_ver,
158 default='django<2.3,>=2.2',
159 help='Specify django version specifier')
160 parser.add_argument(
161 '--nitrate-db',
162 choices=VALID_NITRATE_DB_NAMES,
163 default='sqlite',
164 help='Database engine name')
165 parser.add_argument(
166 '--project-dir',
167 metavar='DIR',
168 type=validate_project_dir,
169 default=os.path.abspath(os.curdir),
170 help='Project root directory. Default to current working directory')
171 parser.add_argument(
172 'targets', nargs='+', help='Test targets')
173
174 args = parser.parse_args()
175
176 container_info = DB_CONTAINER_INFO[args.nitrate_db]
177 db_engine = container_info['db_engine']
178 db_image = container_info['db_image']
179
180 stop_container(DB_CONTAINER_NAME)
181
182 test_box_run_opts = None
183
184 if db_engine == 'mysql':
185 docker_run(
186 db_image,
187 rm=True,
188 name=DB_CONTAINER_NAME,
189 detach=True,
190 envs={
191 'MYSQL_ALLOW_EMPTY_PASSWORD': 'yes',
192 'MYSQL_DATABASE': 'nitrate'
193 },
194 cmd_args=[
195 '--character-set-server=utf8mb4',
196 '--collation-server=utf8mb4_unicode_ci'
197 ])
198 test_box_run_opts = {
199 'link': f'{DB_CONTAINER_NAME}:mysql',
200 'envs': {
201 'NITRATE_DB_ENGINE': db_engine,
202 'NITRATE_DB_NAME': TEST_DB_NAME,
203 'NITRATE_DB_HOST': DB_CONTAINER_NAME,
204 }
205 }
206 elif db_engine == 'pgsql':
207 docker_run(
208 db_image,
209 rm=True,
210 detach=True,
211 name=DB_CONTAINER_NAME,
212 envs={'POSTGRES_PASSWORD': 'admin'}
213 )
214 test_box_run_opts = {
215 'link': f'{DB_CONTAINER_NAME}:postgres',
216 'envs': {
217 'NITRATE_DB_ENGINE': db_engine,
218 'NITRATE_DB_HOST': DB_CONTAINER_NAME,
219 'NITRATE_DB_NAME': TEST_DB_NAME,
220 'NITRATE_DB_USER': 'postgres',
221 'NITRATE_DB_PASSWORD': 'admin',
222 }
223 }
224 elif db_engine == 'sqlite':
225 # No need to launch a SQLite docker image
226 test_box_run_opts = {
227 'envs': {
228 'NITRATE_DB_ENGINE': db_engine,
229 'NITRATE_DB_NAME': "file::memory:",
230 }
231 }
232
233 test_box_container_name = f'nitrate-testbox-py{args.python_ver.replace(".", "")}'
234 test_box_run_opts.update({
235 'rm': True,
236 'interactive': True,
237 'tty': True,
238 'name': test_box_container_name,
239 'volumes': [f'{args.project_dir}:/code:Z'],
240 })
241 test_box_run_opts['envs'].update({
242 'PYTHON_VER': f'py{args.python_ver.replace(".", "")}',
243 'DJANGO_VER': args.django_ver,
244 'TEST_TARGETS': '"{}"'.format(' '.join(args.targets)),
245 })
246
247 try:
248 log.debug('Start testbox to run tests')
249 docker_run(TEST_BOX_IMAGE, **test_box_run_opts)
250 finally:
251 log.debug('Stop container: %s', DB_CONTAINER_NAME)
252 stop_container(DB_CONTAINER_NAME)
253
254
255 if __name__ == '__main__':
256 main()
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/contrib/travis-ci/testrunner.py b/contrib/travis-ci/testrunner.py
--- a/contrib/travis-ci/testrunner.py
+++ b/contrib/travis-ci/testrunner.py
@@ -39,11 +39,11 @@
DB_CONTAINER_INFO = {
'mysql': {
'db_engine': 'mysql',
- 'db_image': 'mysql:5.7',
+ 'db_image': 'mysql:8.0.20',
},
'mariadb': {
'db_engine': 'mysql',
- 'db_image': 'mariadb:10.2.21',
+ 'db_image': 'mariadb:10.4.12',
},
'sqlite': {
'db_engine': 'sqlite',
@@ -51,7 +51,7 @@
},
'postgres': {
'db_engine': 'pgsql',
- 'db_image': 'postgres:10.6',
+ 'db_image': 'postgres:12.2',
},
}
| {"golden_diff": "diff --git a/contrib/travis-ci/testrunner.py b/contrib/travis-ci/testrunner.py\n--- a/contrib/travis-ci/testrunner.py\n+++ b/contrib/travis-ci/testrunner.py\n@@ -39,11 +39,11 @@\n DB_CONTAINER_INFO = {\n 'mysql': {\n 'db_engine': 'mysql',\n- 'db_image': 'mysql:5.7',\n+ 'db_image': 'mysql:8.0.20',\n },\n 'mariadb': {\n 'db_engine': 'mysql',\n- 'db_image': 'mariadb:10.2.21',\n+ 'db_image': 'mariadb:10.4.12',\n },\n 'sqlite': {\n 'db_engine': 'sqlite',\n@@ -51,7 +51,7 @@\n },\n 'postgres': {\n 'db_engine': 'pgsql',\n- 'db_image': 'postgres:10.6',\n+ 'db_image': 'postgres:12.2',\n },\n }\n", "issue": "Upgrade db image to newer version\nUpgrade following images:\r\n\r\n- MySQL 8.0.20\r\n- PostgreSQL 12.2\r\n- MariaDB 10.4.12\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# Nitrate is a test case management system.\n# Copyright (C) 2019 Nitrate Team\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nimport argparse\nimport logging\nimport os\nimport re\nimport subprocess\n\nfrom typing import Dict, List\n\nlogging.basicConfig(level=logging.DEBUG)\nlog = logging.getLogger(__name__)\n\nDB_CONTAINER_NAME = 'nitrate-test-db'\nTEST_DB_NAME = 'nitrate'\nTEST_BOX_IMAGE = 'quay.io/nitrate/testbox:latest'\nVALID_NITRATE_DB_NAMES = ['mysql', 'mariadb', 'postgres', 'sqlite']\n# Since this script was written originally to work inside Travis-CI, using\n# Python version 3.6 and 3.7 would be much easier to match the value of\n# environment variable TRAVIS_PYTHON_VERSION.\nVALID_PYTHON_VERSIONS = ['3.6', '3.7']\nDB_CONTAINER_INFO = {\n 'mysql': {\n 'db_engine': 'mysql',\n 'db_image': 'mysql:5.7',\n },\n 'mariadb': {\n 'db_engine': 'mysql',\n 'db_image': 'mariadb:10.2.21',\n },\n 'sqlite': {\n 'db_engine': 'sqlite',\n 'db_image': '',\n },\n 'postgres': {\n 'db_engine': 'pgsql',\n 'db_image': 'postgres:10.6',\n },\n}\n\n\ndef validate_django_ver(value):\n regex = r'^django(>|>=|<|<=)[0-9]+\\.[0-9]+,(>|>=|<|<=)[0-9]+\\.[0-9]+$'\n if not re.match(regex, value):\n raise argparse.ArgumentTypeError(\n f\"Invalid django version specifier '{value}'.\")\n return value\n\n\ndef validate_project_dir(value):\n if os.path.exists(value):\n return value\n return argparse.ArgumentTypeError(\n 'Invalid project root directory. It might not exist.')\n\n\ndef docker_run(image,\n rm: bool = False,\n detach: bool = False,\n interactive: bool = False,\n tty: bool = False,\n name: str = None,\n link: str = None,\n volumes: List[str] = None,\n envs: Dict[str, str] = None,\n cmd_args: List[str] = None\n ) -> None:\n cmd = ['docker', 'run']\n if rm:\n cmd.append('--rm')\n if detach:\n cmd.append('--detach')\n if interactive:\n cmd.append('-i')\n if tty:\n cmd.append('-t')\n if name:\n cmd.append('--name')\n cmd.append(name)\n if link:\n cmd.append('--link')\n cmd.append(link)\n if volumes:\n for item in volumes:\n cmd.append('--volume')\n cmd.append(item)\n if envs:\n for var_name, var_value in envs.items():\n cmd.append('--env')\n cmd.append(f'{var_name}={var_value}')\n cmd.append(image)\n if cmd_args:\n cmd.extend(cmd_args)\n\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef docker_ps(all_: bool = False,\n filter_: List[str] = None,\n quiet: bool = False) -> str:\n cmd = ['docker', 'ps']\n if all_:\n cmd.append('--all')\n if filter_:\n for item in filter_:\n cmd.append('--filter')\n cmd.append(item)\n if quiet:\n cmd.append('--quiet')\n\n log.debug('Run: %r', cmd)\n return subprocess.check_output(cmd, universal_newlines=True)\n\n\ndef docker_stop(name: str) -> None:\n cmd = ['docker', 'stop', name]\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef stop_container(name: str) -> None:\n c_hash = docker_ps(all_=True, filter_=[f'name={name}'], quiet=True)\n if c_hash:\n docker_stop(name)\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Run tests matrix inside containers. This is particularly '\n 'useful for running tests in Travis-CI.'\n )\n parser.add_argument(\n '--python-ver',\n choices=VALID_PYTHON_VERSIONS,\n default='3.7',\n help='Specify Python version')\n parser.add_argument(\n '--django-ver',\n type=validate_django_ver,\n default='django<2.3,>=2.2',\n help='Specify django version specifier')\n parser.add_argument(\n '--nitrate-db',\n choices=VALID_NITRATE_DB_NAMES,\n default='sqlite',\n help='Database engine name')\n parser.add_argument(\n '--project-dir',\n metavar='DIR',\n type=validate_project_dir,\n default=os.path.abspath(os.curdir),\n help='Project root directory. Default to current working directory')\n parser.add_argument(\n 'targets', nargs='+', help='Test targets')\n\n args = parser.parse_args()\n\n container_info = DB_CONTAINER_INFO[args.nitrate_db]\n db_engine = container_info['db_engine']\n db_image = container_info['db_image']\n\n stop_container(DB_CONTAINER_NAME)\n\n test_box_run_opts = None\n\n if db_engine == 'mysql':\n docker_run(\n db_image,\n rm=True,\n name=DB_CONTAINER_NAME,\n detach=True,\n envs={\n 'MYSQL_ALLOW_EMPTY_PASSWORD': 'yes',\n 'MYSQL_DATABASE': 'nitrate'\n },\n cmd_args=[\n '--character-set-server=utf8mb4',\n '--collation-server=utf8mb4_unicode_ci'\n ])\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:mysql',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n }\n }\n elif db_engine == 'pgsql':\n docker_run(\n db_image,\n rm=True,\n detach=True,\n name=DB_CONTAINER_NAME,\n envs={'POSTGRES_PASSWORD': 'admin'}\n )\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:postgres',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_USER': 'postgres',\n 'NITRATE_DB_PASSWORD': 'admin',\n }\n }\n elif db_engine == 'sqlite':\n # No need to launch a SQLite docker image\n test_box_run_opts = {\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': \"file::memory:\",\n }\n }\n\n test_box_container_name = f'nitrate-testbox-py{args.python_ver.replace(\".\", \"\")}'\n test_box_run_opts.update({\n 'rm': True,\n 'interactive': True,\n 'tty': True,\n 'name': test_box_container_name,\n 'volumes': [f'{args.project_dir}:/code:Z'],\n })\n test_box_run_opts['envs'].update({\n 'PYTHON_VER': f'py{args.python_ver.replace(\".\", \"\")}',\n 'DJANGO_VER': args.django_ver,\n 'TEST_TARGETS': '\"{}\"'.format(' '.join(args.targets)),\n })\n\n try:\n log.debug('Start testbox to run tests')\n docker_run(TEST_BOX_IMAGE, **test_box_run_opts)\n finally:\n log.debug('Stop container: %s', DB_CONTAINER_NAME)\n stop_container(DB_CONTAINER_NAME)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/travis-ci/testrunner.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n#\n# Nitrate is a test case management system.\n# Copyright (C) 2019 Nitrate Team\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nimport argparse\nimport logging\nimport os\nimport re\nimport subprocess\n\nfrom typing import Dict, List\n\nlogging.basicConfig(level=logging.DEBUG)\nlog = logging.getLogger(__name__)\n\nDB_CONTAINER_NAME = 'nitrate-test-db'\nTEST_DB_NAME = 'nitrate'\nTEST_BOX_IMAGE = 'quay.io/nitrate/testbox:latest'\nVALID_NITRATE_DB_NAMES = ['mysql', 'mariadb', 'postgres', 'sqlite']\n# Since this script was written originally to work inside Travis-CI, using\n# Python version 3.6 and 3.7 would be much easier to match the value of\n# environment variable TRAVIS_PYTHON_VERSION.\nVALID_PYTHON_VERSIONS = ['3.6', '3.7']\nDB_CONTAINER_INFO = {\n 'mysql': {\n 'db_engine': 'mysql',\n 'db_image': 'mysql:8.0.20',\n },\n 'mariadb': {\n 'db_engine': 'mysql',\n 'db_image': 'mariadb:10.4.12',\n },\n 'sqlite': {\n 'db_engine': 'sqlite',\n 'db_image': '',\n },\n 'postgres': {\n 'db_engine': 'pgsql',\n 'db_image': 'postgres:12.2',\n },\n}\n\n\ndef validate_django_ver(value):\n regex = r'^django(>|>=|<|<=)[0-9]+\\.[0-9]+,(>|>=|<|<=)[0-9]+\\.[0-9]+$'\n if not re.match(regex, value):\n raise argparse.ArgumentTypeError(\n f\"Invalid django version specifier '{value}'.\")\n return value\n\n\ndef validate_project_dir(value):\n if os.path.exists(value):\n return value\n return argparse.ArgumentTypeError(\n 'Invalid project root directory. It might not exist.')\n\n\ndef docker_run(image,\n rm: bool = False,\n detach: bool = False,\n interactive: bool = False,\n tty: bool = False,\n name: str = None,\n link: str = None,\n volumes: List[str] = None,\n envs: Dict[str, str] = None,\n cmd_args: List[str] = None\n ) -> None:\n cmd = ['docker', 'run']\n if rm:\n cmd.append('--rm')\n if detach:\n cmd.append('--detach')\n if interactive:\n cmd.append('-i')\n if tty:\n cmd.append('-t')\n if name:\n cmd.append('--name')\n cmd.append(name)\n if link:\n cmd.append('--link')\n cmd.append(link)\n if volumes:\n for item in volumes:\n cmd.append('--volume')\n cmd.append(item)\n if envs:\n for var_name, var_value in envs.items():\n cmd.append('--env')\n cmd.append(f'{var_name}={var_value}')\n cmd.append(image)\n if cmd_args:\n cmd.extend(cmd_args)\n\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef docker_ps(all_: bool = False,\n filter_: List[str] = None,\n quiet: bool = False) -> str:\n cmd = ['docker', 'ps']\n if all_:\n cmd.append('--all')\n if filter_:\n for item in filter_:\n cmd.append('--filter')\n cmd.append(item)\n if quiet:\n cmd.append('--quiet')\n\n log.debug('Run: %r', cmd)\n return subprocess.check_output(cmd, universal_newlines=True)\n\n\ndef docker_stop(name: str) -> None:\n cmd = ['docker', 'stop', name]\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef stop_container(name: str) -> None:\n c_hash = docker_ps(all_=True, filter_=[f'name={name}'], quiet=True)\n if c_hash:\n docker_stop(name)\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Run tests matrix inside containers. This is particularly '\n 'useful for running tests in Travis-CI.'\n )\n parser.add_argument(\n '--python-ver',\n choices=VALID_PYTHON_VERSIONS,\n default='3.7',\n help='Specify Python version')\n parser.add_argument(\n '--django-ver',\n type=validate_django_ver,\n default='django<2.3,>=2.2',\n help='Specify django version specifier')\n parser.add_argument(\n '--nitrate-db',\n choices=VALID_NITRATE_DB_NAMES,\n default='sqlite',\n help='Database engine name')\n parser.add_argument(\n '--project-dir',\n metavar='DIR',\n type=validate_project_dir,\n default=os.path.abspath(os.curdir),\n help='Project root directory. Default to current working directory')\n parser.add_argument(\n 'targets', nargs='+', help='Test targets')\n\n args = parser.parse_args()\n\n container_info = DB_CONTAINER_INFO[args.nitrate_db]\n db_engine = container_info['db_engine']\n db_image = container_info['db_image']\n\n stop_container(DB_CONTAINER_NAME)\n\n test_box_run_opts = None\n\n if db_engine == 'mysql':\n docker_run(\n db_image,\n rm=True,\n name=DB_CONTAINER_NAME,\n detach=True,\n envs={\n 'MYSQL_ALLOW_EMPTY_PASSWORD': 'yes',\n 'MYSQL_DATABASE': 'nitrate'\n },\n cmd_args=[\n '--character-set-server=utf8mb4',\n '--collation-server=utf8mb4_unicode_ci'\n ])\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:mysql',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n }\n }\n elif db_engine == 'pgsql':\n docker_run(\n db_image,\n rm=True,\n detach=True,\n name=DB_CONTAINER_NAME,\n envs={'POSTGRES_PASSWORD': 'admin'}\n )\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:postgres',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_USER': 'postgres',\n 'NITRATE_DB_PASSWORD': 'admin',\n }\n }\n elif db_engine == 'sqlite':\n # No need to launch a SQLite docker image\n test_box_run_opts = {\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': \"file::memory:\",\n }\n }\n\n test_box_container_name = f'nitrate-testbox-py{args.python_ver.replace(\".\", \"\")}'\n test_box_run_opts.update({\n 'rm': True,\n 'interactive': True,\n 'tty': True,\n 'name': test_box_container_name,\n 'volumes': [f'{args.project_dir}:/code:Z'],\n })\n test_box_run_opts['envs'].update({\n 'PYTHON_VER': f'py{args.python_ver.replace(\".\", \"\")}',\n 'DJANGO_VER': args.django_ver,\n 'TEST_TARGETS': '\"{}\"'.format(' '.join(args.targets)),\n })\n\n try:\n log.debug('Start testbox to run tests')\n docker_run(TEST_BOX_IMAGE, **test_box_run_opts)\n finally:\n log.debug('Stop container: %s', DB_CONTAINER_NAME)\n stop_container(DB_CONTAINER_NAME)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/travis-ci/testrunner.py"}]} | 2,800 | 233 |
gh_patches_debug_30438 | rasdani/github-patches | git_diff | bridgecrewio__checkov-5301 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TypeError in SecretManagerSecret90days
**Describe the issue**
While running a scan on TF code, I'm getting a TypeError
**Examples**
The relevant TF code is:
```
resource "aws_secretsmanager_secret_rotation" "rds_password_rotation" {
secret_id = aws_secretsmanager_secret.credentials.id
rotation_lambda_arn = "arn:..."
rotation_rules {
automatically_after_days = var.db_password_rotation_days
}
}
variable "db_password_rotation_days" {
description = "Number of days in which the RDS password will be rotated"
type = number
}
```
**Exception Trace**
```
Failed to run check CKV_AWS_304 on rds.tf:aws_secretsmanager_secret_rotation.rds_password_rotation
Traceback (most recent call last):
File "\venv\Lib\site-packages\checkov\common\checks\base_check.py", line 73, in run
check_result["result"] = self.scan_entity_conf(entity_configuration, entity_type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "\venv\Lib\site-packages\checkov\terraform\checks\resource\base_resource_check.py", line 43, in scan_entity_conf
return self.scan_resource_conf(conf)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "\venv\Lib\site-packages\checkov\terraform\checks\resource\aws\SecretManagerSecret90days.py", line 20, in scan_resource_conf
if days < 90:
^^^^^^^^^
TypeError: '<' not supported between instances of 'str' and 'int'
```
**Desktop (please complete the following information):**
- OS: Windows 10 for Workstation
- Checkov Version 2.3.301
**Additional context**
I inspected the value of date at the line causing the error and it is the string `var.db_password_rotation_days`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py`
Content:
```
1
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3 from checkov.common.models.enums import CheckCategories, CheckResult
4
5
6 class SecretManagerSecret90days(BaseResourceCheck):
7
8 def __init__(self):
9 name = "Ensure Secrets Manager secrets should be rotated within 90 days"
10 id = "CKV_AWS_304"
11 supported_resources = ["aws_secretsmanager_secret_rotation"]
12 categories = [CheckCategories.GENERAL_SECURITY]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf) -> CheckResult:
16 if conf.get("rotation_rules") and isinstance(conf.get("rotation_rules"), list):
17 rule = conf.get("rotation_rules")[0]
18 if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):
19 days = rule.get('automatically_after_days')[0]
20 if days < 90:
21 return CheckResult.PASSED
22 return CheckResult.FAILED
23
24
25 check = SecretManagerSecret90days()
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
--- a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
+++ b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
@@ -1,23 +1,27 @@
+from __future__ import annotations
+from typing import Any
+
+from checkov.common.util.type_forcers import force_int
from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
from checkov.common.models.enums import CheckCategories, CheckResult
class SecretManagerSecret90days(BaseResourceCheck):
-
- def __init__(self):
+ def __init__(self) -> None:
name = "Ensure Secrets Manager secrets should be rotated within 90 days"
id = "CKV_AWS_304"
- supported_resources = ["aws_secretsmanager_secret_rotation"]
- categories = [CheckCategories.GENERAL_SECURITY]
+ supported_resources = ("aws_secretsmanager_secret_rotation",)
+ categories = (CheckCategories.GENERAL_SECURITY,)
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
- def scan_resource_conf(self, conf) -> CheckResult:
- if conf.get("rotation_rules") and isinstance(conf.get("rotation_rules"), list):
- rule = conf.get("rotation_rules")[0]
- if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):
- days = rule.get('automatically_after_days')[0]
- if days < 90:
+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:
+ rules = conf.get("rotation_rules")
+ if rules and isinstance(rules, list):
+ days = rules[0].get('automatically_after_days')
+ if days and isinstance(days, list):
+ days = force_int(days[0])
+ if days is not None and days < 90:
return CheckResult.PASSED
return CheckResult.FAILED
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n--- a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n+++ b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n@@ -1,23 +1,27 @@\n+from __future__ import annotations\n \n+from typing import Any\n+\n+from checkov.common.util.type_forcers import force_int\n from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n from checkov.common.models.enums import CheckCategories, CheckResult\n \n \n class SecretManagerSecret90days(BaseResourceCheck):\n-\n- def __init__(self):\n+ def __init__(self) -> None:\n name = \"Ensure Secrets Manager secrets should be rotated within 90 days\"\n id = \"CKV_AWS_304\"\n- supported_resources = [\"aws_secretsmanager_secret_rotation\"]\n- categories = [CheckCategories.GENERAL_SECURITY]\n+ supported_resources = (\"aws_secretsmanager_secret_rotation\",)\n+ categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n- def scan_resource_conf(self, conf) -> CheckResult:\n- if conf.get(\"rotation_rules\") and isinstance(conf.get(\"rotation_rules\"), list):\n- rule = conf.get(\"rotation_rules\")[0]\n- if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):\n- days = rule.get('automatically_after_days')[0]\n- if days < 90:\n+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n+ rules = conf.get(\"rotation_rules\")\n+ if rules and isinstance(rules, list):\n+ days = rules[0].get('automatically_after_days')\n+ if days and isinstance(days, list):\n+ days = force_int(days[0])\n+ if days is not None and days < 90:\n return CheckResult.PASSED\n return CheckResult.FAILED\n", "issue": "TypeError in SecretManagerSecret90days\n**Describe the issue**\r\nWhile running a scan on TF code, I'm getting a TypeError \r\n\r\n\r\n**Examples**\r\nThe relevant TF code is:\r\n```\r\nresource \"aws_secretsmanager_secret_rotation\" \"rds_password_rotation\" {\r\n secret_id = aws_secretsmanager_secret.credentials.id\r\n rotation_lambda_arn = \"arn:...\"\r\n\r\n rotation_rules {\r\n automatically_after_days = var.db_password_rotation_days\r\n }\r\n\r\n}\r\n\r\nvariable \"db_password_rotation_days\" {\r\n description = \"Number of days in which the RDS password will be rotated\"\r\n type = number\r\n}\r\n\r\n```\r\n**Exception Trace**\r\n```\r\nFailed to run check CKV_AWS_304 on rds.tf:aws_secretsmanager_secret_rotation.rds_password_rotation\r\nTraceback (most recent call last):\r\n File \"\\venv\\Lib\\site-packages\\checkov\\common\\checks\\base_check.py\", line 73, in run\r\n check_result[\"result\"] = self.scan_entity_conf(entity_configuration, entity_type)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"\\venv\\Lib\\site-packages\\checkov\\terraform\\checks\\resource\\base_resource_check.py\", line 43, in scan_entity_conf\r\n return self.scan_resource_conf(conf)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"\\venv\\Lib\\site-packages\\checkov\\terraform\\checks\\resource\\aws\\SecretManagerSecret90days.py\", line 20, in scan_resource_conf\r\n if days < 90:\r\n ^^^^^^^^^\r\nTypeError: '<' not supported between instances of 'str' and 'int' \r\n```\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Windows 10 for Workstation\r\n - Checkov Version 2.3.301\r\n\r\n**Additional context**\r\nI inspected the value of date at the line causing the error and it is the string `var.db_password_rotation_days`. \n", "before_files": [{"content": "\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckCategories, CheckResult\n\n\nclass SecretManagerSecret90days(BaseResourceCheck):\n\n def __init__(self):\n name = \"Ensure Secrets Manager secrets should be rotated within 90 days\"\n id = \"CKV_AWS_304\"\n supported_resources = [\"aws_secretsmanager_secret_rotation\"]\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf) -> CheckResult:\n if conf.get(\"rotation_rules\") and isinstance(conf.get(\"rotation_rules\"), list):\n rule = conf.get(\"rotation_rules\")[0]\n if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):\n days = rule.get('automatically_after_days')[0]\n if days < 90:\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = SecretManagerSecret90days()\n", "path": "checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.util.type_forcers import force_int\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckCategories, CheckResult\n\n\nclass SecretManagerSecret90days(BaseResourceCheck):\n def __init__(self) -> None:\n name = \"Ensure Secrets Manager secrets should be rotated within 90 days\"\n id = \"CKV_AWS_304\"\n supported_resources = (\"aws_secretsmanager_secret_rotation\",)\n categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n rules = conf.get(\"rotation_rules\")\n if rules and isinstance(rules, list):\n days = rules[0].get('automatically_after_days')\n if days and isinstance(days, list):\n days = force_int(days[0])\n if days is not None and days < 90:\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = SecretManagerSecret90days()\n", "path": "checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py"}]} | 971 | 476 |
gh_patches_debug_19980 | rasdani/github-patches | git_diff | cfpb__consumerfinance.gov-229 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Centering on mobile
`the-bureau` page contains media blocks whose content (image & body) becomes centered at mobile sizes via a `media__centered` class. The `office` index page, however, introduces a new pattern of media blocks whose image centers on mobile while the body remains left-aligned.
It seems like it would be more useful to add a general-purpose `.centered-on-mobile` class (or two classes, one for inline & the other for block elements) that could be applied to the appropriate parts of the media object rather than handle this behavior through .`media` modifiers.
Thoughts? Preferences?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `_lib/wordpress_office_processor.py`
Content:
```
1 import sys
2 import json
3 import os.path
4 import requests
5
6 def posts_at_url(url):
7
8 current_page = 1
9 max_page = sys.maxint
10
11 while current_page <= max_page:
12
13 url = os.path.expandvars(url)
14 resp = requests.get(url, params={'page':current_page, 'count': '-1'})
15 results = json.loads(resp.content)
16 current_page += 1
17 max_page = results['pages']
18 for p in results['posts']:
19 yield p
20
21 def documents(name, url, **kwargs):
22
23 for post in posts_at_url(url):
24 yield process_office(post)
25
26
27 def process_office(item):
28
29 item['_id'] = item['slug']
30 custom_fields = item['custom_fields']
31
32 # get intro text & subscribe form data from custom fields
33 for attr in ['intro_text', 'intro_subscribe_form', 'related_contact']:
34 if attr in custom_fields:
35 item[attr] = custom_fields[attr][0]
36
37 # build top story dict
38 top_story = {}
39 for attr in ['top_story_head', 'top_story_desc']:
40 if attr in custom_fields:
41 top_story[attr] = custom_fields[attr][0]
42
43 # convert top story links into a proper list
44 top_story_links = []
45 for x in xrange(0,5):
46 key = 'top_story_links_%s' % x
47 if key in custom_fields:
48 top_story_links.append(custom_fields[key])
49
50 if top_story_links:
51 top_story['top_story_links'] = top_story_links
52
53 if top_story:
54 item['top_story'] = top_story
55
56 # create list of office resource dicts
57 item['resources'] = []
58 for x in xrange(1,4):
59 resource = {}
60 fields = ['head', 'desc', 'icon', 'link_0']
61 for field in fields:
62 field_name = 'resource%s_%s' % (str(x), field)
63 if field_name in custom_fields and custom_fields[field_name][0] != '':
64 if field == 'link_0':
65 resource['link'] = custom_fields[field_name]
66 else:
67 resource[field] = custom_fields[field_name][0]
68
69 if resource:
70 item['resources'].append(resource)
71
72 return item
73
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/_lib/wordpress_office_processor.py b/_lib/wordpress_office_processor.py
--- a/_lib/wordpress_office_processor.py
+++ b/_lib/wordpress_office_processor.py
@@ -55,17 +55,17 @@
# create list of office resource dicts
item['resources'] = []
- for x in xrange(1,4):
+ for x in xrange(0,4):
resource = {}
- fields = ['head', 'desc', 'icon', 'link_0']
+ fields = ['head', 'desc', 'icon', 'link']
for field in fields:
- field_name = 'resource%s_%s' % (str(x), field)
+ field_name = 'resource_%s_%s' % (str(x), field)
if field_name in custom_fields and custom_fields[field_name][0] != '':
- if field == 'link_0':
- resource['link'] = custom_fields[field_name]
+ if field == 'link':
+ resource[field] = custom_fields[field_name]
else:
resource[field] = custom_fields[field_name][0]
-
+
if resource:
item['resources'].append(resource)
| {"golden_diff": "diff --git a/_lib/wordpress_office_processor.py b/_lib/wordpress_office_processor.py\n--- a/_lib/wordpress_office_processor.py\n+++ b/_lib/wordpress_office_processor.py\n@@ -55,17 +55,17 @@\n \n # create list of office resource dicts\n item['resources'] = []\n- for x in xrange(1,4):\n+ for x in xrange(0,4):\n resource = {}\n- fields = ['head', 'desc', 'icon', 'link_0']\n+ fields = ['head', 'desc', 'icon', 'link']\n for field in fields:\n- field_name = 'resource%s_%s' % (str(x), field)\n+ field_name = 'resource_%s_%s' % (str(x), field)\n if field_name in custom_fields and custom_fields[field_name][0] != '':\n- if field == 'link_0':\n- resource['link'] = custom_fields[field_name]\n+ if field == 'link':\n+ resource[field] = custom_fields[field_name]\n else:\n resource[field] = custom_fields[field_name][0]\n- \n+ \n if resource:\n item['resources'].append(resource)\n", "issue": "Centering on mobile\n`the-bureau` page contains media blocks whose content (image & body) becomes centered at mobile sizes via a `media__centered` class. The `office` index page, however, introduces a new pattern of media blocks whose image centers on mobile while the body remains left-aligned. \n\nIt seems like it would be more useful to add a general-purpose `.centered-on-mobile` class (or two classes, one for inline & the other for block elements) that could be applied to the appropriate parts of the media object rather than handle this behavior through .`media` modifiers. \n\nThoughts? Preferences?\n\n", "before_files": [{"content": "import sys\nimport json\nimport os.path\nimport requests\n\ndef posts_at_url(url):\n \n current_page = 1\n max_page = sys.maxint\n\n while current_page <= max_page:\n\n url = os.path.expandvars(url)\n resp = requests.get(url, params={'page':current_page, 'count': '-1'})\n results = json.loads(resp.content) \n current_page += 1\n max_page = results['pages']\n for p in results['posts']:\n yield p\n \ndef documents(name, url, **kwargs):\n \n for post in posts_at_url(url):\n yield process_office(post)\n\n\ndef process_office(item):\n \n item['_id'] = item['slug']\n custom_fields = item['custom_fields']\n \n # get intro text & subscribe form data from custom fields\n for attr in ['intro_text', 'intro_subscribe_form', 'related_contact']:\n if attr in custom_fields:\n item[attr] = custom_fields[attr][0]\n \n # build top story dict\n top_story = {}\n for attr in ['top_story_head', 'top_story_desc']:\n if attr in custom_fields:\n top_story[attr] = custom_fields[attr][0]\n \n # convert top story links into a proper list\n top_story_links = []\n for x in xrange(0,5):\n key = 'top_story_links_%s' % x\n if key in custom_fields:\n top_story_links.append(custom_fields[key])\n \n if top_story_links: \n top_story['top_story_links'] = top_story_links\n \n if top_story:\n item['top_story'] = top_story\n \n # create list of office resource dicts\n item['resources'] = []\n for x in xrange(1,4):\n resource = {}\n fields = ['head', 'desc', 'icon', 'link_0']\n for field in fields:\n field_name = 'resource%s_%s' % (str(x), field)\n if field_name in custom_fields and custom_fields[field_name][0] != '':\n if field == 'link_0':\n resource['link'] = custom_fields[field_name]\n else:\n resource[field] = custom_fields[field_name][0]\n \n if resource:\n item['resources'].append(resource)\n\n return item\n\n", "path": "_lib/wordpress_office_processor.py"}], "after_files": [{"content": "import sys\nimport json\nimport os.path\nimport requests\n\ndef posts_at_url(url):\n \n current_page = 1\n max_page = sys.maxint\n\n while current_page <= max_page:\n\n url = os.path.expandvars(url)\n resp = requests.get(url, params={'page':current_page, 'count': '-1'})\n results = json.loads(resp.content) \n current_page += 1\n max_page = results['pages']\n for p in results['posts']:\n yield p\n \ndef documents(name, url, **kwargs):\n \n for post in posts_at_url(url):\n yield process_office(post)\n\n\ndef process_office(item):\n \n item['_id'] = item['slug']\n custom_fields = item['custom_fields']\n \n # get intro text & subscribe form data from custom fields\n for attr in ['intro_text', 'intro_subscribe_form', 'related_contact']:\n if attr in custom_fields:\n item[attr] = custom_fields[attr][0]\n \n # build top story dict\n top_story = {}\n for attr in ['top_story_head', 'top_story_desc']:\n if attr in custom_fields:\n top_story[attr] = custom_fields[attr][0]\n \n # convert top story links into a proper list\n top_story_links = []\n for x in xrange(0,5):\n key = 'top_story_links_%s' % x\n if key in custom_fields:\n top_story_links.append(custom_fields[key])\n \n if top_story_links: \n top_story['top_story_links'] = top_story_links\n \n if top_story:\n item['top_story'] = top_story\n \n # create list of office resource dicts\n item['resources'] = []\n for x in xrange(0,4):\n resource = {}\n fields = ['head', 'desc', 'icon', 'link']\n for field in fields:\n field_name = 'resource_%s_%s' % (str(x), field)\n if field_name in custom_fields and custom_fields[field_name][0] != '':\n if field == 'link':\n resource[field] = custom_fields[field_name]\n else:\n resource[field] = custom_fields[field_name][0]\n \n if resource:\n item['resources'].append(resource)\n\n return item\n\n", "path": "_lib/wordpress_office_processor.py"}]} | 1,024 | 263 |
gh_patches_debug_14209 | rasdani/github-patches | git_diff | ietf-tools__datatracker-4703 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Links to non-existing person profiles are being generated
### What happened?
For example, on http://127.0.0.1:8000/ipr/2670/history/, a link to http://127.0.0.1:8000/person/[email protected] is being generated, which 404s.
### What browser(s) are you seeing the problem on?
_No response_
### Code of Conduct
- [X] I agree to follow the IETF's Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/person/views.py`
Content:
```
1 # Copyright The IETF Trust 2012-2020, All Rights Reserved
2 # -*- coding: utf-8 -*-
3
4
5 from io import StringIO, BytesIO
6 from PIL import Image
7
8 from django.contrib import messages
9 from django.db.models import Q
10 from django.http import HttpResponse, Http404
11 from django.shortcuts import render, get_object_or_404, redirect
12 from django.utils import timezone
13
14 import debug # pyflakes:ignore
15
16 from ietf.ietfauth.utils import role_required
17 from ietf.person.models import Email, Person, Alias
18 from ietf.person.fields import select2_id_name_json
19 from ietf.person.forms import MergeForm
20 from ietf.person.utils import handle_users, merge_persons
21
22
23 def ajax_select2_search(request, model_name):
24 if model_name == "email":
25 model = Email
26 else:
27 model = Person
28
29 q = [w.strip() for w in request.GET.get('q', '').split() if w.strip()]
30
31 if not q:
32 objs = model.objects.none()
33 else:
34 query = Q() # all objects returned if no other terms in the queryset
35 for t in q:
36 if model == Email:
37 query &= Q(person__alias__name__icontains=t) | Q(address__icontains=t)
38 elif model == Person:
39 if "@" in t: # allow searching email address if there's a @ in the search term
40 query &= Q(alias__name__icontains=t) | Q(email__address__icontains=t)
41 else:
42 query &= Q(alias__name__icontains=t)
43
44 objs = model.objects.filter(query)
45
46 # require an account at the Datatracker
47 only_users = request.GET.get("user") == "1"
48 all_emails = request.GET.get("a", "0") == "1"
49
50 if model == Email:
51 objs = objs.exclude(person=None).order_by('person__name')
52 if not all_emails:
53 objs = objs.filter(active=True)
54 if only_users:
55 objs = objs.exclude(person__user=None)
56 elif model == Person:
57 objs = objs.order_by("name")
58 if only_users:
59 objs = objs.exclude(user=None)
60
61 try:
62 page = int(request.GET.get("p", 1)) - 1
63 except ValueError:
64 page = 0
65
66 objs = objs.distinct()[page:page + 10]
67
68 return HttpResponse(select2_id_name_json(objs), content_type='application/json')
69
70 def profile(request, email_or_name):
71 if '@' in email_or_name:
72 persons = [ get_object_or_404(Email, address=email_or_name).person, ]
73 else:
74 aliases = Alias.objects.filter(name=email_or_name)
75 persons = list(set([ a.person for a in aliases ]))
76 persons = [ p for p in persons if p and p.id ]
77 if not persons:
78 raise Http404
79 return render(request, 'person/profile.html', {'persons': persons, 'today': timezone.now()})
80
81
82 def photo(request, email_or_name):
83 if '@' in email_or_name:
84 persons = [ get_object_or_404(Email, address=email_or_name).person, ]
85 else:
86 aliases = Alias.objects.filter(name=email_or_name)
87 persons = list(set([ a.person for a in aliases ]))
88 if not persons:
89 raise Http404("No such person")
90 if len(persons) > 1:
91 return HttpResponse(r"\r\n".join([p.email() for p in persons]), status=300)
92 person = persons[0]
93 if not person.photo:
94 raise Http404("No photo found")
95 size = request.GET.get('s') or request.GET.get('size', '80')
96 if not size.isdigit():
97 return HttpResponse("Size must be integer", status=400)
98 size = int(size)
99 img = Image.open(person.photo)
100 img = img.resize((size, img.height*size//img.width))
101 bytes = BytesIO()
102 try:
103 img.save(bytes, format='JPEG')
104 return HttpResponse(bytes.getvalue(), content_type='image/jpg')
105 except OSError:
106 raise Http404
107
108
109 @role_required("Secretariat")
110 def merge(request):
111 form = MergeForm()
112 method = 'get'
113 change_details = ''
114 warn_messages = []
115 source = None
116 target = None
117
118 if request.method == "GET":
119 form = MergeForm()
120 if request.GET:
121 form = MergeForm(request.GET)
122 if form.is_valid():
123 source = form.cleaned_data.get('source')
124 target = form.cleaned_data.get('target')
125 if source.user and target.user:
126 warn_messages.append('WARNING: Both Person records have logins. Be sure to specify the record to keep in the Target field.')
127 if source.user.last_login and target.user.last_login and source.user.last_login > target.user.last_login:
128 warn_messages.append('WARNING: The most recently used login is being deleted!')
129 change_details = handle_users(source, target, check_only=True)
130 method = 'post'
131 else:
132 method = 'get'
133
134 if request.method == "POST":
135 form = MergeForm(request.POST)
136 if form.is_valid():
137 source = form.cleaned_data.get('source')
138 source_id = source.id
139 target = form.cleaned_data.get('target')
140 # Do merge with force
141 output = StringIO()
142 success, changes = merge_persons(request, source, target, file=output)
143 if success:
144 messages.success(request, 'Merged {} ({}) to {} ({}). {})'.format(
145 source.name, source_id, target.name, target.id, changes))
146 else:
147 messages.error(request, output)
148 return redirect('ietf.secr.rolodex.views.view', id=target.pk)
149
150 return render(request, 'person/merge.html', {
151 'form': form,
152 'method': method,
153 'change_details': change_details,
154 'source': source,
155 'target': target,
156 'warn_messages': warn_messages,
157 })
158
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ietf/person/views.py b/ietf/person/views.py
--- a/ietf/person/views.py
+++ b/ietf/person/views.py
@@ -68,11 +68,13 @@
return HttpResponse(select2_id_name_json(objs), content_type='application/json')
def profile(request, email_or_name):
+ aliases = Alias.objects.filter(name=email_or_name)
+ persons = list(set([ a.person for a in aliases ]))
+
if '@' in email_or_name:
- persons = [ get_object_or_404(Email, address=email_or_name).person, ]
- else:
- aliases = Alias.objects.filter(name=email_or_name)
- persons = list(set([ a.person for a in aliases ]))
+ emails = Email.objects.filter(address=email_or_name)
+ persons += list(set([ e.person for e in emails ]))
+
persons = [ p for p in persons if p and p.id ]
if not persons:
raise Http404
| {"golden_diff": "diff --git a/ietf/person/views.py b/ietf/person/views.py\n--- a/ietf/person/views.py\n+++ b/ietf/person/views.py\n@@ -68,11 +68,13 @@\n return HttpResponse(select2_id_name_json(objs), content_type='application/json')\n \n def profile(request, email_or_name):\n+ aliases = Alias.objects.filter(name=email_or_name)\n+ persons = list(set([ a.person for a in aliases ]))\n+\n if '@' in email_or_name:\n- persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n- else:\n- aliases = Alias.objects.filter(name=email_or_name)\n- persons = list(set([ a.person for a in aliases ]))\n+ emails = Email.objects.filter(address=email_or_name)\n+ persons += list(set([ e.person for e in emails ]))\n+\n persons = [ p for p in persons if p and p.id ]\n if not persons:\n raise Http404\n", "issue": "Links to non-existing person profiles are being generated\n### What happened?\n\nFor example, on http://127.0.0.1:8000/ipr/2670/history/, a link to http://127.0.0.1:8000/person/[email protected] is being generated, which 404s.\n\n### What browser(s) are you seeing the problem on?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow the IETF's Code of Conduct\n", "before_files": [{"content": "# Copyright The IETF Trust 2012-2020, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n\nfrom io import StringIO, BytesIO\nfrom PIL import Image\n\nfrom django.contrib import messages\nfrom django.db.models import Q\nfrom django.http import HttpResponse, Http404\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.utils import timezone\n\nimport debug # pyflakes:ignore\n\nfrom ietf.ietfauth.utils import role_required\nfrom ietf.person.models import Email, Person, Alias\nfrom ietf.person.fields import select2_id_name_json\nfrom ietf.person.forms import MergeForm\nfrom ietf.person.utils import handle_users, merge_persons\n\n\ndef ajax_select2_search(request, model_name):\n if model_name == \"email\":\n model = Email\n else:\n model = Person\n\n q = [w.strip() for w in request.GET.get('q', '').split() if w.strip()]\n\n if not q:\n objs = model.objects.none()\n else:\n query = Q() # all objects returned if no other terms in the queryset\n for t in q:\n if model == Email:\n query &= Q(person__alias__name__icontains=t) | Q(address__icontains=t)\n elif model == Person:\n if \"@\" in t: # allow searching email address if there's a @ in the search term\n query &= Q(alias__name__icontains=t) | Q(email__address__icontains=t)\n else:\n query &= Q(alias__name__icontains=t)\n\n objs = model.objects.filter(query)\n\n # require an account at the Datatracker\n only_users = request.GET.get(\"user\") == \"1\"\n all_emails = request.GET.get(\"a\", \"0\") == \"1\"\n\n if model == Email:\n objs = objs.exclude(person=None).order_by('person__name')\n if not all_emails:\n objs = objs.filter(active=True)\n if only_users:\n objs = objs.exclude(person__user=None)\n elif model == Person:\n objs = objs.order_by(\"name\")\n if only_users:\n objs = objs.exclude(user=None)\n\n try:\n page = int(request.GET.get(\"p\", 1)) - 1\n except ValueError:\n page = 0\n\n objs = objs.distinct()[page:page + 10]\n\n return HttpResponse(select2_id_name_json(objs), content_type='application/json')\n\ndef profile(request, email_or_name):\n if '@' in email_or_name:\n persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n else:\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n persons = [ p for p in persons if p and p.id ]\n if not persons:\n raise Http404\n return render(request, 'person/profile.html', {'persons': persons, 'today': timezone.now()})\n\n\ndef photo(request, email_or_name):\n if '@' in email_or_name:\n persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n else:\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n if not persons:\n raise Http404(\"No such person\")\n if len(persons) > 1:\n return HttpResponse(r\"\\r\\n\".join([p.email() for p in persons]), status=300)\n person = persons[0]\n if not person.photo:\n raise Http404(\"No photo found\")\n size = request.GET.get('s') or request.GET.get('size', '80')\n if not size.isdigit():\n return HttpResponse(\"Size must be integer\", status=400)\n size = int(size)\n img = Image.open(person.photo)\n img = img.resize((size, img.height*size//img.width))\n bytes = BytesIO()\n try:\n img.save(bytes, format='JPEG')\n return HttpResponse(bytes.getvalue(), content_type='image/jpg')\n except OSError:\n raise Http404\n\n\n@role_required(\"Secretariat\")\ndef merge(request):\n form = MergeForm()\n method = 'get'\n change_details = ''\n warn_messages = []\n source = None\n target = None\n\n if request.method == \"GET\":\n form = MergeForm()\n if request.GET:\n form = MergeForm(request.GET)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n target = form.cleaned_data.get('target')\n if source.user and target.user:\n warn_messages.append('WARNING: Both Person records have logins. Be sure to specify the record to keep in the Target field.')\n if source.user.last_login and target.user.last_login and source.user.last_login > target.user.last_login:\n warn_messages.append('WARNING: The most recently used login is being deleted!')\n change_details = handle_users(source, target, check_only=True)\n method = 'post'\n else:\n method = 'get'\n\n if request.method == \"POST\":\n form = MergeForm(request.POST)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n source_id = source.id\n target = form.cleaned_data.get('target')\n # Do merge with force\n output = StringIO()\n success, changes = merge_persons(request, source, target, file=output)\n if success:\n messages.success(request, 'Merged {} ({}) to {} ({}). {})'.format(\n source.name, source_id, target.name, target.id, changes))\n else:\n messages.error(request, output)\n return redirect('ietf.secr.rolodex.views.view', id=target.pk)\n\n return render(request, 'person/merge.html', {\n 'form': form,\n 'method': method,\n 'change_details': change_details,\n 'source': source,\n 'target': target,\n 'warn_messages': warn_messages,\n })\n", "path": "ietf/person/views.py"}], "after_files": [{"content": "# Copyright The IETF Trust 2012-2020, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n\nfrom io import StringIO, BytesIO\nfrom PIL import Image\n\nfrom django.contrib import messages\nfrom django.db.models import Q\nfrom django.http import HttpResponse, Http404\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.utils import timezone\n\nimport debug # pyflakes:ignore\n\nfrom ietf.ietfauth.utils import role_required\nfrom ietf.person.models import Email, Person, Alias\nfrom ietf.person.fields import select2_id_name_json\nfrom ietf.person.forms import MergeForm\nfrom ietf.person.utils import handle_users, merge_persons\n\n\ndef ajax_select2_search(request, model_name):\n if model_name == \"email\":\n model = Email\n else:\n model = Person\n\n q = [w.strip() for w in request.GET.get('q', '').split() if w.strip()]\n\n if not q:\n objs = model.objects.none()\n else:\n query = Q() # all objects returned if no other terms in the queryset\n for t in q:\n if model == Email:\n query &= Q(person__alias__name__icontains=t) | Q(address__icontains=t)\n elif model == Person:\n if \"@\" in t: # allow searching email address if there's a @ in the search term\n query &= Q(alias__name__icontains=t) | Q(email__address__icontains=t)\n else:\n query &= Q(alias__name__icontains=t)\n\n objs = model.objects.filter(query)\n\n # require an account at the Datatracker\n only_users = request.GET.get(\"user\") == \"1\"\n all_emails = request.GET.get(\"a\", \"0\") == \"1\"\n\n if model == Email:\n objs = objs.exclude(person=None).order_by('person__name')\n if not all_emails:\n objs = objs.filter(active=True)\n if only_users:\n objs = objs.exclude(person__user=None)\n elif model == Person:\n objs = objs.order_by(\"name\")\n if only_users:\n objs = objs.exclude(user=None)\n\n try:\n page = int(request.GET.get(\"p\", 1)) - 1\n except ValueError:\n page = 0\n\n objs = objs.distinct()[page:page + 10]\n\n return HttpResponse(select2_id_name_json(objs), content_type='application/json')\n\ndef profile(request, email_or_name):\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n\n if '@' in email_or_name:\n emails = Email.objects.filter(address=email_or_name)\n persons += list(set([ e.person for e in emails ]))\n\n persons = [ p for p in persons if p and p.id ]\n if not persons:\n raise Http404\n return render(request, 'person/profile.html', {'persons': persons, 'today': timezone.now()})\n\n\ndef photo(request, email_or_name):\n if '@' in email_or_name:\n persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n else:\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n if not persons:\n raise Http404(\"No such person\")\n if len(persons) > 1:\n return HttpResponse(r\"\\r\\n\".join([p.email() for p in persons]), status=300)\n person = persons[0]\n if not person.photo:\n raise Http404(\"No photo found\")\n size = request.GET.get('s') or request.GET.get('size', '80')\n if not size.isdigit():\n return HttpResponse(\"Size must be integer\", status=400)\n size = int(size)\n img = Image.open(person.photo)\n img = img.resize((size, img.height*size//img.width))\n bytes = BytesIO()\n try:\n img.save(bytes, format='JPEG')\n return HttpResponse(bytes.getvalue(), content_type='image/jpg')\n except OSError:\n raise Http404\n\n\n@role_required(\"Secretariat\")\ndef merge(request):\n form = MergeForm()\n method = 'get'\n change_details = ''\n warn_messages = []\n source = None\n target = None\n\n if request.method == \"GET\":\n form = MergeForm()\n if request.GET:\n form = MergeForm(request.GET)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n target = form.cleaned_data.get('target')\n if source.user and target.user:\n warn_messages.append('WARNING: Both Person records have logins. Be sure to specify the record to keep in the Target field.')\n if source.user.last_login and target.user.last_login and source.user.last_login > target.user.last_login:\n warn_messages.append('WARNING: The most recently used login is being deleted!')\n change_details = handle_users(source, target, check_only=True)\n method = 'post'\n else:\n method = 'get'\n\n if request.method == \"POST\":\n form = MergeForm(request.POST)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n source_id = source.id\n target = form.cleaned_data.get('target')\n # Do merge with force\n output = StringIO()\n success, changes = merge_persons(request, source, target, file=output)\n if success:\n messages.success(request, 'Merged {} ({}) to {} ({}). {})'.format(\n source.name, source_id, target.name, target.id, changes))\n else:\n messages.error(request, output)\n return redirect('ietf.secr.rolodex.views.view', id=target.pk)\n\n return render(request, 'person/merge.html', {\n 'form': form,\n 'method': method,\n 'change_details': change_details,\n 'source': source,\n 'target': target,\n 'warn_messages': warn_messages,\n })\n", "path": "ietf/person/views.py"}]} | 2,061 | 218 |
gh_patches_debug_111 | rasdani/github-patches | git_diff | vispy__vispy-1794 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add transparent color to internal color dictionary
Hi,
I've been working extending and improving `napari`'s color support (mostly [here](https://github.com/napari/napari/pull/782)) and we'd be very happy to have a "transparent" color in your internal `color_dict`, which simply corresponds to `#00000000`. This modification is very minimal (I'd be happy to do it myself) and can provide us with the bare-bones support we'd like to see.
Is that possible?
Thanks.
_Originally posted by @HagaiHargil in https://github.com/vispy/vispy/issues/1345#issuecomment-566884858_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vispy/color/_color_dict.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4
5
6 def get_color_names():
7 """Get the known color names
8
9 Returns
10 -------
11 names : list
12 List of color names known by Vispy.
13 """
14 names = list(_color_dict.keys())
15 names.sort()
16 return names
17
18
19 def get_color_dict():
20 """Get the known colors
21
22 Returns
23 -------
24 color_dict : dict
25 Dict of colors known by Vispy {name: #rgb}.
26 """
27 return _color_dict.copy()
28
29
30 # This is used by color functions to translate user strings to colors
31 # For now, this is web colors, and all in hex. It will take some simple
32 # but annoying refactoring to deal with non-hex entries if we want them.
33
34 # Add the CSS colors, courtesy MIT-licensed code from Dave Eddy:
35 # github.com/bahamas10/css-color-names/blob/master/css-color-names.json
36
37 _color_dict = {
38 "k": '#000000',
39 "w": '#FFFFFF',
40 "r": '#FF0000',
41 "g": '#00FF00',
42 "b": '#0000FF',
43 "y": '#FFFF00',
44 "m": '#FF00FF',
45 "c": '#00FFFF',
46 "aqua": "#00ffff",
47 "aliceblue": "#f0f8ff",
48 "antiquewhite": "#faebd7",
49 "black": "#000000",
50 "blue": "#0000ff",
51 "cyan": "#00ffff",
52 "darkblue": "#00008b",
53 "darkcyan": "#008b8b",
54 "darkgreen": "#006400",
55 "darkturquoise": "#00ced1",
56 "deepskyblue": "#00bfff",
57 "green": "#008000",
58 "lime": "#00ff00",
59 "mediumblue": "#0000cd",
60 "mediumspringgreen": "#00fa9a",
61 "navy": "#000080",
62 "springgreen": "#00ff7f",
63 "teal": "#008080",
64 "midnightblue": "#191970",
65 "dodgerblue": "#1e90ff",
66 "lightseagreen": "#20b2aa",
67 "forestgreen": "#228b22",
68 "seagreen": "#2e8b57",
69 "darkslategray": "#2f4f4f",
70 "darkslategrey": "#2f4f4f",
71 "limegreen": "#32cd32",
72 "mediumseagreen": "#3cb371",
73 "turquoise": "#40e0d0",
74 "royalblue": "#4169e1",
75 "steelblue": "#4682b4",
76 "darkslateblue": "#483d8b",
77 "mediumturquoise": "#48d1cc",
78 "indigo": "#4b0082",
79 "darkolivegreen": "#556b2f",
80 "cadetblue": "#5f9ea0",
81 "cornflowerblue": "#6495ed",
82 "mediumaquamarine": "#66cdaa",
83 "dimgray": "#696969",
84 "dimgrey": "#696969",
85 "slateblue": "#6a5acd",
86 "olivedrab": "#6b8e23",
87 "slategray": "#708090",
88 "slategrey": "#708090",
89 "lightslategray": "#778899",
90 "lightslategrey": "#778899",
91 "mediumslateblue": "#7b68ee",
92 "lawngreen": "#7cfc00",
93 "aquamarine": "#7fffd4",
94 "chartreuse": "#7fff00",
95 "gray": "#808080",
96 "grey": "#808080",
97 "maroon": "#800000",
98 "olive": "#808000",
99 "purple": "#800080",
100 "lightskyblue": "#87cefa",
101 "skyblue": "#87ceeb",
102 "blueviolet": "#8a2be2",
103 "darkmagenta": "#8b008b",
104 "darkred": "#8b0000",
105 "saddlebrown": "#8b4513",
106 "darkseagreen": "#8fbc8f",
107 "lightgreen": "#90ee90",
108 "mediumpurple": "#9370db",
109 "darkviolet": "#9400d3",
110 "palegreen": "#98fb98",
111 "darkorchid": "#9932cc",
112 "yellowgreen": "#9acd32",
113 "sienna": "#a0522d",
114 "brown": "#a52a2a",
115 "darkgray": "#a9a9a9",
116 "darkgrey": "#a9a9a9",
117 "greenyellow": "#adff2f",
118 "lightblue": "#add8e6",
119 "paleturquoise": "#afeeee",
120 "lightsteelblue": "#b0c4de",
121 "powderblue": "#b0e0e6",
122 "firebrick": "#b22222",
123 "darkgoldenrod": "#b8860b",
124 "mediumorchid": "#ba55d3",
125 "rosybrown": "#bc8f8f",
126 "darkkhaki": "#bdb76b",
127 "silver": "#c0c0c0",
128 "mediumvioletred": "#c71585",
129 "indianred": "#cd5c5c",
130 "peru": "#cd853f",
131 "chocolate": "#d2691e",
132 "tan": "#d2b48c",
133 "lightgray": "#d3d3d3",
134 "lightgrey": "#d3d3d3",
135 "thistle": "#d8bfd8",
136 "goldenrod": "#daa520",
137 "orchid": "#da70d6",
138 "palevioletred": "#db7093",
139 "crimson": "#dc143c",
140 "gainsboro": "#dcdcdc",
141 "plum": "#dda0dd",
142 "burlywood": "#deb887",
143 "lightcyan": "#e0ffff",
144 "lavender": "#e6e6fa",
145 "darksalmon": "#e9967a",
146 "palegoldenrod": "#eee8aa",
147 "violet": "#ee82ee",
148 "azure": "#f0ffff",
149 "honeydew": "#f0fff0",
150 "khaki": "#f0e68c",
151 "lightcoral": "#f08080",
152 "sandybrown": "#f4a460",
153 "beige": "#f5f5dc",
154 "mintcream": "#f5fffa",
155 "wheat": "#f5deb3",
156 "whitesmoke": "#f5f5f5",
157 "ghostwhite": "#f8f8ff",
158 "lightgoldenrodyellow": "#fafad2",
159 "linen": "#faf0e6",
160 "salmon": "#fa8072",
161 "oldlace": "#fdf5e6",
162 "bisque": "#ffe4c4",
163 "blanchedalmond": "#ffebcd",
164 "coral": "#ff7f50",
165 "cornsilk": "#fff8dc",
166 "darkorange": "#ff8c00",
167 "deeppink": "#ff1493",
168 "floralwhite": "#fffaf0",
169 "fuchsia": "#ff00ff",
170 "gold": "#ffd700",
171 "hotpink": "#ff69b4",
172 "ivory": "#fffff0",
173 "lavenderblush": "#fff0f5",
174 "lemonchiffon": "#fffacd",
175 "lightpink": "#ffb6c1",
176 "lightsalmon": "#ffa07a",
177 "lightyellow": "#ffffe0",
178 "magenta": "#ff00ff",
179 "mistyrose": "#ffe4e1",
180 "moccasin": "#ffe4b5",
181 "navajowhite": "#ffdead",
182 "orange": "#ffa500",
183 "orangered": "#ff4500",
184 "papayawhip": "#ffefd5",
185 "peachpuff": "#ffdab9",
186 "pink": "#ffc0cb",
187 "red": "#ff0000",
188 "seashell": "#fff5ee",
189 "snow": "#fffafa",
190 "tomato": "#ff6347",
191 "white": "#ffffff",
192 "yellow": "#ffff00",
193 }
194
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/vispy/color/_color_dict.py b/vispy/color/_color_dict.py
--- a/vispy/color/_color_dict.py
+++ b/vispy/color/_color_dict.py
@@ -190,4 +190,5 @@
"tomato": "#ff6347",
"white": "#ffffff",
"yellow": "#ffff00",
+ "transparent": "#00000000",
}
| {"golden_diff": "diff --git a/vispy/color/_color_dict.py b/vispy/color/_color_dict.py\n--- a/vispy/color/_color_dict.py\n+++ b/vispy/color/_color_dict.py\n@@ -190,4 +190,5 @@\n \"tomato\": \"#ff6347\",\n \"white\": \"#ffffff\",\n \"yellow\": \"#ffff00\",\n+ \"transparent\": \"#00000000\",\n }\n", "issue": "Add transparent color to internal color dictionary\nHi, \r\n\r\nI've been working extending and improving `napari`'s color support (mostly [here](https://github.com/napari/napari/pull/782)) and we'd be very happy to have a \"transparent\" color in your internal `color_dict`, which simply corresponds to `#00000000`. This modification is very minimal (I'd be happy to do it myself) and can provide us with the bare-bones support we'd like to see.\r\n\r\nIs that possible?\r\nThanks.\r\n\r\n_Originally posted by @HagaiHargil in https://github.com/vispy/vispy/issues/1345#issuecomment-566884858_\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\n\ndef get_color_names():\n \"\"\"Get the known color names\n\n Returns\n -------\n names : list\n List of color names known by Vispy.\n \"\"\"\n names = list(_color_dict.keys())\n names.sort()\n return names\n\n\ndef get_color_dict():\n \"\"\"Get the known colors\n\n Returns\n -------\n color_dict : dict\n Dict of colors known by Vispy {name: #rgb}.\n \"\"\"\n return _color_dict.copy()\n\n\n# This is used by color functions to translate user strings to colors\n# For now, this is web colors, and all in hex. It will take some simple\n# but annoying refactoring to deal with non-hex entries if we want them.\n\n# Add the CSS colors, courtesy MIT-licensed code from Dave Eddy:\n# github.com/bahamas10/css-color-names/blob/master/css-color-names.json\n\n_color_dict = {\n \"k\": '#000000',\n \"w\": '#FFFFFF',\n \"r\": '#FF0000',\n \"g\": '#00FF00',\n \"b\": '#0000FF',\n \"y\": '#FFFF00',\n \"m\": '#FF00FF',\n \"c\": '#00FFFF',\n \"aqua\": \"#00ffff\",\n \"aliceblue\": \"#f0f8ff\",\n \"antiquewhite\": \"#faebd7\",\n \"black\": \"#000000\",\n \"blue\": \"#0000ff\",\n \"cyan\": \"#00ffff\",\n \"darkblue\": \"#00008b\",\n \"darkcyan\": \"#008b8b\",\n \"darkgreen\": \"#006400\",\n \"darkturquoise\": \"#00ced1\",\n \"deepskyblue\": \"#00bfff\",\n \"green\": \"#008000\",\n \"lime\": \"#00ff00\",\n \"mediumblue\": \"#0000cd\",\n \"mediumspringgreen\": \"#00fa9a\",\n \"navy\": \"#000080\",\n \"springgreen\": \"#00ff7f\",\n \"teal\": \"#008080\",\n \"midnightblue\": \"#191970\",\n \"dodgerblue\": \"#1e90ff\",\n \"lightseagreen\": \"#20b2aa\",\n \"forestgreen\": \"#228b22\",\n \"seagreen\": \"#2e8b57\",\n \"darkslategray\": \"#2f4f4f\",\n \"darkslategrey\": \"#2f4f4f\",\n \"limegreen\": \"#32cd32\",\n \"mediumseagreen\": \"#3cb371\",\n \"turquoise\": \"#40e0d0\",\n \"royalblue\": \"#4169e1\",\n \"steelblue\": \"#4682b4\",\n \"darkslateblue\": \"#483d8b\",\n \"mediumturquoise\": \"#48d1cc\",\n \"indigo\": \"#4b0082\",\n \"darkolivegreen\": \"#556b2f\",\n \"cadetblue\": \"#5f9ea0\",\n \"cornflowerblue\": \"#6495ed\",\n \"mediumaquamarine\": \"#66cdaa\",\n \"dimgray\": \"#696969\",\n \"dimgrey\": \"#696969\",\n \"slateblue\": \"#6a5acd\",\n \"olivedrab\": \"#6b8e23\",\n \"slategray\": \"#708090\",\n \"slategrey\": \"#708090\",\n \"lightslategray\": \"#778899\",\n \"lightslategrey\": \"#778899\",\n \"mediumslateblue\": \"#7b68ee\",\n \"lawngreen\": \"#7cfc00\",\n \"aquamarine\": \"#7fffd4\",\n \"chartreuse\": \"#7fff00\",\n \"gray\": \"#808080\",\n \"grey\": \"#808080\",\n \"maroon\": \"#800000\",\n \"olive\": \"#808000\",\n \"purple\": \"#800080\",\n \"lightskyblue\": \"#87cefa\",\n \"skyblue\": \"#87ceeb\",\n \"blueviolet\": \"#8a2be2\",\n \"darkmagenta\": \"#8b008b\",\n \"darkred\": \"#8b0000\",\n \"saddlebrown\": \"#8b4513\",\n \"darkseagreen\": \"#8fbc8f\",\n \"lightgreen\": \"#90ee90\",\n \"mediumpurple\": \"#9370db\",\n \"darkviolet\": \"#9400d3\",\n \"palegreen\": \"#98fb98\",\n \"darkorchid\": \"#9932cc\",\n \"yellowgreen\": \"#9acd32\",\n \"sienna\": \"#a0522d\",\n \"brown\": \"#a52a2a\",\n \"darkgray\": \"#a9a9a9\",\n \"darkgrey\": \"#a9a9a9\",\n \"greenyellow\": \"#adff2f\",\n \"lightblue\": \"#add8e6\",\n \"paleturquoise\": \"#afeeee\",\n \"lightsteelblue\": \"#b0c4de\",\n \"powderblue\": \"#b0e0e6\",\n \"firebrick\": \"#b22222\",\n \"darkgoldenrod\": \"#b8860b\",\n \"mediumorchid\": \"#ba55d3\",\n \"rosybrown\": \"#bc8f8f\",\n \"darkkhaki\": \"#bdb76b\",\n \"silver\": \"#c0c0c0\",\n \"mediumvioletred\": \"#c71585\",\n \"indianred\": \"#cd5c5c\",\n \"peru\": \"#cd853f\",\n \"chocolate\": \"#d2691e\",\n \"tan\": \"#d2b48c\",\n \"lightgray\": \"#d3d3d3\",\n \"lightgrey\": \"#d3d3d3\",\n \"thistle\": \"#d8bfd8\",\n \"goldenrod\": \"#daa520\",\n \"orchid\": \"#da70d6\",\n \"palevioletred\": \"#db7093\",\n \"crimson\": \"#dc143c\",\n \"gainsboro\": \"#dcdcdc\",\n \"plum\": \"#dda0dd\",\n \"burlywood\": \"#deb887\",\n \"lightcyan\": \"#e0ffff\",\n \"lavender\": \"#e6e6fa\",\n \"darksalmon\": \"#e9967a\",\n \"palegoldenrod\": \"#eee8aa\",\n \"violet\": \"#ee82ee\",\n \"azure\": \"#f0ffff\",\n \"honeydew\": \"#f0fff0\",\n \"khaki\": \"#f0e68c\",\n \"lightcoral\": \"#f08080\",\n \"sandybrown\": \"#f4a460\",\n \"beige\": \"#f5f5dc\",\n \"mintcream\": \"#f5fffa\",\n \"wheat\": \"#f5deb3\",\n \"whitesmoke\": \"#f5f5f5\",\n \"ghostwhite\": \"#f8f8ff\",\n \"lightgoldenrodyellow\": \"#fafad2\",\n \"linen\": \"#faf0e6\",\n \"salmon\": \"#fa8072\",\n \"oldlace\": \"#fdf5e6\",\n \"bisque\": \"#ffe4c4\",\n \"blanchedalmond\": \"#ffebcd\",\n \"coral\": \"#ff7f50\",\n \"cornsilk\": \"#fff8dc\",\n \"darkorange\": \"#ff8c00\",\n \"deeppink\": \"#ff1493\",\n \"floralwhite\": \"#fffaf0\",\n \"fuchsia\": \"#ff00ff\",\n \"gold\": \"#ffd700\",\n \"hotpink\": \"#ff69b4\",\n \"ivory\": \"#fffff0\",\n \"lavenderblush\": \"#fff0f5\",\n \"lemonchiffon\": \"#fffacd\",\n \"lightpink\": \"#ffb6c1\",\n \"lightsalmon\": \"#ffa07a\",\n \"lightyellow\": \"#ffffe0\",\n \"magenta\": \"#ff00ff\",\n \"mistyrose\": \"#ffe4e1\",\n \"moccasin\": \"#ffe4b5\",\n \"navajowhite\": \"#ffdead\",\n \"orange\": \"#ffa500\",\n \"orangered\": \"#ff4500\",\n \"papayawhip\": \"#ffefd5\",\n \"peachpuff\": \"#ffdab9\",\n \"pink\": \"#ffc0cb\",\n \"red\": \"#ff0000\",\n \"seashell\": \"#fff5ee\",\n \"snow\": \"#fffafa\",\n \"tomato\": \"#ff6347\",\n \"white\": \"#ffffff\",\n \"yellow\": \"#ffff00\",\n}\n", "path": "vispy/color/_color_dict.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\n\ndef get_color_names():\n \"\"\"Get the known color names\n\n Returns\n -------\n names : list\n List of color names known by Vispy.\n \"\"\"\n names = list(_color_dict.keys())\n names.sort()\n return names\n\n\ndef get_color_dict():\n \"\"\"Get the known colors\n\n Returns\n -------\n color_dict : dict\n Dict of colors known by Vispy {name: #rgb}.\n \"\"\"\n return _color_dict.copy()\n\n\n# This is used by color functions to translate user strings to colors\n# For now, this is web colors, and all in hex. It will take some simple\n# but annoying refactoring to deal with non-hex entries if we want them.\n\n# Add the CSS colors, courtesy MIT-licensed code from Dave Eddy:\n# github.com/bahamas10/css-color-names/blob/master/css-color-names.json\n\n_color_dict = {\n \"k\": '#000000',\n \"w\": '#FFFFFF',\n \"r\": '#FF0000',\n \"g\": '#00FF00',\n \"b\": '#0000FF',\n \"y\": '#FFFF00',\n \"m\": '#FF00FF',\n \"c\": '#00FFFF',\n \"aqua\": \"#00ffff\",\n \"aliceblue\": \"#f0f8ff\",\n \"antiquewhite\": \"#faebd7\",\n \"black\": \"#000000\",\n \"blue\": \"#0000ff\",\n \"cyan\": \"#00ffff\",\n \"darkblue\": \"#00008b\",\n \"darkcyan\": \"#008b8b\",\n \"darkgreen\": \"#006400\",\n \"darkturquoise\": \"#00ced1\",\n \"deepskyblue\": \"#00bfff\",\n \"green\": \"#008000\",\n \"lime\": \"#00ff00\",\n \"mediumblue\": \"#0000cd\",\n \"mediumspringgreen\": \"#00fa9a\",\n \"navy\": \"#000080\",\n \"springgreen\": \"#00ff7f\",\n \"teal\": \"#008080\",\n \"midnightblue\": \"#191970\",\n \"dodgerblue\": \"#1e90ff\",\n \"lightseagreen\": \"#20b2aa\",\n \"forestgreen\": \"#228b22\",\n \"seagreen\": \"#2e8b57\",\n \"darkslategray\": \"#2f4f4f\",\n \"darkslategrey\": \"#2f4f4f\",\n \"limegreen\": \"#32cd32\",\n \"mediumseagreen\": \"#3cb371\",\n \"turquoise\": \"#40e0d0\",\n \"royalblue\": \"#4169e1\",\n \"steelblue\": \"#4682b4\",\n \"darkslateblue\": \"#483d8b\",\n \"mediumturquoise\": \"#48d1cc\",\n \"indigo\": \"#4b0082\",\n \"darkolivegreen\": \"#556b2f\",\n \"cadetblue\": \"#5f9ea0\",\n \"cornflowerblue\": \"#6495ed\",\n \"mediumaquamarine\": \"#66cdaa\",\n \"dimgray\": \"#696969\",\n \"dimgrey\": \"#696969\",\n \"slateblue\": \"#6a5acd\",\n \"olivedrab\": \"#6b8e23\",\n \"slategray\": \"#708090\",\n \"slategrey\": \"#708090\",\n \"lightslategray\": \"#778899\",\n \"lightslategrey\": \"#778899\",\n \"mediumslateblue\": \"#7b68ee\",\n \"lawngreen\": \"#7cfc00\",\n \"aquamarine\": \"#7fffd4\",\n \"chartreuse\": \"#7fff00\",\n \"gray\": \"#808080\",\n \"grey\": \"#808080\",\n \"maroon\": \"#800000\",\n \"olive\": \"#808000\",\n \"purple\": \"#800080\",\n \"lightskyblue\": \"#87cefa\",\n \"skyblue\": \"#87ceeb\",\n \"blueviolet\": \"#8a2be2\",\n \"darkmagenta\": \"#8b008b\",\n \"darkred\": \"#8b0000\",\n \"saddlebrown\": \"#8b4513\",\n \"darkseagreen\": \"#8fbc8f\",\n \"lightgreen\": \"#90ee90\",\n \"mediumpurple\": \"#9370db\",\n \"darkviolet\": \"#9400d3\",\n \"palegreen\": \"#98fb98\",\n \"darkorchid\": \"#9932cc\",\n \"yellowgreen\": \"#9acd32\",\n \"sienna\": \"#a0522d\",\n \"brown\": \"#a52a2a\",\n \"darkgray\": \"#a9a9a9\",\n \"darkgrey\": \"#a9a9a9\",\n \"greenyellow\": \"#adff2f\",\n \"lightblue\": \"#add8e6\",\n \"paleturquoise\": \"#afeeee\",\n \"lightsteelblue\": \"#b0c4de\",\n \"powderblue\": \"#b0e0e6\",\n \"firebrick\": \"#b22222\",\n \"darkgoldenrod\": \"#b8860b\",\n \"mediumorchid\": \"#ba55d3\",\n \"rosybrown\": \"#bc8f8f\",\n \"darkkhaki\": \"#bdb76b\",\n \"silver\": \"#c0c0c0\",\n \"mediumvioletred\": \"#c71585\",\n \"indianred\": \"#cd5c5c\",\n \"peru\": \"#cd853f\",\n \"chocolate\": \"#d2691e\",\n \"tan\": \"#d2b48c\",\n \"lightgray\": \"#d3d3d3\",\n \"lightgrey\": \"#d3d3d3\",\n \"thistle\": \"#d8bfd8\",\n \"goldenrod\": \"#daa520\",\n \"orchid\": \"#da70d6\",\n \"palevioletred\": \"#db7093\",\n \"crimson\": \"#dc143c\",\n \"gainsboro\": \"#dcdcdc\",\n \"plum\": \"#dda0dd\",\n \"burlywood\": \"#deb887\",\n \"lightcyan\": \"#e0ffff\",\n \"lavender\": \"#e6e6fa\",\n \"darksalmon\": \"#e9967a\",\n \"palegoldenrod\": \"#eee8aa\",\n \"violet\": \"#ee82ee\",\n \"azure\": \"#f0ffff\",\n \"honeydew\": \"#f0fff0\",\n \"khaki\": \"#f0e68c\",\n \"lightcoral\": \"#f08080\",\n \"sandybrown\": \"#f4a460\",\n \"beige\": \"#f5f5dc\",\n \"mintcream\": \"#f5fffa\",\n \"wheat\": \"#f5deb3\",\n \"whitesmoke\": \"#f5f5f5\",\n \"ghostwhite\": \"#f8f8ff\",\n \"lightgoldenrodyellow\": \"#fafad2\",\n \"linen\": \"#faf0e6\",\n \"salmon\": \"#fa8072\",\n \"oldlace\": \"#fdf5e6\",\n \"bisque\": \"#ffe4c4\",\n \"blanchedalmond\": \"#ffebcd\",\n \"coral\": \"#ff7f50\",\n \"cornsilk\": \"#fff8dc\",\n \"darkorange\": \"#ff8c00\",\n \"deeppink\": \"#ff1493\",\n \"floralwhite\": \"#fffaf0\",\n \"fuchsia\": \"#ff00ff\",\n \"gold\": \"#ffd700\",\n \"hotpink\": \"#ff69b4\",\n \"ivory\": \"#fffff0\",\n \"lavenderblush\": \"#fff0f5\",\n \"lemonchiffon\": \"#fffacd\",\n \"lightpink\": \"#ffb6c1\",\n \"lightsalmon\": \"#ffa07a\",\n \"lightyellow\": \"#ffffe0\",\n \"magenta\": \"#ff00ff\",\n \"mistyrose\": \"#ffe4e1\",\n \"moccasin\": \"#ffe4b5\",\n \"navajowhite\": \"#ffdead\",\n \"orange\": \"#ffa500\",\n \"orangered\": \"#ff4500\",\n \"papayawhip\": \"#ffefd5\",\n \"peachpuff\": \"#ffdab9\",\n \"pink\": \"#ffc0cb\",\n \"red\": \"#ff0000\",\n \"seashell\": \"#fff5ee\",\n \"snow\": \"#fffafa\",\n \"tomato\": \"#ff6347\",\n \"white\": \"#ffffff\",\n \"yellow\": \"#ffff00\",\n \"transparent\": \"#00000000\",\n}\n", "path": "vispy/color/_color_dict.py"}]} | 3,030 | 102 |
gh_patches_debug_29790 | rasdani/github-patches | git_diff | gammapy__gammapy-3336 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix test_wcs_nd_map_data_transpose_issue
I think here we forgot to pass `sparse=True` in `test_wcs_nd_map_data_transpose_issue`?
https://github.com/gammapy/gammapy/pull/1346/files#diff-930fa0f94b49b5d6537396fad7c6512aR137-R140
If I change to `sparse=True` in the write call, I get this fail:
```
E Arrays are not equal
E
E x and y nan location mismatch:
E x: array([[0., 1., 2.],
E [0., 0., 0.]], dtype=float32)
E y: array([[ 0., 1., 2.],
E [ nan, inf, -inf]])
```
@adonath - Is there a bug?
Should we spend 1-2 days on maps basics and sort out dtype and missing value issues (#1440, #2374, maybe this issue), e.g. with pair-coding & debugging? Or defer all or some to v1.1?
This is a reminder issue, noticed this accidentally while working on
https://github.com/gammapy/gammapy/pull/2350#issuecomment-542754564
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gammapy/maps/wcsmap.py`
Content:
```
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 import json
3 import numpy as np
4 from astropy.io import fits
5 from .core import Map
6 from .utils import find_bands_hdu, find_hdu, JsonQuantityEncoder
7 from .wcs import WcsGeom
8
9
10 __all__ = ["WcsMap"]
11
12
13 def identify_wcs_format(hdu):
14 if hdu is None:
15 return "gadf"
16 elif hdu.name == "ENERGIES":
17 return "fgst-template"
18 elif hdu.name == "EBOUNDS":
19 return "fgst-ccube"
20 else:
21 return "gadf"
22
23
24 class WcsMap(Map):
25 """Base class for WCS map classes.
26
27 Parameters
28 ----------
29 geom : `~gammapy.maps.WcsGeom`
30 A WCS geometry object.
31 data : `~numpy.ndarray`
32 Data array.
33 """
34
35 @classmethod
36 def create(
37 cls,
38 map_type="wcs",
39 npix=None,
40 binsz=0.1,
41 width=None,
42 proj="CAR",
43 frame="icrs",
44 refpix=None,
45 axes=None,
46 skydir=None,
47 dtype="float32",
48 meta=None,
49 unit="",
50 ):
51 """Factory method to create an empty WCS map.
52
53 Parameters
54 ----------
55 map_type : {'wcs', 'wcs-sparse'}
56 Map type. Selects the class that will be used to
57 instantiate the map.
58 npix : int or tuple or list
59 Width of the map in pixels. A tuple will be interpreted as
60 parameters for longitude and latitude axes. For maps with
61 non-spatial dimensions, list input can be used to define a
62 different map width in each image plane. This option
63 supersedes width.
64 width : float or tuple or list
65 Width of the map in degrees. A tuple will be interpreted
66 as parameters for longitude and latitude axes. For maps
67 with non-spatial dimensions, list input can be used to
68 define a different map width in each image plane.
69 binsz : float or tuple or list
70 Map pixel size in degrees. A tuple will be interpreted
71 as parameters for longitude and latitude axes. For maps
72 with non-spatial dimensions, list input can be used to
73 define a different bin size in each image plane.
74 skydir : tuple or `~astropy.coordinates.SkyCoord`
75 Sky position of map center. Can be either a SkyCoord
76 object or a tuple of longitude and latitude in deg in the
77 coordinate system of the map.
78 frame : {"icrs", "galactic"}, optional
79 Coordinate system, either Galactic ("galactic") or Equatorial ("icrs").
80 axes : list
81 List of non-spatial axes.
82 proj : string, optional
83 Any valid WCS projection type. Default is 'CAR' (cartesian).
84 refpix : tuple
85 Reference pixel of the projection. If None then this will
86 be chosen to be center of the map.
87 dtype : str, optional
88 Data type, default is float32
89 meta : `dict`
90 Dictionary to store meta data.
91 unit : str or `~astropy.units.Unit`
92 The unit of the map
93
94 Returns
95 -------
96 map : `~WcsMap`
97 A WCS map object.
98 """
99 from .wcsnd import WcsNDMap
100
101 geom = WcsGeom.create(
102 npix=npix,
103 binsz=binsz,
104 width=width,
105 proj=proj,
106 skydir=skydir,
107 frame=frame,
108 refpix=refpix,
109 axes=axes,
110 )
111
112 if map_type == "wcs":
113 return WcsNDMap(geom, dtype=dtype, meta=meta, unit=unit)
114 elif map_type == "wcs-sparse":
115 raise NotImplementedError
116 else:
117 raise ValueError(f"Invalid map type: {map_type!r}")
118
119 @classmethod
120 def from_hdulist(cls, hdu_list, hdu=None, hdu_bands=None, format="gadf"):
121 """Make a WcsMap object from a FITS HDUList.
122
123 Parameters
124 ----------
125 hdu_list : `~astropy.io.fits.HDUList`
126 HDU list containing HDUs for map data and bands.
127 hdu : str
128 Name or index of the HDU with the map data.
129 hdu_bands : str
130 Name or index of the HDU with the BANDS table.
131 format : {'gadf', 'fgst-ccube', 'fgst-template'}
132 FITS format convention.
133
134 Returns
135 -------
136 wcs_map : `WcsMap`
137 Map object
138 """
139 if hdu is None:
140 hdu = find_hdu(hdu_list)
141 else:
142 hdu = hdu_list[hdu]
143
144 if hdu_bands is None:
145 hdu_bands = find_bands_hdu(hdu_list, hdu)
146
147 if hdu_bands is not None:
148 hdu_bands = hdu_list[hdu_bands]
149
150 format = identify_wcs_format(hdu_bands)
151
152 wcs_map = cls.from_hdu(hdu, hdu_bands, format=format)
153
154 if wcs_map.unit.is_equivalent(""):
155 if format == "fgst-template":
156 if "GTI" in hdu_list: # exposure maps have an additional GTI hdu
157 wcs_map.unit = "cm2 s"
158 else:
159 wcs_map.unit = "cm-2 s-1 MeV-1 sr-1"
160
161 return wcs_map
162
163 def to_hdulist(self, hdu=None, hdu_bands=None, sparse=False, format="gadf"):
164 """Convert to `~astropy.io.fits.HDUList`.
165
166 Parameters
167 ----------
168 hdu : str
169 Name or index of the HDU with the map data.
170 hdu_bands : str
171 Name or index of the HDU with the BANDS table.
172 sparse : bool
173 Sparsify the map by only writing pixels with non-zero
174 amplitude.
175 format : {'gadf', 'fgst-ccube','fgst-template'}
176 FITS format convention.
177
178 Returns
179 -------
180 hdu_list : `~astropy.io.fits.HDUList`
181
182 """
183 if sparse:
184 hdu = "SKYMAP" if hdu is None else hdu.upper()
185 else:
186 hdu = "PRIMARY" if hdu is None else hdu.upper()
187
188 if sparse and hdu == "PRIMARY":
189 raise ValueError("Sparse maps cannot be written to the PRIMARY HDU.")
190
191 if format in ["fgst-ccube", "fgst-template"]:
192 if self.geom.axes[0].name != "energy" or len(self.geom.axes) > 1:
193 raise ValueError(
194 "All 'fgst' formats don't support extra axes except for energy."
195 )
196
197 if hdu_bands is None:
198 hdu_bands = f"{hdu.upper()}_BANDS"
199
200 if self.geom.axes:
201 hdu_bands_out = self.geom.to_bands_hdu(
202 hdu_bands=hdu_bands, format=format
203 )
204 hdu_bands = hdu_bands_out.name
205 else:
206 hdu_bands = None
207
208 hdu_out = self.to_hdu(hdu=hdu, hdu_bands=hdu_bands, sparse=sparse)
209
210 hdu_out.header["META"] = json.dumps(self.meta, cls=JsonQuantityEncoder)
211
212 hdu_out.header["BUNIT"] = self.unit.to_string("fits")
213
214 if hdu == "PRIMARY":
215 hdulist = [hdu_out]
216 else:
217 hdulist = [fits.PrimaryHDU(), hdu_out]
218
219 if self.geom.axes:
220 hdulist += [hdu_bands_out]
221
222 return fits.HDUList(hdulist)
223
224 def to_hdu(self, hdu="SKYMAP", hdu_bands=None, sparse=False):
225 """Make a FITS HDU from this map.
226
227 Parameters
228 ----------
229 hdu : str
230 The HDU extension name.
231 hdu_bands : str
232 The HDU extension name for BANDS table.
233 sparse : bool
234 Set INDXSCHM to SPARSE and sparsify the map by only
235 writing pixels with non-zero amplitude.
236
237 Returns
238 -------
239 hdu : `~astropy.io.fits.BinTableHDU` or `~astropy.io.fits.ImageHDU`
240 HDU containing the map data.
241 """
242 header = self.geom.to_header()
243
244 if self.is_mask:
245 data = self.data.astype(int)
246 else:
247 data = self.data
248
249 if hdu_bands is not None:
250 header["BANDSHDU"] = hdu_bands
251
252 if sparse:
253 hdu_out = self._make_hdu_sparse(data, self.geom.npix, hdu, header)
254 elif hdu == "PRIMARY":
255 hdu_out = fits.PrimaryHDU(data, header=header)
256 else:
257 hdu_out = fits.ImageHDU(data, header=header, name=hdu)
258
259 return hdu_out
260
261 @staticmethod
262 def _make_hdu_sparse(data, npix, hdu, header):
263 shape = data.shape
264
265 # We make a copy, because below we modify `data` to handle non-finite entries
266 # TODO: The code below could probably be simplified to use expressions
267 # that create new arrays instead of in-place modifications
268 # But first: do we want / need the non-finite entry handling at all and always cast to 64-bit float?
269 data = data.copy()
270
271 if len(shape) == 2:
272 data_flat = np.ravel(data)
273 data_flat[~np.isfinite(data_flat)] = 0
274 nonzero = np.where(data_flat > 0)
275 value = data_flat[nonzero].astype(float)
276 cols = [
277 fits.Column("PIX", "J", array=nonzero[0]),
278 fits.Column("VALUE", "E", array=value),
279 ]
280 elif npix[0].size == 1:
281 shape_flat = shape[:-2] + (shape[-1] * shape[-2],)
282 data_flat = np.ravel(data).reshape(shape_flat)
283 data_flat[~np.isfinite(data_flat)] = 0
284 nonzero = np.where(data_flat > 0)
285 channel = np.ravel_multi_index(nonzero[:-1], shape[:-2])
286 value = data_flat[nonzero].astype(float)
287 cols = [
288 fits.Column("PIX", "J", array=nonzero[-1]),
289 fits.Column("CHANNEL", "I", array=channel),
290 fits.Column("VALUE", "E", array=value),
291 ]
292 else:
293 data_flat = []
294 channel = []
295 pix = []
296 for i, _ in np.ndenumerate(npix[0]):
297 data_i = np.ravel(data[i[::-1]])
298 data_i[~np.isfinite(data_i)] = 0
299 pix_i = np.where(data_i > 0)
300 data_i = data_i[pix_i]
301 data_flat += [data_i]
302 pix += pix_i
303 channel += [
304 np.ones(data_i.size, dtype=int)
305 * np.ravel_multi_index(i[::-1], shape[:-2])
306 ]
307
308 pix = np.concatenate(pix)
309 channel = np.concatenate(channel)
310 value = np.concatenate(data_flat).astype(float)
311
312 cols = [
313 fits.Column("PIX", "J", array=pix),
314 fits.Column("CHANNEL", "I", array=channel),
315 fits.Column("VALUE", "E", array=value),
316 ]
317
318 return fits.BinTableHDU.from_columns(cols, header=header, name=hdu)
319
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gammapy/maps/wcsmap.py b/gammapy/maps/wcsmap.py
--- a/gammapy/maps/wcsmap.py
+++ b/gammapy/maps/wcsmap.py
@@ -270,18 +270,16 @@
if len(shape) == 2:
data_flat = np.ravel(data)
- data_flat[~np.isfinite(data_flat)] = 0
- nonzero = np.where(data_flat > 0)
- value = data_flat[nonzero].astype(float)
+ non_zero = np.where(~(data_flat == 0))
+ value = data_flat[non_zero].astype(float)
cols = [
- fits.Column("PIX", "J", array=nonzero[0]),
+ fits.Column("PIX", "J", array=non_zero[0]),
fits.Column("VALUE", "E", array=value),
]
elif npix[0].size == 1:
shape_flat = shape[:-2] + (shape[-1] * shape[-2],)
data_flat = np.ravel(data).reshape(shape_flat)
- data_flat[~np.isfinite(data_flat)] = 0
- nonzero = np.where(data_flat > 0)
+ nonzero = np.where(~(data_flat == 0))
channel = np.ravel_multi_index(nonzero[:-1], shape[:-2])
value = data_flat[nonzero].astype(float)
cols = [
@@ -295,8 +293,7 @@
pix = []
for i, _ in np.ndenumerate(npix[0]):
data_i = np.ravel(data[i[::-1]])
- data_i[~np.isfinite(data_i)] = 0
- pix_i = np.where(data_i > 0)
+ pix_i = np.where(~(data_i == 0))
data_i = data_i[pix_i]
data_flat += [data_i]
pix += pix_i
| {"golden_diff": "diff --git a/gammapy/maps/wcsmap.py b/gammapy/maps/wcsmap.py\n--- a/gammapy/maps/wcsmap.py\n+++ b/gammapy/maps/wcsmap.py\n@@ -270,18 +270,16 @@\n \n if len(shape) == 2:\n data_flat = np.ravel(data)\n- data_flat[~np.isfinite(data_flat)] = 0\n- nonzero = np.where(data_flat > 0)\n- value = data_flat[nonzero].astype(float)\n+ non_zero = np.where(~(data_flat == 0))\n+ value = data_flat[non_zero].astype(float)\n cols = [\n- fits.Column(\"PIX\", \"J\", array=nonzero[0]),\n+ fits.Column(\"PIX\", \"J\", array=non_zero[0]),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n elif npix[0].size == 1:\n shape_flat = shape[:-2] + (shape[-1] * shape[-2],)\n data_flat = np.ravel(data).reshape(shape_flat)\n- data_flat[~np.isfinite(data_flat)] = 0\n- nonzero = np.where(data_flat > 0)\n+ nonzero = np.where(~(data_flat == 0))\n channel = np.ravel_multi_index(nonzero[:-1], shape[:-2])\n value = data_flat[nonzero].astype(float)\n cols = [\n@@ -295,8 +293,7 @@\n pix = []\n for i, _ in np.ndenumerate(npix[0]):\n data_i = np.ravel(data[i[::-1]])\n- data_i[~np.isfinite(data_i)] = 0\n- pix_i = np.where(data_i > 0)\n+ pix_i = np.where(~(data_i == 0))\n data_i = data_i[pix_i]\n data_flat += [data_i]\n pix += pix_i\n", "issue": "Fix test_wcs_nd_map_data_transpose_issue\nI think here we forgot to pass `sparse=True` in `test_wcs_nd_map_data_transpose_issue`?\r\n\r\nhttps://github.com/gammapy/gammapy/pull/1346/files#diff-930fa0f94b49b5d6537396fad7c6512aR137-R140\r\n\r\nIf I change to `sparse=True` in the write call, I get this fail:\r\n```\r\nE Arrays are not equal\r\nE \r\nE x and y nan location mismatch:\r\nE x: array([[0., 1., 2.],\r\nE [0., 0., 0.]], dtype=float32)\r\nE y: array([[ 0., 1., 2.],\r\nE [ nan, inf, -inf]])\r\n```\r\n\r\n@adonath - Is there a bug?\r\n\r\nShould we spend 1-2 days on maps basics and sort out dtype and missing value issues (#1440, #2374, maybe this issue), e.g. with pair-coding & debugging? Or defer all or some to v1.1?\r\n\r\nThis is a reminder issue, noticed this accidentally while working on\r\nhttps://github.com/gammapy/gammapy/pull/2350#issuecomment-542754564\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport json\nimport numpy as np\nfrom astropy.io import fits\nfrom .core import Map\nfrom .utils import find_bands_hdu, find_hdu, JsonQuantityEncoder\nfrom .wcs import WcsGeom\n\n\n__all__ = [\"WcsMap\"]\n\n\ndef identify_wcs_format(hdu):\n if hdu is None:\n return \"gadf\"\n elif hdu.name == \"ENERGIES\":\n return \"fgst-template\"\n elif hdu.name == \"EBOUNDS\":\n return \"fgst-ccube\"\n else:\n return \"gadf\"\n\n\nclass WcsMap(Map):\n \"\"\"Base class for WCS map classes.\n\n Parameters\n ----------\n geom : `~gammapy.maps.WcsGeom`\n A WCS geometry object.\n data : `~numpy.ndarray`\n Data array.\n \"\"\"\n\n @classmethod\n def create(\n cls,\n map_type=\"wcs\",\n npix=None,\n binsz=0.1,\n width=None,\n proj=\"CAR\",\n frame=\"icrs\",\n refpix=None,\n axes=None,\n skydir=None,\n dtype=\"float32\",\n meta=None,\n unit=\"\",\n ):\n \"\"\"Factory method to create an empty WCS map.\n\n Parameters\n ----------\n map_type : {'wcs', 'wcs-sparse'}\n Map type. Selects the class that will be used to\n instantiate the map.\n npix : int or tuple or list\n Width of the map in pixels. A tuple will be interpreted as\n parameters for longitude and latitude axes. For maps with\n non-spatial dimensions, list input can be used to define a\n different map width in each image plane. This option\n supersedes width.\n width : float or tuple or list\n Width of the map in degrees. A tuple will be interpreted\n as parameters for longitude and latitude axes. For maps\n with non-spatial dimensions, list input can be used to\n define a different map width in each image plane.\n binsz : float or tuple or list\n Map pixel size in degrees. A tuple will be interpreted\n as parameters for longitude and latitude axes. For maps\n with non-spatial dimensions, list input can be used to\n define a different bin size in each image plane.\n skydir : tuple or `~astropy.coordinates.SkyCoord`\n Sky position of map center. Can be either a SkyCoord\n object or a tuple of longitude and latitude in deg in the\n coordinate system of the map.\n frame : {\"icrs\", \"galactic\"}, optional\n Coordinate system, either Galactic (\"galactic\") or Equatorial (\"icrs\").\n axes : list\n List of non-spatial axes.\n proj : string, optional\n Any valid WCS projection type. Default is 'CAR' (cartesian).\n refpix : tuple\n Reference pixel of the projection. If None then this will\n be chosen to be center of the map.\n dtype : str, optional\n Data type, default is float32\n meta : `dict`\n Dictionary to store meta data.\n unit : str or `~astropy.units.Unit`\n The unit of the map\n\n Returns\n -------\n map : `~WcsMap`\n A WCS map object.\n \"\"\"\n from .wcsnd import WcsNDMap\n\n geom = WcsGeom.create(\n npix=npix,\n binsz=binsz,\n width=width,\n proj=proj,\n skydir=skydir,\n frame=frame,\n refpix=refpix,\n axes=axes,\n )\n\n if map_type == \"wcs\":\n return WcsNDMap(geom, dtype=dtype, meta=meta, unit=unit)\n elif map_type == \"wcs-sparse\":\n raise NotImplementedError\n else:\n raise ValueError(f\"Invalid map type: {map_type!r}\")\n\n @classmethod\n def from_hdulist(cls, hdu_list, hdu=None, hdu_bands=None, format=\"gadf\"):\n \"\"\"Make a WcsMap object from a FITS HDUList.\n\n Parameters\n ----------\n hdu_list : `~astropy.io.fits.HDUList`\n HDU list containing HDUs for map data and bands.\n hdu : str\n Name or index of the HDU with the map data.\n hdu_bands : str\n Name or index of the HDU with the BANDS table.\n format : {'gadf', 'fgst-ccube', 'fgst-template'}\n FITS format convention.\n\n Returns\n -------\n wcs_map : `WcsMap`\n Map object\n \"\"\"\n if hdu is None:\n hdu = find_hdu(hdu_list)\n else:\n hdu = hdu_list[hdu]\n\n if hdu_bands is None:\n hdu_bands = find_bands_hdu(hdu_list, hdu)\n\n if hdu_bands is not None:\n hdu_bands = hdu_list[hdu_bands]\n\n format = identify_wcs_format(hdu_bands)\n\n wcs_map = cls.from_hdu(hdu, hdu_bands, format=format)\n\n if wcs_map.unit.is_equivalent(\"\"):\n if format == \"fgst-template\":\n if \"GTI\" in hdu_list: # exposure maps have an additional GTI hdu\n wcs_map.unit = \"cm2 s\"\n else:\n wcs_map.unit = \"cm-2 s-1 MeV-1 sr-1\"\n\n return wcs_map\n\n def to_hdulist(self, hdu=None, hdu_bands=None, sparse=False, format=\"gadf\"):\n \"\"\"Convert to `~astropy.io.fits.HDUList`.\n\n Parameters\n ----------\n hdu : str\n Name or index of the HDU with the map data.\n hdu_bands : str\n Name or index of the HDU with the BANDS table.\n sparse : bool\n Sparsify the map by only writing pixels with non-zero\n amplitude.\n format : {'gadf', 'fgst-ccube','fgst-template'}\n FITS format convention.\n\n Returns\n -------\n hdu_list : `~astropy.io.fits.HDUList`\n\n \"\"\"\n if sparse:\n hdu = \"SKYMAP\" if hdu is None else hdu.upper()\n else:\n hdu = \"PRIMARY\" if hdu is None else hdu.upper()\n\n if sparse and hdu == \"PRIMARY\":\n raise ValueError(\"Sparse maps cannot be written to the PRIMARY HDU.\")\n\n if format in [\"fgst-ccube\", \"fgst-template\"]:\n if self.geom.axes[0].name != \"energy\" or len(self.geom.axes) > 1:\n raise ValueError(\n \"All 'fgst' formats don't support extra axes except for energy.\"\n )\n\n if hdu_bands is None:\n hdu_bands = f\"{hdu.upper()}_BANDS\"\n\n if self.geom.axes:\n hdu_bands_out = self.geom.to_bands_hdu(\n hdu_bands=hdu_bands, format=format\n )\n hdu_bands = hdu_bands_out.name\n else:\n hdu_bands = None\n\n hdu_out = self.to_hdu(hdu=hdu, hdu_bands=hdu_bands, sparse=sparse)\n\n hdu_out.header[\"META\"] = json.dumps(self.meta, cls=JsonQuantityEncoder)\n\n hdu_out.header[\"BUNIT\"] = self.unit.to_string(\"fits\")\n\n if hdu == \"PRIMARY\":\n hdulist = [hdu_out]\n else:\n hdulist = [fits.PrimaryHDU(), hdu_out]\n\n if self.geom.axes:\n hdulist += [hdu_bands_out]\n\n return fits.HDUList(hdulist)\n\n def to_hdu(self, hdu=\"SKYMAP\", hdu_bands=None, sparse=False):\n \"\"\"Make a FITS HDU from this map.\n\n Parameters\n ----------\n hdu : str\n The HDU extension name.\n hdu_bands : str\n The HDU extension name for BANDS table.\n sparse : bool\n Set INDXSCHM to SPARSE and sparsify the map by only\n writing pixels with non-zero amplitude.\n\n Returns\n -------\n hdu : `~astropy.io.fits.BinTableHDU` or `~astropy.io.fits.ImageHDU`\n HDU containing the map data.\n \"\"\"\n header = self.geom.to_header()\n\n if self.is_mask:\n data = self.data.astype(int)\n else:\n data = self.data\n\n if hdu_bands is not None:\n header[\"BANDSHDU\"] = hdu_bands\n\n if sparse:\n hdu_out = self._make_hdu_sparse(data, self.geom.npix, hdu, header)\n elif hdu == \"PRIMARY\":\n hdu_out = fits.PrimaryHDU(data, header=header)\n else:\n hdu_out = fits.ImageHDU(data, header=header, name=hdu)\n\n return hdu_out\n\n @staticmethod\n def _make_hdu_sparse(data, npix, hdu, header):\n shape = data.shape\n\n # We make a copy, because below we modify `data` to handle non-finite entries\n # TODO: The code below could probably be simplified to use expressions\n # that create new arrays instead of in-place modifications\n # But first: do we want / need the non-finite entry handling at all and always cast to 64-bit float?\n data = data.copy()\n\n if len(shape) == 2:\n data_flat = np.ravel(data)\n data_flat[~np.isfinite(data_flat)] = 0\n nonzero = np.where(data_flat > 0)\n value = data_flat[nonzero].astype(float)\n cols = [\n fits.Column(\"PIX\", \"J\", array=nonzero[0]),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n elif npix[0].size == 1:\n shape_flat = shape[:-2] + (shape[-1] * shape[-2],)\n data_flat = np.ravel(data).reshape(shape_flat)\n data_flat[~np.isfinite(data_flat)] = 0\n nonzero = np.where(data_flat > 0)\n channel = np.ravel_multi_index(nonzero[:-1], shape[:-2])\n value = data_flat[nonzero].astype(float)\n cols = [\n fits.Column(\"PIX\", \"J\", array=nonzero[-1]),\n fits.Column(\"CHANNEL\", \"I\", array=channel),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n else:\n data_flat = []\n channel = []\n pix = []\n for i, _ in np.ndenumerate(npix[0]):\n data_i = np.ravel(data[i[::-1]])\n data_i[~np.isfinite(data_i)] = 0\n pix_i = np.where(data_i > 0)\n data_i = data_i[pix_i]\n data_flat += [data_i]\n pix += pix_i\n channel += [\n np.ones(data_i.size, dtype=int)\n * np.ravel_multi_index(i[::-1], shape[:-2])\n ]\n\n pix = np.concatenate(pix)\n channel = np.concatenate(channel)\n value = np.concatenate(data_flat).astype(float)\n\n cols = [\n fits.Column(\"PIX\", \"J\", array=pix),\n fits.Column(\"CHANNEL\", \"I\", array=channel),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n\n return fits.BinTableHDU.from_columns(cols, header=header, name=hdu)\n", "path": "gammapy/maps/wcsmap.py"}], "after_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport json\nimport numpy as np\nfrom astropy.io import fits\nfrom .core import Map\nfrom .utils import find_bands_hdu, find_hdu, JsonQuantityEncoder\nfrom .wcs import WcsGeom\n\n\n__all__ = [\"WcsMap\"]\n\n\ndef identify_wcs_format(hdu):\n if hdu is None:\n return \"gadf\"\n elif hdu.name == \"ENERGIES\":\n return \"fgst-template\"\n elif hdu.name == \"EBOUNDS\":\n return \"fgst-ccube\"\n else:\n return \"gadf\"\n\n\nclass WcsMap(Map):\n \"\"\"Base class for WCS map classes.\n\n Parameters\n ----------\n geom : `~gammapy.maps.WcsGeom`\n A WCS geometry object.\n data : `~numpy.ndarray`\n Data array.\n \"\"\"\n\n @classmethod\n def create(\n cls,\n map_type=\"wcs\",\n npix=None,\n binsz=0.1,\n width=None,\n proj=\"CAR\",\n frame=\"icrs\",\n refpix=None,\n axes=None,\n skydir=None,\n dtype=\"float32\",\n meta=None,\n unit=\"\",\n ):\n \"\"\"Factory method to create an empty WCS map.\n\n Parameters\n ----------\n map_type : {'wcs', 'wcs-sparse'}\n Map type. Selects the class that will be used to\n instantiate the map.\n npix : int or tuple or list\n Width of the map in pixels. A tuple will be interpreted as\n parameters for longitude and latitude axes. For maps with\n non-spatial dimensions, list input can be used to define a\n different map width in each image plane. This option\n supersedes width.\n width : float or tuple or list\n Width of the map in degrees. A tuple will be interpreted\n as parameters for longitude and latitude axes. For maps\n with non-spatial dimensions, list input can be used to\n define a different map width in each image plane.\n binsz : float or tuple or list\n Map pixel size in degrees. A tuple will be interpreted\n as parameters for longitude and latitude axes. For maps\n with non-spatial dimensions, list input can be used to\n define a different bin size in each image plane.\n skydir : tuple or `~astropy.coordinates.SkyCoord`\n Sky position of map center. Can be either a SkyCoord\n object or a tuple of longitude and latitude in deg in the\n coordinate system of the map.\n frame : {\"icrs\", \"galactic\"}, optional\n Coordinate system, either Galactic (\"galactic\") or Equatorial (\"icrs\").\n axes : list\n List of non-spatial axes.\n proj : string, optional\n Any valid WCS projection type. Default is 'CAR' (cartesian).\n refpix : tuple\n Reference pixel of the projection. If None then this will\n be chosen to be center of the map.\n dtype : str, optional\n Data type, default is float32\n meta : `dict`\n Dictionary to store meta data.\n unit : str or `~astropy.units.Unit`\n The unit of the map\n\n Returns\n -------\n map : `~WcsMap`\n A WCS map object.\n \"\"\"\n from .wcsnd import WcsNDMap\n\n geom = WcsGeom.create(\n npix=npix,\n binsz=binsz,\n width=width,\n proj=proj,\n skydir=skydir,\n frame=frame,\n refpix=refpix,\n axes=axes,\n )\n\n if map_type == \"wcs\":\n return WcsNDMap(geom, dtype=dtype, meta=meta, unit=unit)\n elif map_type == \"wcs-sparse\":\n raise NotImplementedError\n else:\n raise ValueError(f\"Invalid map type: {map_type!r}\")\n\n @classmethod\n def from_hdulist(cls, hdu_list, hdu=None, hdu_bands=None, format=\"gadf\"):\n \"\"\"Make a WcsMap object from a FITS HDUList.\n\n Parameters\n ----------\n hdu_list : `~astropy.io.fits.HDUList`\n HDU list containing HDUs for map data and bands.\n hdu : str\n Name or index of the HDU with the map data.\n hdu_bands : str\n Name or index of the HDU with the BANDS table.\n format : {'gadf', 'fgst-ccube', 'fgst-template'}\n FITS format convention.\n\n Returns\n -------\n wcs_map : `WcsMap`\n Map object\n \"\"\"\n if hdu is None:\n hdu = find_hdu(hdu_list)\n else:\n hdu = hdu_list[hdu]\n\n if hdu_bands is None:\n hdu_bands = find_bands_hdu(hdu_list, hdu)\n\n if hdu_bands is not None:\n hdu_bands = hdu_list[hdu_bands]\n\n format = identify_wcs_format(hdu_bands)\n\n wcs_map = cls.from_hdu(hdu, hdu_bands, format=format)\n\n if wcs_map.unit.is_equivalent(\"\"):\n if format == \"fgst-template\":\n if \"GTI\" in hdu_list: # exposure maps have an additional GTI hdu\n wcs_map.unit = \"cm2 s\"\n else:\n wcs_map.unit = \"cm-2 s-1 MeV-1 sr-1\"\n\n return wcs_map\n\n def to_hdulist(self, hdu=None, hdu_bands=None, sparse=False, format=\"gadf\"):\n \"\"\"Convert to `~astropy.io.fits.HDUList`.\n\n Parameters\n ----------\n hdu : str\n Name or index of the HDU with the map data.\n hdu_bands : str\n Name or index of the HDU with the BANDS table.\n sparse : bool\n Sparsify the map by only writing pixels with non-zero\n amplitude.\n format : {'gadf', 'fgst-ccube','fgst-template'}\n FITS format convention.\n\n Returns\n -------\n hdu_list : `~astropy.io.fits.HDUList`\n\n \"\"\"\n if sparse:\n hdu = \"SKYMAP\" if hdu is None else hdu.upper()\n else:\n hdu = \"PRIMARY\" if hdu is None else hdu.upper()\n\n if sparse and hdu == \"PRIMARY\":\n raise ValueError(\"Sparse maps cannot be written to the PRIMARY HDU.\")\n\n if format in [\"fgst-ccube\", \"fgst-template\"]:\n if self.geom.axes[0].name != \"energy\" or len(self.geom.axes) > 1:\n raise ValueError(\n \"All 'fgst' formats don't support extra axes except for energy.\"\n )\n\n if hdu_bands is None:\n hdu_bands = f\"{hdu.upper()}_BANDS\"\n\n if self.geom.axes:\n hdu_bands_out = self.geom.to_bands_hdu(\n hdu_bands=hdu_bands, format=format\n )\n hdu_bands = hdu_bands_out.name\n else:\n hdu_bands = None\n\n hdu_out = self.to_hdu(hdu=hdu, hdu_bands=hdu_bands, sparse=sparse)\n\n hdu_out.header[\"META\"] = json.dumps(self.meta, cls=JsonQuantityEncoder)\n\n hdu_out.header[\"BUNIT\"] = self.unit.to_string(\"fits\")\n\n if hdu == \"PRIMARY\":\n hdulist = [hdu_out]\n else:\n hdulist = [fits.PrimaryHDU(), hdu_out]\n\n if self.geom.axes:\n hdulist += [hdu_bands_out]\n\n return fits.HDUList(hdulist)\n\n def to_hdu(self, hdu=\"SKYMAP\", hdu_bands=None, sparse=False):\n \"\"\"Make a FITS HDU from this map.\n\n Parameters\n ----------\n hdu : str\n The HDU extension name.\n hdu_bands : str\n The HDU extension name for BANDS table.\n sparse : bool\n Set INDXSCHM to SPARSE and sparsify the map by only\n writing pixels with non-zero amplitude.\n\n Returns\n -------\n hdu : `~astropy.io.fits.BinTableHDU` or `~astropy.io.fits.ImageHDU`\n HDU containing the map data.\n \"\"\"\n header = self.geom.to_header()\n\n if self.is_mask:\n data = self.data.astype(int)\n else:\n data = self.data\n\n if hdu_bands is not None:\n header[\"BANDSHDU\"] = hdu_bands\n\n if sparse:\n hdu_out = self._make_hdu_sparse(data, self.geom.npix, hdu, header)\n elif hdu == \"PRIMARY\":\n hdu_out = fits.PrimaryHDU(data, header=header)\n else:\n hdu_out = fits.ImageHDU(data, header=header, name=hdu)\n\n return hdu_out\n\n @staticmethod\n def _make_hdu_sparse(data, npix, hdu, header):\n shape = data.shape\n\n # We make a copy, because below we modify `data` to handle non-finite entries\n # TODO: The code below could probably be simplified to use expressions\n # that create new arrays instead of in-place modifications\n # But first: do we want / need the non-finite entry handling at all and always cast to 64-bit float?\n data = data.copy()\n\n if len(shape) == 2:\n data_flat = np.ravel(data)\n non_zero = np.where(~(data_flat == 0))\n value = data_flat[non_zero].astype(float)\n cols = [\n fits.Column(\"PIX\", \"J\", array=non_zero[0]),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n elif npix[0].size == 1:\n shape_flat = shape[:-2] + (shape[-1] * shape[-2],)\n data_flat = np.ravel(data).reshape(shape_flat)\n nonzero = np.where(~(data_flat == 0))\n channel = np.ravel_multi_index(nonzero[:-1], shape[:-2])\n value = data_flat[nonzero].astype(float)\n cols = [\n fits.Column(\"PIX\", \"J\", array=nonzero[-1]),\n fits.Column(\"CHANNEL\", \"I\", array=channel),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n else:\n data_flat = []\n channel = []\n pix = []\n for i, _ in np.ndenumerate(npix[0]):\n data_i = np.ravel(data[i[::-1]])\n pix_i = np.where(~(data_i == 0))\n data_i = data_i[pix_i]\n data_flat += [data_i]\n pix += pix_i\n channel += [\n np.ones(data_i.size, dtype=int)\n * np.ravel_multi_index(i[::-1], shape[:-2])\n ]\n\n pix = np.concatenate(pix)\n channel = np.concatenate(channel)\n value = np.concatenate(data_flat).astype(float)\n\n cols = [\n fits.Column(\"PIX\", \"J\", array=pix),\n fits.Column(\"CHANNEL\", \"I\", array=channel),\n fits.Column(\"VALUE\", \"E\", array=value),\n ]\n\n return fits.BinTableHDU.from_columns(cols, header=header, name=hdu)\n", "path": "gammapy/maps/wcsmap.py"}]} | 4,025 | 432 |
gh_patches_debug_39843 | rasdani/github-patches | git_diff | projectmesa__mesa-289 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Minor docstring clean-up needed on time.py and batchrunner.py
A couple of typos and minor content edit items for the two files.
Minor docstring clean-up needed on time.py and batchrunner.py
A couple of typos and minor content edit items for the two files.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mesa/batchrunner.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Batchrunner
4 ===========
5
6 A single class to manage a batch run or parameter sweep of a given model.
7
8 """
9 from itertools import product
10 import pandas as pd
11
12
13 class BatchRunner:
14 """ This class is instantiated with a model class, and model parameters
15 associated with one or more values. It is also instantiated with model- and
16 agent-level reporters, dictionaries mapping a variable name to a function
17 which collects some data from the model or its agents at the end of the run
18 and stores it.
19
20 Note that by default, the reporters only collect data at the *end* of the
21 run. To get step by step data, simply have a reporter store the model's
22 entire DataCollector object.
23
24 """
25 def __init__(self, model_cls, parameter_values, iterations=1,
26 max_steps=1000, model_reporters=None, agent_reporters=None):
27 """ Create a new BatchRunner for a given model with the given
28 parameters.
29
30 Args:
31 model_cls: The class of model to batch-run.
32 parameter_values: Dictionary of parameters to their values or
33 ranges of values. For example:
34 {"param_1": range(5),
35 "param_2": [1, 5, 10],
36 "const_param": 100}
37 iterations: How many times to run the model at each combination of
38 parameters.
39 max_steps: After how many steps to halt each run if it hasn't
40 halted on its own.
41 model_reporters: Dictionary of variables to collect on each run at
42 the end, with variable names mapped to a function to collect
43 them. For example:
44 {"agent_count": lambda m: m.schedule.get_agent_count()}
45 agent_reporters: Like model_reporters, but each variable is now
46 collected at the level of each agent present in the model at
47 the end of the run.
48
49 """
50 self.model_cls = model_cls
51 self.parameter_values = {param: self.make_iterable(vals)
52 for param, vals in parameter_values.items()}
53 self.iterations = iterations
54 self.max_steps = max_steps
55
56 self.model_reporters = model_reporters
57 self.agent_reporters = agent_reporters
58
59 if self.model_reporters:
60 self.model_vars = {}
61
62 if self.agent_reporters:
63 self.agent_vars = {}
64
65 def run_all(self):
66 """ Run the model at all parameter combinations and store results. """
67 params = self.parameter_values.keys()
68 param_ranges = self.parameter_values.values()
69 run_count = 0
70 for param_values in list(product(*param_ranges)):
71 kwargs = dict(zip(params, param_values))
72 for _ in range(self.iterations):
73 model = self.model_cls(**kwargs)
74 self.run_model(model)
75 # Collect and store results:
76 if self.model_reporters:
77 key = tuple(list(param_values) + [run_count])
78 self.model_vars[key] = self.collect_model_vars(model)
79 if self.agent_reporters:
80 agent_vars = self.collect_agent_vars(model)
81 for agent_id, reports in agent_vars.items():
82 key = tuple(list(param_values) + [run_count, agent_id])
83 self.agent_vars[key] = reports
84 run_count += 1
85
86 def run_model(self, model):
87 """ Run a model object to completion, or until reaching max steps.
88
89 If your model runs in a non-standard way, this is the method to modify
90 in your subclass.
91
92 """
93 while model.running and model.schedule.steps < self.max_steps:
94 model.step()
95
96 def collect_model_vars(self, model):
97 """ Run reporters and collect model-level variables. """
98 model_vars = {}
99 for var, reporter in self.model_reporters.items():
100 model_vars[var] = reporter(model)
101 return model_vars
102
103 def collect_agent_vars(self, model):
104 """ Run reporters and collect agent-level variables. """
105 agent_vars = {}
106 for agent in model.schedule.agents:
107 agent_record = {}
108 for var, reporter in self.agent_reporters.items():
109 agent_record[var] = reporter(agent)
110 agent_vars[agent.unique_id] = agent_record
111 return agent_vars
112
113 def get_model_vars_dataframe(self):
114 """ Generate a pandas DataFrame from the model-level collected
115 variables.
116
117 """
118 index_col_names = list(self.parameter_values.keys())
119 index_col_names.append("Run")
120 records = []
121 for key, val in self.model_vars.items():
122 record = dict(zip(index_col_names, key))
123 for k, v in val.items():
124 record[k] = v
125 records.append(record)
126 return pd.DataFrame(records)
127
128 def get_agent_vars_dataframe(self):
129 """ Generate a pandas DataFrame from the agent-level variables
130 collected.
131
132 """
133 index_col_names = list(self.parameter_values.keys())
134 index_col_names += ["Run", "AgentID"]
135 records = []
136 for key, val in self.agent_vars.items():
137 record = dict(zip(index_col_names, key))
138 for k, v in val.items():
139 record[k] = v
140 records.append(record)
141 return pd.DataFrame(records)
142
143 @staticmethod
144 def make_iterable(val):
145 """ Helper method to ensure a value is a non-string iterable. """
146 if hasattr(val, "__iter__") and not isinstance(val, str):
147 return val
148 else:
149 return [val]
150
```
Path: `mesa/time.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Mesa Time Module
4 ================
5
6 Objects for handling the time component of a model. In particular, this module
7 contains Schedulers, which handle agent activation. A Scheduler is an object
8 which controls when agents are called upon to act, and when.
9
10 The activation order can have a serious impact on model behavior, so it's
11 important to specify it explicity. Example simple activation regimes include
12 activating all agents in the same order every step, shuffling the activation
13 order every time, activating each agent *on average* once per step, and more.
14
15 Key concepts:
16 Step: Many models advance in 'steps'. A step may involve the activation of
17 all agents, or a random (or selected) subset of them. Each agent in turn
18 may have their own step() method.
19
20 Time: Some models may simulate a continuous 'clock' instead of discrete
21 steps. However, by default, the Time is equal to the number of steps the
22 model has taken.
23
24
25 TODO: Have the schedulers use the model's randomizer, to keep random number
26 seeds consistent and allow for replication.
27
28 """
29 import random
30
31
32 class BaseScheduler:
33 """ Simplest scheduler; activates agents one at a time, in the order
34 they were added.
35
36 Assumes that each agent added has a *step* method, which accepts a model
37 object as its single argument.
38
39 (This is explicitly meant to replicate the scheduler in MASON).
40
41 """
42 model = None
43 steps = 0
44 time = 0
45 agents = []
46
47 def __init__(self, model):
48 """ Create a new, empty BaseScheduler. """
49 self.model = model
50 self.steps = 0
51 self.time = 0
52 self.agents = []
53
54 def add(self, agent):
55 """ Add an Agent object to the schedule.
56
57 Args:
58 agent: An Agent to be added to the schedule. NOTE: The agent must
59 have a step(model) method.
60
61 """
62 self.agents.append(agent)
63
64 def remove(self, agent):
65 """ Remove all instances of a given agent from the schedule.
66
67 Args:
68 agent: An agent object.
69
70 """
71 while agent in self.agents:
72 self.agents.remove(agent)
73
74 def step(self):
75 """ Execute the step of all the agents, one at a time. """
76 for agent in self.agents:
77 agent.step(self.model)
78 self.steps += 1
79 self.time += 1
80
81 def get_agent_count(self):
82 """ Returns the current number of agents in the queue. """
83 return len(self.agents)
84
85
86 class RandomActivation(BaseScheduler):
87 """ A scheduler which activates each agent once per step, in random order,
88 with the order reshuffled every step.
89
90 This is equivalent to the NetLogo 'ask agents...' and is generally the
91 default behavior for an ABM.
92
93 Assumes that all agents have a step(model) method.
94
95 """
96 def step(self):
97 """ Executes the step of all agents, one at a time, in
98 random order.
99
100 """
101 random.shuffle(self.agents)
102
103 for agent in self.agents:
104 agent.step(self.model)
105 self.steps += 1
106 self.time += 1
107
108
109 class SimultaneousActivation(BaseScheduler):
110 """ A scheduler to simulate the simultaneous activation of all the agents.
111
112 This scheduler requires that each agent have two methods: step and advance.
113 step(model) activates the agent and stages any necessary changes, but does
114 not apply them yet. advance(model) then applies the changes.
115
116 """
117 def step(self):
118 """ Step all agents, then advance them. """
119 for agent in self.agents:
120 agent.step(self.model)
121 for agent in self.agents:
122 agent.advance(self.model)
123 self.steps += 1
124 self.time += 1
125
126
127 class StagedActivation(BaseScheduler):
128 """ A scheduler which allows agent activation to be divided into several
129 stages instead of a single `step` method. All agents execute one stage
130 before moving on to the next.
131
132 Agents must have all the stage methods implemented. Stage methods take a
133 model object as their only argument.
134
135 This schedule tracks steps and time separately. Time advances in fractional
136 increments of 1 / (# of stages), meaning that 1 step = 1 unit of time.
137
138 """
139 stage_list = []
140 shuffle = False
141 shuffle_between_stages = False
142 stage_time = 1
143
144 def __init__(self, model, stage_list=["step"], shuffle=False,
145 shuffle_between_stages=False):
146 """ Create an empty Staged Activation schedule.
147
148 Args:
149 model: Model object associated with the schedule.
150 stage_list: List of strings of names of stages to run, in the
151 order to run them in.
152 shuffle: If True, shuffle the order of agents each step.
153 shuffle_between_stages: If True, shuffle the agents after each
154 stage; otherwise, only shuffle at the start
155 of each step.
156
157 """
158 super().__init__(model)
159 self.stage_list = stage_list
160 self.shuffle = shuffle
161 self.shuffle_between_stages = shuffle_between_stages
162 self.stage_time = 1 / len(self.stage_list)
163
164 def step(self):
165 """ Executes all the stages of all agents. """
166 if self.shuffle:
167 random.shuffle(self.agents)
168 for stage in self.stage_list:
169 for agent in self.agents:
170 getattr(agent, stage)(self.model) # Run stage
171 if self.shuffle_between_stages:
172 random.shuffle(self.agents)
173 self.time += self.stage_time
174
175 self.steps += 1
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mesa/batchrunner.py b/mesa/batchrunner.py
--- a/mesa/batchrunner.py
+++ b/mesa/batchrunner.py
@@ -12,7 +12,7 @@
class BatchRunner:
""" This class is instantiated with a model class, and model parameters
- associated with one or more values. It is also instantiated with model- and
+ associated with one or more values. It is also instantiated with model and
agent-level reporters, dictionaries mapping a variable name to a function
which collects some data from the model or its agents at the end of the run
and stores it.
@@ -34,11 +34,11 @@
{"param_1": range(5),
"param_2": [1, 5, 10],
"const_param": 100}
- iterations: How many times to run the model at each combination of
- parameters.
- max_steps: After how many steps to halt each run if it hasn't
- halted on its own.
- model_reporters: Dictionary of variables to collect on each run at
+ iterations: The total number of times to run the model for each
+ combination of parameters.
+ max_steps: The upper limit of steps above which each run will be halted
+ if it hasn't halted on its own.
+ model_reporters: The dictionary of variables to collect on each run at
the end, with variable names mapped to a function to collect
them. For example:
{"agent_count": lambda m: m.schedule.get_agent_count()}
@@ -111,8 +111,7 @@
return agent_vars
def get_model_vars_dataframe(self):
- """ Generate a pandas DataFrame from the model-level collected
- variables.
+ """ Generate a pandas DataFrame from the model-level variables collected.
"""
index_col_names = list(self.parameter_values.keys())
diff --git a/mesa/time.py b/mesa/time.py
--- a/mesa/time.py
+++ b/mesa/time.py
@@ -8,7 +8,7 @@
which controls when agents are called upon to act, and when.
The activation order can have a serious impact on model behavior, so it's
-important to specify it explicity. Example simple activation regimes include
+important to specify it explicitly. Example simple activation regimes include
activating all agents in the same order every step, shuffling the activation
order every time, activating each agent *on average* once per step, and more.
@@ -162,7 +162,7 @@
self.stage_time = 1 / len(self.stage_list)
def step(self):
- """ Executes all the stages of all agents. """
+ """ Executes all the stages for all agents. """
if self.shuffle:
random.shuffle(self.agents)
for stage in self.stage_list:
| {"golden_diff": "diff --git a/mesa/batchrunner.py b/mesa/batchrunner.py\n--- a/mesa/batchrunner.py\n+++ b/mesa/batchrunner.py\n@@ -12,7 +12,7 @@\n \n class BatchRunner:\n \"\"\" This class is instantiated with a model class, and model parameters\n- associated with one or more values. It is also instantiated with model- and\n+ associated with one or more values. It is also instantiated with model and\n agent-level reporters, dictionaries mapping a variable name to a function\n which collects some data from the model or its agents at the end of the run\n and stores it.\n@@ -34,11 +34,11 @@\n {\"param_1\": range(5),\n \"param_2\": [1, 5, 10],\n \"const_param\": 100}\n- iterations: How many times to run the model at each combination of\n- parameters.\n- max_steps: After how many steps to halt each run if it hasn't\n- halted on its own.\n- model_reporters: Dictionary of variables to collect on each run at\n+ iterations: The total number of times to run the model for each\n+ combination of parameters.\n+ max_steps: The upper limit of steps above which each run will be halted\n+ if it hasn't halted on its own.\n+ model_reporters: The dictionary of variables to collect on each run at\n the end, with variable names mapped to a function to collect\n them. For example:\n {\"agent_count\": lambda m: m.schedule.get_agent_count()}\n@@ -111,8 +111,7 @@\n return agent_vars\n \n def get_model_vars_dataframe(self):\n- \"\"\" Generate a pandas DataFrame from the model-level collected\n- variables.\n+ \"\"\" Generate a pandas DataFrame from the model-level variables collected.\n \n \"\"\"\n index_col_names = list(self.parameter_values.keys())\ndiff --git a/mesa/time.py b/mesa/time.py\n--- a/mesa/time.py\n+++ b/mesa/time.py\n@@ -8,7 +8,7 @@\n which controls when agents are called upon to act, and when.\n \n The activation order can have a serious impact on model behavior, so it's\n-important to specify it explicity. Example simple activation regimes include\n+important to specify it explicitly. Example simple activation regimes include\n activating all agents in the same order every step, shuffling the activation\n order every time, activating each agent *on average* once per step, and more.\n \n@@ -162,7 +162,7 @@\n self.stage_time = 1 / len(self.stage_list)\n \n def step(self):\n- \"\"\" Executes all the stages of all agents. \"\"\"\n+ \"\"\" Executes all the stages for all agents. \"\"\"\n if self.shuffle:\n random.shuffle(self.agents)\n for stage in self.stage_list:\n", "issue": "Minor docstring clean-up needed on time.py and batchrunner.py\nA couple of typos and minor content edit items for the two files.\n\nMinor docstring clean-up needed on time.py and batchrunner.py\nA couple of typos and minor content edit items for the two files.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nBatchrunner\n===========\n\nA single class to manage a batch run or parameter sweep of a given model.\n\n\"\"\"\nfrom itertools import product\nimport pandas as pd\n\n\nclass BatchRunner:\n \"\"\" This class is instantiated with a model class, and model parameters\n associated with one or more values. It is also instantiated with model- and\n agent-level reporters, dictionaries mapping a variable name to a function\n which collects some data from the model or its agents at the end of the run\n and stores it.\n\n Note that by default, the reporters only collect data at the *end* of the\n run. To get step by step data, simply have a reporter store the model's\n entire DataCollector object.\n\n \"\"\"\n def __init__(self, model_cls, parameter_values, iterations=1,\n max_steps=1000, model_reporters=None, agent_reporters=None):\n \"\"\" Create a new BatchRunner for a given model with the given\n parameters.\n\n Args:\n model_cls: The class of model to batch-run.\n parameter_values: Dictionary of parameters to their values or\n ranges of values. For example:\n {\"param_1\": range(5),\n \"param_2\": [1, 5, 10],\n \"const_param\": 100}\n iterations: How many times to run the model at each combination of\n parameters.\n max_steps: After how many steps to halt each run if it hasn't\n halted on its own.\n model_reporters: Dictionary of variables to collect on each run at\n the end, with variable names mapped to a function to collect\n them. For example:\n {\"agent_count\": lambda m: m.schedule.get_agent_count()}\n agent_reporters: Like model_reporters, but each variable is now\n collected at the level of each agent present in the model at\n the end of the run.\n\n \"\"\"\n self.model_cls = model_cls\n self.parameter_values = {param: self.make_iterable(vals)\n for param, vals in parameter_values.items()}\n self.iterations = iterations\n self.max_steps = max_steps\n\n self.model_reporters = model_reporters\n self.agent_reporters = agent_reporters\n\n if self.model_reporters:\n self.model_vars = {}\n\n if self.agent_reporters:\n self.agent_vars = {}\n\n def run_all(self):\n \"\"\" Run the model at all parameter combinations and store results. \"\"\"\n params = self.parameter_values.keys()\n param_ranges = self.parameter_values.values()\n run_count = 0\n for param_values in list(product(*param_ranges)):\n kwargs = dict(zip(params, param_values))\n for _ in range(self.iterations):\n model = self.model_cls(**kwargs)\n self.run_model(model)\n # Collect and store results:\n if self.model_reporters:\n key = tuple(list(param_values) + [run_count])\n self.model_vars[key] = self.collect_model_vars(model)\n if self.agent_reporters:\n agent_vars = self.collect_agent_vars(model)\n for agent_id, reports in agent_vars.items():\n key = tuple(list(param_values) + [run_count, agent_id])\n self.agent_vars[key] = reports\n run_count += 1\n\n def run_model(self, model):\n \"\"\" Run a model object to completion, or until reaching max steps.\n\n If your model runs in a non-standard way, this is the method to modify\n in your subclass.\n\n \"\"\"\n while model.running and model.schedule.steps < self.max_steps:\n model.step()\n\n def collect_model_vars(self, model):\n \"\"\" Run reporters and collect model-level variables. \"\"\"\n model_vars = {}\n for var, reporter in self.model_reporters.items():\n model_vars[var] = reporter(model)\n return model_vars\n\n def collect_agent_vars(self, model):\n \"\"\" Run reporters and collect agent-level variables. \"\"\"\n agent_vars = {}\n for agent in model.schedule.agents:\n agent_record = {}\n for var, reporter in self.agent_reporters.items():\n agent_record[var] = reporter(agent)\n agent_vars[agent.unique_id] = agent_record\n return agent_vars\n\n def get_model_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the model-level collected\n variables.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names.append(\"Run\")\n records = []\n for key, val in self.model_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n def get_agent_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the agent-level variables\n collected.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names += [\"Run\", \"AgentID\"]\n records = []\n for key, val in self.agent_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n @staticmethod\n def make_iterable(val):\n \"\"\" Helper method to ensure a value is a non-string iterable. \"\"\"\n if hasattr(val, \"__iter__\") and not isinstance(val, str):\n return val\n else:\n return [val]\n", "path": "mesa/batchrunner.py"}, {"content": "# -*- coding: utf-8 -*-\n\"\"\"\nMesa Time Module\n================\n\nObjects for handling the time component of a model. In particular, this module\ncontains Schedulers, which handle agent activation. A Scheduler is an object\nwhich controls when agents are called upon to act, and when.\n\nThe activation order can have a serious impact on model behavior, so it's\nimportant to specify it explicity. Example simple activation regimes include\nactivating all agents in the same order every step, shuffling the activation\norder every time, activating each agent *on average* once per step, and more.\n\nKey concepts:\n Step: Many models advance in 'steps'. A step may involve the activation of\n all agents, or a random (or selected) subset of them. Each agent in turn\n may have their own step() method.\n\n Time: Some models may simulate a continuous 'clock' instead of discrete\n steps. However, by default, the Time is equal to the number of steps the\n model has taken.\n\n\nTODO: Have the schedulers use the model's randomizer, to keep random number\nseeds consistent and allow for replication.\n\n\"\"\"\nimport random\n\n\nclass BaseScheduler:\n \"\"\" Simplest scheduler; activates agents one at a time, in the order\n they were added.\n\n Assumes that each agent added has a *step* method, which accepts a model\n object as its single argument.\n\n (This is explicitly meant to replicate the scheduler in MASON).\n\n \"\"\"\n model = None\n steps = 0\n time = 0\n agents = []\n\n def __init__(self, model):\n \"\"\" Create a new, empty BaseScheduler. \"\"\"\n self.model = model\n self.steps = 0\n self.time = 0\n self.agents = []\n\n def add(self, agent):\n \"\"\" Add an Agent object to the schedule.\n\n Args:\n agent: An Agent to be added to the schedule. NOTE: The agent must\n have a step(model) method.\n\n \"\"\"\n self.agents.append(agent)\n\n def remove(self, agent):\n \"\"\" Remove all instances of a given agent from the schedule.\n\n Args:\n agent: An agent object.\n\n \"\"\"\n while agent in self.agents:\n self.agents.remove(agent)\n\n def step(self):\n \"\"\" Execute the step of all the agents, one at a time. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n def get_agent_count(self):\n \"\"\" Returns the current number of agents in the queue. \"\"\"\n return len(self.agents)\n\n\nclass RandomActivation(BaseScheduler):\n \"\"\" A scheduler which activates each agent once per step, in random order,\n with the order reshuffled every step.\n\n This is equivalent to the NetLogo 'ask agents...' and is generally the\n default behavior for an ABM.\n\n Assumes that all agents have a step(model) method.\n\n \"\"\"\n def step(self):\n \"\"\" Executes the step of all agents, one at a time, in\n random order.\n\n \"\"\"\n random.shuffle(self.agents)\n\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass SimultaneousActivation(BaseScheduler):\n \"\"\" A scheduler to simulate the simultaneous activation of all the agents.\n\n This scheduler requires that each agent have two methods: step and advance.\n step(model) activates the agent and stages any necessary changes, but does\n not apply them yet. advance(model) then applies the changes.\n\n \"\"\"\n def step(self):\n \"\"\" Step all agents, then advance them. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n for agent in self.agents:\n agent.advance(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass StagedActivation(BaseScheduler):\n \"\"\" A scheduler which allows agent activation to be divided into several\n stages instead of a single `step` method. All agents execute one stage\n before moving on to the next.\n\n Agents must have all the stage methods implemented. Stage methods take a\n model object as their only argument.\n\n This schedule tracks steps and time separately. Time advances in fractional\n increments of 1 / (# of stages), meaning that 1 step = 1 unit of time.\n\n \"\"\"\n stage_list = []\n shuffle = False\n shuffle_between_stages = False\n stage_time = 1\n\n def __init__(self, model, stage_list=[\"step\"], shuffle=False,\n shuffle_between_stages=False):\n \"\"\" Create an empty Staged Activation schedule.\n\n Args:\n model: Model object associated with the schedule.\n stage_list: List of strings of names of stages to run, in the\n order to run them in.\n shuffle: If True, shuffle the order of agents each step.\n shuffle_between_stages: If True, shuffle the agents after each\n stage; otherwise, only shuffle at the start\n of each step.\n\n \"\"\"\n super().__init__(model)\n self.stage_list = stage_list\n self.shuffle = shuffle\n self.shuffle_between_stages = shuffle_between_stages\n self.stage_time = 1 / len(self.stage_list)\n\n def step(self):\n \"\"\" Executes all the stages of all agents. \"\"\"\n if self.shuffle:\n random.shuffle(self.agents)\n for stage in self.stage_list:\n for agent in self.agents:\n getattr(agent, stage)(self.model) # Run stage\n if self.shuffle_between_stages:\n random.shuffle(self.agents)\n self.time += self.stage_time\n\n self.steps += 1\n", "path": "mesa/time.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nBatchrunner\n===========\n\nA single class to manage a batch run or parameter sweep of a given model.\n\n\"\"\"\nfrom itertools import product\nimport pandas as pd\n\n\nclass BatchRunner:\n \"\"\" This class is instantiated with a model class, and model parameters\n associated with one or more values. It is also instantiated with model and\n agent-level reporters, dictionaries mapping a variable name to a function\n which collects some data from the model or its agents at the end of the run\n and stores it.\n\n Note that by default, the reporters only collect data at the *end* of the\n run. To get step by step data, simply have a reporter store the model's\n entire DataCollector object.\n\n \"\"\"\n def __init__(self, model_cls, parameter_values, iterations=1,\n max_steps=1000, model_reporters=None, agent_reporters=None):\n \"\"\" Create a new BatchRunner for a given model with the given\n parameters.\n\n Args:\n model_cls: The class of model to batch-run.\n parameter_values: Dictionary of parameters to their values or\n ranges of values. For example:\n {\"param_1\": range(5),\n \"param_2\": [1, 5, 10],\n \"const_param\": 100}\n iterations: The total number of times to run the model for each\n combination of parameters.\n max_steps: The upper limit of steps above which each run will be halted\n if it hasn't halted on its own.\n model_reporters: The dictionary of variables to collect on each run at\n the end, with variable names mapped to a function to collect\n them. For example:\n {\"agent_count\": lambda m: m.schedule.get_agent_count()}\n agent_reporters: Like model_reporters, but each variable is now\n collected at the level of each agent present in the model at\n the end of the run.\n\n \"\"\"\n self.model_cls = model_cls\n self.parameter_values = {param: self.make_iterable(vals)\n for param, vals in parameter_values.items()}\n self.iterations = iterations\n self.max_steps = max_steps\n\n self.model_reporters = model_reporters\n self.agent_reporters = agent_reporters\n\n if self.model_reporters:\n self.model_vars = {}\n\n if self.agent_reporters:\n self.agent_vars = {}\n\n def run_all(self):\n \"\"\" Run the model at all parameter combinations and store results. \"\"\"\n params = self.parameter_values.keys()\n param_ranges = self.parameter_values.values()\n run_count = 0\n for param_values in list(product(*param_ranges)):\n kwargs = dict(zip(params, param_values))\n for _ in range(self.iterations):\n model = self.model_cls(**kwargs)\n self.run_model(model)\n # Collect and store results:\n if self.model_reporters:\n key = tuple(list(param_values) + [run_count])\n self.model_vars[key] = self.collect_model_vars(model)\n if self.agent_reporters:\n agent_vars = self.collect_agent_vars(model)\n for agent_id, reports in agent_vars.items():\n key = tuple(list(param_values) + [run_count, agent_id])\n self.agent_vars[key] = reports\n run_count += 1\n\n def run_model(self, model):\n \"\"\" Run a model object to completion, or until reaching max steps.\n\n If your model runs in a non-standard way, this is the method to modify\n in your subclass.\n\n \"\"\"\n while model.running and model.schedule.steps < self.max_steps:\n model.step()\n\n def collect_model_vars(self, model):\n \"\"\" Run reporters and collect model-level variables. \"\"\"\n model_vars = {}\n for var, reporter in self.model_reporters.items():\n model_vars[var] = reporter(model)\n return model_vars\n\n def collect_agent_vars(self, model):\n \"\"\" Run reporters and collect agent-level variables. \"\"\"\n agent_vars = {}\n for agent in model.schedule.agents:\n agent_record = {}\n for var, reporter in self.agent_reporters.items():\n agent_record[var] = reporter(agent)\n agent_vars[agent.unique_id] = agent_record\n return agent_vars\n\n def get_model_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the model-level variables collected.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names.append(\"Run\")\n records = []\n for key, val in self.model_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n def get_agent_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the agent-level variables\n collected.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names += [\"Run\", \"AgentID\"]\n records = []\n for key, val in self.agent_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n @staticmethod\n def make_iterable(val):\n \"\"\" Helper method to ensure a value is a non-string iterable. \"\"\"\n if hasattr(val, \"__iter__\") and not isinstance(val, str):\n return val\n else:\n return [val]\n", "path": "mesa/batchrunner.py"}, {"content": "# -*- coding: utf-8 -*-\n\"\"\"\nMesa Time Module\n================\n\nObjects for handling the time component of a model. In particular, this module\ncontains Schedulers, which handle agent activation. A Scheduler is an object\nwhich controls when agents are called upon to act, and when.\n\nThe activation order can have a serious impact on model behavior, so it's\nimportant to specify it explicitly. Example simple activation regimes include\nactivating all agents in the same order every step, shuffling the activation\norder every time, activating each agent *on average* once per step, and more.\n\nKey concepts:\n Step: Many models advance in 'steps'. A step may involve the activation of\n all agents, or a random (or selected) subset of them. Each agent in turn\n may have their own step() method.\n\n Time: Some models may simulate a continuous 'clock' instead of discrete\n steps. However, by default, the Time is equal to the number of steps the\n model has taken.\n\n\nTODO: Have the schedulers use the model's randomizer, to keep random number\nseeds consistent and allow for replication.\n\n\"\"\"\nimport random\n\n\nclass BaseScheduler:\n \"\"\" Simplest scheduler; activates agents one at a time, in the order\n they were added.\n\n Assumes that each agent added has a *step* method, which accepts a model\n object as its single argument.\n\n (This is explicitly meant to replicate the scheduler in MASON).\n\n \"\"\"\n model = None\n steps = 0\n time = 0\n agents = []\n\n def __init__(self, model):\n \"\"\" Create a new, empty BaseScheduler. \"\"\"\n self.model = model\n self.steps = 0\n self.time = 0\n self.agents = []\n\n def add(self, agent):\n \"\"\" Add an Agent object to the schedule.\n\n Args:\n agent: An Agent to be added to the schedule. NOTE: The agent must\n have a step(model) method.\n\n \"\"\"\n self.agents.append(agent)\n\n def remove(self, agent):\n \"\"\" Remove all instances of a given agent from the schedule.\n\n Args:\n agent: An agent object.\n\n \"\"\"\n while agent in self.agents:\n self.agents.remove(agent)\n\n def step(self):\n \"\"\" Execute the step of all the agents, one at a time. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n def get_agent_count(self):\n \"\"\" Returns the current number of agents in the queue. \"\"\"\n return len(self.agents)\n\n\nclass RandomActivation(BaseScheduler):\n \"\"\" A scheduler which activates each agent once per step, in random order,\n with the order reshuffled every step.\n\n This is equivalent to the NetLogo 'ask agents...' and is generally the\n default behavior for an ABM.\n\n Assumes that all agents have a step(model) method.\n\n \"\"\"\n def step(self):\n \"\"\" Executes the step of all agents, one at a time, in\n random order.\n\n \"\"\"\n random.shuffle(self.agents)\n\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass SimultaneousActivation(BaseScheduler):\n \"\"\" A scheduler to simulate the simultaneous activation of all the agents.\n\n This scheduler requires that each agent have two methods: step and advance.\n step(model) activates the agent and stages any necessary changes, but does\n not apply them yet. advance(model) then applies the changes.\n\n \"\"\"\n def step(self):\n \"\"\" Step all agents, then advance them. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n for agent in self.agents:\n agent.advance(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass StagedActivation(BaseScheduler):\n \"\"\" A scheduler which allows agent activation to be divided into several\n stages instead of a single `step` method. All agents execute one stage\n before moving on to the next.\n\n Agents must have all the stage methods implemented. Stage methods take a\n model object as their only argument.\n\n This schedule tracks steps and time separately. Time advances in fractional\n increments of 1 / (# of stages), meaning that 1 step = 1 unit of time.\n\n \"\"\"\n stage_list = []\n shuffle = False\n shuffle_between_stages = False\n stage_time = 1\n\n def __init__(self, model, stage_list=[\"step\"], shuffle=False,\n shuffle_between_stages=False):\n \"\"\" Create an empty Staged Activation schedule.\n\n Args:\n model: Model object associated with the schedule.\n stage_list: List of strings of names of stages to run, in the\n order to run them in.\n shuffle: If True, shuffle the order of agents each step.\n shuffle_between_stages: If True, shuffle the agents after each\n stage; otherwise, only shuffle at the start\n of each step.\n\n \"\"\"\n super().__init__(model)\n self.stage_list = stage_list\n self.shuffle = shuffle\n self.shuffle_between_stages = shuffle_between_stages\n self.stage_time = 1 / len(self.stage_list)\n\n def step(self):\n \"\"\" Executes all the stages for all agents. \"\"\"\n if self.shuffle:\n random.shuffle(self.agents)\n for stage in self.stage_list:\n for agent in self.agents:\n getattr(agent, stage)(self.model) # Run stage\n if self.shuffle_between_stages:\n random.shuffle(self.agents)\n self.time += self.stage_time\n\n self.steps += 1\n", "path": "mesa/time.py"}]} | 3,495 | 630 |
gh_patches_debug_27775 | rasdani/github-patches | git_diff | bridgecrewio__checkov-4917 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Checkov Python error - kubernetes_pod_v1
I get the following error when parsing a **kubernetes_pod_v1** resource:
https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/pod_v1
```
Error: -18 02:46:45,476 [MainThread ] [ERROR] Failed to run check CKV_K8S_[27](https://github.com/technology-services-and-platforms-accnz/dotc-aks/actions/runs/4728024195/jobs/8389176473#step:21:28) on /tfplan.json:kubernetes_pod_v1.test
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/checkov/common/checks/base_check.py", line 73, in run
check_result["result"] = self.scan_entity_conf(entity_configuration, entity_type)
File "/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/base_resource_check.py", line 43, in scan_entity_conf
return self.scan_resource_conf(conf)
File "/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py", line 36, in scan_resource_conf
if v.get("host_path"):
File "/usr/local/lib/python3.10/site-packages/checkov/common/parsers/node.py", line 189, in __getattr__
raise TemplateAttributeError(f'***name*** is invalid')
checkov.common.parsers.node.TemplateAttributeError: get is invalid
[...]
```
For all the checks that fail.
Checkov Version: :2.3.165
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import Any
4
5 from checkov.common.models.enums import CheckCategories, CheckResult
6 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
7
8
9 class DockerSocketVolume(BaseResourceCheck):
10 def __init__(self) -> None:
11 # Exposing the socket gives container information and increases risk of exploit
12 # read-only is not a solution but only makes it harder to exploit.
13 # Location: Pod.spec.volumes[].hostPath.path
14 # Location: CronJob.spec.jobTemplate.spec.template.spec.volumes[].hostPath.path
15 # Location: *.spec.template.spec.volumes[].hostPath.path
16 id = "CKV_K8S_27"
17 name = "Do not expose the docker daemon socket to containers"
18 supported_resources = ("kubernetes_pod", "kubernetes_pod_v1",
19 "kubernetes_deployment", "kubernetes_deployment_v1",
20 "kubernetes_daemonset", "kubernetes_daemon_set_v1")
21 categories = (CheckCategories.NETWORKING,)
22 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
23
24 def scan_resource_conf(self, conf: dict[str, list[Any]]):
25 if "spec" not in conf:
26 self.evaluated_keys = [""]
27 return CheckResult.FAILED
28
29 spec = conf['spec'][0]
30 if not spec:
31 return CheckResult.UNKNOWN
32
33 if "volume" in spec and spec.get("volume"):
34 volumes = spec.get("volume")
35 for idx, v in enumerate(volumes):
36 if v.get("host_path"):
37 if "path" in v["host_path"][0]:
38 if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
39 self.evaluated_keys = [f"spec/volume/{idx}/host_path/[0]/path"]
40 return CheckResult.FAILED
41 if "template" in spec and spec.get("template"):
42 template = spec.get("template")[0]
43 if "spec" in template:
44 temp_spec = template.get("spec")[0]
45 if "volume" in temp_spec and temp_spec.get("volume"):
46 volumes = temp_spec.get("volume")
47 for idx, v in enumerate(volumes):
48 if isinstance(v, dict) and v.get("host_path"):
49 if "path" in v["host_path"][0]:
50 path = v["host_path"][0]["path"]
51 if path == ["/var/run/docker.sock"]:
52 self.evaluated_keys = [f"spec/template/spec/volume/{idx}/host_path/[0]/path"]
53 return CheckResult.FAILED
54
55 return CheckResult.PASSED
56
57
58 check = DockerSocketVolume()
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
--- a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
+++ b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
@@ -33,7 +33,7 @@
if "volume" in spec and spec.get("volume"):
volumes = spec.get("volume")
for idx, v in enumerate(volumes):
- if v.get("host_path"):
+ if isinstance(v, dict) and v.get("host_path"):
if "path" in v["host_path"][0]:
if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
self.evaluated_keys = [f"spec/volume/{idx}/host_path/[0]/path"]
@@ -47,8 +47,7 @@
for idx, v in enumerate(volumes):
if isinstance(v, dict) and v.get("host_path"):
if "path" in v["host_path"][0]:
- path = v["host_path"][0]["path"]
- if path == ["/var/run/docker.sock"]:
+ if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
self.evaluated_keys = [f"spec/template/spec/volume/{idx}/host_path/[0]/path"]
return CheckResult.FAILED
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n--- a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n+++ b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n@@ -33,7 +33,7 @@\n if \"volume\" in spec and spec.get(\"volume\"):\n volumes = spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n- if v.get(\"host_path\"):\n+ if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/volume/{idx}/host_path/[0]/path\"]\n@@ -47,8 +47,7 @@\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n- path = v[\"host_path\"][0][\"path\"]\n- if path == [\"/var/run/docker.sock\"]:\n+ if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/template/spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n", "issue": "Checkov Python error - kubernetes_pod_v1\nI get the following error when parsing a **kubernetes_pod_v1** resource:\r\nhttps://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/pod_v1\r\n\r\n```\r\nError: -18 02:46:45,476 [MainThread ] [ERROR] Failed to run check CKV_K8S_[27](https://github.com/technology-services-and-platforms-accnz/dotc-aks/actions/runs/4728024195/jobs/8389176473#step:21:28) on /tfplan.json:kubernetes_pod_v1.test\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/common/checks/base_check.py\", line 73, in run\r\n check_result[\"result\"] = self.scan_entity_conf(entity_configuration, entity_type)\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/base_resource_check.py\", line 43, in scan_entity_conf\r\n return self.scan_resource_conf(conf)\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\", line 36, in scan_resource_conf\r\n if v.get(\"host_path\"):\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/common/parsers/node.py\", line 189, in __getattr__\r\n raise TemplateAttributeError(f'***name*** is invalid')\r\ncheckov.common.parsers.node.TemplateAttributeError: get is invalid\r\n[...]\r\n```\r\n\r\nFor all the checks that fail.\r\n\r\nCheckov Version: :2.3.165\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass DockerSocketVolume(BaseResourceCheck):\n def __init__(self) -> None:\n # Exposing the socket gives container information and increases risk of exploit\n # read-only is not a solution but only makes it harder to exploit.\n # Location: Pod.spec.volumes[].hostPath.path\n # Location: CronJob.spec.jobTemplate.spec.template.spec.volumes[].hostPath.path\n # Location: *.spec.template.spec.volumes[].hostPath.path\n id = \"CKV_K8S_27\"\n name = \"Do not expose the docker daemon socket to containers\"\n supported_resources = (\"kubernetes_pod\", \"kubernetes_pod_v1\",\n \"kubernetes_deployment\", \"kubernetes_deployment_v1\",\n \"kubernetes_daemonset\", \"kubernetes_daemon_set_v1\")\n categories = (CheckCategories.NETWORKING,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]):\n if \"spec\" not in conf:\n self.evaluated_keys = [\"\"]\n return CheckResult.FAILED\n\n spec = conf['spec'][0]\n if not spec:\n return CheckResult.UNKNOWN\n\n if \"volume\" in spec and spec.get(\"volume\"):\n volumes = spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n if \"template\" in spec and spec.get(\"template\"):\n template = spec.get(\"template\")[0]\n if \"spec\" in template:\n temp_spec = template.get(\"spec\")[0]\n if \"volume\" in temp_spec and temp_spec.get(\"volume\"):\n volumes = temp_spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n path = v[\"host_path\"][0][\"path\"]\n if path == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/template/spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = DockerSocketVolume()\n", "path": "checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass DockerSocketVolume(BaseResourceCheck):\n def __init__(self) -> None:\n # Exposing the socket gives container information and increases risk of exploit\n # read-only is not a solution but only makes it harder to exploit.\n # Location: Pod.spec.volumes[].hostPath.path\n # Location: CronJob.spec.jobTemplate.spec.template.spec.volumes[].hostPath.path\n # Location: *.spec.template.spec.volumes[].hostPath.path\n id = \"CKV_K8S_27\"\n name = \"Do not expose the docker daemon socket to containers\"\n supported_resources = (\"kubernetes_pod\", \"kubernetes_pod_v1\",\n \"kubernetes_deployment\", \"kubernetes_deployment_v1\",\n \"kubernetes_daemonset\", \"kubernetes_daemon_set_v1\")\n categories = (CheckCategories.NETWORKING,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]):\n if \"spec\" not in conf:\n self.evaluated_keys = [\"\"]\n return CheckResult.FAILED\n\n spec = conf['spec'][0]\n if not spec:\n return CheckResult.UNKNOWN\n\n if \"volume\" in spec and spec.get(\"volume\"):\n volumes = spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n if \"template\" in spec and spec.get(\"template\"):\n template = spec.get(\"template\")[0]\n if \"spec\" in template:\n temp_spec = template.get(\"spec\")[0]\n if \"volume\" in temp_spec and temp_spec.get(\"volume\"):\n volumes = temp_spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/template/spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = DockerSocketVolume()\n", "path": "checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py"}]} | 1,343 | 311 |
gh_patches_debug_3593 | rasdani/github-patches | git_diff | opendatacube__datacube-core-898 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Documentation for indexing from s3 contains mistakes
resolution for EPSG:4326 should be in degrees not in meters:
https://github.com/opendatacube/datacube-core/commit/363a11c9f39a40c8fba958cb265ace193d7849b6#diff-95fd54d5e1fd0aea8de7aacba3ad495cR323
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `datacube/config.py`
Content:
```
1 # coding=utf-8
2 """
3 User configuration.
4 """
5
6 import os
7 from pathlib import Path
8 import configparser
9 from urllib.parse import unquote_plus, urlparse
10 from typing import Optional, Iterable, Union, Any, Tuple, Dict
11
12 PathLike = Union[str, 'os.PathLike[Any]']
13
14
15 ENVIRONMENT_VARNAME = 'DATACUBE_CONFIG_PATH'
16 #: Config locations in order. Properties found in latter locations override
17 #: earlier ones.
18 #:
19 #: - `/etc/datacube.conf`
20 #: - file at `$DATACUBE_CONFIG_PATH` environment variable
21 #: - `~/.datacube.conf`
22 #: - `datacube.conf`
23 DEFAULT_CONF_PATHS = tuple(p for p in ['/etc/datacube.conf',
24 os.environ.get(ENVIRONMENT_VARNAME, ''),
25 str(os.path.expanduser("~/.datacube.conf")),
26 'datacube.conf'] if len(p) > 0)
27
28 DEFAULT_ENV = 'default'
29
30 # Default configuration options.
31 _DEFAULT_CONF = """
32 [DEFAULT]
33 # Blank implies localhost
34 db_hostname:
35 db_database: datacube
36 index_driver: default
37 # If a connection is unused for this length of time, expect it to be invalidated.
38 db_connection_timeout: 60
39
40 [user]
41 # Which environment to use when none is specified explicitly.
42 # note: will fail if default_environment points to non-existent section
43 # default_environment: datacube
44 """
45
46 #: Used in place of None as a default, when None is a valid but not default parameter to a function
47 _UNSET = object()
48
49
50 def read_config(default_text: Optional[str] = None) -> configparser.ConfigParser:
51 config = configparser.ConfigParser()
52 if default_text is not None:
53 config.read_string(default_text)
54 return config
55
56
57 class LocalConfig(object):
58 """
59 System configuration for the user.
60
61 This loads from a set of possible configuration files which define the available environments.
62 An environment contains connection details for a Data Cube Index, which provides access to
63 available data.
64
65 """
66
67 def __init__(self, config: configparser.ConfigParser,
68 files_loaded: Optional[Iterable[str]] = None,
69 env: Optional[str] = None):
70 """
71 Datacube environment resolution precedence is:
72 1. Supplied as a function argument `env`
73 2. DATACUBE_ENVIRONMENT environment variable
74 3. user.default_environment option in the config
75 4. 'default' or 'datacube' whichever is present
76
77 If environment is supplied by any of the first 3 methods is not present
78 in the config, then throw an exception.
79 """
80 self._config = config
81 self.files_loaded = [] if files_loaded is None else list(iter(files_loaded))
82
83 if env is None:
84 env = os.environ.get('DATACUBE_ENVIRONMENT',
85 config.get('user', 'default_environment', fallback=None))
86
87 # If the user specifies a particular env, we either want to use it or Fail
88 if env:
89 if config.has_section(env):
90 self._env = env
91 # All is good
92 return
93 else:
94 raise ValueError('No config section found for environment %r' % (env,))
95 else:
96 # If an env hasn't been specifically selected, we can fall back defaults
97 fallbacks = [DEFAULT_ENV, 'datacube']
98 for fallback_env in fallbacks:
99 if config.has_section(fallback_env):
100 self._env = fallback_env
101 return
102 raise ValueError('No ODC environment, checked configurations for %s' % fallbacks)
103
104 @classmethod
105 def find(cls,
106 paths: Optional[Union[str, Iterable[PathLike]]] = None,
107 env: Optional[str] = None) -> 'LocalConfig':
108 """
109 Find config from environment variables or possible filesystem locations.
110
111 'env' is which environment to use from the config: it corresponds to the name of a
112 config section
113 """
114 config = read_config(_DEFAULT_CONF)
115
116 if paths is None:
117 if env is None:
118 env_opts = parse_env_params()
119 if env_opts:
120 return _cfg_from_env_opts(env_opts, config)
121
122 paths = DEFAULT_CONF_PATHS
123
124 if isinstance(paths, str) or hasattr(paths, '__fspath__'): # Use os.PathLike in 3.6+
125 paths = [str(paths)]
126
127 files_loaded = config.read(str(p) for p in paths if p)
128
129 return LocalConfig(
130 config,
131 files_loaded=files_loaded,
132 env=env,
133 )
134
135 def get(self, item: str, fallback=_UNSET):
136 if fallback is _UNSET:
137 return self._config.get(self._env, item)
138 else:
139 return self._config.get(self._env, item, fallback=fallback)
140
141 def __getitem__(self, item: str):
142 return self.get(item, fallback=None)
143
144 def __str__(self) -> str:
145 return "LocalConfig<loaded_from={}, environment={!r}, config={}>".format(
146 self.files_loaded or 'defaults',
147 self._env,
148 dict(self._config[self._env]),
149 )
150
151 def __repr__(self) -> str:
152 return str(self)
153
154
155 DB_KEYS = ('hostname', 'port', 'database', 'username', 'password')
156
157
158 def parse_connect_url(url: str) -> Dict[str, str]:
159 """ Extract database,hostname,port,username,password from db URL.
160
161 Example: postgresql://username:password@hostname:port/database
162
163 For local password-less db use `postgresql:///<your db>`
164 """
165 def split2(s: str, separator: str) -> Tuple[str, str]:
166 i = s.find(separator)
167 return (s, '') if i < 0 else (s[:i], s[i+1:])
168
169 _, netloc, path, *_ = urlparse(url)
170
171 db = path[1:] if path else ''
172 if '@' in netloc:
173 (user, password), (host, port) = (split2(p, ':') for p in split2(netloc, '@'))
174 else:
175 user, password = '', ''
176 host, port = split2(netloc, ':')
177
178 oo = dict(hostname=host, database=db)
179
180 if port:
181 oo['port'] = port
182 if password:
183 oo['password'] = unquote_plus(password)
184 if user:
185 oo['username'] = user
186 return oo
187
188
189 def parse_env_params() -> Dict[str, str]:
190 """
191 - Extract parameters from DATACUBE_DB_URL if present
192 - Else look for DB_HOSTNAME, DB_USERNAME, DB_PASSWORD, DB_DATABASE
193 - Return {} otherwise
194 """
195
196 db_url = os.environ.get('DATACUBE_DB_URL', None)
197 if db_url is not None:
198 return parse_connect_url(db_url)
199
200 params = {k: os.environ.get('DB_{}'.format(k.upper()), None)
201 for k in DB_KEYS}
202 return {k: v
203 for k, v in params.items()
204 if v is not None and v != ""}
205
206
207 def _cfg_from_env_opts(opts: Dict[str, str],
208 base: configparser.ConfigParser) -> LocalConfig:
209 base['default'] = {'db_'+k: v for k, v in opts.items()}
210 return LocalConfig(base, files_loaded=[], env='default')
211
212
213 def render_dc_config(params: Dict[str, Any],
214 section_name: str = 'default') -> str:
215 """ Render output of parse_env_params to a string that can be written to config file.
216 """
217 oo = '[{}]\n'.format(section_name)
218 for k in DB_KEYS:
219 v = params.get(k, None)
220 if v is not None:
221 oo += 'db_{k}: {v}\n'.format(k=k, v=v)
222 return oo
223
224
225 def auto_config() -> str:
226 """
227 Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.
228
229 option1:
230 DATACUBE_DB_URL postgresql://user:password@host/database
231
232 option2:
233 DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}
234
235 option3:
236 default config
237 """
238 cfg_path = os.environ.get('DATACUBE_CONFIG_PATH', None)
239 cfg_path = Path(cfg_path) if cfg_path else Path.home()/'.datacube.conf'
240
241 if cfg_path.exists():
242 return str(cfg_path)
243
244 opts = parse_env_params()
245
246 if len(opts) == 0:
247 opts['hostname'] = ''
248 opts['database'] = 'datacube'
249
250 cfg_text = render_dc_config(opts)
251 with open(str(cfg_path), 'wt') as f:
252 f.write(cfg_text)
253
254 return str(cfg_path)
255
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/datacube/config.py b/datacube/config.py
--- a/datacube/config.py
+++ b/datacube/config.py
@@ -227,7 +227,7 @@
Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.
option1:
- DATACUBE_DB_URL postgresql://user:password@host/database
+ DATACUBE_DB_URL postgresql://user:password@host:port/database
option2:
DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}
| {"golden_diff": "diff --git a/datacube/config.py b/datacube/config.py\n--- a/datacube/config.py\n+++ b/datacube/config.py\n@@ -227,7 +227,7 @@\n Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.\n \n option1:\n- DATACUBE_DB_URL postgresql://user:password@host/database\n+ DATACUBE_DB_URL postgresql://user:password@host:port/database\n \n option2:\n DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}\n", "issue": "Documentation for indexing from s3 contains mistakes\n\r\nresolution for EPSG:4326 should be in degrees not in meters:\r\n\r\nhttps://github.com/opendatacube/datacube-core/commit/363a11c9f39a40c8fba958cb265ace193d7849b6#diff-95fd54d5e1fd0aea8de7aacba3ad495cR323\r\n\r\n\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\nUser configuration.\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport configparser\nfrom urllib.parse import unquote_plus, urlparse\nfrom typing import Optional, Iterable, Union, Any, Tuple, Dict\n\nPathLike = Union[str, 'os.PathLike[Any]']\n\n\nENVIRONMENT_VARNAME = 'DATACUBE_CONFIG_PATH'\n#: Config locations in order. Properties found in latter locations override\n#: earlier ones.\n#:\n#: - `/etc/datacube.conf`\n#: - file at `$DATACUBE_CONFIG_PATH` environment variable\n#: - `~/.datacube.conf`\n#: - `datacube.conf`\nDEFAULT_CONF_PATHS = tuple(p for p in ['/etc/datacube.conf',\n os.environ.get(ENVIRONMENT_VARNAME, ''),\n str(os.path.expanduser(\"~/.datacube.conf\")),\n 'datacube.conf'] if len(p) > 0)\n\nDEFAULT_ENV = 'default'\n\n# Default configuration options.\n_DEFAULT_CONF = \"\"\"\n[DEFAULT]\n# Blank implies localhost\ndb_hostname:\ndb_database: datacube\nindex_driver: default\n# If a connection is unused for this length of time, expect it to be invalidated.\ndb_connection_timeout: 60\n\n[user]\n# Which environment to use when none is specified explicitly.\n# note: will fail if default_environment points to non-existent section\n# default_environment: datacube\n\"\"\"\n\n#: Used in place of None as a default, when None is a valid but not default parameter to a function\n_UNSET = object()\n\n\ndef read_config(default_text: Optional[str] = None) -> configparser.ConfigParser:\n config = configparser.ConfigParser()\n if default_text is not None:\n config.read_string(default_text)\n return config\n\n\nclass LocalConfig(object):\n \"\"\"\n System configuration for the user.\n\n This loads from a set of possible configuration files which define the available environments.\n An environment contains connection details for a Data Cube Index, which provides access to\n available data.\n\n \"\"\"\n\n def __init__(self, config: configparser.ConfigParser,\n files_loaded: Optional[Iterable[str]] = None,\n env: Optional[str] = None):\n \"\"\"\n Datacube environment resolution precedence is:\n 1. Supplied as a function argument `env`\n 2. DATACUBE_ENVIRONMENT environment variable\n 3. user.default_environment option in the config\n 4. 'default' or 'datacube' whichever is present\n\n If environment is supplied by any of the first 3 methods is not present\n in the config, then throw an exception.\n \"\"\"\n self._config = config\n self.files_loaded = [] if files_loaded is None else list(iter(files_loaded))\n\n if env is None:\n env = os.environ.get('DATACUBE_ENVIRONMENT',\n config.get('user', 'default_environment', fallback=None))\n\n # If the user specifies a particular env, we either want to use it or Fail\n if env:\n if config.has_section(env):\n self._env = env\n # All is good\n return\n else:\n raise ValueError('No config section found for environment %r' % (env,))\n else:\n # If an env hasn't been specifically selected, we can fall back defaults\n fallbacks = [DEFAULT_ENV, 'datacube']\n for fallback_env in fallbacks:\n if config.has_section(fallback_env):\n self._env = fallback_env\n return\n raise ValueError('No ODC environment, checked configurations for %s' % fallbacks)\n\n @classmethod\n def find(cls,\n paths: Optional[Union[str, Iterable[PathLike]]] = None,\n env: Optional[str] = None) -> 'LocalConfig':\n \"\"\"\n Find config from environment variables or possible filesystem locations.\n\n 'env' is which environment to use from the config: it corresponds to the name of a\n config section\n \"\"\"\n config = read_config(_DEFAULT_CONF)\n\n if paths is None:\n if env is None:\n env_opts = parse_env_params()\n if env_opts:\n return _cfg_from_env_opts(env_opts, config)\n\n paths = DEFAULT_CONF_PATHS\n\n if isinstance(paths, str) or hasattr(paths, '__fspath__'): # Use os.PathLike in 3.6+\n paths = [str(paths)]\n\n files_loaded = config.read(str(p) for p in paths if p)\n\n return LocalConfig(\n config,\n files_loaded=files_loaded,\n env=env,\n )\n\n def get(self, item: str, fallback=_UNSET):\n if fallback is _UNSET:\n return self._config.get(self._env, item)\n else:\n return self._config.get(self._env, item, fallback=fallback)\n\n def __getitem__(self, item: str):\n return self.get(item, fallback=None)\n\n def __str__(self) -> str:\n return \"LocalConfig<loaded_from={}, environment={!r}, config={}>\".format(\n self.files_loaded or 'defaults',\n self._env,\n dict(self._config[self._env]),\n )\n\n def __repr__(self) -> str:\n return str(self)\n\n\nDB_KEYS = ('hostname', 'port', 'database', 'username', 'password')\n\n\ndef parse_connect_url(url: str) -> Dict[str, str]:\n \"\"\" Extract database,hostname,port,username,password from db URL.\n\n Example: postgresql://username:password@hostname:port/database\n\n For local password-less db use `postgresql:///<your db>`\n \"\"\"\n def split2(s: str, separator: str) -> Tuple[str, str]:\n i = s.find(separator)\n return (s, '') if i < 0 else (s[:i], s[i+1:])\n\n _, netloc, path, *_ = urlparse(url)\n\n db = path[1:] if path else ''\n if '@' in netloc:\n (user, password), (host, port) = (split2(p, ':') for p in split2(netloc, '@'))\n else:\n user, password = '', ''\n host, port = split2(netloc, ':')\n\n oo = dict(hostname=host, database=db)\n\n if port:\n oo['port'] = port\n if password:\n oo['password'] = unquote_plus(password)\n if user:\n oo['username'] = user\n return oo\n\n\ndef parse_env_params() -> Dict[str, str]:\n \"\"\"\n - Extract parameters from DATACUBE_DB_URL if present\n - Else look for DB_HOSTNAME, DB_USERNAME, DB_PASSWORD, DB_DATABASE\n - Return {} otherwise\n \"\"\"\n\n db_url = os.environ.get('DATACUBE_DB_URL', None)\n if db_url is not None:\n return parse_connect_url(db_url)\n\n params = {k: os.environ.get('DB_{}'.format(k.upper()), None)\n for k in DB_KEYS}\n return {k: v\n for k, v in params.items()\n if v is not None and v != \"\"}\n\n\ndef _cfg_from_env_opts(opts: Dict[str, str],\n base: configparser.ConfigParser) -> LocalConfig:\n base['default'] = {'db_'+k: v for k, v in opts.items()}\n return LocalConfig(base, files_loaded=[], env='default')\n\n\ndef render_dc_config(params: Dict[str, Any],\n section_name: str = 'default') -> str:\n \"\"\" Render output of parse_env_params to a string that can be written to config file.\n \"\"\"\n oo = '[{}]\\n'.format(section_name)\n for k in DB_KEYS:\n v = params.get(k, None)\n if v is not None:\n oo += 'db_{k}: {v}\\n'.format(k=k, v=v)\n return oo\n\n\ndef auto_config() -> str:\n \"\"\"\n Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.\n\n option1:\n DATACUBE_DB_URL postgresql://user:password@host/database\n\n option2:\n DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}\n\n option3:\n default config\n \"\"\"\n cfg_path = os.environ.get('DATACUBE_CONFIG_PATH', None)\n cfg_path = Path(cfg_path) if cfg_path else Path.home()/'.datacube.conf'\n\n if cfg_path.exists():\n return str(cfg_path)\n\n opts = parse_env_params()\n\n if len(opts) == 0:\n opts['hostname'] = ''\n opts['database'] = 'datacube'\n\n cfg_text = render_dc_config(opts)\n with open(str(cfg_path), 'wt') as f:\n f.write(cfg_text)\n\n return str(cfg_path)\n", "path": "datacube/config.py"}], "after_files": [{"content": "# coding=utf-8\n\"\"\"\nUser configuration.\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport configparser\nfrom urllib.parse import unquote_plus, urlparse\nfrom typing import Optional, Iterable, Union, Any, Tuple, Dict\n\nPathLike = Union[str, 'os.PathLike[Any]']\n\n\nENVIRONMENT_VARNAME = 'DATACUBE_CONFIG_PATH'\n#: Config locations in order. Properties found in latter locations override\n#: earlier ones.\n#:\n#: - `/etc/datacube.conf`\n#: - file at `$DATACUBE_CONFIG_PATH` environment variable\n#: - `~/.datacube.conf`\n#: - `datacube.conf`\nDEFAULT_CONF_PATHS = tuple(p for p in ['/etc/datacube.conf',\n os.environ.get(ENVIRONMENT_VARNAME, ''),\n str(os.path.expanduser(\"~/.datacube.conf\")),\n 'datacube.conf'] if len(p) > 0)\n\nDEFAULT_ENV = 'default'\n\n# Default configuration options.\n_DEFAULT_CONF = \"\"\"\n[DEFAULT]\n# Blank implies localhost\ndb_hostname:\ndb_database: datacube\nindex_driver: default\n# If a connection is unused for this length of time, expect it to be invalidated.\ndb_connection_timeout: 60\n\n[user]\n# Which environment to use when none is specified explicitly.\n# note: will fail if default_environment points to non-existent section\n# default_environment: datacube\n\"\"\"\n\n#: Used in place of None as a default, when None is a valid but not default parameter to a function\n_UNSET = object()\n\n\ndef read_config(default_text: Optional[str] = None) -> configparser.ConfigParser:\n config = configparser.ConfigParser()\n if default_text is not None:\n config.read_string(default_text)\n return config\n\n\nclass LocalConfig(object):\n \"\"\"\n System configuration for the user.\n\n This loads from a set of possible configuration files which define the available environments.\n An environment contains connection details for a Data Cube Index, which provides access to\n available data.\n\n \"\"\"\n\n def __init__(self, config: configparser.ConfigParser,\n files_loaded: Optional[Iterable[str]] = None,\n env: Optional[str] = None):\n \"\"\"\n Datacube environment resolution precedence is:\n 1. Supplied as a function argument `env`\n 2. DATACUBE_ENVIRONMENT environment variable\n 3. user.default_environment option in the config\n 4. 'default' or 'datacube' whichever is present\n\n If environment is supplied by any of the first 3 methods is not present\n in the config, then throw an exception.\n \"\"\"\n self._config = config\n self.files_loaded = [] if files_loaded is None else list(iter(files_loaded))\n\n if env is None:\n env = os.environ.get('DATACUBE_ENVIRONMENT',\n config.get('user', 'default_environment', fallback=None))\n\n # If the user specifies a particular env, we either want to use it or Fail\n if env:\n if config.has_section(env):\n self._env = env\n # All is good\n return\n else:\n raise ValueError('No config section found for environment %r' % (env,))\n else:\n # If an env hasn't been specifically selected, we can fall back defaults\n fallbacks = [DEFAULT_ENV, 'datacube']\n for fallback_env in fallbacks:\n if config.has_section(fallback_env):\n self._env = fallback_env\n return\n raise ValueError('No ODC environment, checked configurations for %s' % fallbacks)\n\n @classmethod\n def find(cls,\n paths: Optional[Union[str, Iterable[PathLike]]] = None,\n env: Optional[str] = None) -> 'LocalConfig':\n \"\"\"\n Find config from environment variables or possible filesystem locations.\n\n 'env' is which environment to use from the config: it corresponds to the name of a\n config section\n \"\"\"\n config = read_config(_DEFAULT_CONF)\n\n if paths is None:\n if env is None:\n env_opts = parse_env_params()\n if env_opts:\n return _cfg_from_env_opts(env_opts, config)\n\n paths = DEFAULT_CONF_PATHS\n\n if isinstance(paths, str) or hasattr(paths, '__fspath__'): # Use os.PathLike in 3.6+\n paths = [str(paths)]\n\n files_loaded = config.read(str(p) for p in paths if p)\n\n return LocalConfig(\n config,\n files_loaded=files_loaded,\n env=env,\n )\n\n def get(self, item: str, fallback=_UNSET):\n if fallback is _UNSET:\n return self._config.get(self._env, item)\n else:\n return self._config.get(self._env, item, fallback=fallback)\n\n def __getitem__(self, item: str):\n return self.get(item, fallback=None)\n\n def __str__(self) -> str:\n return \"LocalConfig<loaded_from={}, environment={!r}, config={}>\".format(\n self.files_loaded or 'defaults',\n self._env,\n dict(self._config[self._env]),\n )\n\n def __repr__(self) -> str:\n return str(self)\n\n\nDB_KEYS = ('hostname', 'port', 'database', 'username', 'password')\n\n\ndef parse_connect_url(url: str) -> Dict[str, str]:\n \"\"\" Extract database,hostname,port,username,password from db URL.\n\n Example: postgresql://username:password@hostname:port/database\n\n For local password-less db use `postgresql:///<your db>`\n \"\"\"\n def split2(s: str, separator: str) -> Tuple[str, str]:\n i = s.find(separator)\n return (s, '') if i < 0 else (s[:i], s[i+1:])\n\n _, netloc, path, *_ = urlparse(url)\n\n db = path[1:] if path else ''\n if '@' in netloc:\n (user, password), (host, port) = (split2(p, ':') for p in split2(netloc, '@'))\n else:\n user, password = '', ''\n host, port = split2(netloc, ':')\n\n oo = dict(hostname=host, database=db)\n\n if port:\n oo['port'] = port\n if password:\n oo['password'] = unquote_plus(password)\n if user:\n oo['username'] = user\n return oo\n\n\ndef parse_env_params() -> Dict[str, str]:\n \"\"\"\n - Extract parameters from DATACUBE_DB_URL if present\n - Else look for DB_HOSTNAME, DB_USERNAME, DB_PASSWORD, DB_DATABASE\n - Return {} otherwise\n \"\"\"\n\n db_url = os.environ.get('DATACUBE_DB_URL', None)\n if db_url is not None:\n return parse_connect_url(db_url)\n\n params = {k: os.environ.get('DB_{}'.format(k.upper()), None)\n for k in DB_KEYS}\n return {k: v\n for k, v in params.items()\n if v is not None and v != \"\"}\n\n\ndef _cfg_from_env_opts(opts: Dict[str, str],\n base: configparser.ConfigParser) -> LocalConfig:\n base['default'] = {'db_'+k: v for k, v in opts.items()}\n return LocalConfig(base, files_loaded=[], env='default')\n\n\ndef render_dc_config(params: Dict[str, Any],\n section_name: str = 'default') -> str:\n \"\"\" Render output of parse_env_params to a string that can be written to config file.\n \"\"\"\n oo = '[{}]\\n'.format(section_name)\n for k in DB_KEYS:\n v = params.get(k, None)\n if v is not None:\n oo += 'db_{k}: {v}\\n'.format(k=k, v=v)\n return oo\n\n\ndef auto_config() -> str:\n \"\"\"\n Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.\n\n option1:\n DATACUBE_DB_URL postgresql://user:password@host:port/database\n\n option2:\n DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}\n\n option3:\n default config\n \"\"\"\n cfg_path = os.environ.get('DATACUBE_CONFIG_PATH', None)\n cfg_path = Path(cfg_path) if cfg_path else Path.home()/'.datacube.conf'\n\n if cfg_path.exists():\n return str(cfg_path)\n\n opts = parse_env_params()\n\n if len(opts) == 0:\n opts['hostname'] = ''\n opts['database'] = 'datacube'\n\n cfg_text = render_dc_config(opts)\n with open(str(cfg_path), 'wt') as f:\n f.write(cfg_text)\n\n return str(cfg_path)\n", "path": "datacube/config.py"}]} | 2,917 | 126 |
gh_patches_debug_5691 | rasdani/github-patches | git_diff | chainer__chainer-6050 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add chainerx.ndarray.item
Background: #5797, #6007.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainerx/_docs/array.py`
Content:
```
1 import chainerx
2 from chainerx import _docs
3
4
5 def set_docs():
6 ndarray = chainerx.ndarray
7
8 _docs.set_doc(
9 ndarray,
10 """ndarray(shape, dtype, device=None)
11 Multi-dimensional array, the central data structure of ChainerX.
12
13 This class, along with other APIs in the :mod:`chainerx` module, provides a
14 subset of NumPy APIs. This class works similar to :class:`numpy.ndarray`,
15 except for some differences including the following noticeable points:
16
17 - :class:`chainerx.ndarray` has a :attr:`device` attribute. It indicates on
18 which device the array is allocated.
19 - :class:`chainerx.ndarray` supports :ref:`Define-by-Run <define_by_run>`
20 backpropagation. Once you call :meth:`require_grad`, the array starts
21 recording the operations applied to it recursively. Gradient of the result
22 with respect to the original array can be computed then with the
23 :meth:`backward` method or the :func:`chainerx.backward` function.
24
25 Args:
26 shape (tuple of ints): Shape of the new array.
27 dtype: Data type.
28 device (~chainerx.Device): Device on which the array is allocated.
29 If omitted, :ref:`the default device <chainerx_device>` is chosen.
30
31 .. seealso:: :class:`numpy.ndarray`
32 """)
33
34 _docs.set_doc(
35 ndarray.data_ptr,
36 """int: Address of the underlying memory allocation.
37
38 The meaning of the address is device-dependent.
39 """)
40
41 _docs.set_doc(
42 ndarray.data_size,
43 "int: Total size of the underlying memory allocation.")
44
45 _docs.set_doc(
46 ndarray.device, "~chainerx.Device: Device on which the data exists.")
47
48 _docs.set_doc(ndarray.dtype, "Data type of the array.")
49
50 # TODO(beam2d): Write about backprop id.
51 _docs.set_doc(
52 ndarray.grad,
53 """~chainerx.ndarray: Gradient held by the array.
54
55 It is ``None`` if the gradient is not available.
56 Setter of this property overwrites the gradient.
57 """)
58
59 _docs.set_doc(
60 ndarray.is_contiguous,
61 "bool: ``True`` iff the array is stored in the C-contiguous order.")
62
63 _docs.set_doc(ndarray.itemsize, "int: Size of each element in bytes.")
64
65 _docs.set_doc(
66 ndarray.nbytes,
67 """int: Total size of all elements in bytes.
68
69 It does not count skips between elements.""")
70
71 _docs.set_doc(ndarray.ndim, "int: Number of dimensions.")
72
73 _docs.set_doc(
74 ndarray.offset,
75 "int: Offset of the first element from the memory allocation in bytes."
76 )
77
78 _docs.set_doc(
79 ndarray.shape,
80 """tuple of int: Lengths of axes.
81
82 .. note::
83 Currently, this property does not support setter.""")
84
85 _docs.set_doc(ndarray.size, "int: Number of elements in the array.")
86
87 _docs.set_doc(ndarray.strides, "tuple of int: Strides of axes in bytes.")
88
89 _docs.set_doc(
90 ndarray.T,
91 """~chainerx.ndarray: Shape-reversed view of the array.
92
93 New array is created at every access to this property.
94 ``x.T`` is just a shorthand of ``x.transpose()``.
95 """)
96
97 _docs.set_doc(
98 ndarray.__getitem__,
99 """___getitem__(self, key)
100 Returns self[key].
101
102 .. note::
103 Currently, only basic indexing is supported not advanced indexing.
104 """)
105
106 def unary_op(name, s):
107 _docs.set_doc(getattr(ndarray, name), "{}()\n{}".format(name, s))
108
109 unary_op("__bool__", "Casts a size-one array into a :class:`bool` value.")
110 unary_op("__float__",
111 "Casts a size-one array into a :class:`float` value.")
112 unary_op("__int__", "Casts a size-one array into :class:`int` value.")
113 unary_op("__len__", "Returns the length of the first axis.")
114 unary_op("__neg__", "Computes ``-x`` elementwise.")
115
116 def binary_op(name, s):
117 _docs.set_doc(getattr(ndarray, name), "{}(other)\n{}".format(name, s))
118
119 binary_op("__eq__", "Computes ``x == y`` elementwise.")
120 binary_op("__ne__", "Computes ``x != y`` elementwise.")
121 binary_op("__lt__", "Computes ``x < y`` elementwise.")
122 binary_op("__le__", "Computes ``x <= y`` elementwise.")
123 binary_op("__ge__", "Computes ``x >= y`` elementwise.")
124 binary_op("__gt__", "Computes ``x > y`` elementwise.")
125
126 binary_op("__iadd__", "Computes ``x += y`` elementwise.")
127 binary_op("__isub__", "Computes ``x -= y`` elementwise.")
128 binary_op("__imul__", "Computes ``x *= y`` elementwise.")
129 binary_op("__itruediv__", "Computes ``x /= y`` elementwise.")
130
131 binary_op("__add__", "Computes ``x + y`` elementwise.")
132 binary_op("__sub__", "Computes ``x - y`` elementwise.")
133 binary_op("__mul__", "Computes ``x * y`` elementwise.")
134 binary_op("__truediv__", "Computes ``x / y`` elementwise.")
135
136 binary_op("__radd__", "Computes ``y + x`` elementwise.")
137 binary_op("__rsub__", "Computes ``y - x`` elementwise.")
138 binary_op("__rmul__", "Computes ``y * x`` elementwise.")
139
140 # TODO(beam2d): Write about as_grad_stopped(backprop_ids, copy) overload.
141 _docs.set_doc(
142 ndarray.as_grad_stopped,
143 """as_grad_stopped(copy=False)
144 Creates a view or a copy of the array that stops gradient propagation.
145
146 This method behaves similar to :meth:`view` and :meth:`copy`, except that
147 the gradient is not propagated through this operation (internally, this
148 method creates a copy or view of the array without connecting the computational
149 graph for backprop).
150
151 Args:
152 copy (bool): If ``True``, it copies the array. Otherwise, it returns a view
153 of the original array.
154
155 Returns:
156 ~chainerx.ndarray:
157 A view or a copy of the array without propagating the gradient on
158 backprop.
159 """)
160
161 _docs.set_doc(
162 ndarray.argmax,
163 """argmax(axis=None)
164 Returns the indices of the maximum elements along a given axis.
165
166 See :func:`chainerx.argmax` for the full documentation.
167 """)
168
169 _docs.set_doc(
170 ndarray.astype,
171 """astype(dtype, copy=True)
172 Casts each element to the specified data type.
173
174 Args:
175 dtype: Data type of the new array.
176 copy (bool): If ``True``, this method always copies the data. Otherwise,
177 it creates a view of the array if possible.
178
179 Returns:
180 ~chainerx.ndarray: An array with the specified dtype.
181 """)
182
183 _docs.set_doc(
184 ndarray.backward,
185 """backward(backprop_id=None, enable_double_backprop=False)
186 Performs backpropagation starting from this array.
187
188 This method is equivalent to ``chainerx.backward([self], *args)``.
189 See :func:`chainerx.backward` for the full documentation.
190 """)
191
192 # TODO(beam2d): Write about backprop id.
193 _docs.set_doc(
194 ndarray.cleargrad,
195 """cleargrad()
196 Clears the gradient held by this array.
197 """)
198
199 _docs.set_doc(
200 ndarray.copy,
201 """copy()
202 Creates an array and copies all the elements to it.
203
204 The copied array is allocated on the same device as ``self``.
205
206 .. seealso:: :func:`chainerx.copy`
207 """)
208
209 _docs.set_doc(
210 ndarray.dot,
211 """dot(b)
212 Returns the dot product with a given array.
213
214 See :func:`chainerx.dot` for the full documentation.
215 """)
216
217 _docs.set_doc(
218 ndarray.fill,
219 """fill(value)
220 Fills the array with a scalar value in place.
221
222 Args:
223 value: Scalar value with which the array will be filled.
224 """)
225
226 # TODO(beam2d): Write about backprop_id argument.
227 _docs.set_doc(
228 ndarray.get_grad,
229 """get_grad()
230 Returns the gradient held by the array.
231
232 If the gradient is not available, it returns ``None``.
233 """)
234
235 # TODO(beam2d): Write about backprop_id argument.
236 _docs.set_doc(
237 ndarray.is_backprop_required,
238 """is_backprop_required()
239 Returns ``True`` if gradient propagates through this array on backprop.
240
241 See the note on :meth:`require_grad` for details.
242 """)
243
244 # TODO(beam2d): Write about backprop_id argument.
245 _docs.set_doc(
246 ndarray.is_grad_required,
247 """is_grad_required()
248 Returns ``True`` if the gradient will be set after backprop.
249
250 See the note on :meth:`require_grad` for details.
251 """)
252
253 _docs.set_doc(
254 ndarray.max,
255 """max(axis=None, keepdims=False)
256 Returns the maximum along a given axis.
257
258 See :func:`chainerx.amax` for the full documentation.
259 """)
260
261 # TODO(beam2d): Write about backprop_id argument.
262 _docs.set_doc(
263 ndarray.require_grad,
264 """require_grad()
265 Declares that a gradient for this array will be made available after backprop.
266
267 Once calling this method, any operations applied to this array are recorded for
268 later backprop. After backprop, the :attr:`grad` attribute holds the gradient
269 array.
270
271 .. note::
272 ChainerX distinguishes *gradient requirements* and *backprop requirements*
273 strictly. They are strongly related, but different concepts as follows.
274
275 - *Gradient requirement* indicates that the gradient array should be made
276 available after backprop. This attribute **is not propagated** through
277 any operations. It implicates the backprop requirement.
278 - *Backprop requirement* indicates that the gradient should be propagated
279 through the array during backprop. This attribute **is propagated**
280 through differentiable operations.
281
282 :meth:`require_grad` sets the gradient requirement flag. If you need to
283 extract the gradient after backprop, you have to call :meth:`require_grad`
284 on the array even if the array is an intermediate result of differentiable
285 computations.
286
287 Returns:
288 ~chainerx.ndarray: ``self``
289 """)
290
291 _docs.set_doc(
292 ndarray.reshape,
293 """reshape(newshape)
294 Creates an array with a new shape and the same data.
295
296 See :func:`chainerx.reshape` for the full documentation.
297 """)
298
299 _docs.set_doc(
300 ndarray.set_grad,
301 """set_grad(grad)
302 Sets a gradient to the array.
303
304 This method overwrites the gradient with a given array.
305
306 Args:
307 grad (~chainerx.ndarray): New gradient array.
308 """)
309
310 _docs.set_doc(
311 ndarray.squeeze,
312 """squeeze(axis=None)
313 Removes size-one axes from an array.
314
315 See :func:`chainerx.squeeze` for the full documentation.
316 """)
317
318 _docs.set_doc(
319 ndarray.sum,
320 """sum(axis=None, keepdims=False)
321 Returns the sum of an array along given axes.
322
323 See :func:`chainerx.sum` for the full documentation.
324 """)
325
326 _docs.set_doc(
327 ndarray.take,
328 """take(indices, axis)
329 Takes elements from the array along an axis.
330
331 See :func:`chainerx.take` for the full documentation.
332 """)
333
334 _docs.set_doc(
335 ndarray.to_device,
336 """to_device(device, index=None)
337 Transfers the array to the specified device.
338
339 Args:
340 device (~chainerx.Device or str): Device to which the array is transferred,
341 or a backend name. If it is a backend name, ``index`` should also be
342 specified.
343 index (int): Index of the device for the backend specified by ``device``.
344
345 Returns:
346 ~chainerx.ndarray:
347 An array on the target device.
348 If the original array is already on the device, it is a view of that.
349 Otherwise, it is a copy of the array on the target device.
350 """)
351
352 _docs.set_doc(
353 ndarray.transpose,
354 """transpose(axes=None)
355 Creates a view of an array with permutated axes.
356
357 See :func:`chainerx.transpose` for the full documentation.
358 """)
359
360 _docs.set_doc(
361 ndarray.view,
362 """view()
363 Returns a view of the array.
364
365 The returned array shares the underlying buffer, though it has a different
366 identity as a Python object.
367 """)
368
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/chainerx/_docs/array.py b/chainerx/_docs/array.py
--- a/chainerx/_docs/array.py
+++ b/chainerx/_docs/array.py
@@ -248,6 +248,19 @@
Returns ``True`` if the gradient will be set after backprop.
See the note on :meth:`require_grad` for details.
+""")
+
+ _docs.set_doc(
+ ndarray.item,
+ """item()
+Copies an element of an array to a standard Python scalar and returns it.
+
+Returns:
+ z:
+ A copy of the specified element of the array as a suitable Python
+ scalar.
+
+.. seealso:: :func:`numpy.item`
""")
_docs.set_doc(
| {"golden_diff": "diff --git a/chainerx/_docs/array.py b/chainerx/_docs/array.py\n--- a/chainerx/_docs/array.py\n+++ b/chainerx/_docs/array.py\n@@ -248,6 +248,19 @@\n Returns ``True`` if the gradient will be set after backprop.\n \n See the note on :meth:`require_grad` for details.\n+\"\"\")\n+\n+ _docs.set_doc(\n+ ndarray.item,\n+ \"\"\"item()\n+Copies an element of an array to a standard Python scalar and returns it.\n+\n+Returns:\n+ z:\n+ A copy of the specified element of the array as a suitable Python\n+ scalar.\n+\n+.. seealso:: :func:`numpy.item`\n \"\"\")\n \n _docs.set_doc(\n", "issue": "Add chainerx.ndarray.item\nBackground: #5797, #6007.\n", "before_files": [{"content": "import chainerx\nfrom chainerx import _docs\n\n\ndef set_docs():\n ndarray = chainerx.ndarray\n\n _docs.set_doc(\n ndarray,\n \"\"\"ndarray(shape, dtype, device=None)\nMulti-dimensional array, the central data structure of ChainerX.\n\nThis class, along with other APIs in the :mod:`chainerx` module, provides a\nsubset of NumPy APIs. This class works similar to :class:`numpy.ndarray`,\nexcept for some differences including the following noticeable points:\n\n- :class:`chainerx.ndarray` has a :attr:`device` attribute. It indicates on\n which device the array is allocated.\n- :class:`chainerx.ndarray` supports :ref:`Define-by-Run <define_by_run>`\n backpropagation. Once you call :meth:`require_grad`, the array starts\n recording the operations applied to it recursively. Gradient of the result\n with respect to the original array can be computed then with the\n :meth:`backward` method or the :func:`chainerx.backward` function.\n\nArgs:\n shape (tuple of ints): Shape of the new array.\n dtype: Data type.\n device (~chainerx.Device): Device on which the array is allocated.\n If omitted, :ref:`the default device <chainerx_device>` is chosen.\n\n.. seealso:: :class:`numpy.ndarray`\n\"\"\")\n\n _docs.set_doc(\n ndarray.data_ptr,\n \"\"\"int: Address of the underlying memory allocation.\n\nThe meaning of the address is device-dependent.\n\"\"\")\n\n _docs.set_doc(\n ndarray.data_size,\n \"int: Total size of the underlying memory allocation.\")\n\n _docs.set_doc(\n ndarray.device, \"~chainerx.Device: Device on which the data exists.\")\n\n _docs.set_doc(ndarray.dtype, \"Data type of the array.\")\n\n # TODO(beam2d): Write about backprop id.\n _docs.set_doc(\n ndarray.grad,\n \"\"\"~chainerx.ndarray: Gradient held by the array.\n\nIt is ``None`` if the gradient is not available.\nSetter of this property overwrites the gradient.\n\"\"\")\n\n _docs.set_doc(\n ndarray.is_contiguous,\n \"bool: ``True`` iff the array is stored in the C-contiguous order.\")\n\n _docs.set_doc(ndarray.itemsize, \"int: Size of each element in bytes.\")\n\n _docs.set_doc(\n ndarray.nbytes,\n \"\"\"int: Total size of all elements in bytes.\n\nIt does not count skips between elements.\"\"\")\n\n _docs.set_doc(ndarray.ndim, \"int: Number of dimensions.\")\n\n _docs.set_doc(\n ndarray.offset,\n \"int: Offset of the first element from the memory allocation in bytes.\"\n )\n\n _docs.set_doc(\n ndarray.shape,\n \"\"\"tuple of int: Lengths of axes.\n\n.. note::\n Currently, this property does not support setter.\"\"\")\n\n _docs.set_doc(ndarray.size, \"int: Number of elements in the array.\")\n\n _docs.set_doc(ndarray.strides, \"tuple of int: Strides of axes in bytes.\")\n\n _docs.set_doc(\n ndarray.T,\n \"\"\"~chainerx.ndarray: Shape-reversed view of the array.\n\nNew array is created at every access to this property.\n``x.T`` is just a shorthand of ``x.transpose()``.\n\"\"\")\n\n _docs.set_doc(\n ndarray.__getitem__,\n \"\"\"___getitem__(self, key)\nReturns self[key].\n\n.. note::\n Currently, only basic indexing is supported not advanced indexing.\n\"\"\")\n\n def unary_op(name, s):\n _docs.set_doc(getattr(ndarray, name), \"{}()\\n{}\".format(name, s))\n\n unary_op(\"__bool__\", \"Casts a size-one array into a :class:`bool` value.\")\n unary_op(\"__float__\",\n \"Casts a size-one array into a :class:`float` value.\")\n unary_op(\"__int__\", \"Casts a size-one array into :class:`int` value.\")\n unary_op(\"__len__\", \"Returns the length of the first axis.\")\n unary_op(\"__neg__\", \"Computes ``-x`` elementwise.\")\n\n def binary_op(name, s):\n _docs.set_doc(getattr(ndarray, name), \"{}(other)\\n{}\".format(name, s))\n\n binary_op(\"__eq__\", \"Computes ``x == y`` elementwise.\")\n binary_op(\"__ne__\", \"Computes ``x != y`` elementwise.\")\n binary_op(\"__lt__\", \"Computes ``x < y`` elementwise.\")\n binary_op(\"__le__\", \"Computes ``x <= y`` elementwise.\")\n binary_op(\"__ge__\", \"Computes ``x >= y`` elementwise.\")\n binary_op(\"__gt__\", \"Computes ``x > y`` elementwise.\")\n\n binary_op(\"__iadd__\", \"Computes ``x += y`` elementwise.\")\n binary_op(\"__isub__\", \"Computes ``x -= y`` elementwise.\")\n binary_op(\"__imul__\", \"Computes ``x *= y`` elementwise.\")\n binary_op(\"__itruediv__\", \"Computes ``x /= y`` elementwise.\")\n\n binary_op(\"__add__\", \"Computes ``x + y`` elementwise.\")\n binary_op(\"__sub__\", \"Computes ``x - y`` elementwise.\")\n binary_op(\"__mul__\", \"Computes ``x * y`` elementwise.\")\n binary_op(\"__truediv__\", \"Computes ``x / y`` elementwise.\")\n\n binary_op(\"__radd__\", \"Computes ``y + x`` elementwise.\")\n binary_op(\"__rsub__\", \"Computes ``y - x`` elementwise.\")\n binary_op(\"__rmul__\", \"Computes ``y * x`` elementwise.\")\n\n # TODO(beam2d): Write about as_grad_stopped(backprop_ids, copy) overload.\n _docs.set_doc(\n ndarray.as_grad_stopped,\n \"\"\"as_grad_stopped(copy=False)\nCreates a view or a copy of the array that stops gradient propagation.\n\nThis method behaves similar to :meth:`view` and :meth:`copy`, except that\nthe gradient is not propagated through this operation (internally, this\nmethod creates a copy or view of the array without connecting the computational\ngraph for backprop).\n\nArgs:\n copy (bool): If ``True``, it copies the array. Otherwise, it returns a view\n of the original array.\n\nReturns:\n ~chainerx.ndarray:\n A view or a copy of the array without propagating the gradient on\n backprop.\n\"\"\")\n\n _docs.set_doc(\n ndarray.argmax,\n \"\"\"argmax(axis=None)\nReturns the indices of the maximum elements along a given axis.\n\nSee :func:`chainerx.argmax` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.astype,\n \"\"\"astype(dtype, copy=True)\nCasts each element to the specified data type.\n\nArgs:\n dtype: Data type of the new array.\n copy (bool): If ``True``, this method always copies the data. Otherwise,\n it creates a view of the array if possible.\n\nReturns:\n ~chainerx.ndarray: An array with the specified dtype.\n\"\"\")\n\n _docs.set_doc(\n ndarray.backward,\n \"\"\"backward(backprop_id=None, enable_double_backprop=False)\nPerforms backpropagation starting from this array.\n\nThis method is equivalent to ``chainerx.backward([self], *args)``.\nSee :func:`chainerx.backward` for the full documentation.\n\"\"\")\n\n # TODO(beam2d): Write about backprop id.\n _docs.set_doc(\n ndarray.cleargrad,\n \"\"\"cleargrad()\nClears the gradient held by this array.\n\"\"\")\n\n _docs.set_doc(\n ndarray.copy,\n \"\"\"copy()\nCreates an array and copies all the elements to it.\n\nThe copied array is allocated on the same device as ``self``.\n\n.. seealso:: :func:`chainerx.copy`\n\"\"\")\n\n _docs.set_doc(\n ndarray.dot,\n \"\"\"dot(b)\nReturns the dot product with a given array.\n\nSee :func:`chainerx.dot` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.fill,\n \"\"\"fill(value)\nFills the array with a scalar value in place.\n\nArgs:\n value: Scalar value with which the array will be filled.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.get_grad,\n \"\"\"get_grad()\nReturns the gradient held by the array.\n\nIf the gradient is not available, it returns ``None``.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.is_backprop_required,\n \"\"\"is_backprop_required()\nReturns ``True`` if gradient propagates through this array on backprop.\n\nSee the note on :meth:`require_grad` for details.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.is_grad_required,\n \"\"\"is_grad_required()\nReturns ``True`` if the gradient will be set after backprop.\n\nSee the note on :meth:`require_grad` for details.\n\"\"\")\n\n _docs.set_doc(\n ndarray.max,\n \"\"\"max(axis=None, keepdims=False)\nReturns the maximum along a given axis.\n\nSee :func:`chainerx.amax` for the full documentation.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.require_grad,\n \"\"\"require_grad()\nDeclares that a gradient for this array will be made available after backprop.\n\nOnce calling this method, any operations applied to this array are recorded for\nlater backprop. After backprop, the :attr:`grad` attribute holds the gradient\narray.\n\n.. note::\n ChainerX distinguishes *gradient requirements* and *backprop requirements*\n strictly. They are strongly related, but different concepts as follows.\n\n - *Gradient requirement* indicates that the gradient array should be made\n available after backprop. This attribute **is not propagated** through\n any operations. It implicates the backprop requirement.\n - *Backprop requirement* indicates that the gradient should be propagated\n through the array during backprop. This attribute **is propagated**\n through differentiable operations.\n\n :meth:`require_grad` sets the gradient requirement flag. If you need to\n extract the gradient after backprop, you have to call :meth:`require_grad`\n on the array even if the array is an intermediate result of differentiable\n computations.\n\nReturns:\n ~chainerx.ndarray: ``self``\n\"\"\")\n\n _docs.set_doc(\n ndarray.reshape,\n \"\"\"reshape(newshape)\nCreates an array with a new shape and the same data.\n\nSee :func:`chainerx.reshape` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.set_grad,\n \"\"\"set_grad(grad)\nSets a gradient to the array.\n\nThis method overwrites the gradient with a given array.\n\nArgs:\n grad (~chainerx.ndarray): New gradient array.\n\"\"\")\n\n _docs.set_doc(\n ndarray.squeeze,\n \"\"\"squeeze(axis=None)\nRemoves size-one axes from an array.\n\nSee :func:`chainerx.squeeze` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.sum,\n \"\"\"sum(axis=None, keepdims=False)\nReturns the sum of an array along given axes.\n\nSee :func:`chainerx.sum` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.take,\n \"\"\"take(indices, axis)\nTakes elements from the array along an axis.\n\nSee :func:`chainerx.take` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.to_device,\n \"\"\"to_device(device, index=None)\nTransfers the array to the specified device.\n\nArgs:\n device (~chainerx.Device or str): Device to which the array is transferred,\n or a backend name. If it is a backend name, ``index`` should also be\n specified.\n index (int): Index of the device for the backend specified by ``device``.\n\nReturns:\n ~chainerx.ndarray:\n An array on the target device.\n If the original array is already on the device, it is a view of that.\n Otherwise, it is a copy of the array on the target device.\n\"\"\")\n\n _docs.set_doc(\n ndarray.transpose,\n \"\"\"transpose(axes=None)\nCreates a view of an array with permutated axes.\n\nSee :func:`chainerx.transpose` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.view,\n \"\"\"view()\nReturns a view of the array.\n\nThe returned array shares the underlying buffer, though it has a different\nidentity as a Python object.\n\"\"\")\n", "path": "chainerx/_docs/array.py"}], "after_files": [{"content": "import chainerx\nfrom chainerx import _docs\n\n\ndef set_docs():\n ndarray = chainerx.ndarray\n\n _docs.set_doc(\n ndarray,\n \"\"\"ndarray(shape, dtype, device=None)\nMulti-dimensional array, the central data structure of ChainerX.\n\nThis class, along with other APIs in the :mod:`chainerx` module, provides a\nsubset of NumPy APIs. This class works similar to :class:`numpy.ndarray`,\nexcept for some differences including the following noticeable points:\n\n- :class:`chainerx.ndarray` has a :attr:`device` attribute. It indicates on\n which device the array is allocated.\n- :class:`chainerx.ndarray` supports :ref:`Define-by-Run <define_by_run>`\n backpropagation. Once you call :meth:`require_grad`, the array starts\n recording the operations applied to it recursively. Gradient of the result\n with respect to the original array can be computed then with the\n :meth:`backward` method or the :func:`chainerx.backward` function.\n\nArgs:\n shape (tuple of ints): Shape of the new array.\n dtype: Data type.\n device (~chainerx.Device): Device on which the array is allocated.\n If omitted, :ref:`the default device <chainerx_device>` is chosen.\n\n.. seealso:: :class:`numpy.ndarray`\n\"\"\")\n\n _docs.set_doc(\n ndarray.data_ptr,\n \"\"\"int: Address of the underlying memory allocation.\n\nThe meaning of the address is device-dependent.\n\"\"\")\n\n _docs.set_doc(\n ndarray.data_size,\n \"int: Total size of the underlying memory allocation.\")\n\n _docs.set_doc(\n ndarray.device, \"~chainerx.Device: Device on which the data exists.\")\n\n _docs.set_doc(ndarray.dtype, \"Data type of the array.\")\n\n # TODO(beam2d): Write about backprop id.\n _docs.set_doc(\n ndarray.grad,\n \"\"\"~chainerx.ndarray: Gradient held by the array.\n\nIt is ``None`` if the gradient is not available.\nSetter of this property overwrites the gradient.\n\"\"\")\n\n _docs.set_doc(\n ndarray.is_contiguous,\n \"bool: ``True`` iff the array is stored in the C-contiguous order.\")\n\n _docs.set_doc(ndarray.itemsize, \"int: Size of each element in bytes.\")\n\n _docs.set_doc(\n ndarray.nbytes,\n \"\"\"int: Total size of all elements in bytes.\n\nIt does not count skips between elements.\"\"\")\n\n _docs.set_doc(ndarray.ndim, \"int: Number of dimensions.\")\n\n _docs.set_doc(\n ndarray.offset,\n \"int: Offset of the first element from the memory allocation in bytes.\"\n )\n\n _docs.set_doc(\n ndarray.shape,\n \"\"\"tuple of int: Lengths of axes.\n\n.. note::\n Currently, this property does not support setter.\"\"\")\n\n _docs.set_doc(ndarray.size, \"int: Number of elements in the array.\")\n\n _docs.set_doc(ndarray.strides, \"tuple of int: Strides of axes in bytes.\")\n\n _docs.set_doc(\n ndarray.T,\n \"\"\"~chainerx.ndarray: Shape-reversed view of the array.\n\nNew array is created at every access to this property.\n``x.T`` is just a shorthand of ``x.transpose()``.\n\"\"\")\n\n _docs.set_doc(\n ndarray.__getitem__,\n \"\"\"___getitem__(self, key)\nReturns self[key].\n\n.. note::\n Currently, only basic indexing is supported not advanced indexing.\n\"\"\")\n\n def unary_op(name, s):\n _docs.set_doc(getattr(ndarray, name), \"{}()\\n{}\".format(name, s))\n\n unary_op(\"__bool__\", \"Casts a size-one array into a :class:`bool` value.\")\n unary_op(\"__float__\",\n \"Casts a size-one array into a :class:`float` value.\")\n unary_op(\"__int__\", \"Casts a size-one array into :class:`int` value.\")\n unary_op(\"__len__\", \"Returns the length of the first axis.\")\n unary_op(\"__neg__\", \"Computes ``-x`` elementwise.\")\n\n def binary_op(name, s):\n _docs.set_doc(getattr(ndarray, name), \"{}(other)\\n{}\".format(name, s))\n\n binary_op(\"__eq__\", \"Computes ``x == y`` elementwise.\")\n binary_op(\"__ne__\", \"Computes ``x != y`` elementwise.\")\n binary_op(\"__lt__\", \"Computes ``x < y`` elementwise.\")\n binary_op(\"__le__\", \"Computes ``x <= y`` elementwise.\")\n binary_op(\"__ge__\", \"Computes ``x >= y`` elementwise.\")\n binary_op(\"__gt__\", \"Computes ``x > y`` elementwise.\")\n\n binary_op(\"__iadd__\", \"Computes ``x += y`` elementwise.\")\n binary_op(\"__isub__\", \"Computes ``x -= y`` elementwise.\")\n binary_op(\"__imul__\", \"Computes ``x *= y`` elementwise.\")\n binary_op(\"__itruediv__\", \"Computes ``x /= y`` elementwise.\")\n\n binary_op(\"__add__\", \"Computes ``x + y`` elementwise.\")\n binary_op(\"__sub__\", \"Computes ``x - y`` elementwise.\")\n binary_op(\"__mul__\", \"Computes ``x * y`` elementwise.\")\n binary_op(\"__truediv__\", \"Computes ``x / y`` elementwise.\")\n\n binary_op(\"__radd__\", \"Computes ``y + x`` elementwise.\")\n binary_op(\"__rsub__\", \"Computes ``y - x`` elementwise.\")\n binary_op(\"__rmul__\", \"Computes ``y * x`` elementwise.\")\n\n # TODO(beam2d): Write about as_grad_stopped(backprop_ids, copy) overload.\n _docs.set_doc(\n ndarray.as_grad_stopped,\n \"\"\"as_grad_stopped(copy=False)\nCreates a view or a copy of the array that stops gradient propagation.\n\nThis method behaves similar to :meth:`view` and :meth:`copy`, except that\nthe gradient is not propagated through this operation (internally, this\nmethod creates a copy or view of the array without connecting the computational\ngraph for backprop).\n\nArgs:\n copy (bool): If ``True``, it copies the array. Otherwise, it returns a view\n of the original array.\n\nReturns:\n ~chainerx.ndarray:\n A view or a copy of the array without propagating the gradient on\n backprop.\n\"\"\")\n\n _docs.set_doc(\n ndarray.argmax,\n \"\"\"argmax(axis=None)\nReturns the indices of the maximum elements along a given axis.\n\nSee :func:`chainerx.argmax` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.astype,\n \"\"\"astype(dtype, copy=True)\nCasts each element to the specified data type.\n\nArgs:\n dtype: Data type of the new array.\n copy (bool): If ``True``, this method always copies the data. Otherwise,\n it creates a view of the array if possible.\n\nReturns:\n ~chainerx.ndarray: An array with the specified dtype.\n\"\"\")\n\n _docs.set_doc(\n ndarray.backward,\n \"\"\"backward(backprop_id=None, enable_double_backprop=False)\nPerforms backpropagation starting from this array.\n\nThis method is equivalent to ``chainerx.backward([self], *args)``.\nSee :func:`chainerx.backward` for the full documentation.\n\"\"\")\n\n # TODO(beam2d): Write about backprop id.\n _docs.set_doc(\n ndarray.cleargrad,\n \"\"\"cleargrad()\nClears the gradient held by this array.\n\"\"\")\n\n _docs.set_doc(\n ndarray.copy,\n \"\"\"copy()\nCreates an array and copies all the elements to it.\n\nThe copied array is allocated on the same device as ``self``.\n\n.. seealso:: :func:`chainerx.copy`\n\"\"\")\n\n _docs.set_doc(\n ndarray.dot,\n \"\"\"dot(b)\nReturns the dot product with a given array.\n\nSee :func:`chainerx.dot` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.fill,\n \"\"\"fill(value)\nFills the array with a scalar value in place.\n\nArgs:\n value: Scalar value with which the array will be filled.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.get_grad,\n \"\"\"get_grad()\nReturns the gradient held by the array.\n\nIf the gradient is not available, it returns ``None``.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.is_backprop_required,\n \"\"\"is_backprop_required()\nReturns ``True`` if gradient propagates through this array on backprop.\n\nSee the note on :meth:`require_grad` for details.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.is_grad_required,\n \"\"\"is_grad_required()\nReturns ``True`` if the gradient will be set after backprop.\n\nSee the note on :meth:`require_grad` for details.\n\"\"\")\n\n _docs.set_doc(\n ndarray.item,\n \"\"\"item()\nCopies an element of an array to a standard Python scalar and returns it.\n\nReturns:\n z:\n A copy of the specified element of the array as a suitable Python\n scalar.\n\n.. seealso:: :func:`numpy.item`\n\"\"\")\n\n _docs.set_doc(\n ndarray.max,\n \"\"\"max(axis=None, keepdims=False)\nReturns the maximum along a given axis.\n\nSee :func:`chainerx.amax` for the full documentation.\n\"\"\")\n\n # TODO(beam2d): Write about backprop_id argument.\n _docs.set_doc(\n ndarray.require_grad,\n \"\"\"require_grad()\nDeclares that a gradient for this array will be made available after backprop.\n\nOnce calling this method, any operations applied to this array are recorded for\nlater backprop. After backprop, the :attr:`grad` attribute holds the gradient\narray.\n\n.. note::\n ChainerX distinguishes *gradient requirements* and *backprop requirements*\n strictly. They are strongly related, but different concepts as follows.\n\n - *Gradient requirement* indicates that the gradient array should be made\n available after backprop. This attribute **is not propagated** through\n any operations. It implicates the backprop requirement.\n - *Backprop requirement* indicates that the gradient should be propagated\n through the array during backprop. This attribute **is propagated**\n through differentiable operations.\n\n :meth:`require_grad` sets the gradient requirement flag. If you need to\n extract the gradient after backprop, you have to call :meth:`require_grad`\n on the array even if the array is an intermediate result of differentiable\n computations.\n\nReturns:\n ~chainerx.ndarray: ``self``\n\"\"\")\n\n _docs.set_doc(\n ndarray.reshape,\n \"\"\"reshape(newshape)\nCreates an array with a new shape and the same data.\n\nSee :func:`chainerx.reshape` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.set_grad,\n \"\"\"set_grad(grad)\nSets a gradient to the array.\n\nThis method overwrites the gradient with a given array.\n\nArgs:\n grad (~chainerx.ndarray): New gradient array.\n\"\"\")\n\n _docs.set_doc(\n ndarray.squeeze,\n \"\"\"squeeze(axis=None)\nRemoves size-one axes from an array.\n\nSee :func:`chainerx.squeeze` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.sum,\n \"\"\"sum(axis=None, keepdims=False)\nReturns the sum of an array along given axes.\n\nSee :func:`chainerx.sum` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.take,\n \"\"\"take(indices, axis)\nTakes elements from the array along an axis.\n\nSee :func:`chainerx.take` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.to_device,\n \"\"\"to_device(device, index=None)\nTransfers the array to the specified device.\n\nArgs:\n device (~chainerx.Device or str): Device to which the array is transferred,\n or a backend name. If it is a backend name, ``index`` should also be\n specified.\n index (int): Index of the device for the backend specified by ``device``.\n\nReturns:\n ~chainerx.ndarray:\n An array on the target device.\n If the original array is already on the device, it is a view of that.\n Otherwise, it is a copy of the array on the target device.\n\"\"\")\n\n _docs.set_doc(\n ndarray.transpose,\n \"\"\"transpose(axes=None)\nCreates a view of an array with permutated axes.\n\nSee :func:`chainerx.transpose` for the full documentation.\n\"\"\")\n\n _docs.set_doc(\n ndarray.view,\n \"\"\"view()\nReturns a view of the array.\n\nThe returned array shares the underlying buffer, though it has a different\nidentity as a Python object.\n\"\"\")\n", "path": "chainerx/_docs/array.py"}]} | 4,078 | 169 |
gh_patches_debug_14901 | rasdani/github-patches | git_diff | streamlink__streamlink-2102 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ok.ru VODs
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x ] This is a plugin issue and I have read the contribution guidelines.
### Description
i enter link in #1884 but "https://raw.githubusercontent.com/back-to/plugins/master/plugins/ok_live.py" 404: Not Found. Thanks
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. D:\my\Streamlinkl\bin>streamlink -l debug "https://ok.ru/video/266205792931" best
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[cli][debug] OS: Windows 8.1
[cli][debug] Python: 3.5.2
[cli][debug] Streamlink: 0.14.2
[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)
error: No plugin can handle URL: https://ok.ru/video/266205792931
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/ok_live.py`
Content:
```
1 import re
2
3 from streamlink.plugin import Plugin
4 from streamlink.plugin.api import validate
5 from streamlink.plugin.api import useragents
6 from streamlink.stream import HLSStream
7
8 _url_re = re.compile(r"https?://(www\.)?ok\.ru/live/\d+")
9 _vod_re = re.compile(r";(?P<hlsurl>[^;]+video\.m3u8.+?)\\"")
10
11 _schema = validate.Schema(
12 validate.transform(_vod_re.search),
13 validate.any(
14 None,
15 validate.all(
16 validate.get("hlsurl"),
17 validate.url()
18 )
19 )
20 )
21
22 class OK_live(Plugin):
23 """
24 Support for ok.ru live stream: http://www.ok.ru/live/
25 """
26 @classmethod
27 def can_handle_url(cls, url):
28 return _url_re.match(url) is not None
29
30 def _get_streams(self):
31 headers = {
32 'User-Agent': useragents.CHROME,
33 'Referer': self.url
34 }
35
36 hls = self.session.http.get(self.url, headers=headers, schema=_schema)
37 if hls:
38 hls = hls.replace(u'\\\\u0026', u'&')
39 return HLSStream.parse_variant_playlist(self.session, hls, headers=headers)
40
41
42 __plugin__ = OK_live
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/streamlink/plugins/ok_live.py b/src/streamlink/plugins/ok_live.py
--- a/src/streamlink/plugins/ok_live.py
+++ b/src/streamlink/plugins/ok_live.py
@@ -5,7 +5,7 @@
from streamlink.plugin.api import useragents
from streamlink.stream import HLSStream
-_url_re = re.compile(r"https?://(www\.)?ok\.ru/live/\d+")
+_url_re = re.compile(r"https?://(www\.)?ok\.ru/(live|video)/\d+")
_vod_re = re.compile(r";(?P<hlsurl>[^;]+video\.m3u8.+?)\\"")
_schema = validate.Schema(
@@ -21,7 +21,7 @@
class OK_live(Plugin):
"""
- Support for ok.ru live stream: http://www.ok.ru/live/
+ Support for ok.ru live stream: http://www.ok.ru/live/ and for ok.ru VoDs: http://www.ok.ru/video/
"""
@classmethod
def can_handle_url(cls, url):
| {"golden_diff": "diff --git a/src/streamlink/plugins/ok_live.py b/src/streamlink/plugins/ok_live.py\n--- a/src/streamlink/plugins/ok_live.py\n+++ b/src/streamlink/plugins/ok_live.py\n@@ -5,7 +5,7 @@\n from streamlink.plugin.api import useragents\n from streamlink.stream import HLSStream\n \n-_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/live/\\d+\")\n+_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/(live|video)/\\d+\")\n _vod_re = re.compile(r\";(?P<hlsurl>[^;]+video\\.m3u8.+?)\\\\"\")\n \n _schema = validate.Schema(\n@@ -21,7 +21,7 @@\n \n class OK_live(Plugin):\n \"\"\"\n- Support for ok.ru live stream: http://www.ok.ru/live/\n+ Support for ok.ru live stream: http://www.ok.ru/live/ and for ok.ru VoDs: http://www.ok.ru/video/\n \"\"\"\n @classmethod\n def can_handle_url(cls, url):\n", "issue": "ok.ru VODs\n<!--\r\nThanks for reporting a plugin issue!\r\nUSE THE TEMPLATE. Otherwise your plugin issue may be rejected.\r\n\r\nFirst, see the contribution guidelines:\r\nhttps://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink\r\n\r\nAlso check the list of open and closed plugin issues:\r\nhttps://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22\r\n\r\nPlease see the text preview to avoid unnecessary formatting errors.\r\n-->\r\n\r\n\r\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [x ] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\ni enter link in #1884 but \"https://raw.githubusercontent.com/back-to/plugins/master/plugins/ok_live.py\" 404: Not Found. Thanks\r\n<!-- Explain the plugin issue as thoroughly as you can. -->\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->\r\n\r\n1. D:\\my\\Streamlinkl\\bin>streamlink -l debug \"https://ok.ru/video/266205792931\" best\r\n\r\n\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n-->\r\n\r\n```\r\n[cli][debug] OS: Windows 8.1\r\n[cli][debug] Python: 3.5.2\r\n[cli][debug] Streamlink: 0.14.2\r\n[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)\r\nerror: No plugin can handle URL: https://ok.ru/video/266205792931\r\n\r\n```\r\n\r\n\r\n### Additional comments, screenshots, etc.\r\n\r\n\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\n", "before_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.plugin.api import useragents\nfrom streamlink.stream import HLSStream\n\n_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/live/\\d+\")\n_vod_re = re.compile(r\";(?P<hlsurl>[^;]+video\\.m3u8.+?)\\\\"\")\n\n_schema = validate.Schema(\n validate.transform(_vod_re.search),\n validate.any(\n None,\n validate.all(\n validate.get(\"hlsurl\"),\n validate.url()\n )\n )\n)\n\nclass OK_live(Plugin):\n \"\"\"\n Support for ok.ru live stream: http://www.ok.ru/live/\n \"\"\"\n @classmethod\n def can_handle_url(cls, url):\n return _url_re.match(url) is not None\n\n def _get_streams(self):\n headers = {\n 'User-Agent': useragents.CHROME,\n 'Referer': self.url\n }\n\n hls = self.session.http.get(self.url, headers=headers, schema=_schema)\n if hls:\n hls = hls.replace(u'\\\\\\\\u0026', u'&')\n return HLSStream.parse_variant_playlist(self.session, hls, headers=headers)\n\n\n__plugin__ = OK_live", "path": "src/streamlink/plugins/ok_live.py"}], "after_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.plugin.api import useragents\nfrom streamlink.stream import HLSStream\n\n_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/(live|video)/\\d+\")\n_vod_re = re.compile(r\";(?P<hlsurl>[^;]+video\\.m3u8.+?)\\\\"\")\n\n_schema = validate.Schema(\n validate.transform(_vod_re.search),\n validate.any(\n None,\n validate.all(\n validate.get(\"hlsurl\"),\n validate.url()\n )\n )\n)\n\nclass OK_live(Plugin):\n \"\"\"\n Support for ok.ru live stream: http://www.ok.ru/live/ and for ok.ru VoDs: http://www.ok.ru/video/\n \"\"\"\n @classmethod\n def can_handle_url(cls, url):\n return _url_re.match(url) is not None\n\n def _get_streams(self):\n headers = {\n 'User-Agent': useragents.CHROME,\n 'Referer': self.url\n }\n\n hls = self.session.http.get(self.url, headers=headers, schema=_schema)\n if hls:\n hls = hls.replace(u'\\\\\\\\u0026', u'&')\n return HLSStream.parse_variant_playlist(self.session, hls, headers=headers)\n\n\n__plugin__ = OK_live", "path": "src/streamlink/plugins/ok_live.py"}]} | 1,122 | 239 |
gh_patches_debug_4820 | rasdani/github-patches | git_diff | ivy-llc__ivy-28045 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong key-word argument `name` in `ivy.remainder()` function call
In the following line, the name argument is passed,
https://github.com/unifyai/ivy/blob/bec4752711c314f01298abc3845f02c24a99acab/ivy/functional/frontends/tensorflow/variable.py#L191
From the actual function definition, there is no such argument
https://github.com/unifyai/ivy/blob/8ff497a8c592b75f010160b313dc431218c2b475/ivy/functional/ivy/elementwise.py#L5415-L5422
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/tensorflow/variable.py`
Content:
```
1 # global
2
3 # local
4 import ivy
5 import ivy.functional.frontends.tensorflow as tf_frontend
6
7
8 class Variable:
9 def __init__(self, array, trainable=True, name=None, dtype=None):
10 self._ivy_array = (
11 ivy.array(array) if not isinstance(array, ivy.Array) else array
12 )
13 self._ivy_array = (
14 ivy.astype(self._ivy_array, dtype) if dtype is not None else self._ivy_array
15 )
16 self.trainable = trainable
17
18 def __repr__(self):
19 return (
20 repr(self._ivy_array).replace(
21 "ivy.array", "ivy.frontends.tensorflow.Variable"
22 )[:-1]
23 + ", shape="
24 + str(self._ivy_array.shape)
25 + ", dtype="
26 + str(self._ivy_array.dtype)
27 + ")"
28 )
29
30 # Properties #
31 # ---------- #
32
33 @property
34 def ivy_array(self):
35 return self._ivy_array
36
37 @property
38 def device(self):
39 return self._ivy_array.device
40
41 @property
42 def dtype(self):
43 return tf_frontend.DType(
44 tf_frontend.tensorflow_type_to_enum[self._ivy_array.dtype]
45 )
46
47 @property
48 def shape(self):
49 return self._ivy_array.shape
50
51 # Instance Methods #
52 # ---------------- #
53
54 def assign(self, value, use_locking=None, name=None, read_value=True):
55 ivy.utils.assertions.check_equal(
56 value.shape if hasattr(value, "ivy_array") else ivy.shape(value),
57 self.shape,
58 as_array=False,
59 )
60 self._ivy_array = value._ivy_array
61
62 def assign_add(self, delta, use_locking=None, name=None, read_value=True):
63 ivy.utils.assertions.check_equal(
64 delta.shape if hasattr(delta, "ivy_array") else ivy.shape(delta),
65 self.shape,
66 as_array=False,
67 )
68 self._ivy_array = tf_frontend.math.add(self._ivy_array, delta._ivy_array)
69
70 def assign_sub(self, delta, use_locking=None, name=None, read_value=True):
71 ivy.utils.assertions.check_equal(
72 delta.shape if hasattr(delta, "ivy_array") else ivy.shape(delta),
73 self.shape,
74 as_array=False,
75 )
76 self._ivy_array = tf_frontend.math.subtract(self._ivy_array, delta._ivy_array)
77
78 def batch_scatter_update(
79 self, sparse_delta, use_locking=None, name=None, read_value=True
80 ):
81 pass
82
83 def gather_nd(self, indices, name=None):
84 return tf_frontend.gather_nd(params=self._ivy_array, indices=indices)
85
86 def read_value(self):
87 return tf_frontend.Tensor(self._ivy_array)
88
89 def scatter_add(self, sparse_delta, use_locking=None, name=None, read_value=True):
90 pass
91
92 def scatter_div(self, sparse_delta, use_locking=None, name=None, read_value=True):
93 pass
94
95 def scatter_max(self, sparse_delta, use_locking=None, name=None, read_value=True):
96 pass
97
98 def scatter_min(self, sparse_delta, use_locking=None, name=None, read_value=True):
99 pass
100
101 def scatter_mul(self, sparse_delta, use_locking=None, name=None, read_value=True):
102 pass
103
104 def scatter_nd_add(self, indices, updates, use_locking=None, name=None):
105 pass
106
107 def scatter_nd_sub(self, indices, updates, use_locking=None, name=None):
108 pass
109
110 def scatter_nd_update(self, indices, updates, use_locking=None, name=None):
111 pass
112
113 def scatter_sub(self, sparse_delta, use_locking=None, name=None, read_value=True):
114 pass
115
116 def scatter_update(
117 self, sparse_delta, use_locking=None, name=None, read_value=True
118 ):
119 pass
120
121 def set_shape(self, shape):
122 if shape is None:
123 return
124
125 x_shape = self._ivy_array.shape
126 if len(x_shape) != len(shape):
127 raise ValueError(
128 f"Tensor's shape {x_shape} is not compatible with supplied shape "
129 f"{shape}."
130 )
131 for i, v in enumerate(x_shape):
132 if v != shape[i] and (shape[i] is not None):
133 raise ValueError(
134 f"Tensor's shape {x_shape} is not compatible with supplied shape "
135 f"{shape}."
136 )
137
138 def get_shape(self):
139 return self._ivy_array.shape
140
141 def sparse_read(self, indices, name=None):
142 pass
143
144 def __add__(self, y, name="add"):
145 return self.__radd__(y)
146
147 def __div__(self, x, name="div"):
148 return tf_frontend.math.divide(x, self._ivy_array, name=name)
149
150 def __and__(self, y, name="and"):
151 return y.__rand__(self._ivy_array)
152
153 def __eq__(self, other):
154 return tf_frontend.raw_ops.Equal(
155 x=self._ivy_array, y=other, incompatible_shape_error=False
156 )
157
158 def __floordiv__(self, y, name="floordiv"):
159 return y.__rfloordiv__(self._ivy_array)
160
161 def __ge__(self, y, name="ge"):
162 return tf_frontend.raw_ops.GreaterEqual(
163 x=self._ivy_array, y=y._ivy_array, name=name
164 )
165
166 def __getitem__(self, slice_spec, var=None, name="getitem"):
167 ret = ivy.get_item(self._ivy_array, slice_spec)
168 return Variable(ivy.array(ret, dtype=ivy.dtype(ret), copy=False))
169
170 def __gt__(self, y, name="gt"):
171 return tf_frontend.raw_ops.Greater(x=self._ivy_array, y=y._ivy_array, name=name)
172
173 def __invert__(self, name="invert"):
174 return tf_frontend.raw_ops.Invert(x=self._ivy_array, name=name)
175
176 def __le__(self, y, name="le"):
177 return tf_frontend.raw_ops.LessEqual(
178 x=self._ivy_array, y=y._ivy_array, name=name
179 )
180
181 def __lt__(self, y, name="lt"):
182 return tf_frontend.raw_ops.Less(x=self._ivy_array, y=y._ivy_array, name=name)
183
184 def __matmul__(self, y, name="matmul"):
185 return y.__rmatmul__(self._ivy_array)
186
187 def __mul__(self, x, name="mul"):
188 return tf_frontend.math.multiply(x, self._ivy_array, name=name)
189
190 def __mod__(self, x, name="mod"):
191 return ivy.remainder(x, self._ivy_array, name=name)
192
193 def __ne__(self, other):
194 return tf_frontend.raw_ops.NotEqual(
195 x=self._ivy_array, y=other._ivy_array, incompatible_shape_error=False
196 )
197
198 def __neg__(self, name="neg"):
199 return tf_frontend.raw_ops.Neg(x=self._ivy_array, name=name)
200
201 def __or__(self, y, name="or"):
202 return y.__ror__(self._ivy_array)
203
204 def __pow__(self, y, name="pow"):
205 return tf_frontend.math.pow(x=self, y=y, name=name)
206
207 def __radd__(self, x, name="radd"):
208 return tf_frontend.math.add(x, self._ivy_array, name=name)
209
210 def __rand__(self, x, name="rand"):
211 return tf_frontend.math.logical_and(x, self._ivy_array, name=name)
212
213 def __rfloordiv__(self, x, name="rfloordiv"):
214 return tf_frontend.raw_ops.FloorDiv(x=x, y=self._ivy_array, name=name)
215
216 def __rmatmul__(self, x, name="rmatmul"):
217 return tf_frontend.raw_ops.MatMul(a=x, b=self._ivy_array, name=name)
218
219 def __rmul__(self, x, name="rmul"):
220 return tf_frontend.raw_ops.Mul(x=x, y=self._ivy_array, name=name)
221
222 def __ror__(self, x, name="ror"):
223 return tf_frontend.raw_ops.LogicalOr(x=x, y=self._ivy_array, name=name)
224
225 def __rpow__(self, x, name="rpow"):
226 return tf_frontend.raw_ops.Pow(x=x, y=self._ivy_array, name=name)
227
228 def __rsub__(self, x, name="rsub"):
229 return tf_frontend.math.subtract(x, self._ivy_array, name=name)
230
231 def __rtruediv__(self, x, name="rtruediv"):
232 return tf_frontend.math.truediv(x, self._ivy_array, name=name)
233
234 def __rxor__(self, x, name="rxor"):
235 return tf_frontend.math.logical_xor(x, self._ivy_array, name=name)
236
237 def __sub__(self, y, name="sub"):
238 return y.__rsub__(self._ivy_array)
239
240 def __truediv__(self, y, name="truediv"):
241 dtype = ivy.dtype(self._ivy_array)
242 if dtype in [ivy.uint8, ivy.int8, ivy.uint16, ivy.int16]:
243 return ivy.astype(y, ivy.float32).__rtruediv__(
244 ivy.astype(self._ivy_array, ivy.float32)
245 )
246 if dtype in [ivy.uint32, ivy.int32, ivy.uint64, ivy.int64]:
247 return ivy.astype(y, ivy.float64).__rtruediv__(
248 ivy.astype(self._ivy_array, ivy.float64)
249 )
250 return y.__rtruediv__(self._ivy_array)
251
252 def __xor__(self, y, name="xor"):
253 return y.__rxor__(self._ivy_array)
254
255 def __setitem__(self, key, value):
256 raise ivy.utils.exceptions.IvyException(
257 "ivy.functional.frontends.tensorflow.Variable object "
258 "doesn't support assignment"
259 )
260
261
262 class IndexedSlices:
263 def __init__(self, values, indices, dense_shape=None):
264 self._values = values
265 self._indices = indices
266 self._dense_shape = dense_shape
267
268 @property
269 def values(self):
270 """A `Tensor` containing the values of the slices."""
271 return self._values
272
273 @property
274 def indices(self):
275 """A 1-D `Tensor` containing the indices of the slices."""
276 return self._indices
277
278 @property
279 def dense_shape(self):
280 """A 1-D `Tensor` containing the shape of the corresponding dense
281 tensor."""
282 return self._dense_shape
283
284 @property
285 def device(self):
286 """The name of the device on which `values` will be produced, or
287 `None`."""
288 return self.values.device
289
290 @property
291 def dtype(self):
292 """The `DType` of elements in this tensor."""
293 return self.values.dtype
294
295 def __repr__(self):
296 return "IndexedSlices(\nindices=%s,\nvalues=%s%s\n)" % (
297 self._indices,
298 self._values,
299 (
300 f", dense_shape={self._dense_shape}"
301 if self._dense_shape is not None
302 else ""
303 ),
304 )
305
306 def __neg__(self):
307 return IndexedSlices(-self._values, self._indices, self._dense_shape)
308
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ivy/functional/frontends/tensorflow/variable.py b/ivy/functional/frontends/tensorflow/variable.py
--- a/ivy/functional/frontends/tensorflow/variable.py
+++ b/ivy/functional/frontends/tensorflow/variable.py
@@ -188,7 +188,7 @@
return tf_frontend.math.multiply(x, self._ivy_array, name=name)
def __mod__(self, x, name="mod"):
- return ivy.remainder(x, self._ivy_array, name=name)
+ return tf_frontend.math.mod(x, self._ivy_array, name=name)
def __ne__(self, other):
return tf_frontend.raw_ops.NotEqual(
| {"golden_diff": "diff --git a/ivy/functional/frontends/tensorflow/variable.py b/ivy/functional/frontends/tensorflow/variable.py\n--- a/ivy/functional/frontends/tensorflow/variable.py\n+++ b/ivy/functional/frontends/tensorflow/variable.py\n@@ -188,7 +188,7 @@\n return tf_frontend.math.multiply(x, self._ivy_array, name=name)\n \n def __mod__(self, x, name=\"mod\"):\n- return ivy.remainder(x, self._ivy_array, name=name)\n+ return tf_frontend.math.mod(x, self._ivy_array, name=name)\n \n def __ne__(self, other):\n return tf_frontend.raw_ops.NotEqual(\n", "issue": "Wrong key-word argument `name` in `ivy.remainder()` function call\nIn the following line, the name argument is passed,\r\nhttps://github.com/unifyai/ivy/blob/bec4752711c314f01298abc3845f02c24a99acab/ivy/functional/frontends/tensorflow/variable.py#L191\r\nFrom the actual function definition, there is no such argument\r\nhttps://github.com/unifyai/ivy/blob/8ff497a8c592b75f010160b313dc431218c2b475/ivy/functional/ivy/elementwise.py#L5415-L5422\n", "before_files": [{"content": "# global\n\n# local\nimport ivy\nimport ivy.functional.frontends.tensorflow as tf_frontend\n\n\nclass Variable:\n def __init__(self, array, trainable=True, name=None, dtype=None):\n self._ivy_array = (\n ivy.array(array) if not isinstance(array, ivy.Array) else array\n )\n self._ivy_array = (\n ivy.astype(self._ivy_array, dtype) if dtype is not None else self._ivy_array\n )\n self.trainable = trainable\n\n def __repr__(self):\n return (\n repr(self._ivy_array).replace(\n \"ivy.array\", \"ivy.frontends.tensorflow.Variable\"\n )[:-1]\n + \", shape=\"\n + str(self._ivy_array.shape)\n + \", dtype=\"\n + str(self._ivy_array.dtype)\n + \")\"\n )\n\n # Properties #\n # ---------- #\n\n @property\n def ivy_array(self):\n return self._ivy_array\n\n @property\n def device(self):\n return self._ivy_array.device\n\n @property\n def dtype(self):\n return tf_frontend.DType(\n tf_frontend.tensorflow_type_to_enum[self._ivy_array.dtype]\n )\n\n @property\n def shape(self):\n return self._ivy_array.shape\n\n # Instance Methods #\n # ---------------- #\n\n def assign(self, value, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n value.shape if hasattr(value, \"ivy_array\") else ivy.shape(value),\n self.shape,\n as_array=False,\n )\n self._ivy_array = value._ivy_array\n\n def assign_add(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.add(self._ivy_array, delta._ivy_array)\n\n def assign_sub(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.subtract(self._ivy_array, delta._ivy_array)\n\n def batch_scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def gather_nd(self, indices, name=None):\n return tf_frontend.gather_nd(params=self._ivy_array, indices=indices)\n\n def read_value(self):\n return tf_frontend.Tensor(self._ivy_array)\n\n def scatter_add(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_div(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_max(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_min(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_mul(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_nd_add(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_sub(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_update(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_sub(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def set_shape(self, shape):\n if shape is None:\n return\n\n x_shape = self._ivy_array.shape\n if len(x_shape) != len(shape):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n for i, v in enumerate(x_shape):\n if v != shape[i] and (shape[i] is not None):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n\n def get_shape(self):\n return self._ivy_array.shape\n\n def sparse_read(self, indices, name=None):\n pass\n\n def __add__(self, y, name=\"add\"):\n return self.__radd__(y)\n\n def __div__(self, x, name=\"div\"):\n return tf_frontend.math.divide(x, self._ivy_array, name=name)\n\n def __and__(self, y, name=\"and\"):\n return y.__rand__(self._ivy_array)\n\n def __eq__(self, other):\n return tf_frontend.raw_ops.Equal(\n x=self._ivy_array, y=other, incompatible_shape_error=False\n )\n\n def __floordiv__(self, y, name=\"floordiv\"):\n return y.__rfloordiv__(self._ivy_array)\n\n def __ge__(self, y, name=\"ge\"):\n return tf_frontend.raw_ops.GreaterEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __getitem__(self, slice_spec, var=None, name=\"getitem\"):\n ret = ivy.get_item(self._ivy_array, slice_spec)\n return Variable(ivy.array(ret, dtype=ivy.dtype(ret), copy=False))\n\n def __gt__(self, y, name=\"gt\"):\n return tf_frontend.raw_ops.Greater(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __invert__(self, name=\"invert\"):\n return tf_frontend.raw_ops.Invert(x=self._ivy_array, name=name)\n\n def __le__(self, y, name=\"le\"):\n return tf_frontend.raw_ops.LessEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __lt__(self, y, name=\"lt\"):\n return tf_frontend.raw_ops.Less(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __matmul__(self, y, name=\"matmul\"):\n return y.__rmatmul__(self._ivy_array)\n\n def __mul__(self, x, name=\"mul\"):\n return tf_frontend.math.multiply(x, self._ivy_array, name=name)\n\n def __mod__(self, x, name=\"mod\"):\n return ivy.remainder(x, self._ivy_array, name=name)\n\n def __ne__(self, other):\n return tf_frontend.raw_ops.NotEqual(\n x=self._ivy_array, y=other._ivy_array, incompatible_shape_error=False\n )\n\n def __neg__(self, name=\"neg\"):\n return tf_frontend.raw_ops.Neg(x=self._ivy_array, name=name)\n\n def __or__(self, y, name=\"or\"):\n return y.__ror__(self._ivy_array)\n\n def __pow__(self, y, name=\"pow\"):\n return tf_frontend.math.pow(x=self, y=y, name=name)\n\n def __radd__(self, x, name=\"radd\"):\n return tf_frontend.math.add(x, self._ivy_array, name=name)\n\n def __rand__(self, x, name=\"rand\"):\n return tf_frontend.math.logical_and(x, self._ivy_array, name=name)\n\n def __rfloordiv__(self, x, name=\"rfloordiv\"):\n return tf_frontend.raw_ops.FloorDiv(x=x, y=self._ivy_array, name=name)\n\n def __rmatmul__(self, x, name=\"rmatmul\"):\n return tf_frontend.raw_ops.MatMul(a=x, b=self._ivy_array, name=name)\n\n def __rmul__(self, x, name=\"rmul\"):\n return tf_frontend.raw_ops.Mul(x=x, y=self._ivy_array, name=name)\n\n def __ror__(self, x, name=\"ror\"):\n return tf_frontend.raw_ops.LogicalOr(x=x, y=self._ivy_array, name=name)\n\n def __rpow__(self, x, name=\"rpow\"):\n return tf_frontend.raw_ops.Pow(x=x, y=self._ivy_array, name=name)\n\n def __rsub__(self, x, name=\"rsub\"):\n return tf_frontend.math.subtract(x, self._ivy_array, name=name)\n\n def __rtruediv__(self, x, name=\"rtruediv\"):\n return tf_frontend.math.truediv(x, self._ivy_array, name=name)\n\n def __rxor__(self, x, name=\"rxor\"):\n return tf_frontend.math.logical_xor(x, self._ivy_array, name=name)\n\n def __sub__(self, y, name=\"sub\"):\n return y.__rsub__(self._ivy_array)\n\n def __truediv__(self, y, name=\"truediv\"):\n dtype = ivy.dtype(self._ivy_array)\n if dtype in [ivy.uint8, ivy.int8, ivy.uint16, ivy.int16]:\n return ivy.astype(y, ivy.float32).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float32)\n )\n if dtype in [ivy.uint32, ivy.int32, ivy.uint64, ivy.int64]:\n return ivy.astype(y, ivy.float64).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float64)\n )\n return y.__rtruediv__(self._ivy_array)\n\n def __xor__(self, y, name=\"xor\"):\n return y.__rxor__(self._ivy_array)\n\n def __setitem__(self, key, value):\n raise ivy.utils.exceptions.IvyException(\n \"ivy.functional.frontends.tensorflow.Variable object \"\n \"doesn't support assignment\"\n )\n\n\nclass IndexedSlices:\n def __init__(self, values, indices, dense_shape=None):\n self._values = values\n self._indices = indices\n self._dense_shape = dense_shape\n\n @property\n def values(self):\n \"\"\"A `Tensor` containing the values of the slices.\"\"\"\n return self._values\n\n @property\n def indices(self):\n \"\"\"A 1-D `Tensor` containing the indices of the slices.\"\"\"\n return self._indices\n\n @property\n def dense_shape(self):\n \"\"\"A 1-D `Tensor` containing the shape of the corresponding dense\n tensor.\"\"\"\n return self._dense_shape\n\n @property\n def device(self):\n \"\"\"The name of the device on which `values` will be produced, or\n `None`.\"\"\"\n return self.values.device\n\n @property\n def dtype(self):\n \"\"\"The `DType` of elements in this tensor.\"\"\"\n return self.values.dtype\n\n def __repr__(self):\n return \"IndexedSlices(\\nindices=%s,\\nvalues=%s%s\\n)\" % (\n self._indices,\n self._values,\n (\n f\", dense_shape={self._dense_shape}\"\n if self._dense_shape is not None\n else \"\"\n ),\n )\n\n def __neg__(self):\n return IndexedSlices(-self._values, self._indices, self._dense_shape)\n", "path": "ivy/functional/frontends/tensorflow/variable.py"}], "after_files": [{"content": "# global\n\n# local\nimport ivy\nimport ivy.functional.frontends.tensorflow as tf_frontend\n\n\nclass Variable:\n def __init__(self, array, trainable=True, name=None, dtype=None):\n self._ivy_array = (\n ivy.array(array) if not isinstance(array, ivy.Array) else array\n )\n self._ivy_array = (\n ivy.astype(self._ivy_array, dtype) if dtype is not None else self._ivy_array\n )\n self.trainable = trainable\n\n def __repr__(self):\n return (\n repr(self._ivy_array).replace(\n \"ivy.array\", \"ivy.frontends.tensorflow.Variable\"\n )[:-1]\n + \", shape=\"\n + str(self._ivy_array.shape)\n + \", dtype=\"\n + str(self._ivy_array.dtype)\n + \")\"\n )\n\n # Properties #\n # ---------- #\n\n @property\n def ivy_array(self):\n return self._ivy_array\n\n @property\n def device(self):\n return self._ivy_array.device\n\n @property\n def dtype(self):\n return tf_frontend.DType(\n tf_frontend.tensorflow_type_to_enum[self._ivy_array.dtype]\n )\n\n @property\n def shape(self):\n return self._ivy_array.shape\n\n # Instance Methods #\n # ---------------- #\n\n def assign(self, value, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n value.shape if hasattr(value, \"ivy_array\") else ivy.shape(value),\n self.shape,\n as_array=False,\n )\n self._ivy_array = value._ivy_array\n\n def assign_add(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.add(self._ivy_array, delta._ivy_array)\n\n def assign_sub(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.subtract(self._ivy_array, delta._ivy_array)\n\n def batch_scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def gather_nd(self, indices, name=None):\n return tf_frontend.gather_nd(params=self._ivy_array, indices=indices)\n\n def read_value(self):\n return tf_frontend.Tensor(self._ivy_array)\n\n def scatter_add(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_div(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_max(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_min(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_mul(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_nd_add(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_sub(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_update(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_sub(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def set_shape(self, shape):\n if shape is None:\n return\n\n x_shape = self._ivy_array.shape\n if len(x_shape) != len(shape):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n for i, v in enumerate(x_shape):\n if v != shape[i] and (shape[i] is not None):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n\n def get_shape(self):\n return self._ivy_array.shape\n\n def sparse_read(self, indices, name=None):\n pass\n\n def __add__(self, y, name=\"add\"):\n return self.__radd__(y)\n\n def __div__(self, x, name=\"div\"):\n return tf_frontend.math.divide(x, self._ivy_array, name=name)\n\n def __and__(self, y, name=\"and\"):\n return y.__rand__(self._ivy_array)\n\n def __eq__(self, other):\n return tf_frontend.raw_ops.Equal(\n x=self._ivy_array, y=other, incompatible_shape_error=False\n )\n\n def __floordiv__(self, y, name=\"floordiv\"):\n return y.__rfloordiv__(self._ivy_array)\n\n def __ge__(self, y, name=\"ge\"):\n return tf_frontend.raw_ops.GreaterEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __getitem__(self, slice_spec, var=None, name=\"getitem\"):\n ret = ivy.get_item(self._ivy_array, slice_spec)\n return Variable(ivy.array(ret, dtype=ivy.dtype(ret), copy=False))\n\n def __gt__(self, y, name=\"gt\"):\n return tf_frontend.raw_ops.Greater(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __invert__(self, name=\"invert\"):\n return tf_frontend.raw_ops.Invert(x=self._ivy_array, name=name)\n\n def __le__(self, y, name=\"le\"):\n return tf_frontend.raw_ops.LessEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __lt__(self, y, name=\"lt\"):\n return tf_frontend.raw_ops.Less(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __matmul__(self, y, name=\"matmul\"):\n return y.__rmatmul__(self._ivy_array)\n\n def __mul__(self, x, name=\"mul\"):\n return tf_frontend.math.multiply(x, self._ivy_array, name=name)\n\n def __mod__(self, x, name=\"mod\"):\n return tf_frontend.math.mod(x, self._ivy_array, name=name)\n\n def __ne__(self, other):\n return tf_frontend.raw_ops.NotEqual(\n x=self._ivy_array, y=other._ivy_array, incompatible_shape_error=False\n )\n\n def __neg__(self, name=\"neg\"):\n return tf_frontend.raw_ops.Neg(x=self._ivy_array, name=name)\n\n def __or__(self, y, name=\"or\"):\n return y.__ror__(self._ivy_array)\n\n def __pow__(self, y, name=\"pow\"):\n return tf_frontend.math.pow(x=self, y=y, name=name)\n\n def __radd__(self, x, name=\"radd\"):\n return tf_frontend.math.add(x, self._ivy_array, name=name)\n\n def __rand__(self, x, name=\"rand\"):\n return tf_frontend.math.logical_and(x, self._ivy_array, name=name)\n\n def __rfloordiv__(self, x, name=\"rfloordiv\"):\n return tf_frontend.raw_ops.FloorDiv(x=x, y=self._ivy_array, name=name)\n\n def __rmatmul__(self, x, name=\"rmatmul\"):\n return tf_frontend.raw_ops.MatMul(a=x, b=self._ivy_array, name=name)\n\n def __rmul__(self, x, name=\"rmul\"):\n return tf_frontend.raw_ops.Mul(x=x, y=self._ivy_array, name=name)\n\n def __ror__(self, x, name=\"ror\"):\n return tf_frontend.raw_ops.LogicalOr(x=x, y=self._ivy_array, name=name)\n\n def __rpow__(self, x, name=\"rpow\"):\n return tf_frontend.raw_ops.Pow(x=x, y=self._ivy_array, name=name)\n\n def __rsub__(self, x, name=\"rsub\"):\n return tf_frontend.math.subtract(x, self._ivy_array, name=name)\n\n def __rtruediv__(self, x, name=\"rtruediv\"):\n return tf_frontend.math.truediv(x, self._ivy_array, name=name)\n\n def __rxor__(self, x, name=\"rxor\"):\n return tf_frontend.math.logical_xor(x, self._ivy_array, name=name)\n\n def __sub__(self, y, name=\"sub\"):\n return y.__rsub__(self._ivy_array)\n\n def __truediv__(self, y, name=\"truediv\"):\n dtype = ivy.dtype(self._ivy_array)\n if dtype in [ivy.uint8, ivy.int8, ivy.uint16, ivy.int16]:\n return ivy.astype(y, ivy.float32).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float32)\n )\n if dtype in [ivy.uint32, ivy.int32, ivy.uint64, ivy.int64]:\n return ivy.astype(y, ivy.float64).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float64)\n )\n return y.__rtruediv__(self._ivy_array)\n\n def __xor__(self, y, name=\"xor\"):\n return y.__rxor__(self._ivy_array)\n\n def __setitem__(self, key, value):\n raise ivy.utils.exceptions.IvyException(\n \"ivy.functional.frontends.tensorflow.Variable object \"\n \"doesn't support assignment\"\n )\n\n\nclass IndexedSlices:\n def __init__(self, values, indices, dense_shape=None):\n self._values = values\n self._indices = indices\n self._dense_shape = dense_shape\n\n @property\n def values(self):\n \"\"\"A `Tensor` containing the values of the slices.\"\"\"\n return self._values\n\n @property\n def indices(self):\n \"\"\"A 1-D `Tensor` containing the indices of the slices.\"\"\"\n return self._indices\n\n @property\n def dense_shape(self):\n \"\"\"A 1-D `Tensor` containing the shape of the corresponding dense\n tensor.\"\"\"\n return self._dense_shape\n\n @property\n def device(self):\n \"\"\"The name of the device on which `values` will be produced, or\n `None`.\"\"\"\n return self.values.device\n\n @property\n def dtype(self):\n \"\"\"The `DType` of elements in this tensor.\"\"\"\n return self.values.dtype\n\n def __repr__(self):\n return \"IndexedSlices(\\nindices=%s,\\nvalues=%s%s\\n)\" % (\n self._indices,\n self._values,\n (\n f\", dense_shape={self._dense_shape}\"\n if self._dense_shape is not None\n else \"\"\n ),\n )\n\n def __neg__(self):\n return IndexedSlices(-self._values, self._indices, self._dense_shape)\n", "path": "ivy/functional/frontends/tensorflow/variable.py"}]} | 3,763 | 158 |
gh_patches_debug_8517 | rasdani/github-patches | git_diff | facebookresearch__hydra-1818 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] delete field when using optuna sweeper would throw error
# 🐛 Bug
## Description
<!-- A clear and concise description of what the bug is. -->
I was using optuna sweeper but I noticed that if i delete a field by `~field` it would throw an error.
