
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
9.01k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 465
11.3k
| num_tokens_prompt
int64 557
2.05k
| num_tokens_diff
int64 48
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_33470
|
rasdani/github-patches
|
git_diff
|
hylang__hy-1865
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
setup.py install doesn't run without dependencies
Right now, if you run `setup.py install` without installing the dependencies first, then the install will fail. This is because all the Hy files are compiled *before* installation, but in order to compile them the dependencies need to be present.
Unfortunately, fixing this isn't particularly pretty. As it stands, setup.py doesn't install the dependencies *at all* thanks to this [ever-open setuptools bug](https://github.com/pypa/setuptools/issues/456). Right now, the setuptools install command does this:
- Gathers the distribution information.
- Builds a binary egg.
- Asks easy_install to install said egg, which will also install dependencies.
In order to install the dependencies prior to compiling the Hy bytecode, one of the following would need to be done (in combination for working around the issue mentioned above):
- Figure out some way to reliably iterate through the dependencies and install them first. This would probably involve copying a bit of small code from easy_install.py.
- Get easy_install to install only the dependencies first. I like this approach, but I'm trying to figure out how to do it without calling egg_info which would involve going through the manifest *twice* on install.
Of course, we could always just say the install command is broken. This isn't as insane as it seems, because right now the only reason you'd be forced to use the install command is for distro packaging, in which case the dependencies will already be installed. In all other cases, `pip install .` is superior in every way.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # Copyright 2020 the authors.
3 # This file is part of Hy, which is free software licensed under the Expat
4 # license. See the LICENSE.
5
6 import sys, os
7
8 from setuptools import find_packages, setup
9 from setuptools.command.install import install
10 import fastentrypoints # Monkey-patches setuptools.
11
12 from get_version import __version__
13
14 os.chdir(os.path.split(os.path.abspath(__file__))[0])
15
16 PKG = "hy"
17
18 long_description = """Hy is a Python <--> Lisp layer. It helps
19 make things work nicer, and lets Python and the Hy lisp variant play
20 nice together. """
21
22 class Install(install):
23 def run(self):
24 # Import each Hy module to ensure it's compiled.
25 import os, importlib
26 for dirpath, _, filenames in sorted(os.walk("hy")):
27 for filename in sorted(filenames):
28 if filename.endswith(".hy"):
29 importlib.import_module(
30 dirpath.replace("/", ".").replace("\\", ".") +
31 "." + filename[:-len(".hy")])
32 install.run(self)
33
34 install_requires = [
35 'rply>=0.7.7',
36 'astor>=0.8',
37 'funcparserlib>=0.3.6',
38 'colorama']
39 if os.name == 'nt':
40 install_requires.append('pyreadline>=2.1')
41
42 setup(
43 name=PKG,
44 version=__version__,
45 install_requires=install_requires,
46 cmdclass=dict(install=Install),
47 entry_points={
48 'console_scripts': [
49 'hy = hy.cmdline:hy_main',
50 'hy3 = hy.cmdline:hy_main',
51 'hyc = hy.cmdline:hyc_main',
52 'hyc3 = hy.cmdline:hyc_main',
53 'hy2py = hy.cmdline:hy2py_main',
54 'hy2py3 = hy.cmdline:hy2py_main',
55 ]
56 },
57 packages=find_packages(exclude=['tests*']),
58 package_data={
59 'hy.contrib': ['*.hy', '__pycache__/*'],
60 'hy.core': ['*.hy', '__pycache__/*'],
61 'hy.extra': ['*.hy', '__pycache__/*'],
62 },
63 data_files=[
64 ('get_version', ['get_version.py'])
65 ],
66 author="Paul Tagliamonte",
67 author_email="[email protected]",
68 long_description=long_description,
69 description='Lisp and Python love each other.',
70 license="Expat",
71 url="http://hylang.org/",
72 platforms=['any'],
73 classifiers=[
74 "Development Status :: 4 - Beta",
75 "Intended Audience :: Developers",
76 "License :: DFSG approved",
77 "License :: OSI Approved :: MIT License", # Really "Expat". Ugh.
78 "Operating System :: OS Independent",
79 "Programming Language :: Lisp",
80 "Programming Language :: Python",
81 "Programming Language :: Python :: 3",
82 "Programming Language :: Python :: 3.5",
83 "Programming Language :: Python :: 3.6",
84 "Programming Language :: Python :: 3.7",
85 "Programming Language :: Python :: 3.8",
86 "Topic :: Software Development :: Code Generators",
87 "Topic :: Software Development :: Compilers",
88 "Topic :: Software Development :: Libraries",
89 ]
90 )
91
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,11 @@
# This file is part of Hy, which is free software licensed under the Expat
# license. See the LICENSE.
-import sys, os
+import glob
+import importlib
+import inspect
+import os
+import sys
from setuptools import find_packages, setup
from setuptools.command.install import install
@@ -20,16 +24,42 @@
nice together. """
class Install(install):
+ def __compile_hy_bytecode(self):
+ for path in sorted(glob.iglob('hy/**.hy', recursive=True)):
+ importlib.util.cache_from_source(path, optimize=self.optimize)
+
def run(self):
- # Import each Hy module to ensure it's compiled.
- import os, importlib
- for dirpath, _, filenames in sorted(os.walk("hy")):
- for filename in sorted(filenames):
- if filename.endswith(".hy"):
- importlib.import_module(
- dirpath.replace("/", ".").replace("\\", ".") +
- "." + filename[:-len(".hy")])
- install.run(self)
+ # Don't bother messing around with deps if they wouldn't be installed anyway.
+ # Code is based on setuptools's install.py.
+ if not (self.old_and_unmanageable or self.single_version_externally_managed
+ or not self._called_from_setup(inspect.currentframe())):
+ easy_install = self.distribution.get_command_class('easy_install')
+
+ cmd = easy_install(
+ self.distribution, args="x", root=self.root, record=self.record,
+ )
+ cmd.ensure_finalized()
+ cmd.always_copy_from = '.'
+ cmd.package_index.scan(glob.glob('*.egg'))
+
+ cmd.args = self.distribution.install_requires
+
+ # Avoid deprecation warnings on new setuptools versions.
+ if 'show_deprecation' in inspect.signature(cmd.run).parameters:
+ cmd.run(show_deprecation=False)
+ else:
+ cmd.run()
+
+ # Make sure any new packages get picked up.
+ import site
+ importlib.reload(site)
+ importlib.invalidate_caches()
+
+ self.__compile_hy_bytecode()
+
+ # The deps won't be reinstalled because of:
+ # https://github.com/pypa/setuptools/issues/456
+ return install.run(self)
install_requires = [
'rply>=0.7.7',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -3,7 +3,11 @@\n # This file is part of Hy, which is free software licensed under the Expat\n # license. See the LICENSE.\n \n-import sys, os\n+import glob\n+import importlib\n+import inspect\n+import os\n+import sys\n \n from setuptools import find_packages, setup\n from setuptools.command.install import install\n@@ -20,16 +24,42 @@\n nice together. \"\"\"\n \n class Install(install):\n+ def __compile_hy_bytecode(self):\n+ for path in sorted(glob.iglob('hy/**.hy', recursive=True)):\n+ importlib.util.cache_from_source(path, optimize=self.optimize)\n+\n def run(self):\n- # Import each Hy module to ensure it's compiled.\n- import os, importlib\n- for dirpath, _, filenames in sorted(os.walk(\"hy\")):\n- for filename in sorted(filenames):\n- if filename.endswith(\".hy\"):\n- importlib.import_module(\n- dirpath.replace(\"/\", \".\").replace(\"\\\\\", \".\") +\n- \".\" + filename[:-len(\".hy\")])\n- install.run(self)\n+ # Don't bother messing around with deps if they wouldn't be installed anyway.\n+ # Code is based on setuptools's install.py.\n+ if not (self.old_and_unmanageable or self.single_version_externally_managed\n+ or not self._called_from_setup(inspect.currentframe())):\n+ easy_install = self.distribution.get_command_class('easy_install')\n+\n+ cmd = easy_install(\n+ self.distribution, args=\"x\", root=self.root, record=self.record,\n+ )\n+ cmd.ensure_finalized()\n+ cmd.always_copy_from = '.'\n+ cmd.package_index.scan(glob.glob('*.egg'))\n+\n+ cmd.args = self.distribution.install_requires\n+\n+ # Avoid deprecation warnings on new setuptools versions.\n+ if 'show_deprecation' in inspect.signature(cmd.run).parameters:\n+ cmd.run(show_deprecation=False)\n+ else:\n+ cmd.run()\n+\n+ # Make sure any new packages get picked up.\n+ import site\n+ importlib.reload(site)\n+ importlib.invalidate_caches()\n+\n+ self.__compile_hy_bytecode()\n+\n+ # The deps won't be reinstalled because of:\n+ # https://github.com/pypa/setuptools/issues/456\n+ return install.run(self)\n \n install_requires = [\n 'rply>=0.7.7',\n", "issue": "setup.py install doesn't run without dependencies\nRight now, if you run `setup.py install` without installing the dependencies first, then the install will fail. This is because all the Hy files are compiled *before* installation, but in order to compile them the dependencies need to be present.\n\nUnfortunately, fixing this isn't particularly pretty. As it stands, setup.py doesn't install the dependencies *at all* thanks to this [ever-open setuptools bug](https://github.com/pypa/setuptools/issues/456). Right now, the setuptools install command does this:\n\n- Gathers the distribution information.\n- Builds a binary egg.\n- Asks easy_install to install said egg, which will also install dependencies.\n\nIn order to install the dependencies prior to compiling the Hy bytecode, one of the following would need to be done (in combination for working around the issue mentioned above):\n\n- Figure out some way to reliably iterate through the dependencies and install them first. This would probably involve copying a bit of small code from easy_install.py.\n- Get easy_install to install only the dependencies first. I like this approach, but I'm trying to figure out how to do it without calling egg_info which would involve going through the manifest *twice* on install.\n\nOf course, we could always just say the install command is broken. This isn't as insane as it seems, because right now the only reason you'd be forced to use the install command is for distro packaging, in which case the dependencies will already be installed. In all other cases, `pip install .` is superior in every way.\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright 2020 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nimport sys, os\n\nfrom setuptools import find_packages, setup\nfrom setuptools.command.install import install\nimport fastentrypoints # Monkey-patches setuptools.\n\nfrom get_version import __version__\n\nos.chdir(os.path.split(os.path.abspath(__file__))[0])\n\nPKG = \"hy\"\n\nlong_description = \"\"\"Hy is a Python <--> Lisp layer. It helps\nmake things work nicer, and lets Python and the Hy lisp variant play\nnice together. \"\"\"\n\nclass Install(install):\n def run(self):\n # Import each Hy module to ensure it's compiled.\n import os, importlib\n for dirpath, _, filenames in sorted(os.walk(\"hy\")):\n for filename in sorted(filenames):\n if filename.endswith(\".hy\"):\n importlib.import_module(\n dirpath.replace(\"/\", \".\").replace(\"\\\\\", \".\") +\n \".\" + filename[:-len(\".hy\")])\n install.run(self)\n\ninstall_requires = [\n 'rply>=0.7.7',\n 'astor>=0.8',\n 'funcparserlib>=0.3.6',\n 'colorama']\nif os.name == 'nt':\n install_requires.append('pyreadline>=2.1')\n\nsetup(\n name=PKG,\n version=__version__,\n install_requires=install_requires,\n cmdclass=dict(install=Install),\n entry_points={\n 'console_scripts': [\n 'hy = hy.cmdline:hy_main',\n 'hy3 = hy.cmdline:hy_main',\n 'hyc = hy.cmdline:hyc_main',\n 'hyc3 = hy.cmdline:hyc_main',\n 'hy2py = hy.cmdline:hy2py_main',\n 'hy2py3 = hy.cmdline:hy2py_main',\n ]\n },\n packages=find_packages(exclude=['tests*']),\n package_data={\n 'hy.contrib': ['*.hy', '__pycache__/*'],\n 'hy.core': ['*.hy', '__pycache__/*'],\n 'hy.extra': ['*.hy', '__pycache__/*'],\n },\n data_files=[\n ('get_version', ['get_version.py'])\n ],\n author=\"Paul Tagliamonte\",\n author_email=\"[email protected]\",\n long_description=long_description,\n description='Lisp and Python love each other.',\n license=\"Expat\",\n url=\"http://hylang.org/\",\n platforms=['any'],\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: DFSG approved\",\n \"License :: OSI Approved :: MIT License\", # Really \"Expat\". Ugh.\n \"Operating System :: OS Independent\",\n \"Programming Language :: Lisp\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Software Development :: Code Generators\",\n \"Topic :: Software Development :: Compilers\",\n \"Topic :: Software Development :: Libraries\",\n ]\n)\n", "path": "setup.py"}]}
| 1,745 | 563 |
gh_patches_debug_11683
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs should not use underscores in http headers for auth
**Version**
any
**Describe the bug**
https://docs.pulpproject.org/pulpcore/authentication/webserver.html#webserver-auth-with-reverse-proxy says:
> With nginx providing authentication, all it can do is pass REMOTE_USER (or similar name) to the application webserver, i.e. gunicorn. You can pass the header as part of the proxy request in nginx with a config line like:
>
> proxy_set_header REMOTE_USER $remote_user;
But since gunicorn 22.0 (more precisely https://github.com/benoitc/gunicorn/commit/72b8970dbf2bf3444eb2e8b12aeff1a3d5922a9a/ https://github.com/benoitc/gunicorn/issues/2799) headers with underscores are forbidden by default.
If the docs would use a dash, so `proxy_set_header REMOTE-USER …` things would work :)
**Additional context**
Grant made me file this, and I did not want to post a screenshot of our colorful conversation ;)
</issue>
<code>
[start of pulpcore/app/tasks/repository.py]
1 from gettext import gettext as _
2 from logging import getLogger
3
4 from django.db import transaction
5
6 from pulpcore.app import models, serializers
7
8 log = getLogger(__name__)
9
10
11 def delete(repo_id):
12 """
13 Delete a :class:`~pulpcore.app.models.Repository`
14
15 Args:
16 repo_id (int): The name of the repository to be deleted
17 """
18
19 models.Repository.objects.filter(pk=repo_id).delete()
20
21
22 def update(repo_id, partial=True, data=None):
23 """
24 Updates a :class:`~pulpcore.app.models.Repository`
25
26 Args:
27 repo_id (int): The id of the repository to be updated
28 partial (bool): Boolean to allow partial updates. If set to False, values for all
29 required fields must be passed or a validation error will be raised.
30 Defaults to True
31 data (QueryDict): dict of attributes to change and their new values; if None, no attempt to
32 update the repository object will be made
33 """
34 instance = models.Repository.objects.get(pk=repo_id)
35 serializer = serializers.RepositorySerializer(instance, data=data, partial=partial)
36 serializer.is_valid(raise_exception=True)
37 serializer.save()
38
39
40 def delete_version(pk):
41 """
42 Delete a repository version by squashing its changes with the next newer version. This ensures
43 that the content set for each version stays the same.
44
45 There must be a newer version to squash into. If we deleted the latest version, the next content
46 change would create a new one of the same number, which would violate the immutability
47 guarantee.
48
49 Args:
50 pk (int): the primary key for a RepositoryVersion to delete
51
52 Raises:
53 models.RepositoryVersion.DoesNotExist: if there is not a newer version to squash into.
54 TODO: something more friendly
55 """
56 with transaction.atomic():
57 try:
58 version = models.RepositoryVersion.objects.get(pk=pk)
59 except models.RepositoryVersion.DoesNotExist:
60 log.info(_('The repository version was not found. Nothing to do.'))
61 return
62
63 log.info(_('Deleting and squashing version %(v)d of repository %(r)s'),
64 {'v': version.number, 'r': version.repository.name})
65
66 version.delete()
67
68
69 def add_and_remove(repository_pk, add_content_units, remove_content_units, base_version_pk=None):
70 """
71 Create a new repository version by adding and then removing content units.
72
73 Args:
74 repository_pk (int): The primary key for a Repository for which a new Repository Version
75 should be created.
76 add_content_units (list): List of PKs for :class:`~pulpcore.app.models.Content` that
77 should be added to the previous Repository Version for this Repository.
78 remove_content_units (list): List of PKs for:class:`~pulpcore.app.models.Content` that
79 should be removed from the previous Repository Version for this Repository.
80 base_version_pk (int): the primary key for a RepositoryVersion whose content will be used
81 as the initial set of content for our new RepositoryVersion
82 """
83 repository = models.Repository.objects.get(pk=repository_pk)
84
85 if base_version_pk:
86 base_version = models.RepositoryVersion.objects.get(pk=base_version_pk)
87 else:
88 base_version = None
89
90 if '*' in remove_content_units:
91 latest = models.RepositoryVersion.latest(repository)
92 remove_content_units = latest.content.values_list('pk', flat=True)
93
94 with models.RepositoryVersion.create(repository, base_version=base_version) as new_version:
95 new_version.remove_content(models.Content.objects.filter(pk__in=remove_content_units))
96 new_version.add_content(models.Content.objects.filter(pk__in=add_content_units))
97
[end of pulpcore/app/tasks/repository.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/app/tasks/repository.py b/pulpcore/app/tasks/repository.py
--- a/pulpcore/app/tasks/repository.py
+++ b/pulpcore/app/tasks/repository.py
@@ -89,7 +89,10 @@
if '*' in remove_content_units:
latest = models.RepositoryVersion.latest(repository)
- remove_content_units = latest.content.values_list('pk', flat=True)
+ if latest:
+ remove_content_units = latest.content.values_list('pk', flat=True)
+ else:
+ remove_content_units = []
with models.RepositoryVersion.create(repository, base_version=base_version) as new_version:
new_version.remove_content(models.Content.objects.filter(pk__in=remove_content_units))
|
{"golden_diff": "diff --git a/pulpcore/app/tasks/repository.py b/pulpcore/app/tasks/repository.py\n--- a/pulpcore/app/tasks/repository.py\n+++ b/pulpcore/app/tasks/repository.py\n@@ -89,7 +89,10 @@\n \n if '*' in remove_content_units:\n latest = models.RepositoryVersion.latest(repository)\n- remove_content_units = latest.content.values_list('pk', flat=True)\n+ if latest:\n+ remove_content_units = latest.content.values_list('pk', flat=True)\n+ else:\n+ remove_content_units = []\n \n with models.RepositoryVersion.create(repository, base_version=base_version) as new_version:\n new_version.remove_content(models.Content.objects.filter(pk__in=remove_content_units))\n", "issue": "docs should not use underscores in http headers for auth\n**Version**\r\nany\r\n\r\n**Describe the bug**\r\nhttps://docs.pulpproject.org/pulpcore/authentication/webserver.html#webserver-auth-with-reverse-proxy says:\r\n> With nginx providing authentication, all it can do is pass REMOTE_USER (or similar name) to the application webserver, i.e. gunicorn. You can pass the header as part of the proxy request in nginx with a config line like:\r\n> \r\n> proxy_set_header REMOTE_USER $remote_user;\r\n\r\nBut since gunicorn 22.0 (more precisely https://github.com/benoitc/gunicorn/commit/72b8970dbf2bf3444eb2e8b12aeff1a3d5922a9a/ https://github.com/benoitc/gunicorn/issues/2799) headers with underscores are forbidden by default.\r\n\r\nIf the docs would use a dash, so `proxy_set_header REMOTE-USER \u2026` things would work :)\r\n\r\n**Additional context**\r\nGrant made me file this, and I did not want to post a screenshot of our colorful conversation ;)\n", "before_files": [{"content": "from gettext import gettext as _\nfrom logging import getLogger\n\nfrom django.db import transaction\n\nfrom pulpcore.app import models, serializers\n\nlog = getLogger(__name__)\n\n\ndef delete(repo_id):\n \"\"\"\n Delete a :class:`~pulpcore.app.models.Repository`\n\n Args:\n repo_id (int): The name of the repository to be deleted\n \"\"\"\n\n models.Repository.objects.filter(pk=repo_id).delete()\n\n\ndef update(repo_id, partial=True, data=None):\n \"\"\"\n Updates a :class:`~pulpcore.app.models.Repository`\n\n Args:\n repo_id (int): The id of the repository to be updated\n partial (bool): Boolean to allow partial updates. If set to False, values for all\n required fields must be passed or a validation error will be raised.\n Defaults to True\n data (QueryDict): dict of attributes to change and their new values; if None, no attempt to\n update the repository object will be made\n \"\"\"\n instance = models.Repository.objects.get(pk=repo_id)\n serializer = serializers.RepositorySerializer(instance, data=data, partial=partial)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n\ndef delete_version(pk):\n \"\"\"\n Delete a repository version by squashing its changes with the next newer version. This ensures\n that the content set for each version stays the same.\n\n There must be a newer version to squash into. If we deleted the latest version, the next content\n change would create a new one of the same number, which would violate the immutability\n guarantee.\n\n Args:\n pk (int): the primary key for a RepositoryVersion to delete\n\n Raises:\n models.RepositoryVersion.DoesNotExist: if there is not a newer version to squash into.\n TODO: something more friendly\n \"\"\"\n with transaction.atomic():\n try:\n version = models.RepositoryVersion.objects.get(pk=pk)\n except models.RepositoryVersion.DoesNotExist:\n log.info(_('The repository version was not found. Nothing to do.'))\n return\n\n log.info(_('Deleting and squashing version %(v)d of repository %(r)s'),\n {'v': version.number, 'r': version.repository.name})\n\n version.delete()\n\n\ndef add_and_remove(repository_pk, add_content_units, remove_content_units, base_version_pk=None):\n \"\"\"\n Create a new repository version by adding and then removing content units.\n\n Args:\n repository_pk (int): The primary key for a Repository for which a new Repository Version\n should be created.\n add_content_units (list): List of PKs for :class:`~pulpcore.app.models.Content` that\n should be added to the previous Repository Version for this Repository.\n remove_content_units (list): List of PKs for:class:`~pulpcore.app.models.Content` that\n should be removed from the previous Repository Version for this Repository.\n base_version_pk (int): the primary key for a RepositoryVersion whose content will be used\n as the initial set of content for our new RepositoryVersion\n \"\"\"\n repository = models.Repository.objects.get(pk=repository_pk)\n\n if base_version_pk:\n base_version = models.RepositoryVersion.objects.get(pk=base_version_pk)\n else:\n base_version = None\n\n if '*' in remove_content_units:\n latest = models.RepositoryVersion.latest(repository)\n remove_content_units = latest.content.values_list('pk', flat=True)\n\n with models.RepositoryVersion.create(repository, base_version=base_version) as new_version:\n new_version.remove_content(models.Content.objects.filter(pk__in=remove_content_units))\n new_version.add_content(models.Content.objects.filter(pk__in=add_content_units))\n", "path": "pulpcore/app/tasks/repository.py"}]}
| 1,741 | 156 |
gh_patches_debug_38591
|
rasdani/github-patches
|
git_diff
|
getredash__redash-2653
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add to status page the size of Redash's DB
```sql
SELECT pg_size_pretty(pg_total_relation_size('query_results'));
```
```sql
SELECT pg_size_pretty(pg_database_size('redash'));
```
</issue>
<code>
[start of redash/monitor.py]
1 from redash import redis_connection, models, __version__, settings
2
3
4 def get_status():
5 status = {}
6 info = redis_connection.info()
7 status['redis_used_memory'] = info['used_memory']
8 status['redis_used_memory_human'] = info['used_memory_human']
9 status['version'] = __version__
10 status['queries_count'] = models.db.session.query(models.Query).count()
11 if settings.FEATURE_SHOW_QUERY_RESULTS_COUNT:
12 status['query_results_count'] = models.db.session.query(models.QueryResult).count()
13 status['unused_query_results_count'] = models.QueryResult.unused().count()
14 status['dashboards_count'] = models.Dashboard.query.count()
15 status['widgets_count'] = models.Widget.query.count()
16
17 status['workers'] = []
18
19 status['manager'] = redis_connection.hgetall('redash:status')
20
21 queues = {}
22 for ds in models.DataSource.query:
23 for queue in (ds.queue_name, ds.scheduled_queue_name):
24 queues.setdefault(queue, set())
25 queues[queue].add(ds.name)
26
27 status['manager']['queues'] = {}
28 for queue, sources in queues.iteritems():
29 status['manager']['queues'][queue] = {
30 'data_sources': ', '.join(sources),
31 'size': redis_connection.llen(queue)
32 }
33
34 status['manager']['queues']['celery'] = {
35 'size': redis_connection.llen('celery'),
36 'data_sources': ''
37 }
38
39 return status
40
[end of redash/monitor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/monitor.py b/redash/monitor.py
--- a/redash/monitor.py
+++ b/redash/monitor.py
@@ -1,39 +1,72 @@
from redash import redis_connection, models, __version__, settings
-def get_status():
- status = {}
+def get_redis_status():
info = redis_connection.info()
- status['redis_used_memory'] = info['used_memory']
- status['redis_used_memory_human'] = info['used_memory_human']
- status['version'] = __version__
+ return {'redis_used_memory': info['used_memory'], 'redis_used_memory_human': info['used_memory_human']}
+
+
+def get_object_counts():
+ status = {}
status['queries_count'] = models.db.session.query(models.Query).count()
if settings.FEATURE_SHOW_QUERY_RESULTS_COUNT:
status['query_results_count'] = models.db.session.query(models.QueryResult).count()
status['unused_query_results_count'] = models.QueryResult.unused().count()
status['dashboards_count'] = models.Dashboard.query.count()
status['widgets_count'] = models.Widget.query.count()
+ return status
- status['workers'] = []
-
- status['manager'] = redis_connection.hgetall('redash:status')
+def get_queues():
queues = {}
for ds in models.DataSource.query:
for queue in (ds.queue_name, ds.scheduled_queue_name):
queues.setdefault(queue, set())
queues[queue].add(ds.name)
- status['manager']['queues'] = {}
+ return queues
+
+
+def get_queues_status():
+ queues = get_queues()
+
for queue, sources in queues.iteritems():
- status['manager']['queues'][queue] = {
+ queues[queue] = {
'data_sources': ', '.join(sources),
'size': redis_connection.llen(queue)
}
- status['manager']['queues']['celery'] = {
+ queues['celery'] = {
'size': redis_connection.llen('celery'),
'data_sources': ''
}
+ return queues
+
+
+def get_db_sizes():
+ database_metrics = []
+ queries = [
+ ['Query Results Size', "select pg_total_relation_size('query_results') as size from (select 1) as a"],
+ ['Redash DB Size', "select pg_database_size('postgres') as size"]
+ ]
+ for query_name, query in queries:
+ result = models.db.session.execute(query).first()
+ database_metrics.append([query_name, result[0]])
+
+ return database_metrics
+
+
+def get_status():
+ status = {
+ 'version': __version__,
+ 'workers': []
+ }
+ status.update(get_redis_status())
+ status.update(get_object_counts())
+ status['manager'] = redis_connection.hgetall('redash:status')
+ status['manager']['queues'] = get_queues_status()
+ status['database_metrics'] = {}
+ status['database_metrics']['metrics'] = get_db_sizes()
+
return status
|
{"golden_diff": "diff --git a/redash/monitor.py b/redash/monitor.py\n--- a/redash/monitor.py\n+++ b/redash/monitor.py\n@@ -1,39 +1,72 @@\n from redash import redis_connection, models, __version__, settings\n \n \n-def get_status():\n- status = {}\n+def get_redis_status():\n info = redis_connection.info()\n- status['redis_used_memory'] = info['used_memory']\n- status['redis_used_memory_human'] = info['used_memory_human']\n- status['version'] = __version__\n+ return {'redis_used_memory': info['used_memory'], 'redis_used_memory_human': info['used_memory_human']}\n+\n+\n+def get_object_counts():\n+ status = {}\n status['queries_count'] = models.db.session.query(models.Query).count()\n if settings.FEATURE_SHOW_QUERY_RESULTS_COUNT:\n status['query_results_count'] = models.db.session.query(models.QueryResult).count()\n status['unused_query_results_count'] = models.QueryResult.unused().count()\n status['dashboards_count'] = models.Dashboard.query.count()\n status['widgets_count'] = models.Widget.query.count()\n+ return status\n \n- status['workers'] = []\n-\n- status['manager'] = redis_connection.hgetall('redash:status')\n \n+def get_queues():\n queues = {}\n for ds in models.DataSource.query:\n for queue in (ds.queue_name, ds.scheduled_queue_name):\n queues.setdefault(queue, set())\n queues[queue].add(ds.name)\n \n- status['manager']['queues'] = {}\n+ return queues\n+\n+\n+def get_queues_status():\n+ queues = get_queues()\n+\n for queue, sources in queues.iteritems():\n- status['manager']['queues'][queue] = {\n+ queues[queue] = {\n 'data_sources': ', '.join(sources),\n 'size': redis_connection.llen(queue)\n }\n \n- status['manager']['queues']['celery'] = {\n+ queues['celery'] = {\n 'size': redis_connection.llen('celery'),\n 'data_sources': ''\n }\n \n+ return queues\n+\n+\n+def get_db_sizes():\n+ database_metrics = []\n+ queries = [\n+ ['Query Results Size', \"select pg_total_relation_size('query_results') as size from (select 1) as a\"],\n+ ['Redash DB Size', \"select pg_database_size('postgres') as size\"]\n+ ]\n+ for query_name, query in queries:\n+ result = models.db.session.execute(query).first()\n+ database_metrics.append([query_name, result[0]])\n+\n+ return database_metrics\n+\n+\n+def get_status():\n+ status = {\n+ 'version': __version__,\n+ 'workers': []\n+ }\n+ status.update(get_redis_status())\n+ status.update(get_object_counts())\n+ status['manager'] = redis_connection.hgetall('redash:status')\n+ status['manager']['queues'] = get_queues_status()\n+ status['database_metrics'] = {}\n+ status['database_metrics']['metrics'] = get_db_sizes()\n+\n return status\n", "issue": "Add to status page the size of Redash's DB\n```sql\r\nSELECT pg_size_pretty(pg_total_relation_size('query_results'));\r\n```\r\n\r\n```sql\r\nSELECT pg_size_pretty(pg_database_size('redash'));\r\n```\n", "before_files": [{"content": "from redash import redis_connection, models, __version__, settings\n\n\ndef get_status():\n status = {}\n info = redis_connection.info()\n status['redis_used_memory'] = info['used_memory']\n status['redis_used_memory_human'] = info['used_memory_human']\n status['version'] = __version__\n status['queries_count'] = models.db.session.query(models.Query).count()\n if settings.FEATURE_SHOW_QUERY_RESULTS_COUNT:\n status['query_results_count'] = models.db.session.query(models.QueryResult).count()\n status['unused_query_results_count'] = models.QueryResult.unused().count()\n status['dashboards_count'] = models.Dashboard.query.count()\n status['widgets_count'] = models.Widget.query.count()\n\n status['workers'] = []\n\n status['manager'] = redis_connection.hgetall('redash:status')\n\n queues = {}\n for ds in models.DataSource.query:\n for queue in (ds.queue_name, ds.scheduled_queue_name):\n queues.setdefault(queue, set())\n queues[queue].add(ds.name)\n\n status['manager']['queues'] = {}\n for queue, sources in queues.iteritems():\n status['manager']['queues'][queue] = {\n 'data_sources': ', '.join(sources),\n 'size': redis_connection.llen(queue)\n }\n \n status['manager']['queues']['celery'] = {\n 'size': redis_connection.llen('celery'),\n 'data_sources': ''\n }\n\n return status\n", "path": "redash/monitor.py"}]}
| 970 | 676 |
gh_patches_debug_11745
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-3672
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FV cipher-text data change during decryption.
## Description
During the decryption process, the ciphertext was soft copied and it changed the ciphertext value during decryption. So we lose the value of ciphertext.
## How to Reproduce
1. Create a ciphertext
2. Decrypt that ciphertext
3. Retry to decrypt the same ciphertext (wrong result)
</issue>
<code>
[start of syft/frameworks/torch/he/fv/decryptor.py]
1 from numpy.polynomial import polynomial as poly
2
3
4 from syft.frameworks.torch.he.fv.plaintext import PlainText
5 from syft.frameworks.torch.he.fv.util.operations import get_significant_count
6 from syft.frameworks.torch.he.fv.util.operations import poly_add_mod
7 from syft.frameworks.torch.he.fv.util.operations import poly_mul_mod
8
9
10 class Decryptor:
11 """Decrypts Ciphertext objects into Plaintext objects.
12
13 Args:
14 context (Context): Context for extracting encryption parameters.
15 secret_key: A secret key from same pair of keys(secretkey or publickey) used in encryptor.
16 """
17
18 def __init__(self, context, secret_key):
19 self._context = context
20 self._coeff_modulus = context.param.coeff_modulus
21 self._coeff_count = context.param.poly_modulus
22 self._secret_key = secret_key.data
23
24 def decrypt(self, encrypted):
25 """Decrypts the encrypted ciphertext objects.
26
27 Args:
28 encrypted: A ciphertext object which has to be decrypted.
29
30 Returns:
31 A PlainText object containing the decrypted result.
32 """
33
34 # Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q
35 temp_product_modq = self._mul_ct_sk(encrypted.data)
36
37 # Divide scaling variant using BEHZ FullRNS techniques
38 result = self._context.rns_tool.decrypt_scale_and_round(temp_product_modq)
39
40 # removing leading zeroes in plaintext representation.
41 plain_coeff_count = get_significant_count(result)
42 return PlainText(result[:plain_coeff_count])
43
44 def _mul_ct_sk(self, encrypted):
45 """Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q
46
47 where [c0, c1, ...] represents ciphertext element and sk^n represents
48 secret key raised to the power n.
49
50 Args:
51 encrypted: A ciphertext object of encrypted data.
52
53 Returns:
54 A 2-dim list containing result of [c0 + c1 * sk + c2 * sk^2 ...]_q.
55 """
56 phase = encrypted[0]
57
58 secret_key_array = self._get_sufficient_sk_power(len(encrypted))
59
60 for j in range(1, len(encrypted)):
61 for i in range(len(self._coeff_modulus)):
62 phase[i] = poly_add_mod(
63 poly_mul_mod(
64 encrypted[j][i], secret_key_array[j - 1][i], self._coeff_modulus[i]
65 ),
66 phase[i],
67 self._coeff_modulus[i],
68 )
69
70 return phase
71
72 def _get_sufficient_sk_power(self, max_power):
73 """Generate an list of secret key polynomial raised to 1...max_power.
74
75 Args:
76 max_power: heighest power up to which we want to raise secretkey.
77
78 Returns:
79 A 2-dim list having secretkey powers.
80 """
81 sk_power = [[] for _ in range(max_power)]
82
83 sk_power[0] = self._secret_key
84
85 for i in range(2, max_power + 1):
86 for j in range(len(self._coeff_modulus)):
87 sk_power[i - 1].append(poly.polypow(self._secret_key[j], i).astype(int).tolist())
88 return sk_power
89
[end of syft/frameworks/torch/he/fv/decryptor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/syft/frameworks/torch/he/fv/decryptor.py b/syft/frameworks/torch/he/fv/decryptor.py
--- a/syft/frameworks/torch/he/fv/decryptor.py
+++ b/syft/frameworks/torch/he/fv/decryptor.py
@@ -1,3 +1,4 @@
+import copy
from numpy.polynomial import polynomial as poly
@@ -32,7 +33,7 @@
"""
# Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q
- temp_product_modq = self._mul_ct_sk(encrypted.data)
+ temp_product_modq = self._mul_ct_sk(copy.deepcopy(encrypted.data))
# Divide scaling variant using BEHZ FullRNS techniques
result = self._context.rns_tool.decrypt_scale_and_round(temp_product_modq)
|
{"golden_diff": "diff --git a/syft/frameworks/torch/he/fv/decryptor.py b/syft/frameworks/torch/he/fv/decryptor.py\n--- a/syft/frameworks/torch/he/fv/decryptor.py\n+++ b/syft/frameworks/torch/he/fv/decryptor.py\n@@ -1,3 +1,4 @@\n+import copy\n from numpy.polynomial import polynomial as poly\n \n \n@@ -32,7 +33,7 @@\n \"\"\"\n \n # Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q\n- temp_product_modq = self._mul_ct_sk(encrypted.data)\n+ temp_product_modq = self._mul_ct_sk(copy.deepcopy(encrypted.data))\n \n # Divide scaling variant using BEHZ FullRNS techniques\n result = self._context.rns_tool.decrypt_scale_and_round(temp_product_modq)\n", "issue": "FV cipher-text data change during decryption.\n## Description\r\nDuring the decryption process, the ciphertext was soft copied and it changed the ciphertext value during decryption. So we lose the value of ciphertext.\r\n## How to Reproduce\r\n1. Create a ciphertext\r\n2. Decrypt that ciphertext\r\n3. Retry to decrypt the same ciphertext (wrong result)\r\n\n", "before_files": [{"content": "from numpy.polynomial import polynomial as poly\n\n\nfrom syft.frameworks.torch.he.fv.plaintext import PlainText\nfrom syft.frameworks.torch.he.fv.util.operations import get_significant_count\nfrom syft.frameworks.torch.he.fv.util.operations import poly_add_mod\nfrom syft.frameworks.torch.he.fv.util.operations import poly_mul_mod\n\n\nclass Decryptor:\n \"\"\"Decrypts Ciphertext objects into Plaintext objects.\n\n Args:\n context (Context): Context for extracting encryption parameters.\n secret_key: A secret key from same pair of keys(secretkey or publickey) used in encryptor.\n \"\"\"\n\n def __init__(self, context, secret_key):\n self._context = context\n self._coeff_modulus = context.param.coeff_modulus\n self._coeff_count = context.param.poly_modulus\n self._secret_key = secret_key.data\n\n def decrypt(self, encrypted):\n \"\"\"Decrypts the encrypted ciphertext objects.\n\n Args:\n encrypted: A ciphertext object which has to be decrypted.\n\n Returns:\n A PlainText object containing the decrypted result.\n \"\"\"\n\n # Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q\n temp_product_modq = self._mul_ct_sk(encrypted.data)\n\n # Divide scaling variant using BEHZ FullRNS techniques\n result = self._context.rns_tool.decrypt_scale_and_round(temp_product_modq)\n\n # removing leading zeroes in plaintext representation.\n plain_coeff_count = get_significant_count(result)\n return PlainText(result[:plain_coeff_count])\n\n def _mul_ct_sk(self, encrypted):\n \"\"\"Calculate [c0 + c1 * sk + c2 * sk^2 ...]_q\n\n where [c0, c1, ...] represents ciphertext element and sk^n represents\n secret key raised to the power n.\n\n Args:\n encrypted: A ciphertext object of encrypted data.\n\n Returns:\n A 2-dim list containing result of [c0 + c1 * sk + c2 * sk^2 ...]_q.\n \"\"\"\n phase = encrypted[0]\n\n secret_key_array = self._get_sufficient_sk_power(len(encrypted))\n\n for j in range(1, len(encrypted)):\n for i in range(len(self._coeff_modulus)):\n phase[i] = poly_add_mod(\n poly_mul_mod(\n encrypted[j][i], secret_key_array[j - 1][i], self._coeff_modulus[i]\n ),\n phase[i],\n self._coeff_modulus[i],\n )\n\n return phase\n\n def _get_sufficient_sk_power(self, max_power):\n \"\"\"Generate an list of secret key polynomial raised to 1...max_power.\n\n Args:\n max_power: heighest power up to which we want to raise secretkey.\n\n Returns:\n A 2-dim list having secretkey powers.\n \"\"\"\n sk_power = [[] for _ in range(max_power)]\n\n sk_power[0] = self._secret_key\n\n for i in range(2, max_power + 1):\n for j in range(len(self._coeff_modulus)):\n sk_power[i - 1].append(poly.polypow(self._secret_key[j], i).astype(int).tolist())\n return sk_power\n", "path": "syft/frameworks/torch/he/fv/decryptor.py"}]}
| 1,509 | 197 |
gh_patches_debug_18034
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-833
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move system tests into a separate Kokoro build
At the moment, we run the system tests [at the end of *every* Kokoro build](https://github.com/googleapis/google-auth-library-python/blob/da8bb13c1349e771ffc2e125256030495c53d956/.kokoro/build.sh#L57-L63). Not only should we *not* be running them during e.g. the `docs-presubmit` build, we should also run them separately from the `unit` / `cover` / `lint` sessions, so that we parallelize the long-running systests.
</issue>
<code>
[start of owlbot.py]
1 import synthtool as s
2 from synthtool import gcp
3
4 common = gcp.CommonTemplates()
5
6 # ----------------------------------------------------------------------------
7 # Add templated files
8 # ----------------------------------------------------------------------------
9 templated_files = common.py_library(unit_cov_level=100, cov_level=100)
10
11
12 s.move(
13 templated_files / ".kokoro",
14 excludes=[
15 "continuous/common.cfg",
16 "docs/common.cfg",
17 "presubmit/common.cfg",
18 "build.sh",
19 ],
20 ) # just move kokoro configs
21
22
23 assert 1 == s.replace(
24 ".kokoro/docs/docs-presubmit.cfg",
25 'value: "docs docfx"',
26 'value: "docs"',
27 )
28
29 assert 1 == s.replace(
30 ".kokoro/docker/docs/Dockerfile",
31 """\
32 CMD \["python3\.8"\]""",
33 """\
34 # Install gcloud SDK
35 RUN echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main" | \\
36 tee -a /etc/apt/sources.list.d/google-cloud-sdk.list \\
37 && curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | \\
38 apt-key --keyring /usr/share/keyrings/cloud.google.gpg add - \\
39 && apt-get update -y \\
40 && apt-get install python2 google-cloud-sdk -y
41
42 CMD ["python3.8"]""",
43 )
44
45 s.shell.run(["nox", "-s", "blacken"], hide_output=False)
46
[end of owlbot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/owlbot.py b/owlbot.py
--- a/owlbot.py
+++ b/owlbot.py
@@ -13,7 +13,6 @@
templated_files / ".kokoro",
excludes=[
"continuous/common.cfg",
- "docs/common.cfg",
"presubmit/common.cfg",
"build.sh",
],
@@ -26,20 +25,4 @@
'value: "docs"',
)
-assert 1 == s.replace(
- ".kokoro/docker/docs/Dockerfile",
- """\
-CMD \["python3\.8"\]""",
- """\
-# Install gcloud SDK
-RUN echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main" | \\
- tee -a /etc/apt/sources.list.d/google-cloud-sdk.list \\
- && curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | \\
- apt-key --keyring /usr/share/keyrings/cloud.google.gpg add - \\
- && apt-get update -y \\
- && apt-get install python2 google-cloud-sdk -y
-
-CMD ["python3.8"]""",
-)
-
s.shell.run(["nox", "-s", "blacken"], hide_output=False)
|
{"golden_diff": "diff --git a/owlbot.py b/owlbot.py\n--- a/owlbot.py\n+++ b/owlbot.py\n@@ -13,7 +13,6 @@\n templated_files / \".kokoro\",\n excludes=[\n \"continuous/common.cfg\",\n- \"docs/common.cfg\",\n \"presubmit/common.cfg\",\n \"build.sh\",\n ],\n@@ -26,20 +25,4 @@\n 'value: \"docs\"',\n )\n \n-assert 1 == s.replace(\n- \".kokoro/docker/docs/Dockerfile\",\n- \"\"\"\\\n-CMD \\[\"python3\\.8\"\\]\"\"\",\n- \"\"\"\\\n-# Install gcloud SDK\n-RUN echo \"deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main\" | \\\\\n- tee -a /etc/apt/sources.list.d/google-cloud-sdk.list \\\\\n- && curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | \\\\\n- apt-key --keyring /usr/share/keyrings/cloud.google.gpg add - \\\\\n- && apt-get update -y \\\\\n- && apt-get install python2 google-cloud-sdk -y\n-\n-CMD [\"python3.8\"]\"\"\",\n-)\n-\n s.shell.run([\"nox\", \"-s\", \"blacken\"], hide_output=False)\n", "issue": "Move system tests into a separate Kokoro build\nAt the moment, we run the system tests [at the end of *every* Kokoro build](https://github.com/googleapis/google-auth-library-python/blob/da8bb13c1349e771ffc2e125256030495c53d956/.kokoro/build.sh#L57-L63). Not only should we *not* be running them during e.g. the `docs-presubmit` build, we should also run them separately from the `unit` / `cover` / `lint` sessions, so that we parallelize the long-running systests.\n", "before_files": [{"content": "import synthtool as s\nfrom synthtool import gcp\n\ncommon = gcp.CommonTemplates()\n\n# ----------------------------------------------------------------------------\n# Add templated files\n# ----------------------------------------------------------------------------\ntemplated_files = common.py_library(unit_cov_level=100, cov_level=100)\n\n\ns.move(\n templated_files / \".kokoro\",\n excludes=[\n \"continuous/common.cfg\",\n \"docs/common.cfg\",\n \"presubmit/common.cfg\",\n \"build.sh\",\n ],\n) # just move kokoro configs\n\n\nassert 1 == s.replace(\n \".kokoro/docs/docs-presubmit.cfg\",\n 'value: \"docs docfx\"',\n 'value: \"docs\"',\n)\n\nassert 1 == s.replace(\n \".kokoro/docker/docs/Dockerfile\",\n \"\"\"\\\nCMD \\[\"python3\\.8\"\\]\"\"\",\n \"\"\"\\\n# Install gcloud SDK\nRUN echo \"deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main\" | \\\\\n tee -a /etc/apt/sources.list.d/google-cloud-sdk.list \\\\\n && curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | \\\\\n apt-key --keyring /usr/share/keyrings/cloud.google.gpg add - \\\\\n && apt-get update -y \\\\\n && apt-get install python2 google-cloud-sdk -y\n\nCMD [\"python3.8\"]\"\"\",\n)\n\ns.shell.run([\"nox\", \"-s\", \"blacken\"], hide_output=False)\n", "path": "owlbot.py"}]}
| 1,079 | 284 |
gh_patches_debug_9180
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-1722
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Top Half of Seaborn Chart Title Gets Cut Off
# Summary
When adding a title to a seaborn or perhaps MATPLOTLIB chart (have not tested with MATPLOTLIB yet) chart, the top half of the title is cut off or not displayed
```
# Steps to reproduce
import matplotlib.pyplot as plt
import seaborn as sns
import streamlit as st
mpg = sns.load_dataset("mpg")
option = st.sidebar.multiselect('Choose country of origin:', mpg.origin.unique()
sns.relplot(x="horsepower", y="mpg", hue="origin", size="weight", sizes=(40, 400), alpha=0.5, palette="muted", height=6, data=mpg.query("origin == @option"))
plt.title('MPG vs Weight by Country of Origin')
st.pyplot()
```
## Expected behavior:
seaborn chart title to be fully visible
## Actual behavior:
Top half of seaborn chart title is cut off
## Is this a regression?
That is, did this use to work the way you expected in the past? First time using streamlit, so not sure if worked in the past
yes? maybe?
# Debug info
- Streamlit version: 0.47.4
- Python version: 3.7
- Using Conda
- OS version: Windows 10
- Browser version: Chrome version 77
</issue>
<code>
[start of lib/streamlit/elements/pyplot.py]
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Streamlit support for Matplotlib PyPlot charts."""
16
17 import io
18
19 try:
20 import matplotlib # noqa: F401
21 import matplotlib.pyplot as plt
22
23 plt.ioff()
24 except ImportError:
25 raise ImportError("pyplot() command requires matplotlib")
26
27 import streamlit.elements.image_proto as image_proto
28
29 from streamlit.logger import get_logger
30
31 LOGGER = get_logger(__name__)
32
33
34 def marshall(coordinates, new_element_proto, fig=None, clear_figure=True, **kwargs):
35 """Construct a matplotlib.pyplot figure.
36
37 See DeltaGenerator.vega_lite_chart for docs.
38 """
39 # You can call .savefig() on a Figure object or directly on the pyplot
40 # module, in which case you're doing it to the latest Figure.
41 if not fig:
42 if clear_figure is None:
43 clear_figure = True
44 fig = plt
45
46 # Normally, dpi is set to 'figure', and the figure's dpi is set to 100.
47 # So here we pick double of that to make things look good in a high
48 # DPI display.
49 options = {"dpi": 200, "format": "png"}
50
51 # If some of the options are passed in from kwargs then replace
52 # the values in options with the ones from kwargs
53 options = {a: kwargs.get(a, b) for a, b in options.items()}
54 # Merge options back into kwargs.
55 kwargs.update(options)
56
57 image = io.BytesIO()
58 fig.savefig(image, **kwargs)
59 image_proto.marshall_images(
60 coordinates,
61 image,
62 None,
63 -2,
64 new_element_proto.imgs,
65 False,
66 channels="RGB",
67 format="PNG",
68 )
69
70 # Clear the figure after rendering it. This means that subsequent
71 # plt calls will be starting fresh.
72 if clear_figure:
73 fig.clf()
74
[end of lib/streamlit/elements/pyplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/elements/pyplot.py b/lib/streamlit/elements/pyplot.py
--- a/lib/streamlit/elements/pyplot.py
+++ b/lib/streamlit/elements/pyplot.py
@@ -46,7 +46,7 @@
# Normally, dpi is set to 'figure', and the figure's dpi is set to 100.
# So here we pick double of that to make things look good in a high
# DPI display.
- options = {"dpi": 200, "format": "png"}
+ options = {"bbox_inches": "tight", "dpi": 200, "format": "png"}
# If some of the options are passed in from kwargs then replace
# the values in options with the ones from kwargs
|
{"golden_diff": "diff --git a/lib/streamlit/elements/pyplot.py b/lib/streamlit/elements/pyplot.py\n--- a/lib/streamlit/elements/pyplot.py\n+++ b/lib/streamlit/elements/pyplot.py\n@@ -46,7 +46,7 @@\n # Normally, dpi is set to 'figure', and the figure's dpi is set to 100.\n # So here we pick double of that to make things look good in a high\n # DPI display.\n- options = {\"dpi\": 200, \"format\": \"png\"}\n+ options = {\"bbox_inches\": \"tight\", \"dpi\": 200, \"format\": \"png\"}\n \n # If some of the options are passed in from kwargs then replace\n # the values in options with the ones from kwargs\n", "issue": "Top Half of Seaborn Chart Title Gets Cut Off\n# Summary\r\nWhen adding a title to a seaborn or perhaps MATPLOTLIB chart (have not tested with MATPLOTLIB yet) chart, the top half of the title is cut off or not displayed\r\n\r\n```\r\n# Steps to reproduce\r\nimport matplotlib.pyplot as plt\r\nimport seaborn as sns\r\nimport streamlit as st\r\n\r\nmpg = sns.load_dataset(\"mpg\")\r\noption = st.sidebar.multiselect('Choose country of origin:', mpg.origin.unique()\r\nsns.relplot(x=\"horsepower\", y=\"mpg\", hue=\"origin\", size=\"weight\", sizes=(40, 400), alpha=0.5, palette=\"muted\", height=6, data=mpg.query(\"origin == @option\"))\r\nplt.title('MPG vs Weight by Country of Origin')\r\nst.pyplot()\r\n```\r\n\r\n## Expected behavior:\r\nseaborn chart title to be fully visible\r\n\r\n## Actual behavior:\r\nTop half of seaborn chart title is cut off\r\n\r\n## Is this a regression?\r\nThat is, did this use to work the way you expected in the past? First time using streamlit, so not sure if worked in the past\r\nyes? maybe?\r\n\r\n# Debug info\r\n- Streamlit version: 0.47.4\r\n- Python version: 3.7\r\n- Using Conda\r\n- OS version: Windows 10\r\n- Browser version: Chrome version 77\r\n\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Streamlit support for Matplotlib PyPlot charts.\"\"\"\n\nimport io\n\ntry:\n import matplotlib # noqa: F401\n import matplotlib.pyplot as plt\n\n plt.ioff()\nexcept ImportError:\n raise ImportError(\"pyplot() command requires matplotlib\")\n\nimport streamlit.elements.image_proto as image_proto\n\nfrom streamlit.logger import get_logger\n\nLOGGER = get_logger(__name__)\n\n\ndef marshall(coordinates, new_element_proto, fig=None, clear_figure=True, **kwargs):\n \"\"\"Construct a matplotlib.pyplot figure.\n\n See DeltaGenerator.vega_lite_chart for docs.\n \"\"\"\n # You can call .savefig() on a Figure object or directly on the pyplot\n # module, in which case you're doing it to the latest Figure.\n if not fig:\n if clear_figure is None:\n clear_figure = True\n fig = plt\n\n # Normally, dpi is set to 'figure', and the figure's dpi is set to 100.\n # So here we pick double of that to make things look good in a high\n # DPI display.\n options = {\"dpi\": 200, \"format\": \"png\"}\n\n # If some of the options are passed in from kwargs then replace\n # the values in options with the ones from kwargs\n options = {a: kwargs.get(a, b) for a, b in options.items()}\n # Merge options back into kwargs.\n kwargs.update(options)\n\n image = io.BytesIO()\n fig.savefig(image, **kwargs)\n image_proto.marshall_images(\n coordinates,\n image,\n None,\n -2,\n new_element_proto.imgs,\n False,\n channels=\"RGB\",\n format=\"PNG\",\n )\n\n # Clear the figure after rendering it. This means that subsequent\n # plt calls will be starting fresh.\n if clear_figure:\n fig.clf()\n", "path": "lib/streamlit/elements/pyplot.py"}]}
| 1,526 | 175 |
gh_patches_debug_8060
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-1318
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken links/css in readthedocs 404 page
The [404.html](https://github.com/mkdocs/mkdocs/blob/master/mkdocs/themes/readthedocs/404.html) added in 0.17.0 seems to have broken links and css ([failing CI build](https://travis-ci.org/opensciencegrid/docs/builds/290469999?utm_source=github_status&utm_medium=notification)). The links in the generated `404.html` file all start with a `docs/...` prefix but when I inspect the `site` dir after a `mkdocs build`, there is no `docs` directory.
</issue>
<code>
[start of mkdocs/commands/serve.py]
1 from __future__ import unicode_literals
2
3 import logging
4 import shutil
5 import tempfile
6
7 from os.path import isfile, join
8 from mkdocs.commands.build import build
9 from mkdocs.config import load_config
10
11 log = logging.getLogger(__name__)
12
13
14 def _get_handler(site_dir, StaticFileHandler):
15
16 from tornado.template import Loader
17
18 class WebHandler(StaticFileHandler):
19
20 def write_error(self, status_code, **kwargs):
21
22 if status_code in (404, 500):
23 error_page = '{}.html'.format(status_code)
24 if isfile(join(site_dir, error_page)):
25 self.write(Loader(site_dir).load(error_page).generate())
26 else:
27 super(WebHandler, self).write_error(status_code, **kwargs)
28
29 return WebHandler
30
31
32 def _livereload(host, port, config, builder, site_dir):
33
34 # We are importing here for anyone that has issues with livereload. Even if
35 # this fails, the --no-livereload alternative should still work.
36 from livereload import Server
37 import livereload.handlers
38
39 class LiveReloadServer(Server):
40
41 def get_web_handlers(self, script):
42 handlers = super(LiveReloadServer, self).get_web_handlers(script)
43 # replace livereload handler
44 return [(handlers[0][0], _get_handler(site_dir, livereload.handlers.StaticFileHandler), handlers[0][2],)]
45
46 server = LiveReloadServer()
47
48 # Watch the documentation files, the config file and the theme files.
49 server.watch(config['docs_dir'], builder)
50 server.watch(config['config_file_path'], builder)
51
52 for d in config['theme'].dirs:
53 server.watch(d, builder)
54
55 # Run `serve` plugin events.
56 server = config['plugins'].run_event('serve', server, config=config)
57
58 server.serve(root=site_dir, host=host, port=port, restart_delay=0)
59
60
61 def _static_server(host, port, site_dir):
62
63 # Importing here to seperate the code paths from the --livereload
64 # alternative.
65 from tornado import ioloop
66 from tornado import web
67
68 application = web.Application([
69 (r"/(.*)", _get_handler(site_dir, web.StaticFileHandler), {
70 "path": site_dir,
71 "default_filename": "index.html"
72 }),
73 ])
74 application.listen(port=port, address=host)
75
76 log.info('Running at: http://%s:%s/', host, port)
77 log.info('Hold ctrl+c to quit.')
78 try:
79 ioloop.IOLoop.instance().start()
80 except KeyboardInterrupt:
81 log.info('Stopping server...')
82
83
84 def serve(config_file=None, dev_addr=None, strict=None, theme=None,
85 theme_dir=None, livereload='livereload'):
86 """
87 Start the MkDocs development server
88
89 By default it will serve the documentation on http://localhost:8000/ and
90 it will rebuild the documentation and refresh the page automatically
91 whenever a file is edited.
92 """
93
94 # Create a temporary build directory, and set some options to serve it
95 tempdir = tempfile.mkdtemp()
96
97 def builder():
98 log.info("Building documentation...")
99 config = load_config(
100 config_file=config_file,
101 dev_addr=dev_addr,
102 strict=strict,
103 theme=theme,
104 theme_dir=theme_dir
105 )
106 config['site_dir'] = tempdir
107 live_server = livereload in ['dirty', 'livereload']
108 dirty = livereload == 'dirty'
109 build(config, live_server=live_server, dirty=dirty)
110 return config
111
112 try:
113 # Perform the initial build
114 config = builder()
115
116 host, port = config['dev_addr']
117
118 if livereload in ['livereload', 'dirty']:
119 _livereload(host, port, config, builder, tempdir)
120 else:
121 _static_server(host, port, tempdir)
122 finally:
123 shutil.rmtree(tempdir)
124
[end of mkdocs/commands/serve.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/commands/serve.py b/mkdocs/commands/serve.py
--- a/mkdocs/commands/serve.py
+++ b/mkdocs/commands/serve.py
@@ -103,7 +103,10 @@
theme=theme,
theme_dir=theme_dir
)
+ # Override a few config settings after validation
config['site_dir'] = tempdir
+ config['site_url'] = 'http://{0}/'.format(config['dev_addr'])
+
live_server = livereload in ['dirty', 'livereload']
dirty = livereload == 'dirty'
build(config, live_server=live_server, dirty=dirty)
|
{"golden_diff": "diff --git a/mkdocs/commands/serve.py b/mkdocs/commands/serve.py\n--- a/mkdocs/commands/serve.py\n+++ b/mkdocs/commands/serve.py\n@@ -103,7 +103,10 @@\n theme=theme,\n theme_dir=theme_dir\n )\n+ # Override a few config settings after validation\n config['site_dir'] = tempdir\n+ config['site_url'] = 'http://{0}/'.format(config['dev_addr'])\n+\n live_server = livereload in ['dirty', 'livereload']\n dirty = livereload == 'dirty'\n build(config, live_server=live_server, dirty=dirty)\n", "issue": "Broken links/css in readthedocs 404 page \nThe [404.html](https://github.com/mkdocs/mkdocs/blob/master/mkdocs/themes/readthedocs/404.html) added in 0.17.0 seems to have broken links and css ([failing CI build](https://travis-ci.org/opensciencegrid/docs/builds/290469999?utm_source=github_status&utm_medium=notification)). The links in the generated `404.html` file all start with a `docs/...` prefix but when I inspect the `site` dir after a `mkdocs build`, there is no `docs` directory.\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport logging\nimport shutil\nimport tempfile\n\nfrom os.path import isfile, join\nfrom mkdocs.commands.build import build\nfrom mkdocs.config import load_config\n\nlog = logging.getLogger(__name__)\n\n\ndef _get_handler(site_dir, StaticFileHandler):\n\n from tornado.template import Loader\n\n class WebHandler(StaticFileHandler):\n\n def write_error(self, status_code, **kwargs):\n\n if status_code in (404, 500):\n error_page = '{}.html'.format(status_code)\n if isfile(join(site_dir, error_page)):\n self.write(Loader(site_dir).load(error_page).generate())\n else:\n super(WebHandler, self).write_error(status_code, **kwargs)\n\n return WebHandler\n\n\ndef _livereload(host, port, config, builder, site_dir):\n\n # We are importing here for anyone that has issues with livereload. Even if\n # this fails, the --no-livereload alternative should still work.\n from livereload import Server\n import livereload.handlers\n\n class LiveReloadServer(Server):\n\n def get_web_handlers(self, script):\n handlers = super(LiveReloadServer, self).get_web_handlers(script)\n # replace livereload handler\n return [(handlers[0][0], _get_handler(site_dir, livereload.handlers.StaticFileHandler), handlers[0][2],)]\n\n server = LiveReloadServer()\n\n # Watch the documentation files, the config file and the theme files.\n server.watch(config['docs_dir'], builder)\n server.watch(config['config_file_path'], builder)\n\n for d in config['theme'].dirs:\n server.watch(d, builder)\n\n # Run `serve` plugin events.\n server = config['plugins'].run_event('serve', server, config=config)\n\n server.serve(root=site_dir, host=host, port=port, restart_delay=0)\n\n\ndef _static_server(host, port, site_dir):\n\n # Importing here to seperate the code paths from the --livereload\n # alternative.\n from tornado import ioloop\n from tornado import web\n\n application = web.Application([\n (r\"/(.*)\", _get_handler(site_dir, web.StaticFileHandler), {\n \"path\": site_dir,\n \"default_filename\": \"index.html\"\n }),\n ])\n application.listen(port=port, address=host)\n\n log.info('Running at: http://%s:%s/', host, port)\n log.info('Hold ctrl+c to quit.')\n try:\n ioloop.IOLoop.instance().start()\n except KeyboardInterrupt:\n log.info('Stopping server...')\n\n\ndef serve(config_file=None, dev_addr=None, strict=None, theme=None,\n theme_dir=None, livereload='livereload'):\n \"\"\"\n Start the MkDocs development server\n\n By default it will serve the documentation on http://localhost:8000/ and\n it will rebuild the documentation and refresh the page automatically\n whenever a file is edited.\n \"\"\"\n\n # Create a temporary build directory, and set some options to serve it\n tempdir = tempfile.mkdtemp()\n\n def builder():\n log.info(\"Building documentation...\")\n config = load_config(\n config_file=config_file,\n dev_addr=dev_addr,\n strict=strict,\n theme=theme,\n theme_dir=theme_dir\n )\n config['site_dir'] = tempdir\n live_server = livereload in ['dirty', 'livereload']\n dirty = livereload == 'dirty'\n build(config, live_server=live_server, dirty=dirty)\n return config\n\n try:\n # Perform the initial build\n config = builder()\n\n host, port = config['dev_addr']\n\n if livereload in ['livereload', 'dirty']:\n _livereload(host, port, config, builder, tempdir)\n else:\n _static_server(host, port, tempdir)\n finally:\n shutil.rmtree(tempdir)\n", "path": "mkdocs/commands/serve.py"}]}
| 1,823 | 154 |
gh_patches_debug_19832
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-2461
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fixer la migration vers la 2.44.0
- [x] champs de traductions _xx créés avec NOT NULL et donc impossible à créer
- [x] géométries des sites à transformer en geometrycollection
</issue>
<code>
[start of geotrek/outdoor/migrations/0003_auto_20201214_1408.py]
1 # Generated by Django 3.1.4 on 2020-12-14 14:08
2
3 from django.conf import settings
4 import django.contrib.gis.db.models.fields
5 from django.db import migrations, models
6 import django.db.models.deletion
7
8
9 class Migration(migrations.Migration):
10
11 dependencies = [
12 ('outdoor', '0002_practice_sitepractice'),
13 ]
14
15 operations = [
16 migrations.AlterModelOptions(
17 name='site',
18 options={'ordering': ('name',), 'verbose_name': 'Outdoor site', 'verbose_name_plural': 'Outdoor sites'},
19 ),
20 migrations.AlterField(
21 model_name='site',
22 name='geom',
23 field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),
24 ),
25 migrations.AlterField(
26 model_name='sitepractice',
27 name='site',
28 field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='site_practices', to='outdoor.site', verbose_name='Outdoor site'),
29 ),
30 ]
31
[end of geotrek/outdoor/migrations/0003_auto_20201214_1408.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geotrek/outdoor/migrations/0003_auto_20201214_1408.py b/geotrek/outdoor/migrations/0003_auto_20201214_1408.py
--- a/geotrek/outdoor/migrations/0003_auto_20201214_1408.py
+++ b/geotrek/outdoor/migrations/0003_auto_20201214_1408.py
@@ -17,10 +17,17 @@
name='site',
options={'ordering': ('name',), 'verbose_name': 'Outdoor site', 'verbose_name_plural': 'Outdoor sites'},
),
- migrations.AlterField(
- model_name='site',
- name='geom',
- field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),
+ migrations.SeparateDatabaseAndState(
+ database_operations=[
+ migrations.RunSQL('ALTER TABLE "outdoor_site" ALTER COLUMN "geom" TYPE geometry(GeometryCollection,2154) USING ST_ForceCollection(geom);')
+ ],
+ state_operations=[
+ migrations.AlterField(
+ model_name='site',
+ name='geom',
+ field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),
+ ),
+ ]
),
migrations.AlterField(
model_name='sitepractice',
|
{"golden_diff": "diff --git a/geotrek/outdoor/migrations/0003_auto_20201214_1408.py b/geotrek/outdoor/migrations/0003_auto_20201214_1408.py\n--- a/geotrek/outdoor/migrations/0003_auto_20201214_1408.py\n+++ b/geotrek/outdoor/migrations/0003_auto_20201214_1408.py\n@@ -17,10 +17,17 @@\n name='site',\n options={'ordering': ('name',), 'verbose_name': 'Outdoor site', 'verbose_name_plural': 'Outdoor sites'},\n ),\n- migrations.AlterField(\n- model_name='site',\n- name='geom',\n- field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),\n+ migrations.SeparateDatabaseAndState(\n+ database_operations=[\n+ migrations.RunSQL('ALTER TABLE \"outdoor_site\" ALTER COLUMN \"geom\" TYPE geometry(GeometryCollection,2154) USING ST_ForceCollection(geom);')\n+ ],\n+ state_operations=[\n+ migrations.AlterField(\n+ model_name='site',\n+ name='geom',\n+ field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),\n+ ),\n+ ]\n ),\n migrations.AlterField(\n model_name='sitepractice',\n", "issue": "Fixer la migration vers la 2.44.0\n- [x] champs de traductions _xx cr\u00e9\u00e9s avec NOT NULL et donc impossible \u00e0 cr\u00e9er\r\n- [x] g\u00e9om\u00e9tries des sites \u00e0 transformer en geometrycollection\n", "before_files": [{"content": "# Generated by Django 3.1.4 on 2020-12-14 14:08\n\nfrom django.conf import settings\nimport django.contrib.gis.db.models.fields\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('outdoor', '0002_practice_sitepractice'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='site',\n options={'ordering': ('name',), 'verbose_name': 'Outdoor site', 'verbose_name_plural': 'Outdoor sites'},\n ),\n migrations.AlterField(\n model_name='site',\n name='geom',\n field=django.contrib.gis.db.models.fields.GeometryCollectionField(srid=settings.SRID, verbose_name='Location'),\n ),\n migrations.AlterField(\n model_name='sitepractice',\n name='site',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='site_practices', to='outdoor.site', verbose_name='Outdoor site'),\n ),\n ]\n", "path": "geotrek/outdoor/migrations/0003_auto_20201214_1408.py"}]}
| 917 | 342 |
gh_patches_debug_15166
|
rasdani/github-patches
|
git_diff
|
feast-dev__feast-4025
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate PostgreSQLRegistryStore
Right now we have 2 ways to use postgres as a registry backend. The first is with scalable `SqlRegistry` that uses `sqlalchemy`, another is an older option of using `PostgreSQLRegistryStore` which keeps the whole proto in a single table. Since we are [recommending](https://docs.feast.dev/tutorials/using-scalable-registry) the scalable registry anyway, we should deprecate `PostgreSQLRegistryStore` and remove it soon after. Or maybe remove it directly? It's under contribs as of now.
</issue>
<code>
[start of sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py]
1 from typing import Optional
2
3 import psycopg2
4 from psycopg2 import sql
5
6 from feast.infra.registry.registry_store import RegistryStore
7 from feast.infra.utils.postgres.connection_utils import _get_conn
8 from feast.infra.utils.postgres.postgres_config import PostgreSQLConfig
9 from feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto
10 from feast.repo_config import RegistryConfig
11
12
13 class PostgresRegistryConfig(RegistryConfig):
14 host: str
15 port: int
16 database: str
17 db_schema: str
18 user: str
19 password: str
20 sslmode: Optional[str]
21 sslkey_path: Optional[str]
22 sslcert_path: Optional[str]
23 sslrootcert_path: Optional[str]
24
25
26 class PostgreSQLRegistryStore(RegistryStore):
27 def __init__(self, config: PostgresRegistryConfig, registry_path: str):
28 self.db_config = PostgreSQLConfig(
29 host=config.host,
30 port=config.port,
31 database=config.database,
32 db_schema=config.db_schema,
33 user=config.user,
34 password=config.password,
35 sslmode=getattr(config, "sslmode", None),
36 sslkey_path=getattr(config, "sslkey_path", None),
37 sslcert_path=getattr(config, "sslcert_path", None),
38 sslrootcert_path=getattr(config, "sslrootcert_path", None),
39 )
40 self.table_name = config.path
41 self.cache_ttl_seconds = config.cache_ttl_seconds
42
43 def get_registry_proto(self) -> RegistryProto:
44 registry_proto = RegistryProto()
45 try:
46 with _get_conn(self.db_config) as conn, conn.cursor() as cur:
47 cur.execute(
48 sql.SQL(
49 """
50 SELECT registry
51 FROM {}
52 WHERE version = (SELECT max(version) FROM {})
53 """
54 ).format(
55 sql.Identifier(self.table_name),
56 sql.Identifier(self.table_name),
57 )
58 )
59 row = cur.fetchone()
60 if row:
61 registry_proto = registry_proto.FromString(row[0])
62 except psycopg2.errors.UndefinedTable:
63 pass
64 return registry_proto
65
66 def update_registry_proto(self, registry_proto: RegistryProto):
67 """
68 Overwrites the current registry proto with the proto passed in. This method
69 writes to the registry path.
70
71 Args:
72 registry_proto: the new RegistryProto
73 """
74 schema_name = self.db_config.db_schema or self.db_config.user
75 with _get_conn(self.db_config) as conn, conn.cursor() as cur:
76 cur.execute(
77 """
78 SELECT schema_name
79 FROM information_schema.schemata
80 WHERE schema_name = %s
81 """,
82 (schema_name,),
83 )
84 schema_exists = cur.fetchone()
85 if not schema_exists:
86 cur.execute(
87 sql.SQL("CREATE SCHEMA IF NOT EXISTS {} AUTHORIZATION {}").format(
88 sql.Identifier(schema_name),
89 sql.Identifier(self.db_config.user),
90 ),
91 )
92
93 cur.execute(
94 sql.SQL(
95 """
96 CREATE TABLE IF NOT EXISTS {} (
97 version BIGSERIAL PRIMARY KEY,
98 registry BYTEA NOT NULL
99 );
100 """
101 ).format(sql.Identifier(self.table_name)),
102 )
103 # Do we want to keep track of the history or just keep the latest?
104 cur.execute(
105 sql.SQL(
106 """
107 INSERT INTO {} (registry)
108 VALUES (%s);
109 """
110 ).format(sql.Identifier(self.table_name)),
111 [registry_proto.SerializeToString()],
112 )
113
114 def teardown(self):
115 with _get_conn(self.db_config) as conn, conn.cursor() as cur:
116 cur.execute(
117 sql.SQL(
118 """
119 DROP TABLE IF EXISTS {};
120 """
121 ).format(sql.Identifier(self.table_name))
122 )
123
[end of sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py b/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py
--- a/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py
+++ b/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py
@@ -1,3 +1,4 @@
+import warnings
from typing import Optional
import psycopg2
@@ -37,6 +38,11 @@
sslcert_path=getattr(config, "sslcert_path", None),
sslrootcert_path=getattr(config, "sslrootcert_path", None),
)
+ warnings.warn(
+ "PostgreSQLRegistryStore is deprecated and will be removed in the future releases. Please use SqlRegistry instead.",
+ DeprecationWarning,
+ )
+
self.table_name = config.path
self.cache_ttl_seconds = config.cache_ttl_seconds
|
{"golden_diff": "diff --git a/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py b/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py\n--- a/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py\n+++ b/sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py\n@@ -1,3 +1,4 @@\n+import warnings\n from typing import Optional\n \n import psycopg2\n@@ -37,6 +38,11 @@\n sslcert_path=getattr(config, \"sslcert_path\", None),\n sslrootcert_path=getattr(config, \"sslrootcert_path\", None),\n )\n+ warnings.warn(\n+ \"PostgreSQLRegistryStore is deprecated and will be removed in the future releases. Please use SqlRegistry instead.\",\n+ DeprecationWarning,\n+ )\n+\n self.table_name = config.path\n self.cache_ttl_seconds = config.cache_ttl_seconds\n", "issue": "Deprecate PostgreSQLRegistryStore\nRight now we have 2 ways to use postgres as a registry backend. The first is with scalable `SqlRegistry` that uses `sqlalchemy`, another is an older option of using `PostgreSQLRegistryStore` which keeps the whole proto in a single table. Since we are [recommending](https://docs.feast.dev/tutorials/using-scalable-registry) the scalable registry anyway, we should deprecate `PostgreSQLRegistryStore` and remove it soon after. Or maybe remove it directly? It's under contribs as of now.\n", "before_files": [{"content": "from typing import Optional\n\nimport psycopg2\nfrom psycopg2 import sql\n\nfrom feast.infra.registry.registry_store import RegistryStore\nfrom feast.infra.utils.postgres.connection_utils import _get_conn\nfrom feast.infra.utils.postgres.postgres_config import PostgreSQLConfig\nfrom feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto\nfrom feast.repo_config import RegistryConfig\n\n\nclass PostgresRegistryConfig(RegistryConfig):\n host: str\n port: int\n database: str\n db_schema: str\n user: str\n password: str\n sslmode: Optional[str]\n sslkey_path: Optional[str]\n sslcert_path: Optional[str]\n sslrootcert_path: Optional[str]\n\n\nclass PostgreSQLRegistryStore(RegistryStore):\n def __init__(self, config: PostgresRegistryConfig, registry_path: str):\n self.db_config = PostgreSQLConfig(\n host=config.host,\n port=config.port,\n database=config.database,\n db_schema=config.db_schema,\n user=config.user,\n password=config.password,\n sslmode=getattr(config, \"sslmode\", None),\n sslkey_path=getattr(config, \"sslkey_path\", None),\n sslcert_path=getattr(config, \"sslcert_path\", None),\n sslrootcert_path=getattr(config, \"sslrootcert_path\", None),\n )\n self.table_name = config.path\n self.cache_ttl_seconds = config.cache_ttl_seconds\n\n def get_registry_proto(self) -> RegistryProto:\n registry_proto = RegistryProto()\n try:\n with _get_conn(self.db_config) as conn, conn.cursor() as cur:\n cur.execute(\n sql.SQL(\n \"\"\"\n SELECT registry\n FROM {}\n WHERE version = (SELECT max(version) FROM {})\n \"\"\"\n ).format(\n sql.Identifier(self.table_name),\n sql.Identifier(self.table_name),\n )\n )\n row = cur.fetchone()\n if row:\n registry_proto = registry_proto.FromString(row[0])\n except psycopg2.errors.UndefinedTable:\n pass\n return registry_proto\n\n def update_registry_proto(self, registry_proto: RegistryProto):\n \"\"\"\n Overwrites the current registry proto with the proto passed in. This method\n writes to the registry path.\n\n Args:\n registry_proto: the new RegistryProto\n \"\"\"\n schema_name = self.db_config.db_schema or self.db_config.user\n with _get_conn(self.db_config) as conn, conn.cursor() as cur:\n cur.execute(\n \"\"\"\n SELECT schema_name\n FROM information_schema.schemata\n WHERE schema_name = %s\n \"\"\",\n (schema_name,),\n )\n schema_exists = cur.fetchone()\n if not schema_exists:\n cur.execute(\n sql.SQL(\"CREATE SCHEMA IF NOT EXISTS {} AUTHORIZATION {}\").format(\n sql.Identifier(schema_name),\n sql.Identifier(self.db_config.user),\n ),\n )\n\n cur.execute(\n sql.SQL(\n \"\"\"\n CREATE TABLE IF NOT EXISTS {} (\n version BIGSERIAL PRIMARY KEY,\n registry BYTEA NOT NULL\n );\n \"\"\"\n ).format(sql.Identifier(self.table_name)),\n )\n # Do we want to keep track of the history or just keep the latest?\n cur.execute(\n sql.SQL(\n \"\"\"\n INSERT INTO {} (registry)\n VALUES (%s);\n \"\"\"\n ).format(sql.Identifier(self.table_name)),\n [registry_proto.SerializeToString()],\n )\n\n def teardown(self):\n with _get_conn(self.db_config) as conn, conn.cursor() as cur:\n cur.execute(\n sql.SQL(\n \"\"\"\n DROP TABLE IF EXISTS {};\n \"\"\"\n ).format(sql.Identifier(self.table_name))\n )\n", "path": "sdk/python/feast/infra/registry/contrib/postgres/postgres_registry_store.py"}]}
| 1,715 | 214 |
gh_patches_debug_1584
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-361
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Training classification accuracy >1
**Describe the bug**
Hi, I am training a classification model on MRI brain scans using vgg16 in gandlf. We expect to have accuracy in the range of 0-1. But Training classification accuracy is displayed >1. Validation accuracy seems correct. Attaching the screenshot below. Can you please have a look?
**Screenshots**
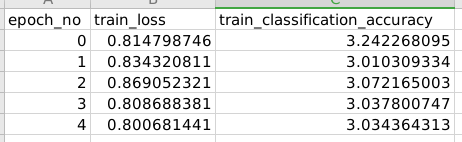
**GaNDLF Version**
0.0.14
</issue>
<code>
[start of GANDLF/metrics/regression.py]
1 """
2 All the metrics are to be called from here
3 """
4 import torch
5 from sklearn.metrics import balanced_accuracy_score
6 import numpy as np
7
8
9 def classification_accuracy(output, label, params):
10 if params["problem_type"] == "classification":
11 predicted_classes = torch.argmax(output, 1)
12 else:
13 predicted_classes = output
14 acc = torch.sum(predicted_classes == label) / len(label)
15 return acc
16
17
18 def balanced_acc_score(output, label, params):
19 if params["problem_type"] == "classification":
20 predicted_classes = torch.argmax(output, 1)
21 else:
22 predicted_classes = output
23
24 return torch.from_numpy(
25 np.array(balanced_accuracy_score(predicted_classes.cpu(), label.cpu()))
26 )
27
[end of GANDLF/metrics/regression.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/GANDLF/metrics/regression.py b/GANDLF/metrics/regression.py
--- a/GANDLF/metrics/regression.py
+++ b/GANDLF/metrics/regression.py
@@ -11,7 +11,8 @@
predicted_classes = torch.argmax(output, 1)
else:
predicted_classes = output
- acc = torch.sum(predicted_classes == label) / len(label)
+
+ acc = torch.sum(predicted_classes == label.squeeze()) / len(label)
return acc
|
{"golden_diff": "diff --git a/GANDLF/metrics/regression.py b/GANDLF/metrics/regression.py\n--- a/GANDLF/metrics/regression.py\n+++ b/GANDLF/metrics/regression.py\n@@ -11,7 +11,8 @@\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n- acc = torch.sum(predicted_classes == label) / len(label)\n+\n+ acc = torch.sum(predicted_classes == label.squeeze()) / len(label)\n return acc\n", "issue": "Training classification accuracy >1\n**Describe the bug**\r\nHi, I am training a classification model on MRI brain scans using vgg16 in gandlf. We expect to have accuracy in the range of 0-1. But Training classification accuracy is displayed >1. Validation accuracy seems correct. Attaching the screenshot below. Can you please have a look?\r\n\r\n**Screenshots**\r\n\r\n\r\n**GaNDLF Version**\r\n0.0.14\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nAll the metrics are to be called from here\n\"\"\"\nimport torch\nfrom sklearn.metrics import balanced_accuracy_score\nimport numpy as np\n\n\ndef classification_accuracy(output, label, params):\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n acc = torch.sum(predicted_classes == label) / len(label)\n return acc\n\n\ndef balanced_acc_score(output, label, params):\n if params[\"problem_type\"] == \"classification\":\n predicted_classes = torch.argmax(output, 1)\n else:\n predicted_classes = output\n\n return torch.from_numpy(\n np.array(balanced_accuracy_score(predicted_classes.cpu(), label.cpu()))\n )\n", "path": "GANDLF/metrics/regression.py"}]}
| 923 | 115 |
gh_patches_debug_3916
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-379
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Execfile does not exist in py3k
<!--
Thanks for reporting issues of python-telegram-bot!
To make it easier for us to help you please enter detailed information below.
Please note, we only support the latest version of python-telegram-bot and
master branch. Please make sure to upgrade & recreate the issue on the latest
version prior to opening an issue.
-->
### Steps to reproduce
1. Use python 3
2. Try to install from git:
`$ pip install -e git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram`
### Expected behaviour
The library should be installed.
### Actual behaviour
NameError due to `execfile` not being a thing in python 3.
See here for alternatives: https://stackoverflow.com/a/437857
I would fix it myself, but I am unable to actually find the execfile call anywhere .-.
### Configuration
**Operating System:**
Windows 10 Education
**Version of Python, python-telegram-bot & dependencies:**
Python 3.5.2 |Continuum Analytics, Inc.| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)]
### Logs
``````
$ pip install -e git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram
Obtaining telegram from git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram
Skipping because already up-to-date.
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Development\telegram\VocaBot2\src\telegram\setup.py", line 20, in <module>
execfile(os.path.join('telegram', 'version.py'))
NameError: name 'execfile' is not defined
Command "python setup.py egg_info" failed with error code 1```
``````
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """The setup and build script for the python-telegram-bot library."""
3
4 import codecs
5 import os
6 from setuptools import setup, find_packages
7
8
9 def requirements():
10 """Build the requirements list for this project"""
11 requirements_list = []
12
13 with open('requirements.txt') as requirements:
14 for install in requirements:
15 requirements_list.append(install.strip())
16
17 return requirements_list
18
19
20 def execfile(fn):
21 with open(fn) as f:
22 code = compile(f.read(), fn, 'exec')
23 exec(code)
24
25
26 with codecs.open('README.rst', 'r', 'utf-8') as fd:
27 execfile(os.path.join('telegram', 'version.py'))
28
29 setup(name='python-telegram-bot',
30 version=__version__,
31 author='Leandro Toledo',
32 author_email='[email protected]',
33 license='LGPLv3',
34 url='https://github.com/python-telegram-bot/python-telegram-bot',
35 keywords='python telegram bot api wrapper',
36 description='Not just a Python wrapper around the Telegram Bot API',
37 long_description=fd.read(),
38 packages=find_packages(exclude=['tests*']),
39 install_requires=requirements(),
40 include_package_data=True,
41 classifiers=[
42 'Development Status :: 5 - Production/Stable',
43 'Intended Audience :: Developers',
44 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',
45 'Operating System :: OS Independent',
46 'Topic :: Software Development :: Libraries :: Python Modules',
47 'Topic :: Communications :: Chat',
48 'Topic :: Internet',
49 'Programming Language :: Python',
50 'Programming Language :: Python :: 2',
51 'Programming Language :: Python :: 2.6',
52 'Programming Language :: Python :: 2.7',
53 'Programming Language :: Python :: 3',
54 'Programming Language :: Python :: 3.3',
55 'Programming Language :: Python :: 3.4',
56 'Programming Language :: Python :: 3.5',
57 ],)
58
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -16,8 +16,12 @@
return requirements_list
+
with codecs.open('README.rst', 'r', 'utf-8') as fd:
- execfile(os.path.join('telegram', 'version.py'))
+ fn = os.path.join('telegram', 'version.py')
+ with open(fn) as fh:
+ code = compile(fh.read(), fn, 'exec')
+ exec(code)
setup(name='python-telegram-bot',
version=__version__,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -16,8 +16,12 @@\n \n return requirements_list\n \n+\n with codecs.open('README.rst', 'r', 'utf-8') as fd:\n- execfile(os.path.join('telegram', 'version.py'))\n+ fn = os.path.join('telegram', 'version.py')\n+ with open(fn) as fh:\n+ code = compile(fh.read(), fn, 'exec')\n+ exec(code)\n \n setup(name='python-telegram-bot',\n version=__version__,\n", "issue": "Execfile does not exist in py3k\n<!--\nThanks for reporting issues of python-telegram-bot!\nTo make it easier for us to help you please enter detailed information below.\n\nPlease note, we only support the latest version of python-telegram-bot and\nmaster branch. Please make sure to upgrade & recreate the issue on the latest\nversion prior to opening an issue.\n-->\n### Steps to reproduce\n1. Use python 3\n2. Try to install from git:\n `$ pip install -e git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram`\n### Expected behaviour\n\nThe library should be installed.\n### Actual behaviour\n\nNameError due to `execfile` not being a thing in python 3.\nSee here for alternatives: https://stackoverflow.com/a/437857\nI would fix it myself, but I am unable to actually find the execfile call anywhere .-.\n### Configuration\n\n**Operating System:**\nWindows 10 Education\n\n**Version of Python, python-telegram-bot & dependencies:**\nPython 3.5.2 |Continuum Analytics, Inc.| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)]\n### Logs\n\n``````\n$ pip install -e git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram\nObtaining telegram from git+https://github.com/python-telegram-bot/python-telegram-bot.git@555e36ee8036a179f157f60dcb0c3fcf958146f4#egg=telegram\n Skipping because already up-to-date.\n Complete output from command python setup.py egg_info:\n Traceback (most recent call last):\n File \"<string>\", line 1, in <module>\n File \"C:\\Development\\telegram\\VocaBot2\\src\\telegram\\setup.py\", line 20, in <module>\n execfile(os.path.join('telegram', 'version.py'))\n NameError: name 'execfile' is not defined\nCommand \"python setup.py egg_info\" failed with error code 1```\n``````\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"The setup and build script for the python-telegram-bot library.\"\"\"\n\nimport codecs\nimport os\nfrom setuptools import setup, find_packages\n\n\ndef requirements():\n \"\"\"Build the requirements list for this project\"\"\"\n requirements_list = []\n\n with open('requirements.txt') as requirements:\n for install in requirements:\n requirements_list.append(install.strip())\n\n return requirements_list\n\n\ndef execfile(fn):\n with open(fn) as f:\n code = compile(f.read(), fn, 'exec')\n exec(code)\n\n\nwith codecs.open('README.rst', 'r', 'utf-8') as fd:\n execfile(os.path.join('telegram', 'version.py'))\n\n setup(name='python-telegram-bot',\n version=__version__,\n author='Leandro Toledo',\n author_email='[email protected]',\n license='LGPLv3',\n url='https://github.com/python-telegram-bot/python-telegram-bot',\n keywords='python telegram bot api wrapper',\n description='Not just a Python wrapper around the Telegram Bot API',\n long_description=fd.read(),\n packages=find_packages(exclude=['tests*']),\n install_requires=requirements(),\n include_package_data=True,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Communications :: Chat',\n 'Topic :: Internet',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n ],)\n", "path": "setup.py"}]}
| 1,625 | 130 |
gh_patches_debug_25537
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2947
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
assemble.py _expand_parameters(circuits, run_config) apparently broken
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**: master
- **Python version**: 3.6.8
- **Operating system**: Linux
### What is the current behavior?
`Parameter` binding does not succeed as reported by user `@Adrian Auer` in Qiskit Slack.
### Steps to reproduce the problem
```
from qiskit import Aer, QuantumCircuit, QuantumRegister, execute
from qiskit.circuit import Parameter
# create m = 2 circuits
qr = QuantumRegister(1)
quantum_circuit_1 = QuantumCircuit(qr)
quantum_circuit_2 = QuantumCircuit(qr)
theta = Parameter('theta')
# add parametrized gates
quantum_circuit_1.u3(theta, 0, 0, qr[0])
quantum_circuit_2.u3(theta, 3.14, 0, qr[0])
circuits = [quantum_circuit_1, quantum_circuit_2]
# inspect parameters property
for circuit in circuits:
print(circuit.parameters)
# bind parameter to n = 1 values
job = execute(circuits,
Aer.get_backend('qasm_simulator'),
shots=512,
parameter_binds=[{theta: 1}])
```
Result is error:
```
Traceback (most recent call last):
File "adrian_auer_example.py", line 25, in <module>
parameter_binds=[{theta: 1}])
File "/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/execute.py", line 218, in execute
run_config=run_config
File "/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/compiler/assemble.py", line 149, in assemble
run_config=run_config)
File "/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/compiler/assemble.py", line 298, in _expand_parameters
'Circuit parameters: {}').format(all_bind_parameters, all_circuit_parameters))
qiskit.exceptions.QiskitError: 'Mismatch between run_config.parameter_binds and all circuit parameters. Parameter binds: [dict_keys([Parameter(theta)])] Circuit parameters: [{Parameter(theta)}, {Parameter(theta)}]'
```
### What is the expected behavior?
Parameter would bind and circuits would execute.
### Suggested solutions
In `qiskit/compiler/assembly.py:_expand_parameters` lines 293-294 both of the following tests are failing:
```
or any(unique_parameters != bind_params for bind_params in all_bind_parameters) \
or any(unique_parameters != parameters for parameters in all_circuit_parameters):
```
It appears to be because `unique_parameters` is a `list` of `Parameter` each of which is being compared to the elements of a list of dictionaries.
The comparison should be re-examined so that types match up.
</issue>
<code>
[start of qiskit/circuit/parameter.py]
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2019.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14 """
15 Parameter Class for variable parameters.
16 """
17
18 import sympy
19
20 from .parameterexpression import ParameterExpression
21
22
23 class Parameter(ParameterExpression):
24 """Parameter Class for variable parameters"""
25 def __init__(self, name):
26 self._name = name
27
28 symbol = sympy.Symbol(name)
29 super().__init__(symbol_map={self: symbol}, expr=symbol)
30
31 def subs(self, parameter_map):
32 """Substitute self with the corresponding parameter in parameter_map."""
33 return parameter_map[self]
34
35 @property
36 def name(self):
37 """Returns the name of the Parameter."""
38 return self._name
39
40 def __str__(self):
41 return self.name
42
43 def __copy__(self):
44 return self
45
46 def __deepcopy__(self, memo=None):
47 return self
48
49 def __repr__(self):
50 return '{}({})'.format(self.__class__.__name__, self.name)
51
[end of qiskit/circuit/parameter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/circuit/parameter.py b/qiskit/circuit/parameter.py
--- a/qiskit/circuit/parameter.py
+++ b/qiskit/circuit/parameter.py
@@ -15,6 +15,8 @@
Parameter Class for variable parameters.
"""
+from uuid import uuid4
+
import sympy
from .parameterexpression import ParameterExpression
@@ -22,6 +24,27 @@
class Parameter(ParameterExpression):
"""Parameter Class for variable parameters"""
+
+ def __new__(cls, _, uuid=None):
+ # Parameter relies on self._uuid being set prior to other attributes
+ # (e.g. symbol_map) which may depend on self._uuid for Parameter's hash
+ # or __eq__ functions.
+
+ obj = object.__new__(cls)
+
+ if uuid is None:
+ obj._uuid = uuid4()
+ else:
+ obj._uuid = uuid
+
+ return obj
+
+ def __getnewargs__(self):
+ # Unpickling won't in general call __init__ but will always call
+ # __new__. Specify arguments to be passed to __new__ when unpickling.
+
+ return (self.name, self._uuid)
+
def __init__(self, name):
self._name = name
@@ -48,3 +71,9 @@
def __repr__(self):
return '{}({})'.format(self.__class__.__name__, self.name)
+
+ def __eq__(self, other):
+ return isinstance(other, Parameter) and self._uuid == other._uuid
+
+ def __hash__(self):
+ return hash(self._uuid)
|
{"golden_diff": "diff --git a/qiskit/circuit/parameter.py b/qiskit/circuit/parameter.py\n--- a/qiskit/circuit/parameter.py\n+++ b/qiskit/circuit/parameter.py\n@@ -15,6 +15,8 @@\n Parameter Class for variable parameters.\n \"\"\"\n \n+from uuid import uuid4\n+\n import sympy\n \n from .parameterexpression import ParameterExpression\n@@ -22,6 +24,27 @@\n \n class Parameter(ParameterExpression):\n \"\"\"Parameter Class for variable parameters\"\"\"\n+\n+ def __new__(cls, _, uuid=None):\n+ # Parameter relies on self._uuid being set prior to other attributes\n+ # (e.g. symbol_map) which may depend on self._uuid for Parameter's hash\n+ # or __eq__ functions.\n+\n+ obj = object.__new__(cls)\n+\n+ if uuid is None:\n+ obj._uuid = uuid4()\n+ else:\n+ obj._uuid = uuid\n+\n+ return obj\n+\n+ def __getnewargs__(self):\n+ # Unpickling won't in general call __init__ but will always call\n+ # __new__. Specify arguments to be passed to __new__ when unpickling.\n+\n+ return (self.name, self._uuid)\n+\n def __init__(self, name):\n self._name = name\n \n@@ -48,3 +71,9 @@\n \n def __repr__(self):\n return '{}({})'.format(self.__class__.__name__, self.name)\n+\n+ def __eq__(self, other):\n+ return isinstance(other, Parameter) and self._uuid == other._uuid\n+\n+ def __hash__(self):\n+ return hash(self._uuid)\n", "issue": "assemble.py _expand_parameters(circuits, run_config) apparently broken\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**: master\r\n- **Python version**: 3.6.8\r\n- **Operating system**: Linux\r\n\r\n### What is the current behavior?\r\n`Parameter` binding does not succeed as reported by user `@Adrian Auer` in Qiskit Slack.\r\n\r\n### Steps to reproduce the problem\r\n\r\n```\r\nfrom qiskit import Aer, QuantumCircuit, QuantumRegister, execute\r\nfrom qiskit.circuit import Parameter\r\n\r\n# create m = 2 circuits\r\nqr = QuantumRegister(1)\r\nquantum_circuit_1 = QuantumCircuit(qr)\r\nquantum_circuit_2 = QuantumCircuit(qr)\r\n\r\ntheta = Parameter('theta')\r\n\r\n# add parametrized gates\r\nquantum_circuit_1.u3(theta, 0, 0, qr[0])\r\nquantum_circuit_2.u3(theta, 3.14, 0, qr[0])\r\n\r\ncircuits = [quantum_circuit_1, quantum_circuit_2]\r\n\r\n# inspect parameters property\r\nfor circuit in circuits:\r\n print(circuit.parameters)\r\n\r\n# bind parameter to n = 1 values\r\njob = execute(circuits,\r\n Aer.get_backend('qasm_simulator'),\r\n shots=512,\r\n parameter_binds=[{theta: 1}])\r\n```\r\nResult is error:\r\n```\r\nTraceback (most recent call last):\r\n File \"adrian_auer_example.py\", line 25, in <module>\r\n parameter_binds=[{theta: 1}])\r\n File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/execute.py\", line 218, in execute\r\n run_config=run_config\r\n File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/compiler/assemble.py\", line 149, in assemble\r\n run_config=run_config)\r\n File \"/home/jax/work/QISKit/DEV/qiskit-terra/qiskit/compiler/assemble.py\", line 298, in _expand_parameters\r\n 'Circuit parameters: {}').format(all_bind_parameters, all_circuit_parameters))\r\nqiskit.exceptions.QiskitError: 'Mismatch between run_config.parameter_binds and all circuit parameters. Parameter binds: [dict_keys([Parameter(theta)])] Circuit parameters: [{Parameter(theta)}, {Parameter(theta)}]'\r\n```\r\n### What is the expected behavior?\r\nParameter would bind and circuits would execute.\r\n\r\n\r\n### Suggested solutions\r\nIn `qiskit/compiler/assembly.py:_expand_parameters` lines 293-294 both of the following tests are failing:\r\n```\r\nor any(unique_parameters != bind_params for bind_params in all_bind_parameters) \\\r\n or any(unique_parameters != parameters for parameters in all_circuit_parameters):\r\n```\r\nIt appears to be because `unique_parameters` is a `list` of `Parameter` each of which is being compared to the elements of a list of dictionaries.\r\nThe comparison should be re-examined so that types match up.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\"\"\"\nParameter Class for variable parameters.\n\"\"\"\n\nimport sympy\n\nfrom .parameterexpression import ParameterExpression\n\n\nclass Parameter(ParameterExpression):\n \"\"\"Parameter Class for variable parameters\"\"\"\n def __init__(self, name):\n self._name = name\n\n symbol = sympy.Symbol(name)\n super().__init__(symbol_map={self: symbol}, expr=symbol)\n\n def subs(self, parameter_map):\n \"\"\"Substitute self with the corresponding parameter in parameter_map.\"\"\"\n return parameter_map[self]\n\n @property\n def name(self):\n \"\"\"Returns the name of the Parameter.\"\"\"\n return self._name\n\n def __str__(self):\n return self.name\n\n def __copy__(self):\n return self\n\n def __deepcopy__(self, memo=None):\n return self\n\n def __repr__(self):\n return '{}({})'.format(self.__class__.__name__, self.name)\n", "path": "qiskit/circuit/parameter.py"}]}
| 1,650 | 378 |
gh_patches_debug_874
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-1497
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
checkov fails with junit-xml==1.8
**Describe the bug**
checkov fails with junit-xml==1.8
**To Reproduce**
Steps to reproduce the behavior:
1. pip3 install junit-xml==1.8
2. checkov -d .
3. See error:
```
Traceback (most recent call last):
File "/usr/local/bin/checkov", line 2, in <module>
from checkov.main import run
File "/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/main.py", line 12, in <module>
from checkov.arm.runner import Runner as arm_runner
File "/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/arm/runner.py", line 7, in <module>
from checkov.common.output.report import Report
File "/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/common/output/report.py", line 5, in <module>
from junit_xml import TestCase, TestSuite, to_xml_report_string
ImportError: cannot import name 'to_xml_report_string' from 'junit_xml' (/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/junit_xml/__init__.py)
```
**Expected behavior**
checkov runs fine with junit-xml==1.9 so a reasonable fix would be to pin that version (or greater) in setup.py install_requires.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: RHEL 7
- Checkov Version [e.g. 22]: 2.0.350
**Additional context**
Add any other context about the problem here (e.g. code snippets).
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import logging
3 import os
4 from importlib import util
5 from os import path
6
7 import setuptools
8 from setuptools import setup
9
10 # read the contents of your README file
11 this_directory = path.abspath(path.dirname(__file__))
12 with open(path.join(this_directory, "README.md"), encoding="utf-8") as f:
13 long_description = f.read()
14
15 logger = logging.getLogger(__name__)
16 spec = util.spec_from_file_location(
17 "checkov.version", os.path.join("checkov", "version.py")
18 )
19 # noinspection PyUnresolvedReferences
20 mod = util.module_from_spec(spec)
21 spec.loader.exec_module(mod) # type: ignore
22 version = mod.version # type: ignore
23
24 setup(
25 extras_require={
26 "dev": [
27 "pytest==5.3.1",
28 "coverage",
29 "coverage-badge",
30 "GitPython==3.1.7",
31 "bandit",
32 "jsonschema",
33 ]
34 },
35 install_requires=[
36 "bc-python-hcl2>=0.3.18",
37 "cloudsplaining>=0.4.1",
38 "deep_merge",
39 "tabulate",
40 "colorama",
41 "termcolor",
42 "junit-xml",
43 "dpath>=1.5.0,<2",
44 "pyyaml>=5.4.1",
45 "boto3==1.17.*",
46 "GitPython",
47 "six==1.15.0",
48 "jmespath",
49 "tqdm",
50 "update_checker",
51 "semantic_version",
52 "packaging",
53 "networkx",
54 "dockerfile-parse",
55 "docker",
56 "configargparse",
57 "detect-secrets",
58 "policyuniverse",
59 "typing-extensions",
60 ],
61 license="Apache License 2.0",
62 name="checkov",
63 version=version,
64 python_requires=">=3.7",
65 description="Infrastructure as code static analysis",
66 author="bridgecrew",
67 author_email="[email protected]",
68 url="https://github.com/bridgecrewio/checkov",
69 packages=setuptools.find_packages(exclude=["tests*", "integration_tests*"]),
70 include_package_data=True,
71 package_dir={
72 "checkov.terraform.checks.graph_checks": "checkov/terraform/checks/graph_checks"
73 },
74 package_data={
75 "checkov.terraform.checks.graph_checks": [
76 "aws/*.yaml",
77 "gcp/*.yaml",
78 "azure/*.yaml",
79 ]
80 },
81 scripts=["bin/checkov", "bin/checkov.cmd"],
82 long_description=long_description,
83 long_description_content_type="text/markdown",
84 classifiers=[
85 "Environment :: Console",
86 "Intended Audience :: Developers",
87 "Intended Audience :: System Administrators",
88 "Programming Language :: Python :: 3.7",
89 "Programming Language :: Python :: 3.8",
90 "Programming Language :: Python :: 3.9",
91 "Topic :: Security",
92 "Topic :: Software Development :: Build Tools",
93 ],
94 )
95
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -39,7 +39,7 @@
"tabulate",
"colorama",
"termcolor",
- "junit-xml",
+ "junit-xml>=1.9",
"dpath>=1.5.0,<2",
"pyyaml>=5.4.1",
"boto3==1.17.*",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -39,7 +39,7 @@\n \"tabulate\",\n \"colorama\",\n \"termcolor\",\n- \"junit-xml\",\n+ \"junit-xml>=1.9\",\n \"dpath>=1.5.0,<2\",\n \"pyyaml>=5.4.1\",\n \"boto3==1.17.*\",\n", "issue": "checkov fails with junit-xml==1.8\n**Describe the bug**\r\ncheckov fails with junit-xml==1.8\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. pip3 install junit-xml==1.8\r\n2. checkov -d .\r\n3. See error: \r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/checkov\", line 2, in <module>\r\n from checkov.main import run\r\n File \"/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/main.py\", line 12, in <module>\r\n from checkov.arm.runner import Runner as arm_runner\r\n File \"/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/arm/runner.py\", line 7, in <module>\r\n from checkov.common.output.report import Report\r\n File \"/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/checkov/common/output/report.py\", line 5, in <module>\r\n from junit_xml import TestCase, TestSuite, to_xml_report_string\r\nImportError: cannot import name 'to_xml_report_string' from 'junit_xml' (/opt/rh/rh-python38/root/usr/local/lib/python3.8/site-packages/junit_xml/__init__.py)\r\n```\r\n\r\n**Expected behavior**\r\ncheckov runs fine with junit-xml==1.9 so a reasonable fix would be to pin that version (or greater) in setup.py install_requires.\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: RHEL 7\r\n - Checkov Version [e.g. 22]: 2.0.350\r\n\r\n**Additional context**\r\nAdd any other context about the problem here (e.g. code snippets).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport logging\nimport os\nfrom importlib import util\nfrom os import path\n\nimport setuptools\nfrom setuptools import setup\n\n# read the contents of your README file\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nlogger = logging.getLogger(__name__)\nspec = util.spec_from_file_location(\n \"checkov.version\", os.path.join(\"checkov\", \"version.py\")\n)\n# noinspection PyUnresolvedReferences\nmod = util.module_from_spec(spec)\nspec.loader.exec_module(mod) # type: ignore\nversion = mod.version # type: ignore\n\nsetup(\n extras_require={\n \"dev\": [\n \"pytest==5.3.1\",\n \"coverage\",\n \"coverage-badge\",\n \"GitPython==3.1.7\",\n \"bandit\",\n \"jsonschema\",\n ]\n },\n install_requires=[\n \"bc-python-hcl2>=0.3.18\",\n \"cloudsplaining>=0.4.1\",\n \"deep_merge\",\n \"tabulate\",\n \"colorama\",\n \"termcolor\",\n \"junit-xml\",\n \"dpath>=1.5.0,<2\",\n \"pyyaml>=5.4.1\",\n \"boto3==1.17.*\",\n \"GitPython\",\n \"six==1.15.0\",\n \"jmespath\",\n \"tqdm\",\n \"update_checker\",\n \"semantic_version\",\n \"packaging\",\n \"networkx\",\n \"dockerfile-parse\",\n \"docker\",\n \"configargparse\",\n \"detect-secrets\",\n \"policyuniverse\",\n \"typing-extensions\",\n ],\n license=\"Apache License 2.0\",\n name=\"checkov\",\n version=version,\n python_requires=\">=3.7\",\n description=\"Infrastructure as code static analysis\",\n author=\"bridgecrew\",\n author_email=\"[email protected]\",\n url=\"https://github.com/bridgecrewio/checkov\",\n packages=setuptools.find_packages(exclude=[\"tests*\", \"integration_tests*\"]),\n include_package_data=True,\n package_dir={\n \"checkov.terraform.checks.graph_checks\": \"checkov/terraform/checks/graph_checks\"\n },\n package_data={\n \"checkov.terraform.checks.graph_checks\": [\n \"aws/*.yaml\",\n \"gcp/*.yaml\",\n \"azure/*.yaml\",\n ]\n },\n scripts=[\"bin/checkov\", \"bin/checkov.cmd\"],\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Environment :: Console\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: System Administrators\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Security\",\n \"Topic :: Software Development :: Build Tools\",\n ],\n)\n", "path": "setup.py"}]}
| 1,769 | 104 |
gh_patches_debug_27849
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1401
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[marathon] 404 when the configured URL has a trailing slash
The web server powering Marathon apparently doesn't like double slashes, so dd-agent is getting a 404 back when trying to hit the /v2/apps endpoint.
e.g., with this configuration:
```
instances:
- url: "http://10.0.10.1:8080/"
```
The agent reports this error:
```
instance #0 [ERROR]: Exception('Got 404 when hitting http://10.0.10.1:8080/',)
```
This works fine if you leave off the trailing slash.