## To reproduce
Let's [start with this](https://github.com/facebookresearch/hydra/tree/main/examples/advanced/defaults_list_interpolation). Let's modify `conf/db/sqlite.yaml` to be this
```yaml
name: sqlite
model:
name: boring
```
then create a directory called `exp`, and create a file `exp/exp.yaml`
```yaml
# @package _global_
defaults:
- override /hydra/sweeper: optuna
- override /db: sqlite
```
Now run the command `python my_app.py -m +exp=exp ~db.model` it would have the error
> Could not delete from config. The value of 'db.model' is {'name': 'boring'} and not None.
However if I did `python my_app.py +exp=exp ~db.model` (not activating sweeper), then the code would run correctly, making the db to be sqlite (the default is mysql) and the `model.name` part deleted.
## System information
- **Hydra Version** : 1.0.0.rc1
- **Python version** : 3.7.10
- **Operating system** : Ubuntu 18.04.2 LTS
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 import sys
4 from typing import Any, Dict, List, MutableMapping, MutableSequence, Optional
5
6 import optuna
7 from hydra.core.override_parser.overrides_parser import OverridesParser
8 from hydra.core.override_parser.types import (
9 ChoiceSweep,
10 IntervalSweep,
11 Override,
12 RangeSweep,
13 Transformer,
14 )
15 from hydra.core.plugins import Plugins
16 from hydra.plugins.sweeper import Sweeper
17 from hydra.types import HydraContext, TaskFunction
18 from omegaconf import DictConfig, OmegaConf
19 from optuna.distributions import (
20 BaseDistribution,
21 CategoricalChoiceType,
22 CategoricalDistribution,
23 DiscreteUniformDistribution,
24 IntLogUniformDistribution,
25 IntUniformDistribution,
26 LogUniformDistribution,
27 UniformDistribution,
28 )
29
30 from .config import Direction, DistributionConfig, DistributionType
31
32 log = logging.getLogger(__name__)
33
34
35 def create_optuna_distribution_from_config(
36 config: MutableMapping[str, Any]
37 ) -> BaseDistribution:
38 kwargs = dict(config)
39 if isinstance(config["type"], str):
40 kwargs["type"] = DistributionType[config["type"]]
41 param = DistributionConfig(**kwargs)
42 if param.type == DistributionType.categorical:
43 assert param.choices is not None
44 return CategoricalDistribution(param.choices)
45 if param.type == DistributionType.int:
46 assert param.low is not None
47 assert param.high is not None
48 if param.log:
49 return IntLogUniformDistribution(int(param.low), int(param.high))
50 step = int(param.step) if param.step is not None else 1
51 return IntUniformDistribution(int(param.low), int(param.high), step=step)
52 if param.type == DistributionType.float:
53 assert param.low is not None
54 assert param.high is not None
55 if param.log:
56 return LogUniformDistribution(param.low, param.high)
57 if param.step is not None:
58 return DiscreteUniformDistribution(param.low, param.high, param.step)
59 return UniformDistribution(param.low, param.high)
60 raise NotImplementedError(f"{param.type} is not supported by Optuna sweeper.")
61
62
63 def create_optuna_distribution_from_override(override: Override) -> Any:
64 value = override.value()
65 if not override.is_sweep_override():
66 return value
67
68 choices: List[CategoricalChoiceType] = []
69 if override.is_choice_sweep():
70 assert isinstance(value, ChoiceSweep)
71 for x in override.sweep_iterator(transformer=Transformer.encode):
72 assert isinstance(
73 x, (str, int, float, bool)
74 ), f"A choice sweep expects str, int, float, or bool type. Got {type(x)}."
75 choices.append(x)
76 return CategoricalDistribution(choices)
77
78 if override.is_range_sweep():
79 assert isinstance(value, RangeSweep)
80 assert value.start is not None
81 assert value.stop is not None
82 if value.shuffle:
83 for x in override.sweep_iterator(transformer=Transformer.encode):
84 assert isinstance(
85 x, (str, int, float, bool)
86 ), f"A choice sweep expects str, int, float, or bool type. Got {type(x)}."
87 choices.append(x)
88 return CategoricalDistribution(choices)
89 return IntUniformDistribution(
90 int(value.start), int(value.stop), step=int(value.step)
91 )
92
93 if override.is_interval_sweep():
94 assert isinstance(value, IntervalSweep)
95 assert value.start is not None
96 assert value.end is not None
97 if "log" in value.tags:
98 if isinstance(value.start, int) and isinstance(value.end, int):
99 return IntLogUniformDistribution(int(value.start), int(value.end))
100 return LogUniformDistribution(value.start, value.end)
101 else:
102 if isinstance(value.start, int) and isinstance(value.end, int):
103 return IntUniformDistribution(value.start, value.end)
104 return UniformDistribution(value.start, value.end)
105
106 raise NotImplementedError(f"{override} is not supported by Optuna sweeper.")
107
108
109 class OptunaSweeperImpl(Sweeper):
110 def __init__(
111 self,
112 sampler: Any,
113 direction: Any,
114 storage: Optional[str],
115 study_name: Optional[str],
116 n_trials: int,
117 n_jobs: int,
118 search_space: Optional[DictConfig],
119 ) -> None:
120 self.sampler = sampler
121 self.direction = direction
122 self.storage = storage
123 self.study_name = study_name
124 self.n_trials = n_trials
125 self.n_jobs = n_jobs
126 self.search_space = {}
127 if search_space:
128 assert isinstance(search_space, DictConfig)
129 self.search_space = {
130 str(x): create_optuna_distribution_from_config(y)
131 for x, y in search_space.items()
132 }
133 self.job_idx: int = 0
134
135 def setup(
136 self,
137 *,
138 hydra_context: HydraContext,
139 task_function: TaskFunction,
140 config: DictConfig,
141 ) -> None:
142 self.job_idx = 0
143 self.config = config
144 self.hydra_context = hydra_context
145 self.launcher = Plugins.instance().instantiate_launcher(
146 config=config, hydra_context=hydra_context, task_function=task_function
147 )
148 self.sweep_dir = config.hydra.sweep.dir
149
150 def sweep(self, arguments: List[str]) -> None:
151 assert self.config is not None
152 assert self.launcher is not None
153 assert self.hydra_context is not None
154 assert self.job_idx is not None
155
156 parser = OverridesParser.create()
157 parsed = parser.parse_overrides(arguments)
158
159 search_space = dict(self.search_space)
160 fixed_params = dict()
161 for override in parsed:
162 value = create_optuna_distribution_from_override(override)
163 if isinstance(value, BaseDistribution):
164 search_space[override.get_key_element()] = value
165 else:
166 fixed_params[override.get_key_element()] = value
167 # Remove fixed parameters from Optuna search space.
168 for param_name in fixed_params:
169 if param_name in search_space:
170 del search_space[param_name]
171
172 directions: List[str]
173 if isinstance(self.direction, MutableSequence):
174 directions = [
175 d.name if isinstance(d, Direction) else d for d in self.direction
176 ]
177 else:
178 if isinstance(self.direction, str):
179 directions = [self.direction]
180 else:
181 directions = [self.direction.name]
182
183 study = optuna.create_study(
184 study_name=self.study_name,
185 storage=self.storage,
186 sampler=self.sampler,
187 directions=directions,
188 load_if_exists=True,
189 )
190 log.info(f"Study name: {study.study_name}")
191 log.info(f"Storage: {self.storage}")
192 log.info(f"Sampler: {type(self.sampler).__name__}")
193 log.info(f"Directions: {directions}")
194
195 batch_size = self.n_jobs
196 n_trials_to_go = self.n_trials
197
198 while n_trials_to_go > 0:
199 batch_size = min(n_trials_to_go, batch_size)
200
201 trials = [study.ask() for _ in range(batch_size)]
202 overrides = []
203 for trial in trials:
204 for param_name, distribution in search_space.items():
205 trial._suggest(param_name, distribution)
206
207 params = dict(trial.params)
208 params.update(fixed_params)
209 overrides.append(tuple(f"{name}={val}" for name, val in params.items()))
210
211 returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)
212 self.job_idx += len(returns)
213 for trial, ret in zip(trials, returns):
214 values: Optional[List[float]] = None
215 state: optuna.trial.TrialState = optuna.trial.TrialState.COMPLETE
216 try:
217 if len(directions) == 1:
218 try:
219 values = [float(ret.return_value)]
220 except (ValueError, TypeError):
221 raise ValueError(
222 f"Return value must be float-castable. Got '{ret.return_value}'."
223 ).with_traceback(sys.exc_info()[2])
224 else:
225 try:
226 values = [float(v) for v in ret.return_value]
227 except (ValueError, TypeError):
228 raise ValueError(
229 "Return value must be a list or tuple of float-castable values."
230 f" Got '{ret.return_value}'."
231 ).with_traceback(sys.exc_info()[2])
232 if len(values) != len(directions):
233 raise ValueError(
234 "The number of the values and the number of the objectives are"
235 f" mismatched. Expect {len(directions)}, but actually {len(values)}."
236 )
237 study.tell(trial=trial, state=state, values=values)
238 except Exception as e:
239 state = optuna.trial.TrialState.FAIL
240 study.tell(trial=trial, state=state, values=values)
241 raise e
242
243 n_trials_to_go -= batch_size
244
245 results_to_serialize: Dict[str, Any]
246 if len(directions) < 2:
247 best_trial = study.best_trial
248 results_to_serialize = {
249 "name": "optuna",
250 "best_params": best_trial.params,
251 "best_value": best_trial.value,
252 }
253 log.info(f"Best parameters: {best_trial.params}")
254 log.info(f"Best value: {best_trial.value}")
255 else:
256 best_trials = study.best_trials
257 pareto_front = [
258 {"params": t.params, "values": t.values} for t in best_trials
259 ]
260 results_to_serialize = {
261 "name": "optuna",
262 "solutions": pareto_front,
263 }
264 log.info(f"Number of Pareto solutions: {len(best_trials)}")
265 for t in best_trials:
266 log.info(f" Values: {t.values}, Params: {t.params}")
267 OmegaConf.save(
268 OmegaConf.create(results_to_serialize),
269 f"{self.config.hydra.sweep.dir}/optimization_results.yaml",
270 )
271
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
--- a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
+++ b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
@@ -61,10 +61,10 @@
def create_optuna_distribution_from_override(override: Override) -> Any:
- value = override.value()
if not override.is_sweep_override():
- return value
+ return override.get_value_element_as_str()
+ value = override.value()
choices: List[CategoricalChoiceType] = []
if override.is_choice_sweep():
assert isinstance(value, ChoiceSweep)
| {"golden_diff": "diff --git a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n--- a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n+++ b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n@@ -61,10 +61,10 @@\n \n \n def create_optuna_distribution_from_override(override: Override) -> Any:\n- value = override.value()\n if not override.is_sweep_override():\n- return value\n+ return override.get_value_element_as_str()\n \n+ value = override.value()\n choices: List[CategoricalChoiceType] = []\n if override.is_choice_sweep():\n assert isinstance(value, ChoiceSweep)\n", "issue": "[Bug] delete field when using optuna sweeper would throw error\n# \ud83d\udc1b Bug\r\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nI was using optuna sweeper but I noticed that if i delete a field by `~field` it would throw an error.\r\n\r\n## To reproduce\r\nLet's [start with this](https://github.com/facebookresearch/hydra/tree/main/examples/advanced/defaults_list_interpolation). Let's modify `conf/db/sqlite.yaml` to be this\r\n```yaml\r\nname: sqlite\r\n\r\nmodel:\r\n name: boring\r\n```\r\nthen create a directory called `exp`, and create a file `exp/exp.yaml`\r\n```yaml\r\n# @package _global_\r\n\r\ndefaults:\r\n - override /hydra/sweeper: optuna\r\n - override /db: sqlite\r\n```\r\nNow run the command `python my_app.py -m +exp=exp ~db.model` it would have the error\r\n> Could not delete from config. The value of 'db.model' is {'name': 'boring'} and not None.\r\n\r\nHowever if I did `python my_app.py +exp=exp ~db.model` (not activating sweeper), then the code would run correctly, making the db to be sqlite (the default is mysql) and the `model.name` part deleted. \r\n\r\n## System information\r\n- **Hydra Version** : 1.0.0.rc1\r\n- **Python version** : 3.7.10\r\n- **Operating system** : Ubuntu 18.04.2 LTS\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nimport sys\nfrom typing import Any, Dict, List, MutableMapping, MutableSequence, Optional\n\nimport optuna\nfrom hydra.core.override_parser.overrides_parser import OverridesParser\nfrom hydra.core.override_parser.types import (\n ChoiceSweep,\n IntervalSweep,\n Override,\n RangeSweep,\n Transformer,\n)\nfrom hydra.core.plugins import Plugins\nfrom hydra.plugins.sweeper import Sweeper\nfrom hydra.types import HydraContext, TaskFunction\nfrom omegaconf import DictConfig, OmegaConf\nfrom optuna.distributions import (\n BaseDistribution,\n CategoricalChoiceType,\n CategoricalDistribution,\n DiscreteUniformDistribution,\n IntLogUniformDistribution,\n IntUniformDistribution,\n LogUniformDistribution,\n UniformDistribution,\n)\n\nfrom .config import Direction, DistributionConfig, DistributionType\n\nlog = logging.getLogger(__name__)\n\n\ndef create_optuna_distribution_from_config(\n config: MutableMapping[str, Any]\n) -> BaseDistribution:\n kwargs = dict(config)\n if isinstance(config[\"type\"], str):\n kwargs[\"type\"] = DistributionType[config[\"type\"]]\n param = DistributionConfig(**kwargs)\n if param.type == DistributionType.categorical:\n assert param.choices is not None\n return CategoricalDistribution(param.choices)\n if param.type == DistributionType.int:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return IntLogUniformDistribution(int(param.low), int(param.high))\n step = int(param.step) if param.step is not None else 1\n return IntUniformDistribution(int(param.low), int(param.high), step=step)\n if param.type == DistributionType.float:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return LogUniformDistribution(param.low, param.high)\n if param.step is not None:\n return DiscreteUniformDistribution(param.low, param.high, param.step)\n return UniformDistribution(param.low, param.high)\n raise NotImplementedError(f\"{param.type} is not supported by Optuna sweeper.\")\n\n\ndef create_optuna_distribution_from_override(override: Override) -> Any:\n value = override.value()\n if not override.is_sweep_override():\n return value\n\n choices: List[CategoricalChoiceType] = []\n if override.is_choice_sweep():\n assert isinstance(value, ChoiceSweep)\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n\n if override.is_range_sweep():\n assert isinstance(value, RangeSweep)\n assert value.start is not None\n assert value.stop is not None\n if value.shuffle:\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n return IntUniformDistribution(\n int(value.start), int(value.stop), step=int(value.step)\n )\n\n if override.is_interval_sweep():\n assert isinstance(value, IntervalSweep)\n assert value.start is not None\n assert value.end is not None\n if \"log\" in value.tags:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntLogUniformDistribution(int(value.start), int(value.end))\n return LogUniformDistribution(value.start, value.end)\n else:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntUniformDistribution(value.start, value.end)\n return UniformDistribution(value.start, value.end)\n\n raise NotImplementedError(f\"{override} is not supported by Optuna sweeper.\")\n\n\nclass OptunaSweeperImpl(Sweeper):\n def __init__(\n self,\n sampler: Any,\n direction: Any,\n storage: Optional[str],\n study_name: Optional[str],\n n_trials: int,\n n_jobs: int,\n search_space: Optional[DictConfig],\n ) -> None:\n self.sampler = sampler\n self.direction = direction\n self.storage = storage\n self.study_name = study_name\n self.n_trials = n_trials\n self.n_jobs = n_jobs\n self.search_space = {}\n if search_space:\n assert isinstance(search_space, DictConfig)\n self.search_space = {\n str(x): create_optuna_distribution_from_config(y)\n for x, y in search_space.items()\n }\n self.job_idx: int = 0\n\n def setup(\n self,\n *,\n hydra_context: HydraContext,\n task_function: TaskFunction,\n config: DictConfig,\n ) -> None:\n self.job_idx = 0\n self.config = config\n self.hydra_context = hydra_context\n self.launcher = Plugins.instance().instantiate_launcher(\n config=config, hydra_context=hydra_context, task_function=task_function\n )\n self.sweep_dir = config.hydra.sweep.dir\n\n def sweep(self, arguments: List[str]) -> None:\n assert self.config is not None\n assert self.launcher is not None\n assert self.hydra_context is not None\n assert self.job_idx is not None\n\n parser = OverridesParser.create()\n parsed = parser.parse_overrides(arguments)\n\n search_space = dict(self.search_space)\n fixed_params = dict()\n for override in parsed:\n value = create_optuna_distribution_from_override(override)\n if isinstance(value, BaseDistribution):\n search_space[override.get_key_element()] = value\n else:\n fixed_params[override.get_key_element()] = value\n # Remove fixed parameters from Optuna search space.\n for param_name in fixed_params:\n if param_name in search_space:\n del search_space[param_name]\n\n directions: List[str]\n if isinstance(self.direction, MutableSequence):\n directions = [\n d.name if isinstance(d, Direction) else d for d in self.direction\n ]\n else:\n if isinstance(self.direction, str):\n directions = [self.direction]\n else:\n directions = [self.direction.name]\n\n study = optuna.create_study(\n study_name=self.study_name,\n storage=self.storage,\n sampler=self.sampler,\n directions=directions,\n load_if_exists=True,\n )\n log.info(f\"Study name: {study.study_name}\")\n log.info(f\"Storage: {self.storage}\")\n log.info(f\"Sampler: {type(self.sampler).__name__}\")\n log.info(f\"Directions: {directions}\")\n\n batch_size = self.n_jobs\n n_trials_to_go = self.n_trials\n\n while n_trials_to_go > 0:\n batch_size = min(n_trials_to_go, batch_size)\n\n trials = [study.ask() for _ in range(batch_size)]\n overrides = []\n for trial in trials:\n for param_name, distribution in search_space.items():\n trial._suggest(param_name, distribution)\n\n params = dict(trial.params)\n params.update(fixed_params)\n overrides.append(tuple(f\"{name}={val}\" for name, val in params.items()))\n\n returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)\n self.job_idx += len(returns)\n for trial, ret in zip(trials, returns):\n values: Optional[List[float]] = None\n state: optuna.trial.TrialState = optuna.trial.TrialState.COMPLETE\n try:\n if len(directions) == 1:\n try:\n values = [float(ret.return_value)]\n except (ValueError, TypeError):\n raise ValueError(\n f\"Return value must be float-castable. Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n else:\n try:\n values = [float(v) for v in ret.return_value]\n except (ValueError, TypeError):\n raise ValueError(\n \"Return value must be a list or tuple of float-castable values.\"\n f\" Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n if len(values) != len(directions):\n raise ValueError(\n \"The number of the values and the number of the objectives are\"\n f\" mismatched. Expect {len(directions)}, but actually {len(values)}.\"\n )\n study.tell(trial=trial, state=state, values=values)\n except Exception as e:\n state = optuna.trial.TrialState.FAIL\n study.tell(trial=trial, state=state, values=values)\n raise e\n\n n_trials_to_go -= batch_size\n\n results_to_serialize: Dict[str, Any]\n if len(directions) < 2:\n best_trial = study.best_trial\n results_to_serialize = {\n \"name\": \"optuna\",\n \"best_params\": best_trial.params,\n \"best_value\": best_trial.value,\n }\n log.info(f\"Best parameters: {best_trial.params}\")\n log.info(f\"Best value: {best_trial.value}\")\n else:\n best_trials = study.best_trials\n pareto_front = [\n {\"params\": t.params, \"values\": t.values} for t in best_trials\n ]\n results_to_serialize = {\n \"name\": \"optuna\",\n \"solutions\": pareto_front,\n }\n log.info(f\"Number of Pareto solutions: {len(best_trials)}\")\n for t in best_trials:\n log.info(f\" Values: {t.values}, Params: {t.params}\")\n OmegaConf.save(\n OmegaConf.create(results_to_serialize),\n f\"{self.config.hydra.sweep.dir}/optimization_results.yaml\",\n )\n", "path": "plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nimport sys\nfrom typing import Any, Dict, List, MutableMapping, MutableSequence, Optional\n\nimport optuna\nfrom hydra.core.override_parser.overrides_parser import OverridesParser\nfrom hydra.core.override_parser.types import (\n ChoiceSweep,\n IntervalSweep,\n Override,\n RangeSweep,\n Transformer,\n)\nfrom hydra.core.plugins import Plugins\nfrom hydra.plugins.sweeper import Sweeper\nfrom hydra.types import HydraContext, TaskFunction\nfrom omegaconf import DictConfig, OmegaConf\nfrom optuna.distributions import (\n BaseDistribution,\n CategoricalChoiceType,\n CategoricalDistribution,\n DiscreteUniformDistribution,\n IntLogUniformDistribution,\n IntUniformDistribution,\n LogUniformDistribution,\n UniformDistribution,\n)\n\nfrom .config import Direction, DistributionConfig, DistributionType\n\nlog = logging.getLogger(__name__)\n\n\ndef create_optuna_distribution_from_config(\n config: MutableMapping[str, Any]\n) -> BaseDistribution:\n kwargs = dict(config)\n if isinstance(config[\"type\"], str):\n kwargs[\"type\"] = DistributionType[config[\"type\"]]\n param = DistributionConfig(**kwargs)\n if param.type == DistributionType.categorical:\n assert param.choices is not None\n return CategoricalDistribution(param.choices)\n if param.type == DistributionType.int:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return IntLogUniformDistribution(int(param.low), int(param.high))\n step = int(param.step) if param.step is not None else 1\n return IntUniformDistribution(int(param.low), int(param.high), step=step)\n if param.type == DistributionType.float:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return LogUniformDistribution(param.low, param.high)\n if param.step is not None:\n return DiscreteUniformDistribution(param.low, param.high, param.step)\n return UniformDistribution(param.low, param.high)\n raise NotImplementedError(f\"{param.type} is not supported by Optuna sweeper.\")\n\n\ndef create_optuna_distribution_from_override(override: Override) -> Any:\n if not override.is_sweep_override():\n return override.get_value_element_as_str()\n\n value = override.value()\n choices: List[CategoricalChoiceType] = []\n if override.is_choice_sweep():\n assert isinstance(value, ChoiceSweep)\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n\n if override.is_range_sweep():\n assert isinstance(value, RangeSweep)\n assert value.start is not None\n assert value.stop is not None\n if value.shuffle:\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n return IntUniformDistribution(\n int(value.start), int(value.stop), step=int(value.step)\n )\n\n if override.is_interval_sweep():\n assert isinstance(value, IntervalSweep)\n assert value.start is not None\n assert value.end is not None\n if \"log\" in value.tags:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntLogUniformDistribution(int(value.start), int(value.end))\n return LogUniformDistribution(value.start, value.end)\n else:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntUniformDistribution(value.start, value.end)\n return UniformDistribution(value.start, value.end)\n\n raise NotImplementedError(f\"{override} is not supported by Optuna sweeper.\")\n\n\nclass OptunaSweeperImpl(Sweeper):\n def __init__(\n self,\n sampler: Any,\n direction: Any,\n storage: Optional[str],\n study_name: Optional[str],\n n_trials: int,\n n_jobs: int,\n search_space: Optional[DictConfig],\n ) -> None:\n self.sampler = sampler\n self.direction = direction\n self.storage = storage\n self.study_name = study_name\n self.n_trials = n_trials\n self.n_jobs = n_jobs\n self.search_space = {}\n if search_space:\n assert isinstance(search_space, DictConfig)\n self.search_space = {\n str(x): create_optuna_distribution_from_config(y)\n for x, y in search_space.items()\n }\n self.job_idx: int = 0\n\n def setup(\n self,\n *,\n hydra_context: HydraContext,\n task_function: TaskFunction,\n config: DictConfig,\n ) -> None:\n self.job_idx = 0\n self.config = config\n self.hydra_context = hydra_context\n self.launcher = Plugins.instance().instantiate_launcher(\n config=config, hydra_context=hydra_context, task_function=task_function\n )\n self.sweep_dir = config.hydra.sweep.dir\n\n def sweep(self, arguments: List[str]) -> None:\n assert self.config is not None\n assert self.launcher is not None\n assert self.hydra_context is not None\n assert self.job_idx is not None\n\n parser = OverridesParser.create()\n parsed = parser.parse_overrides(arguments)\n\n search_space = dict(self.search_space)\n fixed_params = dict()\n for override in parsed:\n value = create_optuna_distribution_from_override(override)\n if isinstance(value, BaseDistribution):\n search_space[override.get_key_element()] = value\n else:\n fixed_params[override.get_key_element()] = value\n # Remove fixed parameters from Optuna search space.\n for param_name in fixed_params:\n if param_name in search_space:\n del search_space[param_name]\n\n directions: List[str]\n if isinstance(self.direction, MutableSequence):\n directions = [\n d.name if isinstance(d, Direction) else d for d in self.direction\n ]\n else:\n if isinstance(self.direction, str):\n directions = [self.direction]\n else:\n directions = [self.direction.name]\n\n study = optuna.create_study(\n study_name=self.study_name,\n storage=self.storage,\n sampler=self.sampler,\n directions=directions,\n load_if_exists=True,\n )\n log.info(f\"Study name: {study.study_name}\")\n log.info(f\"Storage: {self.storage}\")\n log.info(f\"Sampler: {type(self.sampler).__name__}\")\n log.info(f\"Directions: {directions}\")\n\n batch_size = self.n_jobs\n n_trials_to_go = self.n_trials\n\n while n_trials_to_go > 0:\n batch_size = min(n_trials_to_go, batch_size)\n\n trials = [study.ask() for _ in range(batch_size)]\n overrides = []\n for trial in trials:\n for param_name, distribution in search_space.items():\n trial._suggest(param_name, distribution)\n\n params = dict(trial.params)\n params.update(fixed_params)\n overrides.append(tuple(f\"{name}={val}\" for name, val in params.items()))\n\n returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)\n self.job_idx += len(returns)\n for trial, ret in zip(trials, returns):\n values: Optional[List[float]] = None\n state: optuna.trial.TrialState = optuna.trial.TrialState.COMPLETE\n try:\n if len(directions) == 1:\n try:\n values = [float(ret.return_value)]\n except (ValueError, TypeError):\n raise ValueError(\n f\"Return value must be float-castable. Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n else:\n try:\n values = [float(v) for v in ret.return_value]\n except (ValueError, TypeError):\n raise ValueError(\n \"Return value must be a list or tuple of float-castable values.\"\n f\" Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n if len(values) != len(directions):\n raise ValueError(\n \"The number of the values and the number of the objectives are\"\n f\" mismatched. Expect {len(directions)}, but actually {len(values)}.\"\n )\n study.tell(trial=trial, state=state, values=values)\n except Exception as e:\n state = optuna.trial.TrialState.FAIL\n study.tell(trial=trial, state=state, values=values)\n raise e\n\n n_trials_to_go -= batch_size\n\n results_to_serialize: Dict[str, Any]\n if len(directions) < 2:\n best_trial = study.best_trial\n results_to_serialize = {\n \"name\": \"optuna\",\n \"best_params\": best_trial.params,\n \"best_value\": best_trial.value,\n }\n log.info(f\"Best parameters: {best_trial.params}\")\n log.info(f\"Best value: {best_trial.value}\")\n else:\n best_trials = study.best_trials\n pareto_front = [\n {\"params\": t.params, \"values\": t.values} for t in best_trials\n ]\n results_to_serialize = {\n \"name\": \"optuna\",\n \"solutions\": pareto_front,\n }\n log.info(f\"Number of Pareto solutions: {len(best_trials)}\")\n for t in best_trials:\n log.info(f\" Values: {t.values}, Params: {t.params}\")\n OmegaConf.save(\n OmegaConf.create(results_to_serialize),\n f\"{self.config.hydra.sweep.dir}/optimization_results.yaml\",\n )\n", "path": "plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py"}]} | 3,441 | 205 |
gh_patches_debug_11245 | rasdani/github-patches | git_diff | sunpy__sunpy-4596 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rethinking and rewriting sunpy.self_test
We are currently using astropy's test runner for `sunpy.self_test` this was really designed for setup.py and is therefore very full of features which are probably not needed for self_test.
Before we (I) go deleting swathes of code as I love to do. What do we want to achieve with self test? Is a very slim wrapper around `pytest --pyargs sunpy` all we need?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sunpy/__init__.py`
Content:
```
1 """
2 SunPy
3 =====
4
5 An open-source Python library for Solar Physics data analysis.
6
7 * Homepage: https://sunpy.org
8 * Documentation: https://docs.sunpy.org/en/stable/
9 """
10 import os
11 import sys
12 import logging
13
14 from sunpy.tests.runner import SunPyTestRunner
15 from sunpy.util import system_info
16 from sunpy.util.config import load_config, print_config
17 from sunpy.util.logger import _init_log
18 from .version import version as __version__
19
20 # Enforce Python version check during package import.
21 __minimum_python_version__ = "3.7"
22
23
24 class UnsupportedPythonError(Exception):
25 """Running on an unsupported version of Python."""
26
27
28 if sys.version_info < tuple(int(val) for val in __minimum_python_version__.split('.')):
29 # This has to be .format to keep backwards compatibly.
30 raise UnsupportedPythonError(
31 "sunpy does not support Python < {}".format(__minimum_python_version__))
32
33
34 def _get_bibtex():
35 import textwrap
36
37 # Set the bibtex entry to the article referenced in CITATION.rst
38 citation_file = os.path.join(os.path.dirname(__file__), 'CITATION.rst')
39
40 # Explicitly specify UTF-8 encoding in case the system's default encoding is problematic
41 with open(citation_file, 'r', encoding='utf-8') as citation:
42 # Extract the first bibtex block:
43 ref = citation.read().partition(".. code:: bibtex\n\n")[2]
44 lines = ref.split("\n")
45 # Only read the lines which are indented
46 lines = lines[:[l.startswith(" ") for l in lines].index(False)]
47 ref = textwrap.dedent('\n'.join(lines))
48 return ref
49
50
51 __citation__ = __bibtex__ = _get_bibtex()
52
53 self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))
54
55 # Load user configuration
56 config = load_config()
57
58 log = _init_log(config=config)
59
60 __all__ = ['config', 'self_test', 'system_info', 'print_config']
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sunpy/__init__.py b/sunpy/__init__.py
--- a/sunpy/__init__.py
+++ b/sunpy/__init__.py
@@ -11,7 +11,7 @@
import sys
import logging
-from sunpy.tests.runner import SunPyTestRunner
+from sunpy.tests.self_test import self_test
from sunpy.util import system_info
from sunpy.util.config import load_config, print_config
from sunpy.util.logger import _init_log
@@ -50,8 +50,6 @@
__citation__ = __bibtex__ = _get_bibtex()
-self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))
-
# Load user configuration
config = load_config()
| {"golden_diff": "diff --git a/sunpy/__init__.py b/sunpy/__init__.py\n--- a/sunpy/__init__.py\n+++ b/sunpy/__init__.py\n@@ -11,7 +11,7 @@\n import sys\n import logging\n \n-from sunpy.tests.runner import SunPyTestRunner\n+from sunpy.tests.self_test import self_test\n from sunpy.util import system_info\n from sunpy.util.config import load_config, print_config\n from sunpy.util.logger import _init_log\n@@ -50,8 +50,6 @@\n \n __citation__ = __bibtex__ = _get_bibtex()\n \n-self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))\n-\n # Load user configuration\n config = load_config()\n", "issue": "Rethinking and rewriting sunpy.self_test\nWe are currently using astropy's test runner for `sunpy.self_test` this was really designed for setup.py and is therefore very full of features which are probably not needed for self_test.\n\nBefore we (I) go deleting swathes of code as I love to do. What do we want to achieve with self test? Is a very slim wrapper around `pytest --pyargs sunpy` all we need?\n", "before_files": [{"content": "\"\"\"\nSunPy\n=====\n\nAn open-source Python library for Solar Physics data analysis.\n\n* Homepage: https://sunpy.org\n* Documentation: https://docs.sunpy.org/en/stable/\n\"\"\"\nimport os\nimport sys\nimport logging\n\nfrom sunpy.tests.runner import SunPyTestRunner\nfrom sunpy.util import system_info\nfrom sunpy.util.config import load_config, print_config\nfrom sunpy.util.logger import _init_log\nfrom .version import version as __version__\n\n# Enforce Python version check during package import.\n__minimum_python_version__ = \"3.7\"\n\n\nclass UnsupportedPythonError(Exception):\n \"\"\"Running on an unsupported version of Python.\"\"\"\n\n\nif sys.version_info < tuple(int(val) for val in __minimum_python_version__.split('.')):\n # This has to be .format to keep backwards compatibly.\n raise UnsupportedPythonError(\n \"sunpy does not support Python < {}\".format(__minimum_python_version__))\n\n\ndef _get_bibtex():\n import textwrap\n\n # Set the bibtex entry to the article referenced in CITATION.rst\n citation_file = os.path.join(os.path.dirname(__file__), 'CITATION.rst')\n\n # Explicitly specify UTF-8 encoding in case the system's default encoding is problematic\n with open(citation_file, 'r', encoding='utf-8') as citation:\n # Extract the first bibtex block:\n ref = citation.read().partition(\".. code:: bibtex\\n\\n\")[2]\n lines = ref.split(\"\\n\")\n # Only read the lines which are indented\n lines = lines[:[l.startswith(\" \") for l in lines].index(False)]\n ref = textwrap.dedent('\\n'.join(lines))\n return ref\n\n\n__citation__ = __bibtex__ = _get_bibtex()\n\nself_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))\n\n# Load user configuration\nconfig = load_config()\n\nlog = _init_log(config=config)\n\n__all__ = ['config', 'self_test', 'system_info', 'print_config']\n", "path": "sunpy/__init__.py"}], "after_files": [{"content": "\"\"\"\nSunPy\n=====\n\nAn open-source Python library for Solar Physics data analysis.\n\n* Homepage: https://sunpy.org\n* Documentation: https://docs.sunpy.org/en/stable/\n\"\"\"\nimport os\nimport sys\nimport logging\n\nfrom sunpy.tests.self_test import self_test\nfrom sunpy.util import system_info\nfrom sunpy.util.config import load_config, print_config\nfrom sunpy.util.logger import _init_log\nfrom .version import version as __version__\n\n# Enforce Python version check during package import.\n__minimum_python_version__ = \"3.7\"\n\n\nclass UnsupportedPythonError(Exception):\n \"\"\"Running on an unsupported version of Python.\"\"\"\n\n\nif sys.version_info < tuple(int(val) for val in __minimum_python_version__.split('.')):\n # This has to be .format to keep backwards compatibly.\n raise UnsupportedPythonError(\n \"sunpy does not support Python < {}\".format(__minimum_python_version__))\n\n\ndef _get_bibtex():\n import textwrap\n\n # Set the bibtex entry to the article referenced in CITATION.rst\n citation_file = os.path.join(os.path.dirname(__file__), 'CITATION.rst')\n\n # Explicitly specify UTF-8 encoding in case the system's default encoding is problematic\n with open(citation_file, 'r', encoding='utf-8') as citation:\n # Extract the first bibtex block:\n ref = citation.read().partition(\".. code:: bibtex\\n\\n\")[2]\n lines = ref.split(\"\\n\")\n # Only read the lines which are indented\n lines = lines[:[l.startswith(\" \") for l in lines].index(False)]\n ref = textwrap.dedent('\\n'.join(lines))\n return ref\n\n\n__citation__ = __bibtex__ = _get_bibtex()\n\n# Load user configuration\nconfig = load_config()\n\nlog = _init_log(config=config)\n\n__all__ = ['config', 'self_test', 'system_info', 'print_config']\n", "path": "sunpy/__init__.py"}]} | 919 | 168 |
gh_patches_debug_33083 | rasdani/github-patches | git_diff | ipython__ipython-7466 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
interact doesn't work with instance methods
This code:
``` python
from IPython.html.widgets import interact
class Foo(object):
def show(self, x):
print x
f = Foo()
interact(f.show, x=(1,10))
```
produces this exception:
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-58-b03b8685dfc0> in <module>()
7 f = Foo()
8
----> 9 interact(f.show, x=(1,10))
/home/fperez/usr/lib/python2.7/site-packages/IPython/html/widgets/interaction.pyc in interact(__interact_f, **kwargs)
235 f = __interact_f
236 w = interactive(f, **kwargs)
--> 237 f.widget = w
238 display(w)
239 return f
AttributeError: 'instancemethod' object has no attribute 'widget'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/html/widgets/interaction.py`
Content:
```
1 """Interact with functions using widgets."""
2
3 #-----------------------------------------------------------------------------
4 # Copyright (c) 2013, the IPython Development Team.
5 #
6 # Distributed under the terms of the Modified BSD License.
7 #
8 # The full license is in the file COPYING.txt, distributed with this software.
9 #-----------------------------------------------------------------------------
10
11 #-----------------------------------------------------------------------------
12 # Imports
13 #-----------------------------------------------------------------------------
14
15 from __future__ import print_function
16
17 try: # Python >= 3.3
18 from inspect import signature, Parameter
19 except ImportError:
20 from IPython.utils.signatures import signature, Parameter
21 from inspect import getcallargs
22
23 from IPython.core.getipython import get_ipython
24 from IPython.html.widgets import (Widget, Text,
25 FloatSlider, IntSlider, Checkbox, Dropdown,
26 Box, Button, DOMWidget)
27 from IPython.display import display, clear_output
28 from IPython.utils.py3compat import string_types, unicode_type
29 from IPython.utils.traitlets import HasTraits, Any, Unicode
30
31 empty = Parameter.empty
32
33 #-----------------------------------------------------------------------------
34 # Classes and Functions
35 #-----------------------------------------------------------------------------
36
37
38 def _matches(o, pattern):
39 """Match a pattern of types in a sequence."""
40 if not len(o) == len(pattern):
41 return False
42 comps = zip(o,pattern)
43 return all(isinstance(obj,kind) for obj,kind in comps)
44
45
46 def _get_min_max_value(min, max, value=None, step=None):
47 """Return min, max, value given input values with possible None."""
48 if value is None:
49 if not max > min:
50 raise ValueError('max must be greater than min: (min={0}, max={1})'.format(min, max))
51 value = min + abs(min-max)/2
52 value = type(min)(value)
53 elif min is None and max is None:
54 if value == 0.0:
55 min, max, value = 0.0, 1.0, 0.5
56 elif value == 0:
57 min, max, value = 0, 1, 0
58 elif isinstance(value, (int, float)):
59 min, max = (-value, 3*value) if value > 0 else (3*value, -value)
60 else:
61 raise TypeError('expected a number, got: %r' % value)
62 else:
63 raise ValueError('unable to infer range, value from: ({0}, {1}, {2})'.format(min, max, value))
64 if step is not None:
65 # ensure value is on a step
66 r = (value - min) % step
67 value = value - r
68 return min, max, value
69
70 def _widget_abbrev_single_value(o):
71 """Make widgets from single values, which can be used as parameter defaults."""
72 if isinstance(o, string_types):
73 return Text(value=unicode_type(o))
74 elif isinstance(o, dict):
75 return Dropdown(values=o)
76 elif isinstance(o, bool):
77 return Checkbox(value=o)
78 elif isinstance(o, float):
79 min, max, value = _get_min_max_value(None, None, o)
80 return FloatSlider(value=o, min=min, max=max)
81 elif isinstance(o, int):
82 min, max, value = _get_min_max_value(None, None, o)
83 return IntSlider(value=o, min=min, max=max)
84 else:
85 return None
86
87 def _widget_abbrev(o):
88 """Make widgets from abbreviations: single values, lists or tuples."""
89 float_or_int = (float, int)
90 if isinstance(o, (list, tuple)):
91 if o and all(isinstance(x, string_types) for x in o):
92 return Dropdown(values=[unicode_type(k) for k in o])
93 elif _matches(o, (float_or_int, float_or_int)):
94 min, max, value = _get_min_max_value(o[0], o[1])
95 if all(isinstance(_, int) for _ in o):
96 cls = IntSlider
97 else:
98 cls = FloatSlider
99 return cls(value=value, min=min, max=max)
100 elif _matches(o, (float_or_int, float_or_int, float_or_int)):
101 step = o[2]
102 if step <= 0:
103 raise ValueError("step must be >= 0, not %r" % step)
104 min, max, value = _get_min_max_value(o[0], o[1], step=step)
105 if all(isinstance(_, int) for _ in o):
106 cls = IntSlider
107 else:
108 cls = FloatSlider
109 return cls(value=value, min=min, max=max, step=step)
110 else:
111 return _widget_abbrev_single_value(o)
112
113 def _widget_from_abbrev(abbrev, default=empty):
114 """Build a Widget instance given an abbreviation or Widget."""
115 if isinstance(abbrev, Widget) or isinstance(abbrev, fixed):
116 return abbrev
117
118 widget = _widget_abbrev(abbrev)
119 if default is not empty and isinstance(abbrev, (list, tuple, dict)):
120 # if it's not a single-value abbreviation,
121 # set the initial value from the default
122 try:
123 widget.value = default
124 except Exception:
125 # ignore failure to set default
126 pass
127 if widget is None:
128 raise ValueError("%r cannot be transformed to a Widget" % (abbrev,))
129 return widget
130
131 def _yield_abbreviations_for_parameter(param, kwargs):
132 """Get an abbreviation for a function parameter."""
133 name = param.name
134 kind = param.kind
135 ann = param.annotation
136 default = param.default
137 not_found = (name, empty, empty)
138 if kind in (Parameter.POSITIONAL_OR_KEYWORD, Parameter.KEYWORD_ONLY):
139 if name in kwargs:
140 value = kwargs.pop(name)
141 elif ann is not empty:
142 value = ann
143 elif default is not empty:
144 value = default
145 else:
146 yield not_found
147 yield (name, value, default)
148 elif kind == Parameter.VAR_KEYWORD:
149 # In this case name=kwargs and we yield the items in kwargs with their keys.
150 for k, v in kwargs.copy().items():
151 kwargs.pop(k)
152 yield k, v, empty
153
154 def _find_abbreviations(f, kwargs):
155 """Find the abbreviations for a function and kwargs passed to interact."""
156 new_kwargs = []
157 for param in signature(f).parameters.values():
158 for name, value, default in _yield_abbreviations_for_parameter(param, kwargs):
159 if value is empty:
160 raise ValueError('cannot find widget or abbreviation for argument: {!r}'.format(name))
161 new_kwargs.append((name, value, default))
162 return new_kwargs
163
164 def _widgets_from_abbreviations(seq):
165 """Given a sequence of (name, abbrev) tuples, return a sequence of Widgets."""
166 result = []
167 for name, abbrev, default in seq:
168 widget = _widget_from_abbrev(abbrev, default)
169 if not widget.description:
170 widget.description = name
171 result.append(widget)
172 return result
173
174 def interactive(__interact_f, **kwargs):
175 """Build a group of widgets to interact with a function."""
176 f = __interact_f
177 co = kwargs.pop('clear_output', True)
178 manual = kwargs.pop('__manual', False)
179 kwargs_widgets = []
180 container = Box()
181 container.result = None
182 container.args = []
183 container.kwargs = dict()
184 kwargs = kwargs.copy()
185
186 new_kwargs = _find_abbreviations(f, kwargs)
187 # Before we proceed, let's make sure that the user has passed a set of args+kwargs
188 # that will lead to a valid call of the function. This protects against unspecified
189 # and doubly-specified arguments.
190 getcallargs(f, **{n:v for n,v,_ in new_kwargs})
191 # Now build the widgets from the abbreviations.
192 kwargs_widgets.extend(_widgets_from_abbreviations(new_kwargs))
193
194 # This has to be done as an assignment, not using container.children.append,
195 # so that traitlets notices the update. We skip any objects (such as fixed) that
196 # are not DOMWidgets.
197 c = [w for w in kwargs_widgets if isinstance(w, DOMWidget)]
198
199 # If we are only to run the function on demand, add a button to request this
200 if manual:
201 manual_button = Button(description="Run %s" % f.__name__)
202 c.append(manual_button)
203 container.children = c
204
205 # Build the callback
206 def call_f(name=None, old=None, new=None):
207 container.kwargs = {}
208 for widget in kwargs_widgets:
209 value = widget.value
210 container.kwargs[widget.description] = value
211 if co:
212 clear_output(wait=True)
213 if manual:
214 manual_button.disabled = True
215 try:
216 container.result = f(**container.kwargs)
217 except Exception as e:
218 ip = get_ipython()
219 if ip is None:
220 container.log.warn("Exception in interact callback: %s", e, exc_info=True)
221 else:
222 ip.showtraceback()
223 finally:
224 if manual:
225 manual_button.disabled = False
226
227 # Wire up the widgets
228 # If we are doing manual running, the callback is only triggered by the button
229 # Otherwise, it is triggered for every trait change received
230 # On-demand running also suppresses running the fucntion with the initial parameters
231 if manual:
232 manual_button.on_click(call_f)
233 else:
234 for widget in kwargs_widgets:
235 widget.on_trait_change(call_f, 'value')
236
237 container.on_displayed(lambda _: call_f(None, None, None))
238
239 return container
240
241 def interact(__interact_f=None, **kwargs):
242 """interact(f, **kwargs)
243
244 Interact with a function using widgets."""
245 # positional arg support in: https://gist.github.com/8851331
246 if __interact_f is not None:
247 # This branch handles the cases:
248 # 1. interact(f, **kwargs)
249 # 2. @interact
250 # def f(*args, **kwargs):
251 # ...
252 f = __interact_f
253 w = interactive(f, **kwargs)
254 f.widget = w
255 display(w)
256 return f
257 else:
258 # This branch handles the case:
259 # @interact(a=30, b=40)
260 # def f(*args, **kwargs):
261 # ...
262 def dec(f):
263 w = interactive(f, **kwargs)
264 f.widget = w
265 display(w)
266 return f
267 return dec
268
269 def interact_manual(__interact_f=None, **kwargs):
270 """interact_manual(f, **kwargs)
271
272 As `interact()`, generates widgets for each argument, but rather than running
273 the function after each widget change, adds a "Run" button and waits for it
274 to be clicked. Useful if the function is long-running and has several
275 parameters to change.
276 """
277 return interact(__interact_f, __manual=True, **kwargs)
278
279 class fixed(HasTraits):
280 """A pseudo-widget whose value is fixed and never synced to the client."""
281 value = Any(help="Any Python object")
282 description = Unicode('', help="Any Python object")
283 def __init__(self, value, **kwargs):
284 super(fixed, self).__init__(value=value, **kwargs)
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/IPython/html/widgets/interaction.py b/IPython/html/widgets/interaction.py
--- a/IPython/html/widgets/interaction.py
+++ b/IPython/html/widgets/interaction.py
@@ -1,16 +1,7 @@
"""Interact with functions using widgets."""
-#-----------------------------------------------------------------------------
-# Copyright (c) 2013, the IPython Development Team.
-#
+# Copyright (c) IPython Development Team.
# Distributed under the terms of the Modified BSD License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#-----------------------------------------------------------------------------
-
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
from __future__ import print_function
@@ -30,10 +21,6 @@
empty = Parameter.empty
-#-----------------------------------------------------------------------------
-# Classes and Functions
-#-----------------------------------------------------------------------------
-
def _matches(o, pattern):
"""Match a pattern of types in a sequence."""
@@ -251,7 +238,13 @@
# ...
f = __interact_f
w = interactive(f, **kwargs)
- f.widget = w
+ try:
+ f.widget = w
+ except AttributeError:
+ # some things (instancemethods) can't have attributes attached,
+ # so wrap in a lambda
+ f = lambda *args, **kwargs: __interact_f(*args, **kwargs)
+ f.widget = w
display(w)
return f
else:
@@ -260,10 +253,7 @@
# def f(*args, **kwargs):
# ...
def dec(f):
- w = interactive(f, **kwargs)
- f.widget = w
- display(w)
- return f
+ return interact(f, **kwargs)
return dec
def interact_manual(__interact_f=None, **kwargs):
| {"golden_diff": "diff --git a/IPython/html/widgets/interaction.py b/IPython/html/widgets/interaction.py\n--- a/IPython/html/widgets/interaction.py\n+++ b/IPython/html/widgets/interaction.py\n@@ -1,16 +1,7 @@\n \"\"\"Interact with functions using widgets.\"\"\"\n \n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2013, the IPython Development Team.\n-#\n+# Copyright (c) IPython Development Team.\n # Distributed under the terms of the Modified BSD License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#-----------------------------------------------------------------------------\n-\n-#-----------------------------------------------------------------------------\n-# Imports\n-#-----------------------------------------------------------------------------\n \n from __future__ import print_function\n \n@@ -30,10 +21,6 @@\n \n empty = Parameter.empty\n \n-#-----------------------------------------------------------------------------\n-# Classes and Functions\n-#-----------------------------------------------------------------------------\n-\n \n def _matches(o, pattern):\n \"\"\"Match a pattern of types in a sequence.\"\"\"\n@@ -251,7 +238,13 @@\n # ...\n f = __interact_f\n w = interactive(f, **kwargs)\n- f.widget = w\n+ try:\n+ f.widget = w\n+ except AttributeError:\n+ # some things (instancemethods) can't have attributes attached,\n+ # so wrap in a lambda\n+ f = lambda *args, **kwargs: __interact_f(*args, **kwargs)\n+ f.widget = w\n display(w)\n return f\n else:\n@@ -260,10 +253,7 @@\n # def f(*args, **kwargs):\n # ...\n def dec(f):\n- w = interactive(f, **kwargs)\n- f.widget = w\n- display(w)\n- return f\n+ return interact(f, **kwargs)\n return dec\n \n def interact_manual(__interact_f=None, **kwargs):\n", "issue": "interact doesn't work with instance methods\nThis code:\n\n``` python\nfrom IPython.html.widgets import interact\n\nclass Foo(object):\n def show(self, x):\n print x\n\nf = Foo()\n\ninteract(f.show, x=(1,10))\n```\n\nproduces this exception:\n\n```\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-58-b03b8685dfc0> in <module>()\n 7 f = Foo()\n 8 \n----> 9 interact(f.show, x=(1,10))\n\n/home/fperez/usr/lib/python2.7/site-packages/IPython/html/widgets/interaction.pyc in interact(__interact_f, **kwargs)\n 235 f = __interact_f\n 236 w = interactive(f, **kwargs)\n--> 237 f.widget = w\n 238 display(w)\n 239 return f\n\nAttributeError: 'instancemethod' object has no attribute 'widget'\n```\n\n", "before_files": [{"content": "\"\"\"Interact with functions using widgets.\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, the IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\ntry: # Python >= 3.3\n from inspect import signature, Parameter\nexcept ImportError:\n from IPython.utils.signatures import signature, Parameter\nfrom inspect import getcallargs\n\nfrom IPython.core.getipython import get_ipython\nfrom IPython.html.widgets import (Widget, Text,\n FloatSlider, IntSlider, Checkbox, Dropdown,\n Box, Button, DOMWidget)\nfrom IPython.display import display, clear_output\nfrom IPython.utils.py3compat import string_types, unicode_type\nfrom IPython.utils.traitlets import HasTraits, Any, Unicode\n\nempty = Parameter.empty\n\n#-----------------------------------------------------------------------------\n# Classes and Functions\n#-----------------------------------------------------------------------------\n\n\ndef _matches(o, pattern):\n \"\"\"Match a pattern of types in a sequence.\"\"\"\n if not len(o) == len(pattern):\n return False\n comps = zip(o,pattern)\n return all(isinstance(obj,kind) for obj,kind in comps)\n\n\ndef _get_min_max_value(min, max, value=None, step=None):\n \"\"\"Return min, max, value given input values with possible None.\"\"\"\n if value is None:\n if not max > min:\n raise ValueError('max must be greater than min: (min={0}, max={1})'.format(min, max))\n value = min + abs(min-max)/2\n value = type(min)(value)\n elif min is None and max is None:\n if value == 0.0:\n min, max, value = 0.0, 1.0, 0.5\n elif value == 0:\n min, max, value = 0, 1, 0\n elif isinstance(value, (int, float)):\n min, max = (-value, 3*value) if value > 0 else (3*value, -value)\n else:\n raise TypeError('expected a number, got: %r' % value)\n else:\n raise ValueError('unable to infer range, value from: ({0}, {1}, {2})'.format(min, max, value))\n if step is not None:\n # ensure value is on a step\n r = (value - min) % step\n value = value - r\n return min, max, value\n\ndef _widget_abbrev_single_value(o):\n \"\"\"Make widgets from single values, which can be used as parameter defaults.\"\"\"\n if isinstance(o, string_types):\n return Text(value=unicode_type(o))\n elif isinstance(o, dict):\n return Dropdown(values=o)\n elif isinstance(o, bool):\n return Checkbox(value=o)\n elif isinstance(o, float):\n min, max, value = _get_min_max_value(None, None, o)\n return FloatSlider(value=o, min=min, max=max)\n elif isinstance(o, int):\n min, max, value = _get_min_max_value(None, None, o)\n return IntSlider(value=o, min=min, max=max)\n else:\n return None\n\ndef _widget_abbrev(o):\n \"\"\"Make widgets from abbreviations: single values, lists or tuples.\"\"\"\n float_or_int = (float, int)\n if isinstance(o, (list, tuple)):\n if o and all(isinstance(x, string_types) for x in o):\n return Dropdown(values=[unicode_type(k) for k in o])\n elif _matches(o, (float_or_int, float_or_int)):\n min, max, value = _get_min_max_value(o[0], o[1])\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max)\n elif _matches(o, (float_or_int, float_or_int, float_or_int)):\n step = o[2]\n if step <= 0:\n raise ValueError(\"step must be >= 0, not %r\" % step)\n min, max, value = _get_min_max_value(o[0], o[1], step=step)\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max, step=step)\n else:\n return _widget_abbrev_single_value(o)\n\ndef _widget_from_abbrev(abbrev, default=empty):\n \"\"\"Build a Widget instance given an abbreviation or Widget.\"\"\"\n if isinstance(abbrev, Widget) or isinstance(abbrev, fixed):\n return abbrev\n\n widget = _widget_abbrev(abbrev)\n if default is not empty and isinstance(abbrev, (list, tuple, dict)):\n # if it's not a single-value abbreviation,\n # set the initial value from the default\n try:\n widget.value = default\n except Exception:\n # ignore failure to set default\n pass\n if widget is None:\n raise ValueError(\"%r cannot be transformed to a Widget\" % (abbrev,))\n return widget\n\ndef _yield_abbreviations_for_parameter(param, kwargs):\n \"\"\"Get an abbreviation for a function parameter.\"\"\"\n name = param.name\n kind = param.kind\n ann = param.annotation\n default = param.default\n not_found = (name, empty, empty)\n if kind in (Parameter.POSITIONAL_OR_KEYWORD, Parameter.KEYWORD_ONLY):\n if name in kwargs:\n value = kwargs.pop(name)\n elif ann is not empty:\n value = ann\n elif default is not empty:\n value = default\n else:\n yield not_found\n yield (name, value, default)\n elif kind == Parameter.VAR_KEYWORD:\n # In this case name=kwargs and we yield the items in kwargs with their keys.\n for k, v in kwargs.copy().items():\n kwargs.pop(k)\n yield k, v, empty\n\ndef _find_abbreviations(f, kwargs):\n \"\"\"Find the abbreviations for a function and kwargs passed to interact.\"\"\"\n new_kwargs = []\n for param in signature(f).parameters.values():\n for name, value, default in _yield_abbreviations_for_parameter(param, kwargs):\n if value is empty:\n raise ValueError('cannot find widget or abbreviation for argument: {!r}'.format(name))\n new_kwargs.append((name, value, default))\n return new_kwargs\n\ndef _widgets_from_abbreviations(seq):\n \"\"\"Given a sequence of (name, abbrev) tuples, return a sequence of Widgets.\"\"\"\n result = []\n for name, abbrev, default in seq:\n widget = _widget_from_abbrev(abbrev, default)\n if not widget.description:\n widget.description = name\n result.append(widget)\n return result\n\ndef interactive(__interact_f, **kwargs):\n \"\"\"Build a group of widgets to interact with a function.\"\"\"\n f = __interact_f\n co = kwargs.pop('clear_output', True)\n manual = kwargs.pop('__manual', False)\n kwargs_widgets = []\n container = Box()\n container.result = None\n container.args = []\n container.kwargs = dict()\n kwargs = kwargs.copy()\n\n new_kwargs = _find_abbreviations(f, kwargs)\n # Before we proceed, let's make sure that the user has passed a set of args+kwargs\n # that will lead to a valid call of the function. This protects against unspecified\n # and doubly-specified arguments.\n getcallargs(f, **{n:v for n,v,_ in new_kwargs})\n # Now build the widgets from the abbreviations.\n kwargs_widgets.extend(_widgets_from_abbreviations(new_kwargs))\n\n # This has to be done as an assignment, not using container.children.append,\n # so that traitlets notices the update. We skip any objects (such as fixed) that\n # are not DOMWidgets.\n c = [w for w in kwargs_widgets if isinstance(w, DOMWidget)]\n\n # If we are only to run the function on demand, add a button to request this\n if manual:\n manual_button = Button(description=\"Run %s\" % f.__name__)\n c.append(manual_button)\n container.children = c\n\n # Build the callback\n def call_f(name=None, old=None, new=None):\n container.kwargs = {}\n for widget in kwargs_widgets:\n value = widget.value\n container.kwargs[widget.description] = value\n if co:\n clear_output(wait=True)\n if manual:\n manual_button.disabled = True\n try:\n container.result = f(**container.kwargs)\n except Exception as e:\n ip = get_ipython()\n if ip is None:\n container.log.warn(\"Exception in interact callback: %s\", e, exc_info=True)\n else:\n ip.showtraceback()\n finally:\n if manual:\n manual_button.disabled = False\n\n # Wire up the widgets\n # If we are doing manual running, the callback is only triggered by the button\n # Otherwise, it is triggered for every trait change received\n # On-demand running also suppresses running the fucntion with the initial parameters\n if manual:\n manual_button.on_click(call_f)\n else:\n for widget in kwargs_widgets:\n widget.on_trait_change(call_f, 'value')\n\n container.on_displayed(lambda _: call_f(None, None, None))\n\n return container\n\ndef interact(__interact_f=None, **kwargs):\n \"\"\"interact(f, **kwargs)\n\n Interact with a function using widgets.\"\"\"\n # positional arg support in: https://gist.github.com/8851331\n if __interact_f is not None:\n # This branch handles the cases:\n # 1. interact(f, **kwargs)\n # 2. @interact\n # def f(*args, **kwargs):\n # ...\n f = __interact_f\n w = interactive(f, **kwargs)\n f.widget = w\n display(w)\n return f\n else:\n # This branch handles the case:\n # @interact(a=30, b=40)\n # def f(*args, **kwargs):\n # ...\n def dec(f):\n w = interactive(f, **kwargs)\n f.widget = w\n display(w)\n return f\n return dec\n\ndef interact_manual(__interact_f=None, **kwargs):\n \"\"\"interact_manual(f, **kwargs)\n \n As `interact()`, generates widgets for each argument, but rather than running\n the function after each widget change, adds a \"Run\" button and waits for it\n to be clicked. Useful if the function is long-running and has several\n parameters to change.\n \"\"\"\n return interact(__interact_f, __manual=True, **kwargs)\n\nclass fixed(HasTraits):\n \"\"\"A pseudo-widget whose value is fixed and never synced to the client.\"\"\"\n value = Any(help=\"Any Python object\")\n description = Unicode('', help=\"Any Python object\")\n def __init__(self, value, **kwargs):\n super(fixed, self).__init__(value=value, **kwargs)\n", "path": "IPython/html/widgets/interaction.py"}], "after_files": [{"content": "\"\"\"Interact with functions using widgets.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nfrom __future__ import print_function\n\ntry: # Python >= 3.3\n from inspect import signature, Parameter\nexcept ImportError:\n from IPython.utils.signatures import signature, Parameter\nfrom inspect import getcallargs\n\nfrom IPython.core.getipython import get_ipython\nfrom IPython.html.widgets import (Widget, Text,\n FloatSlider, IntSlider, Checkbox, Dropdown,\n Box, Button, DOMWidget)\nfrom IPython.display import display, clear_output\nfrom IPython.utils.py3compat import string_types, unicode_type\nfrom IPython.utils.traitlets import HasTraits, Any, Unicode\n\nempty = Parameter.empty\n\n\ndef _matches(o, pattern):\n \"\"\"Match a pattern of types in a sequence.\"\"\"\n if not len(o) == len(pattern):\n return False\n comps = zip(o,pattern)\n return all(isinstance(obj,kind) for obj,kind in comps)\n\n\ndef _get_min_max_value(min, max, value=None, step=None):\n \"\"\"Return min, max, value given input values with possible None.\"\"\"\n if value is None:\n if not max > min:\n raise ValueError('max must be greater than min: (min={0}, max={1})'.format(min, max))\n value = min + abs(min-max)/2\n value = type(min)(value)\n elif min is None and max is None:\n if value == 0.0:\n min, max, value = 0.0, 1.0, 0.5\n elif value == 0:\n min, max, value = 0, 1, 0\n elif isinstance(value, (int, float)):\n min, max = (-value, 3*value) if value > 0 else (3*value, -value)\n else:\n raise TypeError('expected a number, got: %r' % value)\n else:\n raise ValueError('unable to infer range, value from: ({0}, {1}, {2})'.format(min, max, value))\n if step is not None:\n # ensure value is on a step\n r = (value - min) % step\n value = value - r\n return min, max, value\n\ndef _widget_abbrev_single_value(o):\n \"\"\"Make widgets from single values, which can be used as parameter defaults.\"\"\"\n if isinstance(o, string_types):\n return Text(value=unicode_type(o))\n elif isinstance(o, dict):\n return Dropdown(values=o)\n elif isinstance(o, bool):\n return Checkbox(value=o)\n elif isinstance(o, float):\n min, max, value = _get_min_max_value(None, None, o)\n return FloatSlider(value=o, min=min, max=max)\n elif isinstance(o, int):\n min, max, value = _get_min_max_value(None, None, o)\n return IntSlider(value=o, min=min, max=max)\n else:\n return None\n\ndef _widget_abbrev(o):\n \"\"\"Make widgets from abbreviations: single values, lists or tuples.\"\"\"\n float_or_int = (float, int)\n if isinstance(o, (list, tuple)):\n if o and all(isinstance(x, string_types) for x in o):\n return Dropdown(values=[unicode_type(k) for k in o])\n elif _matches(o, (float_or_int, float_or_int)):\n min, max, value = _get_min_max_value(o[0], o[1])\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max)\n elif _matches(o, (float_or_int, float_or_int, float_or_int)):\n step = o[2]\n if step <= 0:\n raise ValueError(\"step must be >= 0, not %r\" % step)\n min, max, value = _get_min_max_value(o[0], o[1], step=step)\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max, step=step)\n else:\n return _widget_abbrev_single_value(o)\n\ndef _widget_from_abbrev(abbrev, default=empty):\n \"\"\"Build a Widget instance given an abbreviation or Widget.\"\"\"\n if isinstance(abbrev, Widget) or isinstance(abbrev, fixed):\n return abbrev\n\n widget = _widget_abbrev(abbrev)\n if default is not empty and isinstance(abbrev, (list, tuple, dict)):\n # if it's not a single-value abbreviation,\n # set the initial value from the default\n try:\n widget.value = default\n except Exception:\n # ignore failure to set default\n pass\n if widget is None:\n raise ValueError(\"%r cannot be transformed to a Widget\" % (abbrev,))\n return widget\n\ndef _yield_abbreviations_for_parameter(param, kwargs):\n \"\"\"Get an abbreviation for a function parameter.\"\"\"\n name = param.name\n kind = param.kind\n ann = param.annotation\n default = param.default\n not_found = (name, empty, empty)\n if kind in (Parameter.POSITIONAL_OR_KEYWORD, Parameter.KEYWORD_ONLY):\n if name in kwargs:\n value = kwargs.pop(name)\n elif ann is not empty:\n value = ann\n elif default is not empty:\n value = default\n else:\n yield not_found\n yield (name, value, default)\n elif kind == Parameter.VAR_KEYWORD:\n # In this case name=kwargs and we yield the items in kwargs with their keys.\n for k, v in kwargs.copy().items():\n kwargs.pop(k)\n yield k, v, empty\n\ndef _find_abbreviations(f, kwargs):\n \"\"\"Find the abbreviations for a function and kwargs passed to interact.\"\"\"\n new_kwargs = []\n for param in signature(f).parameters.values():\n for name, value, default in _yield_abbreviations_for_parameter(param, kwargs):\n if value is empty:\n raise ValueError('cannot find widget or abbreviation for argument: {!r}'.format(name))\n new_kwargs.append((name, value, default))\n return new_kwargs\n\ndef _widgets_from_abbreviations(seq):\n \"\"\"Given a sequence of (name, abbrev) tuples, return a sequence of Widgets.\"\"\"\n result = []\n for name, abbrev, default in seq:\n widget = _widget_from_abbrev(abbrev, default)\n if not widget.description:\n widget.description = name\n result.append(widget)\n return result\n\ndef interactive(__interact_f, **kwargs):\n \"\"\"Build a group of widgets to interact with a function.\"\"\"\n f = __interact_f\n co = kwargs.pop('clear_output', True)\n manual = kwargs.pop('__manual', False)\n kwargs_widgets = []\n container = Box()\n container.result = None\n container.args = []\n container.kwargs = dict()\n kwargs = kwargs.copy()\n\n new_kwargs = _find_abbreviations(f, kwargs)\n # Before we proceed, let's make sure that the user has passed a set of args+kwargs\n # that will lead to a valid call of the function. This protects against unspecified\n # and doubly-specified arguments.\n getcallargs(f, **{n:v for n,v,_ in new_kwargs})\n # Now build the widgets from the abbreviations.\n kwargs_widgets.extend(_widgets_from_abbreviations(new_kwargs))\n\n # This has to be done as an assignment, not using container.children.append,\n # so that traitlets notices the update. We skip any objects (such as fixed) that\n # are not DOMWidgets.\n c = [w for w in kwargs_widgets if isinstance(w, DOMWidget)]\n\n # If we are only to run the function on demand, add a button to request this\n if manual:\n manual_button = Button(description=\"Run %s\" % f.__name__)\n c.append(manual_button)\n container.children = c\n\n # Build the callback\n def call_f(name=None, old=None, new=None):\n container.kwargs = {}\n for widget in kwargs_widgets:\n value = widget.value\n container.kwargs[widget.description] = value\n if co:\n clear_output(wait=True)\n if manual:\n manual_button.disabled = True\n try:\n container.result = f(**container.kwargs)\n except Exception as e:\n ip = get_ipython()\n if ip is None:\n container.log.warn(\"Exception in interact callback: %s\", e, exc_info=True)\n else:\n ip.showtraceback()\n finally:\n if manual:\n manual_button.disabled = False\n\n # Wire up the widgets\n # If we are doing manual running, the callback is only triggered by the button\n # Otherwise, it is triggered for every trait change received\n # On-demand running also suppresses running the fucntion with the initial parameters\n if manual:\n manual_button.on_click(call_f)\n else:\n for widget in kwargs_widgets:\n widget.on_trait_change(call_f, 'value')\n\n container.on_displayed(lambda _: call_f(None, None, None))\n\n return container\n\ndef interact(__interact_f=None, **kwargs):\n \"\"\"interact(f, **kwargs)\n\n Interact with a function using widgets.\"\"\"\n # positional arg support in: https://gist.github.com/8851331\n if __interact_f is not None:\n # This branch handles the cases:\n # 1. interact(f, **kwargs)\n # 2. @interact\n # def f(*args, **kwargs):\n # ...\n f = __interact_f\n w = interactive(f, **kwargs)\n try:\n f.widget = w\n except AttributeError:\n # some things (instancemethods) can't have attributes attached,\n # so wrap in a lambda\n f = lambda *args, **kwargs: __interact_f(*args, **kwargs)\n f.widget = w\n display(w)\n return f\n else:\n # This branch handles the case:\n # @interact(a=30, b=40)\n # def f(*args, **kwargs):\n # ...\n def dec(f):\n return interact(f, **kwargs)\n return dec\n\ndef interact_manual(__interact_f=None, **kwargs):\n \"\"\"interact_manual(f, **kwargs)\n \n As `interact()`, generates widgets for each argument, but rather than running\n the function after each widget change, adds a \"Run\" button and waits for it\n to be clicked. Useful if the function is long-running and has several\n parameters to change.\n \"\"\"\n return interact(__interact_f, __manual=True, **kwargs)\n\nclass fixed(HasTraits):\n \"\"\"A pseudo-widget whose value is fixed and never synced to the client.\"\"\"\n value = Any(help=\"Any Python object\")\n description = Unicode('', help=\"Any Python object\")\n def __init__(self, value, **kwargs):\n super(fixed, self).__init__(value=value, **kwargs)\n", "path": "IPython/html/widgets/interaction.py"}]} | 3,673 | 407 |
gh_patches_debug_7810 | rasdani/github-patches | git_diff | ManimCommunity__manim-2587 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rendering TeX strings containing % broken
This unfortunately broke rendering of TeX strings containing `%`. Trying to create `Tex(r"\%")` fails in v0.15.0.
_Originally posted by @behackl in https://github.com/ManimCommunity/manim/issues/2574#issuecomment-1054726581_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `manim/utils/tex_file_writing.py`
Content:
```
1 """Interface for writing, compiling, and converting ``.tex`` files.
2
3 .. SEEALSO::
4
5 :mod:`.mobject.svg.tex_mobject`
6
7 """
8
9 from __future__ import annotations
10
11 import hashlib
12 import os
13 import re
14 import unicodedata
15 from pathlib import Path
16
17 from .. import config, logger
18
19
20 def tex_hash(expression):
21 id_str = str(expression)
22 hasher = hashlib.sha256()
23 hasher.update(id_str.encode())
24 # Truncating at 16 bytes for cleanliness
25 return hasher.hexdigest()[:16]
26
27
28 def tex_to_svg_file(expression, environment=None, tex_template=None):
29 """Takes a tex expression and returns the svg version of the compiled tex
30
31 Parameters
32 ----------
33 expression : :class:`str`
34 String containing the TeX expression to be rendered, e.g. ``\\sqrt{2}`` or ``foo``
35 environment : Optional[:class:`str`], optional
36 The string containing the environment in which the expression should be typeset, e.g. ``align*``
37 tex_template : Optional[:class:`~.TexTemplate`], optional
38 Template class used to typesetting. If not set, use default template set via `config["tex_template"]`
39
40 Returns
41 -------
42 :class:`str`
43 Path to generated SVG file.
44 """
45 if tex_template is None:
46 tex_template = config["tex_template"]
47 tex_file = generate_tex_file(expression, environment, tex_template)
48 dvi_file = compile_tex(
49 tex_file,
50 tex_template.tex_compiler,
51 tex_template.output_format,
52 )
53 return convert_to_svg(dvi_file, tex_template.output_format)
54
55
56 def generate_tex_file(expression, environment=None, tex_template=None):
57 """Takes a tex expression (and an optional tex environment),
58 and returns a fully formed tex file ready for compilation.
59
60 Parameters
61 ----------
62 expression : :class:`str`
63 String containing the TeX expression to be rendered, e.g. ``\\sqrt{2}`` or ``foo``
64 environment : Optional[:class:`str`], optional
65 The string containing the environment in which the expression should be typeset, e.g. ``align*``
66 tex_template : Optional[:class:`~.TexTemplate`], optional
67 Template class used to typesetting. If not set, use default template set via `config["tex_template"]`
68
69 Returns
70 -------
71 :class:`str`
72 Path to generated TeX file
73 """
74 if tex_template is None:
75 tex_template = config["tex_template"]
76 if environment is not None:
77 output = tex_template.get_texcode_for_expression_in_env(expression, environment)
78 else:
79 output = tex_template.get_texcode_for_expression(expression)
80
81 tex_dir = config.get_dir("tex_dir")
82 if not os.path.exists(tex_dir):
83 os.makedirs(tex_dir)
84
85 result = os.path.join(tex_dir, tex_hash(output)) + ".tex"
86 if not os.path.exists(result):
87 logger.info(f"Writing {expression} to %(path)s", {"path": f"{result}"})
88 with open(result, "w", encoding="utf-8") as outfile:
89 outfile.write(output)
90 return result
91
92
93 def tex_compilation_command(tex_compiler, output_format, tex_file, tex_dir):
94 """Prepares the tex compilation command with all necessary cli flags
95
96 Parameters
97 ----------
98 tex_compiler : :class:`str`
99 String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``
100 output_format : :class:`str`
101 String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``
102 tex_file : :class:`str`
103 File name of TeX file to be typeset.
104 tex_dir : :class:`str`
105 Path to the directory where compiler output will be stored.
106
107 Returns
108 -------
109 :class:`str`
110 Compilation command according to given parameters
111 """
112 if tex_compiler in {"latex", "pdflatex", "luatex", "lualatex"}:
113 commands = [
114 tex_compiler,
115 "-interaction=batchmode",
116 f'-output-format="{output_format[1:]}"',
117 "-halt-on-error",
118 f'-output-directory="{tex_dir}"',
119 f'"{tex_file}"',
120 ">",
121 os.devnull,
122 ]
123 elif tex_compiler == "xelatex":
124 if output_format == ".xdv":
125 outflag = "-no-pdf"
126 elif output_format == ".pdf":
127 outflag = ""
128 else:
129 raise ValueError("xelatex output is either pdf or xdv")
130 commands = [
131 "xelatex",
132 outflag,
133 "-interaction=batchmode",
134 "-halt-on-error",
135 f'-output-directory="{tex_dir}"',
136 f'"{tex_file}"',
137 ">",
138 os.devnull,
139 ]
140 else:
141 raise ValueError(f"Tex compiler {tex_compiler} unknown.")
142 return " ".join(commands)
143
144
145 def insight_inputenc_error(matching):
146 code_point = chr(int(matching[1], 16))
147 name = unicodedata.name(code_point)
148 yield f"TexTemplate does not support character '{name}' (U+{matching[1]})."
149 yield "See the documentation for manim.mobject.svg.tex_mobject for details on using a custom TexTemplate."
150
151
152 def insight_package_not_found_error(matching):
153 yield f"You do not have package {matching[1]} installed."
154 yield f"Install {matching[1]} it using your LaTeX package manager, or check for typos."
155
156
157 def compile_tex(tex_file, tex_compiler, output_format):
158 """Compiles a tex_file into a .dvi or a .xdv or a .pdf
159
160 Parameters
161 ----------
162 tex_file : :class:`str`
163 File name of TeX file to be typeset.
164 tex_compiler : :class:`str`
165 String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``
166 output_format : :class:`str`
167 String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``
168
169 Returns
170 -------
171 :class:`str`
172 Path to generated output file in desired format (DVI, XDV or PDF).
173 """
174 result = tex_file.replace(".tex", output_format)
175 result = Path(result).as_posix()
176 tex_file = Path(tex_file).as_posix()
177 tex_dir = Path(config.get_dir("tex_dir")).as_posix()
178 if not os.path.exists(result):
179 command = tex_compilation_command(
180 tex_compiler,
181 output_format,
182 tex_file,
183 tex_dir,
184 )
185 exit_code = os.system(command)
186 if exit_code != 0:
187 log_file = tex_file.replace(".tex", ".log")
188 print_all_tex_errors(log_file, tex_compiler, tex_file)
189 raise ValueError(
190 f"{tex_compiler} error converting to"
191 f" {output_format[1:]}. See log output above or"
192 f" the log file: {log_file}",
193 )
194 return result
195
196
197 def convert_to_svg(dvi_file, extension, page=1):
198 """Converts a .dvi, .xdv, or .pdf file into an svg using dvisvgm.
199
200 Parameters
201 ----------
202 dvi_file : :class:`str`
203 File name of the input file to be converted.
204 extension : :class:`str`
205 String containing the file extension and thus indicating the file type, e.g. ``.dvi`` or ``.pdf``
206 page : Optional[:class:`int`], optional
207 Page to be converted if input file is multi-page.
208
209 Returns
210 -------
211 :class:`str`
212 Path to generated SVG file.
213 """
214 result = dvi_file.replace(extension, ".svg")
215 result = Path(result).as_posix()
216 dvi_file = Path(dvi_file).as_posix()
217 if not os.path.exists(result):
218 commands = [
219 "dvisvgm",
220 "--pdf" if extension == ".pdf" else "",
221 "-p " + str(page),
222 f'"{dvi_file}"',
223 "-n",
224 "-v 0",
225 "-o " + f'"{result}"',
226 ">",
227 os.devnull,
228 ]
229 os.system(" ".join(commands))
230
231 # if the file does not exist now, this means conversion failed
232 if not os.path.exists(result):
233 raise ValueError(
234 f"Your installation does not support converting {extension} files to SVG."
235 f" Consider updating dvisvgm to at least version 2.4."
236 f" If this does not solve the problem, please refer to our troubleshooting guide at:"
237 f" https://docs.manim.community/en/stable/installation/troubleshooting.html",
238 )
239
240 return result
241
242
243 def print_all_tex_errors(log_file, tex_compiler, tex_file):
244 if not Path(log_file).exists():
245 raise RuntimeError(
246 f"{tex_compiler} failed but did not produce a log file. "
247 "Check your LaTeX installation.",
248 )
249 with open(log_file) as f:
250 tex_compilation_log = f.readlines()
251 error_indices = [
252 index
253 for index, line in enumerate(tex_compilation_log)
254 if line.startswith("!")
255 ]
256 if error_indices:
257 with open(tex_file) as g:
258 tex = g.readlines()
259 for error_index in error_indices:
260 print_tex_error(tex_compilation_log, error_index, tex)
261
262
263 LATEX_ERROR_INSIGHTS = [
264 (
265 r"inputenc Error: Unicode character (?:.*) \(U\+([0-9a-fA-F]+)\)",
266 insight_inputenc_error,
267 ),
268 (
269 r"LaTeX Error: File `(.*?[clsty])' not found",
270 insight_package_not_found_error,
271 ),
272 ]
273
274
275 def print_tex_error(tex_compilation_log, error_start_index, tex_source):
276 logger.error(
277 f"LaTeX compilation error: {tex_compilation_log[error_start_index][2:]}",
278 )
279
280 # TeX errors eventually contain a line beginning 'l.xxx` where xxx is the line number that caused the compilation
281 # failure. This code finds the next such line after the error current error message
282 line_of_tex_error = (
283 int(
284 [
285 log_line
286 for log_line in tex_compilation_log[error_start_index:]
287 if log_line.startswith("l.")
288 ][0]
289 .split(" ")[0]
290 .split(".")[1],
291 )
292 - 1
293 )
294 # our tex error may be on a line outside our user input because of post-processing
295 if line_of_tex_error >= len(tex_source):
296 return None
297
298 context = ["Context of error: \n"]
299 if line_of_tex_error < 3:
300 context += tex_source[: line_of_tex_error + 3]
301 context[-4] = "-> " + context[-4]
302 elif line_of_tex_error > len(tex_source) - 3:
303 context += tex_source[line_of_tex_error - 1 :]
304 context[1] = "-> " + context[1]
305 else:
306 context += tex_source[line_of_tex_error - 3 : line_of_tex_error + 3]
307 context[-4] = "-> " + context[-4]
308
309 context = "".join(context)
310 logger.error(context)
311
312 for insights in LATEX_ERROR_INSIGHTS:
313 prob, get_insight = insights
314 matching = re.search(
315 prob,
316 "".join(tex_compilation_log[error_start_index])[2:],
317 )
318 if matching is not None:
319 for insight in get_insight(matching):
320 logger.info(insight)
321
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/manim/utils/tex_file_writing.py b/manim/utils/tex_file_writing.py
--- a/manim/utils/tex_file_writing.py
+++ b/manim/utils/tex_file_writing.py
@@ -84,7 +84,10 @@
result = os.path.join(tex_dir, tex_hash(output)) + ".tex"
if not os.path.exists(result):
- logger.info(f"Writing {expression} to %(path)s", {"path": f"{result}"})
+ logger.info(
+ "Writing %(expression)s to %(path)s",
+ {"expression": expression, "path": f"{result}"},
+ )
with open(result, "w", encoding="utf-8") as outfile:
outfile.write(output)
return result
| {"golden_diff": "diff --git a/manim/utils/tex_file_writing.py b/manim/utils/tex_file_writing.py\n--- a/manim/utils/tex_file_writing.py\n+++ b/manim/utils/tex_file_writing.py\n@@ -84,7 +84,10 @@\n \n result = os.path.join(tex_dir, tex_hash(output)) + \".tex\"\n if not os.path.exists(result):\n- logger.info(f\"Writing {expression} to %(path)s\", {\"path\": f\"{result}\"})\n+ logger.info(\n+ \"Writing %(expression)s to %(path)s\",\n+ {\"expression\": expression, \"path\": f\"{result}\"},\n+ )\n with open(result, \"w\", encoding=\"utf-8\") as outfile:\n outfile.write(output)\n return result\n", "issue": "Rendering TeX strings containing % broken\nThis unfortunately broke rendering of TeX strings containing `%`. Trying to create `Tex(r\"\\%\")` fails in v0.15.0.\r\n\r\n_Originally posted by @behackl in https://github.com/ManimCommunity/manim/issues/2574#issuecomment-1054726581_\n", "before_files": [{"content": "\"\"\"Interface for writing, compiling, and converting ``.tex`` files.\n\n.. SEEALSO::\n\n :mod:`.mobject.svg.tex_mobject`\n\n\"\"\"\n\nfrom __future__ import annotations\n\nimport hashlib\nimport os\nimport re\nimport unicodedata\nfrom pathlib import Path\n\nfrom .. import config, logger\n\n\ndef tex_hash(expression):\n id_str = str(expression)\n hasher = hashlib.sha256()\n hasher.update(id_str.encode())\n # Truncating at 16 bytes for cleanliness\n return hasher.hexdigest()[:16]\n\n\ndef tex_to_svg_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression and returns the svg version of the compiled tex\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n tex_file = generate_tex_file(expression, environment, tex_template)\n dvi_file = compile_tex(\n tex_file,\n tex_template.tex_compiler,\n tex_template.output_format,\n )\n return convert_to_svg(dvi_file, tex_template.output_format)\n\n\ndef generate_tex_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression (and an optional tex environment),\n and returns a fully formed tex file ready for compilation.\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated TeX file\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n if environment is not None:\n output = tex_template.get_texcode_for_expression_in_env(expression, environment)\n else:\n output = tex_template.get_texcode_for_expression(expression)\n\n tex_dir = config.get_dir(\"tex_dir\")\n if not os.path.exists(tex_dir):\n os.makedirs(tex_dir)\n\n result = os.path.join(tex_dir, tex_hash(output)) + \".tex\"\n if not os.path.exists(result):\n logger.info(f\"Writing {expression} to %(path)s\", {\"path\": f\"{result}\"})\n with open(result, \"w\", encoding=\"utf-8\") as outfile:\n outfile.write(output)\n return result\n\n\ndef tex_compilation_command(tex_compiler, output_format, tex_file, tex_dir):\n \"\"\"Prepares the tex compilation command with all necessary cli flags\n\n Parameters\n ----------\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_dir : :class:`str`\n Path to the directory where compiler output will be stored.\n\n Returns\n -------\n :class:`str`\n Compilation command according to given parameters\n \"\"\"\n if tex_compiler in {\"latex\", \"pdflatex\", \"luatex\", \"lualatex\"}:\n commands = [\n tex_compiler,\n \"-interaction=batchmode\",\n f'-output-format=\"{output_format[1:]}\"',\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n elif tex_compiler == \"xelatex\":\n if output_format == \".xdv\":\n outflag = \"-no-pdf\"\n elif output_format == \".pdf\":\n outflag = \"\"\n else:\n raise ValueError(\"xelatex output is either pdf or xdv\")\n commands = [\n \"xelatex\",\n outflag,\n \"-interaction=batchmode\",\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n else:\n raise ValueError(f\"Tex compiler {tex_compiler} unknown.\")\n return \" \".join(commands)\n\n\ndef insight_inputenc_error(matching):\n code_point = chr(int(matching[1], 16))\n name = unicodedata.name(code_point)\n yield f\"TexTemplate does not support character '{name}' (U+{matching[1]}).\"\n yield \"See the documentation for manim.mobject.svg.tex_mobject for details on using a custom TexTemplate.\"\n\n\ndef insight_package_not_found_error(matching):\n yield f\"You do not have package {matching[1]} installed.\"\n yield f\"Install {matching[1]} it using your LaTeX package manager, or check for typos.\"\n\n\ndef compile_tex(tex_file, tex_compiler, output_format):\n \"\"\"Compiles a tex_file into a .dvi or a .xdv or a .pdf\n\n Parameters\n ----------\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n\n Returns\n -------\n :class:`str`\n Path to generated output file in desired format (DVI, XDV or PDF).\n \"\"\"\n result = tex_file.replace(\".tex\", output_format)\n result = Path(result).as_posix()\n tex_file = Path(tex_file).as_posix()\n tex_dir = Path(config.get_dir(\"tex_dir\")).as_posix()\n if not os.path.exists(result):\n command = tex_compilation_command(\n tex_compiler,\n output_format,\n tex_file,\n tex_dir,\n )\n exit_code = os.system(command)\n if exit_code != 0:\n log_file = tex_file.replace(\".tex\", \".log\")\n print_all_tex_errors(log_file, tex_compiler, tex_file)\n raise ValueError(\n f\"{tex_compiler} error converting to\"\n f\" {output_format[1:]}. See log output above or\"\n f\" the log file: {log_file}\",\n )\n return result\n\n\ndef convert_to_svg(dvi_file, extension, page=1):\n \"\"\"Converts a .dvi, .xdv, or .pdf file into an svg using dvisvgm.\n\n Parameters\n ----------\n dvi_file : :class:`str`\n File name of the input file to be converted.\n extension : :class:`str`\n String containing the file extension and thus indicating the file type, e.g. ``.dvi`` or ``.pdf``\n page : Optional[:class:`int`], optional\n Page to be converted if input file is multi-page.\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n result = dvi_file.replace(extension, \".svg\")\n result = Path(result).as_posix()\n dvi_file = Path(dvi_file).as_posix()\n if not os.path.exists(result):\n commands = [\n \"dvisvgm\",\n \"--pdf\" if extension == \".pdf\" else \"\",\n \"-p \" + str(page),\n f'\"{dvi_file}\"',\n \"-n\",\n \"-v 0\",\n \"-o \" + f'\"{result}\"',\n \">\",\n os.devnull,\n ]\n os.system(\" \".join(commands))\n\n # if the file does not exist now, this means conversion failed\n if not os.path.exists(result):\n raise ValueError(\n f\"Your installation does not support converting {extension} files to SVG.\"\n f\" Consider updating dvisvgm to at least version 2.4.\"\n f\" If this does not solve the problem, please refer to our troubleshooting guide at:\"\n f\" https://docs.manim.community/en/stable/installation/troubleshooting.html\",\n )\n\n return result\n\n\ndef print_all_tex_errors(log_file, tex_compiler, tex_file):\n if not Path(log_file).exists():\n raise RuntimeError(\n f\"{tex_compiler} failed but did not produce a log file. \"\n \"Check your LaTeX installation.\",\n )\n with open(log_file) as f:\n tex_compilation_log = f.readlines()\n error_indices = [\n index\n for index, line in enumerate(tex_compilation_log)\n if line.startswith(\"!\")\n ]\n if error_indices:\n with open(tex_file) as g:\n tex = g.readlines()\n for error_index in error_indices:\n print_tex_error(tex_compilation_log, error_index, tex)\n\n\nLATEX_ERROR_INSIGHTS = [\n (\n r\"inputenc Error: Unicode character (?:.*) \\(U\\+([0-9a-fA-F]+)\\)\",\n insight_inputenc_error,\n ),\n (\n r\"LaTeX Error: File `(.*?[clsty])' not found\",\n insight_package_not_found_error,\n ),\n]\n\n\ndef print_tex_error(tex_compilation_log, error_start_index, tex_source):\n logger.error(\n f\"LaTeX compilation error: {tex_compilation_log[error_start_index][2:]}\",\n )\n\n # TeX errors eventually contain a line beginning 'l.xxx` where xxx is the line number that caused the compilation\n # failure. This code finds the next such line after the error current error message\n line_of_tex_error = (\n int(\n [\n log_line\n for log_line in tex_compilation_log[error_start_index:]\n if log_line.startswith(\"l.\")\n ][0]\n .split(\" \")[0]\n .split(\".\")[1],\n )\n - 1\n )\n # our tex error may be on a line outside our user input because of post-processing\n if line_of_tex_error >= len(tex_source):\n return None\n\n context = [\"Context of error: \\n\"]\n if line_of_tex_error < 3:\n context += tex_source[: line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n elif line_of_tex_error > len(tex_source) - 3:\n context += tex_source[line_of_tex_error - 1 :]\n context[1] = \"-> \" + context[1]\n else:\n context += tex_source[line_of_tex_error - 3 : line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n\n context = \"\".join(context)\n logger.error(context)\n\n for insights in LATEX_ERROR_INSIGHTS:\n prob, get_insight = insights\n matching = re.search(\n prob,\n \"\".join(tex_compilation_log[error_start_index])[2:],\n )\n if matching is not None:\n for insight in get_insight(matching):\n logger.info(insight)\n", "path": "manim/utils/tex_file_writing.py"}], "after_files": [{"content": "\"\"\"Interface for writing, compiling, and converting ``.tex`` files.\n\n.. SEEALSO::\n\n :mod:`.mobject.svg.tex_mobject`\n\n\"\"\"\n\nfrom __future__ import annotations\n\nimport hashlib\nimport os\nimport re\nimport unicodedata\nfrom pathlib import Path\n\nfrom .. import config, logger\n\n\ndef tex_hash(expression):\n id_str = str(expression)\n hasher = hashlib.sha256()\n hasher.update(id_str.encode())\n # Truncating at 16 bytes for cleanliness\n return hasher.hexdigest()[:16]\n\n\ndef tex_to_svg_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression and returns the svg version of the compiled tex\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n tex_file = generate_tex_file(expression, environment, tex_template)\n dvi_file = compile_tex(\n tex_file,\n tex_template.tex_compiler,\n tex_template.output_format,\n )\n return convert_to_svg(dvi_file, tex_template.output_format)\n\n\ndef generate_tex_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression (and an optional tex environment),\n and returns a fully formed tex file ready for compilation.\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated TeX file\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n if environment is not None:\n output = tex_template.get_texcode_for_expression_in_env(expression, environment)\n else:\n output = tex_template.get_texcode_for_expression(expression)\n\n tex_dir = config.get_dir(\"tex_dir\")\n if not os.path.exists(tex_dir):\n os.makedirs(tex_dir)\n\n result = os.path.join(tex_dir, tex_hash(output)) + \".tex\"\n if not os.path.exists(result):\n logger.info(\n \"Writing %(expression)s to %(path)s\",\n {\"expression\": expression, \"path\": f\"{result}\"},\n )\n with open(result, \"w\", encoding=\"utf-8\") as outfile:\n outfile.write(output)\n return result\n\n\ndef tex_compilation_command(tex_compiler, output_format, tex_file, tex_dir):\n \"\"\"Prepares the tex compilation command with all necessary cli flags\n\n Parameters\n ----------\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_dir : :class:`str`\n Path to the directory where compiler output will be stored.\n\n Returns\n -------\n :class:`str`\n Compilation command according to given parameters\n \"\"\"\n if tex_compiler in {\"latex\", \"pdflatex\", \"luatex\", \"lualatex\"}:\n commands = [\n tex_compiler,\n \"-interaction=batchmode\",\n f'-output-format=\"{output_format[1:]}\"',\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n elif tex_compiler == \"xelatex\":\n if output_format == \".xdv\":\n outflag = \"-no-pdf\"\n elif output_format == \".pdf\":\n outflag = \"\"\n else:\n raise ValueError(\"xelatex output is either pdf or xdv\")\n commands = [\n \"xelatex\",\n outflag,\n \"-interaction=batchmode\",\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n else:\n raise ValueError(f\"Tex compiler {tex_compiler} unknown.\")\n return \" \".join(commands)\n\n\ndef insight_inputenc_error(matching):\n code_point = chr(int(matching[1], 16))\n name = unicodedata.name(code_point)\n yield f\"TexTemplate does not support character '{name}' (U+{matching[1]}).\"\n yield \"See the documentation for manim.mobject.svg.tex_mobject for details on using a custom TexTemplate.\"\n\n\ndef insight_package_not_found_error(matching):\n yield f\"You do not have package {matching[1]} installed.\"\n yield f\"Install {matching[1]} it using your LaTeX package manager, or check for typos.\"\n\n\ndef compile_tex(tex_file, tex_compiler, output_format):\n \"\"\"Compiles a tex_file into a .dvi or a .xdv or a .pdf\n\n Parameters\n ----------\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n\n Returns\n -------\n :class:`str`\n Path to generated output file in desired format (DVI, XDV or PDF).\n \"\"\"\n result = tex_file.replace(\".tex\", output_format)\n result = Path(result).as_posix()\n tex_file = Path(tex_file).as_posix()\n tex_dir = Path(config.get_dir(\"tex_dir\")).as_posix()\n if not os.path.exists(result):\n command = tex_compilation_command(\n tex_compiler,\n output_format,\n tex_file,\n tex_dir,\n )\n exit_code = os.system(command)\n if exit_code != 0:\n log_file = tex_file.replace(\".tex\", \".log\")\n print_all_tex_errors(log_file, tex_compiler, tex_file)\n raise ValueError(\n f\"{tex_compiler} error converting to\"\n f\" {output_format[1:]}. See log output above or\"\n f\" the log file: {log_file}\",\n )\n return result\n\n\ndef convert_to_svg(dvi_file, extension, page=1):\n \"\"\"Converts a .dvi, .xdv, or .pdf file into an svg using dvisvgm.\n\n Parameters\n ----------\n dvi_file : :class:`str`\n File name of the input file to be converted.\n extension : :class:`str`\n String containing the file extension and thus indicating the file type, e.g. ``.dvi`` or ``.pdf``\n page : Optional[:class:`int`], optional\n Page to be converted if input file is multi-page.\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n result = dvi_file.replace(extension, \".svg\")\n result = Path(result).as_posix()\n dvi_file = Path(dvi_file).as_posix()\n if not os.path.exists(result):\n commands = [\n \"dvisvgm\",\n \"--pdf\" if extension == \".pdf\" else \"\",\n \"-p \" + str(page),\n f'\"{dvi_file}\"',\n \"-n\",\n \"-v 0\",\n \"-o \" + f'\"{result}\"',\n \">\",\n os.devnull,\n ]\n os.system(\" \".join(commands))\n\n # if the file does not exist now, this means conversion failed\n if not os.path.exists(result):\n raise ValueError(\n f\"Your installation does not support converting {extension} files to SVG.\"\n f\" Consider updating dvisvgm to at least version 2.4.\"\n f\" If this does not solve the problem, please refer to our troubleshooting guide at:\"\n f\" https://docs.manim.community/en/stable/installation/troubleshooting.html\",\n )\n\n return result\n\n\ndef print_all_tex_errors(log_file, tex_compiler, tex_file):\n if not Path(log_file).exists():\n raise RuntimeError(\n f\"{tex_compiler} failed but did not produce a log file. \"\n \"Check your LaTeX installation.\",\n )\n with open(log_file) as f:\n tex_compilation_log = f.readlines()\n error_indices = [\n index\n for index, line in enumerate(tex_compilation_log)\n if line.startswith(\"!\")\n ]\n if error_indices:\n with open(tex_file) as g:\n tex = g.readlines()\n for error_index in error_indices:\n print_tex_error(tex_compilation_log, error_index, tex)\n\n\nLATEX_ERROR_INSIGHTS = [\n (\n r\"inputenc Error: Unicode character (?:.*) \\(U\\+([0-9a-fA-F]+)\\)\",\n insight_inputenc_error,\n ),\n (\n r\"LaTeX Error: File `(.*?[clsty])' not found\",\n insight_package_not_found_error,\n ),\n]\n\n\ndef print_tex_error(tex_compilation_log, error_start_index, tex_source):\n logger.error(\n f\"LaTeX compilation error: {tex_compilation_log[error_start_index][2:]}\",\n )\n\n # TeX errors eventually contain a line beginning 'l.xxx` where xxx is the line number that caused the compilation\n # failure. This code finds the next such line after the error current error message\n line_of_tex_error = (\n int(\n [\n log_line\n for log_line in tex_compilation_log[error_start_index:]\n if log_line.startswith(\"l.\")\n ][0]\n .split(\" \")[0]\n .split(\".\")[1],\n )\n - 1\n )\n # our tex error may be on a line outside our user input because of post-processing\n if line_of_tex_error >= len(tex_source):\n return None\n\n context = [\"Context of error: \\n\"]\n if line_of_tex_error < 3:\n context += tex_source[: line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n elif line_of_tex_error > len(tex_source) - 3:\n context += tex_source[line_of_tex_error - 1 :]\n context[1] = \"-> \" + context[1]\n else:\n context += tex_source[line_of_tex_error - 3 : line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n\n context = \"\".join(context)\n logger.error(context)\n\n for insights in LATEX_ERROR_INSIGHTS:\n prob, get_insight = insights\n matching = re.search(\n prob,\n \"\".join(tex_compilation_log[error_start_index])[2:],\n )\n if matching is not None:\n for insight in get_insight(matching):\n logger.info(insight)\n", "path": "manim/utils/tex_file_writing.py"}]} | 3,746 | 171 |
gh_patches_debug_30401 | rasdani/github-patches | git_diff | castorini__pyserini-630 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add ability to select random question for interactive demo
hey @saileshnankani - how about we add a `/random` command to ask a random question from the dev set?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyserini/demo/msmarco.py`
Content:
```
1 #
2 # Pyserini: Reproducible IR research with sparse and dense representations
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 import cmd
18 import json
19
20 from pyserini.search import SimpleSearcher
21 from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder
22 from pyserini.hsearch import HybridSearcher
23
24
25 class MsMarcoDemo(cmd.Cmd):
26 ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')
27 dsearcher = None
28 hsearcher = None
29 searcher = ssearcher
30
31 k = 10
32 prompt = '>>> '
33
34 # https://stackoverflow.com/questions/35213134/command-prefixes-in-python-cli-using-cmd-in-pythons-standard-library
35 def precmd(self, line):
36 if line[0] == '/':
37 line = line[1:]
38 return line
39
40 def do_help(self, arg):
41 print(f'/help : returns this message')
42 print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')
43 print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')
44 print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')
45
46 def do_k(self, arg):
47 print(f'setting k = {int(arg)}')
48 self.k = int(arg)
49
50 def do_mode(self, arg):
51 if arg == "sparse":
52 self.searcher = self.ssearcher
53 elif arg == "dense":
54 if self.dsearcher is None:
55 print(f'Specify model through /model before using dense retrieval.')
56 return
57 self.searcher = self.dsearcher
58 elif arg == "hybrid":
59 if self.hsearcher is None:
60 print(f'Specify model through /model before using hybrid retrieval.')
61 return
62 self.searcher = self.hsearcher
63 else:
64 print(
65 f'Mode "{arg}" is invalid. Mode should be one of [sparse, dense, hybrid].')
66 return
67 print(f'setting retriver = {arg}')
68
69 def do_model(self, arg):
70 if arg == "tct":
71 encoder = TctColBertQueryEncoder("castorini/tct_colbert-msmarco")
72 index = "msmarco-passage-tct_colbert-hnsw"
73 elif arg == "ance":
74 encoder = AnceQueryEncoder("castorini/ance-msmarco-passage")
75 index = "msmarco-passage-ance-bf"
76 else:
77 print(
78 f'Model "{arg}" is invalid. Model should be one of [tct, ance].')
79 return
80
81 self.dsearcher = SimpleDenseSearcher.from_prebuilt_index(
82 index,
83 encoder
84 )
85 self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)
86 print(f'setting model = {arg}')
87
88 def do_EOF(self, line):
89 return True
90
91 def default(self, q):
92 hits = self.searcher.search(q, self.k)
93
94 for i in range(0, len(hits)):
95 raw_doc = None
96 if isinstance(self.searcher, SimpleSearcher):
97 raw_doc = hits[i].raw
98 else:
99 doc = self.ssearcher.doc(hits[i].docid)
100 if doc:
101 raw_doc = doc.raw()
102 jsondoc = json.loads(raw_doc)
103 print(f'{i + 1:2} {hits[i].score:.5f} {jsondoc["contents"]}')
104
105
106 if __name__ == '__main__':
107 MsMarcoDemo().cmdloop()
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyserini/demo/msmarco.py b/pyserini/demo/msmarco.py
--- a/pyserini/demo/msmarco.py
+++ b/pyserini/demo/msmarco.py
@@ -16,13 +16,18 @@
import cmd
import json
+import os
+import random
from pyserini.search import SimpleSearcher
from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder
from pyserini.hsearch import HybridSearcher
+from pyserini import search
class MsMarcoDemo(cmd.Cmd):
+ dev_topics = list(search.get_topics('msmarco-passage-dev-subset').values())
+
ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')
dsearcher = None
hsearcher = None
@@ -42,6 +47,7 @@
print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')
print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')
print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')
+ print(f'/random : returns results for a random question from dev subset')
def do_k(self, arg):
print(f'setting k = {int(arg)}')
@@ -85,6 +91,11 @@
self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)
print(f'setting model = {arg}')
+ def do_random(self, arg):
+ q = random.choice(self.dev_topics)['title']
+ print(f'question: {q}')
+ self.default(q)
+
def do_EOF(self, line):
return True
| {"golden_diff": "diff --git a/pyserini/demo/msmarco.py b/pyserini/demo/msmarco.py\n--- a/pyserini/demo/msmarco.py\n+++ b/pyserini/demo/msmarco.py\n@@ -16,13 +16,18 @@\n \n import cmd\n import json\n+import os\n+import random\n \n from pyserini.search import SimpleSearcher\n from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder\n from pyserini.hsearch import HybridSearcher\n+from pyserini import search\n \n \n class MsMarcoDemo(cmd.Cmd):\n+ dev_topics = list(search.get_topics('msmarco-passage-dev-subset').values())\n+\n ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')\n dsearcher = None\n hsearcher = None\n@@ -42,6 +47,7 @@\n print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')\n print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')\n print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')\n+ print(f'/random : returns results for a random question from dev subset')\n \n def do_k(self, arg):\n print(f'setting k = {int(arg)}')\n@@ -85,6 +91,11 @@\n self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)\n print(f'setting model = {arg}')\n \n+ def do_random(self, arg):\n+ q = random.choice(self.dev_topics)['title']\n+ print(f'question: {q}')\n+ self.default(q)\n+\n def do_EOF(self, line):\n return True\n", "issue": "Add ability to select random question for interactive demo\nhey @saileshnankani - how about we add a `/random` command to ask a random question from the dev set?\n", "before_files": [{"content": "#\n# Pyserini: Reproducible IR research with sparse and dense representations\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport cmd\nimport json\n\nfrom pyserini.search import SimpleSearcher\nfrom pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder\nfrom pyserini.hsearch import HybridSearcher\n\n\nclass MsMarcoDemo(cmd.Cmd):\n ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')\n dsearcher = None\n hsearcher = None\n searcher = ssearcher\n\n k = 10\n prompt = '>>> '\n\n # https://stackoverflow.com/questions/35213134/command-prefixes-in-python-cli-using-cmd-in-pythons-standard-library\n def precmd(self, line):\n if line[0] == '/':\n line = line[1:]\n return line\n\n def do_help(self, arg):\n print(f'/help : returns this message')\n print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')\n print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')\n print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')\n\n def do_k(self, arg):\n print(f'setting k = {int(arg)}')\n self.k = int(arg)\n\n def do_mode(self, arg):\n if arg == \"sparse\":\n self.searcher = self.ssearcher\n elif arg == \"dense\":\n if self.dsearcher is None:\n print(f'Specify model through /model before using dense retrieval.')\n return\n self.searcher = self.dsearcher\n elif arg == \"hybrid\":\n if self.hsearcher is None:\n print(f'Specify model through /model before using hybrid retrieval.')\n return\n self.searcher = self.hsearcher\n else:\n print(\n f'Mode \"{arg}\" is invalid. Mode should be one of [sparse, dense, hybrid].')\n return\n print(f'setting retriver = {arg}')\n\n def do_model(self, arg):\n if arg == \"tct\":\n encoder = TctColBertQueryEncoder(\"castorini/tct_colbert-msmarco\")\n index = \"msmarco-passage-tct_colbert-hnsw\"\n elif arg == \"ance\":\n encoder = AnceQueryEncoder(\"castorini/ance-msmarco-passage\")\n index = \"msmarco-passage-ance-bf\"\n else:\n print(\n f'Model \"{arg}\" is invalid. Model should be one of [tct, ance].')\n return\n\n self.dsearcher = SimpleDenseSearcher.from_prebuilt_index(\n index,\n encoder\n )\n self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)\n print(f'setting model = {arg}')\n\n def do_EOF(self, line):\n return True\n\n def default(self, q):\n hits = self.searcher.search(q, self.k)\n\n for i in range(0, len(hits)):\n raw_doc = None\n if isinstance(self.searcher, SimpleSearcher):\n raw_doc = hits[i].raw\n else:\n doc = self.ssearcher.doc(hits[i].docid)\n if doc:\n raw_doc = doc.raw()\n jsondoc = json.loads(raw_doc)\n print(f'{i + 1:2} {hits[i].score:.5f} {jsondoc[\"contents\"]}')\n\n\nif __name__ == '__main__':\n MsMarcoDemo().cmdloop()\n", "path": "pyserini/demo/msmarco.py"}], "after_files": [{"content": "#\n# Pyserini: Reproducible IR research with sparse and dense representations\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport cmd\nimport json\nimport os\nimport random\n\nfrom pyserini.search import SimpleSearcher\nfrom pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder\nfrom pyserini.hsearch import HybridSearcher\nfrom pyserini import search\n\n\nclass MsMarcoDemo(cmd.Cmd):\n dev_topics = list(search.get_topics('msmarco-passage-dev-subset').values())\n\n ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')\n dsearcher = None\n hsearcher = None\n searcher = ssearcher\n\n k = 10\n prompt = '>>> '\n\n # https://stackoverflow.com/questions/35213134/command-prefixes-in-python-cli-using-cmd-in-pythons-standard-library\n def precmd(self, line):\n if line[0] == '/':\n line = line[1:]\n return line\n\n def do_help(self, arg):\n print(f'/help : returns this message')\n print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')\n print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')\n print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')\n print(f'/random : returns results for a random question from dev subset')\n\n def do_k(self, arg):\n print(f'setting k = {int(arg)}')\n self.k = int(arg)\n\n def do_mode(self, arg):\n if arg == \"sparse\":\n self.searcher = self.ssearcher\n elif arg == \"dense\":\n if self.dsearcher is None:\n print(f'Specify model through /model before using dense retrieval.')\n return\n self.searcher = self.dsearcher\n elif arg == \"hybrid\":\n if self.hsearcher is None:\n print(f'Specify model through /model before using hybrid retrieval.')\n return\n self.searcher = self.hsearcher\n else:\n print(\n f'Mode \"{arg}\" is invalid. Mode should be one of [sparse, dense, hybrid].')\n return\n print(f'setting retriver = {arg}')\n\n def do_model(self, arg):\n if arg == \"tct\":\n encoder = TctColBertQueryEncoder(\"castorini/tct_colbert-msmarco\")\n index = \"msmarco-passage-tct_colbert-hnsw\"\n elif arg == \"ance\":\n encoder = AnceQueryEncoder(\"castorini/ance-msmarco-passage\")\n index = \"msmarco-passage-ance-bf\"\n else:\n print(\n f'Model \"{arg}\" is invalid. Model should be one of [tct, ance].')\n return\n\n self.dsearcher = SimpleDenseSearcher.from_prebuilt_index(\n index,\n encoder\n )\n self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)\n print(f'setting model = {arg}')\n\n def do_random(self, arg):\n q = random.choice(self.dev_topics)['title']\n print(f'question: {q}')\n self.default(q)\n\n def do_EOF(self, line):\n return True\n\n def default(self, q):\n hits = self.searcher.search(q, self.k)\n\n for i in range(0, len(hits)):\n raw_doc = None\n if isinstance(self.searcher, SimpleSearcher):\n raw_doc = hits[i].raw\n else:\n doc = self.ssearcher.doc(hits[i].docid)\n if doc:\n raw_doc = doc.raw()\n jsondoc = json.loads(raw_doc)\n print(f'{i + 1:2} {hits[i].score:.5f} {jsondoc[\"contents\"]}')\n\n\nif __name__ == '__main__':\n MsMarcoDemo().cmdloop()\n", "path": "pyserini/demo/msmarco.py"}]} | 1,449 | 408 |
gh_patches_debug_4757 | rasdani/github-patches | git_diff | nonebot__nonebot2-2537 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: websockets 驱动器连接关闭 code 不存在
### 操作系统
Windows
### Python 版本
3.11.6
### NoneBot 版本
2.1.2
### 适配器
nonebot-adapter-kaiheila 0.3.0
### 协议端
kook API(websockets)
### 描述问题
在nonebot库的websockets.py模块中,处理WebSocket异常时出现了AttributeError。这个问题发生在尝试处理ConnectionClosed异常的过程中。
异常信息:
`AttributeError: 'NoneType' object has no attribute 'code'`
相关代码:
```python
def catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:
@wraps(func)
async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:
try:
return await func(*args, **kwargs)
except ConnectionClosed as e:
if e.rcvd_then_sent:
raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
else:
raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
return decorator
```
位于:`nonebot/drivers/websockets.py` Line 56
这个问题是在捕获ConnectionClosed异常时发生的,但e.rcvd或e.sent对象可能为None(在websocket超时这种不是由关闭帧影响的情况下会都不存在)。这导致尝试访问NoneType对象的code属性,从而引发了AttributeError。
### 复现步骤
1.在环境下加载websockets adapter
2.在插件的event handler中存在不使用异步的长时间等待情形(在我的例子是等待语言模型的计算)
### 期望的结果
按照上述描述修改此bug
### 截图或日志
无
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nonebot/drivers/websockets.py`
Content:
```
1 """[websockets](https://websockets.readthedocs.io/) 驱动适配
2
3 ```bash
4 nb driver install websockets
5 # 或者
6 pip install nonebot2[websockets]
7 ```
8
9 :::tip 提示
10 本驱动仅支持客户端 WebSocket 连接
11 :::
12
13 FrontMatter:
14 sidebar_position: 4
15 description: nonebot.drivers.websockets 模块
16 """
17
18 import logging
19 from functools import wraps
20 from contextlib import asynccontextmanager
21 from typing_extensions import ParamSpec, override
22 from typing import TYPE_CHECKING, Union, TypeVar, Callable, Awaitable, AsyncGenerator
23
24 from nonebot.drivers import Request
25 from nonebot.log import LoguruHandler
26 from nonebot.exception import WebSocketClosed
27 from nonebot.drivers.none import Driver as NoneDriver
28 from nonebot.drivers import WebSocket as BaseWebSocket
29 from nonebot.drivers import WebSocketClientMixin, combine_driver
30
31 try:
32 from websockets.exceptions import ConnectionClosed
33 from websockets.legacy.client import Connect, WebSocketClientProtocol
34 except ModuleNotFoundError as e: # pragma: no cover
35 raise ImportError(
36 "Please install websockets first to use this driver. "
37 "Install with pip: `pip install nonebot2[websockets]`"
38 ) from e
39
40 T = TypeVar("T")
41 P = ParamSpec("P")
42
43 logger = logging.Logger("websockets.client", "INFO")
44 logger.addHandler(LoguruHandler())
45
46
47 def catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:
48 @wraps(func)
49 async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:
50 try:
51 return await func(*args, **kwargs)
52 except ConnectionClosed as e:
53 if e.rcvd_then_sent:
54 raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
55 else:
56 raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
57
58 return decorator
59
60
61 class Mixin(WebSocketClientMixin):
62 """Websockets Mixin"""
63
64 @property
65 @override
66 def type(self) -> str:
67 return "websockets"
68
69 @override
70 @asynccontextmanager
71 async def websocket(self, setup: Request) -> AsyncGenerator["WebSocket", None]:
72 connection = Connect(
73 str(setup.url),
74 extra_headers={**setup.headers, **setup.cookies.as_header(setup)},
75 open_timeout=setup.timeout,
76 )
77 async with connection as ws:
78 yield WebSocket(request=setup, websocket=ws)
79
80
81 class WebSocket(BaseWebSocket):
82 """Websockets WebSocket Wrapper"""
83
84 @override
85 def __init__(self, *, request: Request, websocket: WebSocketClientProtocol):
86 super().__init__(request=request)
87 self.websocket = websocket
88
89 @property
90 @override
91 def closed(self) -> bool:
92 return self.websocket.closed
93
94 @override
95 async def accept(self):
96 raise NotImplementedError
97
98 @override
99 async def close(self, code: int = 1000, reason: str = ""):
100 await self.websocket.close(code, reason)
101
102 @override
103 @catch_closed
104 async def receive(self) -> Union[str, bytes]:
105 return await self.websocket.recv()
106
107 @override
108 @catch_closed
109 async def receive_text(self) -> str:
110 msg = await self.websocket.recv()
111 if isinstance(msg, bytes):
112 raise TypeError("WebSocket received unexpected frame type: bytes")
113 return msg
114
115 @override
116 @catch_closed
117 async def receive_bytes(self) -> bytes:
118 msg = await self.websocket.recv()
119 if isinstance(msg, str):
120 raise TypeError("WebSocket received unexpected frame type: str")
121 return msg
122
123 @override
124 async def send_text(self, data: str) -> None:
125 await self.websocket.send(data)
126
127 @override
128 async def send_bytes(self, data: bytes) -> None:
129 await self.websocket.send(data)
130
131
132 if TYPE_CHECKING:
133
134 class Driver(Mixin, NoneDriver):
135 ...
136
137 else:
138 Driver = combine_driver(NoneDriver, Mixin)
139 """Websockets Driver"""
140
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nonebot/drivers/websockets.py b/nonebot/drivers/websockets.py
--- a/nonebot/drivers/websockets.py
+++ b/nonebot/drivers/websockets.py
@@ -50,10 +50,7 @@
try:
return await func(*args, **kwargs)
except ConnectionClosed as e:
- if e.rcvd_then_sent:
- raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
- else:
- raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
+ raise WebSocketClosed(e.code, e.reason)
return decorator
| {"golden_diff": "diff --git a/nonebot/drivers/websockets.py b/nonebot/drivers/websockets.py\n--- a/nonebot/drivers/websockets.py\n+++ b/nonebot/drivers/websockets.py\n@@ -50,10 +50,7 @@\n try:\n return await func(*args, **kwargs)\n except ConnectionClosed as e:\n- if e.rcvd_then_sent:\n- raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\n- else:\n- raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\n+ raise WebSocketClosed(e.code, e.reason)\n \n return decorator\n", "issue": "Bug: websockets \u9a71\u52a8\u5668\u8fde\u63a5\u5173\u95ed code \u4e0d\u5b58\u5728\n### \u64cd\u4f5c\u7cfb\u7edf\r\n\r\nWindows\r\n\r\n### Python \u7248\u672c\r\n\r\n3.11.6\r\n\r\n### NoneBot \u7248\u672c\r\n\r\n2.1.2\r\n\r\n### \u9002\u914d\u5668\r\n\r\nnonebot-adapter-kaiheila 0.3.0\r\n\r\n### \u534f\u8bae\u7aef\r\n\r\nkook API(websockets)\r\n\r\n### \u63cf\u8ff0\u95ee\u9898\r\n\r\n\u5728nonebot\u5e93\u7684websockets.py\u6a21\u5757\u4e2d\uff0c\u5904\u7406WebSocket\u5f02\u5e38\u65f6\u51fa\u73b0\u4e86AttributeError\u3002\u8fd9\u4e2a\u95ee\u9898\u53d1\u751f\u5728\u5c1d\u8bd5\u5904\u7406ConnectionClosed\u5f02\u5e38\u7684\u8fc7\u7a0b\u4e2d\u3002\r\n\u5f02\u5e38\u4fe1\u606f:\r\n`AttributeError: 'NoneType' object has no attribute 'code'`\r\n\u76f8\u5173\u4ee3\u7801:\r\n```python\r\ndef catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:\r\n @wraps(func)\r\n async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:\r\n try:\r\n return await func(*args, **kwargs)\r\n except ConnectionClosed as e:\r\n if e.rcvd_then_sent:\r\n raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\r\n else:\r\n raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\r\n\r\n return decorator\r\n```\r\n\r\n\u4f4d\u4e8e:`nonebot/drivers/websockets.py` Line 56\r\n\u8fd9\u4e2a\u95ee\u9898\u662f\u5728\u6355\u83b7ConnectionClosed\u5f02\u5e38\u65f6\u53d1\u751f\u7684\uff0c\u4f46e.rcvd\u6216e.sent\u5bf9\u8c61\u53ef\u80fd\u4e3aNone(\u5728websocket\u8d85\u65f6\u8fd9\u79cd\u4e0d\u662f\u7531\u5173\u95ed\u5e27\u5f71\u54cd\u7684\u60c5\u51b5\u4e0b\u4f1a\u90fd\u4e0d\u5b58\u5728)\u3002\u8fd9\u5bfc\u81f4\u5c1d\u8bd5\u8bbf\u95eeNoneType\u5bf9\u8c61\u7684code\u5c5e\u6027\uff0c\u4ece\u800c\u5f15\u53d1\u4e86AttributeError\u3002\r\n\r\n### \u590d\u73b0\u6b65\u9aa4\r\n\r\n1.\u5728\u73af\u5883\u4e0b\u52a0\u8f7dwebsockets adapter\r\n2.\u5728\u63d2\u4ef6\u7684event handler\u4e2d\u5b58\u5728\u4e0d\u4f7f\u7528\u5f02\u6b65\u7684\u957f\u65f6\u95f4\u7b49\u5f85\u60c5\u5f62\uff08\u5728\u6211\u7684\u4f8b\u5b50\u662f\u7b49\u5f85\u8bed\u8a00\u6a21\u578b\u7684\u8ba1\u7b97\uff09\r\n\r\n\r\n### \u671f\u671b\u7684\u7ed3\u679c\r\n\r\n\u6309\u7167\u4e0a\u8ff0\u63cf\u8ff0\u4fee\u6539\u6b64bug\r\n\r\n### \u622a\u56fe\u6216\u65e5\u5fd7\r\n\r\n\u65e0\n", "before_files": [{"content": "\"\"\"[websockets](https://websockets.readthedocs.io/) \u9a71\u52a8\u9002\u914d\n\n```bash\nnb driver install websockets\n# \u6216\u8005\npip install nonebot2[websockets]\n```\n\n:::tip \u63d0\u793a\n\u672c\u9a71\u52a8\u4ec5\u652f\u6301\u5ba2\u6237\u7aef WebSocket \u8fde\u63a5\n:::\n\nFrontMatter:\n sidebar_position: 4\n description: nonebot.drivers.websockets \u6a21\u5757\n\"\"\"\n\nimport logging\nfrom functools import wraps\nfrom contextlib import asynccontextmanager\nfrom typing_extensions import ParamSpec, override\nfrom typing import TYPE_CHECKING, Union, TypeVar, Callable, Awaitable, AsyncGenerator\n\nfrom nonebot.drivers import Request\nfrom nonebot.log import LoguruHandler\nfrom nonebot.exception import WebSocketClosed\nfrom nonebot.drivers.none import Driver as NoneDriver\nfrom nonebot.drivers import WebSocket as BaseWebSocket\nfrom nonebot.drivers import WebSocketClientMixin, combine_driver\n\ntry:\n from websockets.exceptions import ConnectionClosed\n from websockets.legacy.client import Connect, WebSocketClientProtocol\nexcept ModuleNotFoundError as e: # pragma: no cover\n raise ImportError(\n \"Please install websockets first to use this driver. \"\n \"Install with pip: `pip install nonebot2[websockets]`\"\n ) from e\n\nT = TypeVar(\"T\")\nP = ParamSpec(\"P\")\n\nlogger = logging.Logger(\"websockets.client\", \"INFO\")\nlogger.addHandler(LoguruHandler())\n\n\ndef catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:\n @wraps(func)\n async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:\n try:\n return await func(*args, **kwargs)\n except ConnectionClosed as e:\n if e.rcvd_then_sent:\n raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\n else:\n raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\n\n return decorator\n\n\nclass Mixin(WebSocketClientMixin):\n \"\"\"Websockets Mixin\"\"\"\n\n @property\n @override\n def type(self) -> str:\n return \"websockets\"\n\n @override\n @asynccontextmanager\n async def websocket(self, setup: Request) -> AsyncGenerator[\"WebSocket\", None]:\n connection = Connect(\n str(setup.url),\n extra_headers={**setup.headers, **setup.cookies.as_header(setup)},\n open_timeout=setup.timeout,\n )\n async with connection as ws:\n yield WebSocket(request=setup, websocket=ws)\n\n\nclass WebSocket(BaseWebSocket):\n \"\"\"Websockets WebSocket Wrapper\"\"\"\n\n @override\n def __init__(self, *, request: Request, websocket: WebSocketClientProtocol):\n super().__init__(request=request)\n self.websocket = websocket\n\n @property\n @override\n def closed(self) -> bool:\n return self.websocket.closed\n\n @override\n async def accept(self):\n raise NotImplementedError\n\n @override\n async def close(self, code: int = 1000, reason: str = \"\"):\n await self.websocket.close(code, reason)\n\n @override\n @catch_closed\n async def receive(self) -> Union[str, bytes]:\n return await self.websocket.recv()\n\n @override\n @catch_closed\n async def receive_text(self) -> str:\n msg = await self.websocket.recv()\n if isinstance(msg, bytes):\n raise TypeError(\"WebSocket received unexpected frame type: bytes\")\n return msg\n\n @override\n @catch_closed\n async def receive_bytes(self) -> bytes:\n msg = await self.websocket.recv()\n if isinstance(msg, str):\n raise TypeError(\"WebSocket received unexpected frame type: str\")\n return msg\n\n @override\n async def send_text(self, data: str) -> None:\n await self.websocket.send(data)\n\n @override\n async def send_bytes(self, data: bytes) -> None:\n await self.websocket.send(data)\n\n\nif TYPE_CHECKING:\n\n class Driver(Mixin, NoneDriver):\n ...\n\nelse:\n Driver = combine_driver(NoneDriver, Mixin)\n \"\"\"Websockets Driver\"\"\"\n", "path": "nonebot/drivers/websockets.py"}], "after_files": [{"content": "\"\"\"[websockets](https://websockets.readthedocs.io/) \u9a71\u52a8\u9002\u914d\n\n```bash\nnb driver install websockets\n# \u6216\u8005\npip install nonebot2[websockets]\n```\n\n:::tip \u63d0\u793a\n\u672c\u9a71\u52a8\u4ec5\u652f\u6301\u5ba2\u6237\u7aef WebSocket \u8fde\u63a5\n:::\n\nFrontMatter:\n sidebar_position: 4\n description: nonebot.drivers.websockets \u6a21\u5757\n\"\"\"\n\nimport logging\nfrom functools import wraps\nfrom contextlib import asynccontextmanager\nfrom typing_extensions import ParamSpec, override\nfrom typing import TYPE_CHECKING, Union, TypeVar, Callable, Awaitable, AsyncGenerator\n\nfrom nonebot.drivers import Request\nfrom nonebot.log import LoguruHandler\nfrom nonebot.exception import WebSocketClosed\nfrom nonebot.drivers.none import Driver as NoneDriver\nfrom nonebot.drivers import WebSocket as BaseWebSocket\nfrom nonebot.drivers import WebSocketClientMixin, combine_driver\n\ntry:\n from websockets.exceptions import ConnectionClosed\n from websockets.legacy.client import Connect, WebSocketClientProtocol\nexcept ModuleNotFoundError as e: # pragma: no cover\n raise ImportError(\n \"Please install websockets first to use this driver. \"\n \"Install with pip: `pip install nonebot2[websockets]`\"\n ) from e\n\nT = TypeVar(\"T\")\nP = ParamSpec(\"P\")\n\nlogger = logging.Logger(\"websockets.client\", \"INFO\")\nlogger.addHandler(LoguruHandler())\n\n\ndef catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:\n @wraps(func)\n async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:\n try:\n return await func(*args, **kwargs)\n except ConnectionClosed as e:\n raise WebSocketClosed(e.code, e.reason)\n\n return decorator\n\n\nclass Mixin(WebSocketClientMixin):\n \"\"\"Websockets Mixin\"\"\"\n\n @property\n @override\n def type(self) -> str:\n return \"websockets\"\n\n @override\n @asynccontextmanager\n async def websocket(self, setup: Request) -> AsyncGenerator[\"WebSocket\", None]:\n connection = Connect(\n str(setup.url),\n extra_headers={**setup.headers, **setup.cookies.as_header(setup)},\n open_timeout=setup.timeout,\n )\n async with connection as ws:\n yield WebSocket(request=setup, websocket=ws)\n\n\nclass WebSocket(BaseWebSocket):\n \"\"\"Websockets WebSocket Wrapper\"\"\"\n\n @override\n def __init__(self, *, request: Request, websocket: WebSocketClientProtocol):\n super().__init__(request=request)\n self.websocket = websocket\n\n @property\n @override\n def closed(self) -> bool:\n return self.websocket.closed\n\n @override\n async def accept(self):\n raise NotImplementedError\n\n @override\n async def close(self, code: int = 1000, reason: str = \"\"):\n await self.websocket.close(code, reason)\n\n @override\n @catch_closed\n async def receive(self) -> Union[str, bytes]:\n return await self.websocket.recv()\n\n @override\n @catch_closed\n async def receive_text(self) -> str:\n msg = await self.websocket.recv()\n if isinstance(msg, bytes):\n raise TypeError(\"WebSocket received unexpected frame type: bytes\")\n return msg\n\n @override\n @catch_closed\n async def receive_bytes(self) -> bytes:\n msg = await self.websocket.recv()\n if isinstance(msg, str):\n raise TypeError(\"WebSocket received unexpected frame type: str\")\n return msg\n\n @override\n async def send_text(self, data: str) -> None:\n await self.websocket.send(data)\n\n @override\n async def send_bytes(self, data: bytes) -> None:\n await self.websocket.send(data)\n\n\nif TYPE_CHECKING:\n\n class Driver(Mixin, NoneDriver):\n ...\n\nelse:\n Driver = combine_driver(NoneDriver, Mixin)\n \"\"\"Websockets Driver\"\"\"\n", "path": "nonebot/drivers/websockets.py"}]} | 1,869 | 142 |
gh_patches_debug_53619 | rasdani/github-patches | git_diff | qtile__qtile-2926 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Systray icon disappears with restart
As reported on IRC:
```
[08:11] < elcaven> this morning I updated qtile from the qtile-git package from the AUR and since then it seems that my systray widget resets every time qtile restarts, so after a qtile restart the systray
is empty until a program spawns there again
[08:12] < elcaven> there don't seem to be any related errors in the logfile, only one I see is "AttributeError: 'Screen' object has
[20:53] < elParaguayo> | elcaven - interesting. That may be a side-effect of the config reloading code that was recently committed.
[21:09] < mcol> What does it mean for the systray to reset? Can it persist state across restarts?
[21:14] < elParaguayo> | I'm guessing that the app is still open but the icon has disappeared from the tray
[21:22] < elParaguayo> | I wonder if SNI has that issue too...
[21:25] < elParaguayo> | No, SNI looks ok.
[21:25] < elParaguayo> | Tested with "restart" and "reload_config"
[21:27] < elParaguayo> | Confirmed, Systray icon disappears on reload_config even though app is open.
[21:28] < elParaguayo> | Icon doesn't disappear with "restart"
```
Tested on latest: 66ce6c28
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/widget/systray.py`
Content:
```
1 # Copyright (c) 2010 Aldo Cortesi
2 # Copyright (c) 2010-2011 dequis
3 # Copyright (c) 2010, 2012 roger
4 # Copyright (c) 2011 Mounier Florian
5 # Copyright (c) 2011-2012, 2014 Tycho Andersen
6 # Copyright (c) 2012 dmpayton
7 # Copyright (c) 2012-2013 Craig Barnes
8 # Copyright (c) 2013 hbc
9 # Copyright (c) 2013 Tao Sauvage
10 # Copyright (c) 2014 Sean Vig
11 #
12 # Permission is hereby granted, free of charge, to any person obtaining a copy
13 # of this software and associated documentation files (the "Software"), to deal
14 # in the Software without restriction, including without limitation the rights
15 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
16 # copies of the Software, and to permit persons to whom the Software is
17 # furnished to do so, subject to the following conditions:
18 #
19 # The above copyright notice and this permission notice shall be included in
20 # all copies or substantial portions of the Software.
21 #
22 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
23 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
24 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
25 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
26 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
27 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
28 # SOFTWARE.
29 import xcffib
30 from xcffib.xproto import (
31 ClientMessageData,
32 ClientMessageEvent,
33 EventMask,
34 SetMode,
35 )
36
37 from libqtile import bar
38 from libqtile.backend.x11 import window
39 from libqtile.widget import base
40
41 XEMBED_PROTOCOL_VERSION = 0
42
43
44 class Icon(window._Window):
45 _window_mask = EventMask.StructureNotify | \
46 EventMask.PropertyChange | \
47 EventMask.Exposure
48
49 def __init__(self, win, qtile, systray):
50 window._Window.__init__(self, win, qtile)
51 self.systray = systray
52 self.update_size()
53
54 def update_size(self):
55 icon_size = self.systray.icon_size
56 self.update_hints()
57
58 width = self.hints.get("min_width", icon_size)
59 height = self.hints.get("min_height", icon_size)
60
61 width = max(width, icon_size)
62 height = max(height, icon_size)
63
64 if height > icon_size:
65 width = width * icon_size // height
66 height = icon_size
67
68 self.width = width
69 self.height = height
70 return False
71
72 def handle_PropertyNotify(self, e): # noqa: N802
73 name = self.qtile.core.conn.atoms.get_name(e.atom)
74 if name == "_XEMBED_INFO":
75 info = self.window.get_property('_XEMBED_INFO', unpack=int)
76 if info and info[1]:
77 self.systray.bar.draw()
78
79 return False
80
81 def handle_DestroyNotify(self, event): # noqa: N802
82 wid = event.window
83 del(self.qtile.windows_map[wid])
84 del(self.systray.icons[wid])
85 self.systray.bar.draw()
86 return False
87
88 handle_UnmapNotify = handle_DestroyNotify # noqa: N815
89
90
91 class Systray(window._Window, base._Widget):
92 """
93 A widget that manages system tray.
94
95 .. note::
96 Icons will not render correctly where the bar/widget is
97 drawn with a semi-transparent background. Instead, icons
98 will be drawn with a transparent background.
99
100 If using this widget it is therefore recommended to use
101 a fully opaque background colour or a fully transparent
102 one.
103 """
104
105 _window_mask = EventMask.StructureNotify | \
106 EventMask.Exposure
107
108 orientations = base.ORIENTATION_HORIZONTAL
109
110 defaults = [
111 ('icon_size', 20, 'Icon width'),
112 ('padding', 5, 'Padding between icons'),
113 ]
114
115 def __init__(self, **config):
116 base._Widget.__init__(self, bar.CALCULATED, **config)
117 self.add_defaults(Systray.defaults)
118 self.icons = {}
119 self.screen = 0
120
121 def calculate_length(self):
122 width = sum(i.width for i in self.icons.values())
123 width += self.padding * len(self.icons)
124 return width
125
126 def _configure(self, qtile, bar):
127 base._Widget._configure(self, qtile, bar)
128
129 if self.configured:
130 return
131
132 self.conn = conn = qtile.core.conn
133 win = conn.create_window(-1, -1, 1, 1)
134 window._Window.__init__(self, window.XWindow(conn, win.wid), qtile)
135 qtile.windows_map[win.wid] = self
136
137 # Even when we have multiple "Screen"s, we are setting up as the system
138 # tray on a particular X display, that is the screen we need to
139 # reference in the atom
140 if qtile.current_screen:
141 self.screen = qtile.current_screen.index
142 self.bar = bar
143 atoms = conn.atoms
144
145 # We need tray to tell icons which visual to use.
146 # This needs to be the same as the bar/widget.
147 # This mainly benefits transparent bars.
148 conn.conn.core.ChangeProperty(
149 xcffib.xproto.PropMode.Replace,
150 win.wid,
151 atoms["_NET_SYSTEM_TRAY_VISUAL"],
152 xcffib.xproto.Atom.VISUALID,
153 32,
154 1,
155 [self.drawer._visual.visual_id]
156 )
157
158 conn.conn.core.SetSelectionOwner(
159 win.wid,
160 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
161 xcffib.CurrentTime
162 )
163 data = [
164 xcffib.CurrentTime,
165 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
166 win.wid, 0, 0
167 ]
168 union = ClientMessageData.synthetic(data, "I" * 5)
169 event = ClientMessageEvent.synthetic(
170 format=32,
171 window=qtile.core._root.wid,
172 type=atoms['MANAGER'],
173 data=union
174 )
175 qtile.core._root.send_event(event, mask=EventMask.StructureNotify)
176
177 def handle_ClientMessage(self, event): # noqa: N802
178 atoms = self.conn.atoms
179
180 opcode = event.type
181 data = event.data.data32
182 message = data[1]
183 wid = data[2]
184
185 parent = self.bar.window.window
186
187 if opcode == atoms['_NET_SYSTEM_TRAY_OPCODE'] and message == 0:
188 w = window.XWindow(self.conn, wid)
189 icon = Icon(w, self.qtile, self)
190 self.icons[wid] = icon
191 self.qtile.windows_map[wid] = icon
192
193 self.conn.conn.core.ChangeSaveSet(SetMode.Insert, wid)
194 self.conn.conn.core.ReparentWindow(wid, parent.wid, 0, 0)
195 self.conn.conn.flush()
196
197 info = icon.window.get_property('_XEMBED_INFO', unpack=int)
198
199 if not info:
200 self.bar.draw()
201 return False
202
203 if info[1]:
204 self.bar.draw()
205
206 return False
207
208 def draw(self):
209 xoffset = self.padding
210 self.drawer.clear(self.background or self.bar.background)
211 self.drawer.draw(offsetx=self.offset, width=self.length)
212 for pos, icon in enumerate(self.icons.values()):
213 icon.window.set_attribute(backpixmap=self.drawer.pixmap)
214 icon.place(
215 self.offset + xoffset,
216 self.bar.height // 2 - self.icon_size // 2,
217 icon.width, self.icon_size,
218 0,
219 None
220 )
221 if icon.hidden:
222 icon.unhide()
223 data = [
224 self.conn.atoms["_XEMBED_EMBEDDED_NOTIFY"],
225 xcffib.xproto.Time.CurrentTime,
226 0,
227 self.bar.window.wid,
228 XEMBED_PROTOCOL_VERSION
229 ]
230 u = xcffib.xproto.ClientMessageData.synthetic(data, "I" * 5)
231 event = xcffib.xproto.ClientMessageEvent.synthetic(
232 format=32,
233 window=icon.wid,
234 type=self.conn.atoms["_XEMBED"],
235 data=u
236 )
237 self.window.send_event(event)
238
239 xoffset += icon.width + self.padding
240
241 def finalize(self):
242 base._Widget.finalize(self)
243 atoms = self.conn.atoms
244 self.conn.conn.core.SetSelectionOwner(
245 0,
246 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
247 xcffib.CurrentTime,
248 )
249 self.hide()
250
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/libqtile/widget/systray.py b/libqtile/widget/systray.py
--- a/libqtile/widget/systray.py
+++ b/libqtile/widget/systray.py
@@ -247,3 +247,11 @@
xcffib.CurrentTime,
)
self.hide()
+
+ root = self.qtile.core._root.wid
+ for wid in self.icons:
+ self.conn.conn.core.ReparentWindow(wid, root, 0, 0)
+ self.conn.conn.flush()
+
+ del self.qtile.windows_map[self.wid]
+ self.conn.conn.core.DestroyWindow(self.wid)
| {"golden_diff": "diff --git a/libqtile/widget/systray.py b/libqtile/widget/systray.py\n--- a/libqtile/widget/systray.py\n+++ b/libqtile/widget/systray.py\n@@ -247,3 +247,11 @@\n xcffib.CurrentTime,\n )\n self.hide()\n+\n+ root = self.qtile.core._root.wid\n+ for wid in self.icons:\n+ self.conn.conn.core.ReparentWindow(wid, root, 0, 0)\n+ self.conn.conn.flush()\n+\n+ del self.qtile.windows_map[self.wid]\n+ self.conn.conn.core.DestroyWindow(self.wid)\n", "issue": "Systray icon disappears with restart\nAs reported on IRC:\r\n```\r\n[08:11] < elcaven> this morning I updated qtile from the qtile-git package from the AUR and since then it seems that my systray widget resets every time qtile restarts, so after a qtile restart the systray\r\n is empty until a program spawns there again\r\n[08:12] < elcaven> there don't seem to be any related errors in the logfile, only one I see is \"AttributeError: 'Screen' object has \r\n[20:53] < elParaguayo> | elcaven - interesting. That may be a side-effect of the config reloading code that was recently committed.\r\n[21:09] < mcol> What does it mean for the systray to reset? Can it persist state across restarts?\r\n[21:14] < elParaguayo> | I'm guessing that the app is still open but the icon has disappeared from the tray\r\n[21:22] < elParaguayo> | I wonder if SNI has that issue too...\r\n[21:25] < elParaguayo> | No, SNI looks ok.\r\n[21:25] < elParaguayo> | Tested with \"restart\" and \"reload_config\"\r\n[21:27] < elParaguayo> | Confirmed, Systray icon disappears on reload_config even though app is open.\r\n[21:28] < elParaguayo> | Icon doesn't disappear with \"restart\"\r\n```\r\n\r\nTested on latest: 66ce6c28\n", "before_files": [{"content": "# Copyright (c) 2010 Aldo Cortesi\n# Copyright (c) 2010-2011 dequis\n# Copyright (c) 2010, 2012 roger\n# Copyright (c) 2011 Mounier Florian\n# Copyright (c) 2011-2012, 2014 Tycho Andersen\n# Copyright (c) 2012 dmpayton\n# Copyright (c) 2012-2013 Craig Barnes\n# Copyright (c) 2013 hbc\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014 Sean Vig\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport xcffib\nfrom xcffib.xproto import (\n ClientMessageData,\n ClientMessageEvent,\n EventMask,\n SetMode,\n)\n\nfrom libqtile import bar\nfrom libqtile.backend.x11 import window\nfrom libqtile.widget import base\n\nXEMBED_PROTOCOL_VERSION = 0\n\n\nclass Icon(window._Window):\n _window_mask = EventMask.StructureNotify | \\\n EventMask.PropertyChange | \\\n EventMask.Exposure\n\n def __init__(self, win, qtile, systray):\n window._Window.__init__(self, win, qtile)\n self.systray = systray\n self.update_size()\n\n def update_size(self):\n icon_size = self.systray.icon_size\n self.update_hints()\n\n width = self.hints.get(\"min_width\", icon_size)\n height = self.hints.get(\"min_height\", icon_size)\n\n width = max(width, icon_size)\n height = max(height, icon_size)\n\n if height > icon_size:\n width = width * icon_size // height\n height = icon_size\n\n self.width = width\n self.height = height\n return False\n\n def handle_PropertyNotify(self, e): # noqa: N802\n name = self.qtile.core.conn.atoms.get_name(e.atom)\n if name == \"_XEMBED_INFO\":\n info = self.window.get_property('_XEMBED_INFO', unpack=int)\n if info and info[1]:\n self.systray.bar.draw()\n\n return False\n\n def handle_DestroyNotify(self, event): # noqa: N802\n wid = event.window\n del(self.qtile.windows_map[wid])\n del(self.systray.icons[wid])\n self.systray.bar.draw()\n return False\n\n handle_UnmapNotify = handle_DestroyNotify # noqa: N815\n\n\nclass Systray(window._Window, base._Widget):\n \"\"\"\n A widget that manages system tray.\n\n .. note::\n Icons will not render correctly where the bar/widget is\n drawn with a semi-transparent background. Instead, icons\n will be drawn with a transparent background.\n\n If using this widget it is therefore recommended to use\n a fully opaque background colour or a fully transparent\n one.\n \"\"\"\n\n _window_mask = EventMask.StructureNotify | \\\n EventMask.Exposure\n\n orientations = base.ORIENTATION_HORIZONTAL\n\n defaults = [\n ('icon_size', 20, 'Icon width'),\n ('padding', 5, 'Padding between icons'),\n ]\n\n def __init__(self, **config):\n base._Widget.__init__(self, bar.CALCULATED, **config)\n self.add_defaults(Systray.defaults)\n self.icons = {}\n self.screen = 0\n\n def calculate_length(self):\n width = sum(i.width for i in self.icons.values())\n width += self.padding * len(self.icons)\n return width\n\n def _configure(self, qtile, bar):\n base._Widget._configure(self, qtile, bar)\n\n if self.configured:\n return\n\n self.conn = conn = qtile.core.conn\n win = conn.create_window(-1, -1, 1, 1)\n window._Window.__init__(self, window.XWindow(conn, win.wid), qtile)\n qtile.windows_map[win.wid] = self\n\n # Even when we have multiple \"Screen\"s, we are setting up as the system\n # tray on a particular X display, that is the screen we need to\n # reference in the atom\n if qtile.current_screen:\n self.screen = qtile.current_screen.index\n self.bar = bar\n atoms = conn.atoms\n\n # We need tray to tell icons which visual to use.\n # This needs to be the same as the bar/widget.\n # This mainly benefits transparent bars.\n conn.conn.core.ChangeProperty(\n xcffib.xproto.PropMode.Replace,\n win.wid,\n atoms[\"_NET_SYSTEM_TRAY_VISUAL\"],\n xcffib.xproto.Atom.VISUALID,\n 32,\n 1,\n [self.drawer._visual.visual_id]\n )\n\n conn.conn.core.SetSelectionOwner(\n win.wid,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime\n )\n data = [\n xcffib.CurrentTime,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n win.wid, 0, 0\n ]\n union = ClientMessageData.synthetic(data, \"I\" * 5)\n event = ClientMessageEvent.synthetic(\n format=32,\n window=qtile.core._root.wid,\n type=atoms['MANAGER'],\n data=union\n )\n qtile.core._root.send_event(event, mask=EventMask.StructureNotify)\n\n def handle_ClientMessage(self, event): # noqa: N802\n atoms = self.conn.atoms\n\n opcode = event.type\n data = event.data.data32\n message = data[1]\n wid = data[2]\n\n parent = self.bar.window.window\n\n if opcode == atoms['_NET_SYSTEM_TRAY_OPCODE'] and message == 0:\n w = window.XWindow(self.conn, wid)\n icon = Icon(w, self.qtile, self)\n self.icons[wid] = icon\n self.qtile.windows_map[wid] = icon\n\n self.conn.conn.core.ChangeSaveSet(SetMode.Insert, wid)\n self.conn.conn.core.ReparentWindow(wid, parent.wid, 0, 0)\n self.conn.conn.flush()\n\n info = icon.window.get_property('_XEMBED_INFO', unpack=int)\n\n if not info:\n self.bar.draw()\n return False\n\n if info[1]:\n self.bar.draw()\n\n return False\n\n def draw(self):\n xoffset = self.padding\n self.drawer.clear(self.background or self.bar.background)\n self.drawer.draw(offsetx=self.offset, width=self.length)\n for pos, icon in enumerate(self.icons.values()):\n icon.window.set_attribute(backpixmap=self.drawer.pixmap)\n icon.place(\n self.offset + xoffset,\n self.bar.height // 2 - self.icon_size // 2,\n icon.width, self.icon_size,\n 0,\n None\n )\n if icon.hidden:\n icon.unhide()\n data = [\n self.conn.atoms[\"_XEMBED_EMBEDDED_NOTIFY\"],\n xcffib.xproto.Time.CurrentTime,\n 0,\n self.bar.window.wid,\n XEMBED_PROTOCOL_VERSION\n ]\n u = xcffib.xproto.ClientMessageData.synthetic(data, \"I\" * 5)\n event = xcffib.xproto.ClientMessageEvent.synthetic(\n format=32,\n window=icon.wid,\n type=self.conn.atoms[\"_XEMBED\"],\n data=u\n )\n self.window.send_event(event)\n\n xoffset += icon.width + self.padding\n\n def finalize(self):\n base._Widget.finalize(self)\n atoms = self.conn.atoms\n self.conn.conn.core.SetSelectionOwner(\n 0,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime,\n )\n self.hide()\n", "path": "libqtile/widget/systray.py"}], "after_files": [{"content": "# Copyright (c) 2010 Aldo Cortesi\n# Copyright (c) 2010-2011 dequis\n# Copyright (c) 2010, 2012 roger\n# Copyright (c) 2011 Mounier Florian\n# Copyright (c) 2011-2012, 2014 Tycho Andersen\n# Copyright (c) 2012 dmpayton\n# Copyright (c) 2012-2013 Craig Barnes\n# Copyright (c) 2013 hbc\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014 Sean Vig\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport xcffib\nfrom xcffib.xproto import (\n ClientMessageData,\n ClientMessageEvent,\n EventMask,\n SetMode,\n)\n\nfrom libqtile import bar\nfrom libqtile.backend.x11 import window\nfrom libqtile.widget import base\n\nXEMBED_PROTOCOL_VERSION = 0\n\n\nclass Icon(window._Window):\n _window_mask = EventMask.StructureNotify | \\\n EventMask.PropertyChange | \\\n EventMask.Exposure\n\n def __init__(self, win, qtile, systray):\n window._Window.__init__(self, win, qtile)\n self.systray = systray\n self.update_size()\n\n def update_size(self):\n icon_size = self.systray.icon_size\n self.update_hints()\n\n width = self.hints.get(\"min_width\", icon_size)\n height = self.hints.get(\"min_height\", icon_size)\n\n width = max(width, icon_size)\n height = max(height, icon_size)\n\n if height > icon_size:\n width = width * icon_size // height\n height = icon_size\n\n self.width = width\n self.height = height\n return False\n\n def handle_PropertyNotify(self, e): # noqa: N802\n name = self.qtile.core.conn.atoms.get_name(e.atom)\n if name == \"_XEMBED_INFO\":\n info = self.window.get_property('_XEMBED_INFO', unpack=int)\n if info and info[1]:\n self.systray.bar.draw()\n\n return False\n\n def handle_DestroyNotify(self, event): # noqa: N802\n wid = event.window\n del(self.qtile.windows_map[wid])\n del(self.systray.icons[wid])\n self.systray.bar.draw()\n return False\n\n handle_UnmapNotify = handle_DestroyNotify # noqa: N815\n\n\nclass Systray(window._Window, base._Widget):\n \"\"\"\n A widget that manages system tray.\n\n .. note::\n Icons will not render correctly where the bar/widget is\n drawn with a semi-transparent background. Instead, icons\n will be drawn with a transparent background.\n\n If using this widget it is therefore recommended to use\n a fully opaque background colour or a fully transparent\n one.\n \"\"\"\n\n _window_mask = EventMask.StructureNotify | \\\n EventMask.Exposure\n\n orientations = base.ORIENTATION_HORIZONTAL\n\n defaults = [\n ('icon_size', 20, 'Icon width'),\n ('padding', 5, 'Padding between icons'),\n ]\n\n def __init__(self, **config):\n base._Widget.__init__(self, bar.CALCULATED, **config)\n self.add_defaults(Systray.defaults)\n self.icons = {}\n self.screen = 0\n\n def calculate_length(self):\n width = sum(i.width for i in self.icons.values())\n width += self.padding * len(self.icons)\n return width\n\n def _configure(self, qtile, bar):\n base._Widget._configure(self, qtile, bar)\n\n if self.configured:\n return\n\n self.conn = conn = qtile.core.conn\n win = conn.create_window(-1, -1, 1, 1)\n window._Window.__init__(self, window.XWindow(conn, win.wid), qtile)\n qtile.windows_map[win.wid] = self\n\n # Even when we have multiple \"Screen\"s, we are setting up as the system\n # tray on a particular X display, that is the screen we need to\n # reference in the atom\n if qtile.current_screen:\n self.screen = qtile.current_screen.index\n self.bar = bar\n atoms = conn.atoms\n\n # We need tray to tell icons which visual to use.\n # This needs to be the same as the bar/widget.\n # This mainly benefits transparent bars.\n conn.conn.core.ChangeProperty(\n xcffib.xproto.PropMode.Replace,\n win.wid,\n atoms[\"_NET_SYSTEM_TRAY_VISUAL\"],\n xcffib.xproto.Atom.VISUALID,\n 32,\n 1,\n [self.drawer._visual.visual_id]\n )\n\n conn.conn.core.SetSelectionOwner(\n win.wid,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime\n )\n data = [\n xcffib.CurrentTime,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n win.wid, 0, 0\n ]\n union = ClientMessageData.synthetic(data, \"I\" * 5)\n event = ClientMessageEvent.synthetic(\n format=32,\n window=qtile.core._root.wid,\n type=atoms['MANAGER'],\n data=union\n )\n qtile.core._root.send_event(event, mask=EventMask.StructureNotify)\n\n def handle_ClientMessage(self, event): # noqa: N802\n atoms = self.conn.atoms\n\n opcode = event.type\n data = event.data.data32\n message = data[1]\n wid = data[2]\n\n parent = self.bar.window.window\n\n if opcode == atoms['_NET_SYSTEM_TRAY_OPCODE'] and message == 0:\n w = window.XWindow(self.conn, wid)\n icon = Icon(w, self.qtile, self)\n self.icons[wid] = icon\n self.qtile.windows_map[wid] = icon\n\n self.conn.conn.core.ChangeSaveSet(SetMode.Insert, wid)\n self.conn.conn.core.ReparentWindow(wid, parent.wid, 0, 0)\n self.conn.conn.flush()\n\n info = icon.window.get_property('_XEMBED_INFO', unpack=int)\n\n if not info:\n self.bar.draw()\n return False\n\n if info[1]:\n self.bar.draw()\n\n return False\n\n def draw(self):\n xoffset = self.padding\n self.drawer.clear(self.background or self.bar.background)\n self.drawer.draw(offsetx=self.offset, width=self.length)\n for pos, icon in enumerate(self.icons.values()):\n icon.window.set_attribute(backpixmap=self.drawer.pixmap)\n icon.place(\n self.offset + xoffset,\n self.bar.height // 2 - self.icon_size // 2,\n icon.width, self.icon_size,\n 0,\n None\n )\n if icon.hidden:\n icon.unhide()\n data = [\n self.conn.atoms[\"_XEMBED_EMBEDDED_NOTIFY\"],\n xcffib.xproto.Time.CurrentTime,\n 0,\n self.bar.window.wid,\n XEMBED_PROTOCOL_VERSION\n ]\n u = xcffib.xproto.ClientMessageData.synthetic(data, \"I\" * 5)\n event = xcffib.xproto.ClientMessageEvent.synthetic(\n format=32,\n window=icon.wid,\n type=self.conn.atoms[\"_XEMBED\"],\n data=u\n )\n self.window.send_event(event)\n\n xoffset += icon.width + self.padding\n\n def finalize(self):\n base._Widget.finalize(self)\n atoms = self.conn.atoms\n self.conn.conn.core.SetSelectionOwner(\n 0,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime,\n )\n self.hide()\n\n root = self.qtile.core._root.wid\n for wid in self.icons:\n self.conn.conn.core.ReparentWindow(wid, root, 0, 0)\n self.conn.conn.flush()\n\n del self.qtile.windows_map[self.wid]\n self.conn.conn.core.DestroyWindow(self.wid)\n", "path": "libqtile/widget/systray.py"}]} | 3,259 | 150 |
gh_patches_debug_31579 | rasdani/github-patches | git_diff | weecology__retriever-1311 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error when running retriever license with no dataset as argument
Currently, when running `retriever license` and providing no dataset as an argument it results into `KeyError: 'No dataset named: None'`
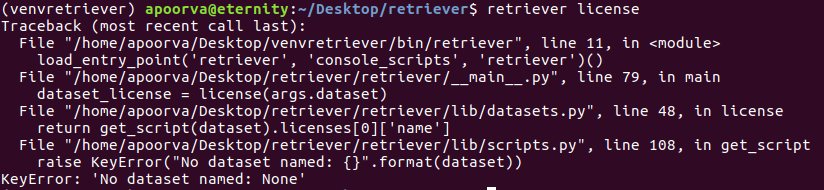
In case of `retriever citation` if no dataset is given we show the citation for retriever.
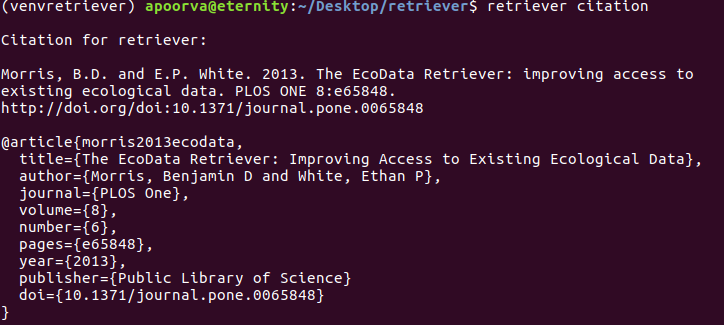
How should we handle this? Show the license for retriever by reading the `LICENSE` file or create a new `LICENSE` variable in `retriever.lib.defaults` and show it?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `retriever/__main__.py`
Content:
```
1 """Data Retriever
2
3 This module handles the CLI for the Data retriever.
4 """
5 from __future__ import absolute_import
6 from __future__ import print_function
7
8 import os
9 import sys
10 from builtins import input
11
12 from retriever.engines import engine_list, choose_engine
13 from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename
14 from retriever.lib.datasets import datasets, dataset_names, license
15 from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS
16 from retriever.lib.engine_tools import name_matches, reset_retriever
17 from retriever.lib.get_opts import parser
18 from retriever.lib.repository import check_for_updates
19 from retriever.lib.scripts import SCRIPT_LIST, reload_scripts, get_script
20
21
22 def main():
23 """This function launches the Data Retriever."""
24 if len(sys.argv) == 1:
25 # if no command line args are passed, show the help options
26 parser.parse_args(['-h'])
27
28 else:
29 # otherwise, parse them
30 args = parser.parse_args()
31
32 if args.command not in ['reset', 'update'] \
33 and not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) \
34 and not [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])
35 if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:
36 check_for_updates()
37 reload_scripts()
38 script_list = SCRIPT_LIST()
39
40 if args.command == "install" and not args.engine:
41 parser.parse_args(['install', '-h'])
42
43 if args.quiet:
44 sys.stdout = open(os.devnull, 'w')
45
46 if args.command == 'help':
47 parser.parse_args(['-h'])
48
49 if hasattr(args, 'compile') and args.compile:
50 script_list = reload_scripts()
51
52 if args.command == 'defaults':
53 for engine_item in engine_list:
54 print("Default options for engine ", engine_item.name)
55 for default_opts in engine_item.required_opts:
56 print(default_opts[0], " ", default_opts[2])
57 print()
58 return
59
60 if args.command == 'update':
61 check_for_updates()
62 reload_scripts()
63 return
64
65 elif args.command == 'citation':
66 if args.dataset is None:
67 print("\nCitation for retriever:\n")
68 print(CITATION)
69 else:
70 scripts = name_matches(script_list, args.dataset)
71 for dataset in scripts:
72 print("\nDataset: {}".format(dataset.name))
73 print("Citation: {}".format(dataset.citation))
74 print("Description: {}\n".format(dataset.description))
75
76 return
77
78 elif args.command == 'license':
79 dataset_license = license(args.dataset)
80 if dataset_license:
81 print(dataset_license)
82 else:
83 print("There is no license information for {}".format(args.dataset))
84 return
85
86 elif args.command == 'new':
87 f = open(args.filename, 'w')
88 f.write(sample_script)
89 f.close()
90
91 return
92
93 elif args.command == 'reset':
94 reset_retriever(args.scope)
95 return
96
97 elif args.command == 'new_json':
98 # create new JSON script
99 create_json()
100 return
101
102 elif args.command == 'edit_json':
103 # edit existing JSON script
104 json_file = get_script_filename(args.dataset.lower())
105 edit_json(json_file)
106 return
107
108 elif args.command == 'delete_json':
109 # delete existing JSON script from home directory and or script directory if exists in current dir
110 confirm = input("Really remove " + args.dataset.lower() +
111 " and all its contents? (y/N): ")
112 if confirm.lower().strip() in ['y', 'yes']:
113 json_file = get_script_filename(args.dataset.lower())
114 delete_json(json_file)
115 return
116
117 if args.command == 'ls':
118 # scripts should never be empty because check_for_updates is run on SCRIPT_LIST init
119 if not (args.l or args.k or isinstance(args.v, list)):
120 all_scripts = dataset_names()
121 print("Available datasets : {}\n".format(len(all_scripts)))
122 from retriever import lscolumns
123
124 lscolumns.printls(all_scripts)
125
126 elif isinstance(args.v, list):
127 if args.v:
128 try:
129 all_scripts = [get_script(dataset) for dataset in args.v]
130 except KeyError:
131 all_scripts = []
132 print("Dataset(s) is not found.")
133 else:
134 all_scripts = datasets()
135 count = 1
136 for script in all_scripts:
137 print(
138 "{count}. {title}\n {name}\n"
139 "{keywords}\n{description}\n"
140 "{licenses}\n{citation}\n"
141 "".format(
142 count=count,
143 title=script.title,
144 name=script.name,
145 keywords=script.keywords,
146 description=script.description,
147 licenses=str(script.licenses[0]['name']),
148 citation=script.citation,
149 )
150 )
151 count += 1
152
153 else:
154 param_licenses = args.l if args.l else None
155 keywords = args.k if args.k else None
156
157 # search
158 searched_scripts = datasets(keywords, param_licenses)
159 if not searched_scripts:
160 print("No available datasets found")
161 else:
162 print("Available datasets : {}\n".format(len(searched_scripts)))
163 count = 1
164 for script in searched_scripts:
165 print(
166 "{count}. {title}\n{name}\n"
167 "{keywords}\n{licenses}\n".format(
168 count=count,
169 title=script.title,
170 name=script.name,
171 keywords=script.keywords,
172 licenses=str(script.licenses[0]['name']),
173 )
174 )
175 count += 1
176 return
177
178 engine = choose_engine(args.__dict__)
179
180 if hasattr(args, 'debug') and args.debug:
181 debug = True
182 else:
183 debug = False
184 sys.tracebacklimit = 0
185
186 if hasattr(args, 'debug') and args.not_cached:
187 engine.use_cache = False
188 else:
189 engine.use_cache = True
190
191 if args.dataset is not None:
192 scripts = name_matches(script_list, args.dataset)
193 else:
194 raise Exception("no dataset specified.")
195 if scripts:
196 for dataset in scripts:
197 print("=> Installing", dataset.name)
198 try:
199 dataset.download(engine, debug=debug)
200 dataset.engine.final_cleanup()
201 except KeyboardInterrupt:
202 pass
203 except Exception as e:
204 print(e)
205 if debug:
206 raise
207 print("Done!")
208 else:
209 print("Run 'retriever ls' to see a list of currently available datasets.")
210
211
212 if __name__ == "__main__":
213 main()
214
```
Path: `retriever/lib/defaults.py`
Content:
```
1 import os
2
3 from retriever._version import __version__
4
5 VERSION = __version__
6 COPYRIGHT = "Copyright (C) 2011-2016 Weecology University of Florida"
7 REPO_URL = "https://raw.githubusercontent.com/weecology/retriever/"
8 MASTER_BRANCH = REPO_URL + "master/"
9 REPOSITORY = MASTER_BRANCH
10 ENCODING = 'ISO-8859-1'
11 HOME_DIR = os.path.expanduser('~/.retriever/')
12 SCRIPT_SEARCH_PATHS = [
13 "./",
14 'scripts',
15 os.path.join(HOME_DIR, 'scripts/')
16 ]
17 SCRIPT_WRITE_PATH = SCRIPT_SEARCH_PATHS[-1]
18 DATA_SEARCH_PATHS = [
19 "./",
20 "{dataset}",
21 "raw_data/{dataset}",
22 os.path.join(HOME_DIR, 'raw_data/{dataset}'),
23 ]
24 DATA_WRITE_PATH = DATA_SEARCH_PATHS[-1]
25
26 # Create default data directory
27 DATA_DIR = '.'
28 sample_script = """
29 {
30 "description": "S. K. Morgan Ernest. 2003. Life history characteristics of placental non-volant mammals. Ecology 84:3402.",
31 "homepage": "http://esapubs.org/archive/ecol/E084/093/default.htm",
32 "name": "MammalLH",
33 "resources": [
34 {
35 "dialect": {},
36 "mediatype": "text/csv",
37 "name": "species",
38 "schema": {},
39 "url": "http://esapubs.org/archive/ecol/E084/093/Mammal_lifehistories_v2.txt"
40 }
41 ],
42 "title": "Mammal Life History Database - Ernest, et al., 2003"
43 }
44 """
45 CITATION = """Morris, B.D. and E.P. White. 2013. The EcoData Retriever: improving access to
46 existing ecological data. PLOS ONE 8:e65848.
47 http://doi.org/doi:10.1371/journal.pone.0065848
48
49 @article{morris2013ecodata,
50 title={The EcoData Retriever: Improving Access to Existing Ecological Data},
51 author={Morris, Benjamin D and White, Ethan P},
52 journal={PLOS One},
53 volume={8},
54 number={6},
55 pages={e65848},
56 year={2013},
57 publisher={Public Library of Science}
58 doi={10.1371/journal.pone.0065848}
59 }
60 """
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/retriever/__main__.py b/retriever/__main__.py
--- a/retriever/__main__.py
+++ b/retriever/__main__.py
@@ -12,7 +12,7 @@
from retriever.engines import engine_list, choose_engine
from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename
from retriever.lib.datasets import datasets, dataset_names, license
-from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS
+from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS, LICENSE
from retriever.lib.engine_tools import name_matches, reset_retriever
from retriever.lib.get_opts import parser
from retriever.lib.repository import check_for_updates
@@ -76,11 +76,14 @@
return
elif args.command == 'license':
- dataset_license = license(args.dataset)
- if dataset_license:
- print(dataset_license)
+ if args.dataset is None:
+ print(LICENSE)
else:
- print("There is no license information for {}".format(args.dataset))
+ dataset_license = license(args.dataset)
+ if dataset_license:
+ print(dataset_license)
+ else:
+ print("There is no license information for {}".format(args.dataset))
return
elif args.command == 'new':
diff --git a/retriever/lib/defaults.py b/retriever/lib/defaults.py
--- a/retriever/lib/defaults.py
+++ b/retriever/lib/defaults.py
@@ -4,6 +4,7 @@
VERSION = __version__
COPYRIGHT = "Copyright (C) 2011-2016 Weecology University of Florida"
+LICENSE = "MIT"
REPO_URL = "https://raw.githubusercontent.com/weecology/retriever/"
MASTER_BRANCH = REPO_URL + "master/"
REPOSITORY = MASTER_BRANCH
| {"golden_diff": "diff --git a/retriever/__main__.py b/retriever/__main__.py\n--- a/retriever/__main__.py\n+++ b/retriever/__main__.py\n@@ -12,7 +12,7 @@\n from retriever.engines import engine_list, choose_engine\n from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\n from retriever.lib.datasets import datasets, dataset_names, license\n-from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS\n+from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS, LICENSE\n from retriever.lib.engine_tools import name_matches, reset_retriever\n from retriever.lib.get_opts import parser\n from retriever.lib.repository import check_for_updates\n@@ -76,11 +76,14 @@\n return\n \n elif args.command == 'license':\n- dataset_license = license(args.dataset)\n- if dataset_license:\n- print(dataset_license)\n+ if args.dataset is None:\n+ print(LICENSE)\n else:\n- print(\"There is no license information for {}\".format(args.dataset))\n+ dataset_license = license(args.dataset)\n+ if dataset_license:\n+ print(dataset_license)\n+ else:\n+ print(\"There is no license information for {}\".format(args.dataset))\n return\n \n elif args.command == 'new':\ndiff --git a/retriever/lib/defaults.py b/retriever/lib/defaults.py\n--- a/retriever/lib/defaults.py\n+++ b/retriever/lib/defaults.py\n@@ -4,6 +4,7 @@\n \n VERSION = __version__\n COPYRIGHT = \"Copyright (C) 2011-2016 Weecology University of Florida\"\n+LICENSE = \"MIT\"\n REPO_URL = \"https://raw.githubusercontent.com/weecology/retriever/\"\n MASTER_BRANCH = REPO_URL + \"master/\"\n REPOSITORY = MASTER_BRANCH\n", "issue": "Error when running retriever license with no dataset as argument\nCurrently, when running `retriever license` and providing no dataset as an argument it results into `KeyError: 'No dataset named: None'`\r\n\r\n\r\nIn case of `retriever citation` if no dataset is given we show the citation for retriever. \r\n\r\n\r\nHow should we handle this? Show the license for retriever by reading the `LICENSE` file or create a new `LICENSE` variable in `retriever.lib.defaults` and show it?\n", "before_files": [{"content": "\"\"\"Data Retriever\n\nThis module handles the CLI for the Data retriever.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport os\nimport sys\nfrom builtins import input\n\nfrom retriever.engines import engine_list, choose_engine\nfrom retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\nfrom retriever.lib.datasets import datasets, dataset_names, license\nfrom retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS\nfrom retriever.lib.engine_tools import name_matches, reset_retriever\nfrom retriever.lib.get_opts import parser\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.scripts import SCRIPT_LIST, reload_scripts, get_script\n\n\ndef main():\n \"\"\"This function launches the Data Retriever.\"\"\"\n if len(sys.argv) == 1:\n # if no command line args are passed, show the help options\n parser.parse_args(['-h'])\n\n else:\n # otherwise, parse them\n args = parser.parse_args()\n\n if args.command not in ['reset', 'update'] \\\n and not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) \\\n and not [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])\n if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:\n check_for_updates()\n reload_scripts()\n script_list = SCRIPT_LIST()\n\n if args.command == \"install\" and not args.engine:\n parser.parse_args(['install', '-h'])\n\n if args.quiet:\n sys.stdout = open(os.devnull, 'w')\n\n if args.command == 'help':\n parser.parse_args(['-h'])\n\n if hasattr(args, 'compile') and args.compile:\n script_list = reload_scripts()\n\n if args.command == 'defaults':\n for engine_item in engine_list:\n print(\"Default options for engine \", engine_item.name)\n for default_opts in engine_item.required_opts:\n print(default_opts[0], \" \", default_opts[2])\n print()\n return\n\n if args.command == 'update':\n check_for_updates()\n reload_scripts()\n return\n\n elif args.command == 'citation':\n if args.dataset is None:\n print(\"\\nCitation for retriever:\\n\")\n print(CITATION)\n else:\n scripts = name_matches(script_list, args.dataset)\n for dataset in scripts:\n print(\"\\nDataset: {}\".format(dataset.name))\n print(\"Citation: {}\".format(dataset.citation))\n print(\"Description: {}\\n\".format(dataset.description))\n\n return\n\n elif args.command == 'license':\n dataset_license = license(args.dataset)\n if dataset_license:\n print(dataset_license)\n else:\n print(\"There is no license information for {}\".format(args.dataset))\n return\n\n elif args.command == 'new':\n f = open(args.filename, 'w')\n f.write(sample_script)\n f.close()\n\n return\n\n elif args.command == 'reset':\n reset_retriever(args.scope)\n return\n\n elif args.command == 'new_json':\n # create new JSON script\n create_json()\n return\n\n elif args.command == 'edit_json':\n # edit existing JSON script\n json_file = get_script_filename(args.dataset.lower())\n edit_json(json_file)\n return\n\n elif args.command == 'delete_json':\n # delete existing JSON script from home directory and or script directory if exists in current dir\n confirm = input(\"Really remove \" + args.dataset.lower() +\n \" and all its contents? (y/N): \")\n if confirm.lower().strip() in ['y', 'yes']:\n json_file = get_script_filename(args.dataset.lower())\n delete_json(json_file)\n return\n\n if args.command == 'ls':\n # scripts should never be empty because check_for_updates is run on SCRIPT_LIST init\n if not (args.l or args.k or isinstance(args.v, list)):\n all_scripts = dataset_names()\n print(\"Available datasets : {}\\n\".format(len(all_scripts)))\n from retriever import lscolumns\n\n lscolumns.printls(all_scripts)\n\n elif isinstance(args.v, list):\n if args.v:\n try:\n all_scripts = [get_script(dataset) for dataset in args.v]\n except KeyError:\n all_scripts = []\n print(\"Dataset(s) is not found.\")\n else:\n all_scripts = datasets()\n count = 1\n for script in all_scripts:\n print(\n \"{count}. {title}\\n {name}\\n\"\n \"{keywords}\\n{description}\\n\"\n \"{licenses}\\n{citation}\\n\"\n \"\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n description=script.description,\n licenses=str(script.licenses[0]['name']),\n citation=script.citation,\n )\n )\n count += 1\n\n else:\n param_licenses = args.l if args.l else None\n keywords = args.k if args.k else None\n\n # search\n searched_scripts = datasets(keywords, param_licenses)\n if not searched_scripts:\n print(\"No available datasets found\")\n else:\n print(\"Available datasets : {}\\n\".format(len(searched_scripts)))\n count = 1\n for script in searched_scripts:\n print(\n \"{count}. {title}\\n{name}\\n\"\n \"{keywords}\\n{licenses}\\n\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n licenses=str(script.licenses[0]['name']),\n )\n )\n count += 1\n return\n\n engine = choose_engine(args.__dict__)\n\n if hasattr(args, 'debug') and args.debug:\n debug = True\n else:\n debug = False\n sys.tracebacklimit = 0\n\n if hasattr(args, 'debug') and args.not_cached:\n engine.use_cache = False\n else:\n engine.use_cache = True\n\n if args.dataset is not None:\n scripts = name_matches(script_list, args.dataset)\n else:\n raise Exception(\"no dataset specified.\")\n if scripts:\n for dataset in scripts:\n print(\"=> Installing\", dataset.name)\n try:\n dataset.download(engine, debug=debug)\n dataset.engine.final_cleanup()\n except KeyboardInterrupt:\n pass\n except Exception as e:\n print(e)\n if debug:\n raise\n print(\"Done!\")\n else:\n print(\"Run 'retriever ls' to see a list of currently available datasets.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "retriever/__main__.py"}, {"content": "import os\n\nfrom retriever._version import __version__\n\nVERSION = __version__\nCOPYRIGHT = \"Copyright (C) 2011-2016 Weecology University of Florida\"\nREPO_URL = \"https://raw.githubusercontent.com/weecology/retriever/\"\nMASTER_BRANCH = REPO_URL + \"master/\"\nREPOSITORY = MASTER_BRANCH\nENCODING = 'ISO-8859-1'\nHOME_DIR = os.path.expanduser('~/.retriever/')\nSCRIPT_SEARCH_PATHS = [\n \"./\",\n 'scripts',\n os.path.join(HOME_DIR, 'scripts/')\n]\nSCRIPT_WRITE_PATH = SCRIPT_SEARCH_PATHS[-1]\nDATA_SEARCH_PATHS = [\n \"./\",\n \"{dataset}\",\n \"raw_data/{dataset}\",\n os.path.join(HOME_DIR, 'raw_data/{dataset}'),\n]\nDATA_WRITE_PATH = DATA_SEARCH_PATHS[-1]\n\n# Create default data directory\nDATA_DIR = '.'\nsample_script = \"\"\"\n{\n \"description\": \"S. K. Morgan Ernest. 2003. Life history characteristics of placental non-volant mammals. Ecology 84:3402.\",\n \"homepage\": \"http://esapubs.org/archive/ecol/E084/093/default.htm\",\n \"name\": \"MammalLH\",\n \"resources\": [\n {\n \"dialect\": {},\n \"mediatype\": \"text/csv\",\n \"name\": \"species\",\n \"schema\": {},\n \"url\": \"http://esapubs.org/archive/ecol/E084/093/Mammal_lifehistories_v2.txt\"\n }\n ],\n \"title\": \"Mammal Life History Database - Ernest, et al., 2003\"\n}\n\"\"\"\nCITATION = \"\"\"Morris, B.D. and E.P. White. 2013. The EcoData Retriever: improving access to\nexisting ecological data. PLOS ONE 8:e65848.\nhttp://doi.org/doi:10.1371/journal.pone.0065848\n\n@article{morris2013ecodata,\n title={The EcoData Retriever: Improving Access to Existing Ecological Data},\n author={Morris, Benjamin D and White, Ethan P},\n journal={PLOS One},\n volume={8},\n number={6},\n pages={e65848},\n year={2013},\n publisher={Public Library of Science}\n doi={10.1371/journal.pone.0065848}\n}\n\"\"\"\n", "path": "retriever/lib/defaults.py"}], "after_files": [{"content": "\"\"\"Data Retriever\n\nThis module handles the CLI for the Data retriever.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport os\nimport sys\nfrom builtins import input\n\nfrom retriever.engines import engine_list, choose_engine\nfrom retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\nfrom retriever.lib.datasets import datasets, dataset_names, license\nfrom retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS, LICENSE\nfrom retriever.lib.engine_tools import name_matches, reset_retriever\nfrom retriever.lib.get_opts import parser\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.scripts import SCRIPT_LIST, reload_scripts, get_script\n\n\ndef main():\n \"\"\"This function launches the Data Retriever.\"\"\"\n if len(sys.argv) == 1:\n # if no command line args are passed, show the help options\n parser.parse_args(['-h'])\n\n else:\n # otherwise, parse them\n args = parser.parse_args()\n\n if args.command not in ['reset', 'update'] \\\n and not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) \\\n and not [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])\n if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:\n check_for_updates()\n reload_scripts()\n script_list = SCRIPT_LIST()\n\n if args.command == \"install\" and not args.engine:\n parser.parse_args(['install', '-h'])\n\n if args.quiet:\n sys.stdout = open(os.devnull, 'w')\n\n if args.command == 'help':\n parser.parse_args(['-h'])\n\n if hasattr(args, 'compile') and args.compile:\n script_list = reload_scripts()\n\n if args.command == 'defaults':\n for engine_item in engine_list:\n print(\"Default options for engine \", engine_item.name)\n for default_opts in engine_item.required_opts:\n print(default_opts[0], \" \", default_opts[2])\n print()\n return\n\n if args.command == 'update':\n check_for_updates()\n reload_scripts()\n return\n\n elif args.command == 'citation':\n if args.dataset is None:\n print(\"\\nCitation for retriever:\\n\")\n print(CITATION)\n else:\n scripts = name_matches(script_list, args.dataset)\n for dataset in scripts:\n print(\"\\nDataset: {}\".format(dataset.name))\n print(\"Citation: {}\".format(dataset.citation))\n print(\"Description: {}\\n\".format(dataset.description))\n\n return\n\n elif args.command == 'license':\n if args.dataset is None:\n print(LICENSE)\n else:\n dataset_license = license(args.dataset)\n if dataset_license:\n print(dataset_license)\n else:\n print(\"There is no license information for {}\".format(args.dataset))\n return\n\n elif args.command == 'new':\n f = open(args.filename, 'w')\n f.write(sample_script)\n f.close()\n\n return\n\n elif args.command == 'reset':\n reset_retriever(args.scope)\n return\n\n elif args.command == 'new_json':\n # create new JSON script\n create_json()\n return\n\n elif args.command == 'edit_json':\n # edit existing JSON script\n json_file = get_script_filename(args.dataset.lower())\n edit_json(json_file)\n return\n\n elif args.command == 'delete_json':\n # delete existing JSON script from home directory and or script directory if exists in current dir\n confirm = input(\"Really remove \" + args.dataset.lower() +\n \" and all its contents? (y/N): \")\n if confirm.lower().strip() in ['y', 'yes']:\n json_file = get_script_filename(args.dataset.lower())\n delete_json(json_file)\n return\n\n if args.command == 'ls':\n # scripts should never be empty because check_for_updates is run on SCRIPT_LIST init\n if not (args.l or args.k or isinstance(args.v, list)):\n all_scripts = dataset_names()\n print(\"Available datasets : {}\\n\".format(len(all_scripts)))\n from retriever import lscolumns\n\n lscolumns.printls(all_scripts)\n\n elif isinstance(args.v, list):\n if args.v:\n try:\n all_scripts = [get_script(dataset) for dataset in args.v]\n except KeyError:\n all_scripts = []\n print(\"Dataset(s) is not found.\")\n else:\n all_scripts = datasets()\n count = 1\n for script in all_scripts:\n print(\n \"{count}. {title}\\n {name}\\n\"\n \"{keywords}\\n{description}\\n\"\n \"{licenses}\\n{citation}\\n\"\n \"\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n description=script.description,\n licenses=str(script.licenses[0]['name']),\n citation=script.citation,\n )\n )\n count += 1\n\n else:\n param_licenses = args.l if args.l else None\n keywords = args.k if args.k else None\n\n # search\n searched_scripts = datasets(keywords, param_licenses)\n if not searched_scripts:\n print(\"No available datasets found\")\n else:\n print(\"Available datasets : {}\\n\".format(len(searched_scripts)))\n count = 1\n for script in searched_scripts:\n print(\n \"{count}. {title}\\n{name}\\n\"\n \"{keywords}\\n{licenses}\\n\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n licenses=str(script.licenses[0]['name']),\n )\n )\n count += 1\n return\n\n engine = choose_engine(args.__dict__)\n\n if hasattr(args, 'debug') and args.debug:\n debug = True\n else:\n debug = False\n sys.tracebacklimit = 0\n\n if hasattr(args, 'debug') and args.not_cached:\n engine.use_cache = False\n else:\n engine.use_cache = True\n\n if args.dataset is not None:\n scripts = name_matches(script_list, args.dataset)\n else:\n raise Exception(\"no dataset specified.\")\n if scripts:\n for dataset in scripts:\n print(\"=> Installing\", dataset.name)\n try:\n dataset.download(engine, debug=debug)\n dataset.engine.final_cleanup()\n except KeyboardInterrupt:\n pass\n except Exception as e:\n print(e)\n if debug:\n raise\n print(\"Done!\")\n else:\n print(\"Run 'retriever ls' to see a list of currently available datasets.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "retriever/__main__.py"}, {"content": "import os\n\nfrom retriever._version import __version__\n\nVERSION = __version__\nCOPYRIGHT = \"Copyright (C) 2011-2016 Weecology University of Florida\"\nLICENSE = \"MIT\"\nREPO_URL = \"https://raw.githubusercontent.com/weecology/retriever/\"\nMASTER_BRANCH = REPO_URL + \"master/\"\nREPOSITORY = MASTER_BRANCH\nENCODING = 'ISO-8859-1'\nHOME_DIR = os.path.expanduser('~/.retriever/')\nSCRIPT_SEARCH_PATHS = [\n \"./\",\n 'scripts',\n os.path.join(HOME_DIR, 'scripts/')\n]\nSCRIPT_WRITE_PATH = SCRIPT_SEARCH_PATHS[-1]\nDATA_SEARCH_PATHS = [\n \"./\",\n \"{dataset}\",\n \"raw_data/{dataset}\",\n os.path.join(HOME_DIR, 'raw_data/{dataset}'),\n]\nDATA_WRITE_PATH = DATA_SEARCH_PATHS[-1]\n\n# Create default data directory\nDATA_DIR = '.'\nsample_script = \"\"\"\n{\n \"description\": \"S. K. Morgan Ernest. 2003. Life history characteristics of placental non-volant mammals. Ecology 84:3402.\",\n \"homepage\": \"http://esapubs.org/archive/ecol/E084/093/default.htm\",\n \"name\": \"MammalLH\",\n \"resources\": [\n {\n \"dialect\": {},\n \"mediatype\": \"text/csv\",\n \"name\": \"species\",\n \"schema\": {},\n \"url\": \"http://esapubs.org/archive/ecol/E084/093/Mammal_lifehistories_v2.txt\"\n }\n ],\n \"title\": \"Mammal Life History Database - Ernest, et al., 2003\"\n}\n\"\"\"\nCITATION = \"\"\"Morris, B.D. and E.P. White. 2013. The EcoData Retriever: improving access to\nexisting ecological data. PLOS ONE 8:e65848.\nhttp://doi.org/doi:10.1371/journal.pone.0065848\n\n@article{morris2013ecodata,\n title={The EcoData Retriever: Improving Access to Existing Ecological Data},\n author={Morris, Benjamin D and White, Ethan P},\n journal={PLOS One},\n volume={8},\n number={6},\n pages={e65848},\n year={2013},\n publisher={Public Library of Science}\n doi={10.1371/journal.pone.0065848}\n}\n\"\"\"\n", "path": "retriever/lib/defaults.py"}]} | 3,167 | 417 |
gh_patches_debug_11400 | rasdani/github-patches | git_diff | ansible__ansible-modules-core-3732 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
os_floating_ip errors if an ip is attached.
##### Issue Type:
Regression (so inevitably a feature idea).
##### Ansible Version:
ansible 2.0.0
##### Ansible Configuration:
```
< lookup_plugins = ./lookup_plugins:~/.ansible/plugins/lookup_plugins/:/usr/share/ansible_plugins/
< timeout = 120
---
> timeout = 10
```
##### Environment:
OSX -> Ubuntu
##### Summary:
If you add an ip with os_floating_ip to a server, when you rerun your play, it errors.
##### Steps To Reproduce:
```
- os_floating_ip:
cloud: envvars
state: present
reuse: yes
server: cwp-goserver-1
network: vlan3320
fixed_address: "{{ lookup('os_private_ip', 'cwp-goserver-1') }}"
wait: true
timeout: 180
```
##### Expected Results:
If the server already has a floating ip from the network, expect the task to pass, as unchanged.
##### Actual Results:
```
unable to bind a floating ip to server f23ce73c-82ad-490a-bf0e-7e3d23dce449: Cannot associate floating IP 10.12.71.112 (57a5b6e0-2843-4ec5-9388-408a098cdcc7) with port f2c6e8bb-b500-4ea0-abc8-980b34fc200f using fixed IP 192.168.101.36, as that fixed IP already has a floating IP on external network 8b3e1a76-f16c-461b-a5b5-f5987936426d
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cloud/openstack/os_floating_ip.py`
Content:
```
1 #!/usr/bin/python
2 # Copyright (c) 2015 Hewlett-Packard Development Company, L.P.
3 # Author: Davide Guerri <[email protected]>
4 #
5 # This module is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # This software is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with this software. If not, see <http://www.gnu.org/licenses/>.
17
18 try:
19 import shade
20 from shade import meta
21
22 HAS_SHADE = True
23 except ImportError:
24 HAS_SHADE = False
25
26 DOCUMENTATION = '''
27 ---
28 module: os_floating_ip
29 version_added: "2.0"
30 short_description: Add/Remove floating IP from an instance
31 extends_documentation_fragment: openstack
32 description:
33 - Add or Remove a floating IP to an instance
34 options:
35 server:
36 description:
37 - The name or ID of the instance to which the IP address
38 should be assigned.
39 required: true
40 network:
41 description:
42 - The name or ID of a neutron external network or a nova pool name.
43 required: false
44 floating_ip_address:
45 description:
46 - A floating IP address to attach or to detach. Required only if I(state)
47 is absent. When I(state) is present can be used to specify a IP address
48 to attach.
49 required: false
50 reuse:
51 description:
52 - When I(state) is present, and I(floating_ip_address) is not present,
53 this parameter can be used to specify whether we should try to reuse
54 a floating IP address already allocated to the project.
55 required: false
56 default: false
57 fixed_address:
58 description:
59 - To which fixed IP of server the floating IP address should be
60 attached to.
61 required: false
62 wait:
63 description:
64 - When attaching a floating IP address, specify whether we should
65 wait for it to appear as attached.
66 required: false
67 default: false
68 timeout:
69 description:
70 - Time to wait for an IP address to appear as attached. See wait.
71 required: false
72 default: 60
73 state:
74 description:
75 - Should the resource be present or absent.
76 choices: [present, absent]
77 required: false
78 default: present
79 purge:
80 description:
81 - When I(state) is absent, indicates whether or not to delete the floating
82 IP completely, or only detach it from the server. Default is to detach only.
83 required: false
84 default: false
85 version_added: "2.1"
86 requirements: ["shade"]
87 '''
88
89 EXAMPLES = '''
90 # Assign a floating IP to the fist interface of `cattle001` from an exiting
91 # external network or nova pool. A new floating IP from the first available
92 # external network is allocated to the project.
93 - os_floating_ip:
94 cloud: dguerri
95 server: cattle001
96
97 # Assign a new floating IP to the instance fixed ip `192.0.2.3` of
98 # `cattle001`. If a free floating IP is already allocated to the project, it is
99 # reused; if not, a new one is created.
100 - os_floating_ip:
101 cloud: dguerri
102 state: present
103 reuse: yes
104 server: cattle001
105 network: ext_net
106 fixed_address: 192.0.2.3
107 wait: true
108 timeout: 180
109
110 # Detach a floating IP address from a server
111 - os_floating_ip:
112 cloud: dguerri
113 state: absent
114 floating_ip_address: 203.0.113.2
115 server: cattle001
116 '''
117
118
119 def _get_floating_ip(cloud, floating_ip_address):
120 f_ips = cloud.search_floating_ips(
121 filters={'floating_ip_address': floating_ip_address})
122 if not f_ips:
123 return None
124
125 return f_ips[0]
126
127
128 def main():
129 argument_spec = openstack_full_argument_spec(
130 server=dict(required=True),
131 state=dict(default='present', choices=['absent', 'present']),
132 network=dict(required=False, default=None),
133 floating_ip_address=dict(required=False, default=None),
134 reuse=dict(required=False, type='bool', default=False),
135 fixed_address=dict(required=False, default=None),
136 wait=dict(required=False, type='bool', default=False),
137 timeout=dict(required=False, type='int', default=60),
138 purge=dict(required=False, type='bool', default=False),
139 )
140
141 module_kwargs = openstack_module_kwargs()
142 module = AnsibleModule(argument_spec, **module_kwargs)
143
144 if not HAS_SHADE:
145 module.fail_json(msg='shade is required for this module')
146
147 server_name_or_id = module.params['server']
148 state = module.params['state']
149 network = module.params['network']
150 floating_ip_address = module.params['floating_ip_address']
151 reuse = module.params['reuse']
152 fixed_address = module.params['fixed_address']
153 wait = module.params['wait']
154 timeout = module.params['timeout']
155 purge = module.params['purge']
156
157 cloud = shade.openstack_cloud(**module.params)
158
159 try:
160 server = cloud.get_server(server_name_or_id)
161 if server is None:
162 module.fail_json(
163 msg="server {0} not found".format(server_name_or_id))
164
165 if state == 'present':
166 server = cloud.add_ips_to_server(
167 server=server, ips=floating_ip_address, ip_pool=network,
168 reuse=reuse, fixed_address=fixed_address, wait=wait,
169 timeout=timeout)
170 fip_address = cloud.get_server_public_ip(server)
171 # Update the floating IP status
172 f_ip = _get_floating_ip(cloud, fip_address)
173 module.exit_json(changed=True, floating_ip=f_ip)
174
175 elif state == 'absent':
176 if floating_ip_address is None:
177 module.fail_json(msg="floating_ip_address is required")
178
179 f_ip = _get_floating_ip(cloud, floating_ip_address)
180
181 if not f_ip:
182 # Nothing to detach
183 module.exit_json(changed=False)
184
185 cloud.detach_ip_from_server(
186 server_id=server['id'], floating_ip_id=f_ip['id'])
187 # Update the floating IP status
188 f_ip = cloud.get_floating_ip(id=f_ip['id'])
189 if purge:
190 cloud.delete_floating_ip(f_ip['id'])
191 module.exit_json(changed=True)
192 module.exit_json(changed=True, floating_ip=f_ip)
193
194 except shade.OpenStackCloudException as e:
195 module.fail_json(msg=str(e), extra_data=e.extra_data)
196
197
198 # this is magic, see lib/ansible/module_common.py
199 from ansible.module_utils.basic import *
200 from ansible.module_utils.openstack import *
201
202
203 if __name__ == '__main__':
204 main()
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cloud/openstack/os_floating_ip.py b/cloud/openstack/os_floating_ip.py
--- a/cloud/openstack/os_floating_ip.py
+++ b/cloud/openstack/os_floating_ip.py
@@ -163,6 +163,10 @@
msg="server {0} not found".format(server_name_or_id))
if state == 'present':
+ fip_address = cloud.get_server_public_ip(server)
+ f_ip = _get_floating_ip(cloud, fip_address)
+ if f_ip:
+ module.exit_json(changed=False, floating_ip=f_ip)
server = cloud.add_ips_to_server(
server=server, ips=floating_ip_address, ip_pool=network,
reuse=reuse, fixed_address=fixed_address, wait=wait,
| {"golden_diff": "diff --git a/cloud/openstack/os_floating_ip.py b/cloud/openstack/os_floating_ip.py\n--- a/cloud/openstack/os_floating_ip.py\n+++ b/cloud/openstack/os_floating_ip.py\n@@ -163,6 +163,10 @@\n msg=\"server {0} not found\".format(server_name_or_id))\n \n if state == 'present':\n+ fip_address = cloud.get_server_public_ip(server)\n+ f_ip = _get_floating_ip(cloud, fip_address)\n+ if f_ip:\n+ module.exit_json(changed=False, floating_ip=f_ip)\n server = cloud.add_ips_to_server(\n server=server, ips=floating_ip_address, ip_pool=network,\n reuse=reuse, fixed_address=fixed_address, wait=wait,\n", "issue": "os_floating_ip errors if an ip is attached.\n##### Issue Type:\n\nRegression (so inevitably a feature idea).\n##### Ansible Version:\n\nansible 2.0.0\n##### Ansible Configuration:\n\n```\n< lookup_plugins = ./lookup_plugins:~/.ansible/plugins/lookup_plugins/:/usr/share/ansible_plugins/\n< timeout = 120\n\n---\n> timeout = 10\n```\n##### Environment:\n\nOSX -> Ubuntu\n##### Summary:\n\nIf you add an ip with os_floating_ip to a server, when you rerun your play, it errors.\n##### Steps To Reproduce:\n\n```\n- os_floating_ip:\n cloud: envvars\n state: present\n reuse: yes\n server: cwp-goserver-1\n network: vlan3320\n fixed_address: \"{{ lookup('os_private_ip', 'cwp-goserver-1') }}\"\n wait: true\n timeout: 180\n```\n##### Expected Results:\n\nIf the server already has a floating ip from the network, expect the task to pass, as unchanged.\n##### Actual Results:\n\n```\nunable to bind a floating ip to server f23ce73c-82ad-490a-bf0e-7e3d23dce449: Cannot associate floating IP 10.12.71.112 (57a5b6e0-2843-4ec5-9388-408a098cdcc7) with port f2c6e8bb-b500-4ea0-abc8-980b34fc200f using fixed IP 192.168.101.36, as that fixed IP already has a floating IP on external network 8b3e1a76-f16c-461b-a5b5-f5987936426d\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# Copyright (c) 2015 Hewlett-Packard Development Company, L.P.\n# Author: Davide Guerri <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\ntry:\n import shade\n from shade import meta\n\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\nDOCUMENTATION = '''\n---\nmodule: os_floating_ip\nversion_added: \"2.0\"\nshort_description: Add/Remove floating IP from an instance\nextends_documentation_fragment: openstack\ndescription:\n - Add or Remove a floating IP to an instance\noptions:\n server:\n description:\n - The name or ID of the instance to which the IP address\n should be assigned.\n required: true\n network:\n description:\n - The name or ID of a neutron external network or a nova pool name.\n required: false\n floating_ip_address:\n description:\n - A floating IP address to attach or to detach. Required only if I(state)\n is absent. When I(state) is present can be used to specify a IP address\n to attach.\n required: false\n reuse:\n description:\n - When I(state) is present, and I(floating_ip_address) is not present,\n this parameter can be used to specify whether we should try to reuse\n a floating IP address already allocated to the project.\n required: false\n default: false\n fixed_address:\n description:\n - To which fixed IP of server the floating IP address should be\n attached to.\n required: false\n wait:\n description:\n - When attaching a floating IP address, specify whether we should\n wait for it to appear as attached.\n required: false\n default: false\n timeout:\n description:\n - Time to wait for an IP address to appear as attached. See wait.\n required: false\n default: 60\n state:\n description:\n - Should the resource be present or absent.\n choices: [present, absent]\n required: false\n default: present\n purge:\n description:\n - When I(state) is absent, indicates whether or not to delete the floating\n IP completely, or only detach it from the server. Default is to detach only.\n required: false\n default: false\n version_added: \"2.1\"\nrequirements: [\"shade\"]\n'''\n\nEXAMPLES = '''\n# Assign a floating IP to the fist interface of `cattle001` from an exiting\n# external network or nova pool. A new floating IP from the first available\n# external network is allocated to the project.\n- os_floating_ip:\n cloud: dguerri\n server: cattle001\n\n# Assign a new floating IP to the instance fixed ip `192.0.2.3` of\n# `cattle001`. If a free floating IP is already allocated to the project, it is\n# reused; if not, a new one is created.\n- os_floating_ip:\n cloud: dguerri\n state: present\n reuse: yes\n server: cattle001\n network: ext_net\n fixed_address: 192.0.2.3\n wait: true\n timeout: 180\n\n# Detach a floating IP address from a server\n- os_floating_ip:\n cloud: dguerri\n state: absent\n floating_ip_address: 203.0.113.2\n server: cattle001\n'''\n\n\ndef _get_floating_ip(cloud, floating_ip_address):\n f_ips = cloud.search_floating_ips(\n filters={'floating_ip_address': floating_ip_address})\n if not f_ips:\n return None\n\n return f_ips[0]\n\n\ndef main():\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n state=dict(default='present', choices=['absent', 'present']),\n network=dict(required=False, default=None),\n floating_ip_address=dict(required=False, default=None),\n reuse=dict(required=False, type='bool', default=False),\n fixed_address=dict(required=False, default=None),\n wait=dict(required=False, type='bool', default=False),\n timeout=dict(required=False, type='int', default=60),\n purge=dict(required=False, type='bool', default=False),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(argument_spec, **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n server_name_or_id = module.params['server']\n state = module.params['state']\n network = module.params['network']\n floating_ip_address = module.params['floating_ip_address']\n reuse = module.params['reuse']\n fixed_address = module.params['fixed_address']\n wait = module.params['wait']\n timeout = module.params['timeout']\n purge = module.params['purge']\n\n cloud = shade.openstack_cloud(**module.params)\n\n try:\n server = cloud.get_server(server_name_or_id)\n if server is None:\n module.fail_json(\n msg=\"server {0} not found\".format(server_name_or_id))\n\n if state == 'present':\n server = cloud.add_ips_to_server(\n server=server, ips=floating_ip_address, ip_pool=network,\n reuse=reuse, fixed_address=fixed_address, wait=wait,\n timeout=timeout)\n fip_address = cloud.get_server_public_ip(server)\n # Update the floating IP status\n f_ip = _get_floating_ip(cloud, fip_address)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n elif state == 'absent':\n if floating_ip_address is None:\n module.fail_json(msg=\"floating_ip_address is required\")\n\n f_ip = _get_floating_ip(cloud, floating_ip_address)\n\n if not f_ip:\n # Nothing to detach\n module.exit_json(changed=False)\n\n cloud.detach_ip_from_server(\n server_id=server['id'], floating_ip_id=f_ip['id'])\n # Update the floating IP status\n f_ip = cloud.get_floating_ip(id=f_ip['id'])\n if purge:\n cloud.delete_floating_ip(f_ip['id'])\n module.exit_json(changed=True)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\n\n\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_floating_ip.py"}], "after_files": [{"content": "#!/usr/bin/python\n# Copyright (c) 2015 Hewlett-Packard Development Company, L.P.\n# Author: Davide Guerri <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\ntry:\n import shade\n from shade import meta\n\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\nDOCUMENTATION = '''\n---\nmodule: os_floating_ip\nversion_added: \"2.0\"\nshort_description: Add/Remove floating IP from an instance\nextends_documentation_fragment: openstack\ndescription:\n - Add or Remove a floating IP to an instance\noptions:\n server:\n description:\n - The name or ID of the instance to which the IP address\n should be assigned.\n required: true\n network:\n description:\n - The name or ID of a neutron external network or a nova pool name.\n required: false\n floating_ip_address:\n description:\n - A floating IP address to attach or to detach. Required only if I(state)\n is absent. When I(state) is present can be used to specify a IP address\n to attach.\n required: false\n reuse:\n description:\n - When I(state) is present, and I(floating_ip_address) is not present,\n this parameter can be used to specify whether we should try to reuse\n a floating IP address already allocated to the project.\n required: false\n default: false\n fixed_address:\n description:\n - To which fixed IP of server the floating IP address should be\n attached to.\n required: false\n wait:\n description:\n - When attaching a floating IP address, specify whether we should\n wait for it to appear as attached.\n required: false\n default: false\n timeout:\n description:\n - Time to wait for an IP address to appear as attached. See wait.\n required: false\n default: 60\n state:\n description:\n - Should the resource be present or absent.\n choices: [present, absent]\n required: false\n default: present\n purge:\n description:\n - When I(state) is absent, indicates whether or not to delete the floating\n IP completely, or only detach it from the server. Default is to detach only.\n required: false\n default: false\n version_added: \"2.1\"\nrequirements: [\"shade\"]\n'''\n\nEXAMPLES = '''\n# Assign a floating IP to the fist interface of `cattle001` from an exiting\n# external network or nova pool. A new floating IP from the first available\n# external network is allocated to the project.\n- os_floating_ip:\n cloud: dguerri\n server: cattle001\n\n# Assign a new floating IP to the instance fixed ip `192.0.2.3` of\n# `cattle001`. If a free floating IP is already allocated to the project, it is\n# reused; if not, a new one is created.\n- os_floating_ip:\n cloud: dguerri\n state: present\n reuse: yes\n server: cattle001\n network: ext_net\n fixed_address: 192.0.2.3\n wait: true\n timeout: 180\n\n# Detach a floating IP address from a server\n- os_floating_ip:\n cloud: dguerri\n state: absent\n floating_ip_address: 203.0.113.2\n server: cattle001\n'''\n\n\ndef _get_floating_ip(cloud, floating_ip_address):\n f_ips = cloud.search_floating_ips(\n filters={'floating_ip_address': floating_ip_address})\n if not f_ips:\n return None\n\n return f_ips[0]\n\n\ndef main():\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n state=dict(default='present', choices=['absent', 'present']),\n network=dict(required=False, default=None),\n floating_ip_address=dict(required=False, default=None),\n reuse=dict(required=False, type='bool', default=False),\n fixed_address=dict(required=False, default=None),\n wait=dict(required=False, type='bool', default=False),\n timeout=dict(required=False, type='int', default=60),\n purge=dict(required=False, type='bool', default=False),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(argument_spec, **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n server_name_or_id = module.params['server']\n state = module.params['state']\n network = module.params['network']\n floating_ip_address = module.params['floating_ip_address']\n reuse = module.params['reuse']\n fixed_address = module.params['fixed_address']\n wait = module.params['wait']\n timeout = module.params['timeout']\n purge = module.params['purge']\n\n cloud = shade.openstack_cloud(**module.params)\n\n try:\n server = cloud.get_server(server_name_or_id)\n if server is None:\n module.fail_json(\n msg=\"server {0} not found\".format(server_name_or_id))\n\n if state == 'present':\n fip_address = cloud.get_server_public_ip(server)\n f_ip = _get_floating_ip(cloud, fip_address)\n if f_ip:\n module.exit_json(changed=False, floating_ip=f_ip)\n server = cloud.add_ips_to_server(\n server=server, ips=floating_ip_address, ip_pool=network,\n reuse=reuse, fixed_address=fixed_address, wait=wait,\n timeout=timeout)\n fip_address = cloud.get_server_public_ip(server)\n # Update the floating IP status\n f_ip = _get_floating_ip(cloud, fip_address)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n elif state == 'absent':\n if floating_ip_address is None:\n module.fail_json(msg=\"floating_ip_address is required\")\n\n f_ip = _get_floating_ip(cloud, floating_ip_address)\n\n if not f_ip:\n # Nothing to detach\n module.exit_json(changed=False)\n\n cloud.detach_ip_from_server(\n server_id=server['id'], floating_ip_id=f_ip['id'])\n # Update the floating IP status\n f_ip = cloud.get_floating_ip(id=f_ip['id'])\n if purge:\n cloud.delete_floating_ip(f_ip['id'])\n module.exit_json(changed=True)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\n\n\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_floating_ip.py"}]} | 2,787 | 173 |
gh_patches_debug_41419 | rasdani/github-patches | git_diff | cookiecutter__cookiecutter-815 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
passing list to template
I would like to be able to pass a list to the templates. See the two code blocks at the end of this post for an example. Right now it appears that if you pass a list in the config object, it's read as a list of options for that key.
I know that you can use `str.split()` in the jinja2 template, but that's not a real solution, since it's impossible to "escape" the character that's used as the delimiter. What's the best solution here? I would prefer to be able to pass a list in the json object and call it a day, but obviously that doesn't work for the user input prompts.
- `cookiecutter.json`:
``` json
{
"build_steps": [
"do_something",
"do_something_else"
]
}
```
- `Dockerfile`:
``` jinja2
FROM something
{% for step in cookiecutter.build_steps %}
RUN {{ step }}
{% endfor %}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/prompt.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """
4 cookiecutter.prompt
5 ---------------------
6
7 Functions for prompting the user for project info.
8 """
9
10 from collections import OrderedDict
11
12 import click
13 from past.builtins import basestring
14
15 from future.utils import iteritems
16
17 from jinja2.exceptions import UndefinedError
18
19 from .exceptions import UndefinedVariableInTemplate
20 from .environment import StrictEnvironment
21
22
23 def read_user_variable(var_name, default_value):
24 """Prompt the user for the given variable and return the entered value
25 or the given default.
26
27 :param str var_name: Variable of the context to query the user
28 :param default_value: Value that will be returned if no input happens
29 """
30 # Please see http://click.pocoo.org/4/api/#click.prompt
31 return click.prompt(var_name, default=default_value)
32
33
34 def read_user_yes_no(question, default_value):
35 """Prompt the user to reply with 'yes' or 'no' (or equivalent values).
36
37 Note:
38 Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'
39
40 :param str question: Question to the user
41 :param default_value: Value that will be returned if no input happens
42 """
43 # Please see http://click.pocoo.org/4/api/#click.prompt
44 return click.prompt(
45 question,
46 default=default_value,
47 type=click.BOOL
48 )
49
50
51 def read_user_choice(var_name, options):
52 """Prompt the user to choose from several options for the given variable.
53
54 The first item will be returned if no input happens.
55
56 :param str var_name: Variable as specified in the context
57 :param list options: Sequence of options that are available to select from
58 :return: Exactly one item of ``options`` that has been chosen by the user
59 """
60 # Please see http://click.pocoo.org/4/api/#click.prompt
61 if not isinstance(options, list):
62 raise TypeError
63
64 if not options:
65 raise ValueError
66
67 choice_map = OrderedDict(
68 (u'{}'.format(i), value) for i, value in enumerate(options, 1)
69 )
70 choices = choice_map.keys()
71 default = u'1'
72
73 choice_lines = [u'{} - {}'.format(*c) for c in choice_map.items()]
74 prompt = u'\n'.join((
75 u'Select {}:'.format(var_name),
76 u'\n'.join(choice_lines),
77 u'Choose from {}'.format(u', '.join(choices))
78 ))
79
80 user_choice = click.prompt(
81 prompt, type=click.Choice(choices), default=default
82 )
83 return choice_map[user_choice]
84
85
86 def render_variable(env, raw, cookiecutter_dict):
87 if raw is None:
88 return None
89 if not isinstance(raw, basestring):
90 raw = str(raw)
91 template = env.from_string(raw)
92
93 rendered_template = template.render(cookiecutter=cookiecutter_dict)
94 return rendered_template
95
96
97 def prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):
98 """Prompt the user which option to choose from the given. Each of the
99 possible choices is rendered beforehand.
100 """
101 rendered_options = [
102 render_variable(env, raw, cookiecutter_dict) for raw in options
103 ]
104
105 if no_input:
106 return rendered_options[0]
107 return read_user_choice(key, rendered_options)
108
109
110 def prompt_for_config(context, no_input=False):
111 """
112 Prompts the user to enter new config, using context as a source for the
113 field names and sample values.
114
115 :param no_input: Prompt the user at command line for manual configuration?
116 """
117 cookiecutter_dict = {}
118 env = StrictEnvironment(context=context)
119
120 for key, raw in iteritems(context[u'cookiecutter']):
121 if key.startswith(u'_'):
122 cookiecutter_dict[key] = raw
123 continue
124
125 try:
126 if isinstance(raw, list):
127 # We are dealing with a choice variable
128 val = prompt_choice_for_config(
129 cookiecutter_dict, env, key, raw, no_input
130 )
131 else:
132 # We are dealing with a regular variable
133 val = render_variable(env, raw, cookiecutter_dict)
134
135 if not no_input:
136 val = read_user_variable(key, val)
137 except UndefinedError as err:
138 msg = "Unable to render variable '{}'".format(key)
139 raise UndefinedVariableInTemplate(msg, err, context)
140
141 cookiecutter_dict[key] = val
142 return cookiecutter_dict
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py
--- a/cookiecutter/prompt.py
+++ b/cookiecutter/prompt.py
@@ -8,6 +8,7 @@
"""
from collections import OrderedDict
+import json
import click
from past.builtins import basestring
@@ -83,11 +84,43 @@
return choice_map[user_choice]
+def read_user_dict(var_name, default_value):
+ """Prompt the user to provide a dictionary of data.
+
+ :param str var_name: Variable as specified in the context
+ :param default_value: Value that will be returned if no input is provided
+ :return: A Python dictionary to use in the context.
+ """
+ # Please see http://click.pocoo.org/4/api/#click.prompt
+ if not isinstance(default_value, dict):
+ raise TypeError
+
+ raw = click.prompt(var_name, default='default')
+ if raw != 'default':
+ value = json.loads(raw, object_hook=OrderedDict)
+ else:
+ value = default_value
+
+ return value
+
+
def render_variable(env, raw, cookiecutter_dict):
if raw is None:
return None
- if not isinstance(raw, basestring):
+ elif isinstance(raw, dict):
+ return {
+ render_variable(env, k, cookiecutter_dict):
+ render_variable(env, v, cookiecutter_dict)
+ for k, v in raw.items()
+ }
+ elif isinstance(raw, list):
+ return [
+ render_variable(env, v, cookiecutter_dict)
+ for v in raw
+ ]
+ elif not isinstance(raw, basestring):
raw = str(raw)
+
template = env.from_string(raw)
rendered_template = template.render(cookiecutter=cookiecutter_dict)
@@ -117,6 +150,9 @@
cookiecutter_dict = {}
env = StrictEnvironment(context=context)
+ # First pass: Handle simple and raw variables, plus choices.
+ # These must be done first because the dictionaries keys and
+ # values might refer to them.
for key, raw in iteritems(context[u'cookiecutter']):
if key.startswith(u'_'):
cookiecutter_dict[key] = raw
@@ -128,15 +164,33 @@
val = prompt_choice_for_config(
cookiecutter_dict, env, key, raw, no_input
)
- else:
+ cookiecutter_dict[key] = val
+ elif not isinstance(raw, dict):
# We are dealing with a regular variable
val = render_variable(env, raw, cookiecutter_dict)
if not no_input:
val = read_user_variable(key, val)
+
+ cookiecutter_dict[key] = val
+ except UndefinedError as err:
+ msg = "Unable to render variable '{}'".format(key)
+ raise UndefinedVariableInTemplate(msg, err, context)
+
+ # Second pass; handle the dictionaries.
+ for key, raw in iteritems(context[u'cookiecutter']):
+
+ try:
+ if isinstance(raw, dict):
+ # We are dealing with a dict variable
+ val = render_variable(env, raw, cookiecutter_dict)
+
+ if not no_input:
+ val = read_user_dict(key, val)
+
+ cookiecutter_dict[key] = val
except UndefinedError as err:
msg = "Unable to render variable '{}'".format(key)
raise UndefinedVariableInTemplate(msg, err, context)
- cookiecutter_dict[key] = val
return cookiecutter_dict
| {"golden_diff": "diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py\n--- a/cookiecutter/prompt.py\n+++ b/cookiecutter/prompt.py\n@@ -8,6 +8,7 @@\n \"\"\"\n \n from collections import OrderedDict\n+import json\n \n import click\n from past.builtins import basestring\n@@ -83,11 +84,43 @@\n return choice_map[user_choice]\n \n \n+def read_user_dict(var_name, default_value):\n+ \"\"\"Prompt the user to provide a dictionary of data.\n+\n+ :param str var_name: Variable as specified in the context\n+ :param default_value: Value that will be returned if no input is provided\n+ :return: A Python dictionary to use in the context.\n+ \"\"\"\n+ # Please see http://click.pocoo.org/4/api/#click.prompt\n+ if not isinstance(default_value, dict):\n+ raise TypeError\n+\n+ raw = click.prompt(var_name, default='default')\n+ if raw != 'default':\n+ value = json.loads(raw, object_hook=OrderedDict)\n+ else:\n+ value = default_value\n+\n+ return value\n+\n+\n def render_variable(env, raw, cookiecutter_dict):\n if raw is None:\n return None\n- if not isinstance(raw, basestring):\n+ elif isinstance(raw, dict):\n+ return {\n+ render_variable(env, k, cookiecutter_dict):\n+ render_variable(env, v, cookiecutter_dict)\n+ for k, v in raw.items()\n+ }\n+ elif isinstance(raw, list):\n+ return [\n+ render_variable(env, v, cookiecutter_dict)\n+ for v in raw\n+ ]\n+ elif not isinstance(raw, basestring):\n raw = str(raw)\n+\n template = env.from_string(raw)\n \n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n@@ -117,6 +150,9 @@\n cookiecutter_dict = {}\n env = StrictEnvironment(context=context)\n \n+ # First pass: Handle simple and raw variables, plus choices.\n+ # These must be done first because the dictionaries keys and\n+ # values might refer to them.\n for key, raw in iteritems(context[u'cookiecutter']):\n if key.startswith(u'_'):\n cookiecutter_dict[key] = raw\n@@ -128,15 +164,33 @@\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n- else:\n+ cookiecutter_dict[key] = val\n+ elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n \n if not no_input:\n val = read_user_variable(key, val)\n+\n+ cookiecutter_dict[key] = val\n+ except UndefinedError as err:\n+ msg = \"Unable to render variable '{}'\".format(key)\n+ raise UndefinedVariableInTemplate(msg, err, context)\n+\n+ # Second pass; handle the dictionaries.\n+ for key, raw in iteritems(context[u'cookiecutter']):\n+\n+ try:\n+ if isinstance(raw, dict):\n+ # We are dealing with a dict variable\n+ val = render_variable(env, raw, cookiecutter_dict)\n+\n+ if not no_input:\n+ val = read_user_dict(key, val)\n+\n+ cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n \n- cookiecutter_dict[key] = val\n return cookiecutter_dict\n", "issue": "passing list to template\nI would like to be able to pass a list to the templates. See the two code blocks at the end of this post for an example. Right now it appears that if you pass a list in the config object, it's read as a list of options for that key.\n\nI know that you can use `str.split()` in the jinja2 template, but that's not a real solution, since it's impossible to \"escape\" the character that's used as the delimiter. What's the best solution here? I would prefer to be able to pass a list in the json object and call it a day, but obviously that doesn't work for the user input prompts.\n- `cookiecutter.json`:\n\n``` json\n{\n \"build_steps\": [\n \"do_something\",\n \"do_something_else\"\n ]\n}\n```\n- `Dockerfile`:\n\n``` jinja2\nFROM something\n\n{% for step in cookiecutter.build_steps %}\nRUN {{ step }}\n{% endfor %}\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.prompt\n---------------------\n\nFunctions for prompting the user for project info.\n\"\"\"\n\nfrom collections import OrderedDict\n\nimport click\nfrom past.builtins import basestring\n\nfrom future.utils import iteritems\n\nfrom jinja2.exceptions import UndefinedError\n\nfrom .exceptions import UndefinedVariableInTemplate\nfrom .environment import StrictEnvironment\n\n\ndef read_user_variable(var_name, default_value):\n \"\"\"Prompt the user for the given variable and return the entered value\n or the given default.\n\n :param str var_name: Variable of the context to query the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(var_name, default=default_value)\n\n\ndef read_user_yes_no(question, default_value):\n \"\"\"Prompt the user to reply with 'yes' or 'no' (or equivalent values).\n\n Note:\n Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'\n\n :param str question: Question to the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(\n question,\n default=default_value,\n type=click.BOOL\n )\n\n\ndef read_user_choice(var_name, options):\n \"\"\"Prompt the user to choose from several options for the given variable.\n\n The first item will be returned if no input happens.\n\n :param str var_name: Variable as specified in the context\n :param list options: Sequence of options that are available to select from\n :return: Exactly one item of ``options`` that has been chosen by the user\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n if not isinstance(options, list):\n raise TypeError\n\n if not options:\n raise ValueError\n\n choice_map = OrderedDict(\n (u'{}'.format(i), value) for i, value in enumerate(options, 1)\n )\n choices = choice_map.keys()\n default = u'1'\n\n choice_lines = [u'{} - {}'.format(*c) for c in choice_map.items()]\n prompt = u'\\n'.join((\n u'Select {}:'.format(var_name),\n u'\\n'.join(choice_lines),\n u'Choose from {}'.format(u', '.join(choices))\n ))\n\n user_choice = click.prompt(\n prompt, type=click.Choice(choices), default=default\n )\n return choice_map[user_choice]\n\n\ndef render_variable(env, raw, cookiecutter_dict):\n if raw is None:\n return None\n if not isinstance(raw, basestring):\n raw = str(raw)\n template = env.from_string(raw)\n\n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n return rendered_template\n\n\ndef prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):\n \"\"\"Prompt the user which option to choose from the given. Each of the\n possible choices is rendered beforehand.\n \"\"\"\n rendered_options = [\n render_variable(env, raw, cookiecutter_dict) for raw in options\n ]\n\n if no_input:\n return rendered_options[0]\n return read_user_choice(key, rendered_options)\n\n\ndef prompt_for_config(context, no_input=False):\n \"\"\"\n Prompts the user to enter new config, using context as a source for the\n field names and sample values.\n\n :param no_input: Prompt the user at command line for manual configuration?\n \"\"\"\n cookiecutter_dict = {}\n env = StrictEnvironment(context=context)\n\n for key, raw in iteritems(context[u'cookiecutter']):\n if key.startswith(u'_'):\n cookiecutter_dict[key] = raw\n continue\n\n try:\n if isinstance(raw, list):\n # We are dealing with a choice variable\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n else:\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_variable(key, val)\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n\n cookiecutter_dict[key] = val\n return cookiecutter_dict\n", "path": "cookiecutter/prompt.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.prompt\n---------------------\n\nFunctions for prompting the user for project info.\n\"\"\"\n\nfrom collections import OrderedDict\nimport json\n\nimport click\nfrom past.builtins import basestring\n\nfrom future.utils import iteritems\n\nfrom jinja2.exceptions import UndefinedError\n\nfrom .exceptions import UndefinedVariableInTemplate\nfrom .environment import StrictEnvironment\n\n\ndef read_user_variable(var_name, default_value):\n \"\"\"Prompt the user for the given variable and return the entered value\n or the given default.\n\n :param str var_name: Variable of the context to query the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(var_name, default=default_value)\n\n\ndef read_user_yes_no(question, default_value):\n \"\"\"Prompt the user to reply with 'yes' or 'no' (or equivalent values).\n\n Note:\n Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'\n\n :param str question: Question to the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(\n question,\n default=default_value,\n type=click.BOOL\n )\n\n\ndef read_user_choice(var_name, options):\n \"\"\"Prompt the user to choose from several options for the given variable.\n\n The first item will be returned if no input happens.\n\n :param str var_name: Variable as specified in the context\n :param list options: Sequence of options that are available to select from\n :return: Exactly one item of ``options`` that has been chosen by the user\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n if not isinstance(options, list):\n raise TypeError\n\n if not options:\n raise ValueError\n\n choice_map = OrderedDict(\n (u'{}'.format(i), value) for i, value in enumerate(options, 1)\n )\n choices = choice_map.keys()\n default = u'1'\n\n choice_lines = [u'{} - {}'.format(*c) for c in choice_map.items()]\n prompt = u'\\n'.join((\n u'Select {}:'.format(var_name),\n u'\\n'.join(choice_lines),\n u'Choose from {}'.format(u', '.join(choices))\n ))\n\n user_choice = click.prompt(\n prompt, type=click.Choice(choices), default=default\n )\n return choice_map[user_choice]\n\n\ndef read_user_dict(var_name, default_value):\n \"\"\"Prompt the user to provide a dictionary of data.\n\n :param str var_name: Variable as specified in the context\n :param default_value: Value that will be returned if no input is provided\n :return: A Python dictionary to use in the context.\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n if not isinstance(default_value, dict):\n raise TypeError\n\n raw = click.prompt(var_name, default='default')\n if raw != 'default':\n value = json.loads(raw, object_hook=OrderedDict)\n else:\n value = default_value\n\n return value\n\n\ndef render_variable(env, raw, cookiecutter_dict):\n if raw is None:\n return None\n elif isinstance(raw, dict):\n return {\n render_variable(env, k, cookiecutter_dict):\n render_variable(env, v, cookiecutter_dict)\n for k, v in raw.items()\n }\n elif isinstance(raw, list):\n return [\n render_variable(env, v, cookiecutter_dict)\n for v in raw\n ]\n elif not isinstance(raw, basestring):\n raw = str(raw)\n\n template = env.from_string(raw)\n\n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n return rendered_template\n\n\ndef prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):\n \"\"\"Prompt the user which option to choose from the given. Each of the\n possible choices is rendered beforehand.\n \"\"\"\n rendered_options = [\n render_variable(env, raw, cookiecutter_dict) for raw in options\n ]\n\n if no_input:\n return rendered_options[0]\n return read_user_choice(key, rendered_options)\n\n\ndef prompt_for_config(context, no_input=False):\n \"\"\"\n Prompts the user to enter new config, using context as a source for the\n field names and sample values.\n\n :param no_input: Prompt the user at command line for manual configuration?\n \"\"\"\n cookiecutter_dict = {}\n env = StrictEnvironment(context=context)\n\n # First pass: Handle simple and raw variables, plus choices.\n # These must be done first because the dictionaries keys and\n # values might refer to them.\n for key, raw in iteritems(context[u'cookiecutter']):\n if key.startswith(u'_'):\n cookiecutter_dict[key] = raw\n continue\n\n try:\n if isinstance(raw, list):\n # We are dealing with a choice variable\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n cookiecutter_dict[key] = val\n elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_variable(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n\n # Second pass; handle the dictionaries.\n for key, raw in iteritems(context[u'cookiecutter']):\n\n try:\n if isinstance(raw, dict):\n # We are dealing with a dict variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_dict(key, val)\n\n cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n\n return cookiecutter_dict\n", "path": "cookiecutter/prompt.py"}]} | 1,790 | 819 |
gh_patches_debug_22064 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-3302 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Broken edit links
Two issues which may or may not be related:
- Module sources: the "Edit on github" links for pages like http://www.tornadoweb.org/en/stable/_modules/tornado/stack_context.html are broken; they point to a non-existent .rst file. Is it possible to suppress the edit link for these pages (or ideally point it to the real source)? (migrated from https://github.com/snide/sphinx_rtd_theme/issues/237)
- Non-latest branches: on a page like http://www.tornadoweb.org/en/stable/, the "edit on github" link in the upper right is broken because it points to https://github.com/tornadoweb/tornado/blob/origin/stable/docs/index.rst (the 'origin' directory needs to be removed from the path). On the lower left, clicking "v: stable" for the menu and then "Edit" works (linking to https://github.com/tornadoweb/tornado/edit/stable/docs/index.rst).
The "latest" branch works fine (linking to "master"); this is only a problem for pages based on other branches (migrated from https://github.com/snide/sphinx_rtd_theme/issues/236)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/vcs_support/backends/git.py`
Content:
```
1 """Git-related utilities."""
2
3 from __future__ import absolute_import
4
5 import csv
6 import logging
7 import os
8 import re
9
10 from builtins import str
11 from six import StringIO
12
13 from readthedocs.projects.exceptions import ProjectImportError
14 from readthedocs.vcs_support.base import BaseVCS, VCSVersion
15
16
17 log = logging.getLogger(__name__)
18
19
20 class Backend(BaseVCS):
21
22 """Git VCS backend."""
23
24 supports_tags = True
25 supports_branches = True
26 fallback_branch = 'master' # default branch
27
28 def __init__(self, *args, **kwargs):
29 super(Backend, self).__init__(*args, **kwargs)
30 self.token = kwargs.get('token', None)
31 self.repo_url = self._get_clone_url()
32
33 def _get_clone_url(self):
34 if '://' in self.repo_url:
35 hacked_url = self.repo_url.split('://')[1]
36 hacked_url = re.sub('.git$', '', hacked_url)
37 clone_url = 'https://%s' % hacked_url
38 if self.token:
39 clone_url = 'https://%s@%s' % (self.token, hacked_url)
40 return clone_url
41 # Don't edit URL because all hosts aren't the same
42
43 # else:
44 # clone_url = 'git://%s' % (hacked_url)
45 return self.repo_url
46
47 def set_remote_url(self, url):
48 return self.run('git', 'remote', 'set-url', 'origin', url)
49
50 def update(self):
51 # Use checkout() to update repo
52 self.checkout()
53
54 def repo_exists(self):
55 code, _, _ = self.run('git', 'status')
56 return code == 0
57
58 def fetch(self):
59 code, _, err = self.run('git', 'fetch', '--tags', '--prune')
60 if code != 0:
61 raise ProjectImportError(
62 "Failed to get code from '%s' (git fetch): %s\n\nStderr:\n\n%s\n\n" % (
63 self.repo_url, code, err)
64 )
65
66 def checkout_revision(self, revision=None):
67 if not revision:
68 branch = self.default_branch or self.fallback_branch
69 revision = 'origin/%s' % branch
70
71 code, out, err = self.run('git', 'checkout',
72 '--force', '--quiet', revision)
73 if code != 0:
74 log.warning("Failed to checkout revision '%s': %s",
75 revision, code)
76 return [code, out, err]
77
78 def clone(self):
79 code, _, err = self.run('git', 'clone', '--recursive', '--quiet',
80 self.repo_url, '.')
81 if code != 0:
82 raise ProjectImportError(
83 (
84 "Failed to get code from '{url}' (git clone): {exit}\n\n"
85 "git clone error output: {sterr}"
86 ).format(
87 url=self.repo_url,
88 exit=code,
89 sterr=err
90 )
91 )
92
93 @property
94 def tags(self):
95 retcode, stdout, _ = self.run('git', 'show-ref', '--tags')
96 # error (or no tags found)
97 if retcode != 0:
98 return []
99 return self.parse_tags(stdout)
100
101 def parse_tags(self, data):
102 """
103 Parses output of show-ref --tags, eg:
104
105 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0
106 bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1
107 c0288a17899b2c6818f74e3a90b77e2a1779f96a refs/tags/2.0.2
108 a63a2de628a3ce89034b7d1a5ca5e8159534eef0 refs/tags/2.1.0.beta2
109 c7fc3d16ed9dc0b19f0d27583ca661a64562d21e refs/tags/2.1.0.rc1
110 edc0a2d02a0cc8eae8b67a3a275f65cd126c05b1 refs/tags/2.1.0.rc2
111
112 Into VCSTag objects with the tag name as verbose_name and the commit
113 hash as identifier.
114 """
115 # parse the lines into a list of tuples (commit-hash, tag ref name)
116 # StringIO below is expecting Unicode data, so ensure that it gets it.
117 if not isinstance(data, str):
118 data = str(data)
119 raw_tags = csv.reader(StringIO(data), delimiter=' ')
120 vcs_tags = []
121 for row in raw_tags:
122 row = [f for f in row if f != '']
123 if row == []:
124 continue
125 commit_hash, name = row
126 clean_name = name.split('/')[-1]
127 vcs_tags.append(VCSVersion(self, commit_hash, clean_name))
128 return vcs_tags
129
130 @property
131 def branches(self):
132 # Only show remote branches
133 retcode, stdout, _ = self.run('git', 'branch', '-r')
134 # error (or no tags found)
135 if retcode != 0:
136 return []
137 return self.parse_branches(stdout)
138
139 def parse_branches(self, data):
140 """
141 Parse output of git branch -r
142
143 e.g.:
144
145 origin/2.0.X
146 origin/HEAD -> origin/master
147 origin/develop
148 origin/master
149 origin/release/2.0.0
150 origin/release/2.1.0
151 """
152 clean_branches = []
153 # StringIO below is expecting Unicode data, so ensure that it gets it.
154 if not isinstance(data, str):
155 data = str(data)
156 raw_branches = csv.reader(StringIO(data), delimiter=' ')
157 for branch in raw_branches:
158 branch = [f for f in branch if f != '' and f != '*']
159 # Handle empty branches
160 if branch:
161 branch = branch[0]
162 if branch.startswith('origin/'):
163 cut_len = len('origin/')
164 slug = branch[cut_len:].replace('/', '-')
165 if slug in ['HEAD']:
166 continue
167 clean_branches.append(VCSVersion(self, branch, slug))
168 else:
169 # Believe this is dead code.
170 slug = branch.replace('/', '-')
171 clean_branches.append(VCSVersion(self, branch, slug))
172 return clean_branches
173
174 @property
175 def commit(self):
176 _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')
177 return stdout.strip()
178
179 def checkout(self, identifier=None):
180 self.check_working_dir()
181
182 # Clone or update repository
183 if self.repo_exists():
184 self.set_remote_url(self.repo_url)
185 self.fetch()
186 else:
187 self.make_clean_working_dir()
188 self.clone()
189
190 # Find proper identifier
191 if not identifier:
192 identifier = self.default_branch or self.fallback_branch
193
194 identifier = self.find_ref(identifier)
195
196 # Checkout the correct identifier for this branch.
197 code, out, err = self.checkout_revision(identifier)
198 if code != 0:
199 return code, out, err
200
201 # Clean any remains of previous checkouts
202 self.run('git', 'clean', '-d', '-f', '-f')
203
204 # Update submodules
205 self.run('git', 'submodule', 'sync')
206 self.run('git', 'submodule', 'update',
207 '--init', '--recursive', '--force')
208
209 return code, out, err
210
211 def find_ref(self, ref):
212 # Check if ref starts with 'origin/'
213 if ref.startswith('origin/'):
214 return ref
215
216 # Check if ref is a branch of the origin remote
217 if self.ref_exists('remotes/origin/' + ref):
218 return 'origin/' + ref
219
220 return ref
221
222 def ref_exists(self, ref):
223 code, _, _ = self.run('git', 'show-ref', ref)
224 return code == 0
225
226 @property
227 def env(self):
228 env = super(Backend, self).env
229 env['GIT_DIR'] = os.path.join(self.working_dir, '.git')
230 return env
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py
--- a/readthedocs/vcs_support/backends/git.py
+++ b/readthedocs/vcs_support/backends/git.py
@@ -92,7 +92,15 @@
@property
def tags(self):
- retcode, stdout, _ = self.run('git', 'show-ref', '--tags')
+ # Hash for non-annotated tag is its commit hash, but for annotated tag it
+ # points to tag itself, so we need to dereference annotated tags.
+ # The output format is the same as `git show-ref --tags`, but with hashes
+ # of annotated tags pointing to tagged commits.
+ retcode, stdout, _ = self.run(
+ 'git', 'for-each-ref',
+ '--format="%(if)%(*objectname)%(then)%(*objectname)'
+ '%(else)%(objectname)%(end) %(refname)"',
+ 'refs/tags')
# error (or no tags found)
if retcode != 0:
return []
@@ -100,7 +108,7 @@
def parse_tags(self, data):
"""
- Parses output of show-ref --tags, eg:
+ Parses output of `git show-ref --tags`, eg:
3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0
bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1
| {"golden_diff": "diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py\n--- a/readthedocs/vcs_support/backends/git.py\n+++ b/readthedocs/vcs_support/backends/git.py\n@@ -92,7 +92,15 @@\n \n @property\n def tags(self):\n- retcode, stdout, _ = self.run('git', 'show-ref', '--tags')\n+ # Hash for non-annotated tag is its commit hash, but for annotated tag it\n+ # points to tag itself, so we need to dereference annotated tags.\n+ # The output format is the same as `git show-ref --tags`, but with hashes\n+ # of annotated tags pointing to tagged commits.\n+ retcode, stdout, _ = self.run(\n+ 'git', 'for-each-ref',\n+ '--format=\"%(if)%(*objectname)%(then)%(*objectname)'\n+ '%(else)%(objectname)%(end) %(refname)\"',\n+ 'refs/tags')\n # error (or no tags found)\n if retcode != 0:\n return []\n@@ -100,7 +108,7 @@\n \n def parse_tags(self, data):\n \"\"\"\n- Parses output of show-ref --tags, eg:\n+ Parses output of `git show-ref --tags`, eg:\n \n 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0\n bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1\n", "issue": "Broken edit links\nTwo issues which may or may not be related:\n- Module sources: the \"Edit on github\" links for pages like http://www.tornadoweb.org/en/stable/_modules/tornado/stack_context.html are broken; they point to a non-existent .rst file. Is it possible to suppress the edit link for these pages (or ideally point it to the real source)? (migrated from https://github.com/snide/sphinx_rtd_theme/issues/237)\n- Non-latest branches: on a page like http://www.tornadoweb.org/en/stable/, the \"edit on github\" link in the upper right is broken because it points to https://github.com/tornadoweb/tornado/blob/origin/stable/docs/index.rst (the 'origin' directory needs to be removed from the path). On the lower left, clicking \"v: stable\" for the menu and then \"Edit\" works (linking to https://github.com/tornadoweb/tornado/edit/stable/docs/index.rst).\n\nThe \"latest\" branch works fine (linking to \"master\"); this is only a problem for pages based on other branches (migrated from https://github.com/snide/sphinx_rtd_theme/issues/236)\n\n", "before_files": [{"content": "\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport csv\nimport logging\nimport os\nimport re\n\nfrom builtins import str\nfrom six import StringIO\n\nfrom readthedocs.projects.exceptions import ProjectImportError\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n fallback_branch = 'master' # default branch\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n # Use checkout() to update repo\n self.checkout()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status')\n return code == 0\n\n def fetch(self):\n code, _, err = self.run('git', 'fetch', '--tags', '--prune')\n if code != 0:\n raise ProjectImportError(\n \"Failed to get code from '%s' (git fetch): %s\\n\\nStderr:\\n\\n%s\\n\\n\" % (\n self.repo_url, code, err)\n )\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout',\n '--force', '--quiet', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\",\n revision, code)\n return [code, out, err]\n\n def clone(self):\n code, _, err = self.run('git', 'clone', '--recursive', '--quiet',\n self.repo_url, '.')\n if code != 0:\n raise ProjectImportError(\n (\n \"Failed to get code from '{url}' (git clone): {exit}\\n\\n\"\n \"git clone error output: {sterr}\"\n ).format(\n url=self.repo_url,\n exit=code,\n sterr=err\n )\n )\n\n @property\n def tags(self):\n retcode, stdout, _ = self.run('git', 'show-ref', '--tags')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_tags(stdout)\n\n def parse_tags(self, data):\n \"\"\"\n Parses output of show-ref --tags, eg:\n\n 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0\n bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1\n c0288a17899b2c6818f74e3a90b77e2a1779f96a refs/tags/2.0.2\n a63a2de628a3ce89034b7d1a5ca5e8159534eef0 refs/tags/2.1.0.beta2\n c7fc3d16ed9dc0b19f0d27583ca661a64562d21e refs/tags/2.1.0.rc1\n edc0a2d02a0cc8eae8b67a3a275f65cd126c05b1 refs/tags/2.1.0.rc2\n\n Into VCSTag objects with the tag name as verbose_name and the commit\n hash as identifier.\n \"\"\"\n # parse the lines into a list of tuples (commit-hash, tag ref name)\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_tags = csv.reader(StringIO(data), delimiter=' ')\n vcs_tags = []\n for row in raw_tags:\n row = [f for f in row if f != '']\n if row == []:\n continue\n commit_hash, name = row\n clean_name = name.split('/')[-1]\n vcs_tags.append(VCSVersion(self, commit_hash, clean_name))\n return vcs_tags\n\n @property\n def branches(self):\n # Only show remote branches\n retcode, stdout, _ = self.run('git', 'branch', '-r')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_branches(stdout)\n\n def parse_branches(self, data):\n \"\"\"\n Parse output of git branch -r\n\n e.g.:\n\n origin/2.0.X\n origin/HEAD -> origin/master\n origin/develop\n origin/master\n origin/release/2.0.0\n origin/release/2.1.0\n \"\"\"\n clean_branches = []\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_branches = csv.reader(StringIO(data), delimiter=' ')\n for branch in raw_branches:\n branch = [f for f in branch if f != '' and f != '*']\n # Handle empty branches\n if branch:\n branch = branch[0]\n if branch.startswith('origin/'):\n cut_len = len('origin/')\n slug = branch[cut_len:].replace('/', '-')\n if slug in ['HEAD']:\n continue\n clean_branches.append(VCSVersion(self, branch, slug))\n else:\n # Believe this is dead code.\n slug = branch.replace('/', '-')\n clean_branches.append(VCSVersion(self, branch, slug))\n return clean_branches\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n self.check_working_dir()\n\n # Clone or update repository\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n self.fetch()\n else:\n self.make_clean_working_dir()\n self.clone()\n\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n\n # Update submodules\n self.run('git', 'submodule', 'sync')\n self.run('git', 'submodule', 'update',\n '--init', '--recursive', '--force')\n\n return code, out, err\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n code, _, _ = self.run('git', 'show-ref', ref)\n return code == 0\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}], "after_files": [{"content": "\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport csv\nimport logging\nimport os\nimport re\n\nfrom builtins import str\nfrom six import StringIO\n\nfrom readthedocs.projects.exceptions import ProjectImportError\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n fallback_branch = 'master' # default branch\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n # Use checkout() to update repo\n self.checkout()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status')\n return code == 0\n\n def fetch(self):\n code, _, err = self.run('git', 'fetch', '--tags', '--prune')\n if code != 0:\n raise ProjectImportError(\n \"Failed to get code from '%s' (git fetch): %s\\n\\nStderr:\\n\\n%s\\n\\n\" % (\n self.repo_url, code, err)\n )\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout',\n '--force', '--quiet', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\",\n revision, code)\n return [code, out, err]\n\n def clone(self):\n code, _, err = self.run('git', 'clone', '--recursive', '--quiet',\n self.repo_url, '.')\n if code != 0:\n raise ProjectImportError(\n (\n \"Failed to get code from '{url}' (git clone): {exit}\\n\\n\"\n \"git clone error output: {sterr}\"\n ).format(\n url=self.repo_url,\n exit=code,\n sterr=err\n )\n )\n\n @property\n def tags(self):\n # Hash for non-annotated tag is its commit hash, but for annotated tag it\n # points to tag itself, so we need to dereference annotated tags.\n # The output format is the same as `git show-ref --tags`, but with hashes\n # of annotated tags pointing to tagged commits.\n retcode, stdout, _ = self.run(\n 'git', 'for-each-ref',\n '--format=\"%(if)%(*objectname)%(then)%(*objectname)'\n '%(else)%(objectname)%(end) %(refname)\"',\n 'refs/tags')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_tags(stdout)\n\n def parse_tags(self, data):\n \"\"\"\n Parses output of `git show-ref --tags`, eg:\n\n 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0\n bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1\n c0288a17899b2c6818f74e3a90b77e2a1779f96a refs/tags/2.0.2\n a63a2de628a3ce89034b7d1a5ca5e8159534eef0 refs/tags/2.1.0.beta2\n c7fc3d16ed9dc0b19f0d27583ca661a64562d21e refs/tags/2.1.0.rc1\n edc0a2d02a0cc8eae8b67a3a275f65cd126c05b1 refs/tags/2.1.0.rc2\n\n Into VCSTag objects with the tag name as verbose_name and the commit\n hash as identifier.\n \"\"\"\n # parse the lines into a list of tuples (commit-hash, tag ref name)\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_tags = csv.reader(StringIO(data), delimiter=' ')\n vcs_tags = []\n for row in raw_tags:\n row = [f for f in row if f != '']\n if row == []:\n continue\n commit_hash, name = row\n clean_name = name.split('/')[-1]\n vcs_tags.append(VCSVersion(self, commit_hash, clean_name))\n return vcs_tags\n\n @property\n def branches(self):\n # Only show remote branches\n retcode, stdout, _ = self.run('git', 'branch', '-r')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_branches(stdout)\n\n def parse_branches(self, data):\n \"\"\"\n Parse output of git branch -r\n\n e.g.:\n\n origin/2.0.X\n origin/HEAD -> origin/master\n origin/develop\n origin/master\n origin/release/2.0.0\n origin/release/2.1.0\n \"\"\"\n clean_branches = []\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_branches = csv.reader(StringIO(data), delimiter=' ')\n for branch in raw_branches:\n branch = [f for f in branch if f != '' and f != '*']\n # Handle empty branches\n if branch:\n branch = branch[0]\n if branch.startswith('origin/'):\n cut_len = len('origin/')\n slug = branch[cut_len:].replace('/', '-')\n if slug in ['HEAD']:\n continue\n clean_branches.append(VCSVersion(self, branch, slug))\n else:\n # Believe this is dead code.\n slug = branch.replace('/', '-')\n clean_branches.append(VCSVersion(self, branch, slug))\n return clean_branches\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n self.check_working_dir()\n\n # Clone or update repository\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n self.fetch()\n else:\n self.make_clean_working_dir()\n self.clone()\n\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n\n # Update submodules\n self.run('git', 'submodule', 'sync')\n self.run('git', 'submodule', 'update',\n '--init', '--recursive', '--force')\n\n return code, out, err\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n code, _, _ = self.run('git', 'show-ref', ref)\n return code == 0\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}]} | 3,006 | 398 |
gh_patches_debug_8880 | rasdani/github-patches | git_diff | liqd__a4-product-606 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
can't see full time when creating an event on small screen

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `liqd_product/apps/actions/apps.py`
Content:
```
1 from django.apps import AppConfig
2
3
4 class Config(AppConfig):
5 name = 'liqd_product.apps.actions'
6 label = 'liqd_product_actions'
7
8 def ready(self):
9 from adhocracy4.actions.models import configure_icon
10 from adhocracy4.actions.models import configure_type
11 from adhocracy4.actions.verbs import Verbs
12 configure_type(
13 'project',
14 ('a4projects', 'project')
15 )
16 configure_type(
17 'phase',
18 ('a4phases', 'phase')
19 )
20 configure_type(
21 'comment',
22 ('a4comments', 'comment')
23 )
24 configure_type(
25 'rating',
26 ('a4ratings', 'rating')
27 )
28 configure_type(
29 'item',
30 ('liqd_product_budgeting', 'proposal'),
31 ('liqd_product_ideas', 'idea'),
32 ('liqd_product_mapideas', 'mapidea')
33 )
34
35 configure_icon('far fa-comment', type='comment')
36 configure_icon('far fa-lightbulb', type='item')
37 configure_icon('fas fa-plus', verb=Verbs.ADD)
38 configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)
39 configure_icon('fas fa-flag', verb=Verbs.START)
40 configure_icon('far fa-clock', verb=Verbs.SCHEDULE)
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/liqd_product/apps/actions/apps.py b/liqd_product/apps/actions/apps.py
--- a/liqd_product/apps/actions/apps.py
+++ b/liqd_product/apps/actions/apps.py
@@ -35,6 +35,6 @@
configure_icon('far fa-comment', type='comment')
configure_icon('far fa-lightbulb', type='item')
configure_icon('fas fa-plus', verb=Verbs.ADD)
- configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)
+ configure_icon('fas fa-pencil', verb=Verbs.UPDATE)
configure_icon('fas fa-flag', verb=Verbs.START)
- configure_icon('far fa-clock', verb=Verbs.SCHEDULE)
+ configure_icon('far fa-clock-o', verb=Verbs.SCHEDULE)
| {"golden_diff": "diff --git a/liqd_product/apps/actions/apps.py b/liqd_product/apps/actions/apps.py\n--- a/liqd_product/apps/actions/apps.py\n+++ b/liqd_product/apps/actions/apps.py\n@@ -35,6 +35,6 @@\n configure_icon('far fa-comment', type='comment')\n configure_icon('far fa-lightbulb', type='item')\n configure_icon('fas fa-plus', verb=Verbs.ADD)\n- configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)\n+ configure_icon('fas fa-pencil', verb=Verbs.UPDATE)\n configure_icon('fas fa-flag', verb=Verbs.START)\n- configure_icon('far fa-clock', verb=Verbs.SCHEDULE)\n+ configure_icon('far fa-clock-o', verb=Verbs.SCHEDULE)\n", "issue": "can't see full time when creating an event on small screen\n\r\n\n", "before_files": [{"content": "from django.apps import AppConfig\n\n\nclass Config(AppConfig):\n name = 'liqd_product.apps.actions'\n label = 'liqd_product_actions'\n\n def ready(self):\n from adhocracy4.actions.models import configure_icon\n from adhocracy4.actions.models import configure_type\n from adhocracy4.actions.verbs import Verbs\n configure_type(\n 'project',\n ('a4projects', 'project')\n )\n configure_type(\n 'phase',\n ('a4phases', 'phase')\n )\n configure_type(\n 'comment',\n ('a4comments', 'comment')\n )\n configure_type(\n 'rating',\n ('a4ratings', 'rating')\n )\n configure_type(\n 'item',\n ('liqd_product_budgeting', 'proposal'),\n ('liqd_product_ideas', 'idea'),\n ('liqd_product_mapideas', 'mapidea')\n )\n\n configure_icon('far fa-comment', type='comment')\n configure_icon('far fa-lightbulb', type='item')\n configure_icon('fas fa-plus', verb=Verbs.ADD)\n configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)\n configure_icon('fas fa-flag', verb=Verbs.START)\n configure_icon('far fa-clock', verb=Verbs.SCHEDULE)\n", "path": "liqd_product/apps/actions/apps.py"}], "after_files": [{"content": "from django.apps import AppConfig\n\n\nclass Config(AppConfig):\n name = 'liqd_product.apps.actions'\n label = 'liqd_product_actions'\n\n def ready(self):\n from adhocracy4.actions.models import configure_icon\n from adhocracy4.actions.models import configure_type\n from adhocracy4.actions.verbs import Verbs\n configure_type(\n 'project',\n ('a4projects', 'project')\n )\n configure_type(\n 'phase',\n ('a4phases', 'phase')\n )\n configure_type(\n 'comment',\n ('a4comments', 'comment')\n )\n configure_type(\n 'rating',\n ('a4ratings', 'rating')\n )\n configure_type(\n 'item',\n ('liqd_product_budgeting', 'proposal'),\n ('liqd_product_ideas', 'idea'),\n ('liqd_product_mapideas', 'mapidea')\n )\n\n configure_icon('far fa-comment', type='comment')\n configure_icon('far fa-lightbulb', type='item')\n configure_icon('fas fa-plus', verb=Verbs.ADD)\n configure_icon('fas fa-pencil', verb=Verbs.UPDATE)\n configure_icon('fas fa-flag', verb=Verbs.START)\n configure_icon('far fa-clock-o', verb=Verbs.SCHEDULE)\n", "path": "liqd_product/apps/actions/apps.py"}]} | 717 | 170 |
gh_patches_debug_40709 | rasdani/github-patches | git_diff | getredash__redash-604 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"'float' object is not iterable" when using coordinates for MongoDB query
I'm trying to run a query using **MongoDB** and the **[$geoNear](http://docs.mongodb.org/manual/reference/operator/aggregation/geoNear/)** function, but every time I type the origin coordinate using floats (to create a [GeoJSON Point](http://docs.mongodb.org/manual/reference/geojson/)), I get an error: [_from Python?_]
`Error running query: 'float' object is not iterable`
I'm trying to run the query below. The problem here is the `[ -22.910079, -43.205161 ]` part.
``` json
{
"collection": "bus",
"aggregate": [
{
"$geoNear": {
"near": { "type": "Point", "coordinates": [ -22.910079, -43.205161 ] },
"maxDistance": 100000000,
"distanceField": "dist.calculated",
"includeLocs": "dist.location",
"spherical": true
}
}
]
}
```
However, if I use the coordinates with integers, such as `[ -22, -43 ]`, the query runs fine, but this coordinate is now meaningless, obviously. Here is an example that doesn't error:
``` json
{
"collection": "bus",
"aggregate": [
{
"$geoNear": {
"near": { "type": "Point", "coordinates": [ -22, -43 ] },
"maxDistance": 100000000,
"distanceField": "dist.calculated",
"includeLocs": "dist.location",
"spherical": true
}
}
]
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/query_runner/mongodb.py`
Content:
```
1 import json
2 import datetime
3 import logging
4 import re
5 from dateutil.parser import parse
6
7 from redash.utils import JSONEncoder
8 from redash.query_runner import *
9
10 logger = logging.getLogger(__name__)
11
12 try:
13 import pymongo
14 from bson.objectid import ObjectId
15 from bson.son import SON
16 enabled = True
17
18 except ImportError:
19 enabled = False
20
21
22 TYPES_MAP = {
23 str: TYPE_STRING,
24 unicode: TYPE_STRING,
25 int: TYPE_INTEGER,
26 long: TYPE_INTEGER,
27 float: TYPE_FLOAT,
28 bool: TYPE_BOOLEAN,
29 datetime.datetime: TYPE_DATETIME,
30 }
31
32 date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
33
34 class MongoDBJSONEncoder(JSONEncoder):
35 def default(self, o):
36 if isinstance(o, ObjectId):
37 return str(o)
38
39 return super(MongoDBJSONEncoder, self).default(o)
40
41 # Simple query example:
42 #
43 # {
44 # "collection" : "my_collection",
45 # "query" : {
46 # "date" : {
47 # "$gt" : "ISODate(\"2015-01-15 11:41\")",
48 # },
49 # "type" : 1
50 # },
51 # "fields" : {
52 # "_id" : 1,
53 # "name" : 2
54 # },
55 # "sort" : [
56 # {
57 # "name" : "date",
58 # "direction" : -1
59 # }
60 # ]
61 #
62 # }
63 #
64 #
65 # Aggregation
66 # ===========
67 # Uses a syntax similar to the one used in PyMongo, however to support the
68 # correct order of sorting, it uses a regular list for the "$sort" operation
69 # that converts into a SON (sorted dictionary) object before execution.
70 #
71 # Aggregation query example:
72 #
73 # {
74 # "collection" : "things",
75 # "aggregate" : [
76 # {
77 # "$unwind" : "$tags"
78 # },
79 # {
80 # "$group" : {
81 # "_id" : "$tags",
82 # "count" : { "$sum" : 1 }
83 # }
84 # },
85 # {
86 # "$sort" : [
87 # {
88 # "name" : "count",
89 # "direction" : -1
90 # },
91 # {
92 # "name" : "_id",
93 # "direction" : -1
94 # }
95 # ]
96 # }
97 # ]
98 # }
99 #
100 #
101 class MongoDB(BaseQueryRunner):
102 @classmethod
103 def configuration_schema(cls):
104 return {
105 'type': 'object',
106 'properties': {
107 'connectionString': {
108 'type': 'string',
109 'title': 'Connection String'
110 },
111 'dbName': {
112 'type': 'string',
113 'title': "Database Name"
114 },
115 'replicaSetName': {
116 'type': 'string',
117 'title': 'Replica Set Name'
118 },
119 },
120 'required': ['connectionString']
121 }
122
123 @classmethod
124 def enabled(cls):
125 return enabled
126
127 @classmethod
128 def annotate_query(cls):
129 return False
130
131 def __init__(self, configuration_json):
132 super(MongoDB, self).__init__(configuration_json)
133
134 self.syntax = 'json'
135
136 self.db_name = self.configuration["dbName"]
137
138 self.is_replica_set = True if "replicaSetName" in self.configuration and self.configuration["replicaSetName"] else False
139
140 def _get_column_by_name(self, columns, column_name):
141 for c in columns:
142 if "name" in c and c["name"] == column_name:
143 return c
144
145 return None
146
147 def _fix_dates(self, data):
148 for k in data:
149 if isinstance(data[k], list):
150 for i in range(0, len(data[k])):
151 if isinstance(data[k][i], (str, unicode)):
152 self._convert_date(data[k], i)
153 elif not isinstance(data[k][i], (int)):
154 self._fix_dates(data[k][i])
155
156 elif isinstance(data[k], dict):
157 self._fix_dates(data[k])
158 else:
159 if isinstance(data[k], (str, unicode)):
160 self._convert_date(data, k)
161
162 def _convert_date(self, q, field_name):
163 m = date_regex.findall(q[field_name])
164 if len(m) > 0:
165 q[field_name] = parse(m[0], yearfirst=True)
166
167 def run_query(self, query):
168 if self.is_replica_set:
169 db_connection = pymongo.MongoReplicaSetClient(self.configuration["connectionString"], replicaSet=self.configuration["replicaSetName"])
170 else:
171 db_connection = pymongo.MongoClient(self.configuration["connectionString"])
172
173 db = db_connection[self.db_name]
174
175 logger.debug("mongodb connection string: %s", self.configuration['connectionString'])
176 logger.debug("mongodb got query: %s", query)
177
178 try:
179 query_data = json.loads(query)
180 self._fix_dates(query_data)
181 except ValueError:
182 return None, "Invalid query format. The query is not a valid JSON."
183
184 if "collection" not in query_data:
185 return None, "'collection' must have a value to run a query"
186 else:
187 collection = query_data["collection"]
188
189 q = query_data.get("query", None)
190 f = None
191
192 aggregate = query_data.get("aggregate", None)
193 if aggregate:
194 for step in aggregate:
195 if "$sort" in step:
196 sort_list = []
197 for sort_item in step["$sort"]:
198 sort_list.append((sort_item["name"], sort_item["direction"]))
199
200 step["$sort"] = SON(sort_list)
201
202 if not aggregate:
203 s = None
204 if "sort" in query_data and query_data["sort"]:
205 s = []
206 for field in query_data["sort"]:
207 s.append((field["name"], field["direction"]))
208
209 if "fields" in query_data:
210 f = query_data["fields"]
211
212 s = None
213 if "sort" in query_data and query_data["sort"]:
214 s = []
215 for field_data in query_data["sort"]:
216 s.append((field_data["name"], field_data["direction"]))
217
218 columns = []
219 rows = []
220
221 cursor = None
222 if q or (not q and not aggregate):
223 if s:
224 cursor = db[collection].find(q, f).sort(s)
225 else:
226 cursor = db[collection].find(q, f)
227
228 if "skip" in query_data:
229 cursor = cursor.skip(query_data["skip"])
230
231 if "limit" in query_data:
232 cursor = cursor.limit(query_data["limit"])
233
234 elif aggregate:
235 r = db[collection].aggregate(aggregate)
236
237 # Backwards compatibility with older pymongo versions.
238 #
239 # Older pymongo version would return a dictionary from an aggregate command.
240 # The dict would contain a "result" key which would hold the cursor.
241 # Newer ones return pymongo.command_cursor.CommandCursor.
242 if isinstance(r, dict):
243 cursor = r["result"]
244 else:
245 cursor = r
246
247 for r in cursor:
248 for k in r:
249 if self._get_column_by_name(columns, k) is None:
250 columns.append({
251 "name": k,
252 "friendly_name": k,
253 "type": TYPES_MAP.get(type(r[k]), TYPE_STRING)
254 })
255
256 rows.append(r)
257
258 if f:
259 ordered_columns = []
260 for k in sorted(f, key=f.get):
261 ordered_columns.append(self._get_column_by_name(columns, k))
262
263 columns = ordered_columns
264
265 data = {
266 "columns": columns,
267 "rows": rows
268 }
269 error = None
270 json_data = json.dumps(data, cls=MongoDBJSONEncoder)
271
272 return json_data, error
273
274 register(MongoDB)
275
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py
--- a/redash/query_runner/mongodb.py
+++ b/redash/query_runner/mongodb.py
@@ -29,7 +29,6 @@
datetime.datetime: TYPE_DATETIME,
}
-date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
class MongoDBJSONEncoder(JSONEncoder):
def default(self, o):
@@ -38,66 +37,25 @@
return super(MongoDBJSONEncoder, self).default(o)
-# Simple query example:
-#
-# {
-# "collection" : "my_collection",
-# "query" : {
-# "date" : {
-# "$gt" : "ISODate(\"2015-01-15 11:41\")",
-# },
-# "type" : 1
-# },
-# "fields" : {
-# "_id" : 1,
-# "name" : 2
-# },
-# "sort" : [
-# {
-# "name" : "date",
-# "direction" : -1
-# }
-# ]
-#
-# }
-#
-#
-# Aggregation
-# ===========
-# Uses a syntax similar to the one used in PyMongo, however to support the
-# correct order of sorting, it uses a regular list for the "$sort" operation
-# that converts into a SON (sorted dictionary) object before execution.
-#
-# Aggregation query example:
-#
-# {
-# "collection" : "things",
-# "aggregate" : [
-# {
-# "$unwind" : "$tags"
-# },
-# {
-# "$group" : {
-# "_id" : "$tags",
-# "count" : { "$sum" : 1 }
-# }
-# },
-# {
-# "$sort" : [
-# {
-# "name" : "count",
-# "direction" : -1
-# },
-# {
-# "name" : "_id",
-# "direction" : -1
-# }
-# ]
-# }
-# ]
-# }
-#
-#
+
+date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
+
+
+def datetime_parser(dct):
+ for k, v in dct.iteritems():
+ if isinstance(v, basestring):
+ m = date_regex.findall(v)
+ if len(m) > 0:
+ dct[k] = parse(m[0], yearfirst=True)
+
+ return dct
+
+
+def parse_query_json(query):
+ query_data = json.loads(query, object_hook=datetime_parser)
+ return query_data
+
+
class MongoDB(BaseQueryRunner):
@classmethod
def configuration_schema(cls):
@@ -144,25 +102,6 @@
return None
- def _fix_dates(self, data):
- for k in data:
- if isinstance(data[k], list):
- for i in range(0, len(data[k])):
- if isinstance(data[k][i], (str, unicode)):
- self._convert_date(data[k], i)
- elif not isinstance(data[k][i], (int)):
- self._fix_dates(data[k][i])
-
- elif isinstance(data[k], dict):
- self._fix_dates(data[k])
- else:
- if isinstance(data[k], (str, unicode)):
- self._convert_date(data, k)
-
- def _convert_date(self, q, field_name):
- m = date_regex.findall(q[field_name])
- if len(m) > 0:
- q[field_name] = parse(m[0], yearfirst=True)
def run_query(self, query):
if self.is_replica_set:
@@ -176,8 +115,7 @@
logger.debug("mongodb got query: %s", query)
try:
- query_data = json.loads(query)
- self._fix_dates(query_data)
+ query_data = parse_query_json(query)
except ValueError:
return None, "Invalid query format. The query is not a valid JSON."
| {"golden_diff": "diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py\n--- a/redash/query_runner/mongodb.py\n+++ b/redash/query_runner/mongodb.py\n@@ -29,7 +29,6 @@\n datetime.datetime: TYPE_DATETIME,\n }\n \n-date_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n \n class MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n@@ -38,66 +37,25 @@\n \n return super(MongoDBJSONEncoder, self).default(o)\n \n-# Simple query example:\n-#\n-# {\n-# \"collection\" : \"my_collection\",\n-# \"query\" : {\n-# \"date\" : {\n-# \"$gt\" : \"ISODate(\\\"2015-01-15 11:41\\\")\",\n-# },\n-# \"type\" : 1\n-# },\n-# \"fields\" : {\n-# \"_id\" : 1,\n-# \"name\" : 2\n-# },\n-# \"sort\" : [\n-# {\n-# \"name\" : \"date\",\n-# \"direction\" : -1\n-# }\n-# ]\n-#\n-# }\n-#\n-#\n-# Aggregation\n-# ===========\n-# Uses a syntax similar to the one used in PyMongo, however to support the\n-# correct order of sorting, it uses a regular list for the \"$sort\" operation\n-# that converts into a SON (sorted dictionary) object before execution.\n-#\n-# Aggregation query example:\n-#\n-# {\n-# \"collection\" : \"things\",\n-# \"aggregate\" : [\n-# {\n-# \"$unwind\" : \"$tags\"\n-# },\n-# {\n-# \"$group\" : {\n-# \"_id\" : \"$tags\",\n-# \"count\" : { \"$sum\" : 1 }\n-# }\n-# },\n-# {\n-# \"$sort\" : [\n-# {\n-# \"name\" : \"count\",\n-# \"direction\" : -1\n-# },\n-# {\n-# \"name\" : \"_id\",\n-# \"direction\" : -1\n-# }\n-# ]\n-# }\n-# ]\n-# }\n-#\n-#\n+\n+date_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n+\n+\n+def datetime_parser(dct):\n+ for k, v in dct.iteritems():\n+ if isinstance(v, basestring):\n+ m = date_regex.findall(v)\n+ if len(m) > 0:\n+ dct[k] = parse(m[0], yearfirst=True)\n+\n+ return dct\n+\n+\n+def parse_query_json(query):\n+ query_data = json.loads(query, object_hook=datetime_parser)\n+ return query_data\n+\n+\n class MongoDB(BaseQueryRunner):\n @classmethod\n def configuration_schema(cls):\n@@ -144,25 +102,6 @@\n \n return None\n \n- def _fix_dates(self, data):\n- for k in data:\n- if isinstance(data[k], list):\n- for i in range(0, len(data[k])):\n- if isinstance(data[k][i], (str, unicode)):\n- self._convert_date(data[k], i)\n- elif not isinstance(data[k][i], (int)):\n- self._fix_dates(data[k][i])\n-\n- elif isinstance(data[k], dict):\n- self._fix_dates(data[k])\n- else:\n- if isinstance(data[k], (str, unicode)):\n- self._convert_date(data, k)\n-\n- def _convert_date(self, q, field_name):\n- m = date_regex.findall(q[field_name])\n- if len(m) > 0:\n- q[field_name] = parse(m[0], yearfirst=True)\n \n def run_query(self, query):\n if self.is_replica_set:\n@@ -176,8 +115,7 @@\n logger.debug(\"mongodb got query: %s\", query)\n \n try:\n- query_data = json.loads(query)\n- self._fix_dates(query_data)\n+ query_data = parse_query_json(query)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n", "issue": "\"'float' object is not iterable\" when using coordinates for MongoDB query\nI'm trying to run a query using **MongoDB** and the **[$geoNear](http://docs.mongodb.org/manual/reference/operator/aggregation/geoNear/)** function, but every time I type the origin coordinate using floats (to create a [GeoJSON Point](http://docs.mongodb.org/manual/reference/geojson/)), I get an error: [_from Python?_]\n\n `Error running query: 'float' object is not iterable`\n\nI'm trying to run the query below. The problem here is the `[ -22.910079, -43.205161 ]` part.\n\n``` json\n{\n \"collection\": \"bus\",\n \"aggregate\": [\n { \n \"$geoNear\": { \n \"near\": { \"type\": \"Point\", \"coordinates\": [ -22.910079, -43.205161 ] },\n \"maxDistance\": 100000000,\n \"distanceField\": \"dist.calculated\",\n \"includeLocs\": \"dist.location\",\n \"spherical\": true\n }\n } \n ]\n}\n```\n\nHowever, if I use the coordinates with integers, such as `[ -22, -43 ]`, the query runs fine, but this coordinate is now meaningless, obviously. Here is an example that doesn't error:\n\n``` json\n{\n \"collection\": \"bus\",\n \"aggregate\": [\n { \n \"$geoNear\": { \n \"near\": { \"type\": \"Point\", \"coordinates\": [ -22, -43 ] },\n \"maxDistance\": 100000000,\n \"distanceField\": \"dist.calculated\",\n \"includeLocs\": \"dist.location\",\n \"spherical\": true\n }\n } \n ]\n}\n```\n\n", "before_files": [{"content": "import json\nimport datetime\nimport logging\nimport re\nfrom dateutil.parser import parse\n\nfrom redash.utils import JSONEncoder\nfrom redash.query_runner import *\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pymongo\n from bson.objectid import ObjectId\n from bson.son import SON\n enabled = True\n\nexcept ImportError:\n enabled = False\n\n\nTYPES_MAP = {\n str: TYPE_STRING,\n unicode: TYPE_STRING,\n int: TYPE_INTEGER,\n long: TYPE_INTEGER,\n float: TYPE_FLOAT,\n bool: TYPE_BOOLEAN,\n datetime.datetime: TYPE_DATETIME,\n}\n\ndate_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n\nclass MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n if isinstance(o, ObjectId):\n return str(o)\n\n return super(MongoDBJSONEncoder, self).default(o)\n\n# Simple query example:\n#\n# {\n# \"collection\" : \"my_collection\",\n# \"query\" : {\n# \"date\" : {\n# \"$gt\" : \"ISODate(\\\"2015-01-15 11:41\\\")\",\n# },\n# \"type\" : 1\n# },\n# \"fields\" : {\n# \"_id\" : 1,\n# \"name\" : 2\n# },\n# \"sort\" : [\n# {\n# \"name\" : \"date\",\n# \"direction\" : -1\n# }\n# ]\n#\n# }\n#\n#\n# Aggregation\n# ===========\n# Uses a syntax similar to the one used in PyMongo, however to support the\n# correct order of sorting, it uses a regular list for the \"$sort\" operation\n# that converts into a SON (sorted dictionary) object before execution.\n#\n# Aggregation query example:\n#\n# {\n# \"collection\" : \"things\",\n# \"aggregate\" : [\n# {\n# \"$unwind\" : \"$tags\"\n# },\n# {\n# \"$group\" : {\n# \"_id\" : \"$tags\",\n# \"count\" : { \"$sum\" : 1 }\n# }\n# },\n# {\n# \"$sort\" : [\n# {\n# \"name\" : \"count\",\n# \"direction\" : -1\n# },\n# {\n# \"name\" : \"_id\",\n# \"direction\" : -1\n# }\n# ]\n# }\n# ]\n# }\n#\n#\nclass MongoDB(BaseQueryRunner):\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'connectionString': {\n 'type': 'string',\n 'title': 'Connection String'\n },\n 'dbName': {\n 'type': 'string',\n 'title': \"Database Name\"\n },\n 'replicaSetName': {\n 'type': 'string',\n 'title': 'Replica Set Name'\n },\n },\n 'required': ['connectionString']\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def annotate_query(cls):\n return False\n\n def __init__(self, configuration_json):\n super(MongoDB, self).__init__(configuration_json)\n\n self.syntax = 'json'\n\n self.db_name = self.configuration[\"dbName\"]\n\n self.is_replica_set = True if \"replicaSetName\" in self.configuration and self.configuration[\"replicaSetName\"] else False\n\n def _get_column_by_name(self, columns, column_name):\n for c in columns:\n if \"name\" in c and c[\"name\"] == column_name:\n return c\n\n return None\n\n def _fix_dates(self, data):\n for k in data:\n if isinstance(data[k], list):\n for i in range(0, len(data[k])):\n if isinstance(data[k][i], (str, unicode)):\n self._convert_date(data[k], i)\n elif not isinstance(data[k][i], (int)):\n self._fix_dates(data[k][i])\n\n elif isinstance(data[k], dict):\n self._fix_dates(data[k])\n else:\n if isinstance(data[k], (str, unicode)):\n self._convert_date(data, k)\n\n def _convert_date(self, q, field_name):\n m = date_regex.findall(q[field_name])\n if len(m) > 0:\n q[field_name] = parse(m[0], yearfirst=True)\n\n def run_query(self, query):\n if self.is_replica_set:\n db_connection = pymongo.MongoReplicaSetClient(self.configuration[\"connectionString\"], replicaSet=self.configuration[\"replicaSetName\"])\n else:\n db_connection = pymongo.MongoClient(self.configuration[\"connectionString\"])\n\n db = db_connection[self.db_name]\n\n logger.debug(\"mongodb connection string: %s\", self.configuration['connectionString'])\n logger.debug(\"mongodb got query: %s\", query)\n\n try:\n query_data = json.loads(query)\n self._fix_dates(query_data)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n\n if \"collection\" not in query_data:\n return None, \"'collection' must have a value to run a query\"\n else:\n collection = query_data[\"collection\"]\n\n q = query_data.get(\"query\", None)\n f = None\n\n aggregate = query_data.get(\"aggregate\", None)\n if aggregate:\n for step in aggregate:\n if \"$sort\" in step:\n sort_list = []\n for sort_item in step[\"$sort\"]:\n sort_list.append((sort_item[\"name\"], sort_item[\"direction\"]))\n\n step[\"$sort\"] = SON(sort_list)\n\n if not aggregate:\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field in query_data[\"sort\"]:\n s.append((field[\"name\"], field[\"direction\"]))\n\n if \"fields\" in query_data:\n f = query_data[\"fields\"]\n\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field_data in query_data[\"sort\"]:\n s.append((field_data[\"name\"], field_data[\"direction\"]))\n\n columns = []\n rows = []\n\n cursor = None\n if q or (not q and not aggregate):\n if s:\n cursor = db[collection].find(q, f).sort(s)\n else:\n cursor = db[collection].find(q, f)\n\n if \"skip\" in query_data:\n cursor = cursor.skip(query_data[\"skip\"])\n\n if \"limit\" in query_data:\n cursor = cursor.limit(query_data[\"limit\"])\n\n elif aggregate:\n r = db[collection].aggregate(aggregate)\n\n # Backwards compatibility with older pymongo versions.\n #\n # Older pymongo version would return a dictionary from an aggregate command.\n # The dict would contain a \"result\" key which would hold the cursor.\n # Newer ones return pymongo.command_cursor.CommandCursor.\n if isinstance(r, dict):\n cursor = r[\"result\"]\n else:\n cursor = r\n\n for r in cursor:\n for k in r:\n if self._get_column_by_name(columns, k) is None:\n columns.append({\n \"name\": k,\n \"friendly_name\": k,\n \"type\": TYPES_MAP.get(type(r[k]), TYPE_STRING)\n })\n\n rows.append(r)\n\n if f:\n ordered_columns = []\n for k in sorted(f, key=f.get):\n ordered_columns.append(self._get_column_by_name(columns, k))\n\n columns = ordered_columns\n\n data = {\n \"columns\": columns,\n \"rows\": rows\n }\n error = None\n json_data = json.dumps(data, cls=MongoDBJSONEncoder)\n\n return json_data, error\n\nregister(MongoDB)\n", "path": "redash/query_runner/mongodb.py"}], "after_files": [{"content": "import json\nimport datetime\nimport logging\nimport re\nfrom dateutil.parser import parse\n\nfrom redash.utils import JSONEncoder\nfrom redash.query_runner import *\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pymongo\n from bson.objectid import ObjectId\n from bson.son import SON\n enabled = True\n\nexcept ImportError:\n enabled = False\n\n\nTYPES_MAP = {\n str: TYPE_STRING,\n unicode: TYPE_STRING,\n int: TYPE_INTEGER,\n long: TYPE_INTEGER,\n float: TYPE_FLOAT,\n bool: TYPE_BOOLEAN,\n datetime.datetime: TYPE_DATETIME,\n}\n\n\nclass MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n if isinstance(o, ObjectId):\n return str(o)\n\n return super(MongoDBJSONEncoder, self).default(o)\n\n\ndate_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n\n\ndef datetime_parser(dct):\n for k, v in dct.iteritems():\n if isinstance(v, basestring):\n m = date_regex.findall(v)\n if len(m) > 0:\n dct[k] = parse(m[0], yearfirst=True)\n\n return dct\n\n\ndef parse_query_json(query):\n query_data = json.loads(query, object_hook=datetime_parser)\n return query_data\n\n\nclass MongoDB(BaseQueryRunner):\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'connectionString': {\n 'type': 'string',\n 'title': 'Connection String'\n },\n 'dbName': {\n 'type': 'string',\n 'title': \"Database Name\"\n },\n 'replicaSetName': {\n 'type': 'string',\n 'title': 'Replica Set Name'\n },\n },\n 'required': ['connectionString']\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def annotate_query(cls):\n return False\n\n def __init__(self, configuration_json):\n super(MongoDB, self).__init__(configuration_json)\n\n self.syntax = 'json'\n\n self.db_name = self.configuration[\"dbName\"]\n\n self.is_replica_set = True if \"replicaSetName\" in self.configuration and self.configuration[\"replicaSetName\"] else False\n\n def _get_column_by_name(self, columns, column_name):\n for c in columns:\n if \"name\" in c and c[\"name\"] == column_name:\n return c\n\n return None\n\n\n def run_query(self, query):\n if self.is_replica_set:\n db_connection = pymongo.MongoReplicaSetClient(self.configuration[\"connectionString\"], replicaSet=self.configuration[\"replicaSetName\"])\n else:\n db_connection = pymongo.MongoClient(self.configuration[\"connectionString\"])\n\n db = db_connection[self.db_name]\n\n logger.debug(\"mongodb connection string: %s\", self.configuration['connectionString'])\n logger.debug(\"mongodb got query: %s\", query)\n\n try:\n query_data = parse_query_json(query)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n\n if \"collection\" not in query_data:\n return None, \"'collection' must have a value to run a query\"\n else:\n collection = query_data[\"collection\"]\n\n q = query_data.get(\"query\", None)\n f = None\n\n aggregate = query_data.get(\"aggregate\", None)\n if aggregate:\n for step in aggregate:\n if \"$sort\" in step:\n sort_list = []\n for sort_item in step[\"$sort\"]:\n sort_list.append((sort_item[\"name\"], sort_item[\"direction\"]))\n\n step[\"$sort\"] = SON(sort_list)\n\n if not aggregate:\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field in query_data[\"sort\"]:\n s.append((field[\"name\"], field[\"direction\"]))\n\n if \"fields\" in query_data:\n f = query_data[\"fields\"]\n\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field_data in query_data[\"sort\"]:\n s.append((field_data[\"name\"], field_data[\"direction\"]))\n\n columns = []\n rows = []\n\n cursor = None\n if q or (not q and not aggregate):\n if s:\n cursor = db[collection].find(q, f).sort(s)\n else:\n cursor = db[collection].find(q, f)\n\n if \"skip\" in query_data:\n cursor = cursor.skip(query_data[\"skip\"])\n\n if \"limit\" in query_data:\n cursor = cursor.limit(query_data[\"limit\"])\n\n elif aggregate:\n r = db[collection].aggregate(aggregate)\n\n # Backwards compatibility with older pymongo versions.\n #\n # Older pymongo version would return a dictionary from an aggregate command.\n # The dict would contain a \"result\" key which would hold the cursor.\n # Newer ones return pymongo.command_cursor.CommandCursor.\n if isinstance(r, dict):\n cursor = r[\"result\"]\n else:\n cursor = r\n\n for r in cursor:\n for k in r:\n if self._get_column_by_name(columns, k) is None:\n columns.append({\n \"name\": k,\n \"friendly_name\": k,\n \"type\": TYPES_MAP.get(type(r[k]), TYPE_STRING)\n })\n\n rows.append(r)\n\n if f:\n ordered_columns = []\n for k in sorted(f, key=f.get):\n ordered_columns.append(self._get_column_by_name(columns, k))\n\n columns = ordered_columns\n\n data = {\n \"columns\": columns,\n \"rows\": rows\n }\n error = None\n json_data = json.dumps(data, cls=MongoDBJSONEncoder)\n\n return json_data, error\n\nregister(MongoDB)\n", "path": "redash/query_runner/mongodb.py"}]} | 3,098 | 972 |
gh_patches_debug_35338 | rasdani/github-patches | git_diff | joke2k__faker-270 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
some generated UK postcodes are invalid
UK postcodes follow strict rules and there are a limited set of codes for each part of the postcode. Faker does not know about these rules and generates postcodes such as: `XC9E 1FL` and `U93 2ZU` which are invalid. See e.g. https://github.com/hamstah/ukpostcodeparser for more info.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/address/en_GB/__init__.py`
Content:
```
1 from __future__ import unicode_literals
2 from ..en import Provider as AddressProvider
3
4
5 class Provider(AddressProvider):
6 city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')
7 city_suffixes = (
8 'town', 'ton', 'land', 'ville', 'berg', 'burgh', 'borough', 'bury', 'view', 'port', 'mouth', 'stad', 'furt',
9 'chester', 'mouth', 'fort', 'haven', 'side', 'shire')
10 building_number_formats = ('#', '##', '###')
11 street_suffixes = (
12 'alley', 'avenue', 'branch', 'bridge', 'brook', 'brooks', 'burg', 'burgs', 'bypass', 'camp', 'canyon', 'cape',
13 'causeway', 'center', 'centers', 'circle', 'circles', 'cliff', 'cliffs', 'club', 'common', 'corner', 'corners',
14 'course', 'court', 'courts', 'cove', 'coves', 'creek', 'crescent', 'crest', 'crossing', 'crossroad', 'curve',
15 'dale', 'dam', 'divide', 'drive', 'drive', 'drives', 'estate', 'estates', 'expressway', 'extension',
16 'extensions',
17 'fall', 'falls', 'ferry', 'field', 'fields', 'flat', 'flats', 'ford', 'fords', 'forest', 'forge', 'forges',
18 'fork',
19 'forks', 'fort', 'freeway', 'garden', 'gardens', 'gateway', 'glen', 'glens', 'green', 'greens', 'grove',
20 'groves',
21 'harbor', 'harbors', 'haven', 'heights', 'highway', 'hill', 'hills', 'hollow', 'inlet', 'inlet', 'island',
22 'island',
23 'islands', 'islands', 'isle', 'isle', 'junction', 'junctions', 'key', 'keys', 'knoll', 'knolls', 'lake',
24 'lakes',
25 'land', 'landing', 'lane', 'light', 'lights', 'loaf', 'lock', 'locks', 'locks', 'lodge', 'lodge', 'loop',
26 'mall',
27 'manor', 'manors', 'meadow', 'meadows', 'mews', 'mill', 'mills', 'mission', 'mission', 'motorway', 'mount',
28 'mountain', 'mountain', 'mountains', 'mountains', 'neck', 'orchard', 'oval', 'overpass', 'park', 'parks',
29 'parkway',
30 'parkways', 'pass', 'passage', 'path', 'pike', 'pine', 'pines', 'place', 'plain', 'plains', 'plains', 'plaza',
31 'plaza', 'point', 'points', 'port', 'port', 'ports', 'ports', 'prairie', 'prairie', 'radial', 'ramp', 'ranch',
32 'rapid', 'rapids', 'rest', 'ridge', 'ridges', 'river', 'road', 'road', 'roads', 'roads', 'route', 'row', 'rue',
33 'run', 'shoal', 'shoals', 'shore', 'shores', 'skyway', 'spring', 'springs', 'springs', 'spur', 'spurs',
34 'square',
35 'square', 'squares', 'squares', 'station', 'station', 'stravenue', 'stravenue', 'stream', 'stream', 'street',
36 'street', 'streets', 'summit', 'summit', 'terrace', 'throughway', 'trace', 'track', 'trafficway', 'trail',
37 'trail',
38 'tunnel', 'tunnel', 'turnpike', 'turnpike', 'underpass', 'union', 'unions', 'valley', 'valleys', 'via',
39 'viaduct',
40 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',
41 'ways', 'well', 'wells')
42
43 postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)
44
45 city_formats = (
46 '{{city_prefix}} {{first_name}}{{city_suffix}}',
47 '{{city_prefix}} {{first_name}}',
48 '{{first_name}}{{city_suffix}}',
49 '{{last_name}}{{city_suffix}}',
50 )
51 street_name_formats = (
52 '{{first_name}} {{street_suffix}}',
53 '{{last_name}} {{street_suffix}}'
54 )
55 street_address_formats = (
56 '{{building_number}} {{street_name}}',
57 '{{secondary_address}}\n{{street_name}}',
58 )
59 address_formats = (
60 "{{street_address}}\n{{city}}\n{{postcode}}",
61 )
62 secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')
63
64 @classmethod
65 def city_prefix(cls):
66 return cls.random_element(cls.city_prefixes)
67
68 @classmethod
69 def secondary_address(cls):
70 return cls.bothify(cls.random_element(cls.secondary_address_formats))
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/faker/providers/address/en_GB/__init__.py b/faker/providers/address/en_GB/__init__.py
--- a/faker/providers/address/en_GB/__init__.py
+++ b/faker/providers/address/en_GB/__init__.py
@@ -40,7 +40,44 @@
'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',
'ways', 'well', 'wells')
- postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)
+ POSTAL_ZONES = (
+ 'AB', 'AL', 'B' , 'BA', 'BB', 'BD', 'BH', 'BL', 'BN', 'BR',
+ 'BS', 'BT', 'CA', 'CB', 'CF', 'CH', 'CM', 'CO', 'CR', 'CT',
+ 'CV', 'CW', 'DA', 'DD', 'DE', 'DG', 'DH', 'DL', 'DN', 'DT',
+ 'DY', 'E' , 'EC', 'EH', 'EN', 'EX', 'FK', 'FY', 'G' , 'GL',
+ 'GY', 'GU', 'HA', 'HD', 'HG', 'HP', 'HR', 'HS', 'HU', 'HX',
+ 'IG', 'IM', 'IP', 'IV', 'JE', 'KA', 'KT', 'KW', 'KY', 'L' ,
+ 'LA', 'LD', 'LE', 'LL', 'LN', 'LS', 'LU', 'M' , 'ME', 'MK',
+ 'ML', 'N' , 'NE', 'NG', 'NN', 'NP', 'NR', 'NW', 'OL', 'OX',
+ 'PA', 'PE', 'PH', 'PL', 'PO', 'PR', 'RG', 'RH', 'RM', 'S' ,
+ 'SA', 'SE', 'SG', 'SK', 'SL', 'SM', 'SN', 'SO', 'SP', 'SR',
+ 'SS', 'ST', 'SW', 'SY', 'TA', 'TD', 'TF', 'TN', 'TQ', 'TR',
+ 'TS', 'TW', 'UB', 'W' , 'WA', 'WC', 'WD', 'WF', 'WN', 'WR',
+ 'WS', 'WV', 'YO', 'ZE'
+ )
+
+ POSTAL_ZONES_ONE_CHAR = [zone for zone in POSTAL_ZONES if len(zone) == 1]
+ POSTAL_ZONES_TWO_CHARS = [zone for zone in POSTAL_ZONES if len(zone) == 2]
+
+ postcode_formats = (
+ 'AN NEE',
+ 'ANN NEE',
+ 'PN NEE',
+ 'PNN NEE',
+ 'ANC NEE',
+ 'PND NEE',
+ )
+
+ _postcode_sets = {
+ ' ': ' ',
+ 'N': [str(i) for i in range(0, 10)],
+ 'A': POSTAL_ZONES_ONE_CHAR,
+ 'B': 'ABCDEFGHKLMNOPQRSTUVWXY',
+ 'C': 'ABCDEFGHJKSTUW',
+ 'D': 'ABEHMNPRVWXY',
+ 'E': 'ABDEFGHJLNPQRSTUWXYZ',
+ 'P': POSTAL_ZONES_TWO_CHARS,
+ }
city_formats = (
'{{city_prefix}} {{first_name}}{{city_suffix}}',
@@ -61,6 +98,17 @@
)
secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')
+ @classmethod
+ def postcode(cls):
+ """
+ See http://web.archive.org/web/20090930140939/http://www.govtalk.gov.uk/gdsc/html/noframes/PostCode-2-1-Release.htm
+ """
+ postcode = ''
+ pattern = cls.random_element(cls.postcode_formats)
+ for placeholder in pattern:
+ postcode += cls.random_element(cls._postcode_sets[placeholder])
+ return postcode
+
@classmethod
def city_prefix(cls):
return cls.random_element(cls.city_prefixes)
| {"golden_diff": "diff --git a/faker/providers/address/en_GB/__init__.py b/faker/providers/address/en_GB/__init__.py\n--- a/faker/providers/address/en_GB/__init__.py\n+++ b/faker/providers/address/en_GB/__init__.py\n@@ -40,7 +40,44 @@\n 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',\n 'ways', 'well', 'wells')\n \n- postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)\n+ POSTAL_ZONES = (\n+ 'AB', 'AL', 'B' , 'BA', 'BB', 'BD', 'BH', 'BL', 'BN', 'BR',\n+ 'BS', 'BT', 'CA', 'CB', 'CF', 'CH', 'CM', 'CO', 'CR', 'CT',\n+ 'CV', 'CW', 'DA', 'DD', 'DE', 'DG', 'DH', 'DL', 'DN', 'DT',\n+ 'DY', 'E' , 'EC', 'EH', 'EN', 'EX', 'FK', 'FY', 'G' , 'GL',\n+ 'GY', 'GU', 'HA', 'HD', 'HG', 'HP', 'HR', 'HS', 'HU', 'HX',\n+ 'IG', 'IM', 'IP', 'IV', 'JE', 'KA', 'KT', 'KW', 'KY', 'L' ,\n+ 'LA', 'LD', 'LE', 'LL', 'LN', 'LS', 'LU', 'M' , 'ME', 'MK',\n+ 'ML', 'N' , 'NE', 'NG', 'NN', 'NP', 'NR', 'NW', 'OL', 'OX',\n+ 'PA', 'PE', 'PH', 'PL', 'PO', 'PR', 'RG', 'RH', 'RM', 'S' ,\n+ 'SA', 'SE', 'SG', 'SK', 'SL', 'SM', 'SN', 'SO', 'SP', 'SR',\n+ 'SS', 'ST', 'SW', 'SY', 'TA', 'TD', 'TF', 'TN', 'TQ', 'TR',\n+ 'TS', 'TW', 'UB', 'W' , 'WA', 'WC', 'WD', 'WF', 'WN', 'WR',\n+ 'WS', 'WV', 'YO', 'ZE'\n+ )\n+\n+ POSTAL_ZONES_ONE_CHAR = [zone for zone in POSTAL_ZONES if len(zone) == 1]\n+ POSTAL_ZONES_TWO_CHARS = [zone for zone in POSTAL_ZONES if len(zone) == 2]\n+\n+ postcode_formats = (\n+ 'AN NEE',\n+ 'ANN NEE',\n+ 'PN NEE',\n+ 'PNN NEE',\n+ 'ANC NEE',\n+ 'PND NEE',\n+ )\n+\n+ _postcode_sets = {\n+ ' ': ' ',\n+ 'N': [str(i) for i in range(0, 10)],\n+ 'A': POSTAL_ZONES_ONE_CHAR,\n+ 'B': 'ABCDEFGHKLMNOPQRSTUVWXY',\n+ 'C': 'ABCDEFGHJKSTUW',\n+ 'D': 'ABEHMNPRVWXY',\n+ 'E': 'ABDEFGHJLNPQRSTUWXYZ',\n+ 'P': POSTAL_ZONES_TWO_CHARS,\n+ }\n \n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n@@ -61,6 +98,17 @@\n )\n secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')\n \n+ @classmethod\n+ def postcode(cls):\n+ \"\"\"\n+ See http://web.archive.org/web/20090930140939/http://www.govtalk.gov.uk/gdsc/html/noframes/PostCode-2-1-Release.htm\n+ \"\"\"\n+ postcode = ''\n+ pattern = cls.random_element(cls.postcode_formats)\n+ for placeholder in pattern:\n+ postcode += cls.random_element(cls._postcode_sets[placeholder])\n+ return postcode\n+\n @classmethod\n def city_prefix(cls):\n return cls.random_element(cls.city_prefixes)\n", "issue": "some generated UK postcodes are invalid\nUK postcodes follow strict rules and there are a limited set of codes for each part of the postcode. Faker does not know about these rules and generates postcodes such as: `XC9E 1FL` and `U93 2ZU` which are invalid. See e.g. https://github.com/hamstah/ukpostcodeparser for more info.\n\n", "before_files": [{"content": "from __future__ import unicode_literals \nfrom ..en import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')\n city_suffixes = (\n 'town', 'ton', 'land', 'ville', 'berg', 'burgh', 'borough', 'bury', 'view', 'port', 'mouth', 'stad', 'furt',\n 'chester', 'mouth', 'fort', 'haven', 'side', 'shire')\n building_number_formats = ('#', '##', '###')\n street_suffixes = (\n 'alley', 'avenue', 'branch', 'bridge', 'brook', 'brooks', 'burg', 'burgs', 'bypass', 'camp', 'canyon', 'cape',\n 'causeway', 'center', 'centers', 'circle', 'circles', 'cliff', 'cliffs', 'club', 'common', 'corner', 'corners',\n 'course', 'court', 'courts', 'cove', 'coves', 'creek', 'crescent', 'crest', 'crossing', 'crossroad', 'curve',\n 'dale', 'dam', 'divide', 'drive', 'drive', 'drives', 'estate', 'estates', 'expressway', 'extension',\n 'extensions',\n 'fall', 'falls', 'ferry', 'field', 'fields', 'flat', 'flats', 'ford', 'fords', 'forest', 'forge', 'forges',\n 'fork',\n 'forks', 'fort', 'freeway', 'garden', 'gardens', 'gateway', 'glen', 'glens', 'green', 'greens', 'grove',\n 'groves',\n 'harbor', 'harbors', 'haven', 'heights', 'highway', 'hill', 'hills', 'hollow', 'inlet', 'inlet', 'island',\n 'island',\n 'islands', 'islands', 'isle', 'isle', 'junction', 'junctions', 'key', 'keys', 'knoll', 'knolls', 'lake',\n 'lakes',\n 'land', 'landing', 'lane', 'light', 'lights', 'loaf', 'lock', 'locks', 'locks', 'lodge', 'lodge', 'loop',\n 'mall',\n 'manor', 'manors', 'meadow', 'meadows', 'mews', 'mill', 'mills', 'mission', 'mission', 'motorway', 'mount',\n 'mountain', 'mountain', 'mountains', 'mountains', 'neck', 'orchard', 'oval', 'overpass', 'park', 'parks',\n 'parkway',\n 'parkways', 'pass', 'passage', 'path', 'pike', 'pine', 'pines', 'place', 'plain', 'plains', 'plains', 'plaza',\n 'plaza', 'point', 'points', 'port', 'port', 'ports', 'ports', 'prairie', 'prairie', 'radial', 'ramp', 'ranch',\n 'rapid', 'rapids', 'rest', 'ridge', 'ridges', 'river', 'road', 'road', 'roads', 'roads', 'route', 'row', 'rue',\n 'run', 'shoal', 'shoals', 'shore', 'shores', 'skyway', 'spring', 'springs', 'springs', 'spur', 'spurs',\n 'square',\n 'square', 'squares', 'squares', 'station', 'station', 'stravenue', 'stravenue', 'stream', 'stream', 'street',\n 'street', 'streets', 'summit', 'summit', 'terrace', 'throughway', 'trace', 'track', 'trafficway', 'trail',\n 'trail',\n 'tunnel', 'tunnel', 'turnpike', 'turnpike', 'underpass', 'union', 'unions', 'valley', 'valleys', 'via',\n 'viaduct',\n 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',\n 'ways', 'well', 'wells')\n\n postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)\n\n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n '{{city_prefix}} {{first_name}}',\n '{{first_name}}{{city_suffix}}',\n '{{last_name}}{{city_suffix}}',\n )\n street_name_formats = (\n '{{first_name}} {{street_suffix}}',\n '{{last_name}} {{street_suffix}}'\n )\n street_address_formats = (\n '{{building_number}} {{street_name}}',\n '{{secondary_address}}\\n{{street_name}}',\n )\n address_formats = (\n \"{{street_address}}\\n{{city}}\\n{{postcode}}\",\n )\n secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')\n\n @classmethod\n def city_prefix(cls):\n return cls.random_element(cls.city_prefixes)\n\n @classmethod\n def secondary_address(cls):\n return cls.bothify(cls.random_element(cls.secondary_address_formats))\n", "path": "faker/providers/address/en_GB/__init__.py"}], "after_files": [{"content": "from __future__ import unicode_literals \nfrom ..en import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')\n city_suffixes = (\n 'town', 'ton', 'land', 'ville', 'berg', 'burgh', 'borough', 'bury', 'view', 'port', 'mouth', 'stad', 'furt',\n 'chester', 'mouth', 'fort', 'haven', 'side', 'shire')\n building_number_formats = ('#', '##', '###')\n street_suffixes = (\n 'alley', 'avenue', 'branch', 'bridge', 'brook', 'brooks', 'burg', 'burgs', 'bypass', 'camp', 'canyon', 'cape',\n 'causeway', 'center', 'centers', 'circle', 'circles', 'cliff', 'cliffs', 'club', 'common', 'corner', 'corners',\n 'course', 'court', 'courts', 'cove', 'coves', 'creek', 'crescent', 'crest', 'crossing', 'crossroad', 'curve',\n 'dale', 'dam', 'divide', 'drive', 'drive', 'drives', 'estate', 'estates', 'expressway', 'extension',\n 'extensions',\n 'fall', 'falls', 'ferry', 'field', 'fields', 'flat', 'flats', 'ford', 'fords', 'forest', 'forge', 'forges',\n 'fork',\n 'forks', 'fort', 'freeway', 'garden', 'gardens', 'gateway', 'glen', 'glens', 'green', 'greens', 'grove',\n 'groves',\n 'harbor', 'harbors', 'haven', 'heights', 'highway', 'hill', 'hills', 'hollow', 'inlet', 'inlet', 'island',\n 'island',\n 'islands', 'islands', 'isle', 'isle', 'junction', 'junctions', 'key', 'keys', 'knoll', 'knolls', 'lake',\n 'lakes',\n 'land', 'landing', 'lane', 'light', 'lights', 'loaf', 'lock', 'locks', 'locks', 'lodge', 'lodge', 'loop',\n 'mall',\n 'manor', 'manors', 'meadow', 'meadows', 'mews', 'mill', 'mills', 'mission', 'mission', 'motorway', 'mount',\n 'mountain', 'mountain', 'mountains', 'mountains', 'neck', 'orchard', 'oval', 'overpass', 'park', 'parks',\n 'parkway',\n 'parkways', 'pass', 'passage', 'path', 'pike', 'pine', 'pines', 'place', 'plain', 'plains', 'plains', 'plaza',\n 'plaza', 'point', 'points', 'port', 'port', 'ports', 'ports', 'prairie', 'prairie', 'radial', 'ramp', 'ranch',\n 'rapid', 'rapids', 'rest', 'ridge', 'ridges', 'river', 'road', 'road', 'roads', 'roads', 'route', 'row', 'rue',\n 'run', 'shoal', 'shoals', 'shore', 'shores', 'skyway', 'spring', 'springs', 'springs', 'spur', 'spurs',\n 'square',\n 'square', 'squares', 'squares', 'station', 'station', 'stravenue', 'stravenue', 'stream', 'stream', 'street',\n 'street', 'streets', 'summit', 'summit', 'terrace', 'throughway', 'trace', 'track', 'trafficway', 'trail',\n 'trail',\n 'tunnel', 'tunnel', 'turnpike', 'turnpike', 'underpass', 'union', 'unions', 'valley', 'valleys', 'via',\n 'viaduct',\n 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',\n 'ways', 'well', 'wells')\n\n POSTAL_ZONES = (\n 'AB', 'AL', 'B' , 'BA', 'BB', 'BD', 'BH', 'BL', 'BN', 'BR',\n 'BS', 'BT', 'CA', 'CB', 'CF', 'CH', 'CM', 'CO', 'CR', 'CT',\n 'CV', 'CW', 'DA', 'DD', 'DE', 'DG', 'DH', 'DL', 'DN', 'DT',\n 'DY', 'E' , 'EC', 'EH', 'EN', 'EX', 'FK', 'FY', 'G' , 'GL',\n 'GY', 'GU', 'HA', 'HD', 'HG', 'HP', 'HR', 'HS', 'HU', 'HX',\n 'IG', 'IM', 'IP', 'IV', 'JE', 'KA', 'KT', 'KW', 'KY', 'L' ,\n 'LA', 'LD', 'LE', 'LL', 'LN', 'LS', 'LU', 'M' , 'ME', 'MK',\n 'ML', 'N' , 'NE', 'NG', 'NN', 'NP', 'NR', 'NW', 'OL', 'OX',\n 'PA', 'PE', 'PH', 'PL', 'PO', 'PR', 'RG', 'RH', 'RM', 'S' ,\n 'SA', 'SE', 'SG', 'SK', 'SL', 'SM', 'SN', 'SO', 'SP', 'SR',\n 'SS', 'ST', 'SW', 'SY', 'TA', 'TD', 'TF', 'TN', 'TQ', 'TR',\n 'TS', 'TW', 'UB', 'W' , 'WA', 'WC', 'WD', 'WF', 'WN', 'WR',\n 'WS', 'WV', 'YO', 'ZE'\n )\n\n POSTAL_ZONES_ONE_CHAR = [zone for zone in POSTAL_ZONES if len(zone) == 1]\n POSTAL_ZONES_TWO_CHARS = [zone for zone in POSTAL_ZONES if len(zone) == 2]\n\n postcode_formats = (\n 'AN NEE',\n 'ANN NEE',\n 'PN NEE',\n 'PNN NEE',\n 'ANC NEE',\n 'PND NEE',\n )\n\n _postcode_sets = {\n ' ': ' ',\n 'N': [str(i) for i in range(0, 10)],\n 'A': POSTAL_ZONES_ONE_CHAR,\n 'B': 'ABCDEFGHKLMNOPQRSTUVWXY',\n 'C': 'ABCDEFGHJKSTUW',\n 'D': 'ABEHMNPRVWXY',\n 'E': 'ABDEFGHJLNPQRSTUWXYZ',\n 'P': POSTAL_ZONES_TWO_CHARS,\n }\n\n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n '{{city_prefix}} {{first_name}}',\n '{{first_name}}{{city_suffix}}',\n '{{last_name}}{{city_suffix}}',\n )\n street_name_formats = (\n '{{first_name}} {{street_suffix}}',\n '{{last_name}} {{street_suffix}}'\n )\n street_address_formats = (\n '{{building_number}} {{street_name}}',\n '{{secondary_address}}\\n{{street_name}}',\n )\n address_formats = (\n \"{{street_address}}\\n{{city}}\\n{{postcode}}\",\n )\n secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')\n\n @classmethod\n def postcode(cls):\n \"\"\"\n See http://web.archive.org/web/20090930140939/http://www.govtalk.gov.uk/gdsc/html/noframes/PostCode-2-1-Release.htm\n \"\"\"\n postcode = ''\n pattern = cls.random_element(cls.postcode_formats)\n for placeholder in pattern:\n postcode += cls.random_element(cls._postcode_sets[placeholder])\n return postcode\n\n @classmethod\n def city_prefix(cls):\n return cls.random_element(cls.city_prefixes)\n\n @classmethod\n def secondary_address(cls):\n return cls.bothify(cls.random_element(cls.secondary_address_formats))\n", "path": "faker/providers/address/en_GB/__init__.py"}]} | 1,691 | 1,001 |
gh_patches_debug_64108 | rasdani/github-patches | git_diff | facebookresearch__hydra-2242 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] Colorlog plugin generates `.log` file in cwd instead of output dir
# 🐛 Bug
I'm using hydra v1.2 with `chdir` set to false.
When I don't use colorlog plugin, the `.log` file with python logs gets generated in my output directory (as expected).
But when I attach colorlog plugin with:
```yaml
defaults:
- override hydra/hydra_logging: colorlog
- override hydra/job_logging: colorlog
```
The `.log` file gets generated in current working directory
## Checklist
- [x] I checked on the latest version of Hydra
- [ ] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).
## Expected Behavior
I would expect the `.log` file to be always saved in output directory by default.
## System information
- **Hydra Version** : 1.2
- **Python version** : 3.10
- **Virtual environment type and version** :
- **Operating system** : linux
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 __version__ = "1.2.0"
4
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
--- a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
+++ b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
@@ -1,3 +1,3 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-__version__ = "1.2.0"
+__version__ = "1.2.1"
| {"golden_diff": "diff --git a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n--- a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n+++ b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n@@ -1,3 +1,3 @@\n # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n \n-__version__ = \"1.2.0\"\n+__version__ = \"1.2.1\"\n", "issue": "[Bug] Colorlog plugin generates `.log` file in cwd instead of output dir\n# \ud83d\udc1b Bug\r\nI'm using hydra v1.2 with `chdir` set to false.\r\n\r\nWhen I don't use colorlog plugin, the `.log` file with python logs gets generated in my output directory (as expected).\r\n\r\nBut when I attach colorlog plugin with:\r\n```yaml\r\ndefaults:\r\n - override hydra/hydra_logging: colorlog\r\n - override hydra/job_logging: colorlog\r\n```\r\nThe `.log` file gets generated in current working directory\r\n\r\n## Checklist\r\n- [x] I checked on the latest version of Hydra\r\n- [ ] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).\r\n\r\n## Expected Behavior\r\nI would expect the `.log` file to be always saved in output directory by default.\r\n\r\n## System information\r\n- **Hydra Version** : 1.2\r\n- **Python version** : 3.10\r\n- **Virtual environment type and version** : \r\n- **Operating system** : linux\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\n__version__ = \"1.2.0\"\n", "path": "plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\n__version__ = \"1.2.1\"\n", "path": "plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py"}]} | 544 | 139 |
gh_patches_debug_11242 | rasdani/github-patches | git_diff | getpelican__pelican-1002 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"'dict_keys' object does not support indexing" in Python 3 using sourcecode directive
When I include a code-block with an option, like this:
```
.. sourcecode:: python
:linenos:
...
```
a WARNING appears and the corresponding file is not processed:
```
WARNING: Could not process /home/juanlu/Development/Python/pelican_test/myproject/content/2013-07-14_hello-world.rst
'dict_keys' object does not support indexing
```
The problem is here:
https://github.com/getpelican/pelican/blob/master/pelican/rstdirectives.py#L35
and the solution is detailed here:
http://stackoverflow.com/questions/8953627/python-dictionary-keys-error
I have read the guidelines but, even being a trivial fix:
```
--- rstdirectives.py 2013-07-14 12:41:00.188687997 +0200
+++ rstdirectives.py.new 2013-07-14 12:36:25.982005000 +0200
@@ -32,7 +32,7 @@
# no lexer found - use the text one instead of an exception
lexer = TextLexer()
# take an arbitrary option if more than one is given
- formatter = self.options and VARIANTS[self.options.keys()[0]] \
+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \
or DEFAULT
parsed = highlight('\n'.join(self.content), lexer, formatter)
return [nodes.raw('', parsed, format='html')]
```
I don't have time to add docs, tests, run the test suite and, summing up, doing it properly. Hence the issue without pull request.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pelican/rstdirectives.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals, print_function
3
4 from docutils import nodes, utils
5 from docutils.parsers.rst import directives, roles, Directive
6 from pygments.formatters import HtmlFormatter
7 from pygments import highlight
8 from pygments.lexers import get_lexer_by_name, TextLexer
9 import re
10
11 INLINESTYLES = False
12 DEFAULT = HtmlFormatter(noclasses=INLINESTYLES)
13 VARIANTS = {
14 'linenos': HtmlFormatter(noclasses=INLINESTYLES, linenos=True),
15 }
16
17
18 class Pygments(Directive):
19 """ Source code syntax hightlighting.
20 """
21 required_arguments = 1
22 optional_arguments = 0
23 final_argument_whitespace = True
24 option_spec = dict([(key, directives.flag) for key in VARIANTS])
25 has_content = True
26
27 def run(self):
28 self.assert_has_content()
29 try:
30 lexer = get_lexer_by_name(self.arguments[0])
31 except ValueError:
32 # no lexer found - use the text one instead of an exception
33 lexer = TextLexer()
34 # take an arbitrary option if more than one is given
35 formatter = self.options and VARIANTS[self.options.keys()[0]] \
36 or DEFAULT
37 parsed = highlight('\n'.join(self.content), lexer, formatter)
38 return [nodes.raw('', parsed, format='html')]
39
40 directives.register_directive('code-block', Pygments)
41 directives.register_directive('sourcecode', Pygments)
42
43
44 class YouTube(Directive):
45 """ Embed YouTube video in posts.
46
47 Courtesy of Brian Hsu: https://gist.github.com/1422773
48
49 VIDEO_ID is required, with / height are optional integer,
50 and align could be left / center / right.
51
52 Usage:
53 .. youtube:: VIDEO_ID
54 :width: 640
55 :height: 480
56 :align: center
57 """
58
59 def align(argument):
60 """Conversion function for the "align" option."""
61 return directives.choice(argument, ('left', 'center', 'right'))
62
63 required_arguments = 1
64 optional_arguments = 2
65 option_spec = {
66 'width': directives.positive_int,
67 'height': directives.positive_int,
68 'align': align
69 }
70
71 final_argument_whitespace = False
72 has_content = False
73
74 def run(self):
75 videoID = self.arguments[0].strip()
76 width = 420
77 height = 315
78 align = 'left'
79
80 if 'width' in self.options:
81 width = self.options['width']
82
83 if 'height' in self.options:
84 height = self.options['height']
85
86 if 'align' in self.options:
87 align = self.options['align']
88
89 url = 'http://www.youtube.com/embed/%s' % videoID
90 div_block = '<div class="youtube" align="%s">' % align
91 embed_block = '<iframe width="%s" height="%s" src="%s" '\
92 'frameborder="0"></iframe>' % (width, height, url)
93
94 return [
95 nodes.raw('', div_block, format='html'),
96 nodes.raw('', embed_block, format='html'),
97 nodes.raw('', '</div>', format='html')]
98
99 directives.register_directive('youtube', YouTube)
100
101 _abbr_re = re.compile('\((.*)\)$')
102
103
104 class abbreviation(nodes.Inline, nodes.TextElement):
105 pass
106
107
108 def abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):
109 text = utils.unescape(text)
110 m = _abbr_re.search(text)
111 if m is None:
112 return [abbreviation(text, text)], []
113 abbr = text[:m.start()].strip()
114 expl = m.group(1)
115 return [abbreviation(abbr, abbr, explanation=expl)], []
116
117 roles.register_local_role('abbr', abbr_role)
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py
--- a/pelican/rstdirectives.py
+++ b/pelican/rstdirectives.py
@@ -32,7 +32,7 @@
# no lexer found - use the text one instead of an exception
lexer = TextLexer()
# take an arbitrary option if more than one is given
- formatter = self.options and VARIANTS[self.options.keys()[0]] \
+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \
or DEFAULT
parsed = highlight('\n'.join(self.content), lexer, formatter)
return [nodes.raw('', parsed, format='html')]
| {"golden_diff": "diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py\n--- a/pelican/rstdirectives.py\n+++ b/pelican/rstdirectives.py\n@@ -32,7 +32,7 @@\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n- formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n", "issue": "\"'dict_keys' object does not support indexing\" in Python 3 using sourcecode directive\nWhen I include a code-block with an option, like this:\n\n```\n.. sourcecode:: python\n :linenos:\n\n ...\n```\n\na WARNING appears and the corresponding file is not processed:\n\n```\nWARNING: Could not process /home/juanlu/Development/Python/pelican_test/myproject/content/2013-07-14_hello-world.rst\n'dict_keys' object does not support indexing\n```\n\nThe problem is here:\n\nhttps://github.com/getpelican/pelican/blob/master/pelican/rstdirectives.py#L35\n\nand the solution is detailed here:\n\nhttp://stackoverflow.com/questions/8953627/python-dictionary-keys-error\n\nI have read the guidelines but, even being a trivial fix:\n\n```\n--- rstdirectives.py 2013-07-14 12:41:00.188687997 +0200\n+++ rstdirectives.py.new 2013-07-14 12:36:25.982005000 +0200\n@@ -32,7 +32,7 @@\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n- formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n```\n\nI don't have time to add docs, tests, run the test suite and, summing up, doing it properly. Hence the issue without pull request.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer_by_name, TextLexer\nimport re\n\nINLINESTYLES = False\nDEFAULT = HtmlFormatter(noclasses=INLINESTYLES)\nVARIANTS = {\n 'linenos': HtmlFormatter(noclasses=INLINESTYLES, linenos=True),\n}\n\n\nclass Pygments(Directive):\n \"\"\" Source code syntax hightlighting.\n \"\"\"\n required_arguments = 1\n optional_arguments = 0\n final_argument_whitespace = True\n option_spec = dict([(key, directives.flag) for key in VARIANTS])\n has_content = True\n\n def run(self):\n self.assert_has_content()\n try:\n lexer = get_lexer_by_name(self.arguments[0])\n except ValueError:\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n\ndirectives.register_directive('code-block', Pygments)\ndirectives.register_directive('sourcecode', Pygments)\n\n\nclass YouTube(Directive):\n \"\"\" Embed YouTube video in posts.\n\n Courtesy of Brian Hsu: https://gist.github.com/1422773\n\n VIDEO_ID is required, with / height are optional integer,\n and align could be left / center / right.\n\n Usage:\n .. youtube:: VIDEO_ID\n :width: 640\n :height: 480\n :align: center\n \"\"\"\n\n def align(argument):\n \"\"\"Conversion function for the \"align\" option.\"\"\"\n return directives.choice(argument, ('left', 'center', 'right'))\n\n required_arguments = 1\n optional_arguments = 2\n option_spec = {\n 'width': directives.positive_int,\n 'height': directives.positive_int,\n 'align': align\n }\n\n final_argument_whitespace = False\n has_content = False\n\n def run(self):\n videoID = self.arguments[0].strip()\n width = 420\n height = 315\n align = 'left'\n\n if 'width' in self.options:\n width = self.options['width']\n\n if 'height' in self.options:\n height = self.options['height']\n\n if 'align' in self.options:\n align = self.options['align']\n\n url = 'http://www.youtube.com/embed/%s' % videoID\n div_block = '<div class=\"youtube\" align=\"%s\">' % align\n embed_block = '<iframe width=\"%s\" height=\"%s\" src=\"%s\" '\\\n 'frameborder=\"0\"></iframe>' % (width, height, url)\n\n return [\n nodes.raw('', div_block, format='html'),\n nodes.raw('', embed_block, format='html'),\n nodes.raw('', '</div>', format='html')]\n\ndirectives.register_directive('youtube', YouTube)\n\n_abbr_re = re.compile('\\((.*)\\)$')\n\n\nclass abbreviation(nodes.Inline, nodes.TextElement):\n pass\n\n\ndef abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):\n text = utils.unescape(text)\n m = _abbr_re.search(text)\n if m is None:\n return [abbreviation(text, text)], []\n abbr = text[:m.start()].strip()\n expl = m.group(1)\n return [abbreviation(abbr, abbr, explanation=expl)], []\n\nroles.register_local_role('abbr', abbr_role)\n", "path": "pelican/rstdirectives.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer_by_name, TextLexer\nimport re\n\nINLINESTYLES = False\nDEFAULT = HtmlFormatter(noclasses=INLINESTYLES)\nVARIANTS = {\n 'linenos': HtmlFormatter(noclasses=INLINESTYLES, linenos=True),\n}\n\n\nclass Pygments(Directive):\n \"\"\" Source code syntax hightlighting.\n \"\"\"\n required_arguments = 1\n optional_arguments = 0\n final_argument_whitespace = True\n option_spec = dict([(key, directives.flag) for key in VARIANTS])\n has_content = True\n\n def run(self):\n self.assert_has_content()\n try:\n lexer = get_lexer_by_name(self.arguments[0])\n except ValueError:\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n formatter = self.options and VARIANTS[list(self.options.keys())[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n\ndirectives.register_directive('code-block', Pygments)\ndirectives.register_directive('sourcecode', Pygments)\n\n\nclass YouTube(Directive):\n \"\"\" Embed YouTube video in posts.\n\n Courtesy of Brian Hsu: https://gist.github.com/1422773\n\n VIDEO_ID is required, with / height are optional integer,\n and align could be left / center / right.\n\n Usage:\n .. youtube:: VIDEO_ID\n :width: 640\n :height: 480\n :align: center\n \"\"\"\n\n def align(argument):\n \"\"\"Conversion function for the \"align\" option.\"\"\"\n return directives.choice(argument, ('left', 'center', 'right'))\n\n required_arguments = 1\n optional_arguments = 2\n option_spec = {\n 'width': directives.positive_int,\n 'height': directives.positive_int,\n 'align': align\n }\n\n final_argument_whitespace = False\n has_content = False\n\n def run(self):\n videoID = self.arguments[0].strip()\n width = 420\n height = 315\n align = 'left'\n\n if 'width' in self.options:\n width = self.options['width']\n\n if 'height' in self.options:\n height = self.options['height']\n\n if 'align' in self.options:\n align = self.options['align']\n\n url = 'http://www.youtube.com/embed/%s' % videoID\n div_block = '<div class=\"youtube\" align=\"%s\">' % align\n embed_block = '<iframe width=\"%s\" height=\"%s\" src=\"%s\" '\\\n 'frameborder=\"0\"></iframe>' % (width, height, url)\n\n return [\n nodes.raw('', div_block, format='html'),\n nodes.raw('', embed_block, format='html'),\n nodes.raw('', '</div>', format='html')]\n\ndirectives.register_directive('youtube', YouTube)\n\n_abbr_re = re.compile('\\((.*)\\)$')\n\n\nclass abbreviation(nodes.Inline, nodes.TextElement):\n pass\n\n\ndef abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):\n text = utils.unescape(text)\n m = _abbr_re.search(text)\n if m is None:\n return [abbreviation(text, text)], []\n abbr = text[:m.start()].strip()\n expl = m.group(1)\n return [abbreviation(abbr, abbr, explanation=expl)], []\n\nroles.register_local_role('abbr', abbr_role)\n", "path": "pelican/rstdirectives.py"}]} | 1,775 | 156 |
gh_patches_debug_4905 | rasdani/github-patches | git_diff | cupy__cupy-1459 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`cupy.split` sometimes fails with a 0-sized input array
```
>>> cupy.split(cupy.ones((3, 0)), [1])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/kataoka/cupy/cupy/manipulation/split.py", line 78, in split
return array_split(ary, indices_or_sections, axis)
File "/home/kataoka/cupy/cupy/manipulation/split.py", line 16, in array_split
return core.array_split(ary, indices_or_sections, axis)
File "cupy/core/core.pyx", line 2338, in cupy.core.core.array_split
v.data = ary.data + prev * stride
File "cupy/cuda/memory.pyx", line 243, in cupy.cuda.memory.MemoryPointer.__add__
assert self.ptr > 0 or offset == 0
AssertionError
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/math/sumprod.py`
Content:
```
1 import numpy
2 import six
3
4 from cupy import core
5
6
7 def sum(a, axis=None, dtype=None, out=None, keepdims=False):
8 """Returns the sum of an array along given axes.
9
10 Args:
11 a (cupy.ndarray): Array to take sum.
12 axis (int or sequence of ints): Axes along which the sum is taken.
13 dtype: Data type specifier.
14 out (cupy.ndarray): Output array.
15 keepdims (bool): If ``True``, the specified axes are remained as axes
16 of length one.
17
18 Returns:
19 cupy.ndarray: The result array.
20
21 .. seealso:: :func:`numpy.sum`
22
23 """
24 # TODO(okuta): check type
25 return a.sum(axis, dtype, out, keepdims)
26
27
28 def prod(a, axis=None, dtype=None, out=None, keepdims=False):
29 """Returns the product of an array along given axes.
30
31 Args:
32 a (cupy.ndarray): Array to take product.
33 axis (int or sequence of ints): Axes along which the product is taken.
34 dtype: Data type specifier.
35 out (cupy.ndarray): Output array.
36 keepdims (bool): If ``True``, the specified axes are remained as axes
37 of length one.
38
39 Returns:
40 cupy.ndarray: The result array.
41
42 .. seealso:: :func:`numpy.prod`
43
44 """
45 # TODO(okuta): check type
46 return a.prod(axis, dtype, out, keepdims)
47
48
49 # TODO(okuta): Implement nansum
50
51
52 def _axis_to_first(x, axis):
53 if axis < 0:
54 axis = x.ndim + axis
55 trans = [axis] + [a for a in six.moves.range(x.ndim) if a != axis]
56 pre = list(six.moves.range(1, axis + 1))
57 succ = list(six.moves.range(axis + 1, x.ndim))
58 revert = pre + [0] + succ
59 return trans, revert
60
61
62 def _proc_as_batch(proc, x, axis):
63 trans, revert = _axis_to_first(x, axis)
64 t = x.transpose(trans)
65 s = t.shape
66 r = t.reshape(x.shape[axis], -1)
67 pos = 1
68 size = r.size
69 batch = r.shape[1]
70 while pos < size:
71 proc(pos, batch, r, size=size)
72 pos <<= 1
73 return r.reshape(s).transpose(revert)
74
75
76 def _cum_core(a, axis, dtype, out, kern, batch_kern):
77 if out is None:
78 if dtype is None:
79 kind = a.dtype.kind
80 if kind == 'b':
81 dtype = numpy.dtype('l')
82 elif kind == 'i' and a.dtype.itemsize < numpy.dtype('l').itemsize:
83 dtype = numpy.dtype('l')
84 elif kind == 'u' and a.dtype.itemsize < numpy.dtype('L').itemsize:
85 dtype = numpy.dtype('L')
86 else:
87 dtype = a.dtype
88
89 out = a.astype(dtype)
90 else:
91 out[...] = a
92
93 if axis is None:
94 out = out.ravel()
95 elif not (-a.ndim <= axis < a.ndim):
96 raise core.core._AxisError('axis(={}) out of bounds'.format(axis))
97 else:
98 return _proc_as_batch(batch_kern, out, axis=axis)
99
100 pos = 1
101 while pos < out.size:
102 kern(pos, out, size=out.size)
103 pos <<= 1
104 return out
105
106
107 _cumsum_batch_kern = core.ElementwiseKernel(
108 'int64 pos, int64 batch', 'raw T x',
109 '''
110 ptrdiff_t b = i % batch;
111 ptrdiff_t j = i / batch;
112 if (j & pos) {
113 const ptrdiff_t dst_index[] = {j, b};
114 const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};
115 x[dst_index] += x[src_index];
116 }
117 ''',
118 'cumsum_batch_kernel'
119 )
120 _cumsum_kern = core.ElementwiseKernel(
121 'int64 pos', 'raw T x',
122 '''
123 if (i & pos) {
124 x[i] += x[i ^ pos | (pos - 1)];
125 }
126 ''',
127 'cumsum_kernel'
128 )
129
130
131 def cumsum(a, axis=None, dtype=None, out=None):
132 """Returns the cumulative sum of an array along a given axis.
133
134 Args:
135 a (cupy.ndarray): Input array.
136 axis (int): Axis along which the cumulative sum is taken. If it is not
137 specified, the input is flattened.
138 dtype: Data type specifier.
139 out (cupy.ndarray): Output array.
140
141 Returns:
142 cupy.ndarray: The result array.
143
144 .. seealso:: :func:`numpy.cumsum`
145
146 """
147 return _cum_core(a, axis, dtype, out, _cumsum_kern, _cumsum_batch_kern)
148
149
150 _cumprod_batch_kern = core.ElementwiseKernel(
151 'int64 pos, int64 batch', 'raw T x',
152 '''
153 ptrdiff_t b = i % batch;
154 ptrdiff_t j = i / batch;
155 if (j & pos) {
156 const ptrdiff_t dst_index[] = {j, b};
157 const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};
158 x[dst_index] *= x[src_index];
159 }
160 ''',
161 'cumprod_batch_kernel'
162 )
163 _cumprod_kern = core.ElementwiseKernel(
164 'int64 pos', 'raw T x',
165 '''
166 if (i & pos) {
167 x[i] *= x[i ^ pos | (pos - 1)];
168 }
169 ''',
170 'cumprod_kernel'
171 )
172
173
174 def cumprod(a, axis=None, dtype=None, out=None):
175 """Returns the cumulative product of an array along a given axis.
176
177 Args:
178 a (cupy.ndarray): Input array.
179 axis (int): Axis along which the cumulative product is taken. If it is
180 not specified, the input is flattened.
181 dtype: Data type specifier.
182 out (cupy.ndarray): Output array.
183
184 Returns:
185 cupy.ndarray: The result array.
186
187 .. seealso:: :func:`numpy.cumprod`
188
189 """
190 return _cum_core(a, axis, dtype, out, _cumprod_kern, _cumprod_batch_kern)
191
192
193 # TODO(okuta): Implement diff
194
195
196 # TODO(okuta): Implement ediff1d
197
198
199 # TODO(okuta): Implement gradient
200
201
202 # TODO(okuta): Implement cross
203
204
205 # TODO(okuta): Implement trapz
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cupy/math/sumprod.py b/cupy/math/sumprod.py
--- a/cupy/math/sumprod.py
+++ b/cupy/math/sumprod.py
@@ -1,6 +1,7 @@
import numpy
import six
+import cupy
from cupy import core
@@ -60,6 +61,8 @@
def _proc_as_batch(proc, x, axis):
+ if x.shape[axis] == 0:
+ return cupy.empty_like(x)
trans, revert = _axis_to_first(x, axis)
t = x.transpose(trans)
s = t.shape
| {"golden_diff": "diff --git a/cupy/math/sumprod.py b/cupy/math/sumprod.py\n--- a/cupy/math/sumprod.py\n+++ b/cupy/math/sumprod.py\n@@ -1,6 +1,7 @@\n import numpy\n import six\n \n+import cupy\n from cupy import core\n \n \n@@ -60,6 +61,8 @@\n \n \n def _proc_as_batch(proc, x, axis):\n+ if x.shape[axis] == 0:\n+ return cupy.empty_like(x)\n trans, revert = _axis_to_first(x, axis)\n t = x.transpose(trans)\n s = t.shape\n", "issue": "`cupy.split` sometimes fails with a 0-sized input array\n```\r\n>>> cupy.split(cupy.ones((3, 0)), [1])\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/kataoka/cupy/cupy/manipulation/split.py\", line 78, in split\r\n return array_split(ary, indices_or_sections, axis)\r\n File \"/home/kataoka/cupy/cupy/manipulation/split.py\", line 16, in array_split\r\n return core.array_split(ary, indices_or_sections, axis)\r\n File \"cupy/core/core.pyx\", line 2338, in cupy.core.core.array_split\r\n v.data = ary.data + prev * stride\r\n File \"cupy/cuda/memory.pyx\", line 243, in cupy.cuda.memory.MemoryPointer.__add__\r\n assert self.ptr > 0 or offset == 0\r\nAssertionError\r\n```\n", "before_files": [{"content": "import numpy\nimport six\n\nfrom cupy import core\n\n\ndef sum(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the sum of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take sum.\n axis (int or sequence of ints): Axes along which the sum is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.sum`\n\n \"\"\"\n # TODO(okuta): check type\n return a.sum(axis, dtype, out, keepdims)\n\n\ndef prod(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the product of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take product.\n axis (int or sequence of ints): Axes along which the product is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.prod`\n\n \"\"\"\n # TODO(okuta): check type\n return a.prod(axis, dtype, out, keepdims)\n\n\n# TODO(okuta): Implement nansum\n\n\ndef _axis_to_first(x, axis):\n if axis < 0:\n axis = x.ndim + axis\n trans = [axis] + [a for a in six.moves.range(x.ndim) if a != axis]\n pre = list(six.moves.range(1, axis + 1))\n succ = list(six.moves.range(axis + 1, x.ndim))\n revert = pre + [0] + succ\n return trans, revert\n\n\ndef _proc_as_batch(proc, x, axis):\n trans, revert = _axis_to_first(x, axis)\n t = x.transpose(trans)\n s = t.shape\n r = t.reshape(x.shape[axis], -1)\n pos = 1\n size = r.size\n batch = r.shape[1]\n while pos < size:\n proc(pos, batch, r, size=size)\n pos <<= 1\n return r.reshape(s).transpose(revert)\n\n\ndef _cum_core(a, axis, dtype, out, kern, batch_kern):\n if out is None:\n if dtype is None:\n kind = a.dtype.kind\n if kind == 'b':\n dtype = numpy.dtype('l')\n elif kind == 'i' and a.dtype.itemsize < numpy.dtype('l').itemsize:\n dtype = numpy.dtype('l')\n elif kind == 'u' and a.dtype.itemsize < numpy.dtype('L').itemsize:\n dtype = numpy.dtype('L')\n else:\n dtype = a.dtype\n\n out = a.astype(dtype)\n else:\n out[...] = a\n\n if axis is None:\n out = out.ravel()\n elif not (-a.ndim <= axis < a.ndim):\n raise core.core._AxisError('axis(={}) out of bounds'.format(axis))\n else:\n return _proc_as_batch(batch_kern, out, axis=axis)\n\n pos = 1\n while pos < out.size:\n kern(pos, out, size=out.size)\n pos <<= 1\n return out\n\n\n_cumsum_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] += x[src_index];\n }\n ''',\n 'cumsum_batch_kernel'\n)\n_cumsum_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] += x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumsum_kernel'\n)\n\n\ndef cumsum(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative sum of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative sum is taken. If it is not\n specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumsum`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumsum_kern, _cumsum_batch_kern)\n\n\n_cumprod_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] *= x[src_index];\n }\n ''',\n 'cumprod_batch_kernel'\n)\n_cumprod_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] *= x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumprod_kernel'\n)\n\n\ndef cumprod(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative product of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative product is taken. If it is\n not specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumprod`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumprod_kern, _cumprod_batch_kern)\n\n\n# TODO(okuta): Implement diff\n\n\n# TODO(okuta): Implement ediff1d\n\n\n# TODO(okuta): Implement gradient\n\n\n# TODO(okuta): Implement cross\n\n\n# TODO(okuta): Implement trapz\n", "path": "cupy/math/sumprod.py"}], "after_files": [{"content": "import numpy\nimport six\n\nimport cupy\nfrom cupy import core\n\n\ndef sum(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the sum of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take sum.\n axis (int or sequence of ints): Axes along which the sum is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.sum`\n\n \"\"\"\n # TODO(okuta): check type\n return a.sum(axis, dtype, out, keepdims)\n\n\ndef prod(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the product of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take product.\n axis (int or sequence of ints): Axes along which the product is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.prod`\n\n \"\"\"\n # TODO(okuta): check type\n return a.prod(axis, dtype, out, keepdims)\n\n\n# TODO(okuta): Implement nansum\n\n\ndef _axis_to_first(x, axis):\n if axis < 0:\n axis = x.ndim + axis\n trans = [axis] + [a for a in six.moves.range(x.ndim) if a != axis]\n pre = list(six.moves.range(1, axis + 1))\n succ = list(six.moves.range(axis + 1, x.ndim))\n revert = pre + [0] + succ\n return trans, revert\n\n\ndef _proc_as_batch(proc, x, axis):\n if x.shape[axis] == 0:\n return cupy.empty_like(x)\n trans, revert = _axis_to_first(x, axis)\n t = x.transpose(trans)\n s = t.shape\n r = t.reshape(x.shape[axis], -1)\n pos = 1\n size = r.size\n batch = r.shape[1]\n while pos < size:\n proc(pos, batch, r, size=size)\n pos <<= 1\n return r.reshape(s).transpose(revert)\n\n\ndef _cum_core(a, axis, dtype, out, kern, batch_kern):\n if out is None:\n if dtype is None:\n kind = a.dtype.kind\n if kind == 'b':\n dtype = numpy.dtype('l')\n elif kind == 'i' and a.dtype.itemsize < numpy.dtype('l').itemsize:\n dtype = numpy.dtype('l')\n elif kind == 'u' and a.dtype.itemsize < numpy.dtype('L').itemsize:\n dtype = numpy.dtype('L')\n else:\n dtype = a.dtype\n\n out = a.astype(dtype)\n else:\n out[...] = a\n\n if axis is None:\n out = out.ravel()\n elif not (-a.ndim <= axis < a.ndim):\n raise core.core._AxisError('axis(={}) out of bounds'.format(axis))\n else:\n return _proc_as_batch(batch_kern, out, axis=axis)\n\n pos = 1\n while pos < out.size:\n kern(pos, out, size=out.size)\n pos <<= 1\n return out\n\n\n_cumsum_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] += x[src_index];\n }\n ''',\n 'cumsum_batch_kernel'\n)\n_cumsum_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] += x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumsum_kernel'\n)\n\n\ndef cumsum(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative sum of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative sum is taken. If it is not\n specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumsum`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumsum_kern, _cumsum_batch_kern)\n\n\n_cumprod_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] *= x[src_index];\n }\n ''',\n 'cumprod_batch_kernel'\n)\n_cumprod_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] *= x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumprod_kernel'\n)\n\n\ndef cumprod(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative product of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative product is taken. If it is\n not specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumprod`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumprod_kern, _cumprod_batch_kern)\n\n\n# TODO(okuta): Implement diff\n\n\n# TODO(okuta): Implement ediff1d\n\n\n# TODO(okuta): Implement gradient\n\n\n# TODO(okuta): Implement cross\n\n\n# TODO(okuta): Implement trapz\n", "path": "cupy/math/sumprod.py"}]} | 2,461 | 138 |
gh_patches_debug_30416 | rasdani/github-patches | git_diff | mesonbuild__meson-9445 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
0.60 fails to build GNOME components
Using the new meson 0.60, either from upstream or Debian, GNOME components started to fail to build
Example of the eog snap build
https://launchpadlibrarian.net/565502418/buildlog_snap_ubuntu_focal_amd64_eog_BUILDING.txt.gz
```
Configuring org.gnome.eog.desktop.in using configuration
../src/data/meson.build:25:5: ERROR: Function does not take positional arguments.
```
Trying to build the current eog deb in Ubuntu with the new meson 0.60 deb from Debian unstable leads to a similar error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mesonbuild/modules/i18n.py`
Content:
```
1 # Copyright 2016 The Meson development team
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from os import path
16 import shutil
17 import typing as T
18
19 from . import ExtensionModule, ModuleReturnValue
20 from .. import build
21 from .. import mesonlib
22 from .. import mlog
23 from ..interpreter.type_checking import CT_BUILD_BY_DEFAULT, CT_INPUT_KW, CT_INSTALL_DIR_KW, CT_INSTALL_TAG_KW, CT_OUTPUT_KW, INSTALL_KW, NoneType, in_set_validator
24 from ..interpreterbase import FeatureNew
25 from ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, noPosargs, typed_kwargs, typed_pos_args
26 from ..scripts.gettext import read_linguas
27
28 if T.TYPE_CHECKING:
29 from typing_extensions import Literal, TypedDict
30
31 from . import ModuleState
32 from ..build import Target
33 from ..interpreter import Interpreter
34 from ..interpreterbase import TYPE_var
35 from ..programs import ExternalProgram
36
37 class MergeFile(TypedDict):
38
39 input: T.List[T.Union[
40 str, build.BuildTarget, build.CustomTarget, build.CustomTargetIndex,
41 build.ExtractedObjects, build.GeneratedList, ExternalProgram,
42 mesonlib.File]]
43 output: T.List[str]
44 build_by_default: bool
45 install: bool
46 install_dir: T.List[T.Union[str, bool]]
47 install_tag: T.List[str]
48 args: T.List[str]
49 data_dirs: T.List[str]
50 po_dir: str
51 type: Literal['xml', 'desktop']
52
53 class Gettext(TypedDict):
54
55 args: T.List[str]
56 data_dirs: T.List[str]
57 install: bool
58 install_dir: T.Optional[str]
59 languages: T.List[str]
60 preset: T.Optional[str]
61
62
63 _ARGS: KwargInfo[T.List[str]] = KwargInfo(
64 'args',
65 ContainerTypeInfo(list, str),
66 default=[],
67 listify=True,
68 )
69
70 _DATA_DIRS: KwargInfo[T.List[str]] = KwargInfo(
71 'data_dirs',
72 ContainerTypeInfo(list, str),
73 default=[],
74 listify=True
75 )
76
77 PRESET_ARGS = {
78 'glib': [
79 '--from-code=UTF-8',
80 '--add-comments',
81
82 # https://developer.gnome.org/glib/stable/glib-I18N.html
83 '--keyword=_',
84 '--keyword=N_',
85 '--keyword=C_:1c,2',
86 '--keyword=NC_:1c,2',
87 '--keyword=g_dcgettext:2',
88 '--keyword=g_dngettext:2,3',
89 '--keyword=g_dpgettext2:2c,3',
90
91 '--flag=N_:1:pass-c-format',
92 '--flag=C_:2:pass-c-format',
93 '--flag=NC_:2:pass-c-format',
94 '--flag=g_dngettext:2:pass-c-format',
95 '--flag=g_strdup_printf:1:c-format',
96 '--flag=g_string_printf:2:c-format',
97 '--flag=g_string_append_printf:2:c-format',
98 '--flag=g_error_new:3:c-format',
99 '--flag=g_set_error:4:c-format',
100 '--flag=g_markup_printf_escaped:1:c-format',
101 '--flag=g_log:3:c-format',
102 '--flag=g_print:1:c-format',
103 '--flag=g_printerr:1:c-format',
104 '--flag=g_printf:1:c-format',
105 '--flag=g_fprintf:2:c-format',
106 '--flag=g_sprintf:2:c-format',
107 '--flag=g_snprintf:3:c-format',
108 ]
109 }
110
111
112 class I18nModule(ExtensionModule):
113 def __init__(self, interpreter: 'Interpreter'):
114 super().__init__(interpreter)
115 self.methods.update({
116 'merge_file': self.merge_file,
117 'gettext': self.gettext,
118 })
119
120 @staticmethod
121 def nogettext_warning() -> None:
122 mlog.warning('Gettext not found, all translation targets will be ignored.', once=True)
123
124 @staticmethod
125 def _get_data_dirs(state: 'ModuleState', dirs: T.Iterable[str]) -> T.List[str]:
126 """Returns source directories of relative paths"""
127 src_dir = path.join(state.environment.get_source_dir(), state.subdir)
128 return [path.join(src_dir, d) for d in dirs]
129
130 @FeatureNew('i18n.merge_file', '0.37.0')
131 @noPosargs
132 @typed_kwargs(
133 'i18n.merge_file',
134 CT_BUILD_BY_DEFAULT,
135 CT_INPUT_KW,
136 CT_INSTALL_DIR_KW,
137 CT_INSTALL_TAG_KW,
138 CT_OUTPUT_KW,
139 INSTALL_KW,
140 _ARGS.evolve(since='0.51.0'),
141 _DATA_DIRS,
142 KwargInfo('po_dir', str, required=True),
143 KwargInfo('type', str, default='xml', validator=in_set_validator({'xml', 'desktop'})),
144 )
145 def merge_file(self, state: 'ModuleState', args: T.List['TYPE_var'], kwargs: 'MergeFile') -> ModuleReturnValue:
146 if not shutil.which('xgettext'):
147 self.nogettext_warning()
148 return ModuleReturnValue(None, [])
149 podir = path.join(state.build_to_src, state.subdir, kwargs['po_dir'])
150
151 ddirs = self._get_data_dirs(state, kwargs['data_dirs'])
152 datadirs = '--datadirs=' + ':'.join(ddirs) if ddirs else None
153
154 command: T.List[T.Union[str, build.BuildTarget, build.CustomTarget,
155 build.CustomTargetIndex, 'ExternalProgram', mesonlib.File]] = []
156 command.extend(state.environment.get_build_command())
157 command.extend([
158 '--internal', 'msgfmthelper',
159 '@INPUT@', '@OUTPUT@', kwargs['type'], podir
160 ])
161 if datadirs:
162 command.append(datadirs)
163
164 if kwargs['args']:
165 command.append('--')
166 command.extend(kwargs['args'])
167
168 build_by_default = kwargs['build_by_default']
169 if build_by_default is None:
170 build_by_default = kwargs['install']
171
172 real_kwargs = {
173 'build_by_default': build_by_default,
174 'command': command,
175 'install': kwargs['install'],
176 'install_dir': kwargs['install_dir'],
177 'output': kwargs['output'],
178 'input': kwargs['input'],
179 'install_tag': kwargs['install_tag'],
180 }
181
182 # We only use this input file to create a name of the custom target.
183 # Thus we can ignore the other entries.
184 inputfile = kwargs['input'][0]
185 if isinstance(inputfile, str):
186 inputfile = mesonlib.File.from_source_file(state.environment.source_dir,
187 state.subdir, inputfile)
188 if isinstance(inputfile, mesonlib.File):
189 # output could be '@BASENAME@' in which case we need to do substitutions
190 # to get a unique target name.
191 outputs = kwargs['output']
192 ifile_abs = inputfile.absolute_path(state.environment.source_dir,
193 state.environment.build_dir)
194 values = mesonlib.get_filenames_templates_dict([ifile_abs], None)
195 outputs = mesonlib.substitute_values(outputs, values)
196 output = outputs[0]
197 ct = build.CustomTarget(
198 output + '_' + state.subdir.replace('/', '@').replace('\\', '@') + '_merge',
199 state.subdir, state.subproject, T.cast(T.Dict[str, T.Any], real_kwargs))
200 else:
201 ct = build.CustomTarget(
202 kwargs['output'][0] + '_merge', state.subdir, state.subproject,
203 T.cast(T.Dict[str, T.Any], real_kwargs))
204
205 return ModuleReturnValue(ct, [ct])
206
207 @typed_pos_args('i81n.gettex', str)
208 @typed_kwargs(
209 'i18n.gettext',
210 _ARGS,
211 _DATA_DIRS,
212 INSTALL_KW.evolve(default=True),
213 KwargInfo('install_dir', (str, NoneType), since='0.50.0'),
214 KwargInfo('languages', ContainerTypeInfo(list, str), default=[], listify=True),
215 KwargInfo(
216 'preset',
217 (str, NoneType),
218 validator=in_set_validator(set(PRESET_ARGS)),
219 since='0.37.0',
220 ),
221 )
222 def gettext(self, state: 'ModuleState', args: T.Tuple[str], kwargs: 'Gettext') -> ModuleReturnValue:
223 if not shutil.which('xgettext'):
224 self.nogettext_warning()
225 return ModuleReturnValue(None, [])
226 packagename = args[0]
227 pkg_arg = f'--pkgname={packagename}'
228
229 languages = kwargs['languages']
230 lang_arg = '--langs=' + '@@'.join(languages) if languages else None
231
232 _datadirs = ':'.join(self._get_data_dirs(state, kwargs['data_dirs']))
233 datadirs = f'--datadirs={_datadirs}' if _datadirs else None
234
235 extra_args = kwargs['args']
236 targets: T.List['Target'] = []
237 gmotargets: T.List['build.CustomTarget'] = []
238
239 preset = kwargs['preset']
240 if preset:
241 preset_args = PRESET_ARGS[preset]
242 extra_args = list(mesonlib.OrderedSet(preset_args + extra_args))
243
244 extra_arg = '--extra-args=' + '@@'.join(extra_args) if extra_args else None
245
246 potargs = state.environment.get_build_command() + ['--internal', 'gettext', 'pot', pkg_arg]
247 if datadirs:
248 potargs.append(datadirs)
249 if extra_arg:
250 potargs.append(extra_arg)
251 pottarget = build.RunTarget(packagename + '-pot', potargs, [], state.subdir, state.subproject)
252 targets.append(pottarget)
253
254 install = kwargs['install']
255 install_dir = kwargs['install_dir'] or state.environment.coredata.get_option(mesonlib.OptionKey('localedir'))
256 assert isinstance(install_dir, str), 'for mypy'
257 if not languages:
258 languages = read_linguas(path.join(state.environment.source_dir, state.subdir))
259 for l in languages:
260 po_file = mesonlib.File.from_source_file(state.environment.source_dir,
261 state.subdir, l+'.po')
262 gmo_kwargs = {'command': ['msgfmt', '@INPUT@', '-o', '@OUTPUT@'],
263 'input': po_file,
264 'output': packagename+'.mo',
265 'install': install,
266 # We have multiple files all installed as packagename+'.mo' in different install subdirs.
267 # What we really wanted to do, probably, is have a rename: kwarg, but that's not available
268 # to custom_targets. Crude hack: set the build target's subdir manually.
269 # Bonus: the build tree has something usable as an uninstalled bindtextdomain() target dir.
270 'install_dir': path.join(install_dir, l, 'LC_MESSAGES'),
271 'install_tag': 'i18n',
272 }
273 gmotarget = build.CustomTarget(f'{packagename}-{l}.mo', path.join(state.subdir, l, 'LC_MESSAGES'), state.subproject, gmo_kwargs)
274 targets.append(gmotarget)
275 gmotargets.append(gmotarget)
276
277 allgmotarget = build.AliasTarget(packagename + '-gmo', gmotargets, state.subdir, state.subproject)
278 targets.append(allgmotarget)
279
280 updatepoargs = state.environment.get_build_command() + ['--internal', 'gettext', 'update_po', pkg_arg]
281 if lang_arg:
282 updatepoargs.append(lang_arg)
283 if datadirs:
284 updatepoargs.append(datadirs)
285 if extra_arg:
286 updatepoargs.append(extra_arg)
287 updatepotarget = build.RunTarget(packagename + '-update-po', updatepoargs, [], state.subdir, state.subproject)
288 targets.append(updatepotarget)
289
290 return ModuleReturnValue([gmotargets, pottarget, updatepotarget], targets)
291
292 def initialize(interp: 'Interpreter') -> I18nModule:
293 return I18nModule(interp)
294
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mesonbuild/modules/i18n.py b/mesonbuild/modules/i18n.py
--- a/mesonbuild/modules/i18n.py
+++ b/mesonbuild/modules/i18n.py
@@ -22,7 +22,7 @@
from .. import mlog
from ..interpreter.type_checking import CT_BUILD_BY_DEFAULT, CT_INPUT_KW, CT_INSTALL_DIR_KW, CT_INSTALL_TAG_KW, CT_OUTPUT_KW, INSTALL_KW, NoneType, in_set_validator
from ..interpreterbase import FeatureNew
-from ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, noPosargs, typed_kwargs, typed_pos_args
+from ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, typed_kwargs, typed_pos_args
from ..scripts.gettext import read_linguas
if T.TYPE_CHECKING:
@@ -128,7 +128,6 @@
return [path.join(src_dir, d) for d in dirs]
@FeatureNew('i18n.merge_file', '0.37.0')
- @noPosargs
@typed_kwargs(
'i18n.merge_file',
CT_BUILD_BY_DEFAULT,
@@ -143,6 +142,9 @@
KwargInfo('type', str, default='xml', validator=in_set_validator({'xml', 'desktop'})),
)
def merge_file(self, state: 'ModuleState', args: T.List['TYPE_var'], kwargs: 'MergeFile') -> ModuleReturnValue:
+ if args:
+ mlog.deprecation('i18n.merge_file does not take any positional arguments. '
+ 'This will become a hard error in the next Meson release.')
if not shutil.which('xgettext'):
self.nogettext_warning()
return ModuleReturnValue(None, [])
| {"golden_diff": "diff --git a/mesonbuild/modules/i18n.py b/mesonbuild/modules/i18n.py\n--- a/mesonbuild/modules/i18n.py\n+++ b/mesonbuild/modules/i18n.py\n@@ -22,7 +22,7 @@\n from .. import mlog\n from ..interpreter.type_checking import CT_BUILD_BY_DEFAULT, CT_INPUT_KW, CT_INSTALL_DIR_KW, CT_INSTALL_TAG_KW, CT_OUTPUT_KW, INSTALL_KW, NoneType, in_set_validator\n from ..interpreterbase import FeatureNew\n-from ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, noPosargs, typed_kwargs, typed_pos_args\n+from ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, typed_kwargs, typed_pos_args\n from ..scripts.gettext import read_linguas\n \n if T.TYPE_CHECKING:\n@@ -128,7 +128,6 @@\n return [path.join(src_dir, d) for d in dirs]\n \n @FeatureNew('i18n.merge_file', '0.37.0')\n- @noPosargs\n @typed_kwargs(\n 'i18n.merge_file',\n CT_BUILD_BY_DEFAULT,\n@@ -143,6 +142,9 @@\n KwargInfo('type', str, default='xml', validator=in_set_validator({'xml', 'desktop'})),\n )\n def merge_file(self, state: 'ModuleState', args: T.List['TYPE_var'], kwargs: 'MergeFile') -> ModuleReturnValue:\n+ if args:\n+ mlog.deprecation('i18n.merge_file does not take any positional arguments. '\n+ 'This will become a hard error in the next Meson release.')\n if not shutil.which('xgettext'):\n self.nogettext_warning()\n return ModuleReturnValue(None, [])\n", "issue": "0.60 fails to build GNOME components\nUsing the new meson 0.60, either from upstream or Debian, GNOME components started to fail to build\r\n\r\nExample of the eog snap build\r\nhttps://launchpadlibrarian.net/565502418/buildlog_snap_ubuntu_focal_amd64_eog_BUILDING.txt.gz\r\n```\r\nConfiguring org.gnome.eog.desktop.in using configuration\r\n\r\n../src/data/meson.build:25:5: ERROR: Function does not take positional arguments.\r\n```\r\n\r\nTrying to build the current eog deb in Ubuntu with the new meson 0.60 deb from Debian unstable leads to a similar error\n", "before_files": [{"content": "# Copyright 2016 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom os import path\nimport shutil\nimport typing as T\n\nfrom . import ExtensionModule, ModuleReturnValue\nfrom .. import build\nfrom .. import mesonlib\nfrom .. import mlog\nfrom ..interpreter.type_checking import CT_BUILD_BY_DEFAULT, CT_INPUT_KW, CT_INSTALL_DIR_KW, CT_INSTALL_TAG_KW, CT_OUTPUT_KW, INSTALL_KW, NoneType, in_set_validator\nfrom ..interpreterbase import FeatureNew\nfrom ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, noPosargs, typed_kwargs, typed_pos_args\nfrom ..scripts.gettext import read_linguas\n\nif T.TYPE_CHECKING:\n from typing_extensions import Literal, TypedDict\n\n from . import ModuleState\n from ..build import Target\n from ..interpreter import Interpreter\n from ..interpreterbase import TYPE_var\n from ..programs import ExternalProgram\n\n class MergeFile(TypedDict):\n\n input: T.List[T.Union[\n str, build.BuildTarget, build.CustomTarget, build.CustomTargetIndex,\n build.ExtractedObjects, build.GeneratedList, ExternalProgram,\n mesonlib.File]]\n output: T.List[str]\n build_by_default: bool\n install: bool\n install_dir: T.List[T.Union[str, bool]]\n install_tag: T.List[str]\n args: T.List[str]\n data_dirs: T.List[str]\n po_dir: str\n type: Literal['xml', 'desktop']\n\n class Gettext(TypedDict):\n\n args: T.List[str]\n data_dirs: T.List[str]\n install: bool\n install_dir: T.Optional[str]\n languages: T.List[str]\n preset: T.Optional[str]\n\n\n_ARGS: KwargInfo[T.List[str]] = KwargInfo(\n 'args',\n ContainerTypeInfo(list, str),\n default=[],\n listify=True,\n)\n\n_DATA_DIRS: KwargInfo[T.List[str]] = KwargInfo(\n 'data_dirs',\n ContainerTypeInfo(list, str),\n default=[],\n listify=True\n)\n\nPRESET_ARGS = {\n 'glib': [\n '--from-code=UTF-8',\n '--add-comments',\n\n # https://developer.gnome.org/glib/stable/glib-I18N.html\n '--keyword=_',\n '--keyword=N_',\n '--keyword=C_:1c,2',\n '--keyword=NC_:1c,2',\n '--keyword=g_dcgettext:2',\n '--keyword=g_dngettext:2,3',\n '--keyword=g_dpgettext2:2c,3',\n\n '--flag=N_:1:pass-c-format',\n '--flag=C_:2:pass-c-format',\n '--flag=NC_:2:pass-c-format',\n '--flag=g_dngettext:2:pass-c-format',\n '--flag=g_strdup_printf:1:c-format',\n '--flag=g_string_printf:2:c-format',\n '--flag=g_string_append_printf:2:c-format',\n '--flag=g_error_new:3:c-format',\n '--flag=g_set_error:4:c-format',\n '--flag=g_markup_printf_escaped:1:c-format',\n '--flag=g_log:3:c-format',\n '--flag=g_print:1:c-format',\n '--flag=g_printerr:1:c-format',\n '--flag=g_printf:1:c-format',\n '--flag=g_fprintf:2:c-format',\n '--flag=g_sprintf:2:c-format',\n '--flag=g_snprintf:3:c-format',\n ]\n}\n\n\nclass I18nModule(ExtensionModule):\n def __init__(self, interpreter: 'Interpreter'):\n super().__init__(interpreter)\n self.methods.update({\n 'merge_file': self.merge_file,\n 'gettext': self.gettext,\n })\n\n @staticmethod\n def nogettext_warning() -> None:\n mlog.warning('Gettext not found, all translation targets will be ignored.', once=True)\n\n @staticmethod\n def _get_data_dirs(state: 'ModuleState', dirs: T.Iterable[str]) -> T.List[str]:\n \"\"\"Returns source directories of relative paths\"\"\"\n src_dir = path.join(state.environment.get_source_dir(), state.subdir)\n return [path.join(src_dir, d) for d in dirs]\n\n @FeatureNew('i18n.merge_file', '0.37.0')\n @noPosargs\n @typed_kwargs(\n 'i18n.merge_file',\n CT_BUILD_BY_DEFAULT,\n CT_INPUT_KW,\n CT_INSTALL_DIR_KW,\n CT_INSTALL_TAG_KW,\n CT_OUTPUT_KW,\n INSTALL_KW,\n _ARGS.evolve(since='0.51.0'),\n _DATA_DIRS,\n KwargInfo('po_dir', str, required=True),\n KwargInfo('type', str, default='xml', validator=in_set_validator({'xml', 'desktop'})),\n )\n def merge_file(self, state: 'ModuleState', args: T.List['TYPE_var'], kwargs: 'MergeFile') -> ModuleReturnValue:\n if not shutil.which('xgettext'):\n self.nogettext_warning()\n return ModuleReturnValue(None, [])\n podir = path.join(state.build_to_src, state.subdir, kwargs['po_dir'])\n\n ddirs = self._get_data_dirs(state, kwargs['data_dirs'])\n datadirs = '--datadirs=' + ':'.join(ddirs) if ddirs else None\n\n command: T.List[T.Union[str, build.BuildTarget, build.CustomTarget,\n build.CustomTargetIndex, 'ExternalProgram', mesonlib.File]] = []\n command.extend(state.environment.get_build_command())\n command.extend([\n '--internal', 'msgfmthelper',\n '@INPUT@', '@OUTPUT@', kwargs['type'], podir\n ])\n if datadirs:\n command.append(datadirs)\n\n if kwargs['args']:\n command.append('--')\n command.extend(kwargs['args'])\n\n build_by_default = kwargs['build_by_default']\n if build_by_default is None:\n build_by_default = kwargs['install']\n\n real_kwargs = {\n 'build_by_default': build_by_default,\n 'command': command,\n 'install': kwargs['install'],\n 'install_dir': kwargs['install_dir'],\n 'output': kwargs['output'],\n 'input': kwargs['input'],\n 'install_tag': kwargs['install_tag'],\n }\n\n # We only use this input file to create a name of the custom target.\n # Thus we can ignore the other entries.\n inputfile = kwargs['input'][0]\n if isinstance(inputfile, str):\n inputfile = mesonlib.File.from_source_file(state.environment.source_dir,\n state.subdir, inputfile)\n if isinstance(inputfile, mesonlib.File):\n # output could be '@BASENAME@' in which case we need to do substitutions\n # to get a unique target name.\n outputs = kwargs['output']\n ifile_abs = inputfile.absolute_path(state.environment.source_dir,\n state.environment.build_dir)\n values = mesonlib.get_filenames_templates_dict([ifile_abs], None)\n outputs = mesonlib.substitute_values(outputs, values)\n output = outputs[0]\n ct = build.CustomTarget(\n output + '_' + state.subdir.replace('/', '@').replace('\\\\', '@') + '_merge',\n state.subdir, state.subproject, T.cast(T.Dict[str, T.Any], real_kwargs))\n else:\n ct = build.CustomTarget(\n kwargs['output'][0] + '_merge', state.subdir, state.subproject,\n T.cast(T.Dict[str, T.Any], real_kwargs))\n\n return ModuleReturnValue(ct, [ct])\n\n @typed_pos_args('i81n.gettex', str)\n @typed_kwargs(\n 'i18n.gettext',\n _ARGS,\n _DATA_DIRS,\n INSTALL_KW.evolve(default=True),\n KwargInfo('install_dir', (str, NoneType), since='0.50.0'),\n KwargInfo('languages', ContainerTypeInfo(list, str), default=[], listify=True),\n KwargInfo(\n 'preset',\n (str, NoneType),\n validator=in_set_validator(set(PRESET_ARGS)),\n since='0.37.0',\n ),\n )\n def gettext(self, state: 'ModuleState', args: T.Tuple[str], kwargs: 'Gettext') -> ModuleReturnValue:\n if not shutil.which('xgettext'):\n self.nogettext_warning()\n return ModuleReturnValue(None, [])\n packagename = args[0]\n pkg_arg = f'--pkgname={packagename}'\n\n languages = kwargs['languages']\n lang_arg = '--langs=' + '@@'.join(languages) if languages else None\n\n _datadirs = ':'.join(self._get_data_dirs(state, kwargs['data_dirs']))\n datadirs = f'--datadirs={_datadirs}' if _datadirs else None\n\n extra_args = kwargs['args']\n targets: T.List['Target'] = []\n gmotargets: T.List['build.CustomTarget'] = []\n\n preset = kwargs['preset']\n if preset:\n preset_args = PRESET_ARGS[preset]\n extra_args = list(mesonlib.OrderedSet(preset_args + extra_args))\n\n extra_arg = '--extra-args=' + '@@'.join(extra_args) if extra_args else None\n\n potargs = state.environment.get_build_command() + ['--internal', 'gettext', 'pot', pkg_arg]\n if datadirs:\n potargs.append(datadirs)\n if extra_arg:\n potargs.append(extra_arg)\n pottarget = build.RunTarget(packagename + '-pot', potargs, [], state.subdir, state.subproject)\n targets.append(pottarget)\n\n install = kwargs['install']\n install_dir = kwargs['install_dir'] or state.environment.coredata.get_option(mesonlib.OptionKey('localedir'))\n assert isinstance(install_dir, str), 'for mypy'\n if not languages:\n languages = read_linguas(path.join(state.environment.source_dir, state.subdir))\n for l in languages:\n po_file = mesonlib.File.from_source_file(state.environment.source_dir,\n state.subdir, l+'.po')\n gmo_kwargs = {'command': ['msgfmt', '@INPUT@', '-o', '@OUTPUT@'],\n 'input': po_file,\n 'output': packagename+'.mo',\n 'install': install,\n # We have multiple files all installed as packagename+'.mo' in different install subdirs.\n # What we really wanted to do, probably, is have a rename: kwarg, but that's not available\n # to custom_targets. Crude hack: set the build target's subdir manually.\n # Bonus: the build tree has something usable as an uninstalled bindtextdomain() target dir.\n 'install_dir': path.join(install_dir, l, 'LC_MESSAGES'),\n 'install_tag': 'i18n',\n }\n gmotarget = build.CustomTarget(f'{packagename}-{l}.mo', path.join(state.subdir, l, 'LC_MESSAGES'), state.subproject, gmo_kwargs)\n targets.append(gmotarget)\n gmotargets.append(gmotarget)\n\n allgmotarget = build.AliasTarget(packagename + '-gmo', gmotargets, state.subdir, state.subproject)\n targets.append(allgmotarget)\n\n updatepoargs = state.environment.get_build_command() + ['--internal', 'gettext', 'update_po', pkg_arg]\n if lang_arg:\n updatepoargs.append(lang_arg)\n if datadirs:\n updatepoargs.append(datadirs)\n if extra_arg:\n updatepoargs.append(extra_arg)\n updatepotarget = build.RunTarget(packagename + '-update-po', updatepoargs, [], state.subdir, state.subproject)\n targets.append(updatepotarget)\n\n return ModuleReturnValue([gmotargets, pottarget, updatepotarget], targets)\n\ndef initialize(interp: 'Interpreter') -> I18nModule:\n return I18nModule(interp)\n", "path": "mesonbuild/modules/i18n.py"}], "after_files": [{"content": "# Copyright 2016 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom os import path\nimport shutil\nimport typing as T\n\nfrom . import ExtensionModule, ModuleReturnValue\nfrom .. import build\nfrom .. import mesonlib\nfrom .. import mlog\nfrom ..interpreter.type_checking import CT_BUILD_BY_DEFAULT, CT_INPUT_KW, CT_INSTALL_DIR_KW, CT_INSTALL_TAG_KW, CT_OUTPUT_KW, INSTALL_KW, NoneType, in_set_validator\nfrom ..interpreterbase import FeatureNew\nfrom ..interpreterbase.decorators import ContainerTypeInfo, KwargInfo, typed_kwargs, typed_pos_args\nfrom ..scripts.gettext import read_linguas\n\nif T.TYPE_CHECKING:\n from typing_extensions import Literal, TypedDict\n\n from . import ModuleState\n from ..build import Target\n from ..interpreter import Interpreter\n from ..interpreterbase import TYPE_var\n from ..programs import ExternalProgram\n\n class MergeFile(TypedDict):\n\n input: T.List[T.Union[\n str, build.BuildTarget, build.CustomTarget, build.CustomTargetIndex,\n build.ExtractedObjects, build.GeneratedList, ExternalProgram,\n mesonlib.File]]\n output: T.List[str]\n build_by_default: bool\n install: bool\n install_dir: T.List[T.Union[str, bool]]\n install_tag: T.List[str]\n args: T.List[str]\n data_dirs: T.List[str]\n po_dir: str\n type: Literal['xml', 'desktop']\n\n class Gettext(TypedDict):\n\n args: T.List[str]\n data_dirs: T.List[str]\n install: bool\n install_dir: T.Optional[str]\n languages: T.List[str]\n preset: T.Optional[str]\n\n\n_ARGS: KwargInfo[T.List[str]] = KwargInfo(\n 'args',\n ContainerTypeInfo(list, str),\n default=[],\n listify=True,\n)\n\n_DATA_DIRS: KwargInfo[T.List[str]] = KwargInfo(\n 'data_dirs',\n ContainerTypeInfo(list, str),\n default=[],\n listify=True\n)\n\nPRESET_ARGS = {\n 'glib': [\n '--from-code=UTF-8',\n '--add-comments',\n\n # https://developer.gnome.org/glib/stable/glib-I18N.html\n '--keyword=_',\n '--keyword=N_',\n '--keyword=C_:1c,2',\n '--keyword=NC_:1c,2',\n '--keyword=g_dcgettext:2',\n '--keyword=g_dngettext:2,3',\n '--keyword=g_dpgettext2:2c,3',\n\n '--flag=N_:1:pass-c-format',\n '--flag=C_:2:pass-c-format',\n '--flag=NC_:2:pass-c-format',\n '--flag=g_dngettext:2:pass-c-format',\n '--flag=g_strdup_printf:1:c-format',\n '--flag=g_string_printf:2:c-format',\n '--flag=g_string_append_printf:2:c-format',\n '--flag=g_error_new:3:c-format',\n '--flag=g_set_error:4:c-format',\n '--flag=g_markup_printf_escaped:1:c-format',\n '--flag=g_log:3:c-format',\n '--flag=g_print:1:c-format',\n '--flag=g_printerr:1:c-format',\n '--flag=g_printf:1:c-format',\n '--flag=g_fprintf:2:c-format',\n '--flag=g_sprintf:2:c-format',\n '--flag=g_snprintf:3:c-format',\n ]\n}\n\n\nclass I18nModule(ExtensionModule):\n def __init__(self, interpreter: 'Interpreter'):\n super().__init__(interpreter)\n self.methods.update({\n 'merge_file': self.merge_file,\n 'gettext': self.gettext,\n })\n\n @staticmethod\n def nogettext_warning() -> None:\n mlog.warning('Gettext not found, all translation targets will be ignored.', once=True)\n\n @staticmethod\n def _get_data_dirs(state: 'ModuleState', dirs: T.Iterable[str]) -> T.List[str]:\n \"\"\"Returns source directories of relative paths\"\"\"\n src_dir = path.join(state.environment.get_source_dir(), state.subdir)\n return [path.join(src_dir, d) for d in dirs]\n\n @FeatureNew('i18n.merge_file', '0.37.0')\n @typed_kwargs(\n 'i18n.merge_file',\n CT_BUILD_BY_DEFAULT,\n CT_INPUT_KW,\n CT_INSTALL_DIR_KW,\n CT_INSTALL_TAG_KW,\n CT_OUTPUT_KW,\n INSTALL_KW,\n _ARGS.evolve(since='0.51.0'),\n _DATA_DIRS,\n KwargInfo('po_dir', str, required=True),\n KwargInfo('type', str, default='xml', validator=in_set_validator({'xml', 'desktop'})),\n )\n def merge_file(self, state: 'ModuleState', args: T.List['TYPE_var'], kwargs: 'MergeFile') -> ModuleReturnValue:\n if args:\n mlog.deprecation('i18n.merge_file does not take any positional arguments. '\n 'This will become a hard error in the next Meson release.')\n if not shutil.which('xgettext'):\n self.nogettext_warning()\n return ModuleReturnValue(None, [])\n podir = path.join(state.build_to_src, state.subdir, kwargs['po_dir'])\n\n ddirs = self._get_data_dirs(state, kwargs['data_dirs'])\n datadirs = '--datadirs=' + ':'.join(ddirs) if ddirs else None\n\n command: T.List[T.Union[str, build.BuildTarget, build.CustomTarget,\n build.CustomTargetIndex, 'ExternalProgram', mesonlib.File]] = []\n command.extend(state.environment.get_build_command())\n command.extend([\n '--internal', 'msgfmthelper',\n '@INPUT@', '@OUTPUT@', kwargs['type'], podir\n ])\n if datadirs:\n command.append(datadirs)\n\n if kwargs['args']:\n command.append('--')\n command.extend(kwargs['args'])\n\n build_by_default = kwargs['build_by_default']\n if build_by_default is None:\n build_by_default = kwargs['install']\n\n real_kwargs = {\n 'build_by_default': build_by_default,\n 'command': command,\n 'install': kwargs['install'],\n 'install_dir': kwargs['install_dir'],\n 'output': kwargs['output'],\n 'input': kwargs['input'],\n 'install_tag': kwargs['install_tag'],\n }\n\n # We only use this input file to create a name of the custom target.\n # Thus we can ignore the other entries.\n inputfile = kwargs['input'][0]\n if isinstance(inputfile, str):\n inputfile = mesonlib.File.from_source_file(state.environment.source_dir,\n state.subdir, inputfile)\n if isinstance(inputfile, mesonlib.File):\n # output could be '@BASENAME@' in which case we need to do substitutions\n # to get a unique target name.\n outputs = kwargs['output']\n ifile_abs = inputfile.absolute_path(state.environment.source_dir,\n state.environment.build_dir)\n values = mesonlib.get_filenames_templates_dict([ifile_abs], None)\n outputs = mesonlib.substitute_values(outputs, values)\n output = outputs[0]\n ct = build.CustomTarget(\n output + '_' + state.subdir.replace('/', '@').replace('\\\\', '@') + '_merge',\n state.subdir, state.subproject, T.cast(T.Dict[str, T.Any], real_kwargs))\n else:\n ct = build.CustomTarget(\n kwargs['output'][0] + '_merge', state.subdir, state.subproject,\n T.cast(T.Dict[str, T.Any], real_kwargs))\n\n return ModuleReturnValue(ct, [ct])\n\n @typed_pos_args('i81n.gettex', str)\n @typed_kwargs(\n 'i18n.gettext',\n _ARGS,\n _DATA_DIRS,\n INSTALL_KW.evolve(default=True),\n KwargInfo('install_dir', (str, NoneType), since='0.50.0'),\n KwargInfo('languages', ContainerTypeInfo(list, str), default=[], listify=True),\n KwargInfo(\n 'preset',\n (str, NoneType),\n validator=in_set_validator(set(PRESET_ARGS)),\n since='0.37.0',\n ),\n )\n def gettext(self, state: 'ModuleState', args: T.Tuple[str], kwargs: 'Gettext') -> ModuleReturnValue:\n if not shutil.which('xgettext'):\n self.nogettext_warning()\n return ModuleReturnValue(None, [])\n packagename = args[0]\n pkg_arg = f'--pkgname={packagename}'\n\n languages = kwargs['languages']\n lang_arg = '--langs=' + '@@'.join(languages) if languages else None\n\n _datadirs = ':'.join(self._get_data_dirs(state, kwargs['data_dirs']))\n datadirs = f'--datadirs={_datadirs}' if _datadirs else None\n\n extra_args = kwargs['args']\n targets: T.List['Target'] = []\n gmotargets: T.List['build.CustomTarget'] = []\n\n preset = kwargs['preset']\n if preset:\n preset_args = PRESET_ARGS[preset]\n extra_args = list(mesonlib.OrderedSet(preset_args + extra_args))\n\n extra_arg = '--extra-args=' + '@@'.join(extra_args) if extra_args else None\n\n potargs = state.environment.get_build_command() + ['--internal', 'gettext', 'pot', pkg_arg]\n if datadirs:\n potargs.append(datadirs)\n if extra_arg:\n potargs.append(extra_arg)\n pottarget = build.RunTarget(packagename + '-pot', potargs, [], state.subdir, state.subproject)\n targets.append(pottarget)\n\n install = kwargs['install']\n install_dir = kwargs['install_dir'] or state.environment.coredata.get_option(mesonlib.OptionKey('localedir'))\n assert isinstance(install_dir, str), 'for mypy'\n if not languages:\n languages = read_linguas(path.join(state.environment.source_dir, state.subdir))\n for l in languages:\n po_file = mesonlib.File.from_source_file(state.environment.source_dir,\n state.subdir, l+'.po')\n gmo_kwargs = {'command': ['msgfmt', '@INPUT@', '-o', '@OUTPUT@'],\n 'input': po_file,\n 'output': packagename+'.mo',\n 'install': install,\n # We have multiple files all installed as packagename+'.mo' in different install subdirs.\n # What we really wanted to do, probably, is have a rename: kwarg, but that's not available\n # to custom_targets. Crude hack: set the build target's subdir manually.\n # Bonus: the build tree has something usable as an uninstalled bindtextdomain() target dir.\n 'install_dir': path.join(install_dir, l, 'LC_MESSAGES'),\n 'install_tag': 'i18n',\n }\n gmotarget = build.CustomTarget(f'{packagename}-{l}.mo', path.join(state.subdir, l, 'LC_MESSAGES'), state.subproject, gmo_kwargs)\n targets.append(gmotarget)\n gmotargets.append(gmotarget)\n\n allgmotarget = build.AliasTarget(packagename + '-gmo', gmotargets, state.subdir, state.subproject)\n targets.append(allgmotarget)\n\n updatepoargs = state.environment.get_build_command() + ['--internal', 'gettext', 'update_po', pkg_arg]\n if lang_arg:\n updatepoargs.append(lang_arg)\n if datadirs:\n updatepoargs.append(datadirs)\n if extra_arg:\n updatepoargs.append(extra_arg)\n updatepotarget = build.RunTarget(packagename + '-update-po', updatepoargs, [], state.subdir, state.subproject)\n targets.append(updatepotarget)\n\n return ModuleReturnValue([gmotargets, pottarget, updatepotarget], targets)\n\ndef initialize(interp: 'Interpreter') -> I18nModule:\n return I18nModule(interp)\n", "path": "mesonbuild/modules/i18n.py"}]} | 3,915 | 392 |
gh_patches_debug_40326 | rasdani/github-patches | git_diff | nextcloud__appstore-201 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Delete user account
A user should be able to delete his account by hitting and confirming it on the download page. The confirmation should not be able to trigger by accident, Github's delete repo ui is a good example.
Before deleting his account, a user will be warned that all his comments and apps will be deleted.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nextcloudappstore/urls.py`
Content:
```
1 from allauth.account.views import signup
2 from allauth.socialaccount.views import signup as social_signup
3 from csp.decorators import csp_exempt
4 from django.conf.urls import url, include
5 from django.contrib import admin
6 from nextcloudappstore.core.user.views import PasswordView, AccountView, \
7 APITokenView
8 from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \
9 app_description, AppReleasesView, AppUploadView, LegalNoticeView
10
11 urlpatterns = [
12 url(r'^$', CategoryAppListView.as_view(), {'id': None}, name='home'),
13 url(r"^signup/$", csp_exempt(signup), name="account_signup"),
14 url(r"^social/signup/$", csp_exempt(social_signup),
15 name="socialaccount_signup"),
16 url(r'^', include('allauth.urls')),
17 url(r'^account/?$', AccountView.as_view(), name='account'),
18 url(r'^account/password/?$', PasswordView.as_view(),
19 name='account-password'),
20 url(r'^account/token/?$', APITokenView.as_view(),
21 name='account-api-token'),
22 url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),
23 url(r'^categories/(?P<id>[\w]*)/?$', CategoryAppListView.as_view(),
24 name='category-app-list'),
25 url(r'^app/upload/?$', AppUploadView.as_view(), name='app-upload'),
26 url(r'^app/(?P<id>[\w_]+)/?$', AppDetailView.as_view(), name='app-detail'),
27 url(r'^app/(?P<id>[\w_]+)/releases/?$', AppReleasesView.as_view(),
28 name='app-releases'),
29 url(r'^app/(?P<id>[\w_]+)/description/?$', app_description,
30 name='app-description'),
31 url(r'^api/', include('nextcloudappstore.core.api.urls',
32 namespace='api')),
33 url(r'^admin/', admin.site.urls),
34 ]
35
```
Path: `nextcloudappstore/core/user/views.py`
Content:
```
1 from allauth.account.views import PasswordChangeView
2 from django.contrib import messages
3 from django.contrib.auth.mixins import LoginRequiredMixin
4 from django.contrib.auth.models import User
5 from django.core.urlresolvers import reverse_lazy
6 from django.views.generic import TemplateView
7 from django.views.generic import UpdateView
8
9
10 class AccountView(LoginRequiredMixin, UpdateView):
11 """Display and allow changing of the user's name."""
12
13 template_name = 'user/account.html'
14 template_name_suffix = ''
15 model = User
16 fields = ['first_name', 'last_name']
17 success_url = reverse_lazy('account')
18
19 def get_context_data(self, **kwargs):
20 context = super().get_context_data(**kwargs)
21 context['acc_page'] = 'account'
22 return context
23
24 def form_valid(self, form):
25 messages.success(self.request, 'Name saved.')
26 return super().form_valid(form)
27
28 def get_object(self, queryset=None):
29 return self.request.user
30
31
32 class PasswordView(LoginRequiredMixin, PasswordChangeView):
33 """Allow the user to change their password."""
34
35 template_name = 'user/password.html'
36 success_url = reverse_lazy('account-password')
37
38 def get_context_data(self, **kwargs):
39 context = super().get_context_data(**kwargs)
40 context['acc_page'] = 'password'
41 return context
42
43
44 class APITokenView(LoginRequiredMixin, TemplateView):
45 """Display the user's API token, and allow it to be regenerated."""
46
47 template_name = 'user/api-token.html'
48
49 def get_context_data(self, **kwargs):
50 context = super().get_context_data(**kwargs)
51 context['acc_page'] = 'api-token'
52 return context
53
```
Path: `nextcloudappstore/core/user/forms.py`
Content:
```
1 from django import forms
2 from captcha.fields import ReCaptchaField
3
4
5 class SignupFormRecaptcha(forms.Form):
6 """integrate a recaptcha field."""
7 recaptcha = ReCaptchaField()
8
9 def signup(self, request, user):
10 pass
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nextcloudappstore/core/user/forms.py b/nextcloudappstore/core/user/forms.py
--- a/nextcloudappstore/core/user/forms.py
+++ b/nextcloudappstore/core/user/forms.py
@@ -1,5 +1,7 @@
from django import forms
from captcha.fields import ReCaptchaField
+from django.forms import EmailField
+from django.utils.translation import ugettext_lazy as _
class SignupFormRecaptcha(forms.Form):
@@ -8,3 +10,19 @@
def signup(self, request, user):
pass
+
+
+class DeleteAccountForm(forms.Form):
+ email = EmailField(required=True, label=_('Your e-mail address'))
+
+ def __init__(self, *args, **kwargs):
+ self.user = kwargs.pop('user', None)
+ super().__init__(*args, **kwargs)
+
+ def clean_email(self):
+ email = self.cleaned_data.get('email')
+ if self.user and self.user.email == email:
+ return email
+ else:
+ raise forms.ValidationError(_(
+ 'The given e-mail address does not match your e-mail address'))
diff --git a/nextcloudappstore/core/user/views.py b/nextcloudappstore/core/user/views.py
--- a/nextcloudappstore/core/user/views.py
+++ b/nextcloudappstore/core/user/views.py
@@ -3,9 +3,30 @@
from django.contrib.auth.mixins import LoginRequiredMixin
from django.contrib.auth.models import User
from django.core.urlresolvers import reverse_lazy
+from django.shortcuts import redirect, render
from django.views.generic import TemplateView
from django.views.generic import UpdateView
+from nextcloudappstore.core.user.forms import DeleteAccountForm
+
+
+class DeleteAccountView(LoginRequiredMixin, TemplateView):
+ template_name = 'user/delete-account.html'
+
+ def get_context_data(self, **kwargs):
+ context = super().get_context_data(**kwargs)
+ context['form'] = DeleteAccountForm()
+ context['acc_page'] = 'delete-account'
+ return context
+
+ def post(self, request, *args, **kwargs):
+ form = DeleteAccountForm(request.POST, user=request.user)
+ if form.is_valid():
+ request.user.delete()
+ return redirect(reverse_lazy('home'))
+ else:
+ return render(request, self.template_name, {'form': form})
+
class AccountView(LoginRequiredMixin, UpdateView):
"""Display and allow changing of the user's name."""
diff --git a/nextcloudappstore/urls.py b/nextcloudappstore/urls.py
--- a/nextcloudappstore/urls.py
+++ b/nextcloudappstore/urls.py
@@ -4,7 +4,7 @@
from django.conf.urls import url, include
from django.contrib import admin
from nextcloudappstore.core.user.views import PasswordView, AccountView, \
- APITokenView
+ APITokenView, DeleteAccountView
from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \
app_description, AppReleasesView, AppUploadView, LegalNoticeView
@@ -19,6 +19,8 @@
name='account-password'),
url(r'^account/token/?$', APITokenView.as_view(),
name='account-api-token'),
+ url(r'^account/delete/?$', DeleteAccountView.as_view(),
+ name='account-deletion'),
url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),
url(r'^categories/(?P<id>[\w]*)/?$', CategoryAppListView.as_view(),
name='category-app-list'),
| {"golden_diff": "diff --git a/nextcloudappstore/core/user/forms.py b/nextcloudappstore/core/user/forms.py\n--- a/nextcloudappstore/core/user/forms.py\n+++ b/nextcloudappstore/core/user/forms.py\n@@ -1,5 +1,7 @@\n from django import forms\n from captcha.fields import ReCaptchaField\n+from django.forms import EmailField\n+from django.utils.translation import ugettext_lazy as _\n \n \n class SignupFormRecaptcha(forms.Form):\n@@ -8,3 +10,19 @@\n \n def signup(self, request, user):\n pass\n+\n+\n+class DeleteAccountForm(forms.Form):\n+ email = EmailField(required=True, label=_('Your e-mail address'))\n+\n+ def __init__(self, *args, **kwargs):\n+ self.user = kwargs.pop('user', None)\n+ super().__init__(*args, **kwargs)\n+\n+ def clean_email(self):\n+ email = self.cleaned_data.get('email')\n+ if self.user and self.user.email == email:\n+ return email\n+ else:\n+ raise forms.ValidationError(_(\n+ 'The given e-mail address does not match your e-mail address'))\ndiff --git a/nextcloudappstore/core/user/views.py b/nextcloudappstore/core/user/views.py\n--- a/nextcloudappstore/core/user/views.py\n+++ b/nextcloudappstore/core/user/views.py\n@@ -3,9 +3,30 @@\n from django.contrib.auth.mixins import LoginRequiredMixin\n from django.contrib.auth.models import User\n from django.core.urlresolvers import reverse_lazy\n+from django.shortcuts import redirect, render\n from django.views.generic import TemplateView\n from django.views.generic import UpdateView\n \n+from nextcloudappstore.core.user.forms import DeleteAccountForm\n+\n+\n+class DeleteAccountView(LoginRequiredMixin, TemplateView):\n+ template_name = 'user/delete-account.html'\n+\n+ def get_context_data(self, **kwargs):\n+ context = super().get_context_data(**kwargs)\n+ context['form'] = DeleteAccountForm()\n+ context['acc_page'] = 'delete-account'\n+ return context\n+\n+ def post(self, request, *args, **kwargs):\n+ form = DeleteAccountForm(request.POST, user=request.user)\n+ if form.is_valid():\n+ request.user.delete()\n+ return redirect(reverse_lazy('home'))\n+ else:\n+ return render(request, self.template_name, {'form': form})\n+\n \n class AccountView(LoginRequiredMixin, UpdateView):\n \"\"\"Display and allow changing of the user's name.\"\"\"\ndiff --git a/nextcloudappstore/urls.py b/nextcloudappstore/urls.py\n--- a/nextcloudappstore/urls.py\n+++ b/nextcloudappstore/urls.py\n@@ -4,7 +4,7 @@\n from django.conf.urls import url, include\n from django.contrib import admin\n from nextcloudappstore.core.user.views import PasswordView, AccountView, \\\n- APITokenView\n+ APITokenView, DeleteAccountView\n from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \\\n app_description, AppReleasesView, AppUploadView, LegalNoticeView\n \n@@ -19,6 +19,8 @@\n name='account-password'),\n url(r'^account/token/?$', APITokenView.as_view(),\n name='account-api-token'),\n+ url(r'^account/delete/?$', DeleteAccountView.as_view(),\n+ name='account-deletion'),\n url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),\n url(r'^categories/(?P<id>[\\w]*)/?$', CategoryAppListView.as_view(),\n name='category-app-list'),\n", "issue": "Delete user account\nA user should be able to delete his account by hitting and confirming it on the download page. The confirmation should not be able to trigger by accident, Github's delete repo ui is a good example.\n\nBefore deleting his account, a user will be warned that all his comments and apps will be deleted.\n\n", "before_files": [{"content": "from allauth.account.views import signup\nfrom allauth.socialaccount.views import signup as social_signup\nfrom csp.decorators import csp_exempt\nfrom django.conf.urls import url, include\nfrom django.contrib import admin\nfrom nextcloudappstore.core.user.views import PasswordView, AccountView, \\\n APITokenView\nfrom nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \\\n app_description, AppReleasesView, AppUploadView, LegalNoticeView\n\nurlpatterns = [\n url(r'^$', CategoryAppListView.as_view(), {'id': None}, name='home'),\n url(r\"^signup/$\", csp_exempt(signup), name=\"account_signup\"),\n url(r\"^social/signup/$\", csp_exempt(social_signup),\n name=\"socialaccount_signup\"),\n url(r'^', include('allauth.urls')),\n url(r'^account/?$', AccountView.as_view(), name='account'),\n url(r'^account/password/?$', PasswordView.as_view(),\n name='account-password'),\n url(r'^account/token/?$', APITokenView.as_view(),\n name='account-api-token'),\n url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),\n url(r'^categories/(?P<id>[\\w]*)/?$', CategoryAppListView.as_view(),\n name='category-app-list'),\n url(r'^app/upload/?$', AppUploadView.as_view(), name='app-upload'),\n url(r'^app/(?P<id>[\\w_]+)/?$', AppDetailView.as_view(), name='app-detail'),\n url(r'^app/(?P<id>[\\w_]+)/releases/?$', AppReleasesView.as_view(),\n name='app-releases'),\n url(r'^app/(?P<id>[\\w_]+)/description/?$', app_description,\n name='app-description'),\n url(r'^api/', include('nextcloudappstore.core.api.urls',\n namespace='api')),\n url(r'^admin/', admin.site.urls),\n]\n", "path": "nextcloudappstore/urls.py"}, {"content": "from allauth.account.views import PasswordChangeView\nfrom django.contrib import messages\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.contrib.auth.models import User\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.views.generic import TemplateView\nfrom django.views.generic import UpdateView\n\n\nclass AccountView(LoginRequiredMixin, UpdateView):\n \"\"\"Display and allow changing of the user's name.\"\"\"\n\n template_name = 'user/account.html'\n template_name_suffix = ''\n model = User\n fields = ['first_name', 'last_name']\n success_url = reverse_lazy('account')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'account'\n return context\n\n def form_valid(self, form):\n messages.success(self.request, 'Name saved.')\n return super().form_valid(form)\n\n def get_object(self, queryset=None):\n return self.request.user\n\n\nclass PasswordView(LoginRequiredMixin, PasswordChangeView):\n \"\"\"Allow the user to change their password.\"\"\"\n\n template_name = 'user/password.html'\n success_url = reverse_lazy('account-password')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'password'\n return context\n\n\nclass APITokenView(LoginRequiredMixin, TemplateView):\n \"\"\"Display the user's API token, and allow it to be regenerated.\"\"\"\n\n template_name = 'user/api-token.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'api-token'\n return context\n", "path": "nextcloudappstore/core/user/views.py"}, {"content": "from django import forms\nfrom captcha.fields import ReCaptchaField\n\n\nclass SignupFormRecaptcha(forms.Form):\n \"\"\"integrate a recaptcha field.\"\"\"\n recaptcha = ReCaptchaField()\n\n def signup(self, request, user):\n pass\n", "path": "nextcloudappstore/core/user/forms.py"}], "after_files": [{"content": "from allauth.account.views import signup\nfrom allauth.socialaccount.views import signup as social_signup\nfrom csp.decorators import csp_exempt\nfrom django.conf.urls import url, include\nfrom django.contrib import admin\nfrom nextcloudappstore.core.user.views import PasswordView, AccountView, \\\n APITokenView, DeleteAccountView\nfrom nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \\\n app_description, AppReleasesView, AppUploadView, LegalNoticeView\n\nurlpatterns = [\n url(r'^$', CategoryAppListView.as_view(), {'id': None}, name='home'),\n url(r\"^signup/$\", csp_exempt(signup), name=\"account_signup\"),\n url(r\"^social/signup/$\", csp_exempt(social_signup),\n name=\"socialaccount_signup\"),\n url(r'^', include('allauth.urls')),\n url(r'^account/?$', AccountView.as_view(), name='account'),\n url(r'^account/password/?$', PasswordView.as_view(),\n name='account-password'),\n url(r'^account/token/?$', APITokenView.as_view(),\n name='account-api-token'),\n url(r'^account/delete/?$', DeleteAccountView.as_view(),\n name='account-deletion'),\n url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),\n url(r'^categories/(?P<id>[\\w]*)/?$', CategoryAppListView.as_view(),\n name='category-app-list'),\n url(r'^app/upload/?$', AppUploadView.as_view(), name='app-upload'),\n url(r'^app/(?P<id>[\\w_]+)/?$', AppDetailView.as_view(), name='app-detail'),\n url(r'^app/(?P<id>[\\w_]+)/releases/?$', AppReleasesView.as_view(),\n name='app-releases'),\n url(r'^app/(?P<id>[\\w_]+)/description/?$', app_description,\n name='app-description'),\n url(r'^api/', include('nextcloudappstore.core.api.urls',\n namespace='api')),\n url(r'^admin/', admin.site.urls),\n]\n", "path": "nextcloudappstore/urls.py"}, {"content": "from allauth.account.views import PasswordChangeView\nfrom django.contrib import messages\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.contrib.auth.models import User\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.shortcuts import redirect, render\nfrom django.views.generic import TemplateView\nfrom django.views.generic import UpdateView\n\nfrom nextcloudappstore.core.user.forms import DeleteAccountForm\n\n\nclass DeleteAccountView(LoginRequiredMixin, TemplateView):\n template_name = 'user/delete-account.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['form'] = DeleteAccountForm()\n context['acc_page'] = 'delete-account'\n return context\n\n def post(self, request, *args, **kwargs):\n form = DeleteAccountForm(request.POST, user=request.user)\n if form.is_valid():\n request.user.delete()\n return redirect(reverse_lazy('home'))\n else:\n return render(request, self.template_name, {'form': form})\n\n\nclass AccountView(LoginRequiredMixin, UpdateView):\n \"\"\"Display and allow changing of the user's name.\"\"\"\n\n template_name = 'user/account.html'\n template_name_suffix = ''\n model = User\n fields = ['first_name', 'last_name']\n success_url = reverse_lazy('account')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'account'\n return context\n\n def form_valid(self, form):\n messages.success(self.request, 'Name saved.')\n return super().form_valid(form)\n\n def get_object(self, queryset=None):\n return self.request.user\n\n\nclass PasswordView(LoginRequiredMixin, PasswordChangeView):\n \"\"\"Allow the user to change their password.\"\"\"\n\n template_name = 'user/password.html'\n success_url = reverse_lazy('account-password')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'password'\n return context\n\n\nclass APITokenView(LoginRequiredMixin, TemplateView):\n \"\"\"Display the user's API token, and allow it to be regenerated.\"\"\"\n\n template_name = 'user/api-token.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'api-token'\n return context\n", "path": "nextcloudappstore/core/user/views.py"}, {"content": "from django import forms\nfrom captcha.fields import ReCaptchaField\nfrom django.forms import EmailField\nfrom django.utils.translation import ugettext_lazy as _\n\n\nclass SignupFormRecaptcha(forms.Form):\n \"\"\"integrate a recaptcha field.\"\"\"\n recaptcha = ReCaptchaField()\n\n def signup(self, request, user):\n pass\n\n\nclass DeleteAccountForm(forms.Form):\n email = EmailField(required=True, label=_('Your e-mail address'))\n\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user', None)\n super().__init__(*args, **kwargs)\n\n def clean_email(self):\n email = self.cleaned_data.get('email')\n if self.user and self.user.email == email:\n return email\n else:\n raise forms.ValidationError(_(\n 'The given e-mail address does not match your e-mail address'))\n", "path": "nextcloudappstore/core/user/forms.py"}]} | 1,359 | 793 |
gh_patches_debug_5702 | rasdani/github-patches | git_diff | sanic-org__sanic-819 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Configs loaded from environmental variables aren't properly typed
When setting configs using environmental variables `export SANIC_REQUEST_TIMEOUT=30`
```
app = Sanic(__name__)
print(type(app.config.REQUEST_TIMEOUT)) # <class 'str'>
```
The problem is in this function
```
# .../sanic/config.py
def load_environment_vars(self):
"""
Looks for any SANIC_ prefixed environment variables and applies
them to the configuration if present.
"""
for k, v in os.environ.items():
if k.startswith(SANIC_PREFIX):
_, config_key = k.split(SANIC_PREFIX, 1)
self[config_key] = v # os.environ values are always of type str
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sanic/config.py`
Content:
```
1 import os
2 import sys
3 import syslog
4 import platform
5 import types
6
7 from sanic.log import DefaultFilter
8
9 SANIC_PREFIX = 'SANIC_'
10
11 _address_dict = {
12 'Windows': ('localhost', 514),
13 'Darwin': '/var/run/syslog',
14 'Linux': '/dev/log',
15 'FreeBSD': '/dev/log'
16 }
17
18 LOGGING = {
19 'version': 1,
20 'filters': {
21 'accessFilter': {
22 '()': DefaultFilter,
23 'param': [0, 10, 20]
24 },
25 'errorFilter': {
26 '()': DefaultFilter,
27 'param': [30, 40, 50]
28 }
29 },
30 'formatters': {
31 'simple': {
32 'format': '%(asctime)s - (%(name)s)[%(levelname)s]: %(message)s',
33 'datefmt': '%Y-%m-%d %H:%M:%S'
34 },
35 'access': {
36 'format': '%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: ' +
37 '%(request)s %(message)s %(status)d %(byte)d',
38 'datefmt': '%Y-%m-%d %H:%M:%S'
39 }
40 },
41 'handlers': {
42 'internal': {
43 'class': 'logging.StreamHandler',
44 'filters': ['accessFilter'],
45 'formatter': 'simple',
46 'stream': sys.stderr
47 },
48 'accessStream': {
49 'class': 'logging.StreamHandler',
50 'filters': ['accessFilter'],
51 'formatter': 'access',
52 'stream': sys.stderr
53 },
54 'errorStream': {
55 'class': 'logging.StreamHandler',
56 'filters': ['errorFilter'],
57 'formatter': 'simple',
58 'stream': sys.stderr
59 },
60 # before you use accessSysLog, be sure that log levels
61 # 0, 10, 20 have been enabled in you syslog configuration
62 # otherwise you won't be able to see the output in syslog
63 # logging file.
64 'accessSysLog': {
65 'class': 'logging.handlers.SysLogHandler',
66 'address': _address_dict.get(platform.system(),
67 ('localhost', 514)),
68 'facility': syslog.LOG_DAEMON,
69 'filters': ['accessFilter'],
70 'formatter': 'access'
71 },
72 'errorSysLog': {
73 'class': 'logging.handlers.SysLogHandler',
74 'address': _address_dict.get(platform.system(),
75 ('localhost', 514)),
76 'facility': syslog.LOG_DAEMON,
77 'filters': ['errorFilter'],
78 'formatter': 'simple'
79 },
80 },
81 'loggers': {
82 'sanic': {
83 'level': 'DEBUG',
84 'handlers': ['internal', 'errorStream']
85 },
86 'network': {
87 'level': 'DEBUG',
88 'handlers': ['accessStream', 'errorStream']
89 }
90 }
91 }
92
93 # this happens when using container or systems without syslog
94 # keep things in config would cause file not exists error
95 _addr = LOGGING['handlers']['accessSysLog']['address']
96 if type(_addr) is str and not os.path.exists(_addr):
97 LOGGING['handlers'].pop('accessSysLog')
98 LOGGING['handlers'].pop('errorSysLog')
99
100
101 class Config(dict):
102 def __init__(self, defaults=None, load_env=True, keep_alive=True):
103 super().__init__(defaults or {})
104 self.LOGO = """
105 ▄▄▄▄▄
106 ▀▀▀██████▄▄▄ _______________
107 ▄▄▄▄▄ █████████▄ / \\
108 ▀▀▀▀█████▌ ▀▐▄ ▀▐█ | Gotta go fast! |
109 ▀▀█████▄▄ ▀██████▄██ | _________________/
110 ▀▄▄▄▄▄ ▀▀█▄▀█════█▀ |/
111 ▀▀▀▄ ▀▀███ ▀ ▄▄
112 ▄███▀▀██▄████████▄ ▄▀▀▀▀▀▀█▌
113 ██▀▄▄▄██▀▄███▀ ▀▀████ ▄██
114 ▄▀▀▀▄██▄▀▀▌████▒▒▒▒▒▒███ ▌▄▄▀
115 ▌ ▐▀████▐███▒▒▒▒▒▐██▌
116 ▀▄▄▄▄▀ ▀▀████▒▒▒▒▄██▀
117 ▀▀█████████▀
118 ▄▄██▀██████▀█
119 ▄██▀ ▀▀▀ █
120 ▄█ ▐▌
121 ▄▄▄▄█▌ ▀█▄▄▄▄▀▀▄
122 ▌ ▐ ▀▀▄▄▄▀
123 ▀▀▄▄▀
124 """
125 self.REQUEST_MAX_SIZE = 100000000 # 100 megabytes
126 self.REQUEST_TIMEOUT = 60 # 60 seconds
127 self.KEEP_ALIVE = keep_alive
128 self.WEBSOCKET_MAX_SIZE = 2 ** 20 # 1 megabytes
129 self.WEBSOCKET_MAX_QUEUE = 32
130
131 if load_env:
132 self.load_environment_vars()
133
134 def __getattr__(self, attr):
135 try:
136 return self[attr]
137 except KeyError as ke:
138 raise AttributeError("Config has no '{}'".format(ke.args[0]))
139
140 def __setattr__(self, attr, value):
141 self[attr] = value
142
143 def from_envvar(self, variable_name):
144 """Load a configuration from an environment variable pointing to
145 a configuration file.
146
147 :param variable_name: name of the environment variable
148 :return: bool. ``True`` if able to load config, ``False`` otherwise.
149 """
150 config_file = os.environ.get(variable_name)
151 if not config_file:
152 raise RuntimeError('The environment variable %r is not set and '
153 'thus configuration could not be loaded.' %
154 variable_name)
155 return self.from_pyfile(config_file)
156
157 def from_pyfile(self, filename):
158 """Update the values in the config from a Python file.
159 Only the uppercase variables in that module are stored in the config.
160
161 :param filename: an absolute path to the config file
162 """
163 module = types.ModuleType('config')
164 module.__file__ = filename
165 try:
166 with open(filename) as config_file:
167 exec(compile(config_file.read(), filename, 'exec'),
168 module.__dict__)
169 except IOError as e:
170 e.strerror = 'Unable to load configuration file (%s)' % e.strerror
171 raise
172 self.from_object(module)
173 return True
174
175 def from_object(self, obj):
176 """Update the values from the given object.
177 Objects are usually either modules or classes.
178
179 Just the uppercase variables in that object are stored in the config.
180 Example usage::
181
182 from yourapplication import default_config
183 app.config.from_object(default_config)
184
185 You should not use this function to load the actual configuration but
186 rather configuration defaults. The actual config should be loaded
187 with :meth:`from_pyfile` and ideally from a location not within the
188 package because the package might be installed system wide.
189
190 :param obj: an object holding the configuration
191 """
192 for key in dir(obj):
193 if key.isupper():
194 self[key] = getattr(obj, key)
195
196 def load_environment_vars(self):
197 """
198 Looks for any SANIC_ prefixed environment variables and applies
199 them to the configuration if present.
200 """
201 for k, v in os.environ.items():
202 if k.startswith(SANIC_PREFIX):
203 _, config_key = k.split(SANIC_PREFIX, 1)
204 self[config_key] = v
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sanic/config.py b/sanic/config.py
--- a/sanic/config.py
+++ b/sanic/config.py
@@ -201,4 +201,10 @@
for k, v in os.environ.items():
if k.startswith(SANIC_PREFIX):
_, config_key = k.split(SANIC_PREFIX, 1)
- self[config_key] = v
+ try:
+ self[config_key] = int(v)
+ except ValueError:
+ try:
+ self[config_key] = float(v)
+ except ValueError:
+ self[config_key] = v
| {"golden_diff": "diff --git a/sanic/config.py b/sanic/config.py\n--- a/sanic/config.py\n+++ b/sanic/config.py\n@@ -201,4 +201,10 @@\n for k, v in os.environ.items():\n if k.startswith(SANIC_PREFIX):\n _, config_key = k.split(SANIC_PREFIX, 1)\n- self[config_key] = v\n+ try:\n+ self[config_key] = int(v)\n+ except ValueError:\n+ try:\n+ self[config_key] = float(v)\n+ except ValueError:\n+ self[config_key] = v\n", "issue": "Configs loaded from environmental variables aren't properly typed\nWhen setting configs using environmental variables `export SANIC_REQUEST_TIMEOUT=30`\r\n\r\n```\r\napp = Sanic(__name__)\r\nprint(type(app.config.REQUEST_TIMEOUT)) # <class 'str'>\r\n```\r\n\r\nThe problem is in this function\r\n```\r\n# .../sanic/config.py\r\n def load_environment_vars(self):\r\n \"\"\"\r\n Looks for any SANIC_ prefixed environment variables and applies\r\n them to the configuration if present.\r\n \"\"\"\r\n for k, v in os.environ.items():\r\n if k.startswith(SANIC_PREFIX):\r\n _, config_key = k.split(SANIC_PREFIX, 1)\r\n self[config_key] = v # os.environ values are always of type str\r\n```\r\n\n", "before_files": [{"content": "import os\nimport sys\nimport syslog\nimport platform\nimport types\n\nfrom sanic.log import DefaultFilter\n\nSANIC_PREFIX = 'SANIC_'\n\n_address_dict = {\n 'Windows': ('localhost', 514),\n 'Darwin': '/var/run/syslog',\n 'Linux': '/dev/log',\n 'FreeBSD': '/dev/log'\n}\n\nLOGGING = {\n 'version': 1,\n 'filters': {\n 'accessFilter': {\n '()': DefaultFilter,\n 'param': [0, 10, 20]\n },\n 'errorFilter': {\n '()': DefaultFilter,\n 'param': [30, 40, 50]\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s]: %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'access': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: ' +\n '%(request)s %(message)s %(status)d %(byte)d',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'internal': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n 'accessStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'access',\n 'stream': sys.stderr\n },\n 'errorStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['errorFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n # before you use accessSysLog, be sure that log levels\n # 0, 10, 20 have been enabled in you syslog configuration\n # otherwise you won't be able to see the output in syslog\n # logging file.\n 'accessSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['accessFilter'],\n 'formatter': 'access'\n },\n 'errorSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['errorFilter'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'sanic': {\n 'level': 'DEBUG',\n 'handlers': ['internal', 'errorStream']\n },\n 'network': {\n 'level': 'DEBUG',\n 'handlers': ['accessStream', 'errorStream']\n }\n }\n}\n\n# this happens when using container or systems without syslog\n# keep things in config would cause file not exists error\n_addr = LOGGING['handlers']['accessSysLog']['address']\nif type(_addr) is str and not os.path.exists(_addr):\n LOGGING['handlers'].pop('accessSysLog')\n LOGGING['handlers'].pop('errorSysLog')\n\n\nclass Config(dict):\n def __init__(self, defaults=None, load_env=True, keep_alive=True):\n super().__init__(defaults or {})\n self.LOGO = \"\"\"\n \u2584\u2584\u2584\u2584\u2584\n \u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2584\u2584 _______________\n \u2584\u2584\u2584\u2584\u2584 \u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 / \\\\\n \u2580\u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u258c \u2580\u2590\u2584 \u2580\u2590\u2588 | Gotta go fast! |\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2584\u2584 \u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2588\u2588 | _________________/\n \u2580\u2584\u2584\u2584\u2584\u2584 \u2580\u2580\u2588\u2584\u2580\u2588\u2550\u2550\u2550\u2550\u2588\u2580 |/\n \u2580\u2580\u2580\u2584 \u2580\u2580\u2588\u2588\u2588 \u2580 \u2584\u2584\n \u2584\u2588\u2588\u2588\u2580\u2580\u2588\u2588\u2584\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 \u2584\u2580\u2580\u2580\u2580\u2580\u2580\u2588\u258c\n \u2588\u2588\u2580\u2584\u2584\u2584\u2588\u2588\u2580\u2584\u2588\u2588\u2588\u2580 \u2580\u2580\u2588\u2588\u2588\u2588 \u2584\u2588\u2588\n\u2584\u2580\u2580\u2580\u2584\u2588\u2588\u2584\u2580\u2580\u258c\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2592\u2588\u2588\u2588 \u258c\u2584\u2584\u2580\n\u258c \u2590\u2580\u2588\u2588\u2588\u2588\u2590\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2590\u2588\u2588\u258c\n\u2580\u2584\u2584\u2584\u2584\u2580 \u2580\u2580\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2584\u2588\u2588\u2580\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2580\n \u2584\u2584\u2588\u2588\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2580\u2588\n \u2584\u2588\u2588\u2580 \u2580\u2580\u2580 \u2588\n \u2584\u2588 \u2590\u258c\n \u2584\u2584\u2584\u2584\u2588\u258c \u2580\u2588\u2584\u2584\u2584\u2584\u2580\u2580\u2584\n\u258c \u2590 \u2580\u2580\u2584\u2584\u2584\u2580\n \u2580\u2580\u2584\u2584\u2580\n\"\"\"\n self.REQUEST_MAX_SIZE = 100000000 # 100 megabytes\n self.REQUEST_TIMEOUT = 60 # 60 seconds\n self.KEEP_ALIVE = keep_alive\n self.WEBSOCKET_MAX_SIZE = 2 ** 20 # 1 megabytes\n self.WEBSOCKET_MAX_QUEUE = 32\n\n if load_env:\n self.load_environment_vars()\n\n def __getattr__(self, attr):\n try:\n return self[attr]\n except KeyError as ke:\n raise AttributeError(\"Config has no '{}'\".format(ke.args[0]))\n\n def __setattr__(self, attr, value):\n self[attr] = value\n\n def from_envvar(self, variable_name):\n \"\"\"Load a configuration from an environment variable pointing to\n a configuration file.\n\n :param variable_name: name of the environment variable\n :return: bool. ``True`` if able to load config, ``False`` otherwise.\n \"\"\"\n config_file = os.environ.get(variable_name)\n if not config_file:\n raise RuntimeError('The environment variable %r is not set and '\n 'thus configuration could not be loaded.' %\n variable_name)\n return self.from_pyfile(config_file)\n\n def from_pyfile(self, filename):\n \"\"\"Update the values in the config from a Python file.\n Only the uppercase variables in that module are stored in the config.\n\n :param filename: an absolute path to the config file\n \"\"\"\n module = types.ModuleType('config')\n module.__file__ = filename\n try:\n with open(filename) as config_file:\n exec(compile(config_file.read(), filename, 'exec'),\n module.__dict__)\n except IOError as e:\n e.strerror = 'Unable to load configuration file (%s)' % e.strerror\n raise\n self.from_object(module)\n return True\n\n def from_object(self, obj):\n \"\"\"Update the values from the given object.\n Objects are usually either modules or classes.\n\n Just the uppercase variables in that object are stored in the config.\n Example usage::\n\n from yourapplication import default_config\n app.config.from_object(default_config)\n\n You should not use this function to load the actual configuration but\n rather configuration defaults. The actual config should be loaded\n with :meth:`from_pyfile` and ideally from a location not within the\n package because the package might be installed system wide.\n\n :param obj: an object holding the configuration\n \"\"\"\n for key in dir(obj):\n if key.isupper():\n self[key] = getattr(obj, key)\n\n def load_environment_vars(self):\n \"\"\"\n Looks for any SANIC_ prefixed environment variables and applies\n them to the configuration if present.\n \"\"\"\n for k, v in os.environ.items():\n if k.startswith(SANIC_PREFIX):\n _, config_key = k.split(SANIC_PREFIX, 1)\n self[config_key] = v\n", "path": "sanic/config.py"}], "after_files": [{"content": "import os\nimport sys\nimport syslog\nimport platform\nimport types\n\nfrom sanic.log import DefaultFilter\n\nSANIC_PREFIX = 'SANIC_'\n\n_address_dict = {\n 'Windows': ('localhost', 514),\n 'Darwin': '/var/run/syslog',\n 'Linux': '/dev/log',\n 'FreeBSD': '/dev/log'\n}\n\nLOGGING = {\n 'version': 1,\n 'filters': {\n 'accessFilter': {\n '()': DefaultFilter,\n 'param': [0, 10, 20]\n },\n 'errorFilter': {\n '()': DefaultFilter,\n 'param': [30, 40, 50]\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s]: %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'access': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: ' +\n '%(request)s %(message)s %(status)d %(byte)d',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'internal': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n 'accessStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'access',\n 'stream': sys.stderr\n },\n 'errorStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['errorFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n # before you use accessSysLog, be sure that log levels\n # 0, 10, 20 have been enabled in you syslog configuration\n # otherwise you won't be able to see the output in syslog\n # logging file.\n 'accessSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['accessFilter'],\n 'formatter': 'access'\n },\n 'errorSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['errorFilter'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'sanic': {\n 'level': 'DEBUG',\n 'handlers': ['internal', 'errorStream']\n },\n 'network': {\n 'level': 'DEBUG',\n 'handlers': ['accessStream', 'errorStream']\n }\n }\n}\n\n# this happens when using container or systems without syslog\n# keep things in config would cause file not exists error\n_addr = LOGGING['handlers']['accessSysLog']['address']\nif type(_addr) is str and not os.path.exists(_addr):\n LOGGING['handlers'].pop('accessSysLog')\n LOGGING['handlers'].pop('errorSysLog')\n\n\nclass Config(dict):\n def __init__(self, defaults=None, load_env=True, keep_alive=True):\n super().__init__(defaults or {})\n self.LOGO = \"\"\"\n \u2584\u2584\u2584\u2584\u2584\n \u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2584\u2584 _______________\n \u2584\u2584\u2584\u2584\u2584 \u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 / \\\\\n \u2580\u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u258c \u2580\u2590\u2584 \u2580\u2590\u2588 | Gotta go fast! |\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2584\u2584 \u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2588\u2588 | _________________/\n \u2580\u2584\u2584\u2584\u2584\u2584 \u2580\u2580\u2588\u2584\u2580\u2588\u2550\u2550\u2550\u2550\u2588\u2580 |/\n \u2580\u2580\u2580\u2584 \u2580\u2580\u2588\u2588\u2588 \u2580 \u2584\u2584\n \u2584\u2588\u2588\u2588\u2580\u2580\u2588\u2588\u2584\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 \u2584\u2580\u2580\u2580\u2580\u2580\u2580\u2588\u258c\n \u2588\u2588\u2580\u2584\u2584\u2584\u2588\u2588\u2580\u2584\u2588\u2588\u2588\u2580 \u2580\u2580\u2588\u2588\u2588\u2588 \u2584\u2588\u2588\n\u2584\u2580\u2580\u2580\u2584\u2588\u2588\u2584\u2580\u2580\u258c\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2592\u2588\u2588\u2588 \u258c\u2584\u2584\u2580\n\u258c \u2590\u2580\u2588\u2588\u2588\u2588\u2590\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2590\u2588\u2588\u258c\n\u2580\u2584\u2584\u2584\u2584\u2580 \u2580\u2580\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2584\u2588\u2588\u2580\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2580\n \u2584\u2584\u2588\u2588\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2580\u2588\n \u2584\u2588\u2588\u2580 \u2580\u2580\u2580 \u2588\n \u2584\u2588 \u2590\u258c\n \u2584\u2584\u2584\u2584\u2588\u258c \u2580\u2588\u2584\u2584\u2584\u2584\u2580\u2580\u2584\n\u258c \u2590 \u2580\u2580\u2584\u2584\u2584\u2580\n \u2580\u2580\u2584\u2584\u2580\n\"\"\"\n self.REQUEST_MAX_SIZE = 100000000 # 100 megabytes\n self.REQUEST_TIMEOUT = 60 # 60 seconds\n self.KEEP_ALIVE = keep_alive\n self.WEBSOCKET_MAX_SIZE = 2 ** 20 # 1 megabytes\n self.WEBSOCKET_MAX_QUEUE = 32\n\n if load_env:\n self.load_environment_vars()\n\n def __getattr__(self, attr):\n try:\n return self[attr]\n except KeyError as ke:\n raise AttributeError(\"Config has no '{}'\".format(ke.args[0]))\n\n def __setattr__(self, attr, value):\n self[attr] = value\n\n def from_envvar(self, variable_name):\n \"\"\"Load a configuration from an environment variable pointing to\n a configuration file.\n\n :param variable_name: name of the environment variable\n :return: bool. ``True`` if able to load config, ``False`` otherwise.\n \"\"\"\n config_file = os.environ.get(variable_name)\n if not config_file:\n raise RuntimeError('The environment variable %r is not set and '\n 'thus configuration could not be loaded.' %\n variable_name)\n return self.from_pyfile(config_file)\n\n def from_pyfile(self, filename):\n \"\"\"Update the values in the config from a Python file.\n Only the uppercase variables in that module are stored in the config.\n\n :param filename: an absolute path to the config file\n \"\"\"\n module = types.ModuleType('config')\n module.__file__ = filename\n try:\n with open(filename) as config_file:\n exec(compile(config_file.read(), filename, 'exec'),\n module.__dict__)\n except IOError as e:\n e.strerror = 'Unable to load configuration file (%s)' % e.strerror\n raise\n self.from_object(module)\n return True\n\n def from_object(self, obj):\n \"\"\"Update the values from the given object.\n Objects are usually either modules or classes.\n\n Just the uppercase variables in that object are stored in the config.\n Example usage::\n\n from yourapplication import default_config\n app.config.from_object(default_config)\n\n You should not use this function to load the actual configuration but\n rather configuration defaults. The actual config should be loaded\n with :meth:`from_pyfile` and ideally from a location not within the\n package because the package might be installed system wide.\n\n :param obj: an object holding the configuration\n \"\"\"\n for key in dir(obj):\n if key.isupper():\n self[key] = getattr(obj, key)\n\n def load_environment_vars(self):\n \"\"\"\n Looks for any SANIC_ prefixed environment variables and applies\n them to the configuration if present.\n \"\"\"\n for k, v in os.environ.items():\n if k.startswith(SANIC_PREFIX):\n _, config_key = k.split(SANIC_PREFIX, 1)\n try:\n self[config_key] = int(v)\n except ValueError:\n try:\n self[config_key] = float(v)\n except ValueError:\n self[config_key] = v\n", "path": "sanic/config.py"}]} | 2,647 | 137 |
gh_patches_debug_37645 | rasdani/github-patches | git_diff | vyperlang__vyper-1672 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unused optimisation.
### Version Information
master
### What's your issue about?
Investigate listed TODO: https://github.com/ethereum/vyper/blame/master/vyper/optimizer.py#L99
```python
# Turns out this is actually not such a good optimization after all
elif node.value == "with" and int_at(argz, 1) and not search_for_set(argz[2], argz[0].value) and False:
o = replace_with_value(argz[2], argz[0].value, argz[1].value)
return o
```
### How can it be fixed?
I have not fully investigated, but I suspect we can just drop the optimisation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vyper/optimizer.py`
Content:
```
1 import operator
2
3 from vyper.parser.parser_utils import (
4 LLLnode,
5 )
6 from vyper.utils import (
7 LOADED_LIMIT_MAP,
8 )
9
10
11 def get_int_at(args, pos, signed=False):
12 value = args[pos].value
13
14 if isinstance(value, int):
15 o = value
16 elif value == "mload" and args[pos].args[0].value in LOADED_LIMIT_MAP.keys():
17 o = LOADED_LIMIT_MAP[args[pos].args[0].value]
18 else:
19 return None
20
21 if signed or o < 0:
22 return ((o + 2**255) % 2**256) - 2**255
23 else:
24 return o % 2**256
25
26
27 def int_at(args, pos):
28 return get_int_at(args, pos) is not None
29
30
31 def search_for_set(node, var):
32 if node.value == "set" and node.args[0].value == var:
33 return True
34
35 for arg in node.args:
36 if search_for_set(arg, var):
37 return True
38
39 return False
40
41
42 def replace_with_value(node, var, value):
43 if node.value == "with" and node.args[0].value == var:
44 return LLLnode(
45 node.value,
46 [
47 node.args[0],
48 replace_with_value(node.args[1], var, value),
49 node.args[2]
50 ],
51 node.typ,
52 node.location,
53 node.annotation,
54 )
55 elif node.value == var:
56 return LLLnode(value, [], node.typ, node.location, node.annotation)
57 else:
58 return LLLnode(
59 node.value,
60 [replace_with_value(arg, var, value) for arg in node.args],
61 node.typ,
62 node.location,
63 node.annotation,
64 )
65
66
67 arith = {
68 "add": (operator.add, '+'),
69 "sub": (operator.sub, '-'),
70 "mul": (operator.mul, '*'),
71 "div": (operator.floordiv, '/'),
72 "mod": (operator.mod, '%'),
73 }
74
75
76 def _is_constant_add(node, args):
77 return (
78 (
79 node.value == "add" and int_at(args, 0)
80 ) and (
81 args[1].value == "add" and int_at(args[1].args, 0)
82 )
83 )
84
85
86 def _is_with_without_set(node, args):
87 # TODO: this unconditionally returns `False`. Corresponding optimizer path
88 # should likely be removed.
89 return (
90 (
91 node.value == "with" and int_at(args, 1)
92 ) and (
93 not search_for_set(args[2], args[0].value)
94 ) and (
95 False
96 )
97 )
98
99
100 def has_cond_arg(node):
101 return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']
102
103
104 def optimize(node: LLLnode) -> LLLnode:
105 argz = [optimize(arg) for arg in node.args]
106 if node.value in arith and int_at(argz, 0) and int_at(argz, 1):
107 left, right = get_int_at(argz, 0), get_int_at(argz, 1)
108 calcer, symb = arith[node.value]
109 new_value = calcer(left, right)
110 if argz[0].annotation and argz[1].annotation:
111 annotation = argz[0].annotation + symb + argz[1].annotation
112 elif argz[0].annotation or argz[1].annotation:
113 annotation = (
114 argz[0].annotation or str(left)
115 ) + symb + (
116 argz[1].annotation or str(right)
117 )
118 else:
119 annotation = ''
120 return LLLnode(
121 new_value,
122 [],
123 node.typ,
124 None,
125 node.pos,
126 annotation,
127 add_gas_estimate=node.add_gas_estimate,
128 valency=node.valency,
129 )
130 elif _is_constant_add(node, argz):
131 calcer, symb = arith[node.value]
132 if argz[0].annotation and argz[1].args[0].annotation:
133 annotation = argz[0].annotation + symb + argz[1].args[0].annotation
134 elif argz[0].annotation or argz[1].args[0].annotation:
135 annotation = (
136 argz[0].annotation or str(argz[0].value)
137 ) + symb + (
138 argz[1].args[0].annotation or str(argz[1].args[0].value)
139 )
140 else:
141 annotation = ''
142 return LLLnode(
143 "add",
144 [
145 LLLnode(argz[0].value + argz[1].args[0].value, annotation=annotation),
146 argz[1].args[1],
147 ],
148 node.typ,
149 None,
150 node.annotation,
151 add_gas_estimate=node.add_gas_estimate,
152 valency=node.valency,
153 )
154 elif node.value == "add" and get_int_at(argz, 0) == 0:
155 return LLLnode(
156 argz[1].value,
157 argz[1].args,
158 node.typ,
159 node.location,
160 node.pos,
161 argz[1].annotation,
162 add_gas_estimate=node.add_gas_estimate,
163 valency=node.valency,
164 )
165 elif node.value == "add" and get_int_at(argz, 1) == 0:
166 return LLLnode(
167 argz[0].value,
168 argz[0].args,
169 node.typ,
170 node.location,
171 node.pos,
172 argz[0].annotation,
173 add_gas_estimate=node.add_gas_estimate,
174 valency=node.valency,
175 )
176 elif node.value == "clamp" and int_at(argz, 0) and int_at(argz, 1) and int_at(argz, 2):
177 if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):
178 raise Exception("Clamp always fails")
179 elif get_int_at(argz, 1, True) > get_int_at(argz, 2, True):
180 raise Exception("Clamp always fails")
181 else:
182 return argz[1]
183 elif node.value == "clamp" and int_at(argz, 0) and int_at(argz, 1):
184 if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):
185 raise Exception("Clamp always fails")
186 else:
187 return LLLnode(
188 "clample",
189 [argz[1], argz[2]],
190 node.typ,
191 node.location,
192 node.pos,
193 node.annotation,
194 add_gas_estimate=node.add_gas_estimate,
195 valency=node.valency,
196 )
197 elif node.value == "clamp_nonzero" and int_at(argz, 0):
198 if get_int_at(argz, 0) != 0:
199 return LLLnode(
200 argz[0].value,
201 [],
202 node.typ,
203 node.location,
204 node.pos,
205 node.annotation,
206 add_gas_estimate=node.add_gas_estimate,
207 valency=node.valency,
208 )
209 else:
210 raise Exception("Clamp always fails")
211 # [eq, x, 0] is the same as [iszero, x].
212 elif node.value == 'eq' and int_at(argz, 1) and argz[1].value == 0:
213 return LLLnode(
214 'iszero',
215 [argz[0]],
216 node.typ,
217 node.location,
218 node.pos,
219 node.annotation,
220 add_gas_estimate=node.add_gas_estimate,
221 valency=node.valency,
222 )
223 # [ne, x, y] has the same truthyness as [xor, x, y]
224 # rewrite 'ne' as 'xor' in places where truthy is accepted.
225 elif has_cond_arg(node) and argz[0].value == 'ne':
226 argz[0] = LLLnode.from_list(['xor'] + argz[0].args)
227 return LLLnode.from_list(
228 [node.value] + argz,
229 typ=node.typ,
230 location=node.location,
231 pos=node.pos,
232 annotation=node.annotation,
233 # let from_list handle valency and gas_estimate
234 )
235 elif _is_with_without_set(node, argz):
236 # TODO: This block is currently unreachable due to
237 # `_is_with_without_set` unconditionally returning `False` this appears
238 # to be because this "is actually not such a good optimization after
239 # all" accordiing to previous comment.
240 o = replace_with_value(argz[2], argz[0].value, argz[1].value)
241 return o
242 elif node.value == "seq":
243 o = []
244 for arg in argz:
245 if arg.value == "seq":
246 o.extend(arg.args)
247 else:
248 o.append(arg)
249 return LLLnode(
250 node.value,
251 o,
252 node.typ,
253 node.location,
254 node.pos,
255 node.annotation,
256 add_gas_estimate=node.add_gas_estimate,
257 valency=node.valency,
258 )
259 elif node.total_gas is not None:
260 o = LLLnode(
261 node.value,
262 argz,
263 node.typ,
264 node.location,
265 node.pos,
266 node.annotation,
267 add_gas_estimate=node.add_gas_estimate,
268 valency=node.valency,
269 )
270 o.total_gas = node.total_gas - node.gas + o.gas
271 o.func_name = node.func_name
272 return o
273 else:
274 return LLLnode(
275 node.value,
276 argz,
277 node.typ,
278 node.location,
279 node.pos,
280 node.annotation,
281 add_gas_estimate=node.add_gas_estimate,
282 valency=node.valency,
283 )
284
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/vyper/optimizer.py b/vyper/optimizer.py
--- a/vyper/optimizer.py
+++ b/vyper/optimizer.py
@@ -1,4 +1,8 @@
import operator
+from typing import (
+ Any,
+ List,
+)
from vyper.parser.parser_utils import (
LLLnode,
@@ -39,31 +43,6 @@
return False
-def replace_with_value(node, var, value):
- if node.value == "with" and node.args[0].value == var:
- return LLLnode(
- node.value,
- [
- node.args[0],
- replace_with_value(node.args[1], var, value),
- node.args[2]
- ],
- node.typ,
- node.location,
- node.annotation,
- )
- elif node.value == var:
- return LLLnode(value, [], node.typ, node.location, node.annotation)
- else:
- return LLLnode(
- node.value,
- [replace_with_value(arg, var, value) for arg in node.args],
- node.typ,
- node.location,
- node.annotation,
- )
-
-
arith = {
"add": (operator.add, '+'),
"sub": (operator.sub, '-'),
@@ -83,20 +62,6 @@
)
-def _is_with_without_set(node, args):
- # TODO: this unconditionally returns `False`. Corresponding optimizer path
- # should likely be removed.
- return (
- (
- node.value == "with" and int_at(args, 1)
- ) and (
- not search_for_set(args[2], args[0].value)
- ) and (
- False
- )
- )
-
-
def has_cond_arg(node):
return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']
@@ -232,23 +197,16 @@
annotation=node.annotation,
# let from_list handle valency and gas_estimate
)
- elif _is_with_without_set(node, argz):
- # TODO: This block is currently unreachable due to
- # `_is_with_without_set` unconditionally returning `False` this appears
- # to be because this "is actually not such a good optimization after
- # all" accordiing to previous comment.
- o = replace_with_value(argz[2], argz[0].value, argz[1].value)
- return o
elif node.value == "seq":
- o = []
+ xs: List[Any] = []
for arg in argz:
if arg.value == "seq":
- o.extend(arg.args)
+ xs.extend(arg.args)
else:
- o.append(arg)
+ xs.append(arg)
return LLLnode(
node.value,
- o,
+ xs,
node.typ,
node.location,
node.pos,
| {"golden_diff": "diff --git a/vyper/optimizer.py b/vyper/optimizer.py\n--- a/vyper/optimizer.py\n+++ b/vyper/optimizer.py\n@@ -1,4 +1,8 @@\n import operator\n+from typing import (\n+ Any,\n+ List,\n+)\n \n from vyper.parser.parser_utils import (\n LLLnode,\n@@ -39,31 +43,6 @@\n return False\n \n \n-def replace_with_value(node, var, value):\n- if node.value == \"with\" and node.args[0].value == var:\n- return LLLnode(\n- node.value,\n- [\n- node.args[0],\n- replace_with_value(node.args[1], var, value),\n- node.args[2]\n- ],\n- node.typ,\n- node.location,\n- node.annotation,\n- )\n- elif node.value == var:\n- return LLLnode(value, [], node.typ, node.location, node.annotation)\n- else:\n- return LLLnode(\n- node.value,\n- [replace_with_value(arg, var, value) for arg in node.args],\n- node.typ,\n- node.location,\n- node.annotation,\n- )\n-\n-\n arith = {\n \"add\": (operator.add, '+'),\n \"sub\": (operator.sub, '-'),\n@@ -83,20 +62,6 @@\n )\n \n \n-def _is_with_without_set(node, args):\n- # TODO: this unconditionally returns `False`. Corresponding optimizer path\n- # should likely be removed.\n- return (\n- (\n- node.value == \"with\" and int_at(args, 1)\n- ) and (\n- not search_for_set(args[2], args[0].value)\n- ) and (\n- False\n- )\n- )\n-\n-\n def has_cond_arg(node):\n return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']\n \n@@ -232,23 +197,16 @@\n annotation=node.annotation,\n # let from_list handle valency and gas_estimate\n )\n- elif _is_with_without_set(node, argz):\n- # TODO: This block is currently unreachable due to\n- # `_is_with_without_set` unconditionally returning `False` this appears\n- # to be because this \"is actually not such a good optimization after\n- # all\" accordiing to previous comment.\n- o = replace_with_value(argz[2], argz[0].value, argz[1].value)\n- return o\n elif node.value == \"seq\":\n- o = []\n+ xs: List[Any] = []\n for arg in argz:\n if arg.value == \"seq\":\n- o.extend(arg.args)\n+ xs.extend(arg.args)\n else:\n- o.append(arg)\n+ xs.append(arg)\n return LLLnode(\n node.value,\n- o,\n+ xs,\n node.typ,\n node.location,\n node.pos,\n", "issue": "Unused optimisation.\n### Version Information\r\n\r\nmaster\r\n\r\n### What's your issue about?\r\nInvestigate listed TODO: https://github.com/ethereum/vyper/blame/master/vyper/optimizer.py#L99\r\n```python\r\n # Turns out this is actually not such a good optimization after all\r\n elif node.value == \"with\" and int_at(argz, 1) and not search_for_set(argz[2], argz[0].value) and False:\r\n o = replace_with_value(argz[2], argz[0].value, argz[1].value)\r\n return o\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nI have not fully investigated, but I suspect we can just drop the optimisation.\n", "before_files": [{"content": "import operator\n\nfrom vyper.parser.parser_utils import (\n LLLnode,\n)\nfrom vyper.utils import (\n LOADED_LIMIT_MAP,\n)\n\n\ndef get_int_at(args, pos, signed=False):\n value = args[pos].value\n\n if isinstance(value, int):\n o = value\n elif value == \"mload\" and args[pos].args[0].value in LOADED_LIMIT_MAP.keys():\n o = LOADED_LIMIT_MAP[args[pos].args[0].value]\n else:\n return None\n\n if signed or o < 0:\n return ((o + 2**255) % 2**256) - 2**255\n else:\n return o % 2**256\n\n\ndef int_at(args, pos):\n return get_int_at(args, pos) is not None\n\n\ndef search_for_set(node, var):\n if node.value == \"set\" and node.args[0].value == var:\n return True\n\n for arg in node.args:\n if search_for_set(arg, var):\n return True\n\n return False\n\n\ndef replace_with_value(node, var, value):\n if node.value == \"with\" and node.args[0].value == var:\n return LLLnode(\n node.value,\n [\n node.args[0],\n replace_with_value(node.args[1], var, value),\n node.args[2]\n ],\n node.typ,\n node.location,\n node.annotation,\n )\n elif node.value == var:\n return LLLnode(value, [], node.typ, node.location, node.annotation)\n else:\n return LLLnode(\n node.value,\n [replace_with_value(arg, var, value) for arg in node.args],\n node.typ,\n node.location,\n node.annotation,\n )\n\n\narith = {\n \"add\": (operator.add, '+'),\n \"sub\": (operator.sub, '-'),\n \"mul\": (operator.mul, '*'),\n \"div\": (operator.floordiv, '/'),\n \"mod\": (operator.mod, '%'),\n}\n\n\ndef _is_constant_add(node, args):\n return (\n (\n node.value == \"add\" and int_at(args, 0)\n ) and (\n args[1].value == \"add\" and int_at(args[1].args, 0)\n )\n )\n\n\ndef _is_with_without_set(node, args):\n # TODO: this unconditionally returns `False`. Corresponding optimizer path\n # should likely be removed.\n return (\n (\n node.value == \"with\" and int_at(args, 1)\n ) and (\n not search_for_set(args[2], args[0].value)\n ) and (\n False\n )\n )\n\n\ndef has_cond_arg(node):\n return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']\n\n\ndef optimize(node: LLLnode) -> LLLnode:\n argz = [optimize(arg) for arg in node.args]\n if node.value in arith and int_at(argz, 0) and int_at(argz, 1):\n left, right = get_int_at(argz, 0), get_int_at(argz, 1)\n calcer, symb = arith[node.value]\n new_value = calcer(left, right)\n if argz[0].annotation and argz[1].annotation:\n annotation = argz[0].annotation + symb + argz[1].annotation\n elif argz[0].annotation or argz[1].annotation:\n annotation = (\n argz[0].annotation or str(left)\n ) + symb + (\n argz[1].annotation or str(right)\n )\n else:\n annotation = ''\n return LLLnode(\n new_value,\n [],\n node.typ,\n None,\n node.pos,\n annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif _is_constant_add(node, argz):\n calcer, symb = arith[node.value]\n if argz[0].annotation and argz[1].args[0].annotation:\n annotation = argz[0].annotation + symb + argz[1].args[0].annotation\n elif argz[0].annotation or argz[1].args[0].annotation:\n annotation = (\n argz[0].annotation or str(argz[0].value)\n ) + symb + (\n argz[1].args[0].annotation or str(argz[1].args[0].value)\n )\n else:\n annotation = ''\n return LLLnode(\n \"add\",\n [\n LLLnode(argz[0].value + argz[1].args[0].value, annotation=annotation),\n argz[1].args[1],\n ],\n node.typ,\n None,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 0) == 0:\n return LLLnode(\n argz[1].value,\n argz[1].args,\n node.typ,\n node.location,\n node.pos,\n argz[1].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 1) == 0:\n return LLLnode(\n argz[0].value,\n argz[0].args,\n node.typ,\n node.location,\n node.pos,\n argz[0].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1) and int_at(argz, 2):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n elif get_int_at(argz, 1, True) > get_int_at(argz, 2, True):\n raise Exception(\"Clamp always fails\")\n else:\n return argz[1]\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n else:\n return LLLnode(\n \"clample\",\n [argz[1], argz[2]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp_nonzero\" and int_at(argz, 0):\n if get_int_at(argz, 0) != 0:\n return LLLnode(\n argz[0].value,\n [],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n else:\n raise Exception(\"Clamp always fails\")\n # [eq, x, 0] is the same as [iszero, x].\n elif node.value == 'eq' and int_at(argz, 1) and argz[1].value == 0:\n return LLLnode(\n 'iszero',\n [argz[0]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n # [ne, x, y] has the same truthyness as [xor, x, y]\n # rewrite 'ne' as 'xor' in places where truthy is accepted.\n elif has_cond_arg(node) and argz[0].value == 'ne':\n argz[0] = LLLnode.from_list(['xor'] + argz[0].args)\n return LLLnode.from_list(\n [node.value] + argz,\n typ=node.typ,\n location=node.location,\n pos=node.pos,\n annotation=node.annotation,\n # let from_list handle valency and gas_estimate\n )\n elif _is_with_without_set(node, argz):\n # TODO: This block is currently unreachable due to\n # `_is_with_without_set` unconditionally returning `False` this appears\n # to be because this \"is actually not such a good optimization after\n # all\" accordiing to previous comment.\n o = replace_with_value(argz[2], argz[0].value, argz[1].value)\n return o\n elif node.value == \"seq\":\n o = []\n for arg in argz:\n if arg.value == \"seq\":\n o.extend(arg.args)\n else:\n o.append(arg)\n return LLLnode(\n node.value,\n o,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.total_gas is not None:\n o = LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n o.total_gas = node.total_gas - node.gas + o.gas\n o.func_name = node.func_name\n return o\n else:\n return LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n", "path": "vyper/optimizer.py"}], "after_files": [{"content": "import operator\nfrom typing import (\n Any,\n List,\n)\n\nfrom vyper.parser.parser_utils import (\n LLLnode,\n)\nfrom vyper.utils import (\n LOADED_LIMIT_MAP,\n)\n\n\ndef get_int_at(args, pos, signed=False):\n value = args[pos].value\n\n if isinstance(value, int):\n o = value\n elif value == \"mload\" and args[pos].args[0].value in LOADED_LIMIT_MAP.keys():\n o = LOADED_LIMIT_MAP[args[pos].args[0].value]\n else:\n return None\n\n if signed or o < 0:\n return ((o + 2**255) % 2**256) - 2**255\n else:\n return o % 2**256\n\n\ndef int_at(args, pos):\n return get_int_at(args, pos) is not None\n\n\ndef search_for_set(node, var):\n if node.value == \"set\" and node.args[0].value == var:\n return True\n\n for arg in node.args:\n if search_for_set(arg, var):\n return True\n\n return False\n\n\narith = {\n \"add\": (operator.add, '+'),\n \"sub\": (operator.sub, '-'),\n \"mul\": (operator.mul, '*'),\n \"div\": (operator.floordiv, '/'),\n \"mod\": (operator.mod, '%'),\n}\n\n\ndef _is_constant_add(node, args):\n return (\n (\n node.value == \"add\" and int_at(args, 0)\n ) and (\n args[1].value == \"add\" and int_at(args[1].args, 0)\n )\n )\n\n\ndef has_cond_arg(node):\n return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']\n\n\ndef optimize(node: LLLnode) -> LLLnode:\n argz = [optimize(arg) for arg in node.args]\n if node.value in arith and int_at(argz, 0) and int_at(argz, 1):\n left, right = get_int_at(argz, 0), get_int_at(argz, 1)\n calcer, symb = arith[node.value]\n new_value = calcer(left, right)\n if argz[0].annotation and argz[1].annotation:\n annotation = argz[0].annotation + symb + argz[1].annotation\n elif argz[0].annotation or argz[1].annotation:\n annotation = (\n argz[0].annotation or str(left)\n ) + symb + (\n argz[1].annotation or str(right)\n )\n else:\n annotation = ''\n return LLLnode(\n new_value,\n [],\n node.typ,\n None,\n node.pos,\n annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif _is_constant_add(node, argz):\n calcer, symb = arith[node.value]\n if argz[0].annotation and argz[1].args[0].annotation:\n annotation = argz[0].annotation + symb + argz[1].args[0].annotation\n elif argz[0].annotation or argz[1].args[0].annotation:\n annotation = (\n argz[0].annotation or str(argz[0].value)\n ) + symb + (\n argz[1].args[0].annotation or str(argz[1].args[0].value)\n )\n else:\n annotation = ''\n return LLLnode(\n \"add\",\n [\n LLLnode(argz[0].value + argz[1].args[0].value, annotation=annotation),\n argz[1].args[1],\n ],\n node.typ,\n None,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 0) == 0:\n return LLLnode(\n argz[1].value,\n argz[1].args,\n node.typ,\n node.location,\n node.pos,\n argz[1].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 1) == 0:\n return LLLnode(\n argz[0].value,\n argz[0].args,\n node.typ,\n node.location,\n node.pos,\n argz[0].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1) and int_at(argz, 2):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n elif get_int_at(argz, 1, True) > get_int_at(argz, 2, True):\n raise Exception(\"Clamp always fails\")\n else:\n return argz[1]\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n else:\n return LLLnode(\n \"clample\",\n [argz[1], argz[2]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp_nonzero\" and int_at(argz, 0):\n if get_int_at(argz, 0) != 0:\n return LLLnode(\n argz[0].value,\n [],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n else:\n raise Exception(\"Clamp always fails\")\n # [eq, x, 0] is the same as [iszero, x].\n elif node.value == 'eq' and int_at(argz, 1) and argz[1].value == 0:\n return LLLnode(\n 'iszero',\n [argz[0]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n # [ne, x, y] has the same truthyness as [xor, x, y]\n # rewrite 'ne' as 'xor' in places where truthy is accepted.\n elif has_cond_arg(node) and argz[0].value == 'ne':\n argz[0] = LLLnode.from_list(['xor'] + argz[0].args)\n return LLLnode.from_list(\n [node.value] + argz,\n typ=node.typ,\n location=node.location,\n pos=node.pos,\n annotation=node.annotation,\n # let from_list handle valency and gas_estimate\n )\n elif node.value == \"seq\":\n xs: List[Any] = []\n for arg in argz:\n if arg.value == \"seq\":\n xs.extend(arg.args)\n else:\n xs.append(arg)\n return LLLnode(\n node.value,\n xs,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.total_gas is not None:\n o = LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n o.total_gas = node.total_gas - node.gas + o.gas\n o.func_name = node.func_name\n return o\n else:\n return LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n", "path": "vyper/optimizer.py"}]} | 3,294 | 664 |
gh_patches_debug_15586 | rasdani/github-patches | git_diff | conan-io__conan-391 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conan install -u traceback
When running `conan install -u` while no previous `conan install` was run (so e.g. no conan conanbuildinfo.cmake exists) I get the following traceback:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/proxy.py`
Content:
```
1 from conans.client.output import ScopedOutput
2 from conans.util.files import path_exists, rmdir
3 from conans.model.ref import PackageReference
4 from conans.errors import (ConanException, ConanConnectionError, ConanOutdatedClient,
5 NotFoundException)
6 from conans.client.remote_registry import RemoteRegistry
7 from conans.util.log import logger
8 import os
9
10
11 class ConanProxy(object):
12 """ Class to access the conan storage, to perform typical tasks as to get packages,
13 getting conanfiles, uploading, removing from remote, etc.
14 It uses the RemoteRegistry to control where the packages come from.
15 """
16 def __init__(self, paths, user_io, remote_manager, remote_name,
17 update=False, check_updates=False, check_integrity=False):
18 self._paths = paths
19 self._out = user_io.out
20 self._remote_manager = remote_manager
21 self._registry = RemoteRegistry(self._paths.registry, self._out)
22 self._remote_name = remote_name
23 self._update = update
24 self._check_updates = check_updates or update # Update forces check
25 self._check_integrity = check_integrity
26
27 @property
28 def registry(self):
29 return self._registry
30
31 def get_package(self, package_reference, force_build):
32 """ obtain a package, either from disk or retrieve from remotes if necessary
33 and not necessary to build
34 """
35 output = ScopedOutput(str(package_reference.conan), self._out)
36 package_folder = self._paths.package(package_reference)
37
38 # Check current package status
39 if path_exists(package_folder, self._paths.store):
40 if self._check_integrity or self._check_updates:
41 read_manifest, expected_manifest = self._paths.package_manifests(package_reference)
42
43 if self._check_integrity: # Check if package is corrupted
44 if read_manifest.file_sums != expected_manifest.file_sums:
45 # If not valid package, ensure empty folder
46 output.warn("Bad package '%s' detected! Removing "
47 "package directory... " % str(package_reference.package_id))
48 rmdir(package_folder)
49
50 if self._check_updates:
51 try: # get_conan_digest can fail, not in server
52 upstream_manifest = self.get_package_digest(package_reference)
53 if upstream_manifest.file_sums != read_manifest.file_sums:
54 if upstream_manifest.time > read_manifest.time:
55 output.warn("Current package is older than remote upstream one")
56 if self._update:
57 output.warn("Removing it to retrieve or build an updated one")
58 rmdir(package_folder)
59 else:
60 output.warn("Current package is newer than remote upstream one")
61 except ConanException:
62 pass
63
64 if not force_build:
65 local_package = os.path.exists(package_folder)
66 if local_package:
67 output = ScopedOutput(str(package_reference.conan), self._out)
68 output.info('Already installed!')
69 return True
70 return self._retrieve_remote_package(package_reference, output)
71
72 return False
73
74 def get_conanfile(self, conan_reference):
75 output = ScopedOutput(str(conan_reference), self._out)
76
77 def _refresh():
78 conan_dir_path = self._paths.export(conan_reference)
79 rmdir(conan_dir_path)
80 rmdir(self._paths.source(conan_reference))
81 current_remote, _ = self._get_remote(conan_reference)
82 output.info("Retrieving from remote '%s'..." % current_remote.name)
83 self._remote_manager.get_conanfile(conan_reference, current_remote)
84 if self._update:
85 output.info("Updated!")
86 else:
87 output.info("Installed!")
88
89 # check if it is in disk
90 conanfile_path = self._paths.conanfile(conan_reference)
91 is_min_path = conan_reference in self._paths.short_path_refs
92 if not is_min_path:
93 path_exist = path_exists(conanfile_path, self._paths.store)
94 else: # Directory doesn't contain the reference, so we don't need to compare the cases
95 path_exist = os.path.exists(conanfile_path)
96
97 if path_exist:
98 if self._check_integrity: # Check if package is corrupted
99 read_manifest, expected_manifest = self._paths.conan_manifests(conan_reference)
100 if read_manifest.file_sums != expected_manifest.file_sums:
101 output.warn("Bad conanfile detected! Removing export directory... ")
102 _refresh()
103 else: # Check for updates
104 if self._check_updates:
105 ret = self.update_available(conan_reference)
106 if ret != 0: # Found and not equal
107 remote, ref_remote = self._get_remote(conan_reference)
108 if ret == 1:
109 if not self._update:
110 if remote != ref_remote: # Forced new remote
111 output.warn("There is a new conanfile in '%s' remote. "
112 "Execute 'install -u -r %s' to update it."
113 % (remote.name, remote.name))
114 else:
115 output.warn("There is a new conanfile in '%s' remote. "
116 "Execute 'install -u' to update it."
117 % remote.name)
118 output.warn("Refused to install!")
119 else:
120 if remote != ref_remote:
121 # Delete packages, could be non coherent with new remote
122 rmdir(self._paths.packages(conan_reference))
123 _refresh()
124 elif ret == -1:
125 if not self._update:
126 output.info("Current conanfile is newer "
127 "than %s's one" % remote.name)
128 else:
129 output.error("Current conanfile is newer than %s's one. "
130 "Run 'conan remove %s' and run install again "
131 "to replace it." % (remote.name, conan_reference))
132
133 else:
134 self._retrieve_conanfile(conan_reference, output)
135 return conanfile_path
136
137 def update_available(self, conan_reference):
138 """Returns 0 if the conanfiles are equal, 1 if there is an update and -1 if
139 the local is newer than the remote"""
140 if not conan_reference:
141 return 0
142 read_manifest, _ = self._paths.conan_manifests(conan_reference)
143 try: # get_conan_digest can fail, not in server
144 upstream_manifest = self.get_conan_digest(conan_reference)
145 if upstream_manifest.file_sums != read_manifest.file_sums:
146 return 1 if upstream_manifest.time > read_manifest.time else -1
147 except ConanException:
148 pass
149
150 return 0
151
152 def _retrieve_conanfile(self, conan_reference, output):
153 """ returns the requested conanfile object, retrieving it from
154 remotes if necessary. Can raise NotFoundException
155 """
156 def _retrieve_from_remote(remote):
157 output.info("Trying with '%s'..." % remote.name)
158 result = self._remote_manager.get_conanfile(conan_reference, remote)
159 self._registry.set_ref(conan_reference, remote)
160 return result
161
162 if self._remote_name:
163 output.info("Not found, retrieving from server '%s' " % self._remote_name)
164 remote = self._registry.remote(self._remote_name)
165 return _retrieve_from_remote(remote)
166 else:
167 output.info("Not found, looking in remotes...")
168
169 remotes = self._registry.remotes
170 for remote in remotes:
171 logger.debug("Trying with remote %s" % remote.name)
172 try:
173 return _retrieve_from_remote(remote)
174 # If exception continue with the next
175 except (ConanOutdatedClient, ConanConnectionError) as exc:
176 output.warn(str(exc))
177 if remote == remotes[-1]: # Last element not found
178 raise ConanConnectionError("All remotes failed")
179 except NotFoundException as exc:
180 if remote == remotes[-1]: # Last element not found
181 logger.debug("Not found in any remote, raising...%s" % exc)
182 raise NotFoundException("Unable to find '%s' in remotes"
183 % str(conan_reference))
184
185 raise ConanException("No remote defined")
186
187 def upload_conan(self, conan_reference):
188 """ upload to defined remote in (-r=remote), to current remote
189 or to default remote, in that order.
190 If the remote is not set, set it
191 """
192 remote, ref_remote = self._get_remote(conan_reference)
193
194 result = self._remote_manager.upload_conan(conan_reference, remote)
195 if not ref_remote:
196 self._registry.set_ref(conan_reference, remote)
197 return result
198
199 def _get_remote(self, conan_ref=None):
200 # Prioritize -r , then reference registry and then the default remote
201 ref_remote = self._registry.get_ref(conan_ref) if conan_ref else None
202 if self._remote_name:
203 remote = self._registry.remote(self._remote_name)
204 else:
205 if ref_remote:
206 remote = ref_remote
207 else:
208 remote = self._registry.default_remote
209 return remote, ref_remote
210
211 def upload_package(self, package_reference):
212 remote, current_remote = self._get_remote(package_reference.conan)
213
214 if not current_remote:
215 self._out.warn("Remote for '%s' not defined, uploading to %s"
216 % (str(package_reference.conan), remote.name))
217 result = self._remote_manager.upload_package(package_reference, remote)
218 if not current_remote:
219 self._registry.set_ref(package_reference.conan, remote)
220 return result
221
222 def get_conan_digest(self, conan_ref):
223 """ used by update to check the date of packages, require force if older
224 """
225 remote, current_remote = self._get_remote(conan_ref)
226 result = self._remote_manager.get_conan_digest(conan_ref, remote)
227 if not current_remote:
228 self._registry.set_ref(conan_ref, remote)
229 return result
230
231 def get_package_digest(self, package_reference):
232 """ used by update to check the date of packages, require force if older
233 """
234 remote, ref_remote = self._get_remote(package_reference.conan)
235 result = self._remote_manager.get_package_digest(package_reference, remote)
236 if not ref_remote:
237 self._registry.set_ref(package_reference.conan, remote)
238 return result
239
240 def search(self, pattern=None, ignorecase=True):
241 remote, _ = self._get_remote()
242 return self._remote_manager.search(remote, pattern, ignorecase)
243
244 def remove(self, conan_ref):
245 if not self._remote_name:
246 raise ConanException("Cannot remove, remote not defined")
247 remote = self._registry.remote(self._remote_name)
248 result = self._remote_manager.remove(conan_ref, remote)
249 current_remote = self._registry.get_ref(conan_ref)
250 if current_remote == remote:
251 self._registry.remove_ref(conan_ref)
252 return result
253
254 def remove_packages(self, conan_ref, remove_ids):
255 if not self._remote_name:
256 raise ConanException("Cannot remove, remote not defined")
257 remote = self._registry.remote(self._remote_name)
258 return self._remote_manager.remove_packages(conan_ref, remove_ids, remote)
259
260 def download_packages(self, reference, package_ids):
261 assert(isinstance(package_ids, list))
262 remote, _ = self._get_remote(reference)
263 self._remote_manager.get_conanfile(reference, remote)
264 self._registry.set_ref(reference, remote)
265 output = ScopedOutput(str(reference), self._out)
266 for package_id in package_ids:
267 package_reference = PackageReference(reference, package_id)
268 self._retrieve_remote_package(package_reference, output, remote)
269
270 def _retrieve_remote_package(self, package_reference, output, remote=None):
271
272 if remote is None:
273 remote = self._registry.get_ref(package_reference.conan)
274 if not remote:
275 output.warn("Package doesn't have a remote defined. "
276 "Probably created locally and not uploaded")
277 return False
278 package_id = str(package_reference.package_id)
279 try:
280 output.info("Looking for package %s in remote '%s' " % (package_id, remote.name))
281 # Will raise if not found NotFoundException
282 self._remote_manager.get_package(package_reference, remote)
283 output.success('Package installed %s' % package_id)
284 return True
285 except ConanConnectionError:
286 raise # This shouldn't be skipped
287 except ConanException as e:
288 output.warn('Binary for %s not in remote: %s' % (package_id, str(e)))
289 return False
290
291 def authenticate(self, name, password):
292 if not name: # List all users, from all remotes
293 remotes = self._registry.remotes
294 if not remotes:
295 self._out.error("No remotes defined")
296 for remote in remotes:
297 self._remote_manager.authenticate(remote, None, None)
298 return
299 remote, _ = self._get_remote()
300 return self._remote_manager.authenticate(remote, name, password)
301
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/conans/client/proxy.py b/conans/client/proxy.py
--- a/conans/client/proxy.py
+++ b/conans/client/proxy.py
@@ -140,12 +140,13 @@
if not conan_reference:
return 0
read_manifest, _ = self._paths.conan_manifests(conan_reference)
- try: # get_conan_digest can fail, not in server
- upstream_manifest = self.get_conan_digest(conan_reference)
- if upstream_manifest.file_sums != read_manifest.file_sums:
- return 1 if upstream_manifest.time > read_manifest.time else -1
- except ConanException:
- pass
+ if read_manifest:
+ try: # get_conan_digest can fail, not in server
+ upstream_manifest = self.get_conan_digest(conan_reference)
+ if upstream_manifest.file_sums != read_manifest.file_sums:
+ return 1 if upstream_manifest.time > read_manifest.time else -1
+ except ConanException:
+ pass
return 0
| {"golden_diff": "diff --git a/conans/client/proxy.py b/conans/client/proxy.py\n--- a/conans/client/proxy.py\n+++ b/conans/client/proxy.py\n@@ -140,12 +140,13 @@\n if not conan_reference:\n return 0\n read_manifest, _ = self._paths.conan_manifests(conan_reference)\n- try: # get_conan_digest can fail, not in server\n- upstream_manifest = self.get_conan_digest(conan_reference)\n- if upstream_manifest.file_sums != read_manifest.file_sums:\n- return 1 if upstream_manifest.time > read_manifest.time else -1\n- except ConanException:\n- pass\n+ if read_manifest:\n+ try: # get_conan_digest can fail, not in server\n+ upstream_manifest = self.get_conan_digest(conan_reference)\n+ if upstream_manifest.file_sums != read_manifest.file_sums:\n+ return 1 if upstream_manifest.time > read_manifest.time else -1\n+ except ConanException:\n+ pass\n \n return 0\n", "issue": "conan install -u traceback\nWhen running `conan install -u` while no previous `conan install` was run (so e.g. no conan conanbuildinfo.cmake exists) I get the following traceback:\n\n\n\n", "before_files": [{"content": "from conans.client.output import ScopedOutput\nfrom conans.util.files import path_exists, rmdir\nfrom conans.model.ref import PackageReference\nfrom conans.errors import (ConanException, ConanConnectionError, ConanOutdatedClient,\n NotFoundException)\nfrom conans.client.remote_registry import RemoteRegistry\nfrom conans.util.log import logger\nimport os\n\n\nclass ConanProxy(object):\n \"\"\" Class to access the conan storage, to perform typical tasks as to get packages,\n getting conanfiles, uploading, removing from remote, etc.\n It uses the RemoteRegistry to control where the packages come from.\n \"\"\"\n def __init__(self, paths, user_io, remote_manager, remote_name,\n update=False, check_updates=False, check_integrity=False):\n self._paths = paths\n self._out = user_io.out\n self._remote_manager = remote_manager\n self._registry = RemoteRegistry(self._paths.registry, self._out)\n self._remote_name = remote_name\n self._update = update\n self._check_updates = check_updates or update # Update forces check\n self._check_integrity = check_integrity\n\n @property\n def registry(self):\n return self._registry\n\n def get_package(self, package_reference, force_build):\n \"\"\" obtain a package, either from disk or retrieve from remotes if necessary\n and not necessary to build\n \"\"\"\n output = ScopedOutput(str(package_reference.conan), self._out)\n package_folder = self._paths.package(package_reference)\n\n # Check current package status\n if path_exists(package_folder, self._paths.store):\n if self._check_integrity or self._check_updates:\n read_manifest, expected_manifest = self._paths.package_manifests(package_reference)\n\n if self._check_integrity: # Check if package is corrupted\n if read_manifest.file_sums != expected_manifest.file_sums:\n # If not valid package, ensure empty folder\n output.warn(\"Bad package '%s' detected! Removing \"\n \"package directory... \" % str(package_reference.package_id))\n rmdir(package_folder)\n\n if self._check_updates:\n try: # get_conan_digest can fail, not in server\n upstream_manifest = self.get_package_digest(package_reference)\n if upstream_manifest.file_sums != read_manifest.file_sums:\n if upstream_manifest.time > read_manifest.time:\n output.warn(\"Current package is older than remote upstream one\")\n if self._update:\n output.warn(\"Removing it to retrieve or build an updated one\")\n rmdir(package_folder)\n else:\n output.warn(\"Current package is newer than remote upstream one\")\n except ConanException:\n pass\n\n if not force_build:\n local_package = os.path.exists(package_folder)\n if local_package:\n output = ScopedOutput(str(package_reference.conan), self._out)\n output.info('Already installed!')\n return True\n return self._retrieve_remote_package(package_reference, output)\n\n return False\n\n def get_conanfile(self, conan_reference):\n output = ScopedOutput(str(conan_reference), self._out)\n\n def _refresh():\n conan_dir_path = self._paths.export(conan_reference)\n rmdir(conan_dir_path)\n rmdir(self._paths.source(conan_reference))\n current_remote, _ = self._get_remote(conan_reference)\n output.info(\"Retrieving from remote '%s'...\" % current_remote.name)\n self._remote_manager.get_conanfile(conan_reference, current_remote)\n if self._update:\n output.info(\"Updated!\")\n else:\n output.info(\"Installed!\")\n\n # check if it is in disk\n conanfile_path = self._paths.conanfile(conan_reference)\n is_min_path = conan_reference in self._paths.short_path_refs\n if not is_min_path:\n path_exist = path_exists(conanfile_path, self._paths.store)\n else: # Directory doesn't contain the reference, so we don't need to compare the cases\n path_exist = os.path.exists(conanfile_path)\n\n if path_exist:\n if self._check_integrity: # Check if package is corrupted\n read_manifest, expected_manifest = self._paths.conan_manifests(conan_reference)\n if read_manifest.file_sums != expected_manifest.file_sums:\n output.warn(\"Bad conanfile detected! Removing export directory... \")\n _refresh()\n else: # Check for updates\n if self._check_updates:\n ret = self.update_available(conan_reference)\n if ret != 0: # Found and not equal\n remote, ref_remote = self._get_remote(conan_reference)\n if ret == 1:\n if not self._update:\n if remote != ref_remote: # Forced new remote\n output.warn(\"There is a new conanfile in '%s' remote. \"\n \"Execute 'install -u -r %s' to update it.\"\n % (remote.name, remote.name))\n else:\n output.warn(\"There is a new conanfile in '%s' remote. \"\n \"Execute 'install -u' to update it.\"\n % remote.name)\n output.warn(\"Refused to install!\")\n else:\n if remote != ref_remote:\n # Delete packages, could be non coherent with new remote\n rmdir(self._paths.packages(conan_reference))\n _refresh()\n elif ret == -1:\n if not self._update:\n output.info(\"Current conanfile is newer \"\n \"than %s's one\" % remote.name)\n else:\n output.error(\"Current conanfile is newer than %s's one. \"\n \"Run 'conan remove %s' and run install again \"\n \"to replace it.\" % (remote.name, conan_reference))\n\n else:\n self._retrieve_conanfile(conan_reference, output)\n return conanfile_path\n\n def update_available(self, conan_reference):\n \"\"\"Returns 0 if the conanfiles are equal, 1 if there is an update and -1 if\n the local is newer than the remote\"\"\"\n if not conan_reference:\n return 0\n read_manifest, _ = self._paths.conan_manifests(conan_reference)\n try: # get_conan_digest can fail, not in server\n upstream_manifest = self.get_conan_digest(conan_reference)\n if upstream_manifest.file_sums != read_manifest.file_sums:\n return 1 if upstream_manifest.time > read_manifest.time else -1\n except ConanException:\n pass\n\n return 0\n\n def _retrieve_conanfile(self, conan_reference, output):\n \"\"\" returns the requested conanfile object, retrieving it from\n remotes if necessary. Can raise NotFoundException\n \"\"\"\n def _retrieve_from_remote(remote):\n output.info(\"Trying with '%s'...\" % remote.name)\n result = self._remote_manager.get_conanfile(conan_reference, remote)\n self._registry.set_ref(conan_reference, remote)\n return result\n\n if self._remote_name:\n output.info(\"Not found, retrieving from server '%s' \" % self._remote_name)\n remote = self._registry.remote(self._remote_name)\n return _retrieve_from_remote(remote)\n else:\n output.info(\"Not found, looking in remotes...\")\n\n remotes = self._registry.remotes\n for remote in remotes:\n logger.debug(\"Trying with remote %s\" % remote.name)\n try:\n return _retrieve_from_remote(remote)\n # If exception continue with the next\n except (ConanOutdatedClient, ConanConnectionError) as exc:\n output.warn(str(exc))\n if remote == remotes[-1]: # Last element not found\n raise ConanConnectionError(\"All remotes failed\")\n except NotFoundException as exc:\n if remote == remotes[-1]: # Last element not found\n logger.debug(\"Not found in any remote, raising...%s\" % exc)\n raise NotFoundException(\"Unable to find '%s' in remotes\"\n % str(conan_reference))\n\n raise ConanException(\"No remote defined\")\n\n def upload_conan(self, conan_reference):\n \"\"\" upload to defined remote in (-r=remote), to current remote\n or to default remote, in that order.\n If the remote is not set, set it\n \"\"\"\n remote, ref_remote = self._get_remote(conan_reference)\n\n result = self._remote_manager.upload_conan(conan_reference, remote)\n if not ref_remote:\n self._registry.set_ref(conan_reference, remote)\n return result\n\n def _get_remote(self, conan_ref=None):\n # Prioritize -r , then reference registry and then the default remote\n ref_remote = self._registry.get_ref(conan_ref) if conan_ref else None\n if self._remote_name:\n remote = self._registry.remote(self._remote_name)\n else:\n if ref_remote:\n remote = ref_remote\n else:\n remote = self._registry.default_remote\n return remote, ref_remote\n\n def upload_package(self, package_reference):\n remote, current_remote = self._get_remote(package_reference.conan)\n\n if not current_remote:\n self._out.warn(\"Remote for '%s' not defined, uploading to %s\"\n % (str(package_reference.conan), remote.name))\n result = self._remote_manager.upload_package(package_reference, remote)\n if not current_remote:\n self._registry.set_ref(package_reference.conan, remote)\n return result\n\n def get_conan_digest(self, conan_ref):\n \"\"\" used by update to check the date of packages, require force if older\n \"\"\"\n remote, current_remote = self._get_remote(conan_ref)\n result = self._remote_manager.get_conan_digest(conan_ref, remote)\n if not current_remote:\n self._registry.set_ref(conan_ref, remote)\n return result\n\n def get_package_digest(self, package_reference):\n \"\"\" used by update to check the date of packages, require force if older\n \"\"\"\n remote, ref_remote = self._get_remote(package_reference.conan)\n result = self._remote_manager.get_package_digest(package_reference, remote)\n if not ref_remote:\n self._registry.set_ref(package_reference.conan, remote)\n return result\n\n def search(self, pattern=None, ignorecase=True):\n remote, _ = self._get_remote()\n return self._remote_manager.search(remote, pattern, ignorecase)\n\n def remove(self, conan_ref):\n if not self._remote_name:\n raise ConanException(\"Cannot remove, remote not defined\")\n remote = self._registry.remote(self._remote_name)\n result = self._remote_manager.remove(conan_ref, remote)\n current_remote = self._registry.get_ref(conan_ref)\n if current_remote == remote:\n self._registry.remove_ref(conan_ref)\n return result\n\n def remove_packages(self, conan_ref, remove_ids):\n if not self._remote_name:\n raise ConanException(\"Cannot remove, remote not defined\")\n remote = self._registry.remote(self._remote_name)\n return self._remote_manager.remove_packages(conan_ref, remove_ids, remote)\n\n def download_packages(self, reference, package_ids):\n assert(isinstance(package_ids, list))\n remote, _ = self._get_remote(reference)\n self._remote_manager.get_conanfile(reference, remote)\n self._registry.set_ref(reference, remote)\n output = ScopedOutput(str(reference), self._out)\n for package_id in package_ids:\n package_reference = PackageReference(reference, package_id)\n self._retrieve_remote_package(package_reference, output, remote)\n\n def _retrieve_remote_package(self, package_reference, output, remote=None):\n\n if remote is None:\n remote = self._registry.get_ref(package_reference.conan)\n if not remote:\n output.warn(\"Package doesn't have a remote defined. \"\n \"Probably created locally and not uploaded\")\n return False\n package_id = str(package_reference.package_id)\n try:\n output.info(\"Looking for package %s in remote '%s' \" % (package_id, remote.name))\n # Will raise if not found NotFoundException\n self._remote_manager.get_package(package_reference, remote)\n output.success('Package installed %s' % package_id)\n return True\n except ConanConnectionError:\n raise # This shouldn't be skipped\n except ConanException as e:\n output.warn('Binary for %s not in remote: %s' % (package_id, str(e)))\n return False\n\n def authenticate(self, name, password):\n if not name: # List all users, from all remotes\n remotes = self._registry.remotes\n if not remotes:\n self._out.error(\"No remotes defined\")\n for remote in remotes:\n self._remote_manager.authenticate(remote, None, None)\n return\n remote, _ = self._get_remote()\n return self._remote_manager.authenticate(remote, name, password)\n", "path": "conans/client/proxy.py"}], "after_files": [{"content": "from conans.client.output import ScopedOutput\nfrom conans.util.files import path_exists, rmdir\nfrom conans.model.ref import PackageReference\nfrom conans.errors import (ConanException, ConanConnectionError, ConanOutdatedClient,\n NotFoundException)\nfrom conans.client.remote_registry import RemoteRegistry\nfrom conans.util.log import logger\nimport os\n\n\nclass ConanProxy(object):\n \"\"\" Class to access the conan storage, to perform typical tasks as to get packages,\n getting conanfiles, uploading, removing from remote, etc.\n It uses the RemoteRegistry to control where the packages come from.\n \"\"\"\n def __init__(self, paths, user_io, remote_manager, remote_name,\n update=False, check_updates=False, check_integrity=False):\n self._paths = paths\n self._out = user_io.out\n self._remote_manager = remote_manager\n self._registry = RemoteRegistry(self._paths.registry, self._out)\n self._remote_name = remote_name\n self._update = update\n self._check_updates = check_updates or update # Update forces check\n self._check_integrity = check_integrity\n\n @property\n def registry(self):\n return self._registry\n\n def get_package(self, package_reference, force_build):\n \"\"\" obtain a package, either from disk or retrieve from remotes if necessary\n and not necessary to build\n \"\"\"\n output = ScopedOutput(str(package_reference.conan), self._out)\n package_folder = self._paths.package(package_reference)\n\n # Check current package status\n if path_exists(package_folder, self._paths.store):\n if self._check_integrity or self._check_updates:\n read_manifest, expected_manifest = self._paths.package_manifests(package_reference)\n\n if self._check_integrity: # Check if package is corrupted\n if read_manifest.file_sums != expected_manifest.file_sums:\n # If not valid package, ensure empty folder\n output.warn(\"Bad package '%s' detected! Removing \"\n \"package directory... \" % str(package_reference.package_id))\n rmdir(package_folder)\n\n if self._check_updates:\n try: # get_conan_digest can fail, not in server\n upstream_manifest = self.get_package_digest(package_reference)\n if upstream_manifest.file_sums != read_manifest.file_sums:\n if upstream_manifest.time > read_manifest.time:\n output.warn(\"Current package is older than remote upstream one\")\n if self._update:\n output.warn(\"Removing it to retrieve or build an updated one\")\n rmdir(package_folder)\n else:\n output.warn(\"Current package is newer than remote upstream one\")\n except ConanException:\n pass\n\n if not force_build:\n local_package = os.path.exists(package_folder)\n if local_package:\n output = ScopedOutput(str(package_reference.conan), self._out)\n output.info('Already installed!')\n return True\n return self._retrieve_remote_package(package_reference, output)\n\n return False\n\n def get_conanfile(self, conan_reference):\n output = ScopedOutput(str(conan_reference), self._out)\n\n def _refresh():\n conan_dir_path = self._paths.export(conan_reference)\n rmdir(conan_dir_path)\n rmdir(self._paths.source(conan_reference))\n current_remote, _ = self._get_remote(conan_reference)\n output.info(\"Retrieving from remote '%s'...\" % current_remote.name)\n self._remote_manager.get_conanfile(conan_reference, current_remote)\n if self._update:\n output.info(\"Updated!\")\n else:\n output.info(\"Installed!\")\n\n # check if it is in disk\n conanfile_path = self._paths.conanfile(conan_reference)\n is_min_path = conan_reference in self._paths.short_path_refs\n if not is_min_path:\n path_exist = path_exists(conanfile_path, self._paths.store)\n else: # Directory doesn't contain the reference, so we don't need to compare the cases\n path_exist = os.path.exists(conanfile_path)\n\n if path_exist:\n if self._check_integrity: # Check if package is corrupted\n read_manifest, expected_manifest = self._paths.conan_manifests(conan_reference)\n if read_manifest.file_sums != expected_manifest.file_sums:\n output.warn(\"Bad conanfile detected! Removing export directory... \")\n _refresh()\n else: # Check for updates\n if self._check_updates:\n ret = self.update_available(conan_reference)\n if ret != 0: # Found and not equal\n remote, ref_remote = self._get_remote(conan_reference)\n if ret == 1:\n if not self._update:\n if remote != ref_remote: # Forced new remote\n output.warn(\"There is a new conanfile in '%s' remote. \"\n \"Execute 'install -u -r %s' to update it.\"\n % (remote.name, remote.name))\n else:\n output.warn(\"There is a new conanfile in '%s' remote. \"\n \"Execute 'install -u' to update it.\"\n % remote.name)\n output.warn(\"Refused to install!\")\n else:\n if remote != ref_remote:\n # Delete packages, could be non coherent with new remote\n rmdir(self._paths.packages(conan_reference))\n _refresh()\n elif ret == -1:\n if not self._update:\n output.info(\"Current conanfile is newer \"\n \"than %s's one\" % remote.name)\n else:\n output.error(\"Current conanfile is newer than %s's one. \"\n \"Run 'conan remove %s' and run install again \"\n \"to replace it.\" % (remote.name, conan_reference))\n\n else:\n self._retrieve_conanfile(conan_reference, output)\n return conanfile_path\n\n def update_available(self, conan_reference):\n \"\"\"Returns 0 if the conanfiles are equal, 1 if there is an update and -1 if\n the local is newer than the remote\"\"\"\n if not conan_reference:\n return 0\n read_manifest, _ = self._paths.conan_manifests(conan_reference)\n if read_manifest:\n try: # get_conan_digest can fail, not in server\n upstream_manifest = self.get_conan_digest(conan_reference)\n if upstream_manifest.file_sums != read_manifest.file_sums:\n return 1 if upstream_manifest.time > read_manifest.time else -1\n except ConanException:\n pass\n\n return 0\n\n def _retrieve_conanfile(self, conan_reference, output):\n \"\"\" returns the requested conanfile object, retrieving it from\n remotes if necessary. Can raise NotFoundException\n \"\"\"\n def _retrieve_from_remote(remote):\n output.info(\"Trying with '%s'...\" % remote.name)\n result = self._remote_manager.get_conanfile(conan_reference, remote)\n self._registry.set_ref(conan_reference, remote)\n return result\n\n if self._remote_name:\n output.info(\"Not found, retrieving from server '%s' \" % self._remote_name)\n remote = self._registry.remote(self._remote_name)\n return _retrieve_from_remote(remote)\n else:\n output.info(\"Not found, looking in remotes...\")\n\n remotes = self._registry.remotes\n for remote in remotes:\n logger.debug(\"Trying with remote %s\" % remote.name)\n try:\n return _retrieve_from_remote(remote)\n # If exception continue with the next\n except (ConanOutdatedClient, ConanConnectionError) as exc:\n output.warn(str(exc))\n if remote == remotes[-1]: # Last element not found\n raise ConanConnectionError(\"All remotes failed\")\n except NotFoundException as exc:\n if remote == remotes[-1]: # Last element not found\n logger.debug(\"Not found in any remote, raising...%s\" % exc)\n raise NotFoundException(\"Unable to find '%s' in remotes\"\n % str(conan_reference))\n\n raise ConanException(\"No remote defined\")\n\n def upload_conan(self, conan_reference):\n \"\"\" upload to defined remote in (-r=remote), to current remote\n or to default remote, in that order.\n If the remote is not set, set it\n \"\"\"\n remote, ref_remote = self._get_remote(conan_reference)\n\n result = self._remote_manager.upload_conan(conan_reference, remote)\n if not ref_remote:\n self._registry.set_ref(conan_reference, remote)\n return result\n\n def _get_remote(self, conan_ref=None):\n # Prioritize -r , then reference registry and then the default remote\n ref_remote = self._registry.get_ref(conan_ref) if conan_ref else None\n if self._remote_name:\n remote = self._registry.remote(self._remote_name)\n else:\n if ref_remote:\n remote = ref_remote\n else:\n remote = self._registry.default_remote\n return remote, ref_remote\n\n def upload_package(self, package_reference):\n remote, current_remote = self._get_remote(package_reference.conan)\n\n if not current_remote:\n self._out.warn(\"Remote for '%s' not defined, uploading to %s\"\n % (str(package_reference.conan), remote.name))\n result = self._remote_manager.upload_package(package_reference, remote)\n if not current_remote:\n self._registry.set_ref(package_reference.conan, remote)\n return result\n\n def get_conan_digest(self, conan_ref):\n \"\"\" used by update to check the date of packages, require force if older\n \"\"\"\n remote, current_remote = self._get_remote(conan_ref)\n result = self._remote_manager.get_conan_digest(conan_ref, remote)\n if not current_remote:\n self._registry.set_ref(conan_ref, remote)\n return result\n\n def get_package_digest(self, package_reference):\n \"\"\" used by update to check the date of packages, require force if older\n \"\"\"\n remote, ref_remote = self._get_remote(package_reference.conan)\n result = self._remote_manager.get_package_digest(package_reference, remote)\n if not ref_remote:\n self._registry.set_ref(package_reference.conan, remote)\n return result\n\n def search(self, pattern=None, ignorecase=True):\n remote, _ = self._get_remote()\n return self._remote_manager.search(remote, pattern, ignorecase)\n\n def remove(self, conan_ref):\n if not self._remote_name:\n raise ConanException(\"Cannot remove, remote not defined\")\n remote = self._registry.remote(self._remote_name)\n result = self._remote_manager.remove(conan_ref, remote)\n current_remote = self._registry.get_ref(conan_ref)\n if current_remote == remote:\n self._registry.remove_ref(conan_ref)\n return result\n\n def remove_packages(self, conan_ref, remove_ids):\n if not self._remote_name:\n raise ConanException(\"Cannot remove, remote not defined\")\n remote = self._registry.remote(self._remote_name)\n return self._remote_manager.remove_packages(conan_ref, remove_ids, remote)\n\n def download_packages(self, reference, package_ids):\n assert(isinstance(package_ids, list))\n remote, _ = self._get_remote(reference)\n self._remote_manager.get_conanfile(reference, remote)\n self._registry.set_ref(reference, remote)\n output = ScopedOutput(str(reference), self._out)\n for package_id in package_ids:\n package_reference = PackageReference(reference, package_id)\n self._retrieve_remote_package(package_reference, output, remote)\n\n def _retrieve_remote_package(self, package_reference, output, remote=None):\n\n if remote is None:\n remote = self._registry.get_ref(package_reference.conan)\n if not remote:\n output.warn(\"Package doesn't have a remote defined. \"\n \"Probably created locally and not uploaded\")\n return False\n package_id = str(package_reference.package_id)\n try:\n output.info(\"Looking for package %s in remote '%s' \" % (package_id, remote.name))\n # Will raise if not found NotFoundException\n self._remote_manager.get_package(package_reference, remote)\n output.success('Package installed %s' % package_id)\n return True\n except ConanConnectionError:\n raise # This shouldn't be skipped\n except ConanException as e:\n output.warn('Binary for %s not in remote: %s' % (package_id, str(e)))\n return False\n\n def authenticate(self, name, password):\n if not name: # List all users, from all remotes\n remotes = self._registry.remotes\n if not remotes:\n self._out.error(\"No remotes defined\")\n for remote in remotes:\n self._remote_manager.authenticate(remote, None, None)\n return\n remote, _ = self._get_remote()\n return self._remote_manager.authenticate(remote, name, password)\n", "path": "conans/client/proxy.py"}]} | 3,960 | 238 |
gh_patches_debug_8970 | rasdani/github-patches | git_diff | pyca__cryptography-5013 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test and build wheels on 3.8
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # This file is dual licensed under the terms of the Apache License, Version
4 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
5 # for complete details.
6
7 from __future__ import absolute_import, division, print_function
8
9 import os
10 import platform
11 import sys
12 from distutils.command.build import build
13
14 import pkg_resources
15
16 import setuptools
17 from setuptools import find_packages, setup
18 from setuptools.command.install import install
19
20
21 if (
22 pkg_resources.parse_version(setuptools.__version__) <
23 pkg_resources.parse_version("18.5")
24 ):
25 raise RuntimeError(
26 "cryptography requires setuptools 18.5 or newer, please upgrade to a "
27 "newer version of setuptools"
28 )
29
30 base_dir = os.path.dirname(__file__)
31 src_dir = os.path.join(base_dir, "src")
32
33 # When executing the setup.py, we need to be able to import ourselves, this
34 # means that we need to add the src/ directory to the sys.path.
35 sys.path.insert(0, src_dir)
36
37 about = {}
38 with open(os.path.join(src_dir, "cryptography", "__about__.py")) as f:
39 exec(f.read(), about)
40
41
42 # `setup_requirements` must be kept in sync with `pyproject.toml`
43 setup_requirements = ["cffi>=1.8,!=1.11.3"]
44
45 if platform.python_implementation() == "PyPy":
46 if sys.pypy_version_info < (5, 4):
47 raise RuntimeError(
48 "cryptography is not compatible with PyPy < 5.4. Please upgrade "
49 "PyPy to use this library."
50 )
51
52
53 def keywords_with_side_effects(argv):
54 """
55 Get a dictionary with setup keywords that (can) have side effects.
56
57 :param argv: A list of strings with command line arguments.
58 :returns: A dictionary with keyword arguments for the ``setup()`` function.
59
60 This setup.py script uses the setuptools 'setup_requires' feature because
61 this is required by the cffi package to compile extension modules. The
62 purpose of ``keywords_with_side_effects()`` is to avoid triggering the cffi
63 build process as a result of setup.py invocations that don't need the cffi
64 module to be built (setup.py serves the dual purpose of exposing package
65 metadata).
66
67 All of the options listed by ``python setup.py --help`` that print
68 information should be recognized here. The commands ``clean``,
69 ``egg_info``, ``register``, ``sdist`` and ``upload`` are also recognized.
70 Any combination of these options and commands is also supported.
71
72 This function was originally based on the `setup.py script`_ of SciPy (see
73 also the discussion in `pip issue #25`_).
74
75 .. _pip issue #25: https://github.com/pypa/pip/issues/25
76 .. _setup.py script: https://github.com/scipy/scipy/blob/master/setup.py
77 """
78 no_setup_requires_arguments = (
79 '-h', '--help',
80 '-n', '--dry-run',
81 '-q', '--quiet',
82 '-v', '--verbose',
83 '-V', '--version',
84 '--author',
85 '--author-email',
86 '--classifiers',
87 '--contact',
88 '--contact-email',
89 '--description',
90 '--egg-base',
91 '--fullname',
92 '--help-commands',
93 '--keywords',
94 '--licence',
95 '--license',
96 '--long-description',
97 '--maintainer',
98 '--maintainer-email',
99 '--name',
100 '--no-user-cfg',
101 '--obsoletes',
102 '--platforms',
103 '--provides',
104 '--requires',
105 '--url',
106 'clean',
107 'egg_info',
108 'register',
109 'sdist',
110 'upload',
111 )
112
113 def is_short_option(argument):
114 """Check whether a command line argument is a short option."""
115 return len(argument) >= 2 and argument[0] == '-' and argument[1] != '-'
116
117 def expand_short_options(argument):
118 """Expand combined short options into canonical short options."""
119 return ('-' + char for char in argument[1:])
120
121 def argument_without_setup_requirements(argv, i):
122 """Check whether a command line argument needs setup requirements."""
123 if argv[i] in no_setup_requires_arguments:
124 # Simple case: An argument which is either an option or a command
125 # which doesn't need setup requirements.
126 return True
127 elif (is_short_option(argv[i]) and
128 all(option in no_setup_requires_arguments
129 for option in expand_short_options(argv[i]))):
130 # Not so simple case: Combined short options none of which need
131 # setup requirements.
132 return True
133 elif argv[i - 1:i] == ['--egg-base']:
134 # Tricky case: --egg-info takes an argument which should not make
135 # us use setup_requires (defeating the purpose of this code).
136 return True
137 else:
138 return False
139
140 if all(argument_without_setup_requirements(argv, i)
141 for i in range(1, len(argv))):
142 return {
143 "cmdclass": {
144 "build": DummyBuild,
145 "install": DummyInstall,
146 }
147 }
148 else:
149 cffi_modules = [
150 "src/_cffi_src/build_openssl.py:ffi",
151 "src/_cffi_src/build_constant_time.py:ffi",
152 "src/_cffi_src/build_padding.py:ffi",
153 ]
154
155 return {
156 "setup_requires": setup_requirements,
157 "cffi_modules": cffi_modules
158 }
159
160
161 setup_requires_error = ("Requested setup command that needs 'setup_requires' "
162 "while command line arguments implied a side effect "
163 "free command or option.")
164
165
166 class DummyBuild(build):
167 """
168 This class makes it very obvious when ``keywords_with_side_effects()`` has
169 incorrectly interpreted the command line arguments to ``setup.py build`` as
170 one of the 'side effect free' commands or options.
171 """
172
173 def run(self):
174 raise RuntimeError(setup_requires_error)
175
176
177 class DummyInstall(install):
178 """
179 This class makes it very obvious when ``keywords_with_side_effects()`` has
180 incorrectly interpreted the command line arguments to ``setup.py install``
181 as one of the 'side effect free' commands or options.
182 """
183
184 def run(self):
185 raise RuntimeError(setup_requires_error)
186
187
188 with open(os.path.join(base_dir, "README.rst")) as f:
189 long_description = f.read()
190
191
192 setup(
193 name=about["__title__"],
194 version=about["__version__"],
195
196 description=about["__summary__"],
197 long_description=long_description,
198 long_description_content_type="text/x-rst",
199 license=about["__license__"],
200 url=about["__uri__"],
201
202 author=about["__author__"],
203 author_email=about["__email__"],
204
205 classifiers=[
206 "Development Status :: 5 - Production/Stable",
207 "Intended Audience :: Developers",
208 "License :: OSI Approved :: Apache Software License",
209 "License :: OSI Approved :: BSD License",
210 "Natural Language :: English",
211 "Operating System :: MacOS :: MacOS X",
212 "Operating System :: POSIX",
213 "Operating System :: POSIX :: BSD",
214 "Operating System :: POSIX :: Linux",
215 "Operating System :: Microsoft :: Windows",
216 "Programming Language :: Python",
217 "Programming Language :: Python :: 2",
218 "Programming Language :: Python :: 2.7",
219 "Programming Language :: Python :: 3",
220 "Programming Language :: Python :: 3.4",
221 "Programming Language :: Python :: 3.5",
222 "Programming Language :: Python :: 3.6",
223 "Programming Language :: Python :: 3.7",
224 "Programming Language :: Python :: Implementation :: CPython",
225 "Programming Language :: Python :: Implementation :: PyPy",
226 "Topic :: Security :: Cryptography",
227 ],
228
229 package_dir={"": "src"},
230 packages=find_packages(where="src", exclude=["_cffi_src", "_cffi_src.*"]),
231 include_package_data=True,
232
233 python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',
234
235 install_requires=[
236 "six >= 1.4.1",
237 ] + setup_requirements,
238 extras_require={
239 ":python_version < '3'": ["enum34", "ipaddress"],
240
241 "test": [
242 "pytest>=3.6.0,!=3.9.0,!=3.9.1,!=3.9.2",
243 "pretend",
244 "iso8601",
245 "pytz",
246 "hypothesis>=1.11.4,!=3.79.2",
247 ],
248 "docs": [
249 "sphinx >= 1.6.5,!=1.8.0",
250 "sphinx_rtd_theme",
251 ],
252 "docstest": [
253 "doc8",
254 "pyenchant >= 1.6.11",
255 "twine >= 1.12.0",
256 "sphinxcontrib-spelling >= 4.0.1",
257 ],
258 "pep8test": [
259 "flake8",
260 "flake8-import-order",
261 "pep8-naming",
262 ],
263 # This extra is for the U-label support that was deprecated in
264 # cryptography 2.1. If you need this deprecated path install with
265 # pip install cryptography[idna]
266 "idna": [
267 "idna >= 2.1",
268 ]
269 },
270
271 # for cffi
272 zip_safe=False,
273 ext_package="cryptography.hazmat.bindings",
274 **keywords_with_side_effects(sys.argv)
275 )
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -221,6 +221,7 @@
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
"Topic :: Security :: Cryptography",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -221,6 +221,7 @@\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Security :: Cryptography\",\n", "issue": "Test and build wheels on 3.8\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport os\nimport platform\nimport sys\nfrom distutils.command.build import build\n\nimport pkg_resources\n\nimport setuptools\nfrom setuptools import find_packages, setup\nfrom setuptools.command.install import install\n\n\nif (\n pkg_resources.parse_version(setuptools.__version__) <\n pkg_resources.parse_version(\"18.5\")\n):\n raise RuntimeError(\n \"cryptography requires setuptools 18.5 or newer, please upgrade to a \"\n \"newer version of setuptools\"\n )\n\nbase_dir = os.path.dirname(__file__)\nsrc_dir = os.path.join(base_dir, \"src\")\n\n# When executing the setup.py, we need to be able to import ourselves, this\n# means that we need to add the src/ directory to the sys.path.\nsys.path.insert(0, src_dir)\n\nabout = {}\nwith open(os.path.join(src_dir, \"cryptography\", \"__about__.py\")) as f:\n exec(f.read(), about)\n\n\n# `setup_requirements` must be kept in sync with `pyproject.toml`\nsetup_requirements = [\"cffi>=1.8,!=1.11.3\"]\n\nif platform.python_implementation() == \"PyPy\":\n if sys.pypy_version_info < (5, 4):\n raise RuntimeError(\n \"cryptography is not compatible with PyPy < 5.4. Please upgrade \"\n \"PyPy to use this library.\"\n )\n\n\ndef keywords_with_side_effects(argv):\n \"\"\"\n Get a dictionary with setup keywords that (can) have side effects.\n\n :param argv: A list of strings with command line arguments.\n :returns: A dictionary with keyword arguments for the ``setup()`` function.\n\n This setup.py script uses the setuptools 'setup_requires' feature because\n this is required by the cffi package to compile extension modules. The\n purpose of ``keywords_with_side_effects()`` is to avoid triggering the cffi\n build process as a result of setup.py invocations that don't need the cffi\n module to be built (setup.py serves the dual purpose of exposing package\n metadata).\n\n All of the options listed by ``python setup.py --help`` that print\n information should be recognized here. The commands ``clean``,\n ``egg_info``, ``register``, ``sdist`` and ``upload`` are also recognized.\n Any combination of these options and commands is also supported.\n\n This function was originally based on the `setup.py script`_ of SciPy (see\n also the discussion in `pip issue #25`_).\n\n .. _pip issue #25: https://github.com/pypa/pip/issues/25\n .. _setup.py script: https://github.com/scipy/scipy/blob/master/setup.py\n \"\"\"\n no_setup_requires_arguments = (\n '-h', '--help',\n '-n', '--dry-run',\n '-q', '--quiet',\n '-v', '--verbose',\n '-V', '--version',\n '--author',\n '--author-email',\n '--classifiers',\n '--contact',\n '--contact-email',\n '--description',\n '--egg-base',\n '--fullname',\n '--help-commands',\n '--keywords',\n '--licence',\n '--license',\n '--long-description',\n '--maintainer',\n '--maintainer-email',\n '--name',\n '--no-user-cfg',\n '--obsoletes',\n '--platforms',\n '--provides',\n '--requires',\n '--url',\n 'clean',\n 'egg_info',\n 'register',\n 'sdist',\n 'upload',\n )\n\n def is_short_option(argument):\n \"\"\"Check whether a command line argument is a short option.\"\"\"\n return len(argument) >= 2 and argument[0] == '-' and argument[1] != '-'\n\n def expand_short_options(argument):\n \"\"\"Expand combined short options into canonical short options.\"\"\"\n return ('-' + char for char in argument[1:])\n\n def argument_without_setup_requirements(argv, i):\n \"\"\"Check whether a command line argument needs setup requirements.\"\"\"\n if argv[i] in no_setup_requires_arguments:\n # Simple case: An argument which is either an option or a command\n # which doesn't need setup requirements.\n return True\n elif (is_short_option(argv[i]) and\n all(option in no_setup_requires_arguments\n for option in expand_short_options(argv[i]))):\n # Not so simple case: Combined short options none of which need\n # setup requirements.\n return True\n elif argv[i - 1:i] == ['--egg-base']:\n # Tricky case: --egg-info takes an argument which should not make\n # us use setup_requires (defeating the purpose of this code).\n return True\n else:\n return False\n\n if all(argument_without_setup_requirements(argv, i)\n for i in range(1, len(argv))):\n return {\n \"cmdclass\": {\n \"build\": DummyBuild,\n \"install\": DummyInstall,\n }\n }\n else:\n cffi_modules = [\n \"src/_cffi_src/build_openssl.py:ffi\",\n \"src/_cffi_src/build_constant_time.py:ffi\",\n \"src/_cffi_src/build_padding.py:ffi\",\n ]\n\n return {\n \"setup_requires\": setup_requirements,\n \"cffi_modules\": cffi_modules\n }\n\n\nsetup_requires_error = (\"Requested setup command that needs 'setup_requires' \"\n \"while command line arguments implied a side effect \"\n \"free command or option.\")\n\n\nclass DummyBuild(build):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py build`` as\n one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nclass DummyInstall(install):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py install``\n as one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nwith open(os.path.join(base_dir, \"README.rst\")) as f:\n long_description = f.read()\n\n\nsetup(\n name=about[\"__title__\"],\n version=about[\"__version__\"],\n\n description=about[\"__summary__\"],\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=about[\"__license__\"],\n url=about[\"__uri__\"],\n\n author=about[\"__author__\"],\n author_email=about[\"__email__\"],\n\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"License :: OSI Approved :: BSD License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Security :: Cryptography\",\n ],\n\n package_dir={\"\": \"src\"},\n packages=find_packages(where=\"src\", exclude=[\"_cffi_src\", \"_cffi_src.*\"]),\n include_package_data=True,\n\n python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n\n install_requires=[\n \"six >= 1.4.1\",\n ] + setup_requirements,\n extras_require={\n \":python_version < '3'\": [\"enum34\", \"ipaddress\"],\n\n \"test\": [\n \"pytest>=3.6.0,!=3.9.0,!=3.9.1,!=3.9.2\",\n \"pretend\",\n \"iso8601\",\n \"pytz\",\n \"hypothesis>=1.11.4,!=3.79.2\",\n ],\n \"docs\": [\n \"sphinx >= 1.6.5,!=1.8.0\",\n \"sphinx_rtd_theme\",\n ],\n \"docstest\": [\n \"doc8\",\n \"pyenchant >= 1.6.11\",\n \"twine >= 1.12.0\",\n \"sphinxcontrib-spelling >= 4.0.1\",\n ],\n \"pep8test\": [\n \"flake8\",\n \"flake8-import-order\",\n \"pep8-naming\",\n ],\n # This extra is for the U-label support that was deprecated in\n # cryptography 2.1. If you need this deprecated path install with\n # pip install cryptography[idna]\n \"idna\": [\n \"idna >= 2.1\",\n ]\n },\n\n # for cffi\n zip_safe=False,\n ext_package=\"cryptography.hazmat.bindings\",\n **keywords_with_side_effects(sys.argv)\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport os\nimport platform\nimport sys\nfrom distutils.command.build import build\n\nimport pkg_resources\n\nimport setuptools\nfrom setuptools import find_packages, setup\nfrom setuptools.command.install import install\n\n\nif (\n pkg_resources.parse_version(setuptools.__version__) <\n pkg_resources.parse_version(\"18.5\")\n):\n raise RuntimeError(\n \"cryptography requires setuptools 18.5 or newer, please upgrade to a \"\n \"newer version of setuptools\"\n )\n\nbase_dir = os.path.dirname(__file__)\nsrc_dir = os.path.join(base_dir, \"src\")\n\n# When executing the setup.py, we need to be able to import ourselves, this\n# means that we need to add the src/ directory to the sys.path.\nsys.path.insert(0, src_dir)\n\nabout = {}\nwith open(os.path.join(src_dir, \"cryptography\", \"__about__.py\")) as f:\n exec(f.read(), about)\n\n\n# `setup_requirements` must be kept in sync with `pyproject.toml`\nsetup_requirements = [\"cffi>=1.8,!=1.11.3\"]\n\nif platform.python_implementation() == \"PyPy\":\n if sys.pypy_version_info < (5, 4):\n raise RuntimeError(\n \"cryptography is not compatible with PyPy < 5.4. Please upgrade \"\n \"PyPy to use this library.\"\n )\n\n\ndef keywords_with_side_effects(argv):\n \"\"\"\n Get a dictionary with setup keywords that (can) have side effects.\n\n :param argv: A list of strings with command line arguments.\n :returns: A dictionary with keyword arguments for the ``setup()`` function.\n\n This setup.py script uses the setuptools 'setup_requires' feature because\n this is required by the cffi package to compile extension modules. The\n purpose of ``keywords_with_side_effects()`` is to avoid triggering the cffi\n build process as a result of setup.py invocations that don't need the cffi\n module to be built (setup.py serves the dual purpose of exposing package\n metadata).\n\n All of the options listed by ``python setup.py --help`` that print\n information should be recognized here. The commands ``clean``,\n ``egg_info``, ``register``, ``sdist`` and ``upload`` are also recognized.\n Any combination of these options and commands is also supported.\n\n This function was originally based on the `setup.py script`_ of SciPy (see\n also the discussion in `pip issue #25`_).\n\n .. _pip issue #25: https://github.com/pypa/pip/issues/25\n .. _setup.py script: https://github.com/scipy/scipy/blob/master/setup.py\n \"\"\"\n no_setup_requires_arguments = (\n '-h', '--help',\n '-n', '--dry-run',\n '-q', '--quiet',\n '-v', '--verbose',\n '-V', '--version',\n '--author',\n '--author-email',\n '--classifiers',\n '--contact',\n '--contact-email',\n '--description',\n '--egg-base',\n '--fullname',\n '--help-commands',\n '--keywords',\n '--licence',\n '--license',\n '--long-description',\n '--maintainer',\n '--maintainer-email',\n '--name',\n '--no-user-cfg',\n '--obsoletes',\n '--platforms',\n '--provides',\n '--requires',\n '--url',\n 'clean',\n 'egg_info',\n 'register',\n 'sdist',\n 'upload',\n )\n\n def is_short_option(argument):\n \"\"\"Check whether a command line argument is a short option.\"\"\"\n return len(argument) >= 2 and argument[0] == '-' and argument[1] != '-'\n\n def expand_short_options(argument):\n \"\"\"Expand combined short options into canonical short options.\"\"\"\n return ('-' + char for char in argument[1:])\n\n def argument_without_setup_requirements(argv, i):\n \"\"\"Check whether a command line argument needs setup requirements.\"\"\"\n if argv[i] in no_setup_requires_arguments:\n # Simple case: An argument which is either an option or a command\n # which doesn't need setup requirements.\n return True\n elif (is_short_option(argv[i]) and\n all(option in no_setup_requires_arguments\n for option in expand_short_options(argv[i]))):\n # Not so simple case: Combined short options none of which need\n # setup requirements.\n return True\n elif argv[i - 1:i] == ['--egg-base']:\n # Tricky case: --egg-info takes an argument which should not make\n # us use setup_requires (defeating the purpose of this code).\n return True\n else:\n return False\n\n if all(argument_without_setup_requirements(argv, i)\n for i in range(1, len(argv))):\n return {\n \"cmdclass\": {\n \"build\": DummyBuild,\n \"install\": DummyInstall,\n }\n }\n else:\n cffi_modules = [\n \"src/_cffi_src/build_openssl.py:ffi\",\n \"src/_cffi_src/build_constant_time.py:ffi\",\n \"src/_cffi_src/build_padding.py:ffi\",\n ]\n\n return {\n \"setup_requires\": setup_requirements,\n \"cffi_modules\": cffi_modules\n }\n\n\nsetup_requires_error = (\"Requested setup command that needs 'setup_requires' \"\n \"while command line arguments implied a side effect \"\n \"free command or option.\")\n\n\nclass DummyBuild(build):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py build`` as\n one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nclass DummyInstall(install):\n \"\"\"\n This class makes it very obvious when ``keywords_with_side_effects()`` has\n incorrectly interpreted the command line arguments to ``setup.py install``\n as one of the 'side effect free' commands or options.\n \"\"\"\n\n def run(self):\n raise RuntimeError(setup_requires_error)\n\n\nwith open(os.path.join(base_dir, \"README.rst\")) as f:\n long_description = f.read()\n\n\nsetup(\n name=about[\"__title__\"],\n version=about[\"__version__\"],\n\n description=about[\"__summary__\"],\n long_description=long_description,\n long_description_content_type=\"text/x-rst\",\n license=about[\"__license__\"],\n url=about[\"__uri__\"],\n\n author=about[\"__author__\"],\n author_email=about[\"__email__\"],\n\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"License :: OSI Approved :: BSD License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Security :: Cryptography\",\n ],\n\n package_dir={\"\": \"src\"},\n packages=find_packages(where=\"src\", exclude=[\"_cffi_src\", \"_cffi_src.*\"]),\n include_package_data=True,\n\n python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n\n install_requires=[\n \"six >= 1.4.1\",\n ] + setup_requirements,\n extras_require={\n \":python_version < '3'\": [\"enum34\", \"ipaddress\"],\n\n \"test\": [\n \"pytest>=3.6.0,!=3.9.0,!=3.9.1,!=3.9.2\",\n \"pretend\",\n \"iso8601\",\n \"pytz\",\n \"hypothesis>=1.11.4,!=3.79.2\",\n ],\n \"docs\": [\n \"sphinx >= 1.6.5,!=1.8.0\",\n \"sphinx_rtd_theme\",\n ],\n \"docstest\": [\n \"doc8\",\n \"pyenchant >= 1.6.11\",\n \"twine >= 1.12.0\",\n \"sphinxcontrib-spelling >= 4.0.1\",\n ],\n \"pep8test\": [\n \"flake8\",\n \"flake8-import-order\",\n \"pep8-naming\",\n ],\n # This extra is for the U-label support that was deprecated in\n # cryptography 2.1. If you need this deprecated path install with\n # pip install cryptography[idna]\n \"idna\": [\n \"idna >= 2.1\",\n ]\n },\n\n # for cffi\n zip_safe=False,\n ext_package=\"cryptography.hazmat.bindings\",\n **keywords_with_side_effects(sys.argv)\n)\n", "path": "setup.py"}]} | 3,098 | 116 |
gh_patches_debug_27720 | rasdani/github-patches | git_diff | scikit-hep__pyhf-383 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use Binder Build API for Builds in PRs
# Description
After a discussion with @minrk and @betatim on the jupyterhub/binder Gitter, it was made clear that the use of Selenium in [`binder/trigger_binder.py`](https://github.com/diana-hep/pyhf/blob/c81f6007309f4c13241f9efac187594337d0bd08/binder/trigger_binder.py) (and the script itself) is unnecessary. Instead a simple API call can be made just using Python's `webbrowser` with an [endpoint of the form `https://mybinder.org/build/gh/owner/repo/ref`](https://gitter.im/jupyterhub/binder?at=5c2f87038dafa715c73ff54f) as can be [seen in the Binder Hub demo](https://github.com/jupyterhub/binderhub/blob/9ca8fa68bb8b69c6a2736f2275279583073f314f/examples/binder-api.py#L28) (thanks Tim for the link).