</issue>
<code>
[start of checks.d/marathon.py]
1 # project
2 from checks import AgentCheck
3
4 # 3rd party
5 import requests
6
7 class Marathon(AgentCheck):
8
9 DEFAULT_TIMEOUT = 5
10 SERVICE_CHECK_NAME = 'marathon.can_connect'
11
12 APP_METRICS = [
13 'backoffFactor',
14 'backoffSeconds',
15 'cpus',
16 'dist',
17 'instances',
18 'mem',
19 'taskRateLimit',
20 'tasksRunning',
21 'tasksStaged'
22 ]
23
24 def check(self, instance):
25 if 'url' not in instance:
26 raise Exception('Marathon instance missing "url" value.')
27
28 # Load values from the instance config
29 url = instance['url']
30 instance_tags = instance.get('tags', [])
31 default_timeout = self.init_config.get('default_timeout', self.DEFAULT_TIMEOUT)
32 timeout = float(instance.get('timeout', default_timeout))
33
34 response = self.get_json(url + "/v2/apps", timeout)
35 if response is not None:
36 self.gauge('marathon.apps', len(response['apps']), tags=instance_tags)
37 for app in response['apps']:
38 tags = ['app_id:' + app['id'], 'version:' + app['version']] + instance_tags
39 for attr in self.APP_METRICS:
40 if attr in app:
41 self.gauge('marathon.' + attr, app[attr], tags=tags)
42 versions_reply = self.get_json(url + "/v2/apps/" + app['id'] + "/versions", timeout)
43 if versions_reply is not None:
44 self.gauge('marathon.versions', len(versions_reply['versions']), tags=tags)
45
46 def get_json(self, url, timeout):
47 try:
48 r = requests.get(url, timeout=timeout)
49 r.raise_for_status()
50 except requests.exceptions.Timeout:
51 # If there's a timeout
52 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,
53 message='%s timed out after %s seconds.' % (url, timeout),
54 tags = ["url:{}".format(url)])
55 raise Exception("Timeout when hitting %s" % url)
56
57 except requests.exceptions.HTTPError:
58 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,
59 message='%s returned a status of %s' % (url, r.status_code),
60 tags = ["url:{}".format(url)])
61 raise Exception("Got %s when hitting %s" % (r.status_code, url))
62
63 else:
64 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK,
65 tags = ["url:{}".format(url)]
66 )
67
68 return r.json()
69
[end of checks.d/marathon.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checks.d/marathon.py b/checks.d/marathon.py
--- a/checks.d/marathon.py
+++ b/checks.d/marathon.py
@@ -1,3 +1,6 @@
+# stdlib
+from urlparse import urljoin
+
# project
from checks import AgentCheck
@@ -31,7 +34,7 @@
default_timeout = self.init_config.get('default_timeout', self.DEFAULT_TIMEOUT)
timeout = float(instance.get('timeout', default_timeout))
- response = self.get_json(url + "/v2/apps", timeout)
+ response = self.get_json(urljoin(url, "/v2/apps"), timeout)
if response is not None:
self.gauge('marathon.apps', len(response['apps']), tags=instance_tags)
for app in response['apps']:
@@ -39,7 +42,10 @@
for attr in self.APP_METRICS:
if attr in app:
self.gauge('marathon.' + attr, app[attr], tags=tags)
- versions_reply = self.get_json(url + "/v2/apps/" + app['id'] + "/versions", timeout)
+
+ query_url = urljoin(url, "/v2/apps/{0}/versions".format(app['id']))
+ versions_reply = self.get_json(query_url, timeout)
+
if versions_reply is not None:
self.gauge('marathon.versions', len(versions_reply['versions']), tags=tags)
|
{"golden_diff": "diff --git a/checks.d/marathon.py b/checks.d/marathon.py\n--- a/checks.d/marathon.py\n+++ b/checks.d/marathon.py\n@@ -1,3 +1,6 @@\n+# stdlib\n+from urlparse import urljoin\n+\n # project\n from checks import AgentCheck\n \n@@ -31,7 +34,7 @@\n default_timeout = self.init_config.get('default_timeout', self.DEFAULT_TIMEOUT)\n timeout = float(instance.get('timeout', default_timeout))\n \n- response = self.get_json(url + \"/v2/apps\", timeout)\n+ response = self.get_json(urljoin(url, \"/v2/apps\"), timeout)\n if response is not None:\n self.gauge('marathon.apps', len(response['apps']), tags=instance_tags)\n for app in response['apps']:\n@@ -39,7 +42,10 @@\n for attr in self.APP_METRICS:\n if attr in app:\n self.gauge('marathon.' + attr, app[attr], tags=tags)\n- versions_reply = self.get_json(url + \"/v2/apps/\" + app['id'] + \"/versions\", timeout)\n+\n+ query_url = urljoin(url, \"/v2/apps/{0}/versions\".format(app['id']))\n+ versions_reply = self.get_json(query_url, timeout)\n+\n if versions_reply is not None:\n self.gauge('marathon.versions', len(versions_reply['versions']), tags=tags)\n", "issue": "[marathon] 404 when the configured URL has a trailing slash\nThe web server powering Marathon apparently doesn't like double slashes, so dd-agent is getting a 404 back when trying to hit the /v2/apps endpoint.\n\ne.g., with this configuration:\n\n```\ninstances:\n- url: \"http://10.0.10.1:8080/\"\n```\n\nThe agent reports this error:\n\n```\ninstance #0 [ERROR]: Exception('Got 404 when hitting http://10.0.10.1:8080/',)\n```\n\nThis works fine if you leave off the trailing slash. \n\n", "before_files": [{"content": "# project\nfrom checks import AgentCheck\n\n# 3rd party\nimport requests\n\nclass Marathon(AgentCheck):\n\n DEFAULT_TIMEOUT = 5\n SERVICE_CHECK_NAME = 'marathon.can_connect'\n\n APP_METRICS = [\n 'backoffFactor',\n 'backoffSeconds',\n 'cpus',\n 'dist',\n 'instances',\n 'mem',\n 'taskRateLimit',\n 'tasksRunning',\n 'tasksStaged'\n ]\n\n def check(self, instance):\n if 'url' not in instance:\n raise Exception('Marathon instance missing \"url\" value.')\n\n # Load values from the instance config\n url = instance['url']\n instance_tags = instance.get('tags', [])\n default_timeout = self.init_config.get('default_timeout', self.DEFAULT_TIMEOUT)\n timeout = float(instance.get('timeout', default_timeout))\n\n response = self.get_json(url + \"/v2/apps\", timeout)\n if response is not None:\n self.gauge('marathon.apps', len(response['apps']), tags=instance_tags)\n for app in response['apps']:\n tags = ['app_id:' + app['id'], 'version:' + app['version']] + instance_tags\n for attr in self.APP_METRICS:\n if attr in app:\n self.gauge('marathon.' + attr, app[attr], tags=tags)\n versions_reply = self.get_json(url + \"/v2/apps/\" + app['id'] + \"/versions\", timeout)\n if versions_reply is not None:\n self.gauge('marathon.versions', len(versions_reply['versions']), tags=tags)\n\n def get_json(self, url, timeout):\n try:\n r = requests.get(url, timeout=timeout)\n r.raise_for_status()\n except requests.exceptions.Timeout:\n # If there's a timeout\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,\n message='%s timed out after %s seconds.' % (url, timeout),\n tags = [\"url:{}\".format(url)])\n raise Exception(\"Timeout when hitting %s\" % url)\n\n except requests.exceptions.HTTPError:\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,\n message='%s returned a status of %s' % (url, r.status_code),\n tags = [\"url:{}\".format(url)])\n raise Exception(\"Got %s when hitting %s\" % (r.status_code, url))\n\n else:\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK,\n tags = [\"url:{}\".format(url)]\n )\n\n return r.json()\n", "path": "checks.d/marathon.py"}]}
| 1,361 | 320 |
gh_patches_debug_14725
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1218
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
wagtailfrontendcache throws an error when a root page is created without a site
On a new install of wagtail w/ wagtailfrontendcache enabled, I go through the following steps:
1. Go to the admin
2. Delete the default "welcome" page from the database
3. Create a new root page
After I create the new root page, I get the following error:
```
[17/Apr/2015 20:02:28] ERROR [django.request:231] Internal Server Error: /admin/pages/new/pages/genericpage/1/
Traceback (most recent call last):
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/core/handlers/base.py", line 111, in get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/contrib/auth/decorators.py", line 21, in _wrapped_view
return view_func(request, *args, **kwargs)
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/wagtailadmin/views/pages.py", line 211, in create
revision.publish()
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/wagtailcore/models.py", line 1141, in publish
page_published.send(sender=page.specific_class, instance=page.specific)
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/dispatch/dispatcher.py", line 198, in send
response = receiver(signal=self, sender=sender, **named)
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/contrib/wagtailfrontendcache/signal_handlers.py", line 9, in page_published_signal_handler
purge_page_from_cache(instance)
File "/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/contrib/wagtailfrontendcache/utils.py", line 100, in purge_page_from_cache
logger.info("[%s] Purging URL: %s", backend_name, page.full_url + path[1:])
TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
```
Digging into the code, this error is the request of the following line:
```
logger.info("[%s] Purging URL: %s", backend_name, page.full_url + path[1:])
```
This line failes because `page.full_url` is set to `None` when it executes, which results in the line throwing an exception. The new page model is still saved, so I just need to refresh the admin in my browser to get back into a good working state.
</issue>
<code>
[start of wagtail/contrib/wagtailfrontendcache/utils.py]
1 import logging
2
3 from django.conf import settings
4 from django.utils.module_loading import import_string
5 from django.core.exceptions import ImproperlyConfigured
6
7
8 logger = logging.getLogger('wagtail.frontendcache')
9
10
11 class InvalidFrontendCacheBackendError(ImproperlyConfigured):
12 pass
13
14
15 def get_backends(backend_settings=None, backends=None):
16 # Get backend settings from WAGTAILFRONTENDCACHE setting
17 if backend_settings is None:
18 backend_settings = getattr(settings, 'WAGTAILFRONTENDCACHE', None)
19
20 # Fallback to using WAGTAILFRONTENDCACHE_LOCATION setting (backwards compatibility)
21 if backend_settings is None:
22 cache_location = getattr(settings, 'WAGTAILFRONTENDCACHE_LOCATION', None)
23
24 if cache_location is not None:
25 backend_settings = {
26 'default': {
27 'BACKEND': 'wagtail.contrib.wagtailfrontendcache.backends.HTTPBackend',
28 'LOCATION': cache_location,
29 },
30 }
31
32 # No settings found, return empty list
33 if backend_settings is None:
34 return {}
35
36 backend_objects = {}
37
38 for backend_name, _backend_config in backend_settings.items():
39 if backends is not None and backend_name not in backends:
40 continue
41
42 backend_config = _backend_config.copy()
43 backend = backend_config.pop('BACKEND')
44
45 # Try to import the backend
46 try:
47 backend_cls = import_string(backend)
48 except ImportError as e:
49 raise InvalidFrontendCacheBackendError("Could not find backend '%s': %s" % (
50 backend, e))
51
52 backend_objects[backend_name] = backend_cls(backend_config)
53
54 return backend_objects
55
56
57 def purge_url_from_cache(url, backend_settings=None, backends=None):
58 for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():
59 logger.info("[%s] Purging URL: %s", backend_name, url)
60 backend.purge(url)
61
62
63 def purge_page_from_cache(page, backend_settings=None, backends=None):
64 for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():
65 # Purge cached paths from cache
66 for path in page.specific.get_cached_paths():
67 logger.info("[%s] Purging URL: %s", backend_name, page.full_url + path[1:])
68 backend.purge(page.full_url + path[1:])
69
[end of wagtail/contrib/wagtailfrontendcache/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/contrib/wagtailfrontendcache/utils.py b/wagtail/contrib/wagtailfrontendcache/utils.py
--- a/wagtail/contrib/wagtailfrontendcache/utils.py
+++ b/wagtail/contrib/wagtailfrontendcache/utils.py
@@ -61,8 +61,12 @@
def purge_page_from_cache(page, backend_settings=None, backends=None):
+ page_url = page.full_url
+ if page_url is None: # nothing to be done if the page has no routable URL
+ return
+
for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():
# Purge cached paths from cache
for path in page.specific.get_cached_paths():
- logger.info("[%s] Purging URL: %s", backend_name, page.full_url + path[1:])
- backend.purge(page.full_url + path[1:])
+ logger.info("[%s] Purging URL: %s", backend_name, page_url + path[1:])
+ backend.purge(page_url + path[1:])
|
{"golden_diff": "diff --git a/wagtail/contrib/wagtailfrontendcache/utils.py b/wagtail/contrib/wagtailfrontendcache/utils.py\n--- a/wagtail/contrib/wagtailfrontendcache/utils.py\n+++ b/wagtail/contrib/wagtailfrontendcache/utils.py\n@@ -61,8 +61,12 @@\n \n \n def purge_page_from_cache(page, backend_settings=None, backends=None):\n+ page_url = page.full_url\n+ if page_url is None: # nothing to be done if the page has no routable URL\n+ return\n+\n for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():\n # Purge cached paths from cache\n for path in page.specific.get_cached_paths():\n- logger.info(\"[%s] Purging URL: %s\", backend_name, page.full_url + path[1:])\n- backend.purge(page.full_url + path[1:])\n+ logger.info(\"[%s] Purging URL: %s\", backend_name, page_url + path[1:])\n+ backend.purge(page_url + path[1:])\n", "issue": "wagtailfrontendcache throws an error when a root page is created without a site\nOn a new install of wagtail w/ wagtailfrontendcache enabled, I go through the following steps:\n1. Go to the admin\n2. Delete the default \"welcome\" page from the database\n3. Create a new root page\n\nAfter I create the new root page, I get the following error:\n\n```\n[17/Apr/2015 20:02:28] ERROR [django.request:231] Internal Server Error: /admin/pages/new/pages/genericpage/1/\nTraceback (most recent call last):\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/core/handlers/base.py\", line 111, in get_response\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/contrib/auth/decorators.py\", line 21, in _wrapped_view\n return view_func(request, *args, **kwargs)\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/wagtailadmin/views/pages.py\", line 211, in create\n revision.publish()\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/wagtailcore/models.py\", line 1141, in publish\n page_published.send(sender=page.specific_class, instance=page.specific)\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/django/dispatch/dispatcher.py\", line 198, in send\n response = receiver(signal=self, sender=sender, **named)\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/contrib/wagtailfrontendcache/signal_handlers.py\", line 9, in page_published_signal_handler\n purge_page_from_cache(instance)\n File \"/Users/jryding/.virtualenvs/cms/lib/python2.7/site-packages/wagtail/contrib/wagtailfrontendcache/utils.py\", line 100, in purge_page_from_cache\n logger.info(\"[%s] Purging URL: %s\", backend_name, page.full_url + path[1:])\nTypeError: unsupported operand type(s) for +: 'NoneType' and 'str'\n```\n\nDigging into the code, this error is the request of the following line:\n\n```\nlogger.info(\"[%s] Purging URL: %s\", backend_name, page.full_url + path[1:])\n```\n\nThis line failes because `page.full_url` is set to `None` when it executes, which results in the line throwing an exception. The new page model is still saved, so I just need to refresh the admin in my browser to get back into a good working state.\n\n", "before_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom django.utils.module_loading import import_string\nfrom django.core.exceptions import ImproperlyConfigured\n\n\nlogger = logging.getLogger('wagtail.frontendcache')\n\n\nclass InvalidFrontendCacheBackendError(ImproperlyConfigured):\n pass\n\n\ndef get_backends(backend_settings=None, backends=None):\n # Get backend settings from WAGTAILFRONTENDCACHE setting\n if backend_settings is None:\n backend_settings = getattr(settings, 'WAGTAILFRONTENDCACHE', None)\n\n # Fallback to using WAGTAILFRONTENDCACHE_LOCATION setting (backwards compatibility)\n if backend_settings is None:\n cache_location = getattr(settings, 'WAGTAILFRONTENDCACHE_LOCATION', None)\n\n if cache_location is not None:\n backend_settings = {\n 'default': {\n 'BACKEND': 'wagtail.contrib.wagtailfrontendcache.backends.HTTPBackend',\n 'LOCATION': cache_location,\n },\n }\n\n # No settings found, return empty list\n if backend_settings is None:\n return {}\n\n backend_objects = {}\n\n for backend_name, _backend_config in backend_settings.items():\n if backends is not None and backend_name not in backends:\n continue\n\n backend_config = _backend_config.copy()\n backend = backend_config.pop('BACKEND')\n\n # Try to import the backend\n try:\n backend_cls = import_string(backend)\n except ImportError as e:\n raise InvalidFrontendCacheBackendError(\"Could not find backend '%s': %s\" % (\n backend, e))\n\n backend_objects[backend_name] = backend_cls(backend_config)\n\n return backend_objects\n\n\ndef purge_url_from_cache(url, backend_settings=None, backends=None):\n for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():\n logger.info(\"[%s] Purging URL: %s\", backend_name, url)\n backend.purge(url)\n\n\ndef purge_page_from_cache(page, backend_settings=None, backends=None):\n for backend_name, backend in get_backends(backend_settings=backend_settings, backends=backends).items():\n # Purge cached paths from cache\n for path in page.specific.get_cached_paths():\n logger.info(\"[%s] Purging URL: %s\", backend_name, page.full_url + path[1:])\n backend.purge(page.full_url + path[1:])\n", "path": "wagtail/contrib/wagtailfrontendcache/utils.py"}]}
| 1,835 | 245 |
gh_patches_debug_61672
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-640
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MacOS 10.13 OSError: [Errno 24] Too many open files
```shell
return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]
OSError: [Errno 24] Too many open files: '/Users/abcdefg/.pyenv/versions/3.6.3/envs/weixin3/lib/python3.6/site-packages/faker/providers/address'
```
</issue>
<code>
[start of faker/utils/loading.py]
1 import os
2 from importlib import import_module
3 import pkgutil
4
5
6 def list_module(module):
7 path = os.path.dirname(module.__file__)
8 modules = [name for finder, name, is_pkg in pkgutil.iter_modules([path]) if is_pkg]
9 if len(modules) > 0:
10 return modules
11 return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]
12
13
14 def find_available_locales(providers):
15 available_locales = set()
16
17 for provider_path in providers:
18
19 provider_module = import_module(provider_path)
20 if getattr(provider_module, 'localized', False):
21 langs = list_module(provider_module)
22 available_locales.update(langs)
23 return available_locales
24
25
26 def find_available_providers(modules):
27 available_providers = set()
28 for providers_mod in modules:
29 providers = ['.'.join([providers_mod.__package__, mod]) for mod in list_module(providers_mod)]
30 available_providers.update(providers)
31 return sorted(available_providers)
32
[end of faker/utils/loading.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/faker/utils/loading.py b/faker/utils/loading.py
--- a/faker/utils/loading.py
+++ b/faker/utils/loading.py
@@ -6,9 +6,7 @@
def list_module(module):
path = os.path.dirname(module.__file__)
modules = [name for finder, name, is_pkg in pkgutil.iter_modules([path]) if is_pkg]
- if len(modules) > 0:
- return modules
- return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]
+ return modules
def find_available_locales(providers):
|
{"golden_diff": "diff --git a/faker/utils/loading.py b/faker/utils/loading.py\n--- a/faker/utils/loading.py\n+++ b/faker/utils/loading.py\n@@ -6,9 +6,7 @@\n def list_module(module):\n path = os.path.dirname(module.__file__)\n modules = [name for finder, name, is_pkg in pkgutil.iter_modules([path]) if is_pkg]\n- if len(modules) > 0:\n- return modules\n- return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]\n+ return modules\n \n \n def find_available_locales(providers):\n", "issue": "MacOS 10.13 OSError: [Errno 24] Too many open files\n```shell\r\n return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]\r\nOSError: [Errno 24] Too many open files: '/Users/abcdefg/.pyenv/versions/3.6.3/envs/weixin3/lib/python3.6/site-packages/faker/providers/address'\r\n```\r\n\r\n\n", "before_files": [{"content": "import os\nfrom importlib import import_module\nimport pkgutil\n\n\ndef list_module(module):\n path = os.path.dirname(module.__file__)\n modules = [name for finder, name, is_pkg in pkgutil.iter_modules([path]) if is_pkg]\n if len(modules) > 0:\n return modules\n return [i for i in os.listdir(path) if os.path.isdir(os.path.join(path, i)) and not i.startswith('_')]\n\n\ndef find_available_locales(providers):\n available_locales = set()\n\n for provider_path in providers:\n\n provider_module = import_module(provider_path)\n if getattr(provider_module, 'localized', False):\n langs = list_module(provider_module)\n available_locales.update(langs)\n return available_locales\n\n\ndef find_available_providers(modules):\n available_providers = set()\n for providers_mod in modules:\n providers = ['.'.join([providers_mod.__package__, mod]) for mod in list_module(providers_mod)]\n available_providers.update(providers)\n return sorted(available_providers)\n", "path": "faker/utils/loading.py"}]}
| 923 | 141 |
gh_patches_debug_25216
|
rasdani/github-patches
|
git_diff
|
TileDB-Inc__TileDB-Py-167
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tiledb.open doesn't accept an optional ctx
it accepts a config which creates a ctx, would it make sense to have both?
</issue>
<code>
[start of tiledb/highlevel.py]
1 import tiledb
2 from tiledb.libtiledb import *
3
4 import numpy as np
5
6 def open(uri, key=None, attr=None, mode='r', config=None):
7 """
8 Open a TileDB array at the given URI
9
10 :param uri: any TileDB supported URI
11 :param key: encryption key, str or None
12 :param str mode: (default 'r') Open the array object in read 'r' or write 'w' mode
13 :param attr: attribute name to select from a multi-attribute array, str or None
14 :param config: TileDB config dictionary, dict or None
15 :return:
16 """
17 if config:
18 cfg = tiledb.Config(config)
19 ctx = tiledb.Ctx(cfg)
20 else:
21 ctx = default_ctx()
22
23 schema = ArraySchema.load(uri, ctx=ctx)
24 if not schema:
25 raise Exception("Unable to load tiledb ArraySchema from URI: '{}'".format(uri))
26
27 if schema.sparse:
28 return tiledb.SparseArray(uri, mode=mode, key=key, attr=attr, ctx=ctx)
29 elif not schema.sparse:
30 return tiledb.DenseArray(uri, mode=mode, key=key, attr=attr, ctx=ctx)
31 else:
32 raise Exception("Unknown TileDB array type")
33
34
35 def save(uri, array, config=None, **kw):
36 """
37 Save array-like object at the given URI.
38
39 :param uri: str or None
40 :param array: array-like object convertible to NumPy
41 :param config: TileDB config dictionary, dict or None
42 :param kw: optional keyword args will be forwarded to tiledb.Array constructor
43 :return:
44 """
45 if not isinstance(array, np.ndarray):
46 raise ValueError("expected NumPy ndarray, not '{}'".format(type(array)))
47 if config:
48 cfg = Config(config)
49 ctx = tiledb.Ctx(cfg)
50 else:
51 ctx = default_ctx()
52
53 return tiledb.from_numpy(uri, array, ctx=ctx)
54
55
56 def empty_like(uri, arr, config=None, key=None, tile=None):
57 """
58 Create and return an empty, writeable DenseArray with schema based on
59 a NumPy-array like object.
60
61 :param uri:
62 :param arr: NumPy ndarray, or shape tuple
63 :param ctx:
64 :param kw:
65 :return:
66 """
67 if config:
68 cfg = tiledb.Config(config)
69 ctx = tiledb.Ctx(cfg)
70 else:
71 ctx = default_ctx()
72
73 if arr is ArraySchema:
74 schema = arr
75 else:
76 schema = schema_like(arr, tile=tile, ctx=ctx)
77
78 tiledb.DenseArray.create(uri, key=key, schema=schema)
79 return tiledb.DenseArray(uri, mode='w', key=key, ctx=ctx)
80
81
82 def from_numpy(uri, array, ctx=default_ctx(), **kw):
83 """
84 Convenience method, see `tiledb.DenseArray.from_numpy`
85 """
86 if not isinstance(array, np.ndarray):
87 raise Exception("from_numpy is only currently supported for numpy.ndarray")
88
89 return DenseArray.from_numpy(uri, array, ctx=ctx, **kw)
90
91
[end of tiledb/highlevel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tiledb/highlevel.py b/tiledb/highlevel.py
--- a/tiledb/highlevel.py
+++ b/tiledb/highlevel.py
@@ -3,7 +3,7 @@
import numpy as np
-def open(uri, key=None, attr=None, mode='r', config=None):
+def open(uri, key=None, attr=None, mode='r', config=None, ctx=None):
"""
Open a TileDB array at the given URI
@@ -14,10 +14,14 @@
:param config: TileDB config dictionary, dict or None
:return:
"""
+ if ctx and config:
+ raise ValueError("Received extra Ctx or Config argument: either one may be provided, but not both")
+
if config:
cfg = tiledb.Config(config)
ctx = tiledb.Ctx(cfg)
- else:
+
+ if ctx is None:
ctx = default_ctx()
schema = ArraySchema.load(uri, ctx=ctx)
@@ -88,3 +92,23 @@
return DenseArray.from_numpy(uri, array, ctx=ctx, **kw)
+def array_exists(uri, isdense=False, issparse=False):
+ """
+ Check if arrays exists and is open-able at the given URI
+
+ Optionally restrict to `isdense` or `issparse` array types.
+ """
+ try:
+ a = tiledb.open(uri)
+ except TileDBError as exc:
+ return False
+
+ if isdense:
+ rval = not a.schema.sparse
+ elif issparse:
+ rval = a.schema.sparse
+ else:
+ rval = True
+
+ a.close()
+ return rval
|
{"golden_diff": "diff --git a/tiledb/highlevel.py b/tiledb/highlevel.py\n--- a/tiledb/highlevel.py\n+++ b/tiledb/highlevel.py\n@@ -3,7 +3,7 @@\n \n import numpy as np\n \n-def open(uri, key=None, attr=None, mode='r', config=None):\n+def open(uri, key=None, attr=None, mode='r', config=None, ctx=None):\n \"\"\"\n Open a TileDB array at the given URI\n \n@@ -14,10 +14,14 @@\n :param config: TileDB config dictionary, dict or None\n :return:\n \"\"\"\n+ if ctx and config:\n+ raise ValueError(\"Received extra Ctx or Config argument: either one may be provided, but not both\")\n+\n if config:\n cfg = tiledb.Config(config)\n ctx = tiledb.Ctx(cfg)\n- else:\n+\n+ if ctx is None:\n ctx = default_ctx()\n \n schema = ArraySchema.load(uri, ctx=ctx)\n@@ -88,3 +92,23 @@\n \n return DenseArray.from_numpy(uri, array, ctx=ctx, **kw)\n \n+def array_exists(uri, isdense=False, issparse=False):\n+ \"\"\"\n+ Check if arrays exists and is open-able at the given URI\n+\n+ Optionally restrict to `isdense` or `issparse` array types.\n+ \"\"\"\n+ try:\n+ a = tiledb.open(uri)\n+ except TileDBError as exc:\n+ return False\n+\n+ if isdense:\n+ rval = not a.schema.sparse\n+ elif issparse:\n+ rval = a.schema.sparse\n+ else:\n+ rval = True\n+\n+ a.close()\n+ return rval\n", "issue": "tiledb.open doesn't accept an optional ctx\nit accepts a config which creates a ctx, would it make sense to have both?\n", "before_files": [{"content": "import tiledb\nfrom tiledb.libtiledb import *\n\nimport numpy as np\n\ndef open(uri, key=None, attr=None, mode='r', config=None):\n \"\"\"\n Open a TileDB array at the given URI\n\n :param uri: any TileDB supported URI\n :param key: encryption key, str or None\n :param str mode: (default 'r') Open the array object in read 'r' or write 'w' mode\n :param attr: attribute name to select from a multi-attribute array, str or None\n :param config: TileDB config dictionary, dict or None\n :return:\n \"\"\"\n if config:\n cfg = tiledb.Config(config)\n ctx = tiledb.Ctx(cfg)\n else:\n ctx = default_ctx()\n\n schema = ArraySchema.load(uri, ctx=ctx)\n if not schema:\n raise Exception(\"Unable to load tiledb ArraySchema from URI: '{}'\".format(uri))\n\n if schema.sparse:\n return tiledb.SparseArray(uri, mode=mode, key=key, attr=attr, ctx=ctx)\n elif not schema.sparse:\n return tiledb.DenseArray(uri, mode=mode, key=key, attr=attr, ctx=ctx)\n else:\n raise Exception(\"Unknown TileDB array type\")\n\n\ndef save(uri, array, config=None, **kw):\n \"\"\"\n Save array-like object at the given URI.\n\n :param uri: str or None\n :param array: array-like object convertible to NumPy\n :param config: TileDB config dictionary, dict or None\n :param kw: optional keyword args will be forwarded to tiledb.Array constructor\n :return:\n \"\"\"\n if not isinstance(array, np.ndarray):\n raise ValueError(\"expected NumPy ndarray, not '{}'\".format(type(array)))\n if config:\n cfg = Config(config)\n ctx = tiledb.Ctx(cfg)\n else:\n ctx = default_ctx()\n\n return tiledb.from_numpy(uri, array, ctx=ctx)\n\n\ndef empty_like(uri, arr, config=None, key=None, tile=None):\n \"\"\"\n Create and return an empty, writeable DenseArray with schema based on\n a NumPy-array like object.\n\n :param uri:\n :param arr: NumPy ndarray, or shape tuple\n :param ctx:\n :param kw:\n :return:\n \"\"\"\n if config:\n cfg = tiledb.Config(config)\n ctx = tiledb.Ctx(cfg)\n else:\n ctx = default_ctx()\n\n if arr is ArraySchema:\n schema = arr\n else:\n schema = schema_like(arr, tile=tile, ctx=ctx)\n\n tiledb.DenseArray.create(uri, key=key, schema=schema)\n return tiledb.DenseArray(uri, mode='w', key=key, ctx=ctx)\n\n\ndef from_numpy(uri, array, ctx=default_ctx(), **kw):\n \"\"\"\n Convenience method, see `tiledb.DenseArray.from_numpy`\n \"\"\"\n if not isinstance(array, np.ndarray):\n raise Exception(\"from_numpy is only currently supported for numpy.ndarray\")\n\n return DenseArray.from_numpy(uri, array, ctx=ctx, **kw)\n\n", "path": "tiledb/highlevel.py"}]}
| 1,419 | 385 |
gh_patches_debug_13516
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-19895
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dropout2d
</issue>
<code>
[start of ivy/functional/frontends/mindspore/ops/function/nn_func.py]
1 """Includes Mindspore Frontend functions listed in the TODO list
2 https://github.com/unifyai/ivy/issues/14951."""
3
4 # local
5 import ivy
6 from ivy.func_wrapper import with_supported_dtypes
7 from ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back
8
9
10 @with_supported_dtypes({"2.0.0 and below": ("float16", "float32")}, "mindspore")
11 @to_ivy_arrays_and_back
12 def selu(input_x):
13 return ivy.selu(input_x)
14
15
16 @with_supported_dtypes({"2.0 and below": ("float16", "float32")}, "mindspore")
17 @to_ivy_arrays_and_back
18 def softsign(x):
19 return ivy.divide(x, ivy.add(1, ivy.abs(x)))
20
[end of ivy/functional/frontends/mindspore/ops/function/nn_func.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/mindspore/ops/function/nn_func.py b/ivy/functional/frontends/mindspore/ops/function/nn_func.py
--- a/ivy/functional/frontends/mindspore/ops/function/nn_func.py
+++ b/ivy/functional/frontends/mindspore/ops/function/nn_func.py
@@ -6,6 +6,23 @@
from ivy.func_wrapper import with_supported_dtypes
from ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back
+@with_supported_dtypes(
+ {
+ "2.0.0 and below": (
+ "int8",
+ "int16",
+ "int32",
+ "int64",
+ "float16",
+ "float32",
+ "float64",
+ )
+ },
+ "mindspore",
+)
+@to_ivy_arrays_and_back
+def dropout2d(input, p=0.5, training=True):
+ return ivy.dropout2d(input, p, training=training, data_format="NCHW")
@with_supported_dtypes({"2.0.0 and below": ("float16", "float32")}, "mindspore")
@to_ivy_arrays_and_back
|
{"golden_diff": "diff --git a/ivy/functional/frontends/mindspore/ops/function/nn_func.py b/ivy/functional/frontends/mindspore/ops/function/nn_func.py\n--- a/ivy/functional/frontends/mindspore/ops/function/nn_func.py\n+++ b/ivy/functional/frontends/mindspore/ops/function/nn_func.py\n@@ -6,6 +6,23 @@\n from ivy.func_wrapper import with_supported_dtypes\n from ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back\n \n+@with_supported_dtypes(\n+ {\n+ \"2.0.0 and below\": (\n+ \"int8\",\n+ \"int16\",\n+ \"int32\",\n+ \"int64\",\n+ \"float16\",\n+ \"float32\",\n+ \"float64\",\n+ )\n+ },\n+ \"mindspore\",\n+)\n+@to_ivy_arrays_and_back\n+def dropout2d(input, p=0.5, training=True):\n+ return ivy.dropout2d(input, p, training=training, data_format=\"NCHW\")\n \n @with_supported_dtypes({\"2.0.0 and below\": (\"float16\", \"float32\")}, \"mindspore\")\n @to_ivy_arrays_and_back\n", "issue": "dropout2d\n\n", "before_files": [{"content": "\"\"\"Includes Mindspore Frontend functions listed in the TODO list\nhttps://github.com/unifyai/ivy/issues/14951.\"\"\"\n\n# local\nimport ivy\nfrom ivy.func_wrapper import with_supported_dtypes\nfrom ivy.functional.frontends.paddle.func_wrapper import to_ivy_arrays_and_back\n\n\n@with_supported_dtypes({\"2.0.0 and below\": (\"float16\", \"float32\")}, \"mindspore\")\n@to_ivy_arrays_and_back\ndef selu(input_x):\n return ivy.selu(input_x)\n\n\n@with_supported_dtypes({\"2.0 and below\": (\"float16\", \"float32\")}, \"mindspore\")\n@to_ivy_arrays_and_back\ndef softsign(x):\n return ivy.divide(x, ivy.add(1, ivy.abs(x)))\n", "path": "ivy/functional/frontends/mindspore/ops/function/nn_func.py"}]}
| 779 | 293 |
gh_patches_debug_39053
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2444
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create a Deployment type 1 specific script.
Create a script to download docker-compose from the Mathesar repo and help the user in setting up Mathesar.
- [ ] The script should be self-documenting, i.e., the prompts during interactive portions should help the user understand the implications of what they're doing, and any error states should give enough info for the user to find solutions in the troubleshooting documentation on docs.mathesar.org
- [ ] The script should also add help text in the installation CLI that would list the database Privileges needed for Mathesar to function effectively.
</issue>
<code>
[start of install.py]
1 """
2 This script installs functions and types for Mathesar onto the configured DB.
3 """
4 import getopt
5 import sys
6
7 import getpass
8
9 import django
10 from decouple import UndefinedValueError, config as decouple_config
11 from django.contrib.auth import get_user_model
12 from django.core import management
13
14 from django.conf import settings
15 from db import install
16
17
18 def main():
19 skip_confirm = False
20 (opts, _) = getopt.getopt(sys.argv[1:], ":s", ["skip-confirm"])
21 for (opt, value) in opts:
22 if (opt == "-s") or (opt == "--skip-confirm"):
23 skip_confirm = True
24 check_missing_dj_config()
25 django.setup()
26 management.call_command('migrate')
27 debug_mode = decouple_config('DEBUG', default=False, cast=bool)
28 #
29 if not debug_mode:
30 management.call_command('collectstatic', no_input='y')
31 if not superuser_exists():
32 print("------------Setting up Admin user------------")
33 print("Admin user does not exists. We need at least one admin")
34 create_superuser(skip_confirm)
35
36 print("------------Setting up User Databases------------")
37 user_databases = [key for key in settings.DATABASES if key != "default"]
38 for database_key in user_databases:
39 install_on_db_with_key(database_key, skip_confirm)
40
41
42 def superuser_exists():
43 return get_user_model().objects.filter(is_superuser=True).exists()
44
45
46 def create_superuser(skip_confirm):
47 # TODO Replace argument name used for default admin user creation.
48 if not skip_confirm:
49 print("Please enter the details to create a new admin user ")
50 username = input("Username: ")
51 email = input("Email: ")
52 password = getpass.getpass('Password: ')
53 else:
54 username = "admin"
55 email = "[email protected]"
56 password = "password"
57 get_user_model().objects.create_superuser(username, email, password)
58 print(f"Admin user with username {username} was created successfully")
59
60
61 def check_missing_dj_config():
62 # TODO Add documentation link
63 documentation_link = ""
64 try:
65 decouple_config('ALLOWED_HOSTS')
66 decouple_config('SECRET_KEY')
67 decouple_config('DJANGO_DATABASE_KEY')
68 decouple_config('DJANGO_SETTINGS_MODULE')
69 decouple_config('DJANGO_DATABASE_URL')
70 decouple_config('MATHESAR_DATABASES')
71 except UndefinedValueError as e:
72 missing_config_key = e.args[0]
73 raise Exception(f"{missing_config_key} environment variable is missing."
74 f" Please follow the documentation {documentation_link} to add the missing environment variable.")
75
76
77 def install_on_db_with_key(database_key, skip_confirm):
78 install.install_mathesar(
79 database_name=settings.DATABASES[database_key]["NAME"],
80 username=settings.DATABASES[database_key]["USER"],
81 password=settings.DATABASES[database_key]["PASSWORD"],
82 hostname=settings.DATABASES[database_key]["HOST"],
83 port=settings.DATABASES[database_key]["PORT"],
84 skip_confirm=skip_confirm
85 )
86
87
88 if __name__ == "__main__":
89 main()
90
[end of install.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/install.py b/install.py
--- a/install.py
+++ b/install.py
@@ -4,11 +4,7 @@
import getopt
import sys
-import getpass
-
import django
-from decouple import UndefinedValueError, config as decouple_config
-from django.contrib.auth import get_user_model
from django.core import management
from django.conf import settings
@@ -16,64 +12,20 @@
def main():
- skip_confirm = False
+ # skip_confirm is temporarily enabled by default as we don't have any use for interactive prompts with docker only deployments
+ skip_confirm = True
(opts, _) = getopt.getopt(sys.argv[1:], ":s", ["skip-confirm"])
for (opt, value) in opts:
if (opt == "-s") or (opt == "--skip-confirm"):
skip_confirm = True
- check_missing_dj_config()
django.setup()
management.call_command('migrate')
- debug_mode = decouple_config('DEBUG', default=False, cast=bool)
- #
- if not debug_mode:
- management.call_command('collectstatic', no_input='y')
- if not superuser_exists():
- print("------------Setting up Admin user------------")
- print("Admin user does not exists. We need at least one admin")
- create_superuser(skip_confirm)
-
print("------------Setting up User Databases------------")
user_databases = [key for key in settings.DATABASES if key != "default"]
for database_key in user_databases:
install_on_db_with_key(database_key, skip_confirm)
-def superuser_exists():
- return get_user_model().objects.filter(is_superuser=True).exists()
-
-
-def create_superuser(skip_confirm):
- # TODO Replace argument name used for default admin user creation.
- if not skip_confirm:
- print("Please enter the details to create a new admin user ")
- username = input("Username: ")
- email = input("Email: ")
- password = getpass.getpass('Password: ')
- else:
- username = "admin"
- email = "[email protected]"
- password = "password"
- get_user_model().objects.create_superuser(username, email, password)
- print(f"Admin user with username {username} was created successfully")
-
-
-def check_missing_dj_config():
- # TODO Add documentation link
- documentation_link = ""
- try:
- decouple_config('ALLOWED_HOSTS')
- decouple_config('SECRET_KEY')
- decouple_config('DJANGO_DATABASE_KEY')
- decouple_config('DJANGO_SETTINGS_MODULE')
- decouple_config('DJANGO_DATABASE_URL')
- decouple_config('MATHESAR_DATABASES')
- except UndefinedValueError as e:
- missing_config_key = e.args[0]
- raise Exception(f"{missing_config_key} environment variable is missing."
- f" Please follow the documentation {documentation_link} to add the missing environment variable.")
-
-
def install_on_db_with_key(database_key, skip_confirm):
install.install_mathesar(
database_name=settings.DATABASES[database_key]["NAME"],
|
{"golden_diff": "diff --git a/install.py b/install.py\n--- a/install.py\n+++ b/install.py\n@@ -4,11 +4,7 @@\n import getopt\n import sys\n \n-import getpass\n-\n import django\n-from decouple import UndefinedValueError, config as decouple_config\n-from django.contrib.auth import get_user_model\n from django.core import management\n \n from django.conf import settings\n@@ -16,64 +12,20 @@\n \n \n def main():\n- skip_confirm = False\n+ # skip_confirm is temporarily enabled by default as we don't have any use for interactive prompts with docker only deployments\n+ skip_confirm = True\n (opts, _) = getopt.getopt(sys.argv[1:], \":s\", [\"skip-confirm\"])\n for (opt, value) in opts:\n if (opt == \"-s\") or (opt == \"--skip-confirm\"):\n skip_confirm = True\n- check_missing_dj_config()\n django.setup()\n management.call_command('migrate')\n- debug_mode = decouple_config('DEBUG', default=False, cast=bool)\n- #\n- if not debug_mode:\n- management.call_command('collectstatic', no_input='y')\n- if not superuser_exists():\n- print(\"------------Setting up Admin user------------\")\n- print(\"Admin user does not exists. We need at least one admin\")\n- create_superuser(skip_confirm)\n-\n print(\"------------Setting up User Databases------------\")\n user_databases = [key for key in settings.DATABASES if key != \"default\"]\n for database_key in user_databases:\n install_on_db_with_key(database_key, skip_confirm)\n \n \n-def superuser_exists():\n- return get_user_model().objects.filter(is_superuser=True).exists()\n-\n-\n-def create_superuser(skip_confirm):\n- # TODO Replace argument name used for default admin user creation.\n- if not skip_confirm:\n- print(\"Please enter the details to create a new admin user \")\n- username = input(\"Username: \")\n- email = input(\"Email: \")\n- password = getpass.getpass('Password: ')\n- else:\n- username = \"admin\"\n- email = \"[email protected]\"\n- password = \"password\"\n- get_user_model().objects.create_superuser(username, email, password)\n- print(f\"Admin user with username {username} was created successfully\")\n-\n-\n-def check_missing_dj_config():\n- # TODO Add documentation link\n- documentation_link = \"\"\n- try:\n- decouple_config('ALLOWED_HOSTS')\n- decouple_config('SECRET_KEY')\n- decouple_config('DJANGO_DATABASE_KEY')\n- decouple_config('DJANGO_SETTINGS_MODULE')\n- decouple_config('DJANGO_DATABASE_URL')\n- decouple_config('MATHESAR_DATABASES')\n- except UndefinedValueError as e:\n- missing_config_key = e.args[0]\n- raise Exception(f\"{missing_config_key} environment variable is missing.\"\n- f\" Please follow the documentation {documentation_link} to add the missing environment variable.\")\n-\n-\n def install_on_db_with_key(database_key, skip_confirm):\n install.install_mathesar(\n database_name=settings.DATABASES[database_key][\"NAME\"],\n", "issue": "Create a Deployment type 1 specific script.\nCreate a script to download docker-compose from the Mathesar repo and help the user in setting up Mathesar.\r\n\r\n- [ ] The script should be self-documenting, i.e., the prompts during interactive portions should help the user understand the implications of what they're doing, and any error states should give enough info for the user to find solutions in the troubleshooting documentation on docs.mathesar.org\r\n \r\n- [ ] The script should also add help text in the installation CLI that would list the database Privileges needed for Mathesar to function effectively.\n", "before_files": [{"content": "\"\"\"\nThis script installs functions and types for Mathesar onto the configured DB.\n\"\"\"\nimport getopt\nimport sys\n\nimport getpass\n\nimport django\nfrom decouple import UndefinedValueError, config as decouple_config\nfrom django.contrib.auth import get_user_model\nfrom django.core import management\n\nfrom django.conf import settings\nfrom db import install\n\n\ndef main():\n skip_confirm = False\n (opts, _) = getopt.getopt(sys.argv[1:], \":s\", [\"skip-confirm\"])\n for (opt, value) in opts:\n if (opt == \"-s\") or (opt == \"--skip-confirm\"):\n skip_confirm = True\n check_missing_dj_config()\n django.setup()\n management.call_command('migrate')\n debug_mode = decouple_config('DEBUG', default=False, cast=bool)\n #\n if not debug_mode:\n management.call_command('collectstatic', no_input='y')\n if not superuser_exists():\n print(\"------------Setting up Admin user------------\")\n print(\"Admin user does not exists. We need at least one admin\")\n create_superuser(skip_confirm)\n\n print(\"------------Setting up User Databases------------\")\n user_databases = [key for key in settings.DATABASES if key != \"default\"]\n for database_key in user_databases:\n install_on_db_with_key(database_key, skip_confirm)\n\n\ndef superuser_exists():\n return get_user_model().objects.filter(is_superuser=True).exists()\n\n\ndef create_superuser(skip_confirm):\n # TODO Replace argument name used for default admin user creation.\n if not skip_confirm:\n print(\"Please enter the details to create a new admin user \")\n username = input(\"Username: \")\n email = input(\"Email: \")\n password = getpass.getpass('Password: ')\n else:\n username = \"admin\"\n email = \"[email protected]\"\n password = \"password\"\n get_user_model().objects.create_superuser(username, email, password)\n print(f\"Admin user with username {username} was created successfully\")\n\n\ndef check_missing_dj_config():\n # TODO Add documentation link\n documentation_link = \"\"\n try:\n decouple_config('ALLOWED_HOSTS')\n decouple_config('SECRET_KEY')\n decouple_config('DJANGO_DATABASE_KEY')\n decouple_config('DJANGO_SETTINGS_MODULE')\n decouple_config('DJANGO_DATABASE_URL')\n decouple_config('MATHESAR_DATABASES')\n except UndefinedValueError as e:\n missing_config_key = e.args[0]\n raise Exception(f\"{missing_config_key} environment variable is missing.\"\n f\" Please follow the documentation {documentation_link} to add the missing environment variable.\")\n\n\ndef install_on_db_with_key(database_key, skip_confirm):\n install.install_mathesar(\n database_name=settings.DATABASES[database_key][\"NAME\"],\n username=settings.DATABASES[database_key][\"USER\"],\n password=settings.DATABASES[database_key][\"PASSWORD\"],\n hostname=settings.DATABASES[database_key][\"HOST\"],\n port=settings.DATABASES[database_key][\"PORT\"],\n skip_confirm=skip_confirm\n )\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "install.py"}]}
| 1,482 | 681 |
gh_patches_debug_11189
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-1520
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
modules install to also print/write `include` statements
### Description of feature
print `include` statements to terminal for easy copy to destination files
</issue>
<code>
[start of nf_core/modules/install.py]
1 import os
2 import questionary
3 import logging
4
5 import nf_core.utils
6 import nf_core.modules.module_utils
7
8 from .modules_command import ModuleCommand
9 from .module_utils import get_module_git_log, module_exist_in_repo
10
11 log = logging.getLogger(__name__)
12
13
14 class ModuleInstall(ModuleCommand):
15 def __init__(self, pipeline_dir, force=False, prompt=False, sha=None, update_all=False):
16 super().__init__(pipeline_dir)
17 self.force = force
18 self.prompt = prompt
19 self.sha = sha
20 self.update_all = update_all
21
22 def install(self, module):
23 if self.repo_type == "modules":
24 log.error("You cannot install a module in a clone of nf-core/modules")
25 return False
26 # Check whether pipelines is valid
27 if not self.has_valid_directory():
28 return False
29
30 # Verify that 'modules.json' is consistent with the installed modules
31 self.modules_json_up_to_date()
32
33 # Get the available modules
34 try:
35 self.modules_repo.get_modules_file_tree()
36 except LookupError as e:
37 log.error(e)
38 return False
39
40 if self.prompt and self.sha is not None:
41 log.error("Cannot use '--sha' and '--prompt' at the same time!")
42 return False
43
44 # Verify that the provided SHA exists in the repo
45 if self.sha:
46 try:
47 nf_core.modules.module_utils.sha_exists(self.sha, self.modules_repo)
48 except UserWarning:
49 log.error(f"Commit SHA '{self.sha}' doesn't exist in '{self.modules_repo.name}'")
50 return False
51 except LookupError as e:
52 log.error(e)
53 return False
54
55 if module is None:
56 module = questionary.autocomplete(
57 "Tool name:",
58 choices=self.modules_repo.modules_avail_module_names,
59 style=nf_core.utils.nfcore_question_style,
60 ).unsafe_ask()
61
62 # Check that the supplied name is an available module
63 if module and module not in self.modules_repo.modules_avail_module_names:
64 log.error("Module '{}' not found in list of available modules.".format(module))
65 log.info("Use the command 'nf-core modules list' to view available software")
66 return False
67
68 # Load 'modules.json'
69 modules_json = self.load_modules_json()
70 if not modules_json:
71 return False
72
73 if not module_exist_in_repo(module, self.modules_repo):
74 warn_msg = f"Module '{module}' not found in remote '{self.modules_repo.name}' ({self.modules_repo.branch})"
75 log.warning(warn_msg)
76 return False
77
78 if self.modules_repo.name in modules_json["repos"]:
79 current_entry = modules_json["repos"][self.modules_repo.name].get(module)
80 else:
81 current_entry = None
82
83 # Set the install folder based on the repository name
84 install_folder = [self.dir, "modules", self.modules_repo.owner, self.modules_repo.repo]
85
86 # Compute the module directory
87 module_dir = os.path.join(*install_folder, module)
88
89 # Check that the module is not already installed
90 if (current_entry is not None and os.path.exists(module_dir)) and not self.force:
91
92 log.error(f"Module is already installed.")
93 repo_flag = "" if self.modules_repo.name == "nf-core/modules" else f"-g {self.modules_repo.name} "
94 branch_flag = "" if self.modules_repo.branch == "master" else f"-b {self.modules_repo.branch} "
95
96 log.info(
97 f"To update '{module}' run 'nf-core modules {repo_flag}{branch_flag}update {module}'. To force reinstallation use '--force'"
98 )
99 return False
100
101 if self.sha:
102 version = self.sha
103 elif self.prompt:
104 try:
105 version = nf_core.modules.module_utils.prompt_module_version_sha(
106 module,
107 installed_sha=current_entry["git_sha"] if not current_entry is None else None,
108 modules_repo=self.modules_repo,
109 )
110 except SystemError as e:
111 log.error(e)
112 return False
113 else:
114 # Fetch the latest commit for the module
115 try:
116 git_log = get_module_git_log(module, modules_repo=self.modules_repo, per_page=1, page_nbr=1)
117 except UserWarning:
118 log.error(f"Was unable to fetch version of module '{module}'")
119 return False
120 version = git_log[0]["git_sha"]
121
122 if self.force:
123 log.info(f"Removing installed version of '{self.modules_repo.name}/{module}'")
124 self.clear_module_dir(module, module_dir)
125
126 log.info(f"{'Rei' if self.force else 'I'}nstalling '{module}'")
127 log.debug(f"Installing module '{module}' at modules hash {version} from {self.modules_repo.name}")
128
129 # Download module files
130 if not self.download_module_file(module, version, self.modules_repo, install_folder):
131 return False
132
133 # Update module.json with newly installed module
134 self.update_modules_json(modules_json, self.modules_repo.name, module, version)
135 return True
136
[end of nf_core/modules/install.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nf_core/modules/install.py b/nf_core/modules/install.py
--- a/nf_core/modules/install.py
+++ b/nf_core/modules/install.py
@@ -130,6 +130,10 @@
if not self.download_module_file(module, version, self.modules_repo, install_folder):
return False
+ # Print include statement
+ module_name = "_".join(module.upper().split("/"))
+ log.info(f"Include statement: include {{ {module_name} }} from '.{os.path.join(*install_folder, module)}/main’")
+
# Update module.json with newly installed module
self.update_modules_json(modules_json, self.modules_repo.name, module, version)
return True
|
{"golden_diff": "diff --git a/nf_core/modules/install.py b/nf_core/modules/install.py\n--- a/nf_core/modules/install.py\n+++ b/nf_core/modules/install.py\n@@ -130,6 +130,10 @@\n if not self.download_module_file(module, version, self.modules_repo, install_folder):\n return False\n \n+ # Print include statement\n+ module_name = \"_\".join(module.upper().split(\"/\"))\n+ log.info(f\"Include statement: include {{ {module_name} }} from '.{os.path.join(*install_folder, module)}/main\u2019\")\n+\n # Update module.json with newly installed module\n self.update_modules_json(modules_json, self.modules_repo.name, module, version)\n return True\n", "issue": "modules install to also print/write `include` statements\n### Description of feature\n\nprint `include` statements to terminal for easy copy to destination files\n", "before_files": [{"content": "import os\nimport questionary\nimport logging\n\nimport nf_core.utils\nimport nf_core.modules.module_utils\n\nfrom .modules_command import ModuleCommand\nfrom .module_utils import get_module_git_log, module_exist_in_repo\n\nlog = logging.getLogger(__name__)\n\n\nclass ModuleInstall(ModuleCommand):\n def __init__(self, pipeline_dir, force=False, prompt=False, sha=None, update_all=False):\n super().__init__(pipeline_dir)\n self.force = force\n self.prompt = prompt\n self.sha = sha\n self.update_all = update_all\n\n def install(self, module):\n if self.repo_type == \"modules\":\n log.error(\"You cannot install a module in a clone of nf-core/modules\")\n return False\n # Check whether pipelines is valid\n if not self.has_valid_directory():\n return False\n\n # Verify that 'modules.json' is consistent with the installed modules\n self.modules_json_up_to_date()\n\n # Get the available modules\n try:\n self.modules_repo.get_modules_file_tree()\n except LookupError as e:\n log.error(e)\n return False\n\n if self.prompt and self.sha is not None:\n log.error(\"Cannot use '--sha' and '--prompt' at the same time!\")\n return False\n\n # Verify that the provided SHA exists in the repo\n if self.sha:\n try:\n nf_core.modules.module_utils.sha_exists(self.sha, self.modules_repo)\n except UserWarning:\n log.error(f\"Commit SHA '{self.sha}' doesn't exist in '{self.modules_repo.name}'\")\n return False\n except LookupError as e:\n log.error(e)\n return False\n\n if module is None:\n module = questionary.autocomplete(\n \"Tool name:\",\n choices=self.modules_repo.modules_avail_module_names,\n style=nf_core.utils.nfcore_question_style,\n ).unsafe_ask()\n\n # Check that the supplied name is an available module\n if module and module not in self.modules_repo.modules_avail_module_names:\n log.error(\"Module '{}' not found in list of available modules.\".format(module))\n log.info(\"Use the command 'nf-core modules list' to view available software\")\n return False\n\n # Load 'modules.json'\n modules_json = self.load_modules_json()\n if not modules_json:\n return False\n\n if not module_exist_in_repo(module, self.modules_repo):\n warn_msg = f\"Module '{module}' not found in remote '{self.modules_repo.name}' ({self.modules_repo.branch})\"\n log.warning(warn_msg)\n return False\n\n if self.modules_repo.name in modules_json[\"repos\"]:\n current_entry = modules_json[\"repos\"][self.modules_repo.name].get(module)\n else:\n current_entry = None\n\n # Set the install folder based on the repository name\n install_folder = [self.dir, \"modules\", self.modules_repo.owner, self.modules_repo.repo]\n\n # Compute the module directory\n module_dir = os.path.join(*install_folder, module)\n\n # Check that the module is not already installed\n if (current_entry is not None and os.path.exists(module_dir)) and not self.force:\n\n log.error(f\"Module is already installed.\")\n repo_flag = \"\" if self.modules_repo.name == \"nf-core/modules\" else f\"-g {self.modules_repo.name} \"\n branch_flag = \"\" if self.modules_repo.branch == \"master\" else f\"-b {self.modules_repo.branch} \"\n\n log.info(\n f\"To update '{module}' run 'nf-core modules {repo_flag}{branch_flag}update {module}'. To force reinstallation use '--force'\"\n )\n return False\n\n if self.sha:\n version = self.sha\n elif self.prompt:\n try:\n version = nf_core.modules.module_utils.prompt_module_version_sha(\n module,\n installed_sha=current_entry[\"git_sha\"] if not current_entry is None else None,\n modules_repo=self.modules_repo,\n )\n except SystemError as e:\n log.error(e)\n return False\n else:\n # Fetch the latest commit for the module\n try:\n git_log = get_module_git_log(module, modules_repo=self.modules_repo, per_page=1, page_nbr=1)\n except UserWarning:\n log.error(f\"Was unable to fetch version of module '{module}'\")\n return False\n version = git_log[0][\"git_sha\"]\n\n if self.force:\n log.info(f\"Removing installed version of '{self.modules_repo.name}/{module}'\")\n self.clear_module_dir(module, module_dir)\n\n log.info(f\"{'Rei' if self.force else 'I'}nstalling '{module}'\")\n log.debug(f\"Installing module '{module}' at modules hash {version} from {self.modules_repo.name}\")\n\n # Download module files\n if not self.download_module_file(module, version, self.modules_repo, install_folder):\n return False\n\n # Update module.json with newly installed module\n self.update_modules_json(modules_json, self.modules_repo.name, module, version)\n return True\n", "path": "nf_core/modules/install.py"}]}
| 1,943 | 160 |
gh_patches_debug_64335
|
rasdani/github-patches
|
git_diff
|
sopel-irc__sopel-1442
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[wiktionary] Relax case sensitivity a bit?
Looking up anything other than the exact capitalization in Wiktionary's database appears to fail. It might be worthwhile, for user experience, to always try the all-lowercase version of a query if no results are returned for it as entered.
That said, the MediaWiki API would allow querying automatically for several variants (using `action=query&titles=variant1|Variant2|etc.`) and then fetching the first one that exists for display, if making multiple requests is OK in the plugin.
</issue>
<code>
[start of sopel/modules/wiktionary.py]
1 # coding=utf-8
2 """
3 wiktionary.py - Sopel Wiktionary Module
4 Copyright 2009, Sean B. Palmer, inamidst.com
5 Licensed under the Eiffel Forum License 2.
6
7 https://sopel.chat
8 """
9 from __future__ import unicode_literals, absolute_import, print_function, division
10
11 import re
12 import requests
13 from sopel import web
14 from sopel.module import commands, example
15
16 uri = 'https://en.wiktionary.org/w/index.php?title=%s&printable=yes'
17 r_sup = re.compile(r'<sup[^>]+>.+</sup>') # Superscripts that are references only, not ordinal indicators, etc...
18 r_tag = re.compile(r'<[^>]+>')
19 r_ul = re.compile(r'(?ims)<ul>.*?</ul>')
20
21
22 def text(html):
23 text = r_sup.sub('', html) # Remove superscripts that are references from definition
24 text = r_tag.sub('', text).strip()
25 text = text.replace('\n', ' ')
26 text = text.replace('\r', '')
27 text = text.replace('(intransitive', '(intr.')
28 text = text.replace('(transitive', '(trans.')
29 text = web.decode(text)
30 return text
31
32
33 def wikt(word):
34 bytes = requests.get(uri % web.quote(word)).text
35 bytes = r_ul.sub('', bytes)
36
37 mode = None
38 etymology = None
39 definitions = {}
40 for line in bytes.splitlines():
41 if 'id="Etymology"' in line:
42 mode = 'etymology'
43 elif 'id="Noun"' in line:
44 mode = 'noun'
45 elif 'id="Verb"' in line:
46 mode = 'verb'
47 elif 'id="Adjective"' in line:
48 mode = 'adjective'
49 elif 'id="Adverb"' in line:
50 mode = 'adverb'
51 elif 'id="Interjection"' in line:
52 mode = 'interjection'
53 elif 'id="Particle"' in line:
54 mode = 'particle'
55 elif 'id="Preposition"' in line:
56 mode = 'preposition'
57 elif 'id="Prefix"' in line:
58 mode = 'prefix'
59 elif 'id="Suffix"' in line:
60 mode = 'suffix'
61 # 'id="' can occur in definition lines <li> when <sup> tag is used for references;
62 # make sure those are not excluded (see e.g., abecedarian).
63 elif ('id="' in line) and ('<li>' not in line):
64 mode = None
65
66 elif (mode == 'etmyology') and ('<p>' in line):
67 etymology = text(line)
68 elif (mode is not None) and ('<li>' in line):
69 definitions.setdefault(mode, []).append(text(line))
70
71 if '<hr' in line:
72 break
73 return etymology, definitions
74
75
76 parts = ('preposition', 'particle', 'noun', 'verb',
77 'adjective', 'adverb', 'interjection',
78 'prefix', 'suffix')
79
80
81 def format(result, definitions, number=2):
82 for part in parts:
83 if part in definitions:
84 defs = definitions[part][:number]
85 result += u' — {}: '.format(part)
86 n = ['%s. %s' % (i + 1, e.strip(' .')) for i, e in enumerate(defs)]
87 result += ', '.join(n)
88 return result.strip(' .,')
89
90
91 @commands('wt', 'define', 'dict')
92 @example('.wt bailiwick')
93 def wiktionary(bot, trigger):
94 """Look up a word on Wiktionary."""
95 word = trigger.group(2)
96 if word is None:
97 bot.reply('You must tell me what to look up!')
98 return
99
100 _etymology, definitions = wikt(word)
101 if not definitions:
102 bot.say("Couldn't get any definitions for %s." % word)
103 return
104
105 result = format(word, definitions)
106 if len(result) < 150:
107 result = format(word, definitions, 3)
108 if len(result) < 150:
109 result = format(word, definitions, 5)
110
111 if len(result) > 300:
112 result = result[:295] + '[...]'
113 bot.say(result)
114
[end of sopel/modules/wiktionary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sopel/modules/wiktionary.py b/sopel/modules/wiktionary.py
--- a/sopel/modules/wiktionary.py
+++ b/sopel/modules/wiktionary.py
@@ -99,8 +99,11 @@
_etymology, definitions = wikt(word)
if not definitions:
- bot.say("Couldn't get any definitions for %s." % word)
- return
+ # Cast word to lower to check in case of mismatched user input
+ _etymology, definitions = wikt(word.lower())
+ if not definitions:
+ bot.say("Couldn't get any definitions for %s." % word)
+ return
result = format(word, definitions)
if len(result) < 150:
|
{"golden_diff": "diff --git a/sopel/modules/wiktionary.py b/sopel/modules/wiktionary.py\n--- a/sopel/modules/wiktionary.py\n+++ b/sopel/modules/wiktionary.py\n@@ -99,8 +99,11 @@\n \n _etymology, definitions = wikt(word)\n if not definitions:\n- bot.say(\"Couldn't get any definitions for %s.\" % word)\n- return\n+ # Cast word to lower to check in case of mismatched user input\n+ _etymology, definitions = wikt(word.lower())\n+ if not definitions:\n+ bot.say(\"Couldn't get any definitions for %s.\" % word)\n+ return\n \n result = format(word, definitions)\n if len(result) < 150:\n", "issue": "[wiktionary] Relax case sensitivity a bit?\nLooking up anything other than the exact capitalization in Wiktionary's database appears to fail. It might be worthwhile, for user experience, to always try the all-lowercase version of a query if no results are returned for it as entered.\r\n\r\nThat said, the MediaWiki API would allow querying automatically for several variants (using `action=query&titles=variant1|Variant2|etc.`) and then fetching the first one that exists for display, if making multiple requests is OK in the plugin.\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\nwiktionary.py - Sopel Wiktionary Module\nCopyright 2009, Sean B. Palmer, inamidst.com\nLicensed under the Eiffel Forum License 2.\n\nhttps://sopel.chat\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\nimport requests\nfrom sopel import web\nfrom sopel.module import commands, example\n\nuri = 'https://en.wiktionary.org/w/index.php?title=%s&printable=yes'\nr_sup = re.compile(r'<sup[^>]+>.+</sup>') # Superscripts that are references only, not ordinal indicators, etc...\nr_tag = re.compile(r'<[^>]+>')\nr_ul = re.compile(r'(?ims)<ul>.*?</ul>')\n\n\ndef text(html):\n text = r_sup.sub('', html) # Remove superscripts that are references from definition\n text = r_tag.sub('', text).strip()\n text = text.replace('\\n', ' ')\n text = text.replace('\\r', '')\n text = text.replace('(intransitive', '(intr.')\n text = text.replace('(transitive', '(trans.')\n text = web.decode(text)\n return text\n\n\ndef wikt(word):\n bytes = requests.get(uri % web.quote(word)).text\n bytes = r_ul.sub('', bytes)\n\n mode = None\n etymology = None\n definitions = {}\n for line in bytes.splitlines():\n if 'id=\"Etymology\"' in line:\n mode = 'etymology'\n elif 'id=\"Noun\"' in line:\n mode = 'noun'\n elif 'id=\"Verb\"' in line:\n mode = 'verb'\n elif 'id=\"Adjective\"' in line:\n mode = 'adjective'\n elif 'id=\"Adverb\"' in line:\n mode = 'adverb'\n elif 'id=\"Interjection\"' in line:\n mode = 'interjection'\n elif 'id=\"Particle\"' in line:\n mode = 'particle'\n elif 'id=\"Preposition\"' in line:\n mode = 'preposition'\n elif 'id=\"Prefix\"' in line:\n mode = 'prefix'\n elif 'id=\"Suffix\"' in line:\n mode = 'suffix'\n # 'id=\"' can occur in definition lines <li> when <sup> tag is used for references;\n # make sure those are not excluded (see e.g., abecedarian).\n elif ('id=\"' in line) and ('<li>' not in line):\n mode = None\n\n elif (mode == 'etmyology') and ('<p>' in line):\n etymology = text(line)\n elif (mode is not None) and ('<li>' in line):\n definitions.setdefault(mode, []).append(text(line))\n\n if '<hr' in line:\n break\n return etymology, definitions\n\n\nparts = ('preposition', 'particle', 'noun', 'verb',\n 'adjective', 'adverb', 'interjection',\n 'prefix', 'suffix')\n\n\ndef format(result, definitions, number=2):\n for part in parts:\n if part in definitions:\n defs = definitions[part][:number]\n result += u' \u2014 {}: '.format(part)\n n = ['%s. %s' % (i + 1, e.strip(' .')) for i, e in enumerate(defs)]\n result += ', '.join(n)\n return result.strip(' .,')\n\n\n@commands('wt', 'define', 'dict')\n@example('.wt bailiwick')\ndef wiktionary(bot, trigger):\n \"\"\"Look up a word on Wiktionary.\"\"\"\n word = trigger.group(2)\n if word is None:\n bot.reply('You must tell me what to look up!')\n return\n\n _etymology, definitions = wikt(word)\n if not definitions:\n bot.say(\"Couldn't get any definitions for %s.\" % word)\n return\n\n result = format(word, definitions)\n if len(result) < 150:\n result = format(word, definitions, 3)\n if len(result) < 150:\n result = format(word, definitions, 5)\n\n if len(result) > 300:\n result = result[:295] + '[...]'\n bot.say(result)\n", "path": "sopel/modules/wiktionary.py"}]}
| 1,832 | 176 |
gh_patches_debug_41108
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1070
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ios cannot add widgets to main_window.content
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Try to run this app in ios:
```
import toga
class MyApp(toga.App):
def startup(self):
"""
Construct and show the Toga application.
Usually, you would add your application to a main content box.
We then create a main window (with a name matching the app), and
show the main window.
"""
self.state = GameState()
self.main_window = toga.MainWindow(title=self.formal_name)
box = toga.Box()
label = toga.Label("Test1")
box.add(label)
self.main_window.content = box
label2 = toga.Label("Test2")
box.add(label2)
self.main_window.show()
MyApp().main_loop()
```
**Expected behavior**
The application should open and shows the labels "Test1" and "Test2". Instead, you get a black screen. In the xcode debugger there is a log message on the "box.add(label2)" line about the label (test2) not having the attribute "viewport".
If you comment out box.add(label2), you correctly get a window that has "Test1".
On targets macos and android, the above test will correctly show "Test1 Test2"
**Environment:**
- Operating System: macos
- Python version: 3.8
- Software versions:
- Briefcase: 0.3.3
- Toga: 0.3.0.dev23
- IOS: iphone 11
This may be related to #225, as you will get a similar error if you try to rebind main_window.content to a different widget.
ios cannot add widgets to main_window.content
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Try to run this app in ios:
```
import toga
class MyApp(toga.App):
def startup(self):
"""
Construct and show the Toga application.
Usually, you would add your application to a main content box.
We then create a main window (with a name matching the app), and
show the main window.
"""
self.state = GameState()
self.main_window = toga.MainWindow(title=self.formal_name)
box = toga.Box()
label = toga.Label("Test1")
box.add(label)
self.main_window.content = box
label2 = toga.Label("Test2")
box.add(label2)
self.main_window.show()
MyApp().main_loop()
```
**Expected behavior**
The application should open and shows the labels "Test1" and "Test2". Instead, you get a black screen. In the xcode debugger there is a log message on the "box.add(label2)" line about the label (test2) not having the attribute "viewport".
If you comment out box.add(label2), you correctly get a window that has "Test1".
On targets macos and android, the above test will correctly show "Test1 Test2"
**Environment:**
- Operating System: macos
- Python version: 3.8
- Software versions:
- Briefcase: 0.3.3
- Toga: 0.3.0.dev23
- IOS: iphone 11
This may be related to #225, as you will get a similar error if you try to rebind main_window.content to a different widget.
</issue>
<code>
[start of src/iOS/toga_iOS/widgets/base.py]
1 from toga_iOS.constraints import Constraints
2
3
4 class Widget:
5 def __init__(self, interface):
6 self.interface = interface
7 self.interface._impl = self
8 self._container = None
9 self.constraints = None
10 self.native = None
11 self.create()
12 self.interface.style.reapply()
13
14 def set_app(self, app):
15 pass
16
17 def set_window(self, window):
18 pass
19
20 @property
21 def container(self):
22 return self._container
23
24 @container.setter
25 def container(self, container):
26 self._container = container
27 if self.constraints:
28 self._container.native.addSubview(self.native)
29 self.constraints.container = container
30
31 for child in self.interface.children:
32 child._impl.container = container
33 self.rehint()
34
35 def set_enabled(self, value):
36 self.native.enabled = self.interface.enabled
37
38 def focus(self):
39 self.interface.factory.not_implemented("Widget.focus()")
40
41 # APPLICATOR
42
43 def set_bounds(self, x, y, width, height):
44 if self.container:
45 viewport = self.container.viewport
46 else:
47 viewport = self.viewport
48
49 self.constraints.update(
50 x, y + viewport.statusbar_height,
51 width, height
52 )
53
54 def set_alignment(self, alignment):
55 pass
56
57 def set_hidden(self, hidden):
58 if self._container:
59 for view in self._container._impl.subviews:
60 if view._impl:
61 view.setHidden(hidden)
62
63 def set_font(self, font):
64 # By default, font can't be changed
65 pass
66
67 def set_color(self, color):
68 # By default, color can't be changed
69 pass
70
71 def set_background_color(self, color):
72 # By default, background color can't be changed
73 pass
74
75 # INTERFACE
76
77 def add_child(self, child):
78 if self.container:
79 child.viewport = self.root.viewport
80 child.container = self.container
81
82 def add_constraints(self):
83 self.native.translatesAutoresizingMaskIntoConstraints = False
84 self.constraints = Constraints(self)
85
86 def rehint(self):
87 pass
88
[end of src/iOS/toga_iOS/widgets/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/iOS/toga_iOS/widgets/base.py b/src/iOS/toga_iOS/widgets/base.py
--- a/src/iOS/toga_iOS/widgets/base.py
+++ b/src/iOS/toga_iOS/widgets/base.py
@@ -6,10 +6,12 @@
self.interface = interface
self.interface._impl = self
self._container = None
+ self._viewport = None
self.constraints = None
self.native = None
self.create()
self.interface.style.reapply()
+ self.set_enabled(self.interface.enabled)
def set_app(self, app):
pass
@@ -23,15 +25,35 @@
@container.setter
def container(self, container):
- self._container = container
- if self.constraints:
+ if self.container:
+ if container:
+ raise RuntimeError('Already have a container')
+ else:
+ # existing container should be removed
+ self.constraints = None
+ self._container = None
+ self.native.removeFromSuperview()
+ elif container:
+ # setting container
+ self._container = container
self._container.native.addSubview(self.native)
+ if not self.constraints:
+ self.add_constraints()
self.constraints.container = container
for child in self.interface.children:
child._impl.container = container
+
self.rehint()
+ @property
+ def viewport(self):
+ return self._viewport
+
+ @viewport.setter
+ def viewport(self, viewport):
+ self._viewport = viewport
+
def set_enabled(self, value):
self.native.enabled = self.interface.enabled
@@ -41,13 +63,13 @@
# APPLICATOR
def set_bounds(self, x, y, width, height):
+ offset_y = 0
if self.container:
- viewport = self.container.viewport
- else:
- viewport = self.viewport
-
+ offset_y = self.container.viewport.statusbar_height
+ elif self.viewport:
+ offset_y = self.viewport.statusbar_height
self.constraints.update(
- x, y + viewport.statusbar_height,
+ x, y + offset_y,
width, height
)
@@ -55,8 +77,8 @@
pass
def set_hidden(self, hidden):
- if self._container:
- for view in self._container._impl.subviews:
+ if self.container:
+ for view in self.container._impl.subviews:
if view._impl:
view.setHidden(hidden)
@@ -75,10 +97,16 @@
# INTERFACE
def add_child(self, child):
- if self.container:
- child.viewport = self.root.viewport
+
+ if self.viewport:
+ # we are the the top level UIView
+ child.container = self
+ else:
child.container = self.container
+ def remove_child(self, child):
+ child.container = None
+
def add_constraints(self):
self.native.translatesAutoresizingMaskIntoConstraints = False
self.constraints = Constraints(self)
|
{"golden_diff": "diff --git a/src/iOS/toga_iOS/widgets/base.py b/src/iOS/toga_iOS/widgets/base.py\n--- a/src/iOS/toga_iOS/widgets/base.py\n+++ b/src/iOS/toga_iOS/widgets/base.py\n@@ -6,10 +6,12 @@\n self.interface = interface\n self.interface._impl = self\n self._container = None\n+ self._viewport = None\n self.constraints = None\n self.native = None\n self.create()\n self.interface.style.reapply()\n+ self.set_enabled(self.interface.enabled)\n \n def set_app(self, app):\n pass\n@@ -23,15 +25,35 @@\n \n @container.setter\n def container(self, container):\n- self._container = container\n- if self.constraints:\n+ if self.container:\n+ if container:\n+ raise RuntimeError('Already have a container')\n+ else:\n+ # existing container should be removed\n+ self.constraints = None\n+ self._container = None\n+ self.native.removeFromSuperview()\n+ elif container:\n+ # setting container\n+ self._container = container\n self._container.native.addSubview(self.native)\n+ if not self.constraints:\n+ self.add_constraints()\n self.constraints.container = container\n \n for child in self.interface.children:\n child._impl.container = container\n+\n self.rehint()\n \n+ @property\n+ def viewport(self):\n+ return self._viewport\n+\n+ @viewport.setter\n+ def viewport(self, viewport):\n+ self._viewport = viewport\n+\n def set_enabled(self, value):\n self.native.enabled = self.interface.enabled\n \n@@ -41,13 +63,13 @@\n # APPLICATOR\n \n def set_bounds(self, x, y, width, height):\n+ offset_y = 0\n if self.container:\n- viewport = self.container.viewport\n- else:\n- viewport = self.viewport\n-\n+ offset_y = self.container.viewport.statusbar_height\n+ elif self.viewport:\n+ offset_y = self.viewport.statusbar_height\n self.constraints.update(\n- x, y + viewport.statusbar_height,\n+ x, y + offset_y,\n width, height\n )\n \n@@ -55,8 +77,8 @@\n pass\n \n def set_hidden(self, hidden):\n- if self._container:\n- for view in self._container._impl.subviews:\n+ if self.container:\n+ for view in self.container._impl.subviews:\n if view._impl:\n view.setHidden(hidden)\n \n@@ -75,10 +97,16 @@\n # INTERFACE\n \n def add_child(self, child):\n- if self.container:\n- child.viewport = self.root.viewport\n+\n+ if self.viewport:\n+ # we are the the top level UIView\n+ child.container = self\n+ else:\n child.container = self.container\n \n+ def remove_child(self, child):\n+ child.container = None\n+\n def add_constraints(self):\n self.native.translatesAutoresizingMaskIntoConstraints = False\n self.constraints = Constraints(self)\n", "issue": "ios cannot add widgets to main_window.content \n**Describe the bug**\r\nA clear and concise description of what the bug is.\r\n\r\n**To Reproduce**\r\nTry to run this app in ios:\r\n```\r\nimport toga\r\nclass MyApp(toga.App):\r\n\r\n def startup(self):\r\n \"\"\"\r\n Construct and show the Toga application.\r\n\r\n Usually, you would add your application to a main content box.\r\n We then create a main window (with a name matching the app), and\r\n show the main window.\r\n \"\"\"\r\n self.state = GameState()\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n box = toga.Box()\r\n label = toga.Label(\"Test1\")\r\n box.add(label)\r\n self.main_window.content = box\r\n label2 = toga.Label(\"Test2\")\r\n box.add(label2)\r\n self.main_window.show()\r\nMyApp().main_loop()\r\n```\r\n\r\n**Expected behavior**\r\nThe application should open and shows the labels \"Test1\" and \"Test2\". Instead, you get a black screen. In the xcode debugger there is a log message on the \"box.add(label2)\" line about the label (test2) not having the attribute \"viewport\".\r\n\r\nIf you comment out box.add(label2), you correctly get a window that has \"Test1\".\r\n\r\nOn targets macos and android, the above test will correctly show \"Test1 Test2\"\r\n\r\n**Environment:**\r\n - Operating System: macos\r\n - Python version: 3.8\r\n - Software versions:\r\n - Briefcase: 0.3.3\r\n - Toga: 0.3.0.dev23\r\n - IOS: iphone 11\r\n\r\nThis may be related to #225, as you will get a similar error if you try to rebind main_window.content to a different widget.\nios cannot add widgets to main_window.content \n**Describe the bug**\r\nA clear and concise description of what the bug is.\r\n\r\n**To Reproduce**\r\nTry to run this app in ios:\r\n```\r\nimport toga\r\nclass MyApp(toga.App):\r\n\r\n def startup(self):\r\n \"\"\"\r\n Construct and show the Toga application.\r\n\r\n Usually, you would add your application to a main content box.\r\n We then create a main window (with a name matching the app), and\r\n show the main window.\r\n \"\"\"\r\n self.state = GameState()\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n box = toga.Box()\r\n label = toga.Label(\"Test1\")\r\n box.add(label)\r\n self.main_window.content = box\r\n label2 = toga.Label(\"Test2\")\r\n box.add(label2)\r\n self.main_window.show()\r\nMyApp().main_loop()\r\n```\r\n\r\n**Expected behavior**\r\nThe application should open and shows the labels \"Test1\" and \"Test2\". Instead, you get a black screen. In the xcode debugger there is a log message on the \"box.add(label2)\" line about the label (test2) not having the attribute \"viewport\".\r\n\r\nIf you comment out box.add(label2), you correctly get a window that has \"Test1\".\r\n\r\nOn targets macos and android, the above test will correctly show \"Test1 Test2\"\r\n\r\n**Environment:**\r\n - Operating System: macos\r\n - Python version: 3.8\r\n - Software versions:\r\n - Briefcase: 0.3.3\r\n - Toga: 0.3.0.dev23\r\n - IOS: iphone 11\r\n\r\nThis may be related to #225, as you will get a similar error if you try to rebind main_window.content to a different widget.\n", "before_files": [{"content": "from toga_iOS.constraints import Constraints\n\n\nclass Widget:\n def __init__(self, interface):\n self.interface = interface\n self.interface._impl = self\n self._container = None\n self.constraints = None\n self.native = None\n self.create()\n self.interface.style.reapply()\n\n def set_app(self, app):\n pass\n\n def set_window(self, window):\n pass\n\n @property\n def container(self):\n return self._container\n\n @container.setter\n def container(self, container):\n self._container = container\n if self.constraints:\n self._container.native.addSubview(self.native)\n self.constraints.container = container\n\n for child in self.interface.children:\n child._impl.container = container\n self.rehint()\n\n def set_enabled(self, value):\n self.native.enabled = self.interface.enabled\n\n def focus(self):\n self.interface.factory.not_implemented(\"Widget.focus()\")\n\n # APPLICATOR\n\n def set_bounds(self, x, y, width, height):\n if self.container:\n viewport = self.container.viewport\n else:\n viewport = self.viewport\n\n self.constraints.update(\n x, y + viewport.statusbar_height,\n width, height\n )\n\n def set_alignment(self, alignment):\n pass\n\n def set_hidden(self, hidden):\n if self._container:\n for view in self._container._impl.subviews:\n if view._impl:\n view.setHidden(hidden)\n\n def set_font(self, font):\n # By default, font can't be changed\n pass\n\n def set_color(self, color):\n # By default, color can't be changed\n pass\n\n def set_background_color(self, color):\n # By default, background color can't be changed\n pass\n\n # INTERFACE\n\n def add_child(self, child):\n if self.container:\n child.viewport = self.root.viewport\n child.container = self.container\n\n def add_constraints(self):\n self.native.translatesAutoresizingMaskIntoConstraints = False\n self.constraints = Constraints(self)\n\n def rehint(self):\n pass\n", "path": "src/iOS/toga_iOS/widgets/base.py"}]}
| 1,933 | 682 |
gh_patches_debug_3372
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-6638
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SBU download is failing
This is happening since roughly a month (first detection in #6274), but was masked by #6268.
http://www.cs.virginia.edu/~vicente/sbucaptions/
The server is still up, but the path is no longer valid. I'll reach out to the author to see if this can be fixed. In the meantime we should probably disable the test.
cc @pmeier @YosuaMichael
</issue>
<code>
[start of torchvision/datasets/sbu.py]
1 import os
2 from typing import Any, Callable, Optional, Tuple
3
4 from PIL import Image
5
6 from .utils import check_integrity, download_url
7 from .vision import VisionDataset
8
9
10 class SBU(VisionDataset):
11 """`SBU Captioned Photo <http://www.cs.virginia.edu/~vicente/sbucaptions/>`_ Dataset.
12
13 Args:
14 root (string): Root directory of dataset where tarball
15 ``SBUCaptionedPhotoDataset.tar.gz`` exists.
16 transform (callable, optional): A function/transform that takes in a PIL image
17 and returns a transformed version. E.g, ``transforms.RandomCrop``
18 target_transform (callable, optional): A function/transform that takes in the
19 target and transforms it.
20 download (bool, optional): If True, downloads the dataset from the internet and
21 puts it in root directory. If dataset is already downloaded, it is not
22 downloaded again.
23 """
24
25 url = "http://www.cs.virginia.edu/~vicente/sbucaptions/SBUCaptionedPhotoDataset.tar.gz"
26 filename = "SBUCaptionedPhotoDataset.tar.gz"
27 md5_checksum = "9aec147b3488753cf758b4d493422285"
28
29 def __init__(
30 self,
31 root: str,
32 transform: Optional[Callable] = None,
33 target_transform: Optional[Callable] = None,
34 download: bool = True,
35 ) -> None:
36 super().__init__(root, transform=transform, target_transform=target_transform)
37
38 if download:
39 self.download()
40
41 if not self._check_integrity():
42 raise RuntimeError("Dataset not found or corrupted. You can use download=True to download it")
43
44 # Read the caption for each photo
45 self.photos = []
46 self.captions = []
47
48 file1 = os.path.join(self.root, "dataset", "SBU_captioned_photo_dataset_urls.txt")
49 file2 = os.path.join(self.root, "dataset", "SBU_captioned_photo_dataset_captions.txt")
50
51 for line1, line2 in zip(open(file1), open(file2)):
52 url = line1.rstrip()
53 photo = os.path.basename(url)
54 filename = os.path.join(self.root, "dataset", photo)
55 if os.path.exists(filename):
56 caption = line2.rstrip()
57 self.photos.append(photo)
58 self.captions.append(caption)
59
60 def __getitem__(self, index: int) -> Tuple[Any, Any]:
61 """
62 Args:
63 index (int): Index
64
65 Returns:
66 tuple: (image, target) where target is a caption for the photo.
67 """
68 filename = os.path.join(self.root, "dataset", self.photos[index])
69 img = Image.open(filename).convert("RGB")
70 if self.transform is not None:
71 img = self.transform(img)
72
73 target = self.captions[index]
74 if self.target_transform is not None:
75 target = self.target_transform(target)
76
77 return img, target
78
79 def __len__(self) -> int:
80 """The number of photos in the dataset."""
81 return len(self.photos)
82
83 def _check_integrity(self) -> bool:
84 """Check the md5 checksum of the downloaded tarball."""
85 root = self.root
86 fpath = os.path.join(root, self.filename)
87 if not check_integrity(fpath, self.md5_checksum):
88 return False
89 return True
90
91 def download(self) -> None:
92 """Download and extract the tarball, and download each individual photo."""
93 import tarfile
94
95 if self._check_integrity():
96 print("Files already downloaded and verified")
97 return
98
99 download_url(self.url, self.root, self.filename, self.md5_checksum)
100
101 # Extract file
102 with tarfile.open(os.path.join(self.root, self.filename), "r:gz") as tar:
103 tar.extractall(path=self.root)
104
105 # Download individual photos
106 with open(os.path.join(self.root, "dataset", "SBU_captioned_photo_dataset_urls.txt")) as fh:
107 for line in fh:
108 url = line.rstrip()
109 try:
110 download_url(url, os.path.join(self.root, "dataset"))
111 except OSError:
112 # The images point to public images on Flickr.
113 # Note: Images might be removed by users at anytime.
114 pass
115
[end of torchvision/datasets/sbu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/datasets/sbu.py b/torchvision/datasets/sbu.py
--- a/torchvision/datasets/sbu.py
+++ b/torchvision/datasets/sbu.py
@@ -22,7 +22,7 @@
downloaded again.
"""
- url = "http://www.cs.virginia.edu/~vicente/sbucaptions/SBUCaptionedPhotoDataset.tar.gz"
+ url = "https://www.cs.rice.edu/~vo9/sbucaptions/SBUCaptionedPhotoDataset.tar.gz"
filename = "SBUCaptionedPhotoDataset.tar.gz"
md5_checksum = "9aec147b3488753cf758b4d493422285"
|
{"golden_diff": "diff --git a/torchvision/datasets/sbu.py b/torchvision/datasets/sbu.py\n--- a/torchvision/datasets/sbu.py\n+++ b/torchvision/datasets/sbu.py\n@@ -22,7 +22,7 @@\n downloaded again.\n \"\"\"\n \n- url = \"http://www.cs.virginia.edu/~vicente/sbucaptions/SBUCaptionedPhotoDataset.tar.gz\"\n+ url = \"https://www.cs.rice.edu/~vo9/sbucaptions/SBUCaptionedPhotoDataset.tar.gz\"\n filename = \"SBUCaptionedPhotoDataset.tar.gz\"\n md5_checksum = \"9aec147b3488753cf758b4d493422285\"\n", "issue": "SBU download is failing\nThis is happening since roughly a month (first detection in #6274), but was masked by #6268. \r\n\r\nhttp://www.cs.virginia.edu/~vicente/sbucaptions/\r\n\r\nThe server is still up, but the path is no longer valid. I'll reach out to the author to see if this can be fixed. In the meantime we should probably disable the test.\r\n\r\ncc @pmeier @YosuaMichael\n", "before_files": [{"content": "import os\nfrom typing import Any, Callable, Optional, Tuple\n\nfrom PIL import Image\n\nfrom .utils import check_integrity, download_url\nfrom .vision import VisionDataset\n\n\nclass SBU(VisionDataset):\n \"\"\"`SBU Captioned Photo <http://www.cs.virginia.edu/~vicente/sbucaptions/>`_ Dataset.\n\n Args:\n root (string): Root directory of dataset where tarball\n ``SBUCaptionedPhotoDataset.tar.gz`` exists.\n transform (callable, optional): A function/transform that takes in a PIL image\n and returns a transformed version. E.g, ``transforms.RandomCrop``\n target_transform (callable, optional): A function/transform that takes in the\n target and transforms it.\n download (bool, optional): If True, downloads the dataset from the internet and\n puts it in root directory. If dataset is already downloaded, it is not\n downloaded again.\n \"\"\"\n\n url = \"http://www.cs.virginia.edu/~vicente/sbucaptions/SBUCaptionedPhotoDataset.tar.gz\"\n filename = \"SBUCaptionedPhotoDataset.tar.gz\"\n md5_checksum = \"9aec147b3488753cf758b4d493422285\"\n\n def __init__(\n self,\n root: str,\n transform: Optional[Callable] = None,\n target_transform: Optional[Callable] = None,\n download: bool = True,\n ) -> None:\n super().__init__(root, transform=transform, target_transform=target_transform)\n\n if download:\n self.download()\n\n if not self._check_integrity():\n raise RuntimeError(\"Dataset not found or corrupted. You can use download=True to download it\")\n\n # Read the caption for each photo\n self.photos = []\n self.captions = []\n\n file1 = os.path.join(self.root, \"dataset\", \"SBU_captioned_photo_dataset_urls.txt\")\n file2 = os.path.join(self.root, \"dataset\", \"SBU_captioned_photo_dataset_captions.txt\")\n\n for line1, line2 in zip(open(file1), open(file2)):\n url = line1.rstrip()\n photo = os.path.basename(url)\n filename = os.path.join(self.root, \"dataset\", photo)\n if os.path.exists(filename):\n caption = line2.rstrip()\n self.photos.append(photo)\n self.captions.append(caption)\n\n def __getitem__(self, index: int) -> Tuple[Any, Any]:\n \"\"\"\n Args:\n index (int): Index\n\n Returns:\n tuple: (image, target) where target is a caption for the photo.\n \"\"\"\n filename = os.path.join(self.root, \"dataset\", self.photos[index])\n img = Image.open(filename).convert(\"RGB\")\n if self.transform is not None:\n img = self.transform(img)\n\n target = self.captions[index]\n if self.target_transform is not None:\n target = self.target_transform(target)\n\n return img, target\n\n def __len__(self) -> int:\n \"\"\"The number of photos in the dataset.\"\"\"\n return len(self.photos)\n\n def _check_integrity(self) -> bool:\n \"\"\"Check the md5 checksum of the downloaded tarball.\"\"\"\n root = self.root\n fpath = os.path.join(root, self.filename)\n if not check_integrity(fpath, self.md5_checksum):\n return False\n return True\n\n def download(self) -> None:\n \"\"\"Download and extract the tarball, and download each individual photo.\"\"\"\n import tarfile\n\n if self._check_integrity():\n print(\"Files already downloaded and verified\")\n return\n\n download_url(self.url, self.root, self.filename, self.md5_checksum)\n\n # Extract file\n with tarfile.open(os.path.join(self.root, self.filename), \"r:gz\") as tar:\n tar.extractall(path=self.root)\n\n # Download individual photos\n with open(os.path.join(self.root, \"dataset\", \"SBU_captioned_photo_dataset_urls.txt\")) as fh:\n for line in fh:\n url = line.rstrip()\n try:\n download_url(url, os.path.join(self.root, \"dataset\"))\n except OSError:\n # The images point to public images on Flickr.\n # Note: Images might be removed by users at anytime.\n pass\n", "path": "torchvision/datasets/sbu.py"}]}
| 1,829 | 175 |
gh_patches_debug_25013
|
rasdani/github-patches
|
git_diff
|
pandas-dev__pandas-24034
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add columns-parameter like in feather.read_dataframe
Wes suggested to raise this feature request here again, after I wondered why `pandas.read_feather` is lacking a `columns`-parameter like the [`feather-format`](https://github.com/wesm/feather) package has it.
You can read in only a subset of columns from a feather-file with e.g.:
`df = feather.read_dataframe('df_test.feather', columns='b')`
It would be really nice if `pandas.read_feather` also had this built in, so you don't have to install and import the feather-package just for that.
</issue>
<code>
[start of pandas/io/feather_format.py]
1 """ feather-format compat """
2
3 from distutils.version import LooseVersion
4
5 from pandas.compat import range
6 from pandas.util._decorators import deprecate_kwarg
7
8 from pandas import DataFrame, Int64Index, RangeIndex
9
10 from pandas.io.common import _stringify_path
11
12
13 def _try_import():
14 # since pandas is a dependency of pyarrow
15 # we need to import on first use
16 try:
17 import pyarrow
18 from pyarrow import feather
19 except ImportError:
20 # give a nice error message
21 raise ImportError("pyarrow is not installed\n\n"
22 "you can install via conda\n"
23 "conda install pyarrow -c conda-forge\n"
24 "or via pip\n"
25 "pip install -U pyarrow\n")
26
27 if LooseVersion(pyarrow.__version__) < LooseVersion('0.4.1'):
28 raise ImportError("pyarrow >= 0.4.1 required for feather support\n\n"
29 "you can install via conda\n"
30 "conda install pyarrow -c conda-forge"
31 "or via pip\n"
32 "pip install -U pyarrow\n")
33
34 return feather, pyarrow
35
36
37 def to_feather(df, path):
38 """
39 Write a DataFrame to the feather-format
40
41 Parameters
42 ----------
43 df : DataFrame
44 path : string file path, or file-like object
45
46 """
47 path = _stringify_path(path)
48 if not isinstance(df, DataFrame):
49 raise ValueError("feather only support IO with DataFrames")
50
51 feather = _try_import()[0]
52 valid_types = {'string', 'unicode'}
53
54 # validate index
55 # --------------
56
57 # validate that we have only a default index
58 # raise on anything else as we don't serialize the index
59
60 if not isinstance(df.index, Int64Index):
61 raise ValueError("feather does not support serializing {} "
62 "for the index; you can .reset_index()"
63 "to make the index into column(s)".format(
64 type(df.index)))
65
66 if not df.index.equals(RangeIndex.from_range(range(len(df)))):
67 raise ValueError("feather does not support serializing a "
68 "non-default index for the index; you "
69 "can .reset_index() to make the index "
70 "into column(s)")
71
72 if df.index.name is not None:
73 raise ValueError("feather does not serialize index meta-data on a "
74 "default index")
75
76 # validate columns
77 # ----------------
78
79 # must have value column names (strings only)
80 if df.columns.inferred_type not in valid_types:
81 raise ValueError("feather must have string column names")
82
83 feather.write_feather(df, path)
84
85
86 @deprecate_kwarg(old_arg_name='nthreads', new_arg_name='use_threads')
87 def read_feather(path, use_threads=True):
88 """
89 Load a feather-format object from the file path
90
91 .. versionadded 0.20.0
92
93 Parameters
94 ----------
95 path : string file path, or file-like object
96 nthreads : int, default 1
97 Number of CPU threads to use when reading to pandas.DataFrame
98
99 .. versionadded 0.21.0
100 .. deprecated 0.24.0
101 use_threads : bool, default True
102 Whether to parallelize reading using multiple threads
103
104 .. versionadded 0.24.0
105
106 Returns
107 -------
108 type of object stored in file
109
110 """
111
112 feather, pyarrow = _try_import()
113 path = _stringify_path(path)
114
115 if LooseVersion(pyarrow.__version__) < LooseVersion('0.11.0'):
116 int_use_threads = int(use_threads)
117 if int_use_threads < 1:
118 int_use_threads = 1
119 return feather.read_feather(path, nthreads=int_use_threads)
120
121 return feather.read_feather(path, use_threads=bool(use_threads))
122
[end of pandas/io/feather_format.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pandas/io/feather_format.py b/pandas/io/feather_format.py
--- a/pandas/io/feather_format.py
+++ b/pandas/io/feather_format.py
@@ -84,7 +84,7 @@
@deprecate_kwarg(old_arg_name='nthreads', new_arg_name='use_threads')
-def read_feather(path, use_threads=True):
+def read_feather(path, columns=None, use_threads=True):
"""
Load a feather-format object from the file path
@@ -93,6 +93,10 @@
Parameters
----------
path : string file path, or file-like object
+ columns : sequence, default None
+ If not provided, all columns are read
+
+ .. versionadded 0.24.0
nthreads : int, default 1
Number of CPU threads to use when reading to pandas.DataFrame
@@ -116,6 +120,8 @@
int_use_threads = int(use_threads)
if int_use_threads < 1:
int_use_threads = 1
- return feather.read_feather(path, nthreads=int_use_threads)
+ return feather.read_feather(path, columns=columns,
+ nthreads=int_use_threads)
- return feather.read_feather(path, use_threads=bool(use_threads))
+ return feather.read_feather(path, columns=columns,
+ use_threads=bool(use_threads))
|
{"golden_diff": "diff --git a/pandas/io/feather_format.py b/pandas/io/feather_format.py\n--- a/pandas/io/feather_format.py\n+++ b/pandas/io/feather_format.py\n@@ -84,7 +84,7 @@\n \n \n @deprecate_kwarg(old_arg_name='nthreads', new_arg_name='use_threads')\n-def read_feather(path, use_threads=True):\n+def read_feather(path, columns=None, use_threads=True):\n \"\"\"\n Load a feather-format object from the file path\n \n@@ -93,6 +93,10 @@\n Parameters\n ----------\n path : string file path, or file-like object\n+ columns : sequence, default None\n+ If not provided, all columns are read\n+\n+ .. versionadded 0.24.0\n nthreads : int, default 1\n Number of CPU threads to use when reading to pandas.DataFrame\n \n@@ -116,6 +120,8 @@\n int_use_threads = int(use_threads)\n if int_use_threads < 1:\n int_use_threads = 1\n- return feather.read_feather(path, nthreads=int_use_threads)\n+ return feather.read_feather(path, columns=columns,\n+ nthreads=int_use_threads)\n \n- return feather.read_feather(path, use_threads=bool(use_threads))\n+ return feather.read_feather(path, columns=columns,\n+ use_threads=bool(use_threads))\n", "issue": "Add columns-parameter like in feather.read_dataframe\nWes suggested to raise this feature request here again, after I wondered why `pandas.read_feather` is lacking a `columns`-parameter like the [`feather-format`](https://github.com/wesm/feather) package has it.\r\n\r\nYou can read in only a subset of columns from a feather-file with e.g.: \r\n`df = feather.read_dataframe('df_test.feather', columns='b')`\r\n\r\nIt would be really nice if `pandas.read_feather` also had this built in, so you don't have to install and import the feather-package just for that.\n", "before_files": [{"content": "\"\"\" feather-format compat \"\"\"\n\nfrom distutils.version import LooseVersion\n\nfrom pandas.compat import range\nfrom pandas.util._decorators import deprecate_kwarg\n\nfrom pandas import DataFrame, Int64Index, RangeIndex\n\nfrom pandas.io.common import _stringify_path\n\n\ndef _try_import():\n # since pandas is a dependency of pyarrow\n # we need to import on first use\n try:\n import pyarrow\n from pyarrow import feather\n except ImportError:\n # give a nice error message\n raise ImportError(\"pyarrow is not installed\\n\\n\"\n \"you can install via conda\\n\"\n \"conda install pyarrow -c conda-forge\\n\"\n \"or via pip\\n\"\n \"pip install -U pyarrow\\n\")\n\n if LooseVersion(pyarrow.__version__) < LooseVersion('0.4.1'):\n raise ImportError(\"pyarrow >= 0.4.1 required for feather support\\n\\n\"\n \"you can install via conda\\n\"\n \"conda install pyarrow -c conda-forge\"\n \"or via pip\\n\"\n \"pip install -U pyarrow\\n\")\n\n return feather, pyarrow\n\n\ndef to_feather(df, path):\n \"\"\"\n Write a DataFrame to the feather-format\n\n Parameters\n ----------\n df : DataFrame\n path : string file path, or file-like object\n\n \"\"\"\n path = _stringify_path(path)\n if not isinstance(df, DataFrame):\n raise ValueError(\"feather only support IO with DataFrames\")\n\n feather = _try_import()[0]\n valid_types = {'string', 'unicode'}\n\n # validate index\n # --------------\n\n # validate that we have only a default index\n # raise on anything else as we don't serialize the index\n\n if not isinstance(df.index, Int64Index):\n raise ValueError(\"feather does not support serializing {} \"\n \"for the index; you can .reset_index()\"\n \"to make the index into column(s)\".format(\n type(df.index)))\n\n if not df.index.equals(RangeIndex.from_range(range(len(df)))):\n raise ValueError(\"feather does not support serializing a \"\n \"non-default index for the index; you \"\n \"can .reset_index() to make the index \"\n \"into column(s)\")\n\n if df.index.name is not None:\n raise ValueError(\"feather does not serialize index meta-data on a \"\n \"default index\")\n\n # validate columns\n # ----------------\n\n # must have value column names (strings only)\n if df.columns.inferred_type not in valid_types:\n raise ValueError(\"feather must have string column names\")\n\n feather.write_feather(df, path)\n\n\n@deprecate_kwarg(old_arg_name='nthreads', new_arg_name='use_threads')\ndef read_feather(path, use_threads=True):\n \"\"\"\n Load a feather-format object from the file path\n\n .. versionadded 0.20.0\n\n Parameters\n ----------\n path : string file path, or file-like object\n nthreads : int, default 1\n Number of CPU threads to use when reading to pandas.DataFrame\n\n .. versionadded 0.21.0\n .. deprecated 0.24.0\n use_threads : bool, default True\n Whether to parallelize reading using multiple threads\n\n .. versionadded 0.24.0\n\n Returns\n -------\n type of object stored in file\n\n \"\"\"\n\n feather, pyarrow = _try_import()\n path = _stringify_path(path)\n\n if LooseVersion(pyarrow.__version__) < LooseVersion('0.11.0'):\n int_use_threads = int(use_threads)\n if int_use_threads < 1:\n int_use_threads = 1\n return feather.read_feather(path, nthreads=int_use_threads)\n\n return feather.read_feather(path, use_threads=bool(use_threads))\n", "path": "pandas/io/feather_format.py"}]}
| 1,785 | 315 |
gh_patches_debug_2620
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-4189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SyntaxWarning for loading indicator widget
I receive this warning after upgrading to `0.52.0`:
```
/Users/cthompson/Library/Caches/pypoetry/virtualenvs/dolphie-z84eXs3q-py3.11/lib/python3.11/site-packages/textual/widgets/_loading_indicator.py:57: SyntaxWarning: "is" with a literal. Did you mean "=="?
if self.app.animation_level is "none":
```
https://github.com/Textualize/textual/blob/main/src/textual/widgets/_loading_indicator.py#L57
Seems we just need to change `is "none"` to `== "none"`
</issue>
<code>
[start of src/textual/widgets/_loading_indicator.py]
1 from __future__ import annotations
2
3 from time import time
4
5 from rich.console import RenderableType
6 from rich.style import Style
7 from rich.text import Text
8
9 from ..color import Gradient
10 from ..events import Mount
11 from ..widget import Widget
12
13
14 class LoadingIndicator(Widget):
15 """Display an animated loading indicator."""