So, for example
```
python -m webbrowser "https://mybinder.org/build/gh/diana-hep/pyhf/master"
```
So asking [WWKHTD](https://github.com/kelseyhightower/nocode), this means that `binder/trigger_binder.py` is unnecessary and should be removed and `.travis.yml` should be updated to use the API calls.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `binder/trigger_binder.py`
Content:
```
1 #!/usr/bin/env python
2
3 import argparse
4 from contextlib import contextmanager
5 from selenium import webdriver
6 from selenium.webdriver.chrome.options import Options
7 from selenium.webdriver.support.ui import WebDriverWait
8 from selenium.webdriver.support.expected_conditions import staleness_of
9
10
11 class SeleniumSession:
12 def __init__(self, args):
13 self.options = Options()
14 self.options.set_headless()
15 self.options.add_argument('--no-sandbox')
16 if args.chromedriver_path is not None:
17 self.browser = webdriver.Chrome(
18 args.chromedriver_path, chrome_options=self.options
19 )
20 else:
21 self.browser = webdriver.Chrome(chrome_options=self.options)
22
23 @contextmanager
24 def wait_for_page_load(self, timeout=20):
25 old_page = self.browser.find_element_by_tag_name('html')
26 yield
27 WebDriverWait(self.browser, timeout).until(staleness_of(old_page))
28
29 def trigger_binder(self, url):
30 with self.wait_for_page_load():
31 self.browser.get(url)
32
33
34 def main(args):
35 driver = SeleniumSession(args)
36 if args.is_verbose:
37 print('Chrome Headless Browser Invoked')
38 driver.trigger_binder(args.url)
39
40
41 if __name__ == '__main__':
42 parser = argparse.ArgumentParser()
43 parser.add_argument(
44 '-v',
45 '--verbose',
46 dest='is_verbose',
47 action='store_true',
48 help='Print out more information',
49 )
50 parser.add_argument(
51 '--chromedriver-path',
52 dest='chromedriver_path',
53 type=str,
54 default=None,
55 help='System path to ChromeDriver',
56 )
57 parser.add_argument(
58 '--url', dest='url', type=str, default=None, help='URL for Selinium to open'
59 )
60 args = parser.parse_args()
61
62 main(args)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/binder/trigger_binder.py b/binder/trigger_binder.py
deleted file mode 100644
--- a/binder/trigger_binder.py
+++ /dev/null
@@ -1,62 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-from contextlib import contextmanager
-from selenium import webdriver
-from selenium.webdriver.chrome.options import Options
-from selenium.webdriver.support.ui import WebDriverWait
-from selenium.webdriver.support.expected_conditions import staleness_of
-
-
-class SeleniumSession:
- def __init__(self, args):
- self.options = Options()
- self.options.set_headless()
- self.options.add_argument('--no-sandbox')
- if args.chromedriver_path is not None:
- self.browser = webdriver.Chrome(
- args.chromedriver_path, chrome_options=self.options
- )
- else:
- self.browser = webdriver.Chrome(chrome_options=self.options)
-
- @contextmanager
- def wait_for_page_load(self, timeout=20):
- old_page = self.browser.find_element_by_tag_name('html')
- yield
- WebDriverWait(self.browser, timeout).until(staleness_of(old_page))
-
- def trigger_binder(self, url):
- with self.wait_for_page_load():
- self.browser.get(url)
-
-
-def main(args):
- driver = SeleniumSession(args)
- if args.is_verbose:
- print('Chrome Headless Browser Invoked')
- driver.trigger_binder(args.url)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument(
- '-v',
- '--verbose',
- dest='is_verbose',
- action='store_true',
- help='Print out more information',
- )
- parser.add_argument(
- '--chromedriver-path',
- dest='chromedriver_path',
- type=str,
- default=None,
- help='System path to ChromeDriver',
- )
- parser.add_argument(
- '--url', dest='url', type=str, default=None, help='URL for Selinium to open'
- )
- args = parser.parse_args()
-
- main(args)
| {"golden_diff": "diff --git a/binder/trigger_binder.py b/binder/trigger_binder.py\ndeleted file mode 100644\n--- a/binder/trigger_binder.py\n+++ /dev/null\n@@ -1,62 +0,0 @@\n-#!/usr/bin/env python\n-\n-import argparse\n-from contextlib import contextmanager\n-from selenium import webdriver\n-from selenium.webdriver.chrome.options import Options\n-from selenium.webdriver.support.ui import WebDriverWait\n-from selenium.webdriver.support.expected_conditions import staleness_of\n-\n-\n-class SeleniumSession:\n- def __init__(self, args):\n- self.options = Options()\n- self.options.set_headless()\n- self.options.add_argument('--no-sandbox')\n- if args.chromedriver_path is not None:\n- self.browser = webdriver.Chrome(\n- args.chromedriver_path, chrome_options=self.options\n- )\n- else:\n- self.browser = webdriver.Chrome(chrome_options=self.options)\n-\n- @contextmanager\n- def wait_for_page_load(self, timeout=20):\n- old_page = self.browser.find_element_by_tag_name('html')\n- yield\n- WebDriverWait(self.browser, timeout).until(staleness_of(old_page))\n-\n- def trigger_binder(self, url):\n- with self.wait_for_page_load():\n- self.browser.get(url)\n-\n-\n-def main(args):\n- driver = SeleniumSession(args)\n- if args.is_verbose:\n- print('Chrome Headless Browser Invoked')\n- driver.trigger_binder(args.url)\n-\n-\n-if __name__ == '__main__':\n- parser = argparse.ArgumentParser()\n- parser.add_argument(\n- '-v',\n- '--verbose',\n- dest='is_verbose',\n- action='store_true',\n- help='Print out more information',\n- )\n- parser.add_argument(\n- '--chromedriver-path',\n- dest='chromedriver_path',\n- type=str,\n- default=None,\n- help='System path to ChromeDriver',\n- )\n- parser.add_argument(\n- '--url', dest='url', type=str, default=None, help='URL for Selinium to open'\n- )\n- args = parser.parse_args()\n-\n- main(args)\n", "issue": "Use Binder Build API for Builds in PRs\n# Description\r\n\r\nAfter a discussion with @minrk and @betatim on the jupyterhub/binder Gitter, it was made clear that the use of Selenium in [`binder/trigger_binder.py`](https://github.com/diana-hep/pyhf/blob/c81f6007309f4c13241f9efac187594337d0bd08/binder/trigger_binder.py) (and the script itself) is unnecessary. Instead a simple API call can be made just using Python's `webbrowser` with an [endpoint of the form `https://mybinder.org/build/gh/owner/repo/ref`](https://gitter.im/jupyterhub/binder?at=5c2f87038dafa715c73ff54f) as can be [seen in the Binder Hub demo](https://github.com/jupyterhub/binderhub/blob/9ca8fa68bb8b69c6a2736f2275279583073f314f/examples/binder-api.py#L28) (thanks Tim for the link).\r\n\r\nSo, for example\r\n\r\n```\r\npython -m webbrowser \"https://mybinder.org/build/gh/diana-hep/pyhf/master\"\r\n```\r\n\r\nSo asking [WWKHTD](https://github.com/kelseyhightower/nocode), this means that `binder/trigger_binder.py` is unnecessary and should be removed and `.travis.yml` should be updated to use the API calls.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport argparse\nfrom contextlib import contextmanager\nfrom selenium import webdriver\nfrom selenium.webdriver.chrome.options import Options\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support.expected_conditions import staleness_of\n\n\nclass SeleniumSession:\n def __init__(self, args):\n self.options = Options()\n self.options.set_headless()\n self.options.add_argument('--no-sandbox')\n if args.chromedriver_path is not None:\n self.browser = webdriver.Chrome(\n args.chromedriver_path, chrome_options=self.options\n )\n else:\n self.browser = webdriver.Chrome(chrome_options=self.options)\n\n @contextmanager\n def wait_for_page_load(self, timeout=20):\n old_page = self.browser.find_element_by_tag_name('html')\n yield\n WebDriverWait(self.browser, timeout).until(staleness_of(old_page))\n\n def trigger_binder(self, url):\n with self.wait_for_page_load():\n self.browser.get(url)\n\n\ndef main(args):\n driver = SeleniumSession(args)\n if args.is_verbose:\n print('Chrome Headless Browser Invoked')\n driver.trigger_binder(args.url)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument(\n '-v',\n '--verbose',\n dest='is_verbose',\n action='store_true',\n help='Print out more information',\n )\n parser.add_argument(\n '--chromedriver-path',\n dest='chromedriver_path',\n type=str,\n default=None,\n help='System path to ChromeDriver',\n )\n parser.add_argument(\n '--url', dest='url', type=str, default=None, help='URL for Selinium to open'\n )\n args = parser.parse_args()\n\n main(args)\n", "path": "binder/trigger_binder.py"}], "after_files": [{"content": null, "path": "binder/trigger_binder.py"}]} | 1,111 | 476 |
gh_patches_debug_42929 | rasdani/github-patches | git_diff | goauthentik__authentik-7341 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Listing all permissions
**Describe the bug**
When attempting to list all the permissions in order to select which ones to assign to a permission, hangs when gets to 141+
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Directory'
2. Click on 'Roles'
3. Select (or create a new) role.
4. Click on 'Assign Permissions'
5. Click on '+' to Select Permissions to Grant
6. Scroll through permissions by clicking on '>' until arrive at 121 - 140
**Expected behavior**
Continue displaying all permissions until reaching end of list (Displays 377 Permissions)
**Screenshots**

**Logs**
[logs](https://pastebin.com/v4Fd6PDN)
**Version and Deployment (please complete the following information):**
- authentik version: 2023.10.1
- Deployment: docker-compose
**Additional context**
Upgraded from 2023.8 -> 2023.10.0 -> 2023.10.1
Can provide more logs or anything else, if needed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/rbac/api/rbac.py`
Content:
```
1 """common RBAC serializers"""
2 from django.apps import apps
3 from django.contrib.auth.models import Permission
4 from django.db.models import QuerySet
5 from django_filters.filters import ModelChoiceFilter
6 from django_filters.filterset import FilterSet
7 from rest_framework.exceptions import ValidationError
8 from rest_framework.fields import (
9 CharField,
10 ChoiceField,
11 ListField,
12 ReadOnlyField,
13 SerializerMethodField,
14 )
15 from rest_framework.serializers import ModelSerializer
16 from rest_framework.viewsets import ReadOnlyModelViewSet
17
18 from authentik.core.api.utils import PassiveSerializer
19 from authentik.core.models import User
20 from authentik.lib.validators import RequiredTogetherValidator
21 from authentik.policies.event_matcher.models import model_choices
22 from authentik.rbac.models import Role
23
24
25 class PermissionSerializer(ModelSerializer):
26 """Global permission"""
27
28 app_label = ReadOnlyField(source="content_type.app_label")
29 app_label_verbose = SerializerMethodField()
30 model = ReadOnlyField(source="content_type.model")
31 model_verbose = SerializerMethodField()
32
33 def get_app_label_verbose(self, instance: Permission) -> str:
34 """Human-readable app label"""
35 return apps.get_app_config(instance.content_type.app_label).verbose_name
36
37 def get_model_verbose(self, instance: Permission) -> str:
38 """Human-readable model name"""
39 return apps.get_model(
40 instance.content_type.app_label, instance.content_type.model
41 )._meta.verbose_name
42
43 class Meta:
44 model = Permission
45 fields = [
46 "id",
47 "name",
48 "codename",
49 "model",
50 "app_label",
51 "app_label_verbose",
52 "model_verbose",
53 ]
54
55
56 class PermissionFilter(FilterSet):
57 """Filter permissions"""
58
59 role = ModelChoiceFilter(queryset=Role.objects.all(), method="filter_role")
60 user = ModelChoiceFilter(queryset=User.objects.all())
61
62 def filter_role(self, queryset: QuerySet, name, value: Role) -> QuerySet:
63 """Filter permissions based on role"""
64 return queryset.filter(group__role=value)
65
66 class Meta:
67 model = Permission
68 fields = [
69 "codename",
70 "content_type__model",
71 "content_type__app_label",
72 "role",
73 "user",
74 ]
75
76
77 class RBACPermissionViewSet(ReadOnlyModelViewSet):
78 """Read-only list of all permissions, filterable by model and app"""
79
80 queryset = Permission.objects.none()
81 serializer_class = PermissionSerializer
82 ordering = ["name"]
83 filterset_class = PermissionFilter
84 search_fields = [
85 "codename",
86 "content_type__model",
87 "content_type__app_label",
88 ]
89
90 def get_queryset(self) -> QuerySet:
91 return (
92 Permission.objects.all()
93 .select_related("content_type")
94 .filter(
95 content_type__app_label__startswith="authentik",
96 )
97 )
98
99
100 class PermissionAssignSerializer(PassiveSerializer):
101 """Request to assign a new permission"""
102
103 permissions = ListField(child=CharField())
104 model = ChoiceField(choices=model_choices(), required=False)
105 object_pk = CharField(required=False)
106
107 validators = [RequiredTogetherValidator(fields=["model", "object_pk"])]
108
109 def validate(self, attrs: dict) -> dict:
110 model_instance = None
111 # Check if we're setting an object-level perm or global
112 model = attrs.get("model")
113 object_pk = attrs.get("object_pk")
114 if model and object_pk:
115 model = apps.get_model(attrs["model"])
116 model_instance = model.objects.filter(pk=attrs["object_pk"]).first()
117 attrs["model_instance"] = model_instance
118 if attrs.get("model"):
119 return attrs
120 permissions = attrs.get("permissions", [])
121 if not all("." in perm for perm in permissions):
122 raise ValidationError(
123 {
124 "permissions": (
125 "When assigning global permissions, codename must be given as "
126 "app_label.codename"
127 )
128 }
129 )
130 return attrs
131
```
Path: `authentik/rbac/api/rbac_roles.py`
Content:
```
1 """common RBAC serializers"""
2 from typing import Optional
3
4 from django.apps import apps
5 from django_filters.filters import UUIDFilter
6 from django_filters.filterset import FilterSet
7 from guardian.models import GroupObjectPermission
8 from guardian.shortcuts import get_objects_for_group
9 from rest_framework.fields import SerializerMethodField
10 from rest_framework.mixins import ListModelMixin
11 from rest_framework.viewsets import GenericViewSet
12
13 from authentik.api.pagination import SmallerPagination
14 from authentik.rbac.api.rbac_assigned_by_roles import RoleObjectPermissionSerializer
15
16
17 class ExtraRoleObjectPermissionSerializer(RoleObjectPermissionSerializer):
18 """User permission with additional object-related data"""
19
20 app_label_verbose = SerializerMethodField()
21 model_verbose = SerializerMethodField()
22
23 object_description = SerializerMethodField()
24
25 def get_app_label_verbose(self, instance: GroupObjectPermission) -> str:
26 """Get app label from permission's model"""
27 return apps.get_app_config(instance.content_type.app_label).verbose_name
28
29 def get_model_verbose(self, instance: GroupObjectPermission) -> str:
30 """Get model label from permission's model"""
31 return apps.get_model(
32 instance.content_type.app_label, instance.content_type.model
33 )._meta.verbose_name
34
35 def get_object_description(self, instance: GroupObjectPermission) -> Optional[str]:
36 """Get model description from attached model. This operation takes at least
37 one additional query, and the description is only shown if the user/role has the
38 view_ permission on the object"""
39 app_label = instance.content_type.app_label
40 model = instance.content_type.model
41 model_class = apps.get_model(app_label, model)
42 objects = get_objects_for_group(instance.group, f"{app_label}.view_{model}", model_class)
43 obj = objects.first()
44 if not obj:
45 return None
46 return str(obj)
47
48 class Meta(RoleObjectPermissionSerializer.Meta):
49 fields = RoleObjectPermissionSerializer.Meta.fields + [
50 "app_label_verbose",
51 "model_verbose",
52 "object_description",
53 ]
54
55
56 class RolePermissionFilter(FilterSet):
57 """Role permission filter"""
58
59 uuid = UUIDFilter("group__role__uuid", required=True)
60
61
62 class RolePermissionViewSet(ListModelMixin, GenericViewSet):
63 """Get a role's assigned object permissions"""
64
65 serializer_class = ExtraRoleObjectPermissionSerializer
66 ordering = ["group__role__name"]
67 pagination_class = SmallerPagination
68 # The filtering is done in the filterset,
69 # which has a required filter that does the heavy lifting
70 queryset = GroupObjectPermission.objects.select_related("content_type", "group__role").all()
71 filterset_class = RolePermissionFilter
72
```
Path: `authentik/rbac/api/rbac_users.py`
Content:
```
1 """common RBAC serializers"""
2 from typing import Optional
3
4 from django.apps import apps
5 from django_filters.filters import NumberFilter
6 from django_filters.filterset import FilterSet
7 from guardian.models import UserObjectPermission
8 from guardian.shortcuts import get_objects_for_user
9 from rest_framework.fields import SerializerMethodField
10 from rest_framework.mixins import ListModelMixin
11 from rest_framework.viewsets import GenericViewSet
12
13 from authentik.api.pagination import SmallerPagination
14 from authentik.rbac.api.rbac_assigned_by_users import UserObjectPermissionSerializer
15
16
17 class ExtraUserObjectPermissionSerializer(UserObjectPermissionSerializer):
18 """User permission with additional object-related data"""
19
20 app_label_verbose = SerializerMethodField()
21 model_verbose = SerializerMethodField()
22
23 object_description = SerializerMethodField()
24
25 def get_app_label_verbose(self, instance: UserObjectPermission) -> str:
26 """Get app label from permission's model"""
27 return apps.get_app_config(instance.content_type.app_label).verbose_name
28
29 def get_model_verbose(self, instance: UserObjectPermission) -> str:
30 """Get model label from permission's model"""
31 return apps.get_model(
32 instance.content_type.app_label, instance.content_type.model
33 )._meta.verbose_name
34
35 def get_object_description(self, instance: UserObjectPermission) -> Optional[str]:
36 """Get model description from attached model. This operation takes at least
37 one additional query, and the description is only shown if the user/role has the
38 view_ permission on the object"""
39 app_label = instance.content_type.app_label
40 model = instance.content_type.model
41 model_class = apps.get_model(app_label, model)
42 objects = get_objects_for_user(instance.user, f"{app_label}.view_{model}", model_class)
43 obj = objects.first()
44 if not obj:
45 return None
46 return str(obj)
47
48 class Meta(UserObjectPermissionSerializer.Meta):
49 fields = UserObjectPermissionSerializer.Meta.fields + [
50 "app_label_verbose",
51 "model_verbose",
52 "object_description",
53 ]
54
55
56 class UserPermissionFilter(FilterSet):
57 """User-assigned permission filter"""
58
59 user_id = NumberFilter("user__id", required=True)
60
61
62 class UserPermissionViewSet(ListModelMixin, GenericViewSet):
63 """Get a users's assigned object permissions"""
64
65 serializer_class = ExtraUserObjectPermissionSerializer
66 ordering = ["user__username"]
67 pagination_class = SmallerPagination
68 # The filtering is done in the filterset,
69 # which has a required filter that does the heavy lifting
70 queryset = UserObjectPermission.objects.select_related("content_type", "user").all()
71 filterset_class = UserPermissionFilter
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/authentik/rbac/api/rbac.py b/authentik/rbac/api/rbac.py
--- a/authentik/rbac/api/rbac.py
+++ b/authentik/rbac/api/rbac.py
@@ -32,13 +32,19 @@
def get_app_label_verbose(self, instance: Permission) -> str:
"""Human-readable app label"""
- return apps.get_app_config(instance.content_type.app_label).verbose_name
+ try:
+ return apps.get_app_config(instance.content_type.app_label).verbose_name
+ except LookupError:
+ return f"{instance.content_type.app_label}.{instance.content_type.model}"
def get_model_verbose(self, instance: Permission) -> str:
"""Human-readable model name"""
- return apps.get_model(
- instance.content_type.app_label, instance.content_type.model
- )._meta.verbose_name
+ try:
+ return apps.get_model(
+ instance.content_type.app_label, instance.content_type.model
+ )._meta.verbose_name
+ except LookupError:
+ return f"{instance.content_type.app_label}.{instance.content_type.model}"
class Meta:
model = Permission
diff --git a/authentik/rbac/api/rbac_roles.py b/authentik/rbac/api/rbac_roles.py
--- a/authentik/rbac/api/rbac_roles.py
+++ b/authentik/rbac/api/rbac_roles.py
@@ -28,9 +28,12 @@
def get_model_verbose(self, instance: GroupObjectPermission) -> str:
"""Get model label from permission's model"""
- return apps.get_model(
- instance.content_type.app_label, instance.content_type.model
- )._meta.verbose_name
+ try:
+ return apps.get_model(
+ instance.content_type.app_label, instance.content_type.model
+ )._meta.verbose_name
+ except LookupError:
+ return f"{instance.content_type.app_label}.{instance.content_type.model}"
def get_object_description(self, instance: GroupObjectPermission) -> Optional[str]:
"""Get model description from attached model. This operation takes at least
@@ -38,7 +41,10 @@
view_ permission on the object"""
app_label = instance.content_type.app_label
model = instance.content_type.model
- model_class = apps.get_model(app_label, model)
+ try:
+ model_class = apps.get_model(app_label, model)
+ except LookupError:
+ return None
objects = get_objects_for_group(instance.group, f"{app_label}.view_{model}", model_class)
obj = objects.first()
if not obj:
diff --git a/authentik/rbac/api/rbac_users.py b/authentik/rbac/api/rbac_users.py
--- a/authentik/rbac/api/rbac_users.py
+++ b/authentik/rbac/api/rbac_users.py
@@ -28,9 +28,12 @@
def get_model_verbose(self, instance: UserObjectPermission) -> str:
"""Get model label from permission's model"""
- return apps.get_model(
- instance.content_type.app_label, instance.content_type.model
- )._meta.verbose_name
+ try:
+ return apps.get_model(
+ instance.content_type.app_label, instance.content_type.model
+ )._meta.verbose_name
+ except LookupError:
+ return f"{instance.content_type.app_label}.{instance.content_type.model}"
def get_object_description(self, instance: UserObjectPermission) -> Optional[str]:
"""Get model description from attached model. This operation takes at least
@@ -38,7 +41,10 @@
view_ permission on the object"""
app_label = instance.content_type.app_label
model = instance.content_type.model
- model_class = apps.get_model(app_label, model)
+ try:
+ model_class = apps.get_model(app_label, model)
+ except LookupError:
+ return None
objects = get_objects_for_user(instance.user, f"{app_label}.view_{model}", model_class)
obj = objects.first()
if not obj:
| {"golden_diff": "diff --git a/authentik/rbac/api/rbac.py b/authentik/rbac/api/rbac.py\n--- a/authentik/rbac/api/rbac.py\n+++ b/authentik/rbac/api/rbac.py\n@@ -32,13 +32,19 @@\n \n def get_app_label_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable app label\"\"\"\n- return apps.get_app_config(instance.content_type.app_label).verbose_name\n+ try:\n+ return apps.get_app_config(instance.content_type.app_label).verbose_name\n+ except LookupError:\n+ return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n \n def get_model_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable model name\"\"\"\n- return apps.get_model(\n- instance.content_type.app_label, instance.content_type.model\n- )._meta.verbose_name\n+ try:\n+ return apps.get_model(\n+ instance.content_type.app_label, instance.content_type.model\n+ )._meta.verbose_name\n+ except LookupError:\n+ return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n \n class Meta:\n model = Permission\ndiff --git a/authentik/rbac/api/rbac_roles.py b/authentik/rbac/api/rbac_roles.py\n--- a/authentik/rbac/api/rbac_roles.py\n+++ b/authentik/rbac/api/rbac_roles.py\n@@ -28,9 +28,12 @@\n \n def get_model_verbose(self, instance: GroupObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n- return apps.get_model(\n- instance.content_type.app_label, instance.content_type.model\n- )._meta.verbose_name\n+ try:\n+ return apps.get_model(\n+ instance.content_type.app_label, instance.content_type.model\n+ )._meta.verbose_name\n+ except LookupError:\n+ return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n \n def get_object_description(self, instance: GroupObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n@@ -38,7 +41,10 @@\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n- model_class = apps.get_model(app_label, model)\n+ try:\n+ model_class = apps.get_model(app_label, model)\n+ except LookupError:\n+ return None\n objects = get_objects_for_group(instance.group, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\ndiff --git a/authentik/rbac/api/rbac_users.py b/authentik/rbac/api/rbac_users.py\n--- a/authentik/rbac/api/rbac_users.py\n+++ b/authentik/rbac/api/rbac_users.py\n@@ -28,9 +28,12 @@\n \n def get_model_verbose(self, instance: UserObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n- return apps.get_model(\n- instance.content_type.app_label, instance.content_type.model\n- )._meta.verbose_name\n+ try:\n+ return apps.get_model(\n+ instance.content_type.app_label, instance.content_type.model\n+ )._meta.verbose_name\n+ except LookupError:\n+ return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n \n def get_object_description(self, instance: UserObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n@@ -38,7 +41,10 @@\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n- model_class = apps.get_model(app_label, model)\n+ try:\n+ model_class = apps.get_model(app_label, model)\n+ except LookupError:\n+ return None\n objects = get_objects_for_user(instance.user, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\n", "issue": "Listing all permissions\n**Describe the bug**\r\nWhen attempting to list all the permissions in order to select which ones to assign to a permission, hangs when gets to 141+\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. Go to 'Directory'\r\n2. Click on 'Roles'\r\n3. Select (or create a new) role.\r\n4. Click on 'Assign Permissions'\r\n5. Click on '+' to Select Permissions to Grant\r\n6. Scroll through permissions by clicking on '>' until arrive at 121 - 140\r\n\r\n**Expected behavior**\r\nContinue displaying all permissions until reaching end of list (Displays 377 Permissions)\r\n\r\n**Screenshots**\r\n\r\n\r\n**Logs**\r\n[logs](https://pastebin.com/v4Fd6PDN)\r\n\r\n**Version and Deployment (please complete the following information):**\r\n\r\n- authentik version: 2023.10.1\r\n- Deployment: docker-compose\r\n\r\n**Additional context**\r\nUpgraded from 2023.8 -> 2023.10.0 -> 2023.10.1\r\n\r\nCan provide more logs or anything else, if needed.\n", "before_files": [{"content": "\"\"\"common RBAC serializers\"\"\"\nfrom django.apps import apps\nfrom django.contrib.auth.models import Permission\nfrom django.db.models import QuerySet\nfrom django_filters.filters import ModelChoiceFilter\nfrom django_filters.filterset import FilterSet\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import (\n CharField,\n ChoiceField,\n ListField,\n ReadOnlyField,\n SerializerMethodField,\n)\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ReadOnlyModelViewSet\n\nfrom authentik.core.api.utils import PassiveSerializer\nfrom authentik.core.models import User\nfrom authentik.lib.validators import RequiredTogetherValidator\nfrom authentik.policies.event_matcher.models import model_choices\nfrom authentik.rbac.models import Role\n\n\nclass PermissionSerializer(ModelSerializer):\n \"\"\"Global permission\"\"\"\n\n app_label = ReadOnlyField(source=\"content_type.app_label\")\n app_label_verbose = SerializerMethodField()\n model = ReadOnlyField(source=\"content_type.model\")\n model_verbose = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable app label\"\"\"\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n\n def get_model_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable model name\"\"\"\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n\n class Meta:\n model = Permission\n fields = [\n \"id\",\n \"name\",\n \"codename\",\n \"model\",\n \"app_label\",\n \"app_label_verbose\",\n \"model_verbose\",\n ]\n\n\nclass PermissionFilter(FilterSet):\n \"\"\"Filter permissions\"\"\"\n\n role = ModelChoiceFilter(queryset=Role.objects.all(), method=\"filter_role\")\n user = ModelChoiceFilter(queryset=User.objects.all())\n\n def filter_role(self, queryset: QuerySet, name, value: Role) -> QuerySet:\n \"\"\"Filter permissions based on role\"\"\"\n return queryset.filter(group__role=value)\n\n class Meta:\n model = Permission\n fields = [\n \"codename\",\n \"content_type__model\",\n \"content_type__app_label\",\n \"role\",\n \"user\",\n ]\n\n\nclass RBACPermissionViewSet(ReadOnlyModelViewSet):\n \"\"\"Read-only list of all permissions, filterable by model and app\"\"\"\n\n queryset = Permission.objects.none()\n serializer_class = PermissionSerializer\n ordering = [\"name\"]\n filterset_class = PermissionFilter\n search_fields = [\n \"codename\",\n \"content_type__model\",\n \"content_type__app_label\",\n ]\n\n def get_queryset(self) -> QuerySet:\n return (\n Permission.objects.all()\n .select_related(\"content_type\")\n .filter(\n content_type__app_label__startswith=\"authentik\",\n )\n )\n\n\nclass PermissionAssignSerializer(PassiveSerializer):\n \"\"\"Request to assign a new permission\"\"\"\n\n permissions = ListField(child=CharField())\n model = ChoiceField(choices=model_choices(), required=False)\n object_pk = CharField(required=False)\n\n validators = [RequiredTogetherValidator(fields=[\"model\", \"object_pk\"])]\n\n def validate(self, attrs: dict) -> dict:\n model_instance = None\n # Check if we're setting an object-level perm or global\n model = attrs.get(\"model\")\n object_pk = attrs.get(\"object_pk\")\n if model and object_pk:\n model = apps.get_model(attrs[\"model\"])\n model_instance = model.objects.filter(pk=attrs[\"object_pk\"]).first()\n attrs[\"model_instance\"] = model_instance\n if attrs.get(\"model\"):\n return attrs\n permissions = attrs.get(\"permissions\", [])\n if not all(\".\" in perm for perm in permissions):\n raise ValidationError(\n {\n \"permissions\": (\n \"When assigning global permissions, codename must be given as \"\n \"app_label.codename\"\n )\n }\n )\n return attrs\n", "path": "authentik/rbac/api/rbac.py"}, {"content": "\"\"\"common RBAC serializers\"\"\"\nfrom typing import Optional\n\nfrom django.apps import apps\nfrom django_filters.filters import UUIDFilter\nfrom django_filters.filterset import FilterSet\nfrom guardian.models import GroupObjectPermission\nfrom guardian.shortcuts import get_objects_for_group\nfrom rest_framework.fields import SerializerMethodField\nfrom rest_framework.mixins import ListModelMixin\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.api.pagination import SmallerPagination\nfrom authentik.rbac.api.rbac_assigned_by_roles import RoleObjectPermissionSerializer\n\n\nclass ExtraRoleObjectPermissionSerializer(RoleObjectPermissionSerializer):\n \"\"\"User permission with additional object-related data\"\"\"\n\n app_label_verbose = SerializerMethodField()\n model_verbose = SerializerMethodField()\n\n object_description = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: GroupObjectPermission) -> str:\n \"\"\"Get app label from permission's model\"\"\"\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n\n def get_model_verbose(self, instance: GroupObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n\n def get_object_description(self, instance: GroupObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n one additional query, and the description is only shown if the user/role has the\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n model_class = apps.get_model(app_label, model)\n objects = get_objects_for_group(instance.group, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\n return None\n return str(obj)\n\n class Meta(RoleObjectPermissionSerializer.Meta):\n fields = RoleObjectPermissionSerializer.Meta.fields + [\n \"app_label_verbose\",\n \"model_verbose\",\n \"object_description\",\n ]\n\n\nclass RolePermissionFilter(FilterSet):\n \"\"\"Role permission filter\"\"\"\n\n uuid = UUIDFilter(\"group__role__uuid\", required=True)\n\n\nclass RolePermissionViewSet(ListModelMixin, GenericViewSet):\n \"\"\"Get a role's assigned object permissions\"\"\"\n\n serializer_class = ExtraRoleObjectPermissionSerializer\n ordering = [\"group__role__name\"]\n pagination_class = SmallerPagination\n # The filtering is done in the filterset,\n # which has a required filter that does the heavy lifting\n queryset = GroupObjectPermission.objects.select_related(\"content_type\", \"group__role\").all()\n filterset_class = RolePermissionFilter\n", "path": "authentik/rbac/api/rbac_roles.py"}, {"content": "\"\"\"common RBAC serializers\"\"\"\nfrom typing import Optional\n\nfrom django.apps import apps\nfrom django_filters.filters import NumberFilter\nfrom django_filters.filterset import FilterSet\nfrom guardian.models import UserObjectPermission\nfrom guardian.shortcuts import get_objects_for_user\nfrom rest_framework.fields import SerializerMethodField\nfrom rest_framework.mixins import ListModelMixin\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.api.pagination import SmallerPagination\nfrom authentik.rbac.api.rbac_assigned_by_users import UserObjectPermissionSerializer\n\n\nclass ExtraUserObjectPermissionSerializer(UserObjectPermissionSerializer):\n \"\"\"User permission with additional object-related data\"\"\"\n\n app_label_verbose = SerializerMethodField()\n model_verbose = SerializerMethodField()\n\n object_description = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: UserObjectPermission) -> str:\n \"\"\"Get app label from permission's model\"\"\"\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n\n def get_model_verbose(self, instance: UserObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n\n def get_object_description(self, instance: UserObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n one additional query, and the description is only shown if the user/role has the\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n model_class = apps.get_model(app_label, model)\n objects = get_objects_for_user(instance.user, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\n return None\n return str(obj)\n\n class Meta(UserObjectPermissionSerializer.Meta):\n fields = UserObjectPermissionSerializer.Meta.fields + [\n \"app_label_verbose\",\n \"model_verbose\",\n \"object_description\",\n ]\n\n\nclass UserPermissionFilter(FilterSet):\n \"\"\"User-assigned permission filter\"\"\"\n\n user_id = NumberFilter(\"user__id\", required=True)\n\n\nclass UserPermissionViewSet(ListModelMixin, GenericViewSet):\n \"\"\"Get a users's assigned object permissions\"\"\"\n\n serializer_class = ExtraUserObjectPermissionSerializer\n ordering = [\"user__username\"]\n pagination_class = SmallerPagination\n # The filtering is done in the filterset,\n # which has a required filter that does the heavy lifting\n queryset = UserObjectPermission.objects.select_related(\"content_type\", \"user\").all()\n filterset_class = UserPermissionFilter\n", "path": "authentik/rbac/api/rbac_users.py"}], "after_files": [{"content": "\"\"\"common RBAC serializers\"\"\"\nfrom django.apps import apps\nfrom django.contrib.auth.models import Permission\nfrom django.db.models import QuerySet\nfrom django_filters.filters import ModelChoiceFilter\nfrom django_filters.filterset import FilterSet\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import (\n CharField,\n ChoiceField,\n ListField,\n ReadOnlyField,\n SerializerMethodField,\n)\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ReadOnlyModelViewSet\n\nfrom authentik.core.api.utils import PassiveSerializer\nfrom authentik.core.models import User\nfrom authentik.lib.validators import RequiredTogetherValidator\nfrom authentik.policies.event_matcher.models import model_choices\nfrom authentik.rbac.models import Role\n\n\nclass PermissionSerializer(ModelSerializer):\n \"\"\"Global permission\"\"\"\n\n app_label = ReadOnlyField(source=\"content_type.app_label\")\n app_label_verbose = SerializerMethodField()\n model = ReadOnlyField(source=\"content_type.model\")\n model_verbose = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable app label\"\"\"\n try:\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n except LookupError:\n return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n\n def get_model_verbose(self, instance: Permission) -> str:\n \"\"\"Human-readable model name\"\"\"\n try:\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n except LookupError:\n return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n\n class Meta:\n model = Permission\n fields = [\n \"id\",\n \"name\",\n \"codename\",\n \"model\",\n \"app_label\",\n \"app_label_verbose\",\n \"model_verbose\",\n ]\n\n\nclass PermissionFilter(FilterSet):\n \"\"\"Filter permissions\"\"\"\n\n role = ModelChoiceFilter(queryset=Role.objects.all(), method=\"filter_role\")\n user = ModelChoiceFilter(queryset=User.objects.all())\n\n def filter_role(self, queryset: QuerySet, name, value: Role) -> QuerySet:\n \"\"\"Filter permissions based on role\"\"\"\n return queryset.filter(group__role=value)\n\n class Meta:\n model = Permission\n fields = [\n \"codename\",\n \"content_type__model\",\n \"content_type__app_label\",\n \"role\",\n \"user\",\n ]\n\n\nclass RBACPermissionViewSet(ReadOnlyModelViewSet):\n \"\"\"Read-only list of all permissions, filterable by model and app\"\"\"\n\n queryset = Permission.objects.none()\n serializer_class = PermissionSerializer\n ordering = [\"name\"]\n filterset_class = PermissionFilter\n search_fields = [\n \"codename\",\n \"content_type__model\",\n \"content_type__app_label\",\n ]\n\n def get_queryset(self) -> QuerySet:\n return (\n Permission.objects.all()\n .select_related(\"content_type\")\n .filter(\n content_type__app_label__startswith=\"authentik\",\n )\n )\n\n\nclass PermissionAssignSerializer(PassiveSerializer):\n \"\"\"Request to assign a new permission\"\"\"\n\n permissions = ListField(child=CharField())\n model = ChoiceField(choices=model_choices(), required=False)\n object_pk = CharField(required=False)\n\n validators = [RequiredTogetherValidator(fields=[\"model\", \"object_pk\"])]\n\n def validate(self, attrs: dict) -> dict:\n model_instance = None\n # Check if we're setting an object-level perm or global\n model = attrs.get(\"model\")\n object_pk = attrs.get(\"object_pk\")\n if model and object_pk:\n model = apps.get_model(attrs[\"model\"])\n model_instance = model.objects.filter(pk=attrs[\"object_pk\"]).first()\n attrs[\"model_instance\"] = model_instance\n if attrs.get(\"model\"):\n return attrs\n permissions = attrs.get(\"permissions\", [])\n if not all(\".\" in perm for perm in permissions):\n raise ValidationError(\n {\n \"permissions\": (\n \"When assigning global permissions, codename must be given as \"\n \"app_label.codename\"\n )\n }\n )\n return attrs\n", "path": "authentik/rbac/api/rbac.py"}, {"content": "\"\"\"common RBAC serializers\"\"\"\nfrom typing import Optional\n\nfrom django.apps import apps\nfrom django_filters.filters import UUIDFilter\nfrom django_filters.filterset import FilterSet\nfrom guardian.models import GroupObjectPermission\nfrom guardian.shortcuts import get_objects_for_group\nfrom rest_framework.fields import SerializerMethodField\nfrom rest_framework.mixins import ListModelMixin\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.api.pagination import SmallerPagination\nfrom authentik.rbac.api.rbac_assigned_by_roles import RoleObjectPermissionSerializer\n\n\nclass ExtraRoleObjectPermissionSerializer(RoleObjectPermissionSerializer):\n \"\"\"User permission with additional object-related data\"\"\"\n\n app_label_verbose = SerializerMethodField()\n model_verbose = SerializerMethodField()\n\n object_description = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: GroupObjectPermission) -> str:\n \"\"\"Get app label from permission's model\"\"\"\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n\n def get_model_verbose(self, instance: GroupObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n try:\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n except LookupError:\n return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n\n def get_object_description(self, instance: GroupObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n one additional query, and the description is only shown if the user/role has the\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n try:\n model_class = apps.get_model(app_label, model)\n except LookupError:\n return None\n objects = get_objects_for_group(instance.group, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\n return None\n return str(obj)\n\n class Meta(RoleObjectPermissionSerializer.Meta):\n fields = RoleObjectPermissionSerializer.Meta.fields + [\n \"app_label_verbose\",\n \"model_verbose\",\n \"object_description\",\n ]\n\n\nclass RolePermissionFilter(FilterSet):\n \"\"\"Role permission filter\"\"\"\n\n uuid = UUIDFilter(\"group__role__uuid\", required=True)\n\n\nclass RolePermissionViewSet(ListModelMixin, GenericViewSet):\n \"\"\"Get a role's assigned object permissions\"\"\"\n\n serializer_class = ExtraRoleObjectPermissionSerializer\n ordering = [\"group__role__name\"]\n pagination_class = SmallerPagination\n # The filtering is done in the filterset,\n # which has a required filter that does the heavy lifting\n queryset = GroupObjectPermission.objects.select_related(\"content_type\", \"group__role\").all()\n filterset_class = RolePermissionFilter\n", "path": "authentik/rbac/api/rbac_roles.py"}, {"content": "\"\"\"common RBAC serializers\"\"\"\nfrom typing import Optional\n\nfrom django.apps import apps\nfrom django_filters.filters import NumberFilter\nfrom django_filters.filterset import FilterSet\nfrom guardian.models import UserObjectPermission\nfrom guardian.shortcuts import get_objects_for_user\nfrom rest_framework.fields import SerializerMethodField\nfrom rest_framework.mixins import ListModelMixin\nfrom rest_framework.viewsets import GenericViewSet\n\nfrom authentik.api.pagination import SmallerPagination\nfrom authentik.rbac.api.rbac_assigned_by_users import UserObjectPermissionSerializer\n\n\nclass ExtraUserObjectPermissionSerializer(UserObjectPermissionSerializer):\n \"\"\"User permission with additional object-related data\"\"\"\n\n app_label_verbose = SerializerMethodField()\n model_verbose = SerializerMethodField()\n\n object_description = SerializerMethodField()\n\n def get_app_label_verbose(self, instance: UserObjectPermission) -> str:\n \"\"\"Get app label from permission's model\"\"\"\n return apps.get_app_config(instance.content_type.app_label).verbose_name\n\n def get_model_verbose(self, instance: UserObjectPermission) -> str:\n \"\"\"Get model label from permission's model\"\"\"\n try:\n return apps.get_model(\n instance.content_type.app_label, instance.content_type.model\n )._meta.verbose_name\n except LookupError:\n return f\"{instance.content_type.app_label}.{instance.content_type.model}\"\n\n def get_object_description(self, instance: UserObjectPermission) -> Optional[str]:\n \"\"\"Get model description from attached model. This operation takes at least\n one additional query, and the description is only shown if the user/role has the\n view_ permission on the object\"\"\"\n app_label = instance.content_type.app_label\n model = instance.content_type.model\n try:\n model_class = apps.get_model(app_label, model)\n except LookupError:\n return None\n objects = get_objects_for_user(instance.user, f\"{app_label}.view_{model}\", model_class)\n obj = objects.first()\n if not obj:\n return None\n return str(obj)\n\n class Meta(UserObjectPermissionSerializer.Meta):\n fields = UserObjectPermissionSerializer.Meta.fields + [\n \"app_label_verbose\",\n \"model_verbose\",\n \"object_description\",\n ]\n\n\nclass UserPermissionFilter(FilterSet):\n \"\"\"User-assigned permission filter\"\"\"\n\n user_id = NumberFilter(\"user__id\", required=True)\n\n\nclass UserPermissionViewSet(ListModelMixin, GenericViewSet):\n \"\"\"Get a users's assigned object permissions\"\"\"\n\n serializer_class = ExtraUserObjectPermissionSerializer\n ordering = [\"user__username\"]\n pagination_class = SmallerPagination\n # The filtering is done in the filterset,\n # which has a required filter that does the heavy lifting\n queryset = UserObjectPermission.objects.select_related(\"content_type\", \"user\").all()\n filterset_class = UserPermissionFilter\n", "path": "authentik/rbac/api/rbac_users.py"}]} | 3,123 | 897 |
gh_patches_debug_14777 | rasdani/github-patches | git_diff | Mailu__Mailu-1941 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Letsencrypt Force Renewal
Is there a limit on the Subject Alt Name entries?
I have updated my /mailu/mailu.env "HOSTNAMES" variable, but when I restart Mailu it doesn't update the Subject Alt Names on the mailu cert.
Previously it has worked, so I am guessing that I need to force Letsencrypt to refresh as it isnt within the renewal window. But there is no guidance for the new letsencrypt certbot.
I am using the latest Mailu version (1.7) and this is the command I am using to restart mailu '/mailu/docker-compose -p mailu up -d'
Letsencrypt Force Renewal
Is there a limit on the Subject Alt Name entries?
I have updated my /mailu/mailu.env "HOSTNAMES" variable, but when I restart Mailu it doesn't update the Subject Alt Names on the mailu cert.
Previously it has worked, so I am guessing that I need to force Letsencrypt to refresh as it isnt within the renewal window. But there is no guidance for the new letsencrypt certbot.
I am using the latest Mailu version (1.7) and this is the command I am using to restart mailu '/mailu/docker-compose -p mailu up -d'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/nginx/letsencrypt.py`
Content:
```
1 #!/usr/bin/python3
2
3 import os
4 import time
5 import subprocess
6
7 command = [
8 "certbot",
9 "-n", "--agree-tos", # non-interactive
10 "-d", os.environ["HOSTNAMES"],
11 "-m", "{}@{}".format(os.environ["POSTMASTER"], os.environ["DOMAIN"]),
12 "certonly", "--standalone",
13 "--cert-name", "mailu",
14 "--preferred-challenges", "http", "--http-01-port", "8008",
15 "--keep-until-expiring",
16 "--config-dir", "/certs/letsencrypt",
17 "--post-hook", "/config.py"
18 ]
19 command2 = [
20 "certbot",
21 "-n", "--agree-tos", # non-interactive
22 "-d", os.environ["HOSTNAMES"],
23 "-m", "{}@{}".format(os.environ["POSTMASTER"], os.environ["DOMAIN"]),
24 "certonly", "--standalone",
25 "--cert-name", "mailu-ecdsa",
26 "--preferred-challenges", "http", "--http-01-port", "8008",
27 "--keep-until-expiring",
28 "--key-type", "ecdsa",
29 "--config-dir", "/certs/letsencrypt",
30 "--post-hook", "/config.py"
31 ]
32
33 def format_for_nginx(fullchain, output):
34 """ We may want to strip ISRG Root X1 out
35 """
36 certs = []
37 with open(fullchain, 'r') as pem:
38 cert = ''
39 for line in pem:
40 cert += line
41 if '-----END CERTIFICATE-----' in line:
42 certs += [cert]
43 cert = ''
44 with open(output, 'w') as pem:
45 for cert in certs[:-1] if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN', default="False") else certs:
46 pem.write(cert)
47
48 # Wait for nginx to start
49 time.sleep(5)
50
51 # Run certbot every day
52 while True:
53 subprocess.call(command)
54 format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')
55 subprocess.call(command2)
56 format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')
57 time.sleep(86400)
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/nginx/letsencrypt.py b/core/nginx/letsencrypt.py
--- a/core/nginx/letsencrypt.py
+++ b/core/nginx/letsencrypt.py
@@ -13,6 +13,7 @@
"--cert-name", "mailu",
"--preferred-challenges", "http", "--http-01-port", "8008",
"--keep-until-expiring",
+ "--renew-with-new-domains",
"--config-dir", "/certs/letsencrypt",
"--post-hook", "/config.py"
]
@@ -26,6 +27,7 @@
"--preferred-challenges", "http", "--http-01-port", "8008",
"--keep-until-expiring",
"--key-type", "ecdsa",
+ "--renew-with-new-domains",
"--config-dir", "/certs/letsencrypt",
"--post-hook", "/config.py"
]
| {"golden_diff": "diff --git a/core/nginx/letsencrypt.py b/core/nginx/letsencrypt.py\n--- a/core/nginx/letsencrypt.py\n+++ b/core/nginx/letsencrypt.py\n@@ -13,6 +13,7 @@\n \"--cert-name\", \"mailu\",\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n+ \"--renew-with-new-domains\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n ]\n@@ -26,6 +27,7 @@\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n \"--key-type\", \"ecdsa\",\n+ \"--renew-with-new-domains\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n ]\n", "issue": "Letsencrypt Force Renewal\nIs there a limit on the Subject Alt Name entries?\r\n\r\nI have updated my /mailu/mailu.env \"HOSTNAMES\" variable, but when I restart Mailu it doesn't update the Subject Alt Names on the mailu cert.\r\n\r\nPreviously it has worked, so I am guessing that I need to force Letsencrypt to refresh as it isnt within the renewal window. But there is no guidance for the new letsencrypt certbot.\r\n\r\nI am using the latest Mailu version (1.7) and this is the command I am using to restart mailu '/mailu/docker-compose -p mailu up -d'\nLetsencrypt Force Renewal\nIs there a limit on the Subject Alt Name entries?\r\n\r\nI have updated my /mailu/mailu.env \"HOSTNAMES\" variable, but when I restart Mailu it doesn't update the Subject Alt Names on the mailu cert.\r\n\r\nPreviously it has worked, so I am guessing that I need to force Letsencrypt to refresh as it isnt within the renewal window. But there is no guidance for the new letsencrypt certbot.\r\n\r\nI am using the latest Mailu version (1.7) and this is the command I am using to restart mailu '/mailu/docker-compose -p mailu up -d'\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport time\nimport subprocess\n\ncommand = [\n \"certbot\",\n \"-n\", \"--agree-tos\", # non-interactive\n \"-d\", os.environ[\"HOSTNAMES\"],\n \"-m\", \"{}@{}\".format(os.environ[\"POSTMASTER\"], os.environ[\"DOMAIN\"]),\n \"certonly\", \"--standalone\",\n \"--cert-name\", \"mailu\",\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n]\ncommand2 = [\n \"certbot\",\n \"-n\", \"--agree-tos\", # non-interactive\n \"-d\", os.environ[\"HOSTNAMES\"],\n \"-m\", \"{}@{}\".format(os.environ[\"POSTMASTER\"], os.environ[\"DOMAIN\"]),\n \"certonly\", \"--standalone\",\n \"--cert-name\", \"mailu-ecdsa\",\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n \"--key-type\", \"ecdsa\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n]\n\ndef format_for_nginx(fullchain, output):\n \"\"\" We may want to strip ISRG Root X1 out\n \"\"\"\n certs = []\n with open(fullchain, 'r') as pem:\n cert = ''\n for line in pem:\n cert += line\n if '-----END CERTIFICATE-----' in line:\n certs += [cert]\n cert = ''\n with open(output, 'w') as pem:\n for cert in certs[:-1] if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN', default=\"False\") else certs:\n pem.write(cert)\n\n# Wait for nginx to start\ntime.sleep(5)\n\n# Run certbot every day\nwhile True:\n subprocess.call(command)\n format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')\n subprocess.call(command2)\n format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')\n time.sleep(86400)\n", "path": "core/nginx/letsencrypt.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport time\nimport subprocess\n\ncommand = [\n \"certbot\",\n \"-n\", \"--agree-tos\", # non-interactive\n \"-d\", os.environ[\"HOSTNAMES\"],\n \"-m\", \"{}@{}\".format(os.environ[\"POSTMASTER\"], os.environ[\"DOMAIN\"]),\n \"certonly\", \"--standalone\",\n \"--cert-name\", \"mailu\",\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n \"--renew-with-new-domains\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n]\ncommand2 = [\n \"certbot\",\n \"-n\", \"--agree-tos\", # non-interactive\n \"-d\", os.environ[\"HOSTNAMES\"],\n \"-m\", \"{}@{}\".format(os.environ[\"POSTMASTER\"], os.environ[\"DOMAIN\"]),\n \"certonly\", \"--standalone\",\n \"--cert-name\", \"mailu-ecdsa\",\n \"--preferred-challenges\", \"http\", \"--http-01-port\", \"8008\",\n \"--keep-until-expiring\",\n \"--key-type\", \"ecdsa\",\n \"--renew-with-new-domains\",\n \"--config-dir\", \"/certs/letsencrypt\",\n \"--post-hook\", \"/config.py\"\n]\n\ndef format_for_nginx(fullchain, output):\n \"\"\" We may want to strip ISRG Root X1 out\n \"\"\"\n certs = []\n with open(fullchain, 'r') as pem:\n cert = ''\n for line in pem:\n cert += line\n if '-----END CERTIFICATE-----' in line:\n certs += [cert]\n cert = ''\n with open(output, 'w') as pem:\n for cert in certs[:-1] if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN', default=\"False\") else certs:\n pem.write(cert)\n\n# Wait for nginx to start\ntime.sleep(5)\n\n# Run certbot every day\nwhile True:\n subprocess.call(command)\n format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')\n subprocess.call(command2)\n format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')\n time.sleep(86400)\n", "path": "core/nginx/letsencrypt.py"}]} | 1,146 | 202 |
gh_patches_debug_16656 | rasdani/github-patches | git_diff | AnalogJ__lexicon-133 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix logging TypeError (digitalocean.py)
[This same issue](https://github.com/AnalogJ/lexicon/pull/128/commits/903af58378ab9942d817c57e0330b5f7ac26b4e9) exists in `lexicon/providers/digitalocean.py` line 111. The same edit is needed to fix it.
The error generated is:
```
Traceback (most recent call last):
File "/usr/lib/python2.7/logging/__init__.py", line 861, in emit
msg = self.format(record)
File "/usr/lib/python2.7/logging/__init__.py", line 734, in format
return fmt.format(record)
File "/usr/lib/python2.7/logging/__init__.py", line 465, in format
record.message = record.getMessage()
File "/usr/lib/python2.7/logging/__init__.py", line 329, in getMessage
msg = msg % self.args
TypeError: not all arguments converted during string formatting
Logged from file digitalocean.py, line 111
```
That section is:
```
Line 110: # is always True at this point, if a non 200 response is returned an error is raised.
Line 111: logger.debug('delete_record: {0}', True)
Line 112: return True
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/digitalocean.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import print_function
3
4 import json
5 import logging
6
7 import requests
8
9 from .base import Provider as BaseProvider
10
11 logger = logging.getLogger(__name__)
12
13
14 def ProviderParser(subparser):
15 subparser.add_argument("--auth-token", help="specify token used authenticate to DNS provider")
16
17 class Provider(BaseProvider):
18
19 def __init__(self, options, engine_overrides=None):
20 super(Provider, self).__init__(options, engine_overrides)
21 self.domain_id = None
22 self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.digitalocean.com/v2')
23
24 def authenticate(self):
25
26 payload = self._get('/domains/{0}'.format(self.options['domain']))
27 self.domain_id = self.options['domain']
28
29 def create_record(self, type, name, content):
30 record = {
31 'type': type,
32 'name': self._relative_name(name),
33 'data': content,
34
35 }
36 if type == 'CNAME':
37 record['data'] = record['data'].rstrip('.') + '.' # make sure a the data is always a FQDN for CNAMe.
38
39 payload = self._post('/domains/{0}/records'.format(self.domain_id), record)
40
41 logger.debug('create_record: %s', True)
42 return True
43
44 # List all records. Return an empty list if no records found
45 # type, name and content are used to filter records.
46 # If possible filter during the query, otherwise filter after response is received.
47 def list_records(self, type=None, name=None, content=None):
48 url = '/domains/{0}/records'.format(self.domain_id)
49 records = []
50 payload = {}
51
52 next = url
53 while next is not None:
54 payload = self._get(next)
55 if 'links' in payload \
56 and 'pages' in payload['links'] \
57 and 'next' in payload['links']['pages']:
58 next = payload['links']['pages']['next']
59 else:
60 next = None
61
62 for record in payload['domain_records']:
63 processed_record = {
64 'type': record['type'],
65 'name': "{0}.{1}".format(record['name'], self.domain_id),
66 'ttl': '',
67 'content': record['data'],
68 'id': record['id']
69 }
70 records.append(processed_record)
71
72 if type:
73 records = [record for record in records if record['type'] == type]
74 if name:
75 records = [record for record in records if record['name'] == self._full_name(name)]
76 if content:
77 records = [record for record in records if record['content'].lower() == content.lower()]
78
79 logger.debug('list_records: %s', records)
80 return records
81
82 # Create or update a record.
83 def update_record(self, identifier, type=None, name=None, content=None):
84
85 data = {}
86 if type:
87 data['type'] = type
88 if name:
89 data['name'] = self._relative_name(name)
90 if content:
91 data['data'] = content
92
93 payload = self._put('/domains/{0}/records/{1}'.format(self.domain_id, identifier), data)
94
95 logger.debug('update_record: %s', True)
96 return True
97
98 # Delete an existing record.
99 # If record does not exist, do nothing.
100 def delete_record(self, identifier=None, type=None, name=None, content=None):
101 if not identifier:
102 records = self.list_records(type, name, content)
103 logger.debug('records: %s', records)
104 if len(records) == 1:
105 identifier = records[0]['id']
106 else:
107 raise Exception('Record identifier could not be found.')
108 payload = self._delete('/domains/{0}/records/{1}'.format(self.domain_id, identifier))
109
110 # is always True at this point, if a non 200 response is returned an error is raised.
111 logger.debug('delete_record: {0}', True)
112 return True
113
114
115 # Helpers
116 def _request(self, action='GET', url='/', data=None, query_params=None):
117 if data is None:
118 data = {}
119 if query_params is None:
120 query_params = {}
121 default_headers = {
122 'Accept': 'application/json',
123 'Content-Type': 'application/json',
124 'Authorization': 'Bearer {0}'.format(self.options.get('auth_token'))
125 }
126 if not url.startswith(self.api_endpoint):
127 url = self.api_endpoint + url
128
129 r = requests.request(action, url, params=query_params,
130 data=json.dumps(data),
131 headers=default_headers)
132 r.raise_for_status() # if the request fails for any reason, throw an error.
133 if action == 'DELETE':
134 return ''
135 else:
136 return r.json()
137
```
Path: `lexicon/providers/dnsmadeeasy.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import print_function
3
4 import contextlib
5 import datetime
6 import hmac
7 import json
8 import locale
9 import logging
10 from hashlib import sha1
11
12 import requests
13 from builtins import bytes
14
15 from .base import Provider as BaseProvider
16
17 logger = logging.getLogger(__name__)
18
19
20 def ProviderParser(subparser):
21 subparser.add_argument("--auth-username", help="specify username used to authenticate")
22 subparser.add_argument("--auth-token", help="specify token used authenticate=")
23
24 class Provider(BaseProvider):
25
26 def __init__(self, options, engine_overrides=None):
27 super(Provider, self).__init__(options, engine_overrides)
28 self.domain_id = None
29 self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.dnsmadeeasy.com/V2.0')
30
31 def authenticate(self):
32
33 try:
34 payload = self._get('/dns/managed/name', {'domainname': self.options['domain']})
35 except requests.exceptions.HTTPError as e:
36 if e.response.status_code == 404:
37 payload = {}
38 else:
39 raise e
40
41 if not payload or not payload['id']:
42 raise Exception('No domain found')
43
44 self.domain_id = payload['id']
45
46
47 # Create record. If record already exists with the same content, do nothing'
48 def create_record(self, type, name, content):
49 record = {
50 'type': type,
51 'name': self._relative_name(name),
52 'value': content,
53 'ttl': self.options['ttl']
54 }
55 payload = {}
56 try:
57 payload = self._post('/dns/managed/{0}/records/'.format(self.domain_id), record)
58 except requests.exceptions.HTTPError as e:
59 if e.response.status_code == 400:
60 payload = {}
61
62 # http 400 is ok here, because the record probably already exists
63 logger.debug('create_record: %s', 'name' in payload)
64 return 'name' in payload
65
66 # List all records. Return an empty list if no records found
67 # type, name and content are used to filter records.
68 # If possible filter during the query, otherwise filter after response is received.
69 def list_records(self, type=None, name=None, content=None):
70 filter = {}
71 if type:
72 filter['type'] = type
73 if name:
74 filter['recordName'] = self._relative_name(name)
75 payload = self._get('/dns/managed/{0}/records'.format(self.domain_id), filter)
76
77 records = []
78 for record in payload['data']:
79 processed_record = {
80 'type': record['type'],
81 'name': '{0}.{1}'.format(record['name'], self.options['domain']),
82 'ttl': record['ttl'],
83 'content': record['value'],
84 'id': record['id']
85 }
86
87 processed_record = self._clean_TXT_record(processed_record)
88 records.append(processed_record)
89
90 logger.debug('list_records: %s', records)
91 return records
92
93 # Create or update a record.
94 def update_record(self, identifier, type=None, name=None, content=None):
95
96 data = {
97 'id': identifier,
98 'ttl': self.options['ttl']
99 }
100
101 if name:
102 data['name'] = self._relative_name(name)
103 if content:
104 data['value'] = content
105 if type:
106 data['type'] = type
107
108 payload = self._put('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)
109
110 logger.debug('update_record: {0}', True)
111 return True
112
113 # Delete an existing record.
114 # If record does not exist, do nothing.
115 def delete_record(self, identifier=None, type=None, name=None, content=None):
116 if not identifier:
117 records = self.list_records(type, name, content)
118 logger.debug('records: %s', records)
119 if len(records) == 1:
120 identifier = records[0]['id']
121 else:
122 raise Exception('Record identifier could not be found.')
123 payload = self._delete('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier))
124
125 # is always True at this point, if a non 200 response is returned an error is raised.
126 logger.debug('delete_record: %s', True)
127 return True
128
129
130 # Helpers
131
132 # this method allows you to set the locale when doing datetime string formatting.
133 # https://stackoverflow.com/questions/18593661/how-do-i-strftime-a-date-object-in-a-different-locale
134 @contextlib.contextmanager
135 def setlocale(self, *args, **kw):
136 saved = locale.setlocale(locale.LC_ALL)
137 #yield locale.setlocale(*args, **kw)
138 yield locale.setlocale(locale.LC_TIME, 'en_US.UTF-8')
139 locale.setlocale(locale.LC_ALL, saved)
140
141 def _request(self, action='GET', url='/', data=None, query_params=None):
142 if data is None:
143 data = {}
144 if query_params is None:
145 query_params = {}
146 default_headers = {
147 'Accept': 'application/json',
148 'Content-Type': 'application/json',
149 'x-dnsme-apiKey': self.options['auth_username']
150 }
151 default_auth = None
152
153 # all requests require a HMAC header and timestamp header.
154 now = datetime.datetime.utcnow()
155 # required format: Sat, 12 Feb 2011 20:59:04 GMT
156 with self.setlocale(locale.LC_TIME, 'en_US.utf8'):
157 request_date = now.strftime('%a, %d %b %Y %H:%M:%S GMT')
158 hashed = hmac.new(bytes(self.options['auth_token'], 'ascii'),
159 bytes(request_date, 'ascii'), sha1)
160
161 default_headers['x-dnsme-requestDate'] = request_date
162 default_headers['x-dnsme-hmac'] = hashed.hexdigest()
163
164 r = requests.request(action, self.api_endpoint + url, params=query_params,
165 data=json.dumps(data),
166 headers=default_headers,
167 auth=default_auth)
168 r.raise_for_status() # if the request fails for any reason, throw an error.
169
170 # PUT and DELETE actions dont return valid json.
171 if action == 'DELETE' or action == 'PUT':
172 return r.text
173 return r.json()
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lexicon/providers/digitalocean.py b/lexicon/providers/digitalocean.py
--- a/lexicon/providers/digitalocean.py
+++ b/lexicon/providers/digitalocean.py
@@ -108,7 +108,7 @@
payload = self._delete('/domains/{0}/records/{1}'.format(self.domain_id, identifier))
# is always True at this point, if a non 200 response is returned an error is raised.
- logger.debug('delete_record: {0}', True)
+ logger.debug('delete_record: %s', True)
return True
diff --git a/lexicon/providers/dnsmadeeasy.py b/lexicon/providers/dnsmadeeasy.py
--- a/lexicon/providers/dnsmadeeasy.py
+++ b/lexicon/providers/dnsmadeeasy.py
@@ -107,7 +107,7 @@
payload = self._put('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)
- logger.debug('update_record: {0}', True)
+ logger.debug('update_record: %s', True)
return True
# Delete an existing record.
| {"golden_diff": "diff --git a/lexicon/providers/digitalocean.py b/lexicon/providers/digitalocean.py\n--- a/lexicon/providers/digitalocean.py\n+++ b/lexicon/providers/digitalocean.py\n@@ -108,7 +108,7 @@\n payload = self._delete('/domains/{0}/records/{1}'.format(self.domain_id, identifier))\n \n # is always True at this point, if a non 200 response is returned an error is raised.\n- logger.debug('delete_record: {0}', True)\n+ logger.debug('delete_record: %s', True)\n return True\n \n \ndiff --git a/lexicon/providers/dnsmadeeasy.py b/lexicon/providers/dnsmadeeasy.py\n--- a/lexicon/providers/dnsmadeeasy.py\n+++ b/lexicon/providers/dnsmadeeasy.py\n@@ -107,7 +107,7 @@\n \n payload = self._put('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)\n \n- logger.debug('update_record: {0}', True)\n+ logger.debug('update_record: %s', True)\n return True\n \n # Delete an existing record.\n", "issue": "Fix logging TypeError (digitalocean.py)\n[This same issue](https://github.com/AnalogJ/lexicon/pull/128/commits/903af58378ab9942d817c57e0330b5f7ac26b4e9) exists in `lexicon/providers/digitalocean.py` line 111. The same edit is needed to fix it. \r\n\r\nThe error generated is:\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python2.7/logging/__init__.py\", line 861, in emit\r\n msg = self.format(record)\r\n File \"/usr/lib/python2.7/logging/__init__.py\", line 734, in format\r\n return fmt.format(record)\r\n File \"/usr/lib/python2.7/logging/__init__.py\", line 465, in format\r\n record.message = record.getMessage()\r\n File \"/usr/lib/python2.7/logging/__init__.py\", line 329, in getMessage\r\n msg = msg % self.args\r\nTypeError: not all arguments converted during string formatting\r\nLogged from file digitalocean.py, line 111\r\n```\r\nThat section is:\r\n```\r\n Line 110: # is always True at this point, if a non 200 response is returned an error is raised.\r\n Line 111: logger.debug('delete_record: {0}', True)\r\n Line 112: return True\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport logging\n\nimport requests\n\nfrom .base import Provider as BaseProvider\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n subparser.add_argument(\"--auth-token\", help=\"specify token used authenticate to DNS provider\")\n\nclass Provider(BaseProvider):\n\n def __init__(self, options, engine_overrides=None):\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.digitalocean.com/v2')\n\n def authenticate(self):\n\n payload = self._get('/domains/{0}'.format(self.options['domain']))\n self.domain_id = self.options['domain']\n\n def create_record(self, type, name, content):\n record = {\n 'type': type,\n 'name': self._relative_name(name),\n 'data': content,\n\n }\n if type == 'CNAME':\n record['data'] = record['data'].rstrip('.') + '.' # make sure a the data is always a FQDN for CNAMe.\n\n payload = self._post('/domains/{0}/records'.format(self.domain_id), record)\n\n logger.debug('create_record: %s', True)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def list_records(self, type=None, name=None, content=None):\n url = '/domains/{0}/records'.format(self.domain_id)\n records = []\n payload = {}\n\n next = url\n while next is not None:\n payload = self._get(next)\n if 'links' in payload \\\n and 'pages' in payload['links'] \\\n and 'next' in payload['links']['pages']:\n next = payload['links']['pages']['next']\n else:\n next = None\n\n for record in payload['domain_records']:\n processed_record = {\n 'type': record['type'],\n 'name': \"{0}.{1}\".format(record['name'], self.domain_id),\n 'ttl': '',\n 'content': record['data'],\n 'id': record['id']\n }\n records.append(processed_record)\n\n if type:\n records = [record for record in records if record['type'] == type]\n if name:\n records = [record for record in records if record['name'] == self._full_name(name)]\n if content:\n records = [record for record in records if record['content'].lower() == content.lower()]\n\n logger.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def update_record(self, identifier, type=None, name=None, content=None):\n\n data = {}\n if type:\n data['type'] = type\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['data'] = content\n\n payload = self._put('/domains/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n logger.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n if not identifier:\n records = self.list_records(type, name, content)\n logger.debug('records: %s', records)\n if len(records) == 1:\n identifier = records[0]['id']\n else:\n raise Exception('Record identifier could not be found.')\n payload = self._delete('/domains/{0}/records/{1}'.format(self.domain_id, identifier))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n logger.debug('delete_record: {0}', True)\n return True\n\n\n # Helpers\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'Authorization': 'Bearer {0}'.format(self.options.get('auth_token'))\n }\n if not url.startswith(self.api_endpoint):\n url = self.api_endpoint + url\n\n r = requests.request(action, url, params=query_params,\n data=json.dumps(data),\n headers=default_headers)\n r.raise_for_status() # if the request fails for any reason, throw an error.\n if action == 'DELETE':\n return ''\n else:\n return r.json()\n", "path": "lexicon/providers/digitalocean.py"}, {"content": "from __future__ import absolute_import\nfrom __future__ import print_function\n\nimport contextlib\nimport datetime\nimport hmac\nimport json\nimport locale\nimport logging\nfrom hashlib import sha1\n\nimport requests\nfrom builtins import bytes\n\nfrom .base import Provider as BaseProvider\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n subparser.add_argument(\"--auth-username\", help=\"specify username used to authenticate\")\n subparser.add_argument(\"--auth-token\", help=\"specify token used authenticate=\")\n\nclass Provider(BaseProvider):\n\n def __init__(self, options, engine_overrides=None):\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.dnsmadeeasy.com/V2.0')\n\n def authenticate(self):\n\n try:\n payload = self._get('/dns/managed/name', {'domainname': self.options['domain']})\n except requests.exceptions.HTTPError as e:\n if e.response.status_code == 404:\n payload = {}\n else:\n raise e\n\n if not payload or not payload['id']:\n raise Exception('No domain found')\n\n self.domain_id = payload['id']\n\n\n # Create record. If record already exists with the same content, do nothing'\n def create_record(self, type, name, content):\n record = {\n 'type': type,\n 'name': self._relative_name(name),\n 'value': content,\n 'ttl': self.options['ttl']\n }\n payload = {}\n try:\n payload = self._post('/dns/managed/{0}/records/'.format(self.domain_id), record)\n except requests.exceptions.HTTPError as e:\n if e.response.status_code == 400:\n payload = {}\n\n # http 400 is ok here, because the record probably already exists\n logger.debug('create_record: %s', 'name' in payload)\n return 'name' in payload\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def list_records(self, type=None, name=None, content=None):\n filter = {}\n if type:\n filter['type'] = type\n if name:\n filter['recordName'] = self._relative_name(name)\n payload = self._get('/dns/managed/{0}/records'.format(self.domain_id), filter)\n\n records = []\n for record in payload['data']:\n processed_record = {\n 'type': record['type'],\n 'name': '{0}.{1}'.format(record['name'], self.options['domain']),\n 'ttl': record['ttl'],\n 'content': record['value'],\n 'id': record['id']\n }\n\n processed_record = self._clean_TXT_record(processed_record)\n records.append(processed_record)\n\n logger.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def update_record(self, identifier, type=None, name=None, content=None):\n\n data = {\n 'id': identifier,\n 'ttl': self.options['ttl']\n }\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['value'] = content\n if type:\n data['type'] = type\n\n payload = self._put('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n logger.debug('update_record: {0}', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n if not identifier:\n records = self.list_records(type, name, content)\n logger.debug('records: %s', records)\n if len(records) == 1:\n identifier = records[0]['id']\n else:\n raise Exception('Record identifier could not be found.')\n payload = self._delete('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n logger.debug('delete_record: %s', True)\n return True\n\n\n # Helpers\n\n # this method allows you to set the locale when doing datetime string formatting.\n # https://stackoverflow.com/questions/18593661/how-do-i-strftime-a-date-object-in-a-different-locale\n @contextlib.contextmanager\n def setlocale(self, *args, **kw):\n saved = locale.setlocale(locale.LC_ALL)\n #yield locale.setlocale(*args, **kw)\n yield locale.setlocale(locale.LC_TIME, 'en_US.UTF-8')\n locale.setlocale(locale.LC_ALL, saved)\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'x-dnsme-apiKey': self.options['auth_username']\n }\n default_auth = None\n\n # all requests require a HMAC header and timestamp header.\n now = datetime.datetime.utcnow()\n # required format: Sat, 12 Feb 2011 20:59:04 GMT\n with self.setlocale(locale.LC_TIME, 'en_US.utf8'):\n request_date = now.strftime('%a, %d %b %Y %H:%M:%S GMT')\n hashed = hmac.new(bytes(self.options['auth_token'], 'ascii'), \n bytes(request_date, 'ascii'), sha1)\n\n default_headers['x-dnsme-requestDate'] = request_date\n default_headers['x-dnsme-hmac'] = hashed.hexdigest()\n\n r = requests.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n r.raise_for_status() # if the request fails for any reason, throw an error.\n\n # PUT and DELETE actions dont return valid json.\n if action == 'DELETE' or action == 'PUT':\n return r.text\n return r.json()\n", "path": "lexicon/providers/dnsmadeeasy.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\nimport logging\n\nimport requests\n\nfrom .base import Provider as BaseProvider\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n subparser.add_argument(\"--auth-token\", help=\"specify token used authenticate to DNS provider\")\n\nclass Provider(BaseProvider):\n\n def __init__(self, options, engine_overrides=None):\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.digitalocean.com/v2')\n\n def authenticate(self):\n\n payload = self._get('/domains/{0}'.format(self.options['domain']))\n self.domain_id = self.options['domain']\n\n def create_record(self, type, name, content):\n record = {\n 'type': type,\n 'name': self._relative_name(name),\n 'data': content,\n\n }\n if type == 'CNAME':\n record['data'] = record['data'].rstrip('.') + '.' # make sure a the data is always a FQDN for CNAMe.\n\n payload = self._post('/domains/{0}/records'.format(self.domain_id), record)\n\n logger.debug('create_record: %s', True)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def list_records(self, type=None, name=None, content=None):\n url = '/domains/{0}/records'.format(self.domain_id)\n records = []\n payload = {}\n\n next = url\n while next is not None:\n payload = self._get(next)\n if 'links' in payload \\\n and 'pages' in payload['links'] \\\n and 'next' in payload['links']['pages']:\n next = payload['links']['pages']['next']\n else:\n next = None\n\n for record in payload['domain_records']:\n processed_record = {\n 'type': record['type'],\n 'name': \"{0}.{1}\".format(record['name'], self.domain_id),\n 'ttl': '',\n 'content': record['data'],\n 'id': record['id']\n }\n records.append(processed_record)\n\n if type:\n records = [record for record in records if record['type'] == type]\n if name:\n records = [record for record in records if record['name'] == self._full_name(name)]\n if content:\n records = [record for record in records if record['content'].lower() == content.lower()]\n\n logger.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def update_record(self, identifier, type=None, name=None, content=None):\n\n data = {}\n if type:\n data['type'] = type\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['data'] = content\n\n payload = self._put('/domains/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n logger.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n if not identifier:\n records = self.list_records(type, name, content)\n logger.debug('records: %s', records)\n if len(records) == 1:\n identifier = records[0]['id']\n else:\n raise Exception('Record identifier could not be found.')\n payload = self._delete('/domains/{0}/records/{1}'.format(self.domain_id, identifier))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n logger.debug('delete_record: %s', True)\n return True\n\n\n # Helpers\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'Authorization': 'Bearer {0}'.format(self.options.get('auth_token'))\n }\n if not url.startswith(self.api_endpoint):\n url = self.api_endpoint + url\n\n r = requests.request(action, url, params=query_params,\n data=json.dumps(data),\n headers=default_headers)\n r.raise_for_status() # if the request fails for any reason, throw an error.\n if action == 'DELETE':\n return ''\n else:\n return r.json()\n", "path": "lexicon/providers/digitalocean.py"}, {"content": "from __future__ import absolute_import\nfrom __future__ import print_function\n\nimport contextlib\nimport datetime\nimport hmac\nimport json\nimport locale\nimport logging\nfrom hashlib import sha1\n\nimport requests\nfrom builtins import bytes\n\nfrom .base import Provider as BaseProvider\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n subparser.add_argument(\"--auth-username\", help=\"specify username used to authenticate\")\n subparser.add_argument(\"--auth-token\", help=\"specify token used authenticate=\")\n\nclass Provider(BaseProvider):\n\n def __init__(self, options, engine_overrides=None):\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.dnsmadeeasy.com/V2.0')\n\n def authenticate(self):\n\n try:\n payload = self._get('/dns/managed/name', {'domainname': self.options['domain']})\n except requests.exceptions.HTTPError as e:\n if e.response.status_code == 404:\n payload = {}\n else:\n raise e\n\n if not payload or not payload['id']:\n raise Exception('No domain found')\n\n self.domain_id = payload['id']\n\n\n # Create record. If record already exists with the same content, do nothing'\n def create_record(self, type, name, content):\n record = {\n 'type': type,\n 'name': self._relative_name(name),\n 'value': content,\n 'ttl': self.options['ttl']\n }\n payload = {}\n try:\n payload = self._post('/dns/managed/{0}/records/'.format(self.domain_id), record)\n except requests.exceptions.HTTPError as e:\n if e.response.status_code == 400:\n payload = {}\n\n # http 400 is ok here, because the record probably already exists\n logger.debug('create_record: %s', 'name' in payload)\n return 'name' in payload\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def list_records(self, type=None, name=None, content=None):\n filter = {}\n if type:\n filter['type'] = type\n if name:\n filter['recordName'] = self._relative_name(name)\n payload = self._get('/dns/managed/{0}/records'.format(self.domain_id), filter)\n\n records = []\n for record in payload['data']:\n processed_record = {\n 'type': record['type'],\n 'name': '{0}.{1}'.format(record['name'], self.options['domain']),\n 'ttl': record['ttl'],\n 'content': record['value'],\n 'id': record['id']\n }\n\n processed_record = self._clean_TXT_record(processed_record)\n records.append(processed_record)\n\n logger.debug('list_records: %s', records)\n return records\n\n # Create or update a record.\n def update_record(self, identifier, type=None, name=None, content=None):\n\n data = {\n 'id': identifier,\n 'ttl': self.options['ttl']\n }\n\n if name:\n data['name'] = self._relative_name(name)\n if content:\n data['value'] = content\n if type:\n data['type'] = type\n\n payload = self._put('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier), data)\n\n logger.debug('update_record: %s', True)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n if not identifier:\n records = self.list_records(type, name, content)\n logger.debug('records: %s', records)\n if len(records) == 1:\n identifier = records[0]['id']\n else:\n raise Exception('Record identifier could not be found.')\n payload = self._delete('/dns/managed/{0}/records/{1}'.format(self.domain_id, identifier))\n\n # is always True at this point, if a non 200 response is returned an error is raised.\n logger.debug('delete_record: %s', True)\n return True\n\n\n # Helpers\n\n # this method allows you to set the locale when doing datetime string formatting.\n # https://stackoverflow.com/questions/18593661/how-do-i-strftime-a-date-object-in-a-different-locale\n @contextlib.contextmanager\n def setlocale(self, *args, **kw):\n saved = locale.setlocale(locale.LC_ALL)\n #yield locale.setlocale(*args, **kw)\n yield locale.setlocale(locale.LC_TIME, 'en_US.UTF-8')\n locale.setlocale(locale.LC_ALL, saved)\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n default_headers = {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json',\n 'x-dnsme-apiKey': self.options['auth_username']\n }\n default_auth = None\n\n # all requests require a HMAC header and timestamp header.\n now = datetime.datetime.utcnow()\n # required format: Sat, 12 Feb 2011 20:59:04 GMT\n with self.setlocale(locale.LC_TIME, 'en_US.utf8'):\n request_date = now.strftime('%a, %d %b %Y %H:%M:%S GMT')\n hashed = hmac.new(bytes(self.options['auth_token'], 'ascii'), \n bytes(request_date, 'ascii'), sha1)\n\n default_headers['x-dnsme-requestDate'] = request_date\n default_headers['x-dnsme-hmac'] = hashed.hexdigest()\n\n r = requests.request(action, self.api_endpoint + url, params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=default_auth)\n r.raise_for_status() # if the request fails for any reason, throw an error.\n\n # PUT and DELETE actions dont return valid json.\n if action == 'DELETE' or action == 'PUT':\n return r.text\n return r.json()\n", "path": "lexicon/providers/dnsmadeeasy.py"}]} | 3,790 | 271 |
gh_patches_debug_29691 | rasdani/github-patches | git_diff | litestar-org__litestar-1838 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/_openapi/responses.py`
Content:
```
1 from __future__ import annotations
2
3 import re
4 from copy import copy
5 from dataclasses import asdict
6 from http import HTTPStatus
7 from inspect import Signature
8 from operator import attrgetter
9 from typing import TYPE_CHECKING, Any, Iterator
10
11 from litestar._openapi.schema_generation import create_schema
12 from litestar._signature.field import SignatureField
13 from litestar.enums import MediaType
14 from litestar.exceptions import HTTPException, ValidationException
15 from litestar.openapi.spec import OpenAPIResponse
16 from litestar.openapi.spec.enums import OpenAPIFormat, OpenAPIType
17 from litestar.openapi.spec.header import OpenAPIHeader
18 from litestar.openapi.spec.media_type import OpenAPIMediaType
19 from litestar.openapi.spec.schema import Schema
20 from litestar.response import (
21 File,
22 Redirect,
23 Stream,
24 Template,
25 )
26 from litestar.response import (
27 Response as LitestarResponse,
28 )
29 from litestar.response.base import ASGIResponse
30 from litestar.types.builtin_types import NoneType
31 from litestar.utils import get_enum_string_value, get_name
32
33 if TYPE_CHECKING:
34 from litestar.datastructures.cookie import Cookie
35 from litestar.handlers.http_handlers import HTTPRouteHandler
36 from litestar.openapi.spec.responses import Responses
37 from litestar.plugins import OpenAPISchemaPluginProtocol
38
39
40 __all__ = (
41 "create_additional_responses",
42 "create_cookie_schema",
43 "create_error_responses",
44 "create_responses",
45 "create_success_response",
46 )
47
48 CAPITAL_LETTERS_PATTERN = re.compile(r"(?=[A-Z])")
49
50
51 def pascal_case_to_text(string: str) -> str:
52 """Given a 'PascalCased' string, return its split form- 'Pascal Cased'."""
53 return " ".join(re.split(CAPITAL_LETTERS_PATTERN, string)).strip()
54
55
56 def create_cookie_schema(cookie: Cookie) -> Schema:
57 """Given a Cookie instance, return its corresponding OpenAPI schema.
58
59 Args:
60 cookie: Cookie
61
62 Returns:
63 Schema
64 """
65 cookie_copy = copy(cookie)
66 cookie_copy.value = "<string>"
67 value = cookie_copy.to_header(header="")
68 return Schema(description=cookie.description or "", example=value)
69
70
71 def create_success_response( # noqa: C901
72 route_handler: HTTPRouteHandler,
73 generate_examples: bool,
74 plugins: list[OpenAPISchemaPluginProtocol],
75 schemas: dict[str, Schema],
76 ) -> OpenAPIResponse:
77 """Create the schema for a success response."""
78 return_type = route_handler.parsed_fn_signature.return_type
79 return_annotation = return_type.annotation
80 default_descriptions: dict[Any, str] = {
81 Stream: "Stream Response",
82 Redirect: "Redirect Response",
83 File: "File Download",
84 }
85 description = (
86 route_handler.response_description
87 or default_descriptions.get(return_annotation)
88 or HTTPStatus(route_handler.status_code).description
89 )
90
91 if return_annotation is not Signature.empty and not return_type.is_subclass_of(
92 (NoneType, File, Redirect, Stream, ASGIResponse)
93 ):
94 if return_annotation is Template:
95 return_annotation = str
96 route_handler.media_type = get_enum_string_value(MediaType.HTML)
97 elif return_type.is_subclass_of(LitestarResponse):
98 return_annotation = return_type.inner_types[0].annotation if return_type.inner_types else Any
99 if not route_handler.media_type:
100 route_handler.media_type = get_enum_string_value(MediaType.JSON)
101
102 if dto := route_handler.resolve_return_dto():
103 result = dto.create_openapi_schema("return", str(route_handler), generate_examples, schemas, False)
104 else:
105 result = create_schema(
106 field=SignatureField.create(field_type=return_annotation),
107 generate_examples=generate_examples,
108 plugins=plugins,
109 schemas=schemas,
110 prefer_alias=False,
111 )
112
113 schema = result if isinstance(result, Schema) else schemas[result.value]
114
115 schema.content_encoding = route_handler.content_encoding
116 schema.content_media_type = route_handler.content_media_type
117
118 response = OpenAPIResponse(
119 content={route_handler.media_type: OpenAPIMediaType(schema=result)},
120 description=description,
121 )
122
123 elif return_type.is_subclass_of(Redirect):
124 response = OpenAPIResponse(
125 content=None,
126 description=description,
127 headers={
128 "location": OpenAPIHeader(
129 schema=Schema(type=OpenAPIType.STRING), description="target path for the redirect"
130 )
131 },
132 )
133
134 elif return_type.is_subclass_of((File, Stream)):
135 response = OpenAPIResponse(
136 content={
137 route_handler.media_type: OpenAPIMediaType(
138 schema=Schema(
139 type=OpenAPIType.STRING,
140 content_encoding=route_handler.content_encoding or "application/octet-stream",
141 content_media_type=route_handler.content_media_type,
142 ),
143 )
144 },
145 description=description,
146 headers={
147 "content-length": OpenAPIHeader(
148 schema=Schema(type=OpenAPIType.STRING), description="File size in bytes"
149 ),
150 "last-modified": OpenAPIHeader(
151 schema=Schema(type=OpenAPIType.STRING, format=OpenAPIFormat.DATE_TIME),
152 description="Last modified data-time in RFC 2822 format",
153 ),
154 "etag": OpenAPIHeader(schema=Schema(type=OpenAPIType.STRING), description="Entity tag"),
155 },
156 )
157
158 else:
159 response = OpenAPIResponse(
160 content=None,
161 description=description,
162 )
163
164 if response.headers is None:
165 response.headers = {}
166
167 for response_header in route_handler.resolve_response_headers():
168 header = OpenAPIHeader()
169 for attribute_name, attribute_value in ((k, v) for k, v in asdict(response_header).items() if v is not None):
170 if attribute_name == "value":
171 header.schema = create_schema(
172 field=SignatureField.create(field_type=type(attribute_value)),
173 generate_examples=False,
174 plugins=plugins,
175 schemas=schemas,
176 prefer_alias=False,
177 )
178
179 elif attribute_name != "documentation_only":
180 setattr(header, attribute_name, attribute_value)
181
182 response.headers[response_header.name] = header
183
184 if cookies := route_handler.resolve_response_cookies():
185 response.headers["Set-Cookie"] = OpenAPIHeader(
186 schema=Schema(
187 all_of=[create_cookie_schema(cookie=cookie) for cookie in sorted(cookies, key=attrgetter("key"))]
188 )
189 )
190
191 return response
192
193
194 def create_error_responses(exceptions: list[type[HTTPException]]) -> Iterator[tuple[str, OpenAPIResponse]]:
195 """Create the schema for error responses, if any."""
196 grouped_exceptions: dict[int, list[type[HTTPException]]] = {}
197 for exc in exceptions:
198 if not grouped_exceptions.get(exc.status_code):
199 grouped_exceptions[exc.status_code] = []
200 grouped_exceptions[exc.status_code].append(exc)
201 for status_code, exception_group in grouped_exceptions.items():
202 exceptions_schemas = [
203 Schema(
204 type=OpenAPIType.OBJECT,
205 required=["detail", "status_code"],
206 properties={
207 "status_code": Schema(type=OpenAPIType.INTEGER),
208 "detail": Schema(type=OpenAPIType.STRING),
209 "extra": Schema(
210 type=[OpenAPIType.NULL, OpenAPIType.OBJECT, OpenAPIType.ARRAY], additional_properties=Schema()
211 ),
212 },
213 description=pascal_case_to_text(get_name(exc)),
214 examples=[{"status_code": status_code, "detail": HTTPStatus(status_code).phrase, "extra": {}}],
215 )
216 for exc in exception_group
217 ]
218 if len(exceptions_schemas) > 1: # noqa: SIM108
219 schema = Schema(one_of=exceptions_schemas)
220 else:
221 schema = exceptions_schemas[0]
222 yield str(status_code), OpenAPIResponse(
223 description=HTTPStatus(status_code).description,
224 content={MediaType.JSON: OpenAPIMediaType(schema=schema)},
225 )
226
227
228 def create_additional_responses(
229 route_handler: HTTPRouteHandler,
230 plugins: list[OpenAPISchemaPluginProtocol],
231 schemas: dict[str, Schema],
232 ) -> Iterator[tuple[str, OpenAPIResponse]]:
233 """Create the schema for additional responses, if any."""
234 if not route_handler.responses:
235 return
236
237 for status_code, additional_response in route_handler.responses.items():
238 schema = create_schema(
239 field=SignatureField.create(field_type=additional_response.data_container),
240 generate_examples=additional_response.generate_examples,
241 plugins=plugins,
242 schemas=schemas,
243 prefer_alias=False,
244 )
245 yield str(status_code), OpenAPIResponse(
246 description=additional_response.description,
247 content={additional_response.media_type: OpenAPIMediaType(schema=schema)},
248 )
249
250
251 def create_responses(
252 route_handler: HTTPRouteHandler,
253 raises_validation_error: bool,
254 generate_examples: bool,
255 plugins: list[OpenAPISchemaPluginProtocol],
256 schemas: dict[str, Schema],
257 ) -> Responses | None:
258 """Create a Response model embedded in a `Responses` dictionary for the given RouteHandler or return None."""
259
260 responses: Responses = {
261 str(route_handler.status_code): create_success_response(
262 generate_examples=generate_examples, plugins=plugins, route_handler=route_handler, schemas=schemas
263 ),
264 }
265
266 exceptions = list(route_handler.raises or [])
267 if raises_validation_error and ValidationException not in exceptions:
268 exceptions.append(ValidationException)
269 for status_code, response in create_error_responses(exceptions=exceptions):
270 responses[status_code] = response
271
272 for status_code, response in create_additional_responses(
273 route_handler=route_handler, plugins=plugins, schemas=schemas
274 ):
275 responses[status_code] = response
276
277 return responses or None
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/litestar/_openapi/responses.py b/litestar/_openapi/responses.py
--- a/litestar/_openapi/responses.py
+++ b/litestar/_openapi/responses.py
@@ -91,13 +91,13 @@
if return_annotation is not Signature.empty and not return_type.is_subclass_of(
(NoneType, File, Redirect, Stream, ASGIResponse)
):
+ media_type = route_handler.media_type
if return_annotation is Template:
return_annotation = str
- route_handler.media_type = get_enum_string_value(MediaType.HTML)
+ media_type = media_type or MediaType.HTML
elif return_type.is_subclass_of(LitestarResponse):
return_annotation = return_type.inner_types[0].annotation if return_type.inner_types else Any
- if not route_handler.media_type:
- route_handler.media_type = get_enum_string_value(MediaType.JSON)
+ media_type = media_type or MediaType.JSON
if dto := route_handler.resolve_return_dto():
result = dto.create_openapi_schema("return", str(route_handler), generate_examples, schemas, False)
@@ -116,8 +116,7 @@
schema.content_media_type = route_handler.content_media_type
response = OpenAPIResponse(
- content={route_handler.media_type: OpenAPIMediaType(schema=result)},
- description=description,
+ content={get_enum_string_value(media_type): OpenAPIMediaType(schema=result)}, description=description
)
elif return_type.is_subclass_of(Redirect):
| {"golden_diff": "diff --git a/litestar/_openapi/responses.py b/litestar/_openapi/responses.py\n--- a/litestar/_openapi/responses.py\n+++ b/litestar/_openapi/responses.py\n@@ -91,13 +91,13 @@\n if return_annotation is not Signature.empty and not return_type.is_subclass_of(\n (NoneType, File, Redirect, Stream, ASGIResponse)\n ):\n+ media_type = route_handler.media_type\n if return_annotation is Template:\n return_annotation = str\n- route_handler.media_type = get_enum_string_value(MediaType.HTML)\n+ media_type = media_type or MediaType.HTML\n elif return_type.is_subclass_of(LitestarResponse):\n return_annotation = return_type.inner_types[0].annotation if return_type.inner_types else Any\n- if not route_handler.media_type:\n- route_handler.media_type = get_enum_string_value(MediaType.JSON)\n+ media_type = media_type or MediaType.JSON\n \n if dto := route_handler.resolve_return_dto():\n result = dto.create_openapi_schema(\"return\", str(route_handler), generate_examples, schemas, False)\n@@ -116,8 +116,7 @@\n schema.content_media_type = route_handler.content_media_type\n \n response = OpenAPIResponse(\n- content={route_handler.media_type: OpenAPIMediaType(schema=result)},\n- description=description,\n+ content={get_enum_string_value(media_type): OpenAPIMediaType(schema=result)}, description=description\n )\n \n elif return_type.is_subclass_of(Redirect):\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom copy import copy\nfrom dataclasses import asdict\nfrom http import HTTPStatus\nfrom inspect import Signature\nfrom operator import attrgetter\nfrom typing import TYPE_CHECKING, Any, Iterator\n\nfrom litestar._openapi.schema_generation import create_schema\nfrom litestar._signature.field import SignatureField\nfrom litestar.enums import MediaType\nfrom litestar.exceptions import HTTPException, ValidationException\nfrom litestar.openapi.spec import OpenAPIResponse\nfrom litestar.openapi.spec.enums import OpenAPIFormat, OpenAPIType\nfrom litestar.openapi.spec.header import OpenAPIHeader\nfrom litestar.openapi.spec.media_type import OpenAPIMediaType\nfrom litestar.openapi.spec.schema import Schema\nfrom litestar.response import (\n File,\n Redirect,\n Stream,\n Template,\n)\nfrom litestar.response import (\n Response as LitestarResponse,\n)\nfrom litestar.response.base import ASGIResponse\nfrom litestar.types.builtin_types import NoneType\nfrom litestar.utils import get_enum_string_value, get_name\n\nif TYPE_CHECKING:\n from litestar.datastructures.cookie import Cookie\n from litestar.handlers.http_handlers import HTTPRouteHandler\n from litestar.openapi.spec.responses import Responses\n from litestar.plugins import OpenAPISchemaPluginProtocol\n\n\n__all__ = (\n \"create_additional_responses\",\n \"create_cookie_schema\",\n \"create_error_responses\",\n \"create_responses\",\n \"create_success_response\",\n)\n\nCAPITAL_LETTERS_PATTERN = re.compile(r\"(?=[A-Z])\")\n\n\ndef pascal_case_to_text(string: str) -> str:\n \"\"\"Given a 'PascalCased' string, return its split form- 'Pascal Cased'.\"\"\"\n return \" \".join(re.split(CAPITAL_LETTERS_PATTERN, string)).strip()\n\n\ndef create_cookie_schema(cookie: Cookie) -> Schema:\n \"\"\"Given a Cookie instance, return its corresponding OpenAPI schema.\n\n Args:\n cookie: Cookie\n\n Returns:\n Schema\n \"\"\"\n cookie_copy = copy(cookie)\n cookie_copy.value = \"<string>\"\n value = cookie_copy.to_header(header=\"\")\n return Schema(description=cookie.description or \"\", example=value)\n\n\ndef create_success_response( # noqa: C901\n route_handler: HTTPRouteHandler,\n generate_examples: bool,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> OpenAPIResponse:\n \"\"\"Create the schema for a success response.\"\"\"\n return_type = route_handler.parsed_fn_signature.return_type\n return_annotation = return_type.annotation\n default_descriptions: dict[Any, str] = {\n Stream: \"Stream Response\",\n Redirect: \"Redirect Response\",\n File: \"File Download\",\n }\n description = (\n route_handler.response_description\n or default_descriptions.get(return_annotation)\n or HTTPStatus(route_handler.status_code).description\n )\n\n if return_annotation is not Signature.empty and not return_type.is_subclass_of(\n (NoneType, File, Redirect, Stream, ASGIResponse)\n ):\n if return_annotation is Template:\n return_annotation = str\n route_handler.media_type = get_enum_string_value(MediaType.HTML)\n elif return_type.is_subclass_of(LitestarResponse):\n return_annotation = return_type.inner_types[0].annotation if return_type.inner_types else Any\n if not route_handler.media_type:\n route_handler.media_type = get_enum_string_value(MediaType.JSON)\n\n if dto := route_handler.resolve_return_dto():\n result = dto.create_openapi_schema(\"return\", str(route_handler), generate_examples, schemas, False)\n else:\n result = create_schema(\n field=SignatureField.create(field_type=return_annotation),\n generate_examples=generate_examples,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n\n schema = result if isinstance(result, Schema) else schemas[result.value]\n\n schema.content_encoding = route_handler.content_encoding\n schema.content_media_type = route_handler.content_media_type\n\n response = OpenAPIResponse(\n content={route_handler.media_type: OpenAPIMediaType(schema=result)},\n description=description,\n )\n\n elif return_type.is_subclass_of(Redirect):\n response = OpenAPIResponse(\n content=None,\n description=description,\n headers={\n \"location\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING), description=\"target path for the redirect\"\n )\n },\n )\n\n elif return_type.is_subclass_of((File, Stream)):\n response = OpenAPIResponse(\n content={\n route_handler.media_type: OpenAPIMediaType(\n schema=Schema(\n type=OpenAPIType.STRING,\n content_encoding=route_handler.content_encoding or \"application/octet-stream\",\n content_media_type=route_handler.content_media_type,\n ),\n )\n },\n description=description,\n headers={\n \"content-length\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING), description=\"File size in bytes\"\n ),\n \"last-modified\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING, format=OpenAPIFormat.DATE_TIME),\n description=\"Last modified data-time in RFC 2822 format\",\n ),\n \"etag\": OpenAPIHeader(schema=Schema(type=OpenAPIType.STRING), description=\"Entity tag\"),\n },\n )\n\n else:\n response = OpenAPIResponse(\n content=None,\n description=description,\n )\n\n if response.headers is None:\n response.headers = {}\n\n for response_header in route_handler.resolve_response_headers():\n header = OpenAPIHeader()\n for attribute_name, attribute_value in ((k, v) for k, v in asdict(response_header).items() if v is not None):\n if attribute_name == \"value\":\n header.schema = create_schema(\n field=SignatureField.create(field_type=type(attribute_value)),\n generate_examples=False,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n\n elif attribute_name != \"documentation_only\":\n setattr(header, attribute_name, attribute_value)\n\n response.headers[response_header.name] = header\n\n if cookies := route_handler.resolve_response_cookies():\n response.headers[\"Set-Cookie\"] = OpenAPIHeader(\n schema=Schema(\n all_of=[create_cookie_schema(cookie=cookie) for cookie in sorted(cookies, key=attrgetter(\"key\"))]\n )\n )\n\n return response\n\n\ndef create_error_responses(exceptions: list[type[HTTPException]]) -> Iterator[tuple[str, OpenAPIResponse]]:\n \"\"\"Create the schema for error responses, if any.\"\"\"\n grouped_exceptions: dict[int, list[type[HTTPException]]] = {}\n for exc in exceptions:\n if not grouped_exceptions.get(exc.status_code):\n grouped_exceptions[exc.status_code] = []\n grouped_exceptions[exc.status_code].append(exc)\n for status_code, exception_group in grouped_exceptions.items():\n exceptions_schemas = [\n Schema(\n type=OpenAPIType.OBJECT,\n required=[\"detail\", \"status_code\"],\n properties={\n \"status_code\": Schema(type=OpenAPIType.INTEGER),\n \"detail\": Schema(type=OpenAPIType.STRING),\n \"extra\": Schema(\n type=[OpenAPIType.NULL, OpenAPIType.OBJECT, OpenAPIType.ARRAY], additional_properties=Schema()\n ),\n },\n description=pascal_case_to_text(get_name(exc)),\n examples=[{\"status_code\": status_code, \"detail\": HTTPStatus(status_code).phrase, \"extra\": {}}],\n )\n for exc in exception_group\n ]\n if len(exceptions_schemas) > 1: # noqa: SIM108\n schema = Schema(one_of=exceptions_schemas)\n else:\n schema = exceptions_schemas[0]\n yield str(status_code), OpenAPIResponse(\n description=HTTPStatus(status_code).description,\n content={MediaType.JSON: OpenAPIMediaType(schema=schema)},\n )\n\n\ndef create_additional_responses(\n route_handler: HTTPRouteHandler,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> Iterator[tuple[str, OpenAPIResponse]]:\n \"\"\"Create the schema for additional responses, if any.\"\"\"\n if not route_handler.responses:\n return\n\n for status_code, additional_response in route_handler.responses.items():\n schema = create_schema(\n field=SignatureField.create(field_type=additional_response.data_container),\n generate_examples=additional_response.generate_examples,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n yield str(status_code), OpenAPIResponse(\n description=additional_response.description,\n content={additional_response.media_type: OpenAPIMediaType(schema=schema)},\n )\n\n\ndef create_responses(\n route_handler: HTTPRouteHandler,\n raises_validation_error: bool,\n generate_examples: bool,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> Responses | None:\n \"\"\"Create a Response model embedded in a `Responses` dictionary for the given RouteHandler or return None.\"\"\"\n\n responses: Responses = {\n str(route_handler.status_code): create_success_response(\n generate_examples=generate_examples, plugins=plugins, route_handler=route_handler, schemas=schemas\n ),\n }\n\n exceptions = list(route_handler.raises or [])\n if raises_validation_error and ValidationException not in exceptions:\n exceptions.append(ValidationException)\n for status_code, response in create_error_responses(exceptions=exceptions):\n responses[status_code] = response\n\n for status_code, response in create_additional_responses(\n route_handler=route_handler, plugins=plugins, schemas=schemas\n ):\n responses[status_code] = response\n\n return responses or None\n", "path": "litestar/_openapi/responses.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport re\nfrom copy import copy\nfrom dataclasses import asdict\nfrom http import HTTPStatus\nfrom inspect import Signature\nfrom operator import attrgetter\nfrom typing import TYPE_CHECKING, Any, Iterator\n\nfrom litestar._openapi.schema_generation import create_schema\nfrom litestar._signature.field import SignatureField\nfrom litestar.enums import MediaType\nfrom litestar.exceptions import HTTPException, ValidationException\nfrom litestar.openapi.spec import OpenAPIResponse\nfrom litestar.openapi.spec.enums import OpenAPIFormat, OpenAPIType\nfrom litestar.openapi.spec.header import OpenAPIHeader\nfrom litestar.openapi.spec.media_type import OpenAPIMediaType\nfrom litestar.openapi.spec.schema import Schema\nfrom litestar.response import (\n File,\n Redirect,\n Stream,\n Template,\n)\nfrom litestar.response import (\n Response as LitestarResponse,\n)\nfrom litestar.response.base import ASGIResponse\nfrom litestar.types.builtin_types import NoneType\nfrom litestar.utils import get_enum_string_value, get_name\n\nif TYPE_CHECKING:\n from litestar.datastructures.cookie import Cookie\n from litestar.handlers.http_handlers import HTTPRouteHandler\n from litestar.openapi.spec.responses import Responses\n from litestar.plugins import OpenAPISchemaPluginProtocol\n\n\n__all__ = (\n \"create_additional_responses\",\n \"create_cookie_schema\",\n \"create_error_responses\",\n \"create_responses\",\n \"create_success_response\",\n)\n\nCAPITAL_LETTERS_PATTERN = re.compile(r\"(?=[A-Z])\")\n\n\ndef pascal_case_to_text(string: str) -> str:\n \"\"\"Given a 'PascalCased' string, return its split form- 'Pascal Cased'.\"\"\"\n return \" \".join(re.split(CAPITAL_LETTERS_PATTERN, string)).strip()\n\n\ndef create_cookie_schema(cookie: Cookie) -> Schema:\n \"\"\"Given a Cookie instance, return its corresponding OpenAPI schema.\n\n Args:\n cookie: Cookie\n\n Returns:\n Schema\n \"\"\"\n cookie_copy = copy(cookie)\n cookie_copy.value = \"<string>\"\n value = cookie_copy.to_header(header=\"\")\n return Schema(description=cookie.description or \"\", example=value)\n\n\ndef create_success_response( # noqa: C901\n route_handler: HTTPRouteHandler,\n generate_examples: bool,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> OpenAPIResponse:\n \"\"\"Create the schema for a success response.\"\"\"\n return_type = route_handler.parsed_fn_signature.return_type\n return_annotation = return_type.annotation\n default_descriptions: dict[Any, str] = {\n Stream: \"Stream Response\",\n Redirect: \"Redirect Response\",\n File: \"File Download\",\n }\n description = (\n route_handler.response_description\n or default_descriptions.get(return_annotation)\n or HTTPStatus(route_handler.status_code).description\n )\n\n if return_annotation is not Signature.empty and not return_type.is_subclass_of(\n (NoneType, File, Redirect, Stream, ASGIResponse)\n ):\n media_type = route_handler.media_type\n if return_annotation is Template:\n return_annotation = str\n media_type = media_type or MediaType.HTML\n elif return_type.is_subclass_of(LitestarResponse):\n return_annotation = return_type.inner_types[0].annotation if return_type.inner_types else Any\n media_type = media_type or MediaType.JSON\n\n if dto := route_handler.resolve_return_dto():\n result = dto.create_openapi_schema(\"return\", str(route_handler), generate_examples, schemas, False)\n else:\n result = create_schema(\n field=SignatureField.create(field_type=return_annotation),\n generate_examples=generate_examples,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n\n schema = result if isinstance(result, Schema) else schemas[result.value]\n\n schema.content_encoding = route_handler.content_encoding\n schema.content_media_type = route_handler.content_media_type\n\n response = OpenAPIResponse(\n content={get_enum_string_value(media_type): OpenAPIMediaType(schema=result)}, description=description\n )\n\n elif return_type.is_subclass_of(Redirect):\n response = OpenAPIResponse(\n content=None,\n description=description,\n headers={\n \"location\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING), description=\"target path for the redirect\"\n )\n },\n )\n\n elif return_type.is_subclass_of((File, Stream)):\n response = OpenAPIResponse(\n content={\n route_handler.media_type: OpenAPIMediaType(\n schema=Schema(\n type=OpenAPIType.STRING,\n content_encoding=route_handler.content_encoding or \"application/octet-stream\",\n content_media_type=route_handler.content_media_type,\n ),\n )\n },\n description=description,\n headers={\n \"content-length\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING), description=\"File size in bytes\"\n ),\n \"last-modified\": OpenAPIHeader(\n schema=Schema(type=OpenAPIType.STRING, format=OpenAPIFormat.DATE_TIME),\n description=\"Last modified data-time in RFC 2822 format\",\n ),\n \"etag\": OpenAPIHeader(schema=Schema(type=OpenAPIType.STRING), description=\"Entity tag\"),\n },\n )\n\n else:\n response = OpenAPIResponse(\n content=None,\n description=description,\n )\n\n if response.headers is None:\n response.headers = {}\n\n for response_header in route_handler.resolve_response_headers():\n header = OpenAPIHeader()\n for attribute_name, attribute_value in ((k, v) for k, v in asdict(response_header).items() if v is not None):\n if attribute_name == \"value\":\n header.schema = create_schema(\n field=SignatureField.create(field_type=type(attribute_value)),\n generate_examples=False,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n\n elif attribute_name != \"documentation_only\":\n setattr(header, attribute_name, attribute_value)\n\n response.headers[response_header.name] = header\n\n if cookies := route_handler.resolve_response_cookies():\n response.headers[\"Set-Cookie\"] = OpenAPIHeader(\n schema=Schema(\n all_of=[create_cookie_schema(cookie=cookie) for cookie in sorted(cookies, key=attrgetter(\"key\"))]\n )\n )\n\n return response\n\n\ndef create_error_responses(exceptions: list[type[HTTPException]]) -> Iterator[tuple[str, OpenAPIResponse]]:\n \"\"\"Create the schema for error responses, if any.\"\"\"\n grouped_exceptions: dict[int, list[type[HTTPException]]] = {}\n for exc in exceptions:\n if not grouped_exceptions.get(exc.status_code):\n grouped_exceptions[exc.status_code] = []\n grouped_exceptions[exc.status_code].append(exc)\n for status_code, exception_group in grouped_exceptions.items():\n exceptions_schemas = [\n Schema(\n type=OpenAPIType.OBJECT,\n required=[\"detail\", \"status_code\"],\n properties={\n \"status_code\": Schema(type=OpenAPIType.INTEGER),\n \"detail\": Schema(type=OpenAPIType.STRING),\n \"extra\": Schema(\n type=[OpenAPIType.NULL, OpenAPIType.OBJECT, OpenAPIType.ARRAY], additional_properties=Schema()\n ),\n },\n description=pascal_case_to_text(get_name(exc)),\n examples=[{\"status_code\": status_code, \"detail\": HTTPStatus(status_code).phrase, \"extra\": {}}],\n )\n for exc in exception_group\n ]\n if len(exceptions_schemas) > 1: # noqa: SIM108\n schema = Schema(one_of=exceptions_schemas)\n else:\n schema = exceptions_schemas[0]\n yield str(status_code), OpenAPIResponse(\n description=HTTPStatus(status_code).description,\n content={MediaType.JSON: OpenAPIMediaType(schema=schema)},\n )\n\n\ndef create_additional_responses(\n route_handler: HTTPRouteHandler,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> Iterator[tuple[str, OpenAPIResponse]]:\n \"\"\"Create the schema for additional responses, if any.\"\"\"\n if not route_handler.responses:\n return\n\n for status_code, additional_response in route_handler.responses.items():\n schema = create_schema(\n field=SignatureField.create(field_type=additional_response.data_container),\n generate_examples=additional_response.generate_examples,\n plugins=plugins,\n schemas=schemas,\n prefer_alias=False,\n )\n yield str(status_code), OpenAPIResponse(\n description=additional_response.description,\n content={additional_response.media_type: OpenAPIMediaType(schema=schema)},\n )\n\n\ndef create_responses(\n route_handler: HTTPRouteHandler,\n raises_validation_error: bool,\n generate_examples: bool,\n plugins: list[OpenAPISchemaPluginProtocol],\n schemas: dict[str, Schema],\n) -> Responses | None:\n \"\"\"Create a Response model embedded in a `Responses` dictionary for the given RouteHandler or return None.\"\"\"\n\n responses: Responses = {\n str(route_handler.status_code): create_success_response(\n generate_examples=generate_examples, plugins=plugins, route_handler=route_handler, schemas=schemas\n ),\n }\n\n exceptions = list(route_handler.raises or [])\n if raises_validation_error and ValidationException not in exceptions:\n exceptions.append(ValidationException)\n for status_code, response in create_error_responses(exceptions=exceptions):\n responses[status_code] = response\n\n for status_code, response in create_additional_responses(\n route_handler=route_handler, plugins=plugins, schemas=schemas\n ):\n responses[status_code] = response\n\n return responses or None\n", "path": "litestar/_openapi/responses.py"}]} | 3,221 | 338 |
gh_patches_debug_23201 | rasdani/github-patches | git_diff | matrix-org__synapse-11530 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Synapse is overly accepting of content in the `unsigned` object in events received over federation
Synapse makes use of various properties within the `unsigned` object of events - either internally, or by passing them on to clients. One example is `replaces_state`, which is used to store the event id of the previous event with the same `type` and `state_key`, and is later used to populate the `prev_content` property for events served to clients.
The problem is that homeservers are free to populate `unsigned`, without it affecting the event hashes or signatures; a malicious or buggy homeserver could therefore populate the content with incorrect data.
Taking the example of `replaces_state`, Synapse overwrites this property when receiving an event, but only if there was previously an event with the same `type` and `state_key` in the room state; it is otherwise passed through unchanged. So, a malicious homeserver could confuse remote servers' clients by sending incorrect values of `replaces_state` over federation.
---
The specification is not clear on how unspecified properties within `unsigned` should be handled, but I think they should be stripped off by the receiving homeserver. This will ensure that if, in future, the C-S API spec is extended to specify new properties be added to `unsigned`, there will be no confusion about whether they were added by the local or remote homeserver.
As far as I am aware, the only properties that *should* be allowed in `unsigned` over federation are:
* `invite_room_state`
* `knock_room_state`
* `age` - though see also https://github.com/matrix-org/synapse/issues/8429.
[Aside: in an ideal world, we might have different properties for "things added by the remote homeserver - treat with caution!" vs "things added by the local homeserver - can be trusted". However, that ship has probably sailed for now.]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `synapse/federation/federation_base.py`
Content:
```
1 # Copyright 2015, 2016 OpenMarket Ltd
2 # Copyright 2020 The Matrix.org Foundation C.I.C.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 import logging
16 from typing import TYPE_CHECKING
17
18 from synapse.api.constants import MAX_DEPTH, EventContentFields, EventTypes, Membership
19 from synapse.api.errors import Codes, SynapseError
20 from synapse.api.room_versions import EventFormatVersions, RoomVersion
21 from synapse.crypto.event_signing import check_event_content_hash
22 from synapse.crypto.keyring import Keyring
23 from synapse.events import EventBase, make_event_from_dict
24 from synapse.events.utils import prune_event, validate_canonicaljson
25 from synapse.http.servlet import assert_params_in_dict
26 from synapse.types import JsonDict, get_domain_from_id
27
28 if TYPE_CHECKING:
29 from synapse.server import HomeServer
30
31
32 logger = logging.getLogger(__name__)
33
34
35 class FederationBase:
36 def __init__(self, hs: "HomeServer"):
37 self.hs = hs
38
39 self.server_name = hs.hostname
40 self.keyring = hs.get_keyring()
41 self.spam_checker = hs.get_spam_checker()
42 self.store = hs.get_datastore()
43 self._clock = hs.get_clock()
44
45 async def _check_sigs_and_hash(
46 self, room_version: RoomVersion, pdu: EventBase
47 ) -> EventBase:
48 """Checks that event is correctly signed by the sending server.
49
50 Args:
51 room_version: The room version of the PDU
52 pdu: the event to be checked
53
54 Returns:
55 * the original event if the checks pass
56 * a redacted version of the event (if the signature
57 matched but the hash did not)
58 * throws a SynapseError if the signature check failed."""
59 try:
60 await _check_sigs_on_pdu(self.keyring, room_version, pdu)
61 except SynapseError as e:
62 logger.warning(
63 "Signature check failed for %s: %s",
64 pdu.event_id,
65 e,
66 )
67 raise
68
69 if not check_event_content_hash(pdu):
70 # let's try to distinguish between failures because the event was
71 # redacted (which are somewhat expected) vs actual ball-tampering
72 # incidents.
73 #
74 # This is just a heuristic, so we just assume that if the keys are
75 # about the same between the redacted and received events, then the
76 # received event was probably a redacted copy (but we then use our
77 # *actual* redacted copy to be on the safe side.)
78 redacted_event = prune_event(pdu)
79 if set(redacted_event.keys()) == set(pdu.keys()) and set(
80 redacted_event.content.keys()
81 ) == set(pdu.content.keys()):
82 logger.info(
83 "Event %s seems to have been redacted; using our redacted copy",
84 pdu.event_id,
85 )
86 else:
87 logger.warning(
88 "Event %s content has been tampered, redacting",
89 pdu.event_id,
90 )
91 return redacted_event
92
93 result = await self.spam_checker.check_event_for_spam(pdu)
94
95 if result:
96 logger.warning("Event contains spam, soft-failing %s", pdu.event_id)
97 # we redact (to save disk space) as well as soft-failing (to stop
98 # using the event in prev_events).
99 redacted_event = prune_event(pdu)
100 redacted_event.internal_metadata.soft_failed = True
101 return redacted_event
102
103 return pdu
104
105
106 async def _check_sigs_on_pdu(
107 keyring: Keyring, room_version: RoomVersion, pdu: EventBase
108 ) -> None:
109 """Check that the given events are correctly signed
110
111 Raise a SynapseError if the event wasn't correctly signed.
112
113 Args:
114 keyring: keyring object to do the checks
115 room_version: the room version of the PDUs
116 pdus: the events to be checked
117 """
118
119 # we want to check that the event is signed by:
120 #
121 # (a) the sender's server
122 #
123 # - except in the case of invites created from a 3pid invite, which are exempt
124 # from this check, because the sender has to match that of the original 3pid
125 # invite, but the event may come from a different HS, for reasons that I don't
126 # entirely grok (why do the senders have to match? and if they do, why doesn't the
127 # joining server ask the inviting server to do the switcheroo with
128 # exchange_third_party_invite?).
129 #
130 # That's pretty awful, since redacting such an invite will render it invalid
131 # (because it will then look like a regular invite without a valid signature),
132 # and signatures are *supposed* to be valid whether or not an event has been
133 # redacted. But this isn't the worst of the ways that 3pid invites are broken.
134 #
135 # (b) for V1 and V2 rooms, the server which created the event_id
136 #
137 # let's start by getting the domain for each pdu, and flattening the event back
138 # to JSON.
139
140 # First we check that the sender event is signed by the sender's domain
141 # (except if its a 3pid invite, in which case it may be sent by any server)
142 if not _is_invite_via_3pid(pdu):
143 try:
144 await keyring.verify_event_for_server(
145 get_domain_from_id(pdu.sender),
146 pdu,
147 pdu.origin_server_ts if room_version.enforce_key_validity else 0,
148 )
149 except Exception as e:
150 errmsg = "event id %s: unable to verify signature for sender %s: %s" % (
151 pdu.event_id,
152 get_domain_from_id(pdu.sender),
153 e,
154 )
155 raise SynapseError(403, errmsg, Codes.FORBIDDEN)
156
157 # now let's look for events where the sender's domain is different to the
158 # event id's domain (normally only the case for joins/leaves), and add additional
159 # checks. Only do this if the room version has a concept of event ID domain
160 # (ie, the room version uses old-style non-hash event IDs).
161 if room_version.event_format == EventFormatVersions.V1 and get_domain_from_id(
162 pdu.event_id
163 ) != get_domain_from_id(pdu.sender):
164 try:
165 await keyring.verify_event_for_server(
166 get_domain_from_id(pdu.event_id),
167 pdu,
168 pdu.origin_server_ts if room_version.enforce_key_validity else 0,
169 )
170 except Exception as e:
171 errmsg = (
172 "event id %s: unable to verify signature for event id domain %s: %s"
173 % (
174 pdu.event_id,
175 get_domain_from_id(pdu.event_id),
176 e,
177 )
178 )
179 raise SynapseError(403, errmsg, Codes.FORBIDDEN)
180
181 # If this is a join event for a restricted room it may have been authorised
182 # via a different server from the sending server. Check those signatures.
183 if (
184 room_version.msc3083_join_rules
185 and pdu.type == EventTypes.Member
186 and pdu.membership == Membership.JOIN
187 and EventContentFields.AUTHORISING_USER in pdu.content
188 ):
189 authorising_server = get_domain_from_id(
190 pdu.content[EventContentFields.AUTHORISING_USER]
191 )
192 try:
193 await keyring.verify_event_for_server(
194 authorising_server,
195 pdu,
196 pdu.origin_server_ts if room_version.enforce_key_validity else 0,
197 )
198 except Exception as e:
199 errmsg = (
200 "event id %s: unable to verify signature for authorising server %s: %s"
201 % (
202 pdu.event_id,
203 authorising_server,
204 e,
205 )
206 )
207 raise SynapseError(403, errmsg, Codes.FORBIDDEN)
208
209
210 def _is_invite_via_3pid(event: EventBase) -> bool:
211 return (
212 event.type == EventTypes.Member
213 and event.membership == Membership.INVITE
214 and "third_party_invite" in event.content
215 )
216
217
218 def event_from_pdu_json(pdu_json: JsonDict, room_version: RoomVersion) -> EventBase:
219 """Construct an EventBase from an event json received over federation
220
221 Args:
222 pdu_json: pdu as received over federation
223 room_version: The version of the room this event belongs to
224
225 Raises:
226 SynapseError: if the pdu is missing required fields or is otherwise
227 not a valid matrix event
228 """
229 # we could probably enforce a bunch of other fields here (room_id, sender,
230 # origin, etc etc)
231 assert_params_in_dict(pdu_json, ("type", "depth"))
232
233 depth = pdu_json["depth"]
234 if not isinstance(depth, int):
235 raise SynapseError(400, "Depth %r not an intger" % (depth,), Codes.BAD_JSON)
236
237 if depth < 0:
238 raise SynapseError(400, "Depth too small", Codes.BAD_JSON)
239 elif depth > MAX_DEPTH:
240 raise SynapseError(400, "Depth too large", Codes.BAD_JSON)
241
242 # Validate that the JSON conforms to the specification.
243 if room_version.strict_canonicaljson:
244 validate_canonicaljson(pdu_json)
245
246 event = make_event_from_dict(pdu_json, room_version)
247 return event
248
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/synapse/federation/federation_base.py b/synapse/federation/federation_base.py
--- a/synapse/federation/federation_base.py
+++ b/synapse/federation/federation_base.py
@@ -230,6 +230,10 @@
# origin, etc etc)
assert_params_in_dict(pdu_json, ("type", "depth"))
+ # Strip any unauthorized values from "unsigned" if they exist
+ if "unsigned" in pdu_json:
+ _strip_unsigned_values(pdu_json)
+
depth = pdu_json["depth"]
if not isinstance(depth, int):
raise SynapseError(400, "Depth %r not an intger" % (depth,), Codes.BAD_JSON)
@@ -245,3 +249,24 @@
event = make_event_from_dict(pdu_json, room_version)
return event
+
+
+def _strip_unsigned_values(pdu_dict: JsonDict) -> None:
+ """
+ Strip any unsigned values unless specifically allowed, as defined by the whitelist.
+
+ pdu: the json dict to strip values from. Note that the dict is mutated by this
+ function
+ """
+ unsigned = pdu_dict["unsigned"]
+
+ if not isinstance(unsigned, dict):
+ pdu_dict["unsigned"] = {}
+
+ if pdu_dict["type"] == "m.room.member":
+ whitelist = ["knock_room_state", "invite_room_state", "age"]
+ else:
+ whitelist = ["age"]
+
+ filtered_unsigned = {k: v for k, v in unsigned.items() if k in whitelist}
+ pdu_dict["unsigned"] = filtered_unsigned
| {"golden_diff": "diff --git a/synapse/federation/federation_base.py b/synapse/federation/federation_base.py\n--- a/synapse/federation/federation_base.py\n+++ b/synapse/federation/federation_base.py\n@@ -230,6 +230,10 @@\n # origin, etc etc)\n assert_params_in_dict(pdu_json, (\"type\", \"depth\"))\n \n+ # Strip any unauthorized values from \"unsigned\" if they exist\n+ if \"unsigned\" in pdu_json:\n+ _strip_unsigned_values(pdu_json)\n+\n depth = pdu_json[\"depth\"]\n if not isinstance(depth, int):\n raise SynapseError(400, \"Depth %r not an intger\" % (depth,), Codes.BAD_JSON)\n@@ -245,3 +249,24 @@\n \n event = make_event_from_dict(pdu_json, room_version)\n return event\n+\n+\n+def _strip_unsigned_values(pdu_dict: JsonDict) -> None:\n+ \"\"\"\n+ Strip any unsigned values unless specifically allowed, as defined by the whitelist.\n+\n+ pdu: the json dict to strip values from. Note that the dict is mutated by this\n+ function\n+ \"\"\"\n+ unsigned = pdu_dict[\"unsigned\"]\n+\n+ if not isinstance(unsigned, dict):\n+ pdu_dict[\"unsigned\"] = {}\n+\n+ if pdu_dict[\"type\"] == \"m.room.member\":\n+ whitelist = [\"knock_room_state\", \"invite_room_state\", \"age\"]\n+ else:\n+ whitelist = [\"age\"]\n+\n+ filtered_unsigned = {k: v for k, v in unsigned.items() if k in whitelist}\n+ pdu_dict[\"unsigned\"] = filtered_unsigned\n", "issue": "Synapse is overly accepting of content in the `unsigned` object in events received over federation\nSynapse makes use of various properties within the `unsigned` object of events - either internally, or by passing them on to clients. One example is `replaces_state`, which is used to store the event id of the previous event with the same `type` and `state_key`, and is later used to populate the `prev_content` property for events served to clients.\r\n\r\nThe problem is that homeservers are free to populate `unsigned`, without it affecting the event hashes or signatures; a malicious or buggy homeserver could therefore populate the content with incorrect data.\r\n\r\nTaking the example of `replaces_state`, Synapse overwrites this property when receiving an event, but only if there was previously an event with the same `type` and `state_key` in the room state; it is otherwise passed through unchanged. So, a malicious homeserver could confuse remote servers' clients by sending incorrect values of `replaces_state` over federation.\r\n\r\n---\r\n\r\nThe specification is not clear on how unspecified properties within `unsigned` should be handled, but I think they should be stripped off by the receiving homeserver. This will ensure that if, in future, the C-S API spec is extended to specify new properties be added to `unsigned`, there will be no confusion about whether they were added by the local or remote homeserver.\r\n\r\nAs far as I am aware, the only properties that *should* be allowed in `unsigned` over federation are:\r\n * `invite_room_state`\r\n * `knock_room_state`\r\n * `age` - though see also https://github.com/matrix-org/synapse/issues/8429.\r\n\r\n[Aside: in an ideal world, we might have different properties for \"things added by the remote homeserver - treat with caution!\" vs \"things added by the local homeserver - can be trusted\". However, that ship has probably sailed for now.] \n", "before_files": [{"content": "# Copyright 2015, 2016 OpenMarket Ltd\n# Copyright 2020 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport logging\nfrom typing import TYPE_CHECKING\n\nfrom synapse.api.constants import MAX_DEPTH, EventContentFields, EventTypes, Membership\nfrom synapse.api.errors import Codes, SynapseError\nfrom synapse.api.room_versions import EventFormatVersions, RoomVersion\nfrom synapse.crypto.event_signing import check_event_content_hash\nfrom synapse.crypto.keyring import Keyring\nfrom synapse.events import EventBase, make_event_from_dict\nfrom synapse.events.utils import prune_event, validate_canonicaljson\nfrom synapse.http.servlet import assert_params_in_dict\nfrom synapse.types import JsonDict, get_domain_from_id\n\nif TYPE_CHECKING:\n from synapse.server import HomeServer\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass FederationBase:\n def __init__(self, hs: \"HomeServer\"):\n self.hs = hs\n\n self.server_name = hs.hostname\n self.keyring = hs.get_keyring()\n self.spam_checker = hs.get_spam_checker()\n self.store = hs.get_datastore()\n self._clock = hs.get_clock()\n\n async def _check_sigs_and_hash(\n self, room_version: RoomVersion, pdu: EventBase\n ) -> EventBase:\n \"\"\"Checks that event is correctly signed by the sending server.\n\n Args:\n room_version: The room version of the PDU\n pdu: the event to be checked\n\n Returns:\n * the original event if the checks pass\n * a redacted version of the event (if the signature\n matched but the hash did not)\n * throws a SynapseError if the signature check failed.\"\"\"\n try:\n await _check_sigs_on_pdu(self.keyring, room_version, pdu)\n except SynapseError as e:\n logger.warning(\n \"Signature check failed for %s: %s\",\n pdu.event_id,\n e,\n )\n raise\n\n if not check_event_content_hash(pdu):\n # let's try to distinguish between failures because the event was\n # redacted (which are somewhat expected) vs actual ball-tampering\n # incidents.\n #\n # This is just a heuristic, so we just assume that if the keys are\n # about the same between the redacted and received events, then the\n # received event was probably a redacted copy (but we then use our\n # *actual* redacted copy to be on the safe side.)\n redacted_event = prune_event(pdu)\n if set(redacted_event.keys()) == set(pdu.keys()) and set(\n redacted_event.content.keys()\n ) == set(pdu.content.keys()):\n logger.info(\n \"Event %s seems to have been redacted; using our redacted copy\",\n pdu.event_id,\n )\n else:\n logger.warning(\n \"Event %s content has been tampered, redacting\",\n pdu.event_id,\n )\n return redacted_event\n\n result = await self.spam_checker.check_event_for_spam(pdu)\n\n if result:\n logger.warning(\"Event contains spam, soft-failing %s\", pdu.event_id)\n # we redact (to save disk space) as well as soft-failing (to stop\n # using the event in prev_events).\n redacted_event = prune_event(pdu)\n redacted_event.internal_metadata.soft_failed = True\n return redacted_event\n\n return pdu\n\n\nasync def _check_sigs_on_pdu(\n keyring: Keyring, room_version: RoomVersion, pdu: EventBase\n) -> None:\n \"\"\"Check that the given events are correctly signed\n\n Raise a SynapseError if the event wasn't correctly signed.\n\n Args:\n keyring: keyring object to do the checks\n room_version: the room version of the PDUs\n pdus: the events to be checked\n \"\"\"\n\n # we want to check that the event is signed by:\n #\n # (a) the sender's server\n #\n # - except in the case of invites created from a 3pid invite, which are exempt\n # from this check, because the sender has to match that of the original 3pid\n # invite, but the event may come from a different HS, for reasons that I don't\n # entirely grok (why do the senders have to match? and if they do, why doesn't the\n # joining server ask the inviting server to do the switcheroo with\n # exchange_third_party_invite?).\n #\n # That's pretty awful, since redacting such an invite will render it invalid\n # (because it will then look like a regular invite without a valid signature),\n # and signatures are *supposed* to be valid whether or not an event has been\n # redacted. But this isn't the worst of the ways that 3pid invites are broken.\n #\n # (b) for V1 and V2 rooms, the server which created the event_id\n #\n # let's start by getting the domain for each pdu, and flattening the event back\n # to JSON.\n\n # First we check that the sender event is signed by the sender's domain\n # (except if its a 3pid invite, in which case it may be sent by any server)\n if not _is_invite_via_3pid(pdu):\n try:\n await keyring.verify_event_for_server(\n get_domain_from_id(pdu.sender),\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = \"event id %s: unable to verify signature for sender %s: %s\" % (\n pdu.event_id,\n get_domain_from_id(pdu.sender),\n e,\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n # now let's look for events where the sender's domain is different to the\n # event id's domain (normally only the case for joins/leaves), and add additional\n # checks. Only do this if the room version has a concept of event ID domain\n # (ie, the room version uses old-style non-hash event IDs).\n if room_version.event_format == EventFormatVersions.V1 and get_domain_from_id(\n pdu.event_id\n ) != get_domain_from_id(pdu.sender):\n try:\n await keyring.verify_event_for_server(\n get_domain_from_id(pdu.event_id),\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = (\n \"event id %s: unable to verify signature for event id domain %s: %s\"\n % (\n pdu.event_id,\n get_domain_from_id(pdu.event_id),\n e,\n )\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n # If this is a join event for a restricted room it may have been authorised\n # via a different server from the sending server. Check those signatures.\n if (\n room_version.msc3083_join_rules\n and pdu.type == EventTypes.Member\n and pdu.membership == Membership.JOIN\n and EventContentFields.AUTHORISING_USER in pdu.content\n ):\n authorising_server = get_domain_from_id(\n pdu.content[EventContentFields.AUTHORISING_USER]\n )\n try:\n await keyring.verify_event_for_server(\n authorising_server,\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = (\n \"event id %s: unable to verify signature for authorising server %s: %s\"\n % (\n pdu.event_id,\n authorising_server,\n e,\n )\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n\ndef _is_invite_via_3pid(event: EventBase) -> bool:\n return (\n event.type == EventTypes.Member\n and event.membership == Membership.INVITE\n and \"third_party_invite\" in event.content\n )\n\n\ndef event_from_pdu_json(pdu_json: JsonDict, room_version: RoomVersion) -> EventBase:\n \"\"\"Construct an EventBase from an event json received over federation\n\n Args:\n pdu_json: pdu as received over federation\n room_version: The version of the room this event belongs to\n\n Raises:\n SynapseError: if the pdu is missing required fields or is otherwise\n not a valid matrix event\n \"\"\"\n # we could probably enforce a bunch of other fields here (room_id, sender,\n # origin, etc etc)\n assert_params_in_dict(pdu_json, (\"type\", \"depth\"))\n\n depth = pdu_json[\"depth\"]\n if not isinstance(depth, int):\n raise SynapseError(400, \"Depth %r not an intger\" % (depth,), Codes.BAD_JSON)\n\n if depth < 0:\n raise SynapseError(400, \"Depth too small\", Codes.BAD_JSON)\n elif depth > MAX_DEPTH:\n raise SynapseError(400, \"Depth too large\", Codes.BAD_JSON)\n\n # Validate that the JSON conforms to the specification.\n if room_version.strict_canonicaljson:\n validate_canonicaljson(pdu_json)\n\n event = make_event_from_dict(pdu_json, room_version)\n return event\n", "path": "synapse/federation/federation_base.py"}], "after_files": [{"content": "# Copyright 2015, 2016 OpenMarket Ltd\n# Copyright 2020 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport logging\nfrom typing import TYPE_CHECKING\n\nfrom synapse.api.constants import MAX_DEPTH, EventContentFields, EventTypes, Membership\nfrom synapse.api.errors import Codes, SynapseError\nfrom synapse.api.room_versions import EventFormatVersions, RoomVersion\nfrom synapse.crypto.event_signing import check_event_content_hash\nfrom synapse.crypto.keyring import Keyring\nfrom synapse.events import EventBase, make_event_from_dict\nfrom synapse.events.utils import prune_event, validate_canonicaljson\nfrom synapse.http.servlet import assert_params_in_dict\nfrom synapse.types import JsonDict, get_domain_from_id\n\nif TYPE_CHECKING:\n from synapse.server import HomeServer\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass FederationBase:\n def __init__(self, hs: \"HomeServer\"):\n self.hs = hs\n\n self.server_name = hs.hostname\n self.keyring = hs.get_keyring()\n self.spam_checker = hs.get_spam_checker()\n self.store = hs.get_datastore()\n self._clock = hs.get_clock()\n\n async def _check_sigs_and_hash(\n self, room_version: RoomVersion, pdu: EventBase\n ) -> EventBase:\n \"\"\"Checks that event is correctly signed by the sending server.\n\n Args:\n room_version: The room version of the PDU\n pdu: the event to be checked\n\n Returns:\n * the original event if the checks pass\n * a redacted version of the event (if the signature\n matched but the hash did not)\n * throws a SynapseError if the signature check failed.\"\"\"\n try:\n await _check_sigs_on_pdu(self.keyring, room_version, pdu)\n except SynapseError as e:\n logger.warning(\n \"Signature check failed for %s: %s\",\n pdu.event_id,\n e,\n )\n raise\n\n if not check_event_content_hash(pdu):\n # let's try to distinguish between failures because the event was\n # redacted (which are somewhat expected) vs actual ball-tampering\n # incidents.\n #\n # This is just a heuristic, so we just assume that if the keys are\n # about the same between the redacted and received events, then the\n # received event was probably a redacted copy (but we then use our\n # *actual* redacted copy to be on the safe side.)\n redacted_event = prune_event(pdu)\n if set(redacted_event.keys()) == set(pdu.keys()) and set(\n redacted_event.content.keys()\n ) == set(pdu.content.keys()):\n logger.info(\n \"Event %s seems to have been redacted; using our redacted copy\",\n pdu.event_id,\n )\n else:\n logger.warning(\n \"Event %s content has been tampered, redacting\",\n pdu.event_id,\n )\n return redacted_event\n\n result = await self.spam_checker.check_event_for_spam(pdu)\n\n if result:\n logger.warning(\"Event contains spam, soft-failing %s\", pdu.event_id)\n # we redact (to save disk space) as well as soft-failing (to stop\n # using the event in prev_events).\n redacted_event = prune_event(pdu)\n redacted_event.internal_metadata.soft_failed = True\n return redacted_event\n\n return pdu\n\n\nasync def _check_sigs_on_pdu(\n keyring: Keyring, room_version: RoomVersion, pdu: EventBase\n) -> None:\n \"\"\"Check that the given events are correctly signed\n\n Raise a SynapseError if the event wasn't correctly signed.\n\n Args:\n keyring: keyring object to do the checks\n room_version: the room version of the PDUs\n pdus: the events to be checked\n \"\"\"\n\n # we want to check that the event is signed by:\n #\n # (a) the sender's server\n #\n # - except in the case of invites created from a 3pid invite, which are exempt\n # from this check, because the sender has to match that of the original 3pid\n # invite, but the event may come from a different HS, for reasons that I don't\n # entirely grok (why do the senders have to match? and if they do, why doesn't the\n # joining server ask the inviting server to do the switcheroo with\n # exchange_third_party_invite?).\n #\n # That's pretty awful, since redacting such an invite will render it invalid\n # (because it will then look like a regular invite without a valid signature),\n # and signatures are *supposed* to be valid whether or not an event has been\n # redacted. But this isn't the worst of the ways that 3pid invites are broken.\n #\n # (b) for V1 and V2 rooms, the server which created the event_id\n #\n # let's start by getting the domain for each pdu, and flattening the event back\n # to JSON.\n\n # First we check that the sender event is signed by the sender's domain\n # (except if its a 3pid invite, in which case it may be sent by any server)\n if not _is_invite_via_3pid(pdu):\n try:\n await keyring.verify_event_for_server(\n get_domain_from_id(pdu.sender),\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = \"event id %s: unable to verify signature for sender %s: %s\" % (\n pdu.event_id,\n get_domain_from_id(pdu.sender),\n e,\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n # now let's look for events where the sender's domain is different to the\n # event id's domain (normally only the case for joins/leaves), and add additional\n # checks. Only do this if the room version has a concept of event ID domain\n # (ie, the room version uses old-style non-hash event IDs).\n if room_version.event_format == EventFormatVersions.V1 and get_domain_from_id(\n pdu.event_id\n ) != get_domain_from_id(pdu.sender):\n try:\n await keyring.verify_event_for_server(\n get_domain_from_id(pdu.event_id),\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = (\n \"event id %s: unable to verify signature for event id domain %s: %s\"\n % (\n pdu.event_id,\n get_domain_from_id(pdu.event_id),\n e,\n )\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n # If this is a join event for a restricted room it may have been authorised\n # via a different server from the sending server. Check those signatures.\n if (\n room_version.msc3083_join_rules\n and pdu.type == EventTypes.Member\n and pdu.membership == Membership.JOIN\n and EventContentFields.AUTHORISING_USER in pdu.content\n ):\n authorising_server = get_domain_from_id(\n pdu.content[EventContentFields.AUTHORISING_USER]\n )\n try:\n await keyring.verify_event_for_server(\n authorising_server,\n pdu,\n pdu.origin_server_ts if room_version.enforce_key_validity else 0,\n )\n except Exception as e:\n errmsg = (\n \"event id %s: unable to verify signature for authorising server %s: %s\"\n % (\n pdu.event_id,\n authorising_server,\n e,\n )\n )\n raise SynapseError(403, errmsg, Codes.FORBIDDEN)\n\n\ndef _is_invite_via_3pid(event: EventBase) -> bool:\n return (\n event.type == EventTypes.Member\n and event.membership == Membership.INVITE\n and \"third_party_invite\" in event.content\n )\n\n\ndef event_from_pdu_json(pdu_json: JsonDict, room_version: RoomVersion) -> EventBase:\n \"\"\"Construct an EventBase from an event json received over federation\n\n Args:\n pdu_json: pdu as received over federation\n room_version: The version of the room this event belongs to\n\n Raises:\n SynapseError: if the pdu is missing required fields or is otherwise\n not a valid matrix event\n \"\"\"\n # we could probably enforce a bunch of other fields here (room_id, sender,\n # origin, etc etc)\n assert_params_in_dict(pdu_json, (\"type\", \"depth\"))\n\n # Strip any unauthorized values from \"unsigned\" if they exist\n if \"unsigned\" in pdu_json:\n _strip_unsigned_values(pdu_json)\n\n depth = pdu_json[\"depth\"]\n if not isinstance(depth, int):\n raise SynapseError(400, \"Depth %r not an intger\" % (depth,), Codes.BAD_JSON)\n\n if depth < 0:\n raise SynapseError(400, \"Depth too small\", Codes.BAD_JSON)\n elif depth > MAX_DEPTH:\n raise SynapseError(400, \"Depth too large\", Codes.BAD_JSON)\n\n # Validate that the JSON conforms to the specification.\n if room_version.strict_canonicaljson:\n validate_canonicaljson(pdu_json)\n\n event = make_event_from_dict(pdu_json, room_version)\n return event\n\n\ndef _strip_unsigned_values(pdu_dict: JsonDict) -> None:\n \"\"\"\n Strip any unsigned values unless specifically allowed, as defined by the whitelist.\n\n pdu: the json dict to strip values from. Note that the dict is mutated by this\n function\n \"\"\"\n unsigned = pdu_dict[\"unsigned\"]\n\n if not isinstance(unsigned, dict):\n pdu_dict[\"unsigned\"] = {}\n\n if pdu_dict[\"type\"] == \"m.room.member\":\n whitelist = [\"knock_room_state\", \"invite_room_state\", \"age\"]\n else:\n whitelist = [\"age\"]\n\n filtered_unsigned = {k: v for k, v in unsigned.items() if k in whitelist}\n pdu_dict[\"unsigned\"] = filtered_unsigned\n", "path": "synapse/federation/federation_base.py"}]} | 3,487 | 371 |
gh_patches_debug_13333 | rasdani/github-patches | git_diff | DDMAL__CantusDB-156 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
need to have fields of chant and sequence models synced
or else, it'll lead to errors, such as not being able to retrieve chants from /chant-search
please fix
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/cantusdb_project/main_app/models/sequence.py`
Content:
```
1 from django.contrib.postgres.search import SearchVectorField
2 from django.db import models
3 from main_app.models import BaseModel
4 from users.models import User
5
6
7 class Sequence(BaseModel):
8 visible_status = models.CharField(max_length=1, blank=True, null=True)
9 title = models.CharField(blank=True, null=True, max_length=255)
10 incipit = models.CharField(blank=True, null=True, max_length=255)
11 siglum = models.CharField(blank=True, null=True, max_length=255)
12 folio = models.CharField(blank=True, null=True, max_length=255)
13 sequence = models.CharField(blank=True, null=True, max_length=255)
14 genre = models.ForeignKey("Genre", blank=True, null=True, on_delete=models.PROTECT)
15 rubrics = models.CharField(blank=True, null=True, max_length=255)
16 analecta_hymnica = models.CharField(blank=True, null=True, max_length=255)
17 indexing_notes = models.TextField(blank=True, null=True)
18 date = models.CharField(blank=True, null=True, max_length=255)
19 col1 = models.CharField(blank=True, null=True, max_length=255)
20 col2 = models.CharField(blank=True, null=True, max_length=255)
21 col3 = models.CharField(blank=True, null=True, max_length=255)
22 ah_volume = models.CharField(blank=True, null=True, max_length=255)
23 source = models.ForeignKey(
24 "Source", on_delete=models.PROTECT, blank=True, null=True
25 )
26 cantus_id = models.CharField(blank=True, null=True, max_length=255)
27 image_link = models.URLField(blank=True, null=True)
28 json_info = models.JSONField(null=True, blank=True)
29
30 # The following fields (dummy fields) are just for harmonizing the chant and sequence models to have the same fields
31 # They should never be populated or displayed
32 # The order of the fields must be exactly the same between the seq and chant models
33 marginalia = models.CharField(max_length=63, null=True, blank=True)
34 sequence_number = models.PositiveIntegerField(
35 help_text='Each folio starts with "1"', null=True, blank=True
36 )
37 office = models.ForeignKey(
38 "Office", on_delete=models.PROTECT, null=True, blank=True
39 )
40 position = models.CharField(max_length=63, null=True, blank=True)
41 feast = models.ForeignKey("Feast", on_delete=models.PROTECT, null=True, blank=True)
42 mode = models.CharField(max_length=63, null=True, blank=True)
43 differentia = models.CharField(blank=True, null=True, max_length=63)
44 finalis = models.CharField(blank=True, null=True, max_length=63)
45 extra = models.CharField(blank=True, null=True, max_length=63)
46 chant_range = models.CharField(
47 blank=True,
48 null=True,
49 help_text='Example: "1-c-k-4". Optional field',
50 max_length=255,
51 )
52 addendum = models.CharField(blank=True, null=True, max_length=255)
53 manuscript_full_text_std_spelling = models.TextField(
54 help_text="Manuscript full text with standardized spelling. Enter the words "
55 "according to the manuscript but normalize their spellings following "
56 "Classical Latin forms. Use upper-case letters for proper nouns, "
57 'the first word of each chant, and the first word after "Alleluia" for '
58 "Mass Alleluias. Punctuation is omitted.",
59 null=True,
60 blank=True,
61 )
62 manuscript_full_text_std_proofread = models.BooleanField(blank=True, null=True)
63 manuscript_full_text = models.TextField(
64 help_text="Enter the wording, word order and spellings as found in the manuscript"
65 ", with abbreviations resolved to standard words. Use upper-case letters as found"
66 " in the source. Retain “Xpistum” (Christum), “Ihc” (Jesus) and other instances of "
67 "Greek characters with their closest approximations of Latin letters. Some punctuation"
68 " signs and vertical dividing lines | are employed in this field. Repetenda and psalm "
69 "cues can also be recorded here. For more information, contact Cantus Database staff.",
70 null=True,
71 blank=True,
72 )
73 manuscript_full_text_proofread = models.BooleanField(blank=True, null=True)
74 manuscript_syllabized_full_text = models.TextField(null=True, blank=True)
75 volpiano = models.TextField(null=True, blank=True)
76 volpiano_proofread = models.BooleanField(blank=True, null=True)
77 volpiano_notes = models.TextField(null=True, blank=True)
78 volpiano_intervals = models.TextField(null=True, blank=True)
79 # volpiano_intervals = ArrayField(base_field=models.IntegerField(), null=True, blank=True)
80 cao_concordances = models.CharField(blank=True, null=True, max_length=63)
81 proofread_by = models.ForeignKey(
82 User, on_delete=models.PROTECT, null=True, blank=True
83 )
84 melody_id = models.CharField(blank=True, null=True, max_length=63)
85 search_vector = SearchVectorField(null=True, editable=False)
86 content_structure = models.CharField(
87 blank=True,
88 null=True,
89 max_length=64,
90 help_text="Additional folio number field, if folio numbers appear on the leaves but are not in the 'binding order'.",
91 )
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/django/cantusdb_project/main_app/models/sequence.py b/django/cantusdb_project/main_app/models/sequence.py
--- a/django/cantusdb_project/main_app/models/sequence.py
+++ b/django/cantusdb_project/main_app/models/sequence.py
@@ -41,6 +41,7 @@
feast = models.ForeignKey("Feast", on_delete=models.PROTECT, null=True, blank=True)
mode = models.CharField(max_length=63, null=True, blank=True)
differentia = models.CharField(blank=True, null=True, max_length=63)
+ differentia_id = models.CharField(blank=True, null=True, max_length=12)
finalis = models.CharField(blank=True, null=True, max_length=63)
extra = models.CharField(blank=True, null=True, max_length=63)
chant_range = models.CharField(
| {"golden_diff": "diff --git a/django/cantusdb_project/main_app/models/sequence.py b/django/cantusdb_project/main_app/models/sequence.py\n--- a/django/cantusdb_project/main_app/models/sequence.py\n+++ b/django/cantusdb_project/main_app/models/sequence.py\n@@ -41,6 +41,7 @@\n feast = models.ForeignKey(\"Feast\", on_delete=models.PROTECT, null=True, blank=True)\n mode = models.CharField(max_length=63, null=True, blank=True)\n differentia = models.CharField(blank=True, null=True, max_length=63)\n+ differentia_id = models.CharField(blank=True, null=True, max_length=12)\n finalis = models.CharField(blank=True, null=True, max_length=63)\n extra = models.CharField(blank=True, null=True, max_length=63)\n chant_range = models.CharField(\n", "issue": "need to have fields of chant and sequence models synced \nor else, it'll lead to errors, such as not being able to retrieve chants from /chant-search\r\nplease fix\n", "before_files": [{"content": "from django.contrib.postgres.search import SearchVectorField\nfrom django.db import models\nfrom main_app.models import BaseModel\nfrom users.models import User\n\n\nclass Sequence(BaseModel):\n visible_status = models.CharField(max_length=1, blank=True, null=True)\n title = models.CharField(blank=True, null=True, max_length=255)\n incipit = models.CharField(blank=True, null=True, max_length=255)\n siglum = models.CharField(blank=True, null=True, max_length=255)\n folio = models.CharField(blank=True, null=True, max_length=255)\n sequence = models.CharField(blank=True, null=True, max_length=255)\n genre = models.ForeignKey(\"Genre\", blank=True, null=True, on_delete=models.PROTECT)\n rubrics = models.CharField(blank=True, null=True, max_length=255)\n analecta_hymnica = models.CharField(blank=True, null=True, max_length=255)\n indexing_notes = models.TextField(blank=True, null=True)\n date = models.CharField(blank=True, null=True, max_length=255)\n col1 = models.CharField(blank=True, null=True, max_length=255)\n col2 = models.CharField(blank=True, null=True, max_length=255)\n col3 = models.CharField(blank=True, null=True, max_length=255)\n ah_volume = models.CharField(blank=True, null=True, max_length=255)\n source = models.ForeignKey(\n \"Source\", on_delete=models.PROTECT, blank=True, null=True\n )\n cantus_id = models.CharField(blank=True, null=True, max_length=255)\n image_link = models.URLField(blank=True, null=True)\n json_info = models.JSONField(null=True, blank=True)\n\n # The following fields (dummy fields) are just for harmonizing the chant and sequence models to have the same fields\n # They should never be populated or displayed\n # The order of the fields must be exactly the same between the seq and chant models\n marginalia = models.CharField(max_length=63, null=True, blank=True)\n sequence_number = models.PositiveIntegerField(\n help_text='Each folio starts with \"1\"', null=True, blank=True\n )\n office = models.ForeignKey(\n \"Office\", on_delete=models.PROTECT, null=True, blank=True\n )\n position = models.CharField(max_length=63, null=True, blank=True)\n feast = models.ForeignKey(\"Feast\", on_delete=models.PROTECT, null=True, blank=True)\n mode = models.CharField(max_length=63, null=True, blank=True)\n differentia = models.CharField(blank=True, null=True, max_length=63)\n finalis = models.CharField(blank=True, null=True, max_length=63)\n extra = models.CharField(blank=True, null=True, max_length=63)\n chant_range = models.CharField(\n blank=True,\n null=True,\n help_text='Example: \"1-c-k-4\". Optional field',\n max_length=255,\n )\n addendum = models.CharField(blank=True, null=True, max_length=255)\n manuscript_full_text_std_spelling = models.TextField(\n help_text=\"Manuscript full text with standardized spelling. Enter the words \"\n \"according to the manuscript but normalize their spellings following \"\n \"Classical Latin forms. Use upper-case letters for proper nouns, \"\n 'the first word of each chant, and the first word after \"Alleluia\" for '\n \"Mass Alleluias. Punctuation is omitted.\",\n null=True,\n blank=True,\n )\n manuscript_full_text_std_proofread = models.BooleanField(blank=True, null=True)\n manuscript_full_text = models.TextField(\n help_text=\"Enter the wording, word order and spellings as found in the manuscript\"\n \", with abbreviations resolved to standard words. Use upper-case letters as found\"\n \" in the source. Retain \u201cXpistum\u201d (Christum), \u201cIhc\u201d (Jesus) and other instances of \"\n \"Greek characters with their closest approximations of Latin letters. Some punctuation\"\n \" signs and vertical dividing lines | are employed in this field. Repetenda and psalm \"\n \"cues can also be recorded here. For more information, contact Cantus Database staff.\",\n null=True,\n blank=True,\n )\n manuscript_full_text_proofread = models.BooleanField(blank=True, null=True)\n manuscript_syllabized_full_text = models.TextField(null=True, blank=True)\n volpiano = models.TextField(null=True, blank=True)\n volpiano_proofread = models.BooleanField(blank=True, null=True)\n volpiano_notes = models.TextField(null=True, blank=True)\n volpiano_intervals = models.TextField(null=True, blank=True)\n # volpiano_intervals = ArrayField(base_field=models.IntegerField(), null=True, blank=True)\n cao_concordances = models.CharField(blank=True, null=True, max_length=63)\n proofread_by = models.ForeignKey(\n User, on_delete=models.PROTECT, null=True, blank=True\n )\n melody_id = models.CharField(blank=True, null=True, max_length=63)\n search_vector = SearchVectorField(null=True, editable=False)\n content_structure = models.CharField(\n blank=True,\n null=True,\n max_length=64,\n help_text=\"Additional folio number field, if folio numbers appear on the leaves but are not in the 'binding order'.\",\n )\n", "path": "django/cantusdb_project/main_app/models/sequence.py"}], "after_files": [{"content": "from django.contrib.postgres.search import SearchVectorField\nfrom django.db import models\nfrom main_app.models import BaseModel\nfrom users.models import User\n\n\nclass Sequence(BaseModel):\n visible_status = models.CharField(max_length=1, blank=True, null=True)\n title = models.CharField(blank=True, null=True, max_length=255)\n incipit = models.CharField(blank=True, null=True, max_length=255)\n siglum = models.CharField(blank=True, null=True, max_length=255)\n folio = models.CharField(blank=True, null=True, max_length=255)\n sequence = models.CharField(blank=True, null=True, max_length=255)\n genre = models.ForeignKey(\"Genre\", blank=True, null=True, on_delete=models.PROTECT)\n rubrics = models.CharField(blank=True, null=True, max_length=255)\n analecta_hymnica = models.CharField(blank=True, null=True, max_length=255)\n indexing_notes = models.TextField(blank=True, null=True)\n date = models.CharField(blank=True, null=True, max_length=255)\n col1 = models.CharField(blank=True, null=True, max_length=255)\n col2 = models.CharField(blank=True, null=True, max_length=255)\n col3 = models.CharField(blank=True, null=True, max_length=255)\n ah_volume = models.CharField(blank=True, null=True, max_length=255)\n source = models.ForeignKey(\n \"Source\", on_delete=models.PROTECT, blank=True, null=True\n )\n cantus_id = models.CharField(blank=True, null=True, max_length=255)\n image_link = models.URLField(blank=True, null=True)\n json_info = models.JSONField(null=True, blank=True)\n\n # The following fields (dummy fields) are just for harmonizing the chant and sequence models to have the same fields\n # They should never be populated or displayed\n # The order of the fields must be exactly the same between the seq and chant models\n marginalia = models.CharField(max_length=63, null=True, blank=True)\n sequence_number = models.PositiveIntegerField(\n help_text='Each folio starts with \"1\"', null=True, blank=True\n )\n office = models.ForeignKey(\n \"Office\", on_delete=models.PROTECT, null=True, blank=True\n )\n position = models.CharField(max_length=63, null=True, blank=True)\n feast = models.ForeignKey(\"Feast\", on_delete=models.PROTECT, null=True, blank=True)\n mode = models.CharField(max_length=63, null=True, blank=True)\n differentia = models.CharField(blank=True, null=True, max_length=63)\n differentia_id = models.CharField(blank=True, null=True, max_length=12)\n finalis = models.CharField(blank=True, null=True, max_length=63)\n extra = models.CharField(blank=True, null=True, max_length=63)\n chant_range = models.CharField(\n blank=True,\n null=True,\n help_text='Example: \"1-c-k-4\". Optional field',\n max_length=255,\n )\n addendum = models.CharField(blank=True, null=True, max_length=255)\n manuscript_full_text_std_spelling = models.TextField(\n help_text=\"Manuscript full text with standardized spelling. Enter the words \"\n \"according to the manuscript but normalize their spellings following \"\n \"Classical Latin forms. Use upper-case letters for proper nouns, \"\n 'the first word of each chant, and the first word after \"Alleluia\" for '\n \"Mass Alleluias. Punctuation is omitted.\",\n null=True,\n blank=True,\n )\n manuscript_full_text_std_proofread = models.BooleanField(blank=True, null=True)\n manuscript_full_text = models.TextField(\n help_text=\"Enter the wording, word order and spellings as found in the manuscript\"\n \", with abbreviations resolved to standard words. Use upper-case letters as found\"\n \" in the source. Retain \u201cXpistum\u201d (Christum), \u201cIhc\u201d (Jesus) and other instances of \"\n \"Greek characters with their closest approximations of Latin letters. Some punctuation\"\n \" signs and vertical dividing lines | are employed in this field. Repetenda and psalm \"\n \"cues can also be recorded here. For more information, contact Cantus Database staff.\",\n null=True,\n blank=True,\n )\n manuscript_full_text_proofread = models.BooleanField(blank=True, null=True)\n manuscript_syllabized_full_text = models.TextField(null=True, blank=True)\n volpiano = models.TextField(null=True, blank=True)\n volpiano_proofread = models.BooleanField(blank=True, null=True)\n volpiano_notes = models.TextField(null=True, blank=True)\n volpiano_intervals = models.TextField(null=True, blank=True)\n # volpiano_intervals = ArrayField(base_field=models.IntegerField(), null=True, blank=True)\n cao_concordances = models.CharField(blank=True, null=True, max_length=63)\n proofread_by = models.ForeignKey(\n User, on_delete=models.PROTECT, null=True, blank=True\n )\n melody_id = models.CharField(blank=True, null=True, max_length=63)\n search_vector = SearchVectorField(null=True, editable=False)\n content_structure = models.CharField(\n blank=True,\n null=True,\n max_length=64,\n help_text=\"Additional folio number field, if folio numbers appear on the leaves but are not in the 'binding order'.\",\n )\n", "path": "django/cantusdb_project/main_app/models/sequence.py"}]} | 1,653 | 194 |
gh_patches_debug_5033 | rasdani/github-patches | git_diff | meltano__meltano-7488 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Cloud CLI logs auth token at info level
### Meltano Version
cloud branch
### Python Version
NA
### Bug scope
CLI (options, error messages, logging, etc.)
### Operating System
N/A
### Description
Running `meltano cloud login` results in the input shown below. Running `meltano-cloud login` does not.
A good resolution to this would probably be to figure out what is logging these HTTP requests, and silence those log messages. My guess is that it has to do with the recent change to use `aiohttp` instead of Flask for the local auth server.
### Code
```python
Logging in to Meltano Cloud.
You will be directed to a web browser to complete login.
If a web browser does not open, open the following link:
https://auth.meltano.cloud/oauth2/authorize?client_id=45rpn5ep3g4qjut8jd3s4iq872&response_type=token&scope=email+openid+profile&redirect_uri=http%3A%2F%2Flocalhost%3A9999
2023-04-04T16:09:25.658362Z [info ] 127.0.0.1 [04/Apr/2023:16:09:25 +0000] "GET / HTTP/1.1" 200 236 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/111.0"
2023-04-04T16:09:25.780667Z [info ] 127.0.0.1 [04/Apr/2023:16:09:25 +0000] "GET /tokens?access_token=<redacted>&token_type=Bearer&expires_in=28800 HTTP/1.1" 204 99 "http://localhost:9999/" "Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/111.0"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cloud-cli/meltano/cloud/api/auth/auth.py`
Content:
```
1 """Authentication for Meltano Cloud."""
2
3 from __future__ import annotations
4
5 import asyncio
6 import sys
7 import tempfile
8 import typing as t
9 import webbrowser
10 from contextlib import asynccontextmanager
11 from http import HTTPStatus
12 from pathlib import Path
13 from urllib.parse import urlencode, urljoin
14
15 import aiohttp
16 import click
17 import jinja2
18 from aiohttp import web
19
20 from meltano.cloud.api.config import MeltanoCloudConfig
21
22 if sys.version_info <= (3, 8):
23 from cached_property import cached_property
24 else:
25 from functools import cached_property
26
27 if sys.version_info < (3, 9):
28 import importlib_resources
29 else:
30 from importlib import resources as importlib_resources
31
32 LOGIN_STATUS_CHECK_DELAY_SECONDS = 0.2
33
34
35 class MeltanoCloudAuthError(Exception):
36 """Raised when an API call returns a 403."""
37
38
39 class MeltanoCloudAuth: # noqa: WPS214
40 """Authentication methods for Meltano Cloud."""
41
42 def __init__(self, config: MeltanoCloudConfig | None = None):
43 """Initialize a MeltanoCloudAuth instance.
44
45 Args:
46 config: the MeltanoCloudConfig to use
47 """
48 self.config = config or MeltanoCloudConfig.find()
49 self.base_url = self.config.base_auth_url
50 self.client_id = self.config.app_client_id
51
52 @cached_property
53 def login_url(self) -> str:
54 """Get the oauth2 authorization URL.
55
56 Returns:
57 the oauth2 authorization URL.
58 """
59 query_params = urlencode(
60 {
61 "client_id": self.client_id,
62 "response_type": "token",
63 "scope": "email openid profile",
64 "redirect_uri": f"http://localhost:{self.config.auth_callback_port}",
65 },
66 )
67 return f"{self.base_url}/oauth2/authorize?{query_params}"
68
69 @cached_property
70 def logout_url(self) -> str:
71 """Get the Meltano Cloud logout URL.
72
73 Returns:
74 the Meltano Cloud logout URL.
75 """
76 params = urlencode(
77 {
78 "client_id": self.client_id,
79 "logout_uri": f"http://localhost:{self.config.auth_callback_port}/logout", # noqa: E501)
80 },
81 )
82 return urljoin(self.base_url, f"logout?{params}")
83
84 @asynccontextmanager
85 async def _callback_server(
86 self,
87 rendered_template_dir: Path,
88 ) -> t.AsyncIterator[web.Application]:
89 app = web.Application()
90 resource_root = importlib_resources.files(__package__)
91
92 async def callback_page(_):
93 with importlib_resources.as_file(
94 resource_root / "callback.jinja2",
95 ) as template_file, (rendered_template_dir / "callback.html").open(
96 "w",
97 ) as rendered_template_file:
98 rendered_template_file.write(
99 jinja2.Template(template_file.read_text()).render(
100 port=self.config.auth_callback_port,
101 ),
102 )
103 return web.FileResponse(rendered_template_file.name)
104
105 async def handle_tokens(request: web.Request):
106 self.config.id_token = request.query["id_token"]
107 self.config.access_token = request.query["access_token"]
108 self.config.write_to_file()
109 return web.Response(status=HTTPStatus.NO_CONTENT)
110
111 async def handle_logout(_):
112 self.config.id_token = None
113 self.config.access_token = None
114 self.config.write_to_file()
115 with importlib_resources.as_file(
116 resource_root / "logout.html",
117 ) as html_file:
118 return web.FileResponse(html_file)
119
120 app.add_routes(
121 (
122 web.get("/", callback_page),
123 web.get("/tokens", handle_tokens),
124 web.get("/logout", handle_logout),
125 ),
126 )
127 runner = web.AppRunner(app)
128 await runner.setup()
129 site = web.TCPSite(runner, "localhost", self.config.auth_callback_port)
130 await site.start()
131 try:
132 yield app
133 finally:
134 await runner.cleanup()
135
136 @asynccontextmanager
137 async def callback_server(self) -> t.AsyncIterator[web.Application]:
138 """Context manager to run callback server locally.
139
140 Yields:
141 The aiohttp web application.
142 """
143 with tempfile.TemporaryDirectory(prefix="meltano-cloud-") as tmpdir:
144 async with self._callback_server(Path(tmpdir)) as app:
145 yield app
146
147 async def login(self) -> None:
148 """Take user through login flow and get auth and id tokens."""
149 if await self.logged_in():
150 return
151 async with self.callback_server():
152 click.echo("Logging in to Meltano Cloud.")
153 click.echo("You will be directed to a web browser to complete login.")
154 click.echo("If a web browser does not open, open the following link:")
155 click.secho(self.login_url, fg="green")
156 webbrowser.open_new_tab(self.login_url)
157 while not await self.logged_in():
158 self.config.refresh()
159 await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)
160
161 async def logout(self) -> None: # noqa: WPS213
162 """Log out."""
163 if not await self.logged_in():
164 click.secho("Not logged in.", fg="green")
165 return
166 async with self.callback_server():
167 click.echo("Logging out of Meltano Cloud.")
168 click.echo("You will be directed to a web browser to complete logout.")
169 click.echo("If a web browser does not open, open the following link:")
170 click.secho(self.logout_url, fg="green")
171 webbrowser.open_new_tab(self.logout_url)
172 while await self.logged_in():
173 self.config.refresh()
174 await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)
175 click.secho("Successfully logged out.", fg="green")
176
177 def get_auth_header(self) -> dict[str, str]:
178 """Get the authorization header.
179
180 Used for authenticating to cloud API endpoints.
181
182 Returns:
183 Authorization header using ID token as bearer token.
184
185 """
186 return {"Authorization": f"Bearer {self.config.id_token}"}
187
188 def get_access_token_header(self) -> dict[str, str]:
189 """Get the access token header.
190
191 Used for authenticating to auth endpoints.
192
193 Returns:
194 Authorization header using access token as bearer token.
195 """
196 return {"Authorization": f"Bearer {self.config.access_token}"}
197
198 @asynccontextmanager
199 async def _get_user_info_response(self) -> t.AsyncIterator[aiohttp.ClientResponse]:
200 async with aiohttp.ClientSession() as session:
201 async with session.get(
202 urljoin(self.base_url, "oauth2/userInfo"),
203 headers=self.get_access_token_header(),
204 ) as response:
205 yield response
206
207 async def get_user_info_response(self) -> aiohttp.ClientResponse:
208 """Get user info.
209
210 Returns:
211 User info response
212 """
213 async with self._get_user_info_response() as response:
214 return response
215
216 async def get_user_info_json(self) -> dict:
217 """Get user info as dict.
218
219 Returns:
220 User info json
221 """
222 async with self._get_user_info_response() as response:
223 return await response.json()
224
225 async def logged_in(self) -> bool:
226 """Check if this instance is currently logged in.
227
228 Returns:
229 True if logged in, else False
230 """
231 return bool(
232 self.config.access_token
233 and self.config.id_token
234 # Perform this check at the end to avoid
235 # spamming our servers if logout fails
236 and (await self.get_user_info_response()).ok,
237 )
238
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/cloud-cli/meltano/cloud/api/auth/auth.py b/src/cloud-cli/meltano/cloud/api/auth/auth.py
--- a/src/cloud-cli/meltano/cloud/api/auth/auth.py
+++ b/src/cloud-cli/meltano/cloud/api/auth/auth.py
@@ -124,7 +124,7 @@
web.get("/logout", handle_logout),
),
)
- runner = web.AppRunner(app)
+ runner = web.AppRunner(app, access_log=None)
await runner.setup()
site = web.TCPSite(runner, "localhost", self.config.auth_callback_port)
await site.start()
| {"golden_diff": "diff --git a/src/cloud-cli/meltano/cloud/api/auth/auth.py b/src/cloud-cli/meltano/cloud/api/auth/auth.py\n--- a/src/cloud-cli/meltano/cloud/api/auth/auth.py\n+++ b/src/cloud-cli/meltano/cloud/api/auth/auth.py\n@@ -124,7 +124,7 @@\n web.get(\"/logout\", handle_logout),\n ),\n )\n- runner = web.AppRunner(app)\n+ runner = web.AppRunner(app, access_log=None)\n await runner.setup()\n site = web.TCPSite(runner, \"localhost\", self.config.auth_callback_port)\n await site.start()\n", "issue": "bug: Cloud CLI logs auth token at info level\n### Meltano Version\n\ncloud branch\n\n### Python Version\n\nNA\n\n### Bug scope\n\nCLI (options, error messages, logging, etc.)\n\n### Operating System\n\nN/A\n\n### Description\n\nRunning `meltano cloud login` results in the input shown below. Running `meltano-cloud login` does not.\r\n\r\nA good resolution to this would probably be to figure out what is logging these HTTP requests, and silence those log messages. My guess is that it has to do with the recent change to use `aiohttp` instead of Flask for the local auth server.\n\n### Code\n\n```python\nLogging in to Meltano Cloud.\r\nYou will be directed to a web browser to complete login.\r\nIf a web browser does not open, open the following link:\r\nhttps://auth.meltano.cloud/oauth2/authorize?client_id=45rpn5ep3g4qjut8jd3s4iq872&response_type=token&scope=email+openid+profile&redirect_uri=http%3A%2F%2Flocalhost%3A9999\r\n2023-04-04T16:09:25.658362Z [info ] 127.0.0.1 [04/Apr/2023:16:09:25 +0000] \"GET / HTTP/1.1\" 200 236 \"-\" \"Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/111.0\"\r\n2023-04-04T16:09:25.780667Z [info ] 127.0.0.1 [04/Apr/2023:16:09:25 +0000] \"GET /tokens?access_token=<redacted>&token_type=Bearer&expires_in=28800 HTTP/1.1\" 204 99 \"http://localhost:9999/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/111.0\"\n```\n\n", "before_files": [{"content": "\"\"\"Authentication for Meltano Cloud.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport sys\nimport tempfile\nimport typing as t\nimport webbrowser\nfrom contextlib import asynccontextmanager\nfrom http import HTTPStatus\nfrom pathlib import Path\nfrom urllib.parse import urlencode, urljoin\n\nimport aiohttp\nimport click\nimport jinja2\nfrom aiohttp import web\n\nfrom meltano.cloud.api.config import MeltanoCloudConfig\n\nif sys.version_info <= (3, 8):\n from cached_property import cached_property\nelse:\n from functools import cached_property\n\nif sys.version_info < (3, 9):\n import importlib_resources\nelse:\n from importlib import resources as importlib_resources\n\nLOGIN_STATUS_CHECK_DELAY_SECONDS = 0.2\n\n\nclass MeltanoCloudAuthError(Exception):\n \"\"\"Raised when an API call returns a 403.\"\"\"\n\n\nclass MeltanoCloudAuth: # noqa: WPS214\n \"\"\"Authentication methods for Meltano Cloud.\"\"\"\n\n def __init__(self, config: MeltanoCloudConfig | None = None):\n \"\"\"Initialize a MeltanoCloudAuth instance.\n\n Args:\n config: the MeltanoCloudConfig to use\n \"\"\"\n self.config = config or MeltanoCloudConfig.find()\n self.base_url = self.config.base_auth_url\n self.client_id = self.config.app_client_id\n\n @cached_property\n def login_url(self) -> str:\n \"\"\"Get the oauth2 authorization URL.\n\n Returns:\n the oauth2 authorization URL.\n \"\"\"\n query_params = urlencode(\n {\n \"client_id\": self.client_id,\n \"response_type\": \"token\",\n \"scope\": \"email openid profile\",\n \"redirect_uri\": f\"http://localhost:{self.config.auth_callback_port}\",\n },\n )\n return f\"{self.base_url}/oauth2/authorize?{query_params}\"\n\n @cached_property\n def logout_url(self) -> str:\n \"\"\"Get the Meltano Cloud logout URL.\n\n Returns:\n the Meltano Cloud logout URL.\n \"\"\"\n params = urlencode(\n {\n \"client_id\": self.client_id,\n \"logout_uri\": f\"http://localhost:{self.config.auth_callback_port}/logout\", # noqa: E501)\n },\n )\n return urljoin(self.base_url, f\"logout?{params}\")\n\n @asynccontextmanager\n async def _callback_server(\n self,\n rendered_template_dir: Path,\n ) -> t.AsyncIterator[web.Application]:\n app = web.Application()\n resource_root = importlib_resources.files(__package__)\n\n async def callback_page(_):\n with importlib_resources.as_file(\n resource_root / \"callback.jinja2\",\n ) as template_file, (rendered_template_dir / \"callback.html\").open(\n \"w\",\n ) as rendered_template_file:\n rendered_template_file.write(\n jinja2.Template(template_file.read_text()).render(\n port=self.config.auth_callback_port,\n ),\n )\n return web.FileResponse(rendered_template_file.name)\n\n async def handle_tokens(request: web.Request):\n self.config.id_token = request.query[\"id_token\"]\n self.config.access_token = request.query[\"access_token\"]\n self.config.write_to_file()\n return web.Response(status=HTTPStatus.NO_CONTENT)\n\n async def handle_logout(_):\n self.config.id_token = None\n self.config.access_token = None\n self.config.write_to_file()\n with importlib_resources.as_file(\n resource_root / \"logout.html\",\n ) as html_file:\n return web.FileResponse(html_file)\n\n app.add_routes(\n (\n web.get(\"/\", callback_page),\n web.get(\"/tokens\", handle_tokens),\n web.get(\"/logout\", handle_logout),\n ),\n )\n runner = web.AppRunner(app)\n await runner.setup()\n site = web.TCPSite(runner, \"localhost\", self.config.auth_callback_port)\n await site.start()\n try:\n yield app\n finally:\n await runner.cleanup()\n\n @asynccontextmanager\n async def callback_server(self) -> t.AsyncIterator[web.Application]:\n \"\"\"Context manager to run callback server locally.\n\n Yields:\n The aiohttp web application.\n \"\"\"\n with tempfile.TemporaryDirectory(prefix=\"meltano-cloud-\") as tmpdir:\n async with self._callback_server(Path(tmpdir)) as app:\n yield app\n\n async def login(self) -> None:\n \"\"\"Take user through login flow and get auth and id tokens.\"\"\"\n if await self.logged_in():\n return\n async with self.callback_server():\n click.echo(\"Logging in to Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete login.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.login_url, fg=\"green\")\n webbrowser.open_new_tab(self.login_url)\n while not await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n\n async def logout(self) -> None: # noqa: WPS213\n \"\"\"Log out.\"\"\"\n if not await self.logged_in():\n click.secho(\"Not logged in.\", fg=\"green\")\n return\n async with self.callback_server():\n click.echo(\"Logging out of Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete logout.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.logout_url, fg=\"green\")\n webbrowser.open_new_tab(self.logout_url)\n while await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n click.secho(\"Successfully logged out.\", fg=\"green\")\n\n def get_auth_header(self) -> dict[str, str]:\n \"\"\"Get the authorization header.\n\n Used for authenticating to cloud API endpoints.\n\n Returns:\n Authorization header using ID token as bearer token.\n\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.id_token}\"}\n\n def get_access_token_header(self) -> dict[str, str]:\n \"\"\"Get the access token header.\n\n Used for authenticating to auth endpoints.\n\n Returns:\n Authorization header using access token as bearer token.\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.access_token}\"}\n\n @asynccontextmanager\n async def _get_user_info_response(self) -> t.AsyncIterator[aiohttp.ClientResponse]:\n async with aiohttp.ClientSession() as session:\n async with session.get(\n urljoin(self.base_url, \"oauth2/userInfo\"),\n headers=self.get_access_token_header(),\n ) as response:\n yield response\n\n async def get_user_info_response(self) -> aiohttp.ClientResponse:\n \"\"\"Get user info.\n\n Returns:\n User info response\n \"\"\"\n async with self._get_user_info_response() as response:\n return response\n\n async def get_user_info_json(self) -> dict:\n \"\"\"Get user info as dict.\n\n Returns:\n User info json\n \"\"\"\n async with self._get_user_info_response() as response:\n return await response.json()\n\n async def logged_in(self) -> bool:\n \"\"\"Check if this instance is currently logged in.\n\n Returns:\n True if logged in, else False\n \"\"\"\n return bool(\n self.config.access_token\n and self.config.id_token\n # Perform this check at the end to avoid\n # spamming our servers if logout fails\n and (await self.get_user_info_response()).ok,\n )\n", "path": "src/cloud-cli/meltano/cloud/api/auth/auth.py"}], "after_files": [{"content": "\"\"\"Authentication for Meltano Cloud.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport sys\nimport tempfile\nimport typing as t\nimport webbrowser\nfrom contextlib import asynccontextmanager\nfrom http import HTTPStatus\nfrom pathlib import Path\nfrom urllib.parse import urlencode, urljoin\n\nimport aiohttp\nimport click\nimport jinja2\nfrom aiohttp import web\n\nfrom meltano.cloud.api.config import MeltanoCloudConfig\n\nif sys.version_info <= (3, 8):\n from cached_property import cached_property\nelse:\n from functools import cached_property\n\nif sys.version_info < (3, 9):\n import importlib_resources\nelse:\n from importlib import resources as importlib_resources\n\nLOGIN_STATUS_CHECK_DELAY_SECONDS = 0.2\n\n\nclass MeltanoCloudAuthError(Exception):\n \"\"\"Raised when an API call returns a 403.\"\"\"\n\n\nclass MeltanoCloudAuth: # noqa: WPS214\n \"\"\"Authentication methods for Meltano Cloud.\"\"\"\n\n def __init__(self, config: MeltanoCloudConfig | None = None):\n \"\"\"Initialize a MeltanoCloudAuth instance.\n\n Args:\n config: the MeltanoCloudConfig to use\n \"\"\"\n self.config = config or MeltanoCloudConfig.find()\n self.base_url = self.config.base_auth_url\n self.client_id = self.config.app_client_id\n\n @cached_property\n def login_url(self) -> str:\n \"\"\"Get the oauth2 authorization URL.\n\n Returns:\n the oauth2 authorization URL.\n \"\"\"\n query_params = urlencode(\n {\n \"client_id\": self.client_id,\n \"response_type\": \"token\",\n \"scope\": \"email openid profile\",\n \"redirect_uri\": f\"http://localhost:{self.config.auth_callback_port}\",\n },\n )\n return f\"{self.base_url}/oauth2/authorize?{query_params}\"\n\n @cached_property\n def logout_url(self) -> str:\n \"\"\"Get the Meltano Cloud logout URL.\n\n Returns:\n the Meltano Cloud logout URL.\n \"\"\"\n params = urlencode(\n {\n \"client_id\": self.client_id,\n \"logout_uri\": f\"http://localhost:{self.config.auth_callback_port}/logout\", # noqa: E501)\n },\n )\n return urljoin(self.base_url, f\"logout?{params}\")\n\n @asynccontextmanager\n async def _callback_server(\n self,\n rendered_template_dir: Path,\n ) -> t.AsyncIterator[web.Application]:\n app = web.Application()\n resource_root = importlib_resources.files(__package__)\n\n async def callback_page(_):\n with importlib_resources.as_file(\n resource_root / \"callback.jinja2\",\n ) as template_file, (rendered_template_dir / \"callback.html\").open(\n \"w\",\n ) as rendered_template_file:\n rendered_template_file.write(\n jinja2.Template(template_file.read_text()).render(\n port=self.config.auth_callback_port,\n ),\n )\n return web.FileResponse(rendered_template_file.name)\n\n async def handle_tokens(request: web.Request):\n self.config.id_token = request.query[\"id_token\"]\n self.config.access_token = request.query[\"access_token\"]\n self.config.write_to_file()\n return web.Response(status=HTTPStatus.NO_CONTENT)\n\n async def handle_logout(_):\n self.config.id_token = None\n self.config.access_token = None\n self.config.write_to_file()\n with importlib_resources.as_file(\n resource_root / \"logout.html\",\n ) as html_file:\n return web.FileResponse(html_file)\n\n app.add_routes(\n (\n web.get(\"/\", callback_page),\n web.get(\"/tokens\", handle_tokens),\n web.get(\"/logout\", handle_logout),\n ),\n )\n runner = web.AppRunner(app, access_log=None)\n await runner.setup()\n site = web.TCPSite(runner, \"localhost\", self.config.auth_callback_port)\n await site.start()\n try:\n yield app\n finally:\n await runner.cleanup()\n\n @asynccontextmanager\n async def callback_server(self) -> t.AsyncIterator[web.Application]:\n \"\"\"Context manager to run callback server locally.\n\n Yields:\n The aiohttp web application.\n \"\"\"\n with tempfile.TemporaryDirectory(prefix=\"meltano-cloud-\") as tmpdir:\n async with self._callback_server(Path(tmpdir)) as app:\n yield app\n\n async def login(self) -> None:\n \"\"\"Take user through login flow and get auth and id tokens.\"\"\"\n if await self.logged_in():\n return\n async with self.callback_server():\n click.echo(\"Logging in to Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete login.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.login_url, fg=\"green\")\n webbrowser.open_new_tab(self.login_url)\n while not await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n\n async def logout(self) -> None: # noqa: WPS213\n \"\"\"Log out.\"\"\"\n if not await self.logged_in():\n click.secho(\"Not logged in.\", fg=\"green\")\n return\n async with self.callback_server():\n click.echo(\"Logging out of Meltano Cloud.\")\n click.echo(\"You will be directed to a web browser to complete logout.\")\n click.echo(\"If a web browser does not open, open the following link:\")\n click.secho(self.logout_url, fg=\"green\")\n webbrowser.open_new_tab(self.logout_url)\n while await self.logged_in():\n self.config.refresh()\n await asyncio.sleep(LOGIN_STATUS_CHECK_DELAY_SECONDS)\n click.secho(\"Successfully logged out.\", fg=\"green\")\n\n def get_auth_header(self) -> dict[str, str]:\n \"\"\"Get the authorization header.\n\n Used for authenticating to cloud API endpoints.\n\n Returns:\n Authorization header using ID token as bearer token.\n\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.id_token}\"}\n\n def get_access_token_header(self) -> dict[str, str]:\n \"\"\"Get the access token header.\n\n Used for authenticating to auth endpoints.\n\n Returns:\n Authorization header using access token as bearer token.\n \"\"\"\n return {\"Authorization\": f\"Bearer {self.config.access_token}\"}\n\n @asynccontextmanager\n async def _get_user_info_response(self) -> t.AsyncIterator[aiohttp.ClientResponse]:\n async with aiohttp.ClientSession() as session:\n async with session.get(\n urljoin(self.base_url, \"oauth2/userInfo\"),\n headers=self.get_access_token_header(),\n ) as response:\n yield response\n\n async def get_user_info_response(self) -> aiohttp.ClientResponse:\n \"\"\"Get user info.\n\n Returns:\n User info response\n \"\"\"\n async with self._get_user_info_response() as response:\n return response\n\n async def get_user_info_json(self) -> dict:\n \"\"\"Get user info as dict.\n\n Returns:\n User info json\n \"\"\"\n async with self._get_user_info_response() as response:\n return await response.json()\n\n async def logged_in(self) -> bool:\n \"\"\"Check if this instance is currently logged in.\n\n Returns:\n True if logged in, else False\n \"\"\"\n return bool(\n self.config.access_token\n and self.config.id_token\n # Perform this check at the end to avoid\n # spamming our servers if logout fails\n and (await self.get_user_info_response()).ok,\n )\n", "path": "src/cloud-cli/meltano/cloud/api/auth/auth.py"}]} | 3,031 | 135 |
gh_patches_debug_28234 | rasdani/github-patches | git_diff | quantumlib__Cirq-3054 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support multi-qubit measurements in `cirq.plot_state_histogram`
Quote from the docstring: "Currently this function assumes each measurement gate applies to only a single qubit."
Currently, I get an incorrect histogram if I didn't read the docstring and used a multi-qubit measurement (I always make circuits like this):
```python
qubits = cirq.LineQubit.range(3)
c = cirq.Circuit(
(cirq.X**0.4).on_each(*qubits),
cirq.measure(*qubits), # One multi-qubit measurement
)
cirq.plot_state_histogram(cirq.sample(c, repetitions=10000))
# Incorrect output, no warning or error
```

If I use single-qubit measurement gates, I get the expected histogram:
```python
qubits = cirq.LineQubit.range(3)
c = cirq.Circuit(
(cirq.X**0.4).on_each(*qubits),
cirq.measure_each(*qubits), # One measurement per qubit
)
cirq.plot_state_histogram(cirq.sample(c, repetitions=10000))
```

This looks like it could be fixed by adding some logic to `plot_state_histogram` (https://github.com/quantumlib/Cirq/blob/master/cirq/study/visualize.py#L22) that checks for multi-qubit measurements and either correctly interpret them or raise an error.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq/study/visualize.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Tool to visualize the results of a study."""
16
17 import numpy as np
18
19 from cirq.study import trial_result
20
21
22 def plot_state_histogram(result: trial_result.TrialResult) -> np.ndarray:
23 """Plot the state histogram from a single result with repetitions.
24
25 States is a bitstring representation of all the qubit states in a single
26 result.
27 Currently this function assumes each measurement gate applies to only
28 a single qubit.
29
30 Args:
31 result: The trial results to plot.
32
33 Returns:
34 The histogram. A list of values plotted on the y-axis.
35 """
36
37 # pyplot import is deferred because it requires a system dependency
38 # (python3-tk) that `python -m pip install cirq` can't handle for the user.
39 # This allows cirq to be usable without python3-tk.
40 import matplotlib.pyplot as plt
41
42 num_qubits = len(result.measurements.keys())
43 states = 2**num_qubits
44 values = np.zeros(states)
45
46 # measurements is a dict of {measurement gate key:
47 # array(repetitions, boolean result)}
48 # Convert this to an array of repetitions, each with an array of booleans.
49 # e.g. {q1: array([[True, True]]), q2: array([[False, False]])}
50 # --> array([[True, False], [True, False]])
51 measurement_by_result = np.array([
52 v.transpose()[0] for k, v in result.measurements.items()]).transpose()
53
54 for meas in measurement_by_result:
55 # Convert each array of booleans to a string representation.
56 # e.g. [True, False] -> [1, 0] -> '10' -> 2
57 state_ind = int(''.join([str(x) for x in [int(x) for x in meas]]), 2)
58 values[state_ind] += 1
59
60 plot_labels = [bin(x)[2:].zfill(num_qubits) for x in range(states)]
61 plt.bar(np.arange(states), values, tick_label=plot_labels)
62 plt.xlabel('qubit state')
63 plt.ylabel('result count')
64 plt.show()
65
66 return values
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cirq/study/visualize.py b/cirq/study/visualize.py
--- a/cirq/study/visualize.py
+++ b/cirq/study/visualize.py
@@ -24,8 +24,6 @@
States is a bitstring representation of all the qubit states in a single
result.
- Currently this function assumes each measurement gate applies to only
- a single qubit.
Args:
result: The trial results to plot.
@@ -39,17 +37,15 @@
# This allows cirq to be usable without python3-tk.
import matplotlib.pyplot as plt
- num_qubits = len(result.measurements.keys())
+ num_qubits = sum([value.shape[1] for value in result.measurements.values()])
states = 2**num_qubits
values = np.zeros(states)
-
# measurements is a dict of {measurement gate key:
# array(repetitions, boolean result)}
# Convert this to an array of repetitions, each with an array of booleans.
# e.g. {q1: array([[True, True]]), q2: array([[False, False]])}
# --> array([[True, False], [True, False]])
- measurement_by_result = np.array([
- v.transpose()[0] for k, v in result.measurements.items()]).transpose()
+ measurement_by_result = np.hstack(list(result.measurements.values()))
for meas in measurement_by_result:
# Convert each array of booleans to a string representation.
| {"golden_diff": "diff --git a/cirq/study/visualize.py b/cirq/study/visualize.py\n--- a/cirq/study/visualize.py\n+++ b/cirq/study/visualize.py\n@@ -24,8 +24,6 @@\n \n States is a bitstring representation of all the qubit states in a single\n result.\n- Currently this function assumes each measurement gate applies to only\n- a single qubit.\n \n Args:\n result: The trial results to plot.\n@@ -39,17 +37,15 @@\n # This allows cirq to be usable without python3-tk.\n import matplotlib.pyplot as plt\n \n- num_qubits = len(result.measurements.keys())\n+ num_qubits = sum([value.shape[1] for value in result.measurements.values()])\n states = 2**num_qubits\n values = np.zeros(states)\n-\n # measurements is a dict of {measurement gate key:\n # array(repetitions, boolean result)}\n # Convert this to an array of repetitions, each with an array of booleans.\n # e.g. {q1: array([[True, True]]), q2: array([[False, False]])}\n # --> array([[True, False], [True, False]])\n- measurement_by_result = np.array([\n- v.transpose()[0] for k, v in result.measurements.items()]).transpose()\n+ measurement_by_result = np.hstack(list(result.measurements.values()))\n \n for meas in measurement_by_result:\n # Convert each array of booleans to a string representation.\n", "issue": "Support multi-qubit measurements in `cirq.plot_state_histogram`\nQuote from the docstring: \"Currently this function assumes each measurement gate applies to only a single qubit.\"\r\n\r\nCurrently, I get an incorrect histogram if I didn't read the docstring and used a multi-qubit measurement (I always make circuits like this):\r\n```python\r\nqubits = cirq.LineQubit.range(3)\r\nc = cirq.Circuit(\r\n (cirq.X**0.4).on_each(*qubits),\r\n cirq.measure(*qubits), # One multi-qubit measurement\r\n)\r\ncirq.plot_state_histogram(cirq.sample(c, repetitions=10000))\r\n# Incorrect output, no warning or error\r\n```\r\n\r\n\r\nIf I use single-qubit measurement gates, I get the expected histogram:\r\n```python\r\nqubits = cirq.LineQubit.range(3)\r\nc = cirq.Circuit(\r\n (cirq.X**0.4).on_each(*qubits),\r\n cirq.measure_each(*qubits), # One measurement per qubit\r\n)\r\ncirq.plot_state_histogram(cirq.sample(c, repetitions=10000))\r\n```\r\n\r\n\r\nThis looks like it could be fixed by adding some logic to `plot_state_histogram` (https://github.com/quantumlib/Cirq/blob/master/cirq/study/visualize.py#L22) that checks for multi-qubit measurements and either correctly interpret them or raise an error.\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Tool to visualize the results of a study.\"\"\"\n\nimport numpy as np\n\nfrom cirq.study import trial_result\n\n\ndef plot_state_histogram(result: trial_result.TrialResult) -> np.ndarray:\n \"\"\"Plot the state histogram from a single result with repetitions.\n\n States is a bitstring representation of all the qubit states in a single\n result.\n Currently this function assumes each measurement gate applies to only\n a single qubit.\n\n Args:\n result: The trial results to plot.\n\n Returns:\n The histogram. A list of values plotted on the y-axis.\n \"\"\"\n\n # pyplot import is deferred because it requires a system dependency\n # (python3-tk) that `python -m pip install cirq` can't handle for the user.\n # This allows cirq to be usable without python3-tk.\n import matplotlib.pyplot as plt\n\n num_qubits = len(result.measurements.keys())\n states = 2**num_qubits\n values = np.zeros(states)\n\n # measurements is a dict of {measurement gate key:\n # array(repetitions, boolean result)}\n # Convert this to an array of repetitions, each with an array of booleans.\n # e.g. {q1: array([[True, True]]), q2: array([[False, False]])}\n # --> array([[True, False], [True, False]])\n measurement_by_result = np.array([\n v.transpose()[0] for k, v in result.measurements.items()]).transpose()\n\n for meas in measurement_by_result:\n # Convert each array of booleans to a string representation.\n # e.g. [True, False] -> [1, 0] -> '10' -> 2\n state_ind = int(''.join([str(x) for x in [int(x) for x in meas]]), 2)\n values[state_ind] += 1\n\n plot_labels = [bin(x)[2:].zfill(num_qubits) for x in range(states)]\n plt.bar(np.arange(states), values, tick_label=plot_labels)\n plt.xlabel('qubit state')\n plt.ylabel('result count')\n plt.show()\n\n return values\n", "path": "cirq/study/visualize.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Tool to visualize the results of a study.\"\"\"\n\nimport numpy as np\n\nfrom cirq.study import trial_result\n\n\ndef plot_state_histogram(result: trial_result.TrialResult) -> np.ndarray:\n \"\"\"Plot the state histogram from a single result with repetitions.\n\n States is a bitstring representation of all the qubit states in a single\n result.\n\n Args:\n result: The trial results to plot.\n\n Returns:\n The histogram. A list of values plotted on the y-axis.\n \"\"\"\n\n # pyplot import is deferred because it requires a system dependency\n # (python3-tk) that `python -m pip install cirq` can't handle for the user.\n # This allows cirq to be usable without python3-tk.\n import matplotlib.pyplot as plt\n\n num_qubits = sum([value.shape[1] for value in result.measurements.values()])\n states = 2**num_qubits\n values = np.zeros(states)\n # measurements is a dict of {measurement gate key:\n # array(repetitions, boolean result)}\n # Convert this to an array of repetitions, each with an array of booleans.\n # e.g. {q1: array([[True, True]]), q2: array([[False, False]])}\n # --> array([[True, False], [True, False]])\n measurement_by_result = np.hstack(list(result.measurements.values()))\n\n for meas in measurement_by_result:\n # Convert each array of booleans to a string representation.\n # e.g. [True, False] -> [1, 0] -> '10' -> 2\n state_ind = int(''.join([str(x) for x in [int(x) for x in meas]]), 2)\n values[state_ind] += 1\n\n plot_labels = [bin(x)[2:].zfill(num_qubits) for x in range(states)]\n plt.bar(np.arange(states), values, tick_label=plot_labels)\n plt.xlabel('qubit state')\n plt.ylabel('result count')\n plt.show()\n\n return values\n", "path": "cirq/study/visualize.py"}]} | 1,416 | 344 |
gh_patches_debug_26493 | rasdani/github-patches | git_diff | Pylons__pyramid-2567 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
exception views squash the original exception if an exception view predicate is tested and fails
If you register an exception view with a predicate such as `config.add_view(view, context=Exception, request_method='GET')`, this will cause any errors from a POST request (without a matching exception view) to be squashed into a `PredicateMismatch` exception which will be propagated up the wsgi stack instead of the original exception.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyramid/tweens.py`
Content:
```
1 import sys
2
3 from pyramid.interfaces import (
4 IExceptionViewClassifier,
5 IRequest,
6 )
7
8 from zope.interface import providedBy
9 from pyramid.view import _call_view
10
11 def excview_tween_factory(handler, registry):
12 """ A :term:`tween` factory which produces a tween that catches an
13 exception raised by downstream tweens (or the main Pyramid request
14 handler) and, if possible, converts it into a Response using an
15 :term:`exception view`."""
16
17 def excview_tween(request):
18 attrs = request.__dict__
19 try:
20 response = handler(request)
21 except Exception as exc:
22 # WARNING: do not assign the result of sys.exc_info() to a local
23 # var here, doing so will cause a leak. We used to actually
24 # explicitly delete both "exception" and "exc_info" from ``attrs``
25 # in a ``finally:`` clause below, but now we do not because these
26 # attributes are useful to upstream tweens. This actually still
27 # apparently causes a reference cycle, but it is broken
28 # successfully by the garbage collector (see
29 # https://github.com/Pylons/pyramid/issues/1223).
30 attrs['exc_info'] = sys.exc_info()
31 attrs['exception'] = exc
32 # clear old generated request.response, if any; it may
33 # have been mutated by the view, and its state is not
34 # sane (e.g. caching headers)
35 if 'response' in attrs:
36 del attrs['response']
37 # we use .get instead of .__getitem__ below due to
38 # https://github.com/Pylons/pyramid/issues/700
39 request_iface = attrs.get('request_iface', IRequest)
40 provides = providedBy(exc)
41 response = _call_view(
42 registry,
43 request,
44 exc,
45 provides,
46 '',
47 view_classifier=IExceptionViewClassifier,
48 request_iface=request_iface.combined
49 )
50 if response is None:
51 raise
52
53 return response
54
55 return excview_tween
56
57 MAIN = 'MAIN'
58 INGRESS = 'INGRESS'
59 EXCVIEW = 'pyramid.tweens.excview_tween_factory'
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyramid/tweens.py b/pyramid/tweens.py
--- a/pyramid/tweens.py
+++ b/pyramid/tweens.py
@@ -1,5 +1,7 @@
import sys
+from pyramid.compat import reraise
+from pyramid.exceptions import PredicateMismatch
from pyramid.interfaces import (
IExceptionViewClassifier,
IRequest,
@@ -38,17 +40,26 @@
# https://github.com/Pylons/pyramid/issues/700
request_iface = attrs.get('request_iface', IRequest)
provides = providedBy(exc)
- response = _call_view(
- registry,
- request,
- exc,
- provides,
- '',
- view_classifier=IExceptionViewClassifier,
- request_iface=request_iface.combined
- )
+ try:
+ response = _call_view(
+ registry,
+ request,
+ exc,
+ provides,
+ '',
+ view_classifier=IExceptionViewClassifier,
+ request_iface=request_iface.combined
+ )
+
+ # if views matched but did not pass predicates, squash the error
+ # and re-raise the original exception
+ except PredicateMismatch:
+ response = None
+
+ # re-raise the original exception as no exception views were
+ # able to handle the error
if response is None:
- raise
+ reraise(*attrs['exc_info'])
return response
| {"golden_diff": "diff --git a/pyramid/tweens.py b/pyramid/tweens.py\n--- a/pyramid/tweens.py\n+++ b/pyramid/tweens.py\n@@ -1,5 +1,7 @@\n import sys\n \n+from pyramid.compat import reraise\n+from pyramid.exceptions import PredicateMismatch\n from pyramid.interfaces import (\n IExceptionViewClassifier,\n IRequest,\n@@ -38,17 +40,26 @@\n # https://github.com/Pylons/pyramid/issues/700\n request_iface = attrs.get('request_iface', IRequest)\n provides = providedBy(exc)\n- response = _call_view(\n- registry,\n- request,\n- exc,\n- provides,\n- '',\n- view_classifier=IExceptionViewClassifier,\n- request_iface=request_iface.combined\n- )\n+ try:\n+ response = _call_view(\n+ registry,\n+ request,\n+ exc,\n+ provides,\n+ '',\n+ view_classifier=IExceptionViewClassifier,\n+ request_iface=request_iface.combined\n+ )\n+\n+ # if views matched but did not pass predicates, squash the error\n+ # and re-raise the original exception\n+ except PredicateMismatch:\n+ response = None\n+\n+ # re-raise the original exception as no exception views were\n+ # able to handle the error\n if response is None:\n- raise\n+ reraise(*attrs['exc_info'])\n \n return response\n", "issue": "exception views squash the original exception if an exception view predicate is tested and fails\nIf you register an exception view with a predicate such as `config.add_view(view, context=Exception, request_method='GET')`, this will cause any errors from a POST request (without a matching exception view) to be squashed into a `PredicateMismatch` exception which will be propagated up the wsgi stack instead of the original exception.\n\n", "before_files": [{"content": "import sys\n\nfrom pyramid.interfaces import (\n IExceptionViewClassifier,\n IRequest,\n )\n\nfrom zope.interface import providedBy\nfrom pyramid.view import _call_view\n\ndef excview_tween_factory(handler, registry):\n \"\"\" A :term:`tween` factory which produces a tween that catches an\n exception raised by downstream tweens (or the main Pyramid request\n handler) and, if possible, converts it into a Response using an\n :term:`exception view`.\"\"\"\n\n def excview_tween(request):\n attrs = request.__dict__\n try:\n response = handler(request)\n except Exception as exc:\n # WARNING: do not assign the result of sys.exc_info() to a local\n # var here, doing so will cause a leak. We used to actually\n # explicitly delete both \"exception\" and \"exc_info\" from ``attrs``\n # in a ``finally:`` clause below, but now we do not because these\n # attributes are useful to upstream tweens. This actually still\n # apparently causes a reference cycle, but it is broken\n # successfully by the garbage collector (see\n # https://github.com/Pylons/pyramid/issues/1223).\n attrs['exc_info'] = sys.exc_info()\n attrs['exception'] = exc\n # clear old generated request.response, if any; it may\n # have been mutated by the view, and its state is not\n # sane (e.g. caching headers)\n if 'response' in attrs:\n del attrs['response']\n # we use .get instead of .__getitem__ below due to\n # https://github.com/Pylons/pyramid/issues/700\n request_iface = attrs.get('request_iface', IRequest)\n provides = providedBy(exc)\n response = _call_view(\n registry,\n request,\n exc,\n provides,\n '',\n view_classifier=IExceptionViewClassifier,\n request_iface=request_iface.combined\n )\n if response is None:\n raise\n\n return response\n\n return excview_tween\n\nMAIN = 'MAIN'\nINGRESS = 'INGRESS'\nEXCVIEW = 'pyramid.tweens.excview_tween_factory'\n", "path": "pyramid/tweens.py"}], "after_files": [{"content": "import sys\n\nfrom pyramid.compat import reraise\nfrom pyramid.exceptions import PredicateMismatch\nfrom pyramid.interfaces import (\n IExceptionViewClassifier,\n IRequest,\n )\n\nfrom zope.interface import providedBy\nfrom pyramid.view import _call_view\n\ndef excview_tween_factory(handler, registry):\n \"\"\" A :term:`tween` factory which produces a tween that catches an\n exception raised by downstream tweens (or the main Pyramid request\n handler) and, if possible, converts it into a Response using an\n :term:`exception view`.\"\"\"\n\n def excview_tween(request):\n attrs = request.__dict__\n try:\n response = handler(request)\n except Exception as exc:\n # WARNING: do not assign the result of sys.exc_info() to a local\n # var here, doing so will cause a leak. We used to actually\n # explicitly delete both \"exception\" and \"exc_info\" from ``attrs``\n # in a ``finally:`` clause below, but now we do not because these\n # attributes are useful to upstream tweens. This actually still\n # apparently causes a reference cycle, but it is broken\n # successfully by the garbage collector (see\n # https://github.com/Pylons/pyramid/issues/1223).\n attrs['exc_info'] = sys.exc_info()\n attrs['exception'] = exc\n # clear old generated request.response, if any; it may\n # have been mutated by the view, and its state is not\n # sane (e.g. caching headers)\n if 'response' in attrs:\n del attrs['response']\n # we use .get instead of .__getitem__ below due to\n # https://github.com/Pylons/pyramid/issues/700\n request_iface = attrs.get('request_iface', IRequest)\n provides = providedBy(exc)\n try:\n response = _call_view(\n registry,\n request,\n exc,\n provides,\n '',\n view_classifier=IExceptionViewClassifier,\n request_iface=request_iface.combined\n )\n\n # if views matched but did not pass predicates, squash the error\n # and re-raise the original exception\n except PredicateMismatch:\n response = None\n\n # re-raise the original exception as no exception views were\n # able to handle the error\n if response is None:\n reraise(*attrs['exc_info'])\n\n return response\n\n return excview_tween\n\nMAIN = 'MAIN'\nINGRESS = 'INGRESS'\nEXCVIEW = 'pyramid.tweens.excview_tween_factory'\n", "path": "pyramid/tweens.py"}]} | 935 | 325 |
gh_patches_debug_8056 | rasdani/github-patches | git_diff | googleapis__python-bigquery-80 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
chore: replace Artman with bazel for synthesizing code
The synthtool should start using bazel instead of Artman.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `synth.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """This script is used to synthesize generated parts of this library."""
16
17 import synthtool as s
18 from synthtool import gcp
19
20 gapic = gcp.GAPICGenerator()
21 common = gcp.CommonTemplates()
22 version = 'v2'
23
24 library = gapic.py_library(
25 'bigquery',
26 version,
27 config_path='/google/cloud/bigquery/'
28 'artman_bigquery_v2.yaml',
29 artman_output_name='bigquery-v2',
30 include_protos=True,
31 )
32
33 s.move(
34 [
35 library / "google/cloud/bigquery_v2/gapic/enums.py",
36 library / "google/cloud/bigquery_v2/types.py",
37 library / "google/cloud/bigquery_v2/proto/location*",
38 library / "google/cloud/bigquery_v2/proto/encryption_config*",
39 library / "google/cloud/bigquery_v2/proto/model*",
40 library / "google/cloud/bigquery_v2/proto/standard_sql*",
41 ],
42 )
43
44 # Fix up proto docs that are missing summary line.
45 s.replace(
46 "google/cloud/bigquery_v2/proto/model_pb2.py",
47 '"""Attributes:',
48 '"""Protocol buffer.\n\n Attributes:',
49 )
50 s.replace(
51 "google/cloud/bigquery_v2/proto/encryption_config_pb2.py",
52 '"""Attributes:',
53 '"""Encryption configuration.\n\n Attributes:',
54 )
55
56 # Remove non-ascii characters from docstrings for Python 2.7.
57 # Format quoted strings as plain text.
58 s.replace("google/cloud/bigquery_v2/proto/*.py", "[“”]", '``')
59
60 # ----------------------------------------------------------------------------
61 # Add templated files
62 # ----------------------------------------------------------------------------
63 templated_files = common.py_library(cov_level=100)
64 s.move(templated_files, excludes=["noxfile.py"])
65
66 s.shell.run(["nox", "-s", "blacken"], hide_output=False)
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/synth.py b/synth.py
--- a/synth.py
+++ b/synth.py
@@ -17,16 +17,14 @@
import synthtool as s
from synthtool import gcp
-gapic = gcp.GAPICGenerator()
+gapic = gcp.GAPICBazel()
common = gcp.CommonTemplates()
version = 'v2'
library = gapic.py_library(
- 'bigquery',
- version,
- config_path='/google/cloud/bigquery/'
- 'artman_bigquery_v2.yaml',
- artman_output_name='bigquery-v2',
+ service='bigquery',
+ version=version,
+ bazel_target=f"//google/cloud/bigquery/{version}:bigquery-{version}-py",
include_protos=True,
)
| {"golden_diff": "diff --git a/synth.py b/synth.py\n--- a/synth.py\n+++ b/synth.py\n@@ -17,16 +17,14 @@\n import synthtool as s\n from synthtool import gcp\n \n-gapic = gcp.GAPICGenerator()\n+gapic = gcp.GAPICBazel()\n common = gcp.CommonTemplates()\n version = 'v2'\n \n library = gapic.py_library(\n- 'bigquery',\n- version,\n- config_path='/google/cloud/bigquery/'\n- 'artman_bigquery_v2.yaml',\n- artman_output_name='bigquery-v2',\n+ service='bigquery',\n+ version=version,\n+ bazel_target=f\"//google/cloud/bigquery/{version}:bigquery-{version}-py\",\n include_protos=True,\n )\n", "issue": "chore: replace Artman with bazel for synthesizing code\nThe synthtool should start using bazel instead of Artman.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is used to synthesize generated parts of this library.\"\"\"\n\nimport synthtool as s\nfrom synthtool import gcp\n\ngapic = gcp.GAPICGenerator()\ncommon = gcp.CommonTemplates()\nversion = 'v2'\n\nlibrary = gapic.py_library(\n 'bigquery',\n version,\n config_path='/google/cloud/bigquery/'\n 'artman_bigquery_v2.yaml',\n artman_output_name='bigquery-v2',\n include_protos=True,\n)\n\ns.move(\n [\n library / \"google/cloud/bigquery_v2/gapic/enums.py\",\n library / \"google/cloud/bigquery_v2/types.py\",\n library / \"google/cloud/bigquery_v2/proto/location*\",\n library / \"google/cloud/bigquery_v2/proto/encryption_config*\",\n library / \"google/cloud/bigquery_v2/proto/model*\",\n library / \"google/cloud/bigquery_v2/proto/standard_sql*\",\n ],\n)\n\n# Fix up proto docs that are missing summary line.\ns.replace(\n \"google/cloud/bigquery_v2/proto/model_pb2.py\",\n '\"\"\"Attributes:',\n '\"\"\"Protocol buffer.\\n\\n Attributes:',\n)\ns.replace(\n \"google/cloud/bigquery_v2/proto/encryption_config_pb2.py\",\n '\"\"\"Attributes:',\n '\"\"\"Encryption configuration.\\n\\n Attributes:',\n)\n\n# Remove non-ascii characters from docstrings for Python 2.7.\n# Format quoted strings as plain text.\ns.replace(\"google/cloud/bigquery_v2/proto/*.py\", \"[\u201c\u201d]\", '``')\n\n# ----------------------------------------------------------------------------\n# Add templated files\n# ----------------------------------------------------------------------------\ntemplated_files = common.py_library(cov_level=100)\ns.move(templated_files, excludes=[\"noxfile.py\"])\n\ns.shell.run([\"nox\", \"-s\", \"blacken\"], hide_output=False)\n", "path": "synth.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is used to synthesize generated parts of this library.\"\"\"\n\nimport synthtool as s\nfrom synthtool import gcp\n\ngapic = gcp.GAPICBazel()\ncommon = gcp.CommonTemplates()\nversion = 'v2'\n\nlibrary = gapic.py_library(\n service='bigquery',\n version=version,\n bazel_target=f\"//google/cloud/bigquery/{version}:bigquery-{version}-py\",\n include_protos=True,\n)\n\ns.move(\n [\n library / \"google/cloud/bigquery_v2/gapic/enums.py\",\n library / \"google/cloud/bigquery_v2/types.py\",\n library / \"google/cloud/bigquery_v2/proto/location*\",\n library / \"google/cloud/bigquery_v2/proto/encryption_config*\",\n library / \"google/cloud/bigquery_v2/proto/model*\",\n library / \"google/cloud/bigquery_v2/proto/standard_sql*\",\n ],\n)\n\n# Fix up proto docs that are missing summary line.\ns.replace(\n \"google/cloud/bigquery_v2/proto/model_pb2.py\",\n '\"\"\"Attributes:',\n '\"\"\"Protocol buffer.\\n\\n Attributes:',\n)\ns.replace(\n \"google/cloud/bigquery_v2/proto/encryption_config_pb2.py\",\n '\"\"\"Attributes:',\n '\"\"\"Encryption configuration.\\n\\n Attributes:',\n)\n\n# Remove non-ascii characters from docstrings for Python 2.7.\n# Format quoted strings as plain text.\ns.replace(\"google/cloud/bigquery_v2/proto/*.py\", \"[\u201c\u201d]\", '``')\n\n# ----------------------------------------------------------------------------\n# Add templated files\n# ----------------------------------------------------------------------------\ntemplated_files = common.py_library(cov_level=100)\ns.move(templated_files, excludes=[\"noxfile.py\"])\n\ns.shell.run([\"nox\", \"-s\", \"blacken\"], hide_output=False)\n", "path": "synth.py"}]} | 928 | 179 |
gh_patches_debug_3011 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-10572 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Most recent available `mambaforge=4.10` is simply too old
Hello guys, just wanted to ask you if it's possible to have a more modern version available for `mambaforge` - the best and latest available to be sourced on RTD via the configuration file is 4.10 which is simply too old (maximum conda 4.10 and mamba 0.19) - updating to a modern mamba doesn't work, as you can see from me changing the conf file in https://github.com/ESMValGroup/ESMValTool/pull/3310/files with output in https://readthedocs.org/projects/esmvaltool/builds/21390633/ - mamba is stuck at 0.19.0, which, in turn, slows down the environment creation process to around 10 minutes (for more recent conda's, updating mamba to something like >=1.4.8 works very well, and updates conda to 23.3 or 23.4 too, but in this case the base versions are too old). If you need any help whatsoever, I offer to help, and once more, many thanks for your great work on RTD :beer:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `readthedocs/builds/constants_docker.py`
Content:
```
1 """
2 Define constants here to allow import them without any external dependency.
3
4 There are situations where we want to have access to these values without Django installed
5 (e.g. common/dockerfiles/tasks.py)
6
7 Note these constants where previously defined as Django settings in ``readthedocs/settings/base.py``.
8 """
9
10 DOCKER_DEFAULT_IMAGE = "readthedocs/build"
11
12 # Adding a new tool/version to this setting requires:
13 #
14 # - a mapping between the expected version in the config file, to the full
15 # version installed via asdf (found via ``asdf list all <tool>``)
16 #
17 # - running the script ``./scripts/compile_version_upload.sh`` in
18 # development and production environments to compile and cache the new
19 # tool/version
20 #
21 # Note that when updating this options, you should also update the file:
22 # readthedocs/rtd_tests/fixtures/spec/v2/schema.json
23 RTD_DOCKER_BUILD_SETTINGS = {
24 # Mapping of build.os options to docker image.
25 "os": {
26 "ubuntu-20.04": f"{DOCKER_DEFAULT_IMAGE}:ubuntu-20.04",
27 "ubuntu-22.04": f"{DOCKER_DEFAULT_IMAGE}:ubuntu-22.04",
28 },
29 # Mapping of build.tools options to specific versions.
30 "tools": {
31 "python": {
32 "2.7": "2.7.18",
33 "3.6": "3.6.15",
34 "3.7": "3.7.17",
35 "3.8": "3.8.17",
36 "3.9": "3.9.17",
37 "3.10": "3.10.12",
38 "3.11": "3.11.4",
39 # Always point to the latest stable release.
40 "3": "3.11.4",
41 "miniconda3-4.7": "miniconda3-4.7.12",
42 "mambaforge-4.10": "mambaforge-4.10.3-10",
43 },
44 "nodejs": {
45 "14": "14.20.1",
46 "16": "16.18.1",
47 "18": "18.16.1", # LTS
48 "19": "19.0.1",
49 "20": "20.3.1",
50 },
51 "rust": {
52 "1.55": "1.55.0",
53 "1.61": "1.61.0",
54 "1.64": "1.64.0",
55 "1.70": "1.70.0",
56 },
57 "golang": {
58 "1.17": "1.17.13",
59 "1.18": "1.18.10",
60 "1.19": "1.19.10",
61 "1.20": "1.20.5",
62 },
63 },
64 }
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/readthedocs/builds/constants_docker.py b/readthedocs/builds/constants_docker.py
--- a/readthedocs/builds/constants_docker.py
+++ b/readthedocs/builds/constants_docker.py
@@ -40,6 +40,7 @@
"3": "3.11.4",
"miniconda3-4.7": "miniconda3-4.7.12",
"mambaforge-4.10": "mambaforge-4.10.3-10",
+ "mambaforge-22.9": "mambaforge-22.9.0-3",
},
"nodejs": {
"14": "14.20.1",
| {"golden_diff": "diff --git a/readthedocs/builds/constants_docker.py b/readthedocs/builds/constants_docker.py\n--- a/readthedocs/builds/constants_docker.py\n+++ b/readthedocs/builds/constants_docker.py\n@@ -40,6 +40,7 @@\n \"3\": \"3.11.4\",\n \"miniconda3-4.7\": \"miniconda3-4.7.12\",\n \"mambaforge-4.10\": \"mambaforge-4.10.3-10\",\n+ \"mambaforge-22.9\": \"mambaforge-22.9.0-3\",\n },\n \"nodejs\": {\n \"14\": \"14.20.1\",\n", "issue": "Most recent available `mambaforge=4.10` is simply too old\nHello guys, just wanted to ask you if it's possible to have a more modern version available for `mambaforge` - the best and latest available to be sourced on RTD via the configuration file is 4.10 which is simply too old (maximum conda 4.10 and mamba 0.19) - updating to a modern mamba doesn't work, as you can see from me changing the conf file in https://github.com/ESMValGroup/ESMValTool/pull/3310/files with output in https://readthedocs.org/projects/esmvaltool/builds/21390633/ - mamba is stuck at 0.19.0, which, in turn, slows down the environment creation process to around 10 minutes (for more recent conda's, updating mamba to something like >=1.4.8 works very well, and updates conda to 23.3 or 23.4 too, but in this case the base versions are too old). If you need any help whatsoever, I offer to help, and once more, many thanks for your great work on RTD :beer: \n", "before_files": [{"content": "\"\"\"\nDefine constants here to allow import them without any external dependency.\n\nThere are situations where we want to have access to these values without Django installed\n(e.g. common/dockerfiles/tasks.py)\n\nNote these constants where previously defined as Django settings in ``readthedocs/settings/base.py``.\n\"\"\"\n\nDOCKER_DEFAULT_IMAGE = \"readthedocs/build\"\n\n# Adding a new tool/version to this setting requires:\n#\n# - a mapping between the expected version in the config file, to the full\n# version installed via asdf (found via ``asdf list all <tool>``)\n#\n# - running the script ``./scripts/compile_version_upload.sh`` in\n# development and production environments to compile and cache the new\n# tool/version\n#\n# Note that when updating this options, you should also update the file:\n# readthedocs/rtd_tests/fixtures/spec/v2/schema.json\nRTD_DOCKER_BUILD_SETTINGS = {\n # Mapping of build.os options to docker image.\n \"os\": {\n \"ubuntu-20.04\": f\"{DOCKER_DEFAULT_IMAGE}:ubuntu-20.04\",\n \"ubuntu-22.04\": f\"{DOCKER_DEFAULT_IMAGE}:ubuntu-22.04\",\n },\n # Mapping of build.tools options to specific versions.\n \"tools\": {\n \"python\": {\n \"2.7\": \"2.7.18\",\n \"3.6\": \"3.6.15\",\n \"3.7\": \"3.7.17\",\n \"3.8\": \"3.8.17\",\n \"3.9\": \"3.9.17\",\n \"3.10\": \"3.10.12\",\n \"3.11\": \"3.11.4\",\n # Always point to the latest stable release.\n \"3\": \"3.11.4\",\n \"miniconda3-4.7\": \"miniconda3-4.7.12\",\n \"mambaforge-4.10\": \"mambaforge-4.10.3-10\",\n },\n \"nodejs\": {\n \"14\": \"14.20.1\",\n \"16\": \"16.18.1\",\n \"18\": \"18.16.1\", # LTS\n \"19\": \"19.0.1\",\n \"20\": \"20.3.1\",\n },\n \"rust\": {\n \"1.55\": \"1.55.0\",\n \"1.61\": \"1.61.0\",\n \"1.64\": \"1.64.0\",\n \"1.70\": \"1.70.0\",\n },\n \"golang\": {\n \"1.17\": \"1.17.13\",\n \"1.18\": \"1.18.10\",\n \"1.19\": \"1.19.10\",\n \"1.20\": \"1.20.5\",\n },\n },\n}\n", "path": "readthedocs/builds/constants_docker.py"}], "after_files": [{"content": "\"\"\"\nDefine constants here to allow import them without any external dependency.\n\nThere are situations where we want to have access to these values without Django installed\n(e.g. common/dockerfiles/tasks.py)\n\nNote these constants where previously defined as Django settings in ``readthedocs/settings/base.py``.\n\"\"\"\n\nDOCKER_DEFAULT_IMAGE = \"readthedocs/build\"\n\n# Adding a new tool/version to this setting requires:\n#\n# - a mapping between the expected version in the config file, to the full\n# version installed via asdf (found via ``asdf list all <tool>``)\n#\n# - running the script ``./scripts/compile_version_upload.sh`` in\n# development and production environments to compile and cache the new\n# tool/version\n#\n# Note that when updating this options, you should also update the file:\n# readthedocs/rtd_tests/fixtures/spec/v2/schema.json\nRTD_DOCKER_BUILD_SETTINGS = {\n # Mapping of build.os options to docker image.\n \"os\": {\n \"ubuntu-20.04\": f\"{DOCKER_DEFAULT_IMAGE}:ubuntu-20.04\",\n \"ubuntu-22.04\": f\"{DOCKER_DEFAULT_IMAGE}:ubuntu-22.04\",\n },\n # Mapping of build.tools options to specific versions.\n \"tools\": {\n \"python\": {\n \"2.7\": \"2.7.18\",\n \"3.6\": \"3.6.15\",\n \"3.7\": \"3.7.17\",\n \"3.8\": \"3.8.17\",\n \"3.9\": \"3.9.17\",\n \"3.10\": \"3.10.12\",\n \"3.11\": \"3.11.4\",\n # Always point to the latest stable release.\n \"3\": \"3.11.4\",\n \"miniconda3-4.7\": \"miniconda3-4.7.12\",\n \"mambaforge-4.10\": \"mambaforge-4.10.3-10\",\n \"mambaforge-22.9\": \"mambaforge-22.9.0-3\",\n },\n \"nodejs\": {\n \"14\": \"14.20.1\",\n \"16\": \"16.18.1\",\n \"18\": \"18.16.1\", # LTS\n \"19\": \"19.0.1\",\n \"20\": \"20.3.1\",\n },\n \"rust\": {\n \"1.55\": \"1.55.0\",\n \"1.61\": \"1.61.0\",\n \"1.64\": \"1.64.0\",\n \"1.70\": \"1.70.0\",\n },\n \"golang\": {\n \"1.17\": \"1.17.13\",\n \"1.18\": \"1.18.10\",\n \"1.19\": \"1.19.10\",\n \"1.20\": \"1.20.5\",\n },\n },\n}\n", "path": "readthedocs/builds/constants_docker.py"}]} | 1,331 | 170 |
gh_patches_debug_36753 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-contrib-1079 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Inject trace_configs as an argument to opentelemetry aiohttp_client._instrument instrumentation
**Is your feature request related to a problem?**
I would like to add data to a span based on on_request_chunk_sent event. Using the request/response hooks doesn't provide a good solution for my use case since it's "too late" in the timeline.
**Describe the solution you'd like**
I would like to pass trace_configs (or a single trace_config) to aiohttp_client opentelemetry instrumentation. It will allow me to specify which events I would like to "catch" and will allow more customization solving many use-cases that the request/response hooks cannot.
**Describe alternatives you've considered**
I've doubled the instrument_init method and set it up with my own trace_configs, bypassing opentelemetry implementation.
**Additional context**
If this issue will be approved I would like to contribute my solution, thanks
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py`
Content:
```
1 # Copyright 2020, OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 The opentelemetry-instrumentation-aiohttp-client package allows tracing HTTP
17 requests made by the aiohttp client library.
18
19 Usage
20 -----
21 Explicitly instrumenting a single client session:
22
23 .. code:: python
24
25 import aiohttp
26 from opentelemetry.instrumentation.aiohttp_client import create_trace_config
27 import yarl
28
29 def strip_query_params(url: yarl.URL) -> str:
30 return str(url.with_query(None))
31
32 async with aiohttp.ClientSession(trace_configs=[create_trace_config(
33 # Remove all query params from the URL attribute on the span.
34 url_filter=strip_query_params,
35 )]) as session:
36 async with session.get(url) as response:
37 await response.text()
38
39 Instrumenting all client sessions:
40
41 .. code:: python
42
43 import aiohttp
44 from opentelemetry.instrumentation.aiohttp_client import (
45 AioHttpClientInstrumentor
46 )
47
48 # Enable instrumentation
49 AioHttpClientInstrumentor().instrument()
50
51 # Create a session and make an HTTP get request
52 async with aiohttp.ClientSession() as session:
53 async with session.get(url) as response:
54 await response.text()
55
56 Configuration
57 -------------
58
59 Request/Response hooks
60 **********************
61
62 Utilize request/reponse hooks to execute custom logic to be performed before/after performing a request.
63
64 .. code-block:: python
65
66 def request_hook(span: Span, params: aiohttp.TraceRequestStartParams):
67 if span and span.is_recording():
68 span.set_attribute("custom_user_attribute_from_request_hook", "some-value")
69
70 def response_hook(span: Span, params: typing.Union[
71 aiohttp.TraceRequestEndParams,
72 aiohttp.TraceRequestExceptionParams,
73 ]):
74 if span and span.is_recording():
75 span.set_attribute("custom_user_attribute_from_response_hook", "some-value")
76
77 AioHttpClientInstrumentor().instrument(request_hook=request_hook, response_hook=response_hook)
78
79 API
80 ---
81 """
82
83 import types
84 import typing
85 from typing import Collection
86
87 import aiohttp
88 import wrapt
89 import yarl
90
91 from opentelemetry import context as context_api
92 from opentelemetry import trace
93 from opentelemetry.instrumentation.aiohttp_client.package import _instruments
94 from opentelemetry.instrumentation.aiohttp_client.version import __version__
95 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
96 from opentelemetry.instrumentation.utils import (
97 _SUPPRESS_INSTRUMENTATION_KEY,
98 http_status_to_status_code,
99 unwrap,
100 )
101 from opentelemetry.propagate import inject
102 from opentelemetry.semconv.trace import SpanAttributes
103 from opentelemetry.trace import Span, SpanKind, TracerProvider, get_tracer
104 from opentelemetry.trace.status import Status, StatusCode
105 from opentelemetry.util.http import remove_url_credentials
106
107 _UrlFilterT = typing.Optional[typing.Callable[[yarl.URL], str]]
108 _RequestHookT = typing.Optional[
109 typing.Callable[[Span, aiohttp.TraceRequestStartParams], None]
110 ]
111 _ResponseHookT = typing.Optional[
112 typing.Callable[
113 [
114 Span,
115 typing.Union[
116 aiohttp.TraceRequestEndParams,
117 aiohttp.TraceRequestExceptionParams,
118 ],
119 ],
120 None,
121 ]
122 ]
123
124
125 def create_trace_config(
126 url_filter: _UrlFilterT = None,
127 request_hook: _RequestHookT = None,
128 response_hook: _ResponseHookT = None,
129 tracer_provider: TracerProvider = None,
130 ) -> aiohttp.TraceConfig:
131 """Create an aiohttp-compatible trace configuration.
132
133 One span is created for the entire HTTP request, including initial
134 TCP/TLS setup if the connection doesn't exist.
135
136 By default the span name is set to the HTTP request method.
137
138 Example usage:
139
140 .. code:: python
141
142 import aiohttp
143 from opentelemetry.instrumentation.aiohttp_client import create_trace_config
144
145 async with aiohttp.ClientSession(trace_configs=[create_trace_config()]) as session:
146 async with session.get(url) as response:
147 await response.text()
148
149
150 :param url_filter: A callback to process the requested URL prior to adding
151 it as a span attribute. This can be useful to remove sensitive data
152 such as API keys or user personal information.
153
154 :param Callable request_hook: Optional callback that can modify span name and request params.
155 :param Callable response_hook: Optional callback that can modify span name and response params.
156 :param tracer_provider: optional TracerProvider from which to get a Tracer
157
158 :return: An object suitable for use with :py:class:`aiohttp.ClientSession`.
159 :rtype: :py:class:`aiohttp.TraceConfig`
160 """
161 # `aiohttp.TraceRequestStartParams` resolves to `aiohttp.tracing.TraceRequestStartParams`
162 # which doesn't exist in the aiohttp intersphinx inventory.
163 # Explicitly specify the type for the `request_hook` and `response_hook` param and rtype to work
164 # around this issue.
165
166 tracer = get_tracer(__name__, __version__, tracer_provider)
167
168 def _end_trace(trace_config_ctx: types.SimpleNamespace):
169 context_api.detach(trace_config_ctx.token)
170 trace_config_ctx.span.end()
171
172 async def on_request_start(
173 unused_session: aiohttp.ClientSession,
174 trace_config_ctx: types.SimpleNamespace,
175 params: aiohttp.TraceRequestStartParams,
176 ):
177 if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):
178 trace_config_ctx.span = None
179 return
180
181 http_method = params.method.upper()
182 request_span_name = f"HTTP {http_method}"
183 request_url = (
184 remove_url_credentials(trace_config_ctx.url_filter(params.url))
185 if callable(trace_config_ctx.url_filter)
186 else remove_url_credentials(str(params.url))
187 )
188
189 span_attributes = {
190 SpanAttributes.HTTP_METHOD: http_method,
191 SpanAttributes.HTTP_URL: request_url,
192 }
193
194 trace_config_ctx.span = trace_config_ctx.tracer.start_span(
195 request_span_name, kind=SpanKind.CLIENT, attributes=span_attributes
196 )
197
198 if callable(request_hook):
199 request_hook(trace_config_ctx.span, params)
200
201 trace_config_ctx.token = context_api.attach(
202 trace.set_span_in_context(trace_config_ctx.span)
203 )
204
205 inject(params.headers)
206
207 async def on_request_end(
208 unused_session: aiohttp.ClientSession,
209 trace_config_ctx: types.SimpleNamespace,
210 params: aiohttp.TraceRequestEndParams,
211 ):
212 if trace_config_ctx.span is None:
213 return
214
215 if callable(response_hook):
216 response_hook(trace_config_ctx.span, params)
217
218 if trace_config_ctx.span.is_recording():
219 trace_config_ctx.span.set_status(
220 Status(http_status_to_status_code(int(params.response.status)))
221 )
222 trace_config_ctx.span.set_attribute(
223 SpanAttributes.HTTP_STATUS_CODE, params.response.status
224 )
225 _end_trace(trace_config_ctx)
226
227 async def on_request_exception(
228 unused_session: aiohttp.ClientSession,
229 trace_config_ctx: types.SimpleNamespace,
230 params: aiohttp.TraceRequestExceptionParams,
231 ):
232 if trace_config_ctx.span is None:
233 return
234
235 if callable(response_hook):
236 response_hook(trace_config_ctx.span, params)
237
238 if trace_config_ctx.span.is_recording() and params.exception:
239 trace_config_ctx.span.set_status(Status(StatusCode.ERROR))
240 trace_config_ctx.span.record_exception(params.exception)
241 _end_trace(trace_config_ctx)
242
243 def _trace_config_ctx_factory(**kwargs):
244 kwargs.setdefault("trace_request_ctx", {})
245 return types.SimpleNamespace(
246 tracer=tracer, url_filter=url_filter, **kwargs
247 )
248
249 trace_config = aiohttp.TraceConfig(
250 trace_config_ctx_factory=_trace_config_ctx_factory
251 )
252
253 trace_config.on_request_start.append(on_request_start)
254 trace_config.on_request_end.append(on_request_end)
255 trace_config.on_request_exception.append(on_request_exception)
256
257 return trace_config
258
259
260 def _instrument(
261 tracer_provider: TracerProvider = None,
262 url_filter: _UrlFilterT = None,
263 request_hook: _RequestHookT = None,
264 response_hook: _ResponseHookT = None,
265 ):
266 """Enables tracing of all ClientSessions
267
268 When a ClientSession gets created a TraceConfig is automatically added to
269 the session's trace_configs.
270 """
271 # pylint:disable=unused-argument
272 def instrumented_init(wrapped, instance, args, kwargs):
273 if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):
274 return wrapped(*args, **kwargs)
275
276 trace_configs = list(kwargs.get("trace_configs") or ())
277
278 trace_config = create_trace_config(
279 url_filter=url_filter,
280 request_hook=request_hook,
281 response_hook=response_hook,
282 tracer_provider=tracer_provider,
283 )
284 trace_config._is_instrumented_by_opentelemetry = True
285 trace_configs.append(trace_config)
286
287 kwargs["trace_configs"] = trace_configs
288 return wrapped(*args, **kwargs)
289
290 wrapt.wrap_function_wrapper(
291 aiohttp.ClientSession, "__init__", instrumented_init
292 )
293
294
295 def _uninstrument():
296 """Disables instrumenting for all newly created ClientSessions"""
297 unwrap(aiohttp.ClientSession, "__init__")
298
299
300 def _uninstrument_session(client_session: aiohttp.ClientSession):
301 """Disables instrumentation for the given ClientSession"""
302 # pylint: disable=protected-access
303 trace_configs = client_session._trace_configs
304 client_session._trace_configs = [
305 trace_config
306 for trace_config in trace_configs
307 if not hasattr(trace_config, "_is_instrumented_by_opentelemetry")
308 ]
309
310
311 class AioHttpClientInstrumentor(BaseInstrumentor):
312 """An instrumentor for aiohttp client sessions
313
314 See `BaseInstrumentor`
315 """
316
317 def instrumentation_dependencies(self) -> Collection[str]:
318 return _instruments
319
320 def _instrument(self, **kwargs):
321 """Instruments aiohttp ClientSession
322
323 Args:
324 **kwargs: Optional arguments
325 ``tracer_provider``: a TracerProvider, defaults to global
326 ``url_filter``: A callback to process the requested URL prior to adding
327 it as a span attribute. This can be useful to remove sensitive data
328 such as API keys or user personal information.
329 ``request_hook``: An optional callback that is invoked right after a span is created.
330 ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.
331 """
332 _instrument(
333 tracer_provider=kwargs.get("tracer_provider"),
334 url_filter=kwargs.get("url_filter"),
335 request_hook=kwargs.get("request_hook"),
336 response_hook=kwargs.get("response_hook"),
337 )
338
339 def _uninstrument(self, **kwargs):
340 _uninstrument()
341
342 @staticmethod
343 def uninstrument_session(client_session: aiohttp.ClientSession):
344 """Disables instrumentation for the given session"""
345 _uninstrument_session(client_session)
346
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py b/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py
@@ -262,18 +262,24 @@
url_filter: _UrlFilterT = None,
request_hook: _RequestHookT = None,
response_hook: _ResponseHookT = None,
+ trace_configs: typing.Optional[aiohttp.TraceConfig] = None,
):
"""Enables tracing of all ClientSessions
When a ClientSession gets created a TraceConfig is automatically added to
the session's trace_configs.
"""
+
+ if trace_configs is None:
+ trace_configs = []
+
# pylint:disable=unused-argument
def instrumented_init(wrapped, instance, args, kwargs):
if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):
return wrapped(*args, **kwargs)
- trace_configs = list(kwargs.get("trace_configs") or ())
+ if kwargs.get("trace_configs"):
+ trace_configs.extend(kwargs.get("trace_configs"))
trace_config = create_trace_config(
url_filter=url_filter,
@@ -328,12 +334,15 @@
such as API keys or user personal information.
``request_hook``: An optional callback that is invoked right after a span is created.
``response_hook``: An optional callback which is invoked right before the span is finished processing a response.
+ ``trace_configs``: An optional list of aiohttp.TraceConfig items, allowing customize enrichment of spans
+ based on aiohttp events (see specification: https://docs.aiohttp.org/en/stable/tracing_reference.html)
"""
_instrument(
tracer_provider=kwargs.get("tracer_provider"),
url_filter=kwargs.get("url_filter"),
request_hook=kwargs.get("request_hook"),
response_hook=kwargs.get("response_hook"),
+ trace_configs=kwargs.get("trace_configs"),
)
def _uninstrument(self, **kwargs):
| {"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py b/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py\n@@ -262,18 +262,24 @@\n url_filter: _UrlFilterT = None,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n+ trace_configs: typing.Optional[aiohttp.TraceConfig] = None,\n ):\n \"\"\"Enables tracing of all ClientSessions\n \n When a ClientSession gets created a TraceConfig is automatically added to\n the session's trace_configs.\n \"\"\"\n+\n+ if trace_configs is None:\n+ trace_configs = []\n+\n # pylint:disable=unused-argument\n def instrumented_init(wrapped, instance, args, kwargs):\n if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):\n return wrapped(*args, **kwargs)\n \n- trace_configs = list(kwargs.get(\"trace_configs\") or ())\n+ if kwargs.get(\"trace_configs\"):\n+ trace_configs.extend(kwargs.get(\"trace_configs\"))\n \n trace_config = create_trace_config(\n url_filter=url_filter,\n@@ -328,12 +334,15 @@\n such as API keys or user personal information.\n ``request_hook``: An optional callback that is invoked right after a span is created.\n ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.\n+ ``trace_configs``: An optional list of aiohttp.TraceConfig items, allowing customize enrichment of spans\n+ based on aiohttp events (see specification: https://docs.aiohttp.org/en/stable/tracing_reference.html)\n \"\"\"\n _instrument(\n tracer_provider=kwargs.get(\"tracer_provider\"),\n url_filter=kwargs.get(\"url_filter\"),\n request_hook=kwargs.get(\"request_hook\"),\n response_hook=kwargs.get(\"response_hook\"),\n+ trace_configs=kwargs.get(\"trace_configs\"),\n )\n \n def _uninstrument(self, **kwargs):\n", "issue": "Inject trace_configs as an argument to opentelemetry aiohttp_client._instrument instrumentation\n**Is your feature request related to a problem?**\r\n\r\nI would like to add data to a span based on on_request_chunk_sent event. Using the request/response hooks doesn't provide a good solution for my use case since it's \"too late\" in the timeline. \r\n\r\n**Describe the solution you'd like**\r\n\r\nI would like to pass trace_configs (or a single trace_config) to aiohttp_client opentelemetry instrumentation. It will allow me to specify which events I would like to \"catch\" and will allow more customization solving many use-cases that the request/response hooks cannot.\r\n\r\n**Describe alternatives you've considered**\r\n\r\nI've doubled the instrument_init method and set it up with my own trace_configs, bypassing opentelemetry implementation. \r\n\r\n**Additional context**\r\nIf this issue will be approved I would like to contribute my solution, thanks\r\n\n", "before_files": [{"content": "# Copyright 2020, OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThe opentelemetry-instrumentation-aiohttp-client package allows tracing HTTP\nrequests made by the aiohttp client library.\n\nUsage\n-----\nExplicitly instrumenting a single client session:\n\n.. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import create_trace_config\n import yarl\n\n def strip_query_params(url: yarl.URL) -> str:\n return str(url.with_query(None))\n\n async with aiohttp.ClientSession(trace_configs=[create_trace_config(\n # Remove all query params from the URL attribute on the span.\n url_filter=strip_query_params,\n )]) as session:\n async with session.get(url) as response:\n await response.text()\n\nInstrumenting all client sessions:\n\n.. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import (\n AioHttpClientInstrumentor\n )\n\n # Enable instrumentation\n AioHttpClientInstrumentor().instrument()\n\n # Create a session and make an HTTP get request\n async with aiohttp.ClientSession() as session:\n async with session.get(url) as response:\n await response.text()\n\nConfiguration\n-------------\n\nRequest/Response hooks\n**********************\n\nUtilize request/reponse hooks to execute custom logic to be performed before/after performing a request.\n\n.. code-block:: python\n\n def request_hook(span: Span, params: aiohttp.TraceRequestStartParams):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_request_hook\", \"some-value\")\n\n def response_hook(span: Span, params: typing.Union[\n aiohttp.TraceRequestEndParams,\n aiohttp.TraceRequestExceptionParams,\n ]):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_response_hook\", \"some-value\")\n\n AioHttpClientInstrumentor().instrument(request_hook=request_hook, response_hook=response_hook)\n\nAPI\n---\n\"\"\"\n\nimport types\nimport typing\nfrom typing import Collection\n\nimport aiohttp\nimport wrapt\nimport yarl\n\nfrom opentelemetry import context as context_api\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.aiohttp_client.package import _instruments\nfrom opentelemetry.instrumentation.aiohttp_client.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.utils import (\n _SUPPRESS_INSTRUMENTATION_KEY,\n http_status_to_status_code,\n unwrap,\n)\nfrom opentelemetry.propagate import inject\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.trace import Span, SpanKind, TracerProvider, get_tracer\nfrom opentelemetry.trace.status import Status, StatusCode\nfrom opentelemetry.util.http import remove_url_credentials\n\n_UrlFilterT = typing.Optional[typing.Callable[[yarl.URL], str]]\n_RequestHookT = typing.Optional[\n typing.Callable[[Span, aiohttp.TraceRequestStartParams], None]\n]\n_ResponseHookT = typing.Optional[\n typing.Callable[\n [\n Span,\n typing.Union[\n aiohttp.TraceRequestEndParams,\n aiohttp.TraceRequestExceptionParams,\n ],\n ],\n None,\n ]\n]\n\n\ndef create_trace_config(\n url_filter: _UrlFilterT = None,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n tracer_provider: TracerProvider = None,\n) -> aiohttp.TraceConfig:\n \"\"\"Create an aiohttp-compatible trace configuration.\n\n One span is created for the entire HTTP request, including initial\n TCP/TLS setup if the connection doesn't exist.\n\n By default the span name is set to the HTTP request method.\n\n Example usage:\n\n .. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import create_trace_config\n\n async with aiohttp.ClientSession(trace_configs=[create_trace_config()]) as session:\n async with session.get(url) as response:\n await response.text()\n\n\n :param url_filter: A callback to process the requested URL prior to adding\n it as a span attribute. This can be useful to remove sensitive data\n such as API keys or user personal information.\n\n :param Callable request_hook: Optional callback that can modify span name and request params.\n :param Callable response_hook: Optional callback that can modify span name and response params.\n :param tracer_provider: optional TracerProvider from which to get a Tracer\n\n :return: An object suitable for use with :py:class:`aiohttp.ClientSession`.\n :rtype: :py:class:`aiohttp.TraceConfig`\n \"\"\"\n # `aiohttp.TraceRequestStartParams` resolves to `aiohttp.tracing.TraceRequestStartParams`\n # which doesn't exist in the aiohttp intersphinx inventory.\n # Explicitly specify the type for the `request_hook` and `response_hook` param and rtype to work\n # around this issue.\n\n tracer = get_tracer(__name__, __version__, tracer_provider)\n\n def _end_trace(trace_config_ctx: types.SimpleNamespace):\n context_api.detach(trace_config_ctx.token)\n trace_config_ctx.span.end()\n\n async def on_request_start(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestStartParams,\n ):\n if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):\n trace_config_ctx.span = None\n return\n\n http_method = params.method.upper()\n request_span_name = f\"HTTP {http_method}\"\n request_url = (\n remove_url_credentials(trace_config_ctx.url_filter(params.url))\n if callable(trace_config_ctx.url_filter)\n else remove_url_credentials(str(params.url))\n )\n\n span_attributes = {\n SpanAttributes.HTTP_METHOD: http_method,\n SpanAttributes.HTTP_URL: request_url,\n }\n\n trace_config_ctx.span = trace_config_ctx.tracer.start_span(\n request_span_name, kind=SpanKind.CLIENT, attributes=span_attributes\n )\n\n if callable(request_hook):\n request_hook(trace_config_ctx.span, params)\n\n trace_config_ctx.token = context_api.attach(\n trace.set_span_in_context(trace_config_ctx.span)\n )\n\n inject(params.headers)\n\n async def on_request_end(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestEndParams,\n ):\n if trace_config_ctx.span is None:\n return\n\n if callable(response_hook):\n response_hook(trace_config_ctx.span, params)\n\n if trace_config_ctx.span.is_recording():\n trace_config_ctx.span.set_status(\n Status(http_status_to_status_code(int(params.response.status)))\n )\n trace_config_ctx.span.set_attribute(\n SpanAttributes.HTTP_STATUS_CODE, params.response.status\n )\n _end_trace(trace_config_ctx)\n\n async def on_request_exception(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestExceptionParams,\n ):\n if trace_config_ctx.span is None:\n return\n\n if callable(response_hook):\n response_hook(trace_config_ctx.span, params)\n\n if trace_config_ctx.span.is_recording() and params.exception:\n trace_config_ctx.span.set_status(Status(StatusCode.ERROR))\n trace_config_ctx.span.record_exception(params.exception)\n _end_trace(trace_config_ctx)\n\n def _trace_config_ctx_factory(**kwargs):\n kwargs.setdefault(\"trace_request_ctx\", {})\n return types.SimpleNamespace(\n tracer=tracer, url_filter=url_filter, **kwargs\n )\n\n trace_config = aiohttp.TraceConfig(\n trace_config_ctx_factory=_trace_config_ctx_factory\n )\n\n trace_config.on_request_start.append(on_request_start)\n trace_config.on_request_end.append(on_request_end)\n trace_config.on_request_exception.append(on_request_exception)\n\n return trace_config\n\n\ndef _instrument(\n tracer_provider: TracerProvider = None,\n url_filter: _UrlFilterT = None,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n):\n \"\"\"Enables tracing of all ClientSessions\n\n When a ClientSession gets created a TraceConfig is automatically added to\n the session's trace_configs.\n \"\"\"\n # pylint:disable=unused-argument\n def instrumented_init(wrapped, instance, args, kwargs):\n if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):\n return wrapped(*args, **kwargs)\n\n trace_configs = list(kwargs.get(\"trace_configs\") or ())\n\n trace_config = create_trace_config(\n url_filter=url_filter,\n request_hook=request_hook,\n response_hook=response_hook,\n tracer_provider=tracer_provider,\n )\n trace_config._is_instrumented_by_opentelemetry = True\n trace_configs.append(trace_config)\n\n kwargs[\"trace_configs\"] = trace_configs\n return wrapped(*args, **kwargs)\n\n wrapt.wrap_function_wrapper(\n aiohttp.ClientSession, \"__init__\", instrumented_init\n )\n\n\ndef _uninstrument():\n \"\"\"Disables instrumenting for all newly created ClientSessions\"\"\"\n unwrap(aiohttp.ClientSession, \"__init__\")\n\n\ndef _uninstrument_session(client_session: aiohttp.ClientSession):\n \"\"\"Disables instrumentation for the given ClientSession\"\"\"\n # pylint: disable=protected-access\n trace_configs = client_session._trace_configs\n client_session._trace_configs = [\n trace_config\n for trace_config in trace_configs\n if not hasattr(trace_config, \"_is_instrumented_by_opentelemetry\")\n ]\n\n\nclass AioHttpClientInstrumentor(BaseInstrumentor):\n \"\"\"An instrumentor for aiohttp client sessions\n\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments aiohttp ClientSession\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global\n ``url_filter``: A callback to process the requested URL prior to adding\n it as a span attribute. This can be useful to remove sensitive data\n such as API keys or user personal information.\n ``request_hook``: An optional callback that is invoked right after a span is created.\n ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.\n \"\"\"\n _instrument(\n tracer_provider=kwargs.get(\"tracer_provider\"),\n url_filter=kwargs.get(\"url_filter\"),\n request_hook=kwargs.get(\"request_hook\"),\n response_hook=kwargs.get(\"response_hook\"),\n )\n\n def _uninstrument(self, **kwargs):\n _uninstrument()\n\n @staticmethod\n def uninstrument_session(client_session: aiohttp.ClientSession):\n \"\"\"Disables instrumentation for the given session\"\"\"\n _uninstrument_session(client_session)\n", "path": "instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py"}], "after_files": [{"content": "# Copyright 2020, OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThe opentelemetry-instrumentation-aiohttp-client package allows tracing HTTP\nrequests made by the aiohttp client library.\n\nUsage\n-----\nExplicitly instrumenting a single client session:\n\n.. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import create_trace_config\n import yarl\n\n def strip_query_params(url: yarl.URL) -> str:\n return str(url.with_query(None))\n\n async with aiohttp.ClientSession(trace_configs=[create_trace_config(\n # Remove all query params from the URL attribute on the span.\n url_filter=strip_query_params,\n )]) as session:\n async with session.get(url) as response:\n await response.text()\n\nInstrumenting all client sessions:\n\n.. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import (\n AioHttpClientInstrumentor\n )\n\n # Enable instrumentation\n AioHttpClientInstrumentor().instrument()\n\n # Create a session and make an HTTP get request\n async with aiohttp.ClientSession() as session:\n async with session.get(url) as response:\n await response.text()\n\nConfiguration\n-------------\n\nRequest/Response hooks\n**********************\n\nUtilize request/reponse hooks to execute custom logic to be performed before/after performing a request.\n\n.. code-block:: python\n\n def request_hook(span: Span, params: aiohttp.TraceRequestStartParams):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_request_hook\", \"some-value\")\n\n def response_hook(span: Span, params: typing.Union[\n aiohttp.TraceRequestEndParams,\n aiohttp.TraceRequestExceptionParams,\n ]):\n if span and span.is_recording():\n span.set_attribute(\"custom_user_attribute_from_response_hook\", \"some-value\")\n\n AioHttpClientInstrumentor().instrument(request_hook=request_hook, response_hook=response_hook)\n\nAPI\n---\n\"\"\"\n\nimport types\nimport typing\nfrom typing import Collection\n\nimport aiohttp\nimport wrapt\nimport yarl\n\nfrom opentelemetry import context as context_api\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.aiohttp_client.package import _instruments\nfrom opentelemetry.instrumentation.aiohttp_client.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.utils import (\n _SUPPRESS_INSTRUMENTATION_KEY,\n http_status_to_status_code,\n unwrap,\n)\nfrom opentelemetry.propagate import inject\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.trace import Span, SpanKind, TracerProvider, get_tracer\nfrom opentelemetry.trace.status import Status, StatusCode\nfrom opentelemetry.util.http import remove_url_credentials\n\n_UrlFilterT = typing.Optional[typing.Callable[[yarl.URL], str]]\n_RequestHookT = typing.Optional[\n typing.Callable[[Span, aiohttp.TraceRequestStartParams], None]\n]\n_ResponseHookT = typing.Optional[\n typing.Callable[\n [\n Span,\n typing.Union[\n aiohttp.TraceRequestEndParams,\n aiohttp.TraceRequestExceptionParams,\n ],\n ],\n None,\n ]\n]\n\n\ndef create_trace_config(\n url_filter: _UrlFilterT = None,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n tracer_provider: TracerProvider = None,\n) -> aiohttp.TraceConfig:\n \"\"\"Create an aiohttp-compatible trace configuration.\n\n One span is created for the entire HTTP request, including initial\n TCP/TLS setup if the connection doesn't exist.\n\n By default the span name is set to the HTTP request method.\n\n Example usage:\n\n .. code:: python\n\n import aiohttp\n from opentelemetry.instrumentation.aiohttp_client import create_trace_config\n\n async with aiohttp.ClientSession(trace_configs=[create_trace_config()]) as session:\n async with session.get(url) as response:\n await response.text()\n\n\n :param url_filter: A callback to process the requested URL prior to adding\n it as a span attribute. This can be useful to remove sensitive data\n such as API keys or user personal information.\n\n :param Callable request_hook: Optional callback that can modify span name and request params.\n :param Callable response_hook: Optional callback that can modify span name and response params.\n :param tracer_provider: optional TracerProvider from which to get a Tracer\n\n :return: An object suitable for use with :py:class:`aiohttp.ClientSession`.\n :rtype: :py:class:`aiohttp.TraceConfig`\n \"\"\"\n # `aiohttp.TraceRequestStartParams` resolves to `aiohttp.tracing.TraceRequestStartParams`\n # which doesn't exist in the aiohttp intersphinx inventory.\n # Explicitly specify the type for the `request_hook` and `response_hook` param and rtype to work\n # around this issue.\n\n tracer = get_tracer(__name__, __version__, tracer_provider)\n\n def _end_trace(trace_config_ctx: types.SimpleNamespace):\n context_api.detach(trace_config_ctx.token)\n trace_config_ctx.span.end()\n\n async def on_request_start(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestStartParams,\n ):\n if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):\n trace_config_ctx.span = None\n return\n\n http_method = params.method.upper()\n request_span_name = f\"HTTP {http_method}\"\n request_url = (\n remove_url_credentials(trace_config_ctx.url_filter(params.url))\n if callable(trace_config_ctx.url_filter)\n else remove_url_credentials(str(params.url))\n )\n\n span_attributes = {\n SpanAttributes.HTTP_METHOD: http_method,\n SpanAttributes.HTTP_URL: request_url,\n }\n\n trace_config_ctx.span = trace_config_ctx.tracer.start_span(\n request_span_name, kind=SpanKind.CLIENT, attributes=span_attributes\n )\n\n if callable(request_hook):\n request_hook(trace_config_ctx.span, params)\n\n trace_config_ctx.token = context_api.attach(\n trace.set_span_in_context(trace_config_ctx.span)\n )\n\n inject(params.headers)\n\n async def on_request_end(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestEndParams,\n ):\n if trace_config_ctx.span is None:\n return\n\n if callable(response_hook):\n response_hook(trace_config_ctx.span, params)\n\n if trace_config_ctx.span.is_recording():\n trace_config_ctx.span.set_status(\n Status(http_status_to_status_code(int(params.response.status)))\n )\n trace_config_ctx.span.set_attribute(\n SpanAttributes.HTTP_STATUS_CODE, params.response.status\n )\n _end_trace(trace_config_ctx)\n\n async def on_request_exception(\n unused_session: aiohttp.ClientSession,\n trace_config_ctx: types.SimpleNamespace,\n params: aiohttp.TraceRequestExceptionParams,\n ):\n if trace_config_ctx.span is None:\n return\n\n if callable(response_hook):\n response_hook(trace_config_ctx.span, params)\n\n if trace_config_ctx.span.is_recording() and params.exception:\n trace_config_ctx.span.set_status(Status(StatusCode.ERROR))\n trace_config_ctx.span.record_exception(params.exception)\n _end_trace(trace_config_ctx)\n\n def _trace_config_ctx_factory(**kwargs):\n kwargs.setdefault(\"trace_request_ctx\", {})\n return types.SimpleNamespace(\n tracer=tracer, url_filter=url_filter, **kwargs\n )\n\n trace_config = aiohttp.TraceConfig(\n trace_config_ctx_factory=_trace_config_ctx_factory\n )\n\n trace_config.on_request_start.append(on_request_start)\n trace_config.on_request_end.append(on_request_end)\n trace_config.on_request_exception.append(on_request_exception)\n\n return trace_config\n\n\ndef _instrument(\n tracer_provider: TracerProvider = None,\n url_filter: _UrlFilterT = None,\n request_hook: _RequestHookT = None,\n response_hook: _ResponseHookT = None,\n trace_configs: typing.Optional[aiohttp.TraceConfig] = None,\n):\n \"\"\"Enables tracing of all ClientSessions\n\n When a ClientSession gets created a TraceConfig is automatically added to\n the session's trace_configs.\n \"\"\"\n\n if trace_configs is None:\n trace_configs = []\n\n # pylint:disable=unused-argument\n def instrumented_init(wrapped, instance, args, kwargs):\n if context_api.get_value(_SUPPRESS_INSTRUMENTATION_KEY):\n return wrapped(*args, **kwargs)\n\n if kwargs.get(\"trace_configs\"):\n trace_configs.extend(kwargs.get(\"trace_configs\"))\n\n trace_config = create_trace_config(\n url_filter=url_filter,\n request_hook=request_hook,\n response_hook=response_hook,\n tracer_provider=tracer_provider,\n )\n trace_config._is_instrumented_by_opentelemetry = True\n trace_configs.append(trace_config)\n\n kwargs[\"trace_configs\"] = trace_configs\n return wrapped(*args, **kwargs)\n\n wrapt.wrap_function_wrapper(\n aiohttp.ClientSession, \"__init__\", instrumented_init\n )\n\n\ndef _uninstrument():\n \"\"\"Disables instrumenting for all newly created ClientSessions\"\"\"\n unwrap(aiohttp.ClientSession, \"__init__\")\n\n\ndef _uninstrument_session(client_session: aiohttp.ClientSession):\n \"\"\"Disables instrumentation for the given ClientSession\"\"\"\n # pylint: disable=protected-access\n trace_configs = client_session._trace_configs\n client_session._trace_configs = [\n trace_config\n for trace_config in trace_configs\n if not hasattr(trace_config, \"_is_instrumented_by_opentelemetry\")\n ]\n\n\nclass AioHttpClientInstrumentor(BaseInstrumentor):\n \"\"\"An instrumentor for aiohttp client sessions\n\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments aiohttp ClientSession\n\n Args:\n **kwargs: Optional arguments\n ``tracer_provider``: a TracerProvider, defaults to global\n ``url_filter``: A callback to process the requested URL prior to adding\n it as a span attribute. This can be useful to remove sensitive data\n such as API keys or user personal information.\n ``request_hook``: An optional callback that is invoked right after a span is created.\n ``response_hook``: An optional callback which is invoked right before the span is finished processing a response.\n ``trace_configs``: An optional list of aiohttp.TraceConfig items, allowing customize enrichment of spans\n based on aiohttp events (see specification: https://docs.aiohttp.org/en/stable/tracing_reference.html)\n \"\"\"\n _instrument(\n tracer_provider=kwargs.get(\"tracer_provider\"),\n url_filter=kwargs.get(\"url_filter\"),\n request_hook=kwargs.get(\"request_hook\"),\n response_hook=kwargs.get(\"response_hook\"),\n trace_configs=kwargs.get(\"trace_configs\"),\n )\n\n def _uninstrument(self, **kwargs):\n _uninstrument()\n\n @staticmethod\n def uninstrument_session(client_session: aiohttp.ClientSession):\n \"\"\"Disables instrumentation for the given session\"\"\"\n _uninstrument_session(client_session)\n", "path": "instrumentation/opentelemetry-instrumentation-aiohttp-client/src/opentelemetry/instrumentation/aiohttp_client/__init__.py"}]} | 3,868 | 523 |
gh_patches_debug_29058 | rasdani/github-patches | git_diff | modin-project__modin-2149 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add note about braceexpand for cloud examples.