16
17 DEFAULT_CSS = """
18 LoadingIndicator {
19 width: 100%;
20 height: 100%;
21 min-height: 1;
22 content-align: center middle;
23 color: $accent;
24 }
25 LoadingIndicator.-textual-loading-indicator {
26 layer: _loading;
27 background: $boost;
28 dock: top;
29 }
30 """
31
32 def __init__(
33 self,
34 name: str | None = None,
35 id: str | None = None,
36 classes: str | None = None,
37 disabled: bool = False,
38 ):
39 """Initialize a loading indicator.
40
41 Args:
42 name: The name of the widget.
43 id: The ID of the widget in the DOM.
44 classes: The CSS classes for the widget.
45 disabled: Whether the widget is disabled or not.
46 """
47 super().__init__(name=name, id=id, classes=classes, disabled=disabled)
48
49 self._start_time: float = 0.0
50 """The time the loading indicator was mounted (a Unix timestamp)."""
51
52 def _on_mount(self, _: Mount) -> None:
53 self._start_time = time()
54 self.auto_refresh = 1 / 16
55
56 def render(self) -> RenderableType:
57 if self.app.animation_level is "none":
58 return Text("Loading...")
59
60 elapsed = time() - self._start_time
61 speed = 0.8
62 dot = "\u25cf"
63 _, _, background, color = self.colors
64
65 gradient = Gradient(
66 (0.0, background.blend(color, 0.1)),
67 (0.7, color),
68 (1.0, color.lighten(0.1)),
69 )
70
71 blends = [(elapsed * speed - dot_number / 8) % 1 for dot_number in range(5)]
72
73 dots = [
74 (
75 f"{dot} ",
76 Style.from_color(gradient.get_color((1 - blend) ** 2).rich_color),
77 )
78 for blend in blends
79 ]
80 indicator = Text.assemble(*dots)
81 indicator.rstrip()
82 return indicator
83
[end of src/textual/widgets/_loading_indicator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/textual/widgets/_loading_indicator.py b/src/textual/widgets/_loading_indicator.py
--- a/src/textual/widgets/_loading_indicator.py
+++ b/src/textual/widgets/_loading_indicator.py
@@ -54,7 +54,7 @@
self.auto_refresh = 1 / 16
def render(self) -> RenderableType:
- if self.app.animation_level is "none":
+ if self.app.animation_level == "none":
return Text("Loading...")
elapsed = time() - self._start_time
|
{"golden_diff": "diff --git a/src/textual/widgets/_loading_indicator.py b/src/textual/widgets/_loading_indicator.py\n--- a/src/textual/widgets/_loading_indicator.py\n+++ b/src/textual/widgets/_loading_indicator.py\n@@ -54,7 +54,7 @@\n self.auto_refresh = 1 / 16\n \n def render(self) -> RenderableType:\n- if self.app.animation_level is \"none\":\n+ if self.app.animation_level == \"none\":\n return Text(\"Loading...\")\n \n elapsed = time() - self._start_time\n", "issue": "SyntaxWarning for loading indicator widget\nI receive this warning after upgrading to `0.52.0`:\r\n\r\n```\r\n/Users/cthompson/Library/Caches/pypoetry/virtualenvs/dolphie-z84eXs3q-py3.11/lib/python3.11/site-packages/textual/widgets/_loading_indicator.py:57: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n if self.app.animation_level is \"none\":\r\n```\r\n\r\nhttps://github.com/Textualize/textual/blob/main/src/textual/widgets/_loading_indicator.py#L57\r\n\r\nSeems we just need to change `is \"none\"` to `== \"none\"`\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom time import time\n\nfrom rich.console import RenderableType\nfrom rich.style import Style\nfrom rich.text import Text\n\nfrom ..color import Gradient\nfrom ..events import Mount\nfrom ..widget import Widget\n\n\nclass LoadingIndicator(Widget):\n \"\"\"Display an animated loading indicator.\"\"\"\n\n DEFAULT_CSS = \"\"\"\n LoadingIndicator {\n width: 100%;\n height: 100%;\n min-height: 1;\n content-align: center middle;\n color: $accent;\n }\n LoadingIndicator.-textual-loading-indicator {\n layer: _loading;\n background: $boost;\n dock: top;\n }\n \"\"\"\n\n def __init__(\n self,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n disabled: bool = False,\n ):\n \"\"\"Initialize a loading indicator.\n\n Args:\n name: The name of the widget.\n id: The ID of the widget in the DOM.\n classes: The CSS classes for the widget.\n disabled: Whether the widget is disabled or not.\n \"\"\"\n super().__init__(name=name, id=id, classes=classes, disabled=disabled)\n\n self._start_time: float = 0.0\n \"\"\"The time the loading indicator was mounted (a Unix timestamp).\"\"\"\n\n def _on_mount(self, _: Mount) -> None:\n self._start_time = time()\n self.auto_refresh = 1 / 16\n\n def render(self) -> RenderableType:\n if self.app.animation_level is \"none\":\n return Text(\"Loading...\")\n\n elapsed = time() - self._start_time\n speed = 0.8\n dot = \"\\u25cf\"\n _, _, background, color = self.colors\n\n gradient = Gradient(\n (0.0, background.blend(color, 0.1)),\n (0.7, color),\n (1.0, color.lighten(0.1)),\n )\n\n blends = [(elapsed * speed - dot_number / 8) % 1 for dot_number in range(5)]\n\n dots = [\n (\n f\"{dot} \",\n Style.from_color(gradient.get_color((1 - blend) ** 2).rich_color),\n )\n for blend in blends\n ]\n indicator = Text.assemble(*dots)\n indicator.rstrip()\n return indicator\n", "path": "src/textual/widgets/_loading_indicator.py"}]}
| 1,373 | 119 |
gh_patches_debug_17695
|
rasdani/github-patches
|
git_diff
|
geopandas__geopandas-1359
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DOC: update read_postgis docstring for CRS changes
The read_postgis docstring still mentions to use a dict:
https://github.com/geopandas/geopandas/blob/078062d303e401aaa5e37e04c0e7c3ce188920fe/geopandas/io/sql.py#L33-L36
we should update this to follow how CRS is explained in other places now we use pyproj.
</issue>
<code>
[start of geopandas/io/sql.py]
1 import sys
2
3 import pandas as pd
4
5 import shapely.wkb
6
7 from geopandas import GeoDataFrame
8
9
10 def read_postgis(
11 sql,
12 con,
13 geom_col="geom",
14 crs=None,
15 index_col=None,
16 coerce_float=True,
17 parse_dates=None,
18 params=None,
19 ):
20 """
21 Returns a GeoDataFrame corresponding to the result of the query
22 string, which must contain a geometry column in WKB representation.
23
24 Parameters
25 ----------
26 sql : string
27 SQL query to execute in selecting entries from database, or name
28 of the table to read from the database.
29 con : DB connection object or SQLAlchemy engine
30 Active connection to the database to query.
31 geom_col : string, default 'geom'
32 column name to convert to shapely geometries
33 crs : dict or str, optional
34 CRS to use for the returned GeoDataFrame; if not set, tries to
35 determine CRS from the SRID associated with the first geometry in
36 the database, and assigns that to all geometries.
37
38 See the documentation for pandas.read_sql for further explanation
39 of the following parameters:
40 index_col, coerce_float, parse_dates, params
41
42 Returns
43 -------
44 GeoDataFrame
45
46 Example
47 -------
48 PostGIS
49 >>> sql = "SELECT geom, kind FROM polygons"
50 SpatiaLite
51 >>> sql = "SELECT ST_AsBinary(geom) AS geom, kind FROM polygons"
52 >>> df = geopandas.read_postgis(sql, con)
53 """
54
55 df = pd.read_sql(
56 sql,
57 con,
58 index_col=index_col,
59 coerce_float=coerce_float,
60 parse_dates=parse_dates,
61 params=params,
62 )
63
64 if geom_col not in df:
65 raise ValueError("Query missing geometry column '{}'".format(geom_col))
66
67 geoms = df[geom_col].dropna()
68
69 if not geoms.empty:
70 load_geom_bytes = shapely.wkb.loads
71 """Load from Python 3 binary."""
72
73 def load_geom_buffer(x):
74 """Load from Python 2 binary."""
75 return shapely.wkb.loads(str(x))
76
77 def load_geom_text(x):
78 """Load from binary encoded as text."""
79 return shapely.wkb.loads(str(x), hex=True)
80
81 if sys.version_info.major < 3:
82 if isinstance(geoms.iat[0], buffer):
83 load_geom = load_geom_buffer
84 else:
85 load_geom = load_geom_text
86 elif isinstance(geoms.iat[0], bytes):
87 load_geom = load_geom_bytes
88 else:
89 load_geom = load_geom_text
90
91 df[geom_col] = geoms = geoms.apply(load_geom)
92 if crs is None:
93 srid = shapely.geos.lgeos.GEOSGetSRID(geoms.iat[0]._geom)
94 # if no defined SRID in geodatabase, returns SRID of 0
95 if srid != 0:
96 crs = "epsg:{}".format(srid)
97
98 return GeoDataFrame(df, crs=crs, geometry=geom_col)
99
[end of geopandas/io/sql.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geopandas/io/sql.py b/geopandas/io/sql.py
--- a/geopandas/io/sql.py
+++ b/geopandas/io/sql.py
@@ -30,10 +30,12 @@
Active connection to the database to query.
geom_col : string, default 'geom'
column name to convert to shapely geometries
- crs : dict or str, optional
- CRS to use for the returned GeoDataFrame; if not set, tries to
- determine CRS from the SRID associated with the first geometry in
- the database, and assigns that to all geometries.
+ crs : pyproj.CRS, optional
+ CRS to use for the returned GeoDataFrame. The value can be anything accepted
+ by :meth:`pyproj.CRS.from_user_input() <pyproj.crs.CRS.from_user_input>`,
+ such as an authority string (eg "EPSG:4326") or a WKT string.
+ If not set, tries to determine CRS from the SRID associated with the
+ first geometry in the database, and assigns that to all geometries.
See the documentation for pandas.read_sql for further explanation
of the following parameters:
|
{"golden_diff": "diff --git a/geopandas/io/sql.py b/geopandas/io/sql.py\n--- a/geopandas/io/sql.py\n+++ b/geopandas/io/sql.py\n@@ -30,10 +30,12 @@\n Active connection to the database to query.\n geom_col : string, default 'geom'\n column name to convert to shapely geometries\n- crs : dict or str, optional\n- CRS to use for the returned GeoDataFrame; if not set, tries to\n- determine CRS from the SRID associated with the first geometry in\n- the database, and assigns that to all geometries.\n+ crs : pyproj.CRS, optional\n+ CRS to use for the returned GeoDataFrame. The value can be anything accepted\n+ by :meth:`pyproj.CRS.from_user_input() <pyproj.crs.CRS.from_user_input>`,\n+ such as an authority string (eg \"EPSG:4326\") or a WKT string.\n+ If not set, tries to determine CRS from the SRID associated with the\n+ first geometry in the database, and assigns that to all geometries.\n \n See the documentation for pandas.read_sql for further explanation\n of the following parameters:\n", "issue": "DOC: update read_postgis docstring for CRS changes\nThe read_postgis docstring still mentions to use a dict:\r\n\r\nhttps://github.com/geopandas/geopandas/blob/078062d303e401aaa5e37e04c0e7c3ce188920fe/geopandas/io/sql.py#L33-L36\r\n\r\nwe should update this to follow how CRS is explained in other places now we use pyproj.\n", "before_files": [{"content": "import sys\n\nimport pandas as pd\n\nimport shapely.wkb\n\nfrom geopandas import GeoDataFrame\n\n\ndef read_postgis(\n sql,\n con,\n geom_col=\"geom\",\n crs=None,\n index_col=None,\n coerce_float=True,\n parse_dates=None,\n params=None,\n):\n \"\"\"\n Returns a GeoDataFrame corresponding to the result of the query\n string, which must contain a geometry column in WKB representation.\n\n Parameters\n ----------\n sql : string\n SQL query to execute in selecting entries from database, or name\n of the table to read from the database.\n con : DB connection object or SQLAlchemy engine\n Active connection to the database to query.\n geom_col : string, default 'geom'\n column name to convert to shapely geometries\n crs : dict or str, optional\n CRS to use for the returned GeoDataFrame; if not set, tries to\n determine CRS from the SRID associated with the first geometry in\n the database, and assigns that to all geometries.\n\n See the documentation for pandas.read_sql for further explanation\n of the following parameters:\n index_col, coerce_float, parse_dates, params\n\n Returns\n -------\n GeoDataFrame\n\n Example\n -------\n PostGIS\n >>> sql = \"SELECT geom, kind FROM polygons\"\n SpatiaLite\n >>> sql = \"SELECT ST_AsBinary(geom) AS geom, kind FROM polygons\"\n >>> df = geopandas.read_postgis(sql, con)\n \"\"\"\n\n df = pd.read_sql(\n sql,\n con,\n index_col=index_col,\n coerce_float=coerce_float,\n parse_dates=parse_dates,\n params=params,\n )\n\n if geom_col not in df:\n raise ValueError(\"Query missing geometry column '{}'\".format(geom_col))\n\n geoms = df[geom_col].dropna()\n\n if not geoms.empty:\n load_geom_bytes = shapely.wkb.loads\n \"\"\"Load from Python 3 binary.\"\"\"\n\n def load_geom_buffer(x):\n \"\"\"Load from Python 2 binary.\"\"\"\n return shapely.wkb.loads(str(x))\n\n def load_geom_text(x):\n \"\"\"Load from binary encoded as text.\"\"\"\n return shapely.wkb.loads(str(x), hex=True)\n\n if sys.version_info.major < 3:\n if isinstance(geoms.iat[0], buffer):\n load_geom = load_geom_buffer\n else:\n load_geom = load_geom_text\n elif isinstance(geoms.iat[0], bytes):\n load_geom = load_geom_bytes\n else:\n load_geom = load_geom_text\n\n df[geom_col] = geoms = geoms.apply(load_geom)\n if crs is None:\n srid = shapely.geos.lgeos.GEOSGetSRID(geoms.iat[0]._geom)\n # if no defined SRID in geodatabase, returns SRID of 0\n if srid != 0:\n crs = \"epsg:{}\".format(srid)\n\n return GeoDataFrame(df, crs=crs, geometry=geom_col)\n", "path": "geopandas/io/sql.py"}]}
| 1,515 | 272 |
gh_patches_debug_5532
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3216
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HKDF key-length inconsistency
For too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:
Program:
```python
#!/usr/bin/env python3.5
import cryptography
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.hkdf import HKDF
from cryptography.hazmat.backends import default_backend
print("cryptography.io:{}".format(cryptography.__version__))
hkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b"salt",
info=b"some-test", backend=default_backend())
key = hkdf.derive(b"my secret passphrase")
print("Derived key: {}".format(key))
```
Output:
```
cryptography.io:1.5.2
Derived key: b''
```
Suggested fix:
I am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.
```python
# class HKDFExpand
def _expand(self, key_material):
output = [b""]
counter = 1
while (self._algorithm.digest_size // 8) * len(output) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
h.update(six.int2byte(counter))
output.append(h.finalize())
counter += 1
return b"".join(output)[:self._length]
```
</issue>
<code>
[start of src/cryptography/hazmat/primitives/kdf/hkdf.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import six
8
9 from cryptography import utils
10 from cryptography.exceptions import (
11 AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons
12 )
13 from cryptography.hazmat.backends.interfaces import HMACBackend
14 from cryptography.hazmat.primitives import constant_time, hmac
15 from cryptography.hazmat.primitives.kdf import KeyDerivationFunction
16
17
18 @utils.register_interface(KeyDerivationFunction)
19 class HKDF(object):
20 def __init__(self, algorithm, length, salt, info, backend):
21 if not isinstance(backend, HMACBackend):
22 raise UnsupportedAlgorithm(
23 "Backend object does not implement HMACBackend.",
24 _Reasons.BACKEND_MISSING_INTERFACE
25 )
26
27 self._algorithm = algorithm
28
29 if not (salt is None or isinstance(salt, bytes)):
30 raise TypeError("salt must be bytes.")
31
32 if salt is None:
33 salt = b"\x00" * (self._algorithm.digest_size // 8)
34
35 self._salt = salt
36
37 self._backend = backend
38
39 self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)
40
41 def _extract(self, key_material):
42 h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)
43 h.update(key_material)
44 return h.finalize()
45
46 def derive(self, key_material):
47 if not isinstance(key_material, bytes):
48 raise TypeError("key_material must be bytes.")
49
50 return self._hkdf_expand.derive(self._extract(key_material))
51
52 def verify(self, key_material, expected_key):
53 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
54 raise InvalidKey
55
56
57 @utils.register_interface(KeyDerivationFunction)
58 class HKDFExpand(object):
59 def __init__(self, algorithm, length, info, backend):
60 if not isinstance(backend, HMACBackend):
61 raise UnsupportedAlgorithm(
62 "Backend object does not implement HMACBackend.",
63 _Reasons.BACKEND_MISSING_INTERFACE
64 )
65
66 self._algorithm = algorithm
67
68 self._backend = backend
69
70 max_length = 255 * (algorithm.digest_size // 8)
71
72 if length > max_length:
73 raise ValueError(
74 "Can not derive keys larger than {0} octets.".format(
75 max_length
76 ))
77
78 self._length = length
79
80 if not (info is None or isinstance(info, bytes)):
81 raise TypeError("info must be bytes.")
82
83 if info is None:
84 info = b""
85
86 self._info = info
87
88 self._used = False
89
90 def _expand(self, key_material):
91 output = [b""]
92 counter = 1
93
94 while (self._algorithm.digest_size // 8) * len(output) < self._length:
95 h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
96 h.update(output[-1])
97 h.update(self._info)
98 h.update(six.int2byte(counter))
99 output.append(h.finalize())
100 counter += 1
101
102 return b"".join(output)[:self._length]
103
104 def derive(self, key_material):
105 if not isinstance(key_material, bytes):
106 raise TypeError("key_material must be bytes.")
107
108 if self._used:
109 raise AlreadyFinalized
110
111 self._used = True
112 return self._expand(key_material)
113
114 def verify(self, key_material, expected_key):
115 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
116 raise InvalidKey
117
[end of src/cryptography/hazmat/primitives/kdf/hkdf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py
--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py
+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py
@@ -91,7 +91,7 @@
output = [b""]
counter = 1
- while (self._algorithm.digest_size // 8) * len(output) < self._length:
+ while self._algorithm.digest_size * (len(output) - 1) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py\n+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n@@ -91,7 +91,7 @@\n output = [b\"\"]\n counter = 1\n \n- while (self._algorithm.digest_size // 8) * len(output) < self._length:\n+ while self._algorithm.digest_size * (len(output) - 1) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n", "issue": "HKDF key-length inconsistency\nFor too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:\r\n\r\nProgram:\r\n```python\r\n#!/usr/bin/env python3.5\r\nimport cryptography\r\nfrom cryptography.hazmat.primitives import hashes\r\nfrom cryptography.hazmat.primitives.kdf.hkdf import HKDF\r\nfrom cryptography.hazmat.backends import default_backend\r\n\r\nprint(\"cryptography.io:{}\".format(cryptography.__version__))\r\n\r\nhkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b\"salt\",\r\n info=b\"some-test\", backend=default_backend())\r\n\r\nkey = hkdf.derive(b\"my secret passphrase\")\r\nprint(\"Derived key: {}\".format(key))\r\n```\r\n\r\nOutput:\r\n```\r\ncryptography.io:1.5.2\r\nDerived key: b''\r\n```\r\n\r\nSuggested fix:\r\n\r\nI am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.\r\n\r\n```python\r\n# class HKDFExpand\r\ndef _expand(self, key_material):\r\n output = [b\"\"]\r\n counter = 1\r\n\r\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\r\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\r\n h.update(output[-1])\r\n h.update(self._info)\r\n h.update(six.int2byte(counter))\r\n output.append(h.finalize())\r\n counter += 1\r\n\r\n return b\"\".join(output)[:self._length]\r\n```\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.backends.interfaces import HMACBackend\nfrom cryptography.hazmat.primitives import constant_time, hmac\nfrom cryptography.hazmat.primitives.kdf import KeyDerivationFunction\n\n\[email protected]_interface(KeyDerivationFunction)\nclass HKDF(object):\n def __init__(self, algorithm, length, salt, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n if not (salt is None or isinstance(salt, bytes)):\n raise TypeError(\"salt must be bytes.\")\n\n if salt is None:\n salt = b\"\\x00\" * (self._algorithm.digest_size // 8)\n\n self._salt = salt\n\n self._backend = backend\n\n self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)\n\n def _extract(self, key_material):\n h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)\n h.update(key_material)\n return h.finalize()\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n return self._hkdf_expand.derive(self._extract(key_material))\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n\n\[email protected]_interface(KeyDerivationFunction)\nclass HKDFExpand(object):\n def __init__(self, algorithm, length, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n self._backend = backend\n\n max_length = 255 * (algorithm.digest_size // 8)\n\n if length > max_length:\n raise ValueError(\n \"Can not derive keys larger than {0} octets.\".format(\n max_length\n ))\n\n self._length = length\n\n if not (info is None or isinstance(info, bytes)):\n raise TypeError(\"info must be bytes.\")\n\n if info is None:\n info = b\"\"\n\n self._info = info\n\n self._used = False\n\n def _expand(self, key_material):\n output = [b\"\"]\n counter = 1\n\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n h.update(six.int2byte(counter))\n output.append(h.finalize())\n counter += 1\n\n return b\"\".join(output)[:self._length]\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n if self._used:\n raise AlreadyFinalized\n\n self._used = True\n return self._expand(key_material)\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n", "path": "src/cryptography/hazmat/primitives/kdf/hkdf.py"}]}
| 1,999 | 170 |
gh_patches_debug_20557
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-5408
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dvc exp gc: can't run experiments after garbage collection
# Bug Report
## Description
Experiments fail after garbage collection via `dvc exp gc`.
### Reproduce
1. dvc init
2. dvc stage add -n foo -M foo.yaml 'echo "score: 1" > foo.yaml'
3. git add .
4. git commit -m "add stage"
5. dvc exp run
6. dvc exp gc -fT
7. dvc exp run
```console
Stage 'foo' didn't change, skipping
ERROR: Failed to set 'refs/exps/d1/5cee9fd7a4fc20c5d7167671df4ed78b3cfb7a/exp-985c5'
ERROR: Failed to set 'refs/exps/d1/5cee9fd7a4fc20c5d7167671df4ed78b3cfb7a/exp-985c5'
```
### Expected
`dvc exp run` to successfully run experiment.
### Environment information
**Output of `dvc version`:**
```console
$ dvc version
DVC version: 2.0.0a0+adedd1
---------------------------------
Platform: Python 3.9.1 on Linux-5.8.0-38-generic-x86_64-with-glibc2.31
Supports: http, https
Cache types: <https://error.dvc.org/no-dvc-cache>
Caches: local
Remotes: None
Workspace directory: ext4 on /dev/mapper/vgubuntu-root
Repo: dvc, git
```
**Additional Information (if any):**
<!--
If applicable, please also provide a `--verbose` output of the command, eg: `dvc add --verbose`.
-->
</issue>
<code>
[start of dvc/repo/experiments/gc.py]
1 import logging
2 from typing import Optional
3
4 from dvc.repo import locked
5
6 from .utils import exp_refs
7
8 logger = logging.getLogger(__name__)
9
10
11 @locked
12 def gc(
13 repo,
14 all_branches: Optional[bool] = False,
15 all_tags: Optional[bool] = False,
16 all_commits: Optional[bool] = False,
17 workspace: Optional[bool] = False,
18 queued: Optional[bool] = False,
19 ):
20 keep_revs = set(
21 repo.brancher(
22 all_branches=all_branches,
23 all_tags=all_tags,
24 all_commits=all_commits,
25 sha_only=True,
26 )
27 )
28 if workspace:
29 keep_revs.add(repo.scm.get_rev())
30
31 if not keep_revs:
32 return 0
33
34 removed = 0
35 for ref_info in exp_refs(repo.scm):
36 if ref_info.baseline_sha not in keep_revs:
37 repo.scm.remove_ref(str(ref_info))
38 removed += 1
39
40 delete_stashes = []
41 for _, entry in repo.experiments.stash_revs.items():
42 if not queued or entry.baseline_rev not in keep_revs:
43 delete_stashes.append(entry.index)
44 for index in sorted(delete_stashes, reverse=True):
45 repo.experiments.stash.drop(index)
46 removed += len(delete_stashes)
47
48 return removed
49
[end of dvc/repo/experiments/gc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/repo/experiments/gc.py b/dvc/repo/experiments/gc.py
--- a/dvc/repo/experiments/gc.py
+++ b/dvc/repo/experiments/gc.py
@@ -3,6 +3,7 @@
from dvc.repo import locked
+from .base import EXEC_APPLY, EXEC_BRANCH, EXEC_CHECKPOINT
from .utils import exp_refs
logger = logging.getLogger(__name__)
@@ -31,9 +32,20 @@
if not keep_revs:
return 0
+ exec_branch = repo.scm.get_ref(EXEC_BRANCH, follow=False)
+ exec_apply = repo.scm.get_ref(EXEC_APPLY)
+ exec_checkpoint = repo.scm.get_ref(EXEC_CHECKPOINT)
+
removed = 0
for ref_info in exp_refs(repo.scm):
if ref_info.baseline_sha not in keep_revs:
+ ref = repo.scm.get_ref(str(ref_info))
+ if exec_branch and str(ref_info):
+ repo.scm.remove_ref(EXEC_BRANCH)
+ if exec_apply and exec_apply == ref:
+ repo.scm.remove_ref(EXEC_APPLY)
+ if exec_checkpoint and exec_checkpoint == ref:
+ repo.scm.remove_ref(EXEC_CHECKPOINT)
repo.scm.remove_ref(str(ref_info))
removed += 1
|
{"golden_diff": "diff --git a/dvc/repo/experiments/gc.py b/dvc/repo/experiments/gc.py\n--- a/dvc/repo/experiments/gc.py\n+++ b/dvc/repo/experiments/gc.py\n@@ -3,6 +3,7 @@\n \n from dvc.repo import locked\n \n+from .base import EXEC_APPLY, EXEC_BRANCH, EXEC_CHECKPOINT\n from .utils import exp_refs\n \n logger = logging.getLogger(__name__)\n@@ -31,9 +32,20 @@\n if not keep_revs:\n return 0\n \n+ exec_branch = repo.scm.get_ref(EXEC_BRANCH, follow=False)\n+ exec_apply = repo.scm.get_ref(EXEC_APPLY)\n+ exec_checkpoint = repo.scm.get_ref(EXEC_CHECKPOINT)\n+\n removed = 0\n for ref_info in exp_refs(repo.scm):\n if ref_info.baseline_sha not in keep_revs:\n+ ref = repo.scm.get_ref(str(ref_info))\n+ if exec_branch and str(ref_info):\n+ repo.scm.remove_ref(EXEC_BRANCH)\n+ if exec_apply and exec_apply == ref:\n+ repo.scm.remove_ref(EXEC_APPLY)\n+ if exec_checkpoint and exec_checkpoint == ref:\n+ repo.scm.remove_ref(EXEC_CHECKPOINT)\n repo.scm.remove_ref(str(ref_info))\n removed += 1\n", "issue": "dvc exp gc: can't run experiments after garbage collection\n# Bug Report\r\n\r\n## Description\r\n\r\nExperiments fail after garbage collection via `dvc exp gc`.\r\n\r\n### Reproduce\r\n\r\n1. dvc init\r\n2. dvc stage add -n foo -M foo.yaml 'echo \"score: 1\" > foo.yaml'\r\n3. git add .\r\n4. git commit -m \"add stage\"\r\n5. dvc exp run\r\n6. dvc exp gc -fT\r\n7. dvc exp run\r\n\r\n```console\r\nStage 'foo' didn't change, skipping\r\nERROR: Failed to set 'refs/exps/d1/5cee9fd7a4fc20c5d7167671df4ed78b3cfb7a/exp-985c5'\r\nERROR: Failed to set 'refs/exps/d1/5cee9fd7a4fc20c5d7167671df4ed78b3cfb7a/exp-985c5'\r\n```\r\n\r\n### Expected\r\n\r\n`dvc exp run` to successfully run experiment.\r\n\r\n### Environment information\r\n\r\n**Output of `dvc version`:**\r\n\r\n```console\r\n$ dvc version\r\nDVC version: 2.0.0a0+adedd1\r\n---------------------------------\r\nPlatform: Python 3.9.1 on Linux-5.8.0-38-generic-x86_64-with-glibc2.31\r\nSupports: http, https\r\nCache types: <https://error.dvc.org/no-dvc-cache>\r\nCaches: local\r\nRemotes: None\r\nWorkspace directory: ext4 on /dev/mapper/vgubuntu-root\r\nRepo: dvc, git\r\n```\r\n\r\n**Additional Information (if any):**\r\n\r\n<!--\r\nIf applicable, please also provide a `--verbose` output of the command, eg: `dvc add --verbose`.\r\n-->\n", "before_files": [{"content": "import logging\nfrom typing import Optional\n\nfrom dvc.repo import locked\n\nfrom .utils import exp_refs\n\nlogger = logging.getLogger(__name__)\n\n\n@locked\ndef gc(\n repo,\n all_branches: Optional[bool] = False,\n all_tags: Optional[bool] = False,\n all_commits: Optional[bool] = False,\n workspace: Optional[bool] = False,\n queued: Optional[bool] = False,\n):\n keep_revs = set(\n repo.brancher(\n all_branches=all_branches,\n all_tags=all_tags,\n all_commits=all_commits,\n sha_only=True,\n )\n )\n if workspace:\n keep_revs.add(repo.scm.get_rev())\n\n if not keep_revs:\n return 0\n\n removed = 0\n for ref_info in exp_refs(repo.scm):\n if ref_info.baseline_sha not in keep_revs:\n repo.scm.remove_ref(str(ref_info))\n removed += 1\n\n delete_stashes = []\n for _, entry in repo.experiments.stash_revs.items():\n if not queued or entry.baseline_rev not in keep_revs:\n delete_stashes.append(entry.index)\n for index in sorted(delete_stashes, reverse=True):\n repo.experiments.stash.drop(index)\n removed += len(delete_stashes)\n\n return removed\n", "path": "dvc/repo/experiments/gc.py"}]}
| 1,337 | 296 |
gh_patches_debug_18481
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-4966
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing chair email aliases for research area groups
### Describe the issue
There are two Research Area Groups in the datatracker, anrw and irtfopen. These groups have a chair listed, but the email expansions at https://datatracker.ietf.org/group/irtfopen/email/ appear to be missing the chairs alias ([email protected]) and email sent to that address bounces. Similarly, presumably, for anrw.
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of ietf/group/management/commands/generate_group_aliases.py]
1 # Copyright The IETF Trust 2012-2021, All Rights Reserved
2 # -*- coding: utf-8 -*-
3
4 # This was written as a script by Markus Stenberg <[email protected]>.
5 # It was turned into a management command by Russ Housley <[email protected]>.
6
7 import datetime
8 import io
9 import os
10 import shutil
11 import stat
12 import time
13
14 from tempfile import mkstemp
15
16 from django.conf import settings
17 from django.core.management.base import BaseCommand
18 from django.utils import timezone
19
20 import debug # pyflakes:ignore
21
22 from ietf.group.models import Group
23 from ietf.group.utils import get_group_ad_emails, get_group_role_emails, get_child_group_role_emails
24 from ietf.name.models import GroupTypeName
25 from ietf.utils.aliases import dump_sublist
26
27 DEFAULT_YEARS = 5
28 ACTIVE_STATES=['active', 'bof', 'proposed']
29 GROUP_TYPES=['wg', 'rg', 'dir', 'team', 'review', 'program', 'rfcedtyp']
30 NO_AD_GROUP_TYPES=['rg', 'team', 'program', 'rfcedtyp']
31 IETF_DOMAIN=['ietf.org', ]
32 IRTF_DOMAIN=['irtf.org', ]
33 IAB_DOMAIN=['iab.org', ]
34
35 class Command(BaseCommand):
36 help = ('Generate the group-aliases and group-virtual files for Internet-Draft '
37 'mail aliases, placing them in the file configured in '
38 'settings.GROUP_ALIASES_PATH and settings.GROUP_VIRTUAL_PATH, '
39 'respectively. The generation includes aliases for groups that '
40 'have seen activity in the last %s years.' % (DEFAULT_YEARS))
41
42 def handle(self, *args, **options):
43 show_since = timezone.now() - datetime.timedelta(DEFAULT_YEARS*365)
44
45 date = time.strftime("%Y-%m-%d_%H:%M:%S")
46 signature = '# Generated by %s at %s\n' % (os.path.abspath(__file__), date)
47
48 ahandle, aname = mkstemp()
49 os.close(ahandle)
50 afile = io.open(aname,"w")
51
52 vhandle, vname = mkstemp()
53 os.close(vhandle)
54 vfile = io.open(vname,"w")
55
56 afile.write(signature)
57 vfile.write(signature)
58 vfile.write("%s anything\n" % settings.GROUP_VIRTUAL_DOMAIN)
59
60 # Loop through each group type and build -ads and -chairs entries
61 for g in GROUP_TYPES:
62 domains = []
63 domains += IETF_DOMAIN
64 if g == 'rg':
65 domains += IRTF_DOMAIN
66 if g == 'program':
67 domains += IAB_DOMAIN
68
69 entries = Group.objects.filter(type=g).all()
70 active_entries = entries.filter(state__in=ACTIVE_STATES)
71 inactive_recent_entries = entries.exclude(state__in=ACTIVE_STATES).filter(time__gte=show_since)
72 interesting_entries = active_entries | inactive_recent_entries
73
74 for e in interesting_entries.distinct().iterator():
75 name = e.acronym
76
77 # Research groups, teams, and programs do not have -ads lists
78 if not g in NO_AD_GROUP_TYPES:
79 dump_sublist(afile, vfile, name+'-ads', domains, settings.GROUP_VIRTUAL_DOMAIN, get_group_ad_emails(e))
80 # All group types have -chairs lists
81 dump_sublist(afile, vfile, name+'-chairs', domains, settings.GROUP_VIRTUAL_DOMAIN, get_group_role_emails(e, ['chair', 'secr']))
82
83 # The area lists include every chair in active working groups in the area
84 areas = Group.objects.filter(type='area').all()
85 active_areas = areas.filter(state__in=ACTIVE_STATES)
86 for area in active_areas:
87 name = area.acronym
88 area_ad_emails = get_group_role_emails(area, ['pre-ad', 'ad', 'chair'])
89 dump_sublist(afile, vfile, name+'-ads', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, area_ad_emails)
90 dump_sublist(afile, vfile, name+'-chairs', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, (get_child_group_role_emails(area, ['chair', 'secr']) | area_ad_emails))
91
92 # Other groups with chairs that require Internet-Draft submission approval
93 gtypes = GroupTypeName.objects.values_list('slug', flat=True)
94 special_groups = Group.objects.filter(type__features__req_subm_approval=True, acronym__in=gtypes, state='active')
95 for group in special_groups:
96 dump_sublist(afile, vfile, group.acronym+'-chairs', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, get_group_role_emails(group, ['chair', 'delegate']))
97
98 afile.close()
99 vfile.close()
100
101 os.chmod(aname, stat.S_IWUSR|stat.S_IRUSR|stat.S_IRGRP|stat.S_IROTH)
102 os.chmod(vname, stat.S_IWUSR|stat.S_IRUSR|stat.S_IRGRP|stat.S_IROTH)
103
104 shutil.move(aname, settings.GROUP_ALIASES_PATH)
105 shutil.move(vname, settings.GROUP_VIRTUAL_PATH)
106
[end of ietf/group/management/commands/generate_group_aliases.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ietf/group/management/commands/generate_group_aliases.py b/ietf/group/management/commands/generate_group_aliases.py
--- a/ietf/group/management/commands/generate_group_aliases.py
+++ b/ietf/group/management/commands/generate_group_aliases.py
@@ -26,8 +26,8 @@
DEFAULT_YEARS = 5
ACTIVE_STATES=['active', 'bof', 'proposed']
-GROUP_TYPES=['wg', 'rg', 'dir', 'team', 'review', 'program', 'rfcedtyp']
-NO_AD_GROUP_TYPES=['rg', 'team', 'program', 'rfcedtyp']
+GROUP_TYPES=['wg', 'rg', 'rag', 'dir', 'team', 'review', 'program', 'rfcedtyp']
+NO_AD_GROUP_TYPES=['rg', 'rag', 'team', 'program', 'rfcedtyp']
IETF_DOMAIN=['ietf.org', ]
IRTF_DOMAIN=['irtf.org', ]
IAB_DOMAIN=['iab.org', ]
@@ -61,7 +61,7 @@
for g in GROUP_TYPES:
domains = []
domains += IETF_DOMAIN
- if g == 'rg':
+ if g in ('rg', 'rag'):
domains += IRTF_DOMAIN
if g == 'program':
domains += IAB_DOMAIN
|
{"golden_diff": "diff --git a/ietf/group/management/commands/generate_group_aliases.py b/ietf/group/management/commands/generate_group_aliases.py\n--- a/ietf/group/management/commands/generate_group_aliases.py\n+++ b/ietf/group/management/commands/generate_group_aliases.py\n@@ -26,8 +26,8 @@\n \n DEFAULT_YEARS = 5\n ACTIVE_STATES=['active', 'bof', 'proposed']\n-GROUP_TYPES=['wg', 'rg', 'dir', 'team', 'review', 'program', 'rfcedtyp']\n-NO_AD_GROUP_TYPES=['rg', 'team', 'program', 'rfcedtyp']\n+GROUP_TYPES=['wg', 'rg', 'rag', 'dir', 'team', 'review', 'program', 'rfcedtyp']\n+NO_AD_GROUP_TYPES=['rg', 'rag', 'team', 'program', 'rfcedtyp']\n IETF_DOMAIN=['ietf.org', ]\n IRTF_DOMAIN=['irtf.org', ]\n IAB_DOMAIN=['iab.org', ]\n@@ -61,7 +61,7 @@\n for g in GROUP_TYPES:\n domains = []\n domains += IETF_DOMAIN\n- if g == 'rg':\n+ if g in ('rg', 'rag'):\n domains += IRTF_DOMAIN\n if g == 'program':\n domains += IAB_DOMAIN\n", "issue": "Missing chair email aliases for research area groups\n### Describe the issue\n\nThere are two Research Area Groups in the datatracker, anrw and irtfopen. These groups have a chair listed, but the email expansions at https://datatracker.ietf.org/group/irtfopen/email/ appear to be missing the chairs alias ([email protected]) and email sent to that address bounces. Similarly, presumably, for anrw.\r\n\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Copyright The IETF Trust 2012-2021, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n# This was written as a script by Markus Stenberg <[email protected]>.\n# It was turned into a management command by Russ Housley <[email protected]>.\n\nimport datetime\nimport io\nimport os\nimport shutil\nimport stat\nimport time\n\nfrom tempfile import mkstemp\n \nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom django.utils import timezone\n\nimport debug # pyflakes:ignore\n\nfrom ietf.group.models import Group\nfrom ietf.group.utils import get_group_ad_emails, get_group_role_emails, get_child_group_role_emails\nfrom ietf.name.models import GroupTypeName\nfrom ietf.utils.aliases import dump_sublist\n\nDEFAULT_YEARS = 5\nACTIVE_STATES=['active', 'bof', 'proposed']\nGROUP_TYPES=['wg', 'rg', 'dir', 'team', 'review', 'program', 'rfcedtyp']\nNO_AD_GROUP_TYPES=['rg', 'team', 'program', 'rfcedtyp']\nIETF_DOMAIN=['ietf.org', ]\nIRTF_DOMAIN=['irtf.org', ]\nIAB_DOMAIN=['iab.org', ]\n\nclass Command(BaseCommand):\n help = ('Generate the group-aliases and group-virtual files for Internet-Draft '\n 'mail aliases, placing them in the file configured in '\n 'settings.GROUP_ALIASES_PATH and settings.GROUP_VIRTUAL_PATH, '\n 'respectively. The generation includes aliases for groups that '\n 'have seen activity in the last %s years.' % (DEFAULT_YEARS))\n\n def handle(self, *args, **options):\n show_since = timezone.now() - datetime.timedelta(DEFAULT_YEARS*365)\n\n date = time.strftime(\"%Y-%m-%d_%H:%M:%S\")\n signature = '# Generated by %s at %s\\n' % (os.path.abspath(__file__), date)\n\n ahandle, aname = mkstemp()\n os.close(ahandle)\n afile = io.open(aname,\"w\")\n\n vhandle, vname = mkstemp()\n os.close(vhandle)\n vfile = io.open(vname,\"w\")\n\n afile.write(signature)\n vfile.write(signature)\n vfile.write(\"%s anything\\n\" % settings.GROUP_VIRTUAL_DOMAIN)\n\n # Loop through each group type and build -ads and -chairs entries\n for g in GROUP_TYPES:\n domains = []\n domains += IETF_DOMAIN\n if g == 'rg':\n domains += IRTF_DOMAIN\n if g == 'program':\n domains += IAB_DOMAIN\n\n entries = Group.objects.filter(type=g).all()\n active_entries = entries.filter(state__in=ACTIVE_STATES)\n inactive_recent_entries = entries.exclude(state__in=ACTIVE_STATES).filter(time__gte=show_since)\n interesting_entries = active_entries | inactive_recent_entries\n\n for e in interesting_entries.distinct().iterator():\n name = e.acronym\n \n # Research groups, teams, and programs do not have -ads lists\n if not g in NO_AD_GROUP_TYPES:\n dump_sublist(afile, vfile, name+'-ads', domains, settings.GROUP_VIRTUAL_DOMAIN, get_group_ad_emails(e))\n # All group types have -chairs lists\n dump_sublist(afile, vfile, name+'-chairs', domains, settings.GROUP_VIRTUAL_DOMAIN, get_group_role_emails(e, ['chair', 'secr']))\n\n # The area lists include every chair in active working groups in the area\n areas = Group.objects.filter(type='area').all()\n active_areas = areas.filter(state__in=ACTIVE_STATES)\n for area in active_areas:\n name = area.acronym\n area_ad_emails = get_group_role_emails(area, ['pre-ad', 'ad', 'chair'])\n dump_sublist(afile, vfile, name+'-ads', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, area_ad_emails)\n dump_sublist(afile, vfile, name+'-chairs', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, (get_child_group_role_emails(area, ['chair', 'secr']) | area_ad_emails))\n\n # Other groups with chairs that require Internet-Draft submission approval\n gtypes = GroupTypeName.objects.values_list('slug', flat=True)\n special_groups = Group.objects.filter(type__features__req_subm_approval=True, acronym__in=gtypes, state='active')\n for group in special_groups:\n dump_sublist(afile, vfile, group.acronym+'-chairs', IETF_DOMAIN, settings.GROUP_VIRTUAL_DOMAIN, get_group_role_emails(group, ['chair', 'delegate']))\n\n afile.close()\n vfile.close()\n\n os.chmod(aname, stat.S_IWUSR|stat.S_IRUSR|stat.S_IRGRP|stat.S_IROTH) \n os.chmod(vname, stat.S_IWUSR|stat.S_IRUSR|stat.S_IRGRP|stat.S_IROTH) \n\n shutil.move(aname, settings.GROUP_ALIASES_PATH)\n shutil.move(vname, settings.GROUP_VIRTUAL_PATH)\n", "path": "ietf/group/management/commands/generate_group_aliases.py"}]}
| 2,029 | 289 |
gh_patches_debug_9214
|
rasdani/github-patches
|
git_diff
|
Frojd__Wagtail-Pipit-35
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use Werkzeug
Add django-extensions and Werkzeug to local requirements, and use runserver_plus in docker-entrypoint.sh.
It is a lot faster than regular runserver in Docker.
</issue>
<code>
[start of Example-Project/src/core/settings/local.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """
5 Write local settings here, or override base settings
6 """
7 from __future__ import absolute_import, unicode_literals
8
9 from core.settings.base import * # NOQA
10
11
12 DEBUG = True
13 TEMPLATES[0]['OPTIONS']['debug'] = DEBUG
14
15 DEBUG_TOOLBAR_PATCH_SETTINGS = False
16
17 # Add django debug toolbar when using local version
18 INSTALLED_APPS += [
19 'debug_toolbar',
20 ]
21
22 MIDDLEWARE_CLASSES += [
23 'debug_toolbar.middleware.DebugToolbarMiddleware',
24 ]
25
26 # Allow weak local passwords
27 AUTH_PASSWORD_VALIDATORS = []
28
29 INTERNAL_IPS = get_env('INTERNAL_IPS', default="").split(',')
30
31
32 # Allow django-debug-bar under docker
33 def show_toolbar(request):
34 # https://gist.github.com/douglasmiranda/9de51aaba14543851ca3
35 return not request.is_ajax()
36
37 DEBUG_TOOLBAR_CONFIG = {
38 'SHOW_TOOLBAR_CALLBACK': 'core.settings.local.show_toolbar',
39 }
40
[end of Example-Project/src/core/settings/local.py]
[start of {{cookiecutter.project_name}}/src/core/settings/local.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 """
5 Write local settings here, or override base settings
6 """
7 from __future__ import absolute_import, unicode_literals
8
9 from core.settings.base import * # NOQA
10
11
12 DEBUG = True
13 TEMPLATES[0]['OPTIONS']['debug'] = DEBUG
14
15 DEBUG_TOOLBAR_PATCH_SETTINGS = False
16
17 # Add django debug toolbar when using local version
18 INSTALLED_APPS += [
19 'debug_toolbar',
20 ]
21
22 MIDDLEWARE_CLASSES += [
23 'debug_toolbar.middleware.DebugToolbarMiddleware',
24 ]
25
26 # Allow weak local passwords
27 AUTH_PASSWORD_VALIDATORS = []
28
29 INTERNAL_IPS = get_env('INTERNAL_IPS', default="").split(',')
30
31
32 # Allow django-debug-bar under docker
33 def show_toolbar(request):
34 # https://gist.github.com/douglasmiranda/9de51aaba14543851ca3
35 return not request.is_ajax()
36
37 DEBUG_TOOLBAR_CONFIG = {
38 'SHOW_TOOLBAR_CALLBACK': 'core.settings.local.show_toolbar',
39 }
40
[end of {{cookiecutter.project_name}}/src/core/settings/local.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Example-Project/src/core/settings/local.py b/Example-Project/src/core/settings/local.py
--- a/Example-Project/src/core/settings/local.py
+++ b/Example-Project/src/core/settings/local.py
@@ -17,6 +17,7 @@
# Add django debug toolbar when using local version
INSTALLED_APPS += [
'debug_toolbar',
+ 'django_extensions',
]
MIDDLEWARE_CLASSES += [
diff --git a/{{cookiecutter.project_name}}/src/core/settings/local.py b/{{cookiecutter.project_name}}/src/core/settings/local.py
--- a/{{cookiecutter.project_name}}/src/core/settings/local.py
+++ b/{{cookiecutter.project_name}}/src/core/settings/local.py
@@ -17,6 +17,7 @@
# Add django debug toolbar when using local version
INSTALLED_APPS += [
'debug_toolbar',
+ 'django_extensions',
]
MIDDLEWARE_CLASSES += [
|
{"golden_diff": "diff --git a/Example-Project/src/core/settings/local.py b/Example-Project/src/core/settings/local.py\n--- a/Example-Project/src/core/settings/local.py\n+++ b/Example-Project/src/core/settings/local.py\n@@ -17,6 +17,7 @@\n # Add django debug toolbar when using local version\n INSTALLED_APPS += [\n 'debug_toolbar',\n+ 'django_extensions',\n ]\n \n MIDDLEWARE_CLASSES += [\ndiff --git a/{{cookiecutter.project_name}}/src/core/settings/local.py b/{{cookiecutter.project_name}}/src/core/settings/local.py\n--- a/{{cookiecutter.project_name}}/src/core/settings/local.py\n+++ b/{{cookiecutter.project_name}}/src/core/settings/local.py\n@@ -17,6 +17,7 @@\n # Add django debug toolbar when using local version\n INSTALLED_APPS += [\n 'debug_toolbar',\n+ 'django_extensions',\n ]\n \n MIDDLEWARE_CLASSES += [\n", "issue": "Use Werkzeug\nAdd django-extensions and Werkzeug to local requirements, and use runserver_plus in docker-entrypoint.sh.\r\nIt is a lot faster than regular runserver in Docker.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nWrite local settings here, or override base settings\n\"\"\"\nfrom __future__ import absolute_import, unicode_literals\n\nfrom core.settings.base import * # NOQA\n\n\nDEBUG = True\nTEMPLATES[0]['OPTIONS']['debug'] = DEBUG\n\nDEBUG_TOOLBAR_PATCH_SETTINGS = False\n\n# Add django debug toolbar when using local version\nINSTALLED_APPS += [\n 'debug_toolbar',\n]\n\nMIDDLEWARE_CLASSES += [\n 'debug_toolbar.middleware.DebugToolbarMiddleware',\n]\n\n# Allow weak local passwords\nAUTH_PASSWORD_VALIDATORS = []\n\nINTERNAL_IPS = get_env('INTERNAL_IPS', default=\"\").split(',')\n\n\n# Allow django-debug-bar under docker\ndef show_toolbar(request):\n # https://gist.github.com/douglasmiranda/9de51aaba14543851ca3\n return not request.is_ajax()\n\nDEBUG_TOOLBAR_CONFIG = {\n 'SHOW_TOOLBAR_CALLBACK': 'core.settings.local.show_toolbar',\n}\n", "path": "Example-Project/src/core/settings/local.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nWrite local settings here, or override base settings\n\"\"\"\nfrom __future__ import absolute_import, unicode_literals\n\nfrom core.settings.base import * # NOQA\n\n\nDEBUG = True\nTEMPLATES[0]['OPTIONS']['debug'] = DEBUG\n\nDEBUG_TOOLBAR_PATCH_SETTINGS = False\n\n# Add django debug toolbar when using local version\nINSTALLED_APPS += [\n 'debug_toolbar',\n]\n\nMIDDLEWARE_CLASSES += [\n 'debug_toolbar.middleware.DebugToolbarMiddleware',\n]\n\n# Allow weak local passwords\nAUTH_PASSWORD_VALIDATORS = []\n\nINTERNAL_IPS = get_env('INTERNAL_IPS', default=\"\").split(',')\n\n\n# Allow django-debug-bar under docker\ndef show_toolbar(request):\n # https://gist.github.com/douglasmiranda/9de51aaba14543851ca3\n return not request.is_ajax()\n\nDEBUG_TOOLBAR_CONFIG = {\n 'SHOW_TOOLBAR_CALLBACK': 'core.settings.local.show_toolbar',\n}\n", "path": "{{cookiecutter.project_name}}/src/core/settings/local.py"}]}
| 1,201 | 205 |
gh_patches_debug_40022
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-5062
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ensure_spacing function may be slow
## Description
The `skimage._shared.coord.ensure_spacing` function introduced in #4760 may be slow when the number of input points is large.
## Way to reproduce
```python
In [1]: import numpy as np
In [2]: from skimage._shared.coord import ensure_spacing
In [3]: for n in range(500, 10001, 500):
...: print(f"n = {n}")
...: x = np.random.rand(n, 2)
...: %timeit ensure_spacing(x, 0.2)
...:
n = 500
27.6 ms ± 857 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
n = 1000
64.7 ms ± 1.93 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
n = 1500
105 ms ± 2.27 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
n = 2000
158 ms ± 1.18 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
n = 2500
213 ms ± 7.32 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 3000
299 ms ± 11.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 3500
378 ms ± 3.05 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 4000
428 ms ± 11.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 4500
554 ms ± 14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 5000
647 ms ± 9.42 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 5500
777 ms ± 7.05 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 6000
870 ms ± 13.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 6500
1.03 s ± 9.56 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 7000
1.17 s ± 12.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 7500
1.33 s ± 28 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 8000
1.45 s ± 18.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 8500
1.63 s ± 36.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 9000
1.87 s ± 50.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 9500
2.07 s ± 23.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
n = 10000
2.29 s ± 51.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
</issue>
<code>
[start of skimage/_shared/coord.py]
1 import numpy as np
2 from scipy.spatial import cKDTree, distance
3
4
5 def ensure_spacing(coord, spacing=1, p_norm=np.inf):
6 """Returns a subset of coord where a minimum spacing is guaranteed.
7
8 Parameters
9 ----------
10 coord : ndarray
11 The coordinates of the considered points.
12 spacing : float
13 the maximum allowed spacing between the points.
14 p_norm : float
15 Which Minkowski p-norm to use. Should be in the range [1, inf].
16 A finite large p may cause a ValueError if overflow can occur.
17 ``inf`` corresponds to the Chebyshev distance and 2 to the
18 Euclidean distance.
19
20 Returns
21 -------
22 output : ndarray
23 A subset of coord where a minimum spacing is guaranteed.
24
25 """
26
27 output = coord
28 if len(coord):
29 # Use KDtree to find the peaks that are too close to each other
30 tree = cKDTree(coord)
31
32 indices = tree.query_ball_point(coord, r=spacing, p=p_norm)
33 rejected_peaks_indices = set()
34 for idx, candidates in enumerate(indices):
35 if idx not in rejected_peaks_indices:
36 # keep current point and the points at exactly spacing from it
37 candidates.remove(idx)
38 dist = distance.cdist([coord[idx]],
39 coord[candidates],
40 distance.minkowski,
41 p=p_norm).reshape(-1)
42 candidates = [c for c, d in zip(candidates, dist)
43 if d < spacing]
44
45 # candidates.remove(keep)
46 rejected_peaks_indices.update(candidates)
47
48 # Remove the peaks that are too close to each other
49 output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)
50
51 return output
52
[end of skimage/_shared/coord.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/_shared/coord.py b/skimage/_shared/coord.py
--- a/skimage/_shared/coord.py
+++ b/skimage/_shared/coord.py
@@ -2,7 +2,7 @@
from scipy.spatial import cKDTree, distance
-def ensure_spacing(coord, spacing=1, p_norm=np.inf):
+def _ensure_spacing(coord, spacing, p_norm):
"""Returns a subset of coord where a minimum spacing is guaranteed.
Parameters
@@ -24,28 +24,72 @@
"""
- output = coord
- if len(coord):
- # Use KDtree to find the peaks that are too close to each other
- tree = cKDTree(coord)
-
- indices = tree.query_ball_point(coord, r=spacing, p=p_norm)
- rejected_peaks_indices = set()
- for idx, candidates in enumerate(indices):
- if idx not in rejected_peaks_indices:
- # keep current point and the points at exactly spacing from it
- candidates.remove(idx)
- dist = distance.cdist([coord[idx]],
- coord[candidates],
- distance.minkowski,
- p=p_norm).reshape(-1)
- candidates = [c for c, d in zip(candidates, dist)
- if d < spacing]
-
- # candidates.remove(keep)
- rejected_peaks_indices.update(candidates)
-
- # Remove the peaks that are too close to each other
- output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)
+ # Use KDtree to find the peaks that are too close to each other
+ tree = cKDTree(coord)
+
+ indices = tree.query_ball_point(coord, r=spacing, p=p_norm)
+ rejected_peaks_indices = set()
+ for idx, candidates in enumerate(indices):
+ if idx not in rejected_peaks_indices:
+ # keep current point and the points at exactly spacing from it
+ candidates.remove(idx)
+ dist = distance.cdist([coord[idx]],
+ coord[candidates],
+ distance.minkowski,
+ p=p_norm).reshape(-1)
+ candidates = [c for c, d in zip(candidates, dist)
+ if d < spacing]
+
+ # candidates.remove(keep)
+ rejected_peaks_indices.update(candidates)
+
+ # Remove the peaks that are too close to each other
+ output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)
+
+ return output
+
+
+def ensure_spacing(coords, spacing=1, p_norm=np.inf, min_split_size=50):
+ """Returns a subset of coord where a minimum spacing is guaranteed.
+
+ Parameters
+ ----------
+ coord : array_like
+ The coordinates of the considered points.
+ spacing : float
+ the maximum allowed spacing between the points.
+ p_norm : float
+ Which Minkowski p-norm to use. Should be in the range [1, inf].
+ A finite large p may cause a ValueError if overflow can occur.
+ ``inf`` corresponds to the Chebyshev distance and 2 to the
+ Euclidean distance.
+ min_split_size : int
+ Minimum split size used to process ``coord`` by batch to save
+ memory. If None, the memory saving strategy is not applied.
+
+ Returns
+ -------
+ output : array_like
+ A subset of coord where a minimum spacing is guaranteed.
+
+ """
+
+ output = coords
+ if len(coords):
+
+ coords = np.atleast_2d(coords)
+ if min_split_size is None:
+ batch_list = [coords]
+ else:
+ coord_count = len(coords)
+ split_count = int(np.log2(coord_count / min_split_size)) + 1
+ split_idx = np.cumsum(
+ [coord_count // (2 ** i) for i in range(1, split_count)])
+ batch_list = np.array_split(coords, split_idx)
+
+ output = np.zeros((0, coords.shape[1]), dtype=coords.dtype)
+ for batch in batch_list:
+ output = _ensure_spacing(np.vstack([output, batch]),
+ spacing, p_norm)
return output
|
{"golden_diff": "diff --git a/skimage/_shared/coord.py b/skimage/_shared/coord.py\n--- a/skimage/_shared/coord.py\n+++ b/skimage/_shared/coord.py\n@@ -2,7 +2,7 @@\n from scipy.spatial import cKDTree, distance\n \n \n-def ensure_spacing(coord, spacing=1, p_norm=np.inf):\n+def _ensure_spacing(coord, spacing, p_norm):\n \"\"\"Returns a subset of coord where a minimum spacing is guaranteed.\n \n Parameters\n@@ -24,28 +24,72 @@\n \n \"\"\"\n \n- output = coord\n- if len(coord):\n- # Use KDtree to find the peaks that are too close to each other\n- tree = cKDTree(coord)\n-\n- indices = tree.query_ball_point(coord, r=spacing, p=p_norm)\n- rejected_peaks_indices = set()\n- for idx, candidates in enumerate(indices):\n- if idx not in rejected_peaks_indices:\n- # keep current point and the points at exactly spacing from it\n- candidates.remove(idx)\n- dist = distance.cdist([coord[idx]],\n- coord[candidates],\n- distance.minkowski,\n- p=p_norm).reshape(-1)\n- candidates = [c for c, d in zip(candidates, dist)\n- if d < spacing]\n-\n- # candidates.remove(keep)\n- rejected_peaks_indices.update(candidates)\n-\n- # Remove the peaks that are too close to each other\n- output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)\n+ # Use KDtree to find the peaks that are too close to each other\n+ tree = cKDTree(coord)\n+\n+ indices = tree.query_ball_point(coord, r=spacing, p=p_norm)\n+ rejected_peaks_indices = set()\n+ for idx, candidates in enumerate(indices):\n+ if idx not in rejected_peaks_indices:\n+ # keep current point and the points at exactly spacing from it\n+ candidates.remove(idx)\n+ dist = distance.cdist([coord[idx]],\n+ coord[candidates],\n+ distance.minkowski,\n+ p=p_norm).reshape(-1)\n+ candidates = [c for c, d in zip(candidates, dist)\n+ if d < spacing]\n+\n+ # candidates.remove(keep)\n+ rejected_peaks_indices.update(candidates)\n+\n+ # Remove the peaks that are too close to each other\n+ output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)\n+\n+ return output\n+\n+\n+def ensure_spacing(coords, spacing=1, p_norm=np.inf, min_split_size=50):\n+ \"\"\"Returns a subset of coord where a minimum spacing is guaranteed.\n+\n+ Parameters\n+ ----------\n+ coord : array_like\n+ The coordinates of the considered points.\n+ spacing : float\n+ the maximum allowed spacing between the points.\n+ p_norm : float\n+ Which Minkowski p-norm to use. Should be in the range [1, inf].\n+ A finite large p may cause a ValueError if overflow can occur.\n+ ``inf`` corresponds to the Chebyshev distance and 2 to the\n+ Euclidean distance.\n+ min_split_size : int\n+ Minimum split size used to process ``coord`` by batch to save\n+ memory. If None, the memory saving strategy is not applied.\n+\n+ Returns\n+ -------\n+ output : array_like\n+ A subset of coord where a minimum spacing is guaranteed.\n+\n+ \"\"\"\n+\n+ output = coords\n+ if len(coords):\n+\n+ coords = np.atleast_2d(coords)\n+ if min_split_size is None:\n+ batch_list = [coords]\n+ else:\n+ coord_count = len(coords)\n+ split_count = int(np.log2(coord_count / min_split_size)) + 1\n+ split_idx = np.cumsum(\n+ [coord_count // (2 ** i) for i in range(1, split_count)])\n+ batch_list = np.array_split(coords, split_idx)\n+\n+ output = np.zeros((0, coords.shape[1]), dtype=coords.dtype)\n+ for batch in batch_list:\n+ output = _ensure_spacing(np.vstack([output, batch]),\n+ spacing, p_norm)\n \n return output\n", "issue": "ensure_spacing function may be slow\n## Description\r\n\r\nThe `skimage._shared.coord.ensure_spacing` function introduced in #4760 may be slow when the number of input points is large.\r\n\r\n## Way to reproduce\r\n```python\r\nIn [1]: import numpy as np\r\n\r\nIn [2]: from skimage._shared.coord import ensure_spacing\r\n\r\nIn [3]: for n in range(500, 10001, 500):\r\n ...: print(f\"n = {n}\")\r\n ...: x = np.random.rand(n, 2)\r\n ...: %timeit ensure_spacing(x, 0.2)\r\n ...: \r\nn = 500\r\n27.6 ms \u00b1 857 \u00b5s per loop (mean \u00b1 std. dev. of 7 runs, 10 loops each)\r\nn = 1000\r\n64.7 ms \u00b1 1.93 ms per loop (mean \u00b1 std. dev. of 7 runs, 10 loops each)\r\nn = 1500\r\n105 ms \u00b1 2.27 ms per loop (mean \u00b1 std. dev. of 7 runs, 10 loops each)\r\nn = 2000\r\n158 ms \u00b1 1.18 ms per loop (mean \u00b1 std. dev. of 7 runs, 10 loops each)\r\nn = 2500\r\n213 ms \u00b1 7.32 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 3000\r\n299 ms \u00b1 11.9 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 3500\r\n378 ms \u00b1 3.05 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 4000\r\n428 ms \u00b1 11.7 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 4500\r\n554 ms \u00b1 14 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 5000\r\n647 ms \u00b1 9.42 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 5500\r\n777 ms \u00b1 7.05 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 6000\r\n870 ms \u00b1 13.2 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 6500\r\n1.03 s \u00b1 9.56 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 7000\r\n1.17 s \u00b1 12.8 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 7500\r\n1.33 s \u00b1 28 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 8000\r\n1.45 s \u00b1 18.5 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 8500\r\n1.63 s \u00b1 36.6 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 9000\r\n1.87 s \u00b1 50.4 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 9500\r\n2.07 s \u00b1 23.3 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\nn = 10000\r\n2.29 s \u00b1 51.3 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\n```\r\n\n", "before_files": [{"content": "import numpy as np\nfrom scipy.spatial import cKDTree, distance\n\n\ndef ensure_spacing(coord, spacing=1, p_norm=np.inf):\n \"\"\"Returns a subset of coord where a minimum spacing is guaranteed.\n\n Parameters\n ----------\n coord : ndarray\n The coordinates of the considered points.\n spacing : float\n the maximum allowed spacing between the points.\n p_norm : float\n Which Minkowski p-norm to use. Should be in the range [1, inf].\n A finite large p may cause a ValueError if overflow can occur.\n ``inf`` corresponds to the Chebyshev distance and 2 to the\n Euclidean distance.\n\n Returns\n -------\n output : ndarray\n A subset of coord where a minimum spacing is guaranteed.\n\n \"\"\"\n\n output = coord\n if len(coord):\n # Use KDtree to find the peaks that are too close to each other\n tree = cKDTree(coord)\n\n indices = tree.query_ball_point(coord, r=spacing, p=p_norm)\n rejected_peaks_indices = set()\n for idx, candidates in enumerate(indices):\n if idx not in rejected_peaks_indices:\n # keep current point and the points at exactly spacing from it\n candidates.remove(idx)\n dist = distance.cdist([coord[idx]],\n coord[candidates],\n distance.minkowski,\n p=p_norm).reshape(-1)\n candidates = [c for c, d in zip(candidates, dist)\n if d < spacing]\n\n # candidates.remove(keep)\n rejected_peaks_indices.update(candidates)\n\n # Remove the peaks that are too close to each other\n output = np.delete(coord, tuple(rejected_peaks_indices), axis=0)\n\n return output\n", "path": "skimage/_shared/coord.py"}]}
| 1,921 | 953 |
gh_patches_debug_12945
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-333
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add Device Name Filter to Secrets API
Filter secrets by the devices they're associated to.
</issue>
<code>
[start of netbox/secrets/filters.py]
1 import django_filters
2
3 from .models import Secret, SecretRole
4
5
6 class SecretFilter(django_filters.FilterSet):
7 role_id = django_filters.ModelMultipleChoiceFilter(
8 name='role',
9 queryset=SecretRole.objects.all(),
10 label='Role (ID)',
11 )
12 role = django_filters.ModelMultipleChoiceFilter(
13 name='role',
14 queryset=SecretRole.objects.all(),
15 to_field_name='slug',
16 label='Role (slug)',
17 )
18
19 class Meta:
20 model = Secret
21 fields = ['name', 'role_id', 'role']
22
[end of netbox/secrets/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/secrets/filters.py b/netbox/secrets/filters.py
--- a/netbox/secrets/filters.py
+++ b/netbox/secrets/filters.py
@@ -1,6 +1,7 @@
import django_filters
from .models import Secret, SecretRole
+from dcim.models import Device
class SecretFilter(django_filters.FilterSet):
@@ -15,7 +16,13 @@
to_field_name='slug',
label='Role (slug)',
)
+ device = django_filters.ModelMultipleChoiceFilter(
+ name='device',
+ queryset=Device.objects.all(),
+ to_field_name='name',
+ label='Device (Name)',
+ )
class Meta:
model = Secret
- fields = ['name', 'role_id', 'role']
+ fields = ['name', 'role_id', 'role', 'device']
|
{"golden_diff": "diff --git a/netbox/secrets/filters.py b/netbox/secrets/filters.py\n--- a/netbox/secrets/filters.py\n+++ b/netbox/secrets/filters.py\n@@ -1,6 +1,7 @@\n import django_filters\n \n from .models import Secret, SecretRole\n+from dcim.models import Device\n \n \n class SecretFilter(django_filters.FilterSet):\n@@ -15,7 +16,13 @@\n to_field_name='slug',\n label='Role (slug)',\n )\n+ device = django_filters.ModelMultipleChoiceFilter(\n+ name='device',\n+ queryset=Device.objects.all(),\n+ to_field_name='name',\n+ label='Device (Name)',\n+ )\n \n class Meta:\n model = Secret\n- fields = ['name', 'role_id', 'role']\n+ fields = ['name', 'role_id', 'role', 'device']\n", "issue": "Add Device Name Filter to Secrets API\nFilter secrets by the devices they're associated to.\n\n", "before_files": [{"content": "import django_filters\n\nfrom .models import Secret, SecretRole\n\n\nclass SecretFilter(django_filters.FilterSet):\n role_id = django_filters.ModelMultipleChoiceFilter(\n name='role',\n queryset=SecretRole.objects.all(),\n label='Role (ID)',\n )\n role = django_filters.ModelMultipleChoiceFilter(\n name='role',\n queryset=SecretRole.objects.all(),\n to_field_name='slug',\n label='Role (slug)',\n )\n\n class Meta:\n model = Secret\n fields = ['name', 'role_id', 'role']\n", "path": "netbox/secrets/filters.py"}]}
| 713 | 196 |
gh_patches_debug_12737
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-495
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Failing `socket_info.getpeername()` with uvloop against a UDS.
When running against a unix domain socket, we seem to occassionaly get an OSError when looking up the remote address. This appears to only occur with `uvloop`.
```
ERROR: Exception in callback HttpToolsProtocol.connection_made(<_SelectorSoc...e, bufsize=0>>)
handle: <Handle HttpToolsProtocol.connection_made(<_SelectorSoc...e, bufsize=0>>)>
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/events.py", line 127, in _run
self._callback(*self._args)
File "/Users/tomchristie/GitHub/encode/uvicorn/uvicorn/protocols/http/httptools_impl.py", line 129, in connection_made
self.client = get_remote_addr(transport)
File "/Users/tomchristie/GitHub/encode/uvicorn/uvicorn/protocols/utils.py", line 8, in get_remote_addr
info = socket_info.getpeername()
OSError: [Errno 22] Invalid argument
```
</issue>
<code>
[start of uvicorn/protocols/utils.py]
1 import socket
2
3
4 def get_remote_addr(transport):
5 socket_info = transport.get_extra_info("socket")
6 if socket_info is not None:
7 info = socket_info.getpeername()
8 family = socket_info.family
9 if family in (socket.AF_INET, socket.AF_INET6):
10 return (str(info[0]), int(info[1]))
11 return None
12 info = transport.get_extra_info("peername")
13 if info is not None and isinstance(info, (list, tuple)) and len(info) == 2:
14 return (str(info[0]), int(info[1]))
15 return None
16
17
18 def get_local_addr(transport):
19 socket_info = transport.get_extra_info("socket")
20 if socket_info is not None:
21 info = socket_info.getsockname()
22 family = socket_info.family
23 if family in (socket.AF_INET, socket.AF_INET6):
24 return (str(info[0]), int(info[1]))
25 return None
26 info = transport.get_extra_info("sockname")
27 if info is not None and isinstance(info, (list, tuple)) and len(info) == 2:
28 return (str(info[0]), int(info[1]))
29 return None
30
31
32 def is_ssl(transport):
33 return bool(transport.get_extra_info("sslcontext"))
34
35
36 def get_client_addr(scope):
37 client = scope.get("client")
38 if not client:
39 return ""
40 return "%s:%d" % client
41
42
43 def get_path_with_query_string(scope):
44 path_with_query_string = scope.get("root_path", "") + scope["path"]
45 if scope["query_string"]:
46 path_with_query_string = "{}?{}".format(
47 path_with_query_string, scope["query_string"].decode("ascii")
48 )
49 return path_with_query_string
50
[end of uvicorn/protocols/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/uvicorn/protocols/utils.py b/uvicorn/protocols/utils.py
--- a/uvicorn/protocols/utils.py
+++ b/uvicorn/protocols/utils.py
@@ -4,8 +4,16 @@
def get_remote_addr(transport):
socket_info = transport.get_extra_info("socket")
if socket_info is not None:
- info = socket_info.getpeername()
- family = socket_info.family
+ try:
+ info = socket_info.getpeername()
+ except OSError:
+ # This case appears to inconsistently occur with uvloop
+ # bound to a unix domain socket.
+ family = None
+ info = None
+ else:
+ family = socket_info.family
+
if family in (socket.AF_INET, socket.AF_INET6):
return (str(info[0]), int(info[1]))
return None
|
{"golden_diff": "diff --git a/uvicorn/protocols/utils.py b/uvicorn/protocols/utils.py\n--- a/uvicorn/protocols/utils.py\n+++ b/uvicorn/protocols/utils.py\n@@ -4,8 +4,16 @@\n def get_remote_addr(transport):\n socket_info = transport.get_extra_info(\"socket\")\n if socket_info is not None:\n- info = socket_info.getpeername()\n- family = socket_info.family\n+ try:\n+ info = socket_info.getpeername()\n+ except OSError:\n+ # This case appears to inconsistently occur with uvloop\n+ # bound to a unix domain socket.\n+ family = None\n+ info = None\n+ else:\n+ family = socket_info.family\n+\n if family in (socket.AF_INET, socket.AF_INET6):\n return (str(info[0]), int(info[1]))\n return None\n", "issue": "Failing `socket_info.getpeername()` with uvloop against a UDS.\nWhen running against a unix domain socket, we seem to occassionaly get an OSError when looking up the remote address. This appears to only occur with `uvloop`.\r\n\r\n```\r\nERROR: Exception in callback HttpToolsProtocol.connection_made(<_SelectorSoc...e, bufsize=0>>)\r\nhandle: <Handle HttpToolsProtocol.connection_made(<_SelectorSoc...e, bufsize=0>>)>\r\nTraceback (most recent call last):\r\n File \"/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/events.py\", line 127, in _run\r\n self._callback(*self._args)\r\n File \"/Users/tomchristie/GitHub/encode/uvicorn/uvicorn/protocols/http/httptools_impl.py\", line 129, in connection_made\r\n self.client = get_remote_addr(transport)\r\n File \"/Users/tomchristie/GitHub/encode/uvicorn/uvicorn/protocols/utils.py\", line 8, in get_remote_addr\r\n info = socket_info.getpeername()\r\nOSError: [Errno 22] Invalid argument\r\n```\n", "before_files": [{"content": "import socket\n\n\ndef get_remote_addr(transport):\n socket_info = transport.get_extra_info(\"socket\")\n if socket_info is not None:\n info = socket_info.getpeername()\n family = socket_info.family\n if family in (socket.AF_INET, socket.AF_INET6):\n return (str(info[0]), int(info[1]))\n return None\n info = transport.get_extra_info(\"peername\")\n if info is not None and isinstance(info, (list, tuple)) and len(info) == 2:\n return (str(info[0]), int(info[1]))\n return None\n\n\ndef get_local_addr(transport):\n socket_info = transport.get_extra_info(\"socket\")\n if socket_info is not None:\n info = socket_info.getsockname()\n family = socket_info.family\n if family in (socket.AF_INET, socket.AF_INET6):\n return (str(info[0]), int(info[1]))\n return None\n info = transport.get_extra_info(\"sockname\")\n if info is not None and isinstance(info, (list, tuple)) and len(info) == 2:\n return (str(info[0]), int(info[1]))\n return None\n\n\ndef is_ssl(transport):\n return bool(transport.get_extra_info(\"sslcontext\"))\n\n\ndef get_client_addr(scope):\n client = scope.get(\"client\")\n if not client:\n return \"\"\n return \"%s:%d\" % client\n\n\ndef get_path_with_query_string(scope):\n path_with_query_string = scope.get(\"root_path\", \"\") + scope[\"path\"]\n if scope[\"query_string\"]:\n path_with_query_string = \"{}?{}\".format(\n path_with_query_string, scope[\"query_string\"].decode(\"ascii\")\n )\n return path_with_query_string\n", "path": "uvicorn/protocols/utils.py"}]}
| 1,271 | 195 |
gh_patches_debug_41978
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-3239
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
break history page into multiple pages
Each week should get its own page, with paging nav added in the box.
break history page into multiple pages
Each week should get its own page, with paging nav added in the box.
Total Given on history pages for teams includes takes
On the history pages for teams, the "Total Given" amount includes both tips to people **and** takes by members, which is not _correct_.
</issue>
<code>
[start of gratipay/utils/history.py]
1 def iter_payday_events(db, participant):
2 """Yields payday events for the given participant.
3 """
4 username = participant.username
5 exchanges = db.all("""
6 SELECT *
7 FROM exchanges
8 WHERE participant=%s
9 """, (username,), back_as=dict)
10 transfers = db.all("""
11 SELECT *
12 FROM transfers
13 WHERE tipper=%(username)s OR tippee=%(username)s
14 """, locals(), back_as=dict)
15
16 if not (exchanges or transfers):
17 return
18
19 if transfers:
20 yield dict(
21 kind='totals',
22 given=sum(t['amount'] for t in transfers if t['tipper'] == username),
23 received=sum(t['amount'] for t in transfers if t['tippee'] == username),
24 )
25
26 payday_dates = db.all("""
27 SELECT ts_start::date
28 FROM paydays
29 ORDER BY ts_start ASC
30 """)
31
32 balance = participant.balance
33 prev_date = None
34 get_timestamp = lambda e: e['timestamp']
35 events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)
36 for event in events:
37
38 event['balance'] = balance
39
40 event_date = event['timestamp'].date()
41 if event_date != prev_date:
42 if prev_date:
43 yield dict(kind='day-close', balance=balance)
44 day_open = dict(kind='day-open', date=event_date, balance=balance)
45 if payday_dates:
46 while payday_dates and payday_dates[-1] > event_date:
47 payday_dates.pop()
48 payday_date = payday_dates[-1] if payday_dates else None
49 if event_date == payday_date:
50 day_open['payday_number'] = len(payday_dates) - 1
51 yield day_open
52 prev_date = event_date
53
54 if 'fee' in event:
55 if event['amount'] > 0:
56 kind = 'charge'
57 if event['status'] in (None, 'succeeded'):
58 balance -= event['amount']
59 else:
60 kind = 'credit'
61 if event['status'] != 'failed':
62 balance -= event['amount'] - event['fee']
63 else:
64 kind = 'transfer'
65 if event['tippee'] == username:
66 balance -= event['amount']
67 else:
68 balance += event['amount']
69 event['kind'] = kind
70
71 yield event
72
73 yield dict(kind='day-close', balance='0.00')
74
[end of gratipay/utils/history.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gratipay/utils/history.py b/gratipay/utils/history.py
--- a/gratipay/utils/history.py
+++ b/gratipay/utils/history.py
@@ -1,16 +1,83 @@
-def iter_payday_events(db, participant):
+from datetime import datetime
+from decimal import Decimal
+
+from psycopg2 import IntegrityError
+
+
+def get_end_of_year_balance(db, participant, year, current_year):
+ if year == current_year:
+ return participant.balance
+ if year < participant.claimed_time.year:
+ return Decimal('0.00')
+
+ balance = db.one("""
+ SELECT balance
+ FROM balances_at
+ WHERE participant = %s
+ AND "at" = %s
+ """, (participant.id, datetime(year+1, 1, 1)))
+ if balance is not None:
+ return balance
+
+ username = participant.username
+ start_balance = get_end_of_year_balance(db, participant, year-1, current_year)
+ delta = db.one("""
+ SELECT (
+ SELECT COALESCE(sum(amount), 0) AS a
+ FROM exchanges
+ WHERE participant = %(username)s
+ AND extract(year from timestamp) = %(year)s
+ AND amount > 0
+ AND (status is null OR status = 'succeeded')
+ ) + (
+ SELECT COALESCE(sum(amount-fee), 0) AS a
+ FROM exchanges
+ WHERE participant = %(username)s
+ AND extract(year from timestamp) = %(year)s
+ AND amount < 0
+ AND (status is null OR status <> 'failed')
+ ) + (
+ SELECT COALESCE(sum(-amount), 0) AS a
+ FROM transfers
+ WHERE tipper = %(username)s
+ AND extract(year from timestamp) = %(year)s
+ ) + (
+ SELECT COALESCE(sum(amount), 0) AS a
+ FROM transfers
+ WHERE tippee = %(username)s
+ AND extract(year from timestamp) = %(year)s
+ ) AS delta
+ """, locals())
+ balance = start_balance + delta
+ try:
+ db.run("""
+ INSERT INTO balances_at
+ (participant, at, balance)
+ VALUES (%s, %s, %s)
+ """, (participant.id, datetime(year+1, 1, 1), balance))
+ except IntegrityError:
+ pass
+ return balance
+
+
+def iter_payday_events(db, participant, year=None):
"""Yields payday events for the given participant.
"""
+ current_year = datetime.utcnow().year
+ year = year or current_year
+
username = participant.username
exchanges = db.all("""
SELECT *
FROM exchanges
- WHERE participant=%s
- """, (username,), back_as=dict)
+ WHERE participant=%(username)s
+ AND extract(year from timestamp) = %(year)s
+ """, locals(), back_as=dict)
transfers = db.all("""
SELECT *
FROM transfers
- WHERE tipper=%(username)s OR tippee=%(username)s
+ WHERE (tipper=%(username)s OR tippee=%(username)s)
+ AND extract(year from timestamp) = %(year)s
""", locals(), back_as=dict)
if not (exchanges or transfers):
@@ -19,7 +86,7 @@
if transfers:
yield dict(
kind='totals',
- given=sum(t['amount'] for t in transfers if t['tipper'] == username),
+ given=sum(t['amount'] for t in transfers if t['tipper'] == username and t['context'] != 'take'),
received=sum(t['amount'] for t in transfers if t['tippee'] == username),
)
@@ -29,7 +96,7 @@
ORDER BY ts_start ASC
""")
- balance = participant.balance
+ balance = get_end_of_year_balance(db, participant, year, current_year)
prev_date = None
get_timestamp = lambda e: e['timestamp']
events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)
@@ -70,4 +137,4 @@
yield event
- yield dict(kind='day-close', balance='0.00')
+ yield dict(kind='day-close', balance=balance)
|
{"golden_diff": "diff --git a/gratipay/utils/history.py b/gratipay/utils/history.py\n--- a/gratipay/utils/history.py\n+++ b/gratipay/utils/history.py\n@@ -1,16 +1,83 @@\n-def iter_payday_events(db, participant):\n+from datetime import datetime\n+from decimal import Decimal\n+\n+from psycopg2 import IntegrityError\n+\n+\n+def get_end_of_year_balance(db, participant, year, current_year):\n+ if year == current_year:\n+ return participant.balance\n+ if year < participant.claimed_time.year:\n+ return Decimal('0.00')\n+\n+ balance = db.one(\"\"\"\n+ SELECT balance\n+ FROM balances_at\n+ WHERE participant = %s\n+ AND \"at\" = %s\n+ \"\"\", (participant.id, datetime(year+1, 1, 1)))\n+ if balance is not None:\n+ return balance\n+\n+ username = participant.username\n+ start_balance = get_end_of_year_balance(db, participant, year-1, current_year)\n+ delta = db.one(\"\"\"\n+ SELECT (\n+ SELECT COALESCE(sum(amount), 0) AS a\n+ FROM exchanges\n+ WHERE participant = %(username)s\n+ AND extract(year from timestamp) = %(year)s\n+ AND amount > 0\n+ AND (status is null OR status = 'succeeded')\n+ ) + (\n+ SELECT COALESCE(sum(amount-fee), 0) AS a\n+ FROM exchanges\n+ WHERE participant = %(username)s\n+ AND extract(year from timestamp) = %(year)s\n+ AND amount < 0\n+ AND (status is null OR status <> 'failed')\n+ ) + (\n+ SELECT COALESCE(sum(-amount), 0) AS a\n+ FROM transfers\n+ WHERE tipper = %(username)s\n+ AND extract(year from timestamp) = %(year)s\n+ ) + (\n+ SELECT COALESCE(sum(amount), 0) AS a\n+ FROM transfers\n+ WHERE tippee = %(username)s\n+ AND extract(year from timestamp) = %(year)s\n+ ) AS delta\n+ \"\"\", locals())\n+ balance = start_balance + delta\n+ try:\n+ db.run(\"\"\"\n+ INSERT INTO balances_at\n+ (participant, at, balance)\n+ VALUES (%s, %s, %s)\n+ \"\"\", (participant.id, datetime(year+1, 1, 1), balance))\n+ except IntegrityError:\n+ pass\n+ return balance\n+\n+\n+def iter_payday_events(db, participant, year=None):\n \"\"\"Yields payday events for the given participant.\n \"\"\"\n+ current_year = datetime.utcnow().year\n+ year = year or current_year\n+\n username = participant.username\n exchanges = db.all(\"\"\"\n SELECT *\n FROM exchanges\n- WHERE participant=%s\n- \"\"\", (username,), back_as=dict)\n+ WHERE participant=%(username)s\n+ AND extract(year from timestamp) = %(year)s\n+ \"\"\", locals(), back_as=dict)\n transfers = db.all(\"\"\"\n SELECT *\n FROM transfers\n- WHERE tipper=%(username)s OR tippee=%(username)s\n+ WHERE (tipper=%(username)s OR tippee=%(username)s)\n+ AND extract(year from timestamp) = %(year)s\n \"\"\", locals(), back_as=dict)\n \n if not (exchanges or transfers):\n@@ -19,7 +86,7 @@\n if transfers:\n yield dict(\n kind='totals',\n- given=sum(t['amount'] for t in transfers if t['tipper'] == username),\n+ given=sum(t['amount'] for t in transfers if t['tipper'] == username and t['context'] != 'take'),\n received=sum(t['amount'] for t in transfers if t['tippee'] == username),\n )\n \n@@ -29,7 +96,7 @@\n ORDER BY ts_start ASC\n \"\"\")\n \n- balance = participant.balance\n+ balance = get_end_of_year_balance(db, participant, year, current_year)\n prev_date = None\n get_timestamp = lambda e: e['timestamp']\n events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)\n@@ -70,4 +137,4 @@\n \n yield event\n \n- yield dict(kind='day-close', balance='0.00')\n+ yield dict(kind='day-close', balance=balance)\n", "issue": "break history page into multiple pages\nEach week should get its own page, with paging nav added in the box.\n\nbreak history page into multiple pages\nEach week should get its own page, with paging nav added in the box.\n\nTotal Given on history pages for teams includes takes\nOn the history pages for teams, the \"Total Given\" amount includes both tips to people **and** takes by members, which is not _correct_. \n\n", "before_files": [{"content": "def iter_payday_events(db, participant):\n \"\"\"Yields payday events for the given participant.\n \"\"\"\n username = participant.username\n exchanges = db.all(\"\"\"\n SELECT *\n FROM exchanges\n WHERE participant=%s\n \"\"\", (username,), back_as=dict)\n transfers = db.all(\"\"\"\n SELECT *\n FROM transfers\n WHERE tipper=%(username)s OR tippee=%(username)s\n \"\"\", locals(), back_as=dict)\n\n if not (exchanges or transfers):\n return\n\n if transfers:\n yield dict(\n kind='totals',\n given=sum(t['amount'] for t in transfers if t['tipper'] == username),\n received=sum(t['amount'] for t in transfers if t['tippee'] == username),\n )\n\n payday_dates = db.all(\"\"\"\n SELECT ts_start::date\n FROM paydays\n ORDER BY ts_start ASC\n \"\"\")\n\n balance = participant.balance\n prev_date = None\n get_timestamp = lambda e: e['timestamp']\n events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)\n for event in events:\n\n event['balance'] = balance\n\n event_date = event['timestamp'].date()\n if event_date != prev_date:\n if prev_date:\n yield dict(kind='day-close', balance=balance)\n day_open = dict(kind='day-open', date=event_date, balance=balance)\n if payday_dates:\n while payday_dates and payday_dates[-1] > event_date:\n payday_dates.pop()\n payday_date = payday_dates[-1] if payday_dates else None\n if event_date == payday_date:\n day_open['payday_number'] = len(payday_dates) - 1\n yield day_open\n prev_date = event_date\n\n if 'fee' in event:\n if event['amount'] > 0:\n kind = 'charge'\n if event['status'] in (None, 'succeeded'):\n balance -= event['amount']\n else:\n kind = 'credit'\n if event['status'] != 'failed':\n balance -= event['amount'] - event['fee']\n else:\n kind = 'transfer'\n if event['tippee'] == username:\n balance -= event['amount']\n else:\n balance += event['amount']\n event['kind'] = kind\n\n yield event\n\n yield dict(kind='day-close', balance='0.00')\n", "path": "gratipay/utils/history.py"}]}
| 1,287 | 991 |
gh_patches_debug_34415
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-639
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Clean library/frameworks from backtraces
We should clean all non-user code from backtraces as much as possible. Here's a heroku app running 2.13.0:
<img width="890" alt="Screenshot 2020-04-13 14 39 56" src="https://user-images.githubusercontent.com/102774/79160522-26a36e80-7d97-11ea-8376-f8dfcfd6ece0.png">
</issue>
<code>
[start of src/scout_apm/core/backtrace.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import sys
5 import traceback
6
7 # Maximum non-Scout frames to target retrieving
8 LIMIT = 50
9 # How many upper frames from inside Scout to ignore
10 IGNORED = 1
11
12
13 if sys.version_info >= (3, 5):
14
15 def capture():
16 return [
17 {"file": frame.filename, "line": frame.lineno, "function": frame.name}
18 for frame in reversed(
19 traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]
20 )
21 ]
22
23
24 else:
25
26 def capture():
27 return [
28 {"file": frame[0], "line": frame[1], "function": frame[3]}
29 for frame in reversed(
30 traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]
31 )
32 ]
33
[end of src/scout_apm/core/backtrace.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/core/backtrace.py b/src/scout_apm/core/backtrace.py
--- a/src/scout_apm/core/backtrace.py
+++ b/src/scout_apm/core/backtrace.py
@@ -1,7 +1,9 @@
# coding=utf-8
from __future__ import absolute_import, division, print_function, unicode_literals
+import itertools
import sys
+import sysconfig
import traceback
# Maximum non-Scout frames to target retrieving
@@ -10,23 +12,55 @@
IGNORED = 1
+def filter_frames(frames):
+ """Filter the stack trace frames down to non-library code."""
+ paths = sysconfig.get_paths()
+ library_paths = {paths["purelib"], paths["platlib"]}
+ for frame in frames:
+ if not any(frame["file"].startswith(exclusion) for exclusion in library_paths):
+ yield frame
+
+
if sys.version_info >= (3, 5):
+ def frame_walker():
+ """Iterate over each frame of the stack.
+
+ Taken from python3/traceback.ExtractSummary.extract to support
+ iterating over the entire stack, but without creating a large
+ data structure.
+ """
+ for frame, lineno in traceback.walk_stack(sys._getframe().f_back):
+ co = frame.f_code
+ filename = co.co_filename
+ name = co.co_name
+ yield {"file": filename, "line": lineno, "function": name}
+
def capture():
- return [
- {"file": frame.filename, "line": frame.lineno, "function": frame.name}
- for frame in reversed(
- traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]
- )
- ]
+ return list(itertools.islice(filter_frames(frame_walker()), LIMIT))
else:
+ def frame_walker():
+ """Iterate over each frame of the stack.
+
+ Taken from python2.7/traceback.extract_stack to support iterating
+ over the entire stack, but without creating a large data structure.
+ """
+ try:
+ raise ZeroDivisionError
+ except ZeroDivisionError:
+ # Get the current frame
+ f = sys.exc_info()[2].tb_frame.f_back
+
+ while f is not None:
+ lineno = f.f_lineno
+ co = f.f_code
+ filename = co.co_filename
+ name = co.co_name
+ yield {"file": filename, "line": lineno, "function": name}
+ f = f.f_back
+
def capture():
- return [
- {"file": frame[0], "line": frame[1], "function": frame[3]}
- for frame in reversed(
- traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]
- )
- ]
+ return list(itertools.islice(filter_frames(frame_walker()), LIMIT))
|
{"golden_diff": "diff --git a/src/scout_apm/core/backtrace.py b/src/scout_apm/core/backtrace.py\n--- a/src/scout_apm/core/backtrace.py\n+++ b/src/scout_apm/core/backtrace.py\n@@ -1,7 +1,9 @@\n # coding=utf-8\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n+import itertools\n import sys\n+import sysconfig\n import traceback\n \n # Maximum non-Scout frames to target retrieving\n@@ -10,23 +12,55 @@\n IGNORED = 1\n \n \n+def filter_frames(frames):\n+ \"\"\"Filter the stack trace frames down to non-library code.\"\"\"\n+ paths = sysconfig.get_paths()\n+ library_paths = {paths[\"purelib\"], paths[\"platlib\"]}\n+ for frame in frames:\n+ if not any(frame[\"file\"].startswith(exclusion) for exclusion in library_paths):\n+ yield frame\n+\n+\n if sys.version_info >= (3, 5):\n \n+ def frame_walker():\n+ \"\"\"Iterate over each frame of the stack.\n+\n+ Taken from python3/traceback.ExtractSummary.extract to support\n+ iterating over the entire stack, but without creating a large\n+ data structure.\n+ \"\"\"\n+ for frame, lineno in traceback.walk_stack(sys._getframe().f_back):\n+ co = frame.f_code\n+ filename = co.co_filename\n+ name = co.co_name\n+ yield {\"file\": filename, \"line\": lineno, \"function\": name}\n+\n def capture():\n- return [\n- {\"file\": frame.filename, \"line\": frame.lineno, \"function\": frame.name}\n- for frame in reversed(\n- traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]\n- )\n- ]\n+ return list(itertools.islice(filter_frames(frame_walker()), LIMIT))\n \n \n else:\n \n+ def frame_walker():\n+ \"\"\"Iterate over each frame of the stack.\n+\n+ Taken from python2.7/traceback.extract_stack to support iterating\n+ over the entire stack, but without creating a large data structure.\n+ \"\"\"\n+ try:\n+ raise ZeroDivisionError\n+ except ZeroDivisionError:\n+ # Get the current frame\n+ f = sys.exc_info()[2].tb_frame.f_back\n+\n+ while f is not None:\n+ lineno = f.f_lineno\n+ co = f.f_code\n+ filename = co.co_filename\n+ name = co.co_name\n+ yield {\"file\": filename, \"line\": lineno, \"function\": name}\n+ f = f.f_back\n+\n def capture():\n- return [\n- {\"file\": frame[0], \"line\": frame[1], \"function\": frame[3]}\n- for frame in reversed(\n- traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]\n- )\n- ]\n+ return list(itertools.islice(filter_frames(frame_walker()), LIMIT))\n", "issue": "Clean library/frameworks from backtraces\nWe should clean all non-user code from backtraces as much as possible. Here's a heroku app running 2.13.0:\r\n\r\n<img width=\"890\" alt=\"Screenshot 2020-04-13 14 39 56\" src=\"https://user-images.githubusercontent.com/102774/79160522-26a36e80-7d97-11ea-8376-f8dfcfd6ece0.png\">\r\n\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport sys\nimport traceback\n\n# Maximum non-Scout frames to target retrieving\nLIMIT = 50\n# How many upper frames from inside Scout to ignore\nIGNORED = 1\n\n\nif sys.version_info >= (3, 5):\n\n def capture():\n return [\n {\"file\": frame.filename, \"line\": frame.lineno, \"function\": frame.name}\n for frame in reversed(\n traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]\n )\n ]\n\n\nelse:\n\n def capture():\n return [\n {\"file\": frame[0], \"line\": frame[1], \"function\": frame[3]}\n for frame in reversed(\n traceback.extract_stack(limit=LIMIT + IGNORED)[:-IGNORED]\n )\n ]\n", "path": "src/scout_apm/core/backtrace.py"}]}
| 921 | 655 |
gh_patches_debug_571
|
rasdani/github-patches
|
git_diff
|
Uberspace__lab-28
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change project name to lab in config
</issue>
<code>
[start of source/conf.py]
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Uberspace 7 lab documentation build configuration file, created by
5 # sphinx-quickstart on Tue Feb 13 12:19:29 2018.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 # import os
21 # import sys
22 # sys.path.insert(0, os.path.abspath('.'))
23
24 import sphinx_rtd_theme
25
26 # -- General configuration ------------------------------------------------
27
28 # If your documentation needs a minimal Sphinx version, state it here.
29 #
30 # needs_sphinx = '1.0'
31
32 # Add any Sphinx extension module names here, as strings. They can be
33 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
34 # ones.
35 extensions = []
36
37 # Add any paths that contain templates here, relative to this directory.
38 templates_path = ['_templates']
39
40 # The suffix(es) of source filenames.
41 # You can specify multiple suffix as a list of string:
42 #
43 # source_suffix = ['.rst', '.md']
44 source_suffix = '.rst'
45
46 # The master toctree document.
47 master_doc = 'index'
48
49 # General information about the project.
50 project = 'Uberspace 7 Lab'
51 copyright = '2018, uberspace.de'
52 author = 'uberspace.de'
53
54 # The version info for the project you're documenting, acts as replacement for
55 # |version| and |release|, also used in various other places throughout the
56 # built documents.
57 #
58 # The short X.Y version.
59 release = version = '7'
60
61 # The language for content autogenerated by Sphinx. Refer to documentation
62 # for a list of supported languages.
63 #
64 # This is also used if you do content translation via gettext catalogs.
65 # Usually you set "language" from the command line for these cases.
66 language = None
67
68 # List of patterns, relative to source directory, that match files and
69 # directories to ignore when looking for source files.
70 # This patterns also effect to html_static_path and html_extra_path
71 exclude_patterns = []
72
73 # The name of the Pygments (syntax highlighting) style to use.
74 pygments_style = 'sphinx'
75
76 # If true, `todo` and `todoList` produce output, else they produce nothing.
77 todo_include_todos = False
78
79
80 # -- Options for HTML output ----------------------------------------------
81
82 html_theme = 'sphinx_rtd_theme'
83 html_theme_options = {
84 'display_version': False,
85 'navigation_depth': 2,
86 'collapse_navigation': True
87 }
88 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
89 html_last_updated_fmt = '%b %d, %Y'
90 html_context = {
91 'css_files': ['_static/css/custom.css'],
92 'display_github': True,
93 'github_user': 'Uberspace',
94 'github_repo': 'lab',
95 'github_version': 'master',
96 'conf_py_path': '/source/'
97 }
98 html_show_copyright = False
99 html_favicon = '_static/favicon.ico'
100
101
102 # Theme options are theme-specific and customize the look and feel of a theme
103 # further. For a list of options available for each theme, see the
104 # documentation.
105 #
106 # html_theme_options = {}
107
108 # Add any paths that contain custom static files (such as style sheets) here,
109 # relative to this directory. They are copied after the builtin static files,
110 # so a file named "default.css" will overwrite the builtin "default.css".
111 html_static_path = ['_static']
112
113 # Custom sidebar templates, must be a dictionary that maps document names
114 # to template names.
115 #
116 # This is required for the alabaster theme
117 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
118 html_sidebars = {
119 '**': [
120 'relations.html', # needs 'show_related': True theme option to display
121 'searchbox.html',
122 ]
123 }
124
125
126 # -- Options for HTMLHelp output ------------------------------------------
127
128 # Output file base name for HTML help builder.
129 htmlhelp_basename = 'Uberspace7labdoc'
130
[end of source/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/source/conf.py b/source/conf.py
--- a/source/conf.py
+++ b/source/conf.py
@@ -47,7 +47,7 @@
master_doc = 'index'
# General information about the project.
-project = 'Uberspace 7 Lab'
+project = 'UberLab'
copyright = '2018, uberspace.de'
author = 'uberspace.de'
|
{"golden_diff": "diff --git a/source/conf.py b/source/conf.py\n--- a/source/conf.py\n+++ b/source/conf.py\n@@ -47,7 +47,7 @@\n master_doc = 'index'\n \n # General information about the project.\n-project = 'Uberspace 7 Lab'\n+project = 'UberLab'\n copyright = '2018, uberspace.de'\n author = 'uberspace.de'\n", "issue": "Change project name to lab in config\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Uberspace 7 lab documentation build configuration file, created by\n# sphinx-quickstart on Tue Feb 13 12:19:29 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\nimport sphinx_rtd_theme\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = []\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Uberspace 7 Lab'\ncopyright = '2018, uberspace.de'\nauthor = 'uberspace.de'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nrelease = version = '7'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'display_version': False,\n 'navigation_depth': 2,\n 'collapse_navigation': True\n}\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\nhtml_last_updated_fmt = '%b %d, %Y'\nhtml_context = {\n 'css_files': ['_static/css/custom.css'],\n 'display_github': True,\n 'github_user': 'Uberspace', \n 'github_repo': 'lab', \n 'github_version': 'master',\n 'conf_py_path': '/source/'\n}\nhtml_show_copyright = False\nhtml_favicon = '_static/favicon.ico'\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Uberspace7labdoc'\n", "path": "source/conf.py"}]}
| 1,799 | 89 |
gh_patches_debug_1093
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-755
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Handle NoneType comparison in _scores_to_ranks
```
TypeError: '<' not supported between instances of 'NoneType' and 'float'
```
</issue>
<code>
[start of app/grandchallenge/evaluation/utils.py]
1 from collections import OrderedDict
2 from typing import Tuple, NamedTuple, List, Callable, Iterable, Dict
3
4 from grandchallenge.evaluation.models import Result
5 from grandchallenge.evaluation.templatetags.evaluation_extras import (
6 get_jsonpath
7 )
8
9
10 class Metric(NamedTuple):
11 path: str
12 reverse: bool
13
14
15 class Positions(NamedTuple):
16 ranks: Dict[str, float]
17 rank_scores: Dict[str, float]
18 rank_per_metric: Dict[str, Dict[str, float]]
19
20
21 def rank_results(
22 *,
23 results: Tuple[Result, ...],
24 metrics: Tuple[Metric, ...],
25 score_method: Callable,
26 ) -> Positions:
27 """
28 Calculates the overall rank for each result, along with the rank_score
29 and the rank per metric.
30 """
31
32 results = _filter_valid_results(results=results, metrics=metrics)
33
34 rank_per_metric = _get_rank_per_metric(results=results, metrics=metrics)
35
36 rank_scores = {
37 pk: score_method([m for m in metrics.values()])
38 for pk, metrics in rank_per_metric.items()
39 }
40
41 return Positions(
42 ranks=_scores_to_ranks(scores=rank_scores, reverse=False),
43 rank_scores=rank_scores,
44 rank_per_metric=rank_per_metric,
45 )
46
47
48 def _filter_valid_results(
49 *, results: Iterable[Result], metrics: Tuple[Metric, ...]
50 ) -> List[Result]:
51 """ Ensure that all of the metrics are in every result """
52 return [
53 res
54 for res in results
55 if all(get_jsonpath(res.metrics, m.path) != "" for m in metrics)
56 ]
57
58
59 def _get_rank_per_metric(
60 *, results: Iterable[Result], metrics: Tuple[Metric, ...]
61 ) -> Dict[str, Dict[str, float]]:
62 """
63 Takes results and calculates the rank for each of the individual metrics
64
65 Returns a dictionary where the key is the pk of the result, and the
66 values is another dictionary where the key is the path of the metric and
67 the value is the rank of this result for this metric
68 """
69 metric_rank = {}
70 for metric in metrics:
71 # Extract the value of the metric for this primary key and sort on the
72 # value of the metric
73 metric_scores = {
74 res.pk: get_jsonpath(res.metrics, metric.path) for res in results
75 }
76 metric_rank[metric.path] = _scores_to_ranks(
77 scores=metric_scores, reverse=metric.reverse
78 )
79
80 return {
81 res.pk: {
82 metric_path: ranks[res.pk]
83 for metric_path, ranks in metric_rank.items()
84 }
85 for res in results
86 }
87
88
89 def _scores_to_ranks(
90 *, scores: Dict, reverse: bool = False
91 ) -> Dict[str, float]:
92 """
93 Go from a score (a scalar) to a rank (integer). If two scalars are the
94 same then they will have the same rank.
95
96 Takes a dictionary where the keys are the pk of the results and the values
97 are the scores.
98
99 Outputs a dictionary where they keys are the pk of the results and the
100 values are the ranks.
101 """
102 scores = OrderedDict(
103 sorted(scores.items(), key=lambda t: t[1], reverse=reverse)
104 )
105
106 ranks = {}
107 current_score = current_rank = None
108
109 for idx, (pk, score) in enumerate(scores.items()):
110 if score != current_score:
111 current_score = score
112 current_rank = idx + 1
113
114 ranks[pk] = current_rank
115
116 return ranks
117
[end of app/grandchallenge/evaluation/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/evaluation/utils.py b/app/grandchallenge/evaluation/utils.py
--- a/app/grandchallenge/evaluation/utils.py
+++ b/app/grandchallenge/evaluation/utils.py
@@ -52,7 +52,10 @@
return [
res
for res in results
- if all(get_jsonpath(res.metrics, m.path) != "" for m in metrics)
+ if all(
+ get_jsonpath(res.metrics, m.path) not in ["", None]
+ for m in metrics
+ )
]
|
{"golden_diff": "diff --git a/app/grandchallenge/evaluation/utils.py b/app/grandchallenge/evaluation/utils.py\n--- a/app/grandchallenge/evaluation/utils.py\n+++ b/app/grandchallenge/evaluation/utils.py\n@@ -52,7 +52,10 @@\n return [\n res\n for res in results\n- if all(get_jsonpath(res.metrics, m.path) != \"\" for m in metrics)\n+ if all(\n+ get_jsonpath(res.metrics, m.path) not in [\"\", None]\n+ for m in metrics\n+ )\n ]\n", "issue": "Handle NoneType comparison in _scores_to_ranks\n```\r\nTypeError: '<' not supported between instances of 'NoneType' and 'float'\r\n```\n", "before_files": [{"content": "from collections import OrderedDict\nfrom typing import Tuple, NamedTuple, List, Callable, Iterable, Dict\n\nfrom grandchallenge.evaluation.models import Result\nfrom grandchallenge.evaluation.templatetags.evaluation_extras import (\n get_jsonpath\n)\n\n\nclass Metric(NamedTuple):\n path: str\n reverse: bool\n\n\nclass Positions(NamedTuple):\n ranks: Dict[str, float]\n rank_scores: Dict[str, float]\n rank_per_metric: Dict[str, Dict[str, float]]\n\n\ndef rank_results(\n *,\n results: Tuple[Result, ...],\n metrics: Tuple[Metric, ...],\n score_method: Callable,\n) -> Positions:\n \"\"\"\n Calculates the overall rank for each result, along with the rank_score\n and the rank per metric.\n \"\"\"\n\n results = _filter_valid_results(results=results, metrics=metrics)\n\n rank_per_metric = _get_rank_per_metric(results=results, metrics=metrics)\n\n rank_scores = {\n pk: score_method([m for m in metrics.values()])\n for pk, metrics in rank_per_metric.items()\n }\n\n return Positions(\n ranks=_scores_to_ranks(scores=rank_scores, reverse=False),\n rank_scores=rank_scores,\n rank_per_metric=rank_per_metric,\n )\n\n\ndef _filter_valid_results(\n *, results: Iterable[Result], metrics: Tuple[Metric, ...]\n) -> List[Result]:\n \"\"\" Ensure that all of the metrics are in every result \"\"\"\n return [\n res\n for res in results\n if all(get_jsonpath(res.metrics, m.path) != \"\" for m in metrics)\n ]\n\n\ndef _get_rank_per_metric(\n *, results: Iterable[Result], metrics: Tuple[Metric, ...]\n) -> Dict[str, Dict[str, float]]:\n \"\"\"\n Takes results and calculates the rank for each of the individual metrics\n\n Returns a dictionary where the key is the pk of the result, and the\n values is another dictionary where the key is the path of the metric and\n the value is the rank of this result for this metric\n \"\"\"\n metric_rank = {}\n for metric in metrics:\n # Extract the value of the metric for this primary key and sort on the\n # value of the metric\n metric_scores = {\n res.pk: get_jsonpath(res.metrics, metric.path) for res in results\n }\n metric_rank[metric.path] = _scores_to_ranks(\n scores=metric_scores, reverse=metric.reverse\n )\n\n return {\n res.pk: {\n metric_path: ranks[res.pk]\n for metric_path, ranks in metric_rank.items()\n }\n for res in results\n }\n\n\ndef _scores_to_ranks(\n *, scores: Dict, reverse: bool = False\n) -> Dict[str, float]:\n \"\"\"\n Go from a score (a scalar) to a rank (integer). If two scalars are the\n same then they will have the same rank.\n\n Takes a dictionary where the keys are the pk of the results and the values\n are the scores.\n\n Outputs a dictionary where they keys are the pk of the results and the\n values are the ranks.\n \"\"\"\n scores = OrderedDict(\n sorted(scores.items(), key=lambda t: t[1], reverse=reverse)\n )\n\n ranks = {}\n current_score = current_rank = None\n\n for idx, (pk, score) in enumerate(scores.items()):\n if score != current_score:\n current_score = score\n current_rank = idx + 1\n\n ranks[pk] = current_rank\n\n return ranks\n", "path": "app/grandchallenge/evaluation/utils.py"}]}
| 1,594 | 124 |
gh_patches_debug_7745
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1302
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TVCatchup plugin is not working - "This service is ending soon"
### Checklist
- [x] This is a bug report.
- [ ] This is a feature request.
- [x] This is a plugin (improvement) request.
- [ ] I have read the contribution guidelines.
### Description
TVCatchup plugin is not working for some time. The problem is that plugin is able to connect to a stream without any errors but the stream is different comparing to the TVCatchup website's stream. It looks like streamlink gets a different type of stream deliberately prepared by the service provider to send the message: "This service is ending soon. Please download TVCatchup from the app store". Assuming that there is a real stream available on the website and mobile app, is it still possible to open it by streamlink?
Current stream for all of the channels:

Thanks
### Reproduction steps / Explicit stream URLs to test
streamlink http://tvcatchup.com/watch/bbctwo best
### Environment details
Operating system and version: Windows/Linux
Streamlink and Python version: Streamlink 0.8.1
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
</issue>
<code>
[start of src/streamlink/plugins/tvcatchup.py]
1 import re
2
3 from streamlink.plugin import Plugin
4 from streamlink.plugin.api import http
5 from streamlink.stream import HLSStream
6
7 USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
8 _url_re = re.compile(r"http://(?:www\.)?tvcatchup.com/watch/\w+")
9 _stream_re = re.compile(r'''(?P<q>["'])(?P<stream_url>https?://.*m3u8\?.*clientKey=.*?)(?P=q)''')
10
11
12 class TVCatchup(Plugin):
13 @classmethod
14 def can_handle_url(cls, url):
15 return _url_re.match(url)
16
17 def _get_streams(self):
18 """
19 Finds the streams from tvcatchup.com.
20 """
21 http.headers.update({"User-Agent": USER_AGENT})
22 res = http.get(self.url)
23
24 match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)
25
26 if match:
27 stream_url = match.group("stream_url")
28
29 if stream_url:
30 if "_adp" in stream_url:
31 return HLSStream.parse_variant_playlist(self.session, stream_url)
32 else:
33 return {'576p': HLSStream(self.session, stream_url)}
34
35
36 __plugin__ = TVCatchup
37
[end of src/streamlink/plugins/tvcatchup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/tvcatchup.py b/src/streamlink/plugins/tvcatchup.py
--- a/src/streamlink/plugins/tvcatchup.py
+++ b/src/streamlink/plugins/tvcatchup.py
@@ -6,7 +6,7 @@
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
_url_re = re.compile(r"http://(?:www\.)?tvcatchup.com/watch/\w+")
-_stream_re = re.compile(r'''(?P<q>["'])(?P<stream_url>https?://.*m3u8\?.*clientKey=.*?)(?P=q)''')
+_stream_re = re.compile(r'''source.*?(?P<q>["'])(?P<stream_url>https?://.*m3u8\?.*clientKey=.*?)(?P=q)''')
class TVCatchup(Plugin):
|
{"golden_diff": "diff --git a/src/streamlink/plugins/tvcatchup.py b/src/streamlink/plugins/tvcatchup.py\n--- a/src/streamlink/plugins/tvcatchup.py\n+++ b/src/streamlink/plugins/tvcatchup.py\n@@ -6,7 +6,7 @@\n \n USER_AGENT = \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36\"\n _url_re = re.compile(r\"http://(?:www\\.)?tvcatchup.com/watch/\\w+\")\n-_stream_re = re.compile(r'''(?P<q>[\"'])(?P<stream_url>https?://.*m3u8\\?.*clientKey=.*?)(?P=q)''')\n+_stream_re = re.compile(r'''source.*?(?P<q>[\"'])(?P<stream_url>https?://.*m3u8\\?.*clientKey=.*?)(?P=q)''')\n \n \n class TVCatchup(Plugin):\n", "issue": "TVCatchup plugin is not working - \"This service is ending soon\"\n### Checklist\r\n\r\n- [x] This is a bug report.\r\n- [ ] This is a feature request.\r\n- [x] This is a plugin (improvement) request.\r\n- [ ] I have read the contribution guidelines.\r\n\r\n### Description\r\n\r\nTVCatchup plugin is not working for some time. The problem is that plugin is able to connect to a stream without any errors but the stream is different comparing to the TVCatchup website's stream. It looks like streamlink gets a different type of stream deliberately prepared by the service provider to send the message: \"This service is ending soon. Please download TVCatchup from the app store\". Assuming that there is a real stream available on the website and mobile app, is it still possible to open it by streamlink?\r\n\r\nCurrent stream for all of the channels:\r\n\r\n\r\n\r\nThanks\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\nstreamlink http://tvcatchup.com/watch/bbctwo best\r\n\r\n### Environment details\r\n\r\nOperating system and version: Windows/Linux\r\nStreamlink and Python version: Streamlink 0.8.1\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\n", "before_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.stream import HLSStream\n\nUSER_AGENT = \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36\"\n_url_re = re.compile(r\"http://(?:www\\.)?tvcatchup.com/watch/\\w+\")\n_stream_re = re.compile(r'''(?P<q>[\"'])(?P<stream_url>https?://.*m3u8\\?.*clientKey=.*?)(?P=q)''')\n\n\nclass TVCatchup(Plugin):\n @classmethod\n def can_handle_url(cls, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n \"\"\"\n Finds the streams from tvcatchup.com.\n \"\"\"\n http.headers.update({\"User-Agent\": USER_AGENT})\n res = http.get(self.url)\n\n match = _stream_re.search(res.text, re.IGNORECASE | re.MULTILINE)\n\n if match:\n stream_url = match.group(\"stream_url\")\n\n if stream_url:\n if \"_adp\" in stream_url:\n return HLSStream.parse_variant_playlist(self.session, stream_url)\n else:\n return {'576p': HLSStream(self.session, stream_url)}\n\n\n__plugin__ = TVCatchup\n", "path": "src/streamlink/plugins/tvcatchup.py"}]}
| 1,247 | 237 |
gh_patches_debug_2018
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-1237
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
0.5 fails to compile on OS X 10.8
Full traceback: http://pastebin.com/raw.php?i=M9N6Fgzi
@reaperhulk has diagnosed, but this will require an 0.5.2 release to fix for supported platform.
</issue>
<code>
[start of cryptography/hazmat/bindings/commoncrypto/secitem.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from __future__ import absolute_import, division, print_function
15
16 INCLUDES = """
17 #include <Security/SecItem.h>
18 """
19
20 TYPES = """
21 const CFTypeRef kSecAttrKeyType;
22 const CFTypeRef kSecAttrKeySizeInBits;
23 const CFTypeRef kSecAttrIsPermanent;
24 const CFTypeRef kSecAttrKeyTypeRSA;
25 const CFTypeRef kSecAttrKeyTypeDSA;
26 const CFTypeRef kSecAttrKeyTypeEC;
27 const CFTypeRef kSecAttrKeyTypeEC;
28 const CFTypeRef kSecUseKeychain;
29 """
30
31 FUNCTIONS = """
32 """
33
34 MACROS = """
35 """
36
37 CUSTOMIZATIONS = """
38 """
39
40 CONDITIONAL_NAMES = {}
41
[end of cryptography/hazmat/bindings/commoncrypto/secitem.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cryptography/hazmat/bindings/commoncrypto/secitem.py b/cryptography/hazmat/bindings/commoncrypto/secitem.py
--- a/cryptography/hazmat/bindings/commoncrypto/secitem.py
+++ b/cryptography/hazmat/bindings/commoncrypto/secitem.py
@@ -23,8 +23,6 @@
const CFTypeRef kSecAttrIsPermanent;
const CFTypeRef kSecAttrKeyTypeRSA;
const CFTypeRef kSecAttrKeyTypeDSA;
-const CFTypeRef kSecAttrKeyTypeEC;
-const CFTypeRef kSecAttrKeyTypeEC;
const CFTypeRef kSecUseKeychain;
"""
|
{"golden_diff": "diff --git a/cryptography/hazmat/bindings/commoncrypto/secitem.py b/cryptography/hazmat/bindings/commoncrypto/secitem.py\n--- a/cryptography/hazmat/bindings/commoncrypto/secitem.py\n+++ b/cryptography/hazmat/bindings/commoncrypto/secitem.py\n@@ -23,8 +23,6 @@\n const CFTypeRef kSecAttrIsPermanent;\n const CFTypeRef kSecAttrKeyTypeRSA;\n const CFTypeRef kSecAttrKeyTypeDSA;\n-const CFTypeRef kSecAttrKeyTypeEC;\n-const CFTypeRef kSecAttrKeyTypeEC;\n const CFTypeRef kSecUseKeychain;\n \"\"\"\n", "issue": "0.5 fails to compile on OS X 10.8\nFull traceback: http://pastebin.com/raw.php?i=M9N6Fgzi\n\n@reaperhulk has diagnosed, but this will require an 0.5.2 release to fix for supported platform.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nINCLUDES = \"\"\"\n#include <Security/SecItem.h>\n\"\"\"\n\nTYPES = \"\"\"\nconst CFTypeRef kSecAttrKeyType;\nconst CFTypeRef kSecAttrKeySizeInBits;\nconst CFTypeRef kSecAttrIsPermanent;\nconst CFTypeRef kSecAttrKeyTypeRSA;\nconst CFTypeRef kSecAttrKeyTypeDSA;\nconst CFTypeRef kSecAttrKeyTypeEC;\nconst CFTypeRef kSecAttrKeyTypeEC;\nconst CFTypeRef kSecUseKeychain;\n\"\"\"\n\nFUNCTIONS = \"\"\"\n\"\"\"\n\nMACROS = \"\"\"\n\"\"\"\n\nCUSTOMIZATIONS = \"\"\"\n\"\"\"\n\nCONDITIONAL_NAMES = {}\n", "path": "cryptography/hazmat/bindings/commoncrypto/secitem.py"}]}
| 942 | 136 |
gh_patches_debug_3327
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-5135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Presubmit failure
If you look into the test it said
```
Traceback (most recent call last):
File "<string>", line 3, in <module>
File "/usr/local/lib/python3.6/site-packages/kfp/__init__.py", line 24, in <module>
from ._client import Client
File "/usr/local/lib/python3.6/site-packages/kfp/_client.py", line 31, in <module>
from kfp.compiler import compiler
File "/usr/local/lib/python3.6/site-packages/kfp/compiler/__init__.py", line 17, in <module>
from ..containers._component_builder import build_python_component, build_docker_image, VersionedDependency
File "/usr/local/lib/python3.6/site-packages/kfp/containers/_component_builder.py", line 32, in <module>
from kfp.containers import entrypoint
File "/usr/local/lib/python3.6/site-packages/kfp/containers/entrypoint.py", line 23, in <module>
from kfp.containers import entrypoint_utils
File "/usr/local/lib/python3.6/site-packages/kfp/containers/entrypoint_utils.py", line 23, in <module>
from kfp.pipeline_spec import pipeline_spec_pb2
File "/usr/local/lib/python3.6/site-packages/kfp/pipeline_spec/pipeline_spec_pb2.py", line 23, in <module>
create_key=_descriptor._internal_create_key,
AttributeError: module 'google.protobuf.descriptor' has no attribute '_internal_create_key'
```
Looks like the `protobuf` version is not matching in this case. @Bobgy are you aware of this error? Thanks.
_Originally posted by @Tomcli in https://github.com/kubeflow/pipelines/pull/5059#issuecomment-777656530_
/cc @numerology @chensun @Ark-kun
Can you take a look at this issue? I have seen multiple reports, this error seems to fail consistently.
</issue>
<code>
[start of api/v2alpha1/python/setup.py]
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import subprocess
17 import sys
18 import setuptools
19 try:
20 from distutils.spawn import find_executable
21 except ImportError:
22 from shutil import which as find_executable
23
24 NAME = "kfp-pipeline-spec"
25 VERSION = "0.1.5"
26
27 PROTO_DIR = os.path.realpath(
28 os.path.join(os.path.dirname(__file__), os.pardir))
29
30 PKG_DIR = os.path.realpath(
31 os.path.join(os.path.dirname(__file__), "kfp", "pipeline_spec"))
32
33 # Find the Protocol Compiler. (Taken from protobuf/python/setup.py)
34 if "PROTOC" in os.environ and os.path.exists(os.environ["PROTOC"]):
35 PROTOC = os.environ["PROTOC"]
36 else:
37 PROTOC = find_executable("protoc")
38
39
40 def GenerateProto(source):
41 """Generate a _pb2.py from a .proto file.
42
43 Invokes the Protocol Compiler to generate a _pb2.py from the given
44 .proto file. Does nothing if the output already exists and is newer than
45 the input.
46
47 Args:
48 source: The source proto file that needs to be compiled.
49 """
50
51 output = source.replace(".proto", "_pb2.py")
52
53 if not os.path.exists(output) or (
54 os.path.exists(source) and
55 os.path.getmtime(source) > os.path.getmtime(output)):
56 print("Generating %s..." % output)
57
58 if not os.path.exists(source):
59 sys.stderr.write("Can't find required file: %s\n" % source)
60 sys.exit(-1)
61
62 if PROTOC is None:
63 sys.stderr.write("protoc is not found. Please compile it "
64 "or install the binary package.\n")
65 sys.exit(-1)
66
67 protoc_command = [
68 PROTOC, "-I%s" % PROTO_DIR,
69 "--python_out=%s" % PKG_DIR, source
70 ]
71 if subprocess.call(protoc_command) != 0:
72 sys.exit(-1)
73
74
75 # Generate the protobuf files that we depend on.
76 GenerateProto(os.path.join(PROTO_DIR, "pipeline_spec.proto"))
77
78 setuptools.setup(
79 name=NAME,
80 version=VERSION,
81 description="Kubeflow Pipelines pipeline spec",
82 author="google",
83 author_email="[email protected]",
84 url="https://github.com/kubeflow/pipelines",
85 packages=setuptools.find_namespace_packages(include=['kfp.*']),
86 python_requires=">=3.5.3",
87 include_package_data=True,
88 license="Apache 2.0",
89 )
90
[end of api/v2alpha1/python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/api/v2alpha1/python/setup.py b/api/v2alpha1/python/setup.py
--- a/api/v2alpha1/python/setup.py
+++ b/api/v2alpha1/python/setup.py
@@ -84,6 +84,7 @@
url="https://github.com/kubeflow/pipelines",
packages=setuptools.find_namespace_packages(include=['kfp.*']),
python_requires=">=3.5.3",
+ install_requires=["protobuf>=3.13.0,<4"],
include_package_data=True,
license="Apache 2.0",
)
|
{"golden_diff": "diff --git a/api/v2alpha1/python/setup.py b/api/v2alpha1/python/setup.py\n--- a/api/v2alpha1/python/setup.py\n+++ b/api/v2alpha1/python/setup.py\n@@ -84,6 +84,7 @@\n url=\"https://github.com/kubeflow/pipelines\",\n packages=setuptools.find_namespace_packages(include=['kfp.*']),\n python_requires=\">=3.5.3\",\n+ install_requires=[\"protobuf>=3.13.0,<4\"],\n include_package_data=True,\n license=\"Apache 2.0\",\n )\n", "issue": "Presubmit failure\nIf you look into the test it said\r\n```\r\nTraceback (most recent call last):\r\n File \"<string>\", line 3, in <module>\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/__init__.py\", line 24, in <module>\r\n from ._client import Client\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/_client.py\", line 31, in <module>\r\n from kfp.compiler import compiler\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/compiler/__init__.py\", line 17, in <module>\r\n from ..containers._component_builder import build_python_component, build_docker_image, VersionedDependency\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/containers/_component_builder.py\", line 32, in <module>\r\n from kfp.containers import entrypoint\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/containers/entrypoint.py\", line 23, in <module>\r\n from kfp.containers import entrypoint_utils\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/containers/entrypoint_utils.py\", line 23, in <module>\r\n from kfp.pipeline_spec import pipeline_spec_pb2\r\n File \"/usr/local/lib/python3.6/site-packages/kfp/pipeline_spec/pipeline_spec_pb2.py\", line 23, in <module>\r\n create_key=_descriptor._internal_create_key,\r\nAttributeError: module 'google.protobuf.descriptor' has no attribute '_internal_create_key'\r\n```\r\n\r\nLooks like the `protobuf` version is not matching in this case. @Bobgy are you aware of this error? Thanks.\n\n_Originally posted by @Tomcli in https://github.com/kubeflow/pipelines/pull/5059#issuecomment-777656530_\n\n/cc @numerology @chensun @Ark-kun \nCan you take a look at this issue? I have seen multiple reports, this error seems to fail consistently.\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport subprocess\nimport sys\nimport setuptools\ntry:\n from distutils.spawn import find_executable\nexcept ImportError:\n from shutil import which as find_executable\n\nNAME = \"kfp-pipeline-spec\"\nVERSION = \"0.1.5\"\n\nPROTO_DIR = os.path.realpath(\n os.path.join(os.path.dirname(__file__), os.pardir))\n\nPKG_DIR = os.path.realpath(\n os.path.join(os.path.dirname(__file__), \"kfp\", \"pipeline_spec\"))\n\n# Find the Protocol Compiler. (Taken from protobuf/python/setup.py)\nif \"PROTOC\" in os.environ and os.path.exists(os.environ[\"PROTOC\"]):\n PROTOC = os.environ[\"PROTOC\"]\nelse:\n PROTOC = find_executable(\"protoc\")\n\n\ndef GenerateProto(source):\n \"\"\"Generate a _pb2.py from a .proto file.\n\n Invokes the Protocol Compiler to generate a _pb2.py from the given\n .proto file. Does nothing if the output already exists and is newer than\n the input.\n\n Args:\n source: The source proto file that needs to be compiled.\n \"\"\"\n\n output = source.replace(\".proto\", \"_pb2.py\")\n\n if not os.path.exists(output) or (\n os.path.exists(source) and\n os.path.getmtime(source) > os.path.getmtime(output)):\n print(\"Generating %s...\" % output)\n\n if not os.path.exists(source):\n sys.stderr.write(\"Can't find required file: %s\\n\" % source)\n sys.exit(-1)\n\n if PROTOC is None:\n sys.stderr.write(\"protoc is not found. Please compile it \"\n \"or install the binary package.\\n\")\n sys.exit(-1)\n\n protoc_command = [\n PROTOC, \"-I%s\" % PROTO_DIR,\n \"--python_out=%s\" % PKG_DIR, source\n ]\n if subprocess.call(protoc_command) != 0:\n sys.exit(-1)\n\n\n# Generate the protobuf files that we depend on.\nGenerateProto(os.path.join(PROTO_DIR, \"pipeline_spec.proto\"))\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=\"Kubeflow Pipelines pipeline spec\",\n author=\"google\",\n author_email=\"[email protected]\",\n url=\"https://github.com/kubeflow/pipelines\",\n packages=setuptools.find_namespace_packages(include=['kfp.*']),\n python_requires=\">=3.5.3\",\n include_package_data=True,\n license=\"Apache 2.0\",\n)\n", "path": "api/v2alpha1/python/setup.py"}]}
| 1,845 | 127 |
gh_patches_debug_26964
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-4274
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyPI sends emails with unicode in header
**Describe the bug**
<!-- A clear and concise description the bug -->
I created a new account on pypi.org, but I am not receiving any email verification link by email - not after accouunt creation and also not after resending the verification link (even if pypi.org claims "Verification email for [email protected] resent").
test.pypi.org works for me, using the same account name and email address. I deleted and recreated the account on both pypi.org and test.pypi.org - same behaviour (well, the initial email did sometimes not arrive on test.pypi.org, but the the verification resend always arrived right away).
**Expected behavior**
<!-- A clear and concise description of what you expected to happen -->
I should get an email token after registering, and also when I resend the verification mail from the account page. I know it might take a while, but I am experiencing this since Friday.
**To Reproduce**
<!-- Steps to reproduce the bug, or a link to PyPI where the bug is visible -->
Register on pypi.org, wait for email. Resend the verification email from the account settings page, wait again.
**My Platform**
<!--
Any details about your specific platform:
* If the problem is in the browser, what browser, version, and OS?
* If the problem is with a command-line tool, what version of that tool?
* If the problem is with connecting to PyPI, include some details about
your network, including SSL/TLS implementation in use, internet service
provider, and if there are any firewalls or proxies in use.
-->
Firefox 52
</issue>
<code>
[start of warehouse/email/services.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from email.headerregistry import Address
14 from email.utils import parseaddr
15
16 from pyramid_mailer import get_mailer
17 from pyramid_mailer.message import Message
18 from zope.interface import implementer
19
20 from warehouse.email.interfaces import IEmailSender
21 from warehouse.email.ses.models import EmailMessage
22
23
24 def _format_sender(sitename, sender):
25 if sender is not None:
26 return str(Address(sitename, addr_spec=sender))
27
28
29 @implementer(IEmailSender)
30 class SMTPEmailSender:
31 def __init__(self, mailer, sender=None):
32 self.mailer = mailer
33 self.sender = sender
34
35 @classmethod
36 def create_service(cls, context, request):
37 sitename = request.registry.settings["site.name"]
38 sender = _format_sender(sitename, request.registry.settings.get("mail.sender"))
39 return cls(get_mailer(request), sender=sender)
40
41 def send(self, subject, body, *, recipient):
42 message = Message(
43 subject=subject, body=body, recipients=[recipient], sender=self.sender
44 )
45 self.mailer.send_immediately(message)
46
47
48 @implementer(IEmailSender)
49 class SESEmailSender:
50 def __init__(self, client, *, sender=None, db):
51 self._client = client
52 self._sender = sender
53 self._db = db
54
55 @classmethod
56 def create_service(cls, context, request):
57 sitename = request.registry.settings["site.name"]
58 sender = _format_sender(sitename, request.registry.settings.get("mail.sender"))
59
60 aws_session = request.find_service(name="aws.session")
61
62 return cls(
63 aws_session.client(
64 "ses", region_name=request.registry.settings.get("mail.region")
65 ),
66 sender=sender,
67 db=request.db,
68 )
69
70 def send(self, subject, body, *, recipient):
71 resp = self._client.send_email(
72 Source=self._sender,
73 Destination={"ToAddresses": [recipient]},
74 Message={
75 "Subject": {"Data": subject, "Charset": "UTF-8"},
76 "Body": {"Text": {"Data": body, "Charset": "UTF-8"}},
77 },
78 )
79
80 self._db.add(
81 EmailMessage(
82 message_id=resp["MessageId"],
83 from_=parseaddr(self._sender)[1],
84 to=parseaddr(recipient)[1],
85 subject=subject,
86 )
87 )
88
[end of warehouse/email/services.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/email/services.py b/warehouse/email/services.py
--- a/warehouse/email/services.py
+++ b/warehouse/email/services.py
@@ -11,7 +11,9 @@
# limitations under the License.
from email.headerregistry import Address
-from email.utils import parseaddr
+from email.mime.multipart import MIMEMultipart
+from email.mime.text import MIMEText
+from email.utils import parseaddr, formataddr
from pyramid_mailer import get_mailer
from pyramid_mailer.message import Message
@@ -68,13 +70,25 @@
)
def send(self, subject, body, *, recipient):
- resp = self._client.send_email(
+ message = MIMEMultipart("mixed")
+ message["Subject"] = subject
+ message["From"] = self._sender
+
+ # The following is necessary to support friendly names with Unicode characters,
+ # otherwise the entire value will get encoded and will not be accepted by SES:
+ #
+ # >>> parseaddr("Fööbar <[email protected]>")
+ # ('Fööbar', '[email protected]')
+ # >>> formataddr(_)
+ # '=?utf-8?b?RsO2w7ZiYXI=?= <[email protected]>'
+ message["To"] = formataddr(parseaddr(recipient))
+
+ message.attach(MIMEText(body, "plain", "utf-8"))
+
+ resp = self._client.send_raw_email(
Source=self._sender,
- Destination={"ToAddresses": [recipient]},
- Message={
- "Subject": {"Data": subject, "Charset": "UTF-8"},
- "Body": {"Text": {"Data": body, "Charset": "UTF-8"}},
- },
+ Destinations=[recipient],
+ RawMessage={"Data": message.as_string()},
)
self._db.add(
|
{"golden_diff": "diff --git a/warehouse/email/services.py b/warehouse/email/services.py\n--- a/warehouse/email/services.py\n+++ b/warehouse/email/services.py\n@@ -11,7 +11,9 @@\n # limitations under the License.\n \n from email.headerregistry import Address\n-from email.utils import parseaddr\n+from email.mime.multipart import MIMEMultipart\n+from email.mime.text import MIMEText\n+from email.utils import parseaddr, formataddr\n \n from pyramid_mailer import get_mailer\n from pyramid_mailer.message import Message\n@@ -68,13 +70,25 @@\n )\n \n def send(self, subject, body, *, recipient):\n- resp = self._client.send_email(\n+ message = MIMEMultipart(\"mixed\")\n+ message[\"Subject\"] = subject\n+ message[\"From\"] = self._sender\n+\n+ # The following is necessary to support friendly names with Unicode characters,\n+ # otherwise the entire value will get encoded and will not be accepted by SES:\n+ #\n+ # >>> parseaddr(\"F\u00f6\u00f6bar <[email protected]>\")\n+ # ('F\u00f6\u00f6bar', '[email protected]')\n+ # >>> formataddr(_)\n+ # '=?utf-8?b?RsO2w7ZiYXI=?= <[email protected]>'\n+ message[\"To\"] = formataddr(parseaddr(recipient))\n+\n+ message.attach(MIMEText(body, \"plain\", \"utf-8\"))\n+\n+ resp = self._client.send_raw_email(\n Source=self._sender,\n- Destination={\"ToAddresses\": [recipient]},\n- Message={\n- \"Subject\": {\"Data\": subject, \"Charset\": \"UTF-8\"},\n- \"Body\": {\"Text\": {\"Data\": body, \"Charset\": \"UTF-8\"}},\n- },\n+ Destinations=[recipient],\n+ RawMessage={\"Data\": message.as_string()},\n )\n \n self._db.add(\n", "issue": "PyPI sends emails with unicode in header\n**Describe the bug**\r\n<!-- A clear and concise description the bug -->\r\nI created a new account on pypi.org, but I am not receiving any email verification link by email - not after accouunt creation and also not after resending the verification link (even if pypi.org claims \"Verification email for [email protected] resent\").\r\n\r\ntest.pypi.org works for me, using the same account name and email address. I deleted and recreated the account on both pypi.org and test.pypi.org - same behaviour (well, the initial email did sometimes not arrive on test.pypi.org, but the the verification resend always arrived right away).\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen -->\r\nI should get an email token after registering, and also when I resend the verification mail from the account page. I know it might take a while, but I am experiencing this since Friday.\r\n\r\n**To Reproduce**\r\n<!-- Steps to reproduce the bug, or a link to PyPI where the bug is visible -->\r\nRegister on pypi.org, wait for email. Resend the verification email from the account settings page, wait again.\r\n\r\n**My Platform**\r\n<!--\r\n Any details about your specific platform:\r\n * If the problem is in the browser, what browser, version, and OS?\r\n * If the problem is with a command-line tool, what version of that tool?\r\n * If the problem is with connecting to PyPI, include some details about\r\n your network, including SSL/TLS implementation in use, internet service\r\n provider, and if there are any firewalls or proxies in use.\r\n-->\r\nFirefox 52\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom email.headerregistry import Address\nfrom email.utils import parseaddr\n\nfrom pyramid_mailer import get_mailer\nfrom pyramid_mailer.message import Message\nfrom zope.interface import implementer\n\nfrom warehouse.email.interfaces import IEmailSender\nfrom warehouse.email.ses.models import EmailMessage\n\n\ndef _format_sender(sitename, sender):\n if sender is not None:\n return str(Address(sitename, addr_spec=sender))\n\n\n@implementer(IEmailSender)\nclass SMTPEmailSender:\n def __init__(self, mailer, sender=None):\n self.mailer = mailer\n self.sender = sender\n\n @classmethod\n def create_service(cls, context, request):\n sitename = request.registry.settings[\"site.name\"]\n sender = _format_sender(sitename, request.registry.settings.get(\"mail.sender\"))\n return cls(get_mailer(request), sender=sender)\n\n def send(self, subject, body, *, recipient):\n message = Message(\n subject=subject, body=body, recipients=[recipient], sender=self.sender\n )\n self.mailer.send_immediately(message)\n\n\n@implementer(IEmailSender)\nclass SESEmailSender:\n def __init__(self, client, *, sender=None, db):\n self._client = client\n self._sender = sender\n self._db = db\n\n @classmethod\n def create_service(cls, context, request):\n sitename = request.registry.settings[\"site.name\"]\n sender = _format_sender(sitename, request.registry.settings.get(\"mail.sender\"))\n\n aws_session = request.find_service(name=\"aws.session\")\n\n return cls(\n aws_session.client(\n \"ses\", region_name=request.registry.settings.get(\"mail.region\")\n ),\n sender=sender,\n db=request.db,\n )\n\n def send(self, subject, body, *, recipient):\n resp = self._client.send_email(\n Source=self._sender,\n Destination={\"ToAddresses\": [recipient]},\n Message={\n \"Subject\": {\"Data\": subject, \"Charset\": \"UTF-8\"},\n \"Body\": {\"Text\": {\"Data\": body, \"Charset\": \"UTF-8\"}},\n },\n )\n\n self._db.add(\n EmailMessage(\n message_id=resp[\"MessageId\"],\n from_=parseaddr(self._sender)[1],\n to=parseaddr(recipient)[1],\n subject=subject,\n )\n )\n", "path": "warehouse/email/services.py"}]}
| 1,684 | 426 |
gh_patches_debug_4268
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-685
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove unnecessary warning when using `download`
When running `retriever download` an unnecessary warning displays
```
ethan@gandalf:~$ retriever download Clark2006
Creating database Clark2006...
Couldn't create database ('NoneType' object has no attribute 'execute').
...
```
The command executes correctly, but this warning isn't really correct (there is no database to create since we're just downloading the raw data files) and could be distracting to users.
</issue>
<code>
[start of engines/download_only.py]
1 from __future__ import print_function
2 from builtins import object
3 import os
4 import platform
5 import shutil
6 import inspect
7
8 from retriever.lib.engine import filename_from_url
9 from retriever.lib.models import Engine, no_cleanup
10 from retriever import DATA_DIR, HOME_DIR
11
12
13 class DummyConnection(object):
14
15 def cursor(self):
16 pass
17
18 def commit(self):
19 pass
20
21 def rollback(self):
22 pass
23
24 def close(self):
25 pass
26
27
28 class DummyCursor(DummyConnection):
29 pass
30
31
32 class engine(Engine):
33 """Engine instance for writing data to a CSV file."""
34 name = "Download Only"
35 abbreviation = "download"
36 required_opts = [("path",
37 "File path to copy data files",
38 "./"),
39 ("subdir",
40 "Keep the subdirectories for archived files",
41 False)
42 ]
43
44 def table_exists(self, dbname, tablename):
45 """Checks if the file to be downloaded already exists"""
46 try:
47 tablename = self.table_name(name=tablename, dbname=dbname)
48 return os.path.exists(tablename)
49 except:
50 return False
51
52 def get_connection(self):
53 """Gets the db connection."""
54 self.get_input()
55 return DummyConnection()
56
57 def final_cleanup(self):
58 """Copies downloaded files to desired directory
59
60 Copies the downloaded files into the chosen directory unless files with the same
61 name already exist in the directory.
62
63 """
64 if hasattr(self, "all_files"):
65 for file_name in self.all_files:
66 file_path, file_name_nopath = os.path.split(file_name)
67 subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''
68 dest_path = os.path.join(self.opts['path'], subdir)
69 if os.path.isfile(os.path.join(dest_path, file_name_nopath)):
70 print ("File already exists at specified location")
71 elif os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):
72 print ("%s is already in the working directory" %
73 file_name_nopath)
74 print("Keeping existing copy.")
75 else:
76 print("Copying %s from %s" % (file_name_nopath, file_path))
77 if os.path.isdir(dest_path):
78 try:
79 shutil.copy(file_name, dest_path)
80 except:
81 print("Couldn't copy file to %s" % dest_path)
82 else:
83 try:
84 print("Creating directory %s" % dest_path)
85 os.makedirs(dest_path)
86 shutil.copy(file_name, dest_path)
87 except:
88 print("Couldn't create directory %s" % dest_path)
89 self.all_files = set()
90
91 def auto_create_table(self, table, url=None, filename=None, pk=None):
92 """Download the file if it doesn't exist"""
93 if url and not filename:
94 filename = filename_from_url(url)
95
96 if url and not self.find_file(filename):
97 # If the file doesn't exist, download it
98 self.download_file(url, filename)
99
100 def insert_data_from_url(self, url):
101 """Insert data from a web resource"""
102 filename = filename_from_url(url)
103 find = self.find_file(filename)
104 if not find:
105 self.create_raw_data_dir()
106 self.download_file(url, filename)
107
108 def find_file(self, filename):
109 """Checks for the given file and adds it to the list of all files"""
110 result = Engine.find_file(self, filename)
111 if not hasattr(self, "all_files"):
112 self.all_files = set()
113 if result:
114 self.all_files.add(result)
115 return result
116
117 def register_files(self, filenames):
118 """Identify a list of files to be moved by the download
119
120 When downloading archives with multiple files the engine needs to be
121 informed of all of the file names so that it can move them.
122
123 """
124 full_filenames = {self.find_file(filename) for filename in filenames
125 if self.find_file(filename)}
126 self.all_files = self.all_files.union(full_filenames)
127
128
129 # replace all other methods with a function that does nothing
130 def dummy_method(self, *args, **kwargs):
131 pass
132
133
134 methods = inspect.getmembers(engine, predicate=inspect.ismethod)
135 keep_methods = {'table_exists',
136 'get_connection',
137 'final_cleanup',
138 'auto_create_table',
139 'insert_data_from_url',
140 }
141 remove_methods = ['insert_data_from_file']
142 for name, method in methods:
143 if (name not in keep_methods and
144 'download' not in name and
145 'file' not in name and
146 'dir' not in name):
147 setattr(engine, name, dummy_method)
148 for name in remove_methods:
149 setattr(engine, name, dummy_method)
150
[end of engines/download_only.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/engines/download_only.py b/engines/download_only.py
--- a/engines/download_only.py
+++ b/engines/download_only.py
@@ -138,7 +138,7 @@
'auto_create_table',
'insert_data_from_url',
}
-remove_methods = ['insert_data_from_file']
+remove_methods = ['insert_data_from_file', 'create_db']
for name, method in methods:
if (name not in keep_methods and
'download' not in name and
|
{"golden_diff": "diff --git a/engines/download_only.py b/engines/download_only.py\n--- a/engines/download_only.py\n+++ b/engines/download_only.py\n@@ -138,7 +138,7 @@\n 'auto_create_table',\n 'insert_data_from_url',\n }\n-remove_methods = ['insert_data_from_file']\n+remove_methods = ['insert_data_from_file', 'create_db']\n for name, method in methods:\n if (name not in keep_methods and\n 'download' not in name and\n", "issue": "Remove unnecessary warning when using `download`\nWhen running `retriever download` an unnecessary warning displays\n\n```\nethan@gandalf:~$ retriever download Clark2006\nCreating database Clark2006...\nCouldn't create database ('NoneType' object has no attribute 'execute').\n...\n```\n\nThe command executes correctly, but this warning isn't really correct (there is no database to create since we're just downloading the raw data files) and could be distracting to users.\n\n", "before_files": [{"content": "from __future__ import print_function\nfrom builtins import object\nimport os\nimport platform\nimport shutil\nimport inspect\n\nfrom retriever.lib.engine import filename_from_url\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import DATA_DIR, HOME_DIR\n\n\nclass DummyConnection(object):\n\n def cursor(self):\n pass\n\n def commit(self):\n pass\n\n def rollback(self):\n pass\n\n def close(self):\n pass\n\n\nclass DummyCursor(DummyConnection):\n pass\n\n\nclass engine(Engine):\n \"\"\"Engine instance for writing data to a CSV file.\"\"\"\n name = \"Download Only\"\n abbreviation = \"download\"\n required_opts = [(\"path\",\n \"File path to copy data files\",\n \"./\"),\n (\"subdir\",\n \"Keep the subdirectories for archived files\",\n False)\n ]\n\n def table_exists(self, dbname, tablename):\n \"\"\"Checks if the file to be downloaded already exists\"\"\"\n try:\n tablename = self.table_name(name=tablename, dbname=dbname)\n return os.path.exists(tablename)\n except:\n return False\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n self.get_input()\n return DummyConnection()\n\n def final_cleanup(self):\n \"\"\"Copies downloaded files to desired directory\n\n Copies the downloaded files into the chosen directory unless files with the same\n name already exist in the directory.\n\n \"\"\"\n if hasattr(self, \"all_files\"):\n for file_name in self.all_files:\n file_path, file_name_nopath = os.path.split(file_name)\n subdir = os.path.split(file_path)[1] if self.opts['subdir'] else ''\n dest_path = os.path.join(self.opts['path'], subdir)\n if os.path.isfile(os.path.join(dest_path, file_name_nopath)):\n print (\"File already exists at specified location\")\n elif os.path.abspath(file_path) == os.path.abspath(os.path.join(DATA_DIR, subdir)):\n print (\"%s is already in the working directory\" %\n file_name_nopath)\n print(\"Keeping existing copy.\")\n else:\n print(\"Copying %s from %s\" % (file_name_nopath, file_path))\n if os.path.isdir(dest_path):\n try:\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't copy file to %s\" % dest_path)\n else:\n try:\n print(\"Creating directory %s\" % dest_path)\n os.makedirs(dest_path)\n shutil.copy(file_name, dest_path)\n except:\n print(\"Couldn't create directory %s\" % dest_path)\n self.all_files = set()\n\n def auto_create_table(self, table, url=None, filename=None, pk=None):\n \"\"\"Download the file if it doesn't exist\"\"\"\n if url and not filename:\n filename = filename_from_url(url)\n\n if url and not self.find_file(filename):\n # If the file doesn't exist, download it\n self.download_file(url, filename)\n\n def insert_data_from_url(self, url):\n \"\"\"Insert data from a web resource\"\"\"\n filename = filename_from_url(url)\n find = self.find_file(filename)\n if not find:\n self.create_raw_data_dir()\n self.download_file(url, filename)\n\n def find_file(self, filename):\n \"\"\"Checks for the given file and adds it to the list of all files\"\"\"\n result = Engine.find_file(self, filename)\n if not hasattr(self, \"all_files\"):\n self.all_files = set()\n if result:\n self.all_files.add(result)\n return result\n\n def register_files(self, filenames):\n \"\"\"Identify a list of files to be moved by the download\n\n When downloading archives with multiple files the engine needs to be\n informed of all of the file names so that it can move them.\n\n \"\"\"\n full_filenames = {self.find_file(filename) for filename in filenames\n if self.find_file(filename)}\n self.all_files = self.all_files.union(full_filenames)\n\n\n# replace all other methods with a function that does nothing\ndef dummy_method(self, *args, **kwargs):\n pass\n\n\nmethods = inspect.getmembers(engine, predicate=inspect.ismethod)\nkeep_methods = {'table_exists',\n 'get_connection',\n 'final_cleanup',\n 'auto_create_table',\n 'insert_data_from_url',\n }\nremove_methods = ['insert_data_from_file']\nfor name, method in methods:\n if (name not in keep_methods and\n 'download' not in name and\n 'file' not in name and\n 'dir' not in name):\n setattr(engine, name, dummy_method)\nfor name in remove_methods:\n setattr(engine, name, dummy_method)\n", "path": "engines/download_only.py"}]}
| 1,982 | 115 |
gh_patches_debug_938
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-1735
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
KeyError in robotstxt middleware
I'm getting these errors in robots.txt middleware:
```
2016-01-27 16:18:21 [scrapy.core.scraper] ERROR: Error downloading <GET http://yellowpages.co.th>
Traceback (most recent call last):
File "/Users/kmike/envs/scraping/lib/python2.7/site-packages/twisted/internet/defer.py", line 150, in maybeDeferred
result = f(*args, **kw)
File "/Users/kmike/svn/scrapy/scrapy/downloadermiddlewares/robotstxt.py", line 65, in robot_parser
if isinstance(self._parsers[netloc], Deferred):
KeyError: 'yellowpages.co.th'
```
It looks like https://github.com/scrapy/scrapy/pull/1473 caused it (I can't get this issue in Scrapy 1.0.4, but it present in Scrapy master). It happens when page failed to download and HTTP cache is enabled. I haven't debugged it further.
</issue>
<code>
[start of scrapy/downloadermiddlewares/robotstxt.py]
1 """
2 This is a middleware to respect robots.txt policies. To activate it you must
3 enable this middleware and enable the ROBOTSTXT_OBEY setting.
4
5 """
6
7 import logging
8
9 from six.moves.urllib import robotparser
10
11 from twisted.internet.defer import Deferred, maybeDeferred
12 from scrapy.exceptions import NotConfigured, IgnoreRequest
13 from scrapy.http import Request
14 from scrapy.utils.httpobj import urlparse_cached
15 from scrapy.utils.log import failure_to_exc_info
16
17 logger = logging.getLogger(__name__)
18
19
20 class RobotsTxtMiddleware(object):
21 DOWNLOAD_PRIORITY = 1000
22
23 def __init__(self, crawler):
24 if not crawler.settings.getbool('ROBOTSTXT_OBEY'):
25 raise NotConfigured
26
27 self.crawler = crawler
28 self._useragent = crawler.settings.get('USER_AGENT')
29 self._parsers = {}
30
31 @classmethod
32 def from_crawler(cls, crawler):
33 return cls(crawler)
34
35 def process_request(self, request, spider):
36 if request.meta.get('dont_obey_robotstxt'):
37 return
38 d = maybeDeferred(self.robot_parser, request, spider)
39 d.addCallback(self.process_request_2, request, spider)
40 return d
41
42 def process_request_2(self, rp, request, spider):
43 if rp is not None and not rp.can_fetch(self._useragent, request.url):
44 logger.debug("Forbidden by robots.txt: %(request)s",
45 {'request': request}, extra={'spider': spider})
46 raise IgnoreRequest()
47
48 def robot_parser(self, request, spider):
49 url = urlparse_cached(request)
50 netloc = url.netloc
51
52 if netloc not in self._parsers:
53 self._parsers[netloc] = Deferred()
54 robotsurl = "%s://%s/robots.txt" % (url.scheme, url.netloc)
55 robotsreq = Request(
56 robotsurl,
57 priority=self.DOWNLOAD_PRIORITY,
58 meta={'dont_obey_robotstxt': True}
59 )
60 dfd = self.crawler.engine.download(robotsreq, spider)
61 dfd.addCallback(self._parse_robots, netloc)
62 dfd.addErrback(self._logerror, robotsreq, spider)
63 dfd.addErrback(self._robots_error, netloc)
64
65 if isinstance(self._parsers[netloc], Deferred):
66 d = Deferred()
67 def cb(result):
68 d.callback(result)
69 return result
70 self._parsers[netloc].addCallback(cb)
71 return d
72 else:
73 return self._parsers[netloc]
74
75 def _logerror(self, failure, request, spider):
76 if failure.type is not IgnoreRequest:
77 logger.error("Error downloading %(request)s: %(f_exception)s",
78 {'request': request, 'f_exception': failure.value},
79 exc_info=failure_to_exc_info(failure),
80 extra={'spider': spider})
81 return failure
82
83 def _parse_robots(self, response, netloc):
84 rp = robotparser.RobotFileParser(response.url)
85 body = ''
86 if hasattr(response, 'text'):
87 body = response.text
88 else: # last effort try
89 try:
90 body = response.body.decode('utf-8')
91 except UnicodeDecodeError:
92 # If we found garbage, disregard it:,
93 # but keep the lookup cached (in self._parsers)
94 # Running rp.parse() will set rp state from
95 # 'disallow all' to 'allow any'.
96 pass
97 rp.parse(body.splitlines())
98
99 rp_dfd = self._parsers[netloc]
100 self._parsers[netloc] = rp
101 rp_dfd.callback(rp)
102
103 def _robots_error(self, failure, netloc):
104 self._parsers.pop(netloc).callback(None)
105
[end of scrapy/downloadermiddlewares/robotstxt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/downloadermiddlewares/robotstxt.py b/scrapy/downloadermiddlewares/robotstxt.py
--- a/scrapy/downloadermiddlewares/robotstxt.py
+++ b/scrapy/downloadermiddlewares/robotstxt.py
@@ -101,4 +101,6 @@
rp_dfd.callback(rp)
def _robots_error(self, failure, netloc):
- self._parsers.pop(netloc).callback(None)
+ rp_dfd = self._parsers[netloc]
+ self._parsers[netloc] = None
+ rp_dfd.callback(None)
|
{"golden_diff": "diff --git a/scrapy/downloadermiddlewares/robotstxt.py b/scrapy/downloadermiddlewares/robotstxt.py\n--- a/scrapy/downloadermiddlewares/robotstxt.py\n+++ b/scrapy/downloadermiddlewares/robotstxt.py\n@@ -101,4 +101,6 @@\n rp_dfd.callback(rp)\n \n def _robots_error(self, failure, netloc):\n- self._parsers.pop(netloc).callback(None)\n+ rp_dfd = self._parsers[netloc]\n+ self._parsers[netloc] = None\n+ rp_dfd.callback(None)\n", "issue": "KeyError in robotstxt middleware\nI'm getting these errors in robots.txt middleware:\n\n```\n2016-01-27 16:18:21 [scrapy.core.scraper] ERROR: Error downloading <GET http://yellowpages.co.th>\nTraceback (most recent call last):\n File \"/Users/kmike/envs/scraping/lib/python2.7/site-packages/twisted/internet/defer.py\", line 150, in maybeDeferred\n result = f(*args, **kw)\n File \"/Users/kmike/svn/scrapy/scrapy/downloadermiddlewares/robotstxt.py\", line 65, in robot_parser\n if isinstance(self._parsers[netloc], Deferred):\nKeyError: 'yellowpages.co.th'\n```\n\nIt looks like https://github.com/scrapy/scrapy/pull/1473 caused it (I can't get this issue in Scrapy 1.0.4, but it present in Scrapy master). It happens when page failed to download and HTTP cache is enabled. I haven't debugged it further.\n\n", "before_files": [{"content": "\"\"\"\nThis is a middleware to respect robots.txt policies. To activate it you must\nenable this middleware and enable the ROBOTSTXT_OBEY setting.\n\n\"\"\"\n\nimport logging\n\nfrom six.moves.urllib import robotparser\n\nfrom twisted.internet.defer import Deferred, maybeDeferred\nfrom scrapy.exceptions import NotConfigured, IgnoreRequest\nfrom scrapy.http import Request\nfrom scrapy.utils.httpobj import urlparse_cached\nfrom scrapy.utils.log import failure_to_exc_info\n\nlogger = logging.getLogger(__name__)\n\n\nclass RobotsTxtMiddleware(object):\n DOWNLOAD_PRIORITY = 1000\n\n def __init__(self, crawler):\n if not crawler.settings.getbool('ROBOTSTXT_OBEY'):\n raise NotConfigured\n\n self.crawler = crawler\n self._useragent = crawler.settings.get('USER_AGENT')\n self._parsers = {}\n\n @classmethod\n def from_crawler(cls, crawler):\n return cls(crawler)\n\n def process_request(self, request, spider):\n if request.meta.get('dont_obey_robotstxt'):\n return\n d = maybeDeferred(self.robot_parser, request, spider)\n d.addCallback(self.process_request_2, request, spider)\n return d\n\n def process_request_2(self, rp, request, spider):\n if rp is not None and not rp.can_fetch(self._useragent, request.url):\n logger.debug(\"Forbidden by robots.txt: %(request)s\",\n {'request': request}, extra={'spider': spider})\n raise IgnoreRequest()\n\n def robot_parser(self, request, spider):\n url = urlparse_cached(request)\n netloc = url.netloc\n\n if netloc not in self._parsers:\n self._parsers[netloc] = Deferred()\n robotsurl = \"%s://%s/robots.txt\" % (url.scheme, url.netloc)\n robotsreq = Request(\n robotsurl,\n priority=self.DOWNLOAD_PRIORITY,\n meta={'dont_obey_robotstxt': True}\n )\n dfd = self.crawler.engine.download(robotsreq, spider)\n dfd.addCallback(self._parse_robots, netloc)\n dfd.addErrback(self._logerror, robotsreq, spider)\n dfd.addErrback(self._robots_error, netloc)\n\n if isinstance(self._parsers[netloc], Deferred):\n d = Deferred()\n def cb(result):\n d.callback(result)\n return result\n self._parsers[netloc].addCallback(cb)\n return d\n else:\n return self._parsers[netloc]\n\n def _logerror(self, failure, request, spider):\n if failure.type is not IgnoreRequest:\n logger.error(\"Error downloading %(request)s: %(f_exception)s\",\n {'request': request, 'f_exception': failure.value},\n exc_info=failure_to_exc_info(failure),\n extra={'spider': spider})\n return failure\n\n def _parse_robots(self, response, netloc):\n rp = robotparser.RobotFileParser(response.url)\n body = ''\n if hasattr(response, 'text'):\n body = response.text\n else: # last effort try\n try:\n body = response.body.decode('utf-8')\n except UnicodeDecodeError:\n # If we found garbage, disregard it:,\n # but keep the lookup cached (in self._parsers)\n # Running rp.parse() will set rp state from\n # 'disallow all' to 'allow any'.\n pass\n rp.parse(body.splitlines())\n\n rp_dfd = self._parsers[netloc]\n self._parsers[netloc] = rp\n rp_dfd.callback(rp)\n\n def _robots_error(self, failure, netloc):\n self._parsers.pop(netloc).callback(None)\n", "path": "scrapy/downloadermiddlewares/robotstxt.py"}]}
| 1,787 | 132 |
gh_patches_debug_22224
|
rasdani/github-patches
|
git_diff
|
quantopian__zipline-1723
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs build script requires `path.py` without specifying it as a dependency.
We should probably just remove it.
</issue>
<code>
[start of docs/deploy.py]
1 #!/usr/bin/env python
2 from __future__ import print_function
3 from contextlib import contextmanager
4 from glob import glob
5 from path import path
6 import os
7 from os.path import abspath, basename, dirname, exists, isfile
8 from shutil import move, rmtree
9 from subprocess import check_call
10
11 HERE = dirname(abspath(__file__))
12 ZIPLINE_ROOT = dirname(HERE)
13 TEMP_LOCATION = '/tmp/zipline-doc'
14 TEMP_LOCATION_GLOB = TEMP_LOCATION + '/*'
15
16
17 @contextmanager
18 def removing(path):
19 try:
20 yield
21 finally:
22 rmtree(path)
23
24
25 def ensure_not_exists(path):
26 if not exists(path):
27 return
28 if isfile(path):
29 os.unlink(path)
30 else:
31 rmtree(path)
32
33
34 def main():
35 print("Moving to %s." % HERE)
36 with path(HERE):
37 print("Building docs with 'make html'")
38 check_call(['make', 'html'])
39
40 print("Clearing temp location '%s'" % TEMP_LOCATION)
41 rmtree(TEMP_LOCATION, ignore_errors=True)
42
43 with removing(TEMP_LOCATION):
44 print("Copying built files to temp location.")
45 move('build/html', TEMP_LOCATION)
46
47 print("Moving to '%s'" % ZIPLINE_ROOT)
48 os.chdir(ZIPLINE_ROOT)
49
50 print("Checking out gh-pages branch.")
51 check_call(
52 [
53 'git', 'branch', '-f',
54 '--track', 'gh-pages', 'origin/gh-pages'
55 ]
56 )
57 check_call(['git', 'checkout', 'gh-pages'])
58 check_call(['git', 'reset', '--hard', 'origin/gh-pages'])
59
60 print("Copying built files:")
61 for file_ in glob(TEMP_LOCATION_GLOB):
62 base = basename(file_)
63
64 print("%s -> %s" % (file_, base))
65 ensure_not_exists(base)
66 move(file_, '.')
67
68 print()
69 print("Updated documentation branch in directory %s" % ZIPLINE_ROOT)
70 print("If you are happy with these changes, commit and push to gh-pages.")
71
72 if __name__ == '__main__':
73 main()
74
[end of docs/deploy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/deploy.py b/docs/deploy.py
--- a/docs/deploy.py
+++ b/docs/deploy.py
@@ -2,7 +2,6 @@
from __future__ import print_function
from contextlib import contextmanager
from glob import glob
-from path import path
import os
from os.path import abspath, basename, dirname, exists, isfile
from shutil import move, rmtree
@@ -32,8 +31,11 @@
def main():
+ old_dir = os.getcwd()
print("Moving to %s." % HERE)
- with path(HERE):
+ os.chdir(HERE)
+
+ try:
print("Building docs with 'make html'")
check_call(['make', 'html'])
@@ -64,6 +66,8 @@
print("%s -> %s" % (file_, base))
ensure_not_exists(base)
move(file_, '.')
+ finally:
+ os.chdir(old_dir)
print()
print("Updated documentation branch in directory %s" % ZIPLINE_ROOT)
|
{"golden_diff": "diff --git a/docs/deploy.py b/docs/deploy.py\n--- a/docs/deploy.py\n+++ b/docs/deploy.py\n@@ -2,7 +2,6 @@\n from __future__ import print_function\n from contextlib import contextmanager\n from glob import glob\n-from path import path\n import os\n from os.path import abspath, basename, dirname, exists, isfile\n from shutil import move, rmtree\n@@ -32,8 +31,11 @@\n \n \n def main():\n+ old_dir = os.getcwd()\n print(\"Moving to %s.\" % HERE)\n- with path(HERE):\n+ os.chdir(HERE)\n+\n+ try:\n print(\"Building docs with 'make html'\")\n check_call(['make', 'html'])\n \n@@ -64,6 +66,8 @@\n print(\"%s -> %s\" % (file_, base))\n ensure_not_exists(base)\n move(file_, '.')\n+ finally:\n+ os.chdir(old_dir)\n \n print()\n print(\"Updated documentation branch in directory %s\" % ZIPLINE_ROOT)\n", "issue": "Docs build script requires `path.py` without specifying it as a dependency.\nWe should probably just remove it.\n\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import print_function\nfrom contextlib import contextmanager\nfrom glob import glob\nfrom path import path\nimport os\nfrom os.path import abspath, basename, dirname, exists, isfile\nfrom shutil import move, rmtree\nfrom subprocess import check_call\n\nHERE = dirname(abspath(__file__))\nZIPLINE_ROOT = dirname(HERE)\nTEMP_LOCATION = '/tmp/zipline-doc'\nTEMP_LOCATION_GLOB = TEMP_LOCATION + '/*'\n\n\n@contextmanager\ndef removing(path):\n try:\n yield\n finally:\n rmtree(path)\n\n\ndef ensure_not_exists(path):\n if not exists(path):\n return\n if isfile(path):\n os.unlink(path)\n else:\n rmtree(path)\n\n\ndef main():\n print(\"Moving to %s.\" % HERE)\n with path(HERE):\n print(\"Building docs with 'make html'\")\n check_call(['make', 'html'])\n\n print(\"Clearing temp location '%s'\" % TEMP_LOCATION)\n rmtree(TEMP_LOCATION, ignore_errors=True)\n\n with removing(TEMP_LOCATION):\n print(\"Copying built files to temp location.\")\n move('build/html', TEMP_LOCATION)\n\n print(\"Moving to '%s'\" % ZIPLINE_ROOT)\n os.chdir(ZIPLINE_ROOT)\n\n print(\"Checking out gh-pages branch.\")\n check_call(\n [\n 'git', 'branch', '-f',\n '--track', 'gh-pages', 'origin/gh-pages'\n ]\n )\n check_call(['git', 'checkout', 'gh-pages'])\n check_call(['git', 'reset', '--hard', 'origin/gh-pages'])\n\n print(\"Copying built files:\")\n for file_ in glob(TEMP_LOCATION_GLOB):\n base = basename(file_)\n\n print(\"%s -> %s\" % (file_, base))\n ensure_not_exists(base)\n move(file_, '.')\n\n print()\n print(\"Updated documentation branch in directory %s\" % ZIPLINE_ROOT)\n print(\"If you are happy with these changes, commit and push to gh-pages.\")\n\nif __name__ == '__main__':\n main()\n", "path": "docs/deploy.py"}]}
| 1,159 | 237 |
gh_patches_debug_12484
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PORT] Slack adapter updates for dialog interactions
> Port this change from botbuilder-dotnet/master branch:
https://github.com/microsoft/botbuilder-dotnet/pull/3744
Fixes #3733 #3726 #3725 #3724
* Adds missing values to SlackPayload model
* Expose SlackClientWrapper via public property
# Changed projects
* Adapters
</issue>
<code>
[start of libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 from typing import Optional, List
5 from slack.web.classes.actions import Action
6 from botbuilder.adapters.slack.slack_message import SlackMessage
7
8
9 class SlackPayload:
10 def __init__(self, **kwargs):
11 self.type: [str] = kwargs.get("type")
12 self.token: str = kwargs.get("token")
13 self.channel: str = kwargs.get("channel")
14 self.thread_ts: str = kwargs.get("thread_ts")
15 self.team: str = kwargs.get("team")
16 self.user: str = kwargs.get("user")
17 self.actions: Optional[List[Action]] = None
18
19 if "message" in kwargs:
20 message = kwargs.get("message")
21 self.message = (
22 message
23 if isinstance(message) is SlackMessage
24 else SlackMessage(**message)
25 )
26
[end of libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py b/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py
--- a/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py
+++ b/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py
@@ -15,6 +15,12 @@
self.team: str = kwargs.get("team")
self.user: str = kwargs.get("user")
self.actions: Optional[List[Action]] = None
+ self.trigger_id: str = kwargs.get("trigger_id")
+ self.action_ts: str = kwargs.get("action_ts")
+ self.submission: str = kwargs.get("submission")
+ self.callback_id: str = kwargs.get("callback_id")
+ self.state: str = kwargs.get("state")
+ self.response_url: str = kwargs.get("response_url")
if "message" in kwargs:
message = kwargs.get("message")
|
{"golden_diff": "diff --git a/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py b/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py\n--- a/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py\n+++ b/libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py\n@@ -15,6 +15,12 @@\n self.team: str = kwargs.get(\"team\")\r\n self.user: str = kwargs.get(\"user\")\r\n self.actions: Optional[List[Action]] = None\r\n+ self.trigger_id: str = kwargs.get(\"trigger_id\")\r\n+ self.action_ts: str = kwargs.get(\"action_ts\")\r\n+ self.submission: str = kwargs.get(\"submission\")\r\n+ self.callback_id: str = kwargs.get(\"callback_id\")\r\n+ self.state: str = kwargs.get(\"state\")\r\n+ self.response_url: str = kwargs.get(\"response_url\")\r\n \r\n if \"message\" in kwargs:\r\n message = kwargs.get(\"message\")\n", "issue": "[PORT] Slack adapter updates for dialog interactions\n> Port this change from botbuilder-dotnet/master branch:\nhttps://github.com/microsoft/botbuilder-dotnet/pull/3744\n\nFixes #3733 #3726 #3725 #3724 \r\n\r\n* Adds missing values to SlackPayload model \r\n* Expose SlackClientWrapper via public property\n\n\r\n# Changed projects\r\n* Adapters\r\n\r\n\r\n\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License.\r\n\r\nfrom typing import Optional, List\r\nfrom slack.web.classes.actions import Action\r\nfrom botbuilder.adapters.slack.slack_message import SlackMessage\r\n\r\n\r\nclass SlackPayload:\r\n def __init__(self, **kwargs):\r\n self.type: [str] = kwargs.get(\"type\")\r\n self.token: str = kwargs.get(\"token\")\r\n self.channel: str = kwargs.get(\"channel\")\r\n self.thread_ts: str = kwargs.get(\"thread_ts\")\r\n self.team: str = kwargs.get(\"team\")\r\n self.user: str = kwargs.get(\"user\")\r\n self.actions: Optional[List[Action]] = None\r\n\r\n if \"message\" in kwargs:\r\n message = kwargs.get(\"message\")\r\n self.message = (\r\n message\r\n if isinstance(message) is SlackMessage\r\n else SlackMessage(**message)\r\n )\r\n", "path": "libraries/botbuilder-adapters-slack/botbuilder/adapters/slack/slack_payload.py"}]}
| 890 | 238 |
gh_patches_debug_25644
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-3810
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tokens are able to enumerate project names regardless of organization membership.
We respond with 404s when there are missing project names, but 403s when there is an existing project. Probably should just check for organization membership before even going into the project fetching.
# Original HackerOne Report
Title: Project Enumeration of Other Teams
Types: Information Disclosure
Link: https://hackerone.com/reports/154048
Date: 2016-07-26 05:25:05 -0700
By: vagg-a-bond
Details:
Hello,
It is possible for any valid user of @sentry to enumerate project names in other team by comparing errors.
For example, if user user accesses `GET /api/0/projects/sumne/project_sumne_001/` which is not of his/her, then error will be `403 FORBIDDEN` and for `GET /api/0/projects/sumne/project_sumne_001_not_there/` application responds with `404 NOT FOUND`
So an attacker can enumerate all the projects available in a team by automating the process to request `GET /api/0/projects/TARGET_TEAM_NAME/PROJECT_NAME/`.
**Vulnerable Endpoint:**
> GET /api/0/projects/sumne/project_sumne_001/*
**Recommended Fix:**
Respond with `404 NOT FOUND` for both.
</issue>
<code>
[start of src/sentry/api/bases/project.py]
1 from __future__ import absolute_import
2
3 from sentry.auth import access
4 from sentry.api.base import Endpoint
5 from sentry.api.exceptions import ResourceDoesNotExist
6 from sentry.api.permissions import ScopedPermission
7 from sentry.models import Project, ProjectStatus
8 from sentry.models.apikey import ROOT_KEY
9
10
11 class ProjectPermission(ScopedPermission):
12 scope_map = {
13 'GET': ['project:read', 'project:write', 'project:delete'],
14 'POST': ['project:write', 'project:delete'],
15 'PUT': ['project:write', 'project:delete'],
16 'DELETE': ['project:delete'],
17 }
18
19 def has_object_permission(self, request, view, project):
20 if request.user and request.user.is_authenticated() and request.auth:
21 request.access = access.from_request(
22 request, project.organization, scopes=request.auth.get_scopes(),
23 )
24
25 elif request.auth:
26 if request.auth is ROOT_KEY:
27 return True
28 return request.auth.organization_id == project.organization_id
29
30 else:
31 request.access = access.from_request(request, project.organization)
32
33 allowed_scopes = set(self.scope_map.get(request.method, []))
34 return any(
35 request.access.has_team_scope(project.team, s)
36 for s in allowed_scopes
37 )
38
39
40 class ProjectReleasePermission(ProjectPermission):
41 scope_map = {
42 'GET': ['project:read', 'project:write', 'project:delete', 'project:releases'],
43 'POST': ['project:write', 'project:delete', 'project:releases'],
44 'PUT': ['project:write', 'project:delete', 'project:releases'],
45 'DELETE': ['project:delete', 'project:releases'],
46 }
47
48
49 class ProjectEventPermission(ProjectPermission):
50 scope_map = {
51 'GET': ['event:read', 'event:write', 'event:delete'],
52 'POST': ['event:write', 'event:delete'],
53 'PUT': ['event:write', 'event:delete'],
54 'DELETE': ['event:delete'],
55 }
56
57
58 class ProjectEndpoint(Endpoint):
59 permission_classes = (ProjectPermission,)
60
61 def convert_args(self, request, organization_slug, project_slug, *args, **kwargs):
62 try:
63 project = Project.objects.get_from_cache(
64 organization__slug=organization_slug,
65 slug=project_slug,
66 )
67 except Project.DoesNotExist:
68 raise ResourceDoesNotExist
69
70 if project.status != ProjectStatus.VISIBLE:
71 raise ResourceDoesNotExist
72
73 self.check_object_permissions(request, project)
74
75 kwargs['project'] = project
76 return (args, kwargs)
77
[end of src/sentry/api/bases/project.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/api/bases/project.py b/src/sentry/api/bases/project.py
--- a/src/sentry/api/bases/project.py
+++ b/src/sentry/api/bases/project.py
@@ -4,7 +4,7 @@
from sentry.api.base import Endpoint
from sentry.api.exceptions import ResourceDoesNotExist
from sentry.api.permissions import ScopedPermission
-from sentry.models import Project, ProjectStatus
+from sentry.models import Organization, Project, ProjectStatus
from sentry.models.apikey import ROOT_KEY
@@ -59,9 +59,21 @@
permission_classes = (ProjectPermission,)
def convert_args(self, request, organization_slug, project_slug, *args, **kwargs):
+ try:
+ org = Organization.objects.get_from_cache(slug=organization_slug)
+ if request.user:
+ can_access_org = any(access.from_request(request, org).memberships)
+ if request.auth:
+ can_access_org = request.auth.organization_id == org.id
+ if not can_access_org:
+ raise ResourceDoesNotExist
+
+ except Organization.DoesNotExist:
+ raise ResourceDoesNotExist
+
try:
project = Project.objects.get_from_cache(
- organization__slug=organization_slug,
+ organization=org,
slug=project_slug,
)
except Project.DoesNotExist:
|
{"golden_diff": "diff --git a/src/sentry/api/bases/project.py b/src/sentry/api/bases/project.py\n--- a/src/sentry/api/bases/project.py\n+++ b/src/sentry/api/bases/project.py\n@@ -4,7 +4,7 @@\n from sentry.api.base import Endpoint\n from sentry.api.exceptions import ResourceDoesNotExist\n from sentry.api.permissions import ScopedPermission\n-from sentry.models import Project, ProjectStatus\n+from sentry.models import Organization, Project, ProjectStatus\n from sentry.models.apikey import ROOT_KEY\n \n \n@@ -59,9 +59,21 @@\n permission_classes = (ProjectPermission,)\n \n def convert_args(self, request, organization_slug, project_slug, *args, **kwargs):\n+ try:\n+ org = Organization.objects.get_from_cache(slug=organization_slug)\n+ if request.user:\n+ can_access_org = any(access.from_request(request, org).memberships)\n+ if request.auth:\n+ can_access_org = request.auth.organization_id == org.id\n+ if not can_access_org:\n+ raise ResourceDoesNotExist\n+\n+ except Organization.DoesNotExist:\n+ raise ResourceDoesNotExist\n+\n try:\n project = Project.objects.get_from_cache(\n- organization__slug=organization_slug,\n+ organization=org,\n slug=project_slug,\n )\n except Project.DoesNotExist:\n", "issue": "Tokens are able to enumerate project names regardless of organization membership.\nWe respond with 404s when there are missing project names, but 403s when there is an existing project. Probably should just check for organization membership before even going into the project fetching.\n# Original HackerOne Report\n\nTitle: Project Enumeration of Other Teams\nTypes: Information Disclosure\nLink: https://hackerone.com/reports/154048\nDate: 2016-07-26 05:25:05 -0700\nBy: vagg-a-bond\n\nDetails:\nHello,\n\nIt is possible for any valid user of @sentry to enumerate project names in other team by comparing errors. \n\nFor example, if user user accesses `GET /api/0/projects/sumne/project_sumne_001/` which is not of his/her, then error will be `403 FORBIDDEN` and for `GET /api/0/projects/sumne/project_sumne_001_not_there/` application responds with `404 NOT FOUND`\n\nSo an attacker can enumerate all the projects available in a team by automating the process to request `GET /api/0/projects/TARGET_TEAM_NAME/PROJECT_NAME/`. \n\n**Vulnerable Endpoint:**\n\n> GET /api/0/projects/sumne/project_sumne_001/*\n\n**Recommended Fix:**\nRespond with `404 NOT FOUND` for both. \n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom sentry.auth import access\nfrom sentry.api.base import Endpoint\nfrom sentry.api.exceptions import ResourceDoesNotExist\nfrom sentry.api.permissions import ScopedPermission\nfrom sentry.models import Project, ProjectStatus\nfrom sentry.models.apikey import ROOT_KEY\n\n\nclass ProjectPermission(ScopedPermission):\n scope_map = {\n 'GET': ['project:read', 'project:write', 'project:delete'],\n 'POST': ['project:write', 'project:delete'],\n 'PUT': ['project:write', 'project:delete'],\n 'DELETE': ['project:delete'],\n }\n\n def has_object_permission(self, request, view, project):\n if request.user and request.user.is_authenticated() and request.auth:\n request.access = access.from_request(\n request, project.organization, scopes=request.auth.get_scopes(),\n )\n\n elif request.auth:\n if request.auth is ROOT_KEY:\n return True\n return request.auth.organization_id == project.organization_id\n\n else:\n request.access = access.from_request(request, project.organization)\n\n allowed_scopes = set(self.scope_map.get(request.method, []))\n return any(\n request.access.has_team_scope(project.team, s)\n for s in allowed_scopes\n )\n\n\nclass ProjectReleasePermission(ProjectPermission):\n scope_map = {\n 'GET': ['project:read', 'project:write', 'project:delete', 'project:releases'],\n 'POST': ['project:write', 'project:delete', 'project:releases'],\n 'PUT': ['project:write', 'project:delete', 'project:releases'],\n 'DELETE': ['project:delete', 'project:releases'],\n }\n\n\nclass ProjectEventPermission(ProjectPermission):\n scope_map = {\n 'GET': ['event:read', 'event:write', 'event:delete'],\n 'POST': ['event:write', 'event:delete'],\n 'PUT': ['event:write', 'event:delete'],\n 'DELETE': ['event:delete'],\n }\n\n\nclass ProjectEndpoint(Endpoint):\n permission_classes = (ProjectPermission,)\n\n def convert_args(self, request, organization_slug, project_slug, *args, **kwargs):\n try:\n project = Project.objects.get_from_cache(\n organization__slug=organization_slug,\n slug=project_slug,\n )\n except Project.DoesNotExist:\n raise ResourceDoesNotExist\n\n if project.status != ProjectStatus.VISIBLE:\n raise ResourceDoesNotExist\n\n self.check_object_permissions(request, project)\n\n kwargs['project'] = project\n return (args, kwargs)\n", "path": "src/sentry/api/bases/project.py"}]}
| 1,563 | 289 |
gh_patches_debug_10868
|
rasdani/github-patches
|
git_diff
|
coreruleset__coreruleset-2615
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regex assembler seems to be broken again.
### Describe the bug
`util/regexp-assemble/regexp-assemble.py --log-level DEBUG update 942521`
```
Processing 942521, chain offset 0
detected processor: <class 'NoneType'>
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found simple comment
Found regular input '##!^ ^\n'
Found regular input '##!+ i\n'
Found simple comment
Found simple comment
Found regular input "[^']*?(?:'[^']*?'[^']*?)*?'\\s*(\\w+)\\b\n"
Found regular input '[^\\"]*?(?:\\"[^\\"]*?\\"[^\\"]*?)*?\\"\\s*(\\w+)\\b\n'
Found regular input '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\s*(\\w+)\\b\n'
processor will process: ['##!^ ^\n', '##!+ i\n', "[^']*?(?:'[^']*?'[^']*?)*?'\\s*(\\w+)\\b\n", '[^\\"]*?(?:\\"[^\\"]*?\\"[^\\"]*?)*?\\"\\s*(\\w+)\\b\n', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\s*(\\w+)\\b\n']
preprocessed lines: ['##!^ ^\n', '##!+ i\n', "[^']*?(?:'[^']*?'[^']*?)*?'\\s*(\\w+)\\b\n", '[^\\"]*?(?:\\"[^\\"]*?\\"[^\\"]*?)*?\\"\\s*(\\w+)\\b\n', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\s*(\\w+)\\b\n']
Completing assembly
Running assembler with lines: ['##!^ ^', '##!+ i', "[^']*?(?:'[^']*?'[^']*?)*?'\\s*(\\w+)\\b", '[^\\"]*?(?:\\"[^\\"]*?\\"[^\\"]*?)*?\\"\\s*(\\w+)\\b', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\s*(\\w+)\\b']
Assembler errors: b'', output b'(?i)^(?:[^\\"]*?(?:\\"[^\\"]*?\\"[^\\"]*?)*?\\"|[^\']*?(?:\'[^\']*?\'[^\']*?)*?\'|[^`]*?(?:`[^`]*?`[^`]*?)*?`)\\s*(\\w+)\\b\n'
Completed assembly: (?i)^(?:[^\"]*?(?:\"[^\"]*?\"[^\"]*?)*?\"|[^']*?(?:'[^']*?'[^']*?)*?'|[^`]*?(?:`[^`]*?`[^`]*?)*?`)\s*(\w+)\b
Traceback (most recent call last):
File "util/regexp-assemble/regexp-assemble.py", line 227, in <module>
namespace.func(namespace)
File "util/regexp-assemble/regexp-assemble.py", line 146, in handle_update
updater.run(False)
File "/home/janek/crs-waf/coreruleset/util/regexp-assemble/lib/operators/updater.py", line 8, in run
self.write_updates()
File "/home/janek/crs-waf/coreruleset/util/regexp-assemble/lib/operators/updater.py", line 24, in write_updates
with open(file_path, "w") as handle:
FileNotFoundError: [Errno 2] No such file or directory: 'rules/rules/REQUEST-942-APPLICATION-ATTACK-SQLI.conf'
```
It seems that there is double `rules/rules` so updating a rule doesn't work.
@theseion
</issue>
<code>
[start of util/regexp-assemble/lib/operators/updater.py]
1 from msc_pyparser import MSCWriter
2 from lib.operators.parser import Parser
3
4
5 class Updater(Parser):
6 def run(self, process_all: bool):
7 self.perform_compare_or_update(process_all, self.update_regex)
8 self.write_updates()
9
10 def update_regex(
11 self,
12 rule_id: str,
13 generated_regex: str,
14 current_regex: str,
15 config: dict,
16 config_key: str,
17 ):
18 config[config_key] = generated_regex
19
20 def write_updates(self):
21 for rule_prefix, parser in self.parsers.items():
22 writer = MSCWriter(parser.configlines)
23 file_path = self.context.rules_directory / self.prefix_to_file_map[rule_prefix]
24 with open(file_path, "w") as handle:
25 writer.generate()
26 # add extra new line at the end of file
27 writer.output.append("")
28 handle.write("\n".join(writer.output))
29
[end of util/regexp-assemble/lib/operators/updater.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/util/regexp-assemble/lib/operators/updater.py b/util/regexp-assemble/lib/operators/updater.py
--- a/util/regexp-assemble/lib/operators/updater.py
+++ b/util/regexp-assemble/lib/operators/updater.py
@@ -20,8 +20,7 @@
def write_updates(self):
for rule_prefix, parser in self.parsers.items():
writer = MSCWriter(parser.configlines)
- file_path = self.context.rules_directory / self.prefix_to_file_map[rule_prefix]
- with open(file_path, "w") as handle:
+ with self.prefix_to_file_map[rule_prefix].open("w") as handle:
writer.generate()
# add extra new line at the end of file
writer.output.append("")
|
{"golden_diff": "diff --git a/util/regexp-assemble/lib/operators/updater.py b/util/regexp-assemble/lib/operators/updater.py\n--- a/util/regexp-assemble/lib/operators/updater.py\n+++ b/util/regexp-assemble/lib/operators/updater.py\n@@ -20,8 +20,7 @@\n def write_updates(self):\n for rule_prefix, parser in self.parsers.items():\n writer = MSCWriter(parser.configlines)\n- file_path = self.context.rules_directory / self.prefix_to_file_map[rule_prefix]\n- with open(file_path, \"w\") as handle:\n+ with self.prefix_to_file_map[rule_prefix].open(\"w\") as handle:\n writer.generate()\n # add extra new line at the end of file\n writer.output.append(\"\")\n", "issue": "Regex assembler seems to be broken again.\n### Describe the bug\r\n`util/regexp-assemble/regexp-assemble.py --log-level DEBUG update 942521`\r\n\r\n```\r\nProcessing 942521, chain offset 0\r\ndetected processor: <class 'NoneType'>\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound simple comment\r\nFound regular input '##!^ ^\\n'\r\nFound regular input '##!+ i\\n'\r\nFound simple comment\r\nFound simple comment\r\nFound regular input \"[^']*?(?:'[^']*?'[^']*?)*?'\\\\s*(\\\\w+)\\\\b\\n\"\r\nFound regular input '[^\\\\\"]*?(?:\\\\\"[^\\\\\"]*?\\\\\"[^\\\\\"]*?)*?\\\\\"\\\\s*(\\\\w+)\\\\b\\n'\r\nFound regular input '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\\\s*(\\\\w+)\\\\b\\n'\r\nprocessor will process: ['##!^ ^\\n', '##!+ i\\n', \"[^']*?(?:'[^']*?'[^']*?)*?'\\\\s*(\\\\w+)\\\\b\\n\", '[^\\\\\"]*?(?:\\\\\"[^\\\\\"]*?\\\\\"[^\\\\\"]*?)*?\\\\\"\\\\s*(\\\\w+)\\\\b\\n', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\\\s*(\\\\w+)\\\\b\\n']\r\npreprocessed lines: ['##!^ ^\\n', '##!+ i\\n', \"[^']*?(?:'[^']*?'[^']*?)*?'\\\\s*(\\\\w+)\\\\b\\n\", '[^\\\\\"]*?(?:\\\\\"[^\\\\\"]*?\\\\\"[^\\\\\"]*?)*?\\\\\"\\\\s*(\\\\w+)\\\\b\\n', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\\\s*(\\\\w+)\\\\b\\n']\r\nCompleting assembly\r\nRunning assembler with lines: ['##!^ ^', '##!+ i', \"[^']*?(?:'[^']*?'[^']*?)*?'\\\\s*(\\\\w+)\\\\b\", '[^\\\\\"]*?(?:\\\\\"[^\\\\\"]*?\\\\\"[^\\\\\"]*?)*?\\\\\"\\\\s*(\\\\w+)\\\\b', '[^`]*?(?:`[^`]*?`[^`]*?)*?`\\\\s*(\\\\w+)\\\\b']\r\nAssembler errors: b'', output b'(?i)^(?:[^\\\\\"]*?(?:\\\\\"[^\\\\\"]*?\\\\\"[^\\\\\"]*?)*?\\\\\"|[^\\']*?(?:\\'[^\\']*?\\'[^\\']*?)*?\\'|[^`]*?(?:`[^`]*?`[^`]*?)*?`)\\\\s*(\\\\w+)\\\\b\\n'\r\nCompleted assembly: (?i)^(?:[^\\\"]*?(?:\\\"[^\\\"]*?\\\"[^\\\"]*?)*?\\\"|[^']*?(?:'[^']*?'[^']*?)*?'|[^`]*?(?:`[^`]*?`[^`]*?)*?`)\\s*(\\w+)\\b\r\nTraceback (most recent call last):\r\n File \"util/regexp-assemble/regexp-assemble.py\", line 227, in <module>\r\n namespace.func(namespace)\r\n File \"util/regexp-assemble/regexp-assemble.py\", line 146, in handle_update\r\n updater.run(False)\r\n File \"/home/janek/crs-waf/coreruleset/util/regexp-assemble/lib/operators/updater.py\", line 8, in run\r\n self.write_updates()\r\n File \"/home/janek/crs-waf/coreruleset/util/regexp-assemble/lib/operators/updater.py\", line 24, in write_updates\r\n with open(file_path, \"w\") as handle:\r\nFileNotFoundError: [Errno 2] No such file or directory: 'rules/rules/REQUEST-942-APPLICATION-ATTACK-SQLI.conf'\r\n```\r\n\r\nIt seems that there is double `rules/rules` so updating a rule doesn't work. \r\n\r\n@theseion \n", "before_files": [{"content": "from msc_pyparser import MSCWriter\nfrom lib.operators.parser import Parser\n\n\nclass Updater(Parser):\n def run(self, process_all: bool):\n self.perform_compare_or_update(process_all, self.update_regex)\n self.write_updates()\n\n def update_regex(\n self,\n rule_id: str,\n generated_regex: str,\n current_regex: str,\n config: dict,\n config_key: str,\n ):\n config[config_key] = generated_regex\n\n def write_updates(self):\n for rule_prefix, parser in self.parsers.items():\n writer = MSCWriter(parser.configlines)\n file_path = self.context.rules_directory / self.prefix_to_file_map[rule_prefix]\n with open(file_path, \"w\") as handle:\n writer.generate()\n # add extra new line at the end of file\n writer.output.append(\"\")\n handle.write(\"\\n\".join(writer.output))\n", "path": "util/regexp-assemble/lib/operators/updater.py"}]}
| 1,737 | 163 |
gh_patches_debug_15905
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1085
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LibibertyConan: 404: Not Found
```bash
conans.errors.NotFoundException: Not found: https://github.com/gcc-mirror/gcc/archive/gcc-9_1_0-release.tar.gz
```
when i open url above in browser:
```bash
404: Not Found
```
Provide more mirrors, please
Related to https://github.com/conan-io/conan-center-index/blob/master/recipes/libiberty/all/conanfile.py#L40
</issue>
<code>
[start of recipes/libiberty/all/conanfile.py]
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 from conans.errors import ConanInvalidConfiguration
3 import os
4
5
6 class LibibertyConan(ConanFile):
7 name = "libiberty"
8 version = "9.1.0"
9 description = "A collection of subroutines used by various GNU programs"
10 topics = ("conan", "libiberty", "gnu", "gnu-collection")
11 url = "https://github.com/conan-io/conan-center-index"
12 homepage = "https://gcc.gnu.org/onlinedocs/libiberty"
13 license = "LGPL-2.1"
14 settings = "os", "arch", "compiler", "build_type"
15 options = {"fPIC": [True, False]}
16 default_options = {"fPIC": True}
17 _autotools = None
18
19 @property
20 def _source_subfolder(self):
21 return "source_subfolder"
22
23 @property
24 def _libiberty_folder(self):
25 return os.path.join(self._source_subfolder, self.name)
26
27 def config_options(self):
28 if self.settings.os == 'Windows':
29 del self.options.fPIC
30
31 def configure(self):
32 if self.settings.compiler == "Visual Studio":
33 raise ConanInvalidConfiguration("libiberty can not be built by Visual Studio.")
34 del self.settings.compiler.libcxx
35 del self.settings.compiler.cppstd
36
37 def source(self):
38 tools.get(**self.conan_data["sources"][self.version])
39 pkg_version = self.version.replace('.', '_')
40 extracted_dir = "gcc-gcc-{}-release".format(pkg_version)
41 os.rename(extracted_dir, self._source_subfolder)
42 tools.rmdir(os.path.join(self._source_subfolder, 'gcc'))
43 tools.rmdir(os.path.join(self._source_subfolder, 'libstdc++-v3'))
44
45 def _configure_autotools(self):
46 if not self._autotools:
47 args = ["--enable-install-libiberty"]
48 self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)
49 self._autotools.configure(args=args, configure_dir=self._libiberty_folder)
50 return self._autotools
51
52 def build(self):
53 autotools = self._configure_autotools()
54 autotools.make()
55
56 def package(self):
57 self.copy(pattern="COPYING.LIB", src=self._libiberty_folder, dst="licenses")
58 autotools = self._configure_autotools()
59 autotools.install()
60 self._package_x86()
61
62 def _package_x86(self):
63 lib32dir = os.path.join(self.package_folder, "lib32")
64 if os.path.exists(lib32dir):
65 libdir = os.path.join(self.package_folder, "lib")
66 tools.rmdir(libdir)
67 os.rename(lib32dir, libdir)
68
69 def package_info(self):
70 self.cpp_info.libs = tools.collect_libs(self)
71
72
[end of recipes/libiberty/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/libiberty/all/conanfile.py b/recipes/libiberty/all/conanfile.py
--- a/recipes/libiberty/all/conanfile.py
+++ b/recipes/libiberty/all/conanfile.py
@@ -36,8 +36,7 @@
def source(self):
tools.get(**self.conan_data["sources"][self.version])
- pkg_version = self.version.replace('.', '_')
- extracted_dir = "gcc-gcc-{}-release".format(pkg_version)
+ extracted_dir = "gcc-" + self.version
os.rename(extracted_dir, self._source_subfolder)
tools.rmdir(os.path.join(self._source_subfolder, 'gcc'))
tools.rmdir(os.path.join(self._source_subfolder, 'libstdc++-v3'))
@@ -68,4 +67,3 @@
def package_info(self):
self.cpp_info.libs = tools.collect_libs(self)
-
|
{"golden_diff": "diff --git a/recipes/libiberty/all/conanfile.py b/recipes/libiberty/all/conanfile.py\n--- a/recipes/libiberty/all/conanfile.py\n+++ b/recipes/libiberty/all/conanfile.py\n@@ -36,8 +36,7 @@\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n- pkg_version = self.version.replace('.', '_')\n- extracted_dir = \"gcc-gcc-{}-release\".format(pkg_version)\n+ extracted_dir = \"gcc-\" + self.version\n os.rename(extracted_dir, self._source_subfolder)\n tools.rmdir(os.path.join(self._source_subfolder, 'gcc'))\n tools.rmdir(os.path.join(self._source_subfolder, 'libstdc++-v3'))\n@@ -68,4 +67,3 @@\n \n def package_info(self):\n self.cpp_info.libs = tools.collect_libs(self)\n-\n", "issue": "LibibertyConan: 404: Not Found\n```bash\r\nconans.errors.NotFoundException: Not found: https://github.com/gcc-mirror/gcc/archive/gcc-9_1_0-release.tar.gz\r\n```\r\n\r\nwhen i open url above in browser:\r\n\r\n```bash\r\n404: Not Found\r\n```\r\n\r\nProvide more mirrors, please\r\n\r\nRelated to https://github.com/conan-io/conan-center-index/blob/master/recipes/libiberty/all/conanfile.py#L40\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom conans.errors import ConanInvalidConfiguration\nimport os\n\n\nclass LibibertyConan(ConanFile):\n name = \"libiberty\"\n version = \"9.1.0\"\n description = \"A collection of subroutines used by various GNU programs\"\n topics = (\"conan\", \"libiberty\", \"gnu\", \"gnu-collection\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://gcc.gnu.org/onlinedocs/libiberty\"\n license = \"LGPL-2.1\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\"fPIC\": [True, False]}\n default_options = {\"fPIC\": True}\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _libiberty_folder(self):\n return os.path.join(self._source_subfolder, self.name)\n\n def config_options(self):\n if self.settings.os == 'Windows':\n del self.options.fPIC\n\n def configure(self):\n if self.settings.compiler == \"Visual Studio\":\n raise ConanInvalidConfiguration(\"libiberty can not be built by Visual Studio.\")\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n pkg_version = self.version.replace('.', '_')\n extracted_dir = \"gcc-gcc-{}-release\".format(pkg_version)\n os.rename(extracted_dir, self._source_subfolder)\n tools.rmdir(os.path.join(self._source_subfolder, 'gcc'))\n tools.rmdir(os.path.join(self._source_subfolder, 'libstdc++-v3'))\n\n def _configure_autotools(self):\n if not self._autotools:\n args = [\"--enable-install-libiberty\"]\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n self._autotools.configure(args=args, configure_dir=self._libiberty_folder)\n return self._autotools\n\n def build(self):\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"COPYING.LIB\", src=self._libiberty_folder, dst=\"licenses\")\n autotools = self._configure_autotools()\n autotools.install()\n self._package_x86()\n\n def _package_x86(self):\n lib32dir = os.path.join(self.package_folder, \"lib32\")\n if os.path.exists(lib32dir):\n libdir = os.path.join(self.package_folder, \"lib\")\n tools.rmdir(libdir)\n os.rename(lib32dir, libdir)\n\n def package_info(self):\n self.cpp_info.libs = tools.collect_libs(self)\n\n", "path": "recipes/libiberty/all/conanfile.py"}]}
| 1,430 | 209 |
gh_patches_debug_9199
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-166
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Kalender-URL schöner anzeigen
Als Nutzer möchte ich auf meiner Profilseite ein read-only-Feld sehen, in dem die URL zu meinem Kalender-Feed steht. Der Link soll nicht klickbar sein, damit die ics-Datei nicht heruntergeladen wird. Neben dem Link soll ein Button zum Kopieren der URL vorhanden sein.
</issue>
<code>
[start of ephios/extra/context.py]
1 import importlib
2 import subprocess
3
4 from django.templatetags.static import static
5 from django.utils.translation import get_language
6
7 from ephios.extra.signals import footer_link
8
9 try:
10 EPHIOS_VERSION = (
11 subprocess.check_output(["git", "rev-parse", "--short", "HEAD"]).decode().strip()
12 )
13 except (subprocess.CalledProcessError, FileNotFoundError):
14 # suggested in https://github.com/python-poetry/poetry/issues/273
15 EPHIOS_VERSION = "v" + importlib.metadata.version("ephios")
16
17
18 def ephios_base_context(request):
19 footer = {}
20 for receiver, result in footer_link.send(None, request=request):
21 for label, url in result.items():
22 footer[label] = url
23
24 datatables_translation_url = None
25 if get_language() == "de-de":
26 datatables_translation_url = static("datatables/german.json")
27
28 return {
29 "footer": footer,
30 "datatables_translation_url": datatables_translation_url,
31 "ephios_version": EPHIOS_VERSION,
32 }
33
[end of ephios/extra/context.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ephios/extra/context.py b/ephios/extra/context.py
--- a/ephios/extra/context.py
+++ b/ephios/extra/context.py
@@ -5,6 +5,7 @@
from django.utils.translation import get_language
from ephios.extra.signals import footer_link
+from ephios.settings import SITE_URL
try:
EPHIOS_VERSION = (
@@ -29,4 +30,5 @@
"footer": footer,
"datatables_translation_url": datatables_translation_url,
"ephios_version": EPHIOS_VERSION,
+ "SITE_URL": SITE_URL,
}
|
{"golden_diff": "diff --git a/ephios/extra/context.py b/ephios/extra/context.py\n--- a/ephios/extra/context.py\n+++ b/ephios/extra/context.py\n@@ -5,6 +5,7 @@\n from django.utils.translation import get_language\n \n from ephios.extra.signals import footer_link\n+from ephios.settings import SITE_URL\n \n try:\n EPHIOS_VERSION = (\n@@ -29,4 +30,5 @@\n \"footer\": footer,\n \"datatables_translation_url\": datatables_translation_url,\n \"ephios_version\": EPHIOS_VERSION,\n+ \"SITE_URL\": SITE_URL,\n }\n", "issue": "Kalender-URL sch\u00f6ner anzeigen\nAls Nutzer m\u00f6chte ich auf meiner Profilseite ein read-only-Feld sehen, in dem die URL zu meinem Kalender-Feed steht. Der Link soll nicht klickbar sein, damit die ics-Datei nicht heruntergeladen wird. Neben dem Link soll ein Button zum Kopieren der URL vorhanden sein.\n", "before_files": [{"content": "import importlib\nimport subprocess\n\nfrom django.templatetags.static import static\nfrom django.utils.translation import get_language\n\nfrom ephios.extra.signals import footer_link\n\ntry:\n EPHIOS_VERSION = (\n subprocess.check_output([\"git\", \"rev-parse\", \"--short\", \"HEAD\"]).decode().strip()\n )\nexcept (subprocess.CalledProcessError, FileNotFoundError):\n # suggested in https://github.com/python-poetry/poetry/issues/273\n EPHIOS_VERSION = \"v\" + importlib.metadata.version(\"ephios\")\n\n\ndef ephios_base_context(request):\n footer = {}\n for receiver, result in footer_link.send(None, request=request):\n for label, url in result.items():\n footer[label] = url\n\n datatables_translation_url = None\n if get_language() == \"de-de\":\n datatables_translation_url = static(\"datatables/german.json\")\n\n return {\n \"footer\": footer,\n \"datatables_translation_url\": datatables_translation_url,\n \"ephios_version\": EPHIOS_VERSION,\n }\n", "path": "ephios/extra/context.py"}]}
| 906 | 140 |
gh_patches_debug_2639
|
rasdani/github-patches
|
git_diff
|
pypa__pip-10009
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update quickstart guide to reflect user research
Updates quickstart guide to reflect most common tasks as discovered in our "buy a feature" user research.
Preview: https://pip--9137.org.readthedocs.build/en/9137/quickstart/
</issue>
<code>
[start of docs/html/conf.py]
1 """Sphinx configuration file for pip's documentation."""
2
3 import glob
4 import os
5 import pathlib
6 import re
7 import sys
8 from typing import List, Tuple
9
10 # Add the docs/ directory to sys.path, because pip_sphinxext.py is there.
11 docs_dir = os.path.dirname(os.path.dirname(__file__))
12 sys.path.insert(0, docs_dir)
13
14 # -- General configuration ------------------------------------------------------------
15
16 extensions = [
17 # first-party extensions
18 "sphinx.ext.autodoc",
19 "sphinx.ext.todo",
20 "sphinx.ext.extlinks",
21 "sphinx.ext.intersphinx",
22 # our extensions
23 "pip_sphinxext",
24 # third-party extensions
25 "myst_parser",
26 "sphinx_copybutton",
27 "sphinx_inline_tabs",
28 "sphinxcontrib.towncrier",
29 ]
30
31 # General information about the project.
32 project = "pip"
33 copyright = "2008-2020, PyPA"
34
35 # Find the version and release information.
36 # We have a single source of truth for our version number: pip's __init__.py file.
37 # This next bit of code reads from it.
38 file_with_version = os.path.join(docs_dir, "..", "src", "pip", "__init__.py")
39 with open(file_with_version) as f:
40 for line in f:
41 m = re.match(r'__version__ = "(.*)"', line)
42 if m:
43 __version__ = m.group(1)
44 # The short X.Y version.
45 version = ".".join(__version__.split(".")[:2])
46 # The full version, including alpha/beta/rc tags.
47 release = __version__
48 break
49 else: # AKA no-break
50 version = release = "dev"
51
52 print("pip version:", version)
53 print("pip release:", release)
54
55 # -- Options for smartquotes ----------------------------------------------------------
56
57 # Disable the conversion of dashes so that long options like "--find-links" won't
58 # render as "-find-links" if included in the text.The default of "qDe" converts normal
59 # quote characters ('"' and "'"), en and em dashes ("--" and "---"), and ellipses "..."
60 smartquotes_action = "qe"
61
62 # -- Options for intersphinx ----------------------------------------------------------
63
64 intersphinx_mapping = {
65 "python": ("https://docs.python.org/3", None),
66 "pypug": ("https://packaging.python.org", None),
67 }
68
69 # -- Options for extlinks -------------------------------------------------------------
70
71 extlinks = {
72 "issue": ("https://github.com/pypa/pip/issues/%s", "#"),
73 "pull": ("https://github.com/pypa/pip/pull/%s", "PR #"),
74 "pypi": ("https://pypi.org/project/%s/", ""),
75 }
76
77 # -- Options for towncrier_draft extension --------------------------------------------
78
79 towncrier_draft_autoversion_mode = "draft" # or: 'sphinx-release', 'sphinx-version'
80 towncrier_draft_include_empty = True
81 towncrier_draft_working_directory = pathlib.Path(docs_dir).parent
82 # Not yet supported: towncrier_draft_config_path = 'pyproject.toml' # relative to cwd
83
84 # -- Options for HTML -----------------------------------------------------------------
85
86 html_theme = "furo"
87 html_title = f"{project} documentation v{release}"
88
89 # Disable the generation of the various indexes
90 html_use_modindex = False
91 html_use_index = False
92
93 # -- Options for Manual Pages ---------------------------------------------------------
94
95
96 # List of manual pages generated
97 def determine_man_pages() -> List[Tuple[str, str, str, str, int]]:
98 """Determine which man pages need to be generated."""
99
100 def to_document_name(path: str, base_dir: str) -> str:
101 """Convert a provided path to a Sphinx "document name"."""
102 relative_path = os.path.relpath(path, base_dir)
103 root, _ = os.path.splitext(relative_path)
104 return root.replace(os.sep, "/")
105
106 # Crawl the entire man/commands/ directory and list every file with appropriate
107 # name and details.
108 man_dir = os.path.join(docs_dir, "man")
109 raw_subcommands = glob.glob(os.path.join(man_dir, "commands/*.rst"))
110 if not raw_subcommands:
111 raise FileNotFoundError(
112 "The individual subcommand manpages could not be found!"