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
- **Modin version** (`modin.__version__`):
- **Python version**:
- **Code we can use to reproduce**:
<!--
You can obtain the Modin version with
python -c "import modin; print(modin.__version__)"
-->
### Describe the problem
<!-- Describe the problem clearly here. -->
### Source code / logs
<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/cluster/h2o-runner.py`
Content:
```
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14
15 # pip install git+https://github.com/intel-go/ibis.git@develop
16
17 # NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
18
19 # the following import turns on experimental mode in Modin,
20 # including enabling running things in remote cloud
21 import modin.experimental.pandas as pd # noqa: F401
22 from modin.experimental.cloud import create_cluster
23
24 from h2o import run_benchmark
25
26 test_cluster = create_cluster(
27 "aws",
28 "aws_credentials",
29 cluster_name="rayscale-test",
30 region="eu-north-1",
31 zone="eu-north-1b",
32 image="ami-00e1e82d7d4ca80d3",
33 )
34 with test_cluster:
35 parameters = {
36 "no_pandas": False,
37 "pandas_mode": "Modin_on_ray",
38 "ray_tmpdir": "/tmp",
39 "ray_memory": 1024 * 1024 * 1024,
40 "extended_functionality": False,
41 }
42
43 # G1... - for groupby queries; J1... - for join queries;
44 # Additional required files inside h2o-data folder:
45 # - J1_1e6_1e0_0_0.csv
46 # - J1_1e6_1e3_0_0.csv
47 # - J1_1e6_1e6_0_0.csv
48 for data_file in ["G1_5e5_1e2_0_0.csv", "J1_1e6_NA_0_0.csv"]:
49 parameters["data_file"] = f"https://modin-datasets.s3.amazonaws.com/h2o/{data_file}"
50 run_benchmark(parameters)
51
```
Path: `examples/cluster/mortgage-runner.py`
Content:
```
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14
15 # pip install git+https://github.com/intel-go/ibis.git@develop
16
17 # NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
18
19 # the following import turns on experimental mode in Modin,
20 # including enabling running things in remote cloud
21 import modin.experimental.pandas as pd # noqa: F401
22 from modin.experimental.cloud import create_cluster
23
24 from mortgage import run_benchmark
25
26 test_cluster = create_cluster(
27 "aws",
28 "aws_credentials",
29 cluster_name="rayscale-test",
30 region="eu-north-1",
31 zone="eu-north-1b",
32 image="ami-00e1e82d7d4ca80d3",
33 )
34 with test_cluster:
35
36 parameters = {
37 "data_file": "https://modin-datasets.s3.amazonaws.com/mortgage",
38 # "data_file": "s3://modin-datasets/mortgage",
39 "dfiles_num": 1,
40 "no_ml": True,
41 "validation": False,
42 "no_ibis": True,
43 "no_pandas": False,
44 "pandas_mode": "Modin_on_ray",
45 "ray_tmpdir": "/tmp",
46 "ray_memory": 1024 * 1024 * 1024,
47 }
48
49 run_benchmark(parameters)
50
```
Path: `examples/cluster/taxi-runner.py`
Content:
```
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14
15 # pip install git+https://github.com/intel-go/ibis.git@develop
16
17 # NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
18
19 import sys
20
21 USE_OMNISCI = "--omnisci" in sys.argv
22
23 # the following import turns on experimental mode in Modin,
24 # including enabling running things in remote cloud
25 import modin.experimental.pandas as pd # noqa: F401
26 from modin.experimental.cloud import create_cluster
27
28 from taxi import run_benchmark as run_benchmark
29
30 cluster_params = {}
31 if USE_OMNISCI:
32 cluster_params["cluster_type"] = "omnisci"
33 test_cluster = create_cluster(
34 "aws",
35 "aws_credentials",
36 cluster_name="rayscale-test",
37 region="eu-north-1",
38 zone="eu-north-1b",
39 image="ami-00e1e82d7d4ca80d3",
40 **cluster_params,
41 )
42 with test_cluster:
43 data_file = "https://modin-datasets.s3.amazonaws.com/trips_data.csv"
44 if USE_OMNISCI:
45 # Workaround for GH#2099
46 from modin.experimental.cloud import get_connection
47
48 data_file, remote_data_file = "/tmp/trips_data.csv", data_file
49 get_connection().modules["subprocess"].check_call(
50 ["wget", remote_data_file, "-O", data_file]
51 )
52
53 # Omniscripts check for files being present when given local file paths,
54 # so replace "glob" there with a remote one
55 import utils.utils
56
57 utils.utils.glob = get_connection().modules["glob"]
58
59 parameters = {
60 "data_file": data_file,
61 # "data_file": "s3://modin-datasets/trips_data.csv",
62 "dfiles_num": 1,
63 "validation": False,
64 "no_ibis": True,
65 "no_pandas": False,
66 "pandas_mode": "Modin_on_omnisci" if USE_OMNISCI else "Modin_on_ray",
67 "ray_tmpdir": "/tmp",
68 "ray_memory": 1024 * 1024 * 1024,
69 }
70
71 run_benchmark(parameters)
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/cluster/h2o-runner.py b/examples/cluster/h2o-runner.py
--- a/examples/cluster/h2o-runner.py
+++ b/examples/cluster/h2o-runner.py
@@ -12,9 +12,10 @@
# governing permissions and limitations under the License.
-# pip install git+https://github.com/intel-go/ibis.git@develop
+# pip install git+https://github.com/intel-ai/ibis.git@develop
+# pip install braceexpand
-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH
# the following import turns on experimental mode in Modin,
# including enabling running things in remote cloud
diff --git a/examples/cluster/mortgage-runner.py b/examples/cluster/mortgage-runner.py
--- a/examples/cluster/mortgage-runner.py
+++ b/examples/cluster/mortgage-runner.py
@@ -12,9 +12,10 @@
# governing permissions and limitations under the License.
-# pip install git+https://github.com/intel-go/ibis.git@develop
+# pip install git+https://github.com/intel-ai/ibis.git@develop
+# pip install braceexpand
-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH
# the following import turns on experimental mode in Modin,
# including enabling running things in remote cloud
diff --git a/examples/cluster/taxi-runner.py b/examples/cluster/taxi-runner.py
--- a/examples/cluster/taxi-runner.py
+++ b/examples/cluster/taxi-runner.py
@@ -12,9 +12,10 @@
# governing permissions and limitations under the License.
-# pip install git+https://github.com/intel-go/ibis.git@develop
+# pip install git+https://github.com/intel-ai/ibis.git@develop
+# pip install braceexpand
-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH
+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH
import sys
| {"golden_diff": "diff --git a/examples/cluster/h2o-runner.py b/examples/cluster/h2o-runner.py\n--- a/examples/cluster/h2o-runner.py\n+++ b/examples/cluster/h2o-runner.py\n@@ -12,9 +12,10 @@\n # governing permissions and limitations under the License.\n \n \n-# pip install git+https://github.com/intel-go/ibis.git@develop\n+# pip install git+https://github.com/intel-ai/ibis.git@develop\n+# pip install braceexpand\n \n-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n \n # the following import turns on experimental mode in Modin,\n # including enabling running things in remote cloud\ndiff --git a/examples/cluster/mortgage-runner.py b/examples/cluster/mortgage-runner.py\n--- a/examples/cluster/mortgage-runner.py\n+++ b/examples/cluster/mortgage-runner.py\n@@ -12,9 +12,10 @@\n # governing permissions and limitations under the License.\n \n \n-# pip install git+https://github.com/intel-go/ibis.git@develop\n+# pip install git+https://github.com/intel-ai/ibis.git@develop\n+# pip install braceexpand\n \n-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n \n # the following import turns on experimental mode in Modin,\n # including enabling running things in remote cloud\ndiff --git a/examples/cluster/taxi-runner.py b/examples/cluster/taxi-runner.py\n--- a/examples/cluster/taxi-runner.py\n+++ b/examples/cluster/taxi-runner.py\n@@ -12,9 +12,10 @@\n # governing permissions and limitations under the License.\n \n \n-# pip install git+https://github.com/intel-go/ibis.git@develop\n+# pip install git+https://github.com/intel-ai/ibis.git@develop\n+# pip install braceexpand\n \n-# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n+# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n \n import sys\n", "issue": "Add note about braceexpand for cloud examples.\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:\r\n- **Modin version** (`modin.__version__`):\r\n- **Python version**:\r\n- **Code we can use to reproduce**:\r\n\r\n<!--\r\nYou can obtain the Modin version with\r\n\r\npython -c \"import modin; print(modin.__version__)\"\r\n-->\r\n\r\n### Describe the problem\r\n<!-- Describe the problem clearly here. -->\r\n\r\n### Source code / logs\r\n<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->\r\n\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-go/ibis.git@develop\n\n# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom h2o import run_benchmark\n\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n)\nwith test_cluster:\n parameters = {\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n \"extended_functionality\": False,\n }\n\n # G1... - for groupby queries; J1... - for join queries;\n # Additional required files inside h2o-data folder:\n # - J1_1e6_1e0_0_0.csv\n # - J1_1e6_1e3_0_0.csv\n # - J1_1e6_1e6_0_0.csv\n for data_file in [\"G1_5e5_1e2_0_0.csv\", \"J1_1e6_NA_0_0.csv\"]:\n parameters[\"data_file\"] = f\"https://modin-datasets.s3.amazonaws.com/h2o/{data_file}\"\n run_benchmark(parameters)\n", "path": "examples/cluster/h2o-runner.py"}, {"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-go/ibis.git@develop\n\n# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom mortgage import run_benchmark\n\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n)\nwith test_cluster:\n\n parameters = {\n \"data_file\": \"https://modin-datasets.s3.amazonaws.com/mortgage\",\n # \"data_file\": \"s3://modin-datasets/mortgage\",\n \"dfiles_num\": 1,\n \"no_ml\": True,\n \"validation\": False,\n \"no_ibis\": True,\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n }\n\n run_benchmark(parameters)\n", "path": "examples/cluster/mortgage-runner.py"}, {"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-go/ibis.git@develop\n\n# NOTE: expects https://github.com/intel-go/omniscripts/ checked out and in PYTHONPATH\n\nimport sys\n\nUSE_OMNISCI = \"--omnisci\" in sys.argv\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom taxi import run_benchmark as run_benchmark\n\ncluster_params = {}\nif USE_OMNISCI:\n cluster_params[\"cluster_type\"] = \"omnisci\"\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n **cluster_params,\n)\nwith test_cluster:\n data_file = \"https://modin-datasets.s3.amazonaws.com/trips_data.csv\"\n if USE_OMNISCI:\n # Workaround for GH#2099\n from modin.experimental.cloud import get_connection\n\n data_file, remote_data_file = \"/tmp/trips_data.csv\", data_file\n get_connection().modules[\"subprocess\"].check_call(\n [\"wget\", remote_data_file, \"-O\", data_file]\n )\n\n # Omniscripts check for files being present when given local file paths,\n # so replace \"glob\" there with a remote one\n import utils.utils\n\n utils.utils.glob = get_connection().modules[\"glob\"]\n\n parameters = {\n \"data_file\": data_file,\n # \"data_file\": \"s3://modin-datasets/trips_data.csv\",\n \"dfiles_num\": 1,\n \"validation\": False,\n \"no_ibis\": True,\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_omnisci\" if USE_OMNISCI else \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n }\n\n run_benchmark(parameters)\n", "path": "examples/cluster/taxi-runner.py"}], "after_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-ai/ibis.git@develop\n# pip install braceexpand\n\n# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom h2o import run_benchmark\n\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n)\nwith test_cluster:\n parameters = {\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n \"extended_functionality\": False,\n }\n\n # G1... - for groupby queries; J1... - for join queries;\n # Additional required files inside h2o-data folder:\n # - J1_1e6_1e0_0_0.csv\n # - J1_1e6_1e3_0_0.csv\n # - J1_1e6_1e6_0_0.csv\n for data_file in [\"G1_5e5_1e2_0_0.csv\", \"J1_1e6_NA_0_0.csv\"]:\n parameters[\"data_file\"] = f\"https://modin-datasets.s3.amazonaws.com/h2o/{data_file}\"\n run_benchmark(parameters)\n", "path": "examples/cluster/h2o-runner.py"}, {"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-ai/ibis.git@develop\n# pip install braceexpand\n\n# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom mortgage import run_benchmark\n\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n)\nwith test_cluster:\n\n parameters = {\n \"data_file\": \"https://modin-datasets.s3.amazonaws.com/mortgage\",\n # \"data_file\": \"s3://modin-datasets/mortgage\",\n \"dfiles_num\": 1,\n \"no_ml\": True,\n \"validation\": False,\n \"no_ibis\": True,\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n }\n\n run_benchmark(parameters)\n", "path": "examples/cluster/mortgage-runner.py"}, {"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\n\n# pip install git+https://github.com/intel-ai/ibis.git@develop\n# pip install braceexpand\n\n# NOTE: expects https://github.com/intel-ai/omniscripts checked out and in PYTHONPATH\n\nimport sys\n\nUSE_OMNISCI = \"--omnisci\" in sys.argv\n\n# the following import turns on experimental mode in Modin,\n# including enabling running things in remote cloud\nimport modin.experimental.pandas as pd # noqa: F401\nfrom modin.experimental.cloud import create_cluster\n\nfrom taxi import run_benchmark as run_benchmark\n\ncluster_params = {}\nif USE_OMNISCI:\n cluster_params[\"cluster_type\"] = \"omnisci\"\ntest_cluster = create_cluster(\n \"aws\",\n \"aws_credentials\",\n cluster_name=\"rayscale-test\",\n region=\"eu-north-1\",\n zone=\"eu-north-1b\",\n image=\"ami-00e1e82d7d4ca80d3\",\n **cluster_params,\n)\nwith test_cluster:\n data_file = \"https://modin-datasets.s3.amazonaws.com/trips_data.csv\"\n if USE_OMNISCI:\n # Workaround for GH#2099\n from modin.experimental.cloud import get_connection\n\n data_file, remote_data_file = \"/tmp/trips_data.csv\", data_file\n get_connection().modules[\"subprocess\"].check_call(\n [\"wget\", remote_data_file, \"-O\", data_file]\n )\n\n # Omniscripts check for files being present when given local file paths,\n # so replace \"glob\" there with a remote one\n import utils.utils\n\n utils.utils.glob = get_connection().modules[\"glob\"]\n\n parameters = {\n \"data_file\": data_file,\n # \"data_file\": \"s3://modin-datasets/trips_data.csv\",\n \"dfiles_num\": 1,\n \"validation\": False,\n \"no_ibis\": True,\n \"no_pandas\": False,\n \"pandas_mode\": \"Modin_on_omnisci\" if USE_OMNISCI else \"Modin_on_ray\",\n \"ray_tmpdir\": \"/tmp\",\n \"ray_memory\": 1024 * 1024 * 1024,\n }\n\n run_benchmark(parameters)\n", "path": "examples/cluster/taxi-runner.py"}]} | 2,480 | 525 |
gh_patches_debug_18135 | rasdani/github-patches | git_diff | streamlink__streamlink-3484 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Turkuvaz Plugin missing Streams
Hi,
first of all to be sure installed Streamlink 2.0.0 via Python3 again.
After that tested all streams one by one with the turkuvaz.py
Most of them are working, only 2 of 9 channels missing, "error: No plugin can handle URL"
A2 and A Haber TV:
https://www.atv.com.tr/a2tv/canli-yayin
https://www.ahaber.com.tr/video/canli-yayin
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/turkuvaz.py`
Content:
```
1 import logging
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import useragents, validate
6 from streamlink.stream import HLSStream
7
8 log = logging.getLogger(__name__)
9
10
11 class Turkuvaz(Plugin):
12 """
13 Plugin to support ATV/A2TV Live streams from www.atv.com.tr and www.a2tv.com.tr
14 """
15
16 _url_re = re.compile(r"""(?x)https?://(?:www\.)?
17 (?:
18 (?:
19 (atvavrupa)\.tv
20 |
21 (atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\.com\.tr
22 )/webtv/(?:live-broadcast|canli-yayin)
23 |
24 sabah\.com\.tr/(apara)/canli-yayin
25 )""")
26 _hls_url = "https://trkvz-live.ercdn.net/{channel}/{channel}.m3u8"
27 _token_url = "https://securevideotoken.tmgrup.com.tr/webtv/secure"
28 _token_schema = validate.Schema(validate.all(
29 {
30 "Success": True,
31 "Url": validate.url(),
32 },
33 validate.get("Url"))
34 )
35
36 @classmethod
37 def can_handle_url(cls, url):
38 return cls._url_re.match(url) is not None
39
40 def _get_streams(self):
41 url_m = self._url_re.match(self.url)
42 domain = url_m.group(1) or url_m.group(2) or url_m.group(3)
43 # remap the domain to channel
44 channel = {"atv": "atvhd",
45 "ahaber": "ahaberhd",
46 "apara": "aparahd",
47 "aspor": "asporhd",
48 "anews": "anewshd",
49 "minikacocuk": "minikagococuk"}.get(domain, domain)
50 hls_url = self._hls_url.format(channel=channel)
51 # get the secure HLS URL
52 res = self.session.http.get(self._token_url,
53 params="url={0}".format(hls_url),
54 headers={"Referer": self.url,
55 "User-Agent": useragents.CHROME})
56
57 secure_hls_url = self.session.http.json(res, schema=self._token_schema)
58
59 log.debug("Found HLS URL: {0}".format(secure_hls_url))
60 return HLSStream.parse_variant_playlist(self.session, secure_hls_url)
61
62
63 __plugin__ = Turkuvaz
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/streamlink/plugins/turkuvaz.py b/src/streamlink/plugins/turkuvaz.py
--- a/src/streamlink/plugins/turkuvaz.py
+++ b/src/streamlink/plugins/turkuvaz.py
@@ -20,6 +20,10 @@
|
(atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\.com\.tr
)/webtv/(?:live-broadcast|canli-yayin)
+ |
+ (ahaber)\.com\.tr/video/canli-yayin
+ |
+ atv\.com\.tr/(a2tv)/canli-yayin
|
sabah\.com\.tr/(apara)/canli-yayin
)""")
@@ -39,7 +43,7 @@
def _get_streams(self):
url_m = self._url_re.match(self.url)
- domain = url_m.group(1) or url_m.group(2) or url_m.group(3)
+ domain = url_m.group(1) or url_m.group(2) or url_m.group(3) or url_m.group(4) or url_m.group(5)
# remap the domain to channel
channel = {"atv": "atvhd",
"ahaber": "ahaberhd",
| {"golden_diff": "diff --git a/src/streamlink/plugins/turkuvaz.py b/src/streamlink/plugins/turkuvaz.py\n--- a/src/streamlink/plugins/turkuvaz.py\n+++ b/src/streamlink/plugins/turkuvaz.py\n@@ -20,6 +20,10 @@\n |\n (atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\\.com\\.tr\n )/webtv/(?:live-broadcast|canli-yayin)\n+ |\n+ (ahaber)\\.com\\.tr/video/canli-yayin\n+ |\n+ atv\\.com\\.tr/(a2tv)/canli-yayin\n |\n sabah\\.com\\.tr/(apara)/canli-yayin\n )\"\"\")\n@@ -39,7 +43,7 @@\n \n def _get_streams(self):\n url_m = self._url_re.match(self.url)\n- domain = url_m.group(1) or url_m.group(2) or url_m.group(3)\n+ domain = url_m.group(1) or url_m.group(2) or url_m.group(3) or url_m.group(4) or url_m.group(5)\n # remap the domain to channel\n channel = {\"atv\": \"atvhd\",\n \"ahaber\": \"ahaberhd\",\n", "issue": "Turkuvaz Plugin missing Streams\nHi,\r\n\r\nfirst of all to be sure installed Streamlink 2.0.0 via Python3 again.\r\n\r\nAfter that tested all streams one by one with the turkuvaz.py\r\n\r\nMost of them are working, only 2 of 9 channels missing, \"error: No plugin can handle URL\"\r\n\r\nA2 and A Haber TV:\r\n\r\nhttps://www.atv.com.tr/a2tv/canli-yayin\r\nhttps://www.ahaber.com.tr/video/canli-yayin\r\n\r\n\n", "before_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import useragents, validate\nfrom streamlink.stream import HLSStream\n\nlog = logging.getLogger(__name__)\n\n\nclass Turkuvaz(Plugin):\n \"\"\"\n Plugin to support ATV/A2TV Live streams from www.atv.com.tr and www.a2tv.com.tr\n \"\"\"\n\n _url_re = re.compile(r\"\"\"(?x)https?://(?:www\\.)?\n (?:\n (?:\n (atvavrupa)\\.tv\n |\n (atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\\.com\\.tr\n )/webtv/(?:live-broadcast|canli-yayin)\n |\n sabah\\.com\\.tr/(apara)/canli-yayin\n )\"\"\")\n _hls_url = \"https://trkvz-live.ercdn.net/{channel}/{channel}.m3u8\"\n _token_url = \"https://securevideotoken.tmgrup.com.tr/webtv/secure\"\n _token_schema = validate.Schema(validate.all(\n {\n \"Success\": True,\n \"Url\": validate.url(),\n },\n validate.get(\"Url\"))\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def _get_streams(self):\n url_m = self._url_re.match(self.url)\n domain = url_m.group(1) or url_m.group(2) or url_m.group(3)\n # remap the domain to channel\n channel = {\"atv\": \"atvhd\",\n \"ahaber\": \"ahaberhd\",\n \"apara\": \"aparahd\",\n \"aspor\": \"asporhd\",\n \"anews\": \"anewshd\",\n \"minikacocuk\": \"minikagococuk\"}.get(domain, domain)\n hls_url = self._hls_url.format(channel=channel)\n # get the secure HLS URL\n res = self.session.http.get(self._token_url,\n params=\"url={0}\".format(hls_url),\n headers={\"Referer\": self.url,\n \"User-Agent\": useragents.CHROME})\n\n secure_hls_url = self.session.http.json(res, schema=self._token_schema)\n\n log.debug(\"Found HLS URL: {0}\".format(secure_hls_url))\n return HLSStream.parse_variant_playlist(self.session, secure_hls_url)\n\n\n__plugin__ = Turkuvaz\n", "path": "src/streamlink/plugins/turkuvaz.py"}], "after_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import useragents, validate\nfrom streamlink.stream import HLSStream\n\nlog = logging.getLogger(__name__)\n\n\nclass Turkuvaz(Plugin):\n \"\"\"\n Plugin to support ATV/A2TV Live streams from www.atv.com.tr and www.a2tv.com.tr\n \"\"\"\n\n _url_re = re.compile(r\"\"\"(?x)https?://(?:www\\.)?\n (?:\n (?:\n (atvavrupa)\\.tv\n |\n (atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\\.com\\.tr\n )/webtv/(?:live-broadcast|canli-yayin)\n |\n (ahaber)\\.com\\.tr/video/canli-yayin\n |\n atv\\.com\\.tr/(a2tv)/canli-yayin\n |\n sabah\\.com\\.tr/(apara)/canli-yayin\n )\"\"\")\n _hls_url = \"https://trkvz-live.ercdn.net/{channel}/{channel}.m3u8\"\n _token_url = \"https://securevideotoken.tmgrup.com.tr/webtv/secure\"\n _token_schema = validate.Schema(validate.all(\n {\n \"Success\": True,\n \"Url\": validate.url(),\n },\n validate.get(\"Url\"))\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def _get_streams(self):\n url_m = self._url_re.match(self.url)\n domain = url_m.group(1) or url_m.group(2) or url_m.group(3) or url_m.group(4) or url_m.group(5)\n # remap the domain to channel\n channel = {\"atv\": \"atvhd\",\n \"ahaber\": \"ahaberhd\",\n \"apara\": \"aparahd\",\n \"aspor\": \"asporhd\",\n \"anews\": \"anewshd\",\n \"minikacocuk\": \"minikagococuk\"}.get(domain, domain)\n hls_url = self._hls_url.format(channel=channel)\n # get the secure HLS URL\n res = self.session.http.get(self._token_url,\n params=\"url={0}\".format(hls_url),\n headers={\"Referer\": self.url,\n \"User-Agent\": useragents.CHROME})\n\n secure_hls_url = self.session.http.json(res, schema=self._token_schema)\n\n log.debug(\"Found HLS URL: {0}\".format(secure_hls_url))\n return HLSStream.parse_variant_playlist(self.session, secure_hls_url)\n\n\n__plugin__ = Turkuvaz\n", "path": "src/streamlink/plugins/turkuvaz.py"}]} | 1,051 | 305 |
gh_patches_debug_30776 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-223 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Marshall's
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/marshalls.py`
Content:
```
1 import json
2 import re
3 import scrapy
4 from locations.items import GeojsonPointItem
5
6 STATES = ["AL", "AK", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA",
7 "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD",
8 "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ",
9 "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC",
10 "SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
11
12 DAYS = {'Mon': 'Mo', 'Tue': 'Tu',
13 'Wed': 'We', 'Thu': 'Th',
14 'Fri': 'Fr', 'Sat': 'Sa',
15 'Sun': 'Su'}
16
17 URL = 'https://mktsvc.tjx.com/storelocator/GetSearchResultsByState'
18
19
20 def normalize_time(hours):
21
22 if not hours:
23 return ''
24
25 day_times = hours.split(',')
26 normalize_day_times = []
27
28 for day_time in day_times:
29 day, hours = [x.strip() for x in day_time.split(': ')]
30 normalize_hours = []
31
32 if re.search('-', day):
33 days = [x.strip() for x in day.split('-')]
34 norm_days = '-'.join([DAYS.get(x, '') for x in days])
35 else:
36 norm_days = DAYS.get(day, '')
37
38 if re.search('CLOSED', hours):
39 norm_hours = ' off'
40 normalize_hours.append(norm_hours)
41 else:
42 if re.search('-', hours):
43 hours = [x.strip() for x in hours.split('-')]
44
45 for hour in hours:
46
47 if hour[-1] == 'p':
48 if re.search(':', hour[:-1]):
49 hora, minute = [x.strip() for x in hour[:-1].split(':')]
50 if int(hora) < 12:
51 norm_hours = str(int(hora) + 12) + ':' + minute
52 else:
53 if int(hour[:-1]) < 12:
54 norm_hours = str(int(hour[:-1]) + 12) + ":00"
55
56 elif hour[-1] == 'a':
57 if re.search(':', hour[:-1]):
58 hora, minute = [x.strip() for x in hour[:-1].split(':')]
59 norm_hours = hora + ':' + minute
60 else:
61 norm_hours = hour[:-1] + ":00"
62
63 normalize_hours.append(norm_hours)
64
65 normalize_day_times.append(' '.join([norm_days, '-'.join(normalize_hours)]))
66 return '; '.join(normalize_day_times)
67
68
69 class MarshallsSpider(scrapy.Spider):
70
71 name = "marshalls"
72 allowed_domains = ["mktsvc.tjx.com", 'www.marshallsonline.com']
73
74 def start_requests(self):
75 url = URL
76
77 headers = {
78 'Accept-Language': 'en-US,en;q=0.8,ru;q=0.6',
79 'Origin': 'https://www.marshallsonline.com',
80 'Accept-Encoding': 'gzip, deflate, br',
81 'Accept': 'application/json, text/plain, */*',
82 'Referer': 'https://www.marshallsonline.com/store-finder/by-state',
83 'Connection': 'keep-alive',
84 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
85 }
86
87 for state in STATES:
88 form_data = {'chain': '10', 'lang': 'en', 'state': state}
89
90 yield scrapy.http.FormRequest(url=url, method='POST', formdata=form_data,
91 headers=headers, callback=self.parse)
92
93 def parse(self, response):
94
95 data = json.loads(response.body_as_unicode())
96 stores = data.get('Stores', None)
97
98 for store in stores:
99 lon_lat = [store.pop('Longitude', None), store.pop('Latitude', None)]
100 store['ref'] = URL + str(store.get('StoreID', None))
101
102 opening_hours = normalize_time(store.get('Hours', ''))
103
104 if opening_hours:
105 store['opening_hours'] = opening_hours
106 store.pop('Hours', None)
107
108 yield GeojsonPointItem(
109 properties=store,
110 lon_lat=lon_lat
111 )
112
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/locations/spiders/marshalls.py b/locations/spiders/marshalls.py
--- a/locations/spiders/marshalls.py
+++ b/locations/spiders/marshalls.py
@@ -17,10 +17,20 @@
URL = 'https://mktsvc.tjx.com/storelocator/GetSearchResultsByState'
+NORMALIZE_KEYS = (
+ ('addr:full', ['Address', 'Address2']),
+ ('addr:city', ['City']),
+ ('addr:state', ['State']),
+ ('addr:postcode', ['Zip']),
+ ('addr:country', ['Country']),
+ ('phone', ['Phone']),
+ )
+
+
def normalize_time(hours):
if not hours:
- return ''
+ return ''
day_times = hours.split(',')
normalize_day_times = []
@@ -94,18 +104,23 @@
data = json.loads(response.body_as_unicode())
stores = data.get('Stores', None)
+ props = {}
for store in stores:
- lon_lat = [store.pop('Longitude', None), store.pop('Latitude', None)]
- store['ref'] = URL + str(store.get('StoreID', None))
+ lon_lat = [store.pop('Longitude', ''), store.pop('Latitude', None)]
+ props['ref'] = store.pop('StoreID', None)
+ props['website'] = URL
+
+ for new_key, old_keys in NORMALIZE_KEYS:
+ props[new_key] = ", ".join([store.pop(key, '').strip() for key in old_keys if store[key]])
- opening_hours = normalize_time(store.get('Hours', ''))
+ opening_hours = normalize_time(store.pop('Hours', ''))
if opening_hours:
- store['opening_hours'] = opening_hours
- store.pop('Hours', None)
+ props['opening_hours'] = opening_hours
+ props.pop('Hours', None)
yield GeojsonPointItem(
- properties=store,
+ properties=props,
lon_lat=lon_lat
)
| {"golden_diff": "diff --git a/locations/spiders/marshalls.py b/locations/spiders/marshalls.py\n--- a/locations/spiders/marshalls.py\n+++ b/locations/spiders/marshalls.py\n@@ -17,10 +17,20 @@\n URL = 'https://mktsvc.tjx.com/storelocator/GetSearchResultsByState'\n \n \n+NORMALIZE_KEYS = (\n+ ('addr:full', ['Address', 'Address2']),\n+ ('addr:city', ['City']),\n+ ('addr:state', ['State']),\n+ ('addr:postcode', ['Zip']),\n+ ('addr:country', ['Country']),\n+ ('phone', ['Phone']),\n+ )\n+\n+\n def normalize_time(hours):\n \n if not hours:\n- return ''\n+ return ''\n \n day_times = hours.split(',')\n normalize_day_times = []\n@@ -94,18 +104,23 @@\n \n data = json.loads(response.body_as_unicode())\n stores = data.get('Stores', None)\n+ props = {}\n \n for store in stores:\n- lon_lat = [store.pop('Longitude', None), store.pop('Latitude', None)]\n- store['ref'] = URL + str(store.get('StoreID', None))\n+ lon_lat = [store.pop('Longitude', ''), store.pop('Latitude', None)]\n+ props['ref'] = store.pop('StoreID', None)\n+ props['website'] = URL\n+\n+ for new_key, old_keys in NORMALIZE_KEYS:\n+ props[new_key] = \", \".join([store.pop(key, '').strip() for key in old_keys if store[key]])\n \n- opening_hours = normalize_time(store.get('Hours', ''))\n+ opening_hours = normalize_time(store.pop('Hours', ''))\n \n if opening_hours:\n- store['opening_hours'] = opening_hours\n- store.pop('Hours', None)\n+ props['opening_hours'] = opening_hours\n+ props.pop('Hours', None)\n \n yield GeojsonPointItem(\n- properties=store,\n+ properties=props,\n lon_lat=lon_lat\n )\n", "issue": "Marshall's\n\n", "before_files": [{"content": "import json\nimport re\nimport scrapy\nfrom locations.items import GeojsonPointItem\n\nSTATES = [\"AL\", \"AK\", \"AZ\", \"AR\", \"CA\", \"CO\", \"CT\", \"DC\", \"DE\", \"FL\", \"GA\",\n \"HI\", \"ID\", \"IL\", \"IN\", \"IA\", \"KS\", \"KY\", \"LA\", \"ME\", \"MD\",\n \"MA\", \"MI\", \"MN\", \"MS\", \"MO\", \"MT\", \"NE\", \"NV\", \"NH\", \"NJ\",\n \"NM\", \"NY\", \"NC\", \"ND\", \"OH\", \"OK\", \"OR\", \"PA\", \"RI\", \"SC\",\n \"SD\", \"TN\", \"TX\", \"UT\", \"VT\", \"VA\", \"WA\", \"WV\", \"WI\", \"WY\"]\n\nDAYS = {'Mon': 'Mo', 'Tue': 'Tu',\n 'Wed': 'We', 'Thu': 'Th',\n 'Fri': 'Fr', 'Sat': 'Sa',\n 'Sun': 'Su'}\n\nURL = 'https://mktsvc.tjx.com/storelocator/GetSearchResultsByState'\n\n\ndef normalize_time(hours):\n\n if not hours:\n return ''\n\n day_times = hours.split(',')\n normalize_day_times = []\n\n for day_time in day_times:\n day, hours = [x.strip() for x in day_time.split(': ')]\n normalize_hours = []\n\n if re.search('-', day):\n days = [x.strip() for x in day.split('-')]\n norm_days = '-'.join([DAYS.get(x, '') for x in days])\n else:\n norm_days = DAYS.get(day, '')\n\n if re.search('CLOSED', hours):\n norm_hours = ' off'\n normalize_hours.append(norm_hours)\n else:\n if re.search('-', hours):\n hours = [x.strip() for x in hours.split('-')]\n\n for hour in hours:\n\n if hour[-1] == 'p':\n if re.search(':', hour[:-1]):\n hora, minute = [x.strip() for x in hour[:-1].split(':')]\n if int(hora) < 12:\n norm_hours = str(int(hora) + 12) + ':' + minute\n else:\n if int(hour[:-1]) < 12:\n norm_hours = str(int(hour[:-1]) + 12) + \":00\"\n\n elif hour[-1] == 'a':\n if re.search(':', hour[:-1]):\n hora, minute = [x.strip() for x in hour[:-1].split(':')]\n norm_hours = hora + ':' + minute\n else:\n norm_hours = hour[:-1] + \":00\"\n\n normalize_hours.append(norm_hours)\n\n normalize_day_times.append(' '.join([norm_days, '-'.join(normalize_hours)]))\n return '; '.join(normalize_day_times)\n\n\nclass MarshallsSpider(scrapy.Spider):\n\n name = \"marshalls\"\n allowed_domains = [\"mktsvc.tjx.com\", 'www.marshallsonline.com']\n\n def start_requests(self):\n url = URL\n\n headers = {\n 'Accept-Language': 'en-US,en;q=0.8,ru;q=0.6',\n 'Origin': 'https://www.marshallsonline.com',\n 'Accept-Encoding': 'gzip, deflate, br',\n 'Accept': 'application/json, text/plain, */*',\n 'Referer': 'https://www.marshallsonline.com/store-finder/by-state',\n 'Connection': 'keep-alive',\n 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',\n }\n\n for state in STATES:\n form_data = {'chain': '10', 'lang': 'en', 'state': state}\n\n yield scrapy.http.FormRequest(url=url, method='POST', formdata=form_data,\n headers=headers, callback=self.parse)\n\n def parse(self, response):\n\n data = json.loads(response.body_as_unicode())\n stores = data.get('Stores', None)\n\n for store in stores:\n lon_lat = [store.pop('Longitude', None), store.pop('Latitude', None)]\n store['ref'] = URL + str(store.get('StoreID', None))\n\n opening_hours = normalize_time(store.get('Hours', ''))\n\n if opening_hours:\n store['opening_hours'] = opening_hours\n store.pop('Hours', None)\n\n yield GeojsonPointItem(\n properties=store,\n lon_lat=lon_lat\n )\n", "path": "locations/spiders/marshalls.py"}], "after_files": [{"content": "import json\nimport re\nimport scrapy\nfrom locations.items import GeojsonPointItem\n\nSTATES = [\"AL\", \"AK\", \"AZ\", \"AR\", \"CA\", \"CO\", \"CT\", \"DC\", \"DE\", \"FL\", \"GA\",\n \"HI\", \"ID\", \"IL\", \"IN\", \"IA\", \"KS\", \"KY\", \"LA\", \"ME\", \"MD\",\n \"MA\", \"MI\", \"MN\", \"MS\", \"MO\", \"MT\", \"NE\", \"NV\", \"NH\", \"NJ\",\n \"NM\", \"NY\", \"NC\", \"ND\", \"OH\", \"OK\", \"OR\", \"PA\", \"RI\", \"SC\",\n \"SD\", \"TN\", \"TX\", \"UT\", \"VT\", \"VA\", \"WA\", \"WV\", \"WI\", \"WY\"]\n\nDAYS = {'Mon': 'Mo', 'Tue': 'Tu',\n 'Wed': 'We', 'Thu': 'Th',\n 'Fri': 'Fr', 'Sat': 'Sa',\n 'Sun': 'Su'}\n\nURL = 'https://mktsvc.tjx.com/storelocator/GetSearchResultsByState'\n\n\nNORMALIZE_KEYS = (\n ('addr:full', ['Address', 'Address2']),\n ('addr:city', ['City']),\n ('addr:state', ['State']),\n ('addr:postcode', ['Zip']),\n ('addr:country', ['Country']),\n ('phone', ['Phone']),\n )\n\n\ndef normalize_time(hours):\n\n if not hours:\n return ''\n\n day_times = hours.split(',')\n normalize_day_times = []\n\n for day_time in day_times:\n day, hours = [x.strip() for x in day_time.split(': ')]\n normalize_hours = []\n\n if re.search('-', day):\n days = [x.strip() for x in day.split('-')]\n norm_days = '-'.join([DAYS.get(x, '') for x in days])\n else:\n norm_days = DAYS.get(day, '')\n\n if re.search('CLOSED', hours):\n norm_hours = ' off'\n normalize_hours.append(norm_hours)\n else:\n if re.search('-', hours):\n hours = [x.strip() for x in hours.split('-')]\n\n for hour in hours:\n\n if hour[-1] == 'p':\n if re.search(':', hour[:-1]):\n hora, minute = [x.strip() for x in hour[:-1].split(':')]\n if int(hora) < 12:\n norm_hours = str(int(hora) + 12) + ':' + minute\n else:\n if int(hour[:-1]) < 12:\n norm_hours = str(int(hour[:-1]) + 12) + \":00\"\n\n elif hour[-1] == 'a':\n if re.search(':', hour[:-1]):\n hora, minute = [x.strip() for x in hour[:-1].split(':')]\n norm_hours = hora + ':' + minute\n else:\n norm_hours = hour[:-1] + \":00\"\n\n normalize_hours.append(norm_hours)\n\n normalize_day_times.append(' '.join([norm_days, '-'.join(normalize_hours)]))\n return '; '.join(normalize_day_times)\n\n\nclass MarshallsSpider(scrapy.Spider):\n\n name = \"marshalls\"\n allowed_domains = [\"mktsvc.tjx.com\", 'www.marshallsonline.com']\n\n def start_requests(self):\n url = URL\n\n headers = {\n 'Accept-Language': 'en-US,en;q=0.8,ru;q=0.6',\n 'Origin': 'https://www.marshallsonline.com',\n 'Accept-Encoding': 'gzip, deflate, br',\n 'Accept': 'application/json, text/plain, */*',\n 'Referer': 'https://www.marshallsonline.com/store-finder/by-state',\n 'Connection': 'keep-alive',\n 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',\n }\n\n for state in STATES:\n form_data = {'chain': '10', 'lang': 'en', 'state': state}\n\n yield scrapy.http.FormRequest(url=url, method='POST', formdata=form_data,\n headers=headers, callback=self.parse)\n\n def parse(self, response):\n\n data = json.loads(response.body_as_unicode())\n stores = data.get('Stores', None)\n props = {}\n\n for store in stores:\n lon_lat = [store.pop('Longitude', ''), store.pop('Latitude', None)]\n props['ref'] = store.pop('StoreID', None)\n props['website'] = URL\n\n for new_key, old_keys in NORMALIZE_KEYS:\n props[new_key] = \", \".join([store.pop(key, '').strip() for key in old_keys if store[key]])\n\n opening_hours = normalize_time(store.pop('Hours', ''))\n\n if opening_hours:\n props['opening_hours'] = opening_hours\n props.pop('Hours', None)\n\n yield GeojsonPointItem(\n properties=props,\n lon_lat=lon_lat\n )\n", "path": "locations/spiders/marshalls.py"}]} | 1,478 | 464 |
gh_patches_debug_9921 | rasdani/github-patches | git_diff | scikit-hep__pyhf-175 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add binderexample/StatisticalAnalysis.ipynb to docs examples
At the moment the Binder example notebook `binderexample/StatisticalAnalysis.ipynb` is not being included in the build of the docs. Lukas has put some really nice examples in there and it would be nice to have this in the docs in the even that people don't check out the Binder.
# Relevant Issues and Pull Requests
This is also somewhat relevant to Issue #168
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # pyhf documentation build configuration file, created by
4 # sphinx-quickstart on Fri Feb 9 11:58:49 2018.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19 import os
20 import sys
21 sys.path.insert(0, os.path.abspath('..'))
22
23 # -- General configuration ------------------------------------------------
24
25 # If your documentation needs a minimal Sphinx version, state it here.
26 #
27 # needs_sphinx = '1.0'
28
29 # Add any Sphinx extension module names here, as strings. They can be
30 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
31 # ones.
32 extensions = [
33 'sphinx.ext.autodoc',
34 'sphinx.ext.autosummary',
35 'sphinx.ext.coverage',
36 'sphinx.ext.mathjax',
37 'sphinx.ext.ifconfig',
38 'sphinx.ext.viewcode',
39 'sphinx.ext.githubpages',
40 'sphinxcontrib.napoleon',
41 'nbsphinx',
42 ]
43
44 # Generate the API documentation when building
45 autosummary_generate = True
46 numpydoc_show_class_members = False
47
48 # Add any paths that contain templates here, relative to this directory.
49 templates_path = ['_templates']
50
51 # The suffix(es) of source filenames.
52 # You can specify multiple suffix as a list of string:
53 #
54 # source_suffix = ['.rst', '.md']
55 source_suffix = '.rst'
56
57 # The encoding of source files.
58 #
59 # source_encoding = 'utf-8-sig'
60
61 # The master toctree document.
62 master_doc = 'index'
63
64 # General information about the project.
65 project = u'pyhf'
66 copyright = u'2018, Lukas Heinrich, Matthew Feickert, Giordon Stark'
67 author = u'Lukas Heinrich, Matthew Feickert, Giordon Stark'
68
69 # The version info for the project you're documenting, acts as replacement for
70 # |version| and |release|, also used in various other places throughout the
71 # built documents.
72 #
73 # The short X.Y version.
74 version = u'0.0.4'
75 # The full version, including alpha/beta/rc tags.
76 release = u'0.0.4'
77
78 # The language for content autogenerated by Sphinx. Refer to documentation
79 # for a list of supported languages.
80 #
81 # This is also used if you do content translation via gettext catalogs.
82 # Usually you set "language" from the command line for these cases.
83 language = None
84
85 # There are two options for replacing |today|: either, you set today to some
86 # non-false value, then it is used:
87 #
88 # today = ''
89 #
90 # Else, today_fmt is used as the format for a strftime call.
91 #
92 # today_fmt = '%B %d, %Y'
93
94 # List of patterns, relative to source directory, that match files and
95 # directories to ignore when looking for source files.
96 # This patterns also effect to html_static_path and html_extra_path
97 exclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments', 'examples/notebooks/binderexample']
98
99 # The reST default role (used for this markup: `text`) to use for all
100 # documents.
101 #
102 # default_role = None
103
104 # If true, '()' will be appended to :func: etc. cross-reference text.
105 #
106 # add_function_parentheses = True
107
108 # If true, the current module name will be prepended to all description
109 # unit titles (such as .. function::).
110 #
111 # add_module_names = True
112
113 # If true, sectionauthor and moduleauthor directives will be shown in the
114 # output. They are ignored by default.
115 #
116 # show_authors = False
117
118 # The name of the Pygments (syntax highlighting) style to use.
119 pygments_style = 'sphinx'
120
121 # A list of ignored prefixes for module index sorting.
122 # modindex_common_prefix = []
123
124 # If true, keep warnings as "system message" paragraphs in the built documents.
125 # keep_warnings = False
126
127 # If true, `todo` and `todoList` produce output, else they produce nothing.
128 todo_include_todos = False
129
130
131 # -- Options for HTML output ----------------------------------------------
132
133 # The theme to use for HTML and HTML Help pages. See the documentation for
134 # a list of builtin themes.
135 #
136 html_theme = 'sphinx_rtd_theme'
137
138 # Theme options are theme-specific and customize the look and feel of a theme
139 # further. For a list of options available for each theme, see the
140 # documentation.
141 #
142 html_theme_options = {}
143
144 # Add any paths that contain custom themes here, relative to this directory.
145 html_theme_path = []
146
147 # The name for this set of Sphinx documents.
148 # "<project> v<release> documentation" by default.
149 #
150 # html_title = u'pyhf v0.0.4'
151
152 # A shorter title for the navigation bar. Default is the same as html_title.
153 #
154 # html_short_title = None
155
156 # The name of an image file (relative to this directory) to place at the top
157 # of the sidebar.
158 #
159 # html_logo = None
160
161 # The name of an image file (relative to this directory) to use as a favicon of
162 # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
163 # pixels large.
164 #
165 # html_favicon = None
166
167 # Add any paths that contain custom static files (such as style sheets) here,
168 # relative to this directory. They are copied after the builtin static files,
169 # so a file named "default.css" will overwrite the builtin "default.css".
170 html_static_path = ['_static']
171
172 # Add any extra paths that contain custom files (such as robots.txt or
173 # .htaccess) here, relative to this directory. These files are copied
174 # directly to the root of the documentation.
175 #
176 # html_extra_path = []
177
178 # If not None, a 'Last updated on:' timestamp is inserted at every page
179 # bottom, using the given strftime format.
180 # The empty string is equivalent to '%b %d, %Y'.
181 #
182 # html_last_updated_fmt = None
183
184 # If true, SmartyPants will be used to convert quotes and dashes to
185 # typographically correct entities.
186 #
187 # html_use_smartypants = True
188
189 # Custom sidebar templates, maps document names to template names.
190 #
191 # html_sidebars = {}
192
193 # Additional templates that should be rendered to pages, maps page names to
194 # template names.
195 #
196 # html_additional_pages = {}
197
198 # If false, no module index is generated.
199 #
200 # html_domain_indices = True
201
202 # If false, no index is generated.
203 #
204 # html_use_index = True
205
206 # If true, the index is split into individual pages for each letter.
207 #
208 # html_split_index = False
209
210 # If true, links to the reST sources are added to the pages.
211 #
212 # html_show_sourcelink = True
213
214 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
215 #
216 # html_show_sphinx = True
217
218 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
219 #
220 # html_show_copyright = True
221
222 # If true, an OpenSearch description file will be output, and all pages will
223 # contain a <link> tag referring to it. The value of this option must be the
224 # base URL from which the finished HTML is served.
225 #
226 # html_use_opensearch = ''
227
228 # This is the file name suffix for HTML files (e.g. ".xhtml").
229 # html_file_suffix = None
230
231 # Language to be used for generating the HTML full-text search index.
232 # Sphinx supports the following languages:
233 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
234 # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr', 'zh'
235 #
236 # html_search_language = 'en'
237
238 # A dictionary with options for the search language support, empty by default.
239 # 'ja' uses this config value.
240 # 'zh' user can custom change `jieba` dictionary path.
241 #
242 # html_search_options = {'type': 'default'}
243
244 # The name of a javascript file (relative to the configuration directory) that
245 # implements a search results scorer. If empty, the default will be used.
246 #
247 # html_search_scorer = 'scorer.js'
248
249 # Output file base name for HTML help builder.
250 htmlhelp_basename = 'pyhfdoc'
251
252 # -- Options for LaTeX output ---------------------------------------------
253
254 latex_elements = {
255 # The paper size ('letterpaper' or 'a4paper').
256 #
257 # 'papersize': 'letterpaper',
258
259 # The font size ('10pt', '11pt' or '12pt').
260 #
261 # 'pointsize': '10pt',
262
263 # Additional stuff for the LaTeX preamble.
264 #
265 # 'preamble': '',
266
267 # Latex figure (float) alignment
268 #
269 # 'figure_align': 'htbp',
270 }
271
272 # Grouping the document tree into LaTeX files. List of tuples
273 # (source start file, target name, title,
274 # author, documentclass [howto, manual, or own class]).
275 latex_documents = [
276 (master_doc, 'pyhf.tex', u'pyhf Documentation',
277 u'Lukas Heinrich, Matthew Feickert', 'manual'),
278 ]
279
280 # The name of an image file (relative to this directory) to place at the top of
281 # the title page.
282 #
283 # latex_logo = None
284
285 # For "manual" documents, if this is true, then toplevel headings are parts,
286 # not chapters.
287 #
288 # latex_use_parts = False
289
290 # If true, show page references after internal links.
291 #
292 # latex_show_pagerefs = False
293
294 # If true, show URL addresses after external links.
295 #
296 # latex_show_urls = False
297
298 # Documents to append as an appendix to all manuals.
299 #
300 # latex_appendices = []
301
302 # It false, will not define \strong, \code, itleref, \crossref ... but only
303 # \sphinxstrong, ..., \sphinxtitleref, ... To help avoid clash with user added
304 # packages.
305 #
306 # latex_keep_old_macro_names = True
307
308 # If false, no module index is generated.
309 #
310 # latex_domain_indices = True
311
312
313 # -- Options for manual page output ---------------------------------------
314
315 # One entry per manual page. List of tuples
316 # (source start file, name, description, authors, manual section).
317 man_pages = [
318 (master_doc, 'pyhf', u'pyhf Documentation',
319 [author], 1)
320 ]
321
322 # If true, show URL addresses after external links.
323 #
324 # man_show_urls = False
325
326
327 # -- Options for Texinfo output -------------------------------------------
328
329 # Grouping the document tree into Texinfo files. List of tuples
330 # (source start file, target name, title, author,
331 # dir menu entry, description, category)
332 texinfo_documents = [
333 (master_doc, 'pyhf', u'pyhf Documentation',
334 author, 'pyhf', 'One line description of project.',
335 'Miscellaneous'),
336 ]
337
338 # Documents to append as an appendix to all manuals.
339 #
340 # texinfo_appendices = []
341
342 # If false, no module index is generated.
343 #
344 # texinfo_domain_indices = True
345
346 # How to display URL addresses: 'footnote', 'no', or 'inline'.
347 #
348 # texinfo_show_urls = 'footnote'
349
350 # If true, do not generate a @detailmenu in the "Top" node's menu.
351 #
352 # texinfo_no_detailmenu = False
353
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -94,7 +94,7 @@
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This patterns also effect to html_static_path and html_extra_path
-exclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments', 'examples/notebooks/binderexample']
+exclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments']
# The reST default role (used for this markup: `text`) to use for all
# documents.
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -94,7 +94,7 @@\n # List of patterns, relative to source directory, that match files and\n # directories to ignore when looking for source files.\n # This patterns also effect to html_static_path and html_extra_path\n-exclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments', 'examples/notebooks/binderexample']\n+exclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments']\n \n # The reST default role (used for this markup: `text`) to use for all\n # documents.\n", "issue": "Add binderexample/StatisticalAnalysis.ipynb to docs examples\nAt the moment the Binder example notebook `binderexample/StatisticalAnalysis.ipynb` is not being included in the build of the docs. Lukas has put some really nice examples in there and it would be nice to have this in the docs in the even that people don't check out the Binder.\r\n\r\n# Relevant Issues and Pull Requests\r\n\r\nThis is also somewhat relevant to Issue #168 \r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# pyhf documentation build configuration file, created by\n# sphinx-quickstart on Fri Feb 9 11:58:49 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('..'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.ifconfig',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.githubpages',\n 'sphinxcontrib.napoleon',\n 'nbsphinx',\n]\n\n# Generate the API documentation when building\nautosummary_generate = True\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'pyhf'\ncopyright = u'2018, Lukas Heinrich, Matthew Feickert, Giordon Stark'\nauthor = u'Lukas Heinrich, Matthew Feickert, Giordon Stark'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u'0.0.4'\n# The full version, including alpha/beta/rc tags.\nrelease = u'0.0.4'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#\n# today = ''\n#\n# Else, today_fmt is used as the format for a strftime call.\n#\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments', 'examples/notebooks/binderexample']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#\n# default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = []\n\n# The name for this set of Sphinx documents.\n# \"<project> v<release> documentation\" by default.\n#\n# html_title = u'pyhf v0.0.4'\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#\n# html_logo = None\n\n# The name of an image file (relative to this directory) to use as a favicon of\n# the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#\n# html_extra_path = []\n\n# If not None, a 'Last updated on:' timestamp is inserted at every page\n# bottom, using the given strftime format.\n# The empty string is equivalent to '%b %d, %Y'.\n#\n# html_last_updated_fmt = None\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n#\n# html_domain_indices = True\n\n# If false, no index is generated.\n#\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr', 'zh'\n#\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# 'ja' uses this config value.\n# 'zh' user can custom change `jieba` dictionary path.\n#\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'pyhfdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'pyhf.tex', u'pyhf Documentation',\n u'Lukas Heinrich, Matthew Feickert', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n#\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#\n# latex_appendices = []\n\n# It false, will not define \\strong, \\code, \titleref, \\crossref ... but only\n# \\sphinxstrong, ..., \\sphinxtitleref, ... To help avoid clash with user added\n# packages.\n#\n# latex_keep_old_macro_names = True\n\n# If false, no module index is generated.\n#\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'pyhf', u'pyhf Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'pyhf', u'pyhf Documentation',\n author, 'pyhf', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n#\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# pyhf documentation build configuration file, created by\n# sphinx-quickstart on Fri Feb 9 11:58:49 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('..'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.ifconfig',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.githubpages',\n 'sphinxcontrib.napoleon',\n 'nbsphinx',\n]\n\n# Generate the API documentation when building\nautosummary_generate = True\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'pyhf'\ncopyright = u'2018, Lukas Heinrich, Matthew Feickert, Giordon Stark'\nauthor = u'Lukas Heinrich, Matthew Feickert, Giordon Stark'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = u'0.0.4'\n# The full version, including alpha/beta/rc tags.\nrelease = u'0.0.4'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#\n# today = ''\n#\n# Else, today_fmt is used as the format for a strftime call.\n#\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', '**.ipynb_checkpoints', 'examples/experiments']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#\n# default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#\n# add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#\n# add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#\n# show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n# modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n# keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = []\n\n# The name for this set of Sphinx documents.\n# \"<project> v<release> documentation\" by default.\n#\n# html_title = u'pyhf v0.0.4'\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#\n# html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#\n# html_logo = None\n\n# The name of an image file (relative to this directory) to use as a favicon of\n# the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#\n# html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#\n# html_extra_path = []\n\n# If not None, a 'Last updated on:' timestamp is inserted at every page\n# bottom, using the given strftime format.\n# The empty string is equivalent to '%b %d, %Y'.\n#\n# html_last_updated_fmt = None\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#\n# html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#\n# html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#\n# html_additional_pages = {}\n\n# If false, no module index is generated.\n#\n# html_domain_indices = True\n\n# If false, no index is generated.\n#\n# html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#\n# html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#\n# html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr', 'zh'\n#\n# html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# 'ja' uses this config value.\n# 'zh' user can custom change `jieba` dictionary path.\n#\n# html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#\n# html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'pyhfdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'pyhf.tex', u'pyhf Documentation',\n u'Lukas Heinrich, Matthew Feickert', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#\n# latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#\n# latex_use_parts = False\n\n# If true, show page references after internal links.\n#\n# latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#\n# latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#\n# latex_appendices = []\n\n# It false, will not define \\strong, \\code, \titleref, \\crossref ... but only\n# \\sphinxstrong, ..., \\sphinxtitleref, ... To help avoid clash with user added\n# packages.\n#\n# latex_keep_old_macro_names = True\n\n# If false, no module index is generated.\n#\n# latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'pyhf', u'pyhf Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#\n# man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'pyhf', u'pyhf Documentation',\n author, 'pyhf', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#\n# texinfo_appendices = []\n\n# If false, no module index is generated.\n#\n# texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#\n# texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#\n# texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}]} | 3,940 | 150 |
gh_patches_debug_11984 | rasdani/github-patches | git_diff | dotkom__onlineweb4-420 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mark rules error for anonymous users on events
'AnonymousUser' object has no attribute 'mark_rules'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/events/forms.py`
Content:
```
1 from django import forms
2 from captcha.fields import CaptchaField
3
4 class CaptchaForm(forms.Form):
5 def __init__(self, *args, **kwargs):
6 user = kwargs.pop('user', None)
7 super(CaptchaForm, self).__init__(*args, **kwargs)
8 # Removing mark rules field if user has already accepted the rules
9 if user and user.mark_rules:
10 del self.fields['mark_rules']
11 mark_rules = forms.BooleanField(label=u'Jeg godtar <a href="/profile/#marks" target="_blank">prikkreglene</a>')
12 captcha = CaptchaField()
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/apps/events/forms.py b/apps/events/forms.py
--- a/apps/events/forms.py
+++ b/apps/events/forms.py
@@ -6,7 +6,7 @@
user = kwargs.pop('user', None)
super(CaptchaForm, self).__init__(*args, **kwargs)
# Removing mark rules field if user has already accepted the rules
- if user and user.mark_rules:
+ if user and user.is_authenticated() and user.mark_rules:
del self.fields['mark_rules']
mark_rules = forms.BooleanField(label=u'Jeg godtar <a href="/profile/#marks" target="_blank">prikkreglene</a>')
captcha = CaptchaField()
| {"golden_diff": "diff --git a/apps/events/forms.py b/apps/events/forms.py\n--- a/apps/events/forms.py\n+++ b/apps/events/forms.py\n@@ -6,7 +6,7 @@\n user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n # Removing mark rules field if user has already accepted the rules\n- if user and user.mark_rules:\n+ if user and user.is_authenticated() and user.mark_rules:\n del self.fields['mark_rules']\n mark_rules = forms.BooleanField(label=u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>')\n captcha = CaptchaField()\n", "issue": "Mark rules error for anonymous users on events\n'AnonymousUser' object has no attribute 'mark_rules'\n\n", "before_files": [{"content": "from django import forms\nfrom captcha.fields import CaptchaField\n\nclass CaptchaForm(forms.Form):\n def __init__(self, *args, **kwargs):\n user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n # Removing mark rules field if user has already accepted the rules\n if user and user.mark_rules:\n del self.fields['mark_rules']\n mark_rules = forms.BooleanField(label=u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>')\n captcha = CaptchaField()\n", "path": "apps/events/forms.py"}], "after_files": [{"content": "from django import forms\nfrom captcha.fields import CaptchaField\n\nclass CaptchaForm(forms.Form):\n def __init__(self, *args, **kwargs):\n user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n # Removing mark rules field if user has already accepted the rules\n if user and user.is_authenticated() and user.mark_rules:\n del self.fields['mark_rules']\n mark_rules = forms.BooleanField(label=u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>')\n captcha = CaptchaField()\n", "path": "apps/events/forms.py"}]} | 425 | 148 |
gh_patches_debug_219 | rasdani/github-patches | git_diff | pypa__setuptools-2427 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sphinx setup should be stricter
I noticed that some of the docs pages are unreachable when navigating from the main RTD page. In particular, _I know_ that there's `history.rst` that is only accessible if one knows the URL upfront.
I tracked this to https://github.com/pypa/setuptools/pull/2097 which removes entries from the TOC but doesn't reintroduce them in other places.
Sphinx has a few toggles that make it nitpicky about warnings. I think this should be enabled in the CI to prevent such problems in the future. This should catch implicit orphan pages as well as dead references or typos.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 import subprocess
2 import sys
3 import os
4
5
6 # hack to run the bootstrap script so that jaraco.packaging.sphinx
7 # can invoke setup.py
8 'READTHEDOCS' in os.environ and subprocess.check_call(
9 [sys.executable, '-m', 'bootstrap'],
10 cwd=os.path.join(os.path.dirname(__file__), os.path.pardir),
11 )
12
13 # -- Project information -----------------------------------------------------
14
15 github_url = 'https://github.com'
16 github_sponsors_url = f'{github_url}/sponsors'
17
18 # -- General configuration --
19
20 extensions = [
21 'sphinx.ext.extlinks', # allows to create custom roles easily
22 'jaraco.packaging.sphinx',
23 'rst.linker',
24 ]
25
26 # Add any paths that contain templates here, relative to this directory.
27 templates_path = ['_templates']
28
29 # The master toctree document.
30 master_doc = 'index'
31
32 # List of directories, relative to source directory, that shouldn't be searched
33 # for source files.
34 exclude_trees = []
35
36 # The name of the Pygments (syntax highlighting) style to use.
37 pygments_style = 'sphinx'
38
39 # -- Options for extlinks extension ---------------------------------------
40 extlinks = {
41 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323
42 }
43
44 # -- Options for HTML output --
45
46 # The theme to use for HTML and HTML Help pages. Major themes that come with
47 # Sphinx are currently 'default' and 'sphinxdoc'.
48 html_theme = 'nature'
49
50 # Add any paths that contain custom themes here, relative to this directory.
51 html_theme_path = ['_theme']
52
53 # If true, SmartyPants will be used to convert quotes and dashes to
54 # typographically correct entities.
55 html_use_smartypants = True
56
57 # Custom sidebar templates, maps document names to template names.
58 html_sidebars = {
59 'index': [
60 'relations.html', 'sourcelink.html', 'indexsidebar.html',
61 'searchbox.html']}
62
63 # If false, no module index is generated.
64 html_use_modindex = False
65
66 # If false, no index is generated.
67 html_use_index = False
68
69 # -- Options for LaTeX output --
70
71 # Grouping the document tree into LaTeX files. List of tuples
72 # (source start file, target name, title, author,
73 # documentclass [howto/manual]).
74 latex_documents = [(
75 'index', 'Setuptools.tex', 'Setuptools Documentation',
76 'The fellowship of the packaging', 'manual',
77 )]
78
79 link_files = {
80 '../CHANGES.rst': dict(
81 using=dict(
82 BB='https://bitbucket.org',
83 GH='https://github.com',
84 ),
85 replace=[
86 dict(
87 pattern=r'(Issue )?#(?P<issue>\d+)',
88 url='{package_url}/issues/{issue}',
89 ),
90 dict(
91 pattern=r'BB Pull Request ?#(?P<bb_pull_request>\d+)',
92 url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',
93 ),
94 dict(
95 pattern=r'Distribute #(?P<distribute>\d+)',
96 url='{BB}/tarek/distribute/issue/{distribute}',
97 ),
98 dict(
99 pattern=r'Buildout #(?P<buildout>\d+)',
100 url='{GH}/buildout/buildout/issues/{buildout}',
101 ),
102 dict(
103 pattern=r'Old Setuptools #(?P<old_setuptools>\d+)',
104 url='http://bugs.python.org/setuptools/issue{old_setuptools}',
105 ),
106 dict(
107 pattern=r'Jython #(?P<jython>\d+)',
108 url='http://bugs.jython.org/issue{jython}',
109 ),
110 dict(
111 pattern=r'(Python #|bpo-)(?P<python>\d+)',
112 url='http://bugs.python.org/issue{python}',
113 ),
114 dict(
115 pattern=r'Interop #(?P<interop>\d+)',
116 url='{GH}/pypa/interoperability-peps/issues/{interop}',
117 ),
118 dict(
119 pattern=r'Pip #(?P<pip>\d+)',
120 url='{GH}/pypa/pip/issues/{pip}',
121 ),
122 dict(
123 pattern=r'Packaging #(?P<packaging>\d+)',
124 url='{GH}/pypa/packaging/issues/{packaging}',
125 ),
126 dict(
127 pattern=r'[Pp]ackaging (?P<packaging_ver>\d+(\.\d+)+)',
128 url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',
129 ),
130 dict(
131 pattern=r'PEP[- ](?P<pep_number>\d+)',
132 url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',
133 ),
134 dict(
135 pattern=r'setuptools_svn #(?P<setuptools_svn>\d+)',
136 url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',
137 ),
138 dict(
139 pattern=r'pypa/distutils#(?P<distutils>\d+)',
140 url='{GH}/pypa/distutils/issues/{distutils}',
141 ),
142 dict(
143 pattern=r'^(?m)((?P<scm_version>v?\d+(\.\d+){1,2}))\n[-=]+\n',
144 with_scm='{text}\n{rev[timestamp]:%d %b %Y}\n',
145 ),
146 ],
147 ),
148 }
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -146,3 +146,12 @@
],
),
}
+
+
+# Be strict about any broken references:
+nitpicky = True
+
+
+# Ref: https://github.com/python-attrs/attrs/pull/571/files\
+# #diff-85987f48f1258d9ee486e3191495582dR82
+default_role = 'any'
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -146,3 +146,12 @@\n ],\n ),\n }\n+\n+\n+# Be strict about any broken references:\n+nitpicky = True\n+\n+\n+# Ref: https://github.com/python-attrs/attrs/pull/571/files\\\n+# #diff-85987f48f1258d9ee486e3191495582dR82\n+default_role = 'any'\n", "issue": "Sphinx setup should be stricter\nI noticed that some of the docs pages are unreachable when navigating from the main RTD page. In particular, _I know_ that there's `history.rst` that is only accessible if one knows the URL upfront.\r\n\r\nI tracked this to https://github.com/pypa/setuptools/pull/2097 which removes entries from the TOC but doesn't reintroduce them in other places.\r\n\r\nSphinx has a few toggles that make it nitpicky about warnings. I think this should be enabled in the CI to prevent such problems in the future. This should catch implicit orphan pages as well as dead references or typos.\n", "before_files": [{"content": "import subprocess\nimport sys\nimport os\n\n\n# hack to run the bootstrap script so that jaraco.packaging.sphinx\n# can invoke setup.py\n'READTHEDOCS' in os.environ and subprocess.check_call(\n [sys.executable, '-m', 'bootstrap'],\n cwd=os.path.join(os.path.dirname(__file__), os.path.pardir),\n)\n\n# -- Project information -----------------------------------------------------\n\ngithub_url = 'https://github.com'\ngithub_sponsors_url = f'{github_url}/sponsors'\n\n# -- General configuration --\n\nextensions = [\n 'sphinx.ext.extlinks', # allows to create custom roles easily\n 'jaraco.packaging.sphinx',\n 'rst.linker',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# List of directories, relative to source directory, that shouldn't be searched\n# for source files.\nexclude_trees = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# -- Options for extlinks extension ---------------------------------------\nextlinks = {\n 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323\n}\n\n# -- Options for HTML output --\n\n# The theme to use for HTML and HTML Help pages. Major themes that come with\n# Sphinx are currently 'default' and 'sphinxdoc'.\nhtml_theme = 'nature'\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = ['_theme']\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\nhtml_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\nhtml_sidebars = {\n 'index': [\n 'relations.html', 'sourcelink.html', 'indexsidebar.html',\n 'searchbox.html']}\n\n# If false, no module index is generated.\nhtml_use_modindex = False\n\n# If false, no index is generated.\nhtml_use_index = False\n\n# -- Options for LaTeX output --\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author,\n# documentclass [howto/manual]).\nlatex_documents = [(\n 'index', 'Setuptools.tex', 'Setuptools Documentation',\n 'The fellowship of the packaging', 'manual',\n)]\n\nlink_files = {\n '../CHANGES.rst': dict(\n using=dict(\n BB='https://bitbucket.org',\n GH='https://github.com',\n ),\n replace=[\n dict(\n pattern=r'(Issue )?#(?P<issue>\\d+)',\n url='{package_url}/issues/{issue}',\n ),\n dict(\n pattern=r'BB Pull Request ?#(?P<bb_pull_request>\\d+)',\n url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',\n ),\n dict(\n pattern=r'Distribute #(?P<distribute>\\d+)',\n url='{BB}/tarek/distribute/issue/{distribute}',\n ),\n dict(\n pattern=r'Buildout #(?P<buildout>\\d+)',\n url='{GH}/buildout/buildout/issues/{buildout}',\n ),\n dict(\n pattern=r'Old Setuptools #(?P<old_setuptools>\\d+)',\n url='http://bugs.python.org/setuptools/issue{old_setuptools}',\n ),\n dict(\n pattern=r'Jython #(?P<jython>\\d+)',\n url='http://bugs.jython.org/issue{jython}',\n ),\n dict(\n pattern=r'(Python #|bpo-)(?P<python>\\d+)',\n url='http://bugs.python.org/issue{python}',\n ),\n dict(\n pattern=r'Interop #(?P<interop>\\d+)',\n url='{GH}/pypa/interoperability-peps/issues/{interop}',\n ),\n dict(\n pattern=r'Pip #(?P<pip>\\d+)',\n url='{GH}/pypa/pip/issues/{pip}',\n ),\n dict(\n pattern=r'Packaging #(?P<packaging>\\d+)',\n url='{GH}/pypa/packaging/issues/{packaging}',\n ),\n dict(\n pattern=r'[Pp]ackaging (?P<packaging_ver>\\d+(\\.\\d+)+)',\n url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',\n ),\n dict(\n pattern=r'PEP[- ](?P<pep_number>\\d+)',\n url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',\n ),\n dict(\n pattern=r'setuptools_svn #(?P<setuptools_svn>\\d+)',\n url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',\n ),\n dict(\n pattern=r'pypa/distutils#(?P<distutils>\\d+)',\n url='{GH}/pypa/distutils/issues/{distutils}',\n ),\n dict(\n pattern=r'^(?m)((?P<scm_version>v?\\d+(\\.\\d+){1,2}))\\n[-=]+\\n',\n with_scm='{text}\\n{rev[timestamp]:%d %b %Y}\\n',\n ),\n ],\n ),\n}\n", "path": "docs/conf.py"}], "after_files": [{"content": "import subprocess\nimport sys\nimport os\n\n\n# hack to run the bootstrap script so that jaraco.packaging.sphinx\n# can invoke setup.py\n'READTHEDOCS' in os.environ and subprocess.check_call(\n [sys.executable, '-m', 'bootstrap'],\n cwd=os.path.join(os.path.dirname(__file__), os.path.pardir),\n)\n\n# -- Project information -----------------------------------------------------\n\ngithub_url = 'https://github.com'\ngithub_sponsors_url = f'{github_url}/sponsors'\n\n# -- General configuration --\n\nextensions = [\n 'sphinx.ext.extlinks', # allows to create custom roles easily\n 'jaraco.packaging.sphinx',\n 'rst.linker',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# List of directories, relative to source directory, that shouldn't be searched\n# for source files.\nexclude_trees = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# -- Options for extlinks extension ---------------------------------------\nextlinks = {\n 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323\n}\n\n# -- Options for HTML output --\n\n# The theme to use for HTML and HTML Help pages. Major themes that come with\n# Sphinx are currently 'default' and 'sphinxdoc'.\nhtml_theme = 'nature'\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = ['_theme']\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\nhtml_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\nhtml_sidebars = {\n 'index': [\n 'relations.html', 'sourcelink.html', 'indexsidebar.html',\n 'searchbox.html']}\n\n# If false, no module index is generated.\nhtml_use_modindex = False\n\n# If false, no index is generated.\nhtml_use_index = False\n\n# -- Options for LaTeX output --\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author,\n# documentclass [howto/manual]).\nlatex_documents = [(\n 'index', 'Setuptools.tex', 'Setuptools Documentation',\n 'The fellowship of the packaging', 'manual',\n)]\n\nlink_files = {\n '../CHANGES.rst': dict(\n using=dict(\n BB='https://bitbucket.org',\n GH='https://github.com',\n ),\n replace=[\n dict(\n pattern=r'(Issue )?#(?P<issue>\\d+)',\n url='{package_url}/issues/{issue}',\n ),\n dict(\n pattern=r'BB Pull Request ?#(?P<bb_pull_request>\\d+)',\n url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',\n ),\n dict(\n pattern=r'Distribute #(?P<distribute>\\d+)',\n url='{BB}/tarek/distribute/issue/{distribute}',\n ),\n dict(\n pattern=r'Buildout #(?P<buildout>\\d+)',\n url='{GH}/buildout/buildout/issues/{buildout}',\n ),\n dict(\n pattern=r'Old Setuptools #(?P<old_setuptools>\\d+)',\n url='http://bugs.python.org/setuptools/issue{old_setuptools}',\n ),\n dict(\n pattern=r'Jython #(?P<jython>\\d+)',\n url='http://bugs.jython.org/issue{jython}',\n ),\n dict(\n pattern=r'(Python #|bpo-)(?P<python>\\d+)',\n url='http://bugs.python.org/issue{python}',\n ),\n dict(\n pattern=r'Interop #(?P<interop>\\d+)',\n url='{GH}/pypa/interoperability-peps/issues/{interop}',\n ),\n dict(\n pattern=r'Pip #(?P<pip>\\d+)',\n url='{GH}/pypa/pip/issues/{pip}',\n ),\n dict(\n pattern=r'Packaging #(?P<packaging>\\d+)',\n url='{GH}/pypa/packaging/issues/{packaging}',\n ),\n dict(\n pattern=r'[Pp]ackaging (?P<packaging_ver>\\d+(\\.\\d+)+)',\n url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',\n ),\n dict(\n pattern=r'PEP[- ](?P<pep_number>\\d+)',\n url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',\n ),\n dict(\n pattern=r'setuptools_svn #(?P<setuptools_svn>\\d+)',\n url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',\n ),\n dict(\n pattern=r'pypa/distutils#(?P<distutils>\\d+)',\n url='{GH}/pypa/distutils/issues/{distutils}',\n ),\n dict(\n pattern=r'^(?m)((?P<scm_version>v?\\d+(\\.\\d+){1,2}))\\n[-=]+\\n',\n with_scm='{text}\\n{rev[timestamp]:%d %b %Y}\\n',\n ),\n ],\n ),\n}\n\n\n# Be strict about any broken references:\nnitpicky = True\n\n\n# Ref: https://github.com/python-attrs/attrs/pull/571/files\\\n# #diff-85987f48f1258d9ee486e3191495582dR82\ndefault_role = 'any'\n", "path": "docs/conf.py"}]} | 1,918 | 130 |
gh_patches_debug_24596 | rasdani/github-patches | git_diff | ddionrails__ddionrails-201 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change "templates" path in staging and production settings
In `settings/hewing.py`and `settings/production.py` the path in `TEMPLATES` `DIRS` is hard coded. This leads to `TemplateDoesNotExist` if the path on a server changes.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `settings/hewing.py`
Content:
```
1 from .base import * # noqa
2
3 WSGI_APPLICATION = "ddionrails.wsgi_hewing.application"
4
5 DEBUG = True
6
7 ALLOWED_HOSTS = ["hewing.soep.de", "ddionrails.soep.de"]
8
9 # django-debug-toolbar
10 # ------------------------------------------------------------------------------
11 # https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#prerequisites
12 INSTALLED_APPS += ["debug_toolbar"]
13 # https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#middleware
14 MIDDLEWARE = ["debug_toolbar.middleware.DebugToolbarMiddleware"] + MIDDLEWARE
15 # https://django-debug-toolbar.readthedocs.io/en/latest/configuration.html#debug-toolbar-config
16
17 SYSTEM_NAME = "system"
18 SYSTEM_REPO_URL = "https://github.com/paneldata/system.git"
19 BACKUP_NAME = "backup"
20 BACKUP_REPO_URL = "https://github.com/ddionrails/test-backup.git"
21 IMPORT_BRANCH = "development"
22
23 LOGGING = {
24 "version": 1,
25 "disable_existing_loggers": False,
26 "handlers": {
27 "file": {
28 "level": "DEBUG",
29 "class": "logging.FileHandler",
30 "filename": "/tmp/dor-debug.log",
31 }
32 },
33 "loggers": {
34 "django.request": {"handlers": ["file"], "level": "DEBUG", "propagate": True},
35 "imports": {"handlers": ["file"], "level": "DEBUG", "propagate": True},
36 },
37 }
38
39 RQ_QUEUES = {
40 "default": {"HOST": "localhost", "PORT": 6379, "DB": 0, "DEFAULT_TIMEOUT": 360},
41 "high": {
42 "URL": os.getenv(
43 "REDISTOGO_URL", "redis://localhost:6379/0"
44 ), # If you're on Heroku
45 "DEFAULT_TIMEOUT": 500,
46 },
47 "low": {"HOST": "localhost", "PORT": 6379, "DB": 0},
48 }
49
50
51 TEMPLATES = [
52 {
53 "BACKEND": "django.template.backends.django.DjangoTemplates",
54 "DIRS": ["/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates"],
55 "APP_DIRS": True,
56 "OPTIONS": {
57 "context_processors": [
58 "django.template.context_processors.debug",
59 "django.template.context_processors.request",
60 "django.contrib.auth.context_processors.auth",
61 "django.contrib.messages.context_processors.messages",
62 "studies.models.context",
63 ]
64 },
65 }
66 ]
67
68 # SECURITY
69 # ------------------------------------------------------------------------------
70 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header
71 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
72 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect
73 SECURE_SSL_REDIRECT = True
74 # https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure
75 SESSION_COOKIE_SECURE = True
76 # https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly
77 SESSION_COOKIE_HTTPONLY = True
78 # https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure
79 CSRF_COOKIE_SECURE = True
80 # https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly
81 CSRF_COOKIE_HTTPONLY = True
82 # https://docs.djangoproject.com/en/dev/topics/security/#ssl-https
83 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds
84 SECURE_HSTS_SECONDS = 60
85 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains
86 SECURE_HSTS_INCLUDE_SUBDOMAINS = True
87 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload
88 SECURE_HSTS_PRELOAD = True
89 # https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff
90 SECURE_CONTENT_TYPE_NOSNIFF = True
91 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter
92 SECURE_BROWSER_XSS_FILTER = True
93 # https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options
94 X_FRAME_OPTIONS = "DENY"
95
```
Path: `settings/production.py`
Content:
```
1 from .base import * # noqa
2
3 WSGI_APPLICATION = "ddionrails.wsgi_production.application"
4 DEBUG = False
5 ALLOWED_HOSTS = [".paneldata.org", "paneldata.soep.de", "data.soep.de"]
6
7 SYSTEM_NAME = "system"
8 SYSTEM_REPO_URL = "https://github.com/paneldata/system.git"
9 BACKUP_NAME = "backup"
10 BACKUP_REPO_URL = "https://github.com/ddionrails/test-backup.git"
11 IMPORT_BRANCH = "master"
12
13 LOGGING = {
14 "version": 1,
15 "disable_existing_loggers": False,
16 "handlers": {
17 "file": {
18 "level": "DEBUG",
19 "class": "logging.FileHandler",
20 "filename": "/tmp/dor-debug.log",
21 }
22 },
23 "loggers": {
24 "django.request": {"handlers": ["file"], "level": "DEBUG", "propagate": True},
25 "imports": {"handlers": ["file"], "level": "DEBUG", "propagate": True},
26 },
27 }
28
29 RQ_QUEUES = {
30 "default": {"HOST": "localhost", "PORT": 6379, "DB": 0, "DEFAULT_TIMEOUT": 360},
31 "high": {
32 "URL": os.getenv(
33 "REDISTOGO_URL", "redis://localhost:6379/0"
34 ), # If you're on Heroku
35 "DEFAULT_TIMEOUT": 500,
36 },
37 "low": {"HOST": "localhost", "PORT": 6379, "DB": 0},
38 }
39
40
41 TEMPLATES = [
42 {
43 "BACKEND": "django.template.backends.django.DjangoTemplates",
44 "DIRS": ["/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates"],
45 "APP_DIRS": True,
46 "OPTIONS": {
47 "context_processors": [
48 "django.template.context_processors.debug",
49 "django.template.context_processors.request",
50 "django.contrib.auth.context_processors.auth",
51 "django.contrib.messages.context_processors.messages",
52 "studies.models.context",
53 ]
54 },
55 }
56 ]
57
58 # SECURITY
59 # ------------------------------------------------------------------------------
60 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header
61 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
62 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect
63 SECURE_SSL_REDIRECT = True
64 # https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure
65 SESSION_COOKIE_SECURE = True
66 # https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly
67 SESSION_COOKIE_HTTPONLY = True
68 # https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure
69 CSRF_COOKIE_SECURE = True
70 # https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly
71 CSRF_COOKIE_HTTPONLY = True
72 # https://docs.djangoproject.com/en/dev/topics/security/#ssl-https
73 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds
74 SECURE_HSTS_SECONDS = 60
75 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains
76 SECURE_HSTS_INCLUDE_SUBDOMAINS = True
77 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload
78 SECURE_HSTS_PRELOAD = True
79 # https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff
80 SECURE_CONTENT_TYPE_NOSNIFF = True
81 # https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter
82 SECURE_BROWSER_XSS_FILTER = True
83 # https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options
84 X_FRAME_OPTIONS = "DENY"
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/settings/hewing.py b/settings/hewing.py
--- a/settings/hewing.py
+++ b/settings/hewing.py
@@ -1,4 +1,4 @@
-from .base import * # noqa
+from .base import * # noqa
WSGI_APPLICATION = "ddionrails.wsgi_hewing.application"
@@ -51,7 +51,7 @@
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
- "DIRS": ["/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates"],
+ "DIRS": [BASE_DIR + "/templates"],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
diff --git a/settings/production.py b/settings/production.py
--- a/settings/production.py
+++ b/settings/production.py
@@ -1,4 +1,4 @@
-from .base import * # noqa
+from .base import * # noqa
WSGI_APPLICATION = "ddionrails.wsgi_production.application"
DEBUG = False
@@ -41,7 +41,7 @@
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
- "DIRS": ["/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates"],
+ "DIRS": [BASE_DIR + "/templates"],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
| {"golden_diff": "diff --git a/settings/hewing.py b/settings/hewing.py\n--- a/settings/hewing.py\n+++ b/settings/hewing.py\n@@ -1,4 +1,4 @@\n-from .base import * # noqa\n+from .base import * # noqa\n \n WSGI_APPLICATION = \"ddionrails.wsgi_hewing.application\"\n \n@@ -51,7 +51,7 @@\n TEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n- \"DIRS\": [\"/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates\"],\n+ \"DIRS\": [BASE_DIR + \"/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\ndiff --git a/settings/production.py b/settings/production.py\n--- a/settings/production.py\n+++ b/settings/production.py\n@@ -1,4 +1,4 @@\n-from .base import * # noqa\n+from .base import * # noqa\n \n WSGI_APPLICATION = \"ddionrails.wsgi_production.application\"\n DEBUG = False\n@@ -41,7 +41,7 @@\n TEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n- \"DIRS\": [\"/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates\"],\n+ \"DIRS\": [BASE_DIR + \"/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n", "issue": "Change \"templates\" path in staging and production settings\nIn `settings/hewing.py`and `settings/production.py` the path in `TEMPLATES` `DIRS` is hard coded. This leads to `TemplateDoesNotExist` if the path on a server changes.\n", "before_files": [{"content": "from .base import * # noqa\n\nWSGI_APPLICATION = \"ddionrails.wsgi_hewing.application\"\n\nDEBUG = True\n\nALLOWED_HOSTS = [\"hewing.soep.de\", \"ddionrails.soep.de\"]\n\n# django-debug-toolbar\n# ------------------------------------------------------------------------------\n# https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#prerequisites\nINSTALLED_APPS += [\"debug_toolbar\"]\n# https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#middleware\nMIDDLEWARE = [\"debug_toolbar.middleware.DebugToolbarMiddleware\"] + MIDDLEWARE\n# https://django-debug-toolbar.readthedocs.io/en/latest/configuration.html#debug-toolbar-config\n\nSYSTEM_NAME = \"system\"\nSYSTEM_REPO_URL = \"https://github.com/paneldata/system.git\"\nBACKUP_NAME = \"backup\"\nBACKUP_REPO_URL = \"https://github.com/ddionrails/test-backup.git\"\nIMPORT_BRANCH = \"development\"\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"handlers\": {\n \"file\": {\n \"level\": \"DEBUG\",\n \"class\": \"logging.FileHandler\",\n \"filename\": \"/tmp/dor-debug.log\",\n }\n },\n \"loggers\": {\n \"django.request\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n \"imports\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n },\n}\n\nRQ_QUEUES = {\n \"default\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0, \"DEFAULT_TIMEOUT\": 360},\n \"high\": {\n \"URL\": os.getenv(\n \"REDISTOGO_URL\", \"redis://localhost:6379/0\"\n ), # If you're on Heroku\n \"DEFAULT_TIMEOUT\": 500,\n },\n \"low\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0},\n}\n\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\"/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"studies.models.context\",\n ]\n },\n }\n]\n\n# SECURITY\n# ------------------------------------------------------------------------------\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect\nSECURE_SSL_REDIRECT = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure\nSESSION_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly\nSESSION_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure\nCSRF_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly\nCSRF_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/topics/security/#ssl-https\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds\nSECURE_HSTS_SECONDS = 60\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains\nSECURE_HSTS_INCLUDE_SUBDOMAINS = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload\nSECURE_HSTS_PRELOAD = True\n# https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff\nSECURE_CONTENT_TYPE_NOSNIFF = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter\nSECURE_BROWSER_XSS_FILTER = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options\nX_FRAME_OPTIONS = \"DENY\"\n", "path": "settings/hewing.py"}, {"content": "from .base import * # noqa\n\nWSGI_APPLICATION = \"ddionrails.wsgi_production.application\"\nDEBUG = False\nALLOWED_HOSTS = [\".paneldata.org\", \"paneldata.soep.de\", \"data.soep.de\"]\n\nSYSTEM_NAME = \"system\"\nSYSTEM_REPO_URL = \"https://github.com/paneldata/system.git\"\nBACKUP_NAME = \"backup\"\nBACKUP_REPO_URL = \"https://github.com/ddionrails/test-backup.git\"\nIMPORT_BRANCH = \"master\"\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"handlers\": {\n \"file\": {\n \"level\": \"DEBUG\",\n \"class\": \"logging.FileHandler\",\n \"filename\": \"/tmp/dor-debug.log\",\n }\n },\n \"loggers\": {\n \"django.request\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n \"imports\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n },\n}\n\nRQ_QUEUES = {\n \"default\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0, \"DEFAULT_TIMEOUT\": 360},\n \"high\": {\n \"URL\": os.getenv(\n \"REDISTOGO_URL\", \"redis://localhost:6379/0\"\n ), # If you're on Heroku\n \"DEFAULT_TIMEOUT\": 500,\n },\n \"low\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0},\n}\n\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\"/data/WWW/vhosts/paneldata.soep.de/ddionrails2/ddionrails/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"studies.models.context\",\n ]\n },\n }\n]\n\n# SECURITY\n# ------------------------------------------------------------------------------\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect\nSECURE_SSL_REDIRECT = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure\nSESSION_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly\nSESSION_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure\nCSRF_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly\nCSRF_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/topics/security/#ssl-https\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds\nSECURE_HSTS_SECONDS = 60\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains\nSECURE_HSTS_INCLUDE_SUBDOMAINS = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload\nSECURE_HSTS_PRELOAD = True\n# https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff\nSECURE_CONTENT_TYPE_NOSNIFF = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter\nSECURE_BROWSER_XSS_FILTER = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options\nX_FRAME_OPTIONS = \"DENY\"\n", "path": "settings/production.py"}], "after_files": [{"content": "from .base import * # noqa\n\nWSGI_APPLICATION = \"ddionrails.wsgi_hewing.application\"\n\nDEBUG = True\n\nALLOWED_HOSTS = [\"hewing.soep.de\", \"ddionrails.soep.de\"]\n\n# django-debug-toolbar\n# ------------------------------------------------------------------------------\n# https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#prerequisites\nINSTALLED_APPS += [\"debug_toolbar\"]\n# https://django-debug-toolbar.readthedocs.io/en/latest/installation.html#middleware\nMIDDLEWARE = [\"debug_toolbar.middleware.DebugToolbarMiddleware\"] + MIDDLEWARE\n# https://django-debug-toolbar.readthedocs.io/en/latest/configuration.html#debug-toolbar-config\n\nSYSTEM_NAME = \"system\"\nSYSTEM_REPO_URL = \"https://github.com/paneldata/system.git\"\nBACKUP_NAME = \"backup\"\nBACKUP_REPO_URL = \"https://github.com/ddionrails/test-backup.git\"\nIMPORT_BRANCH = \"development\"\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"handlers\": {\n \"file\": {\n \"level\": \"DEBUG\",\n \"class\": \"logging.FileHandler\",\n \"filename\": \"/tmp/dor-debug.log\",\n }\n },\n \"loggers\": {\n \"django.request\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n \"imports\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n },\n}\n\nRQ_QUEUES = {\n \"default\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0, \"DEFAULT_TIMEOUT\": 360},\n \"high\": {\n \"URL\": os.getenv(\n \"REDISTOGO_URL\", \"redis://localhost:6379/0\"\n ), # If you're on Heroku\n \"DEFAULT_TIMEOUT\": 500,\n },\n \"low\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0},\n}\n\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [BASE_DIR + \"/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"studies.models.context\",\n ]\n },\n }\n]\n\n# SECURITY\n# ------------------------------------------------------------------------------\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect\nSECURE_SSL_REDIRECT = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure\nSESSION_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly\nSESSION_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure\nCSRF_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly\nCSRF_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/topics/security/#ssl-https\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds\nSECURE_HSTS_SECONDS = 60\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains\nSECURE_HSTS_INCLUDE_SUBDOMAINS = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload\nSECURE_HSTS_PRELOAD = True\n# https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff\nSECURE_CONTENT_TYPE_NOSNIFF = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter\nSECURE_BROWSER_XSS_FILTER = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options\nX_FRAME_OPTIONS = \"DENY\"\n", "path": "settings/hewing.py"}, {"content": "from .base import * # noqa\n\nWSGI_APPLICATION = \"ddionrails.wsgi_production.application\"\nDEBUG = False\nALLOWED_HOSTS = [\".paneldata.org\", \"paneldata.soep.de\", \"data.soep.de\"]\n\nSYSTEM_NAME = \"system\"\nSYSTEM_REPO_URL = \"https://github.com/paneldata/system.git\"\nBACKUP_NAME = \"backup\"\nBACKUP_REPO_URL = \"https://github.com/ddionrails/test-backup.git\"\nIMPORT_BRANCH = \"master\"\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"handlers\": {\n \"file\": {\n \"level\": \"DEBUG\",\n \"class\": \"logging.FileHandler\",\n \"filename\": \"/tmp/dor-debug.log\",\n }\n },\n \"loggers\": {\n \"django.request\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n \"imports\": {\"handlers\": [\"file\"], \"level\": \"DEBUG\", \"propagate\": True},\n },\n}\n\nRQ_QUEUES = {\n \"default\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0, \"DEFAULT_TIMEOUT\": 360},\n \"high\": {\n \"URL\": os.getenv(\n \"REDISTOGO_URL\", \"redis://localhost:6379/0\"\n ), # If you're on Heroku\n \"DEFAULT_TIMEOUT\": 500,\n },\n \"low\": {\"HOST\": \"localhost\", \"PORT\": 6379, \"DB\": 0},\n}\n\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [BASE_DIR + \"/templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"studies.models.context\",\n ]\n },\n }\n]\n\n# SECURITY\n# ------------------------------------------------------------------------------\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header\nSECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-ssl-redirect\nSECURE_SSL_REDIRECT = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-secure\nSESSION_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#session-cookie-httponly\nSESSION_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-secure\nCSRF_COOKIE_SECURE = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#csrf-cookie-httponly\nCSRF_COOKIE_HTTPONLY = True\n# https://docs.djangoproject.com/en/dev/topics/security/#ssl-https\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-seconds\nSECURE_HSTS_SECONDS = 60\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-include-subdomains\nSECURE_HSTS_INCLUDE_SUBDOMAINS = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-hsts-preload\nSECURE_HSTS_PRELOAD = True\n# https://docs.djangoproject.com/en/dev/ref/middleware/#x-content-type-options-nosniff\nSECURE_CONTENT_TYPE_NOSNIFF = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#secure-browser-xss-filter\nSECURE_BROWSER_XSS_FILTER = True\n# https://docs.djangoproject.com/en/dev/ref/settings/#x-frame-options\nX_FRAME_OPTIONS = \"DENY\"\n", "path": "settings/production.py"}]} | 2,354 | 332 |
gh_patches_debug_31907 | rasdani/github-patches | git_diff | oppia__oppia-2972 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Images in explorations should have descriptive alt attributes
The accessibility audit in issue #2862 identified that there were some essential images in explorations with a empty alt attributes.
To test, use the WebAIM WAVE accessibility tool on the Equivalent Fractions exploration.
<img width="983" alt="screen shot 2017-01-21 at 5 43 02 pm" src="https://cloud.githubusercontent.com/assets/10858542/22178606/1a57a5a6-e001-11e6-8406-363d3efa4897.png">
Because images in explorations will tend to convey essential information, the alt attributes should be descriptive. We need a feature of the editor that makes alt attributes compulsory for images added to explorations. A possible avenue is to prevent closure of image component modal until alt attribute is added.
<img width="1439" alt="screen shot 2017-01-21 at 5 45 04 pm" src="https://cloud.githubusercontent.com/assets/10858542/22178619/694e9930-e001-11e6-93bd-991d1b4fda4d.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `extensions/rich_text_components/Image/Image.py`
Content:
```
1 # coding: utf-8
2 #
3 # Copyright 2014 The Oppia Authors. All Rights Reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, softwar
12 # distributed under the License is distributed on an "AS-IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 from extensions.rich_text_components import base
18
19
20 class Image(base.BaseRichTextComponent):
21 """A rich-text component representing an inline image."""
22
23 name = 'Image'
24 category = 'Basic Input'
25 description = 'An image.'
26 frontend_name = 'image'
27 tooltip = 'Insert image'
28 requires_fs = True
29 is_block_element = True
30
31 _customization_arg_specs = [{
32 'name': 'filepath',
33 'description': (
34 'The name of the image file. (Allowed extensions: gif, jpeg, jpg, '
35 'png.)'),
36 'schema': {
37 'type': 'custom',
38 'obj_type': 'Filepath',
39 },
40 'default_value': '',
41 }, {
42 'name': 'caption',
43 'description': ('Caption for image (optional)'),
44 'schema': {
45 'type': 'unicode',
46 },
47 'default_value': '',
48 }, {
49 'name': 'alt',
50 'description': 'Alternative text (for screen readers)',
51 'schema': {
52 'type': 'unicode',
53 },
54 'default_value': '',
55 }]
56
57 @property
58 def preview_url_template(self):
59 return '/imagehandler/<[explorationId]>/<[filepath]>'
60
```
Path: `schema_utils.py`
Content:
```
1 # Copyright 2014 The Oppia Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS-IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utility functions for managing schemas and schema-based validation.
16
17 A schema is a way to specify the type of an object. For example, one might
18 want to require that an object is an integer, or that it is a dict with two
19 keys named 'abc' and 'def', each with values that are unicode strings. This
20 file contains utilities for validating schemas and for checking that objects
21 follow the definitions given by the schemas.
22
23 The objects that can be described by these schemas must be composable from the
24 following Python types: bool, dict, float, int, list, unicode.
25 """
26
27 import numbers
28 import urllib
29 import urlparse
30
31 from core.domain import html_cleaner # pylint: disable=relative-import
32
33
34 SCHEMA_KEY_ITEMS = 'items'
35 SCHEMA_KEY_LEN = 'len'
36 SCHEMA_KEY_PROPERTIES = 'properties'
37 SCHEMA_KEY_TYPE = 'type'
38 SCHEMA_KEY_POST_NORMALIZERS = 'post_normalizers'
39 SCHEMA_KEY_CHOICES = 'choices'
40 SCHEMA_KEY_NAME = 'name'
41 SCHEMA_KEY_SCHEMA = 'schema'
42 SCHEMA_KEY_OBJ_TYPE = 'obj_type'
43 SCHEMA_KEY_VALIDATORS = 'validators'
44
45 SCHEMA_TYPE_BOOL = 'bool'
46 SCHEMA_TYPE_CUSTOM = 'custom'
47 SCHEMA_TYPE_DICT = 'dict'
48 SCHEMA_TYPE_FLOAT = 'float'
49 SCHEMA_TYPE_HTML = 'html'
50 SCHEMA_TYPE_INT = 'int'
51 SCHEMA_TYPE_LIST = 'list'
52 SCHEMA_TYPE_UNICODE = 'unicode'
53
54
55 def normalize_against_schema(obj, schema):
56 """Validate the given object using the schema, normalizing if necessary.
57
58 Returns:
59 the normalized object.
60
61 Raises:
62 AssertionError: if the object fails to validate against the schema.
63 """
64 normalized_obj = None
65
66 if schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_BOOL:
67 assert isinstance(obj, bool), ('Expected bool, received %s' % obj)
68 normalized_obj = obj
69 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_CUSTOM:
70 # Importing this at the top of the file causes a circular dependency.
71 # TODO(sll): Either get rid of custom objects or find a way to merge
72 # them into the schema framework -- probably the latter.
73 from core.domain import obj_services # pylint: disable=relative-import
74 obj_class = obj_services.Registry.get_object_class_by_type(
75 schema[SCHEMA_KEY_OBJ_TYPE])
76 normalized_obj = obj_class.normalize(obj)
77 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_DICT:
78 assert isinstance(obj, dict), ('Expected dict, received %s' % obj)
79 expected_dict_keys = [
80 p[SCHEMA_KEY_NAME] for p in schema[SCHEMA_KEY_PROPERTIES]]
81 assert set(obj.keys()) == set(expected_dict_keys)
82
83 normalized_obj = {}
84 for prop in schema[SCHEMA_KEY_PROPERTIES]:
85 key = prop[SCHEMA_KEY_NAME]
86 normalized_obj[key] = normalize_against_schema(
87 obj[key], prop[SCHEMA_KEY_SCHEMA])
88 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_FLOAT:
89 obj = float(obj)
90 assert isinstance(obj, numbers.Real), (
91 'Expected float, received %s' % obj)
92 normalized_obj = obj
93 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_INT:
94 obj = int(obj)
95 assert isinstance(obj, numbers.Integral), (
96 'Expected int, received %s' % obj)
97 assert isinstance(obj, int), ('Expected int, received %s' % obj)
98 normalized_obj = obj
99 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_HTML:
100 assert isinstance(obj, basestring), (
101 'Expected unicode HTML string, received %s' % obj)
102 obj = unicode(obj)
103 assert isinstance(obj, unicode), (
104 'Expected unicode, received %s' % obj)
105 normalized_obj = html_cleaner.clean(obj)
106 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_LIST:
107 assert isinstance(obj, list), ('Expected list, received %s' % obj)
108 item_schema = schema[SCHEMA_KEY_ITEMS]
109 if SCHEMA_KEY_LEN in schema:
110 assert len(obj) == schema[SCHEMA_KEY_LEN]
111 normalized_obj = [
112 normalize_against_schema(item, item_schema) for item in obj
113 ]
114 elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_UNICODE:
115 assert isinstance(obj, basestring), (
116 'Expected unicode string, received %s' % obj)
117 obj = unicode(obj)
118 assert isinstance(obj, unicode), (
119 'Expected unicode, received %s' % obj)
120 normalized_obj = obj
121 else:
122 raise Exception('Invalid schema type: %s' % schema[SCHEMA_KEY_TYPE])
123
124 if SCHEMA_KEY_CHOICES in schema:
125 assert normalized_obj in schema[SCHEMA_KEY_CHOICES], (
126 'Received %s which is not in the allowed range of choices: %s' %
127 (normalized_obj, schema[SCHEMA_KEY_CHOICES]))
128
129 # When type normalization is finished, apply the post-normalizers in the
130 # given order.
131 if SCHEMA_KEY_POST_NORMALIZERS in schema:
132 for normalizer in schema[SCHEMA_KEY_POST_NORMALIZERS]:
133 kwargs = dict(normalizer)
134 del kwargs['id']
135 normalized_obj = Normalizers.get(normalizer['id'])(
136 normalized_obj, **kwargs)
137
138 # Validate the normalized object.
139 if SCHEMA_KEY_VALIDATORS in schema:
140 for validator in schema[SCHEMA_KEY_VALIDATORS]:
141 kwargs = dict(validator)
142 del kwargs['id']
143 assert _Validators.get(validator['id'])(normalized_obj, **kwargs), (
144 'Validation failed: %s (%s) for object %s' % (
145 validator['id'], kwargs, normalized_obj))
146
147 return normalized_obj
148
149
150 class Normalizers(object):
151 """Various normalizers.
152
153 A normalizer is a function that takes an object, attempts to normalize
154 it to a canonical representation, and/or performs validity checks on the
155 object pre- and post-normalization. If the normalization succeeds, the
156 function returns the transformed object; if it fails, it raises an
157 exception.
158
159 Some normalizers require additional arguments. It is the responsibility of
160 callers of normalizer functions to ensure that the arguments they supply to
161 the normalizer are valid. What exactly this entails is provided in the
162 docstring for each normalizer.
163 """
164
165 @classmethod
166 def get(cls, normalizer_id):
167 if not hasattr(cls, normalizer_id):
168 raise Exception('Invalid normalizer id: %s' % normalizer_id)
169 return getattr(cls, normalizer_id)
170
171 @staticmethod
172 def normalize_spaces(obj):
173 """Collapses multiple spaces into single spaces.
174
175 Args:
176 obj: a string.
177
178 Returns:
179 a string that is the same as `obj`, except that each block of
180 whitespace is collapsed into a single space character.
181 """
182 return ' '.join(obj.split())
183
184 @staticmethod
185 def sanitize_url(obj):
186 """Takes a string representing a URL and sanitizes it.
187
188 Args:
189 obj: a string representing a URL.
190
191 Returns:
192 An empty string if the URL does not start with http:// or https://.
193 Otherwise, returns the original URL.
194 """
195 url_components = urlparse.urlsplit(obj)
196 quoted_url_components = (
197 urllib.quote(component) for component in url_components)
198 raw = urlparse.urlunsplit(quoted_url_components)
199
200 acceptable = html_cleaner.filter_a('href', obj)
201 assert acceptable, (
202 'Invalid URL: Sanitized URL should start with '
203 '\'http://\' or \'https://\'; received %s' % raw)
204 return raw
205
206
207 class _Validators(object):
208 """Various validators.
209
210 A validator is a function that takes an object and returns True if it is
211 valid, and False if it isn't.
212
213 Validators should only be accessed from the checker methods in
214 schema_utils.py and schema_utils_test.py, since these methods do
215 preliminary checks on the arguments passed to the validator.
216 """
217 @classmethod
218 def get(cls, validator_id):
219 if not hasattr(cls, validator_id):
220 raise Exception('Invalid validator id: %s' % validator_id)
221 return getattr(cls, validator_id)
222
223 @staticmethod
224 def has_length_at_least(obj, min_value):
225 """Returns True iff the given object (a list) has at least
226 `min_value` elements.
227 """
228 return len(obj) >= min_value
229
230 @staticmethod
231 def has_length_at_most(obj, max_value):
232 """Returns True iff the given object (a list) has at most
233 `max_value` elements.
234 """
235 return len(obj) <= max_value
236
237 @staticmethod
238 def is_nonempty(obj):
239 """Returns True iff the given object (a string) is nonempty."""
240 return bool(obj)
241
242 @staticmethod
243 def is_uniquified(obj):
244 """Returns True iff the given object (a list) has no duplicates."""
245 return sorted(list(set(obj))) == sorted(obj)
246
247 @staticmethod
248 def is_at_least(obj, min_value):
249 """Ensures that `obj` (an int/float) is at least `min_value`."""
250 return obj >= min_value
251
252 @staticmethod
253 def is_at_most(obj, max_value):
254 """Ensures that `obj` (an int/float) is at most `max_value`."""
255 return obj <= max_value
256
257 @staticmethod
258 def is_regex(obj):
259 """Ensures that `obj` (a string) defines a valid regex."""
260 raise NotImplementedError
261
262 @staticmethod
263 def matches_regex(obj, regex):
264 """Ensures that `obj` (a string) matches the given regex."""
265 raise NotImplementedError
266
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/extensions/rich_text_components/Image/Image.py b/extensions/rich_text_components/Image/Image.py
--- a/extensions/rich_text_components/Image/Image.py
+++ b/extensions/rich_text_components/Image/Image.py
@@ -47,9 +47,19 @@
'default_value': '',
}, {
'name': 'alt',
- 'description': 'Alternative text (for screen readers)',
+ 'description': (
+ 'Briefly explain this image to a visually impaired '
+ 'learner'),
'schema': {
'type': 'unicode',
+ 'validators': [{
+ 'id': 'is_nonempty',
+ }],
+ 'ui_config': {
+ 'placeholder': (
+ 'Description of Image (Example : George Handel, '
+ '18th century baroque composer)'),
+ },
},
'default_value': '',
}]
diff --git a/schema_utils.py b/schema_utils.py
--- a/schema_utils.py
+++ b/schema_utils.py
@@ -52,7 +52,7 @@
SCHEMA_TYPE_UNICODE = 'unicode'
-def normalize_against_schema(obj, schema):
+def normalize_against_schema(obj, schema, apply_custom_validators=True):
"""Validate the given object using the schema, normalizing if necessary.
Returns:
@@ -136,13 +136,15 @@
normalized_obj, **kwargs)
# Validate the normalized object.
- if SCHEMA_KEY_VALIDATORS in schema:
- for validator in schema[SCHEMA_KEY_VALIDATORS]:
- kwargs = dict(validator)
- del kwargs['id']
- assert _Validators.get(validator['id'])(normalized_obj, **kwargs), (
- 'Validation failed: %s (%s) for object %s' % (
- validator['id'], kwargs, normalized_obj))
+ if apply_custom_validators:
+ if SCHEMA_KEY_VALIDATORS in schema:
+ for validator in schema[SCHEMA_KEY_VALIDATORS]:
+ kwargs = dict(validator)
+ del kwargs['id']
+ assert _Validators.get(
+ validator['id'])(normalized_obj, **kwargs), (
+ 'Validation failed: %s (%s) for object %s' % (
+ validator['id'], kwargs, normalized_obj))
return normalized_obj
| {"golden_diff": "diff --git a/extensions/rich_text_components/Image/Image.py b/extensions/rich_text_components/Image/Image.py\n--- a/extensions/rich_text_components/Image/Image.py\n+++ b/extensions/rich_text_components/Image/Image.py\n@@ -47,9 +47,19 @@\n 'default_value': '',\n }, {\n 'name': 'alt',\n- 'description': 'Alternative text (for screen readers)',\n+ 'description': (\n+ 'Briefly explain this image to a visually impaired '\n+ 'learner'),\n 'schema': {\n 'type': 'unicode',\n+ 'validators': [{\n+ 'id': 'is_nonempty',\n+ }],\n+ 'ui_config': {\n+ 'placeholder': (\n+ 'Description of Image (Example : George Handel, '\n+ '18th century baroque composer)'),\n+ },\n },\n 'default_value': '',\n }]\ndiff --git a/schema_utils.py b/schema_utils.py\n--- a/schema_utils.py\n+++ b/schema_utils.py\n@@ -52,7 +52,7 @@\n SCHEMA_TYPE_UNICODE = 'unicode'\n \n \n-def normalize_against_schema(obj, schema):\n+def normalize_against_schema(obj, schema, apply_custom_validators=True):\n \"\"\"Validate the given object using the schema, normalizing if necessary.\n \n Returns:\n@@ -136,13 +136,15 @@\n normalized_obj, **kwargs)\n \n # Validate the normalized object.\n- if SCHEMA_KEY_VALIDATORS in schema:\n- for validator in schema[SCHEMA_KEY_VALIDATORS]:\n- kwargs = dict(validator)\n- del kwargs['id']\n- assert _Validators.get(validator['id'])(normalized_obj, **kwargs), (\n- 'Validation failed: %s (%s) for object %s' % (\n- validator['id'], kwargs, normalized_obj))\n+ if apply_custom_validators:\n+ if SCHEMA_KEY_VALIDATORS in schema:\n+ for validator in schema[SCHEMA_KEY_VALIDATORS]:\n+ kwargs = dict(validator)\n+ del kwargs['id']\n+ assert _Validators.get(\n+ validator['id'])(normalized_obj, **kwargs), (\n+ 'Validation failed: %s (%s) for object %s' % (\n+ validator['id'], kwargs, normalized_obj))\n \n return normalized_obj\n", "issue": "Images in explorations should have descriptive alt attributes\nThe accessibility audit in issue #2862 identified that there were some essential images in explorations with a empty alt attributes.\r\n\r\nTo test, use the WebAIM WAVE accessibility tool on the Equivalent Fractions exploration.\r\n<img width=\"983\" alt=\"screen shot 2017-01-21 at 5 43 02 pm\" src=\"https://cloud.githubusercontent.com/assets/10858542/22178606/1a57a5a6-e001-11e6-8406-363d3efa4897.png\">\r\n\r\nBecause images in explorations will tend to convey essential information, the alt attributes should be descriptive. We need a feature of the editor that makes alt attributes compulsory for images added to explorations. A possible avenue is to prevent closure of image component modal until alt attribute is added.\r\n\r\n<img width=\"1439\" alt=\"screen shot 2017-01-21 at 5 45 04 pm\" src=\"https://cloud.githubusercontent.com/assets/10858542/22178619/694e9930-e001-11e6-93bd-991d1b4fda4d.png\">\r\n\n", "before_files": [{"content": "# coding: utf-8\n#\n# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softwar\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom extensions.rich_text_components import base\n\n\nclass Image(base.BaseRichTextComponent):\n \"\"\"A rich-text component representing an inline image.\"\"\"\n\n name = 'Image'\n category = 'Basic Input'\n description = 'An image.'\n frontend_name = 'image'\n tooltip = 'Insert image'\n requires_fs = True\n is_block_element = True\n\n _customization_arg_specs = [{\n 'name': 'filepath',\n 'description': (\n 'The name of the image file. (Allowed extensions: gif, jpeg, jpg, '\n 'png.)'),\n 'schema': {\n 'type': 'custom',\n 'obj_type': 'Filepath',\n },\n 'default_value': '',\n }, {\n 'name': 'caption',\n 'description': ('Caption for image (optional)'),\n 'schema': {\n 'type': 'unicode',\n },\n 'default_value': '',\n }, {\n 'name': 'alt',\n 'description': 'Alternative text (for screen readers)',\n 'schema': {\n 'type': 'unicode',\n },\n 'default_value': '',\n }]\n\n @property\n def preview_url_template(self):\n return '/imagehandler/<[explorationId]>/<[filepath]>'\n", "path": "extensions/rich_text_components/Image/Image.py"}, {"content": "# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utility functions for managing schemas and schema-based validation.\n\nA schema is a way to specify the type of an object. For example, one might\nwant to require that an object is an integer, or that it is a dict with two\nkeys named 'abc' and 'def', each with values that are unicode strings. This\nfile contains utilities for validating schemas and for checking that objects\nfollow the definitions given by the schemas.\n\nThe objects that can be described by these schemas must be composable from the\nfollowing Python types: bool, dict, float, int, list, unicode.\n\"\"\"\n\nimport numbers\nimport urllib\nimport urlparse\n\nfrom core.domain import html_cleaner # pylint: disable=relative-import\n\n\nSCHEMA_KEY_ITEMS = 'items'\nSCHEMA_KEY_LEN = 'len'\nSCHEMA_KEY_PROPERTIES = 'properties'\nSCHEMA_KEY_TYPE = 'type'\nSCHEMA_KEY_POST_NORMALIZERS = 'post_normalizers'\nSCHEMA_KEY_CHOICES = 'choices'\nSCHEMA_KEY_NAME = 'name'\nSCHEMA_KEY_SCHEMA = 'schema'\nSCHEMA_KEY_OBJ_TYPE = 'obj_type'\nSCHEMA_KEY_VALIDATORS = 'validators'\n\nSCHEMA_TYPE_BOOL = 'bool'\nSCHEMA_TYPE_CUSTOM = 'custom'\nSCHEMA_TYPE_DICT = 'dict'\nSCHEMA_TYPE_FLOAT = 'float'\nSCHEMA_TYPE_HTML = 'html'\nSCHEMA_TYPE_INT = 'int'\nSCHEMA_TYPE_LIST = 'list'\nSCHEMA_TYPE_UNICODE = 'unicode'\n\n\ndef normalize_against_schema(obj, schema):\n \"\"\"Validate the given object using the schema, normalizing if necessary.\n\n Returns:\n the normalized object.\n\n Raises:\n AssertionError: if the object fails to validate against the schema.\n \"\"\"\n normalized_obj = None\n\n if schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_BOOL:\n assert isinstance(obj, bool), ('Expected bool, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_CUSTOM:\n # Importing this at the top of the file causes a circular dependency.\n # TODO(sll): Either get rid of custom objects or find a way to merge\n # them into the schema framework -- probably the latter.\n from core.domain import obj_services # pylint: disable=relative-import\n obj_class = obj_services.Registry.get_object_class_by_type(\n schema[SCHEMA_KEY_OBJ_TYPE])\n normalized_obj = obj_class.normalize(obj)\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_DICT:\n assert isinstance(obj, dict), ('Expected dict, received %s' % obj)\n expected_dict_keys = [\n p[SCHEMA_KEY_NAME] for p in schema[SCHEMA_KEY_PROPERTIES]]\n assert set(obj.keys()) == set(expected_dict_keys)\n\n normalized_obj = {}\n for prop in schema[SCHEMA_KEY_PROPERTIES]:\n key = prop[SCHEMA_KEY_NAME]\n normalized_obj[key] = normalize_against_schema(\n obj[key], prop[SCHEMA_KEY_SCHEMA])\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_FLOAT:\n obj = float(obj)\n assert isinstance(obj, numbers.Real), (\n 'Expected float, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_INT:\n obj = int(obj)\n assert isinstance(obj, numbers.Integral), (\n 'Expected int, received %s' % obj)\n assert isinstance(obj, int), ('Expected int, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_HTML:\n assert isinstance(obj, basestring), (\n 'Expected unicode HTML string, received %s' % obj)\n obj = unicode(obj)\n assert isinstance(obj, unicode), (\n 'Expected unicode, received %s' % obj)\n normalized_obj = html_cleaner.clean(obj)\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_LIST:\n assert isinstance(obj, list), ('Expected list, received %s' % obj)\n item_schema = schema[SCHEMA_KEY_ITEMS]\n if SCHEMA_KEY_LEN in schema:\n assert len(obj) == schema[SCHEMA_KEY_LEN]\n normalized_obj = [\n normalize_against_schema(item, item_schema) for item in obj\n ]\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_UNICODE:\n assert isinstance(obj, basestring), (\n 'Expected unicode string, received %s' % obj)\n obj = unicode(obj)\n assert isinstance(obj, unicode), (\n 'Expected unicode, received %s' % obj)\n normalized_obj = obj\n else:\n raise Exception('Invalid schema type: %s' % schema[SCHEMA_KEY_TYPE])\n\n if SCHEMA_KEY_CHOICES in schema:\n assert normalized_obj in schema[SCHEMA_KEY_CHOICES], (\n 'Received %s which is not in the allowed range of choices: %s' %\n (normalized_obj, schema[SCHEMA_KEY_CHOICES]))\n\n # When type normalization is finished, apply the post-normalizers in the\n # given order.\n if SCHEMA_KEY_POST_NORMALIZERS in schema:\n for normalizer in schema[SCHEMA_KEY_POST_NORMALIZERS]:\n kwargs = dict(normalizer)\n del kwargs['id']\n normalized_obj = Normalizers.get(normalizer['id'])(\n normalized_obj, **kwargs)\n\n # Validate the normalized object.\n if SCHEMA_KEY_VALIDATORS in schema:\n for validator in schema[SCHEMA_KEY_VALIDATORS]:\n kwargs = dict(validator)\n del kwargs['id']\n assert _Validators.get(validator['id'])(normalized_obj, **kwargs), (\n 'Validation failed: %s (%s) for object %s' % (\n validator['id'], kwargs, normalized_obj))\n\n return normalized_obj\n\n\nclass Normalizers(object):\n \"\"\"Various normalizers.\n\n A normalizer is a function that takes an object, attempts to normalize\n it to a canonical representation, and/or performs validity checks on the\n object pre- and post-normalization. If the normalization succeeds, the\n function returns the transformed object; if it fails, it raises an\n exception.\n\n Some normalizers require additional arguments. It is the responsibility of\n callers of normalizer functions to ensure that the arguments they supply to\n the normalizer are valid. What exactly this entails is provided in the\n docstring for each normalizer.\n \"\"\"\n\n @classmethod\n def get(cls, normalizer_id):\n if not hasattr(cls, normalizer_id):\n raise Exception('Invalid normalizer id: %s' % normalizer_id)\n return getattr(cls, normalizer_id)\n\n @staticmethod\n def normalize_spaces(obj):\n \"\"\"Collapses multiple spaces into single spaces.\n\n Args:\n obj: a string.\n\n Returns:\n a string that is the same as `obj`, except that each block of\n whitespace is collapsed into a single space character.\n \"\"\"\n return ' '.join(obj.split())\n\n @staticmethod\n def sanitize_url(obj):\n \"\"\"Takes a string representing a URL and sanitizes it.\n\n Args:\n obj: a string representing a URL.\n\n Returns:\n An empty string if the URL does not start with http:// or https://.\n Otherwise, returns the original URL.\n \"\"\"\n url_components = urlparse.urlsplit(obj)\n quoted_url_components = (\n urllib.quote(component) for component in url_components)\n raw = urlparse.urlunsplit(quoted_url_components)\n\n acceptable = html_cleaner.filter_a('href', obj)\n assert acceptable, (\n 'Invalid URL: Sanitized URL should start with '\n '\\'http://\\' or \\'https://\\'; received %s' % raw)\n return raw\n\n\nclass _Validators(object):\n \"\"\"Various validators.\n\n A validator is a function that takes an object and returns True if it is\n valid, and False if it isn't.\n\n Validators should only be accessed from the checker methods in\n schema_utils.py and schema_utils_test.py, since these methods do\n preliminary checks on the arguments passed to the validator.\n \"\"\"\n @classmethod\n def get(cls, validator_id):\n if not hasattr(cls, validator_id):\n raise Exception('Invalid validator id: %s' % validator_id)\n return getattr(cls, validator_id)\n\n @staticmethod\n def has_length_at_least(obj, min_value):\n \"\"\"Returns True iff the given object (a list) has at least\n `min_value` elements.\n \"\"\"\n return len(obj) >= min_value\n\n @staticmethod\n def has_length_at_most(obj, max_value):\n \"\"\"Returns True iff the given object (a list) has at most\n `max_value` elements.\n \"\"\"\n return len(obj) <= max_value\n\n @staticmethod\n def is_nonempty(obj):\n \"\"\"Returns True iff the given object (a string) is nonempty.\"\"\"\n return bool(obj)\n\n @staticmethod\n def is_uniquified(obj):\n \"\"\"Returns True iff the given object (a list) has no duplicates.\"\"\"\n return sorted(list(set(obj))) == sorted(obj)\n\n @staticmethod\n def is_at_least(obj, min_value):\n \"\"\"Ensures that `obj` (an int/float) is at least `min_value`.\"\"\"\n return obj >= min_value\n\n @staticmethod\n def is_at_most(obj, max_value):\n \"\"\"Ensures that `obj` (an int/float) is at most `max_value`.\"\"\"\n return obj <= max_value\n\n @staticmethod\n def is_regex(obj):\n \"\"\"Ensures that `obj` (a string) defines a valid regex.\"\"\"\n raise NotImplementedError\n\n @staticmethod\n def matches_regex(obj, regex):\n \"\"\"Ensures that `obj` (a string) matches the given regex.\"\"\"\n raise NotImplementedError\n", "path": "schema_utils.py"}], "after_files": [{"content": "# coding: utf-8\n#\n# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, softwar\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom extensions.rich_text_components import base\n\n\nclass Image(base.BaseRichTextComponent):\n \"\"\"A rich-text component representing an inline image.\"\"\"\n\n name = 'Image'\n category = 'Basic Input'\n description = 'An image.'\n frontend_name = 'image'\n tooltip = 'Insert image'\n requires_fs = True\n is_block_element = True\n\n _customization_arg_specs = [{\n 'name': 'filepath',\n 'description': (\n 'The name of the image file. (Allowed extensions: gif, jpeg, jpg, '\n 'png.)'),\n 'schema': {\n 'type': 'custom',\n 'obj_type': 'Filepath',\n },\n 'default_value': '',\n }, {\n 'name': 'caption',\n 'description': ('Caption for image (optional)'),\n 'schema': {\n 'type': 'unicode',\n },\n 'default_value': '',\n }, {\n 'name': 'alt',\n 'description': (\n 'Briefly explain this image to a visually impaired '\n 'learner'),\n 'schema': {\n 'type': 'unicode',\n 'validators': [{\n 'id': 'is_nonempty',\n }],\n 'ui_config': {\n 'placeholder': (\n 'Description of Image (Example : George Handel, '\n '18th century baroque composer)'),\n },\n },\n 'default_value': '',\n }]\n\n @property\n def preview_url_template(self):\n return '/imagehandler/<[explorationId]>/<[filepath]>'\n", "path": "extensions/rich_text_components/Image/Image.py"}, {"content": "# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utility functions for managing schemas and schema-based validation.\n\nA schema is a way to specify the type of an object. For example, one might\nwant to require that an object is an integer, or that it is a dict with two\nkeys named 'abc' and 'def', each with values that are unicode strings. This\nfile contains utilities for validating schemas and for checking that objects\nfollow the definitions given by the schemas.\n\nThe objects that can be described by these schemas must be composable from the\nfollowing Python types: bool, dict, float, int, list, unicode.\n\"\"\"\n\nimport numbers\nimport urllib\nimport urlparse\n\nfrom core.domain import html_cleaner # pylint: disable=relative-import\n\n\nSCHEMA_KEY_ITEMS = 'items'\nSCHEMA_KEY_LEN = 'len'\nSCHEMA_KEY_PROPERTIES = 'properties'\nSCHEMA_KEY_TYPE = 'type'\nSCHEMA_KEY_POST_NORMALIZERS = 'post_normalizers'\nSCHEMA_KEY_CHOICES = 'choices'\nSCHEMA_KEY_NAME = 'name'\nSCHEMA_KEY_SCHEMA = 'schema'\nSCHEMA_KEY_OBJ_TYPE = 'obj_type'\nSCHEMA_KEY_VALIDATORS = 'validators'\n\nSCHEMA_TYPE_BOOL = 'bool'\nSCHEMA_TYPE_CUSTOM = 'custom'\nSCHEMA_TYPE_DICT = 'dict'\nSCHEMA_TYPE_FLOAT = 'float'\nSCHEMA_TYPE_HTML = 'html'\nSCHEMA_TYPE_INT = 'int'\nSCHEMA_TYPE_LIST = 'list'\nSCHEMA_TYPE_UNICODE = 'unicode'\n\n\ndef normalize_against_schema(obj, schema, apply_custom_validators=True):\n \"\"\"Validate the given object using the schema, normalizing if necessary.\n\n Returns:\n the normalized object.\n\n Raises:\n AssertionError: if the object fails to validate against the schema.\n \"\"\"\n normalized_obj = None\n\n if schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_BOOL:\n assert isinstance(obj, bool), ('Expected bool, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_CUSTOM:\n # Importing this at the top of the file causes a circular dependency.\n # TODO(sll): Either get rid of custom objects or find a way to merge\n # them into the schema framework -- probably the latter.\n from core.domain import obj_services # pylint: disable=relative-import\n obj_class = obj_services.Registry.get_object_class_by_type(\n schema[SCHEMA_KEY_OBJ_TYPE])\n normalized_obj = obj_class.normalize(obj)\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_DICT:\n assert isinstance(obj, dict), ('Expected dict, received %s' % obj)\n expected_dict_keys = [\n p[SCHEMA_KEY_NAME] for p in schema[SCHEMA_KEY_PROPERTIES]]\n assert set(obj.keys()) == set(expected_dict_keys)\n\n normalized_obj = {}\n for prop in schema[SCHEMA_KEY_PROPERTIES]:\n key = prop[SCHEMA_KEY_NAME]\n normalized_obj[key] = normalize_against_schema(\n obj[key], prop[SCHEMA_KEY_SCHEMA])\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_FLOAT:\n obj = float(obj)\n assert isinstance(obj, numbers.Real), (\n 'Expected float, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_INT:\n obj = int(obj)\n assert isinstance(obj, numbers.Integral), (\n 'Expected int, received %s' % obj)\n assert isinstance(obj, int), ('Expected int, received %s' % obj)\n normalized_obj = obj\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_HTML:\n assert isinstance(obj, basestring), (\n 'Expected unicode HTML string, received %s' % obj)\n obj = unicode(obj)\n assert isinstance(obj, unicode), (\n 'Expected unicode, received %s' % obj)\n normalized_obj = html_cleaner.clean(obj)\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_LIST:\n assert isinstance(obj, list), ('Expected list, received %s' % obj)\n item_schema = schema[SCHEMA_KEY_ITEMS]\n if SCHEMA_KEY_LEN in schema:\n assert len(obj) == schema[SCHEMA_KEY_LEN]\n normalized_obj = [\n normalize_against_schema(item, item_schema) for item in obj\n ]\n elif schema[SCHEMA_KEY_TYPE] == SCHEMA_TYPE_UNICODE:\n assert isinstance(obj, basestring), (\n 'Expected unicode string, received %s' % obj)\n obj = unicode(obj)\n assert isinstance(obj, unicode), (\n 'Expected unicode, received %s' % obj)\n normalized_obj = obj\n else:\n raise Exception('Invalid schema type: %s' % schema[SCHEMA_KEY_TYPE])\n\n if SCHEMA_KEY_CHOICES in schema:\n assert normalized_obj in schema[SCHEMA_KEY_CHOICES], (\n 'Received %s which is not in the allowed range of choices: %s' %\n (normalized_obj, schema[SCHEMA_KEY_CHOICES]))\n\n # When type normalization is finished, apply the post-normalizers in the\n # given order.\n if SCHEMA_KEY_POST_NORMALIZERS in schema:\n for normalizer in schema[SCHEMA_KEY_POST_NORMALIZERS]:\n kwargs = dict(normalizer)\n del kwargs['id']\n normalized_obj = Normalizers.get(normalizer['id'])(\n normalized_obj, **kwargs)\n\n # Validate the normalized object.\n if apply_custom_validators:\n if SCHEMA_KEY_VALIDATORS in schema:\n for validator in schema[SCHEMA_KEY_VALIDATORS]:\n kwargs = dict(validator)\n del kwargs['id']\n assert _Validators.get(\n validator['id'])(normalized_obj, **kwargs), (\n 'Validation failed: %s (%s) for object %s' % (\n validator['id'], kwargs, normalized_obj))\n\n return normalized_obj\n\n\nclass Normalizers(object):\n \"\"\"Various normalizers.\n\n A normalizer is a function that takes an object, attempts to normalize\n it to a canonical representation, and/or performs validity checks on the\n object pre- and post-normalization. If the normalization succeeds, the\n function returns the transformed object; if it fails, it raises an\n exception.\n\n Some normalizers require additional arguments. It is the responsibility of\n callers of normalizer functions to ensure that the arguments they supply to\n the normalizer are valid. What exactly this entails is provided in the\n docstring for each normalizer.\n \"\"\"\n\n @classmethod\n def get(cls, normalizer_id):\n if not hasattr(cls, normalizer_id):\n raise Exception('Invalid normalizer id: %s' % normalizer_id)\n return getattr(cls, normalizer_id)\n\n @staticmethod\n def normalize_spaces(obj):\n \"\"\"Collapses multiple spaces into single spaces.\n\n Args:\n obj: a string.\n\n Returns:\n a string that is the same as `obj`, except that each block of\n whitespace is collapsed into a single space character.\n \"\"\"\n return ' '.join(obj.split())\n\n @staticmethod\n def sanitize_url(obj):\n \"\"\"Takes a string representing a URL and sanitizes it.\n\n Args:\n obj: a string representing a URL.\n\n Returns:\n An empty string if the URL does not start with http:// or https://.\n Otherwise, returns the original URL.\n \"\"\"\n url_components = urlparse.urlsplit(obj)\n quoted_url_components = (\n urllib.quote(component) for component in url_components)\n raw = urlparse.urlunsplit(quoted_url_components)\n\n acceptable = html_cleaner.filter_a('href', obj)\n assert acceptable, (\n 'Invalid URL: Sanitized URL should start with '\n '\\'http://\\' or \\'https://\\'; received %s' % raw)\n return raw\n\n\nclass _Validators(object):\n \"\"\"Various validators.\n\n A validator is a function that takes an object and returns True if it is\n valid, and False if it isn't.\n\n Validators should only be accessed from the checker methods in\n schema_utils.py and schema_utils_test.py, since these methods do\n preliminary checks on the arguments passed to the validator.\n \"\"\"\n @classmethod\n def get(cls, validator_id):\n if not hasattr(cls, validator_id):\n raise Exception('Invalid validator id: %s' % validator_id)\n return getattr(cls, validator_id)\n\n @staticmethod\n def has_length_at_least(obj, min_value):\n \"\"\"Returns True iff the given object (a list) has at least\n `min_value` elements.\n \"\"\"\n return len(obj) >= min_value\n\n @staticmethod\n def has_length_at_most(obj, max_value):\n \"\"\"Returns True iff the given object (a list) has at most\n `max_value` elements.\n \"\"\"\n return len(obj) <= max_value\n\n @staticmethod\n def is_nonempty(obj):\n \"\"\"Returns True iff the given object (a string) is nonempty.\"\"\"\n return bool(obj)\n\n @staticmethod\n def is_uniquified(obj):\n \"\"\"Returns True iff the given object (a list) has no duplicates.\"\"\"\n return sorted(list(set(obj))) == sorted(obj)\n\n @staticmethod\n def is_at_least(obj, min_value):\n \"\"\"Ensures that `obj` (an int/float) is at least `min_value`.\"\"\"\n return obj >= min_value\n\n @staticmethod\n def is_at_most(obj, max_value):\n \"\"\"Ensures that `obj` (an int/float) is at most `max_value`.\"\"\"\n return obj <= max_value\n\n @staticmethod\n def is_regex(obj):\n \"\"\"Ensures that `obj` (a string) defines a valid regex.\"\"\"\n raise NotImplementedError\n\n @staticmethod\n def matches_regex(obj, regex):\n \"\"\"Ensures that `obj` (a string) matches the given regex.\"\"\"\n raise NotImplementedError\n", "path": "schema_utils.py"}]} | 4,027 | 502 |
gh_patches_debug_34686 | rasdani/github-patches | git_diff | wagtail__wagtail-1225 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Memory leak in RoutablePage
When resolving/reversing URLs, `RoutablePage` calls Djangos `django.core.urlresolvers.get_resolver` function to build a resolver object.
This function is wrapped in an unlimited lru cache. As each time we call it is usually with a different page instance, this lru cache would grow forever.
I've not seen any issues caused by this in the wild, but worth fixing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/contrib/wagtailroutablepage/models.py`
Content:
```
1 from __future__ import unicode_literals
2
3 from six import string_types
4
5 from django.http import Http404
6 from django.core.urlresolvers import get_resolver
7 from django.core.exceptions import ImproperlyConfigured
8
9 from wagtail.wagtailcore.models import Page
10 from wagtail.wagtailcore.url_routing import RouteResult
11
12
13 class RoutablePageMixin(object):
14 """
15 This class can be mixed in to a Page subclass to allow urlconfs to be
16 embedded inside pages.
17 """
18 #: Set this to a tuple of ``django.conf.urls.url`` objects.
19 subpage_urls = None
20
21 def reverse_subpage(self, name, args=None, kwargs=None):
22 """
23 This method does the same job as Djangos' built in "urlresolvers.reverse()" function for subpage urlconfs.
24 """
25 args = args or []
26 kwargs = kwargs or {}
27
28 if self.subpage_urls is None:
29 raise ImproperlyConfigured("You must set 'subpage_urls' on " + type(self).__name__)
30
31 resolver = get_resolver(self.subpage_urls)
32 return resolver.reverse(name, *args, **kwargs)
33
34 def resolve_subpage(self, path):
35 """
36 This finds a view method/function from a URL path.
37 """
38 if self.subpage_urls is None:
39 raise ImproperlyConfigured("You must set 'subpage_urls' on " + type(self).__name__)
40
41 resolver = get_resolver(self.subpage_urls)
42 view, args, kwargs = resolver.resolve(path)
43
44 # If view is a string, find it as an attribute of self
45 if isinstance(view, string_types):
46 view = getattr(self, view)
47
48 return view, args, kwargs
49
50 def route(self, request, path_components):
51 """
52 This hooks the subpage urls into Wagtails routing.
53 """
54 if self.live:
55 try:
56 path = '/'
57 if path_components:
58 path += '/'.join(path_components) + '/'
59
60 view, args, kwargs = self.resolve_subpage(path)
61 return RouteResult(self, args=(view, args, kwargs))
62 except Http404:
63 pass
64
65 return super(RoutablePageMixin, self).route(request, path_components)
66
67 def serve(self, request, view, args, kwargs):
68 return view(request, *args, **kwargs)
69
70 def serve_preview(self, request, mode_name):
71 view, args, kwargs = self.resolve_subpage('/')
72 return view(request, *args, **kwargs)
73
74
75 class RoutablePage(RoutablePageMixin, Page):
76 """
77 This class extends Page by adding methods to allow urlconfs
78 to be embedded inside pages
79 """
80
81 is_abstract = True
82
83 class Meta:
84 abstract = True
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/wagtail/contrib/wagtailroutablepage/models.py b/wagtail/contrib/wagtailroutablepage/models.py
--- a/wagtail/contrib/wagtailroutablepage/models.py
+++ b/wagtail/contrib/wagtailroutablepage/models.py
@@ -3,8 +3,7 @@
from six import string_types
from django.http import Http404
-from django.core.urlresolvers import get_resolver
-from django.core.exceptions import ImproperlyConfigured
+from django.core.urlresolvers import RegexURLResolver
from wagtail.wagtailcore.models import Page
from wagtail.wagtailcore.url_routing import RouteResult
@@ -18,28 +17,36 @@
#: Set this to a tuple of ``django.conf.urls.url`` objects.
subpage_urls = None
+ @classmethod
+ def get_subpage_urls(cls):
+ if cls.subpage_urls:
+ return cls.subpage_urls
+
+ return ()
+
+ @classmethod
+ def get_resolver(cls):
+ if '_routablepage_urlresolver' not in cls.__dict__:
+ subpage_urls = cls.get_subpage_urls()
+ cls._routablepage_urlresolver = RegexURLResolver(r'^/', subpage_urls)
+
+ return cls._routablepage_urlresolver
+
def reverse_subpage(self, name, args=None, kwargs=None):
"""
- This method does the same job as Djangos' built in "urlresolvers.reverse()" function for subpage urlconfs.
+ This method does the same job as Djangos' built in
+ "urlresolvers.reverse()" function for subpage urlconfs.
"""
args = args or []
kwargs = kwargs or {}
- if self.subpage_urls is None:
- raise ImproperlyConfigured("You must set 'subpage_urls' on " + type(self).__name__)
-
- resolver = get_resolver(self.subpage_urls)
- return resolver.reverse(name, *args, **kwargs)
+ return self.get_resolver().reverse(name, *args, **kwargs)
def resolve_subpage(self, path):
"""
This finds a view method/function from a URL path.
"""
- if self.subpage_urls is None:
- raise ImproperlyConfigured("You must set 'subpage_urls' on " + type(self).__name__)
-
- resolver = get_resolver(self.subpage_urls)
- view, args, kwargs = resolver.resolve(path)
+ view, args, kwargs = self.get_resolver().resolve(path)
# If view is a string, find it as an attribute of self
if isinstance(view, string_types):
| {"golden_diff": "diff --git a/wagtail/contrib/wagtailroutablepage/models.py b/wagtail/contrib/wagtailroutablepage/models.py\n--- a/wagtail/contrib/wagtailroutablepage/models.py\n+++ b/wagtail/contrib/wagtailroutablepage/models.py\n@@ -3,8 +3,7 @@\n from six import string_types\n \n from django.http import Http404\n-from django.core.urlresolvers import get_resolver\n-from django.core.exceptions import ImproperlyConfigured\n+from django.core.urlresolvers import RegexURLResolver\n \n from wagtail.wagtailcore.models import Page\n from wagtail.wagtailcore.url_routing import RouteResult\n@@ -18,28 +17,36 @@\n #: Set this to a tuple of ``django.conf.urls.url`` objects.\n subpage_urls = None\n \n+ @classmethod\n+ def get_subpage_urls(cls):\n+ if cls.subpage_urls:\n+ return cls.subpage_urls\n+\n+ return ()\n+\n+ @classmethod\n+ def get_resolver(cls):\n+ if '_routablepage_urlresolver' not in cls.__dict__:\n+ subpage_urls = cls.get_subpage_urls()\n+ cls._routablepage_urlresolver = RegexURLResolver(r'^/', subpage_urls)\n+\n+ return cls._routablepage_urlresolver\n+\n def reverse_subpage(self, name, args=None, kwargs=None):\n \"\"\"\n- This method does the same job as Djangos' built in \"urlresolvers.reverse()\" function for subpage urlconfs.\n+ This method does the same job as Djangos' built in\n+ \"urlresolvers.reverse()\" function for subpage urlconfs.\n \"\"\"\n args = args or []\n kwargs = kwargs or {}\n \n- if self.subpage_urls is None:\n- raise ImproperlyConfigured(\"You must set 'subpage_urls' on \" + type(self).__name__)\n-\n- resolver = get_resolver(self.subpage_urls)\n- return resolver.reverse(name, *args, **kwargs)\n+ return self.get_resolver().reverse(name, *args, **kwargs)\n \n def resolve_subpage(self, path):\n \"\"\"\n This finds a view method/function from a URL path.\n \"\"\"\n- if self.subpage_urls is None:\n- raise ImproperlyConfigured(\"You must set 'subpage_urls' on \" + type(self).__name__)\n-\n- resolver = get_resolver(self.subpage_urls)\n- view, args, kwargs = resolver.resolve(path)\n+ view, args, kwargs = self.get_resolver().resolve(path)\n \n # If view is a string, find it as an attribute of self\n if isinstance(view, string_types):\n", "issue": "Memory leak in RoutablePage\nWhen resolving/reversing URLs, `RoutablePage` calls Djangos `django.core.urlresolvers.get_resolver` function to build a resolver object.\n\nThis function is wrapped in an unlimited lru cache. As each time we call it is usually with a different page instance, this lru cache would grow forever.\n\nI've not seen any issues caused by this in the wild, but worth fixing.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom six import string_types\n\nfrom django.http import Http404\nfrom django.core.urlresolvers import get_resolver\nfrom django.core.exceptions import ImproperlyConfigured\n\nfrom wagtail.wagtailcore.models import Page\nfrom wagtail.wagtailcore.url_routing import RouteResult\n\n\nclass RoutablePageMixin(object):\n \"\"\"\n This class can be mixed in to a Page subclass to allow urlconfs to be\n embedded inside pages.\n \"\"\"\n #: Set this to a tuple of ``django.conf.urls.url`` objects.\n subpage_urls = None\n\n def reverse_subpage(self, name, args=None, kwargs=None):\n \"\"\"\n This method does the same job as Djangos' built in \"urlresolvers.reverse()\" function for subpage urlconfs.\n \"\"\"\n args = args or []\n kwargs = kwargs or {}\n\n if self.subpage_urls is None:\n raise ImproperlyConfigured(\"You must set 'subpage_urls' on \" + type(self).__name__)\n\n resolver = get_resolver(self.subpage_urls)\n return resolver.reverse(name, *args, **kwargs)\n\n def resolve_subpage(self, path):\n \"\"\"\n This finds a view method/function from a URL path.\n \"\"\"\n if self.subpage_urls is None:\n raise ImproperlyConfigured(\"You must set 'subpage_urls' on \" + type(self).__name__)\n\n resolver = get_resolver(self.subpage_urls)\n view, args, kwargs = resolver.resolve(path)\n\n # If view is a string, find it as an attribute of self\n if isinstance(view, string_types):\n view = getattr(self, view)\n\n return view, args, kwargs\n\n def route(self, request, path_components):\n \"\"\"\n This hooks the subpage urls into Wagtails routing.\n \"\"\"\n if self.live:\n try:\n path = '/'\n if path_components:\n path += '/'.join(path_components) + '/'\n\n view, args, kwargs = self.resolve_subpage(path)\n return RouteResult(self, args=(view, args, kwargs))\n except Http404:\n pass\n\n return super(RoutablePageMixin, self).route(request, path_components)\n\n def serve(self, request, view, args, kwargs):\n return view(request, *args, **kwargs)\n\n def serve_preview(self, request, mode_name):\n view, args, kwargs = self.resolve_subpage('/')\n return view(request, *args, **kwargs)\n\n\nclass RoutablePage(RoutablePageMixin, Page):\n \"\"\"\n This class extends Page by adding methods to allow urlconfs\n to be embedded inside pages\n \"\"\"\n\n is_abstract = True\n\n class Meta:\n abstract = True\n", "path": "wagtail/contrib/wagtailroutablepage/models.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nfrom six import string_types\n\nfrom django.http import Http404\nfrom django.core.urlresolvers import RegexURLResolver\n\nfrom wagtail.wagtailcore.models import Page\nfrom wagtail.wagtailcore.url_routing import RouteResult\n\n\nclass RoutablePageMixin(object):\n \"\"\"\n This class can be mixed in to a Page subclass to allow urlconfs to be\n embedded inside pages.\n \"\"\"\n #: Set this to a tuple of ``django.conf.urls.url`` objects.\n subpage_urls = None\n\n @classmethod\n def get_subpage_urls(cls):\n if cls.subpage_urls:\n return cls.subpage_urls\n\n return ()\n\n @classmethod\n def get_resolver(cls):\n if '_routablepage_urlresolver' not in cls.__dict__:\n subpage_urls = cls.get_subpage_urls()\n cls._routablepage_urlresolver = RegexURLResolver(r'^/', subpage_urls)\n\n return cls._routablepage_urlresolver\n\n def reverse_subpage(self, name, args=None, kwargs=None):\n \"\"\"\n This method does the same job as Djangos' built in\n \"urlresolvers.reverse()\" function for subpage urlconfs.\n \"\"\"\n args = args or []\n kwargs = kwargs or {}\n\n return self.get_resolver().reverse(name, *args, **kwargs)\n\n def resolve_subpage(self, path):\n \"\"\"\n This finds a view method/function from a URL path.\n \"\"\"\n view, args, kwargs = self.get_resolver().resolve(path)\n\n # If view is a string, find it as an attribute of self\n if isinstance(view, string_types):\n view = getattr(self, view)\n\n return view, args, kwargs\n\n def route(self, request, path_components):\n \"\"\"\n This hooks the subpage urls into Wagtails routing.\n \"\"\"\n if self.live:\n try:\n path = '/'\n if path_components:\n path += '/'.join(path_components) + '/'\n\n view, args, kwargs = self.resolve_subpage(path)\n return RouteResult(self, args=(view, args, kwargs))\n except Http404:\n pass\n\n return super(RoutablePageMixin, self).route(request, path_components)\n\n def serve(self, request, view, args, kwargs):\n return view(request, *args, **kwargs)\n\n def serve_preview(self, request, mode_name):\n view, args, kwargs = self.resolve_subpage('/')\n return view(request, *args, **kwargs)\n\n\nclass RoutablePage(RoutablePageMixin, Page):\n \"\"\"\n This class extends Page by adding methods to allow urlconfs\n to be embedded inside pages\n \"\"\"\n\n is_abstract = True\n\n class Meta:\n abstract = True\n", "path": "wagtail/contrib/wagtailroutablepage/models.py"}]} | 1,117 | 594 |
gh_patches_debug_24360 | rasdani/github-patches | git_diff | rasterio__rasterio-2827 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Turn down logging level for non-existing files in the Python file VSI plugin
To prevent pointless sidecar searching as discussed in https://github.com/rasterio/rasterio/discussions/2825.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/io.py`
Content:
```
1 """Classes capable of reading and writing datasets
2
3 Instances of these classes are called dataset objects.
4 """
5
6 import logging
7
8 from rasterio._base import get_dataset_driver, driver_can_create, driver_can_create_copy
9 from rasterio._io import (
10 DatasetReaderBase,
11 DatasetWriterBase,
12 BufferedDatasetWriterBase,
13 MemoryFileBase,
14 )
15 from rasterio.windows import WindowMethodsMixin
16 from rasterio.env import ensure_env
17 from rasterio.transform import TransformMethodsMixin
18 from rasterio._path import _UnparsedPath
19
20 try:
21 from rasterio._filepath import FilePathBase
22 except ImportError:
23 FilePathBase = object
24
25
26 log = logging.getLogger(__name__)
27
28
29 class DatasetReader(DatasetReaderBase, WindowMethodsMixin, TransformMethodsMixin):
30 """An unbuffered data and metadata reader"""
31
32 def __repr__(self):
33 return "<{} DatasetReader name='{}' mode='{}'>".format(
34 self.closed and 'closed' or 'open', self.name, self.mode)
35
36
37 class DatasetWriter(DatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin):
38 """An unbuffered data and metadata writer. Its methods write data
39 directly to disk.
40 """
41
42 def __repr__(self):
43 return "<{} DatasetWriter name='{}' mode='{}'>".format(
44 self.closed and 'closed' or 'open', self.name, self.mode)
45
46
47 class BufferedDatasetWriter(
48 BufferedDatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin
49 ):
50 """Maintains data and metadata in a buffer, writing to disk or
51 network only when `close()` is called.
52
53 This allows incremental updates to datasets using formats that don't
54 otherwise support updates, such as JPEG.
55 """
56
57 def __repr__(self):
58 return "<{} BufferedDatasetWriter name='{}' mode='{}'>".format(
59 self.closed and 'closed' or 'open', self.name, self.mode)
60
61
62 class MemoryFile(MemoryFileBase):
63 """A BytesIO-like object, backed by an in-memory file.
64
65 This allows formatted files to be read and written without I/O.
66
67 A MemoryFile created with initial bytes becomes immutable. A
68 MemoryFile created without initial bytes may be written to using
69 either file-like or dataset interfaces.
70
71 Examples
72 --------
73
74 A GeoTIFF can be loaded in memory and accessed using the GeoTIFF
75 format driver
76
77 >>> with open('tests/data/RGB.byte.tif', 'rb') as f, MemoryFile(f) as memfile:
78 ... with memfile.open() as src:
79 ... pprint.pprint(src.profile)
80 ...
81 {'count': 3,
82 'crs': CRS({'init': 'epsg:32618'}),
83 'driver': 'GTiff',
84 'dtype': 'uint8',
85 'height': 718,
86 'interleave': 'pixel',
87 'nodata': 0.0,
88 'tiled': False,
89 'transform': Affine(300.0379266750948, 0.0, 101985.0,
90 0.0, -300.041782729805, 2826915.0),
91 'width': 791}
92
93 """
94
95 def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=".tif"):
96 """Create a new file in memory
97
98 Parameters
99 ----------
100 file_or_bytes : file-like object or bytes, optional
101 File or bytes holding initial data.
102 filename : str, optional
103 An optional filename. A unique one will otherwise be generated.
104 ext : str, optional
105 An optional extension.
106
107 Returns
108 -------
109 MemoryFile
110 """
111 super().__init__(
112 file_or_bytes=file_or_bytes, dirname=dirname, filename=filename, ext=ext
113 )
114
115 @ensure_env
116 def open(self, driver=None, width=None, height=None, count=None, crs=None,
117 transform=None, dtype=None, nodata=None, sharing=False, **kwargs):
118 """Open the file and return a Rasterio dataset object.
119
120 If data has already been written, the file is opened in 'r'
121 mode. Otherwise, the file is opened in 'w' mode.
122
123 Parameters
124 ----------
125 Note well that there is no `path` parameter: a `MemoryFile`
126 contains a single dataset and there is no need to specify a
127 path.
128
129 Other parameters are optional and have the same semantics as the
130 parameters of `rasterio.open()`.
131 """
132 mempath = _UnparsedPath(self.name)
133
134 if self.closed:
135 raise OSError("I/O operation on closed file.")
136 if len(self) > 0:
137 log.debug("VSI path: {}".format(mempath.path))
138 return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)
139 else:
140 writer = get_writer_for_driver(driver)
141 return writer(
142 mempath,
143 "w+",
144 driver=driver,
145 width=width,
146 height=height,
147 count=count,
148 crs=crs,
149 transform=transform,
150 dtype=dtype,
151 nodata=nodata,
152 sharing=sharing,
153 **kwargs
154 )
155
156 def __enter__(self):
157 return self
158
159 def __exit__(self, *args):
160 self.close()
161
162
163 class _FilePath(FilePathBase):
164 """A BytesIO-like object, backed by a Python file object.
165
166 Examples
167 --------
168
169 A GeoTIFF can be loaded in memory and accessed using the GeoTIFF
170 format driver
171
172 >>> with open('tests/data/RGB.byte.tif', 'rb') as f, FilePath(f) as vsi_file:
173 ... with vsi_file.open() as src:
174 ... pprint.pprint(src.profile)
175 ...
176 {'count': 3,
177 'crs': CRS({'init': 'epsg:32618'}),
178 'driver': 'GTiff',
179 'dtype': 'uint8',
180 'height': 718,
181 'interleave': 'pixel',
182 'nodata': 0.0,
183 'tiled': False,
184 'transform': Affine(300.0379266750948, 0.0, 101985.0,
185 0.0, -300.041782729805, 2826915.0),
186 'width': 791}
187
188 """
189
190 def __init__(self, filelike_obj, dirname=None, filename=None):
191 """Create a new wrapper around the provided file-like object.
192
193 Parameters
194 ----------
195 filelike_obj : file-like object
196 Open file-like object. Currently only reading is supported.
197 filename : str, optional
198 An optional filename. A unique one will otherwise be generated.
199
200 Returns
201 -------
202 PythonVSIFile
203 """
204 super().__init__(
205 filelike_obj, dirname=dirname, filename=filename
206 )
207
208 @ensure_env
209 def open(self, driver=None, sharing=False, **kwargs):
210 """Open the file and return a Rasterio dataset object.
211
212 The provided file-like object is assumed to be readable.
213 Writing is currently not supported.
214
215 Parameters are optional and have the same semantics as the
216 parameters of `rasterio.open()`.
217 """
218 mempath = _UnparsedPath(self.name)
219
220 if self.closed:
221 raise IOError("I/O operation on closed file.")
222 # Assume we were given a non-empty file-like object
223 log.debug("VSI path: {}".format(mempath.path))
224 return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)
225
226 def __enter__(self):
227 return self
228
229 def __exit__(self, *args):
230 self.close()
231
232
233 if FilePathBase is not object:
234 # only make this object available if the cython extension was compiled
235 FilePath = _FilePath
236
237
238 class ZipMemoryFile(MemoryFile):
239 """A read-only BytesIO-like object backed by an in-memory zip file.
240
241 This allows a zip file containing formatted files to be read
242 without I/O.
243 """
244
245 def __init__(self, file_or_bytes=None):
246 super().__init__(file_or_bytes, ext="zip")
247
248 @ensure_env
249 def open(self, path, driver=None, sharing=False, **kwargs):
250 """Open a dataset within the zipped stream.
251
252 Parameters
253 ----------
254 path : str
255 Path to a dataset in the zip file, relative to the root of the
256 archive.
257
258 Other parameters are optional and have the same semantics as the
259 parameters of `rasterio.open()`.
260
261 Returns
262 -------
263 A Rasterio dataset object
264 """
265 zippath = _UnparsedPath('/vsizip{0}/{1}'.format(self.name, path.lstrip('/')))
266
267 if self.closed:
268 raise OSError("I/O operation on closed file.")
269 return DatasetReader(zippath, driver=driver, sharing=sharing, **kwargs)
270
271
272 def get_writer_for_driver(driver):
273 """Return the writer class appropriate for the specified driver."""
274 if not driver:
275 raise ValueError("'driver' is required to read/write dataset.")
276 cls = None
277 if driver_can_create(driver):
278 cls = DatasetWriter
279 elif driver_can_create_copy(driver): # pragma: no branch
280 cls = BufferedDatasetWriter
281 return cls
282
283
284 def get_writer_for_path(path, driver=None):
285 """Return the writer class appropriate for the existing dataset."""
286 if not driver:
287 driver = get_dataset_driver(path)
288 return get_writer_for_driver(driver)
289
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/rasterio/io.py b/rasterio/io.py
--- a/rasterio/io.py
+++ b/rasterio/io.py
@@ -13,7 +13,7 @@
MemoryFileBase,
)
from rasterio.windows import WindowMethodsMixin
-from rasterio.env import ensure_env
+from rasterio.env import Env, ensure_env
from rasterio.transform import TransformMethodsMixin
from rasterio._path import _UnparsedPath
@@ -214,13 +214,25 @@
Parameters are optional and have the same semantics as the
parameters of `rasterio.open()`.
+
+ Returns
+ -------
+ DatasetReader
+
+ Raises
+ ------
+ IOError
+ If the memory file is closed.
+
"""
mempath = _UnparsedPath(self.name)
if self.closed:
raise IOError("I/O operation on closed file.")
+
# Assume we were given a non-empty file-like object
log.debug("VSI path: {}".format(mempath.path))
+
return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)
def __enter__(self):
| {"golden_diff": "diff --git a/rasterio/io.py b/rasterio/io.py\n--- a/rasterio/io.py\n+++ b/rasterio/io.py\n@@ -13,7 +13,7 @@\n MemoryFileBase,\n )\n from rasterio.windows import WindowMethodsMixin\n-from rasterio.env import ensure_env\n+from rasterio.env import Env, ensure_env\n from rasterio.transform import TransformMethodsMixin\n from rasterio._path import _UnparsedPath\n \n@@ -214,13 +214,25 @@\n \n Parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n+\n+ Returns\n+ -------\n+ DatasetReader\n+\n+ Raises\n+ ------\n+ IOError\n+ If the memory file is closed.\n+\n \"\"\"\n mempath = _UnparsedPath(self.name)\n \n if self.closed:\n raise IOError(\"I/O operation on closed file.\")\n+\n # Assume we were given a non-empty file-like object\n log.debug(\"VSI path: {}\".format(mempath.path))\n+\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n \n def __enter__(self):\n", "issue": "Turn down logging level for non-existing files in the Python file VSI plugin\nTo prevent pointless sidecar searching as discussed in https://github.com/rasterio/rasterio/discussions/2825.\n", "before_files": [{"content": "\"\"\"Classes capable of reading and writing datasets\n\nInstances of these classes are called dataset objects.\n\"\"\"\n\nimport logging\n\nfrom rasterio._base import get_dataset_driver, driver_can_create, driver_can_create_copy\nfrom rasterio._io import (\n DatasetReaderBase,\n DatasetWriterBase,\n BufferedDatasetWriterBase,\n MemoryFileBase,\n)\nfrom rasterio.windows import WindowMethodsMixin\nfrom rasterio.env import ensure_env\nfrom rasterio.transform import TransformMethodsMixin\nfrom rasterio._path import _UnparsedPath\n\ntry:\n from rasterio._filepath import FilePathBase\nexcept ImportError:\n FilePathBase = object\n\n\nlog = logging.getLogger(__name__)\n\n\nclass DatasetReader(DatasetReaderBase, WindowMethodsMixin, TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata reader\"\"\"\n\n def __repr__(self):\n return \"<{} DatasetReader name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass DatasetWriter(DatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata writer. Its methods write data\n directly to disk.\n \"\"\"\n\n def __repr__(self):\n return \"<{} DatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass BufferedDatasetWriter(\n BufferedDatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin\n):\n \"\"\"Maintains data and metadata in a buffer, writing to disk or\n network only when `close()` is called.\n\n This allows incremental updates to datasets using formats that don't\n otherwise support updates, such as JPEG.\n \"\"\"\n\n def __repr__(self):\n return \"<{} BufferedDatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass MemoryFile(MemoryFileBase):\n \"\"\"A BytesIO-like object, backed by an in-memory file.\n\n This allows formatted files to be read and written without I/O.\n\n A MemoryFile created with initial bytes becomes immutable. A\n MemoryFile created without initial bytes may be written to using\n either file-like or dataset interfaces.\n\n Examples\n --------\n\n A GeoTIFF can be loaded in memory and accessed using the GeoTIFF\n format driver\n\n >>> with open('tests/data/RGB.byte.tif', 'rb') as f, MemoryFile(f) as memfile:\n ... with memfile.open() as src:\n ... pprint.pprint(src.profile)\n ...\n {'count': 3,\n 'crs': CRS({'init': 'epsg:32618'}),\n 'driver': 'GTiff',\n 'dtype': 'uint8',\n 'height': 718,\n 'interleave': 'pixel',\n 'nodata': 0.0,\n 'tiled': False,\n 'transform': Affine(300.0379266750948, 0.0, 101985.0,\n 0.0, -300.041782729805, 2826915.0),\n 'width': 791}\n\n \"\"\"\n\n def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=\".tif\"):\n \"\"\"Create a new file in memory\n\n Parameters\n ----------\n file_or_bytes : file-like object or bytes, optional\n File or bytes holding initial data.\n filename : str, optional\n An optional filename. A unique one will otherwise be generated.\n ext : str, optional\n An optional extension.\n\n Returns\n -------\n MemoryFile\n \"\"\"\n super().__init__(\n file_or_bytes=file_or_bytes, dirname=dirname, filename=filename, ext=ext\n )\n\n @ensure_env\n def open(self, driver=None, width=None, height=None, count=None, crs=None,\n transform=None, dtype=None, nodata=None, sharing=False, **kwargs):\n \"\"\"Open the file and return a Rasterio dataset object.\n\n If data has already been written, the file is opened in 'r'\n mode. Otherwise, the file is opened in 'w' mode.\n\n Parameters\n ----------\n Note well that there is no `path` parameter: a `MemoryFile`\n contains a single dataset and there is no need to specify a\n path.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n \"\"\"\n mempath = _UnparsedPath(self.name)\n\n if self.closed:\n raise OSError(\"I/O operation on closed file.\")\n if len(self) > 0:\n log.debug(\"VSI path: {}\".format(mempath.path))\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n else:\n writer = get_writer_for_driver(driver)\n return writer(\n mempath,\n \"w+\",\n driver=driver,\n width=width,\n height=height,\n count=count,\n crs=crs,\n transform=transform,\n dtype=dtype,\n nodata=nodata,\n sharing=sharing,\n **kwargs\n )\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n\nclass _FilePath(FilePathBase):\n \"\"\"A BytesIO-like object, backed by a Python file object.\n\n Examples\n --------\n\n A GeoTIFF can be loaded in memory and accessed using the GeoTIFF\n format driver\n\n >>> with open('tests/data/RGB.byte.tif', 'rb') as f, FilePath(f) as vsi_file:\n ... with vsi_file.open() as src:\n ... pprint.pprint(src.profile)\n ...\n {'count': 3,\n 'crs': CRS({'init': 'epsg:32618'}),\n 'driver': 'GTiff',\n 'dtype': 'uint8',\n 'height': 718,\n 'interleave': 'pixel',\n 'nodata': 0.0,\n 'tiled': False,\n 'transform': Affine(300.0379266750948, 0.0, 101985.0,\n 0.0, -300.041782729805, 2826915.0),\n 'width': 791}\n\n \"\"\"\n\n def __init__(self, filelike_obj, dirname=None, filename=None):\n \"\"\"Create a new wrapper around the provided file-like object.\n\n Parameters\n ----------\n filelike_obj : file-like object\n Open file-like object. Currently only reading is supported.\n filename : str, optional\n An optional filename. A unique one will otherwise be generated.\n\n Returns\n -------\n PythonVSIFile\n \"\"\"\n super().__init__(\n filelike_obj, dirname=dirname, filename=filename\n )\n\n @ensure_env\n def open(self, driver=None, sharing=False, **kwargs):\n \"\"\"Open the file and return a Rasterio dataset object.\n\n The provided file-like object is assumed to be readable.\n Writing is currently not supported.\n\n Parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n \"\"\"\n mempath = _UnparsedPath(self.name)\n\n if self.closed:\n raise IOError(\"I/O operation on closed file.\")\n # Assume we were given a non-empty file-like object\n log.debug(\"VSI path: {}\".format(mempath.path))\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n\nif FilePathBase is not object:\n # only make this object available if the cython extension was compiled\n FilePath = _FilePath\n\n\nclass ZipMemoryFile(MemoryFile):\n \"\"\"A read-only BytesIO-like object backed by an in-memory zip file.\n\n This allows a zip file containing formatted files to be read\n without I/O.\n \"\"\"\n\n def __init__(self, file_or_bytes=None):\n super().__init__(file_or_bytes, ext=\"zip\")\n\n @ensure_env\n def open(self, path, driver=None, sharing=False, **kwargs):\n \"\"\"Open a dataset within the zipped stream.\n\n Parameters\n ----------\n path : str\n Path to a dataset in the zip file, relative to the root of the\n archive.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n\n Returns\n -------\n A Rasterio dataset object\n \"\"\"\n zippath = _UnparsedPath('/vsizip{0}/{1}'.format(self.name, path.lstrip('/')))\n\n if self.closed:\n raise OSError(\"I/O operation on closed file.\")\n return DatasetReader(zippath, driver=driver, sharing=sharing, **kwargs)\n\n\ndef get_writer_for_driver(driver):\n \"\"\"Return the writer class appropriate for the specified driver.\"\"\"\n if not driver:\n raise ValueError(\"'driver' is required to read/write dataset.\")\n cls = None\n if driver_can_create(driver):\n cls = DatasetWriter\n elif driver_can_create_copy(driver): # pragma: no branch\n cls = BufferedDatasetWriter\n return cls\n\n\ndef get_writer_for_path(path, driver=None):\n \"\"\"Return the writer class appropriate for the existing dataset.\"\"\"\n if not driver:\n driver = get_dataset_driver(path)\n return get_writer_for_driver(driver)\n", "path": "rasterio/io.py"}], "after_files": [{"content": "\"\"\"Classes capable of reading and writing datasets\n\nInstances of these classes are called dataset objects.\n\"\"\"\n\nimport logging\n\nfrom rasterio._base import get_dataset_driver, driver_can_create, driver_can_create_copy\nfrom rasterio._io import (\n DatasetReaderBase,\n DatasetWriterBase,\n BufferedDatasetWriterBase,\n MemoryFileBase,\n)\nfrom rasterio.windows import WindowMethodsMixin\nfrom rasterio.env import Env, ensure_env\nfrom rasterio.transform import TransformMethodsMixin\nfrom rasterio._path import _UnparsedPath\n\ntry:\n from rasterio._filepath import FilePathBase\nexcept ImportError:\n FilePathBase = object\n\n\nlog = logging.getLogger(__name__)\n\n\nclass DatasetReader(DatasetReaderBase, WindowMethodsMixin, TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata reader\"\"\"\n\n def __repr__(self):\n return \"<{} DatasetReader name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass DatasetWriter(DatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin):\n \"\"\"An unbuffered data and metadata writer. Its methods write data\n directly to disk.\n \"\"\"\n\n def __repr__(self):\n return \"<{} DatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass BufferedDatasetWriter(\n BufferedDatasetWriterBase, WindowMethodsMixin, TransformMethodsMixin\n):\n \"\"\"Maintains data and metadata in a buffer, writing to disk or\n network only when `close()` is called.\n\n This allows incremental updates to datasets using formats that don't\n otherwise support updates, such as JPEG.\n \"\"\"\n\n def __repr__(self):\n return \"<{} BufferedDatasetWriter name='{}' mode='{}'>\".format(\n self.closed and 'closed' or 'open', self.name, self.mode)\n\n\nclass MemoryFile(MemoryFileBase):\n \"\"\"A BytesIO-like object, backed by an in-memory file.\n\n This allows formatted files to be read and written without I/O.\n\n A MemoryFile created with initial bytes becomes immutable. A\n MemoryFile created without initial bytes may be written to using\n either file-like or dataset interfaces.\n\n Examples\n --------\n\n A GeoTIFF can be loaded in memory and accessed using the GeoTIFF\n format driver\n\n >>> with open('tests/data/RGB.byte.tif', 'rb') as f, MemoryFile(f) as memfile:\n ... with memfile.open() as src:\n ... pprint.pprint(src.profile)\n ...\n {'count': 3,\n 'crs': CRS({'init': 'epsg:32618'}),\n 'driver': 'GTiff',\n 'dtype': 'uint8',\n 'height': 718,\n 'interleave': 'pixel',\n 'nodata': 0.0,\n 'tiled': False,\n 'transform': Affine(300.0379266750948, 0.0, 101985.0,\n 0.0, -300.041782729805, 2826915.0),\n 'width': 791}\n\n \"\"\"\n\n def __init__(self, file_or_bytes=None, dirname=None, filename=None, ext=\".tif\"):\n \"\"\"Create a new file in memory\n\n Parameters\n ----------\n file_or_bytes : file-like object or bytes, optional\n File or bytes holding initial data.\n filename : str, optional\n An optional filename. A unique one will otherwise be generated.\n ext : str, optional\n An optional extension.\n\n Returns\n -------\n MemoryFile\n \"\"\"\n super().__init__(\n file_or_bytes=file_or_bytes, dirname=dirname, filename=filename, ext=ext\n )\n\n @ensure_env\n def open(self, driver=None, width=None, height=None, count=None, crs=None,\n transform=None, dtype=None, nodata=None, sharing=False, **kwargs):\n \"\"\"Open the file and return a Rasterio dataset object.\n\n If data has already been written, the file is opened in 'r'\n mode. Otherwise, the file is opened in 'w' mode.\n\n Parameters\n ----------\n Note well that there is no `path` parameter: a `MemoryFile`\n contains a single dataset and there is no need to specify a\n path.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n \"\"\"\n mempath = _UnparsedPath(self.name)\n\n if self.closed:\n raise OSError(\"I/O operation on closed file.\")\n if len(self) > 0:\n log.debug(\"VSI path: {}\".format(mempath.path))\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n else:\n writer = get_writer_for_driver(driver)\n return writer(\n mempath,\n \"w+\",\n driver=driver,\n width=width,\n height=height,\n count=count,\n crs=crs,\n transform=transform,\n dtype=dtype,\n nodata=nodata,\n sharing=sharing,\n **kwargs\n )\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n\nclass _FilePath(FilePathBase):\n \"\"\"A BytesIO-like object, backed by a Python file object.\n\n Examples\n --------\n\n A GeoTIFF can be loaded in memory and accessed using the GeoTIFF\n format driver\n\n >>> with open('tests/data/RGB.byte.tif', 'rb') as f, FilePath(f) as vsi_file:\n ... with vsi_file.open() as src:\n ... pprint.pprint(src.profile)\n ...\n {'count': 3,\n 'crs': CRS({'init': 'epsg:32618'}),\n 'driver': 'GTiff',\n 'dtype': 'uint8',\n 'height': 718,\n 'interleave': 'pixel',\n 'nodata': 0.0,\n 'tiled': False,\n 'transform': Affine(300.0379266750948, 0.0, 101985.0,\n 0.0, -300.041782729805, 2826915.0),\n 'width': 791}\n\n \"\"\"\n\n def __init__(self, filelike_obj, dirname=None, filename=None):\n \"\"\"Create a new wrapper around the provided file-like object.\n\n Parameters\n ----------\n filelike_obj : file-like object\n Open file-like object. Currently only reading is supported.\n filename : str, optional\n An optional filename. A unique one will otherwise be generated.\n\n Returns\n -------\n PythonVSIFile\n \"\"\"\n super().__init__(\n filelike_obj, dirname=dirname, filename=filename\n )\n\n @ensure_env\n def open(self, driver=None, sharing=False, **kwargs):\n \"\"\"Open the file and return a Rasterio dataset object.\n\n The provided file-like object is assumed to be readable.\n Writing is currently not supported.\n\n Parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n\n Returns\n -------\n DatasetReader\n\n Raises\n ------\n IOError\n If the memory file is closed.\n\n \"\"\"\n mempath = _UnparsedPath(self.name)\n\n if self.closed:\n raise IOError(\"I/O operation on closed file.\")\n\n # Assume we were given a non-empty file-like object\n log.debug(\"VSI path: {}\".format(mempath.path))\n\n return DatasetReader(mempath, driver=driver, sharing=sharing, **kwargs)\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n\nif FilePathBase is not object:\n # only make this object available if the cython extension was compiled\n FilePath = _FilePath\n\n\nclass ZipMemoryFile(MemoryFile):\n \"\"\"A read-only BytesIO-like object backed by an in-memory zip file.\n\n This allows a zip file containing formatted files to be read\n without I/O.\n \"\"\"\n\n def __init__(self, file_or_bytes=None):\n super().__init__(file_or_bytes, ext=\"zip\")\n\n @ensure_env\n def open(self, path, driver=None, sharing=False, **kwargs):\n \"\"\"Open a dataset within the zipped stream.\n\n Parameters\n ----------\n path : str\n Path to a dataset in the zip file, relative to the root of the\n archive.\n\n Other parameters are optional and have the same semantics as the\n parameters of `rasterio.open()`.\n\n Returns\n -------\n A Rasterio dataset object\n \"\"\"\n zippath = _UnparsedPath('/vsizip{0}/{1}'.format(self.name, path.lstrip('/')))\n\n if self.closed:\n raise OSError(\"I/O operation on closed file.\")\n return DatasetReader(zippath, driver=driver, sharing=sharing, **kwargs)\n\n\ndef get_writer_for_driver(driver):\n \"\"\"Return the writer class appropriate for the specified driver.\"\"\"\n if not driver:\n raise ValueError(\"'driver' is required to read/write dataset.\")\n cls = None\n if driver_can_create(driver):\n cls = DatasetWriter\n elif driver_can_create_copy(driver): # pragma: no branch\n cls = BufferedDatasetWriter\n return cls\n\n\ndef get_writer_for_path(path, driver=None):\n \"\"\"Return the writer class appropriate for the existing dataset.\"\"\"\n if not driver:\n driver = get_dataset_driver(path)\n return get_writer_for_driver(driver)\n", "path": "rasterio/io.py"}]} | 3,202 | 258 |
gh_patches_debug_27871 | rasdani/github-patches | git_diff | kserve__kserve-1640 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Anonymous credentials for single model serving with s3
/kind feature
**Describe the solution you'd like**
[A clear and concise description of what you want to happen.]
Update [download from s3](https://github.com/kubeflow/kfserving/blob/4fd401e348174f954fee7596dc3d54f197f4aa8c/python/kfserving/kfserving/storage.py#L86) to configure boto3 to use anon credentials if anonymous credentials env is set to true.
**Anything else you would like to add:**
[Miscellaneous information that will assist in solving the issue.]
Would be nice if anon e2e test were also added.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kfserving/kfserving/storage.py`
Content:
```
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import glob
16 import gzip
17 import logging
18 import mimetypes
19 import os
20 import re
21 import json
22 import shutil
23 import tarfile
24 import tempfile
25 import zipfile
26 from urllib.parse import urlparse
27
28 import boto3
29 import requests
30 from azure.storage.blob import BlockBlobService
31 from google.auth import exceptions
32 from google.cloud import storage
33
34 from kfserving.kfmodel_repository import MODEL_MOUNT_DIRS
35
36 _GCS_PREFIX = "gs://"
37 _S3_PREFIX = "s3://"
38 _BLOB_RE = "https://(.+?).blob.core.windows.net/(.+)"
39 _LOCAL_PREFIX = "file://"
40 _URI_RE = "https?://(.+)/(.+)"
41 _HTTP_PREFIX = "http(s)://"
42 _HEADERS_SUFFIX = "-headers"
43
44
45 class Storage(object): # pylint: disable=too-few-public-methods
46 @staticmethod
47 def download(uri: str, out_dir: str = None) -> str:
48 logging.info("Copying contents of %s to local", uri)
49
50 is_local = False
51 if uri.startswith(_LOCAL_PREFIX) or os.path.exists(uri):
52 is_local = True
53
54 if out_dir is None:
55 if is_local:
56 # noop if out_dir is not set and the path is local
57 return Storage._download_local(uri)
58 out_dir = tempfile.mkdtemp()
59 elif not os.path.exists(out_dir):
60 os.mkdir(out_dir)
61
62 if uri.startswith(_GCS_PREFIX):
63 Storage._download_gcs(uri, out_dir)
64 elif uri.startswith(_S3_PREFIX):
65 Storage._download_s3(uri, out_dir)
66 elif re.search(_BLOB_RE, uri):
67 Storage._download_blob(uri, out_dir)
68 elif is_local:
69 return Storage._download_local(uri, out_dir)
70 elif re.search(_URI_RE, uri):
71 return Storage._download_from_uri(uri, out_dir)
72 elif uri.startswith(MODEL_MOUNT_DIRS):
73 # Don't need to download models if this InferenceService is running in the multi-model
74 # serving mode. The model agent will download models.
75 return out_dir
76 else:
77 raise Exception("Cannot recognize storage type for " + uri +
78 "\n'%s', '%s', '%s', and '%s' are the current available storage type." %
79 (_GCS_PREFIX, _S3_PREFIX, _LOCAL_PREFIX, _HTTP_PREFIX))
80
81 logging.info("Successfully copied %s to %s", uri, out_dir)
82 return out_dir
83
84 @staticmethod
85 def _download_s3(uri, temp_dir: str):
86 s3 = boto3.resource('s3', endpoint_url=os.getenv("AWS_ENDPOINT_URL", "http://s3.amazonaws.com"))
87 parsed = urlparse(uri, scheme='s3')
88 bucket_name = parsed.netloc
89 bucket_path = parsed.path.lstrip('/')
90
91 bucket = s3.Bucket(bucket_name)
92 for obj in bucket.objects.filter(Prefix=bucket_path):
93 # Skip where boto3 lists the directory as an object
94 if obj.key.endswith("/"):
95 continue
96 # In the case where bucket_path points to a single object, set the target key to bucket_path
97 # Otherwise, remove the bucket_path prefix, strip any extra slashes, then prepend the target_dir
98 target_key = (
99 obj.key
100 if bucket_path == obj.key
101 else obj.key.replace(bucket_path, "", 1).lstrip("/")
102 )
103 target = f"{temp_dir}/{target_key}"
104 if not os.path.exists(os.path.dirname(target)):
105 os.makedirs(os.path.dirname(target), exist_ok=True)
106 bucket.download_file(obj.key, target)
107
108 @staticmethod
109 def _download_gcs(uri, temp_dir: str):
110 try:
111 storage_client = storage.Client()
112 except exceptions.DefaultCredentialsError:
113 storage_client = storage.Client.create_anonymous_client()
114 bucket_args = uri.replace(_GCS_PREFIX, "", 1).split("/", 1)
115 bucket_name = bucket_args[0]
116 bucket_path = bucket_args[1] if len(bucket_args) > 1 else ""
117 bucket = storage_client.bucket(bucket_name)
118 prefix = bucket_path
119 if not prefix.endswith("/"):
120 prefix = prefix + "/"
121 blobs = bucket.list_blobs(prefix=prefix)
122 count = 0
123 for blob in blobs:
124 # Replace any prefix from the object key with temp_dir
125 subdir_object_key = blob.name.replace(bucket_path, "", 1).strip("/")
126
127 # Create necessary subdirectory to store the object locally
128 if "/" in subdir_object_key:
129 local_object_dir = os.path.join(temp_dir, subdir_object_key.rsplit("/", 1)[0])
130 if not os.path.isdir(local_object_dir):
131 os.makedirs(local_object_dir, exist_ok=True)
132 if subdir_object_key.strip() != "":
133 dest_path = os.path.join(temp_dir, subdir_object_key)
134 logging.info("Downloading: %s", dest_path)
135 blob.download_to_filename(dest_path)
136 count = count + 1
137 if count == 0:
138 raise RuntimeError("Failed to fetch model. \
139 The path or model %s does not exist." % uri)
140
141 @staticmethod
142 def _download_blob(uri, out_dir: str): # pylint: disable=too-many-locals
143 match = re.search(_BLOB_RE, uri)
144 account_name = match.group(1)
145 storage_url = match.group(2)
146 container_name, prefix = storage_url.split("/", 1)
147
148 logging.info("Connecting to BLOB account: [%s], container: [%s], prefix: [%s]",
149 account_name,
150 container_name,
151 prefix)
152 try:
153 block_blob_service = BlockBlobService(account_name=account_name)
154 blobs = block_blob_service.list_blobs(container_name, prefix=prefix)
155 except Exception: # pylint: disable=broad-except
156 token = Storage._get_azure_storage_token()
157 if token is None:
158 logging.warning("Azure credentials not found, retrying anonymous access")
159 block_blob_service = BlockBlobService(account_name=account_name, token_credential=token)
160 blobs = block_blob_service.list_blobs(container_name, prefix=prefix)
161 count = 0
162 for blob in blobs:
163 dest_path = os.path.join(out_dir, blob.name)
164 if "/" in blob.name:
165 head, tail = os.path.split(blob.name)
166 if prefix is not None:
167 head = head[len(prefix):]
168 if head.startswith('/'):
169 head = head[1:]
170 dir_path = os.path.join(out_dir, head)
171 dest_path = os.path.join(dir_path, tail)
172 if not os.path.isdir(dir_path):
173 os.makedirs(dir_path)
174
175 logging.info("Downloading: %s to %s", blob.name, dest_path)
176 block_blob_service.get_blob_to_path(container_name, blob.name, dest_path)
177 count = count + 1
178 if count == 0:
179 raise RuntimeError("Failed to fetch model. \
180 The path or model %s does not exist." % (uri))
181
182 @staticmethod
183 def _get_azure_storage_token():
184 tenant_id = os.getenv("AZ_TENANT_ID", "")
185 client_id = os.getenv("AZ_CLIENT_ID", "")
186 client_secret = os.getenv("AZ_CLIENT_SECRET", "")
187 subscription_id = os.getenv("AZ_SUBSCRIPTION_ID", "")
188
189 if tenant_id == "" or client_id == "" or client_secret == "" or subscription_id == "":
190 return None
191
192 # note the SP must have "Storage Blob Data Owner" perms for this to work
193 import adal
194 from azure.storage.common import TokenCredential
195
196 authority_url = "https://login.microsoftonline.com/" + tenant_id
197
198 context = adal.AuthenticationContext(authority_url)
199
200 token = context.acquire_token_with_client_credentials(
201 "https://storage.azure.com/",
202 client_id,
203 client_secret)
204
205 token_credential = TokenCredential(token["accessToken"])
206
207 logging.info("Retrieved SP token credential for client_id: %s", client_id)
208
209 return token_credential
210
211 @staticmethod
212 def _download_local(uri, out_dir=None):
213 local_path = uri.replace(_LOCAL_PREFIX, "", 1)
214 if not os.path.exists(local_path):
215 raise RuntimeError("Local path %s does not exist." % (uri))
216
217 if out_dir is None:
218 return local_path
219 elif not os.path.isdir(out_dir):
220 os.makedirs(out_dir)
221
222 if os.path.isdir(local_path):
223 local_path = os.path.join(local_path, "*")
224
225 for src in glob.glob(local_path):
226 _, tail = os.path.split(src)
227 dest_path = os.path.join(out_dir, tail)
228 logging.info("Linking: %s to %s", src, dest_path)
229 os.symlink(src, dest_path)
230 return out_dir
231
232 @staticmethod
233 def _download_from_uri(uri, out_dir=None):
234 url = urlparse(uri)
235 filename = os.path.basename(url.path)
236 mimetype, encoding = mimetypes.guess_type(url.path)
237 local_path = os.path.join(out_dir, filename)
238
239 if filename == '':
240 raise ValueError('No filename contained in URI: %s' % (uri))
241
242 # Get header information from host url
243 headers = {}
244 host_uri = url.hostname
245
246 headers_json = os.getenv(host_uri + _HEADERS_SUFFIX, "{}")
247 headers = json.loads(headers_json)
248
249 with requests.get(uri, stream=True, headers=headers) as response:
250 if response.status_code != 200:
251 raise RuntimeError("URI: %s returned a %s response code." % (uri, response.status_code))
252 if mimetype == 'application/zip' and not response.headers.get('Content-Type', '')\
253 .startswith('application/zip'):
254 raise RuntimeError("URI: %s did not respond with \'Content-Type\': \'application/zip\'" % uri)
255 if mimetype == 'application/x-tar' and not response.headers.get('Content-Type', '')\
256 .startswith('application/x-tar'):
257 raise RuntimeError("URI: %s did not respond with \'Content-Type\': \'application/x-tar\'" % uri)
258 if (mimetype != 'application/zip' and mimetype != 'application/x-tar') and \
259 not response.headers.get('Content-Type', '').startswith('application/octet-stream'):
260 raise RuntimeError("URI: %s did not respond with \'Content-Type\': \'application/octet-stream\'"
261 % uri)
262
263 if encoding == 'gzip':
264 stream = gzip.GzipFile(fileobj=response.raw)
265 local_path = os.path.join(out_dir, f'{filename}.tar')
266 else:
267 stream = response.raw
268 with open(local_path, 'wb') as out:
269 shutil.copyfileobj(stream, out)
270
271 if mimetype in ["application/x-tar", "application/zip"]:
272 if mimetype == "application/x-tar":
273 archive = tarfile.open(local_path, 'r', encoding='utf-8')
274 else:
275 archive = zipfile.ZipFile(local_path, 'r')
276 archive.extractall(out_dir)
277 archive.close()
278 os.remove(local_path)
279
280 return out_dir
281
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/kfserving/kfserving/storage.py b/python/kfserving/kfserving/storage.py
--- a/python/kfserving/kfserving/storage.py
+++ b/python/kfserving/kfserving/storage.py
@@ -25,6 +25,8 @@
import zipfile
from urllib.parse import urlparse
+from botocore.client import Config
+from botocore import UNSIGNED
import boto3
import requests
from azure.storage.blob import BlockBlobService
@@ -81,9 +83,26 @@
logging.info("Successfully copied %s to %s", uri, out_dir)
return out_dir
+ @staticmethod
+ def get_S3_config():
+ # anon environment variable defined in s3_secret.go
+ anon = ("True" == os.getenv("awsAnonymousCredential", "false").capitalize())
+ if anon:
+ return Config(signature_version=UNSIGNED)
+ else:
+ return None
+
@staticmethod
def _download_s3(uri, temp_dir: str):
- s3 = boto3.resource('s3', endpoint_url=os.getenv("AWS_ENDPOINT_URL", "http://s3.amazonaws.com"))
+ # Boto3 looks at various configuration locations until it finds configuration values.
+ # lookup order:
+ # 1. Config object passed in as the config parameter when creating S3 resource
+ # if awsAnonymousCredential env var true, passed in via config
+ # 2. Environment variables
+ # 3. ~/.aws/config file
+ s3 = boto3.resource('s3',
+ endpoint_url=os.getenv("AWS_ENDPOINT_URL", "http://s3.amazonaws.com"),
+ config=Storage.get_S3_config())
parsed = urlparse(uri, scheme='s3')
bucket_name = parsed.netloc
bucket_path = parsed.path.lstrip('/')
| {"golden_diff": "diff --git a/python/kfserving/kfserving/storage.py b/python/kfserving/kfserving/storage.py\n--- a/python/kfserving/kfserving/storage.py\n+++ b/python/kfserving/kfserving/storage.py\n@@ -25,6 +25,8 @@\n import zipfile\n from urllib.parse import urlparse\n \n+from botocore.client import Config\n+from botocore import UNSIGNED\n import boto3\n import requests\n from azure.storage.blob import BlockBlobService\n@@ -81,9 +83,26 @@\n logging.info(\"Successfully copied %s to %s\", uri, out_dir)\n return out_dir\n \n+ @staticmethod\n+ def get_S3_config():\n+ # anon environment variable defined in s3_secret.go\n+ anon = (\"True\" == os.getenv(\"awsAnonymousCredential\", \"false\").capitalize())\n+ if anon:\n+ return Config(signature_version=UNSIGNED)\n+ else:\n+ return None\n+\n @staticmethod\n def _download_s3(uri, temp_dir: str):\n- s3 = boto3.resource('s3', endpoint_url=os.getenv(\"AWS_ENDPOINT_URL\", \"http://s3.amazonaws.com\"))\n+ # Boto3 looks at various configuration locations until it finds configuration values.\n+ # lookup order:\n+ # 1. Config object passed in as the config parameter when creating S3 resource\n+ # if awsAnonymousCredential env var true, passed in via config\n+ # 2. Environment variables\n+ # 3. ~/.aws/config file\n+ s3 = boto3.resource('s3',\n+ endpoint_url=os.getenv(\"AWS_ENDPOINT_URL\", \"http://s3.amazonaws.com\"),\n+ config=Storage.get_S3_config())\n parsed = urlparse(uri, scheme='s3')\n bucket_name = parsed.netloc\n bucket_path = parsed.path.lstrip('/')\n", "issue": "Anonymous credentials for single model serving with s3\n/kind feature\r\n\r\n**Describe the solution you'd like**\r\n[A clear and concise description of what you want to happen.]\r\nUpdate [download from s3](https://github.com/kubeflow/kfserving/blob/4fd401e348174f954fee7596dc3d54f197f4aa8c/python/kfserving/kfserving/storage.py#L86) to configure boto3 to use anon credentials if anonymous credentials env is set to true.\r\n\r\n**Anything else you would like to add:**\r\n[Miscellaneous information that will assist in solving the issue.]\r\nWould be nice if anon e2e test were also added.\n", "before_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport glob\nimport gzip\nimport logging\nimport mimetypes\nimport os\nimport re\nimport json\nimport shutil\nimport tarfile\nimport tempfile\nimport zipfile\nfrom urllib.parse import urlparse\n\nimport boto3\nimport requests\nfrom azure.storage.blob import BlockBlobService\nfrom google.auth import exceptions\nfrom google.cloud import storage\n\nfrom kfserving.kfmodel_repository import MODEL_MOUNT_DIRS\n\n_GCS_PREFIX = \"gs://\"\n_S3_PREFIX = \"s3://\"\n_BLOB_RE = \"https://(.+?).blob.core.windows.net/(.+)\"\n_LOCAL_PREFIX = \"file://\"\n_URI_RE = \"https?://(.+)/(.+)\"\n_HTTP_PREFIX = \"http(s)://\"\n_HEADERS_SUFFIX = \"-headers\"\n\n\nclass Storage(object): # pylint: disable=too-few-public-methods\n @staticmethod\n def download(uri: str, out_dir: str = None) -> str:\n logging.info(\"Copying contents of %s to local\", uri)\n\n is_local = False\n if uri.startswith(_LOCAL_PREFIX) or os.path.exists(uri):\n is_local = True\n\n if out_dir is None:\n if is_local:\n # noop if out_dir is not set and the path is local\n return Storage._download_local(uri)\n out_dir = tempfile.mkdtemp()\n elif not os.path.exists(out_dir):\n os.mkdir(out_dir)\n\n if uri.startswith(_GCS_PREFIX):\n Storage._download_gcs(uri, out_dir)\n elif uri.startswith(_S3_PREFIX):\n Storage._download_s3(uri, out_dir)\n elif re.search(_BLOB_RE, uri):\n Storage._download_blob(uri, out_dir)\n elif is_local:\n return Storage._download_local(uri, out_dir)\n elif re.search(_URI_RE, uri):\n return Storage._download_from_uri(uri, out_dir)\n elif uri.startswith(MODEL_MOUNT_DIRS):\n # Don't need to download models if this InferenceService is running in the multi-model\n # serving mode. The model agent will download models.\n return out_dir\n else:\n raise Exception(\"Cannot recognize storage type for \" + uri +\n \"\\n'%s', '%s', '%s', and '%s' are the current available storage type.\" %\n (_GCS_PREFIX, _S3_PREFIX, _LOCAL_PREFIX, _HTTP_PREFIX))\n\n logging.info(\"Successfully copied %s to %s\", uri, out_dir)\n return out_dir\n\n @staticmethod\n def _download_s3(uri, temp_dir: str):\n s3 = boto3.resource('s3', endpoint_url=os.getenv(\"AWS_ENDPOINT_URL\", \"http://s3.amazonaws.com\"))\n parsed = urlparse(uri, scheme='s3')\n bucket_name = parsed.netloc\n bucket_path = parsed.path.lstrip('/')\n\n bucket = s3.Bucket(bucket_name)\n for obj in bucket.objects.filter(Prefix=bucket_path):\n # Skip where boto3 lists the directory as an object\n if obj.key.endswith(\"/\"):\n continue\n # In the case where bucket_path points to a single object, set the target key to bucket_path\n # Otherwise, remove the bucket_path prefix, strip any extra slashes, then prepend the target_dir\n target_key = (\n obj.key\n if bucket_path == obj.key\n else obj.key.replace(bucket_path, \"\", 1).lstrip(\"/\")\n )\n target = f\"{temp_dir}/{target_key}\"\n if not os.path.exists(os.path.dirname(target)):\n os.makedirs(os.path.dirname(target), exist_ok=True)\n bucket.download_file(obj.key, target)\n\n @staticmethod\n def _download_gcs(uri, temp_dir: str):\n try:\n storage_client = storage.Client()\n except exceptions.DefaultCredentialsError:\n storage_client = storage.Client.create_anonymous_client()\n bucket_args = uri.replace(_GCS_PREFIX, \"\", 1).split(\"/\", 1)\n bucket_name = bucket_args[0]\n bucket_path = bucket_args[1] if len(bucket_args) > 1 else \"\"\n bucket = storage_client.bucket(bucket_name)\n prefix = bucket_path\n if not prefix.endswith(\"/\"):\n prefix = prefix + \"/\"\n blobs = bucket.list_blobs(prefix=prefix)\n count = 0\n for blob in blobs:\n # Replace any prefix from the object key with temp_dir\n subdir_object_key = blob.name.replace(bucket_path, \"\", 1).strip(\"/\")\n\n # Create necessary subdirectory to store the object locally\n if \"/\" in subdir_object_key:\n local_object_dir = os.path.join(temp_dir, subdir_object_key.rsplit(\"/\", 1)[0])\n if not os.path.isdir(local_object_dir):\n os.makedirs(local_object_dir, exist_ok=True)\n if subdir_object_key.strip() != \"\":\n dest_path = os.path.join(temp_dir, subdir_object_key)\n logging.info(\"Downloading: %s\", dest_path)\n blob.download_to_filename(dest_path)\n count = count + 1\n if count == 0:\n raise RuntimeError(\"Failed to fetch model. \\\nThe path or model %s does not exist.\" % uri)\n\n @staticmethod\n def _download_blob(uri, out_dir: str): # pylint: disable=too-many-locals\n match = re.search(_BLOB_RE, uri)\n account_name = match.group(1)\n storage_url = match.group(2)\n container_name, prefix = storage_url.split(\"/\", 1)\n\n logging.info(\"Connecting to BLOB account: [%s], container: [%s], prefix: [%s]\",\n account_name,\n container_name,\n prefix)\n try:\n block_blob_service = BlockBlobService(account_name=account_name)\n blobs = block_blob_service.list_blobs(container_name, prefix=prefix)\n except Exception: # pylint: disable=broad-except\n token = Storage._get_azure_storage_token()\n if token is None:\n logging.warning(\"Azure credentials not found, retrying anonymous access\")\n block_blob_service = BlockBlobService(account_name=account_name, token_credential=token)\n blobs = block_blob_service.list_blobs(container_name, prefix=prefix)\n count = 0\n for blob in blobs:\n dest_path = os.path.join(out_dir, blob.name)\n if \"/\" in blob.name:\n head, tail = os.path.split(blob.name)\n if prefix is not None:\n head = head[len(prefix):]\n if head.startswith('/'):\n head = head[1:]\n dir_path = os.path.join(out_dir, head)\n dest_path = os.path.join(dir_path, tail)\n if not os.path.isdir(dir_path):\n os.makedirs(dir_path)\n\n logging.info(\"Downloading: %s to %s\", blob.name, dest_path)\n block_blob_service.get_blob_to_path(container_name, blob.name, dest_path)\n count = count + 1\n if count == 0:\n raise RuntimeError(\"Failed to fetch model. \\\nThe path or model %s does not exist.\" % (uri))\n\n @staticmethod\n def _get_azure_storage_token():\n tenant_id = os.getenv(\"AZ_TENANT_ID\", \"\")\n client_id = os.getenv(\"AZ_CLIENT_ID\", \"\")\n client_secret = os.getenv(\"AZ_CLIENT_SECRET\", \"\")\n subscription_id = os.getenv(\"AZ_SUBSCRIPTION_ID\", \"\")\n\n if tenant_id == \"\" or client_id == \"\" or client_secret == \"\" or subscription_id == \"\":\n return None\n\n # note the SP must have \"Storage Blob Data Owner\" perms for this to work\n import adal\n from azure.storage.common import TokenCredential\n\n authority_url = \"https://login.microsoftonline.com/\" + tenant_id\n\n context = adal.AuthenticationContext(authority_url)\n\n token = context.acquire_token_with_client_credentials(\n \"https://storage.azure.com/\",\n client_id,\n client_secret)\n\n token_credential = TokenCredential(token[\"accessToken\"])\n\n logging.info(\"Retrieved SP token credential for client_id: %s\", client_id)\n\n return token_credential\n\n @staticmethod\n def _download_local(uri, out_dir=None):\n local_path = uri.replace(_LOCAL_PREFIX, \"\", 1)\n if not os.path.exists(local_path):\n raise RuntimeError(\"Local path %s does not exist.\" % (uri))\n\n if out_dir is None:\n return local_path\n elif not os.path.isdir(out_dir):\n os.makedirs(out_dir)\n\n if os.path.isdir(local_path):\n local_path = os.path.join(local_path, \"*\")\n\n for src in glob.glob(local_path):\n _, tail = os.path.split(src)\n dest_path = os.path.join(out_dir, tail)\n logging.info(\"Linking: %s to %s\", src, dest_path)\n os.symlink(src, dest_path)\n return out_dir\n\n @staticmethod\n def _download_from_uri(uri, out_dir=None):\n url = urlparse(uri)\n filename = os.path.basename(url.path)\n mimetype, encoding = mimetypes.guess_type(url.path)\n local_path = os.path.join(out_dir, filename)\n\n if filename == '':\n raise ValueError('No filename contained in URI: %s' % (uri))\n\n # Get header information from host url\n headers = {}\n host_uri = url.hostname\n\n headers_json = os.getenv(host_uri + _HEADERS_SUFFIX, \"{}\")\n headers = json.loads(headers_json)\n\n with requests.get(uri, stream=True, headers=headers) as response:\n if response.status_code != 200:\n raise RuntimeError(\"URI: %s returned a %s response code.\" % (uri, response.status_code))\n if mimetype == 'application/zip' and not response.headers.get('Content-Type', '')\\\n .startswith('application/zip'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/zip\\'\" % uri)\n if mimetype == 'application/x-tar' and not response.headers.get('Content-Type', '')\\\n .startswith('application/x-tar'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/x-tar\\'\" % uri)\n if (mimetype != 'application/zip' and mimetype != 'application/x-tar') and \\\n not response.headers.get('Content-Type', '').startswith('application/octet-stream'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/octet-stream\\'\"\n % uri)\n\n if encoding == 'gzip':\n stream = gzip.GzipFile(fileobj=response.raw)\n local_path = os.path.join(out_dir, f'{filename}.tar')\n else:\n stream = response.raw\n with open(local_path, 'wb') as out:\n shutil.copyfileobj(stream, out)\n\n if mimetype in [\"application/x-tar\", \"application/zip\"]:\n if mimetype == \"application/x-tar\":\n archive = tarfile.open(local_path, 'r', encoding='utf-8')\n else:\n archive = zipfile.ZipFile(local_path, 'r')\n archive.extractall(out_dir)\n archive.close()\n os.remove(local_path)\n\n return out_dir\n", "path": "python/kfserving/kfserving/storage.py"}], "after_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport glob\nimport gzip\nimport logging\nimport mimetypes\nimport os\nimport re\nimport json\nimport shutil\nimport tarfile\nimport tempfile\nimport zipfile\nfrom urllib.parse import urlparse\n\nfrom botocore.client import Config\nfrom botocore import UNSIGNED\nimport boto3\nimport requests\nfrom azure.storage.blob import BlockBlobService\nfrom google.auth import exceptions\nfrom google.cloud import storage\n\nfrom kfserving.kfmodel_repository import MODEL_MOUNT_DIRS\n\n_GCS_PREFIX = \"gs://\"\n_S3_PREFIX = \"s3://\"\n_BLOB_RE = \"https://(.+?).blob.core.windows.net/(.+)\"\n_LOCAL_PREFIX = \"file://\"\n_URI_RE = \"https?://(.+)/(.+)\"\n_HTTP_PREFIX = \"http(s)://\"\n_HEADERS_SUFFIX = \"-headers\"\n\n\nclass Storage(object): # pylint: disable=too-few-public-methods\n @staticmethod\n def download(uri: str, out_dir: str = None) -> str:\n logging.info(\"Copying contents of %s to local\", uri)\n\n is_local = False\n if uri.startswith(_LOCAL_PREFIX) or os.path.exists(uri):\n is_local = True\n\n if out_dir is None:\n if is_local:\n # noop if out_dir is not set and the path is local\n return Storage._download_local(uri)\n out_dir = tempfile.mkdtemp()\n elif not os.path.exists(out_dir):\n os.mkdir(out_dir)\n\n if uri.startswith(_GCS_PREFIX):\n Storage._download_gcs(uri, out_dir)\n elif uri.startswith(_S3_PREFIX):\n Storage._download_s3(uri, out_dir)\n elif re.search(_BLOB_RE, uri):\n Storage._download_blob(uri, out_dir)\n elif is_local:\n return Storage._download_local(uri, out_dir)\n elif re.search(_URI_RE, uri):\n return Storage._download_from_uri(uri, out_dir)\n elif uri.startswith(MODEL_MOUNT_DIRS):\n # Don't need to download models if this InferenceService is running in the multi-model\n # serving mode. The model agent will download models.\n return out_dir\n else:\n raise Exception(\"Cannot recognize storage type for \" + uri +\n \"\\n'%s', '%s', '%s', and '%s' are the current available storage type.\" %\n (_GCS_PREFIX, _S3_PREFIX, _LOCAL_PREFIX, _HTTP_PREFIX))\n\n logging.info(\"Successfully copied %s to %s\", uri, out_dir)\n return out_dir\n\n @staticmethod\n def get_S3_config():\n # anon environment variable defined in s3_secret.go\n anon = (\"True\" == os.getenv(\"awsAnonymousCredential\", \"false\").capitalize())\n if anon:\n return Config(signature_version=UNSIGNED)\n else:\n return None\n\n @staticmethod\n def _download_s3(uri, temp_dir: str):\n # Boto3 looks at various configuration locations until it finds configuration values.\n # lookup order:\n # 1. Config object passed in as the config parameter when creating S3 resource\n # if awsAnonymousCredential env var true, passed in via config\n # 2. Environment variables\n # 3. ~/.aws/config file\n s3 = boto3.resource('s3',\n endpoint_url=os.getenv(\"AWS_ENDPOINT_URL\", \"http://s3.amazonaws.com\"),\n config=Storage.get_S3_config())\n parsed = urlparse(uri, scheme='s3')\n bucket_name = parsed.netloc\n bucket_path = parsed.path.lstrip('/')\n\n bucket = s3.Bucket(bucket_name)\n for obj in bucket.objects.filter(Prefix=bucket_path):\n # Skip where boto3 lists the directory as an object\n if obj.key.endswith(\"/\"):\n continue\n # In the case where bucket_path points to a single object, set the target key to bucket_path\n # Otherwise, remove the bucket_path prefix, strip any extra slashes, then prepend the target_dir\n target_key = (\n obj.key\n if bucket_path == obj.key\n else obj.key.replace(bucket_path, \"\", 1).lstrip(\"/\")\n )\n target = f\"{temp_dir}/{target_key}\"\n if not os.path.exists(os.path.dirname(target)):\n os.makedirs(os.path.dirname(target), exist_ok=True)\n bucket.download_file(obj.key, target)\n\n @staticmethod\n def _download_gcs(uri, temp_dir: str):\n try:\n storage_client = storage.Client()\n except exceptions.DefaultCredentialsError:\n storage_client = storage.Client.create_anonymous_client()\n bucket_args = uri.replace(_GCS_PREFIX, \"\", 1).split(\"/\", 1)\n bucket_name = bucket_args[0]\n bucket_path = bucket_args[1] if len(bucket_args) > 1 else \"\"\n bucket = storage_client.bucket(bucket_name)\n prefix = bucket_path\n if not prefix.endswith(\"/\"):\n prefix = prefix + \"/\"\n blobs = bucket.list_blobs(prefix=prefix)\n count = 0\n for blob in blobs:\n # Replace any prefix from the object key with temp_dir\n subdir_object_key = blob.name.replace(bucket_path, \"\", 1).strip(\"/\")\n\n # Create necessary subdirectory to store the object locally\n if \"/\" in subdir_object_key:\n local_object_dir = os.path.join(temp_dir, subdir_object_key.rsplit(\"/\", 1)[0])\n if not os.path.isdir(local_object_dir):\n os.makedirs(local_object_dir, exist_ok=True)\n if subdir_object_key.strip() != \"\":\n dest_path = os.path.join(temp_dir, subdir_object_key)\n logging.info(\"Downloading: %s\", dest_path)\n blob.download_to_filename(dest_path)\n count = count + 1\n if count == 0:\n raise RuntimeError(\"Failed to fetch model. \\\nThe path or model %s does not exist.\" % uri)\n\n @staticmethod\n def _download_blob(uri, out_dir: str): # pylint: disable=too-many-locals\n match = re.search(_BLOB_RE, uri)\n account_name = match.group(1)\n storage_url = match.group(2)\n container_name, prefix = storage_url.split(\"/\", 1)\n\n logging.info(\"Connecting to BLOB account: [%s], container: [%s], prefix: [%s]\",\n account_name,\n container_name,\n prefix)\n try:\n block_blob_service = BlockBlobService(account_name=account_name)\n blobs = block_blob_service.list_blobs(container_name, prefix=prefix)\n except Exception: # pylint: disable=broad-except\n token = Storage._get_azure_storage_token()\n if token is None:\n logging.warning(\"Azure credentials not found, retrying anonymous access\")\n block_blob_service = BlockBlobService(account_name=account_name, token_credential=token)\n blobs = block_blob_service.list_blobs(container_name, prefix=prefix)\n count = 0\n for blob in blobs:\n dest_path = os.path.join(out_dir, blob.name)\n if \"/\" in blob.name:\n head, tail = os.path.split(blob.name)\n if prefix is not None:\n head = head[len(prefix):]\n if head.startswith('/'):\n head = head[1:]\n dir_path = os.path.join(out_dir, head)\n dest_path = os.path.join(dir_path, tail)\n if not os.path.isdir(dir_path):\n os.makedirs(dir_path)\n\n logging.info(\"Downloading: %s to %s\", blob.name, dest_path)\n block_blob_service.get_blob_to_path(container_name, blob.name, dest_path)\n count = count + 1\n if count == 0:\n raise RuntimeError(\"Failed to fetch model. \\\nThe path or model %s does not exist.\" % (uri))\n\n @staticmethod\n def _get_azure_storage_token():\n tenant_id = os.getenv(\"AZ_TENANT_ID\", \"\")\n client_id = os.getenv(\"AZ_CLIENT_ID\", \"\")\n client_secret = os.getenv(\"AZ_CLIENT_SECRET\", \"\")\n subscription_id = os.getenv(\"AZ_SUBSCRIPTION_ID\", \"\")\n\n if tenant_id == \"\" or client_id == \"\" or client_secret == \"\" or subscription_id == \"\":\n return None\n\n # note the SP must have \"Storage Blob Data Owner\" perms for this to work\n import adal\n from azure.storage.common import TokenCredential\n\n authority_url = \"https://login.microsoftonline.com/\" + tenant_id\n\n context = adal.AuthenticationContext(authority_url)\n\n token = context.acquire_token_with_client_credentials(\n \"https://storage.azure.com/\",\n client_id,\n client_secret)\n\n token_credential = TokenCredential(token[\"accessToken\"])\n\n logging.info(\"Retrieved SP token credential for client_id: %s\", client_id)\n\n return token_credential\n\n @staticmethod\n def _download_local(uri, out_dir=None):\n local_path = uri.replace(_LOCAL_PREFIX, \"\", 1)\n if not os.path.exists(local_path):\n raise RuntimeError(\"Local path %s does not exist.\" % (uri))\n\n if out_dir is None:\n return local_path\n elif not os.path.isdir(out_dir):\n os.makedirs(out_dir)\n\n if os.path.isdir(local_path):\n local_path = os.path.join(local_path, \"*\")\n\n for src in glob.glob(local_path):\n _, tail = os.path.split(src)\n dest_path = os.path.join(out_dir, tail)\n logging.info(\"Linking: %s to %s\", src, dest_path)\n os.symlink(src, dest_path)\n return out_dir\n\n @staticmethod\n def _download_from_uri(uri, out_dir=None):\n url = urlparse(uri)\n filename = os.path.basename(url.path)\n mimetype, encoding = mimetypes.guess_type(url.path)\n local_path = os.path.join(out_dir, filename)\n\n if filename == '':\n raise ValueError('No filename contained in URI: %s' % (uri))\n\n # Get header information from host url\n headers = {}\n host_uri = url.hostname\n\n headers_json = os.getenv(host_uri + _HEADERS_SUFFIX, \"{}\")\n headers = json.loads(headers_json)\n\n with requests.get(uri, stream=True, headers=headers) as response:\n if response.status_code != 200:\n raise RuntimeError(\"URI: %s returned a %s response code.\" % (uri, response.status_code))\n if mimetype == 'application/zip' and not response.headers.get('Content-Type', '')\\\n .startswith('application/zip'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/zip\\'\" % uri)\n if mimetype == 'application/x-tar' and not response.headers.get('Content-Type', '')\\\n .startswith('application/x-tar'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/x-tar\\'\" % uri)\n if (mimetype != 'application/zip' and mimetype != 'application/x-tar') and \\\n not response.headers.get('Content-Type', '').startswith('application/octet-stream'):\n raise RuntimeError(\"URI: %s did not respond with \\'Content-Type\\': \\'application/octet-stream\\'\"\n % uri)\n\n if encoding == 'gzip':\n stream = gzip.GzipFile(fileobj=response.raw)\n local_path = os.path.join(out_dir, f'{filename}.tar')\n else:\n stream = response.raw\n with open(local_path, 'wb') as out:\n shutil.copyfileobj(stream, out)\n\n if mimetype in [\"application/x-tar\", \"application/zip\"]:\n if mimetype == \"application/x-tar\":\n archive = tarfile.open(local_path, 'r', encoding='utf-8')\n else:\n archive = zipfile.ZipFile(local_path, 'r')\n archive.extractall(out_dir)\n archive.close()\n os.remove(local_path)\n\n return out_dir\n", "path": "python/kfserving/kfserving/storage.py"}]} | 3,673 | 403 |
gh_patches_debug_39264 | rasdani/github-patches | git_diff | rasterio__rasterio-660 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Skip local rasterfill.cpp for GDAL >= 2.0
Our local rasterfill.cpp (see #253) is in GDAL 2.+: https://github.com/OSGeo/gdal/pull/47.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # Two environmental variables influence this script.
4 #
5 # GDAL_CONFIG: the path to a gdal-config program that points to GDAL headers,
6 # libraries, and data files.
7 #
8 # PACKAGE_DATA: if defined, GDAL and PROJ4 data files will be copied into the
9 # source or binary distribution. This is essential when creating self-contained
10 # binary wheels.
11
12 import logging
13 import os
14 import pprint
15 import shutil
16 import subprocess
17 import sys
18
19 from setuptools import setup
20 from setuptools.extension import Extension
21
22
23 logging.basicConfig()
24 log = logging.getLogger()
25
26
27 def check_output(cmd):
28 # since subprocess.check_output doesn't exist in 2.6
29 # we wrap it here.
30 try:
31 out = subprocess.check_output(cmd)
32 return out.decode('utf')
33 except AttributeError:
34 # For some reasone check_output doesn't exist
35 # So fall back on Popen
36 p = subprocess.Popen(cmd, stdout=subprocess.PIPE)
37 out, err = p.communicate()
38 return out
39
40
41 def copy_data_tree(datadir, destdir):
42 try:
43 shutil.rmtree(destdir)
44 except OSError:
45 pass
46 shutil.copytree(datadir, destdir)
47
48
49 # python -W all setup.py ...
50 if 'all' in sys.warnoptions:
51 log.level = logging.DEBUG
52
53 # Parse the version from the rasterio module.
54 with open('rasterio/__init__.py') as f:
55 for line in f:
56 if line.find("__version__") >= 0:
57 version = line.split("=")[1].strip()
58 version = version.strip('"')
59 version = version.strip("'")
60 continue
61
62 with open('VERSION.txt', 'w') as f:
63 f.write(version)
64
65 # Use Cython if available.
66 try:
67 from Cython.Build import cythonize
68 except ImportError:
69 cythonize = None
70
71 # By default we'll try to get options via gdal-config. On systems without,
72 # options will need to be set in setup.cfg or on the setup command line.
73 include_dirs = []
74 library_dirs = []
75 libraries = []
76 extra_link_args = []
77 gdal_output = [None]*3
78
79 try:
80 import numpy
81 include_dirs.append(numpy.get_include())
82 except ImportError:
83 log.critical("Numpy and its headers are required to run setup(). Exiting.")
84 sys.exit(1)
85
86 try:
87 gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')
88 for i, flag in enumerate(("--cflags", "--libs", "--datadir")):
89 gdal_output[i] = check_output([gdal_config, flag]).strip()
90
91 for item in gdal_output[0].split():
92 if item.startswith("-I"):
93 include_dirs.extend(item[2:].split(":"))
94 for item in gdal_output[1].split():
95 if item.startswith("-L"):
96 library_dirs.extend(item[2:].split(":"))
97 elif item.startswith("-l"):
98 libraries.append(item[2:])
99 else:
100 # e.g. -framework GDAL
101 extra_link_args.append(item)
102
103 except Exception as e:
104 if os.name == "nt":
105 log.info(("Building on Windows requires extra options to setup.py to locate needed GDAL files.\n"
106 "More information is available in the README."))
107 else:
108 log.warning("Failed to get options via gdal-config: %s", str(e))
109
110
111 # Conditionally copy the GDAL data. To be used in conjunction with
112 # the bdist_wheel command to make self-contained binary wheels.
113 if os.environ.get('PACKAGE_DATA'):
114 destdir = 'rasterio/gdal_data'
115 if gdal_output[2]:
116 log.info("Copying gdal data from %s" % gdal_output[2])
117 copy_data_tree(gdal_output[2], destdir)
118 else:
119 # check to see if GDAL_DATA is defined
120 gdal_data = os.environ.get('GDAL_DATA', None)
121 if gdal_data:
122 log.info("Copying gdal_data from %s" % gdal_data)
123 copy_data_tree(gdal_data, destdir)
124
125 # Conditionally copy PROJ.4 data.
126 projdatadir = os.environ.get('PROJ_LIB', '/usr/local/share/proj')
127 if os.path.exists(projdatadir):
128 log.info("Copying proj_data from %s" % projdatadir)
129 copy_data_tree(projdatadir, 'rasterio/proj_data')
130
131 ext_options = dict(
132 include_dirs=include_dirs,
133 library_dirs=library_dirs,
134 libraries=libraries,
135 extra_link_args=extra_link_args)
136
137 if not os.name == "nt":
138 # These options fail on Windows if using Visual Studio
139 ext_options['extra_compile_args'] = ['-Wno-unused-parameter',
140 '-Wno-unused-function']
141
142 cythonize_options = {}
143 if os.environ.get('CYTHON_COVERAGE'):
144 cythonize_options['compiler_directives'] = {'linetrace': True}
145 cythonize_options['annotate'] = True
146 ext_options['define_macros'] = [('CYTHON_TRACE', '1'),
147 ('CYTHON_TRACE_NOGIL', '1')]
148
149 log.debug('ext_options:\n%s', pprint.pformat(ext_options))
150
151 # When building from a repo, Cython is required.
152 if os.path.exists("MANIFEST.in") and "clean" not in sys.argv:
153 log.info("MANIFEST.in found, presume a repo, cythonizing...")
154 if not cythonize:
155 log.critical(
156 "Cython.Build.cythonize not found. "
157 "Cython is required to build from a repo.")
158 sys.exit(1)
159 ext_modules = cythonize([
160 Extension(
161 'rasterio._base', ['rasterio/_base.pyx'], **ext_options),
162 Extension(
163 'rasterio._io', ['rasterio/_io.pyx'], **ext_options),
164 Extension(
165 'rasterio._copy', ['rasterio/_copy.pyx'], **ext_options),
166 Extension(
167 'rasterio._features', ['rasterio/_features.pyx'], **ext_options),
168 Extension(
169 'rasterio._drivers', ['rasterio/_drivers.pyx'], **ext_options),
170 Extension(
171 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),
172 Extension(
173 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),
174 Extension(
175 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),
176 Extension(
177 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),
178 ], quiet=True, **cythonize_options)
179
180 # If there's no manifest template, as in an sdist, we just specify .c files.
181 else:
182 ext_modules = [
183 Extension(
184 'rasterio._base', ['rasterio/_base.c'], **ext_options),
185 Extension(
186 'rasterio._io', ['rasterio/_io.c'], **ext_options),
187 Extension(
188 'rasterio._copy', ['rasterio/_copy.c'], **ext_options),
189 Extension(
190 'rasterio._features', ['rasterio/_features.c'], **ext_options),
191 Extension(
192 'rasterio._drivers', ['rasterio/_drivers.c'], **ext_options),
193 Extension(
194 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),
195 Extension(
196 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),
197 Extension(
198 'rasterio._err', ['rasterio/_err.c'], **ext_options),
199 Extension(
200 'rasterio._example', ['rasterio/_example.c'], **ext_options),
201 ]
202
203 with open('README.rst') as f:
204 readme = f.read()
205
206 # Runtime requirements.
207 inst_reqs = ['affine', 'cligj', 'numpy', 'snuggs', 'click-plugins']
208
209 if sys.version_info < (3, 4):
210 inst_reqs.append('enum34')
211
212 setup_args = dict(
213 name='rasterio',
214 version=version,
215 description="Fast and direct raster I/O for use with Numpy and SciPy",
216 long_description=readme,
217 classifiers=[
218 'Development Status :: 4 - Beta',
219 'Intended Audience :: Developers',
220 'Intended Audience :: Information Technology',
221 'Intended Audience :: Science/Research',
222 'License :: OSI Approved :: BSD License',
223 'Programming Language :: C',
224 'Programming Language :: Python :: 2.6',
225 'Programming Language :: Python :: 2.7',
226 'Programming Language :: Python :: 3.3',
227 'Programming Language :: Python :: 3.4',
228 'Topic :: Multimedia :: Graphics :: Graphics Conversion',
229 'Topic :: Scientific/Engineering :: GIS'],
230 keywords='raster gdal',
231 author='Sean Gillies',
232 author_email='[email protected]',
233 url='https://github.com/mapbox/rasterio',
234 license='BSD',
235 package_dir={'': '.'},
236 packages=['rasterio', 'rasterio.rio', 'rasterio.tools'],
237 entry_points='''
238 [console_scripts]
239 rio=rasterio.rio.main:main_group
240
241 [rasterio.rio_commands]
242 bounds=rasterio.rio.bounds:bounds
243 calc=rasterio.rio.calc:calc
244 clip=rasterio.rio.clip:clip
245 convert=rasterio.rio.convert:convert
246 edit-info=rasterio.rio.edit_info:edit
247 env=rasterio.rio.env:env
248 info=rasterio.rio.info:info
249 insp=rasterio.rio.insp:insp
250 mask=rasterio.rio.mask:mask
251 merge=rasterio.rio.merge:merge
252 overview=rasterio.rio.overview:overview
253 rasterize=rasterio.rio.rasterize:rasterize
254 sample=rasterio.rio.sample:sample
255 shapes=rasterio.rio.shapes:shapes
256 stack=rasterio.rio.stack:stack
257 warp=rasterio.rio.warp:warp
258 transform=rasterio.rio.transform:transform
259 ''',
260 include_package_data=True,
261 ext_modules=ext_modules,
262 zip_safe=False,
263 install_requires=inst_reqs,
264 extras_require={
265 'ipython': ['ipython>=2.0'],
266 's3': ['boto3'],
267 'test': ['boto3', 'packaging']})
268
269 if os.environ.get('PACKAGE_DATA'):
270 setup_args['package_data'] = {'rasterio': ['gdal_data/*', 'proj_data/*']}
271
272 setup(**setup_args)
273
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -74,7 +74,8 @@
library_dirs = []
libraries = []
extra_link_args = []
-gdal_output = [None]*3
+gdal2plus = False
+gdal_output = [None]*4
try:
import numpy
@@ -85,7 +86,7 @@
try:
gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')
- for i, flag in enumerate(("--cflags", "--libs", "--datadir")):
+ for i, flag in enumerate(("--cflags", "--libs", "--datadir", "--version")):
gdal_output[i] = check_output([gdal_config, flag]).strip()
for item in gdal_output[0].split():
@@ -99,6 +100,9 @@
else:
# e.g. -framework GDAL
extra_link_args.append(item)
+ # datadir, gdal_output[2] handled below
+ for item in gdal_output[3].split():
+ gdal2plus = not item.startswith("1.")
except Exception as e:
if os.name == "nt":
@@ -148,6 +152,14 @@
log.debug('ext_options:\n%s', pprint.pformat(ext_options))
+if gdal2plus:
+ # GDAL>=2.0 does not require vendorized rasterfill.cpp
+ cython_fill = ['rasterio/_fill.pyx']
+ sdist_fill = ['rasterio/_fill.cpp']
+else:
+ cython_fill = ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp']
+ sdist_fill = ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp']
+
# When building from a repo, Cython is required.
if os.path.exists("MANIFEST.in") and "clean" not in sys.argv:
log.info("MANIFEST.in found, presume a repo, cythonizing...")
@@ -170,7 +182,7 @@
Extension(
'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),
Extension(
- 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),
+ 'rasterio._fill', cython_fill, **ext_options),
Extension(
'rasterio._err', ['rasterio/_err.pyx'], **ext_options),
Extension(
@@ -193,12 +205,11 @@
Extension(
'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),
Extension(
- 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),
+ 'rasterio._fill', sdist_fill, **ext_options),
Extension(
'rasterio._err', ['rasterio/_err.c'], **ext_options),
Extension(
- 'rasterio._example', ['rasterio/_example.c'], **ext_options),
- ]
+ 'rasterio._example', ['rasterio/_example.c'], **ext_options)]
with open('README.rst') as f:
readme = f.read()
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -74,7 +74,8 @@\n library_dirs = []\n libraries = []\n extra_link_args = []\n-gdal_output = [None]*3\n+gdal2plus = False\n+gdal_output = [None]*4\n \n try:\n import numpy\n@@ -85,7 +86,7 @@\n \n try:\n gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')\n- for i, flag in enumerate((\"--cflags\", \"--libs\", \"--datadir\")):\n+ for i, flag in enumerate((\"--cflags\", \"--libs\", \"--datadir\", \"--version\")):\n gdal_output[i] = check_output([gdal_config, flag]).strip()\n \n for item in gdal_output[0].split():\n@@ -99,6 +100,9 @@\n else:\n # e.g. -framework GDAL\n extra_link_args.append(item)\n+ # datadir, gdal_output[2] handled below\n+ for item in gdal_output[3].split():\n+ gdal2plus = not item.startswith(\"1.\")\n \n except Exception as e:\n if os.name == \"nt\":\n@@ -148,6 +152,14 @@\n \n log.debug('ext_options:\\n%s', pprint.pformat(ext_options))\n \n+if gdal2plus:\n+ # GDAL>=2.0 does not require vendorized rasterfill.cpp\n+ cython_fill = ['rasterio/_fill.pyx']\n+ sdist_fill = ['rasterio/_fill.cpp']\n+else:\n+ cython_fill = ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp']\n+ sdist_fill = ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp']\n+\n # When building from a repo, Cython is required.\n if os.path.exists(\"MANIFEST.in\") and \"clean\" not in sys.argv:\n log.info(\"MANIFEST.in found, presume a repo, cythonizing...\")\n@@ -170,7 +182,7 @@\n Extension(\n 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),\n Extension(\n- 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),\n+ 'rasterio._fill', cython_fill, **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),\n Extension(\n@@ -193,12 +205,11 @@\n Extension(\n 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),\n Extension(\n- 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),\n+ 'rasterio._fill', sdist_fill, **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.c'], **ext_options),\n Extension(\n- 'rasterio._example', ['rasterio/_example.c'], **ext_options),\n- ]\n+ 'rasterio._example', ['rasterio/_example.c'], **ext_options)]\n \n with open('README.rst') as f:\n readme = f.read()\n", "issue": "Skip local rasterfill.cpp for GDAL >= 2.0\nOur local rasterfill.cpp (see #253) is in GDAL 2.+: https://github.com/OSGeo/gdal/pull/47.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Two environmental variables influence this script.\n#\n# GDAL_CONFIG: the path to a gdal-config program that points to GDAL headers,\n# libraries, and data files.\n#\n# PACKAGE_DATA: if defined, GDAL and PROJ4 data files will be copied into the\n# source or binary distribution. This is essential when creating self-contained\n# binary wheels.\n\nimport logging\nimport os\nimport pprint\nimport shutil\nimport subprocess\nimport sys\n\nfrom setuptools import setup\nfrom setuptools.extension import Extension\n\n\nlogging.basicConfig()\nlog = logging.getLogger()\n\n\ndef check_output(cmd):\n # since subprocess.check_output doesn't exist in 2.6\n # we wrap it here.\n try:\n out = subprocess.check_output(cmd)\n return out.decode('utf')\n except AttributeError:\n # For some reasone check_output doesn't exist\n # So fall back on Popen\n p = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n out, err = p.communicate()\n return out\n\n\ndef copy_data_tree(datadir, destdir):\n try:\n shutil.rmtree(destdir)\n except OSError:\n pass\n shutil.copytree(datadir, destdir)\n\n\n# python -W all setup.py ...\nif 'all' in sys.warnoptions:\n log.level = logging.DEBUG\n\n# Parse the version from the rasterio module.\nwith open('rasterio/__init__.py') as f:\n for line in f:\n if line.find(\"__version__\") >= 0:\n version = line.split(\"=\")[1].strip()\n version = version.strip('\"')\n version = version.strip(\"'\")\n continue\n\nwith open('VERSION.txt', 'w') as f:\n f.write(version)\n\n# Use Cython if available.\ntry:\n from Cython.Build import cythonize\nexcept ImportError:\n cythonize = None\n\n# By default we'll try to get options via gdal-config. On systems without,\n# options will need to be set in setup.cfg or on the setup command line.\ninclude_dirs = []\nlibrary_dirs = []\nlibraries = []\nextra_link_args = []\ngdal_output = [None]*3\n\ntry:\n import numpy\n include_dirs.append(numpy.get_include())\nexcept ImportError:\n log.critical(\"Numpy and its headers are required to run setup(). Exiting.\")\n sys.exit(1)\n\ntry:\n gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')\n for i, flag in enumerate((\"--cflags\", \"--libs\", \"--datadir\")):\n gdal_output[i] = check_output([gdal_config, flag]).strip()\n\n for item in gdal_output[0].split():\n if item.startswith(\"-I\"):\n include_dirs.extend(item[2:].split(\":\"))\n for item in gdal_output[1].split():\n if item.startswith(\"-L\"):\n library_dirs.extend(item[2:].split(\":\"))\n elif item.startswith(\"-l\"):\n libraries.append(item[2:])\n else:\n # e.g. -framework GDAL\n extra_link_args.append(item)\n\nexcept Exception as e:\n if os.name == \"nt\":\n log.info((\"Building on Windows requires extra options to setup.py to locate needed GDAL files.\\n\"\n \"More information is available in the README.\"))\n else:\n log.warning(\"Failed to get options via gdal-config: %s\", str(e))\n\n\n# Conditionally copy the GDAL data. To be used in conjunction with\n# the bdist_wheel command to make self-contained binary wheels.\nif os.environ.get('PACKAGE_DATA'):\n destdir = 'rasterio/gdal_data'\n if gdal_output[2]:\n log.info(\"Copying gdal data from %s\" % gdal_output[2])\n copy_data_tree(gdal_output[2], destdir)\n else:\n # check to see if GDAL_DATA is defined\n gdal_data = os.environ.get('GDAL_DATA', None)\n if gdal_data:\n log.info(\"Copying gdal_data from %s\" % gdal_data)\n copy_data_tree(gdal_data, destdir)\n\n # Conditionally copy PROJ.4 data.\n projdatadir = os.environ.get('PROJ_LIB', '/usr/local/share/proj')\n if os.path.exists(projdatadir):\n log.info(\"Copying proj_data from %s\" % projdatadir)\n copy_data_tree(projdatadir, 'rasterio/proj_data')\n\next_options = dict(\n include_dirs=include_dirs,\n library_dirs=library_dirs,\n libraries=libraries,\n extra_link_args=extra_link_args)\n\nif not os.name == \"nt\":\n # These options fail on Windows if using Visual Studio\n ext_options['extra_compile_args'] = ['-Wno-unused-parameter',\n '-Wno-unused-function']\n\ncythonize_options = {}\nif os.environ.get('CYTHON_COVERAGE'):\n cythonize_options['compiler_directives'] = {'linetrace': True}\n cythonize_options['annotate'] = True\n ext_options['define_macros'] = [('CYTHON_TRACE', '1'),\n ('CYTHON_TRACE_NOGIL', '1')]\n\nlog.debug('ext_options:\\n%s', pprint.pformat(ext_options))\n\n# When building from a repo, Cython is required.\nif os.path.exists(\"MANIFEST.in\") and \"clean\" not in sys.argv:\n log.info(\"MANIFEST.in found, presume a repo, cythonizing...\")\n if not cythonize:\n log.critical(\n \"Cython.Build.cythonize not found. \"\n \"Cython is required to build from a repo.\")\n sys.exit(1)\n ext_modules = cythonize([\n Extension(\n 'rasterio._base', ['rasterio/_base.pyx'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.pyx'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.pyx'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.pyx'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.pyx'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),\n Extension(\n 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),\n ], quiet=True, **cythonize_options)\n\n# If there's no manifest template, as in an sdist, we just specify .c files.\nelse:\n ext_modules = [\n Extension(\n 'rasterio._base', ['rasterio/_base.c'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.c'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.c'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.c'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.c'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),\n Extension(\n 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.c'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.c'], **ext_options),\n ]\n\nwith open('README.rst') as f:\n readme = f.read()\n\n# Runtime requirements.\ninst_reqs = ['affine', 'cligj', 'numpy', 'snuggs', 'click-plugins']\n\nif sys.version_info < (3, 4):\n inst_reqs.append('enum34')\n\nsetup_args = dict(\n name='rasterio',\n version=version,\n description=\"Fast and direct raster I/O for use with Numpy and SciPy\",\n long_description=readme,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: Multimedia :: Graphics :: Graphics Conversion',\n 'Topic :: Scientific/Engineering :: GIS'],\n keywords='raster gdal',\n author='Sean Gillies',\n author_email='[email protected]',\n url='https://github.com/mapbox/rasterio',\n license='BSD',\n package_dir={'': '.'},\n packages=['rasterio', 'rasterio.rio', 'rasterio.tools'],\n entry_points='''\n [console_scripts]\n rio=rasterio.rio.main:main_group\n\n [rasterio.rio_commands]\n bounds=rasterio.rio.bounds:bounds\n calc=rasterio.rio.calc:calc\n clip=rasterio.rio.clip:clip\n convert=rasterio.rio.convert:convert\n edit-info=rasterio.rio.edit_info:edit\n env=rasterio.rio.env:env\n info=rasterio.rio.info:info\n insp=rasterio.rio.insp:insp\n mask=rasterio.rio.mask:mask\n merge=rasterio.rio.merge:merge\n overview=rasterio.rio.overview:overview\n rasterize=rasterio.rio.rasterize:rasterize\n sample=rasterio.rio.sample:sample\n shapes=rasterio.rio.shapes:shapes\n stack=rasterio.rio.stack:stack\n warp=rasterio.rio.warp:warp\n transform=rasterio.rio.transform:transform\n ''',\n include_package_data=True,\n ext_modules=ext_modules,\n zip_safe=False,\n install_requires=inst_reqs,\n extras_require={\n 'ipython': ['ipython>=2.0'],\n 's3': ['boto3'],\n 'test': ['boto3', 'packaging']})\n\nif os.environ.get('PACKAGE_DATA'):\n setup_args['package_data'] = {'rasterio': ['gdal_data/*', 'proj_data/*']}\n\nsetup(**setup_args)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# Two environmental variables influence this script.\n#\n# GDAL_CONFIG: the path to a gdal-config program that points to GDAL headers,\n# libraries, and data files.\n#\n# PACKAGE_DATA: if defined, GDAL and PROJ4 data files will be copied into the\n# source or binary distribution. This is essential when creating self-contained\n# binary wheels.\n\nimport logging\nimport os\nimport pprint\nimport shutil\nimport subprocess\nimport sys\n\nfrom setuptools import setup\nfrom setuptools.extension import Extension\n\n\nlogging.basicConfig()\nlog = logging.getLogger()\n\n\ndef check_output(cmd):\n # since subprocess.check_output doesn't exist in 2.6\n # we wrap it here.\n try:\n out = subprocess.check_output(cmd)\n return out.decode('utf')\n except AttributeError:\n # For some reasone check_output doesn't exist\n # So fall back on Popen\n p = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n out, err = p.communicate()\n return out\n\n\ndef copy_data_tree(datadir, destdir):\n try:\n shutil.rmtree(destdir)\n except OSError:\n pass\n shutil.copytree(datadir, destdir)\n\n\n# python -W all setup.py ...\nif 'all' in sys.warnoptions:\n log.level = logging.DEBUG\n\n# Parse the version from the rasterio module.\nwith open('rasterio/__init__.py') as f:\n for line in f:\n if line.find(\"__version__\") >= 0:\n version = line.split(\"=\")[1].strip()\n version = version.strip('\"')\n version = version.strip(\"'\")\n continue\n\nwith open('VERSION.txt', 'w') as f:\n f.write(version)\n\n# Use Cython if available.\ntry:\n from Cython.Build import cythonize\nexcept ImportError:\n cythonize = None\n\n# By default we'll try to get options via gdal-config. On systems without,\n# options will need to be set in setup.cfg or on the setup command line.\ninclude_dirs = []\nlibrary_dirs = []\nlibraries = []\nextra_link_args = []\ngdal2plus = False\ngdal_output = [None]*4\n\ntry:\n import numpy\n include_dirs.append(numpy.get_include())\nexcept ImportError:\n log.critical(\"Numpy and its headers are required to run setup(). Exiting.\")\n sys.exit(1)\n\ntry:\n gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')\n for i, flag in enumerate((\"--cflags\", \"--libs\", \"--datadir\", \"--version\")):\n gdal_output[i] = check_output([gdal_config, flag]).strip()\n\n for item in gdal_output[0].split():\n if item.startswith(\"-I\"):\n include_dirs.extend(item[2:].split(\":\"))\n for item in gdal_output[1].split():\n if item.startswith(\"-L\"):\n library_dirs.extend(item[2:].split(\":\"))\n elif item.startswith(\"-l\"):\n libraries.append(item[2:])\n else:\n # e.g. -framework GDAL\n extra_link_args.append(item)\n # datadir, gdal_output[2] handled below\n for item in gdal_output[3].split():\n gdal2plus = not item.startswith(\"1.\")\n\nexcept Exception as e:\n if os.name == \"nt\":\n log.info((\"Building on Windows requires extra options to setup.py to locate needed GDAL files.\\n\"\n \"More information is available in the README.\"))\n else:\n log.warning(\"Failed to get options via gdal-config: %s\", str(e))\n\n\n# Conditionally copy the GDAL data. To be used in conjunction with\n# the bdist_wheel command to make self-contained binary wheels.\nif os.environ.get('PACKAGE_DATA'):\n destdir = 'rasterio/gdal_data'\n if gdal_output[2]:\n log.info(\"Copying gdal data from %s\" % gdal_output[2])\n copy_data_tree(gdal_output[2], destdir)\n else:\n # check to see if GDAL_DATA is defined\n gdal_data = os.environ.get('GDAL_DATA', None)\n if gdal_data:\n log.info(\"Copying gdal_data from %s\" % gdal_data)\n copy_data_tree(gdal_data, destdir)\n\n # Conditionally copy PROJ.4 data.\n projdatadir = os.environ.get('PROJ_LIB', '/usr/local/share/proj')\n if os.path.exists(projdatadir):\n log.info(\"Copying proj_data from %s\" % projdatadir)\n copy_data_tree(projdatadir, 'rasterio/proj_data')\n\next_options = dict(\n include_dirs=include_dirs,\n library_dirs=library_dirs,\n libraries=libraries,\n extra_link_args=extra_link_args)\n\nif not os.name == \"nt\":\n # These options fail on Windows if using Visual Studio\n ext_options['extra_compile_args'] = ['-Wno-unused-parameter',\n '-Wno-unused-function']\n\ncythonize_options = {}\nif os.environ.get('CYTHON_COVERAGE'):\n cythonize_options['compiler_directives'] = {'linetrace': True}\n cythonize_options['annotate'] = True\n ext_options['define_macros'] = [('CYTHON_TRACE', '1'),\n ('CYTHON_TRACE_NOGIL', '1')]\n\nlog.debug('ext_options:\\n%s', pprint.pformat(ext_options))\n\nif gdal2plus:\n # GDAL>=2.0 does not require vendorized rasterfill.cpp\n cython_fill = ['rasterio/_fill.pyx']\n sdist_fill = ['rasterio/_fill.cpp']\nelse:\n cython_fill = ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp']\n sdist_fill = ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp']\n\n# When building from a repo, Cython is required.\nif os.path.exists(\"MANIFEST.in\") and \"clean\" not in sys.argv:\n log.info(\"MANIFEST.in found, presume a repo, cythonizing...\")\n if not cythonize:\n log.critical(\n \"Cython.Build.cythonize not found. \"\n \"Cython is required to build from a repo.\")\n sys.exit(1)\n ext_modules = cythonize([\n Extension(\n 'rasterio._base', ['rasterio/_base.pyx'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.pyx'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.pyx'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.pyx'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.pyx'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),\n Extension(\n 'rasterio._fill', cython_fill, **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),\n ], quiet=True, **cythonize_options)\n\n# If there's no manifest template, as in an sdist, we just specify .c files.\nelse:\n ext_modules = [\n Extension(\n 'rasterio._base', ['rasterio/_base.c'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.c'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.c'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.c'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.c'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),\n Extension(\n 'rasterio._fill', sdist_fill, **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.c'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.c'], **ext_options)]\n\nwith open('README.rst') as f:\n readme = f.read()\n\n# Runtime requirements.\ninst_reqs = ['affine', 'cligj', 'numpy', 'snuggs', 'click-plugins']\n\nif sys.version_info < (3, 4):\n inst_reqs.append('enum34')\n\nsetup_args = dict(\n name='rasterio',\n version=version,\n description=\"Fast and direct raster I/O for use with Numpy and SciPy\",\n long_description=readme,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: Multimedia :: Graphics :: Graphics Conversion',\n 'Topic :: Scientific/Engineering :: GIS'],\n keywords='raster gdal',\n author='Sean Gillies',\n author_email='[email protected]',\n url='https://github.com/mapbox/rasterio',\n license='BSD',\n package_dir={'': '.'},\n packages=['rasterio', 'rasterio.rio', 'rasterio.tools'],\n entry_points='''\n [console_scripts]\n rio=rasterio.rio.main:main_group\n\n [rasterio.rio_commands]\n bounds=rasterio.rio.bounds:bounds\n calc=rasterio.rio.calc:calc\n clip=rasterio.rio.clip:clip\n convert=rasterio.rio.convert:convert\n edit-info=rasterio.rio.edit_info:edit\n env=rasterio.rio.env:env\n info=rasterio.rio.info:info\n insp=rasterio.rio.insp:insp\n mask=rasterio.rio.mask:mask\n merge=rasterio.rio.merge:merge\n overview=rasterio.rio.overview:overview\n rasterize=rasterio.rio.rasterize:rasterize\n sample=rasterio.rio.sample:sample\n shapes=rasterio.rio.shapes:shapes\n stack=rasterio.rio.stack:stack\n warp=rasterio.rio.warp:warp\n transform=rasterio.rio.transform:transform\n ''',\n include_package_data=True,\n ext_modules=ext_modules,\n zip_safe=False,\n install_requires=inst_reqs,\n extras_require={\n 'ipython': ['ipython>=2.0'],\n 's3': ['boto3'],\n 'test': ['boto3', 'packaging']})\n\nif os.environ.get('PACKAGE_DATA'):\n setup_args['package_data'] = {'rasterio': ['gdal_data/*', 'proj_data/*']}\n\nsetup(**setup_args)\n", "path": "setup.py"}]} | 3,379 | 755 |
gh_patches_debug_39320 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-3323 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider woods_coffee is broken
During the global build at 2021-10-20-14-42-48, spider **woods_coffee** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/logs/woods_coffee.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/output/woods_coffee.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/output/woods_coffee.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/woods_coffee.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from locations.items import GeojsonPointItem
4 import re
5
6 daysKey = {
7 'MONDAY': 'Mo', 'TUESDAY': 'Tu', 'WEDNESDAY': 'We', 'THURSDAY': 'Th',
8 'FRIDAY': 'Fr', 'SATURDAY': 'Sa', 'SUNDAY': 'Su'
9 }
10
11 class WoodsCoffeeSpider(scrapy.Spider):
12 name = "woods_coffee"
13 item_attributes = { 'brand': "Woods Coffee" }
14 allowed_domains = ["www.woodscoffee.com"]
15 start_urls = (
16 'https://woodscoffee.com/locations/',
17 )
18
19 def store_hours(self, hours):
20 hours = hours.replace('–','-')
21 hours = hours.replace(u'\xa0', u' ')
22 days = hours.split(': ')[0].strip()
23
24 if('-' in days):
25 startDay = daysKey[days.split('-')[0]]
26 endDay = daysKey[days.split('-')[1]]
27 dayOutput = startDay + "-" + endDay
28 else:
29 if('DAILY' in days):
30 startDay='Mo'
31 endDay='Su'
32 dayOutput = startDay + "-" + endDay
33 else:
34 dayOutput = daysKey[days]
35
36 bothHours = hours.split(': ')[1].replace(' ','')
37 openHours = bothHours.split("-")[0]
38 closeHours = bothHours.split("-")[1]
39
40 if("AM" in openHours):
41 openHours = openHours.replace("AM","")
42 if(":" in openHours):
43 openH = openHours.split(":")[0]
44 openM = openHours.split(":")[1]
45 else:
46 openH = openHours
47 openM = "00"
48 openHours = openH + ":" + openM
49
50 if("PM" in openHours):
51 openHours = openHours.replace("PM","")
52 if(":" in openHours):
53 openH = openHours.split(":")[0]
54 openM = openHours.split(":")[1]
55 else:
56 openH = openHours
57 openM = "00"
58 openH = str(int(openH) + 12)
59 openHours = openH + ":" + openM
60
61 if("AM" in closeHours):
62 closeHours = closeHours.replace("AM","")
63 if(":" in closeHours):
64 closeH = closeHours.split(":")[0]
65 closeM = closeHours.split(":")[1]
66 else:
67 closeH = closeHours
68 closeM = "00"
69 closeHours = closeH + ":" + closeM
70
71 if("PM" in closeHours):
72 closeHours = closeHours.replace("PM","")
73 if(":" in closeHours):
74 closeH = closeHours.split(":")[0]
75 closeM = closeHours.split(":")[1]
76 else:
77 closeH = closeHours
78 closeM = "00"
79 closeH = str(int(closeH) + 12)
80 closeHours = closeH + ":" + closeM
81
82 return dayOutput +' '+ openHours.replace(' ','') + "-" + closeHours + ';'
83
84 def parse(self, response):
85 for match in response.xpath("//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div"):
86 cityState = match.xpath(".//div[contains(@class,'heading-text el-text')]/div/p/text()").extract_first();
87 cityString = cityState.split(",")[0].strip()
88 stateString = cityState.split(",")[1].strip()
89
90 addressString = match.xpath(".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not(.//strong)]/text()").extract_first().strip()
91 postcodeString = addressString.split(stateString)[1].strip()
92 addressString = addressString.split(stateString)[0].replace(',','').strip().strip(cityString).strip()
93
94
95 if(match.xpath(".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()").extract_first() is None):
96 phoneString = ""
97 else:
98 phoneString = match.xpath(".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()").extract_first()
99 phoneString = phoneString.replace(' ','').strip()
100
101 hoursString = ""
102 for hoursMatch in match.xpath(".//p[contains(@style,'text-align: center;')]/strong//following-sibling::text()"):
103 hoursString = hoursString +' '+self.store_hours(hoursMatch.extract().replace('\n',''))
104 hoursString = hoursString.strip(';').strip()
105
106 yield GeojsonPointItem(
107 ref=match.xpath(".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()").extract_first(),
108 addr_full=addressString,
109 city=cityString,
110 state=stateString,
111 postcode=postcodeString,
112 phone=phoneString,
113 opening_hours=hoursString,
114 website=match.xpath(".//a/@href").extract_first(),
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/locations/spiders/woods_coffee.py b/locations/spiders/woods_coffee.py
--- a/locations/spiders/woods_coffee.py
+++ b/locations/spiders/woods_coffee.py
@@ -1,16 +1,17 @@
# -*- coding: utf-8 -*-
import scrapy
+
from locations.items import GeojsonPointItem
-import re
daysKey = {
'MONDAY': 'Mo', 'TUESDAY': 'Tu', 'WEDNESDAY': 'We', 'THURSDAY': 'Th',
'FRIDAY': 'Fr', 'SATURDAY': 'Sa', 'SUNDAY': 'Su'
}
+
class WoodsCoffeeSpider(scrapy.Spider):
name = "woods_coffee"
- item_attributes = { 'brand': "Woods Coffee" }
+ item_attributes = {'brand': "Woods Coffee", "brand_wikidata": "Q8033255"}
allowed_domains = ["www.woodscoffee.com"]
start_urls = (
'https://woodscoffee.com/locations/',
@@ -82,8 +83,8 @@
return dayOutput +' '+ openHours.replace(' ','') + "-" + closeHours + ';'
def parse(self, response):
- for match in response.xpath("//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div"):
- cityState = match.xpath(".//div[contains(@class,'heading-text el-text')]/div/p/text()").extract_first();
+ for match in response.xpath("//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div/parent::div"):
+ cityState = match.xpath(".//div[contains(@class,'heading-text el-text')]/div/p/text()").extract_first()
cityString = cityState.split(",")[0].strip()
stateString = cityState.split(",")[1].strip()
@@ -103,13 +104,17 @@
hoursString = hoursString +' '+self.store_hours(hoursMatch.extract().replace('\n',''))
hoursString = hoursString.strip(';').strip()
+ name = match.xpath(".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()").extract_first()
+
yield GeojsonPointItem(
- ref=match.xpath(".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()").extract_first(),
+ ref=name,
+ name=name,
addr_full=addressString,
city=cityString,
state=stateString,
postcode=postcodeString,
+ country="USA",
phone=phoneString,
opening_hours=hoursString,
- website=match.xpath(".//a/@href").extract_first(),
+ website=response.urljoin(match.xpath(".//a/@href").extract_first()),
)
| {"golden_diff": "diff --git a/locations/spiders/woods_coffee.py b/locations/spiders/woods_coffee.py\n--- a/locations/spiders/woods_coffee.py\n+++ b/locations/spiders/woods_coffee.py\n@@ -1,16 +1,17 @@\n # -*- coding: utf-8 -*-\n import scrapy\n+\n from locations.items import GeojsonPointItem\n-import re\n \n daysKey = {\n 'MONDAY': 'Mo', 'TUESDAY': 'Tu', 'WEDNESDAY': 'We', 'THURSDAY': 'Th',\n 'FRIDAY': 'Fr', 'SATURDAY': 'Sa', 'SUNDAY': 'Su'\n }\n \n+\n class WoodsCoffeeSpider(scrapy.Spider):\n name = \"woods_coffee\"\n- item_attributes = { 'brand': \"Woods Coffee\" }\n+ item_attributes = {'brand': \"Woods Coffee\", \"brand_wikidata\": \"Q8033255\"}\n allowed_domains = [\"www.woodscoffee.com\"]\n start_urls = (\n 'https://woodscoffee.com/locations/',\n@@ -82,8 +83,8 @@\n return dayOutput +' '+ openHours.replace(' ','') + \"-\" + closeHours + ';'\n \n def parse(self, response):\n- for match in response.xpath(\"//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div\"):\n- cityState = match.xpath(\".//div[contains(@class,'heading-text el-text')]/div/p/text()\").extract_first();\n+ for match in response.xpath(\"//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div/parent::div\"):\n+ cityState = match.xpath(\".//div[contains(@class,'heading-text el-text')]/div/p/text()\").extract_first()\n cityString = cityState.split(\",\")[0].strip()\n stateString = cityState.split(\",\")[1].strip()\n \n@@ -103,13 +104,17 @@\n hoursString = hoursString +' '+self.store_hours(hoursMatch.extract().replace('\\n',''))\n hoursString = hoursString.strip(';').strip()\n \n+ name = match.xpath(\".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()\").extract_first()\n+\n yield GeojsonPointItem(\n- ref=match.xpath(\".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()\").extract_first(),\n+ ref=name,\n+ name=name,\n addr_full=addressString,\n city=cityString,\n state=stateString,\n postcode=postcodeString,\n+ country=\"USA\",\n phone=phoneString,\n opening_hours=hoursString,\n- website=match.xpath(\".//a/@href\").extract_first(),\n+ website=response.urljoin(match.xpath(\".//a/@href\").extract_first()),\n )\n", "issue": "Spider woods_coffee is broken\nDuring the global build at 2021-10-20-14-42-48, spider **woods_coffee** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/logs/woods_coffee.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/output/woods_coffee.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-20-14-42-48/output/woods_coffee.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom locations.items import GeojsonPointItem\nimport re\n\ndaysKey = {\n 'MONDAY': 'Mo', 'TUESDAY': 'Tu', 'WEDNESDAY': 'We', 'THURSDAY': 'Th',\n 'FRIDAY': 'Fr', 'SATURDAY': 'Sa', 'SUNDAY': 'Su'\n}\n\nclass WoodsCoffeeSpider(scrapy.Spider):\n name = \"woods_coffee\"\n item_attributes = { 'brand': \"Woods Coffee\" }\n allowed_domains = [\"www.woodscoffee.com\"]\n start_urls = (\n 'https://woodscoffee.com/locations/',\n )\n\n def store_hours(self, hours):\n hours = hours.replace('\u2013','-')\n hours = hours.replace(u'\\xa0', u' ')\n days = hours.split(': ')[0].strip()\n\n if('-' in days):\n startDay = daysKey[days.split('-')[0]]\n endDay = daysKey[days.split('-')[1]]\n dayOutput = startDay + \"-\" + endDay\n else:\n if('DAILY' in days):\n startDay='Mo'\n endDay='Su'\n dayOutput = startDay + \"-\" + endDay\n else:\n dayOutput = daysKey[days]\n\n bothHours = hours.split(': ')[1].replace(' ','')\n openHours = bothHours.split(\"-\")[0]\n closeHours = bothHours.split(\"-\")[1]\n\n if(\"AM\" in openHours):\n openHours = openHours.replace(\"AM\",\"\")\n if(\":\" in openHours):\n openH = openHours.split(\":\")[0]\n openM = openHours.split(\":\")[1]\n else:\n openH = openHours\n openM = \"00\"\n openHours = openH + \":\" + openM\n\n if(\"PM\" in openHours):\n openHours = openHours.replace(\"PM\",\"\")\n if(\":\" in openHours):\n openH = openHours.split(\":\")[0]\n openM = openHours.split(\":\")[1]\n else:\n openH = openHours\n openM = \"00\"\n openH = str(int(openH) + 12)\n openHours = openH + \":\" + openM\n\n if(\"AM\" in closeHours):\n closeHours = closeHours.replace(\"AM\",\"\")\n if(\":\" in closeHours):\n closeH = closeHours.split(\":\")[0]\n closeM = closeHours.split(\":\")[1]\n else:\n closeH = closeHours\n closeM = \"00\"\n closeHours = closeH + \":\" + closeM\n\n if(\"PM\" in closeHours):\n closeHours = closeHours.replace(\"PM\",\"\")\n if(\":\" in closeHours):\n closeH = closeHours.split(\":\")[0]\n closeM = closeHours.split(\":\")[1]\n else:\n closeH = closeHours\n closeM = \"00\"\n closeH = str(int(closeH) + 12)\n closeHours = closeH + \":\" + closeM\n\n return dayOutput +' '+ openHours.replace(' ','') + \"-\" + closeHours + ';'\n\n def parse(self, response):\n for match in response.xpath(\"//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div\"):\n cityState = match.xpath(\".//div[contains(@class,'heading-text el-text')]/div/p/text()\").extract_first();\n cityString = cityState.split(\",\")[0].strip()\n stateString = cityState.split(\",\")[1].strip()\n\n addressString = match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not(.//strong)]/text()\").extract_first().strip()\n postcodeString = addressString.split(stateString)[1].strip()\n addressString = addressString.split(stateString)[0].replace(',','').strip().strip(cityString).strip()\n\n\n if(match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()\").extract_first() is None):\n phoneString = \"\"\n else:\n phoneString = match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()\").extract_first()\n phoneString = phoneString.replace(' ','').strip()\n\n hoursString = \"\"\n for hoursMatch in match.xpath(\".//p[contains(@style,'text-align: center;')]/strong//following-sibling::text()\"):\n hoursString = hoursString +' '+self.store_hours(hoursMatch.extract().replace('\\n',''))\n hoursString = hoursString.strip(';').strip()\n\n yield GeojsonPointItem(\n ref=match.xpath(\".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()\").extract_first(),\n addr_full=addressString,\n city=cityString,\n state=stateString,\n postcode=postcodeString,\n phone=phoneString,\n opening_hours=hoursString,\n website=match.xpath(\".//a/@href\").extract_first(),\n )\n", "path": "locations/spiders/woods_coffee.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\n\ndaysKey = {\n 'MONDAY': 'Mo', 'TUESDAY': 'Tu', 'WEDNESDAY': 'We', 'THURSDAY': 'Th',\n 'FRIDAY': 'Fr', 'SATURDAY': 'Sa', 'SUNDAY': 'Su'\n}\n\n\nclass WoodsCoffeeSpider(scrapy.Spider):\n name = \"woods_coffee\"\n item_attributes = {'brand': \"Woods Coffee\", \"brand_wikidata\": \"Q8033255\"}\n allowed_domains = [\"www.woodscoffee.com\"]\n start_urls = (\n 'https://woodscoffee.com/locations/',\n )\n\n def store_hours(self, hours):\n hours = hours.replace('\u2013','-')\n hours = hours.replace(u'\\xa0', u' ')\n days = hours.split(': ')[0].strip()\n\n if('-' in days):\n startDay = daysKey[days.split('-')[0]]\n endDay = daysKey[days.split('-')[1]]\n dayOutput = startDay + \"-\" + endDay\n else:\n if('DAILY' in days):\n startDay='Mo'\n endDay='Su'\n dayOutput = startDay + \"-\" + endDay\n else:\n dayOutput = daysKey[days]\n\n bothHours = hours.split(': ')[1].replace(' ','')\n openHours = bothHours.split(\"-\")[0]\n closeHours = bothHours.split(\"-\")[1]\n\n if(\"AM\" in openHours):\n openHours = openHours.replace(\"AM\",\"\")\n if(\":\" in openHours):\n openH = openHours.split(\":\")[0]\n openM = openHours.split(\":\")[1]\n else:\n openH = openHours\n openM = \"00\"\n openHours = openH + \":\" + openM\n\n if(\"PM\" in openHours):\n openHours = openHours.replace(\"PM\",\"\")\n if(\":\" in openHours):\n openH = openHours.split(\":\")[0]\n openM = openHours.split(\":\")[1]\n else:\n openH = openHours\n openM = \"00\"\n openH = str(int(openH) + 12)\n openHours = openH + \":\" + openM\n\n if(\"AM\" in closeHours):\n closeHours = closeHours.replace(\"AM\",\"\")\n if(\":\" in closeHours):\n closeH = closeHours.split(\":\")[0]\n closeM = closeHours.split(\":\")[1]\n else:\n closeH = closeHours\n closeM = \"00\"\n closeHours = closeH + \":\" + closeM\n\n if(\"PM\" in closeHours):\n closeHours = closeHours.replace(\"PM\",\"\")\n if(\":\" in closeHours):\n closeH = closeHours.split(\":\")[0]\n closeM = closeHours.split(\":\")[1]\n else:\n closeH = closeHours\n closeM = \"00\"\n closeH = str(int(closeH) + 12)\n closeHours = closeH + \":\" + closeM\n\n return dayOutput +' '+ openHours.replace(' ','') + \"-\" + closeHours + ';'\n\n def parse(self, response):\n for match in response.xpath(\"//h2[contains(@class,'font-weight-700 text-uppercase')]/parent::div/parent::div/parent::div\"):\n cityState = match.xpath(\".//div[contains(@class,'heading-text el-text')]/div/p/text()\").extract_first()\n cityString = cityState.split(\",\")[0].strip()\n stateString = cityState.split(\",\")[1].strip()\n\n addressString = match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not(.//strong)]/text()\").extract_first().strip()\n postcodeString = addressString.split(stateString)[1].strip()\n addressString = addressString.split(stateString)[0].replace(',','').strip().strip(cityString).strip()\n\n\n if(match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()\").extract_first() is None):\n phoneString = \"\"\n else:\n phoneString = match.xpath(\".//div[contains(@class,'uncode_text_column')]/p[contains(@style,'text-align: center;')][not (.//strong)]/br/following-sibling::text()\").extract_first()\n phoneString = phoneString.replace(' ','').strip()\n\n hoursString = \"\"\n for hoursMatch in match.xpath(\".//p[contains(@style,'text-align: center;')]/strong//following-sibling::text()\"):\n hoursString = hoursString +' '+self.store_hours(hoursMatch.extract().replace('\\n',''))\n hoursString = hoursString.strip(';').strip()\n\n name = match.xpath(\".//h2[contains(@class,'font-weight-700 text-uppercase')]/span/text()\").extract_first()\n\n yield GeojsonPointItem(\n ref=name,\n name=name,\n addr_full=addressString,\n city=cityString,\n state=stateString,\n postcode=postcodeString,\n country=\"USA\",\n phone=phoneString,\n opening_hours=hoursString,\n website=response.urljoin(match.xpath(\".//a/@href\").extract_first()),\n )\n", "path": "locations/spiders/woods_coffee.py"}]} | 1,842 | 634 |
gh_patches_debug_18119 | rasdani/github-patches | git_diff | scipy__scipy-8222 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Documentation should discourage odeint
odeint is not the recommended way to solve an IVP, but that's not mentioned in the documentation. I am not suggesting that odeint be removed, but we should discourage users from using it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scipy/integrate/odepack.py`
Content:
```
1 # Author: Travis Oliphant
2 from __future__ import division, print_function, absolute_import
3
4 __all__ = ['odeint']
5
6 from . import _odepack
7 from copy import copy
8 import warnings
9
10 class ODEintWarning(Warning):
11 pass
12
13 _msgs = {2: "Integration successful.",
14 1: "Nothing was done; the integration time was 0.",
15 -1: "Excess work done on this call (perhaps wrong Dfun type).",
16 -2: "Excess accuracy requested (tolerances too small).",
17 -3: "Illegal input detected (internal error).",
18 -4: "Repeated error test failures (internal error).",
19 -5: "Repeated convergence failures (perhaps bad Jacobian or tolerances).",
20 -6: "Error weight became zero during problem.",
21 -7: "Internal workspace insufficient to finish (internal error)."