113 )
114
115 retval = [
116 ("index", "pip", "package manager for Python packages", "pip developers", 1),
117 ]
118 for fname in raw_subcommands:
119 fname_base = to_document_name(fname, man_dir)
120 outname = "pip-" + fname_base.split("/")[1]
121 description = "description of {} command".format(outname.replace("-", " "))
122
123 retval.append((fname_base, outname, description, "pip developers", 1))
124
125 return retval
126
127
128 man_pages = determine_man_pages()
129
[end of docs/html/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/html/conf.py b/docs/html/conf.py
--- a/docs/html/conf.py
+++ b/docs/html/conf.py
@@ -30,7 +30,7 @@
# General information about the project.
project = "pip"
-copyright = "2008-2020, PyPA"
+copyright = "The pip developers"
# Find the version and release information.
# We have a single source of truth for our version number: pip's __init__.py file.
|
{"golden_diff": "diff --git a/docs/html/conf.py b/docs/html/conf.py\n--- a/docs/html/conf.py\n+++ b/docs/html/conf.py\n@@ -30,7 +30,7 @@\n \n # General information about the project.\n project = \"pip\"\n-copyright = \"2008-2020, PyPA\"\n+copyright = \"The pip developers\"\n \n # Find the version and release information.\n # We have a single source of truth for our version number: pip's __init__.py file.\n", "issue": "Update quickstart guide to reflect user research\nUpdates quickstart guide to reflect most common tasks as discovered in our \"buy a feature\" user research.\r\n\r\nPreview: https://pip--9137.org.readthedocs.build/en/9137/quickstart/\n", "before_files": [{"content": "\"\"\"Sphinx configuration file for pip's documentation.\"\"\"\n\nimport glob\nimport os\nimport pathlib\nimport re\nimport sys\nfrom typing import List, Tuple\n\n# Add the docs/ directory to sys.path, because pip_sphinxext.py is there.\ndocs_dir = os.path.dirname(os.path.dirname(__file__))\nsys.path.insert(0, docs_dir)\n\n# -- General configuration ------------------------------------------------------------\n\nextensions = [\n # first-party extensions\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n # our extensions\n \"pip_sphinxext\",\n # third-party extensions\n \"myst_parser\",\n \"sphinx_copybutton\",\n \"sphinx_inline_tabs\",\n \"sphinxcontrib.towncrier\",\n]\n\n# General information about the project.\nproject = \"pip\"\ncopyright = \"2008-2020, PyPA\"\n\n# Find the version and release information.\n# We have a single source of truth for our version number: pip's __init__.py file.\n# This next bit of code reads from it.\nfile_with_version = os.path.join(docs_dir, \"..\", \"src\", \"pip\", \"__init__.py\")\nwith open(file_with_version) as f:\n for line in f:\n m = re.match(r'__version__ = \"(.*)\"', line)\n if m:\n __version__ = m.group(1)\n # The short X.Y version.\n version = \".\".join(__version__.split(\".\")[:2])\n # The full version, including alpha/beta/rc tags.\n release = __version__\n break\n else: # AKA no-break\n version = release = \"dev\"\n\nprint(\"pip version:\", version)\nprint(\"pip release:\", release)\n\n# -- Options for smartquotes ----------------------------------------------------------\n\n# Disable the conversion of dashes so that long options like \"--find-links\" won't\n# render as \"-find-links\" if included in the text.The default of \"qDe\" converts normal\n# quote characters ('\"' and \"'\"), en and em dashes (\"--\" and \"---\"), and ellipses \"...\"\nsmartquotes_action = \"qe\"\n\n# -- Options for intersphinx ----------------------------------------------------------\n\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3\", None),\n \"pypug\": (\"https://packaging.python.org\", None),\n}\n\n# -- Options for extlinks -------------------------------------------------------------\n\nextlinks = {\n \"issue\": (\"https://github.com/pypa/pip/issues/%s\", \"#\"),\n \"pull\": (\"https://github.com/pypa/pip/pull/%s\", \"PR #\"),\n \"pypi\": (\"https://pypi.org/project/%s/\", \"\"),\n}\n\n# -- Options for towncrier_draft extension --------------------------------------------\n\ntowncrier_draft_autoversion_mode = \"draft\" # or: 'sphinx-release', 'sphinx-version'\ntowncrier_draft_include_empty = True\ntowncrier_draft_working_directory = pathlib.Path(docs_dir).parent\n# Not yet supported: towncrier_draft_config_path = 'pyproject.toml' # relative to cwd\n\n# -- Options for HTML -----------------------------------------------------------------\n\nhtml_theme = \"furo\"\nhtml_title = f\"{project} documentation v{release}\"\n\n# Disable the generation of the various indexes\nhtml_use_modindex = False\nhtml_use_index = False\n\n# -- Options for Manual Pages ---------------------------------------------------------\n\n\n# List of manual pages generated\ndef determine_man_pages() -> List[Tuple[str, str, str, str, int]]:\n \"\"\"Determine which man pages need to be generated.\"\"\"\n\n def to_document_name(path: str, base_dir: str) -> str:\n \"\"\"Convert a provided path to a Sphinx \"document name\".\"\"\"\n relative_path = os.path.relpath(path, base_dir)\n root, _ = os.path.splitext(relative_path)\n return root.replace(os.sep, \"/\")\n\n # Crawl the entire man/commands/ directory and list every file with appropriate\n # name and details.\n man_dir = os.path.join(docs_dir, \"man\")\n raw_subcommands = glob.glob(os.path.join(man_dir, \"commands/*.rst\"))\n if not raw_subcommands:\n raise FileNotFoundError(\n \"The individual subcommand manpages could not be found!\"\n )\n\n retval = [\n (\"index\", \"pip\", \"package manager for Python packages\", \"pip developers\", 1),\n ]\n for fname in raw_subcommands:\n fname_base = to_document_name(fname, man_dir)\n outname = \"pip-\" + fname_base.split(\"/\")[1]\n description = \"description of {} command\".format(outname.replace(\"-\", \" \"))\n\n retval.append((fname_base, outname, description, \"pip developers\", 1))\n\n return retval\n\n\nman_pages = determine_man_pages()\n", "path": "docs/html/conf.py"}]}
| 1,903 | 109 |
gh_patches_debug_3962
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1874
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: fetch failed for source Stavanger Kommune
### I Have A Problem With:
A specific source
### What's Your Problem
Unable to fetch data for Stavanger Norway. Have worked flawless a while, but no there is no data.
### Source (if relevant)
stavanger_no
### Logs
```Shell
This error originated from a custom integration.
Logger: waste_collection_schedule.source_shell
Source: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136
Integration: waste_collection_schedule (documentation)
First occurred: 11:08:21 (2 occurrences)
Last logged: 11:13:26
fetch failed for source Stavanger Kommune: Traceback (most recent call last): File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File "/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py", line 49, in fetch r.raise_for_status() File "/usr/local/lib/python3.12/site-packages/requests/models.py", line 1021, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://www.stavanger.kommune.no/renovasjon-og-miljo/tommekalender/finn-kalender/show?id=###removed###
```
### Relevant Configuration
_No response_
### Checklist Source Error
- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [X] Checked that the website of your service provider is still working
- [X] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py]
1 from datetime import datetime
2
3 import requests
4 from bs4 import BeautifulSoup
5 from waste_collection_schedule import Collection # type: ignore[attr-defined]
6
7 TITLE = "Stavanger Kommune"
8 DESCRIPTION = "Source for Stavanger Kommune, Norway"
9 URL = "https://www.stavanger.kommune.no/"
10 TEST_CASES = {
11 "TestcaseI": {
12 "id": "57bf9d36-722e-400b-ae93-d80f8e354724",
13 "municipality": "Stavanger",
14 "gnumber": "57",
15 "bnumber": "922",
16 "snumber": "0",
17 },
18 }
19
20 ICON_MAP = {
21 "Restavfall": "mdi:trash-can",
22 "Papp/papir": "mdi:recycle",
23 "Bio": "mdi:leaf",
24 "Juletre": "mdi:pine-tree",
25 }
26
27
28 class Source:
29 def __init__(self, id, municipality, gnumber, bnumber, snumber):
30 self._id = id
31 self._municipality = municipality
32 self._gnumber = gnumber
33 self._bnumber = bnumber
34 self._snumber = snumber
35
36 def fetch(self):
37 url = "https://www.stavanger.kommune.no/renovasjon-og-miljo/tommekalender/finn-kalender/show"
38 headers = {"referer": "https://www.stavanger.kommune.no"}
39
40 params = {
41 "id": self._id,
42 "municipality": self._municipality,
43 "gnumber": self._gnumber,
44 "bnumber": self._bnumber,
45 "snumber": self._snumber,
46 }
47
48 r = requests.get(url, params=params, headers=headers)
49 r.raise_for_status()
50
51 soup = BeautifulSoup(r.text, "html.parser")
52
53 tag = soup.find_all("option")
54 entries = []
55 for tag in soup.find_all("tr", {"class": "waste-calendar__item"}):
56 if tag.text.strip() == "Dato og dag\nAvfallstype":
57 continue
58
59 year = tag.parent.attrs["data-month"].split("-")[1]
60 date = tag.text.strip().split(" - ")
61 date = datetime.strptime(date[0] + "." + year, "%d.%m.%Y").date()
62
63 for img in tag.find_all("img"):
64 waste_type = img.get("title")
65 entries.append(
66 Collection(date, waste_type, icon=ICON_MAP.get(waste_type))
67 )
68
69 return entries
70
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py
@@ -38,6 +38,7 @@
headers = {"referer": "https://www.stavanger.kommune.no"}
params = {
+ "ids": self._id,
"id": self._id,
"municipality": self._municipality,
"gnumber": self._gnumber,
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py\n@@ -38,6 +38,7 @@\n headers = {\"referer\": \"https://www.stavanger.kommune.no\"}\n \n params = {\n+ \"ids\": self._id,\n \"id\": self._id,\n \"municipality\": self._municipality,\n \"gnumber\": self._gnumber,\n", "issue": "[Bug]: fetch failed for source Stavanger Kommune\n### I Have A Problem With:\n\nA specific source\n\n### What's Your Problem\n\nUnable to fetch data for Stavanger Norway. Have worked flawless a while, but no there is no data.\n\n### Source (if relevant)\n\nstavanger_no\n\n### Logs\n\n```Shell\nThis error originated from a custom integration.\r\n\r\nLogger: waste_collection_schedule.source_shell\r\nSource: custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py:136\r\nIntegration: waste_collection_schedule (documentation)\r\nFirst occurred: 11:08:21 (2 occurrences)\r\nLast logged: 11:13:26\r\n\r\nfetch failed for source Stavanger Kommune: Traceback (most recent call last): File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source_shell.py\", line 134, in fetch entries = self._source.fetch() ^^^^^^^^^^^^^^^^^^^^ File \"/config/custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py\", line 49, in fetch r.raise_for_status() File \"/usr/local/lib/python3.12/site-packages/requests/models.py\", line 1021, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://www.stavanger.kommune.no/renovasjon-og-miljo/tommekalender/finn-kalender/show?id=###removed###\n```\n\n\n### Relevant Configuration\n\n_No response_\n\n### Checklist Source Error\n\n- [X] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\n- [X] Checked that the website of your service provider is still working\n- [X] Tested my attributes on the service provider website (if possible)\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\n\n### Checklist Sensor Error\n\n- [X] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\n\n### Required\n\n- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "from datetime import datetime\n\nimport requests\nfrom bs4 import BeautifulSoup\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\n\nTITLE = \"Stavanger Kommune\"\nDESCRIPTION = \"Source for Stavanger Kommune, Norway\"\nURL = \"https://www.stavanger.kommune.no/\"\nTEST_CASES = {\n \"TestcaseI\": {\n \"id\": \"57bf9d36-722e-400b-ae93-d80f8e354724\",\n \"municipality\": \"Stavanger\",\n \"gnumber\": \"57\",\n \"bnumber\": \"922\",\n \"snumber\": \"0\",\n },\n}\n\nICON_MAP = {\n \"Restavfall\": \"mdi:trash-can\",\n \"Papp/papir\": \"mdi:recycle\",\n \"Bio\": \"mdi:leaf\",\n \"Juletre\": \"mdi:pine-tree\",\n}\n\n\nclass Source:\n def __init__(self, id, municipality, gnumber, bnumber, snumber):\n self._id = id\n self._municipality = municipality\n self._gnumber = gnumber\n self._bnumber = bnumber\n self._snumber = snumber\n\n def fetch(self):\n url = \"https://www.stavanger.kommune.no/renovasjon-og-miljo/tommekalender/finn-kalender/show\"\n headers = {\"referer\": \"https://www.stavanger.kommune.no\"}\n\n params = {\n \"id\": self._id,\n \"municipality\": self._municipality,\n \"gnumber\": self._gnumber,\n \"bnumber\": self._bnumber,\n \"snumber\": self._snumber,\n }\n\n r = requests.get(url, params=params, headers=headers)\n r.raise_for_status()\n\n soup = BeautifulSoup(r.text, \"html.parser\")\n\n tag = soup.find_all(\"option\")\n entries = []\n for tag in soup.find_all(\"tr\", {\"class\": \"waste-calendar__item\"}):\n if tag.text.strip() == \"Dato og dag\\nAvfallstype\":\n continue\n\n year = tag.parent.attrs[\"data-month\"].split(\"-\")[1]\n date = tag.text.strip().split(\" - \")\n date = datetime.strptime(date[0] + \".\" + year, \"%d.%m.%Y\").date()\n\n for img in tag.find_all(\"img\"):\n waste_type = img.get(\"title\")\n entries.append(\n Collection(date, waste_type, icon=ICON_MAP.get(waste_type))\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/stavanger_no.py"}]}
| 1,810 | 151 |
gh_patches_debug_14847
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmsegmentation-261
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
an unexpected keyword argument 'drop_out_ratio' when using config file ocrnet_r50-d8.py
**Describe the bug**
It seems that there is a small error in the config file:
https://github.com/open-mmlab/mmsegmentation/blob/381eacb9a5e0e8eb475e456845f1d4c55f3c0339/configs/_base_/models/ocrnet_r50-d8.py#L26
and
https://github.com/open-mmlab/mmsegmentation/blob/381eacb9a5e0e8eb475e456845f1d4c55f3c0339/configs/_base_/models/ocrnet_r50-d8.py#L38
**Error traceback**
```
Traceback (most recent call last):
File "./tools/train.py", line 161, in <module>
main()
File "./tools/train.py", line 131, in main
cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
File "/root/userfolder/mmsegmentation/mmseg/models/builder.py", line 56, in build_segmentor
return build(cfg, SEGMENTORS, dict(train_cfg=train_cfg, test_cfg=test_cfg))
File "/root/userfolder/mmsegmentation/mmseg/models/builder.py", line 31, in build
return build_from_cfg(cfg, registry, default_args)
File "/root/userfolder/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/utils/registry.py", line 171, in build_from_cfg
return obj_cls(**args)
File "/root/userfolder/mmsegmentation/mmseg/models/segmentors/cascade_encoder_decoder.py", line 36, in __init__
pretrained=pretrained)
File "/root/userfolder/mmsegmentation/mmseg/models/segmentors/encoder_decoder.py", line 34, in __init__
self._init_decode_head(decode_head)
File "/root/userfolder/mmsegmentation/mmseg/models/segmentors/cascade_encoder_decoder.py", line 44, in _init_decode_head
self.decode_head.append(builder.build_head(decode_head[i]))
File "/root/userfolder/mmsegmentation/mmseg/models/builder.py", line 46, in build_head
return build(cfg, HEADS)
File "/root/userfolder/mmsegmentation/mmseg/models/builder.py", line 31, in build
return build_from_cfg(cfg, registry, default_args)
File "/root/userfolder/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/utils/registry.py", line 171, in build_from_cfg
return obj_cls(**args)
File "/root/userfolder/mmsegmentation/mmseg/models/decode_heads/fcn_head.py", line 31, in __init__
super(FCNHead, self).__init__(**kwargs)
TypeError: __init__() got an unexpected keyword argument 'drop_out_ratio'
```
**Bug fix**
change the keyword `drop_out_ratio=0.1` to `dropout_ratio=0.1` will fix this.
</issue>
<code>
[start of configs/_base_/models/ocrnet_r50-d8.py]
1 # model settings
2 norm_cfg = dict(type='SyncBN', requires_grad=True)
3 model = dict(
4 type='CascadeEncoderDecoder',
5 num_stages=2,
6 pretrained='open-mmlab://resnet50_v1c',
7 backbone=dict(
8 type='ResNetV1c',
9 depth=50,
10 num_stages=4,
11 out_indices=(0, 1, 2, 3),
12 dilations=(1, 1, 2, 4),
13 strides=(1, 2, 1, 1),
14 norm_cfg=norm_cfg,
15 norm_eval=False,
16 style='pytorch',
17 contract_dilation=True),
18 decode_head=[
19 dict(
20 type='FCNHead',
21 in_channels=1024,
22 in_index=2,
23 channels=256,
24 num_convs=1,
25 concat_input=False,
26 drop_out_ratio=0.1,
27 num_classes=19,
28 norm_cfg=norm_cfg,
29 align_corners=False,
30 loss_decode=dict(
31 type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
32 dict(
33 type='OCRHead',
34 in_channels=2048,
35 in_index=3,
36 channels=512,
37 ocr_channels=256,
38 drop_out_ratio=0.1,
39 num_classes=19,
40 norm_cfg=norm_cfg,
41 align_corners=False,
42 loss_decode=dict(
43 type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))
44 ])
45 # model training and testing settings
46 train_cfg = dict()
47 test_cfg = dict(mode='whole')
48
[end of configs/_base_/models/ocrnet_r50-d8.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/configs/_base_/models/ocrnet_r50-d8.py b/configs/_base_/models/ocrnet_r50-d8.py
--- a/configs/_base_/models/ocrnet_r50-d8.py
+++ b/configs/_base_/models/ocrnet_r50-d8.py
@@ -23,7 +23,7 @@
channels=256,
num_convs=1,
concat_input=False,
- drop_out_ratio=0.1,
+ dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
@@ -35,7 +35,7 @@
in_index=3,
channels=512,
ocr_channels=256,
- drop_out_ratio=0.1,
+ dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
|
{"golden_diff": "diff --git a/configs/_base_/models/ocrnet_r50-d8.py b/configs/_base_/models/ocrnet_r50-d8.py\n--- a/configs/_base_/models/ocrnet_r50-d8.py\n+++ b/configs/_base_/models/ocrnet_r50-d8.py\n@@ -23,7 +23,7 @@\n channels=256,\n num_convs=1,\n concat_input=False,\n- drop_out_ratio=0.1,\n+ dropout_ratio=0.1,\n num_classes=19,\n norm_cfg=norm_cfg,\n align_corners=False,\n@@ -35,7 +35,7 @@\n in_index=3,\n channels=512,\n ocr_channels=256,\n- drop_out_ratio=0.1,\n+ dropout_ratio=0.1,\n num_classes=19,\n norm_cfg=norm_cfg,\n align_corners=False,\n", "issue": "an unexpected keyword argument 'drop_out_ratio' when using config file ocrnet_r50-d8.py\n**Describe the bug**\r\n\r\nIt seems that there is a small error in the config file: \r\nhttps://github.com/open-mmlab/mmsegmentation/blob/381eacb9a5e0e8eb475e456845f1d4c55f3c0339/configs/_base_/models/ocrnet_r50-d8.py#L26\r\nand\r\nhttps://github.com/open-mmlab/mmsegmentation/blob/381eacb9a5e0e8eb475e456845f1d4c55f3c0339/configs/_base_/models/ocrnet_r50-d8.py#L38\r\n\r\n**Error traceback**\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"./tools/train.py\", line 161, in <module>\r\n main()\r\n File \"./tools/train.py\", line 131, in main\r\n cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/builder.py\", line 56, in build_segmentor\r\n return build(cfg, SEGMENTORS, dict(train_cfg=train_cfg, test_cfg=test_cfg))\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/builder.py\", line 31, in build\r\n return build_from_cfg(cfg, registry, default_args)\r\n File \"/root/userfolder/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/utils/registry.py\", line 171, in build_from_cfg\r\n return obj_cls(**args)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/segmentors/cascade_encoder_decoder.py\", line 36, in __init__\r\n pretrained=pretrained)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/segmentors/encoder_decoder.py\", line 34, in __init__\r\n self._init_decode_head(decode_head)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/segmentors/cascade_encoder_decoder.py\", line 44, in _init_decode_head\r\n self.decode_head.append(builder.build_head(decode_head[i]))\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/builder.py\", line 46, in build_head\r\n return build(cfg, HEADS)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/builder.py\", line 31, in build\r\n return build_from_cfg(cfg, registry, default_args)\r\n File \"/root/userfolder/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/utils/registry.py\", line 171, in build_from_cfg\r\n return obj_cls(**args)\r\n File \"/root/userfolder/mmsegmentation/mmseg/models/decode_heads/fcn_head.py\", line 31, in __init__\r\n super(FCNHead, self).__init__(**kwargs)\r\nTypeError: __init__() got an unexpected keyword argument 'drop_out_ratio'\r\n```\r\n\r\n**Bug fix**\r\nchange the keyword `drop_out_ratio=0.1` to `dropout_ratio=0.1` will fix this.\r\n\r\n\n", "before_files": [{"content": "# model settings\nnorm_cfg = dict(type='SyncBN', requires_grad=True)\nmodel = dict(\n type='CascadeEncoderDecoder',\n num_stages=2,\n pretrained='open-mmlab://resnet50_v1c',\n backbone=dict(\n type='ResNetV1c',\n depth=50,\n num_stages=4,\n out_indices=(0, 1, 2, 3),\n dilations=(1, 1, 2, 4),\n strides=(1, 2, 1, 1),\n norm_cfg=norm_cfg,\n norm_eval=False,\n style='pytorch',\n contract_dilation=True),\n decode_head=[\n dict(\n type='FCNHead',\n in_channels=1024,\n in_index=2,\n channels=256,\n num_convs=1,\n concat_input=False,\n drop_out_ratio=0.1,\n num_classes=19,\n norm_cfg=norm_cfg,\n align_corners=False,\n loss_decode=dict(\n type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),\n dict(\n type='OCRHead',\n in_channels=2048,\n in_index=3,\n channels=512,\n ocr_channels=256,\n drop_out_ratio=0.1,\n num_classes=19,\n norm_cfg=norm_cfg,\n align_corners=False,\n loss_decode=dict(\n type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0))\n ])\n# model training and testing settings\ntrain_cfg = dict()\ntest_cfg = dict(mode='whole')\n", "path": "configs/_base_/models/ocrnet_r50-d8.py"}]}
| 1,714 | 214 |
gh_patches_debug_19626
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2391
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tasks failing after migration from cfscraper to cloudscraper
Since #2381 one of my tasks stopped returning new entries.
After checking the log I noticed `cloudscraper` returns a ReCaptcha related error during the `rmz` automatic url-rewrite (a problem `cfscrape` doesn't have).
Upon further investigation, it seems that `cloudscraper` has this issue when importing an existing requests session generated by Flexget, since removing the last `task.requests` (for testing purposes) from https://github.com/Flexget/Flexget/blob/a4037da07f7d7707650596670c467ab3b7e748c9/flexget/plugins/operate/cfscraper.py#L39 results in a successful processing of the task.
Another finding: Disabling `urlrewriting` also did not trigger a ReCaptcha error (therefore completing the task) even without meddling with any of Flexget's .py's, however it also doesn't return a download URL if [rmz.py](https://github.com/Flexget/Flexget/blob/master/flexget/components/sites/sites/rmz.py) is not processed.
### Expected behaviour:
Task returning proper entries with populated urls
### Actual behaviour:
Task failing due to `cloudscraper` bumping into ReCaptcha during `rmz`url-rewrite
### Steps to reproduce:
- Step 1:
#### Config:
```
tasks:
cftask:
disable:
- seen
- seen_info_hash
- retry_failed
# - urlrewriting
cfscraper: yes
rss: http://rmz.cr/feed
series:
# Random entry from the feed below#
- Days of our lives
```
#### Log:
<details>
<summary>(click to expand)</summary>
```
$ flexget execute --tasks cftask
2019-05-09 00:34 VERBOSE task_queue There are 1 tasks to execute. Shutdown will commence when they have completed.
2019-05-09 00:34 VERBOSE details cftask Produced 100 entries.
2019-05-09 00:34 VERBOSE series.db cftask identified by is currently on `auto` for Days of our lives. Multiple id types may be accepted until it locks in on the appropriate type.
2019-05-09 00:34 VERBOSE task cftask ACCEPTED: `[RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB)` by series plugin because choosing first acceptable match
2019-05-09 00:35 WARNING urlrewriter cftask URL rewriting rmz failed: Captcha
2019-05-09 00:35 ERROR entry cftask Failed [RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB) (None)
2019-05-09 00:35 VERBOSE task cftask FAILED: `[RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB)` by urlrewriting plugin
2019-05-09 00:35 VERBOSE details cftask Summary - Accepted: 0 (Rejected: 0 Undecided: 99 Failed: 1)
```
</details>
### Additional information:
- FlexGet version: 2.20.26
- Python version: 2.7.14
- Installation method: pip
- Using daemon (yes/no): yes
- OS and version: Windows 10 (1809)
</issue>
<code>
[start of flexget/plugins/operate/cfscraper.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3
4 import logging
5
6 from flexget import plugin
7 from flexget.event import event
8 from flexget.utils.requests import Session
9
10 log = logging.getLogger('cfscraper')
11
12
13 class CFScraper(object):
14 """
15 Plugin that enables scraping of cloudflare protected sites.
16
17 Example::
18 cfscraper: yes
19 """
20
21 schema = {'type': 'boolean'}
22
23 @plugin.priority(253)
24 def on_task_start(self, task, config):
25 try:
26 import cloudscraper
27 except ImportError as e:
28 log.debug('Error importing cloudscraper: %s' % e)
29 raise plugin.DependencyError(
30 'cfscraper', 'cloudscraper', 'cloudscraper module required. ImportError: %s' % e
31 )
32
33 class CFScrapeWrapper(Session, cloudscraper.CloudScraper):
34 """
35 This class allows the FlexGet session to inherit from CloudScraper instead of the requests.Session directly.
36 """
37
38 if config is True:
39 task.requests = CFScrapeWrapper.create_scraper(task.requests)
40
41
42 @event('plugin.register')
43 def register_plugin():
44 plugin.register(CFScraper, 'cfscraper', api_ver=2)
45
[end of flexget/plugins/operate/cfscraper.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/operate/cfscraper.py b/flexget/plugins/operate/cfscraper.py
--- a/flexget/plugins/operate/cfscraper.py
+++ b/flexget/plugins/operate/cfscraper.py
@@ -6,6 +6,7 @@
from flexget import plugin
from flexget.event import event
from flexget.utils.requests import Session
+from collections import OrderedDict
log = logging.getLogger('cfscraper')
@@ -36,6 +37,18 @@
"""
if config is True:
+ task.requests.headers = (
+ OrderedDict(
+ [
+ ('User-Agent', task.requests.headers['User-Agent']),
+ ('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'),
+ ('Accept-Language', 'en-US,en;q=0.5'),
+ ('Accept-Encoding', 'gzip, deflate'),
+ ('Connection', 'close'),
+ ('Upgrade-Insecure-Requests', '1')
+ ]
+ )
+ )
task.requests = CFScrapeWrapper.create_scraper(task.requests)
|
{"golden_diff": "diff --git a/flexget/plugins/operate/cfscraper.py b/flexget/plugins/operate/cfscraper.py\n--- a/flexget/plugins/operate/cfscraper.py\n+++ b/flexget/plugins/operate/cfscraper.py\n@@ -6,6 +6,7 @@\n from flexget import plugin\n from flexget.event import event\n from flexget.utils.requests import Session\n+from collections import OrderedDict\n \n log = logging.getLogger('cfscraper')\n \n@@ -36,6 +37,18 @@\n \"\"\"\n \n if config is True:\n+ task.requests.headers = (\n+ OrderedDict(\n+ [\n+ ('User-Agent', task.requests.headers['User-Agent']),\n+ ('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'),\n+ ('Accept-Language', 'en-US,en;q=0.5'),\n+ ('Accept-Encoding', 'gzip, deflate'),\n+ ('Connection', 'close'),\n+ ('Upgrade-Insecure-Requests', '1')\n+ ]\n+ )\n+ )\n task.requests = CFScrapeWrapper.create_scraper(task.requests)\n", "issue": "Tasks failing after migration from cfscraper to cloudscraper\nSince #2381 one of my tasks stopped returning new entries.\r\nAfter checking the log I noticed `cloudscraper` returns a ReCaptcha related error during the `rmz` automatic url-rewrite (a problem `cfscrape` doesn't have).\r\nUpon further investigation, it seems that `cloudscraper` has this issue when importing an existing requests session generated by Flexget, since removing the last `task.requests` (for testing purposes) from https://github.com/Flexget/Flexget/blob/a4037da07f7d7707650596670c467ab3b7e748c9/flexget/plugins/operate/cfscraper.py#L39 results in a successful processing of the task.\r\n\r\nAnother finding: Disabling `urlrewriting` also did not trigger a ReCaptcha error (therefore completing the task) even without meddling with any of Flexget's .py's, however it also doesn't return a download URL if [rmz.py](https://github.com/Flexget/Flexget/blob/master/flexget/components/sites/sites/rmz.py) is not processed.\r\n### Expected behaviour:\r\nTask returning proper entries with populated urls\r\n\r\n### Actual behaviour:\r\nTask failing due to `cloudscraper` bumping into ReCaptcha during `rmz`url-rewrite\r\n### Steps to reproduce:\r\n- Step 1: \r\n#### Config:\r\n```\r\ntasks:\r\n cftask:\r\n disable:\r\n - seen\r\n - seen_info_hash\r\n - retry_failed\r\n # - urlrewriting\r\n cfscraper: yes\r\n rss: http://rmz.cr/feed\r\n series:\r\n # Random entry from the feed below#\r\n - Days of our lives\r\n```\r\n \r\n#### Log:\r\n<details>\r\n <summary>(click to expand)</summary>\r\n\r\n```\r\n$ flexget execute --tasks cftask\r\n2019-05-09 00:34 VERBOSE task_queue There are 1 tasks to execute. Shutdown will commence when they have completed.\r\n2019-05-09 00:34 VERBOSE details cftask Produced 100 entries.\r\n2019-05-09 00:34 VERBOSE series.db cftask identified by is currently on `auto` for Days of our lives. Multiple id types may be accepted until it locks in on the appropriate type.\r\n2019-05-09 00:34 VERBOSE task cftask ACCEPTED: `[RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB)` by series plugin because choosing first acceptable match\r\n2019-05-09 00:35 WARNING urlrewriter cftask URL rewriting rmz failed: Captcha\r\n2019-05-09 00:35 ERROR entry cftask Failed [RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB) (None)\r\n2019-05-09 00:35 VERBOSE task cftask FAILED: `[RR/NF/UL/OL/CU] Days of our Lives S54E160 720p WEB HEVC x265-RMTeam (198MB)` by urlrewriting plugin\r\n2019-05-09 00:35 VERBOSE details cftask Summary - Accepted: 0 (Rejected: 0 Undecided: 99 Failed: 1)\r\n```\r\n</details>\r\n\r\n### Additional information:\r\n\r\n- FlexGet version: 2.20.26\r\n- Python version: 2.7.14\r\n- Installation method: pip\r\n- Using daemon (yes/no): yes\r\n- OS and version: Windows 10 (1809)\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n\nimport logging\n\nfrom flexget import plugin\nfrom flexget.event import event\nfrom flexget.utils.requests import Session\n\nlog = logging.getLogger('cfscraper')\n\n\nclass CFScraper(object):\n \"\"\"\n Plugin that enables scraping of cloudflare protected sites.\n\n Example::\n cfscraper: yes\n \"\"\"\n\n schema = {'type': 'boolean'}\n\n @plugin.priority(253)\n def on_task_start(self, task, config):\n try:\n import cloudscraper\n except ImportError as e:\n log.debug('Error importing cloudscraper: %s' % e)\n raise plugin.DependencyError(\n 'cfscraper', 'cloudscraper', 'cloudscraper module required. ImportError: %s' % e\n )\n\n class CFScrapeWrapper(Session, cloudscraper.CloudScraper):\n \"\"\"\n This class allows the FlexGet session to inherit from CloudScraper instead of the requests.Session directly.\n \"\"\"\n\n if config is True:\n task.requests = CFScrapeWrapper.create_scraper(task.requests)\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(CFScraper, 'cfscraper', api_ver=2)\n", "path": "flexget/plugins/operate/cfscraper.py"}]}
| 1,829 | 251 |
gh_patches_debug_11241
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1942
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use string form for type checking until Python 3.7 dropped
What the if here? The string form is fine until you drop Pythons that don’t support it.
_Originally posted by @henryiii in https://github.com/scikit-hep/pyhf/pull/1909#discussion_r944456765_
This was in reference to
```python
if T.TYPE_CHECKING:
PathOrStr = T.Union[str, os.PathLike[str]]
else:
PathOrStr = T.Union[str, "os.PathLike[str]"]
```
in PR #190 now in
https://github.com/scikit-hep/pyhf/blob/ad1dd86f1d7c1bcbf737805b6821e07c4ef75fca/src/pyhf/typing.py#L30-L33
So until Python 3.7 is dropped (I think this is the version I am not very up to date with my type checking knowledge) we could instead just drop the `if TYPE_CHECKING` and use
```python
#TODO: Switch to os.PathLike[str] once Python 3.7 dropped
PathOrStr = Union[str, "os.PathLike[str]"]
```
This would also allow for reverting PR #1937.
</issue>
<code>
[start of src/pyhf/typing.py]
1 import os
2 import sys
3 from typing import TYPE_CHECKING, MutableSequence, Sequence, Union
4
5 if sys.version_info >= (3, 8):
6 from typing import Literal, TypedDict
7 else:
8 from typing_extensions import Literal, TypedDict
9
10 __all__ = (
11 "PathOrStr",
12 "ParameterBase",
13 "Parameter",
14 "Measurement",
15 "ModifierBase",
16 "NormSys",
17 "NormFactor",
18 "HistoSys",
19 "StatError",
20 "ShapeSys",
21 "ShapeFactor",
22 "LumiSys",
23 "Modifier",
24 "Sample",
25 "Channel",
26 "Observation",
27 "Workspace",
28 )
29
30 if TYPE_CHECKING:
31 PathOrStr = Union[str, os.PathLike[str]]
32 else:
33 PathOrStr = Union[str, "os.PathLike[str]"]
34
35
36 class ParameterBase(TypedDict, total=False):
37 auxdata: Sequence[float]
38 bounds: Sequence[Sequence[float]]
39 inits: Sequence[float]
40 sigmas: Sequence[float]
41 fixed: bool
42
43
44 class Parameter(ParameterBase):
45 name: str
46
47
48 class Config(TypedDict):
49 poi: str
50 parameters: MutableSequence[Parameter]
51
52
53 class Measurement(TypedDict):
54 name: str
55 config: Config
56
57
58 class ModifierBase(TypedDict):
59 name: str
60
61
62 class NormSysData(TypedDict):
63 lo: float
64 hi: float
65
66
67 class NormSys(ModifierBase):
68 type: Literal['normsys']
69 data: NormSysData
70
71
72 class NormFactor(ModifierBase):
73 type: Literal['normfactor']
74 data: None
75
76
77 class HistoSysData(TypedDict):
78 lo_data: Sequence[float]
79 hi_data: Sequence[float]
80
81
82 class HistoSys(ModifierBase):
83 type: Literal['histosys']
84 data: HistoSysData
85
86
87 class StatError(ModifierBase):
88 type: Literal['staterror']
89 data: Sequence[float]
90
91
92 class ShapeSys(ModifierBase):
93 type: Literal['shapesys']
94 data: Sequence[float]
95
96
97 class ShapeFactor(ModifierBase):
98 type: Literal['shapefactor']
99 data: None
100
101
102 class LumiSys(TypedDict):
103 name: Literal['lumi']
104 type: Literal['lumi']
105 data: None
106
107
108 Modifier = Union[
109 NormSys, NormFactor, HistoSys, StatError, ShapeSys, ShapeFactor, LumiSys
110 ]
111
112
113 class SampleBase(TypedDict, total=False):
114 parameter_configs: Sequence[Parameter]
115
116
117 class Sample(SampleBase):
118 name: str
119 data: Sequence[float]
120 modifiers: Sequence[Modifier]
121
122
123 class Channel(TypedDict):
124 name: str
125 samples: Sequence[Sample]
126
127
128 class Observation(TypedDict):
129 name: str
130 data: Sequence[float]
131
132
133 class Workspace(TypedDict):
134 measurements: Sequence[Measurement]
135 channels: Sequence[Channel]
136 observations: Sequence[Observation]
137
[end of src/pyhf/typing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/typing.py b/src/pyhf/typing.py
--- a/src/pyhf/typing.py
+++ b/src/pyhf/typing.py
@@ -1,6 +1,6 @@
import os
import sys
-from typing import TYPE_CHECKING, MutableSequence, Sequence, Union
+from typing import MutableSequence, Sequence, Union
if sys.version_info >= (3, 8):
from typing import Literal, TypedDict
@@ -27,10 +27,8 @@
"Workspace",
)
-if TYPE_CHECKING:
- PathOrStr = Union[str, os.PathLike[str]]
-else:
- PathOrStr = Union[str, "os.PathLike[str]"]
+# TODO: Switch to os.PathLike[str] once Python 3.8 support dropped
+PathOrStr = Union[str, "os.PathLike[str]"]
class ParameterBase(TypedDict, total=False):
|
{"golden_diff": "diff --git a/src/pyhf/typing.py b/src/pyhf/typing.py\n--- a/src/pyhf/typing.py\n+++ b/src/pyhf/typing.py\n@@ -1,6 +1,6 @@\n import os\n import sys\n-from typing import TYPE_CHECKING, MutableSequence, Sequence, Union\n+from typing import MutableSequence, Sequence, Union\n \n if sys.version_info >= (3, 8):\n from typing import Literal, TypedDict\n@@ -27,10 +27,8 @@\n \"Workspace\",\n )\n \n-if TYPE_CHECKING:\n- PathOrStr = Union[str, os.PathLike[str]]\n-else:\n- PathOrStr = Union[str, \"os.PathLike[str]\"]\n+# TODO: Switch to os.PathLike[str] once Python 3.8 support dropped\n+PathOrStr = Union[str, \"os.PathLike[str]\"]\n \n \n class ParameterBase(TypedDict, total=False):\n", "issue": "Use string form for type checking until Python 3.7 dropped\nWhat the if here? The string form is fine until you drop Pythons that don\u2019t support it.\r\n\r\n_Originally posted by @henryiii in https://github.com/scikit-hep/pyhf/pull/1909#discussion_r944456765_\r\n\r\nThis was in reference to \r\n\r\n```python\r\nif T.TYPE_CHECKING:\r\n PathOrStr = T.Union[str, os.PathLike[str]]\r\nelse:\r\n PathOrStr = T.Union[str, \"os.PathLike[str]\"]\r\n```\r\n\r\nin PR #190 now in \r\n\r\nhttps://github.com/scikit-hep/pyhf/blob/ad1dd86f1d7c1bcbf737805b6821e07c4ef75fca/src/pyhf/typing.py#L30-L33\r\n\r\nSo until Python 3.7 is dropped (I think this is the version I am not very up to date with my type checking knowledge) we could instead just drop the `if TYPE_CHECKING` and use\r\n\r\n```python\r\n#TODO: Switch to os.PathLike[str] once Python 3.7 dropped\r\nPathOrStr = Union[str, \"os.PathLike[str]\"]\r\n```\r\n\r\nThis would also allow for reverting PR #1937.\n", "before_files": [{"content": "import os\nimport sys\nfrom typing import TYPE_CHECKING, MutableSequence, Sequence, Union\n\nif sys.version_info >= (3, 8):\n from typing import Literal, TypedDict\nelse:\n from typing_extensions import Literal, TypedDict\n\n__all__ = (\n \"PathOrStr\",\n \"ParameterBase\",\n \"Parameter\",\n \"Measurement\",\n \"ModifierBase\",\n \"NormSys\",\n \"NormFactor\",\n \"HistoSys\",\n \"StatError\",\n \"ShapeSys\",\n \"ShapeFactor\",\n \"LumiSys\",\n \"Modifier\",\n \"Sample\",\n \"Channel\",\n \"Observation\",\n \"Workspace\",\n)\n\nif TYPE_CHECKING:\n PathOrStr = Union[str, os.PathLike[str]]\nelse:\n PathOrStr = Union[str, \"os.PathLike[str]\"]\n\n\nclass ParameterBase(TypedDict, total=False):\n auxdata: Sequence[float]\n bounds: Sequence[Sequence[float]]\n inits: Sequence[float]\n sigmas: Sequence[float]\n fixed: bool\n\n\nclass Parameter(ParameterBase):\n name: str\n\n\nclass Config(TypedDict):\n poi: str\n parameters: MutableSequence[Parameter]\n\n\nclass Measurement(TypedDict):\n name: str\n config: Config\n\n\nclass ModifierBase(TypedDict):\n name: str\n\n\nclass NormSysData(TypedDict):\n lo: float\n hi: float\n\n\nclass NormSys(ModifierBase):\n type: Literal['normsys']\n data: NormSysData\n\n\nclass NormFactor(ModifierBase):\n type: Literal['normfactor']\n data: None\n\n\nclass HistoSysData(TypedDict):\n lo_data: Sequence[float]\n hi_data: Sequence[float]\n\n\nclass HistoSys(ModifierBase):\n type: Literal['histosys']\n data: HistoSysData\n\n\nclass StatError(ModifierBase):\n type: Literal['staterror']\n data: Sequence[float]\n\n\nclass ShapeSys(ModifierBase):\n type: Literal['shapesys']\n data: Sequence[float]\n\n\nclass ShapeFactor(ModifierBase):\n type: Literal['shapefactor']\n data: None\n\n\nclass LumiSys(TypedDict):\n name: Literal['lumi']\n type: Literal['lumi']\n data: None\n\n\nModifier = Union[\n NormSys, NormFactor, HistoSys, StatError, ShapeSys, ShapeFactor, LumiSys\n]\n\n\nclass SampleBase(TypedDict, total=False):\n parameter_configs: Sequence[Parameter]\n\n\nclass Sample(SampleBase):\n name: str\n data: Sequence[float]\n modifiers: Sequence[Modifier]\n\n\nclass Channel(TypedDict):\n name: str\n samples: Sequence[Sample]\n\n\nclass Observation(TypedDict):\n name: str\n data: Sequence[float]\n\n\nclass Workspace(TypedDict):\n measurements: Sequence[Measurement]\n channels: Sequence[Channel]\n observations: Sequence[Observation]\n", "path": "src/pyhf/typing.py"}]}
| 1,783 | 200 |
gh_patches_debug_31813
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-206
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Capture Celery Time-in-queue
</issue>
<code>
[start of src/scout_apm/celery.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from celery.signals import task_postrun, task_prerun
5
6 import scout_apm.core
7 from scout_apm.core.tracked_request import TrackedRequest
8
9
10 def prerun_callback(task=None, **kwargs):
11 tracked_request = TrackedRequest.instance()
12 tracked_request.mark_real_request()
13
14 delivery_info = task.request.delivery_info
15 tracked_request.tag("is_eager", delivery_info.get("is_eager", False))
16 tracked_request.tag("exchange", delivery_info.get("exchange", "unknown"))
17 tracked_request.tag("routing_key", delivery_info.get("routing_key", "unknown"))
18 tracked_request.tag("queue", delivery_info.get("queue", "unknown"))
19
20 tracked_request.start_span(operation=("Job/" + task.name))
21
22
23 def postrun_callback(task=None, **kwargs):
24 tracked_request = TrackedRequest.instance()
25 tracked_request.stop_span()
26
27
28 def install():
29 installed = scout_apm.core.install()
30 if not installed:
31 return
32
33 task_prerun.connect(prerun_callback)
34 task_postrun.connect(postrun_callback)
35
36
37 def uninstall():
38 task_prerun.disconnect(prerun_callback)
39 task_postrun.disconnect(postrun_callback)
40
[end of src/scout_apm/celery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py
--- a/src/scout_apm/celery.py
+++ b/src/scout_apm/celery.py
@@ -1,16 +1,34 @@
# coding=utf-8
from __future__ import absolute_import, division, print_function, unicode_literals
-from celery.signals import task_postrun, task_prerun
+import datetime as dt
+
+from celery.signals import before_task_publish, task_postrun, task_prerun
import scout_apm.core
+from scout_apm.compat import datetime_to_timestamp
from scout_apm.core.tracked_request import TrackedRequest
+def before_publish_callback(headers=None, properties=None, **kwargs):
+ if "scout_task_start" not in headers:
+ headers["scout_task_start"] = datetime_to_timestamp(dt.datetime.utcnow())
+
+
def prerun_callback(task=None, **kwargs):
tracked_request = TrackedRequest.instance()
tracked_request.mark_real_request()
+ start = getattr(task.request, "scout_task_start", None)
+ if start is not None:
+ now = datetime_to_timestamp(dt.datetime.utcnow())
+ try:
+ queue_time = now - start
+ except TypeError:
+ pass
+ else:
+ tracked_request.tag("queue_time", queue_time)
+
delivery_info = task.request.delivery_info
tracked_request.tag("is_eager", delivery_info.get("is_eager", False))
tracked_request.tag("exchange", delivery_info.get("exchange", "unknown"))
@@ -30,10 +48,12 @@
if not installed:
return
+ before_task_publish.connect(before_publish_callback)
task_prerun.connect(prerun_callback)
task_postrun.connect(postrun_callback)
def uninstall():
+ before_task_publish.disconnect(before_publish_callback)
task_prerun.disconnect(prerun_callback)
task_postrun.disconnect(postrun_callback)
|
{"golden_diff": "diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py\n--- a/src/scout_apm/celery.py\n+++ b/src/scout_apm/celery.py\n@@ -1,16 +1,34 @@\n # coding=utf-8\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n-from celery.signals import task_postrun, task_prerun\n+import datetime as dt\n+\n+from celery.signals import before_task_publish, task_postrun, task_prerun\n \n import scout_apm.core\n+from scout_apm.compat import datetime_to_timestamp\n from scout_apm.core.tracked_request import TrackedRequest\n \n \n+def before_publish_callback(headers=None, properties=None, **kwargs):\n+ if \"scout_task_start\" not in headers:\n+ headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n+\n+\n def prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.mark_real_request()\n \n+ start = getattr(task.request, \"scout_task_start\", None)\n+ if start is not None:\n+ now = datetime_to_timestamp(dt.datetime.utcnow())\n+ try:\n+ queue_time = now - start\n+ except TypeError:\n+ pass\n+ else:\n+ tracked_request.tag(\"queue_time\", queue_time)\n+\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n@@ -30,10 +48,12 @@\n if not installed:\n return\n \n+ before_task_publish.connect(before_publish_callback)\n task_prerun.connect(prerun_callback)\n task_postrun.connect(postrun_callback)\n \n \n def uninstall():\n+ before_task_publish.disconnect(before_publish_callback)\n task_prerun.disconnect(prerun_callback)\n task_postrun.disconnect(postrun_callback)\n", "issue": "Capture Celery Time-in-queue\n\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom celery.signals import task_postrun, task_prerun\n\nimport scout_apm.core\nfrom scout_apm.core.tracked_request import TrackedRequest\n\n\ndef prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.mark_real_request()\n\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n tracked_request.tag(\"routing_key\", delivery_info.get(\"routing_key\", \"unknown\"))\n tracked_request.tag(\"queue\", delivery_info.get(\"queue\", \"unknown\"))\n\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n\n\ndef postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n\n\ndef install():\n installed = scout_apm.core.install()\n if not installed:\n return\n\n task_prerun.connect(prerun_callback)\n task_postrun.connect(postrun_callback)\n\n\ndef uninstall():\n task_prerun.disconnect(prerun_callback)\n task_postrun.disconnect(postrun_callback)\n", "path": "src/scout_apm/celery.py"}]}
| 901 | 435 |
gh_patches_debug_13458
|
rasdani/github-patches
|
git_diff
|
explosion__spaCy-3499
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect lemma from lemmatizer
**Right:**
`[w.lemma_ for w in nlp('funnier')]` -> `['funny']`
**Wrong:**
`[w.lemma_ for w in nlp('faster')]` ->`['faster']`
I think for word _faster_ lemma should be _fast_
</issue>
<code>
[start of spacy/lang/en/lemmatizer/_adverbs_irreg.py]
1 # coding: utf8
2 from __future__ import unicode_literals
3
4
5 ADVERBS_IRREG = {
6 "best": ("well",),
7 "better": ("well",),
8 "deeper": ("deeply",),
9 "farther": ("far",),
10 "further": ("far",),
11 "harder": ("hard",),
12 "hardest": ("hard",),
13 }
14
[end of spacy/lang/en/lemmatizer/_adverbs_irreg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/spacy/lang/en/lemmatizer/_adverbs_irreg.py b/spacy/lang/en/lemmatizer/_adverbs_irreg.py
--- a/spacy/lang/en/lemmatizer/_adverbs_irreg.py
+++ b/spacy/lang/en/lemmatizer/_adverbs_irreg.py
@@ -5,9 +5,27 @@
ADVERBS_IRREG = {
"best": ("well",),
"better": ("well",),
+ "closer": ("close",),
+ "closest": ("close",),
"deeper": ("deeply",),
+ "earlier": ("early",),
+ "earliest": ("early",),
"farther": ("far",),
"further": ("far",),
+ "faster": ("fast",),
+ "fastest": ("fast",),
"harder": ("hard",),
"hardest": ("hard",),
+ "longer": ("long",),
+ "longest": ("long",),
+ "nearer": ("near",),
+ "nearest": ("near",),
+ "nigher": ("nigh",),
+ "nighest": ("nigh",),
+ "quicker": ("quick",),
+ "quickest": ("quick",),
+ "slower": ("slow",),
+ "slowest": ("slowest",),
+ "sooner": ("soon",),
+ "soonest": ("soon",)
}
|
{"golden_diff": "diff --git a/spacy/lang/en/lemmatizer/_adverbs_irreg.py b/spacy/lang/en/lemmatizer/_adverbs_irreg.py\n--- a/spacy/lang/en/lemmatizer/_adverbs_irreg.py\n+++ b/spacy/lang/en/lemmatizer/_adverbs_irreg.py\n@@ -5,9 +5,27 @@\n ADVERBS_IRREG = {\n \"best\": (\"well\",),\n \"better\": (\"well\",),\n+ \"closer\": (\"close\",),\n+ \"closest\": (\"close\",),\n \"deeper\": (\"deeply\",),\n+ \"earlier\": (\"early\",),\n+ \"earliest\": (\"early\",),\n \"farther\": (\"far\",),\n \"further\": (\"far\",),\n+ \"faster\": (\"fast\",),\n+ \"fastest\": (\"fast\",),\n \"harder\": (\"hard\",),\n \"hardest\": (\"hard\",),\n+ \"longer\": (\"long\",),\n+ \"longest\": (\"long\",),\n+ \"nearer\": (\"near\",),\n+ \"nearest\": (\"near\",),\n+ \"nigher\": (\"nigh\",),\n+ \"nighest\": (\"nigh\",),\n+ \"quicker\": (\"quick\",),\n+ \"quickest\": (\"quick\",),\n+ \"slower\": (\"slow\",),\n+ \"slowest\": (\"slowest\",),\n+ \"sooner\": (\"soon\",),\n+ \"soonest\": (\"soon\",)\n }\n", "issue": "Incorrect lemma from lemmatizer\n**Right:**\r\n`[w.lemma_ for w in nlp('funnier')]` -> `['funny']` \r\n\r\n**Wrong:**\r\n`[w.lemma_ for w in nlp('faster')]` ->`['faster']`\r\n\r\nI think for word _faster_ lemma should be _fast_\n", "before_files": [{"content": "# coding: utf8\nfrom __future__ import unicode_literals\n\n\nADVERBS_IRREG = {\n \"best\": (\"well\",),\n \"better\": (\"well\",),\n \"deeper\": (\"deeply\",),\n \"farther\": (\"far\",),\n \"further\": (\"far\",),\n \"harder\": (\"hard\",),\n \"hardest\": (\"hard\",),\n}\n", "path": "spacy/lang/en/lemmatizer/_adverbs_irreg.py"}]}
| 737 | 332 |
gh_patches_debug_67335
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-284
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
base_url is used twice in redirects
For jupyterhub running at _http://address/prefix/_ almost every redirect has `base_url` twice. It was caused by PR #276. Reverting changes to jupyterhub/handlers/pages.py:27 [1] fixes the issue.
[1] https://github.com/Crunch-io/jupyterhub/commit/05e4ab41fe6691dd697eecc27d9abee2ac4e23b6
</issue>
<code>
[start of jupyterhub/handlers/pages.py]
1 """Basic html-rendering handlers."""
2
3 # Copyright (c) Jupyter Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 from tornado import web
7
8 from .. import orm
9 from ..utils import admin_only, url_path_join
10 from .base import BaseHandler
11
12
13 class RootHandler(BaseHandler):
14 """Render the Hub root page.
15
16 If logged in, redirects to:
17
18 - single-user server if running
19 - hub home, otherwise
20
21 Otherwise, renders login page.
22 """
23 def get(self):
24 user = self.get_current_user()
25 if user:
26 if user.running:
27 url = url_path_join(self.hub.server.base_url, user.server.base_url)
28 self.log.debug("User is running: %s", url)
29 else:
30 url = url_path_join(self.hub.server.base_url, 'home')
31 self.log.debug("User is not running: %s", url)
32 self.redirect(url, permanent=False)
33 return
34 # Redirect to the authenticator login page instead of rendering the
35 # login html page
36 url = self.authenticator.login_url(self.hub.server.base_url)
37 self.log.debug("No user logged in: %s", url)
38 self.redirect(url, permanent=False)
39
40 class HomeHandler(BaseHandler):
41 """Render the user's home page."""
42
43 @web.authenticated
44 def get(self):
45 html = self.render_template('home.html',
46 user=self.get_current_user(),
47 )
48 self.finish(html)
49
50
51 class AdminHandler(BaseHandler):
52 """Render the admin page."""
53
54 @admin_only
55 def get(self):
56 available = {'name', 'admin', 'running', 'last_activity'}
57 default_sort = ['admin', 'name']
58 mapping = {
59 'running': '_server_id'
60 }
61 default_order = {
62 'name': 'asc',
63 'last_activity': 'desc',
64 'admin': 'desc',
65 'running': 'desc',
66 }
67 sorts = self.get_arguments('sort') or default_sort
68 orders = self.get_arguments('order')
69
70 for bad in set(sorts).difference(available):
71 self.log.warn("ignoring invalid sort: %r", bad)
72 sorts.remove(bad)
73 for bad in set(orders).difference({'asc', 'desc'}):
74 self.log.warn("ignoring invalid order: %r", bad)
75 orders.remove(bad)
76
77 # add default sort as secondary
78 for s in default_sort:
79 if s not in sorts:
80 sorts.append(s)
81 if len(orders) < len(sorts):
82 for col in sorts[len(orders):]:
83 orders.append(default_order[col])
84 else:
85 orders = orders[:len(sorts)]
86
87 # this could be one incomprehensible nested list comprehension
88 # get User columns
89 cols = [ getattr(orm.User, mapping.get(c, c)) for c in sorts ]
90 # get User.col.desc() order objects
91 ordered = [ getattr(c, o)() for c, o in zip(cols, orders) ]
92
93 users = self.db.query(orm.User).order_by(*ordered)
94 running = users.filter(orm.User.server != None)
95
96 html = self.render_template('admin.html',
97 user=self.get_current_user(),
98 admin_access=self.settings.get('admin_access', False),
99 users=users,
100 running=running,
101 sort={s:o for s,o in zip(sorts, orders)},
102 )
103 self.finish(html)
104
105
106 default_handlers = [
107 (r'/', RootHandler),
108 (r'/home', HomeHandler),
109 (r'/admin', AdminHandler),
110 ]
111
[end of jupyterhub/handlers/pages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jupyterhub/handlers/pages.py b/jupyterhub/handlers/pages.py
--- a/jupyterhub/handlers/pages.py
+++ b/jupyterhub/handlers/pages.py
@@ -24,7 +24,7 @@
user = self.get_current_user()
if user:
if user.running:
- url = url_path_join(self.hub.server.base_url, user.server.base_url)
+ url = user.server.base_url
self.log.debug("User is running: %s", url)
else:
url = url_path_join(self.hub.server.base_url, 'home')
|
{"golden_diff": "diff --git a/jupyterhub/handlers/pages.py b/jupyterhub/handlers/pages.py\n--- a/jupyterhub/handlers/pages.py\n+++ b/jupyterhub/handlers/pages.py\n@@ -24,7 +24,7 @@\n user = self.get_current_user()\n if user:\n if user.running:\n- url = url_path_join(self.hub.server.base_url, user.server.base_url)\n+ url = user.server.base_url\n self.log.debug(\"User is running: %s\", url)\n else:\n url = url_path_join(self.hub.server.base_url, 'home')\n", "issue": "base_url is used twice in redirects\nFor jupyterhub running at _http://address/prefix/_ almost every redirect has `base_url` twice. It was caused by PR #276. Reverting changes to jupyterhub/handlers/pages.py:27 [1] fixes the issue.\n\n[1] https://github.com/Crunch-io/jupyterhub/commit/05e4ab41fe6691dd697eecc27d9abee2ac4e23b6\n\n", "before_files": [{"content": "\"\"\"Basic html-rendering handlers.\"\"\"\n\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nfrom tornado import web\n\nfrom .. import orm\nfrom ..utils import admin_only, url_path_join\nfrom .base import BaseHandler\n\n\nclass RootHandler(BaseHandler):\n \"\"\"Render the Hub root page.\n \n If logged in, redirects to:\n \n - single-user server if running\n - hub home, otherwise\n \n Otherwise, renders login page.\n \"\"\"\n def get(self):\n user = self.get_current_user()\n if user:\n if user.running:\n url = url_path_join(self.hub.server.base_url, user.server.base_url)\n self.log.debug(\"User is running: %s\", url)\n else:\n url = url_path_join(self.hub.server.base_url, 'home')\n self.log.debug(\"User is not running: %s\", url)\n self.redirect(url, permanent=False)\n return\n # Redirect to the authenticator login page instead of rendering the\n # login html page\n url = self.authenticator.login_url(self.hub.server.base_url)\n self.log.debug(\"No user logged in: %s\", url)\n self.redirect(url, permanent=False)\n\nclass HomeHandler(BaseHandler):\n \"\"\"Render the user's home page.\"\"\"\n\n @web.authenticated\n def get(self):\n html = self.render_template('home.html',\n user=self.get_current_user(),\n )\n self.finish(html)\n\n\nclass AdminHandler(BaseHandler):\n \"\"\"Render the admin page.\"\"\"\n\n @admin_only\n def get(self):\n available = {'name', 'admin', 'running', 'last_activity'}\n default_sort = ['admin', 'name']\n mapping = {\n 'running': '_server_id'\n }\n default_order = {\n 'name': 'asc',\n 'last_activity': 'desc',\n 'admin': 'desc',\n 'running': 'desc',\n }\n sorts = self.get_arguments('sort') or default_sort\n orders = self.get_arguments('order')\n \n for bad in set(sorts).difference(available):\n self.log.warn(\"ignoring invalid sort: %r\", bad)\n sorts.remove(bad)\n for bad in set(orders).difference({'asc', 'desc'}):\n self.log.warn(\"ignoring invalid order: %r\", bad)\n orders.remove(bad)\n \n # add default sort as secondary\n for s in default_sort:\n if s not in sorts:\n sorts.append(s)\n if len(orders) < len(sorts):\n for col in sorts[len(orders):]:\n orders.append(default_order[col])\n else:\n orders = orders[:len(sorts)]\n \n # this could be one incomprehensible nested list comprehension\n # get User columns\n cols = [ getattr(orm.User, mapping.get(c, c)) for c in sorts ]\n # get User.col.desc() order objects\n ordered = [ getattr(c, o)() for c, o in zip(cols, orders) ]\n \n users = self.db.query(orm.User).order_by(*ordered)\n running = users.filter(orm.User.server != None)\n \n html = self.render_template('admin.html',\n user=self.get_current_user(),\n admin_access=self.settings.get('admin_access', False),\n users=users,\n running=running,\n sort={s:o for s,o in zip(sorts, orders)},\n )\n self.finish(html)\n\n\ndefault_handlers = [\n (r'/', RootHandler),\n (r'/home', HomeHandler),\n (r'/admin', AdminHandler),\n]\n", "path": "jupyterhub/handlers/pages.py"}]}
| 1,656 | 135 |
gh_patches_debug_1591
|
rasdani/github-patches
|
git_diff
|
evennia__evennia-600
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
'<' character is an "escape" character when messaging characters?
Hi! I'm not sure if anyone else has stumbled across this issue. I first discovered this using a custom character typeclass that didn't have its msg method overloaded, and then tested it again with the default character typeclass. I haven't messed/overrode any functions found in /src. It seems as though the character '<' works like an escape character, as of the latest Evennia patch when messaging characters.
Examples of testing in-game with @py (using the default character typeclass):

It's pretty weird, and it likely doesn't affect anyone sorely, but I was using the '<' and '>' character for my prompt, so I was surprised and baffled when half of my prompt disappeared! It used to work as of last night, before I pulled in the latest Evennia changes. I was browsing through Evennia's latest commits, but I haven't found anything that I thought would affect this.
</issue>
<code>
[start of src/server/portal/mxp.py]
1 """
2 MXP - Mud eXtension Protocol.
3
4 Partial implementation of the MXP protocol.
5 The MXP protocol allows more advanced formatting options for telnet clients
6 that supports it (mudlet, zmud, mushclient are a few)
7
8 This only implements the SEND tag.
9
10 More information can be found on the following links:
11 http://www.zuggsoft.com/zmud/mxp.htm
12 http://www.mushclient.com/mushclient/mxp.htm
13 http://www.gammon.com.au/mushclient/addingservermxp.htm
14 """
15 import re
16
17 LINKS_SUB = re.compile(r'\{lc(.*?)\{lt(.*?)\{le', re.DOTALL)
18
19 MXP = "\x5B"
20 MXP_TEMPSECURE = "\x1B[4z"
21 MXP_SEND = MXP_TEMPSECURE + \
22 "<SEND HREF='\\1'>" + \
23 "\\2" + \
24 MXP_TEMPSECURE + \
25 "</SEND>"
26
27 def mxp_parse(text):
28 """
29 Replaces links to the correct format for MXP.
30 """
31 text = LINKS_SUB.sub(MXP_SEND, text)
32 return text
33
34 class Mxp(object):
35 """
36 Implements the MXP protocol.
37 """
38
39 def __init__(self, protocol):
40 """Initializes the protocol by checking if the client supports it."""
41 self.protocol = protocol
42 self.protocol.protocol_flags["MXP"] = False
43 self.protocol.will(MXP).addCallbacks(self.do_mxp, self.no_mxp)
44
45 def no_mxp(self, option):
46 """
47 Client does not support MXP.
48 """
49 self.protocol.protocol_flags["MXP"] = False
50
51 def do_mxp(self, option):
52 """
53 Client does support MXP.
54 """
55 self.protocol.protocol_flags["MXP"] = True
56 self.protocol.handshake_done()
57 self.protocol.requestNegotiation(MXP, '')
58
[end of src/server/portal/mxp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/server/portal/mxp.py b/src/server/portal/mxp.py
--- a/src/server/portal/mxp.py
+++ b/src/server/portal/mxp.py
@@ -28,6 +28,10 @@
"""
Replaces links to the correct format for MXP.
"""
+ text = text.replace("&", "&") \
+ .replace("<", "<") \
+ .replace(">", ">")
+
text = LINKS_SUB.sub(MXP_SEND, text)
return text
|
{"golden_diff": "diff --git a/src/server/portal/mxp.py b/src/server/portal/mxp.py\n--- a/src/server/portal/mxp.py\n+++ b/src/server/portal/mxp.py\n@@ -28,6 +28,10 @@\n \"\"\"\n Replaces links to the correct format for MXP.\n \"\"\"\n+ text = text.replace(\"&\", \"&\") \\\n+ .replace(\"<\", \"<\") \\\n+ .replace(\">\", \">\")\n+\n text = LINKS_SUB.sub(MXP_SEND, text)\n return text\n", "issue": "'<' character is an \"escape\" character when messaging characters?\nHi! I'm not sure if anyone else has stumbled across this issue. I first discovered this using a custom character typeclass that didn't have its msg method overloaded, and then tested it again with the default character typeclass. I haven't messed/overrode any functions found in /src. It seems as though the character '<' works like an escape character, as of the latest Evennia patch when messaging characters.\n\nExamples of testing in-game with @py (using the default character typeclass):\n\n\nIt's pretty weird, and it likely doesn't affect anyone sorely, but I was using the '<' and '>' character for my prompt, so I was surprised and baffled when half of my prompt disappeared! It used to work as of last night, before I pulled in the latest Evennia changes. I was browsing through Evennia's latest commits, but I haven't found anything that I thought would affect this.\n\n", "before_files": [{"content": "\"\"\"\nMXP - Mud eXtension Protocol.\n\nPartial implementation of the MXP protocol.\nThe MXP protocol allows more advanced formatting options for telnet clients\nthat supports it (mudlet, zmud, mushclient are a few)\n\nThis only implements the SEND tag.\n\nMore information can be found on the following links:\nhttp://www.zuggsoft.com/zmud/mxp.htm\nhttp://www.mushclient.com/mushclient/mxp.htm\nhttp://www.gammon.com.au/mushclient/addingservermxp.htm\n\"\"\"\nimport re\n\nLINKS_SUB = re.compile(r'\\{lc(.*?)\\{lt(.*?)\\{le', re.DOTALL)\n\nMXP = \"\\x5B\"\nMXP_TEMPSECURE = \"\\x1B[4z\"\nMXP_SEND = MXP_TEMPSECURE + \\\n \"<SEND HREF='\\\\1'>\" + \\\n \"\\\\2\" + \\\n MXP_TEMPSECURE + \\\n \"</SEND>\"\n\ndef mxp_parse(text):\n \"\"\"\n Replaces links to the correct format for MXP.\n \"\"\"\n text = LINKS_SUB.sub(MXP_SEND, text)\n return text\n\nclass Mxp(object):\n \"\"\"\n Implements the MXP protocol.\n \"\"\"\n\n def __init__(self, protocol):\n \"\"\"Initializes the protocol by checking if the client supports it.\"\"\"\n self.protocol = protocol\n self.protocol.protocol_flags[\"MXP\"] = False\n self.protocol.will(MXP).addCallbacks(self.do_mxp, self.no_mxp)\n\n def no_mxp(self, option):\n \"\"\"\n Client does not support MXP.\n \"\"\"\n self.protocol.protocol_flags[\"MXP\"] = False\n\n def do_mxp(self, option):\n \"\"\"\n Client does support MXP.\n \"\"\"\n self.protocol.protocol_flags[\"MXP\"] = True\n self.protocol.handshake_done()\n self.protocol.requestNegotiation(MXP, '')\n", "path": "src/server/portal/mxp.py"}]}
| 1,325 | 121 |
gh_patches_debug_1718
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-6683
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
alias `list` as `ls`?
I have been reaching for `dvc ls` out of habit instead of `dvc list`. Should we introduce an alias for `dvc list`?
</issue>
<code>
[start of dvc/command/ls/__init__.py]
1 import argparse
2 import logging
3
4 from dvc.command import completion
5 from dvc.command.base import CmdBaseNoRepo, append_doc_link
6 from dvc.command.ls.ls_colors import LsColors
7 from dvc.exceptions import DvcException
8 from dvc.ui import ui
9
10 logger = logging.getLogger(__name__)
11
12
13 def _prettify(entries, with_color=False):
14 if with_color:
15 ls_colors = LsColors()
16 fmt = ls_colors.format
17 else:
18
19 def fmt(entry):
20 return entry["path"]
21
22 return [fmt(entry) for entry in entries]
23
24
25 class CmdList(CmdBaseNoRepo):
26 def run(self):
27 from dvc.repo import Repo
28
29 try:
30 entries = Repo.ls(
31 self.args.url,
32 self.args.path,
33 rev=self.args.rev,
34 recursive=self.args.recursive,
35 dvc_only=self.args.dvc_only,
36 )
37 if self.args.show_json:
38 import json
39
40 ui.write(json.dumps(entries))
41 elif entries:
42 entries = _prettify(entries, with_color=True)
43 ui.write("\n".join(entries))
44 return 0
45 except DvcException:
46 logger.exception(f"failed to list '{self.args.url}'")
47 return 1
48
49
50 def add_parser(subparsers, parent_parser):
51 LIST_HELP = (
52 "List repository contents, including files"
53 " and directories tracked by DVC and by Git."
54 )
55 list_parser = subparsers.add_parser(
56 "list",
57 parents=[parent_parser],
58 description=append_doc_link(LIST_HELP, "list"),
59 help=LIST_HELP,
60 formatter_class=argparse.RawTextHelpFormatter,
61 )
62 list_parser.add_argument("url", help="Location of DVC repository to list")
63 list_parser.add_argument(
64 "-R",
65 "--recursive",
66 action="store_true",
67 help="Recursively list files.",
68 )
69 list_parser.add_argument(
70 "--dvc-only", action="store_true", help="Show only DVC outputs."
71 )
72 list_parser.add_argument(
73 "--show-json", action="store_true", help="Show output in JSON format."
74 )
75 list_parser.add_argument(
76 "--rev",
77 nargs="?",
78 help="Git revision (e.g. SHA, branch, tag)",
79 metavar="<commit>",
80 )
81 list_parser.add_argument(
82 "path",
83 nargs="?",
84 help="Path to directory within the repository to list outputs for",
85 ).complete = completion.DIR
86 list_parser.set_defaults(func=CmdList)
87
[end of dvc/command/ls/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/command/ls/__init__.py b/dvc/command/ls/__init__.py
--- a/dvc/command/ls/__init__.py
+++ b/dvc/command/ls/__init__.py
@@ -54,6 +54,7 @@
)
list_parser = subparsers.add_parser(
"list",
+ aliases=["ls"],
parents=[parent_parser],
description=append_doc_link(LIST_HELP, "list"),
help=LIST_HELP,
|
{"golden_diff": "diff --git a/dvc/command/ls/__init__.py b/dvc/command/ls/__init__.py\n--- a/dvc/command/ls/__init__.py\n+++ b/dvc/command/ls/__init__.py\n@@ -54,6 +54,7 @@\n )\n list_parser = subparsers.add_parser(\n \"list\",\n+ aliases=[\"ls\"],\n parents=[parent_parser],\n description=append_doc_link(LIST_HELP, \"list\"),\n help=LIST_HELP,\n", "issue": "alias `list` as `ls`?\nI have been reaching for `dvc ls` out of habit instead of `dvc list`. Should we introduce an alias for `dvc list`?\n", "before_files": [{"content": "import argparse\nimport logging\n\nfrom dvc.command import completion\nfrom dvc.command.base import CmdBaseNoRepo, append_doc_link\nfrom dvc.command.ls.ls_colors import LsColors\nfrom dvc.exceptions import DvcException\nfrom dvc.ui import ui\n\nlogger = logging.getLogger(__name__)\n\n\ndef _prettify(entries, with_color=False):\n if with_color:\n ls_colors = LsColors()\n fmt = ls_colors.format\n else:\n\n def fmt(entry):\n return entry[\"path\"]\n\n return [fmt(entry) for entry in entries]\n\n\nclass CmdList(CmdBaseNoRepo):\n def run(self):\n from dvc.repo import Repo\n\n try:\n entries = Repo.ls(\n self.args.url,\n self.args.path,\n rev=self.args.rev,\n recursive=self.args.recursive,\n dvc_only=self.args.dvc_only,\n )\n if self.args.show_json:\n import json\n\n ui.write(json.dumps(entries))\n elif entries:\n entries = _prettify(entries, with_color=True)\n ui.write(\"\\n\".join(entries))\n return 0\n except DvcException:\n logger.exception(f\"failed to list '{self.args.url}'\")\n return 1\n\n\ndef add_parser(subparsers, parent_parser):\n LIST_HELP = (\n \"List repository contents, including files\"\n \" and directories tracked by DVC and by Git.\"\n )\n list_parser = subparsers.add_parser(\n \"list\",\n parents=[parent_parser],\n description=append_doc_link(LIST_HELP, \"list\"),\n help=LIST_HELP,\n formatter_class=argparse.RawTextHelpFormatter,\n )\n list_parser.add_argument(\"url\", help=\"Location of DVC repository to list\")\n list_parser.add_argument(\n \"-R\",\n \"--recursive\",\n action=\"store_true\",\n help=\"Recursively list files.\",\n )\n list_parser.add_argument(\n \"--dvc-only\", action=\"store_true\", help=\"Show only DVC outputs.\"\n )\n list_parser.add_argument(\n \"--show-json\", action=\"store_true\", help=\"Show output in JSON format.\"\n )\n list_parser.add_argument(\n \"--rev\",\n nargs=\"?\",\n help=\"Git revision (e.g. SHA, branch, tag)\",\n metavar=\"<commit>\",\n )\n list_parser.add_argument(\n \"path\",\n nargs=\"?\",\n help=\"Path to directory within the repository to list outputs for\",\n ).complete = completion.DIR\n list_parser.set_defaults(func=CmdList)\n", "path": "dvc/command/ls/__init__.py"}]}
| 1,292 | 107 |
gh_patches_debug_35244
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-567
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
EHN: New accessor `fillna_regresssion`
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [ ] closes #xxxx
- [x] whatsnew entry
Fill na value with regression method
</issue>
<code>
[start of dtoolkit/accessor/dataframe/fillna_regression.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 import pandas as pd
6
7 from dtoolkit._typing import IntOrStr
8 from dtoolkit.accessor.register import register_dataframe_method
9
10 if TYPE_CHECKING:
11 from sklearn.base import RegressorMixin
12
13
14 @register_dataframe_method
15 def fillna_regression(
16 df: pd.DataFrame,
17 method: RegressorMixin,
18 X: IntOrStr | list[IntOrStr] | pd.Index,
19 y: IntOrStr,
20 how: str = "na",
21 **kwargs,
22 ) -> pd.DataFrame:
23 """
24 Fill na value with regression algorithm.
25
26 Parameters
27 ----------
28 method : RegressorMixin
29 Regression transformer.
30
31 X : int or str, list of int or str, Index
32 Feature columns.
33
34 y : int or str
35 Target column.
36
37 how : {'na', 'all'}, default 'na'
38 Only fill na value or apply regression to entire target column.
39
40 **kwargs
41 See the documentation for ``method`` for complete details on
42 the keyword arguments.
43
44 See Also
45 --------
46 sklearn.kernel_ridge
47 sklearn.linear_model
48 sklearn.dummy.DummyRegressor
49 sklearn.ensemble.AdaBoostRegressor
50 sklearn.ensemble.BaggingRegressor
51 sklearn.ensemble.ExtraTreesRegressor
52 sklearn.ensemble.GradientBoostingRegressor
53 sklearn.ensemble.RandomForestRegressor
54 sklearn.ensemble.StackingRegressor
55 sklearn.ensemble.VotingRegressor
56 sklearn.ensemble.HistGradientBoostingRegressor
57 sklearn.gaussian_process.GaussianProcessRegressor
58 sklearn.isotonic.IsotonicRegression
59 sklearn.kernel_ridge.KernelRidge
60 sklearn.neighbors.KNeighborsRegressor
61 sklearn.neighbors.RadiusNeighborsRegressor
62 sklearn.neural_network.MLPRegressor
63 sklearn.svm.LinearSVR
64 sklearn.svm.NuSVR
65 sklearn.svm.SVR
66 sklearn.tree.DecisionTreeRegressor
67 sklearn.tree.ExtraTreeRegressor
68
69 Examples
70 --------
71 >>> import dtoolkit.accessor
72 >>> import pandas as pd
73 >>> from sklearn.linear_model import LinearRegression
74
75 .. math:: y = 1 \\times x_0 + 2 \\times x_1 + 3
76
77 >>> df = pd.DataFrame(
78 ... [
79 ... [1, 1, 6],
80 ... [1, 2, 8],
81 ... [2, 2, 9],
82 ... [2, 3, 11],
83 ... [3, 5, None],
84 ... ],
85 ... columns=['x1', 'x2', 'y'],
86 ... )
87 >>> df
88 x1 x2 y
89 0 1 1 6.0
90 1 1 2 8.0
91 2 2 2 9.0
92 3 2 3 11.0
93 4 3 5 NaN
94
95 Use 'x1' and 'x2' columns to fit 'y' column and fill the value.
96
97 >>> df.fillna_regression(LinearRegression, ['x1', 'x2'], 'y')
98 x1 x2 y
99 0 1 1 6.0
100 1 1 2 8.0
101 2 2 2 9.0
102 3 2 3 11.0
103 4 3 5 16.0
104 """
105
106 if how not in {"na", "all"}:
107 raise ValueError(f"invalid inf option: {how!r}")
108
109 if isinstance(X, (str, int)):
110 X = [X]
111
112 index_notnull = df[df[y].notnull()].index
113 model = method(**kwargs).fit(
114 df.loc[index_notnull, X],
115 df.loc[index_notnull, y],
116 )
117
118 if how == "all":
119 df[y] = model.predict(df[X])
120 elif how == "na":
121 index_null = df[df[y].isnull()].index
122 df.loc[index_null, y] = model.predict(df.loc[index_null, X])
123
124 return df
125
[end of dtoolkit/accessor/dataframe/fillna_regression.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dtoolkit/accessor/dataframe/fillna_regression.py b/dtoolkit/accessor/dataframe/fillna_regression.py
--- a/dtoolkit/accessor/dataframe/fillna_regression.py
+++ b/dtoolkit/accessor/dataframe/fillna_regression.py
@@ -15,8 +15,7 @@
def fillna_regression(
df: pd.DataFrame,
method: RegressorMixin,
- X: IntOrStr | list[IntOrStr] | pd.Index,
- y: IntOrStr,
+ columns: dict[IntOrStr, IntOrStr | list[IntOrStr] | pd.Index],
how: str = "na",
**kwargs,
) -> pd.DataFrame:
@@ -28,11 +27,9 @@
method : RegressorMixin
Regression transformer.
- X : int or str, list of int or str, Index
- Feature columns.
-
- y : int or str
- Target column.
+ columns : dict, ``{y: X}``
+ A series of column names pairs. The key is the y (or target) column name, and
+ values are X (or feature) column names.
how : {'na', 'all'}, default 'na'
Only fill na value or apply regression to entire target column.
@@ -41,6 +38,10 @@
See the documentation for ``method`` for complete details on
the keyword arguments.
+ Returns
+ -------
+ DataFrame
+
See Also
--------
sklearn.kernel_ridge
@@ -94,7 +95,7 @@
Use 'x1' and 'x2' columns to fit 'y' column and fill the value.
- >>> df.fillna_regression(LinearRegression, ['x1', 'x2'], 'y')
+ >>> df.fillna_regression(LinearRegression, {'y': ['x1', 'x2']})
x1 x2 y
0 1 1 6.0
1 1 2 8.0
@@ -106,6 +107,22 @@
if how not in {"na", "all"}:
raise ValueError(f"invalid inf option: {how!r}")
+ for y, X in columns.items():
+ df = _fillna_regression(df, method, y, X, how=how, **kwargs)
+
+ return df
+
+
+def _fillna_regression(
+ df: pd.DataFrame,
+ method: RegressorMixin,
+ y: IntOrStr,
+ X: IntOrStr | list[IntOrStr] | pd.Index,
+ how: str = "na",
+ **kwargs,
+):
+ """Fill single na column at once."""
+
if isinstance(X, (str, int)):
X = [X]
|
{"golden_diff": "diff --git a/dtoolkit/accessor/dataframe/fillna_regression.py b/dtoolkit/accessor/dataframe/fillna_regression.py\n--- a/dtoolkit/accessor/dataframe/fillna_regression.py\n+++ b/dtoolkit/accessor/dataframe/fillna_regression.py\n@@ -15,8 +15,7 @@\n def fillna_regression(\n df: pd.DataFrame,\n method: RegressorMixin,\n- X: IntOrStr | list[IntOrStr] | pd.Index,\n- y: IntOrStr,\n+ columns: dict[IntOrStr, IntOrStr | list[IntOrStr] | pd.Index],\n how: str = \"na\",\n **kwargs,\n ) -> pd.DataFrame:\n@@ -28,11 +27,9 @@\n method : RegressorMixin\n Regression transformer.\n \n- X : int or str, list of int or str, Index\n- Feature columns.\n-\n- y : int or str\n- Target column.\n+ columns : dict, ``{y: X}``\n+ A series of column names pairs. The key is the y (or target) column name, and\n+ values are X (or feature) column names.\n \n how : {'na', 'all'}, default 'na'\n Only fill na value or apply regression to entire target column.\n@@ -41,6 +38,10 @@\n See the documentation for ``method`` for complete details on\n the keyword arguments.\n \n+ Returns\n+ -------\n+ DataFrame\n+\n See Also\n --------\n sklearn.kernel_ridge\n@@ -94,7 +95,7 @@\n \n Use 'x1' and 'x2' columns to fit 'y' column and fill the value.\n \n- >>> df.fillna_regression(LinearRegression, ['x1', 'x2'], 'y')\n+ >>> df.fillna_regression(LinearRegression, {'y': ['x1', 'x2']})\n x1 x2 y\n 0 1 1 6.0\n 1 1 2 8.0\n@@ -106,6 +107,22 @@\n if how not in {\"na\", \"all\"}:\n raise ValueError(f\"invalid inf option: {how!r}\")\n \n+ for y, X in columns.items():\n+ df = _fillna_regression(df, method, y, X, how=how, **kwargs)\n+\n+ return df\n+\n+\n+def _fillna_regression(\n+ df: pd.DataFrame,\n+ method: RegressorMixin,\n+ y: IntOrStr,\n+ X: IntOrStr | list[IntOrStr] | pd.Index,\n+ how: str = \"na\",\n+ **kwargs,\n+):\n+ \"\"\"Fill single na column at once.\"\"\"\n+\n if isinstance(X, (str, int)):\n X = [X]\n", "issue": "EHN: New accessor `fillna_regresssion`\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [ ] closes #xxxx\r\n- [x] whatsnew entry\r\n\r\nFill na value with regression method\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nimport pandas as pd\n\nfrom dtoolkit._typing import IntOrStr\nfrom dtoolkit.accessor.register import register_dataframe_method\n\nif TYPE_CHECKING:\n from sklearn.base import RegressorMixin\n\n\n@register_dataframe_method\ndef fillna_regression(\n df: pd.DataFrame,\n method: RegressorMixin,\n X: IntOrStr | list[IntOrStr] | pd.Index,\n y: IntOrStr,\n how: str = \"na\",\n **kwargs,\n) -> pd.DataFrame:\n \"\"\"\n Fill na value with regression algorithm.\n\n Parameters\n ----------\n method : RegressorMixin\n Regression transformer.\n\n X : int or str, list of int or str, Index\n Feature columns.\n\n y : int or str\n Target column.\n\n how : {'na', 'all'}, default 'na'\n Only fill na value or apply regression to entire target column.\n\n **kwargs\n See the documentation for ``method`` for complete details on\n the keyword arguments.\n\n See Also\n --------\n sklearn.kernel_ridge\n sklearn.linear_model\n sklearn.dummy.DummyRegressor\n sklearn.ensemble.AdaBoostRegressor\n sklearn.ensemble.BaggingRegressor\n sklearn.ensemble.ExtraTreesRegressor\n sklearn.ensemble.GradientBoostingRegressor\n sklearn.ensemble.RandomForestRegressor\n sklearn.ensemble.StackingRegressor\n sklearn.ensemble.VotingRegressor\n sklearn.ensemble.HistGradientBoostingRegressor\n sklearn.gaussian_process.GaussianProcessRegressor\n sklearn.isotonic.IsotonicRegression\n sklearn.kernel_ridge.KernelRidge\n sklearn.neighbors.KNeighborsRegressor\n sklearn.neighbors.RadiusNeighborsRegressor\n sklearn.neural_network.MLPRegressor\n sklearn.svm.LinearSVR\n sklearn.svm.NuSVR\n sklearn.svm.SVR\n sklearn.tree.DecisionTreeRegressor\n sklearn.tree.ExtraTreeRegressor\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import pandas as pd\n >>> from sklearn.linear_model import LinearRegression\n\n .. math:: y = 1 \\\\times x_0 + 2 \\\\times x_1 + 3\n\n >>> df = pd.DataFrame(\n ... [\n ... [1, 1, 6],\n ... [1, 2, 8],\n ... [2, 2, 9],\n ... [2, 3, 11],\n ... [3, 5, None],\n ... ],\n ... columns=['x1', 'x2', 'y'],\n ... )\n >>> df\n x1 x2 y\n 0 1 1 6.0\n 1 1 2 8.0\n 2 2 2 9.0\n 3 2 3 11.0\n 4 3 5 NaN\n\n Use 'x1' and 'x2' columns to fit 'y' column and fill the value.\n\n >>> df.fillna_regression(LinearRegression, ['x1', 'x2'], 'y')\n x1 x2 y\n 0 1 1 6.0\n 1 1 2 8.0\n 2 2 2 9.0\n 3 2 3 11.0\n 4 3 5 16.0\n \"\"\"\n\n if how not in {\"na\", \"all\"}:\n raise ValueError(f\"invalid inf option: {how!r}\")\n\n if isinstance(X, (str, int)):\n X = [X]\n\n index_notnull = df[df[y].notnull()].index\n model = method(**kwargs).fit(\n df.loc[index_notnull, X],\n df.loc[index_notnull, y],\n )\n\n if how == \"all\":\n df[y] = model.predict(df[X])\n elif how == \"na\":\n index_null = df[df[y].isnull()].index\n df.loc[index_null, y] = model.predict(df.loc[index_null, X])\n\n return df\n", "path": "dtoolkit/accessor/dataframe/fillna_regression.py"}]}
| 1,965 | 641 |
gh_patches_debug_18756
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-3678
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mouse movements example does not work
When I run the example at https://textual.textualize.io/guide/input/#mouse-movements in gnome-terminal all I can see is black screen, and nothing I do (apart from CTRL+C) seems to have any effect.
```
textual diagnose
```
# Textual Diagnostics
## Versions
| Name | Value |
|---------|--------|
| Textual | 0.41.0 |
| Rich | 13.6.0 |
## Python
| Name | Value |
|----------------|---------------------------------------------------------------------------|
| Version | 3.11.2 |
| Implementation | CPython |
| Compiler | GCC 12.2.0 |
| Executable | /srv/home/porridge/.local/share/virtualenvs/reconcile-Vnvz65ja/bin/python |
## Operating System
| Name | Value |
|---------|-----------------------------------------------------|
| System | Linux |
| Release | 6.1.0-13-amd64 |
| Version | #1 SMP PREEMPT_DYNAMIC Debian 6.1.55-1 (2023-09-29) |
## Terminal
| Name | Value |
|----------------------|----------------|
| Terminal Application | *Unknown* |
| TERM | xterm-256color |
| COLORTERM | truecolor |
| FORCE_COLOR | *Not set* |
| NO_COLOR | *Not set* |
## Rich Console options
| Name | Value |
|----------------|---------------------|
| size | width=87, height=27 |
| legacy_windows | False |
| min_width | 1 |
| max_width | 87 |
| is_terminal | True |
| encoding | utf-8 |
| max_height | 27 |
| justify | None |
| overflow | None |
| no_wrap | False |
| highlight | None |
| markup | None |
| height | None |
</issue>
<code>
[start of docs/examples/guide/input/mouse01.py]
1 from textual import events
2 from textual.app import App, ComposeResult
3 from textual.containers import Container
4 from textual.widgets import RichLog, Static
5
6
7 class PlayArea(Container):
8 def on_mount(self) -> None:
9 self.capture_mouse()
10
11 def on_mouse_move(self, event: events.MouseMove) -> None:
12 self.screen.query_one(RichLog).write(event)
13 self.query_one(Ball).offset = event.offset - (8, 2)
14
15
16 class Ball(Static):
17 pass
18
19
20 class MouseApp(App):
21 CSS_PATH = "mouse01.tcss"
22
23 def compose(self) -> ComposeResult:
24 yield RichLog()
25 yield PlayArea(Ball("Textual"))
26
27
28 if __name__ == "__main__":
29 app = MouseApp()
30 app.run()
31
[end of docs/examples/guide/input/mouse01.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/examples/guide/input/mouse01.py b/docs/examples/guide/input/mouse01.py
--- a/docs/examples/guide/input/mouse01.py
+++ b/docs/examples/guide/input/mouse01.py
@@ -1,18 +1,8 @@
from textual import events
from textual.app import App, ComposeResult
-from textual.containers import Container
from textual.widgets import RichLog, Static
-class PlayArea(Container):
- def on_mount(self) -> None:
- self.capture_mouse()
-
- def on_mouse_move(self, event: events.MouseMove) -> None:
- self.screen.query_one(RichLog).write(event)
- self.query_one(Ball).offset = event.offset - (8, 2)
-
-
class Ball(Static):
pass
@@ -22,7 +12,11 @@
def compose(self) -> ComposeResult:
yield RichLog()
- yield PlayArea(Ball("Textual"))
+ yield Ball("Textual")
+
+ def on_mouse_move(self, event: events.MouseMove) -> None:
+ self.screen.query_one(RichLog).write(event)
+ self.query_one(Ball).offset = event.screen_offset - (8, 2)
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/docs/examples/guide/input/mouse01.py b/docs/examples/guide/input/mouse01.py\n--- a/docs/examples/guide/input/mouse01.py\n+++ b/docs/examples/guide/input/mouse01.py\n@@ -1,18 +1,8 @@\n from textual import events\n from textual.app import App, ComposeResult\n-from textual.containers import Container\n from textual.widgets import RichLog, Static\n \n \n-class PlayArea(Container):\n- def on_mount(self) -> None:\n- self.capture_mouse()\n-\n- def on_mouse_move(self, event: events.MouseMove) -> None:\n- self.screen.query_one(RichLog).write(event)\n- self.query_one(Ball).offset = event.offset - (8, 2)\n-\n-\n class Ball(Static):\n pass\n \n@@ -22,7 +12,11 @@\n \n def compose(self) -> ComposeResult:\n yield RichLog()\n- yield PlayArea(Ball(\"Textual\"))\n+ yield Ball(\"Textual\")\n+\n+ def on_mouse_move(self, event: events.MouseMove) -> None:\n+ self.screen.query_one(RichLog).write(event)\n+ self.query_one(Ball).offset = event.screen_offset - (8, 2)\n \n \n if __name__ == \"__main__\":\n", "issue": "Mouse movements example does not work\nWhen I run the example at https://textual.textualize.io/guide/input/#mouse-movements in gnome-terminal all I can see is black screen, and nothing I do (apart from CTRL+C) seems to have any effect.\r\n\r\n```\r\ntextual diagnose\r\n```\r\n\r\n# Textual Diagnostics\r\n\r\n## Versions\r\n\r\n| Name | Value |\r\n|---------|--------|\r\n| Textual | 0.41.0 |\r\n| Rich | 13.6.0 |\r\n\r\n## Python\r\n\r\n| Name | Value |\r\n|----------------|---------------------------------------------------------------------------|\r\n| Version | 3.11.2 |\r\n| Implementation | CPython |\r\n| Compiler | GCC 12.2.0 |\r\n| Executable | /srv/home/porridge/.local/share/virtualenvs/reconcile-Vnvz65ja/bin/python |\r\n\r\n## Operating System\r\n\r\n| Name | Value |\r\n|---------|-----------------------------------------------------|\r\n| System | Linux |\r\n| Release | 6.1.0-13-amd64 |\r\n| Version | #1 SMP PREEMPT_DYNAMIC Debian 6.1.55-1 (2023-09-29) |\r\n\r\n## Terminal\r\n\r\n| Name | Value |\r\n|----------------------|----------------|\r\n| Terminal Application | *Unknown* |\r\n| TERM | xterm-256color |\r\n| COLORTERM | truecolor |\r\n| FORCE_COLOR | *Not set* |\r\n| NO_COLOR | *Not set* |\r\n\r\n## Rich Console options\r\n\r\n| Name | Value |\r\n|----------------|---------------------|\r\n| size | width=87, height=27 |\r\n| legacy_windows | False |\r\n| min_width | 1 |\r\n| max_width | 87 |\r\n| is_terminal | True |\r\n| encoding | utf-8 |\r\n| max_height | 27 |\r\n| justify | None |\r\n| overflow | None |\r\n| no_wrap | False |\r\n| highlight | None |\r\n| markup | None |\r\n| height | None |\r\n\r\n\r\n\n", "before_files": [{"content": "from textual import events\nfrom textual.app import App, ComposeResult\nfrom textual.containers import Container\nfrom textual.widgets import RichLog, Static\n\n\nclass PlayArea(Container):\n def on_mount(self) -> None:\n self.capture_mouse()\n\n def on_mouse_move(self, event: events.MouseMove) -> None:\n self.screen.query_one(RichLog).write(event)\n self.query_one(Ball).offset = event.offset - (8, 2)\n\n\nclass Ball(Static):\n pass\n\n\nclass MouseApp(App):\n CSS_PATH = \"mouse01.tcss\"\n\n def compose(self) -> ComposeResult:\n yield RichLog()\n yield PlayArea(Ball(\"Textual\"))\n\n\nif __name__ == \"__main__\":\n app = MouseApp()\n app.run()\n", "path": "docs/examples/guide/input/mouse01.py"}]}
| 1,241 | 285 |
gh_patches_debug_16171
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-1992
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken date handling in careeropportunity display date
## What kind of an issue is this?
- [x] Bug report
- [ ] Feature request
## What is the expected behaviour?
A careeropportunity should be displayed from the start date.
## What is the current behaviour?
If the start date is in the past, but sufficiently close to the current date, the careeropportunity is not displayed. Setting the start date to an earlier date fixes the problem.
<!-- if this is a bug report -->
## How do you reproduce this problem?
Set start date to the middle of the night the day before the current day.
Broken date handling in careeropportunity display date
## What kind of an issue is this?
- [x] Bug report
- [ ] Feature request
## What is the expected behaviour?
A careeropportunity should be displayed from the start date.
## What is the current behaviour?
If the start date is in the past, but sufficiently close to the current date, the careeropportunity is not displayed. Setting the start date to an earlier date fixes the problem.
<!-- if this is a bug report -->
## How do you reproduce this problem?
Set start date to the middle of the night the day before the current day.
</issue>
<code>
[start of apps/careeropportunity/views.py]
1 # -*- coding: utf-8 -*-
2
3 from django.shortcuts import render
4 from django.utils import timezone
5 # API v1
6 from rest_framework import mixins, viewsets
7 from rest_framework.pagination import PageNumberPagination
8 from rest_framework.permissions import AllowAny
9
10 from apps.careeropportunity.models import CareerOpportunity
11 from apps.careeropportunity.serializers import CareerSerializer
12
13
14 def index(request, id=None):
15 return render(request, 'careeropportunity/index.html')
16
17
18 class HundredItemsPaginator(PageNumberPagination):
19 page_size = 100
20
21
22 class CareerViewSet(viewsets.GenericViewSet, mixins.RetrieveModelMixin, mixins.ListModelMixin):
23 """
24 Viewset for Career serializer
25 """
26
27 queryset = CareerOpportunity.objects.filter(
28 start__lte=timezone.now(),
29 end__gte=timezone.now()
30 ).order_by('-featured', '-start')
31 serializer_class = CareerSerializer
32 permission_classes = (AllowAny,)
33 pagination_class = HundredItemsPaginator
34
[end of apps/careeropportunity/views.py]
[start of apps/careeropportunity/urls.py]
1 # -*- coding: utf-8 -*-
2
3 from django.conf.urls import url
4
5 from apps.api.utils import SharedAPIRootRouter
6 from apps.careeropportunity import views
7
8 urlpatterns = [
9 url(r'^$', views.index, name='careeropportunity_index'),
10 url(r'^(\d+)/$', views.index, name='careeropportunity_details'),
11 ]
12
13 # API v1
14 router = SharedAPIRootRouter()
15 router.register(r'career', views.CareerViewSet)
16
[end of apps/careeropportunity/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/careeropportunity/urls.py b/apps/careeropportunity/urls.py
--- a/apps/careeropportunity/urls.py
+++ b/apps/careeropportunity/urls.py
@@ -12,4 +12,4 @@
# API v1
router = SharedAPIRootRouter()
-router.register(r'career', views.CareerViewSet)
+router.register(r'career', views.CareerViewSet, base_name='careeropportunity')
diff --git a/apps/careeropportunity/views.py b/apps/careeropportunity/views.py
--- a/apps/careeropportunity/views.py
+++ b/apps/careeropportunity/views.py
@@ -24,10 +24,12 @@
Viewset for Career serializer
"""
- queryset = CareerOpportunity.objects.filter(
- start__lte=timezone.now(),
- end__gte=timezone.now()
- ).order_by('-featured', '-start')
serializer_class = CareerSerializer
permission_classes = (AllowAny,)
pagination_class = HundredItemsPaginator
+
+ def get_queryset(self, *args, **kwargs):
+ return CareerOpportunity.objects.filter(
+ start__lte=timezone.now(),
+ end__gte=timezone.now()
+ ).order_by('-featured', '-start')
|
{"golden_diff": "diff --git a/apps/careeropportunity/urls.py b/apps/careeropportunity/urls.py\n--- a/apps/careeropportunity/urls.py\n+++ b/apps/careeropportunity/urls.py\n@@ -12,4 +12,4 @@\n \n # API v1\n router = SharedAPIRootRouter()\n-router.register(r'career', views.CareerViewSet)\n+router.register(r'career', views.CareerViewSet, base_name='careeropportunity')\ndiff --git a/apps/careeropportunity/views.py b/apps/careeropportunity/views.py\n--- a/apps/careeropportunity/views.py\n+++ b/apps/careeropportunity/views.py\n@@ -24,10 +24,12 @@\n Viewset for Career serializer\n \"\"\"\n \n- queryset = CareerOpportunity.objects.filter(\n- start__lte=timezone.now(),\n- end__gte=timezone.now()\n- ).order_by('-featured', '-start')\n serializer_class = CareerSerializer\n permission_classes = (AllowAny,)\n pagination_class = HundredItemsPaginator\n+\n+ def get_queryset(self, *args, **kwargs):\n+ return CareerOpportunity.objects.filter(\n+ start__lte=timezone.now(),\n+ end__gte=timezone.now()\n+ ).order_by('-featured', '-start')\n", "issue": "Broken date handling in careeropportunity display date\n## What kind of an issue is this?\r\n\r\n- [x] Bug report\r\n- [ ] Feature request\r\n\r\n\r\n## What is the expected behaviour?\r\nA careeropportunity should be displayed from the start date.\r\n\r\n## What is the current behaviour?\r\nIf the start date is in the past, but sufficiently close to the current date, the careeropportunity is not displayed. Setting the start date to an earlier date fixes the problem.\r\n\r\n<!-- if this is a bug report -->\r\n\r\n\r\n## How do you reproduce this problem? \r\n\r\nSet start date to the middle of the night the day before the current day.\nBroken date handling in careeropportunity display date\n## What kind of an issue is this?\r\n\r\n- [x] Bug report\r\n- [ ] Feature request\r\n\r\n\r\n## What is the expected behaviour?\r\nA careeropportunity should be displayed from the start date.\r\n\r\n## What is the current behaviour?\r\nIf the start date is in the past, but sufficiently close to the current date, the careeropportunity is not displayed. Setting the start date to an earlier date fixes the problem.\r\n\r\n<!-- if this is a bug report -->\r\n\r\n\r\n## How do you reproduce this problem? \r\n\r\nSet start date to the middle of the night the day before the current day.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom django.shortcuts import render\nfrom django.utils import timezone\n# API v1\nfrom rest_framework import mixins, viewsets\nfrom rest_framework.pagination import PageNumberPagination\nfrom rest_framework.permissions import AllowAny\n\nfrom apps.careeropportunity.models import CareerOpportunity\nfrom apps.careeropportunity.serializers import CareerSerializer\n\n\ndef index(request, id=None):\n return render(request, 'careeropportunity/index.html')\n\n\nclass HundredItemsPaginator(PageNumberPagination):\n page_size = 100\n\n\nclass CareerViewSet(viewsets.GenericViewSet, mixins.RetrieveModelMixin, mixins.ListModelMixin):\n \"\"\"\n Viewset for Career serializer\n \"\"\"\n\n queryset = CareerOpportunity.objects.filter(\n start__lte=timezone.now(),\n end__gte=timezone.now()\n ).order_by('-featured', '-start')\n serializer_class = CareerSerializer\n permission_classes = (AllowAny,)\n pagination_class = HundredItemsPaginator\n", "path": "apps/careeropportunity/views.py"}, {"content": "# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import url\n\nfrom apps.api.utils import SharedAPIRootRouter\nfrom apps.careeropportunity import views\n\nurlpatterns = [\n url(r'^$', views.index, name='careeropportunity_index'),\n url(r'^(\\d+)/$', views.index, name='careeropportunity_details'),\n]\n\n# API v1\nrouter = SharedAPIRootRouter()\nrouter.register(r'career', views.CareerViewSet)\n", "path": "apps/careeropportunity/urls.py"}]}
| 1,218 | 288 |
gh_patches_debug_26083
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-559
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some Docs Have Disappeared
Not sure if this is the right place to report this, but it looks like package documentation has disappeared from readthedocs. For example:
http://luigi.readthedocs.org/en/latest/api/luigi.html#luigi-file-module
I swear there used to be a lot of useful information here, now there is nothing.
</issue>
<code>
[start of setup.py]
1 # Copyright (c) 2012 Spotify AB
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"); you may not
4 # use this file except in compliance with the License. You may obtain a copy of
5 # the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
11 # WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
12 # License for the specific language governing permissions and limitations under
13 # the License.