22 }
23
24
25 def odeint(func, y0, t, args=(), Dfun=None, col_deriv=0, full_output=0,
26 ml=None, mu=None, rtol=None, atol=None, tcrit=None, h0=0.0,
27 hmax=0.0, hmin=0.0, ixpr=0, mxstep=0, mxhnil=0, mxordn=12,
28 mxords=5, printmessg=0):
29 """
30 Integrate a system of ordinary differential equations.
31
32 Solve a system of ordinary differential equations using lsoda from the
33 FORTRAN library odepack.
34
35 Solves the initial value problem for stiff or non-stiff systems
36 of first order ode-s::
37
38 dy/dt = func(y, t, ...)
39
40 where y can be a vector.
41
42 *Note*: The first two arguments of ``func(y, t, ...)`` are in the
43 opposite order of the arguments in the system definition function used
44 by the `scipy.integrate.ode` class.
45
46 Parameters
47 ----------
48 func : callable(y, t, ...)
49 Computes the derivative of y at t.
50 y0 : array
51 Initial condition on y (can be a vector).
52 t : array
53 A sequence of time points for which to solve for y. The initial
54 value point should be the first element of this sequence.
55 args : tuple, optional
56 Extra arguments to pass to function.
57 Dfun : callable(y, t, ...)
58 Gradient (Jacobian) of `func`.
59 col_deriv : bool, optional
60 True if `Dfun` defines derivatives down columns (faster),
61 otherwise `Dfun` should define derivatives across rows.
62 full_output : bool, optional
63 True if to return a dictionary of optional outputs as the second output
64 printmessg : bool, optional
65 Whether to print the convergence message
66
67 Returns
68 -------
69 y : array, shape (len(t), len(y0))
70 Array containing the value of y for each desired time in t,
71 with the initial value `y0` in the first row.
72 infodict : dict, only returned if full_output == True
73 Dictionary containing additional output information
74
75 ======= ============================================================
76 key meaning
77 ======= ============================================================
78 'hu' vector of step sizes successfully used for each time step.
79 'tcur' vector with the value of t reached for each time step.
80 (will always be at least as large as the input times).
81 'tolsf' vector of tolerance scale factors, greater than 1.0,
82 computed when a request for too much accuracy was detected.
83 'tsw' value of t at the time of the last method switch
84 (given for each time step)
85 'nst' cumulative number of time steps
86 'nfe' cumulative number of function evaluations for each time step
87 'nje' cumulative number of jacobian evaluations for each time step
88 'nqu' a vector of method orders for each successful step.
89 'imxer' index of the component of largest magnitude in the
90 weighted local error vector (e / ewt) on an error return, -1
91 otherwise.
92 'lenrw' the length of the double work array required.
93 'leniw' the length of integer work array required.
94 'mused' a vector of method indicators for each successful time step:
95 1: adams (nonstiff), 2: bdf (stiff)
96 ======= ============================================================
97
98 Other Parameters
99 ----------------
100 ml, mu : int, optional
101 If either of these are not None or non-negative, then the
102 Jacobian is assumed to be banded. These give the number of
103 lower and upper non-zero diagonals in this banded matrix.
104 For the banded case, `Dfun` should return a matrix whose
105 rows contain the non-zero bands (starting with the lowest diagonal).
106 Thus, the return matrix `jac` from `Dfun` should have shape
107 ``(ml + mu + 1, len(y0))`` when ``ml >=0`` or ``mu >=0``.
108 The data in `jac` must be stored such that ``jac[i - j + mu, j]``
109 holds the derivative of the `i`th equation with respect to the `j`th
110 state variable. If `col_deriv` is True, the transpose of this
111 `jac` must be returned.
112 rtol, atol : float, optional
113 The input parameters `rtol` and `atol` determine the error
114 control performed by the solver. The solver will control the
115 vector, e, of estimated local errors in y, according to an
116 inequality of the form ``max-norm of (e / ewt) <= 1``,
117 where ewt is a vector of positive error weights computed as
118 ``ewt = rtol * abs(y) + atol``.
119 rtol and atol can be either vectors the same length as y or scalars.
120 Defaults to 1.49012e-8.
121 tcrit : ndarray, optional
122 Vector of critical points (e.g. singularities) where integration
123 care should be taken.
124 h0 : float, (0: solver-determined), optional
125 The step size to be attempted on the first step.
126 hmax : float, (0: solver-determined), optional
127 The maximum absolute step size allowed.
128 hmin : float, (0: solver-determined), optional
129 The minimum absolute step size allowed.
130 ixpr : bool, optional
131 Whether to generate extra printing at method switches.
132 mxstep : int, (0: solver-determined), optional
133 Maximum number of (internally defined) steps allowed for each
134 integration point in t.
135 mxhnil : int, (0: solver-determined), optional
136 Maximum number of messages printed.
137 mxordn : int, (0: solver-determined), optional
138 Maximum order to be allowed for the non-stiff (Adams) method.
139 mxords : int, (0: solver-determined), optional
140 Maximum order to be allowed for the stiff (BDF) method.
141
142 See Also
143 --------
144 ode : a more object-oriented integrator based on VODE.
145 quad : for finding the area under a curve.
146
147 Examples
148 --------
149 The second order differential equation for the angle `theta` of a
150 pendulum acted on by gravity with friction can be written::
151
152 theta''(t) + b*theta'(t) + c*sin(theta(t)) = 0
153
154 where `b` and `c` are positive constants, and a prime (') denotes a
155 derivative. To solve this equation with `odeint`, we must first convert
156 it to a system of first order equations. By defining the angular
157 velocity ``omega(t) = theta'(t)``, we obtain the system::
158
159 theta'(t) = omega(t)
160 omega'(t) = -b*omega(t) - c*sin(theta(t))
161
162 Let `y` be the vector [`theta`, `omega`]. We implement this system
163 in python as:
164
165 >>> def pend(y, t, b, c):
166 ... theta, omega = y
167 ... dydt = [omega, -b*omega - c*np.sin(theta)]
168 ... return dydt
169 ...
170
171 We assume the constants are `b` = 0.25 and `c` = 5.0:
172
173 >>> b = 0.25
174 >>> c = 5.0
175
176 For initial conditions, we assume the pendulum is nearly vertical
177 with `theta(0)` = `pi` - 0.1, and it initially at rest, so
178 `omega(0)` = 0. Then the vector of initial conditions is
179
180 >>> y0 = [np.pi - 0.1, 0.0]
181
182 We generate a solution 101 evenly spaced samples in the interval
183 0 <= `t` <= 10. So our array of times is:
184
185 >>> t = np.linspace(0, 10, 101)
186
187 Call `odeint` to generate the solution. To pass the parameters
188 `b` and `c` to `pend`, we give them to `odeint` using the `args`
189 argument.
190
191 >>> from scipy.integrate import odeint
192 >>> sol = odeint(pend, y0, t, args=(b, c))
193
194 The solution is an array with shape (101, 2). The first column
195 is `theta(t)`, and the second is `omega(t)`. The following code
196 plots both components.
197
198 >>> import matplotlib.pyplot as plt
199 >>> plt.plot(t, sol[:, 0], 'b', label='theta(t)')
200 >>> plt.plot(t, sol[:, 1], 'g', label='omega(t)')
201 >>> plt.legend(loc='best')
202 >>> plt.xlabel('t')
203 >>> plt.grid()
204 >>> plt.show()
205 """
206
207 if ml is None:
208 ml = -1 # changed to zero inside function call
209 if mu is None:
210 mu = -1 # changed to zero inside function call
211 t = copy(t)
212 y0 = copy(y0)
213 output = _odepack.odeint(func, y0, t, args, Dfun, col_deriv, ml, mu,
214 full_output, rtol, atol, tcrit, h0, hmax, hmin,
215 ixpr, mxstep, mxhnil, mxordn, mxords)
216 if output[-1] < 0:
217 warning_msg = _msgs[output[-1]] + " Run with full_output = 1 to get quantitative information."
218 warnings.warn(warning_msg, ODEintWarning)
219 elif printmessg:
220 warning_msg = _msgs[output[-1]]
221 warnings.warn(warning_msg, ODEintWarning)
222
223 if full_output:
224 output[1]['message'] = _msgs[output[-1]]
225
226 output = output[:-1]
227 if len(output) == 1:
228 return output[0]
229 else:
230 return output
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/scipy/integrate/odepack.py b/scipy/integrate/odepack.py
--- a/scipy/integrate/odepack.py
+++ b/scipy/integrate/odepack.py
@@ -28,6 +28,9 @@
mxords=5, printmessg=0):
"""
Integrate a system of ordinary differential equations.
+
+ .. note:: For new code, use `scipy.integrate.solve_ivp` to solve a
+ differential equation.
Solve a system of ordinary differential equations using lsoda from the
FORTRAN library odepack.
@@ -39,9 +42,9 @@
where y can be a vector.
- *Note*: The first two arguments of ``func(y, t, ...)`` are in the
- opposite order of the arguments in the system definition function used
- by the `scipy.integrate.ode` class.
+ .. note:: The first two arguments of ``func(y, t, ...)`` are in the
+ opposite order of the arguments in the system definition
+ function used by the `scipy.integrate.ode` class.
Parameters
----------
| {"golden_diff": "diff --git a/scipy/integrate/odepack.py b/scipy/integrate/odepack.py\n--- a/scipy/integrate/odepack.py\n+++ b/scipy/integrate/odepack.py\n@@ -28,6 +28,9 @@\n mxords=5, printmessg=0):\n \"\"\"\n Integrate a system of ordinary differential equations.\n+ \n+ .. note:: For new code, use `scipy.integrate.solve_ivp` to solve a\n+ differential equation.\n \n Solve a system of ordinary differential equations using lsoda from the\n FORTRAN library odepack.\n@@ -39,9 +42,9 @@\n \n where y can be a vector.\n \n- *Note*: The first two arguments of ``func(y, t, ...)`` are in the\n- opposite order of the arguments in the system definition function used\n- by the `scipy.integrate.ode` class.\n+ .. note:: The first two arguments of ``func(y, t, ...)`` are in the\n+ opposite order of the arguments in the system definition\n+ function used by the `scipy.integrate.ode` class.\n \n Parameters\n ----------\n", "issue": "Documentation should discourage odeint\nodeint is not the recommended way to solve an IVP, but that's not mentioned in the documentation. I am not suggesting that odeint be removed, but we should discourage users from using it.\n", "before_files": [{"content": "# Author: Travis Oliphant\nfrom __future__ import division, print_function, absolute_import\n\n__all__ = ['odeint']\n\nfrom . import _odepack\nfrom copy import copy\nimport warnings\n\nclass ODEintWarning(Warning):\n pass\n\n_msgs = {2: \"Integration successful.\",\n 1: \"Nothing was done; the integration time was 0.\",\n -1: \"Excess work done on this call (perhaps wrong Dfun type).\",\n -2: \"Excess accuracy requested (tolerances too small).\",\n -3: \"Illegal input detected (internal error).\",\n -4: \"Repeated error test failures (internal error).\",\n -5: \"Repeated convergence failures (perhaps bad Jacobian or tolerances).\",\n -6: \"Error weight became zero during problem.\",\n -7: \"Internal workspace insufficient to finish (internal error).\"\n }\n\n\ndef odeint(func, y0, t, args=(), Dfun=None, col_deriv=0, full_output=0,\n ml=None, mu=None, rtol=None, atol=None, tcrit=None, h0=0.0,\n hmax=0.0, hmin=0.0, ixpr=0, mxstep=0, mxhnil=0, mxordn=12,\n mxords=5, printmessg=0):\n \"\"\"\n Integrate a system of ordinary differential equations.\n\n Solve a system of ordinary differential equations using lsoda from the\n FORTRAN library odepack.\n\n Solves the initial value problem for stiff or non-stiff systems\n of first order ode-s::\n\n dy/dt = func(y, t, ...)\n\n where y can be a vector.\n\n *Note*: The first two arguments of ``func(y, t, ...)`` are in the\n opposite order of the arguments in the system definition function used\n by the `scipy.integrate.ode` class.\n\n Parameters\n ----------\n func : callable(y, t, ...)\n Computes the derivative of y at t.\n y0 : array\n Initial condition on y (can be a vector).\n t : array\n A sequence of time points for which to solve for y. The initial\n value point should be the first element of this sequence.\n args : tuple, optional\n Extra arguments to pass to function.\n Dfun : callable(y, t, ...)\n Gradient (Jacobian) of `func`.\n col_deriv : bool, optional\n True if `Dfun` defines derivatives down columns (faster),\n otherwise `Dfun` should define derivatives across rows.\n full_output : bool, optional\n True if to return a dictionary of optional outputs as the second output\n printmessg : bool, optional\n Whether to print the convergence message\n\n Returns\n -------\n y : array, shape (len(t), len(y0))\n Array containing the value of y for each desired time in t,\n with the initial value `y0` in the first row.\n infodict : dict, only returned if full_output == True\n Dictionary containing additional output information\n\n ======= ============================================================\n key meaning\n ======= ============================================================\n 'hu' vector of step sizes successfully used for each time step.\n 'tcur' vector with the value of t reached for each time step.\n (will always be at least as large as the input times).\n 'tolsf' vector of tolerance scale factors, greater than 1.0,\n computed when a request for too much accuracy was detected.\n 'tsw' value of t at the time of the last method switch\n (given for each time step)\n 'nst' cumulative number of time steps\n 'nfe' cumulative number of function evaluations for each time step\n 'nje' cumulative number of jacobian evaluations for each time step\n 'nqu' a vector of method orders for each successful step.\n 'imxer' index of the component of largest magnitude in the\n weighted local error vector (e / ewt) on an error return, -1\n otherwise.\n 'lenrw' the length of the double work array required.\n 'leniw' the length of integer work array required.\n 'mused' a vector of method indicators for each successful time step:\n 1: adams (nonstiff), 2: bdf (stiff)\n ======= ============================================================\n\n Other Parameters\n ----------------\n ml, mu : int, optional\n If either of these are not None or non-negative, then the\n Jacobian is assumed to be banded. These give the number of\n lower and upper non-zero diagonals in this banded matrix.\n For the banded case, `Dfun` should return a matrix whose\n rows contain the non-zero bands (starting with the lowest diagonal).\n Thus, the return matrix `jac` from `Dfun` should have shape\n ``(ml + mu + 1, len(y0))`` when ``ml >=0`` or ``mu >=0``.\n The data in `jac` must be stored such that ``jac[i - j + mu, j]``\n holds the derivative of the `i`th equation with respect to the `j`th\n state variable. If `col_deriv` is True, the transpose of this\n `jac` must be returned.\n rtol, atol : float, optional\n The input parameters `rtol` and `atol` determine the error\n control performed by the solver. The solver will control the\n vector, e, of estimated local errors in y, according to an\n inequality of the form ``max-norm of (e / ewt) <= 1``,\n where ewt is a vector of positive error weights computed as\n ``ewt = rtol * abs(y) + atol``.\n rtol and atol can be either vectors the same length as y or scalars.\n Defaults to 1.49012e-8.\n tcrit : ndarray, optional\n Vector of critical points (e.g. singularities) where integration\n care should be taken.\n h0 : float, (0: solver-determined), optional\n The step size to be attempted on the first step.\n hmax : float, (0: solver-determined), optional\n The maximum absolute step size allowed.\n hmin : float, (0: solver-determined), optional\n The minimum absolute step size allowed.\n ixpr : bool, optional\n Whether to generate extra printing at method switches.\n mxstep : int, (0: solver-determined), optional\n Maximum number of (internally defined) steps allowed for each\n integration point in t.\n mxhnil : int, (0: solver-determined), optional\n Maximum number of messages printed.\n mxordn : int, (0: solver-determined), optional\n Maximum order to be allowed for the non-stiff (Adams) method.\n mxords : int, (0: solver-determined), optional\n Maximum order to be allowed for the stiff (BDF) method.\n\n See Also\n --------\n ode : a more object-oriented integrator based on VODE.\n quad : for finding the area under a curve.\n\n Examples\n --------\n The second order differential equation for the angle `theta` of a\n pendulum acted on by gravity with friction can be written::\n\n theta''(t) + b*theta'(t) + c*sin(theta(t)) = 0\n\n where `b` and `c` are positive constants, and a prime (') denotes a\n derivative. To solve this equation with `odeint`, we must first convert\n it to a system of first order equations. By defining the angular\n velocity ``omega(t) = theta'(t)``, we obtain the system::\n\n theta'(t) = omega(t)\n omega'(t) = -b*omega(t) - c*sin(theta(t))\n\n Let `y` be the vector [`theta`, `omega`]. We implement this system\n in python as:\n\n >>> def pend(y, t, b, c):\n ... theta, omega = y\n ... dydt = [omega, -b*omega - c*np.sin(theta)]\n ... return dydt\n ...\n \n We assume the constants are `b` = 0.25 and `c` = 5.0:\n\n >>> b = 0.25\n >>> c = 5.0\n\n For initial conditions, we assume the pendulum is nearly vertical\n with `theta(0)` = `pi` - 0.1, and it initially at rest, so\n `omega(0)` = 0. Then the vector of initial conditions is\n\n >>> y0 = [np.pi - 0.1, 0.0]\n\n We generate a solution 101 evenly spaced samples in the interval\n 0 <= `t` <= 10. So our array of times is:\n\n >>> t = np.linspace(0, 10, 101)\n\n Call `odeint` to generate the solution. To pass the parameters\n `b` and `c` to `pend`, we give them to `odeint` using the `args`\n argument.\n\n >>> from scipy.integrate import odeint\n >>> sol = odeint(pend, y0, t, args=(b, c))\n\n The solution is an array with shape (101, 2). The first column\n is `theta(t)`, and the second is `omega(t)`. The following code\n plots both components.\n\n >>> import matplotlib.pyplot as plt\n >>> plt.plot(t, sol[:, 0], 'b', label='theta(t)')\n >>> plt.plot(t, sol[:, 1], 'g', label='omega(t)')\n >>> plt.legend(loc='best')\n >>> plt.xlabel('t')\n >>> plt.grid()\n >>> plt.show()\n \"\"\"\n\n if ml is None:\n ml = -1 # changed to zero inside function call\n if mu is None:\n mu = -1 # changed to zero inside function call\n t = copy(t)\n y0 = copy(y0)\n output = _odepack.odeint(func, y0, t, args, Dfun, col_deriv, ml, mu,\n full_output, rtol, atol, tcrit, h0, hmax, hmin,\n ixpr, mxstep, mxhnil, mxordn, mxords)\n if output[-1] < 0:\n warning_msg = _msgs[output[-1]] + \" Run with full_output = 1 to get quantitative information.\"\n warnings.warn(warning_msg, ODEintWarning)\n elif printmessg:\n warning_msg = _msgs[output[-1]]\n warnings.warn(warning_msg, ODEintWarning)\n\n if full_output:\n output[1]['message'] = _msgs[output[-1]]\n\n output = output[:-1]\n if len(output) == 1:\n return output[0]\n else:\n return output\n", "path": "scipy/integrate/odepack.py"}], "after_files": [{"content": "# Author: Travis Oliphant\nfrom __future__ import division, print_function, absolute_import\n\n__all__ = ['odeint']\n\nfrom . import _odepack\nfrom copy import copy\nimport warnings\n\nclass ODEintWarning(Warning):\n pass\n\n_msgs = {2: \"Integration successful.\",\n 1: \"Nothing was done; the integration time was 0.\",\n -1: \"Excess work done on this call (perhaps wrong Dfun type).\",\n -2: \"Excess accuracy requested (tolerances too small).\",\n -3: \"Illegal input detected (internal error).\",\n -4: \"Repeated error test failures (internal error).\",\n -5: \"Repeated convergence failures (perhaps bad Jacobian or tolerances).\",\n -6: \"Error weight became zero during problem.\",\n -7: \"Internal workspace insufficient to finish (internal error).\"\n }\n\n\ndef odeint(func, y0, t, args=(), Dfun=None, col_deriv=0, full_output=0,\n ml=None, mu=None, rtol=None, atol=None, tcrit=None, h0=0.0,\n hmax=0.0, hmin=0.0, ixpr=0, mxstep=0, mxhnil=0, mxordn=12,\n mxords=5, printmessg=0):\n \"\"\"\n Integrate a system of ordinary differential equations.\n \n .. note:: For new code, use `scipy.integrate.solve_ivp` to solve a\n differential equation.\n\n Solve a system of ordinary differential equations using lsoda from the\n FORTRAN library odepack.\n\n Solves the initial value problem for stiff or non-stiff systems\n of first order ode-s::\n\n dy/dt = func(y, t, ...)\n\n where y can be a vector.\n\n .. note:: The first two arguments of ``func(y, t, ...)`` are in the\n opposite order of the arguments in the system definition\n function used by the `scipy.integrate.ode` class.\n\n Parameters\n ----------\n func : callable(y, t, ...)\n Computes the derivative of y at t.\n y0 : array\n Initial condition on y (can be a vector).\n t : array\n A sequence of time points for which to solve for y. The initial\n value point should be the first element of this sequence.\n args : tuple, optional\n Extra arguments to pass to function.\n Dfun : callable(y, t, ...)\n Gradient (Jacobian) of `func`.\n col_deriv : bool, optional\n True if `Dfun` defines derivatives down columns (faster),\n otherwise `Dfun` should define derivatives across rows.\n full_output : bool, optional\n True if to return a dictionary of optional outputs as the second output\n printmessg : bool, optional\n Whether to print the convergence message\n\n Returns\n -------\n y : array, shape (len(t), len(y0))\n Array containing the value of y for each desired time in t,\n with the initial value `y0` in the first row.\n infodict : dict, only returned if full_output == True\n Dictionary containing additional output information\n\n ======= ============================================================\n key meaning\n ======= ============================================================\n 'hu' vector of step sizes successfully used for each time step.\n 'tcur' vector with the value of t reached for each time step.\n (will always be at least as large as the input times).\n 'tolsf' vector of tolerance scale factors, greater than 1.0,\n computed when a request for too much accuracy was detected.\n 'tsw' value of t at the time of the last method switch\n (given for each time step)\n 'nst' cumulative number of time steps\n 'nfe' cumulative number of function evaluations for each time step\n 'nje' cumulative number of jacobian evaluations for each time step\n 'nqu' a vector of method orders for each successful step.\n 'imxer' index of the component of largest magnitude in the\n weighted local error vector (e / ewt) on an error return, -1\n otherwise.\n 'lenrw' the length of the double work array required.\n 'leniw' the length of integer work array required.\n 'mused' a vector of method indicators for each successful time step:\n 1: adams (nonstiff), 2: bdf (stiff)\n ======= ============================================================\n\n Other Parameters\n ----------------\n ml, mu : int, optional\n If either of these are not None or non-negative, then the\n Jacobian is assumed to be banded. These give the number of\n lower and upper non-zero diagonals in this banded matrix.\n For the banded case, `Dfun` should return a matrix whose\n rows contain the non-zero bands (starting with the lowest diagonal).\n Thus, the return matrix `jac` from `Dfun` should have shape\n ``(ml + mu + 1, len(y0))`` when ``ml >=0`` or ``mu >=0``.\n The data in `jac` must be stored such that ``jac[i - j + mu, j]``\n holds the derivative of the `i`th equation with respect to the `j`th\n state variable. If `col_deriv` is True, the transpose of this\n `jac` must be returned.\n rtol, atol : float, optional\n The input parameters `rtol` and `atol` determine the error\n control performed by the solver. The solver will control the\n vector, e, of estimated local errors in y, according to an\n inequality of the form ``max-norm of (e / ewt) <= 1``,\n where ewt is a vector of positive error weights computed as\n ``ewt = rtol * abs(y) + atol``.\n rtol and atol can be either vectors the same length as y or scalars.\n Defaults to 1.49012e-8.\n tcrit : ndarray, optional\n Vector of critical points (e.g. singularities) where integration\n care should be taken.\n h0 : float, (0: solver-determined), optional\n The step size to be attempted on the first step.\n hmax : float, (0: solver-determined), optional\n The maximum absolute step size allowed.\n hmin : float, (0: solver-determined), optional\n The minimum absolute step size allowed.\n ixpr : bool, optional\n Whether to generate extra printing at method switches.\n mxstep : int, (0: solver-determined), optional\n Maximum number of (internally defined) steps allowed for each\n integration point in t.\n mxhnil : int, (0: solver-determined), optional\n Maximum number of messages printed.\n mxordn : int, (0: solver-determined), optional\n Maximum order to be allowed for the non-stiff (Adams) method.\n mxords : int, (0: solver-determined), optional\n Maximum order to be allowed for the stiff (BDF) method.\n\n See Also\n --------\n ode : a more object-oriented integrator based on VODE.\n quad : for finding the area under a curve.\n\n Examples\n --------\n The second order differential equation for the angle `theta` of a\n pendulum acted on by gravity with friction can be written::\n\n theta''(t) + b*theta'(t) + c*sin(theta(t)) = 0\n\n where `b` and `c` are positive constants, and a prime (') denotes a\n derivative. To solve this equation with `odeint`, we must first convert\n it to a system of first order equations. By defining the angular\n velocity ``omega(t) = theta'(t)``, we obtain the system::\n\n theta'(t) = omega(t)\n omega'(t) = -b*omega(t) - c*sin(theta(t))\n\n Let `y` be the vector [`theta`, `omega`]. We implement this system\n in python as:\n\n >>> def pend(y, t, b, c):\n ... theta, omega = y\n ... dydt = [omega, -b*omega - c*np.sin(theta)]\n ... return dydt\n ...\n \n We assume the constants are `b` = 0.25 and `c` = 5.0:\n\n >>> b = 0.25\n >>> c = 5.0\n\n For initial conditions, we assume the pendulum is nearly vertical\n with `theta(0)` = `pi` - 0.1, and it initially at rest, so\n `omega(0)` = 0. Then the vector of initial conditions is\n\n >>> y0 = [np.pi - 0.1, 0.0]\n\n We generate a solution 101 evenly spaced samples in the interval\n 0 <= `t` <= 10. So our array of times is:\n\n >>> t = np.linspace(0, 10, 101)\n\n Call `odeint` to generate the solution. To pass the parameters\n `b` and `c` to `pend`, we give them to `odeint` using the `args`\n argument.\n\n >>> from scipy.integrate import odeint\n >>> sol = odeint(pend, y0, t, args=(b, c))\n\n The solution is an array with shape (101, 2). The first column\n is `theta(t)`, and the second is `omega(t)`. The following code\n plots both components.\n\n >>> import matplotlib.pyplot as plt\n >>> plt.plot(t, sol[:, 0], 'b', label='theta(t)')\n >>> plt.plot(t, sol[:, 1], 'g', label='omega(t)')\n >>> plt.legend(loc='best')\n >>> plt.xlabel('t')\n >>> plt.grid()\n >>> plt.show()\n \"\"\"\n\n if ml is None:\n ml = -1 # changed to zero inside function call\n if mu is None:\n mu = -1 # changed to zero inside function call\n t = copy(t)\n y0 = copy(y0)\n output = _odepack.odeint(func, y0, t, args, Dfun, col_deriv, ml, mu,\n full_output, rtol, atol, tcrit, h0, hmax, hmin,\n ixpr, mxstep, mxhnil, mxordn, mxords)\n if output[-1] < 0:\n warning_msg = _msgs[output[-1]] + \" Run with full_output = 1 to get quantitative information.\"\n warnings.warn(warning_msg, ODEintWarning)\n elif printmessg:\n warning_msg = _msgs[output[-1]]\n warnings.warn(warning_msg, ODEintWarning)\n\n if full_output:\n output[1]['message'] = _msgs[output[-1]]\n\n output = output[:-1]\n if len(output) == 1:\n return output[0]\n else:\n return output\n", "path": "scipy/integrate/odepack.py"}]} | 3,352 | 260 |
gh_patches_debug_20028 | rasdani/github-patches | git_diff | pypa__setuptools-3207 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Removal of convert_path break some packages
### setuptools version
setuptools=61.0.0
### Python version
Python 3.9
### OS
all
### Additional environment information
_No response_
### Description
Some packages such as Cartopy have been broken by upgrade to setuptools=61.0.0
https://github.com/SciTools/cartopy/issues/2021
This is because of commit https://github.com/pypa/setuptools/commit/1ee962510ba66578f6069e6a675b3715ad12ac0b which removes the import
```python
from distutils.util import convert_path
```
This should at least be in the changelog as breakage of API
### Expected behavior
Removing import from __init__.py should be documented in the [CHANGES.rst file](https://github.com/pypa/setuptools/blob/main/CHANGES.rst) for version 61.0.0
### How to Reproduce
Try installing Cartopy with lastest setuptools version
### Output
```console
ImportError: cannot import name 'convert_path' from 'setuptools'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setuptools/__init__.py`
Content:
```
1 """Extensions to the 'distutils' for large or complex distributions"""
2
3 import functools
4 import os
5 import re
6
7 import _distutils_hack.override # noqa: F401
8
9 import distutils.core
10 from distutils.errors import DistutilsOptionError
11
12 from ._deprecation_warning import SetuptoolsDeprecationWarning
13
14 import setuptools.version
15 from setuptools.extension import Extension
16 from setuptools.dist import Distribution
17 from setuptools.depends import Require
18 from setuptools.discovery import PackageFinder, PEP420PackageFinder
19 from . import monkey
20 from . import logging
21
22
23 __all__ = [
24 'setup',
25 'Distribution',
26 'Command',
27 'Extension',
28 'Require',
29 'SetuptoolsDeprecationWarning',
30 'find_packages',
31 'find_namespace_packages',
32 ]
33
34 __version__ = setuptools.version.__version__
35
36 bootstrap_install_from = None
37
38
39 find_packages = PackageFinder.find
40 find_namespace_packages = PEP420PackageFinder.find
41
42
43 def _install_setup_requires(attrs):
44 # Note: do not use `setuptools.Distribution` directly, as
45 # our PEP 517 backend patch `distutils.core.Distribution`.
46 class MinimalDistribution(distutils.core.Distribution):
47 """
48 A minimal version of a distribution for supporting the
49 fetch_build_eggs interface.
50 """
51
52 def __init__(self, attrs):
53 _incl = 'dependency_links', 'setup_requires'
54 filtered = {k: attrs[k] for k in set(_incl) & set(attrs)}
55 super().__init__(filtered)
56 # Prevent accidentally triggering discovery with incomplete set of attrs
57 self.set_defaults._disable()
58
59 def finalize_options(self):
60 """
61 Disable finalize_options to avoid building the working set.
62 Ref #2158.
63 """
64
65 dist = MinimalDistribution(attrs)
66
67 # Honor setup.cfg's options.
68 dist.parse_config_files(ignore_option_errors=True)
69 if dist.setup_requires:
70 dist.fetch_build_eggs(dist.setup_requires)
71
72
73 def setup(**attrs):
74 # Make sure we have any requirements needed to interpret 'attrs'.
75 logging.configure()
76 _install_setup_requires(attrs)
77 return distutils.core.setup(**attrs)
78
79
80 setup.__doc__ = distutils.core.setup.__doc__
81
82
83 _Command = monkey.get_unpatched(distutils.core.Command)
84
85
86 class Command(_Command):
87 __doc__ = _Command.__doc__
88
89 command_consumes_arguments = False
90
91 def __init__(self, dist, **kw):
92 """
93 Construct the command for dist, updating
94 vars(self) with any keyword parameters.
95 """
96 super().__init__(dist)
97 vars(self).update(kw)
98
99 def _ensure_stringlike(self, option, what, default=None):
100 val = getattr(self, option)
101 if val is None:
102 setattr(self, option, default)
103 return default
104 elif not isinstance(val, str):
105 raise DistutilsOptionError(
106 "'%s' must be a %s (got `%s`)" % (option, what, val)
107 )
108 return val
109
110 def ensure_string_list(self, option):
111 r"""Ensure that 'option' is a list of strings. If 'option' is
112 currently a string, we split it either on /,\s*/ or /\s+/, so
113 "foo bar baz", "foo,bar,baz", and "foo, bar baz" all become
114 ["foo", "bar", "baz"].
115 """
116 val = getattr(self, option)
117 if val is None:
118 return
119 elif isinstance(val, str):
120 setattr(self, option, re.split(r',\s*|\s+', val))
121 else:
122 if isinstance(val, list):
123 ok = all(isinstance(v, str) for v in val)
124 else:
125 ok = False
126 if not ok:
127 raise DistutilsOptionError(
128 "'%s' must be a list of strings (got %r)" % (option, val)
129 )
130
131 def reinitialize_command(self, command, reinit_subcommands=0, **kw):
132 cmd = _Command.reinitialize_command(self, command, reinit_subcommands)
133 vars(cmd).update(kw)
134 return cmd
135
136
137 def _find_all_simple(path):
138 """
139 Find all files under 'path'
140 """
141 results = (
142 os.path.join(base, file)
143 for base, dirs, files in os.walk(path, followlinks=True)
144 for file in files
145 )
146 return filter(os.path.isfile, results)
147
148
149 def findall(dir=os.curdir):
150 """
151 Find all files under 'dir' and return the list of full filenames.
152 Unless dir is '.', return full filenames with dir prepended.
153 """
154 files = _find_all_simple(dir)
155 if dir == os.curdir:
156 make_rel = functools.partial(os.path.relpath, start=dir)
157 files = map(make_rel, files)
158 return list(files)
159
160
161 class sic(str):
162 """Treat this string as-is (https://en.wikipedia.org/wiki/Sic)"""
163
164
165 # Apply monkey patches
166 monkey.patch_all()
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setuptools/__init__.py b/setuptools/__init__.py
--- a/setuptools/__init__.py
+++ b/setuptools/__init__.py
@@ -3,11 +3,13 @@
import functools
import os
import re
+import warnings
import _distutils_hack.override # noqa: F401
import distutils.core
from distutils.errors import DistutilsOptionError
+from distutils.util import convert_path as _convert_path
from ._deprecation_warning import SetuptoolsDeprecationWarning
@@ -158,6 +160,19 @@
return list(files)
[email protected](_convert_path)
+def convert_path(pathname):
+ from inspect import cleandoc
+
+ msg = """
+ The function `convert_path` is considered internal and not part of the public API.
+ Its direct usage by 3rd-party packages is considered deprecated and the function
+ may be removed in the future.
+ """
+ warnings.warn(cleandoc(msg), SetuptoolsDeprecationWarning)
+ return _convert_path(pathname)
+
+
class sic(str):
"""Treat this string as-is (https://en.wikipedia.org/wiki/Sic)"""
| {"golden_diff": "diff --git a/setuptools/__init__.py b/setuptools/__init__.py\n--- a/setuptools/__init__.py\n+++ b/setuptools/__init__.py\n@@ -3,11 +3,13 @@\n import functools\n import os\n import re\n+import warnings\n \n import _distutils_hack.override # noqa: F401\n \n import distutils.core\n from distutils.errors import DistutilsOptionError\n+from distutils.util import convert_path as _convert_path\n \n from ._deprecation_warning import SetuptoolsDeprecationWarning\n \n@@ -158,6 +160,19 @@\n return list(files)\n \n \[email protected](_convert_path)\n+def convert_path(pathname):\n+ from inspect import cleandoc\n+\n+ msg = \"\"\"\n+ The function `convert_path` is considered internal and not part of the public API.\n+ Its direct usage by 3rd-party packages is considered deprecated and the function\n+ may be removed in the future.\n+ \"\"\"\n+ warnings.warn(cleandoc(msg), SetuptoolsDeprecationWarning)\n+ return _convert_path(pathname)\n+\n+\n class sic(str):\n \"\"\"Treat this string as-is (https://en.wikipedia.org/wiki/Sic)\"\"\"\n", "issue": "[BUG] Removal of convert_path break some packages\n### setuptools version\n\nsetuptools=61.0.0\n\n### Python version\n\nPython 3.9\n\n### OS\n\nall\n\n### Additional environment information\n\n_No response_\n\n### Description\n\nSome packages such as Cartopy have been broken by upgrade to setuptools=61.0.0\r\n\r\nhttps://github.com/SciTools/cartopy/issues/2021\r\n\r\nThis is because of commit https://github.com/pypa/setuptools/commit/1ee962510ba66578f6069e6a675b3715ad12ac0b which removes the import\r\n```python\r\nfrom distutils.util import convert_path\r\n```\r\n\r\nThis should at least be in the changelog as breakage of API\n\n### Expected behavior\n\nRemoving import from __init__.py should be documented in the [CHANGES.rst file](https://github.com/pypa/setuptools/blob/main/CHANGES.rst) for version 61.0.0\n\n### How to Reproduce\n\nTry installing Cartopy with lastest setuptools version\n\n### Output\n\n```console\r\nImportError: cannot import name 'convert_path' from 'setuptools'\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Extensions to the 'distutils' for large or complex distributions\"\"\"\n\nimport functools\nimport os\nimport re\n\nimport _distutils_hack.override # noqa: F401\n\nimport distutils.core\nfrom distutils.errors import DistutilsOptionError\n\nfrom ._deprecation_warning import SetuptoolsDeprecationWarning\n\nimport setuptools.version\nfrom setuptools.extension import Extension\nfrom setuptools.dist import Distribution\nfrom setuptools.depends import Require\nfrom setuptools.discovery import PackageFinder, PEP420PackageFinder\nfrom . import monkey\nfrom . import logging\n\n\n__all__ = [\n 'setup',\n 'Distribution',\n 'Command',\n 'Extension',\n 'Require',\n 'SetuptoolsDeprecationWarning',\n 'find_packages',\n 'find_namespace_packages',\n]\n\n__version__ = setuptools.version.__version__\n\nbootstrap_install_from = None\n\n\nfind_packages = PackageFinder.find\nfind_namespace_packages = PEP420PackageFinder.find\n\n\ndef _install_setup_requires(attrs):\n # Note: do not use `setuptools.Distribution` directly, as\n # our PEP 517 backend patch `distutils.core.Distribution`.\n class MinimalDistribution(distutils.core.Distribution):\n \"\"\"\n A minimal version of a distribution for supporting the\n fetch_build_eggs interface.\n \"\"\"\n\n def __init__(self, attrs):\n _incl = 'dependency_links', 'setup_requires'\n filtered = {k: attrs[k] for k in set(_incl) & set(attrs)}\n super().__init__(filtered)\n # Prevent accidentally triggering discovery with incomplete set of attrs\n self.set_defaults._disable()\n\n def finalize_options(self):\n \"\"\"\n Disable finalize_options to avoid building the working set.\n Ref #2158.\n \"\"\"\n\n dist = MinimalDistribution(attrs)\n\n # Honor setup.cfg's options.\n dist.parse_config_files(ignore_option_errors=True)\n if dist.setup_requires:\n dist.fetch_build_eggs(dist.setup_requires)\n\n\ndef setup(**attrs):\n # Make sure we have any requirements needed to interpret 'attrs'.\n logging.configure()\n _install_setup_requires(attrs)\n return distutils.core.setup(**attrs)\n\n\nsetup.__doc__ = distutils.core.setup.__doc__\n\n\n_Command = monkey.get_unpatched(distutils.core.Command)\n\n\nclass Command(_Command):\n __doc__ = _Command.__doc__\n\n command_consumes_arguments = False\n\n def __init__(self, dist, **kw):\n \"\"\"\n Construct the command for dist, updating\n vars(self) with any keyword parameters.\n \"\"\"\n super().__init__(dist)\n vars(self).update(kw)\n\n def _ensure_stringlike(self, option, what, default=None):\n val = getattr(self, option)\n if val is None:\n setattr(self, option, default)\n return default\n elif not isinstance(val, str):\n raise DistutilsOptionError(\n \"'%s' must be a %s (got `%s`)\" % (option, what, val)\n )\n return val\n\n def ensure_string_list(self, option):\n r\"\"\"Ensure that 'option' is a list of strings. If 'option' is\n currently a string, we split it either on /,\\s*/ or /\\s+/, so\n \"foo bar baz\", \"foo,bar,baz\", and \"foo, bar baz\" all become\n [\"foo\", \"bar\", \"baz\"].\n \"\"\"\n val = getattr(self, option)\n if val is None:\n return\n elif isinstance(val, str):\n setattr(self, option, re.split(r',\\s*|\\s+', val))\n else:\n if isinstance(val, list):\n ok = all(isinstance(v, str) for v in val)\n else:\n ok = False\n if not ok:\n raise DistutilsOptionError(\n \"'%s' must be a list of strings (got %r)\" % (option, val)\n )\n\n def reinitialize_command(self, command, reinit_subcommands=0, **kw):\n cmd = _Command.reinitialize_command(self, command, reinit_subcommands)\n vars(cmd).update(kw)\n return cmd\n\n\ndef _find_all_simple(path):\n \"\"\"\n Find all files under 'path'\n \"\"\"\n results = (\n os.path.join(base, file)\n for base, dirs, files in os.walk(path, followlinks=True)\n for file in files\n )\n return filter(os.path.isfile, results)\n\n\ndef findall(dir=os.curdir):\n \"\"\"\n Find all files under 'dir' and return the list of full filenames.\n Unless dir is '.', return full filenames with dir prepended.\n \"\"\"\n files = _find_all_simple(dir)\n if dir == os.curdir:\n make_rel = functools.partial(os.path.relpath, start=dir)\n files = map(make_rel, files)\n return list(files)\n\n\nclass sic(str):\n \"\"\"Treat this string as-is (https://en.wikipedia.org/wiki/Sic)\"\"\"\n\n\n# Apply monkey patches\nmonkey.patch_all()\n", "path": "setuptools/__init__.py"}], "after_files": [{"content": "\"\"\"Extensions to the 'distutils' for large or complex distributions\"\"\"\n\nimport functools\nimport os\nimport re\nimport warnings\n\nimport _distutils_hack.override # noqa: F401\n\nimport distutils.core\nfrom distutils.errors import DistutilsOptionError\nfrom distutils.util import convert_path as _convert_path\n\nfrom ._deprecation_warning import SetuptoolsDeprecationWarning\n\nimport setuptools.version\nfrom setuptools.extension import Extension\nfrom setuptools.dist import Distribution\nfrom setuptools.depends import Require\nfrom setuptools.discovery import PackageFinder, PEP420PackageFinder\nfrom . import monkey\nfrom . import logging\n\n\n__all__ = [\n 'setup',\n 'Distribution',\n 'Command',\n 'Extension',\n 'Require',\n 'SetuptoolsDeprecationWarning',\n 'find_packages',\n 'find_namespace_packages',\n]\n\n__version__ = setuptools.version.__version__\n\nbootstrap_install_from = None\n\n\nfind_packages = PackageFinder.find\nfind_namespace_packages = PEP420PackageFinder.find\n\n\ndef _install_setup_requires(attrs):\n # Note: do not use `setuptools.Distribution` directly, as\n # our PEP 517 backend patch `distutils.core.Distribution`.\n class MinimalDistribution(distutils.core.Distribution):\n \"\"\"\n A minimal version of a distribution for supporting the\n fetch_build_eggs interface.\n \"\"\"\n\n def __init__(self, attrs):\n _incl = 'dependency_links', 'setup_requires'\n filtered = {k: attrs[k] for k in set(_incl) & set(attrs)}\n super().__init__(filtered)\n # Prevent accidentally triggering discovery with incomplete set of attrs\n self.set_defaults._disable()\n\n def finalize_options(self):\n \"\"\"\n Disable finalize_options to avoid building the working set.\n Ref #2158.\n \"\"\"\n\n dist = MinimalDistribution(attrs)\n\n # Honor setup.cfg's options.\n dist.parse_config_files(ignore_option_errors=True)\n if dist.setup_requires:\n dist.fetch_build_eggs(dist.setup_requires)\n\n\ndef setup(**attrs):\n # Make sure we have any requirements needed to interpret 'attrs'.\n logging.configure()\n _install_setup_requires(attrs)\n return distutils.core.setup(**attrs)\n\n\nsetup.__doc__ = distutils.core.setup.__doc__\n\n\n_Command = monkey.get_unpatched(distutils.core.Command)\n\n\nclass Command(_Command):\n __doc__ = _Command.__doc__\n\n command_consumes_arguments = False\n\n def __init__(self, dist, **kw):\n \"\"\"\n Construct the command for dist, updating\n vars(self) with any keyword parameters.\n \"\"\"\n super().__init__(dist)\n vars(self).update(kw)\n\n def _ensure_stringlike(self, option, what, default=None):\n val = getattr(self, option)\n if val is None:\n setattr(self, option, default)\n return default\n elif not isinstance(val, str):\n raise DistutilsOptionError(\n \"'%s' must be a %s (got `%s`)\" % (option, what, val)\n )\n return val\n\n def ensure_string_list(self, option):\n r\"\"\"Ensure that 'option' is a list of strings. If 'option' is\n currently a string, we split it either on /,\\s*/ or /\\s+/, so\n \"foo bar baz\", \"foo,bar,baz\", and \"foo, bar baz\" all become\n [\"foo\", \"bar\", \"baz\"].\n \"\"\"\n val = getattr(self, option)\n if val is None:\n return\n elif isinstance(val, str):\n setattr(self, option, re.split(r',\\s*|\\s+', val))\n else:\n if isinstance(val, list):\n ok = all(isinstance(v, str) for v in val)\n else:\n ok = False\n if not ok:\n raise DistutilsOptionError(\n \"'%s' must be a list of strings (got %r)\" % (option, val)\n )\n\n def reinitialize_command(self, command, reinit_subcommands=0, **kw):\n cmd = _Command.reinitialize_command(self, command, reinit_subcommands)\n vars(cmd).update(kw)\n return cmd\n\n\ndef _find_all_simple(path):\n \"\"\"\n Find all files under 'path'\n \"\"\"\n results = (\n os.path.join(base, file)\n for base, dirs, files in os.walk(path, followlinks=True)\n for file in files\n )\n return filter(os.path.isfile, results)\n\n\ndef findall(dir=os.curdir):\n \"\"\"\n Find all files under 'dir' and return the list of full filenames.\n Unless dir is '.', return full filenames with dir prepended.\n \"\"\"\n files = _find_all_simple(dir)\n if dir == os.curdir:\n make_rel = functools.partial(os.path.relpath, start=dir)\n files = map(make_rel, files)\n return list(files)\n\n\[email protected](_convert_path)\ndef convert_path(pathname):\n from inspect import cleandoc\n\n msg = \"\"\"\n The function `convert_path` is considered internal and not part of the public API.\n Its direct usage by 3rd-party packages is considered deprecated and the function\n may be removed in the future.\n \"\"\"\n warnings.warn(cleandoc(msg), SetuptoolsDeprecationWarning)\n return _convert_path(pathname)\n\n\nclass sic(str):\n \"\"\"Treat this string as-is (https://en.wikipedia.org/wiki/Sic)\"\"\"\n\n\n# Apply monkey patches\nmonkey.patch_all()\n", "path": "setuptools/__init__.py"}]} | 2,014 | 272 |
gh_patches_debug_1446 | rasdani/github-patches | git_diff | deis__deis-427 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
permalinks in the documentation
It would be nice to permalink a specific header in the Deis documentation, much like how Stackato's documentation is built: http://docs.stackato.com/client/index.html#getting-help
This is probably a flag set somewhere in Sphinx to get this set up, but would be awesome for referential purposes on IRC or by email.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # deis documentation build configuration file, created by
4 # sphinx-quickstart on Fri Jul 26 12:12:00 2013.
5 #
6 # This file is execfile()d with the current directory set to its containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import sys
16
17 # If extensions (or modules to document with autodoc) are in another directory,
18 # add these directories to sys.path here. If the directory is relative to the
19 # documentation root, use os.path.abspath to make it absolute, like shown here.
20 #sys.path.insert(0, os.path.abspath('.'))
21 sys.path.insert(0, os.path.abspath('..'))
22 # create local_settings.py for SECRET_KEY if necessary
23 local_settings_path = os.path.abspath(
24 os.path.join('..', 'deis', 'local_settings.py'))
25 if not os.path.exists(local_settings_path):
26 with open(local_settings_path, 'w') as local_settings:
27 local_settings.write("SECRET_KEY = 'DummySecretKey'\n")
28 # set up Django
29 os.environ['DJANGO_SETTINGS_MODULE'] = 'deis.settings'
30 from django.conf import settings # noqa
31
32 # -- General configuration -----------------------------------------------------
33
34 # If your documentation needs a minimal Sphinx version, state it here.
35 #needs_sphinx = '1.0'
36
37 # Add any Sphinx extension module names here, as strings. They can be extensions
38 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
39 extensions = ['sphinx.ext.autodoc', 'sphinx.ext.autosummary',
40 'sphinx.ext.viewcode', 'sphinxcontrib.httpdomain']
41
42 # Add any paths that contain templates here, relative to this directory.
43 templates_path = ['_templates']
44
45 # The suffix of source filenames.
46 source_suffix = '.rst'
47
48 # The encoding of source files.
49 #source_encoding = 'utf-8-sig'
50
51 # The master toctree document.
52 master_doc = 'toctree'
53
54 # General information about the project.
55 project = u'deis'
56 copyright = u'2013, OpDemand LLC'
57
58 # The version info for the project you're documenting, acts as replacement for
59 # |version| and |release|, also used in various other places throughout the
60 # built documents.
61 #
62 from deis import __version__
63
64 # The short X.Y version.
65 version = __version__.rsplit('.', 1)[0]
66 # The full version, including alpha/beta/rc tags.
67 release = __version__
68
69 # The language for content autogenerated by Sphinx. Refer to documentation
70 # for a list of supported languages.
71 #language = None
72
73 # There are two options for replacing |today|: either, you set today to some
74 # non-false value, then it is used:
75 #today = ''
76 # Else, today_fmt is used as the format for a strftime call.
77 #today_fmt = '%B %d, %Y'
78
79 # List of patterns, relative to source directory, that match files and
80 # directories to ignore when looking for source files.
81 exclude_patterns = ['_build']
82
83 # The reST default role (used for this markup: `text`) to use for all documents.
84 #default_role = None
85
86 # If true, '()' will be appended to :func: etc. cross-reference text.
87 #add_function_parentheses = True
88
89 # If true, the current module name will be prepended to all description
90 # unit titles (such as .. function::).
91 #add_module_names = True
92
93 # If true, sectionauthor and moduleauthor directives will be shown in the
94 # output. They are ignored by default.
95 #show_authors = False
96
97 # The name of the Pygments (syntax highlighting) style to use.
98 pygments_style = 'sphinx'
99
100 # A list of ignored prefixes for module index sorting.
101 #modindex_common_prefix = []
102
103 # If true, keep warnings as "system message" paragraphs in the built documents.
104 #keep_warnings = False
105
106
107 # -- Options for HTML output ---------------------------------------------------
108
109 # The theme to use for HTML and HTML Help pages. See the documentation for
110 # a list of builtin themes.
111 html_theme = 'deis'
112
113 # Theme options are theme-specific and customize the look and feel of a theme
114 # further. For a list of options available for each theme, see the
115 # documentation.
116 #html_theme_options = {}
117
118 # Add any paths that contain custom themes here, relative to this directory.
119 html_theme_path = ['theme']
120
121 # The name for this set of Sphinx documents. If None, it defaults to
122 # "<project> v<release> documentation".
123 #html_title = None
124
125 # A shorter title for the navigation bar. Default is the same as html_title.
126 #html_short_title = None
127
128 # The name of an image file (relative to this directory) to place at the top
129 # of the sidebar.
130 #html_logo = None
131
132 # The name of an image file (within the static path) to use as favicon of the
133 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
134 # pixels large.
135 #html_favicon = None
136
137 # Add any paths that contain custom static files (such as style sheets) here,
138 # relative to this directory. They are copied after the builtin static files,
139 # so a file named "default.css" will overwrite the builtin "default.css".
140 html_static_path = ['../web/static']
141
142 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
143 # using the given strftime format.
144 #html_last_updated_fmt = '%b %d, %Y'
145
146 # If true, SmartyPants will be used to convert quotes and dashes to
147 # typographically correct entities.
148 html_use_smartypants = True
149
150 html_add_permalinks = None
151
152 # Custom sidebar templates, maps document names to template names.
153 #html_sidebars = {}
154
155 # Additional templates that should be rendered to pages, maps page names to
156 # template names.
157 #html_additional_pages = {}
158
159 # If false, no module index is generated.
160 #html_domain_indices = True
161
162 # If false, no index is generated.
163 #html_use_index = True
164
165 # If true, the index is split into individual pages for each letter.
166 #html_split_index = False
167
168 # If true, links to the reST sources are added to the pages.
169 #html_show_sourcelink = True
170
171 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
172 #html_show_sphinx = True
173
174 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
175 #html_show_copyright = True
176
177 # If true, an OpenSearch description file will be output, and all pages will
178 # contain a <link> tag referring to it. The value of this option must be the
179 # base URL from which the finished HTML is served.
180 #html_use_opensearch = ''
181
182 # This is the file name suffix for HTML files (e.g. ".xhtml").
183 #html_file_suffix = None
184
185 # Output file base name for HTML help builder.
186 htmlhelp_basename = 'deisdoc'
187
188
189 # -- Options for LaTeX output --------------------------------------------------
190
191 latex_elements = {
192 # The paper size ('letterpaper' or 'a4paper').
193 #'papersize': 'letterpaper',
194
195 # The font size ('10pt', '11pt' or '12pt').
196 #'pointsize': '10pt',
197
198 # Additional stuff for the LaTeX preamble.
199 #'preamble': '',
200 }
201
202 # Grouping the document tree into LaTeX files. List of tuples
203 # (source start file, target name, title, author, documentclass [howto/manual]).
204 latex_documents = [
205 ('index', 'deis.tex', u'deis Documentation',
206 u'Author', 'manual'),
207 ]
208
209 # The name of an image file (relative to this directory) to place at the top of
210 # the title page.
211 #latex_logo = None
212
213 # For "manual" documents, if this is true, then toplevel headings are parts,
214 # not chapters.
215 #latex_use_parts = False
216
217 # If true, show page references after internal links.
218 #latex_show_pagerefs = False
219
220 # If true, show URL addresses after external links.
221 #latex_show_urls = False
222
223 # Documents to append as an appendix to all manuals.
224 #latex_appendices = []
225
226 # If false, no module index is generated.
227 #latex_domain_indices = True
228
229
230 # -- Options for manual page output --------------------------------------------
231
232 # One entry per manual page. List of tuples
233 # (source start file, name, description, authors, manual section).
234 man_pages = [
235 ('index', 'deis', u'deis Documentation',
236 [u'Author'], 1)
237 ]
238
239 # If true, show URL addresses after external links.
240 #man_show_urls = False
241
242
243 # -- Options for Texinfo output ------------------------------------------------
244
245 # Grouping the document tree into Texinfo files. List of tuples
246 # (source start file, target name, title, author,
247 # dir menu entry, description, category)
248 texinfo_documents = [
249 ('index', 'deis', u'deis Documentation',
250 u'Author', 'deis', 'One line description of project.',
251 'Miscellaneous'),
252 ]
253
254 # Documents to append as an appendix to all manuals.
255 #texinfo_appendices = []
256
257 # If false, no module index is generated.
258 #texinfo_domain_indices = True
259
260 # How to display URL addresses: 'footnote', 'no', or 'inline'.
261 #texinfo_show_urls = 'footnote'
262
263 # If true, do not generate a @detailmenu in the "Top" node's menu.
264 #texinfo_no_detailmenu = False
265
266
267 # -- Options for Epub output ---------------------------------------------------
268
269 # Bibliographic Dublin Core info.
270 epub_title = u'deis'
271 epub_author = u'OpDemand LLC'
272 epub_publisher = u'OpDemand LLC'
273 epub_copyright = u'2013, OpDemand LLC'
274
275 # The language of the text. It defaults to the language option
276 # or en if the language is not set.
277 #epub_language = ''
278
279 # The scheme of the identifier. Typical schemes are ISBN or URL.
280 #epub_scheme = ''
281
282 # The unique identifier of the text. This can be a ISBN number
283 # or the project homepage.
284 #epub_identifier = ''
285
286 # A unique identification for the text.
287 #epub_uid = ''
288
289 # A tuple containing the cover image and cover page html template filenames.
290 #epub_cover = ()
291
292 # A sequence of (type, uri, title) tuples for the guide element of content.opf.
293 #epub_guide = ()
294
295 # HTML files that should be inserted before the pages created by sphinx.
296 # The format is a list of tuples containing the path and title.
297 #epub_pre_files = []
298
299 # HTML files shat should be inserted after the pages created by sphinx.
300 # The format is a list of tuples containing the path and title.
301 #epub_post_files = []
302
303 # A list of files that should not be packed into the epub file.
304 #epub_exclude_files = []
305
306 # The depth of the table of contents in toc.ncx.
307 #epub_tocdepth = 3
308
309 # Allow duplicate toc entries.
310 #epub_tocdup = True
311
312 # Fix unsupported image types using the PIL.
313 #epub_fix_images = False
314
315 # Scale large images.
316 #epub_max_image_width = 0
317
318 # If 'no', URL addresses will not be shown.
319 #epub_show_urls = 'inline'
320
321 # If false, no index is generated.
322 #epub_use_index = True
323
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -147,7 +147,7 @@
# typographically correct entities.
html_use_smartypants = True
-html_add_permalinks = None
+html_add_permalinks = True
# Custom sidebar templates, maps document names to template names.
#html_sidebars = {}
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -147,7 +147,7 @@\n # typographically correct entities.\n html_use_smartypants = True\n \n-html_add_permalinks = None\n+html_add_permalinks = True\n \n # Custom sidebar templates, maps document names to template names.\n #html_sidebars = {}\n", "issue": "permalinks in the documentation\nIt would be nice to permalink a specific header in the Deis documentation, much like how Stackato's documentation is built: http://docs.stackato.com/client/index.html#getting-help\n\nThis is probably a flag set somewhere in Sphinx to get this set up, but would be awesome for referential purposes on IRC or by email.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# deis documentation build configuration file, created by\n# sphinx-quickstart on Fri Jul 26 12:12:00 2013.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#sys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('..'))\n# create local_settings.py for SECRET_KEY if necessary\nlocal_settings_path = os.path.abspath(\n os.path.join('..', 'deis', 'local_settings.py'))\nif not os.path.exists(local_settings_path):\n with open(local_settings_path, 'w') as local_settings:\n local_settings.write(\"SECRET_KEY = 'DummySecretKey'\\n\")\n# set up Django\nos.environ['DJANGO_SETTINGS_MODULE'] = 'deis.settings'\nfrom django.conf import settings # noqa\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.autosummary',\n 'sphinx.ext.viewcode', 'sphinxcontrib.httpdomain']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'toctree'\n\n# General information about the project.\nproject = u'deis'\ncopyright = u'2013, OpDemand LLC'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\nfrom deis import __version__\n\n# The short X.Y version.\nversion = __version__.rsplit('.', 1)[0]\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# -- Options for HTML output ---------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = 'deis'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = ['theme']\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['../web/static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\nhtml_use_smartypants = True\n\nhtml_add_permalinks = None\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'deisdoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'deis.tex', u'deis Documentation',\n u'Author', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'deis', u'deis Documentation',\n [u'Author'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'deis', u'deis Documentation',\n u'Author', 'deis', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\n\n# -- Options for Epub output ---------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = u'deis'\nepub_author = u'OpDemand LLC'\nepub_publisher = u'OpDemand LLC'\nepub_copyright = u'2013, OpDemand LLC'\n\n# The language of the text. It defaults to the language option\n# or en if the language is not set.\n#epub_language = ''\n\n# The scheme of the identifier. Typical schemes are ISBN or URL.\n#epub_scheme = ''\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#epub_identifier = ''\n\n# A unique identification for the text.\n#epub_uid = ''\n\n# A tuple containing the cover image and cover page html template filenames.\n#epub_cover = ()\n\n# A sequence of (type, uri, title) tuples for the guide element of content.opf.\n#epub_guide = ()\n\n# HTML files that should be inserted before the pages created by sphinx.\n# The format is a list of tuples containing the path and title.\n#epub_pre_files = []\n\n# HTML files shat should be inserted after the pages created by sphinx.\n# The format is a list of tuples containing the path and title.\n#epub_post_files = []\n\n# A list of files that should not be packed into the epub file.\n#epub_exclude_files = []\n\n# The depth of the table of contents in toc.ncx.\n#epub_tocdepth = 3\n\n# Allow duplicate toc entries.\n#epub_tocdup = True\n\n# Fix unsupported image types using the PIL.\n#epub_fix_images = False\n\n# Scale large images.\n#epub_max_image_width = 0\n\n# If 'no', URL addresses will not be shown.\n#epub_show_urls = 'inline'\n\n# If false, no index is generated.\n#epub_use_index = True\n", "path": "docs/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# deis documentation build configuration file, created by\n# sphinx-quickstart on Fri Jul 26 12:12:00 2013.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#sys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('..'))\n# create local_settings.py for SECRET_KEY if necessary\nlocal_settings_path = os.path.abspath(\n os.path.join('..', 'deis', 'local_settings.py'))\nif not os.path.exists(local_settings_path):\n with open(local_settings_path, 'w') as local_settings:\n local_settings.write(\"SECRET_KEY = 'DummySecretKey'\\n\")\n# set up Django\nos.environ['DJANGO_SETTINGS_MODULE'] = 'deis.settings'\nfrom django.conf import settings # noqa\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.autosummary',\n 'sphinx.ext.viewcode', 'sphinxcontrib.httpdomain']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'toctree'\n\n# General information about the project.\nproject = u'deis'\ncopyright = u'2013, OpDemand LLC'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\nfrom deis import __version__\n\n# The short X.Y version.\nversion = __version__.rsplit('.', 1)[0]\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# -- Options for HTML output ---------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = 'deis'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\nhtml_theme_path = ['theme']\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['../web/static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\nhtml_use_smartypants = True\n\nhtml_add_permalinks = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'deisdoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'deis.tex', u'deis Documentation',\n u'Author', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'deis', u'deis Documentation',\n [u'Author'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'deis', u'deis Documentation',\n u'Author', 'deis', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\n\n# -- Options for Epub output ---------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = u'deis'\nepub_author = u'OpDemand LLC'\nepub_publisher = u'OpDemand LLC'\nepub_copyright = u'2013, OpDemand LLC'\n\n# The language of the text. It defaults to the language option\n# or en if the language is not set.\n#epub_language = ''\n\n# The scheme of the identifier. Typical schemes are ISBN or URL.\n#epub_scheme = ''\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#epub_identifier = ''\n\n# A unique identification for the text.\n#epub_uid = ''\n\n# A tuple containing the cover image and cover page html template filenames.\n#epub_cover = ()\n\n# A sequence of (type, uri, title) tuples for the guide element of content.opf.\n#epub_guide = ()\n\n# HTML files that should be inserted before the pages created by sphinx.\n# The format is a list of tuples containing the path and title.\n#epub_pre_files = []\n\n# HTML files shat should be inserted after the pages created by sphinx.\n# The format is a list of tuples containing the path and title.\n#epub_post_files = []\n\n# A list of files that should not be packed into the epub file.\n#epub_exclude_files = []\n\n# The depth of the table of contents in toc.ncx.\n#epub_tocdepth = 3\n\n# Allow duplicate toc entries.\n#epub_tocdup = True\n\n# Fix unsupported image types using the PIL.\n#epub_fix_images = False\n\n# Scale large images.\n#epub_max_image_width = 0\n\n# If 'no', URL addresses will not be shown.\n#epub_show_urls = 'inline'\n\n# If false, no index is generated.\n#epub_use_index = True\n", "path": "docs/conf.py"}]} | 3,757 | 87 |
gh_patches_debug_22579 | rasdani/github-patches | git_diff | pydantic__pydantic-7184 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow inheriting `dataclasses.dataclass` with defaults
### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
Currently, inheriting a pure dataclass to a subclass that is also a `BaseModel` works. This is great, and this feature has been used extensively in v1 in a code base i maintain. v2 seems to have the added feature of not requiring to re-declare the fields, which is awesome.
However, if the dataclass defines a default for a field, it crashes with a `NameError`
```console
Traceback (most recent call last):
...
File "<input>", line 19, in <module>
File ".../lib/python3.10/site-packages/pydantic/_internal/_model_construction.py", line 172, in __new__
set_model_fields(cls, bases, config_wrapper, types_namespace)
File ".../lib/python3.10/site-packages/pydantic/_internal/_model_construction.py", line 400, in set_model_fields
fields, class_vars = collect_model_fields(cls, bases, config_wrapper, types_namespace, typevars_map=typevars_map)
File ".../lib/python3.10/site-packages/pydantic/_internal/_fields.py", line 155, in collect_model_fields
raise NameError(
NameError: Field name "a" shadows an attribute in parent "A"; you might want to use a different field name with "alias='a'".
```
### Example Code
```Python
import pydantic
from dataclasses import dataclass
import pydantic
@dataclass
class A:
a: None
class B(pydantic.BaseModel, A): # Ok
pass
@dataclass
class A:
a: None = None
class B(pydantic.BaseModel, A): # Not ok
pass
```
### Python, Pydantic & OS Version
```Text
pydantic version: 2.1.1
pydantic-core version: 2.4.0
pydantic-core build: profile=release pgo=true mimalloc=true
install path: .../lib/python3.10/site-packages/pydantic
python version: 3.10.2 (main, Mar 3 2022, 12:03:29) [GCC 9.3.0]
platform: Linux-5.14.0-1054-oem-x86_64-with-glibc2.35
optional deps. installed: ['typing-extensions']
```
Selected Assignee: @lig
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pydantic/_internal/_fields.py`
Content:
```
1 """Private logic related to fields (the `Field()` function and `FieldInfo` class), and arguments to `Annotated`."""
2 from __future__ import annotations as _annotations
3
4 import dataclasses
5 import sys
6 import warnings
7 from copy import copy
8 from typing import TYPE_CHECKING, Any
9
10 from annotated_types import BaseMetadata
11 from pydantic_core import PydanticUndefined
12
13 from . import _typing_extra
14 from ._config import ConfigWrapper
15 from ._repr import Representation
16 from ._typing_extra import get_cls_type_hints_lenient, get_type_hints, is_classvar, is_finalvar
17
18 if TYPE_CHECKING:
19 from ..fields import FieldInfo
20 from ..main import BaseModel
21 from ._dataclasses import StandardDataclass
22
23
24 def get_type_hints_infer_globalns(
25 obj: Any,
26 localns: dict[str, Any] | None = None,
27 include_extras: bool = False,
28 ) -> dict[str, Any]:
29 """Gets type hints for an object by inferring the global namespace.
30
31 It uses the `typing.get_type_hints`, The only thing that we do here is fetching
32 global namespace from `obj.__module__` if it is not `None`.
33
34 Args:
35 obj: The object to get its type hints.
36 localns: The local namespaces.
37 include_extras: Whether to recursively include annotation metadata.
38
39 Returns:
40 The object type hints.
41 """
42 module_name = getattr(obj, '__module__', None)
43 globalns: dict[str, Any] | None = None
44 if module_name:
45 try:
46 globalns = sys.modules[module_name].__dict__
47 except KeyError:
48 # happens occasionally, see https://github.com/pydantic/pydantic/issues/2363
49 pass
50 return get_type_hints(obj, globalns=globalns, localns=localns, include_extras=include_extras)
51
52
53 class PydanticMetadata(Representation):
54 """Base class for annotation markers like `Strict`."""
55
56 __slots__ = ()
57
58
59 class PydanticGeneralMetadata(PydanticMetadata, BaseMetadata):
60 """Pydantic general metada like `max_digits`."""
61
62 def __init__(self, **metadata: Any):
63 self.__dict__ = metadata
64
65
66 def collect_model_fields( # noqa: C901
67 cls: type[BaseModel],
68 bases: tuple[type[Any], ...],
69 config_wrapper: ConfigWrapper,
70 types_namespace: dict[str, Any] | None,
71 *,
72 typevars_map: dict[Any, Any] | None = None,
73 ) -> tuple[dict[str, FieldInfo], set[str]]:
74 """Collect the fields of a nascent pydantic model.
75
76 Also collect the names of any ClassVars present in the type hints.
77
78 The returned value is a tuple of two items: the fields dict, and the set of ClassVar names.
79
80 Args:
81 cls: BaseModel or dataclass.
82 bases: Parents of the class, generally `cls.__bases__`.
83 config_wrapper: The config wrapper instance.
84 types_namespace: Optional extra namespace to look for types in.
85 typevars_map: A dictionary mapping type variables to their concrete types.
86
87 Returns:
88 A tuple contains fields and class variables.
89
90 Raises:
91 NameError:
92 - If there is a conflict between a field name and protected namespaces.
93 - If there is a field other than `root` in `RootModel`.
94 - If a field shadows an attribute in the parent model.
95 """
96 from ..fields import FieldInfo
97
98 type_hints = get_cls_type_hints_lenient(cls, types_namespace)
99
100 # https://docs.python.org/3/howto/annotations.html#accessing-the-annotations-dict-of-an-object-in-python-3-9-and-older
101 # annotations is only used for finding fields in parent classes
102 annotations = cls.__dict__.get('__annotations__', {})
103 fields: dict[str, FieldInfo] = {}
104
105 class_vars: set[str] = set()
106 for ann_name, ann_type in type_hints.items():
107 if ann_name == 'model_config':
108 # We never want to treat `model_config` as a field
109 # Note: we may need to change this logic if/when we introduce a `BareModel` class with no
110 # protected namespaces (where `model_config` might be allowed as a field name)
111 continue
112 for protected_namespace in config_wrapper.protected_namespaces:
113 if ann_name.startswith(protected_namespace):
114 for b in bases:
115 if hasattr(b, ann_name):
116 from ..main import BaseModel
117
118 if not (issubclass(b, BaseModel) and ann_name in b.model_fields):
119 raise NameError(
120 f'Field "{ann_name}" conflicts with member {getattr(b, ann_name)}'
121 f' of protected namespace "{protected_namespace}".'
122 )
123 else:
124 valid_namespaces = tuple(
125 x for x in config_wrapper.protected_namespaces if not ann_name.startswith(x)
126 )
127 warnings.warn(
128 f'Field "{ann_name}" has conflict with protected namespace "{protected_namespace}".'
129 '\n\nYou may be able to resolve this warning by setting'
130 f" `model_config['protected_namespaces'] = {valid_namespaces}`.",
131 UserWarning,
132 )
133 if is_classvar(ann_type):
134 class_vars.add(ann_name)
135 continue
136 if _is_finalvar_with_default_val(ann_type, getattr(cls, ann_name, PydanticUndefined)):
137 class_vars.add(ann_name)
138 continue
139 if not is_valid_field_name(ann_name):
140 continue
141 if cls.__pydantic_root_model__ and ann_name != 'root':
142 raise NameError(
143 f"Unexpected field with name {ann_name!r}; only 'root' is allowed as a field of a `RootModel`"
144 )
145
146 # when building a generic model with `MyModel[int]`, the generic_origin check makes sure we don't get
147 # "... shadows an attribute" errors
148 generic_origin = getattr(cls, '__pydantic_generic_metadata__', {}).get('origin')
149 for base in bases:
150 if hasattr(base, ann_name):
151 if base is generic_origin:
152 # Don't error when "shadowing" of attributes in parametrized generics
153 continue
154 warnings.warn(
155 f'Field name "{ann_name}" shadows an attribute in parent "{base.__qualname__}"; ',
156 UserWarning,
157 )
158
159 try:
160 default = getattr(cls, ann_name, PydanticUndefined)
161 if default is PydanticUndefined:
162 raise AttributeError
163 except AttributeError:
164 if ann_name in annotations:
165 field_info = FieldInfo.from_annotation(ann_type)
166 else:
167 # if field has no default value and is not in __annotations__ this means that it is
168 # defined in a base class and we can take it from there
169 model_fields_lookup: dict[str, FieldInfo] = {}
170 for x in cls.__bases__[::-1]:
171 model_fields_lookup.update(getattr(x, 'model_fields', {}))
172 if ann_name in model_fields_lookup:
173 # The field was present on one of the (possibly multiple) base classes
174 # copy the field to make sure typevar substitutions don't cause issues with the base classes
175 field_info = copy(model_fields_lookup[ann_name])
176 else:
177 # The field was not found on any base classes; this seems to be caused by fields not getting
178 # generated thanks to models not being fully defined while initializing recursive models.
179 # Nothing stops us from just creating a new FieldInfo for this type hint, so we do this.
180 field_info = FieldInfo.from_annotation(ann_type)
181 else:
182 field_info = FieldInfo.from_annotated_attribute(ann_type, default)
183 # attributes which are fields are removed from the class namespace:
184 # 1. To match the behaviour of annotation-only fields
185 # 2. To avoid false positives in the NameError check above
186 try:
187 delattr(cls, ann_name)
188 except AttributeError:
189 pass # indicates the attribute was on a parent class
190
191 fields[ann_name] = field_info
192
193 if typevars_map:
194 for field in fields.values():
195 field.apply_typevars_map(typevars_map, types_namespace)
196
197 return fields, class_vars
198
199
200 def _is_finalvar_with_default_val(type_: type[Any], val: Any) -> bool:
201 from ..fields import FieldInfo
202
203 if not is_finalvar(type_):
204 return False
205 elif val is PydanticUndefined:
206 return False
207 elif isinstance(val, FieldInfo) and (val.default is PydanticUndefined and val.default_factory is None):
208 return False
209 else:
210 return True
211
212
213 def collect_dataclass_fields(
214 cls: type[StandardDataclass], types_namespace: dict[str, Any] | None, *, typevars_map: dict[Any, Any] | None = None
215 ) -> dict[str, FieldInfo]:
216 """Collect the fields of a dataclass.
217
218 Args:
219 cls: dataclass.
220 types_namespace: Optional extra namespace to look for types in.
221 typevars_map: A dictionary mapping type variables to their concrete types.
222
223 Returns:
224 The dataclass fields.
225 """
226 from ..fields import FieldInfo
227
228 fields: dict[str, FieldInfo] = {}
229 dataclass_fields: dict[str, dataclasses.Field] = cls.__dataclass_fields__
230 cls_localns = dict(vars(cls)) # this matches get_cls_type_hints_lenient, but all tests pass with `= None` instead
231
232 for ann_name, dataclass_field in dataclass_fields.items():
233 ann_type = _typing_extra.eval_type_lenient(dataclass_field.type, types_namespace, cls_localns)
234 if is_classvar(ann_type):
235 continue
236
237 if not dataclass_field.init and dataclass_field.default_factory == dataclasses.MISSING:
238 # TODO: We should probably do something with this so that validate_assignment behaves properly
239 # Issue: https://github.com/pydantic/pydantic/issues/5470
240 continue
241
242 if isinstance(dataclass_field.default, FieldInfo):
243 if dataclass_field.default.init_var:
244 # TODO: same note as above
245 continue
246 field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field.default)
247 else:
248 field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field)
249 fields[ann_name] = field_info
250
251 if field_info.default is not PydanticUndefined and isinstance(getattr(cls, ann_name, field_info), FieldInfo):
252 # We need this to fix the default when the "default" from __dataclass_fields__ is a pydantic.FieldInfo
253 setattr(cls, ann_name, field_info.default)
254
255 if typevars_map:
256 for field in fields.values():
257 field.apply_typevars_map(typevars_map, types_namespace)
258
259 return fields
260
261
262 def is_valid_field_name(name: str) -> bool:
263 return not name.startswith('_')
264
265
266 def is_valid_privateattr_name(name: str) -> bool:
267 return name.startswith('_') and not name.startswith('__')
268
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pydantic/_internal/_fields.py b/pydantic/_internal/_fields.py
--- a/pydantic/_internal/_fields.py
+++ b/pydantic/_internal/_fields.py
@@ -147,10 +147,18 @@
# "... shadows an attribute" errors
generic_origin = getattr(cls, '__pydantic_generic_metadata__', {}).get('origin')
for base in bases:
+ dataclass_fields = {
+ field.name for field in (dataclasses.fields(base) if dataclasses.is_dataclass(base) else ())
+ }
if hasattr(base, ann_name):
if base is generic_origin:
# Don't error when "shadowing" of attributes in parametrized generics
continue
+
+ if ann_name in dataclass_fields:
+ # Don't error when inheriting stdlib dataclasses whose fields are "shadowed" by defaults being set
+ # on the class instance.
+ continue
warnings.warn(
f'Field name "{ann_name}" shadows an attribute in parent "{base.__qualname__}"; ',
UserWarning,
| {"golden_diff": "diff --git a/pydantic/_internal/_fields.py b/pydantic/_internal/_fields.py\n--- a/pydantic/_internal/_fields.py\n+++ b/pydantic/_internal/_fields.py\n@@ -147,10 +147,18 @@\n # \"... shadows an attribute\" errors\n generic_origin = getattr(cls, '__pydantic_generic_metadata__', {}).get('origin')\n for base in bases:\n+ dataclass_fields = {\n+ field.name for field in (dataclasses.fields(base) if dataclasses.is_dataclass(base) else ())\n+ }\n if hasattr(base, ann_name):\n if base is generic_origin:\n # Don't error when \"shadowing\" of attributes in parametrized generics\n continue\n+\n+ if ann_name in dataclass_fields:\n+ # Don't error when inheriting stdlib dataclasses whose fields are \"shadowed\" by defaults being set\n+ # on the class instance.\n+ continue\n warnings.warn(\n f'Field name \"{ann_name}\" shadows an attribute in parent \"{base.__qualname__}\"; ',\n UserWarning,\n", "issue": "Allow inheriting `dataclasses.dataclass` with defaults\n### Initial Checks\r\n\r\n- [X] I confirm that I'm using Pydantic V2\r\n\r\n### Description\r\n\r\nCurrently, inheriting a pure dataclass to a subclass that is also a `BaseModel` works. This is great, and this feature has been used extensively in v1 in a code base i maintain. v2 seems to have the added feature of not requiring to re-declare the fields, which is awesome.\r\n\r\nHowever, if the dataclass defines a default for a field, it crashes with a `NameError`\r\n\r\n```console\r\nTraceback (most recent call last):\r\n...\r\n File \"<input>\", line 19, in <module>\r\n File \".../lib/python3.10/site-packages/pydantic/_internal/_model_construction.py\", line 172, in __new__\r\n set_model_fields(cls, bases, config_wrapper, types_namespace)\r\n File \".../lib/python3.10/site-packages/pydantic/_internal/_model_construction.py\", line 400, in set_model_fields\r\n fields, class_vars = collect_model_fields(cls, bases, config_wrapper, types_namespace, typevars_map=typevars_map)\r\n File \".../lib/python3.10/site-packages/pydantic/_internal/_fields.py\", line 155, in collect_model_fields\r\n raise NameError(\r\nNameError: Field name \"a\" shadows an attribute in parent \"A\"; you might want to use a different field name with \"alias='a'\".\r\n```\r\n\r\n### Example Code\r\n\r\n```Python\r\nimport pydantic\r\n\r\nfrom dataclasses import dataclass\r\n\r\nimport pydantic\r\n\r\n\r\n@dataclass\r\nclass A:\r\n a: None\r\n\r\nclass B(pydantic.BaseModel, A): # Ok\r\n pass\r\n\r\n\r\n@dataclass\r\nclass A:\r\n a: None = None\r\n \r\n\r\nclass B(pydantic.BaseModel, A): # Not ok\r\n pass\r\n```\r\n\r\n\r\n### Python, Pydantic & OS Version\r\n\r\n```Text\r\npydantic version: 2.1.1\r\n pydantic-core version: 2.4.0\r\n pydantic-core build: profile=release pgo=true mimalloc=true\r\n install path: .../lib/python3.10/site-packages/pydantic\r\n python version: 3.10.2 (main, Mar 3 2022, 12:03:29) [GCC 9.3.0]\r\n platform: Linux-5.14.0-1054-oem-x86_64-with-glibc2.35\r\n optional deps. installed: ['typing-extensions']\r\n```\r\n\r\n\r\nSelected Assignee: @lig\n", "before_files": [{"content": "\"\"\"Private logic related to fields (the `Field()` function and `FieldInfo` class), and arguments to `Annotated`.\"\"\"\nfrom __future__ import annotations as _annotations\n\nimport dataclasses\nimport sys\nimport warnings\nfrom copy import copy\nfrom typing import TYPE_CHECKING, Any\n\nfrom annotated_types import BaseMetadata\nfrom pydantic_core import PydanticUndefined\n\nfrom . import _typing_extra\nfrom ._config import ConfigWrapper\nfrom ._repr import Representation\nfrom ._typing_extra import get_cls_type_hints_lenient, get_type_hints, is_classvar, is_finalvar\n\nif TYPE_CHECKING:\n from ..fields import FieldInfo\n from ..main import BaseModel\n from ._dataclasses import StandardDataclass\n\n\ndef get_type_hints_infer_globalns(\n obj: Any,\n localns: dict[str, Any] | None = None,\n include_extras: bool = False,\n) -> dict[str, Any]:\n \"\"\"Gets type hints for an object by inferring the global namespace.\n\n It uses the `typing.get_type_hints`, The only thing that we do here is fetching\n global namespace from `obj.__module__` if it is not `None`.\n\n Args:\n obj: The object to get its type hints.\n localns: The local namespaces.\n include_extras: Whether to recursively include annotation metadata.\n\n Returns:\n The object type hints.\n \"\"\"\n module_name = getattr(obj, '__module__', None)\n globalns: dict[str, Any] | None = None\n if module_name:\n try:\n globalns = sys.modules[module_name].__dict__\n except KeyError:\n # happens occasionally, see https://github.com/pydantic/pydantic/issues/2363\n pass\n return get_type_hints(obj, globalns=globalns, localns=localns, include_extras=include_extras)\n\n\nclass PydanticMetadata(Representation):\n \"\"\"Base class for annotation markers like `Strict`.\"\"\"\n\n __slots__ = ()\n\n\nclass PydanticGeneralMetadata(PydanticMetadata, BaseMetadata):\n \"\"\"Pydantic general metada like `max_digits`.\"\"\"\n\n def __init__(self, **metadata: Any):\n self.__dict__ = metadata\n\n\ndef collect_model_fields( # noqa: C901\n cls: type[BaseModel],\n bases: tuple[type[Any], ...],\n config_wrapper: ConfigWrapper,\n types_namespace: dict[str, Any] | None,\n *,\n typevars_map: dict[Any, Any] | None = None,\n) -> tuple[dict[str, FieldInfo], set[str]]:\n \"\"\"Collect the fields of a nascent pydantic model.\n\n Also collect the names of any ClassVars present in the type hints.\n\n The returned value is a tuple of two items: the fields dict, and the set of ClassVar names.\n\n Args:\n cls: BaseModel or dataclass.\n bases: Parents of the class, generally `cls.__bases__`.\n config_wrapper: The config wrapper instance.\n types_namespace: Optional extra namespace to look for types in.\n typevars_map: A dictionary mapping type variables to their concrete types.\n\n Returns:\n A tuple contains fields and class variables.\n\n Raises:\n NameError:\n - If there is a conflict between a field name and protected namespaces.\n - If there is a field other than `root` in `RootModel`.\n - If a field shadows an attribute in the parent model.\n \"\"\"\n from ..fields import FieldInfo\n\n type_hints = get_cls_type_hints_lenient(cls, types_namespace)\n\n # https://docs.python.org/3/howto/annotations.html#accessing-the-annotations-dict-of-an-object-in-python-3-9-and-older\n # annotations is only used for finding fields in parent classes\n annotations = cls.__dict__.get('__annotations__', {})\n fields: dict[str, FieldInfo] = {}\n\n class_vars: set[str] = set()\n for ann_name, ann_type in type_hints.items():\n if ann_name == 'model_config':\n # We never want to treat `model_config` as a field\n # Note: we may need to change this logic if/when we introduce a `BareModel` class with no\n # protected namespaces (where `model_config` might be allowed as a field name)\n continue\n for protected_namespace in config_wrapper.protected_namespaces:\n if ann_name.startswith(protected_namespace):\n for b in bases:\n if hasattr(b, ann_name):\n from ..main import BaseModel\n\n if not (issubclass(b, BaseModel) and ann_name in b.model_fields):\n raise NameError(\n f'Field \"{ann_name}\" conflicts with member {getattr(b, ann_name)}'\n f' of protected namespace \"{protected_namespace}\".'\n )\n else:\n valid_namespaces = tuple(\n x for x in config_wrapper.protected_namespaces if not ann_name.startswith(x)\n )\n warnings.warn(\n f'Field \"{ann_name}\" has conflict with protected namespace \"{protected_namespace}\".'\n '\\n\\nYou may be able to resolve this warning by setting'\n f\" `model_config['protected_namespaces'] = {valid_namespaces}`.\",\n UserWarning,\n )\n if is_classvar(ann_type):\n class_vars.add(ann_name)\n continue\n if _is_finalvar_with_default_val(ann_type, getattr(cls, ann_name, PydanticUndefined)):\n class_vars.add(ann_name)\n continue\n if not is_valid_field_name(ann_name):\n continue\n if cls.__pydantic_root_model__ and ann_name != 'root':\n raise NameError(\n f\"Unexpected field with name {ann_name!r}; only 'root' is allowed as a field of a `RootModel`\"\n )\n\n # when building a generic model with `MyModel[int]`, the generic_origin check makes sure we don't get\n # \"... shadows an attribute\" errors\n generic_origin = getattr(cls, '__pydantic_generic_metadata__', {}).get('origin')\n for base in bases:\n if hasattr(base, ann_name):\n if base is generic_origin:\n # Don't error when \"shadowing\" of attributes in parametrized generics\n continue\n warnings.warn(\n f'Field name \"{ann_name}\" shadows an attribute in parent \"{base.__qualname__}\"; ',\n UserWarning,\n )\n\n try:\n default = getattr(cls, ann_name, PydanticUndefined)\n if default is PydanticUndefined:\n raise AttributeError\n except AttributeError:\n if ann_name in annotations:\n field_info = FieldInfo.from_annotation(ann_type)\n else:\n # if field has no default value and is not in __annotations__ this means that it is\n # defined in a base class and we can take it from there\n model_fields_lookup: dict[str, FieldInfo] = {}\n for x in cls.__bases__[::-1]:\n model_fields_lookup.update(getattr(x, 'model_fields', {}))\n if ann_name in model_fields_lookup:\n # The field was present on one of the (possibly multiple) base classes\n # copy the field to make sure typevar substitutions don't cause issues with the base classes\n field_info = copy(model_fields_lookup[ann_name])\n else:\n # The field was not found on any base classes; this seems to be caused by fields not getting\n # generated thanks to models not being fully defined while initializing recursive models.\n # Nothing stops us from just creating a new FieldInfo for this type hint, so we do this.\n field_info = FieldInfo.from_annotation(ann_type)\n else:\n field_info = FieldInfo.from_annotated_attribute(ann_type, default)\n # attributes which are fields are removed from the class namespace:\n # 1. To match the behaviour of annotation-only fields\n # 2. To avoid false positives in the NameError check above\n try:\n delattr(cls, ann_name)\n except AttributeError:\n pass # indicates the attribute was on a parent class\n\n fields[ann_name] = field_info\n\n if typevars_map:\n for field in fields.values():\n field.apply_typevars_map(typevars_map, types_namespace)\n\n return fields, class_vars\n\n\ndef _is_finalvar_with_default_val(type_: type[Any], val: Any) -> bool:\n from ..fields import FieldInfo\n\n if not is_finalvar(type_):\n return False\n elif val is PydanticUndefined:\n return False\n elif isinstance(val, FieldInfo) and (val.default is PydanticUndefined and val.default_factory is None):\n return False\n else:\n return True\n\n\ndef collect_dataclass_fields(\n cls: type[StandardDataclass], types_namespace: dict[str, Any] | None, *, typevars_map: dict[Any, Any] | None = None\n) -> dict[str, FieldInfo]:\n \"\"\"Collect the fields of a dataclass.\n\n Args:\n cls: dataclass.\n types_namespace: Optional extra namespace to look for types in.\n typevars_map: A dictionary mapping type variables to their concrete types.\n\n Returns:\n The dataclass fields.\n \"\"\"\n from ..fields import FieldInfo\n\n fields: dict[str, FieldInfo] = {}\n dataclass_fields: dict[str, dataclasses.Field] = cls.__dataclass_fields__\n cls_localns = dict(vars(cls)) # this matches get_cls_type_hints_lenient, but all tests pass with `= None` instead\n\n for ann_name, dataclass_field in dataclass_fields.items():\n ann_type = _typing_extra.eval_type_lenient(dataclass_field.type, types_namespace, cls_localns)\n if is_classvar(ann_type):\n continue\n\n if not dataclass_field.init and dataclass_field.default_factory == dataclasses.MISSING:\n # TODO: We should probably do something with this so that validate_assignment behaves properly\n # Issue: https://github.com/pydantic/pydantic/issues/5470\n continue\n\n if isinstance(dataclass_field.default, FieldInfo):\n if dataclass_field.default.init_var:\n # TODO: same note as above\n continue\n field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field.default)\n else:\n field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field)\n fields[ann_name] = field_info\n\n if field_info.default is not PydanticUndefined and isinstance(getattr(cls, ann_name, field_info), FieldInfo):\n # We need this to fix the default when the \"default\" from __dataclass_fields__ is a pydantic.FieldInfo\n setattr(cls, ann_name, field_info.default)\n\n if typevars_map:\n for field in fields.values():\n field.apply_typevars_map(typevars_map, types_namespace)\n\n return fields\n\n\ndef is_valid_field_name(name: str) -> bool:\n return not name.startswith('_')\n\n\ndef is_valid_privateattr_name(name: str) -> bool:\n return name.startswith('_') and not name.startswith('__')\n", "path": "pydantic/_internal/_fields.py"}], "after_files": [{"content": "\"\"\"Private logic related to fields (the `Field()` function and `FieldInfo` class), and arguments to `Annotated`.\"\"\"\nfrom __future__ import annotations as _annotations\n\nimport dataclasses\nimport sys\nimport warnings\nfrom copy import copy\nfrom typing import TYPE_CHECKING, Any\n\nfrom annotated_types import BaseMetadata\nfrom pydantic_core import PydanticUndefined\n\nfrom . import _typing_extra\nfrom ._config import ConfigWrapper\nfrom ._repr import Representation\nfrom ._typing_extra import get_cls_type_hints_lenient, get_type_hints, is_classvar, is_finalvar\n\nif TYPE_CHECKING:\n from ..fields import FieldInfo\n from ..main import BaseModel\n from ._dataclasses import StandardDataclass\n\n\ndef get_type_hints_infer_globalns(\n obj: Any,\n localns: dict[str, Any] | None = None,\n include_extras: bool = False,\n) -> dict[str, Any]:\n \"\"\"Gets type hints for an object by inferring the global namespace.\n\n It uses the `typing.get_type_hints`, The only thing that we do here is fetching\n global namespace from `obj.__module__` if it is not `None`.\n\n Args:\n obj: The object to get its type hints.\n localns: The local namespaces.\n include_extras: Whether to recursively include annotation metadata.\n\n Returns:\n The object type hints.\n \"\"\"\n module_name = getattr(obj, '__module__', None)\n globalns: dict[str, Any] | None = None\n if module_name:\n try:\n globalns = sys.modules[module_name].__dict__\n except KeyError:\n # happens occasionally, see https://github.com/pydantic/pydantic/issues/2363\n pass\n return get_type_hints(obj, globalns=globalns, localns=localns, include_extras=include_extras)\n\n\nclass PydanticMetadata(Representation):\n \"\"\"Base class for annotation markers like `Strict`.\"\"\"\n\n __slots__ = ()\n\n\nclass PydanticGeneralMetadata(PydanticMetadata, BaseMetadata):\n \"\"\"Pydantic general metada like `max_digits`.\"\"\"\n\n def __init__(self, **metadata: Any):\n self.__dict__ = metadata\n\n\ndef collect_model_fields( # noqa: C901\n cls: type[BaseModel],\n bases: tuple[type[Any], ...],\n config_wrapper: ConfigWrapper,\n types_namespace: dict[str, Any] | None,\n *,\n typevars_map: dict[Any, Any] | None = None,\n) -> tuple[dict[str, FieldInfo], set[str]]:\n \"\"\"Collect the fields of a nascent pydantic model.\n\n Also collect the names of any ClassVars present in the type hints.\n\n The returned value is a tuple of two items: the fields dict, and the set of ClassVar names.\n\n Args:\n cls: BaseModel or dataclass.\n bases: Parents of the class, generally `cls.__bases__`.\n config_wrapper: The config wrapper instance.\n types_namespace: Optional extra namespace to look for types in.\n typevars_map: A dictionary mapping type variables to their concrete types.\n\n Returns:\n A tuple contains fields and class variables.\n\n Raises:\n NameError:\n - If there is a conflict between a field name and protected namespaces.\n - If there is a field other than `root` in `RootModel`.\n - If a field shadows an attribute in the parent model.\n \"\"\"\n from ..fields import FieldInfo\n\n type_hints = get_cls_type_hints_lenient(cls, types_namespace)\n\n # https://docs.python.org/3/howto/annotations.html#accessing-the-annotations-dict-of-an-object-in-python-3-9-and-older\n # annotations is only used for finding fields in parent classes\n annotations = cls.__dict__.get('__annotations__', {})\n fields: dict[str, FieldInfo] = {}\n\n class_vars: set[str] = set()\n for ann_name, ann_type in type_hints.items():\n if ann_name == 'model_config':\n # We never want to treat `model_config` as a field\n # Note: we may need to change this logic if/when we introduce a `BareModel` class with no\n # protected namespaces (where `model_config` might be allowed as a field name)\n continue\n for protected_namespace in config_wrapper.protected_namespaces:\n if ann_name.startswith(protected_namespace):\n for b in bases:\n if hasattr(b, ann_name):\n from ..main import BaseModel\n\n if not (issubclass(b, BaseModel) and ann_name in b.model_fields):\n raise NameError(\n f'Field \"{ann_name}\" conflicts with member {getattr(b, ann_name)}'\n f' of protected namespace \"{protected_namespace}\".'\n )\n else:\n valid_namespaces = tuple(\n x for x in config_wrapper.protected_namespaces if not ann_name.startswith(x)\n )\n warnings.warn(\n f'Field \"{ann_name}\" has conflict with protected namespace \"{protected_namespace}\".'\n '\\n\\nYou may be able to resolve this warning by setting'\n f\" `model_config['protected_namespaces'] = {valid_namespaces}`.\",\n UserWarning,\n )\n if is_classvar(ann_type):\n class_vars.add(ann_name)\n continue\n if _is_finalvar_with_default_val(ann_type, getattr(cls, ann_name, PydanticUndefined)):\n class_vars.add(ann_name)\n continue\n if not is_valid_field_name(ann_name):\n continue\n if cls.__pydantic_root_model__ and ann_name != 'root':\n raise NameError(\n f\"Unexpected field with name {ann_name!r}; only 'root' is allowed as a field of a `RootModel`\"\n )\n\n # when building a generic model with `MyModel[int]`, the generic_origin check makes sure we don't get\n # \"... shadows an attribute\" errors\n generic_origin = getattr(cls, '__pydantic_generic_metadata__', {}).get('origin')\n for base in bases:\n dataclass_fields = {\n field.name for field in (dataclasses.fields(base) if dataclasses.is_dataclass(base) else ())\n }\n if hasattr(base, ann_name):\n if base is generic_origin:\n # Don't error when \"shadowing\" of attributes in parametrized generics\n continue\n\n if ann_name in dataclass_fields:\n # Don't error when inheriting stdlib dataclasses whose fields are \"shadowed\" by defaults being set\n # on the class instance.\n continue\n warnings.warn(\n f'Field name \"{ann_name}\" shadows an attribute in parent \"{base.__qualname__}\"; ',\n UserWarning,\n )\n\n try:\n default = getattr(cls, ann_name, PydanticUndefined)\n if default is PydanticUndefined:\n raise AttributeError\n except AttributeError:\n if ann_name in annotations:\n field_info = FieldInfo.from_annotation(ann_type)\n else:\n # if field has no default value and is not in __annotations__ this means that it is\n # defined in a base class and we can take it from there\n model_fields_lookup: dict[str, FieldInfo] = {}\n for x in cls.__bases__[::-1]:\n model_fields_lookup.update(getattr(x, 'model_fields', {}))\n if ann_name in model_fields_lookup:\n # The field was present on one of the (possibly multiple) base classes\n # copy the field to make sure typevar substitutions don't cause issues with the base classes\n field_info = copy(model_fields_lookup[ann_name])\n else:\n # The field was not found on any base classes; this seems to be caused by fields not getting\n # generated thanks to models not being fully defined while initializing recursive models.\n # Nothing stops us from just creating a new FieldInfo for this type hint, so we do this.\n field_info = FieldInfo.from_annotation(ann_type)\n else:\n field_info = FieldInfo.from_annotated_attribute(ann_type, default)\n # attributes which are fields are removed from the class namespace:\n # 1. To match the behaviour of annotation-only fields\n # 2. To avoid false positives in the NameError check above\n try:\n delattr(cls, ann_name)\n except AttributeError:\n pass # indicates the attribute was on a parent class\n\n fields[ann_name] = field_info\n\n if typevars_map:\n for field in fields.values():\n field.apply_typevars_map(typevars_map, types_namespace)\n\n return fields, class_vars\n\n\ndef _is_finalvar_with_default_val(type_: type[Any], val: Any) -> bool:\n from ..fields import FieldInfo\n\n if not is_finalvar(type_):\n return False\n elif val is PydanticUndefined:\n return False\n elif isinstance(val, FieldInfo) and (val.default is PydanticUndefined and val.default_factory is None):\n return False\n else:\n return True\n\n\ndef collect_dataclass_fields(\n cls: type[StandardDataclass], types_namespace: dict[str, Any] | None, *, typevars_map: dict[Any, Any] | None = None\n) -> dict[str, FieldInfo]:\n \"\"\"Collect the fields of a dataclass.\n\n Args:\n cls: dataclass.\n types_namespace: Optional extra namespace to look for types in.\n typevars_map: A dictionary mapping type variables to their concrete types.\n\n Returns:\n The dataclass fields.\n \"\"\"\n from ..fields import FieldInfo\n\n fields: dict[str, FieldInfo] = {}\n dataclass_fields: dict[str, dataclasses.Field] = cls.__dataclass_fields__\n cls_localns = dict(vars(cls)) # this matches get_cls_type_hints_lenient, but all tests pass with `= None` instead\n\n for ann_name, dataclass_field in dataclass_fields.items():\n ann_type = _typing_extra.eval_type_lenient(dataclass_field.type, types_namespace, cls_localns)\n if is_classvar(ann_type):\n continue\n\n if not dataclass_field.init and dataclass_field.default_factory == dataclasses.MISSING:\n # TODO: We should probably do something with this so that validate_assignment behaves properly\n # Issue: https://github.com/pydantic/pydantic/issues/5470\n continue\n\n if isinstance(dataclass_field.default, FieldInfo):\n if dataclass_field.default.init_var:\n # TODO: same note as above\n continue\n field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field.default)\n else:\n field_info = FieldInfo.from_annotated_attribute(ann_type, dataclass_field)\n fields[ann_name] = field_info\n\n if field_info.default is not PydanticUndefined and isinstance(getattr(cls, ann_name, field_info), FieldInfo):\n # We need this to fix the default when the \"default\" from __dataclass_fields__ is a pydantic.FieldInfo\n setattr(cls, ann_name, field_info.default)\n\n if typevars_map:\n for field in fields.values():\n field.apply_typevars_map(typevars_map, types_namespace)\n\n return fields\n\n\ndef is_valid_field_name(name: str) -> bool:\n return not name.startswith('_')\n\n\ndef is_valid_privateattr_name(name: str) -> bool:\n return name.startswith('_') and not name.startswith('__')\n", "path": "pydantic/_internal/_fields.py"}]} | 3,954 | 242 |
gh_patches_debug_9280 | rasdani/github-patches | git_diff | nerfstudio-project__nerfstudio-2002 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
a simple mistake in ExponentialDecayScheduler
When training nerfacto with --optimizers.fields.scheduler.warmup-steps 5000, it will crash soon.
**Expected behavior**
The lr should ramps up to 1e-2 in 5000 steps. However, the lr increase like this.

**Additional context**
This is caused by a typo in [ExponentialDecayScheduler](https://github.com/nerfstudio-project/nerfstudio/blob/e94d9031ab711bd755655adafba1b986e980f27b/nerfstudio/engine/schedulers.py#LL125C27-L125C27),
where `lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1))`
should be `lr = self.config.lr_pre_warmup + (lr_init - self.config.lr_pre_warmup) * np.sin(0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1))`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nerfstudio/engine/schedulers.py`
Content:
```
1 # Copyright 2022 the Regents of the University of California, Nerfstudio Team and contributors. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 """Scheduler Classes"""
17
18 from abc import abstractmethod
19 from dataclasses import dataclass, field
20 from typing import Literal, Optional, Tuple, Type
21
22 import numpy as np
23 from torch.optim import Optimizer, lr_scheduler
24
25 try:
26 from torch.optim.lr_scheduler import LRScheduler
27 except ImportError:
28 # Backwards compatibility for PyTorch 1.x
29 from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
30
31 from nerfstudio.configs.base_config import InstantiateConfig
32
33
34 @dataclass
35 class SchedulerConfig(InstantiateConfig):
36 """Basic scheduler config"""
37
38 _target: Type = field(default_factory=lambda: Scheduler)
39 """target class to instantiate"""
40
41
42 class Scheduler:
43 """Base scheduler"""
44
45 config: SchedulerConfig
46
47 def __init__(self, config: SchedulerConfig) -> None:
48 super().__init__()
49 self.config = config
50
51 @abstractmethod
52 def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:
53 """Abstract method that returns a scheduler object.
54
55 Args:
56 optimizer: The optimizer to use.
57 lr_init: The initial learning rate.
58 Returns:
59 The scheduler object.
60 """
61
62
63 @dataclass
64 class MultiStepSchedulerConfig(SchedulerConfig):
65 """Config for multi step scheduler where lr decays by gamma every milestone"""
66
67 _target: Type = field(default_factory=lambda: MultiStepScheduler)
68 """target class to instantiate"""
69 max_steps: int = 1000000
70 """The maximum number of steps."""
71 gamma: float = 0.33
72 """The learning rate decay factor."""
73 milestones: Tuple[int, ...] = (500000, 750000, 900000)
74 """The milestone steps at which to decay the learning rate."""
75
76
77 class MultiStepScheduler(Scheduler):
78 """Multi step scheduler where lr decays by gamma every milestone"""
79
80 config: MultiStepSchedulerConfig
81
82 def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:
83 scheduler = lr_scheduler.MultiStepLR(
84 optimizer=optimizer,
85 milestones=self.config.milestones,
86 gamma=self.config.gamma,
87 )
88 return scheduler
89
90
91 @dataclass
92 class ExponentialDecaySchedulerConfig(SchedulerConfig):
93 """Config for exponential decay scheduler with warmup"""
94
95 _target: Type = field(default_factory=lambda: ExponentialDecayScheduler)
96 """target class to instantiate"""
97 lr_pre_warmup: float = 1e-8
98 """Learning rate before warmup."""
99 lr_final: Optional[float] = None
100 """Final learning rate. If not provided, it will be set to the optimizers learning rate."""
101 warmup_steps: int = 0
102 """Number of warmup steps."""
103 max_steps: int = 100000
104 """The maximum number of steps."""
105 ramp: Literal["linear", "cosine"] = "cosine"
106 """The ramp function to use during the warmup."""
107
108
109 class ExponentialDecayScheduler(Scheduler):
110 """Exponential decay scheduler with linear warmup. Scheduler first ramps up to `lr_init` in `warmup_steps`
111 steps, then exponentially decays to `lr_final` in `max_steps` steps.
112 """
113
114 config: ExponentialDecaySchedulerConfig
115
116 def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:
117 if self.config.lr_final is None:
118 lr_final = lr_init
119 else:
120 lr_final = self.config.lr_final
121
122 def func(step):
123 if step < self.config.warmup_steps:
124 if self.config.ramp == "cosine":
125 lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(
126 0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1)
127 )
128 else:
129 lr = (
130 self.config.lr_pre_warmup
131 + (lr_init - self.config.lr_pre_warmup) * step / self.config.warmup_steps
132 )
133 else:
134 t = np.clip(
135 (step - self.config.warmup_steps) / (self.config.max_steps - self.config.warmup_steps), 0, 1
136 )
137 lr = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t)
138 return lr / lr_init # divided by lr_init because the multiplier is with the initial learning rate
139
140 scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)
141 return scheduler
142
143
144 @dataclass
145 class CosineDecaySchedulerConfig(SchedulerConfig):
146 """Config for cosine decay schedule"""
147
148 _target: Type = field(default_factory=lambda: CosineDecayScheduler)
149 """target class to instantiate"""
150 warm_up_end: int = 5000
151 """Iteration number where warmp ends"""
152 learning_rate_alpha: float = 0.05
153 """Learning rate alpha value"""
154 max_steps: int = 300000
155 """The maximum number of steps."""
156
157
158 class CosineDecayScheduler(Scheduler):
159 """Cosine decay scheduler with linear warmup"""
160
161 config: CosineDecaySchedulerConfig
162
163 def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:
164 def func(step):
165 if step < self.config.warm_up_end:
166 learning_factor = step / self.config.warm_up_end
167 else:
168 alpha = self.config.learning_rate_alpha
169 progress = (step - self.config.warm_up_end) / (self.config.max_steps - self.config.warm_up_end)
170 learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha
171 return learning_factor
172
173 scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)
174 return scheduler
175
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nerfstudio/engine/schedulers.py b/nerfstudio/engine/schedulers.py
--- a/nerfstudio/engine/schedulers.py
+++ b/nerfstudio/engine/schedulers.py
@@ -122,7 +122,7 @@
def func(step):
if step < self.config.warmup_steps:
if self.config.ramp == "cosine":
- lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(
+ lr = self.config.lr_pre_warmup + (lr_init - self.config.lr_pre_warmup) * np.sin(
0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1)
)
else:
| {"golden_diff": "diff --git a/nerfstudio/engine/schedulers.py b/nerfstudio/engine/schedulers.py\n--- a/nerfstudio/engine/schedulers.py\n+++ b/nerfstudio/engine/schedulers.py\n@@ -122,7 +122,7 @@\n def func(step):\n if step < self.config.warmup_steps:\n if self.config.ramp == \"cosine\":\n- lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(\n+ lr = self.config.lr_pre_warmup + (lr_init - self.config.lr_pre_warmup) * np.sin(\n 0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1)\n )\n else:\n", "issue": "a simple mistake in ExponentialDecayScheduler\nWhen training nerfacto with --optimizers.fields.scheduler.warmup-steps 5000, it will crash soon.\r\n\r\n**Expected behavior**\r\nThe lr should ramps up to 1e-2 in 5000 steps. However, the lr increase like this.\r\n\r\n\r\n**Additional context**\r\nThis is caused by a typo in [ExponentialDecayScheduler](https://github.com/nerfstudio-project/nerfstudio/blob/e94d9031ab711bd755655adafba1b986e980f27b/nerfstudio/engine/schedulers.py#LL125C27-L125C27), \r\nwhere `lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1))` \r\nshould be `lr = self.config.lr_pre_warmup + (lr_init - self.config.lr_pre_warmup) * np.sin(0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1))`\r\n\n", "before_files": [{"content": "# Copyright 2022 the Regents of the University of California, Nerfstudio Team and contributors. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n\"\"\"Scheduler Classes\"\"\"\n\nfrom abc import abstractmethod\nfrom dataclasses import dataclass, field\nfrom typing import Literal, Optional, Tuple, Type\n\nimport numpy as np\nfrom torch.optim import Optimizer, lr_scheduler\n\ntry:\n from torch.optim.lr_scheduler import LRScheduler\nexcept ImportError:\n # Backwards compatibility for PyTorch 1.x\n from torch.optim.lr_scheduler import _LRScheduler as LRScheduler\n\nfrom nerfstudio.configs.base_config import InstantiateConfig\n\n\n@dataclass\nclass SchedulerConfig(InstantiateConfig):\n \"\"\"Basic scheduler config\"\"\"\n\n _target: Type = field(default_factory=lambda: Scheduler)\n \"\"\"target class to instantiate\"\"\"\n\n\nclass Scheduler:\n \"\"\"Base scheduler\"\"\"\n\n config: SchedulerConfig\n\n def __init__(self, config: SchedulerConfig) -> None:\n super().__init__()\n self.config = config\n\n @abstractmethod\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n \"\"\"Abstract method that returns a scheduler object.\n\n Args:\n optimizer: The optimizer to use.\n lr_init: The initial learning rate.\n Returns:\n The scheduler object.\n \"\"\"\n\n\n@dataclass\nclass MultiStepSchedulerConfig(SchedulerConfig):\n \"\"\"Config for multi step scheduler where lr decays by gamma every milestone\"\"\"\n\n _target: Type = field(default_factory=lambda: MultiStepScheduler)\n \"\"\"target class to instantiate\"\"\"\n max_steps: int = 1000000\n \"\"\"The maximum number of steps.\"\"\"\n gamma: float = 0.33\n \"\"\"The learning rate decay factor.\"\"\"\n milestones: Tuple[int, ...] = (500000, 750000, 900000)\n \"\"\"The milestone steps at which to decay the learning rate.\"\"\"\n\n\nclass MultiStepScheduler(Scheduler):\n \"\"\"Multi step scheduler where lr decays by gamma every milestone\"\"\"\n\n config: MultiStepSchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n scheduler = lr_scheduler.MultiStepLR(\n optimizer=optimizer,\n milestones=self.config.milestones,\n gamma=self.config.gamma,\n )\n return scheduler\n\n\n@dataclass\nclass ExponentialDecaySchedulerConfig(SchedulerConfig):\n \"\"\"Config for exponential decay scheduler with warmup\"\"\"\n\n _target: Type = field(default_factory=lambda: ExponentialDecayScheduler)\n \"\"\"target class to instantiate\"\"\"\n lr_pre_warmup: float = 1e-8\n \"\"\"Learning rate before warmup.\"\"\"\n lr_final: Optional[float] = None\n \"\"\"Final learning rate. If not provided, it will be set to the optimizers learning rate.\"\"\"\n warmup_steps: int = 0\n \"\"\"Number of warmup steps.\"\"\"\n max_steps: int = 100000\n \"\"\"The maximum number of steps.\"\"\"\n ramp: Literal[\"linear\", \"cosine\"] = \"cosine\"\n \"\"\"The ramp function to use during the warmup.\"\"\"\n\n\nclass ExponentialDecayScheduler(Scheduler):\n \"\"\"Exponential decay scheduler with linear warmup. Scheduler first ramps up to `lr_init` in `warmup_steps`\n steps, then exponentially decays to `lr_final` in `max_steps` steps.\n \"\"\"\n\n config: ExponentialDecaySchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n if self.config.lr_final is None:\n lr_final = lr_init\n else:\n lr_final = self.config.lr_final\n\n def func(step):\n if step < self.config.warmup_steps:\n if self.config.ramp == \"cosine\":\n lr = self.config.lr_pre_warmup + (1 - self.config.lr_pre_warmup) * np.sin(\n 0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1)\n )\n else:\n lr = (\n self.config.lr_pre_warmup\n + (lr_init - self.config.lr_pre_warmup) * step / self.config.warmup_steps\n )\n else:\n t = np.clip(\n (step - self.config.warmup_steps) / (self.config.max_steps - self.config.warmup_steps), 0, 1\n )\n lr = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t)\n return lr / lr_init # divided by lr_init because the multiplier is with the initial learning rate\n\n scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)\n return scheduler\n\n\n@dataclass\nclass CosineDecaySchedulerConfig(SchedulerConfig):\n \"\"\"Config for cosine decay schedule\"\"\"\n\n _target: Type = field(default_factory=lambda: CosineDecayScheduler)\n \"\"\"target class to instantiate\"\"\"\n warm_up_end: int = 5000\n \"\"\"Iteration number where warmp ends\"\"\"\n learning_rate_alpha: float = 0.05\n \"\"\"Learning rate alpha value\"\"\"\n max_steps: int = 300000\n \"\"\"The maximum number of steps.\"\"\"\n\n\nclass CosineDecayScheduler(Scheduler):\n \"\"\"Cosine decay scheduler with linear warmup\"\"\"\n\n config: CosineDecaySchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n def func(step):\n if step < self.config.warm_up_end:\n learning_factor = step / self.config.warm_up_end\n else:\n alpha = self.config.learning_rate_alpha\n progress = (step - self.config.warm_up_end) / (self.config.max_steps - self.config.warm_up_end)\n learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha\n return learning_factor\n\n scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)\n return scheduler\n", "path": "nerfstudio/engine/schedulers.py"}], "after_files": [{"content": "# Copyright 2022 the Regents of the University of California, Nerfstudio Team and contributors. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n\"\"\"Scheduler Classes\"\"\"\n\nfrom abc import abstractmethod\nfrom dataclasses import dataclass, field\nfrom typing import Literal, Optional, Tuple, Type\n\nimport numpy as np\nfrom torch.optim import Optimizer, lr_scheduler\n\ntry:\n from torch.optim.lr_scheduler import LRScheduler\nexcept ImportError:\n # Backwards compatibility for PyTorch 1.x\n from torch.optim.lr_scheduler import _LRScheduler as LRScheduler\n\nfrom nerfstudio.configs.base_config import InstantiateConfig\n\n\n@dataclass\nclass SchedulerConfig(InstantiateConfig):\n \"\"\"Basic scheduler config\"\"\"\n\n _target: Type = field(default_factory=lambda: Scheduler)\n \"\"\"target class to instantiate\"\"\"\n\n\nclass Scheduler:\n \"\"\"Base scheduler\"\"\"\n\n config: SchedulerConfig\n\n def __init__(self, config: SchedulerConfig) -> None:\n super().__init__()\n self.config = config\n\n @abstractmethod\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n \"\"\"Abstract method that returns a scheduler object.\n\n Args:\n optimizer: The optimizer to use.\n lr_init: The initial learning rate.\n Returns:\n The scheduler object.\n \"\"\"\n\n\n@dataclass\nclass MultiStepSchedulerConfig(SchedulerConfig):\n \"\"\"Config for multi step scheduler where lr decays by gamma every milestone\"\"\"\n\n _target: Type = field(default_factory=lambda: MultiStepScheduler)\n \"\"\"target class to instantiate\"\"\"\n max_steps: int = 1000000\n \"\"\"The maximum number of steps.\"\"\"\n gamma: float = 0.33\n \"\"\"The learning rate decay factor.\"\"\"\n milestones: Tuple[int, ...] = (500000, 750000, 900000)\n \"\"\"The milestone steps at which to decay the learning rate.\"\"\"\n\n\nclass MultiStepScheduler(Scheduler):\n \"\"\"Multi step scheduler where lr decays by gamma every milestone\"\"\"\n\n config: MultiStepSchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n scheduler = lr_scheduler.MultiStepLR(\n optimizer=optimizer,\n milestones=self.config.milestones,\n gamma=self.config.gamma,\n )\n return scheduler\n\n\n@dataclass\nclass ExponentialDecaySchedulerConfig(SchedulerConfig):\n \"\"\"Config for exponential decay scheduler with warmup\"\"\"\n\n _target: Type = field(default_factory=lambda: ExponentialDecayScheduler)\n \"\"\"target class to instantiate\"\"\"\n lr_pre_warmup: float = 1e-8\n \"\"\"Learning rate before warmup.\"\"\"\n lr_final: Optional[float] = None\n \"\"\"Final learning rate. If not provided, it will be set to the optimizers learning rate.\"\"\"\n warmup_steps: int = 0\n \"\"\"Number of warmup steps.\"\"\"\n max_steps: int = 100000\n \"\"\"The maximum number of steps.\"\"\"\n ramp: Literal[\"linear\", \"cosine\"] = \"cosine\"\n \"\"\"The ramp function to use during the warmup.\"\"\"\n\n\nclass ExponentialDecayScheduler(Scheduler):\n \"\"\"Exponential decay scheduler with linear warmup. Scheduler first ramps up to `lr_init` in `warmup_steps`\n steps, then exponentially decays to `lr_final` in `max_steps` steps.\n \"\"\"\n\n config: ExponentialDecaySchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n if self.config.lr_final is None:\n lr_final = lr_init\n else:\n lr_final = self.config.lr_final\n\n def func(step):\n if step < self.config.warmup_steps:\n if self.config.ramp == \"cosine\":\n lr = self.config.lr_pre_warmup + (lr_init - self.config.lr_pre_warmup) * np.sin(\n 0.5 * np.pi * np.clip(step / self.config.warmup_steps, 0, 1)\n )\n else:\n lr = (\n self.config.lr_pre_warmup\n + (lr_init - self.config.lr_pre_warmup) * step / self.config.warmup_steps\n )\n else:\n t = np.clip(\n (step - self.config.warmup_steps) / (self.config.max_steps - self.config.warmup_steps), 0, 1\n )\n lr = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t)\n return lr / lr_init # divided by lr_init because the multiplier is with the initial learning rate\n\n scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)\n return scheduler\n\n\n@dataclass\nclass CosineDecaySchedulerConfig(SchedulerConfig):\n \"\"\"Config for cosine decay schedule\"\"\"\n\n _target: Type = field(default_factory=lambda: CosineDecayScheduler)\n \"\"\"target class to instantiate\"\"\"\n warm_up_end: int = 5000\n \"\"\"Iteration number where warmp ends\"\"\"\n learning_rate_alpha: float = 0.05\n \"\"\"Learning rate alpha value\"\"\"\n max_steps: int = 300000\n \"\"\"The maximum number of steps.\"\"\"\n\n\nclass CosineDecayScheduler(Scheduler):\n \"\"\"Cosine decay scheduler with linear warmup\"\"\"\n\n config: CosineDecaySchedulerConfig\n\n def get_scheduler(self, optimizer: Optimizer, lr_init: float) -> LRScheduler:\n def func(step):\n if step < self.config.warm_up_end:\n learning_factor = step / self.config.warm_up_end\n else:\n alpha = self.config.learning_rate_alpha\n progress = (step - self.config.warm_up_end) / (self.config.max_steps - self.config.warm_up_end)\n learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha\n return learning_factor\n\n scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=func)\n return scheduler\n", "path": "nerfstudio/engine/schedulers.py"}]} | 2,468 | 171 |
gh_patches_debug_12137 | rasdani/github-patches | git_diff | Textualize__rich-2029 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Incorrect type for print_json indent in __init__.py
**Describe the bug**
The type for `indent` (`indent: int = 2`) in `print_json` from the `__init__.py` file seems to be incorrect. In `console.py` it is typed as `indent: Union[None, int, str] = 2` and `print_json` in the init calls from console.py so it seems like they should have the same type.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rich/__init__.py`
Content:
```
1 """Rich text and beautiful formatting in the terminal."""
2
3 import os
4 from typing import Callable, IO, TYPE_CHECKING, Any, Optional
5
6 from ._extension import load_ipython_extension
7
8 __all__ = ["get_console", "reconfigure", "print", "inspect"]
9
10 if TYPE_CHECKING:
11 from .console import Console
12
13 # Global console used by alternative print
14 _console: Optional["Console"] = None
15
16 _IMPORT_CWD = os.path.abspath(os.getcwd())
17
18
19 def get_console() -> "Console":
20 """Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,
21 and hasn't been explicitly given one.
22
23 Returns:
24 Console: A console instance.
25 """
26 global _console
27 if _console is None:
28 from .console import Console
29
30 _console = Console()
31
32 return _console
33
34
35 def reconfigure(*args: Any, **kwargs: Any) -> None:
36 """Reconfigures the global console by replacing it with another.
37
38 Args:
39 console (Console): Replacement console instance.
40 """
41 from rich.console import Console
42
43 new_console = Console(*args, **kwargs)
44 _console = get_console()
45 _console.__dict__ = new_console.__dict__
46
47
48 def print(
49 *objects: Any,
50 sep: str = " ",
51 end: str = "\n",
52 file: Optional[IO[str]] = None,
53 flush: bool = False,
54 ) -> None:
55 r"""Print object(s) supplied via positional arguments.
56 This function has an identical signature to the built-in print.
57 For more advanced features, see the :class:`~rich.console.Console` class.
58
59 Args:
60 sep (str, optional): Separator between printed objects. Defaults to " ".
61 end (str, optional): Character to write at end of output. Defaults to "\\n".
62 file (IO[str], optional): File to write to, or None for stdout. Defaults to None.
63 flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.
64
65 """
66 from .console import Console
67
68 write_console = get_console() if file is None else Console(file=file)
69 return write_console.print(*objects, sep=sep, end=end)
70
71
72 def print_json(
73 json: Optional[str] = None,
74 *,
75 data: Any = None,
76 indent: int = 2,
77 highlight: bool = True,
78 skip_keys: bool = False,
79 ensure_ascii: bool = True,
80 check_circular: bool = True,
81 allow_nan: bool = True,
82 default: Optional[Callable[[Any], Any]] = None,
83 sort_keys: bool = False,
84 ) -> None:
85 """Pretty prints JSON. Output will be valid JSON.
86
87 Args:
88 json (str): A string containing JSON.
89 data (Any): If json is not supplied, then encode this data.
90 indent (int, optional): Number of spaces to indent. Defaults to 2.
91 highlight (bool, optional): Enable highlighting of output: Defaults to True.
92 skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
93 ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
94 check_circular (bool, optional): Check for circular references. Defaults to True.
95 allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
96 default (Callable, optional): A callable that converts values that can not be encoded
97 in to something that can be JSON encoded. Defaults to None.
98 sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
99 """
100
101 get_console().print_json(
102 json,
103 data=data,
104 indent=indent,
105 highlight=highlight,
106 skip_keys=skip_keys,
107 ensure_ascii=ensure_ascii,
108 check_circular=check_circular,
109 allow_nan=allow_nan,
110 default=default,
111 sort_keys=sort_keys,
112 )
113
114
115 def inspect(
116 obj: Any,
117 *,
118 console: Optional["Console"] = None,
119 title: Optional[str] = None,
120 help: bool = False,
121 methods: bool = False,
122 docs: bool = True,
123 private: bool = False,
124 dunder: bool = False,
125 sort: bool = True,
126 all: bool = False,
127 value: bool = True,
128 ) -> None:
129 """Inspect any Python object.
130
131 * inspect(<OBJECT>) to see summarized info.
132 * inspect(<OBJECT>, methods=True) to see methods.
133 * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.
134 * inspect(<OBJECT>, private=True) to see private attributes (single underscore).
135 * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.
136 * inspect(<OBJECT>, all=True) to see all attributes.
137
138 Args:
139 obj (Any): An object to inspect.
140 title (str, optional): Title to display over inspect result, or None use type. Defaults to None.
141 help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.
142 methods (bool, optional): Enable inspection of callables. Defaults to False.
143 docs (bool, optional): Also render doc strings. Defaults to True.
144 private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.
145 dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.
146 sort (bool, optional): Sort attributes alphabetically. Defaults to True.
147 all (bool, optional): Show all attributes. Defaults to False.
148 value (bool, optional): Pretty print value. Defaults to True.
149 """
150 _console = console or get_console()
151 from rich._inspect import Inspect
152
153 # Special case for inspect(inspect)
154 is_inspect = obj is inspect
155
156 _inspect = Inspect(
157 obj,
158 title=title,
159 help=is_inspect or help,
160 methods=is_inspect or methods,
161 docs=is_inspect or docs,
162 private=private,
163 dunder=dunder,
164 sort=sort,
165 all=all,
166 value=value,
167 )
168 _console.print(_inspect)
169
170
171 if __name__ == "__main__": # pragma: no cover
172 print("Hello, **World**")
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/rich/__init__.py b/rich/__init__.py
--- a/rich/__init__.py
+++ b/rich/__init__.py
@@ -1,7 +1,7 @@
"""Rich text and beautiful formatting in the terminal."""
import os
-from typing import Callable, IO, TYPE_CHECKING, Any, Optional
+from typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union
from ._extension import load_ipython_extension
@@ -73,7 +73,7 @@
json: Optional[str] = None,
*,
data: Any = None,
- indent: int = 2,
+ indent: Union[None, int, str] = 2,
highlight: bool = True,
skip_keys: bool = False,
ensure_ascii: bool = True,
| {"golden_diff": "diff --git a/rich/__init__.py b/rich/__init__.py\n--- a/rich/__init__.py\n+++ b/rich/__init__.py\n@@ -1,7 +1,7 @@\n \"\"\"Rich text and beautiful formatting in the terminal.\"\"\"\n \n import os\n-from typing import Callable, IO, TYPE_CHECKING, Any, Optional\n+from typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union\n \n from ._extension import load_ipython_extension\n \n@@ -73,7 +73,7 @@\n json: Optional[str] = None,\n *,\n data: Any = None,\n- indent: int = 2,\n+ indent: Union[None, int, str] = 2,\n highlight: bool = True,\n skip_keys: bool = False,\n ensure_ascii: bool = True,\n", "issue": "[BUG] Incorrect type for print_json indent in __init__.py\n**Describe the bug**\r\n\r\nThe type for `indent` (`indent: int = 2`) in `print_json` from the `__init__.py` file seems to be incorrect. In `console.py` it is typed as `indent: Union[None, int, str] = 2` and `print_json` in the init calls from console.py so it seems like they should have the same type.\n", "before_files": [{"content": "\"\"\"Rich text and beautiful formatting in the terminal.\"\"\"\n\nimport os\nfrom typing import Callable, IO, TYPE_CHECKING, Any, Optional\n\nfrom ._extension import load_ipython_extension\n\n__all__ = [\"get_console\", \"reconfigure\", \"print\", \"inspect\"]\n\nif TYPE_CHECKING:\n from .console import Console\n\n# Global console used by alternative print\n_console: Optional[\"Console\"] = None\n\n_IMPORT_CWD = os.path.abspath(os.getcwd())\n\n\ndef get_console() -> \"Console\":\n \"\"\"Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,\n and hasn't been explicitly given one.\n\n Returns:\n Console: A console instance.\n \"\"\"\n global _console\n if _console is None:\n from .console import Console\n\n _console = Console()\n\n return _console\n\n\ndef reconfigure(*args: Any, **kwargs: Any) -> None:\n \"\"\"Reconfigures the global console by replacing it with another.\n\n Args:\n console (Console): Replacement console instance.\n \"\"\"\n from rich.console import Console\n\n new_console = Console(*args, **kwargs)\n _console = get_console()\n _console.__dict__ = new_console.__dict__\n\n\ndef print(\n *objects: Any,\n sep: str = \" \",\n end: str = \"\\n\",\n file: Optional[IO[str]] = None,\n flush: bool = False,\n) -> None:\n r\"\"\"Print object(s) supplied via positional arguments.\n This function has an identical signature to the built-in print.\n For more advanced features, see the :class:`~rich.console.Console` class.\n\n Args:\n sep (str, optional): Separator between printed objects. Defaults to \" \".\n end (str, optional): Character to write at end of output. Defaults to \"\\\\n\".\n file (IO[str], optional): File to write to, or None for stdout. Defaults to None.\n flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.\n\n \"\"\"\n from .console import Console\n\n write_console = get_console() if file is None else Console(file=file)\n return write_console.print(*objects, sep=sep, end=end)\n\n\ndef print_json(\n json: Optional[str] = None,\n *,\n data: Any = None,\n indent: int = 2,\n highlight: bool = True,\n skip_keys: bool = False,\n ensure_ascii: bool = True,\n check_circular: bool = True,\n allow_nan: bool = True,\n default: Optional[Callable[[Any], Any]] = None,\n sort_keys: bool = False,\n) -> None:\n \"\"\"Pretty prints JSON. Output will be valid JSON.\n\n Args:\n json (str): A string containing JSON.\n data (Any): If json is not supplied, then encode this data.\n indent (int, optional): Number of spaces to indent. Defaults to 2.\n highlight (bool, optional): Enable highlighting of output: Defaults to True.\n skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.\n ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.\n check_circular (bool, optional): Check for circular references. Defaults to True.\n allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.\n default (Callable, optional): A callable that converts values that can not be encoded\n in to something that can be JSON encoded. Defaults to None.\n sort_keys (bool, optional): Sort dictionary keys. Defaults to False.\n \"\"\"\n\n get_console().print_json(\n json,\n data=data,\n indent=indent,\n highlight=highlight,\n skip_keys=skip_keys,\n ensure_ascii=ensure_ascii,\n check_circular=check_circular,\n allow_nan=allow_nan,\n default=default,\n sort_keys=sort_keys,\n )\n\n\ndef inspect(\n obj: Any,\n *,\n console: Optional[\"Console\"] = None,\n title: Optional[str] = None,\n help: bool = False,\n methods: bool = False,\n docs: bool = True,\n private: bool = False,\n dunder: bool = False,\n sort: bool = True,\n all: bool = False,\n value: bool = True,\n) -> None:\n \"\"\"Inspect any Python object.\n\n * inspect(<OBJECT>) to see summarized info.\n * inspect(<OBJECT>, methods=True) to see methods.\n * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.\n * inspect(<OBJECT>, private=True) to see private attributes (single underscore).\n * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.\n * inspect(<OBJECT>, all=True) to see all attributes.\n\n Args:\n obj (Any): An object to inspect.\n title (str, optional): Title to display over inspect result, or None use type. Defaults to None.\n help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.\n methods (bool, optional): Enable inspection of callables. Defaults to False.\n docs (bool, optional): Also render doc strings. Defaults to True.\n private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.\n dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.\n sort (bool, optional): Sort attributes alphabetically. Defaults to True.\n all (bool, optional): Show all attributes. Defaults to False.\n value (bool, optional): Pretty print value. Defaults to True.\n \"\"\"\n _console = console or get_console()\n from rich._inspect import Inspect\n\n # Special case for inspect(inspect)\n is_inspect = obj is inspect\n\n _inspect = Inspect(\n obj,\n title=title,\n help=is_inspect or help,\n methods=is_inspect or methods,\n docs=is_inspect or docs,\n private=private,\n dunder=dunder,\n sort=sort,\n all=all,\n value=value,\n )\n _console.print(_inspect)\n\n\nif __name__ == \"__main__\": # pragma: no cover\n print(\"Hello, **World**\")\n", "path": "rich/__init__.py"}], "after_files": [{"content": "\"\"\"Rich text and beautiful formatting in the terminal.\"\"\"\n\nimport os\nfrom typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union\n\nfrom ._extension import load_ipython_extension\n\n__all__ = [\"get_console\", \"reconfigure\", \"print\", \"inspect\"]\n\nif TYPE_CHECKING:\n from .console import Console\n\n# Global console used by alternative print\n_console: Optional[\"Console\"] = None\n\n_IMPORT_CWD = os.path.abspath(os.getcwd())\n\n\ndef get_console() -> \"Console\":\n \"\"\"Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,\n and hasn't been explicitly given one.\n\n Returns:\n Console: A console instance.\n \"\"\"\n global _console\n if _console is None:\n from .console import Console\n\n _console = Console()\n\n return _console\n\n\ndef reconfigure(*args: Any, **kwargs: Any) -> None:\n \"\"\"Reconfigures the global console by replacing it with another.\n\n Args:\n console (Console): Replacement console instance.\n \"\"\"\n from rich.console import Console\n\n new_console = Console(*args, **kwargs)\n _console = get_console()\n _console.__dict__ = new_console.__dict__\n\n\ndef print(\n *objects: Any,\n sep: str = \" \",\n end: str = \"\\n\",\n file: Optional[IO[str]] = None,\n flush: bool = False,\n) -> None:\n r\"\"\"Print object(s) supplied via positional arguments.\n This function has an identical signature to the built-in print.\n For more advanced features, see the :class:`~rich.console.Console` class.\n\n Args:\n sep (str, optional): Separator between printed objects. Defaults to \" \".\n end (str, optional): Character to write at end of output. Defaults to \"\\\\n\".\n file (IO[str], optional): File to write to, or None for stdout. Defaults to None.\n flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.\n\n \"\"\"\n from .console import Console\n\n write_console = get_console() if file is None else Console(file=file)\n return write_console.print(*objects, sep=sep, end=end)\n\n\ndef print_json(\n json: Optional[str] = None,\n *,\n data: Any = None,\n indent: Union[None, int, str] = 2,\n highlight: bool = True,\n skip_keys: bool = False,\n ensure_ascii: bool = True,\n check_circular: bool = True,\n allow_nan: bool = True,\n default: Optional[Callable[[Any], Any]] = None,\n sort_keys: bool = False,\n) -> None:\n \"\"\"Pretty prints JSON. Output will be valid JSON.\n\n Args:\n json (str): A string containing JSON.\n data (Any): If json is not supplied, then encode this data.\n indent (int, optional): Number of spaces to indent. Defaults to 2.\n highlight (bool, optional): Enable highlighting of output: Defaults to True.\n skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.\n ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.\n check_circular (bool, optional): Check for circular references. Defaults to True.\n allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.\n default (Callable, optional): A callable that converts values that can not be encoded\n in to something that can be JSON encoded. Defaults to None.\n sort_keys (bool, optional): Sort dictionary keys. Defaults to False.\n \"\"\"\n\n get_console().print_json(\n json,\n data=data,\n indent=indent,\n highlight=highlight,\n skip_keys=skip_keys,\n ensure_ascii=ensure_ascii,\n check_circular=check_circular,\n allow_nan=allow_nan,\n default=default,\n sort_keys=sort_keys,\n )\n\n\ndef inspect(\n obj: Any,\n *,\n console: Optional[\"Console\"] = None,\n title: Optional[str] = None,\n help: bool = False,\n methods: bool = False,\n docs: bool = True,\n private: bool = False,\n dunder: bool = False,\n sort: bool = True,\n all: bool = False,\n value: bool = True,\n) -> None:\n \"\"\"Inspect any Python object.\n\n * inspect(<OBJECT>) to see summarized info.\n * inspect(<OBJECT>, methods=True) to see methods.\n * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.\n * inspect(<OBJECT>, private=True) to see private attributes (single underscore).\n * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.\n * inspect(<OBJECT>, all=True) to see all attributes.\n\n Args:\n obj (Any): An object to inspect.\n title (str, optional): Title to display over inspect result, or None use type. Defaults to None.\n help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.\n methods (bool, optional): Enable inspection of callables. Defaults to False.\n docs (bool, optional): Also render doc strings. Defaults to True.\n private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.\n dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.\n sort (bool, optional): Sort attributes alphabetically. Defaults to True.\n all (bool, optional): Show all attributes. Defaults to False.\n value (bool, optional): Pretty print value. Defaults to True.\n \"\"\"\n _console = console or get_console()\n from rich._inspect import Inspect\n\n # Special case for inspect(inspect)\n is_inspect = obj is inspect\n\n _inspect = Inspect(\n obj,\n title=title,\n help=is_inspect or help,\n methods=is_inspect or methods,\n docs=is_inspect or docs,\n private=private,\n dunder=dunder,\n sort=sort,\n all=all,\n value=value,\n )\n _console.print(_inspect)\n\n\nif __name__ == \"__main__\": # pragma: no cover\n print(\"Hello, **World**\")\n", "path": "rich/__init__.py"}]} | 2,136 | 180 |
gh_patches_debug_33079 | rasdani/github-patches | git_diff | ytdl-org__youtube-dl-16054 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to download videos from http://channel.nationalgeographic.com.
Example:
$ youtube-dl -v "http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/"
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['-v', 'http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2018.03.26.1
[debug] Python version 3.4.2 (CPython) - Linux-3.16.0-5-amd64-x86_64-with-debian-8.10
[debug] exe versions: ffmpeg 3.2.10-1, ffprobe 3.2.10-1, rtmpdump 2.4
[debug] Proxy map: {}
[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Requesting header
WARNING: Falling back on generic information extractor.
[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Downloading webpage
[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Extracting information
ERROR: Unsupported URL: http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/
Traceback (most recent call last):
File "/home/ant/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 785, in extract_info
ie_result = ie.extract(url)
File "/home/ant/bin/youtube-dl/youtube_dl/extractor/common.py", line 440, in extract
ie_result = self._real_extract(url)
File "/home/ant/bin/youtube-dl/youtube_dl/extractor/generic.py", line 3143, in _real_extract
raise UnsupportedError(url)
youtube_dl.utils.UnsupportedError: Unsupported URL: http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/
Thank you in advance. :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/nationalgeographic.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import re
4
5 from .common import InfoExtractor
6 from .adobepass import AdobePassIE
7 from .theplatform import ThePlatformIE
8 from ..utils import (
9 smuggle_url,
10 url_basename,
11 update_url_query,
12 get_element_by_class,
13 )
14
15
16 class NationalGeographicVideoIE(InfoExtractor):
17 IE_NAME = 'natgeo:video'
18 _VALID_URL = r'https?://video\.nationalgeographic\.com/.*?'
19
20 _TESTS = [
21 {
22 'url': 'http://video.nationalgeographic.com/video/news/150210-news-crab-mating-vin?source=featuredvideo',
23 'md5': '730855d559abbad6b42c2be1fa584917',
24 'info_dict': {
25 'id': '0000014b-70a1-dd8c-af7f-f7b559330001',
26 'ext': 'mp4',
27 'title': 'Mating Crabs Busted by Sharks',
28 'description': 'md5:16f25aeffdeba55aaa8ec37e093ad8b3',
29 'timestamp': 1423523799,
30 'upload_date': '20150209',
31 'uploader': 'NAGS',
32 },
33 'add_ie': ['ThePlatform'],
34 },
35 {
36 'url': 'http://video.nationalgeographic.com/wild/when-sharks-attack/the-real-jaws',
37 'md5': '6a3105eb448c070503b3105fb9b320b5',
38 'info_dict': {
39 'id': 'ngc-I0IauNSWznb_UV008GxSbwY35BZvgi2e',
40 'ext': 'mp4',
41 'title': 'The Real Jaws',
42 'description': 'md5:8d3e09d9d53a85cd397b4b21b2c77be6',
43 'timestamp': 1433772632,
44 'upload_date': '20150608',
45 'uploader': 'NAGS',
46 },
47 'add_ie': ['ThePlatform'],
48 },
49 ]
50
51 def _real_extract(self, url):
52 name = url_basename(url)
53
54 webpage = self._download_webpage(url, name)
55 guid = self._search_regex(
56 r'id="(?:videoPlayer|player-container)"[^>]+data-guid="([^"]+)"',
57 webpage, 'guid')
58
59 return {
60 '_type': 'url_transparent',
61 'ie_key': 'ThePlatform',
62 'url': smuggle_url(
63 'http://link.theplatform.com/s/ngs/media/guid/2423130747/%s?mbr=true' % guid,
64 {'force_smil_url': True}),
65 'id': guid,
66 }
67
68
69 class NationalGeographicIE(ThePlatformIE, AdobePassIE):
70 IE_NAME = 'natgeo'
71 _VALID_URL = r'https?://channel\.nationalgeographic\.com/(?:(?:wild/)?[^/]+/)?(?:videos|episodes)/(?P<id>[^/?]+)'
72
73 _TESTS = [
74 {
75 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',
76 'md5': '518c9aa655686cf81493af5cc21e2a04',
77 'info_dict': {
78 'id': 'vKInpacll2pC',
79 'ext': 'mp4',
80 'title': 'Uncovering a Universal Knowledge',
81 'description': 'md5:1a89148475bf931b3661fcd6ddb2ae3a',
82 'timestamp': 1458680907,
83 'upload_date': '20160322',
84 'uploader': 'NEWA-FNG-NGTV',
85 },
86 'add_ie': ['ThePlatform'],
87 },
88 {
89 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',
90 'md5': 'c4912f656b4cbe58f3e000c489360989',
91 'info_dict': {
92 'id': 'Pok5lWCkiEFA',
93 'ext': 'mp4',
94 'title': 'The Stunning Red Bird of Paradise',
95 'description': 'md5:7bc8cd1da29686be4d17ad1230f0140c',
96 'timestamp': 1459362152,
97 'upload_date': '20160330',
98 'uploader': 'NEWA-FNG-NGTV',
99 },
100 'add_ie': ['ThePlatform'],
101 },
102 {
103 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episodes/the-power-of-miracles/',
104 'only_matching': True,
105 },
106 {
107 'url': 'http://channel.nationalgeographic.com/videos/treasures-rediscovered/',
108 'only_matching': True,
109 }
110 ]
111
112 def _real_extract(self, url):
113 display_id = self._match_id(url)
114 webpage = self._download_webpage(url, display_id)
115 release_url = self._search_regex(
116 r'video_auth_playlist_url\s*=\s*"([^"]+)"',
117 webpage, 'release url')
118 theplatform_path = self._search_regex(r'https?://link\.theplatform\.com/s/([^?]+)', release_url, 'theplatform path')
119 video_id = theplatform_path.split('/')[-1]
120 query = {
121 'mbr': 'true',
122 }
123 is_auth = self._search_regex(r'video_is_auth\s*=\s*"([^"]+)"', webpage, 'is auth', fatal=False)
124 if is_auth == 'auth':
125 auth_resource_id = self._search_regex(
126 r"video_auth_resourceId\s*=\s*'([^']+)'",
127 webpage, 'auth resource id')
128 query['auth'] = self._extract_mvpd_auth(url, video_id, 'natgeo', auth_resource_id)
129
130 formats = []
131 subtitles = {}
132 for key, value in (('switch', 'http'), ('manifest', 'm3u')):
133 tp_query = query.copy()
134 tp_query.update({
135 key: value,
136 })
137 tp_formats, tp_subtitles = self._extract_theplatform_smil(
138 update_url_query(release_url, tp_query), video_id, 'Downloading %s SMIL data' % value)
139 formats.extend(tp_formats)
140 subtitles = self._merge_subtitles(subtitles, tp_subtitles)
141 self._sort_formats(formats)
142
143 info = self._extract_theplatform_metadata(theplatform_path, display_id)
144 info.update({
145 'id': video_id,
146 'formats': formats,
147 'subtitles': subtitles,
148 'display_id': display_id,
149 })
150 return info
151
152
153 class NationalGeographicEpisodeGuideIE(InfoExtractor):
154 IE_NAME = 'natgeo:episodeguide'
155 _VALID_URL = r'https?://channel\.nationalgeographic\.com/(?:wild/)?(?P<id>[^/]+)/episode-guide'
156 _TESTS = [
157 {
158 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episode-guide/',
159 'info_dict': {
160 'id': 'the-story-of-god-with-morgan-freeman-season-1',
161 'title': 'The Story of God with Morgan Freeman - Season 1',
162 },
163 'playlist_mincount': 6,
164 },
165 {
166 'url': 'http://channel.nationalgeographic.com/underworld-inc/episode-guide/?s=2',
167 'info_dict': {
168 'id': 'underworld-inc-season-2',
169 'title': 'Underworld, Inc. - Season 2',
170 },
171 'playlist_mincount': 7,
172 },
173 ]
174
175 def _real_extract(self, url):
176 display_id = self._match_id(url)
177 webpage = self._download_webpage(url, display_id)
178 show = get_element_by_class('show', webpage)
179 selected_season = self._search_regex(
180 r'<div[^>]+class="select-seasons[^"]*".*?<a[^>]*>(.*?)</a>',
181 webpage, 'selected season')
182 entries = [
183 self.url_result(self._proto_relative_url(entry_url), 'NationalGeographic')
184 for entry_url in re.findall('(?s)<div[^>]+class="col-inner"[^>]*?>.*?<a[^>]+href="([^"]+)"', webpage)]
185 return self.playlist_result(
186 entries, '%s-%s' % (display_id, selected_season.lower().replace(' ', '-')),
187 '%s - %s' % (show, selected_season))
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/youtube_dl/extractor/nationalgeographic.py b/youtube_dl/extractor/nationalgeographic.py
--- a/youtube_dl/extractor/nationalgeographic.py
+++ b/youtube_dl/extractor/nationalgeographic.py
@@ -68,11 +68,11 @@
class NationalGeographicIE(ThePlatformIE, AdobePassIE):
IE_NAME = 'natgeo'
- _VALID_URL = r'https?://channel\.nationalgeographic\.com/(?:(?:wild/)?[^/]+/)?(?:videos|episodes)/(?P<id>[^/?]+)'
+ _VALID_URL = r'https?://channel\.nationalgeographic\.com/(?:(?:(?:wild/)?[^/]+/)?(?:videos|episodes)|u)/(?P<id>[^/?]+)'
_TESTS = [
{
- 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',
+ 'url': 'http://channel.nationalgeographic.com/u/kdi9Ld0PN2molUUIMSBGxoeDhD729KRjQcnxtetilWPMevo8ZwUBIDuPR0Q3D2LVaTsk0MPRkRWDB8ZhqWVeyoxfsZZm36yRp1j-zPfsHEyI_EgAeFY/',
'md5': '518c9aa655686cf81493af5cc21e2a04',
'info_dict': {
'id': 'vKInpacll2pC',
@@ -86,7 +86,7 @@
'add_ie': ['ThePlatform'],
},
{
- 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',
+ 'url': 'http://channel.nationalgeographic.com/u/kdvOstqYaBY-vSBPyYgAZRUL4sWUJ5XUUPEhc7ISyBHqoIO4_dzfY3K6EjHIC0hmFXoQ7Cpzm6RkET7S3oMlm6CFnrQwSUwo/',
'md5': 'c4912f656b4cbe58f3e000c489360989',
'info_dict': {
'id': 'Pok5lWCkiEFA',
@@ -106,6 +106,14 @@
{
'url': 'http://channel.nationalgeographic.com/videos/treasures-rediscovered/',
'only_matching': True,
+ },
+ {
+ 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',
+ 'only_matching': True,
+ },
+ {
+ 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',
+ 'only_matching': True,
}
]
| {"golden_diff": "diff --git a/youtube_dl/extractor/nationalgeographic.py b/youtube_dl/extractor/nationalgeographic.py\n--- a/youtube_dl/extractor/nationalgeographic.py\n+++ b/youtube_dl/extractor/nationalgeographic.py\n@@ -68,11 +68,11 @@\n \n class NationalGeographicIE(ThePlatformIE, AdobePassIE):\n IE_NAME = 'natgeo'\n- _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:(?:wild/)?[^/]+/)?(?:videos|episodes)/(?P<id>[^/?]+)'\n+ _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:(?:(?:wild/)?[^/]+/)?(?:videos|episodes)|u)/(?P<id>[^/?]+)'\n \n _TESTS = [\n {\n- 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',\n+ 'url': 'http://channel.nationalgeographic.com/u/kdi9Ld0PN2molUUIMSBGxoeDhD729KRjQcnxtetilWPMevo8ZwUBIDuPR0Q3D2LVaTsk0MPRkRWDB8ZhqWVeyoxfsZZm36yRp1j-zPfsHEyI_EgAeFY/',\n 'md5': '518c9aa655686cf81493af5cc21e2a04',\n 'info_dict': {\n 'id': 'vKInpacll2pC',\n@@ -86,7 +86,7 @@\n 'add_ie': ['ThePlatform'],\n },\n {\n- 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',\n+ 'url': 'http://channel.nationalgeographic.com/u/kdvOstqYaBY-vSBPyYgAZRUL4sWUJ5XUUPEhc7ISyBHqoIO4_dzfY3K6EjHIC0hmFXoQ7Cpzm6RkET7S3oMlm6CFnrQwSUwo/',\n 'md5': 'c4912f656b4cbe58f3e000c489360989',\n 'info_dict': {\n 'id': 'Pok5lWCkiEFA',\n@@ -106,6 +106,14 @@\n {\n 'url': 'http://channel.nationalgeographic.com/videos/treasures-rediscovered/',\n 'only_matching': True,\n+ },\n+ {\n+ 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',\n+ 'only_matching': True,\n+ },\n+ {\n+ 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',\n+ 'only_matching': True,\n }\n ]\n", "issue": "Unable to download videos from http://channel.nationalgeographic.com.\nExample:\r\n\r\n$ youtube-dl -v \"http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/\"\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: ['-v', 'http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/']\r\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2018.03.26.1\r\n[debug] Python version 3.4.2 (CPython) - Linux-3.16.0-5-amd64-x86_64-with-debian-8.10\r\n[debug] exe versions: ffmpeg 3.2.10-1, ffprobe 3.2.10-1, rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Requesting header\r\nWARNING: Falling back on generic information extractor.\r\n[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Downloading webpage\r\n[generic] kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg: Extracting information\r\nERROR: Unsupported URL: http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/\r\nTraceback (most recent call last):\r\n File \"/home/ant/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 785, in extract_info\r\n ie_result = ie.extract(url)\r\n File \"/home/ant/bin/youtube-dl/youtube_dl/extractor/common.py\", line 440, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/home/ant/bin/youtube-dl/youtube_dl/extractor/generic.py\", line 3143, in _real_extract\r\n raise UnsupportedError(url)\r\nyoutube_dl.utils.UnsupportedError: Unsupported URL: http://channel.nationalgeographic.com/u/kcOIVhcWjca1n65QtmFg_5vIMZ9j1S1CXT46o65HkAANx6SUvJvQAQfYjGC0CkQwGNSgnX54f2aoFg/\r\n\r\nThank you in advance. :)\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom .adobepass import AdobePassIE\nfrom .theplatform import ThePlatformIE\nfrom ..utils import (\n smuggle_url,\n url_basename,\n update_url_query,\n get_element_by_class,\n)\n\n\nclass NationalGeographicVideoIE(InfoExtractor):\n IE_NAME = 'natgeo:video'\n _VALID_URL = r'https?://video\\.nationalgeographic\\.com/.*?'\n\n _TESTS = [\n {\n 'url': 'http://video.nationalgeographic.com/video/news/150210-news-crab-mating-vin?source=featuredvideo',\n 'md5': '730855d559abbad6b42c2be1fa584917',\n 'info_dict': {\n 'id': '0000014b-70a1-dd8c-af7f-f7b559330001',\n 'ext': 'mp4',\n 'title': 'Mating Crabs Busted by Sharks',\n 'description': 'md5:16f25aeffdeba55aaa8ec37e093ad8b3',\n 'timestamp': 1423523799,\n 'upload_date': '20150209',\n 'uploader': 'NAGS',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://video.nationalgeographic.com/wild/when-sharks-attack/the-real-jaws',\n 'md5': '6a3105eb448c070503b3105fb9b320b5',\n 'info_dict': {\n 'id': 'ngc-I0IauNSWznb_UV008GxSbwY35BZvgi2e',\n 'ext': 'mp4',\n 'title': 'The Real Jaws',\n 'description': 'md5:8d3e09d9d53a85cd397b4b21b2c77be6',\n 'timestamp': 1433772632,\n 'upload_date': '20150608',\n 'uploader': 'NAGS',\n },\n 'add_ie': ['ThePlatform'],\n },\n ]\n\n def _real_extract(self, url):\n name = url_basename(url)\n\n webpage = self._download_webpage(url, name)\n guid = self._search_regex(\n r'id=\"(?:videoPlayer|player-container)\"[^>]+data-guid=\"([^\"]+)\"',\n webpage, 'guid')\n\n return {\n '_type': 'url_transparent',\n 'ie_key': 'ThePlatform',\n 'url': smuggle_url(\n 'http://link.theplatform.com/s/ngs/media/guid/2423130747/%s?mbr=true' % guid,\n {'force_smil_url': True}),\n 'id': guid,\n }\n\n\nclass NationalGeographicIE(ThePlatformIE, AdobePassIE):\n IE_NAME = 'natgeo'\n _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:(?:wild/)?[^/]+/)?(?:videos|episodes)/(?P<id>[^/?]+)'\n\n _TESTS = [\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',\n 'md5': '518c9aa655686cf81493af5cc21e2a04',\n 'info_dict': {\n 'id': 'vKInpacll2pC',\n 'ext': 'mp4',\n 'title': 'Uncovering a Universal Knowledge',\n 'description': 'md5:1a89148475bf931b3661fcd6ddb2ae3a',\n 'timestamp': 1458680907,\n 'upload_date': '20160322',\n 'uploader': 'NEWA-FNG-NGTV',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',\n 'md5': 'c4912f656b4cbe58f3e000c489360989',\n 'info_dict': {\n 'id': 'Pok5lWCkiEFA',\n 'ext': 'mp4',\n 'title': 'The Stunning Red Bird of Paradise',\n 'description': 'md5:7bc8cd1da29686be4d17ad1230f0140c',\n 'timestamp': 1459362152,\n 'upload_date': '20160330',\n 'uploader': 'NEWA-FNG-NGTV',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episodes/the-power-of-miracles/',\n 'only_matching': True,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/videos/treasures-rediscovered/',\n 'only_matching': True,\n }\n ]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n release_url = self._search_regex(\n r'video_auth_playlist_url\\s*=\\s*\"([^\"]+)\"',\n webpage, 'release url')\n theplatform_path = self._search_regex(r'https?://link\\.theplatform\\.com/s/([^?]+)', release_url, 'theplatform path')\n video_id = theplatform_path.split('/')[-1]\n query = {\n 'mbr': 'true',\n }\n is_auth = self._search_regex(r'video_is_auth\\s*=\\s*\"([^\"]+)\"', webpage, 'is auth', fatal=False)\n if is_auth == 'auth':\n auth_resource_id = self._search_regex(\n r\"video_auth_resourceId\\s*=\\s*'([^']+)'\",\n webpage, 'auth resource id')\n query['auth'] = self._extract_mvpd_auth(url, video_id, 'natgeo', auth_resource_id)\n\n formats = []\n subtitles = {}\n for key, value in (('switch', 'http'), ('manifest', 'm3u')):\n tp_query = query.copy()\n tp_query.update({\n key: value,\n })\n tp_formats, tp_subtitles = self._extract_theplatform_smil(\n update_url_query(release_url, tp_query), video_id, 'Downloading %s SMIL data' % value)\n formats.extend(tp_formats)\n subtitles = self._merge_subtitles(subtitles, tp_subtitles)\n self._sort_formats(formats)\n\n info = self._extract_theplatform_metadata(theplatform_path, display_id)\n info.update({\n 'id': video_id,\n 'formats': formats,\n 'subtitles': subtitles,\n 'display_id': display_id,\n })\n return info\n\n\nclass NationalGeographicEpisodeGuideIE(InfoExtractor):\n IE_NAME = 'natgeo:episodeguide'\n _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:wild/)?(?P<id>[^/]+)/episode-guide'\n _TESTS = [\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episode-guide/',\n 'info_dict': {\n 'id': 'the-story-of-god-with-morgan-freeman-season-1',\n 'title': 'The Story of God with Morgan Freeman - Season 1',\n },\n 'playlist_mincount': 6,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/underworld-inc/episode-guide/?s=2',\n 'info_dict': {\n 'id': 'underworld-inc-season-2',\n 'title': 'Underworld, Inc. - Season 2',\n },\n 'playlist_mincount': 7,\n },\n ]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n show = get_element_by_class('show', webpage)\n selected_season = self._search_regex(\n r'<div[^>]+class=\"select-seasons[^\"]*\".*?<a[^>]*>(.*?)</a>',\n webpage, 'selected season')\n entries = [\n self.url_result(self._proto_relative_url(entry_url), 'NationalGeographic')\n for entry_url in re.findall('(?s)<div[^>]+class=\"col-inner\"[^>]*?>.*?<a[^>]+href=\"([^\"]+)\"', webpage)]\n return self.playlist_result(\n entries, '%s-%s' % (display_id, selected_season.lower().replace(' ', '-')),\n '%s - %s' % (show, selected_season))\n", "path": "youtube_dl/extractor/nationalgeographic.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom .adobepass import AdobePassIE\nfrom .theplatform import ThePlatformIE\nfrom ..utils import (\n smuggle_url,\n url_basename,\n update_url_query,\n get_element_by_class,\n)\n\n\nclass NationalGeographicVideoIE(InfoExtractor):\n IE_NAME = 'natgeo:video'\n _VALID_URL = r'https?://video\\.nationalgeographic\\.com/.*?'\n\n _TESTS = [\n {\n 'url': 'http://video.nationalgeographic.com/video/news/150210-news-crab-mating-vin?source=featuredvideo',\n 'md5': '730855d559abbad6b42c2be1fa584917',\n 'info_dict': {\n 'id': '0000014b-70a1-dd8c-af7f-f7b559330001',\n 'ext': 'mp4',\n 'title': 'Mating Crabs Busted by Sharks',\n 'description': 'md5:16f25aeffdeba55aaa8ec37e093ad8b3',\n 'timestamp': 1423523799,\n 'upload_date': '20150209',\n 'uploader': 'NAGS',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://video.nationalgeographic.com/wild/when-sharks-attack/the-real-jaws',\n 'md5': '6a3105eb448c070503b3105fb9b320b5',\n 'info_dict': {\n 'id': 'ngc-I0IauNSWznb_UV008GxSbwY35BZvgi2e',\n 'ext': 'mp4',\n 'title': 'The Real Jaws',\n 'description': 'md5:8d3e09d9d53a85cd397b4b21b2c77be6',\n 'timestamp': 1433772632,\n 'upload_date': '20150608',\n 'uploader': 'NAGS',\n },\n 'add_ie': ['ThePlatform'],\n },\n ]\n\n def _real_extract(self, url):\n name = url_basename(url)\n\n webpage = self._download_webpage(url, name)\n guid = self._search_regex(\n r'id=\"(?:videoPlayer|player-container)\"[^>]+data-guid=\"([^\"]+)\"',\n webpage, 'guid')\n\n return {\n '_type': 'url_transparent',\n 'ie_key': 'ThePlatform',\n 'url': smuggle_url(\n 'http://link.theplatform.com/s/ngs/media/guid/2423130747/%s?mbr=true' % guid,\n {'force_smil_url': True}),\n 'id': guid,\n }\n\n\nclass NationalGeographicIE(ThePlatformIE, AdobePassIE):\n IE_NAME = 'natgeo'\n _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:(?:(?:wild/)?[^/]+/)?(?:videos|episodes)|u)/(?P<id>[^/?]+)'\n\n _TESTS = [\n {\n 'url': 'http://channel.nationalgeographic.com/u/kdi9Ld0PN2molUUIMSBGxoeDhD729KRjQcnxtetilWPMevo8ZwUBIDuPR0Q3D2LVaTsk0MPRkRWDB8ZhqWVeyoxfsZZm36yRp1j-zPfsHEyI_EgAeFY/',\n 'md5': '518c9aa655686cf81493af5cc21e2a04',\n 'info_dict': {\n 'id': 'vKInpacll2pC',\n 'ext': 'mp4',\n 'title': 'Uncovering a Universal Knowledge',\n 'description': 'md5:1a89148475bf931b3661fcd6ddb2ae3a',\n 'timestamp': 1458680907,\n 'upload_date': '20160322',\n 'uploader': 'NEWA-FNG-NGTV',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://channel.nationalgeographic.com/u/kdvOstqYaBY-vSBPyYgAZRUL4sWUJ5XUUPEhc7ISyBHqoIO4_dzfY3K6EjHIC0hmFXoQ7Cpzm6RkET7S3oMlm6CFnrQwSUwo/',\n 'md5': 'c4912f656b4cbe58f3e000c489360989',\n 'info_dict': {\n 'id': 'Pok5lWCkiEFA',\n 'ext': 'mp4',\n 'title': 'The Stunning Red Bird of Paradise',\n 'description': 'md5:7bc8cd1da29686be4d17ad1230f0140c',\n 'timestamp': 1459362152,\n 'upload_date': '20160330',\n 'uploader': 'NEWA-FNG-NGTV',\n },\n 'add_ie': ['ThePlatform'],\n },\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episodes/the-power-of-miracles/',\n 'only_matching': True,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/videos/treasures-rediscovered/',\n 'only_matching': True,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/videos/uncovering-a-universal-knowledge/',\n 'only_matching': True,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/wild/destination-wild/videos/the-stunning-red-bird-of-paradise/',\n 'only_matching': True,\n }\n ]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n release_url = self._search_regex(\n r'video_auth_playlist_url\\s*=\\s*\"([^\"]+)\"',\n webpage, 'release url')\n theplatform_path = self._search_regex(r'https?://link\\.theplatform\\.com/s/([^?]+)', release_url, 'theplatform path')\n video_id = theplatform_path.split('/')[-1]\n query = {\n 'mbr': 'true',\n }\n is_auth = self._search_regex(r'video_is_auth\\s*=\\s*\"([^\"]+)\"', webpage, 'is auth', fatal=False)\n if is_auth == 'auth':\n auth_resource_id = self._search_regex(\n r\"video_auth_resourceId\\s*=\\s*'([^']+)'\",\n webpage, 'auth resource id')\n query['auth'] = self._extract_mvpd_auth(url, video_id, 'natgeo', auth_resource_id)\n\n formats = []\n subtitles = {}\n for key, value in (('switch', 'http'), ('manifest', 'm3u')):\n tp_query = query.copy()\n tp_query.update({\n key: value,\n })\n tp_formats, tp_subtitles = self._extract_theplatform_smil(\n update_url_query(release_url, tp_query), video_id, 'Downloading %s SMIL data' % value)\n formats.extend(tp_formats)\n subtitles = self._merge_subtitles(subtitles, tp_subtitles)\n self._sort_formats(formats)\n\n info = self._extract_theplatform_metadata(theplatform_path, display_id)\n info.update({\n 'id': video_id,\n 'formats': formats,\n 'subtitles': subtitles,\n 'display_id': display_id,\n })\n return info\n\n\nclass NationalGeographicEpisodeGuideIE(InfoExtractor):\n IE_NAME = 'natgeo:episodeguide'\n _VALID_URL = r'https?://channel\\.nationalgeographic\\.com/(?:wild/)?(?P<id>[^/]+)/episode-guide'\n _TESTS = [\n {\n 'url': 'http://channel.nationalgeographic.com/the-story-of-god-with-morgan-freeman/episode-guide/',\n 'info_dict': {\n 'id': 'the-story-of-god-with-morgan-freeman-season-1',\n 'title': 'The Story of God with Morgan Freeman - Season 1',\n },\n 'playlist_mincount': 6,\n },\n {\n 'url': 'http://channel.nationalgeographic.com/underworld-inc/episode-guide/?s=2',\n 'info_dict': {\n 'id': 'underworld-inc-season-2',\n 'title': 'Underworld, Inc. - Season 2',\n },\n 'playlist_mincount': 7,\n },\n ]\n\n def _real_extract(self, url):\n display_id = self._match_id(url)\n webpage = self._download_webpage(url, display_id)\n show = get_element_by_class('show', webpage)\n selected_season = self._search_regex(\n r'<div[^>]+class=\"select-seasons[^\"]*\".*?<a[^>]*>(.*?)</a>',\n webpage, 'selected season')\n entries = [\n self.url_result(self._proto_relative_url(entry_url), 'NationalGeographic')\n for entry_url in re.findall('(?s)<div[^>]+class=\"col-inner\"[^>]*?>.*?<a[^>]+href=\"([^\"]+)\"', webpage)]\n return self.playlist_result(\n entries, '%s-%s' % (display_id, selected_season.lower().replace(' ', '-')),\n '%s - %s' % (show, selected_season))\n", "path": "youtube_dl/extractor/nationalgeographic.py"}]} | 3,651 | 719 |
gh_patches_debug_1103 | rasdani/github-patches | git_diff | Pylons__pyramid-2226 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update to Sphinx 1.3.4 when released
There is a [bug in Sphinx 1.3.3 and 1.3.1](https://github.com/sphinx-doc/sphinx/issues/2189) (I haven't tried 1.3.2) where next and previous links in Sphinx documentation are broken when going into children and across sibling directories.
When 1.3.4 is released, we need to pin sphinx to 1.3.4, which will include the commit made 8 days after the 1.3.3 release.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 ##############################################################################
2 #
3 # Copyright (c) 2008-2013 Agendaless Consulting and Contributors.
4 # All Rights Reserved.
5 #
6 # This software is subject to the provisions of the BSD-like license at
7 # http://www.repoze.org/LICENSE.txt. A copy of the license should accompany
8 # this distribution. THIS SOFTWARE IS PROVIDED "AS IS" AND ANY AND ALL
9 # EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,
10 # THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND
11 # FITNESS FOR A PARTICULAR PURPOSE
12 #
13 ##############################################################################
14
15 import os
16 import sys
17
18 from setuptools import setup, find_packages
19
20 py_version = sys.version_info[:2]
21
22 PY3 = py_version[0] == 3
23
24 if PY3:
25 if py_version < (3, 2):
26 raise RuntimeError('On Python 3, Pyramid requires Python 3.2 or better')
27 else:
28 if py_version < (2, 6):
29 raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')
30
31 here = os.path.abspath(os.path.dirname(__file__))
32 try:
33 with open(os.path.join(here, 'README.rst')) as f:
34 README = f.read()
35 with open(os.path.join(here, 'CHANGES.txt')) as f:
36 CHANGES = f.read()
37 except IOError:
38 README = CHANGES = ''
39
40 install_requires=[
41 'setuptools',
42 'WebOb >= 1.3.1', # request.domain and CookieProfile
43 'repoze.lru >= 0.4', # py3 compat
44 'zope.interface >= 3.8.0', # has zope.interface.registry
45 'zope.deprecation >= 3.5.0', # py3 compat
46 'venusian >= 1.0a3', # ``ignore``
47 'translationstring >= 0.4', # py3 compat
48 'PasteDeploy >= 1.5.0', # py3 compat
49 ]
50
51 tests_require = [
52 'WebTest >= 1.3.1', # py3 compat
53 ]
54
55 if not PY3:
56 tests_require.append('zope.component>=3.11.0')
57
58 docs_extras = [
59 'Sphinx >= 1.3.1',
60 'docutils',
61 'repoze.sphinx.autointerface',
62 'pylons_sphinx_latesturl',
63 'pylons-sphinx-themes',
64 'sphinxcontrib-programoutput',
65 ]
66
67 testing_extras = tests_require + [
68 'nose',
69 'coverage',
70 'virtualenv', # for scaffolding tests
71 ]
72
73 setup(name='pyramid',
74 version='1.5.8',
75 description='The Pyramid Web Framework, a Pylons project',
76 long_description=README + '\n\n' + CHANGES,
77 classifiers=[
78 "Intended Audience :: Developers",
79 "Programming Language :: Python",
80 "Programming Language :: Python :: 2.6",
81 "Programming Language :: Python :: 2.7",
82 "Programming Language :: Python :: 3",
83 "Programming Language :: Python :: 3.2",
84 "Programming Language :: Python :: 3.3",
85 "Programming Language :: Python :: 3.4",
86 "Programming Language :: Python :: 3.5",
87 "Programming Language :: Python :: Implementation :: CPython",
88 "Programming Language :: Python :: Implementation :: PyPy",
89 "Framework :: Pyramid",
90 "Topic :: Internet :: WWW/HTTP",
91 "Topic :: Internet :: WWW/HTTP :: WSGI",
92 "License :: Repoze Public License",
93 ],
94 keywords='web wsgi pylons pyramid',
95 author="Chris McDonough, Agendaless Consulting",
96 author_email="[email protected]",
97 url="http://docs.pylonsproject.org/en/latest/docs/pyramid.html",
98 license="BSD-derived (http://www.repoze.org/LICENSE.txt)",
99 packages=find_packages(),
100 include_package_data=True,
101 zip_safe=False,
102 install_requires = install_requires,
103 extras_require = {
104 'testing':testing_extras,
105 'docs':docs_extras,
106 },
107 tests_require = tests_require,
108 test_suite="pyramid.tests",
109 entry_points = """\
110 [pyramid.scaffold]
111 starter=pyramid.scaffolds:StarterProjectTemplate
112 zodb=pyramid.scaffolds:ZODBProjectTemplate
113 alchemy=pyramid.scaffolds:AlchemyProjectTemplate
114 [console_scripts]
115 pcreate = pyramid.scripts.pcreate:main
116 pserve = pyramid.scripts.pserve:main
117 pshell = pyramid.scripts.pshell:main
118 proutes = pyramid.scripts.proutes:main
119 pviews = pyramid.scripts.pviews:main
120 ptweens = pyramid.scripts.ptweens:main
121 prequest = pyramid.scripts.prequest:main
122 pdistreport = pyramid.scripts.pdistreport:main
123 [paste.server_runner]
124 wsgiref = pyramid.scripts.pserve:wsgiref_server_runner
125 cherrypy = pyramid.scripts.pserve:cherrypy_server_runner
126 """
127 )
128
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,7 +56,7 @@
tests_require.append('zope.component>=3.11.0')
docs_extras = [
- 'Sphinx >= 1.3.1',
+ 'Sphinx >= 1.3.4',
'docutils',
'repoze.sphinx.autointerface',
'pylons_sphinx_latesturl',
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -56,7 +56,7 @@\n tests_require.append('zope.component>=3.11.0')\n \n docs_extras = [\n- 'Sphinx >= 1.3.1',\n+ 'Sphinx >= 1.3.4',\n 'docutils',\n 'repoze.sphinx.autointerface',\n 'pylons_sphinx_latesturl',\n", "issue": "Update to Sphinx 1.3.4 when released\nThere is a [bug in Sphinx 1.3.3 and 1.3.1](https://github.com/sphinx-doc/sphinx/issues/2189) (I haven't tried 1.3.2) where next and previous links in Sphinx documentation are broken when going into children and across sibling directories.\n\nWhen 1.3.4 is released, we need to pin sphinx to 1.3.4, which will include the commit made 8 days after the 1.3.3 release.\n\n", "before_files": [{"content": "##############################################################################\n#\n# Copyright (c) 2008-2013 Agendaless Consulting and Contributors.\n# All Rights Reserved.\n#\n# This software is subject to the provisions of the BSD-like license at\n# http://www.repoze.org/LICENSE.txt. A copy of the license should accompany\n# this distribution. THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY AND ALL\n# EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,\n# THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND\n# FITNESS FOR A PARTICULAR PURPOSE\n#\n##############################################################################\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\npy_version = sys.version_info[:2]\n\nPY3 = py_version[0] == 3\n\nif PY3:\n if py_version < (3, 2):\n raise RuntimeError('On Python 3, Pyramid requires Python 3.2 or better')\nelse:\n if py_version < (2, 6):\n raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')\n\nhere = os.path.abspath(os.path.dirname(__file__))\ntry:\n with open(os.path.join(here, 'README.rst')) as f:\n README = f.read()\n with open(os.path.join(here, 'CHANGES.txt')) as f:\n CHANGES = f.read()\nexcept IOError:\n README = CHANGES = ''\n\ninstall_requires=[\n 'setuptools',\n 'WebOb >= 1.3.1', # request.domain and CookieProfile\n 'repoze.lru >= 0.4', # py3 compat\n 'zope.interface >= 3.8.0', # has zope.interface.registry\n 'zope.deprecation >= 3.5.0', # py3 compat\n 'venusian >= 1.0a3', # ``ignore``\n 'translationstring >= 0.4', # py3 compat\n 'PasteDeploy >= 1.5.0', # py3 compat\n ]\n\ntests_require = [\n 'WebTest >= 1.3.1', # py3 compat\n ]\n\nif not PY3:\n tests_require.append('zope.component>=3.11.0')\n\ndocs_extras = [\n 'Sphinx >= 1.3.1',\n 'docutils',\n 'repoze.sphinx.autointerface',\n 'pylons_sphinx_latesturl',\n 'pylons-sphinx-themes',\n 'sphinxcontrib-programoutput',\n ]\n\ntesting_extras = tests_require + [\n 'nose',\n 'coverage',\n 'virtualenv', # for scaffolding tests\n ]\n\nsetup(name='pyramid',\n version='1.5.8',\n description='The Pyramid Web Framework, a Pylons project',\n long_description=README + '\\n\\n' + CHANGES,\n classifiers=[\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.2\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Framework :: Pyramid\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"License :: Repoze Public License\",\n ],\n keywords='web wsgi pylons pyramid',\n author=\"Chris McDonough, Agendaless Consulting\",\n author_email=\"[email protected]\",\n url=\"http://docs.pylonsproject.org/en/latest/docs/pyramid.html\",\n license=\"BSD-derived (http://www.repoze.org/LICENSE.txt)\",\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n install_requires = install_requires,\n extras_require = {\n 'testing':testing_extras,\n 'docs':docs_extras,\n },\n tests_require = tests_require,\n test_suite=\"pyramid.tests\",\n entry_points = \"\"\"\\\n [pyramid.scaffold]\n starter=pyramid.scaffolds:StarterProjectTemplate\n zodb=pyramid.scaffolds:ZODBProjectTemplate\n alchemy=pyramid.scaffolds:AlchemyProjectTemplate\n [console_scripts]\n pcreate = pyramid.scripts.pcreate:main\n pserve = pyramid.scripts.pserve:main\n pshell = pyramid.scripts.pshell:main\n proutes = pyramid.scripts.proutes:main\n pviews = pyramid.scripts.pviews:main\n ptweens = pyramid.scripts.ptweens:main\n prequest = pyramid.scripts.prequest:main\n pdistreport = pyramid.scripts.pdistreport:main\n [paste.server_runner]\n wsgiref = pyramid.scripts.pserve:wsgiref_server_runner\n cherrypy = pyramid.scripts.pserve:cherrypy_server_runner\n \"\"\"\n )\n\n", "path": "setup.py"}], "after_files": [{"content": "##############################################################################\n#\n# Copyright (c) 2008-2013 Agendaless Consulting and Contributors.\n# All Rights Reserved.\n#\n# This software is subject to the provisions of the BSD-like license at\n# http://www.repoze.org/LICENSE.txt. A copy of the license should accompany\n# this distribution. THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY AND ALL\n# EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,\n# THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND\n# FITNESS FOR A PARTICULAR PURPOSE\n#\n##############################################################################\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\npy_version = sys.version_info[:2]\n\nPY3 = py_version[0] == 3\n\nif PY3:\n if py_version < (3, 2):\n raise RuntimeError('On Python 3, Pyramid requires Python 3.2 or better')\nelse:\n if py_version < (2, 6):\n raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')\n\nhere = os.path.abspath(os.path.dirname(__file__))\ntry:\n with open(os.path.join(here, 'README.rst')) as f:\n README = f.read()\n with open(os.path.join(here, 'CHANGES.txt')) as f:\n CHANGES = f.read()\nexcept IOError:\n README = CHANGES = ''\n\ninstall_requires=[\n 'setuptools',\n 'WebOb >= 1.3.1', # request.domain and CookieProfile\n 'repoze.lru >= 0.4', # py3 compat\n 'zope.interface >= 3.8.0', # has zope.interface.registry\n 'zope.deprecation >= 3.5.0', # py3 compat\n 'venusian >= 1.0a3', # ``ignore``\n 'translationstring >= 0.4', # py3 compat\n 'PasteDeploy >= 1.5.0', # py3 compat\n ]\n\ntests_require = [\n 'WebTest >= 1.3.1', # py3 compat\n ]\n\nif not PY3:\n tests_require.append('zope.component>=3.11.0')\n\ndocs_extras = [\n 'Sphinx >= 1.3.4',\n 'docutils',\n 'repoze.sphinx.autointerface',\n 'pylons_sphinx_latesturl',\n 'pylons-sphinx-themes',\n 'sphinxcontrib-programoutput',\n ]\n\ntesting_extras = tests_require + [\n 'nose',\n 'coverage',\n 'virtualenv', # for scaffolding tests\n ]\n\nsetup(name='pyramid',\n version='1.5.8',\n description='The Pyramid Web Framework, a Pylons project',\n long_description=README + '\\n\\n' + CHANGES,\n classifiers=[\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.2\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Framework :: Pyramid\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"License :: Repoze Public License\",\n ],\n keywords='web wsgi pylons pyramid',\n author=\"Chris McDonough, Agendaless Consulting\",\n author_email=\"[email protected]\",\n url=\"http://docs.pylonsproject.org/en/latest/docs/pyramid.html\",\n license=\"BSD-derived (http://www.repoze.org/LICENSE.txt)\",\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n install_requires = install_requires,\n extras_require = {\n 'testing':testing_extras,\n 'docs':docs_extras,\n },\n tests_require = tests_require,\n test_suite=\"pyramid.tests\",\n entry_points = \"\"\"\\\n [pyramid.scaffold]\n starter=pyramid.scaffolds:StarterProjectTemplate\n zodb=pyramid.scaffolds:ZODBProjectTemplate\n alchemy=pyramid.scaffolds:AlchemyProjectTemplate\n [console_scripts]\n pcreate = pyramid.scripts.pcreate:main\n pserve = pyramid.scripts.pserve:main\n pshell = pyramid.scripts.pshell:main\n proutes = pyramid.scripts.proutes:main\n pviews = pyramid.scripts.pviews:main\n ptweens = pyramid.scripts.ptweens:main\n prequest = pyramid.scripts.prequest:main\n pdistreport = pyramid.scripts.pdistreport:main\n [paste.server_runner]\n wsgiref = pyramid.scripts.pserve:wsgiref_server_runner\n cherrypy = pyramid.scripts.pserve:cherrypy_server_runner\n \"\"\"\n )\n\n", "path": "setup.py"}]} | 1,782 | 106 |
gh_patches_debug_9329 | rasdani/github-patches | git_diff | pypa__pip-481 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bad error message on malformed VCS string
The item in my requirements.txt:
```
git://github.com/alex/django-fixture-generator.git#egg=fixture_generator
```
The resulting error message:
``` python
Downloading/unpacking fixture-generator from git://github.com/alex/django-fixture-generator.git (from -r requirements/development.txt (line 3))
Exception:
Traceback (most recent call last):
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/basecommand.py", line 126, in main
self.run(options, args)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/commands/install.py", line 223, in run
requirement_set.prepare_files(finder, force_root_egg_info=self.bundle, bundle=self.bundle)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/req.py", line 961, in prepare_files
self.unpack_url(url, location, self.is_download)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/req.py", line 1073, in unpack_url
return unpack_vcs_link(link, location, only_download)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/download.py", line 293, in unpack_vcs_link
vcs_backend.unpack(location)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/__init__.py", line 225, in unpack
self.obtain(location)
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/git.py", line 97, in obtain
url, rev = self.get_url_rev()
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/git.py", line 183, in get_url_rev
url, rev = super(Git, self).get_url_rev()
File "/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/__init__.py", line 117, in get_url_rev
url = self.url.split('+', 1)[1]
IndexError: list index out of range
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pip/vcs/__init__.py`
Content:
```
1 """Handles all VCS (version control) support"""
2
3 import os
4 import shutil
5
6 from pip.backwardcompat import urlparse, urllib
7 from pip.log import logger
8 from pip.util import (display_path, backup_dir, find_command,
9 ask, rmtree, ask_path_exists)
10
11
12 __all__ = ['vcs', 'get_src_requirement']
13
14
15 class VcsSupport(object):
16 _registry = {}
17 schemes = ['ssh', 'git', 'hg', 'bzr', 'sftp', 'svn']
18
19 def __init__(self):
20 # Register more schemes with urlparse for various version control systems
21 urlparse.uses_netloc.extend(self.schemes)
22 urlparse.uses_fragment.extend(self.schemes)
23 super(VcsSupport, self).__init__()
24
25 def __iter__(self):
26 return self._registry.__iter__()
27
28 @property
29 def backends(self):
30 return list(self._registry.values())
31
32 @property
33 def dirnames(self):
34 return [backend.dirname for backend in self.backends]
35
36 @property
37 def all_schemes(self):
38 schemes = []
39 for backend in self.backends:
40 schemes.extend(backend.schemes)
41 return schemes
42
43 def register(self, cls):
44 if not hasattr(cls, 'name'):
45 logger.warn('Cannot register VCS %s' % cls.__name__)
46 return
47 if cls.name not in self._registry:
48 self._registry[cls.name] = cls
49
50 def unregister(self, cls=None, name=None):
51 if name in self._registry:
52 del self._registry[name]
53 elif cls in self._registry.values():
54 del self._registry[cls.name]
55 else:
56 logger.warn('Cannot unregister because no class or name given')
57
58 def get_backend_name(self, location):
59 """
60 Return the name of the version control backend if found at given
61 location, e.g. vcs.get_backend_name('/path/to/vcs/checkout')
62 """
63 for vc_type in self._registry.values():
64 path = os.path.join(location, vc_type.dirname)
65 if os.path.exists(path):
66 return vc_type.name
67 return None
68
69 def get_backend(self, name):
70 name = name.lower()
71 if name in self._registry:
72 return self._registry[name]
73
74 def get_backend_from_location(self, location):
75 vc_type = self.get_backend_name(location)
76 if vc_type:
77 return self.get_backend(vc_type)
78 return None
79
80
81 vcs = VcsSupport()
82
83
84 class VersionControl(object):
85 name = ''
86 dirname = ''
87
88 def __init__(self, url=None, *args, **kwargs):
89 self.url = url
90 self._cmd = None
91 super(VersionControl, self).__init__(*args, **kwargs)
92
93 def _filter(self, line):
94 return (logger.INFO, line)
95
96 def _is_local_repository(self, repo):
97 """
98 posix absolute paths start with os.path.sep,
99 win32 ones ones start with drive (like c:\\folder)
100 """
101 drive, tail = os.path.splitdrive(repo)
102 return repo.startswith(os.path.sep) or drive
103
104 @property
105 def cmd(self):
106 if self._cmd is not None:
107 return self._cmd
108 command = find_command(self.name)
109 logger.info('Found command %r at %r' % (self.name, command))
110 self._cmd = command
111 return command
112
113 def get_url_rev(self):
114 """
115 Returns the correct repository URL and revision by parsing the given
116 repository URL
117 """
118 url = self.url.split('+', 1)[1]
119 scheme, netloc, path, query, frag = urlparse.urlsplit(url)
120 rev = None
121 if '@' in path:
122 path, rev = path.rsplit('@', 1)
123 url = urlparse.urlunsplit((scheme, netloc, path, query, ''))
124 return url, rev
125
126 def get_info(self, location):
127 """
128 Returns (url, revision), where both are strings
129 """
130 assert not location.rstrip('/').endswith(self.dirname), 'Bad directory: %s' % location
131 return self.get_url(location), self.get_revision(location)
132
133 def normalize_url(self, url):
134 """
135 Normalize a URL for comparison by unquoting it and removing any trailing slash.
136 """
137 return urllib.unquote(url).rstrip('/')
138
139 def compare_urls(self, url1, url2):
140 """
141 Compare two repo URLs for identity, ignoring incidental differences.
142 """
143 return (self.normalize_url(url1) == self.normalize_url(url2))
144
145 def parse_vcs_bundle_file(self, content):
146 """
147 Takes the contents of the bundled text file that explains how to revert
148 the stripped off version control data of the given package and returns
149 the URL and revision of it.
150 """
151 raise NotImplementedError
152
153 def obtain(self, dest):
154 """
155 Called when installing or updating an editable package, takes the
156 source path of the checkout.
157 """
158 raise NotImplementedError
159
160 def switch(self, dest, url, rev_options):
161 """
162 Switch the repo at ``dest`` to point to ``URL``.
163 """
164 raise NotImplemented
165
166 def update(self, dest, rev_options):
167 """
168 Update an already-existing repo to the given ``rev_options``.
169 """
170 raise NotImplementedError
171
172 def check_destination(self, dest, url, rev_options, rev_display):
173 """
174 Prepare a location to receive a checkout/clone.
175
176 Return True if the location is ready for (and requires) a
177 checkout/clone, False otherwise.
178 """
179 checkout = True
180 prompt = False
181 if os.path.exists(dest):
182 checkout = False
183 if os.path.exists(os.path.join(dest, self.dirname)):
184 existing_url = self.get_url(dest)
185 if self.compare_urls(existing_url, url):
186 logger.info('%s in %s exists, and has correct URL (%s)' %
187 (self.repo_name.title(), display_path(dest),
188 url))
189 logger.notify('Updating %s %s%s' %
190 (display_path(dest), self.repo_name,
191 rev_display))
192 self.update(dest, rev_options)
193 else:
194 logger.warn('%s %s in %s exists with URL %s' %
195 (self.name, self.repo_name,
196 display_path(dest), existing_url))
197 prompt = ('(s)witch, (i)gnore, (w)ipe, (b)ackup ',
198 ('s', 'i', 'w', 'b'))
199 else:
200 logger.warn('Directory %s already exists, '
201 'and is not a %s %s.' %
202 (dest, self.name, self.repo_name))
203 prompt = ('(i)gnore, (w)ipe, (b)ackup ', ('i', 'w', 'b'))
204 if prompt:
205 logger.warn('The plan is to install the %s repository %s' %
206 (self.name, url))
207 response = ask_path_exists('What to do? %s' % prompt[0],
208 prompt[1])
209
210 if response == 's':
211 logger.notify('Switching %s %s to %s%s' %
212 (self.repo_name, display_path(dest), url,
213 rev_display))
214 self.switch(dest, url, rev_options)
215 elif response == 'i':
216 # do nothing
217 pass
218 elif response == 'w':
219 logger.warn('Deleting %s' % display_path(dest))
220 rmtree(dest)
221 checkout = True
222 elif response == 'b':
223 dest_dir = backup_dir(dest)
224 logger.warn('Backing up %s to %s'
225 % (display_path(dest), dest_dir))
226 shutil.move(dest, dest_dir)
227 checkout = True
228 return checkout
229
230 def unpack(self, location):
231 if os.path.exists(location):
232 rmtree(location)
233 self.obtain(location)
234
235 def get_src_requirement(self, dist, location, find_tags=False):
236 raise NotImplementedError
237
238
239 def get_src_requirement(dist, location, find_tags):
240 version_control = vcs.get_backend_from_location(location)
241 if version_control:
242 return version_control().get_src_requirement(dist, location, find_tags)
243 logger.warn('cannot determine version of editable source in %s (is not SVN checkout, Git clone, Mercurial clone or Bazaar branch)' % location)
244 return dist.as_requirement()
245
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pip/vcs/__init__.py b/pip/vcs/__init__.py
--- a/pip/vcs/__init__.py
+++ b/pip/vcs/__init__.py
@@ -115,6 +115,9 @@
Returns the correct repository URL and revision by parsing the given
repository URL
"""
+ error_message= "Sorry, '{}' is a malformed url. In requirements files, the \
+format is <vcs>+<protocol>://<url>, e.g. svn+http://myrepo/svn/MyApp#egg=MyApp"
+ assert '+' in self.url, error_message.format(self.url)
url = self.url.split('+', 1)[1]
scheme, netloc, path, query, frag = urlparse.urlsplit(url)
rev = None
| {"golden_diff": "diff --git a/pip/vcs/__init__.py b/pip/vcs/__init__.py\n--- a/pip/vcs/__init__.py\n+++ b/pip/vcs/__init__.py\n@@ -115,6 +115,9 @@\n Returns the correct repository URL and revision by parsing the given\n repository URL\n \"\"\"\n+ error_message= \"Sorry, '{}' is a malformed url. In requirements files, the \\\n+format is <vcs>+<protocol>://<url>, e.g. svn+http://myrepo/svn/MyApp#egg=MyApp\"\n+ assert '+' in self.url, error_message.format(self.url)\n url = self.url.split('+', 1)[1]\n scheme, netloc, path, query, frag = urlparse.urlsplit(url)\n rev = None\n", "issue": "Bad error message on malformed VCS string\nThe item in my requirements.txt:\n\n```\ngit://github.com/alex/django-fixture-generator.git#egg=fixture_generator\n```\n\nThe resulting error message:\n\n``` python\nDownloading/unpacking fixture-generator from git://github.com/alex/django-fixture-generator.git (from -r requirements/development.txt (line 3))\nException:\nTraceback (most recent call last):\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/basecommand.py\", line 126, in main\n self.run(options, args)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/commands/install.py\", line 223, in run\n requirement_set.prepare_files(finder, force_root_egg_info=self.bundle, bundle=self.bundle)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/req.py\", line 961, in prepare_files\n self.unpack_url(url, location, self.is_download)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/req.py\", line 1073, in unpack_url\n return unpack_vcs_link(link, location, only_download)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/download.py\", line 293, in unpack_vcs_link\n vcs_backend.unpack(location)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/__init__.py\", line 225, in unpack\n self.obtain(location)\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/git.py\", line 97, in obtain\n url, rev = self.get_url_rev()\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/git.py\", line 183, in get_url_rev\n url, rev = super(Git, self).get_url_rev()\n File \"/home/alex/.virtualenvs/tracebin/local/lib/python2.7/site-packages/pip-1.0.2-py2.7.egg/pip/vcs/__init__.py\", line 117, in get_url_rev\n url = self.url.split('+', 1)[1]\nIndexError: list index out of range\n```\n\n", "before_files": [{"content": "\"\"\"Handles all VCS (version control) support\"\"\"\n\nimport os\nimport shutil\n\nfrom pip.backwardcompat import urlparse, urllib\nfrom pip.log import logger\nfrom pip.util import (display_path, backup_dir, find_command,\n ask, rmtree, ask_path_exists)\n\n\n__all__ = ['vcs', 'get_src_requirement']\n\n\nclass VcsSupport(object):\n _registry = {}\n schemes = ['ssh', 'git', 'hg', 'bzr', 'sftp', 'svn']\n\n def __init__(self):\n # Register more schemes with urlparse for various version control systems\n urlparse.uses_netloc.extend(self.schemes)\n urlparse.uses_fragment.extend(self.schemes)\n super(VcsSupport, self).__init__()\n\n def __iter__(self):\n return self._registry.__iter__()\n\n @property\n def backends(self):\n return list(self._registry.values())\n\n @property\n def dirnames(self):\n return [backend.dirname for backend in self.backends]\n\n @property\n def all_schemes(self):\n schemes = []\n for backend in self.backends:\n schemes.extend(backend.schemes)\n return schemes\n\n def register(self, cls):\n if not hasattr(cls, 'name'):\n logger.warn('Cannot register VCS %s' % cls.__name__)\n return\n if cls.name not in self._registry:\n self._registry[cls.name] = cls\n\n def unregister(self, cls=None, name=None):\n if name in self._registry:\n del self._registry[name]\n elif cls in self._registry.values():\n del self._registry[cls.name]\n else:\n logger.warn('Cannot unregister because no class or name given')\n\n def get_backend_name(self, location):\n \"\"\"\n Return the name of the version control backend if found at given\n location, e.g. vcs.get_backend_name('/path/to/vcs/checkout')\n \"\"\"\n for vc_type in self._registry.values():\n path = os.path.join(location, vc_type.dirname)\n if os.path.exists(path):\n return vc_type.name\n return None\n\n def get_backend(self, name):\n name = name.lower()\n if name in self._registry:\n return self._registry[name]\n\n def get_backend_from_location(self, location):\n vc_type = self.get_backend_name(location)\n if vc_type:\n return self.get_backend(vc_type)\n return None\n\n\nvcs = VcsSupport()\n\n\nclass VersionControl(object):\n name = ''\n dirname = ''\n\n def __init__(self, url=None, *args, **kwargs):\n self.url = url\n self._cmd = None\n super(VersionControl, self).__init__(*args, **kwargs)\n\n def _filter(self, line):\n return (logger.INFO, line)\n\n def _is_local_repository(self, repo):\n \"\"\"\n posix absolute paths start with os.path.sep,\n win32 ones ones start with drive (like c:\\\\folder)\n \"\"\"\n drive, tail = os.path.splitdrive(repo)\n return repo.startswith(os.path.sep) or drive\n\n @property\n def cmd(self):\n if self._cmd is not None:\n return self._cmd\n command = find_command(self.name)\n logger.info('Found command %r at %r' % (self.name, command))\n self._cmd = command\n return command\n\n def get_url_rev(self):\n \"\"\"\n Returns the correct repository URL and revision by parsing the given\n repository URL\n \"\"\"\n url = self.url.split('+', 1)[1]\n scheme, netloc, path, query, frag = urlparse.urlsplit(url)\n rev = None\n if '@' in path:\n path, rev = path.rsplit('@', 1)\n url = urlparse.urlunsplit((scheme, netloc, path, query, ''))\n return url, rev\n\n def get_info(self, location):\n \"\"\"\n Returns (url, revision), where both are strings\n \"\"\"\n assert not location.rstrip('/').endswith(self.dirname), 'Bad directory: %s' % location\n return self.get_url(location), self.get_revision(location)\n\n def normalize_url(self, url):\n \"\"\"\n Normalize a URL for comparison by unquoting it and removing any trailing slash.\n \"\"\"\n return urllib.unquote(url).rstrip('/')\n\n def compare_urls(self, url1, url2):\n \"\"\"\n Compare two repo URLs for identity, ignoring incidental differences.\n \"\"\"\n return (self.normalize_url(url1) == self.normalize_url(url2))\n\n def parse_vcs_bundle_file(self, content):\n \"\"\"\n Takes the contents of the bundled text file that explains how to revert\n the stripped off version control data of the given package and returns\n the URL and revision of it.\n \"\"\"\n raise NotImplementedError\n\n def obtain(self, dest):\n \"\"\"\n Called when installing or updating an editable package, takes the\n source path of the checkout.\n \"\"\"\n raise NotImplementedError\n\n def switch(self, dest, url, rev_options):\n \"\"\"\n Switch the repo at ``dest`` to point to ``URL``.\n \"\"\"\n raise NotImplemented\n\n def update(self, dest, rev_options):\n \"\"\"\n Update an already-existing repo to the given ``rev_options``.\n \"\"\"\n raise NotImplementedError\n\n def check_destination(self, dest, url, rev_options, rev_display):\n \"\"\"\n Prepare a location to receive a checkout/clone.\n\n Return True if the location is ready for (and requires) a\n checkout/clone, False otherwise.\n \"\"\"\n checkout = True\n prompt = False\n if os.path.exists(dest):\n checkout = False\n if os.path.exists(os.path.join(dest, self.dirname)):\n existing_url = self.get_url(dest)\n if self.compare_urls(existing_url, url):\n logger.info('%s in %s exists, and has correct URL (%s)' %\n (self.repo_name.title(), display_path(dest),\n url))\n logger.notify('Updating %s %s%s' %\n (display_path(dest), self.repo_name,\n rev_display))\n self.update(dest, rev_options)\n else:\n logger.warn('%s %s in %s exists with URL %s' %\n (self.name, self.repo_name,\n display_path(dest), existing_url))\n prompt = ('(s)witch, (i)gnore, (w)ipe, (b)ackup ',\n ('s', 'i', 'w', 'b'))\n else:\n logger.warn('Directory %s already exists, '\n 'and is not a %s %s.' %\n (dest, self.name, self.repo_name))\n prompt = ('(i)gnore, (w)ipe, (b)ackup ', ('i', 'w', 'b'))\n if prompt:\n logger.warn('The plan is to install the %s repository %s' %\n (self.name, url))\n response = ask_path_exists('What to do? %s' % prompt[0],\n prompt[1])\n\n if response == 's':\n logger.notify('Switching %s %s to %s%s' %\n (self.repo_name, display_path(dest), url,\n rev_display))\n self.switch(dest, url, rev_options)\n elif response == 'i':\n # do nothing\n pass\n elif response == 'w':\n logger.warn('Deleting %s' % display_path(dest))\n rmtree(dest)\n checkout = True\n elif response == 'b':\n dest_dir = backup_dir(dest)\n logger.warn('Backing up %s to %s'\n % (display_path(dest), dest_dir))\n shutil.move(dest, dest_dir)\n checkout = True\n return checkout\n\n def unpack(self, location):\n if os.path.exists(location):\n rmtree(location)\n self.obtain(location)\n\n def get_src_requirement(self, dist, location, find_tags=False):\n raise NotImplementedError\n\n\ndef get_src_requirement(dist, location, find_tags):\n version_control = vcs.get_backend_from_location(location)\n if version_control:\n return version_control().get_src_requirement(dist, location, find_tags)\n logger.warn('cannot determine version of editable source in %s (is not SVN checkout, Git clone, Mercurial clone or Bazaar branch)' % location)\n return dist.as_requirement()\n", "path": "pip/vcs/__init__.py"}], "after_files": [{"content": "\"\"\"Handles all VCS (version control) support\"\"\"\n\nimport os\nimport shutil\n\nfrom pip.backwardcompat import urlparse, urllib\nfrom pip.log import logger\nfrom pip.util import (display_path, backup_dir, find_command,\n ask, rmtree, ask_path_exists)\n\n\n__all__ = ['vcs', 'get_src_requirement']\n\n\nclass VcsSupport(object):\n _registry = {}\n schemes = ['ssh', 'git', 'hg', 'bzr', 'sftp', 'svn']\n\n def __init__(self):\n # Register more schemes with urlparse for various version control systems\n urlparse.uses_netloc.extend(self.schemes)\n urlparse.uses_fragment.extend(self.schemes)\n super(VcsSupport, self).__init__()\n\n def __iter__(self):\n return self._registry.__iter__()\n\n @property\n def backends(self):\n return list(self._registry.values())\n\n @property\n def dirnames(self):\n return [backend.dirname for backend in self.backends]\n\n @property\n def all_schemes(self):\n schemes = []\n for backend in self.backends:\n schemes.extend(backend.schemes)\n return schemes\n\n def register(self, cls):\n if not hasattr(cls, 'name'):\n logger.warn('Cannot register VCS %s' % cls.__name__)\n return\n if cls.name not in self._registry:\n self._registry[cls.name] = cls\n\n def unregister(self, cls=None, name=None):\n if name in self._registry:\n del self._registry[name]\n elif cls in self._registry.values():\n del self._registry[cls.name]\n else:\n logger.warn('Cannot unregister because no class or name given')\n\n def get_backend_name(self, location):\n \"\"\"\n Return the name of the version control backend if found at given\n location, e.g. vcs.get_backend_name('/path/to/vcs/checkout')\n \"\"\"\n for vc_type in self._registry.values():\n path = os.path.join(location, vc_type.dirname)\n if os.path.exists(path):\n return vc_type.name\n return None\n\n def get_backend(self, name):\n name = name.lower()\n if name in self._registry:\n return self._registry[name]\n\n def get_backend_from_location(self, location):\n vc_type = self.get_backend_name(location)\n if vc_type:\n return self.get_backend(vc_type)\n return None\n\n\nvcs = VcsSupport()\n\n\nclass VersionControl(object):\n name = ''\n dirname = ''\n\n def __init__(self, url=None, *args, **kwargs):\n self.url = url\n self._cmd = None\n super(VersionControl, self).__init__(*args, **kwargs)\n\n def _filter(self, line):\n return (logger.INFO, line)\n\n def _is_local_repository(self, repo):\n \"\"\"\n posix absolute paths start with os.path.sep,\n win32 ones ones start with drive (like c:\\\\folder)\n \"\"\"\n drive, tail = os.path.splitdrive(repo)\n return repo.startswith(os.path.sep) or drive\n\n @property\n def cmd(self):\n if self._cmd is not None:\n return self._cmd\n command = find_command(self.name)\n logger.info('Found command %r at %r' % (self.name, command))\n self._cmd = command\n return command\n\n def get_url_rev(self):\n \"\"\"\n Returns the correct repository URL and revision by parsing the given\n repository URL\n \"\"\"\n error_message= \"Sorry, '{}' is a malformed url. In requirements files, the \\\nformat is <vcs>+<protocol>://<url>, e.g. svn+http://myrepo/svn/MyApp#egg=MyApp\"\n assert '+' in self.url, error_message.format(self.url)\n url = self.url.split('+', 1)[1]\n scheme, netloc, path, query, frag = urlparse.urlsplit(url)\n rev = None\n if '@' in path:\n path, rev = path.rsplit('@', 1)\n url = urlparse.urlunsplit((scheme, netloc, path, query, ''))\n return url, rev\n\n def get_info(self, location):\n \"\"\"\n Returns (url, revision), where both are strings\n \"\"\"\n assert not location.rstrip('/').endswith(self.dirname), 'Bad directory: %s' % location\n return self.get_url(location), self.get_revision(location)\n\n def normalize_url(self, url):\n \"\"\"\n Normalize a URL for comparison by unquoting it and removing any trailing slash.\n \"\"\"\n return urllib.unquote(url).rstrip('/')\n\n def compare_urls(self, url1, url2):\n \"\"\"\n Compare two repo URLs for identity, ignoring incidental differences.\n \"\"\"\n return (self.normalize_url(url1) == self.normalize_url(url2))\n\n def parse_vcs_bundle_file(self, content):\n \"\"\"\n Takes the contents of the bundled text file that explains how to revert\n the stripped off version control data of the given package and returns\n the URL and revision of it.\n \"\"\"\n raise NotImplementedError\n\n def obtain(self, dest):\n \"\"\"\n Called when installing or updating an editable package, takes the\n source path of the checkout.\n \"\"\"\n raise NotImplementedError\n\n def switch(self, dest, url, rev_options):\n \"\"\"\n Switch the repo at ``dest`` to point to ``URL``.\n \"\"\"\n raise NotImplemented\n\n def update(self, dest, rev_options):\n \"\"\"\n Update an already-existing repo to the given ``rev_options``.\n \"\"\"\n raise NotImplementedError\n\n def check_destination(self, dest, url, rev_options, rev_display):\n \"\"\"\n Prepare a location to receive a checkout/clone.\n\n Return True if the location is ready for (and requires) a\n checkout/clone, False otherwise.\n \"\"\"\n checkout = True\n prompt = False\n if os.path.exists(dest):\n checkout = False\n if os.path.exists(os.path.join(dest, self.dirname)):\n existing_url = self.get_url(dest)\n if self.compare_urls(existing_url, url):\n logger.info('%s in %s exists, and has correct URL (%s)' %\n (self.repo_name.title(), display_path(dest),\n url))\n logger.notify('Updating %s %s%s' %\n (display_path(dest), self.repo_name,\n rev_display))\n self.update(dest, rev_options)\n else:\n logger.warn('%s %s in %s exists with URL %s' %\n (self.name, self.repo_name,\n display_path(dest), existing_url))\n prompt = ('(s)witch, (i)gnore, (w)ipe, (b)ackup ',\n ('s', 'i', 'w', 'b'))\n else:\n logger.warn('Directory %s already exists, '\n 'and is not a %s %s.' %\n (dest, self.name, self.repo_name))\n prompt = ('(i)gnore, (w)ipe, (b)ackup ', ('i', 'w', 'b'))\n if prompt:\n logger.warn('The plan is to install the %s repository %s' %\n (self.name, url))\n response = ask_path_exists('What to do? %s' % prompt[0],\n prompt[1])\n\n if response == 's':\n logger.notify('Switching %s %s to %s%s' %\n (self.repo_name, display_path(dest), url,\n rev_display))\n self.switch(dest, url, rev_options)\n elif response == 'i':\n # do nothing\n pass\n elif response == 'w':\n logger.warn('Deleting %s' % display_path(dest))\n rmtree(dest)\n checkout = True\n elif response == 'b':\n dest_dir = backup_dir(dest)\n logger.warn('Backing up %s to %s'\n % (display_path(dest), dest_dir))\n shutil.move(dest, dest_dir)\n checkout = True\n return checkout\n\n def unpack(self, location):\n if os.path.exists(location):\n rmtree(location)\n self.obtain(location)\n\n def get_src_requirement(self, dist, location, find_tags=False):\n raise NotImplementedError\n\n\ndef get_src_requirement(dist, location, find_tags):\n version_control = vcs.get_backend_from_location(location)\n if version_control:\n return version_control().get_src_requirement(dist, location, find_tags)\n logger.warn('cannot determine version of editable source in %s (is not SVN checkout, Git clone, Mercurial clone or Bazaar branch)' % location)\n return dist.as_requirement()\n", "path": "pip/vcs/__init__.py"}]} | 3,368 | 180 |
gh_patches_debug_20865 | rasdani/github-patches | git_diff | nilearn__nilearn-742 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve task mask pattern in examples
``` python
classification_target = stimuli[
np.logical_not(resting_state)] == category
```
From #740, @AlexandreAbraham said:
> I already found this line hard to understand before (I particularly dislike playing with the priority of operators = and ==) but now the new_line make it even more obscure. Maybe we could change by:
>
> ```
> task_mask = np.logical_not(resting_state) # or sample_mask?
> classification_target = (stimuli[task_mask] == category)
> ```
Quickly git-grepping it looks like this pattern is both present in:
examples/decoding/plot_haxby_different_estimators.py
examples/decoding/plot_haxby_full_analysis.py
They may be other places where this is used.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/decoding/plot_haxby_different_estimators.py`
Content:
```
1 """
2 Different classifiers in decoding the Haxby dataset
3 =====================================================
4
5 Here we compare different classifiers on a visual object recognition
6 decoding task.
7 """
8
9 import time
10
11 ### Fetch data using nilearn dataset fetcher ################################
12 from nilearn import datasets
13 haxby_dataset = datasets.fetch_haxby(n_subjects=1)
14
15 # print basic information on the dataset
16 print('First subject anatomical nifti image (3D) located is at: %s' %
17 haxby_dataset.anat[0])
18 print('First subject functional nifti image (4D) is located at: %s' %
19 haxby_dataset.func[0])
20
21 # load labels
22 import numpy as np
23 labels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=" ")
24 stimuli = labels['labels']
25 # identify resting state labels in order to be able to remove them
26 resting_state = stimuli == b'rest'
27
28 # find names of remaining active labels
29 categories = np.unique(stimuli[np.logical_not(resting_state)])
30
31 # extract tags indicating to which acquisition run a tag belongs
32 session_labels = labels["chunks"][np.logical_not(resting_state)]
33
34 # Load the fMRI data
35 from nilearn.input_data import NiftiMasker
36
37 # For decoding, standardizing is often very important
38 mask_filename = haxby_dataset.mask_vt[0]
39 masker = NiftiMasker(mask_img=mask_filename, standardize=True)
40 func_filename = haxby_dataset.func[0]
41 masked_timecourses = masker.fit_transform(
42 func_filename)[np.logical_not(resting_state)]
43
44 # Classifiers definition
45
46 # A support vector classifier
47 from sklearn.svm import SVC
48 svm = SVC(C=1., kernel="linear")
49
50 from sklearn.grid_search import GridSearchCV
51 # GridSearchCV is slow, but note that it takes an 'n_jobs' parameter that
52 # can significantly speed up the fitting process on computers with
53 # multiple cores
54 svm_cv = GridSearchCV(SVC(C=1., kernel="linear"),
55 param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},
56 scoring='f1')
57
58 # The logistic regression
59 from sklearn.linear_model import LogisticRegression, RidgeClassifier, \
60 RidgeClassifierCV
61 logistic = LogisticRegression(C=1., penalty="l1")
62 logistic_50 = LogisticRegression(C=50., penalty="l1")
63 logistic_l2 = LogisticRegression(C=1., penalty="l2")
64
65 logistic_cv = GridSearchCV(LogisticRegression(C=1., penalty="l1"),
66 param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},
67 scoring='f1')
68 logistic_l2_cv = GridSearchCV(LogisticRegression(C=1., penalty="l2"),
69 param_grid={
70 'C': [.1, .5, 1., 5., 10., 50., 100.]},
71 scoring='f1')
72
73 ridge = RidgeClassifier()
74 ridge_cv = RidgeClassifierCV()
75
76
77 # Make a data splitting object for cross validation
78 from sklearn.cross_validation import LeaveOneLabelOut, cross_val_score
79 cv = LeaveOneLabelOut(session_labels)
80
81 classifiers = {'SVC': svm,
82 'SVC cv': svm_cv,
83 'log l1': logistic,
84 'log l1 50': logistic_50,
85 'log l1 cv': logistic_cv,
86 'log l2': logistic_l2,
87 'log l2 cv': logistic_l2_cv,
88 'ridge': ridge,
89 'ridge cv': ridge_cv}
90
91 classifiers_scores = {}
92
93 for classifier_name, classifier in sorted(classifiers.items()):
94 classifiers_scores[classifier_name] = {}
95 print(70 * '_')
96
97 for category in categories:
98 classification_target = stimuli[
99 np.logical_not(resting_state)] == category
100 t0 = time.time()
101 classifiers_scores[classifier_name][category] = cross_val_score(
102 classifier,
103 masked_timecourses,
104 classification_target,
105 cv=cv, scoring="f1")
106
107 print("%10s: %14s -- scores: %1.2f +- %1.2f, time %.2fs" % (
108 classifier_name, category,
109 classifiers_scores[classifier_name][category].mean(),
110 classifiers_scores[classifier_name][category].std(),
111 time.time() - t0))
112
113 ###############################################################################
114 # make a rudimentary diagram
115 import matplotlib.pyplot as plt
116 plt.figure()
117
118 tick_position = np.arange(len(categories))
119 plt.xticks(tick_position, categories, rotation=45)
120
121 for color, classifier_name in zip(
122 ['b', 'c', 'm', 'g', 'y', 'k', '.5', 'r', '#ffaaaa'],
123 sorted(classifiers)):
124 score_means = [classifiers_scores[classifier_name][category].mean()
125 for category in categories]
126 plt.bar(tick_position, score_means, label=classifier_name,
127 width=.11, color=color)
128 tick_position = tick_position + .09
129
130 plt.ylabel('Classification accurancy (f1 score)')
131 plt.xlabel('Visual stimuli category')
132 plt.ylim(ymin=0)
133 plt.legend(loc='lower center', ncol=3)
134 plt.title('Category-specific classification accuracy for different classifiers')
135 plt.tight_layout()
136
137 ###############################################################################
138 # Plot the face vs house map for the different estimators
139
140 # use the average EPI as a background
141 from nilearn import image
142 mean_epi_img = image.mean_img(func_filename)
143
144 # Restrict the decoding to face vs house
145 condition_mask = np.logical_or(stimuli == b'face', stimuli == b'house')
146 masked_timecourses = masked_timecourses[
147 condition_mask[np.logical_not(resting_state)]]
148 stimuli = stimuli[condition_mask]
149 # Transform the stimuli to binary values
150 stimuli = (stimuli == b'face').astype(np.int)
151
152 from nilearn.plotting import plot_stat_map, show
153
154 for classifier_name, classifier in sorted(classifiers.items()):
155 classifier.fit(masked_timecourses, stimuli)
156
157 if hasattr(classifier, 'coef_'):
158 weights = classifier.coef_[0]
159 elif hasattr(classifier, 'best_estimator_'):
160 weights = classifier.best_estimator_.coef_[0]
161 else:
162 continue
163 weight_img = masker.inverse_transform(weights)
164 weight_map = weight_img.get_data()
165 threshold = np.max(np.abs(weight_map)) * 1e-3
166 plot_stat_map(weight_img, bg_img=mean_epi_img,
167 display_mode='z', cut_coords=[-17],
168 threshold=threshold,
169 title='%s: face vs house' % classifier_name)
170
171 show()
172
```
Path: `examples/decoding/plot_haxby_full_analysis.py`
Content:
```
1 """
2 ROI-based decoding analysis in Haxby et al. dataset
3 =====================================================
4
5 In this script we reproduce the data analysis conducted by
6 Haxby et al. in "Distributed and Overlapping Representations of Faces and
7 Objects in Ventral Temporal Cortex".
8
9 Specifically, we look at decoding accuracy for different objects in
10 three different masks: the full ventral stream (mask_vt), the house
11 selective areas (mask_house) and the face selective areas (mask_face),
12 that have been defined via a standard GLM-based analysis.
13
14 """
15
16
17 ### Fetch data using nilearn dataset fetcher ################################
18 from nilearn import datasets
19 haxby_dataset = datasets.fetch_haxby(n_subjects=1)
20
21 # print basic information on the dataset
22 print('First subject anatomical nifti image (3D) located is at: %s' %
23 haxby_dataset.anat[0])
24 print('First subject functional nifti image (4D) is located at: %s' %
25 haxby_dataset.func[0])
26
27 # Load nilearn NiftiMasker, the practical masking and unmasking tool
28 from nilearn.input_data import NiftiMasker
29
30 # load labels
31 import numpy as np
32 labels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=" ")
33 stimuli = labels['labels']
34
35 # identify resting state labels in order to be able to remove them
36 resting_state = stimuli == b"rest"
37
38 # find names of remaining active labels
39 categories = np.unique(stimuli[np.logical_not(resting_state)])
40
41 # extract tags indicating to which acquisition run a tag belongs
42 session_labels = labels["chunks"][np.logical_not(resting_state)]
43
44 # The classifier: a support vector classifier
45 from sklearn.svm import SVC
46 classifier = SVC(C=1., kernel="linear")
47
48 # A classifier to set the chance level
49 from sklearn.dummy import DummyClassifier
50 dummy_classifier = DummyClassifier()
51
52 # Make a data splitting object for cross validation
53 from sklearn.cross_validation import LeaveOneLabelOut, cross_val_score
54 cv = LeaveOneLabelOut(session_labels)
55
56 func_filename = haxby_dataset.func[0]
57 mask_names = ['mask_vt', 'mask_face', 'mask_house']
58
59 mask_scores = {}
60 mask_chance_scores = {}
61
62 for mask_name in mask_names:
63 print("Working on mask %s" % mask_name)
64 # For decoding, standardizing is often very important
65 mask_filename = haxby_dataset[mask_name][0]
66 masker = NiftiMasker(mask_img=mask_filename, standardize=True)
67 masked_timecourses = masker.fit_transform(
68 func_filename)[np.logical_not(resting_state)]
69
70 mask_scores[mask_name] = {}
71 mask_chance_scores[mask_name] = {}
72
73 for category in categories:
74 print("Processing %s %s" % (mask_name, category))
75 classification_target = stimuli[
76 np.logical_not(resting_state)] == category
77 mask_scores[mask_name][category] = cross_val_score(
78 classifier,
79 masked_timecourses,
80 classification_target,
81 cv=cv, scoring="f1")
82
83 mask_chance_scores[mask_name][category] = cross_val_score(
84 dummy_classifier,
85 masked_timecourses,
86 classification_target,
87 cv=cv, scoring="f1")
88
89 print("Scores: %1.2f +- %1.2f" % (
90 mask_scores[mask_name][category].mean(),
91 mask_scores[mask_name][category].std()))
92
93 # make a rudimentary diagram
94 import matplotlib.pyplot as plt
95 plt.figure()
96
97 tick_position = np.arange(len(categories))
98 plt.xticks(tick_position, categories, rotation=45)
99
100 for color, mask_name in zip('rgb', mask_names):
101 score_means = [mask_scores[mask_name][category].mean()
102 for category in categories]
103 plt.bar(tick_position, score_means, label=mask_name,
104 width=.25, color=color)
105
106 score_chance = [mask_chance_scores[mask_name][category].mean()
107 for category in categories]
108 plt.bar(tick_position, score_chance,
109 width=.25, edgecolor='k', facecolor='none')
110
111 tick_position = tick_position + .2
112
113 plt.ylabel('Classification accurancy (f1 score)')
114 plt.xlabel('Visual stimuli category')
115 plt.legend(loc='best')
116 plt.title('Category-specific classification accuracy for different masks')
117 plt.tight_layout()
118
119
120 plt.show()
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/decoding/plot_haxby_different_estimators.py b/examples/decoding/plot_haxby_different_estimators.py
--- a/examples/decoding/plot_haxby_different_estimators.py
+++ b/examples/decoding/plot_haxby_different_estimators.py
@@ -95,8 +95,8 @@
print(70 * '_')
for category in categories:
- classification_target = stimuli[
- np.logical_not(resting_state)] == category
+ task_mask = np.logical_not(resting_state)
+ classification_target = (stimuli[task_mask] == category)
t0 = time.time()
classifiers_scores[classifier_name][category] = cross_val_score(
classifier,
diff --git a/examples/decoding/plot_haxby_full_analysis.py b/examples/decoding/plot_haxby_full_analysis.py
--- a/examples/decoding/plot_haxby_full_analysis.py
+++ b/examples/decoding/plot_haxby_full_analysis.py
@@ -72,8 +72,8 @@
for category in categories:
print("Processing %s %s" % (mask_name, category))
- classification_target = stimuli[
- np.logical_not(resting_state)] == category
+ task_mask = np.logical_not(resting_state)
+ classification_target = (stimuli[task_mask] == category)
mask_scores[mask_name][category] = cross_val_score(
classifier,
masked_timecourses,
| {"golden_diff": "diff --git a/examples/decoding/plot_haxby_different_estimators.py b/examples/decoding/plot_haxby_different_estimators.py\n--- a/examples/decoding/plot_haxby_different_estimators.py\n+++ b/examples/decoding/plot_haxby_different_estimators.py\n@@ -95,8 +95,8 @@\n print(70 * '_')\n \n for category in categories:\n- classification_target = stimuli[\n- np.logical_not(resting_state)] == category\n+ task_mask = np.logical_not(resting_state)\n+ classification_target = (stimuli[task_mask] == category)\n t0 = time.time()\n classifiers_scores[classifier_name][category] = cross_val_score(\n classifier,\ndiff --git a/examples/decoding/plot_haxby_full_analysis.py b/examples/decoding/plot_haxby_full_analysis.py\n--- a/examples/decoding/plot_haxby_full_analysis.py\n+++ b/examples/decoding/plot_haxby_full_analysis.py\n@@ -72,8 +72,8 @@\n \n for category in categories:\n print(\"Processing %s %s\" % (mask_name, category))\n- classification_target = stimuli[\n- np.logical_not(resting_state)] == category\n+ task_mask = np.logical_not(resting_state)\n+ classification_target = (stimuli[task_mask] == category)\n mask_scores[mask_name][category] = cross_val_score(\n classifier,\n masked_timecourses,\n", "issue": "Improve task mask pattern in examples\n``` python\nclassification_target = stimuli[\n np.logical_not(resting_state)] == category\n```\n\nFrom #740, @AlexandreAbraham said:\n\n> I already found this line hard to understand before (I particularly dislike playing with the priority of operators = and ==) but now the new_line make it even more obscure. Maybe we could change by:\n> \n> ```\n> task_mask = np.logical_not(resting_state) # or sample_mask?\n> classification_target = (stimuli[task_mask] == category)\n> ```\n\nQuickly git-grepping it looks like this pattern is both present in:\nexamples/decoding/plot_haxby_different_estimators.py\nexamples/decoding/plot_haxby_full_analysis.py\n\nThey may be other places where this is used.\n\n", "before_files": [{"content": "\"\"\"\nDifferent classifiers in decoding the Haxby dataset\n=====================================================\n\nHere we compare different classifiers on a visual object recognition\ndecoding task.\n\"\"\"\n\nimport time\n\n### Fetch data using nilearn dataset fetcher ################################\nfrom nilearn import datasets\nhaxby_dataset = datasets.fetch_haxby(n_subjects=1)\n\n# print basic information on the dataset\nprint('First subject anatomical nifti image (3D) located is at: %s' %\n haxby_dataset.anat[0])\nprint('First subject functional nifti image (4D) is located at: %s' %\n haxby_dataset.func[0])\n\n# load labels\nimport numpy as np\nlabels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=\" \")\nstimuli = labels['labels']\n# identify resting state labels in order to be able to remove them\nresting_state = stimuli == b'rest'\n\n# find names of remaining active labels\ncategories = np.unique(stimuli[np.logical_not(resting_state)])\n\n# extract tags indicating to which acquisition run a tag belongs\nsession_labels = labels[\"chunks\"][np.logical_not(resting_state)]\n\n# Load the fMRI data\nfrom nilearn.input_data import NiftiMasker\n\n# For decoding, standardizing is often very important\nmask_filename = haxby_dataset.mask_vt[0]\nmasker = NiftiMasker(mask_img=mask_filename, standardize=True)\nfunc_filename = haxby_dataset.func[0]\nmasked_timecourses = masker.fit_transform(\n func_filename)[np.logical_not(resting_state)]\n\n# Classifiers definition\n\n# A support vector classifier\nfrom sklearn.svm import SVC\nsvm = SVC(C=1., kernel=\"linear\")\n\nfrom sklearn.grid_search import GridSearchCV\n# GridSearchCV is slow, but note that it takes an 'n_jobs' parameter that\n# can significantly speed up the fitting process on computers with\n# multiple cores\nsvm_cv = GridSearchCV(SVC(C=1., kernel=\"linear\"),\n param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\n\n# The logistic regression\nfrom sklearn.linear_model import LogisticRegression, RidgeClassifier, \\\n RidgeClassifierCV\nlogistic = LogisticRegression(C=1., penalty=\"l1\")\nlogistic_50 = LogisticRegression(C=50., penalty=\"l1\")\nlogistic_l2 = LogisticRegression(C=1., penalty=\"l2\")\n\nlogistic_cv = GridSearchCV(LogisticRegression(C=1., penalty=\"l1\"),\n param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\nlogistic_l2_cv = GridSearchCV(LogisticRegression(C=1., penalty=\"l2\"),\n param_grid={\n 'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\n\nridge = RidgeClassifier()\nridge_cv = RidgeClassifierCV()\n\n\n# Make a data splitting object for cross validation\nfrom sklearn.cross_validation import LeaveOneLabelOut, cross_val_score\ncv = LeaveOneLabelOut(session_labels)\n\nclassifiers = {'SVC': svm,\n 'SVC cv': svm_cv,\n 'log l1': logistic,\n 'log l1 50': logistic_50,\n 'log l1 cv': logistic_cv,\n 'log l2': logistic_l2,\n 'log l2 cv': logistic_l2_cv,\n 'ridge': ridge,\n 'ridge cv': ridge_cv}\n\nclassifiers_scores = {}\n\nfor classifier_name, classifier in sorted(classifiers.items()):\n classifiers_scores[classifier_name] = {}\n print(70 * '_')\n\n for category in categories:\n classification_target = stimuli[\n np.logical_not(resting_state)] == category\n t0 = time.time()\n classifiers_scores[classifier_name][category] = cross_val_score(\n classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n print(\"%10s: %14s -- scores: %1.2f +- %1.2f, time %.2fs\" % (\n classifier_name, category,\n classifiers_scores[classifier_name][category].mean(),\n classifiers_scores[classifier_name][category].std(),\n time.time() - t0))\n\n###############################################################################\n# make a rudimentary diagram\nimport matplotlib.pyplot as plt\nplt.figure()\n\ntick_position = np.arange(len(categories))\nplt.xticks(tick_position, categories, rotation=45)\n\nfor color, classifier_name in zip(\n ['b', 'c', 'm', 'g', 'y', 'k', '.5', 'r', '#ffaaaa'],\n sorted(classifiers)):\n score_means = [classifiers_scores[classifier_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_means, label=classifier_name,\n width=.11, color=color)\n tick_position = tick_position + .09\n\nplt.ylabel('Classification accurancy (f1 score)')\nplt.xlabel('Visual stimuli category')\nplt.ylim(ymin=0)\nplt.legend(loc='lower center', ncol=3)\nplt.title('Category-specific classification accuracy for different classifiers')\nplt.tight_layout()\n\n###############################################################################\n# Plot the face vs house map for the different estimators\n\n# use the average EPI as a background\nfrom nilearn import image\nmean_epi_img = image.mean_img(func_filename)\n\n# Restrict the decoding to face vs house\ncondition_mask = np.logical_or(stimuli == b'face', stimuli == b'house')\nmasked_timecourses = masked_timecourses[\n condition_mask[np.logical_not(resting_state)]]\nstimuli = stimuli[condition_mask]\n# Transform the stimuli to binary values\nstimuli = (stimuli == b'face').astype(np.int)\n\nfrom nilearn.plotting import plot_stat_map, show\n\nfor classifier_name, classifier in sorted(classifiers.items()):\n classifier.fit(masked_timecourses, stimuli)\n\n if hasattr(classifier, 'coef_'):\n weights = classifier.coef_[0]\n elif hasattr(classifier, 'best_estimator_'):\n weights = classifier.best_estimator_.coef_[0]\n else:\n continue\n weight_img = masker.inverse_transform(weights)\n weight_map = weight_img.get_data()\n threshold = np.max(np.abs(weight_map)) * 1e-3\n plot_stat_map(weight_img, bg_img=mean_epi_img,\n display_mode='z', cut_coords=[-17],\n threshold=threshold,\n title='%s: face vs house' % classifier_name)\n\nshow()\n", "path": "examples/decoding/plot_haxby_different_estimators.py"}, {"content": "\"\"\"\nROI-based decoding analysis in Haxby et al. dataset\n=====================================================\n\nIn this script we reproduce the data analysis conducted by\nHaxby et al. in \"Distributed and Overlapping Representations of Faces and\nObjects in Ventral Temporal Cortex\".\n\nSpecifically, we look at decoding accuracy for different objects in\nthree different masks: the full ventral stream (mask_vt), the house\nselective areas (mask_house) and the face selective areas (mask_face),\nthat have been defined via a standard GLM-based analysis.\n\n\"\"\"\n\n\n### Fetch data using nilearn dataset fetcher ################################\nfrom nilearn import datasets\nhaxby_dataset = datasets.fetch_haxby(n_subjects=1)\n\n# print basic information on the dataset\nprint('First subject anatomical nifti image (3D) located is at: %s' %\n haxby_dataset.anat[0])\nprint('First subject functional nifti image (4D) is located at: %s' %\n haxby_dataset.func[0])\n\n# Load nilearn NiftiMasker, the practical masking and unmasking tool\nfrom nilearn.input_data import NiftiMasker\n\n# load labels\nimport numpy as np\nlabels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=\" \")\nstimuli = labels['labels']\n\n# identify resting state labels in order to be able to remove them\nresting_state = stimuli == b\"rest\"\n\n# find names of remaining active labels\ncategories = np.unique(stimuli[np.logical_not(resting_state)])\n\n# extract tags indicating to which acquisition run a tag belongs\nsession_labels = labels[\"chunks\"][np.logical_not(resting_state)]\n\n# The classifier: a support vector classifier\nfrom sklearn.svm import SVC\nclassifier = SVC(C=1., kernel=\"linear\")\n\n# A classifier to set the chance level\nfrom sklearn.dummy import DummyClassifier\ndummy_classifier = DummyClassifier()\n\n# Make a data splitting object for cross validation\nfrom sklearn.cross_validation import LeaveOneLabelOut, cross_val_score\ncv = LeaveOneLabelOut(session_labels)\n\nfunc_filename = haxby_dataset.func[0]\nmask_names = ['mask_vt', 'mask_face', 'mask_house']\n\nmask_scores = {}\nmask_chance_scores = {}\n\nfor mask_name in mask_names:\n print(\"Working on mask %s\" % mask_name)\n # For decoding, standardizing is often very important\n mask_filename = haxby_dataset[mask_name][0]\n masker = NiftiMasker(mask_img=mask_filename, standardize=True)\n masked_timecourses = masker.fit_transform(\n func_filename)[np.logical_not(resting_state)]\n\n mask_scores[mask_name] = {}\n mask_chance_scores[mask_name] = {}\n\n for category in categories:\n print(\"Processing %s %s\" % (mask_name, category))\n classification_target = stimuli[\n np.logical_not(resting_state)] == category\n mask_scores[mask_name][category] = cross_val_score(\n classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n mask_chance_scores[mask_name][category] = cross_val_score(\n dummy_classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n print(\"Scores: %1.2f +- %1.2f\" % (\n mask_scores[mask_name][category].mean(),\n mask_scores[mask_name][category].std()))\n\n# make a rudimentary diagram\nimport matplotlib.pyplot as plt\nplt.figure()\n\ntick_position = np.arange(len(categories))\nplt.xticks(tick_position, categories, rotation=45)\n\nfor color, mask_name in zip('rgb', mask_names):\n score_means = [mask_scores[mask_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_means, label=mask_name,\n width=.25, color=color)\n\n score_chance = [mask_chance_scores[mask_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_chance,\n width=.25, edgecolor='k', facecolor='none')\n\n tick_position = tick_position + .2\n\nplt.ylabel('Classification accurancy (f1 score)')\nplt.xlabel('Visual stimuli category')\nplt.legend(loc='best')\nplt.title('Category-specific classification accuracy for different masks')\nplt.tight_layout()\n\n\nplt.show()\n", "path": "examples/decoding/plot_haxby_full_analysis.py"}], "after_files": [{"content": "\"\"\"\nDifferent classifiers in decoding the Haxby dataset\n=====================================================\n\nHere we compare different classifiers on a visual object recognition\ndecoding task.\n\"\"\"\n\nimport time\n\n### Fetch data using nilearn dataset fetcher ################################\nfrom nilearn import datasets\nhaxby_dataset = datasets.fetch_haxby(n_subjects=1)\n\n# print basic information on the dataset\nprint('First subject anatomical nifti image (3D) located is at: %s' %\n haxby_dataset.anat[0])\nprint('First subject functional nifti image (4D) is located at: %s' %\n haxby_dataset.func[0])\n\n# load labels\nimport numpy as np\nlabels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=\" \")\nstimuli = labels['labels']\n# identify resting state labels in order to be able to remove them\nresting_state = stimuli == b'rest'\n\n# find names of remaining active labels\ncategories = np.unique(stimuli[np.logical_not(resting_state)])\n\n# extract tags indicating to which acquisition run a tag belongs\nsession_labels = labels[\"chunks\"][np.logical_not(resting_state)]\n\n# Load the fMRI data\nfrom nilearn.input_data import NiftiMasker\n\n# For decoding, standardizing is often very important\nmask_filename = haxby_dataset.mask_vt[0]\nmasker = NiftiMasker(mask_img=mask_filename, standardize=True)\nfunc_filename = haxby_dataset.func[0]\nmasked_timecourses = masker.fit_transform(\n func_filename)[np.logical_not(resting_state)]\n\n# Classifiers definition\n\n# A support vector classifier\nfrom sklearn.svm import SVC\nsvm = SVC(C=1., kernel=\"linear\")\n\nfrom sklearn.grid_search import GridSearchCV\n# GridSearchCV is slow, but note that it takes an 'n_jobs' parameter that\n# can significantly speed up the fitting process on computers with\n# multiple cores\nsvm_cv = GridSearchCV(SVC(C=1., kernel=\"linear\"),\n param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\n\n# The logistic regression\nfrom sklearn.linear_model import LogisticRegression, RidgeClassifier, \\\n RidgeClassifierCV\nlogistic = LogisticRegression(C=1., penalty=\"l1\")\nlogistic_50 = LogisticRegression(C=50., penalty=\"l1\")\nlogistic_l2 = LogisticRegression(C=1., penalty=\"l2\")\n\nlogistic_cv = GridSearchCV(LogisticRegression(C=1., penalty=\"l1\"),\n param_grid={'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\nlogistic_l2_cv = GridSearchCV(LogisticRegression(C=1., penalty=\"l2\"),\n param_grid={\n 'C': [.1, .5, 1., 5., 10., 50., 100.]},\n scoring='f1')\n\nridge = RidgeClassifier()\nridge_cv = RidgeClassifierCV()\n\n\n# Make a data splitting object for cross validation\nfrom sklearn.cross_validation import LeaveOneLabelOut, cross_val_score\ncv = LeaveOneLabelOut(session_labels)\n\nclassifiers = {'SVC': svm,\n 'SVC cv': svm_cv,\n 'log l1': logistic,\n 'log l1 50': logistic_50,\n 'log l1 cv': logistic_cv,\n 'log l2': logistic_l2,\n 'log l2 cv': logistic_l2_cv,\n 'ridge': ridge,\n 'ridge cv': ridge_cv}\n\nclassifiers_scores = {}\n\nfor classifier_name, classifier in sorted(classifiers.items()):\n classifiers_scores[classifier_name] = {}\n print(70 * '_')\n\n for category in categories:\n task_mask = np.logical_not(resting_state)\n classification_target = (stimuli[task_mask] == category)\n t0 = time.time()\n classifiers_scores[classifier_name][category] = cross_val_score(\n classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n print(\"%10s: %14s -- scores: %1.2f +- %1.2f, time %.2fs\" % (\n classifier_name, category,\n classifiers_scores[classifier_name][category].mean(),\n classifiers_scores[classifier_name][category].std(),\n time.time() - t0))\n\n###############################################################################\n# make a rudimentary diagram\nimport matplotlib.pyplot as plt\nplt.figure()\n\ntick_position = np.arange(len(categories))\nplt.xticks(tick_position, categories, rotation=45)\n\nfor color, classifier_name in zip(\n ['b', 'c', 'm', 'g', 'y', 'k', '.5', 'r', '#ffaaaa'],\n sorted(classifiers)):\n score_means = [classifiers_scores[classifier_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_means, label=classifier_name,\n width=.11, color=color)\n tick_position = tick_position + .09\n\nplt.ylabel('Classification accurancy (f1 score)')\nplt.xlabel('Visual stimuli category')\nplt.ylim(ymin=0)\nplt.legend(loc='lower center', ncol=3)\nplt.title('Category-specific classification accuracy for different classifiers')\nplt.tight_layout()\n\n###############################################################################\n# Plot the face vs house map for the different estimators\n\n# use the average EPI as a background\nfrom nilearn import image\nmean_epi_img = image.mean_img(func_filename)\n\n# Restrict the decoding to face vs house\ncondition_mask = np.logical_or(stimuli == b'face', stimuli == b'house')\nmasked_timecourses = masked_timecourses[\n condition_mask[np.logical_not(resting_state)]]\nstimuli = stimuli[condition_mask]\n# Transform the stimuli to binary values\nstimuli = (stimuli == b'face').astype(np.int)\n\nfrom nilearn.plotting import plot_stat_map, show\n\nfor classifier_name, classifier in sorted(classifiers.items()):\n classifier.fit(masked_timecourses, stimuli)\n\n if hasattr(classifier, 'coef_'):\n weights = classifier.coef_[0]\n elif hasattr(classifier, 'best_estimator_'):\n weights = classifier.best_estimator_.coef_[0]\n else:\n continue\n weight_img = masker.inverse_transform(weights)\n weight_map = weight_img.get_data()\n threshold = np.max(np.abs(weight_map)) * 1e-3\n plot_stat_map(weight_img, bg_img=mean_epi_img,\n display_mode='z', cut_coords=[-17],\n threshold=threshold,\n title='%s: face vs house' % classifier_name)\n\nshow()\n", "path": "examples/decoding/plot_haxby_different_estimators.py"}, {"content": "\"\"\"\nROI-based decoding analysis in Haxby et al. dataset\n=====================================================\n\nIn this script we reproduce the data analysis conducted by\nHaxby et al. in \"Distributed and Overlapping Representations of Faces and\nObjects in Ventral Temporal Cortex\".\n\nSpecifically, we look at decoding accuracy for different objects in\nthree different masks: the full ventral stream (mask_vt), the house\nselective areas (mask_house) and the face selective areas (mask_face),\nthat have been defined via a standard GLM-based analysis.\n\n\"\"\"\n\n\n### Fetch data using nilearn dataset fetcher ################################\nfrom nilearn import datasets\nhaxby_dataset = datasets.fetch_haxby(n_subjects=1)\n\n# print basic information on the dataset\nprint('First subject anatomical nifti image (3D) located is at: %s' %\n haxby_dataset.anat[0])\nprint('First subject functional nifti image (4D) is located at: %s' %\n haxby_dataset.func[0])\n\n# Load nilearn NiftiMasker, the practical masking and unmasking tool\nfrom nilearn.input_data import NiftiMasker\n\n# load labels\nimport numpy as np\nlabels = np.recfromcsv(haxby_dataset.session_target[0], delimiter=\" \")\nstimuli = labels['labels']\n\n# identify resting state labels in order to be able to remove them\nresting_state = stimuli == b\"rest\"\n\n# find names of remaining active labels\ncategories = np.unique(stimuli[np.logical_not(resting_state)])\n\n# extract tags indicating to which acquisition run a tag belongs\nsession_labels = labels[\"chunks\"][np.logical_not(resting_state)]\n\n# The classifier: a support vector classifier\nfrom sklearn.svm import SVC\nclassifier = SVC(C=1., kernel=\"linear\")\n\n# A classifier to set the chance level\nfrom sklearn.dummy import DummyClassifier\ndummy_classifier = DummyClassifier()\n\n# Make a data splitting object for cross validation\nfrom sklearn.cross_validation import LeaveOneLabelOut, cross_val_score\ncv = LeaveOneLabelOut(session_labels)\n\nfunc_filename = haxby_dataset.func[0]\nmask_names = ['mask_vt', 'mask_face', 'mask_house']\n\nmask_scores = {}\nmask_chance_scores = {}\n\nfor mask_name in mask_names:\n print(\"Working on mask %s\" % mask_name)\n # For decoding, standardizing is often very important\n mask_filename = haxby_dataset[mask_name][0]\n masker = NiftiMasker(mask_img=mask_filename, standardize=True)\n masked_timecourses = masker.fit_transform(\n func_filename)[np.logical_not(resting_state)]\n\n mask_scores[mask_name] = {}\n mask_chance_scores[mask_name] = {}\n\n for category in categories:\n print(\"Processing %s %s\" % (mask_name, category))\n task_mask = np.logical_not(resting_state)\n classification_target = (stimuli[task_mask] == category)\n mask_scores[mask_name][category] = cross_val_score(\n classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n mask_chance_scores[mask_name][category] = cross_val_score(\n dummy_classifier,\n masked_timecourses,\n classification_target,\n cv=cv, scoring=\"f1\")\n\n print(\"Scores: %1.2f +- %1.2f\" % (\n mask_scores[mask_name][category].mean(),\n mask_scores[mask_name][category].std()))\n\n# make a rudimentary diagram\nimport matplotlib.pyplot as plt\nplt.figure()\n\ntick_position = np.arange(len(categories))\nplt.xticks(tick_position, categories, rotation=45)\n\nfor color, mask_name in zip('rgb', mask_names):\n score_means = [mask_scores[mask_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_means, label=mask_name,\n width=.25, color=color)\n\n score_chance = [mask_chance_scores[mask_name][category].mean()\n for category in categories]\n plt.bar(tick_position, score_chance,\n width=.25, edgecolor='k', facecolor='none')\n\n tick_position = tick_position + .2\n\nplt.ylabel('Classification accurancy (f1 score)')\nplt.xlabel('Visual stimuli category')\nplt.legend(loc='best')\nplt.title('Category-specific classification accuracy for different masks')\nplt.tight_layout()\n\n\nplt.show()\n", "path": "examples/decoding/plot_haxby_full_analysis.py"}]} | 3,517 | 319 |
gh_patches_debug_49140 | rasdani/github-patches | git_diff | horovod__horovod-2121 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error in computing gradients when using allgather
**Environment:**
1. Framework: TensorFlow
2. Framework version: 2.0
3. Horovod version: 0.18.2
I am trying to get the median of a tensor computed across all batches and all processes. However, I got an error TypeError: Expected int32, got None of type 'NoneType' instead.It seems that computing gradients does not work well with horovod's allgather operation. A simple illustration of what I would like to achieve is as follows:
>with tf.GradientTape() as tape:
    my_tensor = compute_my_tensor()
    gathered_my_tensor = hvd.allgather(my_tensor)
    median = get_median(gathered_my_tensor)
    loss = get_loss(my_tensor, median, training=True)
tape = hvd.DistributedGradientTape(tape)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
BTW, when I use eager mode of tensorflow, there will be no error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `horovod/tensorflow/mpi_ops.py`
Content:
```
1 # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
2 # Modifications copyright (C) 2019 Uber Technologies, Inc.
3 # Modifications copyright Microsoft
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 # =============================================================================
17 """Inter-process communication using MPI."""
18
19 import re
20 import tensorflow as tf
21 from tensorflow.python.framework import load_library
22 from tensorflow.python.framework import ops
23 from tensorflow.python.platform import resource_loader
24
25 from horovod.common.util import get_ext_suffix, get_average_backwards_compatibility_fun, gpu_available, \
26 num_rank_is_power_2
27 from horovod.common.basics import HorovodBasics as _HorovodBasics
28 from horovod.tensorflow.util import _executing_eagerly
29
30
31 def _load_library(name):
32 """Loads a .so file containing the specified operators.
33
34 Args:
35 name: The name of the .so file to load.
36
37 Raises:
38 NotFoundError if were not able to load .so file.
39 """
40 filename = resource_loader.get_path_to_datafile(name)
41 library = load_library.load_op_library(filename)
42 return library
43
44
45 MPI_LIB = _load_library('mpi_lib' + get_ext_suffix())
46
47 _basics = _HorovodBasics(__file__, 'mpi_lib')
48
49 # import basic methods
50 init = _basics.init
51 shutdown = _basics.shutdown
52 size = _basics.size
53 local_size = _basics.local_size
54 rank = _basics.rank
55 local_rank = _basics.local_rank
56 mpi_threads_supported = _basics.mpi_threads_supported
57 mpi_enabled = _basics.mpi_enabled
58 mpi_built = _basics.mpi_built
59 gloo_enabled = _basics.gloo_enabled
60 gloo_built = _basics.gloo_built
61 nccl_built = _basics.nccl_built
62 ddl_built = _basics.ddl_built
63 ccl_built = _basics.ccl_built
64
65 # import reduction op values
66 Average = _basics.Average
67 Sum = _basics.Sum
68 Adasum = _basics.Adasum
69
70 is_homogeneous = _basics.is_homogeneous
71
72 handle_average_backwards_compatibility = get_average_backwards_compatibility_fun(_basics)
73
74 check_num_rank_power_of_2 = num_rank_is_power_2
75
76
77 # This function will create a default device map which includes all visible devices.
78 # Please run this function in a subprocess
79 def _check_has_gpu():
80 import tensorflow as tf
81 return tf.test.is_gpu_available()
82
83
84 def _normalize_name(name):
85 """Normalizes operation name to TensorFlow rules."""
86 return re.sub('[^a-zA-Z0-9_]', '_', name)
87
88
89 def _allreduce(tensor, name=None, op=Sum):
90 """An op which reduces an input tensor over all the Horovod processes. The
91 default reduction is a sum.
92
93 The reduction operation is keyed by the name of the op. The tensor type and
94 shape must be the same on all Horovod processes for a given name. The reduction
95 will not start until all processes are ready to send and receive the tensor.
96
97 Returns:
98 A tensor of the same shape and type as `tensor`, summed across all
99 processes.
100 """
101 if name is None and not _executing_eagerly():
102 name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)
103 return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op)
104
105
106 @ops.RegisterGradient('HorovodAllreduce')
107 def _allreduce_grad(op, grad):
108 """Gradient for allreduce op.
109
110 Args:
111 op: An operation.
112 grad: `Tensor` gradient with respect to the output of the op.
113
114 Returns:
115 The gradient with respect to the input of the op.
116 """
117 reduce_op = op.get_attr('reduce_op')
118 return _allreduce(grad, op=reduce_op)
119
120
121 def allgather(tensor, name=None):
122 """An op which concatenates the input tensor with the same input tensor on
123 all other Horovod processes.
124
125 The concatenation is done on the first dimension, so the input tensors on the
126 different processes must have the same rank and shape, except for the first
127 dimension, which is allowed to be different.
128
129 Returns:
130 A tensor of the same type as `tensor`, concatenated on dimension zero
131 across all processes. The shape is identical to the input shape, except for
132 the first dimension, which may be greater and is the sum of all first
133 dimensions of the tensors in different Horovod processes.
134 """
135 if name is None and not _executing_eagerly():
136 name = 'HorovodAllgather_%s' % _normalize_name(tensor.name)
137 return MPI_LIB.horovod_allgather(tensor, name=name)
138
139
140 @ops.RegisterGradient('HorovodAllgather')
141 def _allgather_grad(op, grad):
142 """Gradient for allgather op.
143
144 Args:
145 op: An operation.
146 grad: `Tensor` gradient with respect to the output of the op.
147
148 Returns:
149 The gradient with respect to the input of the op.
150 """
151 grad = _allreduce(grad)
152
153 with tf.device('/cpu:0'):
154 # Keep the tensor of split sizes on CPU.
155 x = op.inputs[0]
156 d0 = x.get_shape().as_list()[0]
157 d = tf.convert_to_tensor([d0], dtype=tf.int32)
158
159 s = size()
160 d = tf.reshape(allgather(d), [s])
161
162 splits = tf.split(grad, num_or_size_splits=d, axis=0)
163 return splits[rank()]
164
165
166 def broadcast(tensor, root_rank, name=None):
167 """An op which broadcasts the input tensor on root rank to the same input tensor
168 on all other Horovod processes.
169
170 The broadcast operation is keyed by the name of the op. The tensor type and
171 shape must be the same on all Horovod processes for a given name. The broadcast
172 will not start until all processes are ready to send and receive the tensor.
173
174 Returns:
175 A tensor of the same shape and type as `tensor`, with the value broadcasted
176 from root rank.
177 """
178 if name is None and not _executing_eagerly():
179 name = 'HorovodBroadcast_%s' % _normalize_name(tensor.name)
180 return MPI_LIB.horovod_broadcast(tensor, name=name, root_rank=root_rank)
181
182
183 @ops.RegisterGradient('HorovodBroadcast')
184 def _broadcast_grad(op, grad):
185 """Gradient for broadcast op.
186
187 Args:
188 op: An operation.
189 grad: `Tensor` gradient with respect to the output of the op.
190
191 Returns:
192 The gradient with respect to the input of the op.
193 """
194 root_rank = op.get_attr('root_rank')
195 grad_reduced = _allreduce(grad)
196 if rank() != root_rank:
197 return grad_reduced * 0
198 return grad_reduced
199
200
201 def join():
202 return MPI_LIB.horovod_join()
203
204
205 def size_op(name=None):
206 """An op that returns the number of Horovod processes.
207
208 This operation determines the return value at the graph execution time,
209 rather than at the graph construction time, and so allows for a graph to be
210 constructed in a different environment than where it will be executed.
211
212 Returns:
213 An integer scalar containing the number of Horovod processes.
214 """
215 return MPI_LIB.horovod_size(name=name)
216
217
218 ops.NotDifferentiable('HorovodSize')
219
220
221 def local_size_op(name=None):
222 """An op that returns the number of Horovod processes within the
223 node the current process is running on.
224
225 This operation determines the return value at the graph execution time,
226 rather than at the graph construction time, and so allows for a graph to be
227 constructed in a different environment than where it will be executed.
228
229 Returns:
230 An integer scalar containing the number of local Horovod processes.
231 """
232 return MPI_LIB.horovod_local_size(name=name)
233
234
235 ops.NotDifferentiable('HorovodLocalSize')
236
237
238 def rank_op(name=None):
239 """An op that returns the Horovod rank of the calling process.
240
241 This operation determines the return value at the graph execution time,
242 rather than at the graph construction time, and so allows for a graph to be
243 constructed in a different environment than where it will be executed.
244
245 Returns:
246 An integer scalar with the Horovod rank of the calling process.
247 """
248 return MPI_LIB.horovod_rank(name=name)
249
250
251 ops.NotDifferentiable('HorovodRank')
252
253
254 def local_rank_op(name=None):
255 """An op that returns the local Horovod rank of the calling process, within the
256 node that it is running on. For example, if there are seven processes running
257 on a node, their local ranks will be zero through six, inclusive.
258
259 This operation determines the return value at the graph execution time,
260 rather than at the graph construction time, and so allows for a graph to be
261 constructed in a different environment than where it will be executed.
262
263 Returns:
264 An integer scalar with the local Horovod rank of the calling process.
265 """
266 return MPI_LIB.horovod_rank(name=name)
267
268
269 ops.NotDifferentiable('HorovodLocalRank')
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/horovod/tensorflow/mpi_ops.py b/horovod/tensorflow/mpi_ops.py
--- a/horovod/tensorflow/mpi_ops.py
+++ b/horovod/tensorflow/mpi_ops.py
@@ -152,8 +152,8 @@
with tf.device('/cpu:0'):
# Keep the tensor of split sizes on CPU.
x = op.inputs[0]
- d0 = x.get_shape().as_list()[0]
- d = tf.convert_to_tensor([d0], dtype=tf.int32)
+ d = tf.shape(x)
+ d = tf.reshape(d[0], [1])
s = size()
d = tf.reshape(allgather(d), [s])
| {"golden_diff": "diff --git a/horovod/tensorflow/mpi_ops.py b/horovod/tensorflow/mpi_ops.py\n--- a/horovod/tensorflow/mpi_ops.py\n+++ b/horovod/tensorflow/mpi_ops.py\n@@ -152,8 +152,8 @@\n with tf.device('/cpu:0'):\n # Keep the tensor of split sizes on CPU.\n x = op.inputs[0]\n- d0 = x.get_shape().as_list()[0]\n- d = tf.convert_to_tensor([d0], dtype=tf.int32)\n+ d = tf.shape(x)\n+ d = tf.reshape(d[0], [1])\n \n s = size()\n d = tf.reshape(allgather(d), [s])\n", "issue": "Error in computing gradients when using allgather\n**Environment:**\r\n1. Framework: TensorFlow\r\n2. Framework version: 2.0\r\n3. Horovod version: 0.18.2\r\n\r\nI am trying to get the median of a tensor computed across all batches and all processes. However, I got an error TypeError: Expected int32, got None of type 'NoneType' instead.It seems that computing gradients does not work well with horovod's allgather operation. A simple illustration of what I would like to achieve is as follows:\r\n\r\n>with tf.GradientTape() as tape: \r\n    my_tensor = compute_my_tensor() \r\n    gathered_my_tensor = hvd.allgather(my_tensor) \r\n    median = get_median(gathered_my_tensor)\r\n    loss = get_loss(my_tensor, median, training=True)\r\ntape = hvd.DistributedGradientTape(tape)\r\ngrads = tape.gradient(loss, trainable_variables)\r\noptimizer.apply_gradients(zip(grads, trainable_variables))\r\n\r\nBTW, when I use eager mode of tensorflow, there will be no error\r\n\r\n\n", "before_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n# Modifications copyright (C) 2019 Uber Technologies, Inc.\n# Modifications copyright Microsoft\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# =============================================================================\n\"\"\"Inter-process communication using MPI.\"\"\"\n\nimport re\nimport tensorflow as tf\nfrom tensorflow.python.framework import load_library\nfrom tensorflow.python.framework import ops\nfrom tensorflow.python.platform import resource_loader\n\nfrom horovod.common.util import get_ext_suffix, get_average_backwards_compatibility_fun, gpu_available, \\\n num_rank_is_power_2\nfrom horovod.common.basics import HorovodBasics as _HorovodBasics\nfrom horovod.tensorflow.util import _executing_eagerly\n\n\ndef _load_library(name):\n \"\"\"Loads a .so file containing the specified operators.\n\n Args:\n name: The name of the .so file to load.\n\n Raises:\n NotFoundError if were not able to load .so file.\n \"\"\"\n filename = resource_loader.get_path_to_datafile(name)\n library = load_library.load_op_library(filename)\n return library\n\n\nMPI_LIB = _load_library('mpi_lib' + get_ext_suffix())\n\n_basics = _HorovodBasics(__file__, 'mpi_lib')\n\n# import basic methods\ninit = _basics.init\nshutdown = _basics.shutdown\nsize = _basics.size\nlocal_size = _basics.local_size\nrank = _basics.rank\nlocal_rank = _basics.local_rank\nmpi_threads_supported = _basics.mpi_threads_supported\nmpi_enabled = _basics.mpi_enabled\nmpi_built = _basics.mpi_built\ngloo_enabled = _basics.gloo_enabled\ngloo_built = _basics.gloo_built\nnccl_built = _basics.nccl_built\nddl_built = _basics.ddl_built\nccl_built = _basics.ccl_built\n\n# import reduction op values\nAverage = _basics.Average\nSum = _basics.Sum\nAdasum = _basics.Adasum\n\nis_homogeneous = _basics.is_homogeneous\n\nhandle_average_backwards_compatibility = get_average_backwards_compatibility_fun(_basics)\n\ncheck_num_rank_power_of_2 = num_rank_is_power_2\n\n\n# This function will create a default device map which includes all visible devices.\n# Please run this function in a subprocess\ndef _check_has_gpu():\n import tensorflow as tf\n return tf.test.is_gpu_available()\n\n\ndef _normalize_name(name):\n \"\"\"Normalizes operation name to TensorFlow rules.\"\"\"\n return re.sub('[^a-zA-Z0-9_]', '_', name)\n\n\ndef _allreduce(tensor, name=None, op=Sum):\n \"\"\"An op which reduces an input tensor over all the Horovod processes. The\n default reduction is a sum.\n\n The reduction operation is keyed by the name of the op. The tensor type and\n shape must be the same on all Horovod processes for a given name. The reduction\n will not start until all processes are ready to send and receive the tensor.\n\n Returns:\n A tensor of the same shape and type as `tensor`, summed across all\n processes.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op)\n\n\[email protected]('HorovodAllreduce')\ndef _allreduce_grad(op, grad):\n \"\"\"Gradient for allreduce op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n reduce_op = op.get_attr('reduce_op')\n return _allreduce(grad, op=reduce_op)\n\n\ndef allgather(tensor, name=None):\n \"\"\"An op which concatenates the input tensor with the same input tensor on\n all other Horovod processes.\n\n The concatenation is done on the first dimension, so the input tensors on the\n different processes must have the same rank and shape, except for the first\n dimension, which is allowed to be different.\n\n Returns:\n A tensor of the same type as `tensor`, concatenated on dimension zero\n across all processes. The shape is identical to the input shape, except for\n the first dimension, which may be greater and is the sum of all first\n dimensions of the tensors in different Horovod processes.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodAllgather_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_allgather(tensor, name=name)\n\n\[email protected]('HorovodAllgather')\ndef _allgather_grad(op, grad):\n \"\"\"Gradient for allgather op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n grad = _allreduce(grad)\n\n with tf.device('/cpu:0'):\n # Keep the tensor of split sizes on CPU.\n x = op.inputs[0]\n d0 = x.get_shape().as_list()[0]\n d = tf.convert_to_tensor([d0], dtype=tf.int32)\n\n s = size()\n d = tf.reshape(allgather(d), [s])\n\n splits = tf.split(grad, num_or_size_splits=d, axis=0)\n return splits[rank()]\n\n\ndef broadcast(tensor, root_rank, name=None):\n \"\"\"An op which broadcasts the input tensor on root rank to the same input tensor\n on all other Horovod processes.\n\n The broadcast operation is keyed by the name of the op. The tensor type and\n shape must be the same on all Horovod processes for a given name. The broadcast\n will not start until all processes are ready to send and receive the tensor.\n\n Returns:\n A tensor of the same shape and type as `tensor`, with the value broadcasted\n from root rank.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodBroadcast_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_broadcast(tensor, name=name, root_rank=root_rank)\n\n\[email protected]('HorovodBroadcast')\ndef _broadcast_grad(op, grad):\n \"\"\"Gradient for broadcast op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n root_rank = op.get_attr('root_rank')\n grad_reduced = _allreduce(grad)\n if rank() != root_rank:\n return grad_reduced * 0\n return grad_reduced\n\n\ndef join():\n return MPI_LIB.horovod_join()\n\n\ndef size_op(name=None):\n \"\"\"An op that returns the number of Horovod processes.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar containing the number of Horovod processes.\n \"\"\"\n return MPI_LIB.horovod_size(name=name)\n\n\nops.NotDifferentiable('HorovodSize')\n\n\ndef local_size_op(name=None):\n \"\"\"An op that returns the number of Horovod processes within the\n node the current process is running on.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar containing the number of local Horovod processes.\n \"\"\"\n return MPI_LIB.horovod_local_size(name=name)\n\n\nops.NotDifferentiable('HorovodLocalSize')\n\n\ndef rank_op(name=None):\n \"\"\"An op that returns the Horovod rank of the calling process.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar with the Horovod rank of the calling process.\n \"\"\"\n return MPI_LIB.horovod_rank(name=name)\n\n\nops.NotDifferentiable('HorovodRank')\n\n\ndef local_rank_op(name=None):\n \"\"\"An op that returns the local Horovod rank of the calling process, within the\n node that it is running on. For example, if there are seven processes running\n on a node, their local ranks will be zero through six, inclusive.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar with the local Horovod rank of the calling process.\n \"\"\"\n return MPI_LIB.horovod_rank(name=name)\n\n\nops.NotDifferentiable('HorovodLocalRank')\n", "path": "horovod/tensorflow/mpi_ops.py"}], "after_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n# Modifications copyright (C) 2019 Uber Technologies, Inc.\n# Modifications copyright Microsoft\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# =============================================================================\n\"\"\"Inter-process communication using MPI.\"\"\"\n\nimport re\nimport tensorflow as tf\nfrom tensorflow.python.framework import load_library\nfrom tensorflow.python.framework import ops\nfrom tensorflow.python.platform import resource_loader\n\nfrom horovod.common.util import get_ext_suffix, get_average_backwards_compatibility_fun, gpu_available, \\\n num_rank_is_power_2\nfrom horovod.common.basics import HorovodBasics as _HorovodBasics\nfrom horovod.tensorflow.util import _executing_eagerly\n\n\ndef _load_library(name):\n \"\"\"Loads a .so file containing the specified operators.\n\n Args:\n name: The name of the .so file to load.\n\n Raises:\n NotFoundError if were not able to load .so file.\n \"\"\"\n filename = resource_loader.get_path_to_datafile(name)\n library = load_library.load_op_library(filename)\n return library\n\n\nMPI_LIB = _load_library('mpi_lib' + get_ext_suffix())\n\n_basics = _HorovodBasics(__file__, 'mpi_lib')\n\n# import basic methods\ninit = _basics.init\nshutdown = _basics.shutdown\nsize = _basics.size\nlocal_size = _basics.local_size\nrank = _basics.rank\nlocal_rank = _basics.local_rank\nmpi_threads_supported = _basics.mpi_threads_supported\nmpi_enabled = _basics.mpi_enabled\nmpi_built = _basics.mpi_built\ngloo_enabled = _basics.gloo_enabled\ngloo_built = _basics.gloo_built\nnccl_built = _basics.nccl_built\nddl_built = _basics.ddl_built\nccl_built = _basics.ccl_built\n\n# import reduction op values\nAverage = _basics.Average\nSum = _basics.Sum\nAdasum = _basics.Adasum\n\nis_homogeneous = _basics.is_homogeneous\n\nhandle_average_backwards_compatibility = get_average_backwards_compatibility_fun(_basics)\n\ncheck_num_rank_power_of_2 = num_rank_is_power_2\n\n\n# This function will create a default device map which includes all visible devices.\n# Please run this function in a subprocess\ndef _check_has_gpu():\n import tensorflow as tf\n return tf.test.is_gpu_available()\n\n\ndef _normalize_name(name):\n \"\"\"Normalizes operation name to TensorFlow rules.\"\"\"\n return re.sub('[^a-zA-Z0-9_]', '_', name)\n\n\ndef _allreduce(tensor, name=None, op=Sum):\n \"\"\"An op which reduces an input tensor over all the Horovod processes. The\n default reduction is a sum.\n\n The reduction operation is keyed by the name of the op. The tensor type and\n shape must be the same on all Horovod processes for a given name. The reduction\n will not start until all processes are ready to send and receive the tensor.\n\n Returns:\n A tensor of the same shape and type as `tensor`, summed across all\n processes.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodAllreduce_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op)\n\n\[email protected]('HorovodAllreduce')\ndef _allreduce_grad(op, grad):\n \"\"\"Gradient for allreduce op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n return _allreduce(grad)\n\n\ndef allgather(tensor, name=None):\n \"\"\"An op which concatenates the input tensor with the same input tensor on\n all other Horovod processes.\n\n The concatenation is done on the first dimension, so the input tensors on the\n different processes must have the same rank and shape, except for the first\n dimension, which is allowed to be different.\n\n Returns:\n A tensor of the same type as `tensor`, concatenated on dimension zero\n across all processes. The shape is identical to the input shape, except for\n the first dimension, which may be greater and is the sum of all first\n dimensions of the tensors in different Horovod processes.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodAllgather_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_allgather(tensor, name=name)\n\n\[email protected]('HorovodAllgather')\ndef _allgather_grad(op, grad):\n \"\"\"Gradient for allgather op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n grad = _allreduce(grad)\n\n with tf.device('/cpu:0'):\n # Keep the tensor of split sizes on CPU.\n x = op.inputs[0]\n d = tf.shape(x)\n d = tf.reshape(d[0], [1])\n\n s = size()\n d = tf.reshape(allgather(d), [s])\n\n splits = tf.split(grad, num_or_size_splits=d, axis=0)\n return splits[rank()]\n\n\ndef broadcast(tensor, root_rank, name=None):\n \"\"\"An op which broadcasts the input tensor on root rank to the same input tensor\n on all other Horovod processes.\n\n The broadcast operation is keyed by the name of the op. The tensor type and\n shape must be the same on all Horovod processes for a given name. The broadcast\n will not start until all processes are ready to send and receive the tensor.\n\n Returns:\n A tensor of the same shape and type as `tensor`, with the value broadcasted\n from root rank.\n \"\"\"\n if name is None and not _executing_eagerly():\n name = 'HorovodBroadcast_%s' % _normalize_name(tensor.name)\n return MPI_LIB.horovod_broadcast(tensor, name=name, root_rank=root_rank)\n\n\[email protected]('HorovodBroadcast')\ndef _broadcast_grad(op, grad):\n \"\"\"Gradient for broadcast op.\n\n Args:\n op: An operation.\n grad: `Tensor` gradient with respect to the output of the op.\n\n Returns:\n The gradient with respect to the input of the op.\n \"\"\"\n root_rank = op.get_attr('root_rank')\n grad_reduced = _allreduce(grad)\n if rank() != root_rank:\n return grad_reduced * 0\n return grad_reduced\n\n\ndef join():\n return MPI_LIB.horovod_join()\n\n\ndef size_op(name=None):\n \"\"\"An op that returns the number of Horovod processes.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar containing the number of Horovod processes.\n \"\"\"\n return MPI_LIB.horovod_size(name=name)\n\n\nops.NotDifferentiable('HorovodSize')\n\n\ndef local_size_op(name=None):\n \"\"\"An op that returns the number of Horovod processes within the\n node the current process is running on.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar containing the number of local Horovod processes.\n \"\"\"\n return MPI_LIB.horovod_local_size(name=name)\n\n\nops.NotDifferentiable('HorovodLocalSize')\n\n\ndef rank_op(name=None):\n \"\"\"An op that returns the Horovod rank of the calling process.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar with the Horovod rank of the calling process.\n \"\"\"\n return MPI_LIB.horovod_rank(name=name)\n\n\nops.NotDifferentiable('HorovodRank')\n\n\ndef local_rank_op(name=None):\n \"\"\"An op that returns the local Horovod rank of the calling process, within the\n node that it is running on. For example, if there are seven processes running\n on a node, their local ranks will be zero through six, inclusive.\n\n This operation determines the return value at the graph execution time,\n rather than at the graph construction time, and so allows for a graph to be\n constructed in a different environment than where it will be executed.\n\n Returns:\n An integer scalar with the local Horovod rank of the calling process.\n \"\"\"\n return MPI_LIB.horovod_rank(name=name)\n\n\nops.NotDifferentiable('HorovodLocalRank')\n", "path": "horovod/tensorflow/mpi_ops.py"}]} | 3,391 | 169 |
gh_patches_debug_33923 | rasdani/github-patches | git_diff | fidals__shopelectro-861 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update_pack.py:17: Update Product.in_pack and render...
The puzzle `827-907829af` from #827 has to be resolved:
https://github.com/fidals/shopelectro/blob/39281ed9b9d945b4518b411769db4a3f454f2916/shopelectro/management/commands/_update_catalog/update_pack.py#L17-L17
The puzzle was created by Artemiy on 30-May-19.
Estimate: 60 minutes, role: DEV.
If you have any technical questions, don't ask me, submit new tickets instead. The task will be \"done\" when the problem is fixed and the text of the puzzle is _removed_ from the source code. Here is more about [PDD](http://www.yegor256.com/2009/03/04/pdd.html) and [about me](http://www.yegor256.com/2017/04/05/pdd-in-action.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shopelectro/models.py`
Content:
```
1 import enum
2 import random
3 import string
4 import typing
5 from uuid import uuid4
6
7 from django.conf import settings
8 from django.db import models
9 from django.urls import reverse
10 from django.utils.translation import ugettext_lazy as _
11
12 from catalog import models as catalog_models
13 from ecommerce import models as ecommerce_models
14 from pages import models as pages_models
15
16
17 def randomize_slug(slug: str) -> str:
18 slug_hash = ''.join(
19 random.choices(string.ascii_lowercase, k=settings.SLUG_HASH_SIZE)
20 )
21 return f'{slug}_{slug_hash}'
22
23
24 class SECategoryQuerySet(catalog_models.CategoryQuerySet):
25 def get_categories_tree_with_pictures(self) -> 'SECategoryQuerySet':
26 categories_with_pictures = (
27 self
28 .filter(products__page__images__isnull=False)
29 .distinct()
30 )
31
32 return categories_with_pictures.get_ancestors(include_self=True)
33
34
35 class SECategoryManager(
36 catalog_models.CategoryManager.from_queryset(SECategoryQuerySet)
37 ):
38 pass
39
40
41 class Category(catalog_models.AbstractCategory, pages_models.SyncPageMixin):
42
43 objects = SECategoryManager()
44 uuid = models.UUIDField(default=uuid4, editable=False)
45
46 @classmethod
47 def get_default_parent(cls):
48 return pages_models.CustomPage.objects.filter(slug='catalog').first()
49
50 @property
51 def image(self):
52 products = self.products.all()
53 return products[0].image if products else None
54
55 def get_absolute_url(self):
56 return reverse('category', args=(self.page.slug,))
57
58
59 class Product(
60 catalog_models.AbstractProduct,
61 catalog_models.AbstractPosition,
62 pages_models.SyncPageMixin
63 ):
64
65 # That's why we are needed to explicitly add objects manager here
66 # because of Django special managers behaviour.
67 # Se se#480 for details.
68 objects = catalog_models.ProductManager()
69
70 category = models.ForeignKey(
71 Category,
72 on_delete=models.CASCADE,
73 null=True,
74 related_name='products',
75 verbose_name=_('category'),
76 )
77
78 tags = models.ManyToManyField(
79 'Tag',
80 related_name='products',
81 blank=True,
82 verbose_name=_('tags'),
83 )
84
85 vendor_code = models.SmallIntegerField(verbose_name=_('vendor_code'))
86 uuid = models.UUIDField(default=uuid4, editable=False)
87 purchase_price = models.FloatField(
88 default=0, verbose_name=_('purchase_price'))
89 wholesale_small = models.FloatField(
90 default=0, verbose_name=_('wholesale_small'))
91 wholesale_medium = models.FloatField(
92 default=0, verbose_name=_('wholesale_medium'))
93 wholesale_large = models.FloatField(
94 default=0, verbose_name=_('wholesale_large'))
95
96 in_pack = models.PositiveSmallIntegerField(
97 default=1,
98 verbose_name=_('in pack'),
99 )
100
101 def get_absolute_url(self):
102 return reverse('product', args=(self.vendor_code,))
103
104 @property
105 def average_rate(self):
106 """Return rounded to first decimal averaged rating."""
107 rating = self.product_feedbacks.aggregate(
108 avg=models.Avg('rating')).get('avg', 0)
109 return round(rating, 1)
110
111 @property
112 def feedback_count(self):
113 return self.product_feedbacks.count()
114
115 @property
116 def feedback(self):
117 return self.product_feedbacks.all().order_by('-date')
118
119 def get_params(self):
120 return Tag.objects.filter_by_products([self]).group_tags()
121
122 def get_brand_name(self) -> str:
123 brand: typing.Optional['Tag'] = Tag.objects.get_brands([self]).get(self)
124 return brand.name if brand else ''
125
126
127 class ProductFeedback(models.Model):
128 product = models.ForeignKey(
129 Product, on_delete=models.CASCADE, null=True,
130 related_name='product_feedbacks'
131 )
132
133 date = models.DateTimeField(
134 auto_now=True, db_index=True, verbose_name=_('date'))
135 name = models.CharField(
136 max_length=255, db_index=True, verbose_name=_('name'))
137 rating = models.PositiveSmallIntegerField(
138 default=1, db_index=True, verbose_name=_('rating'))
139 dignities = models.TextField(
140 default='', blank=True, verbose_name=_('dignities'))
141 limitations = models.TextField(
142 default='', blank=True, verbose_name=_('limitations'))
143 general = models.TextField(
144 default='', blank=True, verbose_name=_('limitations'))
145
146
147 class ItemsEnum(enum.EnumMeta):
148 """
149 Provide dict-like `items` method.
150
151 https://docs.python.org/3/library/enum.html#enum-classes
152 """
153
154 def items(self):
155 return [(i.name, i.value) for i in self]
156
157 def __repr__(self):
158 fields = ', '.join(i.name for i in self)
159 return f"<enum '{self.__name__}: {fields}'>"
160
161
162 class PaymentOptions(enum.Enum, metaclass=ItemsEnum):
163 cash = 'Наличные'
164 cashless = 'Безналичные и денежные переводы'
165 AC = 'Банковская карта'
166 PC = 'Яндекс.Деньги'
167 GP = 'Связной (терминал)'
168 AB = 'Альфа-Клик'
169
170 @staticmethod
171 def default():
172 return PaymentOptions.cash
173
174
175 class Order(ecommerce_models.Order):
176 address = models.TextField(blank=True, default='')
177 payment_type = models.CharField(
178 max_length=255,
179 choices=PaymentOptions.items(),
180 default=PaymentOptions.default().name,
181 )
182 comment = models.TextField(blank=True, default='')
183 # total price - total purchase price
184 revenue = models.FloatField(default=0, null=True, verbose_name=_('revenue'))
185
186 @property
187 def payment_type_label(self):
188 """Return label for an order's payment option."""
189 return PaymentOptions[self.payment_type].value
190
191 def set_positions(self, cart):
192 """
193 Save cart's state into Order instance.
194
195 @todo #589:60m Create Cart model.
196 See details here: https://github.com/fidals/shopelectro/pull/590#discussion_r222544672
197 """
198 self.revenue = cart.total_revenue()
199 self.save()
200 for id_, position in cart:
201 self.positions.create(
202 order=self,
203 product_id=id_,
204 vendor_code=position['vendor_code'],
205 name=position['name'],
206 price=position['price'],
207 quantity=position['quantity'],
208 )
209 return self
210
211
212 class CategoryPage(pages_models.ModelPage):
213 """Create proxy model for Admin."""
214
215 class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)
216 proxy = True
217
218 # noinspection PyTypeChecker
219 objects = pages_models.ModelPage.create_model_page_managers(Category)
220
221
222 class ProductPage(pages_models.ModelPage):
223 """Create proxy model for Admin."""
224
225 class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)
226 proxy = True
227
228 # noinspection PyTypeChecker
229 objects = (
230 pages_models.ModelPage
231 .create_model_page_managers(Product)
232 )
233
234
235 class TagGroup(catalog_models.TagGroup):
236 pass
237
238
239 class TagQuerySet(catalog_models.TagQuerySet):
240 pass
241
242
243 class Tag(catalog_models.Tag):
244 group = models.ForeignKey(
245 TagGroup, on_delete=models.CASCADE, null=True, related_name='tags',
246 )
247
```
Path: `shopelectro/management/commands/_update_catalog/update_pack.py`
Content:
```
1 import logging
2
3 from django.db import transaction
4
5 from shopelectro.models import TagGroup
6
7 logger = logging.getLogger(__name__)
8
9
10 def main(*args, kwargs):
11 uuid = 'ae30f766-0bb8-11e6-80ea-02d2cc20e118'
12 pack_group = TagGroup.objects.filter(uuid=uuid).first()
13 if not pack_group:
14 logger.error(f'Couldn\'t find "Упаковка" tag group with uuid = "{uuid}".')
15 return
16
17 # @todo #827:60m Update Product.in_pack and render prices properly.
18
19 return
20 packs = pack_group.tags.all().prefetch_related('products')
21 with transaction.atomic():
22 for pack in packs:
23 ...
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/shopelectro/management/commands/_update_catalog/update_pack.py b/shopelectro/management/commands/_update_catalog/update_pack.py
--- a/shopelectro/management/commands/_update_catalog/update_pack.py
+++ b/shopelectro/management/commands/_update_catalog/update_pack.py
@@ -1,10 +1,33 @@
+"""
+Update Product.in_pack and prices.
+
+The update_catalog command always resets product prices to per unit format, so:
+1. Parse in pack quantity from Tag.name and save it to Product.in_pack
+2. Multiply product prices by in_pack value and save.
+"""
import logging
-from django.db import transaction
+from django.db import models, transaction
-from shopelectro.models import TagGroup
+from shopelectro.models import TagQuerySet, TagGroup
logger = logging.getLogger(__name__)
+PRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']
+
+
+def update_in_packs(packs: TagQuerySet):
+ """Parse and save in pack quantity values."""
+ # @todo #859:60m Implement update_pack and render prices properly.
+
+
+def update_prices(packs: TagQuerySet):
+ """Multiply product prices on in pack quantity."""
+ fields_to_update = {}
+ for price in PRICES:
+ fields_to_update[price] = models.F(price) * models.F('in_pack')
+
+ with transaction.atomic():
+ packs.products().update(**fields_to_update)
def main(*args, kwargs):
@@ -14,10 +37,8 @@
logger.error(f'Couldn\'t find "Упаковка" tag group with uuid = "{uuid}".')
return
- # @todo #827:60m Update Product.in_pack and render prices properly.
-
return
+
packs = pack_group.tags.all().prefetch_related('products')
- with transaction.atomic():
- for pack in packs:
- ...
+ update_in_packs(packs)
+ update_prices(packs)
diff --git a/shopelectro/models.py b/shopelectro/models.py
--- a/shopelectro/models.py
+++ b/shopelectro/models.py
@@ -237,6 +237,13 @@
class TagQuerySet(catalog_models.TagQuerySet):
+
+ def products(self):
+ ids = Tag.objects.all().values_list('products__id', flat=True)
+ return Product.objects.filter(id__in=ids).distinct()
+
+
+class TagManager(catalog_models.TagManager.from_queryset(TagQuerySet)):
pass
@@ -244,3 +251,5 @@
group = models.ForeignKey(
TagGroup, on_delete=models.CASCADE, null=True, related_name='tags',
)
+
+ objects = TagManager()
| {"golden_diff": "diff --git a/shopelectro/management/commands/_update_catalog/update_pack.py b/shopelectro/management/commands/_update_catalog/update_pack.py\n--- a/shopelectro/management/commands/_update_catalog/update_pack.py\n+++ b/shopelectro/management/commands/_update_catalog/update_pack.py\n@@ -1,10 +1,33 @@\n+\"\"\"\n+Update Product.in_pack and prices.\n+\n+The update_catalog command always resets product prices to per unit format, so:\n+1. Parse in pack quantity from Tag.name and save it to Product.in_pack\n+2. Multiply product prices by in_pack value and save.\n+\"\"\"\n import logging\n \n-from django.db import transaction\n+from django.db import models, transaction\n \n-from shopelectro.models import TagGroup\n+from shopelectro.models import TagQuerySet, TagGroup\n \n logger = logging.getLogger(__name__)\n+PRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']\n+\n+\n+def update_in_packs(packs: TagQuerySet):\n+ \"\"\"Parse and save in pack quantity values.\"\"\"\n+ # @todo #859:60m Implement update_pack and render prices properly.\n+\n+\n+def update_prices(packs: TagQuerySet):\n+ \"\"\"Multiply product prices on in pack quantity.\"\"\"\n+ fields_to_update = {}\n+ for price in PRICES:\n+ fields_to_update[price] = models.F(price) * models.F('in_pack')\n+\n+ with transaction.atomic():\n+ packs.products().update(**fields_to_update)\n \n \n def main(*args, kwargs):\n@@ -14,10 +37,8 @@\n logger.error(f'Couldn\\'t find \"\u0423\u043f\u0430\u043a\u043e\u0432\u043a\u0430\" tag group with uuid = \"{uuid}\".')\n return\n \n- # @todo #827:60m Update Product.in_pack and render prices properly.\n-\n return\n+\n packs = pack_group.tags.all().prefetch_related('products')\n- with transaction.atomic():\n- for pack in packs:\n- ...\n+ update_in_packs(packs)\n+ update_prices(packs)\ndiff --git a/shopelectro/models.py b/shopelectro/models.py\n--- a/shopelectro/models.py\n+++ b/shopelectro/models.py\n@@ -237,6 +237,13 @@\n \n \n class TagQuerySet(catalog_models.TagQuerySet):\n+\n+ def products(self):\n+ ids = Tag.objects.all().values_list('products__id', flat=True)\n+ return Product.objects.filter(id__in=ids).distinct()\n+\n+\n+class TagManager(catalog_models.TagManager.from_queryset(TagQuerySet)):\n pass\n \n \n@@ -244,3 +251,5 @@\n group = models.ForeignKey(\n TagGroup, on_delete=models.CASCADE, null=True, related_name='tags',\n )\n+\n+ objects = TagManager()\n", "issue": "update_pack.py:17: Update Product.in_pack and render...\nThe puzzle `827-907829af` from #827 has to be resolved: \n\nhttps://github.com/fidals/shopelectro/blob/39281ed9b9d945b4518b411769db4a3f454f2916/shopelectro/management/commands/_update_catalog/update_pack.py#L17-L17\n\nThe puzzle was created by Artemiy on 30-May-19. \n\nEstimate: 60 minutes, role: DEV. \n\nIf you have any technical questions, don't ask me, submit new tickets instead. The task will be \\\"done\\\" when the problem is fixed and the text of the puzzle is _removed_ from the source code. Here is more about [PDD](http://www.yegor256.com/2009/03/04/pdd.html) and [about me](http://www.yegor256.com/2017/04/05/pdd-in-action.html). \n\n", "before_files": [{"content": "import enum\nimport random\nimport string\nimport typing\nfrom uuid import uuid4\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom catalog import models as catalog_models\nfrom ecommerce import models as ecommerce_models\nfrom pages import models as pages_models\n\n\ndef randomize_slug(slug: str) -> str:\n slug_hash = ''.join(\n random.choices(string.ascii_lowercase, k=settings.SLUG_HASH_SIZE)\n )\n return f'{slug}_{slug_hash}'\n\n\nclass SECategoryQuerySet(catalog_models.CategoryQuerySet):\n def get_categories_tree_with_pictures(self) -> 'SECategoryQuerySet':\n categories_with_pictures = (\n self\n .filter(products__page__images__isnull=False)\n .distinct()\n )\n\n return categories_with_pictures.get_ancestors(include_self=True)\n\n\nclass SECategoryManager(\n catalog_models.CategoryManager.from_queryset(SECategoryQuerySet)\n):\n pass\n\n\nclass Category(catalog_models.AbstractCategory, pages_models.SyncPageMixin):\n\n objects = SECategoryManager()\n uuid = models.UUIDField(default=uuid4, editable=False)\n\n @classmethod\n def get_default_parent(cls):\n return pages_models.CustomPage.objects.filter(slug='catalog').first()\n\n @property\n def image(self):\n products = self.products.all()\n return products[0].image if products else None\n\n def get_absolute_url(self):\n return reverse('category', args=(self.page.slug,))\n\n\nclass Product(\n catalog_models.AbstractProduct,\n catalog_models.AbstractPosition,\n pages_models.SyncPageMixin\n):\n\n # That's why we are needed to explicitly add objects manager here\n # because of Django special managers behaviour.\n # Se se#480 for details.\n objects = catalog_models.ProductManager()\n\n category = models.ForeignKey(\n Category,\n on_delete=models.CASCADE,\n null=True,\n related_name='products',\n verbose_name=_('category'),\n )\n\n tags = models.ManyToManyField(\n 'Tag',\n related_name='products',\n blank=True,\n verbose_name=_('tags'),\n )\n\n vendor_code = models.SmallIntegerField(verbose_name=_('vendor_code'))\n uuid = models.UUIDField(default=uuid4, editable=False)\n purchase_price = models.FloatField(\n default=0, verbose_name=_('purchase_price'))\n wholesale_small = models.FloatField(\n default=0, verbose_name=_('wholesale_small'))\n wholesale_medium = models.FloatField(\n default=0, verbose_name=_('wholesale_medium'))\n wholesale_large = models.FloatField(\n default=0, verbose_name=_('wholesale_large'))\n\n in_pack = models.PositiveSmallIntegerField(\n default=1,\n verbose_name=_('in pack'),\n )\n\n def get_absolute_url(self):\n return reverse('product', args=(self.vendor_code,))\n\n @property\n def average_rate(self):\n \"\"\"Return rounded to first decimal averaged rating.\"\"\"\n rating = self.product_feedbacks.aggregate(\n avg=models.Avg('rating')).get('avg', 0)\n return round(rating, 1)\n\n @property\n def feedback_count(self):\n return self.product_feedbacks.count()\n\n @property\n def feedback(self):\n return self.product_feedbacks.all().order_by('-date')\n\n def get_params(self):\n return Tag.objects.filter_by_products([self]).group_tags()\n\n def get_brand_name(self) -> str:\n brand: typing.Optional['Tag'] = Tag.objects.get_brands([self]).get(self)\n return brand.name if brand else ''\n\n\nclass ProductFeedback(models.Model):\n product = models.ForeignKey(\n Product, on_delete=models.CASCADE, null=True,\n related_name='product_feedbacks'\n )\n\n date = models.DateTimeField(\n auto_now=True, db_index=True, verbose_name=_('date'))\n name = models.CharField(\n max_length=255, db_index=True, verbose_name=_('name'))\n rating = models.PositiveSmallIntegerField(\n default=1, db_index=True, verbose_name=_('rating'))\n dignities = models.TextField(\n default='', blank=True, verbose_name=_('dignities'))\n limitations = models.TextField(\n default='', blank=True, verbose_name=_('limitations'))\n general = models.TextField(\n default='', blank=True, verbose_name=_('limitations'))\n\n\nclass ItemsEnum(enum.EnumMeta):\n \"\"\"\n Provide dict-like `items` method.\n\n https://docs.python.org/3/library/enum.html#enum-classes\n \"\"\"\n\n def items(self):\n return [(i.name, i.value) for i in self]\n\n def __repr__(self):\n fields = ', '.join(i.name for i in self)\n return f\"<enum '{self.__name__}: {fields}'>\"\n\n\nclass PaymentOptions(enum.Enum, metaclass=ItemsEnum):\n cash = '\u041d\u0430\u043b\u0438\u0447\u043d\u044b\u0435'\n cashless = '\u0411\u0435\u0437\u043d\u0430\u043b\u0438\u0447\u043d\u044b\u0435 \u0438 \u0434\u0435\u043d\u0435\u0436\u043d\u044b\u0435 \u043f\u0435\u0440\u0435\u0432\u043e\u0434\u044b'\n AC = '\u0411\u0430\u043d\u043a\u043e\u0432\u0441\u043a\u0430\u044f \u043a\u0430\u0440\u0442\u0430'\n PC = '\u042f\u043d\u0434\u0435\u043a\u0441.\u0414\u0435\u043d\u044c\u0433\u0438'\n GP = '\u0421\u0432\u044f\u0437\u043d\u043e\u0439 (\u0442\u0435\u0440\u043c\u0438\u043d\u0430\u043b)'\n AB = '\u0410\u043b\u044c\u0444\u0430-\u041a\u043b\u0438\u043a'\n\n @staticmethod\n def default():\n return PaymentOptions.cash\n\n\nclass Order(ecommerce_models.Order):\n address = models.TextField(blank=True, default='')\n payment_type = models.CharField(\n max_length=255,\n choices=PaymentOptions.items(),\n default=PaymentOptions.default().name,\n )\n comment = models.TextField(blank=True, default='')\n # total price - total purchase price\n revenue = models.FloatField(default=0, null=True, verbose_name=_('revenue'))\n\n @property\n def payment_type_label(self):\n \"\"\"Return label for an order's payment option.\"\"\"\n return PaymentOptions[self.payment_type].value\n\n def set_positions(self, cart):\n \"\"\"\n Save cart's state into Order instance.\n\n @todo #589:60m Create Cart model.\n See details here: https://github.com/fidals/shopelectro/pull/590#discussion_r222544672\n \"\"\"\n self.revenue = cart.total_revenue()\n self.save()\n for id_, position in cart:\n self.positions.create(\n order=self,\n product_id=id_,\n vendor_code=position['vendor_code'],\n name=position['name'],\n price=position['price'],\n quantity=position['quantity'],\n )\n return self\n\n\nclass CategoryPage(pages_models.ModelPage):\n \"\"\"Create proxy model for Admin.\"\"\"\n\n class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)\n proxy = True\n\n # noinspection PyTypeChecker\n objects = pages_models.ModelPage.create_model_page_managers(Category)\n\n\nclass ProductPage(pages_models.ModelPage):\n \"\"\"Create proxy model for Admin.\"\"\"\n\n class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)\n proxy = True\n\n # noinspection PyTypeChecker\n objects = (\n pages_models.ModelPage\n .create_model_page_managers(Product)\n )\n\n\nclass TagGroup(catalog_models.TagGroup):\n pass\n\n\nclass TagQuerySet(catalog_models.TagQuerySet):\n pass\n\n\nclass Tag(catalog_models.Tag):\n group = models.ForeignKey(\n TagGroup, on_delete=models.CASCADE, null=True, related_name='tags',\n )\n", "path": "shopelectro/models.py"}, {"content": "import logging\n\nfrom django.db import transaction\n\nfrom shopelectro.models import TagGroup\n\nlogger = logging.getLogger(__name__)\n\n\ndef main(*args, kwargs):\n uuid = 'ae30f766-0bb8-11e6-80ea-02d2cc20e118'\n pack_group = TagGroup.objects.filter(uuid=uuid).first()\n if not pack_group:\n logger.error(f'Couldn\\'t find \"\u0423\u043f\u0430\u043a\u043e\u0432\u043a\u0430\" tag group with uuid = \"{uuid}\".')\n return\n\n # @todo #827:60m Update Product.in_pack and render prices properly.\n\n return\n packs = pack_group.tags.all().prefetch_related('products')\n with transaction.atomic():\n for pack in packs:\n ...\n", "path": "shopelectro/management/commands/_update_catalog/update_pack.py"}], "after_files": [{"content": "import enum\nimport random\nimport string\nimport typing\nfrom uuid import uuid4\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom catalog import models as catalog_models\nfrom ecommerce import models as ecommerce_models\nfrom pages import models as pages_models\n\n\ndef randomize_slug(slug: str) -> str:\n slug_hash = ''.join(\n random.choices(string.ascii_lowercase, k=settings.SLUG_HASH_SIZE)\n )\n return f'{slug}_{slug_hash}'\n\n\nclass SECategoryQuerySet(catalog_models.CategoryQuerySet):\n def get_categories_tree_with_pictures(self) -> 'SECategoryQuerySet':\n categories_with_pictures = (\n self\n .filter(products__page__images__isnull=False)\n .distinct()\n )\n\n return categories_with_pictures.get_ancestors(include_self=True)\n\n\nclass SECategoryManager(\n catalog_models.CategoryManager.from_queryset(SECategoryQuerySet)\n):\n pass\n\n\nclass Category(catalog_models.AbstractCategory, pages_models.SyncPageMixin):\n\n objects = SECategoryManager()\n uuid = models.UUIDField(default=uuid4, editable=False)\n\n @classmethod\n def get_default_parent(cls):\n return pages_models.CustomPage.objects.filter(slug='catalog').first()\n\n @property\n def image(self):\n products = self.products.all()\n return products[0].image if products else None\n\n def get_absolute_url(self):\n return reverse('category', args=(self.page.slug,))\n\n\nclass Product(\n catalog_models.AbstractProduct,\n catalog_models.AbstractPosition,\n pages_models.SyncPageMixin\n):\n\n # That's why we are needed to explicitly add objects manager here\n # because of Django special managers behaviour.\n # Se se#480 for details.\n objects = catalog_models.ProductManager()\n\n category = models.ForeignKey(\n Category,\n on_delete=models.CASCADE,\n null=True,\n related_name='products',\n verbose_name=_('category'),\n )\n\n tags = models.ManyToManyField(\n 'Tag',\n related_name='products',\n blank=True,\n verbose_name=_('tags'),\n )\n\n vendor_code = models.SmallIntegerField(verbose_name=_('vendor_code'))\n uuid = models.UUIDField(default=uuid4, editable=False)\n purchase_price = models.FloatField(\n default=0, verbose_name=_('purchase_price'))\n wholesale_small = models.FloatField(\n default=0, verbose_name=_('wholesale_small'))\n wholesale_medium = models.FloatField(\n default=0, verbose_name=_('wholesale_medium'))\n wholesale_large = models.FloatField(\n default=0, verbose_name=_('wholesale_large'))\n\n in_pack = models.PositiveSmallIntegerField(\n default=1,\n verbose_name=_('in pack'),\n )\n\n def get_absolute_url(self):\n return reverse('product', args=(self.vendor_code,))\n\n @property\n def average_rate(self):\n \"\"\"Return rounded to first decimal averaged rating.\"\"\"\n rating = self.product_feedbacks.aggregate(\n avg=models.Avg('rating')).get('avg', 0)\n return round(rating, 1)\n\n @property\n def feedback_count(self):\n return self.product_feedbacks.count()\n\n @property\n def feedback(self):\n return self.product_feedbacks.all().order_by('-date')\n\n def get_params(self):\n return Tag.objects.filter_by_products([self]).group_tags()\n\n def get_brand_name(self) -> str:\n brand: typing.Optional['Tag'] = Tag.objects.get_brands([self]).get(self)\n return brand.name if brand else ''\n\n\nclass ProductFeedback(models.Model):\n product = models.ForeignKey(\n Product, on_delete=models.CASCADE, null=True,\n related_name='product_feedbacks'\n )\n\n date = models.DateTimeField(\n auto_now=True, db_index=True, verbose_name=_('date'))\n name = models.CharField(\n max_length=255, db_index=True, verbose_name=_('name'))\n rating = models.PositiveSmallIntegerField(\n default=1, db_index=True, verbose_name=_('rating'))\n dignities = models.TextField(\n default='', blank=True, verbose_name=_('dignities'))\n limitations = models.TextField(\n default='', blank=True, verbose_name=_('limitations'))\n general = models.TextField(\n default='', blank=True, verbose_name=_('limitations'))\n\n\nclass ItemsEnum(enum.EnumMeta):\n \"\"\"\n Provide dict-like `items` method.\n\n https://docs.python.org/3/library/enum.html#enum-classes\n \"\"\"\n\n def items(self):\n return [(i.name, i.value) for i in self]\n\n def __repr__(self):\n fields = ', '.join(i.name for i in self)\n return f\"<enum '{self.__name__}: {fields}'>\"\n\n\nclass PaymentOptions(enum.Enum, metaclass=ItemsEnum):\n cash = '\u041d\u0430\u043b\u0438\u0447\u043d\u044b\u0435'\n cashless = '\u0411\u0435\u0437\u043d\u0430\u043b\u0438\u0447\u043d\u044b\u0435 \u0438 \u0434\u0435\u043d\u0435\u0436\u043d\u044b\u0435 \u043f\u0435\u0440\u0435\u0432\u043e\u0434\u044b'\n AC = '\u0411\u0430\u043d\u043a\u043e\u0432\u0441\u043a\u0430\u044f \u043a\u0430\u0440\u0442\u0430'\n PC = '\u042f\u043d\u0434\u0435\u043a\u0441.\u0414\u0435\u043d\u044c\u0433\u0438'\n GP = '\u0421\u0432\u044f\u0437\u043d\u043e\u0439 (\u0442\u0435\u0440\u043c\u0438\u043d\u0430\u043b)'\n AB = '\u0410\u043b\u044c\u0444\u0430-\u041a\u043b\u0438\u043a'\n\n @staticmethod\n def default():\n return PaymentOptions.cash\n\n\nclass Order(ecommerce_models.Order):\n address = models.TextField(blank=True, default='')\n payment_type = models.CharField(\n max_length=255,\n choices=PaymentOptions.items(),\n default=PaymentOptions.default().name,\n )\n comment = models.TextField(blank=True, default='')\n # total price - total purchase price\n revenue = models.FloatField(default=0, null=True, verbose_name=_('revenue'))\n\n @property\n def payment_type_label(self):\n \"\"\"Return label for an order's payment option.\"\"\"\n return PaymentOptions[self.payment_type].value\n\n def set_positions(self, cart):\n \"\"\"\n Save cart's state into Order instance.\n\n @todo #589:60m Create Cart model.\n See details here: https://github.com/fidals/shopelectro/pull/590#discussion_r222544672\n \"\"\"\n self.revenue = cart.total_revenue()\n self.save()\n for id_, position in cart:\n self.positions.create(\n order=self,\n product_id=id_,\n vendor_code=position['vendor_code'],\n name=position['name'],\n price=position['price'],\n quantity=position['quantity'],\n )\n return self\n\n\nclass CategoryPage(pages_models.ModelPage):\n \"\"\"Create proxy model for Admin.\"\"\"\n\n class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)\n proxy = True\n\n # noinspection PyTypeChecker\n objects = pages_models.ModelPage.create_model_page_managers(Category)\n\n\nclass ProductPage(pages_models.ModelPage):\n \"\"\"Create proxy model for Admin.\"\"\"\n\n class Meta(pages_models.ModelPage.Meta): # Ignore PycodestyleBear (E303)\n proxy = True\n\n # noinspection PyTypeChecker\n objects = (\n pages_models.ModelPage\n .create_model_page_managers(Product)\n )\n\n\nclass TagGroup(catalog_models.TagGroup):\n pass\n\n\nclass TagQuerySet(catalog_models.TagQuerySet):\n\n def products(self):\n ids = Tag.objects.all().values_list('products__id', flat=True)\n return Product.objects.filter(id__in=ids).distinct()\n\n\nclass TagManager(catalog_models.TagManager.from_queryset(TagQuerySet)):\n pass\n\n\nclass Tag(catalog_models.Tag):\n group = models.ForeignKey(\n TagGroup, on_delete=models.CASCADE, null=True, related_name='tags',\n )\n\n objects = TagManager()\n", "path": "shopelectro/models.py"}, {"content": "\"\"\"\nUpdate Product.in_pack and prices.\n\nThe update_catalog command always resets product prices to per unit format, so:\n1. Parse in pack quantity from Tag.name and save it to Product.in_pack\n2. Multiply product prices by in_pack value and save.\n\"\"\"\nimport logging\n\nfrom django.db import models, transaction\n\nfrom shopelectro.models import TagQuerySet, TagGroup\n\nlogger = logging.getLogger(__name__)\nPRICES = ['price', 'purchase_price', 'wholesale_small', 'wholesale_medium', 'wholesale_large']\n\n\ndef update_in_packs(packs: TagQuerySet):\n \"\"\"Parse and save in pack quantity values.\"\"\"\n # @todo #859:60m Implement update_pack and render prices properly.\n\n\ndef update_prices(packs: TagQuerySet):\n \"\"\"Multiply product prices on in pack quantity.\"\"\"\n fields_to_update = {}\n for price in PRICES:\n fields_to_update[price] = models.F(price) * models.F('in_pack')\n\n with transaction.atomic():\n packs.products().update(**fields_to_update)\n\n\ndef main(*args, kwargs):\n uuid = 'ae30f766-0bb8-11e6-80ea-02d2cc20e118'\n pack_group = TagGroup.objects.filter(uuid=uuid).first()\n if not pack_group:\n logger.error(f'Couldn\\'t find \"\u0423\u043f\u0430\u043a\u043e\u0432\u043a\u0430\" tag group with uuid = \"{uuid}\".')\n return\n\n return\n\n packs = pack_group.tags.all().prefetch_related('products')\n update_in_packs(packs)\n update_prices(packs)\n", "path": "shopelectro/management/commands/_update_catalog/update_pack.py"}]} | 2,982 | 632 |
gh_patches_debug_40767 | rasdani/github-patches | git_diff | run-house__runhouse-53 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Consider adding `-y` option to `runhouse login` CLI command
## Feature
Simple use case is logging in with `system` command instead of Python API:
```
!runhouse login [TOKEN]
```
Currently, the CLI is hardcoded with `interactive=True`:
https://github.com/run-house/runhouse/blob/560a52880a333e17e8a1aca01c1048f4527fc375/runhouse/main.py#L27
## Motivation
It's a minor quality of life improvement.
## Ideal Solution
See above
## Additional context
Excited to get Runhouse integration up on NatML 😄
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `runhouse/rns/login.py`
Content:
```
1 import logging
2 from typing import Union
3
4 import typer
5
6 from runhouse.rh_config import configs, rns_client
7
8 logger = logging.getLogger(__name__)
9
10
11 def is_interactive():
12 import __main__ as main
13
14 return not hasattr(main, "__file__")
15
16
17 def login(
18 token: str = None,
19 download_config: bool = None,
20 upload_config: bool = None,
21 download_secrets: bool = None,
22 upload_secrets: bool = None,
23 ret_token: bool = False,
24 interactive: bool = False,
25 ):
26 """Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between
27 local environment and Runhouse / Vault.
28 """
29 from runhouse import Secrets
30
31 if is_interactive() or interactive:
32 from getpass import getpass
33
34 from rich.console import Console
35
36 console = Console()
37 console.print(
38 """
39 ____ __ @ @ @
40 / __ \__ ______ / /_ ____ __ __________ []___
41 / /_/ / / / / __ \/ __ \/ __ \/ / / / ___/ _ \ / /\____ @@
42 / _, _/ /_/ / / / / / / / /_/ / /_/ (__ ) __/ /_/\_//____/\ @@@@
43 /_/ |_|\__,_/_/ /_/_/ /_/\____/\__,_/____/\___/ | || |||__||| ||
44 """
45 )
46 link = (
47 f'[link={configs.get("api_server_url")}/dashboard/?option=token]https://api.run.house[/link]'
48 if is_interactive()
49 else f'{configs.get("api_server_url")}/dashboard/?option=token'
50 )
51 console.print(
52 f"Retrieve your token :key: here to use :person_running: :house: Runhouse for "
53 f"secrets and artifact management: {link}",
54 style="bold yellow",
55 )
56 if not token:
57 token = getpass("Token: ")
58
59 download_config = (
60 download_config
61 if download_config is not None
62 else typer.confirm(
63 "Download config from Runhouse to your local .rh folder?"
64 )
65 )
66 download_secrets = (
67 download_secrets
68 if download_secrets is not None
69 else typer.confirm(
70 "Download secrets from Vault to your local Runhouse config?"
71 )
72 )
73 upload_config = (
74 upload_config
75 if upload_config is not None
76 else typer.confirm("Upload your local config to Runhouse?")
77 )
78 upload_secrets = (
79 upload_secrets
80 if upload_secrets is not None
81 else typer.confirm("Upload your enabled cloud provider secrets to Vault?")
82 )
83
84 if token:
85 configs.set("token", token)
86
87 if download_config:
88 configs.download_and_save_defaults()
89 # We need to fresh the RNSClient to use the newly loaded configs
90 rns_client.refresh_defaults()
91 elif upload_config:
92 configs.upload_defaults(defaults=configs.defaults_cache)
93 else:
94 # If we are not downloading or uploading config, we still want to make sure the token is valid
95 try:
96 configs.download_defaults()
97 except:
98 logger.error("Failed to validate token")
99 return None
100
101 if download_secrets:
102 Secrets.download_into_env()
103
104 if upload_secrets:
105 Secrets.extract_and_upload(interactive=interactive)
106
107 logger.info("Successfully logged into Runhouse.")
108 if ret_token:
109 return token
110
111
112 def logout(
113 delete_loaded_secrets: bool = None,
114 delete_rh_config_file: bool = None,
115 interactive: bool = None,
116 ):
117 """Logout from Runhouse. Provides option to delete credentials from the Runhouse config and the underlying
118 credentials file. Token is also deleted from the config.
119
120 Args:
121 delete_loaded_secrets (bool, optional): If True, deletes the provider credentials file. Defaults to None.
122 delete_rh_config_file (bool, optional): If True, deletes the rh config file. Defaults to None.
123 interactive (bool, optional): If True, runs the logout process in interactive mode. Defaults to None.
124
125 Returns:
126 None
127 """
128 from runhouse import Secrets
129
130 interactive_session: bool = (
131 interactive if interactive is not None else is_interactive()
132 )
133 for provider in Secrets.enabled_providers():
134 provider_name: str = provider.PROVIDER_NAME
135 provider_creds_path: Union[str, tuple] = provider.default_credentials_path()
136
137 if interactive_session:
138 delete_loaded_secrets = typer.confirm(
139 f"Delete credentials file for {provider_name}?"
140 )
141
142 configs.delete(provider_name)
143
144 if delete_loaded_secrets:
145 provider.delete_secrets_file(provider_creds_path)
146 logger.info(
147 f"Deleted {provider_name} credentials file from path: {provider_creds_path}"
148 )
149
150 # Delete token from rh config file
151 configs.delete(key="token")
152
153 rh_config_path = configs.CONFIG_PATH
154 if not delete_rh_config_file and interactive_session:
155 delete_rh_config_file = typer.confirm("Delete your local Runhouse config file?")
156
157 if delete_rh_config_file:
158 # Delete the credentials file on the file system
159 configs.delete_defaults(rh_config_path)
160 logger.info(f"Deleted Runhouse config file from path: {rh_config_path}")
161
162 logger.info("Successfully logged out of Runhouse.")
163
```
Path: `runhouse/main.py`
Content:
```
1 import subprocess
2 import webbrowser
3 from typing import Optional
4
5 import pkg_resources
6 import typer
7 from rich.console import Console
8
9 from runhouse import cluster, configs
10 from runhouse.rns import ( # Need to rename it because it conflicts with the login command
11 login as login_module,
12 )
13
14 # create an explicit Typer application
15 app = typer.Typer(add_completion=False)
16 state = {"verbose": False}
17
18 # For printing with typer
19 console = Console()
20
21
22 @app.command()
23 def login(token: Optional[str] = typer.Argument(None, help="Your Runhouse API token")):
24 """Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between
25 local environment and Runhouse / Vault.
26 """
27 valid_token: str = login_module.login(token=token, interactive=True, ret_token=True)
28 if valid_token:
29 webbrowser.open(
30 f"{configs.get('api_server_url')}/dashboard?token={valid_token}"
31 )
32 raise typer.Exit()
33 else:
34 raise typer.Exit(code=1)
35
36
37 @app.command()
38 def logout():
39 """Logout of Runhouse. Provides options to delete locally configured secrets and local Runhouse configs"""
40 login_module.logout(interactive=True)
41 raise typer.Exit()
42
43
44 @app.command()
45 def notebook(
46 cluster_name: str, up: bool = typer.Option(False, help="Start the cluster")
47 ):
48 """Open a Jupyter notebook on a cluster."""
49 c = cluster(name=cluster_name)
50 if up:
51 c.up_if_not()
52 if not c.is_up():
53 console.print(
54 f"Cluster {cluster_name} is not up. Please run `runhouse notebook {cluster_name} --up`."
55 )
56 raise typer.Exit(1)
57 c.notebook()
58
59
60 @app.command()
61 def ssh(cluster_name: str, up: bool = typer.Option(False, help="Start the cluster")):
62 """SSH into a cluster created elsewhere (so `ssh cluster` doesn't work out of the box) or not yet up."""
63 c = cluster(name=cluster_name)
64 if up:
65 c.up_if_not()
66 if not c.is_up():
67 console.print(
68 f"Cluster {cluster_name} is not up. Please run `runhouse ssh {cluster_name} --up`."
69 )
70 raise typer.Exit(1)
71 subprocess.call(f"ssh {c.name}", shell=True)
72
73
74 @app.command()
75 def cancel(
76 cluster_name: str,
77 run_key: str,
78 force: Optional[bool] = typer.Option(False, help="Force cancel"),
79 all: Optional[bool] = typer.Option(False, help="Cancel all jobs"),
80 ):
81 """Cancel a run on a cluster."""
82 c = cluster(name=cluster_name)
83 c.cancel(run_key, force=force, all=all)
84
85
86 @app.command()
87 def logs(
88 cluster_name: str,
89 run_key: str,
90 print_results: Optional[bool] = typer.Option(False, help="Print results"),
91 ):
92 """Get logs from a run on a cluster."""
93 c = cluster(name=cluster_name)
94 res = c.get(run_key, stream_logs=True)
95 if print_results:
96 console.print(res)
97
98
99 def load_cluster(cluster_name: str):
100 """Load a cluster from RNS into the local environment, e.g. to be able to ssh."""
101 c = cluster(name=cluster_name)
102 if not c.address:
103 c.update_from_sky_status(dryrun=True)
104
105
106 @app.command()
107 def restart_grpc(
108 cluster_name: str,
109 restart_ray: bool = typer.Option(False, help="Restart the Ray runtime"),
110 resync_rh: bool = typer.Option(False, help="Resync the Runhouse package"),
111 ):
112 """Restart the gRPC server on a cluster."""
113 c = cluster(name=cluster_name)
114 c.restart_grpc_server(resync_rh=resync_rh, restart_ray=restart_ray)
115
116
117 @app.callback()
118 def main(verbose: bool = False):
119 """
120 Runhouse CLI
121 """
122 if verbose:
123 name = "runhouse"
124 version = pkg_resources.get_distribution(name).version
125 console.print(f"{name}=={version}", style="bold green")
126 state["verbose"] = True
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/runhouse/main.py b/runhouse/main.py
--- a/runhouse/main.py
+++ b/runhouse/main.py
@@ -20,11 +20,27 @@
@app.command()
-def login(token: Optional[str] = typer.Argument(None, help="Your Runhouse API token")):
+def login(
+ token: Optional[str] = typer.Argument(None, help="Your Runhouse API token"),
+ yes: Optional[bool] = typer.Option(
+ False, "--yes", "-y", help="Sets any confirmations to 'yes' automatically."
+ ),
+):
"""Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between
local environment and Runhouse / Vault.
"""
- valid_token: str = login_module.login(token=token, interactive=True, ret_token=True)
+ valid_token: str = (
+ login_module.login(
+ token=token,
+ download_config=True,
+ upload_config=True,
+ download_secrets=True,
+ upload_secrets=True,
+ )
+ if yes
+ else login_module.login(token=token, interactive=True, ret_token=True)
+ )
+
if valid_token:
webbrowser.open(
f"{configs.get('api_server_url')}/dashboard?token={valid_token}"
diff --git a/runhouse/rns/login.py b/runhouse/rns/login.py
--- a/runhouse/rns/login.py
+++ b/runhouse/rns/login.py
@@ -21,14 +21,24 @@
download_secrets: bool = None,
upload_secrets: bool = None,
ret_token: bool = False,
- interactive: bool = False,
+ interactive: bool = None,
):
"""Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between
local environment and Runhouse / Vault.
"""
from runhouse import Secrets
- if is_interactive() or interactive:
+ all_options_set = token and not any(
+ arg is None
+ for arg in (download_config, upload_config, download_secrets, upload_secrets)
+ )
+
+ if interactive is False and not token:
+ raise Exception(
+ "`interactive` can only be set to `False` if token is provided."
+ )
+
+ if interactive or (interactive is None and not all_options_set):
from getpass import getpass
from rich.console import Console
@@ -48,12 +58,12 @@
if is_interactive()
else f'{configs.get("api_server_url")}/dashboard/?option=token'
)
- console.print(
- f"Retrieve your token :key: here to use :person_running: :house: Runhouse for "
- f"secrets and artifact management: {link}",
- style="bold yellow",
- )
if not token:
+ console.print(
+ f"Retrieve your token :key: here to use :person_running: :house: Runhouse for "
+ f"secrets and artifact management: {link}",
+ style="bold yellow",
+ )
token = getpass("Token: ")
download_config = (
@@ -132,6 +142,8 @@
)
for provider in Secrets.enabled_providers():
provider_name: str = provider.PROVIDER_NAME
+ if provider_name == "ssh":
+ continue
provider_creds_path: Union[str, tuple] = provider.default_credentials_path()
if interactive_session:
| {"golden_diff": "diff --git a/runhouse/main.py b/runhouse/main.py\n--- a/runhouse/main.py\n+++ b/runhouse/main.py\n@@ -20,11 +20,27 @@\n \n \n @app.command()\n-def login(token: Optional[str] = typer.Argument(None, help=\"Your Runhouse API token\")):\n+def login(\n+ token: Optional[str] = typer.Argument(None, help=\"Your Runhouse API token\"),\n+ yes: Optional[bool] = typer.Option(\n+ False, \"--yes\", \"-y\", help=\"Sets any confirmations to 'yes' automatically.\"\n+ ),\n+):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n- valid_token: str = login_module.login(token=token, interactive=True, ret_token=True)\n+ valid_token: str = (\n+ login_module.login(\n+ token=token,\n+ download_config=True,\n+ upload_config=True,\n+ download_secrets=True,\n+ upload_secrets=True,\n+ )\n+ if yes\n+ else login_module.login(token=token, interactive=True, ret_token=True)\n+ )\n+\n if valid_token:\n webbrowser.open(\n f\"{configs.get('api_server_url')}/dashboard?token={valid_token}\"\ndiff --git a/runhouse/rns/login.py b/runhouse/rns/login.py\n--- a/runhouse/rns/login.py\n+++ b/runhouse/rns/login.py\n@@ -21,14 +21,24 @@\n download_secrets: bool = None,\n upload_secrets: bool = None,\n ret_token: bool = False,\n- interactive: bool = False,\n+ interactive: bool = None,\n ):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n from runhouse import Secrets\n \n- if is_interactive() or interactive:\n+ all_options_set = token and not any(\n+ arg is None\n+ for arg in (download_config, upload_config, download_secrets, upload_secrets)\n+ )\n+\n+ if interactive is False and not token:\n+ raise Exception(\n+ \"`interactive` can only be set to `False` if token is provided.\"\n+ )\n+\n+ if interactive or (interactive is None and not all_options_set):\n from getpass import getpass\n \n from rich.console import Console\n@@ -48,12 +58,12 @@\n if is_interactive()\n else f'{configs.get(\"api_server_url\")}/dashboard/?option=token'\n )\n- console.print(\n- f\"Retrieve your token :key: here to use :person_running: :house: Runhouse for \"\n- f\"secrets and artifact management: {link}\",\n- style=\"bold yellow\",\n- )\n if not token:\n+ console.print(\n+ f\"Retrieve your token :key: here to use :person_running: :house: Runhouse for \"\n+ f\"secrets and artifact management: {link}\",\n+ style=\"bold yellow\",\n+ )\n token = getpass(\"Token: \")\n \n download_config = (\n@@ -132,6 +142,8 @@\n )\n for provider in Secrets.enabled_providers():\n provider_name: str = provider.PROVIDER_NAME\n+ if provider_name == \"ssh\":\n+ continue\n provider_creds_path: Union[str, tuple] = provider.default_credentials_path()\n \n if interactive_session:\n", "issue": "Consider adding `-y` option to `runhouse login` CLI command\n## Feature\r\nSimple use case is logging in with `system` command instead of Python API:\r\n```\r\n!runhouse login [TOKEN]\r\n```\r\nCurrently, the CLI is hardcoded with `interactive=True`:\r\nhttps://github.com/run-house/runhouse/blob/560a52880a333e17e8a1aca01c1048f4527fc375/runhouse/main.py#L27\r\n\r\n## Motivation\r\nIt's a minor quality of life improvement.\r\n\r\n## Ideal Solution\r\nSee above\r\n\r\n## Additional context\r\nExcited to get Runhouse integration up on NatML \ud83d\ude04 \r\n\n", "before_files": [{"content": "import logging\nfrom typing import Union\n\nimport typer\n\nfrom runhouse.rh_config import configs, rns_client\n\nlogger = logging.getLogger(__name__)\n\n\ndef is_interactive():\n import __main__ as main\n\n return not hasattr(main, \"__file__\")\n\n\ndef login(\n token: str = None,\n download_config: bool = None,\n upload_config: bool = None,\n download_secrets: bool = None,\n upload_secrets: bool = None,\n ret_token: bool = False,\n interactive: bool = False,\n):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n from runhouse import Secrets\n\n if is_interactive() or interactive:\n from getpass import getpass\n\n from rich.console import Console\n\n console = Console()\n console.print(\n \"\"\"\n ____ __ @ @ @\n / __ \\__ ______ / /_ ____ __ __________ []___\n / /_/ / / / / __ \\/ __ \\/ __ \\/ / / / ___/ _ \\ / /\\____ @@\n / _, _/ /_/ / / / / / / / /_/ / /_/ (__ ) __/ /_/\\_//____/\\ @@@@\n /_/ |_|\\__,_/_/ /_/_/ /_/\\____/\\__,_/____/\\___/ | || |||__||| ||\n \"\"\"\n )\n link = (\n f'[link={configs.get(\"api_server_url\")}/dashboard/?option=token]https://api.run.house[/link]'\n if is_interactive()\n else f'{configs.get(\"api_server_url\")}/dashboard/?option=token'\n )\n console.print(\n f\"Retrieve your token :key: here to use :person_running: :house: Runhouse for \"\n f\"secrets and artifact management: {link}\",\n style=\"bold yellow\",\n )\n if not token:\n token = getpass(\"Token: \")\n\n download_config = (\n download_config\n if download_config is not None\n else typer.confirm(\n \"Download config from Runhouse to your local .rh folder?\"\n )\n )\n download_secrets = (\n download_secrets\n if download_secrets is not None\n else typer.confirm(\n \"Download secrets from Vault to your local Runhouse config?\"\n )\n )\n upload_config = (\n upload_config\n if upload_config is not None\n else typer.confirm(\"Upload your local config to Runhouse?\")\n )\n upload_secrets = (\n upload_secrets\n if upload_secrets is not None\n else typer.confirm(\"Upload your enabled cloud provider secrets to Vault?\")\n )\n\n if token:\n configs.set(\"token\", token)\n\n if download_config:\n configs.download_and_save_defaults()\n # We need to fresh the RNSClient to use the newly loaded configs\n rns_client.refresh_defaults()\n elif upload_config:\n configs.upload_defaults(defaults=configs.defaults_cache)\n else:\n # If we are not downloading or uploading config, we still want to make sure the token is valid\n try:\n configs.download_defaults()\n except:\n logger.error(\"Failed to validate token\")\n return None\n\n if download_secrets:\n Secrets.download_into_env()\n\n if upload_secrets:\n Secrets.extract_and_upload(interactive=interactive)\n\n logger.info(\"Successfully logged into Runhouse.\")\n if ret_token:\n return token\n\n\ndef logout(\n delete_loaded_secrets: bool = None,\n delete_rh_config_file: bool = None,\n interactive: bool = None,\n):\n \"\"\"Logout from Runhouse. Provides option to delete credentials from the Runhouse config and the underlying\n credentials file. Token is also deleted from the config.\n\n Args:\n delete_loaded_secrets (bool, optional): If True, deletes the provider credentials file. Defaults to None.\n delete_rh_config_file (bool, optional): If True, deletes the rh config file. Defaults to None.\n interactive (bool, optional): If True, runs the logout process in interactive mode. Defaults to None.\n\n Returns:\n None\n \"\"\"\n from runhouse import Secrets\n\n interactive_session: bool = (\n interactive if interactive is not None else is_interactive()\n )\n for provider in Secrets.enabled_providers():\n provider_name: str = provider.PROVIDER_NAME\n provider_creds_path: Union[str, tuple] = provider.default_credentials_path()\n\n if interactive_session:\n delete_loaded_secrets = typer.confirm(\n f\"Delete credentials file for {provider_name}?\"\n )\n\n configs.delete(provider_name)\n\n if delete_loaded_secrets:\n provider.delete_secrets_file(provider_creds_path)\n logger.info(\n f\"Deleted {provider_name} credentials file from path: {provider_creds_path}\"\n )\n\n # Delete token from rh config file\n configs.delete(key=\"token\")\n\n rh_config_path = configs.CONFIG_PATH\n if not delete_rh_config_file and interactive_session:\n delete_rh_config_file = typer.confirm(\"Delete your local Runhouse config file?\")\n\n if delete_rh_config_file:\n # Delete the credentials file on the file system\n configs.delete_defaults(rh_config_path)\n logger.info(f\"Deleted Runhouse config file from path: {rh_config_path}\")\n\n logger.info(\"Successfully logged out of Runhouse.\")\n", "path": "runhouse/rns/login.py"}, {"content": "import subprocess\nimport webbrowser\nfrom typing import Optional\n\nimport pkg_resources\nimport typer\nfrom rich.console import Console\n\nfrom runhouse import cluster, configs\nfrom runhouse.rns import ( # Need to rename it because it conflicts with the login command\n login as login_module,\n)\n\n# create an explicit Typer application\napp = typer.Typer(add_completion=False)\nstate = {\"verbose\": False}\n\n# For printing with typer\nconsole = Console()\n\n\[email protected]()\ndef login(token: Optional[str] = typer.Argument(None, help=\"Your Runhouse API token\")):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n valid_token: str = login_module.login(token=token, interactive=True, ret_token=True)\n if valid_token:\n webbrowser.open(\n f\"{configs.get('api_server_url')}/dashboard?token={valid_token}\"\n )\n raise typer.Exit()\n else:\n raise typer.Exit(code=1)\n\n\[email protected]()\ndef logout():\n \"\"\"Logout of Runhouse. Provides options to delete locally configured secrets and local Runhouse configs\"\"\"\n login_module.logout(interactive=True)\n raise typer.Exit()\n\n\[email protected]()\ndef notebook(\n cluster_name: str, up: bool = typer.Option(False, help=\"Start the cluster\")\n):\n \"\"\"Open a Jupyter notebook on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n if up:\n c.up_if_not()\n if not c.is_up():\n console.print(\n f\"Cluster {cluster_name} is not up. Please run `runhouse notebook {cluster_name} --up`.\"\n )\n raise typer.Exit(1)\n c.notebook()\n\n\[email protected]()\ndef ssh(cluster_name: str, up: bool = typer.Option(False, help=\"Start the cluster\")):\n \"\"\"SSH into a cluster created elsewhere (so `ssh cluster` doesn't work out of the box) or not yet up.\"\"\"\n c = cluster(name=cluster_name)\n if up:\n c.up_if_not()\n if not c.is_up():\n console.print(\n f\"Cluster {cluster_name} is not up. Please run `runhouse ssh {cluster_name} --up`.\"\n )\n raise typer.Exit(1)\n subprocess.call(f\"ssh {c.name}\", shell=True)\n\n\[email protected]()\ndef cancel(\n cluster_name: str,\n run_key: str,\n force: Optional[bool] = typer.Option(False, help=\"Force cancel\"),\n all: Optional[bool] = typer.Option(False, help=\"Cancel all jobs\"),\n):\n \"\"\"Cancel a run on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n c.cancel(run_key, force=force, all=all)\n\n\[email protected]()\ndef logs(\n cluster_name: str,\n run_key: str,\n print_results: Optional[bool] = typer.Option(False, help=\"Print results\"),\n):\n \"\"\"Get logs from a run on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n res = c.get(run_key, stream_logs=True)\n if print_results:\n console.print(res)\n\n\ndef load_cluster(cluster_name: str):\n \"\"\"Load a cluster from RNS into the local environment, e.g. to be able to ssh.\"\"\"\n c = cluster(name=cluster_name)\n if not c.address:\n c.update_from_sky_status(dryrun=True)\n\n\[email protected]()\ndef restart_grpc(\n cluster_name: str,\n restart_ray: bool = typer.Option(False, help=\"Restart the Ray runtime\"),\n resync_rh: bool = typer.Option(False, help=\"Resync the Runhouse package\"),\n):\n \"\"\"Restart the gRPC server on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n c.restart_grpc_server(resync_rh=resync_rh, restart_ray=restart_ray)\n\n\[email protected]()\ndef main(verbose: bool = False):\n \"\"\"\n Runhouse CLI\n \"\"\"\n if verbose:\n name = \"runhouse\"\n version = pkg_resources.get_distribution(name).version\n console.print(f\"{name}=={version}\", style=\"bold green\")\n state[\"verbose\"] = True\n", "path": "runhouse/main.py"}], "after_files": [{"content": "import logging\nfrom typing import Union\n\nimport typer\n\nfrom runhouse.rh_config import configs, rns_client\n\nlogger = logging.getLogger(__name__)\n\n\ndef is_interactive():\n import __main__ as main\n\n return not hasattr(main, \"__file__\")\n\n\ndef login(\n token: str = None,\n download_config: bool = None,\n upload_config: bool = None,\n download_secrets: bool = None,\n upload_secrets: bool = None,\n ret_token: bool = False,\n interactive: bool = None,\n):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n from runhouse import Secrets\n\n all_options_set = token and not any(\n arg is None\n for arg in (download_config, upload_config, download_secrets, upload_secrets)\n )\n\n if interactive is False and not token:\n raise Exception(\n \"`interactive` can only be set to `False` if token is provided.\"\n )\n\n if interactive or (interactive is None and not all_options_set):\n from getpass import getpass\n\n from rich.console import Console\n\n console = Console()\n console.print(\n \"\"\"\n ____ __ @ @ @\n / __ \\__ ______ / /_ ____ __ __________ []___\n / /_/ / / / / __ \\/ __ \\/ __ \\/ / / / ___/ _ \\ / /\\____ @@\n / _, _/ /_/ / / / / / / / /_/ / /_/ (__ ) __/ /_/\\_//____/\\ @@@@\n /_/ |_|\\__,_/_/ /_/_/ /_/\\____/\\__,_/____/\\___/ | || |||__||| ||\n \"\"\"\n )\n link = (\n f'[link={configs.get(\"api_server_url\")}/dashboard/?option=token]https://api.run.house[/link]'\n if is_interactive()\n else f'{configs.get(\"api_server_url\")}/dashboard/?option=token'\n )\n if not token:\n console.print(\n f\"Retrieve your token :key: here to use :person_running: :house: Runhouse for \"\n f\"secrets and artifact management: {link}\",\n style=\"bold yellow\",\n )\n token = getpass(\"Token: \")\n\n download_config = (\n download_config\n if download_config is not None\n else typer.confirm(\n \"Download config from Runhouse to your local .rh folder?\"\n )\n )\n download_secrets = (\n download_secrets\n if download_secrets is not None\n else typer.confirm(\n \"Download secrets from Vault to your local Runhouse config?\"\n )\n )\n upload_config = (\n upload_config\n if upload_config is not None\n else typer.confirm(\"Upload your local config to Runhouse?\")\n )\n upload_secrets = (\n upload_secrets\n if upload_secrets is not None\n else typer.confirm(\"Upload your enabled cloud provider secrets to Vault?\")\n )\n\n if token:\n configs.set(\"token\", token)\n\n if download_config:\n configs.download_and_save_defaults()\n # We need to fresh the RNSClient to use the newly loaded configs\n rns_client.refresh_defaults()\n elif upload_config:\n configs.upload_defaults(defaults=configs.defaults_cache)\n else:\n # If we are not downloading or uploading config, we still want to make sure the token is valid\n try:\n configs.download_defaults()\n except:\n logger.error(\"Failed to validate token\")\n return None\n\n if download_secrets:\n Secrets.download_into_env()\n\n if upload_secrets:\n Secrets.extract_and_upload(interactive=interactive)\n\n logger.info(\"Successfully logged into Runhouse.\")\n if ret_token:\n return token\n\n\ndef logout(\n delete_loaded_secrets: bool = None,\n delete_rh_config_file: bool = None,\n interactive: bool = None,\n):\n \"\"\"Logout from Runhouse. Provides option to delete credentials from the Runhouse config and the underlying\n credentials file. Token is also deleted from the config.\n\n Args:\n delete_loaded_secrets (bool, optional): If True, deletes the provider credentials file. Defaults to None.\n delete_rh_config_file (bool, optional): If True, deletes the rh config file. Defaults to None.\n interactive (bool, optional): If True, runs the logout process in interactive mode. Defaults to None.\n\n Returns:\n None\n \"\"\"\n from runhouse import Secrets\n\n interactive_session: bool = (\n interactive if interactive is not None else is_interactive()\n )\n for provider in Secrets.enabled_providers():\n provider_name: str = provider.PROVIDER_NAME\n if provider_name == \"ssh\":\n continue\n provider_creds_path: Union[str, tuple] = provider.default_credentials_path()\n\n if interactive_session:\n delete_loaded_secrets = typer.confirm(\n f\"Delete credentials file for {provider_name}?\"\n )\n\n configs.delete(provider_name)\n\n if delete_loaded_secrets:\n provider.delete_secrets_file(provider_creds_path)\n logger.info(\n f\"Deleted {provider_name} credentials file from path: {provider_creds_path}\"\n )\n\n # Delete token from rh config file\n configs.delete(key=\"token\")\n\n rh_config_path = configs.CONFIG_PATH\n if not delete_rh_config_file and interactive_session:\n delete_rh_config_file = typer.confirm(\"Delete your local Runhouse config file?\")\n\n if delete_rh_config_file:\n # Delete the credentials file on the file system\n configs.delete_defaults(rh_config_path)\n logger.info(f\"Deleted Runhouse config file from path: {rh_config_path}\")\n\n logger.info(\"Successfully logged out of Runhouse.\")\n", "path": "runhouse/rns/login.py"}, {"content": "import subprocess\nimport webbrowser\nfrom typing import Optional\n\nimport pkg_resources\nimport typer\nfrom rich.console import Console\n\nfrom runhouse import cluster, configs\nfrom runhouse.rns import ( # Need to rename it because it conflicts with the login command\n login as login_module,\n)\n\n# create an explicit Typer application\napp = typer.Typer(add_completion=False)\nstate = {\"verbose\": False}\n\n# For printing with typer\nconsole = Console()\n\n\[email protected]()\ndef login(\n token: Optional[str] = typer.Argument(None, help=\"Your Runhouse API token\"),\n yes: Optional[bool] = typer.Option(\n False, \"--yes\", \"-y\", help=\"Sets any confirmations to 'yes' automatically.\"\n ),\n):\n \"\"\"Login to Runhouse. Validates token provided, with options to upload or download stored secrets or config between\n local environment and Runhouse / Vault.\n \"\"\"\n valid_token: str = (\n login_module.login(\n token=token,\n download_config=True,\n upload_config=True,\n download_secrets=True,\n upload_secrets=True,\n )\n if yes\n else login_module.login(token=token, interactive=True, ret_token=True)\n )\n\n if valid_token:\n webbrowser.open(\n f\"{configs.get('api_server_url')}/dashboard?token={valid_token}\"\n )\n raise typer.Exit()\n else:\n raise typer.Exit(code=1)\n\n\[email protected]()\ndef logout():\n \"\"\"Logout of Runhouse. Provides options to delete locally configured secrets and local Runhouse configs\"\"\"\n login_module.logout(interactive=True)\n raise typer.Exit()\n\n\[email protected]()\ndef notebook(\n cluster_name: str, up: bool = typer.Option(False, help=\"Start the cluster\")\n):\n \"\"\"Open a Jupyter notebook on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n if up:\n c.up_if_not()\n if not c.is_up():\n console.print(\n f\"Cluster {cluster_name} is not up. Please run `runhouse notebook {cluster_name} --up`.\"\n )\n raise typer.Exit(1)\n c.notebook()\n\n\[email protected]()\ndef ssh(cluster_name: str, up: bool = typer.Option(False, help=\"Start the cluster\")):\n \"\"\"SSH into a cluster created elsewhere (so `ssh cluster` doesn't work out of the box) or not yet up.\"\"\"\n c = cluster(name=cluster_name)\n if up:\n c.up_if_not()\n if not c.is_up():\n console.print(\n f\"Cluster {cluster_name} is not up. Please run `runhouse ssh {cluster_name} --up`.\"\n )\n raise typer.Exit(1)\n subprocess.call(f\"ssh {c.name}\", shell=True)\n\n\[email protected]()\ndef cancel(\n cluster_name: str,\n run_key: str,\n force: Optional[bool] = typer.Option(False, help=\"Force cancel\"),\n all: Optional[bool] = typer.Option(False, help=\"Cancel all jobs\"),\n):\n \"\"\"Cancel a run on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n c.cancel(run_key, force=force, all=all)\n\n\[email protected]()\ndef logs(\n cluster_name: str,\n run_key: str,\n print_results: Optional[bool] = typer.Option(False, help=\"Print results\"),\n):\n \"\"\"Get logs from a run on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n res = c.get(run_key, stream_logs=True)\n if print_results:\n console.print(res)\n\n\ndef load_cluster(cluster_name: str):\n \"\"\"Load a cluster from RNS into the local environment, e.g. to be able to ssh.\"\"\"\n c = cluster(name=cluster_name)\n if not c.address:\n c.update_from_sky_status(dryrun=True)\n\n\[email protected]()\ndef restart_grpc(\n cluster_name: str,\n restart_ray: bool = typer.Option(False, help=\"Restart the Ray runtime\"),\n resync_rh: bool = typer.Option(False, help=\"Resync the Runhouse package\"),\n):\n \"\"\"Restart the gRPC server on a cluster.\"\"\"\n c = cluster(name=cluster_name)\n c.restart_grpc_server(resync_rh=resync_rh, restart_ray=restart_ray)\n\n\[email protected]()\ndef main(verbose: bool = False):\n \"\"\"\n Runhouse CLI\n \"\"\"\n if verbose:\n name = \"runhouse\"\n version = pkg_resources.get_distribution(name).version\n console.print(f\"{name}=={version}\", style=\"bold green\")\n state[\"verbose\"] = True\n", "path": "runhouse/main.py"}]} | 3,193 | 781 |
gh_patches_debug_29072 | rasdani/github-patches | git_diff | evennia__evennia-2922 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG - Develop] Global Scripts loading doesn't catch parse errors
#### Describe the bug
When there's an error with loading a global scripts module, e.g. it imports the `Room` class but that class has a syntax error, the loading error isn't caught and the traceback points to [this line](https://github.com/evennia/evennia/blob/251a70275bbd98a3e157cbb4c025597a4bb24ac9/evennia/utils/containers.py#L135) with a KeyError
#### To Reproduce
Steps to reproduce the behavior:
1. Create a simple global script which imports a class such as `Room` from your game dir, and add it to `settings.py`
2. Introduce a syntax error to your `Room` class, such as an extra space in an indent.
3. Reload the server.
4. See error
#### Expected behavior
It'd be more useful if there was an error thrown which indicated that the script had failed being loaded (and, ideally, why), as the current error invariably leads people to think there is a problem with the global scripts dict in `settings.py`.
#### Develop-branch commit
f093c8bcb
#### Additional context
I feel like it should be catching that kind of an error in [`class_from_module`](https://github.com/evennia/evennia/blob/f093c8bcb1321a44e33003cf91cf9f565e028de7/evennia/utils/utils.py#L1524) or it should at least be throwing an exception in [`load_data`](https://github.com/evennia/evennia/blob/f093c8bcb1321a44e33003cf91cf9f565e028de7/evennia/utils/containers.py#L202) but neither seem to be doing so. Instead, they just silently don't load the script.
[BUG - Develop] Evennia can no longer create global scripts from settings.py
#### Describe the bug
As of merging #2882 any attempt to create a new game with global scripts defined in settings does not create the script. It simply fails the assertion check and moves on without attempting to create them.
#### To Reproduce
Steps to reproduce the behavior:
1. Set up a new freshly-made game with `GLOBAL_SCRIPTS` defined in the settings. (I included what I used at the bottom.)
2. Attempt to start the game.
4. See error
#### Expected behavior
It's supposed to automatically create the script if it doesn't exist.
#### Develop-branch commit
b0f24f997
#### Additional context
```py
# added to typeclasses/scripts.py
from evennia.utils import logger
class TestScript(DefaultScript):
key = "global_test_script"
def at_repeat(self):
logger.log_msg("This just prints a nice message.")
```
```py
# added to server/conf/settings.py
GLOBAL_SCRIPTS = {
"global_test_script": {
"typeclass": "typeclasses.scripts.TestScript",
"persistent": True,
"interval": 60,
"desc": "A simple script to test creation.",
},
}
```
```
2022-10-08 04:42:58 [!!] Traceback (most recent call last):
2022-10-08 04:42:58 [!!] File "./evgames/evennia/evennia/utils/containers.py", line 214, in load_data
2022-10-08 04:42:58 [!!] assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)
2022-10-08 04:42:58 [!!] AssertionError
2022-10-08 04:42:58 [!!] GlobalScriptContainer could not start import global script global_test_script. It will be removed (skipped).
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evennia/utils/containers.py`
Content:
```
1 """
2 Containers
3
4 Containers are storage classes usually initialized from a setting. They
5 represent Singletons and acts as a convenient place to find resources (
6 available as properties on the singleton)
7
8 evennia.GLOBAL_SCRIPTS
9 evennia.OPTION_CLASSES
10
11 """
12
13
14 from pickle import dumps
15
16 from django.conf import settings
17 from django.db.utils import OperationalError, ProgrammingError
18 from evennia.utils import logger
19 from evennia.utils.utils import callables_from_module, class_from_module
20
21 SCRIPTDB = None
22 _BASE_SCRIPT_TYPECLASS = None
23
24
25 class Container:
26 """
27 Base container class. A container is simply a storage object whose
28 properties can be acquired as a property on it. This is generally
29 considered a read-only affair.
30
31 The container is initialized by a list of modules containing callables.
32
33 """
34
35 storage_modules = []
36
37 def __init__(self):
38 """
39 Read data from module.
40
41 """
42 self.loaded_data = None
43
44 def load_data(self):
45 """
46 Delayed import to avoid eventual circular imports from inside
47 the storage modules.
48
49 """
50 if self.loaded_data is None:
51 self.loaded_data = {}
52 for module in self.storage_modules:
53 self.loaded_data.update(callables_from_module(module))
54
55 def __getattr__(self, key):
56 return self.get(key)
57
58 def get(self, key, default=None):
59 """
60 Retrive data by key (in case of not knowing it beforehand).
61
62 Args:
63 key (str): The name of the script.
64 default (any, optional): Value to return if key is not found.
65
66 Returns:
67 any (any): The data loaded on this container.
68
69 """
70 self.load_data()
71 return self.loaded_data.get(key, default)
72
73 def all(self):
74 """
75 Get all stored data
76
77 Returns:
78 scripts (list): All global script objects stored on the container.
79
80 """
81 self.load_data()
82 return list(self.loaded_data.values())
83
84
85 class OptionContainer(Container):
86 """
87 Loads and stores the final list of OPTION CLASSES.
88
89 Can access these as properties or dictionary-contents.
90 """
91
92 storage_modules = settings.OPTION_CLASS_MODULES
93
94
95 class GlobalScriptContainer(Container):
96 """
97 Simple Handler object loaded by the Evennia API to contain and manage a
98 game's Global Scripts. This will list global Scripts created on their own
99 but will also auto-(re)create scripts defined in `settings.GLOBAL_SCRIPTS`.
100
101 Example:
102 import evennia
103 evennia.GLOBAL_SCRIPTS.scriptname
104
105 Note:
106 This does not use much of the BaseContainer since it's not loading
107 callables from settings but a custom dict of tuples.
108
109 """
110
111 def __init__(self):
112 """
113 Note: We must delay loading of typeclasses since this module may get
114 initialized before Scripts are actually initialized.
115
116 """
117 self.typeclass_storage = None
118 self.loaded_data = {
119 key: {} if data is None else data for key, data in settings.GLOBAL_SCRIPTS.items()
120 }
121
122 def _get_scripts(self, key=None, default=None):
123 global SCRIPTDB
124 if not SCRIPTDB:
125 from evennia.scripts.models import ScriptDB as SCRIPTDB
126 if key:
127 try:
128 return SCRIPTDB.objects.get(db_key__exact=key, db_obj__isnull=True)
129 except SCRIPTDB.DoesNotExist:
130 return default
131 else:
132 return SCRIPTDB.objects.filter(db_obj__isnull=True)
133
134 def _load_script(self, key):
135 self.load_data()
136
137 typeclass = self.typeclass_storage[key]
138 script = typeclass.objects.filter(
139 db_key=key, db_account__isnull=True, db_obj__isnull=True
140 ).first()
141
142 kwargs = {**self.loaded_data[key]}
143 kwargs["key"] = key
144 kwargs["persistent"] = kwargs.get("persistent", True)
145
146 compare_hash = str(dumps(kwargs, protocol=4))
147
148 if script:
149 script_hash = script.attributes.get("global_script_settings", category="settings_hash")
150 if script_hash is None:
151 # legacy - store the hash anew and assume no change
152 script.attributes.add(
153 "global_script_settings", compare_hash, category="settings_hash"
154 )
155 elif script_hash != compare_hash:
156 # wipe the old version and create anew
157 logger.log_info(f"GLOBAL_SCRIPTS: Settings changed for {key} ({typeclass}).")
158 script.stop()
159 script.delete()
160 script = None
161
162 if not script:
163 logger.log_info(f"GLOBAL_SCRIPTS: (Re)creating {key} ({typeclass}).")
164
165 script, errors = typeclass.create(**kwargs)
166 if errors:
167 logger.log_err("\n".join(errors))
168 return None
169
170 # store a hash representation of the setup
171 script.attributes.add("_global_script_settings", compare_hash, category="settings_hash")
172
173 return script
174
175 def start(self):
176 """
177 Called last in evennia.__init__ to initialize the container late
178 (after script typeclasses have finished loading).
179
180 We include all global scripts in the handler and
181 make sure to auto-load time-based scripts.
182
183 """
184 # populate self.typeclass_storage
185 self.load_data()
186
187 # make sure settings-defined scripts are loaded
188 for key in self.loaded_data:
189 self._load_script(key)
190 # start all global scripts
191 try:
192 for script in self._get_scripts():
193 script.start()
194 except (OperationalError, ProgrammingError):
195 # this can happen if db is not loaded yet (such as when building docs)
196 pass
197
198 def load_data(self):
199 """
200 This delayed import avoids trying to load Scripts before they are
201 initialized.
202
203 """
204 if self.loaded_data:
205 # we don't always load this, it collides with doc generation
206 global _BASE_SCRIPT_TYPECLASS
207 if not _BASE_SCRIPT_TYPECLASS:
208 _BASE_SCRIPT_TYPECLASS = class_from_module(settings.BASE_SCRIPT_TYPECLASS)
209
210 if self.typeclass_storage is None:
211 self.typeclass_storage = {}
212 for key, data in list(self.loaded_data.items()):
213 try:
214 typeclass = data.get("typeclass", settings.BASE_SCRIPT_TYPECLASS)
215 script_typeclass = class_from_module(typeclass)
216 assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)
217 self.typeclass_storage[key] = script_typeclass
218 except Exception:
219 logger.log_trace(
220 f"GlobalScriptContainer could not start import global script {key}. "
221 "It will be removed (skipped)."
222 )
223 # Let's remove this key/value. We want to let other scripts load.
224 self.loaded_data.pop(key)
225
226 def get(self, key, default=None):
227 """
228 Retrive data by key (in case of not knowing it beforehand). Any
229 scripts that are in settings.GLOBAL_SCRIPTS that are not found
230 will be recreated on-demand.
231
232 Args:
233 key (str): The name of the script.
234 default (any, optional): Value to return if key is not found
235 at all on this container (i.e it cannot be loaded at all).
236
237 Returns:
238 any (any): The data loaded on this container.
239 """
240 res = self._get_scripts(key)
241 if not res:
242 if key in self.loaded_data:
243 # recreate if we have the info
244 return self._load_script(key) or default
245 return default
246 return res
247
248 def all(self):
249 """
250 Get all global scripts. Note that this will not auto-start
251 scripts defined in settings.
252
253 Returns:
254 scripts (list): All global script objects stored on the container.
255
256 """
257 self.typeclass_storage = None
258 self.load_data()
259 for key in self.loaded_data:
260 self._load_script(key)
261 return self._get_scripts(None)
262
263
264 # Create all singletons
265
266 GLOBAL_SCRIPTS = GlobalScriptContainer()
267 OPTION_CLASSES = OptionContainer()
268
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/evennia/utils/containers.py b/evennia/utils/containers.py
--- a/evennia/utils/containers.py
+++ b/evennia/utils/containers.py
@@ -19,8 +19,6 @@
from evennia.utils.utils import callables_from_module, class_from_module
SCRIPTDB = None
-_BASE_SCRIPT_TYPECLASS = None
-
class Container:
"""
@@ -201,27 +199,11 @@
initialized.
"""
- if self.loaded_data:
- # we don't always load this, it collides with doc generation
- global _BASE_SCRIPT_TYPECLASS
- if not _BASE_SCRIPT_TYPECLASS:
- _BASE_SCRIPT_TYPECLASS = class_from_module(settings.BASE_SCRIPT_TYPECLASS)
-
if self.typeclass_storage is None:
self.typeclass_storage = {}
for key, data in list(self.loaded_data.items()):
- try:
- typeclass = data.get("typeclass", settings.BASE_SCRIPT_TYPECLASS)
- script_typeclass = class_from_module(typeclass)
- assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)
- self.typeclass_storage[key] = script_typeclass
- except Exception:
- logger.log_trace(
- f"GlobalScriptContainer could not start import global script {key}. "
- "It will be removed (skipped)."
- )
- # Let's remove this key/value. We want to let other scripts load.
- self.loaded_data.pop(key)
+ typeclass = data.get("typeclass", settings.BASE_SCRIPT_TYPECLASS)
+ self.typeclass_storage[key] = class_from_module(typeclass, fallback=settings.BASE_SCRIPT_TYPECLASS)
def get(self, key, default=None):
"""
| {"golden_diff": "diff --git a/evennia/utils/containers.py b/evennia/utils/containers.py\n--- a/evennia/utils/containers.py\n+++ b/evennia/utils/containers.py\n@@ -19,8 +19,6 @@\n from evennia.utils.utils import callables_from_module, class_from_module\n \n SCRIPTDB = None\n-_BASE_SCRIPT_TYPECLASS = None\n-\n \n class Container:\n \"\"\"\n@@ -201,27 +199,11 @@\n initialized.\n \n \"\"\"\n- if self.loaded_data:\n- # we don't always load this, it collides with doc generation\n- global _BASE_SCRIPT_TYPECLASS\n- if not _BASE_SCRIPT_TYPECLASS:\n- _BASE_SCRIPT_TYPECLASS = class_from_module(settings.BASE_SCRIPT_TYPECLASS)\n-\n if self.typeclass_storage is None:\n self.typeclass_storage = {}\n for key, data in list(self.loaded_data.items()):\n- try:\n- typeclass = data.get(\"typeclass\", settings.BASE_SCRIPT_TYPECLASS)\n- script_typeclass = class_from_module(typeclass)\n- assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)\n- self.typeclass_storage[key] = script_typeclass\n- except Exception:\n- logger.log_trace(\n- f\"GlobalScriptContainer could not start import global script {key}. \"\n- \"It will be removed (skipped).\"\n- )\n- # Let's remove this key/value. We want to let other scripts load.\n- self.loaded_data.pop(key)\n+ typeclass = data.get(\"typeclass\", settings.BASE_SCRIPT_TYPECLASS)\n+ self.typeclass_storage[key] = class_from_module(typeclass, fallback=settings.BASE_SCRIPT_TYPECLASS)\n \n def get(self, key, default=None):\n \"\"\"\n", "issue": "[BUG - Develop] Global Scripts loading doesn't catch parse errors\n#### Describe the bug\r\nWhen there's an error with loading a global scripts module, e.g. it imports the `Room` class but that class has a syntax error, the loading error isn't caught and the traceback points to [this line](https://github.com/evennia/evennia/blob/251a70275bbd98a3e157cbb4c025597a4bb24ac9/evennia/utils/containers.py#L135) with a KeyError\r\n\r\n#### To Reproduce\r\nSteps to reproduce the behavior:\r\n1. Create a simple global script which imports a class such as `Room` from your game dir, and add it to `settings.py`\r\n2. Introduce a syntax error to your `Room` class, such as an extra space in an indent.\r\n3. Reload the server.\r\n4. See error\r\n\r\n#### Expected behavior\r\nIt'd be more useful if there was an error thrown which indicated that the script had failed being loaded (and, ideally, why), as the current error invariably leads people to think there is a problem with the global scripts dict in `settings.py`.\r\n\r\n#### Develop-branch commit\r\nf093c8bcb\r\n\r\n#### Additional context\r\nI feel like it should be catching that kind of an error in [`class_from_module`](https://github.com/evennia/evennia/blob/f093c8bcb1321a44e33003cf91cf9f565e028de7/evennia/utils/utils.py#L1524) or it should at least be throwing an exception in [`load_data`](https://github.com/evennia/evennia/blob/f093c8bcb1321a44e33003cf91cf9f565e028de7/evennia/utils/containers.py#L202) but neither seem to be doing so. Instead, they just silently don't load the script.\n[BUG - Develop] Evennia can no longer create global scripts from settings.py\n#### Describe the bug\r\nAs of merging #2882 any attempt to create a new game with global scripts defined in settings does not create the script. It simply fails the assertion check and moves on without attempting to create them.\r\n\r\n#### To Reproduce\r\nSteps to reproduce the behavior:\r\n1. Set up a new freshly-made game with `GLOBAL_SCRIPTS` defined in the settings. (I included what I used at the bottom.)\r\n2. Attempt to start the game.\r\n4. See error\r\n\r\n#### Expected behavior\r\nIt's supposed to automatically create the script if it doesn't exist.\r\n\r\n#### Develop-branch commit\r\nb0f24f997\r\n\r\n#### Additional context\r\n```py\r\n# added to typeclasses/scripts.py\r\nfrom evennia.utils import logger\r\n\r\nclass TestScript(DefaultScript):\r\n key = \"global_test_script\"\r\n\r\n def at_repeat(self):\r\n logger.log_msg(\"This just prints a nice message.\")\r\n```\r\n\r\n```py\r\n# added to server/conf/settings.py\r\nGLOBAL_SCRIPTS = {\r\n \"global_test_script\": {\r\n \"typeclass\": \"typeclasses.scripts.TestScript\",\r\n \"persistent\": True,\r\n \"interval\": 60,\r\n \"desc\": \"A simple script to test creation.\",\r\n },\r\n}\r\n```\r\n\r\n```\r\n2022-10-08 04:42:58 [!!] Traceback (most recent call last):\r\n2022-10-08 04:42:58 [!!] File \"./evgames/evennia/evennia/utils/containers.py\", line 214, in load_data\r\n2022-10-08 04:42:58 [!!] assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)\r\n2022-10-08 04:42:58 [!!] AssertionError\r\n2022-10-08 04:42:58 [!!] GlobalScriptContainer could not start import global script global_test_script. It will be removed (skipped).\r\n```\n", "before_files": [{"content": "\"\"\"\nContainers\n\nContainers are storage classes usually initialized from a setting. They\nrepresent Singletons and acts as a convenient place to find resources (\navailable as properties on the singleton)\n\nevennia.GLOBAL_SCRIPTS\nevennia.OPTION_CLASSES\n\n\"\"\"\n\n\nfrom pickle import dumps\n\nfrom django.conf import settings\nfrom django.db.utils import OperationalError, ProgrammingError\nfrom evennia.utils import logger\nfrom evennia.utils.utils import callables_from_module, class_from_module\n\nSCRIPTDB = None\n_BASE_SCRIPT_TYPECLASS = None\n\n\nclass Container:\n \"\"\"\n Base container class. A container is simply a storage object whose\n properties can be acquired as a property on it. This is generally\n considered a read-only affair.\n\n The container is initialized by a list of modules containing callables.\n\n \"\"\"\n\n storage_modules = []\n\n def __init__(self):\n \"\"\"\n Read data from module.\n\n \"\"\"\n self.loaded_data = None\n\n def load_data(self):\n \"\"\"\n Delayed import to avoid eventual circular imports from inside\n the storage modules.\n\n \"\"\"\n if self.loaded_data is None:\n self.loaded_data = {}\n for module in self.storage_modules:\n self.loaded_data.update(callables_from_module(module))\n\n def __getattr__(self, key):\n return self.get(key)\n\n def get(self, key, default=None):\n \"\"\"\n Retrive data by key (in case of not knowing it beforehand).\n\n Args:\n key (str): The name of the script.\n default (any, optional): Value to return if key is not found.\n\n Returns:\n any (any): The data loaded on this container.\n\n \"\"\"\n self.load_data()\n return self.loaded_data.get(key, default)\n\n def all(self):\n \"\"\"\n Get all stored data\n\n Returns:\n scripts (list): All global script objects stored on the container.\n\n \"\"\"\n self.load_data()\n return list(self.loaded_data.values())\n\n\nclass OptionContainer(Container):\n \"\"\"\n Loads and stores the final list of OPTION CLASSES.\n\n Can access these as properties or dictionary-contents.\n \"\"\"\n\n storage_modules = settings.OPTION_CLASS_MODULES\n\n\nclass GlobalScriptContainer(Container):\n \"\"\"\n Simple Handler object loaded by the Evennia API to contain and manage a\n game's Global Scripts. This will list global Scripts created on their own\n but will also auto-(re)create scripts defined in `settings.GLOBAL_SCRIPTS`.\n\n Example:\n import evennia\n evennia.GLOBAL_SCRIPTS.scriptname\n\n Note:\n This does not use much of the BaseContainer since it's not loading\n callables from settings but a custom dict of tuples.\n\n \"\"\"\n\n def __init__(self):\n \"\"\"\n Note: We must delay loading of typeclasses since this module may get\n initialized before Scripts are actually initialized.\n\n \"\"\"\n self.typeclass_storage = None\n self.loaded_data = {\n key: {} if data is None else data for key, data in settings.GLOBAL_SCRIPTS.items()\n }\n\n def _get_scripts(self, key=None, default=None):\n global SCRIPTDB\n if not SCRIPTDB:\n from evennia.scripts.models import ScriptDB as SCRIPTDB\n if key:\n try:\n return SCRIPTDB.objects.get(db_key__exact=key, db_obj__isnull=True)\n except SCRIPTDB.DoesNotExist:\n return default\n else:\n return SCRIPTDB.objects.filter(db_obj__isnull=True)\n\n def _load_script(self, key):\n self.load_data()\n\n typeclass = self.typeclass_storage[key]\n script = typeclass.objects.filter(\n db_key=key, db_account__isnull=True, db_obj__isnull=True\n ).first()\n\n kwargs = {**self.loaded_data[key]}\n kwargs[\"key\"] = key\n kwargs[\"persistent\"] = kwargs.get(\"persistent\", True)\n\n compare_hash = str(dumps(kwargs, protocol=4))\n\n if script:\n script_hash = script.attributes.get(\"global_script_settings\", category=\"settings_hash\")\n if script_hash is None:\n # legacy - store the hash anew and assume no change\n script.attributes.add(\n \"global_script_settings\", compare_hash, category=\"settings_hash\"\n )\n elif script_hash != compare_hash:\n # wipe the old version and create anew\n logger.log_info(f\"GLOBAL_SCRIPTS: Settings changed for {key} ({typeclass}).\")\n script.stop()\n script.delete()\n script = None\n\n if not script:\n logger.log_info(f\"GLOBAL_SCRIPTS: (Re)creating {key} ({typeclass}).\")\n\n script, errors = typeclass.create(**kwargs)\n if errors:\n logger.log_err(\"\\n\".join(errors))\n return None\n\n # store a hash representation of the setup\n script.attributes.add(\"_global_script_settings\", compare_hash, category=\"settings_hash\")\n\n return script\n\n def start(self):\n \"\"\"\n Called last in evennia.__init__ to initialize the container late\n (after script typeclasses have finished loading).\n\n We include all global scripts in the handler and\n make sure to auto-load time-based scripts.\n\n \"\"\"\n # populate self.typeclass_storage\n self.load_data()\n\n # make sure settings-defined scripts are loaded\n for key in self.loaded_data:\n self._load_script(key)\n # start all global scripts\n try:\n for script in self._get_scripts():\n script.start()\n except (OperationalError, ProgrammingError):\n # this can happen if db is not loaded yet (such as when building docs)\n pass\n\n def load_data(self):\n \"\"\"\n This delayed import avoids trying to load Scripts before they are\n initialized.\n\n \"\"\"\n if self.loaded_data:\n # we don't always load this, it collides with doc generation\n global _BASE_SCRIPT_TYPECLASS\n if not _BASE_SCRIPT_TYPECLASS:\n _BASE_SCRIPT_TYPECLASS = class_from_module(settings.BASE_SCRIPT_TYPECLASS)\n\n if self.typeclass_storage is None:\n self.typeclass_storage = {}\n for key, data in list(self.loaded_data.items()):\n try:\n typeclass = data.get(\"typeclass\", settings.BASE_SCRIPT_TYPECLASS)\n script_typeclass = class_from_module(typeclass)\n assert issubclass(script_typeclass, _BASE_SCRIPT_TYPECLASS)\n self.typeclass_storage[key] = script_typeclass\n except Exception:\n logger.log_trace(\n f\"GlobalScriptContainer could not start import global script {key}. \"\n \"It will be removed (skipped).\"\n )\n # Let's remove this key/value. We want to let other scripts load.\n self.loaded_data.pop(key)\n\n def get(self, key, default=None):\n \"\"\"\n Retrive data by key (in case of not knowing it beforehand). Any\n scripts that are in settings.GLOBAL_SCRIPTS that are not found\n will be recreated on-demand.\n\n Args:\n key (str): The name of the script.\n default (any, optional): Value to return if key is not found\n at all on this container (i.e it cannot be loaded at all).\n\n Returns:\n any (any): The data loaded on this container.\n \"\"\"\n res = self._get_scripts(key)\n if not res:\n if key in self.loaded_data:\n # recreate if we have the info\n return self._load_script(key) or default\n return default\n return res\n\n def all(self):\n \"\"\"\n Get all global scripts. Note that this will not auto-start\n scripts defined in settings.\n\n Returns:\n scripts (list): All global script objects stored on the container.\n\n \"\"\"\n self.typeclass_storage = None\n self.load_data()\n for key in self.loaded_data:\n self._load_script(key)\n return self._get_scripts(None)\n\n\n# Create all singletons\n\nGLOBAL_SCRIPTS = GlobalScriptContainer()\nOPTION_CLASSES = OptionContainer()\n", "path": "evennia/utils/containers.py"}], "after_files": [{"content": "\"\"\"\nContainers\n\nContainers are storage classes usually initialized from a setting. They\nrepresent Singletons and acts as a convenient place to find resources (\navailable as properties on the singleton)\n\nevennia.GLOBAL_SCRIPTS\nevennia.OPTION_CLASSES\n\n\"\"\"\n\n\nfrom pickle import dumps\n\nfrom django.conf import settings\nfrom django.db.utils import OperationalError, ProgrammingError\nfrom evennia.utils import logger\nfrom evennia.utils.utils import callables_from_module, class_from_module\n\nSCRIPTDB = None\n\nclass Container:\n \"\"\"\n Base container class. A container is simply a storage object whose\n properties can be acquired as a property on it. This is generally\n considered a read-only affair.\n\n The container is initialized by a list of modules containing callables.\n\n \"\"\"\n\n storage_modules = []\n\n def __init__(self):\n \"\"\"\n Read data from module.\n\n \"\"\"\n self.loaded_data = None\n\n def load_data(self):\n \"\"\"\n Delayed import to avoid eventual circular imports from inside\n the storage modules.\n\n \"\"\"\n if self.loaded_data is None:\n self.loaded_data = {}\n for module in self.storage_modules:\n self.loaded_data.update(callables_from_module(module))\n\n def __getattr__(self, key):\n return self.get(key)\n\n def get(self, key, default=None):\n \"\"\"\n Retrive data by key (in case of not knowing it beforehand).\n\n Args:\n key (str): The name of the script.\n default (any, optional): Value to return if key is not found.\n\n Returns:\n any (any): The data loaded on this container.\n\n \"\"\"\n self.load_data()\n return self.loaded_data.get(key, default)\n\n def all(self):\n \"\"\"\n Get all stored data\n\n Returns:\n scripts (list): All global script objects stored on the container.\n\n \"\"\"\n self.load_data()\n return list(self.loaded_data.values())\n\n\nclass OptionContainer(Container):\n \"\"\"\n Loads and stores the final list of OPTION CLASSES.\n\n Can access these as properties or dictionary-contents.\n \"\"\"\n\n storage_modules = settings.OPTION_CLASS_MODULES\n\n\nclass GlobalScriptContainer(Container):\n \"\"\"\n Simple Handler object loaded by the Evennia API to contain and manage a\n game's Global Scripts. This will list global Scripts created on their own\n but will also auto-(re)create scripts defined in `settings.GLOBAL_SCRIPTS`.\n\n Example:\n import evennia\n evennia.GLOBAL_SCRIPTS.scriptname\n\n Note:\n This does not use much of the BaseContainer since it's not loading\n callables from settings but a custom dict of tuples.\n\n \"\"\"\n\n def __init__(self):\n \"\"\"\n Note: We must delay loading of typeclasses since this module may get\n initialized before Scripts are actually initialized.\n\n \"\"\"\n self.typeclass_storage = None\n self.loaded_data = {\n key: {} if data is None else data for key, data in settings.GLOBAL_SCRIPTS.items()\n }\n\n def _get_scripts(self, key=None, default=None):\n global SCRIPTDB\n if not SCRIPTDB:\n from evennia.scripts.models import ScriptDB as SCRIPTDB\n if key:\n try:\n return SCRIPTDB.objects.get(db_key__exact=key, db_obj__isnull=True)\n except SCRIPTDB.DoesNotExist:\n return default\n else:\n return SCRIPTDB.objects.filter(db_obj__isnull=True)\n\n def _load_script(self, key):\n self.load_data()\n\n typeclass = self.typeclass_storage[key]\n script = typeclass.objects.filter(\n db_key=key, db_account__isnull=True, db_obj__isnull=True\n ).first()\n\n kwargs = {**self.loaded_data[key]}\n kwargs[\"key\"] = key\n kwargs[\"persistent\"] = kwargs.get(\"persistent\", True)\n\n compare_hash = str(dumps(kwargs, protocol=4))\n\n if script:\n script_hash = script.attributes.get(\"global_script_settings\", category=\"settings_hash\")\n if script_hash is None:\n # legacy - store the hash anew and assume no change\n script.attributes.add(\n \"global_script_settings\", compare_hash, category=\"settings_hash\"\n )\n elif script_hash != compare_hash:\n # wipe the old version and create anew\n logger.log_info(f\"GLOBAL_SCRIPTS: Settings changed for {key} ({typeclass}).\")\n script.stop()\n script.delete()\n script = None\n\n if not script:\n logger.log_info(f\"GLOBAL_SCRIPTS: (Re)creating {key} ({typeclass}).\")\n\n script, errors = typeclass.create(**kwargs)\n if errors:\n logger.log_err(\"\\n\".join(errors))\n return None\n\n # store a hash representation of the setup\n script.attributes.add(\"_global_script_settings\", compare_hash, category=\"settings_hash\")\n\n return script\n\n def start(self):\n \"\"\"\n Called last in evennia.__init__ to initialize the container late\n (after script typeclasses have finished loading).\n\n We include all global scripts in the handler and\n make sure to auto-load time-based scripts.\n\n \"\"\"\n # populate self.typeclass_storage\n self.load_data()\n\n # make sure settings-defined scripts are loaded\n for key in self.loaded_data:\n self._load_script(key)\n # start all global scripts\n try:\n for script in self._get_scripts():\n script.start()\n except (OperationalError, ProgrammingError):\n # this can happen if db is not loaded yet (such as when building docs)\n pass\n\n def load_data(self):\n \"\"\"\n This delayed import avoids trying to load Scripts before they are\n initialized.\n\n \"\"\"\n if self.typeclass_storage is None:\n self.typeclass_storage = {}\n for key, data in list(self.loaded_data.items()):\n typeclass = data.get(\"typeclass\", settings.BASE_SCRIPT_TYPECLASS)\n self.typeclass_storage[key] = class_from_module(typeclass, fallback=settings.BASE_SCRIPT_TYPECLASS)\n\n def get(self, key, default=None):\n \"\"\"\n Retrive data by key (in case of not knowing it beforehand). Any\n scripts that are in settings.GLOBAL_SCRIPTS that are not found\n will be recreated on-demand.\n\n Args:\n key (str): The name of the script.\n default (any, optional): Value to return if key is not found\n at all on this container (i.e it cannot be loaded at all).\n\n Returns:\n any (any): The data loaded on this container.\n \"\"\"\n res = self._get_scripts(key)\n if not res:\n if key in self.loaded_data:\n # recreate if we have the info\n return self._load_script(key) or default\n return default\n return res\n\n def all(self):\n \"\"\"\n Get all global scripts. Note that this will not auto-start\n scripts defined in settings.\n\n Returns:\n scripts (list): All global script objects stored on the container.\n\n \"\"\"\n self.typeclass_storage = None\n self.load_data()\n for key in self.loaded_data:\n self._load_script(key)\n return self._get_scripts(None)\n\n\n# Create all singletons\n\nGLOBAL_SCRIPTS = GlobalScriptContainer()\nOPTION_CLASSES = OptionContainer()\n", "path": "evennia/utils/containers.py"}]} | 3,582 | 380 |
gh_patches_debug_43353 | rasdani/github-patches | git_diff | conan-io__conan-center-index-3151 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ixwebsocket: add 10.2.5 + several improvements
Specify library name and version: **ixwebsocket/10.2.5**
- [x] I've read the [guidelines](https://github.com/conan-io/conan-center-index/blob/master/docs/how_to_add_packages.md) for contributing.
- [x] I've followed the [PEP8](https://www.python.org/dev/peps/pep-0008/) style guides for Python code in the recipes.
- [x] I've used the [latest](https://github.com/conan-io/conan/releases/latest) Conan client version.
- [x] I've tried at least one configuration locally with the
[conan-center hook](https://github.com/conan-io/hooks.git) activated.
Others modifications:
- use transparent cmake integration in test_package
- optional zlib for version >= 10.1.5
- don't force PIC for version >= 9.5.7
- add public definitions in cpp_info
- fix system libs on Windows
poco: fix hooks
Specify library name and version: **poco/all**
- [x] I've read the [guidelines](https://github.com/conan-io/conan-center-index/blob/master/docs/how_to_add_packages.md) for contributing.
- [x] I've followed the [PEP8](https://www.python.org/dev/peps/pep-0008/) style guides for Python code in the recipes.
- [x] I've used the [latest](https://github.com/conan-io/conan/releases/latest) Conan client version.
- [x] I've tried at least one configuration locally with the
[conan-center hook](https://github.com/conan-io/hooks.git) activated.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/poco/all/conanfile.py`
Content:
```
1 from conans import ConanFile, CMake, tools
2 from conans.errors import ConanException, ConanInvalidConfiguration
3 from collections import namedtuple, OrderedDict
4 import os
5
6
7 class PocoConan(ConanFile):
8 name = "poco"
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "https://pocoproject.org"
11 topics = ("conan", "poco", "building", "networking", "server", "mobile", "embedded")
12 exports_sources = "CMakeLists.txt", "patches/**"
13 generators = "cmake", "cmake_find_package"
14 settings = "os", "arch", "compiler", "build_type"
15 license = "BSL-1.0"
16 description = "Modern, powerful open source C++ class libraries for building network- and internet-based " \
17 "applications that run on desktop, server, mobile and embedded systems."
18 options = {
19 "shared": [True, False],
20 "fPIC": [True, False],
21 }
22 default_options = {
23 "shared": False,
24 "fPIC": True,
25 }
26
27 _PocoComponent = namedtuple("_PocoComponent", ("option", "default_option", "dependencies", "is_lib"))
28 _poco_component_tree = {
29 "mod_poco": _PocoComponent("enable_apacheconnector", False, ("PocoUtil", "PocoNet", ), False), # also external apr and apr-util
30 "PocoCppParser": _PocoComponent("enable_cppparser", False, ("PocoFoundation", ), False),
31 # "PocoCppUnit": _PocoComponent("enable_cppunit", False, ("PocoFoundation", ), False)),
32 "PocoCrypto": _PocoComponent("enable_crypto", True, ("PocoFoundation", ), True), # also external openssl
33 "PocoData": _PocoComponent("enable_data", True, ("PocoFoundation", ), True),
34 "PocoDataMySQL": _PocoComponent("enable_data_mysql", False, ("PocoData", ), True),
35 "PocoDataODBC": _PocoComponent("enable_data_odbc", False, ("PocoData", ), True),
36 "PocoDataPostgreSQL": _PocoComponent("enable_data_postgresql", False, ("PocoData", ), True), # also external postgresql
37 "PocoDataSQLite": _PocoComponent("enable_data_sqlite", True, ("PocoData", ), True), # also external sqlite3
38 "PocoEncodings": _PocoComponent("enable_encodings", True, ("PocoFoundation", ), True),
39 # "PocoEncodingsCompiler": _PocoComponent("enable_encodingscompiler", False, ("PocoNet", "PocoUtil", ), False),
40 "PocoFoundation": _PocoComponent(None, "PocoFoundation", (), True),
41 "PocoJSON": _PocoComponent("enable_json", True, ("PocoFoundation", ), True),
42 "PocoJWT": _PocoComponent("enable_jwt", True, ("PocoJSON", "PocoCrypto", ), True),
43 "PocoMongoDB": _PocoComponent("enable_mongodb", True, ("PocoNet", ), True),
44 "PocoNet": _PocoComponent("enable_net", True, ("PocoFoundation", ), True),
45 "PocoNetSSL": _PocoComponent("enable_netssl", True, ("PocoCrypto", "PocoUtil", "PocoNet", ), True), # also external openssl
46 "PocoNetSSLWin": _PocoComponent("enable_netssl_win", True, ("PocoNet", "PocoUtil", ), True),
47 "PocoPDF": _PocoComponent("enable_pdf", False, ("PocoXML", "PocoUtil", ), True),
48 "PocoPageCompiler": _PocoComponent("enable_pagecompiler", False, ("PocoNet", "PocoUtil", ), False),
49 "PocoFile2Page": _PocoComponent("enable_pagecompiler_file2page", False, ("PocoNet", "PocoUtil", "PocoXML", "PocoJSON", ), False),
50 "PocoPocoDoc": _PocoComponent("enable_pocodoc", False, ("PocoUtil", "PocoXML", "PocoCppParser", ), False),
51 "PocoRedis": _PocoComponent("enable_redis", True, ("PocoNet", ), True),
52 "PocoSevenZip": _PocoComponent("enable_sevenzip", False, ("PocoUtil", "PocoXML", ), True),
53 "PocoUtil": _PocoComponent("enable_util", True, ("PocoFoundation", "PocoXML", "PocoJSON", ), True),
54 "PocoXML": _PocoComponent("enable_xml", True, ("PocoFoundation", ), True),
55 "PocoZip": _PocoComponent("enable_zip", True, ("PocoUtil", "PocoXML", ), True),
56 }
57
58 for comp in _poco_component_tree.values():
59 if comp.option:
60 options[comp.option] = [True, False]
61 default_options[comp.option] = comp.default_option
62 del comp
63
64 @property
65 def _poco_ordered_components(self):
66 remaining_components = dict((compname, set(compopts.dependencies)) for compname, compopts in self._poco_component_tree.items())
67 ordered_components = []
68 while remaining_components:
69 components_no_deps = set(compname for compname, compopts in remaining_components.items() if not compopts)
70 if not components_no_deps:
71 raise ConanException("The poco dependency tree is invalid and contains a cycle")
72 for c in components_no_deps:
73 remaining_components.pop(c)
74 ordered_components.extend(components_no_deps)
75 for rname in remaining_components.keys():
76 remaining_components[rname] = remaining_components[rname].difference(components_no_deps)
77 ordered_components.reverse()
78 return ordered_components
79
80 _cmake = None
81
82 @property
83 def _source_subfolder(self):
84 return "source_subfolder"
85
86 @property
87 def _build_subfolder(self):
88 return "build_subfolder"
89
90 def source(self):
91 tools.get(**self.conan_data["sources"][self.version])
92 extracted_folder = "poco-poco-{}-release".format(self.version)
93 os.rename(extracted_folder, self._source_subfolder)
94
95 def config_options(self):
96 if self.settings.os == "Windows":
97 del self.options.fPIC
98 else:
99 del self.options.enable_netssl_win
100 if tools.Version(self.version) < "1.9":
101 del self.options.enable_encodings
102 if tools.Version(self.version) < "1.10":
103 del self.options.enable_data_postgresql
104 del self.options.enable_jwt
105
106 def configure(self):
107 if self.options.enable_apacheconnector:
108 raise ConanInvalidConfiguration("Apache connector not supported: https://github.com/pocoproject/poco/issues/1764")
109 if self.options.enable_data_mysql:
110 raise ConanInvalidConfiguration("MySQL not supported yet, open an issue here please: %s" % self.url)
111 if self.options.get_safe("enable_data_postgresql", False):
112 raise ConanInvalidConfiguration("PostgreSQL not supported yet, open an issue here please: %s" % self.url)
113 for compopt in self._poco_component_tree.values():
114 if not compopt.option:
115 continue
116 if self.options.get_safe(compopt.option, False):
117 for compdep in compopt.dependencies:
118 if not self._poco_component_tree[compdep].option:
119 continue
120 if not self.options.get_safe(self._poco_component_tree[compdep].option, False):
121 raise ConanInvalidConfiguration("option {} requires also option {}".format(compopt.option, self._poco_component_tree[compdep].option))
122
123 def requirements(self):
124 self.requires("pcre/8.41")
125 self.requires("zlib/1.2.11")
126 if self.options.enable_xml:
127 self.requires("expat/2.2.9")
128 if self.options.enable_data_sqlite:
129 self.requires("sqlite3/3.31.1")
130 if self.options.enable_apacheconnector:
131 self.requires("apr/1.7.0")
132 self.requires("apr-util/1.6.1")
133 raise ConanInvalidConfiguration("apache2 is not (yet) available on CCI")
134 self.requires("apache2/x.y.z")
135 if self.options.enable_netssl or \
136 self.options.enable_crypto or \
137 self.options.get_safe("enable_jwt", False):
138 self.requires("openssl/1.1.1g")
139
140 def _patch_sources(self):
141 for patch in self.conan_data.get("patches", {}).get(self.version, []):
142 tools.patch(**patch)
143
144 def _configure_cmake(self):
145 if self._cmake:
146 return self._cmake
147 self._cmake = CMake(self)
148 if tools.Version(self.version) < "1.10.1":
149 self._cmake.definitions["POCO_STATIC"] = not self.options.shared
150 for comp in self._poco_component_tree.values():
151 if not comp.option:
152 continue
153 self._cmake.definitions[comp.option.upper()] = self.options.get_safe(comp.option, False)
154 self._cmake.definitions["POCO_UNBUNDLED"] = True
155 self._cmake.definitions["CMAKE_INSTALL_SYSTEM_RUNTIME_LIBS_SKIP"] = True
156 if self.settings.os == "Windows" and self.settings.compiler == "Visual Studio": # MT or MTd
157 self._cmake.definitions["POCO_MT"] = "ON" if "MT" in str(self.settings.compiler.runtime) else "OFF"
158 self.output.info(self._cmake.definitions)
159 # On Windows, Poco needs a message (MC) compiler.
160 with tools.vcvars(self.settings) if self.settings.compiler == "Visual Studio" else tools.no_op():
161 self._cmake.configure(build_dir=self._build_subfolder)
162 return self._cmake
163
164 def build(self):
165 if self.options.enable_data_sqlite:
166 if self.options["sqlite3"].threadsafe == 0:
167 raise ConanInvalidConfiguration("sqlite3 must be built with threadsafe enabled")
168 self._patch_sources()
169 cmake = self._configure_cmake()
170 cmake.build()
171
172 def package(self):
173 self.copy("LICENSE", dst="licenses", src=self._source_subfolder)
174 cmake = self._configure_cmake()
175 cmake.install()
176 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
177 tools.rmdir(os.path.join(self.package_folder, "cmake"))
178
179 @property
180 def _ordered_libs(self):
181 libs = []
182 for compname in self._poco_ordered_components:
183 comp_options = self._poco_component_tree[compname]
184 if comp_options.is_lib:
185 if not comp_options.option:
186 libs.append(compname)
187 elif self.options.get_safe(comp_options.option, False):
188 libs.append(compname)
189 return libs
190
191 def package_info(self):
192 suffix = str(self.settings.compiler.runtime).lower() \
193 if self.settings.compiler == "Visual Studio" and not self.options.shared \
194 else ("d" if self.settings.build_type == "Debug" else "")
195
196 self.cpp_info.libs = list("{}{}".format(lib, suffix) for lib in self._ordered_libs)
197
198 if self.settings.os == "Linux":
199 self.cpp_info.system_libs.extend(["pthread", "dl", "rt"])
200
201 if self.settings.compiler == "Visual Studio":
202 self.cpp_info.defines.append("POCO_NO_AUTOMATIC_LIBS")
203 if not self.options.shared:
204 self.cpp_info.defines.append("POCO_STATIC=ON")
205 if self.settings.compiler == "Visual Studio":
206 self.cpp_info.system_libs.extend(["ws2_32", "iphlpapi", "crypt32"])
207 self.cpp_info.names["cmake_find_package"] = "Poco"
208 self.cpp_info.names["cmake_find_package_multi"] = "Poco"
209
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/recipes/poco/all/conanfile.py b/recipes/poco/all/conanfile.py
--- a/recipes/poco/all/conanfile.py
+++ b/recipes/poco/all/conanfile.py
@@ -54,7 +54,7 @@
"PocoXML": _PocoComponent("enable_xml", True, ("PocoFoundation", ), True),
"PocoZip": _PocoComponent("enable_zip", True, ("PocoUtil", "PocoXML", ), True),
}
-
+
for comp in _poco_component_tree.values():
if comp.option:
options[comp.option] = [True, False]
@@ -108,6 +108,9 @@
raise ConanInvalidConfiguration("Apache connector not supported: https://github.com/pocoproject/poco/issues/1764")
if self.options.enable_data_mysql:
raise ConanInvalidConfiguration("MySQL not supported yet, open an issue here please: %s" % self.url)
+ if self.settings.compiler == "Visual Studio":
+ if self.options.shared and "MT" in str(self.settings.compiler.runtime):
+ raise ConanInvalidConfiguration("Cannot build shared poco libraries with MT(d) runtime")
if self.options.get_safe("enable_data_postgresql", False):
raise ConanInvalidConfiguration("PostgreSQL not supported yet, open an issue here please: %s" % self.url)
for compopt in self._poco_component_tree.values():
@@ -124,18 +127,18 @@
self.requires("pcre/8.41")
self.requires("zlib/1.2.11")
if self.options.enable_xml:
- self.requires("expat/2.2.9")
+ self.requires("expat/2.2.10")
if self.options.enable_data_sqlite:
- self.requires("sqlite3/3.31.1")
+ self.requires("sqlite3/3.33.0")
if self.options.enable_apacheconnector:
self.requires("apr/1.7.0")
self.requires("apr-util/1.6.1")
+ # FIXME: missing apache2 recipe
raise ConanInvalidConfiguration("apache2 is not (yet) available on CCI")
- self.requires("apache2/x.y.z")
if self.options.enable_netssl or \
self.options.enable_crypto or \
self.options.get_safe("enable_jwt", False):
- self.requires("openssl/1.1.1g")
+ self.requires("openssl/1.1.1h")
def _patch_sources(self):
for patch in self.conan_data.get("patches", {}).get(self.version, []):
@@ -194,7 +197,7 @@
else ("d" if self.settings.build_type == "Debug" else "")
self.cpp_info.libs = list("{}{}".format(lib, suffix) for lib in self._ordered_libs)
-
+
if self.settings.os == "Linux":
self.cpp_info.system_libs.extend(["pthread", "dl", "rt"])
@@ -202,7 +205,7 @@
self.cpp_info.defines.append("POCO_NO_AUTOMATIC_LIBS")
if not self.options.shared:
self.cpp_info.defines.append("POCO_STATIC=ON")
- if self.settings.compiler == "Visual Studio":
+ if self.settings.os == "Windows":
self.cpp_info.system_libs.extend(["ws2_32", "iphlpapi", "crypt32"])
self.cpp_info.names["cmake_find_package"] = "Poco"
self.cpp_info.names["cmake_find_package_multi"] = "Poco"
| {"golden_diff": "diff --git a/recipes/poco/all/conanfile.py b/recipes/poco/all/conanfile.py\n--- a/recipes/poco/all/conanfile.py\n+++ b/recipes/poco/all/conanfile.py\n@@ -54,7 +54,7 @@\n \"PocoXML\": _PocoComponent(\"enable_xml\", True, (\"PocoFoundation\", ), True),\n \"PocoZip\": _PocoComponent(\"enable_zip\", True, (\"PocoUtil\", \"PocoXML\", ), True),\n }\n- \n+\n for comp in _poco_component_tree.values():\n if comp.option:\n options[comp.option] = [True, False]\n@@ -108,6 +108,9 @@\n raise ConanInvalidConfiguration(\"Apache connector not supported: https://github.com/pocoproject/poco/issues/1764\")\n if self.options.enable_data_mysql:\n raise ConanInvalidConfiguration(\"MySQL not supported yet, open an issue here please: %s\" % self.url)\n+ if self.settings.compiler == \"Visual Studio\":\n+ if self.options.shared and \"MT\" in str(self.settings.compiler.runtime):\n+ raise ConanInvalidConfiguration(\"Cannot build shared poco libraries with MT(d) runtime\")\n if self.options.get_safe(\"enable_data_postgresql\", False):\n raise ConanInvalidConfiguration(\"PostgreSQL not supported yet, open an issue here please: %s\" % self.url)\n for compopt in self._poco_component_tree.values():\n@@ -124,18 +127,18 @@\n self.requires(\"pcre/8.41\")\n self.requires(\"zlib/1.2.11\")\n if self.options.enable_xml:\n- self.requires(\"expat/2.2.9\")\n+ self.requires(\"expat/2.2.10\")\n if self.options.enable_data_sqlite:\n- self.requires(\"sqlite3/3.31.1\")\n+ self.requires(\"sqlite3/3.33.0\")\n if self.options.enable_apacheconnector:\n self.requires(\"apr/1.7.0\")\n self.requires(\"apr-util/1.6.1\")\n+ # FIXME: missing apache2 recipe\n raise ConanInvalidConfiguration(\"apache2 is not (yet) available on CCI\")\n- self.requires(\"apache2/x.y.z\")\n if self.options.enable_netssl or \\\n self.options.enable_crypto or \\\n self.options.get_safe(\"enable_jwt\", False):\n- self.requires(\"openssl/1.1.1g\")\n+ self.requires(\"openssl/1.1.1h\")\n \n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n@@ -194,7 +197,7 @@\n else (\"d\" if self.settings.build_type == \"Debug\" else \"\")\n \n self.cpp_info.libs = list(\"{}{}\".format(lib, suffix) for lib in self._ordered_libs)\n- \n+\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"pthread\", \"dl\", \"rt\"])\n \n@@ -202,7 +205,7 @@\n self.cpp_info.defines.append(\"POCO_NO_AUTOMATIC_LIBS\")\n if not self.options.shared:\n self.cpp_info.defines.append(\"POCO_STATIC=ON\")\n- if self.settings.compiler == \"Visual Studio\":\n+ if self.settings.os == \"Windows\":\n self.cpp_info.system_libs.extend([\"ws2_32\", \"iphlpapi\", \"crypt32\"])\n self.cpp_info.names[\"cmake_find_package\"] = \"Poco\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Poco\"\n", "issue": "ixwebsocket: add 10.2.5 + several improvements\nSpecify library name and version: **ixwebsocket/10.2.5**\r\n\r\n- [x] I've read the [guidelines](https://github.com/conan-io/conan-center-index/blob/master/docs/how_to_add_packages.md) for contributing.\r\n- [x] I've followed the [PEP8](https://www.python.org/dev/peps/pep-0008/) style guides for Python code in the recipes.\r\n- [x] I've used the [latest](https://github.com/conan-io/conan/releases/latest) Conan client version.\r\n- [x] I've tried at least one configuration locally with the\r\n [conan-center hook](https://github.com/conan-io/hooks.git) activated.\r\n\r\nOthers modifications:\r\n- use transparent cmake integration in test_package\r\n- optional zlib for version >= 10.1.5\r\n- don't force PIC for version >= 9.5.7\r\n- add public definitions in cpp_info\r\n- fix system libs on Windows\npoco: fix hooks\nSpecify library name and version: **poco/all**\r\n\r\n- [x] I've read the [guidelines](https://github.com/conan-io/conan-center-index/blob/master/docs/how_to_add_packages.md) for contributing.\r\n- [x] I've followed the [PEP8](https://www.python.org/dev/peps/pep-0008/) style guides for Python code in the recipes.\r\n- [x] I've used the [latest](https://github.com/conan-io/conan/releases/latest) Conan client version.\r\n- [x] I've tried at least one configuration locally with the\r\n [conan-center hook](https://github.com/conan-io/hooks.git) activated.\r\n\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nfrom conans.errors import ConanException, ConanInvalidConfiguration\nfrom collections import namedtuple, OrderedDict\nimport os\n\n\nclass PocoConan(ConanFile):\n name = \"poco\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://pocoproject.org\"\n topics = (\"conan\", \"poco\", \"building\", \"networking\", \"server\", \"mobile\", \"embedded\")\n exports_sources = \"CMakeLists.txt\", \"patches/**\"\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n license = \"BSL-1.0\"\n description = \"Modern, powerful open source C++ class libraries for building network- and internet-based \" \\\n \"applications that run on desktop, server, mobile and embedded systems.\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n }\n\n _PocoComponent = namedtuple(\"_PocoComponent\", (\"option\", \"default_option\", \"dependencies\", \"is_lib\"))\n _poco_component_tree = {\n \"mod_poco\": _PocoComponent(\"enable_apacheconnector\", False, (\"PocoUtil\", \"PocoNet\", ), False), # also external apr and apr-util\n \"PocoCppParser\": _PocoComponent(\"enable_cppparser\", False, (\"PocoFoundation\", ), False),\n # \"PocoCppUnit\": _PocoComponent(\"enable_cppunit\", False, (\"PocoFoundation\", ), False)),\n \"PocoCrypto\": _PocoComponent(\"enable_crypto\", True, (\"PocoFoundation\", ), True), # also external openssl\n \"PocoData\": _PocoComponent(\"enable_data\", True, (\"PocoFoundation\", ), True),\n \"PocoDataMySQL\": _PocoComponent(\"enable_data_mysql\", False, (\"PocoData\", ), True),\n \"PocoDataODBC\": _PocoComponent(\"enable_data_odbc\", False, (\"PocoData\", ), True),\n \"PocoDataPostgreSQL\": _PocoComponent(\"enable_data_postgresql\", False, (\"PocoData\", ), True), # also external postgresql\n \"PocoDataSQLite\": _PocoComponent(\"enable_data_sqlite\", True, (\"PocoData\", ), True), # also external sqlite3\n \"PocoEncodings\": _PocoComponent(\"enable_encodings\", True, (\"PocoFoundation\", ), True),\n # \"PocoEncodingsCompiler\": _PocoComponent(\"enable_encodingscompiler\", False, (\"PocoNet\", \"PocoUtil\", ), False),\n \"PocoFoundation\": _PocoComponent(None, \"PocoFoundation\", (), True),\n \"PocoJSON\": _PocoComponent(\"enable_json\", True, (\"PocoFoundation\", ), True),\n \"PocoJWT\": _PocoComponent(\"enable_jwt\", True, (\"PocoJSON\", \"PocoCrypto\", ), True),\n \"PocoMongoDB\": _PocoComponent(\"enable_mongodb\", True, (\"PocoNet\", ), True),\n \"PocoNet\": _PocoComponent(\"enable_net\", True, (\"PocoFoundation\", ), True),\n \"PocoNetSSL\": _PocoComponent(\"enable_netssl\", True, (\"PocoCrypto\", \"PocoUtil\", \"PocoNet\", ), True), # also external openssl\n \"PocoNetSSLWin\": _PocoComponent(\"enable_netssl_win\", True, (\"PocoNet\", \"PocoUtil\", ), True),\n \"PocoPDF\": _PocoComponent(\"enable_pdf\", False, (\"PocoXML\", \"PocoUtil\", ), True),\n \"PocoPageCompiler\": _PocoComponent(\"enable_pagecompiler\", False, (\"PocoNet\", \"PocoUtil\", ), False),\n \"PocoFile2Page\": _PocoComponent(\"enable_pagecompiler_file2page\", False, (\"PocoNet\", \"PocoUtil\", \"PocoXML\", \"PocoJSON\", ), False),\n \"PocoPocoDoc\": _PocoComponent(\"enable_pocodoc\", False, (\"PocoUtil\", \"PocoXML\", \"PocoCppParser\", ), False),\n \"PocoRedis\": _PocoComponent(\"enable_redis\", True, (\"PocoNet\", ), True),\n \"PocoSevenZip\": _PocoComponent(\"enable_sevenzip\", False, (\"PocoUtil\", \"PocoXML\", ), True),\n \"PocoUtil\": _PocoComponent(\"enable_util\", True, (\"PocoFoundation\", \"PocoXML\", \"PocoJSON\", ), True),\n \"PocoXML\": _PocoComponent(\"enable_xml\", True, (\"PocoFoundation\", ), True),\n \"PocoZip\": _PocoComponent(\"enable_zip\", True, (\"PocoUtil\", \"PocoXML\", ), True),\n }\n \n for comp in _poco_component_tree.values():\n if comp.option:\n options[comp.option] = [True, False]\n default_options[comp.option] = comp.default_option\n del comp\n\n @property\n def _poco_ordered_components(self):\n remaining_components = dict((compname, set(compopts.dependencies)) for compname, compopts in self._poco_component_tree.items())\n ordered_components = []\n while remaining_components:\n components_no_deps = set(compname for compname, compopts in remaining_components.items() if not compopts)\n if not components_no_deps:\n raise ConanException(\"The poco dependency tree is invalid and contains a cycle\")\n for c in components_no_deps:\n remaining_components.pop(c)\n ordered_components.extend(components_no_deps)\n for rname in remaining_components.keys():\n remaining_components[rname] = remaining_components[rname].difference(components_no_deps)\n ordered_components.reverse()\n return ordered_components\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_folder = \"poco-poco-{}-release\".format(self.version)\n os.rename(extracted_folder, self._source_subfolder)\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n else:\n del self.options.enable_netssl_win\n if tools.Version(self.version) < \"1.9\":\n del self.options.enable_encodings\n if tools.Version(self.version) < \"1.10\":\n del self.options.enable_data_postgresql\n del self.options.enable_jwt\n\n def configure(self):\n if self.options.enable_apacheconnector:\n raise ConanInvalidConfiguration(\"Apache connector not supported: https://github.com/pocoproject/poco/issues/1764\")\n if self.options.enable_data_mysql:\n raise ConanInvalidConfiguration(\"MySQL not supported yet, open an issue here please: %s\" % self.url)\n if self.options.get_safe(\"enable_data_postgresql\", False):\n raise ConanInvalidConfiguration(\"PostgreSQL not supported yet, open an issue here please: %s\" % self.url)\n for compopt in self._poco_component_tree.values():\n if not compopt.option:\n continue\n if self.options.get_safe(compopt.option, False):\n for compdep in compopt.dependencies:\n if not self._poco_component_tree[compdep].option:\n continue\n if not self.options.get_safe(self._poco_component_tree[compdep].option, False):\n raise ConanInvalidConfiguration(\"option {} requires also option {}\".format(compopt.option, self._poco_component_tree[compdep].option))\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n self.requires(\"zlib/1.2.11\")\n if self.options.enable_xml:\n self.requires(\"expat/2.2.9\")\n if self.options.enable_data_sqlite:\n self.requires(\"sqlite3/3.31.1\")\n if self.options.enable_apacheconnector:\n self.requires(\"apr/1.7.0\")\n self.requires(\"apr-util/1.6.1\")\n raise ConanInvalidConfiguration(\"apache2 is not (yet) available on CCI\")\n self.requires(\"apache2/x.y.z\")\n if self.options.enable_netssl or \\\n self.options.enable_crypto or \\\n self.options.get_safe(\"enable_jwt\", False):\n self.requires(\"openssl/1.1.1g\")\n\n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n if tools.Version(self.version) < \"1.10.1\":\n self._cmake.definitions[\"POCO_STATIC\"] = not self.options.shared\n for comp in self._poco_component_tree.values():\n if not comp.option:\n continue\n self._cmake.definitions[comp.option.upper()] = self.options.get_safe(comp.option, False)\n self._cmake.definitions[\"POCO_UNBUNDLED\"] = True\n self._cmake.definitions[\"CMAKE_INSTALL_SYSTEM_RUNTIME_LIBS_SKIP\"] = True\n if self.settings.os == \"Windows\" and self.settings.compiler == \"Visual Studio\": # MT or MTd\n self._cmake.definitions[\"POCO_MT\"] = \"ON\" if \"MT\" in str(self.settings.compiler.runtime) else \"OFF\"\n self.output.info(self._cmake.definitions)\n # On Windows, Poco needs a message (MC) compiler.\n with tools.vcvars(self.settings) if self.settings.compiler == \"Visual Studio\" else tools.no_op():\n self._cmake.configure(build_dir=self._build_subfolder)\n return self._cmake\n\n def build(self):\n if self.options.enable_data_sqlite:\n if self.options[\"sqlite3\"].threadsafe == 0:\n raise ConanInvalidConfiguration(\"sqlite3 must be built with threadsafe enabled\")\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"cmake\"))\n\n @property\n def _ordered_libs(self):\n libs = []\n for compname in self._poco_ordered_components:\n comp_options = self._poco_component_tree[compname]\n if comp_options.is_lib:\n if not comp_options.option:\n libs.append(compname)\n elif self.options.get_safe(comp_options.option, False):\n libs.append(compname)\n return libs\n\n def package_info(self):\n suffix = str(self.settings.compiler.runtime).lower() \\\n if self.settings.compiler == \"Visual Studio\" and not self.options.shared \\\n else (\"d\" if self.settings.build_type == \"Debug\" else \"\")\n\n self.cpp_info.libs = list(\"{}{}\".format(lib, suffix) for lib in self._ordered_libs)\n \n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"pthread\", \"dl\", \"rt\"])\n\n if self.settings.compiler == \"Visual Studio\":\n self.cpp_info.defines.append(\"POCO_NO_AUTOMATIC_LIBS\")\n if not self.options.shared:\n self.cpp_info.defines.append(\"POCO_STATIC=ON\")\n if self.settings.compiler == \"Visual Studio\":\n self.cpp_info.system_libs.extend([\"ws2_32\", \"iphlpapi\", \"crypt32\"])\n self.cpp_info.names[\"cmake_find_package\"] = \"Poco\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Poco\"\n", "path": "recipes/poco/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, CMake, tools\nfrom conans.errors import ConanException, ConanInvalidConfiguration\nfrom collections import namedtuple, OrderedDict\nimport os\n\n\nclass PocoConan(ConanFile):\n name = \"poco\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://pocoproject.org\"\n topics = (\"conan\", \"poco\", \"building\", \"networking\", \"server\", \"mobile\", \"embedded\")\n exports_sources = \"CMakeLists.txt\", \"patches/**\"\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n license = \"BSL-1.0\"\n description = \"Modern, powerful open source C++ class libraries for building network- and internet-based \" \\\n \"applications that run on desktop, server, mobile and embedded systems.\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n }\n\n _PocoComponent = namedtuple(\"_PocoComponent\", (\"option\", \"default_option\", \"dependencies\", \"is_lib\"))\n _poco_component_tree = {\n \"mod_poco\": _PocoComponent(\"enable_apacheconnector\", False, (\"PocoUtil\", \"PocoNet\", ), False), # also external apr and apr-util\n \"PocoCppParser\": _PocoComponent(\"enable_cppparser\", False, (\"PocoFoundation\", ), False),\n # \"PocoCppUnit\": _PocoComponent(\"enable_cppunit\", False, (\"PocoFoundation\", ), False)),\n \"PocoCrypto\": _PocoComponent(\"enable_crypto\", True, (\"PocoFoundation\", ), True), # also external openssl\n \"PocoData\": _PocoComponent(\"enable_data\", True, (\"PocoFoundation\", ), True),\n \"PocoDataMySQL\": _PocoComponent(\"enable_data_mysql\", False, (\"PocoData\", ), True),\n \"PocoDataODBC\": _PocoComponent(\"enable_data_odbc\", False, (\"PocoData\", ), True),\n \"PocoDataPostgreSQL\": _PocoComponent(\"enable_data_postgresql\", False, (\"PocoData\", ), True), # also external postgresql\n \"PocoDataSQLite\": _PocoComponent(\"enable_data_sqlite\", True, (\"PocoData\", ), True), # also external sqlite3\n \"PocoEncodings\": _PocoComponent(\"enable_encodings\", True, (\"PocoFoundation\", ), True),\n # \"PocoEncodingsCompiler\": _PocoComponent(\"enable_encodingscompiler\", False, (\"PocoNet\", \"PocoUtil\", ), False),\n \"PocoFoundation\": _PocoComponent(None, \"PocoFoundation\", (), True),\n \"PocoJSON\": _PocoComponent(\"enable_json\", True, (\"PocoFoundation\", ), True),\n \"PocoJWT\": _PocoComponent(\"enable_jwt\", True, (\"PocoJSON\", \"PocoCrypto\", ), True),\n \"PocoMongoDB\": _PocoComponent(\"enable_mongodb\", True, (\"PocoNet\", ), True),\n \"PocoNet\": _PocoComponent(\"enable_net\", True, (\"PocoFoundation\", ), True),\n \"PocoNetSSL\": _PocoComponent(\"enable_netssl\", True, (\"PocoCrypto\", \"PocoUtil\", \"PocoNet\", ), True), # also external openssl\n \"PocoNetSSLWin\": _PocoComponent(\"enable_netssl_win\", True, (\"PocoNet\", \"PocoUtil\", ), True),\n \"PocoPDF\": _PocoComponent(\"enable_pdf\", False, (\"PocoXML\", \"PocoUtil\", ), True),\n \"PocoPageCompiler\": _PocoComponent(\"enable_pagecompiler\", False, (\"PocoNet\", \"PocoUtil\", ), False),\n \"PocoFile2Page\": _PocoComponent(\"enable_pagecompiler_file2page\", False, (\"PocoNet\", \"PocoUtil\", \"PocoXML\", \"PocoJSON\", ), False),\n \"PocoPocoDoc\": _PocoComponent(\"enable_pocodoc\", False, (\"PocoUtil\", \"PocoXML\", \"PocoCppParser\", ), False),\n \"PocoRedis\": _PocoComponent(\"enable_redis\", True, (\"PocoNet\", ), True),\n \"PocoSevenZip\": _PocoComponent(\"enable_sevenzip\", False, (\"PocoUtil\", \"PocoXML\", ), True),\n \"PocoUtil\": _PocoComponent(\"enable_util\", True, (\"PocoFoundation\", \"PocoXML\", \"PocoJSON\", ), True),\n \"PocoXML\": _PocoComponent(\"enable_xml\", True, (\"PocoFoundation\", ), True),\n \"PocoZip\": _PocoComponent(\"enable_zip\", True, (\"PocoUtil\", \"PocoXML\", ), True),\n }\n\n for comp in _poco_component_tree.values():\n if comp.option:\n options[comp.option] = [True, False]\n default_options[comp.option] = comp.default_option\n del comp\n\n @property\n def _poco_ordered_components(self):\n remaining_components = dict((compname, set(compopts.dependencies)) for compname, compopts in self._poco_component_tree.items())\n ordered_components = []\n while remaining_components:\n components_no_deps = set(compname for compname, compopts in remaining_components.items() if not compopts)\n if not components_no_deps:\n raise ConanException(\"The poco dependency tree is invalid and contains a cycle\")\n for c in components_no_deps:\n remaining_components.pop(c)\n ordered_components.extend(components_no_deps)\n for rname in remaining_components.keys():\n remaining_components[rname] = remaining_components[rname].difference(components_no_deps)\n ordered_components.reverse()\n return ordered_components\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_folder = \"poco-poco-{}-release\".format(self.version)\n os.rename(extracted_folder, self._source_subfolder)\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n else:\n del self.options.enable_netssl_win\n if tools.Version(self.version) < \"1.9\":\n del self.options.enable_encodings\n if tools.Version(self.version) < \"1.10\":\n del self.options.enable_data_postgresql\n del self.options.enable_jwt\n\n def configure(self):\n if self.options.enable_apacheconnector:\n raise ConanInvalidConfiguration(\"Apache connector not supported: https://github.com/pocoproject/poco/issues/1764\")\n if self.options.enable_data_mysql:\n raise ConanInvalidConfiguration(\"MySQL not supported yet, open an issue here please: %s\" % self.url)\n if self.settings.compiler == \"Visual Studio\":\n if self.options.shared and \"MT\" in str(self.settings.compiler.runtime):\n raise ConanInvalidConfiguration(\"Cannot build shared poco libraries with MT(d) runtime\")\n if self.options.get_safe(\"enable_data_postgresql\", False):\n raise ConanInvalidConfiguration(\"PostgreSQL not supported yet, open an issue here please: %s\" % self.url)\n for compopt in self._poco_component_tree.values():\n if not compopt.option:\n continue\n if self.options.get_safe(compopt.option, False):\n for compdep in compopt.dependencies:\n if not self._poco_component_tree[compdep].option:\n continue\n if not self.options.get_safe(self._poco_component_tree[compdep].option, False):\n raise ConanInvalidConfiguration(\"option {} requires also option {}\".format(compopt.option, self._poco_component_tree[compdep].option))\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n self.requires(\"zlib/1.2.11\")\n if self.options.enable_xml:\n self.requires(\"expat/2.2.10\")\n if self.options.enable_data_sqlite:\n self.requires(\"sqlite3/3.33.0\")\n if self.options.enable_apacheconnector:\n self.requires(\"apr/1.7.0\")\n self.requires(\"apr-util/1.6.1\")\n # FIXME: missing apache2 recipe\n raise ConanInvalidConfiguration(\"apache2 is not (yet) available on CCI\")\n if self.options.enable_netssl or \\\n self.options.enable_crypto or \\\n self.options.get_safe(\"enable_jwt\", False):\n self.requires(\"openssl/1.1.1h\")\n\n def _patch_sources(self):\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n tools.patch(**patch)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n if tools.Version(self.version) < \"1.10.1\":\n self._cmake.definitions[\"POCO_STATIC\"] = not self.options.shared\n for comp in self._poco_component_tree.values():\n if not comp.option:\n continue\n self._cmake.definitions[comp.option.upper()] = self.options.get_safe(comp.option, False)\n self._cmake.definitions[\"POCO_UNBUNDLED\"] = True\n self._cmake.definitions[\"CMAKE_INSTALL_SYSTEM_RUNTIME_LIBS_SKIP\"] = True\n if self.settings.os == \"Windows\" and self.settings.compiler == \"Visual Studio\": # MT or MTd\n self._cmake.definitions[\"POCO_MT\"] = \"ON\" if \"MT\" in str(self.settings.compiler.runtime) else \"OFF\"\n self.output.info(self._cmake.definitions)\n # On Windows, Poco needs a message (MC) compiler.\n with tools.vcvars(self.settings) if self.settings.compiler == \"Visual Studio\" else tools.no_op():\n self._cmake.configure(build_dir=self._build_subfolder)\n return self._cmake\n\n def build(self):\n if self.options.enable_data_sqlite:\n if self.options[\"sqlite3\"].threadsafe == 0:\n raise ConanInvalidConfiguration(\"sqlite3 must be built with threadsafe enabled\")\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"cmake\"))\n\n @property\n def _ordered_libs(self):\n libs = []\n for compname in self._poco_ordered_components:\n comp_options = self._poco_component_tree[compname]\n if comp_options.is_lib:\n if not comp_options.option:\n libs.append(compname)\n elif self.options.get_safe(comp_options.option, False):\n libs.append(compname)\n return libs\n\n def package_info(self):\n suffix = str(self.settings.compiler.runtime).lower() \\\n if self.settings.compiler == \"Visual Studio\" and not self.options.shared \\\n else (\"d\" if self.settings.build_type == \"Debug\" else \"\")\n\n self.cpp_info.libs = list(\"{}{}\".format(lib, suffix) for lib in self._ordered_libs)\n\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"pthread\", \"dl\", \"rt\"])\n\n if self.settings.compiler == \"Visual Studio\":\n self.cpp_info.defines.append(\"POCO_NO_AUTOMATIC_LIBS\")\n if not self.options.shared:\n self.cpp_info.defines.append(\"POCO_STATIC=ON\")\n if self.settings.os == \"Windows\":\n self.cpp_info.system_libs.extend([\"ws2_32\", \"iphlpapi\", \"crypt32\"])\n self.cpp_info.names[\"cmake_find_package\"] = \"Poco\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"Poco\"\n", "path": "recipes/poco/all/conanfile.py"}]} | 3,794 | 803 |
gh_patches_debug_25558 | rasdani/github-patches | git_diff | interlegis__sapl-2525 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sem acesso anônimo de Documento Acessório de Audiencia Pública
<!--- Forneça um resumo geral da _issue_ no título acima -->
## Comportamento Esperado
Usuários anônimos poderem acessar documento acessório das Audiências Públicas
## Comportamento Atual
Usuário anônimo não acessa a parte de "Documento Acessório" da Audiência Pública pedindo um login com a aplicação de documento administrativo "Restritiva", acredito que Audiência Pública não deveria se enquadrar nessa regra.
## Passos para Reproduzir (para bugs)
<!--- Forneça um link para um exemplo, ou um conjunto de passos inequívocos -->
<!--- para reproduzir esse bug. Inclua código para reproduzir, se relevante. -->
1. Com opção de Visibilidade de Documentos Administrativos "Restritiva" -Está deslogado - Institucional - Audiências Públicas - Acessar uma audiência cadastrada - clicar em Documento Acessório
<!-- ## Imagens do Ocorrido -->
## Seu Ambiente
<!--- Inclua detalhes relevantes sobre o ambiente em que você presenciou/experienciou o bug. -->
* Versão usada (_Release_): 3.1.143
* Nome e versão do navegador: Chrome
* Nome e versão do Sistema Operacional (desktop ou mobile): Windows 10
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/audiencia/views.py`
Content:
```
1 import sapl
2
3 from django.http import HttpResponse
4 from django.core.urlresolvers import reverse
5 from django.views.decorators.clickjacking import xframe_options_exempt
6 from django.views.generic import UpdateView
7 from sapl.crud.base import RP_DETAIL, RP_LIST, Crud, MasterDetailCrud
8
9 from .forms import AudienciaForm, AnexoAudienciaPublicaForm
10 from .models import AudienciaPublica, AnexoAudienciaPublica
11
12
13 def index(request):
14 return HttpResponse("Audiência Pública")
15
16
17 class AudienciaCrud(Crud):
18 model = AudienciaPublica
19 public = [RP_LIST, RP_DETAIL, ]
20
21 class BaseMixin(Crud.BaseMixin):
22 list_field_names = ['numero', 'nome', 'tipo', 'materia',
23 'data']
24 ordering = 'nome', 'numero', 'tipo', 'data'
25
26 class ListView(Crud.ListView):
27 paginate_by = 10
28
29 def get_context_data(self, **kwargs):
30 context = super().get_context_data(**kwargs)
31
32 audiencia_materia = {}
33 for o in context['object_list']:
34 # indexado pelo numero da audiencia
35 audiencia_materia[str(o.numero)] = o.materia
36
37 for row in context['rows']:
38 coluna_materia = row[3] # se mudar a ordem de listagem mudar aqui
39 if coluna_materia[0]:
40 materia = audiencia_materia[row[0][0]]
41 url_materia = reverse('sapl.materia:materialegislativa_detail',
42 kwargs={'pk': materia.id})
43 row[3] = (coluna_materia[0], url_materia)
44 return context
45
46 class CreateView(Crud.CreateView):
47 form_class = AudienciaForm
48
49 def form_valid(self, form):
50 return super(Crud.CreateView, self).form_valid(form)
51
52 class UpdateView(Crud.UpdateView):
53 form_class = AudienciaForm
54
55 def get_initial(self):
56 initial = super(UpdateView, self).get_initial()
57 if self.object.materia:
58 initial['tipo_materia'] = self.object.materia.tipo.id
59 initial['numero_materia'] = self.object.materia.numero
60 initial['ano_materia'] = self.object.materia.ano
61 return initial
62
63 class DeleteView(Crud.DeleteView):
64 pass
65
66 class DetailView(Crud.DetailView):
67
68 layout_key = 'AudienciaPublicaDetail'
69
70 @xframe_options_exempt
71 def get(self, request, *args, **kwargs):
72 return super().get(request, *args, **kwargs)
73
74
75 class AudienciaPublicaMixin:
76
77 def has_permission(self):
78 app_config = sapl.base.models.AppConfig.objects.last()
79 if app_config and app_config.documentos_administrativos == 'O':
80 return True
81
82 return super().has_permission()
83
84
85 class AnexoAudienciaPublicaCrud(MasterDetailCrud):
86 model = AnexoAudienciaPublica
87 parent_field = 'audiencia'
88 help_topic = 'numeracao_docsacess'
89
90 class BaseMixin(MasterDetailCrud.BaseMixin):
91 list_field_names = ['assunto']
92
93 class CreateView(MasterDetailCrud.CreateView):
94 form_class = AnexoAudienciaPublicaForm
95 layout_key = None
96
97 class UpdateView(MasterDetailCrud.UpdateView):
98 form_class = AnexoAudienciaPublicaForm
99
100 class ListView(AudienciaPublicaMixin, MasterDetailCrud.ListView):
101
102 def get_queryset(self):
103 qs = super(MasterDetailCrud.ListView, self).get_queryset()
104 kwargs = {self.crud.parent_field: self.kwargs['pk']}
105 return qs.filter(**kwargs).order_by('-data', '-id')
106
107 class DetailView(AudienciaPublicaMixin,
108 MasterDetailCrud.DetailView):
109 pass
110
```
Path: `sapl/audiencia/urls.py`
Content:
```
1 from django.conf.urls import include, url
2 from sapl.audiencia.views import (index, AudienciaCrud,AnexoAudienciaPublicaCrud)
3
4 from .apps import AppConfig
5
6 app_name = AppConfig.name
7
8 urlpatterns = [
9 url(r'^audiencia/', include(AudienciaCrud.get_urls() +
10 AnexoAudienciaPublicaCrud.get_urls())),
11 ]
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sapl/audiencia/urls.py b/sapl/audiencia/urls.py
--- a/sapl/audiencia/urls.py
+++ b/sapl/audiencia/urls.py
@@ -1,11 +1,10 @@
from django.conf.urls import include, url
-from sapl.audiencia.views import (index, AudienciaCrud,AnexoAudienciaPublicaCrud)
+from sapl.audiencia.views import (index, AudienciaCrud, AnexoAudienciaPublicaCrud)
from .apps import AppConfig
app_name = AppConfig.name
urlpatterns = [
- url(r'^audiencia/', include(AudienciaCrud.get_urls() +
- AnexoAudienciaPublicaCrud.get_urls())),
+ url(r'^audiencia/', include(AudienciaCrud.get_urls() + AnexoAudienciaPublicaCrud.get_urls())),
]
\ No newline at end of file
diff --git a/sapl/audiencia/views.py b/sapl/audiencia/views.py
--- a/sapl/audiencia/views.py
+++ b/sapl/audiencia/views.py
@@ -86,6 +86,7 @@
model = AnexoAudienciaPublica
parent_field = 'audiencia'
help_topic = 'numeracao_docsacess'
+ public = [RP_LIST, RP_DETAIL, ]
class BaseMixin(MasterDetailCrud.BaseMixin):
list_field_names = ['assunto']
@@ -104,7 +105,5 @@
kwargs = {self.crud.parent_field: self.kwargs['pk']}
return qs.filter(**kwargs).order_by('-data', '-id')
- class DetailView(AudienciaPublicaMixin,
- MasterDetailCrud.DetailView):
+ class DetailView(AudienciaPublicaMixin, MasterDetailCrud.DetailView):
pass
-
\ No newline at end of file
| {"golden_diff": "diff --git a/sapl/audiencia/urls.py b/sapl/audiencia/urls.py\n--- a/sapl/audiencia/urls.py\n+++ b/sapl/audiencia/urls.py\n@@ -1,11 +1,10 @@\n from django.conf.urls import include, url\n-from sapl.audiencia.views import (index, AudienciaCrud,AnexoAudienciaPublicaCrud)\n+from sapl.audiencia.views import (index, AudienciaCrud, AnexoAudienciaPublicaCrud)\n \n from .apps import AppConfig\n \n app_name = AppConfig.name\n \n urlpatterns = [\n- url(r'^audiencia/', include(AudienciaCrud.get_urls() +\n- \t\t\t\t\t\t\tAnexoAudienciaPublicaCrud.get_urls())),\n+ url(r'^audiencia/', include(AudienciaCrud.get_urls() + AnexoAudienciaPublicaCrud.get_urls())),\n ]\n\\ No newline at end of file\ndiff --git a/sapl/audiencia/views.py b/sapl/audiencia/views.py\n--- a/sapl/audiencia/views.py\n+++ b/sapl/audiencia/views.py\n@@ -86,6 +86,7 @@\n model = AnexoAudienciaPublica\n parent_field = 'audiencia'\n help_topic = 'numeracao_docsacess'\n+ public = [RP_LIST, RP_DETAIL, ]\n \n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['assunto']\n@@ -104,7 +105,5 @@\n kwargs = {self.crud.parent_field: self.kwargs['pk']}\n return qs.filter(**kwargs).order_by('-data', '-id')\n \n- class DetailView(AudienciaPublicaMixin,\n- MasterDetailCrud.DetailView):\n+ class DetailView(AudienciaPublicaMixin, MasterDetailCrud.DetailView):\n pass\n- \n\\ No newline at end of file\n", "issue": "Sem acesso an\u00f4nimo de Documento Acess\u00f3rio de Audiencia P\u00fablica \n<!--- Forne\u00e7a um resumo geral da _issue_ no t\u00edtulo acima -->\r\n\r\n## Comportamento Esperado\r\nUsu\u00e1rios an\u00f4nimos poderem acessar documento acess\u00f3rio das Audi\u00eancias P\u00fablicas \r\n\r\n## Comportamento Atual\r\nUsu\u00e1rio an\u00f4nimo n\u00e3o acessa a parte de \"Documento Acess\u00f3rio\" da Audi\u00eancia P\u00fablica pedindo um login com a aplica\u00e7\u00e3o de documento administrativo \"Restritiva\", acredito que Audi\u00eancia P\u00fablica n\u00e3o deveria se enquadrar nessa regra.\r\n\r\n## Passos para Reproduzir (para bugs)\r\n<!--- Forne\u00e7a um link para um exemplo, ou um conjunto de passos inequ\u00edvocos -->\r\n<!--- para reproduzir esse bug. Inclua c\u00f3digo para reproduzir, se relevante. -->\r\n1. Com op\u00e7\u00e3o de Visibilidade de Documentos Administrativos \"Restritiva\" -Est\u00e1 deslogado - Institucional - Audi\u00eancias P\u00fablicas - Acessar uma audi\u00eancia cadastrada - clicar em Documento Acess\u00f3rio\r\n\r\n<!-- ## Imagens do Ocorrido -->\r\n\r\n## Seu Ambiente\r\n<!--- Inclua detalhes relevantes sobre o ambiente em que voc\u00ea presenciou/experienciou o bug. -->\r\n* Vers\u00e3o usada (_Release_): 3.1.143\r\n* Nome e vers\u00e3o do navegador: Chrome\r\n* Nome e vers\u00e3o do Sistema Operacional (desktop ou mobile): Windows 10\r\n\n", "before_files": [{"content": "import sapl\n\nfrom django.http import HttpResponse\nfrom django.core.urlresolvers import reverse\nfrom django.views.decorators.clickjacking import xframe_options_exempt\nfrom django.views.generic import UpdateView\nfrom sapl.crud.base import RP_DETAIL, RP_LIST, Crud, MasterDetailCrud\n\nfrom .forms import AudienciaForm, AnexoAudienciaPublicaForm\nfrom .models import AudienciaPublica, AnexoAudienciaPublica\n\n\ndef index(request):\n return HttpResponse(\"Audi\u00eancia P\u00fablica\")\n\n\nclass AudienciaCrud(Crud):\n model = AudienciaPublica\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['numero', 'nome', 'tipo', 'materia',\n 'data'] \n ordering = 'nome', 'numero', 'tipo', 'data'\n\n class ListView(Crud.ListView):\n paginate_by = 10\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n audiencia_materia = {}\n for o in context['object_list']:\n # indexado pelo numero da audiencia\n audiencia_materia[str(o.numero)] = o.materia\n\n for row in context['rows']:\n coluna_materia = row[3] # se mudar a ordem de listagem mudar aqui\n if coluna_materia[0]:\n materia = audiencia_materia[row[0][0]]\n url_materia = reverse('sapl.materia:materialegislativa_detail',\n kwargs={'pk': materia.id})\n row[3] = (coluna_materia[0], url_materia)\n return context\n\n class CreateView(Crud.CreateView):\n form_class = AudienciaForm\n\n def form_valid(self, form):\n return super(Crud.CreateView, self).form_valid(form)\n\n class UpdateView(Crud.UpdateView):\n form_class = AudienciaForm\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n if self.object.materia:\n initial['tipo_materia'] = self.object.materia.tipo.id\n initial['numero_materia'] = self.object.materia.numero\n initial['ano_materia'] = self.object.materia.ano\n return initial\n \n class DeleteView(Crud.DeleteView):\n pass\n\n class DetailView(Crud.DetailView):\n\n layout_key = 'AudienciaPublicaDetail'\n\n @xframe_options_exempt\n def get(self, request, *args, **kwargs):\n return super().get(request, *args, **kwargs)\n\n\nclass AudienciaPublicaMixin:\n\n def has_permission(self):\n app_config = sapl.base.models.AppConfig.objects.last()\n if app_config and app_config.documentos_administrativos == 'O':\n return True\n\n return super().has_permission()\n\n\nclass AnexoAudienciaPublicaCrud(MasterDetailCrud):\n model = AnexoAudienciaPublica\n parent_field = 'audiencia'\n help_topic = 'numeracao_docsacess'\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['assunto']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = AnexoAudienciaPublicaForm\n layout_key = None\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = AnexoAudienciaPublicaForm\n\n class ListView(AudienciaPublicaMixin, MasterDetailCrud.ListView):\n\n def get_queryset(self):\n qs = super(MasterDetailCrud.ListView, self).get_queryset()\n kwargs = {self.crud.parent_field: self.kwargs['pk']}\n return qs.filter(**kwargs).order_by('-data', '-id')\n\n class DetailView(AudienciaPublicaMixin,\n MasterDetailCrud.DetailView):\n pass\n ", "path": "sapl/audiencia/views.py"}, {"content": "from django.conf.urls import include, url\nfrom sapl.audiencia.views import (index, AudienciaCrud,AnexoAudienciaPublicaCrud)\n\nfrom .apps import AppConfig\n\napp_name = AppConfig.name\n\nurlpatterns = [\n url(r'^audiencia/', include(AudienciaCrud.get_urls() +\n \t\t\t\t\t\t\tAnexoAudienciaPublicaCrud.get_urls())),\n]", "path": "sapl/audiencia/urls.py"}], "after_files": [{"content": "import sapl\n\nfrom django.http import HttpResponse\nfrom django.core.urlresolvers import reverse\nfrom django.views.decorators.clickjacking import xframe_options_exempt\nfrom django.views.generic import UpdateView\nfrom sapl.crud.base import RP_DETAIL, RP_LIST, Crud, MasterDetailCrud\n\nfrom .forms import AudienciaForm, AnexoAudienciaPublicaForm\nfrom .models import AudienciaPublica, AnexoAudienciaPublica\n\n\ndef index(request):\n return HttpResponse(\"Audi\u00eancia P\u00fablica\")\n\n\nclass AudienciaCrud(Crud):\n model = AudienciaPublica\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['numero', 'nome', 'tipo', 'materia',\n 'data'] \n ordering = 'nome', 'numero', 'tipo', 'data'\n\n class ListView(Crud.ListView):\n paginate_by = 10\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n audiencia_materia = {}\n for o in context['object_list']:\n # indexado pelo numero da audiencia\n audiencia_materia[str(o.numero)] = o.materia\n\n for row in context['rows']:\n coluna_materia = row[3] # se mudar a ordem de listagem mudar aqui\n if coluna_materia[0]:\n materia = audiencia_materia[row[0][0]]\n url_materia = reverse('sapl.materia:materialegislativa_detail',\n kwargs={'pk': materia.id})\n row[3] = (coluna_materia[0], url_materia)\n return context\n\n class CreateView(Crud.CreateView):\n form_class = AudienciaForm\n\n def form_valid(self, form):\n return super(Crud.CreateView, self).form_valid(form)\n\n class UpdateView(Crud.UpdateView):\n form_class = AudienciaForm\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n if self.object.materia:\n initial['tipo_materia'] = self.object.materia.tipo.id\n initial['numero_materia'] = self.object.materia.numero\n initial['ano_materia'] = self.object.materia.ano\n return initial\n \n class DeleteView(Crud.DeleteView):\n pass\n\n class DetailView(Crud.DetailView):\n\n layout_key = 'AudienciaPublicaDetail'\n\n @xframe_options_exempt\n def get(self, request, *args, **kwargs):\n return super().get(request, *args, **kwargs)\n\n\nclass AudienciaPublicaMixin:\n\n def has_permission(self):\n app_config = sapl.base.models.AppConfig.objects.last()\n if app_config and app_config.documentos_administrativos == 'O':\n return True\n\n return super().has_permission()\n\n\nclass AnexoAudienciaPublicaCrud(MasterDetailCrud):\n model = AnexoAudienciaPublica\n parent_field = 'audiencia'\n help_topic = 'numeracao_docsacess'\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['assunto']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = AnexoAudienciaPublicaForm\n layout_key = None\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = AnexoAudienciaPublicaForm\n\n class ListView(AudienciaPublicaMixin, MasterDetailCrud.ListView):\n\n def get_queryset(self):\n qs = super(MasterDetailCrud.ListView, self).get_queryset()\n kwargs = {self.crud.parent_field: self.kwargs['pk']}\n return qs.filter(**kwargs).order_by('-data', '-id')\n\n class DetailView(AudienciaPublicaMixin, MasterDetailCrud.DetailView):\n pass\n", "path": "sapl/audiencia/views.py"}, {"content": "from django.conf.urls import include, url\nfrom sapl.audiencia.views import (index, AudienciaCrud, AnexoAudienciaPublicaCrud)\n\nfrom .apps import AppConfig\n\napp_name = AppConfig.name\n\nurlpatterns = [\n url(r'^audiencia/', include(AudienciaCrud.get_urls() + AnexoAudienciaPublicaCrud.get_urls())),\n]", "path": "sapl/audiencia/urls.py"}]} | 1,761 | 410 |
gh_patches_debug_23485 | rasdani/github-patches | git_diff | mindsdb__mindsdb-1954 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
selecting from datasource error
Repoted by David F.
```
use Postgres_Sample;
SELECT * FROM data.insurance LIMIT 200;
```
error:
```
SQL Error [1149] [42000]: 'str' object has no attribute '__name__'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py`
Content:
```
1 import pandas as pd
2 from mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender
3
4 from mindsdb.api.mysql.mysql_proxy.datahub.datanodes.datanode import DataNode
5 from mindsdb.utilities.log import log
6
7
8 class IntegrationDataNode(DataNode):
9 type = 'integration'
10
11 def __init__(self, integration_name, data_store, ds_type):
12 self.integration_name = integration_name
13 self.data_store = data_store
14 self.ds_type = ds_type
15
16 def get_type(self):
17 return self.type
18
19 def get_tables(self):
20 return []
21
22 def has_table(self, tableName):
23 return True
24
25 def get_table_columns(self, tableName):
26 return []
27
28 def select(self, query):
29 if self.ds_type in ('postgres', 'snowflake'):
30 dialect = 'postgres'
31 else:
32 dialect = 'mysql'
33 render = SqlalchemyRender(dialect)
34 try:
35 query_str = render.get_string(query, with_failback=False)
36 except Exception as e:
37 log.error(f"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}")
38 query_str = render.get_string(query, with_failback=True)
39
40 dso, _creation_info = self.data_store.create_datasource(self.integration_name, {'query': query_str})
41 data = dso.df.to_dict(orient='records')
42 column_names = list(dso.df.columns)
43
44 for column_name in column_names:
45 if pd.core.dtypes.common.is_datetime_or_timedelta_dtype(dso.df[column_name]):
46 pass_data = dso.df[column_name].dt.to_pydatetime()
47 for i, rec in enumerate(data):
48 rec[column_name] = pass_data[i].timestamp()
49
50 if len(column_names) == 0:
51 column_names = ['dataframe_is_empty']
52
53 return data, column_names
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py b/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py
--- a/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py
+++ b/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py
@@ -26,16 +26,19 @@
return []
def select(self, query):
- if self.ds_type in ('postgres', 'snowflake'):
- dialect = 'postgres'
+ if isinstance(query, str):
+ query_str = query
else:
- dialect = 'mysql'
- render = SqlalchemyRender(dialect)
- try:
- query_str = render.get_string(query, with_failback=False)
- except Exception as e:
- log.error(f"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}")
- query_str = render.get_string(query, with_failback=True)
+ if self.ds_type in ('postgres', 'snowflake'):
+ dialect = 'postgres'
+ else:
+ dialect = 'mysql'
+ render = SqlalchemyRender(dialect)
+ try:
+ query_str = render.get_string(query, with_failback=False)
+ except Exception as e:
+ log.error(f"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}")
+ query_str = render.get_string(query, with_failback=True)
dso, _creation_info = self.data_store.create_datasource(self.integration_name, {'query': query_str})
data = dso.df.to_dict(orient='records')
| {"golden_diff": "diff --git a/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py b/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py\n--- a/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py\n+++ b/mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py\n@@ -26,16 +26,19 @@\n return []\n \n def select(self, query):\n- if self.ds_type in ('postgres', 'snowflake'):\n- dialect = 'postgres'\n+ if isinstance(query, str):\n+ query_str = query\n else:\n- dialect = 'mysql'\n- render = SqlalchemyRender(dialect)\n- try:\n- query_str = render.get_string(query, with_failback=False)\n- except Exception as e:\n- log.error(f\"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}\")\n- query_str = render.get_string(query, with_failback=True)\n+ if self.ds_type in ('postgres', 'snowflake'):\n+ dialect = 'postgres'\n+ else:\n+ dialect = 'mysql'\n+ render = SqlalchemyRender(dialect)\n+ try:\n+ query_str = render.get_string(query, with_failback=False)\n+ except Exception as e:\n+ log.error(f\"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}\")\n+ query_str = render.get_string(query, with_failback=True)\n \n dso, _creation_info = self.data_store.create_datasource(self.integration_name, {'query': query_str})\n data = dso.df.to_dict(orient='records')\n", "issue": "selecting from datasource error\nRepoted by David F.\r\n```\r\nuse Postgres_Sample;\r\n\r\nSELECT * FROM data.insurance LIMIT 200;\r\n```\r\nerror:\r\n```\r\nSQL Error [1149] [42000]: 'str' object has no attribute '__name__'\r\n```\n", "before_files": [{"content": "import pandas as pd\nfrom mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n\nfrom mindsdb.api.mysql.mysql_proxy.datahub.datanodes.datanode import DataNode\nfrom mindsdb.utilities.log import log\n\n\nclass IntegrationDataNode(DataNode):\n type = 'integration'\n\n def __init__(self, integration_name, data_store, ds_type):\n self.integration_name = integration_name\n self.data_store = data_store\n self.ds_type = ds_type\n\n def get_type(self):\n return self.type\n\n def get_tables(self):\n return []\n\n def has_table(self, tableName):\n return True\n\n def get_table_columns(self, tableName):\n return []\n\n def select(self, query):\n if self.ds_type in ('postgres', 'snowflake'):\n dialect = 'postgres'\n else:\n dialect = 'mysql'\n render = SqlalchemyRender(dialect)\n try:\n query_str = render.get_string(query, with_failback=False)\n except Exception as e:\n log.error(f\"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}\")\n query_str = render.get_string(query, with_failback=True)\n\n dso, _creation_info = self.data_store.create_datasource(self.integration_name, {'query': query_str})\n data = dso.df.to_dict(orient='records')\n column_names = list(dso.df.columns)\n\n for column_name in column_names:\n if pd.core.dtypes.common.is_datetime_or_timedelta_dtype(dso.df[column_name]):\n pass_data = dso.df[column_name].dt.to_pydatetime()\n for i, rec in enumerate(data):\n rec[column_name] = pass_data[i].timestamp()\n\n if len(column_names) == 0:\n column_names = ['dataframe_is_empty']\n\n return data, column_names\n", "path": "mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py"}], "after_files": [{"content": "import pandas as pd\nfrom mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n\nfrom mindsdb.api.mysql.mysql_proxy.datahub.datanodes.datanode import DataNode\nfrom mindsdb.utilities.log import log\n\n\nclass IntegrationDataNode(DataNode):\n type = 'integration'\n\n def __init__(self, integration_name, data_store, ds_type):\n self.integration_name = integration_name\n self.data_store = data_store\n self.ds_type = ds_type\n\n def get_type(self):\n return self.type\n\n def get_tables(self):\n return []\n\n def has_table(self, tableName):\n return True\n\n def get_table_columns(self, tableName):\n return []\n\n def select(self, query):\n if isinstance(query, str):\n query_str = query\n else:\n if self.ds_type in ('postgres', 'snowflake'):\n dialect = 'postgres'\n else:\n dialect = 'mysql'\n render = SqlalchemyRender(dialect)\n try:\n query_str = render.get_string(query, with_failback=False)\n except Exception as e:\n log.error(f\"Exception during query casting to '{dialect}' dialect. Query: {query}. Error: {e}\")\n query_str = render.get_string(query, with_failback=True)\n\n dso, _creation_info = self.data_store.create_datasource(self.integration_name, {'query': query_str})\n data = dso.df.to_dict(orient='records')\n column_names = list(dso.df.columns)\n\n for column_name in column_names:\n if pd.core.dtypes.common.is_datetime_or_timedelta_dtype(dso.df[column_name]):\n pass_data = dso.df[column_name].dt.to_pydatetime()\n for i, rec in enumerate(data):\n rec[column_name] = pass_data[i].timestamp()\n\n if len(column_names) == 0:\n column_names = ['dataframe_is_empty']\n\n return data, column_names\n", "path": "mindsdb/api/mysql/mysql_proxy/datahub/datanodes/integration_datanode.py"}]} | 836 | 381 |
gh_patches_debug_40307 | rasdani/github-patches | git_diff | Project-MONAI__MONAI-1946 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add `strict_shape` option to CheckpointLoader
**Is your feature request related to a problem? Please describe.**
Currently, we don't support the transfer-learning case that load a checkpoint with same layer names but different shape.
We can refer to below code:
```py
model_3 = get_model_with_3_classes()
state_dict_model_4 = torch.load("best_model_4.pt")
@trainer.on(Events.STARTED, model_3, state_dict_model_4)
def permissive_model_loader(model, state_dict):
this_state_dict = model.state_dict()
matched_state_dict = {
k: v for k, v in state_dict.items()
if k in this_state_dict and v.shape == this_state_dict[k].shape
}
model.load_state_dict(matched_state_dict, strict=False)
trainer.run(...)
```
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `monai/handlers/checkpoint_loader.py`
Content:
```
1 # Copyright 2020 - 2021 MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11
12 import logging
13 from typing import TYPE_CHECKING, Dict, Optional
14
15 import torch
16
17 from monai.utils import exact_version, optional_import
18
19 Events, _ = optional_import("ignite.engine", "0.4.4", exact_version, "Events")
20 Checkpoint, _ = optional_import("ignite.handlers", "0.4.4", exact_version, "Checkpoint")
21 if TYPE_CHECKING:
22 from ignite.engine import Engine
23 else:
24 Engine, _ = optional_import("ignite.engine", "0.4.4", exact_version, "Engine")
25
26
27 class CheckpointLoader:
28 """
29 CheckpointLoader acts as an Ignite handler to load checkpoint data from file.
30 It can load variables for network, optimizer, lr_scheduler, etc.
31 If saving checkpoint after `torch.nn.DataParallel`, need to save `model.module` instead
32 as PyTorch recommended and then use this loader to load the model.
33
34 Args:
35 load_path: the file path of checkpoint, it should be a PyTorch `pth` file.
36 load_dict: target objects that load checkpoint to. examples::
37
38 {'network': net, 'optimizer': optimizer, 'lr_scheduler': lr_scheduler}
39
40 name: identifier of logging.logger to use, if None, defaulting to ``engine.logger``.
41 map_location: when loading the module for distributed training/evaluation,
42 need to provide an appropriate map_location argument to prevent a process
43 to step into others’ devices. If map_location is missing, torch.load will
44 first load the module to CPU and then copy each parameter to where it was
45 saved, which would result in all processes on the same machine using the
46 same set of devices.
47 strict: whether to strictly enforce that the keys in :attr:`state_dict` match the keys
48 returned by this module's :meth:`~torch.nn.Module.state_dict` function. Default: ``True``
49
50 """
51
52 def __init__(
53 self,
54 load_path: str,
55 load_dict: Dict,
56 name: Optional[str] = None,
57 map_location: Optional[Dict] = None,
58 strict: bool = True,
59 ) -> None:
60 if load_path is None:
61 raise AssertionError("must provide clear path to load checkpoint.")
62 self.load_path = load_path
63 if not (load_dict is not None and len(load_dict) > 0):
64 raise AssertionError("must provide target objects to load.")
65 self.logger = logging.getLogger(name)
66 self.load_dict = load_dict
67 self._name = name
68 self.map_location = map_location
69 self.strict = strict
70
71 def attach(self, engine: Engine) -> None:
72 """
73 Args:
74 engine: Ignite Engine, it can be a trainer, validator or evaluator.
75 """
76 if self._name is None:
77 self.logger = engine.logger
78 engine.add_event_handler(Events.STARTED, self)
79
80 def __call__(self, engine: Engine) -> None:
81 """
82 Args:
83 engine: Ignite Engine, it can be a trainer, validator or evaluator.
84 """
85 checkpoint = torch.load(self.load_path, map_location=self.map_location)
86
87 # save current max epochs setting in the engine, don't overwrite it if larger than max_epochs in checkpoint
88 prior_max_epochs = engine.state.max_epochs
89 Checkpoint.load_objects(to_load=self.load_dict, checkpoint=checkpoint, strict=self.strict)
90 if engine.state.epoch > prior_max_epochs:
91 raise ValueError(
92 f"Epoch count ({engine.state.epoch}) in checkpoint is larger than "
93 f"the `engine.state.max_epochs` ({prior_max_epochs}) of engine. To further train from checkpoint, "
94 "construct trainer with `max_epochs` larger than checkpoint's epoch count. "
95 "To use checkpoint for inference, no need to load state_dict for the engine."
96 )
97 engine.state.max_epochs = prior_max_epochs
98
99 self.logger.info(f"Restored all variables from {self.load_path}")
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/monai/handlers/checkpoint_loader.py b/monai/handlers/checkpoint_loader.py
--- a/monai/handlers/checkpoint_loader.py
+++ b/monai/handlers/checkpoint_loader.py
@@ -13,6 +13,7 @@
from typing import TYPE_CHECKING, Dict, Optional
import torch
+import torch.nn as nn
from monai.utils import exact_version, optional_import
@@ -44,8 +45,12 @@
first load the module to CPU and then copy each parameter to where it was
saved, which would result in all processes on the same machine using the
same set of devices.
- strict: whether to strictly enforce that the keys in :attr:`state_dict` match the keys
- returned by this module's :meth:`~torch.nn.Module.state_dict` function. Default: ``True``
+ strict: whether to strictly enforce that the keys in `state_dict` match the keys
+ returned by `torch.nn.Module.state_dict` function. default to `True`.
+ strict_shape: whether to enforce the data shape of the matched layers in the checkpoint,
+ `if `False`, it will skip the layers that have different data shape with checkpoint content.
+ This can be useful advanced feature for transfer learning. users should totally
+ understand which layers will have different shape. default to `True`.
"""
@@ -56,6 +61,7 @@
name: Optional[str] = None,
map_location: Optional[Dict] = None,
strict: bool = True,
+ strict_shape: bool = True,
) -> None:
if load_path is None:
raise AssertionError("must provide clear path to load checkpoint.")
@@ -67,6 +73,7 @@
self._name = name
self.map_location = map_location
self.strict = strict
+ self.strict_shape = strict_shape
def attach(self, engine: Engine) -> None:
"""
@@ -84,6 +91,20 @@
"""
checkpoint = torch.load(self.load_path, map_location=self.map_location)
+ if not self.strict_shape:
+ k, _ = list(self.load_dict.items())[0]
+ # single object and checkpoint is directly a state_dict
+ if len(self.load_dict) == 1 and k not in checkpoint:
+ checkpoint = {k: checkpoint}
+
+ # skip items that don't match data shape
+ for k, obj in self.load_dict.items():
+ if isinstance(obj, (nn.DataParallel, nn.parallel.DistributedDataParallel)):
+ obj = obj.module
+ if isinstance(obj, torch.nn.Module):
+ d = obj.state_dict()
+ checkpoint[k] = {k: v for k, v in checkpoint[k].items() if k in d and v.shape == d[k].shape}
+
# save current max epochs setting in the engine, don't overwrite it if larger than max_epochs in checkpoint
prior_max_epochs = engine.state.max_epochs
Checkpoint.load_objects(to_load=self.load_dict, checkpoint=checkpoint, strict=self.strict)
| {"golden_diff": "diff --git a/monai/handlers/checkpoint_loader.py b/monai/handlers/checkpoint_loader.py\n--- a/monai/handlers/checkpoint_loader.py\n+++ b/monai/handlers/checkpoint_loader.py\n@@ -13,6 +13,7 @@\n from typing import TYPE_CHECKING, Dict, Optional\n \n import torch\n+import torch.nn as nn\n \n from monai.utils import exact_version, optional_import\n \n@@ -44,8 +45,12 @@\n first load the module to CPU and then copy each parameter to where it was\n saved, which would result in all processes on the same machine using the\n same set of devices.\n- strict: whether to strictly enforce that the keys in :attr:`state_dict` match the keys\n- returned by this module's :meth:`~torch.nn.Module.state_dict` function. Default: ``True``\n+ strict: whether to strictly enforce that the keys in `state_dict` match the keys\n+ returned by `torch.nn.Module.state_dict` function. default to `True`.\n+ strict_shape: whether to enforce the data shape of the matched layers in the checkpoint,\n+ `if `False`, it will skip the layers that have different data shape with checkpoint content.\n+ This can be useful advanced feature for transfer learning. users should totally\n+ understand which layers will have different shape. default to `True`.\n \n \"\"\"\n \n@@ -56,6 +61,7 @@\n name: Optional[str] = None,\n map_location: Optional[Dict] = None,\n strict: bool = True,\n+ strict_shape: bool = True,\n ) -> None:\n if load_path is None:\n raise AssertionError(\"must provide clear path to load checkpoint.\")\n@@ -67,6 +73,7 @@\n self._name = name\n self.map_location = map_location\n self.strict = strict\n+ self.strict_shape = strict_shape\n \n def attach(self, engine: Engine) -> None:\n \"\"\"\n@@ -84,6 +91,20 @@\n \"\"\"\n checkpoint = torch.load(self.load_path, map_location=self.map_location)\n \n+ if not self.strict_shape:\n+ k, _ = list(self.load_dict.items())[0]\n+ # single object and checkpoint is directly a state_dict\n+ if len(self.load_dict) == 1 and k not in checkpoint:\n+ checkpoint = {k: checkpoint}\n+\n+ # skip items that don't match data shape\n+ for k, obj in self.load_dict.items():\n+ if isinstance(obj, (nn.DataParallel, nn.parallel.DistributedDataParallel)):\n+ obj = obj.module\n+ if isinstance(obj, torch.nn.Module):\n+ d = obj.state_dict()\n+ checkpoint[k] = {k: v for k, v in checkpoint[k].items() if k in d and v.shape == d[k].shape}\n+\n # save current max epochs setting in the engine, don't overwrite it if larger than max_epochs in checkpoint\n prior_max_epochs = engine.state.max_epochs\n Checkpoint.load_objects(to_load=self.load_dict, checkpoint=checkpoint, strict=self.strict)\n", "issue": "Add `strict_shape` option to CheckpointLoader\n**Is your feature request related to a problem? Please describe.**\r\nCurrently, we don't support the transfer-learning case that load a checkpoint with same layer names but different shape.\r\nWe can refer to below code:\r\n```py\r\nmodel_3 = get_model_with_3_classes()\r\nstate_dict_model_4 = torch.load(\"best_model_4.pt\")\r\n\r\[email protected](Events.STARTED, model_3, state_dict_model_4)\r\ndef permissive_model_loader(model, state_dict):\r\n this_state_dict = model.state_dict()\r\n matched_state_dict = {\r\n k: v for k, v in state_dict.items()\r\n if k in this_state_dict and v.shape == this_state_dict[k].shape\r\n }\r\n model.load_state_dict(matched_state_dict, strict=False)\r\n\r\ntrainer.run(...)\r\n```\r\n\r\nThanks.\r\n\n", "before_files": [{"content": "# Copyright 2020 - 2021 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom typing import TYPE_CHECKING, Dict, Optional\n\nimport torch\n\nfrom monai.utils import exact_version, optional_import\n\nEvents, _ = optional_import(\"ignite.engine\", \"0.4.4\", exact_version, \"Events\")\nCheckpoint, _ = optional_import(\"ignite.handlers\", \"0.4.4\", exact_version, \"Checkpoint\")\nif TYPE_CHECKING:\n from ignite.engine import Engine\nelse:\n Engine, _ = optional_import(\"ignite.engine\", \"0.4.4\", exact_version, \"Engine\")\n\n\nclass CheckpointLoader:\n \"\"\"\n CheckpointLoader acts as an Ignite handler to load checkpoint data from file.\n It can load variables for network, optimizer, lr_scheduler, etc.\n If saving checkpoint after `torch.nn.DataParallel`, need to save `model.module` instead\n as PyTorch recommended and then use this loader to load the model.\n\n Args:\n load_path: the file path of checkpoint, it should be a PyTorch `pth` file.\n load_dict: target objects that load checkpoint to. examples::\n\n {'network': net, 'optimizer': optimizer, 'lr_scheduler': lr_scheduler}\n\n name: identifier of logging.logger to use, if None, defaulting to ``engine.logger``.\n map_location: when loading the module for distributed training/evaluation,\n need to provide an appropriate map_location argument to prevent a process\n to step into others\u2019 devices. If map_location is missing, torch.load will\n first load the module to CPU and then copy each parameter to where it was\n saved, which would result in all processes on the same machine using the\n same set of devices.\n strict: whether to strictly enforce that the keys in :attr:`state_dict` match the keys\n returned by this module's :meth:`~torch.nn.Module.state_dict` function. Default: ``True``\n\n \"\"\"\n\n def __init__(\n self,\n load_path: str,\n load_dict: Dict,\n name: Optional[str] = None,\n map_location: Optional[Dict] = None,\n strict: bool = True,\n ) -> None:\n if load_path is None:\n raise AssertionError(\"must provide clear path to load checkpoint.\")\n self.load_path = load_path\n if not (load_dict is not None and len(load_dict) > 0):\n raise AssertionError(\"must provide target objects to load.\")\n self.logger = logging.getLogger(name)\n self.load_dict = load_dict\n self._name = name\n self.map_location = map_location\n self.strict = strict\n\n def attach(self, engine: Engine) -> None:\n \"\"\"\n Args:\n engine: Ignite Engine, it can be a trainer, validator or evaluator.\n \"\"\"\n if self._name is None:\n self.logger = engine.logger\n engine.add_event_handler(Events.STARTED, self)\n\n def __call__(self, engine: Engine) -> None:\n \"\"\"\n Args:\n engine: Ignite Engine, it can be a trainer, validator or evaluator.\n \"\"\"\n checkpoint = torch.load(self.load_path, map_location=self.map_location)\n\n # save current max epochs setting in the engine, don't overwrite it if larger than max_epochs in checkpoint\n prior_max_epochs = engine.state.max_epochs\n Checkpoint.load_objects(to_load=self.load_dict, checkpoint=checkpoint, strict=self.strict)\n if engine.state.epoch > prior_max_epochs:\n raise ValueError(\n f\"Epoch count ({engine.state.epoch}) in checkpoint is larger than \"\n f\"the `engine.state.max_epochs` ({prior_max_epochs}) of engine. To further train from checkpoint, \"\n \"construct trainer with `max_epochs` larger than checkpoint's epoch count. \"\n \"To use checkpoint for inference, no need to load state_dict for the engine.\"\n )\n engine.state.max_epochs = prior_max_epochs\n\n self.logger.info(f\"Restored all variables from {self.load_path}\")\n", "path": "monai/handlers/checkpoint_loader.py"}], "after_files": [{"content": "# Copyright 2020 - 2021 MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom typing import TYPE_CHECKING, Dict, Optional\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.utils import exact_version, optional_import\n\nEvents, _ = optional_import(\"ignite.engine\", \"0.4.4\", exact_version, \"Events\")\nCheckpoint, _ = optional_import(\"ignite.handlers\", \"0.4.4\", exact_version, \"Checkpoint\")\nif TYPE_CHECKING:\n from ignite.engine import Engine\nelse:\n Engine, _ = optional_import(\"ignite.engine\", \"0.4.4\", exact_version, \"Engine\")\n\n\nclass CheckpointLoader:\n \"\"\"\n CheckpointLoader acts as an Ignite handler to load checkpoint data from file.\n It can load variables for network, optimizer, lr_scheduler, etc.\n If saving checkpoint after `torch.nn.DataParallel`, need to save `model.module` instead\n as PyTorch recommended and then use this loader to load the model.\n\n Args:\n load_path: the file path of checkpoint, it should be a PyTorch `pth` file.\n load_dict: target objects that load checkpoint to. examples::\n\n {'network': net, 'optimizer': optimizer, 'lr_scheduler': lr_scheduler}\n\n name: identifier of logging.logger to use, if None, defaulting to ``engine.logger``.\n map_location: when loading the module for distributed training/evaluation,\n need to provide an appropriate map_location argument to prevent a process\n to step into others\u2019 devices. If map_location is missing, torch.load will\n first load the module to CPU and then copy each parameter to where it was\n saved, which would result in all processes on the same machine using the\n same set of devices.\n strict: whether to strictly enforce that the keys in `state_dict` match the keys\n returned by `torch.nn.Module.state_dict` function. default to `True`.\n strict_shape: whether to enforce the data shape of the matched layers in the checkpoint,\n `if `False`, it will skip the layers that have different data shape with checkpoint content.\n This can be useful advanced feature for transfer learning. users should totally\n understand which layers will have different shape. default to `True`.\n\n \"\"\"\n\n def __init__(\n self,\n load_path: str,\n load_dict: Dict,\n name: Optional[str] = None,\n map_location: Optional[Dict] = None,\n strict: bool = True,\n strict_shape: bool = True,\n ) -> None:\n if load_path is None:\n raise AssertionError(\"must provide clear path to load checkpoint.\")\n self.load_path = load_path\n if not (load_dict is not None and len(load_dict) > 0):\n raise AssertionError(\"must provide target objects to load.\")\n self.logger = logging.getLogger(name)\n self.load_dict = load_dict\n self._name = name\n self.map_location = map_location\n self.strict = strict\n self.strict_shape = strict_shape\n\n def attach(self, engine: Engine) -> None:\n \"\"\"\n Args:\n engine: Ignite Engine, it can be a trainer, validator or evaluator.\n \"\"\"\n if self._name is None:\n self.logger = engine.logger\n engine.add_event_handler(Events.STARTED, self)\n\n def __call__(self, engine: Engine) -> None:\n \"\"\"\n Args:\n engine: Ignite Engine, it can be a trainer, validator or evaluator.\n \"\"\"\n checkpoint = torch.load(self.load_path, map_location=self.map_location)\n\n if not self.strict_shape:\n k, _ = list(self.load_dict.items())[0]\n # single object and checkpoint is directly a state_dict\n if len(self.load_dict) == 1 and k not in checkpoint:\n checkpoint = {k: checkpoint}\n\n # skip items that don't match data shape\n for k, obj in self.load_dict.items():\n if isinstance(obj, (nn.DataParallel, nn.parallel.DistributedDataParallel)):\n obj = obj.module\n if isinstance(obj, torch.nn.Module):\n d = obj.state_dict()\n checkpoint[k] = {k: v for k, v in checkpoint[k].items() if k in d and v.shape == d[k].shape}\n\n # save current max epochs setting in the engine, don't overwrite it if larger than max_epochs in checkpoint\n prior_max_epochs = engine.state.max_epochs\n Checkpoint.load_objects(to_load=self.load_dict, checkpoint=checkpoint, strict=self.strict)\n if engine.state.epoch > prior_max_epochs:\n raise ValueError(\n f\"Epoch count ({engine.state.epoch}) in checkpoint is larger than \"\n f\"the `engine.state.max_epochs` ({prior_max_epochs}) of engine. To further train from checkpoint, \"\n \"construct trainer with `max_epochs` larger than checkpoint's epoch count. \"\n \"To use checkpoint for inference, no need to load state_dict for the engine.\"\n )\n engine.state.max_epochs = prior_max_epochs\n\n self.logger.info(f\"Restored all variables from {self.load_path}\")\n", "path": "monai/handlers/checkpoint_loader.py"}]} | 1,612 | 680 |
gh_patches_debug_22520 | rasdani/github-patches | git_diff | fossasia__open-event-server-5102 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use identifier instead of id to send order receipts
**Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently, the endpoint to send order receipts uses order ids, but purchasers do not know about order ids, instead they know of order identifiers. Thus, it's more appropriate to use order identifiers instead of ids in that endpoint.
**Describe the solution you'd like**
Use order identifiers instead of order endpoints.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/attendees.py`
Content:
```
1 from flask import Blueprint, request, jsonify, abort, make_response
2 from flask_jwt import current_identity, jwt_required
3 from flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship
4 from flask_rest_jsonapi.exceptions import ObjectNotFound
5 from sqlalchemy.orm.exc import NoResultFound
6
7 from app.api.bootstrap import api
8 from app.api.helpers.db import safe_query, get_count
9 from app.api.helpers.exceptions import (
10 ConflictException,
11 ForbiddenException,
12 UnprocessableEntity,
13 )
14 from app.api.helpers.mail import send_email_to_attendees
15 from app.api.helpers.permission_manager import has_access
16 from app.api.helpers.permissions import jwt_required
17 from app.api.helpers.query import event_query
18 from app.api.helpers.utilities import require_relationship
19 from app.api.schema.attendees import AttendeeSchema
20 from app.models import db
21 from app.models.order import Order
22 from app.models.ticket import Ticket
23 from app.models.ticket_holder import TicketHolder
24 from app.models.user import User
25
26 attendee_misc_routes = Blueprint('attendee_misc', __name__, url_prefix='/v1')
27
28 class AttendeeListPost(ResourceList):
29 """
30 List and create Attendees through direct URL
31 """
32
33 def before_post(self, args, kwargs, data):
34 """
35 Before post method to check for required relationship and proper permissions
36 :param args:
37 :param kwargs:
38 :param data:
39 :return:
40 """
41 require_relationship(['ticket', 'event'], data)
42
43 ticket = db.session.query(Ticket).filter_by(
44 id=int(data['ticket']), deleted_at=None
45 ).first()
46 if ticket is None:
47 raise UnprocessableEntity(
48 {'pointer': '/data/relationships/ticket'}, "Invalid Ticket"
49 )
50 if ticket.event_id != int(data['event']):
51 raise UnprocessableEntity(
52 {'pointer': '/data/relationships/ticket'},
53 "Ticket belongs to a different Event"
54 )
55 # Check if the ticket is already sold out or not.
56 if get_count(db.session.query(TicketHolder.id).
57 filter_by(ticket_id=int(data['ticket']), deleted_at=None)) >= ticket.quantity:
58 raise ConflictException(
59 {'pointer': '/data/attributes/ticket_id'},
60 "Ticket already sold out"
61 )
62
63 decorators = (jwt_required,)
64 methods = ['POST']
65 schema = AttendeeSchema
66 data_layer = {'session': db.session,
67 'model': TicketHolder}
68
69
70 class AttendeeList(ResourceList):
71 """
72 List Attendees
73 """
74 def query(self, view_kwargs):
75 """
76 query method for Attendees List
77 :param view_kwargs:
78 :return:
79 """
80 query_ = self.session.query(TicketHolder)
81
82 if view_kwargs.get('order_identifier'):
83 order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')
84 if not has_access('is_registrar', event_id=order.event_id) and not has_access('is_user_itself',
85 user_id=order.user_id):
86 raise ForbiddenException({'source': ''}, 'Access Forbidden')
87 query_ = query_.join(Order).filter(Order.id == order.id)
88
89 if view_kwargs.get('ticket_id'):
90 ticket = safe_query(self, Ticket, 'id', view_kwargs['ticket_id'], 'ticket_id')
91 if not has_access('is_registrar', event_id=ticket.event_id):
92 raise ForbiddenException({'source': ''}, 'Access Forbidden')
93 query_ = query_.join(Ticket).filter(Ticket.id == ticket.id)
94
95 if view_kwargs.get('user_id'):
96 user = safe_query(self, User, 'id', view_kwargs['user_id'], 'user_id')
97 if not has_access('is_user_itself', user_id=user.id):
98 raise ForbiddenException({'source': ''}, 'Access Forbidden')
99 query_ = query_.join(User, User.email == TicketHolder.email).filter(User.id == user.id)
100
101 query_ = event_query(self, query_, view_kwargs, permission='is_registrar')
102 return query_
103
104 view_kwargs = True
105 methods = ['GET', ]
106 schema = AttendeeSchema
107 data_layer = {'session': db.session,
108 'model': TicketHolder,
109 'methods': {
110 'query': query
111 }}
112
113
114 class AttendeeDetail(ResourceDetail):
115 """
116 Attendee detail by id
117 """
118 def before_get_object(self, view_kwargs):
119 """
120 before get object method for attendee detail
121 :param view_kwargs:
122 :return:
123 """
124 attendee = safe_query(self, TicketHolder, 'id', view_kwargs['id'], 'attendee_id')
125 if not has_access('is_registrar_or_user_itself', user_id=current_identity.id, event_id=attendee.event_id):
126 raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')
127
128 def before_delete_object(self, obj, kwargs):
129 """
130 before delete object method for attendee detail
131 :param obj:
132 :param kwargs:
133 :return:
134 """
135 if not has_access('is_registrar', event_id=obj.event_id):
136 raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')
137
138 def before_update_object(self, obj, data, kwargs):
139 """
140 before update object method for attendee detail
141 :param obj:
142 :param data:
143 :param kwargs:
144 :return:
145 """
146 if not has_access('is_registrar', event_id=obj.event_id):
147 raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')
148
149 if 'is_checked_in' in data and data['is_checked_in']:
150 if 'checkin_times' not in data:
151 raise UnprocessableEntity({'pointer': '/data/attributes/checkin_times'},
152 "Check in time missing while trying to check in attendee")
153 else:
154 if obj.checkin_times and data['checkin_times'] not in obj.checkin_times.split(","):
155 data['checkin_times'] = '{},{}'.format(obj.checkin_times, data['checkin_times'])
156
157 if 'attendee_notes' in data:
158 if obj.attendee_notes and data['attendee_notes'] not in obj.attendee_notes.split(","):
159 data['attendee_notes'] = '{},{}'.format(obj.attendee_notes, data['attendee_notes'])
160
161 decorators = (jwt_required,)
162 schema = AttendeeSchema
163 data_layer = {'session': db.session,
164 'model': TicketHolder,
165 'methods': {
166 'before_get_object': before_get_object,
167 'before_update_object': before_update_object,
168 'before_delete_object': before_delete_object
169 }}
170
171
172 class AttendeeRelationshipRequired(ResourceRelationship):
173 """
174 Attendee Relationship (Required)
175 """
176 decorators = (jwt_required,)
177 methods = ['GET', 'PATCH']
178 schema = AttendeeSchema
179 data_layer = {'session': db.session,
180 'model': TicketHolder}
181
182
183 class AttendeeRelationshipOptional(ResourceRelationship):
184 """
185 Attendee Relationship(Optional)
186 """
187 decorators = (api.has_permission('is_user_itself', fetch="user_id", fetch_as="id", model=TicketHolder),)
188 schema = AttendeeSchema
189 data_layer = {'session': db.session,
190 'model': TicketHolder}
191
192
193 @attendee_misc_routes.route('/attendees/send-receipt', methods=['POST'])
194 @jwt_required
195 def send_receipt():
196 order_id = request.json.get('order-id')
197 if order_id:
198 try:
199 order = db.session.query(Order).filter_by(id=int(order_id)).one()
200 except NoResultFound:
201 raise ObjectNotFound({'parameter': '{id}'}, "Order not found")
202
203 if order.user_id != current_identity.id:
204 abort(
205 make_response(jsonify(error="You cannot send reciept for an order not created by you"), 403)
206 )
207 elif order.status != 'completed':
208 abort(
209 make_response(jsonify(error="Cannot send receipt for an incomplete order"), 409)
210 )
211 else:
212 send_email_to_attendees(order, current_identity.id)
213 return jsonify(message="receipt sent to attendees")
214 else:
215 abort(
216 make_response(jsonify(error="Order id missing"), 422)
217 )
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/api/attendees.py b/app/api/attendees.py
--- a/app/api/attendees.py
+++ b/app/api/attendees.py
@@ -193,12 +193,14 @@
@attendee_misc_routes.route('/attendees/send-receipt', methods=['POST'])
@jwt_required
def send_receipt():
- order_id = request.json.get('order-id')
- if order_id:
+ # Function to send receipts to attendees related to the provided order.
+
+ order_identifier = request.json.get('order-identifier')
+ if order_identifier:
try:
- order = db.session.query(Order).filter_by(id=int(order_id)).one()
+ order = db.session.query(Order).filter_by(identifier=order_identifier).one()
except NoResultFound:
- raise ObjectNotFound({'parameter': '{id}'}, "Order not found")
+ raise ObjectNotFound({'parameter': '{identifier}'}, "Order not found")
if order.user_id != current_identity.id:
abort(
@@ -213,5 +215,5 @@
return jsonify(message="receipt sent to attendees")
else:
abort(
- make_response(jsonify(error="Order id missing"), 422)
+ make_response(jsonify(error="Order identifier missing"), 422)
)
| {"golden_diff": "diff --git a/app/api/attendees.py b/app/api/attendees.py\n--- a/app/api/attendees.py\n+++ b/app/api/attendees.py\n@@ -193,12 +193,14 @@\n @attendee_misc_routes.route('/attendees/send-receipt', methods=['POST'])\n @jwt_required\n def send_receipt():\n- order_id = request.json.get('order-id')\n- if order_id:\n+ # Function to send receipts to attendees related to the provided order.\n+\n+ order_identifier = request.json.get('order-identifier')\n+ if order_identifier:\n try:\n- order = db.session.query(Order).filter_by(id=int(order_id)).one()\n+ order = db.session.query(Order).filter_by(identifier=order_identifier).one()\n except NoResultFound:\n- raise ObjectNotFound({'parameter': '{id}'}, \"Order not found\")\n+ raise ObjectNotFound({'parameter': '{identifier}'}, \"Order not found\")\n \n if order.user_id != current_identity.id:\n abort(\n@@ -213,5 +215,5 @@\n return jsonify(message=\"receipt sent to attendees\")\n else:\n abort(\n- make_response(jsonify(error=\"Order id missing\"), 422)\n+ make_response(jsonify(error=\"Order identifier missing\"), 422)\n )\n", "issue": "Use identifier instead of id to send order receipts\n**Is your feature request related to a problem? Please describe.**\r\n<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->\r\nCurrently, the endpoint to send order receipts uses order ids, but purchasers do not know about order ids, instead they know of order identifiers. Thus, it's more appropriate to use order identifiers instead of ids in that endpoint.\r\n\r\n**Describe the solution you'd like**\r\nUse order identifiers instead of order endpoints.\n", "before_files": [{"content": "from flask import Blueprint, request, jsonify, abort, make_response\nfrom flask_jwt import current_identity, jwt_required\nfrom flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship\nfrom flask_rest_jsonapi.exceptions import ObjectNotFound\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom app.api.bootstrap import api\nfrom app.api.helpers.db import safe_query, get_count\nfrom app.api.helpers.exceptions import (\n ConflictException,\n ForbiddenException,\n UnprocessableEntity,\n)\nfrom app.api.helpers.mail import send_email_to_attendees\nfrom app.api.helpers.permission_manager import has_access\nfrom app.api.helpers.permissions import jwt_required\nfrom app.api.helpers.query import event_query\nfrom app.api.helpers.utilities import require_relationship\nfrom app.api.schema.attendees import AttendeeSchema\nfrom app.models import db\nfrom app.models.order import Order\nfrom app.models.ticket import Ticket\nfrom app.models.ticket_holder import TicketHolder\nfrom app.models.user import User\n\nattendee_misc_routes = Blueprint('attendee_misc', __name__, url_prefix='/v1')\n\nclass AttendeeListPost(ResourceList):\n \"\"\"\n List and create Attendees through direct URL\n \"\"\"\n\n def before_post(self, args, kwargs, data):\n \"\"\"\n Before post method to check for required relationship and proper permissions\n :param args:\n :param kwargs:\n :param data:\n :return:\n \"\"\"\n require_relationship(['ticket', 'event'], data)\n\n ticket = db.session.query(Ticket).filter_by(\n id=int(data['ticket']), deleted_at=None\n ).first()\n if ticket is None:\n raise UnprocessableEntity(\n {'pointer': '/data/relationships/ticket'}, \"Invalid Ticket\"\n )\n if ticket.event_id != int(data['event']):\n raise UnprocessableEntity(\n {'pointer': '/data/relationships/ticket'},\n \"Ticket belongs to a different Event\"\n )\n # Check if the ticket is already sold out or not.\n if get_count(db.session.query(TicketHolder.id).\n filter_by(ticket_id=int(data['ticket']), deleted_at=None)) >= ticket.quantity:\n raise ConflictException(\n {'pointer': '/data/attributes/ticket_id'},\n \"Ticket already sold out\"\n )\n\n decorators = (jwt_required,)\n methods = ['POST']\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\nclass AttendeeList(ResourceList):\n \"\"\"\n List Attendees\n \"\"\"\n def query(self, view_kwargs):\n \"\"\"\n query method for Attendees List\n :param view_kwargs:\n :return:\n \"\"\"\n query_ = self.session.query(TicketHolder)\n\n if view_kwargs.get('order_identifier'):\n order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')\n if not has_access('is_registrar', event_id=order.event_id) and not has_access('is_user_itself',\n user_id=order.user_id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(Order).filter(Order.id == order.id)\n\n if view_kwargs.get('ticket_id'):\n ticket = safe_query(self, Ticket, 'id', view_kwargs['ticket_id'], 'ticket_id')\n if not has_access('is_registrar', event_id=ticket.event_id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(Ticket).filter(Ticket.id == ticket.id)\n\n if view_kwargs.get('user_id'):\n user = safe_query(self, User, 'id', view_kwargs['user_id'], 'user_id')\n if not has_access('is_user_itself', user_id=user.id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(User, User.email == TicketHolder.email).filter(User.id == user.id)\n\n query_ = event_query(self, query_, view_kwargs, permission='is_registrar')\n return query_\n\n view_kwargs = True\n methods = ['GET', ]\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder,\n 'methods': {\n 'query': query\n }}\n\n\nclass AttendeeDetail(ResourceDetail):\n \"\"\"\n Attendee detail by id\n \"\"\"\n def before_get_object(self, view_kwargs):\n \"\"\"\n before get object method for attendee detail\n :param view_kwargs:\n :return:\n \"\"\"\n attendee = safe_query(self, TicketHolder, 'id', view_kwargs['id'], 'attendee_id')\n if not has_access('is_registrar_or_user_itself', user_id=current_identity.id, event_id=attendee.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n def before_delete_object(self, obj, kwargs):\n \"\"\"\n before delete object method for attendee detail\n :param obj:\n :param kwargs:\n :return:\n \"\"\"\n if not has_access('is_registrar', event_id=obj.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n def before_update_object(self, obj, data, kwargs):\n \"\"\"\n before update object method for attendee detail\n :param obj:\n :param data:\n :param kwargs:\n :return:\n \"\"\"\n if not has_access('is_registrar', event_id=obj.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n if 'is_checked_in' in data and data['is_checked_in']:\n if 'checkin_times' not in data:\n raise UnprocessableEntity({'pointer': '/data/attributes/checkin_times'},\n \"Check in time missing while trying to check in attendee\")\n else:\n if obj.checkin_times and data['checkin_times'] not in obj.checkin_times.split(\",\"):\n data['checkin_times'] = '{},{}'.format(obj.checkin_times, data['checkin_times'])\n\n if 'attendee_notes' in data:\n if obj.attendee_notes and data['attendee_notes'] not in obj.attendee_notes.split(\",\"):\n data['attendee_notes'] = '{},{}'.format(obj.attendee_notes, data['attendee_notes'])\n\n decorators = (jwt_required,)\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder,\n 'methods': {\n 'before_get_object': before_get_object,\n 'before_update_object': before_update_object,\n 'before_delete_object': before_delete_object\n }}\n\n\nclass AttendeeRelationshipRequired(ResourceRelationship):\n \"\"\"\n Attendee Relationship (Required)\n \"\"\"\n decorators = (jwt_required,)\n methods = ['GET', 'PATCH']\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\nclass AttendeeRelationshipOptional(ResourceRelationship):\n \"\"\"\n Attendee Relationship(Optional)\n \"\"\"\n decorators = (api.has_permission('is_user_itself', fetch=\"user_id\", fetch_as=\"id\", model=TicketHolder),)\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\n@attendee_misc_routes.route('/attendees/send-receipt', methods=['POST'])\n@jwt_required\ndef send_receipt():\n order_id = request.json.get('order-id')\n if order_id:\n try:\n order = db.session.query(Order).filter_by(id=int(order_id)).one()\n except NoResultFound:\n raise ObjectNotFound({'parameter': '{id}'}, \"Order not found\")\n\n if order.user_id != current_identity.id:\n abort(\n make_response(jsonify(error=\"You cannot send reciept for an order not created by you\"), 403)\n )\n elif order.status != 'completed':\n abort(\n make_response(jsonify(error=\"Cannot send receipt for an incomplete order\"), 409)\n )\n else:\n send_email_to_attendees(order, current_identity.id)\n return jsonify(message=\"receipt sent to attendees\")\n else:\n abort(\n make_response(jsonify(error=\"Order id missing\"), 422)\n )\n", "path": "app/api/attendees.py"}], "after_files": [{"content": "from flask import Blueprint, request, jsonify, abort, make_response\nfrom flask_jwt import current_identity, jwt_required\nfrom flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship\nfrom flask_rest_jsonapi.exceptions import ObjectNotFound\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom app.api.bootstrap import api\nfrom app.api.helpers.db import safe_query, get_count\nfrom app.api.helpers.exceptions import (\n ConflictException,\n ForbiddenException,\n UnprocessableEntity,\n)\nfrom app.api.helpers.mail import send_email_to_attendees\nfrom app.api.helpers.permission_manager import has_access\nfrom app.api.helpers.permissions import jwt_required\nfrom app.api.helpers.query import event_query\nfrom app.api.helpers.utilities import require_relationship\nfrom app.api.schema.attendees import AttendeeSchema\nfrom app.models import db\nfrom app.models.order import Order\nfrom app.models.ticket import Ticket\nfrom app.models.ticket_holder import TicketHolder\nfrom app.models.user import User\n\nattendee_misc_routes = Blueprint('attendee_misc', __name__, url_prefix='/v1')\n\nclass AttendeeListPost(ResourceList):\n \"\"\"\n List and create Attendees through direct URL\n \"\"\"\n\n def before_post(self, args, kwargs, data):\n \"\"\"\n Before post method to check for required relationship and proper permissions\n :param args:\n :param kwargs:\n :param data:\n :return:\n \"\"\"\n require_relationship(['ticket', 'event'], data)\n\n ticket = db.session.query(Ticket).filter_by(\n id=int(data['ticket']), deleted_at=None\n ).first()\n if ticket is None:\n raise UnprocessableEntity(\n {'pointer': '/data/relationships/ticket'}, \"Invalid Ticket\"\n )\n if ticket.event_id != int(data['event']):\n raise UnprocessableEntity(\n {'pointer': '/data/relationships/ticket'},\n \"Ticket belongs to a different Event\"\n )\n # Check if the ticket is already sold out or not.\n if get_count(db.session.query(TicketHolder.id).\n filter_by(ticket_id=int(data['ticket']), deleted_at=None)) >= ticket.quantity:\n raise ConflictException(\n {'pointer': '/data/attributes/ticket_id'},\n \"Ticket already sold out\"\n )\n\n decorators = (jwt_required,)\n methods = ['POST']\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\nclass AttendeeList(ResourceList):\n \"\"\"\n List Attendees\n \"\"\"\n def query(self, view_kwargs):\n \"\"\"\n query method for Attendees List\n :param view_kwargs:\n :return:\n \"\"\"\n query_ = self.session.query(TicketHolder)\n\n if view_kwargs.get('order_identifier'):\n order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')\n if not has_access('is_registrar', event_id=order.event_id) and not has_access('is_user_itself',\n user_id=order.user_id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(Order).filter(Order.id == order.id)\n\n if view_kwargs.get('ticket_id'):\n ticket = safe_query(self, Ticket, 'id', view_kwargs['ticket_id'], 'ticket_id')\n if not has_access('is_registrar', event_id=ticket.event_id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(Ticket).filter(Ticket.id == ticket.id)\n\n if view_kwargs.get('user_id'):\n user = safe_query(self, User, 'id', view_kwargs['user_id'], 'user_id')\n if not has_access('is_user_itself', user_id=user.id):\n raise ForbiddenException({'source': ''}, 'Access Forbidden')\n query_ = query_.join(User, User.email == TicketHolder.email).filter(User.id == user.id)\n\n query_ = event_query(self, query_, view_kwargs, permission='is_registrar')\n return query_\n\n view_kwargs = True\n methods = ['GET', ]\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder,\n 'methods': {\n 'query': query\n }}\n\n\nclass AttendeeDetail(ResourceDetail):\n \"\"\"\n Attendee detail by id\n \"\"\"\n def before_get_object(self, view_kwargs):\n \"\"\"\n before get object method for attendee detail\n :param view_kwargs:\n :return:\n \"\"\"\n attendee = safe_query(self, TicketHolder, 'id', view_kwargs['id'], 'attendee_id')\n if not has_access('is_registrar_or_user_itself', user_id=current_identity.id, event_id=attendee.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n def before_delete_object(self, obj, kwargs):\n \"\"\"\n before delete object method for attendee detail\n :param obj:\n :param kwargs:\n :return:\n \"\"\"\n if not has_access('is_registrar', event_id=obj.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n def before_update_object(self, obj, data, kwargs):\n \"\"\"\n before update object method for attendee detail\n :param obj:\n :param data:\n :param kwargs:\n :return:\n \"\"\"\n if not has_access('is_registrar', event_id=obj.event_id):\n raise ForbiddenException({'source': 'User'}, 'You are not authorized to access this.')\n\n if 'is_checked_in' in data and data['is_checked_in']:\n if 'checkin_times' not in data:\n raise UnprocessableEntity({'pointer': '/data/attributes/checkin_times'},\n \"Check in time missing while trying to check in attendee\")\n else:\n if obj.checkin_times and data['checkin_times'] not in obj.checkin_times.split(\",\"):\n data['checkin_times'] = '{},{}'.format(obj.checkin_times, data['checkin_times'])\n\n if 'attendee_notes' in data:\n if obj.attendee_notes and data['attendee_notes'] not in obj.attendee_notes.split(\",\"):\n data['attendee_notes'] = '{},{}'.format(obj.attendee_notes, data['attendee_notes'])\n\n decorators = (jwt_required,)\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder,\n 'methods': {\n 'before_get_object': before_get_object,\n 'before_update_object': before_update_object,\n 'before_delete_object': before_delete_object\n }}\n\n\nclass AttendeeRelationshipRequired(ResourceRelationship):\n \"\"\"\n Attendee Relationship (Required)\n \"\"\"\n decorators = (jwt_required,)\n methods = ['GET', 'PATCH']\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\nclass AttendeeRelationshipOptional(ResourceRelationship):\n \"\"\"\n Attendee Relationship(Optional)\n \"\"\"\n decorators = (api.has_permission('is_user_itself', fetch=\"user_id\", fetch_as=\"id\", model=TicketHolder),)\n schema = AttendeeSchema\n data_layer = {'session': db.session,\n 'model': TicketHolder}\n\n\n@attendee_misc_routes.route('/attendees/send-receipt', methods=['POST'])\n@jwt_required\ndef send_receipt():\n # Function to send receipts to attendees related to the provided order.\n\n order_identifier = request.json.get('order-identifier')\n if order_identifier:\n try:\n order = db.session.query(Order).filter_by(identifier=order_identifier).one()\n except NoResultFound:\n raise ObjectNotFound({'parameter': '{identifier}'}, \"Order not found\")\n\n if order.user_id != current_identity.id:\n abort(\n make_response(jsonify(error=\"You cannot send reciept for an order not created by you\"), 403)\n )\n elif order.status != 'completed':\n abort(\n make_response(jsonify(error=\"Cannot send receipt for an incomplete order\"), 409)\n )\n else:\n send_email_to_attendees(order, current_identity.id)\n return jsonify(message=\"receipt sent to attendees\")\n else:\n abort(\n make_response(jsonify(error=\"Order identifier missing\"), 422)\n )\n", "path": "app/api/attendees.py"}]} | 2,665 | 289 |
gh_patches_debug_53494 | rasdani/github-patches | git_diff | cocotb__cocotb-1980 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GHDL waveform documentation
I could not find how to make a cocotb+ghdl sim produce a vcd waveform. I eventually tracked it down by looking at makefile.ghdl. All that's needed is: make SIM=ghdl SIM_ARGS=--vcd=anyname.vcd. I tried it on the dff example and it seems to work fine.
If you're interested, I added a waveform sub-section to the ghdl section of https://github.com/jwrr/cocotb/blob/readme/documentation/source/simulator_support.rst. I used the Verilator waveform section as a template.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `documentation/source/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # cocotb documentation build configuration file
4 #
5 # This file is execfile()d with the current directory set to its containing dir.
6 #
7 # All configuration values have a default; values that are commented out
8 # serve to show the default.
9
10 import datetime
11 import os
12 import subprocess
13 import sys
14
15 # Add in-tree extensions to path
16 sys.path.insert(0, os.path.abspath('../sphinxext'))
17
18 import cocotb
19 from distutils.version import LooseVersion
20
21 os.environ["SPHINX_BUILD"] = "1"
22
23 # -- General configuration -----------------------------------------------------
24
25 # If your documentation needs a minimal Sphinx version, state it here.
26 #needs_sphinx = '1.0'
27
28 # Add any Sphinx extension module names here, as strings. They can be extensions
29 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
30 extensions = [
31 'sphinx.ext.autodoc',
32 'sphinx.ext.doctest',
33 'sphinx.ext.todo',
34 'sphinx.ext.coverage',
35 'sphinx.ext.imgmath',
36 'sphinx.ext.viewcode',
37 'sphinx.ext.napoleon',
38 'sphinx.ext.intersphinx',
39 'sphinxcontrib.makedomain',
40 'sphinx.ext.inheritance_diagram',
41 'cairosvgconverter',
42 'breathe',
43 'sphinx_issues',
44 'sphinxarg.ext',
45 'sphinxcontrib.spelling',
46 'sphinx_tabs.tabs',
47 ]
48
49 intersphinx_mapping = {'python': ('https://docs.python.org/3', None)}
50
51 # Github repo
52 issues_github_path = "cocotb/cocotb"
53
54 # Add any paths that contain templates here, relative to this directory.
55 templates_path = ['_templates']
56
57 # The suffix of source filenames.
58 source_suffix = '.rst'
59
60 # The encoding of source files.
61 #source_encoding = 'utf-8-sig'
62
63 # The master toctree document.
64 master_doc = 'index'
65
66 # General information about the project.
67 project = 'cocotb'
68 copyright = '2014-{0}, cocotb contributors'.format(datetime.datetime.now().year)
69
70 # The version info for the project you're documenting, acts as replacement for
71 # |version| and |release|, also used in various other places throughout the
72 # built documents.
73 #
74 # The full version, including alpha/beta/rc tags.
75 release = cocotb.__version__
76 # The short X.Y version.
77 v_major, v_minor = LooseVersion(release).version[:2]
78 version = '{}.{}'.format(v_major, v_minor)
79
80 autoclass_content = "both"
81
82 # The language for content autogenerated by Sphinx. Refer to documentation
83 # for a list of supported languages.
84 #language = None
85
86 # There are two options for replacing |today|: either, you set today to some
87 # non-false value, then it is used:
88 #today = ''
89 # Else, today_fmt is used as the format for a strftime call.
90 #today_fmt = '%B %d, %Y'
91
92 # List of patterns, relative to source directory, that match files and
93 # directories to ignore when looking for source files.
94 exclude_patterns = [
95 # these are compiled into a single file at build-time,
96 # so there is no need to build them separately:
97 "newsfragments/*.rst",
98 # unused outputs from breathe:
99 "generated/namespacelist.rst",
100 "generated/namespace/*.rst",
101 ]
102
103 # The reST default role (used for this markup: `text`) to use for all documents.
104 #default_role = None
105
106 # If true, '()' will be appended to :func: etc. cross-reference text.
107 #add_function_parentheses = True
108
109 # If true, the current module name will be prepended to all description
110 # unit titles (such as .. function::).
111 #add_module_names = True
112
113 # If true, sectionauthor and moduleauthor directives will be shown in the
114 # output. They are ignored by default.
115 #show_authors = False
116
117 # The name of the Pygments (syntax highlighting) style to use.
118 pygments_style = 'sphinx'
119
120 # A list of ignored prefixes for module index sorting.
121 #modindex_common_prefix = []
122
123 # If true, keep warnings as "system message" paragraphs in the built documents.
124 #keep_warnings = False
125
126
127 # -- Options for HTML output ---------------------------------------------------
128
129 # The theme to use for HTML and HTML Help pages. See the documentation for
130 # a list of builtin themes.
131
132 # The Read the Docs theme is available from
133 # https://github.com/snide/sphinx_rtd_theme
134 #
135 # Install with
136 # - pip install sphinx_rtd_theme
137 # or
138 # - apt-get install python-sphinx-rtd-theme
139
140 try:
141 import sphinx_rtd_theme
142 html_theme = 'sphinx_rtd_theme'
143 except ImportError:
144 sys.stderr.write('Warning: The Sphinx \'sphinx_rtd_theme\' HTML theme was '+
145 'not found. Make sure you have the theme installed to produce pretty '+
146 'HTML output. Falling back to the default theme.\n')
147
148 html_theme = 'default'
149
150 # Theme options are theme-specific and customize the look and feel of a theme
151 # further. For a list of options available for each theme, see the
152 # documentation.
153 #html_theme_options = {}
154
155 # Add any paths that contain custom themes here, relative to this directory.
156 #html_theme_path = []
157
158 # The name for this set of Sphinx documents. If None, it defaults to
159 # "<project> v<release> documentation".
160 #html_title = None
161
162 # A shorter title for the navigation bar. Default is the same as html_title.
163 #html_short_title = None
164
165 # The name of an image file (relative to this directory) to place at the top
166 # of the sidebar.
167 #html_logo = None
168
169 # The name of an image file (within the static path) to use as favicon of the
170 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
171 # pixels large.
172 #html_favicon = None
173
174 # Add any paths that contain custom static files (such as style sheets) here,
175 # relative to this directory. They are copied after the builtin static files,
176 # so a file named "default.css" will overwrite the builtin "default.css".
177 #html_static_path = ['_static']
178
179 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
180 # using the given strftime format.
181 #html_last_updated_fmt = '%b %d, %Y'
182
183 # If true, SmartyPants will be used to convert quotes and dashes to
184 # typographically correct entities.
185 #html_use_smartypants = True
186
187 # Custom sidebar templates, maps document names to template names.
188 #html_sidebars = {}
189
190 # Additional templates that should be rendered to pages, maps page names to
191 # template names.
192 #html_additional_pages = {}
193
194 # If false, no module index is generated.
195 #html_domain_indices = True
196
197 # If false, no index is generated.
198 #html_use_index = True
199
200 # If true, the index is split into individual pages for each letter.
201 #html_split_index = False
202
203 # If true, links to the reST sources are added to the pages.
204 #html_show_sourcelink = True
205
206 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
207 #html_show_sphinx = True
208
209 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
210 #html_show_copyright = True
211
212 # If true, an OpenSearch description file will be output, and all pages will
213 # contain a <link> tag referring to it. The value of this option must be the
214 # base URL from which the finished HTML is served.
215 #html_use_opensearch = ''
216
217 # This is the file name suffix for HTML files (e.g. ".xhtml").
218 #html_file_suffix = None
219
220 # Output file base name for HTML help builder.
221 htmlhelp_basename = 'cocotbdoc'
222
223
224 # -- Options for LaTeX output --------------------------------------------------
225
226 latex_elements = {
227 # The paper size ('letterpaper' or 'a4paper').
228 #'papersize': 'letterpaper',
229
230 # The font size ('10pt', '11pt' or '12pt').
231 #'pointsize': '10pt',
232
233 # Additional stuff for the LaTeX preamble.
234 #'preamble': '',
235 }
236
237 # Grouping the document tree into LaTeX files. List of tuples
238 # (source start file, target name, title, author, documentclass [howto/manual]).
239 latex_documents = [
240 ('index', 'cocotb.tex', 'cocotb Documentation',
241 'cocotb contributors', 'manual'),
242 ]
243
244 # The name of an image file (relative to this directory) to place at the top of
245 # the title page.
246 #latex_logo = None
247
248 # For "manual" documents, if this is true, then toplevel headings are parts,
249 # not chapters.
250 #latex_use_parts = False
251
252 # If true, show page references after internal links.
253 #latex_show_pagerefs = False
254
255 # If true, show URL addresses after external links.
256 #latex_show_urls = False
257
258 # Documents to append as an appendix to all manuals.
259 #latex_appendices = []
260
261 # If false, no module index is generated.
262 #latex_domain_indices = True
263
264
265 # -- Options for manual page output --------------------------------------------
266
267 # One entry per manual page. List of tuples
268 # (source start file, name, description, authors, manual section).
269 man_pages = [
270 ('index', 'cocotb', 'cocotb Documentation',
271 ['cocotb contributors'], 1)
272 ]
273
274 # If true, show URL addresses after external links.
275 #man_show_urls = False
276
277
278 # -- Options for Texinfo output ------------------------------------------------
279
280 # Grouping the document tree into Texinfo files. List of tuples
281 # (source start file, target name, title, author,
282 # dir menu entry, description, category)
283 texinfo_documents = [
284 ('index', 'cocotb', 'cocotb Documentation',
285 'cocotb contributors', 'cocotb', 'Coroutine Cosimulation TestBench \
286 environment for efficient verification of RTL using Python.',
287 'Miscellaneous'),
288 ]
289
290 # Documents to append as an appendix to all manuals.
291 #texinfo_appendices = []
292
293 # If false, no module index is generated.
294 #texinfo_domain_indices = True
295
296 # How to display URL addresses: 'footnote', 'no', or 'inline'.
297 #texinfo_show_urls = 'footnote'
298
299 # If true, do not generate a @detailmenu in the "Top" node's menu.
300 #texinfo_no_detailmenu = False
301
302 todo_include_todos = False
303
304 # -- Extra setup for C documentation with Doxygen and breathe ------------------
305 # see also https://breathe.readthedocs.io/en/latest/readthedocs.html
306
307 env = os.environ.copy()
308 env['PATH'] += ':.venv/bin'
309 subprocess.call('doxygen', cwd='..')
310 subprocess.call(['breathe-apidoc', '-o', 'source/generated', 'source/doxygen/_xml', '-f'], env=env, cwd='..')
311
312
313 breathe_projects = { "cocotb": "doxygen/_xml" }
314 breathe_default_project = "cocotb"
315 breathe_domain_by_extension = {
316 "h" : "cpp",
317 }
318 breathe_show_define_initializer = True
319
320 # -- Extra setup for spelling check --------------------------------------------
321
322 # Spelling language.
323 spelling_lang = 'en_US'
324 tokenizer_lang = spelling_lang
325
326 # Location of word list.