14
15 import os
16 import sys
17
18 try:
19 from setuptools import setup
20 from setuptools.command.test import test as TestCommand
21 except:
22 from distutils.core import setup
23 from distutils.cmd import Command as TestCommand
24
25
26 class Tox(TestCommand):
27 user_options = [('tox-args=', None, "Arguments to pass to tox")]
28 def initialize_options(self):
29 TestCommand.initialize_options(self)
30 self.tox_args = ''
31 def finalize_options(self):
32 TestCommand.finalize_options(self)
33 self.test_args = []
34 self.test_suite = True
35 def run_tests(self):
36 #import here, cause outside the eggs aren't loaded
37 import tox
38 errno = tox.cmdline(args=self.tox_args.split())
39 sys.exit(errno)
40
41
42 def get_static_files(path):
43 return [os.path.join(dirpath.replace("luigi/", ""), ext)
44 for (dirpath, dirnames, filenames) in os.walk(path)
45 for ext in ["*.html", "*.js", "*.css", "*.png"]]
46
47
48 luigi_package_data = sum(map(get_static_files, ["luigi/static", "luigi/templates"]), [])
49
50 readme_note = """\
51 .. note::
52
53 For the latest source, discussion, etc, please visit the
54 `GitHub repository <https://github.com/spotify/luigi>`_\n\n
55 """
56
57 with open('README.rst') as fobj:
58 long_description = readme_note + fobj.read()
59
60
61 setup(
62 name='luigi',
63 version='1.0.19',
64 description='Workflow mgmgt + task scheduling + dependency resolution',
65 long_description=long_description,
66 author='Erik Bernhardsson',
67 author_email='[email protected]',
68 url='https://github.com/spotify/luigi',
69 license='Apache License 2.0',
70 packages=[
71 'luigi',
72 'luigi.contrib',
73 'luigi.tools'
74 ],
75 package_data={
76 'luigi': luigi_package_data
77 },
78 scripts=[
79 'bin/luigid',
80 'bin/luigi'
81 ],
82 tests_require=['tox', 'virtualenv'],
83 cmdclass={'test': Tox},
84 )
85
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -17,26 +17,8 @@
try:
from setuptools import setup
- from setuptools.command.test import test as TestCommand
except:
from distutils.core import setup
- from distutils.cmd import Command as TestCommand
-
-
-class Tox(TestCommand):
- user_options = [('tox-args=', None, "Arguments to pass to tox")]
- def initialize_options(self):
- TestCommand.initialize_options(self)
- self.tox_args = ''
- def finalize_options(self):
- TestCommand.finalize_options(self)
- self.test_args = []
- self.test_suite = True
- def run_tests(self):
- #import here, cause outside the eggs aren't loaded
- import tox
- errno = tox.cmdline(args=self.tox_args.split())
- sys.exit(errno)
def get_static_files(path):
@@ -57,6 +39,18 @@
with open('README.rst') as fobj:
long_description = readme_note + fobj.read()
+install_requires = [
+ 'boto',
+ 'pyparsing',
+ 'requests',
+ 'sqlalchemy',
+ 'tornado',
+ 'whoops',
+ 'snakebite>=2.4.10',
+]
+
+if sys.version_info[:2] < (2, 7):
+ install_requires.extend(['argparse', 'ordereddict'])
setup(
name='luigi',
@@ -79,6 +73,5 @@
'bin/luigid',
'bin/luigi'
],
- tests_require=['tox', 'virtualenv'],
- cmdclass={'test': Tox},
+ install_requires=install_requires,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -17,26 +17,8 @@\n \n try:\n from setuptools import setup\n- from setuptools.command.test import test as TestCommand\n except:\n from distutils.core import setup\n- from distutils.cmd import Command as TestCommand\n-\n-\n-class Tox(TestCommand):\n- user_options = [('tox-args=', None, \"Arguments to pass to tox\")]\n- def initialize_options(self):\n- TestCommand.initialize_options(self)\n- self.tox_args = ''\n- def finalize_options(self):\n- TestCommand.finalize_options(self)\n- self.test_args = []\n- self.test_suite = True\n- def run_tests(self):\n- #import here, cause outside the eggs aren't loaded\n- import tox\n- errno = tox.cmdline(args=self.tox_args.split())\n- sys.exit(errno)\n \n \n def get_static_files(path):\n@@ -57,6 +39,18 @@\n with open('README.rst') as fobj:\n long_description = readme_note + fobj.read()\n \n+install_requires = [\n+ 'boto',\n+ 'pyparsing',\n+ 'requests',\n+ 'sqlalchemy',\n+ 'tornado',\n+ 'whoops',\n+ 'snakebite>=2.4.10',\n+]\n+\n+if sys.version_info[:2] < (2, 7):\n+ install_requires.extend(['argparse', 'ordereddict'])\n \n setup(\n name='luigi',\n@@ -79,6 +73,5 @@\n 'bin/luigid',\n 'bin/luigi'\n ],\n- tests_require=['tox', 'virtualenv'],\n- cmdclass={'test': Tox},\n+ install_requires=install_requires,\n )\n", "issue": "Some Docs Have Disappeared\nNot sure if this is the right place to report this, but it looks like package documentation has disappeared from readthedocs. For example:\n\nhttp://luigi.readthedocs.org/en/latest/api/luigi.html#luigi-file-module\n\nI swear there used to be a lot of useful information here, now there is nothing.\n\n", "before_files": [{"content": "# Copyright (c) 2012 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"); you may not\n# use this file except in compliance with the License. You may obtain a copy of\n# the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT\n# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations under\n# the License.\n\nimport os\nimport sys\n\ntry:\n from setuptools import setup\n from setuptools.command.test import test as TestCommand\nexcept:\n from distutils.core import setup\n from distutils.cmd import Command as TestCommand\n\n\nclass Tox(TestCommand):\n user_options = [('tox-args=', None, \"Arguments to pass to tox\")]\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.tox_args = ''\n def finalize_options(self):\n TestCommand.finalize_options(self)\n self.test_args = []\n self.test_suite = True\n def run_tests(self):\n #import here, cause outside the eggs aren't loaded\n import tox\n errno = tox.cmdline(args=self.tox_args.split())\n sys.exit(errno)\n\n\ndef get_static_files(path):\n return [os.path.join(dirpath.replace(\"luigi/\", \"\"), ext) \n for (dirpath, dirnames, filenames) in os.walk(path)\n for ext in [\"*.html\", \"*.js\", \"*.css\", \"*.png\"]]\n\n\nluigi_package_data = sum(map(get_static_files, [\"luigi/static\", \"luigi/templates\"]), [])\n\nreadme_note = \"\"\"\\\n.. note::\n\n For the latest source, discussion, etc, please visit the\n `GitHub repository <https://github.com/spotify/luigi>`_\\n\\n\n\"\"\"\n\nwith open('README.rst') as fobj:\n long_description = readme_note + fobj.read()\n\n\nsetup(\n name='luigi',\n version='1.0.19',\n description='Workflow mgmgt + task scheduling + dependency resolution',\n long_description=long_description,\n author='Erik Bernhardsson',\n author_email='[email protected]',\n url='https://github.com/spotify/luigi',\n license='Apache License 2.0',\n packages=[\n 'luigi',\n 'luigi.contrib',\n 'luigi.tools'\n ],\n package_data={\n 'luigi': luigi_package_data\n },\n scripts=[\n 'bin/luigid',\n 'bin/luigi'\n ],\n tests_require=['tox', 'virtualenv'],\n cmdclass={'test': Tox},\n)\n", "path": "setup.py"}]}
| 1,375 | 401 |
gh_patches_debug_26630
|
rasdani/github-patches
|
git_diff
|
spack__spack-14473
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
spack extensions behavior when no extendable package is specified
If you run `spack extensions` with no extendable package, it prints an error message telling you that a package spec is required. It would be nice if Spack also printed a list of installed extendable packages to choose from.
</issue>
<code>
[start of lib/spack/spack/cmd/extensions.py]
1 # Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 import argparse
7
8 import llnl.util.tty as tty
9 from llnl.util.tty.colify import colify
10
11 import spack.environment as ev
12 import spack.cmd as cmd
13 import spack.cmd.common.arguments as arguments
14 import spack.repo
15 import spack.store
16 from spack.filesystem_view import YamlFilesystemView
17
18 description = "list extensions for package"
19 section = "extensions"
20 level = "long"
21
22
23 def setup_parser(subparser):
24 arguments.add_common_arguments(subparser, ['long', 'very_long'])
25 subparser.add_argument('-d', '--deps', action='store_true',
26 help='output dependencies along with found specs')
27
28 subparser.add_argument('-p', '--paths', action='store_true',
29 help='show paths to package install directories')
30 subparser.add_argument(
31 '-s', '--show', action='store', default='all',
32 choices=("packages", "installed", "activated", "all"),
33 help="show only part of output")
34 subparser.add_argument(
35 '-v', '--view', metavar='VIEW', type=str,
36 help="the view to operate on")
37
38 subparser.add_argument(
39 'spec', nargs=argparse.REMAINDER,
40 help='spec of package to list extensions for', metavar='extendable')
41
42
43 def extensions(parser, args):
44 if not args.spec:
45 tty.die("extensions requires a package spec.")
46
47 # Checks
48 spec = cmd.parse_specs(args.spec)
49 if len(spec) > 1:
50 tty.die("Can only list extensions for one package.")
51
52 if not spec[0].package.extendable:
53 tty.die("%s is not an extendable package." % spec[0].name)
54
55 env = ev.get_env(args, 'extensions')
56 spec = cmd.disambiguate_spec(spec[0], env)
57
58 if not spec.package.extendable:
59 tty.die("%s does not have extensions." % spec.short_spec)
60
61 if args.show in ("packages", "all"):
62 # List package names of extensions
63 extensions = spack.repo.path.extensions_for(spec)
64 if not extensions:
65 tty.msg("%s has no extensions." % spec.cshort_spec)
66 else:
67 tty.msg(spec.cshort_spec)
68 tty.msg("%d extensions:" % len(extensions))
69 colify(ext.name for ext in extensions)
70
71 if args.view:
72 target = args.view
73 else:
74 target = spec.prefix
75
76 view = YamlFilesystemView(target, spack.store.layout)
77
78 if args.show in ("installed", "all"):
79 # List specs of installed extensions.
80 installed = [
81 s.spec for s in spack.store.db.installed_extensions_for(spec)]
82
83 if args.show == "all":
84 print
85 if not installed:
86 tty.msg("None installed.")
87 else:
88 tty.msg("%d installed:" % len(installed))
89 cmd.display_specs(installed, args)
90
91 if args.show in ("activated", "all"):
92 # List specs of activated extensions.
93 activated = view.extensions_layout.extension_map(spec)
94 if args.show == "all":
95 print
96 if not activated:
97 tty.msg("None activated.")
98 else:
99 tty.msg("%d activated:" % len(activated))
100 cmd.display_specs(activated.values(), args)
101
[end of lib/spack/spack/cmd/extensions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/spack/spack/cmd/extensions.py b/lib/spack/spack/cmd/extensions.py
--- a/lib/spack/spack/cmd/extensions.py
+++ b/lib/spack/spack/cmd/extensions.py
@@ -4,6 +4,7 @@
# SPDX-License-Identifier: (Apache-2.0 OR MIT)
import argparse
+import sys
import llnl.util.tty as tty
from llnl.util.tty.colify import colify
@@ -21,6 +22,8 @@
def setup_parser(subparser):
+ subparser.epilog = 'If called without argument returns ' \
+ 'the list of all valid extendable packages'
arguments.add_common_arguments(subparser, ['long', 'very_long'])
subparser.add_argument('-d', '--deps', action='store_true',
help='output dependencies along with found specs')
@@ -42,7 +45,19 @@
def extensions(parser, args):
if not args.spec:
- tty.die("extensions requires a package spec.")
+ # If called without arguments, list all the extendable packages
+ isatty = sys.stdout.isatty()
+ if isatty:
+ tty.info('Extendable packages:')
+
+ extendable_pkgs = []
+ for name in spack.repo.all_package_names():
+ pkg = spack.repo.get(name)
+ if pkg.extendable:
+ extendable_pkgs.append(name)
+
+ colify(extendable_pkgs, indent=4)
+ return
# Checks
spec = cmd.parse_specs(args.spec)
|
{"golden_diff": "diff --git a/lib/spack/spack/cmd/extensions.py b/lib/spack/spack/cmd/extensions.py\n--- a/lib/spack/spack/cmd/extensions.py\n+++ b/lib/spack/spack/cmd/extensions.py\n@@ -4,6 +4,7 @@\n # SPDX-License-Identifier: (Apache-2.0 OR MIT)\n \n import argparse\n+import sys\n \n import llnl.util.tty as tty\n from llnl.util.tty.colify import colify\n@@ -21,6 +22,8 @@\n \n \n def setup_parser(subparser):\n+ subparser.epilog = 'If called without argument returns ' \\\n+ 'the list of all valid extendable packages'\n arguments.add_common_arguments(subparser, ['long', 'very_long'])\n subparser.add_argument('-d', '--deps', action='store_true',\n help='output dependencies along with found specs')\n@@ -42,7 +45,19 @@\n \n def extensions(parser, args):\n if not args.spec:\n- tty.die(\"extensions requires a package spec.\")\n+ # If called without arguments, list all the extendable packages\n+ isatty = sys.stdout.isatty()\n+ if isatty:\n+ tty.info('Extendable packages:')\n+\n+ extendable_pkgs = []\n+ for name in spack.repo.all_package_names():\n+ pkg = spack.repo.get(name)\n+ if pkg.extendable:\n+ extendable_pkgs.append(name)\n+\n+ colify(extendable_pkgs, indent=4)\n+ return\n \n # Checks\n spec = cmd.parse_specs(args.spec)\n", "issue": "spack extensions behavior when no extendable package is specified\nIf you run `spack extensions` with no extendable package, it prints an error message telling you that a package spec is required. It would be nice if Spack also printed a list of installed extendable packages to choose from.\n\n", "before_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nimport argparse\n\nimport llnl.util.tty as tty\nfrom llnl.util.tty.colify import colify\n\nimport spack.environment as ev\nimport spack.cmd as cmd\nimport spack.cmd.common.arguments as arguments\nimport spack.repo\nimport spack.store\nfrom spack.filesystem_view import YamlFilesystemView\n\ndescription = \"list extensions for package\"\nsection = \"extensions\"\nlevel = \"long\"\n\n\ndef setup_parser(subparser):\n arguments.add_common_arguments(subparser, ['long', 'very_long'])\n subparser.add_argument('-d', '--deps', action='store_true',\n help='output dependencies along with found specs')\n\n subparser.add_argument('-p', '--paths', action='store_true',\n help='show paths to package install directories')\n subparser.add_argument(\n '-s', '--show', action='store', default='all',\n choices=(\"packages\", \"installed\", \"activated\", \"all\"),\n help=\"show only part of output\")\n subparser.add_argument(\n '-v', '--view', metavar='VIEW', type=str,\n help=\"the view to operate on\")\n\n subparser.add_argument(\n 'spec', nargs=argparse.REMAINDER,\n help='spec of package to list extensions for', metavar='extendable')\n\n\ndef extensions(parser, args):\n if not args.spec:\n tty.die(\"extensions requires a package spec.\")\n\n # Checks\n spec = cmd.parse_specs(args.spec)\n if len(spec) > 1:\n tty.die(\"Can only list extensions for one package.\")\n\n if not spec[0].package.extendable:\n tty.die(\"%s is not an extendable package.\" % spec[0].name)\n\n env = ev.get_env(args, 'extensions')\n spec = cmd.disambiguate_spec(spec[0], env)\n\n if not spec.package.extendable:\n tty.die(\"%s does not have extensions.\" % spec.short_spec)\n\n if args.show in (\"packages\", \"all\"):\n # List package names of extensions\n extensions = spack.repo.path.extensions_for(spec)\n if not extensions:\n tty.msg(\"%s has no extensions.\" % spec.cshort_spec)\n else:\n tty.msg(spec.cshort_spec)\n tty.msg(\"%d extensions:\" % len(extensions))\n colify(ext.name for ext in extensions)\n\n if args.view:\n target = args.view\n else:\n target = spec.prefix\n\n view = YamlFilesystemView(target, spack.store.layout)\n\n if args.show in (\"installed\", \"all\"):\n # List specs of installed extensions.\n installed = [\n s.spec for s in spack.store.db.installed_extensions_for(spec)]\n\n if args.show == \"all\":\n print\n if not installed:\n tty.msg(\"None installed.\")\n else:\n tty.msg(\"%d installed:\" % len(installed))\n cmd.display_specs(installed, args)\n\n if args.show in (\"activated\", \"all\"):\n # List specs of activated extensions.\n activated = view.extensions_layout.extension_map(spec)\n if args.show == \"all\":\n print\n if not activated:\n tty.msg(\"None activated.\")\n else:\n tty.msg(\"%d activated:\" % len(activated))\n cmd.display_specs(activated.values(), args)\n", "path": "lib/spack/spack/cmd/extensions.py"}]}
| 1,559 | 344 |
gh_patches_debug_10265
|
rasdani/github-patches
|
git_diff
|
yt-project__yt-3278
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reminder: remove dead module mods
As discussed in #3083, the `mods.py` module should be removed **after the 4.0 release**.
</issue>
<code>
[start of yt/mods.py]
1 #
2 # ALL IMPORTS GO HERE
3 #
4
5 import os
6
7 import numpy as np
8
9 # This next item will handle most of the actual startup procedures, but it will
10 # also attempt to parse the command line and set up the global state of various
11 # operations. The variable unparsed_args is not used internally but is
12 # provided as a convenience for users who wish to parse arguments in scripts.
13 # https://mail.python.org/archives/list/[email protected]/thread/L6AQPJ3OIMJC5SNKVM7CJG32YVQZRJWA/
14 import yt.startup_tasks as __startup_tasks
15 from yt import *
16 from yt.config import ytcfg, ytcfg_defaults
17 from yt.utilities.logger import _level
18
19 unparsed_args = __startup_tasks.unparsed_args
20
21
22 if _level >= int(ytcfg_defaults["yt"]["log_level"]):
23 # This won't get displayed.
24 mylog.debug("Turning off NumPy error reporting")
25 np.seterr(all="ignore")
26
27 # We load plugins. Keep in mind, this can be fairly dangerous -
28 # the primary purpose is to allow people to have a set of functions
29 # that get used every time that they don't have to *define* every time.
30 # This way, other command-line tools can be used very simply.
31 # Unfortunately, for now, I think the easiest and simplest way of doing
32 # this is also the most dangerous way.
33 if ytcfg.get("yt", "load_field_plugins"):
34 enable_plugins()
35
[end of yt/mods.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt/mods.py b/yt/mods.py
--- a/yt/mods.py
+++ b/yt/mods.py
@@ -13,9 +13,14 @@
# https://mail.python.org/archives/list/[email protected]/thread/L6AQPJ3OIMJC5SNKVM7CJG32YVQZRJWA/
import yt.startup_tasks as __startup_tasks
from yt import *
+from yt._maintenance.deprecation import issue_deprecation_warning
from yt.config import ytcfg, ytcfg_defaults
from yt.utilities.logger import _level
+issue_deprecation_warning(
+ "The yt.mods module is deprecated.", since="4.1.0", removal="4.2.0"
+)
+
unparsed_args = __startup_tasks.unparsed_args
|
{"golden_diff": "diff --git a/yt/mods.py b/yt/mods.py\n--- a/yt/mods.py\n+++ b/yt/mods.py\n@@ -13,9 +13,14 @@\n # https://mail.python.org/archives/list/[email protected]/thread/L6AQPJ3OIMJC5SNKVM7CJG32YVQZRJWA/\n import yt.startup_tasks as __startup_tasks\n from yt import *\n+from yt._maintenance.deprecation import issue_deprecation_warning\n from yt.config import ytcfg, ytcfg_defaults\n from yt.utilities.logger import _level\n \n+issue_deprecation_warning(\n+ \"The yt.mods module is deprecated.\", since=\"4.1.0\", removal=\"4.2.0\"\n+)\n+\n unparsed_args = __startup_tasks.unparsed_args\n", "issue": "Reminder: remove dead module mods\nAs discussed in #3083, the `mods.py` module should be removed **after the 4.0 release**.\r\n\n", "before_files": [{"content": "#\n# ALL IMPORTS GO HERE\n#\n\nimport os\n\nimport numpy as np\n\n# This next item will handle most of the actual startup procedures, but it will\n# also attempt to parse the command line and set up the global state of various\n# operations. The variable unparsed_args is not used internally but is\n# provided as a convenience for users who wish to parse arguments in scripts.\n# https://mail.python.org/archives/list/[email protected]/thread/L6AQPJ3OIMJC5SNKVM7CJG32YVQZRJWA/\nimport yt.startup_tasks as __startup_tasks\nfrom yt import *\nfrom yt.config import ytcfg, ytcfg_defaults\nfrom yt.utilities.logger import _level\n\nunparsed_args = __startup_tasks.unparsed_args\n\n\nif _level >= int(ytcfg_defaults[\"yt\"][\"log_level\"]):\n # This won't get displayed.\n mylog.debug(\"Turning off NumPy error reporting\")\n np.seterr(all=\"ignore\")\n\n# We load plugins. Keep in mind, this can be fairly dangerous -\n# the primary purpose is to allow people to have a set of functions\n# that get used every time that they don't have to *define* every time.\n# This way, other command-line tools can be used very simply.\n# Unfortunately, for now, I think the easiest and simplest way of doing\n# this is also the most dangerous way.\nif ytcfg.get(\"yt\", \"load_field_plugins\"):\n enable_plugins()\n", "path": "yt/mods.py"}]}
| 958 | 182 |
gh_patches_debug_67260
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-5487
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Hyperoptable parameter type: CategoricalParameter is not returning correctly.
## Describe your environment
* Operating system: MacOS 11.2.3 (20D91)
* Python Version: using the version shiped freqtradeorg/freqtrade:stable (Image ID 73a48178c043)
* CCXT version: using the version shiped freqtradeorg/freqtrade:stable (Image ID 73a48178c043)
* Freqtrade Version: freqtrade 2021.4
Note: All issues other than enhancement requests will be closed without further comment if the above template is deleted or not filled out.
## Describe the problem:
Hi! It appears the Hyperoptable parameter type: `CategoricalParameter` is not returning correctly.
If I run the example as per the Freqtrade Docs [here](https://www.freqtrade.io/en/stable/hyperopt/#hyperoptable-parameters), namely setting a `CategoricalParameter` like so:
```
buy_rsi_enabled = CategoricalParameter([True, False]),
```
...then when running the Hyperopt tool there is an error in the `populate_buy_trend` as below:
```
if self.buy_adx_enabled.value:
AttributeError: 'tuple' object has no attribute 'value'
```
It would appear that the `CategoricalParameter` is not actually returning one of the categories (even a default) but instead returning a Python Tuple.
### Steps to reproduce:
1. Follow the example in the [Docs](https://www.freqtrade.io/en/stable/hyperopt/#hyperoptable-parameters)
### Observed Results:
* What happened? There was an AttributeError: 'tuple' object has no attribute 'value'.
* What did you expect to happen? The 'value' property to exist and be set to either True or False
### Relevant code exceptions or logs
Note: Please copy/paste text of the messages, no screenshots of logs please.
```
2021-05-02 09:48:02,421 - freqtrade - ERROR - Fatal exception!
joblib.externals.loky.process_executor._RemoteTraceback:
"""
Traceback (most recent call last):
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py", line 431, in _process_worker
r = call_item()
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py", line 285, in __call__
return self.fn(*self.args, **self.kwargs)
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/_parallel_backends.py", line 595, in __call__
return self.func(*args, **kwargs)
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/parallel.py", line 262, in __call__
return [func(*args, **kwargs)
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/parallel.py", line 262, in <listcomp>
return [func(*args, **kwargs)
File "/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/cloudpickle_wrapper.py", line 38, in __call__
return self._obj(*args, **kwargs)
File "/freqtrade/freqtrade/optimize/hyperopt.py", line 288, in generate_optimizer
backtesting_results = self.backtesting.backtest(
File "/freqtrade/freqtrade/optimize/backtesting.py", line 352, in backtest
data: Dict = self._get_ohlcv_as_lists(processed)
File "/freqtrade/freqtrade/optimize/backtesting.py", line 196, in _get_ohlcv_as_lists
self.strategy.advise_buy(pair_data, {'pair': pair}), {'pair': pair})[headers].copy()
File "/freqtrade/freqtrade/optimize/hyperopt_auto.py", line 31, in populate_buy_trend
return self.strategy.populate_buy_trend(dataframe, metadata)
File "/freqtrade/user_data/strategies/Strategy004.py", line 149, in populate_buy_trend
if self.buy_adx_enabled.value:
AttributeError: 'tuple' object has no attribute 'value'
```
</issue>
<code>
[start of freqtrade/__init__.py]
1 """ Freqtrade bot """
2 __version__ = 'develop'
3
4 if __version__ == 'develop':
5
6 try:
7 import subprocess
8
9 __version__ = 'develop-' + subprocess.check_output(
10 ['git', 'log', '--format="%h"', '-n 1'],
11 stderr=subprocess.DEVNULL).decode("utf-8").rstrip().strip('"')
12
13 # from datetime import datetime
14 # last_release = subprocess.check_output(
15 # ['git', 'tag']
16 # ).decode('utf-8').split()[-1].split(".")
17 # # Releases are in the format "2020.1" - we increment the latest version for dev.
18 # prefix = f"{last_release[0]}.{int(last_release[1]) + 1}"
19 # dev_version = int(datetime.now().timestamp() // 1000)
20 # __version__ = f"{prefix}.dev{dev_version}"
21
22 # subprocess.check_output(
23 # ['git', 'log', '--format="%h"', '-n 1'],
24 # stderr=subprocess.DEVNULL).decode("utf-8").rstrip().strip('"')
25 except Exception:
26 # git not available, ignore
27 try:
28 # Try Fallback to freqtrade_commit file (created by CI while building docker image)
29 from pathlib import Path
30 versionfile = Path('./freqtrade_commit')
31 if versionfile.is_file():
32 __version__ = f"docker-{versionfile.read_text()[:8]}"
33 except Exception:
34 pass
35
[end of freqtrade/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/freqtrade/__init__.py b/freqtrade/__init__.py
--- a/freqtrade/__init__.py
+++ b/freqtrade/__init__.py
@@ -1,5 +1,5 @@
""" Freqtrade bot """
-__version__ = 'develop'
+__version__ = '2021.8'
if __version__ == 'develop':
|
{"golden_diff": "diff --git a/freqtrade/__init__.py b/freqtrade/__init__.py\n--- a/freqtrade/__init__.py\n+++ b/freqtrade/__init__.py\n@@ -1,5 +1,5 @@\n \"\"\" Freqtrade bot \"\"\"\n-__version__ = 'develop'\n+__version__ = '2021.8'\n \n if __version__ == 'develop':\n", "issue": "Hyperoptable parameter type: CategoricalParameter is not returning correctly.\n## Describe your environment\r\n\r\n * Operating system: MacOS 11.2.3 (20D91)\r\n * Python Version: using the version shiped freqtradeorg/freqtrade:stable (Image ID 73a48178c043)\r\n * CCXT version: using the version shiped freqtradeorg/freqtrade:stable (Image ID 73a48178c043)\r\n * Freqtrade Version: freqtrade 2021.4\r\n \r\nNote: All issues other than enhancement requests will be closed without further comment if the above template is deleted or not filled out.\r\n\r\n## Describe the problem:\r\n\r\nHi! It appears the Hyperoptable parameter type: `CategoricalParameter` is not returning correctly.\r\n\r\nIf I run the example as per the Freqtrade Docs [here](https://www.freqtrade.io/en/stable/hyperopt/#hyperoptable-parameters), namely setting a `CategoricalParameter` like so:\r\n\r\n```\r\nbuy_rsi_enabled = CategoricalParameter([True, False]),\r\n```\r\n\r\n...then when running the Hyperopt tool there is an error in the `populate_buy_trend` as below:\r\n\r\n```\r\nif self.buy_adx_enabled.value:\r\nAttributeError: 'tuple' object has no attribute 'value'\r\n```\r\n\r\nIt would appear that the `CategoricalParameter` is not actually returning one of the categories (even a default) but instead returning a Python Tuple.\r\n\r\n### Steps to reproduce:\r\n\r\n 1. Follow the example in the [Docs](https://www.freqtrade.io/en/stable/hyperopt/#hyperoptable-parameters)\r\n \r\n### Observed Results:\r\n\r\n * What happened? There was an AttributeError: 'tuple' object has no attribute 'value'. \r\n * What did you expect to happen? The 'value' property to exist and be set to either True or False\r\n\r\n### Relevant code exceptions or logs\r\n\r\nNote: Please copy/paste text of the messages, no screenshots of logs please.\r\n\r\n ```\r\n2021-05-02 09:48:02,421 - freqtrade - ERROR - Fatal exception!\r\njoblib.externals.loky.process_executor._RemoteTraceback:\r\n\"\"\"\r\nTraceback (most recent call last):\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py\", line 431, in _process_worker\r\n r = call_item()\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py\", line 285, in __call__\r\n return self.fn(*self.args, **self.kwargs)\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/_parallel_backends.py\", line 595, in __call__\r\n return self.func(*args, **kwargs)\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/parallel.py\", line 262, in __call__\r\n return [func(*args, **kwargs)\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/parallel.py\", line 262, in <listcomp>\r\n return [func(*args, **kwargs)\r\n File \"/home/ftuser/.local/lib/python3.9/site-packages/joblib/externals/loky/cloudpickle_wrapper.py\", line 38, in __call__\r\n return self._obj(*args, **kwargs)\r\n File \"/freqtrade/freqtrade/optimize/hyperopt.py\", line 288, in generate_optimizer\r\n backtesting_results = self.backtesting.backtest(\r\n File \"/freqtrade/freqtrade/optimize/backtesting.py\", line 352, in backtest\r\n data: Dict = self._get_ohlcv_as_lists(processed)\r\n File \"/freqtrade/freqtrade/optimize/backtesting.py\", line 196, in _get_ohlcv_as_lists\r\n self.strategy.advise_buy(pair_data, {'pair': pair}), {'pair': pair})[headers].copy()\r\n File \"/freqtrade/freqtrade/optimize/hyperopt_auto.py\", line 31, in populate_buy_trend\r\n return self.strategy.populate_buy_trend(dataframe, metadata)\r\n File \"/freqtrade/user_data/strategies/Strategy004.py\", line 149, in populate_buy_trend\r\n if self.buy_adx_enabled.value:\r\nAttributeError: 'tuple' object has no attribute 'value'\r\n ```\r\n\n", "before_files": [{"content": "\"\"\" Freqtrade bot \"\"\"\n__version__ = 'develop'\n\nif __version__ == 'develop':\n\n try:\n import subprocess\n\n __version__ = 'develop-' + subprocess.check_output(\n ['git', 'log', '--format=\"%h\"', '-n 1'],\n stderr=subprocess.DEVNULL).decode(\"utf-8\").rstrip().strip('\"')\n\n # from datetime import datetime\n # last_release = subprocess.check_output(\n # ['git', 'tag']\n # ).decode('utf-8').split()[-1].split(\".\")\n # # Releases are in the format \"2020.1\" - we increment the latest version for dev.\n # prefix = f\"{last_release[0]}.{int(last_release[1]) + 1}\"\n # dev_version = int(datetime.now().timestamp() // 1000)\n # __version__ = f\"{prefix}.dev{dev_version}\"\n\n # subprocess.check_output(\n # ['git', 'log', '--format=\"%h\"', '-n 1'],\n # stderr=subprocess.DEVNULL).decode(\"utf-8\").rstrip().strip('\"')\n except Exception:\n # git not available, ignore\n try:\n # Try Fallback to freqtrade_commit file (created by CI while building docker image)\n from pathlib import Path\n versionfile = Path('./freqtrade_commit')\n if versionfile.is_file():\n __version__ = f\"docker-{versionfile.read_text()[:8]}\"\n except Exception:\n pass\n", "path": "freqtrade/__init__.py"}]}
| 1,916 | 87 |
gh_patches_debug_17333
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-2651
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ASGI websocket must pass thru bytes as is
_Originally posted by @Tronic in https://github.com/sanic-org/sanic/pull/2640#discussion_r1058027028_
</issue>
<code>
[start of sanic/server/websockets/connection.py]
1 from typing import (
2 Any,
3 Awaitable,
4 Callable,
5 Dict,
6 List,
7 MutableMapping,
8 Optional,
9 Union,
10 )
11
12 from sanic.exceptions import InvalidUsage
13
14
15 ASGIMessage = MutableMapping[str, Any]
16
17
18 class WebSocketConnection:
19 """
20 This is for ASGI Connections.
21 It provides an interface similar to WebsocketProtocol, but
22 sends/receives over an ASGI connection.
23 """
24
25 # TODO
26 # - Implement ping/pong
27
28 def __init__(
29 self,
30 send: Callable[[ASGIMessage], Awaitable[None]],
31 receive: Callable[[], Awaitable[ASGIMessage]],
32 subprotocols: Optional[List[str]] = None,
33 ) -> None:
34 self._send = send
35 self._receive = receive
36 self._subprotocols = subprotocols or []
37
38 async def send(self, data: Union[str, bytes], *args, **kwargs) -> None:
39 message: Dict[str, Union[str, bytes]] = {"type": "websocket.send"}
40
41 if isinstance(data, bytes):
42 message.update({"bytes": data})
43 else:
44 message.update({"text": str(data)})
45
46 await self._send(message)
47
48 async def recv(self, *args, **kwargs) -> Optional[str]:
49 message = await self._receive()
50
51 if message["type"] == "websocket.receive":
52 try:
53 return message["text"]
54 except KeyError:
55 try:
56 return message["bytes"].decode()
57 except KeyError:
58 raise InvalidUsage("Bad ASGI message received")
59 elif message["type"] == "websocket.disconnect":
60 pass
61
62 return None
63
64 receive = recv
65
66 async def accept(self, subprotocols: Optional[List[str]] = None) -> None:
67 subprotocol = None
68 if subprotocols:
69 for subp in subprotocols:
70 if subp in self.subprotocols:
71 subprotocol = subp
72 break
73
74 await self._send(
75 {
76 "type": "websocket.accept",
77 "subprotocol": subprotocol,
78 }
79 )
80
81 async def close(self, code: int = 1000, reason: str = "") -> None:
82 pass
83
84 @property
85 def subprotocols(self):
86 return self._subprotocols
87
88 @subprotocols.setter
89 def subprotocols(self, subprotocols: Optional[List[str]] = None):
90 self._subprotocols = subprotocols or []
91
[end of sanic/server/websockets/connection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/server/websockets/connection.py b/sanic/server/websockets/connection.py
--- a/sanic/server/websockets/connection.py
+++ b/sanic/server/websockets/connection.py
@@ -45,7 +45,7 @@
await self._send(message)
- async def recv(self, *args, **kwargs) -> Optional[str]:
+ async def recv(self, *args, **kwargs) -> Optional[Union[str, bytes]]:
message = await self._receive()
if message["type"] == "websocket.receive":
@@ -53,7 +53,7 @@
return message["text"]
except KeyError:
try:
- return message["bytes"].decode()
+ return message["bytes"]
except KeyError:
raise InvalidUsage("Bad ASGI message received")
elif message["type"] == "websocket.disconnect":
|
{"golden_diff": "diff --git a/sanic/server/websockets/connection.py b/sanic/server/websockets/connection.py\n--- a/sanic/server/websockets/connection.py\n+++ b/sanic/server/websockets/connection.py\n@@ -45,7 +45,7 @@\n \n await self._send(message)\n \n- async def recv(self, *args, **kwargs) -> Optional[str]:\n+ async def recv(self, *args, **kwargs) -> Optional[Union[str, bytes]]:\n message = await self._receive()\n \n if message[\"type\"] == \"websocket.receive\":\n@@ -53,7 +53,7 @@\n return message[\"text\"]\n except KeyError:\n try:\n- return message[\"bytes\"].decode()\n+ return message[\"bytes\"]\n except KeyError:\n raise InvalidUsage(\"Bad ASGI message received\")\n elif message[\"type\"] == \"websocket.disconnect\":\n", "issue": "ASGI websocket must pass thru bytes as is\n\r\n\r\n_Originally posted by @Tronic in https://github.com/sanic-org/sanic/pull/2640#discussion_r1058027028_\r\n \n", "before_files": [{"content": "from typing import (\n Any,\n Awaitable,\n Callable,\n Dict,\n List,\n MutableMapping,\n Optional,\n Union,\n)\n\nfrom sanic.exceptions import InvalidUsage\n\n\nASGIMessage = MutableMapping[str, Any]\n\n\nclass WebSocketConnection:\n \"\"\"\n This is for ASGI Connections.\n It provides an interface similar to WebsocketProtocol, but\n sends/receives over an ASGI connection.\n \"\"\"\n\n # TODO\n # - Implement ping/pong\n\n def __init__(\n self,\n send: Callable[[ASGIMessage], Awaitable[None]],\n receive: Callable[[], Awaitable[ASGIMessage]],\n subprotocols: Optional[List[str]] = None,\n ) -> None:\n self._send = send\n self._receive = receive\n self._subprotocols = subprotocols or []\n\n async def send(self, data: Union[str, bytes], *args, **kwargs) -> None:\n message: Dict[str, Union[str, bytes]] = {\"type\": \"websocket.send\"}\n\n if isinstance(data, bytes):\n message.update({\"bytes\": data})\n else:\n message.update({\"text\": str(data)})\n\n await self._send(message)\n\n async def recv(self, *args, **kwargs) -> Optional[str]:\n message = await self._receive()\n\n if message[\"type\"] == \"websocket.receive\":\n try:\n return message[\"text\"]\n except KeyError:\n try:\n return message[\"bytes\"].decode()\n except KeyError:\n raise InvalidUsage(\"Bad ASGI message received\")\n elif message[\"type\"] == \"websocket.disconnect\":\n pass\n\n return None\n\n receive = recv\n\n async def accept(self, subprotocols: Optional[List[str]] = None) -> None:\n subprotocol = None\n if subprotocols:\n for subp in subprotocols:\n if subp in self.subprotocols:\n subprotocol = subp\n break\n\n await self._send(\n {\n \"type\": \"websocket.accept\",\n \"subprotocol\": subprotocol,\n }\n )\n\n async def close(self, code: int = 1000, reason: str = \"\") -> None:\n pass\n\n @property\n def subprotocols(self):\n return self._subprotocols\n\n @subprotocols.setter\n def subprotocols(self, subprotocols: Optional[List[str]] = None):\n self._subprotocols = subprotocols or []\n", "path": "sanic/server/websockets/connection.py"}]}
| 1,294 | 187 |
gh_patches_debug_11443
|
rasdani/github-patches
|
git_diff
|
pytorch__text-1067
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip install torchtext==0.7.0 installs incompatible PyTorch 1.7.0
## 🐛 Bug
**Describe the bug**
Recently, after I do `pip install torchtext==0.7.0`, import torchtext would cause segmentation fault. I found that degrading pytorch to 1.6.0 fixes this issue.
**To Reproduce**
Steps to reproduce the behavior:
1. `pip install torchtext==0.7.0` (assuming that pytorch is not installed yet, and this command will install the latest pytorch)
2. python -c "import torchtext"
**Expected behavior**
Segmentation Fault
**Environment**
- PyTorch Version (e.g., 1.0): 1.7.0
- OS (e.g., Linux): Linux/MacOS
- Python: 3.8.3
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import io
3 import os
4 import shutil
5 import subprocess
6 from pathlib import Path
7 import distutils.command.clean
8 from setuptools import setup, find_packages
9
10 from build_tools import setup_helpers
11
12 ROOT_DIR = Path(__file__).parent.resolve()
13
14
15 def read(*names, **kwargs):
16 with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get("encoding", "utf8")) as fp:
17 return fp.read()
18
19
20 def _get_version():
21 version = '0.9.0a0'
22 sha = None
23
24 try:
25 cmd = ['git', 'rev-parse', 'HEAD']
26 sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode('ascii').strip()
27 except Exception:
28 pass
29
30 if os.getenv('BUILD_VERSION'):
31 version = os.getenv('BUILD_VERSION')
32 elif sha is not None:
33 version += '+' + sha[:7]
34
35 if sha is None:
36 sha = 'Unknown'
37 return version, sha
38
39
40 def _export_version(version, sha):
41 version_path = ROOT_DIR / 'torchtext' / 'version.py'
42 with open(version_path, 'w') as fileobj:
43 fileobj.write("__version__ = '{}'\n".format(version))
44 fileobj.write("git_version = {}\n".format(repr(sha)))
45
46
47 VERSION, SHA = _get_version()
48 _export_version(VERSION, SHA)
49
50 print('-- Building version ' + VERSION)
51
52
53 class clean(distutils.command.clean.clean):
54 def run(self):
55 # Run default behavior first
56 distutils.command.clean.clean.run(self)
57
58 # Remove torchtext extension
59 for path in (ROOT_DIR / 'torchtext').glob('**/*.so'):
60 print(f'removing \'{path}\'')
61 path.unlink()
62 # Remove build directory
63 build_dirs = [
64 ROOT_DIR / 'build',
65 ROOT_DIR / 'third_party' / 'build',
66 ]
67 for path in build_dirs:
68 if path.exists():
69 print(f'removing \'{path}\' (and everything under it)')
70 shutil.rmtree(str(path), ignore_errors=True)
71
72
73 setup_info = dict(
74 # Metadata
75 name='torchtext',
76 version=VERSION,
77 author='PyTorch core devs and James Bradbury',
78 author_email='[email protected]',
79 url='https://github.com/pytorch/text',
80 description='Text utilities and datasets for PyTorch',
81 long_description=read('README.rst'),
82 license='BSD',
83
84 install_requires=[
85 'tqdm', 'requests', 'torch', 'numpy'
86 ],
87 python_requires='>=3.5',
88 classifiers=[
89 'Programming Language :: Python :: 3',
90 'Programming Language :: Python :: 3.5',
91 'Programming Language :: Python :: 3.6',
92 'Programming Language :: Python :: 3.7',
93 'Programming Language :: Python :: 3.8',
94 'Programming Language :: Python :: 3 :: Only',
95 ],
96 # Package info
97 packages=find_packages(exclude=('test*', 'build_tools*')),
98 zip_safe=False,
99 # Extension info
100 # If you are trying to use torchtext.so and see no registered op.
101 # See here: https://github.com/pytorch/vision/issues/2134"
102 ext_modules=setup_helpers.get_ext_modules(),
103 cmdclass={
104 'build_ext': setup_helpers.BuildExtension.with_options(no_python_abi_suffix=True),
105 'clean': clean,
106 },
107 )
108
109 setup(**setup_info)
110
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -49,6 +49,12 @@
print('-- Building version ' + VERSION)
+pytorch_package_version = os.getenv('PYTORCH_VERSION')
+
+pytorch_package_dep = 'torch'
+if pytorch_package_version is not None:
+ pytorch_package_dep += "==" + pytorch_package_version
+
class clean(distutils.command.clean.clean):
def run(self):
@@ -82,7 +88,7 @@
license='BSD',
install_requires=[
- 'tqdm', 'requests', 'torch', 'numpy'
+ 'tqdm', 'requests', pytorch_package_dep, 'numpy'
],
python_requires='>=3.5',
classifiers=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -49,6 +49,12 @@\n \n print('-- Building version ' + VERSION)\n \n+pytorch_package_version = os.getenv('PYTORCH_VERSION')\n+\n+pytorch_package_dep = 'torch'\n+if pytorch_package_version is not None:\n+ pytorch_package_dep += \"==\" + pytorch_package_version\n+\n \n class clean(distutils.command.clean.clean):\n def run(self):\n@@ -82,7 +88,7 @@\n license='BSD',\n \n install_requires=[\n- 'tqdm', 'requests', 'torch', 'numpy'\n+ 'tqdm', 'requests', pytorch_package_dep, 'numpy'\n ],\n python_requires='>=3.5',\n classifiers=[\n", "issue": "pip install torchtext==0.7.0 installs incompatible PyTorch 1.7.0\n## \ud83d\udc1b Bug\r\n**Describe the bug**\r\nRecently, after I do `pip install torchtext==0.7.0`, import torchtext would cause segmentation fault. I found that degrading pytorch to 1.6.0 fixes this issue. \r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. `pip install torchtext==0.7.0` (assuming that pytorch is not installed yet, and this command will install the latest pytorch)\r\n2. python -c \"import torchtext\"\r\n\r\n**Expected behavior**\r\nSegmentation Fault\r\n\r\n**Environment**\r\n\r\n - PyTorch Version (e.g., 1.0): 1.7.0\r\n - OS (e.g., Linux): Linux/MacOS\r\n - Python: 3.8.3\n", "before_files": [{"content": "#!/usr/bin/env python\nimport io\nimport os\nimport shutil\nimport subprocess\nfrom pathlib import Path\nimport distutils.command.clean\nfrom setuptools import setup, find_packages\n\nfrom build_tools import setup_helpers\n\nROOT_DIR = Path(__file__).parent.resolve()\n\n\ndef read(*names, **kwargs):\n with io.open(ROOT_DIR.joinpath(*names), encoding=kwargs.get(\"encoding\", \"utf8\")) as fp:\n return fp.read()\n\n\ndef _get_version():\n version = '0.9.0a0'\n sha = None\n\n try:\n cmd = ['git', 'rev-parse', 'HEAD']\n sha = subprocess.check_output(cmd, cwd=str(ROOT_DIR)).decode('ascii').strip()\n except Exception:\n pass\n\n if os.getenv('BUILD_VERSION'):\n version = os.getenv('BUILD_VERSION')\n elif sha is not None:\n version += '+' + sha[:7]\n\n if sha is None:\n sha = 'Unknown'\n return version, sha\n\n\ndef _export_version(version, sha):\n version_path = ROOT_DIR / 'torchtext' / 'version.py'\n with open(version_path, 'w') as fileobj:\n fileobj.write(\"__version__ = '{}'\\n\".format(version))\n fileobj.write(\"git_version = {}\\n\".format(repr(sha)))\n\n\nVERSION, SHA = _get_version()\n_export_version(VERSION, SHA)\n\nprint('-- Building version ' + VERSION)\n\n\nclass clean(distutils.command.clean.clean):\n def run(self):\n # Run default behavior first\n distutils.command.clean.clean.run(self)\n\n # Remove torchtext extension\n for path in (ROOT_DIR / 'torchtext').glob('**/*.so'):\n print(f'removing \\'{path}\\'')\n path.unlink()\n # Remove build directory\n build_dirs = [\n ROOT_DIR / 'build',\n ROOT_DIR / 'third_party' / 'build',\n ]\n for path in build_dirs:\n if path.exists():\n print(f'removing \\'{path}\\' (and everything under it)')\n shutil.rmtree(str(path), ignore_errors=True)\n\n\nsetup_info = dict(\n # Metadata\n name='torchtext',\n version=VERSION,\n author='PyTorch core devs and James Bradbury',\n author_email='[email protected]',\n url='https://github.com/pytorch/text',\n description='Text utilities and datasets for PyTorch',\n long_description=read('README.rst'),\n license='BSD',\n\n install_requires=[\n 'tqdm', 'requests', 'torch', 'numpy'\n ],\n python_requires='>=3.5',\n classifiers=[\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3 :: Only',\n ],\n # Package info\n packages=find_packages(exclude=('test*', 'build_tools*')),\n zip_safe=False,\n # Extension info\n # If you are trying to use torchtext.so and see no registered op.\n # See here: https://github.com/pytorch/vision/issues/2134\"\n ext_modules=setup_helpers.get_ext_modules(),\n cmdclass={\n 'build_ext': setup_helpers.BuildExtension.with_options(no_python_abi_suffix=True),\n 'clean': clean,\n },\n)\n\nsetup(**setup_info)\n", "path": "setup.py"}]}
| 1,700 | 178 |
gh_patches_debug_14685
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-370
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ruby hooks failing with rbenv installed
Pre-commit has been failing for the past few weeks.
https://gist.github.com/ThatGerber/d6533155848076b25e5e0d5cb02e20eb
Seems to be an issue with the ruby (rbenv) environment.
Tried running `pre-commit clean && pre-commit` but it returns the same issue. Setting `rbenv global 2.2.4` and `rbenv shell 2.2.4` does help either.
</issue>
<code>
[start of pre_commit/languages/ruby.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import io
5 import os.path
6 import shutil
7
8 from pre_commit.envcontext import envcontext
9 from pre_commit.envcontext import Var
10 from pre_commit.languages import helpers
11 from pre_commit.util import CalledProcessError
12 from pre_commit.util import clean_path_on_failure
13 from pre_commit.util import resource_filename
14 from pre_commit.util import tarfile_open
15 from pre_commit.xargs import xargs
16
17
18 ENVIRONMENT_DIR = 'rbenv'
19
20
21 def get_env_patch(venv, language_version):
22 return (
23 ('GEM_HOME', os.path.join(venv, 'gems')),
24 ('RBENV_ROOT', venv),
25 ('RBENV_VERSION', language_version),
26 ('PATH', (
27 os.path.join(venv, 'gems', 'bin'), os.pathsep,
28 os.path.join(venv, 'shims'), os.pathsep,
29 os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),
30 )),
31 )
32
33
34 @contextlib.contextmanager
35 def in_env(repo_cmd_runner, language_version):
36 envdir = os.path.join(
37 repo_cmd_runner.prefix_dir,
38 helpers.environment_dir(ENVIRONMENT_DIR, language_version),
39 )
40 with envcontext(get_env_patch(envdir, language_version)):
41 yield
42
43
44 def _install_rbenv(repo_cmd_runner, version='default'):
45 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
46
47 with tarfile_open(resource_filename('rbenv.tar.gz')) as tf:
48 tf.extractall(repo_cmd_runner.path('.'))
49 shutil.move(
50 repo_cmd_runner.path('rbenv'), repo_cmd_runner.path(directory),
51 )
52
53 # Only install ruby-build if the version is specified
54 if version != 'default':
55 # ruby-download
56 with tarfile_open(resource_filename('ruby-download.tar.gz')) as tf:
57 tf.extractall(repo_cmd_runner.path(directory, 'plugins'))
58
59 # ruby-build
60 with tarfile_open(resource_filename('ruby-build.tar.gz')) as tf:
61 tf.extractall(repo_cmd_runner.path(directory, 'plugins'))
62
63 activate_path = repo_cmd_runner.path(directory, 'bin', 'activate')
64 with io.open(activate_path, 'w') as activate_file:
65 # This is similar to how you would install rbenv to your home directory
66 # However we do a couple things to make the executables exposed and
67 # configure it to work in our directory.
68 # We also modify the PS1 variable for manual debugging sake.
69 activate_file.write(
70 '#!/usr/bin/env bash\n'
71 "export RBENV_ROOT='{0}'\n"
72 'export PATH="$RBENV_ROOT/bin:$PATH"\n'
73 'eval "$(rbenv init -)"\n'
74 'export PS1="(rbenv)$PS1"\n'
75 # This lets us install gems in an isolated and repeatable
76 # directory
77 "export GEM_HOME='{0}/gems'\n"
78 'export PATH="$GEM_HOME/bin:$PATH"\n'
79 '\n'.format(repo_cmd_runner.path(directory))
80 )
81
82 # If we aren't using the system ruby, add a version here
83 if version != 'default':
84 activate_file.write('export RBENV_VERSION="{0}"\n'.format(version))
85
86
87 def _install_ruby(runner, version):
88 try:
89 helpers.run_setup_cmd(runner, ('rbenv', 'download', version))
90 except CalledProcessError: # pragma: no cover (usually find with download)
91 # Failed to download from mirror for some reason, build it instead
92 helpers.run_setup_cmd(runner, ('rbenv', 'install', version))
93
94
95 def install_environment(
96 repo_cmd_runner,
97 version='default',
98 additional_dependencies=(),
99 ):
100 additional_dependencies = tuple(additional_dependencies)
101 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
102 with clean_path_on_failure(repo_cmd_runner.path(directory)):
103 # TODO: this currently will fail if there's no version specified and
104 # there's no system ruby installed. Is this ok?
105 _install_rbenv(repo_cmd_runner, version=version)
106 with in_env(repo_cmd_runner, version):
107 # Need to call this before installing so rbenv's directories are
108 # set up
109 helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'init', '-'))
110 if version != 'default':
111 _install_ruby(repo_cmd_runner, version)
112 # Need to call this after installing to set up the shims
113 helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'rehash'))
114 helpers.run_setup_cmd(
115 repo_cmd_runner,
116 ('gem', 'build') + repo_cmd_runner.star('.gemspec'),
117 )
118 helpers.run_setup_cmd(
119 repo_cmd_runner,
120 (
121 ('gem', 'install', '--no-ri', '--no-rdoc') +
122 repo_cmd_runner.star('.gem') + additional_dependencies
123 ),
124 )
125
126
127 def run_hook(repo_cmd_runner, hook, file_args):
128 with in_env(repo_cmd_runner, hook['language_version']):
129 return xargs((hook['entry'],) + tuple(hook['args']), file_args)
130
[end of pre_commit/languages/ruby.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py
--- a/pre_commit/languages/ruby.py
+++ b/pre_commit/languages/ruby.py
@@ -19,16 +19,18 @@
def get_env_patch(venv, language_version):
- return (
+ patches = (
('GEM_HOME', os.path.join(venv, 'gems')),
('RBENV_ROOT', venv),
- ('RBENV_VERSION', language_version),
('PATH', (
os.path.join(venv, 'gems', 'bin'), os.pathsep,
os.path.join(venv, 'shims'), os.pathsep,
os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),
)),
)
+ if language_version != 'default':
+ patches += (('RBENV_VERSION', language_version),)
+ return patches
@contextlib.contextmanager
|
{"golden_diff": "diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py\n--- a/pre_commit/languages/ruby.py\n+++ b/pre_commit/languages/ruby.py\n@@ -19,16 +19,18 @@\n \n \n def get_env_patch(venv, language_version):\n- return (\n+ patches = (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('RBENV_ROOT', venv),\n- ('RBENV_VERSION', language_version),\n ('PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),\n )),\n )\n+ if language_version != 'default':\n+ patches += (('RBENV_VERSION', language_version),)\n+ return patches\n \n \n @contextlib.contextmanager\n", "issue": "Ruby hooks failing with rbenv installed\nPre-commit has been failing for the past few weeks.\n\nhttps://gist.github.com/ThatGerber/d6533155848076b25e5e0d5cb02e20eb\n\nSeems to be an issue with the ruby (rbenv) environment.\n\nTried running `pre-commit clean && pre-commit` but it returns the same issue. Setting `rbenv global 2.2.4` and `rbenv shell 2.2.4` does help either.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport os.path\nimport shutil\n\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import resource_filename\nfrom pre_commit.util import tarfile_open\nfrom pre_commit.xargs import xargs\n\n\nENVIRONMENT_DIR = 'rbenv'\n\n\ndef get_env_patch(venv, language_version):\n return (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('RBENV_ROOT', venv),\n ('RBENV_VERSION', language_version),\n ('PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),\n )),\n )\n\n\[email protected]\ndef in_env(repo_cmd_runner, language_version):\n envdir = os.path.join(\n repo_cmd_runner.prefix_dir,\n helpers.environment_dir(ENVIRONMENT_DIR, language_version),\n )\n with envcontext(get_env_patch(envdir, language_version)):\n yield\n\n\ndef _install_rbenv(repo_cmd_runner, version='default'):\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n with tarfile_open(resource_filename('rbenv.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path('.'))\n shutil.move(\n repo_cmd_runner.path('rbenv'), repo_cmd_runner.path(directory),\n )\n\n # Only install ruby-build if the version is specified\n if version != 'default':\n # ruby-download\n with tarfile_open(resource_filename('ruby-download.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n # ruby-build\n with tarfile_open(resource_filename('ruby-build.tar.gz')) as tf:\n tf.extractall(repo_cmd_runner.path(directory, 'plugins'))\n\n activate_path = repo_cmd_runner.path(directory, 'bin', 'activate')\n with io.open(activate_path, 'w') as activate_file:\n # This is similar to how you would install rbenv to your home directory\n # However we do a couple things to make the executables exposed and\n # configure it to work in our directory.\n # We also modify the PS1 variable for manual debugging sake.\n activate_file.write(\n '#!/usr/bin/env bash\\n'\n \"export RBENV_ROOT='{0}'\\n\"\n 'export PATH=\"$RBENV_ROOT/bin:$PATH\"\\n'\n 'eval \"$(rbenv init -)\"\\n'\n 'export PS1=\"(rbenv)$PS1\"\\n'\n # This lets us install gems in an isolated and repeatable\n # directory\n \"export GEM_HOME='{0}/gems'\\n\"\n 'export PATH=\"$GEM_HOME/bin:$PATH\"\\n'\n '\\n'.format(repo_cmd_runner.path(directory))\n )\n\n # If we aren't using the system ruby, add a version here\n if version != 'default':\n activate_file.write('export RBENV_VERSION=\"{0}\"\\n'.format(version))\n\n\ndef _install_ruby(runner, version):\n try:\n helpers.run_setup_cmd(runner, ('rbenv', 'download', version))\n except CalledProcessError: # pragma: no cover (usually find with download)\n # Failed to download from mirror for some reason, build it instead\n helpers.run_setup_cmd(runner, ('rbenv', 'install', version))\n\n\ndef install_environment(\n repo_cmd_runner,\n version='default',\n additional_dependencies=(),\n):\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n with clean_path_on_failure(repo_cmd_runner.path(directory)):\n # TODO: this currently will fail if there's no version specified and\n # there's no system ruby installed. Is this ok?\n _install_rbenv(repo_cmd_runner, version=version)\n with in_env(repo_cmd_runner, version):\n # Need to call this before installing so rbenv's directories are\n # set up\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'init', '-'))\n if version != 'default':\n _install_ruby(repo_cmd_runner, version)\n # Need to call this after installing to set up the shims\n helpers.run_setup_cmd(repo_cmd_runner, ('rbenv', 'rehash'))\n helpers.run_setup_cmd(\n repo_cmd_runner,\n ('gem', 'build') + repo_cmd_runner.star('.gemspec'),\n )\n helpers.run_setup_cmd(\n repo_cmd_runner,\n (\n ('gem', 'install', '--no-ri', '--no-rdoc') +\n repo_cmd_runner.star('.gem') + additional_dependencies\n ),\n )\n\n\ndef run_hook(repo_cmd_runner, hook, file_args):\n with in_env(repo_cmd_runner, hook['language_version']):\n return xargs((hook['entry'],) + tuple(hook['args']), file_args)\n", "path": "pre_commit/languages/ruby.py"}]}
| 2,042 | 207 |
gh_patches_debug_7386
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-3499
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CSRF Failed Error
## Description
The error message
"CSRF Failed: Origin checking failed - https://internal.mathesar.org/ does not match any trusted origins."
is appearing when performing certain actions in Mathesar like creating a new internal db or saving a record.
## Additional context
This happened while testing internal.mathesar.org
</issue>
<code>
[start of config/settings/production.py]
1 from config.settings.common_settings import * # noqa
2
3 # Override default settings
4 DEBUG = False
5 MATHESAR_MODE = 'PRODUCTION'
6 # Use a local.py module for settings that shouldn't be version tracked
7 try:
8 from .local import * # noqa
9 except ImportError:
10 pass
11
[end of config/settings/production.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/config/settings/production.py b/config/settings/production.py
--- a/config/settings/production.py
+++ b/config/settings/production.py
@@ -3,6 +3,14 @@
# Override default settings
DEBUG = False
MATHESAR_MODE = 'PRODUCTION'
+
+'''
+This tells Django to trust the X-Forwarded-Proto header that comes from our proxy,
+and any time its value is 'https', then the request is guaranteed to be secure
+(i.e., it originally came in via HTTPS).
+'''
+SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https')
+
# Use a local.py module for settings that shouldn't be version tracked
try:
from .local import * # noqa
|
{"golden_diff": "diff --git a/config/settings/production.py b/config/settings/production.py\n--- a/config/settings/production.py\n+++ b/config/settings/production.py\n@@ -3,6 +3,14 @@\n # Override default settings\n DEBUG = False\n MATHESAR_MODE = 'PRODUCTION'\n+\n+'''\n+This tells Django to trust the X-Forwarded-Proto header that comes from our proxy,\n+and any time its value is 'https', then the request is guaranteed to be secure\n+(i.e., it originally came in via HTTPS).\n+'''\n+SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https')\n+\n # Use a local.py module for settings that shouldn't be version tracked\n try:\n from .local import * # noqa\n", "issue": "CSRF Failed Error\n## Description\r\nThe error message \r\n\"CSRF Failed: Origin checking failed - https://internal.mathesar.org/ does not match any trusted origins.\"\r\nis appearing when performing certain actions in Mathesar like creating a new internal db or saving a record. \r\n\r\n## Additional context\r\nThis happened while testing internal.mathesar.org\n", "before_files": [{"content": "from config.settings.common_settings import * # noqa\n\n# Override default settings\nDEBUG = False\nMATHESAR_MODE = 'PRODUCTION'\n# Use a local.py module for settings that shouldn't be version tracked\ntry:\n from .local import * # noqa \nexcept ImportError:\n pass\n", "path": "config/settings/production.py"}]}
| 680 | 162 |
gh_patches_debug_2722
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-13420
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
standard_gamma
</issue>
<code>
[start of ivy/functional/frontends/numpy/random/functions.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.numpy.func_wrapper import (
4 to_ivy_arrays_and_back,
5 from_zero_dim_arrays_to_scalar,
6 )
7
8
9 @to_ivy_arrays_and_back
10 @from_zero_dim_arrays_to_scalar
11 def random_sample(size=None):
12 return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
13
14
15 @to_ivy_arrays_and_back
16 @from_zero_dim_arrays_to_scalar
17 def dirichlet(alpha, size=None):
18 return ivy.dirichlet(alpha, size=size)
19
20
21 @to_ivy_arrays_and_back
22 @from_zero_dim_arrays_to_scalar
23 def uniform(low=0.0, high=1.0, size=None):
24 return ivy.random_uniform(low=low, high=high, shape=size, dtype="float64")
25
26
27 @to_ivy_arrays_and_back
28 @from_zero_dim_arrays_to_scalar
29 def geometric(p, size=None):
30 if p < 0 or p > 1:
31 raise ValueError("p must be in the interval [0, 1]")
32 oneMinusP = ivy.subtract(1, p)
33 sizeMinusOne = ivy.subtract(size, 1)
34
35 return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)
36
37
38 @to_ivy_arrays_and_back
39 @from_zero_dim_arrays_to_scalar
40 def normal(loc=0.0, scale=1.0, size=None):
41 return ivy.random_normal(mean=loc, std=scale, shape=size, dtype="float64")
42
43
44 @to_ivy_arrays_and_back
45 @from_zero_dim_arrays_to_scalar
46 def poisson(lam=1.0, size=None):
47 return ivy.poisson(lam=lam, shape=size)
48
49
50 @to_ivy_arrays_and_back
51 @from_zero_dim_arrays_to_scalar
52 def multinomial(n, pvals, size=None):
53 assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)
54 batch_size = 1
55 if ivy.exists(size):
56 if len(size) == 2:
57 batch_size = size[0]
58 num_samples = size[1]
59 else:
60 num_samples = size[0]
61 else:
62 num_samples = len(pvals)
63 return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)
64
65
66 @to_ivy_arrays_and_back
67 @from_zero_dim_arrays_to_scalar
68 def permutation(x, /):
69 if isinstance(x, int):
70 x = ivy.arange(x)
71 return ivy.shuffle(x)
72
73
74 @to_ivy_arrays_and_back
75 @from_zero_dim_arrays_to_scalar
76 def beta(a, b, size=None):
77 return ivy.beta(a, b, shape=size)
78
79
80 @to_ivy_arrays_and_back
81 @from_zero_dim_arrays_to_scalar
82 def shuffle(x, /):
83 if isinstance(x, int):
84 x = ivy.arange(x)
85 return ivy.shuffle(x)
86
87
88 @to_ivy_arrays_and_back
89 @from_zero_dim_arrays_to_scalar
90 def standard_normal(size=None):
91 return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
92
[end of ivy/functional/frontends/numpy/random/functions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py
--- a/ivy/functional/frontends/numpy/random/functions.py
+++ b/ivy/functional/frontends/numpy/random/functions.py
@@ -89,3 +89,9 @@
@from_zero_dim_arrays_to_scalar
def standard_normal(size=None):
return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
+
+
+@to_ivy_arrays_and_back
+@from_zero_dim_arrays_to_scalar
+def standard_gamma(alpha):
+ return ivy.gamma(alpha, beta=1.0, dtype="float64")
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py\n--- a/ivy/functional/frontends/numpy/random/functions.py\n+++ b/ivy/functional/frontends/numpy/random/functions.py\n@@ -89,3 +89,9 @@\n @from_zero_dim_arrays_to_scalar\n def standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n+\n+\n+@to_ivy_arrays_and_back\n+@from_zero_dim_arrays_to_scalar\n+def standard_gamma(alpha):\n+ return ivy.gamma(alpha, beta=1.0, dtype=\"float64\")\n", "issue": "standard_gamma\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}]}
| 1,428 | 156 |
gh_patches_debug_17898
|
rasdani/github-patches
|
git_diff
|
OCA__social-531
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[12.0][mail_tracking] many MailTracking email not found warnings
This code snippet is polluting my logs with warning messages.
https://github.com/OCA/social/blob/8d985d8da9fa864113f87cd59a2b3173f7f89193/mail_tracking/controllers/main.py#L69-L78
How can this work if state will be marked 'opened' the first time? Each successive open will trigger above warning, because state is now 'opened' and will not match the above domain `('state', 'in', ['sent', 'delivered'])`.
Is it intended to generate warnings each time mail is opened? Or what am I missing?
</issue>
<code>
[start of mail_tracking/controllers/main.py]
1 # Copyright 2016 Antonio Espinosa - <[email protected]>
2 # License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).
3
4 import werkzeug
5 import odoo
6 from contextlib import contextmanager
7 from odoo import api, http, SUPERUSER_ID
8
9 from odoo.addons.mail.controllers.main import MailController
10 import logging
11 import base64
12 _logger = logging.getLogger(__name__)
13
14 BLANK = 'R0lGODlhAQABAIAAANvf7wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw=='
15
16
17 @contextmanager
18 def db_env(dbname):
19 if not http.db_filter([dbname]):
20 raise werkzeug.exceptions.BadRequest()
21 cr = None
22 if dbname == http.request.db:
23 cr = http.request.cr
24 if not cr:
25 cr = odoo.sql_db.db_connect(dbname).cursor()
26 with api.Environment.manage():
27 yield api.Environment(cr, SUPERUSER_ID, {})
28
29
30 class MailTrackingController(MailController):
31
32 def _request_metadata(self):
33 """Prepare remote info metadata"""
34 request = http.request.httprequest
35 return {
36 'ip': request.remote_addr or False,
37 'user_agent': request.user_agent or False,
38 'os_family': request.user_agent.platform or False,
39 'ua_family': request.user_agent.browser or False,
40 }
41
42 @http.route(['/mail/tracking/all/<string:db>',
43 '/mail/tracking/event/<string:db>/<string:event_type>'],
44 type='http', auth='none', csrf=False)
45 def mail_tracking_event(self, db, event_type=None, **kw):
46 """Route used by external mail service"""
47 metadata = self._request_metadata()
48 res = None
49 with db_env(db) as env:
50 try:
51 res = env['mail.tracking.email'].event_process(
52 http.request, kw, metadata, event_type=event_type)
53 except Exception:
54 pass
55 if not res or res == 'NOT FOUND':
56 return werkzeug.exceptions.NotAcceptable()
57 return res
58
59 @http.route(['/mail/tracking/open/<string:db>'
60 '/<int:tracking_email_id>/blank.gif',
61 '/mail/tracking/open/<string:db>'
62 '/<int:tracking_email_id>/<string:token>/blank.gif'],
63 type='http', auth='none', methods=['GET'])
64 def mail_tracking_open(self, db, tracking_email_id, token=False, **kw):
65 """Route used to track mail openned (With & Without Token)"""
66 metadata = self._request_metadata()
67 with db_env(db) as env:
68 try:
69 tracking_email = env['mail.tracking.email'].search([
70 ('id', '=', tracking_email_id),
71 ('state', 'in', ['sent', 'delivered']),
72 ('token', '=', token),
73 ])
74 if tracking_email:
75 tracking_email.event_create('open', metadata)
76 else:
77 _logger.warning(
78 "MailTracking email '%s' not found", tracking_email_id)
79 except Exception:
80 pass
81
82 # Always return GIF blank image
83 response = werkzeug.wrappers.Response()
84 response.mimetype = 'image/gif'
85 response.data = base64.b64decode(BLANK)
86 return response
87
88 @http.route()
89 def mail_init_messaging(self):
90 """Route used to initial values of Discuss app"""
91 values = super().mail_init_messaging()
92 values.update({
93 'failed_counter':
94 http.request.env['mail.message'].get_failed_count(),
95 })
96 return values
97
[end of mail_tracking/controllers/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mail_tracking/controllers/main.py b/mail_tracking/controllers/main.py
--- a/mail_tracking/controllers/main.py
+++ b/mail_tracking/controllers/main.py
@@ -68,14 +68,13 @@
try:
tracking_email = env['mail.tracking.email'].search([
('id', '=', tracking_email_id),
- ('state', 'in', ['sent', 'delivered']),
('token', '=', token),
])
- if tracking_email:
- tracking_email.event_create('open', metadata)
- else:
+ if not tracking_email:
_logger.warning(
"MailTracking email '%s' not found", tracking_email_id)
+ elif tracking_email.state in ('sent', 'delivered'):
+ tracking_email.event_create('open', metadata)
except Exception:
pass
|
{"golden_diff": "diff --git a/mail_tracking/controllers/main.py b/mail_tracking/controllers/main.py\n--- a/mail_tracking/controllers/main.py\n+++ b/mail_tracking/controllers/main.py\n@@ -68,14 +68,13 @@\n try:\n tracking_email = env['mail.tracking.email'].search([\n ('id', '=', tracking_email_id),\n- ('state', 'in', ['sent', 'delivered']),\n ('token', '=', token),\n ])\n- if tracking_email:\n- tracking_email.event_create('open', metadata)\n- else:\n+ if not tracking_email:\n _logger.warning(\n \"MailTracking email '%s' not found\", tracking_email_id)\n+ elif tracking_email.state in ('sent', 'delivered'):\n+ tracking_email.event_create('open', metadata)\n except Exception:\n pass\n", "issue": "[12.0][mail_tracking] many MailTracking email not found warnings\nThis code snippet is polluting my logs with warning messages.\r\n\r\nhttps://github.com/OCA/social/blob/8d985d8da9fa864113f87cd59a2b3173f7f89193/mail_tracking/controllers/main.py#L69-L78\r\n\r\nHow can this work if state will be marked 'opened' the first time? Each successive open will trigger above warning, because state is now 'opened' and will not match the above domain `('state', 'in', ['sent', 'delivered'])`.\r\n\r\n Is it intended to generate warnings each time mail is opened? Or what am I missing?\n", "before_files": [{"content": "# Copyright 2016 Antonio Espinosa - <[email protected]>\n# License AGPL-3.0 or later (http://www.gnu.org/licenses/agpl.html).\n\nimport werkzeug\nimport odoo\nfrom contextlib import contextmanager\nfrom odoo import api, http, SUPERUSER_ID\n\nfrom odoo.addons.mail.controllers.main import MailController\nimport logging\nimport base64\n_logger = logging.getLogger(__name__)\n\nBLANK = 'R0lGODlhAQABAIAAANvf7wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw=='\n\n\n@contextmanager\ndef db_env(dbname):\n if not http.db_filter([dbname]):\n raise werkzeug.exceptions.BadRequest()\n cr = None\n if dbname == http.request.db:\n cr = http.request.cr\n if not cr:\n cr = odoo.sql_db.db_connect(dbname).cursor()\n with api.Environment.manage():\n yield api.Environment(cr, SUPERUSER_ID, {})\n\n\nclass MailTrackingController(MailController):\n\n def _request_metadata(self):\n \"\"\"Prepare remote info metadata\"\"\"\n request = http.request.httprequest\n return {\n 'ip': request.remote_addr or False,\n 'user_agent': request.user_agent or False,\n 'os_family': request.user_agent.platform or False,\n 'ua_family': request.user_agent.browser or False,\n }\n\n @http.route(['/mail/tracking/all/<string:db>',\n '/mail/tracking/event/<string:db>/<string:event_type>'],\n type='http', auth='none', csrf=False)\n def mail_tracking_event(self, db, event_type=None, **kw):\n \"\"\"Route used by external mail service\"\"\"\n metadata = self._request_metadata()\n res = None\n with db_env(db) as env:\n try:\n res = env['mail.tracking.email'].event_process(\n http.request, kw, metadata, event_type=event_type)\n except Exception:\n pass\n if not res or res == 'NOT FOUND':\n return werkzeug.exceptions.NotAcceptable()\n return res\n\n @http.route(['/mail/tracking/open/<string:db>'\n '/<int:tracking_email_id>/blank.gif',\n '/mail/tracking/open/<string:db>'\n '/<int:tracking_email_id>/<string:token>/blank.gif'],\n type='http', auth='none', methods=['GET'])\n def mail_tracking_open(self, db, tracking_email_id, token=False, **kw):\n \"\"\"Route used to track mail openned (With & Without Token)\"\"\"\n metadata = self._request_metadata()\n with db_env(db) as env:\n try:\n tracking_email = env['mail.tracking.email'].search([\n ('id', '=', tracking_email_id),\n ('state', 'in', ['sent', 'delivered']),\n ('token', '=', token),\n ])\n if tracking_email:\n tracking_email.event_create('open', metadata)\n else:\n _logger.warning(\n \"MailTracking email '%s' not found\", tracking_email_id)\n except Exception:\n pass\n\n # Always return GIF blank image\n response = werkzeug.wrappers.Response()\n response.mimetype = 'image/gif'\n response.data = base64.b64decode(BLANK)\n return response\n\n @http.route()\n def mail_init_messaging(self):\n \"\"\"Route used to initial values of Discuss app\"\"\"\n values = super().mail_init_messaging()\n values.update({\n 'failed_counter':\n http.request.env['mail.message'].get_failed_count(),\n })\n return values\n", "path": "mail_tracking/controllers/main.py"}]}
| 1,659 | 176 |
gh_patches_debug_29976
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-1275
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add release meta issue template for 1.1.1
Signed-off-by: Peter Zhu <[email protected]>
### Description
Add release meta issue template for 1.1.1
### Issues Resolved
[List any issues this PR will resolve]
### Check List
- [x] Commits are signed per the DCO using --signoff
By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
For more information on following Developer Certificate of Origin and signing off your commits, please check [here](https://github.com/opensearch-project/OpenSearch/blob/main/CONTRIBUTING.md#developer-certificate-of-origin).
</issue>
<code>
[start of src/ci_workflow/ci_input_manifest.py]
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import logging
8
9 from ci_workflow.ci_check_lists import CiCheckLists
10 from ci_workflow.ci_manifest import CiManifest
11 from ci_workflow.ci_target import CiTarget
12 from manifests.input_manifest import InputManifest
13 from system.temporary_directory import TemporaryDirectory
14
15
16 class CiInputManifest(CiManifest):
17 def __init__(self, file, args):
18 super().__init__(InputManifest.from_file(file), args)
19
20 def __check__(self):
21
22 target = CiTarget(version=self.manifest.build.version, snapshot=self.args.snapshot)
23
24 with TemporaryDirectory(keep=self.args.keep, chdir=True) as work_dir:
25 logging.info(f"Sanity-testing in {work_dir.name}")
26
27 logging.info(f"Sanity testing {self.manifest.build.name}")
28
29 for component in self.manifest.components.select(focus=self.args.component):
30 logging.info(f"Sanity testing {component.name}")
31
32 ci_check_list = CiCheckLists.from_component(component, target)
33 ci_check_list.checkout(work_dir.name)
34 ci_check_list.check()
35 logging.info("Done.")
36
[end of src/ci_workflow/ci_input_manifest.py]
[start of src/ci_workflow/ci_target.py]
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7
8 class CiTarget:
9 version: str
10 snapshot: bool
11
12 def __init__(self, version, snapshot=True):
13 self.version = version
14 self.snapshot = snapshot
15
16 @property
17 def opensearch_version(self):
18 return self.version + "-SNAPSHOT" if self.snapshot else self.version
19
20 @property
21 def component_version(self):
22 # BUG: the 4th digit is dictated by the component, it's not .0, this will break for 1.1.0.1
23 return self.version + ".0-SNAPSHOT" if self.snapshot else f"{self.version}.0"
24
[end of src/ci_workflow/ci_target.py]
[start of src/ci_workflow/ci_check_manifest_component.py]
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import logging
8
9 from build_workflow.build_args import BuildArgs
10 from ci_workflow.ci_check import CiCheckDist
11 from manifests.build_manifest import BuildManifest
12
13
14 class CiCheckManifestComponent(CiCheckDist):
15 class MissingComponentError(Exception):
16 def __init__(self, component, url):
17 super().__init__(f"Missing {component} in {url}.")
18
19 def check(self):
20 for architecture in BuildArgs.SUPPORTED_ARCHITECTURES:
21 url = "/".join([self.component.dist, architecture, "manifest.yml"])
22 self.build_manifest = BuildManifest.from_url(url)
23 if self.component.name in self.build_manifest.components:
24 logging.info(f"Found {self.component.name} in {url}.")
25 else:
26 raise CiCheckManifestComponent.MissingComponentError(self.component.name, url)
27
[end of src/ci_workflow/ci_check_manifest_component.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/ci_workflow/ci_check_manifest_component.py b/src/ci_workflow/ci_check_manifest_component.py
--- a/src/ci_workflow/ci_check_manifest_component.py
+++ b/src/ci_workflow/ci_check_manifest_component.py
@@ -18,7 +18,9 @@
def check(self):
for architecture in BuildArgs.SUPPORTED_ARCHITECTURES:
- url = "/".join([self.component.dist, architecture, "manifest.yml"])
+ # Since we only have 'linux' builds now we hard code it to 'linux'
+ # Once we have all platform builds on S3 we can then add a second loop for 'BuildArgs.SUPPORTED_PLATFORMS'
+ url = "/".join([self.component.dist, "linux", architecture, "builds", self.target.name, "manifest.yml"])
self.build_manifest = BuildManifest.from_url(url)
if self.component.name in self.build_manifest.components:
logging.info(f"Found {self.component.name} in {url}.")
diff --git a/src/ci_workflow/ci_input_manifest.py b/src/ci_workflow/ci_input_manifest.py
--- a/src/ci_workflow/ci_input_manifest.py
+++ b/src/ci_workflow/ci_input_manifest.py
@@ -19,7 +19,7 @@
def __check__(self):
- target = CiTarget(version=self.manifest.build.version, snapshot=self.args.snapshot)
+ target = CiTarget(version=self.manifest.build.version, name=self.manifest.build.filename, snapshot=self.args.snapshot)
with TemporaryDirectory(keep=self.args.keep, chdir=True) as work_dir:
logging.info(f"Sanity-testing in {work_dir.name}")
diff --git a/src/ci_workflow/ci_target.py b/src/ci_workflow/ci_target.py
--- a/src/ci_workflow/ci_target.py
+++ b/src/ci_workflow/ci_target.py
@@ -7,10 +7,12 @@
class CiTarget:
version: str
+ name: str
snapshot: bool
- def __init__(self, version, snapshot=True):
+ def __init__(self, version, name, snapshot=True):
self.version = version
+ self.name = name
self.snapshot = snapshot
@property
|
{"golden_diff": "diff --git a/src/ci_workflow/ci_check_manifest_component.py b/src/ci_workflow/ci_check_manifest_component.py\n--- a/src/ci_workflow/ci_check_manifest_component.py\n+++ b/src/ci_workflow/ci_check_manifest_component.py\n@@ -18,7 +18,9 @@\n \n def check(self):\n for architecture in BuildArgs.SUPPORTED_ARCHITECTURES:\n- url = \"/\".join([self.component.dist, architecture, \"manifest.yml\"])\n+ # Since we only have 'linux' builds now we hard code it to 'linux'\n+ # Once we have all platform builds on S3 we can then add a second loop for 'BuildArgs.SUPPORTED_PLATFORMS'\n+ url = \"/\".join([self.component.dist, \"linux\", architecture, \"builds\", self.target.name, \"manifest.yml\"])\n self.build_manifest = BuildManifest.from_url(url)\n if self.component.name in self.build_manifest.components:\n logging.info(f\"Found {self.component.name} in {url}.\")\ndiff --git a/src/ci_workflow/ci_input_manifest.py b/src/ci_workflow/ci_input_manifest.py\n--- a/src/ci_workflow/ci_input_manifest.py\n+++ b/src/ci_workflow/ci_input_manifest.py\n@@ -19,7 +19,7 @@\n \n def __check__(self):\n \n- target = CiTarget(version=self.manifest.build.version, snapshot=self.args.snapshot)\n+ target = CiTarget(version=self.manifest.build.version, name=self.manifest.build.filename, snapshot=self.args.snapshot)\n \n with TemporaryDirectory(keep=self.args.keep, chdir=True) as work_dir:\n logging.info(f\"Sanity-testing in {work_dir.name}\")\ndiff --git a/src/ci_workflow/ci_target.py b/src/ci_workflow/ci_target.py\n--- a/src/ci_workflow/ci_target.py\n+++ b/src/ci_workflow/ci_target.py\n@@ -7,10 +7,12 @@\n \n class CiTarget:\n version: str\n+ name: str\n snapshot: bool\n \n- def __init__(self, version, snapshot=True):\n+ def __init__(self, version, name, snapshot=True):\n self.version = version\n+ self.name = name\n self.snapshot = snapshot\n \n @property\n", "issue": "Add release meta issue template for 1.1.1\nSigned-off-by: Peter Zhu <[email protected]>\r\n\r\n### Description\r\nAdd release meta issue template for 1.1.1\r\n \r\n### Issues Resolved\r\n[List any issues this PR will resolve]\r\n \r\n### Check List\r\n- [x] Commits are signed per the DCO using --signoff \r\n\r\nBy submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.\r\nFor more information on following Developer Certificate of Origin and signing off your commits, please check [here](https://github.com/opensearch-project/OpenSearch/blob/main/CONTRIBUTING.md#developer-certificate-of-origin).\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\n\nfrom ci_workflow.ci_check_lists import CiCheckLists\nfrom ci_workflow.ci_manifest import CiManifest\nfrom ci_workflow.ci_target import CiTarget\nfrom manifests.input_manifest import InputManifest\nfrom system.temporary_directory import TemporaryDirectory\n\n\nclass CiInputManifest(CiManifest):\n def __init__(self, file, args):\n super().__init__(InputManifest.from_file(file), args)\n\n def __check__(self):\n\n target = CiTarget(version=self.manifest.build.version, snapshot=self.args.snapshot)\n\n with TemporaryDirectory(keep=self.args.keep, chdir=True) as work_dir:\n logging.info(f\"Sanity-testing in {work_dir.name}\")\n\n logging.info(f\"Sanity testing {self.manifest.build.name}\")\n\n for component in self.manifest.components.select(focus=self.args.component):\n logging.info(f\"Sanity testing {component.name}\")\n\n ci_check_list = CiCheckLists.from_component(component, target)\n ci_check_list.checkout(work_dir.name)\n ci_check_list.check()\n logging.info(\"Done.\")\n", "path": "src/ci_workflow/ci_input_manifest.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\n\nclass CiTarget:\n version: str\n snapshot: bool\n\n def __init__(self, version, snapshot=True):\n self.version = version\n self.snapshot = snapshot\n\n @property\n def opensearch_version(self):\n return self.version + \"-SNAPSHOT\" if self.snapshot else self.version\n\n @property\n def component_version(self):\n # BUG: the 4th digit is dictated by the component, it's not .0, this will break for 1.1.0.1\n return self.version + \".0-SNAPSHOT\" if self.snapshot else f\"{self.version}.0\"\n", "path": "src/ci_workflow/ci_target.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\n\nfrom build_workflow.build_args import BuildArgs\nfrom ci_workflow.ci_check import CiCheckDist\nfrom manifests.build_manifest import BuildManifest\n\n\nclass CiCheckManifestComponent(CiCheckDist):\n class MissingComponentError(Exception):\n def __init__(self, component, url):\n super().__init__(f\"Missing {component} in {url}.\")\n\n def check(self):\n for architecture in BuildArgs.SUPPORTED_ARCHITECTURES:\n url = \"/\".join([self.component.dist, architecture, \"manifest.yml\"])\n self.build_manifest = BuildManifest.from_url(url)\n if self.component.name in self.build_manifest.components:\n logging.info(f\"Found {self.component.name} in {url}.\")\n else:\n raise CiCheckManifestComponent.MissingComponentError(self.component.name, url)\n", "path": "src/ci_workflow/ci_check_manifest_component.py"}]}
| 1,558 | 490 |
gh_patches_debug_27608
|
rasdani/github-patches
|
git_diff
|
pypa__virtualenv-2324
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Virtualenv 20.14.0 bundles broken setuptools
**Issue**
Virtualenv 20.14.0 has broken version of setuptools 61.0.0 bundled in. This causes broken installations of packages, especially missing package data files.
**Environment**
Various
</issue>
<code>
[start of src/virtualenv/seed/wheels/embed/__init__.py]
1 from __future__ import absolute_import, unicode_literals
2
3 from virtualenv.seed.wheels.util import Wheel
4 from virtualenv.util.path import Path
5
6 BUNDLE_FOLDER = Path(__file__).absolute().parent
7 BUNDLE_SUPPORT = {
8 "3.11": {
9 "pip": "pip-22.0.4-py3-none-any.whl",
10 "setuptools": "setuptools-61.0.0-py3-none-any.whl",
11 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
12 },
13 "3.10": {
14 "pip": "pip-22.0.4-py3-none-any.whl",
15 "setuptools": "setuptools-61.0.0-py3-none-any.whl",
16 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
17 },
18 "3.9": {
19 "pip": "pip-22.0.4-py3-none-any.whl",
20 "setuptools": "setuptools-61.0.0-py3-none-any.whl",
21 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
22 },
23 "3.8": {
24 "pip": "pip-22.0.4-py3-none-any.whl",
25 "setuptools": "setuptools-61.0.0-py3-none-any.whl",
26 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
27 },
28 "3.7": {
29 "pip": "pip-22.0.4-py3-none-any.whl",
30 "setuptools": "setuptools-61.0.0-py3-none-any.whl",
31 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
32 },
33 "3.6": {
34 "pip": "pip-21.3.1-py3-none-any.whl",
35 "setuptools": "setuptools-59.6.0-py3-none-any.whl",
36 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
37 },
38 "3.5": {
39 "pip": "pip-20.3.4-py2.py3-none-any.whl",
40 "setuptools": "setuptools-50.3.2-py3-none-any.whl",
41 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
42 },
43 "2.7": {
44 "pip": "pip-20.3.4-py2.py3-none-any.whl",
45 "setuptools": "setuptools-44.1.1-py2.py3-none-any.whl",
46 "wheel": "wheel-0.37.1-py2.py3-none-any.whl",
47 },
48 }
49 MAX = "3.11"
50
51
52 def get_embed_wheel(distribution, for_py_version):
53 path = BUNDLE_FOLDER / (BUNDLE_SUPPORT.get(for_py_version, {}) or BUNDLE_SUPPORT[MAX]).get(distribution)
54 return Wheel.from_path(path)
55
56
57 __all__ = (
58 "get_embed_wheel",
59 "BUNDLE_SUPPORT",
60 "MAX",
61 "BUNDLE_FOLDER",
62 )
63
[end of src/virtualenv/seed/wheels/embed/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/virtualenv/seed/wheels/embed/__init__.py b/src/virtualenv/seed/wheels/embed/__init__.py
--- a/src/virtualenv/seed/wheels/embed/__init__.py
+++ b/src/virtualenv/seed/wheels/embed/__init__.py
@@ -7,27 +7,27 @@
BUNDLE_SUPPORT = {
"3.11": {
"pip": "pip-22.0.4-py3-none-any.whl",
- "setuptools": "setuptools-61.0.0-py3-none-any.whl",
+ "setuptools": "setuptools-62.1.0-py3-none-any.whl",
"wheel": "wheel-0.37.1-py2.py3-none-any.whl",
},
"3.10": {
"pip": "pip-22.0.4-py3-none-any.whl",
- "setuptools": "setuptools-61.0.0-py3-none-any.whl",
+ "setuptools": "setuptools-62.1.0-py3-none-any.whl",
"wheel": "wheel-0.37.1-py2.py3-none-any.whl",
},
"3.9": {
"pip": "pip-22.0.4-py3-none-any.whl",
- "setuptools": "setuptools-61.0.0-py3-none-any.whl",
+ "setuptools": "setuptools-62.1.0-py3-none-any.whl",
"wheel": "wheel-0.37.1-py2.py3-none-any.whl",
},
"3.8": {
"pip": "pip-22.0.4-py3-none-any.whl",
- "setuptools": "setuptools-61.0.0-py3-none-any.whl",
+ "setuptools": "setuptools-62.1.0-py3-none-any.whl",
"wheel": "wheel-0.37.1-py2.py3-none-any.whl",
},
"3.7": {
"pip": "pip-22.0.4-py3-none-any.whl",
- "setuptools": "setuptools-61.0.0-py3-none-any.whl",
+ "setuptools": "setuptools-62.1.0-py3-none-any.whl",
"wheel": "wheel-0.37.1-py2.py3-none-any.whl",
},
"3.6": {
|
{"golden_diff": "diff --git a/src/virtualenv/seed/wheels/embed/__init__.py b/src/virtualenv/seed/wheels/embed/__init__.py\n--- a/src/virtualenv/seed/wheels/embed/__init__.py\n+++ b/src/virtualenv/seed/wheels/embed/__init__.py\n@@ -7,27 +7,27 @@\n BUNDLE_SUPPORT = {\n \"3.11\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n- \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n+ \"setuptools\": \"setuptools-62.1.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.10\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n- \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n+ \"setuptools\": \"setuptools-62.1.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.9\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n- \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n+ \"setuptools\": \"setuptools-62.1.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.8\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n- \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n+ \"setuptools\": \"setuptools-62.1.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.7\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n- \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n+ \"setuptools\": \"setuptools-62.1.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.6\": {\n", "issue": "Virtualenv 20.14.0 bundles broken setuptools\n**Issue**\r\n\r\nVirtualenv 20.14.0 has broken version of setuptools 61.0.0 bundled in. This causes broken installations of packages, especially missing package data files.\r\n\r\n**Environment**\r\n\r\nVarious\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nfrom virtualenv.seed.wheels.util import Wheel\nfrom virtualenv.util.path import Path\n\nBUNDLE_FOLDER = Path(__file__).absolute().parent\nBUNDLE_SUPPORT = {\n \"3.11\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.10\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.9\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.8\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.7\": {\n \"pip\": \"pip-22.0.4-py3-none-any.whl\",\n \"setuptools\": \"setuptools-61.0.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.6\": {\n \"pip\": \"pip-21.3.1-py3-none-any.whl\",\n \"setuptools\": \"setuptools-59.6.0-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"3.5\": {\n \"pip\": \"pip-20.3.4-py2.py3-none-any.whl\",\n \"setuptools\": \"setuptools-50.3.2-py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n \"2.7\": {\n \"pip\": \"pip-20.3.4-py2.py3-none-any.whl\",\n \"setuptools\": \"setuptools-44.1.1-py2.py3-none-any.whl\",\n \"wheel\": \"wheel-0.37.1-py2.py3-none-any.whl\",\n },\n}\nMAX = \"3.11\"\n\n\ndef get_embed_wheel(distribution, for_py_version):\n path = BUNDLE_FOLDER / (BUNDLE_SUPPORT.get(for_py_version, {}) or BUNDLE_SUPPORT[MAX]).get(distribution)\n return Wheel.from_path(path)\n\n\n__all__ = (\n \"get_embed_wheel\",\n \"BUNDLE_SUPPORT\",\n \"MAX\",\n \"BUNDLE_FOLDER\",\n)\n", "path": "src/virtualenv/seed/wheels/embed/__init__.py"}]}
| 1,481 | 596 |
gh_patches_debug_21141
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-7505
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
matplotlib import issue: ImportError DLL load failed while importing _path...
Hey,
From searching around, matplotlib import errors occur here and there, usually the fix is to downgrade the matplotlib version, or to change the hook-matplotlib.py file. This did not resolve the issue.
matplotlib import is to blame because running the same `pyinstaller --onefile Script.py` command where matplotlib import is commented out works as expected.
Otherwise opening the newly created exe file writes these few lines before exiting (excuse me for not copying everything from the screenshot I took moments before it closed):

The error:
```
ImportError: DLL load failed while importing _path: The specific module could not be found.
[5780] Failed to execute script 'Script' due to unhandled exeption!
```
During the pyinstaller run, the WARNINGS regarding matplotlib packages:
```
2149 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\backends\_backend_agg.cp39-win_amd64.pyd
2189 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\_path.cp39-win_amd64.pyd
2209 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\backends\_tkagg.cp39-win_amd64.pyd
2239 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\_tri.cp39-win_amd64.pyd
2249 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\_qhull.cp39-win_amd64.pyd
2259 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\Users\...\venv\lib\site-packages\matplotlib\ft2font.cp39-win_amd64.pyd
```
A thing to note is that my python is Anaconda distribution, so I also get this warning:
`WARNING: Assuming this is not an Anaconda environment or an additional venv/pipenv/... environment manager is being used on top, because the conda-meta folder C:\Users\...\venv\conda-meta does not exist.`
But the warning comes up with matplotlib import commented out and everything works as expected, so I doubt this has something to do with the issue.
I tried:
- Reinstalling matplotlib and pyinstaller
- Im using the Anaconda Prompt, otherwise it doesn't even get to creating the Script.exe file.
- Installing Microsoft Visual C++ 2015-2022 Redistribution.
- Changing the hook-matplotlib.py in hooks folder (it is already set right - the suggestion is old).
Info:
- Windows 10 Enterprise 64-bit
- python --version
'Python 3.9.7'
- pyinstaller --version
'5.9.0'
- matplotlib.__version__
'3.7.1'
</issue>
<code>
[start of PyInstaller/hooks/hook-matplotlib.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013-2023, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 from PyInstaller import isolated
13
14
15 @isolated.decorate
16 def mpl_data_dir():
17 import matplotlib
18 return matplotlib.get_data_path()
19
20
21 datas = [
22 (mpl_data_dir(), "matplotlib/mpl-data"),
23 ]
24
[end of PyInstaller/hooks/hook-matplotlib.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/hook-matplotlib.py b/PyInstaller/hooks/hook-matplotlib.py
--- a/PyInstaller/hooks/hook-matplotlib.py
+++ b/PyInstaller/hooks/hook-matplotlib.py
@@ -10,6 +10,8 @@
#-----------------------------------------------------------------------------
from PyInstaller import isolated
+from PyInstaller import compat
+from PyInstaller.utils import hooks as hookutils
@isolated.decorate
@@ -21,3 +23,16 @@
datas = [
(mpl_data_dir(), "matplotlib/mpl-data"),
]
+
+binaries = []
+
+# Windows PyPI wheels for `matplotlib` >= 3.7.0 use `delvewheel`.
+# In addition to DLLs from `matplotlib.libs` directory, which should be picked up automatically by dependency analysis
+# in contemporary PyInstaller versions, we also need to collect the load-order file. This used to be required for
+# python <= 3.7 (that lacked `os.add_dll_directory`), but is also needed for Anaconda python 3.8 and 3.9, where
+# `delvewheel` falls back to load-order file codepath due to Anaconda breaking `os.add_dll_directory` implementation.
+if compat.is_win and hookutils.is_module_satisfies('matplotlib >= 3.7.0'):
+ delvewheel_datas, delvewheel_binaries = hookutils.collect_delvewheel_libs_directory('matplotlib')
+
+ datas += delvewheel_datas
+ binaries += delvewheel_binaries
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-matplotlib.py b/PyInstaller/hooks/hook-matplotlib.py\n--- a/PyInstaller/hooks/hook-matplotlib.py\n+++ b/PyInstaller/hooks/hook-matplotlib.py\n@@ -10,6 +10,8 @@\n #-----------------------------------------------------------------------------\n \n from PyInstaller import isolated\n+from PyInstaller import compat\n+from PyInstaller.utils import hooks as hookutils\n \n \n @isolated.decorate\n@@ -21,3 +23,16 @@\n datas = [\n (mpl_data_dir(), \"matplotlib/mpl-data\"),\n ]\n+\n+binaries = []\n+\n+# Windows PyPI wheels for `matplotlib` >= 3.7.0 use `delvewheel`.\n+# In addition to DLLs from `matplotlib.libs` directory, which should be picked up automatically by dependency analysis\n+# in contemporary PyInstaller versions, we also need to collect the load-order file. This used to be required for\n+# python <= 3.7 (that lacked `os.add_dll_directory`), but is also needed for Anaconda python 3.8 and 3.9, where\n+# `delvewheel` falls back to load-order file codepath due to Anaconda breaking `os.add_dll_directory` implementation.\n+if compat.is_win and hookutils.is_module_satisfies('matplotlib >= 3.7.0'):\n+ delvewheel_datas, delvewheel_binaries = hookutils.collect_delvewheel_libs_directory('matplotlib')\n+\n+ datas += delvewheel_datas\n+ binaries += delvewheel_binaries\n", "issue": "matplotlib import issue: ImportError DLL load failed while importing _path...\nHey,\r\nFrom searching around, matplotlib import errors occur here and there, usually the fix is to downgrade the matplotlib version, or to change the hook-matplotlib.py file. This did not resolve the issue.\r\n\r\nmatplotlib import is to blame because running the same `pyinstaller --onefile Script.py` command where matplotlib import is commented out works as expected.\r\nOtherwise opening the newly created exe file writes these few lines before exiting (excuse me for not copying everything from the screenshot I took moments before it closed):\r\n\r\nThe error:\r\n```\r\nImportError: DLL load failed while importing _path: The specific module could not be found.\r\n[5780] Failed to execute script 'Script' due to unhandled exeption!\r\n\r\n```\r\n\r\nDuring the pyinstaller run, the WARNINGS regarding matplotlib packages:\r\n```\r\n2149 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\backends\\_backend_agg.cp39-win_amd64.pyd\r\n2189 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\_path.cp39-win_amd64.pyd\r\n2209 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\backends\\_tkagg.cp39-win_amd64.pyd\r\n2239 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\_tri.cp39-win_amd64.pyd\r\n2249 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\_qhull.cp39-win_amd64.pyd\r\n2259 WARNING: lib not found: msvcp140-e78ebc24b6ffa690be9375aacad743a7.dll dependency of C:\\Users\\...\\venv\\lib\\site-packages\\matplotlib\\ft2font.cp39-win_amd64.pyd\r\n```\r\n\r\nA thing to note is that my python is Anaconda distribution, so I also get this warning:\r\n`WARNING: Assuming this is not an Anaconda environment or an additional venv/pipenv/... environment manager is being used on top, because the conda-meta folder C:\\Users\\...\\venv\\conda-meta does not exist.`\r\nBut the warning comes up with matplotlib import commented out and everything works as expected, so I doubt this has something to do with the issue.\r\n\r\nI tried:\r\n- Reinstalling matplotlib and pyinstaller\r\n- Im using the Anaconda Prompt, otherwise it doesn't even get to creating the Script.exe file.\r\n- Installing Microsoft Visual C++ 2015-2022 Redistribution.\r\n- Changing the hook-matplotlib.py in hooks folder (it is already set right - the suggestion is old).\r\n\r\nInfo:\r\n- Windows 10 Enterprise 64-bit\r\n- python --version\r\n'Python 3.9.7'\r\n- pyinstaller --version\r\n'5.9.0'\r\n- matplotlib.__version__\r\n'3.7.1'\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2023, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller import isolated\n\n\[email protected]\ndef mpl_data_dir():\n import matplotlib\n return matplotlib.get_data_path()\n\n\ndatas = [\n (mpl_data_dir(), \"matplotlib/mpl-data\"),\n]\n", "path": "PyInstaller/hooks/hook-matplotlib.py"}]}
| 1,630 | 343 |
gh_patches_debug_21548
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-3329
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature request: optionally suppress "Manim Comunity v{version}"
## Description of proposed feature
Hello! As of recent versions of Manim, it is not possible to suppress the `Manim Community v{version}` message that is printed out when importing `manim`.
Actually, this is because importing `manim` imports `manim.__init__`, which in turn imports `manim.__main__` with this: https://github.com/ManimCommunity/manim/blob/88836df8ab1ea153ed57848a74a694c517962163/manim/__init__.py#L104-L113
Before, I could suppress the message using some redirect, but now if fails
```python
>>> import os
>>> from contextlib import redirect_stdout
>>>
>>> with redirect_stdout(open(os.devnull, "w")):
>>> print("HELLO")
>>> import manim
Manim Community v0.17.2
```
because Rich will still print to `stdout` (since the console was created before `stdout` was redirected).
Rich's console has an optional `file` argument, but there currently seem to be a bug with it, reported in https://github.com/Textualize/rich/issues/3083, that makes Rich's consoles only print to stdout.
A **nice feature** would be to make the behavior optional.
## How can the new feature be used?
There are a few possible solutions:
- Not printing the version at all;
- Moving the print message inside the `__main__`:
https://github.com/ManimCommunity/manim/blob/88836df8ab1ea153ed57848a74a694c517962163/manim/__main__.py#L59-L60
- Optionally print (or disable print) with some environ variable
- ...
## Additional comments
I develop Manim Slides, a Manim plugin, and I'd like to avoid printing the Manim Community version every time I import this package, because the user does not really need to know that.
</issue>
<code>
[start of manim/__main__.py]
1 from __future__ import annotations
2
3 import sys
4
5 import cloup
6
7 from . import __version__, cli_ctx_settings, console
8 from .cli.cfg.group import cfg
9 from .cli.checkhealth.commands import checkhealth
10 from .cli.default_group import DefaultGroup
11 from .cli.init.commands import init
12 from .cli.plugins.commands import plugins
13 from .cli.render.commands import render
14 from .constants import EPILOG
15
16
17 def exit_early(ctx, param, value):
18 if value:
19 sys.exit()
20
21
22 console.print(f"Manim Community [green]v{__version__}[/green]\n")
23
24
25 @cloup.group(
26 context_settings=cli_ctx_settings,
27 cls=DefaultGroup,
28 default="render",
29 no_args_is_help=True,
30 help="Animation engine for explanatory math videos.",
31 epilog="See 'manim <command>' to read about a specific subcommand.\n\n"
32 "Note: the subcommand 'manim render' is called if no other subcommand "
33 "is specified. Run 'manim render --help' if you would like to know what the "
34 f"'-ql' or '-p' flags do, for example.\n\n{EPILOG}",
35 )
36 @cloup.option(
37 "--version",
38 is_flag=True,
39 help="Show version and exit.",
40 callback=exit_early,
41 is_eager=True,
42 expose_value=False,
43 )
44 @cloup.pass_context
45 def main(ctx):
46 """The entry point for manim."""
47 pass
48
49
50 main.add_command(checkhealth)
51 main.add_command(cfg)
52 main.add_command(plugins)
53 main.add_command(init)
54 main.add_command(render)
55
56 if __name__ == "__main__":
57 main()
58
[end of manim/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/manim/__main__.py b/manim/__main__.py
--- a/manim/__main__.py
+++ b/manim/__main__.py
@@ -2,6 +2,7 @@
import sys
+import click
import cloup
from . import __version__, cli_ctx_settings, console
@@ -14,12 +15,15 @@
from .constants import EPILOG
-def exit_early(ctx, param, value):
+def show_splash(ctx, param, value):
if value:
- sys.exit()
+ console.print(f"Manim Community [green]v{__version__}[/green]\n")
-console.print(f"Manim Community [green]v{__version__}[/green]\n")
+def print_version_and_exit(ctx, param, value):
+ show_splash(ctx, param, value)
+ if value:
+ ctx.exit()
@cloup.group(
@@ -37,7 +41,16 @@
"--version",
is_flag=True,
help="Show version and exit.",
- callback=exit_early,
+ callback=print_version_and_exit,
+ is_eager=True,
+ expose_value=False,
+)
[email protected](
+ "--show-splash/--hide-splash",
+ is_flag=True,
+ default=True,
+ help="Print splash message with version information.",
+ callback=show_splash,
is_eager=True,
expose_value=False,
)
|
{"golden_diff": "diff --git a/manim/__main__.py b/manim/__main__.py\n--- a/manim/__main__.py\n+++ b/manim/__main__.py\n@@ -2,6 +2,7 @@\n \n import sys\n \n+import click\n import cloup\n \n from . import __version__, cli_ctx_settings, console\n@@ -14,12 +15,15 @@\n from .constants import EPILOG\n \n \n-def exit_early(ctx, param, value):\n+def show_splash(ctx, param, value):\n if value:\n- sys.exit()\n+ console.print(f\"Manim Community [green]v{__version__}[/green]\\n\")\n \n \n-console.print(f\"Manim Community [green]v{__version__}[/green]\\n\")\n+def print_version_and_exit(ctx, param, value):\n+ show_splash(ctx, param, value)\n+ if value:\n+ ctx.exit()\n \n \n @cloup.group(\n@@ -37,7 +41,16 @@\n \"--version\",\n is_flag=True,\n help=\"Show version and exit.\",\n- callback=exit_early,\n+ callback=print_version_and_exit,\n+ is_eager=True,\n+ expose_value=False,\n+)\[email protected](\n+ \"--show-splash/--hide-splash\",\n+ is_flag=True,\n+ default=True,\n+ help=\"Print splash message with version information.\",\n+ callback=show_splash,\n is_eager=True,\n expose_value=False,\n )\n", "issue": "Feature request: optionally suppress \"Manim Comunity v{version}\"\n## Description of proposed feature\r\n\r\nHello! As of recent versions of Manim, it is not possible to suppress the `Manim Community v{version}` message that is printed out when importing `manim`.\r\n\r\nActually, this is because importing `manim` imports `manim.__init__`, which in turn imports `manim.__main__` with this: https://github.com/ManimCommunity/manim/blob/88836df8ab1ea153ed57848a74a694c517962163/manim/__init__.py#L104-L113\r\n\r\nBefore, I could suppress the message using some redirect, but now if fails\r\n\r\n```python\r\n>>> import os\r\n>>> from contextlib import redirect_stdout\r\n>>> \r\n>>> with redirect_stdout(open(os.devnull, \"w\")):\r\n>>> print(\"HELLO\")\r\n>>> import manim\r\nManim Community v0.17.2\r\n```\r\nbecause Rich will still print to `stdout` (since the console was created before `stdout` was redirected). \r\n\r\nRich's console has an optional `file` argument, but there currently seem to be a bug with it, reported in https://github.com/Textualize/rich/issues/3083, that makes Rich's consoles only print to stdout.\r\n\r\nA **nice feature** would be to make the behavior optional.\r\n\r\n## How can the new feature be used?\r\n\r\nThere are a few possible solutions:\r\n\r\n- Not printing the version at all;\r\n- Moving the print message inside the `__main__`:\r\nhttps://github.com/ManimCommunity/manim/blob/88836df8ab1ea153ed57848a74a694c517962163/manim/__main__.py#L59-L60\r\n- Optionally print (or disable print) with some environ variable\r\n- ...\r\n\r\n## Additional comments\r\n\r\nI develop Manim Slides, a Manim plugin, and I'd like to avoid printing the Manim Community version every time I import this package, because the user does not really need to know that.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport sys\n\nimport cloup\n\nfrom . import __version__, cli_ctx_settings, console\nfrom .cli.cfg.group import cfg\nfrom .cli.checkhealth.commands import checkhealth\nfrom .cli.default_group import DefaultGroup\nfrom .cli.init.commands import init\nfrom .cli.plugins.commands import plugins\nfrom .cli.render.commands import render\nfrom .constants import EPILOG\n\n\ndef exit_early(ctx, param, value):\n if value:\n sys.exit()\n\n\nconsole.print(f\"Manim Community [green]v{__version__}[/green]\\n\")\n\n\[email protected](\n context_settings=cli_ctx_settings,\n cls=DefaultGroup,\n default=\"render\",\n no_args_is_help=True,\n help=\"Animation engine for explanatory math videos.\",\n epilog=\"See 'manim <command>' to read about a specific subcommand.\\n\\n\"\n \"Note: the subcommand 'manim render' is called if no other subcommand \"\n \"is specified. Run 'manim render --help' if you would like to know what the \"\n f\"'-ql' or '-p' flags do, for example.\\n\\n{EPILOG}\",\n)\[email protected](\n \"--version\",\n is_flag=True,\n help=\"Show version and exit.\",\n callback=exit_early,\n is_eager=True,\n expose_value=False,\n)\[email protected]_context\ndef main(ctx):\n \"\"\"The entry point for manim.\"\"\"\n pass\n\n\nmain.add_command(checkhealth)\nmain.add_command(cfg)\nmain.add_command(plugins)\nmain.add_command(init)\nmain.add_command(render)\n\nif __name__ == \"__main__\":\n main()\n", "path": "manim/__main__.py"}]}
| 1,487 | 328 |
gh_patches_debug_708
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-2879
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
'TypeError' object has no attribute 'tb_frame'
While fetching object details from insight inspect, getting kicked out from the ipython console with the following error.
'TypeError' object has no attribute 'tb_frame'
(gss-rules) ⌊gss-rules⌋»$ insights inspect insights.parsers.installed_rpms.InstalledRpms ~/scripts/rhel7_sosreport/
IPython Console Usage Info:
Enter 'InstalledRpms.' and tab to get a list of properties
Example:
In [1]: InstalledRpms.<property_name>
Out[1]: <property value>
To exit ipython enter 'exit' and hit enter or use 'CTL D'
Starting IPython Interpreter Now
In [1]: InstalledRpms
'TypeError' object has no attribute 'tb_frame'
</issue>
<code>
[start of setup.py]
1 import os
2 import sys
3 from setuptools import setup, find_packages
4
5 __here__ = os.path.dirname(os.path.abspath(__file__))
6
7 package_info = dict.fromkeys(["RELEASE", "COMMIT", "VERSION", "NAME"])
8
9 for name in package_info:
10 with open(os.path.join(__here__, "insights", name)) as f:
11 package_info[name] = f.read().strip()
12
13 entry_points = {
14 'console_scripts': [
15 'insights-collect = insights.collect:main',
16 'insights-run = insights:main',
17 'insights = insights.command_parser:main',
18 'insights-cat = insights.tools.cat:main',
19 'insights-dupkeycheck = insights.tools.dupkeycheck:main',
20 'insights-inspect = insights.tools.insights_inspect:main',
21 'insights-info = insights.tools.query:main',
22 'insights-ocpshell= insights.ocpshell:main',
23 'client = insights.client:run',
24 'mangle = insights.util.mangle:main'
25 ]
26 }
27
28 runtime = set([
29 'six',
30 'requests',
31 'redis',
32 'cachecontrol',
33 'cachecontrol[redis]',
34 'cachecontrol[filecache]',
35 'defusedxml',
36 'lockfile',
37 'jinja2',
38 ])
39
40 if (sys.version_info < (2, 7)):
41 runtime.add('pyyaml>=3.10,<=3.13')
42 else:
43 runtime.add('pyyaml')
44
45
46 def maybe_require(pkg):
47 try:
48 __import__(pkg)
49 except ImportError:
50 runtime.add(pkg)
51
52
53 maybe_require("importlib")
54 maybe_require("argparse")
55
56
57 client = set([
58 'requests'
59 ])
60
61 develop = set([
62 'futures==3.0.5',
63 'wheel',
64 ])
65
66 docs = set([
67 'Sphinx<=3.0.2',
68 'nbsphinx',
69 'sphinx_rtd_theme',
70 'ipython',
71 'colorama',
72 'jinja2',
73 'Pygments'
74 ])
75
76 testing = set([
77 'coverage==4.3.4',
78 'pytest==3.0.6',
79 'pytest-cov==2.4.0',
80 'mock==2.0.0',
81 ])
82
83 cluster = set([
84 'ansible',
85 'pandas',
86 'colorama',
87 ])
88
89 openshift = set([
90 'openshift'
91 ])
92
93 linting = set([
94 'flake8==2.6.2',
95 ])
96
97 optional = set([
98 'python-cjson',
99 'python-logstash',
100 'python-statsd',
101 'watchdog',
102 ])
103
104 if __name__ == "__main__":
105 # allows for runtime modification of rpm name
106 name = os.environ.get("INSIGHTS_CORE_NAME", package_info["NAME"])
107
108 setup(
109 name=name,
110 version=package_info["VERSION"],
111 description="Insights Core is a data collection and analysis framework",
112 long_description=open("README.rst").read(),
113 url="https://github.com/redhatinsights/insights-core",
114 author="Red Hat, Inc.",
115 author_email="[email protected]",
116 packages=find_packages(),
117 install_requires=list(runtime),
118 package_data={'': ['LICENSE']},
119 license='Apache 2.0',
120 extras_require={
121 'develop': list(runtime | develop | client | docs | linting | testing | cluster),
122 'develop26': list(runtime | develop | client | linting | testing | cluster),
123 'client': list(runtime | client),
124 'client-develop': list(runtime | develop | client | linting | testing),
125 'cluster': list(runtime | cluster),
126 'openshift': list(runtime | openshift),
127 'optional': list(optional),
128 'docs': list(docs),
129 'linting': list(linting | client),
130 'testing': list(testing | client)
131 },
132 classifiers=[
133 'Development Status :: 5 - Production/Stable',
134 'Intended Audience :: Developers',
135 'Natural Language :: English',
136 'License :: OSI Approved :: Apache Software License',
137 'Programming Language :: Python',
138 'Programming Language :: Python :: 2.6',
139 'Programming Language :: Python :: 2.7',
140 'Programming Language :: Python :: 3.3',
141 'Programming Language :: Python :: 3.4',
142 'Programming Language :: Python :: 3.5',
143 'Programming Language :: Python :: 3.6'
144 ],
145 entry_points=entry_points,
146 include_package_data=True
147 )
148
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -70,7 +70,9 @@
'ipython',
'colorama',
'jinja2',
- 'Pygments'
+ 'Pygments',
+ 'jedi<0.18.0' # Open issue with jedi 0.18.0 and iPython <= 7.19
+ # https://github.com/davidhalter/jedi/issues/1714
])
testing = set([
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -70,7 +70,9 @@\n 'ipython',\n 'colorama',\n 'jinja2',\n- 'Pygments'\n+ 'Pygments',\n+ 'jedi<0.18.0' # Open issue with jedi 0.18.0 and iPython <= 7.19\n+ # https://github.com/davidhalter/jedi/issues/1714\n ])\n \n testing = set([\n", "issue": "'TypeError' object has no attribute 'tb_frame'\nWhile fetching object details from insight inspect, getting kicked out from the ipython console with the following error. \r\n 'TypeError' object has no attribute 'tb_frame'\r\n\r\n(gss-rules) \u230agss-rules\u230b\u00bb$ insights inspect insights.parsers.installed_rpms.InstalledRpms ~/scripts/rhel7_sosreport/\r\n\r\nIPython Console Usage Info:\r\n\r\nEnter 'InstalledRpms.' and tab to get a list of properties \r\nExample:\r\nIn [1]: InstalledRpms.<property_name>\r\nOut[1]: <property value>\r\n\r\nTo exit ipython enter 'exit' and hit enter or use 'CTL D'\r\n\r\nStarting IPython Interpreter Now \r\n\r\nIn [1]: InstalledRpms\r\n'TypeError' object has no attribute 'tb_frame'\r\n\n", "before_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\n\n__here__ = os.path.dirname(os.path.abspath(__file__))\n\npackage_info = dict.fromkeys([\"RELEASE\", \"COMMIT\", \"VERSION\", \"NAME\"])\n\nfor name in package_info:\n with open(os.path.join(__here__, \"insights\", name)) as f:\n package_info[name] = f.read().strip()\n\nentry_points = {\n 'console_scripts': [\n 'insights-collect = insights.collect:main',\n 'insights-run = insights:main',\n 'insights = insights.command_parser:main',\n 'insights-cat = insights.tools.cat:main',\n 'insights-dupkeycheck = insights.tools.dupkeycheck:main',\n 'insights-inspect = insights.tools.insights_inspect:main',\n 'insights-info = insights.tools.query:main',\n 'insights-ocpshell= insights.ocpshell:main',\n 'client = insights.client:run',\n 'mangle = insights.util.mangle:main'\n ]\n}\n\nruntime = set([\n 'six',\n 'requests',\n 'redis',\n 'cachecontrol',\n 'cachecontrol[redis]',\n 'cachecontrol[filecache]',\n 'defusedxml',\n 'lockfile',\n 'jinja2',\n])\n\nif (sys.version_info < (2, 7)):\n runtime.add('pyyaml>=3.10,<=3.13')\nelse:\n runtime.add('pyyaml')\n\n\ndef maybe_require(pkg):\n try:\n __import__(pkg)\n except ImportError:\n runtime.add(pkg)\n\n\nmaybe_require(\"importlib\")\nmaybe_require(\"argparse\")\n\n\nclient = set([\n 'requests'\n])\n\ndevelop = set([\n 'futures==3.0.5',\n 'wheel',\n])\n\ndocs = set([\n 'Sphinx<=3.0.2',\n 'nbsphinx',\n 'sphinx_rtd_theme',\n 'ipython',\n 'colorama',\n 'jinja2',\n 'Pygments'\n])\n\ntesting = set([\n 'coverage==4.3.4',\n 'pytest==3.0.6',\n 'pytest-cov==2.4.0',\n 'mock==2.0.0',\n])\n\ncluster = set([\n 'ansible',\n 'pandas',\n 'colorama',\n])\n\nopenshift = set([\n 'openshift'\n])\n\nlinting = set([\n 'flake8==2.6.2',\n])\n\noptional = set([\n 'python-cjson',\n 'python-logstash',\n 'python-statsd',\n 'watchdog',\n])\n\nif __name__ == \"__main__\":\n # allows for runtime modification of rpm name\n name = os.environ.get(\"INSIGHTS_CORE_NAME\", package_info[\"NAME\"])\n\n setup(\n name=name,\n version=package_info[\"VERSION\"],\n description=\"Insights Core is a data collection and analysis framework\",\n long_description=open(\"README.rst\").read(),\n url=\"https://github.com/redhatinsights/insights-core\",\n author=\"Red Hat, Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n install_requires=list(runtime),\n package_data={'': ['LICENSE']},\n license='Apache 2.0',\n extras_require={\n 'develop': list(runtime | develop | client | docs | linting | testing | cluster),\n 'develop26': list(runtime | develop | client | linting | testing | cluster),\n 'client': list(runtime | client),\n 'client-develop': list(runtime | develop | client | linting | testing),\n 'cluster': list(runtime | cluster),\n 'openshift': list(runtime | openshift),\n 'optional': list(optional),\n 'docs': list(docs),\n 'linting': list(linting | client),\n 'testing': list(testing | client)\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6'\n ],\n entry_points=entry_points,\n include_package_data=True\n )\n", "path": "setup.py"}]}
| 2,010 | 124 |
gh_patches_debug_1302
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3803
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Signer/Verifier deprecation warning has wrong stacklevel
Seeing this with Cryptography 2.0:
```
.../python3.5/site-packages/cryptography/hazmat/backends/openssl/rsa.py:477: DeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.
_warn_sign_verify_deprecated()
.../python3.5/site-packages/cryptography/hazmat/backends/openssl/rsa.py:382: DeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.
_warn_sign_verify_deprecated()
```
I see a few open issues related to deprecations (e.g. #3794), but I'm not sure if any of them cover this particular message.
</issue>
<code>
[start of src/cryptography/hazmat/backends/openssl/utils.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import warnings
8
9 from cryptography import utils
10 from cryptography.hazmat.primitives import hashes
11 from cryptography.hazmat.primitives.asymmetric.utils import Prehashed
12
13
14 def _calculate_digest_and_algorithm(backend, data, algorithm):
15 if not isinstance(algorithm, Prehashed):
16 hash_ctx = hashes.Hash(algorithm, backend)
17 hash_ctx.update(data)
18 data = hash_ctx.finalize()
19 else:
20 algorithm = algorithm._algorithm
21
22 if len(data) != algorithm.digest_size:
23 raise ValueError(
24 "The provided data must be the same length as the hash "
25 "algorithm's digest size."
26 )
27
28 return (data, algorithm)
29
30
31 def _check_not_prehashed(signature_algorithm):
32 if isinstance(signature_algorithm, Prehashed):
33 raise TypeError(
34 "Prehashed is only supported in the sign and verify methods. "
35 "It cannot be used with signer or verifier."
36 )
37
38
39 def _warn_sign_verify_deprecated():
40 warnings.warn(
41 "signer and verifier have been deprecated. Please use sign "
42 "and verify instead.",
43 utils.PersistentlyDeprecated,
44 stacklevel=2
45 )
46
[end of src/cryptography/hazmat/backends/openssl/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/backends/openssl/utils.py b/src/cryptography/hazmat/backends/openssl/utils.py
--- a/src/cryptography/hazmat/backends/openssl/utils.py
+++ b/src/cryptography/hazmat/backends/openssl/utils.py
@@ -41,5 +41,5 @@
"signer and verifier have been deprecated. Please use sign "
"and verify instead.",
utils.PersistentlyDeprecated,
- stacklevel=2
+ stacklevel=3
)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/backends/openssl/utils.py b/src/cryptography/hazmat/backends/openssl/utils.py\n--- a/src/cryptography/hazmat/backends/openssl/utils.py\n+++ b/src/cryptography/hazmat/backends/openssl/utils.py\n@@ -41,5 +41,5 @@\n \"signer and verifier have been deprecated. Please use sign \"\n \"and verify instead.\",\n utils.PersistentlyDeprecated,\n- stacklevel=2\n+ stacklevel=3\n )\n", "issue": "Signer/Verifier deprecation warning has wrong stacklevel\nSeeing this with Cryptography 2.0:\r\n\r\n```\r\n.../python3.5/site-packages/cryptography/hazmat/backends/openssl/rsa.py:477: DeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.\r\n _warn_sign_verify_deprecated()\r\n.../python3.5/site-packages/cryptography/hazmat/backends/openssl/rsa.py:382: DeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.\r\n _warn_sign_verify_deprecated()\r\n```\r\n\r\nI see a few open issues related to deprecations (e.g. #3794), but I'm not sure if any of them cover this particular message.\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport warnings\n\nfrom cryptography import utils\nfrom cryptography.hazmat.primitives import hashes\nfrom cryptography.hazmat.primitives.asymmetric.utils import Prehashed\n\n\ndef _calculate_digest_and_algorithm(backend, data, algorithm):\n if not isinstance(algorithm, Prehashed):\n hash_ctx = hashes.Hash(algorithm, backend)\n hash_ctx.update(data)\n data = hash_ctx.finalize()\n else:\n algorithm = algorithm._algorithm\n\n if len(data) != algorithm.digest_size:\n raise ValueError(\n \"The provided data must be the same length as the hash \"\n \"algorithm's digest size.\"\n )\n\n return (data, algorithm)\n\n\ndef _check_not_prehashed(signature_algorithm):\n if isinstance(signature_algorithm, Prehashed):\n raise TypeError(\n \"Prehashed is only supported in the sign and verify methods. \"\n \"It cannot be used with signer or verifier.\"\n )\n\n\ndef _warn_sign_verify_deprecated():\n warnings.warn(\n \"signer and verifier have been deprecated. Please use sign \"\n \"and verify instead.\",\n utils.PersistentlyDeprecated,\n stacklevel=2\n )\n", "path": "src/cryptography/hazmat/backends/openssl/utils.py"}]}
| 1,096 | 116 |
gh_patches_debug_15389
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-381
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bioclim data missing hdr files when downloaded to path
retriever download Bioclim -p
</issue>
<code>
[start of scripts/bioclim_2pt5.py]
1 #retriever
2
3 """Retriever script for direct download of Bioclim data"""
4
5 from retriever.lib.templates import Script
6
7
8 class main(Script):
9 def __init__(self, **kwargs):
10 Script.__init__(self, **kwargs)
11 self.name = "Bioclim 2.5 Minute Climate Data"
12 self.shortname = "Bioclim"
13 self.ref = "http://worldclim.org/bioclim"
14 self.urls = {"climate": "http://biogeo.ucdavis.edu/data/climate/worldclim/1_4/grid/cur/bio_2-5m_bil.zip"}
15 self.description = "Bioclimatic variables that are derived from the monthly temperature and rainfall values in order to generate more biologically meaningful variables."
16 self.citation = "Hijmans, R.J., S.E. Cameron, J.L. Parra, P.G. Jones and A. Jarvis, 2005. Very high resolution interpolated climate surfaces for global land areas. International Journal of Climatology 25: 1965-1978."
17 self.tags = ["Data Type > Compilation"]
18
19 def download(self, engine=None, debug=False):
20 if engine.name != "Download Only":
21 raise Exception("The Bioclim dataset contains only non-tabular data files, and can only be used with the 'download only' engine.")
22 Script.download(self, engine, debug)
23 file_names = ["bio%s.bil" % file_num for file_num in range(1, 20)]
24 self.engine.download_files_from_archive(self.urls["climate"], file_names)
25 self.engine.register_files(file_names)
26
27 SCRIPT = main()
28
[end of scripts/bioclim_2pt5.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/bioclim_2pt5.py b/scripts/bioclim_2pt5.py
--- a/scripts/bioclim_2pt5.py
+++ b/scripts/bioclim_2pt5.py
@@ -20,8 +20,12 @@
if engine.name != "Download Only":
raise Exception("The Bioclim dataset contains only non-tabular data files, and can only be used with the 'download only' engine.")
Script.download(self, engine, debug)
- file_names = ["bio%s.bil" % file_num for file_num in range(1, 20)]
+ file_names = []
+ for file_num in range(1, 20):
+ for ext in (['bil', 'hdr']):
+ file_names += ["bio{0}.{1}".format(file_num, ext)]
self.engine.download_files_from_archive(self.urls["climate"], file_names)
self.engine.register_files(file_names)
SCRIPT = main()
+
|
{"golden_diff": "diff --git a/scripts/bioclim_2pt5.py b/scripts/bioclim_2pt5.py\n--- a/scripts/bioclim_2pt5.py\n+++ b/scripts/bioclim_2pt5.py\n@@ -20,8 +20,12 @@\n if engine.name != \"Download Only\":\n raise Exception(\"The Bioclim dataset contains only non-tabular data files, and can only be used with the 'download only' engine.\")\n Script.download(self, engine, debug)\n- file_names = [\"bio%s.bil\" % file_num for file_num in range(1, 20)]\n+ file_names = []\n+ for file_num in range(1, 20):\n+ for ext in (['bil', 'hdr']):\n+ file_names += [\"bio{0}.{1}\".format(file_num, ext)]\n self.engine.download_files_from_archive(self.urls[\"climate\"], file_names)\n self.engine.register_files(file_names)\n \n SCRIPT = main()\n+\n", "issue": "Bioclim data missing hdr files when downloaded to path\n retriever download Bioclim -p\n\n", "before_files": [{"content": "#retriever\n\n\"\"\"Retriever script for direct download of Bioclim data\"\"\"\n\nfrom retriever.lib.templates import Script\n\n\nclass main(Script):\n def __init__(self, **kwargs):\n Script.__init__(self, **kwargs)\n self.name = \"Bioclim 2.5 Minute Climate Data\"\n self.shortname = \"Bioclim\"\n self.ref = \"http://worldclim.org/bioclim\"\n self.urls = {\"climate\": \"http://biogeo.ucdavis.edu/data/climate/worldclim/1_4/grid/cur/bio_2-5m_bil.zip\"}\n self.description = \"Bioclimatic variables that are derived from the monthly temperature and rainfall values in order to generate more biologically meaningful variables.\"\n self.citation = \"Hijmans, R.J., S.E. Cameron, J.L. Parra, P.G. Jones and A. Jarvis, 2005. Very high resolution interpolated climate surfaces for global land areas. International Journal of Climatology 25: 1965-1978.\"\n self.tags = [\"Data Type > Compilation\"]\n \n def download(self, engine=None, debug=False):\n if engine.name != \"Download Only\":\n raise Exception(\"The Bioclim dataset contains only non-tabular data files, and can only be used with the 'download only' engine.\")\n Script.download(self, engine, debug)\n file_names = [\"bio%s.bil\" % file_num for file_num in range(1, 20)]\n self.engine.download_files_from_archive(self.urls[\"climate\"], file_names)\n self.engine.register_files(file_names)\n\nSCRIPT = main()\n", "path": "scripts/bioclim_2pt5.py"}]}
| 973 | 215 |
gh_patches_debug_64312
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1932
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.108
On the docket:
+ [x] Fix slow PEX boot time when there are many extras. #1929
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.107"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.107"
+__version__ = "2.1.108"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.107\"\n+__version__ = \"2.1.108\"\n", "issue": "Release 2.1.108\nOn the docket:\r\n+ [x] Fix slow PEX boot time when there are many extras. #1929\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.107\"\n", "path": "pex/version.py"}]}
| 621 | 99 |
gh_patches_debug_35624
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-756
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
500 error on FMV Detail View page
I noticed this bug when trying to use the FMV module on Danesfield. I tested it on a fresh RGD instance and it still occured.
To reproduce -
- Run the `rgd_fmv_wasabi` management command to populate your DB with FMV data
- Attempt to navigate to `http://localhost:8000/rgd_fmv/<:id>/` and it will return a 500 error with the error `string indices must be integers
`.
500 error on `/rgd_fmv/{spatial_id}` endpoint
I noticed this bug when trying to use the FMV module on Danesfield. I tested it on a fresh RGD instance and it still occurred.
To reproduce -
- Run the `rgd_fmv_wasabi` management command to populate your DB with FMV data
- Hit the `/rgd_fmv/{spatial_id}` API endpoint and a 500 will be returned with an error ```AttributeError at /api/rgd_fmv/1
Got AttributeError when attempting to get a value for field `file` on serializer `FMVSerializer`.
The serializer field might be named incorrectly and not match any attribute or key on the `FMVMeta` instance.
Original exception text was: 'FMVMeta' object has no attribute 'file'.```
</issue>
<code>
[start of django-rgd-fmv/rgd_fmv/rest/viewsets.py]
1 from rest_framework.decorators import action
2 from rgd.rest.base import ModelViewSet
3 from rgd_fmv import models, serializers
4
5
6 class FMVViewSet(ModelViewSet):
7 queryset = models.FMVMeta.objects.all()
8
9 def get_serializer_class(self):
10 if self.action in ['get', 'list']:
11 return serializers.FMVMetaSerializer
12 return serializers.FMVSerializer
13
14 @action(detail=True, serializer_class=serializers.FMVMetaDataSerializer)
15 def data(self, request, *args, **kwargs):
16 return self.retrieve(request, *args, **kwargs)
17
[end of django-rgd-fmv/rgd_fmv/rest/viewsets.py]
[start of django-rgd-fmv/rgd_fmv/views.py]
1 import json
2
3 from rgd.views import SpatialDetailView
4
5 from . import models
6
7
8 class FMVMetaDetailView(SpatialDetailView):
9 model = models.FMVMeta
10
11 def get_context_data(self, *args, **kwargs):
12 context = super().get_context_data(*args, **kwargs)
13 context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)
14 extents = context['extents']
15 if self.object.ground_union is not None:
16 # All or none of these will be set, only check one
17 extents['collect'] = self.object.ground_union.json
18 extents['ground_frames'] = self.object.ground_frames.json
19 extents['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)
20 return context
21
[end of django-rgd-fmv/rgd_fmv/views.py]
[start of django-rgd-fmv/rgd_fmv/urls.py]
1 from django.urls import path
2 from rest_framework.routers import SimpleRouter
3 from rgd_fmv import models, views
4 from rgd_fmv.rest import viewsets
5
6 router = SimpleRouter(trailing_slash=False)
7 router.register(r'api/rgd_fmv', viewsets.FMVViewSet)
8
9 urlpatterns = [
10 # Pages
11 path(
12 'rgd_fmv/<int:pk>/',
13 views.FMVMetaDetailView.as_view(),
14 name=models.FMVMeta.detail_view_name,
15 ),
16 ] + router.urls
17
[end of django-rgd-fmv/rgd_fmv/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django-rgd-fmv/rgd_fmv/rest/viewsets.py b/django-rgd-fmv/rgd_fmv/rest/viewsets.py
--- a/django-rgd-fmv/rgd_fmv/rest/viewsets.py
+++ b/django-rgd-fmv/rgd_fmv/rest/viewsets.py
@@ -1,16 +1,17 @@
from rest_framework.decorators import action
-from rgd.rest.base import ModelViewSet
+from rgd.rest.base import ModelViewSet, ReadOnlyModelViewSet
from rgd_fmv import models, serializers
-class FMVViewSet(ModelViewSet):
+class FMVMetaViewSet(ReadOnlyModelViewSet):
queryset = models.FMVMeta.objects.all()
-
- def get_serializer_class(self):
- if self.action in ['get', 'list']:
- return serializers.FMVMetaSerializer
- return serializers.FMVSerializer
+ serializer_class = serializers.FMVMetaSerializer
@action(detail=True, serializer_class=serializers.FMVMetaDataSerializer)
def data(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
+
+
+class FMVViewSet(ModelViewSet):
+ queryset = models.FMV.objects.all()
+ serializer_class = serializers.FMVSerializer
diff --git a/django-rgd-fmv/rgd_fmv/urls.py b/django-rgd-fmv/rgd_fmv/urls.py
--- a/django-rgd-fmv/rgd_fmv/urls.py
+++ b/django-rgd-fmv/rgd_fmv/urls.py
@@ -4,7 +4,8 @@
from rgd_fmv.rest import viewsets
router = SimpleRouter(trailing_slash=False)
-router.register(r'api/rgd_fmv', viewsets.FMVViewSet)
+router.register(r'api/rgd_fmv', viewsets.FMVMetaViewSet, basename='fmv-meta')
+router.register(r'api/rgd_fmv/model', viewsets.FMVViewSet, basename='fmv')
urlpatterns = [
# Pages
diff --git a/django-rgd-fmv/rgd_fmv/views.py b/django-rgd-fmv/rgd_fmv/views.py
--- a/django-rgd-fmv/rgd_fmv/views.py
+++ b/django-rgd-fmv/rgd_fmv/views.py
@@ -11,10 +11,11 @@
def get_context_data(self, *args, **kwargs):
context = super().get_context_data(*args, **kwargs)
context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)
- extents = context['extents']
+ extents = json.loads(context['extents'])
if self.object.ground_union is not None:
# All or none of these will be set, only check one
extents['collect'] = self.object.ground_union.json
extents['ground_frames'] = self.object.ground_frames.json
extents['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)
+ context['extents'] = json.dumps(extents)
return context
|
{"golden_diff": "diff --git a/django-rgd-fmv/rgd_fmv/rest/viewsets.py b/django-rgd-fmv/rgd_fmv/rest/viewsets.py\n--- a/django-rgd-fmv/rgd_fmv/rest/viewsets.py\n+++ b/django-rgd-fmv/rgd_fmv/rest/viewsets.py\n@@ -1,16 +1,17 @@\n from rest_framework.decorators import action\n-from rgd.rest.base import ModelViewSet\n+from rgd.rest.base import ModelViewSet, ReadOnlyModelViewSet\n from rgd_fmv import models, serializers\n \n \n-class FMVViewSet(ModelViewSet):\n+class FMVMetaViewSet(ReadOnlyModelViewSet):\n queryset = models.FMVMeta.objects.all()\n-\n- def get_serializer_class(self):\n- if self.action in ['get', 'list']:\n- return serializers.FMVMetaSerializer\n- return serializers.FMVSerializer\n+ serializer_class = serializers.FMVMetaSerializer\n \n @action(detail=True, serializer_class=serializers.FMVMetaDataSerializer)\n def data(self, request, *args, **kwargs):\n return self.retrieve(request, *args, **kwargs)\n+\n+\n+class FMVViewSet(ModelViewSet):\n+ queryset = models.FMV.objects.all()\n+ serializer_class = serializers.FMVSerializer\ndiff --git a/django-rgd-fmv/rgd_fmv/urls.py b/django-rgd-fmv/rgd_fmv/urls.py\n--- a/django-rgd-fmv/rgd_fmv/urls.py\n+++ b/django-rgd-fmv/rgd_fmv/urls.py\n@@ -4,7 +4,8 @@\n from rgd_fmv.rest import viewsets\n \n router = SimpleRouter(trailing_slash=False)\n-router.register(r'api/rgd_fmv', viewsets.FMVViewSet)\n+router.register(r'api/rgd_fmv', viewsets.FMVMetaViewSet, basename='fmv-meta')\n+router.register(r'api/rgd_fmv/model', viewsets.FMVViewSet, basename='fmv')\n \n urlpatterns = [\n # Pages\ndiff --git a/django-rgd-fmv/rgd_fmv/views.py b/django-rgd-fmv/rgd_fmv/views.py\n--- a/django-rgd-fmv/rgd_fmv/views.py\n+++ b/django-rgd-fmv/rgd_fmv/views.py\n@@ -11,10 +11,11 @@\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)\n- extents = context['extents']\n+ extents = json.loads(context['extents'])\n if self.object.ground_union is not None:\n # All or none of these will be set, only check one\n extents['collect'] = self.object.ground_union.json\n extents['ground_frames'] = self.object.ground_frames.json\n extents['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)\n+ context['extents'] = json.dumps(extents)\n return context\n", "issue": "500 error on FMV Detail View page\nI noticed this bug when trying to use the FMV module on Danesfield. I tested it on a fresh RGD instance and it still occured.\r\n\r\nTo reproduce -\r\n- Run the `rgd_fmv_wasabi` management command to populate your DB with FMV data\r\n- Attempt to navigate to `http://localhost:8000/rgd_fmv/<:id>/` and it will return a 500 error with the error `string indices must be integers\r\n`.\n500 error on `/rgd_fmv/{spatial_id}` endpoint\nI noticed this bug when trying to use the FMV module on Danesfield. I tested it on a fresh RGD instance and it still occurred.\r\n\r\nTo reproduce -\r\n\r\n- Run the `rgd_fmv_wasabi` management command to populate your DB with FMV data\r\n- Hit the `/rgd_fmv/{spatial_id}` API endpoint and a 500 will be returned with an error ```AttributeError at /api/rgd_fmv/1\r\nGot AttributeError when attempting to get a value for field `file` on serializer `FMVSerializer`.\r\nThe serializer field might be named incorrectly and not match any attribute or key on the `FMVMeta` instance.\r\nOriginal exception text was: 'FMVMeta' object has no attribute 'file'.```\n", "before_files": [{"content": "from rest_framework.decorators import action\nfrom rgd.rest.base import ModelViewSet\nfrom rgd_fmv import models, serializers\n\n\nclass FMVViewSet(ModelViewSet):\n queryset = models.FMVMeta.objects.all()\n\n def get_serializer_class(self):\n if self.action in ['get', 'list']:\n return serializers.FMVMetaSerializer\n return serializers.FMVSerializer\n\n @action(detail=True, serializer_class=serializers.FMVMetaDataSerializer)\n def data(self, request, *args, **kwargs):\n return self.retrieve(request, *args, **kwargs)\n", "path": "django-rgd-fmv/rgd_fmv/rest/viewsets.py"}, {"content": "import json\n\nfrom rgd.views import SpatialDetailView\n\nfrom . import models\n\n\nclass FMVMetaDetailView(SpatialDetailView):\n model = models.FMVMeta\n\n def get_context_data(self, *args, **kwargs):\n context = super().get_context_data(*args, **kwargs)\n context['frame_rate'] = json.dumps(self.object.fmv_file.frame_rate)\n extents = context['extents']\n if self.object.ground_union is not None:\n # All or none of these will be set, only check one\n extents['collect'] = self.object.ground_union.json\n extents['ground_frames'] = self.object.ground_frames.json\n extents['frame_numbers'] = self.object._blob_to_array(self.object.frame_numbers)\n return context\n", "path": "django-rgd-fmv/rgd_fmv/views.py"}, {"content": "from django.urls import path\nfrom rest_framework.routers import SimpleRouter\nfrom rgd_fmv import models, views\nfrom rgd_fmv.rest import viewsets\n\nrouter = SimpleRouter(trailing_slash=False)\nrouter.register(r'api/rgd_fmv', viewsets.FMVViewSet)\n\nurlpatterns = [\n # Pages\n path(\n 'rgd_fmv/<int:pk>/',\n views.FMVMetaDetailView.as_view(),\n name=models.FMVMeta.detail_view_name,\n ),\n] + router.urls\n", "path": "django-rgd-fmv/rgd_fmv/urls.py"}]}
| 1,402 | 694 |
gh_patches_debug_7468
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1661
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OpenID payload cache uses the wrong cache key
The `cache_key` becomes the same for every access token due to this bug: https://github.com/Kinto/kinto/blob/e1e0d6be0024418fd100210901f9d2ca06344fe1/kinto/plugins/openid/__init__.py#L51
No matter what the `hmac_tokens` variable is the `cache_key` always becomes `'openid:verify:%s'`.
OpenID payload cache uses the wrong cache key
The `cache_key` becomes the same for every access token due to this bug: https://github.com/Kinto/kinto/blob/e1e0d6be0024418fd100210901f9d2ca06344fe1/kinto/plugins/openid/__init__.py#L51
No matter what the `hmac_tokens` variable is the `cache_key` always becomes `'openid:verify:%s'`.
</issue>
<code>
[start of kinto/plugins/openid/__init__.py]
1 import re
2
3 import requests
4 from pyramid import authentication as base_auth
5 from pyramid.interfaces import IAuthenticationPolicy
6 from zope.interface import implementer
7
8 from kinto.core import logger
9 from kinto.core import utils as core_utils
10 from kinto.core.openapi import OpenAPI
11
12 from .utils import fetch_openid_config
13
14
15 @implementer(IAuthenticationPolicy)
16 class OpenIDConnectPolicy(base_auth.CallbackAuthenticationPolicy):
17 def __init__(self, issuer, client_id, realm='Realm', **kwargs):
18 self.realm = realm
19 self.issuer = issuer
20 self.client_id = client_id
21 self.client_secret = kwargs.get('client_secret', '')
22 self.header_type = kwargs.get('header_type', 'Bearer')
23 self.userid_field = kwargs.get('userid_field', 'sub')
24 self.verification_ttl = int(kwargs.get('verification_ttl_seconds', 86400))
25
26 # Fetch OpenID config (at instantiation, ie. startup)
27 self.oid_config = fetch_openid_config(issuer)
28
29 self._jwt_keys = None
30
31 def unauthenticated_userid(self, request):
32 """Return the userid or ``None`` if token could not be verified.
33 """
34 settings = request.registry.settings
35 hmac_secret = settings['userid_hmac_secret']
36
37 authorization = request.headers.get('Authorization', '')
38 try:
39 authmeth, access_token = authorization.split(' ', 1)
40 except ValueError:
41 return None
42
43 if authmeth.lower() != self.header_type.lower():
44 return None
45
46 # XXX JWT Access token
47 # https://auth0.com/docs/tokens/access-token#access-token-format
48
49 # Check cache if these tokens were already verified.
50 hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)
51 cache_key = 'openid:verify:%s'.format(hmac_tokens)
52 payload = request.registry.cache.get(cache_key)
53 if payload is None:
54 # This can take some time.
55 payload = self._verify_token(access_token)
56 if payload is None:
57 return None
58 # Save for next time / refresh ttl.
59 request.registry.cache.set(cache_key, payload, ttl=self.verification_ttl)
60 # Extract meaningful field from userinfo (eg. email or sub)
61 return payload.get(self.userid_field)
62
63 def forget(self, request):
64 """A no-op. Credentials are sent on every request.
65 Return WWW-Authenticate Realm header for Bearer token.
66 """
67 return [('WWW-Authenticate', '%s realm="%s"' % (self.header_type, self.realm))]
68
69 def _verify_token(self, access_token):
70 uri = self.oid_config['userinfo_endpoint']
71 # Opaque access token string. Fetch user info from profile.
72 try:
73 resp = requests.get(uri, headers={'Authorization': 'Bearer ' + access_token})
74 resp.raise_for_status()
75 userprofile = resp.json()
76 return userprofile
77
78 except (requests.exceptions.HTTPError, ValueError, KeyError) as e:
79 logger.debug('Unable to fetch user profile from %s (%s)' % (uri, e))
80 return None
81
82
83 def includeme(config):
84 # Activate end-points.
85 config.scan('kinto.plugins.openid.views')
86
87 settings = config.get_settings()
88
89 openid_policies = []
90 for k, v in settings.items():
91 m = re.match('multiauth\.policy\.(.*)\.use', k)
92 if m:
93 if v.endswith('OpenIDConnectPolicy'):
94 openid_policies.append(m.group(1))
95
96 if len(openid_policies) == 0:
97 # Do not add the capability if no policy is configured.
98 return
99
100 providers_infos = []
101 for name in openid_policies:
102 issuer = settings['multiauth.policy.%s.issuer' % name]
103 openid_config = fetch_openid_config(issuer)
104
105 client_id = settings['multiauth.policy.%s.client_id' % name]
106 header_type = settings.get('multiauth.policy.%s.header_type', 'Bearer')
107
108 providers_infos.append({
109 'name': name,
110 'issuer': openid_config['issuer'],
111 'auth_path': '/openid/%s/login' % name,
112 'client_id': client_id,
113 'header_type': header_type,
114 'userinfo_endpoint': openid_config['userinfo_endpoint'],
115 })
116
117 OpenAPI.expose_authentication_method(name, {
118 'type': 'oauth2',
119 'authorizationUrl': openid_config['authorization_endpoint'],
120 })
121
122 config.add_api_capability(
123 'openid',
124 description='OpenID connect support.',
125 url='http://kinto.readthedocs.io/en/stable/api/1.x/authentication.html',
126 providers=providers_infos)
127
[end of kinto/plugins/openid/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/plugins/openid/__init__.py b/kinto/plugins/openid/__init__.py
--- a/kinto/plugins/openid/__init__.py
+++ b/kinto/plugins/openid/__init__.py
@@ -48,7 +48,7 @@
# Check cache if these tokens were already verified.
hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)
- cache_key = 'openid:verify:%s'.format(hmac_tokens)
+ cache_key = 'openid:verify:{}'.format(hmac_tokens)
payload = request.registry.cache.get(cache_key)
if payload is None:
# This can take some time.
|
{"golden_diff": "diff --git a/kinto/plugins/openid/__init__.py b/kinto/plugins/openid/__init__.py\n--- a/kinto/plugins/openid/__init__.py\n+++ b/kinto/plugins/openid/__init__.py\n@@ -48,7 +48,7 @@\n \n # Check cache if these tokens were already verified.\n hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)\n- cache_key = 'openid:verify:%s'.format(hmac_tokens)\n+ cache_key = 'openid:verify:{}'.format(hmac_tokens)\n payload = request.registry.cache.get(cache_key)\n if payload is None:\n # This can take some time.\n", "issue": "OpenID payload cache uses the wrong cache key\nThe `cache_key` becomes the same for every access token due to this bug: https://github.com/Kinto/kinto/blob/e1e0d6be0024418fd100210901f9d2ca06344fe1/kinto/plugins/openid/__init__.py#L51\r\nNo matter what the `hmac_tokens` variable is the `cache_key` always becomes `'openid:verify:%s'`.\r\n\r\n\nOpenID payload cache uses the wrong cache key\nThe `cache_key` becomes the same for every access token due to this bug: https://github.com/Kinto/kinto/blob/e1e0d6be0024418fd100210901f9d2ca06344fe1/kinto/plugins/openid/__init__.py#L51\r\nNo matter what the `hmac_tokens` variable is the `cache_key` always becomes `'openid:verify:%s'`.\r\n\r\n\n", "before_files": [{"content": "import re\n\nimport requests\nfrom pyramid import authentication as base_auth\nfrom pyramid.interfaces import IAuthenticationPolicy\nfrom zope.interface import implementer\n\nfrom kinto.core import logger\nfrom kinto.core import utils as core_utils\nfrom kinto.core.openapi import OpenAPI\n\nfrom .utils import fetch_openid_config\n\n\n@implementer(IAuthenticationPolicy)\nclass OpenIDConnectPolicy(base_auth.CallbackAuthenticationPolicy):\n def __init__(self, issuer, client_id, realm='Realm', **kwargs):\n self.realm = realm\n self.issuer = issuer\n self.client_id = client_id\n self.client_secret = kwargs.get('client_secret', '')\n self.header_type = kwargs.get('header_type', 'Bearer')\n self.userid_field = kwargs.get('userid_field', 'sub')\n self.verification_ttl = int(kwargs.get('verification_ttl_seconds', 86400))\n\n # Fetch OpenID config (at instantiation, ie. startup)\n self.oid_config = fetch_openid_config(issuer)\n\n self._jwt_keys = None\n\n def unauthenticated_userid(self, request):\n \"\"\"Return the userid or ``None`` if token could not be verified.\n \"\"\"\n settings = request.registry.settings\n hmac_secret = settings['userid_hmac_secret']\n\n authorization = request.headers.get('Authorization', '')\n try:\n authmeth, access_token = authorization.split(' ', 1)\n except ValueError:\n return None\n\n if authmeth.lower() != self.header_type.lower():\n return None\n\n # XXX JWT Access token\n # https://auth0.com/docs/tokens/access-token#access-token-format\n\n # Check cache if these tokens were already verified.\n hmac_tokens = core_utils.hmac_digest(hmac_secret, access_token)\n cache_key = 'openid:verify:%s'.format(hmac_tokens)\n payload = request.registry.cache.get(cache_key)\n if payload is None:\n # This can take some time.\n payload = self._verify_token(access_token)\n if payload is None:\n return None\n # Save for next time / refresh ttl.\n request.registry.cache.set(cache_key, payload, ttl=self.verification_ttl)\n # Extract meaningful field from userinfo (eg. email or sub)\n return payload.get(self.userid_field)\n\n def forget(self, request):\n \"\"\"A no-op. Credentials are sent on every request.\n Return WWW-Authenticate Realm header for Bearer token.\n \"\"\"\n return [('WWW-Authenticate', '%s realm=\"%s\"' % (self.header_type, self.realm))]\n\n def _verify_token(self, access_token):\n uri = self.oid_config['userinfo_endpoint']\n # Opaque access token string. Fetch user info from profile.\n try:\n resp = requests.get(uri, headers={'Authorization': 'Bearer ' + access_token})\n resp.raise_for_status()\n userprofile = resp.json()\n return userprofile\n\n except (requests.exceptions.HTTPError, ValueError, KeyError) as e:\n logger.debug('Unable to fetch user profile from %s (%s)' % (uri, e))\n return None\n\n\ndef includeme(config):\n # Activate end-points.\n config.scan('kinto.plugins.openid.views')\n\n settings = config.get_settings()\n\n openid_policies = []\n for k, v in settings.items():\n m = re.match('multiauth\\.policy\\.(.*)\\.use', k)\n if m:\n if v.endswith('OpenIDConnectPolicy'):\n openid_policies.append(m.group(1))\n\n if len(openid_policies) == 0:\n # Do not add the capability if no policy is configured.\n return\n\n providers_infos = []\n for name in openid_policies:\n issuer = settings['multiauth.policy.%s.issuer' % name]\n openid_config = fetch_openid_config(issuer)\n\n client_id = settings['multiauth.policy.%s.client_id' % name]\n header_type = settings.get('multiauth.policy.%s.header_type', 'Bearer')\n\n providers_infos.append({\n 'name': name,\n 'issuer': openid_config['issuer'],\n 'auth_path': '/openid/%s/login' % name,\n 'client_id': client_id,\n 'header_type': header_type,\n 'userinfo_endpoint': openid_config['userinfo_endpoint'],\n })\n\n OpenAPI.expose_authentication_method(name, {\n 'type': 'oauth2',\n 'authorizationUrl': openid_config['authorization_endpoint'],\n })\n\n config.add_api_capability(\n 'openid',\n description='OpenID connect support.',\n url='http://kinto.readthedocs.io/en/stable/api/1.x/authentication.html',\n providers=providers_infos)\n", "path": "kinto/plugins/openid/__init__.py"}]}
| 2,047 | 146 |
gh_patches_debug_33176
|
rasdani/github-patches
|
git_diff
|
coala__coala-5814
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Imported classes should be arranged lexicographically
Classes being imported in `coala/coalib/bearlib/languages/__init__.py` file should be arranged alphabetically.
A good newcomer issue.
</issue>
<code>
[start of coalib/bearlib/languages/__init__.py]
1 """
2 This directory holds means to get generic information for specific languages.
3 """
4
5 # Start ignoring PyUnusedCodeBear
6 from .Language import Language
7 from .Language import Languages
8
9 from .definitions.Unknown import Unknown
10 from .definitions.antlr import antlr
11 from .definitions.Bash import Bash
12 from .definitions.C import C
13 from .definitions.CPP import CPP
14 from .definitions.CSharp import CSharp
15 from .definitions.CSS import CSS
16 from .definitions.D import D
17 from .definitions.Fortran import Fortran
18 from .definitions.Golang import Golang
19 from .definitions.GraphQL import GraphQL
20 from .definitions.html import HTML
21 from .definitions.Java import Java
22 from .definitions.JavaScript import JavaScript
23 from .definitions.JSON import JSON
24 from .definitions.JSP import JSP
25 from .definitions.KornShell import KornShell
26 from .definitions.m4 import m4
27 from .definitions.Matlab import Matlab
28 from .definitions.Markdown import Markdown
29 from .definitions.ObjectiveC import ObjectiveC
30 from .definitions.PHP import PHP
31 from .definitions.PLSQL import PLSQL
32 from .definitions.PowerShell import PowerShell
33 from .definitions.Python import Python
34 from .definitions.Ruby import Ruby
35 from .definitions.Scala import Scala
36 from .definitions.Swift import Swift
37 from .definitions.Tcl import Tcl
38 from .definitions.TinyBasic import TinyBasic
39 from .definitions.Vala import Vala
40 from .definitions.TypeScript import TypeScript
41 from .definitions.Shell import Shell
42 from .definitions.Jinja2 import Jinja2
43 from .definitions.VisualBasic import VisualBasic
44 from .definitions.XML import XML
45 from.definitions.ZShell import ZShell
46 # Stop ignoring PyUnusedCodeBear
47
[end of coalib/bearlib/languages/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/coalib/bearlib/languages/__init__.py b/coalib/bearlib/languages/__init__.py
--- a/coalib/bearlib/languages/__init__.py
+++ b/coalib/bearlib/languages/__init__.py
@@ -7,6 +7,7 @@
from .Language import Languages
from .definitions.Unknown import Unknown
+
from .definitions.antlr import antlr
from .definitions.Bash import Bash
from .definitions.C import C
@@ -20,12 +21,13 @@
from .definitions.html import HTML
from .definitions.Java import Java
from .definitions.JavaScript import JavaScript
+from .definitions.Jinja2 import Jinja2
from .definitions.JSON import JSON
from .definitions.JSP import JSP
from .definitions.KornShell import KornShell
from .definitions.m4 import m4
-from .definitions.Matlab import Matlab
from .definitions.Markdown import Markdown
+from .definitions.Matlab import Matlab
from .definitions.ObjectiveC import ObjectiveC
from .definitions.PHP import PHP
from .definitions.PLSQL import PLSQL
@@ -33,14 +35,14 @@
from .definitions.Python import Python
from .definitions.Ruby import Ruby
from .definitions.Scala import Scala
+from .definitions.Shell import Shell
from .definitions.Swift import Swift
from .definitions.Tcl import Tcl
from .definitions.TinyBasic import TinyBasic
-from .definitions.Vala import Vala
from .definitions.TypeScript import TypeScript
-from .definitions.Shell import Shell
-from .definitions.Jinja2 import Jinja2
+from .definitions.Vala import Vala
from .definitions.VisualBasic import VisualBasic
from .definitions.XML import XML
-from.definitions.ZShell import ZShell
+from .definitions.ZShell import ZShell
+
# Stop ignoring PyUnusedCodeBear
|
{"golden_diff": "diff --git a/coalib/bearlib/languages/__init__.py b/coalib/bearlib/languages/__init__.py\n--- a/coalib/bearlib/languages/__init__.py\n+++ b/coalib/bearlib/languages/__init__.py\n@@ -7,6 +7,7 @@\n from .Language import Languages\n \n from .definitions.Unknown import Unknown\n+\n from .definitions.antlr import antlr\n from .definitions.Bash import Bash\n from .definitions.C import C\n@@ -20,12 +21,13 @@\n from .definitions.html import HTML\n from .definitions.Java import Java\n from .definitions.JavaScript import JavaScript\n+from .definitions.Jinja2 import Jinja2\n from .definitions.JSON import JSON\n from .definitions.JSP import JSP\n from .definitions.KornShell import KornShell\n from .definitions.m4 import m4\n-from .definitions.Matlab import Matlab\n from .definitions.Markdown import Markdown\n+from .definitions.Matlab import Matlab\n from .definitions.ObjectiveC import ObjectiveC\n from .definitions.PHP import PHP\n from .definitions.PLSQL import PLSQL\n@@ -33,14 +35,14 @@\n from .definitions.Python import Python\n from .definitions.Ruby import Ruby\n from .definitions.Scala import Scala\n+from .definitions.Shell import Shell\n from .definitions.Swift import Swift\n from .definitions.Tcl import Tcl\n from .definitions.TinyBasic import TinyBasic\n-from .definitions.Vala import Vala\n from .definitions.TypeScript import TypeScript\n-from .definitions.Shell import Shell\n-from .definitions.Jinja2 import Jinja2\n+from .definitions.Vala import Vala\n from .definitions.VisualBasic import VisualBasic\n from .definitions.XML import XML\n-from.definitions.ZShell import ZShell\n+from .definitions.ZShell import ZShell\n+\n # Stop ignoring PyUnusedCodeBear\n", "issue": "Imported classes should be arranged lexicographically\nClasses being imported in `coala/coalib/bearlib/languages/__init__.py` file should be arranged alphabetically.\r\n\r\nA good newcomer issue. \n", "before_files": [{"content": "\"\"\"\nThis directory holds means to get generic information for specific languages.\n\"\"\"\n\n# Start ignoring PyUnusedCodeBear\nfrom .Language import Language\nfrom .Language import Languages\n\nfrom .definitions.Unknown import Unknown\nfrom .definitions.antlr import antlr\nfrom .definitions.Bash import Bash\nfrom .definitions.C import C\nfrom .definitions.CPP import CPP\nfrom .definitions.CSharp import CSharp\nfrom .definitions.CSS import CSS\nfrom .definitions.D import D\nfrom .definitions.Fortran import Fortran\nfrom .definitions.Golang import Golang\nfrom .definitions.GraphQL import GraphQL\nfrom .definitions.html import HTML\nfrom .definitions.Java import Java\nfrom .definitions.JavaScript import JavaScript\nfrom .definitions.JSON import JSON\nfrom .definitions.JSP import JSP\nfrom .definitions.KornShell import KornShell\nfrom .definitions.m4 import m4\nfrom .definitions.Matlab import Matlab\nfrom .definitions.Markdown import Markdown\nfrom .definitions.ObjectiveC import ObjectiveC\nfrom .definitions.PHP import PHP\nfrom .definitions.PLSQL import PLSQL\nfrom .definitions.PowerShell import PowerShell\nfrom .definitions.Python import Python\nfrom .definitions.Ruby import Ruby\nfrom .definitions.Scala import Scala\nfrom .definitions.Swift import Swift\nfrom .definitions.Tcl import Tcl\nfrom .definitions.TinyBasic import TinyBasic\nfrom .definitions.Vala import Vala\nfrom .definitions.TypeScript import TypeScript\nfrom .definitions.Shell import Shell\nfrom .definitions.Jinja2 import Jinja2\nfrom .definitions.VisualBasic import VisualBasic\nfrom .definitions.XML import XML\nfrom.definitions.ZShell import ZShell\n# Stop ignoring PyUnusedCodeBear\n", "path": "coalib/bearlib/languages/__init__.py"}]}
| 1,029 | 409 |
gh_patches_debug_5195
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-384
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect render patching in pyramid.
https://github.com/DataDog/dd-trace-py/blob/261136e112b23862a78308a2423e15364ae4aaa6/ddtrace/contrib/pyramid/trace.py#L31
Here we're removing request from kwargs but pyramid's render has a request kwarg so we need to keep it.
</issue>
<code>
[start of ddtrace/contrib/pyramid/trace.py]
1
2 # 3p
3 import logging
4 import pyramid.renderers
5 from pyramid.settings import asbool
6 import wrapt
7
8 # project
9 import ddtrace
10 from ...ext import http, AppTypes
11 from .constants import SETTINGS_SERVICE, SETTINGS_TRACE_ENABLED, SETTINGS_TRACER
12
13 log = logging.getLogger(__name__)
14
15 DD_TWEEN_NAME = 'ddtrace.contrib.pyramid:trace_tween_factory'
16 DD_SPAN = '_datadog_span'
17
18 def trace_pyramid(config):
19 config.include('ddtrace.contrib.pyramid')
20
21 def includeme(config):
22 # Add our tween just before the default exception handler
23 config.add_tween(DD_TWEEN_NAME, over=pyramid.tweens.EXCVIEW)
24 # ensure we only patch the renderer once.
25 if not isinstance(pyramid.renderers.RendererHelper.render, wrapt.ObjectProxy):
26 wrapt.wrap_function_wrapper('pyramid.renderers', 'RendererHelper.render', trace_render)
27
28
29 def trace_render(func, instance, args, kwargs):
30 # If the request is not traced, we do not trace
31 request = kwargs.pop('request', {})
32 if not request:
33 log.debug("No request passed to render, will not be traced")
34 return func(*args, **kwargs)
35 span = getattr(request, DD_SPAN, None)
36 if not span:
37 log.debug("No span found in request, will not be traced")
38 return func(*args, **kwargs)
39
40 tracer = span.tracer()
41 with tracer.trace('pyramid.render') as span:
42 span.span_type = http.TEMPLATE
43 return func(*args, **kwargs)
44
45 def trace_tween_factory(handler, registry):
46 # configuration
47 settings = registry.settings
48 service = settings.get(SETTINGS_SERVICE) or 'pyramid'
49 tracer = settings.get(SETTINGS_TRACER) or ddtrace.tracer
50 enabled = asbool(settings.get(SETTINGS_TRACE_ENABLED, tracer.enabled))
51
52 # set the service info
53 tracer.set_service_info(
54 service=service,
55 app="pyramid",
56 app_type=AppTypes.web)
57
58 if enabled:
59 # make a request tracing function
60 def trace_tween(request):
61 with tracer.trace('pyramid.request', service=service, resource='404') as span:
62 setattr(request, DD_SPAN, span) # used to find the tracer in templates
63 response = None
64 try:
65 response = handler(request)
66 except BaseException:
67 span.set_tag(http.STATUS_CODE, 500)
68 raise
69 finally:
70 span.span_type = http.TYPE
71 # set request tags
72 span.set_tag(http.URL, request.path)
73 span.set_tag(http.METHOD, request.method)
74 if request.matched_route:
75 span.resource = '{} {}'.format(request.method, request.matched_route.name)
76 span.set_tag('pyramid.route.name', request.matched_route.name)
77 # set response tags
78 if response:
79 span.set_tag(http.STATUS_CODE, response.status_code)
80 if 500 <= response.status_code < 600:
81 span.error = 1
82 return response
83 return trace_tween
84
85 # if timing support is not enabled, return the original handler
86 return handler
87
[end of ddtrace/contrib/pyramid/trace.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/pyramid/trace.py b/ddtrace/contrib/pyramid/trace.py
--- a/ddtrace/contrib/pyramid/trace.py
+++ b/ddtrace/contrib/pyramid/trace.py
@@ -28,7 +28,7 @@
def trace_render(func, instance, args, kwargs):
# If the request is not traced, we do not trace
- request = kwargs.pop('request', {})
+ request = kwargs.get('request', {})
if not request:
log.debug("No request passed to render, will not be traced")
return func(*args, **kwargs)
|
{"golden_diff": "diff --git a/ddtrace/contrib/pyramid/trace.py b/ddtrace/contrib/pyramid/trace.py\n--- a/ddtrace/contrib/pyramid/trace.py\n+++ b/ddtrace/contrib/pyramid/trace.py\n@@ -28,7 +28,7 @@\n \n def trace_render(func, instance, args, kwargs):\n # If the request is not traced, we do not trace\n- request = kwargs.pop('request', {})\n+ request = kwargs.get('request', {})\n if not request:\n log.debug(\"No request passed to render, will not be traced\")\n return func(*args, **kwargs)\n", "issue": "Incorrect render patching in pyramid.\nhttps://github.com/DataDog/dd-trace-py/blob/261136e112b23862a78308a2423e15364ae4aaa6/ddtrace/contrib/pyramid/trace.py#L31\r\n\r\nHere we're removing request from kwargs but pyramid's render has a request kwarg so we need to keep it.\n", "before_files": [{"content": "\n# 3p\nimport logging\nimport pyramid.renderers\nfrom pyramid.settings import asbool\nimport wrapt\n\n# project\nimport ddtrace\nfrom ...ext import http, AppTypes\nfrom .constants import SETTINGS_SERVICE, SETTINGS_TRACE_ENABLED, SETTINGS_TRACER\n\nlog = logging.getLogger(__name__)\n\nDD_TWEEN_NAME = 'ddtrace.contrib.pyramid:trace_tween_factory'\nDD_SPAN = '_datadog_span'\n\ndef trace_pyramid(config):\n config.include('ddtrace.contrib.pyramid')\n\ndef includeme(config):\n # Add our tween just before the default exception handler\n config.add_tween(DD_TWEEN_NAME, over=pyramid.tweens.EXCVIEW)\n # ensure we only patch the renderer once.\n if not isinstance(pyramid.renderers.RendererHelper.render, wrapt.ObjectProxy):\n wrapt.wrap_function_wrapper('pyramid.renderers', 'RendererHelper.render', trace_render)\n\n\ndef trace_render(func, instance, args, kwargs):\n # If the request is not traced, we do not trace\n request = kwargs.pop('request', {})\n if not request:\n log.debug(\"No request passed to render, will not be traced\")\n return func(*args, **kwargs)\n span = getattr(request, DD_SPAN, None)\n if not span:\n log.debug(\"No span found in request, will not be traced\")\n return func(*args, **kwargs)\n\n tracer = span.tracer()\n with tracer.trace('pyramid.render') as span:\n span.span_type = http.TEMPLATE\n return func(*args, **kwargs)\n\ndef trace_tween_factory(handler, registry):\n # configuration\n settings = registry.settings\n service = settings.get(SETTINGS_SERVICE) or 'pyramid'\n tracer = settings.get(SETTINGS_TRACER) or ddtrace.tracer\n enabled = asbool(settings.get(SETTINGS_TRACE_ENABLED, tracer.enabled))\n\n # set the service info\n tracer.set_service_info(\n service=service,\n app=\"pyramid\",\n app_type=AppTypes.web)\n\n if enabled:\n # make a request tracing function\n def trace_tween(request):\n with tracer.trace('pyramid.request', service=service, resource='404') as span:\n setattr(request, DD_SPAN, span) # used to find the tracer in templates\n response = None\n try:\n response = handler(request)\n except BaseException:\n span.set_tag(http.STATUS_CODE, 500)\n raise\n finally:\n span.span_type = http.TYPE\n # set request tags\n span.set_tag(http.URL, request.path)\n span.set_tag(http.METHOD, request.method)\n if request.matched_route:\n span.resource = '{} {}'.format(request.method, request.matched_route.name)\n span.set_tag('pyramid.route.name', request.matched_route.name)\n # set response tags\n if response:\n span.set_tag(http.STATUS_CODE, response.status_code)\n if 500 <= response.status_code < 600:\n span.error = 1\n return response\n return trace_tween\n\n # if timing support is not enabled, return the original handler\n return handler\n", "path": "ddtrace/contrib/pyramid/trace.py"}]}
| 1,493 | 136 |
gh_patches_debug_540
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-628
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Port to Pandas 2.0
**Describe the bug**
when running `gandlf_run`, I am encountering:
`ERROR: 'DataFrame' object has no attribute 'append'`
**To Reproduce**
Train a model using `gandlf_run`.
I trained using `2d_rad_segmentation` data from `https://upenn.box.com/shared/static/y8162xkq1zz5555ye3pwadry2m2e39bs.zip` and the config file from samples in the repo `config_classification.yaml`
**Additional context**
- check the changelog of pandas [here](https://pandas.pydata.org/pandas-docs/stable/whatsnew/v2.0.0.html#removal-of-prior-version-deprecations-changes:~:text=Removed%20deprecated%20Series.append()%2C%20DataFrame.append()%2C%20use%20concat()%20instead%20(GH35407))
- The training runs successfully when downgrading `pandas` to `1.5.3`
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 """The setup script."""
4
5
6 import sys, re
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10 from setuptools.command.egg_info import egg_info
11
12 try:
13 with open("README.md") as readme_file:
14 readme = readme_file.read()
15 except Exception as error:
16 readme = "No README information found."
17 sys.stderr.write("Warning: Could not open '%s' due %s\n" % ("README.md", error))
18
19
20 class CustomInstallCommand(install):
21 def run(self):
22 install.run(self)
23
24
25 class CustomDevelopCommand(develop):
26 def run(self):
27 develop.run(self)
28
29
30 class CustomEggInfoCommand(egg_info):
31 def run(self):
32 egg_info.run(self)
33
34
35 try:
36 filepath = "GANDLF/version.py"
37 version_file = open(filepath)
38 (__version__,) = re.findall('__version__ = "(.*)"', version_file.read())
39
40 except Exception as error:
41 __version__ = "0.0.1"
42 sys.stderr.write("Warning: Could not open '%s' due %s\n" % (filepath, error))
43
44 requirements = [
45 "torch==1.13.1",
46 "black",
47 "numpy==1.22.0",
48 "scipy",
49 "SimpleITK!=2.0.*",
50 "SimpleITK!=2.2.1", # https://github.com/mlcommons/GaNDLF/issues/536
51 "torchvision",
52 "tqdm",
53 "torchio==0.18.75",
54 "pandas",
55 "scikit-learn>=0.23.2",
56 "scikit-image>=0.19.1",
57 "setuptools",
58 "seaborn",
59 "pyyaml",
60 "tiffslide",
61 "matplotlib",
62 "requests>=2.25.0",
63 "pytest",
64 "coverage",
65 "pytest-cov",
66 "psutil",
67 "medcam",
68 "opencv-python",
69 "torchmetrics==0.5.1", # newer versions have changed api for f1 invocation
70 "OpenPatchMiner==0.1.8",
71 "zarr==2.10.3",
72 "pydicom",
73 "onnx",
74 "torchinfo==1.7.0",
75 "segmentation-models-pytorch==0.3.2",
76 "ACSConv==0.1.1",
77 "docker",
78 "dicom-anonymizer",
79 "twine",
80 "zarr",
81 "keyring",
82 ]
83
84 if __name__ == "__main__":
85 setup(
86 name="GANDLF",
87 version=__version__,
88 author="MLCommons",
89 author_email="[email protected]",
90 python_requires=">=3.8",
91 packages=find_packages(),
92 cmdclass={
93 "install": CustomInstallCommand,
94 "develop": CustomDevelopCommand,
95 "egg_info": CustomEggInfoCommand,
96 },
97 scripts=[
98 "gandlf_run",
99 "gandlf_constructCSV",
100 "gandlf_collectStats",
101 "gandlf_patchMiner",
102 "gandlf_preprocess",
103 "gandlf_anonymizer",
104 "gandlf_verifyInstall",
105 "gandlf_configGenerator",
106 "gandlf_recoverConfig",
107 "gandlf_deploy",
108 "gandlf_optimizeModel",
109 ],
110 classifiers=[
111 "Development Status :: 3 - Alpha",
112 "Intended Audience :: Science/Research",
113 "License :: OSI Approved :: Apache Software License",
114 "Natural Language :: English",
115 "Operating System :: OS Independent",
116 "Programming Language :: Python :: 3.8",
117 "Programming Language :: Python :: 3.9",
118 "Programming Language :: Python :: 3.10",
119 "Topic :: Scientific/Engineering :: Medical Science Apps.",
120 ],
121 description=(
122 "PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging."
123 ),
124 install_requires=requirements,
125 license="Apache-2.0",
126 long_description=readme,
127 long_description_content_type="text/markdown",
128 include_package_data=True,
129 keywords="semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch",
130 zip_safe=False,
131 )
132
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,7 +51,7 @@
"torchvision",
"tqdm",
"torchio==0.18.75",
- "pandas",
+ "pandas<2.0.0",
"scikit-learn>=0.23.2",
"scikit-image>=0.19.1",
"setuptools",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,7 +51,7 @@\n \"torchvision\",\n \"tqdm\",\n \"torchio==0.18.75\",\n- \"pandas\",\n+ \"pandas<2.0.0\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n \"setuptools\",\n", "issue": "Port to Pandas 2.0\n**Describe the bug**\r\nwhen running `gandlf_run`, I am encountering:\r\n\r\n`ERROR: 'DataFrame' object has no attribute 'append'`\r\n\r\n**To Reproduce**\r\n\r\nTrain a model using `gandlf_run`.\r\n\r\nI trained using `2d_rad_segmentation` data from `https://upenn.box.com/shared/static/y8162xkq1zz5555ye3pwadry2m2e39bs.zip` and the config file from samples in the repo `config_classification.yaml`\r\n\r\n**Additional context**\r\n- check the changelog of pandas [here](https://pandas.pydata.org/pandas-docs/stable/whatsnew/v2.0.0.html#removal-of-prior-version-deprecations-changes:~:text=Removed%20deprecated%20Series.append()%2C%20DataFrame.append()%2C%20use%20concat()%20instead%20(GH35407))\r\n- The training runs successfully when downgrading `pandas` to `1.5.3`\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"The setup script.\"\"\"\n\n\nimport sys, re\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\nfrom setuptools.command.egg_info import egg_info\n\ntry:\n with open(\"README.md\") as readme_file:\n readme = readme_file.read()\nexcept Exception as error:\n readme = \"No README information found.\"\n sys.stderr.write(\"Warning: Could not open '%s' due %s\\n\" % (\"README.md\", error))\n\n\nclass CustomInstallCommand(install):\n def run(self):\n install.run(self)\n\n\nclass CustomDevelopCommand(develop):\n def run(self):\n develop.run(self)\n\n\nclass CustomEggInfoCommand(egg_info):\n def run(self):\n egg_info.run(self)\n\n\ntry:\n filepath = \"GANDLF/version.py\"\n version_file = open(filepath)\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\n\nexcept Exception as error:\n __version__ = \"0.0.1\"\n sys.stderr.write(\"Warning: Could not open '%s' due %s\\n\" % (filepath, error))\n\nrequirements = [\n \"torch==1.13.1\",\n \"black\",\n \"numpy==1.22.0\",\n \"scipy\",\n \"SimpleITK!=2.0.*\",\n \"SimpleITK!=2.2.1\", # https://github.com/mlcommons/GaNDLF/issues/536\n \"torchvision\",\n \"tqdm\",\n \"torchio==0.18.75\",\n \"pandas\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n \"setuptools\",\n \"seaborn\",\n \"pyyaml\",\n \"tiffslide\",\n \"matplotlib\",\n \"requests>=2.25.0\",\n \"pytest\",\n \"coverage\",\n \"pytest-cov\",\n \"psutil\",\n \"medcam\",\n \"opencv-python\",\n \"torchmetrics==0.5.1\", # newer versions have changed api for f1 invocation\n \"OpenPatchMiner==0.1.8\",\n \"zarr==2.10.3\",\n \"pydicom\",\n \"onnx\",\n \"torchinfo==1.7.0\",\n \"segmentation-models-pytorch==0.3.2\",\n \"ACSConv==0.1.1\",\n \"docker\",\n \"dicom-anonymizer\",\n \"twine\",\n \"zarr\",\n \"keyring\",\n]\n\nif __name__ == \"__main__\":\n setup(\n name=\"GANDLF\",\n version=__version__,\n author=\"MLCommons\",\n author_email=\"[email protected]\",\n python_requires=\">=3.8\",\n packages=find_packages(),\n cmdclass={\n \"install\": CustomInstallCommand,\n \"develop\": CustomDevelopCommand,\n \"egg_info\": CustomEggInfoCommand,\n },\n scripts=[\n \"gandlf_run\",\n \"gandlf_constructCSV\",\n \"gandlf_collectStats\",\n \"gandlf_patchMiner\",\n \"gandlf_preprocess\",\n \"gandlf_anonymizer\",\n \"gandlf_verifyInstall\",\n \"gandlf_configGenerator\",\n \"gandlf_recoverConfig\",\n \"gandlf_deploy\",\n \"gandlf_optimizeModel\",\n ],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Medical Science Apps.\",\n ],\n description=(\n \"PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging.\"\n ),\n install_requires=requirements,\n license=\"Apache-2.0\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n keywords=\"semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch\",\n zip_safe=False,\n )\n", "path": "setup.py"}]}
| 2,027 | 107 |
gh_patches_debug_16396
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-2099
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
decimal.Decimal cannot be sent across session
When trying to give data of type decimal.Decimal as data sources to plots, the BokehJSONEncoder does tries to serialise the Decimal object with the standard built-in JSON encoder. This causes an exception "Decimal('...') not JSON serializable". The solution is to edit BokehJSONEncoder.trasnform_python_types to account for this possibility. I have tested the solution and it works.
</issue>
<code>
[start of bokeh/protocol.py]
1 from __future__ import absolute_import
2
3 import json
4 import logging
5 import time
6 import datetime as dt
7 import calendar
8
9 import numpy as np
10 from six.moves import cPickle as pickle
11
12 try:
13 import pandas as pd
14 is_pandas = True
15 except ImportError:
16 is_pandas = False
17
18 try:
19 from dateutil.relativedelta import relativedelta
20 is_dateutil = True
21 except ImportError:
22 is_dateutil = False
23
24 from .settings import settings
25
26 log = logging.getLogger(__name__)
27
28 millifactor = 10**6.0
29
30 class BokehJSONEncoder(json.JSONEncoder):
31 def transform_series(self, obj):
32 """transform series
33 """
34 vals = obj.values
35 return self.transform_array(vals)
36
37 # Check for astype failures (putative Numpy < 1.7)
38 dt2001 = np.datetime64('2001')
39 legacy_datetime64 = (dt2001.astype('int64') ==
40 dt2001.astype('datetime64[ms]').astype('int64'))
41 def transform_array(self, obj):
42 """Transform arrays into lists of json safe types
43 also handles pandas series, and replacing
44 nans and infs with strings
45 """
46 ## not quite correct, truncates to ms..
47 if obj.dtype.kind == 'M':
48 if self.legacy_datetime64:
49 if obj.dtype == np.dtype('datetime64[ns]'):
50 return (obj.astype('int64') / millifactor).tolist()
51 # else punt.
52 else:
53 return obj.astype('datetime64[ms]').astype('int64').tolist()
54 elif obj.dtype.kind in ('u', 'i', 'f'):
55 return self.transform_numerical_array(obj)
56 return obj.tolist()
57
58 def transform_numerical_array(self, obj):
59 """handles nans/inf conversion
60 """
61 if isinstance(obj, np.ma.MaskedArray):
62 obj = obj.filled(np.nan) # Set masked values to nan
63 if not np.isnan(obj).any() and not np.isinf(obj).any():
64 return obj.tolist()
65 else:
66 transformed = obj.astype('object')
67 transformed[np.isnan(obj)] = 'NaN'
68 transformed[np.isposinf(obj)] = 'Infinity'
69 transformed[np.isneginf(obj)] = '-Infinity'
70 return transformed.tolist()
71
72 def transform_python_types(self, obj):
73 """handle special scalars, default to default json encoder
74 """
75 # Pandas Timestamp
76 if is_pandas and isinstance(obj, pd.tslib.Timestamp):
77 return obj.value / millifactor #nanosecond to millisecond
78 elif np.issubdtype(type(obj), np.float):
79 return float(obj)
80 elif np.issubdtype(type(obj), np.int):
81 return int(obj)
82 elif np.issubdtype(type(obj), np.bool_):
83 return bool(obj)
84 # Datetime, Date
85 elif isinstance(obj, (dt.datetime, dt.date)):
86 return calendar.timegm(obj.timetuple()) * 1000.
87 # Numpy datetime64
88 elif isinstance(obj, np.datetime64):
89 epoch_delta = obj - np.datetime64('1970-01-01T00:00:00Z')
90 return (epoch_delta / np.timedelta64(1, 'ms'))
91 # Time
92 elif isinstance(obj, dt.time):
93 return (obj.hour*3600 + obj.minute*60 + obj.second)*1000 + obj.microsecond / 1000.
94 elif is_dateutil and isinstance(obj, relativedelta):
95 return dict(years=obj.years, months=obj.months, days=obj.days, hours=obj.hours,
96 minutes=obj.minutes, seconds=obj.seconds, microseconds=obj.microseconds)
97 else:
98 return super(BokehJSONEncoder, self).default(obj)
99
100 def default(self, obj):
101 #argh! local import!
102 from .plot_object import PlotObject
103 from .properties import HasProps
104 from .colors import Color
105 ## array types
106 if is_pandas and isinstance(obj, (pd.Series, pd.Index)):
107 return self.transform_series(obj)
108 elif isinstance(obj, np.ndarray):
109 return self.transform_array(obj)
110 elif isinstance(obj, PlotObject):
111 return obj.ref
112 elif isinstance(obj, HasProps):
113 return obj.changed_properties_with_values()
114 elif isinstance(obj, Color):
115 return obj.to_css()
116 else:
117 return self.transform_python_types(obj)
118
119 def serialize_json(obj, encoder=BokehJSONEncoder, **kwargs):
120 if settings.pretty(False):
121 kwargs["indent"] = 4
122 return json.dumps(obj, cls=encoder, **kwargs)
123
124 deserialize_json = json.loads
125
126 serialize_web = serialize_json
127
128 deserialize_web = deserialize_json
129
130 def status_obj(status):
131 return {'msgtype': 'status',
132 'status': status}
133
134 def error_obj(error_msg):
135 return {
136 'msgtype': 'error',
137 'error_msg': error_msg}
138
[end of bokeh/protocol.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bokeh/protocol.py b/bokeh/protocol.py
--- a/bokeh/protocol.py
+++ b/bokeh/protocol.py
@@ -5,6 +5,7 @@
import time
import datetime as dt
import calendar
+import decimal
import numpy as np
from six.moves import cPickle as pickle
@@ -94,6 +95,9 @@
elif is_dateutil and isinstance(obj, relativedelta):
return dict(years=obj.years, months=obj.months, days=obj.days, hours=obj.hours,
minutes=obj.minutes, seconds=obj.seconds, microseconds=obj.microseconds)
+ # Decimal
+ elif isinstance(obj, decimal.Decimal):
+ return float(obj)
else:
return super(BokehJSONEncoder, self).default(obj)
|
{"golden_diff": "diff --git a/bokeh/protocol.py b/bokeh/protocol.py\n--- a/bokeh/protocol.py\n+++ b/bokeh/protocol.py\n@@ -5,6 +5,7 @@\n import time\n import datetime as dt\n import calendar\n+import decimal\n \n import numpy as np\n from six.moves import cPickle as pickle\n@@ -94,6 +95,9 @@\n elif is_dateutil and isinstance(obj, relativedelta):\n return dict(years=obj.years, months=obj.months, days=obj.days, hours=obj.hours,\n minutes=obj.minutes, seconds=obj.seconds, microseconds=obj.microseconds)\n+ # Decimal\n+ elif isinstance(obj, decimal.Decimal):\n+ return float(obj)\n else:\n return super(BokehJSONEncoder, self).default(obj)\n", "issue": "decimal.Decimal cannot be sent across session\nWhen trying to give data of type decimal.Decimal as data sources to plots, the BokehJSONEncoder does tries to serialise the Decimal object with the standard built-in JSON encoder. This causes an exception \"Decimal('...') not JSON serializable\". The solution is to edit BokehJSONEncoder.trasnform_python_types to account for this possibility. I have tested the solution and it works.\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport json\nimport logging\nimport time\nimport datetime as dt\nimport calendar\n\nimport numpy as np\nfrom six.moves import cPickle as pickle\n\ntry:\n import pandas as pd\n is_pandas = True\nexcept ImportError:\n is_pandas = False\n\ntry:\n from dateutil.relativedelta import relativedelta\n is_dateutil = True\nexcept ImportError:\n is_dateutil = False\n\nfrom .settings import settings\n\nlog = logging.getLogger(__name__)\n\nmillifactor = 10**6.0\n\nclass BokehJSONEncoder(json.JSONEncoder):\n def transform_series(self, obj):\n \"\"\"transform series\n \"\"\"\n vals = obj.values\n return self.transform_array(vals)\n\n # Check for astype failures (putative Numpy < 1.7)\n dt2001 = np.datetime64('2001')\n legacy_datetime64 = (dt2001.astype('int64') ==\n dt2001.astype('datetime64[ms]').astype('int64'))\n def transform_array(self, obj):\n \"\"\"Transform arrays into lists of json safe types\n also handles pandas series, and replacing\n nans and infs with strings\n \"\"\"\n ## not quite correct, truncates to ms..\n if obj.dtype.kind == 'M':\n if self.legacy_datetime64:\n if obj.dtype == np.dtype('datetime64[ns]'):\n return (obj.astype('int64') / millifactor).tolist()\n # else punt.\n else:\n return obj.astype('datetime64[ms]').astype('int64').tolist()\n elif obj.dtype.kind in ('u', 'i', 'f'):\n return self.transform_numerical_array(obj)\n return obj.tolist()\n\n def transform_numerical_array(self, obj):\n \"\"\"handles nans/inf conversion\n \"\"\"\n if isinstance(obj, np.ma.MaskedArray):\n obj = obj.filled(np.nan) # Set masked values to nan\n if not np.isnan(obj).any() and not np.isinf(obj).any():\n return obj.tolist()\n else:\n transformed = obj.astype('object')\n transformed[np.isnan(obj)] = 'NaN'\n transformed[np.isposinf(obj)] = 'Infinity'\n transformed[np.isneginf(obj)] = '-Infinity'\n return transformed.tolist()\n\n def transform_python_types(self, obj):\n \"\"\"handle special scalars, default to default json encoder\n \"\"\"\n # Pandas Timestamp\n if is_pandas and isinstance(obj, pd.tslib.Timestamp):\n return obj.value / millifactor #nanosecond to millisecond\n elif np.issubdtype(type(obj), np.float):\n return float(obj)\n elif np.issubdtype(type(obj), np.int):\n return int(obj)\n elif np.issubdtype(type(obj), np.bool_):\n return bool(obj)\n # Datetime, Date\n elif isinstance(obj, (dt.datetime, dt.date)):\n return calendar.timegm(obj.timetuple()) * 1000.\n # Numpy datetime64\n elif isinstance(obj, np.datetime64):\n epoch_delta = obj - np.datetime64('1970-01-01T00:00:00Z')\n return (epoch_delta / np.timedelta64(1, 'ms'))\n # Time\n elif isinstance(obj, dt.time):\n return (obj.hour*3600 + obj.minute*60 + obj.second)*1000 + obj.microsecond / 1000.\n elif is_dateutil and isinstance(obj, relativedelta):\n return dict(years=obj.years, months=obj.months, days=obj.days, hours=obj.hours,\n minutes=obj.minutes, seconds=obj.seconds, microseconds=obj.microseconds)\n else:\n return super(BokehJSONEncoder, self).default(obj)\n\n def default(self, obj):\n #argh! local import!\n from .plot_object import PlotObject\n from .properties import HasProps\n from .colors import Color\n ## array types\n if is_pandas and isinstance(obj, (pd.Series, pd.Index)):\n return self.transform_series(obj)\n elif isinstance(obj, np.ndarray):\n return self.transform_array(obj)\n elif isinstance(obj, PlotObject):\n return obj.ref\n elif isinstance(obj, HasProps):\n return obj.changed_properties_with_values()\n elif isinstance(obj, Color):\n return obj.to_css()\n else:\n return self.transform_python_types(obj)\n\ndef serialize_json(obj, encoder=BokehJSONEncoder, **kwargs):\n if settings.pretty(False):\n kwargs[\"indent\"] = 4\n return json.dumps(obj, cls=encoder, **kwargs)\n\ndeserialize_json = json.loads\n\nserialize_web = serialize_json\n\ndeserialize_web = deserialize_json\n\ndef status_obj(status):\n return {'msgtype': 'status',\n 'status': status}\n\ndef error_obj(error_msg):\n return {\n 'msgtype': 'error',\n 'error_msg': error_msg}\n", "path": "bokeh/protocol.py"}]}
| 2,031 | 175 |
gh_patches_debug_25059
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-294
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[feature request]Changing how the loss metric get the shape information
Recently I was working with multi-output models and I was using a pattern that I believe to
be common. The model returns a tuple, for instance `y_pred = (ypred_1, ypred_2)` with the correspondent y of the form `y = (y_1, y_2)` with the `loss_fn` accepting as arguments `ypred` and `y` (`loss_fn(ypred, y)`).
However I have run into problems when using the Loss metric due to the batch size used on the update function of this metric calling the attribute shape of the, presumed, torch.Tensor directly.
I have as suggestion to change the Loss metric class to accept an extra function, for instance `batch_size = lambda x: x.shape[0]` to recover the current behavior and to permit to access the shape attribute from a tuple/list.
</issue>
<code>
[start of ignite/metrics/loss.py]
1 from __future__ import division
2
3 from ignite.exceptions import NotComputableError
4 from ignite.metrics.metric import Metric
5
6
7 class Loss(Metric):
8 """
9 Calculates the average loss according to the passed loss_fn.
10
11 Args:
12 loss_fn (callable): a callable taking a prediction tensor, a target
13 tensor, optionally other arguments, and returns the average loss
14 over all observations in the batch.
15 output_transform (callable): a callable that is used to transform the
16 :class:`ignite.engine.Engine`'s `process_function`'s output into the
17 form expected by the metric.
18 This can be useful if, for example, you have a multi-output model and
19 you want to compute the metric with respect to one of the outputs.
20 The output is is expected to be a tuple (prediction, target) or
21 (prediction, target, kwargs) where kwargs is a dictionary of extra
22 keywords arguments.
23
24 """
25
26 def __init__(self, loss_fn, output_transform=lambda x: x):
27 super(Loss, self).__init__(output_transform)
28 self._loss_fn = loss_fn
29
30 def reset(self):
31 self._sum = 0
32 self._num_examples = 0
33
34 def update(self, output):
35 if len(output) == 2:
36 y_pred, y = output
37 kwargs = {}
38 else:
39 y_pred, y, kwargs = output
40 average_loss = self._loss_fn(y_pred, y, **kwargs)
41
42 if len(average_loss.shape) != 0:
43 raise ValueError('loss_fn did not return the average loss')
44
45 self._sum += average_loss.item() * y.shape[0]
46 self._num_examples += y.shape[0]
47
48 def compute(self):
49 if self._num_examples == 0:
50 raise NotComputableError(
51 'Loss must have at least one example before it can be computed')
52 return self._sum / self._num_examples
53
[end of ignite/metrics/loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/metrics/loss.py b/ignite/metrics/loss.py
--- a/ignite/metrics/loss.py
+++ b/ignite/metrics/loss.py
@@ -20,12 +20,16 @@
The output is is expected to be a tuple (prediction, target) or
(prediction, target, kwargs) where kwargs is a dictionary of extra
keywords arguments.
+ batch_size (callable): a callable taking a target tensor that returns the
+ first dimension size (usually the batch size).
"""
- def __init__(self, loss_fn, output_transform=lambda x: x):
+ def __init__(self, loss_fn, output_transform=lambda x: x,
+ batch_size=lambda x: x.shape[0]):
super(Loss, self).__init__(output_transform)
self._loss_fn = loss_fn
+ self._batch_size = batch_size
def reset(self):
self._sum = 0
@@ -42,8 +46,9 @@
if len(average_loss.shape) != 0:
raise ValueError('loss_fn did not return the average loss')
- self._sum += average_loss.item() * y.shape[0]
- self._num_examples += y.shape[0]
+ N = self._batch_size(y)
+ self._sum += average_loss.item() * N
+ self._num_examples += N
def compute(self):
if self._num_examples == 0:
|
{"golden_diff": "diff --git a/ignite/metrics/loss.py b/ignite/metrics/loss.py\n--- a/ignite/metrics/loss.py\n+++ b/ignite/metrics/loss.py\n@@ -20,12 +20,16 @@\n The output is is expected to be a tuple (prediction, target) or\n (prediction, target, kwargs) where kwargs is a dictionary of extra\n keywords arguments.\n+ batch_size (callable): a callable taking a target tensor that returns the\n+ first dimension size (usually the batch size).\n \n \"\"\"\n \n- def __init__(self, loss_fn, output_transform=lambda x: x):\n+ def __init__(self, loss_fn, output_transform=lambda x: x,\n+ batch_size=lambda x: x.shape[0]):\n super(Loss, self).__init__(output_transform)\n self._loss_fn = loss_fn\n+ self._batch_size = batch_size\n \n def reset(self):\n self._sum = 0\n@@ -42,8 +46,9 @@\n if len(average_loss.shape) != 0:\n raise ValueError('loss_fn did not return the average loss')\n \n- self._sum += average_loss.item() * y.shape[0]\n- self._num_examples += y.shape[0]\n+ N = self._batch_size(y)\n+ self._sum += average_loss.item() * N\n+ self._num_examples += N\n \n def compute(self):\n if self._num_examples == 0:\n", "issue": "[feature request]Changing how the loss metric get the shape information\nRecently I was working with multi-output models and I was using a pattern that I believe to\r\nbe common. The model returns a tuple, for instance `y_pred = (ypred_1, ypred_2)` with the correspondent y of the form `y = (y_1, y_2)` with the `loss_fn` accepting as arguments `ypred` and `y` (`loss_fn(ypred, y)`).\r\n\r\nHowever I have run into problems when using the Loss metric due to the batch size used on the update function of this metric calling the attribute shape of the, presumed, torch.Tensor directly.\r\n\r\nI have as suggestion to change the Loss metric class to accept an extra function, for instance `batch_size = lambda x: x.shape[0]` to recover the current behavior and to permit to access the shape attribute from a tuple/list.\r\n\n", "before_files": [{"content": "from __future__ import division\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric\n\n\nclass Loss(Metric):\n \"\"\"\n Calculates the average loss according to the passed loss_fn.\n\n Args:\n loss_fn (callable): a callable taking a prediction tensor, a target\n tensor, optionally other arguments, and returns the average loss\n over all observations in the batch.\n output_transform (callable): a callable that is used to transform the\n :class:`ignite.engine.Engine`'s `process_function`'s output into the\n form expected by the metric.\n This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n The output is is expected to be a tuple (prediction, target) or\n (prediction, target, kwargs) where kwargs is a dictionary of extra\n keywords arguments.\n\n \"\"\"\n\n def __init__(self, loss_fn, output_transform=lambda x: x):\n super(Loss, self).__init__(output_transform)\n self._loss_fn = loss_fn\n\n def reset(self):\n self._sum = 0\n self._num_examples = 0\n\n def update(self, output):\n if len(output) == 2:\n y_pred, y = output\n kwargs = {}\n else:\n y_pred, y, kwargs = output\n average_loss = self._loss_fn(y_pred, y, **kwargs)\n\n if len(average_loss.shape) != 0:\n raise ValueError('loss_fn did not return the average loss')\n\n self._sum += average_loss.item() * y.shape[0]\n self._num_examples += y.shape[0]\n\n def compute(self):\n if self._num_examples == 0:\n raise NotComputableError(\n 'Loss must have at least one example before it can be computed')\n return self._sum / self._num_examples\n", "path": "ignite/metrics/loss.py"}]}
| 1,254 | 329 |
gh_patches_debug_2294
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-4760
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
upgrade to PyYAML 5.2
PyYAML 5.2 is out, with more security fixes. aws-cli pins to an older version, preventing upgrades. Please update the pin.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 import codecs
3 import os.path
4 import re
5 import sys
6
7 from setuptools import setup, find_packages
8
9
10 here = os.path.abspath(os.path.dirname(__file__))
11
12
13 def read(*parts):
14 return codecs.open(os.path.join(here, *parts), 'r').read()
15
16
17 def find_version(*file_paths):
18 version_file = read(*file_paths)
19 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]",
20 version_file, re.M)
21 if version_match:
22 return version_match.group(1)
23 raise RuntimeError("Unable to find version string.")
24
25
26 install_requires = ['botocore==1.13.38',
27 'docutils>=0.10,<0.16',
28 'rsa>=3.1.2,<=3.5.0',
29 's3transfer>=0.2.0,<0.3.0']
30
31
32 if sys.version_info[:2] == (2, 6):
33 # For python2.6 we have to require argparse since it
34 # was not in stdlib until 2.7.
35 install_requires.append('argparse>=1.1')
36
37 # For Python 2.6, we have to require a different verion of PyYAML since the latest
38 # versions dropped support for Python 2.6.
39 install_requires.append('PyYAML>=3.10,<=3.13')
40
41 # Colorama removed support for EOL pythons.
42 install_requires.append('colorama>=0.2.5,<=0.3.9')
43 elif sys.version_info[:2] == (3, 3):
44 install_requires.append('PyYAML>=3.10,<=3.13')
45 # Colorama removed support for EOL pythons.
46 install_requires.append('colorama>=0.2.5,<=0.3.9')
47 else:
48 install_requires.append('PyYAML>=3.10,<5.2')
49 install_requires.append('colorama>=0.2.5,<0.4.2')
50
51
52 setup_options = dict(
53 name='awscli',
54 version=find_version("awscli", "__init__.py"),
55 description='Universal Command Line Environment for AWS.',
56 long_description=read('README.rst'),
57 author='Amazon Web Services',
58 url='http://aws.amazon.com/cli/',
59 scripts=['bin/aws', 'bin/aws.cmd',
60 'bin/aws_completer', 'bin/aws_zsh_completer.sh',
61 'bin/aws_bash_completer'],
62 packages=find_packages(exclude=['tests*']),
63 package_data={'awscli': ['data/*.json', 'examples/*/*.rst',
64 'examples/*/*.txt', 'examples/*/*/*.txt',
65 'examples/*/*/*.rst', 'topics/*.rst',
66 'topics/*.json']},
67 install_requires=install_requires,
68 extras_require={
69 ':python_version=="2.6"': [
70 'argparse>=1.1',
71 ]
72 },
73 license="Apache License 2.0",
74 classifiers=[
75 'Development Status :: 5 - Production/Stable',
76 'Intended Audience :: Developers',
77 'Intended Audience :: System Administrators',
78 'Natural Language :: English',
79 'License :: OSI Approved :: Apache Software License',
80 'Programming Language :: Python',
81 'Programming Language :: Python :: 2',
82 'Programming Language :: Python :: 2.6',
83 'Programming Language :: Python :: 2.7',
84 'Programming Language :: Python :: 3',
85 'Programming Language :: Python :: 3.3',
86 'Programming Language :: Python :: 3.4',
87 'Programming Language :: Python :: 3.5',
88 'Programming Language :: Python :: 3.6',
89 'Programming Language :: Python :: 3.7',
90 ],
91 )
92
93 if 'py2exe' in sys.argv:
94 # This will actually give us a py2exe command.
95 import py2exe
96 # And we have some py2exe specific options.
97 setup_options['options'] = {
98 'py2exe': {
99 'optimize': 0,
100 'skip_archive': True,
101 'dll_excludes': ['crypt32.dll'],
102 'packages': ['docutils', 'urllib', 'httplib', 'HTMLParser',
103 'awscli', 'ConfigParser', 'xml.etree', 'pipes'],
104 }
105 }
106 setup_options['console'] = ['bin/aws']
107
108
109 setup(**setup_options)
110
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,7 +45,7 @@
# Colorama removed support for EOL pythons.
install_requires.append('colorama>=0.2.5,<=0.3.9')
else:
- install_requires.append('PyYAML>=3.10,<5.2')
+ install_requires.append('PyYAML>=3.10,<5.3')
install_requires.append('colorama>=0.2.5,<0.4.2')
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,7 +45,7 @@\n # Colorama removed support for EOL pythons.\n install_requires.append('colorama>=0.2.5,<=0.3.9')\n else:\n- install_requires.append('PyYAML>=3.10,<5.2')\n+ install_requires.append('PyYAML>=3.10,<5.3')\n install_requires.append('colorama>=0.2.5,<0.4.2')\n", "issue": "upgrade to PyYAML 5.2\nPyYAML 5.2 is out, with more security fixes. aws-cli pins to an older version, preventing upgrades. Please update the pin.\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nimport os.path\nimport re\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n return codecs.open(os.path.join(here, *parts), 'r').read()\n\n\ndef find_version(*file_paths):\n version_file = read(*file_paths)\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n version_file, re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\ninstall_requires = ['botocore==1.13.38',\n 'docutils>=0.10,<0.16',\n 'rsa>=3.1.2,<=3.5.0',\n 's3transfer>=0.2.0,<0.3.0']\n\n\nif sys.version_info[:2] == (2, 6):\n # For python2.6 we have to require argparse since it\n # was not in stdlib until 2.7.\n install_requires.append('argparse>=1.1')\n\n # For Python 2.6, we have to require a different verion of PyYAML since the latest\n # versions dropped support for Python 2.6.\n install_requires.append('PyYAML>=3.10,<=3.13')\n\n # Colorama removed support for EOL pythons.\n install_requires.append('colorama>=0.2.5,<=0.3.9')\nelif sys.version_info[:2] == (3, 3):\n install_requires.append('PyYAML>=3.10,<=3.13')\n # Colorama removed support for EOL pythons.\n install_requires.append('colorama>=0.2.5,<=0.3.9')\nelse:\n install_requires.append('PyYAML>=3.10,<5.2')\n install_requires.append('colorama>=0.2.5,<0.4.2')\n\n\nsetup_options = dict(\n name='awscli',\n version=find_version(\"awscli\", \"__init__.py\"),\n description='Universal Command Line Environment for AWS.',\n long_description=read('README.rst'),\n author='Amazon Web Services',\n url='http://aws.amazon.com/cli/',\n scripts=['bin/aws', 'bin/aws.cmd',\n 'bin/aws_completer', 'bin/aws_zsh_completer.sh',\n 'bin/aws_bash_completer'],\n packages=find_packages(exclude=['tests*']),\n package_data={'awscli': ['data/*.json', 'examples/*/*.rst',\n 'examples/*/*.txt', 'examples/*/*/*.txt',\n 'examples/*/*/*.rst', 'topics/*.rst',\n 'topics/*.json']},\n install_requires=install_requires,\n extras_require={\n ':python_version==\"2.6\"': [\n 'argparse>=1.1',\n ]\n },\n license=\"Apache License 2.0\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n)\n\nif 'py2exe' in sys.argv:\n # This will actually give us a py2exe command.\n import py2exe\n # And we have some py2exe specific options.\n setup_options['options'] = {\n 'py2exe': {\n 'optimize': 0,\n 'skip_archive': True,\n 'dll_excludes': ['crypt32.dll'],\n 'packages': ['docutils', 'urllib', 'httplib', 'HTMLParser',\n 'awscli', 'ConfigParser', 'xml.etree', 'pipes'],\n }\n }\n setup_options['console'] = ['bin/aws']\n\n\nsetup(**setup_options)\n", "path": "setup.py"}]}
| 1,770 | 127 |
gh_patches_debug_33553
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-1098
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Build wheels for manylinux1
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 # Copyright (c) Microsoft Corporation. All rights reserved.
4 # Licensed under the MIT License. See LICENSE in the project root
5 # for license information.
6
7 import os
8 import os.path
9 import subprocess
10 import sys
11
12 from setuptools import setup
13
14 import versioneer
15
16 sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'src'))
17 import ptvsd
18 import ptvsd._vendored
19 del sys.path[0]
20
21
22 PYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')
23 PTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))
24
25
26 def cython_build():
27 print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')
28 subprocess.call([
29 sys.executable,
30 os.path.join(PYDEVD_ROOT, 'setup_cython.py'),
31 'build_ext',
32 '-i',
33 ])
34
35
36 def iter_vendored_files():
37 # Add pydevd files as data files for this package. They are not
38 # treated as a package of their own, because we don't actually
39 # want to provide pydevd - just use our own copy internally.