327 spelling_word_list_filename = ["spelling_wordlist.txt", "c_symbols.txt"]
328
329 spelling_ignore_pypi_package_names = False
330 spelling_ignore_wiki_words = False
331 spelling_show_suggestions = True
332
333 # -- Extra setup for inheritance_diagram directive which uses graphviz ---------
334
335 graphviz_output_format = 'svg'
336
337 # -- Extra setup for towncrier -------------------------------------------------
338 # see also https://towncrier.readthedocs.io/en/actual-freaking-docs/
339
340 # we pass the name and version directly, to avoid towncrier failing to import the non-installed version
341 in_progress_notes = subprocess.check_output(['towncrier', '--draft', '--name', 'cocotb', '--version', release],
342 cwd='../..',
343 universal_newlines=True)
344 with open('generated/master-notes.rst', 'w') as f:
345 f.write(in_progress_notes)
346
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/documentation/source/conf.py b/documentation/source/conf.py
--- a/documentation/source/conf.py
+++ b/documentation/source/conf.py
@@ -46,7 +46,10 @@
'sphinx_tabs.tabs',
]
-intersphinx_mapping = {'python': ('https://docs.python.org/3', None)}
+intersphinx_mapping = {
+ 'python': ('https://docs.python.org/3', None),
+ 'ghdl': ('https://ghdl.readthedocs.io/en/latest', None)
+}
# Github repo
issues_github_path = "cocotb/cocotb"
| {"golden_diff": "diff --git a/documentation/source/conf.py b/documentation/source/conf.py\n--- a/documentation/source/conf.py\n+++ b/documentation/source/conf.py\n@@ -46,7 +46,10 @@\n 'sphinx_tabs.tabs',\n ]\n \n-intersphinx_mapping = {'python': ('https://docs.python.org/3', None)}\n+intersphinx_mapping = {\n+ 'python': ('https://docs.python.org/3', None),\n+ 'ghdl': ('https://ghdl.readthedocs.io/en/latest', None)\n+}\n \n # Github repo\n issues_github_path = \"cocotb/cocotb\"\n", "issue": "GHDL waveform documentation\nI could not find how to make a cocotb+ghdl sim produce a vcd waveform. I eventually tracked it down by looking at makefile.ghdl. All that's needed is: make SIM=ghdl SIM_ARGS=--vcd=anyname.vcd. I tried it on the dff example and it seems to work fine.\r\n \r\nIf you're interested, I added a waveform sub-section to the ghdl section of https://github.com/jwrr/cocotb/blob/readme/documentation/source/simulator_support.rst. I used the Verilator waveform section as a template.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# cocotb documentation build configuration file\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport datetime\nimport os\nimport subprocess\nimport sys\n\n# Add in-tree extensions to path\nsys.path.insert(0, os.path.abspath('../sphinxext'))\n\nimport cocotb\nfrom distutils.version import LooseVersion\n\nos.environ[\"SPHINX_BUILD\"] = \"1\"\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.todo',\n 'sphinx.ext.coverage',\n 'sphinx.ext.imgmath',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.intersphinx',\n 'sphinxcontrib.makedomain',\n 'sphinx.ext.inheritance_diagram',\n 'cairosvgconverter',\n 'breathe',\n 'sphinx_issues',\n 'sphinxarg.ext',\n 'sphinxcontrib.spelling',\n 'sphinx_tabs.tabs',\n ]\n\nintersphinx_mapping = {'python': ('https://docs.python.org/3', None)}\n\n# Github repo\nissues_github_path = \"cocotb/cocotb\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'cocotb'\ncopyright = '2014-{0}, cocotb contributors'.format(datetime.datetime.now().year)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The full version, including alpha/beta/rc tags.\nrelease = cocotb.__version__\n# The short X.Y version.\nv_major, v_minor = LooseVersion(release).version[:2]\nversion = '{}.{}'.format(v_major, v_minor)\n\nautoclass_content = \"both\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\n # these are compiled into a single file at build-time,\n # so there is no need to build them separately:\n \"newsfragments/*.rst\",\n # unused outputs from breathe:\n \"generated/namespacelist.rst\",\n \"generated/namespace/*.rst\",\n ]\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# -- Options for HTML output ---------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\n# The Read the Docs theme is available from\n# https://github.com/snide/sphinx_rtd_theme\n#\n# Install with\n# - pip install sphinx_rtd_theme\n# or\n# - apt-get install python-sphinx-rtd-theme\n\ntry:\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\nexcept ImportError:\n sys.stderr.write('Warning: The Sphinx \\'sphinx_rtd_theme\\' HTML theme was '+\n 'not found. Make sure you have the theme installed to produce pretty '+\n 'HTML output. Falling back to the default theme.\\n')\n\n html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n#html_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'cocotbdoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'cocotb.tex', 'cocotb Documentation',\n 'cocotb contributors', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'cocotb', 'cocotb Documentation',\n ['cocotb contributors'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'cocotb', 'cocotb Documentation',\n 'cocotb contributors', 'cocotb', 'Coroutine Cosimulation TestBench \\\n environment for efficient verification of RTL using Python.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\ntodo_include_todos = False\n\n# -- Extra setup for C documentation with Doxygen and breathe ------------------\n# see also https://breathe.readthedocs.io/en/latest/readthedocs.html\n\nenv = os.environ.copy()\nenv['PATH'] += ':.venv/bin'\nsubprocess.call('doxygen', cwd='..')\nsubprocess.call(['breathe-apidoc', '-o', 'source/generated', 'source/doxygen/_xml', '-f'], env=env, cwd='..')\n\n\nbreathe_projects = { \"cocotb\": \"doxygen/_xml\" }\nbreathe_default_project = \"cocotb\"\nbreathe_domain_by_extension = {\n \"h\" : \"cpp\",\n}\nbreathe_show_define_initializer = True\n\n# -- Extra setup for spelling check --------------------------------------------\n\n# Spelling language.\nspelling_lang = 'en_US'\ntokenizer_lang = spelling_lang\n\n# Location of word list.\nspelling_word_list_filename = [\"spelling_wordlist.txt\", \"c_symbols.txt\"]\n\nspelling_ignore_pypi_package_names = False\nspelling_ignore_wiki_words = False\nspelling_show_suggestions = True\n\n# -- Extra setup for inheritance_diagram directive which uses graphviz ---------\n\ngraphviz_output_format = 'svg'\n\n# -- Extra setup for towncrier -------------------------------------------------\n# see also https://towncrier.readthedocs.io/en/actual-freaking-docs/\n\n# we pass the name and version directly, to avoid towncrier failing to import the non-installed version\nin_progress_notes = subprocess.check_output(['towncrier', '--draft', '--name', 'cocotb', '--version', release],\n cwd='../..',\n universal_newlines=True)\nwith open('generated/master-notes.rst', 'w') as f:\n f.write(in_progress_notes)\n", "path": "documentation/source/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# cocotb documentation build configuration file\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport datetime\nimport os\nimport subprocess\nimport sys\n\n# Add in-tree extensions to path\nsys.path.insert(0, os.path.abspath('../sphinxext'))\n\nimport cocotb\nfrom distutils.version import LooseVersion\n\nos.environ[\"SPHINX_BUILD\"] = \"1\"\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.todo',\n 'sphinx.ext.coverage',\n 'sphinx.ext.imgmath',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.intersphinx',\n 'sphinxcontrib.makedomain',\n 'sphinx.ext.inheritance_diagram',\n 'cairosvgconverter',\n 'breathe',\n 'sphinx_issues',\n 'sphinxarg.ext',\n 'sphinxcontrib.spelling',\n 'sphinx_tabs.tabs',\n ]\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n 'ghdl': ('https://ghdl.readthedocs.io/en/latest', None)\n}\n\n# Github repo\nissues_github_path = \"cocotb/cocotb\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'cocotb'\ncopyright = '2014-{0}, cocotb contributors'.format(datetime.datetime.now().year)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The full version, including alpha/beta/rc tags.\nrelease = cocotb.__version__\n# The short X.Y version.\nv_major, v_minor = LooseVersion(release).version[:2]\nversion = '{}.{}'.format(v_major, v_minor)\n\nautoclass_content = \"both\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\n # these are compiled into a single file at build-time,\n # so there is no need to build them separately:\n \"newsfragments/*.rst\",\n # unused outputs from breathe:\n \"generated/namespacelist.rst\",\n \"generated/namespace/*.rst\",\n ]\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# -- Options for HTML output ---------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\n# The Read the Docs theme is available from\n# https://github.com/snide/sphinx_rtd_theme\n#\n# Install with\n# - pip install sphinx_rtd_theme\n# or\n# - apt-get install python-sphinx-rtd-theme\n\ntry:\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\nexcept ImportError:\n sys.stderr.write('Warning: The Sphinx \\'sphinx_rtd_theme\\' HTML theme was '+\n 'not found. Make sure you have the theme installed to produce pretty '+\n 'HTML output. Falling back to the default theme.\\n')\n\n html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n#html_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'cocotbdoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'cocotb.tex', 'cocotb Documentation',\n 'cocotb contributors', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'cocotb', 'cocotb Documentation',\n ['cocotb contributors'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'cocotb', 'cocotb Documentation',\n 'cocotb contributors', 'cocotb', 'Coroutine Cosimulation TestBench \\\n environment for efficient verification of RTL using Python.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\ntodo_include_todos = False\n\n# -- Extra setup for C documentation with Doxygen and breathe ------------------\n# see also https://breathe.readthedocs.io/en/latest/readthedocs.html\n\nenv = os.environ.copy()\nenv['PATH'] += ':.venv/bin'\nsubprocess.call('doxygen', cwd='..')\nsubprocess.call(['breathe-apidoc', '-o', 'source/generated', 'source/doxygen/_xml', '-f'], env=env, cwd='..')\n\n\nbreathe_projects = { \"cocotb\": \"doxygen/_xml\" }\nbreathe_default_project = \"cocotb\"\nbreathe_domain_by_extension = {\n \"h\" : \"cpp\",\n}\nbreathe_show_define_initializer = True\n\n# -- Extra setup for spelling check --------------------------------------------\n\n# Spelling language.\nspelling_lang = 'en_US'\ntokenizer_lang = spelling_lang\n\n# Location of word list.\nspelling_word_list_filename = [\"spelling_wordlist.txt\", \"c_symbols.txt\"]\n\nspelling_ignore_pypi_package_names = False\nspelling_ignore_wiki_words = False\nspelling_show_suggestions = True\n\n# -- Extra setup for inheritance_diagram directive which uses graphviz ---------\n\ngraphviz_output_format = 'svg'\n\n# -- Extra setup for towncrier -------------------------------------------------\n# see also https://towncrier.readthedocs.io/en/actual-freaking-docs/\n\n# we pass the name and version directly, to avoid towncrier failing to import the non-installed version\nin_progress_notes = subprocess.check_output(['towncrier', '--draft', '--name', 'cocotb', '--version', release],\n cwd='../..',\n universal_newlines=True)\nwith open('generated/master-notes.rst', 'w') as f:\n f.write(in_progress_notes)\n", "path": "documentation/source/conf.py"}]} | 4,031 | 133 |
gh_patches_debug_23199 | rasdani/github-patches | git_diff | great-expectations__great_expectations-7252 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py`
Content:
```
1 from typing import Optional
2
3 import numpy as np
4
5 from great_expectations.core.expectation_configuration import ExpectationConfiguration
6 from great_expectations.execution_engine import PandasExecutionEngine
7 from great_expectations.expectations.expectation import MulticolumnMapExpectation
8 from great_expectations.expectations.metrics.map_metric_provider import (
9 MulticolumnMapMetricProvider,
10 multicolumn_condition_partial,
11 )
12
13
14 # This class defines a Metric to support your Expectation.
15 # For most MulticolumnMapExpectations, the main business logic for calculation will live in this class.
16 class MulticolumnValuesNotAllNull(MulticolumnMapMetricProvider):
17
18 # This is the id string that will be used to reference your metric.
19
20 condition_metric_name = "multicolumn_values.not_all_null"
21
22 # These point your metric at the provided keys to facilitate calculation
23 condition_domain_keys = (
24 "batch_id",
25 "table",
26 "column_list",
27 "row_condition",
28 "condition_parser",
29 "ignore_row_if",
30 )
31 condition_value_keys = ()
32
33 # This method implements the core logic for the PandasExecutionEngine
34
35 @multicolumn_condition_partial(engine=PandasExecutionEngine)
36 def _pandas(cls, column_list, **kwargs):
37 row_wise_cond = column_list.isna().sum(axis=1) < len(column_list)
38 return row_wise_cond
39
40 # This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine
41 # @multicolumn_condition_partial(engine=SqlAlchemyExecutionEngine)
42 # def _sqlalchemy(cls, column_list, **kwargs):
43 # raise NotImplementedError
44
45 # This method defines the business logic for evaluating your metric when using a SparkDFExecutionEngine
46 # @multicolumn_condition_partial(engine=SparkDFExecutionEngine)
47 # def _spark(cls, column_list, **kwargs):
48 # raise NotImplementedError
49
50
51 # This class defines the Expectation itself
52 class ExpectMulticolumnValuesNotToBeAllNull(MulticolumnMapExpectation):
53 """Expect the certain set of columns not to be null at the same time."""
54
55 # These examples will be shown in the public gallery.
56 # They will also be executed as unit tests for your Expectation.
57 examples = [
58 {
59 "data": {
60 "no_nulls": [5, 6, 5, 12, -3],
61 "some_nulls": [np.nan, -3, np.nan, np.nan, -9],
62 "one_non_null": [np.nan, 2, np.nan, np.nan, np.nan],
63 "all_nulls": [np.nan, np.nan, np.nan, np.nan, np.nan],
64 },
65 "tests": [
66 {
67 "title": "basic_positive_test",
68 "exact_match_out": False,
69 "include_in_gallery": True,
70 "in": {"column_list": ["no_nulls", "some_nulls"]},
71 "out": {
72 "success": True,
73 },
74 },
75 {
76 "title": "basic_positive_test",
77 "exact_match_out": False,
78 "include_in_gallery": True,
79 "in": {
80 "column_list": ["some_nulls", "one_non_null"],
81 "mostly": 0.4,
82 },
83 "out": {
84 "success": True,
85 },
86 },
87 {
88 "title": "basic_negative_test",
89 "exact_match_out": False,
90 "include_in_gallery": True,
91 "in": {
92 "column_list": ["some_nulls", "one_non_null", "all_nulls"],
93 "mostly": 1,
94 },
95 "out": {
96 "success": False,
97 },
98 },
99 ],
100 "test_backends": [
101 {
102 "backend": "pandas",
103 "dialects": None,
104 },
105 ],
106 }
107 ]
108
109 # This is the id string of the Metric used by this Expectation.
110 # For most Expectations, it will be the same as the `condition_metric_name` defined in your Metric class above.
111
112 map_metric = "multicolumn_values.not_all_null"
113
114 # This is a list of parameter names that can affect whether the Expectation evaluates to True or False
115 success_keys = (
116 "column_list",
117 "mostly",
118 )
119
120 # This dictionary contains default values for any parameters that should have default values
121 default_kwarg_values = {}
122
123 def validate_configuration(
124 self, configuration: Optional[ExpectationConfiguration] = None
125 ) -> None:
126 """
127 Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that
128 necessary configuration arguments have been provided for the validation of the expectation.
129
130 Args:
131 configuration (OPTIONAL[ExpectationConfiguration]): \
132 An optional Expectation Configuration entry that will be used to configure the expectation
133 Returns:
134 None. Raises InvalidExpectationConfigurationError if the config is not validated successfully
135 """
136
137 super().validate_configuration(configuration)
138 configuration = configuration or self.configuration
139
140 # # Check other things in configuration.kwargs and raise Exceptions if needed
141 # try:
142 # assert (
143 # ...
144 # ), "message"
145 # assert (
146 # ...
147 # ), "message"
148 # except AssertionError as e:
149 # raise InvalidExpectationConfigurationError(str(e))
150
151 # This object contains metadata for display in the public Gallery
152
153 library_metadata = {
154 "tags": ["null_check"], # Tags for this Expectation in the Gallery
155 "contributors": [ # Github handles for all contributors to this Expectation.
156 "@liyusa", # Don't forget to add your github handle here!
157 ],
158 }
159
160
161 if __name__ == "__main__":
162
163 ExpectMulticolumnValuesNotToBeAllNull().print_diagnostic_checklist()
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py b/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py
--- a/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py
+++ b/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py
@@ -34,8 +34,7 @@
@multicolumn_condition_partial(engine=PandasExecutionEngine)
def _pandas(cls, column_list, **kwargs):
- row_wise_cond = column_list.isna().sum(axis=1) < len(column_list)
- return row_wise_cond
+ return column_list.notna().any(axis=1)
# This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine
# @multicolumn_condition_partial(engine=SqlAlchemyExecutionEngine)
@@ -118,7 +117,7 @@
)
# This dictionary contains default values for any parameters that should have default values
- default_kwarg_values = {}
+ default_kwarg_values = {"ignore_row_if": "never"}
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
| {"golden_diff": "diff --git a/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py b/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py\n--- a/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py\n+++ b/contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py\n@@ -34,8 +34,7 @@\n \n @multicolumn_condition_partial(engine=PandasExecutionEngine)\n def _pandas(cls, column_list, **kwargs):\n- row_wise_cond = column_list.isna().sum(axis=1) < len(column_list)\n- return row_wise_cond\n+ return column_list.notna().any(axis=1)\n \n # This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine\n # @multicolumn_condition_partial(engine=SqlAlchemyExecutionEngine)\n@@ -118,7 +117,7 @@\n )\n \n # This dictionary contains default values for any parameters that should have default values\n- default_kwarg_values = {}\n+ default_kwarg_values = {\"ignore_row_if\": \"never\"}\n \n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration] = None\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "from typing import Optional\n\nimport numpy as np\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.execution_engine import PandasExecutionEngine\nfrom great_expectations.expectations.expectation import MulticolumnMapExpectation\nfrom great_expectations.expectations.metrics.map_metric_provider import (\n MulticolumnMapMetricProvider,\n multicolumn_condition_partial,\n)\n\n\n# This class defines a Metric to support your Expectation.\n# For most MulticolumnMapExpectations, the main business logic for calculation will live in this class.\nclass MulticolumnValuesNotAllNull(MulticolumnMapMetricProvider):\n\n # This is the id string that will be used to reference your metric.\n\n condition_metric_name = \"multicolumn_values.not_all_null\"\n\n # These point your metric at the provided keys to facilitate calculation\n condition_domain_keys = (\n \"batch_id\",\n \"table\",\n \"column_list\",\n \"row_condition\",\n \"condition_parser\",\n \"ignore_row_if\",\n )\n condition_value_keys = ()\n\n # This method implements the core logic for the PandasExecutionEngine\n\n @multicolumn_condition_partial(engine=PandasExecutionEngine)\n def _pandas(cls, column_list, **kwargs):\n row_wise_cond = column_list.isna().sum(axis=1) < len(column_list)\n return row_wise_cond\n\n # This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine\n # @multicolumn_condition_partial(engine=SqlAlchemyExecutionEngine)\n # def _sqlalchemy(cls, column_list, **kwargs):\n # raise NotImplementedError\n\n # This method defines the business logic for evaluating your metric when using a SparkDFExecutionEngine\n # @multicolumn_condition_partial(engine=SparkDFExecutionEngine)\n # def _spark(cls, column_list, **kwargs):\n # raise NotImplementedError\n\n\n# This class defines the Expectation itself\nclass ExpectMulticolumnValuesNotToBeAllNull(MulticolumnMapExpectation):\n \"\"\"Expect the certain set of columns not to be null at the same time.\"\"\"\n\n # These examples will be shown in the public gallery.\n # They will also be executed as unit tests for your Expectation.\n examples = [\n {\n \"data\": {\n \"no_nulls\": [5, 6, 5, 12, -3],\n \"some_nulls\": [np.nan, -3, np.nan, np.nan, -9],\n \"one_non_null\": [np.nan, 2, np.nan, np.nan, np.nan],\n \"all_nulls\": [np.nan, np.nan, np.nan, np.nan, np.nan],\n },\n \"tests\": [\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\"column_list\": [\"no_nulls\", \"some_nulls\"]},\n \"out\": {\n \"success\": True,\n },\n },\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"column_list\": [\"some_nulls\", \"one_non_null\"],\n \"mostly\": 0.4,\n },\n \"out\": {\n \"success\": True,\n },\n },\n {\n \"title\": \"basic_negative_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"column_list\": [\"some_nulls\", \"one_non_null\", \"all_nulls\"],\n \"mostly\": 1,\n },\n \"out\": {\n \"success\": False,\n },\n },\n ],\n \"test_backends\": [\n {\n \"backend\": \"pandas\",\n \"dialects\": None,\n },\n ],\n }\n ]\n\n # This is the id string of the Metric used by this Expectation.\n # For most Expectations, it will be the same as the `condition_metric_name` defined in your Metric class above.\n\n map_metric = \"multicolumn_values.not_all_null\"\n\n # This is a list of parameter names that can affect whether the Expectation evaluates to True or False\n success_keys = (\n \"column_list\",\n \"mostly\",\n )\n\n # This dictionary contains default values for any parameters that should have default values\n default_kwarg_values = {}\n\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration] = None\n ) -> None:\n \"\"\"\n Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that\n necessary configuration arguments have been provided for the validation of the expectation.\n\n Args:\n configuration (OPTIONAL[ExpectationConfiguration]): \\\n An optional Expectation Configuration entry that will be used to configure the expectation\n Returns:\n None. Raises InvalidExpectationConfigurationError if the config is not validated successfully\n \"\"\"\n\n super().validate_configuration(configuration)\n configuration = configuration or self.configuration\n\n # # Check other things in configuration.kwargs and raise Exceptions if needed\n # try:\n # assert (\n # ...\n # ), \"message\"\n # assert (\n # ...\n # ), \"message\"\n # except AssertionError as e:\n # raise InvalidExpectationConfigurationError(str(e))\n\n # This object contains metadata for display in the public Gallery\n\n library_metadata = {\n \"tags\": [\"null_check\"], # Tags for this Expectation in the Gallery\n \"contributors\": [ # Github handles for all contributors to this Expectation.\n \"@liyusa\", # Don't forget to add your github handle here!\n ],\n }\n\n\nif __name__ == \"__main__\":\n\n ExpectMulticolumnValuesNotToBeAllNull().print_diagnostic_checklist()\n", "path": "contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py"}], "after_files": [{"content": "from typing import Optional\n\nimport numpy as np\n\nfrom great_expectations.core.expectation_configuration import ExpectationConfiguration\nfrom great_expectations.execution_engine import PandasExecutionEngine\nfrom great_expectations.expectations.expectation import MulticolumnMapExpectation\nfrom great_expectations.expectations.metrics.map_metric_provider import (\n MulticolumnMapMetricProvider,\n multicolumn_condition_partial,\n)\n\n\n# This class defines a Metric to support your Expectation.\n# For most MulticolumnMapExpectations, the main business logic for calculation will live in this class.\nclass MulticolumnValuesNotAllNull(MulticolumnMapMetricProvider):\n\n # This is the id string that will be used to reference your metric.\n\n condition_metric_name = \"multicolumn_values.not_all_null\"\n\n # These point your metric at the provided keys to facilitate calculation\n condition_domain_keys = (\n \"batch_id\",\n \"table\",\n \"column_list\",\n \"row_condition\",\n \"condition_parser\",\n \"ignore_row_if\",\n )\n condition_value_keys = ()\n\n # This method implements the core logic for the PandasExecutionEngine\n\n @multicolumn_condition_partial(engine=PandasExecutionEngine)\n def _pandas(cls, column_list, **kwargs):\n return column_list.notna().any(axis=1)\n\n # This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine\n # @multicolumn_condition_partial(engine=SqlAlchemyExecutionEngine)\n # def _sqlalchemy(cls, column_list, **kwargs):\n # raise NotImplementedError\n\n # This method defines the business logic for evaluating your metric when using a SparkDFExecutionEngine\n # @multicolumn_condition_partial(engine=SparkDFExecutionEngine)\n # def _spark(cls, column_list, **kwargs):\n # raise NotImplementedError\n\n\n# This class defines the Expectation itself\nclass ExpectMulticolumnValuesNotToBeAllNull(MulticolumnMapExpectation):\n \"\"\"Expect the certain set of columns not to be null at the same time.\"\"\"\n\n # These examples will be shown in the public gallery.\n # They will also be executed as unit tests for your Expectation.\n examples = [\n {\n \"data\": {\n \"no_nulls\": [5, 6, 5, 12, -3],\n \"some_nulls\": [np.nan, -3, np.nan, np.nan, -9],\n \"one_non_null\": [np.nan, 2, np.nan, np.nan, np.nan],\n \"all_nulls\": [np.nan, np.nan, np.nan, np.nan, np.nan],\n },\n \"tests\": [\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\"column_list\": [\"no_nulls\", \"some_nulls\"]},\n \"out\": {\n \"success\": True,\n },\n },\n {\n \"title\": \"basic_positive_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"column_list\": [\"some_nulls\", \"one_non_null\"],\n \"mostly\": 0.4,\n },\n \"out\": {\n \"success\": True,\n },\n },\n {\n \"title\": \"basic_negative_test\",\n \"exact_match_out\": False,\n \"include_in_gallery\": True,\n \"in\": {\n \"column_list\": [\"some_nulls\", \"one_non_null\", \"all_nulls\"],\n \"mostly\": 1,\n },\n \"out\": {\n \"success\": False,\n },\n },\n ],\n \"test_backends\": [\n {\n \"backend\": \"pandas\",\n \"dialects\": None,\n },\n ],\n }\n ]\n\n # This is the id string of the Metric used by this Expectation.\n # For most Expectations, it will be the same as the `condition_metric_name` defined in your Metric class above.\n\n map_metric = \"multicolumn_values.not_all_null\"\n\n # This is a list of parameter names that can affect whether the Expectation evaluates to True or False\n success_keys = (\n \"column_list\",\n \"mostly\",\n )\n\n # This dictionary contains default values for any parameters that should have default values\n default_kwarg_values = {\"ignore_row_if\": \"never\"}\n\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration] = None\n ) -> None:\n \"\"\"\n Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that\n necessary configuration arguments have been provided for the validation of the expectation.\n\n Args:\n configuration (OPTIONAL[ExpectationConfiguration]): \\\n An optional Expectation Configuration entry that will be used to configure the expectation\n Returns:\n None. Raises InvalidExpectationConfigurationError if the config is not validated successfully\n \"\"\"\n\n super().validate_configuration(configuration)\n configuration = configuration or self.configuration\n\n # # Check other things in configuration.kwargs and raise Exceptions if needed\n # try:\n # assert (\n # ...\n # ), \"message\"\n # assert (\n # ...\n # ), \"message\"\n # except AssertionError as e:\n # raise InvalidExpectationConfigurationError(str(e))\n\n # This object contains metadata for display in the public Gallery\n\n library_metadata = {\n \"tags\": [\"null_check\"], # Tags for this Expectation in the Gallery\n \"contributors\": [ # Github handles for all contributors to this Expectation.\n \"@liyusa\", # Don't forget to add your github handle here!\n ],\n }\n\n\nif __name__ == \"__main__\":\n\n ExpectMulticolumnValuesNotToBeAllNull().print_diagnostic_checklist()\n", "path": "contrib/experimental/great_expectations_experimental/expectations/expect_multicolumn_values_not_to_be_all_null.py"}]} | 1,957 | 306 |
gh_patches_debug_22178 | rasdani/github-patches | git_diff | cookiecutter__cookiecutter-729 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Empty hook file causes cryptic error
If you have a pre_gen_project.sh or a post_gen_project.sh file with no data in it, cookiecutter fails with an unhelpful traceback.
```
Traceback (most recent call last):
File "/usr/local/bin/cookiecutter", line 11, in <module>
sys.exit(main())
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 716, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 696, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 889, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 534, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/cookiecutter/cli.py", line 100, in main
config_file=user_config
File "/usr/local/lib/python2.7/site-packages/cookiecutter/main.py", line 140, in cookiecutter
output_dir=output_dir
File "/usr/local/lib/python2.7/site-packages/cookiecutter/generate.py", line 273, in generate_files
_run_hook_from_repo_dir(repo_dir, 'pre_gen_project', project_dir, context)
File "/usr/local/lib/python2.7/site-packages/cookiecutter/generate.py", line 232, in _run_hook_from_repo_dir
run_hook(hook_name, project_dir, context)
File "/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py", line 116, in run_hook
run_script_with_context(script, project_dir, context)
File "/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py", line 101, in run_script_with_context
run_script(temp.name, cwd)
File "/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py", line 73, in run_script
cwd=cwd
File "/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 656, in __init__
_cleanup()
File "/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 1335, in _execute_child
raise child_exception
OSError: [Errno 8] Exec format error
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/hooks.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """
5 cookiecutter.hooks
6 ------------------
7
8 Functions for discovering and executing various cookiecutter hooks.
9 """
10
11 import io
12 import logging
13 import os
14 import subprocess
15 import sys
16 import tempfile
17
18 from jinja2 import Template
19
20 from cookiecutter import utils
21 from .exceptions import FailedHookException
22
23
24 _HOOKS = [
25 'pre_gen_project',
26 'post_gen_project',
27 # TODO: other hooks should be listed here
28 ]
29 EXIT_SUCCESS = 0
30
31
32 def find_hooks():
33 """
34 Must be called with the project template as the current working directory.
35 Returns a dict of all hook scripts provided.
36 Dict's key will be the hook/script's name, without extension, while
37 values will be the absolute path to the script.
38 Missing scripts will not be included in the returned dict.
39 """
40 hooks_dir = 'hooks'
41 r = {}
42 logging.debug('hooks_dir is {0}'.format(hooks_dir))
43 if not os.path.isdir(hooks_dir):
44 logging.debug('No hooks/ dir in template_dir')
45 return r
46 for f in os.listdir(hooks_dir):
47 basename = os.path.splitext(os.path.basename(f))[0]
48 if basename in _HOOKS:
49 r[basename] = os.path.abspath(os.path.join(hooks_dir, f))
50 return r
51
52
53 def run_script(script_path, cwd='.'):
54 """
55 Executes a script from a working directory.
56
57 :param script_path: Absolute path to the script to run.
58 :param cwd: The directory to run the script from.
59 """
60 run_thru_shell = sys.platform.startswith('win')
61 if script_path.endswith('.py'):
62 script_command = [sys.executable, script_path]
63 else:
64 script_command = [script_path]
65
66 utils.make_executable(script_path)
67
68 proc = subprocess.Popen(
69 script_command,
70 shell=run_thru_shell,
71 cwd=cwd
72 )
73 exit_status = proc.wait()
74 if exit_status != EXIT_SUCCESS:
75 raise FailedHookException(
76 "Hook script failed (exit status: %d)" % exit_status)
77
78
79 def run_script_with_context(script_path, cwd, context):
80 """
81 Executes a script after rendering with it Jinja.
82
83 :param script_path: Absolute path to the script to run.
84 :param cwd: The directory to run the script from.
85 :param context: Cookiecutter project template context.
86 """
87 _, extension = os.path.splitext(script_path)
88
89 contents = io.open(script_path, 'r', encoding='utf-8').read()
90
91 with tempfile.NamedTemporaryFile(
92 delete=False,
93 mode='wb',
94 suffix=extension
95 ) as temp:
96 output = Template(contents).render(**context)
97 temp.write(output.encode('utf-8'))
98
99 run_script(temp.name, cwd)
100
101
102 def run_hook(hook_name, project_dir, context):
103 """
104 Try to find and execute a hook from the specified project directory.
105
106 :param hook_name: The hook to execute.
107 :param project_dir: The directory to execute the script from.
108 :param context: Cookiecutter project context.
109 """
110 script = find_hooks().get(hook_name)
111 if script is None:
112 logging.debug('No hooks found')
113 return
114 run_script_with_context(script, project_dir, context)
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cookiecutter/hooks.py b/cookiecutter/hooks.py
--- a/cookiecutter/hooks.py
+++ b/cookiecutter/hooks.py
@@ -8,6 +8,7 @@
Functions for discovering and executing various cookiecutter hooks.
"""
+import errno
import io
import logging
import os
@@ -65,15 +66,23 @@
utils.make_executable(script_path)
- proc = subprocess.Popen(
- script_command,
- shell=run_thru_shell,
- cwd=cwd
- )
- exit_status = proc.wait()
- if exit_status != EXIT_SUCCESS:
+ try:
+ proc = subprocess.Popen(
+ script_command,
+ shell=run_thru_shell,
+ cwd=cwd
+ )
+ exit_status = proc.wait()
+ if exit_status != EXIT_SUCCESS:
+ raise FailedHookException(
+ "Hook script failed (exit status: %d)" % exit_status)
+ except OSError as oe:
+ if oe.errno == errno.ENOEXEC:
+ raise FailedHookException(
+ "Hook script failed, might be an "
+ "empty file or missing a shebang")
raise FailedHookException(
- "Hook script failed (exit status: %d)" % exit_status)
+ "Hook script failed (error: %s)" % oe)
def run_script_with_context(script_path, cwd, context):
| {"golden_diff": "diff --git a/cookiecutter/hooks.py b/cookiecutter/hooks.py\n--- a/cookiecutter/hooks.py\n+++ b/cookiecutter/hooks.py\n@@ -8,6 +8,7 @@\n Functions for discovering and executing various cookiecutter hooks.\n \"\"\"\n \n+import errno\n import io\n import logging\n import os\n@@ -65,15 +66,23 @@\n \n utils.make_executable(script_path)\n \n- proc = subprocess.Popen(\n- script_command,\n- shell=run_thru_shell,\n- cwd=cwd\n- )\n- exit_status = proc.wait()\n- if exit_status != EXIT_SUCCESS:\n+ try:\n+ proc = subprocess.Popen(\n+ script_command,\n+ shell=run_thru_shell,\n+ cwd=cwd\n+ )\n+ exit_status = proc.wait()\n+ if exit_status != EXIT_SUCCESS:\n+ raise FailedHookException(\n+ \"Hook script failed (exit status: %d)\" % exit_status)\n+ except OSError as oe:\n+ if oe.errno == errno.ENOEXEC:\n+ raise FailedHookException(\n+ \"Hook script failed, might be an \"\n+ \"empty file or missing a shebang\")\n raise FailedHookException(\n- \"Hook script failed (exit status: %d)\" % exit_status)\n+ \"Hook script failed (error: %s)\" % oe)\n \n \n def run_script_with_context(script_path, cwd, context):\n", "issue": "Empty hook file causes cryptic error\nIf you have a pre_gen_project.sh or a post_gen_project.sh file with no data in it, cookiecutter fails with an unhelpful traceback.\n\n```\nTraceback (most recent call last):\n File \"/usr/local/bin/cookiecutter\", line 11, in <module>\n sys.exit(main())\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 716, in __call__\n return self.main(*args, **kwargs)\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 696, in main\n rv = self.invoke(ctx)\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 889, in invoke\n return ctx.invoke(self.callback, **ctx.params)\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 534, in invoke\n return callback(*args, **kwargs)\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/cli.py\", line 100, in main\n config_file=user_config\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/main.py\", line 140, in cookiecutter\n output_dir=output_dir\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/generate.py\", line 273, in generate_files\n _run_hook_from_repo_dir(repo_dir, 'pre_gen_project', project_dir, context)\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/generate.py\", line 232, in _run_hook_from_repo_dir\n run_hook(hook_name, project_dir, context)\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py\", line 116, in run_hook\n run_script_with_context(script, project_dir, context)\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py\", line 101, in run_script_with_context\n run_script(temp.name, cwd)\n File \"/usr/local/lib/python2.7/site-packages/cookiecutter/hooks.py\", line 73, in run_script\n cwd=cwd\n File \"/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py\", line 656, in __init__\n _cleanup()\n File \"/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py\", line 1335, in _execute_child\n raise child_exception\nOSError: [Errno 8] Exec format error\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.hooks\n------------------\n\nFunctions for discovering and executing various cookiecutter hooks.\n\"\"\"\n\nimport io\nimport logging\nimport os\nimport subprocess\nimport sys\nimport tempfile\n\nfrom jinja2 import Template\n\nfrom cookiecutter import utils\nfrom .exceptions import FailedHookException\n\n\n_HOOKS = [\n 'pre_gen_project',\n 'post_gen_project',\n # TODO: other hooks should be listed here\n]\nEXIT_SUCCESS = 0\n\n\ndef find_hooks():\n \"\"\"\n Must be called with the project template as the current working directory.\n Returns a dict of all hook scripts provided.\n Dict's key will be the hook/script's name, without extension, while\n values will be the absolute path to the script.\n Missing scripts will not be included in the returned dict.\n \"\"\"\n hooks_dir = 'hooks'\n r = {}\n logging.debug('hooks_dir is {0}'.format(hooks_dir))\n if not os.path.isdir(hooks_dir):\n logging.debug('No hooks/ dir in template_dir')\n return r\n for f in os.listdir(hooks_dir):\n basename = os.path.splitext(os.path.basename(f))[0]\n if basename in _HOOKS:\n r[basename] = os.path.abspath(os.path.join(hooks_dir, f))\n return r\n\n\ndef run_script(script_path, cwd='.'):\n \"\"\"\n Executes a script from a working directory.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n \"\"\"\n run_thru_shell = sys.platform.startswith('win')\n if script_path.endswith('.py'):\n script_command = [sys.executable, script_path]\n else:\n script_command = [script_path]\n\n utils.make_executable(script_path)\n\n proc = subprocess.Popen(\n script_command,\n shell=run_thru_shell,\n cwd=cwd\n )\n exit_status = proc.wait()\n if exit_status != EXIT_SUCCESS:\n raise FailedHookException(\n \"Hook script failed (exit status: %d)\" % exit_status)\n\n\ndef run_script_with_context(script_path, cwd, context):\n \"\"\"\n Executes a script after rendering with it Jinja.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n :param context: Cookiecutter project template context.\n \"\"\"\n _, extension = os.path.splitext(script_path)\n\n contents = io.open(script_path, 'r', encoding='utf-8').read()\n\n with tempfile.NamedTemporaryFile(\n delete=False,\n mode='wb',\n suffix=extension\n ) as temp:\n output = Template(contents).render(**context)\n temp.write(output.encode('utf-8'))\n\n run_script(temp.name, cwd)\n\n\ndef run_hook(hook_name, project_dir, context):\n \"\"\"\n Try to find and execute a hook from the specified project directory.\n\n :param hook_name: The hook to execute.\n :param project_dir: The directory to execute the script from.\n :param context: Cookiecutter project context.\n \"\"\"\n script = find_hooks().get(hook_name)\n if script is None:\n logging.debug('No hooks found')\n return\n run_script_with_context(script, project_dir, context)\n", "path": "cookiecutter/hooks.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.hooks\n------------------\n\nFunctions for discovering and executing various cookiecutter hooks.\n\"\"\"\n\nimport errno\nimport io\nimport logging\nimport os\nimport subprocess\nimport sys\nimport tempfile\n\nfrom jinja2 import Template\n\nfrom cookiecutter import utils\nfrom .exceptions import FailedHookException\n\n\n_HOOKS = [\n 'pre_gen_project',\n 'post_gen_project',\n # TODO: other hooks should be listed here\n]\nEXIT_SUCCESS = 0\n\n\ndef find_hooks():\n \"\"\"\n Must be called with the project template as the current working directory.\n Returns a dict of all hook scripts provided.\n Dict's key will be the hook/script's name, without extension, while\n values will be the absolute path to the script.\n Missing scripts will not be included in the returned dict.\n \"\"\"\n hooks_dir = 'hooks'\n r = {}\n logging.debug('hooks_dir is {0}'.format(hooks_dir))\n if not os.path.isdir(hooks_dir):\n logging.debug('No hooks/ dir in template_dir')\n return r\n for f in os.listdir(hooks_dir):\n basename = os.path.splitext(os.path.basename(f))[0]\n if basename in _HOOKS:\n r[basename] = os.path.abspath(os.path.join(hooks_dir, f))\n return r\n\n\ndef run_script(script_path, cwd='.'):\n \"\"\"\n Executes a script from a working directory.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n \"\"\"\n run_thru_shell = sys.platform.startswith('win')\n if script_path.endswith('.py'):\n script_command = [sys.executable, script_path]\n else:\n script_command = [script_path]\n\n utils.make_executable(script_path)\n\n try:\n proc = subprocess.Popen(\n script_command,\n shell=run_thru_shell,\n cwd=cwd\n )\n exit_status = proc.wait()\n if exit_status != EXIT_SUCCESS:\n raise FailedHookException(\n \"Hook script failed (exit status: %d)\" % exit_status)\n except OSError as oe:\n if oe.errno == errno.ENOEXEC:\n raise FailedHookException(\n \"Hook script failed, might be an \"\n \"empty file or missing a shebang\")\n raise FailedHookException(\n \"Hook script failed (error: %s)\" % oe)\n\n\ndef run_script_with_context(script_path, cwd, context):\n \"\"\"\n Executes a script after rendering with it Jinja.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n :param context: Cookiecutter project template context.\n \"\"\"\n _, extension = os.path.splitext(script_path)\n\n contents = io.open(script_path, 'r', encoding='utf-8').read()\n\n with tempfile.NamedTemporaryFile(\n delete=False,\n mode='wb',\n suffix=extension\n ) as temp:\n output = Template(contents).render(**context)\n temp.write(output.encode('utf-8'))\n\n run_script(temp.name, cwd)\n\n\ndef run_hook(hook_name, project_dir, context):\n \"\"\"\n Try to find and execute a hook from the specified project directory.\n\n :param hook_name: The hook to execute.\n :param project_dir: The directory to execute the script from.\n :param context: Cookiecutter project context.\n \"\"\"\n script = find_hooks().get(hook_name)\n if script is None:\n logging.debug('No hooks found')\n return\n run_script_with_context(script, project_dir, context)\n", "path": "cookiecutter/hooks.py"}]} | 1,842 | 317 |
gh_patches_debug_9282 | rasdani/github-patches | git_diff | hpcaitech__ColossalAI-4165 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
[BUG]: colossalai run is stuck during multi-nodes training
### 🐛 Describe the bug
When using colossalai run during multi-nodes training, it's stuck before initializing distributed process group.
This is because potentially wrong launch command.
### Environment
Python 3.8.0
torch 1.12.1+cu113
CUDA 11.4
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/cli/launcher/run.py`
Content:
```
1 import os
2 import sys
3 from typing import List
4
5 import click
6 import torch
7 from packaging import version
8
9 from colossalai.context import Config
10
11 from .hostinfo import HostInfo, HostInfoList
12 from .multinode_runner import MultiNodeRunner
13
14 # Constants that define our syntax
15 NODE_SEP = ','
16
17
18 def fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:
19 """
20 Parse the hostfile to obtain a list of hosts.
21
22 A hostfile should look like:
23 worker-0
24 worker-1
25 worker-2
26 ...
27
28 Args:
29 hostfile_path (str): the path to the hostfile
30 ssh_port (int): the port to connect to the host
31 """
32
33 if not os.path.isfile(hostfile_path):
34 click.echo(f"Error: Unable to find the hostfile, no such file: {hostfile_path}")
35 exit()
36
37 with open(hostfile_path, 'r') as fd:
38 device_pool = HostInfoList()
39
40 for line in fd.readlines():
41 line = line.strip()
42 if line == '':
43 # skip empty lines
44 continue
45
46 # build the HostInfo object
47 hostname = line.strip()
48 hostinfo = HostInfo(hostname=hostname, port=ssh_port)
49
50 if device_pool.has(hostname):
51 click.echo(f"Error: found duplicate host {hostname} in the hostfile")
52 exit()
53
54 device_pool.append(hostinfo)
55 return device_pool
56
57
58 def parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:
59 '''Parse an inclusion or exclusion string and filter a hostfile dictionary.
60
61 Examples:
62 include_str="worker-0,worker-1" will execute jobs only on worker-0 and worker-1.
63 exclude_str="worker-1" will use all available devices except worker-1.
64
65 Args:
66 device_pool (HostInfoList): a list of HostInfo objects
67 include_str (str): --include option passed by user, default None
68 exclude_str (str): --exclude option passed by user, default None
69
70 Returns:
71 filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion
72 '''
73
74 # Ensure include/exclude are mutually exclusive
75 if include_str and exclude_str:
76 click.echo("--include and --exclude are mutually exclusive, only one can be used")
77 exit()
78
79 # no-op
80 if include_str is None and exclude_str is None:
81 return device_pool
82
83 # Either build from scratch or remove items
84 if include_str:
85 parse_str = include_str
86 filtered_hosts = HostInfoList()
87 elif exclude_str:
88 parse_str = exclude_str
89 filtered_hosts = device_pool
90
91 # foreach node in the list
92 for node_config in parse_str.split(NODE_SEP):
93 hostname = node_config
94 hostinfo = device_pool.get_hostinfo(hostname)
95 # sanity check hostname
96 if not device_pool.has(hostname):
97 click.echo(f"Error: Hostname '{hostname}' not found in hostfile")
98 exit()
99
100 if include_str:
101 filtered_hosts.append(hostinfo)
102 elif exclude_str:
103 filtered_hosts.remove(hostname)
104
105 return filtered_hosts
106
107
108 def get_launch_command(
109 master_addr: str,
110 master_port: int,
111 nproc_per_node: int,
112 user_script: str,
113 user_args: List[str],
114 node_rank: int,
115 num_nodes: int,
116 extra_launch_args: str = None,
117 ) -> str:
118 """
119 Generate a command for distributed training.
120
121 Args:
122 master_addr (str): the host of the master node
123 master_port (str): the port of the master node
124 nproc_per_node (str): the number of processes to launch on each node
125 user_script (str): the user Python file
126 user_args (str): the arguments for the user script
127 node_rank (int): the unique ID for the node
128 num_nodes (int): the number of nodes to execute jobs
129
130 Returns:
131 cmd (str): the command the start distributed training
132 """
133
134 def _arg_dict_to_list(arg_dict):
135 ret = []
136
137 for k, v in arg_dict.items():
138 if v:
139 ret.append(f'--{k}={v}')
140 else:
141 ret.append(f'--{k}')
142 return ret
143
144 if extra_launch_args:
145 extra_launch_args_dict = dict()
146 for arg in extra_launch_args.split(','):
147 if '=' in arg:
148 k, v = arg.split('=')
149 extra_launch_args_dict[k] = v
150 else:
151 extra_launch_args_dict[arg] = None
152 extra_launch_args = extra_launch_args_dict
153 else:
154 extra_launch_args = dict()
155
156 torch_version = version.parse(torch.__version__)
157 assert torch_version.major >= 1
158
159 if torch_version.minor < 9:
160 cmd = [
161 sys.executable, "-m", "torch.distributed.launch", f"--nproc_per_node={nproc_per_node}",
162 f"--master_addr={master_addr}", f"--master_port={master_port}", f"--nnodes={num_nodes}",
163 f"--node_rank={node_rank}"
164 ]
165 else:
166 # extra launch args for torch distributed launcher with torch >= 1.9
167 default_torchrun_rdzv_args = dict(rdzv_backend="c10d",
168 rdzv_endpoint=f"{master_addr}:{master_port}",
169 rdzv_id="colossalai-default-job")
170
171 # update rdzv arguments
172 for key in default_torchrun_rdzv_args.keys():
173 if key in extra_launch_args:
174 value = extra_launch_args.pop(key)
175 default_torchrun_rdzv_args[key] = value
176
177 if torch_version.minor < 10:
178 cmd = [
179 sys.executable, "-m", "torch.distributed.run", f"--nproc_per_node={nproc_per_node}",
180 f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
181 ]
182 else:
183 cmd = [
184 "torchrun", f"--nproc_per_node={nproc_per_node}", f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
185 ]
186 cmd += _arg_dict_to_list(default_torchrun_rdzv_args)
187
188 cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args
189 cmd = ' '.join(cmd)
190 return cmd
191
192
193 def launch_multi_processes(args: Config) -> None:
194 """
195 Launch multiple processes on a single node or multiple nodes.
196
197 The overall logic can be summarized as the pseudo code below:
198
199 if hostfile given:
200 hostinfo = parse_hostfile(hostfile)
201 hostinfo = include_or_exclude_hosts(hostinfo)
202 launch_on_multi_nodes(hostinfo)
203 elif hosts given:
204 hostinfo = parse_hosts(hosts)
205 launch_on_multi_nodes(hostinfo)
206 else:
207 launch_on_current_node()
208
209 Args:
210 args (Config): the arguments taken from command line
211
212 """
213 assert isinstance(args, Config)
214
215 if args.nproc_per_node is None:
216 click.echo("--nproc_per_node did not receive any value")
217 exit()
218
219 # cannot accept hosts and hostfile at the same time
220 if args.host and args.hostfile:
221 click.echo("Error: hostfile and hosts are mutually exclusive, only one is required")
222
223 # check if hostfile is given
224 if args.hostfile:
225 device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)
226 active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)
227
228 if args.num_nodes > 0:
229 # only keep the first num_nodes to execute jobs
230 updated_active_device_pool = HostInfoList()
231 for count, hostinfo in enumerate(active_device_pool):
232 if args.num_nodes == count:
233 break
234 updated_active_device_pool.append(hostinfo)
235 active_device_pool = updated_active_device_pool
236 else:
237 active_device_pool = None
238
239 env = os.environ.copy()
240
241 # use hosts if hostfile is not given
242 if args.host and active_device_pool is None:
243 active_device_pool = HostInfoList()
244 host_list = args.host.strip().split(NODE_SEP)
245 for hostname in host_list:
246 hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)
247 active_device_pool.append(hostinfo)
248
249 if not active_device_pool:
250 # run on local node if not hosts or hostfile is given
251 # add local node to host info list
252 active_device_pool = HostInfoList()
253 localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)
254 active_device_pool.append(localhost_info)
255
256 # launch distributed processes
257 runner = MultiNodeRunner()
258 curr_path = os.path.abspath('.')
259
260 # collect current path env
261 env = dict()
262 for k, v in os.environ.items():
263 # do not support multi-line env var
264 if v and '\n' not in v:
265 env[k] = v
266
267 # establish remote connection
268 runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)
269
270 # execute distributed launching command
271 for node_id, hostinfo in enumerate(active_device_pool):
272 cmd = get_launch_command(master_addr=args.master_addr,
273 master_port=args.master_port,
274 nproc_per_node=args.nproc_per_node,
275 user_script=args.user_script,
276 user_args=args.user_args,
277 node_rank=node_id,
278 num_nodes=len(active_device_pool),
279 extra_launch_args=args.extra_launch_args)
280 runner.send(hostinfo=hostinfo, cmd=cmd)
281
282 # start training
283 msg_from_node = runner.recv_from_all()
284 has_error = False
285
286 # print node status
287 click.echo("\n====== Training on All Nodes =====")
288 for hostname, msg in msg_from_node.items():
289 click.echo(f"{hostname}: {msg}")
290
291 # check if a process failed
292 if msg == "failure":
293 has_error = True
294
295 # stop all nodes
296 runner.stop_all()
297
298 # receive the stop status
299 msg_from_node = runner.recv_from_all()
300
301 # print node status
302 click.echo("\n====== Stopping All Nodes =====")
303 for hostname, msg in msg_from_node.items():
304 click.echo(f"{hostname}: {msg}")
305
306 # give the process an exit code
307 # so that it behaves like a normal process
308 if has_error:
309 sys.exit(1)
310 else:
311 sys.exit(0)
312
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py
--- a/colossalai/cli/launcher/run.py
+++ b/colossalai/cli/launcher/run.py
@@ -164,9 +164,7 @@
]
else:
# extra launch args for torch distributed launcher with torch >= 1.9
- default_torchrun_rdzv_args = dict(rdzv_backend="c10d",
- rdzv_endpoint=f"{master_addr}:{master_port}",
- rdzv_id="colossalai-default-job")
+ default_torchrun_rdzv_args = dict(master_addr=master_addr, master_port=master_port)
# update rdzv arguments
for key in default_torchrun_rdzv_args.keys():
| {"golden_diff": "diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py\n--- a/colossalai/cli/launcher/run.py\n+++ b/colossalai/cli/launcher/run.py\n@@ -164,9 +164,7 @@\n ]\n else:\n # extra launch args for torch distributed launcher with torch >= 1.9\n- default_torchrun_rdzv_args = dict(rdzv_backend=\"c10d\",\n- rdzv_endpoint=f\"{master_addr}:{master_port}\",\n- rdzv_id=\"colossalai-default-job\")\n+ default_torchrun_rdzv_args = dict(master_addr=master_addr, master_port=master_port)\n \n # update rdzv arguments\n for key in default_torchrun_rdzv_args.keys():\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[BUG]: colossalai run is stuck during multi-nodes training\n### \ud83d\udc1b Describe the bug\n\nWhen using colossalai run during multi-nodes training, it's stuck before initializing distributed process group.\r\n\r\nThis is because potentially wrong launch command.\n\n### Environment\n\nPython 3.8.0\r\ntorch 1.12.1+cu113\r\nCUDA 11.4\n", "before_files": [{"content": "import os\nimport sys\nfrom typing import List\n\nimport click\nimport torch\nfrom packaging import version\n\nfrom colossalai.context import Config\n\nfrom .hostinfo import HostInfo, HostInfoList\nfrom .multinode_runner import MultiNodeRunner\n\n# Constants that define our syntax\nNODE_SEP = ','\n\n\ndef fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:\n \"\"\"\n Parse the hostfile to obtain a list of hosts.\n\n A hostfile should look like:\n worker-0\n worker-1\n worker-2\n ...\n\n Args:\n hostfile_path (str): the path to the hostfile\n ssh_port (int): the port to connect to the host\n \"\"\"\n\n if not os.path.isfile(hostfile_path):\n click.echo(f\"Error: Unable to find the hostfile, no such file: {hostfile_path}\")\n exit()\n\n with open(hostfile_path, 'r') as fd:\n device_pool = HostInfoList()\n\n for line in fd.readlines():\n line = line.strip()\n if line == '':\n # skip empty lines\n continue\n\n # build the HostInfo object\n hostname = line.strip()\n hostinfo = HostInfo(hostname=hostname, port=ssh_port)\n\n if device_pool.has(hostname):\n click.echo(f\"Error: found duplicate host {hostname} in the hostfile\")\n exit()\n\n device_pool.append(hostinfo)\n return device_pool\n\n\ndef parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:\n '''Parse an inclusion or exclusion string and filter a hostfile dictionary.\n\n Examples:\n include_str=\"worker-0,worker-1\" will execute jobs only on worker-0 and worker-1.\n exclude_str=\"worker-1\" will use all available devices except worker-1.\n\n Args:\n device_pool (HostInfoList): a list of HostInfo objects\n include_str (str): --include option passed by user, default None\n exclude_str (str): --exclude option passed by user, default None\n\n Returns:\n filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion\n '''\n\n # Ensure include/exclude are mutually exclusive\n if include_str and exclude_str:\n click.echo(\"--include and --exclude are mutually exclusive, only one can be used\")\n exit()\n\n # no-op\n if include_str is None and exclude_str is None:\n return device_pool\n\n # Either build from scratch or remove items\n if include_str:\n parse_str = include_str\n filtered_hosts = HostInfoList()\n elif exclude_str:\n parse_str = exclude_str\n filtered_hosts = device_pool\n\n # foreach node in the list\n for node_config in parse_str.split(NODE_SEP):\n hostname = node_config\n hostinfo = device_pool.get_hostinfo(hostname)\n # sanity check hostname\n if not device_pool.has(hostname):\n click.echo(f\"Error: Hostname '{hostname}' not found in hostfile\")\n exit()\n\n if include_str:\n filtered_hosts.append(hostinfo)\n elif exclude_str:\n filtered_hosts.remove(hostname)\n\n return filtered_hosts\n\n\ndef get_launch_command(\n master_addr: str,\n master_port: int,\n nproc_per_node: int,\n user_script: str,\n user_args: List[str],\n node_rank: int,\n num_nodes: int,\n extra_launch_args: str = None,\n) -> str:\n \"\"\"\n Generate a command for distributed training.\n\n Args:\n master_addr (str): the host of the master node\n master_port (str): the port of the master node\n nproc_per_node (str): the number of processes to launch on each node\n user_script (str): the user Python file\n user_args (str): the arguments for the user script\n node_rank (int): the unique ID for the node\n num_nodes (int): the number of nodes to execute jobs\n\n Returns:\n cmd (str): the command the start distributed training\n \"\"\"\n\n def _arg_dict_to_list(arg_dict):\n ret = []\n\n for k, v in arg_dict.items():\n if v:\n ret.append(f'--{k}={v}')\n else:\n ret.append(f'--{k}')\n return ret\n\n if extra_launch_args:\n extra_launch_args_dict = dict()\n for arg in extra_launch_args.split(','):\n if '=' in arg:\n k, v = arg.split('=')\n extra_launch_args_dict[k] = v\n else:\n extra_launch_args_dict[arg] = None\n extra_launch_args = extra_launch_args_dict\n else:\n extra_launch_args = dict()\n\n torch_version = version.parse(torch.__version__)\n assert torch_version.major >= 1\n\n if torch_version.minor < 9:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.launch\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--master_addr={master_addr}\", f\"--master_port={master_port}\", f\"--nnodes={num_nodes}\",\n f\"--node_rank={node_rank}\"\n ]\n else:\n # extra launch args for torch distributed launcher with torch >= 1.9\n default_torchrun_rdzv_args = dict(rdzv_backend=\"c10d\",\n rdzv_endpoint=f\"{master_addr}:{master_port}\",\n rdzv_id=\"colossalai-default-job\")\n\n # update rdzv arguments\n for key in default_torchrun_rdzv_args.keys():\n if key in extra_launch_args:\n value = extra_launch_args.pop(key)\n default_torchrun_rdzv_args[key] = value\n\n if torch_version.minor < 10:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.run\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n else:\n cmd = [\n \"torchrun\", f\"--nproc_per_node={nproc_per_node}\", f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n cmd += _arg_dict_to_list(default_torchrun_rdzv_args)\n\n cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args\n cmd = ' '.join(cmd)\n return cmd\n\n\ndef launch_multi_processes(args: Config) -> None:\n \"\"\"\n Launch multiple processes on a single node or multiple nodes.\n\n The overall logic can be summarized as the pseudo code below:\n\n if hostfile given:\n hostinfo = parse_hostfile(hostfile)\n hostinfo = include_or_exclude_hosts(hostinfo)\n launch_on_multi_nodes(hostinfo)\n elif hosts given:\n hostinfo = parse_hosts(hosts)\n launch_on_multi_nodes(hostinfo)\n else:\n launch_on_current_node()\n\n Args:\n args (Config): the arguments taken from command line\n\n \"\"\"\n assert isinstance(args, Config)\n\n if args.nproc_per_node is None:\n click.echo(\"--nproc_per_node did not receive any value\")\n exit()\n\n # cannot accept hosts and hostfile at the same time\n if args.host and args.hostfile:\n click.echo(\"Error: hostfile and hosts are mutually exclusive, only one is required\")\n\n # check if hostfile is given\n if args.hostfile:\n device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)\n active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)\n\n if args.num_nodes > 0:\n # only keep the first num_nodes to execute jobs\n updated_active_device_pool = HostInfoList()\n for count, hostinfo in enumerate(active_device_pool):\n if args.num_nodes == count:\n break\n updated_active_device_pool.append(hostinfo)\n active_device_pool = updated_active_device_pool\n else:\n active_device_pool = None\n\n env = os.environ.copy()\n\n # use hosts if hostfile is not given\n if args.host and active_device_pool is None:\n active_device_pool = HostInfoList()\n host_list = args.host.strip().split(NODE_SEP)\n for hostname in host_list:\n hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)\n active_device_pool.append(hostinfo)\n\n if not active_device_pool:\n # run on local node if not hosts or hostfile is given\n # add local node to host info list\n active_device_pool = HostInfoList()\n localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)\n active_device_pool.append(localhost_info)\n\n # launch distributed processes\n runner = MultiNodeRunner()\n curr_path = os.path.abspath('.')\n\n # collect current path env\n env = dict()\n for k, v in os.environ.items():\n # do not support multi-line env var\n if v and '\\n' not in v:\n env[k] = v\n\n # establish remote connection\n runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)\n\n # execute distributed launching command\n for node_id, hostinfo in enumerate(active_device_pool):\n cmd = get_launch_command(master_addr=args.master_addr,\n master_port=args.master_port,\n nproc_per_node=args.nproc_per_node,\n user_script=args.user_script,\n user_args=args.user_args,\n node_rank=node_id,\n num_nodes=len(active_device_pool),\n extra_launch_args=args.extra_launch_args)\n runner.send(hostinfo=hostinfo, cmd=cmd)\n\n # start training\n msg_from_node = runner.recv_from_all()\n has_error = False\n\n # print node status\n click.echo(\"\\n====== Training on All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # check if a process failed\n if msg == \"failure\":\n has_error = True\n\n # stop all nodes\n runner.stop_all()\n\n # receive the stop status\n msg_from_node = runner.recv_from_all()\n\n # print node status\n click.echo(\"\\n====== Stopping All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # give the process an exit code\n # so that it behaves like a normal process\n if has_error:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "colossalai/cli/launcher/run.py"}], "after_files": [{"content": "import os\nimport sys\nfrom typing import List\n\nimport click\nimport torch\nfrom packaging import version\n\nfrom colossalai.context import Config\n\nfrom .hostinfo import HostInfo, HostInfoList\nfrom .multinode_runner import MultiNodeRunner\n\n# Constants that define our syntax\nNODE_SEP = ','\n\n\ndef fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:\n \"\"\"\n Parse the hostfile to obtain a list of hosts.\n\n A hostfile should look like:\n worker-0\n worker-1\n worker-2\n ...\n\n Args:\n hostfile_path (str): the path to the hostfile\n ssh_port (int): the port to connect to the host\n \"\"\"\n\n if not os.path.isfile(hostfile_path):\n click.echo(f\"Error: Unable to find the hostfile, no such file: {hostfile_path}\")\n exit()\n\n with open(hostfile_path, 'r') as fd:\n device_pool = HostInfoList()\n\n for line in fd.readlines():\n line = line.strip()\n if line == '':\n # skip empty lines\n continue\n\n # build the HostInfo object\n hostname = line.strip()\n hostinfo = HostInfo(hostname=hostname, port=ssh_port)\n\n if device_pool.has(hostname):\n click.echo(f\"Error: found duplicate host {hostname} in the hostfile\")\n exit()\n\n device_pool.append(hostinfo)\n return device_pool\n\n\ndef parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:\n '''Parse an inclusion or exclusion string and filter a hostfile dictionary.\n\n Examples:\n include_str=\"worker-0,worker-1\" will execute jobs only on worker-0 and worker-1.\n exclude_str=\"worker-1\" will use all available devices except worker-1.\n\n Args:\n device_pool (HostInfoList): a list of HostInfo objects\n include_str (str): --include option passed by user, default None\n exclude_str (str): --exclude option passed by user, default None\n\n Returns:\n filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion\n '''\n\n # Ensure include/exclude are mutually exclusive\n if include_str and exclude_str:\n click.echo(\"--include and --exclude are mutually exclusive, only one can be used\")\n exit()\n\n # no-op\n if include_str is None and exclude_str is None:\n return device_pool\n\n # Either build from scratch or remove items\n if include_str:\n parse_str = include_str\n filtered_hosts = HostInfoList()\n elif exclude_str:\n parse_str = exclude_str\n filtered_hosts = device_pool\n\n # foreach node in the list\n for node_config in parse_str.split(NODE_SEP):\n hostname = node_config\n hostinfo = device_pool.get_hostinfo(hostname)\n # sanity check hostname\n if not device_pool.has(hostname):\n click.echo(f\"Error: Hostname '{hostname}' not found in hostfile\")\n exit()\n\n if include_str:\n filtered_hosts.append(hostinfo)\n elif exclude_str:\n filtered_hosts.remove(hostname)\n\n return filtered_hosts\n\n\ndef get_launch_command(\n master_addr: str,\n master_port: int,\n nproc_per_node: int,\n user_script: str,\n user_args: List[str],\n node_rank: int,\n num_nodes: int,\n extra_launch_args: str = None,\n) -> str:\n \"\"\"\n Generate a command for distributed training.\n\n Args:\n master_addr (str): the host of the master node\n master_port (str): the port of the master node\n nproc_per_node (str): the number of processes to launch on each node\n user_script (str): the user Python file\n user_args (str): the arguments for the user script\n node_rank (int): the unique ID for the node\n num_nodes (int): the number of nodes to execute jobs\n\n Returns:\n cmd (str): the command the start distributed training\n \"\"\"\n\n def _arg_dict_to_list(arg_dict):\n ret = []\n\n for k, v in arg_dict.items():\n if v:\n ret.append(f'--{k}={v}')\n else:\n ret.append(f'--{k}')\n return ret\n\n if extra_launch_args:\n extra_launch_args_dict = dict()\n for arg in extra_launch_args.split(','):\n if '=' in arg:\n k, v = arg.split('=')\n extra_launch_args_dict[k] = v\n else:\n extra_launch_args_dict[arg] = None\n extra_launch_args = extra_launch_args_dict\n else:\n extra_launch_args = dict()\n\n torch_version = version.parse(torch.__version__)\n assert torch_version.major >= 1\n\n if torch_version.minor < 9:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.launch\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--master_addr={master_addr}\", f\"--master_port={master_port}\", f\"--nnodes={num_nodes}\",\n f\"--node_rank={node_rank}\"\n ]\n else:\n # extra launch args for torch distributed launcher with torch >= 1.9\n default_torchrun_rdzv_args = dict(master_addr=master_addr, master_port=master_port)\n\n # update rdzv arguments\n for key in default_torchrun_rdzv_args.keys():\n if key in extra_launch_args:\n value = extra_launch_args.pop(key)\n default_torchrun_rdzv_args[key] = value\n\n if torch_version.minor < 10:\n cmd = [\n sys.executable, \"-m\", \"torch.distributed.run\", f\"--nproc_per_node={nproc_per_node}\",\n f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n else:\n cmd = [\n \"torchrun\", f\"--nproc_per_node={nproc_per_node}\", f\"--nnodes={num_nodes}\", f\"--node_rank={node_rank}\"\n ]\n cmd += _arg_dict_to_list(default_torchrun_rdzv_args)\n\n cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args\n cmd = ' '.join(cmd)\n return cmd\n\n\ndef launch_multi_processes(args: Config) -> None:\n \"\"\"\n Launch multiple processes on a single node or multiple nodes.\n\n The overall logic can be summarized as the pseudo code below:\n\n if hostfile given:\n hostinfo = parse_hostfile(hostfile)\n hostinfo = include_or_exclude_hosts(hostinfo)\n launch_on_multi_nodes(hostinfo)\n elif hosts given:\n hostinfo = parse_hosts(hosts)\n launch_on_multi_nodes(hostinfo)\n else:\n launch_on_current_node()\n\n Args:\n args (Config): the arguments taken from command line\n\n \"\"\"\n assert isinstance(args, Config)\n\n if args.nproc_per_node is None:\n click.echo(\"--nproc_per_node did not receive any value\")\n exit()\n\n # cannot accept hosts and hostfile at the same time\n if args.host and args.hostfile:\n click.echo(\"Error: hostfile and hosts are mutually exclusive, only one is required\")\n\n # check if hostfile is given\n if args.hostfile:\n device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)\n active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)\n\n if args.num_nodes > 0:\n # only keep the first num_nodes to execute jobs\n updated_active_device_pool = HostInfoList()\n for count, hostinfo in enumerate(active_device_pool):\n if args.num_nodes == count:\n break\n updated_active_device_pool.append(hostinfo)\n active_device_pool = updated_active_device_pool\n else:\n active_device_pool = None\n\n env = os.environ.copy()\n\n # use hosts if hostfile is not given\n if args.host and active_device_pool is None:\n active_device_pool = HostInfoList()\n host_list = args.host.strip().split(NODE_SEP)\n for hostname in host_list:\n hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)\n active_device_pool.append(hostinfo)\n\n if not active_device_pool:\n # run on local node if not hosts or hostfile is given\n # add local node to host info list\n active_device_pool = HostInfoList()\n localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)\n active_device_pool.append(localhost_info)\n\n # launch distributed processes\n runner = MultiNodeRunner()\n curr_path = os.path.abspath('.')\n\n # collect current path env\n env = dict()\n for k, v in os.environ.items():\n # do not support multi-line env var\n if v and '\\n' not in v:\n env[k] = v\n\n # establish remote connection\n runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)\n\n # execute distributed launching command\n for node_id, hostinfo in enumerate(active_device_pool):\n cmd = get_launch_command(master_addr=args.master_addr,\n master_port=args.master_port,\n nproc_per_node=args.nproc_per_node,\n user_script=args.user_script,\n user_args=args.user_args,\n node_rank=node_id,\n num_nodes=len(active_device_pool),\n extra_launch_args=args.extra_launch_args)\n runner.send(hostinfo=hostinfo, cmd=cmd)\n\n # start training\n msg_from_node = runner.recv_from_all()\n has_error = False\n\n # print node status\n click.echo(\"\\n====== Training on All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # check if a process failed\n if msg == \"failure\":\n has_error = True\n\n # stop all nodes\n runner.stop_all()\n\n # receive the stop status\n msg_from_node = runner.recv_from_all()\n\n # print node status\n click.echo(\"\\n====== Stopping All Nodes =====\")\n for hostname, msg in msg_from_node.items():\n click.echo(f\"{hostname}: {msg}\")\n\n # give the process an exit code\n # so that it behaves like a normal process\n if has_error:\n sys.exit(1)\n else:\n sys.exit(0)\n", "path": "colossalai/cli/launcher/run.py"}]} | 3,493 | 180 |
gh_patches_debug_48963 | rasdani/github-patches | git_diff | scverse__scanpy-1948 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sphinx 4.1.0 doesn't like ScanpyConfig
Update:
Docs don't build with sphinx 4.1.0 due to a error triggered by `scanpydoc`. Sphinx will be pinned until this is solved (which is when this issue should be closed). It's not obvious to me at the moment whether sphinx or scanpydoc is at fault.
---------------
Trying to build the docs with Sphinx 4.1.0 fails with the following output:
<details>
<summary> </summary>
```sh
$ make html
Running Sphinx v4.1.0
loading intersphinx inventory from https://anndata.readthedocs.io/en/stable/objects.inv...
loading intersphinx inventory from https://bbknn.readthedocs.io/en/latest/objects.inv...
loading intersphinx inventory from https://matplotlib.org/cycler/objects.inv...
loading intersphinx inventory from http://docs.h5py.org/en/stable/objects.inv...
loading intersphinx inventory from https://ipython.readthedocs.io/en/stable/objects.inv...
loading intersphinx inventory from https://leidenalg.readthedocs.io/en/latest/objects.inv...
loading intersphinx inventory from https://louvain-igraph.readthedocs.io/en/latest/objects.inv...
loading intersphinx inventory from https://matplotlib.org/objects.inv...
loading intersphinx inventory from https://networkx.github.io/documentation/networkx-1.10/objects.inv...
loading intersphinx inventory from https://docs.scipy.org/doc/numpy/objects.inv...
loading intersphinx inventory from https://pandas.pydata.org/pandas-docs/stable/objects.inv...
loading intersphinx inventory from https://docs.pytest.org/en/latest/objects.inv...
loading intersphinx inventory from https://docs.python.org/3/objects.inv...
loading intersphinx inventory from https://docs.scipy.org/doc/scipy/reference/objects.inv...
loading intersphinx inventory from https://seaborn.pydata.org/objects.inv...
loading intersphinx inventory from https://scikit-learn.org/stable/objects.inv...
loading intersphinx inventory from https://scanpy-tutorials.readthedocs.io/en/latest/objects.inv...
intersphinx inventory has moved: https://networkx.github.io/documentation/networkx-1.10/objects.inv -> https://networkx.org/documentation/networkx-1.10/objects.inv
intersphinx inventory has moved: https://docs.scipy.org/doc/numpy/objects.inv -> https://numpy.org/doc/stable/objects.inv
intersphinx inventory has moved: http://docs.h5py.org/en/stable/objects.inv -> https://docs.h5py.org/en/stable/objects.inv
[autosummary] generating autosummary for: _key_contributors.rst, api.rst, basic_usage.rst, community.rst, contributors.rst, dev/ci.rst, dev/code.rst, dev/documentation.rst, dev/external-tools.rst, dev/getting-set-up.rst, ..., release-notes/1.7.1.rst, release-notes/1.7.2.rst, release-notes/1.8.0.rst, release-notes/1.8.1.rst, release-notes/1.8.2.rst, release-notes/1.9.0.rst, release-notes/index.rst, release-notes/release-latest.rst, tutorials.rst, usage-principles.rst
Error in github_url('scanpy._settings.ScanpyConfig.N_PCS'):
Extension error (sphinx.ext.autosummary):
Handler <function process_generate_options at 0x139c4a940> for event 'builder-inited' threw an exception (exception: type object 'ScanpyConfig' has no attribute 'N_PCS')
make: *** [html] Error 2
```
</details>
However, I'm entirely sure if this is Sphinx's fault, or our own. Currently the [N_PCS parameter isn't in the rendered documentation](https://scanpy.readthedocs.io/en/stable/generated/scanpy._settings.ScanpyConfig.html#scanpy._settings.ScanpyConfig). I think it should be, and am not sure why it's not showing up here.
To summarize:
* Previous versions of our doc builds didn't seem to be including attribute docstrings for `ScanpyConfig`.
* Sphinx 4.1.0 raises an error when it hits this attribute
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 import os
2 import sys
3 from pathlib import Path
4 from datetime import datetime
5
6 import matplotlib # noqa
7
8 # Don’t use tkinter agg when importing scanpy → … → matplotlib
9 matplotlib.use('agg')
10
11 HERE = Path(__file__).parent
12 sys.path[:0] = [str(HERE.parent), str(HERE / 'extensions')]
13 import scanpy # noqa
14
15 on_rtd = os.environ.get('READTHEDOCS') == 'True'
16
17 # -- General configuration ------------------------------------------------
18
19
20 nitpicky = True # Warn about broken links. This is here for a reason: Do not change.
21 needs_sphinx = '2.0' # Nicer param docs
22 suppress_warnings = ['ref.citation']
23
24 # General information
25 project = 'Scanpy'
26 author = scanpy.__author__
27 copyright = f'{datetime.now():%Y}, {author}.'
28 version = scanpy.__version__.replace('.dirty', '')
29 release = version
30
31 # default settings
32 templates_path = ['_templates']
33 source_suffix = '.rst'
34 master_doc = 'index'
35 default_role = 'literal'
36 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
37 pygments_style = 'sphinx'
38
39 extensions = [
40 'sphinx.ext.autodoc',
41 'sphinx.ext.intersphinx',
42 'sphinx.ext.doctest',
43 'sphinx.ext.coverage',
44 'sphinx.ext.mathjax',
45 'sphinx.ext.napoleon',
46 'sphinx.ext.autosummary',
47 # 'plot_generator',
48 'matplotlib.sphinxext.plot_directive',
49 'sphinx_autodoc_typehints', # needs to be after napoleon
50 # 'ipython_directive',
51 # 'ipython_console_highlighting',
52 'scanpydoc',
53 *[p.stem for p in (HERE / 'extensions').glob('*.py')],
54 ]
55
56 # Generate the API documentation when building
57 autosummary_generate = True
58 autodoc_member_order = 'bysource'
59 # autodoc_default_flags = ['members']
60 napoleon_google_docstring = False
61 napoleon_numpy_docstring = True
62 napoleon_include_init_with_doc = False
63 napoleon_use_rtype = True # having a separate entry generally helps readability
64 napoleon_use_param = True
65 napoleon_custom_sections = [('Params', 'Parameters')]
66 todo_include_todos = False
67 api_dir = HERE / 'api' # function_images
68
69 scanpy_tutorials_url = 'https://scanpy-tutorials.readthedocs.io/en/latest/'
70
71 intersphinx_mapping = dict(
72 anndata=('https://anndata.readthedocs.io/en/stable/', None),
73 bbknn=('https://bbknn.readthedocs.io/en/latest/', None),
74 cycler=('https://matplotlib.org/cycler/', None),
75 h5py=('http://docs.h5py.org/en/stable/', None),
76 ipython=('https://ipython.readthedocs.io/en/stable/', None),
77 leidenalg=('https://leidenalg.readthedocs.io/en/latest/', None),
78 louvain=('https://louvain-igraph.readthedocs.io/en/latest/', None),
79 matplotlib=('https://matplotlib.org/', None),
80 networkx=('https://networkx.github.io/documentation/networkx-1.10/', None),
81 numpy=('https://docs.scipy.org/doc/numpy/', None),
82 pandas=('https://pandas.pydata.org/pandas-docs/stable/', None),
83 pytest=('https://docs.pytest.org/en/latest/', None),
84 python=('https://docs.python.org/3', None),
85 scipy=('https://docs.scipy.org/doc/scipy/reference/', None),
86 seaborn=('https://seaborn.pydata.org/', None),
87 sklearn=('https://scikit-learn.org/stable/', None),
88 scanpy_tutorials=(scanpy_tutorials_url, None),
89 )
90
91
92 # -- Options for HTML output ----------------------------------------------
93
94
95 html_theme = 'scanpydoc'
96 html_theme_options = dict(
97 navigation_depth=4,
98 logo_only=True,
99 docsearch_index='scanpy',
100 docsearch_key='fa4304eb95d2134997e3729553a674b2',
101 )
102 html_context = dict(
103 display_github=True, # Integrate GitHub
104 github_user='theislab', # Username
105 github_repo='scanpy', # Repo name
106 github_version='master', # Version
107 conf_py_path='/docs/', # Path in the checkout to the docs root
108 )
109 html_static_path = ['_static']
110 html_show_sphinx = False
111 html_logo = '_static/img/Scanpy_Logo_BrightFG.svg'
112
113
114 def setup(app):
115 app.warningiserror = on_rtd
116
117
118 # -- Options for other output formats ------------------------------------------
119
120 htmlhelp_basename = f'{project}doc'
121 doc_title = f'{project} Documentation'
122 latex_documents = [(master_doc, f'{project}.tex', doc_title, author, 'manual')]
123 man_pages = [(master_doc, project, doc_title, [author], 1)]
124 texinfo_documents = [
125 (
126 master_doc,
127 project,
128 doc_title,
129 author,
130 project,
131 'One line description of project.',
132 'Miscellaneous',
133 )
134 ]
135
136
137 # -- Suppress link warnings ----------------------------------------------------
138
139 qualname_overrides = {
140 "sklearn.neighbors._dist_metrics.DistanceMetric": "sklearn.neighbors.DistanceMetric",
141 # If the docs are built with an old version of numpy, this will make it work:
142 "numpy.random.RandomState": "numpy.random.mtrand.RandomState",
143 "scanpy.plotting._matrixplot.MatrixPlot": "scanpy.pl.MatrixPlot",
144 "scanpy.plotting._dotplot.DotPlot": "scanpy.pl.DotPlot",
145 "scanpy.plotting._stacked_violin.StackedViolin": "scanpy.pl.StackedViolin",
146 "pandas.core.series.Series": "pandas.Series",
147 }
148
149 nitpick_ignore = [
150 # Will probably be documented
151 ('py:class', 'scanpy._settings.Verbosity'),
152 # Currently undocumented: https://github.com/mwaskom/seaborn/issues/1810
153 ('py:class', 'seaborn.ClusterGrid'),
154 # Won’t be documented
155 ('py:class', 'scanpy.plotting._utils._AxesSubplot'),
156 ('py:class', 'scanpy._utils.Empty'),
157 ('py:class', 'numpy.random.mtrand.RandomState'),
158 ]
159
160 # Options for plot examples
161
162 plot_include_source = True
163 plot_formats = [("png", 90)]
164 plot_html_show_formats = False
165 plot_html_show_source_link = False
166 plot_working_directory = HERE.parent # Project root
167
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -155,6 +155,9 @@
('py:class', 'scanpy.plotting._utils._AxesSubplot'),
('py:class', 'scanpy._utils.Empty'),
('py:class', 'numpy.random.mtrand.RandomState'),
+ # Will work once scipy 1.8 is released
+ ('py:class', 'scipy.sparse.base.spmatrix'),
+ ('py:class', 'scipy.sparse.csr.csr_matrix'),
]
# Options for plot examples
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -155,6 +155,9 @@\n ('py:class', 'scanpy.plotting._utils._AxesSubplot'),\n ('py:class', 'scanpy._utils.Empty'),\n ('py:class', 'numpy.random.mtrand.RandomState'),\n+ # Will work once scipy 1.8 is released\n+ ('py:class', 'scipy.sparse.base.spmatrix'),\n+ ('py:class', 'scipy.sparse.csr.csr_matrix'),\n ]\n \n # Options for plot examples\n", "issue": "Sphinx 4.1.0 doesn't like ScanpyConfig\nUpdate:\r\n\r\nDocs don't build with sphinx 4.1.0 due to a error triggered by `scanpydoc`. Sphinx will be pinned until this is solved (which is when this issue should be closed). It's not obvious to me at the moment whether sphinx or scanpydoc is at fault.\r\n\r\n---------------\r\n\r\nTrying to build the docs with Sphinx 4.1.0 fails with the following output:\r\n\r\n<details>\r\n<summary> </summary>\r\n\r\n```sh\r\n$ make html\r\nRunning Sphinx v4.1.0\r\nloading intersphinx inventory from https://anndata.readthedocs.io/en/stable/objects.inv...\r\nloading intersphinx inventory from https://bbknn.readthedocs.io/en/latest/objects.inv...\r\nloading intersphinx inventory from https://matplotlib.org/cycler/objects.inv...\r\nloading intersphinx inventory from http://docs.h5py.org/en/stable/objects.inv...\r\nloading intersphinx inventory from https://ipython.readthedocs.io/en/stable/objects.inv...\r\nloading intersphinx inventory from https://leidenalg.readthedocs.io/en/latest/objects.inv...\r\nloading intersphinx inventory from https://louvain-igraph.readthedocs.io/en/latest/objects.inv...\r\nloading intersphinx inventory from https://matplotlib.org/objects.inv...\r\nloading intersphinx inventory from https://networkx.github.io/documentation/networkx-1.10/objects.inv...\r\nloading intersphinx inventory from https://docs.scipy.org/doc/numpy/objects.inv...\r\nloading intersphinx inventory from https://pandas.pydata.org/pandas-docs/stable/objects.inv...\r\nloading intersphinx inventory from https://docs.pytest.org/en/latest/objects.inv...\r\nloading intersphinx inventory from https://docs.python.org/3/objects.inv...\r\nloading intersphinx inventory from https://docs.scipy.org/doc/scipy/reference/objects.inv...\r\nloading intersphinx inventory from https://seaborn.pydata.org/objects.inv...\r\nloading intersphinx inventory from https://scikit-learn.org/stable/objects.inv...\r\nloading intersphinx inventory from https://scanpy-tutorials.readthedocs.io/en/latest/objects.inv...\r\nintersphinx inventory has moved: https://networkx.github.io/documentation/networkx-1.10/objects.inv -> https://networkx.org/documentation/networkx-1.10/objects.inv\r\nintersphinx inventory has moved: https://docs.scipy.org/doc/numpy/objects.inv -> https://numpy.org/doc/stable/objects.inv\r\nintersphinx inventory has moved: http://docs.h5py.org/en/stable/objects.inv -> https://docs.h5py.org/en/stable/objects.inv\r\n[autosummary] generating autosummary for: _key_contributors.rst, api.rst, basic_usage.rst, community.rst, contributors.rst, dev/ci.rst, dev/code.rst, dev/documentation.rst, dev/external-tools.rst, dev/getting-set-up.rst, ..., release-notes/1.7.1.rst, release-notes/1.7.2.rst, release-notes/1.8.0.rst, release-notes/1.8.1.rst, release-notes/1.8.2.rst, release-notes/1.9.0.rst, release-notes/index.rst, release-notes/release-latest.rst, tutorials.rst, usage-principles.rst\r\nError in github_url('scanpy._settings.ScanpyConfig.N_PCS'):\r\n\r\nExtension error (sphinx.ext.autosummary):\r\nHandler <function process_generate_options at 0x139c4a940> for event 'builder-inited' threw an exception (exception: type object 'ScanpyConfig' has no attribute 'N_PCS')\r\nmake: *** [html] Error 2\r\n```\r\n\r\n</details>\r\n\r\nHowever, I'm entirely sure if this is Sphinx's fault, or our own. Currently the [N_PCS parameter isn't in the rendered documentation](https://scanpy.readthedocs.io/en/stable/generated/scanpy._settings.ScanpyConfig.html#scanpy._settings.ScanpyConfig). I think it should be, and am not sure why it's not showing up here.\r\n\r\nTo summarize:\r\n\r\n* Previous versions of our doc builds didn't seem to be including attribute docstrings for `ScanpyConfig`.\r\n* Sphinx 4.1.0 raises an error when it hits this attribute\n", "before_files": [{"content": "import os\nimport sys\nfrom pathlib import Path\nfrom datetime import datetime\n\nimport matplotlib # noqa\n\n# Don\u2019t use tkinter agg when importing scanpy \u2192 \u2026 \u2192 matplotlib\nmatplotlib.use('agg')\n\nHERE = Path(__file__).parent\nsys.path[:0] = [str(HERE.parent), str(HERE / 'extensions')]\nimport scanpy # noqa\n\non_rtd = os.environ.get('READTHEDOCS') == 'True'\n\n# -- General configuration ------------------------------------------------\n\n\nnitpicky = True # Warn about broken links. This is here for a reason: Do not change.\nneeds_sphinx = '2.0' # Nicer param docs\nsuppress_warnings = ['ref.citation']\n\n# General information\nproject = 'Scanpy'\nauthor = scanpy.__author__\ncopyright = f'{datetime.now():%Y}, {author}.'\nversion = scanpy.__version__.replace('.dirty', '')\nrelease = version\n\n# default settings\ntemplates_path = ['_templates']\nsource_suffix = '.rst'\nmaster_doc = 'index'\ndefault_role = 'literal'\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\npygments_style = 'sphinx'\n\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.doctest',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.autosummary',\n # 'plot_generator',\n 'matplotlib.sphinxext.plot_directive',\n 'sphinx_autodoc_typehints', # needs to be after napoleon\n # 'ipython_directive',\n # 'ipython_console_highlighting',\n 'scanpydoc',\n *[p.stem for p in (HERE / 'extensions').glob('*.py')],\n]\n\n# Generate the API documentation when building\nautosummary_generate = True\nautodoc_member_order = 'bysource'\n# autodoc_default_flags = ['members']\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_include_init_with_doc = False\nnapoleon_use_rtype = True # having a separate entry generally helps readability\nnapoleon_use_param = True\nnapoleon_custom_sections = [('Params', 'Parameters')]\ntodo_include_todos = False\napi_dir = HERE / 'api' # function_images\n\nscanpy_tutorials_url = 'https://scanpy-tutorials.readthedocs.io/en/latest/'\n\nintersphinx_mapping = dict(\n anndata=('https://anndata.readthedocs.io/en/stable/', None),\n bbknn=('https://bbknn.readthedocs.io/en/latest/', None),\n cycler=('https://matplotlib.org/cycler/', None),\n h5py=('http://docs.h5py.org/en/stable/', None),\n ipython=('https://ipython.readthedocs.io/en/stable/', None),\n leidenalg=('https://leidenalg.readthedocs.io/en/latest/', None),\n louvain=('https://louvain-igraph.readthedocs.io/en/latest/', None),\n matplotlib=('https://matplotlib.org/', None),\n networkx=('https://networkx.github.io/documentation/networkx-1.10/', None),\n numpy=('https://docs.scipy.org/doc/numpy/', None),\n pandas=('https://pandas.pydata.org/pandas-docs/stable/', None),\n pytest=('https://docs.pytest.org/en/latest/', None),\n python=('https://docs.python.org/3', None),\n scipy=('https://docs.scipy.org/doc/scipy/reference/', None),\n seaborn=('https://seaborn.pydata.org/', None),\n sklearn=('https://scikit-learn.org/stable/', None),\n scanpy_tutorials=(scanpy_tutorials_url, None),\n)\n\n\n# -- Options for HTML output ----------------------------------------------\n\n\nhtml_theme = 'scanpydoc'\nhtml_theme_options = dict(\n navigation_depth=4,\n logo_only=True,\n docsearch_index='scanpy',\n docsearch_key='fa4304eb95d2134997e3729553a674b2',\n)\nhtml_context = dict(\n display_github=True, # Integrate GitHub\n github_user='theislab', # Username\n github_repo='scanpy', # Repo name\n github_version='master', # Version\n conf_py_path='/docs/', # Path in the checkout to the docs root\n)\nhtml_static_path = ['_static']\nhtml_show_sphinx = False\nhtml_logo = '_static/img/Scanpy_Logo_BrightFG.svg'\n\n\ndef setup(app):\n app.warningiserror = on_rtd\n\n\n# -- Options for other output formats ------------------------------------------\n\nhtmlhelp_basename = f'{project}doc'\ndoc_title = f'{project} Documentation'\nlatex_documents = [(master_doc, f'{project}.tex', doc_title, author, 'manual')]\nman_pages = [(master_doc, project, doc_title, [author], 1)]\ntexinfo_documents = [\n (\n master_doc,\n project,\n doc_title,\n author,\n project,\n 'One line description of project.',\n 'Miscellaneous',\n )\n]\n\n\n# -- Suppress link warnings ----------------------------------------------------\n\nqualname_overrides = {\n \"sklearn.neighbors._dist_metrics.DistanceMetric\": \"sklearn.neighbors.DistanceMetric\",\n # If the docs are built with an old version of numpy, this will make it work:\n \"numpy.random.RandomState\": \"numpy.random.mtrand.RandomState\",\n \"scanpy.plotting._matrixplot.MatrixPlot\": \"scanpy.pl.MatrixPlot\",\n \"scanpy.plotting._dotplot.DotPlot\": \"scanpy.pl.DotPlot\",\n \"scanpy.plotting._stacked_violin.StackedViolin\": \"scanpy.pl.StackedViolin\",\n \"pandas.core.series.Series\": \"pandas.Series\",\n}\n\nnitpick_ignore = [\n # Will probably be documented\n ('py:class', 'scanpy._settings.Verbosity'),\n # Currently undocumented: https://github.com/mwaskom/seaborn/issues/1810\n ('py:class', 'seaborn.ClusterGrid'),\n # Won\u2019t be documented\n ('py:class', 'scanpy.plotting._utils._AxesSubplot'),\n ('py:class', 'scanpy._utils.Empty'),\n ('py:class', 'numpy.random.mtrand.RandomState'),\n]\n\n# Options for plot examples\n\nplot_include_source = True\nplot_formats = [(\"png\", 90)]\nplot_html_show_formats = False\nplot_html_show_source_link = False\nplot_working_directory = HERE.parent # Project root\n", "path": "docs/conf.py"}], "after_files": [{"content": "import os\nimport sys\nfrom pathlib import Path\nfrom datetime import datetime\n\nimport matplotlib # noqa\n\n# Don\u2019t use tkinter agg when importing scanpy \u2192 \u2026 \u2192 matplotlib\nmatplotlib.use('agg')\n\nHERE = Path(__file__).parent\nsys.path[:0] = [str(HERE.parent), str(HERE / 'extensions')]\nimport scanpy # noqa\n\non_rtd = os.environ.get('READTHEDOCS') == 'True'\n\n# -- General configuration ------------------------------------------------\n\n\nnitpicky = True # Warn about broken links. This is here for a reason: Do not change.\nneeds_sphinx = '2.0' # Nicer param docs\nsuppress_warnings = ['ref.citation']\n\n# General information\nproject = 'Scanpy'\nauthor = scanpy.__author__\ncopyright = f'{datetime.now():%Y}, {author}.'\nversion = scanpy.__version__.replace('.dirty', '')\nrelease = version\n\n# default settings\ntemplates_path = ['_templates']\nsource_suffix = '.rst'\nmaster_doc = 'index'\ndefault_role = 'literal'\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\npygments_style = 'sphinx'\n\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.doctest',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.autosummary',\n # 'plot_generator',\n 'matplotlib.sphinxext.plot_directive',\n 'sphinx_autodoc_typehints', # needs to be after napoleon\n # 'ipython_directive',\n # 'ipython_console_highlighting',\n 'scanpydoc',\n *[p.stem for p in (HERE / 'extensions').glob('*.py')],\n]\n\n# Generate the API documentation when building\nautosummary_generate = True\nautodoc_member_order = 'bysource'\n# autodoc_default_flags = ['members']\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_include_init_with_doc = False\nnapoleon_use_rtype = True # having a separate entry generally helps readability\nnapoleon_use_param = True\nnapoleon_custom_sections = [('Params', 'Parameters')]\ntodo_include_todos = False\napi_dir = HERE / 'api' # function_images\n\nscanpy_tutorials_url = 'https://scanpy-tutorials.readthedocs.io/en/latest/'\n\nintersphinx_mapping = dict(\n anndata=('https://anndata.readthedocs.io/en/stable/', None),\n bbknn=('https://bbknn.readthedocs.io/en/latest/', None),\n cycler=('https://matplotlib.org/cycler/', None),\n h5py=('http://docs.h5py.org/en/stable/', None),\n ipython=('https://ipython.readthedocs.io/en/stable/', None),\n leidenalg=('https://leidenalg.readthedocs.io/en/latest/', None),\n louvain=('https://louvain-igraph.readthedocs.io/en/latest/', None),\n matplotlib=('https://matplotlib.org/', None),\n networkx=('https://networkx.github.io/documentation/networkx-1.10/', None),\n numpy=('https://docs.scipy.org/doc/numpy/', None),\n pandas=('https://pandas.pydata.org/pandas-docs/stable/', None),\n pytest=('https://docs.pytest.org/en/latest/', None),\n python=('https://docs.python.org/3', None),\n scipy=('https://docs.scipy.org/doc/scipy/reference/', None),\n seaborn=('https://seaborn.pydata.org/', None),\n sklearn=('https://scikit-learn.org/stable/', None),\n scanpy_tutorials=(scanpy_tutorials_url, None),\n)\n\n\n# -- Options for HTML output ----------------------------------------------\n\n\nhtml_theme = 'scanpydoc'\nhtml_theme_options = dict(\n navigation_depth=4,\n logo_only=True,\n docsearch_index='scanpy',\n docsearch_key='fa4304eb95d2134997e3729553a674b2',\n)\nhtml_context = dict(\n display_github=True, # Integrate GitHub\n github_user='theislab', # Username\n github_repo='scanpy', # Repo name\n github_version='master', # Version\n conf_py_path='/docs/', # Path in the checkout to the docs root\n)\nhtml_static_path = ['_static']\nhtml_show_sphinx = False\nhtml_logo = '_static/img/Scanpy_Logo_BrightFG.svg'\n\n\ndef setup(app):\n app.warningiserror = on_rtd\n\n\n# -- Options for other output formats ------------------------------------------\n\nhtmlhelp_basename = f'{project}doc'\ndoc_title = f'{project} Documentation'\nlatex_documents = [(master_doc, f'{project}.tex', doc_title, author, 'manual')]\nman_pages = [(master_doc, project, doc_title, [author], 1)]\ntexinfo_documents = [\n (\n master_doc,\n project,\n doc_title,\n author,\n project,\n 'One line description of project.',\n 'Miscellaneous',\n )\n]\n\n\n# -- Suppress link warnings ----------------------------------------------------\n\nqualname_overrides = {\n \"sklearn.neighbors._dist_metrics.DistanceMetric\": \"sklearn.neighbors.DistanceMetric\",\n # If the docs are built with an old version of numpy, this will make it work:\n \"numpy.random.RandomState\": \"numpy.random.mtrand.RandomState\",\n \"scanpy.plotting._matrixplot.MatrixPlot\": \"scanpy.pl.MatrixPlot\",\n \"scanpy.plotting._dotplot.DotPlot\": \"scanpy.pl.DotPlot\",\n \"scanpy.plotting._stacked_violin.StackedViolin\": \"scanpy.pl.StackedViolin\",\n \"pandas.core.series.Series\": \"pandas.Series\",\n}\n\nnitpick_ignore = [\n # Will probably be documented\n ('py:class', 'scanpy._settings.Verbosity'),\n # Currently undocumented: https://github.com/mwaskom/seaborn/issues/1810\n ('py:class', 'seaborn.ClusterGrid'),\n # Won\u2019t be documented\n ('py:class', 'scanpy.plotting._utils._AxesSubplot'),\n ('py:class', 'scanpy._utils.Empty'),\n ('py:class', 'numpy.random.mtrand.RandomState'),\n # Will work once scipy 1.8 is released\n ('py:class', 'scipy.sparse.base.spmatrix'),\n ('py:class', 'scipy.sparse.csr.csr_matrix'),\n]\n\n# Options for plot examples\n\nplot_include_source = True\nplot_formats = [(\"png\", 90)]\nplot_html_show_formats = False\nplot_html_show_source_link = False\nplot_working_directory = HERE.parent # Project root\n", "path": "docs/conf.py"}]} | 3,010 | 133 |
gh_patches_debug_16799 | rasdani/github-patches | git_diff | kserve__kserve-3424 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FileNotFoundError when using an s3 bucket as the model_dir with HuggingFace model server
/kind bug
First of all, I'd like to say thank you for the work on KServe! It's been delightful so far playing around with KServe. But we found a small bug while testing out the HuggingFace model server (which we're aware is a very new addition as well).
**What steps did you take and what happened:**
1. Created an InferenceService using the HuggingFace model server (yaml pasted below)
2. Specified an s3 bucket as the `model_dir` (I suspect this might happen for anything that's not a local dir)
3. Observed that the model is succesfully downloaded to a tmp directory and loaded, but then encountered the `FileNotFoundError` right after
Logs:
```
% k logs huggingface-predictor-00003-deployment-8659bb8b9-m945b
Defaulted container "kserve-container" out of: kserve-container, queue-proxy
INFO:root:Copying contents of s3://kserve-test-models/classifier to local
INFO:root:Downloaded object classifier/config.json to /tmp/tmpckx_trr1/config.json
...
INFO:root:Successfully copied s3://kserve-test-models/classifier to /tmp/tmpckx_trr1
INFO:kserve:successfully loaded tokenizer for task: 4
INFO:kserve:successfully loaded huggingface model from path /tmp/tmpckx_trr1
Traceback (most recent call last):
File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/huggingfaceserver/huggingfaceserver/__main__.py", line 69, in <module>
kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(
File "/huggingfaceserver/huggingfaceserver/huggingface_model_repository.py", line 24, in __init__
self.load_models()
File "/kserve/kserve/model_repository.py", line 37, in load_models
for name in os.listdir(self.models_dir):
FileNotFoundError: [Errno 2] No such file or directory: 's3://kserve-test-models/spam-classifier'
```
**What did you expect to happen:**
I expected that this would work, as the model was successfully downloaded and loaded. But I did find a tmp workaround below and I think I know where the issue is!
**What's the InferenceService yaml:**
```yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: huggingface
spec:
predictor:
serviceAccountName: huggingface-sa
containers:
- args:
- --model_name=spam-classifier
# - --model_id=xyz (see workaround below)
- --model_dir=s3://kserve-test-models/classifier
- --tensor_input_names=input_ids
image: kserve/huggingfaceserver:latest
name: kserve-container
```
**Anything else you would like to add:**
A temporary workaround I found is to supply the `model_id` argument. It can have any value, as the `model_dir` will override it anyway during loading:
https://github.com/kserve/kserve/blob/5172dc80b0a23d2263757de70a02eeef08b18811/python/huggingfaceserver/huggingfaceserver/model.py#L91-L94
<details>
<summary>I have verified that this workaround works (expand to see logs).</summary>
```
% k logs huggingface-predictor-00004-deployment-946b4d6c8-pk5nj -f
Defaulted container "kserve-container" out of: kserve-container, queue-proxy
INFO:root:Copying contents of s3://kserve-test-models/classifier to local
INFO:root:Downloaded object classifier/config.json to /tmp/tmppwjsica7/config.json
...
INFO:kserve:successfully loaded tokenizer for task: 4
INFO:kserve:successfully loaded huggingface model from path /tmp/tmppwjsica7
INFO:kserve:Registering model: classifier
INFO:kserve:Setting max asyncio worker threads as 5
INFO:kserve:Starting uvicorn with 1 workers
2024-02-09 18:57:33.228 uvicorn.error INFO: Started server process [1]
2024-02-09 18:57:33.229 uvicorn.error INFO: Waiting for application startup.
2024-02-09 18:57:33.234 1 kserve INFO [start():62] Starting gRPC server on [::]:8081
2024-02-09 18:57:33.234 uvicorn.error INFO: Application startup complete.
2024-02-09 18:57:33.235 uvicorn.error INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
```
</details>
I think the issue is here:
https://github.com/kserve/kserve/blob/5172dc80b0a23d2263757de70a02eeef08b18811/python/huggingfaceserver/huggingfaceserver/__main__.py#L63-L72
1. `model.load()` will succeed, so we jump to line 68
2. It checks for `args.model_id`, which is empty, so we go inside the if block
3. It will try to instantiate `HuggingfaceModelRepository` with `model_dir`, which is pointing to an s3 bucket and not a local directory, thus causing the `FileNotFoundError`
4. This is how I came up with the workaround of passing `model_id`, so that the else block is executed instead (because the model did load succesfully, so doing `kserve.ModelServer().start([model] if model.ready else [])` won't be a problem)
**Environment:**
- Cloud Environment: aws
- Kubernetes version: (use `kubectl version`): v1.27.9-eks-5e0fdde
- OS (e.g. from `/etc/os-release`): Ubuntu 22.04.3 LTS
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/huggingfaceserver/huggingfaceserver/__main__.py`
Content:
```
1 # Copyright 2024 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import logging
17
18 from kserve.model import PredictorConfig
19 from . import HuggingfaceModel, HuggingfaceModelRepository
20 import kserve
21 from kserve.errors import ModelMissingError
22
23
24 def list_of_strings(arg):
25 return arg.split(',')
26
27
28 parser = argparse.ArgumentParser(parents=[kserve.model_server.parser])
29
30 parser.add_argument('--model_dir', required=False, default=None,
31 help='A URI pointer to the model binary')
32 parser.add_argument('--model_id', required=False,
33 help='Huggingface model id')
34 parser.add_argument('--tensor_parallel_degree', type=int, default=-1,
35 help='tensor parallel degree')
36 parser.add_argument('--max_length', type=int, default=None,
37 help='max sequence length for the tokenizer')
38 parser.add_argument('--do_lower_case', type=bool, default=True,
39 help='do lower case for the tokenizer')
40 parser.add_argument('--add_special_tokens', type=bool, default=True,
41 help='the sequences will be encoded with the special tokens relative to their model')
42 parser.add_argument('--tensor_input_names', type=list_of_strings, default=None,
43 help='the tensor input names passed to the model')
44 parser.add_argument('--task', required=False, help="The ML task name")
45
46 try:
47 from vllm.engine.arg_utils import AsyncEngineArgs
48
49 parser = AsyncEngineArgs.add_cli_args(parser)
50 _vllm = True
51 except ImportError:
52 _vllm = False
53 args, _ = parser.parse_known_args()
54
55 if __name__ == "__main__":
56 engine_args = AsyncEngineArgs.from_cli_args(args) if _vllm else None
57 predictor_config = PredictorConfig(args.predictor_host, args.predictor_protocol,
58 args.predictor_use_ssl,
59 args.predictor_request_timeout_seconds)
60 model = HuggingfaceModel(args.model_name,
61 predictor_config=predictor_config,
62 kwargs=vars(args), engine_args=engine_args)
63 try:
64 model.load()
65 except ModelMissingError:
66 logging.error(f"fail to locate model file for model {args.model_name} under dir {args.model_dir},"
67 f"trying loading from model repository.")
68 if not args.model_id:
69 kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(
70 [model] if model.ready else [])
71 else:
72 kserve.ModelServer().start([model] if model.ready else [])
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/huggingfaceserver/huggingfaceserver/__main__.py b/python/huggingfaceserver/huggingfaceserver/__main__.py
--- a/python/huggingfaceserver/huggingfaceserver/__main__.py
+++ b/python/huggingfaceserver/huggingfaceserver/__main__.py
@@ -62,11 +62,9 @@
kwargs=vars(args), engine_args=engine_args)
try:
model.load()
+ kserve.ModelServer().start([model] if model.ready else [])
except ModelMissingError:
logging.error(f"fail to locate model file for model {args.model_name} under dir {args.model_dir},"
f"trying loading from model repository.")
- if not args.model_id:
kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(
[model] if model.ready else [])
- else:
- kserve.ModelServer().start([model] if model.ready else [])
| {"golden_diff": "diff --git a/python/huggingfaceserver/huggingfaceserver/__main__.py b/python/huggingfaceserver/huggingfaceserver/__main__.py\n--- a/python/huggingfaceserver/huggingfaceserver/__main__.py\n+++ b/python/huggingfaceserver/huggingfaceserver/__main__.py\n@@ -62,11 +62,9 @@\n kwargs=vars(args), engine_args=engine_args)\n try:\n model.load()\n+ kserve.ModelServer().start([model] if model.ready else [])\n except ModelMissingError:\n logging.error(f\"fail to locate model file for model {args.model_name} under dir {args.model_dir},\"\n f\"trying loading from model repository.\")\n- if not args.model_id:\n kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(\n [model] if model.ready else [])\n- else:\n- kserve.ModelServer().start([model] if model.ready else [])\n", "issue": "FileNotFoundError when using an s3 bucket as the model_dir with HuggingFace model server\n/kind bug\r\n\r\nFirst of all, I'd like to say thank you for the work on KServe! It's been delightful so far playing around with KServe. But we found a small bug while testing out the HuggingFace model server (which we're aware is a very new addition as well).\r\n\r\n**What steps did you take and what happened:**\r\n1. Created an InferenceService using the HuggingFace model server (yaml pasted below)\r\n2. Specified an s3 bucket as the `model_dir` (I suspect this might happen for anything that's not a local dir)\r\n3. Observed that the model is succesfully downloaded to a tmp directory and loaded, but then encountered the `FileNotFoundError` right after\r\n\r\nLogs:\r\n```\r\n% k logs huggingface-predictor-00003-deployment-8659bb8b9-m945b\r\nDefaulted container \"kserve-container\" out of: kserve-container, queue-proxy\r\nINFO:root:Copying contents of s3://kserve-test-models/classifier to local\r\nINFO:root:Downloaded object classifier/config.json to /tmp/tmpckx_trr1/config.json\r\n...\r\nINFO:root:Successfully copied s3://kserve-test-models/classifier to /tmp/tmpckx_trr1\r\nINFO:kserve:successfully loaded tokenizer for task: 4\r\nINFO:kserve:successfully loaded huggingface model from path /tmp/tmpckx_trr1\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.10/runpy.py\", line 196, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/usr/lib/python3.10/runpy.py\", line 86, in _run_code\r\n exec(code, run_globals)\r\n File \"/huggingfaceserver/huggingfaceserver/__main__.py\", line 69, in <module>\r\n kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(\r\n File \"/huggingfaceserver/huggingfaceserver/huggingface_model_repository.py\", line 24, in __init__\r\n self.load_models()\r\n File \"/kserve/kserve/model_repository.py\", line 37, in load_models\r\n for name in os.listdir(self.models_dir):\r\nFileNotFoundError: [Errno 2] No such file or directory: 's3://kserve-test-models/spam-classifier'\r\n```\r\n\r\n\r\n**What did you expect to happen:**\r\n\r\nI expected that this would work, as the model was successfully downloaded and loaded. But I did find a tmp workaround below and I think I know where the issue is!\r\n\r\n**What's the InferenceService yaml:**\r\n```yaml\r\napiVersion: serving.kserve.io/v1beta1\r\nkind: InferenceService\r\nmetadata:\r\n name: huggingface\r\nspec:\r\n predictor:\r\n serviceAccountName: huggingface-sa\r\n containers:\r\n - args:\r\n - --model_name=spam-classifier\r\n # - --model_id=xyz (see workaround below)\r\n - --model_dir=s3://kserve-test-models/classifier\r\n - --tensor_input_names=input_ids\r\n image: kserve/huggingfaceserver:latest\r\n name: kserve-container\r\n```\r\n\r\n**Anything else you would like to add:**\r\n\r\nA temporary workaround I found is to supply the `model_id` argument. It can have any value, as the `model_dir` will override it anyway during loading:\r\n\r\nhttps://github.com/kserve/kserve/blob/5172dc80b0a23d2263757de70a02eeef08b18811/python/huggingfaceserver/huggingfaceserver/model.py#L91-L94\r\n\r\n<details>\r\n <summary>I have verified that this workaround works (expand to see logs).</summary>\r\n\r\n```\r\n% k logs huggingface-predictor-00004-deployment-946b4d6c8-pk5nj -f\r\nDefaulted container \"kserve-container\" out of: kserve-container, queue-proxy\r\nINFO:root:Copying contents of s3://kserve-test-models/classifier to local\r\nINFO:root:Downloaded object classifier/config.json to /tmp/tmppwjsica7/config.json\r\n...\r\nINFO:kserve:successfully loaded tokenizer for task: 4\r\nINFO:kserve:successfully loaded huggingface model from path /tmp/tmppwjsica7\r\nINFO:kserve:Registering model: classifier\r\nINFO:kserve:Setting max asyncio worker threads as 5\r\nINFO:kserve:Starting uvicorn with 1 workers\r\n2024-02-09 18:57:33.228 uvicorn.error INFO: Started server process [1]\r\n2024-02-09 18:57:33.229 uvicorn.error INFO: Waiting for application startup.\r\n2024-02-09 18:57:33.234 1 kserve INFO [start():62] Starting gRPC server on [::]:8081\r\n2024-02-09 18:57:33.234 uvicorn.error INFO: Application startup complete.\r\n2024-02-09 18:57:33.235 uvicorn.error INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)\r\n```\r\n</details>\r\n\r\nI think the issue is here:\r\nhttps://github.com/kserve/kserve/blob/5172dc80b0a23d2263757de70a02eeef08b18811/python/huggingfaceserver/huggingfaceserver/__main__.py#L63-L72\r\n\r\n1. `model.load()` will succeed, so we jump to line 68\r\n2. It checks for `args.model_id`, which is empty, so we go inside the if block\r\n3. It will try to instantiate `HuggingfaceModelRepository` with `model_dir`, which is pointing to an s3 bucket and not a local directory, thus causing the `FileNotFoundError`\r\n4. This is how I came up with the workaround of passing `model_id`, so that the else block is executed instead (because the model did load succesfully, so doing `kserve.ModelServer().start([model] if model.ready else [])` won't be a problem)\r\n\r\n**Environment:**\r\n\r\n- Cloud Environment: aws\r\n- Kubernetes version: (use `kubectl version`): v1.27.9-eks-5e0fdde\r\n- OS (e.g. from `/etc/os-release`): Ubuntu 22.04.3 LTS\r\n\n", "before_files": [{"content": "# Copyright 2024 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\n\nfrom kserve.model import PredictorConfig\nfrom . import HuggingfaceModel, HuggingfaceModelRepository\nimport kserve\nfrom kserve.errors import ModelMissingError\n\n\ndef list_of_strings(arg):\n return arg.split(',')\n\n\nparser = argparse.ArgumentParser(parents=[kserve.model_server.parser])\n\nparser.add_argument('--model_dir', required=False, default=None,\n help='A URI pointer to the model binary')\nparser.add_argument('--model_id', required=False,\n help='Huggingface model id')\nparser.add_argument('--tensor_parallel_degree', type=int, default=-1,\n help='tensor parallel degree')\nparser.add_argument('--max_length', type=int, default=None,\n help='max sequence length for the tokenizer')\nparser.add_argument('--do_lower_case', type=bool, default=True,\n help='do lower case for the tokenizer')\nparser.add_argument('--add_special_tokens', type=bool, default=True,\n help='the sequences will be encoded with the special tokens relative to their model')\nparser.add_argument('--tensor_input_names', type=list_of_strings, default=None,\n help='the tensor input names passed to the model')\nparser.add_argument('--task', required=False, help=\"The ML task name\")\n\ntry:\n from vllm.engine.arg_utils import AsyncEngineArgs\n\n parser = AsyncEngineArgs.add_cli_args(parser)\n _vllm = True\nexcept ImportError:\n _vllm = False\nargs, _ = parser.parse_known_args()\n\nif __name__ == \"__main__\":\n engine_args = AsyncEngineArgs.from_cli_args(args) if _vllm else None\n predictor_config = PredictorConfig(args.predictor_host, args.predictor_protocol,\n args.predictor_use_ssl,\n args.predictor_request_timeout_seconds)\n model = HuggingfaceModel(args.model_name,\n predictor_config=predictor_config,\n kwargs=vars(args), engine_args=engine_args)\n try:\n model.load()\n except ModelMissingError:\n logging.error(f\"fail to locate model file for model {args.model_name} under dir {args.model_dir},\"\n f\"trying loading from model repository.\")\n if not args.model_id:\n kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(\n [model] if model.ready else [])\n else:\n kserve.ModelServer().start([model] if model.ready else [])\n", "path": "python/huggingfaceserver/huggingfaceserver/__main__.py"}], "after_files": [{"content": "# Copyright 2024 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\n\nfrom kserve.model import PredictorConfig\nfrom . import HuggingfaceModel, HuggingfaceModelRepository\nimport kserve\nfrom kserve.errors import ModelMissingError\n\n\ndef list_of_strings(arg):\n return arg.split(',')\n\n\nparser = argparse.ArgumentParser(parents=[kserve.model_server.parser])\n\nparser.add_argument('--model_dir', required=False, default=None,\n help='A URI pointer to the model binary')\nparser.add_argument('--model_id', required=False,\n help='Huggingface model id')\nparser.add_argument('--tensor_parallel_degree', type=int, default=-1,\n help='tensor parallel degree')\nparser.add_argument('--max_length', type=int, default=None,\n help='max sequence length for the tokenizer')\nparser.add_argument('--do_lower_case', type=bool, default=True,\n help='do lower case for the tokenizer')\nparser.add_argument('--add_special_tokens', type=bool, default=True,\n help='the sequences will be encoded with the special tokens relative to their model')\nparser.add_argument('--tensor_input_names', type=list_of_strings, default=None,\n help='the tensor input names passed to the model')\nparser.add_argument('--task', required=False, help=\"The ML task name\")\n\ntry:\n from vllm.engine.arg_utils import AsyncEngineArgs\n\n parser = AsyncEngineArgs.add_cli_args(parser)\n _vllm = True\nexcept ImportError:\n _vllm = False\nargs, _ = parser.parse_known_args()\n\nif __name__ == \"__main__\":\n engine_args = AsyncEngineArgs.from_cli_args(args) if _vllm else None\n predictor_config = PredictorConfig(args.predictor_host, args.predictor_protocol,\n args.predictor_use_ssl,\n args.predictor_request_timeout_seconds)\n model = HuggingfaceModel(args.model_name,\n predictor_config=predictor_config,\n kwargs=vars(args), engine_args=engine_args)\n try:\n model.load()\n kserve.ModelServer().start([model] if model.ready else [])\n except ModelMissingError:\n logging.error(f\"fail to locate model file for model {args.model_name} under dir {args.model_dir},\"\n f\"trying loading from model repository.\")\n kserve.ModelServer(registered_models=HuggingfaceModelRepository(args.model_dir)).start(\n [model] if model.ready else [])\n", "path": "python/huggingfaceserver/huggingfaceserver/__main__.py"}]} | 2,539 | 209 |
gh_patches_debug_11771 | rasdani/github-patches | git_diff | google__timesketch-268 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong app context for CSV task
We need to run the CSV importer task in the correct context.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `timesketch/lib/tasks.py`
Content:
```
1 # Copyright 2015 Google Inc. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Celery task for processing Plaso storage files."""
15
16 import os
17 import logging
18 import sys
19
20 from flask import current_app
21 # We currently don't have plaso in our Travis setup. This is a workaround
22 # for that until we fix the Travis environment.
23 # TODO: Add Plaso to our Travis environment we are running our tests in.
24 try:
25 from plaso.frontend import psort
26 except ImportError:
27 pass
28
29 from timesketch import create_celery_app
30 from timesketch.lib.datastores.elastic import ElasticsearchDataStore
31 from timesketch.lib.utils import read_and_validate_csv
32 from timesketch.models import db_session
33 from timesketch.models.sketch import SearchIndex
34
35 celery = create_celery_app()
36
37
38 def get_data_location():
39 """Path to the plaso data directory.
40
41 Returns:
42 The path to where the plaso data directory is or None if not existing.
43 """
44 data_location = current_app.config.get(u'PLASO_DATA_LOCATION', None)
45 if not data_location:
46 data_location = os.path.join(sys.prefix, u'share', u'plaso')
47 if not os.path.exists(data_location):
48 data_location = None
49 return data_location
50
51
52 @celery.task(track_started=True)
53 def run_plaso(source_file_path, timeline_name, index_name, username=None):
54 """Create a Celery task for processing Plaso storage file.
55
56 Args:
57 source_file_path: Path to plaso storage file.
58 timeline_name: Name of the Timesketch timeline.
59 index_name: Name of the datastore index.
60 username: Username of the user who will own the timeline.
61
62 Returns:
63 Dictionary with count of processed events.
64 """
65 plaso_data_location = get_data_location()
66 flush_interval = 1000 # events to queue before bulk index
67 doc_type = u'plaso_event' # Document type for Elasticsearch
68
69 # Use Plaso psort frontend tool.
70 frontend = psort.PsortFrontend()
71 frontend.SetDataLocation(plaso_data_location)
72 storage_reader = frontend.CreateStorageReader(source_file_path)
73
74 # Setup the Timesketch output module.
75 output_module = frontend.CreateOutputModule(u'timesketch')
76 output_module.SetIndexName(index_name)
77 output_module.SetTimelineName(timeline_name)
78 output_module.SetFlushInterval(flush_interval)
79 output_module.SetDocType(doc_type)
80 if username:
81 output_module.SetUserName(username)
82
83 # Start process the Plaso storage file.
84 counter = frontend.ExportEvents(storage_reader, output_module)
85
86 return dict(counter)
87
88
89 @celery.task(track_started=True)
90 def run_csv(source_file_path, timeline_name, index_name, username=None):
91 """Create a Celery task for processing a CSV file.
92
93 Args:
94 source_file_path: Path to CSV file.
95 timeline_name: Name of the Timesketch timeline.
96 index_name: Name of the datastore index.
97
98 Returns:
99 Dictionary with count of processed events.
100 """
101 flush_interval = 1000 # events to queue before bulk index
102 event_type = u'generic_event' # Document type for Elasticsearch
103
104 # Log information to Celery
105 logging.info(u'Index name: %s', index_name)
106 logging.info(u'Timeline name: %s', timeline_name)
107 logging.info(u'Flush interval: %d', flush_interval)
108 logging.info(u'Document type: %s', event_type)
109 logging.info(u'Owner: %s', username)
110
111 es = ElasticsearchDataStore(
112 host=current_app.config[u'ELASTIC_HOST'],
113 port=current_app.config[u'ELASTIC_PORT'])
114
115 es.create_index(index_name=index_name, doc_type=event_type)
116 for event in read_and_validate_csv(source_file_path):
117 es.import_event(
118 flush_interval, index_name, event_type, event)
119
120 # Import the remaining events
121 total_events = es.import_event(flush_interval, index_name, event_type)
122
123 # We are done so let's remove the processing status flag
124 search_index = SearchIndex.query.filter_by(index_name=index_name).first()
125 search_index.status.remove(search_index.status[0])
126 db_session.add(search_index)
127 db_session.commit()
128
129 return {u'Events processed': total_events}
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/timesketch/lib/tasks.py b/timesketch/lib/tasks.py
--- a/timesketch/lib/tasks.py
+++ b/timesketch/lib/tasks.py
@@ -121,9 +121,10 @@
total_events = es.import_event(flush_interval, index_name, event_type)
# We are done so let's remove the processing status flag
- search_index = SearchIndex.query.filter_by(index_name=index_name).first()
- search_index.status.remove(search_index.status[0])
- db_session.add(search_index)
- db_session.commit()
+ with celery.app.app_context():
+ search_index = SearchIndex.query.filter_by(index_name=index_name).first()
+ search_index.status.remove(search_index.status[0])
+ db_session.add(search_index)
+ db_session.commit()
return {u'Events processed': total_events}
| {"golden_diff": "diff --git a/timesketch/lib/tasks.py b/timesketch/lib/tasks.py\n--- a/timesketch/lib/tasks.py\n+++ b/timesketch/lib/tasks.py\n@@ -121,9 +121,10 @@\n total_events = es.import_event(flush_interval, index_name, event_type)\n \n # We are done so let's remove the processing status flag\n- search_index = SearchIndex.query.filter_by(index_name=index_name).first()\n- search_index.status.remove(search_index.status[0])\n- db_session.add(search_index)\n- db_session.commit()\n+ with celery.app.app_context():\n+ search_index = SearchIndex.query.filter_by(index_name=index_name).first()\n+ search_index.status.remove(search_index.status[0])\n+ db_session.add(search_index)\n+ db_session.commit()\n \n return {u'Events processed': total_events}\n", "issue": "Wrong app context for CSV task\nWe need to run the CSV importer task in the correct context.\n", "before_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Celery task for processing Plaso storage files.\"\"\"\n\nimport os\nimport logging\nimport sys\n\nfrom flask import current_app\n# We currently don't have plaso in our Travis setup. This is a workaround\n# for that until we fix the Travis environment.\n# TODO: Add Plaso to our Travis environment we are running our tests in.\ntry:\n from plaso.frontend import psort\nexcept ImportError:\n pass\n\nfrom timesketch import create_celery_app\nfrom timesketch.lib.datastores.elastic import ElasticsearchDataStore\nfrom timesketch.lib.utils import read_and_validate_csv\nfrom timesketch.models import db_session\nfrom timesketch.models.sketch import SearchIndex\n\ncelery = create_celery_app()\n\n\ndef get_data_location():\n \"\"\"Path to the plaso data directory.\n\n Returns:\n The path to where the plaso data directory is or None if not existing.\n \"\"\"\n data_location = current_app.config.get(u'PLASO_DATA_LOCATION', None)\n if not data_location:\n data_location = os.path.join(sys.prefix, u'share', u'plaso')\n if not os.path.exists(data_location):\n data_location = None\n return data_location\n\n\[email protected](track_started=True)\ndef run_plaso(source_file_path, timeline_name, index_name, username=None):\n \"\"\"Create a Celery task for processing Plaso storage file.\n\n Args:\n source_file_path: Path to plaso storage file.\n timeline_name: Name of the Timesketch timeline.\n index_name: Name of the datastore index.\n username: Username of the user who will own the timeline.\n\n Returns:\n Dictionary with count of processed events.\n \"\"\"\n plaso_data_location = get_data_location()\n flush_interval = 1000 # events to queue before bulk index\n doc_type = u'plaso_event' # Document type for Elasticsearch\n\n # Use Plaso psort frontend tool.\n frontend = psort.PsortFrontend()\n frontend.SetDataLocation(plaso_data_location)\n storage_reader = frontend.CreateStorageReader(source_file_path)\n\n # Setup the Timesketch output module.\n output_module = frontend.CreateOutputModule(u'timesketch')\n output_module.SetIndexName(index_name)\n output_module.SetTimelineName(timeline_name)\n output_module.SetFlushInterval(flush_interval)\n output_module.SetDocType(doc_type)\n if username:\n output_module.SetUserName(username)\n\n # Start process the Plaso storage file.\n counter = frontend.ExportEvents(storage_reader, output_module)\n\n return dict(counter)\n\n\[email protected](track_started=True)\ndef run_csv(source_file_path, timeline_name, index_name, username=None):\n \"\"\"Create a Celery task for processing a CSV file.\n\n Args:\n source_file_path: Path to CSV file.\n timeline_name: Name of the Timesketch timeline.\n index_name: Name of the datastore index.\n\n Returns:\n Dictionary with count of processed events.\n \"\"\"\n flush_interval = 1000 # events to queue before bulk index\n event_type = u'generic_event' # Document type for Elasticsearch\n\n # Log information to Celery\n logging.info(u'Index name: %s', index_name)\n logging.info(u'Timeline name: %s', timeline_name)\n logging.info(u'Flush interval: %d', flush_interval)\n logging.info(u'Document type: %s', event_type)\n logging.info(u'Owner: %s', username)\n\n es = ElasticsearchDataStore(\n host=current_app.config[u'ELASTIC_HOST'],\n port=current_app.config[u'ELASTIC_PORT'])\n\n es.create_index(index_name=index_name, doc_type=event_type)\n for event in read_and_validate_csv(source_file_path):\n es.import_event(\n flush_interval, index_name, event_type, event)\n\n # Import the remaining events\n total_events = es.import_event(flush_interval, index_name, event_type)\n\n # We are done so let's remove the processing status flag\n search_index = SearchIndex.query.filter_by(index_name=index_name).first()\n search_index.status.remove(search_index.status[0])\n db_session.add(search_index)\n db_session.commit()\n\n return {u'Events processed': total_events}\n", "path": "timesketch/lib/tasks.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Celery task for processing Plaso storage files.\"\"\"\n\nimport os\nimport logging\nimport sys\n\nfrom flask import current_app\n# We currently don't have plaso in our Travis setup. This is a workaround\n# for that until we fix the Travis environment.\n# TODO: Add Plaso to our Travis environment we are running our tests in.\ntry:\n from plaso.frontend import psort\nexcept ImportError:\n pass\n\nfrom timesketch import create_celery_app\nfrom timesketch.lib.datastores.elastic import ElasticsearchDataStore\nfrom timesketch.lib.utils import read_and_validate_csv\nfrom timesketch.models import db_session\nfrom timesketch.models.sketch import SearchIndex\n\ncelery = create_celery_app()\n\n\ndef get_data_location():\n \"\"\"Path to the plaso data directory.\n\n Returns:\n The path to where the plaso data directory is or None if not existing.\n \"\"\"\n data_location = current_app.config.get(u'PLASO_DATA_LOCATION', None)\n if not data_location:\n data_location = os.path.join(sys.prefix, u'share', u'plaso')\n if not os.path.exists(data_location):\n data_location = None\n return data_location\n\n\[email protected](track_started=True)\ndef run_plaso(source_file_path, timeline_name, index_name, username=None):\n \"\"\"Create a Celery task for processing Plaso storage file.\n\n Args:\n source_file_path: Path to plaso storage file.\n timeline_name: Name of the Timesketch timeline.\n index_name: Name of the datastore index.\n username: Username of the user who will own the timeline.\n\n Returns:\n Dictionary with count of processed events.\n \"\"\"\n plaso_data_location = get_data_location()\n flush_interval = 1000 # events to queue before bulk index\n doc_type = u'plaso_event' # Document type for Elasticsearch\n\n # Use Plaso psort frontend tool.\n frontend = psort.PsortFrontend()\n frontend.SetDataLocation(plaso_data_location)\n storage_reader = frontend.CreateStorageReader(source_file_path)\n\n # Setup the Timesketch output module.\n output_module = frontend.CreateOutputModule(u'timesketch')\n output_module.SetIndexName(index_name)\n output_module.SetTimelineName(timeline_name)\n output_module.SetFlushInterval(flush_interval)\n output_module.SetDocType(doc_type)\n if username:\n output_module.SetUserName(username)\n\n # Start process the Plaso storage file.\n counter = frontend.ExportEvents(storage_reader, output_module)\n\n return dict(counter)\n\n\[email protected](track_started=True)\ndef run_csv(source_file_path, timeline_name, index_name, username=None):\n \"\"\"Create a Celery task for processing a CSV file.\n\n Args:\n source_file_path: Path to CSV file.\n timeline_name: Name of the Timesketch timeline.\n index_name: Name of the datastore index.\n\n Returns:\n Dictionary with count of processed events.\n \"\"\"\n flush_interval = 1000 # events to queue before bulk index\n event_type = u'generic_event' # Document type for Elasticsearch\n\n # Log information to Celery\n logging.info(u'Index name: %s', index_name)\n logging.info(u'Timeline name: %s', timeline_name)\n logging.info(u'Flush interval: %d', flush_interval)\n logging.info(u'Document type: %s', event_type)\n logging.info(u'Owner: %s', username)\n\n es = ElasticsearchDataStore(\n host=current_app.config[u'ELASTIC_HOST'],\n port=current_app.config[u'ELASTIC_PORT'])\n\n es.create_index(index_name=index_name, doc_type=event_type)\n for event in read_and_validate_csv(source_file_path):\n es.import_event(\n flush_interval, index_name, event_type, event)\n\n # Import the remaining events\n total_events = es.import_event(flush_interval, index_name, event_type)\n\n # We are done so let's remove the processing status flag\n with celery.app.app_context():\n search_index = SearchIndex.query.filter_by(index_name=index_name).first()\n search_index.status.remove(search_index.status[0])\n db_session.add(search_index)\n db_session.commit()\n\n return {u'Events processed': total_events}\n", "path": "timesketch/lib/tasks.py"}]} | 1,621 | 193 |
gh_patches_debug_41329 | rasdani/github-patches | git_diff | tensorflow__addons-2008 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keras model save using WeightedKappaLoss errors, not json serializable
**Describe the bug**
Keras model compiled with WeightedKappaLoss errors when saving, "TypeError: ('Not JSON Serializable:', tf.float32)"
**Code to reproduce the issue**
```
model = Sequential()
model._set_inputs(tf.keras.Input((256,256,3)))
model.add(layers.Dense(6, activation='softmax'))
model.compile(Adam(lr=1e-3), tfa.losses.WeightedKappaLoss(num_classes=6, weightage='quadratic'))
model.save('test')
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/losses/kappa_loss.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Implements Weighted kappa loss."""
16
17 import tensorflow as tf
18 from tensorflow_addons.utils.types import Number
19 from typeguard import typechecked
20 from typing import Optional
21
22
23 @tf.keras.utils.register_keras_serializable(package="Addons")
24 class WeightedKappaLoss(tf.keras.losses.Loss):
25 """Implements the Weighted Kappa loss function.
26
27 Weighted Kappa loss was introduced in the
28 [Weighted kappa loss function for multi-class classification
29 of ordinal data in deep learning]
30 (https://www.sciencedirect.com/science/article/abs/pii/S0167865517301666).
31 Weighted Kappa is widely used in Ordinal Classification Problems.
32 The loss value lies in [-inf, log 2], where log 2
33 means the random prediction.
34
35 Usage:
36
37 ```python
38 kappa_loss = WeightedKappaLoss(num_classes=4)
39 y_true = tf.constant([[0, 0, 1, 0], [0, 1, 0, 0],
40 [1, 0, 0, 0], [0, 0, 0, 1]])
41 y_pred = tf.constant([[0.1, 0.2, 0.6, 0.1], [0.1, 0.5, 0.3, 0.1],
42 [0.8, 0.05, 0.05, 0.1], [0.01, 0.09, 0.1, 0.8]])
43 loss = kappa_loss(y_true, y_pred)
44 print('Loss: ', loss.numpy()) # Loss: -1.1611923
45 ```
46
47 Usage with `tf.keras` API:
48 ```python
49 # outputs should be softmax results
50 # if you want to weight the samples, just multiply the outputs
51 # by the sample weight.
52 model = tf.keras.Model(inputs, outputs)
53 model.compile('sgd', loss=tfa.losses.WeightedKappa(num_classes=4))
54 ```
55 """
56
57 @typechecked
58 def __init__(
59 self,
60 num_classes: int,
61 weightage: Optional[str] = "quadratic",
62 name: Optional[str] = "cohen_kappa_loss",
63 epsilon: Optional[Number] = 1e-6,
64 dtype: Optional[tf.DType] = tf.float32,
65 reduction: str = tf.keras.losses.Reduction.NONE,
66 ):
67 """Creates a `WeightedKappa` instance.
68
69 Args:
70 num_classes: Number of unique classes in your dataset.
71 weightage: (Optional) Weighting to be considered for calculating
72 kappa statistics. A valid value is one of
73 ['linear', 'quadratic']. Defaults to `quadratic` since it's
74 mostly used.
75 name: (Optional) String name of the metric instance.
76 epsilon: (Optional) increment to avoid log zero,
77 so the loss will be log(1 - k + epsilon), where k belongs to
78 [-1, 1], usually you can use the default value which is 1e-6.
79 dtype: (Optional) Data type of the metric result.
80 Defaults to `tf.float32`.
81 Raises:
82 ValueError: If the value passed for `weightage` is invalid
83 i.e. not any one of ['linear', 'quadratic']
84 """
85
86 super().__init__(name=name, reduction=reduction)
87
88 if weightage not in ("linear", "quadratic"):
89 raise ValueError("Unknown kappa weighting type.")
90
91 self.weightage = weightage
92 self.num_classes = num_classes
93 self.epsilon = epsilon
94 self.dtype = dtype
95 label_vec = tf.range(num_classes, dtype=dtype)
96 self.row_label_vec = tf.reshape(label_vec, [1, num_classes])
97 self.col_label_vec = tf.reshape(label_vec, [num_classes, 1])
98 col_mat = tf.tile(self.col_label_vec, [1, num_classes])
99 row_mat = tf.tile(self.row_label_vec, [num_classes, 1])
100 if weightage == "linear":
101 self.weight_mat = tf.abs(col_mat - row_mat)
102 else:
103 self.weight_mat = (col_mat - row_mat) ** 2
104
105 def call(self, y_true, y_pred):
106 y_true = tf.cast(y_true, dtype=self.dtype)
107 batch_size = tf.shape(y_true)[0]
108 cat_labels = tf.matmul(y_true, self.col_label_vec)
109 cat_label_mat = tf.tile(cat_labels, [1, self.num_classes])
110 row_label_mat = tf.tile(self.row_label_vec, [batch_size, 1])
111 if self.weightage == "linear":
112 weight = tf.abs(cat_label_mat - row_label_mat)
113 else:
114 weight = (cat_label_mat - row_label_mat) ** 2
115 numerator = tf.reduce_sum(weight * y_pred)
116 label_dist = tf.reduce_sum(y_true, axis=0, keepdims=True)
117 pred_dist = tf.reduce_sum(y_pred, axis=0, keepdims=True)
118 w_pred_dist = tf.matmul(self.weight_mat, pred_dist, transpose_b=True)
119 denominator = tf.reduce_sum(tf.matmul(label_dist, w_pred_dist))
120 denominator /= tf.cast(batch_size, dtype=self.dtype)
121 loss = tf.math.divide_no_nan(numerator, denominator)
122 return tf.math.log(loss + self.epsilon)
123
124 def get_config(self):
125 config = {
126 "num_classes": self.num_classes,
127 "weightage": self.weightage,
128 "epsilon": self.epsilon,
129 "dtype": self.dtype,
130 }
131 base_config = super().get_config()
132 return {**base_config, **config}
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tensorflow_addons/losses/kappa_loss.py b/tensorflow_addons/losses/kappa_loss.py
--- a/tensorflow_addons/losses/kappa_loss.py
+++ b/tensorflow_addons/losses/kappa_loss.py
@@ -14,10 +14,13 @@
# ==============================================================================
"""Implements Weighted kappa loss."""
+import warnings
+from typing import Optional
+
import tensorflow as tf
-from tensorflow_addons.utils.types import Number
from typeguard import typechecked
-from typing import Optional
+
+from tensorflow_addons.utils.types import Number
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -85,14 +88,20 @@
super().__init__(name=name, reduction=reduction)
+ warnings.warn(
+ "The data type for `WeightedKappaLoss` defaults to "
+ "`tf.keras.backend.floatx()`."
+ "The argument `dtype` will be removed in Addons `0.12`.",
+ DeprecationWarning,
+ )
+
if weightage not in ("linear", "quadratic"):
raise ValueError("Unknown kappa weighting type.")
self.weightage = weightage
self.num_classes = num_classes
- self.epsilon = epsilon
- self.dtype = dtype
- label_vec = tf.range(num_classes, dtype=dtype)
+ self.epsilon = epsilon or tf.keras.backend.epsilon()
+ label_vec = tf.range(num_classes, dtype=tf.keras.backend.floatx())
self.row_label_vec = tf.reshape(label_vec, [1, num_classes])
self.col_label_vec = tf.reshape(label_vec, [num_classes, 1])
col_mat = tf.tile(self.col_label_vec, [1, num_classes])
@@ -103,7 +112,8 @@
self.weight_mat = (col_mat - row_mat) ** 2
def call(self, y_true, y_pred):
- y_true = tf.cast(y_true, dtype=self.dtype)
+ y_true = tf.cast(y_true, dtype=self.col_label_vec.dtype)
+ y_pred = tf.cast(y_pred, dtype=self.weight_mat.dtype)
batch_size = tf.shape(y_true)[0]
cat_labels = tf.matmul(y_true, self.col_label_vec)
cat_label_mat = tf.tile(cat_labels, [1, self.num_classes])
@@ -117,7 +127,7 @@
pred_dist = tf.reduce_sum(y_pred, axis=0, keepdims=True)
w_pred_dist = tf.matmul(self.weight_mat, pred_dist, transpose_b=True)
denominator = tf.reduce_sum(tf.matmul(label_dist, w_pred_dist))
- denominator /= tf.cast(batch_size, dtype=self.dtype)
+ denominator /= tf.cast(batch_size, dtype=denominator.dtype)
loss = tf.math.divide_no_nan(numerator, denominator)
return tf.math.log(loss + self.epsilon)
@@ -126,7 +136,6 @@
"num_classes": self.num_classes,
"weightage": self.weightage,
"epsilon": self.epsilon,
- "dtype": self.dtype,
}
base_config = super().get_config()
return {**base_config, **config}
| {"golden_diff": "diff --git a/tensorflow_addons/losses/kappa_loss.py b/tensorflow_addons/losses/kappa_loss.py\n--- a/tensorflow_addons/losses/kappa_loss.py\n+++ b/tensorflow_addons/losses/kappa_loss.py\n@@ -14,10 +14,13 @@\n # ==============================================================================\n \"\"\"Implements Weighted kappa loss.\"\"\"\n \n+import warnings\n+from typing import Optional\n+\n import tensorflow as tf\n-from tensorflow_addons.utils.types import Number\n from typeguard import typechecked\n-from typing import Optional\n+\n+from tensorflow_addons.utils.types import Number\n \n \n @tf.keras.utils.register_keras_serializable(package=\"Addons\")\n@@ -85,14 +88,20 @@\n \n super().__init__(name=name, reduction=reduction)\n \n+ warnings.warn(\n+ \"The data type for `WeightedKappaLoss` defaults to \"\n+ \"`tf.keras.backend.floatx()`.\"\n+ \"The argument `dtype` will be removed in Addons `0.12`.\",\n+ DeprecationWarning,\n+ )\n+\n if weightage not in (\"linear\", \"quadratic\"):\n raise ValueError(\"Unknown kappa weighting type.\")\n \n self.weightage = weightage\n self.num_classes = num_classes\n- self.epsilon = epsilon\n- self.dtype = dtype\n- label_vec = tf.range(num_classes, dtype=dtype)\n+ self.epsilon = epsilon or tf.keras.backend.epsilon()\n+ label_vec = tf.range(num_classes, dtype=tf.keras.backend.floatx())\n self.row_label_vec = tf.reshape(label_vec, [1, num_classes])\n self.col_label_vec = tf.reshape(label_vec, [num_classes, 1])\n col_mat = tf.tile(self.col_label_vec, [1, num_classes])\n@@ -103,7 +112,8 @@\n self.weight_mat = (col_mat - row_mat) ** 2\n \n def call(self, y_true, y_pred):\n- y_true = tf.cast(y_true, dtype=self.dtype)\n+ y_true = tf.cast(y_true, dtype=self.col_label_vec.dtype)\n+ y_pred = tf.cast(y_pred, dtype=self.weight_mat.dtype)\n batch_size = tf.shape(y_true)[0]\n cat_labels = tf.matmul(y_true, self.col_label_vec)\n cat_label_mat = tf.tile(cat_labels, [1, self.num_classes])\n@@ -117,7 +127,7 @@\n pred_dist = tf.reduce_sum(y_pred, axis=0, keepdims=True)\n w_pred_dist = tf.matmul(self.weight_mat, pred_dist, transpose_b=True)\n denominator = tf.reduce_sum(tf.matmul(label_dist, w_pred_dist))\n- denominator /= tf.cast(batch_size, dtype=self.dtype)\n+ denominator /= tf.cast(batch_size, dtype=denominator.dtype)\n loss = tf.math.divide_no_nan(numerator, denominator)\n return tf.math.log(loss + self.epsilon)\n \n@@ -126,7 +136,6 @@\n \"num_classes\": self.num_classes,\n \"weightage\": self.weightage,\n \"epsilon\": self.epsilon,\n- \"dtype\": self.dtype,\n }\n base_config = super().get_config()\n return {**base_config, **config}\n", "issue": "Keras model save using WeightedKappaLoss errors, not json serializable\n**Describe the bug**\r\n\r\nKeras model compiled with WeightedKappaLoss errors when saving, \"TypeError: ('Not JSON Serializable:', tf.float32)\"\r\n\r\n**Code to reproduce the issue**\r\n\r\n```\r\nmodel = Sequential()\r\n\r\nmodel._set_inputs(tf.keras.Input((256,256,3)))\r\nmodel.add(layers.Dense(6, activation='softmax'))\r\n\r\nmodel.compile(Adam(lr=1e-3), tfa.losses.WeightedKappaLoss(num_classes=6, weightage='quadratic'))\r\nmodel.save('test')\r\n```\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements Weighted kappa loss.\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils.types import Number\nfrom typeguard import typechecked\nfrom typing import Optional\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass WeightedKappaLoss(tf.keras.losses.Loss):\n \"\"\"Implements the Weighted Kappa loss function.\n\n Weighted Kappa loss was introduced in the\n [Weighted kappa loss function for multi-class classification\n of ordinal data in deep learning]\n (https://www.sciencedirect.com/science/article/abs/pii/S0167865517301666).\n Weighted Kappa is widely used in Ordinal Classification Problems.\n The loss value lies in [-inf, log 2], where log 2\n means the random prediction.\n\n Usage:\n\n ```python\n kappa_loss = WeightedKappaLoss(num_classes=4)\n y_true = tf.constant([[0, 0, 1, 0], [0, 1, 0, 0],\n [1, 0, 0, 0], [0, 0, 0, 1]])\n y_pred = tf.constant([[0.1, 0.2, 0.6, 0.1], [0.1, 0.5, 0.3, 0.1],\n [0.8, 0.05, 0.05, 0.1], [0.01, 0.09, 0.1, 0.8]])\n loss = kappa_loss(y_true, y_pred)\n print('Loss: ', loss.numpy()) # Loss: -1.1611923\n ```\n\n Usage with `tf.keras` API:\n ```python\n # outputs should be softmax results\n # if you want to weight the samples, just multiply the outputs\n # by the sample weight.\n model = tf.keras.Model(inputs, outputs)\n model.compile('sgd', loss=tfa.losses.WeightedKappa(num_classes=4))\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n num_classes: int,\n weightage: Optional[str] = \"quadratic\",\n name: Optional[str] = \"cohen_kappa_loss\",\n epsilon: Optional[Number] = 1e-6,\n dtype: Optional[tf.DType] = tf.float32,\n reduction: str = tf.keras.losses.Reduction.NONE,\n ):\n \"\"\"Creates a `WeightedKappa` instance.\n\n Args:\n num_classes: Number of unique classes in your dataset.\n weightage: (Optional) Weighting to be considered for calculating\n kappa statistics. A valid value is one of\n ['linear', 'quadratic']. Defaults to `quadratic` since it's\n mostly used.\n name: (Optional) String name of the metric instance.\n epsilon: (Optional) increment to avoid log zero,\n so the loss will be log(1 - k + epsilon), where k belongs to\n [-1, 1], usually you can use the default value which is 1e-6.\n dtype: (Optional) Data type of the metric result.\n Defaults to `tf.float32`.\n Raises:\n ValueError: If the value passed for `weightage` is invalid\n i.e. not any one of ['linear', 'quadratic']\n \"\"\"\n\n super().__init__(name=name, reduction=reduction)\n\n if weightage not in (\"linear\", \"quadratic\"):\n raise ValueError(\"Unknown kappa weighting type.\")\n\n self.weightage = weightage\n self.num_classes = num_classes\n self.epsilon = epsilon\n self.dtype = dtype\n label_vec = tf.range(num_classes, dtype=dtype)\n self.row_label_vec = tf.reshape(label_vec, [1, num_classes])\n self.col_label_vec = tf.reshape(label_vec, [num_classes, 1])\n col_mat = tf.tile(self.col_label_vec, [1, num_classes])\n row_mat = tf.tile(self.row_label_vec, [num_classes, 1])\n if weightage == \"linear\":\n self.weight_mat = tf.abs(col_mat - row_mat)\n else:\n self.weight_mat = (col_mat - row_mat) ** 2\n\n def call(self, y_true, y_pred):\n y_true = tf.cast(y_true, dtype=self.dtype)\n batch_size = tf.shape(y_true)[0]\n cat_labels = tf.matmul(y_true, self.col_label_vec)\n cat_label_mat = tf.tile(cat_labels, [1, self.num_classes])\n row_label_mat = tf.tile(self.row_label_vec, [batch_size, 1])\n if self.weightage == \"linear\":\n weight = tf.abs(cat_label_mat - row_label_mat)\n else:\n weight = (cat_label_mat - row_label_mat) ** 2\n numerator = tf.reduce_sum(weight * y_pred)\n label_dist = tf.reduce_sum(y_true, axis=0, keepdims=True)\n pred_dist = tf.reduce_sum(y_pred, axis=0, keepdims=True)\n w_pred_dist = tf.matmul(self.weight_mat, pred_dist, transpose_b=True)\n denominator = tf.reduce_sum(tf.matmul(label_dist, w_pred_dist))\n denominator /= tf.cast(batch_size, dtype=self.dtype)\n loss = tf.math.divide_no_nan(numerator, denominator)\n return tf.math.log(loss + self.epsilon)\n\n def get_config(self):\n config = {\n \"num_classes\": self.num_classes,\n \"weightage\": self.weightage,\n \"epsilon\": self.epsilon,\n \"dtype\": self.dtype,\n }\n base_config = super().get_config()\n return {**base_config, **config}\n", "path": "tensorflow_addons/losses/kappa_loss.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements Weighted kappa loss.\"\"\"\n\nimport warnings\nfrom typing import Optional\n\nimport tensorflow as tf\nfrom typeguard import typechecked\n\nfrom tensorflow_addons.utils.types import Number\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass WeightedKappaLoss(tf.keras.losses.Loss):\n \"\"\"Implements the Weighted Kappa loss function.\n\n Weighted Kappa loss was introduced in the\n [Weighted kappa loss function for multi-class classification\n of ordinal data in deep learning]\n (https://www.sciencedirect.com/science/article/abs/pii/S0167865517301666).\n Weighted Kappa is widely used in Ordinal Classification Problems.\n The loss value lies in [-inf, log 2], where log 2\n means the random prediction.\n\n Usage:\n\n ```python\n kappa_loss = WeightedKappaLoss(num_classes=4)\n y_true = tf.constant([[0, 0, 1, 0], [0, 1, 0, 0],\n [1, 0, 0, 0], [0, 0, 0, 1]])\n y_pred = tf.constant([[0.1, 0.2, 0.6, 0.1], [0.1, 0.5, 0.3, 0.1],\n [0.8, 0.05, 0.05, 0.1], [0.01, 0.09, 0.1, 0.8]])\n loss = kappa_loss(y_true, y_pred)\n print('Loss: ', loss.numpy()) # Loss: -1.1611923\n ```\n\n Usage with `tf.keras` API:\n ```python\n # outputs should be softmax results\n # if you want to weight the samples, just multiply the outputs\n # by the sample weight.\n model = tf.keras.Model(inputs, outputs)\n model.compile('sgd', loss=tfa.losses.WeightedKappa(num_classes=4))\n ```\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n num_classes: int,\n weightage: Optional[str] = \"quadratic\",\n name: Optional[str] = \"cohen_kappa_loss\",\n epsilon: Optional[Number] = 1e-6,\n dtype: Optional[tf.DType] = tf.float32,\n reduction: str = tf.keras.losses.Reduction.NONE,\n ):\n \"\"\"Creates a `WeightedKappa` instance.\n\n Args:\n num_classes: Number of unique classes in your dataset.\n weightage: (Optional) Weighting to be considered for calculating\n kappa statistics. A valid value is one of\n ['linear', 'quadratic']. Defaults to `quadratic` since it's\n mostly used.\n name: (Optional) String name of the metric instance.\n epsilon: (Optional) increment to avoid log zero,\n so the loss will be log(1 - k + epsilon), where k belongs to\n [-1, 1], usually you can use the default value which is 1e-6.\n dtype: (Optional) Data type of the metric result.\n Defaults to `tf.float32`.\n Raises:\n ValueError: If the value passed for `weightage` is invalid\n i.e. not any one of ['linear', 'quadratic']\n \"\"\"\n\n super().__init__(name=name, reduction=reduction)\n\n warnings.warn(\n \"The data type for `WeightedKappaLoss` defaults to \"\n \"`tf.keras.backend.floatx()`.\"\n \"The argument `dtype` will be removed in Addons `0.12`.\",\n DeprecationWarning,\n )\n\n if weightage not in (\"linear\", \"quadratic\"):\n raise ValueError(\"Unknown kappa weighting type.\")\n\n self.weightage = weightage\n self.num_classes = num_classes\n self.epsilon = epsilon or tf.keras.backend.epsilon()\n label_vec = tf.range(num_classes, dtype=tf.keras.backend.floatx())\n self.row_label_vec = tf.reshape(label_vec, [1, num_classes])\n self.col_label_vec = tf.reshape(label_vec, [num_classes, 1])\n col_mat = tf.tile(self.col_label_vec, [1, num_classes])\n row_mat = tf.tile(self.row_label_vec, [num_classes, 1])\n if weightage == \"linear\":\n self.weight_mat = tf.abs(col_mat - row_mat)\n else:\n self.weight_mat = (col_mat - row_mat) ** 2\n\n def call(self, y_true, y_pred):\n y_true = tf.cast(y_true, dtype=self.col_label_vec.dtype)\n y_pred = tf.cast(y_pred, dtype=self.weight_mat.dtype)\n batch_size = tf.shape(y_true)[0]\n cat_labels = tf.matmul(y_true, self.col_label_vec)\n cat_label_mat = tf.tile(cat_labels, [1, self.num_classes])\n row_label_mat = tf.tile(self.row_label_vec, [batch_size, 1])\n if self.weightage == \"linear\":\n weight = tf.abs(cat_label_mat - row_label_mat)\n else:\n weight = (cat_label_mat - row_label_mat) ** 2\n numerator = tf.reduce_sum(weight * y_pred)\n label_dist = tf.reduce_sum(y_true, axis=0, keepdims=True)\n pred_dist = tf.reduce_sum(y_pred, axis=0, keepdims=True)\n w_pred_dist = tf.matmul(self.weight_mat, pred_dist, transpose_b=True)\n denominator = tf.reduce_sum(tf.matmul(label_dist, w_pred_dist))\n denominator /= tf.cast(batch_size, dtype=denominator.dtype)\n loss = tf.math.divide_no_nan(numerator, denominator)\n return tf.math.log(loss + self.epsilon)\n\n def get_config(self):\n config = {\n \"num_classes\": self.num_classes,\n \"weightage\": self.weightage,\n \"epsilon\": self.epsilon,\n }\n base_config = super().get_config()\n return {**base_config, **config}\n", "path": "tensorflow_addons/losses/kappa_loss.py"}]} | 2,077 | 704 |
gh_patches_debug_6381 | rasdani/github-patches | git_diff | vllm-project__vllm-3578 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The same model cannot be loaded by two different users
As pointed out here, the way lockfiles are created prevents the second user from loading any models that a previous user has loaded at any point: https://github.com/vllm-project/vllm/issues/2179
This is still an issue with the only workaround being to force-delete the lockfile created by another user.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vllm/model_executor/weight_utils.py`
Content:
```
1 """Utilities for downloading and initializing model weights."""
2 import filelock
3 import glob
4 import fnmatch
5 import json
6 import os
7 from collections import defaultdict
8 from typing import Any, Iterator, List, Optional, Tuple
9
10 from huggingface_hub import snapshot_download, HfFileSystem
11 import numpy as np
12 from safetensors.torch import load_file, save_file, safe_open
13 import torch
14 from tqdm.auto import tqdm
15
16 from vllm.config import ModelConfig
17 from vllm.logger import init_logger
18 from vllm.model_executor.layers.quantization import (get_quantization_config,
19 QuantizationConfig)
20
21 logger = init_logger(__name__)
22
23 _xdg_cache_home = os.getenv('XDG_CACHE_HOME', os.path.expanduser('~/.cache'))
24 _vllm_filelocks_path = os.path.join(_xdg_cache_home, 'vllm/locks/')
25
26
27 class Disabledtqdm(tqdm):
28
29 def __init__(self, *args, **kwargs):
30 super().__init__(*args, **kwargs, disable=True)
31
32
33 def get_lock(model_name_or_path: str, cache_dir: Optional[str] = None):
34 lock_dir = cache_dir if cache_dir is not None else _vllm_filelocks_path
35 os.makedirs(os.path.dirname(lock_dir), exist_ok=True)
36 lock_file_name = model_name_or_path.replace("/", "-") + ".lock"
37 lock = filelock.FileLock(os.path.join(lock_dir, lock_file_name))
38 return lock
39
40
41 def _shared_pointers(tensors):
42 ptrs = defaultdict(list)
43 for k, v in tensors.items():
44 ptrs[v.data_ptr()].append(k)
45 failing = []
46 for _, names in ptrs.items():
47 if len(names) > 1:
48 failing.append(names)
49 return failing
50
51
52 def convert_bin_to_safetensor_file(
53 pt_filename: str,
54 sf_filename: str,
55 ) -> None:
56 loaded = torch.load(pt_filename, map_location="cpu")
57 if "state_dict" in loaded:
58 loaded = loaded["state_dict"]
59 shared = _shared_pointers(loaded)
60 for shared_weights in shared:
61 for name in shared_weights[1:]:
62 loaded.pop(name)
63
64 # For tensors to be contiguous
65 loaded = {k: v.contiguous() for k, v in loaded.items()}
66
67 dirname = os.path.dirname(sf_filename)
68 os.makedirs(dirname, exist_ok=True)
69 save_file(loaded, sf_filename, metadata={"format": "pt"})
70
71 # check file size
72 sf_size = os.stat(sf_filename).st_size
73 pt_size = os.stat(pt_filename).st_size
74 if (sf_size - pt_size) / pt_size > 0.01:
75 raise RuntimeError(f"""The file size different is more than 1%:
76 - {sf_filename}: {sf_size}
77 - {pt_filename}: {pt_size}
78 """)
79
80 # check if the tensors are the same
81 reloaded = load_file(sf_filename)
82 for k in loaded:
83 pt_tensor = loaded[k]
84 sf_tensor = reloaded[k]
85 if not torch.equal(pt_tensor, sf_tensor):
86 raise RuntimeError(f"The output tensors do not match for key {k}")
87
88
89 # TODO(woosuk): Move this to other place.
90 def get_quant_config(model_config: ModelConfig) -> QuantizationConfig:
91 quant_cls = get_quantization_config(model_config.quantization)
92 # Read the quantization config from the HF model config, if available.
93 hf_quant_config = getattr(model_config.hf_config, "quantization_config",
94 None)
95 if hf_quant_config is not None:
96 return quant_cls.from_config(hf_quant_config)
97 model_name_or_path = model_config.model
98 is_local = os.path.isdir(model_name_or_path)
99 if not is_local:
100 # Download the config files.
101 with get_lock(model_name_or_path, model_config.download_dir):
102 hf_folder = snapshot_download(model_name_or_path,
103 revision=model_config.revision,
104 allow_patterns="*.json",
105 cache_dir=model_config.download_dir,
106 tqdm_class=Disabledtqdm)
107 else:
108 hf_folder = model_name_or_path
109 config_files = glob.glob(os.path.join(hf_folder, "*.json"))
110
111 quant_config_files = [
112 f for f in config_files if any(
113 f.endswith(x) for x in quant_cls.get_config_filenames())
114 ]
115 if len(quant_config_files) == 0:
116 raise ValueError(
117 f"Cannot find the config file for {model_config.quantization}")
118 if len(quant_config_files) > 1:
119 raise ValueError(
120 f"Found multiple config files for {model_config.quantization}: "
121 f"{quant_config_files}")
122
123 quant_config_file = quant_config_files[0]
124 with open(quant_config_file, "r") as f:
125 config = json.load(f)
126 return quant_cls.from_config(config)
127
128
129 def prepare_hf_model_weights(
130 model_name_or_path: str,
131 cache_dir: Optional[str] = None,
132 load_format: str = "auto",
133 fall_back_to_pt: bool = True,
134 revision: Optional[str] = None,
135 ) -> Tuple[str, List[str], bool]:
136 # Download model weights from huggingface.
137 is_local = os.path.isdir(model_name_or_path)
138 use_safetensors = False
139 # Some quantized models use .pt files for storing the weights.
140 if load_format == "auto":
141 allow_patterns = ["*.safetensors", "*.bin"]
142 elif load_format == "safetensors":
143 use_safetensors = True
144 allow_patterns = ["*.safetensors"]
145 elif load_format == "pt":
146 allow_patterns = ["*.pt"]
147 elif load_format == "npcache":
148 allow_patterns = ["*.bin"]
149 else:
150 raise ValueError(f"Unknown load_format: {load_format}")
151
152 if fall_back_to_pt:
153 allow_patterns += ["*.pt"]
154
155 if not is_local:
156 # Before we download we look at that is available:
157 fs = HfFileSystem()
158 file_list = fs.ls(model_name_or_path, detail=False, revision=revision)
159
160 # depending on what is available we download different things
161 for pattern in allow_patterns:
162 matching = fnmatch.filter(file_list, pattern)
163 if len(matching) > 0:
164 allow_patterns = [pattern]
165 break
166
167 logger.info(f"Using model weights format {allow_patterns}")
168 # Use file lock to prevent multiple processes from
169 # downloading the same model weights at the same time.
170 with get_lock(model_name_or_path, cache_dir):
171 hf_folder = snapshot_download(model_name_or_path,
172 allow_patterns=allow_patterns,
173 cache_dir=cache_dir,
174 tqdm_class=Disabledtqdm,
175 revision=revision)
176 else:
177 hf_folder = model_name_or_path
178 hf_weights_files: List[str] = []
179 for pattern in allow_patterns:
180 hf_weights_files += glob.glob(os.path.join(hf_folder, pattern))
181 if len(hf_weights_files) > 0:
182 if pattern == "*.safetensors":
183 use_safetensors = True
184 break
185 if not use_safetensors:
186 # Exclude files that are not needed for inference.
187 # https://github.com/huggingface/transformers/blob/v4.34.0/src/transformers/trainer.py#L227-L233
188 blacklist = [
189 "training_args.bin",
190 "optimizer.bin",
191 "optimizer.pt",
192 "scheduler.pt",
193 "scaler.pt",
194 ]
195 hf_weights_files = [
196 f for f in hf_weights_files
197 if not any(f.endswith(x) for x in blacklist)
198 ]
199
200 if len(hf_weights_files) == 0:
201 raise RuntimeError(
202 f"Cannot find any model weights with `{model_name_or_path}`")
203
204 return hf_folder, hf_weights_files, use_safetensors
205
206
207 def hf_model_weights_iterator(
208 model_name_or_path: str,
209 cache_dir: Optional[str] = None,
210 load_format: str = "auto",
211 revision: Optional[str] = None,
212 fall_back_to_pt: Optional[bool] = True,
213 ) -> Iterator[Tuple[str, torch.Tensor]]:
214 hf_folder, hf_weights_files, use_safetensors = prepare_hf_model_weights(
215 model_name_or_path,
216 cache_dir=cache_dir,
217 load_format=load_format,
218 fall_back_to_pt=fall_back_to_pt,
219 revision=revision)
220
221 if load_format == "npcache":
222 # Currently np_cache only support *.bin checkpoints
223 assert use_safetensors is False
224
225 # Convert the model weights from torch tensors to numpy arrays for
226 # faster loading.
227 np_folder = os.path.join(hf_folder, "np")
228 os.makedirs(np_folder, exist_ok=True)
229 weight_names_file = os.path.join(np_folder, "weight_names.json")
230 # Use file lock to prevent multiple processes from
231 # dumping the same model weights to numpy at the same time.
232 with get_lock(model_name_or_path, cache_dir):
233 if not os.path.exists(weight_names_file):
234 weight_names = []
235 for bin_file in hf_weights_files:
236 state = torch.load(bin_file, map_location="cpu")
237 for name, param in state.items():
238 param_path = os.path.join(np_folder, name)
239 with open(param_path, "wb") as f:
240 np.save(f, param.cpu().detach().numpy())
241 weight_names.append(name)
242 with open(weight_names_file, "w") as f:
243 json.dump(weight_names, f)
244
245 with open(weight_names_file, "r") as f:
246 weight_names = json.load(f)
247
248 for name in weight_names:
249 param_path = os.path.join(np_folder, name)
250 with open(param_path, "rb") as f:
251 param = np.load(f)
252 yield name, torch.from_numpy(param)
253 elif use_safetensors:
254 for st_file in hf_weights_files:
255 with safe_open(st_file, framework="pt") as f:
256 for name in f.keys(): # noqa: SIM118
257 param = f.get_tensor(name)
258 yield name, param
259 else:
260 for bin_file in hf_weights_files:
261 state = torch.load(bin_file, map_location="cpu")
262 for name, param in state.items():
263 yield name, param
264 del state
265 torch.cuda.empty_cache()
266
267
268 def convert_pyslice_to_tensor(x: Any) -> torch.Tensor:
269 """convert PySafeSlice object from safetensors to torch.Tensor
270
271 PySafeSlice object supports indexing, which is done before loading the
272 actual tensor and can reduce the amount of memory being read into the
273 memory. However, it does not support more advanced functionalities
274 like `.view()` or `.t()`. Therefore, if we need to modify the loaded
275 tensor with these more complicated operators, we need to convert to
276 tensor first.
277 """
278 if not isinstance(x, torch.Tensor):
279 x = x[:]
280 return x
281
282
283 def default_weight_loader(param: torch.Tensor,
284 loaded_weight: torch.Tensor) -> None:
285 """Default weight loader."""
286 assert param.size() == loaded_weight.size()
287 param.data.copy_(loaded_weight)
288
289
290 def initialize_dummy_weights(
291 model: torch.nn.Module,
292 low: float = -1e-3,
293 high: float = 1e-3,
294 ) -> None:
295 """Initialize model weights with random values.
296
297 The model weights must be randomly initialized for accurate performance
298 measurements. Additionally, the model weights should not cause NaNs in the
299 forward pass. We empirically found that initializing the weights with
300 values between -1e-3 and 1e-3 works well for most models.
301 """
302 for param in model.state_dict().values():
303 if torch.is_floating_point(param):
304 param.data.uniform_(low, high)
305
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/vllm/model_executor/weight_utils.py b/vllm/model_executor/weight_utils.py
--- a/vllm/model_executor/weight_utils.py
+++ b/vllm/model_executor/weight_utils.py
@@ -34,7 +34,7 @@
lock_dir = cache_dir if cache_dir is not None else _vllm_filelocks_path
os.makedirs(os.path.dirname(lock_dir), exist_ok=True)
lock_file_name = model_name_or_path.replace("/", "-") + ".lock"
- lock = filelock.FileLock(os.path.join(lock_dir, lock_file_name))
+ lock = filelock.SoftFileLock(os.path.join(lock_dir, lock_file_name))
return lock
| {"golden_diff": "diff --git a/vllm/model_executor/weight_utils.py b/vllm/model_executor/weight_utils.py\n--- a/vllm/model_executor/weight_utils.py\n+++ b/vllm/model_executor/weight_utils.py\n@@ -34,7 +34,7 @@\n lock_dir = cache_dir if cache_dir is not None else _vllm_filelocks_path\n os.makedirs(os.path.dirname(lock_dir), exist_ok=True)\n lock_file_name = model_name_or_path.replace(\"/\", \"-\") + \".lock\"\n- lock = filelock.FileLock(os.path.join(lock_dir, lock_file_name))\n+ lock = filelock.SoftFileLock(os.path.join(lock_dir, lock_file_name))\n return lock\n", "issue": "The same model cannot be loaded by two different users\nAs pointed out here, the way lockfiles are created prevents the second user from loading any models that a previous user has loaded at any point: https://github.com/vllm-project/vllm/issues/2179\r\n\r\nThis is still an issue with the only workaround being to force-delete the lockfile created by another user.\n", "before_files": [{"content": "\"\"\"Utilities for downloading and initializing model weights.\"\"\"\nimport filelock\nimport glob\nimport fnmatch\nimport json\nimport os\nfrom collections import defaultdict\nfrom typing import Any, Iterator, List, Optional, Tuple\n\nfrom huggingface_hub import snapshot_download, HfFileSystem\nimport numpy as np\nfrom safetensors.torch import load_file, save_file, safe_open\nimport torch\nfrom tqdm.auto import tqdm\n\nfrom vllm.config import ModelConfig\nfrom vllm.logger import init_logger\nfrom vllm.model_executor.layers.quantization import (get_quantization_config,\n QuantizationConfig)\n\nlogger = init_logger(__name__)\n\n_xdg_cache_home = os.getenv('XDG_CACHE_HOME', os.path.expanduser('~/.cache'))\n_vllm_filelocks_path = os.path.join(_xdg_cache_home, 'vllm/locks/')\n\n\nclass Disabledtqdm(tqdm):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs, disable=True)\n\n\ndef get_lock(model_name_or_path: str, cache_dir: Optional[str] = None):\n lock_dir = cache_dir if cache_dir is not None else _vllm_filelocks_path\n os.makedirs(os.path.dirname(lock_dir), exist_ok=True)\n lock_file_name = model_name_or_path.replace(\"/\", \"-\") + \".lock\"\n lock = filelock.FileLock(os.path.join(lock_dir, lock_file_name))\n return lock\n\n\ndef _shared_pointers(tensors):\n ptrs = defaultdict(list)\n for k, v in tensors.items():\n ptrs[v.data_ptr()].append(k)\n failing = []\n for _, names in ptrs.items():\n if len(names) > 1:\n failing.append(names)\n return failing\n\n\ndef convert_bin_to_safetensor_file(\n pt_filename: str,\n sf_filename: str,\n) -> None:\n loaded = torch.load(pt_filename, map_location=\"cpu\")\n if \"state_dict\" in loaded:\n loaded = loaded[\"state_dict\"]\n shared = _shared_pointers(loaded)\n for shared_weights in shared:\n for name in shared_weights[1:]:\n loaded.pop(name)\n\n # For tensors to be contiguous\n loaded = {k: v.contiguous() for k, v in loaded.items()}\n\n dirname = os.path.dirname(sf_filename)\n os.makedirs(dirname, exist_ok=True)\n save_file(loaded, sf_filename, metadata={\"format\": \"pt\"})\n\n # check file size\n sf_size = os.stat(sf_filename).st_size\n pt_size = os.stat(pt_filename).st_size\n if (sf_size - pt_size) / pt_size > 0.01:\n raise RuntimeError(f\"\"\"The file size different is more than 1%:\n - {sf_filename}: {sf_size}\n - {pt_filename}: {pt_size}\n \"\"\")\n\n # check if the tensors are the same\n reloaded = load_file(sf_filename)\n for k in loaded:\n pt_tensor = loaded[k]\n sf_tensor = reloaded[k]\n if not torch.equal(pt_tensor, sf_tensor):\n raise RuntimeError(f\"The output tensors do not match for key {k}\")\n\n\n# TODO(woosuk): Move this to other place.\ndef get_quant_config(model_config: ModelConfig) -> QuantizationConfig:\n quant_cls = get_quantization_config(model_config.quantization)\n # Read the quantization config from the HF model config, if available.\n hf_quant_config = getattr(model_config.hf_config, \"quantization_config\",\n None)\n if hf_quant_config is not None:\n return quant_cls.from_config(hf_quant_config)\n model_name_or_path = model_config.model\n is_local = os.path.isdir(model_name_or_path)\n if not is_local:\n # Download the config files.\n with get_lock(model_name_or_path, model_config.download_dir):\n hf_folder = snapshot_download(model_name_or_path,\n revision=model_config.revision,\n allow_patterns=\"*.json\",\n cache_dir=model_config.download_dir,\n tqdm_class=Disabledtqdm)\n else:\n hf_folder = model_name_or_path\n config_files = glob.glob(os.path.join(hf_folder, \"*.json\"))\n\n quant_config_files = [\n f for f in config_files if any(\n f.endswith(x) for x in quant_cls.get_config_filenames())\n ]\n if len(quant_config_files) == 0:\n raise ValueError(\n f\"Cannot find the config file for {model_config.quantization}\")\n if len(quant_config_files) > 1:\n raise ValueError(\n f\"Found multiple config files for {model_config.quantization}: \"\n f\"{quant_config_files}\")\n\n quant_config_file = quant_config_files[0]\n with open(quant_config_file, \"r\") as f:\n config = json.load(f)\n return quant_cls.from_config(config)\n\n\ndef prepare_hf_model_weights(\n model_name_or_path: str,\n cache_dir: Optional[str] = None,\n load_format: str = \"auto\",\n fall_back_to_pt: bool = True,\n revision: Optional[str] = None,\n) -> Tuple[str, List[str], bool]:\n # Download model weights from huggingface.\n is_local = os.path.isdir(model_name_or_path)\n use_safetensors = False\n # Some quantized models use .pt files for storing the weights.\n if load_format == \"auto\":\n allow_patterns = [\"*.safetensors\", \"*.bin\"]\n elif load_format == \"safetensors\":\n use_safetensors = True\n allow_patterns = [\"*.safetensors\"]\n elif load_format == \"pt\":\n allow_patterns = [\"*.pt\"]\n elif load_format == \"npcache\":\n allow_patterns = [\"*.bin\"]\n else:\n raise ValueError(f\"Unknown load_format: {load_format}\")\n\n if fall_back_to_pt:\n allow_patterns += [\"*.pt\"]\n\n if not is_local:\n # Before we download we look at that is available:\n fs = HfFileSystem()\n file_list = fs.ls(model_name_or_path, detail=False, revision=revision)\n\n # depending on what is available we download different things\n for pattern in allow_patterns:\n matching = fnmatch.filter(file_list, pattern)\n if len(matching) > 0:\n allow_patterns = [pattern]\n break\n\n logger.info(f\"Using model weights format {allow_patterns}\")\n # Use file lock to prevent multiple processes from\n # downloading the same model weights at the same time.\n with get_lock(model_name_or_path, cache_dir):\n hf_folder = snapshot_download(model_name_or_path,\n allow_patterns=allow_patterns,\n cache_dir=cache_dir,\n tqdm_class=Disabledtqdm,\n revision=revision)\n else:\n hf_folder = model_name_or_path\n hf_weights_files: List[str] = []\n for pattern in allow_patterns:\n hf_weights_files += glob.glob(os.path.join(hf_folder, pattern))\n if len(hf_weights_files) > 0:\n if pattern == \"*.safetensors\":\n use_safetensors = True\n break\n if not use_safetensors:\n # Exclude files that are not needed for inference.\n # https://github.com/huggingface/transformers/blob/v4.34.0/src/transformers/trainer.py#L227-L233\n blacklist = [\n \"training_args.bin\",\n \"optimizer.bin\",\n \"optimizer.pt\",\n \"scheduler.pt\",\n \"scaler.pt\",\n ]\n hf_weights_files = [\n f for f in hf_weights_files\n if not any(f.endswith(x) for x in blacklist)\n ]\n\n if len(hf_weights_files) == 0:\n raise RuntimeError(\n f\"Cannot find any model weights with `{model_name_or_path}`\")\n\n return hf_folder, hf_weights_files, use_safetensors\n\n\ndef hf_model_weights_iterator(\n model_name_or_path: str,\n cache_dir: Optional[str] = None,\n load_format: str = \"auto\",\n revision: Optional[str] = None,\n fall_back_to_pt: Optional[bool] = True,\n) -> Iterator[Tuple[str, torch.Tensor]]:\n hf_folder, hf_weights_files, use_safetensors = prepare_hf_model_weights(\n model_name_or_path,\n cache_dir=cache_dir,\n load_format=load_format,\n fall_back_to_pt=fall_back_to_pt,\n revision=revision)\n\n if load_format == \"npcache\":\n # Currently np_cache only support *.bin checkpoints\n assert use_safetensors is False\n\n # Convert the model weights from torch tensors to numpy arrays for\n # faster loading.\n np_folder = os.path.join(hf_folder, \"np\")\n os.makedirs(np_folder, exist_ok=True)\n weight_names_file = os.path.join(np_folder, \"weight_names.json\")\n # Use file lock to prevent multiple processes from\n # dumping the same model weights to numpy at the same time.\n with get_lock(model_name_or_path, cache_dir):\n if not os.path.exists(weight_names_file):\n weight_names = []\n for bin_file in hf_weights_files:\n state = torch.load(bin_file, map_location=\"cpu\")\n for name, param in state.items():\n param_path = os.path.join(np_folder, name)\n with open(param_path, \"wb\") as f:\n np.save(f, param.cpu().detach().numpy())\n weight_names.append(name)\n with open(weight_names_file, \"w\") as f:\n json.dump(weight_names, f)\n\n with open(weight_names_file, \"r\") as f:\n weight_names = json.load(f)\n\n for name in weight_names:\n param_path = os.path.join(np_folder, name)\n with open(param_path, \"rb\") as f:\n param = np.load(f)\n yield name, torch.from_numpy(param)\n elif use_safetensors:\n for st_file in hf_weights_files:\n with safe_open(st_file, framework=\"pt\") as f:\n for name in f.keys(): # noqa: SIM118\n param = f.get_tensor(name)\n yield name, param\n else:\n for bin_file in hf_weights_files:\n state = torch.load(bin_file, map_location=\"cpu\")\n for name, param in state.items():\n yield name, param\n del state\n torch.cuda.empty_cache()\n\n\ndef convert_pyslice_to_tensor(x: Any) -> torch.Tensor:\n \"\"\"convert PySafeSlice object from safetensors to torch.Tensor\n\n PySafeSlice object supports indexing, which is done before loading the\n actual tensor and can reduce the amount of memory being read into the\n memory. However, it does not support more advanced functionalities\n like `.view()` or `.t()`. Therefore, if we need to modify the loaded\n tensor with these more complicated operators, we need to convert to\n tensor first.\n \"\"\"\n if not isinstance(x, torch.Tensor):\n x = x[:]\n return x\n\n\ndef default_weight_loader(param: torch.Tensor,\n loaded_weight: torch.Tensor) -> None:\n \"\"\"Default weight loader.\"\"\"\n assert param.size() == loaded_weight.size()\n param.data.copy_(loaded_weight)\n\n\ndef initialize_dummy_weights(\n model: torch.nn.Module,\n low: float = -1e-3,\n high: float = 1e-3,\n) -> None:\n \"\"\"Initialize model weights with random values.\n\n The model weights must be randomly initialized for accurate performance\n measurements. Additionally, the model weights should not cause NaNs in the\n forward pass. We empirically found that initializing the weights with\n values between -1e-3 and 1e-3 works well for most models.\n \"\"\"\n for param in model.state_dict().values():\n if torch.is_floating_point(param):\n param.data.uniform_(low, high)\n", "path": "vllm/model_executor/weight_utils.py"}], "after_files": [{"content": "\"\"\"Utilities for downloading and initializing model weights.\"\"\"\nimport filelock\nimport glob\nimport fnmatch\nimport json\nimport os\nfrom collections import defaultdict\nfrom typing import Any, Iterator, List, Optional, Tuple\n\nfrom huggingface_hub import snapshot_download, HfFileSystem\nimport numpy as np\nfrom safetensors.torch import load_file, save_file, safe_open\nimport torch\nfrom tqdm.auto import tqdm\n\nfrom vllm.config import ModelConfig\nfrom vllm.logger import init_logger\nfrom vllm.model_executor.layers.quantization import (get_quantization_config,\n QuantizationConfig)\n\nlogger = init_logger(__name__)\n\n_xdg_cache_home = os.getenv('XDG_CACHE_HOME', os.path.expanduser('~/.cache'))\n_vllm_filelocks_path = os.path.join(_xdg_cache_home, 'vllm/locks/')\n\n\nclass Disabledtqdm(tqdm):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs, disable=True)\n\n\ndef get_lock(model_name_or_path: str, cache_dir: Optional[str] = None):\n lock_dir = cache_dir if cache_dir is not None else _vllm_filelocks_path\n os.makedirs(os.path.dirname(lock_dir), exist_ok=True)\n lock_file_name = model_name_or_path.replace(\"/\", \"-\") + \".lock\"\n lock = filelock.SoftFileLock(os.path.join(lock_dir, lock_file_name))\n return lock\n\n\ndef _shared_pointers(tensors):\n ptrs = defaultdict(list)\n for k, v in tensors.items():\n ptrs[v.data_ptr()].append(k)\n failing = []\n for _, names in ptrs.items():\n if len(names) > 1:\n failing.append(names)\n return failing\n\n\ndef convert_bin_to_safetensor_file(\n pt_filename: str,\n sf_filename: str,\n) -> None:\n loaded = torch.load(pt_filename, map_location=\"cpu\")\n if \"state_dict\" in loaded:\n loaded = loaded[\"state_dict\"]\n shared = _shared_pointers(loaded)\n for shared_weights in shared:\n for name in shared_weights[1:]:\n loaded.pop(name)\n\n # For tensors to be contiguous\n loaded = {k: v.contiguous() for k, v in loaded.items()}\n\n dirname = os.path.dirname(sf_filename)\n os.makedirs(dirname, exist_ok=True)\n save_file(loaded, sf_filename, metadata={\"format\": \"pt\"})\n\n # check file size\n sf_size = os.stat(sf_filename).st_size\n pt_size = os.stat(pt_filename).st_size\n if (sf_size - pt_size) / pt_size > 0.01:\n raise RuntimeError(f\"\"\"The file size different is more than 1%:\n - {sf_filename}: {sf_size}\n - {pt_filename}: {pt_size}\n \"\"\")\n\n # check if the tensors are the same\n reloaded = load_file(sf_filename)\n for k in loaded:\n pt_tensor = loaded[k]\n sf_tensor = reloaded[k]\n if not torch.equal(pt_tensor, sf_tensor):\n raise RuntimeError(f\"The output tensors do not match for key {k}\")\n\n\n# TODO(woosuk): Move this to other place.\ndef get_quant_config(model_config: ModelConfig) -> QuantizationConfig:\n quant_cls = get_quantization_config(model_config.quantization)\n # Read the quantization config from the HF model config, if available.\n hf_quant_config = getattr(model_config.hf_config, \"quantization_config\",\n None)\n if hf_quant_config is not None:\n return quant_cls.from_config(hf_quant_config)\n model_name_or_path = model_config.model\n is_local = os.path.isdir(model_name_or_path)\n if not is_local:\n # Download the config files.\n with get_lock(model_name_or_path, model_config.download_dir):\n hf_folder = snapshot_download(model_name_or_path,\n revision=model_config.revision,\n allow_patterns=\"*.json\",\n cache_dir=model_config.download_dir,\n tqdm_class=Disabledtqdm)\n else:\n hf_folder = model_name_or_path\n config_files = glob.glob(os.path.join(hf_folder, \"*.json\"))\n\n quant_config_files = [\n f for f in config_files if any(\n f.endswith(x) for x in quant_cls.get_config_filenames())\n ]\n if len(quant_config_files) == 0:\n raise ValueError(\n f\"Cannot find the config file for {model_config.quantization}\")\n if len(quant_config_files) > 1:\n raise ValueError(\n f\"Found multiple config files for {model_config.quantization}: \"\n f\"{quant_config_files}\")\n\n quant_config_file = quant_config_files[0]\n with open(quant_config_file, \"r\") as f:\n config = json.load(f)\n return quant_cls.from_config(config)\n\n\ndef prepare_hf_model_weights(\n model_name_or_path: str,\n cache_dir: Optional[str] = None,\n load_format: str = \"auto\",\n fall_back_to_pt: bool = True,\n revision: Optional[str] = None,\n) -> Tuple[str, List[str], bool]:\n # Download model weights from huggingface.\n is_local = os.path.isdir(model_name_or_path)\n use_safetensors = False\n # Some quantized models use .pt files for storing the weights.\n if load_format == \"auto\":\n allow_patterns = [\"*.safetensors\", \"*.bin\"]\n elif load_format == \"safetensors\":\n use_safetensors = True\n allow_patterns = [\"*.safetensors\"]\n elif load_format == \"pt\":\n allow_patterns = [\"*.pt\"]\n elif load_format == \"npcache\":\n allow_patterns = [\"*.bin\"]\n else:\n raise ValueError(f\"Unknown load_format: {load_format}\")\n\n if fall_back_to_pt:\n allow_patterns += [\"*.pt\"]\n\n if not is_local:\n # Before we download we look at that is available:\n fs = HfFileSystem()\n file_list = fs.ls(model_name_or_path, detail=False, revision=revision)\n\n # depending on what is available we download different things\n for pattern in allow_patterns:\n matching = fnmatch.filter(file_list, pattern)\n if len(matching) > 0:\n allow_patterns = [pattern]\n break\n\n logger.info(f\"Using model weights format {allow_patterns}\")\n # Use file lock to prevent multiple processes from\n # downloading the same model weights at the same time.\n with get_lock(model_name_or_path, cache_dir):\n hf_folder = snapshot_download(model_name_or_path,\n allow_patterns=allow_patterns,\n cache_dir=cache_dir,\n tqdm_class=Disabledtqdm,\n revision=revision)\n else:\n hf_folder = model_name_or_path\n hf_weights_files: List[str] = []\n for pattern in allow_patterns:\n hf_weights_files += glob.glob(os.path.join(hf_folder, pattern))\n if len(hf_weights_files) > 0:\n if pattern == \"*.safetensors\":\n use_safetensors = True\n break\n if not use_safetensors:\n # Exclude files that are not needed for inference.\n # https://github.com/huggingface/transformers/blob/v4.34.0/src/transformers/trainer.py#L227-L233\n blacklist = [\n \"training_args.bin\",\n \"optimizer.bin\",\n \"optimizer.pt\",\n \"scheduler.pt\",\n \"scaler.pt\",\n ]\n hf_weights_files = [\n f for f in hf_weights_files\n if not any(f.endswith(x) for x in blacklist)\n ]\n\n if len(hf_weights_files) == 0:\n raise RuntimeError(\n f\"Cannot find any model weights with `{model_name_or_path}`\")\n\n return hf_folder, hf_weights_files, use_safetensors\n\n\ndef hf_model_weights_iterator(\n model_name_or_path: str,\n cache_dir: Optional[str] = None,\n load_format: str = \"auto\",\n revision: Optional[str] = None,\n fall_back_to_pt: Optional[bool] = True,\n) -> Iterator[Tuple[str, torch.Tensor]]:\n hf_folder, hf_weights_files, use_safetensors = prepare_hf_model_weights(\n model_name_or_path,\n cache_dir=cache_dir,\n load_format=load_format,\n fall_back_to_pt=fall_back_to_pt,\n revision=revision)\n\n if load_format == \"npcache\":\n # Currently np_cache only support *.bin checkpoints\n assert use_safetensors is False\n\n # Convert the model weights from torch tensors to numpy arrays for\n # faster loading.\n np_folder = os.path.join(hf_folder, \"np\")\n os.makedirs(np_folder, exist_ok=True)\n weight_names_file = os.path.join(np_folder, \"weight_names.json\")\n # Use file lock to prevent multiple processes from\n # dumping the same model weights to numpy at the same time.\n with get_lock(model_name_or_path, cache_dir):\n if not os.path.exists(weight_names_file):\n weight_names = []\n for bin_file in hf_weights_files:\n state = torch.load(bin_file, map_location=\"cpu\")\n for name, param in state.items():\n param_path = os.path.join(np_folder, name)\n with open(param_path, \"wb\") as f:\n np.save(f, param.cpu().detach().numpy())\n weight_names.append(name)\n with open(weight_names_file, \"w\") as f:\n json.dump(weight_names, f)\n\n with open(weight_names_file, \"r\") as f:\n weight_names = json.load(f)\n\n for name in weight_names:\n param_path = os.path.join(np_folder, name)\n with open(param_path, \"rb\") as f:\n param = np.load(f)\n yield name, torch.from_numpy(param)\n elif use_safetensors:\n for st_file in hf_weights_files:\n with safe_open(st_file, framework=\"pt\") as f:\n for name in f.keys(): # noqa: SIM118\n param = f.get_tensor(name)\n yield name, param\n else:\n for bin_file in hf_weights_files:\n state = torch.load(bin_file, map_location=\"cpu\")\n for name, param in state.items():\n yield name, param\n del state\n torch.cuda.empty_cache()\n\n\ndef convert_pyslice_to_tensor(x: Any) -> torch.Tensor:\n \"\"\"convert PySafeSlice object from safetensors to torch.Tensor\n\n PySafeSlice object supports indexing, which is done before loading the\n actual tensor and can reduce the amount of memory being read into the\n memory. However, it does not support more advanced functionalities\n like `.view()` or `.t()`. Therefore, if we need to modify the loaded\n tensor with these more complicated operators, we need to convert to\n tensor first.\n \"\"\"\n if not isinstance(x, torch.Tensor):\n x = x[:]\n return x\n\n\ndef default_weight_loader(param: torch.Tensor,\n loaded_weight: torch.Tensor) -> None:\n \"\"\"Default weight loader.\"\"\"\n assert param.size() == loaded_weight.size()\n param.data.copy_(loaded_weight)\n\n\ndef initialize_dummy_weights(\n model: torch.nn.Module,\n low: float = -1e-3,\n high: float = 1e-3,\n) -> None:\n \"\"\"Initialize model weights with random values.\n\n The model weights must be randomly initialized for accurate performance\n measurements. Additionally, the model weights should not cause NaNs in the\n forward pass. We empirically found that initializing the weights with\n values between -1e-3 and 1e-3 works well for most models.\n \"\"\"\n for param in model.state_dict().values():\n if torch.is_floating_point(param):\n param.data.uniform_(low, high)\n", "path": "vllm/model_executor/weight_utils.py"}]} | 3,720 | 153 |
gh_patches_debug_39306 | rasdani/github-patches | git_diff | piskvorky__gensim-2245 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
wiki examples: sample code to get from tfidf doc to wikipedia title/uri and vice versa
I very much like the LSI and LDA [wiki examples](https://github.com/RaRe-Technologies/gensim/blob/develop/docs/src/wiki.rst), but one aspect that i think is missing is: how to get from tf-idf doc vectors (or later LSI / LDA vecs) back to Wikipedia URIs (or titles if easier) and vice versa?
Am i missing something obvious, or do i have to run another pass over the wiki dump, as the titles aren't saved anywhere?
I'll happily make a PR to extend the examples with this...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gensim/scripts/make_wikicorpus.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) 2010 Radim Rehurek <[email protected]>
5 # Copyright (C) 2012 Lars Buitinck <[email protected]>
6 # Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html
7
8
9 """
10 USAGE: %(program)s WIKI_XML_DUMP OUTPUT_PREFIX [VOCABULARY_SIZE]
11
12 Convert articles from a Wikipedia dump to (sparse) vectors. The input is a
13 bz2-compressed dump of Wikipedia articles, in XML format.
14
15 This actually creates three files:
16
17 * `OUTPUT_PREFIX_wordids.txt`: mapping between words and their integer ids
18 * `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation, in
19 Matrix Matrix format
20 * `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation
21 * `OUTPUT_PREFIX.tfidf_model`: TF-IDF model dump
22
23 The output Matrix Market files can then be compressed (e.g., by bzip2) to save
24 disk space; gensim's corpus iterators can work with compressed input, too.
25
26 `VOCABULARY_SIZE` controls how many of the most frequent words to keep (after
27 removing tokens that appear in more than 10%% of all documents). Defaults to
28 100,000.
29
30 If you have the `pattern` package installed, this script will use a fancy
31 lemmatization to get a lemma of each token (instead of plain alphabetic
32 tokenizer). The package is available at https://github.com/clips/pattern .
33
34 Example:
35 python -m gensim.scripts.make_wikicorpus ~/gensim/results/enwiki-latest-pages-articles.xml.bz2 ~/gensim/results/wiki
36 """
37
38
39 import logging
40 import os.path
41 import sys
42
43 from gensim.corpora import Dictionary, HashDictionary, MmCorpus, WikiCorpus
44 from gensim.models import TfidfModel
45
46
47 # Wiki is first scanned for all distinct word types (~7M). The types that
48 # appear in more than 10% of articles are removed and from the rest, the
49 # DEFAULT_DICT_SIZE most frequent types are kept.
50 DEFAULT_DICT_SIZE = 100000
51
52
53 if __name__ == '__main__':
54 program = os.path.basename(sys.argv[0])
55 logger = logging.getLogger(program)
56
57 logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
58 logging.root.setLevel(level=logging.INFO)
59 logger.info("running %s", ' '.join(sys.argv))
60
61 # check and process input arguments
62 if len(sys.argv) < 3:
63 print(globals()['__doc__'] % locals())
64 sys.exit(1)
65 inp, outp = sys.argv[1:3]
66
67 if not os.path.isdir(os.path.dirname(outp)):
68 raise SystemExit("Error: The output directory does not exist. Create the directory and try again.")
69
70 if len(sys.argv) > 3:
71 keep_words = int(sys.argv[3])
72 else:
73 keep_words = DEFAULT_DICT_SIZE
74 online = 'online' in program
75 lemmatize = 'lemma' in program
76 debug = 'nodebug' not in program
77
78 if online:
79 dictionary = HashDictionary(id_range=keep_words, debug=debug)
80 dictionary.allow_update = True # start collecting document frequencies
81 wiki = WikiCorpus(inp, lemmatize=lemmatize, dictionary=dictionary)
82 # ~4h on my macbook pro without lemmatization, 3.1m articles (august 2012)
83 MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000)
84 # with HashDictionary, the token->id mapping is only fully instantiated now, after `serialize`
85 dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)
86 dictionary.save_as_text(outp + '_wordids.txt.bz2')
87 wiki.save(outp + '_corpus.pkl.bz2')
88 dictionary.allow_update = False
89 else:
90 wiki = WikiCorpus(inp, lemmatize=lemmatize) # takes about 9h on a macbook pro, for 3.5m articles (june 2011)
91 # only keep the most frequent words (out of total ~8.2m unique tokens)
92 wiki.dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)
93 # save dictionary and bag-of-words (term-document frequency matrix)
94 MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000) # another ~9h
95 wiki.dictionary.save_as_text(outp + '_wordids.txt.bz2')
96 # load back the id->word mapping directly from file
97 # this seems to save more memory, compared to keeping the wiki.dictionary object from above
98 dictionary = Dictionary.load_from_text(outp + '_wordids.txt.bz2')
99 del wiki
100
101 # initialize corpus reader and word->id mapping
102 mm = MmCorpus(outp + '_bow.mm')
103
104 # build tfidf, ~50min
105 tfidf = TfidfModel(mm, id2word=dictionary, normalize=True)
106 tfidf.save(outp + '.tfidf_model')
107
108 # save tfidf vectors in matrix market format
109 # ~4h; result file is 15GB! bzip2'ed down to 4.5GB
110 MmCorpus.serialize(outp + '_tfidf.mm', tfidf[mm], progress_cnt=10000)
111
112 logger.info("finished running %s", program)
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gensim/scripts/make_wikicorpus.py b/gensim/scripts/make_wikicorpus.py
--- a/gensim/scripts/make_wikicorpus.py
+++ b/gensim/scripts/make_wikicorpus.py
@@ -12,13 +12,15 @@
Convert articles from a Wikipedia dump to (sparse) vectors. The input is a
bz2-compressed dump of Wikipedia articles, in XML format.
-This actually creates three files:
+This actually creates several files:
-* `OUTPUT_PREFIX_wordids.txt`: mapping between words and their integer ids
-* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation, in
- Matrix Matrix format
-* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation
-* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model dump
+* `OUTPUT_PREFIX_wordids.txt.bz2`: mapping between words and their integer ids
+* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation in Matrix Market format
+* `OUTPUT_PREFIX_bow.mm.index`: index for `OUTPUT_PREFIX_bow.mm`
+* `OUTPUT_PREFIX_bow.mm.metadata.cpickle`: titles of documents
+* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation in Matix Market format
+* `OUTPUT_PREFIX_tfidf.mm.index`: index for `OUTPUT_PREFIX_tfidf.mm`
+* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model
The output Matrix Market files can then be compressed (e.g., by bzip2) to save
disk space; gensim's corpus iterators can work with compressed input, too.
@@ -80,7 +82,7 @@
dictionary.allow_update = True # start collecting document frequencies
wiki = WikiCorpus(inp, lemmatize=lemmatize, dictionary=dictionary)
# ~4h on my macbook pro without lemmatization, 3.1m articles (august 2012)
- MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000)
+ MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True)
# with HashDictionary, the token->id mapping is only fully instantiated now, after `serialize`
dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)
dictionary.save_as_text(outp + '_wordids.txt.bz2')
@@ -91,7 +93,7 @@
# only keep the most frequent words (out of total ~8.2m unique tokens)
wiki.dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)
# save dictionary and bag-of-words (term-document frequency matrix)
- MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000) # another ~9h
+ MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True) # another ~9h
wiki.dictionary.save_as_text(outp + '_wordids.txt.bz2')
# load back the id->word mapping directly from file
# this seems to save more memory, compared to keeping the wiki.dictionary object from above
| {"golden_diff": "diff --git a/gensim/scripts/make_wikicorpus.py b/gensim/scripts/make_wikicorpus.py\n--- a/gensim/scripts/make_wikicorpus.py\n+++ b/gensim/scripts/make_wikicorpus.py\n@@ -12,13 +12,15 @@\n Convert articles from a Wikipedia dump to (sparse) vectors. The input is a\n bz2-compressed dump of Wikipedia articles, in XML format.\n \n-This actually creates three files:\n+This actually creates several files:\n \n-* `OUTPUT_PREFIX_wordids.txt`: mapping between words and their integer ids\n-* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation, in\n- Matrix Matrix format\n-* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation\n-* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model dump\n+* `OUTPUT_PREFIX_wordids.txt.bz2`: mapping between words and their integer ids\n+* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation in Matrix Market format\n+* `OUTPUT_PREFIX_bow.mm.index`: index for `OUTPUT_PREFIX_bow.mm`\n+* `OUTPUT_PREFIX_bow.mm.metadata.cpickle`: titles of documents\n+* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation in Matix Market format\n+* `OUTPUT_PREFIX_tfidf.mm.index`: index for `OUTPUT_PREFIX_tfidf.mm`\n+* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model\n \n The output Matrix Market files can then be compressed (e.g., by bzip2) to save\n disk space; gensim's corpus iterators can work with compressed input, too.\n@@ -80,7 +82,7 @@\n dictionary.allow_update = True # start collecting document frequencies\n wiki = WikiCorpus(inp, lemmatize=lemmatize, dictionary=dictionary)\n # ~4h on my macbook pro without lemmatization, 3.1m articles (august 2012)\n- MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000)\n+ MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True)\n # with HashDictionary, the token->id mapping is only fully instantiated now, after `serialize`\n dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n dictionary.save_as_text(outp + '_wordids.txt.bz2')\n@@ -91,7 +93,7 @@\n # only keep the most frequent words (out of total ~8.2m unique tokens)\n wiki.dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n # save dictionary and bag-of-words (term-document frequency matrix)\n- MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000) # another ~9h\n+ MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True) # another ~9h\n wiki.dictionary.save_as_text(outp + '_wordids.txt.bz2')\n # load back the id->word mapping directly from file\n # this seems to save more memory, compared to keeping the wiki.dictionary object from above\n", "issue": "wiki examples: sample code to get from tfidf doc to wikipedia title/uri and vice versa\nI very much like the LSI and LDA [wiki examples](https://github.com/RaRe-Technologies/gensim/blob/develop/docs/src/wiki.rst), but one aspect that i think is missing is: how to get from tf-idf doc vectors (or later LSI / LDA vecs) back to Wikipedia URIs (or titles if easier) and vice versa?\r\n\r\nAm i missing something obvious, or do i have to run another pass over the wiki dump, as the titles aren't saved anywhere?\r\n\r\nI'll happily make a PR to extend the examples with this...\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) 2010 Radim Rehurek <[email protected]>\n# Copyright (C) 2012 Lars Buitinck <[email protected]>\n# Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html\n\n\n\"\"\"\nUSAGE: %(program)s WIKI_XML_DUMP OUTPUT_PREFIX [VOCABULARY_SIZE]\n\nConvert articles from a Wikipedia dump to (sparse) vectors. The input is a\nbz2-compressed dump of Wikipedia articles, in XML format.\n\nThis actually creates three files:\n\n* `OUTPUT_PREFIX_wordids.txt`: mapping between words and their integer ids\n* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation, in\n Matrix Matrix format\n* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation\n* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model dump\n\nThe output Matrix Market files can then be compressed (e.g., by bzip2) to save\ndisk space; gensim's corpus iterators can work with compressed input, too.\n\n`VOCABULARY_SIZE` controls how many of the most frequent words to keep (after\nremoving tokens that appear in more than 10%% of all documents). Defaults to\n100,000.\n\nIf you have the `pattern` package installed, this script will use a fancy\nlemmatization to get a lemma of each token (instead of plain alphabetic\ntokenizer). The package is available at https://github.com/clips/pattern .\n\nExample:\n python -m gensim.scripts.make_wikicorpus ~/gensim/results/enwiki-latest-pages-articles.xml.bz2 ~/gensim/results/wiki\n\"\"\"\n\n\nimport logging\nimport os.path\nimport sys\n\nfrom gensim.corpora import Dictionary, HashDictionary, MmCorpus, WikiCorpus\nfrom gensim.models import TfidfModel\n\n\n# Wiki is first scanned for all distinct word types (~7M). The types that\n# appear in more than 10% of articles are removed and from the rest, the\n# DEFAULT_DICT_SIZE most frequent types are kept.\nDEFAULT_DICT_SIZE = 100000\n\n\nif __name__ == '__main__':\n program = os.path.basename(sys.argv[0])\n logger = logging.getLogger(program)\n\n logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')\n logging.root.setLevel(level=logging.INFO)\n logger.info(\"running %s\", ' '.join(sys.argv))\n\n # check and process input arguments\n if len(sys.argv) < 3:\n print(globals()['__doc__'] % locals())\n sys.exit(1)\n inp, outp = sys.argv[1:3]\n\n if not os.path.isdir(os.path.dirname(outp)):\n raise SystemExit(\"Error: The output directory does not exist. Create the directory and try again.\")\n\n if len(sys.argv) > 3:\n keep_words = int(sys.argv[3])\n else:\n keep_words = DEFAULT_DICT_SIZE\n online = 'online' in program\n lemmatize = 'lemma' in program\n debug = 'nodebug' not in program\n\n if online:\n dictionary = HashDictionary(id_range=keep_words, debug=debug)\n dictionary.allow_update = True # start collecting document frequencies\n wiki = WikiCorpus(inp, lemmatize=lemmatize, dictionary=dictionary)\n # ~4h on my macbook pro without lemmatization, 3.1m articles (august 2012)\n MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000)\n # with HashDictionary, the token->id mapping is only fully instantiated now, after `serialize`\n dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n dictionary.save_as_text(outp + '_wordids.txt.bz2')\n wiki.save(outp + '_corpus.pkl.bz2')\n dictionary.allow_update = False\n else:\n wiki = WikiCorpus(inp, lemmatize=lemmatize) # takes about 9h on a macbook pro, for 3.5m articles (june 2011)\n # only keep the most frequent words (out of total ~8.2m unique tokens)\n wiki.dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n # save dictionary and bag-of-words (term-document frequency matrix)\n MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000) # another ~9h\n wiki.dictionary.save_as_text(outp + '_wordids.txt.bz2')\n # load back the id->word mapping directly from file\n # this seems to save more memory, compared to keeping the wiki.dictionary object from above\n dictionary = Dictionary.load_from_text(outp + '_wordids.txt.bz2')\n del wiki\n\n # initialize corpus reader and word->id mapping\n mm = MmCorpus(outp + '_bow.mm')\n\n # build tfidf, ~50min\n tfidf = TfidfModel(mm, id2word=dictionary, normalize=True)\n tfidf.save(outp + '.tfidf_model')\n\n # save tfidf vectors in matrix market format\n # ~4h; result file is 15GB! bzip2'ed down to 4.5GB\n MmCorpus.serialize(outp + '_tfidf.mm', tfidf[mm], progress_cnt=10000)\n\n logger.info(\"finished running %s\", program)\n", "path": "gensim/scripts/make_wikicorpus.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) 2010 Radim Rehurek <[email protected]>\n# Copyright (C) 2012 Lars Buitinck <[email protected]>\n# Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.html\n\n\n\"\"\"\nUSAGE: %(program)s WIKI_XML_DUMP OUTPUT_PREFIX [VOCABULARY_SIZE]\n\nConvert articles from a Wikipedia dump to (sparse) vectors. The input is a\nbz2-compressed dump of Wikipedia articles, in XML format.\n\nThis actually creates several files:\n\n* `OUTPUT_PREFIX_wordids.txt.bz2`: mapping between words and their integer ids\n* `OUTPUT_PREFIX_bow.mm`: bag-of-words (word counts) representation in Matrix Market format\n* `OUTPUT_PREFIX_bow.mm.index`: index for `OUTPUT_PREFIX_bow.mm`\n* `OUTPUT_PREFIX_bow.mm.metadata.cpickle`: titles of documents\n* `OUTPUT_PREFIX_tfidf.mm`: TF-IDF representation in Matix Market format\n* `OUTPUT_PREFIX_tfidf.mm.index`: index for `OUTPUT_PREFIX_tfidf.mm`\n* `OUTPUT_PREFIX.tfidf_model`: TF-IDF model\n\nThe output Matrix Market files can then be compressed (e.g., by bzip2) to save\ndisk space; gensim's corpus iterators can work with compressed input, too.\n\n`VOCABULARY_SIZE` controls how many of the most frequent words to keep (after\nremoving tokens that appear in more than 10%% of all documents). Defaults to\n100,000.\n\nIf you have the `pattern` package installed, this script will use a fancy\nlemmatization to get a lemma of each token (instead of plain alphabetic\ntokenizer). The package is available at https://github.com/clips/pattern .\n\nExample:\n python -m gensim.scripts.make_wikicorpus ~/gensim/results/enwiki-latest-pages-articles.xml.bz2 ~/gensim/results/wiki\n\"\"\"\n\n\nimport logging\nimport os.path\nimport sys\n\nfrom gensim.corpora import Dictionary, HashDictionary, MmCorpus, WikiCorpus\nfrom gensim.models import TfidfModel\n\n\n# Wiki is first scanned for all distinct word types (~7M). The types that\n# appear in more than 10% of articles are removed and from the rest, the\n# DEFAULT_DICT_SIZE most frequent types are kept.\nDEFAULT_DICT_SIZE = 100000\n\n\nif __name__ == '__main__':\n program = os.path.basename(sys.argv[0])\n logger = logging.getLogger(program)\n\n logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')\n logging.root.setLevel(level=logging.INFO)\n logger.info(\"running %s\", ' '.join(sys.argv))\n\n # check and process input arguments\n if len(sys.argv) < 3:\n print(globals()['__doc__'] % locals())\n sys.exit(1)\n inp, outp = sys.argv[1:3]\n\n if not os.path.isdir(os.path.dirname(outp)):\n raise SystemExit(\"Error: The output directory does not exist. Create the directory and try again.\")\n\n if len(sys.argv) > 3:\n keep_words = int(sys.argv[3])\n else:\n keep_words = DEFAULT_DICT_SIZE\n online = 'online' in program\n lemmatize = 'lemma' in program\n debug = 'nodebug' not in program\n\n if online:\n dictionary = HashDictionary(id_range=keep_words, debug=debug)\n dictionary.allow_update = True # start collecting document frequencies\n wiki = WikiCorpus(inp, lemmatize=lemmatize, dictionary=dictionary)\n # ~4h on my macbook pro without lemmatization, 3.1m articles (august 2012)\n MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True)\n # with HashDictionary, the token->id mapping is only fully instantiated now, after `serialize`\n dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n dictionary.save_as_text(outp + '_wordids.txt.bz2')\n wiki.save(outp + '_corpus.pkl.bz2')\n dictionary.allow_update = False\n else:\n wiki = WikiCorpus(inp, lemmatize=lemmatize) # takes about 9h on a macbook pro, for 3.5m articles (june 2011)\n # only keep the most frequent words (out of total ~8.2m unique tokens)\n wiki.dictionary.filter_extremes(no_below=20, no_above=0.1, keep_n=DEFAULT_DICT_SIZE)\n # save dictionary and bag-of-words (term-document frequency matrix)\n MmCorpus.serialize(outp + '_bow.mm', wiki, progress_cnt=10000, metadata=True) # another ~9h\n wiki.dictionary.save_as_text(outp + '_wordids.txt.bz2')\n # load back the id->word mapping directly from file\n # this seems to save more memory, compared to keeping the wiki.dictionary object from above\n dictionary = Dictionary.load_from_text(outp + '_wordids.txt.bz2')\n del wiki\n\n # initialize corpus reader and word->id mapping\n mm = MmCorpus(outp + '_bow.mm')\n\n # build tfidf, ~50min\n tfidf = TfidfModel(mm, id2word=dictionary, normalize=True)\n tfidf.save(outp + '.tfidf_model')\n\n # save tfidf vectors in matrix market format\n # ~4h; result file is 15GB! bzip2'ed down to 4.5GB\n MmCorpus.serialize(outp + '_tfidf.mm', tfidf[mm], progress_cnt=10000)\n\n logger.info(\"finished running %s\", program)\n", "path": "gensim/scripts/make_wikicorpus.py"}]} | 1,900 | 736 |
gh_patches_debug_19043 | rasdani/github-patches | git_diff | keras-team__keras-nlp-818 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Call `super.config()` in `BartBackbone`'s `get_config()`
We should call `super().config()` here: https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bart/bart_backbone.py#L238, update the config with `BARTBackbone`-specific keys and return the config. Check this for reference: https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_backbone.py#L204.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras_nlp/models/bart/bart_backbone.py`
Content:
```
1 # Copyright 2022 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """BART backbone model."""
16
17 import copy
18
19 import tensorflow as tf
20 from tensorflow import keras
21
22 from keras_nlp.layers.position_embedding import PositionEmbedding
23 from keras_nlp.layers.transformer_decoder import TransformerDecoder
24 from keras_nlp.layers.transformer_encoder import TransformerEncoder
25 from keras_nlp.models.backbone import Backbone
26 from keras_nlp.models.bart.bart_presets import backbone_presets
27 from keras_nlp.utils.python_utils import classproperty
28
29
30 def bart_kernel_initializer(stddev=0.02):
31 return keras.initializers.TruncatedNormal(stddev=stddev)
32
33
34 @keras.utils.register_keras_serializable(package="keras_nlp")
35 class BartBackbone(Backbone):
36 """BART encoder-decoder network.
37
38 This class implements a Transformer-based encoder-decoder model as
39 described in
40 ["BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension"](https://arxiv.org/abs/1910.13461).
41
42 The default constructor gives a fully customizable, randomly initialized BART
43 model with any number of layers, heads, and embedding dimensions. To load
44 preset architectures and weights, use the `from_preset` constructor.
45
46 Disclaimer: Pre-trained models are provided on an "as is" basis, without
47 warranties or conditions of any kind. The underlying model is provided by a
48 third party and subject to a separate license, available
49 [here](https://github.com/facebookresearch/fairseq/).
50
51 Args:
52 vocabulary_size: int. The size of the token vocabulary.
53 num_layers: int. The number of transformer encoder layers and
54 transformer decoder layers.
55 num_heads: int. The number of attention heads for each transformer.
56 The hidden size must be divisible by the number of attention heads.
57 hidden_dim: int. The size of the transformer encoding and pooler layers.
58 intermediate_dim: int. The output dimension of the first Dense layer in
59 a two-layer feedforward network for each transformer.
60 dropout: float. Dropout probability for the Transformer encoder.
61 max_sequence_length: int. The maximum sequence length that this encoder
62 can consume. If None, `max_sequence_length` uses the value from
63 sequence length. This determines the variable shape for positional
64 embeddings.
65
66 Examples:
67 ```python
68 input_data = {
69 "encoder_token_ids": tf.ones(shape=(1, 12), dtype=tf.int64),
70 "encoder_padding_mask": tf.constant(
71 [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], shape=(1, 12)
72 ),
73 "decoder_token_ids": tf.ones(shape=(1, 12), dtype=tf.int64),
74 "decoder_padding_mask": tf.constant(
75 [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0], shape=(1, 12)
76 ),
77 }
78
79 # Randomly initialized BART encoder-decoder model with a custom config
80 model = keras_nlp.models.BartBackbone(
81 vocabulary_size=50265,
82 num_layers=6,
83 num_heads=12,
84 hidden_dim=768,
85 intermediate_dim=3072,
86 max_sequence_length=12,
87 )
88 output = model(input_data)
89 ```
90 """
91
92 def __init__(
93 self,
94 vocabulary_size,
95 num_layers,
96 num_heads,
97 hidden_dim,
98 intermediate_dim,
99 dropout=0.1,
100 max_sequence_length=1024,
101 **kwargs,
102 ):
103 # Encoder inputs
104 encoder_token_id_input = keras.Input(
105 shape=(None,), dtype="int32", name="encoder_token_ids"
106 )
107 encoder_padding_mask = keras.Input(
108 shape=(None,), dtype="int32", name="encoder_padding_mask"
109 )
110
111 # Decoder inputs.
112 decoder_token_id_input = keras.Input(
113 shape=(None,), dtype="int32", name="decoder_token_ids"
114 )
115 decoder_padding_mask = keras.Input(
116 shape=(None,), dtype="int32", name="decoder_padding_mask"
117 )
118
119 # Token embedding layer. This layer is shared by encoder and decoder.
120 token_embedding_layer = keras.layers.Embedding(
121 input_dim=vocabulary_size,
122 output_dim=hidden_dim,
123 embeddings_initializer=bart_kernel_initializer(),
124 name="token_embedding",
125 )
126
127 # ===== Encoder =====
128
129 # Embed tokens and positions.
130 token_embedding = token_embedding_layer(encoder_token_id_input)
131 # Position embedding parameters are not shared by encode and decoder.
132 position_embedding = PositionEmbedding(
133 initializer=bart_kernel_initializer(),
134 sequence_length=max_sequence_length,
135 name="encoder_position_embedding",
136 )(token_embedding)
137
138 # Sum, normalize and apply dropout to embeddings.
139 x = keras.layers.Add()((token_embedding, position_embedding))
140 x = keras.layers.LayerNormalization(
141 name="encoder_embeddings_layer_norm",
142 axis=-1,
143 epsilon=1e-5,
144 dtype=tf.float32,
145 )(x)
146 x = keras.layers.Dropout(
147 dropout,
148 name="encoder_embeddings_dropout",
149 )(x)
150
151 # Apply successive transformer encoder blocks.
152 for i in range(num_layers):
153 x = TransformerEncoder(
154 num_heads=num_heads,
155 intermediate_dim=intermediate_dim,
156 activation=lambda x: keras.activations.gelu(
157 x, approximate=False
158 ),
159 dropout=dropout,
160 layer_norm_epsilon=1e-5,
161 kernel_initializer=bart_kernel_initializer(),
162 name=f"transformer_encoder_layer_{i}",
163 )(x, padding_mask=encoder_padding_mask)
164
165 encoder_output = x
166
167 # ===== Decoder =====
168
169 # Embed tokens and positions.
170 token_embedding = token_embedding_layer(decoder_token_id_input)
171 # Position embedding parameters are not shared by encode and decoder.
172 position_embedding = PositionEmbedding(
173 initializer=bart_kernel_initializer(),
174 sequence_length=max_sequence_length,
175 name="decoder_position_embedding",
176 )(token_embedding)
177
178 # Sum, normalize and apply dropout to embeddings.
179 x = keras.layers.Add()((token_embedding, position_embedding))
180 x = keras.layers.LayerNormalization(
181 name="decoder_embeddings_layer_norm",
182 axis=-1,
183 epsilon=1e-5,
184 dtype=tf.float32,
185 )(x)
186 x = keras.layers.Dropout(
187 dropout,
188 name="decoder_embeddings_dropout",
189 )(x)
190
191 # Apply successive transformer decoder blocks.
192 for i in range(num_layers):
193 transformer_decoder_layer = TransformerDecoder(
194 intermediate_dim=intermediate_dim,
195 num_heads=num_heads,
196 dropout=dropout,
197 activation=lambda x: keras.activations.gelu(
198 x, approximate=False
199 ),
200 layer_norm_epsilon=1e-5,
201 kernel_initializer=bart_kernel_initializer(),
202 name=f"transformer_decoder_layer_{i}",
203 has_cross_attention=True,
204 )
205 x = transformer_decoder_layer(
206 decoder_sequence=x,
207 encoder_sequence=encoder_output,
208 decoder_padding_mask=decoder_padding_mask,
209 encoder_padding_mask=encoder_padding_mask,
210 )
211
212 decoder_output = x
213
214 # Instantiate using Functional API Model constructor
215 super().__init__(
216 inputs={
217 "encoder_token_ids": encoder_token_id_input,
218 "encoder_padding_mask": encoder_padding_mask,
219 "decoder_token_ids": decoder_token_id_input,
220 "decoder_padding_mask": decoder_padding_mask,
221 },
222 outputs={
223 "encoder_sequence_output": encoder_output,
224 "decoder_sequence_output": decoder_output,
225 },
226 **kwargs,
227 )
228
229 # All references to `self` below this line
230 self.vocabulary_size = vocabulary_size
231 self.num_layers = num_layers
232 self.num_heads = num_heads
233 self.hidden_dim = hidden_dim
234 self.intermediate_dim = intermediate_dim
235 self.dropout = dropout
236 self.max_sequence_length = max_sequence_length
237
238 def get_config(self):
239 return {
240 "vocabulary_size": self.vocabulary_size,
241 "num_layers": self.num_layers,
242 "num_heads": self.num_heads,
243 "hidden_dim": self.hidden_dim,
244 "intermediate_dim": self.intermediate_dim,
245 "dropout": self.dropout,
246 "max_sequence_length": self.max_sequence_length,
247 "name": self.name,
248 "trainable": self.trainable,
249 }
250
251 @property
252 def token_embedding(self):
253 return self.get_layer("token_embedding")
254
255 @classproperty
256 def presets(cls):
257 return copy.deepcopy(backbone_presets)
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/keras_nlp/models/bart/bart_backbone.py b/keras_nlp/models/bart/bart_backbone.py
--- a/keras_nlp/models/bart/bart_backbone.py
+++ b/keras_nlp/models/bart/bart_backbone.py
@@ -236,17 +236,20 @@
self.max_sequence_length = max_sequence_length
def get_config(self):
- return {
- "vocabulary_size": self.vocabulary_size,
- "num_layers": self.num_layers,
- "num_heads": self.num_heads,
- "hidden_dim": self.hidden_dim,
- "intermediate_dim": self.intermediate_dim,
- "dropout": self.dropout,
- "max_sequence_length": self.max_sequence_length,
- "name": self.name,
- "trainable": self.trainable,
- }
+ config = super().get_config()
+ config.update(
+ {
+ "vocabulary_size": self.vocabulary_size,
+ "num_layers": self.num_layers,
+ "num_heads": self.num_heads,
+ "hidden_dim": self.hidden_dim,
+ "intermediate_dim": self.intermediate_dim,
+ "dropout": self.dropout,
+ "max_sequence_length": self.max_sequence_length,
+ }
+ )
+
+ return config
@property
def token_embedding(self):
| {"golden_diff": "diff --git a/keras_nlp/models/bart/bart_backbone.py b/keras_nlp/models/bart/bart_backbone.py\n--- a/keras_nlp/models/bart/bart_backbone.py\n+++ b/keras_nlp/models/bart/bart_backbone.py\n@@ -236,17 +236,20 @@\n self.max_sequence_length = max_sequence_length\n \n def get_config(self):\n- return {\n- \"vocabulary_size\": self.vocabulary_size,\n- \"num_layers\": self.num_layers,\n- \"num_heads\": self.num_heads,\n- \"hidden_dim\": self.hidden_dim,\n- \"intermediate_dim\": self.intermediate_dim,\n- \"dropout\": self.dropout,\n- \"max_sequence_length\": self.max_sequence_length,\n- \"name\": self.name,\n- \"trainable\": self.trainable,\n- }\n+ config = super().get_config()\n+ config.update(\n+ {\n+ \"vocabulary_size\": self.vocabulary_size,\n+ \"num_layers\": self.num_layers,\n+ \"num_heads\": self.num_heads,\n+ \"hidden_dim\": self.hidden_dim,\n+ \"intermediate_dim\": self.intermediate_dim,\n+ \"dropout\": self.dropout,\n+ \"max_sequence_length\": self.max_sequence_length,\n+ }\n+ )\n+\n+ return config\n \n @property\n def token_embedding(self):\n", "issue": "Call `super.config()` in `BartBackbone`'s `get_config()`\nWe should call `super().config()` here: https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bart/bart_backbone.py#L238, update the config with `BARTBackbone`-specific keys and return the config. Check this for reference: https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_backbone.py#L204.\n", "before_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"BART backbone model.\"\"\"\n\nimport copy\n\nimport tensorflow as tf\nfrom tensorflow import keras\n\nfrom keras_nlp.layers.position_embedding import PositionEmbedding\nfrom keras_nlp.layers.transformer_decoder import TransformerDecoder\nfrom keras_nlp.layers.transformer_encoder import TransformerEncoder\nfrom keras_nlp.models.backbone import Backbone\nfrom keras_nlp.models.bart.bart_presets import backbone_presets\nfrom keras_nlp.utils.python_utils import classproperty\n\n\ndef bart_kernel_initializer(stddev=0.02):\n return keras.initializers.TruncatedNormal(stddev=stddev)\n\n\[email protected]_keras_serializable(package=\"keras_nlp\")\nclass BartBackbone(Backbone):\n \"\"\"BART encoder-decoder network.\n\n This class implements a Transformer-based encoder-decoder model as\n described in\n [\"BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension\"](https://arxiv.org/abs/1910.13461).\n\n The default constructor gives a fully customizable, randomly initialized BART\n model with any number of layers, heads, and embedding dimensions. To load\n preset architectures and weights, use the `from_preset` constructor.\n\n Disclaimer: Pre-trained models are provided on an \"as is\" basis, without\n warranties or conditions of any kind. The underlying model is provided by a\n third party and subject to a separate license, available\n [here](https://github.com/facebookresearch/fairseq/).\n\n Args:\n vocabulary_size: int. The size of the token vocabulary.\n num_layers: int. The number of transformer encoder layers and\n transformer decoder layers.\n num_heads: int. The number of attention heads for each transformer.\n The hidden size must be divisible by the number of attention heads.\n hidden_dim: int. The size of the transformer encoding and pooler layers.\n intermediate_dim: int. The output dimension of the first Dense layer in\n a two-layer feedforward network for each transformer.\n dropout: float. Dropout probability for the Transformer encoder.\n max_sequence_length: int. The maximum sequence length that this encoder\n can consume. If None, `max_sequence_length` uses the value from\n sequence length. This determines the variable shape for positional\n embeddings.\n\n Examples:\n ```python\n input_data = {\n \"encoder_token_ids\": tf.ones(shape=(1, 12), dtype=tf.int64),\n \"encoder_padding_mask\": tf.constant(\n [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], shape=(1, 12)\n ),\n \"decoder_token_ids\": tf.ones(shape=(1, 12), dtype=tf.int64),\n \"decoder_padding_mask\": tf.constant(\n [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0], shape=(1, 12)\n ),\n }\n\n # Randomly initialized BART encoder-decoder model with a custom config\n model = keras_nlp.models.BartBackbone(\n vocabulary_size=50265,\n num_layers=6,\n num_heads=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=12,\n )\n output = model(input_data)\n ```\n \"\"\"\n\n def __init__(\n self,\n vocabulary_size,\n num_layers,\n num_heads,\n hidden_dim,\n intermediate_dim,\n dropout=0.1,\n max_sequence_length=1024,\n **kwargs,\n ):\n # Encoder inputs\n encoder_token_id_input = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"encoder_token_ids\"\n )\n encoder_padding_mask = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"encoder_padding_mask\"\n )\n\n # Decoder inputs.\n decoder_token_id_input = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"decoder_token_ids\"\n )\n decoder_padding_mask = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"decoder_padding_mask\"\n )\n\n # Token embedding layer. This layer is shared by encoder and decoder.\n token_embedding_layer = keras.layers.Embedding(\n input_dim=vocabulary_size,\n output_dim=hidden_dim,\n embeddings_initializer=bart_kernel_initializer(),\n name=\"token_embedding\",\n )\n\n # ===== Encoder =====\n\n # Embed tokens and positions.\n token_embedding = token_embedding_layer(encoder_token_id_input)\n # Position embedding parameters are not shared by encode and decoder.\n position_embedding = PositionEmbedding(\n initializer=bart_kernel_initializer(),\n sequence_length=max_sequence_length,\n name=\"encoder_position_embedding\",\n )(token_embedding)\n\n # Sum, normalize and apply dropout to embeddings.\n x = keras.layers.Add()((token_embedding, position_embedding))\n x = keras.layers.LayerNormalization(\n name=\"encoder_embeddings_layer_norm\",\n axis=-1,\n epsilon=1e-5,\n dtype=tf.float32,\n )(x)\n x = keras.layers.Dropout(\n dropout,\n name=\"encoder_embeddings_dropout\",\n )(x)\n\n # Apply successive transformer encoder blocks.\n for i in range(num_layers):\n x = TransformerEncoder(\n num_heads=num_heads,\n intermediate_dim=intermediate_dim,\n activation=lambda x: keras.activations.gelu(\n x, approximate=False\n ),\n dropout=dropout,\n layer_norm_epsilon=1e-5,\n kernel_initializer=bart_kernel_initializer(),\n name=f\"transformer_encoder_layer_{i}\",\n )(x, padding_mask=encoder_padding_mask)\n\n encoder_output = x\n\n # ===== Decoder =====\n\n # Embed tokens and positions.\n token_embedding = token_embedding_layer(decoder_token_id_input)\n # Position embedding parameters are not shared by encode and decoder.\n position_embedding = PositionEmbedding(\n initializer=bart_kernel_initializer(),\n sequence_length=max_sequence_length,\n name=\"decoder_position_embedding\",\n )(token_embedding)\n\n # Sum, normalize and apply dropout to embeddings.\n x = keras.layers.Add()((token_embedding, position_embedding))\n x = keras.layers.LayerNormalization(\n name=\"decoder_embeddings_layer_norm\",\n axis=-1,\n epsilon=1e-5,\n dtype=tf.float32,\n )(x)\n x = keras.layers.Dropout(\n dropout,\n name=\"decoder_embeddings_dropout\",\n )(x)\n\n # Apply successive transformer decoder blocks.\n for i in range(num_layers):\n transformer_decoder_layer = TransformerDecoder(\n intermediate_dim=intermediate_dim,\n num_heads=num_heads,\n dropout=dropout,\n activation=lambda x: keras.activations.gelu(\n x, approximate=False\n ),\n layer_norm_epsilon=1e-5,\n kernel_initializer=bart_kernel_initializer(),\n name=f\"transformer_decoder_layer_{i}\",\n has_cross_attention=True,\n )\n x = transformer_decoder_layer(\n decoder_sequence=x,\n encoder_sequence=encoder_output,\n decoder_padding_mask=decoder_padding_mask,\n encoder_padding_mask=encoder_padding_mask,\n )\n\n decoder_output = x\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs={\n \"encoder_token_ids\": encoder_token_id_input,\n \"encoder_padding_mask\": encoder_padding_mask,\n \"decoder_token_ids\": decoder_token_id_input,\n \"decoder_padding_mask\": decoder_padding_mask,\n },\n outputs={\n \"encoder_sequence_output\": encoder_output,\n \"decoder_sequence_output\": decoder_output,\n },\n **kwargs,\n )\n\n # All references to `self` below this line\n self.vocabulary_size = vocabulary_size\n self.num_layers = num_layers\n self.num_heads = num_heads\n self.hidden_dim = hidden_dim\n self.intermediate_dim = intermediate_dim\n self.dropout = dropout\n self.max_sequence_length = max_sequence_length\n\n def get_config(self):\n return {\n \"vocabulary_size\": self.vocabulary_size,\n \"num_layers\": self.num_layers,\n \"num_heads\": self.num_heads,\n \"hidden_dim\": self.hidden_dim,\n \"intermediate_dim\": self.intermediate_dim,\n \"dropout\": self.dropout,\n \"max_sequence_length\": self.max_sequence_length,\n \"name\": self.name,\n \"trainable\": self.trainable,\n }\n\n @property\n def token_embedding(self):\n return self.get_layer(\"token_embedding\")\n\n @classproperty\n def presets(cls):\n return copy.deepcopy(backbone_presets)\n", "path": "keras_nlp/models/bart/bart_backbone.py"}], "after_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"BART backbone model.\"\"\"\n\nimport copy\n\nimport tensorflow as tf\nfrom tensorflow import keras\n\nfrom keras_nlp.layers.position_embedding import PositionEmbedding\nfrom keras_nlp.layers.transformer_decoder import TransformerDecoder\nfrom keras_nlp.layers.transformer_encoder import TransformerEncoder\nfrom keras_nlp.models.backbone import Backbone\nfrom keras_nlp.models.bart.bart_presets import backbone_presets\nfrom keras_nlp.utils.python_utils import classproperty\n\n\ndef bart_kernel_initializer(stddev=0.02):\n return keras.initializers.TruncatedNormal(stddev=stddev)\n\n\[email protected]_keras_serializable(package=\"keras_nlp\")\nclass BartBackbone(Backbone):\n \"\"\"BART encoder-decoder network.\n\n This class implements a Transformer-based encoder-decoder model as\n described in\n [\"BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension\"](https://arxiv.org/abs/1910.13461).\n\n The default constructor gives a fully customizable, randomly initialized BART\n model with any number of layers, heads, and embedding dimensions. To load\n preset architectures and weights, use the `from_preset` constructor.\n\n Disclaimer: Pre-trained models are provided on an \"as is\" basis, without\n warranties or conditions of any kind. The underlying model is provided by a\n third party and subject to a separate license, available\n [here](https://github.com/facebookresearch/fairseq/).\n\n Args:\n vocabulary_size: int. The size of the token vocabulary.\n num_layers: int. The number of transformer encoder layers and\n transformer decoder layers.\n num_heads: int. The number of attention heads for each transformer.\n The hidden size must be divisible by the number of attention heads.\n hidden_dim: int. The size of the transformer encoding and pooler layers.\n intermediate_dim: int. The output dimension of the first Dense layer in\n a two-layer feedforward network for each transformer.\n dropout: float. Dropout probability for the Transformer encoder.\n max_sequence_length: int. The maximum sequence length that this encoder\n can consume. If None, `max_sequence_length` uses the value from\n sequence length. This determines the variable shape for positional\n embeddings.\n\n Examples:\n ```python\n input_data = {\n \"encoder_token_ids\": tf.ones(shape=(1, 12), dtype=tf.int64),\n \"encoder_padding_mask\": tf.constant(\n [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], shape=(1, 12)\n ),\n \"decoder_token_ids\": tf.ones(shape=(1, 12), dtype=tf.int64),\n \"decoder_padding_mask\": tf.constant(\n [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0], shape=(1, 12)\n ),\n }\n\n # Randomly initialized BART encoder-decoder model with a custom config\n model = keras_nlp.models.BartBackbone(\n vocabulary_size=50265,\n num_layers=6,\n num_heads=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=12,\n )\n output = model(input_data)\n ```\n \"\"\"\n\n def __init__(\n self,\n vocabulary_size,\n num_layers,\n num_heads,\n hidden_dim,\n intermediate_dim,\n dropout=0.1,\n max_sequence_length=1024,\n **kwargs,\n ):\n # Encoder inputs\n encoder_token_id_input = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"encoder_token_ids\"\n )\n encoder_padding_mask = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"encoder_padding_mask\"\n )\n\n # Decoder inputs.\n decoder_token_id_input = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"decoder_token_ids\"\n )\n decoder_padding_mask = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"decoder_padding_mask\"\n )\n\n # Token embedding layer. This layer is shared by encoder and decoder.\n token_embedding_layer = keras.layers.Embedding(\n input_dim=vocabulary_size,\n output_dim=hidden_dim,\n embeddings_initializer=bart_kernel_initializer(),\n name=\"token_embedding\",\n )\n\n # ===== Encoder =====\n\n # Embed tokens and positions.\n token_embedding = token_embedding_layer(encoder_token_id_input)\n # Position embedding parameters are not shared by encode and decoder.\n position_embedding = PositionEmbedding(\n initializer=bart_kernel_initializer(),\n sequence_length=max_sequence_length,\n name=\"encoder_position_embedding\",\n )(token_embedding)\n\n # Sum, normalize and apply dropout to embeddings.\n x = keras.layers.Add()((token_embedding, position_embedding))\n x = keras.layers.LayerNormalization(\n name=\"encoder_embeddings_layer_norm\",\n axis=-1,\n epsilon=1e-5,\n dtype=tf.float32,\n )(x)\n x = keras.layers.Dropout(\n dropout,\n name=\"encoder_embeddings_dropout\",\n )(x)\n\n # Apply successive transformer encoder blocks.\n for i in range(num_layers):\n x = TransformerEncoder(\n num_heads=num_heads,\n intermediate_dim=intermediate_dim,\n activation=lambda x: keras.activations.gelu(\n x, approximate=False\n ),\n dropout=dropout,\n layer_norm_epsilon=1e-5,\n kernel_initializer=bart_kernel_initializer(),\n name=f\"transformer_encoder_layer_{i}\",\n )(x, padding_mask=encoder_padding_mask)\n\n encoder_output = x\n\n # ===== Decoder =====\n\n # Embed tokens and positions.\n token_embedding = token_embedding_layer(decoder_token_id_input)\n # Position embedding parameters are not shared by encode and decoder.\n position_embedding = PositionEmbedding(\n initializer=bart_kernel_initializer(),\n sequence_length=max_sequence_length,\n name=\"decoder_position_embedding\",\n )(token_embedding)\n\n # Sum, normalize and apply dropout to embeddings.\n x = keras.layers.Add()((token_embedding, position_embedding))\n x = keras.layers.LayerNormalization(\n name=\"decoder_embeddings_layer_norm\",\n axis=-1,\n epsilon=1e-5,\n dtype=tf.float32,\n )(x)\n x = keras.layers.Dropout(\n dropout,\n name=\"decoder_embeddings_dropout\",\n )(x)\n\n # Apply successive transformer decoder blocks.\n for i in range(num_layers):\n transformer_decoder_layer = TransformerDecoder(\n intermediate_dim=intermediate_dim,\n num_heads=num_heads,\n dropout=dropout,\n activation=lambda x: keras.activations.gelu(\n x, approximate=False\n ),\n layer_norm_epsilon=1e-5,\n kernel_initializer=bart_kernel_initializer(),\n name=f\"transformer_decoder_layer_{i}\",\n has_cross_attention=True,\n )\n x = transformer_decoder_layer(\n decoder_sequence=x,\n encoder_sequence=encoder_output,\n decoder_padding_mask=decoder_padding_mask,\n encoder_padding_mask=encoder_padding_mask,\n )\n\n decoder_output = x\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs={\n \"encoder_token_ids\": encoder_token_id_input,\n \"encoder_padding_mask\": encoder_padding_mask,\n \"decoder_token_ids\": decoder_token_id_input,\n \"decoder_padding_mask\": decoder_padding_mask,\n },\n outputs={\n \"encoder_sequence_output\": encoder_output,\n \"decoder_sequence_output\": decoder_output,\n },\n **kwargs,\n )\n\n # All references to `self` below this line\n self.vocabulary_size = vocabulary_size\n self.num_layers = num_layers\n self.num_heads = num_heads\n self.hidden_dim = hidden_dim\n self.intermediate_dim = intermediate_dim\n self.dropout = dropout\n self.max_sequence_length = max_sequence_length\n\n def get_config(self):\n config = super().get_config()\n config.update(\n {\n \"vocabulary_size\": self.vocabulary_size,\n \"num_layers\": self.num_layers,\n \"num_heads\": self.num_heads,\n \"hidden_dim\": self.hidden_dim,\n \"intermediate_dim\": self.intermediate_dim,\n \"dropout\": self.dropout,\n \"max_sequence_length\": self.max_sequence_length,\n }\n )\n\n return config\n\n @property\n def token_embedding(self):\n return self.get_layer(\"token_embedding\")\n\n @classproperty\n def presets(cls):\n return copy.deepcopy(backbone_presets)\n", "path": "keras_nlp/models/bart/bart_backbone.py"}]} | 3,049 | 308 |
gh_patches_debug_28738 | rasdani/github-patches | git_diff | mirumee__ariadne-661 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
snake_case_fallback_resolvers not calling obj.get(attr_name)
**Ariadne version:** 0.13.0
**Python version:** 3.8.11
Hello. I am using the [databases](https://www.encode.io/databases/) package with an [asyncpg](https://magicstack.github.io/asyncpg/current/) backend to interact with a PostgreSQL database. The objects returned from my queries are of the type `databases.backends.postgres.Record`. The desired attributes can only can accessed via the get method. However, when I use `snake_case_fallback_resolvers`, Ariadne has trouble resolving the requested fields and I receive the following error: `Cannot return null for non-nullable field`
If I instead use the regular `fallback_resolvers` (adjusting my schema's naming conventions), Ariadne is able to resolve the requested fields.
Is this a bug or am I doing something wrong? Thank you for your time.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ariadne/utils.py`
Content:
```
1 import asyncio
2 from functools import wraps
3 from typing import Optional, Union, Callable, Dict, Any
4
5 from graphql import GraphQLError, parse
6
7
8 def convert_camel_case_to_snake(graphql_name: str) -> str:
9 # pylint: disable=too-many-boolean-expressions
10 max_index = len(graphql_name) - 1
11 lowered_name = graphql_name.lower()
12
13 python_name = ""
14 for i, c in enumerate(lowered_name):
15 if i > 0 and (
16 # testWord -> test_word
17 (
18 c != graphql_name[i]
19 and graphql_name[i - 1] != "_"
20 and graphql_name[i - 1] == python_name[-1]
21 )
22 # TESTWord -> test_word
23 or (
24 i < max_index
25 and graphql_name[i] != lowered_name[i]
26 and graphql_name[i + 1] == lowered_name[i + 1]
27 )
28 # test134 -> test_134
29 or (c.isdigit() and not graphql_name[i - 1].isdigit())
30 # 134test -> 134_test
31 or (not c.isdigit() and graphql_name[i - 1].isdigit())
32 ):
33 python_name += "_"
34 python_name += c
35 return python_name
36
37
38 def gql(value: str) -> str:
39 parse(value)
40 return value
41
42
43 def unwrap_graphql_error(
44 error: Union[GraphQLError, Optional[Exception]]
45 ) -> Optional[Exception]:
46 if isinstance(error, GraphQLError):
47 return unwrap_graphql_error(error.original_error)
48 return error
49
50
51 def convert_kwargs_to_snake_case(func: Callable) -> Callable:
52 def convert_to_snake_case(d: Dict) -> Dict:
53 converted: Dict = {}
54 for k, v in d.items():
55 if isinstance(v, dict):
56 v = convert_to_snake_case(v)
57 if isinstance(v, list):
58 v = [convert_to_snake_case(i) if isinstance(i, dict) else i for i in v]
59 converted[convert_camel_case_to_snake(k)] = v
60 return converted
61
62 if asyncio.iscoroutinefunction(func):
63
64 @wraps(func)
65 async def async_wrapper(*args: Any, **kwargs: Any) -> Any:
66 return await func(*args, **convert_to_snake_case(kwargs))
67
68 return async_wrapper
69
70 @wraps(func)
71 def wrapper(*args: Any, **kwargs: Any) -> Any:
72 return func(*args, **convert_to_snake_case(kwargs))
73
74 return wrapper
75
```
Path: `ariadne/resolvers.py`
Content:
```
1 from typing import Any
2
3 from graphql import default_field_resolver
4 from graphql.type import (
5 GraphQLField,
6 GraphQLObjectType,
7 GraphQLResolveInfo,
8 GraphQLSchema,
9 )
10
11 from .types import Resolver, SchemaBindable
12 from .utils import convert_camel_case_to_snake
13
14
15 class FallbackResolversSetter(SchemaBindable):
16 def bind_to_schema(self, schema: GraphQLSchema) -> None:
17 for type_object in schema.type_map.values():
18 if isinstance(type_object, GraphQLObjectType):
19 self.add_resolvers_to_object_fields(type_object)
20
21 def add_resolvers_to_object_fields(self, type_object) -> None:
22 for field_name, field_object in type_object.fields.items():
23 self.add_resolver_to_field(field_name, field_object)
24
25 def add_resolver_to_field(self, _: str, field_object: GraphQLField) -> None:
26 if field_object.resolve is None:
27 field_object.resolve = default_field_resolver
28
29
30 class SnakeCaseFallbackResolversSetter(FallbackResolversSetter):
31 def add_resolver_to_field(
32 self, field_name: str, field_object: GraphQLField
33 ) -> None:
34 if field_object.resolve is None:
35 field_name = convert_camel_case_to_snake(field_name)
36 field_object.resolve = resolve_to(field_name)
37
38
39 fallback_resolvers = FallbackResolversSetter()
40 snake_case_fallback_resolvers = SnakeCaseFallbackResolversSetter()
41
42
43 def resolve_parent_field(parent: Any, field_name: str) -> Any:
44 if isinstance(parent, dict):
45 return parent.get(field_name)
46 return getattr(parent, field_name, None)
47
48
49 def resolve_to(field_name: str) -> Resolver:
50 def resolver(parent: Any, info: GraphQLResolveInfo, **kwargs) -> Any:
51 value = resolve_parent_field(parent, field_name)
52 if callable(value):
53 return value(info, **kwargs)
54 return value
55
56 # pylint: disable=protected-access
57 resolver._ariadne_alias_resolver = True # type: ignore
58 return resolver
59
60
61 def is_default_resolver(resolver: Resolver) -> bool:
62 # pylint: disable=comparison-with-callable
63 if resolver == default_field_resolver:
64 return True
65 return hasattr(resolver, "_ariadne_alias_resolver")
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ariadne/resolvers.py b/ariadne/resolvers.py
--- a/ariadne/resolvers.py
+++ b/ariadne/resolvers.py
@@ -1,3 +1,4 @@
+from collections.abc import Mapping
from typing import Any
from graphql import default_field_resolver
@@ -41,7 +42,7 @@
def resolve_parent_field(parent: Any, field_name: str) -> Any:
- if isinstance(parent, dict):
+ if isinstance(parent, Mapping):
return parent.get(field_name)
return getattr(parent, field_name, None)
diff --git a/ariadne/utils.py b/ariadne/utils.py
--- a/ariadne/utils.py
+++ b/ariadne/utils.py
@@ -1,4 +1,5 @@
import asyncio
+from collections.abc import Mapping
from functools import wraps
from typing import Optional, Union, Callable, Dict, Any
@@ -49,13 +50,15 @@
def convert_kwargs_to_snake_case(func: Callable) -> Callable:
- def convert_to_snake_case(d: Dict) -> Dict:
+ def convert_to_snake_case(m: Mapping) -> Dict:
converted: Dict = {}
- for k, v in d.items():
- if isinstance(v, dict):
+ for k, v in m.items():
+ if isinstance(v, Mapping):
v = convert_to_snake_case(v)
if isinstance(v, list):
- v = [convert_to_snake_case(i) if isinstance(i, dict) else i for i in v]
+ v = [
+ convert_to_snake_case(i) if isinstance(i, Mapping) else i for i in v
+ ]
converted[convert_camel_case_to_snake(k)] = v
return converted
| {"golden_diff": "diff --git a/ariadne/resolvers.py b/ariadne/resolvers.py\n--- a/ariadne/resolvers.py\n+++ b/ariadne/resolvers.py\n@@ -1,3 +1,4 @@\n+from collections.abc import Mapping\n from typing import Any\n \n from graphql import default_field_resolver\n@@ -41,7 +42,7 @@\n \n \n def resolve_parent_field(parent: Any, field_name: str) -> Any:\n- if isinstance(parent, dict):\n+ if isinstance(parent, Mapping):\n return parent.get(field_name)\n return getattr(parent, field_name, None)\n \ndiff --git a/ariadne/utils.py b/ariadne/utils.py\n--- a/ariadne/utils.py\n+++ b/ariadne/utils.py\n@@ -1,4 +1,5 @@\n import asyncio\n+from collections.abc import Mapping\n from functools import wraps\n from typing import Optional, Union, Callable, Dict, Any\n \n@@ -49,13 +50,15 @@\n \n \n def convert_kwargs_to_snake_case(func: Callable) -> Callable:\n- def convert_to_snake_case(d: Dict) -> Dict:\n+ def convert_to_snake_case(m: Mapping) -> Dict:\n converted: Dict = {}\n- for k, v in d.items():\n- if isinstance(v, dict):\n+ for k, v in m.items():\n+ if isinstance(v, Mapping):\n v = convert_to_snake_case(v)\n if isinstance(v, list):\n- v = [convert_to_snake_case(i) if isinstance(i, dict) else i for i in v]\n+ v = [\n+ convert_to_snake_case(i) if isinstance(i, Mapping) else i for i in v\n+ ]\n converted[convert_camel_case_to_snake(k)] = v\n return converted\n", "issue": "snake_case_fallback_resolvers not calling obj.get(attr_name)\n**Ariadne version:** 0.13.0\r\n**Python version:** 3.8.11\r\n\r\nHello. I am using the [databases](https://www.encode.io/databases/) package with an [asyncpg](https://magicstack.github.io/asyncpg/current/) backend to interact with a PostgreSQL database. The objects returned from my queries are of the type `databases.backends.postgres.Record`. The desired attributes can only can accessed via the get method. However, when I use `snake_case_fallback_resolvers`, Ariadne has trouble resolving the requested fields and I receive the following error: `Cannot return null for non-nullable field`\r\n\r\nIf I instead use the regular `fallback_resolvers` (adjusting my schema's naming conventions), Ariadne is able to resolve the requested fields.\r\n\r\nIs this a bug or am I doing something wrong? Thank you for your time.\r\n\n", "before_files": [{"content": "import asyncio\nfrom functools import wraps\nfrom typing import Optional, Union, Callable, Dict, Any\n\nfrom graphql import GraphQLError, parse\n\n\ndef convert_camel_case_to_snake(graphql_name: str) -> str:\n # pylint: disable=too-many-boolean-expressions\n max_index = len(graphql_name) - 1\n lowered_name = graphql_name.lower()\n\n python_name = \"\"\n for i, c in enumerate(lowered_name):\n if i > 0 and (\n # testWord -> test_word\n (\n c != graphql_name[i]\n and graphql_name[i - 1] != \"_\"\n and graphql_name[i - 1] == python_name[-1]\n )\n # TESTWord -> test_word\n or (\n i < max_index\n and graphql_name[i] != lowered_name[i]\n and graphql_name[i + 1] == lowered_name[i + 1]\n )\n # test134 -> test_134\n or (c.isdigit() and not graphql_name[i - 1].isdigit())\n # 134test -> 134_test\n or (not c.isdigit() and graphql_name[i - 1].isdigit())\n ):\n python_name += \"_\"\n python_name += c\n return python_name\n\n\ndef gql(value: str) -> str:\n parse(value)\n return value\n\n\ndef unwrap_graphql_error(\n error: Union[GraphQLError, Optional[Exception]]\n) -> Optional[Exception]:\n if isinstance(error, GraphQLError):\n return unwrap_graphql_error(error.original_error)\n return error\n\n\ndef convert_kwargs_to_snake_case(func: Callable) -> Callable:\n def convert_to_snake_case(d: Dict) -> Dict:\n converted: Dict = {}\n for k, v in d.items():\n if isinstance(v, dict):\n v = convert_to_snake_case(v)\n if isinstance(v, list):\n v = [convert_to_snake_case(i) if isinstance(i, dict) else i for i in v]\n converted[convert_camel_case_to_snake(k)] = v\n return converted\n\n if asyncio.iscoroutinefunction(func):\n\n @wraps(func)\n async def async_wrapper(*args: Any, **kwargs: Any) -> Any:\n return await func(*args, **convert_to_snake_case(kwargs))\n\n return async_wrapper\n\n @wraps(func)\n def wrapper(*args: Any, **kwargs: Any) -> Any:\n return func(*args, **convert_to_snake_case(kwargs))\n\n return wrapper\n", "path": "ariadne/utils.py"}, {"content": "from typing import Any\n\nfrom graphql import default_field_resolver\nfrom graphql.type import (\n GraphQLField,\n GraphQLObjectType,\n GraphQLResolveInfo,\n GraphQLSchema,\n)\n\nfrom .types import Resolver, SchemaBindable\nfrom .utils import convert_camel_case_to_snake\n\n\nclass FallbackResolversSetter(SchemaBindable):\n def bind_to_schema(self, schema: GraphQLSchema) -> None:\n for type_object in schema.type_map.values():\n if isinstance(type_object, GraphQLObjectType):\n self.add_resolvers_to_object_fields(type_object)\n\n def add_resolvers_to_object_fields(self, type_object) -> None:\n for field_name, field_object in type_object.fields.items():\n self.add_resolver_to_field(field_name, field_object)\n\n def add_resolver_to_field(self, _: str, field_object: GraphQLField) -> None:\n if field_object.resolve is None:\n field_object.resolve = default_field_resolver\n\n\nclass SnakeCaseFallbackResolversSetter(FallbackResolversSetter):\n def add_resolver_to_field(\n self, field_name: str, field_object: GraphQLField\n ) -> None:\n if field_object.resolve is None:\n field_name = convert_camel_case_to_snake(field_name)\n field_object.resolve = resolve_to(field_name)\n\n\nfallback_resolvers = FallbackResolversSetter()\nsnake_case_fallback_resolvers = SnakeCaseFallbackResolversSetter()\n\n\ndef resolve_parent_field(parent: Any, field_name: str) -> Any:\n if isinstance(parent, dict):\n return parent.get(field_name)\n return getattr(parent, field_name, None)\n\n\ndef resolve_to(field_name: str) -> Resolver:\n def resolver(parent: Any, info: GraphQLResolveInfo, **kwargs) -> Any:\n value = resolve_parent_field(parent, field_name)\n if callable(value):\n return value(info, **kwargs)\n return value\n\n # pylint: disable=protected-access\n resolver._ariadne_alias_resolver = True # type: ignore\n return resolver\n\n\ndef is_default_resolver(resolver: Resolver) -> bool:\n # pylint: disable=comparison-with-callable\n if resolver == default_field_resolver:\n return True\n return hasattr(resolver, \"_ariadne_alias_resolver\")\n", "path": "ariadne/resolvers.py"}], "after_files": [{"content": "import asyncio\nfrom collections.abc import Mapping\nfrom functools import wraps\nfrom typing import Optional, Union, Callable, Dict, Any\n\nfrom graphql import GraphQLError, parse\n\n\ndef convert_camel_case_to_snake(graphql_name: str) -> str:\n # pylint: disable=too-many-boolean-expressions\n max_index = len(graphql_name) - 1\n lowered_name = graphql_name.lower()\n\n python_name = \"\"\n for i, c in enumerate(lowered_name):\n if i > 0 and (\n # testWord -> test_word\n (\n c != graphql_name[i]\n and graphql_name[i - 1] != \"_\"\n and graphql_name[i - 1] == python_name[-1]\n )\n # TESTWord -> test_word\n or (\n i < max_index\n and graphql_name[i] != lowered_name[i]\n and graphql_name[i + 1] == lowered_name[i + 1]\n )\n # test134 -> test_134\n or (c.isdigit() and not graphql_name[i - 1].isdigit())\n # 134test -> 134_test\n or (not c.isdigit() and graphql_name[i - 1].isdigit())\n ):\n python_name += \"_\"\n python_name += c\n return python_name\n\n\ndef gql(value: str) -> str:\n parse(value)\n return value\n\n\ndef unwrap_graphql_error(\n error: Union[GraphQLError, Optional[Exception]]\n) -> Optional[Exception]:\n if isinstance(error, GraphQLError):\n return unwrap_graphql_error(error.original_error)\n return error\n\n\ndef convert_kwargs_to_snake_case(func: Callable) -> Callable:\n def convert_to_snake_case(m: Mapping) -> Dict:\n converted: Dict = {}\n for k, v in m.items():\n if isinstance(v, Mapping):\n v = convert_to_snake_case(v)\n if isinstance(v, list):\n v = [\n convert_to_snake_case(i) if isinstance(i, Mapping) else i for i in v\n ]\n converted[convert_camel_case_to_snake(k)] = v\n return converted\n\n if asyncio.iscoroutinefunction(func):\n\n @wraps(func)\n async def async_wrapper(*args: Any, **kwargs: Any) -> Any:\n return await func(*args, **convert_to_snake_case(kwargs))\n\n return async_wrapper\n\n @wraps(func)\n def wrapper(*args: Any, **kwargs: Any) -> Any:\n return func(*args, **convert_to_snake_case(kwargs))\n\n return wrapper\n", "path": "ariadne/utils.py"}, {"content": "from collections.abc import Mapping\nfrom typing import Any\n\nfrom graphql import default_field_resolver\nfrom graphql.type import (\n GraphQLField,\n GraphQLObjectType,\n GraphQLResolveInfo,\n GraphQLSchema,\n)\n\nfrom .types import Resolver, SchemaBindable\nfrom .utils import convert_camel_case_to_snake\n\n\nclass FallbackResolversSetter(SchemaBindable):\n def bind_to_schema(self, schema: GraphQLSchema) -> None:\n for type_object in schema.type_map.values():\n if isinstance(type_object, GraphQLObjectType):\n self.add_resolvers_to_object_fields(type_object)\n\n def add_resolvers_to_object_fields(self, type_object) -> None:\n for field_name, field_object in type_object.fields.items():\n self.add_resolver_to_field(field_name, field_object)\n\n def add_resolver_to_field(self, _: str, field_object: GraphQLField) -> None:\n if field_object.resolve is None:\n field_object.resolve = default_field_resolver\n\n\nclass SnakeCaseFallbackResolversSetter(FallbackResolversSetter):\n def add_resolver_to_field(\n self, field_name: str, field_object: GraphQLField\n ) -> None:\n if field_object.resolve is None:\n field_name = convert_camel_case_to_snake(field_name)\n field_object.resolve = resolve_to(field_name)\n\n\nfallback_resolvers = FallbackResolversSetter()\nsnake_case_fallback_resolvers = SnakeCaseFallbackResolversSetter()\n\n\ndef resolve_parent_field(parent: Any, field_name: str) -> Any:\n if isinstance(parent, Mapping):\n return parent.get(field_name)\n return getattr(parent, field_name, None)\n\n\ndef resolve_to(field_name: str) -> Resolver:\n def resolver(parent: Any, info: GraphQLResolveInfo, **kwargs) -> Any:\n value = resolve_parent_field(parent, field_name)\n if callable(value):\n return value(info, **kwargs)\n return value\n\n # pylint: disable=protected-access\n resolver._ariadne_alias_resolver = True # type: ignore\n return resolver\n\n\ndef is_default_resolver(resolver: Resolver) -> bool:\n # pylint: disable=comparison-with-callable\n if resolver == default_field_resolver:\n return True\n return hasattr(resolver, \"_ariadne_alias_resolver\")\n", "path": "ariadne/resolvers.py"}]} | 1,781 | 400 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.