40 for project in ptvsd._vendored.list_all():
41 for filename in ptvsd._vendored.iter_packaging_files(project):
42 yield filename
43
44
45 with open('DESCRIPTION.md', 'r') as fh:
46 long_description = fh.read()
47
48
49 if __name__ == '__main__':
50 if not os.getenv('SKIP_CYTHON_BUILD'):
51 cython_build()
52
53 setup(
54 name='ptvsd',
55 version=versioneer.get_version(),
56 description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa
57 long_description=long_description,
58 long_description_content_type='text/markdown',
59 license='MIT',
60 author='Microsoft Corporation',
61 author_email='[email protected]',
62 url='https://aka.ms/ptvs',
63 python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',
64 classifiers=[
65 'Development Status :: 5 - Production/Stable',
66 'Programming Language :: Python :: 2.7',
67 'Programming Language :: Python :: 3.4',
68 'Programming Language :: Python :: 3.5',
69 'Programming Language :: Python :: 3.6',
70 'Programming Language :: Python :: 3.7',
71 'Topic :: Software Development :: Debuggers',
72 'Operating System :: OS Independent',
73 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',
74 'License :: OSI Approved :: MIT License',
75 ],
76 package_dir={'': 'src'},
77 packages=[
78 'ptvsd',
79 'ptvsd._vendored',
80 ],
81 package_data={
82 'ptvsd': ['ThirdPartyNotices.txt'],
83 'ptvsd._vendored': list(iter_vendored_files()),
84 },
85 cmdclass=versioneer.get_cmdclass(),
86 )
87
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -9,13 +9,23 @@
import subprocess
import sys
-from setuptools import setup
+pure = None
+if '--pure' in sys.argv:
+ pure = True
+ sys.argv.remove('--pure')
+elif '--universal' in sys.argv:
+ pure = True
+elif '--abi' in sys.argv:
+ pure = False
+ sys.argv.remove('--abi')
-import versioneer
+
+from setuptools import setup # noqa
+import versioneer # noqa
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'src'))
-import ptvsd
-import ptvsd._vendored
+import ptvsd # noqa
+import ptvsd._vendored # noqa
del sys.path[0]
@@ -23,6 +33,11 @@
PTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))
+def get_buildplatform():
+ if '-p' in sys.argv:
+ return sys.argv[sys.argv.index('-p') + 1]
+ return None
+
def cython_build():
print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')
subprocess.call([
@@ -46,10 +61,29 @@
long_description = fh.read()
+try:
+ from wheel.bdist_wheel import bdist_wheel as _bdist_wheel
+
+ class bdist_wheel(_bdist_wheel):
+ def finalize_options(self):
+ _bdist_wheel.finalize_options(self)
+ self.root_is_pure = pure
+
+except ImportError:
+ bdist_wheel = None
+
if __name__ == '__main__':
if not os.getenv('SKIP_CYTHON_BUILD'):
cython_build()
+ cmds = versioneer.get_cmdclass()
+ cmds['bdist_wheel'] = bdist_wheel
+
+ extras = {}
+ platforms = get_buildplatform()
+ if platforms is not None:
+ extras['platforms'] = platforms
+
setup(
name='ptvsd',
version=versioneer.get_version(),
@@ -82,5 +116,6 @@
'ptvsd': ['ThirdPartyNotices.txt'],
'ptvsd._vendored': list(iter_vendored_files()),
},
- cmdclass=versioneer.get_cmdclass(),
+ cmdclass=cmds,
+ **extras
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -9,13 +9,23 @@\n import subprocess\n import sys\n \n-from setuptools import setup\n+pure = None\n+if '--pure' in sys.argv:\n+ pure = True\n+ sys.argv.remove('--pure')\n+elif '--universal' in sys.argv:\n+ pure = True\n+elif '--abi' in sys.argv:\n+ pure = False\n+ sys.argv.remove('--abi')\n \n-import versioneer\n+\n+from setuptools import setup # noqa\n+import versioneer # noqa\n \n sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'src'))\n-import ptvsd\n-import ptvsd._vendored\n+import ptvsd # noqa\n+import ptvsd._vendored # noqa\n del sys.path[0]\n \n \n@@ -23,6 +33,11 @@\n PTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))\n \n \n+def get_buildplatform():\n+ if '-p' in sys.argv:\n+ return sys.argv[sys.argv.index('-p') + 1]\n+ return None\n+\n def cython_build():\n print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')\n subprocess.call([\n@@ -46,10 +61,29 @@\n long_description = fh.read()\n \n \n+try:\n+ from wheel.bdist_wheel import bdist_wheel as _bdist_wheel\n+\n+ class bdist_wheel(_bdist_wheel):\n+ def finalize_options(self):\n+ _bdist_wheel.finalize_options(self)\n+ self.root_is_pure = pure\n+\n+except ImportError:\n+ bdist_wheel = None\n+\n if __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n \n+ cmds = versioneer.get_cmdclass()\n+ cmds['bdist_wheel'] = bdist_wheel\n+\n+ extras = {}\n+ platforms = get_buildplatform()\n+ if platforms is not None:\n+ extras['platforms'] = platforms\n+\n setup(\n name='ptvsd',\n version=versioneer.get_version(),\n@@ -82,5 +116,6 @@\n 'ptvsd': ['ThirdPartyNotices.txt'],\n 'ptvsd._vendored': list(iter_vendored_files()),\n },\n- cmdclass=versioneer.get_cmdclass(),\n+ cmdclass=cmds,\n+ **extras\n )\n", "issue": "Build wheels for manylinux1\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport os\nimport os.path\nimport subprocess\nimport sys\n\nfrom setuptools import setup\n\nimport versioneer\n\nsys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'src'))\nimport ptvsd\nimport ptvsd._vendored\ndel sys.path[0]\n\n\nPYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')\nPTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))\n\n\ndef cython_build():\n print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')\n subprocess.call([\n sys.executable,\n os.path.join(PYDEVD_ROOT, 'setup_cython.py'),\n 'build_ext',\n '-i',\n ])\n\n\ndef iter_vendored_files():\n # Add pydevd files as data files for this package. They are not\n # treated as a package of their own, because we don't actually\n # want to provide pydevd - just use our own copy internally.\n for project in ptvsd._vendored.list_all():\n for filename in ptvsd._vendored.iter_packaging_files(project):\n yield filename\n\n\nwith open('DESCRIPTION.md', 'r') as fh:\n long_description = fh.read()\n\n\nif __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n\n setup(\n name='ptvsd',\n version=versioneer.get_version(),\n description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa\n long_description=long_description,\n long_description_content_type='text/markdown',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Software Development :: Debuggers',\n 'Operating System :: OS Independent',\n 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',\n 'License :: OSI Approved :: MIT License',\n ],\n package_dir={'': 'src'},\n packages=[\n 'ptvsd',\n 'ptvsd._vendored',\n ],\n package_data={\n 'ptvsd': ['ThirdPartyNotices.txt'],\n 'ptvsd._vendored': list(iter_vendored_files()),\n },\n cmdclass=versioneer.get_cmdclass(),\n )\n", "path": "setup.py"}]}
| 1,373 | 559 |
gh_patches_debug_6568
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-3638
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[CI] Test examples in CI
### Anything you want to discuss about vllm.
Current scripts in `examples/` directory are not tested in CI. We should run them to ensure passing
</issue>
<code>
[start of examples/llava_example.py]
1 import argparse
2 import os
3 import subprocess
4
5 import torch
6
7 from vllm import LLM
8 from vllm.sequence import MultiModalData
9
10 # The assets are located at `s3://air-example-data-2/vllm_opensource_llava/`.
11
12
13 def run_llava_pixel_values():
14 llm = LLM(
15 model="llava-hf/llava-1.5-7b-hf",
16 image_input_type="pixel_values",
17 image_token_id=32000,
18 image_input_shape="1,3,336,336",
19 image_feature_size=576,
20 )
21
22 prompt = "<image>" * 576 + (
23 "\nUSER: What is the content of this image?\nASSISTANT:")
24
25 # This should be provided by another online or offline component.
26 images = torch.load("images/stop_sign_pixel_values.pt")
27
28 outputs = llm.generate(prompt,
29 multi_modal_data=MultiModalData(
30 type=MultiModalData.Type.IMAGE, data=images))
31 for o in outputs:
32 generated_text = o.outputs[0].text
33 print(generated_text)
34
35
36 def run_llava_image_features():
37 llm = LLM(
38 model="llava-hf/llava-1.5-7b-hf",
39 image_input_type="image_features",
40 image_token_id=32000,
41 image_input_shape="1,576,1024",
42 image_feature_size=576,
43 )
44
45 prompt = "<image>" * 576 + (
46 "\nUSER: What is the content of this image?\nASSISTANT:")
47
48 # This should be provided by another online or offline component.
49 images = torch.load("images/stop_sign_image_features.pt")
50
51 outputs = llm.generate(prompt,
52 multi_modal_data=MultiModalData(
53 type=MultiModalData.Type.IMAGE, data=images))
54 for o in outputs:
55 generated_text = o.outputs[0].text
56 print(generated_text)
57
58
59 def main(args):
60 if args.type == "pixel_values":
61 run_llava_pixel_values()
62 else:
63 run_llava_image_features()
64
65
66 if __name__ == "__main__":
67 parser = argparse.ArgumentParser(description="Demo on Llava")
68 parser.add_argument("--type",
69 type=str,
70 choices=["pixel_values", "image_features"],
71 default="pixel_values",
72 help="image input type")
73 args = parser.parse_args()
74 # Download from s3
75 s3_bucket_path = "s3://air-example-data-2/vllm_opensource_llava/"
76 local_directory = "images"
77
78 # Make sure the local directory exists or create it
79 os.makedirs(local_directory, exist_ok=True)
80
81 # Use AWS CLI to sync the directory
82 subprocess.check_call(
83 ["aws", "s3", "sync", s3_bucket_path, local_directory])
84 main(args)
85
[end of examples/llava_example.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/llava_example.py b/examples/llava_example.py
--- a/examples/llava_example.py
+++ b/examples/llava_example.py
@@ -78,7 +78,13 @@
# Make sure the local directory exists or create it
os.makedirs(local_directory, exist_ok=True)
- # Use AWS CLI to sync the directory
- subprocess.check_call(
- ["aws", "s3", "sync", s3_bucket_path, local_directory])
+ # Use AWS CLI to sync the directory, assume anonymous access
+ subprocess.check_call([
+ "aws",
+ "s3",
+ "sync",
+ s3_bucket_path,
+ local_directory,
+ "--no-sign-request",
+ ])
main(args)
|
{"golden_diff": "diff --git a/examples/llava_example.py b/examples/llava_example.py\n--- a/examples/llava_example.py\n+++ b/examples/llava_example.py\n@@ -78,7 +78,13 @@\n # Make sure the local directory exists or create it\n os.makedirs(local_directory, exist_ok=True)\n \n- # Use AWS CLI to sync the directory\n- subprocess.check_call(\n- [\"aws\", \"s3\", \"sync\", s3_bucket_path, local_directory])\n+ # Use AWS CLI to sync the directory, assume anonymous access\n+ subprocess.check_call([\n+ \"aws\",\n+ \"s3\",\n+ \"sync\",\n+ s3_bucket_path,\n+ local_directory,\n+ \"--no-sign-request\",\n+ ])\n main(args)\n", "issue": "[CI] Test examples in CI\n### Anything you want to discuss about vllm.\n\nCurrent scripts in `examples/` directory are not tested in CI. We should run them to ensure passing \n", "before_files": [{"content": "import argparse\nimport os\nimport subprocess\n\nimport torch\n\nfrom vllm import LLM\nfrom vllm.sequence import MultiModalData\n\n# The assets are located at `s3://air-example-data-2/vllm_opensource_llava/`.\n\n\ndef run_llava_pixel_values():\n llm = LLM(\n model=\"llava-hf/llava-1.5-7b-hf\",\n image_input_type=\"pixel_values\",\n image_token_id=32000,\n image_input_shape=\"1,3,336,336\",\n image_feature_size=576,\n )\n\n prompt = \"<image>\" * 576 + (\n \"\\nUSER: What is the content of this image?\\nASSISTANT:\")\n\n # This should be provided by another online or offline component.\n images = torch.load(\"images/stop_sign_pixel_values.pt\")\n\n outputs = llm.generate(prompt,\n multi_modal_data=MultiModalData(\n type=MultiModalData.Type.IMAGE, data=images))\n for o in outputs:\n generated_text = o.outputs[0].text\n print(generated_text)\n\n\ndef run_llava_image_features():\n llm = LLM(\n model=\"llava-hf/llava-1.5-7b-hf\",\n image_input_type=\"image_features\",\n image_token_id=32000,\n image_input_shape=\"1,576,1024\",\n image_feature_size=576,\n )\n\n prompt = \"<image>\" * 576 + (\n \"\\nUSER: What is the content of this image?\\nASSISTANT:\")\n\n # This should be provided by another online or offline component.\n images = torch.load(\"images/stop_sign_image_features.pt\")\n\n outputs = llm.generate(prompt,\n multi_modal_data=MultiModalData(\n type=MultiModalData.Type.IMAGE, data=images))\n for o in outputs:\n generated_text = o.outputs[0].text\n print(generated_text)\n\n\ndef main(args):\n if args.type == \"pixel_values\":\n run_llava_pixel_values()\n else:\n run_llava_image_features()\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(description=\"Demo on Llava\")\n parser.add_argument(\"--type\",\n type=str,\n choices=[\"pixel_values\", \"image_features\"],\n default=\"pixel_values\",\n help=\"image input type\")\n args = parser.parse_args()\n # Download from s3\n s3_bucket_path = \"s3://air-example-data-2/vllm_opensource_llava/\"\n local_directory = \"images\"\n\n # Make sure the local directory exists or create it\n os.makedirs(local_directory, exist_ok=True)\n\n # Use AWS CLI to sync the directory\n subprocess.check_call(\n [\"aws\", \"s3\", \"sync\", s3_bucket_path, local_directory])\n main(args)\n", "path": "examples/llava_example.py"}]}
| 1,387 | 173 |
gh_patches_debug_17874
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1605
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error on Android when converting selection value to String
Sample app:
```
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class AFV(toga.App):
def startup(self):
self.main_window = toga.MainWindow(title=self.formal_name)
box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))
self.label_1 = toga.Label('TESTE 1')
self.comboBox_1 = toga.Selection(items=["ITEM 1", "ITEM 2", "ITEM 3"])
self.lineEdit_1 = toga.TextInput()
self.pushButton_1 = toga.Button('TESTE')
box_test.add(self.label_1, self.comboBox_1, self.lineEdit_1, self.pushButton_1)
self.pushButton_1.on_press = self.print_combo
self.main_window.content = box_test
self.main_window.show()
def print_combo(self, widget):
name_combo = self.comboBox_1.value
print(name_combo)
def main():
return AFV()
```
When the button is pressed, the error:
com.chaquo.python.PyException: AttributeError: 'str' object has no attribute 'toString'
is raised.
Using Briefcase 0.3.10; worked previously on Briefcase 0.3.9.
Error on Android when converting selection value to String
Sample app:
```
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class AFV(toga.App):
def startup(self):
self.main_window = toga.MainWindow(title=self.formal_name)
box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))
self.label_1 = toga.Label('TESTE 1')
self.comboBox_1 = toga.Selection(items=["ITEM 1", "ITEM 2", "ITEM 3"])
self.lineEdit_1 = toga.TextInput()
self.pushButton_1 = toga.Button('TESTE')
box_test.add(self.label_1, self.comboBox_1, self.lineEdit_1, self.pushButton_1)
self.pushButton_1.on_press = self.print_combo
self.main_window.content = box_test
self.main_window.show()
def print_combo(self, widget):
name_combo = self.comboBox_1.value
print(name_combo)
def main():
return AFV()
```
When the button is pressed, the error:
com.chaquo.python.PyException: AttributeError: 'str' object has no attribute 'toString'
is raised.
Using Briefcase 0.3.10; worked previously on Briefcase 0.3.9.
</issue>
<code>
[start of src/android/toga_android/widgets/selection.py]
1 from travertino.size import at_least
2
3 from ..libs.android import R__layout
4 from ..libs.android.view import Gravity, View__MeasureSpec
5 from ..libs.android.widget import ArrayAdapter, OnItemSelectedListener, Spinner
6 from .base import Widget, align
7
8
9 class TogaOnItemSelectedListener(OnItemSelectedListener):
10 def __init__(self, impl):
11 super().__init__()
12 self._impl = impl
13
14 def onItemSelected(self, _parent, _view, _position, _id):
15 if self._impl.interface.on_select:
16 self._impl.interface.on_select(widget=self._impl.interface)
17
18
19 class Selection(Widget):
20 def create(self):
21 self.native = Spinner(self._native_activity, Spinner.MODE_DROPDOWN)
22 self.native.setOnItemSelectedListener(TogaOnItemSelectedListener(
23 impl=self
24 ))
25 # On Android, the list of options is provided to the `Spinner` wrapped in
26 # an `ArrayAdapter`. We store `self.adapter` to avoid having to typecast it
27 # in `add_item()`.
28 self.adapter = ArrayAdapter(
29 self._native_activity,
30 R__layout.simple_spinner_item
31 )
32 self.adapter.setDropDownViewResource(R__layout.simple_spinner_dropdown_item)
33 self.native.setAdapter(self.adapter)
34 # Create a mapping from text to numeric index to support `select_item()`.
35 self._indexByItem = {}
36
37 def add_item(self, item):
38 new_index = self.adapter.getCount()
39 self.adapter.add(str(item))
40 self._indexByItem[item] = new_index
41
42 def select_item(self, item):
43 self.native.setSelection(self._indexByItem[item])
44
45 def get_selected_item(self):
46 selected = self.native.getSelectedItem()
47 if selected:
48 return selected.toString()
49 else:
50 return None
51
52 def remove_all_items(self):
53 self.adapter.clear()
54
55 def rehint(self):
56 self.native.measure(
57 View__MeasureSpec.UNSPECIFIED, View__MeasureSpec.UNSPECIFIED
58 )
59 self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())
60 self.interface.intrinsic.height = self.native.getMeasuredHeight()
61
62 def set_alignment(self, value):
63 self.native.setGravity(Gravity.CENTER_VERTICAL | align(value))
64
65 def set_on_select(self, handler):
66 # No special handling is required.
67 pass
68
[end of src/android/toga_android/widgets/selection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/android/toga_android/widgets/selection.py b/src/android/toga_android/widgets/selection.py
--- a/src/android/toga_android/widgets/selection.py
+++ b/src/android/toga_android/widgets/selection.py
@@ -22,9 +22,6 @@
self.native.setOnItemSelectedListener(TogaOnItemSelectedListener(
impl=self
))
- # On Android, the list of options is provided to the `Spinner` wrapped in
- # an `ArrayAdapter`. We store `self.adapter` to avoid having to typecast it
- # in `add_item()`.
self.adapter = ArrayAdapter(
self._native_activity,
R__layout.simple_spinner_item
@@ -45,7 +42,7 @@
def get_selected_item(self):
selected = self.native.getSelectedItem()
if selected:
- return selected.toString()
+ return str(selected)
else:
return None
|
{"golden_diff": "diff --git a/src/android/toga_android/widgets/selection.py b/src/android/toga_android/widgets/selection.py\n--- a/src/android/toga_android/widgets/selection.py\n+++ b/src/android/toga_android/widgets/selection.py\n@@ -22,9 +22,6 @@\n self.native.setOnItemSelectedListener(TogaOnItemSelectedListener(\n impl=self\n ))\n- # On Android, the list of options is provided to the `Spinner` wrapped in\n- # an `ArrayAdapter`. We store `self.adapter` to avoid having to typecast it\n- # in `add_item()`.\n self.adapter = ArrayAdapter(\n self._native_activity,\n R__layout.simple_spinner_item\n@@ -45,7 +42,7 @@\n def get_selected_item(self):\n selected = self.native.getSelectedItem()\n if selected:\n- return selected.toString()\n+ return str(selected)\n else:\n return None\n", "issue": "Error on Android when converting selection value to String\nSample app:\r\n```\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\nclass AFV(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n\r\n box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))\r\n self.label_1 = toga.Label('TESTE 1')\r\n self.comboBox_1 = toga.Selection(items=[\"ITEM 1\", \"ITEM 2\", \"ITEM 3\"])\r\n self.lineEdit_1 = toga.TextInput()\r\n self.pushButton_1 = toga.Button('TESTE')\r\n\r\n box_test.add(self.label_1, self.comboBox_1, self.lineEdit_1, self.pushButton_1)\r\n\r\n self.pushButton_1.on_press = self.print_combo\r\n\r\n self.main_window.content = box_test\r\n self.main_window.show()\r\n\r\n def print_combo(self, widget):\r\n name_combo = self.comboBox_1.value\r\n print(name_combo)\r\n\r\n\r\n\r\ndef main():\r\n return AFV()\r\n```\r\n\r\nWhen the button is pressed, the error:\r\n\r\n com.chaquo.python.PyException: AttributeError: 'str' object has no attribute 'toString'\r\n\r\nis raised.\r\n\r\nUsing Briefcase 0.3.10; worked previously on Briefcase 0.3.9.\nError on Android when converting selection value to String\nSample app:\r\n```\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\nclass AFV(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n\r\n box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))\r\n self.label_1 = toga.Label('TESTE 1')\r\n self.comboBox_1 = toga.Selection(items=[\"ITEM 1\", \"ITEM 2\", \"ITEM 3\"])\r\n self.lineEdit_1 = toga.TextInput()\r\n self.pushButton_1 = toga.Button('TESTE')\r\n\r\n box_test.add(self.label_1, self.comboBox_1, self.lineEdit_1, self.pushButton_1)\r\n\r\n self.pushButton_1.on_press = self.print_combo\r\n\r\n self.main_window.content = box_test\r\n self.main_window.show()\r\n\r\n def print_combo(self, widget):\r\n name_combo = self.comboBox_1.value\r\n print(name_combo)\r\n\r\n\r\n\r\ndef main():\r\n return AFV()\r\n```\r\n\r\nWhen the button is pressed, the error:\r\n\r\n com.chaquo.python.PyException: AttributeError: 'str' object has no attribute 'toString'\r\n\r\nis raised.\r\n\r\nUsing Briefcase 0.3.10; worked previously on Briefcase 0.3.9.\n", "before_files": [{"content": "from travertino.size import at_least\n\nfrom ..libs.android import R__layout\nfrom ..libs.android.view import Gravity, View__MeasureSpec\nfrom ..libs.android.widget import ArrayAdapter, OnItemSelectedListener, Spinner\nfrom .base import Widget, align\n\n\nclass TogaOnItemSelectedListener(OnItemSelectedListener):\n def __init__(self, impl):\n super().__init__()\n self._impl = impl\n\n def onItemSelected(self, _parent, _view, _position, _id):\n if self._impl.interface.on_select:\n self._impl.interface.on_select(widget=self._impl.interface)\n\n\nclass Selection(Widget):\n def create(self):\n self.native = Spinner(self._native_activity, Spinner.MODE_DROPDOWN)\n self.native.setOnItemSelectedListener(TogaOnItemSelectedListener(\n impl=self\n ))\n # On Android, the list of options is provided to the `Spinner` wrapped in\n # an `ArrayAdapter`. We store `self.adapter` to avoid having to typecast it\n # in `add_item()`.\n self.adapter = ArrayAdapter(\n self._native_activity,\n R__layout.simple_spinner_item\n )\n self.adapter.setDropDownViewResource(R__layout.simple_spinner_dropdown_item)\n self.native.setAdapter(self.adapter)\n # Create a mapping from text to numeric index to support `select_item()`.\n self._indexByItem = {}\n\n def add_item(self, item):\n new_index = self.adapter.getCount()\n self.adapter.add(str(item))\n self._indexByItem[item] = new_index\n\n def select_item(self, item):\n self.native.setSelection(self._indexByItem[item])\n\n def get_selected_item(self):\n selected = self.native.getSelectedItem()\n if selected:\n return selected.toString()\n else:\n return None\n\n def remove_all_items(self):\n self.adapter.clear()\n\n def rehint(self):\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED, View__MeasureSpec.UNSPECIFIED\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = self.native.getMeasuredHeight()\n\n def set_alignment(self, value):\n self.native.setGravity(Gravity.CENTER_VERTICAL | align(value))\n\n def set_on_select(self, handler):\n # No special handling is required.\n pass\n", "path": "src/android/toga_android/widgets/selection.py"}]}
| 1,726 | 197 |
gh_patches_debug_11906
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-4441
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Panel 1.0: Divider takes 100% of window height
I'm on the current `main` branch of Panel. When I use the `Divider` it takes up 100% of the window height.
```python
import panel as pn
pn.extension(sizing_mode="stretch_width")
pn.panel("Header", styles={"background": "lightgray"}).servable()
pn.layout.Divider(styles={"background": "salmon"}).servable()
pn.panel("Footer", styles={"background": "lightgray"}).servable()
```

I don't know if it is on purpose. But the `styles` seem not to apply to the `Divider` either.
</issue>
<code>
[start of panel/layout/spacer.py]
1 """
2 Spacer components to add horizontal or vertical space to a layout.
3 """
4
5 import param
6
7 from bokeh.models import Div as BkDiv, Spacer as BkSpacer
8
9 from ..reactive import Reactive
10
11
12 class Spacer(Reactive):
13 """
14 The `Spacer` layout is a very versatile component which makes it easy to
15 put fixed or responsive spacing between objects.
16
17 Like all other components spacers support both absolute and responsive
18 sizing modes.
19
20 Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers
21
22 :Example:
23
24 >>> pn.Row(
25 ... 1, pn.Spacer(width=200),
26 ... 2, pn.Spacer(width=100),
27 ... 3
28 ... )
29 """
30
31 _bokeh_model = BkSpacer
32
33 def _get_model(self, doc, root=None, parent=None, comm=None):
34 properties = self._process_param_change(self._init_params())
35 model = self._bokeh_model(**properties)
36 if root is None:
37 root = model
38 self._models[root.ref['id']] = (model, parent)
39 return model
40
41
42 class VSpacer(Spacer):
43 """
44 The `VSpacer` layout provides responsive vertical spacing.
45
46 Using this component we can space objects equidistantly in a layout and
47 allow the empty space to shrink when the browser is resized.
48
49 Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers
50
51 :Example:
52
53 >>> pn.Column(
54 ... pn.layout.VSpacer(), 'Item 1',
55 ... pn.layout.VSpacer(), 'Item 2',
56 ... pn.layout.VSpacer()
57 ... )
58 """
59
60 sizing_mode = param.Parameter(default='stretch_height', readonly=True)
61
62
63 class HSpacer(Spacer):
64 """
65 The `HSpacer` layout provides responsive vertical spacing.
66
67 Using this component we can space objects equidistantly in a layout and
68 allow the empty space to shrink when the browser is resized.
69
70 Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers
71
72 :Example:
73
74 >>> pn.Row(
75 ... pn.layout.HSpacer(), 'Item 1',
76 ... pn.layout.HSpacer(), 'Item 2',
77 ... pn.layout.HSpacer()
78 ... )
79 """
80
81 sizing_mode = param.Parameter(default='stretch_width', readonly=True)
82
83
84 class Divider(Reactive):
85 """
86 A `Divider` draws a horizontal rule (a `<hr>` tag in HTML) to separate
87 multiple components in a layout. It automatically spans the full width of
88 the container.
89
90 Reference: https://panel.holoviz.org/reference/layouts/Divider.html
91
92 :Example:
93
94 >>> pn.Column(
95 ... '# Lorem Ipsum',
96 ... pn.layout.Divider(),
97 ... 'A very long text... '
98 >>> )
99 """
100
101 width_policy = param.ObjectSelector(default="fit", readonly=True)
102
103 _bokeh_model = BkDiv
104
105 def _get_model(self, doc, root=None, parent=None, comm=None):
106 properties = self._process_param_change(self._init_params())
107 properties['styles'] = {'width': '100%', 'height': '100%'}
108 model = self._bokeh_model(text='<hr style="margin: 0px">', **properties)
109 if root is None:
110 root = model
111 self._models[root.ref['id']] = (model, parent)
112 return model
113
[end of panel/layout/spacer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/layout/spacer.py b/panel/layout/spacer.py
--- a/panel/layout/spacer.py
+++ b/panel/layout/spacer.py
@@ -102,10 +102,11 @@
_bokeh_model = BkDiv
+ _stylesheets = ["css/divider.css"]
+
def _get_model(self, doc, root=None, parent=None, comm=None):
properties = self._process_param_change(self._init_params())
- properties['styles'] = {'width': '100%', 'height': '100%'}
- model = self._bokeh_model(text='<hr style="margin: 0px">', **properties)
+ model = self._bokeh_model(text='<hr>', **properties)
if root is None:
root = model
self._models[root.ref['id']] = (model, parent)
|
{"golden_diff": "diff --git a/panel/layout/spacer.py b/panel/layout/spacer.py\n--- a/panel/layout/spacer.py\n+++ b/panel/layout/spacer.py\n@@ -102,10 +102,11 @@\n \n _bokeh_model = BkDiv\n \n+ _stylesheets = [\"css/divider.css\"]\n+\n def _get_model(self, doc, root=None, parent=None, comm=None):\n properties = self._process_param_change(self._init_params())\n- properties['styles'] = {'width': '100%', 'height': '100%'}\n- model = self._bokeh_model(text='<hr style=\"margin: 0px\">', **properties)\n+ model = self._bokeh_model(text='<hr>', **properties)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n", "issue": "Panel 1.0: Divider takes 100% of window height\nI'm on the current `main` branch of Panel. When I use the `Divider` it takes up 100% of the window height.\r\n\r\n```python\r\nimport panel as pn\r\n\r\npn.extension(sizing_mode=\"stretch_width\")\r\n\r\npn.panel(\"Header\", styles={\"background\": \"lightgray\"}).servable()\r\npn.layout.Divider(styles={\"background\": \"salmon\"}).servable()\r\npn.panel(\"Footer\", styles={\"background\": \"lightgray\"}).servable()\r\n```\r\n\r\n\r\n\r\nI don't know if it is on purpose. But the `styles` seem not to apply to the `Divider` either.\n", "before_files": [{"content": "\"\"\"\nSpacer components to add horizontal or vertical space to a layout.\n\"\"\"\n\nimport param\n\nfrom bokeh.models import Div as BkDiv, Spacer as BkSpacer\n\nfrom ..reactive import Reactive\n\n\nclass Spacer(Reactive):\n \"\"\"\n The `Spacer` layout is a very versatile component which makes it easy to\n put fixed or responsive spacing between objects.\n\n Like all other components spacers support both absolute and responsive\n sizing modes.\n\n Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers\n\n :Example:\n\n >>> pn.Row(\n ... 1, pn.Spacer(width=200),\n ... 2, pn.Spacer(width=100),\n ... 3\n ... )\n \"\"\"\n\n _bokeh_model = BkSpacer\n\n def _get_model(self, doc, root=None, parent=None, comm=None):\n properties = self._process_param_change(self._init_params())\n model = self._bokeh_model(**properties)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n return model\n\n\nclass VSpacer(Spacer):\n \"\"\"\n The `VSpacer` layout provides responsive vertical spacing.\n\n Using this component we can space objects equidistantly in a layout and\n allow the empty space to shrink when the browser is resized.\n\n Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers\n\n :Example:\n\n >>> pn.Column(\n ... pn.layout.VSpacer(), 'Item 1',\n ... pn.layout.VSpacer(), 'Item 2',\n ... pn.layout.VSpacer()\n ... )\n \"\"\"\n\n sizing_mode = param.Parameter(default='stretch_height', readonly=True)\n\n\nclass HSpacer(Spacer):\n \"\"\"\n The `HSpacer` layout provides responsive vertical spacing.\n\n Using this component we can space objects equidistantly in a layout and\n allow the empty space to shrink when the browser is resized.\n\n Reference: https://panel.holoviz.org/user_guide/Customization.html#spacers\n\n :Example:\n\n >>> pn.Row(\n ... pn.layout.HSpacer(), 'Item 1',\n ... pn.layout.HSpacer(), 'Item 2',\n ... pn.layout.HSpacer()\n ... )\n \"\"\"\n\n sizing_mode = param.Parameter(default='stretch_width', readonly=True)\n\n\nclass Divider(Reactive):\n \"\"\"\n A `Divider` draws a horizontal rule (a `<hr>` tag in HTML) to separate\n multiple components in a layout. It automatically spans the full width of\n the container.\n\n Reference: https://panel.holoviz.org/reference/layouts/Divider.html\n\n :Example:\n\n >>> pn.Column(\n ... '# Lorem Ipsum',\n ... pn.layout.Divider(),\n ... 'A very long text... '\n >>> )\n \"\"\"\n\n width_policy = param.ObjectSelector(default=\"fit\", readonly=True)\n\n _bokeh_model = BkDiv\n\n def _get_model(self, doc, root=None, parent=None, comm=None):\n properties = self._process_param_change(self._init_params())\n properties['styles'] = {'width': '100%', 'height': '100%'}\n model = self._bokeh_model(text='<hr style=\"margin: 0px\">', **properties)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n return model\n", "path": "panel/layout/spacer.py"}]}
| 1,753 | 197 |
gh_patches_debug_30318
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1647
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AWS::Logs::MetricFilter MetricValues permits invalid strings
`cfn-lint 0.30.1`
AWS::Logs::MetricFilter.Properties.MetricTransformations[*].MetricValue allows a bare string not starting with '$' which it appears is never actually valid, ie
"MetricValue: length" vs "MetricValue: $length"
Assuming I'm reading the documentation correctly MetricValue must always either be a number OR start with a '$' character.
The following fragment lints, but is rejected by CloudFormation at runtime without a $ at the start of the named MetricValue field
```
QueueLengthMetricFilter:
Type: AWS::Logs::MetricFilter
Properties:
LogGroupName: !Ref LogGroup
FilterPattern: '[date, time, tag="rh-sched*", x01=throttling, x02="jobs.", ..., x10=Len, x11=of, x12=job, x13="queue*", length]'
MetricTransformations:
- MetricValue: length
MetricNamespace: !Sub '${EnvironmentName}'
MetricName: 'JobsQueued'
```
Note: I believe that this is also missed by the AWS ValidateTemplate API
</issue>
<code>
[start of src/cfnlint/rules/resources/properties/AllowedPattern.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9 from cfnlint.helpers import RESOURCE_SPECS
10
11
12 class AllowedPattern(CloudFormationLintRule):
13 """Check if properties have a valid value"""
14 id = 'E3031'
15 shortdesc = 'Check if property values adhere to a specific pattern'
16 description = 'Check if properties have a valid value in case of a pattern (Regular Expression)'
17 source_url = 'https://github.com/awslabs/cfn-python-lint/blob/master/docs/cfn-resource-specification.md#allowedpattern'
18 tags = ['resources', 'property', 'allowed pattern', 'regex']
19
20 def initialize(self, cfn):
21 """Initialize the rule"""
22 for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes'):
23 self.resource_property_types.append(resource_type_spec)
24 for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes'):
25 self.resource_sub_property_types.append(property_type_spec)
26
27 def check_value(self, value, path, property_name, **kwargs):
28 """Check Value"""
29 matches = []
30
31 # Get the Allowed Pattern Regex
32 value_pattern_regex = kwargs.get('value_specs', {}).get('AllowedPatternRegex', {})
33 # Get the "Human Readable" version for the error message. Optional, if not specified,
34 # the RegEx itself is used.
35 value_pattern = kwargs.get('value_specs', {}).get('AllowedPattern', value_pattern_regex)
36
37 if value_pattern_regex:
38 regex = re.compile(value_pattern_regex)
39
40 # Ignore values with dynamic references. Simple check to prevent false-positives
41 # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html
42 if '{{resolve:' not in value:
43 if not regex.match(value):
44 full_path = ('/'.join(str(x) for x in path))
45
46 message = '{} contains invalid characters (Pattern: {}) at {}'
47 matches.append(RuleMatch(path, message.format(
48 property_name, value_pattern, full_path)))
49
50 return matches
51
52 def check(self, cfn, properties, value_specs, property_specs, path):
53 """Check itself"""
54 matches = list()
55 for p_value, p_path in properties.items_safe(path[:]):
56 for prop in p_value:
57 if prop in value_specs:
58 value = value_specs.get(prop).get('Value', {})
59 if value:
60 value_type = value.get('ValueType', '')
61 property_type = property_specs.get('Properties').get(prop).get('Type')
62 matches.extend(
63 cfn.check_value(
64 p_value, prop, p_path,
65 check_value=self.check_value,
66 value_specs=RESOURCE_SPECS.get(cfn.regions[0]).get(
67 'ValueTypes').get(value_type, {}),
68 cfn=cfn, property_type=property_type, property_name=prop
69 )
70 )
71 return matches
72
73 def match_resource_sub_properties(self, properties, property_type, path, cfn):
74 """Match for sub properties"""
75 matches = list()
76
77 specs = RESOURCE_SPECS.get(cfn.regions[0]).get(
78 'PropertyTypes').get(property_type, {}).get('Properties', {})
79 property_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type)
80 matches.extend(self.check(cfn, properties, specs, property_specs, path))
81
82 return matches
83
84 def match_resource_properties(self, properties, resource_type, path, cfn):
85 """Check CloudFormation Properties"""
86 matches = list()
87
88 specs = RESOURCE_SPECS.get(cfn.regions[0]).get(
89 'ResourceTypes').get(resource_type, {}).get('Properties', {})
90 resource_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type)
91 matches.extend(self.check(cfn, properties, specs, resource_specs, path))
92
93 return matches
94
[end of src/cfnlint/rules/resources/properties/AllowedPattern.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/resources/properties/AllowedPattern.py b/src/cfnlint/rules/resources/properties/AllowedPattern.py
--- a/src/cfnlint/rules/resources/properties/AllowedPattern.py
+++ b/src/cfnlint/rules/resources/properties/AllowedPattern.py
@@ -3,6 +3,7 @@
SPDX-License-Identifier: MIT-0
"""
import re
+import six
from cfnlint.rules import CloudFormationLintRule
from cfnlint.rules import RuleMatch
@@ -34,18 +35,22 @@
# the RegEx itself is used.
value_pattern = kwargs.get('value_specs', {}).get('AllowedPattern', value_pattern_regex)
- if value_pattern_regex:
- regex = re.compile(value_pattern_regex)
+ if isinstance(value, (int, float)):
+ value = str(value)
- # Ignore values with dynamic references. Simple check to prevent false-positives
- # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html
- if '{{resolve:' not in value:
- if not regex.match(value):
- full_path = ('/'.join(str(x) for x in path))
+ if isinstance(value, six.string_types):
+ if value_pattern_regex:
+ regex = re.compile(value_pattern_regex)
- message = '{} contains invalid characters (Pattern: {}) at {}'
- matches.append(RuleMatch(path, message.format(
- property_name, value_pattern, full_path)))
+ # Ignore values with dynamic references. Simple check to prevent false-positives
+ # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html
+ if '{{resolve:' not in value:
+ if not regex.match(value):
+ full_path = ('/'.join(str(x) for x in path))
+
+ message = '{} contains invalid characters (Pattern: {}) at {}'
+ matches.append(RuleMatch(path, message.format(
+ property_name, value_pattern, full_path)))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/properties/AllowedPattern.py b/src/cfnlint/rules/resources/properties/AllowedPattern.py\n--- a/src/cfnlint/rules/resources/properties/AllowedPattern.py\n+++ b/src/cfnlint/rules/resources/properties/AllowedPattern.py\n@@ -3,6 +3,7 @@\n SPDX-License-Identifier: MIT-0\n \"\"\"\n import re\n+import six\n from cfnlint.rules import CloudFormationLintRule\n from cfnlint.rules import RuleMatch\n \n@@ -34,18 +35,22 @@\n # the RegEx itself is used.\n value_pattern = kwargs.get('value_specs', {}).get('AllowedPattern', value_pattern_regex)\n \n- if value_pattern_regex:\n- regex = re.compile(value_pattern_regex)\n+ if isinstance(value, (int, float)):\n+ value = str(value)\n \n- # Ignore values with dynamic references. Simple check to prevent false-positives\n- # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html\n- if '{{resolve:' not in value:\n- if not regex.match(value):\n- full_path = ('/'.join(str(x) for x in path))\n+ if isinstance(value, six.string_types):\n+ if value_pattern_regex:\n+ regex = re.compile(value_pattern_regex)\n \n- message = '{} contains invalid characters (Pattern: {}) at {}'\n- matches.append(RuleMatch(path, message.format(\n- property_name, value_pattern, full_path)))\n+ # Ignore values with dynamic references. Simple check to prevent false-positives\n+ # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html\n+ if '{{resolve:' not in value:\n+ if not regex.match(value):\n+ full_path = ('/'.join(str(x) for x in path))\n+\n+ message = '{} contains invalid characters (Pattern: {}) at {}'\n+ matches.append(RuleMatch(path, message.format(\n+ property_name, value_pattern, full_path)))\n \n return matches\n", "issue": "AWS::Logs::MetricFilter MetricValues permits invalid strings\n`cfn-lint 0.30.1`\r\n\r\nAWS::Logs::MetricFilter.Properties.MetricTransformations[*].MetricValue allows a bare string not starting with '$' which it appears is never actually valid, ie \r\n\"MetricValue: length\" vs \"MetricValue: $length\"\r\n\r\nAssuming I'm reading the documentation correctly MetricValue must always either be a number OR start with a '$' character.\r\n\r\nThe following fragment lints, but is rejected by CloudFormation at runtime without a $ at the start of the named MetricValue field\r\n```\r\n QueueLengthMetricFilter:\r\n Type: AWS::Logs::MetricFilter\r\n Properties:\r\n LogGroupName: !Ref LogGroup\r\n FilterPattern: '[date, time, tag=\"rh-sched*\", x01=throttling, x02=\"jobs.\", ..., x10=Len, x11=of, x12=job, x13=\"queue*\", length]'\r\n MetricTransformations:\r\n - MetricValue: length\r\n MetricNamespace: !Sub '${EnvironmentName}'\r\n MetricName: 'JobsQueued'\r\n```\r\n\r\n\r\nNote: I believe that this is also missed by the AWS ValidateTemplate API\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\nfrom cfnlint.helpers import RESOURCE_SPECS\n\n\nclass AllowedPattern(CloudFormationLintRule):\n \"\"\"Check if properties have a valid value\"\"\"\n id = 'E3031'\n shortdesc = 'Check if property values adhere to a specific pattern'\n description = 'Check if properties have a valid value in case of a pattern (Regular Expression)'\n source_url = 'https://github.com/awslabs/cfn-python-lint/blob/master/docs/cfn-resource-specification.md#allowedpattern'\n tags = ['resources', 'property', 'allowed pattern', 'regex']\n\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes'):\n self.resource_property_types.append(resource_type_spec)\n for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes'):\n self.resource_sub_property_types.append(property_type_spec)\n\n def check_value(self, value, path, property_name, **kwargs):\n \"\"\"Check Value\"\"\"\n matches = []\n\n # Get the Allowed Pattern Regex\n value_pattern_regex = kwargs.get('value_specs', {}).get('AllowedPatternRegex', {})\n # Get the \"Human Readable\" version for the error message. Optional, if not specified,\n # the RegEx itself is used.\n value_pattern = kwargs.get('value_specs', {}).get('AllowedPattern', value_pattern_regex)\n\n if value_pattern_regex:\n regex = re.compile(value_pattern_regex)\n\n # Ignore values with dynamic references. Simple check to prevent false-positives\n # See: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/dynamic-references.html\n if '{{resolve:' not in value:\n if not regex.match(value):\n full_path = ('/'.join(str(x) for x in path))\n\n message = '{} contains invalid characters (Pattern: {}) at {}'\n matches.append(RuleMatch(path, message.format(\n property_name, value_pattern, full_path)))\n\n return matches\n\n def check(self, cfn, properties, value_specs, property_specs, path):\n \"\"\"Check itself\"\"\"\n matches = list()\n for p_value, p_path in properties.items_safe(path[:]):\n for prop in p_value:\n if prop in value_specs:\n value = value_specs.get(prop).get('Value', {})\n if value:\n value_type = value.get('ValueType', '')\n property_type = property_specs.get('Properties').get(prop).get('Type')\n matches.extend(\n cfn.check_value(\n p_value, prop, p_path,\n check_value=self.check_value,\n value_specs=RESOURCE_SPECS.get(cfn.regions[0]).get(\n 'ValueTypes').get(value_type, {}),\n cfn=cfn, property_type=property_type, property_name=prop\n )\n )\n return matches\n\n def match_resource_sub_properties(self, properties, property_type, path, cfn):\n \"\"\"Match for sub properties\"\"\"\n matches = list()\n\n specs = RESOURCE_SPECS.get(cfn.regions[0]).get(\n 'PropertyTypes').get(property_type, {}).get('Properties', {})\n property_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type)\n matches.extend(self.check(cfn, properties, specs, property_specs, path))\n\n return matches\n\n def match_resource_properties(self, properties, resource_type, path, cfn):\n \"\"\"Check CloudFormation Properties\"\"\"\n matches = list()\n\n specs = RESOURCE_SPECS.get(cfn.regions[0]).get(\n 'ResourceTypes').get(resource_type, {}).get('Properties', {})\n resource_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type)\n matches.extend(self.check(cfn, properties, specs, resource_specs, path))\n\n return matches\n", "path": "src/cfnlint/rules/resources/properties/AllowedPattern.py"}]}
| 1,872 | 449 |
gh_patches_debug_64689
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-2992
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Install bug: Mock required for gradient_check
#2972 Install bug
Chainer installed with `pip install chainer`
`from chainer import gradient_check` fails due to unable to find mock to import
Fixed by `conda install mock`
`gradient_check` is included in the block declarations in the tutorial, so it should either be removed from there or mock should be added to default install so that people doing the tutorial do not get an error during the import commands.
```
from chainer import gradient_check
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-1-0ba4708b632d> in <module>()
1 import numpy as np
2 import chainer
----> 3 from chainer import gradient_check
4 from chainer import datasets, iterators, optimizers, serializers
5 from chainer import Link, Chain, ChainList
/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/gradient_check.py in <module>()
7 from chainer import cuda
8 from chainer.functions.math import identity
----> 9 from chainer import testing
10 from chainer import variable
11
/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/testing/__init__.py in <module>()
5 from chainer.testing import parameterized # NOQA
6 from chainer.testing import serializer # NOQA
----> 7 from chainer.testing import training # NOQA
8 from chainer.testing import unary_math_function_test # NOQA
9
/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/testing/training.py in <module>()
1 from __future__ import division
2
----> 3 import mock
4
5 from chainer import training
ImportError: No module named 'mock'
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 import os
4 import pkg_resources
5 import sys
6
7 from setuptools import setup
8
9
10 if sys.version_info[:3] == (3, 5, 0):
11 if not int(os.getenv('CHAINER_PYTHON_350_FORCE', '0')):
12 msg = """
13 Chainer does not work with Python 3.5.0.
14
15 We strongly recommend to use another version of Python.
16 If you want to use Chainer with Python 3.5.0 at your own risk,
17 set CHAINER_PYTHON_350_FORCE environment variable to 1."""
18 print(msg)
19 sys.exit(1)
20
21
22 setup_requires = []
23 install_requires = [
24 'filelock',
25 'nose',
26 'numpy>=1.9.0',
27 'protobuf>=2.6.0',
28 'six>=1.9.0',
29 ]
30 cupy_require = 'cupy==2.0.0a1'
31
32 cupy_pkg = None
33 try:
34 cupy_pkg = pkg_resources.get_distribution('cupy')
35 except pkg_resources.DistributionNotFound:
36 pass
37
38 if cupy_pkg is not None:
39 install_requires.append(cupy_require)
40 print('Use %s' % cupy_require)
41
42 setup(
43 name='chainer',
44 version='3.0.0a1',
45 description='A flexible framework of neural networks',
46 author='Seiya Tokui',
47 author_email='[email protected]',
48 url='https://chainer.org/',
49 license='MIT License',
50 packages=['chainer',
51 'chainer.dataset',
52 'chainer.datasets',
53 'chainer.functions',
54 'chainer.functions.activation',
55 'chainer.functions.array',
56 'chainer.functions.connection',
57 'chainer.functions.evaluation',
58 'chainer.functions.loss',
59 'chainer.functions.math',
60 'chainer.functions.noise',
61 'chainer.functions.normalization',
62 'chainer.functions.pooling',
63 'chainer.functions.theano',
64 'chainer.functions.util',
65 'chainer.function_hooks',
66 'chainer.iterators',
67 'chainer.initializers',
68 'chainer.links',
69 'chainer.links.activation',
70 'chainer.links.caffe',
71 'chainer.links.caffe.protobuf2',
72 'chainer.links.caffe.protobuf3',
73 'chainer.links.connection',
74 'chainer.links.loss',
75 'chainer.links.model',
76 'chainer.links.model.vision',
77 'chainer.links.normalization',
78 'chainer.links.theano',
79 'chainer.optimizers',
80 'chainer.serializers',
81 'chainer.testing',
82 'chainer.training',
83 'chainer.training.extensions',
84 'chainer.training.triggers',
85 'chainer.training.updaters',
86 'chainer.utils'],
87 zip_safe=False,
88 setup_requires=setup_requires,
89 install_requires=install_requires,
90 tests_require=['mock',
91 'nose'],
92 )
93
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -22,6 +22,7 @@
setup_requires = []
install_requires = [
'filelock',
+ 'mock',
'nose',
'numpy>=1.9.0',
'protobuf>=2.6.0',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -22,6 +22,7 @@\n setup_requires = []\n install_requires = [\n 'filelock',\n+ 'mock',\n 'nose',\n 'numpy>=1.9.0',\n 'protobuf>=2.6.0',\n", "issue": "Install bug: Mock required for gradient_check\n#2972 Install bug\r\n\r\nChainer installed with `pip install chainer`\r\n`from chainer import gradient_check` fails due to unable to find mock to import\r\nFixed by `conda install mock`\r\n\r\n`gradient_check` is included in the block declarations in the tutorial, so it should either be removed from there or mock should be added to default install so that people doing the tutorial do not get an error during the import commands.\r\n\r\n```\r\nfrom chainer import gradient_check\r\n\r\n---------------------------------------------------------------------------\r\nImportError Traceback (most recent call last)\r\n<ipython-input-1-0ba4708b632d> in <module>()\r\n 1 import numpy as np\r\n 2 import chainer\r\n----> 3 from chainer import gradient_check\r\n 4 from chainer import datasets, iterators, optimizers, serializers\r\n 5 from chainer import Link, Chain, ChainList\r\n\r\n/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/gradient_check.py in <module>()\r\n 7 from chainer import cuda\r\n 8 from chainer.functions.math import identity\r\n----> 9 from chainer import testing\r\n 10 from chainer import variable\r\n 11 \r\n\r\n/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/testing/__init__.py in <module>()\r\n 5 from chainer.testing import parameterized # NOQA\r\n 6 from chainer.testing import serializer # NOQA\r\n----> 7 from chainer.testing import training # NOQA\r\n 8 from chainer.testing import unary_math_function_test # NOQA\r\n 9 \r\n\r\n/home/crissman/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/chainer/testing/training.py in <module>()\r\n 1 from __future__ import division\r\n 2 \r\n----> 3 import mock\r\n 4 \r\n 5 from chainer import training\r\n\r\nImportError: No module named 'mock'\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport pkg_resources\nimport sys\n\nfrom setuptools import setup\n\n\nif sys.version_info[:3] == (3, 5, 0):\n if not int(os.getenv('CHAINER_PYTHON_350_FORCE', '0')):\n msg = \"\"\"\nChainer does not work with Python 3.5.0.\n\nWe strongly recommend to use another version of Python.\nIf you want to use Chainer with Python 3.5.0 at your own risk,\nset CHAINER_PYTHON_350_FORCE environment variable to 1.\"\"\"\n print(msg)\n sys.exit(1)\n\n\nsetup_requires = []\ninstall_requires = [\n 'filelock',\n 'nose',\n 'numpy>=1.9.0',\n 'protobuf>=2.6.0',\n 'six>=1.9.0',\n]\ncupy_require = 'cupy==2.0.0a1'\n\ncupy_pkg = None\ntry:\n cupy_pkg = pkg_resources.get_distribution('cupy')\nexcept pkg_resources.DistributionNotFound:\n pass\n\nif cupy_pkg is not None:\n install_requires.append(cupy_require)\n print('Use %s' % cupy_require)\n\nsetup(\n name='chainer',\n version='3.0.0a1',\n description='A flexible framework of neural networks',\n author='Seiya Tokui',\n author_email='[email protected]',\n url='https://chainer.org/',\n license='MIT License',\n packages=['chainer',\n 'chainer.dataset',\n 'chainer.datasets',\n 'chainer.functions',\n 'chainer.functions.activation',\n 'chainer.functions.array',\n 'chainer.functions.connection',\n 'chainer.functions.evaluation',\n 'chainer.functions.loss',\n 'chainer.functions.math',\n 'chainer.functions.noise',\n 'chainer.functions.normalization',\n 'chainer.functions.pooling',\n 'chainer.functions.theano',\n 'chainer.functions.util',\n 'chainer.function_hooks',\n 'chainer.iterators',\n 'chainer.initializers',\n 'chainer.links',\n 'chainer.links.activation',\n 'chainer.links.caffe',\n 'chainer.links.caffe.protobuf2',\n 'chainer.links.caffe.protobuf3',\n 'chainer.links.connection',\n 'chainer.links.loss',\n 'chainer.links.model',\n 'chainer.links.model.vision',\n 'chainer.links.normalization',\n 'chainer.links.theano',\n 'chainer.optimizers',\n 'chainer.serializers',\n 'chainer.testing',\n 'chainer.training',\n 'chainer.training.extensions',\n 'chainer.training.triggers',\n 'chainer.training.updaters',\n 'chainer.utils'],\n zip_safe=False,\n setup_requires=setup_requires,\n install_requires=install_requires,\n tests_require=['mock',\n 'nose'],\n)\n", "path": "setup.py"}]}
| 1,808 | 76 |
gh_patches_debug_6471
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-1757
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: `Adapter.bot_disconnect` 不应允许关闭其他适配器创建的 bot
**描述问题:**
当前的 `bot_disconnect` 只会根据 `bot.self_id` 关闭对应 bot。如果 `OneBot V12` 适配器调用 `bot_disconnect` 也能将 `OneBot V11` 适配器创建的 bot 移除。
**如何复现?**
<https://github.com/nonebot/adapter-onebot/pull/45>
<https://github.com/he0119/CoolQBot/issues/264>
**期望的结果**
如果关闭的 bot 不属于当前适配器,则跳过或者报错。
</issue>
<code>
[start of nonebot/internal/adapter/adapter.py]
1 import abc
2 from contextlib import asynccontextmanager
3 from typing import Any, Dict, AsyncGenerator
4
5 from nonebot.config import Config
6 from nonebot.internal.driver import (
7 Driver,
8 Request,
9 Response,
10 WebSocket,
11 ForwardDriver,
12 ReverseDriver,
13 HTTPServerSetup,
14 WebSocketServerSetup,
15 )
16
17 from .bot import Bot
18
19
20 class Adapter(abc.ABC):
21 """协议适配器基类。
22
23 通常,在 Adapter 中编写协议通信相关代码,如: 建立通信连接、处理接收与发送 data 等。
24
25 参数:
26 driver: {ref}`nonebot.drivers.Driver` 实例
27 kwargs: 其他由 {ref}`nonebot.drivers.Driver.register_adapter` 传入的额外参数
28 """
29
30 def __init__(self, driver: Driver, **kwargs: Any):
31 self.driver: Driver = driver
32 """{ref}`nonebot.drivers.Driver` 实例"""
33 self.bots: Dict[str, Bot] = {}
34 """本协议适配器已建立连接的 {ref}`nonebot.adapters.Bot` 实例"""
35
36 def __repr__(self) -> str:
37 return f"Adapter(name={self.get_name()!r})"
38
39 @classmethod
40 @abc.abstractmethod
41 def get_name(cls) -> str:
42 """当前协议适配器的名称"""
43 raise NotImplementedError
44
45 @property
46 def config(self) -> Config:
47 """全局 NoneBot 配置"""
48 return self.driver.config
49
50 def bot_connect(self, bot: Bot) -> None:
51 """告知 NoneBot 建立了一个新的 {ref}`nonebot.adapters.Bot` 连接。
52
53 当有新的 {ref}`nonebot.adapters.Bot` 实例连接建立成功时调用。
54
55 参数:
56 bot: {ref}`nonebot.adapters.Bot` 实例
57 """
58 self.driver._bot_connect(bot)
59 self.bots[bot.self_id] = bot
60
61 def bot_disconnect(self, bot: Bot) -> None:
62 """告知 NoneBot {ref}`nonebot.adapters.Bot` 连接已断开。
63
64 当有 {ref}`nonebot.adapters.Bot` 实例连接断开时调用。
65
66 参数:
67 bot: {ref}`nonebot.adapters.Bot` 实例
68 """
69 self.driver._bot_disconnect(bot)
70 self.bots.pop(bot.self_id, None)
71
72 def setup_http_server(self, setup: HTTPServerSetup):
73 """设置一个 HTTP 服务器路由配置"""
74 if not isinstance(self.driver, ReverseDriver):
75 raise TypeError("Current driver does not support http server")
76 self.driver.setup_http_server(setup)
77
78 def setup_websocket_server(self, setup: WebSocketServerSetup):
79 """设置一个 WebSocket 服务器路由配置"""
80 if not isinstance(self.driver, ReverseDriver):
81 raise TypeError("Current driver does not support websocket server")
82 self.driver.setup_websocket_server(setup)
83
84 async def request(self, setup: Request) -> Response:
85 """进行一个 HTTP 客户端请求"""
86 if not isinstance(self.driver, ForwardDriver):
87 raise TypeError("Current driver does not support http client")
88 return await self.driver.request(setup)
89
90 @asynccontextmanager
91 async def websocket(self, setup: Request) -> AsyncGenerator[WebSocket, None]:
92 """建立一个 WebSocket 客户端连接请求"""
93 if not isinstance(self.driver, ForwardDriver):
94 raise TypeError("Current driver does not support websocket client")
95 async with self.driver.websocket(setup) as ws:
96 yield ws
97
98 @abc.abstractmethod
99 async def _call_api(self, bot: Bot, api: str, **data: Any) -> Any:
100 """`Adapter` 实际调用 api 的逻辑实现函数,实现该方法以调用 api。
101
102 参数:
103 api: API 名称
104 data: API 数据
105 """
106 raise NotImplementedError
107
108
109 __autodoc__ = {"Adapter._call_api": True}
110
[end of nonebot/internal/adapter/adapter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nonebot/internal/adapter/adapter.py b/nonebot/internal/adapter/adapter.py
--- a/nonebot/internal/adapter/adapter.py
+++ b/nonebot/internal/adapter/adapter.py
@@ -66,8 +66,9 @@
参数:
bot: {ref}`nonebot.adapters.Bot` 实例
"""
+ if self.bots.pop(bot.self_id, None) is None:
+ raise RuntimeError(f"{bot} not found in adapter {self.get_name()}")
self.driver._bot_disconnect(bot)
- self.bots.pop(bot.self_id, None)
def setup_http_server(self, setup: HTTPServerSetup):
"""设置一个 HTTP 服务器路由配置"""
|
{"golden_diff": "diff --git a/nonebot/internal/adapter/adapter.py b/nonebot/internal/adapter/adapter.py\n--- a/nonebot/internal/adapter/adapter.py\n+++ b/nonebot/internal/adapter/adapter.py\n@@ -66,8 +66,9 @@\n \u53c2\u6570:\n bot: {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\n \"\"\"\n+ if self.bots.pop(bot.self_id, None) is None:\n+ raise RuntimeError(f\"{bot} not found in adapter {self.get_name()}\")\n self.driver._bot_disconnect(bot)\n- self.bots.pop(bot.self_id, None)\n \n def setup_http_server(self, setup: HTTPServerSetup):\n \"\"\"\u8bbe\u7f6e\u4e00\u4e2a HTTP \u670d\u52a1\u5668\u8def\u7531\u914d\u7f6e\"\"\"\n", "issue": "Bug: `Adapter.bot_disconnect` \u4e0d\u5e94\u5141\u8bb8\u5173\u95ed\u5176\u4ed6\u9002\u914d\u5668\u521b\u5efa\u7684 bot\n**\u63cf\u8ff0\u95ee\u9898\uff1a**\r\n\r\n\u5f53\u524d\u7684 `bot_disconnect` \u53ea\u4f1a\u6839\u636e `bot.self_id` \u5173\u95ed\u5bf9\u5e94 bot\u3002\u5982\u679c `OneBot V12` \u9002\u914d\u5668\u8c03\u7528 `bot_disconnect` \u4e5f\u80fd\u5c06 `OneBot V11` \u9002\u914d\u5668\u521b\u5efa\u7684 bot \u79fb\u9664\u3002\r\n\r\n**\u5982\u4f55\u590d\u73b0\uff1f**\r\n\r\n<https://github.com/nonebot/adapter-onebot/pull/45>\r\n<https://github.com/he0119/CoolQBot/issues/264>\r\n\r\n**\u671f\u671b\u7684\u7ed3\u679c**\r\n\r\n\u5982\u679c\u5173\u95ed\u7684 bot \u4e0d\u5c5e\u4e8e\u5f53\u524d\u9002\u914d\u5668\uff0c\u5219\u8df3\u8fc7\u6216\u8005\u62a5\u9519\u3002\r\n\n", "before_files": [{"content": "import abc\nfrom contextlib import asynccontextmanager\nfrom typing import Any, Dict, AsyncGenerator\n\nfrom nonebot.config import Config\nfrom nonebot.internal.driver import (\n Driver,\n Request,\n Response,\n WebSocket,\n ForwardDriver,\n ReverseDriver,\n HTTPServerSetup,\n WebSocketServerSetup,\n)\n\nfrom .bot import Bot\n\n\nclass Adapter(abc.ABC):\n \"\"\"\u534f\u8bae\u9002\u914d\u5668\u57fa\u7c7b\u3002\n\n \u901a\u5e38\uff0c\u5728 Adapter \u4e2d\u7f16\u5199\u534f\u8bae\u901a\u4fe1\u76f8\u5173\u4ee3\u7801\uff0c\u5982: \u5efa\u7acb\u901a\u4fe1\u8fde\u63a5\u3001\u5904\u7406\u63a5\u6536\u4e0e\u53d1\u9001 data \u7b49\u3002\n\n \u53c2\u6570:\n driver: {ref}`nonebot.drivers.Driver` \u5b9e\u4f8b\n kwargs: \u5176\u4ed6\u7531 {ref}`nonebot.drivers.Driver.register_adapter` \u4f20\u5165\u7684\u989d\u5916\u53c2\u6570\n \"\"\"\n\n def __init__(self, driver: Driver, **kwargs: Any):\n self.driver: Driver = driver\n \"\"\"{ref}`nonebot.drivers.Driver` \u5b9e\u4f8b\"\"\"\n self.bots: Dict[str, Bot] = {}\n \"\"\"\u672c\u534f\u8bae\u9002\u914d\u5668\u5df2\u5efa\u7acb\u8fde\u63a5\u7684 {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\"\"\"\n\n def __repr__(self) -> str:\n return f\"Adapter(name={self.get_name()!r})\"\n\n @classmethod\n @abc.abstractmethod\n def get_name(cls) -> str:\n \"\"\"\u5f53\u524d\u534f\u8bae\u9002\u914d\u5668\u7684\u540d\u79f0\"\"\"\n raise NotImplementedError\n\n @property\n def config(self) -> Config:\n \"\"\"\u5168\u5c40 NoneBot \u914d\u7f6e\"\"\"\n return self.driver.config\n\n def bot_connect(self, bot: Bot) -> None:\n \"\"\"\u544a\u77e5 NoneBot \u5efa\u7acb\u4e86\u4e00\u4e2a\u65b0\u7684 {ref}`nonebot.adapters.Bot` \u8fde\u63a5\u3002\n\n \u5f53\u6709\u65b0\u7684 {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\u8fde\u63a5\u5efa\u7acb\u6210\u529f\u65f6\u8c03\u7528\u3002\n\n \u53c2\u6570:\n bot: {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\n \"\"\"\n self.driver._bot_connect(bot)\n self.bots[bot.self_id] = bot\n\n def bot_disconnect(self, bot: Bot) -> None:\n \"\"\"\u544a\u77e5 NoneBot {ref}`nonebot.adapters.Bot` \u8fde\u63a5\u5df2\u65ad\u5f00\u3002\n\n \u5f53\u6709 {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\u8fde\u63a5\u65ad\u5f00\u65f6\u8c03\u7528\u3002\n\n \u53c2\u6570:\n bot: {ref}`nonebot.adapters.Bot` \u5b9e\u4f8b\n \"\"\"\n self.driver._bot_disconnect(bot)\n self.bots.pop(bot.self_id, None)\n\n def setup_http_server(self, setup: HTTPServerSetup):\n \"\"\"\u8bbe\u7f6e\u4e00\u4e2a HTTP \u670d\u52a1\u5668\u8def\u7531\u914d\u7f6e\"\"\"\n if not isinstance(self.driver, ReverseDriver):\n raise TypeError(\"Current driver does not support http server\")\n self.driver.setup_http_server(setup)\n\n def setup_websocket_server(self, setup: WebSocketServerSetup):\n \"\"\"\u8bbe\u7f6e\u4e00\u4e2a WebSocket \u670d\u52a1\u5668\u8def\u7531\u914d\u7f6e\"\"\"\n if not isinstance(self.driver, ReverseDriver):\n raise TypeError(\"Current driver does not support websocket server\")\n self.driver.setup_websocket_server(setup)\n\n async def request(self, setup: Request) -> Response:\n \"\"\"\u8fdb\u884c\u4e00\u4e2a HTTP \u5ba2\u6237\u7aef\u8bf7\u6c42\"\"\"\n if not isinstance(self.driver, ForwardDriver):\n raise TypeError(\"Current driver does not support http client\")\n return await self.driver.request(setup)\n\n @asynccontextmanager\n async def websocket(self, setup: Request) -> AsyncGenerator[WebSocket, None]:\n \"\"\"\u5efa\u7acb\u4e00\u4e2a WebSocket \u5ba2\u6237\u7aef\u8fde\u63a5\u8bf7\u6c42\"\"\"\n if not isinstance(self.driver, ForwardDriver):\n raise TypeError(\"Current driver does not support websocket client\")\n async with self.driver.websocket(setup) as ws:\n yield ws\n\n @abc.abstractmethod\n async def _call_api(self, bot: Bot, api: str, **data: Any) -> Any:\n \"\"\"`Adapter` \u5b9e\u9645\u8c03\u7528 api \u7684\u903b\u8f91\u5b9e\u73b0\u51fd\u6570\uff0c\u5b9e\u73b0\u8be5\u65b9\u6cd5\u4ee5\u8c03\u7528 api\u3002\n\n \u53c2\u6570:\n api: API \u540d\u79f0\n data: API \u6570\u636e\n \"\"\"\n raise NotImplementedError\n\n\n__autodoc__ = {\"Adapter._call_api\": True}\n", "path": "nonebot/internal/adapter/adapter.py"}]}
| 1,776 | 158 |
gh_patches_debug_9201
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-6154
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PIL version check for enum change appears to break SIMD versions
### 🐛 Describe the bug
This change appears to break current Pillow-SIMD version #5898
```
if tuple(int(part) for part in PIL.__version__.split(".")) >= (9, 1):
File "/home/.../lib/python3.10/site-packages/torchvision/transforms/_pil_constants.py", line 7, in <genexpr>
if tuple(int(part) for part in PIL.__version__.split(".")) >= (9, 1):
ValueError: invalid literal for int() with base 10: 'post1'
```
Amusingly enough, I warned against this approach in a users PR in `timm` https://github.com/rwightman/pytorch-image-models/pull/1256
Would be nice to have it fixed before 1.12 is finalized, I just hit this trying out the RC
### Versions
PT 1.12 RC, TV 0.13.0
</issue>
<code>
[start of torchvision/transforms/_pil_constants.py]
1 import PIL
2 from PIL import Image
3
4 # See https://pillow.readthedocs.io/en/stable/releasenotes/9.1.0.html#deprecations
5 # TODO: Remove this file once PIL minimal version is >= 9.1
6
7 if tuple(int(part) for part in PIL.__version__.split(".")) >= (9, 1):
8 BICUBIC = Image.Resampling.BICUBIC
9 BILINEAR = Image.Resampling.BILINEAR
10 LINEAR = Image.Resampling.BILINEAR
11 NEAREST = Image.Resampling.NEAREST
12
13 AFFINE = Image.Transform.AFFINE
14 FLIP_LEFT_RIGHT = Image.Transpose.FLIP_LEFT_RIGHT
15 FLIP_TOP_BOTTOM = Image.Transpose.FLIP_TOP_BOTTOM
16 PERSPECTIVE = Image.Transform.PERSPECTIVE
17 else:
18 BICUBIC = Image.BICUBIC
19 BILINEAR = Image.BILINEAR
20 NEAREST = Image.NEAREST
21 LINEAR = Image.LINEAR
22
23 AFFINE = Image.AFFINE
24 FLIP_LEFT_RIGHT = Image.FLIP_LEFT_RIGHT
25 FLIP_TOP_BOTTOM = Image.FLIP_TOP_BOTTOM
26 PERSPECTIVE = Image.PERSPECTIVE
27
[end of torchvision/transforms/_pil_constants.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/transforms/_pil_constants.py b/torchvision/transforms/_pil_constants.py
--- a/torchvision/transforms/_pil_constants.py
+++ b/torchvision/transforms/_pil_constants.py
@@ -1,10 +1,9 @@
-import PIL
from PIL import Image
# See https://pillow.readthedocs.io/en/stable/releasenotes/9.1.0.html#deprecations
# TODO: Remove this file once PIL minimal version is >= 9.1
-if tuple(int(part) for part in PIL.__version__.split(".")) >= (9, 1):
+if hasattr(Image, "Resampling"):
BICUBIC = Image.Resampling.BICUBIC
BILINEAR = Image.Resampling.BILINEAR
LINEAR = Image.Resampling.BILINEAR
|
{"golden_diff": "diff --git a/torchvision/transforms/_pil_constants.py b/torchvision/transforms/_pil_constants.py\n--- a/torchvision/transforms/_pil_constants.py\n+++ b/torchvision/transforms/_pil_constants.py\n@@ -1,10 +1,9 @@\n-import PIL\n from PIL import Image\n \n # See https://pillow.readthedocs.io/en/stable/releasenotes/9.1.0.html#deprecations\n # TODO: Remove this file once PIL minimal version is >= 9.1\n \n-if tuple(int(part) for part in PIL.__version__.split(\".\")) >= (9, 1):\n+if hasattr(Image, \"Resampling\"):\n BICUBIC = Image.Resampling.BICUBIC\n BILINEAR = Image.Resampling.BILINEAR\n LINEAR = Image.Resampling.BILINEAR\n", "issue": "PIL version check for enum change appears to break SIMD versions\n### \ud83d\udc1b Describe the bug\n\nThis change appears to break current Pillow-SIMD version #5898 \r\n\r\n```\r\n if tuple(int(part) for part in PIL.__version__.split(\".\")) >= (9, 1):\r\n File \"/home/.../lib/python3.10/site-packages/torchvision/transforms/_pil_constants.py\", line 7, in <genexpr>\r\n if tuple(int(part) for part in PIL.__version__.split(\".\")) >= (9, 1):\r\nValueError: invalid literal for int() with base 10: 'post1'\r\n```\r\n\r\nAmusingly enough, I warned against this approach in a users PR in `timm` https://github.com/rwightman/pytorch-image-models/pull/1256\r\n\r\nWould be nice to have it fixed before 1.12 is finalized, I just hit this trying out the RC\n\n### Versions\n\nPT 1.12 RC, TV 0.13.0\n", "before_files": [{"content": "import PIL\nfrom PIL import Image\n\n# See https://pillow.readthedocs.io/en/stable/releasenotes/9.1.0.html#deprecations\n# TODO: Remove this file once PIL minimal version is >= 9.1\n\nif tuple(int(part) for part in PIL.__version__.split(\".\")) >= (9, 1):\n BICUBIC = Image.Resampling.BICUBIC\n BILINEAR = Image.Resampling.BILINEAR\n LINEAR = Image.Resampling.BILINEAR\n NEAREST = Image.Resampling.NEAREST\n\n AFFINE = Image.Transform.AFFINE\n FLIP_LEFT_RIGHT = Image.Transpose.FLIP_LEFT_RIGHT\n FLIP_TOP_BOTTOM = Image.Transpose.FLIP_TOP_BOTTOM\n PERSPECTIVE = Image.Transform.PERSPECTIVE\nelse:\n BICUBIC = Image.BICUBIC\n BILINEAR = Image.BILINEAR\n NEAREST = Image.NEAREST\n LINEAR = Image.LINEAR\n\n AFFINE = Image.AFFINE\n FLIP_LEFT_RIGHT = Image.FLIP_LEFT_RIGHT\n FLIP_TOP_BOTTOM = Image.FLIP_TOP_BOTTOM\n PERSPECTIVE = Image.PERSPECTIVE\n", "path": "torchvision/transforms/_pil_constants.py"}]}
| 1,083 | 187 |
gh_patches_debug_16865
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-9228
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Updating Slack "Staff PRs" notifications to be more specific
<!-- IMPORTANT: Before posting, be sure to redact or remove sensitive data, such as passwords, secret keys, session cookies, etc. -->
When our daily slack bot runs to tell us of new staff PRs we want to ignore:
- `needs:submitter`
- `draft`
- `blocked`
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
### Describe the problem that you'd like solved
<!-- A clear and concise description of what you want to happen. -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
<!-- Which suggestions or requirements should be considered for how feature needs to appear or be implemented? -->
### Additional context
<!-- Add any other context or screenshots about the feature request here. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
</issue>
<code>
[start of scripts/pr_slack_digest.py]
1 from datetime import datetime
2 import requests
3 import os
4
5
6 def send_slack_message(message: str):
7 response = requests.post(
8 'https://slack.com/api/chat.postMessage',
9 headers={
10 'Authorization': f"Bearer {os.environ.get('SLACK_TOKEN')}",
11 'Content-Type': 'application/json; charset=utf-8',
12 },
13 json={
14 'channel': '#team-abc-plus',
15 'text': message,
16 },
17 )
18 if response.status_code != 200:
19 print(f"Failed to send message to Slack. Status code: {response.status_code}")
20 else:
21 print("Message sent to Slack successfully!")
22 print(response.content)
23
24
25 if __name__ == "__main__":
26 GH_LOGIN_TO_SLACK = {
27 'cdrini': '<@cdrini>',
28 'jimchamp': '<@U01ARTHG9EV>',
29 'mekarpeles': '<@mek>',
30 'scottbarnes': '<@U03MNR6T7FH>',
31 }
32 LABEL_EMOJI = {
33 'Priority: 0': '🚨 ',
34 'Priority: 1': '❗️ ',
35 }
36 # apparently `author` acts like an OR in this API and only this API -_-
37 query = "repo:internetarchive/openlibrary is:open is:pr author:cdrini author:jimchamp author:mekarpeles author:scottbarnes -is:draft"
38 prs = requests.get(
39 "https://api.github.com/search/issues",
40 params={
41 "q": query,
42 },
43 ).json()["items"]
44
45 message = f"{len(prs)} open staff PRs:\n\n"
46 for pr in prs:
47 pr_url = pr['html_url']
48 pr_age_days = (
49 datetime.now() - datetime.strptime(pr['created_at'], '%Y-%m-%dT%H:%M:%SZ')
50 ).days
51 message += f"<{pr_url}|*#{pr['number']}* | {pr['title']}>\n"
52 message += ' | '.join(
53 [
54 f"by {pr['user']['login']} {pr_age_days} days ago",
55 f"Assigned: {GH_LOGIN_TO_SLACK[pr['assignee']['login']] if pr['assignee'] else '⚠️ None'}",
56 f"{', '.join(LABEL_EMOJI.get(label['name'], '') + label['name'] for label in pr['labels'])}\n\n",
57 ]
58 )
59
60 send_slack_message(message)
61
[end of scripts/pr_slack_digest.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/pr_slack_digest.py b/scripts/pr_slack_digest.py
--- a/scripts/pr_slack_digest.py
+++ b/scripts/pr_slack_digest.py
@@ -33,8 +33,18 @@
'Priority: 0': '🚨 ',
'Priority: 1': '❗️ ',
}
+
+ INCLUDE_AUTHORS = ['mekarpeles', 'cdrini', 'scottbarnes', 'jimchamp']
+ EXCLUDE_LABELS = [
+ 'Needs: Submitter Input',
+ 'State: Blocked',
+ ]
+ query = 'repo:internetarchive/openlibrary is:open is:pr -is:draft'
# apparently `author` acts like an OR in this API and only this API -_-
- query = "repo:internetarchive/openlibrary is:open is:pr author:cdrini author:jimchamp author:mekarpeles author:scottbarnes -is:draft"
+ included_authors = " ".join([f"author:{author}" for author in INCLUDE_AUTHORS])
+ excluded_labels = " ".join([f'-label:"{label}"' for label in EXCLUDE_LABELS])
+ query = f'{query} {included_authors} {excluded_labels}'
+
prs = requests.get(
"https://api.github.com/search/issues",
params={
|
{"golden_diff": "diff --git a/scripts/pr_slack_digest.py b/scripts/pr_slack_digest.py\n--- a/scripts/pr_slack_digest.py\n+++ b/scripts/pr_slack_digest.py\n@@ -33,8 +33,18 @@\n 'Priority: 0': '\ud83d\udea8 ',\n 'Priority: 1': '\u2757\ufe0f ',\n }\n+\n+ INCLUDE_AUTHORS = ['mekarpeles', 'cdrini', 'scottbarnes', 'jimchamp']\n+ EXCLUDE_LABELS = [\n+ 'Needs: Submitter Input',\n+ 'State: Blocked',\n+ ]\n+ query = 'repo:internetarchive/openlibrary is:open is:pr -is:draft'\n # apparently `author` acts like an OR in this API and only this API -_-\n- query = \"repo:internetarchive/openlibrary is:open is:pr author:cdrini author:jimchamp author:mekarpeles author:scottbarnes -is:draft\"\n+ included_authors = \" \".join([f\"author:{author}\" for author in INCLUDE_AUTHORS])\n+ excluded_labels = \" \".join([f'-label:\"{label}\"' for label in EXCLUDE_LABELS])\n+ query = f'{query} {included_authors} {excluded_labels}'\n+\n prs = requests.get(\n \"https://api.github.com/search/issues\",\n params={\n", "issue": "Updating Slack \"Staff PRs\" notifications to be more specific\n<!-- IMPORTANT: Before posting, be sure to redact or remove sensitive data, such as passwords, secret keys, session cookies, etc. -->\r\n\r\nWhen our daily slack bot runs to tell us of new staff PRs we want to ignore: \r\n- `needs:submitter`\r\n- `draft`\r\n- `blocked`\r\n\r\n<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->\r\n\r\n### Describe the problem that you'd like solved\r\n<!-- A clear and concise description of what you want to happen. -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\n\r\n<!-- Which suggestions or requirements should be considered for how feature needs to appear or be implemented? -->\r\n\r\n### Additional context\r\n<!-- Add any other context or screenshots about the feature request here. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime\nimport requests\nimport os\n\n\ndef send_slack_message(message: str):\n response = requests.post(\n 'https://slack.com/api/chat.postMessage',\n headers={\n 'Authorization': f\"Bearer {os.environ.get('SLACK_TOKEN')}\",\n 'Content-Type': 'application/json; charset=utf-8',\n },\n json={\n 'channel': '#team-abc-plus',\n 'text': message,\n },\n )\n if response.status_code != 200:\n print(f\"Failed to send message to Slack. Status code: {response.status_code}\")\n else:\n print(\"Message sent to Slack successfully!\")\n print(response.content)\n\n\nif __name__ == \"__main__\":\n GH_LOGIN_TO_SLACK = {\n 'cdrini': '<@cdrini>',\n 'jimchamp': '<@U01ARTHG9EV>',\n 'mekarpeles': '<@mek>',\n 'scottbarnes': '<@U03MNR6T7FH>',\n }\n LABEL_EMOJI = {\n 'Priority: 0': '\ud83d\udea8 ',\n 'Priority: 1': '\u2757\ufe0f ',\n }\n # apparently `author` acts like an OR in this API and only this API -_-\n query = \"repo:internetarchive/openlibrary is:open is:pr author:cdrini author:jimchamp author:mekarpeles author:scottbarnes -is:draft\"\n prs = requests.get(\n \"https://api.github.com/search/issues\",\n params={\n \"q\": query,\n },\n ).json()[\"items\"]\n\n message = f\"{len(prs)} open staff PRs:\\n\\n\"\n for pr in prs:\n pr_url = pr['html_url']\n pr_age_days = (\n datetime.now() - datetime.strptime(pr['created_at'], '%Y-%m-%dT%H:%M:%SZ')\n ).days\n message += f\"<{pr_url}|*#{pr['number']}* | {pr['title']}>\\n\"\n message += ' | '.join(\n [\n f\"by {pr['user']['login']} {pr_age_days} days ago\",\n f\"Assigned: {GH_LOGIN_TO_SLACK[pr['assignee']['login']] if pr['assignee'] else '\u26a0\ufe0f None'}\",\n f\"{', '.join(LABEL_EMOJI.get(label['name'], '') + label['name'] for label in pr['labels'])}\\n\\n\",\n ]\n )\n\n send_slack_message(message)\n", "path": "scripts/pr_slack_digest.py"}]}
| 1,399 | 303 |
gh_patches_debug_9867
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-357
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exception in default_literal_parser() when ValueNode has no "value" member
The [default_literal_parser() function](https://github.com/mirumee/ariadne/blob/master/ariadne/scalars.py#L90) in ariadne.scalars expects nodes to have a "value" member. However, this is not the case with, for example, `ObjectValueNode` or `ListValueNode`. This causes an exception when trying to pass such nodes.
My suggestion is to use `graphql.utilities.value_from_ast_untyped` instead:
```
return value_parser(value_from_ast_untyped(ast))
```
I'm happy to do a PR if you guys like this change.
</issue>
<code>
[start of ariadne/scalars.py]
1 from typing import Optional, cast
2
3 from graphql.language.ast import (
4 BooleanValueNode,
5 FloatValueNode,
6 IntValueNode,
7 StringValueNode,
8 )
9 from graphql.type import (
10 GraphQLNamedType,
11 GraphQLScalarLiteralParser,
12 GraphQLScalarSerializer,
13 GraphQLScalarType,
14 GraphQLScalarValueParser,
15 GraphQLSchema,
16 )
17
18 from .types import SchemaBindable
19
20
21 class ScalarType(SchemaBindable):
22 _serialize: Optional[GraphQLScalarSerializer]
23 _parse_value: Optional[GraphQLScalarValueParser]
24 _parse_literal: Optional[GraphQLScalarLiteralParser]
25
26 def __init__(
27 self,
28 name: str,
29 *,
30 serializer: GraphQLScalarSerializer = None,
31 value_parser: GraphQLScalarValueParser = None,
32 literal_parser: GraphQLScalarLiteralParser = None,
33 ) -> None:
34 self.name = name
35 self._serialize = serializer
36 self._parse_value = value_parser
37 self._parse_literal = literal_parser
38
39 def set_serializer(self, f: GraphQLScalarSerializer) -> GraphQLScalarSerializer:
40 self._serialize = f
41 return f
42
43 def set_value_parser(self, f: GraphQLScalarValueParser) -> GraphQLScalarValueParser:
44 self._parse_value = f
45 if not self._parse_literal:
46 self._parse_literal = create_default_literal_parser(f)
47 return f
48
49 def set_literal_parser(
50 self, f: GraphQLScalarLiteralParser
51 ) -> GraphQLScalarLiteralParser:
52 self._parse_literal = f
53 return f
54
55 # Alias above setters for consistent decorator API
56 serializer = set_serializer
57 value_parser = set_value_parser
58 literal_parser = set_literal_parser
59
60 def bind_to_schema(self, schema: GraphQLSchema) -> None:
61 graphql_type = schema.type_map.get(self.name)
62 self.validate_graphql_type(graphql_type)
63 graphql_type = cast(GraphQLScalarType, graphql_type)
64
65 if self._serialize:
66 # See mypy bug https://github.com/python/mypy/issues/2427
67 graphql_type.serialize = self._serialize # type: ignore
68 if self._parse_value:
69 graphql_type.parse_value = self._parse_value # type: ignore
70 if self._parse_literal:
71 graphql_type.parse_literal = self._parse_literal # type: ignore
72
73 def validate_graphql_type(self, graphql_type: Optional[GraphQLNamedType]) -> None:
74 if not graphql_type:
75 raise ValueError("Scalar %s is not defined in the schema" % self.name)
76 if not isinstance(graphql_type, GraphQLScalarType):
77 raise ValueError(
78 "%s is defined in the schema, but it is instance of %s (expected %s)"
79 % (self.name, type(graphql_type).__name__, GraphQLScalarType.__name__)
80 )
81
82
83 SCALAR_AST_NODES = (BooleanValueNode, FloatValueNode, IntValueNode, StringValueNode)
84
85
86 def create_default_literal_parser(
87 value_parser: GraphQLScalarValueParser,
88 ) -> GraphQLScalarLiteralParser:
89 def default_literal_parser(ast):
90 return value_parser(ast.value)
91
92 return default_literal_parser
93
[end of ariadne/scalars.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ariadne/scalars.py b/ariadne/scalars.py
--- a/ariadne/scalars.py
+++ b/ariadne/scalars.py
@@ -14,6 +14,7 @@
GraphQLScalarValueParser,
GraphQLSchema,
)
+from graphql.utilities import value_from_ast_untyped
from .types import SchemaBindable
@@ -87,6 +88,6 @@
value_parser: GraphQLScalarValueParser,
) -> GraphQLScalarLiteralParser:
def default_literal_parser(ast):
- return value_parser(ast.value)
+ return value_parser(value_from_ast_untyped(ast))
return default_literal_parser
|
{"golden_diff": "diff --git a/ariadne/scalars.py b/ariadne/scalars.py\n--- a/ariadne/scalars.py\n+++ b/ariadne/scalars.py\n@@ -14,6 +14,7 @@\n GraphQLScalarValueParser,\n GraphQLSchema,\n )\n+from graphql.utilities import value_from_ast_untyped\n \n from .types import SchemaBindable\n \n@@ -87,6 +88,6 @@\n value_parser: GraphQLScalarValueParser,\n ) -> GraphQLScalarLiteralParser:\n def default_literal_parser(ast):\n- return value_parser(ast.value)\n+ return value_parser(value_from_ast_untyped(ast))\n \n return default_literal_parser\n", "issue": "Exception in default_literal_parser() when ValueNode has no \"value\" member\nThe [default_literal_parser() function](https://github.com/mirumee/ariadne/blob/master/ariadne/scalars.py#L90) in ariadne.scalars expects nodes to have a \"value\" member. However, this is not the case with, for example, `ObjectValueNode` or `ListValueNode`. This causes an exception when trying to pass such nodes.\r\n\r\nMy suggestion is to use `graphql.utilities.value_from_ast_untyped` instead:\r\n```\r\nreturn value_parser(value_from_ast_untyped(ast))\r\n``` \r\n\r\nI'm happy to do a PR if you guys like this change.\n", "before_files": [{"content": "from typing import Optional, cast\n\nfrom graphql.language.ast import (\n BooleanValueNode,\n FloatValueNode,\n IntValueNode,\n StringValueNode,\n)\nfrom graphql.type import (\n GraphQLNamedType,\n GraphQLScalarLiteralParser,\n GraphQLScalarSerializer,\n GraphQLScalarType,\n GraphQLScalarValueParser,\n GraphQLSchema,\n)\n\nfrom .types import SchemaBindable\n\n\nclass ScalarType(SchemaBindable):\n _serialize: Optional[GraphQLScalarSerializer]\n _parse_value: Optional[GraphQLScalarValueParser]\n _parse_literal: Optional[GraphQLScalarLiteralParser]\n\n def __init__(\n self,\n name: str,\n *,\n serializer: GraphQLScalarSerializer = None,\n value_parser: GraphQLScalarValueParser = None,\n literal_parser: GraphQLScalarLiteralParser = None,\n ) -> None:\n self.name = name\n self._serialize = serializer\n self._parse_value = value_parser\n self._parse_literal = literal_parser\n\n def set_serializer(self, f: GraphQLScalarSerializer) -> GraphQLScalarSerializer:\n self._serialize = f\n return f\n\n def set_value_parser(self, f: GraphQLScalarValueParser) -> GraphQLScalarValueParser:\n self._parse_value = f\n if not self._parse_literal:\n self._parse_literal = create_default_literal_parser(f)\n return f\n\n def set_literal_parser(\n self, f: GraphQLScalarLiteralParser\n ) -> GraphQLScalarLiteralParser:\n self._parse_literal = f\n return f\n\n # Alias above setters for consistent decorator API\n serializer = set_serializer\n value_parser = set_value_parser\n literal_parser = set_literal_parser\n\n def bind_to_schema(self, schema: GraphQLSchema) -> None:\n graphql_type = schema.type_map.get(self.name)\n self.validate_graphql_type(graphql_type)\n graphql_type = cast(GraphQLScalarType, graphql_type)\n\n if self._serialize:\n # See mypy bug https://github.com/python/mypy/issues/2427\n graphql_type.serialize = self._serialize # type: ignore\n if self._parse_value:\n graphql_type.parse_value = self._parse_value # type: ignore\n if self._parse_literal:\n graphql_type.parse_literal = self._parse_literal # type: ignore\n\n def validate_graphql_type(self, graphql_type: Optional[GraphQLNamedType]) -> None:\n if not graphql_type:\n raise ValueError(\"Scalar %s is not defined in the schema\" % self.name)\n if not isinstance(graphql_type, GraphQLScalarType):\n raise ValueError(\n \"%s is defined in the schema, but it is instance of %s (expected %s)\"\n % (self.name, type(graphql_type).__name__, GraphQLScalarType.__name__)\n )\n\n\nSCALAR_AST_NODES = (BooleanValueNode, FloatValueNode, IntValueNode, StringValueNode)\n\n\ndef create_default_literal_parser(\n value_parser: GraphQLScalarValueParser,\n) -> GraphQLScalarLiteralParser:\n def default_literal_parser(ast):\n return value_parser(ast.value)\n\n return default_literal_parser\n", "path": "ariadne/scalars.py"}]}
| 1,528 | 144 |
gh_patches_debug_33234
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-1373
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip install modin[all] should choose what to install based on the OS
When a Windows user runs `pip install modin[all]` it will not work because Ray does not have any Windows releases. We should still support `pip install modin[all]` in Windows.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 import versioneer
3
4 with open("README.md", "r") as fh:
5 long_description = fh.read()
6
7 dask_deps = ["dask>=2.1.0", "distributed>=2.3.2"]
8 ray_deps = ["ray==0.8.3"]
9
10 setup(
11 name="modin",
12 version=versioneer.get_version(),
13 cmdclass=versioneer.get_cmdclass(),
14 description="Modin: Make your pandas code run faster by changing one line of code.",
15 packages=find_packages(),
16 url="https://github.com/modin-project/modin",
17 long_description=long_description,
18 long_description_content_type="text/markdown",
19 install_requires=["pandas==1.0.3", "packaging"],
20 extras_require={
21 # can be installed by pip install modin[dask]
22 "dask": dask_deps,
23 "ray": ray_deps,
24 "all": dask_deps + ray_deps,
25 },
26 python_requires=">=3.5",
27 )
28
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,18 +1,60 @@
from setuptools import setup, find_packages
import versioneer
+import os
+from setuptools.dist import Distribution
+
+try:
+ from wheel.bdist_wheel import bdist_wheel
+
+ HAS_WHEEL = True
+except ImportError:
+ HAS_WHEEL = False
with open("README.md", "r") as fh:
long_description = fh.read()
+if HAS_WHEEL:
+
+ class ModinWheel(bdist_wheel):
+ def finalize_options(self):
+ bdist_wheel.finalize_options(self)
+ self.root_is_pure = False
+
+ def get_tag(self):
+ _, _, plat = bdist_wheel.get_tag(self)
+ py = "py3"
+ abi = "none"
+ return py, abi, plat
+
+
+class ModinDistribution(Distribution):
+ def __init__(self, *attrs):
+ Distribution.__init__(self, *attrs)
+ if HAS_WHEEL:
+ self.cmdclass["bdist_wheel"] = ModinWheel
+
+ def is_pure(self):
+ return False
+
+
dask_deps = ["dask>=2.1.0", "distributed>=2.3.2"]
ray_deps = ["ray==0.8.3"]
+if "SETUP_PLAT_NAME" in os.environ:
+ if "win" in os.environ["SETUP_PLAT_NAME"]:
+ all_deps = dask_deps
+ else:
+ all_deps = dask_deps + ray_deps
+else:
+ all_deps = dask_deps if os.name == "nt" else dask_deps + ray_deps
setup(
name="modin",
version=versioneer.get_version(),
cmdclass=versioneer.get_cmdclass(),
+ distclass=ModinDistribution,
description="Modin: Make your pandas code run faster by changing one line of code.",
packages=find_packages(),
+ license="Apache 2",
url="https://github.com/modin-project/modin",
long_description=long_description,
long_description_content_type="text/markdown",
@@ -21,7 +63,7 @@
# can be installed by pip install modin[dask]
"dask": dask_deps,
"ray": ray_deps,
- "all": dask_deps + ray_deps,
+ "all": all_deps,
},
python_requires=">=3.5",
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,18 +1,60 @@\n from setuptools import setup, find_packages\n import versioneer\n+import os\n+from setuptools.dist import Distribution\n+\n+try:\n+ from wheel.bdist_wheel import bdist_wheel\n+\n+ HAS_WHEEL = True\n+except ImportError:\n+ HAS_WHEEL = False\n \n with open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n \n+if HAS_WHEEL:\n+\n+ class ModinWheel(bdist_wheel):\n+ def finalize_options(self):\n+ bdist_wheel.finalize_options(self)\n+ self.root_is_pure = False\n+\n+ def get_tag(self):\n+ _, _, plat = bdist_wheel.get_tag(self)\n+ py = \"py3\"\n+ abi = \"none\"\n+ return py, abi, plat\n+\n+\n+class ModinDistribution(Distribution):\n+ def __init__(self, *attrs):\n+ Distribution.__init__(self, *attrs)\n+ if HAS_WHEEL:\n+ self.cmdclass[\"bdist_wheel\"] = ModinWheel\n+\n+ def is_pure(self):\n+ return False\n+\n+\n dask_deps = [\"dask>=2.1.0\", \"distributed>=2.3.2\"]\n ray_deps = [\"ray==0.8.3\"]\n+if \"SETUP_PLAT_NAME\" in os.environ:\n+ if \"win\" in os.environ[\"SETUP_PLAT_NAME\"]:\n+ all_deps = dask_deps\n+ else:\n+ all_deps = dask_deps + ray_deps\n+else:\n+ all_deps = dask_deps if os.name == \"nt\" else dask_deps + ray_deps\n \n setup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n+ distclass=ModinDistribution,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n+ license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n@@ -21,7 +63,7 @@\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n- \"all\": dask_deps + ray_deps,\n+ \"all\": all_deps,\n },\n python_requires=\">=3.5\",\n )\n", "issue": "pip install modin[all] should choose what to install based on the OS\nWhen a Windows user runs `pip install modin[all]` it will not work because Ray does not have any Windows releases. We should still support `pip install modin[all]` in Windows.\r\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\ndask_deps = [\"dask>=2.1.0\", \"distributed>=2.3.2\"]\nray_deps = [\"ray==0.8.3\"]\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.0.3\", \"packaging\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"all\": dask_deps + ray_deps,\n },\n python_requires=\">=3.5\",\n)\n", "path": "setup.py"}]}
| 861 | 557 |
gh_patches_debug_20597
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1633
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error when serving images through the URL generator
I posted a comment on https://github.com/torchbox/wagtail/issues/983 but probably better to open a new issue. Looks like the same problem to me though.
Hi guys, I think I'm having the same problem but when serving images using the URL generator. It does work if I'm logged-in in the site (cache not working) but doesn't when I'm not (cache full on).
Cheers,
Jordi
Internal Server Error: /images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/
Traceback (most recent call last):
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/core/handlers/base.py", line 204, in get_response
response = middleware_method(request, response)
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/middleware/cache.py", line 121, in process_response
self.cache.set(cache_key, response, timeout)
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/redis_cache/cache.py", line 239, in set
result = self._set(key, pickle.dumps(value), timeout, client, _add_only)
File "/var/www/buildability/venvs/buildability.co.nz/lib/python2.7/copy_reg.py", line 70, in _reduce_ex
raise TypeError, "can't pickle %s objects" % base.__name__
TypeError: can't pickle instancemethod objects
Request repr():
<WSGIRequest
path:/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/,
GET:<QueryDict: {}>,
POST:<QueryDict: {}>,
COOKIES:{'_ga': 'GA1.3.1219121887.1434427204',
'csrftoken': 'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs'},
META:{'CONTENT_LENGTH': '',
'CONTENT_TYPE': '',
u'CSRF_COOKIE': u'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',
'DOCUMENT_ROOT': '/usr/share/nginx/html',
'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,_/_;q=0.8',
'HTTP_ACCEPT_ENCODING': 'gzip, deflate, sdch',
'HTTP_ACCEPT_LANGUAGE': 'en-US,en;q=0.8',
'HTTP_CACHE_CONTROL': 'max-age=0',
'HTTP_CONNECTION': 'keep-alive',
'HTTP_COOKIE': '_ga=GA1.3.1219121887.1434427204; csrftoken=GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',
'HTTP_HOST': 'www.buildability.co.nz',
'HTTP_UPGRADE_INSECURE_REQUESTS': '1',
'HTTP_USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36',
'PATH_INFO': u'/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/',
'QUERY_STRING': '',
'REMOTE_ADDR': '131.203.137.142',
'REMOTE_PORT': '51455',
'REQUEST_METHOD': 'GET',
'REQUEST_URI': '/images/2dMQIUOPwS5DlZuprp_E_WFdfhw%3D/47/width-75/',
u'SCRIPT_NAME': u'',
'SERVER_NAME': 'www.buildability.co.nz',
'SERVER_PORT': '80',
'SERVER_PROTOCOL': 'HTTP/1.1',
'UWSGI_SCHEME': 'http',
'uwsgi.core': 7,
'uwsgi.node': 'avinton',
'uwsgi.version': '1.9.17.1-debian',
'wsgi.errors': <open file 'wsgi_errors', mode 'w' at 0x7f0548a548a0>,
'wsgi.file_wrapper': <built-in function uwsgi_sendfile>,
'wsgi.input': <uwsgi._Input object at 0x7f0548a20a08>,
'wsgi.multiprocess': True,
'wsgi.multithread': True,
'wsgi.run_once': False,
'wsgi.url_scheme': 'http',
'wsgi.version': (1, 0)}>
</issue>
<code>
[start of wagtail/wagtailimages/views/frontend.py]
1 from wsgiref.util import FileWrapper
2 import imghdr
3
4 from django.shortcuts import get_object_or_404
5 from django.http import HttpResponse
6 from django.core.exceptions import PermissionDenied
7
8 from wagtail.wagtailimages.models import get_image_model
9 from wagtail.wagtailimages.utils import verify_signature
10 from wagtail.wagtailimages.exceptions import InvalidFilterSpecError
11
12
13 def serve(request, signature, image_id, filter_spec):
14 image = get_object_or_404(get_image_model(), id=image_id)
15
16 if not verify_signature(signature.encode(), image_id, filter_spec):
17 raise PermissionDenied
18
19 try:
20 rendition = image.get_rendition(filter_spec)
21 rendition.file.open('rb')
22 image_format = imghdr.what(rendition.file)
23 return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
24 except InvalidFilterSpecError:
25 return HttpResponse("Invalid filter spec: " + filter_spec, content_type='text/plain', status=400)
26
[end of wagtail/wagtailimages/views/frontend.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtailimages/views/frontend.py b/wagtail/wagtailimages/views/frontend.py
--- a/wagtail/wagtailimages/views/frontend.py
+++ b/wagtail/wagtailimages/views/frontend.py
@@ -2,7 +2,7 @@
import imghdr
from django.shortcuts import get_object_or_404
-from django.http import HttpResponse
+from django.http import HttpResponse, StreamingHttpResponse
from django.core.exceptions import PermissionDenied
from wagtail.wagtailimages.models import get_image_model
@@ -20,6 +20,6 @@
rendition = image.get_rendition(filter_spec)
rendition.file.open('rb')
image_format = imghdr.what(rendition.file)
- return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
+ return StreamingHttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
except InvalidFilterSpecError:
return HttpResponse("Invalid filter spec: " + filter_spec, content_type='text/plain', status=400)
|
{"golden_diff": "diff --git a/wagtail/wagtailimages/views/frontend.py b/wagtail/wagtailimages/views/frontend.py\n--- a/wagtail/wagtailimages/views/frontend.py\n+++ b/wagtail/wagtailimages/views/frontend.py\n@@ -2,7 +2,7 @@\n import imghdr\n \n from django.shortcuts import get_object_or_404\n-from django.http import HttpResponse\n+from django.http import HttpResponse, StreamingHttpResponse\n from django.core.exceptions import PermissionDenied\n \n from wagtail.wagtailimages.models import get_image_model\n@@ -20,6 +20,6 @@\n rendition = image.get_rendition(filter_spec)\n rendition.file.open('rb')\n image_format = imghdr.what(rendition.file)\n- return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n+ return StreamingHttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n except InvalidFilterSpecError:\n return HttpResponse(\"Invalid filter spec: \" + filter_spec, content_type='text/plain', status=400)\n", "issue": "Error when serving images through the URL generator\nI posted a comment on https://github.com/torchbox/wagtail/issues/983 but probably better to open a new issue. Looks like the same problem to me though.\n\nHi guys, I think I'm having the same problem but when serving images using the URL generator. It does work if I'm logged-in in the site (cache not working) but doesn't when I'm not (cache full on).\n\nCheers,\nJordi\n\nInternal Server Error: /images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/\nTraceback (most recent call last):\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/core/handlers/base.py\", line 204, in get_response\n response = middleware_method(request, response)\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/middleware/cache.py\", line 121, in process_response\n self.cache.set(cache_key, response, timeout)\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/redis_cache/cache.py\", line 239, in set\n result = self._set(key, pickle.dumps(value), timeout, client, _add_only)\n File \"/var/www/buildability/venvs/buildability.co.nz/lib/python2.7/copy_reg.py\", line 70, in _reduce_ex\n raise TypeError, \"can't pickle %s objects\" % base.__name__\nTypeError: can't pickle instancemethod objects\n\nRequest repr(): \n<WSGIRequest\npath:/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/,\nGET:<QueryDict: {}>,\nPOST:<QueryDict: {}>,\nCOOKIES:{'_ga': 'GA1.3.1219121887.1434427204',\n 'csrftoken': 'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs'},\nMETA:{'CONTENT_LENGTH': '',\n 'CONTENT_TYPE': '',\n u'CSRF_COOKIE': u'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',\n 'DOCUMENT_ROOT': '/usr/share/nginx/html',\n 'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,_/_;q=0.8',\n 'HTTP_ACCEPT_ENCODING': 'gzip, deflate, sdch',\n 'HTTP_ACCEPT_LANGUAGE': 'en-US,en;q=0.8',\n 'HTTP_CACHE_CONTROL': 'max-age=0',\n 'HTTP_CONNECTION': 'keep-alive',\n 'HTTP_COOKIE': '_ga=GA1.3.1219121887.1434427204; csrftoken=GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',\n 'HTTP_HOST': 'www.buildability.co.nz',\n 'HTTP_UPGRADE_INSECURE_REQUESTS': '1',\n 'HTTP_USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36',\n 'PATH_INFO': u'/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/',\n 'QUERY_STRING': '',\n 'REMOTE_ADDR': '131.203.137.142',\n 'REMOTE_PORT': '51455',\n 'REQUEST_METHOD': 'GET',\n 'REQUEST_URI': '/images/2dMQIUOPwS5DlZuprp_E_WFdfhw%3D/47/width-75/',\n u'SCRIPT_NAME': u'',\n 'SERVER_NAME': 'www.buildability.co.nz',\n 'SERVER_PORT': '80',\n 'SERVER_PROTOCOL': 'HTTP/1.1',\n 'UWSGI_SCHEME': 'http',\n 'uwsgi.core': 7,\n 'uwsgi.node': 'avinton',\n 'uwsgi.version': '1.9.17.1-debian',\n 'wsgi.errors': <open file 'wsgi_errors', mode 'w' at 0x7f0548a548a0>,\n 'wsgi.file_wrapper': <built-in function uwsgi_sendfile>,\n 'wsgi.input': <uwsgi._Input object at 0x7f0548a20a08>,\n 'wsgi.multiprocess': True,\n 'wsgi.multithread': True,\n 'wsgi.run_once': False,\n 'wsgi.url_scheme': 'http',\n 'wsgi.version': (1, 0)}>\n\n", "before_files": [{"content": "from wsgiref.util import FileWrapper\nimport imghdr\n\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponse\nfrom django.core.exceptions import PermissionDenied\n\nfrom wagtail.wagtailimages.models import get_image_model\nfrom wagtail.wagtailimages.utils import verify_signature\nfrom wagtail.wagtailimages.exceptions import InvalidFilterSpecError\n\n\ndef serve(request, signature, image_id, filter_spec):\n image = get_object_or_404(get_image_model(), id=image_id)\n\n if not verify_signature(signature.encode(), image_id, filter_spec):\n raise PermissionDenied\n\n try:\n rendition = image.get_rendition(filter_spec)\n rendition.file.open('rb')\n image_format = imghdr.what(rendition.file)\n return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n except InvalidFilterSpecError:\n return HttpResponse(\"Invalid filter spec: \" + filter_spec, content_type='text/plain', status=400)\n", "path": "wagtail/wagtailimages/views/frontend.py"}]}
| 1,897 | 233 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.